清除过滤器
文章
姚 鑫 · 四月 30, 2021
# 第八章 解释SQL查询计划(二)
# SQL语句的详细信息
有两种方式显示SQL语句的详细信息:
- 在SQL Statements选项卡中,通过单击左侧列中的Table/View/Procedure Name链接选择一个SQL Statement。
这将在单独的选项卡中显示SQL语句详细信息。
该界面允许打开多个选项卡进行比较。
它还提供了一个Query Test按钮,用于显示SQL Runtime Statistics页面。
- 从表的Catalog Details选项卡(或SQL Statements选项卡)中,通过单击右边列中的Statement Text链接选择一个SQL语句。
这将在弹出窗口中显示SQL语句详细信息。
可以使用“SQL语句详细信息”显示来查看查询计划,并冻结或解冻查询计划。
“SQL语句详细信息”提供冻结或解冻查询计划的按钮。
它还提供了一个Clear SQL Statistics按钮来清除性能统计,一个`Export`按钮来将一个或多个SQL语句导出到一个文件,以及一个`Refresh`和`Close`页面按钮。
SQL语句详细信息显示包含以下部分。
每个部分都可以通过选择部分标题旁边的箭头图标展开或折叠:
- 语句详细信息,其中包括性能统计
- 编译设置
- 语句在以下例程中定义
- 语句使用如下关系
- 语句文本和查询计划(在其他地方描述)
## 声明的细节部分
- 语句散列Statement hash:语句定义的内部散列表示形式,用作SQL语句索引的键(仅供内部使用)。
有时,看起来相同的SQL语句可能具有不同的语句散列项。
需要生成不同SQL语句的代码的设置/选项的任何差异都会导致不同的语句散列。
这可能发生在支持不同内部优化的不同客户端版本或不同平台上。
- 时间戳`Timestamp`:最初,创建计划时的时间戳。
这个时间戳会在冻结/解冻之后更新,以记录计划解冻的时间,而不是重新编译计划的时间。
可能必须单击Refresh Page按钮来显示解冻时间戳。
将Plan Timestamp与包含该语句的例程/类的`datetime`值进行比较,可以知道,如果再次编译该例程/类,它是否使用了相同的查询计划。
- 版本Version:创建计划的InterSystems IRIS版本。
如果“计划”状态是“冻结/升级”,则这是InterSystems IRIS的早期版本。
解冻查询计划时,“计划”状态变为“解冻”,“版本”变为当前的InterSystems IRIS版本。
- 计划状态Plan state:冻结/显式、冻结/升级、解冻、解冻/并行。
Frozen/Explicit意味着该语句的计划已被显式用户操作冻结,无论生成此SQL语句的代码发生了什么变化,该冻结的计划都将是将要使用的查询计划。
冻结/升级意味着该语句的计划已被InterSystems IRIS版本升级自动冻结。
解冻意味着该计划目前处于解冻状态,可能被冻结。
Unfrozen/Parallel表示该计划被解冻,并使用`%Parallel`处理,因此不能被冻结。
`NULL`(空白)计划状态意味着没有关联的查询计划。
- 自然查询Natural query:一个布尔标志,指示该查询是否是“自然查询”。
如果勾选此项,则该查询是自然查询,不会记录查询性能统计信息。
如果不检查,性能统计可能会被记录;
其他因素决定了统计数据是否真正被记录下来。
自然查询被定义为嵌入式SQL查询,它非常简单,记录统计数据的开销会影响查询性能。
将统计信息保存在自然查询上没有任何好处,因为查询已经非常简单了。
一个很好的自然查询示例是`SELECT Name INTO:n FROM Table WHERE %ID=?`
这个查询的`WHERE`子句是一个相等条件。
此查询不涉及任何循环或任何索引引用。
动态SQL查询(缓存查询)不会被标记为自然查询;
缓存查询的统计数据可能被记录,也可能不被记录。
- 冻结计划不同Frozen plan different:冻结计划时,会显示该字段,显示冻结的计划与未冻结的计划是否不同。
冻结计划时,语句文本和查询计划将并排显示冻结的计划和未冻结的计划,以便进行比较。
本节还包括五个查询性能统计字段,将在下一节中进行描述。
## 性能统计数据
执行查询会将性能统计数据添加到相应的SQL语句。
此信息可用于确定哪些查询执行得最慢,哪些查询执行得最多。
通过使用这些信息,您可以确定哪些查询将通过优化提供显著的好处。
除了SQL语句名称、计划状态、位置和文本之外,还为缓存查询提供了以下附加信息:
- 计数Count:运行此查询次数的整数计数。
如果对该查询产生不同的查询计划(例如向表中添加索引),则将重置该计数。
- 平均计数Average count:每天运行此查询的平均次数。
- 总时间Total time:运行此查询所花费的时间(以秒为单位)。
- 平均时间Average time:运行此查询所花费的平均时间(以秒为单位)。
如果查询是缓存的查询,则查询的第一次执行所花费的时间很可能比从查询缓存中执行优化后的查询所花费的时间要多得多。
- 标准差Standard deviation:总时间和平均时间的标准差。
只运行一次的查询的标准偏差为0。
运行多次的查询通常比只运行几次的查询具有更低的标准偏差。
- 第一次看到的日期Date first seen:查询第一次运行(执行)的日期。
这可能与`Last Compile Time`不同,后者是准备查询的时间。
`UpdateSQLStats`任务会定期更新已完成的查询执行的查询性能统计数据。
这将最小化维护这些统计信息所涉及的开销。
因此,当前运行的查询不会出现在查询性能统计中。
最近完成的查询(大约在最近一个小时内)可能不会立即出现在查询性能统计中。
可以使用Clear SQL Statistics按钮清除这6个字段的值。
InterSystems IRIS不单独记录`%PARALLEL`子查询的性能统计数据。
%PARALLEL子查询统计信息与外部查询的统计信息相加。
由并行运行的实现生成的查询没有单独跟踪其性能统计信息。
InterSystems IRIS不记录“自然”查询的性能统计数据。
如果系统收集了统计信息,则会降低查询性能,而自然查询已经是最优的,因此没有进行优化的可能。
可以在“SQL语句”选项卡显示中查看多个SQL语句的查询性能统计信息。
您可以按任何列对SQL Statements选项卡列表进行排序。
这使得很容易确定,例如,哪个查询具有最大的平均时间。
还可以通过查询`INFORMATION.SCHEMA.STATEMENTS`类属性来访问这些查询性能统计数据,如查询SQL语句中所述。
## 编译设置部分
- 选择模式`Select mode`:编译语句时使用的`SelectMode`。
对于DML命令,可以使用`#SQLCompile Select`;
默认为Logical。
如果`#SQLCompile Select=Runtime`,调用`$SYSTEM.SQL.Util.SetOption()`方法的`SelectMode`选项可以改变查询结果集的显示,但不会改变SelectMode值,它仍然是Runtime。
- 默认模式Default schema(s):编译语句时设置的默认模式名。
这通常是在发出命令时生效的默认模式,尽管SQL可能使用模式搜索路径(如果提供的话)而不是默认模式名来解析非限定名称的模式。
但是,如果该语句是嵌入式SQL中使用一个或多个`#Import`宏指令的DML命令,则`#Import`指令指定的模式将在这里列出。
- 模式路径Schema path:编译语句时定义的模式路径。
如果指定,这是模式搜索路径。
如果没有指定架构搜索路径,则此设置为空。
但是,对于在`#Import`宏指令中指定搜索路径的DML Embedded SQL命令,`#Import`搜索路径显示在默认模式设置中,并且该模式路径设置为空白。
- 计划错误Plan Error:该字段仅在使用冻结计划时发生错误时出现。
例如,如果一个查询计划使用一个索引,则该查询计划被冻结,然后该索引从表中删除,就会出现如下的计划错误:`Map 'NameIDX' not defined in table 'Sample.Person', but it was specified in the frozen plan for the query`.
删除或添加索引将导致重新编译表,从而更改“最后编译时间”值。
一旦导致错误的条件得到纠正,`Clear Error`按钮可用于清除`Plan Error`字段——例如,通过重新创建缺失的索引。
在错误条件被纠正后使用“清除错误”按钮会导致“计划错误”字段和“清除错误”按钮消失。
## 例程和关系部分
语句在以下例程部分中定义:
- 例程`Routine`:与缓存查询关联的类名(对于动态SQL DML),或者例程名(对于嵌入式SQL DML)。
- 类型:类方法或`MAC`例程(对于嵌入式SQL DML)。
- 上次编译时间`Last Compile Time`:例程的上次编译时间或准备时间。如果SQL语句解冻,重新编译MAC例程会同时更新此时间戳和Plan时间戳。如果SQL语句已冻结,则重新编译MAC例程仅更新此时间戳;在您解冻计划之前,Plan时间戳不会更改;然后Plan时间戳将显示计划解冻的时间。
语句使用以下关系部分列出了一个或多个用于创建查询计划的定义表。对于使用查询从另一个表提取值的`INSERT`,或者使用`FROM`子句引用另一个表的`UPDATE`或`DELETE`,这两个表都在此处列出。每个表都列出了下列值:
- 表或视图名称`Table or View Name`:表或视图的限定名称。
- 类型`Type`:表或视图。
- 上次编译时间`Last Compile Time`:表(持久化类)上次编译的时间。
- `Classname`:与表关联的类名。
本节包括用于重新编译类的编译类选项。如果重新编译解冻计划,则所有三个时间字段都会更新。如果重新编译冻结的计划,则会更新两个上次编译时间字段,但不会更新计划时间戳。解冻计划并单击刷新页面按钮后,计划时间戳将更新为计划解冻的时间。
# 查询SQL语句
可以使用`SQLTableStatements()`存储查询返回指定表的SQL语句。下面的示例显示了这一点:
```java
/// w ##class(PHA.TEST.SQL).SQLTableStatements()
ClassMethod SQLTableStatements()
{
SET mycall = "CALL %Library.SQLTableStatements('Sample','Person')"
SET tStatement = ##class(%SQL.Statement).%New()
SET qStatus=tStatement.%Prepare(mycall)
IF qStatus'=1 {WRITE "%Prepare failed:" DO $System.Status.DisplayError(qStatus) QUIT}
SET rset=tStatement.%Execute()
IF rset.%SQLCODE '= 0 {WRITE "SQL error=",rset.%SQLCODE QUIT}
DO rset.%Display()
}
```
```java
DHC-APP>w ##class(PHA.TEST.SQL).SQLTableStatements()
Dumping result #1
SCHEMA RELATION_NAME PLAN_STATE LOCATION STATEMENT
SAMPLE PERSON 0 %sqlcq.DHCdAPP.cls228.1 DECLARE C CURSOR FOR SELECT * INTO :%col(1) , :%col(2) , :%col(3) , :%col(4) , :%col(5) , :%col(6) , :%col(7) , :%col(8) , :%col(9) , :%col(10) , :%col(11) , :%col(12) , :%col(13) , :%col(14) , :%col(15) FROM SAMPLE . PERSON
SAMPLE PERSON 0 Sample.Person.1 SELECT AGE , DOB , FAVORITECOLORS , HOME , NAME , OFFICE , SSN , SPOUSE , X__CLASSNAME , HOME_CITY , HOME_STATE , HOME_STREET , HOME_ZIP , OFFICE_CITY , OFFICE_STATE , OFFICE_STREET , OFFICE_ZIP INTO :%e ( ) FROM %IGNOREINDEX * SAMPLE . PERSON WHERE ID = :%rowid
...
CURSOR FOR SELECT P . NAME , P . AGE , E . NAME , E . AGE FROM %ALLINDEX SAMPLE . PERSON AS P LEFT OUTER JOIN SAMPLE . EMPLOYEE AS E ON P . NAME = E . NAME WHERE P . AGE > 21 AND %NOINDEX E . AGE < 65
SAMPLE PERSON 0 PHA.TEST.SQL.1 SELECT NAME , SPOUSE INTO :name , :spouse FROM SAMPLE . PERSON WHERE SPOUSE IS NULL
SAMPLE PERSON 0 PHA.TEST.ObjectScript.1 SELECT NAME , DOB , HOME INTO :n , :d , :h FROM SAMPLE . PERSON
70 Rows(s) Affected
```
可以使用`INFORMATION_SCHEMA`包表来查询SQL语句列表。InterSystems IRIS支持以下类:
- `INFORMATION_SCHEMA.STATEMENTS`:包含当前名称空间中的当前用户可以访问的SQL语句索引项。
- `INFORMATION_SCHEMA.STATEMENT_LOCATIONS`:包含调用SQL语句的每个例程位置:持久类名或缓存查询名。
- `INFORMATION_SCHEMA.STATEMENT_RELATIONS`:包含SQL语句使用的每个表或视图条目。
以下是使用这些类的一些示例查询:
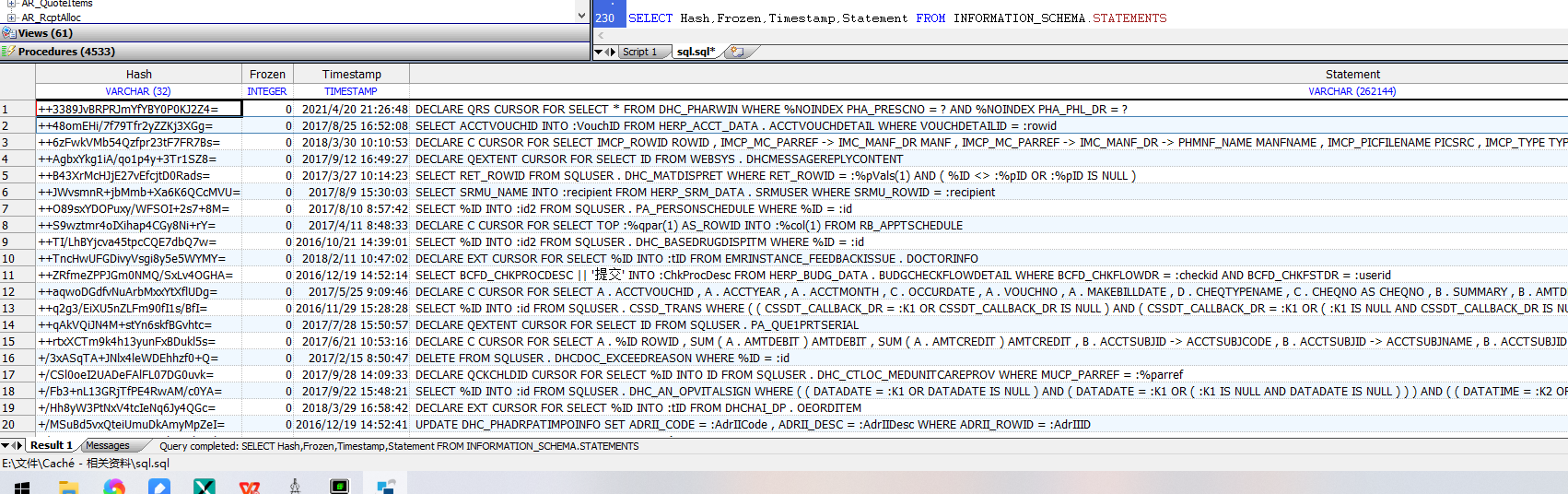
下面的示例返回命名空间中的所有SQL语句,列出哈希值(唯一标识规范化SQL语句的计算ID)、冻结状态标志(值0到3)、准备语句和保存计划时的本地时间戳以及语句文本本身:
```sql
SELECT Hash,Frozen,Timestamp,Statement FROM INFORMATION_SCHEMA.STATEMENTS
```
以下示例返回所有冻结计划的SQL语句,指示冻结的计划是否与未冻结的计划不同。请注意,解冻语句可以是`Frozen=0`或`Frozen=3`。不能冻结的单行INSERT等语句在冻结列中显示NULL:
```sql
SELECT Frozen,FrozenDifferent,Timestamp,Statement FROM INFORMATION_SCHEMA.STATEMENTS
WHERE Frozen=1 OR Frozen=2
```
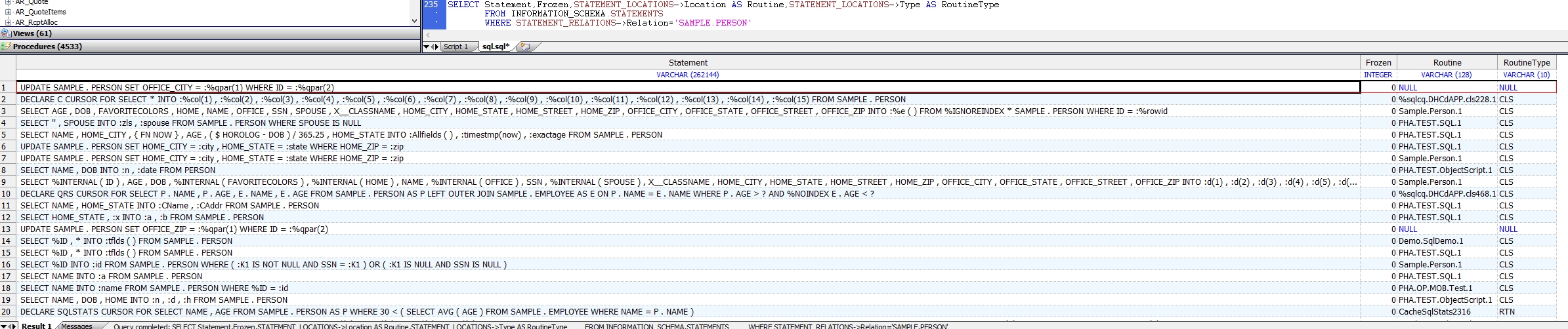
以下示例返回给定SQL表的所有SQL语句和语句所在的例程。(请注意,指定表名(`SAMPLE.PERSON`)时必须使用与SQL语句文本中相同的字母大小写:全部大写字母):
```sql
SELECT Statement,Frozen,STATEMENT_LOCATIONS->Location AS Routine,STATEMENT_LOCATIONS->Type AS RoutineType
FROM INFORMATION_SCHEMA.STATEMENTS
