清除过滤器
文章
Claire Zheng · 七月 8, 2021
2021年7月9日-11日,2021(16th) 中国卫生信息技术/健康医疗大数据应用交流大会暨软硬件与健康医疗产品展览会(CHITEC)在武汉国际博览中心(湖北省武汉市汉阳区鹦鹉大道619号)盛大召开,欢迎莅临InterSystems展位A6-16,了解备受瞩目的InterSystems IRIS医疗版互联互通套件。
InterSystems致力于部署、创建互联互通医疗解决方案,为医院数字化转型提供技术支持。针对医院信息互联互通标准化成熟度测评指标要求,InterSystems IRIS 医疗版互联互通套件从安全管理、监控、数据管理、互联互通文档、互联互通服务、集成与交换六大方面助力医院互联互通建设,以满足医疗机构内部标准化的要求,使医院可基于信息平台提供较为完善的临床决策支持、闭环管理,实现丰富的人工智能和大数据应用,实现丰富的跨机构的业务协同和互联互通应用。
如果您希望进一步了解详细信息,欢迎莅临展位(A6-16),或通过下方二维码联系小助手,添加时注明“CHITEC预约沟通”,确认您的专属预约沟通时段,如果您完成预约并与专家实现现场沟通,将有机会获得神秘礼品!
InterSystems IRIS医疗版互联互通套件具备如下优点:
专——专注医疗领域40余年,针对中国医疗信息化市场量身定制,遵循国家卫生信息标准,公立医院互联互通标准化成熟度测评需求的基石;加强健康数据标准应用,提高数据质量;全——全面支持2020最新版医院互联互通标准化成熟度测评规定的文档、监控、服务、Schema 等组件;快——卓越的互操作性助力医疗机构快速落地互联互通标准化成熟度测评标准化改造;省——有效缩短实施周期,降低实施成本,超高性能有效降低硬件成本;稳——稳定高效,连续多年支持超百家大型公立医院海量数据稳定运行。主流 PC 服务器单实例下,支持日消息吞吐量可达 27亿;目前已知支持国内公立医院日消息吞吐量高达1200万/天(非集群);强——功能强大,该套件具备持久化数据能力,可全面助力医院快速实现创新型数据应用,包括数据库管理、敏捷开发、 API 管理、FHIR资源仓库、分布式扩展、一体化机器学习、自适应分析等;广——广泛专业的本土化生态合作伙伴,具备丰富的互联互通成熟度测评经验与强大的落地能力。
截至2020 年,InterSystems已助力中南大学湘雅医院(五级乙等)、河南省人民医院(五级乙等)、安徽省立医院(五级乙等)、武汉中心医院(五级乙等)、四川大学华西第二医院(五级乙等)、深圳市宝安区妇幼保健院(五级乙等)、广州医科大学附属第二医院(五级乙等)、吉林大学中日联谊医院(五级乙等)、浙江大学医学院附属第四医院(五级乙等)、北京协和医院(四级甲等)等一百余家医院通过互联互通标准化成熟度测评,在全国大型医院中市场份额最高。
2021 CHITEC (7月9日-11日)期间,转发这篇文章到微信朋友圈,可以到InterSystems展位领取小礼品哦~
文章
姚 鑫 · 七月 7, 2021
# 第三十章 从类生成XML架构
本章介绍如何使用`%XML.Schema`从启用了XML的类生成XML架构。
# 概述
要生成为同一XML命名空间中的多个类定义类型的完整架构,请使用`%XML.Schema`构建架构,然后使用`%XML.Writer`为其生成输出。
# 从多个类构建架构
要构建XML架构,请执行以下操作:
1. 创建`%XML.Schema`实例。
2. 可以选择设置实例的属性:
- 若要为任何其他未分配的类型指定命名空间,请指定`DefaultNamespace`属性。默认值为`NULL`。
- 默认情况下,类及其属性的类文档包含在模式的``元素中。
要禁用此功能,请将`IncludeDocumentation`属性指定为0。
注意:必须在调用`AddSchemaType()`方法之前设置这些属性。
3. 调用实例的`AddSchemaType()`方法。
```java
method AddSchemaType(class As %String,
top As %String = "",
format As %String,
summary As %Boolean = 0,
input As %Boolean = 0,
refOnly As %Boolean = 0) as %Status
```
- class是支持xml的类的完整包名和类名。
- top 是可选的;
如果指定,它将覆盖该类的类型名。
- format指定此类型的格式。
它必须是`"literal"`(文字格式,默认),`"encoded"`(用于SOAP编码),`"encoded12"`(用于SOAP 1.2编码),或`"element"`。
值`“element”`与元素位于顶层的文字格式相同。
- summary,如果为true,将导致InterSystems IRIS启用xml的类的`XMLSUMMARY`参数。
如果指定了此参数,则模式将只包含该参数列出的属性。
- input,如果为true,将导致InterSystems IRIS获取输入模式,而不是输出模式。
在大多数情况下,输入模式和输出模式是相同的;
如果为类的属性指定`XMLIO`属性参数,则它们是不同的。
- refOnly如果为true,将导致InterSystems IRIS仅为引用的类型生成模式,而不是为给定的类和所有引用的类型生成模式。
这个方法返回一个应该被检查的状态。
4. 根据需要重复前面的步骤。
5. 如果要定义导入模式的位置,可以调用`DefineLocation()`方法。
```java
method DefineLocation(namespace As %String, location As %String)
```
namespace 是一个或多个引用类使用的名称空间,位置是对应模式(XSD文件)的URL或路径和文件名。
可以重复调用此方法来为多个导入的模式添加位置。
如果不使用这个方法,模式会包含一个``指令,但是不会给出模式的位置。
6. 要定义额外的``指令,可以调用`DefineExtraImports()`方法。
```java
method DefineExtraImports(namespace As %String, ByRef imports)
```
namespace是``指令应该添加到的命名空间,imports是一个多维数组,形式如下:
Node| Value
---|---
`arrayname("namespace URI")` |字符串,给出此名称空间的模式(XSD文件)的位置。
# 为架构生成输出
按照上一节所述创建`%XML.Schema`的实例后,请执行以下操作以生成输出:
1. 调用实例的`GetSchema()`方法将架构作为文档对象模型(DOM)的节点返回。
此方法只有一个参数:模式的目标命名空间的URI。该方法返回`%XML.Node`的一个实例,该实例在“将XML文档表示为DOM”一章中介绍。
如果模式没有命名空间,请使用`“”`作为`GetSchema()`的参数。
2. 可以选择修改此DOM。
3. 要生成架构,请执行以下操作:
a. 创建`%XML.Write`的实例,并可选择设置属性(如缩进)。
b. 可以选择调用编写器的`AddNamespace()`方法和其他方法,将名称空间声明添加到`` 元素。
因为架构可能引用简单的XSD类型,所以调用`AddSchemaNamespace()`来添加XML模式命名空间很有用。
c. 使用架构作为参数,调用编写器的`DocumentNode()`或`Tree()`方法。
# 示例
## 简单的示例
第一个示例显示了基本步骤:
```java
Set schemawriter=##class(%XML.Schema).%New()
//添加类和包(例如)
Set status=schemawriter.AddSchemaType("Facets.Test")
//通过其URI(在本例中为NULL)检索架构
Set schema=schemawriter.GetSchema("")
//create writer
Set writer=##class(%XML.Writer).%New()
Set writer.Indent=1
//use writer
Do writer.DocumentNode(schema)
```
## 更复杂的架构示例
```java
Class SchemaWriter.Person Extends (%Persistent, %XML.Adaptor)
{
Parameter NAMESPACE = "http://www.myapp.com";
Property Name As %Name;
Property DOB As %Date(FORMAT = 5);
Property PatientID as %String;
Property HomeAddress as Address;
Property OtherAddress as AddressOtherNS ;
}
```
`Address`类定义在相同的XML名称空间(`“http://www.myapp.com”`)中,而`OtherAddress`类定义在不同的XML名称空间(`“http://www.other.com”`)中。
`Company`类也被定义在XML名称空间`“http://www.myapp.com”`中。
其定义如下:
```java
Class SchemaWriter.Company Extends (%Persistent, %XML.Adaptor)
{
Parameter NAMESPACE = "http://www.myapp.com";
Property Name As %String;
Property CompanyID As %String;
Property HomeOffice As Address;
}
```
注意,不存在连接`Person`和`Company`类的属性关系。
要为命名空间`"http://www.myapp.com"`生成模式,我们可以使用以下方法:
```java
ClassMethod Demo()
{
Set schema=##class(%XML.Schema).%New()
Set schema.DefaultNamespace="http://www.myapp.com"
Set status=schema.AddSchemaType("SchemaWriter.Person")
Set status=schema.AddSchemaType("SchemaWriter.Company")
Do schema.DefineLocation("http://www.other.com","c:/other-schema.xsd")
Set schema=schema.GetSchema("http://www.myapp.com")
//create writer
Set writer=##class(%XML.Writer).%New()
Set writer.Indent=1
Do writer.AddSchemaNamespace()
Do writer.AddNamespace("http://www.myapp.com")
Do writer.AddNamespace("http://www.other.com")
Set status=writer.DocumentNode(schema)
If $$$ISERR(status) {Do $system.OBJ.DisplayError() Quit }
}
```
输出如下:
```xml
```
请注意以下几点:
- 模式包括`Person`及其所有引用的类的类型,以及`Company`及其所有引用的类的类型。
- ``指令导入了`OtherAddress`类使用的命名空间;
因为我们使用了`DefineLocation()`,所以这个指令还指示了相应模式的位置。
- 因为我们在调用`DocumentNode()`之前使用了`AddSchemaNamespace()`和`AddNamespace()`,所以``元素包含了名称空间声明,它为这些名称空间定义了前缀。
- 如果我们没有使用`AddSchemaNamespace()`和`AddNamespace()`, ``将不会包含这些名称空间声明,模式将会如下所示:
```xml
...
```
文章
姚 鑫 · 七月 6, 2021
# 第二十九章 从XML架构生成类
Studio提供了一个向导,该向导读取XML模式(从文件或URL),并生成一组支持XML的类,这些类对应于模式中定义的类型。
所有的类都扩展`%XML.Adaptor`。
指定一个包来包含类,以及控制类定义细节的各种选项。
向导还可以作为类方法使用,也可以使用该类方法。
在内部,SOAP向导在读取WSDL文档并生成web客户端或web服务时使用此方法;
注意:使用的任何XML文档的XML声明都应该指明该文档的字符编码,并且文档应该按照声明的方式进行编码。如果未声明字符编码,InterSystems IRIS将使用本书前面的“输入和输出的字符编码”中描述的默认值。如果这些默认值不正确,请修改XML声明,使其指定实际使用的字符集。
# 使用向导
要使用XML架构向导,请执行以下操作:
1. 选择 Tools > Add-Ins > XML Schema Wizard.
