清除过滤器
文章
Claire Zheng · 四月 21, 2021
近日,InterSystems极客俱乐部举办了线上直播“InterSystems Caché系统运维培训”,这是系列视频之一。InterSystems中国资深售前顾问吕正之讲解了“InterSystems Caché架构、备份与恢复”。
文章
Claire Zheng · 四月 21, 2021
近日,InterSystems极客俱乐部举办了线上直播“InterSystems Caché系统运维培训”,这是系列视频之一。InterSystems中国资深售前顾问马浩讲解了“InterSystems Caché系统监控和性能数据采集”。
文章
Claire Zheng · 四月 21, 2021
近日,InterSystems极客俱乐部举办了线上直播“InterSystems Caché系统运维培训”,这是系列视频之一。InterSystems中国资深售前顾问祝麟讲解了“InterSystems Caché系统安全”。
文章
Claire Zheng · 四月 21, 2021
在医院信息化建设中,如何打通医院的各个系统,给患者提供连续、无缝的良好体验,集成平台发挥着重要作用。而集成平台方案如何适应现在的多云时代、需要具备什么样的特性、如何与多云环境更好地结合以便为医院的信息化建设带来更多的便利?面对这一系列问题,InterSystems中国业务拓展经理李岩为您解读InterSystems集成平台方案的特点和优势,以及构建在VMware云方案上的最佳实践,让您了解云环境下集成平台方案的新特性和优势。
文章
姚 鑫 · 四月 20, 2021
# 第四章 缓存查询(一)
系统自动维护已准备好的SQL语句(“查询”)的缓存。这允许重新执行SQL查询,而无需重复优化查询和开发查询计划的开销。缓存查询是在准备某些SQL语句时创建的。准备查询发生在运行时,而不是在编译包含SQL查询代码的例程时。通常,`PREPARE`紧跟在SQL语句的第一次执行之后,但在动态SQL中,可以准备查询而不执行它。后续执行会忽略`PREPARE`语句,转而访问缓存的查询。要强制对现有查询进行新的准备,必须清除缓存的查询。
所有SQL调用都会创建缓存查询,无论是在ObjectScript例程中调用还是在类方法中调用。
- 动态SQL、ODBC、JDBC和`$SYSTEM.SQL.DDLImport()`方法在准备查询时创建缓存查询。管理门户执行SQL接口、InterSystems SQL Shell和`%SYSTEM.SQL.Execute()`方法使用动态SQL,因此使用准备操作来创建缓存查询。
它们列在命名空间(或指定方案)的Management Portal常规缓存查询列表、每个正在访问的表的Management Portal Catalog Details缓存查询列表以及SQL语句列表中。动态SQL遵循本章中介绍的缓存查询命名约定。
- 类查询在准备(`%PrepareClassQuery()`方法)或第一次执行(调用)时创建缓存查询。
它们列在命名空间的管理门户常规缓存查询列表中。如果类查询是在持久类中定义的,则缓存的查询也会列在该类的Catalog Details缓存查询中。它没有列在正在访问的表的目录详细信息中。它没有列在SQL语句清单中。类查询遵循本章中介绍的缓存查询命名约定。
- 嵌入式SQL在第一次执行SQL代码或通过调用声明游标的`OPEN`命令启动代码执行时创建缓存查询。嵌入式SQL缓存查询列在管理门户缓存查询列表中,查询类型为嵌入式缓存SQL,SQL语句列表。嵌入式SQL缓存查询遵循不同的缓存查询命名约定。
所有清除缓存查询操作都会删除所有类型的缓存查询。
生成缓存查询的SQL查询语句包括:
- `SELECT`:`SELECT`缓存查询显示在其表的目录详细资料中。如果查询引用了多个表,则会为每个被引用的表列出相同的缓存查询。从这些表中的任何一个清除缓存的查询都会将其从所有表中清除。从表的目录详细资料中,可以选择缓存的查询名称以显示高速缓存的查询详细资料,包括执行和显示计划选项。由`$SYSTEM.SQL.Schema.ImportDDL(“IRIS”)`方法创建的选择缓存查询不提供`Execute`和`Show Plan`选项。
`SELECT`的`DECLARE NAME CURSOR`创建缓存查询。但是,缓存的查询详细信息不包括执行和显示计划选项。
- `CALL`:为其架构创建缓存查询列表中显示的缓存查询。
- `INSERT`、`UPDATE`、`INSERT`或`UPDATE`、`DELETE`:创建其表的`Catalog Details`中显示的缓存查询。
- `TRUNCATE TABLE`:为其表创建一个缓存查询,该查询显示在目录详细信息中。
注意,`$SYSTEM.SQL.Schema.ImportDDL("IRIS")`不支持截断表。
- `SET TRANSACTION`, `START TRANSACTION`, `%INTRANSACTION, COMMIT`, `ROLLBACK`:为命名空间中的每个模式创建一个缓存查询,显示在缓存查询列表中。
**当准备查询时,将创建一个缓存的查询。
因此,不要将`%Prepare()`方法放入循环结构中是很重要的。
同一个查询的后续`%Prepare()`(仅在指定的文字值上有所不同)使用现有的缓存查询,而不是创建新的缓存查询。**
更改表的`SetMapSelectability()`值将使所有引用该表的现有缓存查询失效。
现有查询的后续准备将创建一个新的缓存查询,并从清单中删除旧的缓存查询。
清除缓存查询时,缓存查询将被删除。修改表定义会自动清除引用该表的所有查询。在更新查询缓存元数据时,发出准备或清除命令会自动请求独占的系统范围锁。系统管理员可以修改缓存查询锁定的超时值。
创建缓存的查询不是事务的一部分。缓存查询的创建不会被记录下来。
# 缓存查询提高了性能
第一次准备查询时,SQL引擎会对其进行优化,并生成将执行该查询的程序(一个或多个InterSystems IRIS®Data Platform例程的集合)。然后将优化的查询文本存储为缓存查询类。如果随后尝试执行相同(或类似)的查询,SQL引擎将找到缓存的查询并直接执行该查询的代码,从而绕过优化和代码生成的需要。
缓存查询提供以下好处:
- 频繁使用的查询的后续执行速度更快。更重要的是,无需编写繁琐的存储过程即可自动获得这种性能提升。大多数关系数据库产品建议仅使用存储过程访问数据库。对于IRIS,这不是必需的。
- 单个缓存的查询用于类似的查询,这些查询只是在字面值上有所不同。例如,`SELECT TOP 5 Name FROM Sample.Person WHERE Name %STARTSWITH 'A' and SELECT TOP 1000 Name FROM Sample.Person WHERE Name %STARTSWITH 'Mc'`,只是`top`和`%startswith`条件的文本值不同。为第一查询准备的缓存查询自动用于第二查询。
- 查询缓存在所有数据库用户之间共享;如果用户1准备查询,则用户1023可以利用它。
- 查询优化器可以自由地使用更多的时间为给定的查询找到最佳解决方案,因为这个代价只需要在第一次准备查询时支付。
InterSystems SQL将所有缓存的查询存储在一个位置,即`IRISLOCALDATA`数据库。但是,缓存查询是特定于名称空间的。每个缓存的查询都由准备(生成)它的名称空间标识。只能从准备缓存查询的命名空间中查看或执行缓存查询。可以清除当前命名空间或所有命名空间的缓存查询。
缓存查询不包括注释。但是,它可以在查询文本后面包含注释选项,例如`/*#OPTIONS {"optionName":value} */`。
因为缓存查询使用现有的查询计划,所以它为现有查询提供了操作的连续性。对基础表的更改(如添加索引或重新定义表优化统计信息)不会对现有缓存查询产生任何影响。
# 创建缓存查询
当InterSystems IRIS准备查询时,它会确定:
- 如果查询与查询缓存中已有的查询匹配。如果不是,则向查询分配递增计数。
- 如果查询准备成功。如果不是,则不会将递增计数分配给缓存的查询名称。
- 否则,递增计数被分配给缓存的查询名称,并且该查询被缓存。
## 动态SQL的缓存查询名称
SQL引擎为每个缓存查询分配唯一的类名,格式如下:
```java
%sqlcq.namespace.clsnnn
```
其中,`NAMESPACE`为当前名称空间(大写),`NNN`为连续整数。例如,`%sqlcq.USER.cls16`。
缓存的查询以每个命名空间为基础按顺序编号,从1开始。下一个可用的`nnn`序列号取决于已保留或释放的编号:
- 如果查询与现有缓存查询不匹配,则在开始准备查询时会保留一个数字。如果查询与现有的缓存查询仅在文字值上不同,则查询与现有的缓存查询匹配-这取决于某些其他注意事项:隐藏的文本替换、不同的注释选项或“单独的缓存查询”中描述的情况。
- 如果查询准备不成功,则保留但不分配号码。只有准备成功的查询才会被缓存。
- 如果缓存查询准备成功,则会保留一个编号并将其分配给缓存查询。无论是否从该表访问任何数据,都会为查询中引用的每个表列出该缓存查询。如果查询未引用任何表,则会创建缓存查询,但不能按表列出或清除。
- 清除缓存查询时会释放一个数字。该号码将作为下一个`NNN`序列号可用。清除与表关联的单个缓存查询或清除表的所有缓存查询将释放分配给这些缓存查询的编号。清除命名空间中的所有缓存查询会释放分配给缓存查询的所有编号,包括未引用表的缓存查询,以及保留但未分配的编号。
清除缓存查询将重置`nnn`整数。整数会被重复使用,但剩余的缓存查询不会重新编号。例如,缓存查询的部分清除可能会留下`cls1、cls3、cls4和cls7`。后续缓存查询将编号为`cls2、cls5、cls6和cls8`。
一条CALL语句可能会导致多个缓存查询。例如,SQL语句`CALL Sample.PersonSets('A','MA')` 生成以下缓存查询:
```sql
%sqlcq.USER.cls1: CALL Sample . PersonSets ( ? , ? )
%sqlcq.USER.cls2: SELECT name , dob , spouse FROM sample . person
WHERE name %STARTSWITH ? ORDER BY 1
%sqlcq.USER.cls3: SELECT name , age , home_city , home_state
FROM sample . person WHERE home_state = ? ORDER BY 4 , 1
```
在动态SQL中,准备SQL查询(使用`%PrepareClassQuery()`或`%PrepareClassQuery()`实例方法)后,可以使用`%display()`实例方法或`%GetImplementationDetails()`实例方法返回缓存的查询名称。查看成功准备的结果。
缓存的查询名称也是由`%SQL.Statement`类的`%Execute()`实例方法(以及`%CurrentResult`属性)返回的结果集`OREF`的一个组件。以下示例显示了这两种确定缓存查询名称的方法:
```java
/// w ##class(PHA.TEST.SQL).CacheQuery()
ClassMethod CacheQuery(c)
{
SET randtop=$RANDOM(10)+1
SET randage=$RANDOM(40)+1
SET myquery = "SELECT TOP ? Name,Age FROM Sample.Person WHERE Age < ?"
SET tStatement = ##class(%SQL.Statement).%New()
SET qStatus = tStatement.%Prepare(myquery)
IF qStatus'=1 {
WRITE "%Prepare failed:"
DO $System.Status.DisplayError(qStatus)
QUIT
}
SET x = tStatement.%GetImplementationDetails(.class,.text,.args)
IF x=1 {
WRITE "cached query name is: ",class,!
}
SET rset = tStatement.%Execute(randtop,randage)
WRITE "result set OREF: ",rset.%CurrentResult,!
DO rset.%Display()
WRITE !,"A sample of ",randtop," rows, with age < ",randage
}
```
```java
DHC-APP>w ##class(PHA.TEST.SQL).CacheQuery()
cached query name is: %sqlcq.DHCdAPP.cls51
result set OREF: 5@%sqlcq.DHCdAPP.cls51
Name Age
姚鑫 7
姚鑫 7
O'Rielly,Chris H. 7
Orwell,John V. 4
Zevon,Heloisa O. 11
Smith,Kyra P. 7
6 Rows(s) Affected
A sample of 6 rows, with age < 19
```
在本例中,选定的行数(`TOP`子句)和`WHERE`子句谓词值会随着每次查询调用而改变,但缓存的查询名称不会改变。
## 嵌入式SQL的缓存查询名称
SQL引擎为每个嵌入式SQL缓存查询分配一个唯一的类名,格式如下:
```java
%sqlcq.namespace.hash
```
其中,`NAMESPACE`是当前的名称空间(大写),`HASH`是唯一的哈希值。例如,`%sqlcq.USER.xEM1h5QIeF4l3jhLZrXlnThVJZDh`。
管理门户为每个表列出了嵌入式SQL缓存查询,目录详细信息为每个表列出了具有这个类名的缓存查询,查询类型为嵌入式缓存SQL。
## 单独的缓存查询
两个不应该影响查询优化的查询之间的差异仍然会生成单独的缓存查询:
- 同一函数的不同语法形式会生成单独的缓存查询。因此,`ASCII(‘x’)`和`{fn ASCII(‘x’)}`生成单独的缓存查询,而`{fn CURDATE()}`和`{fn CURDATE}`生成单独的缓存查询。
- 区分大小写的表别名或列别名值以及可选的AS关键字的存在或不存在将生成单独的缓存查询。因此,`ASCII('x')`, `ASCII('x') AChar`, and `ASCII('x') AS AChar`会生成单独的缓存查询。
- 使用不同的`ORDER BY`子句。
- 使用`top all`代替具有整数值的`top`。
# 文字替换
当SQL引擎缓存一个SQL查询时,它会执行文字替换。
查询缓存中的查询用`“?”`
字符,表示输入参数。
这意味着,仅在文字值上不同的查询由单个缓存的查询表示。
例如,两个查询:
```sql
SELECT TOP 11 Name FROM Sample.Person WHERE Name %STARTSWITH 'A'
```
```sql
SELECT TOP 5 Name FROM Sample.Person WHERE Name %STARTSWITH 'Mc'
```
都由单个缓存查询表示:
```sql
SELECT TOP ? Name FROM Sample.Person WHERE Name %STARTSWITH ?