WHERE STATEMENT_RELATIONS->Relation='SAMPLE.PERSON'
```
以下示例返回当前命名空间中具有冻结计划的所有SQL语句:
```sql
SELECT Statement,Frozen,Frozen_Different,STATEMENT_LOCATIONS->Location AS Routine,STATEMENT_LOCATIONS->Type AS RoutineType
FROM INFORMATION_SCHEMA.STATEMENTS
WHERE Frozen=1 OR Frozen=2
```
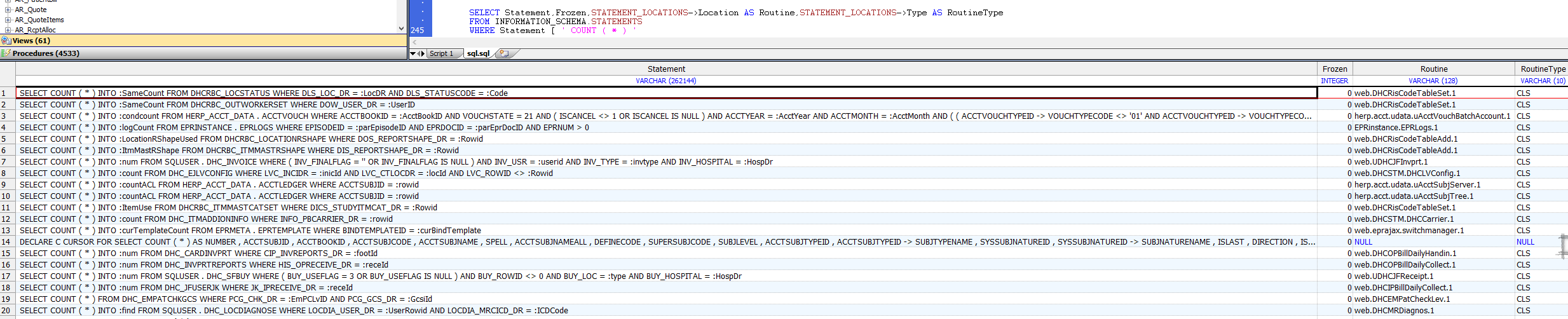
以下示例返回当前命名空间中包含`COUNT(*)`聚合函数的所有SQL语句。(请注意,指定语句文本(`COUNT(*)`)时必须使用与SQL语句文本相同的空格):
```sql
SELECT Statement,Frozen,STATEMENT_LOCATIONS->Location AS Routine,STATEMENT_LOCATIONS->Type AS RoutineType
FROM INFORMATION_SCHEMA.STATEMENTS
WHERE Statement [ ' COUNT ( * )
```
# 导出和导入SQL语句
可以将SQL语句作为`XML`格式的文本文件导出或导入。这使可以将冻结的计划从一个位置移动到另一个位置。SQL语句导出和导入包括关联的查询计划。
可以导出单个SQL语句,也可以导出命名空间中的所有SQL语句。
可以导入先前导出的包含一个或多个SQL语句的XML文件。
注意:将SQL语句作为XML导入不应与从文本文件导入和执行SQL DDL代码混淆。
## 导出SQL语句
导出单个SQL语句:
- 使用SQL语句详细资料页导出按钮。在管理门户系统资源管理器SQL界面中,选择SQL语句选项卡,然后单击语句以打开SQL语句详细信息页。选择导出按钮。这将打开一个对话框,允许选择将文件导出到服务器(数据文件)或浏览器。
- 服务器(默认):输入导出`XML`文件的完整路径名。第一次导出时,此文件的默认名称为`statementexport.xml`。当然,可以指定不同的路径和文件名。成功导出SQL语句文件后,上次使用的文件名将成为默认值。
默认情况下,未选中在后台运行导出复选框。
- Browser:将文件`statementexport.xml`导出到用户默认浏览器中的新页面。可以为浏览器导出文件指定其他名称,或指定其他软件显示选项。
- 使用`$SYSTEM.SQL.Statement.ExportFrozenPlans()`方法。
导出命名空间中的所有SQL语句:
- 使用管理门户中的导出所有对帐单操作。从管理门户系统资源管理器SQL界面中,选择操作下拉列表。从该列表中选择Export all Statements。这将打开一个对话框,允许您将命名空间中的所有SQL语句导出到服务器(数据文件)或浏览器。
- 服务器(默认):输入导出XML文件的完整路径名。第一次导出时,此文件的默认名称为`statementexport.xml`。当然,可以指定不同的路径和文件名。成功导出SQL语句文件后,上次使用的文件名将成为默认值。
默认情况下,在后台运行导出复选框处于选中状态。这是导出所有SQL语句时的建议设置。选中在后台运行导出时,系统会为提供一个查看后台列表页面的链接,可以在该页面中查看后台作业状态。
- Browser:将文件`statementexport.xml`导出到用户默认浏览器中的新页面。可以为浏览器导出文件指定其他名称,或指定其他软件显示选项。
使用`$SYSTEM.SQL.Statement.ExportAllFrozenPlans()`方法。
## 导入SQL语句
从先前导出的文件导入一条或多条SQL语句:
- 使用管理门户中的导入对帐单操作。从管理门户系统资源管理器SQL界面中,选择操作下拉列表。从该列表中选择Import Statements。这将打开一个对话框,允许指定导入XML文件的完整路径名。
默认情况下,在后台运行导入复选框处于选中状态。这是导入SQL语句文件时的推荐设置。选中在后台运行导入时,系统会为您提供一个查看后台列表页面的链接,可以在该页面中查看后台作业状态。
使用`$SYSTEM.SQL.Statement.ImportFrozenPlans()`方法。
## 查看和清除后台任务
在管理门户系统操作选项中,选择后台任务,查看导出和导入后台任务的日志。可以使用清除日志按钮清除此日志。
文章
姚 鑫 · 四月 29, 2021
# 第九章 冻结计划
大多数SQL语句都有一个关联的查询计划。查询计划是在准备SQL语句时创建的。默认情况下,添加索引和重新编译类等操作会清除此查询计划。下次调用查询时,将重新准备查询并创建新的查询计划。冻结计划使可以跨编译保留(冻结)现有查询计划。查询执行使用冻结的计划,而不是执行新的优化并生成新的查询计划。
对系统软件的更改也可能导致不同的查询计划。通常,这些升级会带来更好的查询性能,但软件升级可能会降低特定查询的性能。冻结计划使可以保留(冻结)查询计划,以便查询性能不会因系统软件升级而改变(降级或提高)。
# 如何使用冷冻计划
使用冻结计划有两种策略-乐观策略和悲观策略:
- 乐观:如果假设更改系统软件或类定义会提高性能,请使用此策略。运行查询并冻结计划。导出(备份)冻结的计划。解冻该计划。更改软件。重新运行查询。这会产生一个新的计划。比较这两个查询的性能。如果新计划没有提高性能,可以从备份文件中导入先前冻结的计划。
- 悲观:如果假设系统软件或类定义的更改可能不会提高特定查询的性能,请使用此策略。运行查询并冻结计划。更改软件。使用`%NOFPLAN`关键字重新运行查询(这会导致冻结的计划被忽略)。比较这两个查询的性能。如果忽略冻结的计划没有提高性能,请保持冻结该计划并从查询中删除`%NOFPLAN`。
# 软件版本升级自动冻结计划
将InterSystems IRIS®Data Platform升级到新的主要版本时,现有的查询计划将自动冻结。这可确保重大软件升级永远不会降低现有查询的性能。升级软件版本后,对性能关键型查询执行以下步骤:
1. 执行计划状态为冻结/升级的查询,并监控性能。这是在软件升级之前创建的优化查询计划。
2. 将`%NOFPLAN`关键字添加到查询中,然后执行并监视性能。这将使用软件升级提供的SQL优化器优化查询计划。它不会解冻现有的查询计划。
3. 比较性能指标。
- 如果`%NOFPLAN`性能更好,则软件升级改进了查询计划。解冻查询计划。删除`%NOFPLAN`关键字。
- 如果`%NOFPLAN`性能较差,则软件升级会使查询计划降级。保持查询计划冻结状态,将查询计划从冻结/升级升级为冻结/显式。删除`%NOFPLAN`关键字。
4. 测试性能关键型查询后,可以解冻所有剩余的冻结/升级计划。
当在比最初创建计划时使用的InterSystems软件版本更新的InterSystems软件版本下准备/编译查询时,会发生这种自动冻结。例如,考虑一条在系统软件版本xxxx.1下准备/编译的SQL语句。随后升级到版本xxxx.2,再次准备/编译SQL语句。系统将检测到这是SQL语句在新版本上的第一次准备/编译,并自动将计划状态标记为冻结/升级,并将现有计划用于新的准备/编译。这确保使用的查询计划不会比以前版本的查询计划差。
只有主要版本的InterSystems系统软件升级才会自动冻结现有查询计划。维护发布版本升级不会冻结现有查询计划。例如,主要版本升级(如从2018.1升级到2019.1)将执行此操作。维护版本升级(如2018.1.0到2018.1.1)不执行此操作。
在管理门户SQL界面中,SQL语句计划状态列将这些自动冻结的计划指示为冻结/升级,计划版本指示原始计划的系统间软件版本。
可以使用`INFORMATION.SCHEMA.STATEMENTS` `Frozen=2`属性列出当前命名空间中的所有冻结/升级计划。
可以使用以下`$SYSTEM.SQL.Statement`方法冻结单个查询计划或多个查询计划:`FreezeStatement()`用于单个计划;`FreezeRelation()`用于关系的所有计划;`FreezeSchema()`用于架构的所有计划;`FreezeAll()`用于当前命名空间中的所有计划。有相应的解冻方法。
- 冻结方法可以提升(“冻结”)标记为冻结/升级到冻结/显式的查询计划。通常,可以使用此方法有选择地将适当的冻结/升级计划升级为冻结/显式,然后解冻所有剩余的冻结/升级计划。
- 解冻方法可以解冻指定范围内的冻结/升级查询计划:命名空间、架构、关系(表)或单个查询。
# 冻结计划界面
冻结计划界面有两种,用途不同:
- Management Portal SQL语句界面,用于冻结(或解冻)单个查询的计划。
- `$SYSTEM.SQL.Statement`冻结和解冻方法,用于冻结或解冻命名空间、架构、表或单个查询的所有计划。
在Management Portal SQL界面中,选择`Execute Query`选项卡。编写查询,然后单击显示计划按钮以显示当前查询执行计划。如果计划被冻结,则查询计划部分的第一行是“冻结计划”。
在管理门户SQL界面中,选择SQL语句选项卡。这将显示SQL语句列表。此列表的计划状态列指定解冻、解冻/并行、冻结/显式或冻结/升级。(如果语句没有关联的查询计划,则计划状态列为空。)
可以使用`INFORMATION.SCHEMA.STATEMENTS` Frozen属性值列出当前命名空间中所有SQL语句的计划状态:`UNFRECTED(0)`、`Frozen/EXPLICIT(1)`、`Frozen/Upgrade(2)`或`UNFORMATED/PARALLEL(3)`。
要冻结或解冻计划,请在SQL语句文本列中选择SQL语句。这将显示“SQL语句详细信息”框。在此框的底部显示对帐单文本和查询计划。如果计划未冻结,则这些横断面的背景颜色为绿色,如果计划已冻结,则背景颜色为蓝色。在其正上方的对帐单操作下,可以根据需要选择冻结计划或解冻计划按钮。然后选择关闭。
- 冻结计划按钮:单击此按钮将冻结此语句的查询优化计划。冻结计划并编译该SQL语句时,SQL编译将使用冻结的计划信息并跳过查询优化阶段。
- 解冻计划按钮:点击该按钮将删除该语句冻结的计划,该语句的新编译将进入查询优化阶段,以确定要使用的最佳计划。
还可以使用`$SYSTEM.SQL.Statement`冻结和解冻方法冻结或解冻一个或多个计划。通过指定适当的方法,可以指定冻结或解冻操作的范围:单个计划的`FreezeStatement()`;关系的所有计划的`FreezeRelation()`;架构的所有计划的`FreezeSchema()`;当前命名空间中的所有计划的`FreezeAll()`。有相应的解冻方法。
## 权限
用户只能查看他们具有`EXECUTE`权限的那些SQL语句。这既适用于Management Portal SQL语句列表,也适用于`INFORMATION.SCHEMA.STATEMENTS`类查询。
管理门户SQL语句访问要求对`%Development`资源具有`“USE”`权限。任何可以在管理门户中看到SQL语句的用户都可以冻结或解冻该语句。
对于SQL语句的目录访问,如果您具有执行该语句的权限或对`%Development`资源具有`“Use”`权限,则可以看到这些语句。
对于`$SYSTEM.SQL.Statement`冻结或解冻方法调用,必须对`%Developer`资源拥有`“U”`权限。
## 冻结计划不同
如果计划被冻结,可以确定解冻该计划是否会导致不同的计划,而无需实际解冻该计划。此信息可以帮助您确定哪些SQL语句值得使用`%NOFPLAN`进行测试,以确定解冻计划是否会带来更好的性能。
可以使用`INFORMATION.SCHEMA.STATEMENTS` `FrozenDifferent`属性列出当前命名空间中此类型的所有冻结计划。
冻结的计划可能会因以下任一操作而与当前计划不同:
- 重新编译该表或该表引用的表
- 使用`SetMapSelecability()`激活或停用索引
- 在表上运行`TuneTable`
- 升级InterSystems软件版本
重新编译会自动清除现有的缓存查询。对于其他操作,必须手动清除现有缓存查询才能使新查询计划生效。
这些操作可能会也可能不会产生不同的查询计划。有两种方法可以确定它们是否这样做:
- 手工检查个别冻结计划
- 每天自动扫描所有冻结计划
如果计划尚未由这两个操作中的任何一个检查,或者计划未冻结,则列出新计划的SQL语句列为空。解冻选中的冻结计划会将新建计划列重置为空。
## 手动冻结计划检查
在冻结计划的SQL语句详细资料页的顶部有一个检查冻结按钮。按此按钮将显示解冻不同计划复选框。如果选中此框,则解冻计划将导致不同的查询计划。
对冻结计划执行此检查冻结测试后:
- 如果选中解冻计划不同框,则列出新计划的SQL语句列包含“1”。这表明解冻计划将导致不同的计划。
- 如果未选中解冻计划不同框,则列出新计划的SQL语句列将包含“0”。这表明解冻计划不会产生不同的计划。
- 已冻结的缓存查询的New Plan为“0”;清除缓存查询,然后解冻该计划会导致SQL语句消失。
- 已冻结的`Natura`l查询在New Plan列中为空。
执行此测试后,检查冻结按钮消失。如果要重新测试冻结的计划,请选择刷新页面按钮。这将重新显示检查冻结按钮。
## 日冻结计划自动检查
InterSystems SQL每晚`2:00`自动扫描SQL语句清单中的所有冻结语句。这次扫描最多持续一个小时。如果扫描未在一小时内完成,系统会记下它停止的位置,并从该点继续进行下一次每日扫描。可以使用管理门户监视此每日扫描或强制其立即扫描:选择系统操作、任务管理器、任务计划,然后选择扫描冻结计划任务。
此扫描检查所有冻结的计划:
- 如果冻结的计划具有与当前版本相同的InterSystems软件版本,InterSystems IRIS®Data Platform将计算两个计划的引用表和时间戳的散列,以创建可能已更改的内部计划列表。对于这个子集,它然后执行两个计划的逐个字符串比较,以确定哪些计划实际上不同。如果两个计划之间有任何不同(无论有多小),它都会在列`出New Plan`列的SQL语句中用`“1”`标记SQL语句。这表明解冻计划将导致不同的查询计划。
- 如果冻结的计划具有与当前版本相同的InterSystems IRIS版本,并且两个计划的逐字符串比较完全匹配,则它会将列出新计划的SQL语句列中的SQL语句标记为`“0”`。这表明解冻计划不会导致不同的查询计划。
- 如果冻结的计划具有与当前版本(冻结/更新)不同的InterSystems软件版本,InterSystems IRIS将确定对SQL优化器逻辑的更改是否会导致不同的查询计划。如果是,它将用`“1”`标记“SQL Statements Listing New Plan”列中的SQL语句。否则,它会用`“0”`标记SQL语句`New Plan`列。
可以通过调用`INFORMATION.SCHEMA.STATEMENTS`来检查此扫描的结果。以下示例返回所有冻结计划的SQL语句,指示冻结的计划是否与未冻结的计划不同。请注意,解冻语句可以是`Frozen=0`或`Frozen=3`:
```sql
SELECT Frozen,FrozenDifferent,Timestamp,Statement FROM INFORMATION_SCHEMA.STATEMENTS
WHERE Frozen=1 OR Frozen=2
```
## 冻结计划出错
如果语句的计划被冻结,并且计划使用的定义发生了某些更改,从而导致计划无效,则会发生错误。例如,如果从语句`PLAN`使用的类中删除了索引:
- 该声明的计划仍处于冻结状态。
- 在“SQL语句详细信息”页上,“编译设置”区域显示“计划错误”字段。例如,如果查询计划使用索引名`indxdob`,然后您修改了类定义以删除索引`indxdob`,则会显示如下消息: `Map 'indxdob' not defined in table 'Sample.Mytable', but it was specified in the frozen plan for the query`.
