清除过滤器
公告
Michael Lei · 一月 23, 2023
InterSystems 很高兴地宣布,InterSystems IRIS、InterSystems IRIS for Health 和 HealthShare Health Connect 2022.1.2 的扩展维护版本现已推出。这些版本为 2022.1.0 和 2022.1.1 版本提供了一些选定的功能和错误修复。
您可以在这些页面上找到有关更改内容的更多信息:
InterSystems IRIS
InterSystems IRIS 医疗版
HealthShare HealthConnect
请通过开发者社区分享您的反馈,以便我们共同打造更好的产品。
如何获得软件
该软件以经典安装包和容器镜像的形式提供。有关可用安装程序和容器映像的完整列表,请参阅支持的平台网页。
每个产品的完整安装包都可以从 WRC 的软件分发页面获得。
安装包和预览密钥可从 WRC 的预览下载站点或通过评估服务网站获得。
InterSystems IRIS 和 IRIS for Health 的企业版和社区版的容器镜像以及所有相应的组件都可以从InterSystems Container Registry获得。
此版本中所有套件和容器的数量为2022.1.2.574.0 。
公告
Michael Lei · 三月 19
InterSystems IRIS ®,InterSystems IRIS ® for Health TM和HealthShare ® Health Connect 2024.1版现已全面上市 (GA)。
发布亮点
在此版本中,您可以期待许多令人兴奋的更新,包括:
在ObjectScript中使用向量Vector: 一种强大优化数据操控的能力.
向量搜索Vector Search (试验性): 行业领先的高效数据检索.
多卷数据库: 增强可扩展性和存储管理.
快速在线备份FastOnline Backup (试验性): 优化备份流程.
多种端口支持Multiple Super Server Ports: 提供网络配置的灵活性.
FHIR 2.0.0 支持 Smart
FHIR R4 对象模型生成
改进了 FHIR 查询的性能
删除专用 Web 服务器 (PWS)
。
请通过开发者社区分享您的反馈,以便我们共同构建更好的产品。
文档
有关所有突出显示功能的详细信息可通过以下链接获得:
InterSystems IRIS 2024.1 文档、 发行说明以及已弃用和停产的技术和功能。
InterSystems IRIS for Health 2024.1 文档、 发行说明和升级清单。
HealthShare Health Connect 2024.1 文档、 发行说明和升级清单。
此外,请查看此链接以获取与此版本相关的升级信息。
抢先体验计划 (EAP)
现在有很多 EAP 可用。查看此页面并注册您感兴趣的人。
如何获取软件?
与往常一样,扩展维护 (EM) 版本附带适用于所有受支持平台的经典安装包,以及 Docker 容器格式的容器映像。
经典安装包
安装包可从 WRC 的 InterSystems IRIS for Health 的扩展维护版本页面和 HealthShare Health Connect 的HealthShare 完整套件页面获取。此外,还可以在评估服务网站上找到套件。 InterSystems IRIS Studio 在该版本中仍然可用,您可以从 WRC 的组件分发页面获取它。
供货情况和套餐信息
此版本附带适用于所有受支持平台的经典安装包,以及 Docker 容器格式的容器映像。有关完整列表,请参阅支持的平台文档。
安装包和预览密钥可从 WRC 的预览下载站点或通过评估服务网站获取(使用标记“显示预览软件”来访问 2024.1)。
此开发者预览版的内部版本号是: 2024.1.0.263.0 。
容器镜像可从InterSystems 容器注册表获取。容器被标记为“ 2024.1 ”或“latest-em” 。
文章
Hao Ma · 一月 10, 2021
自 Caché 2017 以后,SQL 引擎包含了一些新的统计信息。 这些统计信息记录了执行查询的次数以及运行查询所花费的时间。
对于想要对包含许多 SQL 语句的应用程序的性能进行监控和尝试优化的人来说,这是一座宝库,但访问数据并不像一些人希望的那么容易。
本文和相关的示例代码说明了如何使用这些信息,以及如何例行提取每日统计信息的摘要,并保存应用程序的 SQL 性能的历史记录。
记录了什么?
每次执行 SQL 语句时,都记录花费的时间。 这是非常轻量的操作,无法关闭。 为了最大程度地降低开销,统计信息保留在内存中并定期写入磁盘。 数据包括一天中执行查询的次数以及所花费的平均时间和总时间。
数据不会立即写入磁盘,并且在写入之后,统计信息将由“更新 SQL 查询统计信息”任务更新,该任务通常计划为每小时运行一次。 该任务可以手动触发,但是如果你希望在测试查询时实时查看统计信息,则整个过程需要一点耐心。
警告:在 InterSystems IRIS 2019 及更早版本中,不会针对已使用 %Studio.Project:Deploy 机制部署的类或例程中的嵌入式 SQL 收集这些统计信息。 示例代码不会有任何中断,但这可能会使你产生误导(我被误导过),让你以为一切正常,因为没有查询显示为高开销。
如何查看信息?
你可以在管理门户中查看查询列表。 转到 SQL 页面,点击“SQL 语句”选项卡。 对于你正在运行并查看的新查询,这种方式很好;但是如果有数千条查询正在运行,则可能变得难以管理。
另一种方法是使用 SQL 搜索查询。 信息存储在 INFORMATION_SCHEMA 模式的表中。 该模式含有大量表,我在本文的最后附上了一些 SQL 查询示例。
何时删除统计信息?
每次重新编辑查询时会删除其数据。 因此对于动态查询,这可能意味着清除缓存的查询时。 对于嵌入式 SQL,则意味着重新编译在其中嵌入 SQL 的类或例程时。
在活跃的站点上,可以合理预期统计信息将保存超过一天,但是存放统计信息的表不能用作运行报告或长期分析的长期参考源。
如何汇总信息?
我建议每天晚上将数据提取到永久表中,这些表在生成性能报告时更易于使用。 如果在白天编译类,可能会丢失一些信息,但这不太可能对慢速查询的分析产生任何实际影响。
下面的代码示例说明了如何将每个查询的统计信息提取到每日汇总中。 它包括三个简短的类:
* 一个应在每晚运行的任务。
* DRL.MonitorSQL 是主类,用于从 INFORMATION_SCHEMA 表提取数据并存储。
第三个类 DRL.MonitorSQLText 是一个优化类,它存储一次(可能很长的)查询文本,并且只将查询的哈希存储在每天的统计信息中。
示例说明
该任务提取前一天的信息,因此应安排在午夜后不久执行。
你可以导出更多历史数据,只要其存在。 要提取过去 120 天的数据
Do ##class(DRL.MonitorSQL).Capture($h-120,$h-1)
该示例代码直接读取全局 ^rIndex,因为最早版本的统计信息未将日期公开给 SQL。
我所包括的变体将循环实例中的所有命名空间,但这并不总是合适的。
如何查询已提取的数据
提取数据后,您可以通过运行以下语句查找最繁重的查询
SELECT top 20
S.RunDate,S.RoutineName,S.TotalHits,S.SumpTIme,S.Hash,t.QueryText
from DRL.MonitorSQL S
left join DRL.MonitorSQLText T on S.Hash=T.Hash
where RunDate='08/25/2019'
order by SumpTime desc
此外,如果选择了开销大的查询的哈希,可以通过以下语句查看该查询的历史记录
SELECT S.RunDate,S.RoutineName,S.TotalHits,S.SumpTIme,S.Hash,t.QueryText
from DRL.MonitorSQL S
left join DRL.MonitorSQLText T on S.Hash=T.Hash
where S.Hash='CgOlfRw7pGL4tYbiijYznQ84kmQ='
order by RunDate
今年早些时候,我获取了一个活跃站点的数据,然后查看了开销最大的查询。 有一个查询的平均时间不到 6 秒,但每天被调用 14000 次,加起来每天消耗的时间将近 24 小时。 实际上,一个核心完全被这个查询占用。 更糟糕的是,第二个查询要花一个小时,它是第一个查询的变体。
运行日期
例程名称
总命中次数
总时间
哈希
查询文本(有节略)
03/16/2019
14,576
85,094
5xDSguu4PvK04se2pPiOexeh6aE=
DECLARE C CURSOR FOR SELECT * INTO :%col(1) , :%col(2) , :%col(3) , :%col(4) …
03/16/2019
15,552
3,326
rCQX+CKPwFR9zOplmtMhxVnQxyw=
DECLARE C CURSOR FOR SELECT * INTO :%col(1) , :%col(2) , :%col(3) , :%col(4) , …
03/16/2019
16,892
597
yW3catzQzC0KE9euvIJ+o4mDwKc=
DECLARE C CURSOR FOR SELECT * INTO :%col(1) , :%col(2) , :%col(3) , :%col(4) , :%col(5) , :%col(6) , :%col(7) ,
03/16/2019
16,664
436
giShyiqNR3K6pZEt7RWAcen55rs=
DECLARE C CURSOR FOR SELECT * , TKGROUP INTO :%col(1) , :%col(2) , :%col(3) , ..
03/16/2019
74,550
342
4ZClMPqMfyje4m9Wed0NJzxz9qw=
DECLARE C CURSOR FOR SELECT …
表 1:客户站点的实际结果
INFORMATION_SCHEMA 模式中的表
除了统计信息外,此模式中的表还会跟踪查询、列、索引等的使用位置。 通常,SQL 语句是起始表,它的连接方式类似于“Statements.Hash=OtherTable.Statement”。
直接访问这些表以查找一天中开销最大的查询,这一操作的等效查询是...
