清除过滤器
文章
jieliang liu · 二月 5, 2021
VSCode 是目前很流行的一款免费开发工具,IRIS也支持使用其进行连接和开发,相比Studio 只能在windows 环境使用,Vscode 可以跨平台使用。
我们传统的工具Studio 是连接代码服务器的形式,不能便捷的使用目前流行的有本地代码的版本控制工具(如git),但VSCode可以存在本地代码,并且能方便的使用各类存在本地代码的版本控制工具。
以下的内容会帮助大家来配置使用VSCode连接IRIS 进行开发。
VSCode 可以在微软的官网免费下载https://code.visualstudio.com/
如果安装为英文要切换为中文则可以通过Command Palette 中运行Configure Display Language,install another language, 选择中文,再根据提示安装相应的语言插件。
接下来在扩展商店里搜索intersystems 安装如图所见的3个扩展包
VSCode目前有两种方式可以链接IRIS:
直接连接代码服务器进行编辑
使用客户端方式连接,将代码下载到本地,便于使用有本地代码的版本控制工具
注:两种连接方式的连接端口都为服务器web port
下面具体讲解两种连接方式。
直接连接代码服务器进行编辑
其总体的使用方式和studio相似,直接连接服务器进行代码编辑。在vscode中可以使用全局只读的方式来浏览代码,从而避免误操作修改了代码。
如果会经常使用这个服务器,可以考虑先建立一个工作区,将设置保存在工作区,当然直连服务器的模式下,建立服务器不是必选项。
如果我们正确的安装了之前提到的三个扩展,其中下面扩展会帮助我们连接IRIS代码服务器,并保存在VSCode的全局 settings.json配置文件中:
进入VSCode 设置中找到“扩展”下的Intersystems Server Manager ,进入设置可见安装自带的服务器连接字符串可以依据用户需要进行添加和修改
配置完成可以回到工作区界面进行连接
选择Choose Server and Namespaces, 从右边的服务器列表中选择要连接的服务器,也可以使用“+”来根据提示信息来添加新的服务器。
选择服务器之后会提示输入密码(如果没有在配置中写明登录用户,也会提示输入登录用户)验证成功后可以选择想查看的命名空间,最后按照提示选择是以编辑或者只读方式来查看代码。
在服务器直连的模式下,可以将多个服务器的多个命名空间的代码添加至当前工作区。
目前的连接方式进入之后会频繁的要求登录验证,输入密码,这里实际可以将密码存在VSCode的钥匙链中:
1.打开命令面板
2.输入store 使用下图中的命令则可以为选定的服务器存储密码,但是每个服务器只能保存一个密码,相应的在命令面板中输入clear 会提示清除密码的选项用来删除已存储的密码
2. 使用客户端方式连接
如果使用客户端的连接方式,则必须要在工作区内添加一个文件夹,以及保存此工作区。当添加文件夹到工作区之后侧边栏会多出图示的按钮:
点击按钮选择Choose server and namespaces
此时如果在vscode中已经添加过想要连接的IRIS 代码服务器,这里会直接显示已存储的服务器,设置法与之前提到的直连方式相同。
连接完成后如果想添加多个命名空间到工作区,可以使用右上角的+号进行添加
接下来可以在客户端模式连接导出ObjectScript代码到本地。从而进行源代码的版本控制管理。
在objectscript explorer中选择任意的包,或者类右键选择export,则可以将其导出到目前工作区的文件夹下
代码会被导出到工作区目录的src文件夹下。
客户端模式中使用 GIT
首先打开一个GIT Repo文件夹,如果本来然后按照客户端连接方式连接用来开发的服务器。在任何的包或文件上点击import and compile 可以将版本控制的代码导入开发服务器。 注意这时候只要在本地新建文件并且保存,新的修改就会被同步到开发服务器实例上。
以客户端方式连接时连接多个服务器或多个命名空间的方式:
首先将一个文件夹添加到工作区,并保存工作区,在保存之后的工作区中可以看到如下的工作区配置文件(
此处我使用的默认工作区配置文件名,实际可以自行定义),其中定义了工作区的目录结构:
此时我们在这个工作区内添加一个子目录,在工作区的列表右键单击,选择“将文件夹添加到工作区”:
添加后可以看到,在工作区配置文件中增加了新的目录,为了这个显示层级更加清楚,可以在settings 中使用files.exclude 来过滤是否显示子目录
此时子再点击侧边栏中的 object script explorer,则会让用户选择使用哪一个子目录进行连接:
要使用另一个目录连接一个服务器的命名空间时,将第一个已连接的文件夹下.vscode 拷贝到第二个文件夹:
直接对这个文件进行修改,将其配置成为想连接的服务器以及命名空间
连接配置文件同样支持如下的写法:
此时再回到object script exploer,可见到添加了的服务器。
可见这里服务器的连接和本地代码编译的目标对象只由当前文件夹下.vscode/settings.json控制。
所有的之前提到的配置文件都可以手工编辑,不必一定在vscode中进行添加文件夹和配置连接。
在VSCode中调试
以客户端方式连接时可以进行调试:
在侧边栏选择调试按钮,首次调试应在工作区创建launch.json,并选择ObjectScript Debug
对于Class Method,可以直接在类中点击“Debug this Method”
下边是一个Class Method 实例的实例调试界面
附加到进程调试:
对于需要附加到的进程,在lauch.json中添加”program” 属性,并填入进程号,保存。
program 中也可以填入要debug的routine 比如“##class(Test.test).test()”, “name”可以修改成自定义的名字,之后会在debug运行按钮的下拉菜单显示。
调试的配置可以添加多个,都会显示在debug下拉菜单中
进入调试界面,点击xDebug 旁边的绿色启动按钮开始调试,其他同Class Method 调试方式
关于VSCode几个编辑器小技巧:
在底部栏点击当前连接的服务器会出现提示菜单,从这里可以便捷进入实例管理界面和class reference
在任意的类或者方法上点击右键可以转到定义。如果使用了#dim预定义变量,则可以在变量上使用转到变量声明,而且可以使用转到类型定义类型的定义。
尾声
当前版本不支持xml 代码文件导入!VSCode community中已经有人提到过这个问题,开发者回复之后的版本很有可能会加入
本项目的Github的issue地址,可以在这里提出问题:https://github.com/intersystems-community/vscode-objectscript/issues
支持的产品 :Caché/Ensemble 2016.2 以及更新, 以及所有的基于IRIS 的产品版本.
调试入参类型为%Library.DynamicAbstractObjec的参数如何输入入参呢 对象入参的话,的确直接调试没法从键盘输入,可能还是需要附加到进程或者写一个临时方法来生成这个入参对象,再调用想调试的方法检查断点。 知乎文章:使用VS Code进行Caché数据库开发 好的,谢谢
文章
姚 鑫 · 二月 15, 2021
# 第三十五章 Caché 变量大全 $ZNSPACE 变量
包含当前命名空间名称。
# 大纲
```java
$ZNSPACE
```
# 描述
`$ZNSPACE`包含当前命名空间的名称。通过设置`$ZNSPACE`,可以更改当前名称空间。
要获取当前命名空间名称,请执行以下操作:
```java
DHC-APP>SET ns=$ZNSPACE
DHC-APP>WRITE ns
DHC-APP
```
还可以通过调用`%SYSTEM.SYS`类的`Namespace()`方法来获取当前命名空间的名称,如下所示:
```java
DHC-APP>SET ns=$SYSTEM.SYS.NameSpace()
DHC-APP>WRITE ns
DHC-APP
```
可以使用`%SYS.Namespace`类的`Existes()`方法测试命名空间是否已定义,如下所示:
```java
DHC-APP>WRITE ##class(%SYS.Namespace).Exists("USER")
1
DHC-APP>WRITE ##class(%SYS.Namespace).Exists("LOSER")
0
```
对于UNIX®系统,默认命名空间建立为系统配置选项。对于Windows系统,它是使用命令行启动选项设置的。
命名空间名称不区分大小写。InterSystems IRIS始终以全大写字母显示显式名称空间名称,以全小写字母显示隐含的名称空间名称。
要获取指定进程的命名空间名称,请使用`%SYS.ProcessQuery`类的方法,如下例所示:
```java
DHC-APP>WRITE ##CLASS(%SYS.ProcessQuery).%OpenId($JOB).NameSpaceGet()
DHC-APP
```
# 设置当前命名空间
可以使用`ZNSPACE`命令、`SET $NAMESPACE`、`SET $ZNSPACE`或`%cd`实用程序更改当前名称空间。
- 在终端命令提示符下,`ZNSPACE`命令是更改名称空间的首选方式。`SET $ZNSPACE`在功能上与`ZNSPACE`命令相同。
- 在代码例程中,新建`$NAMESPACE`,然后设置`$NAMESPACE = NAMESPACE`是更改当前名称空间的首选方式。通过使用`new $NAMESPACE`和`SET $NAMESPACE`,可以建立一个名称空间上下文,该上下文在方法结束或发生意外错误时自动恢复到前一个名称空间。
