清除过滤器
文章
姚 鑫 · 三月 19, 2021
# 第十二章 使用嵌入式SQL(三)
# 主机变量
**主机变量是将文字值传入或传出嵌入式SQL的局部变量。** 最常见的是,主机变量用于将本地变量的值作为输入值传递给Embedded SQL,或者将SQL查询结果值作为输出主机变量传递给Embedded SQL查询。
主机变量不能用于指定SQL标识符,例如架构名称,表名称,字段名称或游标名称。主机变量不能用于指定SQL关键字。
- 输出主机变量仅在嵌入式SQL中使用。它们在`INTO`子句中指定,`INTO`子句是仅嵌入式SQL支持的SQL查询子句。
- 输入主机变量可以在嵌入式SQL或动态SQL中使用。在动态SQL中,还可以使用`“?”`向SQL语句输入文字。输入参数。这 `”?”`语法不能在Embedded SQL中使用。
在嵌入式SQL中,可以在可以使用文字值的任何位置使用输入主机变量。使用SELECT或FETCH语句的`INTO`子句指定输出主机变量。
注意:当SQL `NULL`输出到ObjectScript时,它由一个ObjectScript空字符串(`“”`)表示,该字符串的长度为零。
**要将变量或属性引用用作宿主变量,请在其前面加上一个冒号(`:`)。** 嵌入式InterSystems SQL中的主机变量可以是以下之一:
- 一个或多个ObjectScript局部变量,例如:`myvar`,指定为以逗号分隔的列表。局部变量可以完全形成并且可以包含下标。像所有局部变量一样,它区分大小写,并且可以包含Unicode字母字符。
- 单个ObjectScript局部变量数组,例如:`myvars()`。局部变量数组只能从单个表(而不是联接表或视图)中接收字段值。
- 对象引用,例如:`oref.Prop`,其中`Prop`是属性名称,带有或不带有前导`%`字符。这可以是简单属性或多维数组属性,例如:`oref.Prop(1)`。它可以是一个实例变量,例如:`i%Prop`或:`i %% Data`。属性名称可以定界。例如:`Person."Home City"`.即使停用了对分隔标识符的支持,也可以使用分隔属性名称。多维属性可以包括:`i%Prop()`和:`m%Prop()`主机变量引用。对象引用主机变量可以包含任意数量的点语法级别;例如,例如,:`Person.Address.City`。
当`oref.Prop`用作过程块方法内的宿主变量时,系统会自动将`oref`变量(而不是整个`oref.Prop`引用)添加到`PublicList`并对其进行更新。
主机变量中的双引号指定文字字符串,而不是带分隔符的标识符。例如,`:request.GetValueAt("PID:SetIDPID") o`r `:request.GetValueAt("PID:PatientName(1).FamilyName")`.
主机变量应在ObjectScript过程的PublicList变量列表中列出,并使用`NEW`命令重新初始化。您可以配置InterSystems IRIS以便在注释文本中列出Embedded SQL中使用的所有主机变量。使用InterSystems SQL的注释部分对此进行了描述。
主机变量值具有以下行为:
- **输入主机变量永远不会被SQL语句代码修改。即使嵌入式SQL运行后,它们仍保留其原始值。但是,输入主机变量值在提供给SQL语句代码之前会被“轻度格式化”:有效数字值将去除前导和尾随零,单个前导加号和尾随小数点。时间戳记值将除去尾随空格,以小数秒为单位的尾随零和(如果没有小数秒的话)尾随的小数点。**
- **当`SQLCODE = 0`时,即返回有效行时,将设置`INTO`子句中指定的输出主机变量。如果执行`SELECT`语句或`FETCH`语句导致`SQLCODE = 100`(没有数据与查询匹配),则`INTO`子句中指定的输出主机变量将设置为`null(“”)`。如果在执行`SELECT`语句或`FETCH`语句之前未定义`INTO`变量,导致`SQLCODE = 100`,则该变量将保持未定义状态。主机变量值仅应在`SQLCODE = 0`时使用。在`DECLARE` ... `SELEC`T ... `INTO`语句中,请勿在两个`FETCH`调用之间修改`INTO`子句中的输出主机变量,因为这可能会导致不可预测的查询结果。**
在处理输出主机变量之前,必须检查`SQLCODE`值。仅当`SQLCODE = 0`时才应使用输出主机变量值。
**当在`INTO`子句中使用逗号分隔的主机变量列表时,必须指定与选择项数量相同的主机变量数量(字段,集合函数,标量函数,算术表达式,文字)。宿主变量太多或太少都会在编译时导致`SQLCODE -76`基数错误。**
在嵌入式SQL中使用`SELECT *`时,这通常是一个问题。例如,`SELECT * FROM Sample.Person`仅对以逗号分隔的15个主机变量列表有效(非隐藏列的确切数目,具体取决于表定义,该数目可能包含也可能不包含系统生成的RowID) (`ID`)列)。
因为列数可以更改,所以用单个宿主变量的`INTO`子句列表指定`SELECT *`通常不是一个好主意。使用`SELECT *`时,通常最好使用主机变量下标数组,例如:
```java
/// d ##class(PHA.TEST.SQL).EmbedSQL9()
ClassMethod EmbedSQL9()
{
NEW SQLCODE
&sql(SELECT %ID,* INTO :tflds() FROM Sample.Person )
IF SQLCODEd ##class(PHA.TEST.SQL).EmbedSQL9()
field 1 = 1
field 2 = 30
field 3 = 54536
field 4 = �ReOrangYellow
field 6 = yaoxin
field 8 = 111-11-1117
field 9 = 13
field 11 = St Louis
field 12 = WI
field 13 = 889 Clinton Drive
field 14 = 78672
field 15 = Ukiah
field 16 = AL
field 17 = 9619 Ash Avenue
field 18 = 56589
```
**本示例使用`%ID`返回`RowID`作为字段号1,无论`RowID`是否隐藏。** 注意,在此示例中,字段编号下标可能不是连续序列;有些字段可能被隐藏并被跳过。包含`NULL`的字段以空字符串值列出。
**
退出嵌入式SQL后立即检查`SQLCODE`值是一种良好的编程习惯。仅当`SQLCODE = 0`时才应使用输出主机变量值。**
## 主机变量示例
在下面的ObjectScript示例中,Embedded SQL语句使用输出主机变量将名称和归属状态地址从SQL查询返回到ObjectScript:
```java
/// d ##class(PHA.TEST.SQL).EmbedSQL10()
ClassMethod EmbedSQL10()
{
&sql(SELECT Name,Home_State
INTO :CName,:CAddr
FROM Sample.Person)
IF SQLCODEd ##class(PHA.TEST.SQL).EmbedSQL10()
Name is: yaoxin
State is: WI
```
嵌入式SQL使用`INTO`子句指定主机变量`:CName`和`:CAddr`,以在局部变量`CName`中返回所选客户的姓名,并在局部变量`CAddr`中返回主目录状态。
下面的示例使用带下标的局部变量执行相同的操作:
```java
/// d ##class(PHA.TEST.SQL).EmbedSQL11()
ClassMethod EmbedSQL11()
{
&sql(SELECT Name,Home_State
INTO :CInfo(1),:CInfo(2)
FROM Sample.Person)
IF SQLCODEd ##class(PHA.TEST.SQL).EmbedSQL11()
Name is: yaoxin
State is: WI
```
这些主机变量是带有用户提供的下标(`:CInfo(1)`)的简单局部变量。但是,如果省略下标(`:CInfo()`),则InterSystems IRIS使用`SqlColumnNumber`填充主机变量下标数组,如下所述。
在下面的ObjectScript示例中,嵌入式SQL语句同时使用输入主机变量(在`WHERE`子句中)和输出主机变量(在`INTO`子句中):
```java
/// d ##class(PHA.TEST.SQL).EmbedSQL12()
ClassMethod EmbedSQL12()
{
SET minval = 10000
SET maxval = 50000
&sql(SELECT Name,Salary INTO :outname, :outsalary
FROM Sample.Employee
WHERE Salary > :minval AND Salary < :maxval)
IF SQLCODEd ##class(PHA.TEST.SQL).EmbedSQL12()
Name is: Chadwick,Phyllis L.
Salary is: 16377
```
以下示例在输入主机变量上执行`“light normalization”`。请注意,InterSystems IRIS将输入变量值视为字符串,并且不对其进行规范化,但是Embedded SQL将此数字规范化为`65`,以在`WHERE`子句中执行相等比较:
```java
/// d ##class(PHA.TEST.SQL).EmbedSQL13()
ClassMethod EmbedSQL13()
{
SET x="+065.000"
&sql(SELECT Name,Age
INTO :a,:b
FROM Sample.Person
WHERE Age=:x)
IF SQLCODEd ##class(PHA.TEST.SQL).EmbedSQL13()
Input value is: +065.000
Name value is: Houseman,Martin D.
Age value is: 65
```
在下面的ObjectScript示例中,嵌入式SQL语句使用对象属性作为宿主变量:
```sql
&sql(SELECT Name, Title INTO :obj.Name, :obj.Title
FROM MyApp.Employee
WHERE %ID = :id )
```
在这种情况下,`obj`必须是对具有可变(即可以修改)属性`Name`和`Title`的对象的有效引用。请注意,如果查询包含`INTO`语句并且没有返回任何数据(即`SQLCODE`为`100`),则执行查询可能会导致修改主机变量的值。
## 用列号下标的主机变量
如果`FROM`子句包含一个表,则可以为从该表中选择的字段指定带下标的主机变量;否则,可以为该表指定一个下标主机变量。例如,本地数组`:myvar()`。 InterSystems IRIS使用每个字段的`SqlColumnNumber`作为数字下标填充本地数组。请注意,`SqlColumnNumber`是表定义中的列号,而不是选择列表序列。 (不能将带下标的宿主变量用于视图的字段。)
主机变量数组必须是省略了最低级别下标的局部数组。因此,`:myvar()`, `:myvar(5,)`, and `:myvar(5,2,)`都是有效的主机变量下标数组。
- 主机变量下标数组可以用于`INSERT`,`UPDATE`或`INSERT` OR `UPDATE`语句`VALUES`子句中的输入。当在`INSERT`或`UPDATE`语句中使用时,主机变量数组使您可以定义在运行时而不是在编译时更新哪些列。
- 主机变量下标数组可以用于`SELECT`或`DECLARE`语句`INTO`子句中的输出。在下面的示例中显示了`SELECT`中的下标数组用法。
在下面的示例中,`SELECT`使用指定字段的值填充`Cdata`数组。 `Cdata()`的元素对应于表列定义,而不是`SELECT`元素。因此,在`Sample.Person`中,`“名称”`字段是第6列,`“年龄”`字段是第2列,`“出生日期”`(`DOB`)字段是第3列:
```java
/// d ##class(PHA.TEST.SQL).EmbedSQL14()
ClassMethod EmbedSQL14()
{
&sql(SELECT Name, Age, DOB
INTO :Cdata()
FROM Sample.Person)
IF SQLCODEd ##class(PHA.TEST.SQL).EmbedSQL14()
Name is: yaoxin
Age is: 30
DOB is: 04/25/90
```
以下示例使用带下标的数组主机变量返回行的所有字段值:
```java
/// d ##class(PHA.TEST.SQL).EmbedSQL15()
ClassMethod EmbedSQL15()
{
&sql(SELECT * INTO :Allfields()
FROM Sample.Person)
IF SQLCODE d ##class(PHA.TEST.SQL).EmbedSQL16()
1 field is 1
2 field is 30
3 field is 54536
4 field is �ReOrangYellow
6 field is yaoxin
8 field is 111-11-1117
9 field is 13
11 field is St Louis
12 field is WI
13 field is 889 Clinton Drive
14 field is 78672
15 field is Ukiah
16 field is AL
17 field is 9619 Ash Avenue
18 field is 56589
date & time now is 2021-03-13 16:00:40
exact age is 30.88295687885010267
```
请注意,非数组主机变量必须在数量和顺序上与非列`SELECT`项匹配。
将主机变量用作下标数组受以下限制:
- **只有在`FROM`子句的单个表中选择字段时,才可以使用带下标的列表。这是因为从多个表中选择字段时,`SqlColumnNumber`值可能会发生冲突。**
- 下标列表只能在选择表字段时使用。它不能用于表达式或聚合字段。这是因为这些选择列表项没有`SqlColumnNumber`值。
## `NULL`和未定义的主机变量
如果指定未定义的输入主机变量,则嵌入式SQL将其值视为`NULL`。
```java
/// d ##class(PHA.TEST.SQL).EmbedSQL17()
ClassMethod EmbedSQL17()
{
NEW x
&sql(SELECT Home_State,:x
INTO :a,:b
FROM Sample.Person)
IF SQLCODEd ##class(PHA.TEST.SQL).EmbedSQL17()
Home_State的长度为: 2
x的长度是: 0
```
SQL `NULL`等效于ObjectScript“”字符串(长度为零的字符串)。
如果将`NULL`输出到主机变量,则Embedded SQL会将其值视为ObjectScript`“”`字符串(零长度字符串)。例如,`Sample.Person`中的某些记录具有`NULL Spouse`字段。执行此查询后:
```java
/// d ##class(PHA.TEST.SQL).EmbedSQL18()
ClassMethod EmbedSQL18()
{
&sql(SELECT Name,Spouse
INTO :name, :spouse
FROM Sample.Person
WHERE Spouse IS NULL)
IF SQLCODEd ##class(PHA.TEST.SQL).EmbedSQL18()
Name: xiaoli of length 6 defined: 1
Spouse: of length 0 defined: 1
```
宿主变量`spouse`将设置为`“”`(长度为零的字符串)以指示`NULL`值。因此,不能使用ObjectScript `$DATA`函数来确定SQL字段是否为`NULL`。当传递带有`NULL`值的SQL字段的输出主机变量时,`$DATA`返回true(定义了变量)。
在极少数情况下,表字段包含SQL零长度字符串(`''`),例如,如果应用程序将字段显式设置为SQL `''`字符串,则主机变量将包含特殊标记值`$CHAR(0 )`(长度为1的字符串,仅包含一个ASCII 0字符),它是SQL零长度字符串的ObjectScript表示形式。强烈建议不要使用SQL零长度字符串。
下面的示例比较SQL `NULL`和SQL零长度字符串输出的主机变量:
```java
/// d ##class(PHA.TEST.SQL).EmbedSQL19()
ClassMethod EmbedSQL19()
{
&sql(SELECT '',Spouse
INTO :zls, :spouse
FROM Sample.Person
WHERE Spouse IS NULL)
IF SQLCODEd ##class(PHA.TEST.SQL).EmbedSQL19()
In ObjectScript
ZLS is of length 1 defined: 1
NULL is of length 0 defined: 1
```
请注意,此主机变量`NULL`行为仅在基于服务器的查询(嵌入式SQL和动态SQL)中为true。在ODBC和JDBC中,使用ODBC或JDBC接口显式指定NULL值。
## 主机变量的有效性
- **嵌入式SQL永远不会修改输入主机变量。**
- **仅当`SQLCODE = 0`时,输出主机变量才在Embedded SQL之后可靠地有效。**
例如,以下`OutVal`的用法不可靠:
```java
/// d ##class(PHA.TEST.SQL).EmbedSQL20()
