使用 IRIS 以及 langchain 构建 问答聊天机器人
这篇文章介绍了使用由支持 langchain 框架的IRIS来实现问答聊天机器人,其重点介绍了检索增强生成(RAG)。
文章探讨了IRIS中的向量搜索如何在langchain-iris中完成数据的存储、检索和语义搜索,从而实现对用户查询的精确、快速的响应。通过无缝集成以及索引和检索/生成等流程,由IRIS驱动的RAG应用程序使InterSystems开发者能够利用GenAI系统的能力。
为了帮助读者巩固这些概念,文章提供了Jupyter notebook和一个完整的问答聊天机器人应用程序,以供参考。
什么是RAG以及它在问答聊天机器人中的角色
RAG,即检索增强生成,是一种通过整合超出初始训练集的补充数据来丰富语言模型(LLM)知识库的技术。尽管LLM在跨不同主题进行推理方面具有能力,但它们仅限于在特定截止日期之前训练的公共数据。为了使AI应用程序能够有效处理私有或更近期的数据,RAG通过按需补充特定信息来增强模型的知识。这是一种替代微调LLM的方法,微调可能会很昂贵。
在问答聊天机器人领域,RAG在处理非结构化数据查询中发挥着关键作用,包括两个主要组成部分:索引和检索/生成。
索引从数据源摄取数据开始,然后将其分割成更小、更易于管理的块以进行高效处理。这些分割的块随后被存储和索引,通常使用嵌入模型和向量数据库,确保在运行时能够快速准确地检索。
在检索和生成过程中,系统在接收到用户查询后,使用与索引阶段相同的嵌入模型生成嵌入向量,然后使用检索器组件从索引中检索相关数据块。这些检索到的段落随后传递给LLM以生成答案。
.png)
因此,RAG赋予了问答聊天机器人访问和利用结构化和非结构化数据源的能力,从而通过使用嵌入模型和向量数据库作为LLM微调的替代方案,增强了它们提供精确和最新用户查询响应的能力。
IRIS 向量搜索
InterSystems IRIS的向量搜索是一个新功能,它在数据库内启用了语义搜索和生成式AI能力。它允许用户根据数据的含义而不是原始内容来查询数据,利用了检索增强生成(RAG)架构。这项技术将非结构化数据(如文本)转换为结构化的向量,便于高效处理和响应生成。
该平台支持在关系模式中以压缩和高性能的向量类型(VECTOR)存储向量,允许与现有数据结构无缝集成。向量通过Embeddings表示语言的语义含义,相似的含义在高维几何空间中通过接近度反映出来。
通过使用点积(dot product)操作比较输入向量和存储的向量,用户可以确定两者的语义相似性,这非常适合信息检索等任务。IRIS还通过专用的向量数据类型提供高效的向量存储和操作,增强了对大型数据集操作的性能。
要利用这一能力,文本必须通过一系列步骤转换为嵌入,涉及文本预处理和模型实例化。InterSystems IRIS支持Python代码的无缝集成用于嵌入生成,以及ObjectScript用于数据库交互,使基于向量的应用实现顺畅。
你可以在这里查看更多有关向量搜索的文档和实例。
langchain-iris
简短的说,langchain-iris 是在 langchain 框架中使用 InterSystems IRIS 向量搜索的一种方式。
InterSystems IRIS 向量搜索与 langchain 的向量存储需求非常契合。IRIS 存储和检索embedding的数据,对于相似性搜索至关重要。凭借IRIS的 VECTOR 类型,IRIS 支持存储embeddings,使其可对非结构化数据进行语义搜索,并促进文档无缝处理到向量存储中。
通过利用点积比较等操作,IRIS 促进了语义相似性的比较算法,这对于 langchain 的相似性搜索需求也非常理想。
因此,langchain-iris 允许使用由 InterSystems IRIS 数据平台支持的 langchain 框架开发 RAG 应用程序。
有关 langchain-iris 的更多信息,请查看这里。
将 IRIS 作为 langchain 的向量存储目标
第一步,需要将langchain-iris导入
pip install langchain-iris之后,可以使用 IRISVector 中的方法 from_documents() :
db = IRISVector.from_documents(
embedding=embeddings,
documents=docs,
collection_name=COLLECTION_NAME,
connection_string=CONNECTION_STRING,
)其中:
- embedding:设置langchain.embeddings的embeddings模型实例,比如OpenAI或hugging faces.