可以使用`SET $ZNSPACE`更改进程的当前命名空间。将新命名空间指定为字符串文字或计算结果为带引号的字符串的变量或表达式。可以指定显式名称空间(`“NAMESPACE”`)或隐式名称空间(`“^SYSTEM^DIR”或“^^DIR”`)。
如果指定当前命名空间,则`SET $ZNSPACE`不执行任何操作,也不返回任何错误。如果指定了一个未定义的名称空间,则`SET $ZNSPACE`会生成一个``错误。
不能`new $ZNSPACE`特殊变量。
# 示例
在以下示例中,如果当前命名空间不是`USER`,则`SET $ZNSPACE`命令会将当前命名空间更改为`USER`。请注意,由于`if`测试,命名空间必须全部用大写字母指定。
```java
/// d ##class(PHA.TEST.SpecialVariables).ZNSPACE()
ClassMethod ZNSPACE()
{
SET ns="USER"
IF $ZNSPACE=ns {
WRITE !,"命名空间已经 ",$ZNSPACE
} ELSEIF 1=##class(%SYS.Namespace).Exists(ns) {
WRITE !,"命名空间是 ",$ZNSPACE
SET $ZNSPACE=ns
WRITE !,"将命名空间设置为 ",$ZNSPACE
} ELSE {
WRITE !,ns," 不是定义的命名空间"
}
QUIT
}
```
```java
DHC-APP>d ##class(PHA.TEST.SpecialVariables).ZNSPACE()
命名空间是 DHC-APP
将命名空间设置为 USER
```
此示例要求`UnnownUser`已分配`%DB_IRISSYS`和`%DB_USER`角色。
文章
shaosheng shengshao · 九月 14, 2022
研究Healthshare2018在已经安装完成使用的情况下,部署IIS,并代理平台。之前看到可以通过单独的CSP Gateway安装包进行处理这种问题,该文主要是获取不到该安装包的时候可以如何实现IIS的处理。
第一步:首先按照网上教程部署IIS服务。安装完成之后会在C盘创建一个名叫intepub的包。
第二步:在inetpub包下面直接插入CSPGateway 。这个包是在其他先安装IIS下,后安装Healthshare的CSP网关服务的时候在inetpub下面自动插入的包,直接找一个复制过来。
第三步:打开IIS,创建一个叫csp的网站,按照下图配置。
第四步:在点击模块进行CSPms模块的添加。
接下来是配置好的CSPms的模块。
注意:我们从图中看到的CSPms模块是本机继承的模块,我们在右边添加本机模块的时候并不能找到C:\inetpub\CSPGateway\CSPms.dll这个模块,导致加不进去。那我们就直接在配置文件上面改。找到C:\Windows\System32\inetsrv\config该文件路径下的applicationHost.config文件,为了稳妥起见,我们先备份一下该文件。找到<globalModules>节点,在下面加入<add name="CSPms" image="C:\Inetpub\CSPGateway\CSPms.dll" />找到<modules>节点,在下面加入<add name="CSPms" />找到hiddenSegments节点,找到下面的bin参数,删除<add segment="bin " />,如下图所示。
保存文件,如果保存过程中出现不允许修改的问题,可以把文件贴到桌面,在这个文件上面改造,在copy回去直接替换。再回到iis页面,网站csp的模块里面就会出现对应的CSPms的本机模块。后面进行服务映射,双击点击处理程序映射。 第六步:接下来测试我们打开平台管理页面能不能打开。
如果出现了这个页面,那我们就快成功了,这个错误可能我们大家都有见过。我们打开C:\inetpub\CSPGateway下面的CSP.ini的文件。里面有个
有这个Password字段,因为我们的CSPGateway这个包是从其他服务器上copy过来的,这个密码只能用于那台服务,不能用于这个服务器,那我们可以拿57772端口的apache配置下的这个密码拿过来用。在安装路径下D:\InterSystems\HealthShare\CSP\bin的CSP.ini,也有一个Password字段,把这个密码copy过来放到C:\inetpub\CSPGateway下面的CSP.ini上。重启IIS服务,如果出现权限问题,也把CSP.ini拷贝到桌面,修改好后再贴回去进行替换。再次进行访问,就可以进去桌面了。第七步:点入到CSP网关管理,如果提示出现warning字眼,那是C:\inetpub\CSPGateway下面的用户权限问题。
对CSPGateway右键按照下图示例进行IIS_IUSRS用户权限的添加。对文件夹下的CSP.ini和CSP.log做一样的操作。
好文,欢迎参赛!
文章
Michael Lei · 一月 17, 2023
ZPM 设计用于与 InterSystems IRIS 数据平台的应用程序和模块一起使用。 它由两个组件组成:ZPN 客户端(用于管理模块的 CLI)和注册表(模块和元信息的数据库)。 我们可以使用 ZPM 来搜索、安装、升级、移除和发布模块。 使用 ZPM,可以安装 ObjectScript 类、前端应用程序、互操作性生产环境、IRIS BI 解决方案、IRIS 数据集或任何文件,例如嵌入式 Python wheel。
今天的这份实战宝典将分为 3 个部分:
1. 安装 ZPM
2. 生成模块
3. 在注册表中查找、安装、发布模块
1. 安装 ZPM
* 下载最新版本的 ZPM(它应该是一个 XML 文件)[下载链接](https://pm.community.intersystems.com/packages/zpm/latest/installer)
* 将下载的 XML 导入到 IRIS(它只能部署到已打开 IRIS 的 IRIS 终端)并按 Enter 键
_write $SYSTEM.OBJ.Load("C:\zpm.xml", "c")_
请注意,“C:\zpm.xml”是下载的 XML 文件的路径,这一步可能需要一些时间。
* 安装完成后,只需输入 _zpm_,按 Enter 键,您会看到您在 zpm shell 中
2. 生成模块
在开始生成模块之前,我们需要准备一个文件夹,里面有一个或多个可以加载的文件,因此我在 C 盘下创建了一个名为 zpm 的文件夹。
执行命令 _generate C:/zpm_
在指定所有必要的内容后,您的第一个模块已成功生成,您还会看到

注意:
1. 模块版本正在使用语义化版本控制
2. 模块源文件夹是包含所有类文件的文件夹
3. zpm 还提供了一个选项,可以添加 web 应用程序和依赖项,本例中我将其留空
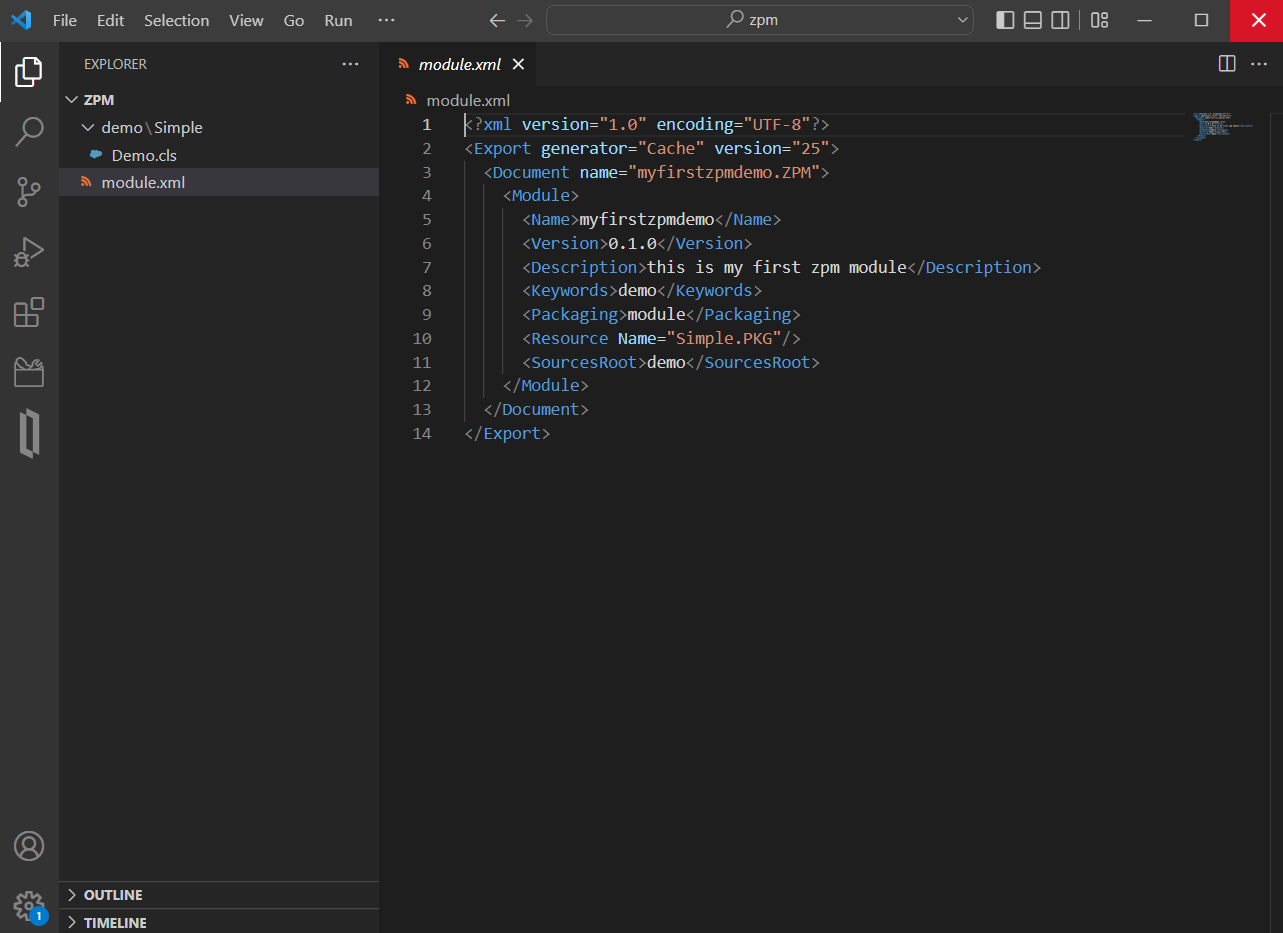
现在,打开文件资源管理器,您会看到一个名为“module.xml”的文件,如下面的屏幕截图所示
输入命令 _load C:\ZPM\ _,您会看到您的模块已重新加载、验证、编译和激活

3. 在注册表中查找、安装、发布模块
在当前注册表中查找可用的软件包:_zpm:USER>search_
举例来说,从当前注册表安装软件包,让我们在公共注册表中安装一个名为 zpmshow 的模块:_zpm:USER>install zpmshow _(命令为 install "moduleName")
加载后发布模块:_zpm:USER>publish myFirstZPMDemo_
可以使用 _zpm:USER>search_ 验证发布,本例中,您可以看到“myfirstzpmdemo 0.1.0”位于当前注册表中。

注意:如果发布模块时遇到以下错误:_“ERROR! Publishing module, something went wrong”(错误!发布模块时出错了)_,确保当前注册表的状态为“已启用”且可用。
可以使用_ zpm:USER>repo -list, _验证当前注册表的状态。

可用视频:[点击此处](https://www.loom.com/share/0ca097f0dea4476ea294841295f972b2%C2%A0%C2%A0)
文章
姚 鑫 · 二月 25, 2022
# 第六十五章 SQL函数 %INTERNAL
返回逻辑格式表达式的格式转换函数。
# 大纲
```
%INTERNAL(expression)
%INTERNAL expression
```
# 参数
- `expression` - 要转换的表达式。
字段名、包含字段名的表达式,或返回可转换数据类型(如`DATE`或`%List`)中的值的函数。
# 描述
`%INTERNAL`将表达式转换为逻辑格式,与当前选择模式(显示模式)无关。逻辑格式是数据的内存格式(对其执行操作的格式)。`%INTERNAL`通常用于选择列表`SELECT-ITEM`。
**可以在`WHERE`子句中使用`%INTERNAL`,但强烈建议不要使用`%INTERNAL`,因为使用`%INTERNAL`会阻止在指定字段上使用索引,并且`%INTERNAL`会强制所有比较区分大小写,即使该字段有默认排序规则也是如此。**
应用`%INTERNAL`会将列标题名称更改为诸如“`Expression_1`”之类的值;因此,通常需要指定列名别名,如下面的示例所示。
`%INTERNAL`将数据类型%DATE的值转换为整数数据类型值。`%INTERNAL`将数据类型`%TIME`的值转换为数字`(15,9)`数据类型值。之所以提供此转换,是因为ODBC或JDBC客户端不识别逻辑`%DATE`和`%TIME`值。