SELECT DS.Day,Loc.Location,DS.StatCount,DS.StatTotal,S.Statement,S.Hash
FROM INFORMATION_SCHEMA.STATEMENT_DAILY_STATS DS
left join INFORMATION_SCHEMA.STATEMENTS S
on S.Hash=DS.Statement
left join INFORMATION_SCHEMA.STATEMENT_LOCATIONS Loc
on S.Hash=Loc.Statement
where Day='08/26/2019'
order by DS.stattotal desc
无论你是否考虑建立一个更系统的过程,我都建议每个使用 SQL 处理大型应用程序的人今天都运行这个查询。
如果某个特定查询显示为高开销,则可以通过运行以下语句获取历史记录
SELECT DS.Day,Loc.Location,DS.StatCount,DS.StatTotal,S.Statement,S.Hash
FROM INFORMATION_SCHEMA.STATEMENT_DAILY_STATS DS
left join INFORMATION_SCHEMA.STATEMENTS S
on S.Hash=DS.Statement
left join INFORMATION_SCHEMA.STATEMENT_LOCATIONS Loc
on S.Hash=Loc.Statement
where S.Hash='jDqCKaksff/4up7Ob0UXlkT2xKY='
order by DS.Day
每日提取统计信息的代码示例
标准免责声明 - 此示例仅用于说明。 不对其提供支持,也不保证其有效。
Class DRL.MonitorSQLTask Extends %SYS.Task.Definition{Parameter TaskName = "SQL Statistics Summary";Method OnTask() As %Status{ set tSC=$$$OK TRY { do ##class(DRL.MonitorSQL).Run() } CATCH exp { set tSC=$SYSTEM.Status.Error("Error in SQL Monitor Summary Task") } quit tSC }}
Class DRL.MonitorSQLText Extends %Persistent{/// Hash of query textProperty Hash As %String;
/// query text for hashProperty QueryText As %String(MAXLEN = 9999);Index IndHash On Hash [ IdKey, Unique ];}
/// Summary of very low cost SQL query statistics collected in Cache 2017.1 and later. /// Refer to documentation on "SQL Statement Details" for information on the source data. /// Data is stored by date and time to support queries over time. /// Typically run to summarise the SQL query data from the previous day.Class DRL.MonitorSQL Extends %Persistent{/// RunDate and RunTime uniquely identify a runProperty RunDate As %Date;/// Time the capture was started/// RunDate and RunTime uniquely identify a runProperty RunTime As %Time;/// Count of total hits for the time period for Property TotalHits As %Integer;/// Sum of pTimeProperty SumPTime As %Numeric(SCALE = 4);/// Routine where SQL is foundProperty RoutineName As %String(MAXLEN = 1024);/// Hash of query textProperty Hash As %String;Property Variance As %Numeric(SCALE = 4);/// Namespace where queries are runProperty Namespace As %String;/// Default run will process the previous days data for a single day./// Other date range combinations can be achieved using the Capture method.ClassMethod Run(){ //Each run is identified by the start date / time to keep related items together set h=$h-1 do ..Capture(+h,+h)}/// Captures historic statistics for a range of datesClassMethod Capture(dfrom, dto){ set oldstatsvalue=$system.SQL.SetSQLStatsJob(-1) set currNS=$znspace set tSC=##class(%SYS.Namespace).ListAll(.nsArray) set ns="" set time=$piece($h,",",2) kill ^||TMP.MonitorSQL do { set ns=$o(nsArray(ns)) quit:ns="" use 0 write !,"processing namespace ",ns zn ns for dateh=dfrom:1:dto { set hash="" set purgedun=0 do { set hash=$order(^rINDEXSQL("sqlidx",1,hash)) continue:hash="" set stats=$get(^rINDEXSQL("sqlidx",1,hash,"stat",dateh)) continue:stats="" set ^||TMP.MonitorSQL(dateh,ns,hash)=stats &SQL(SELECT Location into :tLocation FROM INFORMATION_SCHEMA.STATEMENT_LOCATIONS WHERE Statement=:hash) if SQLCODE'=0 set Location="" set ^||TMP.MonitorSQL(dateh,ns,hash,"Location")=tLocation &SQL(SELECT Statement INTO :Statement FROM INFORMATION_SCHEMA.STATEMENTS WHERE Hash=:hash) if SQLCODE'=0 set Statement="" set ^||TMP.MonitorSQL(dateh,ns,hash,"QueryText")=Statement } while hash'="" } } while ns'="" zn currNS set dateh="" do { set dateh=$o(^||TMP.MonitorSQL(dateh)) quit:dateh="" set ns="" do { set ns=$o(^||TMP.MonitorSQL(dateh,ns)) quit:ns="" set hash="" do { set hash=$o(^||TMP.MonitorSQL(dateh,ns,hash)) quit:hash="" set stats=$g(^||TMP.MonitorSQL(dateh,ns,hash)) continue:stats="" // The first time through the loop delete all statistics for the day so it is re-runnable // But if we run for a day after the raw data has been purged, it will wreck eveything // so do it here, where we already know there are results to insert in their place. if purgedun=0 { &SQL(DELETE FROM websys.MonitorSQL WHERE RunDate=:dateh ) set purgedun=1 } set tObj=##class(DRL.MonitorSQL).%New() set tObj.Namespace=ns set tObj.RunDate=dateh set tObj.RunTime=time set tObj.Hash=hash set tObj.TotalHits=$listget(stats,1) set tObj.SumPTime=$listget(stats,2) set tObj.Variance=$listget(stats,3) set tObj.Variance=$listget(stats,3) set queryText=^||TMP.MonitorSQL(dateh,ns,hash,"QueryText") set tObj.RoutineName=^||TMP.MonitorSQL(dateh,ns,hash,"Location") &SQL(Select ID into :TextID from DRL.MonitorSQLText where Hash=:hash) if SQLCODE'=0 { set textref=##class(DRL.MonitorSQLText).%New() set textref.Hash=tObj.Hash set textref.QueryText=queryText set sc=textref.%Save() } set tSc=tObj.%Save() //avoid dupicating the query text in each record because it can be very long. Use a lookup //table keyed on the hash. If it doesn't exist add it. if $$$ISERR(tSc) do $system.OBJ.DisplayError(tSc) if $$$ISERR(tSc) do $system.OBJ.DisplayError(tSc) } while hash'="" } while ns'="" } while dateh'="" do $system.SQL.SetSQLStatsJob(0)}Query Export(RunDateH1 As %Date, RunDateH2 As %Date) As %SQLQuery{SELECT S.Hash,RoutineName,RunDate,RunTime,SumPTime,TotalHits,Variance,RoutineName,T.QueryText FROM DRL.MonitorSQL S LEFT JOIN DRL.MonitorSQLText T on S.Hash=T.Hash WHERE RunDate>=:RunDateH1 AND RunDate
文章
jieliang liu · 三月 1, 2021
大数据的 5 个 V 与 InterSystems IRIS
参见下表:
Velocity(速度):水平和垂直节点扩展传递出的弹性速度 实现者:分布式内存缓存、分布式处理、分片和多模型架构 https://www.intersystems.com/isc-resources/wp-content/uploads/sites/24/ESG_Technical_Review-InterSystems-IRIS.pdf 和 https://learning.intersystems.com/course/view.php?id=1254&ssoPass=1
Value(价值):Analytics 和 AI产生的指数数据价值实现:BI、NLP、ML、AutoML 和多模型架构 https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=SETAnalytics 和 https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GIML_AUTOML
Veracity(真实性):在公司层面统一的单一真实数据源--实现者:连接器、数据总线、数据集成的 BPL 以及 API 管理 https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=PAGE_interoperability 和 https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=AFL_iam
Volume(容量):多个性能出色的 TB/PB 级数据存储库 实现者:分布式内存缓存、分布式处理、分片和多模型架构 https://www.intersystems.com/isc-resources/wp-content/uploads/sites/24/ESG_Technical_Review-InterSystems-IRIS.pdf 和 https://learning.intersystems.com/course/view.php?id=1254&ssoPass=1
Variety(多样性):同一位置多种数据格式(XML、JSON、SQL、对象)实现者:Repositório e Arquitetura Multimodelohttps://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=PAGE_multimodel
文章
Michael Lei · 五月 12, 2021
本帖将展示为 InterSystems 数据平台上运行的数据库应用调整共享内存需求(包括 global 和例程缓冲区、gmheap 以及 locksize)的方法,以及在配置服务器和虚拟化 Caché 应用程序时应考虑的一些性能提示。 和以往一样,当我谈到 Caché 时,我指的是所有数据平台(Ensemble、HealthShare、iKnow 和 Caché)。
[本系列其他帖子的列表](https://cn.community.intersystems.com/post/intersystems-数据平台的容量规划和性能系列文章)
当我最初开始使用 Caché 时,大多数客户的操作系统是 32 位的,Caché 应用程序的内存有限且昂贵。 通常部署的英特尔服务器只有几个核心,唯一的扩展方式是选择大型服务器,或者使用 ECP 横向扩展。 现在,即使是基本的生产级服务器也具有多个处理器、几十个核心,并且最小内存为 128 或 256 GB,可能达到 TB。 对于大多数数据库安装,ECP 已被遗忘,我们现在可以在单台服务器上大幅提高应用事务处理速率。
Caché 的一个关键特性是我们在共享内存(通常称为数据库缓存或 global 缓冲区)中使用数据的方式。 简单地说,如果适当调整 global 缓冲区的大小并为其分配“更多”内存,通常会提高系统性能 - 访问内存中的数据要比访问磁盘上的数据快得多。 当年,当 32 位系统占主导地位时,对问题_我应该为 global 缓冲区分配多少内存?_的回答很简单 - _尽可能多!_反正也没有很多内存可用,所以人们努力计算操作系统需求、操作系统和 Caché 进程的数量和大小以及每个进程使用的实际内存,以找到剩余的内存来分配尽可能大的 global 缓冲区。
## 趋势已经转变
如果您在当代服务器上运行应用程序,可以为 Caché 实例分配大量内存,并且由于内存现在既“便宜”又充足,因此通常放任其使用。 然而,趋势再次转变,除了最大型的系统,现在部署的几乎所有系统都是虚拟化的。 所以,虽然在需要时可以为“怪兽”虚拟机分配大量内存,但重点仍然回到适当调整系统规模上。 为了最大程度地利用服务器整合,需要进行容量计划以充分利用可用主机内存。
# 什么在使用内存?
通常,Caché 数据库服务器上有四个主要的内存消耗者:
* 操作系统,包括文件系统缓存。
* 其他非 Caché 应用程序(如果已安装)。
* Caché 进程。
* Caché 共享内存(包括 global 和例程缓冲区以及 GMHEAP)。
从高级别看,所需的物理内存量只是将列表上每一项的需求都加起来。 上面的所有项目都使用实际内存,但它们也可以使用虚拟内存,容量计划的一个关键部分是将系统规模调整为有足够的物理内存,使分页不会发生或尽量少发生,或者至少尽量减少或消除必须从磁盘恢复内存的硬页面故障。
在本帖中,我将重点介绍 Caché 共享内存的大小调整以及优化内存性能的一些通用规则。 操作系统和内核的要求因操作系统而异,但大多数情况下为几个 GB。 文件系统缓存视情况而定,将是列表上其他项目获得内存分配之后的其余任何可用内存。
Caché 主要是进程 - 如果在应用程序运行时查看操作系统统计信息,则会看到缓存进程(例如 cache 或 cache.exe)。 因此,观测应用程序内存要求的一个简单方法是查看操作系统指标。 例如,通过 Linux 上的 `vmstat` 或 `ps` 或者 `Windows 进程资源管理器`,以及使用中的实际内存总量,推断出增长需求和峰值需求。 请注意,某些指标会报告包含共享内存的虚拟内存,因此收集实际内存需求时务必小心。
## 调整 global 缓冲区大小 - 一种简化的方法
对于高事务数据库,容量计划的目标之一是将 global 缓冲区的大小调整为使内存中容纳尽可能多的应用数据库工作集。 这将最大程度地减少读取 IOPS,并且通常会使应用程序的性能更好。 我们还需要取得平衡,使其他内存用户(如操作系统和 Caché 进程)不会被移出分页,并且有足够的内存用于文件系统缓存。
我在[本系列的第 2 部分](https://community.intersystems.com/post/intersystems-data-platforms-and-performance-–-part-2)中展示了一个示例,来说明如果对磁盘过度读取会发生什么情况。在该示例中,高读取数是由不良的报告或查询引起的,但是如果 global 缓冲区太小而迫使应用程序不断从磁盘读取数据块,则会产生同样的效果。 另外,值得注意的是,存储的格局一直在变化 - 随着固态硬盘技术的进步,存储速度越来越快,但靠近运行中的进程的内存数据仍然是最好的。
当然,每个应用程序都是不同的,所以必须指出__“您的情况可能有所不同”__,但有一些通用规则可以帮助您开始为应用程序的共享内存制定容量计划。 之后,您可以根据您的具体要求进行调整。