ClassMethod EmbedSQL20()
{
InvalidExample
SET InVal = "1234"
SET OutVal = "None"
&sql(SELECT Name
INTO :OutVal
FROM Sample.Person
WHERE %ID=:InVal)
IF OutVal="None" {
WRITE !,"没有数据返回"
WRITE !,"SQLCODE=",SQLCODE
} ELSE {
WRITE !,"Name is: ",OutVal
}
}
```
```java
DHC-APP>d ##class(PHA.TEST.SQL).EmbedSQL20()
没有数据返回
SQLCODE=100
```
调用嵌入式SQL之前设置的`OutVal`的值在从嵌入式SQL返回之后不应该被IF命令引用。
相反,应该使用`SQLCODE`变量编写如下示例:
```java
/// d ##class(PHA.TEST.SQL).EmbedSQL21()
ClassMethod EmbedSQL21()
{
ValidExample
SET InVal = "1234"
&sql(SELECT Name
INTO :OutVal
FROM Sample.Person
WHERE %ID=:InVal)
IF SQLCODE'=0 {
SET OutVal="None"
IF OutVal="None" {
WRITE !,"没有数据返回"
WRITE !,"SQLCODE=",SQLCODE }
} ELSE {
WRITE !,"Name is: ",OutVal
}
}
```
```java
DHC-APP>d ##class(PHA.TEST.SQL).EmbedSQL21()
没有数据返回
SQLCODE=100
```
**嵌入式SQL将`SQLCODE`变量设置为0,以指示成功地检索输出行。
`SQLCODE`值为`100`表示没有找到与`SELECT`条件匹配的行。
`SQLCODE`负数表示SQL错误条件。**
## 主机变量和程序块
如果嵌入式SQL在过程块内,则所有输入和输出主机变量必须是公共的。可以通过在过程块开始处的`PUBLIC`部分中声明它们,或用一个初始`%`字符命名它们(自动使它们公开)来完成它们。但是请注意,用户定义的`%`主机变量是自动公开的,但不是自动更新的。用户有责任根据需要对这些变量执行`NEW`。如嵌入式SQL变量中所述,某些SQL`%`变量(例如`%ROWCOUNT`,`%ROWID`和`%msg`)既自动公开又自动更新。必须将`SQLCODE`声明为`public`。
在以下过程块示例中,主机变量`zip`,`city`和`state`以及`SQLCODE`变量被声明为`PUBLIC`。 SQL系统变量`%ROWCOUNT`,`%ROWID`和`%msg`已经公开,因为它们的名称以`%`字符开头。然后,过程代码对`SQLCODE`,其他SQL系统变量和状态局部变量执行`NEW`。
```java
/// d ##class(PHA.TEST.SQL).EmbedSQL22()
ClassMethod EmbedSQL22()
{
UpdateTest(zip,city)
[SQLCODE,zip,city,state] PUBLIC {
NEW SQLCODE,%ROWCOUNT,%ROWID,%msg,state
SET state="MA"
&sql(UPDATE Sample.Person
SET Home_City = :city, Home_State = :state
WHERE Home_Zip = :zip)
IF SQLCODE
文章
姚 鑫 · 四月 15, 2021
# 第二章 定义和构建索引(三)
# 位图索引
位图索引是一种特殊类型的索引,它使用一系列位串来表示与给定索引数据值相对应的一组ID值。
位图索引具有以下重要功能:
- 位图是高度压缩的:位图索引可以比标准索引小得多。这大大减少了磁盘和缓存的使用量。
- 位图操作针对事务处理进行了优化:与使用标准索引相比,可以在表中使用位图索引,而不会降低性能。
- 位图上的逻辑操作(`counting`、`AND`和`OR`)经过优化以获得高性能。
- SQL引擎包括许多可以利用位图索引的特殊优化。
位图索引的创建取决于表的唯一标识字段的性质:
- 如果表的`ID`字段定义为具有正整数值的单个字段,则可以使用此`ID`字段为字段定义位图索引。此类型的表使用系统分配的唯一正整数`ID`,或使用`IdKey`定义自定义`ID`值,其中`IdKey`基于类型为`%Integer`且`MINVAL`>的单个属性,或类型`%Numeric`型且`Scale=0`且`MINVA>0`。
- 如果表的`ID`字段未定义为具有正整数值的单个字段(例如,子表),则可以定义采用正整数的`%BID`(位图`ID`)字段作为代理`ID`字段;这允许为该表中的字段创建位图索引。
受下列限制,位图索引的操作方式与标准索引相同。
索引值将被整理,可以在多个字段的组合上建立索引。
## 位图索引操作
位图索引的工作方式如下。
假设`Person`表,其中包含一些列:
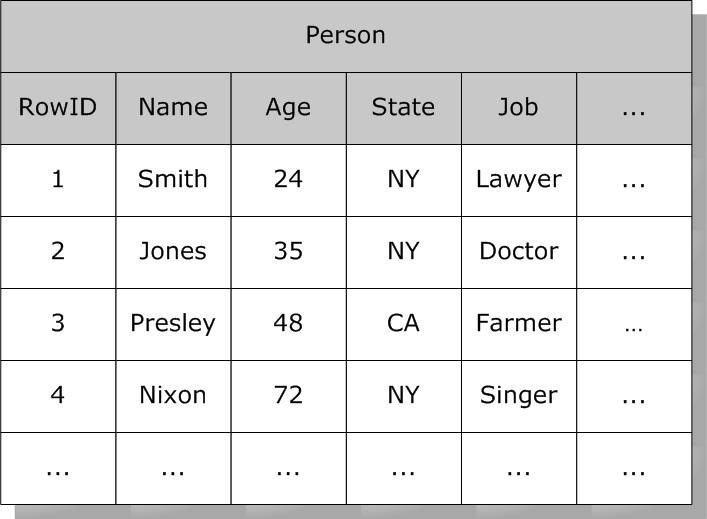
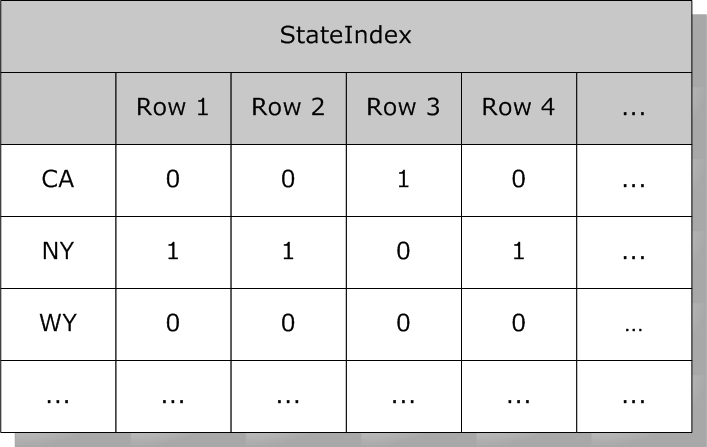
此表中的每一行都有一个系统分配的`RowID`号(一组递增的整数值)。位图索引使用一组位字符串(包含1和0值的字符串)。在位串中,位的序号位置对应于索引表的`RowID`。对于给定值,假设`State`为`“NY”`,则有一个位串,每个位置对应一个包含`“NY”`的行,其他位置为0。
例如,`State`上的位图索引可能如下所示:
而关于`Age` 年龄的索引可能如下所示:
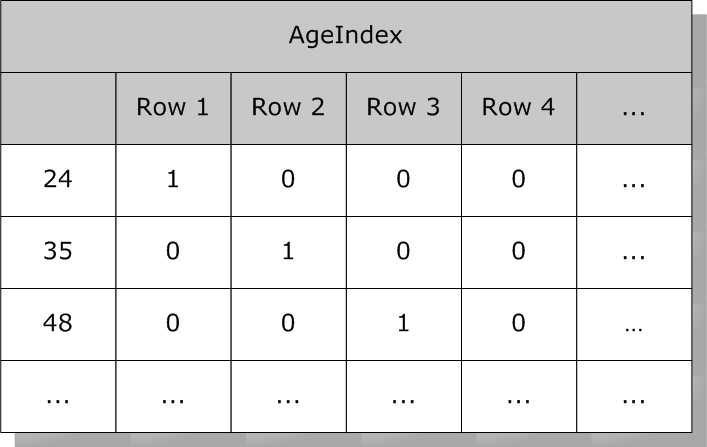
注:此处显示的年龄字段可以是普通数据字段,也可以是其值可以可靠派生(`Calculated` 和`SQLComputed`)的字段。
除了将位图索引用于标准操作外,SQL引擎还可以使用位图索引来使用多个索引的组合来高效地执行特殊的基于集合的操作。例如,要查找居住在纽约的24岁`Person`的所有实例,SQL引擎只需执行`Age`和`State`索引的逻辑与:
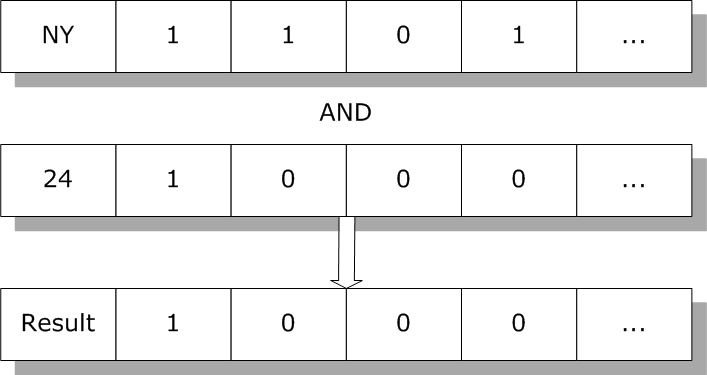
生成的位图包含匹配搜索条件的所有行的集合。SQL引擎使用它从这些行返回数据。
SQL引擎可以将位图索引用于以下操作:
- 对给定表上的多个条件进行`AND`运算。
- 对给定表上的多个条件进行`OR`运算。
- 给定表上的`RANGE`范围条件。
- 对给定表上的操作进行计数`COUNT`。
## 使用类定义定义IdKey位图索引
如果表的`ID`是值限制为唯一正整数的字段,则可以使用新建索引向导或通过与创建标准索引相同的方式编辑类定义的文本,将位图索引定义添加到类定义中。唯一的区别是需要将索引类型指定为“位图”:
```java
Class MyApp.SalesPerson Extends %Persistent [DdlAllowed]
{
Property Name As %String;
Property Region As %Integer;
Index RegionIDX On Region [Type = bitmap];
}
```
## 使用类定义定义`%BID`位图索引
如果表的`ID`不限于正整数,则可以创建`%BID`属性以用于创建位图索引定义。可以将此选项用于具有任何数据类型的`ID`字段的表,以及由多个字段组成的`IDKEY`(包括子表)。可以为以下任一数据存储类型创建`%BID`位图:默认结构表或`%Storage.SQL`表。此功能称为“任意表的位图”或`BAT`。
要在这样的表上启用位图索引,必须执行以下操作:
1. 为类定义`%BID`属性/字段。这可以是类的现有属性,也可以是新属性。它可以有任何名称。如果这是新属性,则必须为表中的所有现有行填充此属性/字段。此`%BID`字段必须定义为将字段数据值限制为唯一正整数的数据类型。例如,将`MyBID`属性设置为`%Counter`;
2. 定义新的类参数以定义哪个属性是`%BID`字段。此参数被命名为`BIDField`。此参数设置为`%BID`属性的`SQLFieldName`。例如,参数`BIDField=“MyBID”`;
3. 定义`%BID`的索引。例如,`MyBID`上的`Index BIDIdx[Type=Key,Unique]`;
4. 定义`%BID`定位器索引。
这将`%BID`索引绑定到表的`ID`键字段。
下面的例子是一个表的一个复合`IDKey`组成两个字段:
```java
Index IDIdx On (IDfield1, IDfield2) [ IdKey, Unique ];
Index BIDLocIdx On (IDfield1, IDfield2, MyBID) [ Data = IdKey, Unique ];
```
此表现在支持位图索引。可以使用标准语法根据需要定义位图索引。例如: `Index RegionIDX On Region [Type = bitmap]`;
此表现在还支持位片索引。可以使用标准语法定义位片索引。
**注意:要构建或重新生成`%BID`位图索引,必须使用`%BuildIndices()`。`%BID`位图索引不支持`%ConstructIndicesParallel()`方法。**
## 使用DDL定义位图索引
如果使用DDL语句定义表,还可以使用以下DDL命令为`ID`为正整数的表格创建和删除位图索引:
```sql
CREATE BITMAP INDEX RegionIDX ON TABLE MyApp.SalesPerson (Region)
```
## 生成位图范围索引
**编译包含位图索引的类时,如果类中存在任何位图索引,并且没有为该类定义位图范围索引,则类编译器会生成位图范围索引。如果位图范围索引存在(无论是定义的还是生成的),该类从主超类继承位图范围索引。为类构建索引时,如果要求构建位图范围索引,或者正在构建另一个位图索引并且位图范围索引结构为空,则会构建位图范围索引。**
除非存在位图索引,否则InterSystems IRIS不会生成位图范围索引。位图范围索引定义为:`type = bitmap`, `extent = true`。这意味着从主要超类继承的位图范围索引被认为是位图索引,并且如果在该子类中没有显式定义位图范围索引,则将触发在子类中生成位图范围索引。
InterSystems IRIS不会基于未来的可能性在超类中生成位图范围索引。这意味着,除非存在`type=bitmap`的索引,否则InterSystems IRIS永远不会在持久类中生成位图范围索引。假设将来的某个子类可能引入`type=bitmap`的索引是不够的。
**注意:在将位图索引添加到生产系统上的类的过程中需要特别小心(在生产系统中,用户正在使用特定的类,编译所述类,然后为其构建位图索引结构)。在这样的系统上,位图范围索引可以在编译完成和索引构建进行之间的过渡期间被填充。这可能导致索引构建过程未隐式构建位图范围索引,这导致部分完整的位图范围索引。**
## 选择索引类型
**下面是在位图和标准索引之间选择的一般准则。
一般来说,所有类型的键和引用都要使用标准索引:**
- Primary key
- Foreign key
- Unique keys
- Relationships
- Simple object references
否则,位图索引通常更可取(假设表使用系统分配的数字ID号)。
其他因素:
- **每个属性上的单独位图索引通常比多个属性上的位图索引具有更好的性能。这是因为SQL引擎可以使用`AND`和`OR`操作有效地组合单独的位图索引。**
- **如果一个属性(或确实需要一起编制索引的一组属性)有超过`10,000-20,000`个不同的值(或值组合),请考虑标准索引。但是,如果这些值的分布非常不均匀,以至于很少的值只占行的很大一部分,那么位图索引可能会更好。一般来说,目标是减少索引所需的总体大小。**
## 位图索引的限制
所有位图索引都有以下限制:
- 不能在唯一列上定义位图索引。
- 不能在位图索引中存储数据值。
- 除非字段的`SqlCategory`是 `INTEGER`, `DATE`, `POSIXTIME`, or `NUMERIC(scale=0)`,否则不能在字段上定义位图索引。
- **对于包含超过100万条记录的表,当惟一值的数量超过`10,000`时,位图索引的效率低于标准索引。
因此,对于大型表,建议避免为任何包含(或可能包含)超过`10,000`个惟一值的字段使用位图索引;
对于任意大小的表,避免对任何可能包含超过`20,000`个惟一值的字段使用位图索引。
这些是一般的近似值,不是确切的数字。**
必须创建一个`%BID`属性来支持一个表上的位图索引:
- 使用非整数字段作为唯一的`ID`键。
- 使用一个多字段`ID`键。
- 是父子关系中的子表。
可以使用`$SYSTEM.SQL.Util.SetOption()`方法`SET status=$SYSTEM.SQL.Util.SetOption("BitmapFriendlyCheck",1,.oldval) `设置系统范围的配置参数,以便在编译时检查此限制,从而确定`%Storage.SQL`类中是否允许定义的位图索引。此检查仅适用于使用`%Storage.SQL`的类。默认值为0可以使用`$SYSTEM.SQL.Util.GetOption(“BitmapFriendlyCheck”)`来确定此选项的当前配置。
### 应用程序逻辑限制
位图结构可以由位串数组表示,其中数组的每个元素表示具有固定位数的`"chunk"`。因为`UNDEFINED`等同于一个全为0位的块,所以该数组可以是稀疏的。表示全部0位的块的数组元素根本不需要存在。因此,应用程序逻辑应该避免依赖于0值位的`$BITCOUNT(str,0)`计数。
由于位串包含内部格式,因此应用程序逻辑不应依赖于位串的物理长度,也不应依赖于将具有相同位值的两个位串相等。在回滚操作之后,位串恢复到事务之前的位值。然而,由于内部格式化,回滚的位串可能不等于或不具有与事务之前的位串相同的物理长度。
## 维护位图索引
**在易失性表(执行许多插入和删除操作)中,位图索引的存储效率可能会逐渐降低。要维护位图索引,可以运行`%SYS.Maint.Bitmap`实用程序方法来压缩位图索引,使其恢复到最佳效率。可以使用`OneClass()`方法压缩单个类的位图索引。或者,可以使用`Namespace()`方法来压缩整个命名空间的位图索引。这些维护方法可以在带电系统上运行。**
运行`%SYS.Maint.Bitmap`实用程序方法的结果将写入调用该方法的进程。这些结果还会写入`%SYS.Maint.BitmapResults`类。
## 位图块的SQL操作
InterSystems SQL提供了以下扩展来直接操作位图索引:
- `%CHUNK`函数
- `%Bitpos`函数
- `%BITMAP`聚合函数
- `%BITMAPCHUNK`聚合函数
- `%SETINCHUNK`谓词条件
所有这些扩展都遵循InterSystems SQL位图表示约定,将一组正整数表示为一系列位图块,每个块最多包含`64,000个`整数。
这些扩展允许在查询和嵌入式SQL中更轻松、更高效地操作某些条件和筛选器。在嵌入式SQL中,它们支持位图的简单输入和输出,特别是在单个块级别。它们支持处理完整的位图,这些位图由`%bitmap()`和`%SQL.Bitmap`类处理。它们还支持非`RowID`值的位图处理,例如外键值、子表的父引用、关联的任一列等。
例如,要输出指定块的位图,请执行以下操作:
```sql
SELECT %BITMAPCHUNK(Home_Zip) FROM Sample.Person
WHERE %CHUNK(Home_Zip)=2
```
要输出整个表的所有块,请执行以下操作:
```sql
SELECT %CHUNK(Home_Zip),%BITMAPCHUNK(Home_Zip) FROM Sample.Person
GROUP BY %CHUNK(Home_Zip) ORDER BY 1
```
### %CHUNK函数
`%%CHUNK(F)`返回位图索引字段f值的块分配。这被计算为`f\64000+1.%%CHUNK(F)`非位图索引字段的任何字段或值`f`的`%chunk(F)`始终返回1。
### %BITPOS函数
`%Bitpos(F)`返回分配给其区块内的位图索引字段`f`值的位位置。这被计算为`f#64000+1`。对于不是位图索引字段的任何字段或值`f`,`%Bitpos(F)`返回的值比其整数值多`1`。字符串的整数值为`0`。
### %BITMAP聚合函数
聚合函数`%bitmap(F)`将许多`f`值组合到一个`%SQL.Bitmap`对象中,在该对象中,对于结果集中的每个值`f`,与适当块中的`f`相对应的位被设置为`1`。上述所有参数中的f通常是正整数字段(或表达式),通常(但不一定)是`RowID`。
### %BITMAPCHUNK聚合函数
聚合函数`%BITMAPCHUNK(F)`将字段f的许多值组合成`64,000`位的InterSystems SQL标准位图字符串,其中对于集合中的每个值`f`,位`f#64000+1=%Bitpos(F)`被设置为`1`。请注意,无论`%chunk(F)`的值是多少,都会在结果中设置该位。`%BITMAPCHUNK()`为空集生成`NULL`,并且与任何其他聚合一样,它忽略输入中的`NULL`值。
### %SETINCHUNK谓词条件
当且仅当($BIT(BM,`%Bitpos(F)=1`时,条件(`f%SETINCHUNK BM`)为真。Bm可以是任何位图表达式字符串,例如输入主机变量:`bm`,或`%BITMAPCHUNK()`聚合函数的结果,等等。请注意,无论`%chunk(F)`的值是多少,都会检查`` 位。如果`` 不是位图或为`NULL`,则条件返回`FALSE`。(`F%SETINCHUNK NULL`)生成`FALSE`(非未知)。
文章
Qiao Peng · 六月 8, 2022
01
智慧医院的本质
什么是智慧医院?
