You have probably heard a lot about LLMs (Large Language Models) and the associated development of RAG (Retrieval Augmented Generation) applications over the last year. Well, in this series of articles we will explain the fundamentals of each term used and see how to develop a simple RAG application.
What is an LLM?
LLM models are part of what we know as generative AI and their foundation is the vectorization of huge amounts of texts. Through this vectorization we will obtain a vector space (excuse the redundancy) in which related words or terms will be closer to each other than to less related words.
.png)
Although the simplest way to visualize it is a 3-dimensional graph like the one in the previous image, the number of dimensions can be as large as desired; the greater the dimensions, the greater the precision in the relationships between terms and words and the greater the resource consumption of the same.
These models are trained with massive data sets that allow them to have enough information to be able to generate texts related to the request made to them, but... how does the model know which terms are related to the question asked? Very simple, by the so-called "similarity" between vectors, this is nothing more than a mathematical calculation that allows us to elucidate the distance between two vectors. The most common calculations are:
Through this type of calculation, the LLM will be able to put together a coherent answer based on terms close to the question asked in relation to its context.
All this is very well, but these LLMs have a limitation when it comes to their application for specific uses, since the information with which they have been trained is usually quite "general." If we want an LLM model to adapt to the specific needs of our business, we will have two options:
Fine tuning
Fine tuning is a technique that allows the retraining of LLM models with data related to a specific topic (procedural language, medical terminology, etc.). Using this technique, we can have models that are better suited to our needs without having to train a model from scratch.
The main drawback of this technique is that we still need to provide the LLM with a huge amount of information for such retraining and sometimes this can fall "short" of the expectations of a particular business.
Retrieval Augmented Generation
RAG is a technique that allows the LLM to include the context necessary to answer a given question without having to train or retrain the model specifically with the relevant information.
How do we include the necessary context in our LLM? It's very simple: when sending the question to the model, we will explicitly tell it to take into account the relevant information that we attach to answer the query made, and to do so, we will use vector databases from which we can extract the context related to the question submitted.
What is the best option for my problem, Fine tuning or RAG?
Both options have their advantages and disadvantages. On the one hand, Fine tuning allows you to include all the information related to the problem you want to solve within the LLM model, without needing third-party technologies such as a vector database to store contexts. On the other hand, it ties you to the retrained model, and if it does not meet the model's expectations, migrating to a new one can be quite tedious.
On the other hand, RAG needs features such as vector searches to be able to know which is the most exact context for the question we are passing to our LLM. This context must be stored in a vector database on which we will later perform queries to extract said information. The main advantage (apart from explicitly telling the LLM to use the context we provide) is that we are not tied to the LLM model, being able to change it for another one that is more suited to our needs.
As we have presented at the beginning of the article, we will focus on the development of an application example in RAG (without great pretensions, just to demonstrate how you can start).
Architecture of a RAG project
Let's briefly look at what architecture would be necessary for a RAG project:
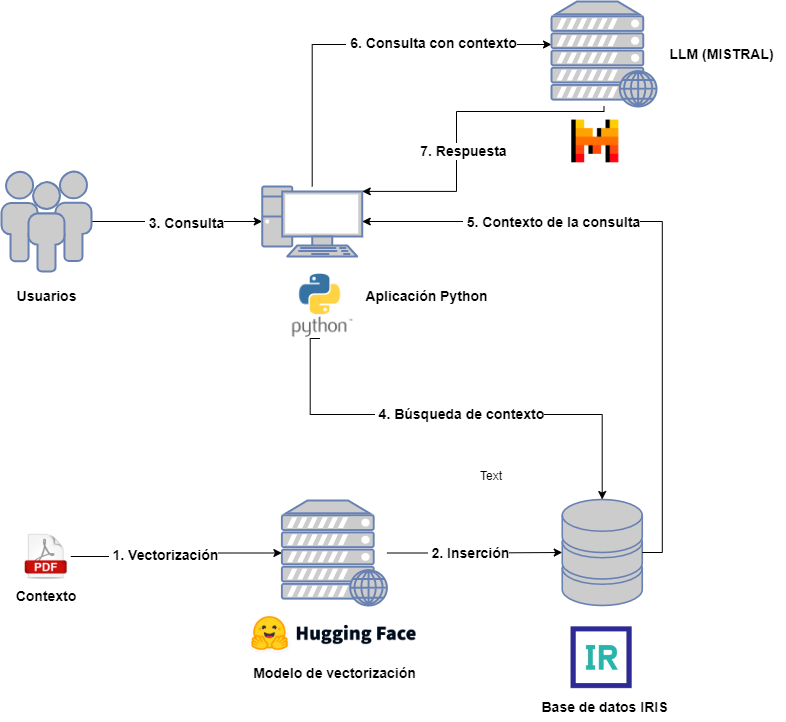
On the one hand we will have the following actors:
- Users : who will interact with the LLM by sending queries.
- Context : Provided in advance to be included in user queries.
- Vectorization model : to vectorize the different documents associated with the context.
- Vector database : in this case it will be IRIS and it will store the different vectorized parts of the context documents.
- LLM : LLM model that will receive the queries, for this example we have chosen MISTRAL.
- Python application : intended for querying the vector database for context extraction and its inclusion in the LLM query.
In order not to complicate the diagram too much, I have omitted the application in charge of capturing the documents from the context, their division and subsequent vectorization and insertion. In the associated application you can consult this step as well as the subsequent one related to the query for extraction, but do not worry, we will see it in more detail in the next articles.
Associated with this article you have the project that we will use as a reference to explain each step in detail. This project is containerized in Docker and you can find a Python application using Jupyter Notebook and an instance of IRIS. You will need an account in MISTRAL AI to include the API Key that allows you to launch queries.
.png)
In the next article we will see how to register our context in a vector database. Stay tuned!
 Open Exchange
Open Exchange