2. 在第一个屏幕上,指定要使用的XML模式。
做以下其中一项:
- 对于模式文件Schema File,选择Browse 以选择XML模式文件。
- 对于URL,指定模式的URL。
3. 选择Next。
下一个屏幕显示模式,以便可以验证选择了正确的模式。
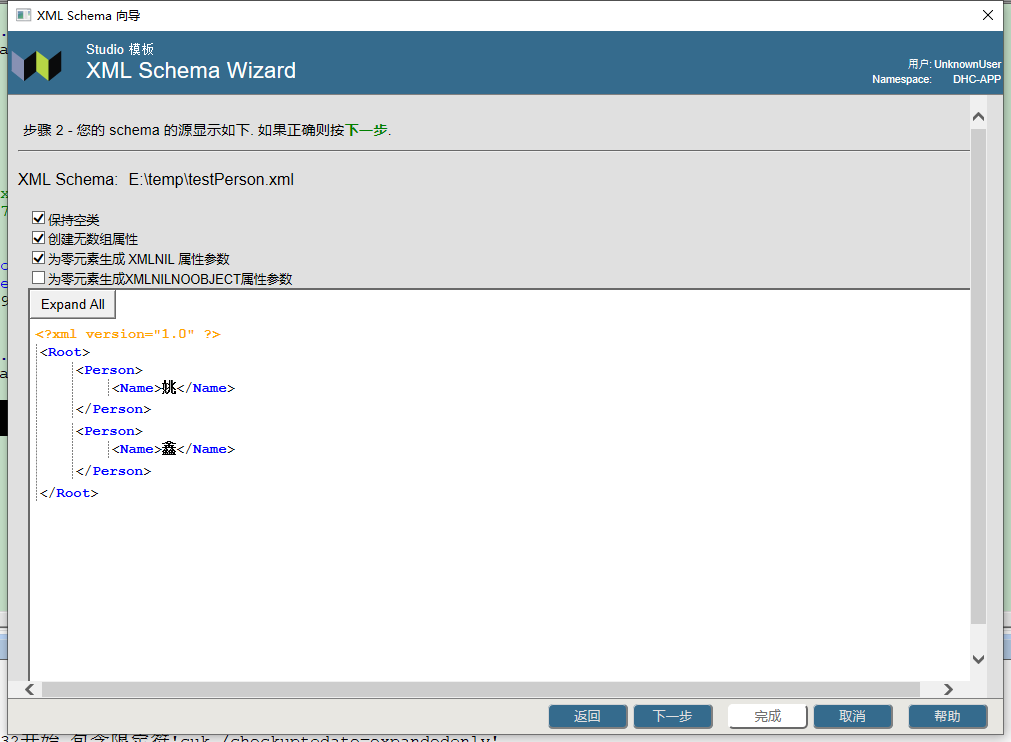
4. 可选择以下选项:
- 保留空类Keep Empty Classes,它指定是否保留没有属性的未使用的类。
如果选择此选项,则不会在向导结束时删除此类;
否则,将删除它们。
- “不创建数组属性”Create No Array Properties控制向导是否生成数组属性。
如果选择此选项,向导不会生成数组属性,而是生成另一个表单。
- 为可为空的元素生成XMLNIL属性参数,它控制向导是否为生成的类中适用的属性指定XMLNIL属性参数。
该选项适用于每个对应于用`nillable="true"`指定的XML元素的属性。
如果选择此选项,向导将向属性定义添加`XMLNIL=1`。
否则不添加该参数。
该参数的详细信息请参见将对象投影到XML中的“处理空字符串和空值”。
- 为可为空的元素生成`XMLNILNOOBJECT`属性参数,它控制向导是否为生成的类中适用的属性指定`XMLNILNOOBJECT`属性参数。
该选项适用于每个对应于用`nillable="true"`指定的XML元素的属性。
如果选择此选项,向导将向属性定义添加`XMLNILNOOBJECT=1`。
否则不添加该参数。
该参数的详细信息请参见将对象投影到XML中的“处理空字符串和空值”。
5. 选择Next。
下一个屏幕显示关于要生成的类的选项的一些基本信息。
6. 在这个屏幕上,指定以下选项:
- 如果希望向导编译生成的类,可以选择“编译生成的类”。
- 可选择“添加NAMESPACE类参数”来指定`NAMESPACE`参数。
在本例中,`NAMESPACE`被设置为模式中`targetNamespace`的值。
如果不设置此选项,则不指定`NAMESPACE`。
建议在所有情况下都选择这个选项,因为每个支持XML的类都应该分配给一个XML名称空间。
(但是,为了向后兼容,可以将此选项清除。)
- 如果希望生成的类是持久类,请选择Create persistent classes。然后类扩展`%Persistent`。
可以稍后在向导中针对各个类更改这一点。
- 如果生成持久类,可以选择如何处理由另一个` b`的``组成的`` a。当向导生成一个包含属性`a`的持久类时,该属性有三种可能的形式。
可以将其定义为对象列表、一对多关系(默认)或父子关系。
下表总结了这些选择:
在持久性类中为集合属性使用关系 |向多对关系添加索引 |使用父子关系|生成的属性A的形式
---|---|---|---
selected (default)| not selected| not selected| 无索引的一对多关系
selected (default) |selected| not selected| 在多侧与索引的一对多关系
selected (default) |如果选择Use parent-child relationship,则忽略此选项| selected| 父子关系
not selected| not selected| not selected |List of objects
此外,如果未选择使用父子关系,则可以选择将`%OnDelete`方法添加到类以级联删除。如果选择此选项,当向导生成类定义时,它会在这些类中包含`%OnDelete()`回调方法的实现。生成的`%OnDelete()`方法删除类引用的所有持久对象。如确实选择了使用父子关系,请不要选择此选项;父子关系已经提供了类似的逻辑。
注意:如果修改生成的类,请确保根据需要修改`%OnDelete()`回调方法。
如果生成持久类,向导可以向每个对象类型类添加临时属性,以便可以为对象投影InterSystems IRIS内部标识符。选项如下:
- None-如果选择此选项,向导不会添加此处描述的任何属性。
- Use Id -如果选择此选项,向导将向每个对象类型类添加以下属性:
```
Property %identity As %XML.Id (XMLNAME="_identity", XMLPROJECTION="ATTRIBUTE") [Transient];
```
- Use Oid -如果选择此选项,向导将向每个对象类型类添加以下属性:
```
Property %identity As %XML.Oid (XMLNAME="_identity", XMLPROJECTION="ATTRIBUTE") [Transient];
```
- Use GUID-如果选择此选项,向导将向每个对象类型类添加以下属性:
```
Property %identity As %XML.GUID (XMLNAME="_identity", XMLPROJECTION="ATTRIBUTE") [Transient];
```
底部的表格列出了模式中的XML名称空间。在这里,指定包含该行中显示的XML名称空间的类的包。要执行此操作,请在程序包名字段中为该行指定程序包名。
7. 选择下一步。
8. 在下一个屏幕上,指定以下选项:
- Java Enabled - 如果选择此选项,则每个类都包括一个Java映射。
- Data Population数据填充-如果选择此选项,则除`%XML.Adaptor`外,每个类还继承会`%Populate`。
- SQL Column Order-如果选择此选项,每个属性将为`SqlColumnNumber`关键字指定一个值,以便属性在SQL中的顺序与它们在架构中的顺序相同。
- No Sequence Check-如果选中此选项,向导将生成的类中的`XMLSEQUENCE`参数设置为0。在某些情况下,如果XML文件的元素顺序与XML架构不同,则此选项非常有用。
默认情况下,`XMLSEQUENCE`参数在生成的类中设置为1。这可确保属性以与架构中相同的顺序包含在类定义中。
- XMLIGNORENULL-如果选择此选项,向导会将`XMLIGNORENULL=1`添加到类定义中。否则,它不会添加此参数。
- 将流用于二进制Use Streams for Binary - 如果选择此选项,向导将为`xsd:base64Binary`类型的任何元素生成`%Stream.GlobalBinary`类型的属性。如果清除此选项,则该属性的类型为`%xsd.base64Binary`。
请注意,向导将忽略`xsd:base64Binary`类型的任何属性。
- 在复选框下方,该表列出了向导将生成的类。对于每个类,确保适当地设置了`Extensions/Type`。在此,可以选择以下选项之一:
- 持久类`Persistent` -如果选择此选项,则类是持久性类。
- `Serial`-如果选择此选项,则类为序列类。
- `Registered Object`-如果选择此选项,则类为注册对象类。
所有生成的类还扩展`%XML.Adaptor`。
- 在表的右列中,为每个应编制索引的属性选择索引。
9. 选择Finish(完成)。
然后,向导将生成这些类,并在需要时编译它们。
对于这些类的属性,如果架构中相应元素的名称以下划线(_)开头,则属性名称以百分号(%)开头。
# 以编程方式生成类
XML架构向导也可用作`%XML.Utils.SchemaReader`类的`process()`方法。要使用此方法,请执行以下操作:
1. 创建`%XML.Utils.SchemaReader`的实例。
2. 可以选择设置实例的属性以控制其行为。
3. 可以选择创建InterSystems IRIS多维数组,以包含有关其他设置的信息。
4. 调用实例的`process()`方法:
```
method Process(LocationURL As %String,
Package As %String = "Test",
ByRef Features As %String) as %Status
```
- LocationURL必须是架构的URL或架构文件的名称(包括其完整路径)。
- Package是用于放置生成的类的包的名称。如果不指定程序包,InterSystems IRIS将使用服务名称作为程序包名称。
- Feature是在上一步中选择创建的多维数组。
# 每种XSD类型的默认IRIS数据类型
对于它生成的每个属性,XML架构向导会根据架构中指定的XSD类型自动使用适当的InterSystems IRIS数据类型类。下表列出了XSD类型和相应的InterSystems IRIS数据类型:
用于XML类型的InterSystems IRIS数据类型
源文档中的XSD类型 |生成的IRIS类中的数据类型
---|---
anyURI | %xsd.anyURI
base64Binary | `%xsd.base64Binary`或`%Stream.GlobalBinary`,具体取决于选择的选项。确定每个字符串是否可能超出字符串长度限制,如果可能,则将生成的属性从`%xsd.base64Binary`修改为适当的流类。)
boolean | `%Boolean`
byte | `%xsd.byte`
date | `%Date`
dateTime | `%TimeStamp`
decimal |`%Numeric`
double | `%xsd.double`
float | `%xsd.float`
hexBinary | `%xsd.hexBinary`
int |`%xsd.int`
integer |`%Integer`
long | `%Integer`
negativeInteger | `%xsd.negativeIntege`
nonNegativeInteger | `%xsd.nonNegativeInteger`
nonPositiveInteger |`%xsd.nonPositiveInteger`
positiveInteger | `%xsd.positiveInteger`
short | `%xsd.short`
string | `%String` (注意:责任确定每个字符串是否可能超出字符串长度限制,如果可能,则将生成的类型修改为适当的流类。)
time | `%Time`
unsignedByte | `%xsd.unsignedByte`
unsignedInt |`%xsd.unsignedInt`
unsignedLong | `%xsd.unsignedLong`
unsignedShort | `%xsd.unsignedShort`
no type given | `%String`
# 生成的属性的属性关键字
对于它生成的每个属性,XML架构向导还使用架构中的信息自动设置以下关键字:
- Description
- Required
- ReadOnly (如果相应的元素或属性是用固定属性定义的)
- InitialExpression (该值取自架构中的固定属性)
- Keywords related to relationships
# 生成的属性的参数
对于它生成的每个属性,XML架构向导会根据需要自动设置`XMLNAME`、`XMLPROJECTION`和所有其他与XML相关的参数。它还根据需要设置其他参数,如`MAXVAL`、`MINVAL`和`VALUELIST`。
# 调整为超长字符串生成的类
在极少数情况下,可能需要编辑生成的类来容纳超长的字符串或二进制值,超出字符串长度限制。
对于任何字符串类型,XML架构都不包含任何指示字符串长度的信息。XML架构向导将所有字符串值映射到InterSystems IRIS `%String`类,并将所有`base64Binary`值映射到`%xsd.base64Binary`类。这些选择可能不合适,具体取决于类要承载的数据。
在使用生成的类之前,应该执行以下操作:
- 检查生成的类,找到定义为`%string`或`%xsd.base64Binary`的属性。考虑将在其中使用这些类的上下文,特别是这些属性。
- 如果认为`%string`属性可能需要包含超出字符串长度限制的字符串,请将该属性重新定义为适当的字符流。同样,如果认为`%xsd.base64Binary`属性可能需要包含超过相同限制的字符串,请将该属性重新定义为适当的二进制流。
- 另请注意,对于类型为`%string`、`%xsd.string`和`%BINARY`的属性,默认情况下,`MAXLEN`属性参数为`50`个字符。可能需要指定更高的限制才能进行正确的验证。
(对于`%xsd.base64Binary`类型的属性,`MAXLEN`为`“”`,这意味着不会通过验证检查长度。但是,字符串长度限制确实适用。)
文章
Claire Zheng · 七月 6, 2021
近日,InterSystems极客俱乐部举办了线上直播“InterSystems Caché系统运维培训”,这是系列视频之一。InterSystems中国资深售前顾问祝麟讲解了“InterSystems Caché系统高可用与数据库镜像”。
文章
Michael Lei · 七月 6, 2021
如果一张图片胜过千言万语,那么一段视频又价值几何? 当然胜过敲一个帖子。
请在 [InterSystems Developers YouTube](https://www.youtube.com/c/InterSystemsDevelopers) 观看我的“Coding talks”:
1. 使用 Yape 分析 InterSystems IRIS 系统性能。 第 1 部分:安装 Yape
在容器中运行 Yape。
2. Yape 容器 SQLite iostat InterSystems
提取和绘制 pButtons 数据,包括时间范围和 iostat。
如果您需要一个简单的方法来捕获和查看 Caché 和 IRIS 以及系统性能指标,可以安排每天运行 pButtons 来轻松实现。 [我之前写过这方面的文章](https://cn.community.intersystems.com/post/intersystems-数据平台的容量规划和性能系列文章)。
我经常需要查看客户系统以进行容量规划和性能检查,这就是我编写 Yape 并在 [GitHub](https://github.com/murrayo/yape "GitHub") 上提供它的原因。 我的 InterSystems 同事 Fabian 将 Yape 的内部结构带入了新方向,并[使其正式在容器中运行](https://community.intersystems.com/post/visualizing-data-jungle-part-iv-running-yape-docker-image)。 Fabian 已经离开 InterSystems,但我继续在 GitHub 上进行开源开发。 在过去一个月左右的时间里,我修复了一些操作系统命令格式错误,使日期处理更智能,在 vmstat 中添加了“Total CPU”图表(倒着看“id”导致我的脖子拉伤),以及其他修饰性更改。
如果您想为 Yape 做出贡献,它在 GitHub 上是开源的。 如果您有功能要求,请[通过建议页面](https://github.com/murrayo/yape/issues)告诉我。
另外,请查看 [Open Exchange 上的 Yape 应用程序](http://bit.ly/2WnqmSt)。
在接下来的几个月,我将分享工作流程中的其他一些技巧,并期望继续开发以使呈现的数据更加有用。 Yape 非常适合检查和查看昨天或过去一周发生的事件的趋势,但是您还需要实时监视和警报... 这里我也对将来的一些帖子做个预告 ;)
文章
Michael Lei · 七月 6, 2021
供应商或内部团队要求说明如何为 VMware vSphere 上运行的_大型生产数据库_进行 CPU 容量规划。
总的来说,在调整大型生产数据库的 CPU 规模时,有几个简单的最佳做法可以遵循:
- 为每个物理 CPU 核心规划一个 vCPU。
- 考虑 NUMA 并按理想情况调整虚拟机规模,以使 CPU 和内存对于 NUMA 节点是本地的。
- 合理调整虚拟机规模。 仅在需要时才添加 vCPU。
通常,这会引出几个常见问题:
- 由于使用超线程技术,VMware 创建的虚拟机的 CPU 数量可以是物理 CPU 数量的两倍。 那不就是双倍容量吗? 创建的虚拟机不应该有尽可能多的 CPU 吗?
- 什么是 NUMA 节点? 我应该在意 NUMA 吗?
- 虚拟机应该合理调整规模,但我如何知道什么时候合理?