### 从哪里开始?
很遗憾,并没有万能答案。但是,正如我在之前的帖子谈到的,一个好的做法是确定系统 CPU 容量规模,使得在达到所需峰值事务处理速率的情况下,峰值处理期间的 CPU 使用率为大约 80%。 为短期增长或意外的活动激增留出 20% 余量。
例如,当我调整 TrakCare 系统的规模时,我通过基准测试和查看客户站点指标来了解已知事务处理速率的 CPU 要求,并且可以针对基于英特尔处理器的服务器使用普遍性的经验法则:
`经验法则:`每个 CPU 核心对应 _n_ GB 大小的物理内存。
- 对于 TrakCare 数据库服务器,_n_ 为 8 GB。 对于小型 Web 服务器则为 4 GB。
`经验法则:`为 Caché global 缓冲区分配 _n_% 的内存。
- 对于中小型 TrakCare 系统,_n_% 为 60%,其余 40% 的内存留给操作系统、文件系统缓存和 Caché 进程。 如果您需要许多文件系统缓存或有许多进程,可以更改该值,例如改为 50%。 或者,在大型系统上使用超大内存配置时,将其调整为更高的百分比。
- 此经验法则假定服务器上只有一个 Caché 实例。
所以如果应用程序需要 10 个 CPU 核心,则虚拟机将有 80 GB 内存,其中 48 GB 为 global 缓冲区,32 GB 用于其他所有用途。
内存大小调整规则适用于物理或虚拟化系统,因此对于 TrakCare 虚拟机,1 vCPU : 8 GB 内存的比例同样适用。
### 调整 global 缓冲区
要查看规模调整的效果如何,需要观察几个项目。 您可以使用操作系统工具观察 Caché 之外的可用内存。 根据最佳计算结果进行设置,然后观察一段时间内的内存使用情况,如果一直有可用内存,则可以重新配置系统以增加 global 缓冲区或适当调整虚拟机规模。
global 缓冲区大小调整适当的另一个关键指标是读取 IOPS 尽可能低 - 这意味着 Caché 缓存效率会很高。 您可以使用 mgstat 观察不同的 global 缓冲区大小对 PhyRds 和 RdRatio 的影响,[本系列的第 2 部分](https://community.intersystems.com/post/intersystems-data-platforms-and-performance-–-part-2)提供了查看这些指标的示例。除非您的整个数据库都在内存中,否则总会有一些对磁盘的读取,目的只是保持尽可能低的读取数。
请记住您的硬件食物群并做好平衡 - 为 global 缓冲区分配更多内存会降低读取 IOPS,但可能会提高 CPU 使用率,因为您的系统现在可以在更短时间内完成更多工作。不过降低 IOPS 终归是好事,您的用户会因为更快的响应时间而更满意。
_有关如何将您的要求应用于__物理内存__,请参见下面的部分。 _
对于虚拟服务器计划,_不要_超额预定生产虚拟机内存,_尤其是 Caché 共享内存_,更多信息也请参见下文。
您的应用程序甜蜜点是每 CPU 核心 8GB 物理内存吗? 我说不准,但要看是否有相似的方法适合您的应用程序。 不管每核心 4GB 还是 10GB, 如果您找到了另一种调整 global 缓冲区大小的方法,请在下面留下评论。
### 监视 Global 缓冲区使用情况
Caché 实用工具 `^GLOBUFF` 可显示 global 缓冲区在任意时间点的使用情况统计。 例如,按百分比显示前 25 名:
do display^GLOBUFF(25)
例如,输出可能如下所示:
Total buffers: 2560000 Buffers in use: 2559981 PPG buffers: 1121 (0.044%)
Item Global Database Percentage (Count)
1 MyGlobal BUILD-MYDB1 29.283 (749651)
2 MyGlobal2 BUILD-MYDB2 23.925 (612478)
3 CacheTemp.xxData CACHETEMP 19.974 (511335)
4 RTx BUILD-MYDB2 10.364 (265309)
5 TMP.CachedObjectD CACHETEMP 2.268 (58073)
6 TMP CACHETEMP 2.152 (55102)
7 RFRED BUILD-RB 2.087 (53428)
8 PANOTFRED BUILD-MYDB2 1.993 (51024)
9 PAPi BUILD-MYDB2 1.770 (45310)
10 HIT BUILD-MYDB2 1.396 (35727)
11 AHOMER BUILD-MYDB1 1.287 (32946)
12 IN BUILD-DATA 0.803 (20550)
13 HIS BUILD-DATA 0.732 (18729)
14 FIRST BUILD-MYDB1 0.561 (14362)
15 GAMEi BUILD-DATA 0.264 (6748)
16 OF BUILD-DATA 0.161 (4111)
17 HISLast BUILD-FROGS 0.102 (2616)
18 %Season CACHE 0.101 (2588)
19 WooHoo BUILD-DATA 0.101 (2573)
20 BLAHi BUILD-GECKOS 0.091 (2329)
21 CTPCP BUILD-DATA 0.059 (1505)
22 BLAHi BUILD-DATA 0.049 (1259)
23 Unknown CACHETEMP 0.048 (1222)
24 COD BUILD-DATA 0.047 (1192)
25 TMP.CachedObjectI CACHETEMP 0.032 (808)
这在几个方面很有用,例如,查看有多少工作集保留在内存中。 如果你觉得此实用工具很有用,请在下面发表评论,让其他社区用户了解它为什么对您有帮助。
## 调整例程缓冲区大小
应用程序运行的例程(包括编译的类)存储在例程缓冲区中。 调整例程缓冲区共享内存大小的目标是让所有例程代码都在例程缓冲区中加载并驻留。 与 global 缓冲区一样,从磁盘读取例程的成本很高且效率低下。 例程缓冲区的最大大小为 1023 MB。 一般来说,您希望获得的例程缓冲区比需要的多,因为将例程缓存总是可以大幅提高性能。
例程缓冲区由不同大小的缓冲区组成。 默认情况下,Caché 确定每种大小的缓冲区数量,在安装时,2016.1 的默认缓冲区为 4、16 和 64 KB。 可以更改不同大小的内存分配,但是要开始容量计划,建议保持 Caché 默认值,除非您有特殊原因需要进行更改。 有关更多信息,请参见 [Caché 文档](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=RCPF_routines)中的《Caché 参数文件参考》的“config”附录中的 routines,以及《Caché 系统管理指南》的“配置 Caché”一章中的“内存和启动设置”。
应用程序运行时,例程从磁盘加载,并存储在可容纳该例程的最小缓冲区中。 例如,如果某个例程为 3 KB,理想情况下将存储在一个 4 KB 缓冲区中,如果没有可用的 4 KB 缓冲区,则使用更大的缓冲区。 大于 32 KB 的例程将根据需要使用多达 64 KB 的例程缓冲区。
### 检查常规缓冲区的使用
#### mgstat 指标 RouLas
了解例程缓冲区是否足够大的一个方法是 mgstat 指标 RouLas(例程加载次数和保存次数)。 一个 RouLas 是指从磁盘获取或保存到磁盘一次。 例程的加载/保存次数多可能表示存在性能问题,在这种情况下,可以增加例程缓冲区数量来提高性能。
#### cstat
如果您已将例程缓冲区增加到最大值 1023 MB,但仍然发现 RouLas 很高,那么可以使用 `cstat` 命令进行更详细的检查,以了解缓冲区中有哪些例程以及它们使用了多少内存。
ccontrol stat cache -R1
这将生成一个例程指标列表,其中包括例程缓冲区列表和缓存中的所有例程。 例如,默认安装 Caché 后,该列表的一部分如下所示:
Number of rtn buf: 4 KB-> 9600, 16 KB-> 7200, 64 KB-> 2400,
gmaxrouvec (cache rtns/proc): 4 KB-> 276, 16 KB-> 276, 64 KB-> 276,
gmaxinitalrouvec: 4 KB-> 276, 16 KB-> 276, 64 KB-> 276,
Dumping Routine Buffer Pool Currently Inuse
hash buf size sys sfn inuse old type rcrc rtime rver rctentry rouname
22: 8937 4096 0 1 1 0 D 6adcb49e 56e34d34 53 dcc5d477 %CSP.UI.Portal.ECP.0
36: 9374 4096 0 1 1 0 M 5c384cae 56e34d88 13 908224b5 %SYSTEM.WorkMgr.1
37: 9375 4096 0 1 1 0 D a4d44485 56e34d88 22 91404e82 %SYSTEM.WorkMgr.0
44: 9455 4096 0 0 1 0 D 9976745d 56e34ca0 57 9699a880 SYS.Monitor.Health.x
2691:16802 16384 0 0 7 0 P da8d596f 56e34c80 27 383da785 START
etc
etc
上面第 2 行中的“rtns/proc”表示,默认情况下,每种大小的缓冲区可以缓存 276 个例程。
使用此信息来调整例程缓冲区大小的另一种方法是,运行应用程序并使用 cstat -R1 列出正在运行的例程。 然后可以计算使用中的例程大小,例如将此列表放在 Excel 中,按大小排序,并精确地查看有哪些例程正在使用中。 如果每种大小的缓冲区没有被全部使用,则说明有足够的例程缓冲区,或者如果每种大小的缓冲区都已全部使用,则需要增加例程缓冲区,或者可以更直接地配置每个存储桶的大小。
## 锁表大小
locksiz 配置参数是为管理并发控制锁而分配的内存大小(以字节为单位),该锁用于防止不同的进程同时更改一个特定的数据元素。 在内部,内存中的锁表包含当前锁,以及持有这些锁的进程的信息。
由于用于分配锁的内存取自 GMHEAP,所以用于锁的内存不能超过 GMHEAP 中的内存。 如果增加 locksiz 的大小,请按照下面 GMHEAP 部分中的公式增加 GMHEAP 的大小以进行匹配。 有关应用程序使用锁表的信息可以使用系统管理门户 (SMP) 进行监视,或者更直接地使用 API 来监视:
set x=##class(SYS.Lock).GetLockSpaceInfo()。
该 API 返回三个值:“可获空间、可用空间、已用空间”。 检查可用空间和已用空间可粗略计算合适的值(某些锁空间为锁结构预留)。 更多信息,请参见 [Caché 文档](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=RCPF_locksiz)。
注:如果编辑 locksiz 设置,更改会立即生效。
## GMHEAP
GMHEAP(通用内存堆)配置参数定义为:Caché 的通用内存堆的大小(以 KB 为单位)。 锁表、NLS 表和 PID 表也是根据它来进行分配的。
注:更改 GMHEAP 需要重启 Caché。
为了帮助您确定应用规模,可以使用 API 来检查 GMHEAP 的使用信息:
%SYSTEM.Config.SharedMemoryHeap
该 API 还提供获取可用的通用内存堆的功能,并推荐了用于配置的 GMHEAP 参数。 例如,`DisplayUsage` 方法显示每个系统组件使用的所有内存以及可用堆内存的数量。 更多信息,请参见 [Caché 文档](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=RCPF_gmheap#RCPF_B172591)。
write $system.Config.SharedMemoryHeap.DisplayUsage()
要了解任何时间点的 GMHEAP 使用情况和建议,可以使用 `RecommendedSize` 方法。 但是,您将需要多次运行该方法才能为系统建立基线和建议。
write $system.Config.SharedMemoryHeap.RecommendedSize()
`经验法则:`再次说明,您的应用情况会有所不同,但仍可以使用以下选项之一来开始调整大小:
(最小 128MB)或(64 MB * 核心数)或(2 倍 locksiz)或采用其中较大者。
记住,必须调整 GMHEAP 的大小以包括锁表。
# 大页内存
Mark Bolinsky 写了一篇非常好的帖子,解释了为什么[在 Linux 中开启大页内存可大幅提高性能](https://community.intersystems.com/post/linux-transparent-hugepages-and-impact-caché)。
## 危险! Windows 大页内存和共享内存
Caché 在所有平台上的所有版本都使用共享内存,它可以大幅提高性能,包括在 Windows 中也总是使用,但您需要注意一些特定于 Windows 的问题。
Caché 在启动时会分配一大块共享内存,用于数据库缓存(global 缓冲区)、例程缓存(例程缓冲区)、共享内存堆、日志缓冲区和其他控制结构。 在 Caché 启动时,可以使用小页或大页来分配共享内存。 在 Windows 2008 R2 及更高版本中,Caché 默认使用大页,但如果系统已长时间运行,由于内存已碎片化,可能无法在 Caché 启动时分配连续内存,Caché 可能会改用小页。
意外地以小页启动 Caché 可导致 Caché 启动时的共享内存小于配置中定义的值,或者 __Caché 可能需要很长时间才能启动或启动失败__。 我在具有故障转移集群的站点上看到过这种情况,这些站点中的备份服务器已经很长时间没有用作数据库服务器了。
` 提示:`一种缓解策略是定期重启离线的 Windows 集群服务器。 另一个策略是使用 Linux。
# 物理内存
物理内存取决于处理器的最佳配置。 不良的内存配置可能会严重影响性能。
## 英特尔内存配置最佳实践
以下信息只适用于__英特尔__处理器。 请与供应商确认哪些规则适用于其他处理器。
决定 DIMM 最优性能的因素包括:
- DIMM 类型
- DIMM rank
- 时钟速度
- 相对于处理器的位置(最近/最远)
- 内存通道数
- 所需的冗余功能。
例如,在 Nehalem 和 Westmere 服务器(至强 5500 和 5600)上,每个处理器有三个内存通道,因此应以三个为一组的方式安装内存。 对于当前处理器(例如 E5-2600),每个处理器有四个内存通道,因此应以四个为一组的方式安装内存。
当存在不平衡的内存配置时(没有以三个/四个为一组的方式安装内存,或者内存 DIMM 的大小不同),不平衡的内存可能导致 23% 的内存性能损失。
请记住,Caché 的特点之一是在内存中进行数据处理,因此获得最佳的内存性能很重要。 另外值得注意的是,为了获得最大带宽,应该为服务器配置最快的内存速度。 对于至强处理器,只有每通道多达 2 条 DIMM 时才支持最大内存性能,因此对于常见的具有 2 个 CPU 的服务器来说,最大内存配置取决于包括 CPU 频率和 DIMM 大小(8GB、16GB 等)在内的因素。
`经验法则:`
- 使用平衡的平台配置:为每个通道和每个插槽填充相同数量的 DIMM
- 在整个平台中使用相同的 DIMM 类型:相同的大小、速度和 rank 数。
- 对于物理服务器,根据这些英特尔处理器最佳实践,将主机服务器的物理内存总数四舍五入到自然断点 - 64GB、128GB 等。
# VMware 虚拟化注意事项
我会在将来另写一篇帖子来继续介绍虚拟化 Caché 的更多准则。 不过,内存分配应考虑以下关键规则:
`规则:`在生产系统上设置 VMware 内存预留。
如上文所述,Caché 在启动时会分配一大块共享内存,用于 global 和例程缓冲区、GMHEAP、日志缓冲区和其他控制结构。
您想要避免任何共享内存交换,所以将_生产数据库虚拟机_内存预留设置为至少是 Caché 共享内存的大小加上 Caché 进程和操作系统及内核服务的内存。 如果有疑问,请预留全部生产数据库虚拟机内存。
一般来说,如果在相同系统上混合使用生产服务器和非生产服务器,则不要在非生产系统上设置内存预留。 让非生产服务器争夺剩下的内存 ;)。 VMware 通常将具有 8 个以上 CPU 的虚拟机称为“怪兽虚拟机”。 高事务 Caché 数据库服务器通常是怪兽虚拟机。 在怪兽虚拟机上设置内存预留还有其他考虑因素,例如,如果要迁移某个怪物虚拟机进行维护,或者由于高可用性触发重启,那么目标主机服务器必须有足够的可用内存。 我会在将来的帖子中讨论这方面的计划策略,以及其他内存考虑因素,如计划充分利用 NUMA。
# 总结
这是对内存进行容量计划(一个混乱的领域)的开始,当然不像调整 CPU 规模那样明确。 如果您有任何疑问或意见,请留下评论。
发布本帖后,我将去参加 Global Summit 2016。 如果您今年也参加,欢迎观看我的两场关于性能主题的演讲,我也很乐意在开发者区域与您当面交流。
文章
Michael Lei · 五月 8, 2021
大家好!
