大家好,
你是否曾希望你的电子健康记录(EHR)能具备思考能力?不仅仅是显示数据,也不仅仅是触发警报。而是能够真正阅读病历、综合临床指南进行分析,并根据临床医生的单条信息,向系统生成结构化的转诊医嘱。
在本文中,我将向大家展示如何创建您自己的定制临床AI助手。
🏥 关于 iris-fhir-agents 应用
iris-fhir-agents是一个完全基于 InterSystems IRIS for Health 构建的多智能体临床 AI 平台
大家好,
你是否曾希望你的电子健康记录(EHR)能具备思考能力?不仅仅是显示数据,也不仅仅是触发警报。而是能够真正阅读病历、综合临床指南进行分析,并根据临床医生的单条信息,向系统生成结构化的转诊医嘱。
在本文中,我将向大家展示如何创建您自己的定制临床AI助手。
iris-fhir-agents是一个完全基于 InterSystems IRIS for Health 构建的多智能体临床 AI 平台

大家好,
在本文中,我将介绍我的应用程序iris-fhir-agents 这是一个由 InterSystems IRIS for Health 驱动的多智能体临床 AI 平台。该平台包含用于分诊、专科会诊、用药安全以及 FHIR 服务器探索的智能体——所有功能均基于 IRIS Vector Search RAG 构建。 平台包含一个无代码代理构建器,让您无需编写任何代码即可设计和部署自定义临床代理。

在基于 InterSystems IRIS 开发 Python 应用时,你很快就会发现存在多种执行上下文:
python3进程;这三种场景都非常有用,但在导入机制、系统配置、对象 API 以及 SQL 访问方面,它们的行为并不完全一致。iris-embedded-python-wrapper项目提供了一个稳定的 Python 门面(Facade),旨在减少这些差异,并提供一个统一的入口点:import iris。
在一个围绕 IRIS 构建的 Python 项目中,同一份代码可能需要在多种环境中运行:
iris python iris或 iris session iris后输入 :py;如果没有抽象层,许多细节往往就需要分别处理:
iris模块只有在 IRIS 运行时被正确加载时才可用;今天,我发布了一个新的Open Exchange 软件包,用于直接在 IRIS 中生成合成数据。
当你想制作一个演示应用程序时,找到合适的数据集是一个令人沮丧的过程。也许数据集并不那么重要,但您仍然希望它看起来有点真实,并有几个链接表,可以直接在 IRIS 中使用 -> 的隐式连接。也许您只是想让链接表可以很容易地安装到 IPM 中,用于基准查询,那么这种数据集生成方式就再好不过了。
我选择使用嵌入式 Python 创建数据集,这些数据集可通过自定义配置文件进行配置。这些数据集直接用一个 IRIS 类方法生成,并可使用乘数进行缩放,以创建任意大小的数据集,而无需测量配置。
目前我有四个数据集:
- 金融服务(如银行卡、账户、交易)
- 零售(商店、产品、用户、库存)
- 供应链(产品、销售订单、库存移动)
- 主题公园管理(公园、区域、游乐设施、事故)
我不是这些领域的专家,所以我怀疑它们是否超级准确,而且数据生成使用了 faker 等 python 库,统计加权生成使用了 numpy,所以感觉有点人工合成。
老实说,作为一个我无法投入大量时间的副业项目,这个项目的成功离不开人工智能。我在设计数据集和生成创建数据集的代码时广泛使用了人工智能。我监督、测试了个人使用的案例,并积极参与了项目设计,但代码都是人工智能生成的,我没有仔细审查过数据集的生成过程。
嘿,社区的朋友们大家好!
是的,我知道我们有很多技巧和窍门类的文章-——我们甚至为此专门设置了一个标签(Tips & Tricks),不是吗?但我不能分享我自己的收藏。在这个合集中,您可以找到适合初学者的代码片段,以及一些日常的 ObjectScript 结构。事实上,这也是一种学习我最喜欢的编程语言的新方法。所以,如果你们有什么要补充的,欢迎提出!
