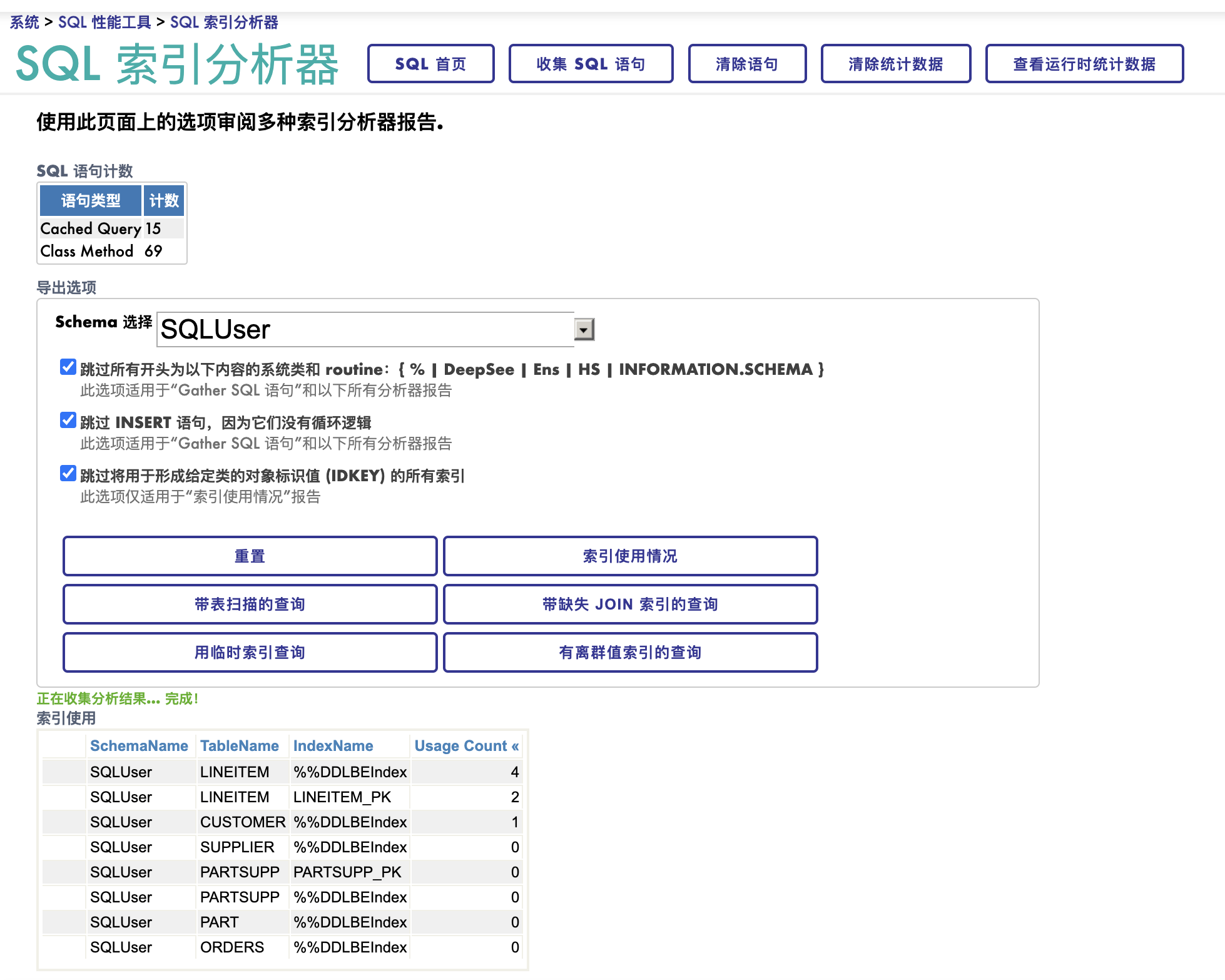
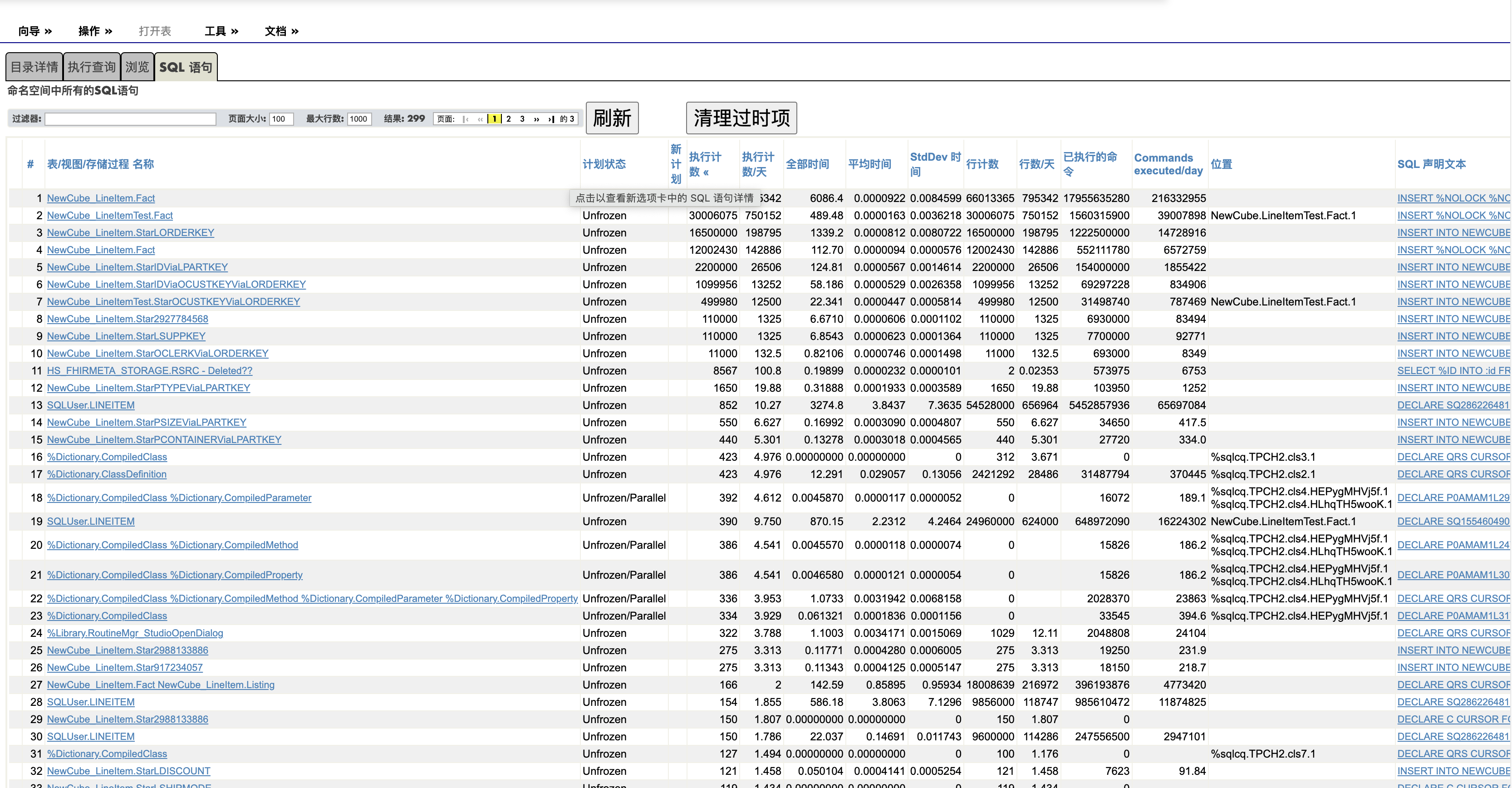
要做分析,首先您需要打开一个采集“SQL runtime Statistics"的开关来收集详细信息,这个开关默认的状态是OFF。 文档里说: The SQL Performance Analysis Toolkit offers support specialists the ability to profile specific SQL statements or groups of statements.
While the SQL compiler tries to make the most efficient use of data as specified by the query, sometimes the author of the query knows more about some aspect of the stored data than is evident to the compiler. In this case, the author can make use of the query plan to modify the original query to provide more information or more guidance to the query compiler.
Jim Coutcher, Senior Director/Principal, Global Head of Enriched Studies, Real World Solutions, IQVIA Qi Li, Physician Executive, InterSystems Matt Stannard, life Sciences Advisor, InterSystems
 按更新时间
按更新时间
.png)
.png)

 Open Exchange app
Open Exchange app.png)
.png)
.png)