清除过滤器
公告
Claire Zheng · 一月 10, 2023
亲爱的社区开发者们,
我很高兴地向大家介绍一位我们的新版主 @牛宇翔!
@牛宇翔 目前担任首都医科大学附属北京友谊医院信息中心临床组组长。
以下是@牛宇翔 的自我介绍:
本人有接近10年的医疗信息化经验,目前在我院,带领一个微型小团队,基于Ensemble数据库做医院信息系统(Hospital Information System, HIS)应用端研发,我们团队熟悉HTML、CSS、JavaScript及衍生前端语言,日常工作主要根据用户需求开发对应功能,结合临床业务难点痛点,不断优化程序功能。经过两年的学习和努力,我们团队已完成临床新增功能和优化需求共计一千余条,随着科室人力的发展,我们的开发力量会越来越强,可以更好地保证临床需求的及时响应,不断优化和完善系统BUG,提高临床工作效率。与此同时,我还担任应急小组成员,负责进行数据库运维和问题处理,保证第一时间排查故障。
InterSystems 提供了一个非常优秀的集成平台,借助该技术,给我们业务带来了非常大的便利。我也希望这么优秀的技术,能给更多的兄弟单位和合作伙伴创造价值。我也希望能够在社区与大家一起交流,分享自己的一些实践经验;同时也希望借助这个平台,向大家学习一些优秀的实践。我们一起成长,共同进步!
再次欢迎我们的新版主 @牛宇翔👏🏼👏🏼👏🏼👏🏼👏🏼
期待你在InterSystems开发者社区成长为一名优秀版主! 热烈欢迎!期待更多大作!@牛宇翔
文章
Johnny Wang · 十一月 21, 2021
在医疗领域,开发创新可以挽救更多的生命。
这也是为什么我们更需要去倾听负责构建未来的人:开发人员。 他们需要什么工具才能更有效地使应用程序更加高效? 他们面对着什么样的障碍?
InterSystems 不想去做无用的猜测,因此我们推动进行了一项研究,该研究综合了 200 名医疗行业开发者的反馈,深入了解了他们的最大需求。我们认为,这些研究结果为医疗单位和医疗技术公司提供了一个机会,可以帮助他们的开发团队为业务带来新机遇,同样也为临床医生和患者带来更光明的未来。
以下是三个关键要点:
1. 开发人员想要一个统一的医疗平台。
在接受本次研究采访的 200 名开发人员中,有88% 的受访者表示他们是医疗 IT 领域的专家或该领域的技术人员——他们都希望能有最好的、为他们的行业量身定制的开发工具。 这就是为什么一半的受访者将统一的、专注于医疗的数据平台列为购买新开发工具的关键原因。
一个合适的医疗行业开发平台应该包括互操作性/集成引擎、分析工具、面向医疗行业的自然语言处理功能、机器学习工具和 FHIR 服务器,以及其他组件。
如果一家公司能够提供一个包含所有上述组件的平台,那么超过 90% 的开发人员将对这项技术非常感兴趣。
2. 临床数据模型必不可少
近 90% 的开发人员表示,技术供应商提供的临床数据模型是必不可少的,如果按照 10 分制来统计,这个需求会达到8 分甚至更高。
来自 EHR 的临床数据被 60% 的开发人员列为最优先的一类。而其他数据还包括CRM、医疗设备、健康的社会决定因素、索赔、财务和运营的数据。
3. 健康数据是实现价值的最快途径
干净、健康的数据将高质量企业与其他企业区分开来。 在开发人员希望技术供应商提供更干净、更健康数据的大背景下,这次研究的受访者表示,选择能够提供最干净数据的平台尤为重要。
一站式医疗保健平台
根据该报告,一线开发人员及管理层都想要这样一个医疗保健数据平台:
(1)专注于医疗IT行业 (2)可扩展性 (3)与现有的开发工具兼容 (4)安全 (5)便于使用
我们推动进行这项研究是为了帮助我们确定 InterSystems IRIS for Health™ 的发展方向,而这也是一个专门设计用于从医疗数据中提取价值的数据平台。 开发人员使用该平台、使用这些旨在满足现代医疗需求的、安全的工具来创建和扩展医疗应用程序。
我们对这次的研究结果感到鼓舞,我们也将继续专注以使平台变得更好!
医疗 IT 软件开发人员面临的关键问题。 点击阅读最新研究结果!
想试用 InterSystems IRIS 数据平台吗?立刻免费编码!
关于作者:Chris Walker 领导 InterSystems 的业务开发团队,该团队正在帮助合作伙伴使用软件工具和服务来加速和增强他们推向市场的数字解决方案。 在他职业生涯的早期,他为麻省总医院开发了临床信息系统,并在健康和生命科学信息管理方面拥有超过 25 年的经验。
点击查看原文
文章
姚 鑫 · 一月 5
# 第十六章 调用Callout Library函数
`Callout` 库是一个共享库(`DLL` 或 `SO` 文件),其中包含 `$ZF Callout` 接口的挂钩,允许各种 $ZF 函数在运行时加载它并调用其函数。 `$ZF Callout` 接口提供了四种不同的接口,可用于在运行时加载 `Callout` 库并从该库调用函数。这些接口的主要区别在于如何识别库并将其加载到内存中:
- 使用 `$ZF()` 访问 `iriszf` 标注库描述了如何使用名为 `iriszf` 的特殊共享库。当该库可用时,可以通过 `$ZF("funcname",args)` 形式的调用来访问其函数,而无需事先加载该库或指定库名称。
- 使用 `$ZF(-3)` 进行简单库函数调用描述了如何通过指定库文件路径和函数名来加载库并调用函数。它使用简单,但虚拟内存中一次只能有一个库。与其他接口不同,它在调用库函数之前不需要任何初始化。
- 使用 `$ZF(-5)` 通过系统 `ID` 访问库描述了一种可用于一次有效维护和访问多个库的接口。可以同时加载和使用多个库,每个库所需的处理开销比 `$ZF(-3)` 少得多。内存中的库由加载库时生成的系统定义的 `ID` 来标识。
- 使用 `$ZF(-6)` 按用户索引访问库描述了处理大量标注库的最有效接口。该接口通过`Global`定义的索引表提供对库的访问。该索引可供 `IRIS` 实例中的所有进程使用,并且多个库可以同时位于内存中。每个索引库都被赋予一个唯一的、用户定义的索引号,并且可以在运行时定义和修改索引表。当库文件被重命名或重新定位时,与给定库 `ID` 关联的文件名可以更改,并且此更改对于按索引号加载库的应用程序来说是透明的。
# 使用 `$ZF()` 访问 `iriszf` 标注库
当名为 `iriszf` 的 `Callout` 库在实例的 `/bin` 目录中可用时,可以通过仅指定函数名称和参数的 `$ZF` 调用来调用其函数(例如,`$ZF("functionName",arg1, arg2))`.。无需事先加载库即可调用 `iriszf` 函数,并且实例中的所有进程都可以使用 `iriszf` 函数。
自定义 `iriszf` 库是通过创建标准 `Callout` 库、将其移动到实例的 `/bin` 目录并将其重命名为 `iriszf`(具体为 `iriszf.dll` 或 `iriszf.so`,具体取决于平台)来定义的。
以下是编译 `simplecallout.c` 示例(请参阅“创建 `Callout` 库”)并将其设置为 `iriszf` 库的步骤。这些示例假设实例在 `Linux` 下运行,安装在名为 `/intersystems/iris` 的目录中,但所有平台上的过程基本相同:
1. 编写并保存 `simplecallout.c`:
```java
#define ZF_DLL
#include "iris-cdzf.h"
int AddTwoIntegers(int a, int b, int *outsum) {
*outsum = a+b; /* set value to be returned by $ZF function call */
return IRIS_SUCCESS; /* set the exit status code */
}
ZFBEGIN
ZFENTRY("AddInt","iiP",AddTwoIntegers)
ZFEND
```
2. 生成`Callout`库文件(`simplecallout.so`):
```java
gcc -c -fPIC simplecallout.c -I /intersystems/iris/dev/iris-callin/include/ -o simplecallout.o
gcc simplecallout.o -shared -o simplecallout.so
```
3. 从 `IRIS` 终端会话中使用 `$ZF(-3)` 测试库:
```java
USER>write $ZF(-3,"/mytest/simplecallout.so","AddInt",1,4)
5
```
4. 现在安装该库以与 `$ZF()` 一起使用。将 `simplecallout.so` 复制到 `/bin`中,并将其重命名为 `iriszf.so`:
```java
cp simplecallout.so /intersystems/iris/bin/iriszf.so
```
5. 确认可以从 `IRIS` 会话中使用 `$ZF()` 调用代码:
```java
USER>write $zf("AddInt",1,4)
5
```
`iriszf` 库在首次使用时加载一次,并且永远不会卸载。它完全独立于本章前面描述的其他 `$ZF` 加载和卸载操作。
注意:静态链接库 `$ZF Callout Interface` 的早期版本允许将代码静态链接到 `InterSystems` 内核并使用 `$ZF()` 进行调用。不再支持静态链接,但 `irisz` 库提供相同的功能,无需重新链接内核。
文章
姚 鑫 · 四月 7, 2021
# 第十九章 存储和使用流数据(BLOBs和CLOBs)
Intersystems SQL支持将流数据存储为Intersystems Iris ®DataPlatform数据库中的 `BLOBs`(二进制大对象)或 `CLOBs`(字符大对象)的功能。
# 流字段和SQL
Intersystems SQL支持两种流字段:
- 字符流 `Character streams`,用于大量文本。
- 二进制流 `Binary streams`,用于图像,音频或视频。
## BLOBs and CLOBs
Intersystems SQL支持将`BLOBs`(二进制大对象)和`CLOBs`(字符大对象)存储为流对象的功能。 `BLOBs`用于存储二进制信息,例如图像,而`CLOBs`用于存储字符信息。 **`BLOBs`和`CLOBs`可以存储多达4千兆字节的数据(JDBC和ODBC规范所强加的限制)。**
在各种方面,诸多方面的操作在通过ODBC或JDBC客户端访问时处理字符编码转换(例如Unicode到多字节):`BLOB`中的数据被视为二进制数据,从未转换为二进制数据另一个编码,而`CLOB`中的数据被视为字符数据并根据需要转换。
如果二进制流文件(`BLOB`)包含单个非打印字符`$CHAR(0)`,则被认为是空二进制流。它相当于`""`空二进制流程值:它存在(不是`null`),但长度为0。
## 定义流数据字段
Intersystems SQL支持流字段的各种数据类型名称。这些Intersystems数据类型名称是与以下内容对应的同义词:
- 字符流:数据类型`LONGVARCHAR`,映射到`%stream.globalcharacter`类和ODBC / JDBC数据类型`-1`。
- 字符流:数据类型`LONGVARBINARY`,映射到`%Stream.GlobalBinary`类和ODBC / JDBC数据类型`-4`。
某些Intersystems流数据类型允许指定数据精度值。此值是no-op,对流数据的允许大小没有影响。提供它以允许用户记录预期的未来数据大小。
以下示例定义包含两个流字段的表:
```sql
CREATE TABLE Sample.MyTable (
Name VARCHAR(50) NOT NULL,
Notes LONGVARCHAR,
Photo LONGVARBINARY)
```
分片表不能包含流数据类型字段。
### 流字段约束
Stream字段的定义符合以下字段数据约束:
流字段可以定义为 `NOT NULL`。
流字段可以占用默认值,更新值或计算码值。
流字段不能定义为唯一,主键字段或`idkey`。试图这样做导致`SQLCode -400`致命错误,其中%MSG如下:` ERROR #5414: Invalid index attribute: Sample.MyTable::MYTABLEUNIQUE2::Notes, Stream property is not allowed in a unique/primary key/idkey index > ERROR #5030: An error occurred while compiling class 'Sample.MyTable'.`
无法使用指定的`COLLATE` 值定义流字段。试图这样做导致`SQLCode -400`致命错误,其中`%MSG`如下:` ERROR #5480: Property parameter not declared: Sample.MyTable:Photo:COLLATION > ERROR #5030: An error occurred while compiling class 'Sample.MyTable'.`
## 将数据插入流数据字段
将数据插入流字段有三种方法:
- `%Stream.Globalcharacter`字段:可以直接插入字符流数据。例如,
```sql
INSERT INTO Sample.MyTable (Name,Notes)
VALUES ('Fred','These are extensive notes about Fred')
```
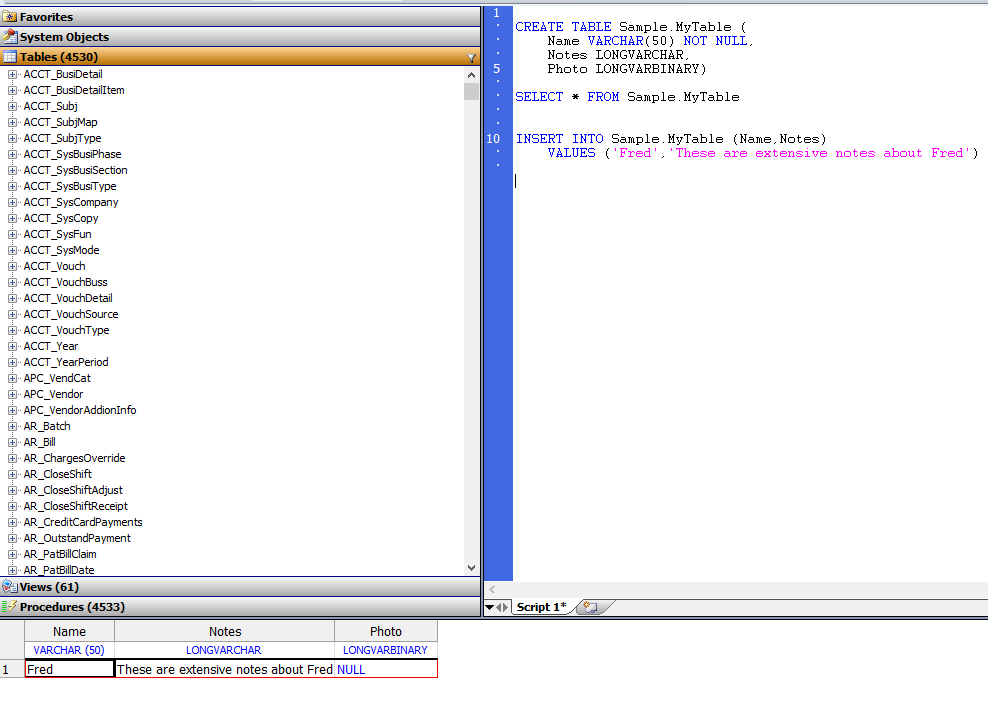
```java
Class Sample.MyTable Extends %Persistent [ ClassType = persistent, DdlAllowed, Final, Owner = {yx}, ProcedureBlock, SqlRowIdPrivate, SqlTableName = MyTable ]
{
Property Name As %Library.String(MAXLEN = 50) [ Required, SqlColumnNumber = 2 ];
Property Notes As %Stream.GlobalCharacter [ SqlColumnNumber = 3 ];
Property Photo As %Stream.GlobalBinary [ SqlColumnNumber = 4 ];
/// Bitmap Extent Index auto-generated by DDL CREATE TABLE statement. Do not edit the SqlName of this index.
Index DDLBEIndex [ Extent, SqlName = "%%DDLBEIndex", Type = bitmap ];
Storage Default
{
Name
Notes
Photo
^Sample.MyTableD
MyTableDefaultData
sequence
^Sample.MyTableD
^Sample.MyTableI
^Sample.MyTableS
%Library.CacheStorage
}
}
```
- `%stream.globalcharacter`和`%stream.globalbinary`字段:可以使用oref插入流数据。可以使用`Write()`方法将字符串附加到字符流,或者写入的方法,以将具有行终结器的字符串附加到字符流。默认情况下,行终结器是`$CHAR(13,10)`(回车返回/线路);可以通过设置`LineTerminator` 属性来更改行终结器。在以下示例中,示例的第一部分创建由两个字符串和其终端组组成的字符流,然后使用嵌入的SQL将其插入流字段。示例的第二部分返回字符流长度,并显示显示终结器的字符流数据:
```java
/// d ##class(PHA.TEST.SQL).StreamField()
ClassMethod StreamField()
{
CreateAndInsertCharacterStream
SET gcoref=##class(%Stream.GlobalCharacter).%New()
DO gcoref.WriteLine("First Line")
DO gcoref.WriteLine("Second Line")
&sql(INSERT INTO Sample.MyTable (Name,Notes)
VALUES ('Fred',:gcoref))
IF SQLCODEd ##class(PHA.TEST.SQL).StreamField()
插入成功
1
^CacheStream=1
^CacheStream(1)=1
^CacheStream(1,0)=25
^CacheStream(1,1)="First Line"_$c(13,10)_"Second Line"_$c(13,10)
```
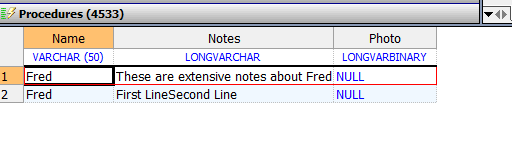
- `%stream.globalcharacter`和`%stream.globalbinary`字段:可以通过从文件读取它来插入流数据。例如,
```java
/// d ##class(PHA.TEST.SQL).StreamField1()
ClassMethod StreamField1()
{
SET myf="E:\temp\game.jpg"
OPEN myf:("RF"):10
USE myf:0
READ x(1):10
&sql(INSERT INTO Sample.MyTable (Name,Photo) VALUES ('George',:x(1)))
IF SQLCODEd ##class(PHA.TEST.SQL).StreamField1()
WRITE "插入成功",!
^
zStreamField1+11^PHA.TEST.SQL.1
DHC-APP 2d0>g
WRITE "插入成功",!