`%INTERNAL`是否转换日期取决于日期字段或函数返回的数据类型。`%INTERNAL`转换`CURDATE`、`CURRENT_DATE`、`CURTIME`和`CURRENT_TIME`值。它不转换`CURRENT_TIMESTAMP`、`GETDATE`、`GETUTCDATE`、`NOW`和`$HOROLOG`值。
不能将流字段指定为ObjectScript一元函数(包括所有格式转换函数,`%Internal`除外)的参数。`%INTERNAL`函数允许将流字段作为表达式值,但不对该流字段执行任何操作。
`%INTERNAL`是InterSystems SQL扩展。
要将表达式转换为显示格式,而不考虑当前的选择模式,请使用`%EXTERNAL`函数。要将表达式转换为`ODBC`格式,而不考虑当前的`SELECT`模式,请使用`%ODBCOUT`函数。
# 示例
下面的动态SQL示例以当前选择模式格式返回出生日期(道布)数据值,并使用`%INTERNAL`函数返回相同的数据。出于演示目的,在此程序中,为每次调用随机确定`%SelectMode`值:
```java
ClassMethod Internal()
{
s tStatement = ##class(%SQL.Statement).%New()
s tStatement.%SelectMode=$RANDOM(3)
if tStatement.%SelectMode=0 {WRITE "Select mode LOGICAL",! }
elseif tStatement.%SelectMode=1 {WRITE "Select mode ODBC",! }
elseif tStatement.%SelectMode=2 {WRITE "Select mode DISPLAY",! }
s myquery = 2
s myquery(1) = "SELECT TOP 5 DOB,%INTERNAL(DOB) AS IntDOB "
s myquery(2) = "FROM Sample.Person"
s qStatus = tStatement.%Prepare(.myquery)
s rset = tStatement.%Execute()
d rset.%Display()
w !,"End of data"
}
```
```java
DHC-APP>d ##class(PHA.TEST.SQLCommand).Internal()
Select mode DISPLAY
DOB IntDOB
04/25/1990 54536
01/02/2014 63189
01/02/2014 63189
01/28/1978 50066
5 Rows(s) Affected
End of data
```
下面的示例显示了此函数的两种语法形式;在其他方面它们是相同的。它们指定`%LIST`字段的`%EXTERNAL`(显示格式)、`%INTERNAL`(逻辑格式)和`%ODBCOUT`(ODBC格式):
```sql
SELECT TOP 10 %EXTERNAL(FavoriteColors) AS ExtColors,
%INTERNAL(FavoriteColors) AS IntColors,
%ODBCOUT(FavoriteColors) AS ODBCColors
FROM Sample.Person
```
```sql
SELECT TOP 10 %EXTERNAL FavoriteColors AS ExtColors,
%INTERNAL FavoriteColors AS IntColors,
%ODBCOUT FavoriteColors AS ODBCColors
FROM Sample.Person
```
文章
YuHao Wan · 十一月 5, 2022
### 0. 算法概述
SM4算法是一种分组密码算法。其分组长度为128bit,密钥长度也为128bit。加密算法与密钥扩展算法均采用32轮非线性迭代结构,以字(32位)为单位进行加密运算,每一次迭代运算均为一轮变换函数F。SM4算法加/解密算法的结构相同,只是使用轮密钥相反,其中解密轮密钥是加密轮密钥的逆序。
### 1. 密钥及轮密钥
密钥长度为128比特,表示为MK=(MK(0),MK(1),MK(2),MK(3)),其中MKi(i=0,1,2,3)为字。
轮密钥表示为(rk(0),rk(1),...,rk(31)),其中rk(i)(i=0,...,31)为32比特字。轮密钥由秘钥生成。

### 2. 消息填充分组
首先,将明文转化为字节,由于SM4加密算法按照128个位进行分组,所以很大几率会出现最后一个分组不够128位的情况,需要进行**填充**,填充方式有很多,比如ZeroPadding、PKCS7Padding、PKCS5Padding,不管使用哪种方式,最后每个分组都是128位。每个分组按照**32位**一个字分成四个字。
#### ECB模式与CBC模式
- ECB模式
电子密码本模式,最古老,最简单的模式,将加密的数据分成若干组,每组的大小跟加密密钥相同。不足的部分进行填充。
按照顺序将计算所得的数据连在一起即可,各段数据之间互不影响。
优点:简单,有利于并行计算,误差不会被传递。
缺点:不能隐藏明文的模式,可能对明文进行主动攻击。
- CBC模式
密文分组链接模式,也需要进行分组,不足的部分按照**指定的数据**进行填充。
需要一个**初始化向量**,每个分组数据与上一个分组数据加密的结果进行**异或运算**,最后再进行加密。将所有分组加密的结果连接起来就形成了最终的结果。
优点:不容易进行主动攻击,安全性好于ECB。
缺点:不利于并行计算,误差传递,需要初始化向量。
#### 三种填充方式的比较
某些加密算法要求明文需要按一定长度对齐,叫做**块大小**(BlockSize),比如16字节,那么对于一段任意的数据,加密前需要对最后一个块填充到16 字节,解密后需要删除掉填充的数据。
- **ZeroPadding**,数据长度不对齐时使用**0**填充,否则不填充。
- **PKCS7Padding**,假设数据长度需要填充n(n>0)个字节才对齐,那么填充n个字节,每个字节都是**n**;如果数据本身就已经对齐了,则填充一块长度为块大小的数据,每个字节都是块大小。
- **PKCS5Padding**,PKCS7Padding的子集,块大小固定为**8**字节。
由于使用PKCS7Padding/PKCS5Padding填充时,最后一个字节肯定为填充数据的长度,所以在解密后可以准确删除填充的数据,而使用ZeroPadding填充时,没办法区分真实数据与填充数据,所以只适合以\0结尾的字符串加解密。
### 3. 迭代运算
本加解密算法由32次迭代运算和1次反序变换R组成。

#### 3.1 轮函数F和合成置换T

### 4. Caché实现
```
/// SM4算法是一种分组密码算法。其分组长度为128bit,密钥长度也为128bit。
/// 加密算法与密钥扩展算法均采用32轮非线性迭代结构,以字(32位)为单位进行加密运算,每一次迭代运算均为一轮变换函数F。
/// SM4算法加/解密算法的结构相同,只是使用轮密钥相反,其中解密轮密钥是加密轮密钥的逆序。
/// 本方法适用于 ECB模式,ZeroPadding填充模式
Class Utility.SM4 Extends %RegisteredObject
{
/// Creator: wyh
/// CreatDate: 2022-11-03
/// Description:SM4加密
/// Input: msg:原文 mk:128位密钥
/// Output: 密文
/// Debug: w ##class(Utility.SM4).Encrypt("342622199009262982", "F2D8D966CD3D47788449C19D5EF2081B")
ClassMethod Encrypt(msg, mk)
{
#; 1. 密钥及轮密钥
#; a) 密钥长度为128比特,表示为MK=(MK(0),MK(1),MK(2),MK(3)),其中MKi(i=0,1,2,3)为字
#; b) 轮密钥表示为(rk(0),rk(1),...,rk(31)),其中rk(i)(i=0,...,31)为32比特字。轮密钥由密钥生成。
#; 密钥扩展算法:
#; (K(0),K(1),K(2),K(3))=(MK(0)^FK(0),MK(1)^FK(1),MK(2)^FK(2),MK(3)^FK(3))
#; rk(i)=K(i+4)=K(i)^T'(K(i+1)^K(i+2)^K(i+3)^CK(i)),i=0,1,...,31
#; 系统参数FK(0)=(A3B1BAC6),FK(1)=(56AA3350),FK(2)=(677D9197),FK(3)=(B27022DC)
#; 固定参数CK(i)(i=0,1,...,31)为:
#; 00070E15, 1C232A31, 383F464D, 545B6269,
#; 70777E85, 8C939AA1, A8AfB6BD, C4CBD2D9,
#; E0E7EEF5, FC030A11, 181F262D, 343B4249,
#; 50575E65, 6C737A81, 888F969D, A4ABB2B9,
#; C0C7CED5, DCE3EAF1, F8FF060D, 141B2229,
#; 30373E45, 4C535A61, 686F767D, 848B9299,
#; A0A7AEb5, BCC3CAD1, D8DFE6ED, F4FB0209,
#; 10171E25, 2C333A41, 484F565D, 646B7279.