国家卫健委提出建设智慧医院的目的是要不断增强人民群众的获得感,要求医院的流程更便捷、服务更高效、管理更精细,主要聚焦于三大领域,面向医务人员的智慧医疗、面向患者的智慧服务以及面向管理的智慧管理。
如果从技术角度进行高度抽象,我们把智慧医院的本质浓缩为一点,就是为智慧的科学决策以及基于科学决策的业务执行闭环。在现实世界里,我们要从真实业务(调查研究)中获得决策依据,同时还要有决策的方法,把决策应用在现实世界上,来影响和改变现实世界。
02
科学决策的三个阶段
第一个时代是人工决策时代。我们医疗行业就是望闻问切,我们能拿到的数据非常有限,所以属于一个数据饥渴的时代。我们通过有限的数据来进行决策,非常容易落入我们经常批判的“三拍”型决策,“拍脑袋决策、拍胸脯保证、拍屁股走人”。显然这个决策效率不是很高。
人工决策时代:“数据稀缺”时代的决策
第二个时代是信息化时代。我们有了很多数据,能够把部分现实世界来进行数字化表达,我们也通过信息辅助人工决策进行智能决策,例如通过药品知识库推动合理用药,通过人工智辅助影像判断等等。
然而我们依旧面临着很多数据问题。首先是数据还不够完整,经常无法获取需要的数据,数据模型也不能完全表达医院的实际业务;其次,我们也还是会遇到很多数据来源问题(我们常常不知道该信任哪一份数据)、数据的关联性、实时性等问题。系统多了、数据多了,但同时孤岛也多了、噪音也多了,如何通过技术的手段让真实世界在数字化的世界里面完整、客观表达,这是实现数字化医院最基础的工作。
此外,我们仍然没有解决人工决策的局限性,例如决策所依赖的依据,我们的大脑能够处理的依据差不多十个左右,但是现在医学发展也有很多的数据,比如有临床数据、有功能遗传学、有蛋白质组学的等等,我们面对着上千个决策因素,但受制于人类自身的限制,我们也很难直观地理解和认识这些数据并发挥其价值。
人工决策的局限
数据来源:Evidence-Based Medicine and the Changing Nature of Healthcare: 2007 IOM Annual Meeting Summary
在数字化时代,决策模式从信息辅助决策升级为人工干预的智能决策。数字化时代的决策有四个要素。
第一是全面的数据表达,我们要把真实世界的所有数据能够挖掘和展现出来,并将其沉淀在数据平台。数据的全面性包含了数据广度、数据深度、数据时效性、数据的关联性、数据的动态变化等等。
第二是数字化的逻辑推理能力,基于知识图谱和基于机器学习来把逻辑推理过程实现数字化,比如深度学习、神经网络等等,都是在试图将我们的逻辑推理进行数字化表现。
第三是流程与场景数字化,我们现在已经有了临床辅助决策,为什么在现实业务中还会遇到例如应该报警的没报警,不该报警的反而误报警等现象,主要原因是现在决策流程都是在各个业务系统内通过人工环节里面来体现的,使得我们并不了解实际业务中的决策流程,所以如果想要真正了解我们的决策是不是正确的、及时的,以及闭环地应用在业务里面,我们需要对业务的流程和场景进行数字化。
第四,对决策本身的绩效评价数字化。我们怎么知道决策是好的还是坏的,是最优的还是次优的?我们应该如何优化我们的决策,让决策能够变得越来越好?我们需要对决策进行可度量的数字化评价,评价的模型、指标,决策的效果等,对应这些我们也需要进行数字化。有了这些评价的结果,我们才能依据这些结果进行推理逻辑的改进,让决策更好。
数字化时代决策的四要素:
全面的数据、逻辑推理数字化、流程与场景数字化、绩效评价数字化
03
数字孪生——智慧医院的未来
这时我们就不难看出为什么数字孪生是智慧医院的未来方向了。
根据Gartner 对数字孪生的定义:“现实世界实体或系统的数字表达。数字孪生体的实现是一套封装的软件对象或模型,它反映了一个独特的物理对象、过程、组织、人或其他抽象概念。”
数字孪生作为现实世界全面的数字化表达,不是为了表达而表达,而是通过全面表达来实现决策方法、决策流程和决策评价的全面数字化。数字孪生是一个能够全面反映真实医院,并且跟实际业务紧密集成、互相打通的数字化世界,在数字孪生世界里很多决策可以由它来产生,不需要由真实世界来产生,数字孪生世界里的决策可以真实地进行模拟、验证、演练,从而最大程度降低我们的试错成本,同时还可以反馈给真实世界,形成一个统一的、闭环的数字——真实一体化的世界。所以数字孪生并不仅仅是一个简单的真实世界的镜像,而是一个更复杂的、跟现实世界有互通性、互操作性的数字世界。
数字孪生:现实+决策+流程+评价的全面数字化
04
InterSystems IRIS医疗版实现数字孪生医院的最佳数智底座
数字孪生的世界里我们有什么样的平台和技术来支撑它?对于数字孪生的智慧医院来说,我们认为应该有一个功能强大的数智基座能满足前面提到数字孪生时代决策的四个关键要素。
第一是数据的全面性。面对复杂的真实世界,我们需要多种数据建模方式,类似思维导图,对某一事物进行N维建模,同时可以随着我们的认知加深而不断扩展的建模方式,而不是简单的关系型二维表来描述我们的实际业务。同时这些数据是实时的、有关联性的,只有这样我们做的决策才能够发现或者反应事物的本质,才有价值。
第二是流程和场景的数字化。现在的流程大部分都是分散在各个业务系统和人工工作里面,相互割裂、理解起来很困难,合理性、是否需要优化、如何优化更是无从谈起。在数字孪生时代,我们需要对于整个流程来建立可视化的、直观的并且能够优化的流程,通过流程建模来建模,同时建立这个流程模型,在数字化的世界里是闭环的,也就是说可以把决策的结果实时反馈给真正在运营的流程,并且反馈给我们真实世界。这个流程是可以优化的,可以不断进行业务流程的再造。
第三,要实现逻辑推理的数字化。我们要借助机器学习、深度学习等技术来提升我们决策的科学水平,对于很多行业里面的非结构化的数据,我们借助自然语言处理来挖掘真实的非结构化数据真实的含义,当然还有许多通过知识图谱认知来分析来提升整体决策的能力。
最后,从决策的评价和改进层面来说,基于行业的模型行业的标准对于决策进行相应评价,通过数据深度的分析对于评价指标进行相应的计算,并且把结果实时反馈给业务流程,通过推理和逻辑来优化决策,提升决策水平。
以上这四个能力就是未来数字孪生智慧医院数智基座应该具有的能力。
InterSystems IRIS医疗版数据平台正是这样一个平台,可以帮助用户从各种数据源收集和编辑相应的数据,并且能够对真实世界使用不同的模型,真实反映真实世界全貌的数据模型,里面包含了我们很多方面的数据,例如说临床的、组学的、物联网的、社交的、健康管理等等数据。同时InterSystems IRIS医疗版数据平台提供完整的互操作平台,可以帮助我们业务流程进行可视化,实现可视化流程的建模——这种方式可以支撑我们对于这个流程的实时优化,同时通过实时数据分析把实时洞察反馈给业务流程,支撑用户做更智能的决策。
通过开放型分析,基于全面的数据,我们可以应用机器学习、自然语言处理、知识图谱等等对数据进行分析、决策和相应决策的评价来驱动业务持续改进。
InterSystems IRIS医疗版数据平台:数字孪生医院最佳数智基座
数字化时代,基于真实业务数据的决策智能和基于合理决策的业务执行闭环是实现智慧医院的核心,而数字孪生开启了一个全新的围绕着智慧决策的建模、管理行动的全新方式,能够帮助医院完整认知和理解医院业务,提高决策质量和效率、优化资源利用,从而提高医疗质量、优化患者体验以及降低运营成本,更重要的是可以支持医院实现可持续的高质量发展和数字化创新能力。
InterSystems IRIS数据平台作为全美排名前20医院、复旦百强中40%的医院以及全国数百家医院的共同选择,毫无疑问是实现数字孪生医院数智底座的最佳选择。
文章
Jingwei Wang · 五月 4, 2022
你是否尝试过[InterSystems IRIS IntegratedML学习平台](https://learning.intersystems.com/course/view.php?id=1535&ssoPass=1)?在这个平台中,你可以在再入院数据集上训练和测试一个模型,并能够预测一个病人何时会再入院,或计算其再入院的概率。
你不需要在你的系统上进行任何安装就可以尝试,你所要做的就是启动一个虚拟实验室环境(Zeppelin),然后玩一玩!
在这篇文章中,我们将利用这个实验室向你简要介绍IntegratedML,向你介绍要处理的问题,如何使用IntegratedML来创建一个再入院预测模型,以及如何分析其性能指标的一些见解。
## 什么是IntegratedML?

来源: https://github.com/intersystems-community/integratedml-demo-template
在开始本教程之前,让我们简单谈谈IRIS IntegratedML。这个工具使你能够直接在SQL语句中执行机器学习(ML)任务,抽象出复杂过程的实现,例如,选择哪些列和ML算法是对目标列进行分类或回归的最佳选择。
IntegratedML的另一个伟大功能是易于部署。一旦你的模型被训练并表现良好,你只需要运行SQL语句,以便让你的模型投入生产。
IntegratedML让你选择使用哪个 [ML提供者](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GIML_Configuration_Providers)。默认的提供者是 [AutoML](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GIML_AUTOML), 这是InterSystems公司使用Python实现的ML库 [scikit-learn](https://scikit-learn.org/stable/). 但是你也可以选择其他三个提供者: PMML, [H2O](https://www.h2o.ai/) and [DataRobot](https://www.datarobot.com/).
在这篇文章中,我们将使用AutoML。
## 问题和解决方案
现在,让我们来介绍一下这个问题,以及我们如何努力提出一种方法来尽量减少其影响。我们将尝试减少由于再入院而产生的问题。
[根据维基百科](https://en.wikipedia.org/wiki/Hospital_readmission), 医院再入院是指病人被批准离开医院(出院),但此人在一个意想不到的短时间间隔内再次回到医院(再入院)的事件。

来源: [https://news.yale.edu/2015/01/15/when-used-effectively-discharge-summari...](https://news.yale.edu/2015/01/15/when-used-effectively-discharge-summaries-reduce-hospital-readmissions)
再入院会造成病人护理质量的损失--出院和再入院之间的时间可能很关键,医院的资源也会优化。
克服这个问题的一个方法是尝试使用历史数据库来创建一个数据集,其中过去的再入院事件可以通过机器学习算法进行分析,创建一个ML模型。如果数据集足够丰富和干净,再入院模式可以被正确检测出来,新的事件可以通过这个模型计算出其概率。
因此,通过使用ML模型来预测再入院,能够避免错误的出院,肯定会成为医院提高服务质量和利润的一个有价值的选择。
## 使用IntegratedML创建和使用一个ML模型
### 模型创建
使用IntegratedML创建一个ML模型,就像执行一个SQL语句一样容易。你只需要定义数据所在的历史数据集,并为你的模型起一个名字。
```
CREATE MODEL Readmission PREDICTING (MxWillReAdmit) FROM EncountersHistory
```
After that statement, you have declared and created a model called Readmission intended to predict the values for a column called MxWillReAdmit, based on a dataset called EncountersHistory.
You can find more information about this statement [here](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GIML_CREATEMODEL). For example, in design phase, it’s handy forces the same results on training, so you can use the USING argument with some arbitrary constant number, like this:
在该声明之后,你已经声明并创建了一个名为Readmission的模型,基于名为EncountersHistory的数据集,预测名为MxWillReAdmit的列的值。
你可以找到关于这个声明的更多信息,[点击这里](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GIML_CREATEMODEL)。例如,在设计阶段,很方便地迫使训练中出现相同的结果,所以你可以用USING参数加上一些任意的常数,像这样。
```
CREATE MODEL Readmission PREDICTING (MxWillReAdmit) FROM EncountersHistory USING {"seed": 3}
```
### 模型训练
现在,通过使用TRAIN MODEL语句,你的模型已经准备好被训练。
```
TRAIN MODEL Readmission
```
在这里,IntegratedML为你做了很多工作(使用AutoML ML供应商):
- [Feature engineering](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GIML_AutoML#GIML_AutoML_Feature): 使用哪些列
- [Data encoding](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GIML_AutoML#GIML_AutoML_Keys): 所选栏目中的数据必须如何呈现给ML算法
- [ML algorithm selection](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GIML_AutoML#GIML_AutoML_Algos): 哪种算法能带来最好的结果
- [Model selection](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GIML_AutoML#GIML_AutoML_Selection): 根据目标列的数据类型,应该选择一个分类模型或回归模型。在这个例子中,一旦目标列有布尔值,就会选择一个分类模型。
这个声明可能需要一些时间,取决于数据集的大小和你的数据的复杂性。
### 模型验证
到现在,我们应该急于知道我们的模型到底有多好。Integrated ML有一个计算性能指标的声明,基于另一个数据集,而不是用于训练的数据集
这个新的数据集被称为测试或验证数据集,这取决于你使用哪种策略进行验证。这个数据集通常是从用于创建训练数据集的同一个数据集中检索出来的。一个常见的方法是随机选择70%或80%的数据集用于训练,其余的用于测试/验证。
在实验室里,之前已经为这项任务准备了一个新的可使用的数据集:EncountersNew数据集。
现在,我们可以找出我们的模型有多好(或多坏)。
```
VALIDATE MODEL Readmission FROM EncountersNew
```
为了得到结果,你应该查询 INFORMATION_SCHEMA.ML_VALIDATION_METRICS 表。
```
SELECT * FROM INFORMATION_SCHEMA.ML_VALIDATION_METRICS
```
模型的性能是用 [IntegratedML的四个指标](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GIML_VALIDATEMODEL#GIML_VALIDATEMODEL_Metrics):
- Accuracy: 预测正确率(数值接近1表示正确率高)。
- Precision:对模型所做的所有阳性预测的正确率(接近1的值意味着很少有假阳性预测)。
- Recall:关于数据集中所有实际阳性值的正确阳性预测率(接近1的值意味着很少有假阴性预测)。
- F-Measure: 另一种衡量准确率的方法,当准确率表现不佳时使用,一般用于不平衡问题(数值接近1意味着高正确率)。
### 关于性能指标的一些讨论
在这里,我们可以看到,该模型的准确率为82%。但是,这个指标不应该被单独分析,其他的指标如精确度和召回率也必须被评估。
让我们思考一下错误预测的影响--假阳性和假阴性。对于我们的模型来说,假阳性意味着预测的再入院并不是实际的再入院。而假阴性,意味着一个病人已经再入院,而模型预测这个病人不会再入院。
这两种情况都会导致错误的决定。一个假阳性的预测可能会导致一个超过必要的病人留在医院的决定;而一个假阴性的预测可能会导致一个提前出院的决定,然后再让这个病人重新入院。
请注意,在我们的模型中,假阴性会导致再入院病例,这正是我们要避免的。所以,我们必须选择能减少假阴性病例的模型,即使假阳性病例的数量增加。
因此,为了选择具有低假阴性率的模型,我们需要选择具有高召回率的模型。这是因为召回率越高,假阴性就越低。
由于我们的模型有84%的召回率,让我们暂时假定它是一个合理的值。
### 预测
一旦你训练好了你的模型,而且它的性能可以接受,现在你就可以执行这个模型,以便预测结果。
你应该使用 [PREDICT](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GIML_PREDICT) 函数,以便用户对模型进行预测。
```
SELECT TOP 100
ID,
PREDICT(Readmission) AS PredictedReadmission,
MxWillReAdmit AS ActualReadmission
FROM
EncountersNew
```
这个函数根据内部阈值,评估模型的目标列的行是真值还是假值的概率。
你可以看到我们的模型做了一些错误的预测--这很正常。
另一个可以用来进行预测的函数,是 [PROBABILITY](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GIML_PROBABILITY) 函数.
```
SELECT TOP 10
ID,
PROBABILITY(Readmission FOR '1') AS ReadmissionProbability,
PREDICT(Readmission) AS PredictedReadmission,
MxWillReAdmit AS ActualReadmission
FROM
EncountersNew
```
与PREDICTION相同,PROBABILITY使用一行的列作为指定模型的输入,但在这里我们需要定义我们想要计算的概率是哪一类。
如果我们想定制用于预测的阈值,这个函数可能很有用。
### 查询训练好的模型
在创建和训练你的模型后,你可以使用 INFORMATION_SCHEMA.ML_TRAINED_MODELS 表来查询它们。
```
SELECT * FROM INFORMATION_SCHEMA.ML_TRAINED_MODELS
```
## 结论
在这篇文章中,我们对历史上的病人再入院数据集进行了创建、训练、验证和预测。这些预测可以作为寻求更好决策的另一个工具,从而改善对病人的护理,降低医院服务的成本。
所有这些步骤都是通过InterSystems IntegratedML使用SQL语言完成的,它为广大的开发者带来了机器学习的力量。
文章
Hao Ma · 三月 25, 2021
继[上一部分](https://community.intersystems.com/post/why-covid-19-also-dangerous-machine-learning-part-i),现在要利用 IntegratedML VALIDATION MODEL 语句提供信息以监视您的 ML 模型。 您可以在[此处](https://www.youtube.com/watch?v=q9ORM32zPjs)观看实际运作。
此处所示代码衍生自 [InterSystems IntegragedML 模板](https://openexchange.intersystems.com/package/integratedml-demo-template)或 [IRIS 文档](https://irisdocs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=GCM_healthmon)提供的示例,我主要是把代码混合了起来。 这是一个简单的示例,目的是为进一步讨论和未来工作提供一个起点。
注:此处提供的代码仅作说明之用。 如果您想尝试,我开发了一个 Open Exchange 技术示例应用 ([iris-integratedml-monitor-example](https://openexchange.intersystems.com/package/iris-integratedml-monitor-example)),并将其提交到 InterSystems IRIS AI Contest。 读完这篇文章后您可以去看看,如果喜欢,就请[投我一票吧](https://openexchange.intersystems.com/contest/current)! :)
# 目录
### 第一部分:
* [IRIS IntegratedML 和 ML 系统](https://community.intersystems.com/post/why-covid-19-also-dangerous-machine-learning-part-i#iris_integratedml_and_ml_systems)
* [新旧常态之间](https://community.intersystems.com/post/why-covid-19-also-dangerous-machine-learning-part-i#between_the_old_and_new_normal)
### 第二部分:
* [监视 ML 性能](#monitoring_ml_performance)
* [简单用例](#a_simple_use_case)
* [未来工作](#future_works)
# 监视 ML 性能
要监视 ML 模型,至少需要两个功能:
1) 性能指标提供程序 2) 监视和通知服务
幸运的是,IRIS 为我们提供了这两个必要的功能。
## 获取 ML 模型性能指标
如[上一部分](https://community.intersystems.com/post/why-covid-19-also-dangerous-machine-learning-part-i)所示,IntegratedML 提供了 VALIDATE MODEL 语句来计算以下性能参数:
* 准确率:模型的好坏(值接近 1 表示正确答案率高)
* 精度:模型处理误报的能力如何(值接近 1 表示**无**误报率高)
* 召回率:模型处理漏报的能力如何(值接近 1 表示**无**漏报率高)
* F 度量:另一种测量准确率的方法,用于准确率表现不佳的情况(值接近 1 表示正确答案率高)
注:这些定义并不是正式的,而且非常浅显! 我推荐您花些时间[了解它们](https://medium.com/analytics-vidhya/accuracy-vs-f1-score-6258237beca2)。
最妙的是,每次调用 VALIDATE MODEL 时,IntegrateML 都会存储它的性能指标,这样的功能可以很好地用于监视。
## 监视引擎
InterSystems IRIS 提供 System Monitor 框架用于处理监视任务。 它还允许您定义自定义规则,以根据这些指标上应用的谓词触发通知。
默认提供磁盘、内存、进程、网络等一系列指标。 此外,System Monitor 还可以让您扩展监视器,覆盖无限的可能性。 这样的自定义监视器在系统监视器术语中称为应用监视器。
您可以在[此处](https://irisdocs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=GCM_healthmon)了解有关 System Monitor 的更多信息。
## 整合
现在,有了一种获取各模型验证性能指标值的方法,还有一个可以根据应用于自定义指标源的自定义规则触发警报的工具.……那么,是时候把它们结合起来了。
首先,我们需要通过扩展 %Monitor.Abstract 类创建自定义应用监视器类,并实现 *Initialize* 和 *GetSample* 方法。
```
Class MyMetric.IntegratedMLModelsValidation Extends %Monitor.Adaptor
{
/// Initialize the list of models validation metrics.
Method Initialize() As %Status
{
Return $$$OK
}
/// Get routine metric sample.
/// A return code of $$$OK indicates there is a new sample instance.
/// Any other return code indicates there is no sample instance.
Method GetSample() As %Status
{
Return $$$OK
}
}
```
系统监视器会定期发出调用以监视类,获取一组称为样本的指标。 这样的样本可以仅用于监视,也可用于检查是否必须提高警报规则。 您可以通过在监视器类中定义标准的非内部属性来定义此类样本的结构。 需要注意的是,必须在参数 INDEX 中指定其中一个属性作为每个样本的主键,否则将抛出键重复错误。
```
Class MyMetric.IntegratedMLModelsValidation1 Extends %Monitor.Adaptor
{
Parameter INDEX = "ModelTrainedName";
/// Name of the model definition
Property ModelName As %Monitor.String;
/// Name of the trained model being validated
Property ModelTrainedName As %Monitor.String;
/// Validation error (if encountered)
Property StatusCode As %Monitor.String;
/// Precision
Property ModelMetricPrecision As %Monitor.Numeric;
/// Recall
Property ModelMetricRecall As %Monitor.Numeric;
/// F-Measure
Property ModelMetricFMeasure As %Monitor.Numeric;
/// Accuracy
Property ModelMetricAccuracy As %Monitor.Numeric;
...
}
```
*Initialize* 方法在每次监视器调用时被调用一次,*GetSample* 方法则被调用到返回 0 为止。
因此,我们可以在 IntegrateML 验证历史上设置 SQL,向监视器提供指标信息,实现 *Initialize* 和*GetSample* 方法:
```
/// Initialize the list of models validation metrics.
Method Initialize() As %Status
{
// Get the latest validation for each model validated by VALIDATION MODEL statement
Set sql =
"SELECT MODEL_NAME, TRAINED_MODEL_NAME, STATUS_CODE, %DLIST(pair) AS METRICS_LIST FROM ("_
"SELECT m.*, $LISTBUILD(m.METRIC_NAME, m.METRIC_VALUE) pair, r.STATUS_CODE "_
"FROM INFORMATION_SCHEMA.ML_VALIDATION_RUNS r "_
"JOIN INFORMATION_SCHEMA.ML_VALIDATION_METRICS m "_
"ON m.MODEL_NAME = r.MODEL_NAME "_
"AND m.TRAINED_MODEL_NAME = r.TRAINED_MODEL_NAME "_
"AND m.VALIDATION_RUN_NAME = r.VALIDATION_RUN_NAME "_
"GROUP BY m.MODEL_NAME, m.METRIC_NAME "_
"HAVING r.COMPLETED_TIMESTAMP = MAX(r.COMPLETED_TIMESTAMP)"_
") "_
"GROUP BY MODEL_NAME"
Set stmt = ##class(%SQL.Statement).%New()
$$$THROWONERROR(status, stmt.%Prepare(sql))
Set ..Rspec = stmt.%Execute()
Return $$$OK
}
/// Get routine metric sample.