^
zStreamField1+11^PHA.TEST.SQL.1
DHC-APP 2d0>g
DHC-APP>
```

作为默认值或计算值插入的字符串数据以适合于流字段的格式存储。
## 查询流字段数据
选择流字段的查询选择项返回流对象的完全形成的OID(对象ID)值,如下例所示:
```sql
SELECT Name,Photo,Notes
FROM Sample.MyTable WHERE Photo IS NOT NULL
```

OID是一个 `%List` 格式化数据地址,如以下内容:`$lb("1","%Stream.GlobalCharacter","^EW3K.Cn9X.S")`。
- OID的第一个元素是一个连续的正整数(从1开始),它被分配给每个插入到表中的流数据值。
例如,如果第1行插入流字段`Photo`和`Notes`的值,则将它们赋值为1和2。
如果第2行插入了一个`Notes`值,则将该值赋给3。
如果用`Photo`和`Notes`的值插入第3行,则将它们赋值为4和5。
分配顺序是表定义中列出字段的顺序,而不是`INSERT`命令中指定字段的顺序。
默认情况下,使用单个整数序列,它对应于流位置全局计数器。
然而,一个表可能有多个流计数器,如下所述。
- 更新操作不会改变初始整数值。
`DELETE`操作可以在整型序列中创建空白,但不会改变这些整型值。
使用`DELETE`删除所有记录不会重置此整数计数器。
如果所有表流字段都使用默认的`StreamLocation`值,则使用`TRUNCATE TABLE`删除所有记录将重置此整数计数器。
不能使用`TRUNCATE`表为嵌入式对象(`%SerialObject`)类重置流整数计数器。
- OID的第二个元素是流数据类型,可以是`%Stream.GlobalCharacter` 或`%Stream.GlobalBinary`。
- OID的第三个元素是一个全局变量。
默认情况下,它的名称是从与表对应的包名和持久类名生成的。
一个`“S”`(用于流)被追加。
- 如果表是使用SQL `CREATE TABLE`命令创建的,这些包和持久化类名称将被散列为每个4个字符(例如,`^EW3K.Cn9X.S`)。
这个全局变量包含流数据插入计数器最近分配的值。
如果没有插入流字段数据,或者使用`TRUNCATE TABLE`删除所有表数据,那么这个全局变量是未定义的。
- 如果表是作为一个持久化类创建的,那么这些包和持久化类名不会被散列(例如`^Sample.MyTableS`)。
默认情况下,这是`StreamLocation`存储关键字`^Sample.MyTableS` 价值。
默认流位置是全局位置,如`^Sample.MyTableS`。此全局变量用于计算插入到没有自定义位置的所有流属性(字段)的次数。例如,如果`Sample.MyTable`中的所有流属性都使用默认流位置,则在`Sample.MyTable`的流属性中插入了10个流数据值时,`^Sample.MyTableS`全局变量包含值10。此全局变量包含最近分配的流数据插入计数器的值。如果没有插入流字段数据,或者使用截断表删除了所有表数据,则此全局变量未定义。
定义流字段属性时,可以定义自定义位置,如下所示:`Property Note2 As %Stream.GlobalCharacter (LOCATION="^MyCustomGlobalS")`;。在这种情况下,`^MyCustomGlobalS`全局用作指定此位置的流属性(或多个属性)的流数据插入计数器;未指定位置的流属性使用默认流位置全局(`^Sample.MyTableS`)作为流数据插入计数器。每个全局计数与该位置相关联的流属性的插入。如果没有插入流场数据,则位置`GLOBAL`是未定义的。如果一个或多个流属性定义了位置,则截断表不重置流计数器。
这些流位置全局变量的下标包含每个流字段的数据。例如,`^EW3K.Cn9X.S(3)`表示第三个插入的流数据项。`^EW3K.Cn9X.S(3,0)`是数据的长度。`^EW3K.Cn9X.S(3,1)`是实际的流数据值。
注意:流字段的`OID`与`RowID`或`Reference`字段返回的`OID`不同。`%OID`函数返回`RowID`或引用字段的`OID`;`%OID`不能与流字段一起使用。试图将流字段用作`%OID`的参数会导致`SQLCODE-37`错误。
在查询的`WHERE`子句或`HAVING`子句中使用流字段受到严格限制。不能将相等条件或其他关系运算符(`=, !=, `)或包含运算符(`]`)或跟随运算符(`[`)与流字段一起使用。尝试将这些运算符与流字段一起使用会导致`SQLCODE-313`错误。
### Result Set Display
- 从程序执行的动态SQL以`$lb("6","%Stream.GlobalCharacter","^EW3K.Cn9X.S")`.格式返回`OID`。
- SQL Shell作为动态SQL执行,并以`$lb("6","%Stream.GlobalCharacter","^EW3K.Cn9X.S")`格式返回`OID`。
- 嵌入式SQL返回相同的`OID`,但以编码`%LIST`的形式返回。可以使用`$LISTTOSTRING`函数将`OID`显示为元素以逗号分隔的字符串:`6,%Stream.GlobalBinary,^EW3K.Cn9X.S`。
从管理门户SQL执行界面运行查询时,不返回`OID`。取而代之的是:
- 字符流字段返回字符流数据的前100个字符。如果字符流数据超过100个字符,则用省略号(`...`)表示。在第100个字符之后。这等效于`SUBSTRING(cstream field,1,100)`。
- 二进制流字段返回字符串``。
在表数据的管理门户SQL界面打开表显示中显示相同的值。
要从管理门户SQL执行界面显示`OID`值,请将空字符串连接到流值,如下所示:`SELECT Name, ''||Photo, ''||Notes FROM Sample.MyTable`。

## `DISTINCT`, `GROUP BY`, and `ORDER BY`
每个流数据字段的`OID`值是唯一的,即使数据本身包含重复。
这些`SELECT`子句操作的是流的`OID`值,而不是数据值。
因此,当应用到查询中的流字段时:
- 不同的子句对重复的流数据值没有影响。
`DISTINCT`子句将流字段为`NULL`的记录数减少为一个`NULL`记录。
- `GROUP BY`子句对重复的流数据值没有影响。
`GROUP BY`子句将流字段为空的记录数量减少为一个空记录。
- `ORDER BY`子句根据数据流的`OID`值来排序数据,而不是数据值。
`ORDER BY`子句列出流字段为空的记录,然后列出带有流字段数据值的记录。
## 谓词条件和流
`IS [NOT] NULL`谓词可以应用于流字段的数据值,示例如下:
```sql
SELECT Name,Notes
FROM Sample.MyTable WHERE Notes IS NOT NULL
```
`BETWEEN`, `EXISTS`, `IN`, `%INLIST`, `LIKE`, `%MATCHES`, and `%PATTERN` 谓词可以应用于流对象的`OID`值,示例如下:
```sql
SELECT Name,Notes
FROM Sample.MyTable WHERE Notes %MATCHES '*1[0-9]*GlobalChar*'
```
尝试在流字段上使用任何其他谓词条件会导致`SQLCODE -313`错误。
## 聚合函数和流
`COUNT`聚合函数接受一个流字段,并对该字段中包含非空值的行进行计数,示例如下:
```sql
SELECT COUNT(Photo) AS PicRows,COUNT(Notes) AS NoteRows
FROM Sample.MyTable
```

但是,流字段不支持`COUNT`(`DISTINCT`)。
对于流字段不支持其他聚合函数。
尝试将流字段与任何其他聚合函数一起使用会导致`SQLCODE -37`错误。
## 标量函数和流
除了`%OBJECT`、`CHARACTER_LENGTH`(或`CHAR_LENGTH或DATALENGTH`)、`SUBSTRING`、`CONVERT`、`XMLCONCAT`、`XMLELEMENT`、`XMLFOREST`和`%INTERNAL`函数外,InterSystems SQL不能对流字段应用任何函数。
尝试使用流字段作为任何其他SQL函数的参数会导致`SQLCODE -37`错误。
尝试使用流字段作为任何其他SQL函数的参数会导致`SQLCODE -37`错误。
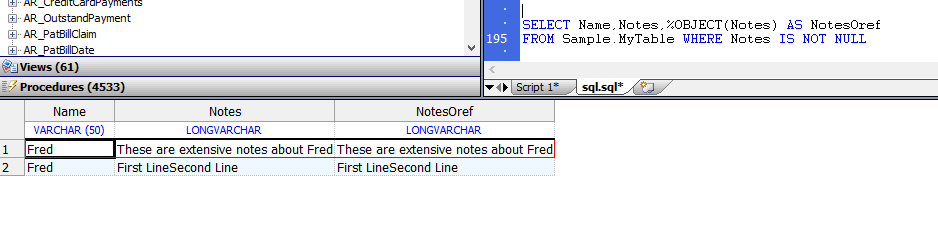
- `%OBJECT`函数打开一个流对象(接受一个`OID`)并返回oref(对象引用),示例如下:
```sql
SELECT Name,Notes,%OBJECT(Notes) AS NotesOref
FROM Sample.MyTable WHERE Notes IS NOT NULL
```
- `CHARACTER_LENGTH`、`CHAR_LENGTH`和`DATALENGTH`函数接受流字段并返回实际的数据长度,如下面的示例所示:
```sql
SELECT Name,DATALENGTH(Notes) AS NotesNumChars,DATALENGTH(Photo) AS PhotoNumChars
FROM Sample.MyTable
```

`SUBSTRING`函数接受一个流字段,并返回流字段的实际数据值的指定子字符串,如下面的示例所示:
```sql
SELECT Name,SUBSTRING(Notes,1,10) AS Notes1st10Chars
FROM Sample.MyTable WHERE Notes IS NOT NULL
```
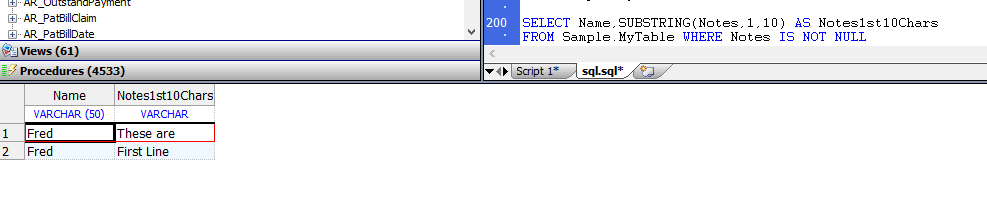
当从管理门户SQL Execute接口发出时,子字符串函数返回流字段数据最多100个字符的子字符串。
如果流数据的指定子字符串大于100个字符,则在第100个字符后用省略号(`…`)表示。
- `CONVERT`函数可用于将流数据类型转换为`VARCHAR`,示例如下:
```sql
SELECT Name,CONVERT(VARCHAR(100),Notes) AS NotesTextAsStr
FROM Sample.MyTable WHERE Notes IS NOT NULL
```
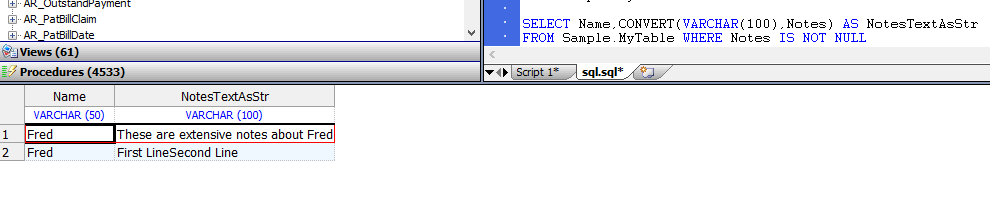
`CONVERT(datatype,expression)`语法支持流数据转换。
如果`VARCHAR`精度小于实际流数据的长度,则将返回值截断为`VARCHAR`精度。
如果`VARCHAR`精度大于实际流数据的长度,则返回值为实际流数据的长度。
不执行填充。
`{fn CONVERT(expression,datatype)}`语法不支持流数据转换;
它发出一个`SQLCODE -37`错误。
- `%INTERNAL`函数可以用于流字段,但不执行任何操作。
# 流字段并发锁
InterSystems IRIS通过取出流数据上的锁来保护流数据值不被另一个进程并发操作。
InterSystems IRIS在执行写操作之前取出一个排他锁。
排他锁在写操作完成后立即释放。
当第一个读操作发生时,InterSystems IRIS取出共享锁。
只有当流实际被读取时才会获取共享锁,并且在整个流从磁盘读取到内部临时输入缓冲区后立即释放共享锁。
# 在Intersystems中使用流字段IRIS方法
不能在Intersystems Iris方法中直接使用嵌入式SQL或动态SQL使用`BLOB`或`CLOB`值;相反,使用SQL来查找`Blob`或`Clob`的流标识符,然后创建`%AbstractStream`对象的实例以访问数据。
# 使用来自ODBC的流字段
ODBC规范不提供对`BLOB`和`CLOB`字段的任何识别或特殊处理。
InterSystems SQL将ODBC中的`CLOB`字段表示为具有`LONGVARCHAR(-1)`类型。
BLOB字段表示为类型为`LONGVARBINARY(-4)`。
对于流数据类型的ODBC/JDBC数据类型映射,请参考InterSystems SQL reference中的数据类型引用页中的数据类型整数代码。
ODBC驱动程序/服务器使用一种特殊协议来访问`BLOB`和`CLOB`字段。
通常,必须在ODBC应用程序中编写特殊的代码来使用`CLOB`和`BLOB`字段;
标准的报告工具通常不支持它们。
# 使用来自JDBC的流字段
在Java程序中,可以使用标准的JDBC `BLOB`和`CLOB`接口从`BLOB`或`CLOB`检索或设置数据。
例如:
```java
Statement st = conn.createStatement();
ResultSet rs = st.executeQuery("SELECT MyCLOB,MyBLOB FROM MyTable");
rs.next(); // fetch the Blob/Clob
java.sql.Clob clob = rs.getClob(1);
java.sql.Blob blob = rs.getBlob(2);
// Length
System.out.println("Clob length = " + clob.length());
System.out.println("Blob length = " + blob.length());
// ...
```
注意:当使用`BLOB`或`CLOB`结束时,必须显式调用`free()`方法来关闭Java中的对象,并向服务器发送消息以释放流资源(对象和锁)。
仅仅让Java对象超出范围并不会发送清理服务器资源的消息。
文章
Qiao Peng · 一月 10, 2021
# Swift-FHIR-Iris
iOS应用程序支持将HealthKit数据导入InterSystems IRIS医疗版(或任何FHIR资源仓库库)
# 目录
* [演示目的](#goal)
* [如何运行此演示](#rundemo)
* [先决条件](#prerequisites)
* [安装Xcode](#installxcode)
* [打开SwiftUi](#openswiftui)
* [配置模拟器](#simulator)
* [启动InterSystems FHIR服务器](#lunchfhir)
* [在iOS应用程序上操作](#iosplay)
* [工作原理](#howtos)
* [iOS](#howtosios)
* [如何检查健康数据的授权](#authorisation)
* [如何连接FHIR资源仓库](#howtoFhir)
* [如何将患者信息保存到FHIR资源仓库](#howtoPatientFhir)
* [如何从HealthKit中提取数据](#queryHK)
* [如何将HealthKit数据转换为FHIR](#HKtoFHIR)
* [后端 (FHIR)](#backend)
* [前端](#frontend)
* [ToDos](#todo)
# 演示目的
目的是创建FHIR协议的端到端演示。
这里的端到端指的是从一个信息源到另一个信息源,例如iPhone。
苹果HealthKit将收集到的健康数据转换为FHIR,再发送到InterSystems IRIS 医疗版存储库。
必须通过web接口访问这些信息。
**TL;DR**: iPhone -> InterSystems FHIR -> web界面.
# 如何运行此演示
## 先决条件
* 客户端 (iOS)
* Xcode 12
* 服务器和Web应用程序
* Docker
## 安装 Xcode
这里没有太多要说的,打开AppStore,搜索Xcode,安装。
## 打开SwiftUi project
Swift是苹果在iOS、Mac、Apple TV和Apple Watch中使用的一种编程语言,是objective-C的替代品。
双击Swift-FHIR-Iris.xcodeproj
单击左上角的箭头打开模拟器。
## 配置模拟器
打开Health
点击“Steps”
添加数据

## 启动InterSystems FHIR服务器
在该git的根目录下,运行以下命令:
```sh
docker-compose up -d
```
构建过程结束时,你将连接到FHIR资源仓库:
http://localhost:32783/fhir/portal/patientlist.html
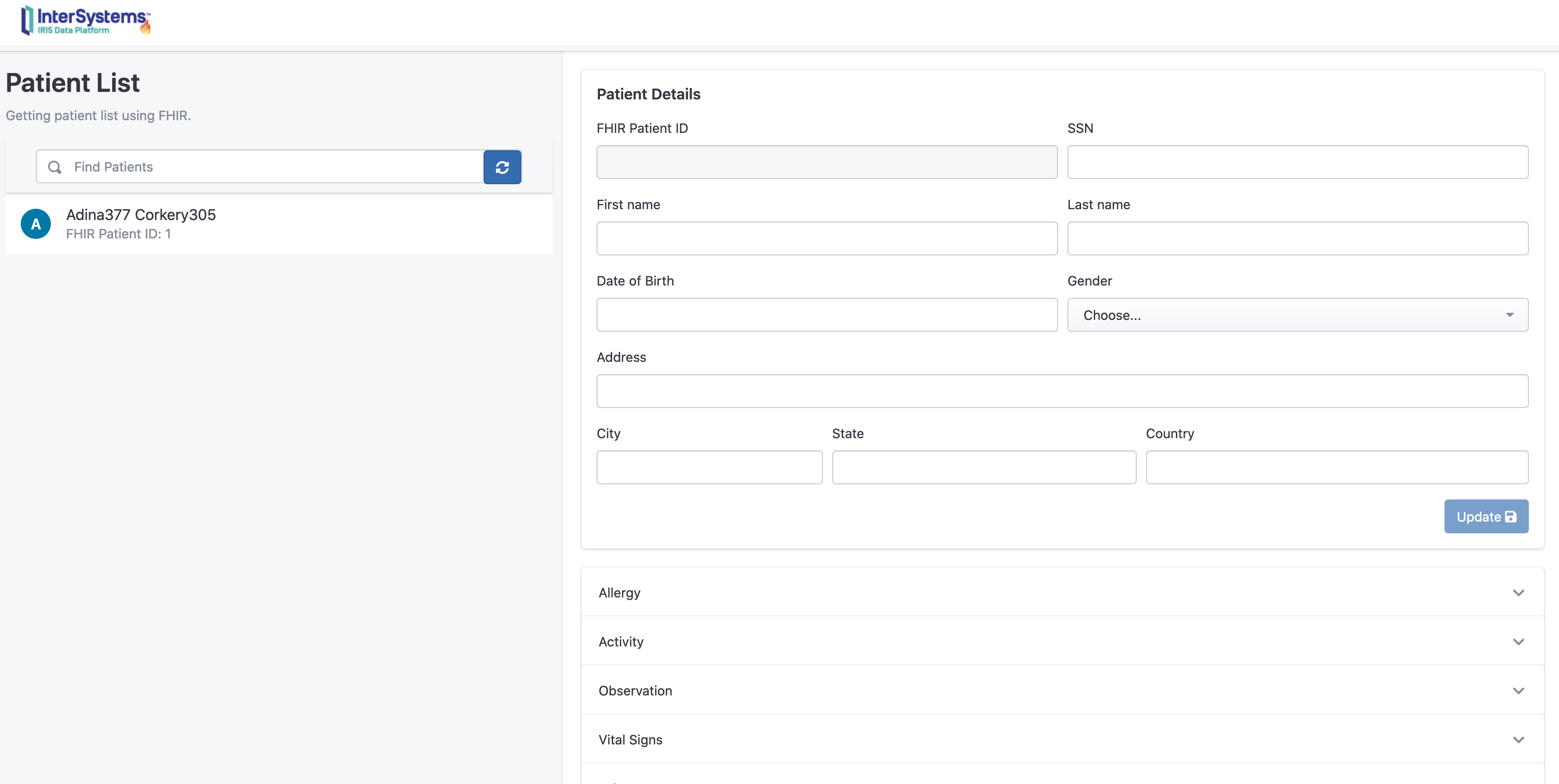
该门户网站由@diashenrique创建.
