清除过滤器
文章
姚 鑫 · 六月 2, 2021
# 第十四章 其他InterSystems %Net工具
下面是`%Net`中其他一些有用类的简短列表:
# %Net.URLParser
InterSystems IRIS提供了一个实用程序`类%Net.URLParser`,可以使用它将URL字符串解析为其组成部分。例如,当您重定向HTTP请求时,这很有用。
该类包含一个类方法`Parse()`,它接受一个包含`URL`值的字符串,并通过引用返回一个包含`URL`各部分的数组。例如:
```java
/// w ##class(PHA.TEST.HTTP).URLParser()
ClassMethod URLParser()
{
Set url = "https://www.google.com/search?q=Java+site%3Adocs.intersystems.com&oq=Java+site%3Adocs.intersystems.com"
Do ##class(%Net.URLParser).Parse(url,.components)
zw components
}
```
```
DHC-APP>w ##class(PHA.TEST.HTTP).URLParser()
components("fragment")=""
components("host")="www.google.com"
components("netloc")="www.google.com"
components("params")=""
components("path")="/search"
components("query")="q=Java+site%3Adocs.intersystems.com&oq=Java+site%3Adocs.intersystems.com"
components("scheme")="https"
```
返回时,组件将包含此URL各部分的数组:
Element | Value |Description
---|---|---
`components("fragment")` | `null` |URL的片段(#字符后面)
`components("host")` | `www.google.com` |URL请求的主机
`components("netloc")` | w`ww.google.com` | URL的网络地址
`components("params")` | |URL中包含的URL参数
`components("path")` | `/search` | URL的文件路径
`components("query")` | `q=Java+site%3Adocs.intersystems.com&oq=Java+site%3Adocs.intersystems.com` |URL中包含的查询字符串
`components("scheme")` | https | 此URL指定的传输方案
# %Net.Charset
可以使用`%Net.Charset`表示InterSystems IRIS内的MIME字符集,并将这些字符集映射到InterSystems IRIS区域设置。此类包括以下类方法:
- `GetDefaultCharset()`返回当前InterSystems IRIS区域设置的默认字符集。
- `GetTranslateTable()`返回给定输入字符集的InterSystems IRIS转换表的名称。
- `TranslateTableExists()`指示是否已加载给定字符集的转换表。
# %Net.TelnetStream
可以使用`%Net.TelnetStream`模拟`Windows NT Telnet.exe`的握手行为。
# %Net Security Classes
`%Net`包提供了许多用于身份验证和安全性的类。
文章
Claire Zheng · 二月 13, 2022
在刚刚过去的2021年,InterSystems举办了多场线上直播,我们汇总了多场重要直播,您可以点击链接或扫描相应二维码进入直播间,即可观看精彩回放!
直播一
聚焦InterSystems数据平台与WRC服务
直播二
InterSystems Caché系统运维培训
直播三
集成平台赋能智慧医院建设
直播四
国内外互联互通标准解读与实践
直播五
Health Connect系统运维培训
直播六
高效实施,加速互联互通标准化成熟度测评
直播七
InterSystems 2021全球线上峰会
直播八
InterSystems TrakCare助力医疗机构运营优化和质量提升
文章
Jingwei Wang · 六月 6, 2022
双击安装文件
选择同意协议,下一步
实例名称默认IRISHEALTH,不需要修改,直接下一步
安装路径,可修改,但不可使用中文路径
安装类型选择Development,点击下一步
选择Unicode,下一步
选择Normal,下一步
默认选项,不做修改,下一步
输入IRIS管理账户密码
输入CSP服务管理密码,和上一步密码保持一致。
点击安装,等待安装成功
公告
Claire Zheng · 一月 4, 2022
亲爱的社区开发者们,大家好!
欢迎积极参与新一轮InterSystems开发者竞赛!
随着 InterSystems IRIS 2021.2 预览版 的发布和全新的 LOAD DATA 功能,我们希望将其与最新的竞赛(数据集)结合起来!
🏆 InterSystems 数据集竞赛🏆
竞赛时间: 2021年12月27日-2022年1月16日
奖金总额: $9,450
奖项设置
1.专家提名奖(Experts Nomination)- 获奖者由我们特别挑选的专家团选出:
🥇 第一名 - $4,000
🥈 第二名 - $2,000
🥉 第三名 - $1,000
🌟 第四名-第十名 - $100
2. 社区提名奖(Community Nomination)- 获得总投票数最多的应用:
🥇 第一名 - $1,000
🥈 第二名 - $500
🥉 第三名 - $250
如果同时多位参赛者获得同样的票数,均被视为优胜者,将平分奖
谁可以参加?
任何开发者社区的成员均可参加,InterSystems内部员工除外(InterSystems contractor员工可以参加)。还没有账号?现在来建一个!
👥 开发者可以组团 创建一个协作应用程序,组团限定人数为2-5人。
请注意,要在您的README文件中标注您的团队成员——社区用户profile
参赛时间安排
🛠 12月27日 - 1月9日: 应用开发、提交阶段
✅ 1月10日 - 16日:投票阶段
注意:在整个参赛期间(开发与投票期间),开发者可持续编辑、提升其应用
主题
在我们此前的竞赛中,最常被提及的问题之一是缺乏数据集(Dataset)。每当您有一个关于特定领域或行业的项目idea时,您就需要一个相关数据集。此次竞赛的部分工作就是寻找/准备/加载数据集。
这就是为什么我们要举办此次数据集竞赛!让我们为社区带来一些有用的数据集吧!
我们在寻找什么?
提供将数据集加载到InterSystems IRIS名称空间中的存储库。
理想情况下,这可以使用ZPM包来完成,数据可以在包(package)中,或者包可以有一个方法,将数据从URL加载到IRIS实例中。 无论如何,一旦安装您的项目,应该带来一个类(class)及其与特定主题、主题领域、想法,行业等相关的数据。
项目应该建议如何使用数据——SQL查询、REST API或两者兼用。
数据的可视化是加分项。可视化和API(如果有的话)都可以与其他项目一起交付,但不是强制性的。
我们不会限制您在存储库中存储数据的方式。 例如,这可能是:
导出global(-s) (最好是XML格式而不是GOF格式)
创建数据的SQL脚本
在IRIS中生成数据的ObjectScript (或 java, js, python等)
与外部数据API集成
以下是一些项目示例:
Dataset-titanic,
Dataset-countries,
Posts and tags,
Synthea
要求:
类(Class)的命名约定。Class命名以 dc.data.your_name.class格式。例如:如果有一个关于交易数据的数据集,Class名可以是dc.data.finance.transaction或者dc.data.finance.instrument.
对数据源的引用。如果您从Internet上的某个地方获取数据集,并将其调整为InterSystems IRIS格式,请提供源链接。 如果这是您自己的数据,请提供使用许可。
ZPM包应以“dataset-”名称开头,例如:dataset-countries, dataset-titanic.
针对docker, demo, 文章, zpm和视频等,我们照例会提供技术奖励。
为数据集提供许可。
👉 数据集的常用许可类型 (源链接)
Spoiler
Common licenses in order of most open to most restrictive:
PUBLIC DOMAIN MARK - PUBLIC DOMAIN
Dedicate your dataset to the public domain: This isn’t technically a license since you are relinquishing all your rights in your dataset by choosing to dedicate your dataset to the public domain. To donate your work to the public domain, you can select “public domain” from the license menu when creating your dataset.
OPEN DATA COMMONS PUBLIC DOMAIN DEDICATION AND LICENSE - PDDL
This license is one of the Open Data Commons licenses and is like a public domain dedication. It allows you, as a dataset owner, to use a license mechanism to surrender your rights in a dataset when you might not otherwise be able to dedicate your dataset to the public domain under applicable law.
CREATIVE COMMONS ATTRIBUTION 4.0 INTERNATIONAL CC-BY
This license is one of the open Creative Commons licenses and allows users to share and adapt your dataset so long as they give credit to you.
COMMUNITY DATA LICENSE AGREEMENT – CDLA PERMISSIVE-2.0
This Community Data License Agreement is similar to permissive open source licenses such as the MIT license. It allows users to use, modify and adapt your dataset and the data within it, and to share it. The CDLA-Permissive-2.0 terms explicitly do not impose any obligations or restrictions on results obtained from users’ computational use of the data. The 2.0 version is significantly shorter, uses plain language to express the grant of permissions and requirements. The only obligation is to "make available the text of this agreement with the shared Data," including the disclaimer of warranties and liability.
OPEN DATA COMMONS ATTRIBUTION LICENSE - ODC-BY
This license is one of the Open Data Commons licenses and allows users to share and adapt your dataset so long as they give credit to you.
CREATIVE COMMONS ATTRIBUTION-SHAREALIKE 4.0 INTERNATIONAL - CC-BY-SA
This license is one of the open Creative Commons licenses and allows users to share and adapt your dataset so long as they give credit to you and distribute any additions, transformations or changes to your dataset under this license. We consider this license (a.k.a a viral license) problematic since others may decide not to work with your CC-BY-SA licensed dataset if there is risk that by doing so their work on your dataset will need to be shared under this license when they would rather use another license.
COMMUNITY DATA LICENSE AGREEMENT – CDLA-SHARING-1.0
This license is one of the Community Data License Agreement licenses and was designed to embody the principles of "copyleft" in a data license. It allows users to use, modify and adapt your dataset and the data within it, and to share the dataset and data with their changes so long as they do so under the CDLA-Sharing and give credit to you. The CDLA-Sharing terms explicitly do not impose any obligations or restrictions on results obtained from users’ computational use of the data.
OPEN DATA COMMONS OPEN DATABASE LICENSE - ODC-ODBL
This license is one of the Open Data Commons licenses and allows users to share and adapt your dataset so long as they give credit to you and distribute any additions, transformation or changes to your dataset under this license. We consider this license (a.k.a a viral license) problematic since others may decide not to work with your ODC-ODbL licensed dataset if there is risk that by doing so their work on your dataset will need to be shared under this license when they would rather use another license.
CREATIVE COMMONS ATTRIBUTION-NONCOMMERCIAL 4.0 INTERNATIONAL - CC BY-NC
This license is one of the more restrictive Creative Commons licenses. Users can share and adapt your dataset if they give credit to you and do not use your dataset for any commercial purposes.
CREATIVE COMMONS ATTRIBUTION-NODERIVATIVES 4.0 INTERNATIONAL - CC BY-ND
This license is one of the more restrictive Creative Commons licenses. Users can share your dataset if they give credit to you, but they cannot make any additions, transformations or changes to your dataset under this license.
CREATIVE COMMONS ATTRIBUTION-NONCOMMERCIAL-SHAREALIKE 4.0 INTERNATIONAL - CC BY-NC-SA
This license is one of the most restrictive Creative Commons licenses. Users can share your dataset only if they (1) give credit to you, (2) do not use your dataset for any commercial purposes, and (3) distribute any additions, transformations or changes to your dataset under this license. We consider this license a viral license since users will need to share their work on your dataset under this same license and any users of the adapted dataset would likewise need to share their work on the adapted dataset under this license and so on for any other changes to those modified datasets.