处理文件通常很简单:打开文件,读取并处理。这种方法非常有效,直到文件碰巧是 Excel 文件。
常见假设
起初,Excel 文件(.xlsx)看起来就像另一个数据文件,行、列和值。因此,我们很自然地认为它可以像 .txt 或 .csv 文件一样被读取。但问题就出在这里。
Excel 文件为何表现不同
关键区别在于数据的存储方式:
-> .txt / .csv - 纯文本,逐行存储。
-> .xlsx - 压缩、结构化格式(非纯文本)
excel 文件实际上不是一个简单的可读行流。从内部看,它是一个包含结构化数据的打包文件,标准文件读取命令无法解释这些数据。
如果把它当作文本文件处理,会发生什么情况?
重要事项 --> 这不是限制,而是工具和文件格式不匹配 。
实用的处理方法
与其只使用基于文本的方法,还有更好的选择、
如果有人曾在 IRIS 中处理过 Excel 文件,或有其他行之有效的方法,请随时分享。)
下面提到几个例子。
在现代医疗保健领域,寻找临床上相似的患者往往感觉像大海捞针。传统的关键字搜索往往会失败,因为医学语言具有高度的细微差别;搜索 "心力衰竭 "可能会漏掉包含 "充血性心力衰竭 "的记录。
我很高兴与大家分享 iris-medmatch,这是一个基于InterSystems IRIS for Health的人工智能患者匹配引擎。通过利用矢量搜索(vector search),该工具能够理解临床意图,而不仅仅是匹配字面字符串。
## 核心创新:语义临床搜索
iris-medmatch "在原始FHIR数据和可操作的人工智能洞察力之间架起了一座桥梁。该引擎利用 "all-MiniLM-L6-v2 "模型,将临床条件转化为数学向量。
标准搜索查找的是准确的单词,而该引擎能理解**临床上下文**。例如,它可以使用数学向量相似性将 "高血压 "患者与 "高血压 "搜索匹配起来。
该解决方案的优势在于其架构效率。通过嵌入式 Python 运行 Transformers,我们消除了 "数据重力 "问题。数据留在 IRIS 中,人工智能处理在数据所在的地方进行。
🚀应用演练
1.
概述
嵌入式 Python改变了 InterSystems IRIS 的游戏规则,可直接在数据库中访问庞大的 Python 生态系统。但是,在 ObjectScript 和 Python 之间架起桥梁有时会让人感觉像是在两个不同的世界之间转换。
为了实现这种无缝过渡,请使用embeddedpy-bridge。
该软件包是一个以开发人员为中心的实用工具包,旨在为嵌入式 Python 提供高级 ObjectScript 封装、熟悉的语法和强大的错误处理功能。它允许开发人员使用他们已经熟悉的本地 IRIS 模式与 Python 数据结构交互。
虽然 %SYS.Python 库功能强大,但开发人员经常面临一些障碍:
While 循环无法与 Python 迭代器进行本地 "对话"。embeddedpy-bridge我的目标是创建一个 "桥梁",让 Python 感觉像是 ObjectScript 中的一等公民。
py 前缀约定:%ZPython.UtilsInteroperability on Python (IoP) 是一个概念验证项目,旨在展示与 Python 优先方式相结合时 InterSystems IRIS Interoperability Framework 的强大功能。IoP 利用Embedded Python(嵌入式 Python,InterSystems IRIS 的一个功能)使开发者能够用 Python 编写互操作性组件,从而可以与强大的 IRIS 平台无缝集成。本指南专为初学者编写,全面介绍了 IoP、其设置以及创建第一个互操作性组件的操作步骤。 阅读完本文,您将能够清楚地了解如何使用 IoP 构建可扩缩、基于 Python 的互操作性解决方案。
InterSystems 宣布 InterSystems IRIS、InterSystems IRIS for Health 和 HealthShare Health Connect 2025.1 正式发布
2025.1 版的 InterSystems IRIS® 数据平台、InterSystems IRIS® for HealthTM 和 HealthShare® Health Connect 现已正式发布 (GA)。 这是扩展维护 (EM) 版本。
版本亮点
在这个激动人心的版本中,用户可以期待一些新功能和增强,包括:
互操作性用户界面现在包括可以在所有互操作性产品中使用的 DTL 编辑器和生产配置应用程序的现代化用户体验。您可以在现代化视图与标准视图之间切换。所有其他互操作性屏幕仍采用标准用户界面。请注意,仅对这两个应用程序进行了更改,我们在下面确定了当前可用的功能。
要在升级前试用新屏幕,您可以点击这里,从我们的社区工具包网页中下载 2025.1 版:https://evaluation.intersystems.com/Eval/。请观看“学习服务”中的简短教程构建集成:一种新的用户体验,了解对这些屏幕进行的用户增强!