为处理Apple活动足迹,进行了一些修改。
## 在iOS应用程序上操作
iOS应用程序首先会请求你同意分享部分信息。
点击授权
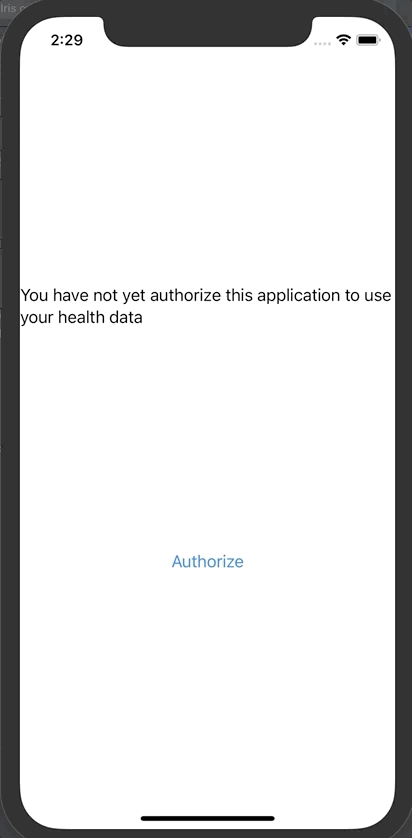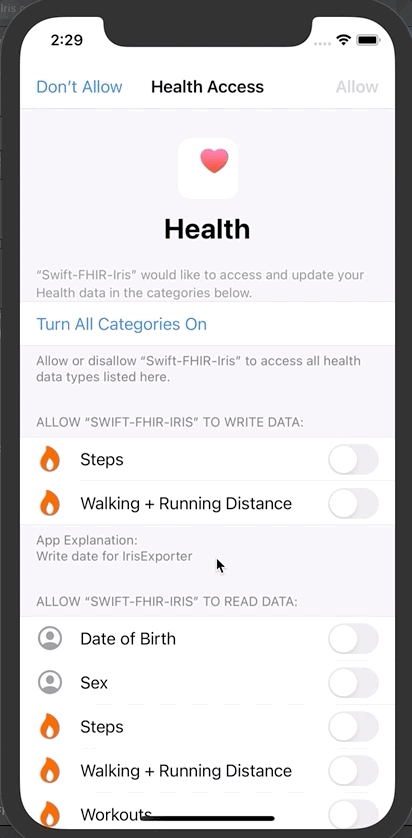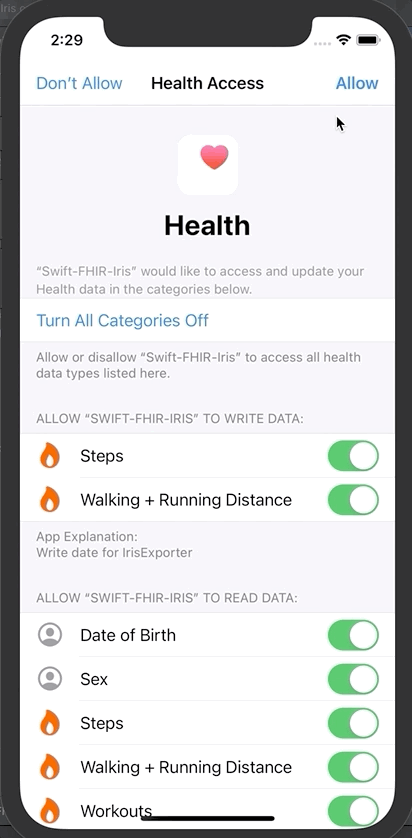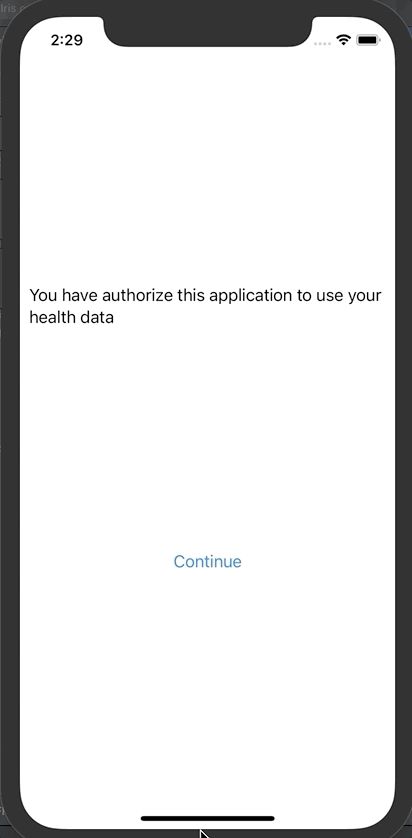
然后点击“Save and test server”对FHIR服务器进行测试
默认设置指向docker配置。
操作成功后,就可以输入患者信息。
名字、姓氏、生日、性别。
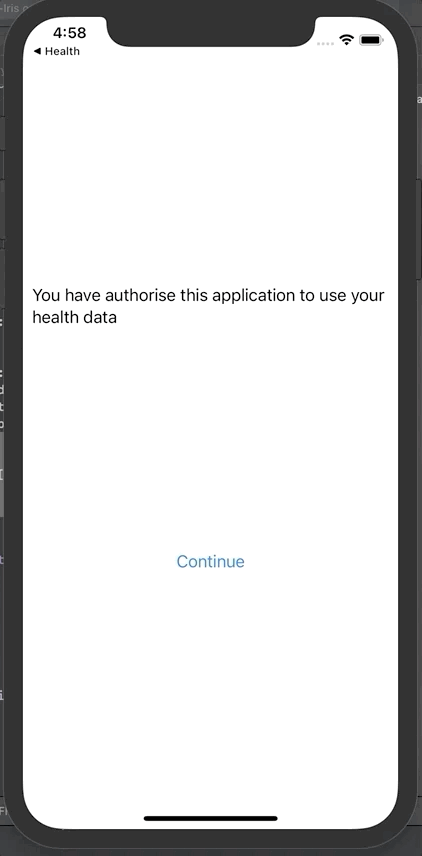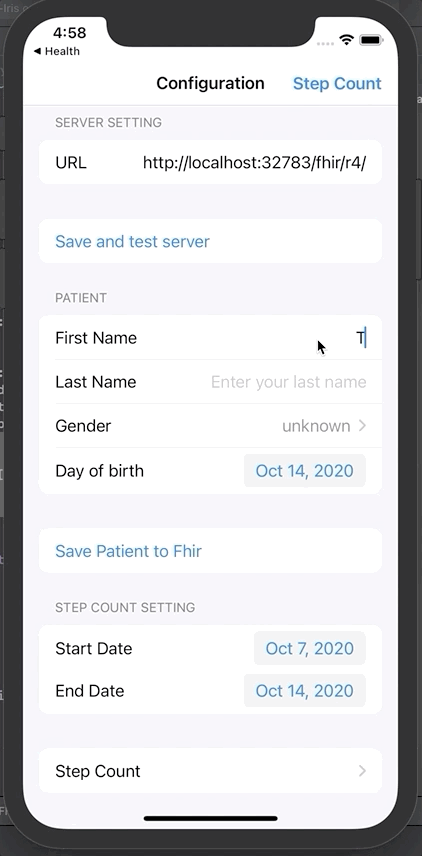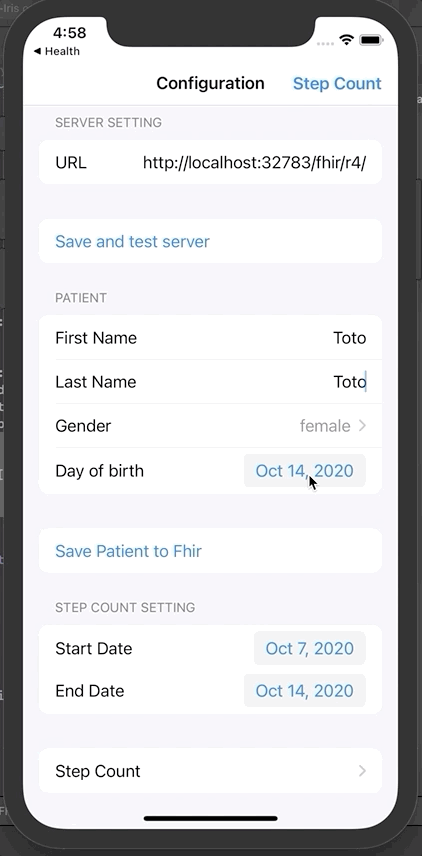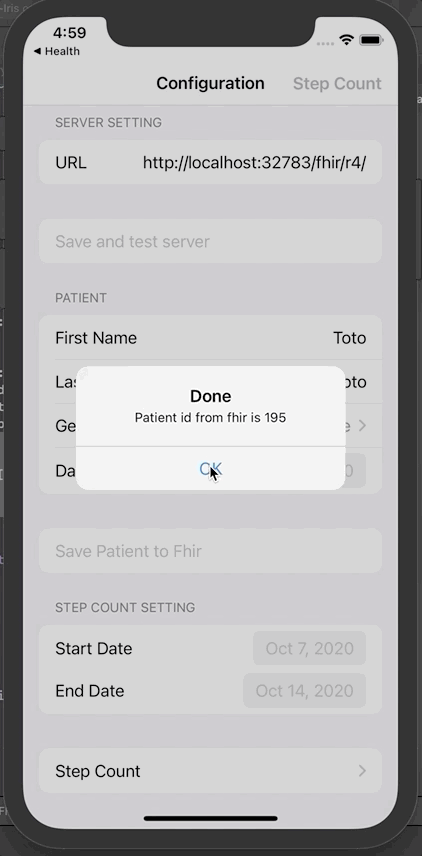
将患者信息保存到Fhir。弹出窗口将显示唯一的Fhir ID。
可在门户网站查阅该患者信息:
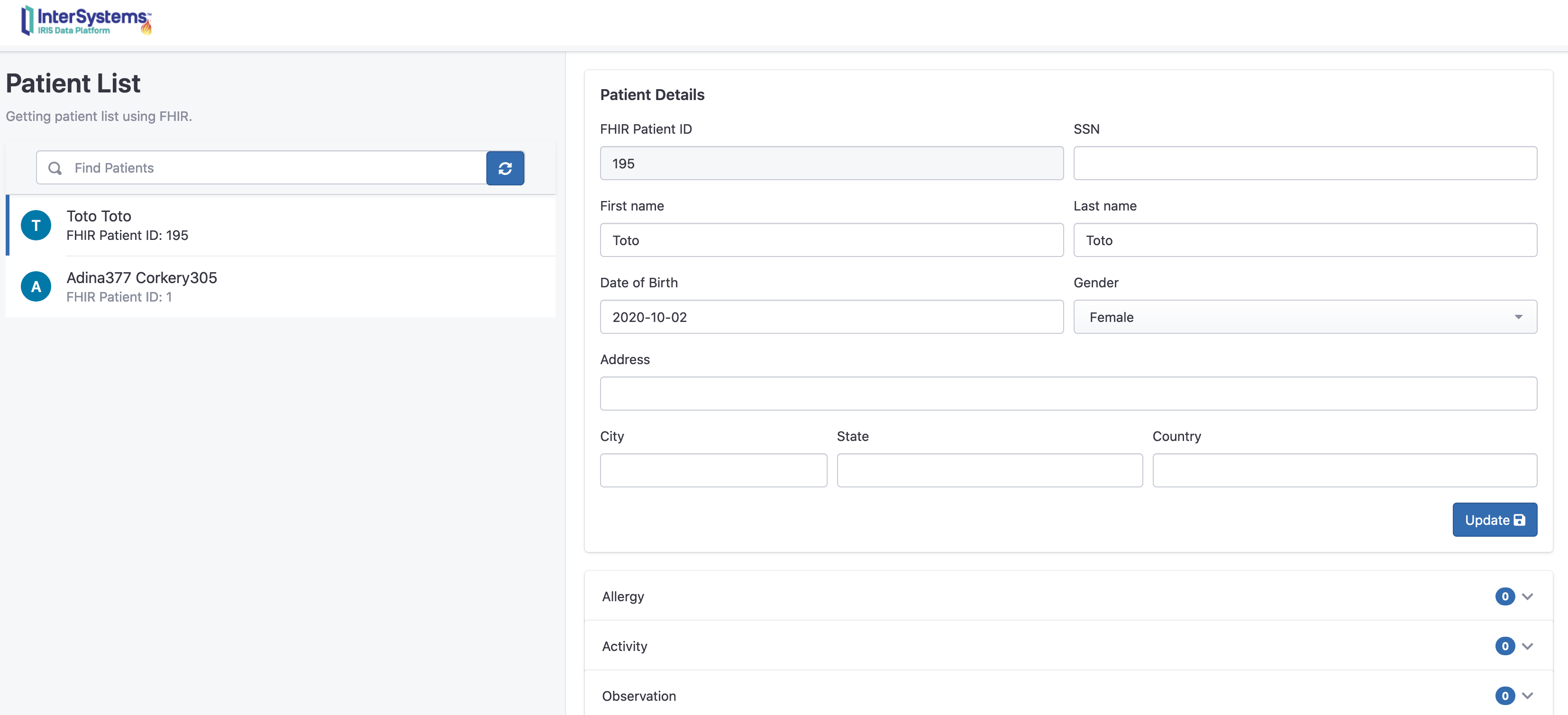
访问: http://localhost:32783/fhir/portal/patientlist.html
在这里我们可以看到,增加了一个新的病人“Toto”,0个活动。
发送她的活动信息:
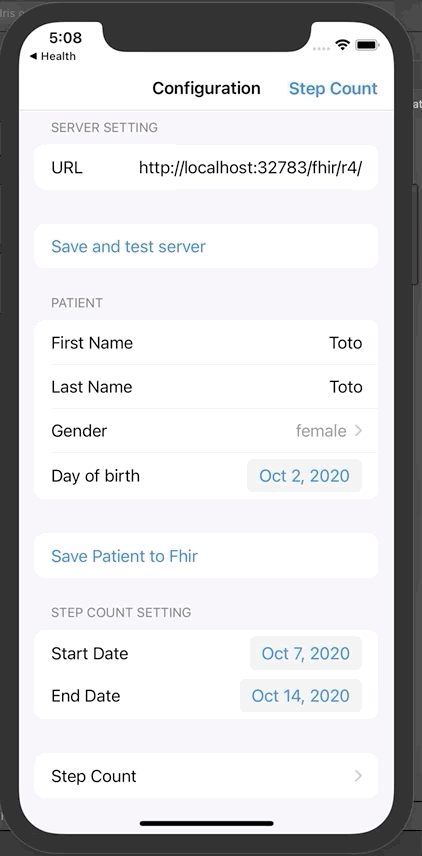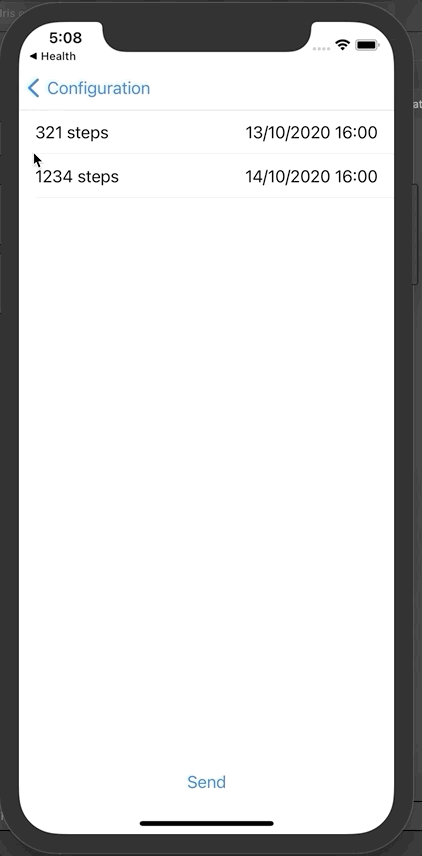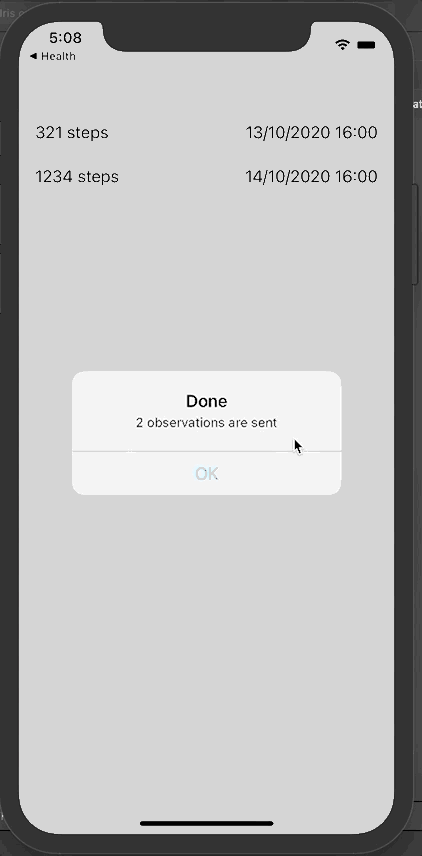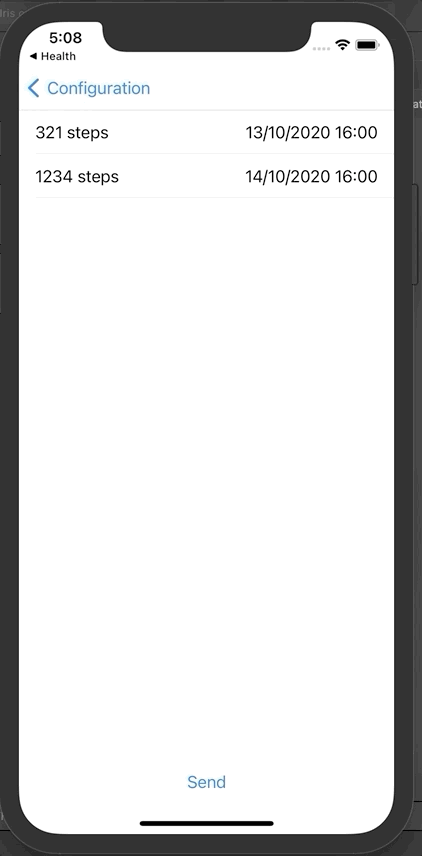
回到iOS应用程序,点击“Step count”。
这里显示的是一周的步数。在我们的案例中有2条记录。
现在可以单击发送,将这些数据发送到InterSystems IRIS FHIR。
从门户网站上查询新的活动记录:
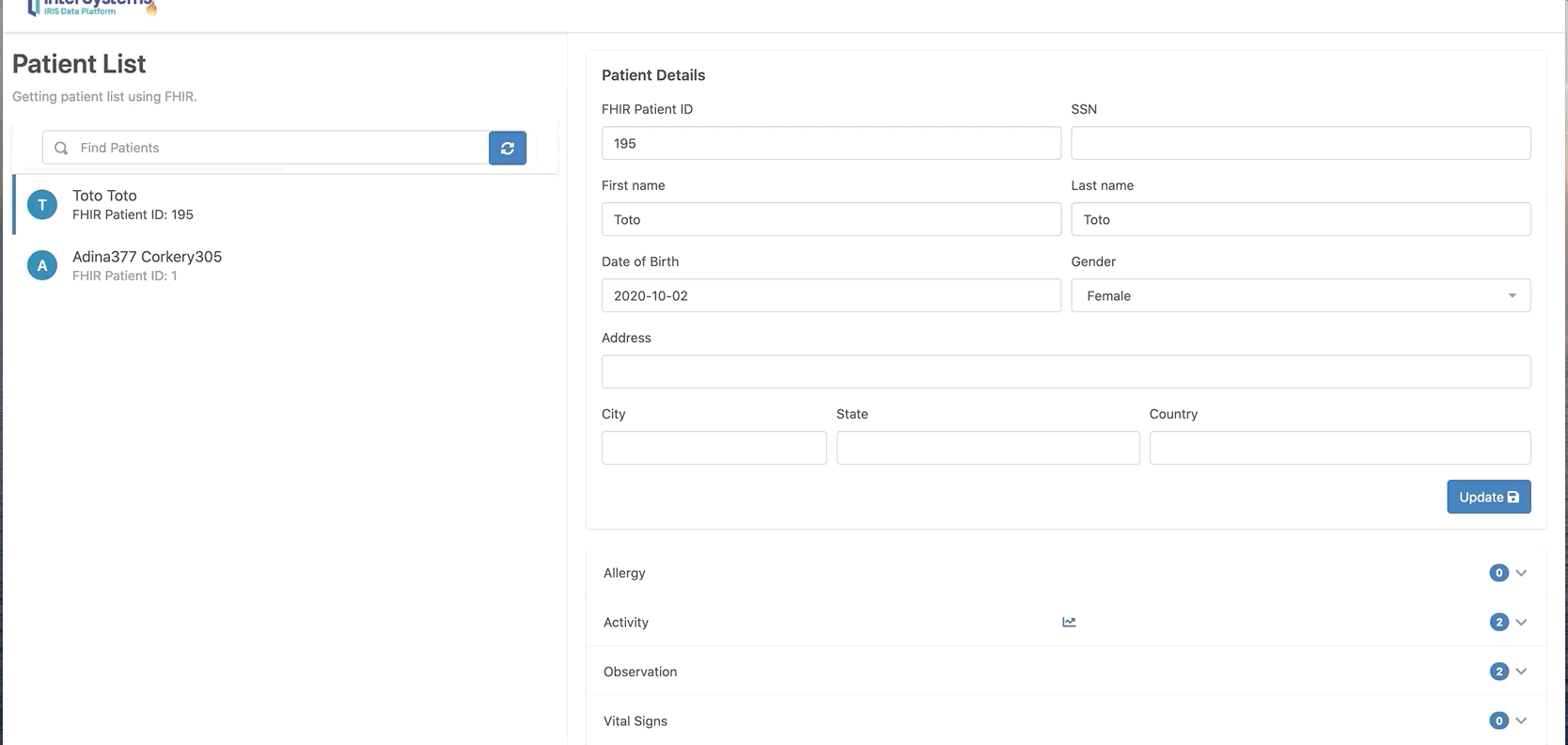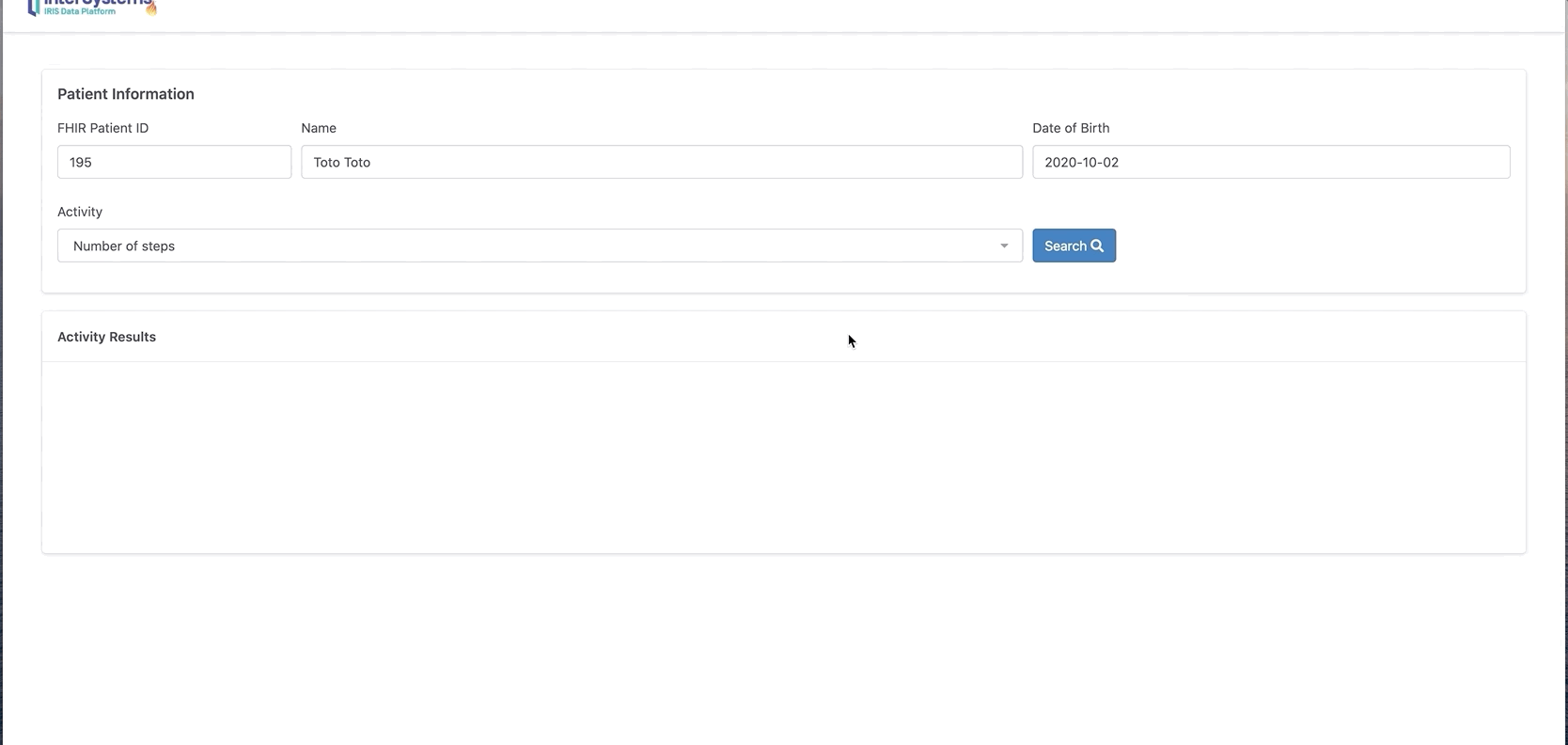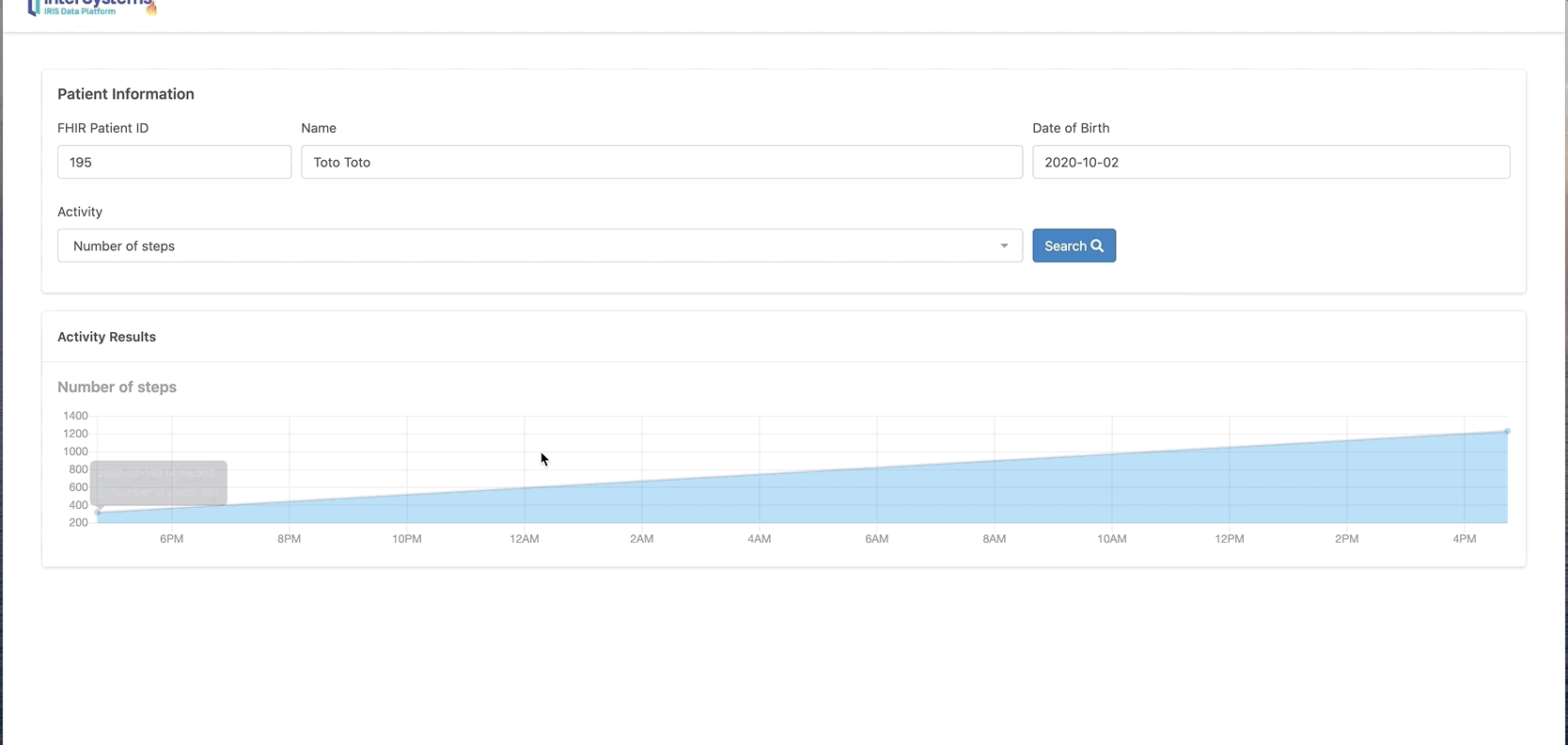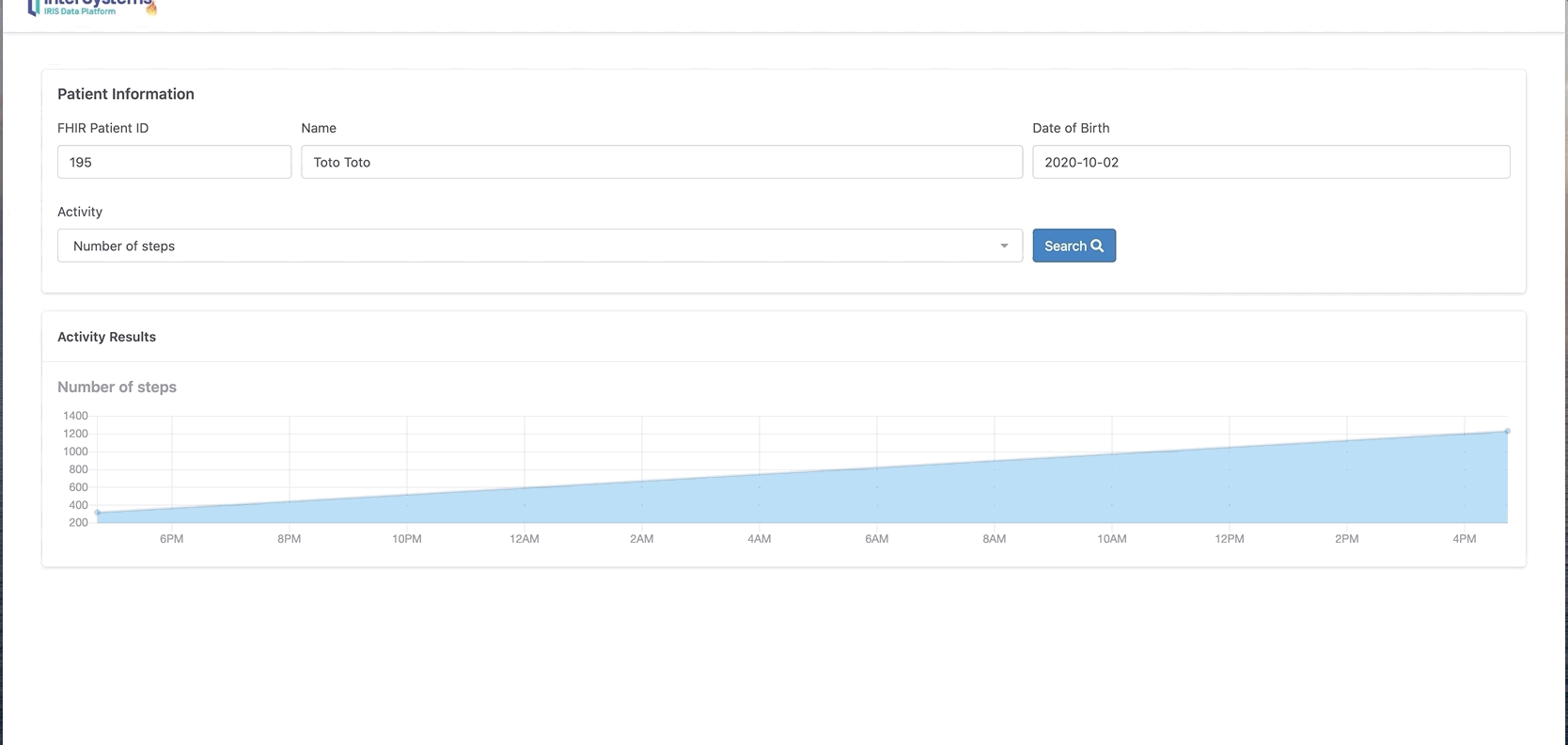
现在我们可以看到Toto有两条新的观察和活动消息。
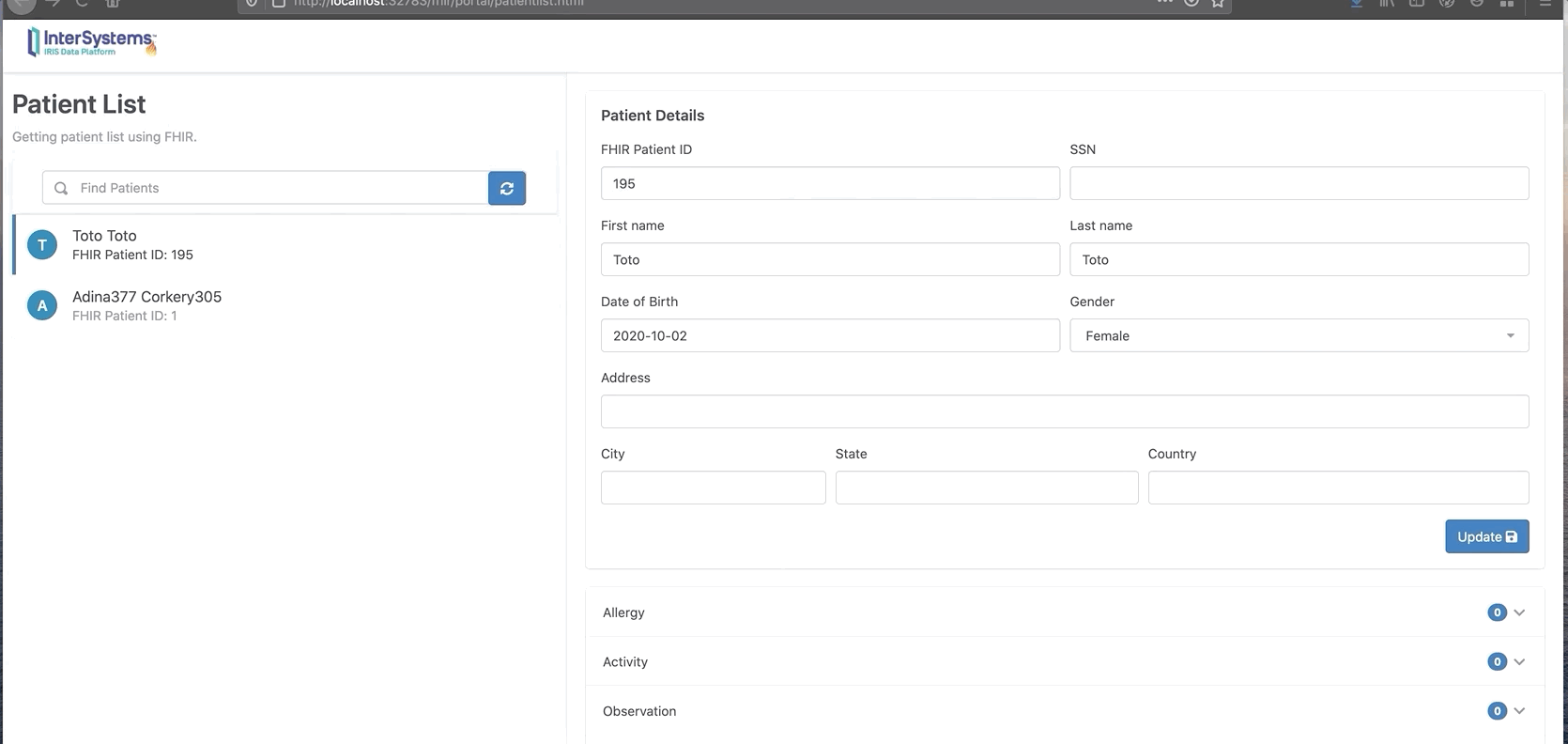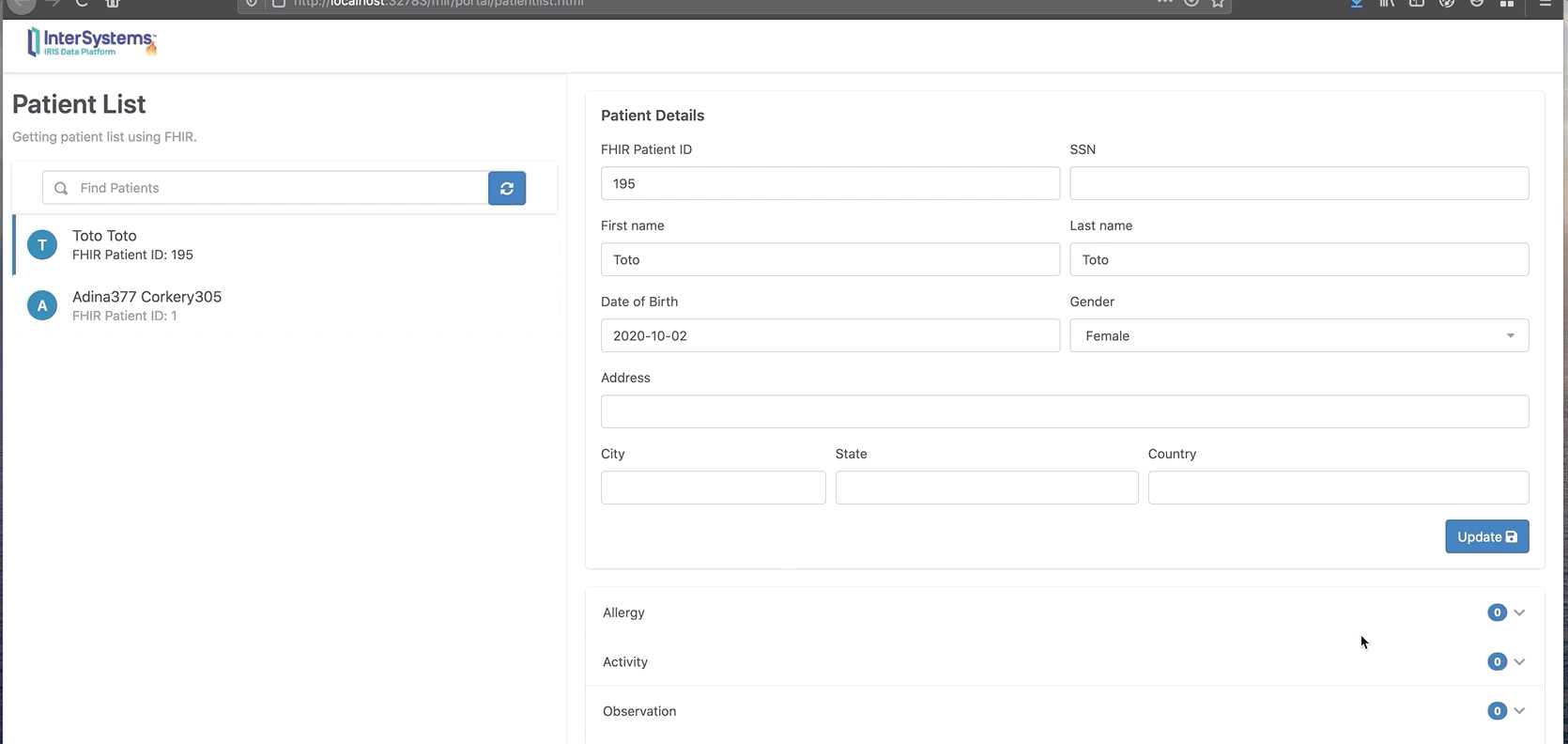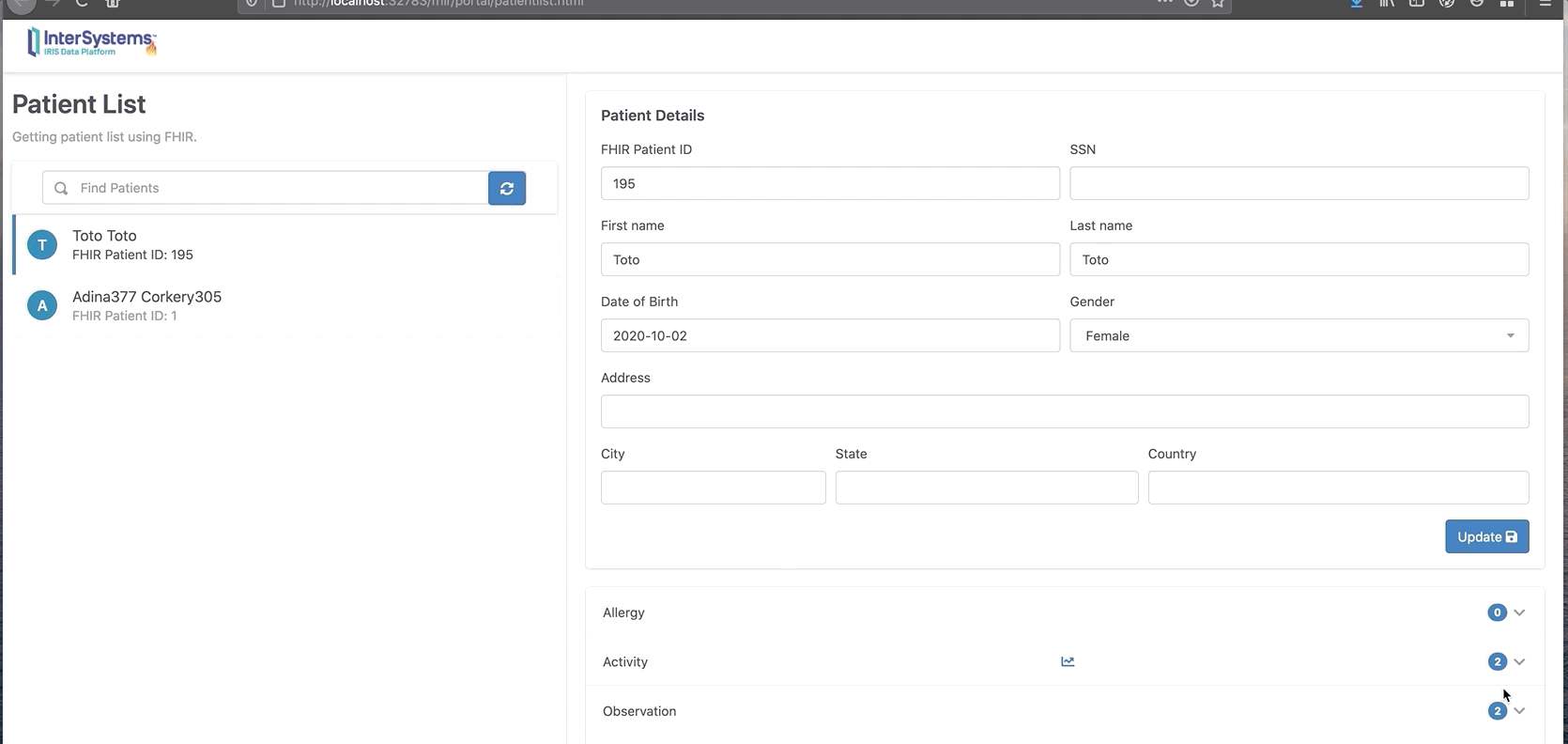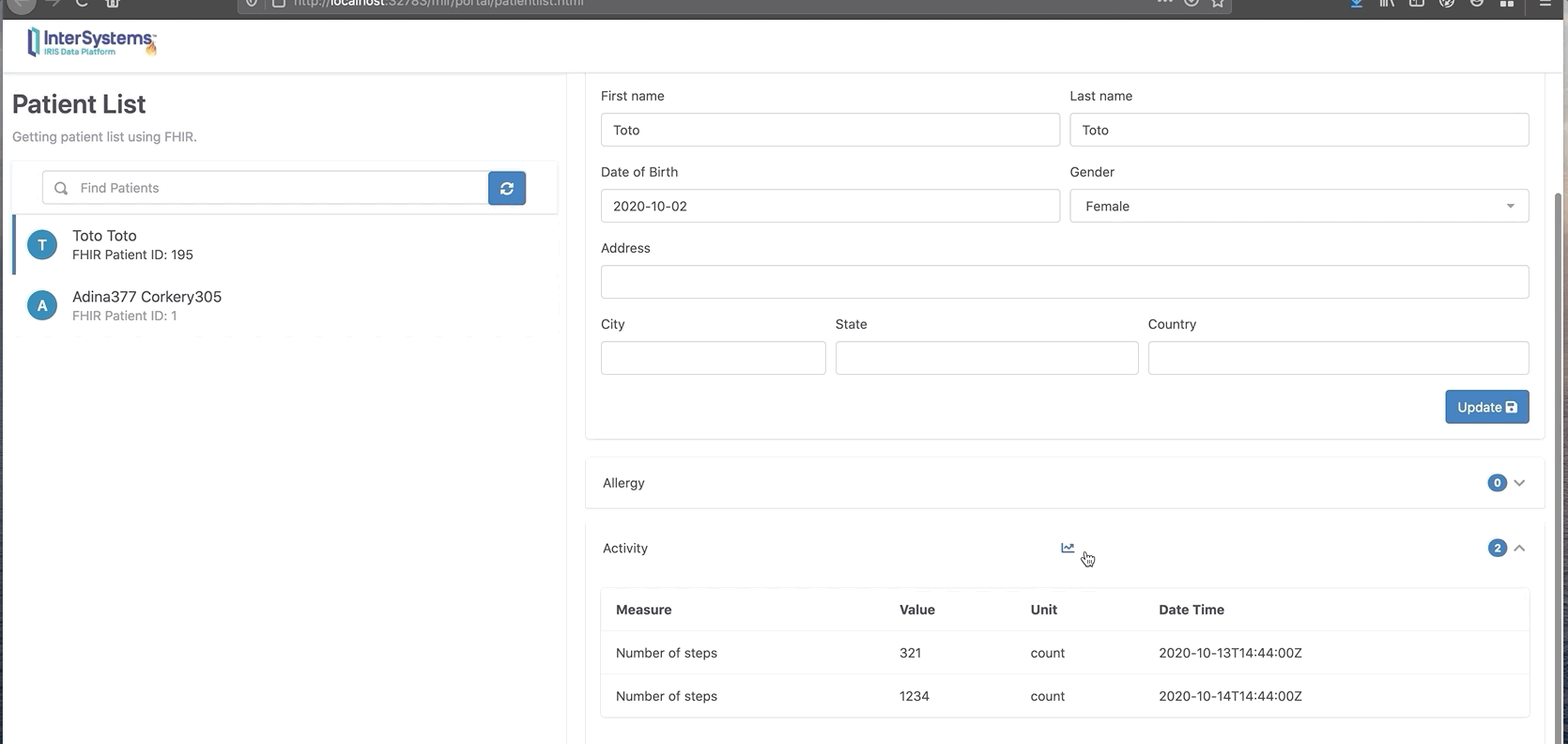
你还可以单击“chart”按钮以图表格式显示。
# 工作原理
## iOS
该demo大部分是基于SwiftUI构建的。
https://developer.apple.com/xcode/swiftui/
iOS和co的最新框架。
### 如何检查健康数据的授权
它在SwiftFhirIrisManager 类中。
该类采用单例模式,可使用@EnvironmentObject对应用程序中进行的所有操作进行注释。
更多信息请访问 : https://www.hackingwithswift.com/quick-start/swiftui/how-to-use-environmentobject-to-share-data-between-views
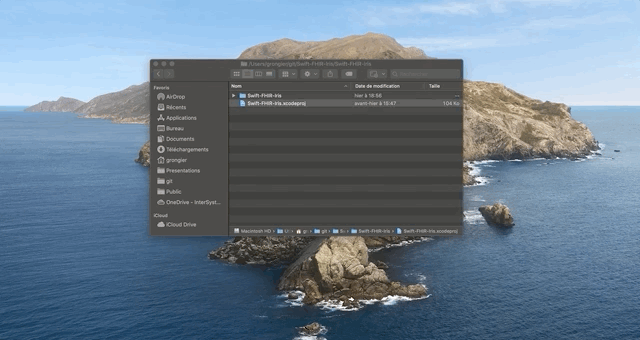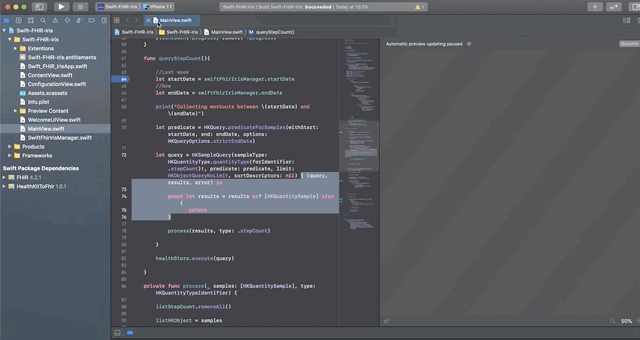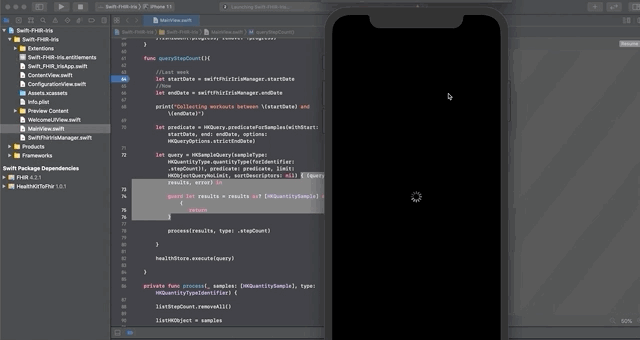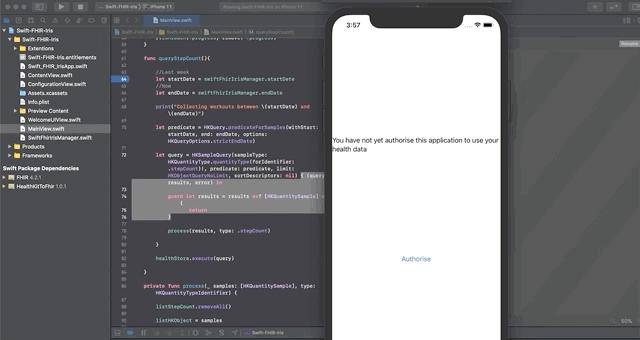
调用requestAuthorization的方法如下:
```swift
// Request authorization to access HealthKit.
func requestAuthorization() {
// Requesting authorization.
/// - Tag: RequestAuthorization
let writeDataTypes: Set = dataTypesToWrite()
let readDataTypes: Set = dataTypesToRead()
// requset authorization
healthStore.requestAuthorization(toShare: writeDataTypes, read: readDataTypes) { (success, error) in
if !success {
// Handle the error here.
} else {
DispatchQueue.main.async {
self.authorizedHK = true
}
}
}
}
```
其中healthStore是HKHealthStore()的对象。
HKHealthStore类似于iOS中的healthdata数据库。
dataTypesToWrite和dataTypesToRead是我们想要在数据库中查询的对象。
授权的目的可以通过在Info.plist xml文件中添加以下内容完成:
```xml
NSHealthClinicalHealthRecordsShareUsageDescription
Read data for IrisExporter
NSHealthShareUsageDescription
Send data to IRIS
NSHealthUpdateUsageDescription
Write date for IrisExporter
```
### 如何连接FHIR资源仓库
对于这一部分,我使用了从Smart-On-FHIR网站下载的FHIR包 : https://github.com/smart-on-fhir/Swift-FHIR
使用的类是FHIROpenServer。.
```swift
private func test() {
progress = true
let url = URL(string: self.url)
swiftIrisManager.fhirServer = FHIROpenServer(baseURL : url! , auth: nil)
swiftIrisManager.fhirServer.getCapabilityStatement() { FHIRError in
progress = false
showingPopup = true
if FHIRError == nil {
showingSuccess = true
textSuccess = "Connected to the fhir repository"
} else {
textError = FHIRError?.description ?? "Unknow error"
showingSuccess = false
}
return
}
}
```
这一步将在单例swiftIrisManager中创建一个新的对象fhirServer。
接下来使用getCapabilityStatement()
如果能够检索到FHIR服务器的capabilityStatement,则意味着已成功连接到FHIR资源仓库。