CREATIVE COMMONS ATTRIBUTION-NONCOMMERCIAL-NODERIVATIVES 4.0 INTERNATIONAL - CC BY-NC-ND
This license is one of the most restrictive Creative Commons licenses. Users can share only your unmodified dataset if they give credit to you and do not share it for commercial purposes. Users cannot make any additions, transformations or changes to your dataset under this license.
ADDITIONAL LICENSE COVERAGE OPTIONS
If a license is not listed in the data.world menu options, you may select Other and specify the details in the summary of your dataset.
NO LICENSE SPECIFIED
No one can use, share, distribute, re-post, add to, transform or change your dataset if you have not specified a license.
These descriptions are only summaries of these licenses. For the actual text of the licenses, which we strongly encourage you to read, click on the links provided.
Summary of common license types:
PUBLIC DOMAIN
The work has been dedicated to the public domain by waiving all rights to the work worldwide under copyright law, including all related and neighboring rights, to the extent allowed by law.
ATTRIBUTION
You must give appropriate credit, provide a link to the license, and indicate if changes were made. You may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your use.
SHARE-ALIKE
If you remix, transform, or build upon the material, you must distribute your contributions under the same license as the original.
NON-COMMERCIAL
You may not use the material for commercial purposes.
DATABASE ONLY
License applies to the database only and not its contents or data.
NO DERIVATIVES
No Derivative Works. You may not alter, transform, or build upon this work.
All licenses that begin with CC-BY in the table above refer to version 4.0 of those licenses.
一般要求:
有效应用程序:100%全新的Open Exchange Apps或已有的应用程序(但有显著提升)。所有参赛者/团队提交的应用程序只有经过我们团队的审核之后才会被批准参赛。
该应用可以在 IRIS Community Edition or IRIS for Health Community Edition or IRIS Advanced Analytics Community Edition上运行。
该应用需开源并在GitHub上发布。
该应用的README文件应为英文,包含安装步骤,并包含视频demo或/和应用程序如何运行的描述。
资源助力
1. InterSystems IRIS初学者:
Build a Server-Side Application with InterSystems IRIS
Learning Path for beginners
2. ObjectScript Package Manager (ZPM) 初学者:
How to Build, Test and Publish ZPM Package with REST Application for InterSystems IRIS
Package First Development Approach with InterSystems IRIS and ZPM
3. 如何将您的APP提交给大赛
如何在InterSystems Open Exchange上发布应用程序
如何把参赛APP提交给大赛
4. 更多
InterSystems IRIS 和 IRIS for Health 2021.2 预览版发布
LOAD DATA
参赛评比
投票规则即将发布,敬请期待!
So!
期待您的精彩提交!加入我们的编程马拉松,赢取大奖。
❗️ 点击此处,查看 官方竞赛条款解读. ❗️
公告
Claire Zheng · 九月 15, 2021
亲爱的社区开发者们,大家好!
InterSystems 开发者竞赛(InterSystems IRIS Analytics) 现已圆满结束!感谢大家的参与支持!
现在是揭晓优胜者的时刻了!
这些开发者和他们的应用程序赢得了雷鸣般的掌声:
🏆 专家提名奖(Experts Nomination)- 获奖者由我们特别挑选的专家团选出:
🥇 第一名,奖金 $4,000,获奖项目 promjet-stats ,作者 @Evgeniy.Potapov
🥈 第二名,奖金 $2,000,获奖项目 iris-analytics-datastudio ,作者 @Dmitry.Maslennikov
🥉 第三名,奖金 $1,000,获奖项目 pop-song-analytics,作者 @Henry.HamonPereira
🏆 社区提名奖(Community Nomination)- 获得总投票数最多的应用:
🥇 第一名,奖金 $1,000,获奖项目 iris-analytics-datastudio ,作者@Dmitry.Maslennikov
🥈 第二名,奖金 $500,获奖项目 AlertDashboard ,作者 @John Pan
🥉 第三名,奖金 $250,获奖项目 promjet-stats ,作者@Evgeniy.Potapov
恭喜所有优胜者!
感谢大家对本次比赛的关注和付出! 恭喜中国参赛者 @John Pan荣获此次竞赛“社区提名奖(Community Nomination)”第三名
公告
Claire Zheng · 二月 29
Hi 开发者们,
我们带来一些令人兴奋的消息!新一届 InterSystems 技术文章写作比赛到了!
✍️技术征文大赛:InterSystems IRIS 教程✍️
不论您是什么级别的程序员(初级/中级/高级),我们都欢迎您于2月19日~3月24日(美国东部时间)期间撰写一篇可以被当作 InterSystems IRIS 教程的文章。
🎁 人人有奖:每位参赛作者可获得一份特别奖品!
奖品
1. 技术征文大赛,人人都是赢家!凡在比赛期间撰写文章的会员将获得特别奖品:
🎁 Terra Thread Fairtrade Waist Pack
2. 专家评审奖——文章将由InterSystems专家评审:
🥇第一名:iPad10th generation
🥈 第二名:Beats Fit Pro True Wireless Earbuds
🥉 第三名:Amazon Kindle Paperwhite Signature Edition (32 GB)
奖品替代方案:任何获奖者都可以从比自己所获奖励级别更低的奖项中选择奖品。
3. 开发者社区奖——点赞数最多的文章:
🎁Amazon Kindle Paperwhite Signature Edition (32 GB)
请注意:
针对每个类别,作者只能获得一次奖励(作者共计将获得两项奖项:一项为专家评审奖,一项为开发者社区奖)
如果出现平局,则以专家评审中对平局文章的投票数作为平局判定标准。
谁可以参加?
任何开发者社区成员,除了InterSystems的员工。创建一个账户
关键参赛节点
📝 2月19日至3月24日(美国东部时间):文章发布及投票时间。
参赛者可以在此期间发表一篇或多篇文章。 开发者社区成员可以通过“点赞”对已发表的文章进行投票——这也是针对“开发者社区奖”的投票。
注意:越早发布文章,就越有时间收集更多点赞。
有什么参赛要求?
❗️任何在比赛期间撰写并满足以下要求的文章将自动*进入比赛:
该文章必须是关于 InterSystems IRIS 主题的教程**。它可以是针对初学者、中级或高级开发人员适用的。
文章必须是英文的(包括插入代码、屏幕截图等)。
该文章必须是 100% 原创的(可以是未参加竞赛的现有文章的延续)。
该文章不能是其他社区已发表文章的翻译。
该文章应仅包含有关 InterSystems 技术的正确且可靠的信息。
文章必须包含“教程(Tutorial)”标签。
文章长短:最少 400 字(链接和代码不计入字数限制)。
允许发表同一主题但具有不同作者的不同示例的文章。
* 我们的专家将对文章进行审核。只有有效的内容才有资格参加比赛。
** 教程为开发人员提供完成特定任务或一组任务的分步说明。
🎯额外奖励
在此次竞赛中,我们增加了额外的奖励机制,帮助您赢得奖品!
奖励主题
奖励分数
细节
主题奖励
5
如果您的文章涉及提议主题列表(如下所列)中的主题,您将获得 5 票专家投票的奖励。
视频奖励
3
您除了发布文章外,还制作了一个解释视频。
讨论奖励
1
由 InterSystems 专家决定,该文章中包含最有用讨论(Discussion)内容。只有 1 篇文章将获得此奖励。
翻译奖励
2
在任何地区社区上发布您文章的译文(如在中文社区发布译文)。 了解更多。
注:每篇文章只能使用一次。
新手奖励
3
如果您没有参加过之前的比赛,您的文章将获得 3 票专家票。
可获得“主题奖励”的主题
以下是我们推荐的主题列表,这些主题将为您的文章带来额外奖励:
✔️ 使用 AI/ML/GenAI✔️ 使用 Cloud SQL✔️ 使用 VSCode✔️ 使用 Kubernetes✔️ 使用 FHIR SQL Builder
注意:允许不同作者发表关于同一主题的文章。
➡️ 欢迎加入InterSystems Discord讨论规则、主题和奖励。
快乐分享技术,期待您的大作!✨✨
重要提示:奖品的交付因国家/地区而异,其中某些国家可能无法交付奖品。可以向 @Liubka.Zelenskaia 索取有限制的国家/地区列表
文章
Claire Zheng · 一月 20, 2021
简介
最近完成了针对IRIS医疗版2020.1版本的性能及可扩展性基准测试,重点关注HL7v2的互操作性。本文介绍了在各种工作负载下观察到的吞吐量,并提供了IRIS医疗版用作HL7v2消息传输互操作性引擎时的系统常规配置和调整准则。
基准测试模拟了与实际环境接近的工作负载(详细信息请参见“工作负载说明和方法”部分)。本次测试的工作负载包括HL7v2患者管理(ADT)和生命体征结果(ORU)数据,并包含数据内容转换和路由。
IRIS医疗版2020.1版本可以表明,采用第二代Intel®Xeon®可扩展处理器和Intel®Optane™SSD DC P4800X系列SSD存储的商用服务器,每天的持续消息吞吐量超过23亿条(入站和出站总量),与此前的Ensemble 2017.1 HL7v2吞吐量基准测试相比,扩展性提高了一倍多。