- 在SQL语句详细资料页上,查询计划区域显示由于冻结计划中的错误而无法确定计划。
如果在冻结计划处于错误状态时重新执行查询,则InterSystems IRIS不使用冻结计划。相反,系统会创建一个新的查询计划,该计划将在给定当前定义的情况下工作,并执行查询。此查询计划被分配了与前一个查询计划相同的缓存查询类名。
在计划解冻或修改定义以使计划返回有效状态之前,出错的计划将一直处于错误状态。
如果修改定义以使计划返回有效状态,请转到SQL语句详细资料页,然后按清除错误按钮以确定是否已更正错误。如果更正,计划错误字段将消失;否则将重新显示计划错误消息。如果已更正定义,则不必显式清除计划错误,SQL即可开始使用冻结计划。如果已更正定义,则清除错误按钮会使SQL语句详细资料页的冻结查询计划区域再次显示执行计划。
计划错误可能是 `“soft error.”`。当计划使用索引,但查询优化器当前无法选择该索引时,可能会出现这种情况,因为`SetMapSelecability()`已将其可选择性设置为`0`。这样做可能是为了[重建]索引。当InterSystems IRIS遇到具有冻结计划的语句的软错误时,查询处理器会尝试自动清除错误并使用冻结计划。如果该计划仍然出错,则该计划将再次标记为出错,并且查询执行将尽可能使用最佳计划。
# %NOFPLAN关键字
可以使用`%NOFPLAN`关键字覆盖冻结的计划。包含`%NOFPLAN`关键字的SQL语句将生成新的查询计划。冻结的计划将保留,但不会使用。这允许测试生成的计划行为,而不会丢失冻结的计划。
```sql
DECLARE CURSOR FOR SELECT %NOFPLAN ...
SELECT %NOFPLAN ....
INSERT [OR UPDATE] %NOFPLAN ...
DELETE %NOFPLAN ...
UPDATE %NOFPLAN
```
在`SELECT`语句中,`%NOFPLAN`关键字只能在查询中的第一个`SELECT`之后立即使用:它只能与`UNION`查询的第一个分支一起使用,不能在子查询中使用。`%NOFPLAN`关键字必须紧跟在`SELECT`关键字之后,位于`DISTINCT`或`TOP`等其他关键字之前。
# 导出和导入冻结计划
可以将SQL语句作为`XML`格式的文本文件导出或导入。这使可以将冻结的计划从一个位置移动到另一个位置。SQL语句导出和导入包括关联查询计划的编码版本和指示该计划是否冻结的标志。
文章
Hao Ma · 四月 29, 2021
经常被问到有关IRIS如何支持SSL,HTTPS的问题,有必要写个东西介绍一下。
##HTTPS的原理
简单的说,https实现两个目的:一是访问网站加密,2是确认被访问的网站是真的。
首先,被访问的网站要申请一个证书,这个证书必须是权威机构发放的,比如google, VeriSign等等,所有的浏览器里有预装了这些组织的公钥(Public Key),因此能确认你提供的证书真是这些组织给出的,而这个证书可以证明你的网站的身份。注意证书证明的是提供服务的组织和服务的真实性,和用什么设备没关系,也就是说,IRIS不管证书的事儿。
接下去,被访问的服务器可以生成公钥和私钥,和客户端交换key,生成整个世界只有两者知道的security code,用来两者之间数据的交换。详细的过程和消息交互可以在网上找到很多很好的文章和视频,比如这个: [How does HTTPS work? What's a CA? What's a self-signed Certificate?](https://www.youtube.com/watch?v=T4Df5_cojAs)。
如果是测试环境或者使用者可以控制的内部网络,self-signed证书非常常用。self-signed证书就是不去花钱找人认证,而是告诉客户端,我这个证书是自己认证的,你知道我这台机器试内网的一个机器,不用权威机构证明我服务器的身份,咱们交换一下钥匙把通信加密了吧。操作系统,各种Web服务器都提供这样的假证书,可以用于测试。浏览器访问这样的网站时会提醒用户这个网站不安全,客户需要确认继续访问。
## IRIS的https访问
如果要访问的是IRIS上的http服务或者页面,需要做的是在连接IRIS的Web服务器配置SSL/TLS。有关IRIS和IRIS WebGateway的介绍,请查看[这个系列前面的文章](https://cn.community.intersystems.com/post/webgateway%E7%B3%BB%E5%88%971-web-gateway%E4%BB%8B%E7%BB%8D)。
*不需要在IRIS或者IRIS Gateway做任何配置。在IRIS文档里有各种有关SSL/TLS的内容,除非你要开发一个TCP层的使用SSL/TLS的应用或者IRIS作为客户端访问其他HTTPS的服务,你根本不用阅读。*
下面简单介绍配置Apache Web服务器简单实现IRIS管理页面的HTTPS访问的步骤。
**1.apache Web服务器安装SSL.**
如果你的Apache没有安装过SSL组件,运行下面命令安装
```
yum -y install mod_ssl
```
命令执行结束安装完成后,在/etc/httpd/modules目录会添加了mod_ssl.so,并且在/etc/httpd/conf.d 目录下会出现一个ssl.conf文件。
如果是Windows, 您需要下载使用Windows的Apache服务器,比如从这个页面:[Apach2.4.46](https://www.apachehaus.com/cgi-bin/download.plx)。 按照说明,您需要将软件解压缩到一个目录,比如c:/Apache24,然后执行 "httpd -k install"安装。
并且, 你要确保httpd.conf文件中下面两行没有被注释
LoadModule ssl_module modules/mod_ssl.so
Include conf/extra/httpd-ssl.conf
访问https://WebServerIP,你会被浏览器提醒这不是个可信任的网站,是不是还要继续访问,确认后会看到Apache的测试页,访问是成功的。
**2.到IRIS的WebGateway的连接。**
我一般放在一个单独的配置文件里,在linux下是在./conf.d/isc.conf, 在Windows系统是在./extra/httpd-isc.conf。这个配置文件是要被include在httpd.conf里面。配置https并不需要修改这个配置文件。下面是在Windows下的httpd-isc.conf的配置示意。
LoadModule csp_module_sa C:/InterSystems/WebGateway/CSPa24.dll
SetHandler csp-handler-sa
SetHandler csp-handler-sa
CSPFileTypes *
Alias /csp/ c:/InterSystems/WebGateway/csp/
AllowOverride None
Options MultiViews FollowSymLinks ExecCGI
Require all granted
Require all denied
这时您应该可以测试到IRIS管理页面的HTTPS访问了。
**3. 获得证书并添加到Web服务器。**
这步是可选的。面向公众服务的Web服务通常会购物证书, 而内部服务个个客户的网络中会有相关的CA的处理方式,相应的如何修改Apache服务器的配置请自行查看文档。
五一节快乐
文章
姚 鑫 · 四月 28, 2021
# 第八章 解释SQL查询计划(一)
# SQL语句
这个SQL语句列表为每个表提供了SQL查询和其他操作的记录,包括插入、更新和删除。
这些SQL语句链接到一个查询计划,该链接提供冻结该查询计划的选项。
系统为每个SQL DML操作创建一条SQL语句。
这提供了一个按表、视图或过程名称列出的SQL操作列表。
如果更改表定义,可以使用此SQL Statements列表来确定每个SQL操作的查询计划是否会受到此DDL更改的影响,以及/或是否需要修改某个SQL操作。
然后,可以:
- 确定每个SQL操作使用哪个查询计划。
可以决定使用反映对表定义所做更改的修改后的查询计划。
或者可以冻结当前查询计划,保留在更改表定义之前生成的查询计划。
- 根据对表定义所做的更改,确定是否对对该表执行SQL操作的例程进行代码更改。
注意:SQL语句是一个SQL例程列表,它们可能会受到表定义更改的影响。
它不应该用作表定义或表数据更改的历史记录。
# 创建SQL语句操作
下面的SQL操作会创建相应的SQL语句:
数据管理(DML)操作包括对表的查询、插入、更新和删除操作。
每个数据管理(DML)操作(动态SQL和嵌入式SQL)在执行时都会创建一个SQL语句。
- 动态SQL `SELECT`命令在准备查询时创建SQL语句。
此外,在管理门户缓存查询列表中创建了一个条目。
- 嵌入式SQL基于指针的`SELECT`命令在`OPEN`命令调用声明的查询时创建SQL语句。管理门户缓存查询列表中不会创建单独的条目。
如果查询引用多个表,则在名称空间的SQL语句中创建一条SQL语句,该语句列出表/视图/过程名列中的所有被引用表,并且对于每个单独的被引用表,该表的SQL语句列表都包含该查询的条目。
SQL语句是在第一次准备查询时创建的。如果多个客户端发出相同的查询,则只记录第一次准备。例如,如果JDBC发出一个查询,然后ODBC发出一个相同的查询,那么SQL语句索引将只有关于第一个JDBC客户端的信息,而不是关于ODBC客户端的信息。
大多数SQL语句都有关联的查询计划。
创建该查询计划时,将解冻该查询计划;
可以随后将该查询计划指定为冻结计划。
带有查询计划的SQL语句包括涉及`SELECT`操作的DML命令。
下面的“计划状态”部分列出了没有查询计划的SQL语句。
注意:SQL语句只列出SQL操作的最新版本。
除非冻结SQL语句,否则InterSystems IRIS®数据平台将用下一个版本替换它。
因此,在例程中重写和调用SQL代码将导致旧的SQL代码从SQL语句中消失。
## 其他SQL语句操作
下面的SQL命令执行更复杂的SQL语句操作:
- `CREATE TRIGGER`: 在定义触发器的表中,无论是在定义触发器还是在提取触发器时,都不会创建SQL语句。
但是,如果触发器对另一个表执行DML操作,那么定义触发器将在被触发器代码修改过的表中创建一个SQL语句。
`Location`指定在其中定义触发器的表。
在定义触发器时定义SQL语句;
删除触发器将删除SQL语句。
触发触发器不会创建SQL语句。
- `CREATE VIEW` 不创建SQL语句,因为没有编译任何内容。
它也不会更改源表的SQL语句的Plan Timestamp。
然而,为视图编译DML命令会为该视图创建一个SQL语句。
# List SQL语句
本节介绍使用Management Portal界面列出SQL语句的详细信息。
也可以使用`^rINDEXSQL`全局返回SQL语句的索引列表。
注意,这个SQL语句List可能包含过时的(不再有效的)List
从Management Portal SQL界面可以列出如下SQL语句:
- SQL语句选项卡:此选项卡列出名称空间中的所有SQL语句,先按模式排序,然后按每个模式中的表名/视图名排序。此列表仅包括当前用户拥有权限的那些表/视图。如果SQL语句引用多个表,则表/视图/过程名列将按字母顺序列出所有被引用的表。
- 通过单击列标题,可以按表/视图/过程名、计划状态、位置、SQL语句文本或列表中的任何其他列对SQL语句列表进行排序。这些可排序列使能够快速查找,例如,所有冻结计划(计划状态)、所有缓存查询(位置)或最慢的查询(平均时间)。
- 可以使用此选项卡提供的`Filter`选项将列出的SQL语句缩小到指定的子集。
指定的筛选器字符串筛选SQL语句列表中的所有数据,最有用的是模式或模式。
表名、例程位置或SQL语句文本中找到的子字符串。
过滤字符串不区分大小写,但必须紧跟语句文本标点空格`(name , age, not name,age)`。
如果查询引用了多个表,如果它选择了表/视图/过程名称列中的任何引用表,则`Filter`包括SQL语句。
过滤选项是用户自定义的。
- 最大行选项默认为`1,000`。
最大值为`10,000`。
最小值为`10`。
要列出超过`10,000`条SQL语句,请使用`INFORMATION_SCHEMA.STATEMENTS`。
页面大小和最大行选项是用户自定义的。
- Catalog Details选项卡:选择一个表并显示其Catalog详细信息。
此选项卡提供了一个表的SQL语句按钮,用于显示与该表关联的SQL语句。
注意,如果一个SQL语句引用了多个表,那么它将在表的SQL语句列表中列出每个被引用的表,但只有当前选择的表在表名列中列出。
通过单击列标题,可以根据列表的任何列对表的SQL语句列表进行排序。
可以使用`SQLTableStatements()`目录查询或`INFORMATION_SCHEMA`。
语句,列出根据各种条件选择的SQL语句,如下面的查询SQL语句中所述。
## 列表列
SQL语句选项卡列出名称空间中的所有SQL语句。目录详细信息选项卡表的SQL语句按钮列出了所选表的SQL语句。这两个列表都包含以下列标题:
- `#`:列表行的顺序编号。这些数字与特定的SQL语句没有关联。
- 表/视图/过程名:限定的SQL表(或视图或过程)名:`schema.name`。如果SQL语句查询引用了多个表或视图,则所有这些表或视图都会在此处列出。
- 计划状态:请参阅下面的计划状态。
- 新计划:见“冻结计划”一章中不同的新计划。
- 自然查询:请参阅下面的语句详细信息部分。
- 计数:请参阅下面的性能统计数据。
- 平均计数:请参阅下面的性能统计数据。
- 总时间:请参阅下面的性能统计数据。
- 平均时间:请参阅下面的性能统计数据。
- 标准开发人员:请参阅下面的性能统计数据。
- Location(S):编译查询的位置,例程名称(对于嵌入式SQL)或缓存查询名称(对于动态SQL)。如果包名为`%sqlcq`,则SQL语句为缓存查询。
- SQL语句文本:规范化格式的SQL语句文本(截断为`128`个字符),可能与以下SQL语句文本中指定的命令文本不同。
## 计划状态
计划状态列出以下内容之一:
- 解冻Unfrozen:未冻结,可冻结。
- 解冻/平行Unfrozen/Parallel::未冻结,不能冻结。
- 冻结/显式Frozen/Explicit:由用户动作冻结,可以解冻。
- Frozen/Upgrade:被InterSystems IRIS版本升级冻结,可以解冻。
- blank:没有关联的查询计划:
- `INSERT... VALUES()` 命令创建的SQL语句没有关联的查询计划,因此无法解冻或冻结(计划状态列为空)。尽管此SQL命令不会生成查询计划,但它在SQL语句中的列表仍然很有用,因为它允许快速定位针对该表的所有SQL操作。例如,如果向表中添加一列,则可能需要找出该表的所有SQL插入的位置,以便可以更新这些命令以包括此新列。
- 基于游标的`UPDATE`或`DELETE`命令没有关联的查询计划,因此不能解冻或冻结(“计划状态”列为空)。对已声明的游标执行`OPEN`命令会生成一条带有关联查询计划的SQL语句。使用该游标的嵌入式SQL语句(`FETCH cursor, UPDATE...WHERE CURRENT OF cursor, DELETE...WHERE CURRENT OF cursor, and CLOSE cursor`)不生成单独的SQL语句。即使基于游标的`UPDATE`或`DELETE`不会产生查询计划,但SQL语句中列出的查询计划仍然很有用,因为它允许快速定位针对该表的所有SQL操作。
## SQL语句文本
SQL语句文本通常不同于SQL命令,因为SQL语句生成规范化了字母和空格。
其他差异如下:
如果从Management Portal接口或SQL Shell接口发出查询,所得到的SQL语句与在`SELECT`语句前面加上`DECLARE QRS CURSOR FOR`(其中“QRS”可以是各种生成的游标名称)的查询不同。
这允许语句文本与Dynamic SQL缓存的查询相匹配。
如果SQL命令指定了一个非限定的表或视图名,那么生成的SQL语句将使用模式搜索路径(如果提供了DML)或默认模式名来提供模式。
SQL语句文本在`1024`个字符之后被截断。
要查看完整的SQL语句文本,请显示SQL语句详细信息。
一个SQL命令可能会产生多个SQL语句。
例如,如果一个查询引用一个视图,SQL Statements将显示两个语句文本,一个列在视图名称下,另一个列在基础表名称下。
冻结任意一条语句都会导致两个语句的Plan State为Frozen。
当通过xDBC准备SQL语句时,如果需要这些选项来生成语句索引散列,则SQL语句生成会向语句文本添加SQL Comment Options (`# Options`)。
如下面的例子所示:
```sql
DECLARE C CURSOR FOR SELECT * INTO :%col(1) , :%col(2) , :%col(3) , :%col(4) , :%col(5) FROM SAMPLE . COMPANY /*#OPTIONS {"xDBCIsoLevel":0} */
```
# 陈旧的SQL语句
删除与SQL语句关联的例程或类时,不会自动删除SQL语句列表。这种类型的SQL语句列表称为陈旧。由于访问此历史信息以及与SQL语句相关联的性能统计信息通常很有用,因此这些过时的条目将保留在管理门户SQL语句列表中。
可以使用`Clean Stale`(清除陈旧)按钮删除这些陈旧条目。清除陈旧删除关联例程或类(表)不再存在或不再包含SQL语句查询的所有非冻结SQL语句。清除陈旧不会删除冻结的SQL语句。
可以使用`$SYSTEM.SQL.Statement.Clean()`方法执行相同的清除陈旧操作。
如果删除与SQL语句关联的表(持久化类),则会修改表/视图/过程名称列,如下例所示:`SAMPLE.MYTESTTABLE - Deleted??;` ;已删除表的名称将转换为全部大写字母,并标记为“`DELETED??`”。或者,如果SQL语句引用了多个表:`SAMPLE.MYTESTTABLE - Deleted?? Sample.Person`.
