按查看数
按查看数前言
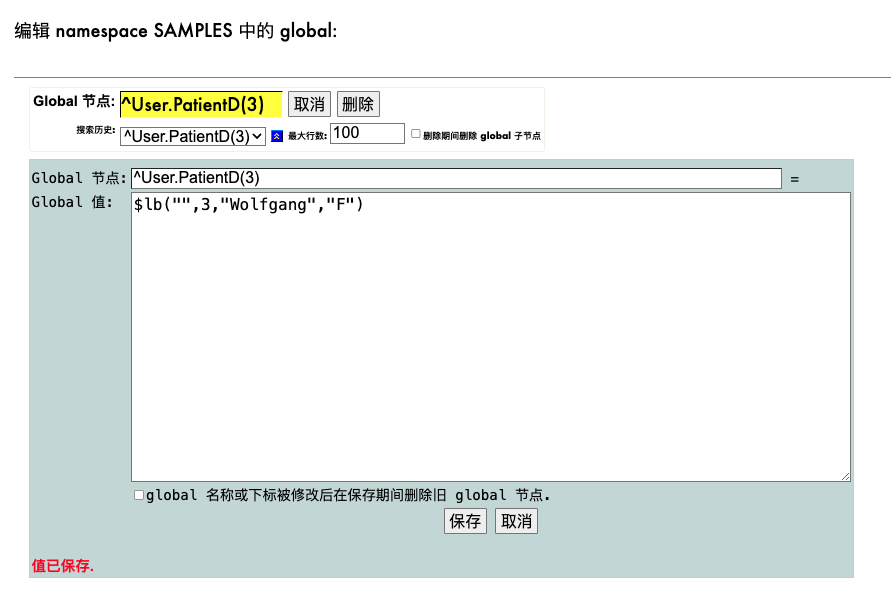
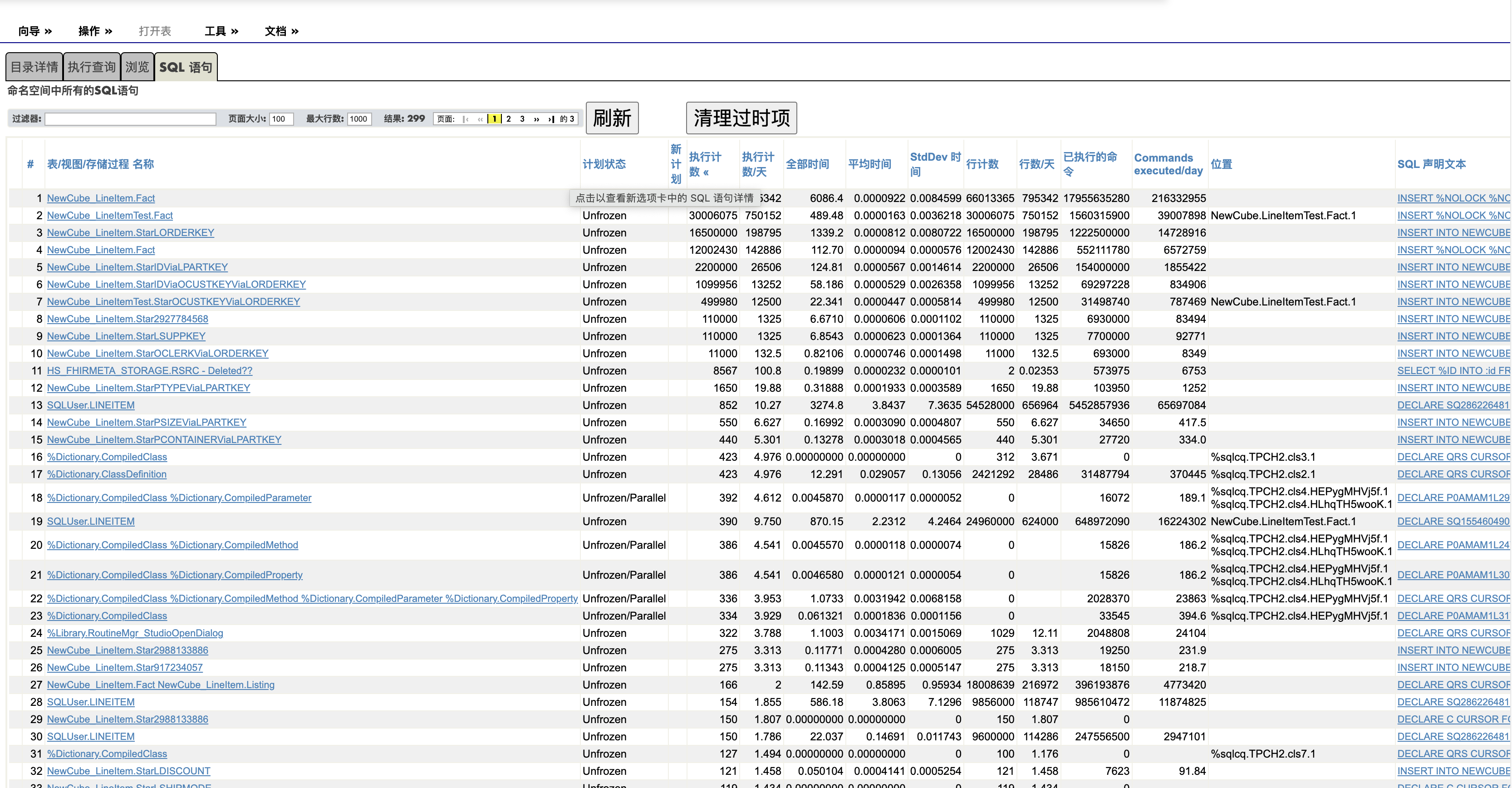
ensemble里边实现分页比较麻烦,毕竟对于sql的书写比较麻烦,单表的查询相对简单,对于多表的关联查询单纯的sql不好查询,我们使用sql进行先查询出主表满足条件的rowId,在根据根据满足条件的rowid进行遍历取值。
思路
我们先取对比一下其他数据库实现的原理。
-
Mysql的实现原理
总数:SELECT COUNT(*) AS total FROM person WHERE (name LIKE ?)
分页:SELECT id,name,age,email FROM person WHERE (name LIKE ?) LIMIT ?,?
.png)
 Open Exchange app
Open Exchange app
.png)

.png)
.png)