基于向量搜索的患者相似度匹配示例程序
演示程序
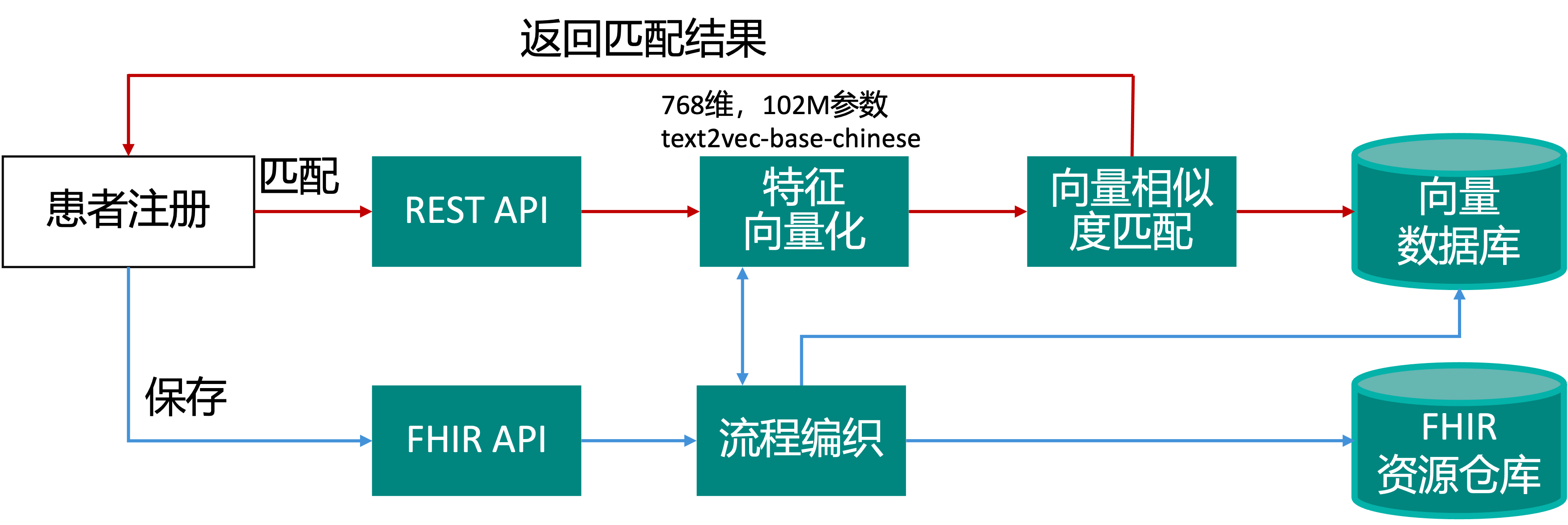
使用向量搜索在 IRIS for Health 上运行的病人相似性比较演示。 使用向量搜索计算相似度,在向量基础上比较不同病人之间的个人属性,如姓名、出生日期、地址等。得分越高,被比较的病人越有可能是同一个人。 本演示程序使用 sentence-transformers model 将文本转换为向量,然后使用 IRIS 向量函数来存储、读取和比较向量。
流程原理
安装
- 使用Git克隆存储库
- 演示程序将使用text2vec-base-chinese。你也可以下载任何你想要的transformer模型,并将其存储到一个 本地路径中,如 D:\Coding\EMPIDemo\image-iris\llm\text2vec-base-chinese ,然后在 docker-compose.yml 文件的 volumes 部分更改目录指向本地模型根目录。
- 启动Docker容器 请注意,程序将下载并安装 Python sentence-transformers模块,并安装 FHIR 存储库以存储患者信息,因此将占用大约 15~16GB 磁盘存储空间。
运行演示
- 访问WebUI
- 处理数据的IRIS Procuction
- 相关代码 嵌入式 python 用于调用sentence-transformers来执行向量化,可在 EMPIDemo.Util.Vector 中找到。 向量搜索用于计算患者之间的相似性,可在 EMPIDemo.REST.Service 中找到。