清除过滤器
文章
Hao Ma · 十一月 2, 2021
本文档将向您介绍 InterSystems IRIS®数据平台如何通过使用应用服务器进行分布式缓存,利用企业缓存协议(Enterprise Cache Protocol,ECP)来扩展用户容量(User Volume)。本指南介绍了如何使用分布式缓存架构进行扩展,并介绍了与部署 InterSystems IRIS 分布式缓存集群相关的一些初始任务。一旦您完成了本指南,您将对分布式缓存集群的工作原理和设置方法有一个基本的了解。这些活动被设计成只使用默认的设置和功能,这样您就可以熟悉该功能的基本原理,而不必处理细节(尽管这些细节在执行实现时可能很重要)。有关使用 InterSystems IRIS 分布式缓存和 ECP 的完整文档,请参见本指南末尾 " For More Information (更多信息)" 部分中的参考资料列表。要浏览所有的技术概要(First Look),包括可以在 InterSystems IRIS 免费的评估实例上执行的那些,请参见 InterSystems First Looks(《InterSystems 技术概要》)。
1 问题:扩展用户容量(User Volume) 当用户通过应用程序连接到您的 InterSystems IRIS 数据库时,他们需要快速、有效地访问数据。无论您的企业是小型、大型,还是介于两者之间,对数据库的大量并发用户请求——用户容量(user volume)——都会在托管数据库的系统上造成性能问题。这可能会影响更多用户,使他们等待更长时间才能收到所需信息。在一个动态业务中,用户容量(User Volume)可能会迅速增长,从而进一步影响性能。特别是,如果很多用户在执行许多不同的查询,这些查询的大小会超过缓存,这意味着,它们不能再存储在内存中,而是需要从磁盘上读取数据。这种低效的过程会导致瓶颈和性能问题。您可以增加系统的内存和缓存大小(垂直扩展),但这种解决方案可能是昂贵的、不灵活的,并最终受限于硬件的最大功能。将用户的工作量分散到多个系统上(水平扩展)是一种更加灵活、高效和可扩展的解决方案。
2 解决方案:分布式缓存(Distributed Caching)为了提高用户访问数据的速度和效率,InterSystems IRIS 可以使用分布式缓存(Distributed Caching)。这种技术允许 InterSystems IRIS 在多个应用服务器(application server)上存储数据库缓存。然后,用户容量(User Volume)可以分布在这些服务器上,从而提高缓存效率。使之成为可能的节点间通信是由 ECP,即企业缓存协议(Enterprise Cache Protocol)启用的。使用分布式缓存(Distributed Caching),您可以让进行类似查询的用户共享一部分缓存,该缓存托管在应用服务器集群中,与托管数据的数据服务器一起。实际数据保留在数据服务器上,但缓存保留在应用服务器上,以加快用户访问。数据服务器负责保持企业中每台应用服务器上的缓存数据是最新的。 分布式缓存是如何工作的?
有了分布式缓存集群,您可以根据需要添加或删除应用服务器,轻松地扩展您的解决方案。所有的应用服务器都会自动维护自己与数据服务器的连接,并在连接中断时尝试恢复连接。您可以在单个集群实例上使用管理门户(Management Portal)配置应用服务器及其相关的数据服务器,或使用 InterSystems 云管理器(InterSystems Cloud Manager,ICM)部署和配置集群。有关 ICM 的更多信息 ,请参见 First Look:ICM(《技术概要:ICM》)和 InterSystems Cloud Manager Guide(《InterSystems 云管理器指南》)。
3 分布式缓存是如何工作的?当您部署一个 InterSystems IRIS 分布式缓存集群时,指定一个实例为数据服务器,指定一个或多个实例为应用服务器。这些实例不需要在相同的操作系统或硬件上运行,它们只需要符合 InterSystems IRIS 系统的要求。• 数据服务器的执行方式与标准的 InterSystems IRIS 服务器一样,在命名空间中托管数据库,并根据请求向其他系统提供数据。• 应用服务器接收来自应用程序的数据请求。当用户打开一个应用程序时,它不是连接到数据服务器,而是连接到应用服务器。用户不会注意到有什么不同。应用服务器从数据服务器获取必要的数据并提供给用户。• 应用服务器将数据存储在自己的缓存中,这样,下次任何用户请求相同的数据时,应用服务器不需要再次联系数据服务器就可以提供。• 数据服务器监控所有的应用服务器,以确保其缓存中的数据是最新的。数据服务器还处理整个系统的数据锁。• 如果应用服务器和数据服务器之间的连接丢失,应用服务器会自动尝试重新连接并恢复任何需要的数据。• 您可以设计您的应用程序,将进行类似查询的用户引导到同一个应用服务器。这样一来,用户可以共享一个包含他们最需要的数据的缓存。例如,在医疗保健设置中,您可能会让临床医生运行一组特定的查询,而前台工作人员使用相同的应用程序和相同的底层数据运行不同的查询;这些用户组可以在不同的应用服务器上分组。再比如,如果集群处理多个应用程序,每个应用程序的用户可以被引导到他们自己的应用服务器上,以获得最大的缓存效率。
4 亲自尝试分布式缓存使用 InterSystems IRIS 建立一个分布式缓存集群很容易。这个简单的程序将引导您完成在几个实例上配置 ECP 的基本步骤。注意: 为了让您体验分布式缓存,而又不至于在细节上陷入困境,我们保持了简单的探索;例如,我们让您尽可能多地使用默认设置。不过,当您把这个功能带到您的生产系统时,您可能需要以不同的方式配置一些设置(例如,安全设置)。本文档末尾提供的参考资料将为您提供更多细节。 亲自尝试分布式缓存4.1 用前须知在这个示例中,您将设置一个InterSystems IRIS 实例作为数据服务器,再设置两个实例作为应用服务器。这意味着您将总共需要三个实例。您对 InterSystems IRIS 的选择包括多种类型的已授权的实例;这些实例不需要由您正在工作的系统托管(尽管它们必须相互有网络访问权限)。关于如何部署每种类型的实例的信息(如果您还没有三个实例可以使用),请参见 InterSystems IRIS Basics: Connecting an IDE(《InterSystems IRIS 基础:连接一个 IDE》)中的 Deploying Licensed Instances(部署已授权的实例)。注意:InterSystems IRIS 数据平台(Data Platform)提供了几种自动部署分布式缓存集群的方法,这些集群在部署后可以完全运行;请参见 Scalability Guide(《可扩展性指南》)中的 Deploying a Distributed Cache Cluster Automatically(自动部署分布式缓存集群)。4.2 启用 ECP 服务器 首先,在三个实例上启用 ECP 服务器,如下所示:1. 使用 InterSystems IRIS Basics:Connecting an IDE(《InterSystems IRIS 基础:连接一个 IDE》)中URL described for your instance(为您的实例描述的 URL),在您的浏览器中打开实例的管理门户(Management Portal)。2. 进入 Services(服务器) 页面(System Administration(系统管理) > Security(安全) > Services(服务器))。3. 选择 %服务_ECP。在 Edit Service(编辑服务器)页面上,选择 Service Enabled(已启用的服务器)复选框,然后选择 Save(保存)。您现在已经在系统上启用了 ECP。只需要几个步骤就可以完成对数据服务器和两个应用服务器的设置。4.3 配置数据服务器 在将要成为您的数据服务器的系统上,只需要两个快速步骤就可以完成设置。首先,您需要将允许的应用服务器的数量从默认值增加一个。然后,您将创建一个新的数据库供应用服务器连接。当然,在生产环境中,您已经有一个正在使用的数据库。要完成数据服务器配置:1. 在管理门户(Management Portal)中,进入 ECP Settings(ECP 设置) 页面(System Administration(系统管理) > Configuration(配置) > Connectivity(连接) > ECP Settings(ECP 设置))。2. 在标有 This System as an ECP Data Server(本系统作为 ECP 数据服务器)的部分中,将 Maximum number of application servers(应用服务器的最大数量) 设置为 2。 选择 Save(保存)。3. 重新启动实例。
有关创建数据服务器和设置可用选项的更多细节,请参见 Scalability Guide(《可扩展性指南》)中 "Horizontally Scaling Systems for User Volume with InterSystems Distributed Caching(《使用 InterSystems 分布式缓存为用户容量水平扩展系统》)"一章中的 Preparing the Data Server(准备数据服务器)。要为这个练习创建一个新的数据库:1. 在管理门户(Management Portal)中,进入 Local Databases(本地数据库) 页面(System Administration(系统管理) > Configuration(配置) > System Configuration(系统配置) > Local Databases(本地数据库))。2. 选择 Create New Database(创建新的数据库)。3. 为新数据库输入一个名称。对这个练习来说,称它为 ECP。4. 选择 Next(下一步) ,然后 Finis(完成)。
您已经创建了新数据库,并且您的数据服务器也已经准备好了。 亲自尝试分布式缓存
在接下来的章节中,您将设置两个应用服务器,并配置它们使其能够与数据服务器进行通信。为此,您需要知道数据服务器的超级服务器端口号(superserver port number),如 InterSystems IRIS Basics:Connecting an IDE(《技术概要:连接一个 IDE》)中所述。
4.4 配置应用服务器 接下来,您将把另外两个实例设置为应用服务器。您将配置每个应用服务器以指向数据服务器,并在每个服务器上创建一个新的命名空间,映射到您在数据服务器上创建的数据库。请确保在每个应用服务器上执行以下两个程序。
4.4.1 设置应用服务器1. 登录管理门户(Management Portal),进入 ECP Settings(ECP 设置) 页面(System Administration(系统管理) > Configuration(配置) > Connectivity(连接) > ECP Settings(ECP 设置))。2. 选择 Data Servers(数据服务器) ,然后选择 Add Server(添加服务器)。3. 填写所需信息:• Server Name(服务器名称)——输入一个名称或标签来识别这个服务器。它不需要与实例名称或实例的主机名称相同。• Host DNS Name or IP Address(主机 DNS 名称或 IP 地址)——输入托管您在上一节配置的数据服务器实例所在系统的主机标识符。• IP Port(IP 端口)——输入数据服务器实例的超级服务器端口号(superserver port number)。
4. 选择 Save(保存)。您的数据服务器现在出现在列表中。应用服务器连接到数据服务器,验证连接可能需要一些时间。4.4.2 创建命名空间和远程数据库现在您已经将应用服务器连接到数据服务器,您需要在每个应用服务器上创建一个命名空间。这个命名空间将是应用服务器的本地命名空间,但它不是包含本地数据库,而是映射到远程数据库——也就是您在上一节创建的数据服务器上的 ECP 数据库。1. 在管理门户(Management Portal)中,进入 Namespaces(名称空间) 页面(System Administration(系统管理) > Configuration(配置) > System Configuration(系统配置)> Namespaces(命名空间))。2. 选择 Create New Namespace(创建新的命名空间)。3. 在 Name of the namespace(命名空间名称) 字段中,输入 ECPNS。4. 对于 The default database for Globals in this namespace is a(这个命名空间中的 Globals 的默认数据库是一个),选择 Remote Database(远程数据库)。然后选择 Create New Database...(创建新数据库...) 按钮。 这将打开 Create Remote Database(创建远程数据库)窗口。5. 填写所需信息:• Remote Server(远程服务器)——使用下拉菜单来选择您在前面的程序中给数据服务器的 Server Name(服务器名称)。• Remote Directory(远程目录)——在数据服务器上,选择包含 ECP 数据库的目录。• Database Name(数据库名称)——输入一个数据库的名称。这可以与它在数据服务器(本例中是 ECP)上的名称相同,也可以不同。
6. 选择 Finish(完成)。窗口关闭,您会返回到 New Namespace(新的命名空间) 页面。 您应该看到,您刚刚创建的数据库现在显示在 Select an existing database for Globals(为 Globals 选择一个现有的数据库) 字段中。 亲自尝试分布式缓存
7. 由于这个命名空间中的例程(Routines)的默认数据库是 a(The default database for Routines in this namespace is a),选择 Remote Database(远程数据库)。现在您应该能够从下拉菜单中选择您刚刚创建的新数据库。8. 清除 Enable namespace for interoperability productions(为互操作性产品启用命名空间) 复选框。9. 选择 Save(保存)。现在新的命名空间出现在列表中。
有关创建命名空间及其相关数据库的更多细节,请参见 System Administration Guide(《系统管理指南》)中 "Configuring InterSystems IRIS(《配置 InterSystems IRIS》)"一章中的 "Create/Modify a Namespace(创建/修改命名空间)"。有关背景信息,请参见 Orientation Guide for Server-Side Programming(《服务器端编程指导手册》)中的"Namespaces and Databases(命名空间和数据库)"。您已经完成了! 一旦您在每个应用服务器实例上执行了这两个程序,您就成功地创建了一个集群 ,这个集群有一个数据服务器和两个应用服务器。在下一节中,您将测试这些连接,以确保所有三个实例都能正确地相互通信。
4.5 测试设置 现在您已经启用了 ECP 服务器,并设置了两个应用服务器,其命名空间指向数据服务器上的数据库,现在是时候做一个快速测试了,以确保这三个系统相互之间的通信。为了达到这个目的,您将在一个应用服务器上设置一个简单的 global,然后在第二个应用服务器上读取并改变它。要了解有关 globals 的更多信息,请参见 Using Globals(《使用 Globals》)。1. 在一个应用服务器上,使用 InterSystems IRIS Basics:Connecting an IDE(《InterSystems IRIS 基础:连接一个 IDE》)中为您的实例描述的程序打开 InterSystems 终端(Terminal),并更改到您在上一节创建的命名空间。在这个示例中,命名空间被称为 ECPNS,因此您将执行以下操作:USER>set $namespace="ECPNS" ECPNS>
2. 创建一个 global,只需给它一个值即可:
ECPNS> set ^MyGlobal = "My Value"
3. 在另一个应用服务器上,登录到终端(Terminal),并按照上面的描述更改到 ECPNS 命名空间。4. 写入 global 的值:
ECPNS> write ^MyGlobal My Value
这表明两个应用服务器正在与数据服务器正常通信。您使用其中一个应用服务器来创建 global,但由于您是在包含远程数据库的命名空间中工作,global 实际上是在数据服务器上创建的。这就是为什么其他应用服务器可以读取它的原因。当然,这只是一个示例,但其机制是相同的,无论您是在终端(Terminal)上手动设置然后读取 global,还是有大量的用户通过十几台应用服务器在同一数据服务器前每秒发行数千个事务。ECP 将确保数据保持同步,并保证所有这些用户与系统交互的事务的一致性。5. 如果您愿意,可以在数据服务器实例上查看 global 作为最后检查。在管理门户(Management Portal)中,进入本地数据库(Local Databases)页面(System Administration(系统管理) > Configuration(配置) > System Configuration(系统配置) > Local Databases(本地数据库))。找到您的应用服务器所指向的数据库,并为该数据库选择 Globals。您应该会看到 MyGlobal 在列表中。 了解有关分布式缓存和 ECP 的更多信息
5 了解有关分布式缓存和 ECP 的更多信息 要了解有关使用 InterSystems IRIS 分布式缓存和 ECP 的更多信息,请参见以下参考资料:• Scalability Guide(《可扩展性指南》)的 "Horizontally Scaling Systems for User Volume with InterSystems Distributed Caching(《使用 InterSystems 分布式缓存为用户容量水平扩展系统》)"章节• Sample Mirroring Architecture and Network Configurations(《镜像架构和网络配置示例》)、Redirecting Application Connections Following Failover or Disaster Recovery(《故障转移或灾难恢复后重定向应用连接》)、Configuring Application Server Connections to a Mirror(《配置应用服务器到镜像的连接》),以及 High Availability Guide(《高可用性指南》)中"Mirroring(《镜像》)"章节中的其他分布式缓存和 ECP 相关章节
文章
Hao Ma · 十一月 2, 2021
本文档介绍了 InterSystems 公钥基础设施(PKI),它可以在开发组织的安全策略中发挥重要作用。它提供有关公钥加密、证书颁发机构和 PKI 的信息。然后介绍一些与使用 InterSystems PKI 相关的初始任务。完成本指南后,您将有能力创建一个证书颁发机构 (CA),然后向 CA 客户端请求并接收证书。 虽然 InterSystems PKI 不用于生产系统,但您可以用它来熟悉 PKI 工具和安全基础设施。作为设计和探索过程的一部分,这对于创建全面的安全方法特别有帮助。本指南使用 InterSystems IRIS®数据平台的默认设置,这使您能够熟悉 PKI 的基本原理,而不必处理其他在执行实现时很重要的细节问题。有关数据库加密的完整文档,请参见 The InterSystems Public Key Infrastructure(《 InterSystems 公钥基础设施》)。要浏览所有的技术概要(First Look),包括可以在 InterSystems IRIS 免费的评估实例上执行的那些,请参见 InterSystems First Looks(《InterSystems 技术概要》)。
1 为什么 PKI 很重要 在许多企业中,关于安全漏洞的新闻频繁出现,这表明有必要保护他们的通信安全。企业需要保护从一个站点到另一个站点的数据,或者当需要某种可验证的、具有法律约束力的数字签名时。解决这些和其他需求的强大、有效和普遍的工具是公钥加密(public-key cryptography)和公钥基础设施(PKI)。公钥加密(Public-key cryptography)能够对数据进行加密和解密。这提供了一种执行与保护数据相关的各种操作的方法。这包括保护在不安全的网络(如 Internet)上传输的数据或确定文档的来源。因此,它启用了关键技术,如传输层安全(Transport Layer Security,TLS),这是浏览器保护我们与网站连接的手段。公钥加密(Public-key cryptography)对不同实体控制的数据进行操作,这些实体可以是人、应用程序、组织等。但是,仅公钥加密(Public-key cryptography)并不能为这些实体在活动中的身份提供足够的信心,特别是在它们彼此不认识的情况下。为了达到这种信任水平,需要有一个更大的结构,同时为所涉及的实体提供值得信赖和可验证的标识信息。这样一个结构被称为 PKI(公钥基础设施)。PKI 为实体建立了一种对彼此的身份有信心的方法,即使彼此没有任何直接的个人了解或接触。这要求每个实体信任第三方——证书颁发机构(CA)——为其他实体(也称为其他对等方)的身份提供担保。通过 PKI,实体可以进行有意义的、具有法律约束力的加密操作,其中包括加密、解密、数字签名和签名验证。InterSystems 提供了一个公钥基础设施(PKI),它使用 InterSystems IRIS 的实例作为 CA,允许您创建密钥对,并允许您创建与这些密钥对有关的证书。InterSystems CA 适合在组织内部和非生产环境中使用。不建议将其作为生产或商业 CA 使用;虽然它的证书在加密上是可靠的,但商业 CA 除了技术基础设施外,还需要一定程度的组织和法律基础设施。 为什么 PKI 很重要
使用 PKI 的公钥加密支持许多的安全活动:• 对电子文档进行数字签名• 验证电子文档的签名• 加密各方之间的通信• 加密文档
1.1 公钥加密和证书颁发机构(CA)如何协同工作的基本原理在使用公钥加密时,每个实体都有一个严格保密的私钥(private key),以及一个广泛使用的公钥(public key)。如果您使用其中一个密钥执行一个操作,您可以使用另一个密钥执行互补的操作;例如,如果您用私钥加密数据,那么只有您的公钥可以解密该数据。如果别人用您的公钥对内容进行加密,只有您的私钥——因此也只有您——能够解密。这意味着公钥加密为两个实体之间的安全和私人通信提供了一种方法。为了使公钥加密在互不相识且不能轻易验证对方身份的实体之间发挥作用,需要有一个双方实体都信任的第三方。这个第三方是证书颁发机构(CA)。证书颁发机构创建证书,这些证书是将公钥绑定到公钥持有者的一组标识信息的数字文档。由于公钥和私钥不可分割地相互绑定,证书也将标识信息绑定到私钥上。一些企业有内部的 CA,它们用来支持内部活动;其他 CA 作为独立的组织运作,通常作为商业服务提供证书。商业 CA 通常在不同程度的身份验证基础上提供证书;在充分验证的情况下,证书可以在组织或个人和公私密钥对之间建立起具有法律约束力的联系。CA 的使用使处于不安全环境中的实体有足够的信心以有意义的和具有法律约束力的方式使用公钥加密。互相通信的实体不需要使用相同的 CA。相反,每一个人只需要信任对方的 CA。这种信任 CA 的关系通常是在没有任何用户干预的情况下建立的,例如让浏览器附带一组预先批准的 CA 证书。事实上,一个实体可以信任一个 CA,因为它有第二个 CA 的证书,而这个 CA 已经被信任了;在这种情况下,第一个 CA 被称为中间 CA ——而且可以有多个中间 CA。当一个实体从一个 CA 获得证书时,会发生许多事情——经常对用户不可见。首先,CA 客户端使用算法来生成密钥对;然后 CA 客户端获得必要的信息来描述使用该密钥对的实体,这与实体的位置、组织等有关。总的来说,这个标识信息包括一个专有名称(distinguished name,DN)。该实体以证书签名请求(certificate signing request,CSR)的形式向 CA 提供公钥和 DN 信息;它不提供私钥,因为这是严格保密的。CA 收到 CSR,然后根据其程序进行处理。然后,CA 签署一份文档,将公钥绑定到 DN 信息,从而创建一个证书(具体来说,就是符合 X.509 标准的证书)。最后,CA 客户端从 CA 获得证书,然后可以将它用于各种活动,如建立 TLS 连接。当两个实体需要相互认证时,它们使用它们的证书和 CA 对它们的信任关系。因此,当 Alice 和 Bob 试图通过 TLS 进行通信时,TLS 握手会对他们每个人执行如下身份验证:• Alice 最终得到了 Bob 的证书。Alice 可以信任这个证书,因为 Bob 的 CA 已经对它进行了签名,而且 Bob 的 CA 是受信任的 CA。• 持有 Alice 证书的 Bob 也是如此。 有关 InterSystems PKI
2 有关 InterSystems PKI 总的来说,CA 和公钥加密的活动是所谓的公钥基础设施(public key infrastructure ,PKI)的一部分。因此,PKI 提供了一种创建和管理密钥对和证书的方法,并可以支持加密操作,包括加密、解密、数字签名和签名验证。InterSystems IRIS 包含 PKI。使用 InterSystems PKI,您可以设置一个证书颁发机构(CA),一个 CA 客户端,并开始在用户之间发送安全数据,只需几个步骤。当 InterSystems IRIS 的一个实例充当 CA 时,它被称为 CA 服务器;当实例使用 CA 的服务时,它被称为 CA 客户端。一个实例既可以是 CA 服务器,也可以是 CA 客户端。在将自己建立为 CA 服务器时,InterSystems IRIS 的实例要么创建一个密钥对,然后将公钥嵌入到自签名的 X.509 证书中,要么使用外部 CA 签名的私钥和 X.509 证书。X.509 是一种行业标准证书结构,它将公钥与专有名称(Distinguished Name, DN)关联起来。
3 亲自尝试 InterSystems PKI设置和使用 InterSystems PKI 很容易。在这个示例中,您将使用 InterSystems IRIS 的两个实例。您将使用实例 #1 作为 CA(这里主要称为 CA 服务器)和实例 #2 作为 CA 客户端进行一系列的初始操作。这些步骤是:1. 将实例 #1 配置为 CA 服务器 2. 将实例 #2 配置为 CA 客户端 3. 在 CA 客户端上,向 CA 服务器提交证书签名请求(CSR)4. 在 CA 服务器上,处理 CSR5. 在 CA 客户端上,从 CA 服务器下载它的证书和 CA 服务器证书
重要提示: InterSystems PKI 不用于生产系统。此外,本文档中的示例以不适合使用任何 PKI 的生产系统的方式简化了设置和使用 CA 的过程。例如,它提供一个建议密码,用于加密和解密 CA 服务器的私钥。在生产系统(或除演示系统以外的任何系统)上,永远不要 使用公开的已知密码,因为这可能会危及您的 CA 的私钥的安全,从而危及您的整个 PKI;如果这个密钥被泄露或破解,那么所有 CA 的证书都变得不可信了。类似地,证书颁发机构的证书和私钥文件的目录与您在本文档练习中使用的 InterSystems IRIS 实例在同一台机器上。对于生产系统来说,这个目录应该总是在一个外部设备上(不是本地硬盘驱动器或网络服务器),最好是在一个加密的外部设备上。这是因为该目录持有 CA 的私钥。如果您创建了一个生产系统,请按照 PKI 供应商的说明操作。有关在开发或测试系统中使用 InterSystems PKI 的更多详细信息,请参见 The InterSystems Public Key Infrastructure(《InterSystems 公钥基础设施》)。 亲自尝试 InterSystems PKI3.1 用前须知要使用这个程序,您需要两个正在运行的 InterSystems IRIS 实例。这些实例可以在相同或不同的主机上,但必须相互有网络访问权限。您对 InterSystems IRIS 的选择包括多种类型的已授权的和免费的评估实例;该实例不需要由您正在工作的系统托管(尽管它们必须相互具有网络访问权限)。关于如何部署每种类型的实例的信息(如果您还没有可使用的实例),请参见 InterSystems IRIS Basics:Connecting an IDE(《InterSystems IRIS 基础:连接一个IDE》)中的 Deploying InterSystems IRIS(部署 InterSystems IRIS)。3.2 将实例 #1 配置为 CA 服务器要将实例 #1 配置为 CA 服务器:1. 使用 InterSystems IRIS Basics: Connecting an IDE(《InterSystems IRIS 基础:连接一个 IDE》)中URL described for your instance(为您的实例描述的 URL),在您的浏览器中打开实例的管理门户(Management Portal)。2. 进入 Public Key Infrastructure(公钥基础设施)页面(System Administration(系统管理) > Security(安全) > Public Key Infrastructure(公钥基础设施))。3. 在 Public Key Infrastructure(公钥基础设施)页面上,在 Certificate Authority Server(证书颁发机构服务器)下,选择 Configure Local Certificate Authority server(配置本地证书颁发机构服务器)。这将显示两个字段:• File name root for Certificate Authority’s Certificate and Private Key files(证书颁发机构的证书和私钥文件的文件名根) (没有扩展名)——输入 FLCA (技术概要证书颁发机构(First Look Certificate Authority))。此处使用 FLCA 作为私钥文件和证书文件的名称,所以私钥是在 FLCA.key 中,而证书则在 FLCA.cer 中。• Directory for Certificate Authority’s Certificate and Private Key files(证书颁发机构的证书和私钥文件的目录)——输入 flca。这将在 install-dir\mgr\ 下创建 flca 目录(install-dir 是实例的安装目录) ,并将 FLCA CA 证书和私钥文件放在那里。您也可以点击 Browse(浏览) 来选择一个不同的位置; 当你这样做时,目录选择(Directory Selection)对话框会打开到 install-dir\mgr\ 。4. 点击 Next(下一步) 继续。5. 在出现的字段中,输入以下值:• Password to Certificate Authority's Private Key file(证书颁发机构私钥文件的密码)和 Confirm Password(确认密码) — 输入密码以加密和解密 CA 的私钥文件。我们建议您使用 myflcapw,这样您在这里就有一份密码的副本。• 在 Certificate Authority Subject Distinguished Name(证书颁发机构主体专有名称)下,在 Common Name(通用名称)中 — 输入标识此 CA 的 First Look CA。
如果您使用 InterSystems PKI 进行更深入的测试和实验,当您配置 CA 服务器时,您将完成本节的字段,以包括负责签署 CA 请求的用户的电子邮件帐户。对于这个技术概要(First Look),您可以跳过它。6. 点击 Save(保存)。InterSystems IRIS 显示如下信息,表示成功:
Certificate Authority server successfully configured.Created new files: C:\InterSystems\MYIRIS1\mgr\flca\FLCA.cer .key, and .srl. Certificate Authority Certificate SHA-1 fingerprint: E3:FB:30:09:53:90:9A:31:30:D3:F0:07:8F:64:65:CD:11:0A:1A:A2
这表明 InterSystems IRIS 已经执行了以下操作:• 创建一个密钥对。• 将私钥保存到您指定的文件位置,并使用您指定的根名称。• 创建一个包含公钥的自签名 CA 证书。 亲自尝试 InterSystems PKI
• 将证书保存到您指定的文件位置,并使用您指定的根名称。• 创建一个颁发的证书数量的计数器,并将其存储在与证书和私钥相同目录中的 SRL(序列)文件中。(每次 CA 颁发新的证书时,InterSystems IRIS 都会根据这个计数器给证书一个唯一的序列号,然后增加 SRL 文件中的值)。
3.3 将实例 #2 配置为 CA 客户端要将实例 #2 配置为 CA 客户端:1. 使用为您的实例描述的 URL,在您的浏览器中打开实例的管理门户(Management Portal)。2. 进入 Public Key Infrastructure(公钥基础设施)页面(System Administration(系统管理) > Security(安全) > Public Key Infrastructure(公钥基础设施))。3. 在 Certificate Authority Client(证书颁发机构客户端)下,选择 Configure Local Certificate Authority Client(配置本地证书颁发机构客户端),这会在此页面上显示多个字段。4. 填写以下字段,其他字段留空或使用默认值。在上一节中,您使用了实例 #1 的主机标识符和 web 服务器端口,您必须在这里输入。在其管理门户(Management Portal) URL 中。• Certificate Authority server hostname(证书颁发机构服务器主机名)——运行 CA 服务器的主机的 IP 地址或 DNS 名称,即实例 #1 的主机。• Certificate Authority WebServer port number(证书颁发机构网络服务器端口号)——作为 CA 服务器的实例的 web 服务器端口号,也就是实例 #1。• 在 Local technical contact(本地技术联系人) 部分,Name(名称)——任何值。(这个字段是必需的,因为 CA 服务器必须有设置 CA 客户端的人的联系信息。因为您既要配置 CA 客户端,又要配置 CA 服务器,所以您是它们的本地技术联系人。)
注意: 在生产环境中,PKI 可能需要带外联系信息,如在 Local technical contact(本地技术联系人)区域。这些信息是为了身份验证,客户端需要提供联系人信息以开始这一过程。
5. 点击 Save(保存)。
InterSystems IRIS 通过诸如"成功配置证书颁发机构(Certificate Authority,CA)客户端"的信息来确认成功。3.4 在实例 #2 上,向 CA 服务器提交证书签名请求(CSR) 接下来,在实例 #2 上,向 CA 服务器提交一个证书签名请求(CSR):1. 仍然在 Public Key Infrastructure(公钥基础设施)页面(System Administration(系统管理) > Security(安全) > Public Key Infrastructure(公钥基础设施)),在 Certificate Authority Client(证书颁发机构客户端)下,选择 Submit Certificate Signing Request to Certificate Authority Server(向证书颁发机构服务器提交证书签名请求),这将显示几个新的字段。2. 按以下方式填写它们,其他字段留空或使用默认值:• File name root for local Certificate and Private Key files(本地证书和私钥文件的文件名根)(没有扩展名)——输入 FLCAclient (技术概要证书颁发机构客户端(First Look Certificate Authority client))。这使用了 FLCAclient 作为私钥文件和证书文件的名称,因此私钥在 FLCAclient.key 中,而证书将很快出现在 FLCAclient.cer 中。• 在 Subject Distinguished Name(主体专有名称)下,在 Common Name(通用名称)字段中——输入 FL CA client。
3. 按要求完成这些字段,并点击 Save(保存)。如果成功,InterSystems IRIS 将显示如下信息: 亲自尝试 InterSystems PKI
Certificate Signing Request FLCAclient successfully submitted to the Certificate Authority at instance MYIRIS1 on node FLCATEST.COM.SHA-1 Fingerprint: C2:B0:D6:0D:D6:AB:43:DF:7F:B1:22:AE:14:D7:45:FF:CC:0C:20:D0
4. 此时,您已经使用 InterSystems IRIS 创建并提交了 CSR。
3.5 在实例 #1 上,处理 CSR 在实例 #1(CA 服务器)上,处理 CSR,将其转换为证书:1. 在管理门户(Management Portal)中,进入 Public Key Infrastructure(公钥基础设施)页面(System Administration(系统管理) > Security(安全) > Public Key Infrastructure(公钥基础设施))。2. 在 Public Key Infrastructure(公钥基础设施)页面上,在 Certificate Authority Server(证书颁发机构服务器)下,选择 Process pending Certificate Signing Requests(处理待处理的证书签名请求),它显示来自 CA 客户端的待处理 CSR。3. 点击 CSR 右侧的 Process(处理),显示 CSR 的内容,显示 CSR 的处理字段。有关这些字段的几个要点:• 因为您要为可以使用 InterSystems IRIS 中安全功能的 CA 客户端颁发证书,所以在 Certificate Usage(证书使用)下,您可以保留默认的 TLS/SSL,XML encryption and signature verification(TLS/SSL、XML 加密和签名验证)。• 在生产环境中,您需要验证 CA 客户端的身份。因此,本节演示如何执行这一行为;例如,在 Request Content(请求内容)下,显示 CA 客户端的电话号码和电子邮件。这将允许您通过电话或亲自联系他们并验证他们的身份。
4. 点击 Issue Certificate(颁发证书),这将导致页面显示 Password for Certificate Authority's Private Key file(证书颁发机构私钥文件的密码)字段。5. 在 Password for Certificate Authority's Private Key file(证书颁发机构私钥文件的密码)字段中,输入 myflcapw,这是您在配置 CA 服务器时创建的密码。6. 点击 Finish(完成) 来创建证书。 IRIS 显示一条信息,如
Certificate number 2 issued for Certificate Signing Request FLCAclient
InterSystems IRIS 现在已经创建了证书。如果 CA 客户端列出了其技术联系人的电子邮件地址,该地址还会收到证书可供下载的通知。
3.6 在实例 #2 上,从 CA 服务器下载它的证书和 CA 服务器证书下一步也是最后一步是 CA 客户端从 CA 服务器下载 CA 服务器的证书和它自己的证书:1. 在管理门户(Management Portal)中,在实例 #2 上,进入 Public Key Infrastructure(公钥基础设施)页面 (System Administration(系统管理) > Security(安全)> Public Key Infrastructure(公钥基础设施))。2. 在 Public Key Infrastructure(公钥基础设施)页面上,在 Certificate Authority Client(证书颁发机构客户端)下,点击 Get Certificate(s) from Certificate Authority server(从证书颁发机构服务器获取证书)。3. 在显示的字段中,有一个 Get Certificate Authority Certificate(获取证书颁发机构证书) 按钮。 点击它,会下载 CA 服务器的证书,并显示一条信息,如:Certificate Authority Certificate(SHA-1 Fingerprint: 8A:38:C9:06:50:A0:4F:71:86:2B:69:4C:A2:42:E0:43:28:C8:70:EB)saved in file "c:\intersystems\MYIRIS2\mgr\FLCA.cer"
4. 再一次点击 Get Certificate(s) from Certificate Authority server(从证书颁发机构服务器获取证书)。 了解有关 InterSystems PKI 的更多信息
5. 已颁发证书表列出了 CA 客户端的证书。点击行旁边的 Get(获取)按钮。这就下载了 CA 客户端的证书,并显示一条信息,如:Certificate number 2(SHA-1 Fingerprint: 2E:82:27:73:72:38:BC:71:36:70:DC:9E:0D:EF:E6:BC:0D:A9:95:CD)saved in file "c:\intersystems\MYIRIS2\mgr\FLCAclient.cer"
3.7 总结和下一步 您现在有:1. 将 InterSystems IRIS 的一个实例配置为 CA 服务器2. 将 InterSystems IRIS 的另一个实例配置为 CA 客户端3. 从 CA 客户端向 CA 服务器提交证书签名请求(CSR)4. 在 CA 服务器上处理 CSR5. 将 CA 服务器的证书和 CA 客户端自己的 CA 证书从 CA 服务器下载到 CA 客户端
这意味着您现在有一个 InterSystems IRIS 实例是一个正常运行的 CA 服务器,另一个 InterSystems IRIS 实例是一个正常运行的 CA 客户端。如果您在另一个 InterSystems IRIS 实例上设置 CA 客户端,并为每个实例创建 TLS 配置,两个客户端可以交换加密的信息。这为各种安全活动提供了基础。注意: 最后提醒一下:这个示例系统并不能帮助建立一个安全的环境,因为 CA 的私钥已经在本文档中公开发布。妥善保护生产系统中的所有私钥是至关重要的,而保护 CA 的私钥则是最重要的。泄露在生产系统中使用的私钥,会导致安全漏洞、数据泄露、财务损失和法律漏洞。除了让您了解 InterSystems IRIS 功能之外,请不要使用此文档的 CA 服务器私钥进行其他任何操作。
4 了解有关 InterSystems PKI 的更多信息有关 InterSystems PKI 的完整文档,请参见 The InterSystems Public Key Infrastructure(《InterSystems 公钥基础设施》)。
文章
Louis Lu · 九月 26, 2021
本技术概要( First Look)通过重点概述和一个基础的、实际操作的示例,向您介绍在 InterSystems IRIS®数据平台上使用 .NET 网关(Gateway)的基础知识。您将了解 InterSystems IRIS 如何与 .NET 程序集进行互操作,在这个示例中,您将创建一个 .NET 网关(Gateway),并从 InterSystems IRIS 中的代理类调用基础 DLL。
本文档设计简单;当您把 .NET 网关(Gateway)引入您的生产系统时,您可能需要做一些不同的事情。本文档末尾的参考资料,提供了有关在生产中使用 .NET 网关(Gateway)的详细和完整的信息。
要浏览所有的技术概要(First Look),包括其他可以在免费的云实例或 web 实例上执行的技术概要(First Look),请参见 InterSystems First Looks(InterSystems 技术概要)。
1. 为什么 .NET 网关(Gateway)很重要
InterSystems IRIS Object Gateway for .NET(也称为".NET 网关(Gateway)")为InterSystems IRIS 与 Microsoft .NET Framework 组件进行互操作提供了一种简便的方法。在使用网关(Gateway)导入 .NET DLL 后,您可以实例化一个外部 .NET 对象,InterSystems IRIS通过代理类将其作为的一个本地对象来操作。
每个代理对象(proxy object)都与相应的 .NET 对象通信,使您能够从 InterSystems IRIS 和 ObjectScript 中访问您的 .NET 类和方法。调用任何 InterSystems IRIS 代理方法都会将消息发送给 .NET 网关(Gateway) 工作线程,该线程会找到合适的方法或构造函数调用。调用的结果发送回代理对象,再将结果返回给 InterSystems IRIS 应用程序。
通常,使用 .NET 网关(Gateway)的最佳方法是在您的应用程序中为第三方 DLL 构建一个小型包装器类(a small wrapper class),然后为包装器生成代理类。包装器类只公开您想要的功能,而不是创建大量应用程序可能不需要的代理类。
2. 探索 .NET 网关(Gateway)
在这个实际操作的示例中,您将:
创建一个 DLL,其中包含要从 InterSystems IRIS 调用的示例类
定义一个 .NET 网关(Gateway),并启动服务器进程
创建一个 ObjectScript 类,从 DLL 生成代理类
创建另一个 ObjectScript 类,以连接到网关(Gateway)并通过代理对象操作 DLL
想试试 InterSystems IRIS .NET 开发和互操作性功能的在线视频演示吗?请看.NET QuickStart(.NET 快速入门)!
2.1 用前须知
要运行这个演示,您需要一个运行 Microsoft .NET Framework 4.5 版本 的 Windows 10 系统、Visual Studio,以及一个已安装的 InterSystems IRIS 实例。(有关安装 InterSystems IRIS 的说明,请参见 InterSystems IRIS Basics:Installation [《InterSystems IRIS 基础:安装》]。)
有关配置 Visual Studio 以连接到您的 InterSystems IRIS 实例的说明,请参见 InterSystems IRIS Basics:Connecting an IDE(《InterSystems IRIS 基础: 连接一个 IDE》)中的 InterSystems IRIS Connection Information(InterSystems IRIS 连接信息)和 .Net IDE。
您还将使用InterSystems 的 Studio IDE(一个在 Windows 系统上运行的客户端应用程序)来创建 ObjectScript 代码;更多信息,请参见InterSystems IRIS Basics: Connecting an IDE(《InterSystems IRIS 基础: 连接一个 IDE》)中的 Using Studio(使用 Studio) 和 Studio。 )
2.2 创建 DLL
使用 Visual Studio,创建一个名为 Person 的类并复制以下 C# 代码。在本例中使用 .NET 4.5。
public class Person {
public int age;
public String name;
//constructor
public Person (int startAge, String Name) {
age = startAge;
name = Name;
}
public void setAge(int newAge) {
age = newAge;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
public static void main(String []args) {
Person myPerson = new Person (5, "Tom");
Console.Out.WriteLine(myPerson.getName());
Console.Out.WriteLine(myPerson.getAge());
}
}
编译 Person 类,并生成一个 Person.dll 文件。注意 DLL 的位置,因为您稍后会需要它。
2.3 创建并启动 .NET 网关
使用 InterSystems IRIS Basics:Connecting an IDE(《InterSystems IRIS 基础: 连接一个 IDE》)中的 InterSystems IRIS Connection Information(InterSystems IRIS 连接信息)描述的 URL,在浏览器中打开您的实例的管理门户(Management Portal)。
导航至 System Administration(系统管理) > Configuration(配置) > Connectivity(连接) > External Language Servers(外部语言服务)。
选择 Create External Language Server(创建外部语言服务)。
输入 Server Name(网关名称)。
在 Server Type (服务类型)中选择 .Net
在 Port(端口)字段中,输入 55000。
对于 .NET Version(.NET 版本),请选择 4.5。
选择 Save(保存)。
在External Language Servers(外部语言服务)页面,找到您刚刚定义的网关(Gateway),并选择 Start(开始)
2.4 生成代理类
使用 Studio, 在实例的 USER 命名空间中创建一个名为 CreateProxyClasses.cls 的新 ObjectScript 类,并粘贴以下代码, 将您的实例的主机标识符替换为 gwyConn.%Connect 中的 server,并用双引号括起来的 Person.dll 文件的完整文件路径替换 YOUR FILEPATH HERE。
Class User.CreateProxyClasses Extends %Persistent
{
ClassMethod run()
{
// get a connection to the .NET Gateway
set gwyConn = ##class(%Net.Remote.Gateway).%New()
set status = gwyConn.%Connect("127.0.0.1", 55000, "USER")
if $$$ISERR(status) {
write !,"error: "_$system.OBJ.DisplayError(status)
quit
}
// add the DLL to the classpath
set classpath = ##class(%ListOfDataTypes).%New()
do classpath.Insert("YOUR FILEPATH HERE")
set status = gwyConn.%AddToCurrentClassPath(classpath)
if $$$ISERR(status) {
write !,"error: "_$system.OBJ.DisplayError(status)
quit
}
// create the proxy ObjectScript classes corresponding to the .NET classes in the DLL
set status = gwyConn.%Import("Person",,,,1)
if $$$ISERR(status) {
write !,"error: "_$system.OBJ.DisplayError(status)
quit
}
//close the connection to the .NET Gateway
set status = gwyConn.%Disconnect()
if $$$ISERR(status) {
write !,"error: "_$system.OBJ.DisplayError(status)
quit
}
}
}
编译并构建该类。然后使用 InterSystems IRIS Basics:Connecting an IDE(InterSystems IRIS 基础: 连接一个 IDE) 中的 instructions for your instance(对您的实例的说明),在 USER 命名空间中打开 InterSystems 终端(InterSystems Terminal), 并执行以下命令:
do ##class(User.CreateProxyClasses).run()
2.5 使用ObjectScript 操作 .NET Object
在 USER 命名空间中创建另一个名为 ManipulateObjects.cls 的 ObjectScript 类,并粘贴以下代码 (注意要将您的实例的主机标识符替换 gwyConn.%Connect 中的 第一个参数):
Class User.ManipulateObjects Extends %Persistent
{
ClassMethod run()
{
// get a connection to the .NET gateway
set gwyConn = ##class(%Net.Remote.Gateway).%New()
set status = gwyConn.%Connect("127.0.0.1", 55000, "USER")
if $$$ISERR(status) {
write !,"error: "_$system.OBJ.DisplayError(status)
quit
}
// manipulate some proxy objects
set person = ##class(User.Person).%New(gwyConn,5,"Tom")
write !,"Name: "_person.getName()
write !,"Age: "_person.getAge()
do person.setAge(100)
write !,"Age: "_person.getAge()
// close the connection to the .NET gateway
set status = gwyConn.%Disconnect()
if $$$ISERR(status) {
write !,"error: "_$system.OBJ.DisplayError(status)
quit
}
}
}
编译并构建该类,然后在终端(Terminal)中的 USER 命名空间中执行以下命令:
do ##class(User.ManipulateObjects).run()
您应该可以看到以下输出:
Name: Tom Age: 5
setting age to 100
Age: 100
现在您已经成功地完成了练习,停止您创建的 .NET 网关(Gateway)。返回到管理门户(Management Portal)中的 External Language Servers(外部语言服务)页面,找到网关(Gateway),并选择 Stop(停止)。
3. 了解更多有关 .NET 网关(Gateway)的信息
从这里,您可以继续探索 .NET 网关(Gateway)和 InterSystems IRIS。请参阅下面的文档和参考资料,了解 .NET、互操作性、应用程序开发等。
Using the Gateway for .NET(使用 .NET 网关) — 了解更多有关 InterSystems IRIS 和 Microsoft .NET Framework 组件之间互操作性的信息。
Skyrocket Your .NET Application Development(Skyrocket Your .NET 应用程序开发) — 这是 InterSystems 关于在 .NET 中作为对象建模和访问数据的演示。
.NET Documentation(.NET 文档) — Microsoft 在 .NET 上的文档,包括架构概念、教程和开发指南。
文章
Weiwei Gu · 十二月 1, 2022
InterSystems 是一家已经深耕数据库平台领域达44年的公司,成立于1978年,现在已经在全球的80多个国家开展相关业务,每天有超过10亿患者的电子病历数据都跑在以我们的数据库平台构建的应用系统之上。
我们的客户遍布国内外,国内的大几百家三甲医院客户,中国复旦排行榜上超过1/3的顶级医院都在使用我们产品(包括北京协和医院,华西医院,湘雅等等),我们的技术合作伙伴,如东华医为,嘉和,和仁等也都是国内医疗信息领域的著名厂商。
而在国外,我们也有非常多的顶级客户,仅仅以美国举例,美国最顶级的排名前20的所有医院,无一例外全部都是使用的interSystems公司的数据库平台产品。
美国排名前20的所有顶级医院
2020-2021《美国新闻与世界报道》(U.S. News & World Report)最顶级医院名单(前20家医疗机构)均应用InterSystems公司的数据库平台:
Mayo Clinic, Rochester, Minnesota (明尼苏达州罗彻斯特市梅奥诊所)Cleveland Clinic(克利夫兰诊所) Johns Hopkins Hospital, Baltimore(巴尔的摩约翰霍普金斯医院)(tie). New York-Presbyterian Hospital-Columbia and Cornell, New York(纽约长老会医院 ) (tie). UCLA Medical Center, Los Angeles(加州大学洛彬矶分校医学中心)Massachusetts General Hospital, Boston(波士顿麻省总医院 )Cedars-Sinai Medical Center, Los Angeles(洛杉矶Cedars-Sinai医疗中心 )UCSF Medical Center, San Francisco(旧金山加州大学旧金山分校医疗中心 )NYU Langone Hospitals, New York(纽约大学朗格尼医学中心)Northwestern Memorial Hospital, Chicago(芝加哥西北纪念医院)University of Michigan Hospitals-Michigan Medicine, Ann Arbor(安娜堡密歇根大学医学院)Brigham and Women’s Hospital, Boston(波士顿哈佛医学院教学附属医院布列根和妇女医院)Stanford Health Care-Stanford Hospital, Stanford, California(斯坦福医疗中心)Mount Sinai Hospital, New York(纽约西奈山医院)Hospitals of the University of Pennsylvania-Penn Presbyterian, Philadelphia(费城宾夕法尼亚大学-宾夕法尼亚长老会医院)Mayo Clinic-Phoenix(凤凰城梅奥诊所)Rush University Medical Center, Chicago(芝加哥拉什大学医学中心)(tie). Barnes-Jewish Hospital, St. Louis(圣路易斯巴恩斯医院)(tie). Keck Hospital of USC, Los Angeles(洛杉矶南加州大学凯克医院)Houston Methodist Hospital(休斯顿卫理公会医院)
InterSystems 公司久负盛名的两款产品: Cache 与 E�nsemble , 以其稳定性好,速度快著称,在国内外均有无数医院用户。
自2018年底InterSystems 公司推出其新一代的 IRIS for Health 数据库平台后,基于新产品更高的性能表现及更强大的功能与扩展能力,我们鼓励所有的Cache 及Ensemble 老用户逐渐向最新一代的IRIS 以及Health Connect 平台迁移。以获得更好的性能及用户体验,并且在未来可以支撑更多新的发展需求。
C�ache 与 Ensemble 的最新版本也止于2018年,未来我们将继续对使用这两款产品的客户提供支持服务,但不会在其之上开发新的功能。
以下附件中,提供了截止目前这两款产品Cache / Ensemble 与其新的下一代的产品 IRIS for Health / Health Connect 的功能清单对比,可点击参考:
文章
Michael Lei · 六月 8, 2023
嗨社区!
想与您分享我在Telegram中使用GPT创建“我自己的”聊天的练习。
这个应用需要用到 Open Exchange 上的两个组件:@Nikolay.Soloviev 的Telegram Adapter和@Francisco.López1549的IRIS Open-AI
因此,通过此示例,您可以在 Telegram 中使用 ChatGPT 设置自己的聊天。
让我们看看如何让它发挥作用!
前提条件
使用@BotFather 帐户创建一个机器人并获取机器人令牌。然后将机器人添加到电报聊天或频道中并赋予其管理员权限。在https://core.telegram.org/bots/api了解更多信息
在https://platform.openai.com/上打开(如果没有,请创建)一个帐户,并获取您的Open AI API Key和Organization id 。
确保您的 InterSystems IRIS 中安装了 IPM。如果没有,这里有一个要安装的衬垫:
USER> s r = ##class ( %Net.HttpRequest ). %New (), r .Server= "pm.community.intersystems.com" , r .SSLConfiguration= "ISC.FeatureTracker.SSL.Config" d r .Get( "/packages/zpm/latest/installer" ), $system .OBJ.LoadStream( r .HttpResponse.Data, "c" )
或者您可以像这样使用带有 IPM 的社区 docker 图像:
安装
在启用互操作性的命名空间中安装 IPM 包。
USER>zpm“安装 Telegram-gpt”
用法
打开Production
将机器人的 Telegram Token 放入 Telegram business service 和 Telegram Business operation 中:
同时使用您的聊天 GPT API 密钥和组织 ID 初始化 St.OpenAi.BO.Api.Connect 操作:
启动Production。
在Telegram聊天中提出任何问题。您将通过 Chat GPT 获得答案。尽情享受吧!
