清除过滤器
文章
姚 鑫 · 九月 12, 2022
# 第三十章 管理许可(三)
# 确定许可证容量和使用情况
如何知道已使用了多少许可证以及由谁使用?类中的 `%SYSTEM.License` 提供了到 `IRIS` 许可证应用程序编程接口 (`API`) 的接口,并提供了许多方法和相关查询,可以使用这些方法和相关查询来查询许可证容量和当前使用情况。
可以使用 `%Library.%ResultSet` 类的 `RunQuery` 方法运行多个许可查询。例如:
```
USER>do ##class(%ResultSet).RunQuery("%SYSTEM.License","Summary")
LicenseUnitUse:Local:Distributed:
当前使用的软件许可单元 :2:2:
使用的最大软件许可单元数 :3:2:
授权的软件许可单元 :25:25:
当前连接 :2:2:
最大连接数 :6:6:
```
可以从管理门户的许可证使用页面(系统操作 > 许可证使用)查看这些查询的输出,详细信息如下表所示:
许可证使用页面上的链接| `License Query`
---|---
`Summary` |`Summary()` — 返回许可证使用摘要,如 `$System.License.ShowSummary` 所示。
`Usage by Process`| `ProcessList()` — 返回操作系统进程标识符 (`PID`) 使用的许可证,如 `$System.License.DumpLocalPID` 所示。
`Usage by User`| `UserList()` —按用户 ID 返回许可证使用。
`Distributed License Usage`| `AllKeyConnectionList()` — 返回按用户排序的当前分布式许可证使用情况。 (当没有连接许可服务器时禁用此功能。)
还可以使用 `%SYSTEM.License` 中的以下类方法来显示信息,或将许可证数据库转储到文件中:
`$System.License.CKEY` 显示密钥。该子例程由 `^CKEY` 程序调用,该程序为保持兼容性而保留:
```java
USER>Do $System.License.CKEY()
InterSystems IRIS Key display:
Based on the active key file 'c:\intersystems\irishealth\mgr\iris.key'
LicenseCapacity = InterSystems IRIS 2021.2 Enterprise - Concurrent Users for x86-64 (Microsoft Windows):25, Natural Language Processing (NLP), En
CustomerName = ISC DC Moderators - Xin Yao
OrderNumber = 202224285
ExpirationDate = 7/15/2023
AuthorizationKey = 4125500002500002500000XXXXXXXXXXXXXXXXX01
MachineID =
当前可用 = 23
最小可用 = 22
最大可用 = 25
```
`$System.License.ShowCounts` 总结了在本地系统共享内存中跟踪的许可证使用情况:
```java
USER> Do $System.License.ShowCounts()
本地软件许可使用视图.
25 授权的总数量 LU
23 当前可用 LU
22 最小可用 LU
2 当前用户处于活动状态
3 处于活动状态的最大用户数
1 当前 CSP 用户处于活动状态
1 处于活动状态的最大 CSP 用户数
0 当前 CSP 会话处于宽限期
0 处于宽限期的最大 CSP 会话数
```
`.License.ShowServer` 显示活动的许可证服务器地址和端口:
```java
USER> Do $System.License.ShowServer()
活动软件许可服务器地址 = 127.0.0.1 端口 = 4002
```
如果开发了基于 `REST` 的应用程序,许可证将随着使用而消耗。为防止这种情况发生,请配置可以建立的 `Web Gateway` 连接数。从 `Web Gateway` 管理部分的管理门户:
1. 导航到服务器访问。
2. 选择无状态参数。
3. 将最大值设置为比许可证小 `2` 或 `3` 的数字,以允许服务器端登录。
**注意:根据应用程序的服务器端需求,需要对此进行调整。**
通过在所有可用连接都忙时执行此操作,新请求将排队而不是被拒绝。由于超出许可计数,不会看到拒绝。随着数量的增长,客户端的响应时间会减慢。这表明需要购买更多许可证。 如果开发了基于 REST 的应用程序,许可证将随着使用而消耗。为防止这种情况发生,请配置可以建立的 Web Gateway 连接数。从 Web Gateway 管理部分的管理门户
姚老师,上面描述的这段是从哪里进入的啊,可以给与相应的导航图吗
公告
Claire Zheng · 十月 19, 2022
2022年9月5日-10月24日(北京时间),我们正在举办🏆InterSystems开发者社区中文版首届技术征文大赛🏆(←点击链接进入参赛页面,浏览所有参赛文章)!投票截止至10月23日,你的支持与喜爱,是优秀作品获得“开发者社区奖”的关键!我们先来看看目前作品排名情况吧!距离投票截止还有五天(截止至10月23日),我们暂时无法获得专家评审分数,以下根据作品“点赞”进行排名。
N
作者
标题
点赞⬇
查看数
奖励项目个数
1
Zhe Wang
IRIS如何进行CRUD操作
36
197
3
2
Meng Cao
Caché数据库私有apache版本升级
33
336
1
3
sun yao
前端操作自动生成BS、BP、BO
22
123
2
4
John Pan
论集成标准的选择对医院信息集成平台建设的影响
21
113
1
5
lizw lizw
关于%Dictionary.CompiledClass类在实际业务中的一些应用
20
114
1
6
聆严 周
使用Prometheus监控Cache集群
18
175
3
7
Chang Liu
在国产系统上安装Healthconnect2021
17
104
2
8
Zhe Wang
IRIS快速查询服务思路分享
17
58
3
9
Zhe Wang
使用Global进行数据可视化---商业智能(BI)
16
37
2
10
John Pan
如何调用Ensemble/IRIS内置的HL7 V2 webservice - Java,PB9,Delphi7样例
14
96
2
11
Zhe Wang
小工具:IRIS管理页打开显示查询功能
14
62
2
12
water huang
对 %XML.PropertyParameters类的探索
13
39
1
13
姚 鑫
IRIS与Caché的23种设计模式
13
59
3
14
Zhe Wang
Rest实现Post、Get、Put、Delete几种操作方式
13
30
2
15
聆严 周
Cache / IRIS 操作数据的3种基本方式
11
153
1
16
he hf
10分钟快速开发一个连接到InterSystems IRIS数据库的C#应用
11
193
2
17
shaosheng shengshao
HEALTHSHARE2018版如何实现AES(CBC)的HEX输出,并可以实现加密和解密
11
63
3
18
water huang
Ens.Util.JSON类的启发
9
54
2
19
bai hongtao
第三方HA软件结合MIRROR使用方法探讨
9
69
1
20
li wang
HealthConnect访问HTTPS开头地址
8
21
2
21
shaosheng shengshao
windows下处理IIS在未安装但Healthshare已安装的时候,部署IIS服务并代理Healthshare
8
43
1
22
zhanglianzhu zhanglianzhu
Cache死循环检测和申明式事务
8
101
0
23
Liu Tangh
在Cache系统中使用负载均衡服务的探讨
8
25
1
24
yaoguai wan
IRIS架构的浅显理解以及windows10、docker安装IRIS Health详解流程及部分问题浅析
6
30
2
25
Zhe Wang
COS的基本语法
3
12
3
*奖励项目详见参赛规则:点击阅读
我们此次征文大赛计分规则如下:
🥇【专家提名奖】评选规则,由经验丰富的专家评审团进行评选打分,与其他加分项综合后进行排名。
🥇【开发者社区奖】评选规则,每个点赞计分为1分,与其他加分项综合后进行排名。
🥇【入围奖】评选规则,成功参赛的其余用户都将获得特别奖励。
每位作者只可以获得一个奖项(即:您只可以获得一次专家提名奖/开发者社区奖/入围奖);
当出现票数相当的平手情况时,将以专家评选投票数作为最终票数高低的判断标准。
那么,抓住最后五天的投票时间,为你喜欢的作品“点赞”投票吧!你的点赞是优秀作品获得【开发者社区奖】的关键!
10月24日,我们将通过Online Meetup宣布获奖名单,敬请留意后续参会信息!