这个资源仓库不在HTTPS下,默认情况下Apple会阻止这种通信。
想要获取HTTP支持,可以对Info.plist xml文件进行如下编辑:
```xml
NSAppTransportSecurity
NSExceptionDomains
localhost
NSIncludesSubdomains
NSExceptionAllowsInsecureHTTPLoads
```
### 如何将患者信息保存到FHIR资源仓库
基本操作:首先检查存储库中是否已经存在该患者的信息
```swift
Patient.search(["family": "\(self.lastName)"]).perform(fhirServer)
```
搜索具有相同姓氏的患者。
在这里,我们可以想象一下其他场景,比如使用Oauth2和JWT令牌加入patientId及其令牌。但在这个演示中,我们简单操作即可。
如果该患者信息已经存在,可以对其进行检索;否则,则创建新的患者信息 :
```swift
func createPatient(callback: @escaping (Patient?, Error?) -> Void) {
// Create the new patient resource
let patient = Patient.createPatient(given: firstName, family: lastName, dateOfBirth: birthDay, gender: gender)
patient?.create(fhirServer, callback: { (error) in
callback(patient, error)
})
}
```
### 如何从HealthKit中提取数据
通过查询healthkit商店 store(HKHealthStore())即可完成。
这里我们查询一下步数。
使用predicate做好查询准备。
```swift
//Last week
let startDate = swiftFhirIrisManager.startDate
//Now
let endDate = swiftFhirIrisManager.endDate
print("Collecting workouts between \(startDate) and \(endDate)")
let predicate = HKQuery.predicateForSamples(withStart: startDate, end: endDate, options: HKQueryOptions.strictEndDate)
```
然后,会根据数据类型(HKQuantityType.quantityType(forIdentifier: .stepCount))和predicate内容进行查询。
```swift
func queryStepCount(){
//Last week
let startDate = swiftFhirIrisManager.startDate
//Now
let endDate = swiftFhirIrisManager.endDate
print("Collecting workouts between \(startDate) and \(endDate)")
let predicate = HKQuery.predicateForSamples(withStart: startDate, end: endDate, options: HKQueryOptions.strictEndDate)
let query = HKSampleQuery(sampleType: HKQuantityType.quantityType(forIdentifier: .stepCount)!, predicate: predicate, limit: HKObjectQueryNoLimit, sortDescriptors: nil) { (query, results, error) in
guard let results = results as? [HKQuantitySample] else {
return
}
process(results, type: .stepCount)
}
healthStore.execute(query)
}
```
### 如何将HealthKit数据转换为FHIR
在这部分,我们使用了微软软件包HealthKitToFHIR
https://github.com/microsoft/healthkit-to-fhir
这个包很有用,为开发商提供了将HKQuantitySample转换为FHIR Observation的功能。
```swift
let observation = try! ObservationFactory().observation(from: item)
let patientReference = try! Reference(json: ["reference" : "Patient/\(patientId)"])
observation.category = try! [CodeableConcept(json: [
"coding": [
[
"system": "http://terminology.hl7.org/CodeSystem/observation-category",
"code": "activity",
"display": "Activity"
]
]
])]
observation.subject = patientReference
observation.status = .final
print(observation)
observation.create(self.fhirServer,callback: { (error) in
if error != nil {
completion(error)
}
})
```
其中item是HKQuantitySample,在我们的例子中是stepCount类型。
这个factory完成了大部分工作,将“unit”和“type”转换为FHIR codeableConcept,并将“value”转换为FHIR valueQuantity。
对PatientId的引用是通过强制转换json fhir引用手动完成的。
```swift
let patientReference = try! Reference(json: ["reference" : "Patient/\(patientId)"])
```
对类别进行同样的操作 :
```swift
observation.category = try! [CodeableConcept(json: [
"coding": [
[
"system": "http://terminology.hl7.org/CodeSystem/observation-category",
"code": "activity",
"display": "Activity"
]
]
])]
```
最后,在fhir资源仓库中创建observation :
```swift
observation.create(self.fhirServer,callback: { (error) in
if error != nil {
completion(error)
}
})
```
## 后端 (FHIR)
没什么好说的,它基于InterSystems社区的fhir模板 :
https://openexchange.intersystems.com/package/iris-fhir-template