生产配置 - 配置任务简介
生产配置:在以下版本的生产配置中受支持:
源代码控制集成:支持上述配置功能的源代码控制集成。
分屏视图:用户可以直接从“生产配置”屏幕打开“规则编辑器”和“DTL 编辑器”,在分屏视图中查看和编辑产品中包含的规则和转换。
增强的筛选功能:使用顶部的搜索框,您可以搜索和筛选各种业务组件,包括多种类别、DTL 和子转换。 使用左侧边栏可以独立于主面板进行搜索,查看各种主机和类别中的搜索结果。
批量编辑主机类别:通过从生产配置中添加主机,您可以为生产添加新类别或编辑现有类别。
可展开路由器:可以展开路由器,内联查看所有规则、转换和连接。
.png)
Hi 大家好
在本文中,我讲介绍我的应用 iris-AgenticAI .
代理式人工智能的兴起标志着人工智能与世界互动方式的变革性飞跃--从静态响应转变为动态、目标驱动的问题解决方式。参看 OpenAI’s Agentic SDK , OpenAI Agents SDK使您能够在一个轻量级、易用且抽象程度极低的软件包中构建代理人工智能应用程序。它是我们之前的代理实验 Swarm 的生产就绪升级版。
该应用展示了下一代自主人工智能系统,这些系统能够进行推理、协作,并以类似人类的适应能力执行复杂任务。
社区朋友们好,
传统的基于关键词的搜索方式在处理具有细微差别的领域特定查询时往往力不从心。而向量搜索则通过语义理解能力,使AI智能体能够根据上下文(而非仅凭关键词)来检索信息并生成响应。
本文将通过逐步指导,带您创建一个具备代理能力的AI RAG(检索增强生成)应用程序。
1. Create Agent Tools 添加文档摄取功能
Implement Document Ingestion: Automated ingestion and indexing of documents
1.1 - 以下是实现文档摄取工具的代码:
def ingestDoc(self):
#Check if document is defined, by selecting from table
#If not defined then INGEST document, Otherwise back
embeddings = OpenAIEmbeddings()
#Load the document based on the fle type
loader = TextLoader("/irisdev/app/docs/IRIS2025-1-Release-Notes.txt", encoding='utf-8')
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=400, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
#COLLECTION_NAME = "rag_document"
db = IRISVector.from_documents(
embedding=embeddings,
documents=texts,
collection_name = self.COLLECTION_NAME,
connection_string=self.CONNECTION_STRING,
)
db = IRISVector.from_documents(embedding=embeddings,documents=texts, collection_name = self.COLLECTION_NAME, connection_string=self.CONNECTION_STRING,)向量搜索智能体(Vector Search Agent)能够自动完成文档的摄取(ingest)与索引构建(index), 该新功能在InterSystems IRIS 2025.1的数据资源文件夹里) 至 IRIS 向量存储, 只有当数据尚未存在时,才执行该操作。.png)
运行以下查询以从向量存储中获取所需数据:
SELECT
id, embedding, document, metadata
FROM SQLUser.AgenticAIRAG
1.2 - 实现向量搜索功能
以下代码为智能体提供了搜索能力:
def ragSearch(self,prompt):
#Check if collections are defined or ingested done.
# if not then call ingest method
embeddings = OpenAIEmbeddings()
db2 = IRISVector (
embedding_function=embeddings,
collection_name=self.COLLECTION_NAME,
connection_string=self.CONNECTION_STRING,
)
docs_with_score = db2.similarity_search_with_score(prompt)
relevant_docs = ["".join(str(doc.page_content)) + " " for doc, _ in docs_with_score]
#Generate Template
template = f"""
Prompt: {prompt}
Relevant Docuemnts: {relevant_docs}
"""
return template
分流代理处理传入的用户查询,并将其委托给矢量搜索代理,后者执行语义搜索操作,以检索最相关的信息。
HI 各位开发者们,
📅2024年9月23日🕑14:00-15:30🕞,InterSystems将举办线上研讨会,点击🔔此处🔔报名参会。
此次研讨会以“面向未来的数据平台——InterSystems IRIS五大亮点提速数据潜力挖掘与AI应用”为主题,帮助您了解InterSystems IRIS数据平台的五大亮点:
随着 IRIS 中向量数据类型和向量搜索功能的引入,应用程序的开发正在开启一个充满各种可能性的全新世界,其中一个应用程序示例是我最近在巴伦西亚卫生局的一次公开竞赛中看到的应用程序,他们要求提供一种工具,能够使用 AI 模型协助进行 ICD-10 编码。
我们如何实现与所要求的应用程序类似的应用程序? 我们来看看需要什么:
IRIS 为我们提供哪些功能来满足上述需求?