约翰·霍普金斯大学每天都会发布有关 COVID-19 疫情的新数据。
我在部署于 GCP Kubernetes 上的 docker 中使用 InterSystems IRIS Community Edition 构建了一个[简单的 InterSystems IRIS Analytics 仪表板](http://34.77.54.254:52773/dsw/index.html#/IRISAPP/Covid19),可显示疾病爆发的关键指标。
[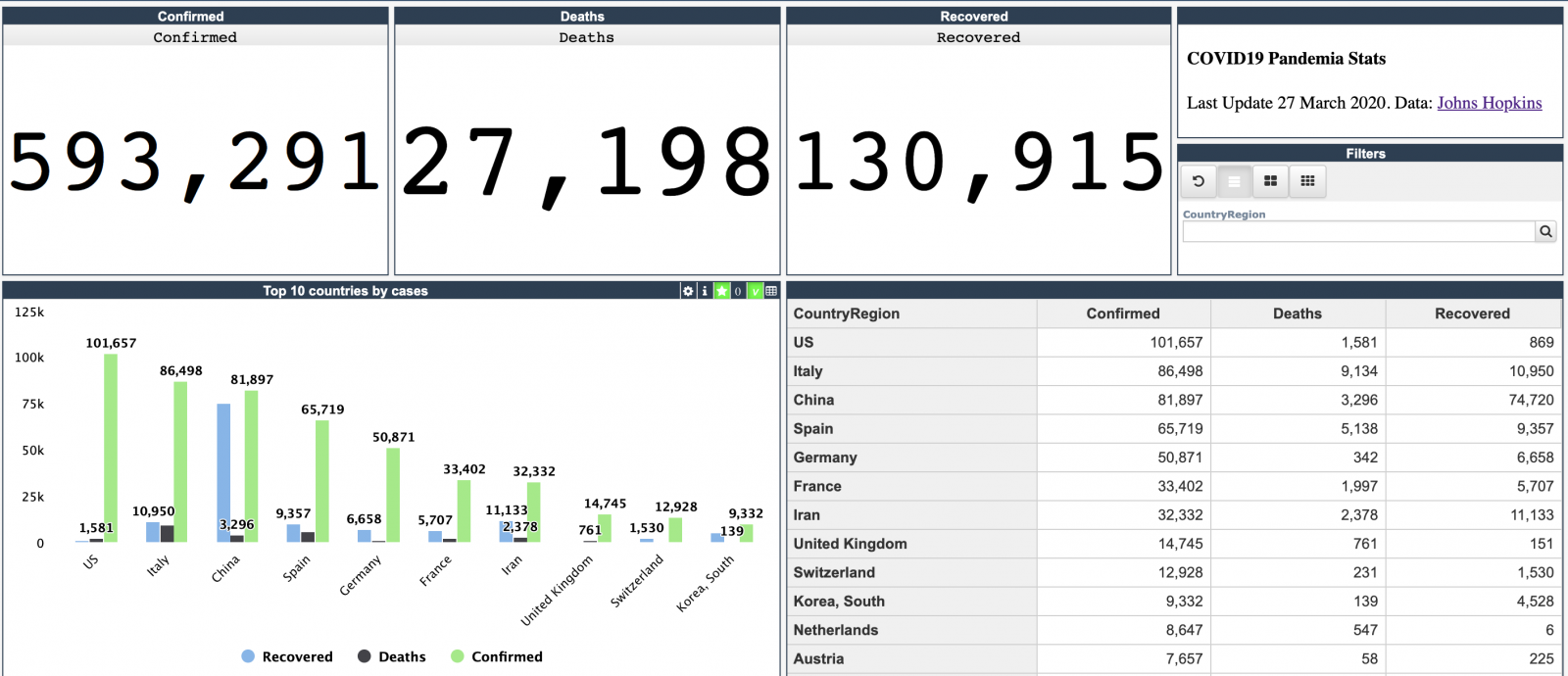](http://34.77.54.254:52773/dsw/index.html#/IRISAPP/Covid19)
这个仪表板的示例说明了如何使用 IRIS Analytics 分析 CSV 中的信息并以 InterSystems IRIS Community Edition 的形式将其部署到 GCP Kubernetes。
添加了[美国的互动式地图](http://34.77.54.254:52773/dsw/index.html#/IRISAPP/Covid19/USA.dashboard):
[](http://34.77.54.254:52773/dsw/index.html#/IRISAPP/Covid19/USA.dashboard)
[下一个仪表板显示时间线](http://34.77.54.254:52773/dsw/index.html#/IRISAPP/Covid19/Daily.dashboard):
[](http://34.77.54.254:52773/dsw/index.html#/IRISAPP/Covid19/Daily.dashboard)
并且可以按国家/地区筛选。 例如, 这是[在美国](http://34.77.54.254:52773/dsw/index.html#!/d/Covid19/Daily.dashboard?ns=IRISAPP&FILTERS=TARGET:*;FILTER:%5BDay%5D.%5BH1%5D.%5BMonth%5D.%26%5BNOW%5D~%5BCountryRegion%5D.%5BH1%5D.%5BCountryRegion%5D.%26%5BUS%5D):
[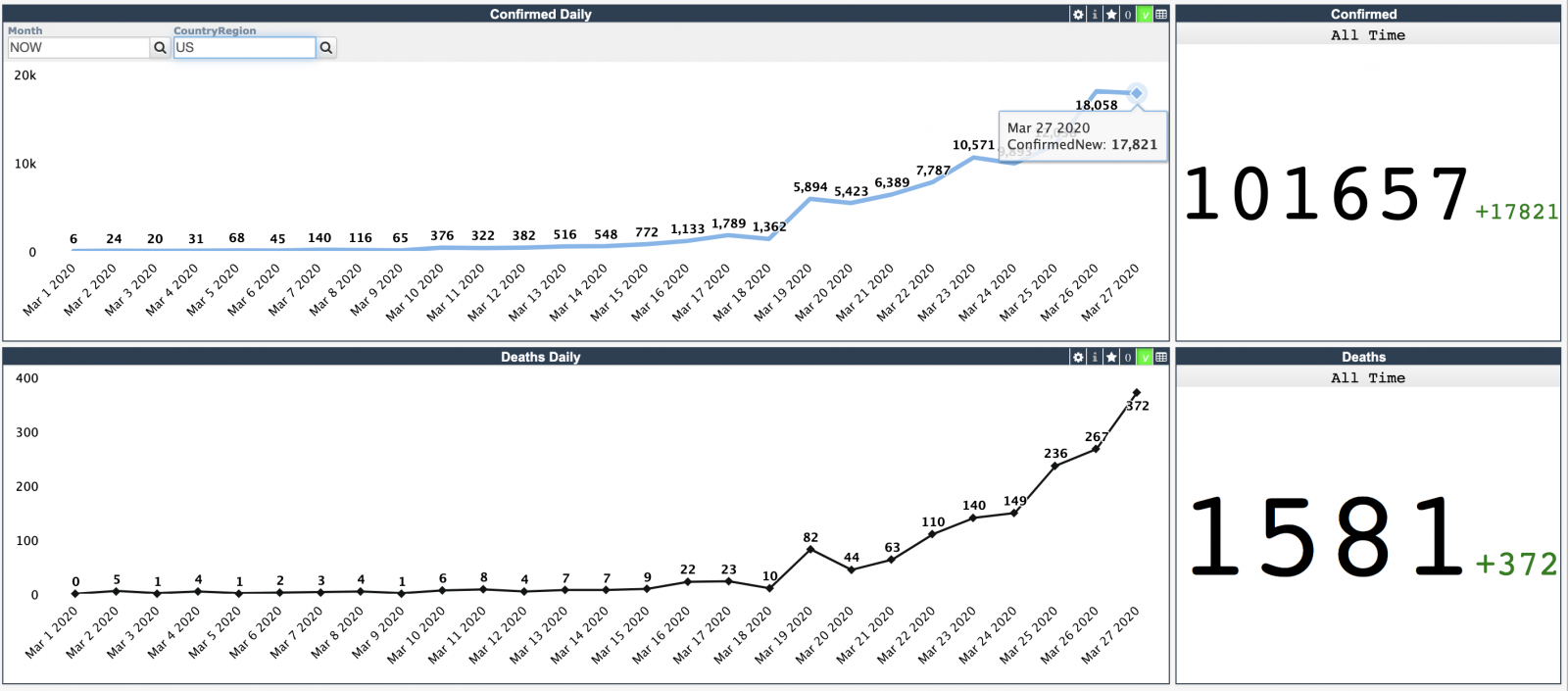](http://34.77.54.254:52773/dsw/index.html#!/d/Covid19/Daily.dashboard?ns=IRISAPP&FILTERS=TARGET:*;FILTER:%5BDay%5D.%5BH1%5D.%5BMonth%5D.%26%5BNOW%5D~%5BCountryRegion%5D.%5BH1%5D.%5BCountryRegion%5D.%26%5BUS%5D)
应用程序的源代码在 [Open Exchange](https://openexchange.intersystems.com/package/covid-19-analytics) 上提供。
工作原理
演示使用 InterSystems IRIS Community Edition docker 容器运行,并通过 MDX2JSON REST API 使用 DeepSee Web 表示层公开 InterSystems IRIS BI 仪表板。 它部署在 GCP 上,使用 Google Kubernetes Engine (GKE) 运行。
**开发方式**
数据以 CSV 格式提取自[约翰·霍普金斯仓库](https://github.com/CSSEGISandData/COVID-19)。
类、多维数据集和初始数据透视通过 [Analyzethis](https://openexchange.intersystems.com/package/AnalyzeThis) 模块生成,感谢 @Peter.Steiwer!
随后使用 CSVTOCLASS 方法引入导入方法,感谢 @Eduard.Lebedyuk!