在可视化追中:
细节
本示例使用 3.5 版本的 Chat GPT Open AI。它可以在模型参数的数据转换规则中更改。
文章
姚 鑫 · 二月 2, 2023
# 第六十四章 使用 SNMP 监控 IRIS - 扩展 IRIS MIB
应用程序员可以添加托管对象定义并扩展 `IRIS` 子代理为其提供数据的 `MIB`。这不是一个完整的 `MIB` 编辑器或` SNMP` 工具包;相反,它是一种添加简单应用程序指标的方法,可以通过 `SNMP` 浏览或查询这些指标。
注意:对象必须遵循基本的 `IRIS SNMP` 结构,对 `SNMP` 表结构的支持有限(仅支持整数值索引),并且不会创建 `SNMP` 陷阱(请参阅新选项卡类中的 `%Monitor.AlertOpens`) 对管理信息的 `SNMP` 结构有一个基本的了解是很有帮助的。
要创建这些对象,请执行以下操作:
1. 在继承 `%Monitor.Adaptor` 的类中创建 `IRIS` 对象定义。
2. 执行 `SNMP` 类方法以在 `SNMP` 中启用这些被管理对象,并创建 `MIB` 定义文件供管理应用程序使用。实现此目的的方法是 `MonitorTools.SNMP.CreateMIB()`。
该方法为 `%Monitor` 数据库中定义的特定应用程序创建私有企业 `MIB` 树的一个分支。除了为应用程序创建实际的 `MIB` 文件之外,该方法还创建了 `MIB` 树的内部轮廓。 `IRIS` 子代理使用它来注册 `MIB` 子树,为 `GETNEXT` 请求遍历树,并引用特定对象方法以在 `GET` 请求中收集实例数据。
所有托管对象定义都使用与 `IRIS` 企业 `MIB` 树相同的通用组织,即:`application.objects.table.row.item.indices`。所有表格的第一个索引是 `IRIS` 应用程序 `ID`。所有应用程序都必须向 IANA 注册以获得自己的私有企业编号,这是 `CreateMIB()` 方法中的参数之一。
要禁用 `SNMP` 中的应用程序,请使用 `MonitorTools.SNMP.DeleteMIB()` 方法。这会删除应用程序 `MIB` 的内部轮廓,因此 `IRIS` 子代理不再注册或回答对该私有企业 MIB 子树的请求。
# `IRIS SNMP` 陷阱
除了通过 `SNMP` 查询提供的对象数据和指标外, `IRIS` 还可以发送异步警报或 `SNMP` 陷阱。下表描述了 `IRIS` 特定的 `SNMP` 陷阱。
### IRIS SNMP 通知对象(陷阱)
Trap Name (Number)| Description
---|---
irisStart (1) | IRIS 实例已启动。
irisStop (2)| IRIS 实例正在关闭。
irisDBExpand (3)| IRIS 数据库已成功扩展。
irisDBOutOfSpace (4)| IRIS 数据库的未来扩展可能会受到限制;文件系统上的可用空间不足,无法再扩展 10 次,或者可用空间不足 `50 MB`。
irisDBStatusChange (5)| IRIS 数据库的读/写状态已更改。
irisDBWriteFail (6) |写入 IRIS 数据库失败。它包括写入失败的 IRIS 错误代码。
irisWDStop (7)| IRIS 实例的写入守护进程已停止。
irisWDPanic (8) | IRIS 实例的写入守护进程已进入“恐慌panic”模式;也就是说,写入守护进程缓冲区不足,必须将数据库块直接写入磁盘,而无需先将它们提交到写入映像日志 (WIJ) 文件。
irisLockTableFull (9)| IRIS 实例的锁表已满,导致后续 `Locks` 失败。
irisProcessFail (10)|进程异常退出 IRIS(由于访问冲突)。
irisECPTroubleDSrv (11)| IRIS 数据库与此 `ECP` 数据服务器的连接遇到了严重的通信问题。
irisECPTroubleASrv (12)|从该 `ECP` 应用程序服务器到远程 IRIS 数据库的连接遇到了严重的通信问题。
irisAuditLost (13)| IRIS 未能记录审核事件。最可能的原因是审计数据库的空间有问题,这需要操作员的帮助。
irisLoggedError (14)|`messages.log` 文件中记录了一个“严重”错误。此陷阱包括在 `irisSysErrorMsg` 中定义的错误消息。
irisLicenseExceed (15)| 许可证请求已超出当前可用或允许的许可证数量。
irisEventLogPost (16)| 互操作性事件日志中发布的条目。
irisAppAlert (100)| 这是一个通用陷阱, IRIS 应用程序可以使用它通过 SNMP 生成警报。有关如何使用此陷阱的详细信息,请参阅 `%Monitor.Alert.External` 类方法。
下表描述了可以在上表中描述的陷阱中发送的 IRIS 特定辅助对象。
Auxiliary Object Name (Number) |Description
---|---
irisDBWriteError (1)| 数据库写入失败的 IRIS 特定错误代码。可能的值为:``、``、``、` `或 ``。
irisApp (2) |一个短文本字符串(最多 `20` 个字符),用于标识生成(或来源)`irisAppAlert` 陷阱的应用程序。
irisAppSeverity (3)|指示 `irisAppAlert` 陷阱问题严重性的代码。代码可以是 `0`(信息)、`1`(警告)、`2`(严重)或 `3`(严重)。
irisApptext (4) |导致 `irisAppAlert` 陷阱的问题、错误或事件的文本字符串描述(最多 `1024` 个字符)。
文章
姚 鑫 · 一月 22, 2023
# 第五十三章 使用 ^SystemPerformance 监视性能 - InterSystems IRIS Linux 平台性能数据报告
- `%SS` - 使用 `ALL^%SS` 命令在运行过程中采集了四个样本。
- `Configuration *` - 来自服务器的 `IRIS` 实例名称和主机名、完整的 `IRIS` 版本字符串、许可客户名称和许可订单号。
- `cpf file *` - 当前活动配置文件的副本。
- `irisstat -c` - 使用命令 `irisstat cache -p-1 -c-1 -e1 -m8 -n2 -N127` 在运行过程中以均匀的间隔采集四个样本。以下是对每个参数的简要说明:
- `-p-1`: 对进程表进行采样以包括进程和全局状态信息。
- `-c-1`: 对共享内存的计数器部分进行采样以显示日志、锁、磁盘和资源使用统计信息。
- `-e1`: SYSLOG 错误表。
- `-m8`: 文件表,其中包括所有 `IRIS.DAT` 文件及其属性。
- `-n2`: 网络结构表,包括本地到远程数据库的映射。
- `-N127`: 客户端和服务器连接的 `ECP` 统计信息。
- `irisstat -D` - 使用命令 `irisstat cache --f1 -D10,100` 在运行过程中以均匀的间隔采集八个样本。以下是对每个参数的简要说明:
- `-fl`: 基本标志。
- `-D10,100`: 在 `10` 秒的总采样周期内,每 `100` 毫秒对块碰撞进行采样。
- `df -m *` - 有关挂载文件系统的信息,包括挂载点、逻辑卷和可用空间; `df -m` 命令的输出。
- `free -m` - 以 `MB` (`-m`) 为单位的内存使用统计信息。
- `iostat` - `CPU` 和磁盘吞吐量。
- `license *` - 使用 `Decode^%LICENSE` 和 `counts^%LICENSE` 的 `IRIS` 许可使用信息。
- `mgstat` - 使用 `^mgstat` 实用程序在运行过程中获取 `IRIS` 特定数据。请参阅 `Monitoring Guide `的 `Monitoring Performance Using ^mgstat` 部分。
- `Profile *` - 有关创建此日志的 `^SystemPerformance` 配置文件的信息。
- `ps:` - 使用命令 `ps -efly` 在运行过程中以均匀的间隔采集四个样本。
- `sar -d` - 磁盘(块)设备吞吐量和延迟统计信息。
- `sar -u` - CPU 使用率统计信息包括 `iowait` 百分比。
- `vmstat -n - CPU`、排队、分页统计。只打印一个标题 (`-n`) 。
- `CPU *` - 从 `lscpu` 和 `/proc/cpuinfo` 收集的信息
- `Linux info *` - 一般操作系统和硬件信息;包括 `uname -a`、`lsb_release -a`、`id` 和 `ulimit -a` 命令的输出以及从 `/etc/issue.net`、`/proc/partitions` 和 `/dev/mapper` 收集的信息。
- `ipcs *` - 进程间通信配置信息,包括共享内存、信号量和消息队列; `ipcs -a` 命令的输出。
- `mount *` - 有关所有文件系统及其挂载选项的信息。
- `fdisk -l *` - `/proc/partitions` 中提到的所有设备的分区表。仅当启动 `^SystemPerformance` 配置文件运行的用户具有 `root` 访问权限时才包括在内。
- `ifconfig *` - 当前活动网络接口的状态信息。
- `sysctl -a *` - 内核和系统参数设置。
文章
Claire Zheng · 九月 12, 2021
2021年9月13日,中国 北京—— 致力于帮助客户解决最关键的可扩展性、互操作性和速度问题的创新数据技术提供商InterSystems今日宣布在中国推出InterSystems IRIS医疗版互联互通套件,以满足医院信息化建设的标准化要求,促进业务协同,助力公立医院高效建设互联互通平台。
中国医院信息互联互通标准化成熟度测评工作自2012年启动以来,已成为医院信息化建设的重要抓手。2020年发布的最新版测评方案(《国家医疗健康信息医院信息互联互通标准化成熟度测评方案(2020年版)》)结合医疗健康信息化建设新需求、新技术应用情况,强化了分级管理机构职责,修订了测评流程,补充完善了测评指标,提升了测评方案的科学性和指导性。
凭借多年来深耕医疗信息化建设领域的丰富经验和强大的医疗数据平台,InterSystems结合新版测评标准,及时推出InterSystems IRIS医疗版互联互通套件,从安全管理、监控、数据管理、互联互通文档、互联互通服务、集成与交换六大方面入手,在满足测评标准化组件的基础上,提供最新版医院互联互通标准化成熟度测评规定的文档、监控、服务、Schema等组件,充分满足医院快速落地互联互通标准化成熟度测评涉及到的标准化改造需求。通过内置的模块化服务,InterSystems IRIS医疗版互联互通套件将有效缩短实施周期,加快互联互通平台建设。
InterSystems IRIS医疗版互联互通套件兼备高性能与稳定性,连续多年支持数百家大型公立医院海量数据稳定运行。
主流 PC 服务器单实例下,支持日消息吞吐量可高达27.64亿。截至2021年,InterSystems技术已助力一百余家医院通过四级及以上医院信息互联互通标准化成熟度评级。目前获评医院互联互通成熟度五级乙等评级的32家医院中,有10家均采用了InterSystems的技术和产品,某大型三甲医院日均处理数据在千万量级。
InterSystems IRIS医疗版互联互通套件包含先进的互操作技术,同时具备强大的创新功能,包括数据库管理、敏捷开发、 API 管理、FHIR资源仓库、分布式扩展、一体化机器学习、自适应分析等,全面支持医院持续开展数字化创新与应用。
InterSystems亚太区总经理卢侠亮表示:“作为一家服务中国医疗信息化市场超过20年的创新数据提供商,InterSystems致力于为中国用户提供卓越服务,此次发布的InterSystems IRIS医疗版互联互通套件专为中国用户打造,将更高效地为医疗机构标准化互联互通和信息共享提供技术保障。接下来,我们会一如既往地与本土合作伙伴和医疗机构紧密合作,将全球领先的医疗信息平台解决方案与中国市场需求相结合,为更多的医院数字化转型提供强大支持。”
InterSystems将于2021年9月17日举办“InterSystems IRIS医疗版互联互通套件”线上发布会,会议详情如下,欢迎点击“此处”或扫描下方二维码报名。
目前已经可以回放,节前错过的小伙伴可以继续注册观看啦
文章
jieliang liu · 一月 7, 2021
假设你想了解 InterSystems 在数据分析方面能提供什么。 你研究了理论,现在想要进行一些实践。 幸运的是,InterSystems 提供了一个项目:Samples BI,其中包含了一些很好的示例。 从 README 文件开始,跳过任何与 Docker 相关的内容,直接进行分步安装。 启动虚拟实例 安装 IRIS,按照说明安装 Samples BI,然后用漂亮的图表和表格让老板眼前一亮。 到目前为止还不错。
但是不可避免地,你需要进行更改。
事实证明,自己保留虚拟机存在一些缺点,交给云服务商保管是更好的选择。 Amazon 看起来很可靠,你只需创建一个 AWS 帐户(入门免费),了解到使用 root 用户身份执行日常任务是有害的,然后创建一个常规的具有管理员权限的 IAM 用户。
点击几下鼠标,就可以创建自己的 VPC 网络、子网和虚拟 EC2 实例,还可以添加安全组来为自己开放 IRIS Web端口 (52773) 和 ssh 端口 (22)。 重复 IRIS 和 Samples BI 的安装。 这次使用 Bash 脚本,如果你喜欢,也可以使用 Python。 再一次让老板刮目相看。
但是无处不在的 DevOps 运动让你开始了解基础架构即代码,并且你想要实现它。 你选择了 Terraform,因为它是众所周知的,而且它的方法非常通用,只需微小调整即可适合各种云提供商。 使用 HCL 语言描述基础架构,并将 IRIS 和 Samples BI 的安装步骤转换到 Ansible。 然后再创建一个 IAM 用户使 Terraform 正常工作。 全部运行一遍。 获得工作奖励。
渐渐地你会得出结论,在我们这个[微服务](https://martinfowler.com/articles/microservices.html)时代,不使用 Docker 就太可惜了,尤其是 InterSystems 还会告诉你[怎么做](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=ADOCK_iris)。 返回到 Samples BI 安装指南并阅读关于 Docker 的几行内容,似乎并不复杂:
$ docker pull intersystemsdc/iris-community:2019.4.0.383.0-zpm$ docker run --name irisce -d --publish 52773:52773 intersystemsdc/iris-community:2019.4.0.383.0-zpm$ docker exec -it irisce iris session irisUSER>zpmzpm: USER>install samples-bi
将浏览器定向到 http://localhost:52773/csp/user/_DeepSee.UserPortal.Home.zen?$NAMESPACE=USER 后,再次去老板那里,因为做得好而获得一天假期。
然后你开始明白,“docker run”只是开始,至少需要使用 docker-compose。 没问题:
$ cat docker-compose.ymlversion: "3.7"services: irisce: container_name: irisce image: intersystemsdc/iris-community:2019.4.0.383.0-zpm ports: - 52773:52773$ docker rm -f irisce # We don’t need the previous container$ docker-compose up -d
这样你使用 Ansible 安装了 Docker 和 docker-compose,然后运行了容器,如果机器上还没有映像,则会下载一个映像。 最后安装了 Samples BI。
你一定喜欢 Docker,因为它是各种内核素材的又酷又简单的接口。 你开始在其他地方使用 Docker,并且经常启动多个容器。 还发现容器必须经常互相通信,这就需要了解如何管理多个容器。
终于,你发现了 Kubernetes。
从 docker-compose 快速切换到 Kubernetes 的一个方法是使用 [kompose](https://kompose.io/)。 我个人更喜欢简单地从手册中复制 Kubernetes 清单,然后自己编辑,但是 kompose 在完成小任务方面做得很好:
$ kompose convert -f docker-compose.ymlINFO Kubernetes file "irisce-service.yaml" createdINFO Kubernetes file "irisce-deployment.yaml" created
现在你有了可以发送到某个 Kubernetes 集群的部署和服务文件。 你发现可以安装 minikube,它允许你运行一个单节点 Kubernetes 集群,这正是你现阶段所需要的。 在摆弄一两天 minikube 沙盒之后,你已经准备好在 AWS 云中的某处使用真实的 Kubernetes 部署。
设置
我们一起来进行吧。 此时,我们做以下几个假设:
首先,我们假设你有一个 AWS 帐户,你[知道其 ID](https://docs.aws.amazon.com/IAM/latest/UserGuide/console_account-alias.html),并且未使用 root 凭据。 你创建了一个具有[管理员权限](https://docs.aws.amazon.com/IAM/latest/UserGuide/getting-started_create-admin-group.html)且只能以编程方式访问的 IAM 用户(我们称之为“my-user”),并存储了其凭据。 你还创建了另一个具有相同权限的 IAM 用户,名为“terraform”:

Terraform 将以它的名义进入你的 AWS 帐户,并创建和删除必要资源。 这两个用户的广泛权限将通过演示来说明。 你在本地保存了这两个 IAM 用户的凭据:
$ cat ~/.aws/credentials[terraform]aws_access_key_id = ABCDEFGHIJKLMNOPQRSTaws_secret_access_key = ABCDEFGHIJKLMNOPQRSTUVWXYZ01234567890123[my-user]aws_access_key_id = TSRQPONMLKJIHGFEDCBAaws_secret_access_key = TSRQPONMLKJIHGFEDCBA01234567890123
注意:不要复制和粘贴上面的凭据。 它们在这里作为示例提供,不再存在。 请编辑 ~/.aws/credentials 文件并引入你自己的记录。
其次,我们将在文中使用虚拟的 AWS 帐户 ID (01234567890) 和 AWS 区域“eu-west-1”。 可以随意使用其他区域。
第三,我们假设你知道 AWS 不是免费的,你需要为使用的资源付费。
接下来,您已经安装了 AWS CLI 实用程序,以便与 AWS 进行命令行通信。 你可以尝试使用 aws2,但你需要在 kube 配置文件中特别设置 aws2 的用法,如这里所述。
你还安装了 kubectl 实用程序来与 AWS Kubernetes 进行命令行通信。
并且你也针对 docker-compose.yml 安装了 kompose 实用程序,来转换 Kubernetes 清单。
最后,你创建了一个空的 GitHub 仓库,并将其克隆到主机上。 我们将其根目录引用为 。 在此仓库中,我们将创建并填充三个目录:.github/workflows/、k8s/ 和 terraform/。
请注意,所有相关代码都在 github-eks-samples-bi 仓库中复制,以简化拷贝和粘贴。
我们继续。
AWS EKS 预置
我们已经在文章使用 Amazon EKS 部署简单的基于 IRIS 的 Web 应用程序中知道了 EKS。 那时,我们以半自动方式创建了一个集群。 即,我们在一个文件中描述集群,然后从本地机器手动启动 eksctl 实用程序,该实用程序根据我们的描述创建集群。
eksctl 是为创建 EKS 集群而开发的,它非常适合概念验证实现,但对于日常使用来说,最好使用更通用的工具,例如 Terraform。 AWS EKS 简介是一个非常好的资源,其中介绍了创建 EKS 集群所需的 Terraform 配置。 花一两个小时熟悉一下,决不会是浪费时间。
你可以在本地操作 Terraform。 为此,你需要一个二进制文件(在撰写本文时,我们使用最新的 Linux 版本 0.12.20),并且 IAM 用户“terraform”需要有足够的权限才能让 Terraform 进入 AWS。 创建目录 /terraform/ 以存储 Terraform 代码:
$ mkdir /terraform$ cd /terraform
你可以创建一个或多个 .tf 文件(它们会在启动时合并)。 只需复制并粘贴 AWS EKS 简介中的代码示例,然后运行如下命令:
$ export AWS_PROFILE=terraform$ export AWS_REGION=eu-west-1$ terraform init$ terraform plan -out eks.plan
你可能会遇到一些错误。 如果遇到的话,可以在调试模式下操作,但记得稍后关闭该模式:
$ export TF_LOG=debug$ terraform plan -out eks.plan$ unset TF_LOG
这个经验会很有用,你很可能会启动一个 EKS 集群(使用“terraform apply”进行该操作)。 在 AWS 控制台中查看:

觉得厌烦时就清理掉:
$ terraform destroy
然后进入下一阶段,开始使用 Terraform EKS 模块,尤其它也基于同一 EKS 简介。 在 examples/ 目录中,你将看到如何使用它。 你还会在那里找到其他示例。
我们对示例进行了一定的简化。 以下是主文件,其中调用了 VPC 创建和 EKS 创建模块:
$ cat /terraform/main.tfterraform { required_version = ">= 0.12.0" backend "s3" { bucket = "eks-github-actions-terraform" key = "terraform-dev.tfstate" region = "eu-west-1" dynamodb_table = "eks-github-actions-terraform-lock" }}
provider "kubernetes" { host = data.aws_eks_cluster.cluster.endpoint cluster_ca_certificate = base64decode(data.aws_eks_cluster.cluster.certificate_authority.0.data) token = data.aws_eks_cluster_auth.cluster.token load_config_file = false version = "1.10.0"}
locals { vpc_name = "dev-vpc" vpc_cidr = "10.42.0.0/16" private_subnets = ["10.42.1.0/24", "10.42.2.0/24"] public_subnets = ["10.42.11.0/24", "10.42.12.0/24"] cluster_name = "dev-cluster" cluster_version = "1.14" worker_group_name = "worker-group-1" instance_type = "t2.medium" asg_desired_capacity = 1}
data "aws_eks_cluster" "cluster" { name = module.eks.cluster_id}
data "aws_eks_cluster_auth" "cluster" { name = module.eks.cluster_id}
data "aws_availability_zones" "available" {}
module "vpc" { source = "git::https://github.com/terraform-aws-modules/terraform-aws-vpc?ref=master"
name = local.vpc_name cidr = local.vpc_cidr azs = data.aws_availability_zones.available.names private_subnets = local.private_subnets public_subnets = local.public_subnets enable_nat_gateway = true single_nat_gateway = true enable_dns_hostnames = true
tags = { "kubernetes.io/cluster/${local.cluster_name}" = "shared" }
public_subnet_tags = { "kubernetes.io/cluster/${local.cluster_name}" = "shared" "kubernetes.io/role/elb" = "1" }
private_subnet_tags = { "kubernetes.io/cluster/${local.cluster_name}" = "shared" "kubernetes.io/role/internal-elb" = "1" }}
module "eks" { source = "git::https://github.com/terraform-aws-modules/terraform-aws-eks?ref=master" cluster_name = local.cluster_name cluster_version = local.cluster_version vpc_id = module.vpc.vpc_id subnets = module.vpc.private_subnets write_kubeconfig = false
worker_groups = [ { name = local.worker_group_name instance_type = local.instance_type asg_desired_capacity = local.asg_desired_capacity } ]
map_accounts = var.map_accounts map_roles = var.map_roles map_users = var.map_users}
我们再仔细看一下 main.tf 中的“_terraform_”块:
terraform { required_version = ">= 0.12.0" backend "s3" { bucket = "eks-github-actions-terraform" key = "terraform-dev.tfstate" region = "eu-west-1" dynamodb_table = "eks-github-actions-terraform-lock" }}
这里需要指出,我们将遵守不低于 Terraform 0.12 的语法(与早期版本相比有了很大变化),同时,Terraform 不应该将其状态存储在本地,而是远程存储在 S3 存储桶中。
不同的人可以从不同的地方更新 terraform 代码确实很方便,这意味着我们需要能够锁定用户的状态,因此我们使用 dynamodb 表添加了一个锁。 有关锁定的更多信息,请参见状态锁定页面。
由于存储桶的名称在整个 AWS 中应该是唯一的,因此你不能再使用名称“eks-github-actions-terraform”。 请想一个你自己的名称,并确保它没有被占用(应该收到 NoSuchBucket 错误):
$ aws s3 ls s3://my-bucket调用 ListObjectsV2 操作时发生错误 (AllAccessDisabled):对此对象的所有访问均已禁用$ aws s3 ls s3://my-bucket-with-name-that-impossible-to-remember调用 ListObjectsV2 操作时发生错误 (NoSuchBucket):指定的存储桶不存在
想好一个名称,创建存储桶(我们这里使用 IAM 用户“terraform”。 它拥有管理员权限,因此可以创建存储桶),并为其启用版本管理(这在配置出错时能让你省心):
$ aws s3 mb s3://eks-github-actions-terraform --region eu-west-1make_bucket: eks-github-actions-terraform$ aws s3api put-bucket-versioning --bucket eks-github-actions-terraform --versioning-configuration Status=Enabled$ aws s3api get-bucket-versioning --bucket eks-github-actions-terraform{ "Status": "Enabled"}
对于 DynamoDB,不需要唯一性,但你需要先创建一个表:
$ aws dynamodb create-table \ --region eu-west-1 \ --table-name eks-github-actions-terraform-lock \ --attribute-definitions AttributeName=LockID,AttributeType=S \ --key-schema AttributeName=LockID,KeyType=HASH \ --provisioned-throughput ReadCapacityUnits=5,WriteCapacityUnits=5

注意,如果 Terraform 操作失败,你可能需要从 AWS 控制台手动删除锁。 但这样做时要小心。
对于 main.tf 中的 eks/vpc 模块,引用 GitHub 上提供的模块很简单:
git::https://github.com/terraform-aws-modules/terraform-aws-vpc?ref=master
现在看一下另外两个 Terraform 文件(variables.tf 和 outputs.tf)。 第一个文件保存了 Terraform 变量:
$ cat /terraform/variables.tfvariable "region" { default = "eu-west-1"}
variable "map_accounts" { description = "Additional AWS account numbers to add to the aws-auth configmap. See examples/basic/variables.tf for example format." type = list(string) default = []}
variable "map_roles" { description = "Additional IAM roles to add to the aws-auth configmap." type = list(object({ rolearn = string username = string groups = list(string) })) default = []}
variable "map_users" { description = "Additional IAM users to add to the aws-auth configmap." type = list(object({ userarn = string username = string groups = list(string) })) default = [ { userarn = "arn:aws:iam::01234567890:user/my-user" username = "my-user" groups = ["system:masters"] } ]}
这里最重要的部分是将 IAM 用户“my-user”添加到 map_users 变量中,但你应该使用自己的帐户 ID 替换 01234567890。
这有什么用? 当通过本地 kubectl 客户端与 EKS 通信时,它会向 Kubernetes API 服务器发送请求,每个请求都要经过身份验证和授权过程,这样 Kubernetes 就可以知道谁发送了请求,以及它们可以做什么。 因此 Kubernetes 的 EKS 版本会要求 AWS IAM 帮助进行用户身份验证。 如果发送请求的用户列在 AWS IAM 中(这里我们指向其 ARN),请求将进入授权阶段,该阶段将由 EKS 自己处理,但要依据我们的设置。 这里要指出的是,IAM 用户“my-user”非常酷(组“system: masters”)。