```
这最小化了查询高速缓存的大小,并且意味着不需要对仅在字面值上不同的查询执行查询优化。
使用输入主机变量(例如`:myvar`)和`?`
输入参数也在相应的缓存查询中用`“?”`
”字符。
因此, `SELECT Name FROM t1 WHERE Name='Adam', SELECT Name FROM t1 WHERE Name=?`, and `SELECT Name FROM t1 WHERE Name=:namevar`
,都是匹配查询,并生成单个缓存查询。
可以使用`%GetImplementationDetails()`方法来确定这些实体中的哪些实体由每个“?”特定准备的字符。
以下注意事项适用于文字替换:
- 指定为文字一部分的加号和减号将生成单独的缓存查询。因此,`ABS(7)`、`ABS(-7)`和`ABS(+7)`各自生成一个单独的缓存查询。多个符号也会生成单独的缓存查询:`ABS(+?)`。`ABS(++?)`。因此,最好使用无符号变量`ABS(?)`。或`ABS(:Num)`,可以为其提供有符号或无符号数字,而无需生成单独的缓存查询。
- 精度和小数值通常不接受文字替换。因此,`ROUND(567.89,2)`被缓存为`ROUND(?,2)`。但是,`CURRENT_TIME(N)`、`CURRENT_TIMESTAMP(N)`、`GETDATE(N)`和`GETUTCDATE(N)`中的可选精度值不接受文字替换。
- `IS NULL`或`IS NOT NULL`条件中使用的文字不接受文字替换。
- `ORDER BY`子句中使用的任何文字都不接受文字替换。这是因为`ORDER BY`可以使用整数来指定列位置。更改此整数将导致根本不同的查询。
- 字母文字必须用单引号引起来。某些函数允许指定带引号或不带引号的字母格式代码;只有带引号的字母格式代码才接受文字替换。因此,`DATENAME(MONTER,64701)`和`DATENAME(‘MONTER’,64701)`在功能上是相同的,但是对应的缓存查询是`DATENAME(MONTER,?)`。和`DATENAME(?,?)`
- 接受可变数量参数的函数会为每个参数计数生成单独的缓存查询。因此,`Coalesce(1,2)`和`Coalesce(1,2,3)`会生成单独的缓存查询。
## DynamicSQLTypeList Comment Option
当匹配查询时,注释选项被视为查询文本的一部分。
因此,在注释选项中不同于现有缓存查询的查询与现有缓存查询不匹配。
注释选项可以作为查询的一部分由用户指定,也可以由SQL预处理器在准备查询之前生成并插入。
如果SQL查询包含文字值,SQL预处理器将生成`DynamicSQLTypeList`注释选项,并将其附加到缓存的查询文本的末尾。此注释选项为每个文字分配数据类型。数据类型按照文字在查询中出现的顺序列出。只列出实际文字,而不是输入主机变量或?输入参数。下面是一个典型的例子:
```sql
SELECT TOP 2 Name,Age FROM Sample.MyTest WHERE Name %STARTSWITH 'B' AND Age > 21.5
```
生成缓存的查询文本:
```sql
SELECT TOP ? Name , Age FROM Sample . MyTest WHERE Name %STARTSWITH ? AND Age > ? /*#OPTIONS {"DynamicSQLTypeList":"10,1,11"} */
```
在本例中,文字2被列为类型10(整数),文字`“B”`被列为类型1(字符串),而文字`21.5`被列为类型11(数字)。
请注意,数据类型分配仅基于文字值本身,而不是关联字段的数据类型。例如,在上面的示例中,`Age`被定义为数据类型`INTEGER`,但是文字值21.5被列为`NUMERIC`。因为InterSystems IRIS将数字转换为规范形式,所以文字值`21.0`将被列为整数,而不是数字。
`DynamicSQLTypeList`返回以下数据类型值:
数字 | 描述
---|---
1| 长度为1到32(包括1到32)的字符串
2| 长度为33到128(含)的字符串
3| 长度为129到512(含)的字符串
4| 长度大于512的字符串
10| Integer
11| Numeric
由于`DynamicSQLTypeList`注释选项是查询文本的一部分,因此更改文本以使其产生不同的数据类型会导致创建单独的缓存查询。例如,增加或减少文字字符串的长度,使其落入不同的范围。
## 文字替换和性能
SQL引擎对`IN`谓词的每个值执行文字替换。大量`IN`谓词值可能会对缓存查询性能产生负面影响。可变数量的`IN`谓词值可能会导致多个缓存查询。将`IN`谓词转换为`%INLIST`谓词会导致谓词只有一个文字替换,而不管列出的值有多少。`%INLIST`还提供了一个数量级大小参数,`SQL`使用该参数来优化性能。
## 取消文字替换
可以取消这种文字替换。在某些情况下,可能希望对文字值进行优化,并为具有该文字值的查询创建单独的缓存查询。若要取消文字替换,请将文字值括在双圆括号中。下面的示例显示了这一点:
```sql
SELECT TOP 11 Name FROM Sample.Person WHERE Name %STARTSWITH (('A'))
```
指定不同的 `%STARTSWITH`值将生成单独的缓存查询。请注意,对每个文字分别指定禁止文字替换。在上面的示例中,指定不同的`TOP`值不会生成单独的缓存查询。
要取消有符号数字的文字替换,请指定诸如 `ABS(-((7)))`之类的语法。
注意:在某些情况下,不同数量的括号也可能会抑制文字替换。InterSystems建议始终使用双圆括号作为此目的最清晰和最一致的语法。
# 共分注释选项
如果一个SQL查询指定了多个分割表,则SQL预处理器会生成一个共分片注释选项,并将该选项附加到缓存的查询文本的末尾。此共分选项显示是否对指定的表进行共分。
在下面的示例中,所有三个指定的表都进行了编码共享:
```
/*#OPTIONS {"Cosharding":[["T1","T2","T3"]]} */
```
在以下示例中,指定的三个表均未进行编码共享:
```
/*#OPTIONS {"Cosharding":[["T1"],["T2"],["T3"]]} */
```
在以下示例中,表`T1`未被编分,但表`T2`和`T3`被编分:
```
/*#OPTIONS {"Cosharding":[["T1"],["T2","T3"]]} */
```
文章
姚 鑫 · 四月 19, 2021
# 第三章 优化表(二)
# 调整表计算值
调优表操作根据表中的代表性数据计算和设置表统计信息:
- `ExtentSize`,它可能是表中的实际行数(行数),也可能不是。
- 表中每个属性(字段)的选择性。
可以选择性地阻止单个属性的选择性计算。
- 属性的离群选择性,其中一个值比其他值出现得更普遍。
有效的查询可以利用离群值优化。
- 标识某些属性特征的每个属性的注释。
- 每个属性的平均字段大小。
- 表的SQL `Map Name`、`BlockCount`和`Source of BlockCount`。
## 区段大小和行计数
从管理门户运行Tune Table工具时,`ExtentSize`是表中当前行的实际计数。默认情况下,`GatherTableStats()`方法还将实际行数用作`ExtentSize`。当表包含大量行时,最好对较少的行执行分析。可以使用SQL tune table命令并指定`%SAMPLE_PERCENT`来仅对总行的一定百分比执行分析。在针对包含大量行的表运行时,可以使用此选项来提高性能。此`%SAMPLE_PERCENT`值应该足够大,以便对代表性数据进行采样。如果`ExtentSize`。
如果`TuneTable`返回异常值选择性,则正常选择性仍然是整个行集内每个非异常值数据值的百分比。例如,如果在`1000`个随机选择的值中检测到`11`个不同的值,其中一个是异常值,则选择性为`1/11(9.09%)`:平均每个条目出现的几率为十一分之一。如果异常值选择性是`80%`,常规选择性是`1%`,那么除了异常值之外,还可以找到大约`20((1-0.80)/0.01)`个额外的非异常值。
如果优化表初始采样仅返回单个值,但附加采样返回多个不同的值,则这些采样结果会修改正常选择性。例如,990个值的初始随机采样仅检测一个值,但后续采样检测其他不同值的10个单个实例。在这种情况下,初始离群值会影响选择性值,该值现在被设置为`1/1000(0.1%)`,因为10个非离群值中的每一个在1000个记录中只出现一次。
异常值选择性的最常见示例是允许`NULL`的属性。如果某个特性具有`NULL`的记录数大大超过该特性具有任何特定数据值的记录数,则`NULL`为异常值。以下是`FavoriteColors`字段的选择性和异常值选择性:
```java
SELECTIVITY of FIELD FavoriteColors
CURRENT = 1.8966%
CALCULATED = 1.4405%
CURRENT OUTLIER = 45.0000%, VALUE =
CALCULATED OUTLIER = 39.5000%, VALUE =
```
如果一个字段只包含一个不同的值(所有行都具有相同的值),则该字段的选择性为`100%`。选择性为`100%`的值不被视为异常值。调谐表通过采样数据来建立选择性和异常值选择值。为了确定这一点,优选表首先测试少量或几条记录,如果这些记录都具有相同的字段值,它将测试多达`100,000`条随机选择的记录,以支持非索引字段的所有值都相同的假设。只有在字段已编制索引,字段是索引的第一个字段,并且字段和索引具有相同的排序规则类型的情况下,优化表才能完全确定该字段的所有值是否相同。
- 如果已知未编制索引的字段具有在测试`100,000`条随机选择的记录中可能检测不到的其他值,则应手动设置选择性和离群值选择性。
- 如果已知非索引字段没有其他值,则可以手动指定`100%`的选择性,删除任何异常值选择性,并设置`CALCSELECTIVITY=0`以防止优选表尝试计算选择性或将此值指定为异常值。
要修改这些选择性、异常值选择性和异常值计算值,请从调谐表显示中选择单个字段。这会在显示屏右侧的详细信息区域中显示该字段的这些值。可以将选择性、异常值选择性和/或异常值修改为更适合预期完整数据集的值。
- 可以将选择性指定为带有百分号(`%`)的行的百分比,也可以指定为整数行(没有百分号)。如果指定为整数行数,InterSystems IRIS将使用区大小来计算选择性百分比。
- 可以为以前没有异常值的字段指定异常值选择性和异常值。将异常值选择性指定为带百分号(`%`)的百分比。如果仅指定异常值选择性,则Tune Table假定异常值为``。如果仅指定异常值,则除非还指定异常值选择性,否则调谐表不会保存此值。
## CALCSELECTIVITY参数与不计算选择性
在某些情况下,可能不希望优化表工具计算属性的选择性。要防止计算选择性,请将属性的`CALCSELECTIVITY`参数的值指定为`0`(默认值为`1`)。在Studio中,可以在“新建属性向导”的“属性参数”页上设置`CALCSELECTIVITY`,也可以在检查器中的属性参数列表中设置`CALCSELECTIVITY`(可能需要收缩并重新展开属性参数列表才能显示它)。
应该指定`CALCSELECTIVITY=0`的一种情况是,如果该字段未编制索引,则已知该字段在所有行中只包含一个值(`选择性=100%`)。
## 离群值的优化
默认情况下,查询优化器假定查询不会选择离群值。
例如,查询通常选择特定的字段值并从数据库返回少量记录,而不是返回大量记录,其中该字段值是离群值。
查询优化器总是使用选择性来构造查询计划,除非执行一些要求考虑离群选择性的操作。
根据选择离群值,可以执行以下几个操作来调整查询优化:
- 如果异常值是``,则在查询`WHERE`子句中为该字段指定一个`is null`或`is NOT null`条件。
这将导致查询优化器在构造查询时使用离群值选择性。
- 如果离群值是一个数据值,查询优化器会假定选择的字段值不是离群值。
例如,总部位于马萨诸塞州的公司的员工记录可能有`Office_State`字段离群值`MA` (`Massachusetts`)。
优化器假设查询不会选择`' MA '`,因为这将返回数据库中的大多数记录。
但是,如果正在编写一个查询来选择离群值,可以通过将离群值封装在双括号中来通知优化器。
在该字段上查询时,指定一个`WHERE`子句,如下所示`:WHERE Office_State=(('MA'))`。
这种技术抑制了文字替换,并迫使查询优化器在构建查询计划时使用离群值选择性。
对于动态SQL查询,以及在使用ODBC/JDBC提供的InterSystems IRIS之外编写的查询,这种语法是必需的。
对于类查询、嵌入式SQL查询或通过视图访问的查询,则不需要这样做。
- 根据参数值SQL设置配置系统范围的优化查询。
该选项为离群值设置了运行时计划选择(RTPC)优化和作为离群值(BQO)优化的偏差查询的适当组合。
注意,更改此配置设置将清除所有名称空间中的所有缓存查询。
使用管理门户,选择System Administration、Configuration、SQL和Object Settings、SQL来查看和更改此选项。
可用的选择有:
- 假设查询参数值不是字段离群值(`BQO=OFF`, `RTPC=OFF`,初始默认值)
- 假设查询参数值经常匹配字段离群值(`BQO=ON`, `RTPC=OFF`)
- 在运行时优化实际查询参数值(`BQO=OFF`, `RTPC=ON`)
要确定当前设置,调用`$SYSTEM.SQL.CurrentSettings()`。
- 覆盖查询的系统范围配置设置。
通过指定`%NORUNTIME restrict`关键字,可以覆盖单个查询的`RTPC`。
如果查询`SELECT Name,HaveContactInfo FROM t1 WHERE HaveContactInfo=?`
将导致`RTPC`处理,查询`SELECT %NORUNTIME Name,HaveContactInfo FROM t1 WHERE HaveContactInfo=?`
将覆盖RTPC,从而产生一个标准的查询计划。
通过指定注释选项`/*#OPTIONS {"BiasAsOutlier":1} */`,可以覆盖偏见查询作为单个查询的离群值。
