清除过滤器
文章
Qiao Peng · 三月 28, 2021
如果您正打算学习FHIR、或者正在基于FHIR开发,最佳的学习和开发环境需要一个完备的FHIR 服务器,帮助您理解FHIR标准和调试FHIR应用。使用InterSystems IRIS医疗行业版可以快速配置出FHIR服务器和FHIR资源仓库。这篇文章介绍如何在5分钟内在InterSystems IRIS医疗行业版上配置FHIR服务器和FHIR资源仓库;同时对初学者介绍FHIR测试数据生成与加载的方法,和基本的FHIR REST API操作。
软件准备
1. InterSystems IRIS医疗行业版
您可以使用已有的2020.1及以上的InterSystems IRIS医疗行业版。如果您还没有,那么就在社区里下载一个最新的、免费的社区版吧。
2. 测试用的FHIR数据
如果您正在做FHIR开发,应该有很多FHIR测试数据。如果您正在学习FHIR,那么Synthea是一个不错的FHIR测试数据生成器选项。
3. REST测试工具
您或许已经有趁手的REST测试工具了。如果还没有,POSTMAN是个不错的选择。我的例子里用到的就是POSTMAN。
FHIR服务器配置
1. 安装InterSystems IRIS医疗行业版或社区版
如果您还没有安装过InterSystems IRIS医疗行业版或社区版,社区里有很多很好的介绍文章。
2. 配置FHIR服务器
2.1 创建一个FHIR 服务器命名空间
在InterSystems IRIS医疗行业版或社区版上,需要创建一个FHIR服务器命名空间。HS.HC.Util.Installer类的方法InstallFoundation可以创建这样的命名空间,例如,我们创建一个名为FHIRSERVER的命名空间:
HSLIB>D ##class(HS.HC.Util.Installer).InstallFoundation("FHIRSERVER")
2.2 为这个命名空间配置FHIR访问端点 (FHIR endpoint)
进入管理门户,切换到FHIRSERVER命名空间,然后Health > FHIR Configuration, 然后点击“Server Configuration”。这里会列出已有的FHIR服务器的访问端点,并可以配置新的端点。
这里点击+号,在弹出的配置页面中进行设置,其配置项是:
选中支持的FHIR版本 (Select a metadata set): 如果要支持最新的FHIR版本4,选中HL7V40,就是FHIR R4;
选中交换策略 (Select an interaction strategy): 默认情况下只会有一个选项 - HS.FHIRServer.Storage.Json.InteractionsStrategy,它会将InterSystems IRIS同时配置为FHIR资源仓库。
设置FHIR服务器REST服务端点 (Enter a name(URL)): 例如/csp/healthshare/fhirserver/fhir/r4
然后点击Finish,让它完成后台的配置,这可能会花费1分钟。
2.3 修改这个FHIR服务端点
因为我们是想利用它来学习和测试FHIR,所以我们先跳过访问认证部分。在端点列表中选中刚才创建的/csp/healthshare/fhirserver/fhir/r4,滚动到最下方,找到Edit按钮,并选中“Debugging”下的“Allow Unauthenticated Access”,让FHIR服务器接受匿名访问。然后点击Update进行更新。
如果您按上述步骤执行完成,并且没有错误,那么FHIR服务器和FHIR资源仓库已经就绪了。看看表,您用了多久完成FHIR服务器的创建。
下面测试一下FHIR服务器是否工作正常。
测试FHIR服务器
即便您还没有任何FHIR测试数据,也可以先看看这个FHIR服务器的能力声明。
通过POSTMAN,使用GET方法,进行REST调用:http://localhost:52776/csp/healthshare/fhirserver/fhir/r4/metadata。这里localhost:52776是我的测试InterSystems IRIS的服务器地址和Web服务端口号,您换成自己的就行。如果您不知道,那么用您访问InterSystems IRIS管理门户的地址和端口号。
因为我们在上一步配置时,允许匿名访问REST API,所以POSTMAN无需设置任何登陆账户,非常方便测试。正常情况下,您应该看到和我一样的结果:
您的FHIR服务器已经正常工作了,如果还没有测试数据,是时候加载一些FHIR数据进来了。
产生FHIR数据
如果您有自己的FHIR测试数据,请跳过此步,查看“加载FHIR数据”。
如果您还没有自己的FHIR数据,试试Synthea,它能方便的产生大量FHIR测试数据。Synthea有清晰的文档,告诉我们如何产生测试数据。(注:如果您是FHIR初学者,建议先少量创建FHIR测试数据文件,例如先创建5个)
通常它会产生3类JSON文件:
医院信息:hospitalInformation******.json, 每批次只会产生一个医院信息文件。
医生信息:practitionerInformation******.json, 每批次只会产生一个医生信息文件。
患者信息:<患者姓名>******.json, 每批次会根据设置产生一个或多个患者信息文件。
这些FHIR文件都是Bundle资源,Bundle里面会有很多FHIR资源数据。其中医院信息文件和医生信息文件的Bundle类型为batch,而患者信息的Bundle是transaction。
而Synthea产生的患者信息Bundle中的资源使用literal reference来引用医院/地点和医生信息,但它产生的literal reference信息不完整,例如:
"serviceProvider": {
"reference": "Organization?identifier=https://github.com/synthetichealth/synthea|731e0f3a-075d-37ab-9ba7-fbf1ab2f45e9",
"display": "THE GENERAL HOSPITAL CORPORATION"
}
需要将reference改为完整的地址,例如:
"serviceProvider": {
"reference": "http://localhost:52776/csp/healthshare/fhirserver/fhir/r4/Organization?identifier=https://github.com/synthetichealth/synthea|731e0f3a-075d-37ab-9ba7-fbf1ab2f45e9",
"display": "THE GENERAL HOSPITAL CORPORATION"
}
也就是增加FHIR服务器的端点。
需要替换/补齐的引用分别是:Location、Organization和Practitioner。
您可以通过文本编辑器进行全局替换,将FHIR服务器的端点信息补充到reference里。如果您产生了很多FHIR数据文件,当然可以用您熟悉的语言写几行代码做这个补充替换。
这里我也附上使用IRIS的Object Script做补充替换的代码示例,它会对指定目录下的所有json文件进行扫描和补充替换,供您参考:
Class Demo.FHIRTools Extends %RegisteredObject
{
/// 修正FHIR文件的引用
/// pFilePath为FHIR json文件目录
/// pFHIREndpoint为FHIR REST的服务端点
ClassMethod CorrectSyntheaFiles(
pFilePath As %String = "C:\Temp\Synthea\output\fhir",
pFHIREndpoint As %String = "http://localhost:52776/csp/healthshare/fhirserver/fhir/r4") As %Status
{
Set tSC = $$$OK
// 遍历目录下的json文件
Set tSM = ##class(%SQL.Statement).%New()
Set tSC = tSM.%PrepareClassQuery("%File", "FileSet")
If $$$ISERR(tSC)
{
Do $system.OBJ.DisplayError(tSC)
Return tSC
}
Set tRS = tSM.%Execute(pFilePath, "*.json", "Name")
While tRS.%Next()
{
// 创建临时文件
Set tFileName = tRS.%Get("Name"),tTempFileName=$Replace(tFileName,".json","temp.json")
Set tFile=##class(%Stream.FileCharacter).%New()
Set tTempFile = ##class(%Stream.FileCharacter).%New()
Set tSC=tTempFile.LinkToFile(tTempFileName)
Set tSC=tFile.LinkToFile(tFileName)
// 从源文件逐行读取,替换后写入临时文件
While 'tFile.AtEnd
{
Set tLine=tFile.ReadLine()
// 执行替换
For tKeyword="Location?identifier=","Organization?identifier=","Practitioner?identifier="
{
Set tLine = $Replace(tLine,tKeyword,pFHIREndpoint_"/"_tKeyword)
}
Set tSC = tTempFile.WriteLine(tLine)
}
Do tTempFile.%Save()
Do tFile.%Close(), tTempFile.%Close()
Kill tFile,tTempFile
// 删除源文件,并将临时文件改名为源文件名
Set tSC = ##class(%File).Delete(tFileName,.tRtn)
Set tSC = ##class(%File).Rename(tTempFileName, tFileName, .tRtn)
}
Return tSC
}
}
加载FHIR数据
当然可以通过FHIR REST API来加载数据,不过,InterSystems IRIS提供了后台的API,可以快速加载特定目录下的大量的FHIR数据文件。
这里我们用后台API:HS.FHIRServer.Tools.DataLoader的SubmitResourceFiles方法进行大量FHIR文件加载:
FHIRSERVER>Set sc=##class(HS.FHIRServer.Tools.DataLoader).SubmitResourceFiles("C:\Temp\Synthea\upload","FHIRSERVER","/csp/healthshare/fhirserver/fhir/r4")
其中第一个入参是需要加载的文件目录;第二个参数是加载的FHIR服务器类型,这里用FHIRSERVER;第三个参数是FHIR REST服务端点。
这个方法同样适用于加载NDJSON格式的FHIR数据文件。
如果您是通过Synthea产生的测试FHIR JSON文件,那么应该先加载 医院信息文件(hospitalInformation******.json)和医生信息文件(practitionerInformation******.json),以确保患者数据加载时,Location、Organization和Practitioner的引用能正确关联到FHIR资源仓库中已保存的对应资源上。
注意:2020.* 版本中有一个bug,需要将医院信息文件(hospitalInformation******.json)和医生信息文件(practitionerInformation******.json)里的"type": "batch"改为"type": "transaction"。这个bug在2021.1版本中已经得到修复,我已经验证过,但如果您在使用2020的版本,请记得提前修改。
加载完医院信息文件(hospitalInformation******.json)和医生信息文件(practitionerInformation******.json)后,再执行相同的方法加载所有患者数据json文件。
使用FHIR 服务器
有了测试数据,现在您可以使用FHIR服务器进行学习或开发测试了。使用POSTMAN,您可以调用FHIR服务器的REST API,查询、更改、提交FHIR资源数据。
如果您是初学者,对FHIR的REST API不熟悉,建议您从FHIR Cheat Sheet开始,它是一个FHIR标准的汇总单页,里面告诉大家如何使用REST API进行操作。
例如:
1. 查询已经加载到FHIR资源仓库中的患者:
使用GET 方法调用REST:
http://localhost:52776/csp/healthshare/fhirserver/fhir/r4/Patient
2. 使用查询参数,查询名为Pedro316的患者:
使用GET 方法调用REST:
http://localhost:52776/csp/healthshare/fhirserver/fhir/r4/Patient?given=Pedro316
或使用POST 方法调用REST:
http://localhost:52776/csp/healthshare/fhirserver/fhir/r4/Patient/_search?given=Pedro316
3. 更复杂的查询参数用例,查询拥有观察项目编码为8302-2(体重)的患者:
使用GET 方法调用REST:
http://localhost:52776/csp/healthshare/fhirserver/fhir/r4/Patient?_has:Observation:patient:code=8302-2
4. 使用operation: $everything 来获取特定患者的所有相关FHIR资源(示例是id为95的患者):使用GET 方法调用REST:
http://localhost:52776/csp/healthshare/fhirserver/fhir/r4/Patient/95/$everything
5. 加载FHIR Bundle资源:
使用POST 方法调用REST:
http://localhost:52776/csp/healthshare/fhirserver/fhir/r4/
,并在Body中直接贴入FHIR资源数据到raw,或选择FHIR资源数据文件到binary。
注意:如果您是想让FHIR服务器解析Bundle中的FHIR资源,应该用http://localhost:52776/csp/healthshare/fhirserver/fhir/r4/,而不是http://localhost:52776/csp/healthshare/fhirserver/fhir/r4/Bundle。后者把POST的FHIR数据按Bundle进行处理,并不会解析其中包含的FHIR资源内容并逐一保存!