在这些测试过程中,将IRIS医疗版配置为先进/先出(FIFO)顺序,并且在磁盘中完整保存每个入站和出站消息以及消息队列信息。通过持久化消息队列和消息内容,IRIS 医疗版能够在系统崩溃时提供数据保护,并提供完整的历史消息搜索和重新发送功能。
下面将继续介绍配置准则,帮助您选择适当的配置和部署,以充分满足工作负载性能和可扩展性需求。
通过实验结果可以证实,IRIS 医疗版能够满足商用硬件上的极端消息吞吐量需求,并且在大多数情况下支持仅用单个小型服务器可为整个组织提供HL7互操作性服务。
结果概述
以下三种工作负载代表了HL7互操作性活动的不同方面:
·T1工作负载:使用HL7消息的简单传递,每条入站消息对应一个出站消息。不需要路由引擎就可以直接将消息从Ensemble业务服务传递到Ensemble业务操作。不使用任何路由规则,也不执行任何消息内容转换。每条入站消息都在数据库中创建了一个HL7消息对象。
·T2工作负载:通过路由引擎将入站消息平均分成4个分段,并将其路由到单个出站接口(1对1转换)。对每条入站消息执行一次数据转换,并在数据库中创建两个HL7消息对象。
·T4工作负载:使用路由引擎将单独修改的消息路由到四个出站接口中的每一个接口。平均而言,每次转换都会修改入站消息的4个分段(1条入站消息对应4条出站消息,进行4次转换)。对于每条入站消息,将执行4次数据转换,向外发送4条消息,并在数据库中创建5个HL7消息对象。
这三个工作负载是在一个物理48核系统上运行的,该系统有两个Intel®可扩展Gold 6252处理器和两个运行Red Hat Enterprise Linux 8的750GB Intel®Optane™SSD DC P4800X SSD驱动器。测试记录每秒(和每小时)入站的消息数、每秒(和每小时)出站的消息数,以及一天10小时内的总消息数(入站与出站)。此外,CPU利用率是用于衡量既定吞吐量水平下可用系统资源的指标。
可扩展性结果
表1:该测试硬件配置的四个工作负载吞吐量汇总
* 包含25%的T1,25%的T2和50%T4的“混合工作负载”
工作负载描述及方法论
测试的工作负载包括HL7v2患者管理(ADT)和生命体征结果(ORU)消息,平均大小为1.2KB,平均14个片段。通过转换大约修改了4个片段(针对T2和T4工作负载)。测试包括48至128个入站接口和48至128个出站接口,通过TCP/IP接收和发送消息。
在T1工作负载中,使用了四个单独的命名空间,每个命名空间有16个接口;T2工作负载使用了三个命名空间,每个命名空间有16个接口;T4工作负载使用了四个命名空间,每个命名空间有32个接口;最后的“混合工作负载”使用了三个命名空间,在所有的接口中:T1工作负载为16个,T2工作负载为16个,T4工作负载为32个。
逐渐增加每个接口上的通信量来衡量可扩展性,以寻找可接受性能标准范围内的最高吞吐量。为了获得可接受的性能标准,必须以持续不变的速率处理消息,无需排队,消息传递没有可测量的延迟,且平均CPU使用率必须保持在80%以下。
之前的测试表明,HL7消息类型对集成的性能或可扩展性没有显著影响;重要的影响因素包括入站消息的数量、入站和出站消息的大小、在路由引擎中创建的新消息的数量,以及修改的消息段的数量。
之前的测试还表明,在数据转换中处理HL7消息的各个字段通常对性能影响不大。这些测试中的转换通过相当简单的赋值来创建新消息。请注意,复杂的处理(例如在数据转换中使用大量的SQL查询)可能会导致结果发生变化。
之前的测试还验证了规则处理的影响通常不大。这些测试中使用的路由规则集平均为32条规则,所有规则都很简单。请注意,非常大或非常复杂的规则集可能会导致结果发生变化。
硬件
服务器配置
测试中使用的服务器采用了第二代Intel®可扩展Gold 6252“Cascade Lake”处理器,带有48核@ 2.1GHz的2插槽系统,每个插槽提供24个核心,并具有192GB DDR4-2933 DRAM和10Gb以太网网络接口。本测试使用的是Red Hat Enterprise Linux Server 8操作系统和InterSystems IRIS医疗版 2020.1。
磁盘配置
通过IRIS 医疗版传递的消息将完全持久化保存到磁盘上。本次测试中系统内部的两个Intel 750GBIntel®Optane™SSD DC P4800X SSD驱动器分开使用,一个用于数据库,一个用于日志。此外,除了确保与真实环境进行比较之外,还对日志启用了同步提交以确保数据持久化。对于本文前面提到的T4工作负载,每条入站HL7消息都会生成大约50KB的数据,这些数据可以进行细分(如表2所述)。事务日志的在线时间通常比消息数据或日志的时间短,在计算总磁盘空间时应该考虑到这一点。
表2:每条入站HL7 T4消息所需的磁盘空间
组成部分
数据要求
分段数据
4.5 KB
HL7消息对象
2 KB
消息头
1.0 KB
路由规则日志
0.5 KB
事务日志
42 KB
总计
50 KB
回顾上文,T4工作负载使用路由引擎将每个修改后的消息路由到四个出站接口中的每一个接口。平均而言,每次转换都会修改入站消息的4个分段(1条入站消息对应4条出站消息,进行4次转换)。每条入站消息将进行4次数据转换,将4条消息发送到出站,并在数据库中创建5个HL7消息对象。
在配置生产系统时,计算净需求时应考虑到每日入站量、HL7消息的删除计划以及日志文件的保留策略。此外,应该在系统上配置适当的日志文件空间,以防止保存日志的磁盘卷被占满。出于性能和可靠性方面的考虑,日志文件和数据库文件应分别保存至两个物理磁盘。
结论
InterSystems IRIS医疗版HL7v2消息吞吐量测试结果表明,简单的2插槽商用服务器配置即具有巨大的吞吐量能力,可满足任何组织中的极限消息工作负载的需求。此外,InterSystems致力于通过不断的版本迭代和升级,利用最新的服务器特性或者云技术,达到更高的性能和扩展性。
下图概述并比较了Ensemble 2015.1和Ensemble 2017.1基于英特尔®E5-2600 v3(Haswell)处理器的基准测试,以及Ensemble 2017.1基于第一代Intel®可扩展白金系列(Skylake)处理器的基准测试,和IRIS医疗版2020.1版本基于第二代Intel®可扩展黄金系列(Cascade Lake)处理器的基准测试最新结果。
图1:单个服务器上每天10小时的消息吞吐量(百万)
InterSystems IRIS 医疗版不断提高版本之间互操作性吞吐量的标准,并提供灵活的连接功能。如上图所示,IRIS 医疗版消息吞吐量已有显著增加,在T2工作负载情况下比2017版翻了一番,与2015版测试相比,在相同的10小时窗口内吞吐量增加了两倍多,24小时总消息速率保持在23亿以上。
证明IRIS 医疗版性能提升的另一个关键指标是更复杂的T2和T4工作负载(包含转换和路由规则,而不是T1工作负载的纯直通操作)中的吞吐量的提高。
InterSystems可随时与您探讨组织中遇到的与互操作性需求相关的解决方案。
注:本文为译文,欢迎点击查看原文,原文由Mark Bolinsky撰写
这篇能不能发个微信公众号?:) 欢迎查看:https://mp.weixin.qq.com/s?__biz=MzA4MTg3OTU4Mg==&mid=2656760711&idx=1&sn=b098179e1947105917517a7ceeede3f4&chksm=842064f6b357ede044475009db72bf3777a5e18427904f893390e466e16703c289830d0beda6&token=2031523301&lang=zh_CN#rd
文章
Louis Lu · 一月 7, 2021
本文介绍了 InterSystems 客户围绕 SDDC 和 HCI 解决方案的注意事项。
采用软件定义数据中心 (SDDC) 和超融合基础架构 (HCI) 解决方案的 InterSystems 客户需要重点关注的事项
越来越多的 IT 组织正在探究使用SDDC 和 HCI 解决方案的可行性。 这些解决方案看上去很有吸引力,其市场定位为跨异构数据中心和云基础设施可以使得 IT 管理更容易、投入的成本花费更少。 对于 IT 组织来说,潜在的好处是巨大的,许多 InterSystems 客户正在拥抱 SDDC、HCI 或两者兼有。
如果您正在考虑 SDDC 或 HCI 解决方案,请联系您的销售客户经理或销售工程师,安排与技术架构师的通话。 这对于确保成功非常重要。
这些解决方案具有高度的可配置性,组织可以从许多软件和硬件的组合中自由选择。 我们看到了我们的客户使用各种 SDDC 和 HCI 解决方案,通过这些经验,我们意识到,仔细考虑解决方案配置以避免风险是非常重要。 在某些情况下,有些客户的实施不符合关键事务型数据库系统所需的性能和弹性需求。 这导致了应用性能不佳和意外停机的出现。 如果客户的目标是为关键事务型数据库系统提供高弹性和低延迟的存储能力,则组件的选择和配置需要针对您的情况进行仔细考虑和规划,包括:
* 选择适当的组件
* 正确配置这些组件
* 使用适当的操作步骤
SDDC 和 HCI 提供了灵活性和易管理性,它们在操作系统和物理存储层之间的管理程序层内或旁路运行。 这会增加不同程度的开销。 如果配置错误,会从根本上影响磁盘延迟,这对于应用的性能而言是灾难性的。
InterSystems IRIS、Caché 和 Ensemble 的设计注意事项
以下最低要求和设计注意事项列表基于我们对 SDDC 和 HCI 解决方案的内部测试。 请注意,这不是一个参考架构,意味着您的应用需求将根据您的实际情况和性能目标有所更改。
网络
* 每节点拥有两个或更多的 10Gb NIC 接口,专门用于存储流量。
* 本地两台无阻塞速率 10Gb 交换机,实现交换机的弹性连接。
* 当然也可以选择 25、40、50 或 100Gb 而不是 10Gb速率,将其作为对 HCI 的前瞻性投资,以满足特定基准和测量应用程序的要求。
**计算**
* 至少一个六节点群集,以便在维护和故障期间提供更高的弹性和可预测的性能。
* 英特尔可扩展 Gold 或 Platinum 处理器或更高版本,2.2Ghz 或更高主频。
* 以每个 CPU 插槽 6 个 DDR4-2666 DIMM 为一组的形式安装 RAM(最少 384GB)。
存储
* 全闪存存储。 这是唯一推荐的存储选项。 InterSystems 强烈建议不要将混合或分层 HCI 存储用于生产工作负载。
* 每个物理节点至少两个磁盘组。 每个磁盘组应支持至少三个大容量驱动器。
* 独占使用写入密集型 12Gbps SAS SSD 或 NVMe SSD。
* 对于具有缓存和容量层的全闪存解决方案,建议将 NVMe 用于缓存层,将写入密集型 12Gbps SAS 用于容量层。
* 对 Linux 虚拟机使用 LVM PE 条带化,从而将 IO 分布在多个磁盘组(请联系 InterSystems 获得指南)。
* 对于 Linux 虚拟机上的所有数据库和写入映像日志 (WIJ) 文件使用异步 IO 及 rtkaio 库。 这样可以绕过文件系统缓存并降低写入延迟(请参见[文档](http://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls)或与 WRC 联系以获取有关在 Linux 上正确启用异步 IO 的帮助)。
这些最低要求建议已证明可以减轻 SDDC 和 HCI 的开销,但并不确保应用性能。 与任何新技术一样,测试您自己的应用的性能和弹性对于任何成功部署都是至关重要的。
重申一次,如果您正在考虑 SDDC 或 HCI 解决方案,请联系您的销售客户经理或销售工程师,他们会为你安排与技术架构师的通话。这对于确保成功至关重要。
文章
Michael Lei · 五月 12, 2021
在本帖中,我将展示使用_外部备份_来备份 Caché 的策略,以及与基于快照的解决方案集成的示例。 如今,大多数解决方案部署在基于 VMware 的 Linux 上,因此许多帖子都以展示解决方案如何集成 VMware 快照技术为例。
## Caché 备份 - 包括电池?
Caché 安装后即包含 Caché 在线备份,可提供不间断的 Caché 数据库备份。 但随着系统规模的扩大,您应该考虑更高效的备份解决方案。 集成了快照技术的_外部备份_是推荐的系统(包括 Caché 数据库)备份解决方案。