我们只需要看看开发的示例:
在本文中,您可以访问开发的应用程序,在后续文章中,我们将详细了解如何实现每个功能,包括模型的使用、向量的存储和向量搜索的使用。
嗨,开发者,
我们很高兴邀请大家参加新的以 Python 为主题的 InterSystems 在线编程竞赛!
🏆 InterSystems 2024 Python 编程大赛 🏆
时间: 2024年7月15日-8月4日(美国东部时间)
奖金池: 14,000美元
.jpg)
这是在 IRIS 中完全运行向量搜索演示的尝试。
没有外部工具,您需要的只是终端/控制台和管理门户。
特别感谢Alvin Ryanputra作为他的软件包iris-vector-search的基础
灵感和测试数据的来源。
我的软件包基于 IRIS 2024.1 版本,需要注意您的处理器功能。
我尝试用纯 ObjectScript 编写演示。
仅描述向量的计算是在嵌入式Python中完成的
计算 2247 个记录的 384 维向量需要时间。
在我的 Docker 容器中,它正在运行 01:53:14 来完全生成它们。
然后被警告了!
所以我将这一步调整为可重入,以允许暂停向量计算。
每 50 条记录,您就会收到一次停止的提议。
该演示如下所示:
用户>做^A.DemoV 测试向量搜索 ============================= 1 - 初始化表 2 - 生成数据 3 - VECTOR_余弦 4 - VECTOR_DOT_产品 5 - 制作苏格兰威士忌 6 - 加载 Scotch.csv 7 - 生成向量 8 - 向量搜索 选择功能或 * 退出:8 默认搜索: 让我们来看看前三名价格低于 100 美元的苏格兰威士忌,具有泥土和奶油的香气, 更改价格限制[100]:50 更改短语[泥土和奶油味]:泥土味 计算搜索向量 总计低于 50 美元:222 ID 价格 名称 1990 年 40 瓶 Wemyss 复古麦芽威士忌“泥炭烟囱”,8 年陈酿,40% 1785 39 著名的禧年,40% 1868 40 托马汀,15 岁,43% 2038 45 格伦·格兰特,10 岁,43% 1733 29 斯凯岛,8 岁,43% 5 行受影响
大型语言模型(例如 OpenAI 的 GPT-4)的发明和普及掀起了一波创新解决方案浪潮,这些解决方案可以利用大量非结构化数据,在此之前,人工处理这些数据是不切实际的,甚至是不可能的。此类应用程序可能包括数据检索(请参阅 Don Woodlock 的 ML301 课程,了解检索增强生成的精彩介绍)、情感分析,甚至完全自主的 AI 代理等!
在本文中,我想演示如何使用 IRIS 的嵌入式 Python 功能直接与 Python OpenAI 库交互,方法是构建一个简单的数据标记应用程序,该应用程序将自动为我们插入IRIS 表中的记录分配关键字。然后,这些关键字可用于搜索和分类数据,以及用于数据分析目的。我将使用客户对产品的评论作为示例用例。
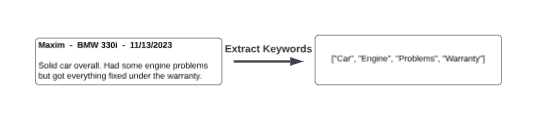
让我们首先创建一个 ObjectScript 类,该类将定义客户评论的数据模型。为了简单起见,我们将只定义 4 个 %String 字段:客户姓名、产品名称、评论正文以及我们将生成的关键字。该类应该扩展%Persistent,以便我们可以将其对象保存到磁盘。
ClassExtends%Persistent如今,关于大语言模型、人工智能等的消息不绝于耳。向量数据库是其中的一部分,并且已经有非IRIS的技术实现了向量数据库。
为什么是向量?
还有许多其他原因。
因此,对于这次 pyhon 竞赛,我决定尝试实现这种支持。不幸的是我没能及时完成它,下面我将解释原因。

嗨,开发者,
我们很高兴邀请大家参加新的以 Python 为主题的 InterSystems 在线编程竞赛!
