一篇文章了解`IRIS/Caché`编码方案
一篇文章了解IRIS/Caché编码方案
一直以来,编码问题像幽灵一般,不少开发人员都受过它的困扰。
试想你请求一个数据,却得到一堆乱码,丈二和尚摸不着头脑。有同事质疑你的数据是乱码,虽然你很确定传了UTF-8 ,却也无法自证清白,更别说帮同事 debug 了。
有时,靠着百度和一手瞎调的手艺,乱码也能解决。尽管如此,还是很羡慕那些骨灰级程序员。为什么他们每次都能犀利地指出问题,并快速修复呢?原因在于,他们早就把编码问题背后的各种来龙去脉搞清楚了。
ASCII
标准
ASCII码,使用7 位二进制数(最高位为0)来表示所有的大写和小写字母,数字0到9、半角标点符号,以及在英语中使用的特殊控制符号。
最早只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母a的编码是97,小写字母z的编码是122。
在IRIS/Caché中获取字符ASCII码与二进制字符串,如下代码示例:
USER>w $a("a")
97
USER>w ##class(M.Code).LogicalToDisplay(97)
10000110
经过如下二进制转十进制计算可得出 1+32+64 = 97
2**0 + 2**5 + 2**6 = 97
Unicode
GB2312、GBK与GB18030都是中文编码字符集。不同国家也推出了自己的字符集和编码方案,彼此不兼容。例如中文编码集,在日文系统无法正常显示,无法适应全球化应用。为了适应全球化,由统一码联盟开发,指定了统一码(Unicode),也叫万国码、单一码,是计算机科学领域里的一项业界标准,包括字符集、编码方案等。
Unicode已经收录的字符数量已经超过 13 万个,每个字符需占用超过 2 字节。由于常用编程语言一般没有 24 位数字类型,因此一般用 32 位数字表示一个字符。如果要用到非常偏僻的字符,就需要4个字节这样一来。同样的一个英文字母,在 ASCII中只需占用 1 字节,在 Unicode 则需要占用4 字节!
在IRIS/Caché中获取字符Unicode编码,如下代码示例:
ClassMethod UnicodeEncode(str As %String) As %String
{
q $replace($zcvt(str, "O", "URL"),"%","\")
}
USER>w ##class(Util.Impl.EncryptionUtils).UnicodeEncode("姚鑫")
\u59DA\u946B
UTF8
UTF-8是Unicode的实现方式之一。UTF-8是一种Unicode的编码方式,主要作用对Unicode码的数据进行转换,转换后方便存储和网络传输。本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码(unicode transformation format)。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间。
Unicode符号范围 (十六进制) |
UTF-8编码方式(二进制) |
|---|---|
0000 0000-0000 007F |
0xxxxxxx |
0000 0080-0000 07FF |
110xxxxx 10xxxxxx |
0000 0800-0000 FFFF |
1110xxxx 10xxxxxx 10xxxxxx |
0001 0000-0010 FFFF |
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
在IRIS/Caché中获取字符ASCII码与UTF8十六进制字符串,如下代码示例:
USER>w $a("鑫")
37995
USER>w $zhex(37995)
946B
GB2312、GBK和GB18030
ASICII、GB2312、GBK、GB18030 之间的关系可以用下图表示:
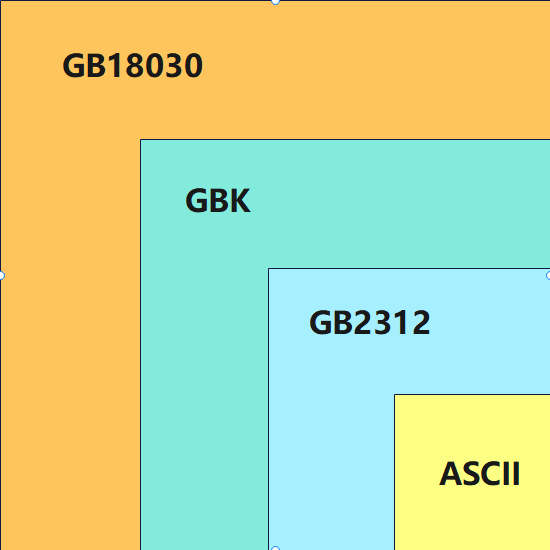
GB2312 兼容 ASICII 编码, GBK 兼容 GB2312 编码,GB18030 兼容 GB2312 编码 和 GBK 编码。
实际生活中,我们用到的 99% 的汉字,都属于 GB2312 编码范围 ,GB2312 每个编码对应的是哪个汉字可以参考 GB2312简体中文编码表, GBK 编码可以参考 GBK编码表, GB18030 可以参考 GB18030-2005 文档。
那么GB系列是如何兼容ASCII码的呢?