## 外部备份有特殊注意事项吗?
[外部备份](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GCDI_backup#GCDI_backup_methods_ext)的在线文档包含了全部详细信息。 一个关键考虑事项是:
> “为确保快照的完整性,Caché 提供了在创建快照时冻结数据库写操作的方法。 在创建快照期间,只冻结对数据库文件的物理写入,从而允许用户进程继续在内存中不间断地执行更新。”
还需要注意的是,虚拟化系统上的部分快照过程会导致正在备份的虚拟机短暂暂停,这段时间通常称为关闭时间。 该时间通常不到一秒,因此不会被用户注意到,也不会影响系统运行,但在某些情况下,关闭时间可能较长。 如果关闭时间长于 Caché 数据库镜像的 QoS 超时时间,那么备份节点将认为主节点出现故障,并将进行故障转移。 在本帖的后面部分,我将说明在需要对镜像 QoS 超时时间进行更改时如何查看关闭时间。
[这里是 InterSystems 数据平台和性能系列的其他帖子的列表。](https://cn.community.intersystems.com/post/intersystems-数据平台的容量规划和性能系列文章)
对于本帖,您还应该查看 Caché 在线文档中的[备份和还原指南](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GCDI_backup)。
# 备份选择
## 最低限度的备份解决方案 - Caché 在线备份
如果您没有其他备份方案,可使用 InterSystems 数据平台附带的这一功能,以实现零停机时间的备份。 请记住,_Caché 在线备份_只备份 Caché 数据库文件,它将捕获数据库中为数据分配的所有块以及写入到顺序文件的输出。 Caché 在线备份支持累积备份和增量备份。
在 VMware 的上下文中,Caché 在线备份是一种客户机内备份解决方案。 与其他客户机内解决方案一样,无论应用程序已虚拟化还是直接在主机上运行,Caché 在线备份的操作都基本相同。 Caché 在线备份必须与系统备份配合使用,才能将 Caché 在线备份输出文件与应用程序使用的所有其他文件系统一起复制到备份介质中。 最低限度的系统备份必须包括安装目录、日志和备用日志目录、应用程序文件以及包含应用程序使用的外部文件的任何目录。
Caché 在线备份应被视为小型站点的入门级方法,这些站点希望实施低成本解决方案,只备份 Caché 数据库或临时备份,例如,该方案在设置镜像时非常有用。 然而,随着数据库规模的扩大,加上 Caché 通常只是客户数据环境的一部分,建议将_外部备份_与快照技术和第三方实用工具相结合来作为最佳做法。这样做的优点包括可备份非数据库文件、更快的还原时间、企业范围的数据视图以及更好的目录和管理工具。
## 推荐的备份解决方案 - 外部备份
以 VMware 为例;VMware 上的虚拟化为保护整个虚拟机增加了额外的功能和选择。 将解决方案虚拟化后,您就有效地将系统(包括操作系统、应用程序和数据)全部封装在 .vmdk(和其他一些)文件中。 需要时,可以非常方便地管理这些文件,并使用它们恢复整个系统,这与物理系统上的操作截然不同。在物理系统中,必须分别恢复和配置各个组件 - 操作系统、驱动程序、第三方应用程序、数据库和数据库文件等。
# VMware 快照
VMware 的 vSphere Data Protection (VDP) 和其他用于虚拟机备份的第三方备份解决方案(如 Veeam 或 Commvault)利用 VMware 虚拟机快照的功能来创建备份。 以下是 VMware 快照的高阶说明,有关更多详细信息,请参见 VMware 文档。
快照应用于整个虚拟机,操作系统和所有应用程序或数据库引擎都不知道快照的进行,记住这一点很重要。 此外,还要记住:
> VMware 快照本身不是备份!
快照_使_备份软件进行备份,但它们本身并不是备份。
VDP 和第三方备份解决方案将 VMware 快照过程与备份应用程序相结合来管理快照的创建及非常重要的删除。 从高级别看,使用 VMware 快照进行外部备份的过程和事件顺序如下:
- 第三方备份软件请求 ESXi 主机触发 VMware 快照。
- 虚拟机的 .vmdk 文件被置于只读状态,并且为虚拟机的每个 .vmdk 文件都创建一个子 vmdk 增量文件。
- 使用写入时复制机制,对虚拟机的所有更改都将写入增量文件。 任何读取都先从增量文件进行。
- 备份软件管理只读父 .vmdk 文件到备份目标的复制。
- 备份完成后,将提交快照(虚拟机磁盘恢复写入,并且增量文件中更新的块将写入父文件)。
- VMware 快照此时已删除。
备份解决方案还使用其他功能,如变更块跟踪 (CBT) 允许增量或累积备份,以提高速度和效率(对节省空间尤为重要),并且通常还增加其他重要功能,如重复数据删除和压缩、调度、挂载已更改 IP 地址的虚拟机以进行完整性检查等、完整的虚拟机和文件级恢复,以及目录管理。
> 管理不当或长时间不运行的 VMware 快照可能会占用过多存储(随着越来越多的数据被更改,增量文件会持续增长),还会拖慢虚拟机的速度。
在生产实例上运行手动快照之前,您应该非常仔细地考虑。 为什么要这么做? 如果*时光倒流*到创建快照的时候,会发生什么? 从创建到回滚之间的所有应用程序事务会发生什么?
如果您的备份软件创建和删除快照,没有问题。 快照应该只存在很短的时间。 备份策略的关键部分是选择系统使用率较低的时间,以最大程度地减少对用户和性能的影响。
## 快照的 Caché 数据库注意事项
拍摄快照之前,数据库必须处于静默状态,以便提交所有待处理的写入,并且数据库处于一致状态。 Caché 提供了方法和 API,以在创建快照时先提交对数据库的写入,再短时间冻结(停止)写入。 这样,在创建快照期间,只冻结对数据库文件的物理写入,从而允许用户进程继续在内存中不间断地执行更新。 触发快照后,将解冻数据库写入,备份继续将数据复制到备份介质。 冻结和解冻的间隔应该非常短(几秒钟)。
除了暂停写入,Caché 冻结还会处理日志文件的切换并向日志写入备份标记。 在物理数据库写入被冻结时,日志文件继续正常写入。 如果在物理数据库写入被冻结时系统崩溃,则在启动过程中,会照常从日志恢复数据。
下图显示了为创建具有一致数据库映像的备份,所执行的冻结和解冻以及 VMware 快照步骤。

> _请注意,冻结和解冻之间的短暂时间只是创建快照的时间,而不是将只读父文件复制到备份目标的时间。_
# 整合 Caché 冻结和解冻
vSphere 允许在创建快照的任一侧自动调用脚本,此时会调用 Caché 冻结和解冻。 注意:为了使此功能正常工作,ESXi 主机会请求客户机操作系统通过 _VMware Tools_ 静默磁盘。
> 客户机操作系统中必须安装 VMware Tools。
脚本必须遵守严格的名称和位置规则。 还必须设置文件权限。 对于 Linux 上的 VMware,脚本名称为:
# /usr/sbin/pre-freeze-script
# /usr/sbin/post-thaw-script
以下是我们团队对内部测试实验室实例进行 Veeam 备份时使用的冻结和解冻脚本示例,这些脚本应该也适用于其他解决方案。 这些示例已在 vSphere 6 和 Red Hat 7 上测试和使用。
> 虽然这些脚本可用作示例并说明了方法,但您必须针对您自己的环境进行验证!
### pre-freeze-script 示例:
#!/bin/sh
#
# Script called by VMWare immediately prior to snapshot for backup.
# Tested on Red Hat 7.2
#
LOGDIR=/var/log
SNAPLOG=$LOGDIR/snapshot.log
echo >> $SNAPLOG
echo "`date`: Pre freeze script started" >> $SNAPLOG
exit_code=0
# Only for running instances
for INST in `ccontrol qall 2>/dev/null | tail -n +3 | grep '^up' | cut -c5- | awk '{print $1}'`; do
echo "`date`: Attempting to freeze $INST" >> $SNAPLOG
# Detailed instances specific log
LOGFILE=$LOGDIR/$INST-pre_post.log
# Freeze
csession $INST -U '%SYS' "##Class(Backup.General).ExternalFreeze(\"$LOGFILE\",,,,,,1800)" >> $SNAPLOG $
status=$?
case $status in
5) echo "`date`: $INST IS FROZEN" >> $SNAPLOG
;;
3) echo "`date`: $INST FREEZE FAILED" >> $SNAPLOG
logger -p user.err "freeze of $INST failed"
exit_code=1
;;
*) echo "`date`: ERROR: Unknown status code: $status" >> $SNAPLOG
logger -p user.err "ERROR when freezing $INST"
exit_code=1
;;
esac
echo "`date`: Completed freeze of $INST" >> $SNAPLOG
done
echo "`date`: Pre freeze script finished" >> $SNAPLOG
exit $exit_code
### 解冻脚本示例:
#!/bin/sh
#
# Script called by VMWare immediately after backup snapshot has been created
# Tested on Red Hat 7.2
#
LOGDIR=/var/log
SNAPLOG=$LOGDIR/snapshot.log
echo >> $SNAPLOG
echo "`date`: Post thaw script started" >> $SNAPLOG
exit_code=0
if [ -d "$LOGDIR" ]; then
# Only for running instances
for INST in `ccontrol qall 2>/dev/null | tail -n +3 | grep '^up' | cut -c5- | awk '{print $1}'`; do
echo "`date`: Attempting to thaw $INST" >> $SNAPLOG
# Detailed instances specific log
LOGFILE=$LOGDIR/$INST-pre_post.log
# Thaw
csession $INST -U%SYS "##Class(Backup.General).ExternalThaw(\"$LOGFILE\")" >> $SNAPLOG 2>&1
status=$?
case $status in
5) echo "`date`: $INST IS THAWED" >> $SNAPLOG
csession $INST -U%SYS "##Class(Backup.General).ExternalSetHistory(\"$LOGFILE\")" >> $SNAPLOG$
;;
3) echo "`date`: $INST THAW FAILED" >> $SNAPLOG
logger -p user.err "thaw of $INST failed"
exit_code=1
;;
*) echo "`date`: ERROR: Unknown status code: $status" >> $SNAPLOG
logger -p user.err "ERROR when thawing $INST"
exit_code=1
;;
esac
echo "`date`: Completed thaw of $INST" >> $SNAPLOG
done
fi
echo "`date`: Post thaw script finished" >> $SNAPLOG
exit $exit_code
### 记得设置权限:
# sudo chown root.root /usr/sbin/pre-freeze-script /usr/sbin/post-thaw-script
# sudo chmod 0700 /usr/sbin/pre-freeze-script /usr/sbin/post-thaw-script
## 测试冻结和解冻
要测试脚本是否正确运行,可以在虚拟机上手动运行快照并检查脚本输出。 以下截图显示了“Take VM Snapshot”(拍摄虚拟机快照)对话框和选项。

**取消选中** -“Snapshot the virtual machine's memory”(拍摄虚拟机内存快照)。
**选中** -“Quiesce guest file system (Needs VMware Tools installed)”(静默客户机文件系统(需要安装 VMware Tools))复选框以暂停客户机操作系统上运行的进程,以便在拍摄快照时文件系统内容处于已知的一致状态。
> 重要! 完成测试后,记得删除快照!!!