注意:记得根据FHIR数据的格式设置Content-Type为application/json+fhir 或 application/xml+fhir,然后将数据贴在Body里:
好了,开启您的FHIR之旅吧 :)
后续我还会更新InterSystems IRIS医疗版作为FHIR服务器和FHIR资源仓库的更多内容,欢迎关注。
文章
Claire Zheng · 四月 21, 2021
近日,InterSystems极客俱乐部举办了线上直播“InterSystems Caché系统运维培训”,这是系列视频之一。InterSystems中国资深售前顾问祝麟讲解了“InterSystems Caché系统安全”。
文章
Claire Zheng · 四月 21, 2021
近日,InterSystems极客俱乐部举办了线上直播“InterSystems Caché系统运维培训”,这是系列视频之一。InterSystems中国资深售前顾问马浩讲解了“InterSystems Caché系统监控和性能数据采集”。
文章
Claire Zheng · 七月 6, 2021
近日,InterSystems极客俱乐部举办了线上直播“InterSystems Caché系统运维培训”,这是系列视频之一。InterSystems中国资深售前顾问祝麟讲解了“InterSystems Caché系统高可用与数据库镜像”。
文章
Claire Zheng · 一月 20, 2021
跨行业用例大多要求具备每秒接收数千或数百万条记录的能力,同时能够支持实时同步查询,例如:股票交易处理、欺诈检测、物联网应用(包括异常检测和实时OEE监控)等。Gartner将这种能力称为“HTAP”(混合事务分析处理)。Forrester等其他公司将其称为Translytics。InterSystems IRIS是功能强大、可扩展、高性能、资源高效的事务分析型数据平台,同时具备内存数据库的高性能以及传统数据库的一致性、可用性、可靠性以及低成本的特性。
混合事务分析处理(HTAP)示例
此示例展示了InterSystems IRIS如何实现每秒接收数千条记录,同时允许对同一集群上的数据进行同步查询,该平台不仅具有很高的接收和查询性能,而且保持了较低的资源利用率。此示例可在单个InterSystems IRIS实例或云端InterSystems IRIS集群上运行。
大家也可以在SAP HANA、MySQL、SqlServer及Amazon Aurora上运行这个示例,以便对性能和资源利用率进行公平、合理的对比。
大家可以在AWS上运行该测试!以下是部分结果:
在AWS上运行InterSystems IRIS和SAP HANA:
o在接收记录量方面,InterSystems IRIS比SAP HANA多39%
o在查询速度方面,InterSystems IRIS比SAP HANA快3699%
在AWS上运行InterSystems IRIS和AWS Aurora(MySQL):
o在接收记录量方面,InterSystems IRIS比AWS Aurora多831%
o在查询速度方面,InterSystems IRIS比AWS Aurora快485%
大家可以在自己的PC上使用Docker(3个CPU和7GB RAM)运行该测试!以下是部分结果:
在个人PC上运行InterSystems IRIS和MySQL 8.0:
o在接收记录量方面,InterSystems IRIS比MySQL 8.0多3043%
o在查询速度方面,InterSystems IRIS比MySQL 8.0快643%
在Ubuntu系统中运行InterSystems IRIS和SQL Server 2019
o在接收记录量方面,InterSystems IRIS比SQL Server 2019多223%,速度也更快
o在查询速度方面,InterSystems IRIS比SQL Server 2019快134,632%(请注意,数字没有打错哦!)
o为公平起见,我们未来将在AWS和Azure上对SQL Server进行测试。敬请期待!
在测试任何数据库的运行速度时,请先将速度测试运行一段时间进行预热,然后再记录结果。这样可以对数据库进行预扩展并执行其他操作。每次启动速度测试时,我们都需要清空表格重新开始。
1-在AWS上运行速度测试
请点击链接,查看如何在AWS上运行速度测试以便将InterSystems IRIS和其他数据库(如SAP HANA和AWS Aurora)进行对比。
2- 如何在PC上运行速度测试
在PC上运行速度测试的前提条件是:
Docker和Docker Compose
Git(可以克隆源代码)
目前,可以使用InterSystems IRIS、MySQL、SqlServer及SAP HANA在PC上运行本示例。
2.1 -在InterSystems IRIS Community上运行速度测试
要想在PC上运行本示例,请确保PC已经安装了Docker。您可以使用以下命令在Mac或Linux系统的PC上快速启动并运行:
wget https://raw.githubusercontent.com/intersystems-community/irisdemo-demo-htap/master/docker-compose.yml
docker-compose up
如果在Windows系统中运行速度测试,请将docker-compose.yml文件下载到一个文件夹中。打开命令提示符,并切换到该文件夹,然后运行docker-compose up
c:\MyFolder\docker-compose up
您也可以将存储库克隆到本地计算机上,从而获得完整的源代码。这时需要安装git,并将其放在git文件夹中:
git clone https://github.com/intersystems-community/irisdemo-demo-htap
cd irisdemo-demo-htap
docker-compose up
这两种技术都可行,并会触发示例中用于演示的镜像文件下载,之后将立刻启动所有的容器。
容器启动过程中,将出现与启动中容器相关的大量消息。这是正常的,不用担心!
启动完成后,它会一直挂在那里,不会把控制权交还给你。这也是正常的。将窗口开着就可以。如果在此窗口上按CTRL+C,docker compose将停止所有容器并停止示例演示。
在所有容器启动之后,在浏览器上打开http://localhost:10000可查看示例的界面。点击“Run Test”按钮即可运行HTAP Demo!