我以下面的示例回答这些问题。 但也要记住,最佳做法并不是一成不变的。 有时需要做出妥协。 例如,大型生产数据库虚拟机很可能不适合 NUMA 节点,但我们会看到,其实是没问题的。 最佳做法是指必须针对应用程序和环境进行评估和验证的准则。
虽然本文中的示例是在 InterSystems 数据平台上运行的数据库,但概念和规则通常适用于任何大型(怪兽)虚拟机的容量和性能规划。
有关虚拟化最佳做法以及有关性能和容量规划的更多帖子,请参见 [InterSystems 数据平台和性能系列的其他帖子列表](https://cn.community.intersystems.com/post/intersystems-数据平台的容量规划和性能系列文章)。
# 怪兽虚拟机
本帖主要是关于部署_怪兽虚拟机_,有时也称为 _Wide 虚拟机_。 高事务数据库的 CPU 资源要求意味着它们通常部署在怪兽虚拟机上。
> 怪兽虚拟机是指虚拟 CPU 或内存多于物理 NUMA 节点的虚拟机。
# CPU 架构和 NUMA
当前的英特尔处理器架构采用非统一内存架构 (NUMA)。 例如,本帖中用来运行测试的服务器有:
- 两个 CPU 插槽,每个插槽一个 12 核处理器(英特尔 E5-2680 v3)。
- 256 GB 内存(16 条 16GB RDIMM)
每个 12 核处理器都有自己的本地内存(128GB RDIMM 及本地高速缓存),还可以访问同一主机中其他处理器上的内存。 每个由 CPU、CPU 高速缓存和 128GB RDIMM 内存组成的 12 核套装都是一个 NUMA 节点。 为了访问其他处理器上的内存,NUMA 节点通过快速互连来连接。
处理器上运行的进程访问本地 RDIMM 和缓存内存的延迟比跨互连访问其他处理器上的远程内存的延迟要低。 跨互连访问会增加延迟,因此性能不一致。 同样的设计也适用于具有两个以上插槽的服务器。 一台四插槽英特尔服务器有四个 NUMA 节点。
ESXi 了解物理 NUMA,ESXi CPU 调度器设计为优化 NUMA 系统的性能。 ESXi 使性能最大化的方法之一是在物理 NUMA 节点上创建数据本地性。 在我们的示例中,如果虚拟机有 12 个 vCPU,并且内存不到 128GB,ESXi 将分配该虚拟机在一个物理 NUMA 节点上运行。 这就形成了规则:
> 如果可能,将虚拟机规模调整为使 CPU 和内存对于 NUMA 节点是本地的。
如果需要比 NUMA 节点规模大的怪兽虚拟机也没有问题,ESXi 可以很好地自动计算和管理要求。 例如,ESXi 将创建能够智能调度到物理 NUMA 节点上的虚拟 NUMA 节点 (vNUMA),以获得最佳性能。 vNUMA 结构对操作系统公开。 例如,如果您有一台具有两个 12 核处理器的主机服务器和一个具有 16 个 vCPU 的虚拟机,ESXi 可能会使用每个处理器上的 8 个物理核心来调度虚拟机 vCPU,操作系统(Linux 或 Windows)将看到两个 NUMA 节点。
同样重要的是,应合理调整虚拟机的规模,并且分配的资源不要超过所需的资源,否则会导致资源浪费和性能损失。 除了有助于调整 NUMA 的规模,具有高(但安全的)CPU 利用率的 12 vCPU 虚拟机比具有中低 CPU 利用率的 24 vCPU 虚拟机更高效、性能更好,特别是该主机上还有其他虚拟机需要调度并且争用资源时。 这也再次强化了该规则:
> 合理调整虚拟机规模。
__注意:__英特尔和 AMD 的 NUMA 实现有区别。 AMD 每个处理器有多个 NUMA 节点。 我已经有一段时间没有在客户服务器中看到 AMD 处理器了,但是如果你有这些处理器,请检查 NUMA 布局,作为规划的一部分。
## Wide 虚拟机和授权
为实现最佳 NUMA 调度,请配置 Wide 虚拟机; 2017 年 6 月更正:按每个插槽 1 个 vCPU 配置虚拟机。 例如,默认情况下,一个具有 24 个 vCPU 的虚拟机应配置为 24 个 CPU 插槽,每个插槽一个核心。
> 遵守 VMware 最佳做法规则。
请参见 [VMware 博客上的这篇文章以查看示例。 ](https://blogs.vmware.com/performance/2017/03/virtual-machine-vcpu-and-vnuma-rightsizing-rules-of-thumb.html)
该 VMware 博客文章进行了详细介绍,但是作者 Mark Achtemichuk 建议遵循以下经验法则:
- 虽然有许多高级 vNUMA 设置,但只有极少数情况下需要更改其默认值。
- 总是将虚拟机 vCPU 数配置为反映每插槽核心数,直到超过单个物理 NUMA 节点的物理核心数。
- 当需要配置的 vCPU 数量超过 NUMA 节点中的物理核心数量时,将 vCPU 均匀分配到最少数量的 NUMA 节点上。
- 当虚拟机规模超过物理 NUMA 节点时,不要分配奇数数量的 vCPU。
- 不要启用 vCPU 热添加,除非您不介意禁用 vNUMA。
- 不要创建规模大于主机物理核心总数的虚拟机。
Caché 授权以核心数为准,因此这不是问题,但是对于除 Caché 以外的软件或数据库,指定虚拟机有 24 个插槽可能会对软件授权产生影响,因此必须与供应商核实。
# 超线程和 CPU 调度器
超线程 (HT) 经常在讨论中出现,我听过“超线程使 CPU 核心数量翻倍”。 这在物理层面上显然是不可能的,物理核心有多少就是多少。 超线程应该被启用,并会提高系统性能。 预计应用程序性能可能会提高 20% 或更多,但实际数字取决于应用程序和工作负载。 但肯定不会翻倍。
正如我在 [VMware 最佳实践](https://cn.community.intersystems.com/post/intersystems-数据平台和性能-–-第-9-篇-intersystems-iris-vmware-最佳实践指南)中所述,_调整大型生产数据库虚拟机规模_的一个很好的起点是假定 vCPU 拥有服务器上完整的物理核心专用资源 — 在进行容量规划时基本忽略超线程。 例如:
> 对于一台 24 核主机服务器,可规划总共多达 24 个 vCPU 的生产数据库虚拟机,且可能还有余量。
在您花时间监测应用程序、操作系统和 VMware 在峰值处理期间的性能后,您可以决定是否进行更高度的虚拟机整合。 在最佳做法帖子中,我将规则表述为:
> 一个物理 CPU(包括超线程)= 一个 vCPU(包括超线程)。
## 为什么超线程不会使 CPU 翻倍
英特尔至强处理器上的超线程是在一个物理核心上创建两个_逻辑_ CPU 的方法。 操作系统可以有效地针对两个逻辑处理器进行调度 — 如果一个逻辑处理器上的进程或线程正在等待,例如等待 IO,则物理 CPU 资源可以被另一个逻辑处理器使用。 在任何时间点都只能有一个逻辑处理器运行,因此虽然物理核心得到了更有效的利用,但_性能并没有翻倍_。
在主机 BIOS 中启用超线程后,当创建虚拟机时,可以为每个超线程逻辑处理器配置一个 vCPU。 例如,在一台启用了超线程的物理 24 核服务器上,可以创建具有多达 48 个 vCPU 的虚拟机。 ESXi CPU 调度器将通过首先在独立的物理核心上运行虚拟机进程来优化处理(同时仍然考虑 NUMA)。 在以后的帖子中,我将探讨在怪兽数据库虚拟机上分配比物理核心数更多的 vCPU 是否有助于扩展。
### 协同停止和 CPU 调度
在监测主机和应用程序性能后,您可以决定是否让主机 CPU 资源过载。 这是否是一个好主意在很大程度上取决于应用程序和工作负载。 了解调度器和要监测的关键指标有助于确保没有使主机资源过载。
我有时听说,要让虚拟机正常运行,空闲逻辑 CPU 的数量必须与虚拟机中的 vCPU 数量相同。 例如,一个 12 vCPU 虚拟机必须“等待”12 个逻辑 CPU“可用”,才能继续执行。 不过应该注意,ESXi 在版本 3 之后就不是这样了。 ESXi 对 CPU 使用宽松的协同调度,以提高应用程序性能。
由于多个协作线程或进程经常相互同步,不一起调度它们可能会增加操作的延迟。 例如,在自旋循环中,一个线程等待被另一个线程调度。 为了获得最佳性能,ESXi 尝试将尽可能多的同级 vCPU 一起调度。 但是,当有多个虚拟机在整合环境中争用 CPU 资源时,CPU 调度器可以灵活地调度 vCPU。 如果一些 vCPU 的进展比同级 vCPU 领先太多(这个时间差称为偏移),领先的 vCPU 将决定是否停止自身(协同停止)。 请注意,协同停止(或协同启动)的是 vCPU,不是整个虚拟机。 这种机制即使在资源有些过载的情况下也非常有效,但正如您所预期,CPU 资源过载太多将不可避免地影响性能。 我在后面的示例 2 中展示了一个过载和协同停止的例子。
记住,这不是虚拟机之间全力争夺 CPU 资源的竞赛;ESXi CPU 调度器的工作是确保 CPU 共享、保留和限制等策略被遵守,同时最大限度地提高 CPU 利用率,并确保公平性、吞吐量、响应速度和可伸缩性。 关于使用保留和共享来确定生产工作负载优先级的讨论不在本帖范围之内,而且取决于应用程序和工作负载组合。 如果我以后发现任何特定于 Caché 的建议,我可能会重新讨论这个话题。 有许多因素会影响到 CPU 调度器,本节只是简单提一下。 要深入了解,请参见帖子末尾的参考资料中的 VMware 白皮书及其他链接。
# 示例
为了说明不同的 vCPU 配置,我使用一个基于浏览器的高事务速率医院信息系统应用程序运行了一系列基准测试。 与 VMware 开发的 DVD 商店数据库基准测试的概念类似。
基准测试的脚本是根据现场医院实施的观测值和指标创建的,包括高使用率的工作流程、事务和使用最多系统资源的组件。 其他主机上的驱动虚拟机以设置的工作流程事务速率执行具有随机输入数据的脚本,来模拟 Web 会话(用户)。 1 倍速率的基准为基线。 速率可以按比例递增和递减。
除了数据库和操作系统指标外,一个很好的用来衡量基准数据库虚拟机性能的指标是在服务器上测量的组件(也可以是事务)响应时间。 一个组件示例是一部分最终用户屏幕。 组件响应时间增加意味着用户将开始看到应用程序响应时间变差。 性能良好的数据库系统必须为最终用户提供_一致的_高性能。 在下面的图表中,我针对一致的测试性能进行测量,并通过对 10 个最慢的高使用率组件的响应时间取平均值来表示最终用户体验。 预计平均组件响应时间为亚秒级,用户屏幕可能由一个组件组成,或者复杂的屏幕可能有多个组件。
> 请记住,您始终针对峰值工作负载进行规模调整,并且为意外的活动峰值留出缓冲区。 我通常以平均 80% 的峰值 CPU 利用率为目标。
基准测试硬件和软件的完整列表在帖子末尾。
## 示例 1. 合理调整规模 - 每个主机一个怪兽虚拟机
可以创建一个可以使用主机服务器所有物理核心的数据库虚拟机,例如 24 物理核心主机上的 24 vCPU 虚拟机。 数据库虚拟机不会在 Caché 数据库镜像中“裸机”运行服务器以实现 HA,也不会引入操作系统故障转移集群的复杂性,而是包含在 vSphere 集群中实现管理和 HA,例如 DRS 和 VMware HA。
我见过有客户遵循老派的思维,根据五年硬件寿命结束时的预期容量来确定主数据库虚拟机的规模,但从上文可知,最好合理调整规模;如果虚拟机没有过度调整,性能和整合度会更好,并且管理 HA 将更容易;如果需要维护或主机出现故障,并且数据库怪兽虚拟机必须迁移或在其他主机上重启,想想俄罗斯方块的玩法就知道了。 如果预计事务速率显著增加,可以在计划维护期间提前增加 vCPU。
> 注意,“热添加”CPU 选项会禁用 vNUMA,因此不要将其用于怪兽虚拟机。
考虑下图显示的在 24 核主机上进行的一系列测试。 对于这个 24 核系统,3 倍事务速率是甜蜜点和容量规划目标。
- 主机上运行一个虚拟机。
- 使用了四种虚拟机规模来展示 12、24、36 和 48 vCPU 的性能。
- 尽可能对每种虚拟机规模都运行一系列事务速率(1 倍、2倍、3 倍、4 倍、5 倍)。
- 性能/用户体验以组件响应时间(条形图)的形式显示。
- 客户机虚拟机的 CPU 利用率百分比为平均值(线条)。
- 所有虚拟机规模中,主机 CPU 利用率都在 4 倍速率时达到 100%(红色虚线)。

这个图表中有许多信息,但我们可以关注几个有趣的事情。
- 24 vCPU 虚拟机(橙色)平稳地增加到目标 3 倍事务速率。 在 3 倍速率时,客户机内虚拟机的平均 CPU 利用率为 76%(峰值为 91% 左右)。 主机 CPU 利用率并不比客户机虚拟机高多少。 在 3 倍速率之前,组件响应时间非常稳定,因此用户很满意。 就我们的目标事务速率而言 — _这个虚拟机已合理调整规模_。
关于合理规模调整先说这么多,那么增加 vCPU 也就是使用超线程又会如何。 性能和可伸缩性有可能翻倍吗? 简短回答是_不可能!_
在这种情况下,可以通过查看 4 倍以上速率的组件响应时间来了解答案。 虽然在分配了更多逻辑核心 (vCPU) 后性能“更好”,但仍然不平稳,不像 3 倍速率之前那样一致。 4 倍速率时,用户将报告响应时间变慢,无论分配多少个 vCPU。 请记住,在 4 倍速率时,_主机_曲线已经持平于 100% CPU 利用率,如 vSphere 所报告。 在 vCPU 数量较多的情况下,即使客户机内 CPU 指标 (vmstat) 报告低于 100% 利用率,对于物理资源来说情况也并非如此。 请记住,客户机操作系统不知道它是虚拟化的,它只是报告它所看到的资源。 另外,客户机操作系统也看不到超线程,所有 vCPU 都表现为物理核心。
关键是,数据库进程(在 3 倍事务速率时有 200 多个 Caché 进程)非常繁忙,并且非常高效地使用处理器,逻辑处理器没有很多空闲资源来调度更多工作,或将更多虚拟机整合到该主机。 例如,很大一部分 Caché 处理是在内存中进行的,因此没有很多 IO 等待。 所以,虽然可以分配比物理核心更多的 vCPU,但由于主机已经被 100% 利用,并不会获益许多。
Caché 非常擅长处理高工作负载。 即使主机和虚拟机的 CPU 利用率达到 100%,应用程序仍在运行,并且事务速率仍在提高 — 扩展不是线性的,如我们所见,响应时间越来越长,用户体验将受到影响 — 但应用程序不会“一落千丈”,尽管情况不是很好,但用户仍可以工作。 如果您的应用程序对响应时间不是那么敏感,那么很高兴地告诉您,您可以将其推向边缘甚至更远,并且 Caché 仍然可以安全地工作。
> 请记住,您不会想要以 100% CPU 运行数据库虚拟机或主机。 您需要容量来应对虚拟机的意外峰值和增长,而 ESXi 虚拟机监控程序需要资源来进行所有网络、存储和其他活动。
我总是针对 80% CPU 利用率的峰值进行规划。 即便如此,vCPU 的规模最多也只调整到物理核心数,这样即使在极端情况下,仍然有余量让 ESXi 虚拟机监控程序处理逻辑线程。
> 如果您运行超融合 (HCI) 解决方案,还必须考虑主机级别的 HCI CPU 要求。 有关详细信息,请参见我[先前关于 HCI](https://community.intersystems.com/post/intersystems-data-platforms-and-performance-%E2%80%93-part-8-hyper-converged-infrastructure-capacity "previous post on HCI") 的帖子。 部署在 HCI 上的虚拟机的基本 CPU 规模调整与其他虚拟机相同。
请记住,您必须在您自己的环境中使用您的应用程序验证和测试所有内容。
## 示例 2. 资源过载
我看到过客户站点报告应用程序性能“慢”,而客户机操作系统却报告有空闲的 CPU 资源。
记住,客户机操作系统并不知道它是虚拟化的。 不幸的是,客户机内指标(例如 vmstat 在 pButtons 中报告的指标)可能具有欺骗性,您还必须获得主机级指标和 ESXi 指标(例如 `esxtop`)才能真正了解系统运行状况和容量。
如上面的图表所示,当主机报告 100% 利用率时,客户机虚拟机可能报告较低的利用率。 36 vCPU 虚拟机(红色)在 4 倍速率时报告 80% 平均 CPU 利用率,而主机报告 100%。 即使规模调整合理的虚拟机也可能出现资源短缺的情况,例如,如果在启动后有其他虚拟机迁移到主机上,或者由于 DRS 规则配置不当而导致资源过载。
为了显示关键指标,在下面的一系列测试中,我进行了以下配置:
- 主机上运行两个数据库虚拟机。
- - 一个 24 vCPU 虚拟机以恒定的 2 倍事务速率运行(图表上未显示)。
- - 一个 24 vCPU 虚拟机以 1 倍、2 倍、3 倍事务速率运行(图表上显示这些指标)。
在另一个数据库使用资源的情况下;在 3 倍速率时,客户机操作系统 (RHEL 7) vmstat 只报告 86% 平均 CPU 利用率,运行队列大小平均只有 25。 然而,该系统的用户将大声抱怨,因为组件响应时间随着进程变慢而迅速增加。
如下图所示,协同停止和就绪时间说明了为什么用户性能如此糟糕。 就绪时间 (`%RDY`) 和协同停止 (`%CoStop`) 指标显示 CPU 资源在目标 3 倍速率下大幅过载。 这实际并不奇怪,因为_主机_以 2 倍速率运行(其他虚拟机),_而_该数据库虚拟机以 3 倍速率运行。

该图表明,当主机上的 总 CPU 负载增加时,就绪时间也会增加。
> 就绪时间是指虚拟机已准备好运行,但由于 CPU 资源不可用而无法运行的时间。
协同停止也会增加。 没有足够的空闲逻辑 CPU 来允许数据库虚拟机运行(正如我在上面的超线程部分详细说明的那样)。 最终结果是由于对物理 CPU 资源的争用而导致处理延迟。
我曾在一个客户站点看到过这种情况,当时通过 pButtons 和 vmstat 获取的支持视图只显示了虚拟化的操作系统。 虽然 vmstat 报告还有 CPU 余量,但用户的性能体验非常糟糕。
这里的教训是,直到 ESXi 指标和主机级视图可用,才能诊断出真正的问题;一般的集群 CPU 资源短缺导致的 CPU 资源过载,以及使情况变得更糟的不良 DRS 规则,会使高事务数据库虚拟机一起迁移并使主机资源不堪重负。
## 示例 3. 资源过载
在此示例中,我使用了一个以 3 倍事务速率运行的基准 24 vCPU 数据库虚拟机,然后使用两个以恒定 3 倍事务速率运行的 24 vCPU 数据库虚拟机。
虚拟机的平均基准 CPU 利用率(见上面的示例 1)为 76%,主机则为 85%。 单个 24 vCPU 数据库虚拟机会使用全部 24 个物理处理器。 运行两个 24 vCPU 虚拟机意味着这两个虚拟机将争用资源,并使用服务器上的全部 48 个逻辑执行线程。

请记住,在运行单个虚拟机时,主机并没有被 100% 利用,我们仍然可以看到,当两个非常繁忙的 24 vCPU 虚拟机试图使用主机上的 24 个物理核心(即使开启了超线程)时,吞吐量和性能显著下降。 尽管 Caché 非常有效地使用了可用的 CPU 资源,但每个虚拟机的数据库吞吐量仍然下降了 16%,更重要的是,组件(用户)响应时间增加了 50% 以上。
## 总结
本帖的目的是回答几个常见问题。 要深入了解 CPU 主机资源和 VMware CPU 调度器,请参见下面的参考部分。
虽然有许多专业级的调整,并且要深入研究 ESXi 才能榨干系统的最后一点性能,但基本规则非常简单。
对于_大型生产数据库_:
- 为每个物理 CPU 核心规划一个 vCPU。
- 考虑 NUMA 并按理想情况调整虚拟机规模,以使 CPU 和内存对于 NUMA 节点是本地的。
- 合理调整虚拟机规模。 仅在需要时才添加 vCPU。
如果您想要整合虚拟机,请记住,大型数据库非常繁忙,在高峰期会大量使用 CPU(物理和逻辑)。 在您的监视系统告诉您安全之前,不要超额预定 CPU。
## 参考
- [VMware 博客 - 怪兽虚拟机何时过载 vCPU:pCPU](https://blogs.vmware.com/vsphere/2014/02/overcommit-vcpupcpu-monster-vms.html)
- [2016 NUMA 深入研究系列介绍](http://frankdenneman.nl/2016/07/06/introduction-2016-numa-deep-dive-series)
- [VMware vSphere 5.1 中的 CPU 调度器](http://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/techpaper/vmware-vsphere-cpu-sched-performance-white-paper.pdf)
## 测试
我在一个 vSphere 集群上运行了本帖中的示例,该集群包括连接到一个全闪存阵列的双处理器 Dell R730。 在示例运行期间,网络或存储没有出现瓶颈。
- Caché 2016.2.1.803.0
PowerEdge R730
- 2 个 Intel(R) Xeon(R) CPU E5-2680 v3 @ 2.50GHz
- 16 条 16GB RDIMM,2133 MT/s,双列,x4 数据宽度
- SAS 12Gbps HBA 外部控制器
- 超线程 (HT) 开启
PowerVault MD3420,12G SAS,2U-24 驱动器
- 24 个 960GB 固态硬盘 SAS 读取密集型 MLC 12Gbps 2.5 英寸热拔插驱动器,PX04SR
- 2 个控制器,12G SAS,2U MD34xx,8G 缓存
VMware ESXi 6.0.0 build-2494585
- 按照最佳实践配置虚拟机;VMXNET3、PVSCSI 等
RHEL 7
- 大页面
基准 1 倍速率下平均每秒 700,000 gloref(每秒数据库访问次数)。 24 vCPU 在 5 倍速率下平均每秒超过 3,000,000 gloref。 测试以老化方式进行,直到达到稳定的性能,然后进行 15 分钟采样并取平均值。
> 这些示例只是为了说明理论,您必须使用自己的应用程序进行验证!
文章
姚 鑫 · 七月 5, 2021
[toc]
# 第二十八章 定制SAX解析器创建自定义内容处理程序
# 创建自定义内容处理程序
如果直接调用InterSystems IRIS SAX解析器,则可以根据自己的需要创建自定义内容处理程序。本节讨论以下主题:
- Overview
- 要在内容处理程序中自定义的方法的描述
- `%XML.SAX.Parser`类中解析方法的参数列表摘要
- 示例
## 创建自定义内容处理程序概述
要定制InterSystems IRIS SAX解析器导入和处理XML的方式,请创建并使用定制的SAX内容处理程序。具体地说,创建`%XML.SAX.ContentHandler`的子类。然后,在新类中,重写任何默认方法以执行所需的操作。在解析XML文档时使用新的内容处理程序作为参数;为此,需要使用`%XML.SAX.Parser`类的解析方法。
此操作如下图所示:
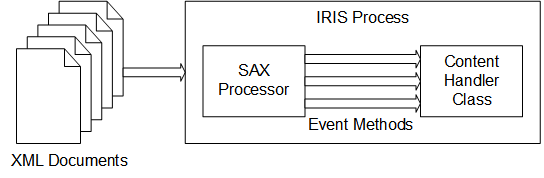
创建和使用自定义导入机制的过程如下:
1. 创建扩展`%XML.SAX.ContentHandler`的类。
2. 在该类中,包括希望覆盖的方法,并根据需要提供新定义。
3. 在使用`%XML.SAX.Parser`的分析方法之一(即`ParseFile()`、`ParseStream()`、`ParseString()`或`ParseURL()`)编写读取XML文档的类方法。
调用分析方法时,请将自定义内容处理程序指定为参数。
## SAX内容处理程序的可定制方法
`%XML.SAX.ContentHandler`类在特定时间自动执行某些方法。通过覆盖它们,您可以自定义内容处理程序的行为。
### 响应事件
`%XML.SAX.ContentHandle`类分析XML文件,并在它到达XML文件中的特定点时生成事件。根据事件的不同,会执行不同的方法。这些方法如下:
- `OnPostParse()` — 在XML解析完成时触发。
- `characters()` — 由字符数据触发。
- `comment()` — 注释触发
- `endCData()` —由CDATA部分的末尾触发。
- `endDocument()` —由文档结尾触发。
- `endDTD()` — 由DTD结束触发。
- `endElement()` —由元素的末尾触发。
- `endEntity()` — 由一个实体的终结触发。
- `endPrefixMapping()` — 由名称空间前缀映射的结束触发。
- `ignorableWhitespace()` — 由元素内容中的可忽略空格触发。
- `processingInstruction()` — 由XML处理指令触发。
- `skippedEntity()` — 被跳过的实体触发。
- `startCData()` —由CDATA部分的开头触发。
- `startDocument()` — 由文档的开头触发。
- `startDTD()` — 由DTD的开头触发。
- `startElement()` — 由元素的开始触发。
- `startEntity()` — 由一个实体的开始触发。
- `startPrefixMapping()` — 由名称空间前缀映射的开始触发。
默认情况下,这些方法是空的,可以在自定义内容处理程序中覆盖它们。
### 处理错误
`%XML.SAX.ContentHandler`类在遇到某些错误时也会执行方法:
- `error()` — 由可恢复的解析器错误触发。
- `fatalError()` — 由致命的XML解析错误触发。
- `warning()` — 由解析器警告通知触发。
默认情况下,这些方法为空,可以在自定义内容处理程序中重写它们。
### 计算事件掩码
当调用InterSystems IRIS SAX解析器(通过`%XML.SAX.Parser`类)时,可以指定一个掩码参数来指示哪些回调是感兴趣的。如果未指定掩码参数,解析器将调用内容处理程序的`Mask()`方法。此方法返回一个整数,该整数指定与内容处理程序的重写方法相对应的复合掩码。
例如,假设创建了一个自定义内容处理程序,其中包含`startElement()`和`endElement()`方法的新版本。在本例中,`Mask()`方法返回一个数值,该数值等于`$$$SAXSTARTELEMENT`和`$$$SAXENDELEMENT`,之和,这两个标志对应于这两个事件。如果没有为解析方法指定掩码参数,则解析器将调用内容处理程序的`Mask()`方法,因此只处理这两个事件。
### 其他有用的方法
`%XML.SAX.ContentHandler`类提供在特殊情况下有用的其他方法:
- `LocatePosition()`-通过引用返回两个参数,这两个参数指示解析的文档中的当前位置。第一个表示行号,第二个表示行偏移。
- `PushHandler()`-在堆栈上推送新的内容处理程序。SAX的所有后续回调都将转到这个新的内容处理程序,直到该处理程序完成处理。
如果在解析一种类型的文档时遇到想要以不同方式解析的一段XML,则可以使用此方法。在本例中,当检测到要以不同方式处理的段时,调用`PushHandler()`方法,该方法将创建一个新的内容处理程序实例。所有回调都会转到此内容处理程序,直到调用`PopHandler()`返回上一个内容处理程序。
- `PopHandler()`-返回堆栈上的上一个内容处理程序。
这些是`final`方法,不能重写。
## SAX解析方法的参数列表
要指定文档源,请使用`%XML.SAX.Parser`类的`ParseFile()`、`ParseStream()`、`ParseString()`或`ParseURL()`方法。在任何情况下,源文档都必须是格式良好的XML文档;也就是说,它必须遵守XML语法的基本规则。完整的参数列表按顺序如下:
1. pFilename, pStream, pString, or pURL — 文档源.
2. pHandler — 内容处理程序,它是`%XML.SAX.ContentHandler`类的实例。
3. pResolver — 分析源时使用的实体解析器。
4. pFlags — 用于控制SAX解析器执行的验证和处理的标志。
5. pMask — 用于指定XML源中感兴趣的项的掩码。通常不需要指定此参数,因为对于`%XML.SAX.Parser`的解析方法,默认掩码为`0`。这意味着解析器调用内容处理程序的`Mask()`方法。该方法通过检测(在编译期间)在事件处理程序中自定义的所有事件回调来计算掩码。只处理那些事件回调。
6. pSchemaSpec — 验证文档源所依据的架构规范。此参数是一个字符串,其中包含以逗号分隔的命名空间/URL对列表:
```
"namespace URL,namespace URL"
```
这里,`Namespace`是用于模式的XML名称空间,`URL`是提供模式文档位置的`URL`。名称空间和`URL`值之间有一个空格字符。
7. pHttpRequest (For the ParseURL() method only) — 这里,`Namespace`是用于模式的XML名称空间,URL是提供模式文档位置的URL。名称空间和URL值之间有一个空格字符。
8. pSSLConfiguration — 客户端`SSL/TLS`配置的配置名称。
注意:请注意,此参数列表与`%XML.TextReader`类的解析方法略有不同。有一点不同,`%XML.TextReader`不提供指定自定义内容处理程序的选项。
## SAX处理程序示例
想要一个文件中出现的所有XML元素的列表。要做到这一点,只需记录每个开始元素。那么这个过程是这样的:
1. 创建一个名为`MyApp.Handler`的类,它扩展`%XML.SAX.ContentHandler`:
```
Class MyApp.Handler Extends %XML.SAX.ContentHandler
{
}
```
2. 使用以下内容覆盖`startElement()`方法:
```
Class MyApp.MyHandler extends %XML.SAX.ContentHandler
{
// ...
Method startElement(uri as %String, localname as %String,
qname as %String, attrs as %List)
{
//we have found an element
write !,"Element: ",localname
}
}
```
3. 将一个类方法添加到读取和分析外部文件的Handler类:
```
Class MyApp.MyHandler extends %XML.SAX.ContentHandler
{
// ...
ClassMethod ReadFile(file as %String) as %Status
{
//create an instance of this class
set handler=..%New()
//parse the given file using this instance
set status=##class(%XML.SAX.Parser).ParseFile(file,handler)
//quit with status
quit status
}
}
```
请注意,这是一个类方法,因为它在应用程序中被调用以执行其处理。此方法执行以下操作:
1. 它创建内容处理程序对象的实例:
```
set handler=..%New()
```
2. 它在一个调用`%XML.SAX.Parser`的`ParseFile()`方法。这将验证并解析文档(由`fileName`指定),并调用内容处理程序对象的各种事件处理方法:
```
set status=##class(%XML.SAX.Parser).ParseFile(file,handler)
```
每次在解析器解析文档时发生事件(如开始或结束元素)时,解析器都会调用内容处理程序对象中的适当方法。在本例中,唯一被覆盖的方法是`startElement()`,它随后写出元素名称。对于其他事件,例如到达`End`元素,不会发生任何事情(默认行为)。
3. 当`ParseFile()`方法到达文件末尾时,它返回。处理程序对象超出作用域,并自动从内存中删除。
4. 在应用程序中的相应点,调用`ReadFile()`方法,将文件传递给解析:
```
Do ##class(Samples.MyHandler).ReadFile(filename)
```
其中,filename是正在读取的文件的路径。
例如,如果文件的内容如下:
```
Edwards,Angela U.