如果静默标志为真,并且在拍摄快照时虚拟机已开机,将使用 VMware Tools 静默虚拟机中的文件系统。 静默文件系统是使磁盘上的数据进入适合备份的状态的过程。 此过程可能包括将脏缓冲区从操作系统的内存中缓存刷新到磁盘等诸如此类的操作。
以下输出显示了在运行将快照包括为操作一部分的备份后,上述冻结/解冻脚本示例中设置的 `$SNAPSHOT` 日志文件的内容。
Wed Jan 4 16:30:35 EST 2017: Pre freeze script started
Wed Jan 4 16:30:35 EST 2017: Attempting to freeze H20152
Wed Jan 4 16:30:36 EST 2017: H20152 IS FROZEN
Wed Jan 4 16:30:36 EST 2017: Completed freeze of H20152
Wed Jan 4 16:30:36 EST 2017: Pre freeze script finished
Wed Jan 4 16:30:41 EST 2017: Post thaw script started
Wed Jan 4 16:30:41 EST 2017: Attempting to thaw H20152
Wed Jan 4 16:30:42 EST 2017: H20152 IS THAWED
Wed Jan 4 16:30:42 EST 2017: Completed thaw of H20152
Wed Jan 4 16:30:42 EST 2017: Post thaw script finished
此示例显示,冻结和解冻之间经过了 6 秒 (16:30:36-16:30:42)。 在此期间,用户操作不会中断。 _您将必须从您自己的系统中收集指标_,但为说明起见,此示例来自在虚拟机上运行应用程序基准测试的系统,该虚拟机没有瓶颈,且平均指标为每秒超过 2 百万 Gloref、每秒 17 万 Gloupd、每秒 1100 次物理读取以及每个写守护进程周期 3000 次写入。
> 请记住,内存不是快照的一部分,因此在重启时,虚拟机将重启并恢复。 数据库文件将保持一致。 您不希望”恢复“备份,而是需要在某个时间点的文件。 恢复文件后,您可以前滚日志,并执行保持应用程序和事务一致性所需的任何其他恢复步骤。
为实现额外的数据保护,系统还可以自行完成[日志切换](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GCDI_journal#GCDI_journal_util_JRNSWTCH "Journal switch"),并将日志备份或复制到其他位置,例如每小时备份一次。
以下是上述冻结/解冻脚本示例中的 `$LOGFILE` 的输出,其中显示了快照的日志详细信息。
01/04/2017 16:30:35: Backup.General.ExternalFreeze: Suspending system
Journal file switched to:
/trak/jnl/jrnpri/h20152/H20152_20170104.011
01/04/2017 16:30:35: Backup.General.ExternalFreeze: Start a journal restore for this backup with journal file: /trak/jnl/jrnpri/h20152/H20152_20170104.011
Journal marker set at
offset 197192 of /trak/jnl/jrnpri/h20152/H20152_20170104.011
01/04/2017 16:30:36: Backup.General.ExternalFreeze: System suspended
01/04/2017 16:30:41: Backup.General.ExternalThaw: Resuming system
01/04/2017 16:30:42: Backup.General.ExternalThaw: System resumed
# 虚拟机关闭时间
在创建虚拟机快照时以及完成备份和提交快照后,虚拟机需要短时间冻结。 这个短时间冻结通常指关闭虚拟机。 [这里](http://cormachogan.com/2015/04/28/when-and-why-do-we-stun-a-virtual-machine/ "Blog Post on stun times")是一篇不错的关于关闭时间的博客文章。 我在下面总结了细节,并将其放在 Caché 数据库注意事项的上下文中。
根据那篇关于关闭时间的文章:”要创建虚拟机快照,需要“关闭”虚拟机,以便 (i) 将设备状态序列化到磁盘,以及 (ii) 关闭当前正在运行的磁盘并创建快照点。进行整合时,“关闭”虚拟机是为了关闭磁盘并将其置于适合整合的状态。”
关闭时间通常是几百毫秒;但是,如果在提交阶段有非常高的磁盘写入活动,关闭时间可能为几秒。
> 如果虚拟机是参与 Caché 数据库镜像的主成员或备份成员,并且关闭时间长于镜像服务质量 (QoS) 超时时间,则镜像将报告主虚拟机故障并启动镜像接管。
**2018 年 3 月更新:** 我的同事 Peter Greskoff 向我指出,在虚拟机关闭期间或主镜像成员不可用的任何其他时间,备份镜像成员可以在稍微超过半个 QoS 超时的时间内启动故障转移。
有关 QoS 注意事项和故障转移方案的详细说明,请参见以下精华帖:[镜像服务质量超时指南](https://community.intersystems.com/post/quality-service-timeout-guide-mirroring),不过关于虚拟机关闭时间和 QoS 的简述是:
> 如果备份镜像在半个 QoS 超时的时间内未收到来自主镜像的任何消息,它将发送一条消息以确保主镜像仍处于活动状态。 然后,备份镜像将再等待半个 QoS 超时的时间,以接收来自主镜像的响应。 如果主镜像没有任何响应,则认为主镜像已关闭,备份镜像将接管。
在繁忙的系统上,日志不断从主镜像发送到备份镜像,并且备份镜像无需检查主镜像是否仍在运行。 但是,在安静的时间内(更可能发生备份),如果应用程序处于空闲状态,则主镜像和备份镜像之间可能在超过半个 QoS 超时的时间内没有消息。
以下是 Peter 的示例;考虑以下空闲系统时间框架,其中 QoS 超时为 :08 秒,虚拟机关闭时间为 :07 秒:
- :00 主成员使用保持连接信号 ping 仲裁器,仲裁器立即响应
- :01 备份成员向主成员发送保持连接信号,主成员立即响应
- :02
- :03 虚拟机关闭开始
- :04 主成员尝试向仲裁器发送保持连接信号,但没有发送成功,直到关闭完成
- :05 备份成员 ping 主成员,因为 QoS 已过半
- :06
- :07
- :08 仲裁器在整个 QoS 超时时间内未收到主成员的响应,因此关闭连接
- :09 备份成员没有收到主成员的响应,并与仲裁器确认连接丢失,因此开始接管
- :10 虚拟机关闭结束,太迟了!!
另请阅读上面链接的帖子中的“_配置服务质量超时时的陷阱和注意事项_”部分,以理解让 QoS 超时只有必要长度的这一平衡。 QoS 太长(尤其是超过 30 秒)也会导致问题。
**2018 年 3 月更新结束:**
有关镜像 QoS 的更多信息,另请参见[文档](https://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GHA_mirror#GHA_mirror_set_tunable_params_qos)。
> 将关闭时间保持在最低限度的策略包括:在数据库活动较少并且存储设置良好时运行备份。
如上文所述,在创建快照时,有几个选项可以指定,其中一个选项是在快照中包含内存状态 - 请记住,_Caché 数据库备份不需要内存状态_。 如果设置了内存标志,则快照中会包含虚拟机内部状态的转储。 创建内存快照需要较长时间。 内存快照可用于恢复到拍摄快照时运行中的虚拟机状态。 数据库文件备份并不需要。
> 拍摄内存快照时,虚拟机的整个状态将关闭,**关闭时间是可变的**。
如前所述,对于备份,必须针对手动快照或通过备份软件将静默标志设置为真,以保证备份的一致性和可用性。
## 查看 VMware 日志以了解关闭时间
从 ESXi 5.0 开始,快照关闭时间会记录在每个虚拟机的日志文件 (vmware.log) 中,消息类似于:
`2017-01-04T22:15:58.846Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 38123 us`
关闭时间以微秒为单位,所以在上面的示例中,`38123 us` 为 38123/1000000 秒或 0.038 秒。
要确保关闭时间在可接受的限制范围内,或者要在怀疑关闭时间长而导致问题时进行故障排除,可以从您感兴趣的虚拟机文件夹中下载并查看 vmware.log 文件。 下载后,您可以提取日志并进行排序,例如使用下面的 Linux 命令示例。
### 下载 vmware.log 文件的示例
下载支持日志有几种方法,包括通过 vSphere 管理控制台或从 ESXi 主机命令行创建 VMware 支持包。 有关所有详细信息,请查阅 VMware 文档,但下面给出一个简单方法来创建和收集小得多的支持包,其中包括 vmware.log 文件,以便查看关闭时间。
您将需要虚拟机文件所在目录的长名称。 使用 ssh 登录到运行数据库虚拟机的 ESXi 主机,并使用命令:`vim-cmd vmsvc/getallvms` 列出 vmx 文件以及与它们唯一关联的长名称。
例如,本帖中使用的数据库虚拟机示例的长名称输出为:`26 vsan-tc2016-db1 [vsanDatastore] e2fe4e58-dbd1-5e79-e3e2-246e9613a6f0/vsan-tc2016-db1.vmx rhel7_64Guest vmx-11`
接下来运行命令以只收集和捆绑日志文件:
`vm-support -a VirtualMachines:logs`。
该命令将回显支持包的位置,例如:`To see the files collected, check '/vmfs/volumes/datastore1 (3)/esx-esxvsan4.iscinternal.com-2016-12-30--07.19-9235879.tgz'`。
您现在可以使用 sftp 将文件传输出主机,以进行进一步处理和查看。
在此示例中,解压缩支持包后,导航到与数据库虚拟机长名称相对应的路径。 例如,在此例中: `/vmfs/volumes//e2fe4e58-dbd1-5e79-e3e2-246e9613a6f0`。
您将看到几个已编号的日志文件,最新的日志文件没有编号,即 `vmware.log`。 该日志可能只有几百 KB,但是有很多信息,不过我们只关心关闭/取消关闭时间,使用 `grep` 可以轻松找到。 例如:
$ grep Unstun vmware.log
2017-01-04T21:30:19.662Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 1091706 us
---
2017-01-04T22:15:58.846Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 38123 us
2017-01-04T22:15:59.573Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 298346 us
2017-01-04T22:16:03.672Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 301099 us
2017-01-04T22:16:06.471Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 341616 us
2017-01-04T22:16:24.813Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 264392 us
2017-01-04T22:16:30.921Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 221633 us
我们可以看到,示例中有两组关闭时间,一组来自快照创建,另一组是删除/整合快照(例如,备份软件复制只读 vmx 文件完毕后)45 分钟后每个磁盘的关闭时间 。 在上面的示例中,我们可以看到大多数关闭时间为亚秒级,尽管初始关闭时间刚刚超过一秒。
短暂的关闭时间对于最终用户来说并不明显。 但是,Caché 数据库镜像等系统进程会持续监视实例是否“活动”。 如果关闭时间超过镜像 QoS 超时时间,那么节点可能被视为不可联系并已“死亡”,并且将触发故障转移。
_提示:_要查看所有日志或进行故障排除,一个方便的命令是 grep 所有 `vmware*.log` 文件,并查找关闭时间接近 QoS 超时时间的任何异常值或实例。 以下命令将输出传输到 awk 进行格式化:
`grep Unstun vmware* | awk '{ printf ("%'"'"'d", $8)} {print " ---" $0}' | sort -nr`
# 总结
您应该在系统正常运行期间定期监视系统,以了解关闭时间以及它们可能对 HA(如镜像)的 QoS 超时有何影响。 如前所述,将关闭/取消关闭时间保持在最低限度的策略包括:在数据库和存储活动较少并且存储设置良好时运行备份。 要持续监视,可以使用 VMware Log insight 或其他工具处理日志。
我将在将来的帖子中重新讨论 InterSystems 数据平台的备份和还原操作。 但现在,如果您基于您的系统工作流程有任何意见或建议,请通过下面的评论部分分享。
文章
Michael Lei · 五月 12, 2021
本周,我将关注 CPU - 主要硬件食物群之一 :) 一位客户请我就以下情况提供建议:他们的生产服务器已接近使用寿命终止,是时候更新硬件了。 他们还考虑通过虚拟化来整合服务器,并希望适当调整裸机或虚拟机的容量规模。 今天我们将关注 CPU,在后面的帖子中,我将介绍适当调整其他主要食物群(内存和 IO)规模的方法。
所以问题是:
- 如何将五年多以前对处理器的应用要求转换成针对当今的处理器?