- 对于动态SQL查询,删除表时`Location`列为空,因为与该表关联的所有缓存查询都已自动清除。`CLEAN STALE`删除SQL语句。
- 对于嵌入式SQL查询,`Location`列包含用于执行查询的例程的名称。当更改例程使其不再执行原始查询时,位置列为空。`CLEAN STALE`删除SQL语句。删除查询使用的表时,该表被标记`“Deleted??”`;Clean Stale不会删除SQL语句。
注:系统任务在所有名称空间中每小时自动运行一次,以清除任何可能过时或具有过时例程引用的SQL语句的索引。执行此操作是为了维护系统性能。此内部清理不会反映在管理门户SQL语句列表中。可以使用管理门户监视此每小时一次的清理或强制其立即执行。要查看此任务上次完成和下次调度的时间,请依次选择系统操作、任务管理器、任务调度,然后查看清理SQL语句索引任务。可以单击任务名称查看任务详细信息。在Task Details(任务详细信息)显示中,可以使用Run(运行)按钮强制立即执行任务。请注意,这些操作不会更改SQL语句清单;必须使用Clean Stale来更新SQL语句清单。
# 数据管理(DML)SQL语句
创建SQL语句的数据管理语言(DML)命令包括:`INSERT`、`UPDATE`、`INSERT`或`UPDATE`、`DELETE`、`TRUNCATE TABLE`、`SELECT`和`OPEN CURSOR`(用于声明的基于游标的`SELECT`)。可以使用动态SQL或嵌入式SQL来调用DML命令。可以为表或视图调用DML命令,InterSystems IRIS将创建相应的SQL语句。
注意:系统在准备动态SQL或打开嵌入式SQL游标时(而不是在执行DML命令时)创建SQL语句。SQL语句时间戳记录此SQL代码调用的时间,而不是查询执行的时间(或是否)。因此,SQL语句可能表示从未实际执行的表数据更改。
准备动态SQL DML命令将创建相应的SQL语句。与此SQL语句关联的位置是缓存查询。动态SQL是在从管理门户SQL界面、SQL Shell界面执行SQL或从`.txt`文件导入时准备的。清除未冻结的缓存查询会将相应的SQL语句标记为清除陈旧删除。清除冻结的缓存查询会删除相应SQL语句的位置值。解冻SQL语句会将其标记为Clean Stale删除。
执行非游标嵌入式SQL数据管理语言(DML)命令将创建相应的SQL语句。每个嵌入式SQL DML命令都会创建相应的SQL语句。如果一个例程包含多个嵌入式SQL命令,则每个嵌入式SQL命令都会创建一个单独的SQL语句。(某些嵌入式SQL命令会创建多条SQL语句。)。SQL语句清单的Location列指定包含嵌入式SQL的例程。通过这种方式,SQL语句维护每个嵌入式SQL DML命令的记录。
打开基于游标的嵌入式SQL数据管理语言(DML)例程将创建带有查询计划的SQL语句。
关联的嵌入式SQL语句(`FETCH`游标、`CLOSE`游标)不会生成单独的SQL语句。
在FETCH游标之后,一个关联的`UPDATE table WHERE CURRENT OF cursor 或DELETE FROM table WHERE CURRENT OF cursor`会生成一个单独的SQL语句,但不会生成单独的`Query Plan`。
插入文字值的`INSERT`命令将创建一个“计划状态”列为空的SQL语句。
由于该命令不会创建查询计划,因此无法冻结SQL语句。
## select命令
调用查询将创建相应的SQL语句。
它可以是一个简单的`SELECT`操作,也可以是一个基于指针的`SELECT/FETCH`操作。
可以对表或视图发出查询。
- 包含`JOIN`的查询为每个表创建相同的SQL语句。
Location是清单中存储的每个表的相同查询。
如SQL语句详细信息例程和关系部分所述,该语句使用以下关系列出所有表。
- 包含选择项子查询的查询为每个表创建相同的SQL语句。
`Location`是清单中存储的每个表的相同查询。
如SQL语句详细信息例程和关系部分所述,该语句使用以下关系列出所有表。
- 引用外部(链接)表的查询不能被冻结。
- 一个包含`FROM`子句`%PARALLEL`关键字的查询可以创建多个SQL语句。
你可以通过调用来显示这些生成的SQL语句:

这将显示包含原始查询的语句哈希的`Statement`列和包含生成的查询版本的语句哈希的`ParentHash`列。
`%PARALLEL`查询的SQL语句的计划状态为“未冻结/并行”,不能被冻结。
- 不包含FROM子句(因此不引用任何表)的查询仍然创建SQL语句。
例如:`SELECT $LENGTH('this string')`创建一个SQL语句,表列值`%TSQL_sys.snf`。
文章
姚 鑫 · 四月 27, 2021
# 第七章 解释SQL查询计划
本章介绍由`ShowPlan`生成的InterSystems SQL查询访问计划中使用的语言和术语。
# 存储在映射中的表
SQL表存储为一组映射。
每个表都有一个包含表中所有数据的主映射;
表还可以有其他的映射,如索引映射和位图。
每个映射可以被描绘成一个多维全局,其中一些字段的数据在一个或多个下标中,其余字段存储在节点值中。
下标控制要访问的数据。
- 对于主映射,`RowID`或`IDKEY`字段通常用作映射下标。
- 对于索引映射,通常将其他字段用作前导下标,将`RowID/IDKEY`字段用作附加的较低级别的下标。
- 对于位图,可以将位图层视为附加的RowID下标级别。但是,位图只能用于为正整数的`RowID`。
# 发展计划
编译SQL查询会生成一组指令来访问和返回查询指定的数据。
这些指令表示为`. int`例程中的ObjectScript代码。
指令及其执行顺序受到SQL编译器中有关查询中涉及的表的结构和内容的数据的影响。
编译器尝试使用表大小和可用索引等信息,以使指令集尽可能高效。
查询访问计划(`ShowPlan`)是对结果指令集的可读翻译。
查询的作者可以使用这个查询访问计划来查看将如何访问数据。
虽然SQL编译器试图最有效地利用查询指定的数据,但有时查询的作者对存储的数据的某些方面的了解要比编译器清楚得多。
在这种情况下,作者可以利用查询计划修改原始查询,为查询编译器提供更多的信息或更多的指导。
# 阅读计划
`“ShowPlan”`的结果是一系列关于访问和显示查询中指定的数据的处理的语句。
下面提供了关于如何解释`ShowPlan`语句的信息。
## 访问映射
一个查询计划可以访问多个表。
当访问一个表时,计划可以访问单个映射(索引或主映射)、两个映射(索引映射后面跟着主映射),或者,对于多索引计划,可以访问多个映射。
在通过映射访问数据时,计划指示使用的下标。
它还指示实际的下标值是什么:一个给定值、一组给定值、一个值范围,或该下标在表中显示的所有值。
选择哪一个取决于查询中指定的条件。
显然,访问单个或几个下标值要比访问该下标级别上的所有值快得多。
## 条件和表达式
当查询运行时,将测试查询指定的各种条件。
除了前面提到的某些限制下标的条件外,`ShowPlan`输出没有显式地指示条件的测试。
尽早测试条件总是最好的。
测试各种条件的最佳地点可以从计划细节中推断出来。
类似地,`ShowPlan`不详细描述表达式和子表达式的计算。
除了简单之外,主要原因是在大多数数据库环境中,表和索引访问构成了处理的更重要方面;
检索表数据的成本占总体查询成本的主要地位,因为磁盘访问速度仍然比CPU处理慢几个数量级。
## 循环
当访问一个表中的数据时,经常需要迭代地检查多个行。
这样的访问是通过一个循环来指示的。
每一次传递要执行的指令称为循环体。
它们可以通过缩进直观地显示出来。
涉及多个表的数据库访问通常需要循环中的循环。
在这种情况下,每个循环级别都通过与前一个级别相比的进一步缩进表示。
## 临时文件
### 定义
查询计划还可能指示需要构建和使用中间临时文件(`TEMP-FILE`)。这是本地数组中的“临时”区域。它用于保存临时结果以用于各种目的,如排序。就像映射一样,临时文件有一个或多个下标,可能还有节点数据。
### 使用
一些临时文件包含处理单个表的数据。在这种情况下,可以将构建临时文件视为对该表中的数据进行预处理。在读取这样的临时文件之后,可以访问源表的主映射,也可以不访问源表的主映射。在其他情况下,临时文件可能包含处理多个表的结果。在其他情况下,临时文件用于存储分组的聚合值、检查DISTINCT等。
## 模块
临时文件的构建,以及其他处理,可以委托给一个称为模块的独立工作单元。
每个模块都被命名。
当列出单独的模块时,该计划将指明调用每个模块的位置。
当模块执行结束时,处理将在模块调用之后的下一条语句中继续进行。
## 发送给处理的查询
对于通过ODBC或JDBC网关连接链接的外部表,该计划显示发送到远程SQL gateway connection的查询文本,以从远程表检索所请求的数据。
对于并行查询处理和分片,该计划显示发送到并行处理或在分片上处理的各种查询。
还将显示用于每个查询的计划。
## 子查询、连接和联合
给定查询中的一些子查询(和视图)也可以单独处理。
它们的计划在单独的子查询部分中指定。
在计划中没有指明子查询部分被调用的精确位置。
这是因为它们经常作为条件或表达式处理的一部分被调用。
对于指定`OUTER JOIN`的查询,如果没有找到匹配的行,该计划可能指示可能生成的`null`行,以满足外部连接语义的要求。
对于`UNION`,该计划可能指示将来自不同`UNION`子查询的结果行组合到一个单独的模块中,在该模块中可以对这些结果行进行进一步处理。
# 计划分析
在分析给定查询的计划时,应用程序开发人员有时可能会觉得不同的计划会更有效率。
应用程序开发人员有多种方法来影响计划。
首先,计划将受到在包含实际应用程序数据的环境中正确运行调优表的影响。
在类源定义中手动定义一些`Tune Table`通常计算的值——例如表`EXTENTSIZE`、字段`SELECTIVITY`和映射`BlockCount`——也可以用于实现所需的计划。
此外,分析计划可能表明对类定义的某些更改可能导致更有效的计划,例如:
## 添加一个索引
在某些情况下(尽管不总是),使用一个临时文件进行预处理可能意味着向原始表添加一个与临时文件具有相同或类似结构的索引将消除构建临时文件的需要。
从查询计划中删除这个处理步骤显然可以使查询运行得更快,但这必须与更新表时维护索引所需的工作量进行平衡。
## 添加字段到索引数据
当计划显示正在使用的索引,然后是对主映射的访问时,这意味着将查询中使用的主映射字段添加到索引节点数据可能会为该查询生成更快的计划。
同样,这必须与额外的更新时间以及添加到处理使用该索引的其他查询的额外时间进行平衡,因为索引会更大,因此需要更多的读取时间。
## 添加连接索引
当计划显示以特定顺序连接两个表时(例如,首先检索`t1`,然后使用连接条件`t1.a=t2.b`连接到`t2`),可能相反的表顺序会产生一个更快的计划。例如,如果`t2`有额外的条件,可以显著限制符合条件的行数。
在这种情况下,在`t1`上添加一个t1索引。
a将允许这样一个连接顺序。
公告
Claire Zheng · 四月 27, 2021
亲爱的社区开发者们:
InterSystems开发者工具编程大赛 顺利结束. 感谢大家对激动人心的编码马拉松的支持参与!
是时候宣布此次竞赛优胜者啦!
掌声送给以下参赛者和他们贡献的优秀应用!
🏆 专家提名奖(Experts Nomination)- 获奖者由我们特别挑选的专家团选出:
🥇 第一名,奖金$4,000 ,项目 Server Manager for VSCode ,提交者 @John.Murray
🥈 并列第二名,奖金 $1,500 ,项目 Config-API ,提交者 @Lorenzo.Scalese
🥈 并列第二名,奖金 $1,500 ,项目 zpm-explorer ,提交者 @Henrique.GonçalvesDias 和 @José.Pereira
🏆 社区提名奖(Community Nomination) - 获得总投票数最多的应用:
🥇 第一名,奖金 $750 ,项目 Server Manager for VSCode ,提交者 @John.Murray
🥈 第二名,奖金 $500 ,项目 zpm-explorer ,提交者 @Henrique.GonçalvesDias and @José.Pereira
🥉 第三名,奖金 $250 ,项目 Config-API ,提交者 @Lorenzo.Scalese
恭喜所有获奖者和参赛者!
感谢大家对本次大赛的关注和在本次大赛中付出的努力!
下一场竞赛是什么时候呢?
我们即将发布最新竞赛信息,敬请期待!
文章
姚 鑫 · 四月 25, 2021
# 第五章 优化查询性能(四)
# 注释选项
可以在`SELECT`、`INSERT`、`UPDATE`、`DELETE`或`TRUNCATE`表命令中为查询优化器指定一个或多个注释选项。
注释选项指定查询优化器在编译SQL查询期间使用的选项。
通常,注释选项用于覆盖特定查询的系统范围默认配置。
## 语法
语法`/*#OPTIONS */`(在`/*`和`#`之间没有空格)指定了一个注释选项。
注释选项不是注释;
它为查询优化器指定一个值。
注释选项使用`JSON`语法指定,通常是`“key:value”`对,例如: `/*#OPTIONS {"optionName":value} */`。
支持更复杂的JSON语法,比如嵌套值。
注释选项不是注释;
除了`JSON`语法之外,它可能不包含任何文本。
包含非`json`文本在`/* ... */`分隔符导致`SQLCODE -153`错误。
InterSystems SQL不验证`JSON`字符串的内容。
`#OPTIONS`关键字必须用大写字母指定。
`JSON`的大括号语法中不应该使用空格。
如果SQL代码用引号括起来,比如动态SQL语句,JSON语法中的引号应该是双引号。
例如:`myquery="SELECT Name FROM Sample.MyTest /*#OPTIONS {""optName"":""optValue""} */"`.
可以在SQL代码中任何可以指定注释的地方指定`/*#OPTIONS */` comment选项。
在显示的语句文本中,注释选项总是作为注释显示在语句文本的末尾。
你可以在SQL代码中指定多个`/*#OPTIONS */` comment选项。
它们按照指定的顺序显示在返回的语句文本中。
如果为同一个选项指定了多个注释选项,则使用`last`指定的选项值。
以下的注释选项被记录在案:
- `/*#OPTIONS {"BiasAsOutlier":1} */`
- `/*#OPTIONS {"DynamicSQLTypeList":"10,1,11"}`
- `/*#OPTIONS {"NoTempFile":1} */`
## 显示
`/*#OPTIONS */` comment选项显示在SQL语句文本的末尾,而不管它们是在SQL命令中指定的位置。
一些显示的`/*#OPTIONS */` comment选项没有在SQL命令中指定,而是由编译器的预处理器生成的。
例如 `/*#OPTIONS {"DynamicSQLTypeList": ...} */`
`/*#OPTIONS */` comment选项显示在`Show Plan`语句文本、缓存的查询查询文本和SQL语句语句文本中。
为仅在`/*#OPTIONS */` comment选项中不同的查询创建一个单独的缓存查询。
# 并行查询处理
并行查询提示指示系统在多处理器系统上运行时执行并行查询处理。
这可以极大地提高某些类型查询的性能。
SQL优化器确定一个特定的查询是否可以从并行处理中受益,并在适当的时候执行并行处理。
指定并行查询提示并不强制对每个查询进行并行处理,只强制那些可能从并行处理中受益的查询。
如果系统不是多处理器系统,则此选项无效。
要确定当前系统上的处理器数量,请使用 `%SYSTEM.Util.NumberOfCPUs() `方法。
可以通过两种方式指定并行查询处理:
- 在系统范围内,通过设置`auto parallel`选项。
- 在每个查询的`FROM`子句中指定`%PARALLEL`关键字。
并行查询处理应用于`SELECT`查询。
它不应用于插入、更新或删除操作。
## 系统范围的并行查询处理
可以使用以下选项之一来配置系统范围的自动并行查询处理:
- 在管理门户中选择System Administration,然后选择Configuration,然后选择SQL和对象设置,最后选择SQL。
查看或更改在单个进程中执行查询复选框。
注意,该复选框的默认值是未选中的,这意味着并行处理在默认情况下是激活的。
- 调用`$SYSTEM.SQL.Util.SetOption()`方法,如下: `SET status=$SYSTEM.SQL.Util.SetOption("AutoParallel",1,.oldval)`.