欢迎关注InterSystems开发者社区中文版首届技术征文大赛
文章
Michael Lei · 三月 21, 2023
InterSystems IRIS 是一个高性能、可靠且可扩展的数据平台,用于为医疗保健、金融服务和其他行业构建和部署关键任务应用程序。它提供了广泛的功能,包括数据管理、集成、分析等。
IRIS 提供的功能之一是能够将 Python 代码嵌入到 ObjectScript 代码中。这意味着您可以在 IRIS 应用程序中使用 Python 库和函数,让您可以访问大量的工具和资源。在本文中,我们将了解如何在 InterSystems IRIS 中使用嵌入式 Python。
设置嵌入式 Python
在 IRIS 中开始使用嵌入式 Python 之前,您需要设置环境。这涉及安装 Python 解释器和配置 IRIS 以识别它。
第一步是安装 Python。您可以从官方网站 ( https://www.python.org/downloads/ ) 下载最新版本的 Python。安装 Python 后,需要将其添加到系统的 PATH 环境变量中。这允许 IRIS 找到 Python 解释器。
接下来,您需要配置 IRIS 以识别 Python。为此,您需要创建一个 Python 网关。网关是一个在 IRIS 之外运行的进程,充当 IRIS 和 Python 之间的桥梁。
要创建网关,请打开一个终端窗口并导航到 Python 安装目录。然后运行以下命令:
python -m irisnative
此命令启动 Python 网关并创建到 IRIS 的连接。您应该看到类似于以下内容的输出:
Python Gateway Version: 0.7 Python Version: 3.8.5 (default, Jan 27 2021, 15:41:15) [GCC 9.3.0] Connected to: IRIS
这表明 Python 网关正在运行并连接到 IRIS。
在 IRIS 中使用嵌入式 Python
现在您已经设置了环境,您可以开始在 IRIS 中使用 Python。为此,您需要使用 ##class(%Net.Remote.Gateway).%New() 方法创建到 Python 网关的连接。此方法返回对可用于执行 Python 代码的 Python 对象的引用。
以下是如何使用嵌入式 Python 计算两个数字之和的示例:
Set gateway = ## class (%Net.Remote.Gateway).% New () Set result = gateway.% Execute ( "2 + 3" ) Write "Result: " , result , !
在此示例中,我们使用 %New() 方法创建到 Python 网关的连接。然后我们执行Python代码"2 + 3",返回结果5。我们将结果存储在result-变量中并输出到控制台。
在 IRIS 中使用 Python 库
在 IRIS 中使用嵌入式 Python 的好处之一是能够使用 Python 库。 Python 拥有庞大的库生态系统,用于数据处理、机器学习等。通过使用这些库,您可以扩展 IRIS 应用程序的功能。
要在 IRIS 中使用 Python 库,您首先需要使用 pip包管理器安装该库。例如,要安装 numpy 库,请运行以下命令:
pip install numpy
安装该库后,您可以通过使用 Python 网关导入它来在 IRIS 应用程序中使用它。以下是如何使用 numpy库创建矩阵的示例:
vbnet
Set gateway = ##class(%Net.Remote.Gateway).%New() Set np = gateway.%Get("numpy") Set matrix = np.%New("array", 10, 10)
在这个例子中,
我们使用 %New()方法创建到 Python 网关的连接。然后我们使用 -%Get() 方法检索对 numpy 库的引用。我们使用 numpy 库中的 array 方法创建一个新矩阵,大小为 10 x 10。我们将矩阵存储在matrix 变量,然后我们可以在我们的 IRIS 应用程序中使用它。
结论
在本文中,我们了解了如何在 InterSystems IRIS 中使用嵌入式 Python。我们已经了解了如何在 IRIS 中设置环境、执行 Python 代码和使用 Python 库。使用嵌入式 Python 可以扩展 IRIS 应用程序的功能,使您能够访问大量的工具和资源。通过将 Python 的强大功能与 IRIS 的性能和可靠性相结合,您可以构建满足组织需求的关键任务应用程序。
文章
Jingwei Wang · 七月 4, 2022
高可用性(HA)指的是使系统或应用程序在很高比例的时间内保持运行,最大限度地减少计划内和计划外的停机时间。
维持系统高可用性的主要机制被称为故障转移。在这种方法下,一个故障的主系统被一个备份系统所取代;也就是说,生产系统故障转移到备份系统上。许多HA配置还提供了灾难恢复(DR)的机制,即在HA机制无法保持系统的可用性时,也能及时恢复系统的可用性。
本文简要讨论了可用于基于InterSystems IRIS的应用程序的HA策略机制,提供了HA解决方案的功能比较,并讨论了使用分布式缓存的故障转移策略。
操作系统级别的集群HA
在操作系统层面上提供的一个常见的HA解决方案是故障转移集群,其中主要的生产系统由一个(通常是相同的)备用系统补充,共享存储和一个跟随活动成员的集群IP地址。在生产系统发生故障的情况下,备用系统承担生产工作量,接管以前在故障主系统上运行的程序和服务。备用机必须能够处理正常的生产工作负载,只要恢复故障主机所需的时间就可以了。也可以选择让备用机成为主机,一旦主机恢复,故障主机将成为备用机。
InterSystems IRIS的设计可以轻松地与所支持的平台的故障转移集群技术相结合(如InterSystems支持的平台中所述)。InterSystems IRIS实例安装在集群的共享存储设备上,以便两个集群成员都能识别它,然后添加到集群配置中,这样它将作为故障转移的一部分在备用机上自动重新启动。在故障转移后重新启动时,系统自动执行正常的启动恢复,保持结构和逻辑的完整性,就像InterSystems IRIS在故障系统上重新启动一样。如果需要,可以在一个集群上安装多个InterSystems IRIS实例。
InterSystems IRIS 镜像
具有自动故障转移功能的 InterSystems IRIS 数据库镜像为计划内和意外停机提供了经济有效的高可用性解决方案。镜像依赖于数据复制而不是共享存储,避免了存储故障导致的重大服务中断。
InterSystems IRIS 镜像由两个物理上独立的 InterSystems IRIS 系统组成,称为故障转移成员。每个故障转移成员在镜像中维护每个镜像数据库的副本;应用程序更新是在主故障转移成员上进行的,而备机故障转移用户的数据库则通过主成员的日志文件保持数据同步。
镜像会自动将主节点的角色分配给两个故障转移成员中的一个,而另一个故障转移成员则自动成为备机系统。当主 InterSystems IRIS 实例失败或变得不可用时,备机将自动快速接管并成为主机。
第三个系统称为仲裁机,它与故障转移成员保持持续的联系,在无法直接通信时安全地做出故障转移决策,为他们提供所需信息。在每个故障转移系统主机上运行的代理(称为 ISCAgents )进程也有助于自动故障转移逻辑。除非备机能够确认主节点确实处于停机状态或不可用状态,并且无法再作为主节点运行,否则备机将无法接管。在仲裁机和 ISCAgents 之间,这可以在几乎每个中断场景下完成。
当镜像配置使用 virtual IP address(虚拟 IP 地址)时,将应用程序连接重定向到新主节点是透明的。如果连接是通过 ECP,它们会自动重置到新的主节点。用于重定向应用程序连接的其他机制也是可用的。
当主机实例恢复正常时,它将自动成为备机实例。操作员启动的故障转移也可在计划的维护或升级停机期间维护可用性。
自动故障转移机制
镜像主旨在当主节点失败或变得不可用时,为备机提供安全的自动故障转移。本部分描述了允许这种情况发生的机制,包括:
• 自动故障转移的安全性要求
• 自动故障转移规则
• 对于各种中断情况的镜像响应
• 自动故障转移机制详节
自动故障转移的安全性要求
备机的 InterSystems IRIS 实例只有在能够确保满足以下两个条件时才能自动接管主节点:
• 备机实例已从主节点接收到最新的日志数据。
这一要求保证了主节点上镜像数据库的所有持久更新都已经或将要对备机的相同数据库进行,从而确保不会丢失任何数据。
• 主机实例不再作为主机实例运行,并且在没有手动干预的情况下无法这样做。