- 目前的处理器有哪些是合适的?
- 虚拟化如何影响 CPU 容量计划?
2017 年 6 月添加: 要深入了解 VMware CPU 注意事项和规划的细节,以及一些常见问题,另请查看以下帖子:[虚拟化大型数据库 - VMware cpu 容量计划](https://community.intersystems.com/post/virtualizing-large-databases-vmware-cpu-capacity-planning)
[本系列其他帖子的列表](https://cn.community.intersystems.com/post/intersystems-数据平台的容量规划和性能系列文章)
# 使用 spec.org 基准比较 CPU 性能
要针对使用 InterSystems 数据平台(Caché、Ensemble、HealthShare)构建的应用程序在不同的处理器类型之间转换 CPU 使用率,可以使用 SPECint 基准作为可靠标准,来粗略计算处理器之间的伸缩性。 [http://www.spec.org](http://www.spec.org) 网站提供了一套标准化基准测试的可信结果,这些测试由硬件供应商运行。
具体来说,SPECint 是一种在同一供应商的不同处理器型号之间以及在不同供应商(例如戴尔、惠普、联想以及英特尔、AMD、IBM POWER 和 SPARC)之间比较处理器的方法。 当需要升级硬件时,或者要将您的应用部署在一系列不同的客户硬件上,而您需要为规模调整指标设置基准(例如英特尔至强 E5-2680 或所选任何处理器的每个 CPU 核心的峰值事务数)时,可以使用 SPECint 来了解您的应用的预期 CPU 要求。
SPECint 网站上使用了多个基准,不过 **SPECint_rate_base2006** 结果最适合 Caché,而且根据多年的客户数据研究和我们自己的基准测试,这一点已得到确认。
在本帖的示例中,我们将比较客户的戴尔 PowerEdge 服务器(运行英特尔至强 5570 处理器)与当前的戴尔服务器(运行英特尔至强 E5-2680 V3 处理器)之间的差异。 当英特尔至强 V4 服务器处理器普遍可用(本帖写于 2016 年初,预计很快就会上市)时,可以应用同样的方法。
## 示例:比较处理器
在 spec.org 的 __SPECint2006_Rates__ 数据库中搜索处理器名称,例如 __E5-2680 V3__,如果目标服务器品牌和型号已知(例如戴尔 R730),可以进一步优化搜索结果,否则请使用流行的供应商。我发现戴尔或惠普的型号是很好的标准服务器基准,不同供应商硬件上的处理器之间通常不会有太大差异。
> 在本帖的最后,我逐步演示了一个使用 spec.org 网站搜索结果的示例。
假设您已搜索 spec.org,并找到现有服务器和一个可能的新服务器,如下所示:
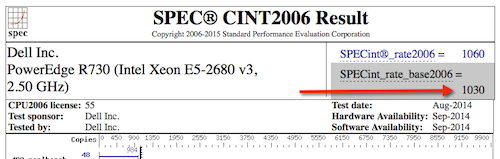
现有:戴尔 PowerEdge R710,搭载至强 5570 2.93 GHz:8 个核心,双芯片,4 个核心/芯片,2 个线程/核心: __SPECint_rate_base2006 = 251__
新服务器:PowerEdge R730,搭载英特尔至强 E5-2680 v3,2.50 GHz:24 个核心,双芯片,12 个核心/芯片,2 个线程/核心: __SPECint_rate_base2006 = 1030__
不出所料,新 24 核服务器的 SPECint_rate_base2006 基准吞吐量是旧 8 核服务器的 4 倍以上,即使新服务器的时钟速度较低。 请注意,示例中的两台双处理器服务器均已插满处理器插槽。
### 为什么对 Caché 使用 SPECint_rate_base2006?
spec.org 网站上有各种基准的解释,但总结起来就是 **SPECint_rate2006** 基准是一个完整的系统级基准,通过超线程使用所有 CPU。
对于具体的 SPECint_rate2006 基准,会报告两个指标:_base_ 和 _peak_。 base 是保守的基准,peak 则更为激进。 要进行容量计划,请使用 __SPECint_rate_base2006__ 结果。
## 四倍的 SPECint_rate_base2006 是否意味着四倍的用户或事务容量?
如果全部 24 个核心均被使用,应用吞吐量可能会扩展为旧服务器容量的四倍。 不过,有几个因素可能会导致不同情况。 SPECint 将提供大致可能的规模和吞吐量结果,但有几点注意事项。
在上面的示例中,虽然 SPECint 给出了两台服务器之间的明确比较,但并不保证 E5-2680 V3 服务器的峰值并发用户容量或峰值事务吞吐量比基于至强 5570 的旧服务器多 75%。 其他因素也会起作用,例如食物群中的其他硬件组件是否已升级,新存储或现有存储是否能满足吞吐量的增长(我很快会写一篇深入探讨存储的帖子)。
根据我对 Caché 进行基准测试的经验和对客户性能数据的研究,随着计算资源(CPU 核心)的增加,__在单台服务器上,Caché 能够线性扩展到极高的吞吐率__,而且 Caché 每年都在改进,性能会进一步提高。 换句话说, 随着 CPU 核心的增加,最大应用吞吐量(例如,应用事务数或 Caché gloref 中反映的值)会线性扩展。 但是,如果存在应用瓶颈,它们可能在较高的事务处理速率下出现,并影响线性扩展。 在以后的帖子中,我将介绍在哪里查找应用瓶颈的症状。 要提高应用性能,最好的方法之一是将 Caché 升级到最新版本。
> **注:**Caché 不支持具有超过 64 个逻辑核心的 Windows 2008 服务器。 例如,40 核服务器必须禁用超线程功能。 对于 Windows 2012,支持多达 640 个逻辑处理器。 Linux 上没有任何限制。
## 应用需要多少个核心?
应用各不相同,并且您知道自己的应用情况,但在为服务器(或虚拟机)规划 CPU 容量时,我常用的方法是通过连续的系统监视来了解某个“标准”处理器的特定数量的 CPU 核心可以维持的峰值事务速率:每分钟 _n_ 个事务。 这些事务可能是情节、遭遇、实验室测试或您的世界中任何有意义的事情。 重点是,标准处理器的吞吐量基于您在当前系统或客户系统上收集的指标。
如果您知道已知的具有 _n_ 个核心的处理器当前的峰值 CPU 资源使用情况,您可以使用 SPECint 结果将其转换为较新或不同的处理器实现相同事务处理速率所需的核心数量。 如果预期的线性扩展结果是每分钟 2 x _n_ 个事务数,则大致相当于需要 2 倍的核心数量。
## 选择处理器
正如您从 spec.org 网站或从首选供应商产品中所见,有许多处理器选择。 本示例中的客户对英特尔很满意,因此如果我坚持推荐当前的英特尔服务器,那么一种方法是力求“物有所值”- 或者每美元和每核心的 SPECint_rate_base2006 分数。 例如,下图绘制了戴尔商用服务器的性能价格图表,您的价格表可能有所不同,但这说明在价格和适合使用虚拟化整合服务器的高核心数中存在着甜蜜点。 我是通过先确定生产服务器(例如戴尔 R730)的价格,然后查看不同的处理器选项来制作这份图表的。
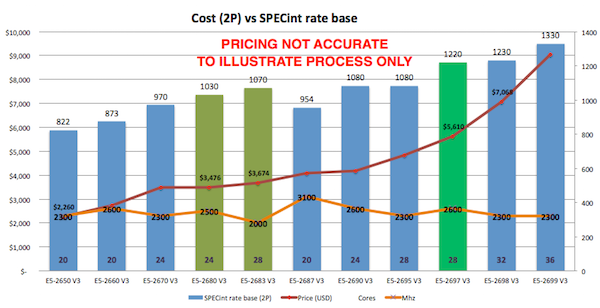
根据图表中的数据和客户站点的经验,E5-2680 V3 处理器显示出良好的性能以及按 SPECint 或按核心计算的出色价格点。
其他因素也在起作用,例如,如果您正在寻找用于虚拟化部署的服务器处理器,以更高的成本增加每个处理器的核心数可能反而更实惠,因为这样做的效果是减少了支持所有虚拟机所需的主机服务器总数,从而节省了按处理器插槽进行授权的软件(例如 VMware 或操作系统)成本。 您还必须根据高可用性 (HA) 要求来平衡主机数量。 我将在以后的帖子中重新讨论 VMware 和 HA。
例如,由三台 24 核主机服务器组成的 VMware HA 集群可提供良好的可用性和强大的处理能力(核心数),允许运行各种灵活配置的生产和非生产虚拟机。 请记住,VMware HA 的规模是 N+1 台服务器,因此三台 24 核服务器相当于总共 48 个核心可用于虚拟机。