/// A return code of $$$OK indicates there is a new sample instance.
/// Any other return code indicates there is no sample instance.
Method GetSample() As %Status
{
Set stat = ..Rspec.%Next(.sc)
$$$THROWONERROR(sc, sc)
// Quit if we have done all the datasets
If 'stat {
Quit 0
}
// populate this instance
Set ..ModelName = ..Rspec.%Get("MODEL_NAME")
Set ..ModelTrainedName = ..Rspec.%Get("TRAINED_MODEL_NAME")_" ["_$zdt($zts,3)_"]"
Set ..StatusCode = ..Rspec.%Get("STATUS_CODE")
Set metricsList = ..Rspec.%Get("METRICS_LIST")
Set len = $LL(metricsList)
For iMetric = 1:1:len {
Set metric = $LG(metricsList, iMetric)
Set metricName = $LG(metric, 1)
Set metricValue = $LG(metric, 2)
Set:(metricName = "PRECISION") ..ModelMetricPrecision = metricValue
Set:(metricName = "RECALL") ..ModelMetricRecall = metricValue
Set:(metricName = "F-MEASURE") ..ModelMetricFMeasure = metricValue
Set:(metricName = "ACCURACY") ..ModelMetricAccuracy = metricValue
}
// quit with return value indicating the sample data is ready
Return $$$OK
}
```
编译监视器类后,您需要重新启动系统监视器,使系统意识到一个新的监视器已经创建并可以使用。 您可以使用 ^%SYSMONMGR 例程或 %SYS.Monitor 类来完成这一步。
# 简单用例
这样就有了所需的工具来收集、监视和发布 ML 性能指标的警报。 接下来要做的是定义自定义警报规则,模拟已部署的 ML 模型开始对性能造成负面影响的场景。
首先,我们必须配置电子邮件警报及其触发规则。 这可以使用 ^%SYSMONMGR 例程完成。 不过,为了方便,我创建了一个设置方法,它可以设置所有电子邮件配置和警报规则。 您需要将 <> 之间的值替换为您的电子邮件服务器和帐户参数。
```
ClassMethod NotificationSetup()
{
// Set E-mail parameters
Set sender = ""
Set password = ""
Set server = ""
Set port = ""
Set sslConfig = "default"
Set useTLS = 1
Set recipients = $LB("")
Do ##class(%Monitor.Manager).AppEmailSender(sender)
Do ##class(%Monitor.Manager).AppSmtpServer(server, port, sslConfig, useTLS)
Do ##class(%Monitor.Manager).AppSmtpUserName(sender)
Do ##class(%Monitor.Manager).AppSmtpPassword(password)
Do ##class(%Monitor.Manager).AppRecipients(recipients)
// E-mail as default notification method
Do ##class(%Monitor.Manager).AppNotify(1)
// Enable e-mail notifications
Do ##class(%Monitor.Manager).AppEnableEmail(1)
Set name = "perf-model-appointments-prediction"
Set appname = $namespace
Set action = 1
Set nmethod = ""
Set nclass = ""
Set mclass = "MyMetric.IntegratedMLModelsValidation"
Set prop = "ModelMetricAccuracy"
Set expr = "%1 < .8"
Set once = 0
Set evalmethod = ""
// Create an alert
Set st = ##class(%Monitor.Alert).Create(name, appname, action, nmethod, nclass, mclass, prop, expr, once, evalmethod)
$$$THROWONERROR(st, st)
// Restart monitor
Do ##class(MyMetric.Install).RestartMonitor()
}
```
在以前的方法中,警报在监视器获得的准确率值小于 90% 时发出。
现在,设置警报规则后,让我们用前 500 条记录创建、训练和验证履约/失约预测模型,并通过前 600 条记录进行验证。
注:*种子*参数只是为了保证可重复性(即没有随机值),通常在生产中必须避免。
```
-- Creates the model
CREATE MODEL AppointmentsPredection PREDICTING (Show) FROM MedicalAppointments USING {\"seed\": 3}
-- Train it using first 500 records from dataset
TRAIN MODEL AppointmentsPredection FROM MedicalAppointments WHERE ID
文章
Hao Ma · 九月 17, 2022
因为篇幅太长, 我把它分为3篇贴在社区
# 配置前的准备
配置Mirror前要准备三件事儿:
1. 规划网络连接。
2. 在所有的服务器中启动ISCAgent服务。
3. 准备服务器的SSL/TLS证书。可选, 但非常推荐。
我假设您在动手前一定已经对Mirror的原理和架构已经不陌生了,对镜像成员,DR(灾备)成员, Arbiter, ISCAgent等术语已经自动切换的概念有大概的认识。如果不是这样,请先阅读在线文档,或者这篇文章。
## 规划网络连接
Mirror应该配置两个网段:一个用于IRIS和外部的通信;另一个用于两个Mirror成员间的内部通信,也就是数据的同步。 尽管不是必须的,但Mirror作为一个高可用方案,为了保证服务器之间的内部通信不受和外部连接的干扰,把内部通信放在单独的网段是通常的做法,尤其是在生产环境。
下图来自IRIS的在线文档:其中绿色所示的是IRIS提供服务的网段,IRIS到所有外部系统的连接,ECP应用服务器,和Arbiter在工作在这个网段。紫色的“Data Center Private LAN for Mirror Communication"用于内部通信,准确的说, 用于journal的同步。为了方便, 我会在后面的步骤中简单的把这两个网段简单的称为**外网网段**和**内网网段**。

也是来自在线文档,上图的IP地址配置像这个样子。(请忽略C栏和D栏,它们是DR服务器的地址)

在安装配置Mirror之前, 您需要检查的是:
( Agent address用的是公网地址,但书上有句话:When attempting to contact this member’s agent, other members try this address first. Critical agent functions (such as those involved in failover decisions) will retry on the mirror private and superserver addresses (if different) when this address is not accessible. Because the agent can send journal data to other members, journal data may travel over this network. )
- ServerA, ServerB, Arbiter三台机器的在绿色网段可以相互访问。ServerA, ServerB的1972端口可以访问,Arbiter的2188端口可以访问。
- ServerA, ServerB在紫色网段可以互相访问2188端口。
- Virtual IP绑定在Server A, 并且IRIS的服务和连接通过Virtual IP提供。
下面是我用的两个服务器的网络配置,因为不方便使用(懒的修改)上图的地址,我自己做的地址配置如下
| Virtual IP Address | | |
| ------------------------------ | -------------- | -------------- |
| Arbiter Address | 172.16.58.100 | |
| Member-Specific Mirror Address | serverA | serverB |
| SuperServer Address | 172.16.58.101 | 172.16.58.102 |
| Mirror Private Address | 172.16.159.101 | 172.16.159.102 |
| Agent Address | 172.16.58.101 | 172.16.58.102 |
其中172.16.58.0网段为外网网段; 172.16.159.0网段为内网网段。 在操作系统上查看IP, 是这个样子:
**servera**
```sh
#servera上的端口配置
[root@servera mgr]# ip -4 -br addr
lo UNKNOWN 127.0.0.1/8
ens33 UP 172.16.58.101/24
ens36 UP 172.16.159.101/24
[root@servera mgr]# firewall-cmd --list-ports
1972/tcp 52773/tcp 2188/tcp
[root@servera ~]#
#serverb上的端口配置
[root@serverb isc]# ip -4 -br addr
lo UNKNOWN 127.0.0.1/8
ens33 UP 172.16.58.102/24
ens36 UP 172.16.159.102/24
[root@serverb isc]# # firewall-cmd --list-ports
1972/tcp 52773/tcp 2188/tcp
```
## 在所有的镜像成员启动ISCAgent服务
无论是同步成员,异步成员,还是Arbiter,它们之间的通信都依赖ISCAgent服务。在操作系统上,它是一个独立于IRIS的服务,IRIS的默认安装也没有把它设置为自动启动,所以您需要在安装IRIS的机器,也就是同步,异步成员上手工启动这个服务。至于Arbiter,您可以理解Arbiter就是一个装了ISCAgent服务的机器,可以是任何一台客户的机器,装上ISCAgent, 能帮助IRIS主备成员自动切换判断,它就是Arbiter了。简单说, 您需要
1. 在Mirror的所有成员上启动ISCAgent
2. 在一台机器上安装ISCAgent并启动,它从此就是这个Mirror的Arbiter了。
Arbiter需要和IRIS服务器用相同的操作系统吗?没必要。很多客户的IRIS装在Linux上,而Arbiter是一个Windows机器, 跑着和IRIS无关的业务, 都不用是Server版的Windows。
默认配置下, ISCAgent通过TCP的2188端口和远端连接,启动ISC Agent后请检查防火墙,保证2188端口访问是可以访问的。
下面是具体的配置细节。
### 在Mirror的所有成员上启动ISCAgent
IRIS服务器不需要单独安装ISCAgent。 你需要做的是启动服务,并服务器重启后ISCAgent能自动启动。
- Windows: 进入管理工具—服务,选择ISCAgent,将启动类型改为自动。点启动ISCAgent,并确认服务已启动。
- Linux: 使用systemctl启动ISCAgent, 并加入系统自启动列表。
```sh
[root@servera isc]# systemctl start ISCAgent
[root@servera isc]# systemctl status ISCAgent
● ISCAgent.service - InterSystems Agent
Loaded: loaded (/etc/systemd/system/ISCAgent.service; disabled; vendor preset: disabled)
Active: active (running) since Fri 2022-04-15 10:26:20 CST; 11s ago
Process: 3651 ExecStart=/usr/local/etc/irissys/ISCAgent (code=exited, status=0/SUCCESS)
Main PID: 3653 (ISCAgent)
CGroup: /system.slice/ISCAgent.service
├─3653 /usr/local/etc/irissys/ISCAgent
└─3654 /usr/local/etc/irissys/ISCAgent
Apr 15 10:26:20 servera systemd[1]: Starting InterSystems Agent...
Apr 15 10:26:20 servera systemd[1]: Started InterSystems Agent.
Apr 15 10:26:20 servera ISCAgent[3653]: Starting
Apr 15 10:26:20 servera ISCAgent[3654]: Starting ApplicationServer on *:2188
[root@servera isc]#systemctl enable ISCAgent
Created symlink from /etc/systemd/system/multi-user.target.wants/ISCAgent.service to /etc/systemd/system/ISCAgent.service.
[root@servera isc]#
```
### Arbiter(仲裁服务)
你需要到WRC的下载网址下载ISCAgent的软件。下面是在Linux下安装ISCAgent的过程。
```sh
[root@serverc isc]# cd ISCAgent-2022.1.0.164.0-lnxrh7x64
[root@serverc ISCAgent-2022.1.0.164.0-lnxrh7x64]# ls
agentinstall cplatname dist package tools
[root@serverc ISCAgent-2022.1.0.164.0-lnxrh7x64]# ./agentinstall
Your system type is 'Red Hat Enterprise Linux (x64)'.
Please review the installation options:
------------------------------------------------------------------
ISCAgent version to install: 2022.1.0.164.0
------------------------------------------------------------------
Do you want to proceed with the installation ? yes
Starting installation...
Installation completed successfully
[root@serverc ISCAgent-2022.1.0.164.0-lnxrh7x64]
```
安装后同上一小节使用systemctl命令启动。
## 准备服务器的SSL/TLS证书
您的每个服务器需要准备两个证书:一个本机的证书, 一个是CA的证书。(如果是公开证书也要吗,openssl应该是没有,除非自己去下载)。 如果您使用的是IRIS自带的PKI签发的self-signed证书,那么每台服务器不仅仅要自己的证书,非CA所在的服务器要:“获取证书颁发机构证书”(‘Get Certificate Authority Certificate’)。这个选项“证书颁发机构客户端的”从证书颁发机构获取证书页面。
举例: servera, serverb为镜像成员。
```sh
[root@servera mgr]# ls *.cer *.key
iris.key iscCA.cer iscCASigned.cer iscCASigned.key
```
忽略iris.key。 其他的iscCA.cer是CA的证书, iscCASigned.cer是servera的证书, iscCASigned.key是servera的私钥。
同样, 在serverb:
```sh
[root@serverb ~]# cd /isc/iris/mgr
[root@serverb mgr]# ls *.cer *.key
iris.key iscCA.cer iscCASignedserverb.cer iscCASignedserverb.key
[root@serverb mgr]#
```
## 增加gmheap的大小
Mirror成员间的数据同步默认使用“Parallel dejournaling", 也就是多个进程并行处理同步数据,而这要求增大gmheap资源。
gmheap又被称为shared memory heap(SMH)。它的默认配置是38MB, 但在实际的生产系统中,gmheap通常配置比这要大。
每一个"parallel dejournalling job"需要增加200M的gmheap。比如说, 为了支持4个并行的同步任务, gmheap至少需要800M。如果系统资源足够,最多可以有16个并行同步任务。
**折中的考虑,当您配置镜像时,请将您系统的gmheap值增加为1GB。**
后面我们进入正式的Mirror的配置工作。Mirror的配置和把数据库添加入镜像。
文章
Hao Ma · 三月 25, 2021
几个月前,我在 MIT Technology Review 读到一篇很有意思的[文章](https://www.technologyreview.com/2020/05/11/1001563/covid-pandemic-broken-ai-machine-learning-amazon-retail-fraud-humans-in-the-loop/),作者解释了新冠疫情如何给全球 IT 团队带来关乎机器学习 (ML) 系统的难题。
这篇文章引起我对 ML 模型部署后如何处理性能问题的思考。
我在一个 Open Exchange 技术示例应用 ([iris-integratedml-monitor-example](https://openexchange.intersystems.com/package/iris-integratedml-monitor-example)) 中模拟了一个简单的性能问题场景,并提交到 InterSystems IRIS AI Contest。 读完这篇文章后您可以去看看,如果喜欢,就请[投我一票吧](https://openexchange.intersystems.com/contest/current)! :)
# 目录
### 第一部分:
* [IRIS IntegratedML 和 ML 系统](#iris_integratedml_and_ml_systems)
* [新旧常态之间](#between_the_old_and_new_normal)
### 第二部分:
* [监视 ML 性能](#monitoring_ml_performance)
* [简单用例](#a_simple_use_case)
* [未来工作](#future_works)
# IRIS IntegratedML 和 ML 系统
讨论 COVID-19 以及它对全球 ML 系统的影响之前,我们先来简单谈谈 InterSystems IRIS IntegratedML。
通过将特征选择之类的任务及其与标准 SQL 数据操作语言的集成自动化,IntegratedML 可以协助开发和部署 ML 解决方案。
例如,对医疗预约的数据进行适当的操作和分析后,可以使用以下 SQL 语句设置 ML 模型,预测患者的履约/失约情况:
```sql
CREATE MODEL AppointmentsPredection PREDICTING (Show) FROM MedicalAppointments
TRAIN MODEL AppointmentsPredection FROM MedicalAppointments
VALIDATE MODEL AppointmentsPredection FROM MedicalAppointments
```
AutoML 提供程序将选择性能最好的特征集和 ML 算法。 这里,AutoML 提供程序使用 scikit-learn 库选择了逻辑回归模型,获得 90% 的准确率。
```
| | MODEL_NAME | TRAINED_MODEL_NAME | PROVIDER | TRAINED_TIMESTAMP | MODEL_TYPE | MODEL_INFO |
|---|------------------------|-------------------------|----------|-------------------------|----------------|---------------------------------------------------|
| 0 | AppointmentsPredection | AppointmentsPredection2 | AutoML | 2020-07-12 04:46:00.615 | classification | ModelType:Logistic Regression, Package:sklearn... |
```
```
| METRIC_NAME | Accuracy | F-Measure | Precision | Recall |
|--------------------------|----------|-----------|-----------|--------|
| AppointmentsPredection21 | 0.9 | 0.94 | 0.98 | 0.91 |
```
集成到 SQL 后,您可以通过估计履约和失约的患者,将 ML 模型无缝集成到现的预约系统中以提高其性能:
```sql
SELECT PREDICT(AppointmentsPredection) As Predicted FROM MedicalAppointments WHERE ID = ?
```
您可以在[此处](https://docs.intersystems.com/iris20202/csp/docbook/DocBook.UI.Page.cls?KEY=GIML)详细了解 IntegrateML。 有关这个简单的预测模型的更多详细信息,可以参考[此处](https://github.com/jrpereirajr/iris-integratedml-monitor-example/blob/master/jupyter-samples/IntegeratedML-Monitor-Example.ipynb)。
然而,由于 AI/ML 模型在设计上是为了直接或间接地适应社会行为,因此当相关行为快速变化时,这些模型可能会受到很大影响。 最近,由于新冠疫情,我们(很遗憾地)得以实验这种场景。
# 新旧常态之间
如[MIT Technology Review 的文章](https://www.technologyreview.com/2020/05/11/1001563/covid-pandemic-broken-ai-machine-learning-amazon-retail-fraud-humans-in-the-loop/)所解释,新冠疫情一直在显著且迅速地改变着社会行为。 我在 Google Trends 中查询了一些文章中引用的词语,如 N95 口罩、卫生纸和消毒洗手液,确认在全球大流行中这些词语的热度有所提高:
文章中提到:
> “但是它们(指由 COVID-19 引起的变化)也影响了人工智能,给库存管理、欺诈检测、营销等幕后运行的算法造成干扰。 根据正常人类行为进行训练的机器学习模型现在发现,所谓的‘正常’已经发生变化,有些模型因而不再能发挥应有的作用。”
即,在“旧常态”和“新常态”之间,我们正在经历一种“新异常”。
文章中还有这样一段话:
> “机器学习模型虽然是为了应对变化而设计的, 但大多数也很脆弱。当输入数据与训练的数据相差太大时,它们的表现就会很糟糕。 (...) AI 是一种活着的引擎。”
本文继续列出一些 AI/ML 模型的示例,这些示例有的是性能突然开始受到负面影响,有的需要立即进行更改。 一些示例:
* 零售公司的非常规产品在批量订购后缺货;
* 由于媒体文章内容过于悲观,投资推荐服务根据情绪分析提出的建议失准;
* 自动短语生成器由于新的语境而开始生成不合适的内容;
* Amazon 更改了卖家推荐系统,选择自己送货的卖家,避免对其仓库物流的过度需求。
因此,我们要监控我们的 AI/ML 模型,确保模型能可靠地持续帮助客户。
到这里,希望您已经明白,对 ML 模型的创建、训练和部署并不是全部,跟踪过程也是必不可少的。 在下一篇文章中,我将展示如何使用 IRIS %Monitor.Abstract 框架来监视 ML 系统的性能,以及如何根据监视器的指标设置警报触发器。
*同时,我很想知道您是否遇到过疫情导致的问题,以及您又是如何应对的。请在评论区留言吧!*
敬请关注!保重身体 😊!
