生成式大语言模型和检索增强生成
近来生成式大语言模型掀起了革命性的AI浪潮。生成式大语言模型是什么原理?我们怎么在业务中利用它?
一. 大语言模型的工作原理
生成式大语言模型是生成式人工智能底层的机器学习模型,是一种用于自然语言处理的深度学习模型。
人工智能、机器学习与大语言模型的关系如下图:
.png)
1.1 为什么我们称之为大语言模型?
大语言模型的“大”体现在多个方面:
- 首先,模型尺寸巨大,尤其是它的参数数量。例如GPT3有1750亿的参数;
- 其次,大语言模型是在巨大的算力基础上,基于海量语料进行训练的。例如Meta的Llama 2 的训练数据达到了两万亿个词(token);
- 再次,大语言模型是为解决通用问题,而非特定问题构建的。
1.2 大语言模型是怎么训练的?
大语言模型是事先训练好的模型。
训练时,大语言模型基于各种语料 - 人类知识库(例如Wikipedia)、公共数据集、网络爬虫数据,让模型进行“填空”练习,并经过人工编辑和“校对” 训练出来的,需要成千上万的GPU建立集群进行训练。根据Meta的信息,其Llama 2 的训练数据达到了两万亿个token,上下文长度为4096,对话上也是使用100万人类标记的数据微调。
运行时,训练产生的大语言模型可以在小的多的硬件上运行。
1.3 大语言模型的机器学习算法
冰冻三尺,非一日之寒;滴水穿石,非一日之功。生成式大语言模型能够落地经历了相当漫长的技术积累与进步。
大语言模型使用的机器学习算法是优化过的神经网络(Neural Network)。
神经网络发明于上世纪40-50年代,本质上是一个曲线拟合算法,通过拟合多个、多层的Softplus(曲线)、ReLU(Rectified Linear Unit 折线)、Sigmoid(对数线),实现对任意曲线的拟合。

“神经网络”名字听起来很高大上,但并不是脑科学的产物。因为发明时,觉得算法中每个节点像神经元、每个连线像神经触突,因此称为神经网络。
它很早就应用于自动控制领域。后来发展出多种神经网络算法,例如用于图像识别的卷积神经网络(CNN)、很早就用于语言学习的递归神经网络(RNN)…
在大语言模型成熟前,自然语言处理进化出过众多的技术,例如词袋、词汇矢量化、基于递归神经网络的模型、超长短期记忆网络(LSTM)… 但都在能力和算力上有众多缺陷,无法用于有实用价值的内容生成领域。

虽然它们不能实现实用化的内容生成,但为内容生成式大语言模型落地打下了基础,也是我们了解大语言模型前必须了解的预备知识。
1.3.1 分词(Tokenization)
词汇是语言模型分析的最小语义单位,所以第一步要把语句拆分成词汇(token)。分词并不简单,例如中文语句的分词就无法通过空格区分。所以用于大语言模型的分词算法也是基于海量语料训练出来的。
而基于大语言模型的内容生成,就是基于当前的所有token,预测下一个token,从而产生完整的内容。
1.3.2 词汇和语句的矢量化
机器学习算法基本只能处理数字,无法处理文本、声音、图像等非数字内容。所以要处理语言,需要对语句进行矢量化的表达,将其转换为数字。
拿我们常玩的一个游戏做解释:一个人在头脑里想象一个事物,让另一个人猜。另一个人可以问任何问题,但第一个人只能回答是和否。例如问:是动物吗?答:是;问:是哺乳动物吗?答:不是。问:有脚吗?答:是。
这个游戏的过程就是用不同维度来验证和归类一个事物,最终可以让这个事物在不同的维度上得以表达,即这个事物在一个高维度矢量空间上可以得到一个定位(矢量),同时相近的概念在矢量空间互相接近。
大语言模型通过大规模语料训练用神经网络将每个词汇在一个高维度空间矢量化,得到表达矢量的数组,将词汇矢量化到如下示意的矢量空间中:

这里的矢量化出来的是密集矢量,即每个维度上都不是0,且维度数固定,从而用更少的字节中存在更多的信息,因此在计算上的利用成本更低。相较于稀疏矢量的例子,例如书籍的归类:科学、言情、教育、音乐… ,词汇和语句的矢量结果密集度高的多,因此是密集矢量。
而语句矢量化在词汇矢量化的基础上,要将词汇在句子中的顺序信息加入,从而将“小明追老虎”和“老虎追小明”这两个词汇完全相同但语义完全不同的句子在矢量化输出上能够加以区分。
1.3.3 基于大语言的矢量化模型
将词汇和语句矢量化,是迈向我们如今看到的生成式大语言模型的第二步。
不同的语言矢量化模型生成的密集矢量维度数是不一样的,越高的维度数的密集矢量需要越大的计算资源和越大的内存消耗。下面是一些常见的矢量化语言模型和它们的维度数:
| 模型 | 维度数量 |
| BERT (Bidirectional Encoder Representations from Transformers) | 768或1024 |
| GPT (Generative Pre-trained Transformer) | 768或1600 |
| Word2Vec | 300 |
| USE (Universal Sentence Encoder) | 512 |
| MiniLM | 384 |
1.3.4 矢量相似度查询
词汇和句子矢量化后,怎么找到相似的词汇和句子?
对两个矢量进行相似度查询,就是计算两个矢量间的“距离”。有很多算法,如下图中所示的这些常见算法。
.png)
在大规模、高维度矢量数据库中查找近义词,如果采用与矢量记录逐一计算相似度的方法,将需要巨大的计算量,其效率并不能满足实用的性能需求。
而实际需求并不需要精确的相似度,因此出现了近似近邻算法(Approximate Nearest Neighbors - ANN)解决效率问题。ANN有多种算法,例如Annoy (Approximate Nearest Neighbors Oh Yeah)、 HNSW (Hierarchical Navigable Small World)。
下图是Annoy算法的示意图:
在矢量数据集中随机找2个矢量,计算出一个矢量平面到2个矢量的距离相同,从而将矢量数据集分割成2个空间;然后再在每个空间里重复上面的过程,直到分割后的空间里矢量数量与目标相似度矢量数量一致(例如我们希望得到返回矢量数量为10个以内的相似度结果集,那么如果空间内的矢量数小于等于10,就停止上述过程);从而我们得到一个决策树,今后可以用这个决策树进行矢量相似度查询,显然会快很多。

因为Annoy是基于最初的随机选择的2个矢量开始决策树构建的,如果这2个矢量本身就是高度相似的,那这2个矢量永远不会被一个矢量相似度查询要求同时命中,从而带来显著的误差。怎么办?可以随机多选几组初始矢量,从而形成多棵决策树的决策森林,提高ANN的精度。
可见ANN是大规模矢量检索查询的核心。
1.3.5 生成式大语言模型
递归神经网络(recurrent neural network - RNN)很早就应用到自然语言处理领域,之后出现了RNN改进模型LSTM (Long short-term memory),它们按顺序处理输入语句的词汇,并行能力不足,而且越高阶的神经网络需要的算力越高,达不到实用化的性能需求。
在2017年Google一个小团队(Transformer八子)发表了一篇论文 - Attention Is All You Need, 阐述了一类特殊的神经网络 – 基于注意力(Attention)机制的Transformer。它的注意力机制根据输入数据的长度执行固定步骤的计算,并且对输入数据的词汇(token)是并行计算的,它奠定了实用的生成式大语言模型的基础。这个团队的成员后大多离开了Google,并创立或加入了目前市场上几个主要生成式大语言模型。
在Transformer并行处理能力和越来越强大的GPU并行算力加持下,生成式大语言模型终是水到渠成,可以说是大力出奇迹!