使用 DeepSee Web (DSW) 模块渲染仪表板。
IRIS BI [项目(枢轴、仪表板)](https://github.com/evshvarov/covid-19/tree/master/src/dfi)由 [ISC.DEV](https://openexchange.intersystems.com/package/ISC-DEV) 模块导出:
IRISAPP> d ##class(dev.code).workdir("/irisdev/app/src")
IRISAPP> d ##class(dev.code).export("*.dfi")
代码采用 [VSCode ObjectScript](https://openexchange.intersystems.com/package/VSCode-ObjectScript) 开发,感谢 @Dmitry.Maslennikov。
**为开发和部署构建 docker 镜像**
所有部署均位于 [Dockerfile](https://github.com/evshvarov/covid-19/blob/master/Dockerfile)。 我们通过 Dockerfile 构建了一个包含数据、Web 应用和模块且正确设置的镜像,然后将映像部署到 GCP Kubernetes。
这个 Dockerfile 是 [Dockerfile 模板](https://github.com/intersystems-community/objectscript-docker-template/blob/master/Dockerfile)的修改版,[本文](https://community.intersystems.com/post/dockerfile-and-friends-or-how-run-and-collaborate-objectscript-projects-intersystems-iris)对其进行了很好的描述。
所以,我只会在新的部分停留。
17 COPY data files
在这里,我们将 CSV 文件从数据文件夹复制到容器
set pfile = "/opt/irisapp/files/covid-"_$tr($zd($h-1),"/","-")_".csv", rc=0 \
do ##class(AnalyzeThis.Generated.covid03162020).Import(,pfile,",", ,1,.rc) \
write "imported records: "_rc \
do ##class(%DeepSee.Utils).%BuildCube("covid03162020") \
这段代码会导入最新数据并构建多维数据集。
zpm "install dsw" \
安装 DeepSee Web。
do EnableDeepSee^%SYS.cspServer("/csp/irisapp/") \
这会为 /csp/irisapp web 应用启用 IRIS Analytics (DeepSee)。
zn "%SYS" \
write "Modify MDX2JSON application security...",! \
set webName = "/mdx2json" \
set webProperties("AutheEnabled") = 64 \
set webProperties("MatchRoles")=":%DB_IRISAPP" \
set sc = ##class(Security.Applications).Modify(webName, .webProperties) \
if sc<1 write $SYSTEM.OBJ.DisplayError(sc)
需要这段代码来使分析 Web 应用无需凭据即可使用。
COPY irisapp.json /usr/irissys/csp/dsw/configs/
这条命令可以帮助设置 DSW 配置。
**部署到 Kubernetes**
部署过程由 GitHub Actions 处理 - 此[工作流](https://github.com/evshvarov/covid-19/blob/master/.github/workflows/workflow.yaml)会在每次提交到仓库时处理。
GitHub 工作流使用我们在上一步构建的 Dockerfile 以及 [Terraform](https://github.com/evshvarov/covid-19/tree/master/terraform) 和 [Kubernetes](https://github.com/evshvarov/covid-19/tree/master/k8s) 设置。
该过程与 @Mikhail.Khomenko 在[这篇文章](https://community.intersystems.com/post/deploying-intersystems-iris-solution-gke-using-github-actions)中描述的过程相同。
**如何在本地运行和开发**
欢迎您运行和开发此项目或与此项目展开协作。
要在本地运行,请使用 docker:
将仓库克隆/git pull 到任意本地目录
$ git clone https://github.com/intersystems-community/objectscript-docker-template.git
在此目录中打开终端,然后运行:
$ docker-compose build
运行 IRIS 容器:
$ docker-compose up -d
构建并运行容器后,在以下位置打开应用程序:
localhost:yourport/dsw/index.html#!/d/Covid19/Countries.dashboard?ns=IRISAPP
**如何开发**
此仓库可以通过 ObjectScript 插件在 VSCode 中编码。 安装VSCode、Docker 和 ObjectScript 插件并在 VSCode 中打开文件夹。
**如何贡献**
创建[仓库](https://github.com/evshvarov/covid-19)分支,进行更改并发送拉取请求。 [观看视频了解更多信息](https://www.youtube.com/watch?v=1x0hC_MlRfg&t=4s)。
期待您的贡献!
文章
Michael Lei · 五月 15, 2022
InterSystems IRIS对加密、解密和哈希操作有很好的支持。在%SYSTEM.Encryption(https://docs.intersystems.com/iris20212/csp/documatic/%25CSP.Documatic.cls?LIBRARY=%25SYS&PRIVATE=1&CLASSNAME=%25SYSTEM.Encryption)类中,有市场上主要算法的类方法。
IRIS算法和加密/解密类型
正如你所看到的,这些操作是基于密钥的,包括3个类:
对称密钥: 进行加密和解密操作的部分共享同一个秘密密钥。
非对称密钥: 进行加密和解密操作的部分共享相同的秘密密钥进行加密。然而,对于解密,每个部分都有一个私人密钥。这个密钥不能与其他人共享,因为它是一个身份证明。
哈希: 当你不需要解密,而只需要加密时使用。当涉及到存储用户密码时,这是一种常见的方法。
对称和非对称加密的区别
对称加密使用一个单一的密钥,需要在需要接收信息的人之间共享,而非对称加密在通信时使用一对公共密钥和一个私人密钥来加密和解密信息。
对称加密是比较老的技术,而非对称加密则相对较新。
非对称加密的出现是为了补充对称加密模式中需要共享密钥的固有问题,通过使用一对公共-私有密钥来消除共享密钥的需要。
非对称加密比对称加密花费的时间相对较多。
主要区别
对称加密
非对称加密
密码文本大小
比原始纯文本文件更小的密码文本
比原始纯文本文件更大的密码文本
数据量
用于传输大数据.
用于传输小数据.
资源消耗
较低.
较高
密钥长度
128 或 256 位
RSA 2048位或者更长.
安全性
由于使用单一密钥进行加密,安全性较低。
由于在加密和解密中涉及两个不同的密钥,因此要安全得多。
密钥数量
加密和解密用单一密钥
加密和解密使用两个不同的密钥
技术
较老.
较新.
保密性
单一密钥,有可能被破解.
两个密钥分别用于加密和解密,从而消除了共享密钥的需要.
速度
较快
较慢.
算法
RC4, AES, DES, 3DES, QUAD.
RSA, Diffie-Hellman, ECC .
来源: https://www.ssl2buy.com/wiki/symmetric-vs-asymmetric-encryption-what-are-differences
使用 %SYSTEM.Encryption 类来实现加密、解密与哈希
要行使IRIS对加密、解密和哈希操作的支持,请访问https://github.com/yurimarx/cryptography-samples,并遵循以下步骤:
1. Clone/git 将 repo 拉入任何本地目录
$ git clone https://github.com/yurimarx/cryptography-samples.git
2. 在目录中打开 Docker 终端并执行:
$ docker-compose build
3. 启动 IRIS 容器:
$ docker-compose up -d
4. 打开 IRIS 终端:
$ docker-compose exec iris iris session iris -U IRISAPP
IRISAPP>
5. 实现非对称RSA 加密:
IRISAPP>Set ciphertext = ##class(dc.cryptosamples.Samples).DoRSAEncrypt("InterSystems")
IRISAPP>Write ciphertext
Ms/eR7pPmE39KBJu75EOYIxpFEd7qqoji61EfahJE1r9mGZX1NYuw5i2cPS5YwE3Aw6vPAeiEKXF
rYW++WtzMeRIRdCMbLG9PrCHD3iQHfZobBnuzx/JMXVc6a4TssbY9gk7qJ5BmlqRTU8zNJiiVmd8
pCFpJgwKzKkNrIgaQn48EgnwblmVkxSFnF2jwXpBt/naNudBguFUBthef2wfULl4uY00aZzHHNxA
bi15mzTdlSJu1vRtCQaEahng9ug7BZ6dyWCHOv74O/L5NEHI+jU+kHQeF2DJneE2yWNESzqhSECa
ZbRjjxNxiRn/HVAKyZdAjkGQVKUkyG8vjnc3Jw==
6. 实现非对称 RSA 解密:
IRISAPP>Set plaintext = ##class(dc.cryptosamples.Samples).DoRSADecrypt(ciphertext)
IRISAPP>Write plaintext
InterSystems
7. 实现对称 AES CBC 加密:
IRISAPP>Do ##class(dc.cryptosamples.Samples).DoAESCBCEncrypt("InterSystems")
8sGVUikDZaJF+Z9UljFVAA==
8. 实现对称AES CBC 解密:
IRISAPP>Do ##class(dc.cryptosamples.Samples).DoAESCBCDecrypt("8sGVUikDZaJF+Z9UljFVAA==")
InterSystems
9. 实现MD5 哈希:
IRISAPP>Do ##class(dc.cryptosamples.Samples).DoHash("InterSystems")
rOs6HXfrnbEY5+JBdUJ8hw==
10. 实现SHA 推荐哈希:
IRISAPP>Do ##class(dc.cryptosamples.Samples).DoSHAHash("InterSystems")
+X0hDlyoViPlWOm/825KvN3rRKB5cTU5EQTDLvPWM+E=
11. 退出终端:
Enter HALT or H (大小写不敏感)
关于源代码
1. 关于对称密钥
# to use with symmetric encrypt/decrypt
ENV SECRETKEY=InterSystemsIRIS
在Dockerfile创建了一个环境密钥,作为对称操作的秘钥。
2. 关于非对称密钥
# to use with asymmetric encrypt/decrypt
RUN openssl req -new -x509 -sha256 -config example-com.conf -newkey rsa:2048 -nodes -keyout example-com.key.pem -days 365 -out example-com.cert.pem
在Dockerfile创建了一个公钥和一个私钥用作非对称操作
3. 对称加密
// Symmetric Keys sample to encrypt
ClassMethod DoAESCBCEncrypt(plaintext As %String) As %Status
{
// convert to utf-8
Set text=$ZCONVERT(plaintext,"O","UTF8")
// set a secret key
Set secretkey = $system.Util.GetEnviron("SECRETKEY")
Set IV = $system.Util.GetEnviron("SECRETKEY")
// encrypt a text
Set text = $SYSTEM.Encryption.AESCBCEncrypt(text, secretkey, IV)
Set ciphertext = $SYSTEM.Encryption.Base64Encode(text)
Write ciphertext
}
AES CBC 加密主要用于加密文本。Base64编码将结果作为一个可读的文本返回给用户。.