## 前端
基于Henrique作品,Henrique是使用jquery制作的FHIR资源仓库的一个很好的前端。
https://openexchange.intersystems.com/package/iris-fhir-portal
文章
Lilian Huang · 八月 1, 2023
VR ICU® 是 InterSystems FHIR 创新孵化器 Caelestinus 的参与者。这篇文章将向您介绍我们利用 InterSystems FHIR Server 为医疗保健提供的 VR 解决方案。
我们是一家技术初创企业虚拟实验室,利用先进的 VR/AR 技术开发解决方案。VR ICU® 是一个针对重症监护室医务人员的培训平台,是在 Covid 时代为满足医院需求而创建的。
与InterSystems合作的优势
我们的 VR ICU® 解决方案符合实践需求,是与医院合作开发的。
除了技术解决方案和技能学习本身,记录培训课程、培训进度和成功率对于医院或麻醉学和重症监护部门的有效管理也至关重要。医务长可以通过了解谁在何时接受了培训,清楚地掌握能够在重症监护室使用设备的人员数量,从而有效地对他们进行培训,以保持技能、有控制地规划人员技能储备并提高他们的能力。
在这方面,与 InterSystems 的合作对我们来说至关重要,它使我们能够在应用程序中存储每次培训期间的数据。目前,我们会记录参与者的姓名、培训日期和时长、培训类型、设备类型、错误数量和类型,必要时还会记录培训成功完成的信息。
如何使用?用户登录应用程序并选择一个账户。
根据 HL7 标准,该账户作为从业人员存在于数据库的资源下。培训课程开始时,会在应用程序中创建一个新的 "任务"--在这里输入培训课程的开始时间和培训课程的类型,课程结束时,再次输入培训课程的结束时间。错误会写入输出表。培训完成后,任务中的数据将序列化为 JSON 格式,并使用 FHIR API 发送到云端。为了使 VR 应用程序之外的数据可视化,我们开发了一款平板电脑应用程序。该应用程序与存储在云端的数据相连,并显示特定用户的个人训练课程。
人力资源部门通过培训数据了解受训人员完成培训的总体情况和水平,从而有效地规划他们的进一步培训,并跟踪了解员工的能力及其在重症监护室护理过程中的替换性。您可以点击这里:https://www.youtube.com/watch?v=3oO0uuHy0kg&t=8s
如今,医院、大学和模拟中心都在使用 VR ICU®。
虚拟现实技术将教育和培训提升到了一个新的水平。通过体验学习,可以提高培训效果和记忆力。
在 VR ICU® 中使用 InterSystems 的 FHIR 云服务器作为存储培训进度数据的工具,并使用 FHIR API 进行通信,这也对我们进军国外市场产生了积极影响,尤其是在德国,FHIR 标准是一种广为接受的解决方案,用于与人力资源部门传输信息,并与第三方调度系统进行通信。
麻醉学和重症监护审查参考:https://www.youtube.com/embed/Qve5xEm89cU?feature=oembed
它是如何开始的?
2020 年,一场大流行病袭击了我国。医院人满为患,人手短缺,尤其是重症监护室。麻醉、复苏和重症医学科主任在晚间新闻中解释说,如果更多的医生被隔离或生病,他就没有足够的合格人员来操作肺部呼吸机。其他医院也证实了同样的情况。我们萌生了制作一个专门用于培训的肺部呼吸机数字拷贝,帮助医院培训其他科室医生的想法。
我们找到了麻醉复苏部(ARO)的负责人、模拟中心的专家。医生们支持我们的想法,有些人还参与了开发工作。我们还得到了医疗设备制造商的支持,他们看到了虚拟现实培训的附加值。
我们是如何开展项目的,解决方案的重要性何在?
1. 我们评估了重症监护室的现状:
- 在没有真实病人和/或医疗设备的情况下,50% 以上的重症监护室程序无法进行培训。
- 医疗设备制造商难以将医务人员集中到一处进行培训(只有 30% 的受训人员能坚持到培训结束)
- 过去两年中,麻醉学和重症监护部门的人员流动率约为 20%。
2. 问题的解决方案:
- 虚拟现实自动培训平台
- 模拟重症监护室的手术过程,无需真实病人,也无需使用真实医疗设备
- 节省技术和医疗用品
- 也可用于远程培训,从不同地点/工作场所进入同一个虚拟空间
- 在安全的环境中进行风险情况演练
- 将人为错误的风险降至最低
3. 潜力:
- 利用人工智能(AI)模拟和练习危急情况,确定正确的程序
- 人工智能可模拟病人-设备-病人之间的互动
- 制造商的设备集中在一个虚拟空间,使医院的培训更加容易
愿景
VR ICU® 的目标是作为一个平台,让医院从实际使用的设备目录中选择 3D 设备,并从中创建培训环境。
我们向医疗设备制造商提出的愿景最初得到了 BBraun、费森尤斯和 Linet 的支持。随后,其他公司也纷纷效仿这些大胆的先行者。我们还根据所进入的市场扩大我们的设备组合。目前,我们在美国、亚洲和南美都有合作伙伴,他们正在补充信息并与制造商进行谈判。
我们正在全球会议上展示 VR ICU®,我们很高兴能成为 Caelestinus 孵化器的一部分。由于我们与 InterSystems 的合作,我们有机会参加在西雅图举行的 InterSystems 2022 年全球峰会,现在我们正在拉斯维加斯参加 HLTH 2022。
VR ICU® 已经赢得了许多奖项,最近在奥地利林茨,我们凭借该解决方案赢得了最佳初创企业奖。
这些成功的展示吸引了投资者的关注。我们欢迎那些希望进一步开发我们产品的人向我们推荐他们。我们计划在 2023 年向捷克、斯洛伐克和德国的医院出售许可证。我们欢迎商业合作伙伴以及能够加快 VR ICU® 实际应用--市场进入进程或希望为人工智能/VR 版本的开发做出贡献的合作伙伴。
原文来自这里:https://community.intersystems.com/node/529381
文章
姚 鑫 · 二月 22, 2021
# 第四十四章 Caché 变量大全 $ZTRAP 变量
包含当前错误陷阱处理程序的名称。
# 大纲
```
$ZTRAP
$ZT
```
# 描述
`$ZTRAP`包含当前错误陷阱处理程序的行标签名和/或例程名。有三种方法可以设置`$ZTRAP`:
- `SET $ZTRAP=“location”`
- `SET $ZTRAP=“*location”`
- `SET $ZTRAP=“^%ET” or “^%ETN”`
在这里,位置可以指定为标签(当前例程中的行标签)、`^routine`(指定外部例程的开始)或`label^routine`(指定外部例程中的指定标签)。
**然而,`$ZTRAP=label^routine`不能用于程序块。过程块中的`$ZTRAP`不能用于转到过程体之外的位置;过程块中的`$ZTRAP`只能引用该过程块中的一个位置**。
## Location
使用设置命令,可以将位置指定为带引号的字符串。
- 在例程中,可以将位置指定为标签(当前例程中的行标签)、`^routine`(指定外部例程的开始)或`label^routine`(指定外部例程中的指定标签)。不要在引用过程或过程中的标签的例程中指定位置。这是一个无效位置;当InterSystems IRIS试图执行`$ZTRAP`时,会导致运行时错误。
- 在过程中,可以将位置指定为标签;过程块中私有标签。过程块中的`$ZTRAP`不能用于转到过程体之外的位置;过程块中的`$ZTRAP`只能引用该过程块中的一个位置。因此,在过程中,不能将`$ZTRAP`设置为`^routine`或`label^routine`.尝试这样做将导致``错误。
在过程中,将`$ZTRAP`设置为私有标签名,但是`$ZTRAP`值不是私有标签名;它是从过程标签(过程的顶部)到私有标签的行位置的偏移量。例如,`+17^myproc`.