时间: 2023年9月4日至24日(美国东部时间)
奖金池: 14,000 美元

写在回复社区帖子《Python能否动态创建HL7消息》中。
使用一个启用了集成的命名空间。
注意:USER命名空间默认不启用互操作性。
如果以下建议创建一个新的互操作性命名空间来探索功能。
# 切换到
ZN "[互操作性名称空间名称]"
# 启动交互式Python shell:
Do $SYSTEM.Python.Shell()
#Load dependencies
import datetime as dt
import uuid
# Cache current time in CCYYMMDDHHMMss format
hl7_datetime_now=dt.datetime.now().strftime('%Y%m%d%H%M%S')
# Create HL7 Message
hl7=iris.cls("EnsLib.HL7.Message")._New()
# Set the doc type
# 2.5.1:ORU_R01 - Unsolicited transmission of an observation message
hl7.PokeDocType("2.5.1:ORU_R01")你好社区
在本文中,我将介绍我的应用程序irisChatGPT ,它是基于LangChain Framework构建的。
首先,让我们对框架进行一个简单的概述。
全世界都在谈论ChatGPT以及大型语言模型 (LLM) 如何变得如此强大,并且表现超出预期,提供类似人类的对话。这只是将其应用于每个企业和每个领域的开始!
大家好!
InterSystems Grand Prix 2023 结合了 InterSystems IRIS 数据平台的所有主要功能!
因此,我们邀请您使用以下功能并收集额外的技术奖励,以帮助您赢得奖品!
如下:
在InterSystems IRIS中重新加载更新后的Python模块的方式和直接使用Python 重新加载模块的方式是一样的。
在Python3.4 之后到版本中,直接使用Python 重新加载模块的方式如下:
import importlib
importlib.reload(module)同样,在在InterSystems IRIS中重新加载Python模块的方式与其没有区别,示例如下:
ClassMethod Hello() As %Status
{
Set sc = $$$OK
Set sm = ##class(%SYS.Python).Import("sample")
Set importlib = ##class(%SYS.Python).Import("importlib")
do importlib.reload(sm)
write sm.hello()
Return sc
}
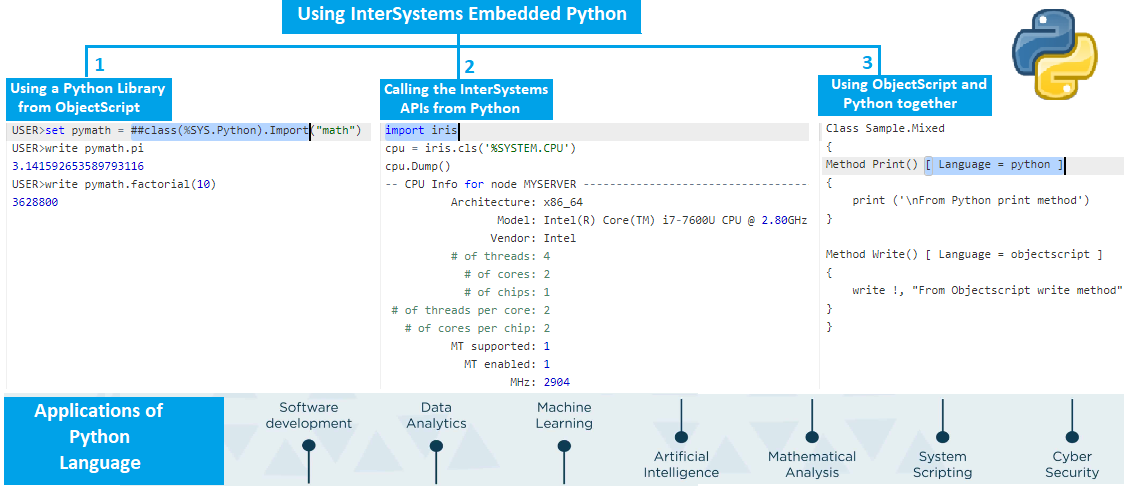
嗨社区,
在本文中,我将演示 InterSystems Embedded Python 的用法,我们将涵盖以下主题:
我们从概述开始
嵌入式 Python 是 InterSystems IRIS 数据平台的一项功能,它允许 Python 开发人员完全直接地访问 InterSystems IRIS 中的数据和功能。
InterSystems IRIS 是一个高性能、可靠且可扩展的数据平台,用于为医疗保健、金融服务和其他行业构建和部署关键任务应用程序。它提供了广泛的功能,包括数据管理、集成、分析等。
IRIS 提供的功能之一是能够将 Python 代码嵌入到 ObjectScript 代码中。这意味着您可以在 IRIS 应用程序中使用 Python 库和函数,让您可以访问大量的工具和资源。在本文中,我们将了解如何在 InterSystems IRIS 中使用嵌入式 Python。
设置嵌入式 Python
在 IRIS 中开始使用嵌入式 Python 之前,您需要设置环境。这涉及安装 Python 解释器和配置 IRIS 以识别它。
第一步是安装 Python。您可以从官方网站 ( https://www.python.org/downloads/ ) 下载最新版本的 Python。安装 Python 后,需要将其添加到系统的 PATH 环境变量中。这允许 IRIS 找到 Python 解释器。