当然Transformer模型具备多个特殊能力支撑内容生成能力。下面这张图解释了Transformer模型的4个核心特性:词汇矢量化(Word Embedding)、词汇在语句中位置的矢量化叠加(Positional Encoding)、自我注意力(Self-Attention)和残值连接(Residual Connections)。可见它其实构建在前面出现的技术基础之上。
.png)
借助这个新神经网络模型思路,众多大厂发布了自己的生成式大语言模型,如下面列出的这些著名的大语言模型。它们的宣传中常常强调其百亿级、甚至千亿级的参数:
|
模型 |
厂商 |
参数 |
|
GPT |
OpenAI (Microsoft) |
1750亿 |
|
Bard/Gemini |
|
18亿,32.5亿 |
|
PaLM2 |
|
3400亿 |
|
Llama 2 |
Meta |
70亿,130亿,700亿 |
|
Claude 2/3 |
Anthropic (Amazon) |
未披露 |
|
Stable Beluga |
Stability AI |
70亿,130亿,700亿 |
|
Coral |
Cohere |
未披露 |
|
Falcon |
Technology Innovation Institute |
13亿,75亿,400亿,1800亿 |
|
MPT |
Mosaic |
70亿,300亿 |
往往参数规模越大,其生成的内容越精确和越富有创造力。那么这些参数指什么?无论是什么样的大语言模型,它们底层都是神经网络,这些参数主要就是指神经网络中的权重和偏差。
.png)
二. 大语言模型应用中的问题和检索增强生成
从机制上,生成式大语言模型并不神秘。虽然它展现出了强大的理解能力甚至“创造力”,但它有以下几个问题:
- 它的知识来自于训练语料,并不知道所有知识。例如GPT-4 截止训练数据的时间是2022年1月份,对于后来的世界一无所知,更不可能知道您的机构中的未开放数据。
- 它是基于通用数据训练的,对于特定领域往往训练不足。
- 它的内容生成机制是使用神经网络逐词预测出回答中的下一个词从而构成完整的语句。因此它本质上不会拒绝回答任何问题,虽然人类限制它回答诸如如何制作病毒类的问题。结合它的“无知”和“创造力”,对不知道的问题,它也能一本正经地胡说八道,这就是生成式大语言模型的“幻觉”。
生成式大语言模型的“幻觉”在目前的应用中非常常见。例如我问了Bing Copilot一个关于“什么是InterSystems IRIS互联互通套件?”的问题,它不懂但没有拒绝回答,而且回答地相当“幻觉”:

如果想在我们自己的业务中直接应用生成式大语言模型,让它提供患者教育,或者回复患者的预约查询、亦或回答患者关于他/她自己的用药注意事项?显然不靠谱。
