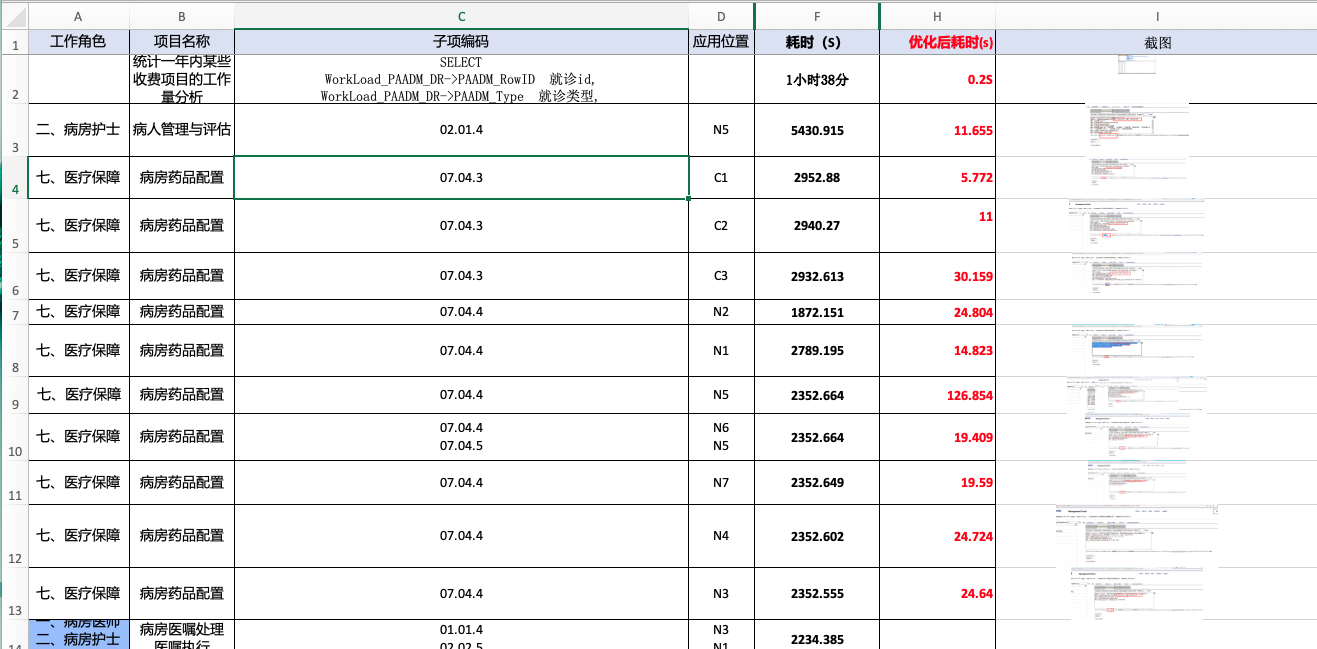
在 OEX 最近一次编程竞赛之后,我有一些令人惊讶的发现。
几乎所有的应用程序都是基于人工智能与预制 Python 模块的结合。
但深入研究后发现,所有示例都使用了 IRIS 的相同技术组件。
从 IRIS 的角度来看,无论是搜索文本还是搜索图像或其他模式都是一样的。 其底层基本都是一样的。
这让我想起了我家里的情况。我的妻子和女儿对家里的大量裙子、衬衫和其他衣服的信息进行了整理。
但无论如何进行整理、分类、归档,我依然通过和我的妻子和女儿说话,来确定我的穿着。
无论怎样包装,其结果都是如此。
回到这次竞赛比赛:
同样的 IRIS 技术内容,却有很多花哨的包装。
每个人都在同一条高速公路上奔跑。没有人提到它有什么限制。
于是我试着深入挖掘,找出新数据类型 VECTOR 的使用限制。
所有向量都有两个基本参数
- 静态 DATATYPE:"整型integer"(或 "int")、"double"、"十进制decimal"、"字符串 "和 "时间戳"。
- 半动态 LEN(gth): > 0 通常也称为 POSITION;纯整数。
 按更新时间
按更新时间
.png)
.png)
.png)
.png)