文章
姚 鑫 · 五月 17, 2021
# 第三章 执行测试
# 示例:执行测试
现在使用`%UnitTest.Manager.RunTest`执行单元测试。以下是方法:
1. 在包含单元测试的名称空间中打开终端;在本例中为用户。如果终端未在正确的命名空间中打开,请使用ZN更改命名空间。
2. 将`^UnitTestRoot`全局值设置为包含导出的测试类的目录的父级。
```java
DHC-APP>Set ^UnitTestRoot="d:\Temp"
```
3. 使用方法`%UnitTest.Manager.RunTest`执行测试。
```java
DHC-APP>do ##class(%UnitTest.Manager).RunTest("test")
```
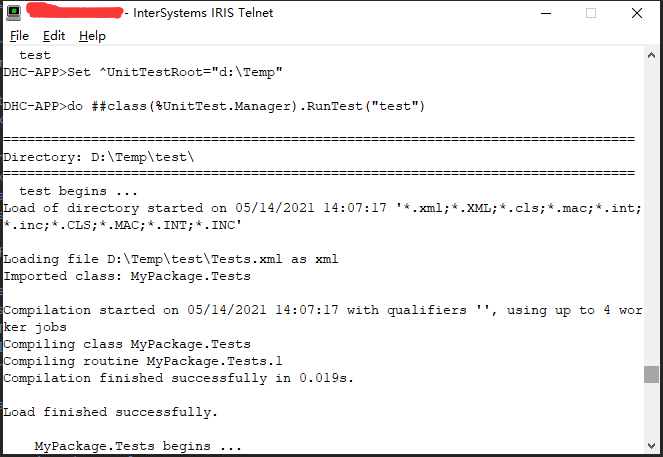
4. IRIS从`XML`文件加载测试类,编译类,执行测试,从服务器删除测试代码,并向终端发送报告。
```java
HC-APP>do ##class(%UnitTest.Manager).RunTest("test")
===============================================================================
Directory: D:\Temp\test\
===============================================================================
test begins ...
Load of directory started on 05/14/2021 14:07:17 '*.xml;*.XML;*.cls;*.mac;*.int;*.inc;*.CLS;*.MAC;*.INT;*.INC'
Loading file D:\Temp\test\Tests.xml as xml
Imported class: MyPackage.Tests
Compilation started on 05/14/2021 14:07:17 with qualifiers '', using up to 4 worker jobs
Compiling class MyPackage.Tests
Compiling routine MyPackage.Tests.1
Compilation finished successfully in 0.019s.
Load finished successfully.
MyPackage.Tests begins ...
TestAdd() begins ...
AssertEquals:Test Add(2,2)=4 (passed)
AssertNotEquals:Test Add(2,2)'=5 (passed)
LogMessage:Duration of execution: .000061 sec.
TestAdd passed
MyPackage.Tests passed
test passed
Use the following URL to view the result:
http://172.18.18.159:52773/csp/sys/%25UnitTest.Portal.Indices.cls?Index=3&$NAMESPACE=DHC-APP
All PASSED
```
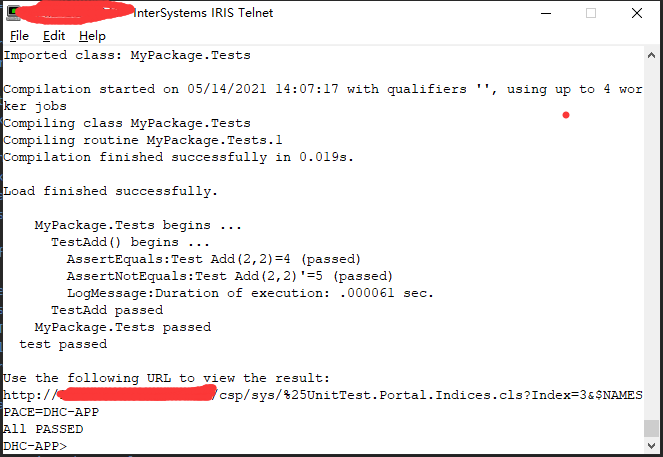
最后一行显示了测试报告的URL。
**注意:以这种方式运行测试会在它们执行后从InterSystems IRIS中删除它们。如果在执行测试后返回到Atelier查看测试,将看到一个指示,表明Atelier中可见的文件与服务器不同步。可以保存或重新编译该类,以将代码添加回服务器。
如果使用的是`.cls`文件而不是XML文件,则必须向`RunTest`提供`/loadudl`限定符。**
```java
USER>do ##class(%UnitTest.Manager).RunTest("mytests","/loadudl")
```
# 示例:UnitTest Portal
运行单元测试将生成测试报告。InterSystems IRIS提供了一个用于查看报告的`UnitTest`门户。报告按命名空间组织。
可以使用系统资源管理器System Explorer > Tools > UnitTest Portal导航到UnitTest门户。如有必要,请切换到用户命名空间。
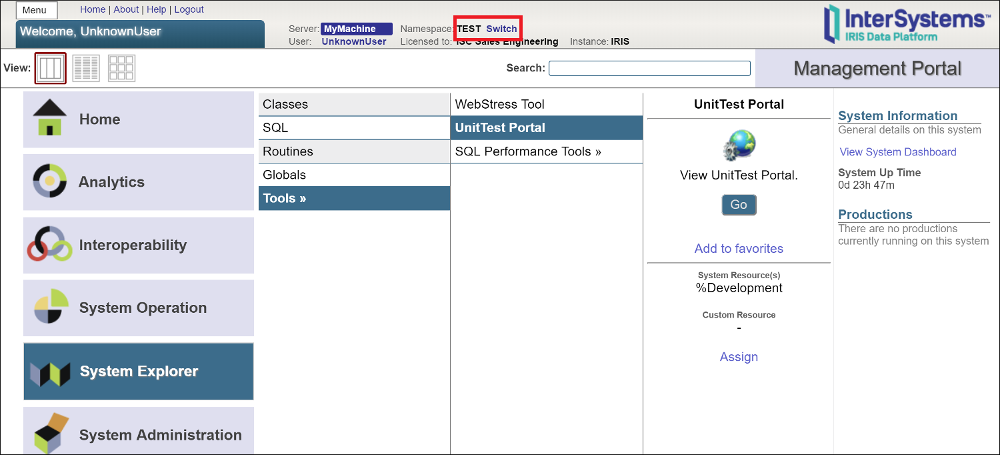
# 示例:在单元测试门户中查看报告
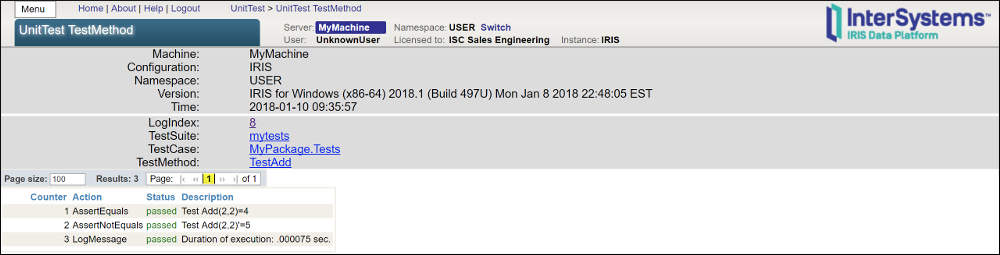
门户将测试结果组织成一系列报告。每个测试报告将测试结果组织到一系列超链接页面中。按照链接查找越来越具体的信息。
第一页提供了所有测试套件的摘要。在这种情况下,所有测试套件都通过了。

单击要查看的报告的`ID`列中的`ID`号。
第二个页面显示每个测试套件的结果。在本例中,`mytest`是测试套件,并且通过了测试。

单击 `mytests`.
第三个页面显示每个测试用例的结果。在本例中,通过了单个测试用例`MyPackage.Tests`。

单击 `MyPackage.Tests`
第四页显示了通过测试方法得出的结果。这里通过了单个测试方法`TestAdd`。
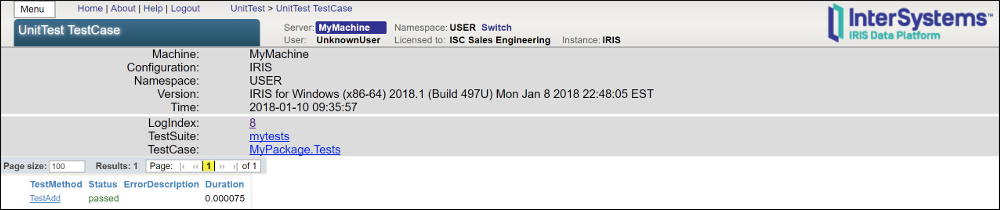
单击 TestAdd.
最后一页显示测试方法中使用的每个`AssertX`宏的结果。在本例中,`AssertEquals`和`AssertNotEquals`都通过了。
# 设置和拆卸
`%UnitTest.TestCase`类提供的方法可用于在一个测试或一组测试执行之前设置测试环境,然后在测试完成后拆除该环境。以下是对这些方法的说明:
方法 | 描述
---|---
`OnBeforeAllTests` |在测试类中的任何测试方法执行之前执行一次。可以设置测试环境。
`OnAfterAllTests` |在测试类中的所有测试方法执行后执行一次。可以破坏测试环境。
`OnBeforeOneTest` |在测试类中的每个测试方法执行之前立即执行。
`OnAfterOneTest` |在文本类中的每个测试方法执行后立即执行。
# 示例:向测试类添加Setup和Tear Down方法
在本例中,将添加一个名为`TestEditContact`的测试方法。此方法验证`MyPackage.Contact`类的`ContactType`属性是否限制为`“Personal”`或`“Business”`。添加了一个`OnBeforeAllTests`方法,该方法在测试执行之前准备数据库。还可以添加一个`OnAfterAllTests`方法,该方法在测试执行后还原数据库状态。
1. 在`Studio`中打开`MyPackage.Tests`(可能需要从`^UnitTestRoot`目录导入它)。
2. 添加`OnBeforeAllTests`和`OnAfterAllTests`方法。
```java
Method OnBeforeAllTests() As %Status
{
Do ##class(MyPackage.Contact).Populate(1)
Return $$$OK
}
```
```java
Method OnAfterAllTests() As %Status
{
Do ##class(MyPackage.Contact).%KillExtent()
Return $$$OK
}
```
`OnBeforeAllTests`方法使用单个`Contact`实例填充数据库。`OnAfterAllTests`方法从数据库中删除所有`Contact`实例。
3. 现在将`TestEditContact`测试方法添加到`MyPackage.Tests`:
```java
Method TestEditContact()
{
set contact=##class(MyPackage.Contact).%OpenId(1)
set contact.Name="Rockwell,Norman"
set contact.ContactType="Friend"
Do $$$AssertStatusNotOK(contact.%Save(),"ContactType = Friend")
Set contact.ContactType="Personal"
Do $$$AssertStatusOK(contact.%Save(),"ContactType = Personal")
}
```
该方法在两种情况下测试执行`%Save on Contact`返回的状态值:为`ContactType`分配无效值之后和为`ContactType`分配有效值之后。
4. 将测试导出到`c:\unittest\mytest`,覆盖现有的`Tests.xml`。
# [源码](https://download.csdn.net/download/yaoxin521123/18703118)
文章
姚 鑫 · 五月 29, 2021
# 第十章 使用FTP
IRIS提供了一个类`%Net.FtpSession`,可以使用它从InterSystems IRIS内建立与FTP服务器的会话。
# 建立FTP会话
要建立FTP会话,请执行以下操作:
1. 创建`%Net.FtpSession`的实例。
2. 可以选择设置此实例的属性,以控制会话的常规行为:
- `Timeout` 超时指定等待FTP服务器回复的时间(以秒为单位)。
- `SSLConfiguration`指定用于连接的激活的`SSL/TLS`配置(如果有)。如果`FTP`服务器使用HTTPS,请使用此选项。
- `TranslateTable`指定在读取文件内容或写入文件内容时要使用的转换表。
- `UsePASV`启用PASV模式。
- 当`FTP`服务器使用`https`时,`SSLCheckServerIdentity`适用。默认情况下,当`%Net.FtpSession`的实例连接到`SSL/TLS`服务器时,它会检查证书服务器名称是否与用于连接到服务器的DNS名称匹配。如果这些名称不匹配,则不允许连接。
若要禁用此检查,请将`SSLCheckServerIdentity`属性设置为0。
3. 调用`Connect()`方法以连接到特定的FTP服务器。
4. 调用`ascii()`或`binary()`方法将传输模式分别设置为ASCII模式或二进制模式。要查看当前传输模式,请检查实例的Type属性的值。
注意:`%Net.FtpSession`的每个方法都返回一个状态,应该检查该状态。这些方法还设置提供有关会话状态的有用信息的属性的值:
- 如果当前已连接,则`CONNECTED`为TRUE,否则为FALSE。
- `ReturnCode`包含上次与FTP服务器通信时的返回代码。
- `ReturnMessage`包含上次与FTP服务器通信时的返回消息。
`Status()`方法返回(通过引用)FTP服务器的状态。
## 命令的转换表
`%Net.FtpSession`在FTP服务器上查看文件名和路径名时,使用`RFC 2640`中介绍的技术自动处理字符集转换。当`%Net.FtpSession`的实例连接到FTP服务器时,它会使用Feat消息来确定服务器是否使用`UTF-8`字符。如果是,它将命令通道通信切换到`UTF-8`,以便所有文件名和路径名都可以正确地与`UTF-8`相互转换。
如果服务器不支持`FEAT`命令或未报告支持`UTF-8`,`%Net.FtpSession`实例将使用`RAW`模式并读取或写入RAW字节。
在极少数情况下,如果需要指定要使用的转换表,请设置`%Net.FtpSession`实例的`CommandTranslateTable`属性。一般情况下,应该没有必要使用此属性。
# FTP文件和系统方法
一旦建立了FTP会话,就可以调用会话实例的方法来执行FTP任务。`%Net.FtpSession`提供以下读写文件的方法:
### Delete()
删除文件。
### Retrieve()
将文件从FTP服务器复制到InterSystems IRIS流中,并通过引用返回该流。要使用此流,请使用标准流方法:`Write()`、`WriteLine()`、`Read()`、`ReadLine()`、`Rewind()`、`MoveToEnd()`和`Clear()`。还可以使用流的`Size`属性。
### RetryRetrieve()
允许继续检索文件,因为给定的流是由上一次使用`Retrieve()`创建的。
### Store()
将 IRIS流的内容写入FTP服务器上的文件。
### Append()
将流的内容追加到指定文件的末尾。
### Rename()
重命名文件。
此外,`%Net.FtpSession`提供了导航和修改FTP服务器上的文件系统的方法:`GetDirectory()`、`SetDirectory()`、`SetToParentDirectory()`和`MakeDirectory()`。
要检查文件系统的内容,请使用`list()`或`NameList()`方法。
- `List()`创建一个流,其中包含其名称与给定模式匹配的所有文件的列表,并通过引用返回该流。
- `NameList()`创建文件名数组并通过引用返回该数组。
还可以使用`ChangeUser()`方法更改为其他用户;这比注销并再次登录要快。使用`Logout()`方法注销。
`System()`方法返回(通过引用)有关托管FTP服务器的计算机类型的信息。
`Size()`和`MDTM()`方法分别返回文件的大小和修改时间。
使用通用`sendCommand()`方法向FTP服务器发送命令并读取响应。此方法可用于发送`%Net.FtpSession`中未明确支持的命令。
# 使用链接的流上载大文件
如果要上传大文件,请考虑使用流接口的`LinkToFile()`方法。也就是说,不是创建流并将文件读入其中,而是创建流并将其链接到文件。在调用`%Net.FtpSession`的`Store()`方法时使用此链接流。
```java
Method SendLargeFile(ftp As %Net.FtpSession, dir As %String, filename As %String)
{
Set filestream=##class(%FileBinaryStream).%New()
Set sc=filestream.LinkToFile(dir_filename)
If $$$ISERR(sc) {do $System.Status.DisplayError(sc) quit }
//上传的文件将与原始文件同名
Set newname=filename
Set sc=ftp.Store(newname,filestream)
If $$$ISERR(sc) {do $System.Status.DisplayError(sc) quit }
}
```
# 自定义FTP服务器发出的回调
可以自定义`FTP`服务器生成的回调。例如,通过这样做,可以向用户提供服务器仍在处理大型传输的指示,或允许用户中止传输。
要自定义FTP回调,请执行以下操作:
1. 创建`%Net.FtpCallback`的子类。
2. 在这个子类中,实现`RetrieveCallback()`方法,该方法在从FTP服务器接收数据时定期调用。
3. 还要实现`StoreCallback()`方法,在将数据写入FTP服务器时会定期调用该方法。
4. 创建`FTP`会话时(如“建立FTP会话”中所述),将回调属性设置为等于的子类`%Net.FtpCallback`。
文章
Qiao Peng · 十月 20, 2022
在InterSystems IRIS医疗版里有一个文件压缩解压的适配器HS.Util.Zip.Adapter和对应的文件压缩解压业务操作HS.Util.Zip.Operations。集成产品可以使用它们进行文件的压缩和解压操作。这2个类的联机文档说明较少,这里介绍它们的使用方法。
1. 基础配置
InterSystems IRIS使用操作系统的压缩和解压缩能力,因此需要注册操作系统执行压缩解压的命令。
在管理门户的Health标签页下,选中配置注册(Configuration Registry):
在其中增加2个注册项目:
\ZipUtility\UnZipCommand 和\ZipUtility\ZipCommand,分别代表解压和压缩命令。适配器HS.Util.Zip.Adapter会检查这2个注册项并得到相应的命令。各个操作系统的命令并不一样,示例如下:
\ZipUtility\UnZipCommand 解压缩命令
Windows
"c:\program files\7-zip\7z" x %1 -o. -r
非Windows
unzip %1 -d .
\ZipUtility\ZipCommand 压缩命令
Windows
"c:\program files\7-zip\7z" a %1 . -r
非Windows
zip -rm %1 .