- documents:是一系列字符串的数组,这些字符串将被应用于embedding模型,并且生成的向量将存储在IRIS中。通常,由于embedding模型的大小限制以及为了更好的管理,文档应该被分割;langchain框架提供了几种分割器。
- collection_name:用于文档以及他的embedding 向量存储的表的名称
- connection_string:用于连接IRIS的参数,通常使用下面的格式 iris://<username>:<password>@<hostname>:<iris_port>/<namespace>
在这里查看完整的使用 langchian-iris 的 hello world 代码。
进一步查看整个过程
首先,我们查看由langchain提供的原始版本的文档机器人示例。
这个原始示例中,使用了Chroma作为向量数据库:
from langchain_chroma import Chroma
…
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
所以,我们这里修改使用IRIS 作为向量数据库:
vectorstore = IRISVector.from_documents(
embedding=OpenAIEmbeddings(),
documents=splits,
collection_name="chatbot_docs",
connection_string=iris://_SYSTEM:SYS@localhost:1972/USER',
)
你可以在这个jupter notebook里查看完整示例代码。
当运行完示例,我们可以在IRIS中查看由 langchain-iris 创建的表,表名由SQLUser包名以及collection_name中设置:
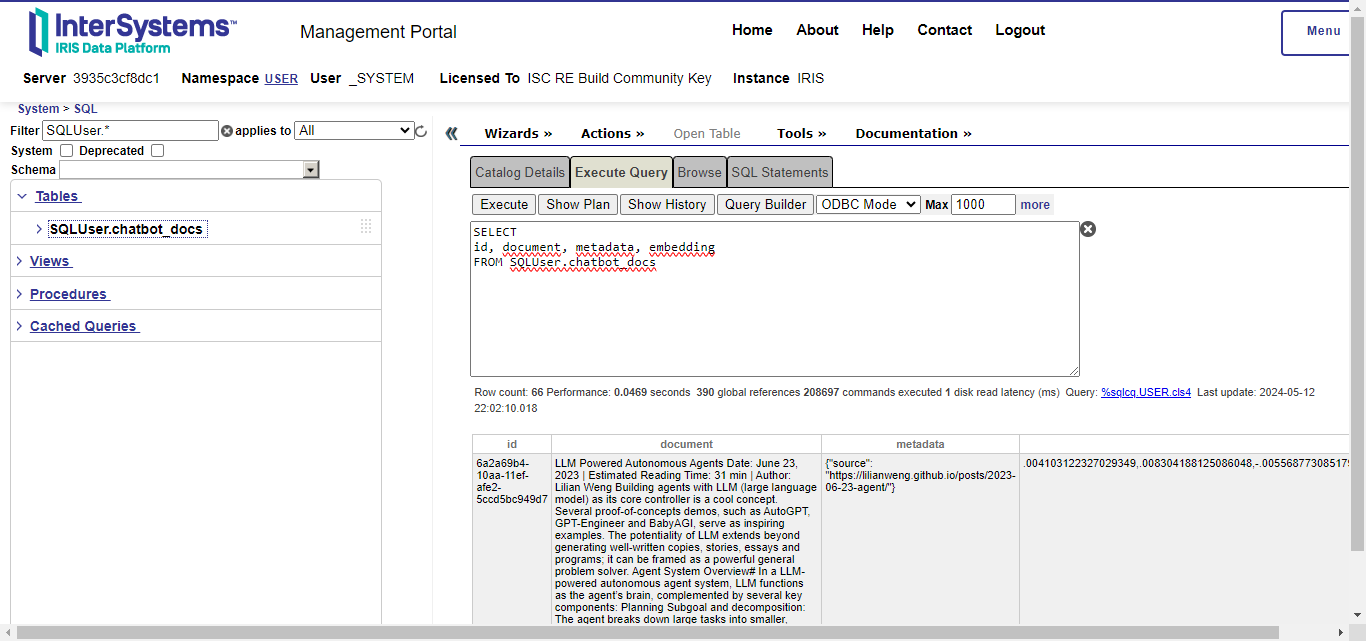
可以看到其中有四个字段组成:
- id:文档id
- dcoument:使用的文档或者将文档分割为文字块后传入的文字块
- metadata:JSON对象包含了文档的相关信息
- embedding::以embedding vector的方式保存的文档信息,这是IRIS的向量搜索功能中的VECTOR类型数据。
上面实现的是创建索引的过程。也就是langchain对每一个文档进行分割后,应用embedding 模型,并将其向量存储在IRIS中。