最后,output.tf 文件描述了 Terraform 在完成工作后应该打印的内容:
$ cat /terraform/outputs.tfoutput "cluster_endpoint" { description = "Endpoint for EKS control plane." value = module.eks.cluster_endpoint}
output "cluster_security_group_id" { description = "Security group ids attached to the cluster control plane." value = module.eks.cluster_security_group_id}
output "config_map_aws_auth" { description = "A kubernetes configuration to authenticate to this EKS cluster." value = module.eks.config_map_aws_auth}
Terraform 部分的描述完成。 我们很快就会回来,看看如何启动这些文件。
Kubernetes 清单
到目前为止,我们已经解决了在哪里启动应用程序的问题。 现在我们来看看要运行什么。
回想一下 /k8s/ 目录中的 docker-compose.yml(我们重命名了服务,添加了几个不久就会被 kompose 用到的标签) :
$ cat /k8s/docker-compose.ymlversion: "3.7"services: samples-bi: container_name: samples-bi image: intersystemsdc/iris-community:2019.4.0.383.0-zpm ports: - 52773:52773 labels: kompose.service.type: loadbalancer kompose.image-pull-policy: IfNotPresent
运行 kompose,然后添加下面突出显示的内容。 删除注释(使内容更容易理解):
$ kompose convert -f docker-compose.yml --replicas=1$ cat /k8s/samples-bi-deployment.yamlapiVersion: extensions/v1beta1kind: Deploymentmetadata: labels: io.kompose.service: samples-bi name: samples-bispec: replicas: 1 strategy: type: Recreate template: metadata: labels: io.kompose.service: samples-bi spec: containers: - image: intersystemsdc/iris-community:2019.4.0.383.0-zpm imagePullPolicy: IfNotPresent name: samples-bi ports: - containerPort: 52773 resources: {} lifecycle: postStart: exec: command: - /bin/bash - -c - | echo -e "write\nhalt" > test until iris session iris < test; do sleep 1; done echo -e "zpm\ninstall samples-bi\nquit\nhalt" > samples_bi_install iris session iris < samples_bi_install rm test samples_bi_install restartPolicy: Always
我们使用 Recreate 更新策略,这意味着先删除 pod,然后重新创建。 这对于演示目的是允许的,让我们可以使用更少的资源。
我们还添加了 postStart 挂钩,该挂钩在 pod 启动后立即触发。 我们等待至 IRIS 启动,然后从默认的 zpm-repository 安装 samples-bi 包。
现在我们添加 Kubernetes 服务(同样没有注释):
$ cat /k8s/samples-bi-service.yamlapiVersion: v1kind: Servicemetadata: labels: io.kompose.service: samples-bi name: samples-bispec: ports: - name: "52773" port: 52773 targetPort: 52773 selector: io.kompose.service: samples-bi type: LoadBalancer
是的,我们将在“默认”命名空间中部署,该命名空间适合演示。
好了,现在我们知道了运行_位置_和_内容_。 还剩下_方式_需要了解。
GitHub Actions 工作流程
我们不需要每件事都从头开始做,而是创建一个工作流程,类似于[使用 GitHub Actions 在 GKE 上部署 InterSystems IRIS 解决方案](https://community.intersystems.com/post/deploying-intersystems-iris-solution-gke-using-github-actions)中所述的工作流程。 这次,我们不必担心构建容器。 GKE 特定的部分已替换为特定于 EKS。 粗体部分与接收提交消息和在条件步骤中使用它有关:
$ cat /.github/workflows/workflow.yamlname: Provision EKS cluster and deploy Samples BI thereon: push: branches: - master
# Environment variables.# ${{ secrets }} are taken from GitHub -> Settings -> Secrets# ${{ github.sha }} is the commit hashenv: AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }} AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }} AWS_REGION: ${{ secrets.AWS_REGION }} CLUSTER_NAME: dev-cluster DEPLOYMENT_NAME: samples-bi
jobs: eks-provisioner: # Inspired by: ## https://www.terraform.io/docs/github-actions/getting-started.html ## https://github.com/hashicorp/terraform-github-actions name: Provision EKS cluster runs-on: ubuntu-18.04 steps: - name: Checkout uses: actions/checkout@v2
- name: Get commit message run: | echo ::set-env name=commit_msg::$(git log --format=%B -n 1 ${{ github.event.after }})
- name: Show commit message run: echo $commit_msg
- name: Terraform init uses: hashicorp/terraform-github-actions@master with: tf_actions_version: 0.12.20 tf_actions_subcommand: 'init' tf_actions_working_dir: 'terraform'
- name: Terraform validate uses: hashicorp/terraform-github-actions@master with: tf_actions_version: 0.12.20 tf_actions_subcommand: 'validate' tf_actions_working_dir: 'terraform'
- name: Terraform plan if: "!contains(env.commit_msg, '[destroy eks]')" uses: hashicorp/terraform-github-actions@master with: tf_actions_version: 0.12.20 tf_actions_subcommand: 'plan' tf_actions_working_dir: 'terraform'
- name: Terraform plan for destroy if: "contains(env.commit_msg, '[destroy eks]')" uses: hashicorp/terraform-github-actions@master with: tf_actions_version: 0.12.20 tf_actions_subcommand: 'plan' args: '-destroy -out=./destroy-plan' tf_actions_working_dir: 'terraform'
- name: Terraform apply if: "!contains(env.commit_msg, '[destroy eks]')" uses: hashicorp/terraform-github-actions@master with: tf_actions_version: 0.12.20 tf_actions_subcommand: 'apply' tf_actions_working_dir: 'terraform'
- name: Terraform apply for destroy if: "contains(env.commit_msg, '[destroy eks]')" uses: hashicorp/terraform-github-actions@master with: tf_actions_version: 0.12.20 tf_actions_subcommand: 'apply' args: './destroy-plan' tf_actions_working_dir: 'terraform'
kubernetes-deploy: name: Deploy Kubernetes manifests to EKS needs: - eks-provisioner runs-on: ubuntu-18.04 steps: - name: Checkout uses: actions/checkout@v2
- name: Get commit message run: | echo ::set-env name=commit_msg::$(git log --format=%B -n 1 ${{ github.event.after }})
- name: Show commit message run: echo $commit_msg
- name: Configure AWS Credentials if: "!contains(env.commit_msg, '[destroy eks]')" uses: aws-actions/configure-aws-credentials@v1 with: aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }} aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }} aws-region: ${{ secrets.AWS_REGION }}
- name: Apply Kubernetes manifests if: "!contains(env.commit_msg, '[destroy eks]')" working-directory: ./k8s/ run: | aws eks update-kubeconfig --name ${CLUSTER_NAME} kubectl apply -f samples-bi-service.yaml kubectl apply -f samples-bi-deployment.yaml kubectl rollout status deployment/${DEPLOYMENT_NAME}
当然,我们需要设置“terraform”用户的凭据(从 ~/.aws/credentials 文件中获取),让 Github 使用它的机密:

注意工作流程的突出显示部分。 我们可以通过推送包含短语“[destroy eks]”的提交消息来销毁 EKS 集群。 请注意,我们不会使用这样的提交消息来运行“kubernetes apply”。
运行管道,但首先要创建一个 .gitignore 文件:
$ cat /.gitignore.DS_Storeterraform/.terraform/terraform/*.planterraform/*.json$ cd $ git add .github/ k8s/ terraform/ .gitignore$ git commit -m "GitHub on EKS"$ git push
在 GitHub 仓库页面的“Actions”选项卡上监视部署过程。 请等待成功完成。
第一次运行工作流程时,“Terraform apply”步骤需要 15 分钟左右,大约与创建集群的时间一样长。 下次启动时(如果未删除集群),工作流程会快很多。 你可以将此签出:
$ cd $ git commit -m "Trigger" --allow-empty$ git push
当然,最好检查一下我们做了什么。 这次可以在你的笔记本电脑上使用 IAM“my-user”的凭据:
$ export AWS_PROFILE=my-user$ export AWS_REGION=eu-west-1$ aws sts get-caller-identity$ aws eks update-kubeconfig --region=eu-west-1 --name=dev-cluster --alias=dev-cluster$ kubectl config current-contextdev-cluster
$ kubectl get nodesNAME STATUS ROLES AGE VERSIONip-10-42-1-125.eu-west-1.compute.internal Ready 6m20s v1.14.8-eks-b8860f
$ kubectl get poNAME READY STATUS RESTARTS AGEsamples-bi-756dddffdb-zd9nw 1/1 Running 0 6m16s
$ kubectl get svcNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEkubernetes ClusterIP 172.20.0.1 443/TCP 11msamples-bi LoadBalancer 172.20.33.235 a2c6f6733557511eab3c302618b2fae2-622862917.eu-west-1.elb.amazonaws.com 52773:31047/TCP 6m33s
访问 _[http://a2c6f6733557511eab3c302618b2fae2-622862917.eu-west-1.elb.amazonaws.com:52773/csp/user/_DeepSee.UserPortal.Home.zen?$NAMESPACE=USER](http://a2c6f6733557511eab3c302618b2fae2-622862917.eu-west-1.elb.amazonaws.com:52773/csp/user/_DeepSee.UserPortal.Home.zen?%24NAMESPACE=USER) _(将链接替换为你的外部 IP),然后输入“_system”、“SYS”并更改默认密码。 您应该看到一系列 BI 仪表板:

点击每个仪表板的箭头可以深入了解:

记住,如果重启 samples-bi pod,所有更改都将丢失。 这是有意的行为,因为这是演示。 如果你需要保留更改,我在 github-gke-zpm-registry/k8s/statefulset.tpl 仓库中创建了一个示例。
完成后,删除你创建的所有内容:
$ git commit -m "Mr Proper [destroy eks]" --allow-empty$ git push
结论
在本文中,我们将 eksctl 实用程序替换成 Terraform 来创建 EKS 集群。 这是向“编纂”您的所有 AWS 基础架构迈出的一步。
我们展示了如何使用 Github Actions 和 Terraform 通过 git push 轻松部署演示应用程序。
我们还向工具箱中添加了 kompose 和 pod 的 postStart 挂钩。
这次我们没有展示 TLS 启用。 我们将在不久的将来完成这项任务。
文章
Qiao Peng · 一月 14, 2021
本文以及后面两篇该系列文章,是为需要在其基于 InterSystems 产品的应用程序中使用 OAuth 2.0 框架(下文简称为 OAUTH)的开发人员或系统管理员提供的指南。
作者:InterSystems 高级销售工程师 Daniel Kutac
# 发布后校正和更改历史记录
* 2016 年 8 月 3 日 - 修正了 Google 客户端配置屏幕截图,更新了 Google API 屏幕截图以反映新版本的页面
* 2016 年 8 月 28 日 - 更改了 JSON 相关代码,反映了对 Cache 2016.2 JSON 支持的更改
* 2017 年 5 月 3 日 - 更新了文本和屏幕,以反映 Cache 2017.1 的新 UI 和功能
* 2018 年 2 月 19 日 - 将 Caché 更改为 InterSystems IRIS 以反映最新的发展。 但是请记住,尽管产品名称发生更改,但**文章涵盖所有的 InterSystems 产品**——InterSystems IRIS 数据平台、Ensemble 和 Caché。
* 2020 年 8 月 17 日 - 大面积更改,软件方面更改更大。 要获取 Google 的更新版 Oauth2 的网址,请咨询 Micholai Mitchko。
_第 1 部分 客户端_
# **简介**
有关开放式授权框架 InterSystems 实现的相关内容,我们分 3 部分讲述,这是第 1 部分。
在第 1 部分中,我们对该主题进行了简短介绍,并提供了一个 InterSystems IRIS 应用程序担当授权服务器客户端并请求一些受保护资源的简单方案。
第 2 部分将讲述一个复杂一些的方案,在该方案中 InterSystems IRIS 本身通过 OpenID Connect 担当授权服务器和身份验证服务器。
本系列的最后一部分将描述 OAUTH 框架类的各个部分,它们由 InterSystems IRIS 实现。
## **什么是开放授权框架 [1] **
许多人已经听说过有关开放授权框架及其用途的信息。 因此这里只做简单介绍,以备未听说过的人参考。
开放授权框架 (OAUTH) 当前为 2.0 版,其是一种协议,允许基于 Web 的主应用程序通过在客户端(应用程序请求数据)和资源所有者(应用程序保存请求的数据)之间建立间接信任来以安全的方式交换信息。 信任本身由客户端和资源服务器都认可并信任的主体提供。 该主体称为授权服务器。
简单举例如下:
假设 Jenny(使用 OAUTH 术语,就是资源所有者)在开展 JennyCorp 公司的一个工作项目。 她为一个潜在的大型业务创建了项目计划,并邀请 JohnInc 公司的业务伙伴 John(客户端用户)审阅此文档。 不过,她并不愿意让 John 访问自己公司的 VPN,因此她将文档放在 Google 云端硬盘(资源服务器)或其他类似的云存储中。 她这样做,已经在她和 Google(授权服务器)之间建立了信任。 她标记了要与 John 共享的文档(John 已经使用 Google 云端硬盘服务,Jenny 知道他的电子邮件)。
当 John 想要阅读该文档时,他进行了 Google 帐户身份验证,然后通过移动设备(平板电脑、笔记本电脑等)启动文档编辑器(客户端服务器)并加载 Jenny 的项目文件。
这听起来很简单,但是两个人与 Google 之间有很多通信。 所有交流均遵循 OAuth 2.0 规范,因此 John 的客户端(阅读器应用程序)必须首先向 Google 进行身份验证(OAUTH 不涵盖此步骤),然后 John 申请获取 Google 对提供表格的同意,经过授权后,Google 就会发出一个访问令牌,授权阅读器应用程序访问文档。 阅读器应用程序使用该访问令牌向 Google 云端硬盘服务发出请求,以检索 Jenny 的文件。
下图说明了各方之间的通信
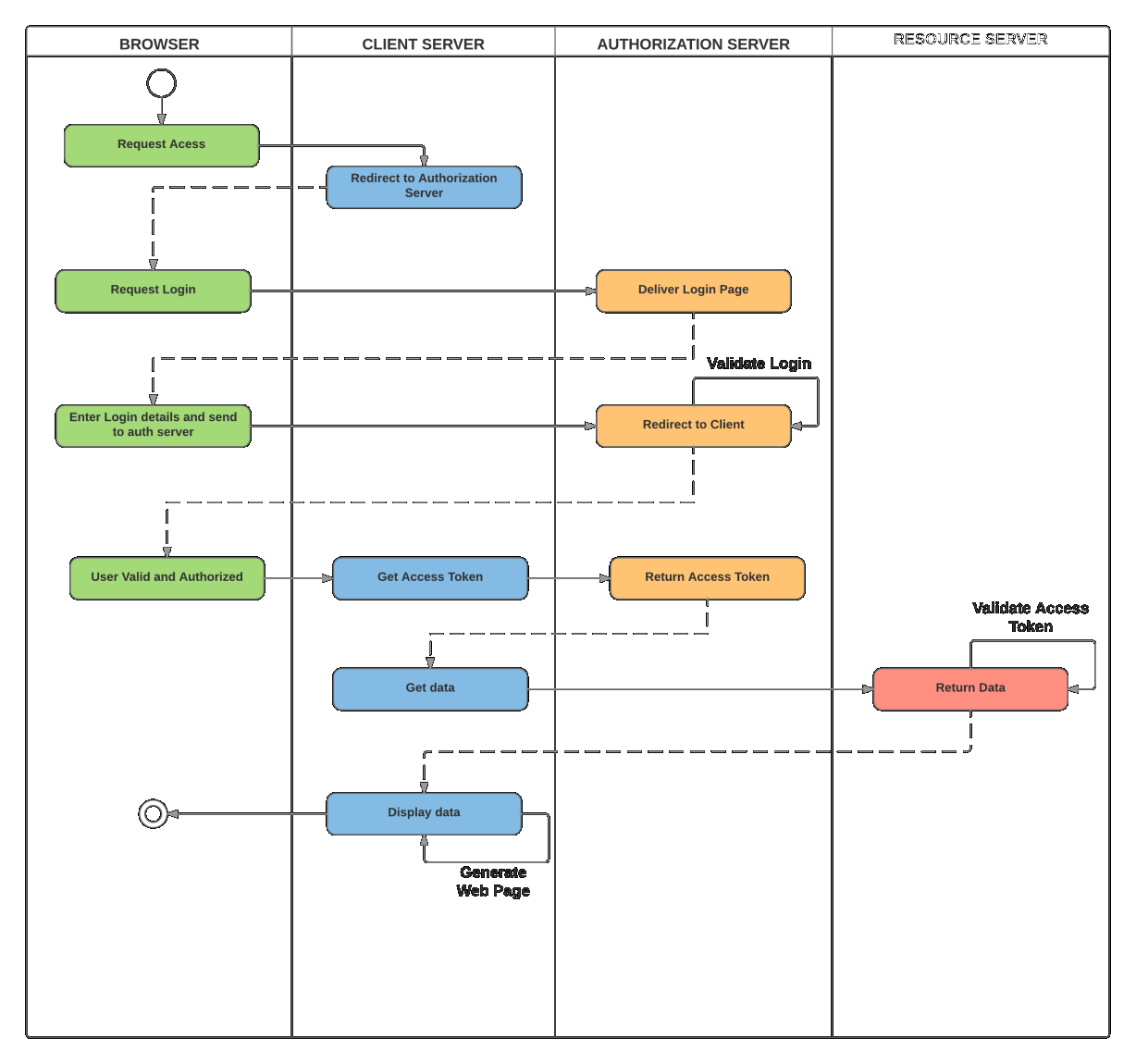
请注意:虽然所有的 OAUTH 2.0 通信都使用 HTTP 请求,但服务器不必非得是 Web 应用程序。
让我们通过 InterSystems IRIS 来说明这一简单方案。
# **简单 Google 云端硬盘演示**
在本演示中,我们将创建一个基于 CSP 的小型应用程序,该应用程序将使用我们自己的帐户(以及作为奖励的日历列表)来请求存储在 Google 云端硬盘服务中的资源(文件列表)。
## **基本要求**
开始应用程序编码之前,我们需要准备环境。 这包括启用 SSL 的 Web 服务器和 Google 配置文件。
### **Web 服务器配置**
如上所述,我们需要使用 SSL 与授权服务器进行通信,因为默认情况下 OAuth 2.0 要求如此。 我们需要确保数据安全,对吧?
解释如何配置 Web 服务器来支持 SSL 的内容超出了本文讨论的范围,因此,请以您喜欢的方式参阅相应 Web 服务器的用户手册。 为了您的好奇心(我们稍后可能会显示一些屏幕截图),在此特定示例中,我们将使用 Microsoft IIS 服务器。
### **Google 配置**
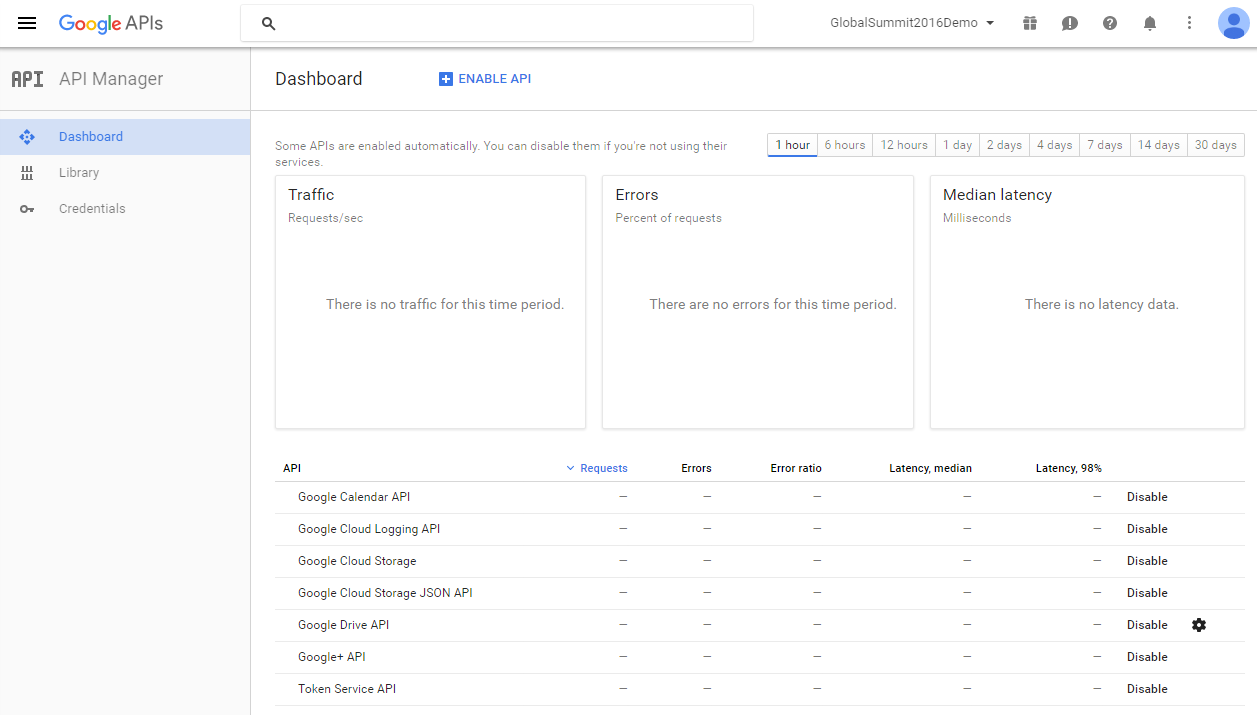
为了向 Google 注册,我们需要使用 Google API Manager-[ https://console.developers.google.com/apis/library?project=globalsummit2016demo ](https://console.developers.google.com/apis/library?project=globalsummit2016demo)
为了进行演示,我们创建了一个帐户 GlobalSummit2016Demo。 确保我们已启用 Drive API
现在,该定义凭据了
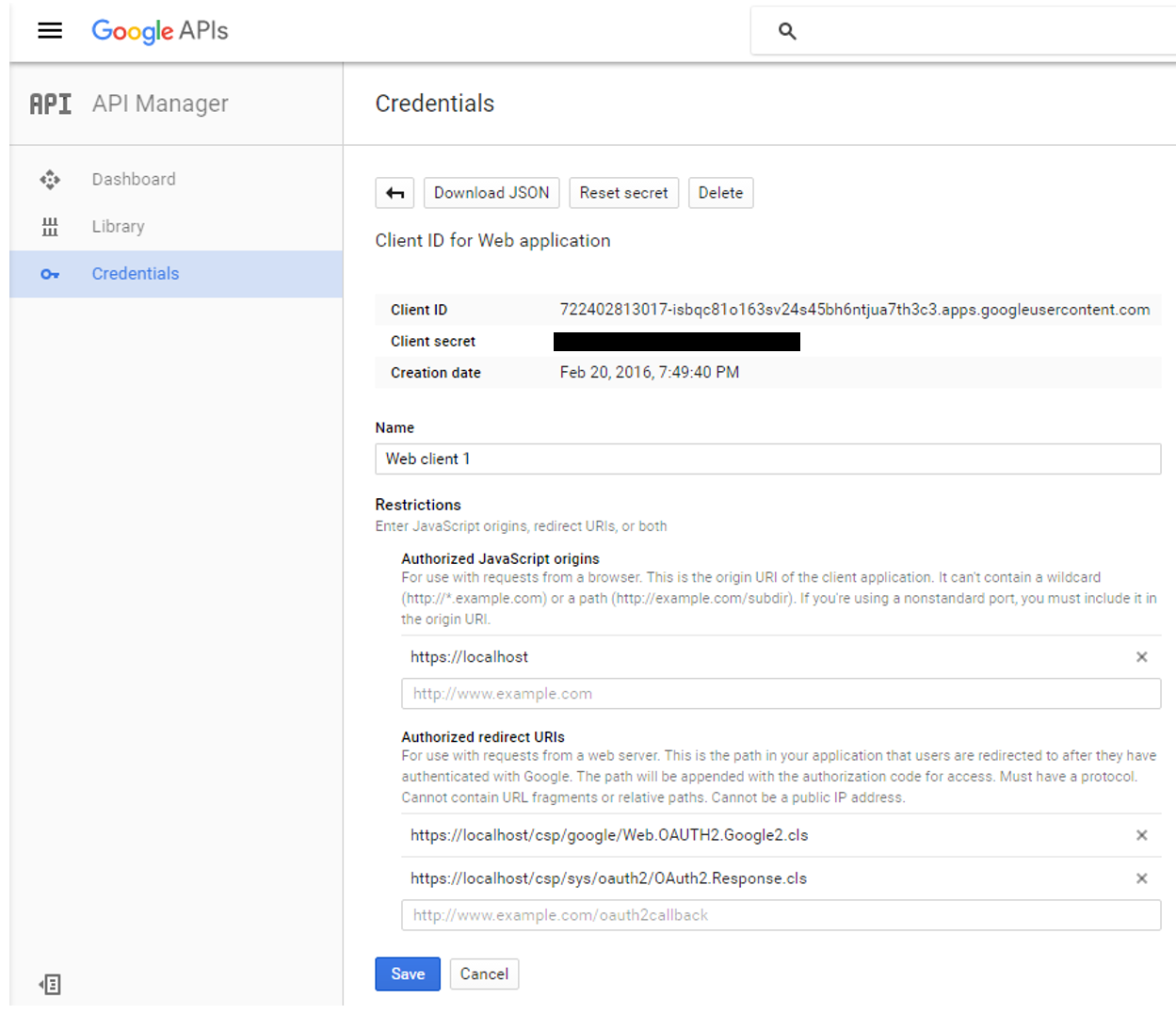
请注意以下事项:
_Authorized JavaScript – _我们仅允许本地生成的脚本(相对于调用页面)
_Authorized redirect URIs – 从理论上讲,我们可以将客户端应用程序重定向到任何站点,但是当使用 InterSystems IRIS OAUTH 实现时,我们必须重定向到** https://localhost/csp/sys/oauth2/OAuth2.Response.cls**。您可以定义多个授权的重定向 URI,如屏幕截图所示,但是对于本演示,我们只需要两者中的第二个条目。
最后,我们需要将 InterSystems IRIS 配置为 Google 授权服务器的客户端
### **Caché /IRIS配置**
InterSystems IRIS OAUTH2 客户端配置需要两步。 首先,我们需要创建服务器配置。
在 SMP 中,导航至**系统管理 > 安全性 > OAuth 2.0 > 客户端配置**。
点击**创建服务器配置**按钮,填写表格并保存。
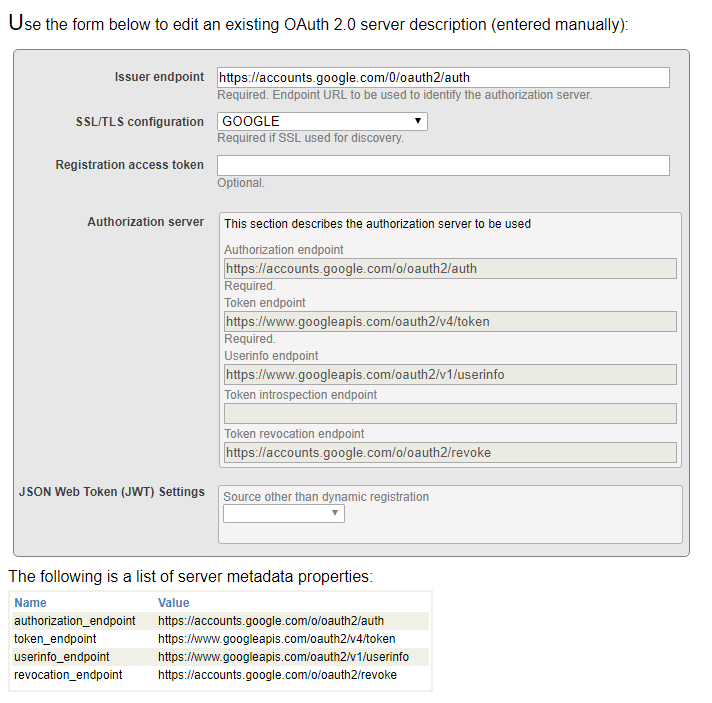
输入到表格的所有信息可以在 Google 开发者控制台网站上找到。 请注意,InterSystems IRIS 支持自动 Open ID 发现。 但是,由于我们没有使用它,因此我们手动输入所有信息
现在,点击新创建的 Issuer Endpoint
旁边的“客户端配置”链接。并点击**创建客户端配置**按钮。
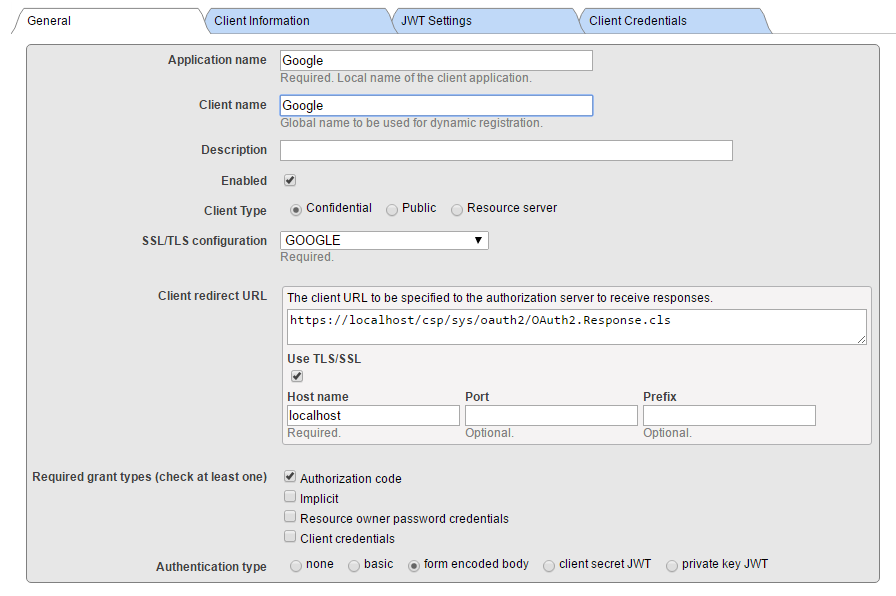
将“客户端信息”和“JWT 设置”选项卡保留为空(默认值),并填写客户端凭据。
请注意:我们正在创建机密客户端(这比公共客户端更安全,这意味着客户端秘密永远不会离开客户端服务器应用程序(永远不会传输到浏览器)
此外,请确保选中**“使用 SSL/TLS**”,并提供主机名(本地主机,因为我们将本地重定向到客户端应用程序),最后提供端口和前缀(当同一台机器上有多个 InterSystems IRIS 实例时,这非常有用)。 根据输入的信息,会计算客户端重定向 URL 并显示在上一行中。
在上面的屏幕截图中,我们提供了一个名为 GOOGLE 的 SSL 配置。 该名称本身实际上仅用于帮助您确定此特定通信通道使用的可能是众多 SSL 配置中的哪个。 Caché 使用 SSL/TLS 配置存储所有必要的信息,以建立与服务器(在本例中,为 Google OAuth 2.0 URI)的安全流量。
有关详细信息,请参阅[文档](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GCAS_ssltls#GCAS_ssltls_aboutconfigs) 。
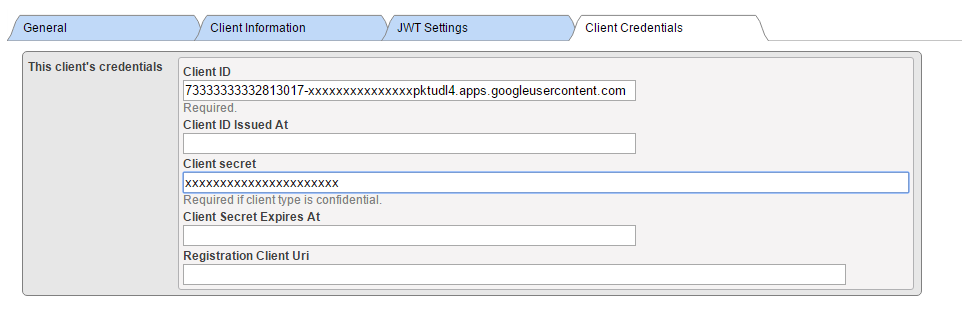
Supply Client ID 和 Client Secret 值从 Google 凭据定义表中获得(使用手动配置时)。
现在,我们完成了所有的配置步骤,可以开始编写 CSP 应用程序代码。
## **客户端应用程序**
客户端应用程序是基于 Web 的简单 CSP 应用程序。 因此,它包含由 Web 服务器定义和执行的服务器端源代码,以及由 Web 浏览器向用户公开的用户界面。 下文提供的示例代码期望客户端应用程序在 GOOGLE 名称空间中运行。 请将路径 /csp/google/ 修改为您的命名空间。
## **客户端服务器**
客户端服务器是一个简单的两页应用程序。 在该应用程序内,我们将:
· 将 URL 重定向到 Google 授权服务器
· 执行向 Google Drive API 和 Google Calendar API 的请求并显示结果
### **第 1 页**
这是应用程序的一页,我们决定在此处调用 Google 的资源。
以下是此页面上简单但功能齐全的代码。
Class Web.OAUTH2.Google1N Extends %CSP.Page
{
Parameter OAUTH2CLIENTREDIRECTURI = "https://localhost/csp/google/Web.OAUTH2.Google2N.cls";
Parameter OAUTH2APPNAME = "Google";
ClassMethod OnPage() As %Status
{
&html
// we need to supply openid scope to authenticate to Google
set scope="openid https://www.googleapis.com/auth/userinfo.email "_
"https://www.googleapis.com/auth/userinfo.profile "_
"https://www.googleapis.com/auth/drive.metadata.readonly "_
"https://www.googleapis.com/auth/calendar.readonly"
set properties("approval_prompt")="force"
set properties("include_granted_scopes")="true"
set url=##class(%SYS.OAuth2.Authorization).GetAuthorizationCodeEndpoint(..#OAUTH2APPNAME,scope,
..#OAUTH2CLIENTREDIRECTURI,.properties,.isAuthorized,.sc)
w !,""
&html
Quit $$$OK
}
ClassMethod OnPreHTTP() As %Boolean [ ServerOnly = 1 ]
{
#dim %response as %CSP.Response
set scope="openid https://www.googleapis.com/auth/userinfo.email "_
"https://www.googleapis.com/auth/userinfo.profile "_
"https://www.googleapis.com/auth/drive.metadata.readonly "_
"https://www.googleapis.com/auth/calendar.readonly"
if ##class(%SYS.OAuth2.AccessToken).IsAuthorized(..#OAUTH2APPNAME,,scope,.accessToken,.idtoken,.responseProperties,.error) {
set %response.ServerSideRedirect="Web.OAUTH2.Google2N.cls"
}
quit 1
}
}
代码的简要说明如下:
1. OnPreHTTP 方法 - 首先,我们有机会时检查一下,我们是否由于 Google 授权而获得了有效的访问令牌——这种情况可能会发生,例如当我们只是刷新页面时。 如果没有,我们需要授权。 如果我们有令牌,我们只需将页面重定向到显示结果的页面
2. OnPage 方法 - 只有在我们没有可用的有效访问令牌时,我们才到这里,因此我们需要开始通信——向 Google 进行身份验证和授权,以便它向我们授予访问令牌。
3. 我们定义了作用域字符串和属性数组,用于修改 Google 身份验证对话框的行为(我们需要先向 Google 进行身份验证,然后它才能根据我们的身份对我们进行授权)。
4. 最后,我们收到 Google 登录页面的 URL,然后将其提供给用户,接着提供同意页面。
还有一点注意事项:
我们在 OAUTH2CLIENTREDIRECTURI 参数的 中指定真正的重定向页面。 但是,我们在 Google 凭据定义中使用了 InterSystems IRIS OAUTH 框架的系统页面! 重定向由我们的 OAUTH 处理程序类在内部处理。
### **第 2 页**
此页面显示 Google 授权的结果,如果成功,我们将调用 Google API 调用以检索数据。 同样,此代码简单,但功能齐全。 相比读者的想象,我们以更结构化的方式来显示输入数据。
Include %occInclude
Class Web.OAUTH2.Google2N Extends %CSP.Page
{
Parameter OAUTH2APPNAME = "Google";
Parameter OAUTH2ROOT = "https://www.googleapis.com";
ClassMethod OnPage() As %Status
{
&html
// Check if we have an access token
set scope="openid https://www.googleapis.com/auth/userinfo.email "_
"https://www.googleapis.com/auth/userinfo.profile "_
"https://www.googleapis.com/auth/drive.metadata.readonly "_
"https://www.googleapis.com/auth/calendar.readonly"
set isAuthorized=##class(%SYS.OAuth2.AccessToken).IsAuthorized(..#OAUTH2APPNAME,,scope,.accessToken,.idtoken,.responseProperties,.error)
if isAuthorized {
// Google has no introspection endpoint - nothing to call - the introspection endpoint and display result -- see RFC 7662.