## “备注”列
管理门户优化表信息选项为每个字段显示一个备注列。此字段中的值是系统定义的,不可修改。它们包括以下内容:
- `RowID`字段:一个表有一个`RowID`,由系统定义。它的名称通常是ID,但可以有不同的系统分配的名称。由于其所有值(根据定义)都是唯一的,因此其选择性始终为1。如果类定义包括`SqlRowIdPrivate`,则`Notes`列值为`RowID`字段、`Hidden`字段。
- 隐藏字段:隐藏字段定义为私有,`SELECT*`不显示。默认情况下,`CREATE TABLE`将`RowID`字段定义为隐藏;可以指定`%PUBLICROWID`关键字以使`RowID`不隐藏和公开。默认情况下,由持久化类定义定义的表将`RowID`定义为非隐藏;可以指定`SqlRowIdPrivate`将`RowID`定义为隐藏和私有。容器字段定义为隐藏。
- 流字段:表示使用流数据类型定义的字段,可以是字符流(`CLOB`),也可以是二进制流(`BLOB`)。流文件没有平均字段大小。
- 父引用字段:引用父表的字段。
注释列中未标识标识字段、`ROWVERSION`字段、序列字段或`UNIQUEIDENTIFIER(GUID)`字段。
## 平均字段大小
运行调谐表根据当前表格数据集计算所有非流字段的平均字段大小(以字符为单位)。这与`AVG($length(Field))`相同(除非另有说明),四舍五入到小数点后两位。可以更改各个字段的平均字段大小,以反映字段数据的预期平均大小。
- NULL:因为`$LENGTH`函数将`NULL`字段视为长度为0,所以将长度为0的`NULL`字段取平均值。这可能会导致平均字段大小小于一个字符。
- 空列:如果列不包含数据(所有行都没有字段值),则平均字段大小值为1,而不是0。对于不包含数据的列,`AVG($length(Field))`为0。
- `ExtentSize=0`:将`ExtentSize`设置为0时,所有字段的平均字段大小将重置为0。
- 逻辑字段值:平均字段大小始终根据字段的逻辑(内部)值计算。
- 列表字段:InterSystems IRIS列表字段根据其逻辑(内部)编码值计算。此编码长度大于列表中元素的总长度。
- 容器字段:集合的容器字段大于其集合对象的总长度。例如,在`Sample.Person`中,`Home`容器字段的`Average Field` Size大于`Home_Street`、`Home_City`、`Home_State`和`Home_Zip`平均字段大小的总和。
- 流字段:流字段没有平均字段大小。
如果特性/字段的特性参数`CALCSELECTIVITY`设置为0,则调谐表不会计算该特性/字段的平均字段大小。
可以通过从调谐表显示中选择单个字段来修改平均字段大小计算值。这将在显示屏右侧的详细信息区域中显示该字段的值。可以将“平均字段大小”修改为更适合预期的完整数据集的值。由于设置此值时优化表不执行验证,因此应确保该字段不是流字段,并且指定的值不大于最大字段大小(`MaxLen`)。
平均字段大小还显示在管理门户目录详细信息选项卡字段选项表中。必须已为字段选项表运行了调整表,才能显示平均字段大小值。
## map BlockCount选项卡
调优表Map `BlockCount`选项卡显示SQL映射名称、`BlockCount`(作为正整数)和`BlockCount`的来源。
块计数的来源可以在类定义中定义、由类编译器估计或由TuneTable度量。
将类编译器估计的调优表更改运行到TuneTable测量;
它不影响在类定义中定义的值。
通过从调优表显示中选择单个SQL映射名称,可以修改`BlockCount`计算值。
这将在显示器右侧的详细信息区域中显示该地图名称的块计数。
可以将块计数修改为一个更适合预期的完整数据集的值。
因为在设置该值时,Tune Table不执行验证,所以应该确保块计数是一个有效值。
修改`BlockCount`会将`BlockCount`的来源更改为类定义中定义的。
# 导出和重新导入调优表统计信息
可以从一个表或一组表导出调优表统计信息,然后将这些调优表统计信息导入一个表或一组表。
以下是可能希望执行此导出/导入的三种情况。
(为简单起见,这些描述了从单个表导出/导入统计数据;
在实际使用中,通常会从多个相互关联的表中导出/导入统计数据):
- 为生产系统建模:生产表完全填充了实际数据,并使用`Tune table`进行优化。
在测试环境中,创建的表具有相同的表定义,但数据少得多。
通过从生产表导出调优表统计信息并将它们导入测试表,可以在测试表上对生产表优化建模。
- 要复制生产系统:生产表完全填充了实际数据,并使用tune Table进行了优化。将创建具有相同表定义的第二个生产表。(例如,生产环境及其备份环境,或者多个相同的表定义,每个表包含不同医院的患者记录。)。通过从第一个表导出调优表统计信息并将其导入第二个表,您可以为第二个表提供与第一个表相同的优化,而无需第二次运行调优表或等待第二个表填充有代表性的数据。
- 要恢复到以前的统计信息集:可以通过运行tune Table或显式设置统计信息来创建表的优化统计信息。通过导出这些统计信息,可以在尝试其他统计信息设置时保留它们。一旦确定了最佳统计信息集,就可以将它们重新导入到表中。
可以使用`$SYSTEM.SQL.Stats.Table.Export()`方法将调优表统计信息导出到`XML`文件。此方法可以导出名称空间中一个、多个或所有表的优化表统计信息,如以下示例所示:
```java
DO $SYSTEM.SQL.Stats.Table.Export("C:\AllStats.xml")
/* 导出当前命名空间中所有架构/表的TuneTable统计信息 */
```
```java
DO $SYSTEM.SQL.Stats.Table.Export("C:\SampleStats.xml","Sample")
/* 导出Sample模式中所有表的可调统计信息 */
```
```java
DO $SYSTEM.SQL.Stats.Table.Export("C:\SamplePStats.xml","Sample","P*")
/* 导出Sample模式中所有以字母“P”开头的表的可调统计信息 */
```
```java
DO $SYSTEM.SQL.Stats.Table.Export("C:\SamplePersonStats.xml","Sample","Person")
/* 导出Sample的可调统计信息Person */
```
可以使用`$SYSTEM.SQL.Stats.Table.Import()`方法重新导入使用`$SYSTEM.SQL.Stats.Table.Import()`方法导出的调优表统计信息。
`$SYSTEM.SQL.Stats.Table.Import()`有一个`KeepClassUpToDate boolean`选项。
如果为真(并且`update`为真),`$SYSTEM.SQL.Stats.Table.Import()`将用新的`EXTENTSIZE`和选择性值更新类定义,但类定义将保持最新。
但是,在许多情况下,最好在调优了类表之后重新编译类,这样类定义中的查询就可以重新编译,SQL查询优化器就可以使用更新后的数据统计信息。
默认值为`FALSE(0)`。请注意,如果该类已部署,则类定义不会更新。
`$SYSTEM.SQL.Stats.Table.Import()`有一个`ClearCurrentStats boolean`选项。
如果为`TRUE`, `$SYSTEM.SQL.Stats.Table.Import()`将在导入统计信息之前从现有表中清除所有先前的区段大小、选择性、块计数和其他调优表统计信息。
如果您想要完全清除导入文件中没有指定的那些表状态,而不是让它们在表的`persistent`类中定义,则可以使用此方法。
默认值是`FALSE(0)`。
如果`$SYSTEM.SQL.Stats.Table.Import()`没有找到相应的表,它将跳过该表并继续导入文件中指定的下一个表。
如果找到了一个表,但是没有找到一些字段,那么这些字段将被跳过。
无法继承类存储定义中映射的`BlockCount`。`BlockCount`只能出现在映射起源的类的存储定义中。如果映射源自超类,则`$SYSTEM.SQL.Stats.Table.Import()`仅设置投影表的`BlockCount`元数据,而不设置类存储`BlockCount`元数据。
问题
Yufeng Li · 四月 19, 2021
现在有windows上的 编译好的nginx 可以做为iris 的web 服务器吗? ngx_http_csp_module_sa.c , cspapi.h 这两个文件在哪下载? 请从Nginx官网:nginx.org 下载,InterSystems不提供nginx 下载。
文中提到的文件可以在InterSystems IRIS 安装目录的 \dev\csp\nginx 文件夹下找到。
公告
Claire Zheng · 四月 18, 2021
Hi 亲爱的社区开发者们,福利来了!
在Global Masters,我们为 Expert, Ambassador and VIP levels(专家级、大使级和VIP级)的用户提供了更多奖励!
Apple AirPods
希望你们喜欢新奖品!
此外,你可以在奖励列表中看到"解锁获奖" 项目,根据提示完成相应目标后,便可解锁并申请奖品。
社区奖励兑换近期更新啦,有帽子,Amzon Echo Dot 等众多新礼品,欢迎大家多赚积分多兑换!!!更多更新还在路上,敬请期待!
关于Global Masters:
如何加入InterSystems Global Masters倡导中心?
Global Masters等级及徽章说明(英文)
如果您还没有加入InterSystems Global Masters倡导中心 , 现在就加入吧!
如果您有任何疑问,欢迎跟帖回复!
👍👍 努力攒积分中 问问题,回答问题,发表文章,看帖子,做小测试。。。都可以获得点数,欢迎大家踊跃参与完成挑战!
详情请访问:https://globalmasters.intersystems.com/challenges
文章
Hao Ma · 四月 18, 2021
IRIS相比Caché在部署上的一个进步是支持docker。即便不是云部署, 使用docker也带来非常多的便利。 尤其是在开发测试环节,由于docker的使用更便捷,除非要模拟客户的环境或者做规定的性能测试,我在测试中基本已经不再使用本机的实例或者虚机。IRIS的联机文档有[详细的IRIS docker安装使用指导](https://irisdocs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=ADOCK#ADOCK_iris_running_compose),本文只是一个简单的,快速上手的**在测试环境**安装IRIS docker的简单步骤,尤其适合初学者。
注意Windows上docker可能会遇到这样那样的问题,因此通常还是推荐在Linux或者Mac OS上使用。正式的生产环境的IRIS docker container也是不支持Windows系统的。
> Referrence
- [First Look: InterSystems Products in Docker Containers](https://irisdocs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=AFL_containers)
- [Running an InterSystems IRIS Container: Docker Run ExamplesRunning an InterSystems IRIS Container: Docker Run Examples](https://irisdocs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=ADOCK#ADOCK_iris_running_dockerrun)
##1. 在操作系统上安装Docker环境
[Docker官方文档的安装步骤](https://docs.docker.com/engine/install/)非常清晰,我按照上面的步骤在MAC和CentOS上安装docker从来没有出现过问题。恰恰是这个文档中没有的Redhat上的安装,过程中曾碰到过几个问题,在网上搜索了答案,也不算困难。
简单的复述一下步骤:root用户的最简单安装,没有权限问题, 没有docker网络修改等等:
1. 安装yum-util, 用于添加yum源,如果您的系统中已经有了yum-utils包这步可以省略
sudo yum install -y yum-utils
2. 添加docker的Repo到yum源并确认
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
sudo yum repolist
3. 安装3个docker组件
sudo yum install docker-ce docker-ce-cli containerd.io
4. 启动Docker
sudo systemctl start docker
5. 确认安装成功。'docker run'命令会去本地的库里找'hello-world',没有找到就去网上下一个"images",然后创建一个docker容器给你使用。
sudo docker run hello-world
安装结束您想要到注册一个账户,用来下载上传docker image。 下载命令使用'docker pull', 比如
```
docker pull nginx
```
## 2. 下载IRIS Docker image
在线文档[Container Images Available from InterSystems](https://docs.intersystems.com/components/csp/docbook/Doc.View.cls?KEY=PAGE_containerregistry#PAGE_containerregistry)中介绍了网站上可以下载的IRIS images的列表,其中community版本不需要license,其他的版本需要从InterSystems处获得IRIS docker版的专用license.