完成Demo演示后,返回到该终端并按CTRL+C。也可以输入以下命令,停止并删除仍在运行的容器:
docker-compose stop
docker-compose rm
这点很重要,特别是要在一个数据库(如InterSystems IRIS)和另一个数据库(如MySQL)之间反复运行速度测试时。
2.2 -PC上的MySQL
基于MySQL运行此示例,可以输入以下命令:
wget https://raw.githubusercontent.com/intersystems-community/irisdemo-demo-htap/master/docker-compose-mysql.yml
docker-compose -f ./docker-compose-mysql.yml up
现在,我们将下载一个不同的docker-compose yml文件:一个带有mysql后缀的文件。我们必须在docker-compose命令中使用-f选项来使用此文件。如前所述,将该终端窗口保持打开状态,并在浏览器上打开http://localhost:10000。
示例运行完成后,请返回终端并按CTRL+C。也可以输入以下命令,停止并删除仍在运行的容器:
docker-compose -f ./docker-compose-mysql.yml stop
docker-compose -f ./docker-compose-mysql.yml rm
这点很重要,特别是要在一个数据库(如InterSystems IRIS)和其他数据库之间反复运行速度测试时。
我们在测试中发现,InterSystems IRIS的数据接收速度比MySQL和Amazon Aurora快25倍。
2.3 -PC上的SQL Server 2019-GA-ubuntu-16.04
基于SQL Server运行此示例,可以输入以下命令:
wget https://raw.githubusercontent.com/intersystems-community/irisdemo-demo-htap/master/docker-compose-sqlserver.yml
docker-compose -f ./docker-compose-sqlserver.yml up
与前面一样,将该终端窗口保持打开状态,并在浏览器上打开http://localhost:10000。
我们在本地PC上运行速度测试后发现,InterSystems IRIS的数据接收速度比SQL Server快2.5倍,查询速率则快400倍!我们将与AWS RDS SQL Server相比较,进行速度测试并生成报告。
2.4 -PC上的SAP Hana
要在PC上基于SAP HANA运行速度测试,需要满足以下条件:
包含了Ubuntu 18 VM、docker和docker-compose的虚拟机——因为SAP HANA要求对Linux内核参数进行一些更改,否则将无法支持Mac或Windows上的Docker。另外,SAP HANA需要Linux内核4或更高版本。
该虚拟机至少配置9GB RAM,否则将无法启动!虚拟机崩溃后将显示无用的错误消息。
基于SAP HANA运行此Demo,可以输入以下命令:
git clone https://github.com/intersystems-community/irisdemo-demo-htap
cd ./irisdemo-demo-htap
./run.sh hana
等待下载镜像和启动容器。当docker-compose停止向屏幕写入时,一切已准备就绪。但是请耐心等待——SAP HANA大约需要6分钟才能启动!因此,屏幕会冻结一分钟左右,然后你会看到SAP HANA写入更多文本。这个重复写入过程大约持续6分钟。看到“启动完成!(Startup finished!)”后,就可以开始下一步了。如果在此过程中因为错误而发生崩溃,则可能需要配置更多的内存。
如您所知,与在InterSystems IRIS和MySQL中运行速度测试一样,使用SAP HANA测试不仅仅是运行docker-compose,还需要对Linux内核进行一些配置。大家可以通过run.sh文件来完成这些配置。
我们在虚拟机上运行速度测试后发现,InterSystems IRIS的数据接收速度比SAP HANA快1.3倍,查询数据的速度快20倍,并且使用了更少的内存。
3-资源
我们正在制作有关本示例的视频。在此期间,您可以点击链接查看一篇有意思的文章,该文章介绍了InterSystems IRIS的体系结构,并解释了为什么它能以更快的速度接收和查询数据。
4-该基准测试与YCSB或TPC-H等标准基准测试相比如何?
Yahoo Cloud Serving Benchmark(YCSB)是一项开源项目,其目的是开发一个框架和一组通用的工作负载,来评估不同的“键-值存储”和“云”服务的性能。
尽管YCSB上有一些工作负载可以描述成HTAP,但YCSB不一定要依靠SQL来完成。但是该基准必须依靠SQL。
TPC-H侧重于决策支持系统(DSS),而这并不是我们正在研究的用例。
此基准测试针对的是接收速度和查询响应时间之间的关系。我们有一个表格,其中包含许多不同数据类型的列。我们想衡量一个数据库在允许响应式查询的同时,其接收记录的速度能有多快。
这是一个复杂的问题。金融服务和物联网等许多行业都要求每秒必须接收数千条记录。在如此高的接收速率下,内存消耗得非常快。传统数据库需要写入磁盘,而内存数据库也将被迫不断写入磁盘(更改log/journal,甚至在某些情况下部分数据会写入内存,就像传统数据库一样)。问题是:如果InterSystems IRIS不仅要将事务日志写入磁盘(像内存数据库一样),还要异步保持数据库的最新状态,那么InterSystems IRIS是如何做到比内存数据库更快的呢?
一切都与效率有关。接收工作负载会使数据库非常繁忙。CPU和内存都将努力运转。一些内存数据库将尝试压缩内存中的数据。其他内存数据库在内存已满时会将数据持久化到磁盘。所有这些在我们试图实时查询数据库时都有发生。
我们想要证明,在某些工作负载上(例如股票交易、高接收吞吐量[物联网]等),内存数据库的性能不及InterSystems IRIS。这就是我们设计本测试的原因。这意味着该测试比一般用途的测试要简单得多:
(1)它只有一个表格,包含19个列和3种差别很大的数据类型
(2)表格上声明了主键(Primary Key)。
(3)我们执行的查询将通过主键(账户ID)获取记录,并使用固定的8个键随机查询:W1A1、W1A10、W1A100、W1A1000、W1A10000、W1A100000、W1A1000000和W1A10000000。这样做的原因如下:
我们知道,在生产系统的内存中保存所有数据是不可能的。内存数据库虽然具有复杂的体系结构,但当内存满了之后,就会将数据移出内存。为了简化测试并使其具有可比性,我们通过主键获取固定记录集,以避免对数据库中可能存在的其他类型的索引进行比较。
通过账号(主键)获取客户账户数据记录是我们许多客户的真实工作负载。数据库在高速接收数据的同时,也需要对查询做出响应。
由于账户ID是主键,因此数据库将使用它的首选(即最优)索引对其进行索引。这样在比较数据库时能够保持公平、简单。
当我们不断请求相同的账号时,数据库有可能将该数据缓存在内存中。这对于内存数据库来说是一项轻松的任务。
InterSystems IRIS是一个混合型数据库。与传统数据库一样,它也尝试将数据保存在内存中。但由于每秒需要接收成千上万的记录,因此内存清理得非常快。通过这个测试可以看到,与其他传统数据库和内存数据库相比,InterSystems IRIS在缓存方面更加智能。你会看到:
(1)传统数据库在同时处理接收和查询时表现不佳
(2)内存数据库:
在测试的最初几分钟内表现良好,随着内存填满,数据压缩变得更加困难,不可避免地要写入磁盘
由于系统忙于接收、压缩数据,以及将数据移出内存等,因此查询性能表现不佳。
5-表是怎样的?
以下是我们发送到所支持的全部数据库的建表语句:
CREATE TABLE SpeedTest.Account
(
account_id VARCHAR(36) PRIMARY KEY,
brokerageaccountnum VARCHAR(16),
org VARCHAR(50),
status VARCHAR(10),
tradingflag VARCHAR(10),
entityaccountnum VARCHAR(16),
clientaccountnum VARCHAR(16),
active_date DATETIME,
topaccountnum VARCHAR(10),
repteamno VARCHAR(8),
repteamname VARCHAR(50),
office_name VARCHAR(50),
region VARCHAR(50),
basecurr VARCHAR(50),
createdby VARCHAR(50),
createdts DATETIME,
group_id VARCHAR(50),
load_version_no BIGINT
)
插入程序Ingestion Worker会尽可能多地发送INSERT数据,以测量每秒插入的记录数据量以及每秒的兆字节数。
查询程序Query worker将通过account_id从此表中进行选择,并尝试选择尽可能多的记录来测量性能(即每秒选择的记录以及每秒选择的兆字节),以测试端到端性能,并提供工作量证明(Proof of Work)。
端到端性能与一些JDBC驱动程序最优化有关。如果仅执行查询操作,JDBC驱动程序可能不会从服务器获取记录,只有当实际请求列值后,JDBC驱动程序才会从服务器获取记录。
为了证明实际读取的正是我们选取的列,我们将返回的所有fild的字节加起来作为工作量证明。
6-如何实现接收和查询的最大吞吐量?
为了实现最大吞吐量,每个ingestion worker将启动多个线程,每个线程将:
(1)为上述表格的每一列准备1000个随机值。这样做是为了让每一列具有不同的数据类型和大小。所以我们希望生成可相应变化的记录
(2)对于要插入的每个新记录,ingestion worker将在每列的1000个值中随机选择一个值,准备好之后,该记录将被添加到批处理中
(3)使用批量插入,默认批量大小为每批1000条记录
Ingestion worker的默认线程数量是15,但是可以在测试过程中单击“设置”进行更改。
另一方面,query worker也启动多个线程来查询尽可能多的记录。如上所述,我们也将提供工作量证明。我们将读取返回的列,并汇总读取的字节数,以确保数据是从数据库通过连接传输进入query worker的,从而避免某些JDBC驱动程序实现优化后,仅在实际使用数据时才通过连接传输数据。我们实际使用返回的数据,并提供每秒读取数据的兆字节总和以及读取的总兆字节数作为工作量证明。
7-占用多少磁盘空间?