s mk = $zcvt(mk, "L")
f i = 0 : 1 : 3 d
.s MK(i) = $e(mk, 8 * i + 1, 8 * (i + 1))
s FK = "a3b1bac656aa3350677d9197b27022dc"
f i = 0 : 1 : 3 d
.s FK(i) = $e(FK, 8 * i + 1, 8 * (i + 1))
s CK = "00070e151c232a31383f464d545b626970777e858c939aa1a8afb6bdc4cbd2d9e0e7eef5fc030a11181f262d343b424950575e656c737a81888f969da4abb2b9c0c7ced5dce3eaf1f8ff060d141b222930373e454c535a61686f767d848b9299a0a7aeb5bcc3cad1d8dfe6edf4fb020910171e252c333a41484f565d646b7279"
f i = 0 : 1 : 31 d
.s CK(i) = $e(CK, 8 * i + 1, 8 * (i + 1))
f i = 0 : 1 : 3 d
.s K(i) = ..HexXOR(MK(i), FK(i))
f i = 4 : 1 : 35 d
.s K(i) = ..HexXOR(K(i - 4), ..T2(..HexXOR(..HexXOR(..HexXOR(K(i + 1 - 4), K(i + 2 - 4)),K(i + 3 - 4)), CK(i - 4))))
f i = 0 : 1 : 31 d
.s rk(i) = K(i + 4)
#; 2. 消息填充分组
#; 每组128位,每组再分X(0),X(1),X(2),X(3)作为明文输入.
s hex = ..s2hex(msg)
s len = $l(hex)/32
s rtn = ""
f i = 0 : 1 : len-1 d
.k X
.s M(i) = $e(hex, 32 * i + 1, 32 * (i + 1))
.f j = 0 : 1 : 3 d
..s X(j) = $e(M(i), 8 * j + 1, 8 * (j + 1))
#; 3. 迭代运算,密文输出(Y(0),Y(1),Y(2),Y(3))
#; a) 32次迭代运算
#; X(i+4)=F(X(i),X(i+1),X(i+2),X(i+3),rk(i)),i=0,1,...,31
#; F(X(i),X(i+1),X(i+2),X(i+3),rk(i))=X(i)^T(X(i+1)^X(i+2)^X(i+3)^rk(i)),i=0,1,...,31
#; b)反序变换
#; (Y(0),Y(1),Y(2),Y(3))=R(X(32),X(33),X(34),X(35))=(X(35),X(34),X(33),X(32))
.f k = 0 : 1 : 31 d
..s X(k + 4) = ..HexXOR(X(k), ..T(..HexXOR(..HexXOR(..HexXOR(X(k + 1), X(k + 2)), X(k + 3)), rk(k))))
.s rtn = rtn_X(35)_X(34)_X(33)_X(32)
q rtn
}
/// Creator: wyh
/// CreatDate: 2022-11-03
/// Description:SM4解密
/// 解密变换与加密变换结构相同,不同的仅是轮密钥的使用顺序,解密时使用轮密钥序(rk(31),rk(32),...,rk(0)).
/// Input: hex:密文 mk:128位密钥
/// Output: 明文
/// Debug: w ##class(Utility.SM4).Decrypt("5efcbbfdb7a326b340295acb1c0e20fe2622730932bdb5302b5a4ee308944ecc", "F2D8D966CD3D47788449C19D5EF2081B")
ClassMethod Decrypt(hex, mk)
{
s mk = $zcvt(mk, "L")
f i = 0 : 1 : 3 d
.s MK(i) = $e(mk, 8 * i + 1, 8 * (i + 1))
s FK = "a3b1bac656aa3350677d9197b27022dc"
f i = 0 : 1 : 3 d
.s FK(i) = $e(FK, 8 * i + 1, 8 * (i + 1))
s CK = "00070e151c232a31383f464d545b626970777e858c939aa1a8afb6bdc4cbd2d9e0e7eef5fc030a11181f262d343b424950575e656c737a81888f969da4abb2b9c0c7ced5dce3eaf1f8ff060d141b222930373e454c535a61686f767d848b9299a0a7aeb5bcc3cad1d8dfe6edf4fb020910171e252c333a41484f565d646b7279"
f i = 0 : 1 : 31 d
.s CK(i) = $e(CK, 8 * i + 1, 8 * (i + 1))
f i = 0 : 1 : 3 d
.s K(i) = ..HexXOR(MK(i), FK(i))
f i = 4 : 1 : 35 d
.s K(i) = ..HexXOR(K(i - 4), ..T2(..HexXOR(..HexXOR(..HexXOR(K(i + 1 - 4), K(i + 2 - 4)),K(i + 3 - 4)), CK(i - 4))))
f i = 0 : 1 : 31 d
.s rk(i) = K(35 - i)
s len = $l(hex)/32
s rtn = ""
f i = 0 : 1 : len-1 d
.k X
.s M(i) = $e(hex, 32 * i + 1, 32 * (i + 1))
.f j = 0 : 1 : 3 d
..s X(j) = $e(M(i), 8 * j + 1, 8 * (j + 1))
.f k = 0 : 1 : 31 d
..s X(k + 4) = ..HexXOR(X(k), ..T(..HexXOR(..HexXOR(..HexXOR(X(k + 1), X(k + 2)), X(k + 3)), rk(k))))
.s rtn = rtn_X(35)_X(34)_X(33)_X(32)
q ..hex2str(rtn)
}
/// 非线性变换τ构成
/// τ由4个并行的S盒,设输入A=(a0,a1,a2,a3),输出为B=(b0,b1,b2,b3)
/// (b0,b1,b2,b3)=τ(A)=(Sbox(a0),Sbox(a1),Sbox(a2),Sbox(a3))
/// w ##class(Utility.SM4).tau("942600f0")
ClassMethod tau(a)
{
f i = 0 : 1 : 7 d
.s a(i) = $e(a, i + 1)
s s(0) = "d690e9fecce13db716b614c228fb2c05"
s s(1) = "2b679a762abe04c3aa44132649860699"
s s(2) = "9c4250f491ef987a33540b43edcfac62"
s s(3) = "e4b31ca9c908e89580df94fa758f3fa6"
s s(4) = "4707a7fcf37317ba83593c19e6854fa8"
s s(5) = "686b81b27164da8bf8eb0f4b70569d35"
s s(6) = "1e240e5e6358d1a225227c3b01217887"
s s(7) = "d40046579fd327524c3602e7a0c4c89e"
s s(8) = "eabf8ad240c738b5a3f7f2cef96115a1"
s s(9) = "e0ae5da49b341a55ad933230f58cb1e3"
s s(10) = "1df6e22e8266ca60c02923ab0d534e6f"
s s(11) = "d5db3745defd8e2f03ff6a726d6c5b51"
s s(12) = "8d1baf92bbddbc7f11d95c411f105ad8"
s s(13) = "0ac13188a5cd7bbd2d74d012b8e5b4b0"
s s(14) = "8969974a0c96777e65b9f109c56ec684"
s s(15) = "18f07dec3adc4d2079ee5f3ed7cb3948"
f i = 0 : 1 : 15 d
.f j = 0 : 1 : 15 d
..s s(i, j) = $e(s(i), 2 * j + 1, 2 * (j + 1))
s rtn = ""
f i = 0 : 1 : 3 d
.s r = ..hex2int(a(2 * i))
.s c = ..hex2int(a(2 * i + 1))
.s rtn = rtn _ s(r, c)
return rtn
}
/// 线性变换L
/// 非线性变换τ的输出是线性变换L的输入.设输入为B,输出为C.
/// C=L(B)=B^(B
文章
Qiao Peng · 一月 5, 2021
各位开发者们大家好!