下面是登录并下载iris docker image的记录。从网页登录,您会得到docker的登录密码"使用的密码"jaRWSBJjcUcNprCKTuMX10PYHNq2IYPrAQoYdp6Siokb"。
[root@centos7 ~]# docker login -u="hma" -p="jaRWSBJjcUcNprCKTuMX10PYHNq2IYPrAQoYdp6Siokb" containers.intersystems.com
WARNING! Using --password via the CLI is insecure. Use --password-stdin.
WARNING! Your password will be stored unencrypted in /root/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded
[root@centos7 ~]# docker pull containers.intersystems.com/intersystems/iris-ml:2020.3.0.304.0
2020.3.0.304.0: Pulling from intersystems/iris-ml
5c939e3a4d10: Pull complete
c63719cdbe7a: Pull complete
19a861ea6baf: Pull complete
651c9d2d6c4f: Pull complete
d21839215a64: Pull complete
7995f836674b: Pull complete
841ee3aaa7aa: Pull complete
739c318c2223: Pull complete
d76886412dda: Pull complete
Digest: sha256:4c62690f4d0391d801d3ac157dc4abbf47ab3d8f6b46144288e0234e68f8f10e
Status: Downloaded newer image for containers.intersystems.com/intersystems/iris-ml:2020.3.0.304.0
containers.intersystems.com/intersystems/iris-ml:2020.3.0.304.0
[root@centos7 ~]#
另外,您也可以从InterSystems的技术支持网站下载iris docker的压缩包"iris*.tar.gz",然后使用"docker load"安装, 比如:
CNMBPHMA:~ hma$ docker load -i iris-2020.4.0.524.0-docker.tar.gz
## 3. 创建并运行IRIS Container
###简单的办法
如果是只是简单的测试,可以直接运行,但如果不是community版本的docker, 您还需要把license拷贝到container内部。 比如下面的步骤
CNMBPHMA:~ hma$ docker run -d -i -p 52773:52773 -p 51773:51773 --name iris20204 intersystems/irishealth:2020.2.0.211.0
CNMBPHMA:~ hma$ docker cp iris.key iris20204:/usr/irissys/mgr/iris.key
需要注意的是,不同版本的超级端口可能不同,有些是1972,有些是51773。为了省事,您也许可以使用"-P"把所有container内部的端口都映射出来。
除了要拷贝license到container内部,在做测试的时候,您可能还要经常的使用"docker cp"把各种测试文件拷入container。而且,当查看和修改container内部文件的使用,还需要使用下面的命令进入container内部:
CNMBPHMA:~ hma$ docker exec -it iris20204 /bin/sh
因此,如果是您需要一个经常使用的iris container环境,我还是建议您使用下面的方法。
### IRIS Container使用外部存储
简单的说,下面的命令
- 使用"--volume"参数为container创建外部存储,将host上的"/root/data/dur"文件夹和container内部的"/dur"文件夹链接起来。(/root/data/dur文件夹要在host上手工创建,这只是一个示意,您可以使用任何可用的目录)
- ISC_DATA_DIRECTORY环境设置会在创建iris container时在/dur文件夹下创建一个子目录”/dur/irisepy",所有IRIS运行的日志,客户配置,mgr目录下的用户数据都会保存在这个目录。因为"/dur"是外部存储,即使docker container被删除数据也不会丢失。这对container的重新创建或者iris升级都带来很大的方便。在线文档上对如果覆盖或者升级带有外部存储的iris container有详细的介绍。
- “key"参数定义了在IRIS container创建时会把"/dur/license"目录下的iris.key拷贝到iris安装目录的mgr下并激活。也就是说,在运行命令前, 您需要在host上在"/root/data/dur"目录下创建"license"子目录并将iris.key拷贝进去。
docker run --name irisepy --init -d\
-p 9091:1972 -p 9092:52773\
-v /root/data/dur:/dur\
--env ISC_DATA_DIRECTORY=/dur/irisepy \
containers.intersystems.com/intersystems/iris-ml:2020.3.0.304.0 \
--key /dur/license/iris.key
希望您喜欢使用docker
文章
姚 鑫 · 四月 18, 2021
# 第三章 优化表(一)
要确保InterSystems IRIS®Data Platform上的InterSystems SQL表的最高性能,可以执行多种操作。优化可以对针对该表运行的任何查询产生重大影响。本章讨论以下性能优化注意事项:
- `ExtentSize`、`Selective`和`BlockCount`用于在用数据填充表之前指定表数据估计;此元数据用于优化未来的查询。
- 运行tune Table来分析填充表中的代表表数据;生成的元数据用于优化未来的查询。
- 优化表计算的值包括扩展大小、选择性、异常值选择性、平均字段大小和块计数
- 导出和重新导入优选表统计数据
# 扩展大小、选择性和块数(ExtentSize, Selectivity, and BlockCount)
当查询优化器决定执行特定SQL查询的最有效方式时,它会考虑以下三种情况:
- 查询中使用的每个表的`ExtentSize`行计数。
- S`electivity`为查询使用的每列计算的DISTINCT值的百分比。
- 查询使用的每个SQL映射的块计数。
为了确保查询优化器能够做出正确的决策,正确设置这些值非常重要。
- 在用数据填充表之前,可以在类(表)定义期间显式设置这些统计信息中的任何一个。
- 在用代表性数据填充表之后,可以运行tune Table来计算这些统计数据。
- 运行TuneTable之后,可以通过指定显式值来覆盖计算的统计信息。
可以将显式设置的统计信息与优化表生成的结果进行比较。如果优化表所做的假设导致查询优化器的结果不是最优的,则可以使用显式设置的统计信息,而不是优化表生成的统计信息。
在Studio中,类编辑器窗口显示类源代码。在源代码的底部,它显示了Storage定义,其中包括类`ExtentSize`和每个属性的选择性(如果合适,还包括`OutlierSelectivity`)。
## ExtentSize
表的`ExtentSize`值就是表中存储的行数(大致)。
**在开发时,可以提供初始`ExtentSize`值。如果未指定`ExtentSize`,则默认值为100,000**。
通常,会提供一个粗略的估计,即在填充数据时该表的大小是多少。
有一个确切的数字并不重要。
此值用于比较扫描不同表的相对成本;
最重要的是确保关联表之间的`ExtentSize`的相对值代表一个准确的比例(也就是说,小表的值应该小,大表的值应该大)。
- `CREATE TABLE`提供了一个`%EXTENTSIZE`参数关键字来指定表中的预期行数,示例如下:
```sql
CREATE TABLE Sample.DaysInAYear (%EXTENTSIZE 366,
MonthName VARCHAR(24),Day INTEGER,
Holiday VARCHAR(24),ZodiacSign VARCHAR(24))
```
表的持久类定义可以在存储定义中指定`ExtentSize`参数:
```xml
...
200
...
```
在本例中,片段是`MyClass`类的存储定义,它为`ExtentSize`指定了200的值。
如果表有真实的(或真实的)数据,可以使用管理门户中的调优表功能自动计算和设置它的区段大小值;
## Selectivity
在InterSystems SQL表(类)中,每个列(属性)都有一个与之相关联的选择性值。
列的选择性值是在查询该列的典型值时返回的表中的行的百分比。
选择性为`1/D`,其中D是字段不同值的数目,除非检测到异常值。
选择性基于大致相等的不同值的数量。例如,假设一个表包含一个性别列,其值大致均匀分布在`“M”`和`“F”`之间。性别栏的选择值将为50%。更具区分性的特性(例如街道名称`Street Name`)的选择性值通常只有很小的百分比。
所有值都相同的字段的选择性为`100%`。为了确定这一点,优化器首先测试一小部分或几条记录,如果这些记录都具有相同的字段值,它将测试多达`100,000`条随机选择的记录,以支持非索引字段的所有值都相同的假设。如果在对`100,000`条随机选择的记录进行的测试中可能未检测到某个字段的其他值,则应手动设置选择性。
**定义为唯一(所有值都不同)的字段的选择性为1(不应与`1.0000%`的选择性混淆)。例如,`RowID`的选择性为1。**
在开发时,可以通过在存储定义中定义一个选择性参数来提供此值,该参数是表的类定义的一部分:
```xml
...
50%
...
