新增
- 引言
流行病学监测是公共卫生的基石之一。 Régis Júnior等人(2026)将其定义为一个针对健康事件的持续性数据收集、分析、解读和传播系统——该功能的有效性在很大程度上取决于信息系统的质量、数据分析能力以及不同医疗层级之间的协调。 在新冠疫情期间,这一职能的战略重要性已毋庸置疑:世界卫生组织(2021)的记录显示,拥有更健全监测系统的国家始终表现得更好,而监测能力方面的区域差异则直接导致了应对措施的不一致,并在发病率和死亡率方面产生了可测量的差异。
尽管医疗系统如今能够收集海量的标准化临床数据,但挑战在于如何将这些数据转化为及时且可付诸行动的洞见。传统的流行病学报告往往依赖于人工分析和定制数据库查询,由此产生的延迟可能会阻碍公共卫生部门的快速响应。
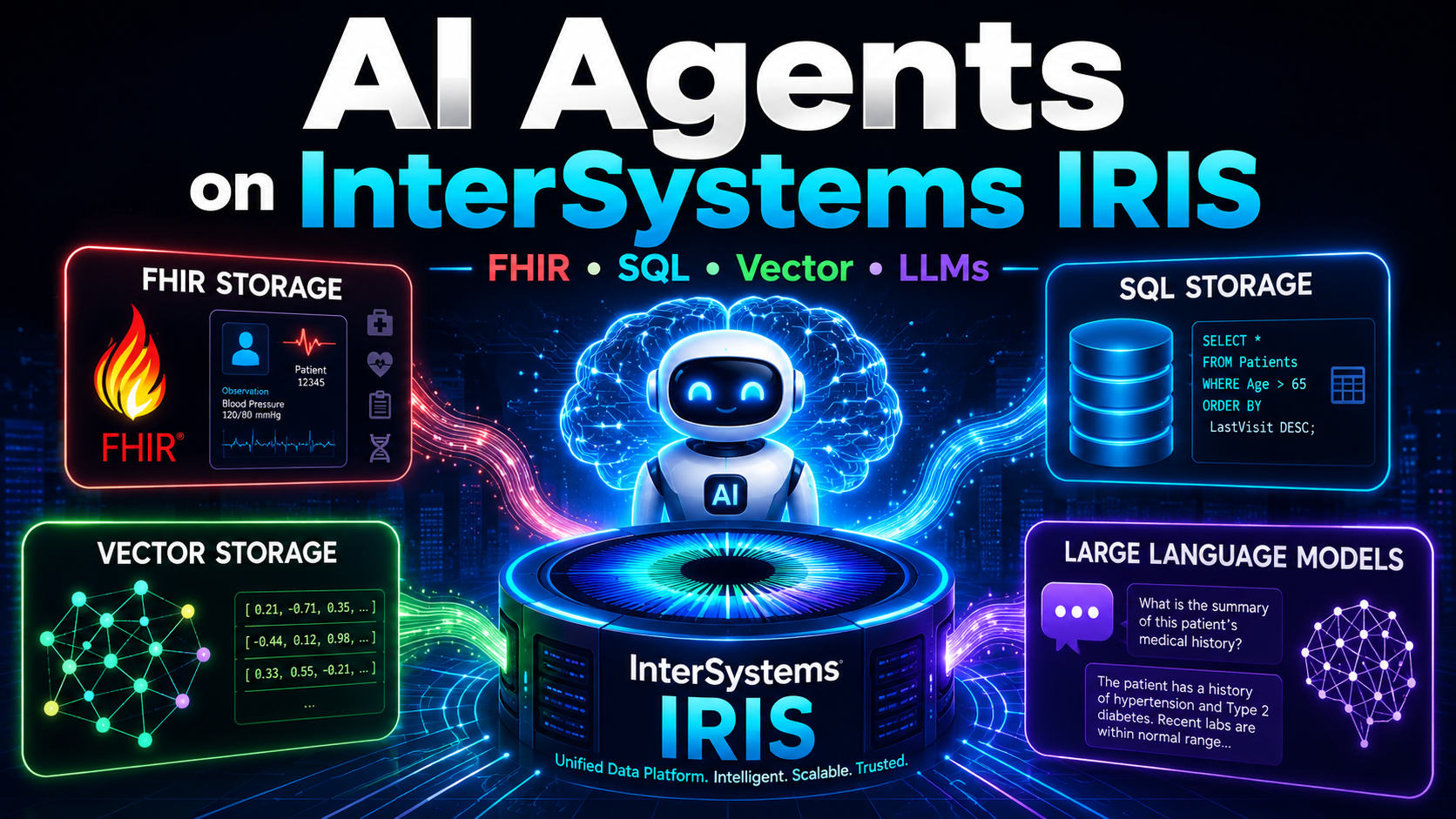
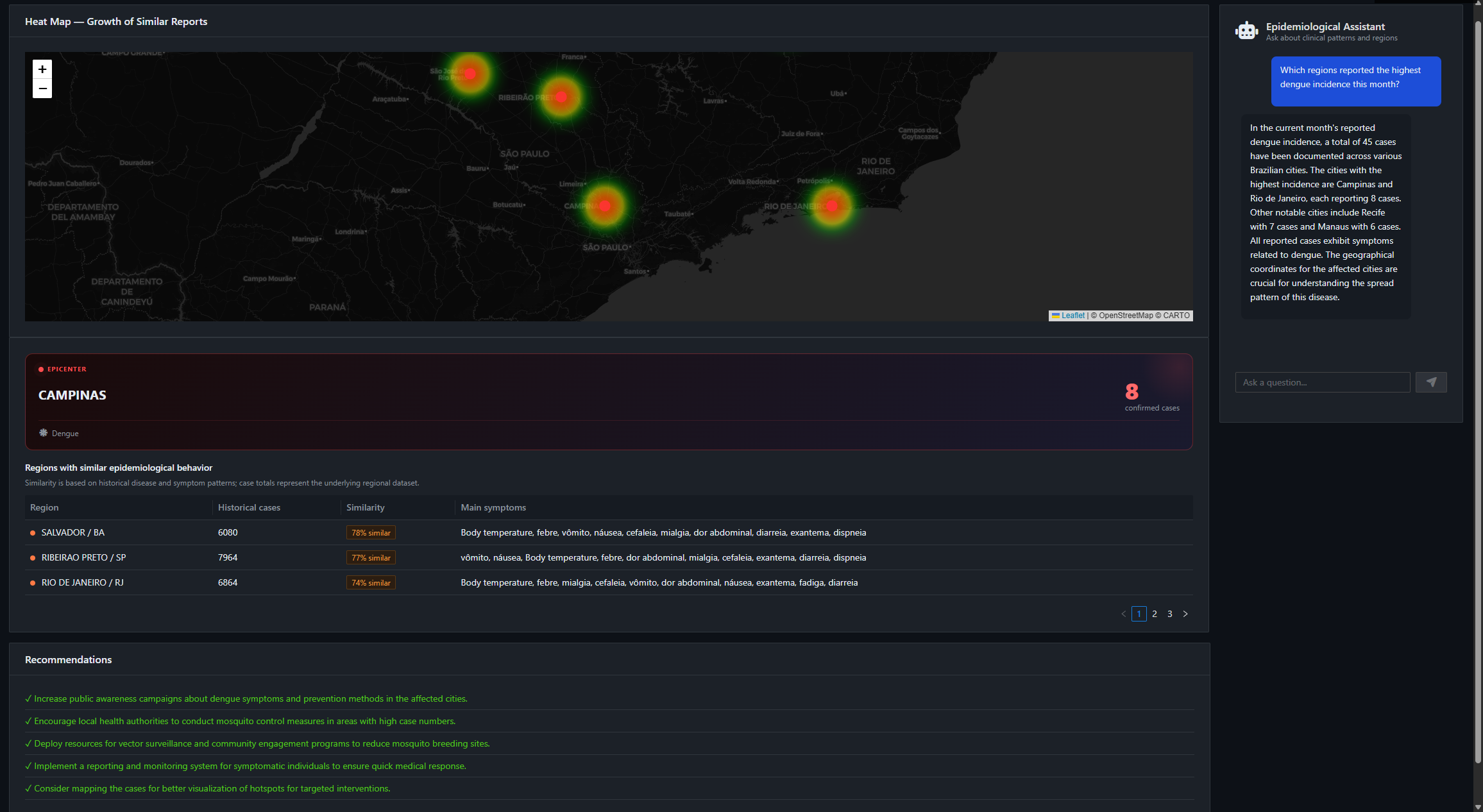
EpInsights通过整合 InterSystems IRIS for