默认值是1(自动并行处理激活)。
要确定当前的设置,调用`$SYSTEM.SQL.CurrentSettings()`,它会显示为`%PARALLEL`选项启用自动提示。
注意,更改此配置设置将清除所有名称空间中的所有缓存查询。
当激活时,自动并行查询提示指示SQL优化器对任何可能受益于这种处理的查询应用并行处理。
在IRIS 2019.1及其后续版本中,自动并行处理是默认激活的。
从IRIS 2018.1升级到IRIS 2019.1的用户需要明确激活自动并行处理。
SQL优化器用于决定是否对查询执行并行处理的一个选项是自动并行阈值。
如果激活了系统范围的自动并行处理(默认),可以使用`$SYSTEM.SQL.Util.SetOption()`方法将自动并行处理的优化阈值设置为整数值,如下所示: `SET status=$SYSTEM.SQL.Util.SetOption("AutoParallelThreshold",n,.oldval)`。
`n`阈值越高,将此特性应用于查询的可能性就越低。
此阈值用于复杂的优化计算,但可以将此值视为必须驻留在已访问映射中的元组的最小数量。
默认值为3200。
最小值为0。
要确定当前的设置,调用`$SYSTEM.SQL.CurrentSettings()`,它显示`%PARALLEL`选项的自动提示阈值。
当自动并行处理被激活时,在分片环境中执行的查询将始终使用并行处理执行,而不管并行阈值是多少。
## 针对特定查询的并行查询处理
可选的`%PARALLEL`关键字在查询的`FROM`子句中指定。
它建议跨系统的IRIS使用多个处理器(如果适用的话)并行处理查询。
这可以显著提高使用一个或多个`COUNT`、`SUM`、`AVG`、`MAX`或`MIN`聚合函数和`/`或`groupby`子句的查询的性能,以及许多其他类型的查询。
这些通常是处理大量数据并返回小结果集的查询。
例如,`SELECT AVG(SaleAmt) FROM %PARALLEL User.AllSales GROUP BY Region`都可使用并行处理。
**仅指定聚合函数、表达式和子查询的“一行”查询执行并行处理,无论是否带有`GROUP BY`子句。
但是,同时指定单个字段和一个或多个聚合函数的“多行”查询不会执行并行处理,除非它包含`GROUP BY`子句。
例如,`SELECT Name,AVG(Age) FROM %PARALLEL Sample.Person`不执行并行处理,但是 `SELECT Name,AVG(Age) FROM %PARALLEL Sample.Person GROUP BY Home_State` 执行并行处理。**
如果在运行时模式下编译指定`%PARALLEL`的查询,则所有常量都被解释为ODBC格式。
指定`%PARALLEL`可能会降低某些查询的性能。
在一个有多个并发用户的系统上运行`%PARALLEL`查询可能会降低整体性能。
在查询视图时可以执行并行处理。
但是,即使显式地指定了`%parallel`关键字,也不会对指定`%VID`的查询执行并行处理。
### `%PARALLEL`的子查询
`%PARALLEL`用于`SELECT`查询及其子查询。
插入命令子查询不能使用`%PARALLEL`。
当应用于与外围查询相关的子查询时,`%PARALLEL`将被忽略。
例如:
```sql
SELECT name,age FROM Sample.Person AS p
WHERE 30 e.dob.` 这是因为SQL优化将这种类型的连接转换为完整的外部连接。
对于完整的外部连接,`%PARALLEL`将被忽略。
- `%PARALLEL`和`%INORDER`优化不能同时使用;
如果两者都指定,`%PARALLEL`将被忽略。
- 查询引用一个视图并返回一个视图ID (`%VID`)。
- 如果表有`BITMAPEXTENT`索引,`COUNT(*)`不使用并行处理。
- `%PARALLEL`用于使用标准数据存储定义的表。
可能不支持将其与自定义存储格式一起使用。
`%PARALLEL`不支持全局临时表或具有扩展全局引用存储的表。
- `%PARALLEL`用于可以访问一个表的所有行的查询,使用行级安全(`ROWLEVELSECURITY`)定义的表不能执行并行处理。
- `%PARALLEL`用于存储在本地数据库中的数据。
它不支持映射到远程数据库的全局节点。
## 共享内存的考虑
对于并行处理,IRIS支持多个进程间队列(`IPQ`)。
每个`IPQ`处理单个并行查询。
它允许并行工作单元子流程将数据行发送回主流程,这样主流程就不必等待工作单元完成。
这使得并行查询能够尽可能快地返回第一行数据,而不必等待整个查询完成。
它还改进了聚合函数的性能。
并行查询执行使用来自通用内存堆(`gmheap`)的共享内存。
如果使用并行SQL查询执行,用户可能需要增加`gmheap`大小。
一般来说,每个`IPQ`的内存需求是`4 x 64k = 256k`。
InterSystems IRIS将一个并行SQL查询拆分为可用的`CPU`核数。
因此,用户需要分配这么多额外的`gmheap`:
```java
x x 256 =
```
注意,这个公式不是100%准确的,因为一个并行查询可以产生同样是并行的子查询。
因此,明智的做法是分配比这个公式指定的更多的额外`gmheap`。
分配足够的`gmheap`失败将导致错误报告给`messages.log`。
SQL查询可能会失败。
其他子系统尝试分配`gmheap`时也可能出现其他错误。
要查看一个实例的`gmheap`使用情况,特别是`IPQ`使用情况,请在管理门户的主页上选择System Operation,然后选择System usage,然后单击Shared Memory Heap usage链接;
要更改通用内存堆或`gmheap`(有时称为共享内存堆或SMH)的大小,请从管理门户的主页选择“系统管理”,然后是“配置”,然后是“附加设置”,最后是“高级内存”;

## 缓存查询注意事项
如果你正在运行一个缓存的SQL查询,使用`%PARALLEL`,当这个查询被初始化时,你做了一些事情来清除缓存的查询,那么这个查询可能会从一个工人作业报告一个``错误。
导致缓存查询被清除的典型情况是调用`$SYSTEM.SQL.Purge()`或重新编译该查询引用的类。
重新编译类将自动清除与该类相关的任何缓存查询。
如果发生此错误,再次运行查询可能会成功执行。
从查询中删除`%PARALLEL`可以避免出现此错误。
## SQL语句和计划状态
使用`%PARALLEL`的SQL查询可以产生多条SQL语句。
这些SQL语句的计划状态是`Unfrozen/Parallel`。
计划状态为“已冻结”/“并行”的查询不能通过用户操作进行冻结。
# 生成报告
可以使用生成报告工具向InterSystems Worldwide Response Center (WRC) customer support提交查询性能报告,以便进行分析。
可以使用以下任意一种方式从管理门户运行生成报告工具:
1. 必须首先从WRC获得WRC跟踪号。可以使用每个管理门户页面顶部的Contact按钮从管理门户联系WRC。在WRC编号区域中输入此跟踪编号。可以使用此跟踪编号来报告单个查询或多个查询的性能。
2. 在“SQL语句”区域中,输入查询文本。右上角将显示一个X图标。可以使用此图标清除SQL语句区。查询完成后,选择保存查询按钮。系统生成查询计划并收集指定查询的运行时统计信息。无论系统范围的运行时统计信息设置如何,生成报告工具始终使用收集选项3:记录查询的所有模块级别的统计信息进行收集。由于在此级别收集统计信息可能需要时间,因此强烈建议您选中“在后台运行保存查询进程”复选框。默认情况下,此复选框处于选中状态。
当后台任务启动时,该工具显示“请等待……”,禁用页面上的所有字段,并显示一个新的视图进程按钮。
单击View Process按钮将在新选项卡中打开Process Details页面。
在流程详细信息页面,您可以查看该流程,并可以“暂停”、“恢复”或“终止”该流程。
进程的状态反映在Save查询页面上。
当流程完成时,当前保存的查询表将被刷新,View process按钮将消失,页面上的所有字段将被启用。
3. 对每个查询执行步骤2。
每个查询将被添加到当前保存的Queries表中。
注意,该表可以包含具有相同WRC跟踪号的查询,也可以包含具有不同跟踪号的查询。
完成所有查询后,继续步骤4。
对于列出的每个查询,可以选择Details链接。
该链接将打开一个单独的页面,其中显示完整的SQL语句、属性(包括WRC跟踪号和IRIS软件版本),以及包含每个模块的性能统计信息的查询计划。
- 要删除单个查询,请从“当前保存的查询”表中选中这些查询的复选框,然后单击“清除”按钮。
- 要删除与WRC跟踪编号关联的所有查询,请从当前保存的查询表中选择一行。WRC编号显示在页面顶部的WRC编号区域。如果您随后单击清除按钮,则对该WRC编号的所有查询都将被删除。
4. 使用查询复选框选择要报告给WRC的查询。要选择与WRC跟踪编号关联的所有查询,请从当前保存的查询表中选择一行,而不是使用复选框。在这两种情况下,都可以选择Generate Report按钮。生成报告工具创建一个XML文件,其中包括查询语句、具有运行时统计信息的查询计划、类定义以及与每个所选查询相关联的SQL int文件。
如果选择与单个WRC跟踪编号关联的查询,则生成的文件将具有默认名称,如`WRC12345.xml`。如果选择与多个WRC跟踪编号关联的查询,则生成的文件将具有默认名称`WRCMultiple.xml`。
将出现一个对话框,要求指定保存报告的位置。保存报告后,可以单击Mail to链接将报告发送给WRC客户支持。使用邮件客户端的附加/插入功能附加文件。
问题
王喆 👀 · 四月 24, 2021
修改过用户门户之后,重新启动就报这个错,然后使用自带的修复功能,修复之后依然报错,日志中显示没有C:\InterSystems\HealthConnect\mgr\IRIS.WIJ,我复制了别人的过来依然报错,由于代码没有做备份我不能重装,有没有什么办法修复一下,或者把代码备份一下,我再重装。
如果由于修改系统文件、误删除文件等问题导致系统启动、初始化等过程失败,还请联系WRC解决故障。 WRC 联系方式:
support@intersystems.com
400-601-9890
https://wrc-china.intersystems.com/wrc/login.csp
文章
Michael Lei · 四月 24, 2021
欢迎大家将相关的经验在这个讨论区分享。
板块
文章列表
征文大赛作品集锦
2022年首届InterSystems 技术征文大赛集锦
官方文档
我司即将推出中文官方文档门户,欢迎大家把需要的官方文档发在评论区,我们会优先发布。谢谢!
IRIS 2021 最新技术文档 First Look 1 技术概要
IRIS 2021 中文文档PDF下载
基础知识与概念
InterSystems-常用术语
多语言字符集系列文章--第一篇 多语言字符集和相关标准简史
基础系列--第一章 SQL中使用的符号
基础系列--Object Script 基础知识(一)
基础系列--InterSystems SQL 的使用 - 第一部分 - 架构及特性介绍
基础系列--WebGateway系列(1): Web Gateway介绍
基础系列 DeepSee 的开发 - 第一部分 - Cube
基础系列--访问IRIS数据平台的四种方式
在集成产品中压缩解压文件
无代码实现SQL业务服务和业务操作
运维与常见问题
InterSystems 最佳实践系列文章
IRIS/Healthconnect-高可用机制-mirror-的配置
系统运维、管理常见问题FAQ系列
运维好文--InterSystems 数据平台互操作功能运行维护管理基础
运维好文--集成平台实例中有哪些文件在占用磁盘?
安全、等保、审计相关系列
虚拟化大型数据库 - VMware CPU 容量规划
InterSystems 数据平台的容量规划和性能系列文章
已经解决的问题清单
使用Prometheus监控Cache集群
医院信息化建设实战教程:如何在不允许使用Git的情况下自动备份代码/自动执行代码?
开发与创新
CDC系列:使用Dejournal Filter在InterSystems IRIS/Caché上通过Mirroring实现CDC功能实操--HealthConnect中创建HTTP服务创新--基于Docker的一体化集成AI环境中部署机器学习/深度学习模型
创新--面向 Google Cloud Platform (GCP) 的 InterSystems IRIS 示例参考架构
创新--在 Windows 主机上运行的 Hyper-V Ubuntu 虚拟机中配置 Docker 使用环境
创新-- 新一代医疗数据互操作标准FHIR系列文章
科研--用IRIS IntegratedML(一体化机器学习)来预测肾病的Web应用
IRIS如何进行CRUD操作
如何调用Ensemble/IRIS内置的HL7 V2 webservice - Java,PB9,Delphi7样例
IRIS与Caché的23种设计模式
10分钟快速开发一个连接到InterSystems IRIS数据库的C#应用
SQLAlchemy - 将 Python 和 SQL 与 IRIS 数据库一起使用的最简单方法
物联网 (IOT) 在 InterSystems IRIS 平台上的应用
本地化
Caché实现SM3密码杂凑算法
在国产系统上安装Healthconnect2021
HEALTHSHARE2018版如何实现AES(CBC)的HEX输出,并可以实现加密和解密
行业观察与洞见
精华文章--《数据二十条》的号角声
论集成标准的选择对医院信息集成平台建设的影响
医疗行业的生态创新:如何实现数据利用和应用创新
精华文章--从软件架构发展谈业务集成技术演进与展望
精华文章--漫谈应用集成的现在与未来
翻译文章:什么是智慧医院数字孪生?
医疗行业数字化转型 —谈谈微服务架构
医院数字化转型之数智底座建设思路(在陕西省数字医学数字化转型论坛上的分享)
行业前沿系列翻译文章--EPIC 电子病历系统: FHIR, API, 互操作性和资源
行业前沿--利用数据编织应对挑战,创造数据价值
医疗行业的生态创新:如何实现数据利用和应用创新
转载:Epic的Cosmos如何用去识别化的数据支持临床研究
前沿探讨--大模型GPT 对医疗行业互操作性协议的影响?
其他
社区文章汇总--跟着社区学习InterSystems 技术
产品对比——Gartner DBMS 魔力象限中的主要领先数据库产品功能对比
产品对比--企业软件的“大众点评”之最新Gartner 云数据管理系统对比,国内医疗信息行业主流的Hadoop(Cloudera)vs Oracle vs Sql Server vs InterSystems Cache
产品对比--Gartner Peer Insight 华山论剑之应用集成平台--InterSystems vs MS vs IBM
学习系列
IRIS/Healthconnect-高可用机制-mirror-的配置
跟版主学caché——大型史诗级免费技术培训caché百讲
git-github入门学习系列
IRIS 快速入门系列讲座
WebGateWay 学习系列
Intersystems IRIS for Health 数据平台医疗版最新在线培训课程
CDC系列
ISC 中国在B站培训视频
如何在社区学习?
初学者资源库
调研—— InterSystems 客户服务满意度调研(长期有效) 互操作系列
消息统一管理
孤立消息管理
HTTP服务
开发系统接口
IRIS 系列
2021版最新官方系列文档
权限管理
容量和性能规划
超融合规划
Web Gateway
数据同步和容灾系列
SOAP 服务
开发
ObjectScript 系列
Object & SQL
运维
系统运维常见问题
B站视频
其他Ensemble相关
文章
姚 鑫 · 四月 24, 2021
# 第五章 优化查询性能(三)
# 查询执行计划
可以使用解释或显示计划工具来显示`SELECT`、`DECLARE`、`UPDATE`、`DELETE`、`TRUNCATE TABLE`和一些`INSERT`操作的执行计划。这些操作统称为查询操作,因为它们使用`SELECT`查询作为其执行的一部分。InterSystems IRIS在准备查询操作时生成执行计划;不必实际执行查询来生成执行计划。
默认情况下,这些工具显示InterSystems IRIS认为的最佳查询计划。对于大多数查询,有多个可能的查询计划。除了InterSystems IRIS认为最佳的查询计划外,还可以生成和显示备用查询执行计划。
InterSystems IRIS提供以下查询计划工具:
- `$SYSTEM.SQL.ExPlan()`方法可用于生成和显示`XML`格式的查询计划以及备选查询计划(可选)。
- SQL `EXPLAIN`命令可用于生成`XML`格式的查询计划,还可以选择生成备选查询计划和SQL统计信息。所有生成的查询计划和统计信息都包含在名为Plan的单个结果集字段中。请注意,`EXPLAIN`命令只能与`SELECT`查询一起使用。
- 管理门户 - >系统资源管理器 - >SQL界面显示计划按钮。
- 管理门户 — >系统资源管理器 — >工具—>SQL性能工具。
对于生成的`%PARALLEL`和分片查询,这些工具显示所有适用的查询计划。
## 使用`Explain()`方法
可以通过运行`$SYSTEM.SQL.Explain()`方法生成查询执行计划,示例如下:
```java
/// w ##class(PHA.TEST.SQL).SQLExplain()
ClassMethod SQLExplain()
{
SET mysql=2
SET mysql(1)="SELECT TOP 10 Name,DOB FROM Sample.Person "
SET mysql(2)="WHERE Name [ 'A' ORDER BY Age"
SET status=$SYSTEM.SQL.Explain(.mysql,{"all":0,"quiet":1,"stats":0,"preparse":0},,.plan)
IF status'=1 {WRITE "Explain() failed:" DO $System.Status.DisplayError(status) QUIT}
ZWRITE plan
}
```
设置`“all”:0`选项会生成InterSystems IRIS认为最优的查询计划。
设置`“all”:1`选项会生成最佳的查询计划和备选的查询计划。
默认值为`“all”:0`。
结果被格式化为表示`xml`格式文本的下标数组。
如果指定单个查询计划`("all":0)`,上述方法调用中的plan变量将具有以下格式:
- `plan`:显示结果中的下标总数。
- `plan(1)`:总是包含XML格式标签`“”`。
最后一个下标总是包含XML格式标记`“”`。
- `plan(2)`:总是包含XML格式标签`""`
- `plan(3)`: 总是包含查询文本的第一行。
如果"`"preparse":0`(默认值),则返回字面查询文本,并为多行查询的每一行使用额外的下标;在上面的例子中,查询有两行,因此使用了两个下标`(plan(3)`和`plan(4)`)。如果`"prepare":1`,则规范化查询文本返回为单行`:plan(3)`。
- `plan(n)`:总是包含XML格式标签`“”`;
在上面的例子中,`3+mysql = plan(5)`。
- `plan(n+1)`:总是包含XML格式的查询`cost""`.