下一步,为了实现RAG应用,我们需要根据给定的查询字符串,在 IRIS 中查询最相关的文档,这是通过实现langchain框架中的检索器(retrievers)来实现的。
你可以使用下面的代码创建一个真对IRIS存储文档的检索器 (retriever):
retriever = vectorstore.as_retriever()
用这个检索器,您可以针对自然语言查询最相似的文档。langchain框架将使用索引步骤中使用的相同embedding模型从查询中提取向量。这样,就可以检索到与查询具有相似语义内容的文档片段。
为了举例说明,让我们使用langchain的例子,它索引了一个包含有关LLM(大型语言模型)代理信息的网页。这个页面解释了几个概念,比如任务分解。让我们看看,如果给定一个查询,比如“What are the approaches to Task Decomposition(任务分解的方法有哪些)?”,检索器会返回什么:
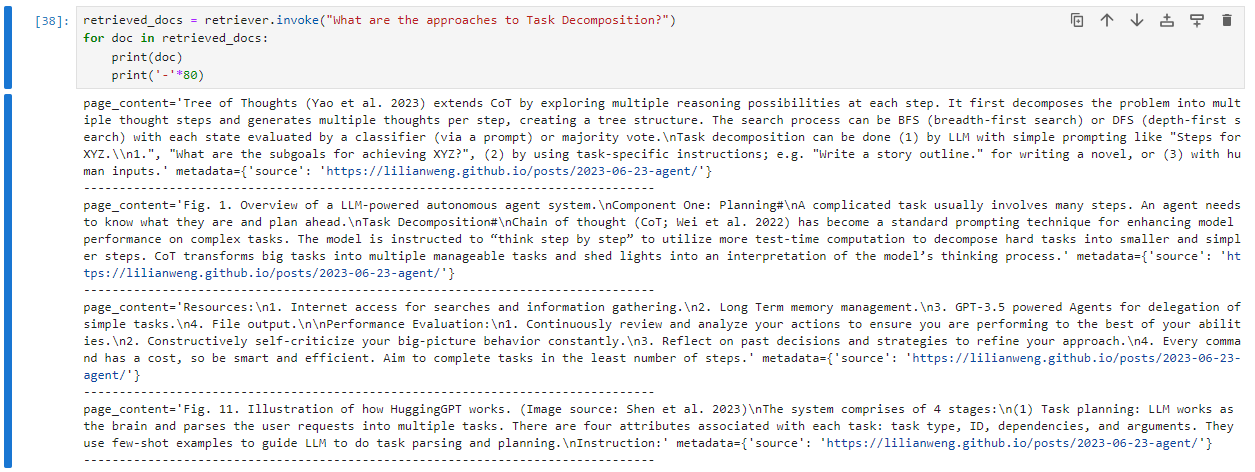
现在让我们执行一个语义上相同但句法上不同的查询,即使用具有相似含义的不同词语提问,来看看向量搜索引擎返回什么结果:
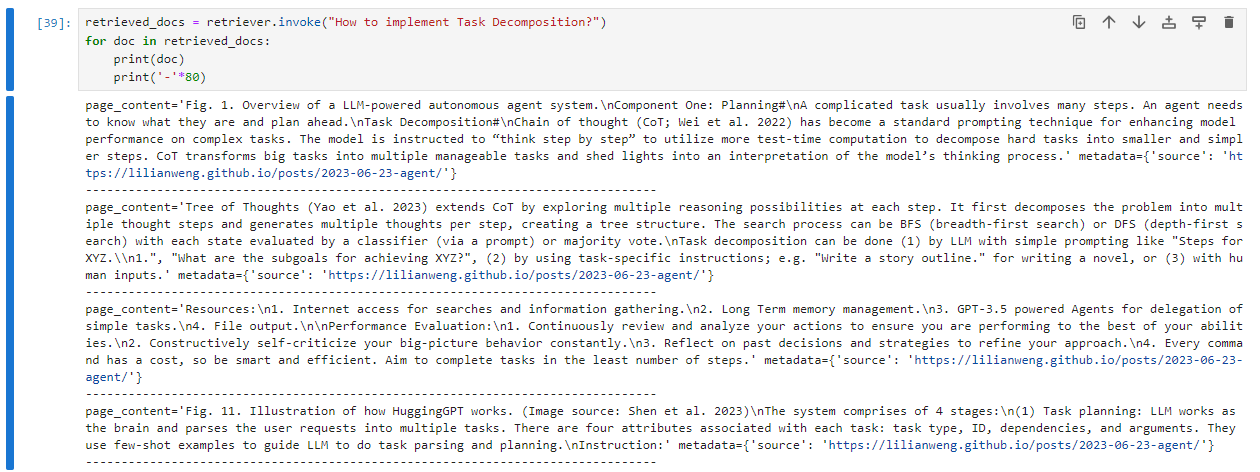
这里,我们可以看到即使传递不同的查询字符串,结果也几乎是相同的。这意味着嵌入向量在某种程度上抽象了文档和查询字符串中的语义。
为了进一步证明这种语义查询能力,现在让我们继续询问有关任务分解的问题,但这次询问它的潜在缺点:
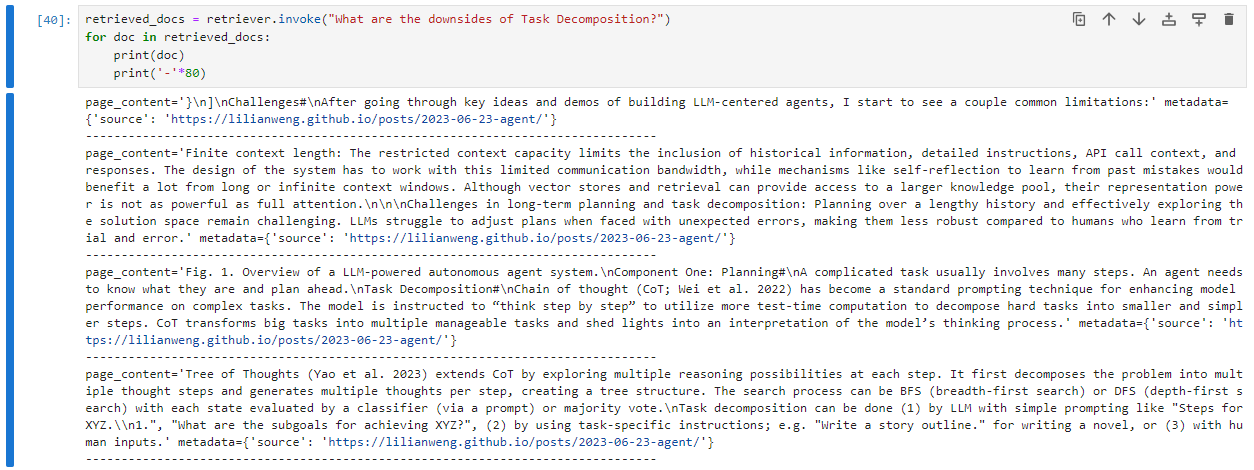
可以看到,这次最相关的结果与之前的查询不同。此外,最初的结果中并没有直接出现“downside”这个词,但包含了一些相关词汇,如“challenges”(挑战)、“limitations”(限制)和“restricted”(受限)。
这加强了嵌入向量在向量数据库中进行语义搜索的能力。
检索步骤之后,最相关的文档被添加为上下文信息,与用户查询一起发送到LLM(大型语言模型)进行处理:
from langchain import hub
prompt = hub.pull("rlm/rag-prompt")
user_query = "What are the approaches to Task Decomposition?"