这个要求消除了两个故障转移成员同时作为主节点的可能性,这可能导致逻辑数据库性能下降和完整性损失。
自动故障转移规则
备机状态和自动故障转移
在正常镜像操作期间,备机故障转移成员的日志传输状态为活动,这意味着它已从主节点接收到所有日志数据,并与其同步。活跃的备机接收写在主机上的当前日志数据,主机等待备机确认收到日志之后才考虑该数据的持久化。因此,备机为活跃状态满足故障转移的第一个条件。
如果活跃备机在Quality of Service(QoS)(服务质量超时)内不能确定已从主节点接收新数据,主节点会撤销备机的活动状态,断开备机并暂时进入故障状态。当处于故障状态时,主节点不提交任何新的日志数据(可能导致应用程序暂停),确保充足的时间,使故障转移成员在不发生异步的情况下恢复联系或进行适当的安全故障转移决策
当备机重新连接到主节点时,它首先通过从主节点获取所有最近的日志数据来跟上,然后变为活动状态。当备机通过从主节点同步了最新的日志数据并确认其接收而跟上时,将恢复其活动状态。
备机处于活动状态时的自动故障转移
当备机处于活动状态时,如果它能够确认故障转移的第二个条件,主节点不可以再作为主节点,并且在没有人工干预的情况下不能继续成为主节点,那么它就有资格作为主机进行接管。备机可以通过以下三种方式中的任意一种来接管主节点:
• 通过接收来自主机的请求接管的通信
这发生在主机实例正常关闭期间或主机实例检测到主机实例挂起时。一旦主节点发送了这条消息,它就不能再作为主机了,活动备机可以安全地接管它。如果前一个主机被挂起,新的主机就会迫使它关机。
• 通过从仲裁机处收到信息,得知其已与主机失去联系。
当一个网络事件同时将主节点与备机和仲裁机隔离时,它将无限期地进入故障状态。因此,如果一个活跃备机与主机失去联系,并且从仲裁机那里得知它也与主机用失去了联系,那么备机可以安全地接管,因为主机用必须要么已经出现故障,要么被隔离并处于故障状态,因此不能再作为主节点运行了。当连接恢复时,如果前一个主节点挂起,新的主节点就会将之前的主节点强制关闭。
• 通过从主机的 ISCAgent 接收主机实例已关闭或挂起的信息。
当仲裁机不可用或未配置仲裁机时,与主机实例失去联系的活动备机可以尝试联系主机实例的 ISCAgent(只有在主机实例主机系统仍在运行时才可能)以确认主机实例已关闭或处于挂起状态。一旦代理确认主节点不能再作为主机,并且故障转移因此是安全的,备机就会接管。
备机不处于活动状态时的自动故障转移
不活动的备机可以尝试与主机实例的 ISCAgent 联系,以确认主机实例处于关闭状态,或在挂起时强制关闭主机实例,并从代理获取主机实例最近的日志数据。如果在这两方面都成功,那么备机可以安全地作为主机接管。
不活动且无法与主机的 ISCAgent 联系的备机无法确保主机不再作为主机,并且无法保证此时的备机拥有主机最新的日志更新,因此无法接管主机。
当备机没有活动时,仲裁机在故障转移机制中不起任何作用。
对于各种中断情况的镜像响应
自动故障转移中主机中断场景的响应
在以下几种主要的主节点中断情况下,活动的备机故障转移成员会自动接管:
主节点的计划中断(例如出于维护目的)通过关闭其 InterSystems IRIS 实例来启动。
自动故障转移发生是因为主机指示活跃备机接管。
主 InterSystems IRIS 实例由于意外情况而挂起。
自动故障转移发生是因为主节点检测到它被挂起并指示活跃备机接管。
主 InterSystems IRIS 实例由于意外情况而被迫关闭或完全失去响应。
在此情况下,主节点不能指示备机接管。然而,活动备机可以在从仲裁机那里得知它也与主节点失去联系后接管,也可以通过与主机的 ISCAgent 联系并获得主机停机的确认后接管。
主机存储的子系统失败。
存储失败的典型后果是主机实例挂起,原因是 I/O 错误,在这种情况下,主节点检测到它被挂起,并指示活动的备机接管(如场景 2)。然而,在某些情况下,场景 3 或场景 5 描述的行为可能适用。
主机的主机系统发生故障或失去响应。
如果活动的备机从仲裁机获悉它也与主机失去联系,则发生自动故障转移。
如果没有配置仲裁机,或者仲裁机在主机故障前已经不可用,则不可能进行自动故障转移;在这些情况下,可以选择手动强制备机成为主机。
一个网络问题隔离了主机。
如果配置了仲裁机,并且在网络故障时两个故障转移成员都不能连接到它,则主节点将无限地进入故障状态。
• 如果活动的备机从仲裁机获悉它也与主机失去联系,则发生自动故障转移。
• 如果备机在与主节点失去联系的同时失去与仲裁机的联系,则不可能进行自动故障转移。如果两个故障转移成员都已启动,则在还原网络时,备机将与主节点联系,主节点恢复操作。或者,可以手动指定主节点。
如果没有配置仲裁机,或者在网络故障发生前,故障转移成员之一已经与仲裁机断开,则无法进行自动故障转移,主节点将继续作为主机运行。
一个未活动的备机(例如备机正在启动或未追上主机最新日志)可以通过与主节点的 ISCAgent 联系并获得最新的日志数据,在上述场景 1 到 4 下接管。未活动的备机不能在场景 5 和 6 中接管,因为它不能与 ISCAgent 联系;在这些情况下,手动强制使备机成为主机可能是一种选择。
自动故障转移机制详解
代理控制模式
当镜像启动时,故障转移成员在代理控制模式下开始操作。如果仲裁机不可用或未配置仲裁机,则保持此模式。当处于代理控制模式时,故障转移成员响应彼此之间的联系丢失,如下所述。
主机对失联的反应
如果主节点失去了与活动备机的连接,或者超过了等待它确认数据接收的 QoS timeout (QoS 超时),则主程序撤消备机的活动状态并进入故障状态,等待备机确认其不再活动。当主节点收到来自备机的确认或故障超时(是 QoS 超时的两倍)过期时,主程序退出故障状态,恢复为主程序运行。
如果主节点失去了与非活动备机的连接,则它将继续作为主程序运行,不会进入故障状态。
备机对失联的反应
如果备机失去了与主节点的连接,或者超过了等待来自主机的消息的 QoS timeout (QoS 超时),那么它将尝试与主客户的 ISCAgent 联系。如果代理报告主机实例仍作为主机实例运行,则备机重新连接。如果代理确认主节点处于关闭状态,或者它已将其强制关闭,则备机行为如下:
• 如果备机处于活动状态,且代理确认主节点在故障超时内处于停机状态,则备机将作为主服务端接管。
• 如果备机未处于活动状态,或者超过了故障超时时间,那么如果代理确认主节点已停机,并且能够从代理获得最新的日志数据,则备机将接管。
无论是否处于活动状态,备机永远无法在代理控制模式下自动接管,除非主节点自身确认它已挂起,或者主服务的代理确认主服务已停机(可能是在强制停机之后),如果主节点已停机或网络隔离,这两种情况备机无法自动接管。
注意: 当其中一个故障转移成员重启时,它会尝试联系另一个成员的 ISCAgent,其行为与不活动备机的描述一样。
仲裁机控制模式
当故障转移成员相互连接时,两者都连接到仲裁机,并且备机是活动的,它们进入仲裁机控制模式,在该模式中,故障转移会员根据仲裁机提供的关于另一个故障转移成员的信息对它们之间的联系丢失做出响应。因为每个故障转移成员通过测试其与另一个故障转移成员的连接来响应其仲裁连接的丢失,反之亦然,由单个网络事件引起的多个连接丢失被作为单个事件处理。
在仲裁机控制模式中,如果故障转移成员仅丢失其仲裁机连接,或者备机 丢失其活动状态,则故障转移成员协调切换到代理控制模式。
如果主节点和备机节点之间的连接在仲裁机控制模式下断开,则每个故障转移成员根据仲裁机连接的状态进行响应,如下图所述。
所有三个系统连接:
镜像进入仲裁机控制模式(如果尚未进入仲裁机控制模式)
备机失去与仲裁机的连接,但仍连接到主节点:
镜像切换到代理控制模式
主节点继续作为主节点运行
备机尝试重新连接仲裁机
主节点失去与仲裁机的连接,但仍连接到备机:
镜像切换到代理控制模式
主节点继续作为主节点运行
主节点尝试重新连接仲裁程序
故障转移成员彼此失去连接,仍然连接到仲裁机:
镜像切换到代理控制模式
主节点继续作为主节点运行
备机尝试重新连接主节点
仲裁机失败或隔离-故障转移成员失去与仲裁机的连接,但仍彼此连接:
镜像切换到代理控制模式
主节点继续作为主节点运行
两个故障转移成员都尝试重新连接仲裁机
备机中断或被隔离-主节点和仲裁机失去与备机的连接,但仍相互连接:
主节点切换到代理控制模式并继续作为主节点操作
备机(如果在操作中)切换到代理控制模式并尝试重新连接到主节点
主节点中断或被隔离-备机和仲裁机失去与主节点的连接,但仍相互连接:
主节点(如果在运行中)将无限期地保持在仲裁控制模式和故障状态
备机作为主机接管,切换到代理控制模式,并在恢复连接时强制主机关闭
三个连接全部丢失:
主节点(如果在运行中)将无限期地保持在仲裁控制模式和故障状态;如果与备机设备联系,则切换到代理控制模式并恢复主设备的运行
备机(如果在操作中)切换到代理控制模式并尝试重新连接到主节点
注意: 由于单个事件(或多个同时发生的事件)而导致所有连接丢失的情况很少见。在大多数情况下,镜像在所有连接丢失之前切换到代理控制模式,在这种情况下:
主节点(如果在运行)继续作为主节点运行
备机(如果正在运行)尝试重新连接到主节点
文章
姚 鑫 · 五月 7, 2021
# 第三章 使用多维存储(全局变量)(三)
# 在全局变量中复制数据
若要将全局变量(全部或部分)的内容复制到另一个全局变量(或局部数组)中,请使用ObjectScript `Merge`命令。
下面的示例演示如何使用`Merge`命令将`OldData`全局变量的全部内容复制到`NewData`全局变量中:
```
Merge ^NewData = ^OldData
```
如果合并命令的`source`参数有下标,则复制该节点及其后代中的所有数据。如果`Destination`参数有下标,则使用目标地址作为顶级节点复制数据。例如,以下代码:
```java
Merge ^NewData(1,2) = ^OldData(5,6,7)
```
将`^OldData(5,6,7)`及其下的所有数据复制到`^NewData(1,2)`。
# 维护全局变量内的共享计数器
大规模事务处理应用程序的一个主要并发瓶颈可能是创建唯一标识符值。例如,考虑一个订单处理应用程序,在该应用程序中,必须为每一张新发票指定一个唯一的标识号。传统的方法是维护某种计数器表。每个创建新发票的进程都会等待获取此计数器上的锁,递增其值,然后将其解锁。这可能会导致对此单个记录的激烈资源争用。
为了解决此问题,InterSystems IRIS提供了ObjectScript `$INCREMENT`函数。`$INCREMENT`自动递增全局节点的值(如果该节点没有值,则设置为1)。`$INCREMENT`的原子性意味着不需要锁;该函数保证返回一个新的增量值,不会受到任何其他进程的干扰。
可以使用`$INCREMENT`,如下所示。首先,必须决定在其中存放计数器的全局节点。接下来,无论何时需要新的计数器值,只需调用`$INCREMENT`:
```java
SET counter = $INCREMENT(^MyCounter)
```
InterSystems IRIS对象和SQL使用的默认存储结构使用`$INCREMENT`来分配唯一的对象(行)标识符值。
# 对全局变量中的数据进行排序
存储在全局变量中的数据会根据下标的值自动排序。例如,下面的ObjectScript代码定义了一组全局变量(按随机顺序),然后遍历它们以演示全局节点按下标自动排序:
```java
/// w ##class(PHA.TEST.Global).GlobalSort()
ClassMethod GlobalSort()
{
Kill ^Data
Set ^Data("Cambridge") = ""
Set ^Data("New York") = ""
Set ^Data("Boston") = ""
Set ^Data("London") = ""
Set ^Data("Athens") = ""
Set key = $Order(^Data(""))
While (key '= "") {
Write key,!
Set key = $Order(^Data(key))
}
q ""
}
```
```java
DHC-APP> w ##class(PHA.TEST.Global).GlobalSort()
Athens
Boston
Cambridge
London
New York
```
应用程序可以利用全局函数提供的自动排序来执行排序操作或维护对某些值的有序、交叉引用的索引。
InterSystems SQL和ObjectScript使用全局变量自动执行这些任务。
# 全局变量节点排序规则
全局变量节点的排序顺序(称为排序)在两个级别上进行控制:全局变量本身内部和使用全局变量的应用程序。
在应用程序级别,可以通过对用作下标的值执行数据转换来控制全局节点的排序方式(InterSystems SQL和对象通过用户指定的排序函数来执行此操作)。
例如,如果创建一个按字母顺序排序但忽略大小写的名称列表,那么通常你会使用名称的大写版本作为下标:
```java
/// w ##class(PHA.TEST.Global).GlobalSortAlpha()
ClassMethod GlobalSortAlpha()
{
Kill ^Data
For name = "Cobra","jackal","zebra","AARDVark" {
Set ^Data($ZCONVERT(name,"U")) = name
}
Set key = $Order(^Data(""))
While (key '= "") {
Write ^Data(key),!
Set key = $Order(^Data(key))
}
q ""
}
```
```
DHC-APP>w ##class(PHA.TEST.Global).GlobalSortAlpha()
AARDVark
Cobra
jackal
zebra
```
此示例将每个名称转换为大写(使用`$ZCONVERT`函数),以便对下标进行排序,而不考虑大小写。每个节点都包含未转换的值,以便可以显示原始值。
## 数值和字符串值下标
**数字值在字符串值之前进行排序;也就是说,值`1`在值`“a”`之前。如果对给定的下标同时使用数值和字符串值,则需要注意这一点。如果将全局变量用于索引(即根据值对数据进行排序),则最常见的是将值排序为数字(如薪水`salaries`)或字符串(如邮政编码`postal codes`)。**
**对于按数字排序的节点,典型的解决方案是使用一元`+`运算符将下标值强制为数字值。例如,如果要构建按年龄对`id`值进行排序的索引,则可以强制年龄始终为数字:**
```java
Set ^Data(+age,id) = ""
```
**如果希望将值排序为字符串(如`“0022”`、`“0342”`、`“1584”`),则可以通过添加空格(`“”`)字符来强制下标值始终为字符串。例如,如果正在构建一个按邮政编码对`id`值进行排序的索引,则可以强制`zipcode`始终为字符串:**
```java
Set ^Data(" "_zipcode,id) = ""
```
这确保带有前导零的值(如`“0022”`)始终被视为字符串。
## `$SORTBEGIN`和`$SORTEND`函数
通常,不必担心在InterSystems IRIS中对数据进行排序。无论使用SQL还是直接全局访问,排序都是自动处理的。
然而,在某些情况下,可以更有效地进行排序。
具体来说,在以下情况下(`1`)需要设置大量随机(即未排序)的全局节点,(`2`)生成的全局节点的总大小接近InterSystems IRIS缓冲池的很大一部分,那么性能可能会受到不利影响-
因为很多SET操作涉及到磁盘操作(因为数据不适合缓存)。
这种情况通常出现在涉及创建索引全局函数的情况下,例如批量数据加载、索引填充或对临时全局函数中的未索引值进行排序
为了有效地处理这些情况,ObjectScript提供了`$SORTBEGIN`和`$SORTEND`函数。
`$SORTBEGIN`函数为全局变量(或其中的一部分)启动了一种特殊模式,在这种模式中,进入全局变量的数据集被写入一个特殊的临时缓冲区,并在内存(或临时磁盘存储)中进行排序。
当在操作结束时调用`$SORTEND`函数时,数据将按顺序写入实际的全局存储中。
总体操作效率更高,因为实际的写操作是按照要求更少磁盘操作的顺序完成的。
`$SORTBEGIN`函数很容易使用;
在开始排序操作之前,用你想要排序的全局变量的名称调用它,并在操作完成时调用`$SORTEND`:
```java
/// w ##class(PHA.TEST.Global).GlobalSortBeginEnd()
ClassMethod GlobalSortBeginEnd()
{
Kill ^Data
// 为^Data全局初始化排序模式
Set ret = $SortBegin(^Data)
For i = 1:1:10000 {
Set ^Data($Random(1000000)) = ""
}
Set ret = $SortEnd(^Data)
// ^Data现在已经设置和排序
Set start = $ZH
// 现在迭代并显示(按顺序)
Set key = $Order(^Data(""))
While (key '= "") {
Write key,!