此前,我向各位介绍了一个非常好用的运行分析监控面板,它能使消息处理过程中的关键指标可视化,例如入站/出站消息的数量和平均处理时间等。
现在,我想用一项许多人已熟悉的工作流程,来展示一个增强型日志监视器——将警告信息作为Production中的消息来处理。我们可以通过创建路由规则来实现对告警消息的过滤和路由,并运用预先构建的组件(例如电子邮件适配器等)来发送粒度级别的通知。
如你所知,监视和管理警告信息是确保任何应用程序平稳运行的关键。对诸如HealthShare和IRIS医疗版这样支撑医疗系统运转的一级应用程序和集成引擎来说对告警信息的处理更显得尤为重要。
让我们先来梳理一下InterSystems产品中已经附带的警告信息监视和管理工具:
通过名为Ens.Alert的组件,你可以使用警告处理器(Alert Processor)为Production中的各类接口配置自定义警报。
系统监视器(System Monitor )能显示Production关键性能指标的实时状态。
日志监视管理器(Log Monitor Manager (^MONMGR) utility )程序能根据消息日志(现在InterSystems IRIS上称messages.log,以往称cconsole.log)生成各种严重级别的通知消息,再通过电子邮件将该通知发送给预设好的收件人。
Production监视器(Production Monitor )显示当前正在运行的Production及其接口(输入/输出连接)、队列、活动作业、事件日志、活动图表等的实时状态。
镜像监视器(Mirror Monitor)显示每个镜像及其构件的运行状态、镜像数据库状态以及关键镜像指标(例如日志传入速率)信息。
尽管由我制作的增强型日志监控器与上述这些日志监控器管理器(^MONMGR)非常相似,它的好处在于给用户提供了一个熟悉的界面和对警告信息的精准路由及管理能力——每个写进消息日志(messages.log文件)的告警条目都会被转换成一条Production里的消息,再按路由规则(Ens.Alert)精细过滤出特定的警告。这些警告可以通过Production中的操作(Business Operation)使用邮件和短信等方式发送出去。不仅如此,现在你还可以在Production中的邮件适配器设置来轻松编辑通知的收件人。
例如:日志监控管理器(^MONMGR)已经具备了按照指定的最低严重性级别发出警告的功能,你可以通过设置在发生二级日志事件时自动向系统管理员发出警告。
如果使用我即将介绍的增强型日志监视器,你就能进一步细化过滤,做到不是所有二级事项都发出,而是只在一个实例的发生了镜像故障转移切换(二级事件范畴下的一个具体情况)时才发出警告。在这个例子中,我们假设该系统部署了由镜像实现的高可用/灾备功能,并且包含这个日志监视器Production需要运行在每个镜像成员中的非镜像命名空间中。
使用增强型日志监控器前,请先从OpenExchange下载示例代码。下载的文件为xml格式,可以直接导入。导入时请转到管理门户,并导航至“Interoperability”->“管理”->“部署变化”->“部署”。
现在点选“Open Local Deployment”选项来打开从OpenExchange下载的xml文件,并在加载后单击“部署”
导航到刚刚部署的“Interoperability”(互操作性->列表->Production)。请勿在设定好全局^lasttimestamp(后面再做说明)之前启动Production。你应该能在Production中看到以下三个组件:
“测试”服务
这其中包含了我所使用的定制底层代码(JK.MONMGR.CustomService class.)该代码会持续检查message.log文件是否被加入了新的行,再为每个新加的行项目创建Ens.AlertRequest消息并将其发送至Ens.Alert。你可以使用它的适配器设置来设定呼叫间隔——即在消息日志(messages.log文件)中检查新行的频率。为了能让设定值尽量贴近实际频率,你可以选则诸如1或5这样较小的整数。
“Ens.Alert”进程
这是一个名叫“Ens.Alerts”的路由规则,你可以利用它把特定的警告(基于警告文本)从消息日志路由到“EnsLib.EmailAlertOperation”以发送邮件通知。请注意要在条件中包含AlertText的内容(即Document.AlertText [ “”后面双引号内的警告文字)。你还可以创建其他的附加规则,也可以用DTL把警告消息转换为向下游发送的电子邮件模板或其他格式的通知。
“EnsLib.EmailAlertOperation”操作
这是一个预先构建好的出站电子邮件操作(BO),让你能直接发送邮件通知。你可以利用Production配置中的邮件适配器设置来设定要发送电子邮件的地址列表,SMTP服务器/端口以及凭据等。
启动Production前应先设置全局^ lasttimestamp以记录下此工具检查最后一行时的时间戳。你需要按“月/日/年 时:分:秒”的格式进行设置–例如,从终端输入:
>> set ^lasttimestamp = “08/28/2020 08:00:00”
现在可以启动这个Production来亲身体会它的功效了!你还可以通过修改示例代码来满足你的特定需求。
如有任何疑问,请在下方留言评论或与我们的销售工程师联系!
文章
Michael Lei · 五月 3, 2022
所有源代码均在: https://github.com/antonum/ha-iris-k8s
在上一篇文章中,我们讨论了如何在k8s集群上建立具有高可用性的IRIS,基于分布式存储,而不是传统的镜像。作为一个例子,那篇文章使用了Azure AKS集群。在这一篇中,我们将继续探讨k8s上的高可用配置。这一次,基于Amazon EKS(AWS管理的Kubernetes服务),并将包括一个基于Kubernetes 快照进行数据库备份和恢复的选项。
安装
开始干活. 首先需要一个AWS账户,安装 AWS CLI, kubectl 和 eksctl 工具. 要创建新的集群,请运行以下命令:
eksctl create cluster \
--name my-cluster \
--node-type m5.2xlarge \
--nodes 3 \
--node-volume-size 500 \
--region us-east-1
这个命令需要大约15分钟,部署EKS集群并使其成为你的kubectl工具的默认集群。你可以通过运行以下代码来验证你的部署:
kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-192-168-19-7.ca-central-1.compute.internal Ready <none> 18d v1.18.9-eks-d1db3c
ip-192-168-37-96.ca-central-1.compute.internal Ready <none> 18d v1.18.9-eks-d1db3c
ip-192-168-76-18.ca-central-1.compute.internal Ready <none> 18d v1.18.9-eks-d1db3c
下一步是安装Longhorn分布式存储引擎.
kubectl create namespace longhorn-system
kubectl apply -f https://raw.githubusercontent.com/longhorn/longhorn/v1.1.0/deploy/iscsi/longhorn-iscsi-installation.yaml --namespace longhorn-system
kubectl apply -f https://raw.githubusercontent.com/longhorn/longhorn/master/deploy/longhorn.yaml --namespace longhorn-system
最后安装 IRIS :
kubectl apply -f https://github.com/antonum/ha-iris-k8s/raw/main/tldr.yaml
现在,你就有了一个功能齐全的EKS集群,并安装了Longhorn分布式存储和IRIS。 你可以回到上一篇文章,尝试对集群和IRIS部署进行各种破坏,看看系统如何自我修复。请看模拟故障Simulate the Failure部分。
Bonus #1 IRIS on ARM
IRIS EKS和Longhorn都支持ARM架构,所以我们可以使用AWS Graviton 2实例部署相同的配置,基于ARM架构。
你只需要将EKS节点的实例类型改为 "m6g "系列,将IRIS镜像改为基于ARM的。
eksctl create cluster \--name my-cluster-arm \--node-type m6g.2xlarge \--nodes 3 \--node-volume-size 500 \--region us-east-1
tldr.yaml
containers:
#- image: store/intersystems/iris-community:2020.4.0.524.0
- image: store/intersystems/irishealth-community-arm64:2020.4.0.524.0
name: iris
或只是用:
kubectl apply -f https://github.com/antonum/ha-iris-k8s/raw/main/tldr-iris4h-arm.yaml
这就行了! 你就有了一个在在ARM平台上运行的IRIS Kubernetes集群.
Bonus #2 - 备份与恢复
生产级架构的一个经常被忽视的部分是创建数据库的备份,并在需要时快速恢复和克隆这些备份的能力。
在Kubernetes中,常见的方式是使用持久化卷快照。
首先--你需要安装所有需要的k8s组件:
#Install CSI Snapshotter and CRDs
kubectl apply -n kube-system -f https://raw.githubusercontent.com/kubernetes-csi/external-snapshotter/master/client/config/crd/snapshot.storage.k8s.io_volumesnapshotcontents.yaml
kubectl apply -n kube-system -f https://github.com/kubernetes-csi/external-snapshotter/raw/master/client/config/crd/snapshot.storage.k8s.io_volumesnapshotclasses.yaml
kubectl apply -n kube-system -f https://raw.githubusercontent.com/kubernetes-csi/external-snapshotter/master/client/config/crd/snapshot.storage.k8s.io_volumesnapshots.yaml
kubectl apply -n kube-system -f https://raw.githubusercontent.com/kubernetes-csi/external-snapshotter/master/deploy/kubernetes/snapshot-controller/setup-snapshot-controller.yaml
kubectl apply -n kube-system -f https://raw.githubusercontent.com/kubernetes-csi/external-snapshotter/master/deploy/kubernetes/snapshot-controller/rbac-snapshot-controller.yaml
下一步 - 为Longhorn配置S3 bucket凭证 (请查看 详细指导):
#Longhorn backup target s3 bucket and credentials longhorn would use to access that bucket
#See https://longhorn.io/docs/1.1.0/snapshots-and-backups/backup-and-restore/set-backup-target/ for manual setup instructions
longhorn_s3_bucket=longhorn-backup-123xx #bucket name should be globally unique, unless you want to reuse existing backups and credentials
longhorn_s3_region=us-east-1
longhorn_aws_key=AKIAVHCUNTEXAMPLE
longhorn_aws_secret=g2q2+5DVXk5p3AHIB5m/Tk6U6dXrEXAMPLE
下面的命令将从上一步骤中获取环境变量,并使用它们来配置Longhorn备份。
#configure Longhorn backup target and credentials
cat <<EOF | kubectl apply -f -
apiVersion: longhorn.io/v1beta1
kind: Setting
metadata:
name: backup-target
namespace: longhorn-system
value: "s3://$longhorn_s3_bucket@$longhorn_s3_region/" # backup target here
---
apiVersion: v1
kind: Secret
metadata:
name: "aws-secret"
namespace: "longhorn-system"
labels:
data:
# echo -n '<secret>' | base64
AWS_ACCESS_KEY_ID: $(echo -n $longhorn_aws_key | base64)
AWS_SECRET_ACCESS_KEY: $(echo -n $longhorn_aws_secret | base64)
---
apiVersion: longhorn.io/v1beta1
kind: Setting
metadata:
name: backup-target-credential-secret
namespace: longhorn-system
value: "aws-secret" # backup secret name here
EOF
它可能看起来很多,但它基本上是告诉Longhorn使用一个特定的S3 bucket,用指定的凭证来存储备份的内容。
搞定! 如果你现在进入Longhorn的用户界面,你就可以创建备份,恢复等等。
关于如何连接到Longhorn用户界面的快速练习:
kubectl get pods -n longhorn-system
# note the full pod name for 'longhorn-ui-...' pod
kubectl port-forward longhorn-ui-df95bdf85-469sz 9000:8000 -n longhorn-system
这将把到Longhorn UI的流量转发到你的本地 http://localhost:9000
程序化的 备份/恢复
通过Longhorn用户界面进行备份和恢复可能是足够好的第一步--但我们将更进一步,使用k8s Snapshot APIs,以编程方式进行备份和恢复.