Health、嵌入式 Python 临床向量化技术、IRIS Vector Search 以及 LangChain4j 对话式智能助手,填补了这一空白。 该平台使流行病学家和卫生管理者能够提出自然语言问题,并即时获得基于真实FHIR数据的地理空间热力图、区域排名、相似聚类检测以及AI生成的建议,所有结果均在数秒内呈现。
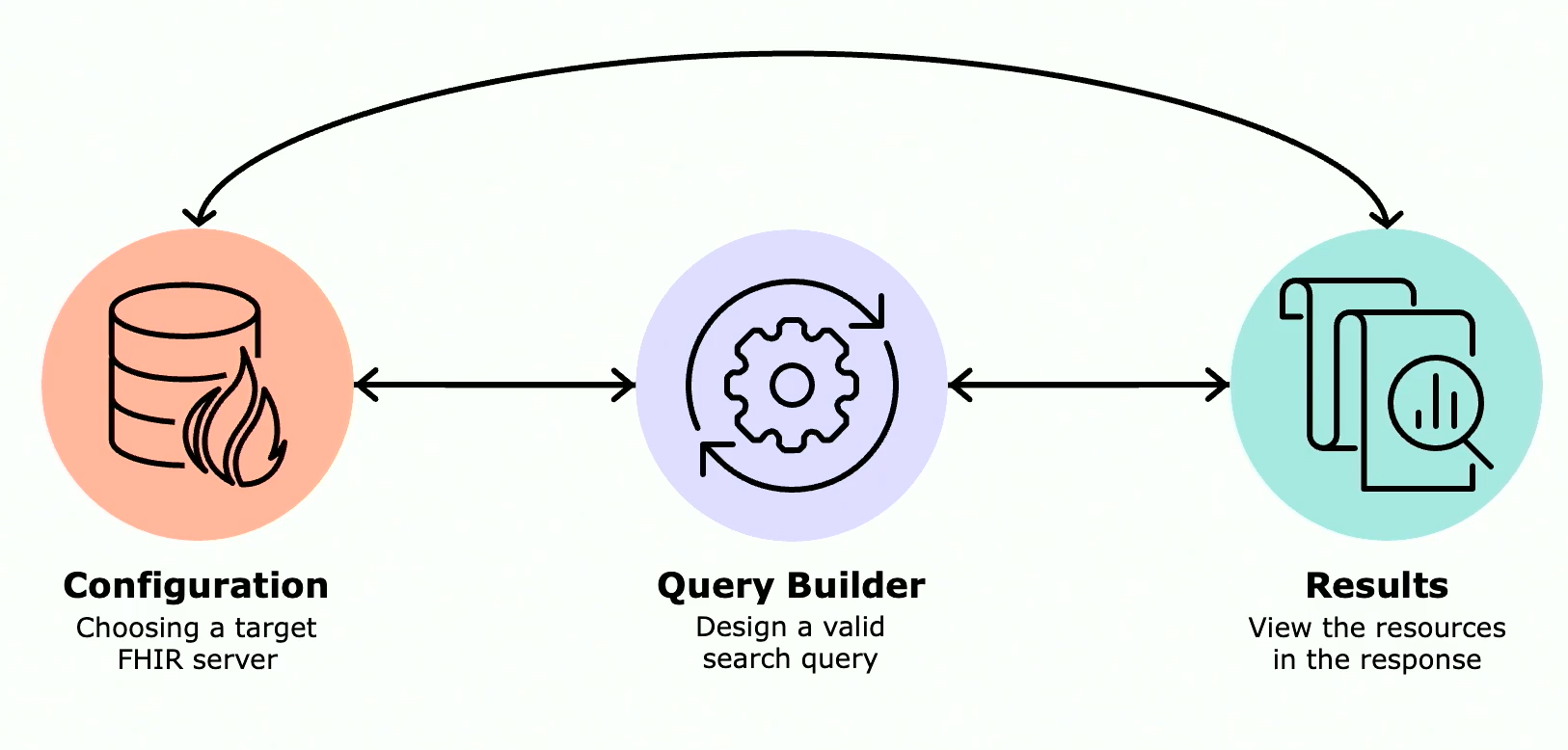
- 架构概述
EpInsights 采用三层架构,各层职责划分明确。