在接收171,421,000条记录后,我填满了一个70Gb的数据文件系统。这意味着,每条记录平均占用439个字节(向上取整)。
我还填写了第一个日志目录的100%和第二个日志目录的59%。这两个文件系统都有100Gb,这意味着171,421,000条记录将占用大约159Gb的日志空间,换言之,每条记录平均占用996个字节。
8-HTAP Demo体系架构
HTAP Demo的体系架构如下图所示:
本示例使用docker compose启动五项服务:
(1)htapui——这是用于运行示例的Angular UI。
(2)htapirisdb——由于本示例在InterSystems IRIS Community上运行,所以不需要InterSystems IRIS许可证即可运行。但请注意,InterSystems IRIS Community有两个重要限制条件:
最多5个连接
数据库最大为10Gb
(3)htapmaster——这是HTAP 示例主程序。UI与主程序对话,主程序与worker对话,以及启动/停止速度测试,并收集指标。
(4)ingest-worker1——这是插入程序ingestion worker。实际上,大家可以拥有多个ingestion worker,只需给每个worker分配不同的服务名称即可。它们将尝试尽快地将记录插入数据库。
(5)query-worker1——这是查询程序query worker,大家也可以拥有多个query worker。它们将尝试尽快地从数据库中读取记录。
在PC上运行示例时,我们使用的是Docker和Docker Compose。Docker Compose需要一个docker-compose.yml来描述这些服务及其使用的Docker镜像。本示例实际上提供了许多docker-compose.yml文件,并且很快将添加更多此类文件:
(1)docker-compose.yml——这是针对InterSystems IRIS Community(上述项目及图片中有所描述)运行速度测试的默认演示程序。
(2)docker-compose-mysql.yml——这是针对MySQL的速度测试。大家应该注意到,该测试结果表明,InterSystems IRIS比MySQL快25倍。在Amazon Aurora MySQL(MySQL的微调版本)上运行此测试可得到相同的结果。
(3)docker-compose-sqlserver.yml——这是针对使用Docker部署的SqlServer的速度测试。
(4)docker-compose-enterprise-iris.yml——如果要在标准版本的InterSystems IRIS上运行速度测试示例,这是一个docker-compose.yml的文件例子。
9. 可以在没有容器的情况下在InterSystems IRIS集群上运行本Demo吗?
可以!完成此示例最简便的方法是将此存储库克隆到即将运行master(主程序)和(在同一服务器上运行的)UI的每台服务器上以及每种worker类型(接收和查询worker)上。你可以根据自己的需要,拥有任意数量的接收worker和查询worker!
对于InterSystems IRIS,请查看文件夹./standalone_scripts/iris-jdbc.中的文件。每个服务器都有一个脚本:
(1)在主程序上:start_master_and_ui.sh——此脚本将启动主程序和UI。
(2)在Ingestion Worker上:start_ingestion_worker.sh——此脚本将启动Ingestion Worker,后者随后将与主程序连接并进行注册。
(3)在Query Worker上:start_query_worker.sh——此脚本将启动query worker,然后query worker将与主程序连接并进行注册。
对于InterSystems IRIS,大家有两种选择:
(1)可以使用start_iris.sh脚本在Docker容器上启动InterSystems IRIS服务器进行快速测试。
(2)可以手动或使用ICM设置InterSystems IRIS集群。然后做一些有趣的事情,比如:
使接收和查询worker都指向同一InterSystems IRIS
使用ECP配置InterSystems IRIS,让ingestion worker指向数据库服务器,同时让query worker指向ECP服务器
配置分片的InterSystems IRIS集群
等等
只要确保更改start_master.sh脚本中对应使用正确的InterSystems IRIS端点、用户名和密码来配置环境变量。
10-自定义
10.1 -如何配置本Demo让其与更多worker、线程等一起工作?
Docker-compose.yml文件中的环境变量支持配置所有内容。docker-compose.yml文件只是个不错的起点:大家可以复制它们并对副本进行更改,从而得到更多的worker(如果在PC上运行,不会有太大区别),每个worker类型都可以得到更多线程数,还可以更改接收数据的批处理大小,以及各查询之间的等待时间(以毫秒为单位)等。
10.2 -可以更改表的名称或结构吗?
可以,但必须:
(1)在PC上将复制此存储库
(2)更改源代码
(3)使用shellscript build.sh在PC上重建demo。
更改表的结构也很简单。
复制了该存储库后,需要更改/image-master/projects/master/src/main/resources文件夹下的文件。
如果更改表的结构,请确保使用与现有表相同的数据类型,这些数据类型是受支持的。另外还可以更改表的名称。
其次,需要配合更改其他* .sql脚本,如INSERT脚本、SELECT脚本等。
最后,只需运行build.sh来重建demo就可以了!
11-其他示例应用程序
我们还有一些其他涉及不同主题的InterSystems IRIS 示例应用程序,例如NLP、ML、与AWS服务的集成、Twitter服务、性能基准测试等。以下是其中的部分内容:
(1)HTAP Demo——混合事务分析处理(HTAP)基准。可以测试InterSystems IRIS同时插入和查询数据的速度。你会发现它的速度比AWS Aurora快20倍!
(2)欺诈预防——InterSystems IRIS通过机器学习和制定业务规则,防止金融服务交易中出现欺诈行为。
(3)Twitter情绪分析——演示InterSystems IRIS如何实时使用Tweet,并通过其NLP(自然语言处理)和业务规则功能来评估Tweet的情绪和元数据,从而决定何时与某人联系以提供支持。
(4)HL7协议和SMS(文本消息)应用程序——演示InterSystems IRIS医疗版如何解析HL7协议消息,从而给患者发送SMS(文本消息)提醒。它还演示了基于存储在标准化数据湖中预约数据的实时仪表板。
(5)Readmission Demo——患者再入院在医疗保健领域被称为"机器学习的Hello World"。针对这个问题,我们在本示例中演示了如何使用InterSystems IRIS安全地构建并运行用于实时预测的ML模型,以及如何将其集成到应用程序中。本InterSystems IRIS医疗版示例旨在展示如何构建针对再入院问题的完整解决方案。
12-支持的数据库
这是目前为止支持的数据库列表:
Runing on your PC with docker-compose (NO mirroring/replication)
InterSystems IRIS 2020.2
MySQL 8.0
MariaDB 10.5.4-focal
MS SQL Server 2019-GA-ubuntu-16.04
SAP HANA Express 2.0 (on Linux VM only)
Postgres 12.3
Running on AWS:
InterSystems IRIS (with or without mirroring)
AWS RDS Aurora (MySql) 5.6.10a (parallel query) with replication
AWS RDS SQL Server 2017 Enterprise Edition (production deployment) with replication
AWS RDS Postgres (production deployment) with replication
AWS RDS MariaDB (production deployment) with replication
SAP HANA Express Edition 2.0 without replication
SAP Sybase ASE 16.0 SP03 PL08, public cloud edition, premium version, without replication
AWS RDS Oracle (production deployment) with replication
注:本文为节选,欢迎点击原文链接,了解更多详情。
文章
Claire Zheng · 一月 20, 2021
大家可能已经听说过,我们近期推出了InterSystems API管理器 (以下简称IAM)。InterSystems IRIS数据平台™新增了一项功能,支持用户监视、控制和管理IT基础架构中基于Web的API间通信。
在本文中,我将向大家展示如何设置IAM,并重点介绍IAM中可用的一些功能。InterSystems API管理器可提供你所需的一切功能。
监视基于HTTP的API通信,并了解谁在使用你的API、你最受欢迎的API是什么,哪些可能需要重新实现。
使用多种方式对API用户进行控制及限制。从简单的访问限制、API流量限制,到请求有效负载微调,你可以进行细粒度控制并快速做出反应。
使用集中式安全机制(如OAuth2.0或密钥和令牌身份验证)保护API。
招募第三方开发人员,为第三方开发人员提供一个专门的开发门户来满足他们的需求,并从一开始就为他们提供良好的开发体验。
扩展API需求并实现低延迟响应。
我很高兴为大家介绍IAM,让您一睹为快。
入门
从WRC Software Distribution站点下载IAM,并将其部署为自身的docker容器。
请确保满足以下最低要求:
Docker引擎可用。最低支持版本是17.04.0+。
Docker-compose CLI工具可用。最低支持版本是1.12.0+。
第一步需要加载docker镜像,通过如下:
docker load -i iam_image.tar
这样一来,IAM镜像可在你的计算机进行后续使用。IAM作为一个独立运行的容器,可以单独从InterSystems IRIS后端对其进行扩展。
启动IAM前,需要访问IRIS实例来加载所需的许可证信息。须进行以下配置更改:
启用/api/IAM web应用程序
启用IAM用户
更改IAM用户密码
现在,我们可以开始配置IAM容器了。在distribution tarball里可以找到一个名为“iam-setup”的Windows和Unix系统脚本。该脚本可帮助你正确地设置环境变量,使IAM容器能够与InterSystems IRIS实例建立连接。这是我在Mac终端会话中的运行示例:
source ./iam-setup.sh Welcome to the InterSystems IRIS and InterSystems API Manager (IAM) setup script.This script sets the ISC_IRIS_URL environment variable that is used by the IAM container to get the IAM license key from InterSystems IRIS.Enter the full image repository, name and tag for your IAM docker image: intersystems/iam:0.34-1-1Enter the IP address for your InterSystems IRIS instance. The IP address has to be accessible from within the IAM container, therefore, do not use "localhost" or "127.0.0.1" if IRIS is running on your local machine. Instead use the public IP address of your local machine. If IRIS is running in a container, use the public IP address of the host environment, not the IP address of the IRIS container. xxx.xxx.xxx.xxx Enter the web server port for your InterSystems IRIS instance: 52773Enter the password for the IAM user for your InterSystems IRIS instance: Re-enter your password: Your inputs are:Full image repository, name and tag for your IAM docker image: intersystems/iam:0.34-1-1IP address for your InterSystems IRIS instance: xxx.xxx.xxx.xxxWeb server port for your InterSystems IRIS instance: 52773Would you like to continue with these inputs (y/n)? yGetting IAM license using your inputs...Successfully got IAM license!The ISC_IRIS_URL environment variable was set to: http://IAM:****************@xxx.xxx.xxx.xxx:52773/api/iam/licenseWARNING: The environment variable is set for this shell only!To start the services, run the following command in the top level directory: docker-compose up -dTo stop the services, run the following command in the top level directory: docker-compose downURL for the IAM Manager portal: http://localhost:8002
我隐藏了IP地址和密码,但这足以让大家了解配置是多么简单。现在我们得到了开始下一步前所需的全部内容:InterSystems IRIS实例的完整镜像名称、IP地址和端口,以及IAM用户密码。
现在可以通过执行以下命令启动IAM容器:
docker-compose up -d
该命令将开始协调IAM容器,并确保以正确的顺序启动所有内容。
你可以使用以下命令检查容器的状态:
docker ps
在浏览器中输入localhost:8002会出现基于web的用户界面:
因为这是一个全新的节点,所以全局报告中未显示任何吞吐量。但我们很快就会改变这个情况。我们可以看到,IAM支持“Workspace(工作区)”概念,将工作划分为“module”和/或“team”。向下滚动并选择“default”工作区会将我们带到“Dashboard”界面。我们将在“default”工作区开始首次实验。
同样,这个工作区的请求数量也是零,但是你可以先在左侧的菜单中了解一下API网关的重要概念。前两个元素——即服务和路由——是最重要的。服务是指向用户公开的API。因此,IRIS实例中的REST API被视为一种服务,就像你所使用的Google API一样。路由决定应将传入请求路由到哪些服务。每个路由都有一组特定的条件,如果满足这些条件,就会将请求路由到相关的服务。大家需要了解的是,路由可以匹配发送者的IP或域、HTTP方法、部分URI,或者其中的几种。
现在让我们创建一个IRIS实例的服务,其值如下:
保留其他所有内容的默认设置。现在让我们创建一个路由:
同样,对其他所有内容保留默认设置。默认情况下,IAM正在监听端口8000上的传入请求。从现在开始,发送到http://localhost:8000并以/api/atelier路径开头的请求将被路由到IRIS实例。
让我们在REST客户端尝试一下(我使用的是Postman)。
向http://localhost:8000/api/atelier/发送一个GET请求会从IRIS实例返回一个响应。每个请求都经过IAM,并监视HTTP状态码、延迟和用户(如果已配置)等指标。我接着发出了另外几个请求(包含对不存在的端点的两个请求,如/api/atelier/test/),可以在Dashboard中看到汇总:
使用插件
既然已经有了一个基本的路由,那么可以开始管理API流量了。现在我们可以开始添加补充服务的行为。现在可以创造奇迹了。
执行某种行为最常见的方法就是添加插件。插件可提供一些功能,并且通常可以附加到IAM的某个部分。它们可能会对全局运行产生影响,也可能只对单个用户(组)、服务或路由等产生影响。首先,我们在路由中添加限速插件。此时需要确保插件和路由之间建立的链接是路由的唯一ID。这些可以从路由的详细信息里找到。
如果按照本文的步骤进行,那么你的路由ID是不一样的。复制ID继续下一步。
单击左侧工具栏菜单上的“Plugins”。通常可以在此界面上看到所有的活动插件,但由于这个节点相对较新,所以未显示任何活动插件。选择“Add New Plugin”继续下一步。
我们要选择的插件在“Traffic Control”类中,名为“Rate Limiting”。选中该插件。由于插件非常灵活,所以我们可以在这里定义非常多的字段,但现在我们只关心两个字段:
如上所示,插件已配置并处于活动状态。你可能已经发现有多种时间间隔可以选择,比如分钟、小时或天。我特意选择了分钟,因为这样可以让我们很容易理解这个插件产生的效果。
如果在Postman中再次发送相同的请求,会发现响应返回了两个附加的头信息:XRateLimit-Limit-minute (value 5) 和XRateLimit-Remaining-minute(value 4)。这是在告诉客户端,每分钟最多可以调用5次,并且在当前时间间隔内还有4个请求可用。
如果不断地发出相同的请求,最终会用完可用配额,得到一个带有以下负载的HTTP状态码429:
等这一分钟结束后,就可以再次调用。这是一个非常方便的机制,可以完成以下工作:
1. 确保后端避免高峰值
2. 为客户端设置一个期望值,即允许以透明的方式为服务进行多少次调用
3. 引入分级制有望从API流量中获利(例如,青铜级别每小时调用100次,而黄金级别则不受限制)
你可以为不同的时间间隔设置值,从而在一定时期内平滑API流量。假设允许某条路由每小时进行600次调用,平均每分钟调用10次。但是,你没有阻止客户端在一小时的第一分钟就用光600次调用(也许这就是你想要的)。也行你想让负载在一个小时内分配得更均匀。将config_minute字段设置为20,这样就可以确保用户每分钟调用的次数不超过20次,每小时不超过600次。这将使分钟级别的间隔出现一些峰值,因为它们平均每分钟只能调用10次,但用户不能在一分钟内用完一小时配额。现在,至少需要30分钟,系统才会达到满负荷运行。客户端将在每个配置的时间间隔内收到附加标头,例如:
header
value
X-RateLimit-Limit-hour
600
X-RateLimit-Remaining-hour
595
X-RateLimit-Limit-minute
20
X-RateLimit-Remaining-minute
16
当然,可以采用多种不同的方法配置rate-limits,这取决于你想要实现的目标。
对此我不再做过多介绍,因为作为一篇介绍InterSystems API Manager的文章,上述介绍已经足够了。IAM还可以用来实现更多的事情。我们刚刚只用了40多个插件中的一个,甚至还没有使用到所有的核心概念,你还可以实现以下任务:
为所有服务添加集中式身份验证机制
通过负载均衡请求扩展到支持同一组API的多个目标
向更小的受众介绍新特性或bugfixes,并在向大家发布之前监视的进展情况
为内部和外部开发人员提供一个专用的、可自定义的开发人员门户,记录他们有权访问的所有API
缓存常见的请求响应,以减少响应延迟和服务系统上的负载
所以,请大家试一试IAM,并在下面评论区留下建议。我们努力推出这一功能,希望了解大家可以使用这项技术克服哪些挑战。
更多资源
官方新闻稿:InterSystems IRIS Data Platform 2019.2 introduces API Management capabilities
短动画视频概述:什么是InterSystems API Manager?(英文) What is InterSystems API Manager
8分钟小视频带你了解主要亮点:InterSystems API管理器简介(英文) Introducing InterSystems API Manager
选自IRIS文档部分内容:InterSystems API管理器文档(英文) InterSystems API Manager Documentation
注:本文为译文,欢迎点击查看原文,原文由Stefan Wittmann撰写 IAM 是只能在docker 里运行吗? 对,目前IAM提供的是容器版本。如果有对IAM的需求,可以联系InterSystems的销售和销售工程师。 欢迎联系Intersystems 中国服务热线:400-601-9890,谢谢!
公告
Claire Zheng · 二月 1, 2021
大家好!
InterSystems IRIS开发者们,我们有一个好消息要跟大家分享! 我们很高兴能够邀请大家参加我们今年的年度大奖赛,利用InterSystems IRIS数据平台创建开源解决方案!
🏆 InterSystems编程大奖赛 🏆
时间: 2021年2月8日 - 3月8日
奖金总额: $16,000
奖项设置
这次我们提升了现金奖励力度! 请看:
1. 专家提名奖(Experts Nomination)- 获奖者由我们特别挑选的专家团选出:
🥇 第一名 - $6,000
🥈 第二名 - $3,000
🥉 第三名 - $2,000
2. 社区提名奖(Community Nomination)- 获得总投票数最多的应用:
🥇 第一名 - $3,000
🥈 第二名 - $1,500
🥉 第三名 - $500
如果同时多位参赛者获得同样的票数,均被视为优胜者,将平分奖金
谁可以参加?
任何开发者社区的成员均可参加,InterSystems内部员工除外。还没有账号?现在来建一个!
参赛时间安排
根据大家的反馈意见,我们做出了调整! 我们为开发留出了更多时间!所以:
🛠 2月8日- 28日: 应用程序开发和注册阶段(在此期间,您可以持续编辑自己的项目)
✅ 3月1日-7日: 投票阶段
🎉 3月8日: 宣布优胜者!
主题
💡 InterSystems IRIS 应用程序 💡
提交使用InterSystems IRIS作为后端(API或数据库)的应用程序,使用任何类型的InterSystems IRIS API或数据模型均可。
我们欢迎您进一步改进您去年在InterSystems系列竞赛中提出的申请,并将其提交参加大奖赛。当然,也欢迎您提交一份全新的申请。
应用程序应该可以在 IRIS Community Edition 或 IRIS for Health Community Edition 或 IRIS Advanced Analytics Community Edition 上运行。
应用程序应该开源并在GitHub上发布。
资源助力
示例程序:
objectscript-docker-template
rest-api-contest-template
native-api-contest-template
integratedml-demo-template
PythonGateway-template
iris-fhir-template
iris-fullstack-template
iris-interoperability-template
iris-analytics-template
如何把您的APP提交给大赛:
如何在 InterSystems Open Exchange 上发布应用程序
如何把参赛APP提交给大赛
公平公正
点击查看 投票规则.