w "Data from GetUserInfo API"
// userinfo has special API, but could be also retrieved by just calling Get() method with appropriate url
try {
set tHttpRequest=##class(%Net.HttpRequest).%New()
$$$THROWONERROR(sc,##class(%SYS.OAuth2.AccessToken).AddAccessToken(tHttpRequest,"query","GOOGLE",..#OAUTH2APPNAME))
$$$THROWONERROR(sc,##class(%SYS.OAuth2.AccessToken).GetUserinfo(..#OAUTH2APPNAME,accessToken,,.jsonObject))
w jsonObject.%ToJSON()
} catch (e) {
w "ERROR: ",$zcvt(e.DisplayString(),"O","HTML")_""
}
/******************************************
* *
* Retrieve info from other APIs *
* *
******************************************/
w ""
do ..RetrieveAPIInfo("/drive/v3/files")
do ..RetrieveAPIInfo("/calendar/v3/users/me/calendarList")
} else {
w "Not authorized!"
}
&html
Quit $$$OK
}
ClassMethod RetrieveAPIInfo(api As %String)
{
w "Data from "_api_""
try {
set tHttpRequest=##class(%Net.HttpRequest).%New()
$$$THROWONERROR(sc,##class(%SYS.OAuth2.AccessToken).AddAccessToken(tHttpRequest,"query","GOOGLE",..#OAUTH2APPNAME))
$$$THROWONERROR(sc,tHttpRequest.Get(..#OAUTH2ROOT_api))
set tHttpResponse=tHttpRequest.HttpResponse
s tJSONString=tHttpResponse.Data.Read()
if $e(tJSONString)'="{" {
// not a JSON
d tHttpResponse.OutputToDevice()
} else {
w tJSONString
w ""
/*
// new JSON API
&html
s tJSONObject={}.%FromJSON(tJSONString)
set iterator=tJSONObject.%GetIterator()
while iterator.%GetNext(.key,.value) {
if $isobject(value) {
set iterator1=value.%GetIterator()
w "",key,""
while iterator1.%GetNext(.key1,.value1) {
if $isobject(value1) {
set iterator2=value1.%GetIterator()
w "",key1,""
while iterator2.%GetNext(.key2,.value2) {
write !, "",key2, "",value2,""
}
// this way we can go on and on into the embedded objects/arrays
w ""
} else {
write !, "",key1, "",value1,""
}
}
w ""
} else {
write !, "",key, "",value,""
}
}
&html
*/
}
} catch (e) {
w "ERROR: ",$zcvt(e.DisplayString(),"O","HTML")_""
}
}
}
让我们快速看一下代码:
1. 首先,我们需要检查一下我们是否具有有效的访问令牌(即我们是否被授权)
2. 如果是,我们可以向 Google 提供且由已发布访问令牌覆盖的 API 发出请求
3. 为此,我们使用标准的 %Net.HttpRequest 类,但根据 API 规范,我们将访问令牌添加到 GET 或 POST 方法中
4. 如您所见,为了方便您,OAUTH 框架已实现 GetUserInfo()方法,但是您可以使用 Google API 规范直接检索用户信息,就像我们在 RetrieveAPIInfo()助手方法中所做的一样。
5. 由于在 OAUTH 世界中以 JSON 格式交换数据司空见惯,因此我们只读取传入的数据,然后简单地将其转储到浏览器。 应用程序开发人员可以解析和格式化接收到的数据,以便用户可以看明白。 但这超出了本演示的范围。 (尽管一些代码有注释,显示了如何完成解析。)
下图是一个输出屏幕截图,显示了原始 JSON 数据。

继续阅读[第 2 部分](https://community.intersystems.com/post/cach%C3%A9-open-authorization-framework-oauth-20-implementation-part-2),该部分讲述 InterSystems IRIS 担当授权服务器和 OpenID Connect 提供程序相关的内容。
[1] https://tools.ietf.org/html/rfc6749, https://tools.ietf.org/html/rfc6750
文章
jieliang liu · 一月 7, 2021
Google Cloud Platform (GCP) 为基础架构即服务 (IaaS) 提供功能丰富的环境,其作为云提供完备的功能,支持所有的 InterSystems 产品,包括最新的 InterSystems IRIS 数据平台。 与任何平台或部署模型一样,必须留心以确保考虑到环境的各个方面,例如性能、可用性、操作和管理程序。 本文将详细阐述所有这些方面。
以下概述和详细内容由谷歌提供,可在此处找到。
概述
### GCP 资源
GCP 由一系列物理资产(例如计算机和硬盘驱动器)和虚拟资源(例如虚拟机(VM))组成,它们分布于谷歌遍布全球的数据中心。 每个数据中心的位置都是一个泛区域。 每个区域都是地区的集合,这些地区在该区域内彼此分离。 每个地区都通过一个名称标识,名称由字母标识符和相应区域的名称组成。
这种资源分配带来众多优势,包括发生故障时提供冗余,以及通过将资源配置在客户端附近来减少延迟。 这种分配也引入一些有关如何统筹资源的规则。
### 访问 GCP 资源
在云计算中,物理硬件和软件变成了服务。 这些服务提供对基础资源的访问。 在 GCP 上开发基于 InterSytems IRIS 的应用程序时,您可混合和匹配这些服务,组合它们来提供您所需的基础架构,然后添加您的代码来实现您要构建的方案。 有关可用服务的详细信息, 可在此处找到。
### 项目
您分配和使用的任何 GCP 资源必须属于一个项目。 项目由设置、权限和其他描述应用程序的元数据组成。 根据区域和地区规则,单个项目中的资源能够轻松协作,例如通过内部网络进行通信。 每个项目包含的资源在项目边界上保持独立;您只能通过外部网络连接来互连它们。
服务交互
GCP 提供 3 种与服务和资源交互的基本方法。
#### 控制台
Google Cloud Platform 控制台提供基于 web 的图形用户界面,供您管理 GCP 项目和资源。 使用 GCP 控制台,您可创建新项目,或选择现有项目,可使用您在项目环境中创建的资源。 您可以创建多个项目,因此您可以使用项目以任何对您有意义的方式分开您的工作。 例如,如果您想确保只有某些团队成员可以访问项目中的资源,而所有团队成员可以继续访问另一个项目中的资源,则可以开始一个新项目。
命令行界面
如果您喜欢在终端窗口中工作,Google Cloud SDK 提供 gcloud 命令行工具,让您可以访问所需的命令。 gcloud 工具可用于管理您的开发工作流程和 GCP 资源。 有关 gcloud 的详细内容可在此处找到。
GCP 也提供 Cloud Shell,一种基于浏览器的 GCP 交互 shell 环境。 可从 GCP 控制台访问 Cloud Shell。 Cloud Shell 提供:
临时计算引擎虚拟机实例。
从 web 浏览器通过命令行访问实例。
内置代码编辑器。
5 GB 持久性磁盘存储。
预安装 Google Cloud SDK 和其他工具。
支持 Java、Go、Python、Node.js、PHP、Ruby 和 .NET 语言。
Web 预览功能。
访问 GCP 控制台项目和资源的内置授权。
客户端库
Cloud SDK 拥有客户端库,让您轻松创建和管理资源。 GCP 客户端库公开 API 有两个主要目的:
应用 API 提供对服务的访问。 应用 API 针对支持的语言(例如 Node.js 和 Python )进行了优化。 客户端库围绕服务隐喻而设计,因此您可以更自然地使用服务,并编写更少的样板代码。 客户端库还提供身份验证和授权助手。 有关详细信息可在此处找到。
管理 API 提供资源管理功能。 例如,如果您想构建自己的自动化工具,可以使用管理 API。
您还可以使用 Google API 客户端库来访问产品的 API,如 Google Map、Google Drive 和 YouTube。 有关 GCP 客户端库的详细信息可在此处找到。
InterSystems IRIS 示例体系结构
本文部分内容阐述了面向 GCP 的 InterSystems IRIS 部署示例,旨在为特定应用程序的部署抛砖引玉。 这些示例可用作很多部署方案的指南。 此参考体系结构拥有非常强大的部署选项,从最小规模的部署,到满足计算和数据需求的大规模可扩展工作负载,不一而足。
本文还介绍了高可用性和灾难恢复选项以及其他建议的系统操作。 个体可对这些进行相应的修改以支持其组织的标准实践和安全策略。
针对您的特定应用,就基于 GCP 的 InterSystems IRIS 部署,您可联系 InterSystems 进一步探讨。
* * *
示例参考体系结构
以下示例体系结构按照容量和功能逐步升级的顺序讲述了几种不同的配置, 分别为小型开发/生产/大型生产/分片集群生产。先从中小型配置讲起,然后讲述具有跨地区高可用性以及多区域灾难恢复的大规模可扩展性解决方案。 此外,还讲述了一个将 InterSystems IRIS 数据平台的新分片功能用于大规模处理并行 SQL 查询的混合工作负载的示例。
###
小型开发配置
在本示例中,显示了一个能支持 10 名开发人员和 100GB 数据的小型开发环境,这基本是最小规模的配置。 只要适当地更改虚拟机实例类型并增加持久性磁盘存储,即可轻松支持更多的开发人员和数据。
这足以支持开发工作,并让您熟悉 InterSystems IRIS 功能以及 Docker 容器的构建和编排(如果需要的话)。 小型配置通常不采用具有高度可用性的数据库镜像,但是如果需要高可用性,则可随时添加。
小型配置示例图
示例图 2.1.1-a 显示了图表 2.1.1-b 中的资源。 其中包含的网关只是示例,可做相应地调整以适应您组织的标准网络实践。
下列 GCP VPC 项目资源是针对最小规模的配置提供的。 可根据需求添加或删除 GCP 资源。
小型配置 GCP 资源
下表提供了小型配置 GCP 资源的示例。
需要考虑适当的网络安全和防火墙规则,以防止对 VPC 的不必要访问。 谷歌提供网络安全最佳做法供您入门使用,可在此处找到。
注意:VM 实例需要公共 IP 地址才能访问 GCP 服务。 谷歌建议使用防火墙规则来限制这些 VM 实例的传入,尽管这种做法可能会引起一些问题。
如果您的安全策略确实需要内部 VM 实例,则您需要在网络上手动设置 NAT 代理和相应的路由,以便内部实例可以访问互联网。 务必要明确,您无法使用 SSH 直接完全连接到内部 VM 实例。 要连接到此类内部机器,必须设置具有外部 IP 地址的堡垒实例,然后建立隧道通过它。 可以配置堡垒主机,以提供进入 VPC 的外部入口点。
有关堡垒主机的详细信息,可在此处找到。
产品配置
在本示例中,展示了一个规模较大的产品配置,其采用 InterSystems IRIS 数据库镜像功能来支持高可用性和灾难恢复。
此配置包括 InterSystems IRIS 数据库服务器同步镜像对,该镜像服务器在区域 1 内分为两个地区,用于自动故障转移,在区域 2 内的第三个 DR 异步镜像成员用于灾难恢复,以防万一整个 GCP 区域脱机 。
InterSystems Arbiter 和 ICM 服务器部署在单独的第三个地区,以提高弹性。 此示例体系结构还包括一组可选的负载均衡 web 服务器,用于支持启用 Web 的应用程序。 这些使用 InterSystems 网关的 web 服务器可以根据需要进行缩放。
产品配置示例图
示例图 2.2.1-a 显示了图表 2.2.1-b 中的资源。 其中包含的网关只是示例,可做相应地调整以适应您组织的标准网络实践。
建议将以下 GPC VPC 项目中的资源作为分片集群部署的最低配置。 可根据需求添加或删除 GCP 资源。
产品配置 GCP 资源
下表提供了产品配置 GCP 资源的示例。
大型产品配置
在本示例中,提供了一个大规模可缩放性配置。该配置通过扩展 InterSystems IRIS 功能也引入使用 InterSystems 企业缓存协议 (ECP:EnterpriseCacheProtocol) 的应用程序服务器,实现对用户的大规模横向缩放。 本示例甚至包含了更高级别的可用性,因为即使在数据库实例发生故障转移的情况下,ECP 客户端也会保留会话细节。 多个 GCP 地区与基于 ECP 的应用程序服务器和部署在多个区域中的数据库镜像成员一起使用。 此配置能够支持每秒数千万次的数据库访问和数万亿字节数据。
大型产品配置示例图
示例图 2.3.1-a 显示了图表 2.3.1-b 中的资源。 其中包含的网关只是示例,可做相应地调整以适应您组织的标准网络实践。
此配置中包括一个故障转移镜像对,四个或更多的 ECP 客户端(应用程序服务器),以及每个应用程序服务器对应一个或多个 Web 服务器。 故障转移数据库镜像对在同一区域中的两个不同 GCP 地区之间进行划分,以提供故障域保护,而 InterSystems Arbiter 和 ICM 服务器则部署在单独的第三地区中,以提高弹性。
灾难恢复扩展至第二个 GCP 区域和地区,与上一示例中的情况类似。 如果需要,可以将多个 DR 区域与多个 DR 异步镜像成员目标一起使用。
建议将以下 GPC VPC 项目中的资源作为大型生产部署的最低配置。 可根据需求添加或删除 GCP 资源。
大型产品配置 GCP 资源
下表提供了大型产品配置 GCP 资源的示例。
采用 InterSystems IRIS 分片集群的生产配置
在此示例中,提供了一个针对 SQL 混合工作负载的横向缩放性配置,其包含 InterSystems IRIS 的新分片集群功能,可实现 SQL 查询和表跨多个系统的大规模横向缩放。 本文后面将详细讨论 InterSystems IRIS 分片集群及其功能。
采用 InterSystems IRIS 分片集群的生产配置
示例图 2.4.1-a 显示了图表 2.4.1-b 中的资源。 其中包含的网关只是示例,可做相应地调整以适应您组织的标准网络实践。
此配置中包括四个镜像对,它们为数据节点。 每个故障转移数据库镜像对在同一区域中的两个不同 GCP 地区之间进行划分,以提供故障域保护,而 InterSystems Arbiter 和 ICM 服务器则部署在单独的第三地区中,以提高弹性。
此配置允许从集群中的任何数据节点使用所有的数据库访问方法。 大型 SQL 表数据在物理上跨所有数据节点进行分区,以实现查询处理和数据卷的大规模并行。 将所有这些功能组合在一起,就可以支持复杂的混合工作负载,比如大规模分析 SQL 查询及引入的新数据,所有这一切均在一个 InterSystems IRIS 数据平台中执行。
注意,上面图表中以及下表“资源类型”列中的术语“计算[Engine]”是一个表示 GCP(虚拟)服务器实例的 GCP 术语,将在本文的 3.1节中做进一步介绍。 它并不表示或暗示本文后面所描述的集群体系结构中对“计算节点”的使用。
建议将以下 GPC VPC 项目中的资源作为分片集群部署的最低配置。 可根据需求添加或删除 GCP 资源。
使用分片集群配置 GCP 资源的产品
下表提供了分片集群配置 GCP 资源的示例。
* * *
云概念简介
Google Cloud Platform (GCP) 为基础架构即服务 (IaaS) 提供功能丰富的云环境,使其具备完备的功能,支持所有的 InterSystems 产品,包括支持基于容器的 DevOps 及最新的 InterSystems IRIS 数据平台。 与任何平台或部署模型一样,必须留心以确保考虑到环境的各个方面,例如性能、可用性、系统操作、高可用性、灾难恢复、安全控制和其他管理程序。 本文档将介绍所有云部署涉及的三个主要组件:计算、存储和网络。
计算引擎(虚拟机)
GCP 中存在数个针对计算引擎资源的选项,以及众多虚拟 CPU 和内存规范及相关存储选项。 在 GCP 中值得注意的一点是,对给定机器类型中 vCPU 数量的引用等于一个 vCPU,其是虚拟机监控程序层上物理主机中的一个超线程。
就本文档的目的而言,将使用 n1-standard * 和 n1-highmem * 实例类型,这些实例类型在大多数 GCP 部署区域中广泛可用。 但是,对于将大量数据缓存在内存中的大型工作数据集而言,使用 n1-ultramem * 实例类型是不错的选择。 除非另有说明,否则使用默认实例设置(例如实例可用性策略)或其他高级功能。 有关各种机器类型的详细信息,可在此处找到。
磁盘存储
与 InterSystems 产品最直接相关的存储类型是持久性磁盘类型,但是,只要了解并适应数据可用性限制,本地存储可以用于高水平的性能。 还有其他一些选项,例如云存储(存储桶),但是这些选项更特定于单个应用程序的需求,而非支持 InterSystems IRIS 数据平台的操作。
与大多数其他云提供商一样,GCP 对可与单个计算引擎关联的持久性存储施加了限制。 这些限制包括每个磁盘的最大容量、关联到每个计算引擎的持久性磁盘的数量,以及每个持久性磁盘的 IOPS 数量,对单个计算引擎实例 IOPS 设置上限。 此外,对每 GB 磁盘空间设有 IOPS 限制,因此有时需要调配更多磁盘容量才能达到所需的 IOPS 速率。
这些限制可能会随着时间而改变,可在适当时与谷歌确认。
磁盘卷有两种类型的持久性存储类型:“标准持久性”磁盘和“SSD 持久性”磁盘。 SSD 持久性磁盘更适合于那些要求低延迟 IOPS 和高吞吐量的生产工作负载。 标准持久性磁盘对于非生产开发和测试或归档类型的工作负载,是一种更经济的选择。
有关各种磁盘类型及限制的详细信息,可在此处找到。
VPC 网络
强烈建议采用虚拟私有云 (VPC) 网络来支持 InterSystems IRIS 数据平台的各个组件,同时提供正确的网络安全控制、各种网关、路由、内部 IP 地址分配、网络接口隔离和访问控制。 本文档中提供了一个详细的 VPC 示例。
有关 VPC 网络和防火墙的详细信息,可在此处找到。
* * *
虚拟私有云 (VPC) 概述
GCP VPC 与其他云提供商略有不同,其更加简单和灵活。 可在此处找到各概念的比较。
在 GCP 项目中,每个项目允许有数个 VPC(目前每个项目最多允许 5 个),且创建 VPC 网络有两个选项——自动模式和自定义模式。
此处提供每个类型的详细信息。
在大多数大型云部署中,采用多个 VPC 将各种网关类型与以应用为中心的 VPC 进行隔离,并利用 VPC 对等进行入站和出站通信。 有关适合您的公司使用的子网和任何组织防火墙规则的详细信息,强烈建议您咨询您的网络管理员。 本文档不阐述 VPC 对等方面的内容。
在本文档提供的示例中,使用 3 个子网的单一 VPC 用于提供各种组件的网络隔离,以应对各种 InterSystems IRIS 组件的可预测延迟和带宽以及安全性隔离。
网络网关和子网定义
本文档的示例中提供了两种网关,以支持互联网和安全 VPN 连接。 要求每个入口访问都具有适当的防火墙和路由规则,从而为应用程序提供足够的安全性。 有关如何使用路由的详细信息,可在此处找到。
提供的示例体系结构中使用了 3 个子网,它们专与 InterSystems IRIS 数据平台一起使用。 这些单独的网络子网和网络接口的使用为上述 3 个主要组件的每一个提供了安全控制、带宽保护和监视方面的灵活性。 有关各种用例的详细信息,可在此处找到。
有关创建具有多个网络接口的虚拟机实例的详细信息,可在此处找到。
这些示例中包含的子网:
用户空间网络用于入站连接用户和查询
分片网络用于分片节点之间的分片间通信
镜像网络通过同步复制和单个数据节点的自动故障转移实现高可用性。
注意:仅在单个 GCP 区域内具有低延迟互连的多个地区之间,才建议进行故障转移同步数据库镜像。 区域之间的延迟通常太高,无法提供积极的用户体验,特别是对于具有高更新率的部署更如此。
### 内部负载均衡器
大多数 IaaS 云提供商缺乏提供虚拟 IP (VIP) 地址的能力,这种地址通常用在自动化数据库故障转移设计中。 为了解决这一问题,InterSystems IRIS 中增强了几种最常用的连接方法,尤其是 ECP 客户端和 Web 网关,从而不再依赖 VIP 功能使它们实现镜像感知和自动化。
xDBC、直接 TCP/IP 套接字等连接方法,或其他的直接连接协议,均需要使用类 VIP 地址。 为了支持这些入站协议,InterSystems 数据库镜像技术使用称作<span class="Characteritalic" style="font-style:italic">mirror_status.cxw</span>的健康检查状态页面为 GCP 中的这些连接方法提供自动化故障转移,以与负载均衡器进行交互,实现负载均衡器的类 VIP 功能,仅将流量重定向至活动的主镜像成员,从而在 GCP 内实现完整且强大的高可用性设计。
此处提供了使用负载均衡器实现类 VIP 功能的详细信息。
示例 VPC 拓扑
下图 4.3-a 中的 VPC 布局组合了所有组件,具有以下特点:
利用一个区域内的多个地区实现高可用性
提供两个区域进行灾难恢复
利用多个子网进行网络隔离
包括分别用于互联网和 VPN 连接的单独网关
使用云负载均衡器进行镜像成员的 IP 故障转移
* * *
持久性存储概述
如简介中所述,建议使用 GCP 持久性磁盘,尤其 SSD 持久性磁盘类型。 之所以推荐 SSD 持久性磁盘,是由于其拥有更高的读写 IOPS 速率以及低的延迟,适合于事务性和分析性数据库工作负载。 在某些情况下,可使用本地 SSD,但值得注意的是,本地 SSD 的性能提升会在可用性、耐用性和灵活性方面做出一定的权衡。
可在此处找到本地 SSD 数据持久性方面的详细信息,您可了解何时保存本地 SSD 数据以及何时不保存它们。
LVM 条带化
与其他的云提供商一样,GCP 在每个虚拟机实例的 IOPS、空间容量和设备数量方面都施加了众多存储限制。 有关当前的限制,请查阅 GCP 文档,可在此处找到。
由于这些限制的存在,使用 LVM 条带化实现数据库实例的单个磁盘设备的 IOPS 最大化变得非常必要。 在提供的此示例虚拟机实例中,建议使用以下磁盘布局。 与 SSD 持久性磁盘相关的性能限制可在此处找到。
注意:目前,每个虚拟机实例最多有 16 个持久性磁盘,但 GCP 近期的方案则增至 128 个(测试),这将是令人欣慰的提高。
LVM 条带化的优势在于可以将随机的 IO 工作负载分散到更多的磁盘设备并继承磁盘队列。 以下是如何在 Linux 中将 LVM 条带化用于数据库卷组的示例。 本示例在一个 LVM PE 条带中使用 4 个磁盘,物理盘区 (PE) 大小为 4MB。 或者,如果需要,可以使用更大的 PE 容量。
步骤 1:根据需要创建标准性磁盘或 SSD 持久性磁盘
步骤 2:使用“lsblk -do NAME,SCHED”将每个磁盘设备的 IO 调度器设置为 NOOP
步骤 3:使用“lsblk -do KNAME,TYPE,SIZE,MODEL”识别磁盘设备
步骤4:使用新的磁盘设备创建磁盘卷组
vgcreate s 4M
示例: vgcreate -s 4M vg_iris_db /dev/sd[h-k]
步骤 4:创建逻辑卷
lvcreate n -L -i -I 4MB
示例:lvcreate -n lv_irisdb01 -L 1000G -i 4 -I 4M vg_iris_db
步骤 5:创建文件系统
mkfs.xfs K
示例:mkfs.xfs -K /dev/vg_iris_db/lv_irisdb01
步骤 6:装载文件系统
使用以下装载条目编辑 /etc/fstab
/dev/mapper/vg_iris_db-lv_irisdb01 /vol-iris/db xfs defaults 0 0
装载 /vol-iris/db
使用上表,每个 InterSystems IRIS 服务器将具有以下配置:2 个 SYS 磁盘、4 个 DB 磁盘、2 个主日志磁盘、2 个备用日志磁盘。
为了增长,LVM 允许在需要的情况下不中断地扩展设备和逻辑卷。 有关持续管理和扩展 LVM 卷的最佳做法,请查阅 Linux 文档。
注意:强烈建议同时为数据库和写入映像日志文件启用异步 IO。 有关在 Linux 上启用的详细信息,请参阅下列社区文章:https://community.intersystems.com/post/lvm-pe-striping-maximize-hyper-converged-storage-throughput
* * *
配置
InterSystems IRIS 新增了 InterSystems Cloud Manager (ICM)。 ICM 执行众多任务,并提供许多用于配置 InterSystems IRIS 数据平台的选项。 ICM 作为 Docker 映像提供,其拥有配置强大的、基于 GCP 云的解决方案所需的一切。
ICM 当前支持以下平台上的配置:
Google Cloud Platform (GCP)
Amazon Web Services,包括 GovCloud (AWS / GovCloud)
Microsoft Azure Resource Manager,包括 Government (ARM / MAG)
VMware vSphere (ESXi)
ICM 和 Docker 可以从台式机/笔记本电脑工作站运行,也可以具有中央专用的适度“配置”服务器和中央存储库。
ICM 在应用程序生命周期中的作用是“定义->配置->部署->管理”
有关安装和使用 ICM 及 Docker 的详细信息,可在此处找到。