```
若要查看类的存储定义,请在Studio中,从“视图”菜单中选择“查看存储”;Studio在类的源代码底部包含存储。
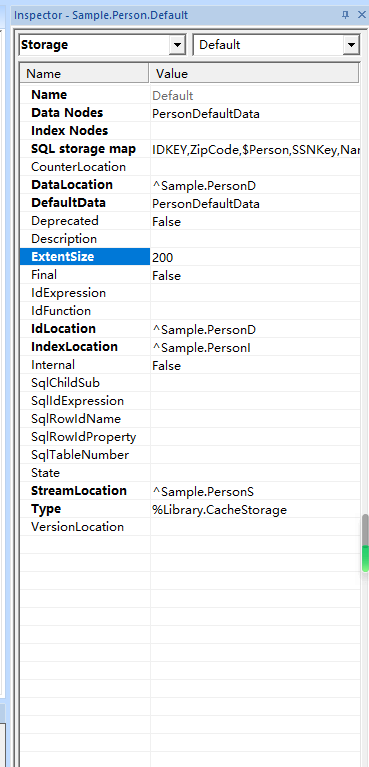
通常,需要提供在应用程序中使用时预期的选择性的估计值。与`ExtentSize`一样,拥有确切的数字并不重要。InterSystems IRIS提供的许多数据类型类将为选择性提供合理的默认值。
还可以使用`SetFieldSelectivity()`方法设置特定字段(属性)的选择值。
如果表中有真实的(或真实的)数据,则可以使用管理门户中的Tune table工具自动计算和设置其选择性值。
调优表确定一个字段是否有一个离群值,这个值比任何其他值都常见得多。
如果是这样,Tune Table将计算一个单独的离群值选择性百分比,并根据这个离群值的存在来计算选择性。
异常值的存在可能会极大地改变选择性值。
选择性用于查询优化。
在`SELECT`查询中指定的字段和在视图的`SELECT`子句中指定的字段使用相同的选择性值。
请注意,视图的行分布可能与源表不同。
这可能会影响视场选择性的精度。
## BlockCount
当编译一个持久化类时,类编译器会根据区段大小和属性定义计算每个SQL映射使用的映射块的大致数量。
可以在调优表工具的Map `BlockCount`选项卡中查看这些`BlockCount`值。
块计数在调优表中由类编译器估计。
注意,如果更改了区段大小,则必须关闭并重新打开SQL Tune Table窗口,以查看该更改反映在`BlockCount`值中。
当运行Tune Table时,它会测量每个SQL映射的实际块计数。
除非另有指定,调优表测量值将替换类编译器的近近值。
这些调优表测量值在类定义中表示为负整数,以区别于指定的`BlockCount`值。
如下面的例子所示:
```xml
-4
```
调优表测量值在调优表中表示为正整数,标识为由调优表测量。
可以在类定义中定义显式的块计数值。
可以显式地指定块计数为正整数,如下面的示例所示:
```xml
12
```
当定义一个类时,可以省略为`map`定义`BlockCount`,显式地指定一个`BlockCount`为正整数,或显式地定义`BlockCount`为`NULL`。
- 如果不指定块计数,或指定块计数为0,则类编译器估计块计数。
运行Tune Table将替换类编译器的估计值。
- 如果指定一个显式的正整数`BlockCount`,运行Tune Table不会替换此显式的`BlockCount`值。
在调优表中,显式的类定义块计数值表示为正整数,标识为在类定义中定义的。
这些块计数值不会通过随后运行Tune Table而更改。
- 如果将显式`BlockCount`指定为`NULL`,则SQL Map将使用类编译器估计的`BlockCount`值。因为`BlockCount`在类定义中是“定义的”,所以运行Tune Table不会替换这个估计的`BlockCount`值。
所有InterSystems SQL映射块的大小为2048字节(2K字节)。
在以下情况下,优化表不测量块计数:
- 如果表是由数组或列表集合投影的子表。这些类型的子表的`BlockCount`值与父表数据映射的`BlockCount`值相同。
- 如果全局映射是远程全局(不同名称空间中的全局)。取而代之的是使用在类编译期间使用的估计的`BlockCount`。
# Tune Table
Tune Table是一个实用程序,它检查表中的数据,并返回关于区段大小(表中的行数)、每个字段中不同值的相对分布以及平均字段大小(每个字段中值的平均长度)的统计信息。
它还为每个SQL映射生成块计数。
可以指定该调优表,使用此信息更新与表及其每个字段相关联的元数据。
查询优化器随后可以使用这些统计信息来确定最有效的查询执行计划。
在外部表上使用Tune Table将只计算区段大小。
调优表无法计算外部表的字段选择性值、平均字段大小或映射块计数值。
## 何时运行调优表
**应该在每个表填充了具有代表性的实际数据之后,在该表上运行tune Table。通常,在数据“激活”之前,只需要运行一次tune Table,这是应用程序开发的最后一步。Tune Table不是维护实用程序;它不应对实时数据定期运行。**
**注:在极少数情况下,运行调优表会降低SQL性能。虽然TuneTable可以在实时数据上运行,但建议在具有实际数据的测试系统上运行TuneTable,而不是在生产系统上运行。可以使用可选的系统模式配置参数来指示当前系统是测试系统还是活动系统。设置后,系统模式将显示在管理门户页面的顶部,并可由`$SYSTEM.Version.SystemMode()`方法返回。**
通常,在添加、修改或删除表数据时不应重新运行Tune Table,除非当前数据的特征发生了数量级的更改,如下所示:
- 相对表大小:Tune Table假设它正在分析具有代表性的数据子集。如果该子集是代表性子集,则该子集只能是整个数据集的一小部分。如果联接或其他关系中涉及的表的`ExtentSize`保持大致相同的相对大小,则当表中的行数发生变化时,Tune Table结果仍然是相关的。如果连接表之间的比率更改了一个数量级,则需要更新`ExtentSize`。这对于`JOIN`语句很重要,因为SQL优化器在优化表连接顺序时使用`ExtentSize`。一般来说,无论查询中指定的联接顺序如何,都会先联接较小的表,然后再联接较大的表。因此,如果`tableA`和`tableB`中的行比从`1000:2000`更改为`10000:2000`,可能在一个或多个表上重新运行tune Table,但如果更改为`2100:4000`,则不需要重新运行tune Table。
- 均匀值分布:优化表假设每个数据值的可能性都是相等的。如果它检测到离群值,它会假定除离群值之外的每个数据值的可能性都是相等的。调谐表通过分析每个字段的当前数据值来建立选择性。真实数据的可能性相等始终是一个粗略的近似值;不同数据值的数量及其相对分布的正态变化不应保证重新运行调优表。但是,字段可能值的数量(不同值与记录的比率)的数量级变化或单个字段值的总体可能性可能会导致不准确的选择性。大幅更改具有单个字段值的记录的百分比可能会导致TuneTable指定一个离群值或删除指定的离群值,从而显著改变计算的选择性。如果字段的选择性不再反映数据值的实际分布,则应重新运行调优表。
- 重大升级或新的站点安装可能需要重新运行Tune Table。
## 运行 Tune Table
运行调优表有三个接口:
- 使用Management Portal SQL interface Actions下拉列表,它允许在单个表或多个表上运行Tune Table。
- 为单个表或当前命名空间中的所有表调用`$SYSTEM.SQL.Stats.Table.GatherTableStats()`方法。
- 对单个表发出SQL命令调优表。
Tune Table清除引用正在调优的表的缓存查询。
调优表命令提供了一个recompile缓存查询选项,以使用新的调优表计算值重新生成缓存的查询。
如果表映射到只读数据库,则无法执行调优表,并生成错误消息。
在运行了调优表工具之后,生成的区段大小和选择性值将保存在类的存储定义中。
要查看存储定义,在Studio中,从“视图”菜单中选择“视图存储”;
Studio在类源代码的底部包含存储。
### 从管理门户调优表
要从管理门户运行Tune Table:
1. 选择System Explorer,然后选择SQL。
通过单击页面顶部的Switch选项选择一个名称空间,然后从显示的列表中选择一个名称空间。
(可以为每个用户设置管理门户的默认名称空间。)
2. 从屏幕左侧的下拉列表中选择模式,或者使用筛选器。
3. 执行下列操作之一:
- 优化单个表:展开表类别,然后从列表中选择一个表。选择表格后,单击操作下拉列表,然后选择调整表格信息。这将显示表的当前`ExtentSize`和选择性信息。如果从未运行过调谐表,`ExtentSize=100000`,则不会显示任何选择性、异常值选择性、异常值或平均字段大小信息(除了选择性为1的行ID),并且会按照类编译器的估计列出映射块计数信息。
从选择性选项卡中,选择调谐表按钮。这将在表上运行tune Table,根据表中的数据计算ExtentSize、选择性、异常值选择性、异常值和Average Field Size值。Map BlockCount(地图块计数)信息按Tune Table(调谐表)测量列出。
单个表上的Tune Table始终作为后台进程运行,并在完成后刷新该表。这可以防止超时问题。当此后台进程正在运行时,将显示一条正在进行的消息。在后台进程执行时,关闭按钮可用于关闭调谐表窗口。
- 优化方案中的所有表:单击操作下拉列表,然后选择优化方案中的所有表。这将显示调谐表方框。选择Finish按钮在方案中的所有表上运行Tune Table。调谐表完成后,此框显示完成按钮。选择Done(完成)退出Tune Table(调谐表)框。
SQL优化表窗口有两个选项卡:选择性和映射块计数。这些选项卡显示由调谐表生成的当前值。它们还允许手动设置与Tune Table生成的值不同的值。
选择性选项卡包含以下字段:
- 当前表扩展大小。此字段有一个编辑按钮,允许输入不同的表格扩展大小。
- “使类保持最新”复选框。对Tune Table生成的统计数据的任何更改,或由Tune Table界面或Tune Table方法中的用户输入值生成的任何更改,都会立即表示在类定义中:
- 如果未选中此框(否),则不会设置修改后的类别定义上的最新标志。这表明类定义已过期,应该重新编译。这是默认设置。
- 如果选中此框(是),类定义将保持标记为最新。在活动系统上更改统计信息时,这是首选选项,因为它降低了重新编译表类定义的可能性。
- 字段表,其中包含字段名称、选择性、备注、异常值选择性、异常值和平均字段大小等列。通过单击`Fields`表格标题,可以按该列的值进行排序。通过单击`Fields`表行,您可以手动设置该字段的选择性、异常值选择性、异常值和平均字段大小的值。
Map BlockCount选项卡包含以下字段:
- 包含SQL Map Name、BlockCount和Source of BlockCount列的映射名称表。索引的SQL映射名称是SQL索引名;这可能不同于持久类索引属性名。
- 通过单击单个map名称,可以手动设置该地图名称的`BlockCount`值。
在选择性选项卡中,可以单击优化表按钮在此表上运行优化表。
### 使用方法调整表
可以使用`$SYSTEM.SQL.Stats.Table.GatherTableStats()`方法在当前名称空间中运行Tune Table工具。
- `GatherTableStats(“Sample.MyTable”)`在单个表上运行TuneTable。
- `GatherSchemaStats(“Sample”)`在指定模式中的所有表上运行tune Table。
- `GatherTableStats(“*”)`在当前命名空间中的所有表上运行TuneTable。
使用`GatherTableStats()`方法时,可能会生成以下错误消息:
- 不存在的表:
```java
DO $SYSTEM.SQL.Stats.Table.GatherTableStats("NoSuchTable")
```
```java
No such table 'SQLUser.NoSuchTable'
```
- `View`视图:
```java
DO $SYSTEM.SQL.Stats.Table.GatherTableStats("Sample.MyView")
```
```java
'Sample.MyView' is a view, not a table. No tuning will be performed.
```
当运行`GatherTableStats(“*”)`或`GatherSchemaStats(“SchemaName”)`时,如果系统支持并行处理,系统将使用多个进程并行调优多个表。
## 在分片表上运行Tune table
如果在一个分片表上运行调优表,那么调优表操作将被转发到每个碎片,并针对该表的那个碎片运行。
调优表不会在调用它的主名称空间中执行。
如果在导出到碎片的类定义的非分片表上运行调优表,因为该表已连接到一个分片表,调优表操作将转发到每个碎片,并且它也在主名称空间中执行。
在分片表上运行Tune Table时,应该遵循以下准则:
- 优化分片主表,而不是分片本地表。
- 区段大小和块计数值是每个分片的值,而不是所有分片的总和。
- 如果使用`$SYSTEM.SQL.Stats.Table.Export()`和`$SYSTEM.SQL.Stats.Table.Import()`,则导出/导入分片主表的调优统计,而不是分片本地表。
- 调优切分表将在切分主类和切分本地类/表定义中定义调优统计。
如果手动编辑类定义中的调优表元数据,建议的过程是修改碎片主类的定义,然后重新编译碎片主类。
在编译碎片主类时,碎片主调优统计信息将被复制到类的碎片本地版本。
如果`GatherTableStats()`或`GatherSchemaStats()`指定了一个`logFile`参数,shard master实例中的日志文件有一个针对指定表的条目,例如:
- Sharded table: `TABLE: Invoking TuneTable on shards for sharded table `
- Non-sharded table: `TABLE: Invoking TuneTable on shards for mapped non-sharded table `
在每个分片实例上,在`mgr/`目录中创建一个同名的日志文件,记录这个分片上这个表的调优表信息。
如果为日志文件指定了目录路径,那么分片将忽略该路径,并且该文件始终存储在`mgr/`中。
问题
water huang · 四月 17, 2021
如图 dll放在
我调用的方式如下