万分期待你的精彩项目!
加入大奖赛吧!
❗️ 点击此处,查看 官方竞赛术语解读. ❗️
顶一下 IRIS 在线培训:https://learning.intersystems.com/
在线实验室Lab:https://learning.intersystems.com/course/view.php?id=929 恭喜发财,大家踊跃报名啊! 这次我们提升了现金奖励力度,欢迎大家积极报名! 投票通道开启,欢迎参赛选手踊跃拉票啊。
https://openexchange.intersystems.com/contest/current
@jingqi.liu @Weiwei.Yang @deming.xu @Botai.Zhang very good 非常棒,都是很好的应用,我会投票的。 积极投票 踊跃投票! 这些应用都是很好的解决方案! 现在这个很火爆,可惜我不会,我也要学习编程了 可以看到这么多优秀的应用,很棒👍
文章
姚 鑫 · 二月 28, 2021
# 第一章 InterSystems SQL简介
InterSystems SQL提供对InterSystems IRIS®Data Platform数据库中存储的数据的无懈可击的标准关系访问。
InterSystems SQL提供以下优势:
- 高性能和可扩展性-InterSystems SQL提供优于其他关系数据库产品的性能和可扩展性。此外,InterSystems SQL可以在各种硬件和操作系统上运行;从笔记本电脑到高端多CPU系统。
- 与InterSystems IRIS对象技术集成-InterSystems SQL与InterSystems IRIS Object技术紧密集成。可以混合使用关系访问和对象访问数据,而不会牺牲任何一种方法的性能。
- 维护成本低-与其他关系数据库不同,InterSystems IRIS应用程序不需要在已部署的应用程序中重建索引和压缩表格。
- 支持标准SQL查询-InterSystems SQL支持SQL-92标准语法和命令。在大多数情况下,可以毫不费力地将现有关系应用程序迁移到InterSystems IRIS,并自动利用InterSystems IRIS更高的性能和对象功能。
可以将InterSystems SQL用于多种目的,包括:
- 基于对象和基于Web的应用程序-可以在InterSystems IRIS对象和Web Server Page应用程序中使用SQL查询来执行强大的数据库操作,如查找和搜索。
- 在线事务处理-InterSystems SQL为INSERT和UPDATE操作以及事务处理应用程序中常见的查询类型提供了出色的性能。
- 商业智能和数据仓库-InterSystems IRIS多维数据库引擎和位图索引技术的结合使其成为数据仓库式应用程序的最佳选择。
- 即时查询和报告-可以使用InterSystems SQL附带的功能齐全的ODBC和JDBC驱动程序连接到流行的报告和查询工具。
- 企业应用程序集成-InterSystems SQL Gateway使能够无缝地通过SQL访问ODBC或JDBC兼容的外部关系数据库中存储的数据。这使得在InterSystems IRIS应用程序中集成来自各种来源的数据变得容易。
# 架构
InterSystems SQL的核心由以下组件组成:
- 统一数据字典-存储为一系列类定义的所有元信息的存储库。InterSystems IRIS自动为统一字典中存储的每个持久类创建关系访问(表)。
- SQL处理器和优化器-一组程序,用于解析和分析SQL查询,确定给定查询的最佳搜索策略(使用复杂的基于成本的优化器),并生成执行查询的代码。
- InterSystems SQL Server-一组InterSystems IRIS服务器进程,负责与InterSystems ODBC和JDBC驱动程序的所有通信。它还管理频繁使用的查询的高速缓存;当同一查询被多次执行时,可以从查询高速缓存中检索其执行计划,而不必由优化器再次处理。
## 特点
InterSystems SQL包括一整套标准的关系型功能。这些措施包括:
- 定义表和视图(DDL或数据定义语言)的能力。
- 对表和视图(DML或数据操作语言)执行查询的能力。
- 能够执行事务,包括插入、更新和删除操作。执行并发操作时,InterSystems SQL使用行级锁。
- 为更高效的查询定义和使用索引的能力。
- 能够使用各种数据类型,包括用户定义的类型。
- 定义用户和角色并为其分配权限的能力。
- 定义外键和其他完整性约束的能力。
- 定义INSERT、UPDATE和DELETE触发器的能力。
- 定义和执行存储过程的能力。
- 能够以不同的格式返回数据:用于客户端访问的ODBC模式;用于在基于服务器的应用程序中使用的显示模式。
## 符合SQL-92
SQL-92标准在算术运算符优先级方面是不精确的;关于这一问题的假设因SQL实现而异。InterSystems SQL支持将系统配置为以下任一系统范围的SQL算术运算符优先级替代方案:
- InterSystems SQL可以配置为严格按照从左到右的顺序解析算术表达式,没有运算符优先级。这与ObjectScript中使用的约定相同。因此,3+3*5=30。可以使用括号来强制执行所需的优先顺序。因此,3+(3*5)=18。
- InterSystems SQL可以配置为使用ANSI优先级分析算术表达式,这为乘法和除法运算符提供了比加法、减法和串联运算符更高的优先级。因此,3+3*5=18。如果需要,可以使用括号覆盖此优先级。因此,(3+3)*5=30。
SQL运算符优先级的默认值取决于InterSystems IRIS版本。
InterSystems SQL支持完整的入门级SQL-92标准,但有以下例外:
- 不支持向表定义添加附加的CHECK约束。
- 不支持SERIALIZABLE(序列化)隔离级别。
- 分隔标识符不区分大小写;标准规定它们应该区分大小写。
- 在HAVING子句中包含的子查询中,应该能够引用该HAVING子句中“可用”的聚合。这不受支持。
## 拓展
- InterSystems SQL支持许多有用的扩展。其中许多都与InterSystems IRIS提供对数据的同步对象和关系访问这一事实有关。
其中一些扩展包括:
- 支持用户可定义的数据类型和函数。
- 以下对象引用的特殊语法。
- 支持子类化和继承。
- 支持对存储在其他数据库中的外部表进行查询。
- 用于控制表的存储结构以实现最高性能的多种机制。
## 互操作性
- InterSystems SQL支持多种与其他应用程序和软件工具互操作的方法。
## JDBC
InterSystems IRIS包括一个符合标准的第4级JDBC客户机(全部是纯Java代码)。
InterSystems JDBC驱动程序提供以下特性:
- 高性能
- 纯JAVA代码实现
- UNICODE支持
- 线程安全
可以将InterSystems JDBC与任何支持JDBC的工具、应用程序或开发环境一起使用。
## ODBC
InterSystems SQL的c语言调用级接口是ODBC。与其他数据库产品不同,InterSystems ODBC驱动程序是一个本机驱动程序——它不是构建在任何其他专有接口之上的。
InterSystems ODBC驱动程序提供以下功能:
- 高性能
- 可移植性
- 原生Unicode支持
- 线程安全
可以将InterSystems ODBC与支持ODBC的任何工具,应用程序或开发环境一起使用。
## 嵌入式SQL
在ObjectScript中,InterSystems SQL支持嵌入式SQL: **将SQL语句放置在方法(或其他代码)主体中的能力。使用嵌入式SQL,可以查询单个记录,或定义一个游标,然后使用该游标查询多个记录。嵌入式SQL已编译。默认情况下,它是在第一次执行(运行时)时进行编译的,而不是在包含它的例程进行编译时进行的。因此,在运行时检查SQLCODE错误很重要。** 还可以与包含嵌入式SQL的ObjectScript例程同时编译嵌入式SQL。
与InterSystems IRIS的对象访问功能结合使用时,嵌入式SQL的功能非常强大。例如,以下方法查找具有给定Name值的记录的RowID:
```
/// w ##class(PHA.TEST.SQL).FindByName("姚鑫")
ClassMethod FindByName(fullname As %String)
{
&sql(SELECT %ID INTO :id FROM Sample.Person WHERE Name = :fullname)
IF SQLCODE < 0 {
SET baderr="SQLCODE ERROR:"_SQLCODE_" "_%msg
RETURN baderr
} ELSEIF SQLCODE = 100 {
SET nodata="Query returns no data"
RETURN nodata
}
RETURN "RowID="_id
}
```
```
DHC-APP>w ##class(PHA.TEST.SQL).FindByName("姚鑫")
RowID=6
```
注意: 如果 Name 查处多条的话 id为查询的第一条数据
指定倒序,为最后一条。
```
&sql(SELECT %ID INTO :id FROM Sample.Person WHERE Name = :fullname order by ID desc)
```
```
DHC-APP>w ##class(PHA.TEST.SQL).FindByName("姚鑫")
RowID=14
```

# 动态SQL
作为其标准库的一部分,InterSystems IRIS提供了一个%SQL.Statement类,可以使用它来执行动态(即在运行时定义的)SQL语句。可以在ObjectScript方法中使用动态SQL。例如,下面的方法查询指定数量的21世纪出生的人。该查询选择1999年12月31日之后出生的所有人,按出生日期对所选记录进行排序,然后选择前x条记录:
```
/// w ##class(PHA.TEST.SQL).Born21stC("姚鑫")
ClassMethod Born21stC(x)
{
/// w ##class(PHA.TEST.SQL).Born21stC("1")
ClassMethod Born21stC(x)
{
SET myquery=2
SET myquery(1) = "SELECT TOP ? Name,%EXTERNAL(DOB) FROM Sample.Person "
SET myquery(2) = "WHERE DOB > 58073 ORDER BY DOB"
SET tStatement = ##class(%SQL.Statement).%New()
SET qStatus = tStatement.%Prepare(.myquery)
IF qStatus'=1 {WRITE "%Prepare failed:" DO $System.Status.DisplayError(qStatus) QUIT}
SET rset = tStatement.%Execute(x)
DO rset.%Display()
WRITE !,"End of data"
q ""
}
```
```
DHC-APP>w ##class(PHA.TEST.SQL).Born21stC("2")
Name Expression_2
Ingrahm,Susan N. 02/10/2001
Goldman,Will H. 09/22/2002
2 Rows(s) Affected
End of data
```
准备查询时,该查询的优化版本将存储为缓存查询。该缓存查询被执行用于查询的后续调用,从而避免了每次执行查询时重新优化查询的开销。
## 限制
请注意InterSystems SQL的以下限制:
NLS可用于为单个全局变量以及当前运行的进程中的局部变量指定特定国家区域设置行为的$ORDER行为。InterSystems SQL可以在任何国家语言环境中使用和良好地工作。然而,InterSystems SQL当前的一个限制是,对于任何特定进程,它引用的所有相关全局变量都必须使用与当前进程区域设置相同的国家区域设置。 文章写得非常棒!学习! 学习到新知识sql动态查询,感谢!