在 GB系列中,如果一个字节最高位 b8 为 0 ,该字节便是单字节编码,即 ASCII 码。如果字节最高位 b8 为 1 ,它就是双字节编码的首字节,与其后字节一起表示一个字符。
下图为GBK码表:

可以根据码表查对应汉字或全角字符对应的十六进制码表值,图中全角符号《对应的GBK码表值为A1B6。
ASICII、GB2312、GBK、GB18030 、Unicode之间的关系可以用下图表示:
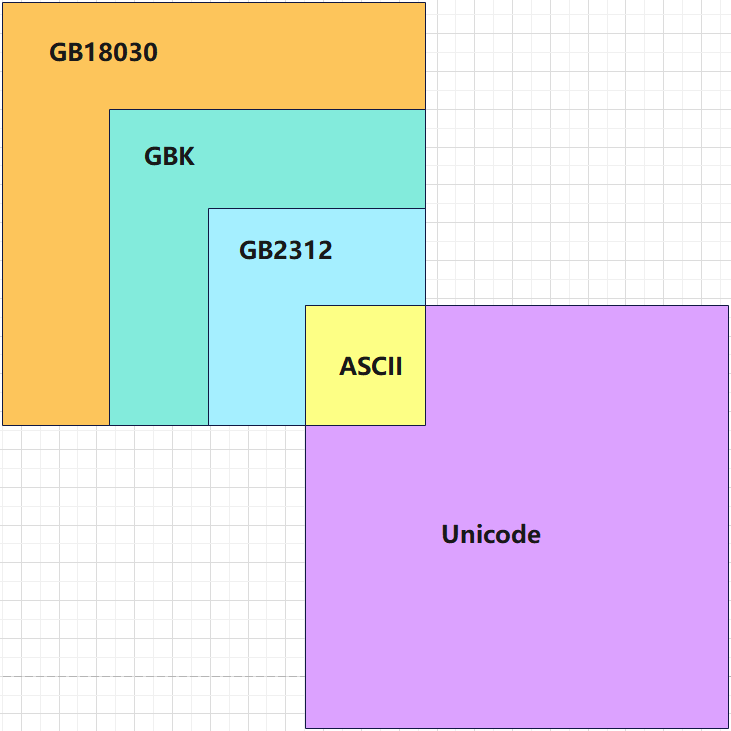
ANSI
不同的国家和地区制定了不同的标准,由此产生了
GB2312、GBK、GB18030、Big5、Shift_JIS等各自的编码标准。这些使用多个字节来代表一个字符的各种汉字延伸编码方式,称为ANSI编码。在简体中文Windows操作系统中,ANSI编码代表GB2312编码;在繁体中文Windows操作系统中,ANSI编码代表Big5;在日文Windows操作系统中,ANSI编码代表JIS编码。
下图中文Windows环境中的ANSI编码为GB18030.