retrieved_docs = [doc.page_content for doc in retriever.invoke(user_query)]
example_messages = prompt.invoke(
{"context": "filler context", "question": user_query}
).to_messages()
print(example_messages[0].content)
这段代码将会生成提示词如下,可以看到,查询的返回结果作为上下文一起递交给LLM进行处理:
"""
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: What are the approaches to Task Decomposition?
Context: Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple ... (truncated in the sake of brevity)
Answer:
"""
于是,RAG应用可以在LLM提示词长度限制的情况下增强查询的准确度。
最后几句
总结来说,将IRIS向量搜索与langchain框架的集成为InterSystems开发者社区中的问答聊天机器人和其他依赖于语义搜索和生成式AI的应用程序的开发开辟了新的视野。
通过langchain-iris将IRIS作为向量存储的无缝集成简化了实现过程,为开发者提供了一个强大而高效的解决方案,用于管理和查询大量结构化和非结构化信息的数据集。
通过索引、检索和生成过程,由IRIS向量搜索驱动的RAG应用程序可以有效地利用公共和私有数据源,增强基于LLM的AI系统的能力,为用户提供更全面和最新的响应。
最后,如果您想更深入地了解并查看一个完整的应用程序实现这些概念,以及与其他功能如互操作性和业务主机一起,与OpenAI和Telegram等外部API通信,请查看我们的应用程序iris-medicopilot。
这种集成展示了如何利用先进的技术来构建智能系统,这些系统不仅能够理解和回应用户的查询,还能够与外部服务和API进行交互,提供更加丰富和动态的用户体验。随着技术的不断发展,我们可以期待看到更多创新的应用程序,它们将利用这些工具和框架来解决现实世界的问题。