是不是可以用我们自己的数据进行训练?一来很多大模型都不是开放的,无法自己训练;二来相信大家都没有训练大语言模型的昂贵算力。
怎么解决这个问题?
大语言模型其实有三次“训练”机会:
.png)
- 预先训练就是大语言模型厂商通过海量语料进行的训练,我们干不了;
- 调优训练需要基于开放的大语言模型,算力成本也不低;
- 所以我们可以通过“提示”,让生成式大语言模型给我们想要的答案。
我又试了一次让Bing Copilot回答“什么是InterSystems IRIS互联互通套件?”,不过这次,我给了它提示,让它先读读关于InterSystems IRIS互联互通套件介绍的网页。这次它回答得相当到位:
.png)
也就是通过合适的提问,把本地数据提示给生成式大语言模型,从而让它可以准确回答而不会产生幻觉。
检索增强生成
基于问题先在本地数据检索,将相关结果提示给生成式大语言模型,从而获得靠谱的回答,这就是检索增强生成(Retrieval Augmented Generation – RAG)。
这里的本地数据检索,是基于大语言的矢量相似度检索。所以,需要借助矢量数据库,对本地的数据矢量化保存、并提供基于问题的矢量相似度查询,从而基于问题给出最匹配的本地数据。
这里是完整的检索增强生成流程示意图,分为2个过程:
1. 基于本地数据建立矢量知识库的过程
- 预先建立知识库, 将本地文档切分成文本段
- 使用矢量化语言模型对数据矢量化
- 将矢量保存到矢量知识库
2. 借助本地矢量知识库和外部大语言模型回答问题的过程
- 使用矢量化模型将问题矢量化
- 在矢量数据库中检索与问题相关的矢量记录
- 将匹配的数据(知识)作为上下文组织到完整的问题与提示中,向大语言模型提问。例如提示模版是:请仅使用以下上下文回答问题
- 从大语言模型得到回答
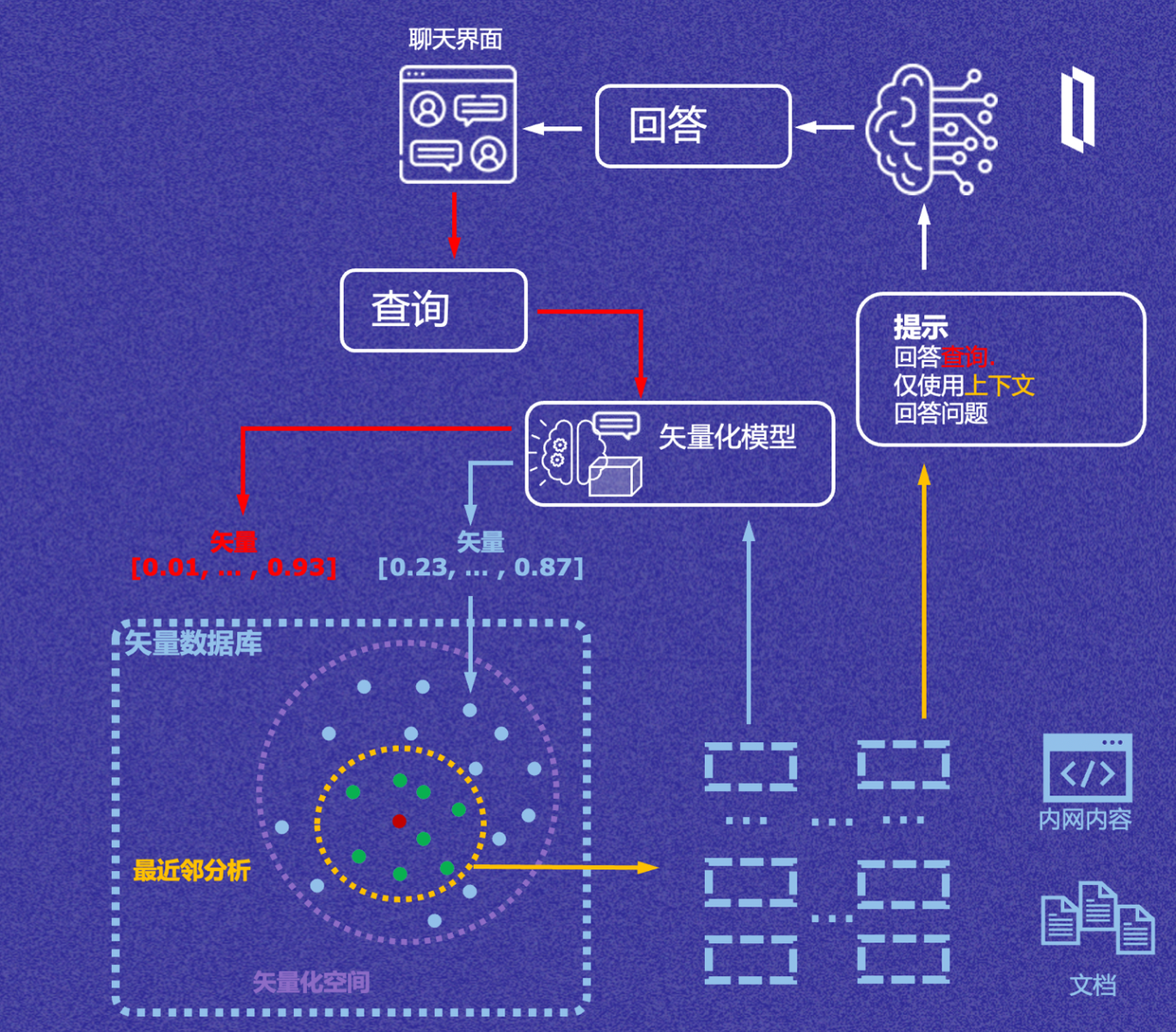
由此可见,检索增强生成至少需要以下3个技术组件:
- 矢量数据库 – 用于本地数据的矢量化保存和矢量化查询
- 矢量化语言模型 – 用于将本地数据和问题矢量化
- 内容生成语言模型 – 用于基于问题和上下文生成自然语言回答
矢量化语言模型、内容生成语言模型都有很多选择,根据需要可以选择能部署到本地的模型、也可以选择厂商提供的云服务。
而矢量数据库是保存本地知识数据的矢量化版本的,市面上常见的是一些nonSQL的专用数据库,也就是说需要将本地数据迁移到矢量数据库,并专门学习其数据操作的API。
可以预见,生成式大语言模型的能力将迅速进化,但本地的知识和数据并不会以如此快的速度发生变化。因此RAG将本地的知识和数据通过矢量化与生成式大语言模型集成,借助其不断提升的强大能力又无需被任何一个模型绑架,将是一个合理的解决方案。
三. InterSystems IRIS的内容生成架构