Set key = $Order(^Data(key))
}
Set elap = $ZH - start
Write "Time (seconds): ",elap
q ""
}
```
`$SORTBEGIN`函数是为全局变量创建的特殊情况而设计的,在使用时必须小心。
特别地,在`$SORTBEGIN`模式下,不能从正在写入的全局变量中读取数据;
由于数据没有写入,读取将是不正确的。
InterSystems SQL自动使用这些函数创建临时全局索引(例如对未索引的字段进行排序)。
## 在全局变量中使用间接
通过间接方式,ObjectScript提供了一种在运行时创建全局变量引用的方法。
这对于在程序编译时不知道全局变量结构或名称的应用程序非常有用。
间接操作符@支持间接操作,它解除了对包含表达式的字符串的引用。
根据@操作符的使用方式,有几种间接类型。
下面的代码提供了一个名称间接引用的示例,在这个示例中,使用`@`操作符对包含全局引用的字符串进行解引用:
```java
/// w ##class(PHA.TEST.Global).GlobalIndirect()
ClassMethod GlobalIndirect()
{
Kill ^Data
Set var = "^Data(100)"
// 现在使用间接设置^Data(100)
Set @var = "This data was set indirectly."
// 现在直接显示值:
Write "Value: ",^Data(100)
q ""
}
```
```java
DHC-APP> w ##class(PHA.TEST.Global).GlobalIndirect()
Value: This data was set indirectly.
```
也可以使用下标间接在间接语句中混合表达式(变量或文字值):
```java
/// w ##class(PHA.TEST.Global).GlobalIndirect1()
ClassMethod GlobalIndirect1()
{
Kill ^Data
Set glvn = "^Data"
For i = 1:1:10 {
Set @glvn@(i) = "This data was set indirectly."
}
Set key = $Order(^Data(""))
While (key '= "") {
Write "Value ",key, ": ", ^Data(key),!
Set key = $Order(^Data(key))
}
q ""
}
```
```javan
DHC-APP>w ##class(PHA.TEST.Global).GlobalIndirect1()
Value 1: This data was set indirectly.
Value 2: This data was set indirectly.
Value 3: This data was set indirectly.
Value 4: This data was set indirectly.
Value 5: This data was set indirectly.
Value 6: This data was set indirectly.
Value 7: This data was set indirectly.
Value 8: This data was set indirectly.
Value 9: This data was set indirectly.
Value 10: This data was set indirectly.
```
间接是ObjectScript的一个基本特性;
它并不局限于全局引用。
问题
water huang · 四月 22, 2021
m 里面如何获取cpu的序列号? 可以调用操作系统的命令来获取CPU序列号。例如在Cache' for Windows上,可以执行:SAMPLES>s args=3SAMPLES>s args(1)="CPU"SAMPLES>s args(2)="get"SAMPLES>s args(3)="ProcessorID"SAMPLES>d $ZF(-100,"","wmic",.args)ProcessorId0FABFBFF000506EX0FABFBFF000006EX0FABFBFF000006EX0FABFBFF000006EX 乔工,请问 $zf函数的使用,在哪里可以查询到它的所有使用说明 InterSystems Cache'InterSystems IRIS 刚才试了一下,这个不行呢 感谢你的回答 但是我用的是ensemble2016 是Windows吗?在Windows命令行,执行wmic CPU get ProcessorID,能得到CPU序列号吗? Ensemble 2016有点久,没有$ZF(-100)。用$ZF(-1):
https://cedocs.intersystems.com/ens20161/csp/docbook/DocBook.UI.Page.cls?KEY=RCOS_fzf-1#RCOS_B80417 是Windows,在Windows命令行,执行wmic CPU get ProcessorID,能得到CPU序列号 刚才试了 还是不行 用$ZF(-1), 可以将OS命令输出保存到文件里。例如:w $ZF(-1,"wmic CPU get ProcessorID > c:\temp\cpuinfo.txt") 系统是windows 10 试了,不行,返回的值是1 返回值是1,说明报错了。确认一下是否OS命令写正确了。另外,输出不是看返回值,是看输出的文件 我直接复制的你写的这个命令。
文章
Michael Lei · 五月 24, 2021
作为一个软件架构师,如果要设计一个企业级的架构来满足当前的业务需求时,你需要达到5级的水平,这是一个巨大的挑战。有了InterSystems IRIS。这是有可能的。通过1个产品,你可以得到SQL + NoSQL + ESB + BI + Open Analytics + Real Time Virtual cubes + NLP + AutoML + ML(使用Python)和高级云支持 + Sharding支持。
以Oracle为例,你需要Oracle数据库+ Oracle NoSQL+ Oracle BI+ Oracle SOA套件+一些附加组件,如R、Partitioning和RAC以及一些Oracle云产品的NLP和AI功能。对于开源架构、IBM或者其他友商来说,也是类似的,你需要的组件只可能更多。
医疗机构在数字化转型在技术上最大的挑战之一,就是技术栈过于丰富、快速变化以及对人的技术要求很高(这也是为什么全栈工程师最值钱的原因);一个统一、高效、稳定、现代化、专为医疗定制的一体化数据平台能帮助客户很好地解决这个问题。IRIS for Health 是您的不二选择。
文章
Michael Lei · 八月 18, 2022
Hi 社区的朋友们,大家好!
有时我们需要以编程方式自动将CSV数据从文件或者UR网址L导入到InterSystems IRIS。我们希望创建具有适当数据类型的类并导入数据。
我在Open Exchange上发布了一个模块csvgen,它正是这样做的。
如果你只需要将CSV文件导入IRIS,你可以这么做:
USER>do ##class(community.csvgen).Generate("/usr/data/titanic.csv",,"Data.Titanic")
Class name: Data.Titanic
Header: PassengerId INTEGER,Survived INTEGER,Pclass INTEGER,Name VARCHAR(250),Sex VARCHAR(250),Age INTEGER,SibSp INTEGER,Parch INTEGER,Ticket VARCHAR(250),Fare MONEY,Cabin VARCHAR(250),Embarked VARCHAR(250)
Records imported: 891
USER>
或者你的CSV文件在互联网上, 例如GitHub上面的新冠疫情数据 你可以这样获得数据:
USER>d ##class(community.csvgen).GenerateFromURL("https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_daily_reports/05-29-2020.csv",",","Data.Covid19")
Class name: Data.Covid19
Header: FIPS INTEGER,Admin2 VARCHAR(250),Province_State VARCHAR(250),Country_Region VARCHAR(250),Last_Update DATE,Lat MONEY,Long_ DOUBLE,Confirmed INTEGER,Deaths INTEGER,Recovered INTEGER,Active INTEGER,Combined_Key VARCHAR(250),Incidence_Rate DOUBLE,Case-Fatality_Ratio DOUBLE
Records imported: 3522
USER>
Installation安装
从ZPM安装:
USER>zpm
zpm:USER>install csvgen
csvgen 模块是打包了 CSV2CLASS method .
ObjectiveScript 的profile还不是很理想,欢迎各种建议意见。谢谢!
公告
Claire Zheng · 十一月 22, 2021
大家好!
我们很高兴地向大家介绍我们开发者社区中文版的新版主——段海华( @Duan.Haihua)!