期待能够在ensemble里面能便捷的调用dll,各种语言开发的dll,至少能支持c#生成的dll, 在Ensemble 2016中,使用$ZF(-4)来操作DLL是Caché的Callout网关的底层实现之一。这种方式比较通用。当然,如果这些DLL(ActiveX/COM)注册在Ensemble服务器上(Windows服务器),还有别的调用方式:使用Caché Activate 网关,用Studio来产生这些DLL的代理类,然后您就可以像使用Ensemble/Caché类一样使用这些DLL里的方法了。 使用Caché Activate 网关 这个并不好用。服务器重启后 需要重启网关,还很可能需要重新导入dll来生成代理类。因此这样的方式 我已经弃用,或者说 “可能需要重新导入dll来生成代理类” 这个是我操作不对才导致这样的结果?使用$ZF(-4)来操作DLL,这个dll具有一些特殊要求?比如? 如果dll重新编译过,那么是需要重新生成代理类的;其它情况下并不需要。另外,Ensemble 2016里有.net 网关,通过Studio来建立dll代理类。不过它依然需要在dll代码发生变化时重新生成代理类。
这也是后续版本(尤其是InterSystems IRIS)推出动态对象网关的原因:通过动态网关就不用生成代理类了,从而避免因为.net/java端发生代码变更而需要重新生成代理类。$ZF()对DLL没有特殊要求。
文章
姚 鑫 · 四月 16, 2021
# 第二章 定义和构建索引(四)
# 位片索引
当数字数据字段用于某些数值运算时,位片索引用于该字段。位片索引将每个数值数据值表示为二进制位串。位片索引不是使用布尔标志来索引数值数据值(如在位图索引中那样),而是以二进制值表示每个值,并为二进制值中的每个数字创建一个位图,以记录哪些行的该二进制数字具有1。这是一种高度专门化的索引类型,可以显著提高以下操作的性能:
- `SUM`、`COUNT`或`AVG` Aggregate计算。(位片索引不用于`COUNT(*)`计算。)。位片索引不用于其他聚合函数。
- 指定的字段 `TOP n ... ORDER BY field`
- 在范围条件运算中指定的字段,`WHERE field > n` 或 `WHERE field BETWEEN lownum AND highnum`、
SQL优化器确定是否应该使用定义的位片索引。通常,优化器仅在处理大量(数千)行时才使用位片索引。
可以为字符串数据字段创建位片索引,但位片索引将这些数据值表示为规范数字。换句话说,任何非数字字符串(如`“abc”`)都将被索引为0。这种类型的位片索引可用于快速计数具有字符串字段值的记录,而不计算那些为空的记录。
在下面的例子中,`Salary`是位片索引的候选项:
```sql
SELECT AVG(Salary) FROM SalesPerson
```
位片索引可用于使用`WHERE`子句的查询中的聚合计算。如果`WHERE`子句包含大量记录,则这是最有效的。在下面的示例中,SQL优化器可能会使用`Salary`上的位片索引(如果已定义);如果定义了位片索引,它还会使用`REGION`上的位图索引,使用定义的位图或为`REGION`生成位图临时文件:
```sql
SELECT AVG(Salary) FROM SalesPerson WHERE Region=2
```
但是,当索引无法满足`WHERE`条件时,不使用位片索引,而必须通过读取包含要聚合的字段的表来执行。以下示例将不使用`Salary`的位片索引:
```sql
SELECT AVG(Salary) FROM SalesPerson WHERE Name LIKE '%Mc%'
```
可以为任何包含数值的字段定义位片索引。InterSystems SQL使用`Scale`参数将小数转换为位字符串,如ObjectScript `$factor`函数中所述。可以为数据类型字符串的字段定义位片索引;在这种情况下,出于位片索引的目的,非数字字符串数据值被视为`0`。
可以为系统分配的行ID为正整数值的表中的字段定义位片索引,也可以为使用`%BID`属性定义以支持位图(和位片)索引的表中的字段定义位片索引。
位片索引只能为单个字段名定义,不能为多个字段的连接定义。
不能指定`WITH DATA`子句。
下面的例子比较了位片索引和位图索引。
如果你为1、5和22行创建一个位图索引,它会为这些值创建一个索引:
```java
^gloI("bitmap",1,1)= "100"
^gloI("bitmap",5,1)= "010"
^gloI("bitmap",22,1)="001"
```
如果为第1、2和3行的值1、5和22创建位切片索引,则会首先将这些值转换为位值:
```java
1 = 00001
5 = 00101
22 = 10110
```
然后,它为这些位创建索引:
```java
^gloI("bitslice",1,1)="110"
^gloI("bitslice",2,1)="001"
^gloI("bitslice",3,1)="011"
^gloI("bitslice",4,1)="000"
^gloI("bitslice",5,1)="001"
```
在本例中,位图索引中的值22需要设置1个全局节点;位片索引中的值22需要设置3个全局节点。
请注意,插入或更新需要在所有`n`个位片中设置一个位,而不是设置单个位串。这些附加的全局设置操作可能会影响涉及填充位片索引的插入和更新操作的性能。使用`INSERT`、`UPDATE`或`DELETE`操作填充和维护位片索引比填充位图索引或常规索引慢。维护多个位片索引和/或在频繁更新的字段上维护位片索引可能具有显著的性能成本。
在易失性表(执行许多插入、更新和删除操作)中,位片索引的存储效率可能会逐渐降低。`%SYS.Maint.Bitmap`实用程序方法同时压缩位图索引和位片索引,从而提高了还原效率。
# 重建索引
可以按如下方式构建/重新构建索引:
- 使用`BUILD INDEX` SQL命令构建指定索引,或构建为表、架构或当前命名空间定义的所有索引。
- 使用管理门户重建指定类(表)的所有索引。
- 使用`%BuildIndices()`(或`%BuildIndicesAsync()`)方法,如本节所述。
当前数据库访问确定应如何重建现有索引:
- 非活动系统(在索引构建或重建期间没有其他进程访问数据)
- `READONLY`活动系统(能够在索引构建或重建期间查询数据的其他进程)
- 读写活动系统(能够在索引构建或重建期间修改数据和查询数据的其他进程)
构建索引的首选方法是使用`%BuildIndices()`方法或`%BuildIndicesAsync()`方法。
- `%Library.Persistent.%BuildIndices()`:`%BuildIndices()`作为后台进程执行,但调用方必须等待`%BuildIndices()`完成才能接收回控制。
- `%Library.Persistent.%BuildIndicesAsync()`:`%BuildIndicesAsync()`将`%BuildIndices()`作为后台进程启动,调用方立即收到控制权。`%BuildIndicesAsync()`的第一个参数是`eueToken`输出参数。其余参数与`%BuildIndices()`相同。
`%BuildIndicesAsync()`返回`%Status`值:`Success`表示`%BuildIndices()`辅助作业已成功排队;失败表示该辅助作业未成功排队。
`%BuildIndicesAsync()`向`eueToken`输出参数返回一个值,该值指示`%BuildIndices()`完成状态。要获取完成状态,请通过引用将`eueToken`值传递`给%BuildIndicesAsyncResponse()`方法。还可以指定等待布尔值。如果`wait=1`,则`%BuildIndicesAsyncResponse()`将等待,直到由`eueToken`标识的`%BuildIndices()` JOB 完成。如果`wait=0`,`%BuildIndicesAsyncResponse()`将尽快返回状态值。如果返回时`%BuildIndicesAsyncResponse() ``eueToken`不为空,则`%BuildIndices()` job尚未完成。在这种情况下,可以使用`eueToken`再次调用`%BuildIndicesAsyncResponse()`。当`%BuildIndicesAsyncResponse()``eueToken`最终为`NULL`时,返回的`%BuildIndicesAsyncResponse()``%Status`值是`%BuildIndicesAsync()`调用的job的完成状态。
## 在非活动系统上构建索引
系统自动生成方法(由`%Persistent`类提供),这些方法构建或清除为类(表)定义的每个索引。可以通过以下两种方式之一使用这些方法:
- 通过管理门户进行交互。
- 以编程方式,作为方法调用。
构建索引执行以下操作:
1. 删除索引的当前内容。
2. 扫描(读取每一行)主表,并为表中的每一行添加索引项。如果可能,使用特殊的`$SortBegin`和`$SortEnd`函数来确保高效地构建大型索引。在构建标准索引时,除了在内存中缓存数据之外,使用`$SortBegin`/`$SortEnd`还可以使用`IRISTEMP`数据库中的空间。因此,在构建非常大的标准索引时,InterSystems IRIS可能需要`IRISTEMP`中大致等于最终索引大小的空间。
注:构建索引的方法仅为使用InterSystems IRIS默认存储结构的类(表)提供。映射到遗留存储结构的类不支持索引构建,因为它假定遗留应用程序管理索引的创建。
### 使用管理门户构建索引
可以通过执行以下操作来构建表的现有索引(重建索引):
1. 从管理门户中选择系统资源管理器,然后选择SQL。使用页面顶部的切换选项选择一个命名空间;这将显示可用命名空间的列表。选择命名空间后,选择屏幕左侧的`Schema`下拉列表。这将显示当前名称空间中的模式列表,其中带有布尔标志,指示是否有任何表或视图与每个模式相关联。
2. 从此列表中选择一个架构;该架构将显示在架构框中。它的正上方是一个下拉列表,允许选择属于该模式的表、系统表、视图、过程或所有这些。选择“表”或“全部”,然后打开“表”文件夹以列出此架构中的表。如果没有表,则打开文件夹将显示空白页。(如果未选择“表”或“全部”,则打开“表”文件夹将列出整个命名空间的表。)
3. 选择其中一个列出的表。这将显示表的目录详细信息。
- 要重建所有索引:单击操作下拉列表,然后选择重建表的索引。
- 要重建单个索引:单击索引按钮以显示现有索引。每个列出的索引都有重建索引的选项。
**注意:当其他用户正在访问表的数据时,不要重建索引。要在活动系统上重建索引,请参阅在活动系统上构建索引。**
### 以编程方式构建索引
为非活动表构建索引的首选方法是使用随表的`Persistent`类提供的`%BuildIndices()`(或`%BuildIndicesAsync()`)方法。
**若要以编程方式生成一个或多个索引,请使用`%Library.Persistent.%BuildIndices()`方法。**
生成所有索引:调用`%BuildIndices()`,不带参数生成为给定类(表)定义的所有索引(为其提供值):
```java
SET sc = ##class(MyApp.SalesPerson).%BuildIndices()
IF sc=1 {
WRITE !,"成功构建索引"
} ELSE {
WRITE !,"索引构建失败",!
DO $System.Status.DisplayError(sc) QUIT
}
```
生成指定索引:调用`%BuildIndices()`,并将`$LIST`索引名作为第一个参数,为给定类(表)生成指定的已定义索引(为其提供值):
```java
SET sc = ##class(MyApp.SalesPerson).%BuildIndices($ListBuild("NameIDX","SSNKey"))
IF sc=1 {
WRITE !,"成功构建索引"
} ELSE {
WRITE !,"索引构建失败",!
DO $System.Status.DisplayError(sc) QUIT
}
```
生成除以下项之外的所有索引:调用`%BuildIndices()`,并将索引名称的`$LIST`作为第七个参数来构建(为其提供值)给定类(表)的所有已定义索引(指定索引除外):
```java
SET sc = ##class(MyApp.SalesPerson).%BuildIndices("",,,,,,$ListBuild("NameIDX","SSNKey"))
IF sc=1 {
WRITE !,"成功构建索引"
} ELSE {
WRITE !,"索引构建失败",!
DO $System.Status.DisplayError(sc) QUIT
}
```
`%BuildIndices()`方法执行以下操作:
1. 对要重建的任何(非位图)索引调用`$SortBegin`函数(这将启动对这些索引的高性能排序操作)。
2. 循环遍历类(表)的主要数据,收集索引使用的值,并将这些值添加到索引(通过适当的排序转换)。
3. 调用`$SortEnd`函数来完成索引排序过程。
如果索引已经有值,则必须使用两个参数调用`%BuildIndices()`,其中第二个参数的值为1。
为此参数指定1将导致该方法在重新生成值之前清除这些值。
例如:
```java
SET sc = ##class(MyApp.SalesPerson).%BuildIndices(,1)
IF sc=1 {
WRITE !,"成功构建索引"
} ELSE {
WRITE !,"索引构建失败",!
DO $System.Status.DisplayError(sc) QUIT
}
```
清除并重建所有的索引。
你也可以清除并重建索引的子集,例如:
```java
SET sc = ##class(MyApp.SalesPerson).%BuildIndices($ListBuild("NameIDX","SSNKey"),1)
IF sc=1 {
WRITE !,"成功构建索引"
} ELSE {
WRITE !,"索引构建失败",!