文章
姚 鑫 · 三月 1, 2021
# 第二章 InterSystems SQL基础
本章概述了InterSystems SQL的特性,特别是那些SQL标准未涵盖的特性,或者与InterSystems IRIS®数据平台统一数据架构相关的特性。
本教程假定读者具备SQL知识,并不是为介绍SQL概念或语法而设计的。
本章讨论以下主题:
- 表
- 查询
- 权限
- 数据显示选项
- 数据排序类型
- 执行SQL
# 表
在InterSystems SQL中,数据显示在表中。每个表都包含许多列。一个表可以包含零个或多个数据值行。以下术语大体上等效:
数据术语 | 关系数据库术语| InterSystems IRIS术语
---|---|---
数据库 | 架构| 包
数据库 | 表 | persistent class(持久类)
字段 | 列 | 属性
记录 | 行 |
表有两种基本类型:基表(包含数据,通常简称为表)和视图(基于一个或多个表提供逻辑视图)。
## 模式与架构
SQL模式提供了一种将相关表,视图,存储过程和缓存查询的集合进行分组的方法。模式的使用有助于防止表级别的命名冲突,因为表,视图或存储过程的名称在其模式内必须唯一。应用程序可以在多个架构中指定表。
SQL模式与持久性类包相对应。通常,模式与其相应的程序包具有相同的名称,但是由于不同的模式命名约定或故意指定了不同的名称,因此这些名称可能有所不同。模式到程序包的映射在SQL到类名的转换中有进一步描述。
**模式是在特定的名称空间中定义的。模式名称在其名称空间内必须是唯一的。将第一个项目分配给它时,会自动创建一个模式(及其对应的程序包),从中删除最后一个项目时,会自动将其删除。**
可以指定一个限定或不限定的SQL名称,限定名称指定模式:schema.name。
非限定名不指定模式名。
如果不指定模式,InterSystems IRIS将提供如下模式:
- 对于DDL操作,InterSystems IRIS使用系统范围的默认架构名称。此默认值可配置。它适用于所有名称空间。
- 对于DML操作,InterSystems IRIS可以使用用户提供的模式搜索路径或系统范围内的默认模式名称。在动态SQL,嵌入式SQL和SQL Shell中,使用了不同的技术来提供模式搜索路径。
DML(data manipulation language):
它们是SELECT、UPDATE、INSERT、DELETE,就象它的名字一样,这4条命令是用来对数据库里的数据进行操作的语言
DDL(data definition language):
DDL比DML要多,主要的命令有CREATE、ALTER、DROP等,DDL主要是用在定义或改变表(TABLE)的结构,数据类型,表之间的链接和约束等初始化工作上,他们大多在建立表时使用
DCL(Data Control Language):
是数据库控制功能。是用来设置或更改数据库用户或角色权限的语句,包括(grant,deny,revoke等)语句。在默认状态下,只有sysadmin,dbcreator,db_owner或db_securityadmin等人员才有权力执行DCL
要查看名称空间内的所有现有模式,请执行以下操作:
1. 在管理门户中,选择“系统资源管理器”,然后选择“ SQL”。使用页面顶部的Switch选项选择一个名称空间;这将显示可用名称空间的列表。选择一个名称空间。
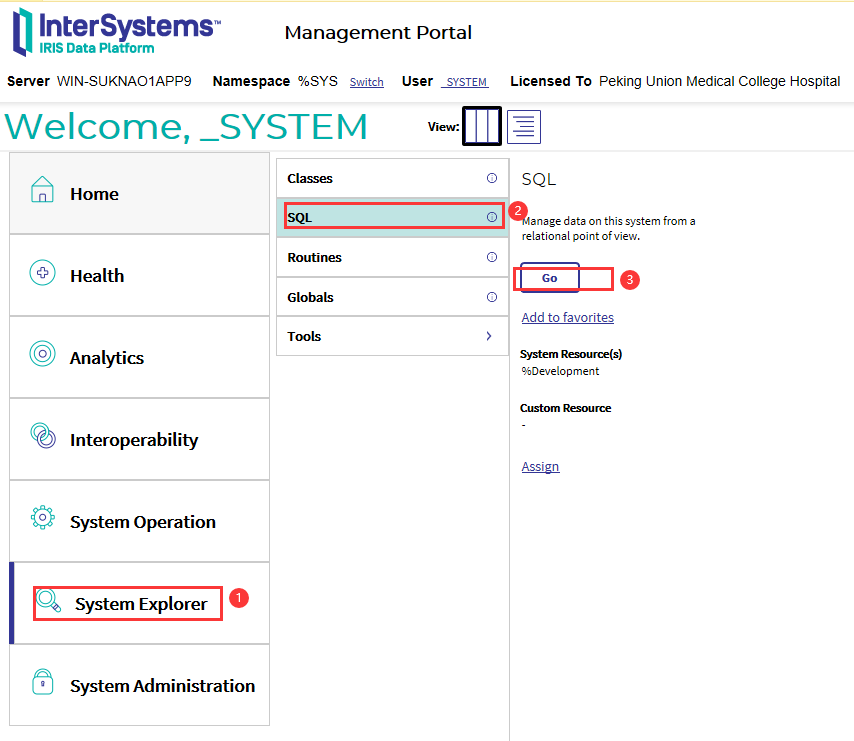
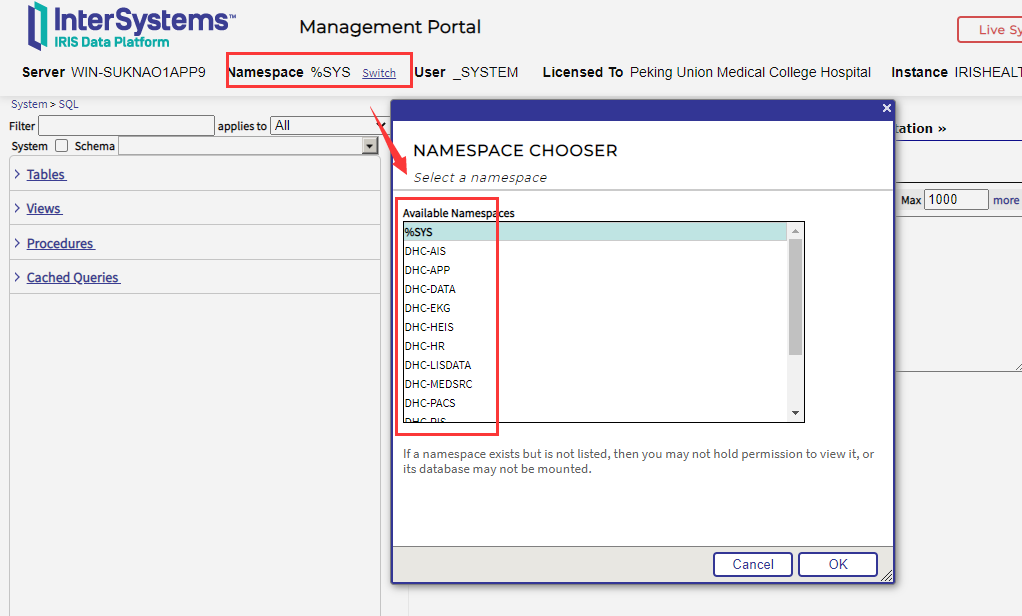
2. 选择屏幕左侧的Schema下拉列表。这将显示当前名称空间中的架构列表。从该列表中选择一个模式;所选名称将出现在“模式”框中。
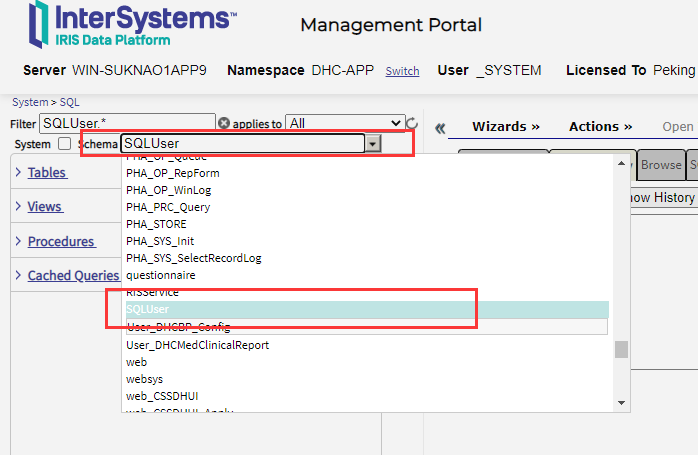
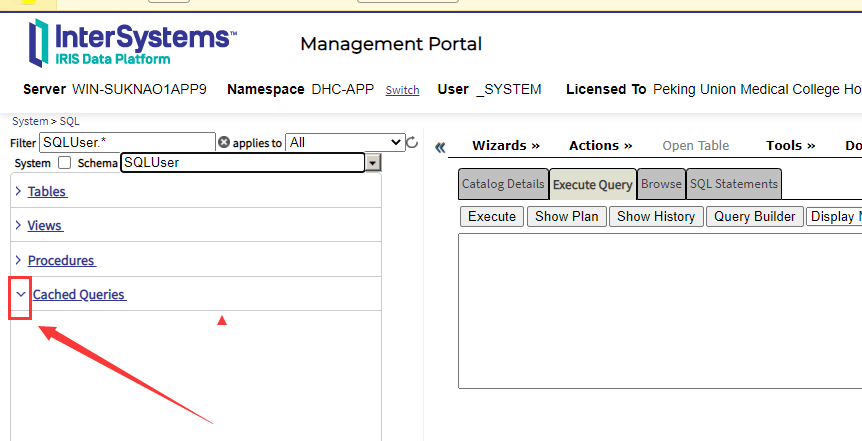
3. 如果有数据下拉列表允许选择表,视图,过程或缓存的查询,或所有属于模式的所有这些。设置此选项后,单击三角形以查看项目列表。如果没有项目,则单击三角形无效。
# 查询
在InterSystems SQL中,可以通过查询查看和修改表中的数据。粗略地说,查询有两种形式:查询数据(SELECT语句)和修改数据(INSERT,UPDATE和DELETE语句)。
可以通过多种方式使用SQL查询:
- 在ObjectScript中使用嵌入式SQL。
- 在ObjectScript中使用动态SQL。
- 调用使用CREATE PROCEDURE或CREATE QUERY创建的存储过程。
- 使用类查询。
- 使用来自各种其他环境的ODBC或JDBC接口。
# 权限
InterSystems SQL提供了一种通过权限来限制对表、视图等的访问的方法。
# 数据显示选项
InterSystems SQL使用SelectMode选项来指定如何显示或存储数据。
可用的选项有Logical、Display和ODBC。
数据在内部以逻辑模式存储,并且可以在这些模式中的任何一种中显示。
通过使用`LogicalToDisplay()`、`LogicalToODBC()`、`DisplayToLogical()`和`odbcological()`方法,每个数据类型类都可以在内部逻辑格式和显示格式或ODBC格式之间进行转换。
当显示SQL SelectMode时,将应用LogicalToDisplay转换,并对返回值进行格式化以便显示。
默认的SQL SelectMode是逻辑的;
因此,默认情况下返回值以存储格式显示。
SelectMode影响查询结果集数据显示的格式,SelectMode还影响应该提供数据值的格式,例如在WHERE子句中。
InterSystems IRIS根据存储模式和指定的SelectMode选择合适的转换方法。
所提供的数据值与SelectMode之间的不匹配可能导致错误或错误的结果。