注意:任何云部署都非必须使用 ICM。 完全支持传统的 tar-ball 分布式安装和部署方法。 但是,建议使用 ICM,以简化云部署中的配置和管理。
容器监视
ICM 包含基本的监视工具,其使用 Weave Scope 进行基于容器的部署。 默认情况下不会部署该工具,需要在默认的文件中使用监视器字段指定它。
有关使用 ICM 进行监视、编排和调度的详细信息,可在此处找到。
有关 Weave Scope 的概述和该文档,可在此处找到。
* * *
高可用性
InterSystems 数据库镜像可在任何云环境中提供最高级别的可用性。 有一些选项可以直接在实例级别提供虚拟机弹性。 有关 GCP 中可用的各种政策的详细信息,可在此处找到。
上文中已讨论了云负载均衡器如何通过数据库镜像为虚拟 IP(类 VIP)功能提供自动化 IP 地址故障转移。 云负载均衡器使用<span class="Characteritalic" style="font-style:italic">mirror_status.cxw</span>健康检查状态页面,上文内部负载均衡器部分提到过该页面。 数据库镜像有两种模式——自动故障转移同步镜像、异步镜像。 在本示例中,将介绍同步故障转移镜像。 有关镜像的详细信息,可在此处找到。
最基本的镜像配置是仲裁器控制配置中的一对故障转移镜像成员。 仲裁器放置在同一区域内的第三个地区中,以防止潜在的地区中断影响仲裁器和其中一个镜像成员。
在网络配置中,有多种方法专供设置镜像。 在本示例中,我们将使用本文档前述网络网关和子网定义部分中定义的网络子网。 下一部分内容将提供 IP 地址方案示例,并且基于本部分内容,将仅描述网络接口和指定的子网。
* * *
灾难恢复
InterSystems 数据库镜像将支持灾难恢复的高可用性功能扩展到另一个 GCP 地理区域,以在整个 GCP 区域万一脱机的情况下支持操作弹性。 应用程序如何耐受此类中断取决于恢复时间目标 (RTO) 和恢复点目标 (RPO)。 这些将为设计适当的灾难恢复计划进行的分析提供初始框架。 以下链接中的指南提供了您在为自己的应用程序制定灾难恢复计划时要考虑的事项。 https://cloud.google.com/solutions/designing-a-disaster-recovery-plan 和 https://cloud.google.com/solutions/disaster-recovery-cookbook
异步数据库镜像
InterSystems IRIS 数据平台的数据库镜像提供强大的功能,可在 GCP 地区和区域之间异步复制数据,以帮助支持您的灾难恢复计划的 RTO 和 RPO 目标。 有关异步镜像成员的详细信息,可在此处找到。
与上述高可用性部分中讲述的内容相似,云负载均衡器也使用上文内部负载均衡器部分中提到过的<span class="Characteritalic" style="font-style:italic">mirror_status.cxw</span>健康检查状态页面为虚拟 IP(类 VIP)功能提供自动化 IP 地址故障转移,以进行 DR 异步镜像。
在本示例中,将介绍 DR 异步故障转移镜像,并介绍 GCP 全局负载均衡服务,以便为上游系统和客户端工作站提供单个任播 IP 地址,不分您的 InterSystems IRIS 部署是否在哪个区域或地区中运行。
GCP 的其中一个发展就是负载均衡器的诞生,这是一种软件定义的全局资源,并且不受制于特定的区域。 由于其不是基于实例或设备的解决方案,因此它具有跨区域利用单个服务的独特功能。 有关通过单个任播 IP 进行 GCP 全局负载均衡的详细信息,可在此处找到。
在上述示例中,所有 3 个 InterSystems IRIS 实例的 IP 地址都提供给了 GCP 全局负载均衡器,它会将流量仅定向到承担主要镜像的镜像成员,而不论其位于哪个地区或区域。
* * *
分片集群
InterSystems IRIS 拥有一系列全面的功能来缩放您的应用程序,您可以根据自己工作负载的性质以及所面临的特定性能挑战来单独或组合应用这些功能。 分片功能是这些功能中的一种,可跨多个服务器对数据及其关联的缓存进行分区,从而为查询和数据引入提供灵活、高性价比的性能扩展,同时通过高效的资源利用最大化基础架构的价值。 InterSystems IRIS 分片群集可以为各种应用提供显著的性能优势,尤其对于工作负载包括以下一项或多项的应用更是如此:
大容量或高速数据引入,或两者的组合。
相对较大的数据集、返回大量数据的查询,或两者。
执行大量数据处理的复杂查询,例如扫描磁盘上大量数据或涉及大量计算工作的查询。
这些因素分别都会影响分片的潜在优势,但组合起来使用它们可能会增加优势。 例如,这 3 个因素的组合——快速引入大量数据、大型数据集、检索和处理大量数据的复杂查询——使得当今的许多分析性工作负载非常适合进行分片。
注意,这些特征都与数据有关;InterSystems IRIS 分片的主要功能是缩放数据量。 不过,当涉及某些或所有这些与数据相关的因素的工作负载也经历大量用户的超高查询量时,分片群集也能提供用户量缩放功能。 分片也可以与纵向缩放相结合。
操作概述
分片架构的核心是跨多个系统对数据及其关联的缓存进行分区。 分片集群跨多个 InterSystems IRIS 实例以行方式(称为数据节点)对大型数据库表进行物理上的横向分区,同时允许应用通过任何节点透明地访问这些表,但仍将整个数据集看作一个逻辑并集。 该架构具有 3 个优点:
并行处理:查询在数据节点上并行运行,然后将结果进行合并和组合后,由节点作为完整查询结果返回给连接的应用。许多情况下,这大大提高了执行速度。
分区缓存:每个数据节点都有自己的缓存,专用于它存储的分片表数据分区,再不是单个实例的缓存服务于整个数据集,这大大降低了缓存溢出的风险,并强制执行性能降低式磁盘读取。
并行加载:数据可以并行加载到数据节点,从而减少了引入工作负载和查询工作负载之间的缓存和磁盘争用,提高了两者的性能。
有关 InterSystems IRIS 分片集群的详细信息,可在此处找到。
分片元素和实例类型
分片集群包含至少一个数据节点,如果特定性能或工作负载有需要,则可添加一定数量的计算节点。 这两种节点类型提供简单的构建块,从而实现简单、透明和高效的调整模型。
数据节点
数据节点存储数据。 在物质层面,分片表[1]数据分布在集群中的所有数据节点上,非分片表数据仅物理存储在第一个数据节点上。 这种区分对用户是透明的,唯一可能的例外是,第一个节点的存储消耗可能比其他节点略高,但是由于分片表数据通常会超出非分片表数据至少一个数量级,因此这种差异可以忽略不计。
需要时,可以跨集群重新均衡分片表数据,这通常发生在添加新的数据节点后。 这将在节点之间移动数据的“存储桶”,以实现数据的近似均匀分布。
在逻辑层面,未分片的表数据和所有分片的表数据的并集在任何节点上都可见,因此客户端会看到整个数据集,这与其连接哪个节点无关。 元数据和代码也会在所有数据节点之间共享。
分片集群的基本架构图仅由在集群中看起来统一的数据节点组成。 客户端应用程序可以连接到任何节点,并且可以像在本地一样体验数据。
[1]为方便起见,术语“分片表数据”在整个文档中用于表示支持分片的任何数据模型的“盘区”数据(标记为已分片)。 术语“未分片表数据”和“未分片数据”用于表示处于可分片盘区但却未这样标记的数据,或表示尚不支持分片的数据模型。
数据节点
对于要求低延迟(可能存在不断涌入数据的冲突)的高级方案,可以添加计算节点以提供用于服务查询的透明缓存层。
计算节点缓存数据。 每个计算节点都与一个数据节点关联,为其缓存相应的分片表数据,此外,它还根据需要缓存非分片表数据,以满足查询的需要。
由于计算节点物理上并不存储任何数据,其只是支持查询执行,因此可对其硬件配置文件进行调整以满足需求,例如通过强调内存和 CPU 并将存储空间保持在最低限度。 当“裸露”应用程序代码在计算节点上运行时,引入数据会被驱动程序 (xDBC, Spark) 直接或被分片管理器代码间接转发到数据节点。
* * *
分片集群说明
分片集群部署有多种组合。 下列各图说明了最常见的部署模型。 These diagrams do not include the networking gateways and details and provide to focus only on the sharded cluster components.
基本分片集群
下图是在一个区域和一个地区中部署了 4 个数据节点的最简单分片群集。 GCP 云负载均衡器用于将客户端连接分发到任何分片集群节点。
在此基本模型中,除了 GCP 为单个虚拟机及其连接的 SSD 持久性存储提供的弹性或高可用性外,没有其他弹性或高可用性。 建议使用两个单独的网络接口适配器,一则为入站客户端连接提供网络安全隔离,二则为客户端流量和分片集群通信之间提供带宽隔离。
具有高可用性的基本分片集群
下图是在一个区域中部署了 4 个镜像数据节点的最简单分片集群,每个节点的镜像在地区之间进行了划分。 GCP 云负载均衡器用于将客户端连接分发到任何分片集群节点。
InterSystems 数据库镜像的使用带来了高可用性,其会在该区域内的第二地区中维护一个同步复制的镜像。
建议使用 3 个单独的网络接口适配器,一方面为入站客户端连接提供网络安全隔离,另一方面为客户端流量、分片集群通信、节点对之间的同步镜像流量之间提供带宽隔离。
此部署模型也引入了本文前面所述的镜像仲裁器。
具有单独计算节点的分片集群
下图采用单独的计算节点和 4 个数据节点扩展了分片集群,以此来应对大量的用户/查询并发。 云负载均衡器服务器池仅包含计算节点的地址。 更新和数据引入将像以前一样继续直接更新到数据节点,以维持超低延迟性能,并避免由于实时数据引入而在查询/分析工作负载之间造成资源的干扰和拥挤。
使用此模型,可以根据计算/查询和数据引入的规模单独微调资源分配,从而在“适时”需要的地方提供最佳资源,实现经济而简单的解决方案,而非只是进行计算或数据的调整,浪费不必要的资源。
计算节点非常适合直接使用 GCP 自动缩放分组(亦称自动缩放),允许基于负载的增加或减少自动从托管实例组添加或删除实例。 自动缩放的工作原理为:负载增加时,将更多的实例添加到实例组(扩展);对实例的需求降低时将其删除(缩减)。
有关 GCP 自动缩放的详细信息,可在此处找到。
自动缩放可帮助基于云的应用程序轻松应对流量增加的情况,并在资源需求降低时降低成本。 只需简单地定义自动缩放策略,自动缩放器就会根据测得的负载执行自动缩放。
* * *
备份操作
备份操作有多个选项。 以下 3 个选项可供您通过 InterSystems IRIS 进行 GCP 部署。
下面的前 2 个选项(下文详细说明)采用快照类型的过程,该过程会在创建快照之前将数据库写入操作挂起到磁盘上,然后在快照成功后恢复更新。
可采取以下高级别步骤通过任一快照方法来创建洁净的备份:
通过数据库外部冻结 API 调用暂停对数据库的写入。
创建操作系统和数据磁盘的快照。
通过外部解冻 API 调用恢复数据库写入。
将设施存档备份到备份位置
有关外部冻结/解冻 API 的详细信息,可在此处找到。
注意:本文档未包含备份示例脚本,但您可定期检查发布到 InterSystems 网站上开发者社区的示例。 请访问 www.community.intersystems.com
第三个选项是 InterSystems 在线备份。 这是小型部署的入门级方法,具有非常简单的用例和界面。 但是,随着数据库的增大,建议将使用快照技术的外部备份作为最佳做法,因为其具有以下优势:备份外部文件、更快的恢复时间,以及企业范围的数据和管理工具。
可以定期添加诸如完整性检查之类的其他步骤,以确保洁净且一致的备份。
决定使用哪种选项取决于您组织的运营要求和策略。 InterSystems 可与您详细讨论各种选项。
GCP 持久性磁盘快照备份
可以使用 GCP gcloud 命令行 API 以及 InterSystems 外部冻结/解冻 API 功能实现备份操作。 这允许实现真正的 24x7 全天候操作弹性,并确保洁净常规备份。 有关管理、创建和自动化 GCP 持久性磁盘快照的详细信息,可在此处找到。
逻辑卷管理器 (LVM) 快照
或者,可以在 VM 本身中部署单个备份代理,利用文件级备份,并结合逻辑卷管理器 (LVM) 快照,来使用市面上的许多第三方备份工具。
该模型的主要优点之一是能够对基于 Windows 或 Linux 的 VM 进行文件级恢复。 此解决方案需要注意的几点是,由于 GCP 和大多数其他 IaaS 云提供商都不提供磁带媒体,因此所有的备份存储库对于短期归档均基于磁盘,并能够利用 Blob 或存储桶类型的低成本存储来进行长期保留 (LTR)。 强烈建议您使用此方法来使用支持重复数据删除技术的备份产品,以最有效地利用基于磁盘的备份存储库。
这些具有云支持的备份产品的示例包括但不限于:Commvault、EMC Networker、HPE Data Protector 和 Veritas Netbackup。
注意:InterSystems 不会验证或认可一种备份产品是否优于其他产品。 选择备份管理软件的责任由客户个人决定。
在线备份
对于小型部署,内置在线备份工具也是可行的选择。 该 InterSystems 数据库在线备份实用工具通过捕获数据库中的所有块来备份数据库文件中的数据,然后将输出写入顺序文件。 这种专有的备份机制旨在使生产系统的用户不停机。 有关在线备份的详细信息,可在此处找到。
在 GCP 中,在线备份完成后,必须将备份输出文件和系统正在使用的所有其他文件复制到该虚拟机实例之外的其他存储位置。 存储桶/对象存储是对其很好的命名。
使用 GCP 存储桶有两种选择。
直接使用 gcloud 脚本 API 来复制和操作新创建的在线备份(和其他非数据库)文件。 有关详细信息可在此处找到。
尽管云存储桶属于对象存储,但将存储桶装载为文件系统,并将其用作类似持久性磁盘的功能足以。
有关装载云存储桶(使用云存储 FUSE )的详细信息,可在此处找到。
公告
jieliang liu · 五月 21, 2021
由于这是一个**预览版**,我们渴望在下个月的通用版发布之前了解您对这个新版本的经验。请通过[开发者社区](https://community.intersystems.com/)分享您的反馈,以便我们能够共同打造一个更好的产品。
**InterSystems IRIS数据平台2021.1**是一个扩展维护(EM)版本。自2020.1(上一个EM版本)以来,在持续交付(CD)版本中增加了许多重要的新功能和改进。请参考[2020.2](https://irisdocs.intersystems.com/iris20202/csp/docbook/DocBook.UI.Page.cls?KEY=GCRN)、[2020.3](https://irisdocs.intersystems.com/iris20203/csp/docbook/DocBook.UI.Page.cls?KEY=GCRN)和[2020.4](https://irisdocs.intersystems.com/iris20204/csp/docbook/DocBook.UI.Page.cls?KEY=GCRN)的发布说明,了解这些内容的概况。
这个版本的增强功能为开发人员提供了更大的自由度,可以用他们选择的语言构建快速和强大的应用程序,并使用户能够通过新的和更快的分析功能更有效地消费大量的信息。
通过InterSystems IRIS 2021.1,客户可以部署**[InterSystems IRIS Adaptive Analytics](https://www.intersystems.com/sg/resources/detail/intersystems-adaptive-analytics/)**,这是一个附加产品,它扩展了InterSystems IRIS,为分析终端用户提供了更大的易用性、灵活性、可扩展性和效率,而不管他们选择何种商业智能(BI)工具。它能够定义一个有利于分析的业务模型,并通过在后台自主构建和维护临时数据结构,透明地加速针对该模型运行的分析查询工作负载。
这个版本中的其他重点新功能包括
* 一套综合的**外部语言网关**,改进了可管理性,现在包括R和Python,可以用你选择的语言构建强大和可扩展的服务器端代码
* **InterSystems Kubernetes Operator**(IKO)为你的环境提供声明式配置和自动化,现在还支持部署InterSystems System Alerting & Monitoring(SAM)。
* **InterSystems API Manager v1.5**,包括改进的用户体验和Kafka支持
* **IntegratedML**的主流版本,使SQL开发人员能够在纯粹的SQL环境中直接构建和部署机器学习模型
**InterSystems IRIS for Health 2021.1**包括InterSystems IRIS的所有增强功能。此外,该版本通过针对FHIR数据解析和评估FHIRPath表达式的API,进一步扩展了该平台对FHIR®标准的广泛支持。这是对2020.1以来发布的重要的FHIR相关功能的补充,包括对**FHIR Profiles**、**FHIR R4 Transforms**和**FHIR客户端API**的支持。
关于所有这些功能的更多细节可以在产品文档中找到:
InterSystems IRIS 2021.1 documentation and 文档和发布说明
InterSystems IRIS for Health 2021.1 documentation and 文档和发布说明
HealthShare Health Connect 2021.1 documentation and 文档和发布说明
EM版本带有所有支持平台的经典安装包,以及OCI(Open Container Initiative)又称Docker容器格式的容器镜像。 完整的清单,请参考[支持平台文件](https://docs.intersystems.com/iris20211/csp/docbook/Doc.View.cls?KEY=ISP_technologies#ISP_platforms_server)。
安装包和预览密钥可以从WRC的[预览版本下载网站](https://wrc.intersystems.com/wrc/coDistPreview.csp)获得。
InterSystems IRIS和IRIS for Health的**企业版**的容器镜像以及所有相应的组件都可以从[InterSystems容器注册表](https://docs.intersystems.com/components/csp/docbook/Doc.View.cls?KEY=PAGE_containerregistry)使用以下命令获得。
docker pull containers.intersystems.com/intersystems/iris:2021.1.0.205.0
docker pull containers.intersystems.com/intersystems/irishealth:2021.1.0.205.0
关于可用镜像的完整列表,请参考[ICR文档](https://docs.intersystems.com/components/csp/docbook/Doc.View.cls?KEY=PAGE_containerregistry#PAGE_containerregistry_images)。
**社区版**的容器镜像也可以使用以下命令从[Docker商店](https://hub.docker.com/_/intersystems-iris-data-platform)拉取:
docker pull store/intersystems/iris-community:2021.1.0.205.0
docker pull store/intersystems/iris-community-arm64:2021.1.0.205.0
docker pull store/intersystems/irishealth-community:2021.1.0.205.0
docker pull store/intersystems/irishealth-community-arm64:2021.1.0.205.0
另外,所有容器镜像的tarball版本都可以通过WRC的[预览版本下载网站](https://wrc.intersystems.com/wrc/coDistPreview.csp)获得。
InterSystems IRIS Studio 2021.1是一个独立的IDE,用于Microsoft Windows,可以通过WRC的[预览版本下载网站](https://wrc.intersystems.com/wrc/coDistPreview.csp)下载。它与InterSystems IRIS和IRIS for Health 2021.1及以下版本一起使用。InterSystems还支持VSCode-ObjectScript插件,用于用**[Visual Studio Code为InterSystems IRIS开发应用程序](https://intersystems-community.github.io/vscode-objectscript/)**,该插件可用于Microsoft Windows、Linux和MacOS。
其他独立的InterSystems IRIS 2021.1组件,如ODBC驱动程序和Web网关,可从同一页面获得。
该预览版的构建号是2021.1.0.205.0。
文章
jieliang liu · 九月 22, 2021
本文档介绍了如何使用 InterSystems JDBC 驱动程序连接到 InterSystems IRIS®数据平台实例,这样您就可以在 InterSystems IRIS 中使用 Java。
要浏览所有的技术概要(First Look),包括可以在 InterSystems IRIS 免费的评估实例上执行的那些,请参见 InterSystems First Looks(《InterSystems 技术概要》)。
JDBC:如何在 InterSystems IRIS 中使用它
InterSystems 提供了完全兼容的(JDBC 4.2)、纯 Java、type 4 JDBC 驱动程序,它是一个独立的 JAR 文件,没有任何依赖性。如果您已经熟悉 JDBC,并且安装了 JDK 1.8,那么您需要做的就是将 JDBC 驱动程序添加到本地 CLASSPATH 中(请参见 JDBC:Exploring It [《JDBC:探索它》] )。JDBC URL(连接字符串)是:
jdbc:IRIS://ipAddress:superserverPort/namespace
其中的变量表示 InterSystems IRIS 实例主机的 IP 地址、实例的超级服务器端口和实例上的命名空间。
如果您连接到本地计算机上的一个实例(使用主机名 localhost 或 IP 地址 127.0.0.1),该连接可以使用一种特殊的、高性能的本地连接,称为共享内存连接(shared memory connection)。有关共享内存连接(shared memory connection)的更多信息,请参见 "JDBC:What's Unique about Shared Memory Connections(《JDBC: 共享内存连接的独特之处》)"。
本文档的重点是让您体验一下在 InterSystems IRIS 中使用 JDBC,而不是让您陷入细节困境 ,所以我们保持了简单的探索。但是,当您把 InterSystems IRIS 引入您的生产系统时,您需要做很多不同的事情,例如(但不限于)安全性方面。所以请确保不要把这种对 InterSystems IRIS 的探索与真实的情况相混淆! 本文档末尾提供的参考资料将使您对在生产中使用 JDBC 与 InterSystems IRIS 的情况有一个很好的了解。
JDBC:InterSystems IRIS Java 连接选项的一部分
InterSystems IRIS JDBC 驱动程序是 InterSystems IRIS 的核心 Java 组件,支持传统的关系(SQL)访问。它还为使用 InterSystems IRIS Native API for Java 的 Java 调用提供连接机制,这些调用可以访问本机存储格式中的数据。对于基于对象的 Java 集成,InterSystems IRIS 还提供一个单独的功能------InterSystems IRIS XEP 组件(InterSystems IRIS XEP component)。
综上所述,InterSystems IRIS 提供了一组独特的功能,可以使用相同的物理连接和事务环境来使用多个范例(本机[native]、关系[relational]和面向对象[object-oriented])操作数据。对于更复杂的应用程序,InterSystems 完全支持 Hibernate。支持所有这些连接形式的------InterSystems IRIS XEP、Hibernate 以及 InterSystems IRIS Spark 连接器(Connector)------是 InterSystems IRIS JDBC 驱动程序。
技术概要: JDBC 和 InterSystems 数据库 1
JDBC:探索它
JDBC: 共享内存连接(Shared Memory Connections)的独特之处
与其他数据库平台一样,到远程 InterSystems IRIS 实例的 JDBC 连接是通过 TCP/IP 进行的。为了最大限度地提高性能,InterSystems IRIS 还提供了 Java 共享内存连接(shared memory connection)。与 InterSystems IRIS 实例在同一计算机上运行的许多 Java 应用程序都可以使用共享内存连接(shared memory connection)。
共享内存连接(shared memory connection)是一个临时设备,支持虚拟内存,由 JDBC 客户端和运行在同一物理计算机上的 InterSystems IRIS 实例共享。此外,这些连接不需要对内核网络堆栈进行潜在的昂贵调用。通过使用直接从 JDBC 客户端到 InterSystems IRIS 的通道,它们最终为 JDBC 操作提供了低延迟和高吞吐量。
有关共享内存(shared memory connection)的详细信息,请参见 Using Java with the InterSystems JDBC Driver(《在 InterSystems JDBC 驱动程序中使用 Java》)中的 "Shared Memory Connections(共享内存连接)"。
JDBC:探索它
我们开发了一个演示,向您展示如何使用 JDBC 和 InterSystems IRIS------以及这是多么地简单。
请注意,这段代码并没有演示 InterSystems Java 共享内存连接(shared memory connection)的性能提升,因为它无法处理共享内存连接(shared memory connection)可以高效处理的大量数据。
想试试 InterSystems IRIS Java 开发和互操作性功能的在线视频演示吗?请查看 Java QuickStart(Java 快速入门)!