- `plan(n+2)`:总是包含执行计划的第一行。
这个plan可以是任何长度,可以包含`…`标签作为单独的下标行,包含生成的执行模块的查询计划。
如果指`"all":1 Explain()`将生成备用查询计划。计划变量遵循相同的格式,不同之处在于它们使用第一级下标来标识查询计划,而使用第二级下标来标识查询计划的行。因此,`plan(1)`包含第一个查询计划结果中的二级下标计数,`plan(2)`包含第二个查询计划结果中的二级下标计数,依此类推。在此格式中,`plan(1,1)`包含第一个查询计划的`XML`格式标记 `""`;`plan(2,1)`包含第二个查询计划的XML格式标记 `""`,依此类推。唯一不同的是,备用查询计划包含二级零下标(`plan(1,0)`变量,该变量包含成本和索引信息;此零下标不计入一级下标(`plan(1)`)值。
如果指`"stats":1`, `Explain()`将为每个查询计划模块生成性能统计信息。
每个模块的这些统计数据都使用` ... `标记,并立即出现在查询成本之后(`""`)和查询计划文本之前。
如果查询计划包含额外的``标记,则生成的模块的``将紧接在``标记之后,在该模块的查询计划之前列出。
对于每个模块,将返回以下项:
- ``:模块名。
- ``:模块的总执行时间,以秒为单位。
- ``:全局引用的计数。
- ``:执行的代码行数。
- ``:磁盘等待时间,单位为秒。
- ``:结果集中的行数。
- ``:此模块被执行的次数。
- ``:这个程序被执行的次数。
## 使用显示计划从InterSystems SQL工具
可以使用`Show Plan`以以下任何一种方式显示查询的执行计划
- 从管理门户SQL接口。
选择`System Explorer`,然后选择SQL。
在页面顶部选择带有`Switch`选项的名称空间。
(可以为每个用户设置管理门户的默认名称空间。)
编写查询,然后按`Show Plan`按钮。
(还可以通过单击列出查询的`Plan`选项,从`Show History`列表调用`Show Plan`。)
- 从管理门户工具界面。
选择“系统资源管理器”,然后选择“工具”,然后选择“SQL性能工具”,然后选择“SQL运行时统计信息”:
- 在`Query Test`选项卡中:在页面顶部选择一个带有`Switch`选项的名称空间。
在文本框中写入查询。
然后按下`Show Plan with SQL Stats`按钮。
这将在不执行查询的情况下生成一个显示计划。
- 在`View Stats`选项卡中:对于列出的查询之一,按`Show Plan`按钮。
列出的查询包括在执行查询时编写的查询和在查询测试时编写的查询。
- 在`SQL Shell`中,可以使用`SHOW PLAN`和`SHOW PLANALT Shell`命令来显示最近执行的查询的执行计划。
- 通过对缓存的查询结果集运行`Show Plan`,使用:`i%Prop`语法将文本替换值存储为属性:
```java
SET cqsql=2
SET cqsql(1)="SELECT TOP :i%PropTopNum Name,DOB FROM Sample.Person "
SET cqsql(2)="WHERE Name [ :i%PropPersonName ORDER BY Age"
DO ShowPlan^%apiSQL(.cqsql,0,"",0,$LB("Sample"),"",1)
```
默认情况下,`Show Plan`以逻辑模式返回值。但是,当从管理门户或SQL Shell调用`Show Plan`时,`Show Plan`使用运行时模式。
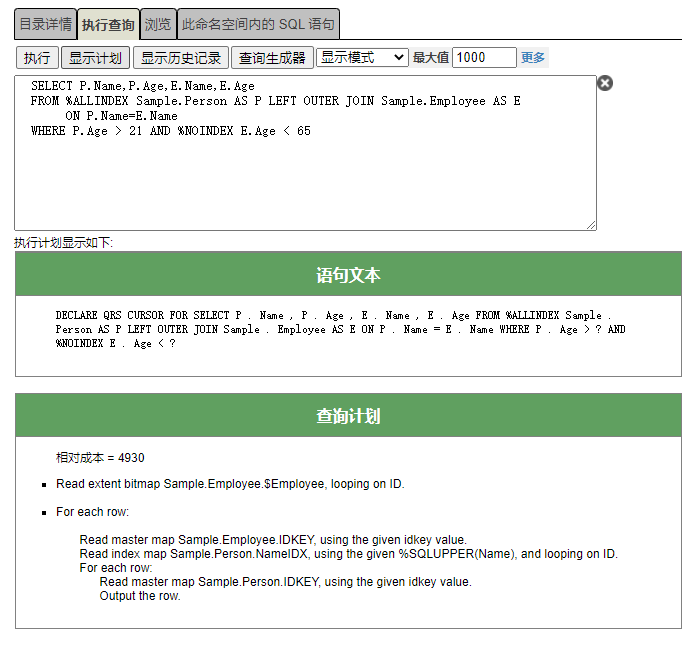
## 执行计划:语句文本和查询计划
显示计划执行计划由两个组件组成,即语句文本和查询计划:
语句文本复制了原始查询,但进行了以下修改:管理门户SQL界面中的显示计划按钮显示删除了注释和换行符的SQL语句。空格是标准化的。显示计划按钮显示还执行文字替换,将每个文字替换为`?`,除非已通过将文字值括在双圆括号中来取消文字替换。使用`EXPLAIN()`方法显示显示计划时,或者使用SQL运行时统计信息或备用显示计划工具显示显示计划时,不会执行这些修改。
查询计划显示将用于执行查询的计划。查询计划可以包括以下内容:
- 如果查询计划已经冻结,则查询计划的第一行为冻结计划,否则第一行为空。
- `“Relative cost”`是一个整数值,它是从许多因素中计算出来的抽象数字,用于比较同一查询的不同执行计划的效率。
这种计算考虑了查询的复杂性、索引的存在和表的大小(以及其他因素)。
相对成本对于比较两个不同的查询是没有用的。
`" Relative cost not available"`由某些聚合查询返回,例如`COUNT(*)`或`MAX(%ID)`不带`WHERE`子句。
- 查询计划由一个主模块和(在需要时)一个或多个子组件组成。
可以显示一个或多个模块子组件,按字母顺序命名, `B: Module:B`, `Module:C`,等等开始,并按执行顺序列出(不一定按字母顺序)。
默认情况下,模块执行处理并使用其结果填充内部临时文件(内部临时表)。
通过指定 `/*#OPTIONS {"NoTempFile":1} */`,可以强制查询优化器创建不生成内部临时文件的查询计划,如注释选项中所述。
对于查询中的每个子查询,都会显示一个命名子查询模块。子查询模块按字母顺序命名。子查询命名在每个命名子查询之前跳过一个或多个字母。因此 `Module:B`, `Subquery:F or Module:D`, `Subquery:G`.当到达字母表末尾时,会对其他子查询进行编号,解析`Z=26`并使用相同的跳过序列。下面的示例是以`Subquery`开头的每三个子查询命名序列`:F:F,I,L,O,R,U,X,27,30,33`。下面的示例是以`Subquery`开头的每秒一次的子查询命名序列`:G:G,I,K,M,O,Q,S,U,W,Y,27,29`。如果子查询调用模块,模块将按字母顺序放在子查询之后,不会跳过。因此,`Subquery:H calls Module:I`。
- `“Read master map”`作为主模块中的第一个项目符号表示查询计划效率低下。查询计划使用以下映射类型语句之一开始执行`Read master map... (no available index), Read index map... (use available index), or Generate a stream of idkey values using the multi-index combination...`因为`master map`读取的是数据本身,而不是数据的索引,所以`Read master map...`。几乎总是指示低效的查询计划。除非表相对较小,否则应该定义一个索引,以便在重新生成查询计划时,第一个映射显示为`read index map...`。
某些操作会创建表示无法生成查询计划的显示计划:
- 非查询插入:`INSERT... VALUES()`命令不执行查询,因此不生成查询计划。
- 查询总是`FALSE`:在少数情况下,InterSystems IRIS可以在准备查询时确定查询条件总是`FALSE`,因此不能返回数据。“显示计划”会在“查询计划”组件中通知这种情况。例如,包含条件的查询`WHERE %ID IS NULL 或 WHERE Name %STARTSWITH('A') AND Name IS NULL `不能返回数据,因此,InterSystems IRIS不生成执行计划。查询计划没有生成执行计划,而是表示`“Output no rows”`。如果查询包含具有这些条件之一的子查询,则查询计划的子查询模块表示`“Subquery result NULL, found no rows”`。这种条件检查仅限于涉及`NULL`的几种情况,并不是为了捕捉所有自相矛盾的查询条件。
- 无效的查询:`Show Plan`为大多数无效查询显示`SQLCODE错误消息`。然而,在少数情况下,`Show Plan`显示为空。例如, `WHERE Name = $$$$$ or WHERE Name %STARTSWITH('A")`。在这些情况下,`Show Plan`不显示语句文本,而`Query Plan[没有为该语句创建的计划]`。这通常发生在分隔文字的引号不平衡时。
当为用户定义的(“外部”)函数指定了两个或多个前置美元符号而没有指定正确的语法时,也会出现这种情况。
# 交替显示计划
可以使用管理门户或`Explain()`方法显示查询的替代执行计划。
使用以下任意一种方法,从管理门户显示查询的备选执行计划:
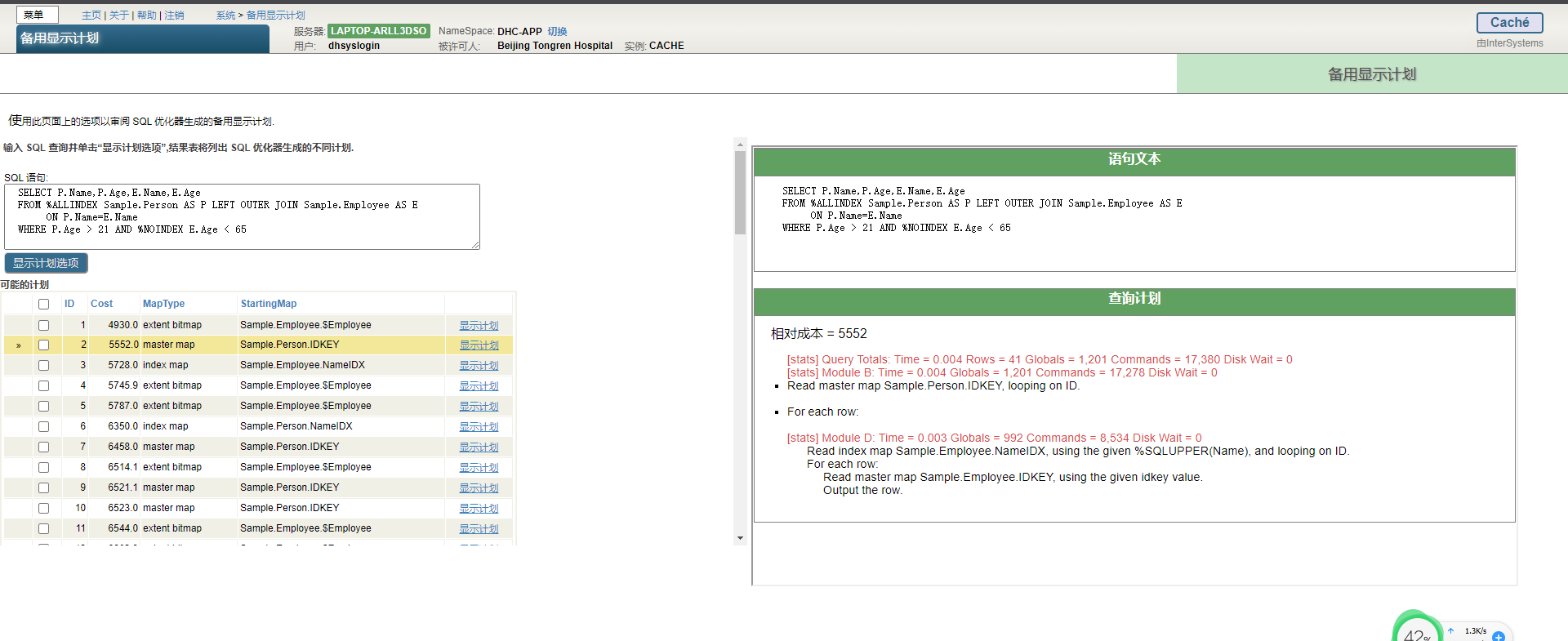
- 选择系统资源管理器,选择工具,选择SQL性能工具,然后选择备用的显示计划。
- 选择`System Explorer`,选择SQL,然后从Tools下拉菜单中选择`Alternate Show Plans`。
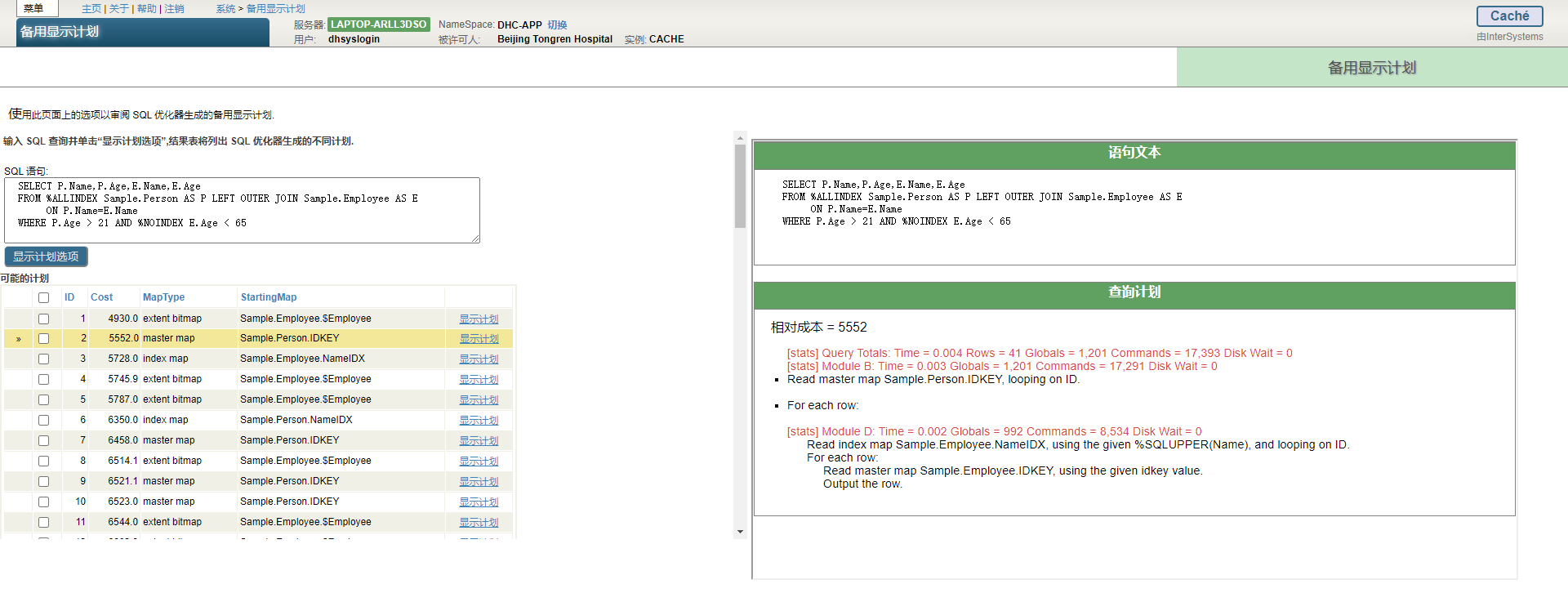
使用备用的“显示计划”工具:
1. 输入一个SQL查询文本,或使用`Show History`按钮检索一个。
可以通过单击右边的圆形“X”圆来清除查询文本字段。
2. 按显示计划选项按钮以显示多个备用显示计划。 `Run ... in the background...`默认情况下不选中复选框,这是大多数查询的首选设置。建议选择`RUN...`。对于大型或复杂的查询,请在后台复选框中。当一个长查询在后台运行时,会显示一个`View process`按钮。单击查看进程将在新选项卡中打开进程详细信息页面。在“进程详细信息”页中,可以查看进程,还可以挂起、继续或终止进程。
3. 可能的计划按成本升序列出,并带有映射类型和起始映射。
4. 从可能的计划列表中,使用复选框选择要比较的计划,然后按比较显示计划与统计信息按钮以运行这些计划并显示其SQL统计信息。
带有`ALL`限定符的`EXPLAIN()`方法显示查询的所有执行计划。它首先显示IRIS认为最优(成本最低)的计划,然后显示备选计划。备选计划按成本升序列出。
以下示例显示最佳执行计划,然后列出备选计划:
```java
DO $SYSTEM.SQL.SetSQLStatsFlagJob(3)
SET mysql=1
SET mysql(1)="SELECT TOP 4 Name,DOB FROM Sample.Person ORDER BY Age"
DO $SYSTEM.SQL.Explain(.mysql,{"all":1},,.plan)
ZWRITE plan
```
## Stats
显示计划选项列表为每个备用显示计划分配一个成本值,使可以在执行计划之间进行相对比较。
`Alternate Show Plan Details`为每个查询计划提供了一组查询总数的统计信息(统计信息),以及(如果适用)每个查询计划模块的统计信息。每个模块的统计信息包括时间(整体性能,以秒为单位)、全局引用(全局引用数)、命令(执行的行数)和读取延迟(磁盘等待,以毫秒为单位)。查询总计统计信息还包括返回的行数。
# 将查询优化计划写入文件
以下实用程序列出了针对文本文件的一个或多个查询的查询优化计划。
```java
QOPlanner^%apiSQL(infile,outfile,eos,schemapath)
```
- `infile` 包含缓存查询列表的文本文件的文件路径名。指定为带引号的字符串。
- `outfile` 要列出查询优化计划的文件路径名。指定为带引号的字符串。如果该文件不存在,系统将创建该文件。如果该文件已存在,则InterSystems IRIS会覆盖该文件。
- `eos` 可选-语句末尾分隔符,用于分隔`Infile`列表中的各个缓存查询。指定为带引号的字符串。默认值为`“GO”`。如果此`EOS`字符串与缓存的查询分隔符不匹配,则不会生成输出文件。
- `schemapath` 可选-以逗号分隔的方案名列表,用于为未限定的表名、视图名或存储过程名指定方案搜索路径。可以包括`DEFAULT_SCHEMA`,这是当前系统范围内的默认架构。如果`infile`包含`#Import`指令,`QOPlanner`会将这些`#Import`包/架构名称添加到`schemapath`的末尾。
以下是调用此查询优化计划列表实用程序的示例。该实用程序将`ExportSQL^%qarDDLExport()`实用程序生成的文件作为输入,如“缓存查询”一章的“将缓存查询列出到文件”一节中所述。可以生成此查询列表文件,也可以将一个(或多个)查询写入文本文件。
```java
DO QOPlanner^%apiSQL("C:\temp\test\qcache.txt","C:\temp\test\qoplans.txt","GO")
```
从终端命令行执行时,进度会显示在终端屏幕上,如下例所示:
```java
Importing SQL Statements from file: C:\temp\test\qcache.txt
Recording any errors to principal device and log file: C:\temp\test\qoplans.txt
SQL statement to process (number 1):
SELECT TOP ? P . Name , E . Name FROM Sample . Person AS P ,
Sample . Employee AS E ORDER BY E . Name
Generating query plan...Done
SQL statement to process (number 2):
SELECT TOP ? P . Name , E . Name FROM %INORDER Sample . Person AS P
NATURAL LEFT OUTER JOIN Sample . Employee AS E ORDER BY E . Name
Generating query plan...Done
Elapsed time: .16532 seconds
```
创建的查询优化计划文件包含如下条目:
```java
SELECT TOP ? P . Name , E . Name FROM Sample . Person AS P , Sample . Employee AS E ORDER BY E . Name
Read index map Sample.Employee.NameIDX.