1980-04-19
K8134
Vail
94059
Uberoth,Wilma I.
Wells,George H.
```
则此示例的输出如下所示:
```
Element: Root
Element: Person
Element: Name
Element: DOB
Element: GroupID
Element: HomeAddress
Element: City
Element: Zip
Element: Doctors
Element: Doctor
Element: Name
Element: Doctor
Element: Name
```
# 使用HTTPS
`%XML.SAX.Parser`支持`HTTPS`。也就是说,可以使用此类执行以下操作:
- (对于`ParseURL()`)解析`HTTPS`位置提供的XML文档。
- (对于所有解析方法)解析`HTTPS`位置的实体。
在所有情况下,如果这些项目中的任何一个是`在HTTPS`位置上提供的,请执行以下操作:
1. 使用管理门户创建包含所需连接详细信息的`SSL/TLS`配置。这是一次性的步骤。
2. 调用`%XML.SAX.Parser`的适用解析方法时,请指定`pSSLConfiguration`参数。
默认情况下,InterSystems IRIS使用`Xerces`图元解析。`%XML.SAX.Parser`仅在以下情况下使用其自己的实体解析:
- `PSSLConfiguration`参数非空。
- 已配置代理服务器。
文章
Michael Lei · 七月 4, 2021
大家好, 在本文中,我比较了 Gartner 最新DBMS 魔力象限中的主要领先数据库产品的功能。 请见按现有功能数量排序的列表。 1. InterSystems IRIS 2020.3 - 60 个功能 (https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls) 2. Oracle Database 21c - 54 个功能 (https://docs.oracle.com/en/database/oracle/oracle-database/index.html) 3. Microsoft SQL Server - 45 个功能 (https://docs.microsoft.com/en-us/sql/sql-server/?view=sql-server-ver15) 4. AWS Aurora - PostgreSQL - 34 个功能 (https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/CHAP_AuroraOverview.html) 我只比较了功能,未进行任何性能比较(关于此内容,请参见性能测试:https://cn.community.intersystems.com/post/intersystems-iris%E6%95%B0%E6%8D%AE%E5%B9%B3%E5%8F%B0%EF%BC%9A%E6%95%B0%E6%8D%AE%E6%8E%A5%E6%94%B6%E9%80%9F%E5%BA%A6%E6%B5%8B%E8%AF%95)。 我使用了上面的产品官方文档链接。 请见比较表格: <colgroup><col style="width:245pt" width="327"><col style="width:88pt" width="118"><col style="width:122pt" width="162"><col style="width:150pt" width="200"><col style="width:146pt" width="195"></colgroup>
功能
InterSystemsIRIS 2020.3
OracleDatabase 21c
MicrosoftSQL Server 2020
AWS Aurora -PostgreSQL
故障转移集群
有
有
有
有
镜像/数据复制
有
有
有
有
分布式缓存/内存中支持
有
有
有
有
备份/恢复 - 增量和完整
有
有
有
有
纵向缩放
有
有
有
有
针对 Insert、Update 和 Delete 进行横向缩放
有
有
无
无
针对 Select 进行横向缩放
有
有
有
有
分片集群
有
有
无
有
云支持和云管理器
有
有
有
有
Kubernetes 支持和 Kubernetes 管理器
有
有
有
有
Docker 支持
有
有
有
无
AWS 托管
有
有
有
有
Azure 托管
有
有
有
无
Google Cloud 托管
有
有
有
无
托管云
有
有
有
有
内部部署支持
有
有
有
无
多模型 - OO
有
无
无
无
多模型 - 文档 - JSON
有
有
有
有
多模型 - XML
有
有
有
有
多模型 - 键/值
有
无
无
无
多模型 - SQL
有
有
有
有
多模型 - 空间
无
有
有
有
多模型 - 图表
无
有
有
无
多模型 - OLAP 多维数据集
有
有
有
无
GIS 平台
无
有
无
无
本机 OO 编程语言
有
有
无
无
Java、.Net、Python、C/C++ 和 PHP 支持
有
有
有
有
Node.js 支持
有
有
有
有
ODBC/JDBC 支持
有
有
有
有
后端应用程序开发
有
有
无
无
前端应用程序开发
有
有
无
无
低代码 Web 应用程序开发
无
有
有
无
数据库应用程序开发
有
有
有
有
OData 支持
无
有
有
无
REST 服务
有
有
有
有
SOAP 服务
有
无
无
无
终端工具
有
有
有
有
IDE 支持
有
有
有
有
Web 管理/IDE 支持
有
有
有
有
嵌入 NLP
有
无
无
无
嵌入 AutoML
有
无
无
无
R/机器学习支持
有
有
有
有
PMML
有
无
无
无
业务报表服务器/开发
有
有
有
无
自主 AI 操作
无
有
无
无
非结构化文本注释/类似 Apache UIMA
有
有
无
无
Spark 支持
有
有
有
有
BI 工具
有
无
有
无
MDX 支持
有
有
有
无
互操作性连接器
有
无
无
无
BPEL/集成编排/工作流
有
无
无
无
ETL - 提取、转换和加载数据
有
无
无
无
IoT/MQTT 支持
有
无
无
无
EDI 支持
有
无
无
无
ESB
有
无
无
无
CDC - 变更数据捕获
有
有
有
有
RBAC 模型
有
有
有
有
LDAP 支持
有
有
有
有
双因素授权/身份验证支持
有
有
有
有
加密
有
有
有
有
标记
有
有
有
无
审计和跟踪
有
有
有
有
SAM
有
有
有
有
多操作系统支持
有
有
有
有
SAML/Oauth/OpenID 支持
有
有
有
有
性能调整 IDE/包
无
有
无
无
特权用户访问管理
无
有
无
无
API 管理
有
无
无
无
功能总数
61
54
45
34
文章
Michael Lei · 七月 4, 2021
(ECP) Caché 出色的可用性和扩展特性之一是企业缓存协议 (ECP)。 在应用程序开发过程中,如对使用 ECP 的分布式处理加以考虑,可以横向扩展 Caché 应用程序的架构。 应用程序处理可以调整为非常高的速率,处理能力从单个应用程序服务器扩展到最多 255 个应用程序服务器,并且不需要任何应用程序更改。
在我参与的 TrakCare 部署中,ECP 已广泛使用多年。 十年前,主要供应商之一的一台“大型”x86 服务器可能总共只有八个核心。 对于大型部署来说,ECP 是横向扩展商业服务器处理能力的方式,不适合单台昂贵的大型企业服务器。 即使是高核心数的企业服务器也有限制,因此 ECP 也用于扩展这些服务器上的部署。
如今,大多数的新 TrakCare 部署或升级到当前硬件_不需要 ECP_ 即可扩展。 目前的双插槽 x86 生产服务器可以拥有数十个核心和巨大容量的内存。 我们看到,在最近的 Caché 版本中,TrakCare 以及许多其他 Caché 应用程序具有可预测的线性扩展能力,能够随着单台服务器中 CPU 核心数量和内存的增加而支持逐渐增多的用户和事务。 在现场,我看到大多数的新部署都是虚拟化的,即使如此,虚拟机也可以根据需要扩展到主机服务器的规模。 如果资源需求超过单个物理主机可以提供的资源,则使用 ECP 进行横向扩展。
- ___提示:___ _为了简化管理和部署规模,在部署 ECP 之前,先在单台服务器内扩展。_
在本帖中,我将展示一个示例架构以及 ECP 工作原理的基础知识,然后评论性能注意事项,重点是存储。
有关配置 ECP 和应用程序开发的具体信息,请参见在线的 [Caché 分布式数据管理指南](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GDDM),并且[社区上有一个 ECP 学习轨迹](https://community.intersystems.com/learning-track/enterprise-cache-protocol-ecp-videos)。
ECP 的其他关键特性之一是提高了应用程序可用性,有关详细信息,请参见 [Caché 高可用性指南](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GHA_ecp)中的 ECP 部分。
[本系列其他帖子的列表](https://cn.community.intersystems.com/post/intersystems-数据平台的容量规划和性能系列文章)
# ECP 架构基础知识
ECP 的架构和运行在概念上很简单,ECP 提供了在多个服务器系统之间有效共享数据、锁定和可执行代码的方法。 从应用程序服务器角度看,数据和代码远程存储在_数据服务器_上,但缓存在_应用程序服务器_的本地内存中,以提供对活动数据的有效访问,同时尽可能减少网络流量。
数据服务器管理对磁盘上持久性存储的数据库读写,而多个应用程序服务器是解决方案的主力,执行大多数应用程序处理。
## 多层架构
ECP 采用多层架构。 描述处理层和它们扮演的角色有多种不同的方式,以下是我在描述基于 Web 浏览器的 Caché 应用程序时发现很有用的方式,也是我的帖子的模型和术语。 我知道可能有不同的方法来细分层级,但现在先使用我的方法 :)
基于浏览器的应用程序(例如 Caché Server Pages (CSP))使用多层架构,其中表示、应用程序处理和数据管理功能在逻辑上是分开的。 具有不同角色的__逻辑__“服务器”填充各层。 逻辑服务器不必保留在单独的物理主机或虚拟服务器上,出于成本效益和可管理性的考虑,部分甚至全部逻辑服务器可能位于单个主机或操作系统实例上。 随着部署规模的扩展,服务器可以通过 ECP 划分到多个物理或虚拟主机上,从而可根据需要分散处理工作负载,而无需更改应用程序。
主机系统可以是物理的或虚拟化的,具体取决于容量和可用性要求。 以下层和逻辑服务器构成了一个部署:
- _表示层:_包括在基于浏览器的客户端和应用程序层之间充当网关的 Web 服务器。
- _应用程序层:_这是 ECP 应用程序服务器所在的位置。 如上文所述,这是一个逻辑模型,其中应用程序服务器不必与数据服务器分开,而且除了最大型的站点外,所有情况下通常都不需要分开。 该层还可能包括进行专门处理的其他服务器,如报告服务器。
- _数据层:_这是数据服务器所在的位置。 数据服务器执行事务处理,是存储在 Caché 数据库中的应用程序代码和数据存储库。 数据服务器负责读写持久性磁盘存储。
## 逻辑架构
下图是一个基于浏览器的应用程序在部署为三层架构时的逻辑视图:
尽管初看之下该架构可能很复杂,但构成它的组件仍然与安装在单台服务器上的 Caché 系统的组件相同,只是逻辑组件安装在多个物理或虚拟服务器上。 服务器之间的所有通信都通过 TCP/IP 进行。
### 逻辑视图中的 ECP 操作
上图从顶部开始,显示用户安全地连接到多个已进行负载平衡的 Web 服务器。 这些 Web 服务器在客户端和应用程序层(应用程序服务器)之间传递 CSP 网页请求,应用程序层进行所有处理,允许动态创建内容,并通过 Web 服务器将完成的页面返回给客户端。
在这个三层模型中,应用程序处理通过 ECP 分散到多个应用程序服务器上。 应用程序只将数据(您的应用程序数据库)视为应用程序服务器的本地数据。
当应用程序服务器发出数据请求时,它将尝试从本地缓存满足请求,如果不能满足,ECP 将向数据服务器请求必要的数据,数据服务器自己的缓存可能会满足请求,否则将从磁盘获取数据。 数据服务器对应用程序服务器的回复包括存储该数据的数据库块。 这些块将被使用,并且此时将缓存到应用程序服务器上。 ECP 自动负责管理整个网络中的缓存一致性,并将变化传播回数据服务器。 客户端会体验到快速响应,因为它们经常使用本地缓存的数据。
默认情况下,Web 服务器与首选的应用程序服务器通信,确保同一应用程序服务器满足相关数据的后续请求,因为这些数据可能已经在本地缓存中。
- ___提示:___ _如 [Caché 文档](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GDDM_develop#GDDM_develop_considerations)中详述,在循环或负载平衡方案中,应避免用户连接到应用程序服务器,因为这会影响应用程序服务器上缓存的优势。 理想情况下,相同的用户或用户组保持连接到同一应用程序服务器。_
该解决方案通过在表示层添加 Web 服务器和在应用程序层添加其他应用程序服务器来进行扩展,无需用户停机。 数据层通过增加数据服务器的 CPU 和内存来进行扩展。
## 物理架构
下图显示了与三层逻辑架构示例相同的三层部署中使用的物理主机示例:
请注意,在每一层部署物理或虚拟主机时均采用 n+1 或 n+2 模式,以确保在主机故障或计划维护时保持 100% 能力。 由于用户分布在多个 Web 和应用程序服务器上,单个服务器故障只会影响少量用户,他们会自动重新连接到其余服务器之一。
数据管理层具有高度可用性,例如,位于连接到一个或多个存储阵列的故障转移集群上(例如,虚拟化 HA、InterSystems 数据库镜像或传统的故障转移集群)。 如果硬件或服务出现故障,集群将在其中一个幸存节点上重启服务。 ECP 的一个附加好处是内置弹性,并且在数据库节点集群发生故障转移时能保持事务完整性,应用程序用户将观察到处理暂停,直到故障转移和自动恢复完成,随后用户将无缝继续,不会断开连接。
同样的架构也可以映射到虚拟化服务器,例如,VMware vSphere 可用于虚拟化应用程序服务器。
# ECP 容量规划
如上文所述,数据服务器管理对持久性磁盘的数据库读写,而多个应用程序服务器是解决方案的主力,执行大多数应用程序处理。 这是考虑系统资源容量规划时的一个关键概念,总结来说:
- ___数据服务器___(有时称为数据库服务器)通常执行很少的应用程序处理,因此_对 CPU 要求低_,但该服务器执行大部分存储 IO,因此可能有_非常高的存储 IOPS_,即数据库读写以及日志写入(稍后将详细介绍日志 IO)。
- ___应用程序服务器___执行大多数应用程序处理,因此_对 CPU 要求高_,但存储 IO 非常少。
通常,调整 ECP 服务器 CPU、内存和 IO 要求的规则与调整非常大的单服务器解决方案的规则相同,同时考虑 N+1 或 N+2 台服务器以确保高可用性。
## 基本 CPU 和存储规模调整:
假设 My_Application 需要最多 72 个 CPU 核心进行应用程序处理(记得还要考虑余量),并且预计在写入守护进程周期期间需要 20,000 次写入,以及 10,000 次随机数据库读取的持续峰值。
一个简单的虚拟或物理服务器规模调整方案为:
- 4 台 32 CPU 应用程序服务器(3 台服务器 + 1 台服务器用于确保 HA)。 低 IOPS 要求。
- 2 台 10 CPU 数据服务器(镜像或集群以确保 HA)。 [低延迟 IOPS 要求](https://cn.community.intersystems.com/post/数据平台和性能-第-6-部分-caché-存储-io-配置文件)为 20K 写入、10K 读取,加上 WIJ 和日志。
虽然数据服务器只执行非常少的处理,但考虑到系统和 Caché 进程,将其规模调整为 8-10 个 CPU。 应用程序服务器的规模可以根据每台物理主机的最佳性价比和/或可用性来进行调整。 横向扩展时会有一些效率损失,但通常可以在服务器块中增加处理能力,并预计吞吐量有近乎线性的增长。 限制更有可能首先在存储 IO 中出现。
- ___提示:____与确保 HA 一样,要考虑主机、机箱或机架故障的影响。 在 VMWare 上虚拟化应用程序和数据服务器时,确保应用 vSphere DRS 和相关性规则以分散处理负载并确保可用性。_
## 日志同步 IO 要求
ECP 部署的另一个容量规划注意事项是,由于日志同步,它们需要较高 IO,并且对存储响应时间的要求非常严格,以保持数据服务器上日志记录的可伸缩性 。 同步请求可以触发对日志中最后一个块的写入,以确保数据耐久性。
不过您的情况可能有所不同;在一个典型的以高事务处理速率运行的客户站点上,我经常看到非 ECP 配置上的日志写入 IOPS 为每秒十几次。 在繁忙的系统上使用 ECP 时,由于 ECP 强制日志同步,可以在日志磁盘上看到 100 到 1000 的写入 IOPS。
- ___提示:____如果在繁忙的系统上显示 mgstat 或查看 [pButtons](https://cn.community.intersystems.com/post/intersystems-数据平台和性能-–-第-1-篇) 中的 mgstat,您将看到 Jrnwrts(日志写入次数),您将在存储 IO 资源规划中对其加以考虑。 在 ECP 数据服务器上,还有未显示在 mgstat 中的对日志磁盘的日志同步写入,要了解这些信息,您需要查看日志磁盘的操作系统指标,例如使用 iostat 查看_。