注意:`$ZTRAP`在某些情况下(而不是在过程中)为`label + offset`提供传统支持。这个可选的`+ offset`是一个整数,指定要从`label`偏移的行数。标签必须在相同的例程中。不建议使用`+offset`,它可能会导致编译警告错误。 InterSystems建议您在指定位置时避免使用行偏移量。
调用过程或IRIS `SYS`%例程时,不能指定`+`偏移量。如果尝试这样做,则InterSystems IRIS会发出错误。
`$ZTRAP`位置必须在当前名称空间中。 `$ZTRAP`不支持扩展的例程引用。
如果指定了不存在的行标签(当前例程中不存在的位置),则会发生以下情况:
- 显示`$ZTRAP`:在例程中,`$ZTRAP`包含`label ^ routine`。例如,`DummyLabel^MyRou`。在一个过程中,`$TRAP`包含最大可能的偏移量:`+ 34463 ^ MyProc`。
- 调用$ZTRAP:InterSystems IRIS发出``错误消息。
每个堆栈级别可以有其自己的`$ZTRAP`值。设置`$ZTRAP`时,系统会将`$ZTRAP`的值保存为先前的堆栈级别。当前堆栈级别结束时,InterSystems IRIS会恢复该值。要在当前堆栈级别启用错误陷阱,请通过指定`$ZTRAP`的位置将其设置为错误陷阱处理程序。例如:
```java
/// d ##class(PHA.TEST.SpecialVariables).ZTRAP()
ClassMethod ZTRAP()
{
IF $ZTRAP="" {
WRITE !,"$ZTRAP not set"
} ELSE {
WRITE !,"$ZTRAP already set: ",$ZTRAP
SET oldtrap=$ZTRAP
}
SET $ZTRAP="Etrap1^Handler"
WRITE !,"$ZTRAP set to: ",$ZTRAP
// program code
SET $ZTRAP=oldtrap
WRITE !,"$ZTRAP restored to: ",$ZTRAP
}
```
发生错误时,此格式将展开调用堆栈,并将控制权转移到指定的错误陷阱处理程序。
在SqlComputeCode中,不要设置`$ZTRAP = $ZTRAP`。这可能导致事务处理和错误报告方面的重大问题。
要禁用错误捕获,请将`$ZTRAP`设置为空字符串(`“”`)。这将清除在当前DO堆栈级别设置的所有错误陷阱。
注意:在“终端”提示符下使用$ZTRAP仅限于当前代码行。 `SET $ZTRAP`命令和生成错误的命令必须在同一行代码中。终端在每个命令行的开头将`$ZTRAP`还原为系统默认值。
## *Location
在例程中,可以选择在发生错误后保留调用堆栈。为此,请在位置之前和双引号内放置一个星号(`*`)。该表格不适用于程序。尝试这样做会导致`` 错误。只能在不是过程的子例程中使用此示例中的:
```java
/// d ##class(PHA.TEST.SpecialVariables).ZTRAP()
ClassMethod ZTRAP()
{
Main
SET $ZTRAP="*OnError"
WRITE !,"$ZTRAP set to: ",$ZTRAP
// program code
OnError
// Error handling code
QUIT
}
```
这种格式只会导致转到`$ZTRAP`中指定的行标签;`$STACK`和`$ESTACK`保持不变。`$ZTRAP`错误处理例程的上下文框架与发生错误的上下文框架相同。但是,InterSystems IRIS会将`$ROLES`重置为设置`$ZTRAP`的执行级别的有效值;这会阻止`$ZTRAP`错误处理程序使用在建立错误处理程序后授予例程的提升权限。完成`$ZTRAP`错误处理例程后,InterSystems IRIS将堆栈展开到上一个上下文级。这种形式的`$ZTRAP`对于分析意外错误特别有用。
请注意,星号设置`$ZTRAP`选项;它不是位置的一部分。因此,在`$ZTRAP`上执行`WRITE`或`ZZDUMP`时不会显示此星号。
## ^%ETN
在例程中,`set $ZTRAP=“^%ETN”`将系统提供的错误例程`%ETN`建立为当前错误捕获处理程序。`%ETN`在调用它的发生错误的上下文中执行。(`%et`是`%etn`的旧名称。它们的功能相同,但`%ETN`的效率略高一些。)。`^%ETN`错误处理程序的行为总是前缀星号(`*`)。
因为过程块中的`$ZTRAP`不能用于转到过程主体之外的位置,所以不能在过程中使用`SET $ZTRAP=“^%ETN”`。尝试这样做会导致``错误。
## TRY / CATCH 与 $ZTRAP
不能在`TRY`块内设置`$ZTRAP`。尝试这样做会生成编译错误。可以在`TRY`块之前或在`CATCH`块内设置`$ZTRAP`。
**无论之前是否设置了`$ZTRAP`,`TRY`块中发生的错误都由`CATCH`块处理。`CATCH`块内发生的错误由当前错误捕获处理程序处理。**
下面的第一个示例显示了`TRY`块中发生的错误。下面的第二个示例显示了`try`块中引发的异常。在这两种情况下,都会采用`CATCH`块,而不是`$ZTRAP`:
```java
/// d ##class(PHA.TEST.SpecialVariables).ZTRAP()
ClassMethod ZTRAP()
{
SET $ZTRAP="Ztrap"
TRY { WRITE 1/0 } /* divide-by-zero error */
CATCH { WRITE "Catch taken" }
QUIT
Ztrap
WRITE "$ZTRAP taken"
SET $ZTRAP=""
QUIT
}
```
```java
DHC-APP>d ##class(PHA.TEST.SpecialVariables).ZTRAP()
Catch taken
```
```java
/// d ##class(PHA.TEST.SpecialVariables).ZTRAP1()
ClassMethod ZTRAP1()
{
SET $ZTRAP="Ztrap"
TRY {
SET myvar=##class(Sample.MyException).%New("Example Error",999,,errdatazero)
WRITE !,"Throwing an exception!",!
THROW myvar
QUIT
} CATCH {
WRITE "Catch taken"
}
QUIT
Ztrap
WRITE "$ZTRAP taken"
SET $ZTRAP=""
QUIT
}
```
```java
DHC-APP>d ##class(PHA.TEST.SpecialVariables).ZTRAP1()
Catch taken
```
但是,`try`块可以调用设置和使用`$ZTRAP`的代码。在下面的示例中,`$ZTRAP`而不是`CATCH`块捕获被零除错误:
```java
/// d ##class(PHA.TEST.SpecialVariables).ZTRAP2()
ClassMethod ZTRAP2()
{
TRY { DO Errsub }
CATCH { WRITE "Catch taken" }
QUIT
Errsub
SET $ZTRAP="Ztrap"
WRITE 1/0 /* divide-by-zero error */
QUIT
Ztrap
WRITE "$ZTRAP taken"
SET $ZTRAP=""
QUIT
}
```
```java
DHC-APP>d ##class(PHA.TEST.SpecialVariables).ZTRAP2()
$ZTRAP taken
```
CATCH块中的`Throw`命令还可以调用`$ZTRAP`错误处理程序。
# 示例
下面的示例将`$ZTRAP`设置为此程序中的`OnError`例程。然后,它调用发生错误的`Suba`(尝试将数字除以0)。当错误发生时,InterSystems IRIS调用`$ZTRAP`中指定的`OnError`例程。`OnError`在设置`$ZTRAP`的上下文级别调用。因为`OnError`与`Main`处于相同的上下文级别,所以执行不会返回`Main`。
```java
/// d ##class(PHA.TEST.SpecialVariables).ZTRAP3()
ClassMethod ZTRAP3()
{
Main
NEW $ESTACK
SET $ZTRAP="OnError"
WRITE !,"$ZTRAP set to: ",$ZTRAP
WRITE !,"Main $ESTACK= ",$ESTACK // 0
WRITE !,"Main $ECODE= ",$ECODE
DO SubA
WRITE !,"Returned from SubA" // not executed
WRITE !,"MainReturn $ECODE= ",$ECODE
QUIT
SubA
WRITE !,"SubA $ESTACK= ",$ESTACK // 1
WRITE !,6/0 // Error: division by zero
WRITE !,"fine with me"
QUIT
OnError
WRITE !,"OnError $ESTACK= ",$ESTACK // 0
WRITE !,"$ECODE= ",$ECODE
QUIT
}
```
```java
DHC-APP>d ##class(PHA.TEST.SpecialVariables).ZTRAP3()
$ZTRAP set to: +970^PHA.TEST.SpecialVariables.1
Main $ESTACK= 0
Main $ECODE= ,ZSYNTAX,ZSYNTAX,ZSYNTAX,ZMETHOD DOES NOT EXIST,M9,M6,M9,
SubA $ESTACK= 1
OnError $ESTACK= 0
$ECODE= ,ZSYNTAX,ZSYNTAX,ZSYNTAX,ZMETHOD DOES NOT EXIST,M9,M6,M9,M9,
```
下面的示例与前面的示例相同,但有一个例外:`$ZTRAP`位置前面有一个星号(`*`)。当错误发生在`SUBA`中时,此星号会导致InterSystems IRIS在`SUBA`(发生错误的地方)的上下文级调用`OnError`例程,而不是在`Main`(设置`$ZTRAP`的地方)的上下文级调用`OnError`例程。因此,当`OnError`完成时,执行将在`do`命令之后的行返回到`Main`。
```java
/// d ##class(PHA.TEST.SpecialVariables).ZTRAP4()
ClassMethod ZTRAP4()
{
Main
NEW $ESTACK
SET $ZTRAP="*OnError"
WRITE !,"$ZTRAP set to: ",$ZTRAP
WRITE !,"Main $ESTACK= ",$ESTACK // 0
WRITE !,"Main $ECODE= ",$ECODE
DO SubA
WRITE !,"Returned from SubA" // executed
WRITE !,"MainReturn $ECODE= ",$ECODE
QUIT
SubA
WRITE !,"SubA $ESTACK= ",$ESTACK // 1
WRITE !,6/0 // Error: division by zero
WRITE !,"fine with me"
QUIT
OnError
WRITE !,"OnError $ESTACK= ",$ESTACK // 1
WRITE !,"$ECODE= ",$ECODE
QUIT
}
```
文章
姚 鑫 · 三月 15, 2021
# 第十章 SQL排序(二)
# 查询排序
InterSystems SQL提供了排序规则功能,可用于更改字段的排序规则或显示。
# 第十章 SQL排序(二)
# 查询排序
InterSystems SQL提供了排序规则功能,可用于更改字段的排序规则或显示。
## 查询明细排序
将排序功能应用于查询选择项会更改该项目的显示。
- 字母大小写:默认情况下,查询显示带有大写和小写字母的字符串。例外情况是对排序规则类型`SQLUPPER`的字段进行`DISTINCT`或`GROUP BY`操作。这些操作以所有大写字母显示该字段。可以使用`%EXACT`排序功能来反转此字母大小写转换,并以大写和小写字母显示该字段。不应在选择项列表中使用`%SQLUPPER`排序规则函数以所有大写字母显示字段。**这是因为`%SQLUPPER`在字符串的长度上添加了一个空格字符。请改用`UPPER`函数:**
```SQL
SELECT TOP 5 Name,$LENGTH(Name) AS NLen,
%SQLUPPER(Name) AS UpCollN,$LENGTH(%SQLUPPER(Name)) AS UpCollLen,
UPPER(Name) AS UpN,$LENGTH(UPPER(Name)) AS UpLen
FROM Sample.Person
```
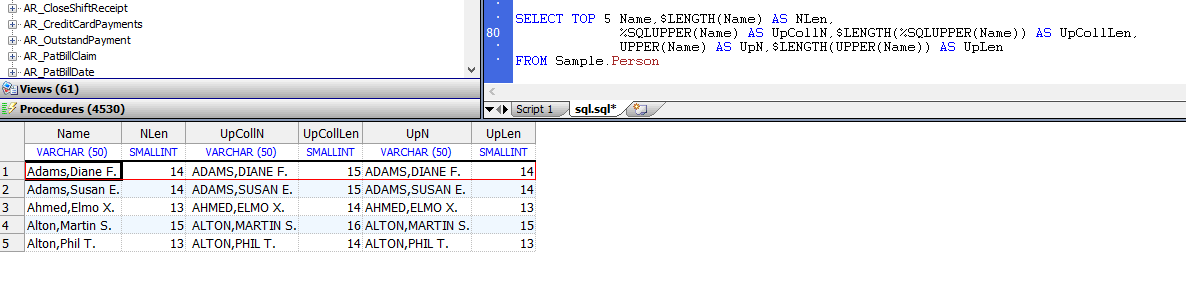
- 字符串截断:可以使用`%TRUNCATE`排序函数来限制显示的字符串数据的长度。 `%TRUNCATE`比`%SQLUPPER`更可取,后者会在字符串的长度上添加一个空格字符。
```SQL
SELECT TOP 5 Name,$LENGTH(Name) AS NLen,
%TRUNCATE(Name,8) AS TruncN,$LENGTH(%TRUNCATE(Name,8)) AS TruncLen
FROM Sample.Person
```

请注意,不能嵌套排序规则函数或大小写转换函数。
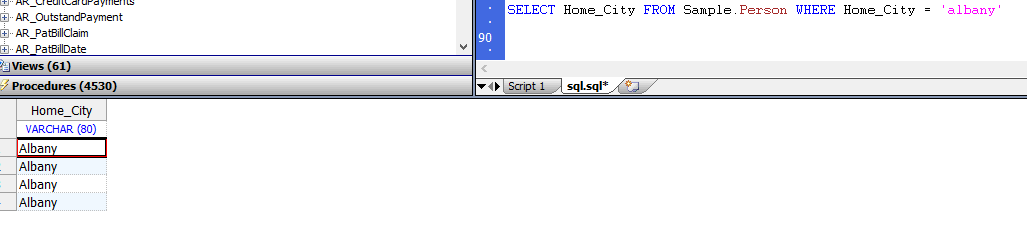
- `WHERE`子句比较:大多数`WHERE`子句谓词条件比较使用字段/属性的排序规则类型。因为字符串字段默认为`SQLUPPER`,所以这些比较通常不区分大小写。可以使用`%EXACT`排序规则功能使它们区分大小写:
-
下面的示例返回`Home_City`字符串匹配项,无论字母大小写如何:
```SQL
SELECT Home_City FROM Sample.Person WHERE Home_City = 'albany'
```
以下示例返回区分大小写的`Home_City`字符串匹配:
```SQL
SELECT Home_City FROM Sample.Person WHERE %EXACT(Home_City) = 'albany'
```

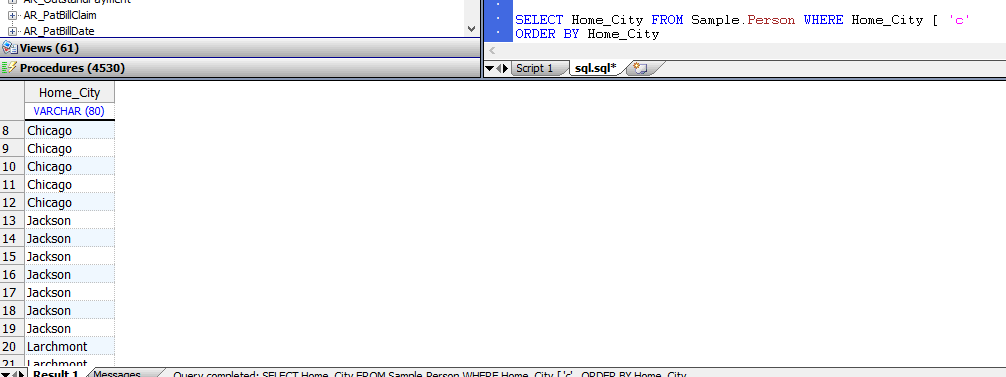
`SQL Follows`运算符(`]`)使用字段/属性归类类型。
但是,无论字段/属性的排序规则类型如何,SQL `Contains`运算符(`[`)都使用EXACT排序规则:
```SQL
SELECT Home_City FROM Sample.Person WHERE Home_City [ 'c'
ORDER BY Home_City
```
`%MATCHES`和`%PATTERN`谓词条件使用EXACT排序规则,而不管字段/属性的排序规则类型如何。 `%PATTERN`谓词提供区分大小写的通配符和不区分大小写的通配符(`'A'`)。
`ORDER BY`子句:`ORDER BY`子句使用名称空间默认排序规则对字符串值进行排序。因此,`ORDER BY`不会基于字母大小写进行排序。可以使用`%EXACT`排序规则根据字母大小写对字符串进行排序。
## `DISTINCT`和`GROUP BY`排序规则
默认情况下,这些操作使用当前的名称空间排序。默认的名称空间排序规则是`SQLUPPER`。
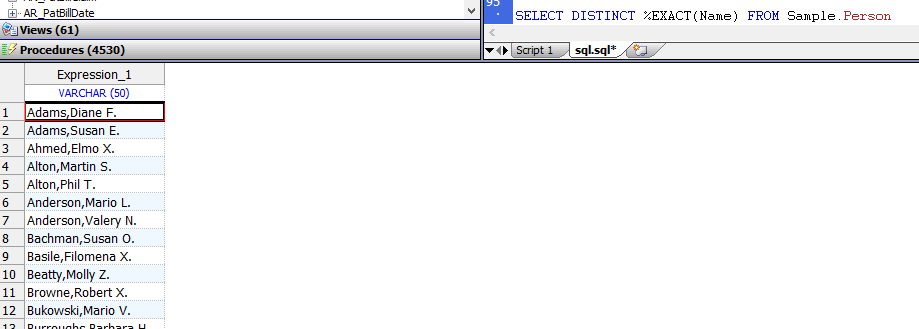
- `DISTINCT`:`DISTINCT`关键字使用名称空间默认排序规则来消除重复值。因此,`DISTINCT Name`返回所有大写字母的值。可以使用`EXACT`排序规则返回大小写混合的值。 `DISTINCT`消除仅字母大小写不同的重复项。**要保留大小写不同的重复项,但要消除确切的重复项,请使用`EXACT`排序规则。** 以下示例消除了精确的重复项(但不消除字母大写的变体),并以混合的大写和小写形式返回所有值:
```SQL
SELECT DISTINCT %EXACT(Name) FROM Sample.Person
```
`UNION`涉及隐式`DISTINCT`操作。
- `GROUP BY`:`GROUP BY`子句使用名称空间默认排序规则来消除重复的值。因此,`GROUP BY Name`返回所有大写字母的值。**可以使用`EXACT`排序规则返回大小写混合的值。** `GROUP BY`消除仅字母大小写不同的重复项。若要保留大小写不同的重复项,但要消除完全相同的重复项,必须在`GROUP BY`子句(而不是`select-item`)上指定`%EXACT`归类函数。
下面的示例返回大小写混合的值; `GROUP BY`消除重复项,包括字母大小写不同的重复项:
```SQL
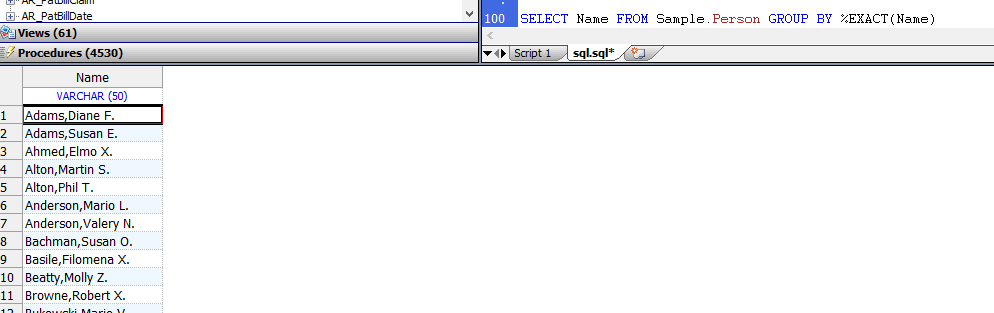
SELECT %EXACT(Name) FROM Sample.Person GROUP BY Name
```
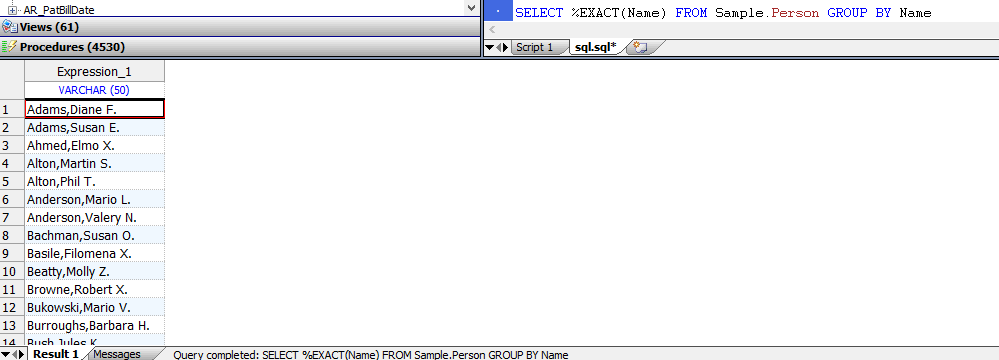
下面的示例返回大小写混合的值; `GROUP BY`消除了精确的重复项(但不消除字母大写的变体):
```SQL
SELECT Name FROM Sample.Person GROUP BY %EXACT(Name)
```
# 旧版排序类型
InterSystems SQL支持多种旧式排序规则类型。它们已被弃用,不建议与新代码一起使用,因为它们的目的是为遗留系统提供持续的支持。他们是:
- **`%ALPHAUP` — 除去问号(`“?”`)和逗号(`“,”`)之外的所有标点符号,并将所有小写字母转换为大写字母。主要用于映射旧全局变量。由`SQLUPPER`代替。**
- **`%STRING` —将逻辑值转换为大写,去除所有标点符号和空格(逗号除外),并在字符串的开头添加一个前导空格。它将所有仅包含空格(空格,制表符等)的值作为SQL空字符串进行整理。由`SQLUPPER`代替。**
- **`%UPPER` —将所有小写字母转换为大写字母。主要用于映射旧全局变量。由`SQLUPPER`代替。**
- `SPACE` — `SPACE`排序将单个前导空格附加到一个值,强制将其作为字符串求值。要建立`SPACE`排序规则,`CREATE TABL`E提供一个`SPACE`排序规则关键字,而ObjectScript在`%SYSTEM.Util`类的`Collation()`方法中提供一个`SPACE`选项。没有相应的SQL排序规则功能。
**注意:如果使用`EXACT`,`UPPER`或`ALPHAUP`排序定义了字符串数据类型字段,并且查询在此字段上应用了`%STARTSWITH`条件,则可能导致不一致的行为。如果指定给`%STARTSWITH`的子字符串是规范数字(尤其是负数和/或小数),则`%STARTSWITH`可能会根据字段是否被索引而给出不同的结果。如果未对列进行索引,则`%STARTSWITH`应该会按预期执行。如果该列已建立索引,则可能会发生意外的结果。**
# SQL和NLS排序
上面描述的SQL排序规则不应与InterSystems IRIS NLS排序规则功能混淆,后者提供符合特定本国语言排序规则要求的下标级别编码。这是提供分页的两个独立系统,它们在产品的不同级别上工作。
InterSystems IRIS NLS排序可以具有当前过程的过程级别排序,并且可以具有特定全局变量的不同排序。
为了确保使用InterSystems SQL时的正常运行,要求进程级NLS排序规则与所涉及的所有全局变量的NLS排序规则完全匹配,包括表所使用的全局变量以及用于临时文件(例如进程专用全局变量和IRIS TEMP)的全局变量。否则,查询处理器设计的不同处理计划可能会得出不同的结果。在发生排序的情况下,例如`ORDER BY`子句或范围条件,查询处理器将选择最有效的排序策略。它可以使用索引,可以在进程专用的全局文件中使用临时文件,可以在本地数组中排序,也可以使用`“]]”`(之后排序)比较。所有这些都是下标类型的比较,遵循有效的InterSystems IRIS NLS归类,这就是为什么所有这些类型的全局变量都必须使用完全相同的NLS归类的原因。
系统使用数据库默认排序规则创建全局变量。可以使用`%Library.GlobalEdit`类的`Create()`方法来创建具有不同排序规则的全局变量。唯一的要求是指定的归类可以是内置的(例如InterSystems IRIS标准),也可以是当前语言环境中可用的国家归类之一。
文章
Michael Lei · 六月 21, 2022
如果您使用InterSystems技术开发了自己的网络应用,现在想在客户端进行验证码验证,以确定用户真实性使其更加安全。有一些现代框架可以解决验证码的问题,然而它们中的大多数需要互联网接入来生成代码,有时实施起来很复杂。考虑到图像识别已经非常成熟,您可以参考本文为基本例子。这就是为什么现在倾向于看到更多的模式识别验证码而不是单纯的阅读验证码。(例如,点击所有有店面的图片)。如果你需要更复杂的东西,请继续开发,改进这个代码并分享它。 继续阅读以了解如何使用这个基本的例子:
Demo.Captcha class
使用这个类,你可以在一个物理目录上创建验证码图像文件,以便在你的应用程序上显示。请注意,创建图像的目录必须是可用的,以便你的Web应用程序访问这些图像。要创建验证码图像,请调用以下方法,将完整的文件名作为一个参数:
创建 image 文件
Set tCount = $Increment(^CacheTemp("CAPTCHA",0)) Set tPath = "C:\InterSystems\Ensemble201710\CSP\user\images\captcha\"If '##class(%File).DirectoryExists(tPath) { Set tSC = ##class(%File).CreateDirectoryChain(tPath) } Set tFileName = %session.SessionId_tCount_".bmp" Set tFullName = tPath_tFileNameSet tCaptcha = ##class(Demo.Captcha).CreateImage(tFullName) Write tCaptcha,!