Read index map Sample.Person.NameIDX.
######
SELECT TOP ? P . Name , E . Name FROM %INORDER Sample . Person AS P
NATURAL LEFT OUTER JOIN Sample . Employee AS E ORDER BY E . Name
Read master map Sample.Person.IDKEY.
Read extent bitmap Sample.Employee.$Employee.
Read master map Sample.Employee.IDKEY.
Update the temp-file.
Read the temp-file.
Read master map Sample.Employee.IDKEY.
Update the temp-file.
Read the temp-file.
######
```
可以使用查询优化计划文本文件来比较使用不同查询变体生成的优化计划,或者比较不同版本的InterSystems IRIS之间的优化计划。
将SQL查询导出到文本文件时,来自类方法或类查询的查询将以代码行开头:
```java
#import
```
这个`#Import`语句告诉`QOPlanner`实用程序使用哪个默认包/模式来生成查询计划。从例程导出SQL查询时,例程代码中SQL语句之前的任何`#import`行也将位于导出文件中的SQL文本之前。假设从缓存查询导出到文本文件的查询包含完全限定的表引用;如果文本文件中的表引用不是完全限定的,则`QOPlanner`实用程序使用在运行`QOPlanner`时在系统上定义的系统范围的默认模式。
问题
water huang · 四月 24, 2021
最近尝试使用 Set Ciphertext=##class(%SYSTEM.Encryption).RSAEncrypt(Plaintext,PublicKeyStr)来加密数据,但是加密失败,参考了以下资料https://community.intersystems.com/post/format-public-key-when-using-rsaencrypt-method-systemencryption-or-systemencryptionrsaencrypt
https://blog.ndpar.com/2017/04/17/p1-p8/
生成的公钥为
-----BEGIN PUBLIC KEY-----MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCvl8YRMOJMUOyK5NzWo+8FD8dGR3DuPwn7M13If+rwYp18TEL58NneFdCL+Jjytx4axq+uhPuup5HtmEm22+PQTzFlXuAhXf3oUm4LQl4zgSb14D6gfqac9DqbVhm+aUjDfItFapM35/DH2cvc+rbBhu4Q5Y6kJwcUK0UbRv3swQIDAQAB-----END PUBLIC KEY-----
转换为pkcs1后的内容为
-----BEGIN RSA PUBLIC KEY-----MIGJAoGBANHPwS9+rVB1TJZM1UGLCBan3CY8TIDPkDAftkI504l68vdUWdPlmcN1YZzCGDK4+LvtzdqLXb/XSA3SxsUrA5toWSh45K7/jDzXRcb0AYiUTWGfpeMrHdcGNL07gVT11FM8M+0Jc5Sw6dvMKVXE9wzAxwgaJo0d8zW8Crbx6iI3AgMBAAE=-----END RSA PUBLIC KEY-----
文件保存为utf-8和ansi格式都不行。错误信息为
error:0906D06C:PEM routines:PEM_read_bio:no start line; 2016之后的版本,RSAEncrypt可以接收X.509证书或RSA公钥,而2016中RSAEncrypt接收证书参数。Ensemble2016上使用RSAEncrypt,如果拿不到证书,仅用公钥,请联系InterSystems 销售工程师。 好的,谢谢
公告
Louis Lu · 四月 23, 2021
InterSystems IRIS、IRIS for Health和HealthShare Health Connect的2021.1版本的预览版现已发布。
由于这是一个预览版,我们希望在下个月的通用版本发布之前了解您对这个新版本的体验。请通过开发者社区分享您的反馈,以便我们能够共同打造一个更好的产品。
InterSystems IRIS数据平台2021.1是一个扩展维护(EM)版本。自2020.1(上一个EM版本)以来,在持续交付(CD)版本中增加了许多重要的新功能和改进。请参考2020.2、2020.3和2020.4的发布说明,了解这些内容的概况。
这个版本的增强功能为开发人员提供了更大的自由度,可以用他们选择的语言构建快速和强大的应用程序,并使用户能够通过新的和更快的分析功能更有效地处理大量的信息。
通过InterSystems IRIS 2021.1,客户可以部署InterSystems IRIS Adaptive Analytics,这是一个附加产品,它扩展了InterSystems IRIS,为分析终端用户提供了更强大的易用性、灵活性、可扩展性以及效率,而不管他们选择何种商业智能(BI)工具。它能够定义一个利于分析的业务模型,并通过在后台自主构建和维护临时数据结构,透明地加速针对该模型运行分析查询时的工作负载。
这个版本中的其他重点新功能包括
一套综合的外部语言网关,改进了可管理性,现在包括R和Python,可以用您选择的语言构建强大和可扩展的服务器端代码InterSystems Kubernetes Operator(IKO)为您的环境提供声明式配置和自动化,现在还支持部署InterSystems System Alerting & Monitoring(SAM)。InterSystems API Manager v1.5,包括改进的用户体验和对Kafka的支持IntegratedML的主流版本,使SQL开发人员能够在纯粹的SQL环境中直接构建和部署机器学习模型
InterSystems IRIS for Health 2021.1包括InterSystems IRIS的所有增强功能。此外,该版本通过针对FHIR数据解析和评估FHIRPath表达式的API,进一步扩展了该平台对FHIR®标准的广泛支持。这是对2020.1以来发布的重要的FHIR相关功能的补充,包括对FHIR Profiles、FHIR R4 Transforms和FHIR客户端API的支持。
关于所有这些功能的更多细节可以在产品文档中找到。
InterSystems IRIS 2021.1文档和发布说明InterSystems IRIS for Health 2021.1文档和发布说明HealthShare Health Connect 2021.1 文档和发布说明
EM版本包括所有支持平台的传统安装包,以及OCI(Open Container Initiative)又称Docker容器格式的容器镜像。 完整的清单,请参考支持平台文档。
安装包和预览密钥可以从WRC的预览下载网站获得。
InterSystems IRIS和IRIS for Health的企业版的容器镜像以及所有相应的组件都可以从InterSystems容器注册处使用以下命令获得。
docker pull containers.intersystems.com/intersystems/iris:2021.1.0.205.0
docker pull containers.intersystems.com/intersystems/irishealth:2021.1.0.205.0
关于可用镜像的完整列表,请参考ICR文档。
社区版的容器镜像也可以使用以下命令从Docker商店拉取。
docker pull store/intersystems/iris-community:2021.1.0.205.0
docker pull store/intersystems/iris-community-arm64:2021.1.0.205.0
docker pull store/intersystems/irishealth-community:2021.1.0.205.0
docker pull store/intersystems/irishealth-community-arm64:2021.1.0.205.0
另外,所有容器镜像的tarball版本都可以通过WRC的预览下载网站获得。
InterSystems IRIS Studio 2021.1是一个独立的IDE,用于Microsoft Windows,可以通过WRC的预览下载网站下载。它与InterSystems IRIS和IRIS for Health 2021.1及以下版本一起使用。InterSystems还支持 VSCode-ObjectScript 插件,用于将 Visual Studio Code 做为 InterSystems IRIS 开发IDE,该插件可用于Microsoft Windows、Linux和MacOS。
其他独立的InterSystems IRIS 2021.1组件,如ODBC驱动程序和Web网关,可从同一页面获得。
该预览版的构建号是 2021.1.0.205.0。
通过www.DeepL.com/Translator(免费版)翻译
文章
姚 鑫 · 四月 23, 2021
# 第五章 优化查询性能(二)
# 使用索引
**索引通过维护常见请求数据的排序子集,提供了一种优化查询的机制。
确定哪些字段应该被索引需要一些思考:太少或错误的索引和关键查询将运行太慢;
太多的索引会降低插入和更新性能(因为必须设置或更新索引值)。**
## 什么索引
要确定添加索引是否会提高查询性能,请从管理门户SQL接口运行查询,并在性能中注意全局引用的数量。
添加索引,然后重新运行查询,注意全局引用的数量。
一个有用的索引应该减少全局引用的数量。
可以通过在`WHERE`子句或`ON`子句条件前使用`%NOINDEX`关键字来防止使用索引。
应该为联接中指定的字段(属性)编制索引。左外部联接从左表开始,然后查看右表;因此,应该为右表中的字段建立索引。在下面的示例中,应该为`T2.f2`编制索引:
```sql
FROM Table1 AS T1 LEFT OUTER JOIN Table2 AS T2 ON T1.f1 = T2.f2
```
内部联接应该在两个`ON`子句字段上都有索引。
执行“显示计划”,然后找到第一张map。
如果查询计划中的第一个项目是`“Read master map”`,或者查询计划调用的模块的第一个项目是`“Read master map”`,则查询的第一个映射是主映射,而不是索引映射。
因为主映射读取数据本身,而不是数据索引,这总是表明查询计划效率低下。
除非表相对较小,否则应该创建一个索引,以便在重新运行该查询时,查询计划的第一个映射表示“读取索引映射”。
应该索引在`WHERE`子句`equal`条件中指定的字段。
可能希望索引在`WHERE`子句范围条件中指定的字段,以及`GROUP BY`和`ORDER BY`子句中指定的字段。
在某些情况下,基于范围条件的索引可能会使查询变慢。如果绝大多数行满足指定的范围条件,则可能会发生这种情况。例如,如果将`QUERY`子句`WHERE Date < CURRENT_DATE` 用于大多数记录来自以前日期的数据库,则在`DATE`上编制索引实际上可能会降低查询速度。这是因为查询优化器假定范围条件将返回相对较少的行数,并针对此情况进行优化。可以通过在范围条件前面加上`%noindex`来确定是否发生这种情况,然后再次运行查询。
如果使用索引字段执行比较,则比较中指定的字段的排序规则类型应与其在相应索引中的排序规则类型相同。例如,`SELECT`的`WHERE`子句或联接的`ON`子句中的`Name`字段应该与为`Name`字段定义的索引具有相同的排序规则。如果字段排序规则和索引排序规则之间存在不匹配,则索引可能效率较低或可能根本不使用。
## 索引配置选项
以下系统范围的配置方法可用于优化查询中索引的使用:
- 要将主键用作`IDKey`索引,请设置`$SYSTEM.SQL.Util.SetOption()`方法,如下所示 `SET status=$SYSTEM.SQL.Util.SetOption("DDLPKeyNotIDKey",0,.oldval)`. 默认为`1`
- 要将索引用于`SELECT DISTINCT`查询,请设置`$SYSTEM.SQL.Util.SetOption()`方法,如下所示: `SET status=$SYSTEM.SQL.Util.SetOption("FastDistinct",1,.oldval)`. 默认为`1`
## 索引使用情况分析
可以使用以下任一方法按SQL缓存查询分析索引使用情况:
- 管理门户索引分析器SQL性能工具。
- `%SYS.PTools.UtilSQLAnalysis`方法`indexUsage()`、`tableScans()`、`tempIndices()`、`joinIndices()`和`outlierIndices()`。、
## 索引分析
可以使用以下任一方法从管理门户分析SQL查询的索引使用情况:
- 选择系统资源管理器,选择工具,选择SQL性能工具,然后选择索引分析器。
- 选择系统资源管理器,选择SQL,然后从工具下拉菜单中选择索引分析器。
索引分析器提供当前命名空间的SQL语句计数显示和五个索引分析报告选项。
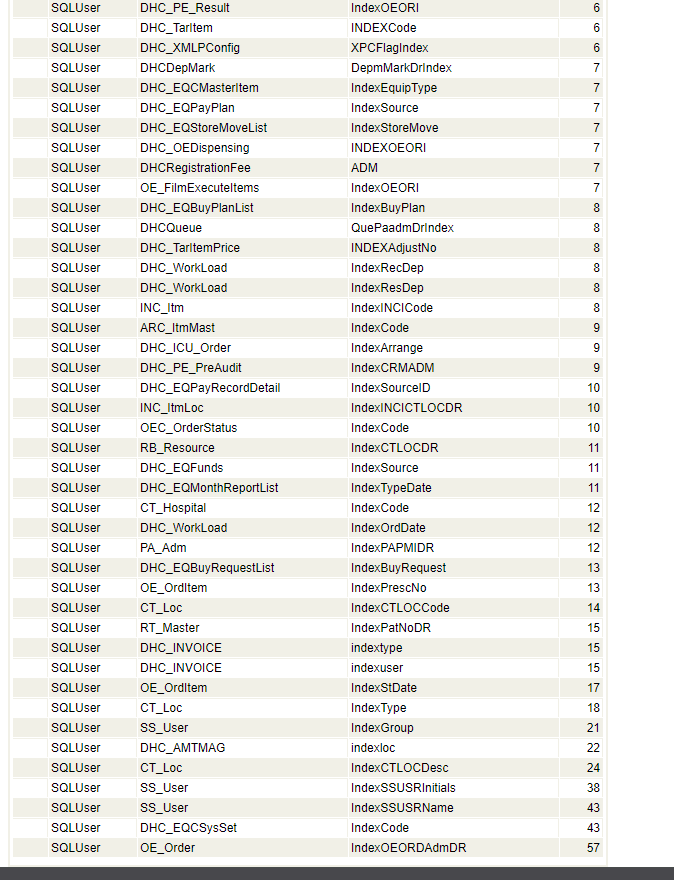
### SQL语句计数
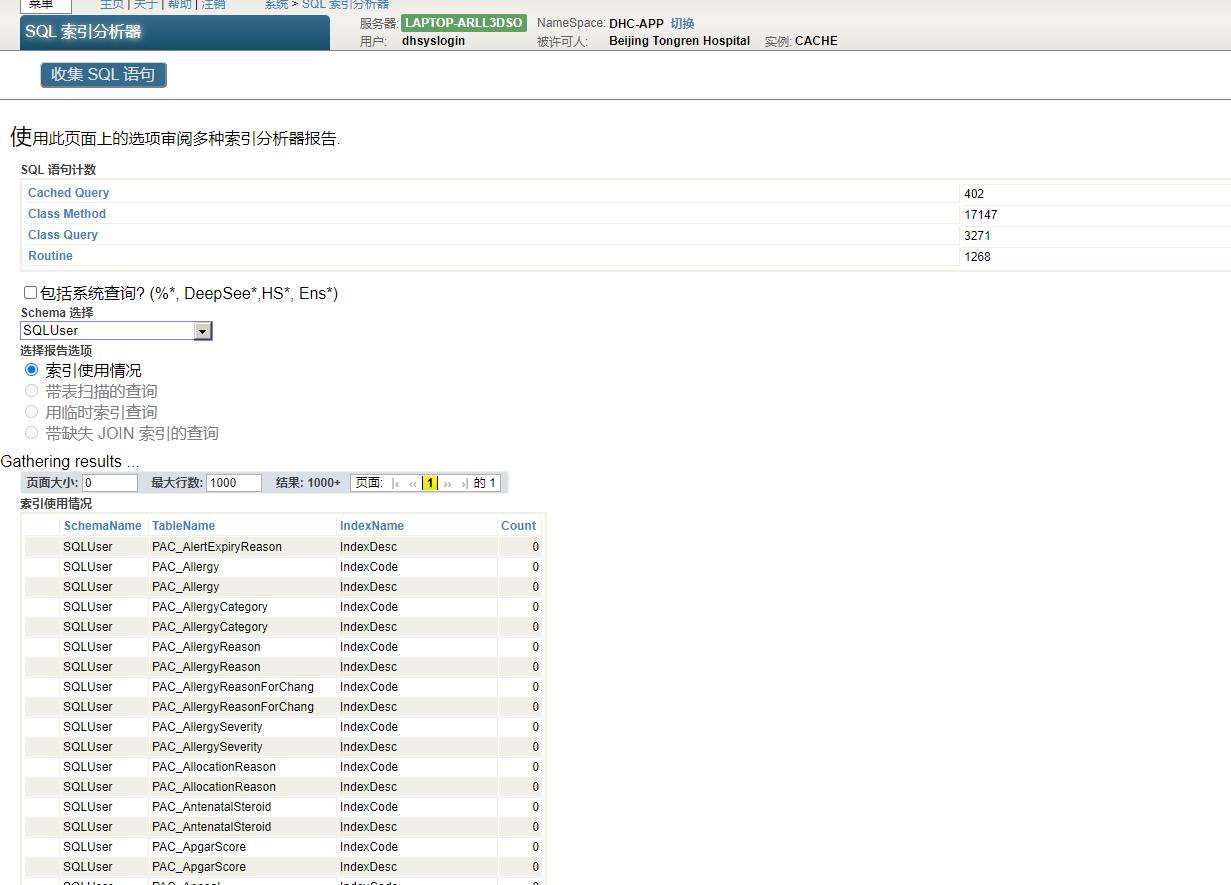
在SQL索引分析器的顶部有一个对命名空间中的所有SQL语句进行计数的选项。按收集SQL语句按钮。SQL索引分析器显示“正在收集SQL语句...”当计票进行时,然后“完成!”当清点完毕后。SQL语句分为三类进行计数:缓存查询计数、类方法计数和类查询计数。这些计数针对整个当前命名空间,不受架构选择选项的影响。
对应的方法是`%SYS.PTools.UtilSQLAnalysis`类中的`getSQLStmts()`。
可以使用清除语句按钮删除当前命名空间中收集的所有语句。该按钮调用`clearSQLStatements()`方法。