### 什么是日志同步?
需要日志同步的原因:
- 确保在数据服务器发生故障时数据的耐久性和可恢复性。
- 它们也是确保应用程序服务器之间的缓存一致性的触发器。
在非 ECP 配置中,对 Caché 数据库的修改将写入日志缓冲区(128 x 64K 缓冲区),当日志缓冲区满时或每两秒由日志守护程序写入磁盘上的日志文件。 Caché 为整个缓冲区分配 64k,并且这些缓冲区总是被重复使用,而不是被销毁和重新创建,Caché 只是跟踪末尾偏移量。 在大多数情况下(除非一次进行大量更新),日志写入次数非常小。
ECP 系统中也有日志同步。 日志同步可以定义为将当前日志缓冲区的相关部分重新写入磁盘,以确保磁盘上的日志始终是最新的。 因此,日志同步会请求多次重新写入同一日志块的某个部分(大小在 2k 到 64k 之间)。
ECP 客户端上可以触发日志同步请求的事件为更新(SET 或 KILL)或 LOCK。 例如,对于每个 SET 或 KILL,都会将当前日志缓冲区写入(或重新写入)磁盘。 在非常繁忙的系统中,单次同步操作中的日志同步可能被捆绑或延迟为多个同步请求。
### 日志同步的容量规划
为确保持续的吞吐量,日志同步的平均写入响应时间必须:
- _
文章
姚 鑫 · 七月 4, 2021
# 第二十七章 定制SAX解析器的执行自定义实体解析
# 执行自定义实体解析
XML文档可能包含对外部DTD或其他实体的引用。默认情况下,InterSystems IRIS尝试查找这些实体的源文档并解析它们。要控制InterSystems IRIS解析外部实体的方式,请使用以下步骤:
1. 定义实体解析程序类。
此类必须在扩展`%XML.SAX.EntityResolver`,并且必须实现 `resolveEntity()`方法,该方法具有以下签名:
```java
method resolveEntity(publicID As %Library.String, systemID As %Library.String) as %Library.Integer
```
每当XML处理器找到对外部实体(如DTD)的引用时,就会调用该方法;这里的public ID和systemID是该实体的Public和系统标识符字符串。
该方法应获取实体或文档,将其作为流返回,然后在将流包装在`%XML.SAX.StreamAdapter`的实例中。此类提供了用于确定流特征的必要方法。
如果无法解析该实体,则该方法应返回`$$$NULLOREF` ,以向SAX解析器指示该实体无法解析)。
尽管方法签名指示返回值为`%Library.Integer`,但该方法应返回`%XML.SAX.StreamAdapter`的实例或该类的子类。
此外,引用外部实体的标识符始终传递给文档中指定的`resolveEntity()`方法。具体地说,如果这样的标识符使用相对URL,则该标识符将作为相对URL传递,这意味着引用文档的实际位置不会传递给`resolveEntity()`方法,并且无法解析该实体。在这种情况下,请使用默认实体解析器,而不是自定义实体解析器。
2. 读取XML文档时,请执行以下操作:
a. 创建实体解析程序类的实例。
b. 读取XML文档时使用该实例,如本章前面的“指定解析器选项”中所述。
## 示例
例如,以下XML文档:
```xml
Some < xhtml-content > with custom entities &entity1; and &entity2;.
Here is another paragraph with &entity1; again.
```
本文档使用以下DTD:
```xml
```
要阅读本文档,需要如下所示的自定义实体解析器:
```java
Class CustomResolver.Resolver Extends %XML.SAX.EntityResolver
{
Method resolveEntity(publicID As %Library.String, systemID As %Library.String) As %Library.Integer
{
Try {
Set res=##class(%Stream.TmpBinary).%New()
//check if we are here to resolve a custom entity
If systemID="http://www.intersystems.com/xml/entities/entity1"
{
Do res.Write("Value for entity1")
Set return=##class(%XML.SAX.StreamAdapter).%New(res)
}
Elseif systemID="http://www.intersystems.com/xml/entities/entity2"
{
Do res.Write("Value for entity2")
Set return=##class(%XML.SAX.StreamAdapter).%New(res)
}
Else //otherwise call the default resolver
{
Set res=##class(%XML.SAX.EntityResolver).%New()
Set return=res.resolveEntity(publicID,systemID)
}
}
Catch
{
Set return=$$$NULLOREF
}
Quit return
}
}
```
下面的类包含一个demo方法,该方法解析前面显示的文件并使用此自定义解析器:
```java
Include (%occInclude, %occSAX)
Class CustomResolver.ParseFileDemo
{
ClassMethod ParseFile()
{
Set res= ##class(CustomResolver.Resolver).%New()
Set file="c:/temp/html.xml"
Set parsemask=$$$SAXALLEVENTS+$$$SAXERROR
Set status=##class(%XML.TextReader).ParseFile(file,.textreader,res,,parsemask,,0)
If $$$ISERR(status) {Do $system.OBJ.DisplayError(status) Quit }
Write !,"Parsing the file ",file,!
Write "Custom entities in this file:"
While textreader.Read()
{
If textreader.NodeType="entity"{
Write !, "Node:", textreader.seq
Write !," name: ", textreader.Name
Write !," value: ", textreader.Value
}
}
}
}
```
下面显示了此方法在终端会话中的输出:
```java
GXML>d ##class(CustomResolver.ParseFileDemo).ParseFile()
Parsing the file c:/temp/html.xml
Custom entities in this file:
Node:13
name: entity1
value: Value for entity1
Node:15
name: entity2
value: Value for entity2
Node:21
name: entity1
value: Value for entity1
```
## 示例2
例如,读取包含以下内容的XML文档:
```xml
```
在本例中,将在`publicId`设置为 `-//OASIS//DTD DocBook XML V4.1.2//EN`并将`systemId`设置为`c:\test\doctypes\docbook\docbookx.dtd.`的情况下调用`resolveEntity`方法。
`resolveEntity`方法确定外部实体的正确源,将其作为流返回,并将其包装在`%XML.StreamAdaptor`的实例中。XML解析器从这个专用流中读取实体定义。
例如,请参考InterSystems IRIS库中包含的`%XML.Catalog`和`%XML.CatalogResolverclass。%XML.Catalog`类定义一个简单的数据库,该数据库将公共和系统标识符与URL相关联。`%XML.CatalogResolver`类是一个实体解析器类,它使用此数据库查找给定标识符的URL。`%XML.Catalogclass`可以从SGML样式的编录文件加载其数据库;该文件将标识符映射到标准格式的URL。
文章
姚 鑫 · 七月 3, 2021
# 第二十六章 定制 SAX解析器的使用方式
每当InterSystems IRIS读取XML文档时,它都会使用InterSystems IRIS SAX(Simple API For XML)解析器。本章介绍用于控制系统间IRIS SAX解析器的选项。
# 关于IRIS SAX解析器
每当InterSystems IRIS读取XML文档时,都会使用InterSystems IRIS SAX解析器。
它是一个事件驱动的XML解析器,读取XML文件,并在找到感兴趣的项(如XML元素的开始、DTD的开始等)时发出回调。
(更准确地说,解析器与内容处理程序协同工作,内容处理程序发出回调。只有在自定义SAX接口时,此区别才很重要,如本章后面的“创建自定义内容处理程序”中所述。)
解析器使用标准Xerces-C++库,该库符合`XML1.0`推荐标准和许多相关标准。
# 可用的解析器选项
可以通过以下方式控制SAX解析器的行为:
- 可以设置标志来指定要执行的验证和处理类型。
请注意,解析器始终检查文档是否为格式良好的XML文档。
- 可以指感兴趣的事件(即希望解析器查找的项目)。为此,需要指定一个掩码来指示感兴趣的事件。
- 可以提供验证文档所依据的架构规范。
- 可以使用特殊用途的实体解析器禁用实体解析。
- 可以指定实体解析的超时期限。
- 如果需要控制解析器如何查找文档中任何实体的定义,则可以指定更通用的自定义实体解析器。
- 如果通过URL访问源文档,则可以将发送到Web服务器的请求指定为%Net.HttpRequest的实例。
- 可以指定自定义内容处理程序。
- 可以使用HTTPS。
可用的选项取决于如何使用InterSystems IRIS SAX Parser,如下表所示:
%XML类中的SAX解析器选项
Option | %XML.Reader | %XML.TextReader |%XML.XPATH.Document | %XML.SAX.Parser
---|---|---|---|---
指定解析器标志 |supported |supported| supported| supported
指定感兴趣的解析事件(例如,元素的开始、元素的结束、注释)| not supported| supported| not supported| supported
指定模式规范| supported| supported| supported| supported
禁用实体解析或以其他方式定制实体解析| supported| supported| supported| supported
指定自定义HTTP请求(如果解析URL)| not supported| supported| not supported |supported
指定内容处理程序| not supported| not supported| not supported| supported
在HTTPS位置解析文档| supported| not supported| not supported| supported
解析HTTPS位置上的实体| not supported| not supported| not supported| supported
# 指定解析器选项
指定不同的解析器行为取决于你如何使用InterSystems IRIS SAX解析器:
- 如果使用`%XML.Reader`,可以设置阅读器实例的`Timeout`、`SAXFlags`、`SAXSchemaSpec`和`EntityResolver`属性。
例如:
```java
#include %occInclude
#include %occSAX
// set the parser options we want
Set flags = $$$SAXVALIDATION
+ $$$SAXNAMESPACES
+ $$$SAXNAMESPACEPREFIXES
+ $$$SAXVALIDATIONSCHEMA
Set reader=##class(%XML.Reader).%New()
Set reader.SAXFlags=flags
```
这些宏是在`%occSAX`中定义的。公司包含文件。
- 在其他情况下,指定所使用方法的参数。例如:
```java
#include %occInclude
#include %occSAX
//set the parser options we want
Set flags = $$$SAXVALIDATION
+ $$$SAXNAMESPACES
+ $$$SAXNAMESPACEPREFIXES
+ $$$SAXVALIDATIONSCHEMA
Set status=##class(%XML.TextReader).ParseFile(myfile,.doc,,flags)
```
# 设置解析器标志
`%occSAX.inc` include文件列出了可用于控制`Xerces`解析器执行的验证的标志。基本标志如下:
- `$$$SAXVALIDATION` -是否执行模式验证。如果此标志为开启(默认值),则报告所有验证错误。
- `$$$SAXNAMESPACES`-指定是否识别命名空间。如果此标志为ON(默认值),解析器将处理命名空间。如果此标志为OFF,InterSystems IRIS会导致`%XML.SAX.ContentHandler`的`startElement()`回调中元素的`localname`为空字符串。
- `$$$SAXNAMESPACEPREFIXES`-指定是否处理命名空间前缀。如果此标志为`ON`,解析器将报告用于名称空间声明的原始前缀名称和属性。默认情况下,此标志处于关闭状态。
- `$$$SAXVALIDATIONDYNAMIC` - 指定是否动态执行验证。如果此标志为`ON`(默认设置),则仅在指定语法时才执行验证。
- `$$$SAXVALIDATIONSCHEMA` -指定是否针对架构执行验证。如果此标志为`ON`(缺省设置),则针对给定模式(如果有的话)执行验证。
- `$$$SAXVALIDATIONSCHEMAFULLCHECKING` - 指定是否执行完整架构约束检查,包括耗时或内存密集型检查。如果此标志处于打开状态,则执行所有约束检查。默认情况下,此标志处于关闭状态。
- `$$$SAXVALIDATIONREUSEGRAMMAR` - 指定是否缓存语法以供以后在同一IRIS进程内的分析中重复使用。默认情况下,此标志处于关闭状态。
- `$$$SAXVALIDATIONPROHIBITDTDS` - 在遇到DTD时导致解析器抛出错误的特殊标志。如果需要阻止处理DTD,请使用此标志。要使用此标志,必须将值`$$$SAXVALIDATIONPROHIBITDTDS`显式添加到传递给`%XML.SAX.Parser`的各种分析方法的分析标志。
以下附加标志提供了基本标志的有用组合:
- `$$$SAXDEFAULTS` - 相当于SAX默认值。
- `$$$SAXFULLDEFAULT` - 等同于SAX默认值,外加处理名称空间前缀的选项。
- `$$$SAXNOVALIDATION` - 不执行架构验证,但可以识别命名空间和命名空间前缀。请注意,SAX解析器总是检查文档是否为格式良好的XML文档。
以下片段显示了如何组合解析器选项:
```
...
#include %occInclude
#include %occSAX
...