用前须知
要使用该程序,您需要在一个系统上工作,安装 JDK 1.8 版本和您选择的 Java IDE,并连接一个正在运行的 InterSystems IRIS 实例。您对 InterSystems IRIS 的选择包括多种已授权的和免费的评估实例;实例不需要由您正在工作的系统托管(尽管它们必须相互具有网络访问权限)。有关如何部署每种类型的实例的信息(如果您还没有可使用的实例),请参见 InterSystems IRIS Basics: Connecting an IDE(《InterSystems IRIS 基础:连接一个 IDE》)中的 Deploying InterSystems IRIS(部署 InterSystems IRIS)。使用同一文档中的 InterSystems IRIS Connection Information(InterSystems IRIS 连接信息)和 Java IDE 中的信息,将 IDE 连接到您的 InterSystems IRIS 实例。对于这个演示,您可以连接到 USERnamespace,如下面的代码所示,或者您可以指定在已安装的实例中创建的另一个命名空间。
您还需要将 InterSystems IRIS JDBC 驱动程序 intersystems-jdbc-3.0.0.jar 添加到您的本地 CLASSPATH。您可以从 https://github.com/intersystems/quickstarts-java/tree/master/lib 下载这个文件。如果您已经在您的本地计算机或您能访问的另一台计算机上安装了 InterSystems IRIS,您可以在 install-dirdevjavalibJDK18 中找到该文件,其中 install-dir 是 InterSystems IRIS 的安装目录。
尝试示例代码
将示例代码剪切并粘贴到您的 IDE 中,使用 InterSystems IRIS Basics: Connecting an IDE(《InterSystems IRIS 基础:连接一个 IDE 》)中的connection settings described for your instance(为您的实例描述的连接设置)更新 url 和连接(connecttion)变量以及用户名和密码。 .
import java.sql.*;
public class JDBCSample {
public static void main(String[] str) throws Exception {
String url = "jdbc:IRIS://127.0.0.1:1972/USER";
Class.forName("com.intersystems.jdbc.IRISDriver");
Connection connection = DriverManager.getConnection(url,"_SYSTEM","SYS");
// Replace _SYSTEM and SYS with a username and password on your system
String createTable = "CREATE TABLE People(ID int, FirstName varchar(255), LastName varchar(255))"; String insert1 = "INSERT INTO People VALUES (1, 'John', 'Smith')";
String insert2 = "INSERT INTO People VALUES (2, 'Jane', 'Doe')"; String query = "SELECT * FROM People";
Statement statement = connection.createStatement(); statement.executeUpdate(createTable); statement.executeUpdate(insert1); statement.executeUpdate(insert2);
ResultSet resultSet = statement.executeQuery(query); System.out.println("Printing out contents of SELECT query: "); while (resultSet.next()) {
System.out.println(resultSet.getString(1) + ", " + resultSet.getString(2) + ", " + resultSet.getString(3));
}
resultSet.close(); statement.close(); connection.close();
}
}
如果连接和查询已经成功完成,您应该会看到一个控制台窗口(console window),其中包含 SELECT 查询的结果。
4 了解有关 JDBC 的更多信息
要了解有关 JDBC、InterSystems IRIS 中的其他 Java 互操作性技术和其他相关主题的更多信息,请参见:
Using Java JDBC with InterSystems IRIS(《在 InterSystems IRIS 中使用 Java JDBC》)中的 "InterSystems Java Connectivity Options(InterSystems Java 连接选项)"------对JDBC 驱动程序支持的所有 InterSystems IRIS Java 技术的概述。
Using Java with the InterSystems JDBC Driver(《在 InterSystems JDBC 驱动程序中使用 Java》)------InterSystems 文档:step-by-step instructions for using JDBC(《使用 JDBC 的详细说明》)。
First Look: XEP Object Persistence with InterSystems IRIS(《技术概要: 使用 InterSystems IRIS 持久化 XEP 对象》)------InterSystems 文档:Java XEP First Look(《Java XEP 技术概要》)
First Look:InterSystems IRIS Native API for Java(《技术概要: InterSystems IRIS Native API for Java》)------InterSystems 文档:InterSystems IRIS Native API First Look(《InterSystems IRIS Native API 技术概要》)
Java Overview(《Java 概述》)------InterSystems 在线学习:介绍视频
Persisting Java Objects with InterSystems XEP(《使用 InterSystems XEP 持久化 Java 对象》)------InterSystems 文档:step-by-step instructions for using XEP(《使用 XEP 的详细说明》)
InterSystems Implementation Reference for Java Third Party APIs (《Java 第三方 API 的 InterSystems 实施参考》)------InterSystems 文档:connecting to InterSystems IRIS using JDBC, Hibernate, and Spark(《使用 JDBC、Hibernate 和 Spark 连接 InterSystems IRIS》)。
Using the InterSystems Spark Connector(《使用 InterSystems Spark 连接器》)------InterSystems 文档:using InterSystems IRIS as an Apache data source(《使用 InterSystems IRIS 作为 Apache 数据源》)
Hibernate and JDBC compared(《Hibernate 和 JDBC 的比较》)------栈溢出(Stack Overflow)的文章
文章
Nicky Zhu · 十一月 2, 2021
目录
技术概要:InterSystems 云管理器(Cloud Manager) 1
ICM 能为您做什么? 1
ICM 是如何工作的? 1
试一试!使用 ICM 在云中部署 InterSystems IRIS 2
安装 Docker 3
下载 ICM 映像 3
启动 ICM 3
获取云供应商帐户和证书 3
生成安全密钥 4
自定义示例配置文件 4
配置基础设施 9
部署 InterSystems IRIS 10
尝试 ICM 管理命令 11
取消配置基础设施 12
ICM 能做的远不止这些! 13
了解有关 ICM 的更多信息 13
插图目录
图 1: ICM 让一切变得简单 2
图 2: 云供应商的 ICM 默认文件示例 8
图 3: 交互式 ICM 命令 11
技术概要:InterSystems 云管理器(Cloud Manager)
本文向您介绍了 InterSystems 云管理器(InterSystems Cloud Manager,ICM),这是基于 InterSystems IRIS®数据平台的应用程序的端到端云配置和部署解决方案。
作为本指南的一部分,您将使用 ICM 在公共云中配置基础设施,并在该基础设施上部署 InterSystems IRIS。
要浏览所有的技术概要(First Looks),包括那些可以在免费的云实例或 web 实例上执行的技术概要(First Looks),请参见 InterSystems First Looks(《InterSystems 技术概要》)。
ICM 能为您做什么?
欢迎来到云时代(Cloud Age)! 您是否对它的机会虎视眈眈,但又对它的挑战保持警惕?具体来说,
您是否渴望利用云,但又犹豫是否要投入资源进行复杂的迁移?
您是否已经在云中,但还在努力寻找一种方法,以便在各种软件环境中管理部署和版本化您的应用程序?
您是否希望将持续集成和交付引入您的软件工厂,并将 DevOps 方法引入您的部署过程?也就是说,您想把自己从传统实践、库依赖、系统漂移、手动升级和其他开销的限制和风险中解放出来吗?
ICM 可以提供帮助! ICM 为您提供了一种简单、直观的方法来配置云基础设施并在其上部署服务,帮助您现在就进入云,而无需进行重大开发或重组。基础设施即代码 (infrastructure as code,IaC) 和容器化部署的优势使得在 Google、Amazon 和 Azure 等公共云平台或私有 VMware vSphere 云上部署基于 InterSystems IRIS 的应用程序变得容易。定义您想要的内容,发布一些命令,剩下的工作由 ICM 来完成。
即使您已经在使用云基础设施、容器,或者同时使用两者,ICM 也可以通过自动化大量手动步骤,极大地减少配置和部署应用程序所需的时间和精力。
ICM 是如何工作的?
在您输入的纯文本配置文件的指导下,ICM 使用 Hashicorp 流行的 Terraform IaC 工具配置您的基础设施,并根据需要配置的主机节点。在下一阶段,ICM 将 InterSystems IRIS 和您的应用程序部署在 Docker 容器中,如果需要,还可以部署其他服务。您想要的部署所需的所有 InterSystems IRIS 配置都是自动执行的。ICM 还可以在现有的虚拟和物理集群上部署容器化服务。
ICM 本身带有一个容器映像,其中包含您所需要的一切。从 InterSystems 的 ICM 映像下载并运行容器,打开命令行,您就可以开始了。ICM 通过组合这些元素,使一切变得简单:
可以用作模板以快速定义所需部署的示例配置文件。
可以向其中添加应用程序的 InterSystems IRIS 映像。
试一试! 使用 ICM 在云中部署 InterSystems IRIS
每个任务的用户友好命令。
管理已配置节点和部署在其上的服务并与之交互的多种方法。
图 1: ICM 让一切变得简单
试一试!使用 ICM 在云中部署 InterSystems IRIS
ICM 为您执行许多任务,并为您提供许多选项,以帮助您准确地部署您所需要的内容,所以在生产中使用它需要一定的计划和准备(尽管比手动方法要少得多!)。但配置和部署过程很简单,ICM 可以为您做出许多决定。这一探索旨在让您亲眼看到 ICM 是如何工作的,以及使用 ICM 在亚马逊网络服务(Amazon Web Services,AWS)上部署 InterSystems IRIS 配置是多么容易。虽然这不是一时的工作,但这种探索不应该占用您太多的时间,您可以在机会出现时分阶段进行。
为了让您体验 ICM 而又不至于在细节上陷入困境,我们保持了简单的探索;例如,我们让您尽可能多地使用默认设置。但是,当您把 ICM 引入您的生产系统时,您需要做很多不同的事情,特别是(但不限于)安全方面。所以请确保不要把这种对 ICM 的探索与真实的情况相混淆! 本文档末尾提供的参考资料将使您对在生产中使用 ICM 的情况有一个很好的了解。ICM Guide(《ICM 指南》)提供了使用 ICM 的完整信息和程序,并在适当的地方提供了链接。
这些说明假定您具备以下条件:
特定于容器的 InterSystems IRIS 分片(sharding)许可证并可以访问 InterSystems 软件下载。
亚马逊网络服务(Amazon Web Services,AWS)、谷歌云平台(Google Cloud Platform,GCP)、微软云(Azure)或腾讯云(Tencent)上的帐户。
在配置文件中指定的许多属性在这些云平台上是通用的,但其他属性是特定于平台的。有关这些差异的详细信息可在 ICM Guide(《ICM 指南》)的"ICM Reference(《ICM 参考资料》)"一章中的"Provider-Specific Parameters(特定于供应商的参数)"部分找到。
试一试! 使用 ICM 在云中部署 InterSystems IRIS
安装 Docker
ICM 是作为容器映像提供的,它包含您需要的所有内容。因此,对启动 ICM 的 Linux、macOS 或 Microsoft Windows 系统的唯一要求是安装 Docker,并运行 Docker 守护进程,以及系统连接到 Internet。有关在您的平台上安装 Docker 的信息,请参见 Docker 文档中的 Install Docker(《安装 Docker》)。
重要提示: Docker 企业版(Enterprise Edition)和社区版(Community Edition)18.09 及更高版本支持 ICM;企业版(Enterprise Edition)仅支持生产环境。
下载 ICM 映像(Image)
要使用 ICM,您需要将 ICM 映像下载到您正在工作的系统中;这要求您识别将从其中下载它的注册表和访问所需的凭证。同样,对于 ICM 部署 InterSystems IRIS 和其他 InterSystems 组件,它需要相关映像的此信息。ICM 下载映像的注册表必须能被您使用的云供应商访问(也就是说,不能在防火墙后面),而且为了安全起见,必须要求 ICM 使用您提供给它的凭证进行身份验证。有关识别所涉及的注册表和下载 ICM 映像的详细信息,请参见 InterSystems Cloud Manager Guide(《InterSystems 云管理器指南》)中的 Downloading the ICM Image(下载 ICM 映像)。
注意: 启动 ICM 的映像的主要版本和部署的 InterSystems 映像必须匹配。例如,您不能使用 2019.3 版本的 ICM 部署 2019.4 版本的 InterSystems IRIS。
有关在容器中使用 InterSystems IRIS 的简要介绍,包括实际操作经验, 请参见 First Look: InterSystems Products in Containers(《技术概要:容器中的 InterSystems 产品》);有关使用 ICM 以外的方法在容器中部署 InterSystems IRIS 和基于 InterSystems IRIS 的应用程序的详细信息,请参见 Running InterSystems IRIS in Containers(《在容器中运行 InterSystems IRIS》)。
启动 ICM
要在命令行上启动 ICM,使用下面的 docker run 命令,从注册表中拉出(下载)ICM 映像,从中创建一个容器,并启动该容器,例如:
docker run --name icm -it --cap-add SYS_TIME containers.intersystems.com/intersystems/icm:2021.1.0.205.0
ICM 容器中的 /Samples 目录,每个供应商都有一个(/AWS,/GCP,等等),旨在使您能够轻松地使用开箱即用的 ICM 进行配置和部署;您可以使用这些目录之一中的示例配置文件 ,也可以从该目录进行配置和部署。然而,由于这些目录在 ICM 容器内,当容器被删除时,其中的数据就会丢失,包括您的配置文件和 ICM 创建并用于管理配置的基础设施的状态目录。在生产中,最好的做法是在启动 ICM 时通过挂载外部卷使用容器外的位置来存储这些数据(请参见 Docker 文档中的 Manage data in Docker(在 Docker 中管理数据))。
获取云供应商帐户和证书
ICM 可以在四个公共云平台上进行配置和部署:亚马逊网络服务(Amazon Web Services,AWS)、谷歌云平台(Google Cloud Platform,GCP)、微软云(Azure)和腾讯云(Tencent)。
登录您的 AWS、GCP、Azure 或 Tencent 帐户。如果您和您的雇主都还没有帐户,您可以进入AWS、GCP、Azure或Tencent 门户页面,快速创建一个免费帐户。
有关获取 ICM 需要向每个云供应商进行身份验证的帐户凭证的信息,请参见 ICM Guide(《ICM 指南》)的 "ICM Reference(《ICM 参考资料》) "一章中的 Security- Related Parameters(安全相关的参数)。
试一试! 使用 ICM 在云中部署 InterSystems IRIS
生成安全密钥
ICM 与配置基础设施的云供应商、配置的节点上的 Docker 以及容器部署后的若干 InterSystems IRIS 服务进行安全的通信。您已经下载或识别了您的云证书;您还需要其他文件来启用安全的 SSH 和 TLS 通信。
您可以使用 ICM 提供的两个脚本来创建您需要的文件,keygenSSH.sh 脚本创建所需的 SSH 文件并将它们放在 ICM 容器的 /Samples/ssh 目录中。keygenTLS.sh 脚本创建所需的 TLS 文件,并将它们放在 /Samples/tls 中。
要在 ICM 命令行上运行这些脚本,请输入以下内容:
# keygenSSH.sh
Generating keys for SSH authentication.
...
# keygenTLS.sh
Generating keys for TLS authentication.
...
有关这些脚本生成的文件的更多信息,请参见 ICM Guide(《ICM指南》)中的 Obtain Security-Related Files(获取安全相关的文件)、ICM Security(ICM 安全)和 Security-Related Parameters(安全相关的参数)。
重要提示: 这些生成的密钥是为了方便您在本文体验和其他测试中使用;在生产中,您应该根据您公司的安全策略来生成或获取所需的密钥。这些脚本生成的密钥以及您的云供应商凭证必须完全安全,因为它们提供了对使用它们的任何 ICM 部署的完全访问权限。
自定义示例配置文件
要定义您希望 ICM 部署的配置,您在两个 JSON 格式的配置文件中包含所需的设置:默认文件和定义文件。前者(defaults.json)包含应用于整个部署的设置 --- 例如,您对云供应商的选择 ------而后者(definitions.json)定义了您想要的节点类型以及每种节点的数量,从而决定了您是部署一个分片集群、一个独立的 IRIS 实例,还是其他配置。
ICM 容器中的 /Samples 目录为所有四个云供应商提供示例配置文件。例如,AWS 的示例配置文件位于 /Samples/AWS 目录中。要自定义这些文件,请选择您要使用的供应商,然后按照下面的表格描述,为该供应商修改示例默认值和定义文件。要做到这一点,您可以使用 vi 等编辑器直接在容器内编辑它们,或者在本地命令行上使用 docker cp 命令将它们从容器复制到本地文件系统,然后在您编辑它们后再次返回,例如:
docker cp icm:/Samples/AWS/defaults.json . docker cp icm:/Samples/AWS/definitions.json .
...
docker cp defaults.json icm:/Samples/AWS docker cp definitions.json icm:/Samples/AWS
重要提示: 字段名和值都是区分大小写的;例如,要选择 AWS 作为云供应商,您必须在默认文件中包含 "Provider":"AWS" ,而不是 "provider": "AWS"、"Provider": "aws"等等。
自定义 defaults.json
下表详细说明了 /Samples 文件中提供的默认文件所需的最小自定义,以及对可选更改的建议。这里没有涉及到的任何设置都可以在示例文件中保持原样。
试一试! 使用 ICM 在云中部署 InterSystems IRIS
每个设置都连接到 ICM Guide(《ICM 指南》)的 "ICM Reference(《ICM 参考资料》)"一章中的 ICM Configuration Parameters(ICM 配置参数)部分中的相关表格,在那里您可以找到更详细的说明;在那里,搜索您想要的参数。最右边的列显示了在示例默认文件中出现的每个参数或参数集。
要查看所有供应商通用的所有设置,请参见该部分的 General Parameters(常规参数) ;要查看特定于特定供应商的所有设置,请参见 Provider-Specific Parameters(特定于供应商的参数)。
下图显示了 AWS、GCP、Azure 和 Tencent 的示例 defaults.json 文件的内容:
设置
说明
示例 defaults.json 文件中的条目
Provider
识别云基础设施供应商;保留示例 defaults.json 中的值。
“Provider”:[”AWS”|"GCP"|"Azure"|"Tencent"],
Label
配置节点的命名方案中的字段, Label-Role-Tag-NNNN (请参见下面的 Role);更新以识别部署的所有者和目的, 例如,使用您的公司名称和“TEST”来创建节点名称,如 Acme-DATA-TEST-0001。
"Label": "Sample",
Tag
(请参见上面的 Label )
"Tag": "TEST",
DataVolumeSize
为每个节点配置的持久化数据卷的大小,这可以在 definitions.json 文件中的各个节点定义中被覆盖;接受示例 defaults.json 中的值,除非您在 Tencent 上配置,在这种情况下,将其改为 60。
"DataVolumeSize": "10",
SSHUser
在配置节点上具有 sudo 访问权限的非根帐户,用于 ICM 访问; 您可以保留示例 defaults.json 中的默认值, 但如果您在 AWS 或 Tencent 上更改了机器映像(如下),则可能需要更新此条目。
"SSHUser": "ubuntu",(AWS & Tencent) "SSHUser": "sample",(GCP & Azure)
SSHPublicKey
SSH 公钥的位置。如果您使用了 Generate Security Keys(生成安全密钥)中讨论的密钥生成脚本, 则密钥位于示例文件指定的目录中,因此无需更改;如果您提供了自己的密钥, 请使用 docker cp 将它们从本地文件系统复制到这些位置。
"SSHPublicKey": "/Samples/ssh/insecure-ssh2.pub",
SSHPrivateKey
SSH 私钥的位置;请参见上面的 SSHPublicKey。
"SSHPrivateKey": "/Samples/ssh/insecure",
TLSKeyDir
TILS 文件的位置;请参见上面的 SSHPublicKey 。
"TLSKeyDir": "/Samples/tls/",
设置
说明
示例 defaults.json 文件中的条目
DockerVersion
要安装在已配置节点上的 Docker 版本;保持默认值。
"DockerVersion": "5:19.03.8~3-0~ubuntu-bionic",
DockerImage
要部署在已配置节点上的映像;更新以反映您在 Identify Docker Repository and Credentials(识别 Docker 存储库和凭证)中识别的存储库和映像信息。
"DockerImage": "containers.intersystems.con/intersystems/iris:2021.1.0.205.0",
DockerUser- name Docker- Password
如果在私有存储库中,则下载 DockerImage 指定的映像所需的凭证;请更新以反映您在 Identify Docker Repository and Credentials(识别 Docker 存储库和凭证)中识别的存储库信息和凭证。
"DockerUsername": "xxxxxxxxxxxx", "DockerPassword": "xxxxxxxxxxxx",
LicenseDir
InterSystems IRIS 许可证的暂存目录;将您的特定于容器的 InterSystems IRIS 分片(sharding)许可证放在这个目录中。
“LicenseDir”: “/Samples/Licenses”,
Region, Location (Azure)
供应商用于配置基础设施的计算资源的地理区域;接受示例 defaults.json 中的默认值,或者从供应商那里选择 region 和 zone 的另一个组合(如下)。
"Region": "us-west-1",(AWS) "Region": "us-east1",(GCP) "Location": "Central US",(Azure) "Region": "na-siliconvalley", (Tencent)
Zone
所选区域内的可用区(如上);接受示例 defaults.json 中的默认值,或者从供应商那里选择 region 和 zone 的另一个组合。
"Zone": "us-west-1c",(AWS) "Zone": "us-east1-b",(GCP) "Zone": "1",(Azure) "Zone": "na-siliconvalley-1", (Tencent)
Machine image (特定于供应商)
配置节点的平台和 OS 模板;接受示例 defaults.json 中的默认值,或者从供应商那里选择 machine image 和 instance type 的不同组合(如下)。
"AMI": "ami-c509eda6",(AWS) "Image": "ubuntu-os-cloud/ubuntu-1804-bionic-v20180617", (GCP) "PublisherName": "Canonical",(Azure) "Offer": "UbuntuServer",(Azure) "Sku": "18.04-LTS",(Azure) "Version": "18.04.201804262",(Azure) "ImageID": "img-pi0ii46r",(Tencent)
设置
说明
示例 defaults.json 文件中的条目
Instance type (特定于供应商)
配置节点的计算资源模板;接受示例 defaults.json 中的值,或者从供应商那里选择 machine image 和 instance type 的不同组合(如上)。
"InstanceType": "m4.large",(AWS) "MachineType": "n1-standard-1",(GCP) "Size": "Standard_DS2_v2",(Azure) "InstanceType": "S2.MEDIUM4",(Tencent)
Credentials and account settings (特定于供应商)
ICM 向供应商进行身份验证所需的文件或 ID,因供应商而异;更新以指定您的帐户所需的文件位置或 ID(有关说明,请点击供应商链接)。
“Credentials”:”/Samples/AWS/credentials”, (AWS) "Credentials": "/Samples/GCP/sample.credentials",(GCP) "Project": "dp-icmdevelopment",(GCP) "SubscriptionId": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",(Azure) "ClientId": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",(Azure) "ClientSecret": "xxxxxxxxxxxx/xxxxxxxxxxxxxxx/xxxxxxxxxxxxxx=", (Azure) "TenantId": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",(Azure) "SecretID": "xxxxxxxxxxxx",(Tencent) "SecretKey": "xxxxxxxxxxxx",(Tencent)
ISCPassword
已部署的 InterSystems IRIS 映像中预定义帐户的密码;要在部署阶段以交互方式提供带有屏蔽输入的密码(为安全起见建议这样做),请删除此字段,否则更改为您的首选密码。
"ISCPassword": "",
Mirror
确定部署在 DATA、DM 和 DS 节点上的 InterSystems IRIS 实例是否被配置为镜像;保留默认值。
“Mirror”: “false”
设置
说明
示例 defaults.json 文件中的条目
UserCPF
指定用于覆盖已部署实例的初始 CPF 设置的配置合并文件。(如果您不熟悉配置合并功能或 CPF,请删除此条目;有关配置合并的信息,请参见 ICM Guide(《ICM**指南》)的 "ICM Reference(《ICM 参考资料》)"一章中的 Deploying with Customized InterSystems IRIS Configurations(使用自定义的 InterSystems IRIS 配置进行部署)。)
"UserCPF": "/Samples/cpf/iris.cpf"
下图显示了 AWS、GCP、Azure 和 Tencent 的示例 defaults.json 文件的内容:
图 2: 云供应商的 ICM 默认文件示例
自定义 definitions.json
在 /Samples 目录中的示例 definitions.json 文件(对所有供应商来说都是一样的),定义了一个有两个数据节点和两个计算节点的分片集群,如下所示:
试一试! 使用 ICM 在云中部署 InterSystems IRIS
[
{
"Role": "DATA",
"Count": "2",
"LicenseKey": "ubuntu-sharding-iris.key"
},
{
"Role": "COMPUTE",
"Count": "2",
"StartCount": "3",
"LicenseKey": "ubuntu-sharding-iris.key"
}
]
Role 字段标识正在配置的节点类型,在这种情况下是 DATA 和 COMPUTE。Count 字段表示要配置多少个该类型的节点;对于 COMPUTE 节点,StartCount 从 0003 开始编号。LicenseKey 字段表示 InterSystems IRIS 许可证文件的名称,该文件位于默认文件中由 LicenseDir 字段指定的目录中。
在这个练习中,删除 COMPUTE 定义,只保留 DATA 定义,如下所示:
[
{
"Role": "DATA",
"Count": "2",
"LicenseKey": "ubuntu-sharding-iris.key"
}
]
部署分片集群时,所有节点必须有分片(sharding)许可证。使用 docker cp 将分片(sharding)许可证复制到 LicenseDir 指定的容器内的位置,如 /Samples/Licenses,并更新 DATA 节点定义中的 LicenseKey 设置,以指定要使用的许可证密钥。
这些是配置基本分片集群所需的唯一 definitions.json 更改。要配置一个独立的 InterSystems IRIS 实例,请使用此定义:
[
{
"Role": "DM",
"Count": "1",
"LicenseKey": "standard-iris.key""
},
]
配置基础设施
默认情况下,ICM 从当前目录中的配置文件中获取输入,因此您需要做的就是将配置基础设施更改为您选择的供应商的 /Samples 目录,例如 /Samples/AWS,并发出这个命令:
icm provision
icm provision 命令在您选择的平台上分配和配置主机节点。在配置操作期间,ICM 在状态子目录中创建或更新状态和日志文件,完成后创建 instances.json 文件,作为后续部署和管理命令的输入。
因为 ICM 同时运行多个任务,所以这些步骤(Terraform 计划和应用、复制文件、挂载卷等等)可能不会以相同的顺序在节点上启动和完成。完成后,ICM 提供了一个已经配置好的主机节点的摘要,并输出一个命令行,可以在以后用来删除基础设施,如下所示:
Machine IP Address DNS Name Region Zone
Acme-DATA-TEST-0001 00.53.183.209 ec2-00-53-183-209.us-west-1.compute.amazonaws.com us-west-1 c Acme-DATA-TEST-0002 00.53.183.185 ec2-00-53-183-185.us-west-1.compute.amazonaws.com us-west-1 c To destroy: icm unprovision [-cleanUp] [-force]
试一试! 使用 ICM 在云中部署 InterSystems IRIS
重要提示: 复制输出中提供的 icm unprovision 命令行,并保存此信息,这样您就可以在取消配置时轻松地复制它。这个输出也出现在 icm.log 文件中。
管理和取消配置您的基础设施所需的文件和目录都在 ICM 容器中,因此当您删除它时就会丢失。因此,在完成基础设施并成功地取消配置之前,您不能删除 ICM 容器。(在生产中,最好的做法是在启动 ICM 时通过挂载外部卷使用容器外的位置来存储这些数据(请参见 Docker 文档中的 Manage data in Docker(在 Docker 中管理数据))。
在配置和部署阶段发生的错误的详细信息写入状态目录子目录中的 terraform.err 文件;当发生错误时,ICM 会将您指向适当的文件,该文件可以帮助您识别问题的原因。
如果 icm provision 由于超时和供应商方面的内部错误,或者配置文件中的错误而没有成功完成,您可以根据需要再次发出该命令,直到 ICM 为所有指定的节点完成所有需要的任务而没有错误。更多信息,请参见 ICM Guide(《ICM 指南》)的 "Using ICM(《使用 ICM》) "一章中的 "Reprovisioning the Infrastructure(重新配置基础设施)"。
有关 icm provision 的更多信息,请参见 ICM Guide(《ICM 指南》)中的 The icm provision Command (icm 配置命令)。
部署 InterSystems IRIS
除了在提供的主机节点上下载映像(Image)并将它们作为容器运行外,ICM 还执行特定于 InterSystems IRIS 的配置和其他任务。要在您已配置的节点上部署 InterSystems IRIS,请留在 /Samples 目录,您在其中自定义了配置文件并配置了基础设施,然后发出以下命令:
icm run
默认情况下,icm run 下载并运行配置文件中 DockerImage 字段指定的映像,在这种情况下,是来自 InterSystems 存储库的 InterSystems IRIS 映像;每个容器都被命名为 iris。在实践中,在定义文件中的节点定义中使用不同的 DockerImage 字段(而不是对默认文件中的所有节点使用一次,如此处),可以让您在不同的节点类型上运行不同的映像,除此之外,您还可以使用某些选项多次执行 icm run 命令,以便在每个配置的节点上或只在指定节点上部署具有唯一名称的多个容器。
InterSystems IRIS 在每个节点上启动后,ICM 会执行实例所需的任何配置 --- 例如,重置密码、配置分片(sharding)等。因为 ICM 同时运行多个任务,因此部署过程中的步骤可能不会以相同的顺序在节点上启动和完成。
完成后,ICM 输出一个链接到相应的 InterSystems IRIS 实例的管理门户(Management Portal):
$ icm run -definitions definitions_cluster.json
Executing command 'docker login' on ACME-DATA-TEST-0001...