注意,其中要有%1,代表解压后的或压缩后的目标文件路径。
2. 适配器配置
可以直接使用业务操作HS.Util.Zip.Operations,无需自己开发业务操作类。这个系统提供的业务操作使用的就是适配器HS.Util.Zip.Adapter。
将业务操作HS.Util.Zip.Operations加入Production,配置其工作目录(WorkingDirectory),就是上面提到压缩/解压命令中%1代表的目录。注意,这个目录并非HS.Util.Zip.Operations输出的目标路径,它只是压缩/解压过程中用到的临时目录。这个业务操作执行压缩/解压后,会自动删除临时目录中的文件,而将目标文件流数据保存到响应消息里。
3. 调用压缩/解压业务操作
这个业务操作的请求消息是HS.Message.ZipRequest,响应消息是HS.Message.ZipResponse。
3.1 请求消息准备
HS.Message.ZipRequest里有如下属性:
Operation:执行的操作,压缩或解压缩。可用值为"FromZip" - 解压缩,和"ToZip" 压缩。
File:解压文件的Stream数据,类型为%Stream.GlobalBinary。在执行文件解压时才需要设置该属性 - 需要将解压文件的Stream赋值给File属性。
Items: 文件项目列表,列表元素类型为HS.Types.ZipItem。在执行文件压缩时才需要设置该属性 - 需要将多个压缩文件的数据赋值给Items列表元素的以下属性:
Filename:未来解压缩出来的目标文件名
Path:未来解压缩出来的目标文件子目录
File:需要压缩的文件流数据
3.2 处理响应消息
HS.Message.ZipResponse有如下属性:
File:在执行文件压缩操作时,该属性保存压缩后的流数据。在执行解压操作时,该属性为空。
Items:文件项目列表,列表元素类型为HS.Types.ZipItem。在执行文件解压操作时,该列表属性的元素保护以下属性:
Filename:解压缩出来的目标文件名
Path:解压缩出来的目标文件子目录
File:解压缩出来的流数据
4. 示例代码
以下是直接调用HS.Util.Zip.Operations的业务服务代码示例。
4.1 压缩示例
Method OnProcessInput(pInput As %RegisteredObject, Output pOutput As %RegisteredObject) As %Status
{
//实例化请求消息
Set tReq = ##class(HS.Message.ZipRequest).%New()
//设置源文件目录
Set tSrcFolder = "/Users/test/irishealth/mgr/Temp/"
//设置请求消息为压缩操作
Set tReq.Operation = "ToZip"
Set tFile = ##class(%Stream.FileBinary).%New()
Set sc=tFile.LinkToFile(tTgtFolder_"output.zip")
Set tReq.File = tFile
//压缩的第一个文件
Set tItem1 = ##class(HS.Types.ZipItem).%New()
//设置未来解压缩的文件名
Set tItem1.Filename = "test.png"
//设置未来解压缩的子文件夹
Set tItem1.Path = "pic/"
//打开目标文件,获取流数据
Set tFileSrc = ##class(%Stream.FileBinary).%New()
Do tFileSrc.LinkToFile(tSrcFolder_tItem1.Filename)
Do tItem1.File.CopyFrom(tFileSrc)
kill tFileSrc
//将压缩文件信息插入列表
Do tReq.Items.Insert(tItem1)
//压缩的第二个文件
Set tItem2 = ##class(HS.Types.ZipItem).%New()
//设置未来解压缩的文件名
Set tItem2.Filename = "HS.SDA3.xsd"
//设置未来解压缩的子文件夹
Set tItem2.Path = "code/"
//打开目标文件,获取流数据
Set tFileSrc = ##class(%Stream.FileBinary).%New()
Do tFileSrc.LinkToFile(tSrcFolder_tItem2.Filename)
Do tItem2.File.CopyFrom(tFileSrc)
kill tFileSrc
//将压缩文件信息插入列表
Do tReq.Items.Insert(tItem2)
//调用业务操作
Do ..SendRequestSync("HS.Util.Zip.Operations",tReq,.tRes)
//设置目标路径
Set tFolder = "/Users/test/irishealth/mgr/Temp/Target/"
//保存压缩文件到目标路径
Set tTgtFile = ##class(%Stream.FileBinary).%New()
Set tFullPath = tFolder_"output.zip"
Set tTgtFile.Filename = tFullPath
Set tSC = tTgtFile.CopyFrom(tRes.File)
Set tSC= tTgtFile.%Save()
Quit $$$OK
}
4.2 解压缩示例
Method OnProcessInput(pInput As %RegisteredObject, Output pOutput As %RegisteredObject) As %Status
{
//实例化请求消息
Set tReq = ##class(HS.Message.ZipRequest).%New()
//设置请求消息为解压缩操作
Set tReq.Operation = "FromZip"
//打开压缩文件,获取流数据
Set tFileSrc = ##class(%Stream.FileBinary).%New()
Set sc=tFileSrc.LinkToFile("/Users/test/Downloads/TestCase.zip")
//Set tReq.File = tFileSrc
Do tReq.File.CopyFrom(tFileSrc)
kill tFileSrc
//调用业务操作
Do ..SendRequestSync("HS.Util.Zip.Operations",tReq,.tRes)
//设置目标文件路径
Set tTgtFolder = "/Users/test/irishealth/mgr/Temp/"
//获取解压后的数据,并保存到目标文件路径下
For i=1:1:tRes.Items.Count()
{
Set tFileItem = tRes.Items.GetAt(i)
Set tSubFolder = tFileItem.Path
Set tFileName = tFileItem.Filename
Set tTgtFile = ##class(%Stream.FileBinary).%New()
Set tFullPath = tTgtFolder_tSubFolder_tFileName
Set tTgtFile.Filename = tFullPath
Set tSC = tTgtFile.CopyFrom(tFileItem.File)
Set tSC= tTgtFile.%Save()
Kill tTgtFile
}
Quit $$$OK
}
文章
Weiwei Gu · 十一月 29, 2021
不是所有的多模型数据库都是相同的
作者:David Menninger
今天,许多现代应用程序需要的数据库管理能力往往不能通过一种方式就能实现。例如,当我建立一个支持旅游推荐和预订业务的应用程序时,我可能需要使用一些不同类型的数据库,包括用于用户会话的键值存储,用于产品目录的文档数据库,用于推荐的图形数据库,以及用于财务数据的关系数据库。由于各种原因,选择一个(关系型)数据库就可以了这种一刀切的数据库时代,已经离我们很远了。虽然关系型数据库仍然是许多应用的正确选择,但对于某些类型的应用,非关系型数据库提供了关系型数据库根本无法提供的优势。
关系型数据库用表和行表示数据,并使用结构化查询语言(SQL)来访问和操作数据。对于需要可靠性和ACID(原子性、一致性、隔离性和持久性)保证的事务性应用,以及需要SQL查询和报告的效率和简单性的应用,它们是一个很好的选择。 但是,关系型数据库是有代价的;它们需要数据库管理员,需要遵守预先定义的关系型结构,而且随着数据规模和工作负载的增加,它们的扩展也不经济。尽管如此,关系型数据库仍然是许多关键任务应用的正确选择,并继续为其提供动力。
相比之下,非关系型数据库,包括文档、对象、图形和键值数据库等,比关系型数据库具有某些优势--尤其是在灵活性和扩展性方面。非关系型数据库不需要DBA创建预先定义的模式,应用程序开发人员能够更容易地存储和管理数据,而不必担心映射固定的数据结构。
幸运的是,所有这些不同种类的数据库技术都是很成熟稳健的,也为应用开发者提供了丰富的功能,他们可以善加利用。
今天市场上有数以百计的数据库;非关系型数据库约占所有部署到生产中的数据库的一半。
但是,将多种数据库技术纳入一个应用程序并不总是那么简单。
多模型的一种方法--称为混合持久化--采用不同的数据库来支持每种类型的数据结构。 这是一种最佳的方法。 但是,在应用程序的整个生命周期中实施、同步和维护不同的数据库系统是复杂的,而且容易出错。
另一种方法是使用业界所称的多模型数据库;一种在同一 "产品 "中支持各种数据表示的数据库。但不是所有的多模型数据库都是一样的。有些数据库坚持混合范式,为不同的数据表示法采用多个独立的数据库引擎,造成数据的重复,并需要在不同的数据存储之间进行映射和整合。 还有一些支持引擎内的不同模型,但不支持相同的数据。
在InterSystems,我们已经开发了一种纯粹的多模型数据库管理方法。我们的产品,InterSystems IRIS数据平台存储了数据的单一表示。它利用了一个单一的数据库引擎,支持关系型和非关系型的数据访问和操作,没有重复。对于非关系型访问,它不需要预先定义的模式。它提供事务性的ACID保证,可以纵向和横向扩展,并支持本地、公共和私有云环境,以及混合(公共/公共、公共/私有、云/本地)部署环境。同样的数据可以使用SQL访问和操作,也可以作为文档、对象或键值数据。应用程序开发人员不需要使用多个数据库,也不需要在多个数据存储中整合和同步数据。
我们的多模型方法整合了关系型和非关系型技术的优点,而摒弃了其缺点,也没有与多角化持久性相关的复杂性或低效率。 所有这些都整合在我们从头开始建立的这个单一的数据库管理系统中了。
(David Menninger是Ventana Research的高级副总裁和研究总监,也是长期的行业老兵,他对多种数据表示的需求以及多模型数据库的各种方法的优势和劣势进行了深刻的分析。你可以在这里阅读他的报告。)
https://www.intersystems.com/data-excellence-blog/not-all-multi-model-dbms-are-created-equal/
文章
姚 鑫 · 四月 30, 2021
# 第八章 解释SQL查询计划(二)
# SQL语句的详细信息
有两种方式显示SQL语句的详细信息:
- 在SQL Statements选项卡中,通过单击左侧列中的Table/View/Procedure Name链接选择一个SQL Statement。
这将在单独的选项卡中显示SQL语句详细信息。
该界面允许打开多个选项卡进行比较。
它还提供了一个Query Test按钮,用于显示SQL Runtime Statistics页面。
- 从表的Catalog Details选项卡(或SQL Statements选项卡)中,通过单击右边列中的Statement Text链接选择一个SQL语句。
这将在弹出窗口中显示SQL语句详细信息。
可以使用“SQL语句详细信息”显示来查看查询计划,并冻结或解冻查询计划。
“SQL语句详细信息”提供冻结或解冻查询计划的按钮。
它还提供了一个Clear SQL Statistics按钮来清除性能统计,一个`Export`按钮来将一个或多个SQL语句导出到一个文件,以及一个`Refresh`和`Close`页面按钮。
SQL语句详细信息显示包含以下部分。
每个部分都可以通过选择部分标题旁边的箭头图标展开或折叠:
- 语句详细信息,其中包括性能统计
- 编译设置
- 语句在以下例程中定义
- 语句使用如下关系
- 语句文本和查询计划(在其他地方描述)
## 声明的细节部分
- 语句散列Statement hash:语句定义的内部散列表示形式,用作SQL语句索引的键(仅供内部使用)。
有时,看起来相同的SQL语句可能具有不同的语句散列项。
需要生成不同SQL语句的代码的设置/选项的任何差异都会导致不同的语句散列。
这可能发生在支持不同内部优化的不同客户端版本或不同平台上。
- 时间戳`Timestamp`:最初,创建计划时的时间戳。
这个时间戳会在冻结/解冻之后更新,以记录计划解冻的时间,而不是重新编译计划的时间。
可能必须单击Refresh Page按钮来显示解冻时间戳。
将Plan Timestamp与包含该语句的例程/类的`datetime`值进行比较,可以知道,如果再次编译该例程/类,它是否使用了相同的查询计划。
- 版本Version:创建计划的InterSystems IRIS版本。
如果“计划”状态是“冻结/升级”,则这是InterSystems IRIS的早期版本。
解冻查询计划时,“计划”状态变为“解冻”,“版本”变为当前的InterSystems IRIS版本。
- 计划状态Plan state:冻结/显式、冻结/升级、解冻、解冻/并行。
Frozen/Explicit意味着该语句的计划已被显式用户操作冻结,无论生成此SQL语句的代码发生了什么变化,该冻结的计划都将是将要使用的查询计划。
冻结/升级意味着该语句的计划已被InterSystems IRIS版本升级自动冻结。
解冻意味着该计划目前处于解冻状态,可能被冻结。
Unfrozen/Parallel表示该计划被解冻,并使用`%Parallel`处理,因此不能被冻结。
`NULL`(空白)计划状态意味着没有关联的查询计划。
- 自然查询Natural query:一个布尔标志,指示该查询是否是“自然查询”。
如果勾选此项,则该查询是自然查询,不会记录查询性能统计信息。
如果不检查,性能统计可能会被记录;
其他因素决定了统计数据是否真正被记录下来。
自然查询被定义为嵌入式SQL查询,它非常简单,记录统计数据的开销会影响查询性能。
将统计信息保存在自然查询上没有任何好处,因为查询已经非常简单了。
一个很好的自然查询示例是`SELECT Name INTO:n FROM Table WHERE %ID=?`
这个查询的`WHERE`子句是一个相等条件。
此查询不涉及任何循环或任何索引引用。
动态SQL查询(缓存查询)不会被标记为自然查询;
缓存查询的统计数据可能被记录,也可能不被记录。
- 冻结计划不同Frozen plan different:冻结计划时,会显示该字段,显示冻结的计划与未冻结的计划是否不同。
冻结计划时,语句文本和查询计划将并排显示冻结的计划和未冻结的计划,以便进行比较。
本节还包括五个查询性能统计字段,将在下一节中进行描述。
## 性能统计数据
执行查询会将性能统计数据添加到相应的SQL语句。
此信息可用于确定哪些查询执行得最慢,哪些查询执行得最多。
通过使用这些信息,您可以确定哪些查询将通过优化提供显著的好处。
除了SQL语句名称、计划状态、位置和文本之外,还为缓存查询提供了以下附加信息:
- 计数Count:运行此查询次数的整数计数。
如果对该查询产生不同的查询计划(例如向表中添加索引),则将重置该计数。
- 平均计数Average count:每天运行此查询的平均次数。
- 总时间Total time:运行此查询所花费的时间(以秒为单位)。
- 平均时间Average time:运行此查询所花费的平均时间(以秒为单位)。
如果查询是缓存的查询,则查询的第一次执行所花费的时间很可能比从查询缓存中执行优化后的查询所花费的时间要多得多。
- 标准差Standard deviation:总时间和平均时间的标准差。
只运行一次的查询的标准偏差为0。
运行多次的查询通常比只运行几次的查询具有更低的标准偏差。
- 第一次看到的日期Date first seen:查询第一次运行(执行)的日期。
这可能与`Last Compile Time`不同,后者是准备查询的时间。
`UpdateSQLStats`任务会定期更新已完成的查询执行的查询性能统计数据。
这将最小化维护这些统计信息所涉及的开销。
因此,当前运行的查询不会出现在查询性能统计中。
最近完成的查询(大约在最近一个小时内)可能不会立即出现在查询性能统计中。
可以使用Clear SQL Statistics按钮清除这6个字段的值。
InterSystems IRIS不单独记录`%PARALLEL`子查询的性能统计数据。
%PARALLEL子查询统计信息与外部查询的统计信息相加。
由并行运行的实现生成的查询没有单独跟踪其性能统计信息。
InterSystems IRIS不记录“自然”查询的性能统计数据。
如果系统收集了统计信息,则会降低查询性能,而自然查询已经是最优的,因此没有进行优化的可能。
可以在“SQL语句”选项卡显示中查看多个SQL语句的查询性能统计信息。
您可以按任何列对SQL Statements选项卡列表进行排序。
这使得很容易确定,例如,哪个查询具有最大的平均时间。
还可以通过查询`INFORMATION.SCHEMA.STATEMENTS`类属性来访问这些查询性能统计数据,如查询SQL语句中所述。
## 编译设置部分
- 选择模式`Select mode`:编译语句时使用的`SelectMode`。
对于DML命令,可以使用`#SQLCompile Select`;
默认为Logical。
如果`#SQLCompile Select=Runtime`,调用`$SYSTEM.SQL.Util.SetOption()`方法的`SelectMode`选项可以改变查询结果集的显示,但不会改变SelectMode值,它仍然是Runtime。
- 默认模式Default schema(s):编译语句时设置的默认模式名。
这通常是在发出命令时生效的默认模式,尽管SQL可能使用模式搜索路径(如果提供的话)而不是默认模式名来解析非限定名称的模式。
但是,如果该语句是嵌入式SQL中使用一个或多个`#Import`宏指令的DML命令,则`#Import`指令指定的模式将在这里列出。
- 模式路径Schema path:编译语句时定义的模式路径。
如果指定,这是模式搜索路径。
如果没有指定架构搜索路径,则此设置为空。
但是,对于在`#Import`宏指令中指定搜索路径的DML Embedded SQL命令,`#Import`搜索路径显示在默认模式设置中,并且该模式路径设置为空白。
- 计划错误Plan Error:该字段仅在使用冻结计划时发生错误时出现。
例如,如果一个查询计划使用一个索引,则该查询计划被冻结,然后该索引从表中删除,就会出现如下的计划错误:`Map 'NameIDX' not defined in table 'Sample.Person', but it was specified in the frozen plan for the query`.
删除或添加索引将导致重新编译表,从而更改“最后编译时间”值。
一旦导致错误的条件得到纠正,`Clear Error`按钮可用于清除`Plan Error`字段——例如,通过重新创建缺失的索引。
在错误条件被纠正后使用“清除错误”按钮会导致“计划错误”字段和“清除错误”按钮消失。
## 例程和关系部分
语句在以下例程部分中定义:
- 例程`Routine`:与缓存查询关联的类名(对于动态SQL DML),或者例程名(对于嵌入式SQL DML)。
- 类型:类方法或`MAC`例程(对于嵌入式SQL DML)。
- 上次编译时间`Last Compile Time`:例程的上次编译时间或准备时间。如果SQL语句解冻,重新编译MAC例程会同时更新此时间戳和Plan时间戳。如果SQL语句已冻结,则重新编译MAC例程仅更新此时间戳;在您解冻计划之前,Plan时间戳不会更改;然后Plan时间戳将显示计划解冻的时间。
语句使用以下关系部分列出了一个或多个用于创建查询计划的定义表。对于使用查询从另一个表提取值的`INSERT`,或者使用`FROM`子句引用另一个表的`UPDATE`或`DELETE`,这两个表都在此处列出。每个表都列出了下列值:
- 表或视图名称`Table or View Name`:表或视图的限定名称。
- 类型`Type`:表或视图。
- 上次编译时间`Last Compile Time`:表(持久化类)上次编译的时间。
- `Classname`:与表关联的类名。
本节包括用于重新编译类的编译类选项。如果重新编译解冻计划,则所有三个时间字段都会更新。如果重新编译冻结的计划,则会更新两个上次编译时间字段,但不会更新计划时间戳。解冻计划并单击刷新页面按钮后,计划时间戳将更新为计划解冻的时间。
# 查询SQL语句
可以使用`SQLTableStatements()`存储查询返回指定表的SQL语句。下面的示例显示了这一点:
```java
/// w ##class(PHA.TEST.SQL).SQLTableStatements()
ClassMethod SQLTableStatements()
{
SET mycall = "CALL %Library.SQLTableStatements('Sample','Person')"
SET tStatement = ##class(%SQL.Statement).%New()
SET qStatus=tStatement.%Prepare(mycall)
IF qStatus'=1 {WRITE "%Prepare failed:" DO $System.Status.DisplayError(qStatus) QUIT}
SET rset=tStatement.%Execute()
IF rset.%SQLCODE '= 0 {WRITE "SQL error=",rset.%SQLCODE QUIT}
DO rset.%Display()
}
```
```java
DHC-APP>w ##class(PHA.TEST.SQL).SQLTableStatements()
Dumping result #1
SCHEMA RELATION_NAME PLAN_STATE LOCATION STATEMENT
SAMPLE PERSON 0 %sqlcq.DHCdAPP.cls228.1 DECLARE C CURSOR FOR SELECT * INTO :%col(1) , :%col(2) , :%col(3) , :%col(4) , :%col(5) , :%col(6) , :%col(7) , :%col(8) , :%col(9) , :%col(10) , :%col(11) , :%col(12) , :%col(13) , :%col(14) , :%col(15) FROM SAMPLE . PERSON
SAMPLE PERSON 0 Sample.Person.1 SELECT AGE , DOB , FAVORITECOLORS , HOME , NAME , OFFICE , SSN , SPOUSE , X__CLASSNAME , HOME_CITY , HOME_STATE , HOME_STREET , HOME_ZIP , OFFICE_CITY , OFFICE_STATE , OFFICE_STREET , OFFICE_ZIP INTO :%e ( ) FROM %IGNOREINDEX * SAMPLE . PERSON WHERE ID = :%rowid
...