让我们以热烈的掌声欢迎段海华( @Duan.Haihua),以下是他的个人介绍。
段海华,东华医为利润中心副主管
以下是他的个人介绍 @Duan.Haihua:
– 我主持参加了多家医院的互联互通评审工作,并主持了互联互通成熟度测评(Health Information Connectivity Maturity Evaluation, HICME)工具的开发与维护。我有丰富的基于InterSystems产品和项目工作经验,对互联互通测评相关标准有较深刻的理解。
– 通过开发者社区,我希望能够帮助刚开始接触互联互通标准的开发者快速理解相应内容,分享互联互通测评过程中常见问题的解决方案,为开发者对系统标准化改造过程提供参考意见。
热烈欢迎!
感谢段海华的付出( @Duan.Haihua)!我们相信你会成为一名优秀的版主! 👏🏼 热烈欢迎👏!!!
文章
Michael Lei · 六月 1, 2022
InterSystems Production 监控是管理门户中的一个页面,用于显示当前运行的Production监控信息。我喜欢这个页面的样子,但这并不适合所有人。
2022年5月13日,我在开发者社区上看到这个帖子。
https://community.intersystems.com/post/creating-custom-monitoring-page
我同意马克的观点,Production监控很复杂。我想创建一个更漂亮干净的监控页面。
我开始着手制作一个利用类方法提供Production数据的 CSP(Cache Server Page)页面。
我与马克分享了我的第一次尝试。他根据自己的想法定制了这个页面。我喜欢他对页面的布局,使其在视觉上更有吸引力。我把他的设计整合到我的应用程序Production监控中。
我看到马克对业务服务的显示进行了过滤,只显示需要注意的服务。他在页面的底部添加了服务器的名称和它的镜像状态。
你可以在Open Exchange和当前的竞赛中找到我的Production监控器的应用。
https://openexchange.intersystems.com/package/production-monitor
文章
Frank Ma · 一月 5, 2022
本文译自 https://community.intersystems.com/post/using-sql-apache-hive-hadoop-big-data-repositories
大家好,
在使用Spark做Hadoop时,InterSystems IRIS有一个很好的连接器。但市场上也提供了大数据Hadoop访问的其他优秀替代方案-Aparche Hive。请看区别:
HIVE
SPARK
Hive是一个数据库,用类似于RDBMS数据库的表格形式存储数据。
Spark不是一个数据库,它是一个数据分析框架,可以在内存中对大至PB字节的大容量数据进行复杂的数据分析。
使用称作HiveQL的自己的SQL引擎,数据可以从Hive中抽取出来。只能使用SQLs来抽取数据。
Spark既能使用复杂SQLs(Complex SQLs)也能使用MapReduce机制进行数据分析。它支持Java, Scala 和Python写的分析框架。
Hive在Hadoop之上运行。
Spark没有自己专用的存储。实际上,它是从外部的分布式数据存储如运行在Hadoop和MongoDB上的Hive、HBase中抽取数据。
Hive是一个基于数据仓库技术的数据库
Spark更适合在内存中进行复杂和快速的数据分析以及对数据进行流式处理。
对于那些需要在可横向扩展的RDBMS数据库上运行数据仓库操作的应用来说,Hive是最适合的。
Spark最适合于那些要求比MapReduce机制更快地进行大数据分析的应用。
来源: https://dzone.com/articles/comparing-apache-hive-vs-spark
我做了一个PEX互操作性服务,可以让你在你的InterSystems IRIS应用内部使用Apache Hive。请试用如下步骤:
1. 在iris-hive-adapter 项目上做一个Git Clone:
$ git clone https://github.com/yurimarx/iris-hive-adapter.git
2. 在这个目录内打开terminal 并运行:
$ docker-compose build
3. 运行IRIS容器:
$ docker-compose up
4. 打开项目中的Hive Prouction,运行一个Hello样例): http://localhost:52773/csp/irisapp/EnsPortal.ProductionConfig.zen?PRODUCTION=dc.irishiveadapter.HiveProduction
5. 点击“开始”运行Production.
6. 现在我们来测试应用!
7. 运行你的REST客户端应用程序(比如Postman),在body部分使用项目的URLS和命令(使用POST请求):
7.1 在大数据中生成一个新的表:POST http://localhost:9980/?Type=DDL. 在BODY中: CREATE TABLE helloworld (消息字符串)
7.2 在表中插入: POST http://localhost:9980/?Type=DDL. 在BODY中: INSERT INTO helloworld VALUES ("hello")
7.3 T从表中得到结果清单: POST http://localhost:9980/?Type=DML. 在BODY中: SELECT * FROM helloworld (注意:这里的类型是)
现在,你有了2个在IRIS中使用大数据的选项:Hive 或者Spark。希望你喜欢。
文章
Michael Lei · 十二月 27, 2022
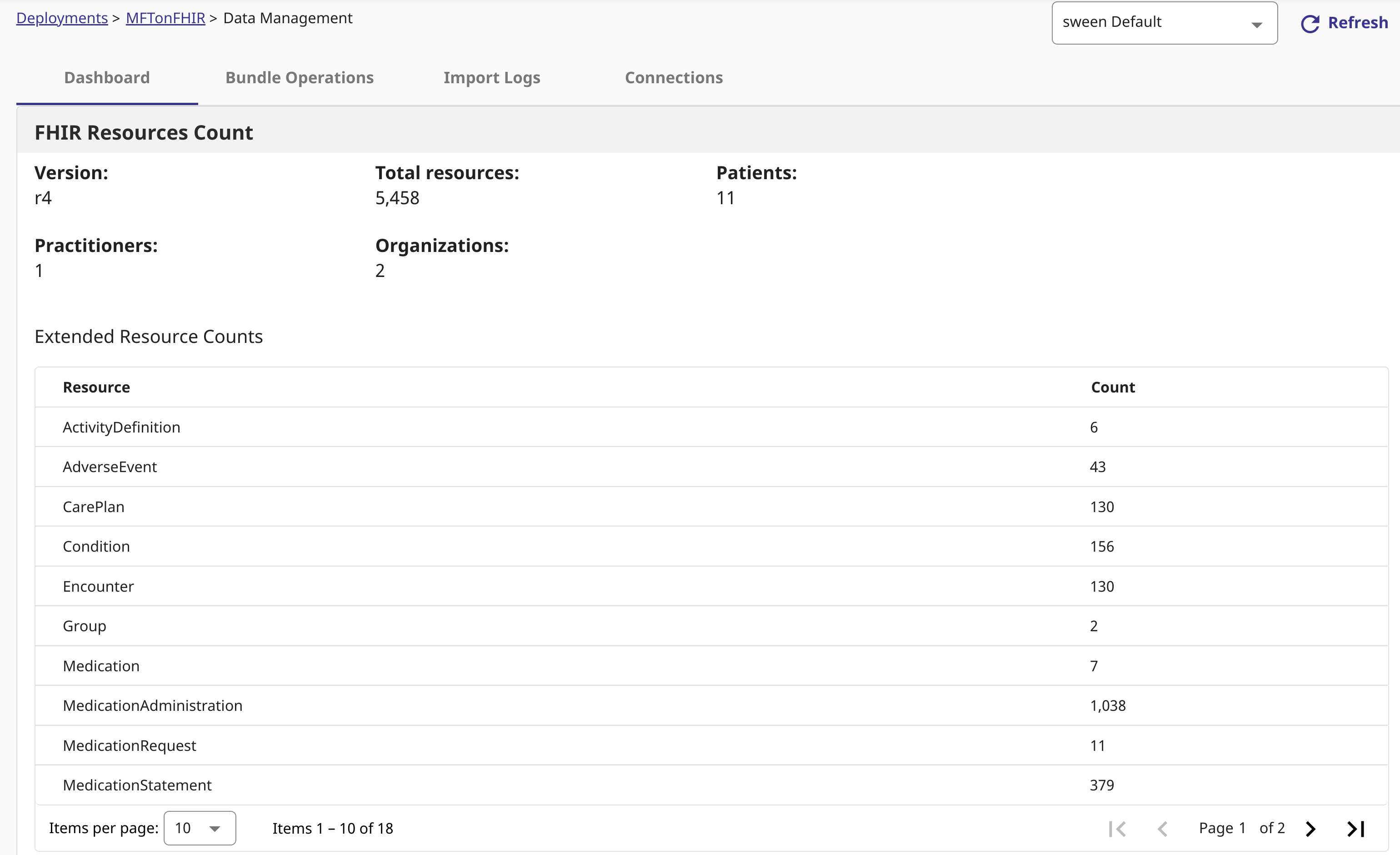
一个简单的生产配置,使 FHIR 交易捆绑包能够通过 Box 和 Dropbox 加载到 InterSystems® FHIR® 服务器中。使用包含的 MFT 连接组件和 14 行自定义业务流程,此生产配置会将您的交易捆绑包处理到 FHIR 资源,以便立即使用,就像哈利·波特的魔法一样。
我首先会展示该生产配置的短视频导览、MFT 连接以及 IRIS 上 Box 和 Dropbox 的 Oauth2 应用配置,接下来循序渐进地展示一些步骤,让您使用您喜欢的任何 MFT 供应商以及您选择的任何工作流程、桌面、API 或 Web 控制台拖放操作。
一些陷阱:
OAUTH2 回调需要使用 IRIS 的 SSL 端点来提供重定向… 最好在 Health Connect Cloud 上尝试一下!