...output in /Samples/AWS/state/ACME-DATA-TEST/ACME-DATA-TEST-0001/docker.out
...
Pulling image intersystems/iris:2021.1.0.205.0 on ACME-DATA-TEST-0001...
...pulled ACME-DATA-TEST-0001 image intersystems/iris:2021.1.0.205.0
...
Creating container iris on ACME-DATA-TEST-0002...
...
Management Portal available at:
http://ec2-00-53-183-209.us-west-1.compute.amazonaws.com:52773/csp/sys/UtilHome.csp
在这种情况下,所提供的链接用于数据节点 1,或者用于独立的实例(如果这是您选择的配置)。在浏览器中打开链接,并使用管理门户(Management Portal)探索 InterSystems IRIS。
与 icm provision 一样,如果 icm run 由于超时和供应商方面的内部错误而没有成功完成,您可以再次发出命令;在大多数情况下,反复尝试,部署就会成功。但是,如果错误仍然存在,并且需要手动干预 --- 例如,如果它是由某个配置文件中的错误引起的 --- 在修复问题后,您可能需要删除受影响的一个或多个节点上的持久化 %SYS 数据,
试一试! 使用 ICM 在云中部署 InterSystems IRIS
在重新发布 icm run 命令之前,如 ICM Guide(《ICM 指南》)的 "Using ICM(《使用 ICM》)"一章中的 Redeploying Services(重新部署服务)所述。在出现错误的情况下,请参见 ICM 指向您访问的日志文件,以获得有助于您确定问题原因的信息。
有关 icm run 命令及其选项的更多信息,请参见 ICM Guide(《ICM 指南》)中的 The icm run Command(icm run 命令)。
尝试 ICM 管理命令
ICM 提供了一系列的命令用于
管理配置的基础设施。
管理部署的容器。
与运行在部署的容器中的服务交互,包括 InterSystems IRIS。
这些命令在 ICM Guide(《ICM 指南》)的 Infrastructure Management Commands(基础设施管理命令)、Container Management Commands(容器管理命令)和 Service Management Commands(服务管理命令)小节中有详细的讨论,并在 ICM Commands and Options(ICM 命令和选项)中全面列出。这里提供了一些示例,供您在部署时试用。特别要注意的是,有三个命令(icm ssh、icm exec 和 icm session)可以让您在多个层次上与您部署的节点交互 --- 与节点本身、与部署在它上面的容器以及与容器内运行的 InterSystems IRIS 实例,如下所示:
图 3: 交互式 ICM 命令
在您新部署的 InterSystems IRIS 配置上试试这些命令吧!
列出配置的主机节点:
试一试! 使用 ICM 在云中部署 InterSystems IRIS
icm inventory
在每个主机节点上运行 shell 命令:
icm ssh -command "df -k"
当一个命令在多个节点上执行时,输出被写入文件,并提供一个输出文件的列表。例如,在这种情况下,如果您部署了分片集群,三个节点各有一个输出文件。
在特定的主机节点上打开交互式 shell:
icm ssh -role DATA -interactive
要做到交互,命令必须使用 -interactive 选项并指定单个节点。例如,虽然 icm ssh 可以在多个节点上执行命令,如前面的示例所示,但它只能使用 -interactive 选项在一个节点上打开交互式 shell,如本例所示。代替 -role DM 选项将命令限制在该类型的节点上(在您的部署中只有一个节点),您也可以使用-machine 选项来指定一个特定节点的名称,例如:
icm ssh -machine Acme-DATA-TEST-0001 -interactive
显示部署的 InterSystems IRIS 容器的状态:
icm ps
当在节点上部署了多个容器时,这个命令会将它们全部列出。
将本地文件复制到 InterSystems IRIS 容器或其中一个容器:
icm cp -localPath /Samples/ssh/ssh_notes -remotePath /home/sshuser
icm cp -localPath /Samples/ssh/ssh_notes -remotePath /home/sshuser -role DM
在每个 InterSystems IRIS 容器中运行 shell 命令:
icm exec -command "ls /irissys/"
在特定的 InterSystems IRIS 容器中打开一个交互式 shell(或运行任何 shell 命令):
icm exec -command "bash" -role DATA -interactive
为 InterSystems IRIS 实例打开一个终端(Terminal)窗口(对于单个实例,总是交互式的):
icm session -machine Acme-DATA-TEST-0001
针对 InterSystems IRIS 的每个实例,或针对特定的实例,运行 SQL 命令:
icm sql -command "SELECT Name FROM Security.Users"
icm sql -command "SELECT Name FROM Security.Users" -machine Acme-DATA-TEST-0002
取消配置基础设施
因为 AWS 和其他公共云平台实例会不断产生费用,所以在完成这一体验后,立即取消配置基础设施是很重要的。
要做到这一点,把您从 icm provision 的输出中保存的 icm unprovision 命令复制到 ICM 命令行,例如:
$ icm unprovision -cleanUp
ICM 能做的远不止这些!
如果您没有从配置输出中保存命令,您可以在工作目录的 icm.log 文件中找到它(例如,/Samples/AWS/icm.log)。-cleanUp 选项在取消配置后会删除状态目录;如果没有这个选项,状态目录会被保留下来。
ICM 能做的远不止这些!
尽管您刚刚完成的 ICM 探索是刻意简化的,但它仍包含了现实世界的基础设施配置和服务部署。添加到您刚刚完成的只是在配置文件中扩展您的部署定义并利用大量命令行选项的问题。例如,您可以
通过定义 AM 节点和 DM 节点,部署应用服务器和数据服务器的分布式缓存集群,或通过仅定义 DM 节点部署独立的 InterSystems IRIS 实例。
部署镜像(mirror) DATA 节点或镜像 DM 节点,只需在默认文件中包含"Mirror":"True",并在定义文件中定义偶数个 DATA 节点或两个 DM 节点和一个 AR(仲裁器)节点。
部署一个包含 COMPUTE 节点的分片集群,以分离查询和数据摄取工作量,同时保持并行处理和分布式缓存的优势,提高两者的性能。
在定义文件中添加 web 服务器(WS)和负载均衡器(LB 或自动)。
通过在定义文件中为不同的节点指定不同的 DockerImage 值,并多次执行 icm run 命令,在不同的节点上部署不同的服务。
通过多次执行 icm run ,同时在命令行中使用 -container 和 -image 选项指定不同的容器名称和映像(包括自定义和第三方映像),在一些或所有节点上部署多个服务。
通过使用第三方工具和内部脚本扩展 ICM 的功能,进一步提高自动化程度,减少工作量。
在已有的虚拟和物理集群上部署服务。
在不部署服务的情况下配置基础设施,只需使用 ICM provision 命令停止。
所有这些可能性以及更多的可能性都在 ICM Guide(《ICM 指南》)中有所涉及。
了解有关 ICM 的更多信息
要了解有关 ICM 和在容器中使用 InterSystems IRIS 的更多信息,请参见
InterSystems Cloud Manager Introduction(《InterSystems 云管理器简介》) (视频)
The Benefits of InterSystems Cloud Manager(《InterSystems 云管理器的优势》) (视频)
Experience InterSystems IRIS in the Cloud(在云中体验 InterSystems IRIS) (在线体验)
InterSystems Cloud Manager Guide(《InterSystems 云管理器指南》)
First Look:InterSystems Products in Containers(《技术概要:容器中的 InterSystems 产品》)
Running InterSystems Products in Containers(《在容器中运行 InterSystems 产品》)
文章
Nicky Zhu · 九月 9, 2021
本文档将您介绍InterSystems IRIS®数据平台的分片(sharding)功能,以及它在分片集群中的使用,以水平扩展 InterSystems IRIS 的数据量。
作为本指南的一部分,您将使用 ICM 在公共云中提供的分片集群,并了解分片表(sharding a table)如何在集群中的分片之间分布其行。
分片(Sharding)如何帮助您?
您感受到大数据(Big Data)的热度了吗?
无论是否准备好了,我们都在管理比以往任何时候都多的数据,并被要求用这些数据做更多的事情——所需的响应时间也越来越短。无论您是照顾一千万名患者、每天处理数十亿的金融订单,追踪一个星系的恒星,还是监控一千个工厂的引擎,数据平台不仅要支持您目前的数据工作量,而且还必须在保持性能的同时进行扩展(Scale),以满足不断增长的需求,避免业务中断。每个特定业务的工作量对其运行的数据平台提出了不同的挑战 — 而随着工作量的增加,这些挑战将变得更加严峻。
InterSystems IRIS 包含一套全面的功能来扩展(Scale)您的应用程序,这些功能可以单独或组合应用,这取决于您的工作量的性质和它所面临的特定性能挑战。其中之一是分片(sharding),它在多个服务器上对数据及其相关缓存进行分区,为查询和数据摄取提供灵活、价优的性能扩展,同时通过高效的资源利用使基础设施价值最大化。InterSystems IRIS 分片集群(sharded cluster) 可以为各种应用程序提供显著的性能优势,特别是对于那些工作量包括以下一项或多项的应用程序:
高容量或高速数据摄入,或组合。
相对较大的数据集,返回大量数据的查询,或两者兼有。
执行大量数据处理的复杂查询,例如扫描磁盘上的大量数据或涉及大量计算工作的查询。
这些因素各自都会影响分片(sharding)的潜在收益,但如果将它们结合起来,收益可能会得到增强。例如,所有这三个因素的组合——快速摄入的大量数据、大型数据集以及检索和处理大量数据的复杂查询——使得如今的许多分析工作量非常适合进行分片(sharding)。
请注意,这些特征都与数据有关;InterSystems IRIS 分片(sharding)的主要功能是扩展数据量(sharded cluster)。但是,当涉及部分或所有这些数据相关因素的工作量也经历了来自大量用户的非常高的查询量时,分片集群也可以包括扩展用户量(scale for user volume)功能。分片(sharding)也可以与垂直扩展相结合。通过 InterSystems IRIS,您可以为工作量的性能挑战创建恰到好处的整体扩展解决方案。
分片(Sharding)是如何工作的?
分片架构的核心是跨多个系统对数据及其相关缓存进行分区。分片集群将大型数据库表水平(即按行)划分为多个 InterSystems IRIS 实例,称为数据节点(data node),同时允许应用程序通过这些实例中的任何一个访问这些表。每个数据节点在集群分片数据中的份额被称为分片(shard)。这种架构有三个优势:
并行处理(Parallel processing)
查询在数据节点上并行运行,合并查询结果,并作为完整的查询结果返回给应用程序,在许多情况下显著提高了执行速度。
分区缓存(Partitioned caching)
每个数据节点都有自己的专用缓存,而不是由单个实例的缓存为整个数据集服务,这大大降低了缓存溢出和强制降低性能的磁盘读取的风险。
并行加载(Parallel loading)
数据可以并行加载到数据节点上,从而减少摄取工作量和查询工作量之间的缓存和磁盘争夺,提高两者的性能。
一个被称为分片管理器(sharding manager)的联合软件组件会跟踪哪些数据位于哪些数据节点上,并相应地指导查询。非分片数据存储在配置的第一个数据节点上,称为数据节点 1 (它也存储代码和元数据)。从应用程序 SQL 的角度来看,分片表(sharded table)和非分片表(nonsharded table)之间的区别是完全透明的。
图 1: 一个基本的分片集群
试一试!部署和演示 InterSystems IRIS 分片集群
在这次探索中,您将
使用 InterSystems 云管理器(InterSystems Cloud Manager,ICM)在公共云中部署基本的分片集群。
ICM 是一个自动化的命令行工具,可以轻松地在云中配置基础设施,并在提供的节点上部署 InterSystems IRIS 和其他服务。ICM 负责所有需要的 InterSystems IRIS 配置,所以如果您指定了一个分片集群,该集群在部署完成后就可以使用了。
使用不同的分片键(shard key)从相同的数据中创建三个分片表(sharded table),并观察数据节点上跨分片的行的不同分布。
分片键是用来确定分片表的哪些行存储在哪些分片上的一个或多个字段。默认情况下,RowID 被用作分片键,这种分布对于大多数分片表来说是最有效的方法,因为它提供了数据均匀分布的最佳保证,并允许最有效的并行数据加载。然而,在一种情况下,用户定义的键可能是有益的。当您对在字段或用于连接它们的字段上的查询中经常连接的两个大表进行分片时,要连接的行被存储在相同的分片上,并且连接可以在每个分片上本地执行,而不是跨分片执行(across the shard),从而提供显著的性能提升。这被称为 cosharded 连接(cosharded join)。
在所有三个分片表上运行相同的查询,以证明跨分片的行分布对查询是完全透明。
为了向您介绍分片(sharding),而又不至于让您在细节上陷入困境,我们保持了简单的探索。生产中的分片集群需要计划和许多决策,所以确保不要把对分片(sharding)的探索和真实情况相混淆!例如,在设计一个生产集群时,您将检查您的架构和表,以决定哪些表将被分片,然后根据分片数据的预期工作集和服务器上数据库缓存的可用内存量,决定部署多少个数据节点(通常为 4 到 16 个)。然而,在本次探索中,您将部署一个由两个数据节点组成的基本集群。本文档末尾列出的参考资料将使您对生产中使用分片(sharding )的情况有一个很好的了解。Scalability Guide(《可扩展性指南》)中的 "Horizontally Scaling for Data Volume Sharding(《水平扩展数据卷分片[Sharding]》)"一章提供了有关分片(sharding)和分片集群的详细信息。
这些说明假定您有 InterSystems IRIS 分片(sharding)许可证并可以访问 InterSystems 软件下载。
使用 ICM 部署集群
您可以在 First Look:InterSystems Cloud Manager(《技术概要:InterSystems 云管理器》)中找到使用 ICM 在亚马逊网络服务(Amazon Web Services)公共云平台上部署分片集群的程序;特别是在 Try It!Deploy InterSystems IRIS in the Cloud with ICM(试一试!使用 ICM 在云中部署 InterSystems IRIS)部分。您可以使用此处显示的整个程序。当您进入自定义定义.json(Customize definitions.json)时,验证每个 LicenseKey 字段的值是否是 defaults.json 文件中 LicenseDir 字段指定的暂存位置中的 InterSystems IRIS 分片(sharding)许可证的文件名。当您完成了部署阶段(部署 InterSystems IRIS[Deploy InterSystems IRIS])后,留在 ICM 容器中。
注意: 正如 Scalability Guide(《可扩展性指南》)中的 Deploying the Sharded Cluster(部署分片集群) 所描述的那样,您也可以在现有的物理、虚拟或云机器上安装 InterSystems IRIS 实例,并使用分片 API(Sharding API) 或管理门户(Management Portal)部署分片集群,或使用多种方法之一自动化部署分片集群。
使用不同的分片键以不同的方式分布行,然后查询分片表
为了了解分片集群如何根据您使用的分片键(shard key)在数据节点上的分片上对分片表(sharded table)进行分区,您将连接到集群并执行以下步骤:
创建并填充一个小型的非分片表。
使用三个不同的分片键,创建三个与非分片表具有相同字段的分片表 。
从非分片表中填充分片表。
从分片表中选择行,以查看在每种情况下,行在分片(数据节点)上的分布情况。
当一个表被分片时,RowID 值被从每个分片的不同范围分配,从相隔甚远的范围开始;相同范围的行在同一个分片上。当处理一个小表时,就像本例一样,分片的 RowID 很容易区分,清楚地告诉您哪些行在一个分片上,哪些在另一个分片上(尽管您无法分辨哪个分片是哪个)。在 RowID 上分片的表的行的分布方式与行中的数据没有关系,如果您清空并重新加载一个表,可能会有所不同。另一方面,用户定义的分片键,根据键中一个或多个字段的值来分配行,因此当您清空并重新加载表(假设值和分片数没有改变)时将是相同的。
查询所有三个表以获得其中一个字段的最大长度,来显示跨分片(across shards)的行的分布对查询是透明的。
对于这部分探索,请使用以下程序:
为任意一个数据节点实例打开终端(Terminal)窗口。
在 ICM 命令行上, 发出命令 icm session 命令,使用 -machine 选项指定一个数据节点的名称,使用 - namespace 选项指定集群命名空间 IRISCLUSTER (或者使用默认文件中的 Namespace 字段指定的命名空间,如果不同的话)。 如果您不确定节点的名称,可以使用 icm inventory 命令来显示节点名称:
$ icm inventory
Machine IP Address DNS Name Region Zone
Acme-DATA-TEST-0001 00.53.183.209 ec2-00-53-183-209.us-west-1.compute.amazonaws.com us-west-1 c
Acme-DATA-TEST-0002 00.53.183.185 ec2-00-53-183-185.us-west-1.compute.amazonaws.com us-west-1 c
选择一个节点(哪个节点并不重要)并发出命令:
icm session -machine Acme-DATA-TEST-0002 -namespace IRISCLUSTER
icm session 命令为指定节点上的 InterSystems IRIS 实例打开一个终端(Terminal)窗口。
如果您使用 %SYSTEM.Cluster.Sharding API 手动部署您的集群,使用 InterSystems IRIS Basics:Connecting an IDE(《技术概要:连接一个 IDE》)中的procedure described for your instance(为您的实例描述的程序),在任一实例上打开一个终端(Terminal)窗口,然后切换到 IRISCLUSTER 命名空间 (或者初始化集群时指定的命名空间,如果不同的话)。
Node: Acme-DATA-TEST-0002, Instance: IRIS USER>set $namespace="IRISCLUSTER" IRISCLUSTER>
打开终端(Terminal)SQL shell:IRISCLUSTER>do $SYSTEM.SQL.Shell() [SQL]IRISCLUSTER>>
使用以下 SQL 语句,创建并填充非分片表 test.nonsharded。
CREATE TABLE test.nonsharded (field1 CHAR(5), field2 CHAR(5)) INSERT INTO test.nonsharded (field1,field2) VALUES ('one','one') INSERT INTO test.nonsharded (field1,field2) VALUES ('one','two') INSERT INTO test.nonsharded (field1,field2) VALUES ('one','three') INSERT INTO test.nonsharded (field1,field2) VALUES ('two','one') INSERT INTO test.nonsharded (field1,field2) VALUES ('two','two') INSERT INTO test.nonsharded (field1,field2) VALUES ('two','three') INSERT INTO test.nonsharded (field1,field2) VALUES ('three','one') INSERT INTO test.nonsharded (field1,field2) VALUES ('three','two')
INSERT INTO test.nonsharded (field1,field2) VALUES ('three','three')
使用 SELECT 来查看表的内容:
SELECT * FROM test.nonsharded field1 field2
one one
one two
one three
two one
two two
two three
three one
three two
three three
使用 test.nonsharded 中的相同字段创建三个分片表,在第一个表中使用默认的分片键(RowID),在第二个表中使用 field1 字段,在第三个表中使用 field2 字段,并使用从 test.nonsharded 中选择的 INSERT INTO 语句填充每一个:
CREATE TABLE test.rowid (field1 CHAR(5), field2 CHAR(5), SHARD)
INSERT INTO test.rowid (field1,field2) SELECT field1,field2 FROM test.nonsharded
CREATE TABLE test.field1 (field1 CHAR(5), field2 CHAR(5), SHARD KEY (field1)) INSERT INTO test.field1 (field1,field2) SELECT field1,field2 FROM test.nonsharded
CREATE TABLE test.field2 (field1 CHAR(5), field2 CHAR(5), SHARD KEY (field2)) INSERT INTO test.field2 (field1,field2) SELECT field1,field2 FROM test.nonsharded
使用 SELECT *,%ID 来显示每个分片表的内容和它在分片上的 RowID。
SELECT *,%ID FROM test.rowid ORDER BY %ID
field1 field2 ID one one 1
one two 2
two one 3
two two 4
three three 5
one three 256000
two three 256001
three one 256002
three two 256003
这个分布并不反映 field1 或 field2 的值(具有各自全部三个值的行位于两个分片上)。如果您删除、重新创建并重新加载 test.rowid,分布可能会有所不同。
SELECT *,%ID FROM test.field1 ORDER BY %ID
field1 one one one
field2
one 1
two 2
three 3
ID
two
one 256000
two
two 256001
two
three 256002
three
one 256003
three
two 256004
three
three 256005
在 field1 字段上分片(sharding)会分布行,使那些具有相同 field1 值的行被放在同一个分片上。在这种情况下,值为 1 的行在一个分片上,值为 2 和 3 的行在另一个分片上,但是哪个数值最终在哪个分片上取决于有多少个分片和多少个数值。
SELECT *,%ID FROM test.field2 ORDER BY %ID
field1 field2 ID
one one 1
two one 2
three one 3
one two 256000
one three 256001
two two 256002
two three 256003
three two 256004
three three 256005
这里,分布是由 field2 字段的值决定的。
最后,作为分片如何将工作分配到数据节点的示例,对所有三个分片表使用以下 SELECT 语句:
SELECT MAX(LENGTH(field2)) FROM <table>
在每种情况下,结果都是 5,即最长值的长度是 3,因为跨分片的行分布对查询来说是完全透明的。 MAX(LENGTH(field2)) 表达式在每个分片上独立计算,分片管理器选择它们返回结果的 MAX()。例如,当查询在 test.field2 表上运行时,一个分片返回 3,因为它在 field2 字段中只有值 1 ,而另一个分片返回 5;然后分片管理器选择 5 作为两个结果中较大的那个。
如果您愿意,可以使用 EXPLAIN 来显示查询计划,明确指出如何将工作发送到分片上:
EXPLAIN SELECT MAX(LENGTH(field2)) FROM <table>
更多分片集群选项
分片集群的其他选项包括如下内容:
您可以随时添加数据节点,并跨扩展的数据节点集重新平衡现有的分片数据。重新平衡(Rebal ancing)不能与查询和更新同时进行,因此只有在分片集群离线并且没有其他分片操作的情况下才能进行。( Scalability Guide[《可扩展性指南》]中的 Add Nodes and Rebalance Data[添加节点和重新平衡数据] )
要为集群上的数据添加高可用性,您可以将数据节点部署为镜像故障转移对。( Scalability Guide[《可扩展性指南》]中的 Mirror for High Availability[高可用性镜像])。
对于需要极低查询延迟的高级用例(可能与不断涌入的数据相冲突),可以添加计算节点 ,为查询服务提供一个透明的缓存层。当集群包含计算节点时,只读的查询会自动在计算节点上并行执行,而不是在数据节点上执行;所有写入操作(插入、更新、删除和 DDL 操作)继续在数据节点上执行。这种分工将查询和数据摄取工作量分开,同时保持并行处理和分布式缓存的优势,提高两者的性能。(Scalability Guide[《可扩展性指南》]中的 Deploy Compute Nodes[部署计算节点])
了解有关分片(Sharding)的更多信息
要了解有关分片的更多信息,请参见
Data Platform Scalability Technology Overview(《数据平台可扩展性技术概要》) (视频)
Introduction to Sharding(《分片简介》) (在线课程)
Sharding Basics(《分片基础》) (在线课程)
Experience InterSystems IRIS in the Cloud(在云中体验 InterSystems IRIS) (在线体验)
Scalability Guide(《可扩展性指南》)
First Look:InterSystems Cloud Manager(《技术概要:InterSystems 云管理器》)