在 System/系统 > Security Management/安全管理 > Web Applications/Web 应用 > Edit Web Application/编辑Web应用菜单下添加“\images\captcha\” , 请注意 CSP 文件物理路径在上面代码里是一样的。
运行上面的代码来创建验证码图像后,请看一下该路径。你会看到所有生成的验证码图像如下(注意,你需要一个%session对象):
Demo.Captcha类中的CreateImage()方法也将返回生成的验证码,它将允许你在你的Web应用程序上对用户输入的验证码进行验证。
例子
为了使大家的工作简单点,我准备了一个简单的CSP文件,可以渲染一个验证码图像并进行验证。你可以导入所附的XML文件,并根据需要验证和改变路径以匹配你的CSP Web应用。
安装在USER命名空间上,打开Studio并导入XML文件;
在浏览器上打开 captcha.csp 文件;
点击 “change image/换一张” 按钮 来创建和显示新的captcha图像;
在空白输入框中输入图像代码;
点击验证按钮并检查信息;
导入类
打开 Studio;
选择 USER 命名空间;
到Tools/工具->Import Local导入本地 菜单下并选择你下载好的 captcha.xml ;
根据下图导入需要的类;
根据你的CSP Web应用改变验证码图像路径;
在浏览器通过点击浏览网页按钮 打开captcha.csp 文件;
如果你需要改变图像,点击改变图像按钮;
查看验证码图像目录;
在空白输入框中输入验证码,并点击验证;
查看结果;
随意重复这些步骤;
希望这些能帮助到您,欢迎随时联系我们.
Fábio Gonçalves
Sales Engineer - Intersystems Brazil
文章
Jingwei Wang · 九月 20, 2022
1. VMWare快照引起的网络中断导致非计划内主备机切换问题
1.1 问题描述
在创建虚拟机快照时,虚拟机需要短时间的冻结,这个短时间冻结通常指虚拟机静默,在静默过程中网络连接处于中断状态。由于数据库的不断增长,使用VMWare快照的方式对虚拟机进行备份的时长也会不断增加,当对虚拟机进行快照的时长长于InterSystems镜像服务质量 (QoS) 超时时间,即当主机网络中断超过QoS超时时间,仲裁机与备机观察并相互确认与主机的连接丢失后,将发起切换过程,使原备机成为主机并将虚拟IP从主机MAC地址解绑后重绑定到备机的MAC地址上。特别需要注意的是,在这种由于网络中断引起的切换中,仲裁与备机都无法得知主机的实际工作状态。因此,在主机网络连接恢复后,为了为了避免因切换期间主机还在处理数据导致主备机间数据不一致,备机主动发起请求让主机下线,关闭主机,此时主机状态显示为关闭(Down)。
1.2 解决方案
对于由于虚拟机快照引起的网络中断造成的非计划内主备切换问题,请参考以下两种解决方案:
使用数据库冻结/解冻脚本,具体脚本和操作方式请参考社区文章虚拟机备份和 Caché 冻结/解冻脚本,如有其他疑问请联系InterSystems WRC
在镜像集群中增加一个异步镜像成员,使用异步镜像成员创建虚拟机快照,由于此异步镜像成员也会同步获取主机数据,但是不会自动切换,所以在此异步镜像成员中创建虚拟机快照,既可以备份虚拟机,也不会引起非计划内主备机切换问题。
2. VMWare资源不足导致的主备机非计划内切换问题:
2.1 问题描述
当虚拟机的物理资源不足,可能会导致网络中断或者InterSystems IRIS 实例日志守护进程不响应超过 30 秒(或300 秒),导致主备非计划内切换。
2.2 解决方案
请扩展虚拟机的物理资源,且增加对虚拟机的状态进行监控,以防再次出现资源不足情况。
监控网络状态Log
由于网络中断造成的镜像主备切换是非计划内主备切换的重要原因之一,所以为了方便排查问题,可以在仲裁机上加一个ping的脚本,用来ping主机和备机,并将ping的结果放入log中,当发生非计划内主备切换时这个log有利于排查问题。也可以使用此ping脚本来监控网络状态,使用户能够第一时间获得网络状态信息。
文章
姚 鑫 · 五月 3, 2021
# 第二章 全局变量结构(一)
本章描述全局变量的逻辑视图,并概述全局变量是如何在磁盘上物理存储的。
# 全局变量的逻辑结构
全局变量是存储在物理InterSystems IRIS®数据库中的命名多维数组。
在应用程序中,全局变量到物理数据库的映射基于当前名称空间——名称空间提供一个或多个物理数据库的逻辑统一视图。
## 全局命名约定和限制
全局名称指定其目标和用途。有两种类型的全局变量和一组单独的变量,称为“进程私有全局变量”:
- 全局变量 - 这就是所谓的标准全局变量;通常,这些变量被简称为全局变量。它是驻留在当前命名空间中的永久性多维数组。
- **扩展全局引用-这是位于当前命名空间以外的命名空间中的全局引用。**
- **进程私有全局变量-这是一个数组变量,只有创建它的进程才能访问。**
全局变量的命名约定如下:
- 全局变量名称以脱字符(`^`)前缀开头。这个插入符号区分全局变量和局部变量。
- 全局变量名称中脱字符(`^`)前缀后的第一个字符可以是:
- 字母或百分号字符(%)-仅适用于标准全局变量。对于全局变量名称,字母被定义为`ASCII 65`到`ASCII 255`范围内的字母字符。如果全局名称以`“%”`开头(但不是`“%Z”`或`“%z”`),则此全局名称供InterSystems IRIS系统使用。`%GLOBAL`通常存储在IRISSYS或IRISLIB数据库中。
- 竖线(`|`)或左方括号(`[`)-表示扩展全局引用或进程专用全局变量。使用取决于后续字符。
- 全局变量名称的其他字符可以是字母、数字或句号(`.`)字符。
百分比(`%`)字符不能使用,除非作为全局名称的第一个字符。
`“.”`字符不能作为全局名称的最后一个字符。
- **全局名称最长可达31个字符(不包括脱字符前缀)。可以指定更长的全局名称,但InterSystems IRIS只将前31个字符视为重要字符。**
- 全局名称区分大小写。
- InterSystems IRIS对全局引用的总长度施加限制,而该限制又对任何下标值的长度施加限制。
**在IRISSYS数据库中,InterSystems将除以`“z”`、`“Z”`、`“%z”`和`“%Z”`开头的所有全局变量名称保留给自己。在所有其他数据库中,InterSystems保留所有以`“ISC”`开头的全局名称。和`“%isc.”`。**
## 示例全局名称及其用法
以下是各种全局名称的示例以及每种名称的用法:
- `^globalname` - 标准全局变量
- `^|"environment"|globalname` - 扩展全局变量引用的环境语法
- `^||globalname` - 进程私有全局变量
- `^|"^"|` - 进程私有全局变量
- `^[namespace]globalname` - 扩展全局变量引用中显式命名空间的括号语法
- `^[directory,system]globalname` - 扩展全局变量引用中隐含命名空间的括号语法
- `^["^"]globalname` - 进程私有全局变量
- `^["^",""]globalname` - 进程私有全局变量
注意:全局名称只能包含有效的标识符字符;默认情况下,这些字符如上所述。但是,NLS(国家语言支持)定义了一组不同的有效标识符字符集。全局名称不能包含`Unicode`字符。
因此,以下都是有效的全局名称:
```java
SET ^a="The quick "
SET ^A="brown fox "
SET ^A7="jumped over "
SET ^A.7="the lazy "
SET ^A1B2C3="dog's back."
WRITE ^a,^A,^A7,!,^A.7,^A1B2C3
KILL ^a,^A,^A7,^A.7,^A1B2C3 // keeps the database clean
```
## 全局节点和下标简介
全局通常有多个节点,通常由一个下标或一组下标标识。下面是一个基本示例:
```java
set ^Demo(1)="Cleopatra"
```
此语句引用全局节点`^Demo(1)`,它是`^Demo`全局节点中的一个节点。此节点由一个下标标识。
再举一个例子:
```java
set ^Demo("subscript1","subscript2","subscript3")=12
```
该语句指的是全局节点`^Demo("subscript1","subscript2","subscript3")`,它是同一全局中的另一个节点。此节点由三个下标标识。
再举一个例子:
```java
set ^Demo="hello world"
```
该语句引用不使用任何下标的全局节点`^Demo`。
全局的节点形成分层结构。ObjectScript提供了利用此结构的命令。例如,可以删除节点或删除节点及其所有子节点。
## 全局变量下标
下标有以下规则:
- 下标数值区分大小写。
- **下标值可以是任何ObjectScript表达式,前提是该表达式的计算结果不是空字符串(`""`)。**
**该值可以包括所有类型的字符,包括空格、非打印字符和Unicode字符。(请注意,非打印字符在下标数值中不太实用。)**
- 在解析全局引用之前,InterSystems IRIS计算每个下标的方式与计算任何其他表达式的方式相同。在下面的示例中,我们设置了`^Demo`全局的一个节点,然后以几种等效的方式引用该节点:
```java
DHC-APP>s ^Demo(1+2+3)="a value"
DHC-APP>w ^Demo(3+3)
a value
DHC-APP>w ^Demo(03+03)
a value
DHC-APP>w ^Demo(03.0+03.0)
a value
DHC-APP>set x=6
DHC-APP>w ^Demo(x)
a value
```
- InterSystems IRIS对全局引用的总长度施加限制,而该限制又对任何下标值的长度施加限制。
**注意:上述规则适用于IRIS支持的所有排序规则。对于出于兼容性原因仍在使用的旧归类,如`“pre-ISM-6.1”`,下标的规则有更多限制。例如,字符下标不能以控制字符作为其初始字符;整数下标中可以使用的位数也有限制。**
## 全局变量节点
在应用程序中,节点通常包含以下类型的结构:
1. 字符串或数字数据,包括本机`Unicode`字符。
2. 具有由特殊字符分隔的多个字段的字符串:
```java
SET ^Data(10) = "Smith^John^Boston"
```
可以使用ObjectScript `$PIECE` 函数来拆分这些数据。
3. InterSystems IRIS `$LIST` 结构中包含多个字段。`$LIST`结构是包含多个长度编码值的字符串。它不需要特殊的分隔符。
4. 空字符串 (`""`)。在下标本身用作数据的情况下,实际节点中不存储任何数据。
5. 一个位串。如果全局变量用于存储位图索引的一部分,那么存储在节点中的值就是位字符串。位串是包含`1`和`0`值的逻辑压缩集的字符串。可以使用`$BIT`函数构造位串。
6. 更大的数据集的一部分。例如,对象和SQL引擎将流(`BLOB`)存储为全局中连续的`32K`节点系列。通过流接口,流的用户不知道流是以这种方式存储的。
请注意,任何全局节点都不能包含长度超过字符串长度限制的字符串,字符串长度限制非常长。
## 全局变量排序规则
在全局中,节点按排序(排序)顺序存储。
**应用程序通常通过将转换应用于用作下标的值来控制节点的排序顺序。例如,SQL引擎在为字符串值创建索引时,会将所有字符串值转换为大写字母,并在前面加上一个空格字符,以确保索引不区分大小写并且以文本形式排序(即使数值存储为字符串)。**
# 全局变量引用的最大长度
**全局变量引用(即对特定全局节点或子树的引用)的总长度限制为`511`个编码字符(少于`511`个键入字符)。**
要保守地确定给定全局变量引用的大小,请使用以下准则:
1. 全局变量名称:每个字符加`1`。
2. 对于纯数字下标:每个数字、符号或小数点加`1`。
3. 对于包含非数字字符的下标:为每个字符添加`3`。
如果下标不是纯数字的,则根据用于编码字符串的字符集的不同,下标的实际长度会有所不同。一个多字节字符最多可以占用`3`个字节。
请注意,ASCII字符可能占用`1`或`2`字节。
如果排序规则进行大小写折叠,那么`ASCII`字符可以使用`1`个字节表示字符,`1`个字节表示消除歧义字节。
如果排序不执行大小写折叠,`ASCII`字符占用`1`字节。
4. 每个下标加`1`。
如果这些数字的总和大于`511`,则引用太长。
由于确定限制的方式,如果必须使用长下标或全局名称,这有助于避免使用大量下标级别。
相反,如果使用多个下标级别,则应避免长全局名称和长下标。
因为无法控制正在使用的字符集,所以保持全局名称和下标更短是很有用的。
当对特定引用有疑问时,创建与最长预期全局变量引用长度相等(甚至稍长一点)的全局变量引用的测试版本是有用的。
这些测试的数据为构建应用程序之前可能修订的命名约定提供了指导。
文章
姚 鑫 · 五月 23, 2021
# 第四章 收发电子邮件
本主题描述如何使用InterSystems IRIS发送和接收`MIME`电子邮件消息。
注意:本主题中的示例是经过组织的,因此管理电子邮件的方法可以用于不同的电子邮件服务器,这在测试和演示期间非常有用。这不一定是最适合生产需要的代码组织。
# 支持电子邮件协议
电子邮件使用标准协议通过Internet发送消息。
InterSystems IRIS支持以下三种协议:
- InterSystems IRIS提供`MIME`电子邮件的对象表示形式。它支持文本和非文本附件、单部分或多部分邮件正文,以及`ASCII`和非`ASCII`字符集的标题。
- 可以通过`SMTP`服务器发送电子邮件。`SMTP`(简单邮件传输协议)是发送电子邮件的Internet标准。
- 还可以通过`POP3`从电子邮件服务器检索电子邮件,`POP3`是从远程服务器检索电子邮件的最常用标准。
注意:InterSystems IRIS不提供邮件服务器。相反,它提供了连接到邮件服务器并与之交互的功能。
# InterSystems IRIS如何表示`MIME`电子邮件
首先,了解InterSystems IRIS如何表示`MIME`电子邮件非常有用。
通常,多部分`MIME`邮件由以下部分组成:
- 一组邮件标头,每个标头都包含邮件发送到的地址等信息。这还包括整个消息的`Mime-Type`标头和`Content-Type`标头。
对于多部分消息,`Content-Type`头必须是多部分/混合或多部分的其他子类型;`MIME`标准有许多变体。
- 多个消息部分,每个消息部分由以下部分组成:
- 一组内容标头,包括`Content-Type`标头和特定于此部件的其他标头。
- 一种正文,它可以是文本或二进制,并且可以使用与其它部分的正文不同的字符集。
InterSystems IRIS使用两个类来表示电子邮件:`%Net.MailMessage`和`%Net.MailMessagePart`,即`%Net.MailMessage`的超类。下图显示了这些类之间的关系:
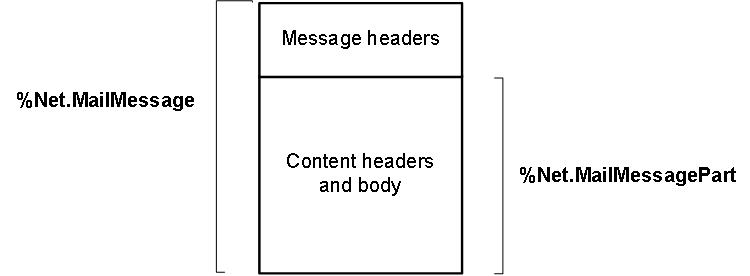
- 要表示普通的、由一部分组成的消息,请使用`%Net.MailMessage`
- 要表示多部分消息,请使用`%Net.MailMessage`作为父消息,并使用`%Net.MailMessagePart`的多个实例作为其部分。
# 创建由单个部分组成的电子邮件
要创建由单个部分组成的电子邮件,请使用`%Net.MailMessage`类。要创建邮件,请执行以下操作:
1. 创建`%Net.MailMessage`的实例。
提示:可以将字符集指定为`%New()`;的参数,如果这样做,则会设置消息的`CharSet`属性。
2. 设置实例的`To`、`From`和`Subject`属性。
- `To`收件人-此邮件将发送到的电子邮件地址列表。此属性是标准的InterSystems IRIS列表类;要使用它,需要使用标准列表方法:`Insert()`、`GetAt()`、`RemoveAt()`、`Count()`和`Clear()`。
- `From`发件人-此邮件的发件人电子邮件地址。
- `Subject`主题-邮件的主题(如果您使用的SMTP服务器需要该主题)。
3. 可以选择设置日期、抄送、密件抄送和其他属性。
4. 如果邮件不是纯文本,请设置以下属性以指示您要创建的邮件的类型:
- 如果这是一封HTML邮件,请将`IsHTML`属性设置为1。
- 如果这是二进制消息,请将`IsBinary`属性设置为1。
5. 若要指定消息及其标头的字符集,请根据需要设置`CharSet`属性。
重要提示:在添加消息内容之前指定字符集非常重要。
6. 添加消息内容:
- 对于纯文本或`HTML`,请使用`TextData`属性,该属性是`%FileCharacterStream`的实例。不需要指定此流的`TranslateTable`属性;当指定邮件的字符集时,该属性会自动发生。
- 对于二进制数据,请使用`BinaryData`属性,该属性是`%FileBinaryStream`的实例。
提示:指定流的`Filename`属性时,请确保使用用户有权写入的目录。
要使用这些属性,请使用标准流方法:`Write()`、`WriteLine()`、`Read()`、`ReadLine()`、`Rewind()`、`MoveToEnd()`和`Clear()`。还可以使用流的`Size`属性,该属性提供消息内容的大小。
注意:应该了解正在使用的`SMTP`服务器的要求。例如,某些`SMTP`服务器要求包含主题标头。同样,某些`SMTP`服务器不允许任意`FROM`标头。
类似地,一些`SMTP`服务器识别优先级报头,而其他服务器则识别`X-Priority`。
示例1:`CreateTextMessage()`
以下方法创建一条简单消息并为其指定地址:
```java
ClassMethod CreateTextMessage() As %Net.MailMessage
{
Set msg = ##class(%Net.MailMessage).%New()
set msg.From = "test@test.com"
Do msg.To.Insert("xxx@xxx.com")
Do msg.Cc.Insert("yyy@yyy.com")
Do msg.Bcc.Insert("zzz@zzz.com")
Set msg.Subject="subject line here"
Set msg.IsBinary=0
Set msg.IsHTML=0
Do msg.TextData.Write("This is the message.")