Dropbox for Business 在基于团队的令牌方面面临挑战,个人 Dropbox 则运行良好。 这不是无法忍受的情形,但需要一些耐心。
配置 MFT 连接时,注意 Dropbox 的 baseurl 上的“/”(确保它存在)。
对于 Box 和 DropBox 的路径,MFT 出站适配器都需要具有结尾“/”。
现在,鉴于以上获奖的 OBS 支持的内容可能有不足之处,如果 InterSytems 文档还不够,下面是需要遵循的步骤。
步骤概览:
将 FHIRDrop 或 FHIRBox 应用创建到一个点,然后停止! (协作和倾听)
在您的 InterSystems FHIR 服务器、HealthConnect 或 I4H 上配置 MFT 连接。
完成您的 FHIRDrop 或 FHIRBox 应用,提供来自 MFT 连接的重定向 URL。
授权您的 MFT 连接。
构建您的生产配置。
正常拖放
创建 FHIRDrop 或 FHIRBox 应用
这里的想法是在每个 Box 和 Dropbox 开发者控制台中“开始”您的应用配置,这会让您看到客户端 ID 和客户端密码,然后让选项卡挂起并移动到 IRIS MFT 连接。
(协作和倾听)只需收集您的客户端 ID 和客户端密码,挂起浏览器选项卡,然后继续:
配置 MFT 连接
基 URL:https://api.box.com/2.0
基 URL:https://api.dropboxapi.com/2/(注意结尾斜杠)
完成应用注册
现在,回到应用注册并完成应用。确保插入上述步骤中的重定向 URL,并添加与 file.read、file.write 有关的范围。
授权您的托管文件传输连接
回到您的托管文件传输连接并通过调用“Get Access Token”(获取访问令牌)来“授权”连接。
构建您的生产配置
生产配置
以下是自定义业务流程,生产配置的源代码:https://gitlab.com/isc_cloud/fhir-drop-fhir-box-mft-2-fhir
正常拖放!
现在,获取 FHIR!
文章
Louis Lu · 六月 12, 2023
文章相关视频参见Synthea生成FHIR测试数据,以及FHIR服务器加载FHIR资源文件
1. 什么是Synthea
Synthea是一个开源软件包,可以模拟生成患者就诊数据。他的github地址在这里。
生成的就诊模版从最初的模拟美国前十种常见病、前十种慢性病到现今超过90种不同的模型。详细模型参见这里。
基于当前版本,Synthea的特性包括:
从出生到死亡的全生命周期
可配置的人口统计学信息(默认为美国马萨诸塞州人口普查数据)
模块化规则系统
插入通用模块
用于附加功能的自定义 Java 规则模块
主要医疗事件就诊、急诊室就诊和症状驱动的就诊
症状、 过敏、药品、 疫苗接种、观察/生命体征、实验室、处置、 护理计划
支持格式
HL7 FHIR(R4、STU3 v3.0.1 和 DSTU2 v1.0.2)
ndjson 格式的批量 FHIR(设置 exporter.fhir.bulk_data = true 以激活)
C-CDA (设置 exporter.ccda.export = true 以激活)
CSV (设置 exporter.csv.export = true 以激活)
CPCDS (设置 exporter.cpcds.export = true 以激活)
使用Graphviz可视化呈现规则和疾病模块
支持的参数可见下图
比如 -p 5 生成5条测试数据
-g M 生成男性测试数据
-a 60-65 生成年龄在60-65周岁患者测试数据
2. 使用Synthea 生成测试数据
为了方便使用,也将该软件做成了docker,所以你可以简单的执行下面命令行
docker run --rm -v $PWD/output:/output --name synthea-docker intersystemsdc/irisdemo-base-synthea:version-1.3.4 -p 5
该命令会在当前路径的output文件夹下生成5条患者符合FHIR标准的就诊数据,数据相关摘要信息如下面终端输出:
3. 加载生成的 FHIR 数据至 InterSystems IRIS for Health
生成完FHIR数据后,需要加载到FHIR服务器(FHIR资源仓库)中。
我们在输出目录下可以看到生成7条json数据,其中5条患者就诊相关,1条就诊医院信息,一条参与者(就诊医生)信息。
在InterSystems IRIS for health中可以方便的使用DataLoader类中的方法,批量加载FHIR资源数据,进入FHIR 资源仓库命名空间后执行:
zw ##class(HS.FHIRServer.Tools.DataLoader).SubmitResourceFiles("/external/fhir/","FHIRServer","/fhir/r4")
该方法中的第一个参数是fhir资源文件路径; 第二个参数服务类型,这里一般是FHIRServer; 第三个参数FHIRServer的service名称。
执行后显示如下:
之后我们可以进入管理门户,或者使用SQL客户端查询相关存储表,表明数据被正确导入
文章
Jingwei Wang · 九月 20, 2022
在虚拟化环境中使用镜像,构成镜像的InterSystems IRIS实例被安装在虚拟主机上,创造了一个混合的高可用性解决方案,将镜像的优点与虚拟化的优点结合起来。镜像通过自动故障切换对计划内或计划外的故障提供即时响应,而虚拟化HA软件在计划外的机器或操作系统故障后自动重新启动承载镜像成员的虚拟机。这允许失败的成员迅速重新加入镜像,充当备份(或在必要时作为主机)。
当镜像被配置在虚拟化环境中时,请参考以下建议:
故障转移成员的虚拟主机和备机不可以配置在同一台物理机上。
为了避免单点存储故障,故障转移成员上的InterSystems IRIS实例所使用的存储应永久隔离在不同磁盘组或存储阵列的独立数据存储中。
在虚拟化平台层面上进行的一些操作,如备份或迁移,可能会导致故障转移成员长时间没有反应,从而导致不需要的故障转移或不理想的警报频率。为了解决这个问题,你可以增加QoS超时设置。
在进行导致故障转移成员连接中断的计划性维护操作时,你可以暂时停止备份上的镜像,以避免不必要的故障转移和警报。
在镜像成员上必须非常谨慎地使用快照管理,因为将一个成员恢复到早期的快照,既会删除该成员的最新状态(例如,自拍摄快照以来,该成员可能已经从主机变为备机),也会删除其他成员仍然拥有的日志数据。 使用虚拟机备份恢复镜像时请特别注意:
被恢复到早期快照的故障转移成员只能从power-off 状态下恢复;从power-on 状态下恢复会造成两个故障转移成员同时作为主机的可能性。
如果被恢复到早期快照的故障转移成员在没有获得自快照以来创建的所有日志数据的情况下成为主要成员--例如,因为它被迫成为主要成员--所有其他镜像成员必须被重建(如需重建镜像,请联系WRC)。
文章
姚 鑫 · 六月 9, 2021
# 第二章 从对象写入XML输出
本章介绍如何从InterSystems IRIS对象生成XML输出。
# 创建XML编写器概述
InterSystems IRIS提供了用于为InterSystems IRIS对象生成`XML`输出的工具。可以指定XML投影的详细信息,如将对象投影到`XML`中所述。然后创建一个`Writer`方法,该方法指定`XML`输出的整体结构:字符编码、对象的显示顺序、是否包括处理指令等。
基本要求如下:
- 如果需要特定对象的输出,则该对象的类定义必须扩展`%XML.Adaptor`。除了少数例外,该对象引用的类还必须扩展`%XML.Adaptor`。
- 输出方法必须创建`%XML.Writer`的实例,然后使用该实例的方法。
下面的终端会话显示了一个简单的示例,在该示例中,我们访问启用了XML的对象并为其生成输出:
```java
/// d ##class(Sample.Person).Populate(100)
/// w ##class(PHA.TEST.Xml).Obj2Xml(1)
ClassMethod Obj2Xml(ID)
{
s obj = ##class(Sample.Person).%OpenId(ID)
s xml = ##class(%XML.Writer).%New()
s xml.Indent=1
s status = xml.RootObject(obj)
q ""
}
```
```java