4. 对称解密
// Symmetric Keys sample to decrypt
ClassMethod DoAESCBCDecrypt(ciphertext As %String) As %Status
{
// set a secret key
Set secretkey = $system.Util.GetEnviron("SECRETKEY")
Set IV = $system.Util.GetEnviron("SECRETKEY")
// decrypt a text
Set text=$SYSTEM.Encryption.Base64Decode(ciphertext)
Set text=$SYSTEM.Encryption.AESCBCDecrypt(text,secretkey,IV)
Set plaintext=$ZCONVERT(text,"I","UTF8")
Write plaintext
}
AES CBC 解密用于解密文本.Base64解码将加密后的文本返回为二进制文本,可以用来解密。
5. 非对称加密
// Asymmetric Keys sample to encrypt
ClassMethod DoRSAEncrypt(plaintext As %String) As %Status
{
// get public certificate
Set pubKeyFileName = "/opt/irisbuild/example-com.cert.pem"
Set objCharFile = ##class(%Stream.FileCharacter).%New()
Set objCharFile.Filename = pubKeyFileName
Set pubKey = objCharFile.Read()
// encrypt using RSA
Set binarytext = $System.Encryption.RSAEncrypt(plaintext, pubKey)
Set ciphertext = $SYSTEM.Encryption.Base64Encode(binarytext)
Return ciphertext
}
必须获得公钥文件内容,用RSA进行加密。RSA加密是用来加密文本的。
6. 非对称解密
// Asymmetric Keys sample to decrypt
ClassMethod DoRSADecrypt(ciphertext As %String) As %Status
{
// get private key
Set privKeyFileName = "/opt/irisbuild/example-com.key.pem"
Set privobjCharFile = ##class(%Stream.FileCharacter).%New()
Set privobjCharFile.Filename = privKeyFileName
Set privKey = privobjCharFile.Read()
// get ciphertext in binary format
Set text=$SYSTEM.Encryption.Base64Decode(ciphertext)
// decrypt text using RSA
Set plaintext = $System.Encryption.RSADecrypt(text, privKey)
Return plaintext
}
要想用RSA解密,必须得到私钥文件内容。RSA解密的操作来解密文本。
7. 使用MD5的哈希文本(老方法)
// Hash sample
ClassMethod DoHash(plaintext As %String) As %Status
{
// convert to utf-8
Set text=$ZCONVERT(plaintext,"O","UTF8")
// hash a text
Set hashtext = $SYSTEM.Encryption.MD5Hash(text)
Set base64text = $SYSTEM.Encryption.Base64Encode(hashtext)
// convert to hex text to following best practices
Set hextext = ..GetHexText(base64text)
// return using lowercase
Write $ZCONVERT(hextext,"L")
}
MD5 哈希加密文本,并且不能被解密Hash will encrypt the text, and it will not be possible to decrypt it.新项目不建议使用MD5的哈希值,因为它被认为是不安全的。这就是为什么它被SHA所取代。InterSystems的IRIS支持SHA(我们的下一个例子将演示它)。
8. 使用SHA的Hash文本 (推荐)
我们将在这个样本中使用SHA-3哈希方法。根据InterSystems公司的文档,该方法使用美国安全哈希算法-3之一生成哈希值((更多信息见联邦信息处理标准出版物202)。
// Hash using SHA
ClassMethod DoSHAHash(plaintext As %String) As %Status
{
// convert to utf-8
Set text=$ZCONVERT(plaintext,"O","UTF8")
// hash a text
Set hashtext = $SYSTEM.Encryption.SHA3Hash(256, text)
Set base64text = $SYSTEM.Encryption.Base64Encode(hashtext)
// convert to hex text to following best practices
Set hextext = ..GetHexText(base64text)
// return using lowercase
Write $ZCONVERT(hextext,"L")
}
对于SHA方法,可以设置哈希操作中使用的比特长度。位数越多,破解哈希就越困难。然而,哈希过程也会变慢。在这个例子中,我们使用了256位。你可以选择以下长度:
224 (SHA-224)
256 (SHA-256)
384 (SHA-384)
512 (SHA-512)
文章
Jingwei Wang · 七月 21, 2022
本章介绍了如何将SQL code从文本文件导入InterSystems SQL。当你导入SQL code时,InterSystems IRIS 数据平台使用动态SQL准备并执行每一行的SQL。如果遇到无法解析的SQL code行,SQL导入会跳过该行code,继续准备和执行后续的code行,直到到达文件的末端。所有的SQL code导入操作都会导入到当前的命名空间。
SQL导入主要用于导入数据定义语言(DDL)命令,如CREATE TABLE,并使用INSERT、UPDATE和DELETE命令来填充表。SQL导入可以准备和执行SELECT查询,但不创建结果集。
SQL导入可以用来导入InterSystems的SQL code。它也可以用于code迁移,从其他供应商(FDBMS、Informix、InterBase、MSSQLServer、MySQL、Oracle、Sybase)导入SQL。来自其他供应商的code被转换为InterSystems的SQL并执行。SQL导入不能将所有的SQL命令导入到InterSystems SQL中。它导入的是那些与InterSystems IRIS实现的SQL标准兼容的命令和条款。不兼容的特征通常会被解析,但会被忽略。
SQL导入可以成功地准备一个SQL查询--在适当的时候创建一个相应的缓存查询--但它不会执行查询。
你通过调用%SYSTEM.SQL.Schema类中的适当方法来执行SQL code导入。当导入SQL code时,这些方法可以创建另外两个文件:一个是Errors.log文件,它记录了解析SQL命令的错误;另一个是Unsupported.log文件,它包含了该方法不能识别为SQL命令的行的字面文本。
导入 InterSystems SQL Code
你可以使用%SYSTEM.SQL.Schema方法从一个文本文件中导入InterSystems的SQL code。
ImportDDL()是一个通用的SQL导入方法。该方法作为一个后台(非交互式)进程运行。如下面的例子中所示,示例中第一个参数mysqlcode.txt为SQL命令文件,第二个参数是默认的错误日志文件mysqlcode_Errors.log,第三个参数指定为 "IRIS "。
DO $SYSTEM.SQL.Schema.ImportDDL("c:\InterSystems\mysqlcode.txt",,"IRIS")
注意:这种SQL DDL代码的导入和执行不应该与管理门户SQL界面的导入语句操作相混淆。管理门户SQL界面的导入语句是以XML格式导入SQL语句。
这个mysqlcode.txt文本文件必须是一个没有格式化的文件,如.txt文件。每条SQL命令必须在自己的行中开始。一个SQL命令可以分成多行,允许缩进。每条SQL命令后面必须有一个GO语句,并在自己的行上,下面是一个有效的InterSystems SQL导入文件文本的例子:
CREATE TABLE Sample.MyStudents (StudentName VARCHAR(32),StudentDOB DATE)
GO
CREATE INDEX NameIdx ON TABLE Sample.MyStudents (StudentName)
GO
INSERT INTO Sample.MyStudents (StudentName,StudentDOB) SELECT Name,
DOB FROM Sample.Person WHERE Age <= '21'
GO
INSERT INTO Sample.MyStudents (StudentName,StudentDOB)
VALUES ('Jones,Mary',60123)
GO
UPDATE Sample.MyStudents SET StudentName='Smith-Jones,Mary' WHERE StudentName='Jones,Mary'
GO
DELETE FROM Sample.MyStudents WHERE StudentName %STARTSWITH 'A'
GO
Run() 是一个InterSystems SQL导入方法。这个方法在终端以交互方式运行。它提示你指定导入文本文件的位置,创建Errors.log文件和Unsupported.log文件的位置,以及其他信息。
支持的SQL命令
不是所有有效的InterSystems SQL命令都能被导入。以下是支持的InterSystems SQL命令的列表。
CREATE TABLE, ALTER TABLE, DROP TABLE
CREATE VIEW, ALTER VIEW, DROP VIEW
CREATE INDEX all index types, except bitslice
CREATE USER, DROP USER
CREATE ROLE
GRANT, REVOKE
INSERT, UPDATE, INSERT OR UPDATE, DELETE
SET OPTION
SELECT for optimizer plan mode only
导入非 InterSystems SQL Code
InterSystems SQL 支持导入其他供应商使用的SQL。来自其他供应商的code被转换为InterSystems的SQL code并执行,我们提供了以下方法。
ImportDDL() 也可以用来导入非InterSystems SQL。
要导入特定格式的SQL,你需要指定该格式的名称作为一个参数,例如 FDBMS, Informix, InterBase, MSSQLServer (或MSSQL), MySQL, Oracle, 或Sybase。下面的例子导入了MSSQL代码文件mssqlcode.txt,在当前命名空间中执行该文件中列出的SQL命令。
DO $SYSTEM.SQL.Schema.ImportDDL($lb("C:\temp\somesql.sql","UTF8"),,"MSSQL")
注意,如果第三个参数是MSSQL、Sybase、Informix或MySQL,第一个参数可以是一个SQL code文件路径名或一个双元素%List,第一个元素是SQL code文件路径名,第二个元素是要使用的I/O转换表。
在%SYSTEM.SQL.Schema中提供了单独的交互式方法来导入以下类型的SQL。LoadFDBMS(), LoadInformix(), LoadInterBase(), LoadMSSQLServer(), LoadOracle(), and LoadSybase()。这些方法从终端交互式地运行。它提示你指定导入文本文件的位置,创建Errors.log文件和Unsupported.log文件的位置,以及其他信息。
ImportDDLDir()允许你从一个目录中的多个文件导入SQL code。该方法作为一个后台进程运行。它支持Informix、MSSQLServer和Sybase。所有要导入的文件必须有一个.sql**的后缀。
ImportDir()允许你从一个目录中的多个文件导入SQL code。比ImportDDLDir()提供更多的选项。该方法作为一个后台进程运行。它支持MSSQLServer,和Sybase。你可以指定一个允许的文件扩展名后缀列表。
公告
Michael Lei · 七月 25, 2022
Hi 大家好!
我们很荣幸地宣布InterSystems 将在剑桥总部举办 推动女性健康-FemTech不止是利基市场 高层论坛,论坛将在线上线下同步举行!
⏱ 时间: 7月 29日, 5:30 AM – 7:30 AM ,北京时间(July 28,5:30 PM – 7:30 PM ,EDT/美国东部时间)📍 地点: InterSystems 总部,1 Memorial Drive, Cambridge, MA
本次活动是由 HealthTech Build 组织的,HTB的愿景是为医疗机构、生物科技数字创新者、健康数据科学家、数字疗法开发者和软件工程师,以颠覆性的富有成效的方式为共同目标而努力。对于这次活动,目标将是交流思想,并以新的方式解决未满足的妇女健康需求。
本次论坛的参与嘉宾包括:
Janine Kopp, Investor & Head of Venture Studio, Takeda Digital Ventures
Uros Kuzmanovic, CEO, Biosens8
Mary Beth Cicero, CEO, 3Daughters
Thom Busby, Senior Vice President, Outcome Capital
不要错过这个极好的机会,在志同道合的同伴中发现挑战并讨论新的解决方案。
>> 注册线上会议 <<
文章
Jingwei Wang · 七月 14, 2022
InterSystems SQL为存储在IRIS数据库中的数据提供不折不扣的、标准的关系型访问。
InterSystems SQL具有以下优点。
高性能和可扩展性 - InterSystems SQL的性能和可扩展性优于其他关系型数据库产品。
与IRIS对象技术的集成 - InterSystems SQL与IRIS对象技术紧密集成。你可以混合使用关系型和对象型的数据访问,而不牺牲任何一种方法的性能。
低维护 - 与其他关系型数据库不同,IRIS应用程序不需要在部署的应用程序中重建索引和压缩表。
支持标准SQL查询 - InterSystems SQL支持SQL-92标准语法和命令。
你可以将InterSystems SQL用于许多目的,包括。
基于对象和Web应用程序 - 你可以在InterSystems Object和Caché Server Page应用程序中使用SQL查询,以执行强大的数据库操作,如查询和搜索。
在线事务处理 - InterSystems SQL为插入和更新操作以及通常在事务处理应用程序中发现的查询类型提供出色的性能。
BI和数据仓库 - IRIS多维数据库引擎和位图索引技术的结合使其成为数据仓库式应用的绝佳选择。
点对点查询和报告 - 你可以使用InterSystems SQL包含的全功能ODBC和JDBC驱动来连接到流行的报告和查询工具。
企业应用集成 - InterSystems SQL网关使你能以SQL方式无缝访问存储在符合ODBC或JDBC标准的外部关系型数据库中的数据。这使得在IRIS应用程序中整合各种来源的数据变得很容易。
架构
IRIS SQL的核心由以下部分组成。
统一数据字典 - 所有元信息的存储库,以一系列的类定义的形式存储。自动为每个存储在统一字典中的持久类创建关系访问(表)。
SQL处理器和优化器 - 是一套解析和分析SQL查询的程序,为给定的查询确定最佳搜索策略,并生成执行查询的代码。
InterSystems SQL Server - 一组InterSystems IRIS服务器进程,负责与InterSystems ODBC和JDBC驱动的所有通信。它还管理着一个常用查询的缓存;当同一个查询被多次执行时,它的执行计划可以从查询缓存中检索出来,而不必由优化器再次处理。
特性
InterSystems SQL包括一整套标准的关系型功能。这些功能包括。
定义表和视图的能力(DDL或数据定义语言)。
对表和视图执行查询的能力(DML或数据操作语言)。
执行事务的能力,包括INSERT、UPDATE和DELETE操作。当执行并发操作时,InterSystems SQL使用行级锁。
能够定义和使用索引以提高查询效率。
能够使用各种各样的数据类型,包括用户定义的类型。
能够定义用户和角色并给他们分配权限。
能够定义外键和其他完整性约束。
能够定义INSERT, UPDATE, 和DELETE触发器。
定义和执行存储程序的能力。
能够以不同的格式返回数据。ODBC模式用于客户端访问;显示模式用于基于服务器的应用程序(如CSP页面)。
SQL-92标准
InterSystems SQL支持完整的入门级SQL-92标准,但有以下例外:
不支持在表定义中添加额外的CHECK约束。
不支持SERIALIZABLE隔离级别。
分隔标识符不区分大小写;标准规定它们应该区分大小写,例如create table "user info" (id number); 和 create table "USER INFO" (id number); 在InterSystems SQL中不区分大小写。
在包含HAVING子句的子查询中,人们应该能够引用HAVING子句中 "可用 "的min(),max(),avg()。这不被支持。即 aggregate函数无法在 WHERE 或 GROUP BY 子句中使用。例如Select DeptID , Avg(Salary) From Employee GROUP BY DeptID, Avg(Salary) HAVING Avg(Salary) > 1000, 但是可以使用Select DeptID , Avg(Salary) From Employee GROUP BY DeptID HAVING Avg(Salary) > 1000
SQL-92标准在算术运算符优先级方面是不精确的;关于这个问题的假设在不同的SQL实现中是不同的。InterSystems SQL支持两种系统范围内的SQL算术运算符优先级的选择。
默认情况下,InterSystems SQL严格按照从左到右的顺序解析算术表达式,没有运算符优先级。这与ObjectScript中使用的惯例相同。因此,3+3*5=30。你可以使用圆括号来强制执行所需的优先级。因此,3+(3*5)=18。
你可以配置InterSystems SQL使用ANSI优先级来解析算术表达式,它给乘法和除法运算符的优先级高于加法、减法和连接运算符。因此,3+3*5=18。如果需要,你可以使用圆括号来覆盖这个优先级。因此,(3+3)*5=30。
扩展功能
InterSystems SQL支持一些有用的扩展。其中许多都与InterSystems IRIS同时提供对象和关系访问数据的事实有关。
其中一些扩展包括:
支持用户定义的数据类型和函数。
用于跟踪对象引用的特殊语法。
支持子类化和继承。
支持对存储在其他数据库中的外部表的查询。
控制用于表的存储结构的一些机制,以实现最大的性能。
支持ODBC,JDBC
使用JDBC驱动和ODBC驱动
嵌入式SQL
在ObjectScript中,InterSystems SQL支持嵌入式SQL:在方法(或其他代码)的内部放置SQL语句的能力。
使用嵌入式SQL,你可以查询一条记录,或者定义一个游标并使用它来查询多条记录。
嵌入式SQL是被编译的;它可以与ObjectScript例程同时被编译(默认),或者你可以将嵌入式SQL的编译推迟到运行时。
当与IRIS的对象访问能力结合使用时,嵌入式SQL是相当强大的。例如,下面的方法可以找到具有给定Name值的记录的RowID。
ClassMethod FindByName(fullname AS %String)
{
&sql(SELECT %ID INTO :id FROM Sample.MyTable WHERE name= :fullname)
IF SQLCODE <0 {SET baderr="SQLCODE ERROR:"_SQLCODE_" "_%msg
RETURN baderr}
ELSEIF SQLCODE=100 {SET nodata="Query returns no data"
RETURN nodata}
RETURN "RowID="_id
}
Dynamic SQL
作为标准库的一部分,InterSystems IRIS提供了一个%SQL.Statement类,你可以用它来执行动态(即在运行时定义)的SQL语句。你可以在ObjectScript方法中使用动态SQL。例如,下面的方法查询指定数量的21世纪出生的人。该查询选择所有在1999年12月31日以后出生的人,按出生日期对所选记录进行排序,然后选择前 x 条记录。
ClassMethod Born21stC(x) [language=objectscript]
{
set myquery =2
set myquery(1) = "SELECT TOP ? Name, %EXTERNAL(DOB) FROM Sample.Person "
set myquery(2) = "WHERE DOB >58073 ORDER BY DOB"
set tStatement = ##class(%SQL.Statement).%New()
set qStatus = tStatement.%Prepare(.myquery)
IF qStatus '=1 {WRITE "%Prepare failed:" DO $System.Status.DisplayError(qStatus) QUIT}
SET rset = tStatement.%Execute(x)
Do rset.%Display()
WRITE !, "End of data"
}
当你prepare一个查询时,该查询的优化版本被存储为一个缓存的查询。这个缓存的查询在随后的查询调用中被执行,避免了每次执行查询时重新优化的开销。
限制
注意InterSystems SQL的以下限制:
NLS可以用来指定$ORDER的行为,用于特定的国家地区语言行为的Global,以及当前运行进程中的本地变量。InterSystems SQL可以在任何国家语言区划内使用,并且运行良好。然而,目前InterSystems SQL的一个限制是,对于任何特定的进程,它所引用的所有相关的globals都必须使用与当前进程locale相同的国家locale。
公告
jieliang liu · 三月 30, 2022
HI 开发者们,
我们在bilibili 发布了新的视频!