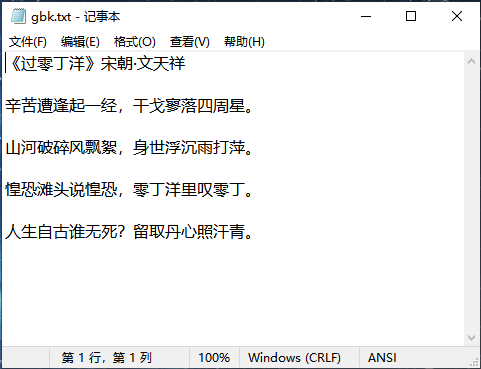
在IRIS/Caché中验证ANSI是否为GB18030
ClassMethod GBK(filename)
{
s stream = ##class(%Stream.FileCharacter).%New()
#; 默认使用GB18030解码
s stream.TranslateTable = "GB18030"
s stream.Filename = filename
w "字符长度:",stream.Size,!
while 'stream.AtEnd {
s line = stream.Read()
w line,!
}
q $$$OK
}
USER>w ##class(M.Code).GBK("E:\m\code\gbk.txt")
字符长度:94
《过零丁洋》宋朝·文天祥
辛苦遭逢起一经,干戈寥落四周星。
山河破碎风飘絮,身世浮沉雨打萍。
惶恐滩头说惶恐,零丁洋里叹零丁。
人生自古谁无死?留取丹心照汗青。
1
在程序中还是用GB18030编码方式可以解析出中文,所以验证ASNI在中文环境中的编码格式为GB18030,如果是GB2312也可以正常解析出,因为是GB18030是向下兼容的。
手写解析UTF8编码
首先创建一个UTF8的txt文件。
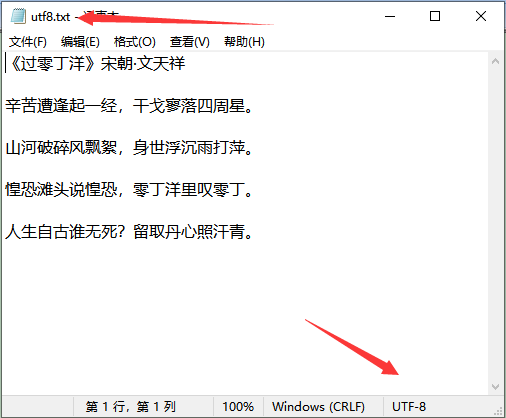
通过如下代码去解析UTF8文件,其中代码s stream.TranslateTable = "UTF8"指定解析方式。
ClassMethod UTF8(filename)
{
s stream = ##class(%Stream.FileCharacter).%New()
s stream.Filename = filename
s stream.TranslateTable = "UTF8"
w "字符长度:",stream.Size,!
while 'stream.AtEnd {
s line = stream.Read()
w line,!
}
q $$$OK
}
可以正常解析出:
USER>w ##class(M.Code).UTF8("E:\m\code\utf8.txt")
字符长度:94
《过零丁洋》宋朝·文天祥
辛苦遭逢起一经,干戈寥落四周星。
山河破碎风飘絮,身世浮沉雨打萍。
惶恐滩头说惶恐,零丁洋里叹零丁。
人生自古谁无死?留取丹心照汗青。
1
如果不指定s stream.TranslateTable = "UTF8"该代码将会得到如下数据:
USER>w ##class(M.Code).UTF8("E:\m\code\utf8.txt")
字符长度:133
銆婅繃闆朵竵娲嬨?嬪畫鏈澛锋枃澶╃ゥ
杈涜嫤閬?㈣捣涓?缁忥紝骞叉垐瀵ヨ惤鍥涘懆鏄熴??
灞辨渤鐮寸椋庨绲紝韬笘娴矇闆ㄦ墦钀嶃??
鎯舵亹婊╁ご璇存兌鎭愶紝闆朵竵娲嬮噷鍙归浂涓併??
浜虹敓鑷彜璋佹棤姝伙紵鐣欏彇涓瑰績鐓ф睏闈掋??