### 报告选项
可以检查当前命名空间中选定架构的缓存查询报告,也可以(通过不选择架构)检查当前命名空间中所有缓存查询的报告。可以在此分析中跳过或包括系统类查询、`INSERT`语句和/或`IDKEY`索引。“架构选择”和“跳过选项”复选框是用户自定义的。
指数分析报告选项包括:
- 索引使用:此选项获取当前名称空间中的所有缓存查询,为每个查询生成显示计划,并记录每个查询使用每个索引的次数以及名称空间中所有查询对每个索引的总使用量。这可用于显示未使用的索引,以便可以删除或修改这些索引以使其更有用。结果集从最少使用的索引到最常使用的索引排序。
对应的方法是`%SYS.PTools.UtilSQLAnalysis`类中的`indexUsage()`。要导出此方法生成的分析数据,请使用`exportIUAnalysis()`方法。
- 使用表扫描的查询:此选项标识当前名称空间中执行表扫描的所有查询。如果可能,应避免表扫描。表扫描并不总是可以避免的,但是如果一个表有大量的表扫描,那么应该检查为该表定义的索引。通常,表扫描列表和临时索引列表会重叠;修复其中一个会删除另一个。结果集按从最大块计数到最小块计数的顺序列出表格。提供了显示计划链接以显示对帐单文本和查询计划。
对应的方法是`%SYS.PTools.UtilSQLAnalysis`类中的`tableScans()`。要导出此方法生成的分析数据,请使用`exportTSAnalysis()`方法。
- 带临时索引的查询:此选项标识当前名称空间中构建临时索引以解析SQL的所有查询。有时,使用临时索引会有所帮助并提高性能,例如,基于范围条件构建一个小索引,然后InterSystems IRIS可以使用该索引按顺序读取主映射。有时,临时索引只是不同索引的子集,可能非常有效。其他情况下,临时索引会降低性能,例如,扫描`master may`以在具有条件的特性上构建临时索引。这种情况表明缺少所需的索引;应该向与临时索引匹配的类添加索引。结果集按从最大块计数到最小块计数的顺序列出表格。提供了显示计划链接以显示对帐单文本和查询计划。
对应的方法是`%SYS.PTools.UtilSQLAnalysis`类中的`tempIndices()`。要导出此方法生成的分析数据,请使用`exportTIAnalysis()`方法。
- 缺少联接索引的查询:此选项检查当前名称空间中具有联接的所有查询,并确定是否定义了支持该联接的索引。它将可用于支持联接的索引从0(不存在索引)排序到4(索引完全支持联接)。外部联接需要一个单向索引。内联接需要双向索引。默认情况下,结果集只包含`JoinIndexFlag 21 AND %NOINDEX E.Age < 65
```
文章
姚 鑫 · 四月 22, 2021
# 第五章 优化查询性能(一)
InterSystems SQL自动使用查询优化器创建在大多数情况下提供最佳查询性能的查询计划。该优化器在许多方面提高了查询性能,包括确定要使用哪些索引、确定多个`AND`条件的求值顺序、在执行多个联接时确定表的顺序,以及许多其他优化操作。可以在查询的`FROM`子句中向此优化器提供“提示”。本章介绍可用于评估查询计划和修改InterSystems SQL将如何优化特定查询的工具。
InterSystems IRIS®Data Platform支持以下优化SQL查询的工具:
- `SQL Runtime Statistics`用于生成查询执行的运行时性能统计信息
- 索引分析器,用于显示当前命名空间中所有查询的各种索引分析器报告。这显示了InterSystems SQL将如何执行查询,可以全面了解索引是如何使用的。此索引分析可能表明应该添加一个或多个索引以提高性能。
- 查询执行计划:显示SQL查询(查询计划)的最佳(默认)执行计划,并可选地显示该SQL查询的备用查询计划以及统计信息。用于显示查询计划的工具包括SQL `EXPLAIN`命令、`$SYSTEM.SQL.ExPlan()`方法以及管理门户和SQL Shell中的各种`Show Plan`工具。查询计划和统计数据是在准备查询时生成的,不需要执行查询。
可以使用以下选项来指导查询优化器,方法是设置配置默认值或在查询代码中编码优化器“提示”:
- 管理所有条件的子句选项中提供的索引优化选项,或单个条件前面的`%NOINDEX`。
- SQL代码中指定的注释选项,使优化器覆盖该查询的系统范围编译选项。
- 在每个查询或系统范围的基础上可用的并行查询处理允许多处理器系统在处理器之间划分查询执行。
以下SQL查询性能工具将在本手册的其他章节中介绍:
- 缓存查询,使动态SQL查询能够重新运行,而无需在每次执行查询时准备查询的开销。
- SQL语句来保留最新编译的嵌入式SQL查询。在“SQL语句和冻结计划”一章中。
- 冻结计划以保留嵌入式SQL查询的特定编译。使用此编译,而不是使用较新的编译。在“SQL语句和冻结计划”一章中。
以下工具用于优化表数据,因此可以对针对该表运行的所有查询产生重大影响:
- 定义索引可以显著提高对特定索引字段中数据的访问速度。
- `ExtentSize`、`Selective`和`BlockCount`用于在用数据填充表之前指定表数据估计;此元数据用于优化未来的查询。
- `Tune Table`用于分析已填充的表中的代表性表数据;生成的元数据用于优化未来的查询。
本章还介绍如何将查询优化计划写入文件,以及如何生成SQL故障排除报告以提交给InterSystems WRC。
# 管理门户SQL性能工具
IRIS管理门户提供对以下SQL性能工具的访问。有两种方式可以从管理门户系统资源管理器选项访问这些工具:
- 选择工具,然后选择SQL性能工具。
- 选择SQL,然后选择工具下拉菜单。
从任一界面中您都可以选择以下SQL性能工具之一:
- SQL运行时统计信息,以生成查询执行的性能统计信息。
- 索引分析器,用于显示当前命名空间中所有查询的各种索引分析器报告。这显示了InterSystems SQL将如何执行查询,可以全面了解索引是如何使用的。此索引分析可能表明应该添加一个或多个索引以提高性能。
- 备用显示计划:显示SQL查询的可用备用查询计划以及统计信息。
- 生成报告以向InterSystems Worldwide Response Center(WRC)客户支持部门提交SQL查询性能报告。要使用此报告工具,必须首先从WRC获得WRC跟踪号。
- 导入报告允许查看SQL查询性能报告。
# SQL运行时统计信息
可以使用SQL运行时统计信息来衡量系统上运行的SQL查询的性能。SQL运行时统计信息衡量`SELECT`、`INSERT`、`UPDATE`和`DELETE`操作(统称为查询操作)的性能。SQL运行时统计信息(SQL Stat)是在准备查询操作时收集的。请参阅使用SQL运行时统计信息工具。
默认情况下,SQL运行时统计信息的收集处于关闭状态。必须激活统计信息收集。强烈建议指定超时以结束统计信息收集。激活统计信息收集后,必须重新编译(准备)现有的动态SQL查询,并重新编译包含嵌入式SQL的类和例程。
性能统计信息包括`ModuleName`、`ModuleCount`(模块被调用的次数)、`RowCount`(返回的行数)、`TimeSpent`(执行性能,单位为秒)、`GlobalRefs`(全局引用数)、`LinesOfCode`(执行的行数)和`ReadLatency`(磁盘读取访问时间,单位为毫秒)。
可以显式清除SQL Stats数据。清除缓存查询会删除所有相关的SQL统计数据。删除表或视图会删除所有相关的SQL Stats数据。
注意:系统任务在所有名称空间中每小时自动运行一次,以将特定于进程的SQL查询统计信息聚合到全局统计信息中。因此,全局统计信息可能不会反映一小时内收集的统计信息。可以使用管理门户监视此每小时一次的聚合或强制其立即发生。要查看此任务上次完成和下次调度的时间,请依次选择系统操作、任务管理器、任务调度,然后查看更新SQL查询统计信息任务。可以单击任务名称查看任务详细信息。在`Task Details`(任务详细信息)显示中,可以使用Run(运行)按钮强制立即执行任务。
# 使用SQL运行时统计信息工具
可以使用以下任一方法从管理门户显示系统范围内的SQL查询的性能统计信息:
- 选择系统资源管理器,选择工具,选择SQL性能工具,然后选择SQL运行时统计信息。
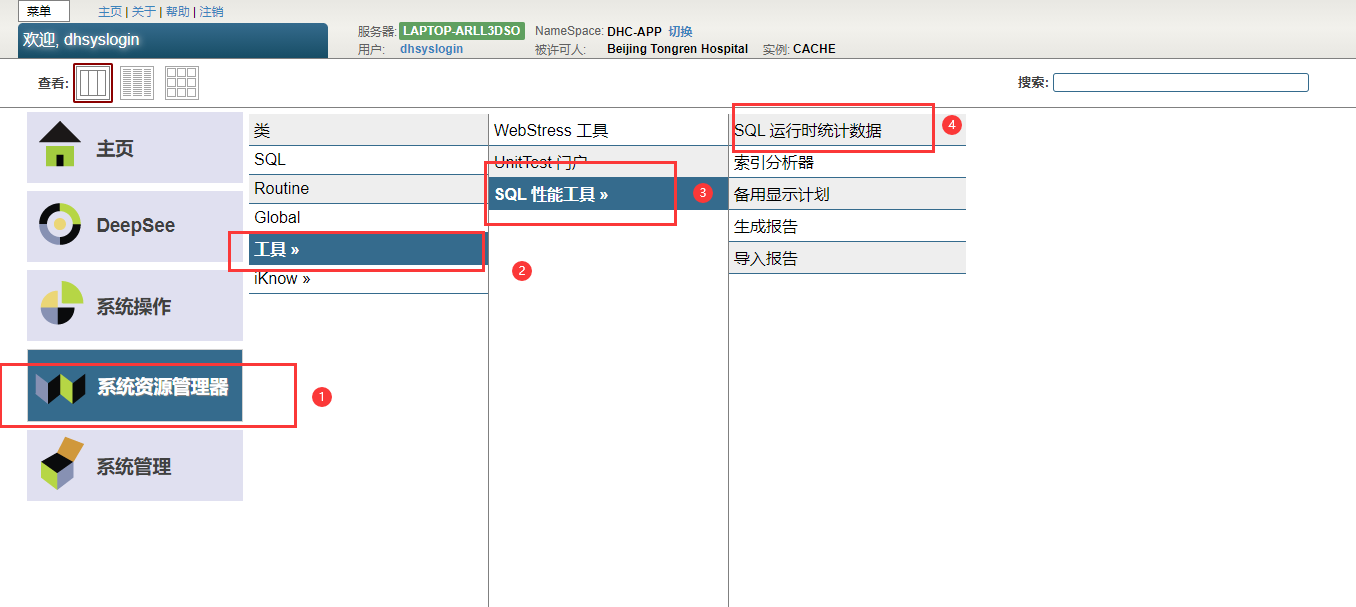
- 选择系统资源管理器,选择SQL,然后从工具下拉菜单中选择SQL运行时统计信息。
## Settings
“设置”选项卡显示当前系统范围的SQL运行时统计信息设置以及此设置的过期时间。
Change Settings(更改设置)按钮允许设置以下统计信息收集选项:
- 收集选项:可以将统计信息收集选项设置为0、1、2或3.0。0=关闭统计信息代码生成;1=为所有查询打开统计信息代码生成,但不收集统计信息;2=仅记录查询外部循环的统计信息(在主模块打开和关闭时收集统计信息);3=记录查询的所有模块级别的统计信息。
- 从0到1:更改SQL Stats选项后,需要编译包含SQL的例程和类以执行统计代码生成。对于xDBC和动态SQL,必须清除缓存查询以强制重新生成代码。
- 要从1变为2:只需更改SQL Stats选项即可开始收集统计信息。这使可以在运行的生产环境中启用SQL性能分析,并将中断降至最低。
- 从1到3(或从2到3):更改SQL Stats选项后,需要编译包含SQL的例程和类,以记录所有模块级别的统计信息。对于xDBC和动态SQL,必须清除缓存查询以强制重新生成代码。选项3通常仅用于非生产环境中已识别的性能较差的查询。
- 从1、2或3变为0:要关闭统计代码生成,不需要清除缓存的查询。
- 超时选项:如果收集选项为2或3,可以按已用时间(小时或分钟)或按完成日期和时间指定超时。可以用分钟或小时和分钟指定运行时间;该工具将指定的分钟值转换为小时和分钟(100分钟=1小时40分钟)。默认值为50分钟。日期和时间选项默认为当天午夜(23:59)之前。强烈建议指定超时选项。
- 重置选项:如果收集选项为2或3,则可以指定超时值到期时要重置为的收集选项。可用选项为0和1。
## 查询测试
查询测试选项卡允许输入SQL查询文本(或从历史记录中检索),然后显示该查询的SQL统计信息和查询计划。查询测试包括查询的所有模块级别的SQL统计信息,而与收集选项设置无关。
输入一个SQL查询文本,或使用`Show History`按钮检索一个。
可以通过单击右边的圆形“X”圆来清除查询文本字段。
使用`Show Plan With SQL Stats`按钮执行。
默认情况下,后台复选框中的“运行`Show Plan`进程”未被选中,这是大多数查询的首选设置。
仅对长时间、运行缓慢的查询选择此复选框。
当这个复选框被选中时,你会看到一个进度条显示“请等待…”的消息。
当运行一个长查询时,带有SQL Stats和`Show History`按钮的`Show Plan`消失,而显示一个`View Process`按钮。
单击`View Process`将在新选项卡中打开流程详细信息页面。
在流程详细信息页面中,可以查看该流程,并可以暂停、恢复或终止该流程。
流程的状态应该反映在显示计划页面上。
当流程完成后,显示计划会显示结果。
`View Process`按钮消失,带有SQL Stats的`Show Plan`和`Show History`按钮重新出现。
使用查询测试显示的语句文本包括注释,不执行文字替换。
## 查看统计信息
`View Stats`(查看统计信息)选项卡为提供了在此系统上收集的运行时统计信息的总体视图。
可以单击任何一个`View Stats`列标题对查询统计信息进行排序。然后,可以单击SQL语句文本以查看所选查询的详细查询统计信息和查询计划。
使用此工具显示的语句文本包括注释,不执行文字替换。`ExportStatsSQL()`和`Show Plan`显示的语句文本会去掉注释并执行文字替换。
### 清除统计信息按钮
清除统计信息按钮清除当前名称空间中所有查询的所有累积统计信息。它会在SQL运行时统计信息页上显示一条消息。如果成功,则会显示一条消息,指示已清除的统计信息数量。如果没有统计信息,则会显示无要清除的消息。如果清除不成功,则会显示一条错误消息。
## 运行时统计信息和显示计划
SQL运行时统计信息工具可用于显示包含运行时统计信息的查询的显示计划。
可以使用`Alternate Show Plans`工具将显示计划与统计数据进行比较,从而显示查询的运行时统计信息。备用显示计划工具在其显示计划选项中显示查询的估计统计信息。如果激活了收集运行时统计信息,则其`Compare Show Plans with Stats`选项将显示实际的运行时统计信息;如果运行时统计信息未处于活动状态,则此选项将显示估计统计信息。
问题
water huang · 四月 22, 2021
m 里面如何获取cpu的序列号? 可以调用操作系统的命令来获取CPU序列号。例如在Cache' for Windows上,可以执行:SAMPLES>s args=3SAMPLES>s args(1)="CPU"SAMPLES>s args(2)="get"SAMPLES>s args(3)="ProcessorID"SAMPLES>d $ZF(-100,"","wmic",.args)ProcessorId0FABFBFF000506EX0FABFBFF000006EX0FABFBFF000006EX0FABFBFF000006EX 乔工,请问 $zf函数的使用,在哪里可以查询到它的所有使用说明 InterSystems Cache'InterSystems IRIS 刚才试了一下,这个不行呢 感谢你的回答 但是我用的是ensemble2016 是Windows吗?在Windows命令行,执行wmic CPU get ProcessorID,能得到CPU序列号吗? Ensemble 2016有点久,没有$ZF(-100)。用$ZF(-1):
https://cedocs.intersystems.com/ens20161/csp/docbook/DocBook.UI.Page.cls?KEY=RCOS_fzf-1#RCOS_B80417 是Windows,在Windows命令行,执行wmic CPU get ProcessorID,能得到CPU序列号 刚才试了 还是不行 用$ZF(-1), 可以将OS命令输出保存到文件里。例如:w $ZF(-1,"wmic CPU get ProcessorID > c:\temp\cpuinfo.txt") 系统是windows 10 试了,不行,返回的值是1 返回值是1,说明报错了。确认一下是否OS命令写正确了。另外,输出不是看返回值,是看输出的文件 我直接复制的你写的这个命令。