InterSystems 常见问题
如果您尝试从顶级节点删除在子脚本级别映射的全局变量,您将收到一个<SLMSPAN>错误,并且它不会被删除。这是因为用于子脚本级别映射全局变量的kill命令不能跨映射使用。
// Suppose subscript-mapped globals exist in different databases, as shown below:
^TEST(A*~K*) -> database A
^TEST(L*~Z*) -> database B
// Trying to kill from the top level will result in a <SLMSPAN> error.
NAMESPACE>Kill ^TEST
<SLMSPAN> <- This error is output.要只删除当前命名空间(数据库)中的全局,请使用以下命令:
NAMESPACE>Kill ^["^^."]TEST在子脚本级别映射的全局变量必须移动到数据库并直接删除。
要切换到数据库,请使用以下命令:
zn "^^c:\intersystems\iris\mgr\user"
or
set $namespace="^^c:\intersystems\iris\mgr\user"使用 $System.OBJ.
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png) 它不会消失。它产生的子进程其实是可以使用
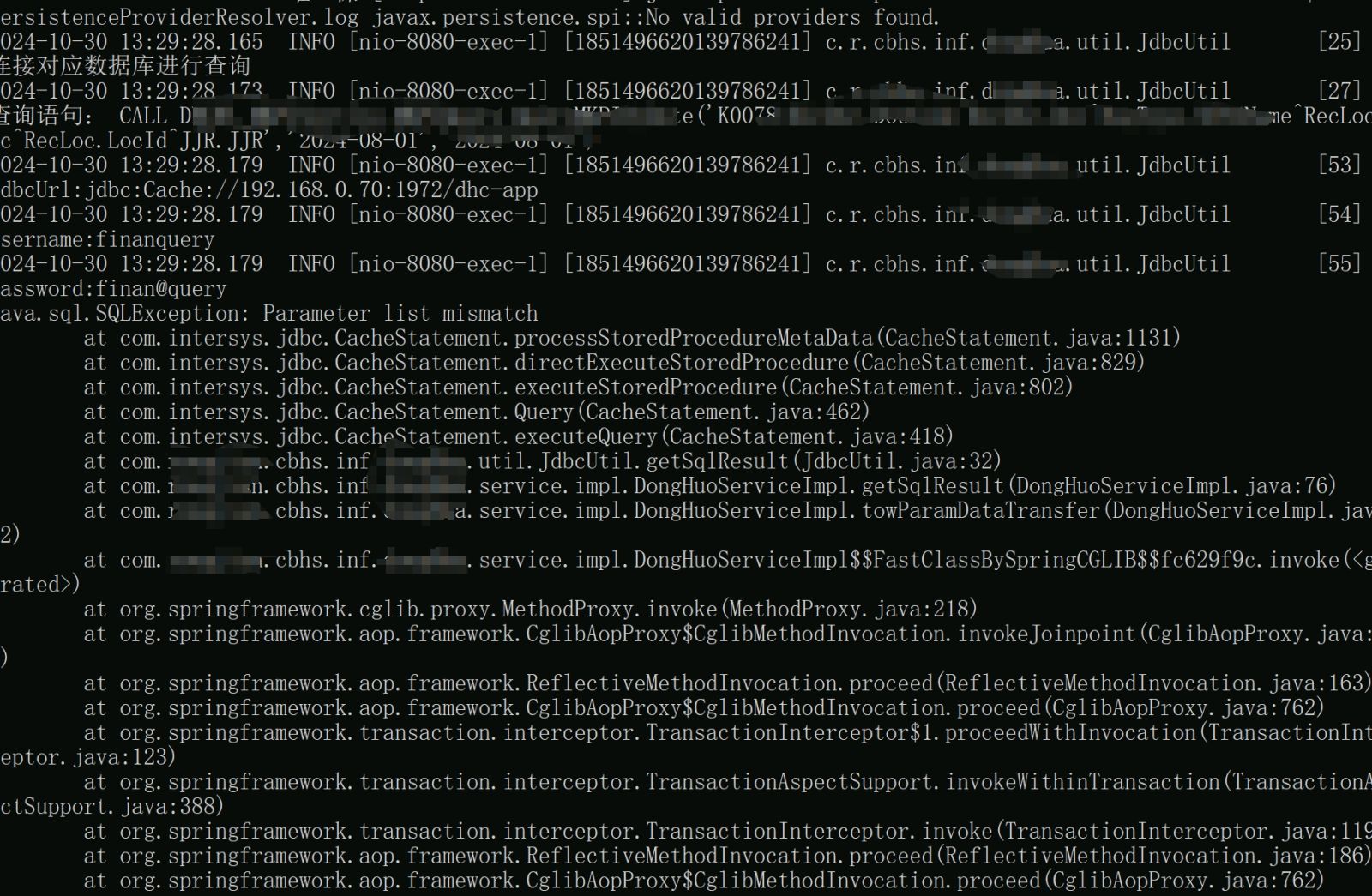
它不会消失。它产生的子进程其实是可以使用.png) 我的问题是如何正确的结束%SYSTEM.WorkMgr产生的子进程,如何避免服务器因此受到影响甚至宕机,为什么他会导致服务器出问题,有什么办法能再使用完成后,把 %SYSTEM.WorkMgr相关的进程正确的快速结束掉
我的问题是如何正确的结束%SYSTEM.WorkMgr产生的子进程,如何避免服务器因此受到影响甚至宕机,为什么他会导致服务器出问题,有什么办法能再使用完成后,把 %SYSTEM.WorkMgr相关的进程正确的快速结束掉