1
那么在无法指定编码方式的字符串当中,该如何解析UTF8编码呢?根据UTF8的编码规则编写如下RAW2UTF8方法。
方法逻辑如下:
-
读取
1个首部字符判断UTF8所占字节大小。 -
获取该字符的
2进制字符串。 -
如果为
ASCII码,长度小于8位,高位补0。 -
如果
UTF8为4字节,一般为不常见的汉字。 -
如果
UTF8为3字节,一般为常用汉字。- 去掉标识高位
- 取剩余字符
- 将剩余字符进行二进制字符串拼接
- 获取该字符的十进制
ASCII
-
如果
UTF8为1字节ASCII码直接取值。
ClassMethod RAW2UTF8(stream As %Stream.FileBinary) As %String
{
s str = ""
while 'stream.AtEnd {
#; 读取1个首部字符判断UTF8所占字节大小
s content = stream.Read(1)
#; 获取该字符的2进制字符串
s ascii = $a(content)
s highBit = ..LogicalToDisplay(ascii)
#; 长度小于8位,高位补0
if ($l(highBit) < 8) {
s highBit = highBit _ ..Repeat(0, 8 - $l(highBit))
}
#; UTF8,4字节,一般为不常见的汉字
if ($e(highBit,4, *) = "01111") {
s bitStr = $e(highBit, 1, 5)
for i = 1 : 1 : 3 {
s lowChar = stream.Read(1)
s bitStr = $e(..LogicalToDisplay($a(lowChar)), 1, 6) _ bitStr
}
s utf8num = ..BitToDec(bitStr)
#; UTF8,3字节,一般为汉字
} elseif ($e(highBit, 5, *) = "0111") {
#; 去掉标识高位
s bitStr = $e(highBit, 1, 4)
#; 取剩余字符
for i = 1 : 1 : 2 {
s lowChar = stream.Read(1)
#; 将剩余字符进行二进制字符串拼接
s bitStr = $e(..LogicalToDisplay($a(lowChar)), 1, 6) _ bitStr
}
#; 获取该字符的十进制ASCII
s utf8num = ..BitToDec(bitStr)
#; UTF8,2字节
} elseif ($e(highBit, 6, *) = "011") {
s bitStr = $e(highBit, 1, 3)
for i = 1 : 1 : 1 {
s lowChar = stream.Read(1)
s bitStr = $e(..LogicalToDisplay($a(lowChar)), 1, 6) _ bitStr
}
s utf8num = ..BitToDec(bitStr)
#; UTF8,1字节 ASCII码
} elseif ($e(highBit, 8, *) = "0") {
s bitStr = highBit
s utf8num = ..BitToDec(bitStr)
}
s str = str _ $c(utf8num)
}
q str
}
通过该RAW2UTF8方法去解析直接的乱码。
注:这里直接通过%Stream.FileBinary方式去解析文件流,解析出来的是不包含编码格式,为二进制串。
ClassMethod TestRAW2UTF8(filename)
{
s stream = ##class(%Stream.FileBinary).%New()
s stream.Filename = filename
s str = ..RAW2UTF8(stream)
q str
}
通过该方法就可以解析出常见的UTF8乱码。
USER> w ##class(M.Code).TestRAW2UTF8("E:\m\code\utf8.txt")
《过零丁洋》宋朝·文天祥
辛苦遭逢起一经,干戈寥落四周星。
山河破碎风飘絮,身世浮沉雨打萍。
惶恐滩头说惶恐,零丁洋里叹零丁。
人生自古谁无死?留取丹心照汗青。
手写解析GB18030编码
首先创建一个GB18030编码格式的文件。之前已经验证ANSI能编码格式为GB18030编码格式
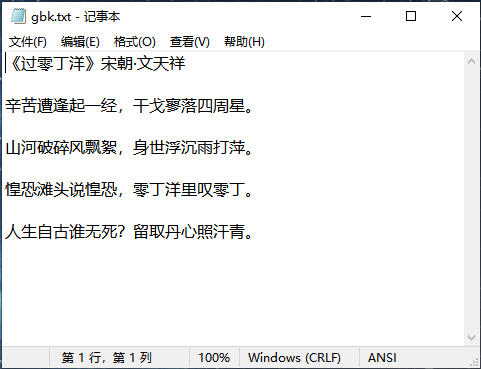
在编写解析GB18030编码之前,需要将码表导入到系统当中:
ClassMethod ImportGB1830Table(filename As %String) As %String
{
s stream = ##class(%Stream.FileCharacter).%New()
s stream.Filename = filename
w stream.Size,!