看看VS Code的InterSystems ObjectScript的调试器如何帮助你浏览和检查代码。了解如何为调试类方法和production组件编写启动配置,并获得VS Code调试器界面的概述--包括变量部分、观察窗格和调试控制台。
请欣赏并继续关注! B 站视频可以支持中文字幕:https://www.bilibili.com/video/BV1cb4y1p7RE?spm_id_from=333.337.search-card.all.click
文章
Jingwei Wang · 七月 28, 2022
定义 Stored Procedures
可以使用以下方式定义stored procedures
使用DDL定义存储过程
使用类方法定义存储过程
使用DDL定义存储过程
CREATE PROCEDURE 可以创建一个查询,它总是作为一个存储过程被预测。一个查询可以返回一个单一的结果集。
CREATE PROCEDURE AgeQuerySP(IN topnum INT 10, IN minage INT 20)
BEGIN
SELECT TOP :topnum Name, Age FROM Sample.Person
WHERE Age > :minage;
END
列表中的每个参数声明包括(按顺序)。指定参数模式是IN(输入值),OUT(输出值),还是INOUT(修改值)。如果省略,默认的参数模式是IN,参数名称是区分大小写的。
CREATE QUERY 可以创建一个可以选择作为存储过程投射的查询。一个查询可以返回一个单一的结果集,这个查询可能是也可能不是作为存储过程公开的。要创建一个作为存储过程公开的查询,你必须指定PROCEDURE关键字作为其特征之一。你也可以使用CREATE PROCEDURE语句来创建一个作为存储过程公开的查询。
为了创建一个查询,你必须拥有%CREATE_QUERY管理权限,正如GRANT命令所指定的那样。如果类的定义是一个已部署的类,你不能在该类中创建一个查询。
CREATE QUERY AgeQuery(IN topnum INT DEFAULT 10,IN minage INT 20)
PROCEDURE
BEGIN
SELECT TOP :topnum Name,Age FROM Sample.Person
WHERE Age > :minage ;
END
使用类定义存储过程
要定义一个方法存储过程,只需定义一个类方法并设置其SqlProc关键字。
Class MyApp.Person Extends %Persistent [DdlAllowed]
{
/// This procedure finds total sales for a territory
ClassMethod FindTotal(territory As %String) As %Integer [SqlProc]
{
// use embedded sql to find total sales
&sql(SELECT SUM(SalesAmount) INTO :total
FROM Sales
WHERE Territory = :territory
)
Quit total
}
}
这个类被编译后,FindTotal()方法将作为存储过程MyApp.Person_FindTotal()投射到SQL。你可以使用该方法的SqlName关键字改变SQL对存储过程的命名。
该方法使用一个存储过程上下文处理程序,在存储过程和其调用者(例如,ODBC服务器)之间来回传递存储过程上下文。这个过程上下文处理程序是由InterSystems IRIS使用%sqlcontext对象自动生成的(作为%qHandle:%SQLProcContext)。
%sqlcontext由SQLCODE错误状态、SQL行数、错误信息等属性组成,使用相应的SQL变量进行设置,如下所示。
SET %sqlcontext.%SQLCODE=SQLCODE
SET %sqlcontext.%ROWCOUNT=%ROWCOUNT
SET %sqlcontext.%Message=%msg
使用 Stored Procedures
当执行一个以SQL函数为参数的存储过程时,使用CALL来调用该存储过程,如下面的例子.
CALL sp.MyProc(CURRENT_DATE)
SELECT查询不支持执行带有SQL函数参数的存储过程。SELECT支持用一个SQL函数参数执行一个存储函数。
xDBC不支持使用SELECT或CALL来执行一个带有SQL函数参数的存储过程。
你可以在一个SQL查询中使用一个存储函数,就像它是一个内置的SQL函数一样。函数的名称是存储函数的SQL名称(在这里是 "Square"),由定义它的schema(包)名称限定(在这里是 "MyApp")。
下面的查询使用了Square函数。
SELECT Cost, MyApp.Utils_Square(Cost) As SquareCost FROM Products
查询Stored Procedures 信息
INFORMATION.SCHEMA.ROUTINES持久化类显示关于当前命名空间中所有routine和程序的信息。
下面的例子返回routine名称,方法或查询名称,routine类型(PROCEDURE或FUNCTION),routine主体(SQL=带SQL的类查询,EXTERNAL=不带SQL的类查询),返回数据类型,以及当前名称空间中模式 "Sample "中所有routine的routine定义。
SELECTROUTINE_NAME,METHOD_OR_QUERY_NAME,ROUTINE_TYPE,ROUTINE_BODY,SQL_DATA_ACCESS,IS_USER_DEFINED_CAST,
DATA_TYPE||' '||CHARACTER_MAXIMUM_LENGTH AS Returns,NUMERIC_PRECISION||':'||NUMERIC_SCALE ASPrecisionScale,
ROUTINE_DEFINITION
FROM INFORMATION_SCHEMA.ROUTINES WHERE ROUTINE_SCHEMA='Sample'
INFORMATION.SCHEMA.PARAMETERS持久化类显示当前命名空间中所有routine和程序的输入和输出参数的信息。
下面的例子返回了当前命名空间中模式 "Sample "中所有routine的routine名称、参数名称、是输入参数还是输出参数,以及参数数据类型信息。
SELECT SPECIFIC_NAME,PARAMETER_NAME,PARAMETER_MODE,ORDINAL_POSITION,
DATA_TYPE,CHARACTER_MAXIMUM_LENGTH AS MaxLen,NUMERIC_PRECISION||':'||NUMERIC_SCALE AS PrecisionScale
FROM INFORMATION_SCHEMA.PARAMETERS WHERE SPECIFIC_SCHEMA='Sample'
文章
Jingwei Wang · 七月 28, 2022
InterSystems SQL支持在InterSystems IRIS数据平台数据库中将流数据存储为BLOB(Binary Large Objects 二进制大对象)或CLOB(Character Large Objects字符大对象)的能力。
InterSystems SQL支持两种流字段:
字符流:用于大量的文本。
二进制流:用于图像、音频或视频。
BLOBs和CLOBs可以存储多达4GB的数据(JDBC和ODBC规范规定的限制)。除了在通过ODBC或JDBC客户端访问时如何处理字符编码转换(如Unicode到多字节)外,BLOB和CLOB的操作在各方面都是相同的:BLOB中的数据被视为二进制数据,决不转换为其他编码,而CLOB中的数据被视为字符数据,在必要时进行转换。
如果一个二进制流文件(BLOB)包含单一的非打印字符$CHAR(0),它被认为是一个空的二进制流。它相当于""空二进制流值:它存在(不是空的),但长度为0。
从对象的角度来看,BLOB和CLOBs被表示为流对象。更多信息请参见定义和使用类中的 "与流合作 "一章。
定义流数据字段
InterSystems SQL支持流字段的各种数据类型名称。这些InterSystems的数据类型名称是对应于以下的同义词。
字符流:数据类型LONGVARCHAR,映射到%Stream.GlobalCharacter类和ODBC/JDBC数据类型-1。
字符流:数据类型LONGVARBINARY,映射到%Stream.GlobalBinary类和ODBC/JDBC数据类型-4。
下面的例子定义了一个包含两个流字段的表。
CREATE TABLE Sample.MyTable (
Name VARCHAR(50) NOT NULL,
Notes LONGVARCHAR,
Photo LONGVARBINARY)
流字段的限制:
一个流字段可以被定义为NOT NULL。
一个流字段可以取一个DEFAULT值,一个ON UPDATE值,或者一个COMPUTECODE值。
一个流字段不能被定义为UNIQUE,一个主键字段,或一个IdKey。试图这样做会导致一个SQLCODE -400的致命错误,并带有%msg,如以下。ERROR #5414: 无效的索引属性。Sample.MyTable::MYTABLEUNIQUE2::Notes, Stream属性在唯一/主键/idkey索引中是不允许的 > ERROR #5030: 在编译'Sample.MyTable'类时发生错误。
不能用指定的COLLATE值定义一个流字段。试图这样做会导致一个SQLCODE -400的致命错误,并带有%msg,如以下。ERROR #5480: 属性参数没有声明。Sample.MyTable:Photo:COLLATION > ERROR #5030: 在编译'Sample.MyTable'类时发生错误。
在流数据字段中插入数据
有三种方法可以将数据插入到流字段。
%Stream.GlobalCharacter字段:你可以直接插入字符流数据。例如:
INSERT INTO Sample.MyTable (Name,Notes)
VALUES ('Fred','These are extensive notes about Fred')
%Stream.GlobalCharacter和%Stream.GlobalBinary字段:你可以使用OREF插入流数据。你可以使用Write()方法将一个字符串追加到字符流中,或者使用WriteLine()方法将一个带有行终止符的字符串追加到字符流中。默认情况下,行结束符是$CHAR(13,10)(回车/换行);你可以通过设置LineTerminator属性改变行结束符。 在下面的例子中,第一部分创建了一个由两个字符串和它们的终止符组成的字符流,然后使用嵌入式SQL将其插入到一个流字段中。例子的第二部分返回字符流的长度并显示字符流数据,显示终止符。
ClassMethod CreateAndInsertCharacterStream()
{
Set gcoref = ##class(%Stream.GlobalCharacter).%New()
DO gcoref.WriteLine("First Line")
Do gcoref.WriteLine("Second Line")
&sql(INSERT INTO Sample.MyTable(Name, Notes)
VALUES('Fred',:gcoref))
IF SQLCODE<0 {WRITE "SQLCODE ERROR:"_SQLCODE_" "_%msg QUIT}
ELSE {WRITE "Insert successful",!}
do ..DisplayTheCharacterStream(gcoref)
}
ClassMethod DisplayTheCharacterStream(gcoref As %Stream.GlobalCharacter)
{
KILL ^CacheStream
WRITE gcoref.%Save(),!