接下来,您需要配置 IRIS 以识别 Python。为此,您需要创建一个 Python 网关。网关是一个在 IRIS 之外运行的进程,充当 IRIS 和 Python 之间的桥梁。
要创建网关,请打开一个终端窗口并导航到 Python 安装目录。
简单来说,网络抓取、网络收获或网络数据提取是从网站收集大数据(非结构化)的自动化过程。用户可以根据需要提取特定站点上的所有数据或特定数据。收集的数据可以以结构化格式存储以供进一步分析。
就这么简单!
Beautiful Soup 是一个纯 Python 库,用于从网站中提取结构化数据。它允许您解析来自 HTML 和 XML 文件的数据。它充当辅助模块,并以与使用其他可用开发人员工具以网页交互的方式与 HTML 交互。
Python 已成为世界上使用最广泛的编程语言(来源:https://www.tiobe.com/tiobe-index/),SQL 作为数据库语言继续引领潮流。 Python 和 SQL 一起工作以提供 SQL 单独无法提供的新功能不是很好吗?毕竟,Python 拥有超过 380,000 个已发布的库(来源:https://pypi.org/),它们具有非常有趣的功能,可以在 Python 中扩展您的 SQL 查询。本文详细介绍了如何使用嵌入式 Python 在 InterSystems IRIS 数据库中创建新的 SQL 存储过程。
本文将使用两个非常有用的库:Geopy 和 Chronyk。
Geopy 是一个用于将地理编码(地址和地理坐标的限定)应用于地址数据的库。有了它,就可以从街道名称中获取邮局格式的邮政编码和完整地址。非常有用,因为许多记录都有地址。
Chronyk 用于使用人类语言处理日期和时间。这非常有用,因为在内部,对于 IRIS 和 Python,日期是一个数字,表示自初始日期以来经过的时间量。对于人类来说,日期是 7 月 20 日,或者昨天,或者明天,或者两个小时前。 Chronyk 接受接收这样的日期,然后将其转换为通用日期格式。
从 2021.
这个项目是在我考虑如何通过Embedded Python让Python代码自然地处理IRIS globals所提供的可扩展的存储和高效的检索机制时想到的。
我最初的想法是使用globals创建一种Python字典的实现,但很快我就意识到,我应该首先处理对象的抽象问题。
所以,我开始创建一些可以包装Python对象的Python类,在globals中存储和检索它们的数据,也就是说,在IRIS globals中序列化和反序列化Python对象。
像 ObjectScript 的%DispatchGetProperty(), %DispatchSetProperty() 和%DispatchMethod()一样, Python 有委托对象的属性和方法调用的方式。
当你设置或获取一个对象属性时,Python 解释器让你通过方式 和 来截获这个操作。
请看这个相当基本的例子。
>>> class Test:
... def __init(self, prop1):
... self.prop1 = prop1
... def __setattr__(self, name, value):
... print(f"setting property {name} to value {value}")
... def __getattr__(self, name):
... print(f"getting property {name}")
...
>>> obj = Test()
>>> obj.prop1 = "test"
setting property prop1 to value test
>>> obj.prop1
getting property prop1
>>> obj.prop2
getting property prop2
>>> obj.prop2
getting property prop2
>>>
嵌入式 Python 模板
今天你们分享一个简单的嵌入式 Python 模板,我建议将其作为任何使用 InterSystems IRIS 并将使用嵌入式 Python 的通用项目的起点。
功能:
下面讨论一下这些功能!