while 'stream.AtEnd {
s str = stream.ReadLine()
s char = $e(str, 2)
s word = $replace($p(str, ",", 1), char, "")
s gbkCode = $replace($p(str, ",", 2), char, "")
s unicode = $replace($p(str, ",", 3), char, "")
continue:(unicode = "")
s ^GB18030(gbkCode) = word
}
q $$$OK
}
w ##class(M.Code).ImportGB1830Table("E:\m\code\GB18030对照表.csv")
查看导入的码表Global
USER>zw ^GB18030
^GB18030(8140)="丂"
^GB18030(8141)="丄"
^GB18030(8142)="丅"
^GB18030(8143)="丆"
^GB18030(8144)="丏"
...
^GB18030(9481)="攣"
^GB18030(9482)="攤"
^GB18030(9483)="攦"
^GB18030(9484)="攧"
^GB18030(9485)="攨"
^GB18030(9486)="攩"
^GB18030(9487)="攪"
根据UTF8的编码规则编写如下RAW2UTF8方法。
方法逻辑如下:
- 读取
1个首部字符判断UTF8所占字节大小。 - 如果高为
0为ASCII直接解析即可。 - 如果高为
1直接根据对照码表直接解析即可。
ClassMethod RAW2GB18030(stream As %Stream.FileBinary) As %String
{
s str= ""
while 'stream.AtEnd {
//s line = stream.Read(2)
#; 读取1个首部字符判断UTF8所占字节大小
s content = stream.Read(1)
#; 获取该字符的2进制字符串
s ascii = $a(content)
s highBit = ..LogicalToDisplay(ascii)
#; 长度小于8位,高位补0
if ($l(highBit) < 8) {
s highBit = highBit _ ..Repeat(0, 8 - $l(highBit))
}
if ($e(highBit, 8, *) = "0") {
s bitStr = highBit
s ascii = ..BitToDec(bitStr)
s char = $c(ascii)
} else {
s hex = ""
s hex = hex _ $zhex($a(content))
s content = stream.Read(1)
s hex = hex _ $zhex($a(content))
if ($d(^GB18030(hex))) {
s char = $g(^GB18030(hex))
}
}
s str = str _ char
}
q str
}
通过该RAW2GB18030方法去解析18030编码。
ClassMethod TestRAW2GB18030(filename)
{
s stream = ##class(%Stream.FileBinary).%New()
s stream.Filename = filename
s str = ..RAW2GB18030(stream)
q str
}
USER>w ##class(M.Code).TestRAW2GB18030("E:\m\code\gbk.txt")
《过零丁洋》宋朝·文天祥
辛苦遭逢起一经,干戈寥落四周星。
山河破碎风飘絮,身世浮沉雨打萍。
惶恐滩头说惶恐,零丁洋里叹零丁。
人生自古谁无死?留取丹心照汗青。
在IRIS/Caché中哪些情况如要指定编码
- 读取文件需要指定编码,示例如下:
s stream.TranslateTable = "UTF8"
ClassMethod UTF8(filename)
{
s stream = ##class(%Stream.FileCharacter).%New()
s stream.Filename = filename
s stream.TranslateTable = "UTF8"
w "字符长度:",stream.Size,!
while 'stream.AtEnd {
s line = stream.Read()
w line,!