## 核心数与 GHz - 哪个更适合 Caché?
如果在更快的 CPU 核心与更多的 CPU 核心之间进行选择,您应该考虑以下几点:
- 如果您的应用需要许多 cache.exe 线程/进程,那么更多核心将允许更多线程/进程同时运行。
- 如果您的应用进程较少,您希望每个进程都尽可能快地运行。
另一种考虑方式是,如果您的客户端/服务器应用有许多进程,假设每个并发用户一个(或多个),那么您需要更多可用核心。 对于使用 CSP 的基于浏览器的应用程序,用户被绑定到数量较少但非常繁忙的 CSP 服务器进程,那么您的应用程序将受益于数量可能较少但速度更快的核心。
在理想情况下,假设当多个 cache.exe 进程在所有核心中同时运行时没有资源争用,则两种应用程序类型都将受益于多个快速核心。 上文已叙述,但值得重申的是,每个 Caché 版本在 CPU 资源使用方面都有改进,因此将应用程序升级到最新版的 Caché 确实可以从更多的可用核心中受益。
另一个关键考虑事项是在使用虚拟化时最大程度地增加每个主机的核心数。 单个虚拟机的核心数量可能不高,但综合来看,您必须在可用性所需的主机数量与最大程度地减少主机数量(为了管理和成本考虑,通过增加核心数量来实现)之间取得平衡。
## VMware 虚拟化和 CPU
在配合使用当前服务器和存储组件的情况下,VMware 虚拟化很适合 Caché。 通过遵循与物理容量计划相同的规则,在正确配置的存储、网络和服务器上使用 VMware 虚拟化不会有明显的性能影响。 较新型号的英特尔至强处理器对虚拟化的支持更好,具体来说,您只应考虑在英特尔至强 5500 (Nehalem) 及更高版本(即英特尔至强 5500、5600、7500、E7 系列和 E5 系列)上进行虚拟化。
---
# 示例:硬件更新 - 计算最低 CPU 要求
如果我们考虑这样一个示例:对在具有 8 个核心(两个 4 核至强 5570 处理器)的戴尔 PowerEdge R710 上运行的工作负载进行服务器升级,那么将上述提示和程序结合在一起。
通过绘制客户的主生产服务器的当前 CPU 利用率,我们看到,服务器在当天最繁忙时段的峰值不到 80%。 运行队列没有压力。 IO 和应用也表现良好,因此不存在人为抑制 CPU 的瓶颈。
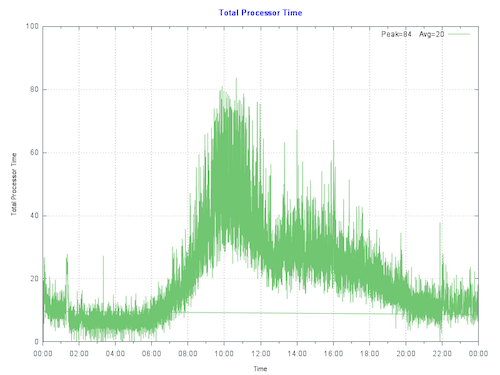
> **经验法则**:首先在考虑到预期增长(例如用户数/事务数增长)的前提下调整系统规模,使得在硬件寿命结束时的最大 CPU 利用率为 80%。 这样可以容许出乎预期的增长、异常事件或意外的活动激增。
为了使计算更清楚,我们假设在新硬件的生命周期内,预计吞吐量不会有任何增长:
每核心的扩展可以计算为:(251/8) : (1030/24),或者每核心吞吐量增长 26%。
**8 核心**旧服务器上的 80% CPU 大致相当于新的 **6 核心** E5-2680 V3 处理器上的 80% CPU。 因此,6 个核心即可支持相同数量的事务。
客户有几个选择,他们可以购买新的裸机服务器以满足 6 核 E5-2680 V3 或相同 CPU 核心数的最低 CPU 要求,或者继续推进在 VMware 上虚拟化生产工作负载的计划。
虚拟化对于利用服务器整合、灵活性和高可用性更有意义。 由于我们已经得出 CPU 要求,客户可以放心地继续在 VMware 上适当调整生产虚拟机的规模。 另外,目前低核心数的服务器很难采购到或者价格昂贵,这使得虚拟化更具吸引力。
如果预期有显著增长,虚拟化也是一个优势。 可以根据前几年的增长来计算 CPU 要求。 在持续监视的前提下,一个有效策略是只在出现资源需求之前才添加额外资源。
---
# CPU 和虚拟化注意事项
正如我们所看到的,Caché 生产系统的规模根据实际客户站点的基准测试和测量结果来确定。 通过裸机监视来确定 VMware 虚拟 CPU (vCPU) 的规模需求也是有效的。 与裸机相比,使用共享存储的虚拟化所增加的 CPU 开销非常小**。 对于生产系统,使用的策略是将系统初始规模调整为与裸机 CPU 核心数相同。
__**注:__对于 VMware VSAN 部署,必须添加 10% 的主机级 CPU 缓冲区才能进行 VSAN 处理。
虚拟 CPU 分配应考虑以下关键规则:
__建议:__分配的 vCPU 数量不要超过满足性能需求的安全数量。
- 虽然可以为虚拟机分配大量 vCPU,但最佳做法是不要分配超过所需数量的 vCPU,因为管理未使用的 vCPU 会有性能开销(通常很小)。 这里的关键是定期监视系统,以确保虚拟机的规模合适。
__建议:__生产系统,特别是数据库服务器,按 1 个物理 CPU = 1 个虚拟 CPU 进行初始规模设置。
- 生产服务器,特别是数据库服务器预计将被高度利用。 如果需要六个物理核心,则设置六个虚拟核心的规模。 另请参见下文关于超线程的说明。
## 超额预定
通过超额预订方法,可以将比物理主机上可用资源更多的资源分配给该主机支持的虚拟服务器。 通常,可以通过超额预定虚拟机中的处理、内存和存储资源来整合服务器。
运行生产 Caché 数据库时,仍然可以对主机进行超额预定,但是对于_生产_系统的初始规模设置,假定 vCPU 能够完全发挥核心能力。 例如,如果您有一台 24 核(2 个 12 核)E5-2680 V3 服务器 – 总共多达 24 个 vCPU 的容量规模,且可能还有余量可供整合。 此配置假定在主机级别启用了超线程。 在您花时间监测应用程序、操作系统和 VMware 在峰值处理期间的性能后,您可以决定是否进行更高度的整合。
如果混合非生产虚拟机,要计算 CPU 核心总数,我经常使用的系统规模调整经验法则是_最初_将非生产虚拟机的物理 CPU 与虚拟 CPU 的比例调整为 2:1。 但是,这并不是绝对的,具体情况可能各不相同,需要监视来帮助您进行容量计划。 如果您有疑问或没有经验,可以在主机级别或使用 vSphere 配置将生产虚拟机与非生产虚拟机分开,直到了解工作负载为止。
VMware vRealize Operations 和其他第三方工具能够随时间监视系统,并可提供整合建议或发出虚拟机需要更多资源的提醒。 在将来的帖子中,我将讨论更多可用于监视的工具。
最重要的是,在我们的客户示例中,他们可以确信他们的 6 vCPU 生产虚拟机会很好地工作,当然前提是其他主要食物群组件(如 IO 和存储)有足够容量 ;)
## 超线程和容量计划
根据物理服务器的已知规则调整虚拟机规模的一个良好起点是,针对启用了超线程功能的目标处理器计算物理服务器 CPU 要求,然后简单地进行转换:
> 一个物理 CPU(包括超线程)= 一个 vCPU(包括超线程)。
一个常见的误解是,超线程以某种方式使 vCPU 容量增加了一倍。 这对于物理服务器或逻辑 vCPU 来说并不正确。 根据经验,开启超线程的裸机服务器可能比未开启超线程的相同服务器多提供 30% 的性能。 同样的 30% 规则也适用于虚拟化的服务器。
## 授权和 vCPU
在 vSphere 中,您可以将虚拟机配置为具有一定数量的插槽或核心。 例如,如果您有一个双处理器虚拟机,可以将其配置为具有两个 CPU 插槽,或者具有单个插槽,但支持两个 CPU 核心。 从执行的角度看,并没有多大区别,因为虚拟机监控程序将最终决定虚拟机是在一个还是两个物理插槽上执行。 但是,指定双 CPU 虚拟机实际有两个核心而不是两个插槽,会对非 Caché 软件许可证产生影响。
---
# 总结
在本帖中,我概述了如何使用 SPECint 基准结果比较不同供应商、服务器或型号的处理器。 以及如何根据性能和体系结构进行容量计划和选择处理器,而不管是否使用虚拟化。
这些都是很深的主题,很容易陷入牛角尖... 不过,与其他帖子一样,如果您想要转移到其他方向,请评论或提问。
—
# 示例:搜索 SPECint_rate2006 结果。
#### 下图显示了如何选择 SPECint_rate2006 结果。
----
#### 使用搜索屏幕缩小结果范围。
#### 请注意,您还可以将所有记录转储为一个大约 20MB 的 .csv 文件,以进行本地处理,例如使用 Excel 处理。
#### 搜索的结果显示戴尔 R730。

---
#### 选择 HTML 以提供完整的基准结果。
---
在我们的示例中,您可以看到以下服务器及处理器结果。
戴尔 PowerEdge R710,2.93 GHz:8 个核心,双芯片,4 个核心/芯片,2 个线程/核心 至强 5570:__SPECint_rate_base2006 = 251__
PowerEdge R730(英特尔至强 E5-2680 v3,2.50 GHz),24 个核心,双芯片,12 个核心/芯片,2 个线程/核心 至强 E5-2680 v3:__SPECint_rate_base2006 = 1030__
文章
Michael Lei · 六月 1, 2021
什么是 Data Fabric?
“这是一套用于在公司中实施、管控、管理和执行数据操作的硬件基础架构、软件、工具和资源,功能包括跨所有数据存储平台的数据采集、转换、存储、分发、整合、复制、可用性、安全性、保护、灾难恢复、演示、分析、保存、保留、备份、恢复、归档、召回、删除、监视和容量规划,并可使应用程序的使用满足公司的数据需求”。
(Alan McSweeney)
Data Fabric 是一种可利用包括多模型数据库、Analytics、AI、ESB/SOA、微服务和 API 管理在内的所有可用资源和技术创新来获取商业价值的新型数据操作方法。
Data Fabric 原则
Alan McSweeney 列出了以下 Data Fabric 使用原则:
管控、管理和控制 - 无论数据位于何处,均可掌控数据并能够有效管理和管控数据
稳定性、可靠性和一致性 - 使用通用工具和实用工具在所有数据层之间提供稳定可靠的 Data Fabric
安全性 - 符合 Data Fabric、治理自动化、合规性和风险管理方面的各项安全标准
开放、灵活和自由选择 - 能够选择和更改数据存储、访问权限和位置
自动化 - 自动化管理和维护活动、DevOps 和 DevSecOps
性能、恢复、访问和使用 - 应用程序和用户可以在需要时、根据需求以及以适用格式访问数据
一体化 - 所有组件在所有数据层上均可互操作
Data Fabric 架构
McSweeney 设计了一幅在组织内部采用 Data Fabric 的详细概念图,如下所示:
您可以看到,需要采用某些技术才能将数据输入、处理和输出操作融合到一个流程中,进而“编织”数据并为数据使用者提供业务价值。 这些元素可以概括为下图:
数据操作位于数据接收网关 (Data Intake Gateway) 中,使用 ESB 和 API 网关技术捕获、编排、转换、丰富数据,并将数据资产整合到企业数据资产中。
借助 Analytics 和 AI 处理数据操作结果,从而为数据使用者提供数据分析。
由于数据量庞大且种类繁多,以及人们对于“黄金数据”这一“获得真理的唯一渠道”的需求,因此多模型存储库同样是一个重要角色。
InterSystems IRIS 与 Data Fabric
InterSystems IRIS 是一款支持在组织内部采用 Data Fabric 架构的 Data Fabric 平台,如下文所示:
Data Fabric 组件
InterSystems IRIS 组件
多功能存储库
IRIS 数据库
Java、Python、.NET 和对象脚本中受支持的 SQL Relational 对象
NoSQL 到 JSON – DocDB
可以使用 MDX 多维数据集进行分析
分片支持以支持大数据(与 MongoDB 相同)
企业缓存 – ECP
通过集成总线实现的 MDM
RBAC、密码学和标签
Transanalytic 和数据湖
使用 ORM 进行对象脚本的 JDBC、ODBC 或本机 SQL 访问
通过集成总线/服务总线和 API 网关实现数据接收/网关
IRIS 互操作性
REST API 和 API 管理
数据总线 - SOA、EAI、ESB
集成和 EDI 适配器
流程自动化 - BPL 和 DTL、规则
原生集成 Java、.NET 和 C Python 和 JavaScript
MFT - 托管文件传输