首先 - 快照本身. iris-volume-snapshot.yaml
apiVersion: snapshot.storage.k8s.io/v1beta1
kind: VolumeSnapshot
metadata:
name: iris-longhorn-snapshot
spec:
volumeSnapshotClassName: longhorn
source:
persistentVolumeClaimName: iris-pvc
这个卷快照指的是源卷 "iris-pvc",我们确实在IRIS部署中使用。因此,只要应用这个就可以立即开始备份过程.
在快照之前/之后执行IRIS Write Daemon Freeze/Thaw是一个好主意.
#Freeze Write Daemon
echo "Freezing IRIS Write Daemon"
kubectl exec -it -n $namespace $pod_name -- iris session iris -U%SYS "##Class(Backup.General).ExternalFreeze()"
status=$?
if [[ $status -eq 5 ]]; then
echo "IRIS WD IS FROZEN, Performing backup"
kubectl apply -f backup/iris-volume-snapshot.yaml -n $namespace
elif [[ $status -eq 3 ]]; then
echo "IRIS WD FREEZE FAILED"
fi
#Thaw Write Daemon
kubectl exec -it -n $namespace $pod_name -- iris session iris -U%SYS "##Class(Backup.General).ExternalThaw()"
恢复过程是非常直接的。它基本上是创建一个新的PVC,并指定快照为源。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: iris-pvc-restored
spec:
storageClassName: longhorn
dataSource:
name: iris-longhorn-snapshot
kind: VolumeSnapshot
apiGroup: snapshot.storage.k8s.io
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
然后你就根据这个PVC创建一个新的部署。检查github repo中的这个测试脚本,它将依次进行。
创建全新的IRIS部署
向IRIS添加一些数据
冻结写Daemon,拍摄快照,解冻写Daemon
在快照的基础上,创建一个IRIS部署的克隆
验证所有的数据是否还在那里
验证所有的数据是否还在那里,现在你将有两个相同的IRIS部署,一个是另一个的克隆备份。
Enjoy!
文章
姚 鑫 · 七月 2, 2021
# 第二十五章 添加和使用XSLT扩展函数
# 自定义错误处理
当出现错误时,XSLT处理器(`Xalan`或`Saxon`)执行当前错误处理程序的`error()`方法,将消息作为参数发送到该方法。类似地,当发生致命错误或警告时,XSLT处理器会根据需要执行`datalError()`或`Warning()`方法。
对于所有这三种方法,默认行为是将消息写入当前设备。
要自定义错误处理,请执行以下操作:
- 对于`Xalan`或`Saxon`处理器,在创建`%XML.XSLT.ErrorHandler`的子类。在这个子类中,根据需要实现`Error()`、`FatealError()`和`Warning()`方法。
这些方法中的每一个都接受单个参数,即包含由XSLT处理器发送的消息的字符串。
这些方法不返回值。
- 要在编译样式表时使用此错误处理程序,请创建子类的实例,并在编译样式表时在参数列表中使用它。
- 若要在执行XSLT转换时使用此错误处理程序,请创建子类的实例,并在使用的`Transform`方法的参数列表中使用它。
# 指定样式表使用的参数
要指定样式表使用的参数,请执行以下操作:
1. 创建`%ArrayOfDataTypes`的实例在。
2. 调用此实例的`SetAt()`方法将参数及其值添加到此实例。对于`SetAt()`,将第一个参数指定为参数值,将第二个参数指定为参数名称。
根据需要添加任意多个参数。
```java
Set tParameters=##class(%ArrayOfDataTypes).%New()
Set tSC=tParameters.SetAt(1,"myparameter")
Set tSC=tParameters.SetAt(2,"anotherparameter")
```
3. 将此实例用作`Transform`方法的`pParms`参数。
可以不使用`%ArrayOfDataType`,而是使用 IRIS多维数组,该数组可以具有任意数量的具有以下结构和值的节点:
Node| Value
---|---
arrayname("parameter_name") |Value of the parameter named by parameter_name
# 添加和使用XSLT扩展函数
可以在InterSystems IRIS中创建`XSLT`扩展函数,然后在样式表中使用它们,如下所示:
- 对于`XSLT2.0`(`Saxon`处理器),可以使用名称空间`com.intersystems.xsltgateway.XSLTGateway`中的`evaluate`函数或名称空间`http://extension-functions.intersystems.com`中的`evaluate`函数
- 对于`XSLT1.0`(`Xalan`处理器),只能在名称空间`http://extension-functions.intersystems.com`中使用`evaluate`函数
默认情况下(举个例子),后一个函数反转它接收到的字符。但是,通常不使用默认行为,因为实现了一些其他行为。要模拟多个单独的函数,需要传递一个选择器作为第一个参数,并实现一个开关,该开关使用该值选择要执行的处理。
在内部,`evaluate`函数作为XSLT回调处理程序中的方法(`evaluate()`)实现。
要添加和使用XSLT扩展函数,请执行以下操作:
1. 对于`Xalan`或`Saxon`处理器,在创建`%XML.XSLT.CallbackHandler`的子类。在这个子类中,根据需要实现`evaluate()`方法。请参阅下一小节。
2. 在样式表中,声明`evaluate`函数所属的命名空间,并根据需要使用`evaluate`函数。请参阅下一小节。
3. 执行XSLT转换时,创建子类的实例,并在使用的`Transform`方法的参数列表中使用它。请参阅“执行XSLT转换”。
## 实现evaluate()方法
在内部,调用`XSLT`处理器的代码可以将任意数量的位置参数传递给当前回调处理程序的`evaluate()`方法,该方法将它们作为具有以下结构的数组接收:
Node| Value
---|---
Args| 参数数量
Args(index) |位置索引中参数的值
该方法只有一个返回值。返回值可以是:
- 标量变量(如字符串或数字)。
- 流对象。这允许返回超过字符串长度限制的超长字符串。流必须包装在新窗口中的`%XML.XSLT.StreamAdapter`实例中,使XSLT处理器能够读取流。以下是部分示例:
```java
Method evaluate(Args...) As %String
{
//create stream
///...
// create instance of %XML.XSLT.StreamAdapter to
// contain the stream
Set return=##class(%XML.XSLT.StreamAdapter).%New(tStream)
Quit return
}
```
## 在样式表中使用计算
要在XSLT中使用XSLT扩展函数,必须在XSLT样式表中声明扩展函数的名称空间。对于InterSystems evaluate函数,此命名空间是`http://extension-functions.intersystems.com`或`com.intersystems.xsltgateway.XSLTGateway`,如前所述。
下面的示例显示使用evaluate的样式表:
```xml
```
## 使用ISC:计算缓存
XSLT2.0网关将`evaluate`函数调用缓存在`isc:evaluate`缓存中。缓存的默认最大大小为`1000`个项目,但可以将大小设置为不同的值。此外,还可以清除缓存、转储缓存,还可以从`%List`中预先填充缓存。使用以下格式:
- 缓存条目总数
- 对于每个条目:
1. 求值参数总数
2. 所有求值参数
3. 计算值
缓存还包括可缓存的函数名称的过滤器列表。请注意以下事项:
- 可以在筛选器列表中添加或删除函数名。
- 可以清除过滤器列表。
- 可以通过设置一个布尔值来覆盖筛选器列表,该布尔值将缓存每个`evaluate`调用。
将函数名添加到筛选器列表不会限制求值缓存的大小。可以对同一函数进行任意数量的调用,但具有不同的参数和返回值。函数名和参数的每个组合都是求值缓存中的一个单独条目。
可以使用`%XML.XSLT2.Transformer`中的方法来操作求值缓存。
# 使用XSL转换向导
Studio提供了一个执行XSLT转换的向导,当希望快速测试样式表或自定义XSLT扩展函数时,该向导非常有用。要使用此架构向导,请执行以下操作:
1. Tools > Add-Ins > XSLT Schema Wizard.
2. 指定以下必需的详细信息:
- 对于XML文件,选择浏览以选择要转换的XML文件。
- 对于XSL文件,选择浏览以选择要使用的XSL样式表。
- 对于呈现为,选择文本或XML以控制转换的显示方式。
3. 如果已在要在此转换中使用的创建了`%XML.XSLT.CallbackHandler`的子类,请指定以下详细信息:
- 对于XSLT Helper Class中的第一个下拉列表,选择一个命名空间。
- 对于XSLT Helper Class中的第二个下拉列表,选择该类。
4. 选择Finish(完成)。
对话框底部显示转换后的文件。可以从该区域复制和粘贴。
5. 要关闭此对话框,请选择取消。
文章
姚 鑫 · 四月 20, 2021
# 第四章 缓存查询(一)
系统自动维护已准备好的SQL语句(“查询”)的缓存。这允许重新执行SQL查询,而无需重复优化查询和开发查询计划的开销。缓存查询是在准备某些SQL语句时创建的。准备查询发生在运行时,而不是在编译包含SQL查询代码的例程时。通常,`PREPARE`紧跟在SQL语句的第一次执行之后,但在动态SQL中,可以准备查询而不执行它。后续执行会忽略`PREPARE`语句,转而访问缓存的查询。要强制对现有查询进行新的准备,必须清除缓存的查询。
所有SQL调用都会创建缓存查询,无论是在ObjectScript例程中调用还是在类方法中调用。
- 动态SQL、ODBC、JDBC和`$SYSTEM.SQL.DDLImport()`方法在准备查询时创建缓存查询。管理门户执行SQL接口、InterSystems SQL Shell和`%SYSTEM.SQL.Execute()`方法使用动态SQL,因此使用准备操作来创建缓存查询。
它们列在命名空间(或指定方案)的Management Portal常规缓存查询列表、每个正在访问的表的Management Portal Catalog Details缓存查询列表以及SQL语句列表中。动态SQL遵循本章中介绍的缓存查询命名约定。
- 类查询在准备(`%PrepareClassQuery()`方法)或第一次执行(调用)时创建缓存查询。
它们列在命名空间的管理门户常规缓存查询列表中。如果类查询是在持久类中定义的,则缓存的查询也会列在该类的Catalog Details缓存查询中。它没有列在正在访问的表的目录详细信息中。它没有列在SQL语句清单中。类查询遵循本章中介绍的缓存查询命名约定。
- 嵌入式SQL在第一次执行SQL代码或通过调用声明游标的`OPEN`命令启动代码执行时创建缓存查询。嵌入式SQL缓存查询列在管理门户缓存查询列表中,查询类型为嵌入式缓存SQL,SQL语句列表。嵌入式SQL缓存查询遵循不同的缓存查询命名约定。
所有清除缓存查询操作都会删除所有类型的缓存查询。
生成缓存查询的SQL查询语句包括:
- `SELECT`:`SELECT`缓存查询显示在其表的目录详细资料中。如果查询引用了多个表,则会为每个被引用的表列出相同的缓存查询。从这些表中的任何一个清除缓存的查询都会将其从所有表中清除。从表的目录详细资料中,可以选择缓存的查询名称以显示高速缓存的查询详细资料,包括执行和显示计划选项。由`$SYSTEM.SQL.Schema.ImportDDL(“IRIS”)`方法创建的选择缓存查询不提供`Execute`和`Show Plan`选项。
`SELECT`的`DECLARE NAME CURSOR`创建缓存查询。但是,缓存的查询详细信息不包括执行和显示计划选项。
- `CALL`:为其架构创建缓存查询列表中显示的缓存查询。
- `INSERT`、`UPDATE`、`INSERT`或`UPDATE`、`DELETE`:创建其表的`Catalog Details`中显示的缓存查询。
- `TRUNCATE TABLE`:为其表创建一个缓存查询,该查询显示在目录详细信息中。
注意,`$SYSTEM.SQL.Schema.ImportDDL("IRIS")`不支持截断表。
- `SET TRANSACTION`, `START TRANSACTION`, `%INTRANSACTION, COMMIT`, `ROLLBACK`:为命名空间中的每个模式创建一个缓存查询,显示在缓存查询列表中。
**当准备查询时,将创建一个缓存的查询。
因此,不要将`%Prepare()`方法放入循环结构中是很重要的。
同一个查询的后续`%Prepare()`(仅在指定的文字值上有所不同)使用现有的缓存查询,而不是创建新的缓存查询。**
更改表的`SetMapSelectability()`值将使所有引用该表的现有缓存查询失效。
现有查询的后续准备将创建一个新的缓存查询,并从清单中删除旧的缓存查询。
清除缓存查询时,缓存查询将被删除。修改表定义会自动清除引用该表的所有查询。在更新查询缓存元数据时,发出准备或清除命令会自动请求独占的系统范围锁。系统管理员可以修改缓存查询锁定的超时值。
创建缓存的查询不是事务的一部分。缓存查询的创建不会被记录下来。
# 缓存查询提高了性能
第一次准备查询时,SQL引擎会对其进行优化,并生成将执行该查询的程序(一个或多个InterSystems IRIS®Data Platform例程的集合)。然后将优化的查询文本存储为缓存查询类。如果随后尝试执行相同(或类似)的查询,SQL引擎将找到缓存的查询并直接执行该查询的代码,从而绕过优化和代码生成的需要。
缓存查询提供以下好处:
- 频繁使用的查询的后续执行速度更快。更重要的是,无需编写繁琐的存储过程即可自动获得这种性能提升。大多数关系数据库产品建议仅使用存储过程访问数据库。对于IRIS,这不是必需的。
- 单个缓存的查询用于类似的查询,这些查询只是在字面值上有所不同。例如,`SELECT TOP 5 Name FROM Sample.Person WHERE Name %STARTSWITH 'A' and SELECT TOP 1000 Name FROM Sample.Person WHERE Name %STARTSWITH 'Mc'`,只是`top`和`%startswith`条件的文本值不同。为第一查询准备的缓存查询自动用于第二查询。
- 查询缓存在所有数据库用户之间共享;如果用户1准备查询,则用户1023可以利用它。
- 查询优化器可以自由地使用更多的时间为给定的查询找到最佳解决方案,因为这个代价只需要在第一次准备查询时支付。
InterSystems SQL将所有缓存的查询存储在一个位置,即`IRISLOCALDATA`数据库。但是,缓存查询是特定于名称空间的。每个缓存的查询都由准备(生成)它的名称空间标识。只能从准备缓存查询的命名空间中查看或执行缓存查询。可以清除当前命名空间或所有命名空间的缓存查询。
缓存查询不包括注释。但是,它可以在查询文本后面包含注释选项,例如`/*#OPTIONS {"optionName":value} */`。
因为缓存查询使用现有的查询计划,所以它为现有查询提供了操作的连续性。对基础表的更改(如添加索引或重新定义表优化统计信息)不会对现有缓存查询产生任何影响。
# 创建缓存查询
当InterSystems IRIS准备查询时,它会确定:
- 如果查询与查询缓存中已有的查询匹配。如果不是,则向查询分配递增计数。
- 如果查询准备成功。如果不是,则不会将递增计数分配给缓存的查询名称。
- 否则,递增计数被分配给缓存的查询名称,并且该查询被缓存。
## 动态SQL的缓存查询名称
SQL引擎为每个缓存查询分配唯一的类名,格式如下:
```java
%sqlcq.namespace.clsnnn
```
其中,`NAMESPACE`为当前名称空间(大写),`NNN`为连续整数。例如,`%sqlcq.USER.cls16`。
缓存的查询以每个命名空间为基础按顺序编号,从1开始。下一个可用的`nnn`序列号取决于已保留或释放的编号:
- 如果查询与现有缓存查询不匹配,则在开始准备查询时会保留一个数字。如果查询与现有的缓存查询仅在文字值上不同,则查询与现有的缓存查询匹配-这取决于某些其他注意事项:隐藏的文本替换、不同的注释选项或“单独的缓存查询”中描述的情况。
- 如果查询准备不成功,则保留但不分配号码。只有准备成功的查询才会被缓存。
- 如果缓存查询准备成功,则会保留一个编号并将其分配给缓存查询。无论是否从该表访问任何数据,都会为查询中引用的每个表列出该缓存查询。如果查询未引用任何表,则会创建缓存查询,但不能按表列出或清除。
- 清除缓存查询时会释放一个数字。该号码将作为下一个`NNN`序列号可用。清除与表关联的单个缓存查询或清除表的所有缓存查询将释放分配给这些缓存查询的编号。清除命名空间中的所有缓存查询会释放分配给缓存查询的所有编号,包括未引用表的缓存查询,以及保留但未分配的编号。
清除缓存查询将重置`nnn`整数。整数会被重复使用,但剩余的缓存查询不会重新编号。例如,缓存查询的部分清除可能会留下`cls1、cls3、cls4和cls7`。后续缓存查询将编号为`cls2、cls5、cls6和cls8`。
一条CALL语句可能会导致多个缓存查询。例如,SQL语句`CALL Sample.PersonSets('A','MA')` 生成以下缓存查询:
```sql
%sqlcq.USER.cls1: CALL Sample . PersonSets ( ? , ? )
%sqlcq.USER.cls2: SELECT name , dob , spouse FROM sample . person
WHERE name %STARTSWITH ? ORDER BY 1
%sqlcq.USER.cls3: SELECT name , age , home_city , home_state
FROM sample . person WHERE home_state = ? ORDER BY 4 , 1
```
在动态SQL中,准备SQL查询(使用`%PrepareClassQuery()`或`%PrepareClassQuery()`实例方法)后,可以使用`%display()`实例方法或`%GetImplementationDetails()`实例方法返回缓存的查询名称。查看成功准备的结果。
缓存的查询名称也是由`%SQL.Statement`类的`%Execute()`实例方法(以及`%CurrentResult`属性)返回的结果集`OREF`的一个组件。以下示例显示了这两种确定缓存查询名称的方法:
```java
/// w ##class(PHA.TEST.SQL).CacheQuery()
ClassMethod CacheQuery(c)
{
SET randtop=$RANDOM(10)+1
SET randage=$RANDOM(40)+1
SET myquery = "SELECT TOP ? Name,Age FROM Sample.Person WHERE Age < ?"
SET tStatement = ##class(%SQL.Statement).%New()
SET qStatus = tStatement.%Prepare(myquery)
IF qStatus'=1 {
WRITE "%Prepare failed:"
DO $System.Status.DisplayError(qStatus)
QUIT
}
SET x = tStatement.%GetImplementationDetails(.class,.text,.args)
IF x=1 {
WRITE "cached query name is: ",class,!
}
SET rset = tStatement.%Execute(randtop,randage)
WRITE "result set OREF: ",rset.%CurrentResult,!