}
q $$$OK
}
- 在读取
HTTP请求时需要指定编码,示例如下:s request.ContentCharset="UTF-8"
ClassMethod HttpGetDemo() As %String
{
/* 定义request对象 */
#dim request as %Net.HttpRequest= ##class(%Net.HttpRequest).%New()
/* 请求地址不用加http:// */
s request.Server = "192.168.1.21"
//s request.ContentType
/* Timeout指定等待web服务器响应的时间,以秒为单位。 缺省值是30秒。 */
s request.Timeout = 5
/* WriteTimeout指定等待Web服务器完成写入的时间(以秒为单位)。默认情况下,它将无限期等待。可接受的最小值为2秒。 */
s request.WriteTimeout = 5
#;指定编码
s request.ContentCharset="UTF-8"
/* 添加地址对象参数 */
d request.InsertParam("CacheUserName", "yx")
d request.InsertParam("CachePassword", "123456")
d request.InsertParam("CacheNoRedirect", "1")
d request.InsertParam("ClassName", "PHA.PCCP.MOB.API")
d request.InsertParam("MethodName", "GetPhaWardRound")
d request.InsertParam("params", "172#O")
/* 设置cookies 防止占用多个lic */
d:($g(%cookies) '= "") request.SetHeader("cookie", %cookies)
/* 请求地址路径 */
s status = request.Get("/dthealth/web/csp/pha.mob.broker.csp")
if (status '= 1) {
d $System.Status.DisplayError(status)
q "请求失败"
}
/* 定义response对象 */
#dim response as %Net.HttpResponse = request.HttpResponse
/* 获取HTTP状态码 */
s statusCode= response.StatusCode
if (statusCode = 200){
/* 获取头信息两种方式(一) */
s encoding = response.GetHeader("CONTENT-ENCODING")
/* 获取头信息两种方式(二) */
s cookie = response.Headers("SET-COOKIE")
s %cookies = $p(cookie, ";", 1)
w "输出所有头部信息:",!
d response.OutputHeaders()
w !
/* 获取流数据 */
#dim stream as %GlobalBinaryStream = response.Data
s data = stream.Read()
}
q $g(data)
}
- 读取
xml时需要指定编码。
<?xml version='1.0' encoding='UTF-8'?>
HL7数据格式时需要指定编码。
Class IHE.Msg.MSH Extends (%Persistent, %JSON.Adaptor)
{
Property FieldSeparator(CAPTION = "字段分隔符") [ InitialExpression = "|", Required ];
Property EncodingCharacters(CAPTION = "编码字符") [ InitialExpression = "^~\&", Required ];
...
Property CharacterSet(CAPTION = "字符集") [ InitialExpression = "UTF-8" ];
}

获取系统默认的编码格式
USER>w $$GetPDefIO^%SYS.NLS(3)
GB18030
判断文件BOM的编码格式
BOM(Byte Order Mark),字节顺序标记,出现在文本文件头部,Unicode编码标准中用于标识文件是采用哪种格式的编码。
注:大多数文本文件都不含有BOM。
- 判断是否为
UTF8BOM
ClassMethod IsUTF8BOM(filename As %String) As %Boolean
{
s file = ##class(%FileBinaryStream).%New()
s file.Filename = filename
s bom = file.Read(3, .sc)
if (bom = $c(239, 187, 191)) {
q $$$YES
}
q $$$NO
}
- 判断判断是否为
GB18030BOM
ClassMethod IsGB18030BOM(filename As %String) As %Boolean
{
s file = ##class(%FileBinaryStream).%New()
s file.Filename = filename
s bom = file.Read(4, .sc)
if (bom = $c(132, 49, 149, 51)) {
q $$$YES
}
q $$$NO
}
- 判断文件是否为
UTF16BOM
ClassMethod IsUTF16BOM(filename As %String) As %Boolean
{
s file = ##class(%FileBinaryStream).%New()
s file.Filename = filename
s bom = file.Read(2, .sc)
if (bom = $c(255, 254) || bom = $c(254, 255)) {
q $$$YES
}
q $$$NO
}
- 判断文件是否有
BOM
ClassMethod IsBOM(filename As %String) As %Boolean
{
q:(..IsUTF8BOM(filename)) $$$YES
q:(..IsUTF16BOM(filename)) $$$YES
q:(..IsGB18030BOM(filename)) $$$YES
q $$$NO
}
总结
- 通过了解常见的编码格式与原理,可以在遇到乱码时,知道如何去处理。
- 在国内环境中,使用手动解析
UTF8与GB18030两种解码方法,可以满足日常遇到的99%乱码问题。
以上是个人对常见编码的一些理解,由于个人能力有限,欢迎大家提出意见,共同交流。