DHC-APP>w ##class(PHA.TEST.Xml).Obj2Xml(1)
yaoxin
111-11-1117
1990-04-25
889 Clinton Drive
St Louis
WI
78672
9619 Ash Avenue
Ukiah
AL
56589
濮氶懌
111-11-1115
Red
Orange
Yellow
Green
Red
Orange
Yellow
31
```
# 创建输出方法
输出方法按照指定的顺序逐段构造一个XML文档。输出方法的整体结构取决于需要输出完整的XML文档,还是仅仅输出一个片段。
## 输出方法的整体结构
方法应按以下顺序执行以下部分或全部操作:
1. 如果使用的对象可能无效,请调用该对象的`%ValidateObject()`方法并检查返回的状态。如果对象无效,则XML也将无效。
**`%XML.Writer` 在导出对象之前不会对其进行验证。这意味着,如果刚刚创建了一个对象,但尚未对其进行验证,则该对象(以及XML)可能是无效的(例如,因为缺少必需的属性)。**
2. 创建`%XML.Writer`类的实例,并根据需要设置其属性。
特别是,需要设置以下属性:
- `Indent` 缩进-控制输出是在缩进和换行中生成(如果缩进等于1),还是作为单个长行生成(如果缩进等于0)。后者是默认设置。
- `IndentChars` 缩进字符-指定用于缩进的字符。默认值为两个空格的字符串。如果缩进为0,则此属性无效。
- `Charset` 字符集-指定要使用的字符集。
为了提高可读性,本文档中的示例使用缩进等于1。
3. 指定输出目标。
默认情况下,输出写入当前设备。要指定输出目标,请在开始编写文档之前调用以下方法之一:
- `OutputToDevice()`-将输出定向到当前设备。
- `OutputToFile()`-将输出定向到指定文件。可以指定绝对路径或相对路径。请注意,该目录路径必须已经存在。
- `OutputToString()`-将输出定向到字符串。稍后,可以使用另一种方法来检索此字符串。
- `OutputToStream()`-将输出定向到指定的流。
4. 启动文档。可以使用`StartDocument()`方法。请注意,如果尚未通过`StartDocument()`启动文档,则以下方法会隐式启动文档:`Write()`、`WriteDocType()`、`RootElement()`、`WriteComment()`和`WriteProcessingInstruction()`。
5. 可以选择写入文档的序言行。可以使用以下方法:
- `WriteDocType()` - 编写DOCTYPE声明。
- `WriteProcessingInstructions()`-编写处理指令。
6. 可以选择指定默认命名空间。编写器将其用于没有定义的XML命名空间的类。
7. 可以选择将命名空间声明添加到根元素。为此,可以在启动根元素之前调用几个实用程序方法。
8. 启动文档的根元素。详细信息取决于该文档的根元素是否对应于InterSystems IRIS对象。有两种可能性:
- 根元素可能直接对应于InterSystems IRIS对象。如果要为单个对象生成输出,通常会出现这种情况。
在本例中,使用`RootObject()`方法,该方法将指定的启用XML的对象作为根元素写入。
- 根元素可能只是一组元素的包装器,而这些元素是InterSystems IRIS对象。
在本例中,使用`RootElement()`方法,该方法插入具有指定名称的根级元素。
9. 如果使用`RootElement()`方法,请调用方法来为根元素内的一个或多个元素生成输出。可以按照选择的任何顺序或逻辑在根元素中编写任何元素。有几种方法可以编写单个元素,并且可以结合使用这些技术:
- 可以使用`object()`方法,该方法写入启用XML的对象。可以指定此元素的名称,也可以使用由对象定义的默认值。
- 可以使用`element()`方法,该方法使用提供的名称写入元素的开始标记。然后,可以使用`WriteAttribute()`、`WriteChars()`、`WriteCData()`等方法编写内容、属性和子元素。子元素可以是另一个`Element()`,也可以是`Object()`。使用`EndElement()`方法指示元素的结束。
- 可以使用`%XML.Element`并手动构造元素。
10. 如果使用的是`RootElement()`方法,请调用`EndRootElement()`方法。此方法关闭文档的根元素,并根据需要减少缩进(如果有)。
11. 如果文档是从`StartDocument()`开始的,请调用`EndDocument()`方法关闭文档。
12. 如果将输出定向到字符串,请使用`GetXMLString()`方法检索该字符串。
还有许多其他可能的组织,但请注意,某些方法只能在某些上下文中调用。具体地说,一旦开始一个文档,在结束第一个文档之前,不能开始另一个文档。如果这样做,`Writer`方法将返回以下状态:
```java
#6275: Cannot output a new XML document or change %XML.Writer properties
until the current document is completed.
#6275:在当前文档完成之前,无法输出新的XML文档或更改%XML。Writer属性。
```
`StartDocument()`方法的作用是:显式启动文档。如前所述,其他方法隐式启动文档:`write()`、`WriteDocType()`、`RootElement()`、`WriteComment()`和`WriteProcessingInstruction()`。
注意:这里描述的方法旨在使够向XML文档写入特定的单元,但在某些情况下,可能需要更多的控制。在`%XML.Writer`提供了一个额外的方法`Write()`,可以使用该方法将任意字符串写入输出中的任何位置。
此外,还可以使用`Reset()`方法重新初始化编写器属性和输出方法。如果已经生成了一个XML文档,并且希望在不创建新的编写器实例的情况下生成另一个文档,这将非常有用。
## 错误检查
**%XML.Writer的大多数方法都会返回状态。应该在每个步骤之后检查状态,并在适当的情况下退出。**
## 插入注释行
如前所述,使用`WriteComment()`方法插入注释行。可以在文档中的任何位置使用此方法。如果尚未启动XML文档,此方法将隐式启动文档。
## 示例
```java
/// w ##class(PHA.TEST.Xml).Write()
ClassMethod Write() As %Status
{
s obj = ##class(Sample.Person).%OpenId(1)
set writer=##class(%XML.Writer).%New()
set writer.Indent=1
set status=writer.OutputToDevice()
if $$$ISERR(status) {
do $System.Status.DisplayError(status)
quit $$$ERROR($$$GeneralError, "输出目标无效")
}
set status=writer.RootObject(obj)
if $$$ISERR(status) {
do $System.Status.DisplayError(status)
quit $$$ERROR($$$GeneralError, "写入根对象时出错")
}
quit status
}
```
请注意,此方法使用`OutputToDevice()`方法将输出定向到当前设备(默认目标)。这不是必需的,但仅用于演示目的。
当然,输出取决于所使用的类,但可能如下所示:
```java
DHC-APP>w ##class(PHA.TEST.Xml).Write()
xiaoli
111-11-1111
test
2662
1
```
## 有关缩进选项的详细信息
如前所述,可以使用编写器的缩进属性来获取包含附加换行符的输出,以获得更好的可读性。此格式没有正式规范。本节介绍`%XML.Writer`使用的规则。如果缩进等于`1`:
- 任何只包含空格字符的元素都会转换为空元素。
- 每个元素都放在自己的行上。
- 如果某个元素是前一个元素的子元素,则该元素相对于该父元素缩进。缩进由`IndentChars`属性确定,该属性默认为两个空格。