DO $System.Status.DisplayError(sc) QUIT
}
```
注意:当表的数据被其他用户访问时,不要重建索引。
若要在活动系统上重建索引,请参见在活动系统上构建索引。
## 在活动系统上构建索引
在活动系统上构建(或重建)索引时,有两个问题:
- 除非正在构建的索引对`SELECT` `Query`隐藏,否则活动`Query`可能返回不正确的结果。这是在构建索引之前使用`SetMapSelecability()`方法处理的。
- 索引构建期间对数据的活动更新不会反映在索引条目中。这是通过在生成索引时使生成操作锁定单个行来处理的。
**注意:如果应用程序在单个事务内对数据执行大量更新,则可能会出现锁表争用问题。**
### 在Readonly主动系统上构建索引
如果表当前仅用于查询操作(`READONLY`),则可以在不中断查询操作的情况下构建新索引或重建现有索引。这是通过在重建索引时使索引对查询优化器不可用来实现的。
如果要为其构建一个或多个索引的所有类当前都是`READONLY`,请使用“在读写活动系统上构建索引”中描述的相同系列操作,但有以下区别:使用`%BuildIndices()`时,设置`pLockFlag=3`(共享区锁定)。
### 在读写活动系统上构建索引
如果持久化类(表)当前正在使用并且可用于读写访问(查询和数据修改),则可以在不中断这些操作的情况下构建新索引或重建现有索引。如果要为其重建一个或多个索引的类当前可读写访问,则构建索引的首选方法是使用与表的持久类一起提供的`%BuildIndices()`(或`%BuildIndicesAsync()`)方法。
**注意:以下信息适用于动态SQL查询,而不适用于嵌入式SQL。嵌入式SQL在编译时(而不是在运行时)检查`MapSelecability`设置。因此,关闭索引的`MapSelecability`对已经编译的嵌入式SQL查询没有任何影响。因此,嵌入式SQL查询仍可能尝试使用禁用的索引,并将给出不正确的结果。**
在并发读写访问期间,需要执行以下一系列操作来构建一个或多个索引:
1. 望构建的索引对查询不可用(读取访问权限)。这是使用`SetMapSelecability()`完成的。这使得查询优化器无法使用该索引。在重建现有索引和创建新索引时都应执行此操作。例如:
```java
SET status=$SYSTEM.SQL.Util.SetMapSelectability("Sample.MyStudents","StudentNameIDX",0)
```
- 第一个参数是`Schema.Table`名称,它是`SqlTableName`,而不是持久类名称。例如,默认模式是`SQLUser`,而不是`User`。该值区分大小写。
- 第二个参数是SQL索引映射名称。这通常是索引的名称,指的是磁盘上存储索引的名称。对于新索引,这是在创建索引时将使用的名称。该值不区分大小写。
- 第三个参数是`MapSelecability`标志,其中0将索引映射定义为不可选择(`OFF`),1将索引映射定义为可选择(`ON`)。指定0。
可以通过调用`GetMapSelecability()`方法来确定索引是否不可选。如果已将索引显式标记为不可选,则此方法返回0。在所有其他情况下,它返回1;它不执行表或索引是否存在的验证检查。请注意,`Schema.Table`名称是`SqlTableName`,并且区分大小写。
`SetMapSelecability()`和`GetMapSelecability()`仅适用于当前命名空间中的索引映射。如果该表映射到多个命名空间,并且需要在每个命名空间中构建索引,则应该在每个命名空间中调用`SetMapSelecability()`。
2. 在索引构建期间建立并发操作:
- 对于新索引:在类中创建索引定义(或在类的`%Storage.SQL`中创建新的SQL Index Map规范)。编译类。此时,索引存在于表定义中;这意味着对象保存、SQL `INSERT`操作和SQL `UPDATE`操作都记录在索引中。但是,由于在步骤1中调用了`SetMapSelecability()`,因此不会为任何数据检索选择此索引映射。`SetMapSelecability()`阻止查询使用区索引,但是数据映射将被投影到SQL以使用索引全局和数据全局。对于新索引,这是合适的,因为索引尚未填充。在对表运行查询之前,需要填充区索引。
- 对于现有索引:清除任何引用该表的缓存查询。索引构建执行的第一个操作是终止索引。因此,在重新生成索引时,不能依赖任何经过优化以使用该索引的代码。
3. 使用`pLockFlag=2`(行级锁定)的持久化类(表)的`%BuildIndices()`方法构建一个或多个索引。`PLockFlag=2`标志在重建过程中在单个行上建立独占写锁,以便并发数据修改操作与构建索引操作相协调。
默认情况下,`%BuildIndices()`构建为持久类定义的所有索引;可以使用`pIgnoreIndexList`从重建中排除索引。
默认情况下,`%BuildIndices()`为所有`ID`构建索引项。但是,可以使用`pStartID`和`pEndID`来定义`ID`范围。`%BuildIndices()`将仅为该范围内(含)的ID构建索引项。例如,如果使用带有`%NOINDEX`限制的`INSERT`将一系列新记录添加到表中,则可以稍后使用具有ID范围的`%BuildIndices()`为这些新记录构建索引项。还可以使用`pStartID`和`pEndID`在节中构建极大的索引。
`%BuildIndices()`返回`%Status`值。如果`%BuildIndices()`因检索数据时出现问题而失败,系统将生成一个`SQLCODE`错误和一条消息(`%msg`),其中包含遇到错误的`%ROWID`。
4. 构建完索引后,启用映射以供查询优化器选择。将第三个参数`MapSelecability`标志设置为1,如下例所示:
```java
SET status=$SYSTEM.SQL.Util.SetMapSelectability("Sample.MyStudents","StudentNameIDX",1)
```
5. 再次清除引用该表的所有缓存查询。这将消除在此程序中创建的缓存查询,这些查询无法使用索引,因此不如使用索引的相同查询最佳。
这就完成了这个过程。索引已完全填充,查询优化器能够考虑该索引。
注意:`%BuildIndices()`只能用于重建`ID`值为正整数的表的索引。如果父表具有正整数`ID`值,还可以使用`%BuildIndices()`重建子表中的索引。对于其他表,请使用`%ValidateIndices()`方法,如验证索引中所述。因为`%ValidateIndices()`是构建索引的最慢方法,所以只有在没有其他选项的情况下才应该使用它。
文章
姚 鑫 · 四月 15, 2021
# 第二章 定义和构建索引(三)
# 位图索引
位图索引是一种特殊类型的索引,它使用一系列位串来表示与给定索引数据值相对应的一组ID值。
位图索引具有以下重要功能:
- 位图是高度压缩的:位图索引可以比标准索引小得多。这大大减少了磁盘和缓存的使用量。
- 位图操作针对事务处理进行了优化:与使用标准索引相比,可以在表中使用位图索引,而不会降低性能。
- 位图上的逻辑操作(`counting`、`AND`和`OR`)经过优化以获得高性能。
- SQL引擎包括许多可以利用位图索引的特殊优化。
位图索引的创建取决于表的唯一标识字段的性质:
- 如果表的`ID`字段定义为具有正整数值的单个字段,则可以使用此`ID`字段为字段定义位图索引。此类型的表使用系统分配的唯一正整数`ID`,或使用`IdKey`定义自定义`ID`值,其中`IdKey`基于类型为`%Integer`且`MINVAL`>的单个属性,或类型`%Numeric`型且`Scale=0`且`MINVA>0`。
- 如果表的`ID`字段未定义为具有正整数值的单个字段(例如,子表),则可以定义采用正整数的`%BID`(位图`ID`)字段作为代理`ID`字段;这允许为该表中的字段创建位图索引。
受下列限制,位图索引的操作方式与标准索引相同。
索引值将被整理,可以在多个字段的组合上建立索引。
## 位图索引操作
位图索引的工作方式如下。
假设`Person`表,其中包含一些列:
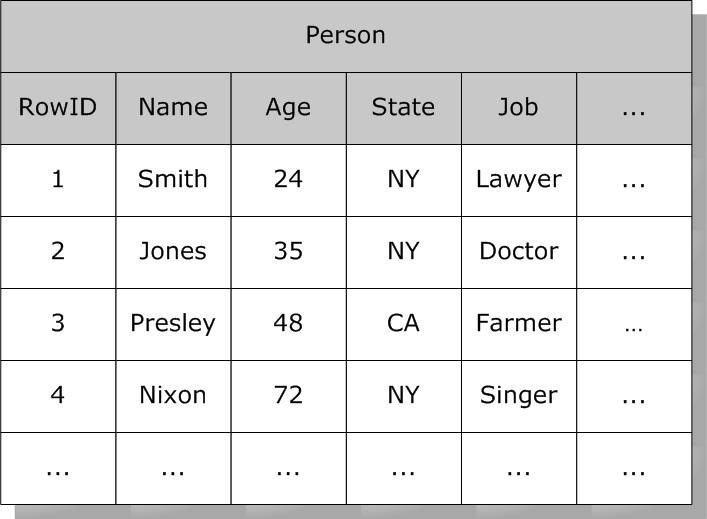
此表中的每一行都有一个系统分配的`RowID`号(一组递增的整数值)。位图索引使用一组位字符串(包含1和0值的字符串)。在位串中,位的序号位置对应于索引表的`RowID`。对于给定值,假设`State`为`“NY”`,则有一个位串,每个位置对应一个包含`“NY”`的行,其他位置为0。
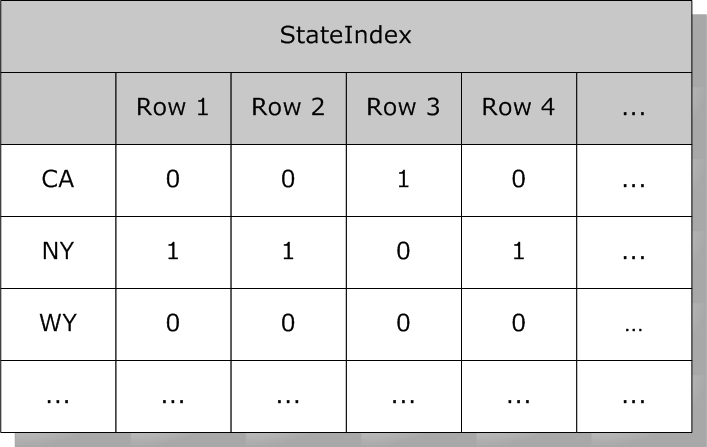
例如,`State`上的位图索引可能如下所示:
而关于`Age` 年龄的索引可能如下所示:
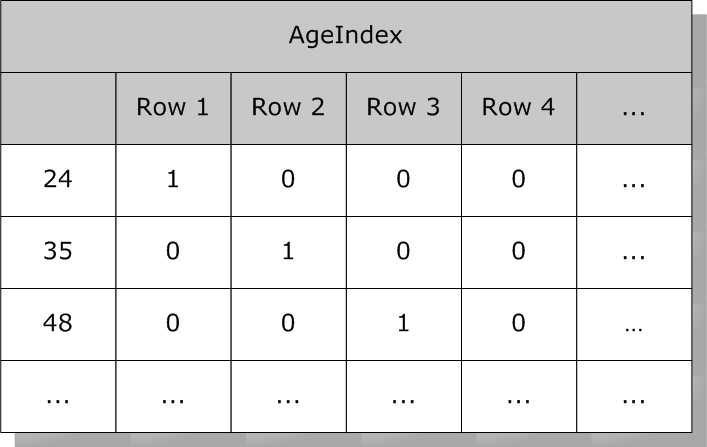
注:此处显示的年龄字段可以是普通数据字段,也可以是其值可以可靠派生(`Calculated` 和`SQLComputed`)的字段。
除了将位图索引用于标准操作外,SQL引擎还可以使用位图索引来使用多个索引的组合来高效地执行特殊的基于集合的操作。例如,要查找居住在纽约的24岁`Person`的所有实例,SQL引擎只需执行`Age`和`State`索引的逻辑与:
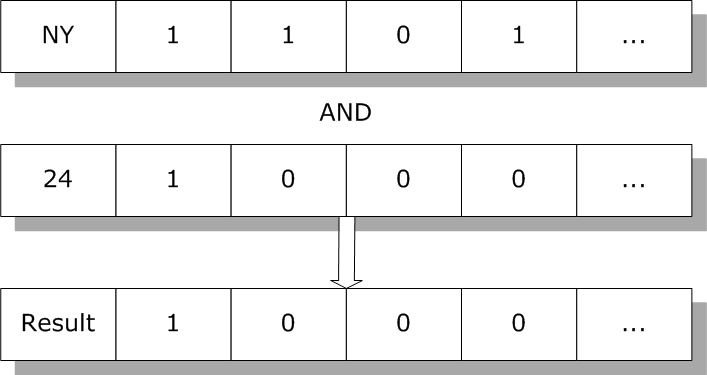
生成的位图包含匹配搜索条件的所有行的集合。SQL引擎使用它从这些行返回数据。
SQL引擎可以将位图索引用于以下操作:
- 对给定表上的多个条件进行`AND`运算。
- 对给定表上的多个条件进行`OR`运算。
- 给定表上的`RANGE`范围条件。
- 对给定表上的操作进行计数`COUNT`。
## 使用类定义定义IdKey位图索引
如果表的`ID`是值限制为唯一正整数的字段,则可以使用新建索引向导或通过与创建标准索引相同的方式编辑类定义的文本,将位图索引定义添加到类定义中。唯一的区别是需要将索引类型指定为“位图”:
```java
Class MyApp.SalesPerson Extends %Persistent [DdlAllowed]
{
Property Name As %String;
Property Region As %Integer;
Index RegionIDX On Region [Type = bitmap];
}
```
## 使用类定义定义`%BID`位图索引
如果表的`ID`不限于正整数,则可以创建`%BID`属性以用于创建位图索引定义。可以将此选项用于具有任何数据类型的`ID`字段的表,以及由多个字段组成的`IDKEY`(包括子表)。可以为以下任一数据存储类型创建`%BID`位图:默认结构表或`%Storage.SQL`表。此功能称为“任意表的位图”或`BAT`。
要在这样的表上启用位图索引,必须执行以下操作:
1. 为类定义`%BID`属性/字段。这可以是类的现有属性,也可以是新属性。它可以有任何名称。如果这是新属性,则必须为表中的所有现有行填充此属性/字段。此`%BID`字段必须定义为将字段数据值限制为唯一正整数的数据类型。例如,将`MyBID`属性设置为`%Counter`;
2. 定义新的类参数以定义哪个属性是`%BID`字段。此参数被命名为`BIDField`。此参数设置为`%BID`属性的`SQLFieldName`。例如,参数`BIDField=“MyBID”`;
3. 定义`%BID`的索引。例如,`MyBID`上的`Index BIDIdx[Type=Key,Unique]`;
4. 定义`%BID`定位器索引。
这将`%BID`索引绑定到表的`ID`键字段。
下面的例子是一个表的一个复合`IDKey`组成两个字段:
```java
Index IDIdx On (IDfield1, IDfield2) [ IdKey, Unique ];
Index BIDLocIdx On (IDfield1, IDfield2, MyBID) [ Data = IdKey, Unique ];
```
此表现在支持位图索引。可以使用标准语法根据需要定义位图索引。例如: `Index RegionIDX On Region [Type = bitmap]`;
此表现在还支持位片索引。可以使用标准语法定义位片索引。
**注意:要构建或重新生成`%BID`位图索引,必须使用`%BuildIndices()`。`%BID`位图索引不支持`%ConstructIndicesParallel()`方法。**
## 使用DDL定义位图索引
如果使用DDL语句定义表,还可以使用以下DDL命令为`ID`为正整数的表格创建和删除位图索引:
```sql
CREATE BITMAP INDEX RegionIDX ON TABLE MyApp.SalesPerson (Region)
```
## 生成位图范围索引
**编译包含位图索引的类时,如果类中存在任何位图索引,并且没有为该类定义位图范围索引,则类编译器会生成位图范围索引。如果位图范围索引存在(无论是定义的还是生成的),该类从主超类继承位图范围索引。为类构建索引时,如果要求构建位图范围索引,或者正在构建另一个位图索引并且位图范围索引结构为空,则会构建位图范围索引。**
除非存在位图索引,否则InterSystems IRIS不会生成位图范围索引。位图范围索引定义为:`type = bitmap`, `extent = true`。这意味着从主要超类继承的位图范围索引被认为是位图索引,并且如果在该子类中没有显式定义位图范围索引,则将触发在子类中生成位图范围索引。