Quit msg
}
```
示例2:`SimpleMessage()`
在实际发送邮件时指定地。上例的以下变体生成一条没有地址的文本消息:
```java
ClassMethod SimpleMessage() As %Net.MailMessage
{
Set msg = ##class(%Net.MailMessage).%New()
Set msg.Subject="Simple message "_$h
Set msg.IsBinary=0
Set msg.IsHTML=0
Do msg.TextData.Write("This is the message.")
Quit msg
}
```
`Samples`命名空间中还有其他示例。要查找它们,请在该命名空间中搜索`%Net.MailMessage`。
# 创建多部分电子邮件
要创建由多部分组成的电子邮件,请执行以下操作:
1. 创建`%Net.MailMessage`的实例,并将其`To`、`From`和`Subject`属性设置为。可以选择设置其他属性以指定其他邮件标头。
2. 将`IsMultiPart`属性设置为1。
3. 将`MultiPartType`属性设置为以下值之一: `"related"`, `"alternative"`, 或 `"mixed"`。这会影响整个消息的`Content-Type`标头。
4. 对于邮件应包含的每个部分,创建`%Net.MailMessagePart`的实例并指定其属性,如从步骤4开始的“创建由单个部分组成的电子邮件”中所述。
5. 对于父电子邮件,设置`Parts`属性,该属性是一个数组。将每个子消息部分插入到此数组中。
发送邮件时,`%Net.SMTP`类会根据需要自动设置邮件的`Content-Type`标头(给定`MultiPartType`属性值)。
# 指定电子邮件标题
如前所述,消息本身和消息的每个部分都有一组标头。
`%Net.MailMessage`和`%Net.MailMessagePart`类提供的属性使可以轻松访问最常用的标头,但可以添加所需的任何标头。本节提供有关所有标头以及如何创建自定义标头的信息。
给定消息部分的标头使用由该部分的`CharSet`属性指定的字符集。
注意:应该了解正在使用的`SMTP`服务器的要求。例如,某些`SMTP`服务器要求包含主题标头。同样,某些`SMTP`服务器不允许任意`FROM`标头。
类似地,一些`SMTP`服务器识别优先级报头,而其他服务器则识别`X-Priority`。
# 指定基本电子邮件标题
设置以下属性(仅在`%Net.MailMessage`中)以设置邮件本身最常用的标头:
- `To`-(必填)此邮件将发送到的电子邮件地址列表。此属性是标准的InterSystems IRIS列表;要使用它,请使用标准列表方法:`Insert()`、`GetAt()`、`RemoveAt()`、`Count()`和`Clear()`。
- From-(必填)发送此邮件的电子邮件地址。
- Date-此消息的日期。
- Subject-(必选)包含此邮件主题的字符串。
- Sender-邮件的实际发件人。
- Cc-此邮件将发送到的抄送地址列表。
- Bcc-此邮件将被发送到的密件副本地址列表。
## 内容类型标题
发送邮件时,邮件和每个邮件部分的`Content-Type`标头会自动设置如下:
- 如果消息是纯文本(`IsHTML`等于0,`IsBinary`等于0),则`Content-Type`标头被设置为 `"text/plain`。
- 如果消息是`HTML`(`IsHTML`等于1,`IsBinary`等于0),则`Content-Type`标头设置为`“text/html”`。
- 如果消息是二进制的(`IsBinary`等于1),则`Content-Type`报头设置为如果消息是二进制的(`IsBinary`等于1),则`Content-Type`报头设置为`"application/octet-stream"`.
- 如果邮件是多部分邮件,则会为`MultiPartType`属性的值适当设置`Content-Type`标头。
`%Net.MailMessage`和`%Net.MailMessagePart`都提供了`contentType`属性,使可以访问`Content-Type`标头。
## 内容传输编码标头
`%Net.MailMessage`和`%Net.MailMessagePart`都提供了`ContentTransferEncoding`属性,该属性提供了一种指定消息或消息部分的`Content-Transfer-Encoding`头的简单方法。
此属性可以是以下属性之一:`"base64" "quoted-printable" "7bit" "8bit"`
默认值如下:
对于二进制消息或消息部分:`"base64"`
**重要提示:请注意,如果内容为`“Base64”`编码,则不能包含任何Unicode字符。如果要发送的内容包括Unicode字符,请确保使用`$ZCONVERT`将内容转换为`UTF-8`,然后对其进行`base-64`编码。例如:**
```java
set BinaryText=$ZCONVERT(UnicodeText,"O","UTF8")
set Base64Encoded=$system.Encryption.Base64Encode(BinaryText)
```
收件人必须使用相反的过程来解码文本:
```java
set BinaryText=$system.Encryption.Base64Decode(Base64Encoded)
set UnicodeText=$ZCONVERT(BinaryText,"I","UTF8")
```
对于文本消息或消息部分:`"quoted-printable"`
## 自定义标题
使用`%Net.MailMessage`和`%Net.MailMessagePart`,可以通过访问`Headers`属性设置或获取自定义标题,该属性是一个具有以下结构的数组:
数组键 |数组值
---|---
标头的名称,如`“Priority”` | 标头的值
此属性用于包含其他标头,如`X-Priority`和其他标头。例如:
```java
do msg.Headers.SetAt(1,"X-Priority")
do msg.Headers.SetAt("High","X-MSMail-Priority")
do msg.Headers.SetAt("High","Importance")
```
不同的电子邮件服务器和客户端可以识别不同的标头,因此设置多个相似的标头以确保服务器或客户端接收到的邮件具有它可以识别的标头是很有用的。
文章
姚 鑫 · 五月 30, 2021
# 第十一章 发送和接收IBM WebSphere MQ消息
InterSystems IRIS为IBM `WebSphere MQ`提供了一个接口,可以使用该接口在InterSystems IRIS和IBM `WebSphere MQ`的消息队列之间交换消息。要使用此接口,必须能够访问IBM `WebSphere MQ`服务器,并且IBM `WebSphere MQ`客户端必须与InterSystems IRIS在同一台计算机上运行。
该接口由`%Net.MQSend`和`%Net.MQRecv`类组成,这两个类都是`%Net.abstractMQ`的子类。这些类使用由InterSystems IRIS在所有合适的平台上自动安装的动态链接库。(这是Windows上的`MQInterface.dll`;其他平台的文件扩展名不同。)。反过来,InterSystems IRIS动态链接库需要IBM `WebSphere MQ`动态链接库。
该界面仅支持发送和接收文本数据,不支持二进制数据。
# 使用IBM WebSphere MQ的RIS接口
通常,要使用IBM `WebSphere MQ`的InterSystems IRIS接口,请执行以下操作:
1. 确保有权访问`IBM WebSphereMQv7.x`或更高版本。具体而言:
- IBM `WebSphere MQ`客户端必须与InterSystems IRIS安装在同一台计算机上。请注意,安装程序会根据需要更新`PATH`环境变量并添加其他系统变量。
- 确保在安装客户端后重新启动计算机,以便InterSystems IRIS能够识别该客户端。
- 客户端必须能够访问IBM `WebSphere MQ`服务器。
- 将用来访问服务器的用户名必须具有使用队列管理器和计划使用的队列的权限。
2. 创建`%Net.MQSend`或`%Net.MQRecv`的新实例,具体取决于要发送还是接收消息。
3. 连接到IBM `WebSphere MQ`服务器。执行此操作时,您需要提供以下信息:
- 队列管理器的名称。
- 要使用的队列的名称。
- 与该队列通信的通道。可以指定IBM `WebSphere MQ`服务器的通道名称、传输机制以及IP地址和端口。
如果正在使用IBM `WebSphere MQ`的身份验证功能,还可以提供名称和密码。
4. 调用`%Net.MQSend`或`%Net.MQRecv`的相应方法来发送或接收消息。
注意:要在64位Linux平台上使用IBM `Websphere MQ`,必须设置`LD_LIBRARY_PATH`以包括`MQ`库的位置。因为必须为任何使用`MQ`接口的InterSystems IRIS进程设置路径,所以如果正在运行后台进程,则必须在启动InterSystems IRIS之前设置该路径,并在运行IRIS终端之前在任何UNIX®终端中设置该路径。
## 获取错误代码
`%Net.MQSend`和`%Net.MQRecv`的方法如果成功则返回1,如果不成功则返回0。在出现错误的情况下,调用`%GetLastError()`方法,该方法返回IBM `WebSphere MQ`给出的最后一个原因代码。
# 创建连接对象
在可以通过IBM `WebSphere MQ`发送或接收消息之前,必须创建一个`Connection`对象,该对象可以建立到队列管理器的连接、打开通道和打开队列以供使用。有两种方法可以做到这一点:
- 可以使用`%Init`方法,该方法接受指定所有所需信息的参数。
- 可以在首次设置指定所有所需信息的属性后使用`%Connect`方法。
## 使用%Init()方法
要使用`%Init()`方法创建连接对象,请执行以下操作:
1. 创建`%Net.MQSend`(如果要发送消息)或`%Net.MQRecv`(如果要接收消息)的实例。本主题将此实例称为连接对象。
注意:如果收到 ``错误,则表示缺少动态链接库,并且`messages.log`文件(在系统管理器的目录中)有更多详细信息。
2. 如果需要身份验证,请设置`Connection`对象的以下属性:
- 用户名-指定有权使用此频道的用户名。
- 密码-指定给定用户的密码。
3. 调用`Connection`对象的`%Init()`方法。此方法按顺序接受以下参数。
a. 指定队列名称的字符串;这应该是指定队列管理器的有效队列。
b. 指定队列管理器的字符串;它应该是IBM `WebSphere MQ`服务器上的有效队列管理器。
如果省略此参数,系统将使用IBM `WebSphere MQ`中配置的默认队列管理器。或者,如果IBM `WebSphere MQ`已配置为队列管理器由队列名称确定,则系统将使用适合给定队列名称的队列管理器。
c. 指定频道规范的字符串,格式如下:
```java
"channel_name/transport/host_name(port)"
```
这里,`channel_name`是要使用的通道的名称,`Transport`是通道使用的传输,`host_name`是运行IBM `WebSphere MQ`服务器的服务器名称(或IP地址),`port`是该通道应该使用的端口。
传输可以是以下之一:`TCP`、`LU62`、`NETBIOS`、`SPX`
例如:
```java
"CHAN_1/TCP/rodan(1401)"
```
```java
"CHAN_1/TCP/127.0.0.1(1401)"
```
如果省略此参数,系统将使用IBM `WebSphere MQ`中配置的默认通道规范。或者,如果系统已配置为通道由队列名称确定,则系统使用适合给定队列名称的通道。
d. 一个可选字符串,它指定要向其中写入错误消息的日志文件。默认情况下,不进行日志记录。
4. 检查`%Init()`方法返回的值。如果该方法返回1,则表明连接已成功建立,可以使用`Connection`对象发送或接收消息(具体取决于使用的类)。
## 使用%Connect()方法
在某些情况下,可能更喜欢单独指定连接的所有详细信息。为此,请使用`%Connect()`方法,如下所示:
1. 创建`%Net.MQSend`(如果要发送消息)或`%Net.MQRecv`(如果要接收消息)的实例。如前所述,本主题将此实例称为连接对象。
注意:如果收到`` 错误,则表示缺少动态链接库,并且`messages.log`文件(在系统管理器的目录中)有更多详细信息。
2. 设置`Connection`对象的以下属性:
- `QName`-(必选)指定队列名称;这应该是指定队列管理器的有效队列。
- `QMgr`-指定要使用的队列管理器;它应该是IBM `WebSphere MQ`服务器上的有效队列管理器。
如果省略此参数,系统将使用IBM `WebSphere MQ`中配置的默认队列管理器。或者,如果IBM `WebSphere MQ`已配置为队列管理器由队列名称确定,则系统将使用适合给定队列名称的队列管理器。
3. 或者,通过设置`Connection`对象的以下属性来指定要使用的频道:
- `Connection` - 指定IBM `WebSphere MQ`服务器的主机和端口。例如:`"127.0.0.1:1401"`。
- `Channel` - 指定要使用的频道的名称。这必须是IBM WebSphere MQ服务器上的有效通道。
- `Transport` - 指定通道使用的传输。此属性可以是以下之一: `"TCP"`, `"LU62"`, `"NETBIOS"`, `"SPX"`
如果省略这些参数,系统将使用IBM `WebSphere MQ`中配置的默认通道规范。或者,如果系统已配置为通道由队列名称确定,则系统使用适合给定队列名称的通道。
4. 如果频道需要身份验证,请设置`Connection`对象的以下属性:
- 用户名-指定有权使用此频道的用户名。
- 密码-指定给定用户的密码。
5. 调用`Connection`对象的`%ErrLog()`方法。此方法接受一个参数,即要用于此连接对象的日志文件的名称。
6. 检查`%ErrLog()`方法返回的值。
7. 调用`Connection`对象的`%Connect()`方法。
8. 检查`%Connect()`方法返回的值。如果该方法返回1,则表明连接已成功建立,可以使用`Connection`对象发送或接收消息(具体取决于您使用的类)。
# 指定字符集(CCSID)
要设置用于消息转换的字符集,请调用`Connection`对象的`%SetCharSet()`方法。指定在IBM `WebSphere MQ`中使用的整数编码字符集`ID(CCSID)`。
- 如果正在发送消息,这应该是这些消息的字符集。如果不指定字符集,则MQ系统假定消息使用为`MQ`客户端指定的默认字符集。
- 如果要检索邮件,则这是要将这些邮件翻译为的字符集。
要获取当前正在使用的`CCSID`,请调用`%charset()`方法。此方法通过引用返回`CCSID`,并返回1或0以指示是否成功.
# 指定其他消息选项
要指定消息描述符选项,可以选择设置连接对象的以下属性:
- `ApplIdentityData`指定应用程序标识消息描述符选项。
- `PutApplType`指定`PUT Application Type`消息描述符选项。
## 发送消息
要发送邮件,请执行以下操作:
1. 按照“创建连接对象”中的说明创建连接对象。在这种情况下,请创建`%Net.MQSend`的实例。`Connection`对象有一个消息队列,可以向该队列发送消息。
2. 根据需要调用以下方法:
- `%put()`-给定一个字符串,此方法将该字符串写入消息队列。
- `%PutStream()`-给定初始化的文件字符流,此方法将该字符串写入消息队列。请注意,必须设置流的`Filename`属性才能对其进行初始化。不支持二进制流。
- `%SetMsgId()`-给定一个字符串,此方法使用该字符串作为发送的下一条消息的消息ID。
3. 检查调用的方法返回的值。
4. 检索完消息后,调用`Connection`对象的`%Close()`方法以释放动态链接库的句柄。
示例1:`SendString()`
下面的类方法使用队列管理器`QM_antigua`和名为 `S_antigua`的队列通道向队列`mqtest`发送一条简单的字符串消息。通道使用TCP传输,IBM `WebSphere MQ`服务器运行在名为`Antigua`的机器上,并侦听端口1401。
```java
///Method returns reason code from IBM WebSphere MQ
ClassMethod SendString() As %Integer
{
Set send=##class(%Net.MQSend).%New()
Set queue="mqtest"
Set qm="QM_antigua"
Set chan="S_antigua/TCP/antigua(1414)"
Set logfile="c:\mq-send-log.txt"
Set check=send.%Init(queue,qm,chan,logfile)
If 'check Quit send.%GetLastError()
//send a unique message
Set check=send.%Put("This is a test message "_$h)
If 'check Quit send.%GetLastError()
Quit check
}
```
示例2:`SendCharacterStream()`
下面的类方法发送文件字符流的内容。它使用的队列与上一个示例中使用的队列相同:
```java
///Method returns reason code from IBM WebSphere MQ
ClassMethod SendCharacterStream() As %Integer
{
Set send=##class(%Net.MQSend).%New()
Set queue="mqtest"
Set qm="QM_antigua"
Set chan="S_antigua/TCP/antigua(1414)"
Set logfile="c:\mq-send-log.txt"
Set check=send.%Init(queue,qm,chan,logfile)
If 'check Quit send.%GetLastError()
//initialize the stream and tell it what file to use
Set longmsg=##class(%FileCharacterStream).%New()
Set longmsg.Filename="c:\input-sample.txt"
Set check=send.%PutStream(longmsg)
If 'check Quit send.%GetLastError()
Quit check
}
```
示例3:从终端发送消息
以下示例显示了向IBM `WebSphere MQ`队列发送消息的终端会话。这只能在配置了IBM `WebSphere MQ`客户端的计算机上运行。
```java
Set MySendQ = ##class(%Net.MQSend).%New()
Do MySendQ.%Init("Q_1", "QM_1","QC_1/TCP/127.0.0.1(1401)","C:\mq.log")
Do MySendQ.%Put("Hello from tester")
Set MyRecvQ =##class(%Net.MQRecv).%New()
Do MyRecvQ.%Init("Q_1", "QM_1","QC_1","C:\mq.log")
Do MyRecvQ.%Get(.msg, 10000)
Write msg,!
```
文章
Claire Zheng · 二月 1, 2021
Hi, 大家好!
我们正在努力改进本网站,让大家可以在 InterSystems 开发者社区舒适地阅读、贡献、分享和获取答案!
虽然有一些 UI 问题还没有得到修复,但本帖提供了一些关于如何使用开发者社区的简单回答。
如何添加帖子?
打开社区页面, 选择所需产品,例如 Caché 然后点击 "创建新帖"。
如何订阅帖子的更新?
要订阅帖子的更新并通过电子邮件获取它们,请点击帖子摘要下方的“收藏”,例如:
如何管理帖子的标题?
假设您已经创建文章,并且想要在其注释中添加几句话。
为此,将编辑器切换到“筛选的 HTML”模式,然后在注释末尾输入<!--break--> 标签。
否则注释会被修剪为一两句话。 就像这样:
未完待续。 敬请期待!
文章
Michael Lei · 十一月 9, 2021
https://www.appeon.com/products/powerbuilder
Appeon PowerBuilder 是一个企业级开发工具,可以用来建立数据驱动的商业应用程序和组件。它是Appeon产品套件之一,同时提供了开发C/S、Web、移动和分布式应用程序的工具。
在这篇文章中,我将展示通过使用ODBC用Appeon PowerBuilder连接Caché的步骤。
步骤1 :确保在安装IRIS时选择ODBC驱动程序选项。
步骤2:通过使用ODBC数据源管理器配置ODBC IRIS数据源
步骤 3: 配置InterSystems ODBC 数据源
步骤 4: 测试连接 (确保 IRIS 实例在运行)
步骤 5: 从 PowerBuilder 打开数据库Profiles, 在列表选中ODB ODBC并单击“新建 New”... 按钮
步骤 6: 选择我们已经用ODBC管理器创建的 "IRISHealth User"数据源
步骤 7: 点击“测试连接Test Connection” 按钮,在Preview页面下测试连接
恭喜! 我们已经成功建立了IRIS链接。现在我们可以用PowerBuilder database painter来看表和数据了
谢谢