;; set the parser options we want
set opt = $$$SAXVALIDATION
+ $$$SAXNAMESPACES
+ $$$SAXNAMESPACEPREFIXES
+ $$$SAXVALIDATIONSCHEMA
...
set status=##class(%XML.TextReader).ParseFile(myfile,.doc,,opt)
//check status
if $$$ISERR(status) {do $System.Status.DisplayError(status) quit}
```
# 指定事件掩码
基本标志如下:
- `$$$SAXSTARTDOCUMENT` — 指示分析器在启动文档时发出回调。
- `$$$SAXENDDOCUMENT` — 指示分析器在结束文档时发出回调。
- `$$$SAXSTARTELEMENT` — 指示分析器在找到元素开头时发出回调。
- `$$$SAXENDELEMENT` — 指示分析器在找到元素末尾时发出回调。
- `$$$SAXCHARACTERS` — 指示分析器在找到字符时发出回调。
- `$$$SAXPROCESSINGINSTRUCTION` — 指示分析器在找到处理指令时发出回调。
- `$$$SAXSTARTPREFIXMAPPING` — 指示分析器在找到前缀映射的开始时发出回调。
- `$$$SAXENDPREFIXMAPPING` — 指示分析器在找到前缀映射末尾时发出回调。
- `$$$SAXIGNORABLEWHITESPACE` — 指示分析器在发现可忽略的空格时发出回调。这仅适用于文档具有DTD并且启用了验证的情况。
- `$$$SAXSKIPPEDENTITY` — 指示分析器在找到跳过的实体时发出回调。
- `$$$SAXCOMMENT` — 指示分析器在找到注释时发出回调。
- `$$$SAXSTARTCDATA` — 指示分析器在找到`CDATA`节的开头时发出回调。
- `$$$SAXENDCDATA` —指示分析器在找到`CDATA`节末尾时发出回调。
- `$$$SAXSTARTDTD` —指示分析器在找到`DTD`的开头时发出回调。
- `$$$SAXENDDTD` —指示分析器在找到`DTD`结尾时发出回调。
- `$$$SAXSTARTENTITY` — 指示分析器在找到实体的开头时发出回调。
- `$$$SAXENDENTITY` — 指示分析器在找到实体末尾时发出回调。
## 方便的组合标志
以下附加标志提供了基本标志的有用组合:
- `$$$SAXCONTENTEVENTS` — 指示解析器对任何包含`“content”`的事件发出回调。
- `$$$SAXLEXICALEVENT` — 指示解析器向任何词汇事件发出回调。
- `$$$SAXALLEVENTS` —指示解析器对所有事件发出回调。
## 将标志组合成单个掩码
下面的片段展示了如何将多个标志组合成一个掩码:
```java
...
#include %occInclude
#include %occSAX
...
// set the mask options we want
set mask = $$$SAXSTARTDOCUMENT
+ $$$SAXENDDOCUMENT
+ $$$SAXSTARTELEMENT
+ $$$SAXENDELEMENT
+ $$$SAXCHARACTERS
...
// create a TextReader object (doc) by reference
set status = ##class(%XML.TextReader).ParseFile(myfile,.doc,,,mask)
```
# 指定模式文档
可以指定用于验证文档源的模式规范。指定一个包含逗号分隔的命名空间/URL对列表的字符串:
```java
"namespace URL,namespace URL,namespace URL,..."
```
这里的名称空间是XML名称空间(而不是名称空间前缀),URL是提供该名称空间的模式文档位置的URL。
在命名空间和URL值之间有一个空格字符。
例如,下面显示了一个具有单个命名空间的模式规范:
```java
"http://www.myapp.org http://localhost/myschemas/myapp.xsd"
```
下面是一个包含两个命名空间的模式规范:
```java
"http://www.myapp.org http://localhost/myschemas/myapp.xsd,http://www.other.org http://localhost/myschemas/other.xsd"
```
# 禁用实体解析
即使在设置SAX标志以禁用验证时,SAX解析器仍然试图解析外部实体,这可能非常耗时,具体取决于它们的位置。
类`%XML.SAX.NullEntityResolver`实现始终返回空流的实体解析器。如果要禁用实体解析,请使用此类。具体地说,在读取XML文档时,请使用`%XML.SAX.NullEntityResolver`的实例作为实体解析器。例如:
```java
Set resolver=##class(%XML.SAX.NullEntityResolver).%New()
Set reader=##class(%XML.Reader).%New()
Set reader.EntityResolver=resolver
Set status=reader.OpenFile(myfile)
...
```
重要提示:由于此更改将禁用所有外部实体解析,因此此技术还将禁用XML文档中的所有外部DTD和模式引用。
文章
姚 鑫 · 七月 2, 2021
# 第二十五章 添加和使用XSLT扩展函数
# 自定义错误处理
当出现错误时,XSLT处理器(`Xalan`或`Saxon`)执行当前错误处理程序的`error()`方法,将消息作为参数发送到该方法。类似地,当发生致命错误或警告时,XSLT处理器会根据需要执行`datalError()`或`Warning()`方法。
对于所有这三种方法,默认行为是将消息写入当前设备。
要自定义错误处理,请执行以下操作:
- 对于`Xalan`或`Saxon`处理器,在创建`%XML.XSLT.ErrorHandler`的子类。在这个子类中,根据需要实现`Error()`、`FatealError()`和`Warning()`方法。
这些方法中的每一个都接受单个参数,即包含由XSLT处理器发送的消息的字符串。
这些方法不返回值。
- 要在编译样式表时使用此错误处理程序,请创建子类的实例,并在编译样式表时在参数列表中使用它。
- 若要在执行XSLT转换时使用此错误处理程序,请创建子类的实例,并在使用的`Transform`方法的参数列表中使用它。
# 指定样式表使用的参数
要指定样式表使用的参数,请执行以下操作:
1. 创建`%ArrayOfDataTypes`的实例在。
2. 调用此实例的`SetAt()`方法将参数及其值添加到此实例。对于`SetAt()`,将第一个参数指定为参数值,将第二个参数指定为参数名称。
根据需要添加任意多个参数。
```java
Set tParameters=##class(%ArrayOfDataTypes).%New()
Set tSC=tParameters.SetAt(1,"myparameter")
Set tSC=tParameters.SetAt(2,"anotherparameter")
```
3. 将此实例用作`Transform`方法的`pParms`参数。
可以不使用`%ArrayOfDataType`,而是使用 IRIS多维数组,该数组可以具有任意数量的具有以下结构和值的节点:
Node| Value
---|---
arrayname("parameter_name") |Value of the parameter named by parameter_name
# 添加和使用XSLT扩展函数
可以在InterSystems IRIS中创建`XSLT`扩展函数,然后在样式表中使用它们,如下所示:
- 对于`XSLT2.0`(`Saxon`处理器),可以使用名称空间`com.intersystems.xsltgateway.XSLTGateway`中的`evaluate`函数或名称空间`http://extension-functions.intersystems.com`中的`evaluate`函数
- 对于`XSLT1.0`(`Xalan`处理器),只能在名称空间`http://extension-functions.intersystems.com`中使用`evaluate`函数
默认情况下(举个例子),后一个函数反转它接收到的字符。但是,通常不使用默认行为,因为实现了一些其他行为。要模拟多个单独的函数,需要传递一个选择器作为第一个参数,并实现一个开关,该开关使用该值选择要执行的处理。
在内部,`evaluate`函数作为XSLT回调处理程序中的方法(`evaluate()`)实现。
要添加和使用XSLT扩展函数,请执行以下操作:
1. 对于`Xalan`或`Saxon`处理器,在创建`%XML.XSLT.CallbackHandler`的子类。在这个子类中,根据需要实现`evaluate()`方法。请参阅下一小节。
2. 在样式表中,声明`evaluate`函数所属的命名空间,并根据需要使用`evaluate`函数。请参阅下一小节。
3. 执行XSLT转换时,创建子类的实例,并在使用的`Transform`方法的参数列表中使用它。请参阅“执行XSLT转换”。
## 实现evaluate()方法
在内部,调用`XSLT`处理器的代码可以将任意数量的位置参数传递给当前回调处理程序的`evaluate()`方法,该方法将它们作为具有以下结构的数组接收:
Node| Value
---|---
Args| 参数数量
Args(index) |位置索引中参数的值
该方法只有一个返回值。返回值可以是:
- 标量变量(如字符串或数字)。
- 流对象。这允许返回超过字符串长度限制的超长字符串。流必须包装在新窗口中的`%XML.XSLT.StreamAdapter`实例中,使XSLT处理器能够读取流。以下是部分示例:
```java
Method evaluate(Args...) As %String
{
//create stream
///...
// create instance of %XML.XSLT.StreamAdapter to
// contain the stream
Set return=##class(%XML.XSLT.StreamAdapter).%New(tStream)
Quit return
}
```
## 在样式表中使用计算
要在XSLT中使用XSLT扩展函数,必须在XSLT样式表中声明扩展函数的名称空间。对于InterSystems evaluate函数,此命名空间是`http://extension-functions.intersystems.com`或`com.intersystems.xsltgateway.XSLTGateway`,如前所述。
下面的示例显示使用evaluate的样式表:
```xml
```
## 使用ISC:计算缓存
XSLT2.0网关将`evaluate`函数调用缓存在`isc:evaluate`缓存中。缓存的默认最大大小为`1000`个项目,但可以将大小设置为不同的值。此外,还可以清除缓存、转储缓存,还可以从`%List`中预先填充缓存。使用以下格式:
- 缓存条目总数
- 对于每个条目:
1. 求值参数总数
2. 所有求值参数
3. 计算值
缓存还包括可缓存的函数名称的过滤器列表。请注意以下事项:
- 可以在筛选器列表中添加或删除函数名。
- 可以清除过滤器列表。
- 可以通过设置一个布尔值来覆盖筛选器列表,该布尔值将缓存每个`evaluate`调用。
将函数名添加到筛选器列表不会限制求值缓存的大小。可以对同一函数进行任意数量的调用,但具有不同的参数和返回值。函数名和参数的每个组合都是求值缓存中的一个单独条目。
可以使用`%XML.XSLT2.Transformer`中的方法来操作求值缓存。
# 使用XSL转换向导
Studio提供了一个执行XSLT转换的向导,当希望快速测试样式表或自定义XSLT扩展函数时,该向导非常有用。要使用此架构向导,请执行以下操作:
1. Tools > Add-Ins > XSLT Schema Wizard.
2. 指定以下必需的详细信息:
- 对于XML文件,选择浏览以选择要转换的XML文件。
- 对于XSL文件,选择浏览以选择要使用的XSL样式表。
- 对于呈现为,选择文本或XML以控制转换的显示方式。
3. 如果已在要在此转换中使用的创建了`%XML.XSLT.CallbackHandler`的子类,请指定以下详细信息:
- 对于XSLT Helper Class中的第一个下拉列表,选择一个命名空间。
- 对于XSLT Helper Class中的第二个下拉列表,选择该类。
4. 选择Finish(完成)。
对话框底部显示转换后的文件。可以从该区域复制和粘贴。
5. 要关闭此对话框,请选择取消。
文章
姚 鑫 · 七月 1, 2021
# 第二十四章 执行XSLT转换
# 执行XSLT转换
要执行`XSLT`转换,请执行以下操作:
- 如果使用的是`Xalan`处理器(对于`XSLT 1.0`),请使用`%XML.XSLT.Transformer`的以下类方法之一:
- `TransformFile()`——转换给定XSLT样式表的文件。
- `TransformFileWithCompiledXSL()`——转换一个文件,给定一个已编译的XSLT样式表。
- `TransformStream()`——转换给定XSLT样式表的流。
- `TransformStreamWithCompiledXSL()`——转换一个流,给定一个已编译的XSLT样式表。
- `TransformStringWithCompiledXSL()`——转换给定已编译XSLT样式表的字符串。
- 如果使用`Saxon`处理器(用于XSLT 2.0),请使用`%XML.XSLT2.Transformer`的以下类方法之一:
- `TransformFile()`——转换给定XSLT样式表的文件。
- `TransformFileWithCompiledXSL()`——转换一个文件,给定一个已编译的XSLT样式表。
- `TransformStream()`——转换给定XSLT样式表的流。
- `TransformStreamWithCompiledXSL()`——转换一个流,给定一个已编译的XSLT样式表。
这些方法具有相似的签名。这些方法的参数列表按顺序如下:
- pSource—要转换的源XML。请参见此列表后面的表。
- pXSL -样式表或编译样式表。请参阅此列表后面的表格。
- pOutput -作为输出参数返回的结果XML。请参阅此列表后面的表格。
- pErrorHandler -一个可选的自定义错误处理程序。请参阅本章后面的“自定义错误处理”。如果不指定自定义错误处理程序,该方法将使用%XML.XSLT.ErrorHandler的新实例(对于两个类)。
- pParms -一个可选的InterSystems IRIS多维数组,包含要传递给样式表的参数。
- pCallbackHandler -定义`XSLT`扩展函数的可选回调处理程序。
- pResolver -一个可选的实体解析器。
8. (仅适用于`%XML.XSLT2.Transformer`)网关-`%Net.Remote.Gateway`的可选实例。如果要重用XSLT网关连接以获得更好的性能,请指定此参数;
作为参考,下表显示了这些方法的前三个参数,并进行了对比:
XSLT变换方法的比较
Method | pSource (Input XML) |pXSL (Stylesheet) |pOutput(Output XML)
---|---|---|---
TransformFile() |String that gives a file name| String that gives a file name |String that gives a file name
TransformFileWithCompiledXSL()| String that gives a file name |Compiled style sheet| String that gives a file name
TransformStream()| Stream| Stream |Stream, returned by reference
TransformStreamWithCompiledXSL()| Stream |Compiled style sheet |Stream, returned by reference
TransformStringWithCompiledXSL()| String |Compiled style sheet| String that gives a file name
# 示例
本节使用以下代码(但不同的输入文件)展示了几种转换:
```java
Set in="c:\0test\xslt-example-input.xml"
Set xsl="c:\0test\xslt-example-stylesheet.xsl"
Set out="c:\0test\xslt-example-output.xml"
Set tSC=##class(%XML.XSLT.Transformer).TransformFile(in,xsl,.out)
Write tSC
```
## 示例1:简单替换
在本例中,我们从以下输入XML开始:
```xml
Content
```
我们使用以下样式表:
```xml
Content Replaced
```
在这种情况下,输出文件将如下所示:
```xml
Content Replaced
```
## 示例2:内容提取
在本例中,我们从以下输入XML开始:
```xml
Some text
Some more text
```
我们使用以下样式表:
```xml
:
```
在这种情况下,输出文件将如下所示:
```java
13: Some text
14: Some more text
```
## 其他示例
InterSystems IRIS提供了以下附加示例:
- 对于`XSLT 1.0`,请参阅`%XML.XSLT.Transformer`中的`Example()`、`Example2()`和其它方法。
- 对于`XSLT 2.0`,请参见`Samples`命名空间中的类`XSLT2.Examples`。
文章
姚 鑫 · 六月 30, 2021
# 第二十三章 执行XSLT转换概述
XSLT(Extensible StyleSheet Language Transformations,可扩展样式表语言转换)是一种基于XML的语言,用于描述如何将给定的XML文档转换为另一个XML或其他“人类可读”的文档。可以使用`%XML.XSLT`和`%XML.XSLT2`包中的类来执行`XSLT 1.0`和`2.0`转换。
注意:使用的任何XML文档的XML声明都应该指明该文档的字符编码,并且文档应该按照声明的方式进行编码。如果未声明字符编码, IRIS将使用本书前面的“输入和输出的字符编码”中描述的默认值。如果这些默认值不正确,请修改XML声明,使其指定实际使用的字符集。
# 在IRIS中执行XSLT转换概述
IRIS提供两个XSLT处理器,每个处理器都有自己的API:
- `Xalan`处理器支持`XSLT 1.0`。`XML.XSLT`包为该处理器提供API。
- `Saxon`处理器支持`XSLT 2.0`。`%XML.XSLT2`程序包为该处理器提供API。
`XML.XSLT2` API通过到`XSLT 2.0`网关的连接向`Saxon`发送请求。网关允许多个连接。这意味着,例如,可以将两个独立的 IRIS进程连接到网关,每个进程都有自己的一组编译样式表,同时发送转换请求。
使用Saxon处理器,编译的样式表和`isc:Evaluate`缓存是特定于连接的;必须管理自己的连接才能利用这两个特性。如果打开连接并创建编译样式表或计算填充`isc:Evaluate`缓存的转换,则在该连接上计算的所有其他转换都将访问编译样式表和`isc:Evaluate`缓存条目。如果打开新连接,其他连接(及其编译的样式表和缓存)将被忽略。
这两个处理器的API相似,不同之处在于`%XML.XSLT2`中的方法使用另一个参数来指定要使用的网关连接。
要执行`XSLT`转换,请执行以下操作:
1. 如果使用的是`Saxon`处理器,请按照下一节所述配置`XSLT`网关服务器。或使用默认配置。
如果使用的是`Xalan`处理器,则不需要网关。
系统会在需要时自动启动网关。或者也可以手动启动它。
2. 如果使用的是`Saxon`处理器,则可以选择创建`%Net.Remote.Gateway`的实例,表示到`XSLT`网关的单个连接。
请注意,当使用`Saxon`处理器时,要利用已编译的样式表和`isc:Evaluate`缓存,这一步是必需的。
3. 可以选择创建已编译的样式表并将其加载到内存中。请参阅本章后面的“创建编译样式表”。如果使用的是`Saxon`处理器,请确保在创建编译后的样式表时指定网关参数。
如果打算重复使用同一样式表,则此步骤非常有用。然而,此步骤也会消耗内存。当不再需要编译的样式表时,请务必将其删除。
4. 调用适用API的转换方法之一。如果使用的是`Saxon`处理器,则在调用`Transform`方法时可以选择指定网关参数。
5. 可以选择调用其他转换方法。如果使用的是`Saxon`处理器,则在调用`Transform`方法时可以选择指定网关参数;这使能够使用相同的连接计算另一个转换。此转换将访问与此连接相关联的所有编译样式表和`isc:Evaluate`缓存条目。如果打开新连接,其他连接(及其编译的样式表和缓存)将被忽略。
Studio还提供了一个向导,可以使用该向导测试XSLT转换;本章稍后将对此进行介绍。
# 配置、启动和停止XSLT 2.0网关
当使用`Saxon`处理器(执行`XSLT 2.0`转换)时, IRIS使用`XSLT 2.0`网关(后者使用Java)。要配置此网关,请执行以下操作:
1. 在管理门户中,选择 System Administration > Configuration > Connectivity > XSLT 2.0 Gateway Server.