例如,如果`DOB`是一个以`$HOROLOG`逻辑格式存储的日期,并且WHERE子句指定`DOB > 2000-01-01 `(ODBC格式),则SelectMode = ODBC返回预期的结果。
`SelectMode = Display`生成`SQLCODE -146`,无法将日期输入转换为有效的逻辑日期值。
`SelectMode =Logic`将 `2000-01-01`解析为逻辑日期值,并返回零行。
对于大多数数据类型,三种SelectMode模式返回相同的结果。
以下数据类型受SelectMode选项影响:
- 日期,时间和时间戳数据类型。 InterSystems SQL支持多种日期,时间和时间戳数据类型(`%Library.Date`,`%Library.Time`,`%Library.PosixTime`,`%Library.TimeStamp`和`%MV.Date`)。除`%Library.TimeStamp`外,这些数据类型对逻辑,显示和ODBC模式使用不同的表示形式。在其中的几种数据类型中,InterSystems IRIS以`$HOROLOG`格式存储日期。此逻辑模式内部表示包括从任意起始日期(1840年12月31日)起的天数的整数,逗号分隔符以及从当天午夜开始的秒数的整数。 InterSystems IRIS将`%PosixTime`时间戳存储为编码的64位带符号整数。在“显示”模式下,日期和时间通常以数据类型的FORMAT参数指定的格式显示,或者当前语言环境的日期和时间格式默认为`%SYS.NLS.Format`。美国语言环境的默认值为`DD / MM / YYYY hh:mm:ss`。在ODBC模式下,日期和时间始终表示为`YYYY-MM-DD hh:mm:ss.fff`。 `%Library.TimeStamp`数据类型还将这种ODBC格式用于逻辑和显示模式。
- `%LIST`数据类型。InterSystems IRIS逻辑模式使用两个非打印字符存储列表,这两个字符出现在列表中的第一个项目之前,并显示为列表项目之间的分隔符。在ODBC SelectMode中,列表项显示时列表项之间带有逗号分隔符。在Display SelectMode中,列表项显示时,列表项之间有空格分隔符。
- 指定`VALUELIST`和`DISPLAYLIST`的数据类型。如果处于显示模式,并且在字段具有`DISPLAYLIST`的表中插入一个值,则输入的显示值必须与`DISPLAYLIST`中的一项完全匹配。
- 空字符串和空BLOB(流字段)。在逻辑模式下,空字符串和BLOB由非显示字符`$CHAR(0)`表示。在显示模式下,它们由空字符串(“”)表示。
SQL SelectMode可以指定如下:
- 对于当前进程,请使用`$SYSTEM.SQL.SetSelectMode()`。
- 对于InterSystems SQL Shell会话,请使用SET SELECTMODE命令。
- 使用“显示模式”下拉列表,从管理门户“执行查询”用户界面(系统资源管理器,SQL)获得查询结果集。
- 对于动态SQL `%SQL.Statement`实例,请使用`%SelectMode`属性。
- 对于嵌入式SQL,请使用ObjectScript `#SQLCompile` Select预处理器指令设置。该伪指令允许使用第四个值Runtime,它将选择模式设置为RuntimeMode属性设置为:逻辑,显示或ODBC。 RuntimeMode的默认值为Logical。
- 对于使用SELECTMODE关键字的SQL命令CREATE QUERY,CREATE METHOD,CREATE PROCEDURE和CREATE FUNCTION。
- 通过使用`%EXTERNAL`,`%INTERNAL`和`%ODBCOUT`函数在SQL查询中的单个列。
# 数据排序
Collation种类决定了值的排序和比较方式,它是InterSystems SQL和InterSystems IRIS对象的一部分。
**可以指定排序规则类型作为字段/属性保护的一部分。除非另有说明,否则字符串字段/属性默认为命名空间默认排序规则。默认情况下,字符串的命名空间默认排序规则是SQLUPPER。
SQLUPPER排序规则将字符串转换为大写,以便排序和比较。因此,除非另有说明,字符串排序和比较不区分大小写。**
可以指定排序规则类型作为索引保护的一部分,或者使用索引字段的排序规则类型。
通过将排序函数应用于字段名,SQL查询可以覆盖未保护的字段/属性排序规则类型。ORDER BY子句指定查询的结果集序列;如果指定的字符串字段被保护为SQLUPPER,查询结果顺序不区分大小写。
# 执行SQL
InterSystems IRIS支持多种方法来编写和执行SQL代码。其中包括:
- 嵌入式SQL:嵌入在ObjectScript代码中的SQL代码。
- 动态SQL:使用`%SQL.Statement`类从ObjectScript中执行的SQL代码。
- `Execute()`方法:使用`%SYSTEM.SQL`类的`Execute()`方法执行SQL代码。
- 包含SQL代码的存储过程,使用CREATE PROCEDURE或CREATE Query创建。
- SQL Shell:从终端界面执行的SQL语句。
- 执行查询界面:从管理门户执行的SQL语句。
可以使用InterSystems IRIS对象(类和方法)执行以下操作:
- 持久性类(SQL表)。
- 定义索引。
- 定义并使用类查询。
关于动态SQL能再详细说说吗? 实用帖,非常好的学习知识,感谢!
文章
Qiao Peng · 三月 5, 2021
InterSystems IRIS 元素周期表
PDF 版本:
GIT 源:
InterSystems IRIS 是一个具有许多功能的数据平台。 这些功能和相关的 IRIS 主题都体现在元素周期表中。