消息、事件和 JMS
采用 MQTT/API 的物联网
数据抽取/引入、转换和加载
分析和报告实用工具
IRIS Analytics
BI/分析和 ETL (BPL/DTL)
分级面板、分析和数据透视
SQL、MDX 和 Power BI 连接器访问
报告和嵌入式报告
UIMA - 非结构化内容分析
语义和情感分析
实时或计划分析
AutoML – IntegratedML
采用 R 或 Pyhton 的 AI/机器学习
NLP - 自然语言处理
R 、Python 和对象脚本中的统计信息
数据总线和认知流
文本分析
PMML
自适应运营分析 (AtScale)
用户门户
AI 实用工具
## 结语
InterSystems IRIS 并非简单的数据库或互操作平台,而是帮助您实现 Data Fabric 的核心角色。 如果您使用其他公司的其他解决方案,则需要购买 4 至 7 套解决方案,但使用 InterSystems,您只需要由多模型数据库、ESB/APIM、Analytics 和 AI 组成的一套解决方案即可创建 Data Fabric。 它为您提供了价格低廉、易于使用的优势。
了解详情:
文章
Jingwei Wang · 七月 21, 2022
在InterSystems IRIS数据平台管理门户中,有一些工具用于导入和导出数据。这些工具使用动态SQL,这意味着查询是在运行时准备和执行的。可以导入或导出的行的最大尺寸是3,641,144个字符。
你也可以使用%SQL.Import.Mgr类或LOAD DATA SQL命令导入数据,并使用%SQL.Export.Mgr类导出数据。
从文本文件中导入数据(.csv 和.txt)
你可以从一个文本文件中导入数据到一个合适的InterSystems IRIS类。当你这样做时,系统会在该类的表中创建并保存新的行。该类必须已经存在并且必须被编译。
步骤如下:
从管理门户中 选择系统资源管理器,然后选择SQL。用页面顶部的切换选项选择一个命名空间;这会显示可用的命名空间的列表。
在页面顶部,点击向导下拉列表,并选择数据导入。
在向导的第一页,首先指定外部文件的位置。对于导入文件所在的位置,点击要使用的服务器的名称。
然后输入文件的完整路径和文件名,文件可以是.csv 和 .txt格式。
然后选择你想要导入到schema的名称。
选择表名。
然后点击下一步。
在向导的第二页,选择需要导入数据的列。
然后点击下一步。
在向导的第三页,描述外部文件的格式。
在 "您的列所使用的分隔符? "中,点击与导入文件中的分隔符相对应的选项。
如果文件的第一行不包含数据,请点‘第一行是否包含列标题?’复选框。
对于字符串引号,点击表示该文件用于开始和结束字符串数据的引号定界符的选项。
对于日期格式,单击表示此文件中的日期格式的选项。
对于时间格式,点击表示此文件中的时间格式的选项。
对于时间戳格式,点击表示此文件中的时间戳格式的选项。
如果你不希望向导在导入时验证数据,请点击禁用验证复选框。
如果您不希望向导在导入时重建索引,请点击 ‘推迟 %SortBegin/%SortEnd 的索引构建?’ 复选框。如果勾选了 "延迟建立索引",向导会在将导入的数据插入到表中之前调用类的%SortBegin方法。当导入完成后,向导会调用%SortEnd方法。没有进行验证(与带有%NOCHECK的INSERT相同)。这是因为当使用%SortBegin/%SortEnd时,在SQL插入过程中不能检查索引的唯一性。
可以选择点击预览数据,看看向导将如何解析这个文件中的数据。
点击 "下一步"。
审查你的条目并点击完成。该向导显示数据导入结果对话框。
点击关闭。或者点击给定的链接,查看背景任务页面。在这两种情况下,向导会启动一个后台任务来完成导入工作。
导出数据到文本文件
你可以将一个给定类的数据导出到一个文本文件。
步骤如下:
从管理门户中 选择系统资源管理器,然后选择SQL。用页面顶部的切换选项选择一个命名空间;这将显示可用的命名空间的列表。
在页面的顶部,点击向导下拉列表,选择数据导出。
在向导的第一页。
输入你要创建的文件的完整路径和文件名,以保存导出的数据。
从下拉列表中,选择你要导出数据的命名空间、模式名称和表名称。
可以选择从字符集下拉列表中选择一个字符集;默认是设备默认值。
然后点击下一步。
在向导的第二页,选择要导出的列。然后点击下一步。
在向导的第三页,描述外部文件的格式。
在 "用什么分隔符分隔你的列?"中,单击与该文件中的分隔符相对应的选项。
如果你想把列头作为文件的第一行导出,请点击 ‘是否导出列标题?’ 复选框。
对于字符串引号,点击一个选项来表示如何在这个文件中开始和结束字符串数据。
对于日期格式,点击一个选项来表示在这个文件中使用的日期格式。
对于时间格式,点击一个选项来指示在此文件中使用的时间格式。
可以选择点击预览数据,看看结果会是什么样子。
然后点击下一步。
审查你的条目并点击完成。向导会显示 "数据导出结果 "对话框。
点击关闭。或者点击给定的链接,查看背景任务页面,向导会启动一个后台任务来完成导出工作。
文章
Johnny Wang · 十二月 12, 2021
您可能已经听说,我们目前正在为所有正在使用 Caché 和 Ensemble 的客户提供限时免费迁移到我们的下一代数据平台 InterSystems IRIS 的机会。
虽然我们依旧如往常一样全力支持那些正在使用 Caché 数据库和 Ensemble 集成引擎的客户,但我们还是认为 InterSystems IRIS 是未来的关键。它结合了 Caché 和 Ensemble 的所有功能,并添加了大量令人兴奋的强大功能,从机器学习到原生 Python。
这也正是我们为现有客户提供迁移到 InterSystems IRIS 并使用这些新功能的原因。 我们也通过就地迁移支持轻松迁移,这意味着无需数据库转换、分步迁移指南、教程等。
听起来挺有趣对吗? 以下是我针对当前 Caché 和 Ensemble 应迁移到 InterSystems IRIS 的五个主要原因。
1. 根据您的需求量身定制的工具:
InterSystems IRIS 本身有标准工具,例如根据 InterSystems IRIS 开发人员量身定制的 Visual Studio Code 编辑器。InterSystems IRIS 允许您在容器中运行应用程序,在 Kubernetes 中工作,并在您选择的云中轻松部署,这对于初学者有非常大的帮助。
2. 面向 SQL 开发人员的机器学习:
我们在 InterSystems IRIS 中嵌入了 IntegratedML 功能,使 SQL 开发人员无需成为数据科学或机器学习工具方面的专家,只需要几个类似 SQL 的命令即可轻松开发机器学习模型。 最重要的是,这些功能使您能够将机器学习模型无缝嵌入到 InterSystems IRIS 应用程序中,从而将它们转换为支持机器学习的智能应用程序。
3. 使用嵌入式 Python 提高生产力:
由于我们实现了 Python 的内置服务器端支持,我们的下一代技术使应用程序开发人员的工作效率更高。所有强大的功能都可以使用 Python 或 ObjectScript 调用,并且您的 Python 代码可以与 ObjectScript 代码无缝交互。 此外,我们为大量开发语言提供广泛的客户端支持,包括 Python、Java、C# 和 Node.js 等等。
4. 为 InterSystems IRIS 准备您的应用程序:
我们已经记录了 Caché 和 Ensemble 以及 InterSystems IRIS 之间的差异。在某些情况下,您可能需要对现有应用程序进行一些调整以满足与 InterSystems IRIS 相关的要求。
或者,您也可以采用与 Caché、Ensemble 和 InterSystems IRIS 兼容的通用代码库。这种方法的好处是您可以立即开始,确保您只有一个代码库需要维护,并在执行迁移时消除任何额外的调整。 这是我们许多大型企业客户经常采用的方法。
5. 易于迁移:
将您现有的 Caché 和 Ensemble 应用程序迁移到 InterSystems IRIS 是快速、简单且经过验证的。 查看我们的“迁移到 InterSystems IRIS”操作指南,您可以从我们的全球响应中心(需要登录 WRC)下载该指南,以确保无缝迁移。
现在是最好的时间
迁移只是旅程的开始,因此为了确保您从强大的 InterSystems IRIS 功能中获得最大收益,我们创建了各种文档、视频和在线学习资源,以帮助您解锁所有这些强大的功能。
现在是迁移到 InterSystems IRIS 的最佳时机。 只需联系您的 InterSystems 销售工程师或销售总监,即可享受此限时优惠。
了解更多信息:InterSystems.com/migrate。
关于作者:Jeff Fried
InterSystems 产品管理总监 Jeff Fried 是一位长期从事数据管理的,尤其热衷于帮助人们创建强大的数据驱动应用程序。 在加入 InterSystems 之前,Jeff 曾担任 BA Insight、Empirix 和 Teloquent 的 CTO,并负责 FAST Search and Transfer 和 Microsoft 的产品管理。 他在数据管理、文本分析、企业搜索和互操作性方面拥有丰富的经验。Jeff是该行业的常客和作家;拥有15项专利;并撰写了 50 多篇技术论文并合着了三本技术书籍。
查看原文
公告
jieliang liu · 十月 18, 2023
嘿开发者,
欣赏Bilibili InterSystems 中国上的新视频:
⏯如何在 2023 年全球峰会上定制 InterSystems IRIS for Health FHIR 存储库
InterSystems IRIS for Health 不仅提供世界一流的 FHIR 存储库,还提供灵活性和可扩展性。了解自定义 FHIR 存储库的选项,并了解如何通过几个具体用例来实现它们,例如强制标识符的唯一性和引用完整性。
🗣 演讲者: @Teunis.Stolker,InterSystems 高级销售工程师
享受这个视频并继续关注更多视频! 👍
文章
Lilian Huang · 七月 31, 2023
FHIR® SQL Builder或 Builder 是 InterSystems IRIS 医疗版数据平台 的一个组件。它是一种复杂的投射工具,用于将 InterSystems IRIS 医疗版数据平台FHIR 存储库中的数据创建为自定义的 SQL 模式,而无需将数据移动到单独的 SQL 存储库中。 Builder 专门设计用于与 InterSystems IRIS 医疗版数据平台中的 FHIR 存储库和多模型数据库配合使用。
Builder 的目标是使数据分析师和商业智能开发人员能够使用熟悉的SQL分析工具使用 FHIR,而无需学习新的查询语法。 FHIR 数据以复杂的有向图编码,无法使用标准 SQL 语法进行查询。基于图的查询语言 FHIRPath 旨在查询 FHIR 数据,但它是非关系型的。 Builder 使数据管理员能够使用表、列和索引创建其 FHIR 存储库的自定义 SQL 来投射,使数据分析师能够查询 FHIR 数据,而无需学习 FHIRPath 或 FHIR 搜索语法的复杂性。存储库将加载 FHIR 资源,您所需要做的就是配置 FHIR SQL BUILDER。对于配置,导航到http://localhost:55037/csp/fhirsql/index.csp# /有关如何进行配置的更多详细信息,请观看此教程视频
要查看配置,请导航到http://localhost:55037/csp/fhirsql/index.csp#/spec/1
现在让我们使用irisChatGPT应用程序,使用以下命令连接到终端
docker-compose exec iris iris session iris
创建 dc.irisChatGPT 类的新实例并使用 SetApiKey 方法设置 OpenAI API 密钥
set chat = ##class(dc.irisChatGPT).%New() do chat.SetAPIKey("Enter your Open API Key here")
谢谢