InterSystems IRIS不会基于未来的可能性在超类中生成位图范围索引。这意味着,除非存在`type=bitmap`的索引,否则InterSystems IRIS永远不会在持久类中生成位图范围索引。假设将来的某个子类可能引入`type=bitmap`的索引是不够的。
**注意:在将位图索引添加到生产系统上的类的过程中需要特别小心(在生产系统中,用户正在使用特定的类,编译所述类,然后为其构建位图索引结构)。在这样的系统上,位图范围索引可以在编译完成和索引构建进行之间的过渡期间被填充。这可能导致索引构建过程未隐式构建位图范围索引,这导致部分完整的位图范围索引。**
## 选择索引类型
**下面是在位图和标准索引之间选择的一般准则。
一般来说,所有类型的键和引用都要使用标准索引:**
- Primary key
- Foreign key
- Unique keys
- Relationships
- Simple object references
否则,位图索引通常更可取(假设表使用系统分配的数字ID号)。
其他因素:
- **每个属性上的单独位图索引通常比多个属性上的位图索引具有更好的性能。这是因为SQL引擎可以使用`AND`和`OR`操作有效地组合单独的位图索引。**
- **如果一个属性(或确实需要一起编制索引的一组属性)有超过`10,000-20,000`个不同的值(或值组合),请考虑标准索引。但是,如果这些值的分布非常不均匀,以至于很少的值只占行的很大一部分,那么位图索引可能会更好。一般来说,目标是减少索引所需的总体大小。**
## 位图索引的限制
所有位图索引都有以下限制:
- 不能在唯一列上定义位图索引。
- 不能在位图索引中存储数据值。
- 除非字段的`SqlCategory`是 `INTEGER`, `DATE`, `POSIXTIME`, or `NUMERIC(scale=0)`,否则不能在字段上定义位图索引。
- **对于包含超过100万条记录的表,当惟一值的数量超过`10,000`时,位图索引的效率低于标准索引。
因此,对于大型表,建议避免为任何包含(或可能包含)超过`10,000`个惟一值的字段使用位图索引;
对于任意大小的表,避免对任何可能包含超过`20,000`个惟一值的字段使用位图索引。
这些是一般的近似值,不是确切的数字。**
必须创建一个`%BID`属性来支持一个表上的位图索引:
- 使用非整数字段作为唯一的`ID`键。
- 使用一个多字段`ID`键。
- 是父子关系中的子表。
可以使用`$SYSTEM.SQL.Util.SetOption()`方法`SET status=$SYSTEM.SQL.Util.SetOption("BitmapFriendlyCheck",1,.oldval) `设置系统范围的配置参数,以便在编译时检查此限制,从而确定`%Storage.SQL`类中是否允许定义的位图索引。此检查仅适用于使用`%Storage.SQL`的类。默认值为0可以使用`$SYSTEM.SQL.Util.GetOption(“BitmapFriendlyCheck”)`来确定此选项的当前配置。
### 应用程序逻辑限制
位图结构可以由位串数组表示,其中数组的每个元素表示具有固定位数的`"chunk"`。因为`UNDEFINED`等同于一个全为0位的块,所以该数组可以是稀疏的。表示全部0位的块的数组元素根本不需要存在。因此,应用程序逻辑应该避免依赖于0值位的`$BITCOUNT(str,0)`计数。
由于位串包含内部格式,因此应用程序逻辑不应依赖于位串的物理长度,也不应依赖于将具有相同位值的两个位串相等。在回滚操作之后,位串恢复到事务之前的位值。然而,由于内部格式化,回滚的位串可能不等于或不具有与事务之前的位串相同的物理长度。
## 维护位图索引
**在易失性表(执行许多插入和删除操作)中,位图索引的存储效率可能会逐渐降低。要维护位图索引,可以运行`%SYS.Maint.Bitmap`实用程序方法来压缩位图索引,使其恢复到最佳效率。可以使用`OneClass()`方法压缩单个类的位图索引。或者,可以使用`Namespace()`方法来压缩整个命名空间的位图索引。这些维护方法可以在带电系统上运行。**
运行`%SYS.Maint.Bitmap`实用程序方法的结果将写入调用该方法的进程。这些结果还会写入`%SYS.Maint.BitmapResults`类。
## 位图块的SQL操作
InterSystems SQL提供了以下扩展来直接操作位图索引:
- `%CHUNK`函数
- `%Bitpos`函数
- `%BITMAP`聚合函数
- `%BITMAPCHUNK`聚合函数
- `%SETINCHUNK`谓词条件
所有这些扩展都遵循InterSystems SQL位图表示约定,将一组正整数表示为一系列位图块,每个块最多包含`64,000个`整数。
这些扩展允许在查询和嵌入式SQL中更轻松、更高效地操作某些条件和筛选器。在嵌入式SQL中,它们支持位图的简单输入和输出,特别是在单个块级别。它们支持处理完整的位图,这些位图由`%bitmap()`和`%SQL.Bitmap`类处理。它们还支持非`RowID`值的位图处理,例如外键值、子表的父引用、关联的任一列等。
例如,要输出指定块的位图,请执行以下操作:
```sql
SELECT %BITMAPCHUNK(Home_Zip) FROM Sample.Person
WHERE %CHUNK(Home_Zip)=2
```
要输出整个表的所有块,请执行以下操作:
```sql
SELECT %CHUNK(Home_Zip),%BITMAPCHUNK(Home_Zip) FROM Sample.Person
GROUP BY %CHUNK(Home_Zip) ORDER BY 1
```
### %CHUNK函数
`%%CHUNK(F)`返回位图索引字段f值的块分配。这被计算为`f\64000+1.%%CHUNK(F)`非位图索引字段的任何字段或值`f`的`%chunk(F)`始终返回1。
### %BITPOS函数
`%Bitpos(F)`返回分配给其区块内的位图索引字段`f`值的位位置。这被计算为`f#64000+1`。对于不是位图索引字段的任何字段或值`f`,`%Bitpos(F)`返回的值比其整数值多`1`。字符串的整数值为`0`。
### %BITMAP聚合函数
聚合函数`%bitmap(F)`将许多`f`值组合到一个`%SQL.Bitmap`对象中,在该对象中,对于结果集中的每个值`f`,与适当块中的`f`相对应的位被设置为`1`。上述所有参数中的f通常是正整数字段(或表达式),通常(但不一定)是`RowID`。
### %BITMAPCHUNK聚合函数
聚合函数`%BITMAPCHUNK(F)`将字段f的许多值组合成`64,000`位的InterSystems SQL标准位图字符串,其中对于集合中的每个值`f`,位`f#64000+1=%Bitpos(F)`被设置为`1`。请注意,无论`%chunk(F)`的值是多少,都会在结果中设置该位。`%BITMAPCHUNK()`为空集生成`NULL`,并且与任何其他聚合一样,它忽略输入中的`NULL`值。
### %SETINCHUNK谓词条件
当且仅当($BIT(BM,`%Bitpos(F)=1`时,条件(`f%SETINCHUNK BM`)为真。Bm可以是任何位图表达式字符串,例如输入主机变量:`bm`,或`%BITMAPCHUNK()`聚合函数的结果,等等。请注意,无论`%chunk(F)`的值是多少,都会检查`` 位。如果`` 不是位图或为`NULL`,则条件返回`FALSE`。(`F%SETINCHUNK NULL`)生成`FALSE`(非未知)。
公告
Michael Lei · 四月 15, 2021
开发者们现在可以下载一套InterSystems ObjectScript扩展插件,并开始使用微软的Visual Studio Code IDE编写应用程序。我们培训部门的新VS Code资源指南提供了大量开发人员入门需要的内容,包括:
连接到InterSystems实例:安装和使用VS Code的ObjectScript扩展VS Code开发应用程序文档:使用开源社区。 播客集: 在VS代码中编写ObjectScript (20m) 开发者社区文章。如何报告问题 Github Repository。InterSystems语言服务器 Github Repository。InterSystems服务器管理器 Github Repository。VS代码的InterSystems ObjectScript扩展 了解IDE。 微软文档。Visual Studio代码 - 入门 微软视频。Visual Studio代码入门 (5m)
更多详情欢迎访问:https://learning.intersystems.com/course/view.php?id=1678&ssoPass=1
文章
Qiao Peng · 四月 15, 2021
圆满结束!
所有的专题会议都已经播出了。当然,我们全部102部预录制的专题会议现在可以点播了,您可以随意观看,即使您错过了现场问答的机会。
说到现场问答,我们已经举办了6次现场会议,您也可以观看。我之前写过一篇单独的博客文章,题目是如何让您的问题会帮助我们做得更好。
智能工厂启动包
今天备受关注的亮点之一是Intersystems IRIS智能工厂启动包在OpenExchange上发布。为此,我们的合作伙伴ITVisors和他们的客户Vlisco与我们的Joe Lichtenberg一起举办了一场精彩的会议“MFG001:介绍适用于制造业的InterSystems IRIS智能工厂启动包”。
容器和Kubernetes平台
今天我们宣布了一个高度安全的新版IRIS容器,名为“iris-lockeddown”,这个容器非常适合在Kubernetes中使用加固型pod安全策略的团队。说到Kubernetes,Steve Lubars演示了我们新的InterSystems Kubernetes Operator,它让您可以很轻松地在Kubernetes 中部署IRIS集群。而Luca Ravazzolo则演示了如何用CPF合并文件配置您的IRIS实例,特别是如何自动化进行镜像配置。还有其他一些有趣的问题。
以上精彩内容尽在对话Ontario Systems公司企业架构师Jim Howell中,讲述了他们从庞大的旧系统迁移到Kubernetes现代化微服务架构的经历。
更多分析:
如果您觉得我们在分析领域没什么可谈论和宣布的了,再想想!Sergey在“DA014平台内AI的最佳实践”中分享了我们对平台内AI的观点,以及如何通过IRIS协调机器学习操作从而实现持续集成和交付(CI & CD)。作为“分析”板块的压轴,Benjamin展示了我们采用Alteryx的新协作项目,其允许业务分析师和主题专家不需要编程就可以构建分析工作流,并且可以轻松地将他们的工作融合到IRIS中。观看“DA011使用Alteryx搭配IRIS打造您的分析工作流”,了解更多关于这项合作的详情。
更多VS Code - ObjectScript https://intersystems.6connex.com/event/virtual-summit/en-us/contents/434914/share?rid=FocusSessions&nid=851040
我在第1天的博客中谈过这个,今天我们再次更深入地探讨了最热门的话题之一:源代码控制,观看“DEE006使用Visual Studio Code进行ObjectScript开发:选择IDE/源代码控制组合”和“DEE005使用Visual Studio Code进行ObjectScript开发:服务器端源代码控制”。我还注意到人们深入探讨了实战实验室并给与了高度评价——值得一试!
让我感到特别兴奋的是,我们在保持这一社区作为真正的开源社区的同时,还能提供大量InterSystems核心开发周期和InterSystems的深度支持。请加入社区并将您的建议反馈给我们!
是的,更多关于FHIR的内容
我们的FHIR板块一直很棒,第3天也不例外。
Russ Leftwich展示了一部很棒的动画,这部动画描绘了FHIR从起源到如今的整个发展历程,其中包括了所有最新的InterSystems FHIR技术。“FH008 FHIR:为未来设计的医疗数据标准”20分钟的总结,是我见过的最棒的关于FHIR的总结。
Kurt Dawn介绍了InterSystems客户非常关注的热门话题FHIR Profiles。他展示了如何将用于实现规范的FHIR包轻松导入IRIS医疗版。Jeff Morgan的IRIS医疗版中的FHIR实现模式演示了如何使用带生产和定制逻辑的FHIR服务器——高级开发者肯定想了解一下。
持续学习
还有很多其他的会议我没有提到;我建议大家去会议网站搜索自己感兴趣的话题——您可以看到所有板块的专题会议,演示区的各种演示,以及资源区的各种内容。
如果您先想看看亮点,然后再选择观看其他内容,您可以查看我的第1天和第2天总结,我们的紧密合作伙伴J2也一直在发布每日精彩回顾(查看J2第1天专题会议的精彩回顾和第2天专题会议的精彩回顾)
请教专家是深入了解任何您感兴趣的主题的好方法。现在预约10月30日或11月2日与专家或培训师会面也不迟!而且下周是实验室周——可以尝试实战实验室!您可以选择Office Hours以及On-Demand和Live Labs。
感谢参与我们的首次线上峰会!
您可以在下面评论或通过任何您喜欢的方式告诉我们您的想法。
查看原帖 由 @Jeff Fried 撰写