CURSOR FOR SELECT P . NAME , P . AGE , E . NAME , E . AGE FROM %ALLINDEX SAMPLE . PERSON AS P LEFT OUTER JOIN SAMPLE . EMPLOYEE AS E ON P . NAME = E . NAME WHERE P . AGE > 21 AND %NOINDEX E . AGE < 65
SAMPLE PERSON 0 PHA.TEST.SQL.1 SELECT NAME , SPOUSE INTO :name , :spouse FROM SAMPLE . PERSON WHERE SPOUSE IS NULL
SAMPLE PERSON 0 PHA.TEST.ObjectScript.1 SELECT NAME , DOB , HOME INTO :n , :d , :h FROM SAMPLE . PERSON
70 Rows(s) Affected
```
可以使用`INFORMATION_SCHEMA`包表来查询SQL语句列表。InterSystems IRIS支持以下类:
- `INFORMATION_SCHEMA.STATEMENTS`:包含当前名称空间中的当前用户可以访问的SQL语句索引项。
- `INFORMATION_SCHEMA.STATEMENT_LOCATIONS`:包含调用SQL语句的每个例程位置:持久类名或缓存查询名。
- `INFORMATION_SCHEMA.STATEMENT_RELATIONS`:包含SQL语句使用的每个表或视图条目。
以下是使用这些类的一些示例查询:
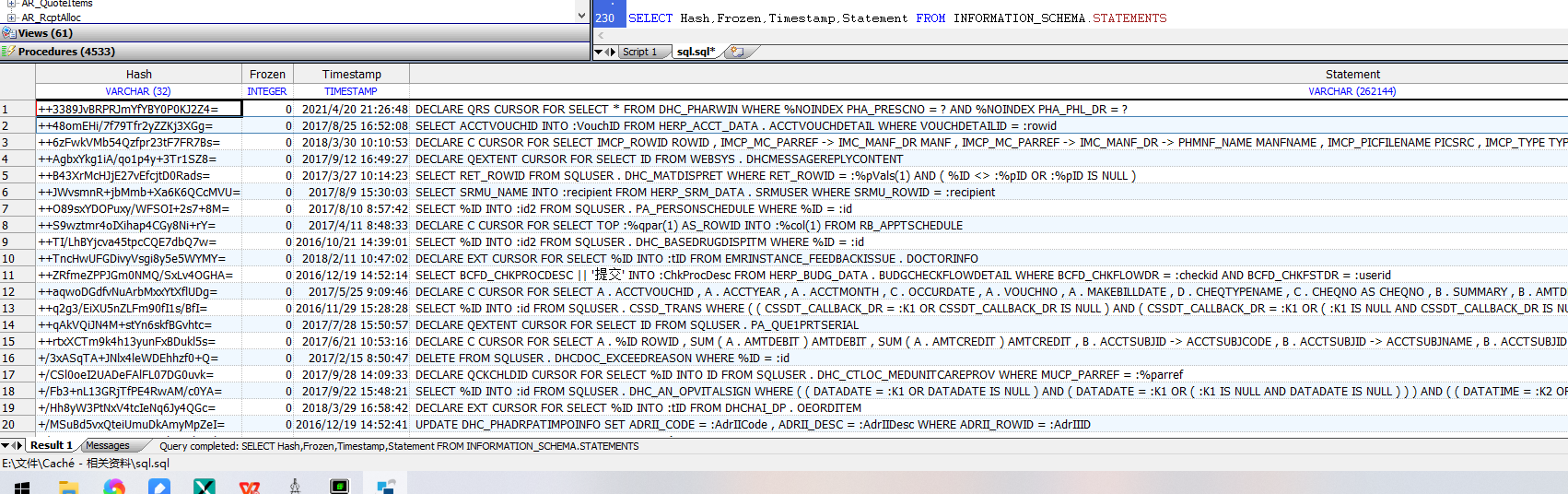
下面的示例返回命名空间中的所有SQL语句,列出哈希值(唯一标识规范化SQL语句的计算ID)、冻结状态标志(值0到3)、准备语句和保存计划时的本地时间戳以及语句文本本身:
```sql
SELECT Hash,Frozen,Timestamp,Statement FROM INFORMATION_SCHEMA.STATEMENTS
```
以下示例返回所有冻结计划的SQL语句,指示冻结的计划是否与未冻结的计划不同。请注意,解冻语句可以是`Frozen=0`或`Frozen=3`。不能冻结的单行INSERT等语句在冻结列中显示NULL:
```sql
SELECT Frozen,FrozenDifferent,Timestamp,Statement FROM INFORMATION_SCHEMA.STATEMENTS
WHERE Frozen=1 OR Frozen=2
```
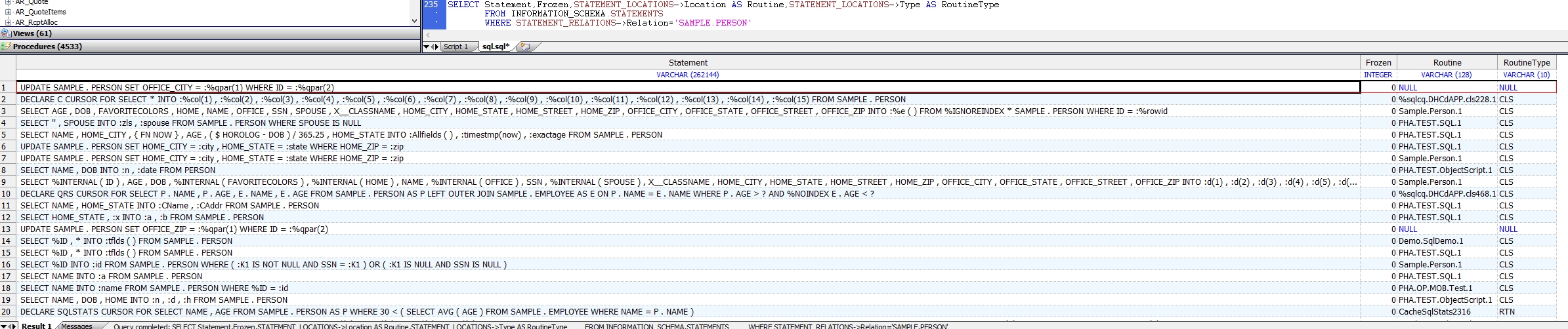
以下示例返回给定SQL表的所有SQL语句和语句所在的例程。(请注意,指定表名(`SAMPLE.PERSON`)时必须使用与SQL语句文本中相同的字母大小写:全部大写字母):
```sql
SELECT Statement,Frozen,STATEMENT_LOCATIONS->Location AS Routine,STATEMENT_LOCATIONS->Type AS RoutineType
FROM INFORMATION_SCHEMA.STATEMENTS
WHERE STATEMENT_RELATIONS->Relation='SAMPLE.PERSON'
```
以下示例返回当前命名空间中具有冻结计划的所有SQL语句:
```sql
SELECT Statement,Frozen,Frozen_Different,STATEMENT_LOCATIONS->Location AS Routine,STATEMENT_LOCATIONS->Type AS RoutineType
FROM INFORMATION_SCHEMA.STATEMENTS
WHERE Frozen=1 OR Frozen=2
```
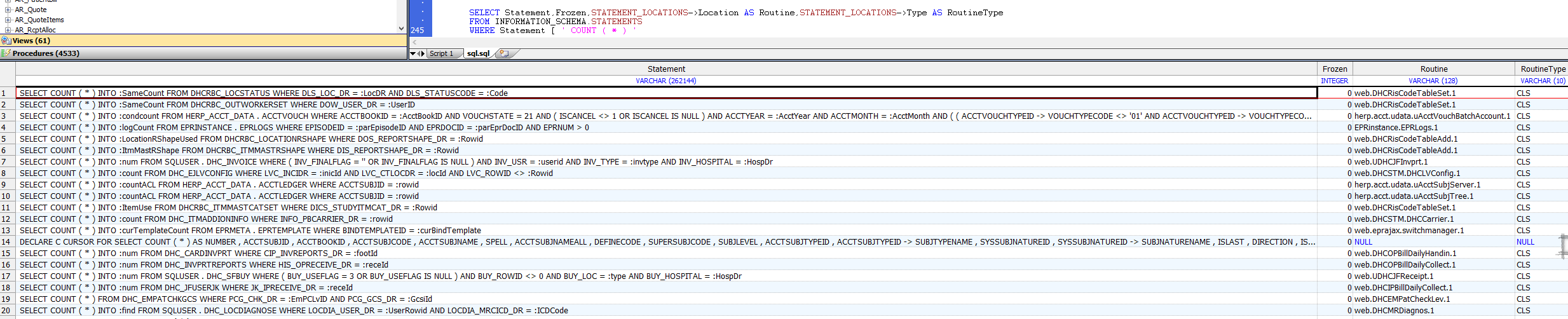
以下示例返回当前命名空间中包含`COUNT(*)`聚合函数的所有SQL语句。(请注意,指定语句文本(`COUNT(*)`)时必须使用与SQL语句文本相同的空格):
```sql
SELECT Statement,Frozen,STATEMENT_LOCATIONS->Location AS Routine,STATEMENT_LOCATIONS->Type AS RoutineType
FROM INFORMATION_SCHEMA.STATEMENTS
WHERE Statement [ ' COUNT ( * )
```
# 导出和导入SQL语句
可以将SQL语句作为`XML`格式的文本文件导出或导入。这使可以将冻结的计划从一个位置移动到另一个位置。SQL语句导出和导入包括关联的查询计划。
可以导出单个SQL语句,也可以导出命名空间中的所有SQL语句。
可以导入先前导出的包含一个或多个SQL语句的XML文件。
注意:将SQL语句作为XML导入不应与从文本文件导入和执行SQL DDL代码混淆。
## 导出SQL语句
导出单个SQL语句:
- 使用SQL语句详细资料页导出按钮。在管理门户系统资源管理器SQL界面中,选择SQL语句选项卡,然后单击语句以打开SQL语句详细信息页。选择导出按钮。这将打开一个对话框,允许选择将文件导出到服务器(数据文件)或浏览器。
- 服务器(默认):输入导出`XML`文件的完整路径名。第一次导出时,此文件的默认名称为`statementexport.xml`。当然,可以指定不同的路径和文件名。成功导出SQL语句文件后,上次使用的文件名将成为默认值。
默认情况下,未选中在后台运行导出复选框。
- Browser:将文件`statementexport.xml`导出到用户默认浏览器中的新页面。可以为浏览器导出文件指定其他名称,或指定其他软件显示选项。
- 使用`$SYSTEM.SQL.Statement.ExportFrozenPlans()`方法。
导出命名空间中的所有SQL语句:
- 使用管理门户中的导出所有对帐单操作。从管理门户系统资源管理器SQL界面中,选择操作下拉列表。从该列表中选择Export all Statements。这将打开一个对话框,允许您将命名空间中的所有SQL语句导出到服务器(数据文件)或浏览器。
- 服务器(默认):输入导出XML文件的完整路径名。第一次导出时,此文件的默认名称为`statementexport.xml`。当然,可以指定不同的路径和文件名。成功导出SQL语句文件后,上次使用的文件名将成为默认值。
默认情况下,在后台运行导出复选框处于选中状态。这是导出所有SQL语句时的建议设置。选中在后台运行导出时,系统会为提供一个查看后台列表页面的链接,可以在该页面中查看后台作业状态。
- Browser:将文件`statementexport.xml`导出到用户默认浏览器中的新页面。可以为浏览器导出文件指定其他名称,或指定其他软件显示选项。
使用`$SYSTEM.SQL.Statement.ExportAllFrozenPlans()`方法。
## 导入SQL语句
从先前导出的文件导入一条或多条SQL语句:
- 使用管理门户中的导入对帐单操作。从管理门户系统资源管理器SQL界面中,选择操作下拉列表。从该列表中选择Import Statements。这将打开一个对话框,允许指定导入XML文件的完整路径名。
默认情况下,在后台运行导入复选框处于选中状态。这是导入SQL语句文件时的推荐设置。选中在后台运行导入时,系统会为您提供一个查看后台列表页面的链接,可以在该页面中查看后台作业状态。
使用`$SYSTEM.SQL.Statement.ImportFrozenPlans()`方法。
## 查看和清除后台任务
在管理门户系统操作选项中,选择后台任务,查看导出和导入后台任务的日志。可以使用清除日志按钮清除此日志。
文章
Qiao Peng · 一月 14, 2021

您好! 本文介绍另一种为基于 InterSystems Caché 的解决方案创建安装程序的简单方法。 主题将涵盖只需一项操作即可安装或从 Caché 中完全删除的应用程序。 如果您仍在编写需要执行多个步骤才能安装应用程序的安装说明,是时候将这个过程自动化了。
问题的提出
假设我们为 Caché 开发了一个小型实用程序,之后我们想要将其分发。 当然,最好不要让不必要的配置和安装细节打扰到安装它的用户。 此外,这些说明必须非常全面,而且要面向可能对 Caché 一无所知的用户。如果是 Web 实用程序,安装程序不仅会要求用户将其类导入 Caché,而且至少还要配置 Web 应用程序才能对其进行访问,这是相当大的工作量:
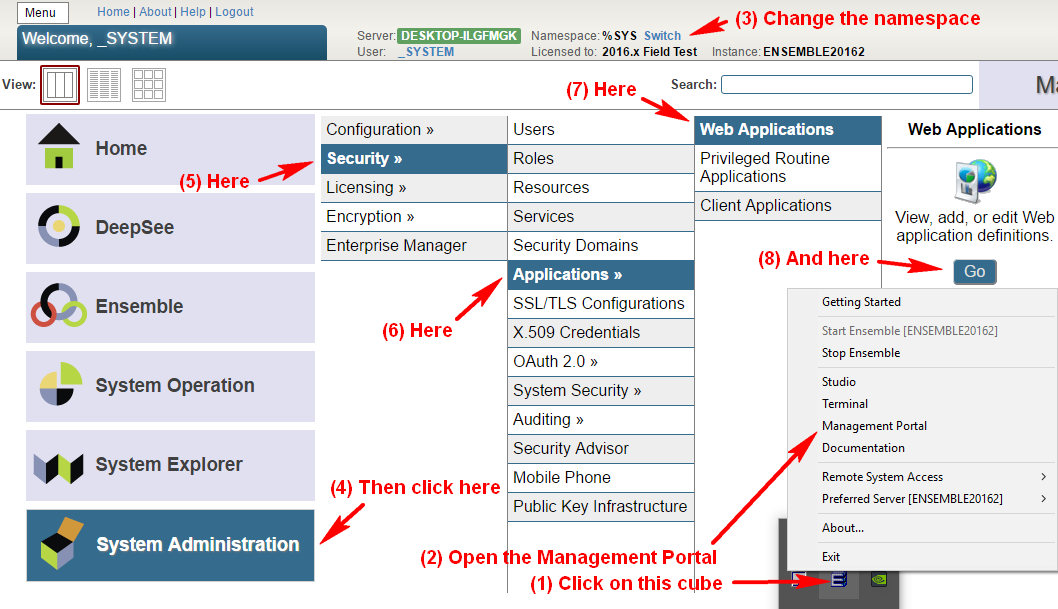

当然,所有这些操作都可以通过编程方式执行。 您只需要了解如何实现。 但即使是这样,我们也需要让用户执行操作,例如在终端中执行一个命令。
通过单次导入操作进行安装
Caché 允许我们在类导入期间执行安装。 这意味着用户只需要使用任一方便的方法导入包含类包的 XML 文件:
将 XML 文件拖放到 Studio 区域。
通过管理门户:系统资源管理器 -> 类 -> 导入。
通过终端:do $system.OBJ.Load("C:\FileToImport.xml","ck")。
我们为安装应用程序而预先准备的代码将在类导入和编译后立即执行。 如果用户要卸载我们的应用程序(删除软件包),我们还可以清理应用程序在安装过程中创建的所有内容。
创建投影
为了扩展 Caché 编译器的行为,或者,在我们的示例中,为了在类的编译或反编译期间执行代码,我们需要在软件包中创建一个投影类。 它是一个扩展了 %Projection.AbstractProjection 的类,并重载了它的两个方法:CreateProjection(在编译过程中执行)和 RemoveProjection(在重新编译或删除类时触发)。
通常,将这个类命名为 Installer 是个好方法。 我们来看一个名为“MyPackage”的软件包的简单安装程序示例:
Class MyPackage.Installer Extends %Projection.AbstractProjection [ CompileAfter = (Class1, Class2) ]
{Projection Reference As Installer;/// This method is invoked when a class is compiled.ClassMethod CreateProjection(cls As %String, ByRef params) As %Status{ write !, "Installing..."}/// This method is invoked when a class is 'uncompiled'.ClassMethod RemoveProjection(cls As %String, ByRef params, recompile As %Boolean) As %Status{ write !, "Uninstalling..."}}
这里的行为可以描述为:
第一次导入和编译软件包时,只触发 CreateProjection 方法。
以后再编译 MyApp.Installer 时,或者导入“新”的安装程序类覆盖“旧”类时,将触发旧类的 RemoveProjection 方法,且 %recompile 参数等于 1,之后调用新类的 CreateProjection 方法。
删除软件包(同时删除 MyApp.Installer)时,将只调用 RemoveProjection 方法,参数 recompile = 0。
还需要注意以下几点:
类关键字 CompileAfter 应该包括应用程序的类名列表,在执行投影类的方法之前,需要对它们进行编译。 始终建议在此列表中填入应用程序中的所有类,因为如果安装过程中出错,我们不需要执行投影类的代码;
两个方法都接受 cls 参数 - 它是顶级类名,在我们的示例中为 MyApp.Installer。 这个理念来自于创建投影类的本义 - 通过从派生自 %Projection.AbstractProjection 的类再派生,可以单独为我们的应用程序的任何类制作“安装程序”。 只有在这种情况下才会体现出意义,但对于我们的任务来说是多余的;
CreateProjection 和 RemoveProjection 方法都接受第二个参数 params - 它是一个关联数组,以“参数名称”-“值”对的形式处理有关当前编译设置和当前类的参数值的信息。 通过执行 zwrite params 可以非常容易地探索该参数的内容;
RemoveProjection 方法接受 recompile 参数,只有删除类时,该参数才等于 0,重新编译时不等于 0。
类 %Projection.AbstractProjection 还有其他方法,我们可以重新定义这些方法,但我们的任务并不需要这样做。
一个示例
让我们更深入地了解为我们的实用程序创建 Web 应用程序的任务,并创建一个简单示例。 假设我们的实用程序是一个 REST 应用程序,在浏览器中打开时,它只发送一个响应“I am installed!”。 要创建这样的应用程序,我们需要创建一个描述它的类:
Class MyPackage.REST Extends %CSP.REST{XData UrlMap{ }ClassMethod Index() As %Status{ write "I am installed!" return $$$OK}}
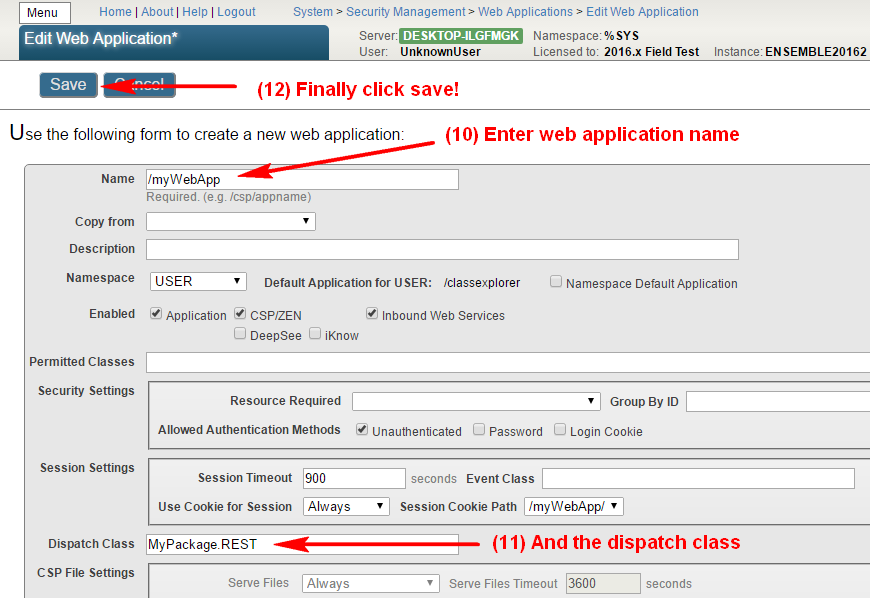
创建并编译该类后,我们需要将其注册为 Web 应用程序入口点。 我在本文的顶部图示了如何进行配置。 在执行所有这些步骤后,最好通过访问 http://localhost:57772/myWebApp/ 来检查我们的应用程序是否正常工作(注意以下几点:1. 末尾的斜线是必需的;2. 端口 57772 在您的系统中可能有所不同。 它将匹配您的管理门户端口)。
当然,所有这些步骤都可以通过 Web 应用程序创建方法 CreateProjection 以及删除方法 RemoveProjection 中的一些代码来自动执行。 在这种情况下,我们的投影类如下所示:
Class MyPackage.Installer Extends %Projection.AbstractProjection [ CompileAfter = MyPackage.REST ]{Projection Reference As Installer;Parameter WebAppName As %String = "/myWebApp";Parameter DispatchClass As %String = "MyPackage.REST";ClassMethod CreateProjection(cls As %String, ByRef params) As %Status{ set currentNamespace = $Namespace write !, "Changing namespace to %SYS..." znspace "%SYS" // we need to change the namespace to %SYS, as Security.Applications class exists only there write !, "Configuring WEB application..." set cspProperties("AutheEnabled") = $$$AutheUnauthenticated // public application set cspProperties("NameSpace") = currentNamespace // web-application for the namespace we import classes to set cspProperties("Description") = "A test WEB application." // web-application description set cspProperties("IsNameSpaceDefault") = $$$NO // this application is not the default application for the namespace set cspProperties("DispatchClass") = ..#DispatchClass // the class we created before that handles the requests return ##class(Security.Applications).Create(..#WebAppName, .cspProperties)}ClassMethod RemoveProjection(cls As %String, ByRef params, recompile As %Boolean) As %Status{ write !, "Changing namespace to %SYS..." znspace "%SYS" write !, "Deleting WEB application..." return ##class(Security.Applications).Delete(..#WebAppName)}}
在此示例中,每次编译 MyPackage.Installer 类都将创建一个 Web 应用程序,每次“反编译”都将其删除。 最好在创建或删除应用程序之前检查该应用程序是否存在(例如,使用 ##class(Security.Applications).Exists(“Name”) ),但是为了使本示例简单起见,这个作业就留给阅读本文的读者来完成了。
在创建 MyPackage.REST 和 MyPackage.Installer 类之后,我们可以将这些类导出为一个 XML 文件,并将该文件分享给所有有需要的人。 导入此 XML 的用户将自动设置 Web 应用程序,然后可以开始在浏览器中使用。
结果
与 InterSystems 社区上介绍的使用 %Installer 类部署应用程序的方法不同,这种方法有以下优点:
使用“纯”Caché ObjectScript。 至于 %Installer,需要用特定标签来填充 xData 块,大量文档对此进行了介绍。
安装我们的应用程序的方法是在类编译后立即执行的,我们不需要手动执行;
如果类(包)被删除,将自动执行删除我们的应用程序的方法,这不能通过使用 %Installer 来实现。