ZWRITE ^CacheStream
}
%Stream.GlobalCharacter和%Stream.GlobalBinary字段:你可以通过从文件中读取数据来插入流数据。比如说
ClassMethod InsertDataFromImage()
{
Set myf = "C:\Temps\IMG.png"
OPEN myf:("RF"):10
USE myf:0
READ x(1):10
&sql(INSERT INTO Sample.MyTable (Name,Photo) VALUES ('George',:x(1)))
IF SQLCODE <0 {WRITE "INSERT Failed:"_SQLCODE_" "_%msg QUIT}
CLOSE myf
}
作为DEFAULT值或计算值插入的字符串数据将以适合于流字段的格式存储。
查询流字段数据
二进制流字段返回字符串<binary>。
SELECT Name,Photo,Notes
FROM Sample.MyTable WHERE Photo IS NOT NULL
DISTINCT, GROUP BY, 和 ORDER BY
每个流数据字段的OID值都是唯一的,即使数据本身包含重复的内容。这些SELECT子句对流的OID值进行操作,而不是数据值。因此,当应用于查询中的流字段时。
DISTINCT子句对重复的流数据值没有影响。DISTINCT子句将流字段为NULL的所有记录记录减少到一个NULL记录。DISTINCT对流字段的OID进行操作,而不是它的实际数据。
GROUP BY子句对重复的流数据值没有影响。GROUP BY子句将流字段为NULL的所有记录数减少到一个NULL记录。GROUP BY StreamField的操作对象是一个流字段的OID,而不是它的实际数据。
ORDER BY子句根据流数据值的OID值,而不是数据值来排序。ORDER BY子句在列出有流字段数据值的记录之前,先列出流字段为NULL的记录。
predicate 条件和流
IS [NOT] NULL 可以应用于流字段的数据值,如下面的例子中所示。
SELECT Name,Notes
FROM Sample.MyTable WHERE Notes IS NOT NULL
BETWEEN, EXISTS, IN, %INLIST, LIKE, %MATCHES, 和 %PATTERN谓词可以应用于流对象的OID值,如下面的例子所示。
SELECT Name,Notes
FROM Sample.MyTable WHERE Notes %MATCHES '*1[0-9]*GlobalChar*' 。
试图在一个流字段上使用任何其他的predicate条件会导致SQLCODE -313错误。
聚合函数和流
COUNT聚合函数接收一个流字段,并对包含该字段非空值的记录进行计数,如下面的例子所示:
SELECT COUNT(Photo) AS PicRows,COUNT(Notes) AS NoteRows
FROM Sample.MyTable
然而,COUNT(DISTINCT)不支持流字段。对流字段不支持其他聚合函数。试图用任何其他聚合函数来使用流字段会导致SQLCODE -37错误。
标量函数和流
除了%OBJECT、CHARACTER_LENGTH(或CHAR_LENGTH或DATALENGTH)、SUBSTRING、CONVERT、XMLCONCAT、XMLELEMENT、XMLFOREST和%INTERNAL函数外,InterSystems SQL不能将任何函数应用到流字段。试图使用流字段作为任何其他SQL函数的参数会导致SQLCODE -37错误。
%OBJECT函数打开一个流对象(接受一个OID),并返回oref(对象引用),如以下例子所示:
SELECT Name,Notes,%OBJECT(Notes) AS NotesOref
FROM Sample.MyTable WHERE Notes IS NOT NULL
CHARACTER_LENGTH,CHAR_LENGTH和DATALENGTH函数取一个流字段,并返回实际的数据长度,如下面的例子所示。
SELECT Name,DATALENGTH(Notes) AS NotesNumChars
FROM Sample.MyTable WHERE Notes IS NOT NULL
SUBSTRING函数接收一个流字段,并返回流字段实际数据值的指定子串,如下面的例子所示。
SELECT Name,SUBSTRING(Notes,1,10) AS Notes1st10Chars
FROM Sample.MyTable WHERE Notes IS NOT NULL
当从管理门户的SQL执行界面发出时,SUBSTRING函数最多返回流字段数据的100个字符的子串。如果指定的流数据子串长于100个字符,会在第100个字符后面用省略号(...)表示。
CONVERT函数可以用来将流数据类型转换为VARCHAR,如下面的例子所示。
SELECT Name,CONVERT(VARCHAR(100),Notes) AS NotesTextAsStr
FROM Sample.MyTable WHERE Notes IS NOT NULL
CONVERT(datatype,expression)语法支持流数据转换。如果VARCHAR精度小于实际流数据的长度,它将返回值截断为VARCHAR精度。如果VARCHAR精度大于实际流数据的长度,返回值就有实际流数据的长度。不进行填充。
{fn CONVERT(expression,datatype)}语法不支持流数据转换;它发出SQLCODE -37错误。
%INTERNAL函数可以在流字段上使用,但不执行任何操作。
流字段并发锁定
InterSystems IRIS通过在流数据上加锁来保护流数据值不受另一个进程的并发操作。
InterSystems IRIS在执行写操作之前会拿出一个独占锁。写操作完成后,独占锁会立即释放。
InterSystems IRIS在第一次读操作发生时取出一个共享锁。只有在实际读取流时才会获得共享锁,并且在整个流从磁盘读入内部临时输入缓冲区后立即释放。
在InterSystems IRIS方法中使用流字段
你不能在InterSystems IRIS方法中直接使用嵌入式SQL或动态SQL来使用BLOB或CLOB值;而是要使用SQL来找到BLOB或CLOB的流标识符,然后创建%AbstractStream对象的实例来访问数据。
从ODBC使用流字段
ODBC规范没有为BLOB和CLOB字段提供任何识别或特殊处理。
InterSystems SQL在ODBC中表示CLOB字段为LONGVARCHAR (-1)类型。BLOB字段被表示为LONGVARBINARY类型(-4)。
从JDBC使用流字段
在一个Java程序中,你可以使用标准的JDBC BLOB和CLOB接口从BLOB或CLOB中检索或设置数据。比如说
Statement st = conn.createStatement()。
ResultSet rs = st.executeQuery("SELECT MyCLOB,MyBLOB FROM MyTable")。
rs.next(); // 取出Blob/Clob
java.sql.Clob clob = rs.getClob(1);
java.sql.Blob blob = rs.getBlob(2);
// Length
System.out.println("Clob length = " + clob.length())。
System.out.println("Blob length = " + blob.length())。
// ...
注意:当完成对BLOB或CLOB的处理时,你必须明确地调用free()方法来关闭Java中的对象,并向服务器发送消息以释放流资源(对象和锁)。
公告
Claire Zheng · 八月 22, 2022
2022年8月22日,中国 北京 —— 致力于帮助客户解决最关键的可扩展性、互操作性和速度问题的创新数据技术提供商InterSystems今日宣布在中国推出InterSystems IRIS医疗版互联互通套件2.0版,更好地满足用户对数据利用的需求。医疗技术的进步带来了呈指数级增长的数据量,医疗数据变得更分散、异构性更强、数据量更大,互操作性变得比以往任何时候都更加重要,更具挑战性。在国内,中国医院信息互联互通标准化成熟度测评工作自启动以来,已成为医院数据实现互联互通的重要建设标准。在国际上,HL7 FHIR®(快速医疗互操作性资源)缩小了医疗数据爆炸与数据应用能力之间的差距,成为面向未来的医疗数据互操作的标准。近年来,FHIR引起国内业内人士越来越多的关注与认可。此次推出的InterSystems IRIS医疗版互联互通套件2.0版本打通了国际、国内互联互通生态,有助于推动医疗数据的有效利用。
作为医疗行业数据技术和基于标准的互操作性的领导者,InterSystems长期致力于基于FHIR提供解决方案以解决医疗行业面临的挑战。2021年,InterSystems中国结合国内新版测评标准推出InterSystems IRIS医疗版互联互通套件,满足了医院快速落地互联互通标准化成熟度测评涉及到的标准化改造需求,广受市场认可。点击此处了解“InterSystems IRIS医疗版互联互通套件”详情。
InterSystems最新推出的InterSystems IRIS医疗版互联互通套件2.0版在原有服务基础上,打通了国内互联互通生态与FHIR生态,支持互联互通文档转换为FHIR资源,这一创新举措有效填补了市场空白。通过转换,满足FHIR标准的医疗数据能够在多种业务场景下更易获取和应用。InterSystems IRIS医疗版互联互通套件2.0版解决了长期以来大量医疗数据无法得到有效利用的难题,有利于提升医疗数据的利用价值,助力医疗机构持续实现业务创新。对用户而言,基于InterSystems IRIS医疗版数据平台,即可一键部署FHIR资源仓库,并基于FHIR API和资源开发临床、科研和健康管理等新应用。
此外,InterSystems IRIS医疗版互联互通套件2.0版可为用户提供一套完整的API,实现对互联互通平台的监控和管理,提升用户的业务管理能力。
InterSystems技术兼备高性能与稳定性,在国内连续多年支持数百家大型公立医院海量数据稳定运行。主流PC服务器单实例下,支持日消息吞吐量可高达27.64亿。截至2021年,InterSystems技术已助力一百余家医院通过四级及以上医院信息互联互通标准化成熟度评级,其中,五乙用户占全国30%以上。
InterSystems 亚太区总经理卢侠亮表示:“FHIR能够实时访问分布在各系统、数据库和设备上的数据,因此被行业称为面向未来的医疗数据标准,对于希望有效利用数据价值的用户来说,FHIR是不容错过的。InterSystems多年来始终致力于FHIR建设,我相信InterSystems IRIS医疗版互联互通套件2.0将为中国用户带来更高效的标准化互联互通技术保障。”
2022年8月19日,“InterSystems IRIS医疗版互联互通套件2.0”线上发布会成功举办,会议包括“产品演示”与“互动答疑”两个环节,欢迎点击此处观看发布会回放,了解更多详情。
如果您希望了解更多相关内容,欢迎跟帖回复!
文章
Louis Lu · 一月 26, 2022
许多使用InterSystems IRIS的用户在调试代码的时候习惯使用命令行的方式,比如运行一个函数查看输出或者查看代码运行过程中保存在global中的数据等等。
对于将 InterSystems IRIS 安装在 Windows 操作系统的用户,只需要点击右下角图标选择Terminal 就可以很方便的使用。
但是对于将其安装到 Linux 或者Docker 容器中的用户,要使用命令行却不那么方便,下面我将会介绍在我们 Openexchange 中的一个应用 -- Web Terminal。
也就是说可以在网页中直接执行Terminal中的命令。
或者查看SQL执行结果:
可以在其中输入 /help ,获取更多帮助信息
安装
1. 点击进入项目下载页面,选择下载最新的版本。
2. 在任意的命名空间下导入下载的xml文件。
注意在这里选择导入文件的同时也要勾选上 “编译导入的项”
3. 之后会出现下面提示导入成功的提示
如果出现类似于下面的错误提示:
请将下载的 WebTerminal-v4.9.3.xml 文件编辑做下面修改
1 . 第1611行:修改为
set requiredRole = "%DB_IRISSYS"
2. 第1730行:修改为
set dbPrefix = "IRIS"
重新导入就可以了。
使用
安装上面步骤安装完后,只需要在浏览器中输入网址:http://[host]:[port]/terminal/ (注意最后的 / 符号必须有)(比如:http://localhost:52777/terminal/)
输入访问的用户名密码后,就可以进入网页版本的terminal了
在Openexchange中详细介绍的地址在这里,更详细的文档可以点击这里