2. 选择Go。
系统将显示XSLT网关服务器页面。
左侧区域显示配置详细信息,右侧区域显示最近的活动。
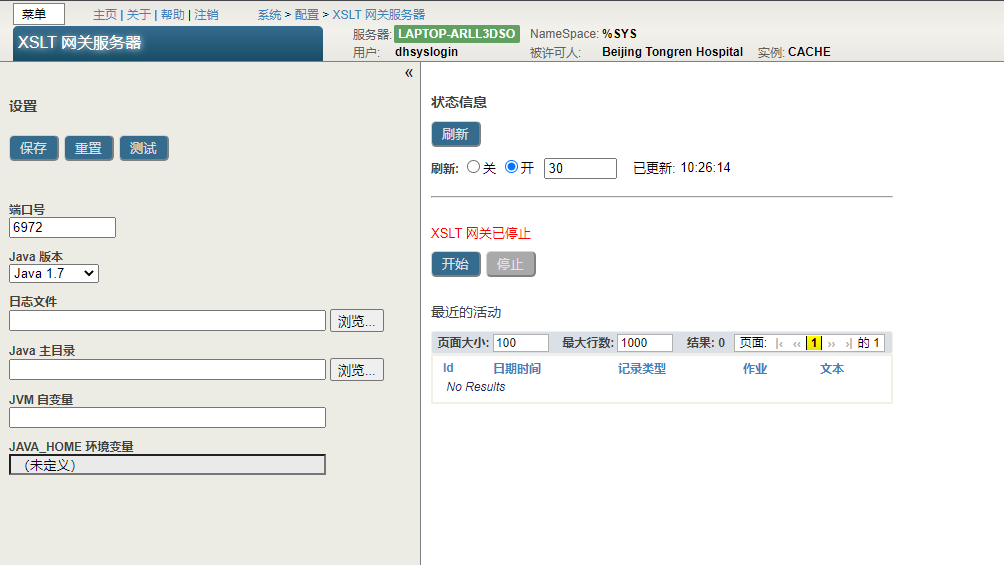
3. 在左侧区域中,可以选择指定以下设置:
- Port Number -`XSLT 2.0`网关独占使用的TCP端口号。此端口号不得与服务器上的任何其他本地TCP端口冲突。
默认值为 IRIS SuperServer端口号加`3000`。如果此数字大于`65535`,则系统使用`54773`。
- Java Version - 使用的Java版本。
- Log File - 日志文件的路径名。如果忽略此设置,则不执行日志记录。如果指定了文件名但忽略了目录,则将日志文件写入系统管理器的目录。
- Java Home Directory -包含Java bin目录的目录路径。如果服务器上没有默认Java,或者如果想使用不同的Java,请指定此选项。
要查看默认Java,请在服务器上的Shell中执行以下命令:
```
java -version
```
- JVM Arguments - Java虚拟机要使用的任何其他参数。
此区域还显示`JAVA_HOME`环境变量的当前值。
请注意,在网关运行时,不能编辑这些值中的任何一个。
4. 如果已进行更改,请选择保存以保存更改。或选择重置以。
5. (可选)选择测试以测试更改。
在此页面上,还可以执行以下操作:
- 启动网关。要执行此操作,请选择右侧区域中的Start。
请注意, IRIS会在需要时自动启动网关。不需要手动启动网关。
- 关闭网关。要执行此操作,请选择右侧区域中的Stop(停止)。
# 重用XSLT网关服务器连接(XSLT 2.0)
如果使用的是`Saxon`处理器,InterSystems IRIS将使用之前配置的`XSLT 2.0`网关。为了与此网关通信,InterSystems IRIS在内部创建一个`XSLT`网关连接(`%Net.Remote.Gateway`的实例)。默认情况下,系统创建一个连接,将其用于转换,然后丢弃该连接。打开新连接会产生开销,因此为多个转换维护一个连接可提供最佳性能。此外,必须维护自己的连接,以便利用已编译的样式表和`isc:Evaluate`缓存。
要重用XSLT网关连接,请执行以下操作:
1. 调用`%XML.XSLT2.Transformer`的`StartGateway()`方法:
```
set status=##class(%XML.XSLT2.Transformer).StartGateway(.gateway)
```
此方法启动XSLT 2.0网关(如果它尚未运行),并返回`%Net.Remote.Gateway`的实例作为输出。请注意,该方法还返回状态。
在`%Net.Remote.Gateway`实例表示与网关的连接。
`StartGateway()`有一个可选的第二个参数`useSharedMemory`。如果此参数为真(缺省值),则与`localhost`或`127.0.0.1`的连接将使用共享内存(如果可能)。要强制连接仅使用`TCP/IP`,请将此参数设置为False。
2. 检查上一步返回的状态:
```java
if $$$ISERR(status) {
quit
}
```
3. 创建任何已编译的样式表。执行此操作时,请将网关参数指定为`%Net.Remote.GatewayInstance`的实例在步骤1中创建。
4. 根据需要调用`%XML.XSLT2.Transformer`的`Transform`方法(`TransformFile()`、`TransformFileWithCompiledXSL()`、`TransformStream()`和`TransformStreamWithCompiledXSL()`)。执行此操作时,请将网关参数指定为在步骤1中创建的`%Net.Remote.Gateway`的实例。
5. 如果不再需要给定的编译样式表,请在调用`%XML.XSLT2.CompiledStyleSheet`的`ReleaseFromServer()`方法:
```java
Set status=##class(%XML.XSLT2.CompiledStyleSheet).ReleaseFromServer(compiledStyleSheet,,gateway)
```
重要提示:当不再需要已编译的样式表时,请务必使用此方法。
6. 当不再需要XSLT网关连接时,调用`%XML.XSLT2.Transformer`的`StopGateway()`方法,并将网关连接作为参数传递:
```java
set status=##class(%XML.XSLT2.Transformer).StopGateway(gateway)
```
此方法丢弃连接并重置当前设备。它不会停止`XSLT 2.0`网关。
重要提示:当不再需要连接时,请务必使用此方法。
有关示例,请参见XSLT2中的`Example10()`方法。`Samples`命名空间中的`Examples`。
# 排除XSLT 2.0网关服务器连接故障
当XSLT 2.0网关打开时,InterSystems IRIS和网关服务器之间的连接可能会变得无效。例如,如果出现网络错误或在InterSystems IRIS连接到网关服务器后重新启动网关服务器,则连接可能无法正常关闭。因此,可能会遇到错误。
可以通过连续调用XSLT网关连接对象的`%LostConnectionCleanup()`方法和`%reconnect`方法,尝试将InterSystems IRIS重新连接到网关服务器。
如果希望在断开连接时自动重新连接到网关服务器,请将网关连接对象的`AttemptReconnect`属性设置为true。
# 创建编译的样式表
如果打算重复使用同一样式表,则可能需要编译该样式表以提高速度。请注意,此步骤会消耗内存。当不再需要编译的样式表时,请务必将其删除。
要创建编译的样式表,请执行以下操作:
- 如果使用的是`Xalan`处理器(对于`XSLT 1.0`),请使用`%XML.XSLT.CompiledStyleSheet`的以下类方法之一:
- `CreateFromFile()`
- `CreateFromStream()`
- 如果使用的是`Saxon`处理器(用于`XSLT 2.0`),请在使用`%XML.XSLT2.CompiledStyleSheet`的以下类方法之一:
- `CreateFromFile()`
- `CreateFromStream()`
另请注意,将需要创建一个XSLT网关连接;请参阅“重用XSLT网关服务器连接(`XSLT 2.0`)”。
对于所有这些方法,完整的参数列表按顺序如下:
1. source - 样式表。
对于`CreateFromFile()`,此参数是文件名。对于`CreateFromStream()`,此参数是一个流。
2. compiledStyleSheet - 编译后的样式表,作为输出参数返回。
这是样式表类(`%XML.XSLT.CompiledStyleSheet`或`%XL.XSLT2.CompiledStyleSheet`,视情况而定)的实例。
3. errorHandler - 编译样式表时使用的可选自定义错误处理程序。
对于这两个类中的方法,这是`%XML.XSLT.ErrorHandler`实例。
4. (仅适用于`%XML.XSLT2.CompiledStyleSheet`)网关-`%Net.Remote.Gateway`的实例
```
//将tXSL设置为等于适当流的OREF
Set tSC=##class(%XML.XSLT.CompiledStyleSheet).CreateFromStream(tXSL,.tCompiledStyleSheet)
If $$$ISERR(tSC) Quit
```
文章
jieliang liu · 六月 30, 2021
嗨,开发者们!
在这篇文章中,我们想告诉你如何充分利用开发者社区,从InterSystems的技术专家那里学到尽可能多的东西!
请注意这些步骤,以成为我们社区的高级用户!
关注你感兴趣的社区成员
如果你喜欢他们发布的内容,你可以关注社区的任何成员。只需点击任何成员右侧边栏上的 "关注 "按钮,当该成员在社区上发表文章(文章/问题/公告等)时,你将收到电子邮件通知。
此外,在主页的顶部菜单中,你可以点击 "成员",搜索特定的人或有更多意见的成员,或更多的喜欢......并开始关注他们。
关注你感兴趣的标签
用于描述社区上的帖子的所有标签都可以在DC主页上的 "标签 "部分找到:
在DC标签树中, 您可以找到您感兴趣的主题并关注相关的 标签。只需选择一个标签并点击其旁边的 "关注 "按钮即可。当您关注任何标签时,您会收到一封包含所有使用该标签的帖子的电子邮件。
我们建议从以下标签开始: 最佳实践 | 技巧和窍门 | 初学者 | 教程
关注你所感兴趣的帖子
关注一个帖子,你将收到(通过电子邮件)该帖子的所有更新,如新的评论,或如果发表了第二部分,或任何其他与你关注的帖子有关的活动。
要关注一个帖子,你只需要点击每个帖子下面的铃铛图标。
-> 我如何知道我在关注哪些会员、标签和帖子?
要知道你所关注的会员、标签和帖子,你只需要进入你的账户,在右上角
然后进入左栏的 "订阅"。
在这个页面的底部,你可以在三个标签中看到并定制你的订阅--每个标签都显示你所关注的成员、标签和帖子。例如,下面的截图显示,用户正在关注一些标签和DC成员。
注意: 如果你想关注不同语言的会员或标签,你需要将你的订阅设置切换到你感兴趣的语言。
添加帖子到你的书
把你喜欢的帖子加入书签,这样你以后就可以快速而方便地访问该帖子。
如果你喜欢一个帖子(文章、问题或公告)并想把它保存起来,你可以把它添加到你的书签中。这样,你就可以快速和容易地访问该帖子,并在你想要时阅读它。
要将一个帖子添加到你的书签,你只需要点击每个帖子下面的星星图标。
要查看您的所有书签,请进入您的账户,然后在左栏中进入 "书签"。
所以,开发者们!
请使用我们所有的DC功能,这些功能可以帮助你成为InterSystems技术的专家!
而且非常欢迎你在下面的评论中提交关于如何在开发者社区学习InterSystems技术的其他方法和建议。