InterSystems IRIS是应用在众多行业的通用数据平台,并在2024版本中加入了对矢量存储和查询的支持,无需将IRIS中已经保存的本地知识数据迁移到别的矢量数据库中,从而消除数据迁移时间差、额外部署矢量数据库的运维成本,同时降低敏感数据泄露风险、确保遵循特定行业中对数据迁移监管的要求。而InterSystems IRIS作为一个具有互操作能力的数据平台,可以轻松集成大语言模型,并建立和管理检索增强生成的pipeline,降低RAG的技术实现复杂度。
3.1 IRIS的矢量存储和矢量查询
IRIS提供矢量数据类型,它被完全集成在IRIS多模型的架构中,尤其使用SQL就可以完整使用矢量存储和查询。
例如要创建含有矢量类型字段vec的表:
CREATE TABLE t (txt VARCHAR(1000), vec VECTOR(INT, 200));向矢量字段vec中插入数据:
INSERT INTO t VALUES (‘…’, TO_VECTOR(‘1,2,3,…’, INT));这里的矢量数据是需要通过调用矢量化模型产生的。
基于矢量相似度查询最接近的10条记录:
SELECT TOP 10 * FROM
FROM ( SELECT t.*, VECTOR_DOT_PRODUCT(vec, TO_VECTOR(…)) AS similarity FROM t )
ORDER BY similarity DESC;
3.2 IRIS的矢量索引
IRIS进一步提供了更易使用的矢量索引:无需创建矢量字段,直接在现有数据表上就可以创建声明式的矢量索引,并自动调用集成的矢量化模型,从而使用SQL就可以免代码方式进行开发。
创建矢量索引 – 通过索引对title、author和article这3个字段组合进行矢量化:
CREATE INDEX Vec ON MyNews(Title, Author, Article) AS VectorIndex(MODEL=‘BERT’);执行矢量查询 – 查询与条件最近似的3条记录:
SELECT TOP 3 * FROM MyNews WHERE Category = ‘NYT’
ORDER BY MyTable_VecSim(%ID, ‘climate change’);
3.3 基于IRIS构建完整的RAG方案
基于最新发布的InterSystems IRIS 2024.1,和部署到本地的矢量化模型(all-MiniLM-L12-v2)、内容生成模型(llama2),我构建了一个RAG原型:

这里IRIS实例即是保存本地数据的数据平台,也是本地数据的矢量化数据库,从而避免了数据的跨平台迁移。而全SQL的数据操作能力,让构建在自己数据上的检索增强生成方案能快速落地。
现在就把生成式大语言模型集成到您自己的业务中吧!
注:本文中的部分图片来自StatQuest、medium、wikipedia和weaviate。