我的项目中已经使用这种应用程序安装方法 - Caché WEB Terminal、Caché Class Explorer 和 Caché Visual Editor。 您可以在此处找到 Installer 类的示例。
顺便提一下,开发者社区还有一个帖子介绍了投影的功能,作者是 John Murray。
另外值得一提的是 Package Manager 项目,该项目旨在让 InterSystems 数据平台的第三方应用程序只需通过一个命令或一次点击即可安装,就像类似 npm 的包管理器一样。
文章
姚 鑫 · 五月 21, 2021
# 第二章 设置和获取HTTP标头
# 设置和获取HTTP标头
可以设置和获取HTTP标头的值。
`%Net.HttpRequest`的以下每个属性都包含具有相应名称的HTTP标头的值。如果不设置这些属性,则会自动计算它们:
- `Authorization`
- `ContentEncoding`
- `ContentLength`(此属性为只读。)
- `ContentType` (指定`Content-Type`标头的Internet媒体类型(MIME类型)。)
- `ContentCharset` (指定`Content-Type`标题的字符集部分。如果设置此属性,则必须首先设置`ContentType`属性。)
- `Date`
- `From`
- `IfModifiedSince`
- `Pragma`
- `ProxyAuthorization`
- `Referer`
- `UserAgent`
`%Net.HttpRequest`类提供可用于设置和获取主HTTP标头的常规方法。这些方法忽略`Content-Type`和其他实体标头。
### ReturnHeaders()
返回包含此请求中的主`HTTP`标头的字符串。
### OutputHeaders()
将主`HTTP`标头写入当前设备。
### GetHeader()
返回此请求中设置的任何主HTTP标头的当前值。此方法接受一个参数,即头的名称(不区分大小写);这是一个字符串,如Host或Date
### SetHeader()
设置标题的值。通常,可以使用它来设置非标准标头;大多数常用标头都是通过Date等属性设置的。此方法有两个参数:
- 标头的名称(不区分大小写),不带冒号(`:`)分隔符;这是一个字符串,如Host或Date
- 标头值
不能使用此方法设置实体标头或只读标头(`Content-Length`和`Connection`)。
# 管理保活(Keep-alive)行为
如果重复使用`%Net.HttpRequest`的同一实例来发送多个HTTP请求,则默认情况下,InterSystems IRIS会使TCP/IP套接字保持打开状态,这样InterSystems IRIS就不需要关闭并重新打开它。
如果不想重复使用TCP/IP套接字,请执行以下任一操作:
- 设置`SocketTimeout`属性为0。
- 在你的HTTP请求中添加`'Connection: close'` HTTP头。
要做到这一点,在发送请求之前添加如下代码:
```java
Set sc=http.SetHeader("Connection","close")
```
注意,每个请求之后都会清除HTTP请求头,因此需要在每个请求之前包含此代码。
`%Net.HttpRequest`的`SocketTimeout`属性指定InterSystems IRIS将重用给定套接字的时间窗口(以秒为单位)。此超时旨在避免使用可能已被防火墙静默关闭的套接字。此属性的默认值为115。可以将其设置为不同的值。
# 处理HTTP请求参数
发送HTTP请求时(请参阅“发送HTTP请求”),可以在位置参数中包括参数;例如:`"/test.html?PARAM=%25VALUE"`将`PARAM`设置为等于`%value`。
还可以使用以下方法控制`%Net.HttpRequest`实例处理参数的方式:
### InsertParam()
将参数插入到请求中。此方法接受两个字符串参数:参数的名称和参数的值。例如:
```java
do req.InsertParam("arg1","1")
```
可以为给定参数插入多个值。如果这样做,这些值将接收从1开始的下标。在其他方法中,可以使用这些下标来引用目标值。
### DeleteParam()
从请求中删除参数。第一个参数是参数的名称。第二个参数是要删除的值的下标;仅当请求包含同一参数的多个值时才使用此参数。
### CountParam()
统计与给定参数关联的值数。
### GetParam()
获取请求中给定参数的值。第一个参数是参数的名称。如果请求没有同名的参数,则第二个参数是要返回的默认值;该默认值的初始值为空值。第三个参数是要获取的值的下标;仅当请求包含同一参数的多个值时才使用此参数。
### IsParamDefined()
检查是否定义了给定参数。如果参数有值,则此方法返回`TRUE`。参数与`DeleteParam()`相同。
### NextParam()
通过`$order()`对参数名称进行排序后,检索下一个参数的名称(如果有)。
### ReturnParams()
返回此请求中的参数列表。
# 包括请求正文
HTTP请求可以包括请求正文或表单数据。要包括请求正文,请执行以下操作:
1. 创建`%GlobalBinaryStream`的实例或子类。将此实例用于HTTP请求的`EntityBody`属性。
2. 使用标准流接口将数据写入此流。例如:
```java
Do oref.EntityBody.Write("Data into stream")
```
例如,可以读取一个文件并将其用作自定义HTTP请求的实体正文:
```java
set file=##class(%File).%New("G:\customer\catalog.xml")
set status=file.Open("RS")
if $$$ISERR(status) do $System.Status.DisplayError(status)
set hr=##class(%Net.HttpRequest).%New()
do hr.EntityBody.CopyFrom(file)
do file.Close()
```
# 发送分块请求
如果使用的是HTTP1.1,则可以分块发送HTTP请求。这涉及到设置`Transfer-Encoding`以指示消息已分块,并使用大小为零的块来指示完成。
当服务器返回大量数据并且在完全处理请求之前不知道响应的总大小时,分块编码非常有用。在这种情况下,通常需要缓冲整个消息,直到可以计算出内容长度(`%Net.HttpRequest`会自动计算)。
要发送分块请求,请执行以下操作:
1. 创建`%Net.ChunkedWriter`的子类,`%Net.ChunkedWriter`是定义以块形式写入数据的接口的抽象流类。在这个子类中,实现`OutputStream()`方法。
2. 在`%Net.HttpRequest`的实例中,创建`%Net.ChunkedWriter`子类的实例,并用要发送的请求数据填充它。
3. 将`%Net.HttpRequest`实例的`EntityBody`属性设置为等于此`%Net.ChunkedWriter实`例。
当发送HTTP请求时(请参见“发送HTTP请求”),它将调用`EntityBody`属性的`OutputStream()`方法。
在`%Net.ChunkedWriter`的子类中,`OutputStream()`方法应该检查流数据,决定是否分块以及如何分块,并调用类的继承方法来编写输出。
有以下方法可用:
### WriteSingleChunk()
接受字符串参数并将该字符串作为非分块输出写入。
### WriteFirstChunk()
接受字符串参数。写入适当的`Transfer-Encoding`标题以指示分块的消息,然后将字符串作为第一个分块写入。
### WriteChunk()
接受字符串参数并将字符串作为块写入。
### WriteLastChunk()
接受字符串参数,并将字符串作为块写入,后跟零长度块以标记结尾。
如果非NULL,则`TranslateTable`属性指定用于在写入时转换每个字符串的转换表。前面的所有方法都检查此属性。
# 发送表单数据
HTTP请求可以包括请求正文或表单数据。要包括表单数据,请使用以下方法:
### InsertFormData()
将表单数据插入到请求中。此方法接受两个字符串参数:表单项的名称和关联值。可以为给定表单项插入多个值。如果这样做,值将接收从1开始的下标。在其他方法中,可以使用这些下标来引用目标值
### DeleteFormData()
从请求中删除表单数据。第一个参数是表单项的名称。第二个参数是要删除的值的下标;仅当请求包含同一表单项的多个值时才使用此参数。
### CountFormData()
统计请求中与给定名称关联的值数。
### IsFormDataDefined()
检查是否定义了给定的名称
### NextFormData()
通过`$order()`对名称进行排序后,检索下一个表单项的名称(如果有)。
例1
插入表单数据后,通常调用`Post()`方法。例如:
```java
Do httprequest.InsertFormData("element","value")
Do httprequest.Post("/cgi-bin/script.CGI")
```
例2
```java
Set httprequest=##class(%Net.HttpRequest).%New()
set httprequest.SSLConfiguration="MySSLConfiguration"
set httprequest.Https=1
set httprequest.Server="myserver.com"
set httprequest.Port=443
Do httprequest.InsertFormData("portalid","2000000")
set tSc = httprequest.Post("/url-path/")
Quit httprequest.HttpResponse
```
# 插入、列出和删除Cookie
`%Net.HttpRequest`自动管理从服务器发送的`Cookie`;如果服务器发送`Cookie`,`%Net.HttpRequest`实例将在下一次请求时返回此`Cookie`。(要使此机制正常工作需要重用`%Net.HttpRequest`的同一实例。)
使用以下方法管理`%Net.HttpRequest`实例中的`Cookie`:
### InsertCookie()
将`Cookie`插入到请求中。指定以下参数:
- `Cookie`的名称。
- `Cookie`的值。
- 应存储`Cookie`的路径。
- 要从中下载`Cookie`的计算机的名称。
- `Cookie`过期的日期和时间。
### GetFullCookieList()
返回`Cookie`的数量,并(通过引用)返回`Cookie`数组。
### DeleteCookie()
请记住,`Cookie`是特定于HTTP服务器的。当插入`Cookie`时,使用的是到特定服务器的连接,而该`Cookie`在其他服务器上不可用。
文章
Jingwei Wang · 三月 28, 2023
IRIS 配置和用户帐户包含需要跟踪的各种数据元素,许多人难以在 IRIS 实例之间复制或同步这些系统配置和用户帐户。那么如何简化这个过程呢?
在软件工程中,CI/CD 或 CICD 是持续集成 (CI) 和(更常见的)持续交付或(较少见的)持续部署 (CD) 的组合实践集。 CI/CD 能消除我们所有的挣扎吗?
我在一个开发和部署 IRIS 集群的团队工作。我们在 Red Hat OpenShift 容器平台上的容器中运行 IRIS。
如果您当前没有使用 Kubernetes,请不要停止阅读。即使您没有使用 Kubernetes 或在容器中运行 IRIS,您也可能会遇到与我和我的团队面临的挑战类似的挑战。
我们决定将代码与配置分开,并将它们放在不同的 GitHub 存储库中。每次在代码库中进行提交时,都会触发管道运行。结果,从代码库中的文件构建了一个新image。
我们通过将 YAML 文件和其他配置工件添加到部署 GitHub 存储库,将配置定义为以 GitOps 方式使用的代码。 GitOps 是一个软件开发框架,它使组织能够持续交付软件应用程序,同时使用 Git 作为单一事实来源有效地管理 IT 基础设施(以及更多)。 GitOps 的好处之一是能够轻松回滚。您所需要做的就是恢复到 Git 中的先前状态。
DevOps 是软件开发和 IT 行业的一种方法论。作为一套实践和工具使用,DevOps 将软件开发(Dev) 和IT 运营(Ops) 的工作集成并自动化,作为改进和缩短系统开发生命周期的一种手段。 [1]
我在维基百科上读到持续交付是“当团队在短周期内以高速和频率生产软件时,以便可以随时发布可靠的软件,并在决定部署时采用简单且可重复的部署过程。”
同时,维基百科将持续部署定义为“当新软件功能完全自动推出时”。
我们已决定将 YAML 文件存储在部署 GitHub 存储库中。
iris-cpf(上面的第 19 行)指的是一个 ConfigMap,其中包含用于 CPF Merge 的文件。
有多种可用的 CD 管道工具可以将配置作为代码推送部署,而不必手动应用文件。
例如,我的团队使用Argo CD 。它是一个 GitOps 工具,作为 Kubernetes 扩展部署在集群中。它很特别,因为它在集群中具有可见性。它的用户界面在浏览器中显示应用程序状态,因为 Argo CD 是 Kubernetes 扩展。
与仅启用基于推送的部署的外部 CD 工具不同,Argo CD 可以从 Git 存储库中拉取更新的(类似)代码并将其直接部署到 Kubernetes 资源。
像 Argo CD 这样的拉动部署工具将我们的 Kubernetes 集群的实际状态与我们的部署 repo 中描述的期望状态进行比较。
Argo CD 监视我们的部署 repo 和我们的 Kubernetes 集群。我们的部署repo 是唯一的真实来源。如果 GitHub 存储库中发生某些更改,Argo CD 将更新集群以匹配存储库中定义的所需状态。
Argo CD 代理同步 GitHub 存储库和 Kubernetes 集群。如果我们手动应用一个更改,当 Argo CD 将已部署的应用程序同步到 Git 中定义的所需状态时,它将被删除。
为了将不同的配置部署到不同的集群,我们使用Kustomize 。我们在部署仓库中定义了一个基本配置。我们还在部署 GitHub 存储库中定义了覆盖,以便为开发、SQA、阶段和生产等各种环境配置不同的系统默认设置和不同的images。
在第 417 行中,我们确定基于环境的系统默认设置存储在 SDS_ENV.xml 中。
那些没有使用 Kubernetes 的情况呢?我创建了许多可在 Open Exchange 中使用的应用程序。我学习了如何使用 Installer 类在 GitHub 存储库中定义 IRIS 配置,然后构建image并运行容器。
然而,如果在部署应用程序后需要对配置或用户帐户进行一些修改,情况会怎样呢?当涉及到持久卷时,事情就变得复杂了。发生这种情况是因为我们不想丢失存在于持久卷上的数据。
存储在持久卷上的所有这些东西是什么? IRIS 配置保存在数据目录的 mgr 目录中。 CPF Merge 功能应该使我们能够修改 iris.cpf 中的任何配置设置。
我的团队已将大量代码添加到 %ZSTART routines中,这些routines在 IRIS 计算或数据实例启动时执行。我们担心的一个问题是所谓的零大小 CPF 错误。我们经常遇到 IRIS 实例因大小为零的 CPF 文件而崩溃的情况。不幸的是,我们尚未发现该问题的根本原因。我们怀疑 CPF 合并操作以及在 %ZSTART routine中添加和删除的大量Routine、Global和包映射会导致零大小的 CPF 错误。
我们编写了代码来删除所有系统默认设置,并从作为卷安装在 IRIS 容器中的 Kubernetes ConfigMap 中导入它们。事实上,我们有两组系统默认设置:一组是在所有环境中导入的基本设置,另一组是因环境而异的环境特定设置。
我们决定从 XML 文件中导入用户。有时,当我们直接从 %ZSTART routine 执行这段代码时,我们会遇到问题。我们根据 InterSystems 的建议将此代码移至计划任务中。显然,我们发现了一个在某些情况下可能会破坏全局安全性的错误。无论如何,出于某种我现在不记得的原因,当用户帐户导入由计划从 %ZSTART routine 按需运行的任务执行时,此问题不再是问题。这一定是时间问题。计划任务晚于 %ZSTART routine运行。
我们创建了一个自定义密码验证routine来强制执行密码规则。
当我们需要一个新的 Web 应用程序时,我们应该怎么做?除了 CPF Merge,CSP Merge 怎么样?
我相信 Web 应用程序存储在 %SYS IRIS.dat 文件中。我考虑尝试在可以使用 ConfigMap 挂载的文件中定义 Web 应用程序。我们可以将代码添加到 %ZSTART 例程或添加另一个计划任务来查找文件并创建 IRIS 中尚不存在的任何 Web 应用程序。
使用 InterSystems Kubernetes Operator 部署的 Webgateway 容器具有一个持久数据卷,其中包含 CSP.conf 和 CSP.ini。但是,我们还没有实现在添加新的 Web 应用程序时根据需要自动更新这些文件的方法。
Lorenzo Scalese 创建了可在 Open Exchange 中使用的 config-api 和 config-copy 应用程序。他建议在您的应用程序安装程序模块中使用 IRS-Config-API 库。
IRIS-Config-API 可以在一个环境将 IRIS 配置导出到 JSON 文档,并在另一个环境中从 JSON 文档导入 IRIS 配置。
Lorenzo 创建了 iris-config-copy 工具,用于从一个 InterSystems IRIS 实例导出配置并将其导入另一个实例。如果我们在源实例和目标实例上都安装 iris-config-copy,则目标实例使用 REST 从源实例获取配置。
我们需要在源实例上创建一个 Web 应用程序,以使目标实例能够从源实例中检索 IRIS 配置。
Iris-config-copy 可以导出本地实例或远程实例的 IRIS 配置。
有一些方法可以导入特定的配置文件。我们可以导入Security、包含 SQL 连接的globals、CPF 配置数据或任务。