DO rset.%Display()
WRITE !,"A sample of ",randtop," rows, with age < ",randage
}
```
```java
DHC-APP>w ##class(PHA.TEST.SQL).CacheQuery()
cached query name is: %sqlcq.DHCdAPP.cls51
result set OREF: 5@%sqlcq.DHCdAPP.cls51
Name Age
姚鑫 7
姚鑫 7
O'Rielly,Chris H. 7
Orwell,John V. 4
Zevon,Heloisa O. 11
Smith,Kyra P. 7
6 Rows(s) Affected
A sample of 6 rows, with age < 19
```
在本例中,选定的行数(`TOP`子句)和`WHERE`子句谓词值会随着每次查询调用而改变,但缓存的查询名称不会改变。
## 嵌入式SQL的缓存查询名称
SQL引擎为每个嵌入式SQL缓存查询分配一个唯一的类名,格式如下:
```java
%sqlcq.namespace.hash
```
其中,`NAMESPACE`是当前的名称空间(大写),`HASH`是唯一的哈希值。例如,`%sqlcq.USER.xEM1h5QIeF4l3jhLZrXlnThVJZDh`。
管理门户为每个表列出了嵌入式SQL缓存查询,目录详细信息为每个表列出了具有这个类名的缓存查询,查询类型为嵌入式缓存SQL。
## 单独的缓存查询
两个不应该影响查询优化的查询之间的差异仍然会生成单独的缓存查询:
- 同一函数的不同语法形式会生成单独的缓存查询。因此,`ASCII(‘x’)`和`{fn ASCII(‘x’)}`生成单独的缓存查询,而`{fn CURDATE()}`和`{fn CURDATE}`生成单独的缓存查询。
- 区分大小写的表别名或列别名值以及可选的AS关键字的存在或不存在将生成单独的缓存查询。因此,`ASCII('x')`, `ASCII('x') AChar`, and `ASCII('x') AS AChar`会生成单独的缓存查询。
- 使用不同的`ORDER BY`子句。
- 使用`top all`代替具有整数值的`top`。
# 文字替换
当SQL引擎缓存一个SQL查询时,它会执行文字替换。
查询缓存中的查询用`“?”`
字符,表示输入参数。
这意味着,仅在文字值上不同的查询由单个缓存的查询表示。
例如,两个查询:
```sql
SELECT TOP 11 Name FROM Sample.Person WHERE Name %STARTSWITH 'A'
```
```sql
SELECT TOP 5 Name FROM Sample.Person WHERE Name %STARTSWITH 'Mc'
```
都由单个缓存查询表示:
```sql
SELECT TOP ? Name FROM Sample.Person WHERE Name %STARTSWITH ?
```
这最小化了查询高速缓存的大小,并且意味着不需要对仅在字面值上不同的查询执行查询优化。
使用输入主机变量(例如`:myvar`)和`?`
输入参数也在相应的缓存查询中用`“?”`
”字符。
因此, `SELECT Name FROM t1 WHERE Name='Adam', SELECT Name FROM t1 WHERE Name=?`, and `SELECT Name FROM t1 WHERE Name=:namevar`
,都是匹配查询,并生成单个缓存查询。
可以使用`%GetImplementationDetails()`方法来确定这些实体中的哪些实体由每个“?”特定准备的字符。
以下注意事项适用于文字替换:
- 指定为文字一部分的加号和减号将生成单独的缓存查询。因此,`ABS(7)`、`ABS(-7)`和`ABS(+7)`各自生成一个单独的缓存查询。多个符号也会生成单独的缓存查询:`ABS(+?)`。`ABS(++?)`。因此,最好使用无符号变量`ABS(?)`。或`ABS(:Num)`,可以为其提供有符号或无符号数字,而无需生成单独的缓存查询。
- 精度和小数值通常不接受文字替换。因此,`ROUND(567.89,2)`被缓存为`ROUND(?,2)`。但是,`CURRENT_TIME(N)`、`CURRENT_TIMESTAMP(N)`、`GETDATE(N)`和`GETUTCDATE(N)`中的可选精度值不接受文字替换。
- `IS NULL`或`IS NOT NULL`条件中使用的文字不接受文字替换。
- `ORDER BY`子句中使用的任何文字都不接受文字替换。这是因为`ORDER BY`可以使用整数来指定列位置。更改此整数将导致根本不同的查询。
- 字母文字必须用单引号引起来。某些函数允许指定带引号或不带引号的字母格式代码;只有带引号的字母格式代码才接受文字替换。因此,`DATENAME(MONTER,64701)`和`DATENAME(‘MONTER’,64701)`在功能上是相同的,但是对应的缓存查询是`DATENAME(MONTER,?)`。和`DATENAME(?,?)`
- 接受可变数量参数的函数会为每个参数计数生成单独的缓存查询。因此,`Coalesce(1,2)`和`Coalesce(1,2,3)`会生成单独的缓存查询。
## DynamicSQLTypeList Comment Option
当匹配查询时,注释选项被视为查询文本的一部分。
因此,在注释选项中不同于现有缓存查询的查询与现有缓存查询不匹配。
注释选项可以作为查询的一部分由用户指定,也可以由SQL预处理器在准备查询之前生成并插入。
如果SQL查询包含文字值,SQL预处理器将生成`DynamicSQLTypeList`注释选项,并将其附加到缓存的查询文本的末尾。此注释选项为每个文字分配数据类型。数据类型按照文字在查询中出现的顺序列出。只列出实际文字,而不是输入主机变量或?输入参数。下面是一个典型的例子:
```sql
SELECT TOP 2 Name,Age FROM Sample.MyTest WHERE Name %STARTSWITH 'B' AND Age > 21.5
```
生成缓存的查询文本:
```sql
SELECT TOP ? Name , Age FROM Sample . MyTest WHERE Name %STARTSWITH ? AND Age > ? /*#OPTIONS {"DynamicSQLTypeList":"10,1,11"} */
```
在本例中,文字2被列为类型10(整数),文字`“B”`被列为类型1(字符串),而文字`21.5`被列为类型11(数字)。
请注意,数据类型分配仅基于文字值本身,而不是关联字段的数据类型。例如,在上面的示例中,`Age`被定义为数据类型`INTEGER`,但是文字值21.5被列为`NUMERIC`。因为InterSystems IRIS将数字转换为规范形式,所以文字值`21.0`将被列为整数,而不是数字。
`DynamicSQLTypeList`返回以下数据类型值:
数字 | 描述
---|---
1| 长度为1到32(包括1到32)的字符串
2| 长度为33到128(含)的字符串
3| 长度为129到512(含)的字符串
4| 长度大于512的字符串
10| Integer
11| Numeric
由于`DynamicSQLTypeList`注释选项是查询文本的一部分,因此更改文本以使其产生不同的数据类型会导致创建单独的缓存查询。例如,增加或减少文字字符串的长度,使其落入不同的范围。
## 文字替换和性能
SQL引擎对`IN`谓词的每个值执行文字替换。大量`IN`谓词值可能会对缓存查询性能产生负面影响。可变数量的`IN`谓词值可能会导致多个缓存查询。将`IN`谓词转换为`%INLIST`谓词会导致谓词只有一个文字替换,而不管列出的值有多少。`%INLIST`还提供了一个数量级大小参数,`SQL`使用该参数来优化性能。
## 取消文字替换
可以取消这种文字替换。在某些情况下,可能希望对文字值进行优化,并为具有该文字值的查询创建单独的缓存查询。若要取消文字替换,请将文字值括在双圆括号中。下面的示例显示了这一点:
```sql
SELECT TOP 11 Name FROM Sample.Person WHERE Name %STARTSWITH (('A'))
```
指定不同的 `%STARTSWITH`值将生成单独的缓存查询。请注意,对每个文字分别指定禁止文字替换。在上面的示例中,指定不同的`TOP`值不会生成单独的缓存查询。
要取消有符号数字的文字替换,请指定诸如 `ABS(-((7)))`之类的语法。
注意:在某些情况下,不同数量的括号也可能会抑制文字替换。InterSystems建议始终使用双圆括号作为此目的最清晰和最一致的语法。
# 共分注释选项
如果一个SQL查询指定了多个分割表,则SQL预处理器会生成一个共分片注释选项,并将该选项附加到缓存的查询文本的末尾。此共分选项显示是否对指定的表进行共分。
在下面的示例中,所有三个指定的表都进行了编码共享:
```
/*#OPTIONS {"Cosharding":[["T1","T2","T3"]]} */
```
在以下示例中,指定的三个表均未进行编码共享:
```
/*#OPTIONS {"Cosharding":[["T1"],["T2"],["T3"]]} */
```
在以下示例中,表`T1`未被编分,但表`T2`和`T3`被编分:
```
/*#OPTIONS {"Cosharding":[["T1"],["T2","T3"]]} */
```
文章
姚 鑫 · 三月 14, 2021
# 第十章 SQL排序
排序规则指定值的排序和比较方式,并且是InterSystems SQL和InterSystemsIRIS®数据平台对象的一部分。有两种基本排序规则:数字和字符串。
- 数值排序规则按以下顺序基于完整数字对数字进行排序:`null`,然后是负数,从最大到最小,零,然后是正数,从最小到最大。这将创建如下序列:`–210,–185,–54,–34,-.02、0、1、2、10、17、100、120`。
- 字符串归类通过对每个顺序字符进行归类来对字符串进行排序。这将创建以下顺序:`null,A,AA,AA,AAA,AAB,AB,B`。对于数字,这将创建以下顺序:`–.02,–185,–210,–34,–54 ,0、1、10、100、120、17、2`。
**默认的字符串排序规则是`SQLUPPER`;为每个名称空间设置此默认值。 `SQLUPPER`排序规则将所有字母都转换为大写(出于排序的目的),并在字符串的开头附加一个空格字符。此转换仅用于整理目的;在InterSystems中,无论所应用的排序规则如何,SQL字符串通常以大写和小写字母显示,并且字符串的长度不包括附加的空格字符。**
时间戳记是一个字符串,因此遵循当前的字符串排序规则。但是,由于时间戳是ODBC格式,因此如果指定了前导零,则字符串排序规则与时间顺序相同。
- 字符串表达式(例如使用标量字符串函数`LEFT`或`SUBSTR`的表达式)使其结果归类为`EXACT`。
- 两个文字的任何比较都使用`EXACT`归类。
可以使用“ObjectScript排序后”运算符来确定两个值的相对排序顺序。
可以按以下方式指定排序规则:
- 命名空间默认值
- 表字段/属性定义
- 索引定义查询
- `SELECT`项
- 查询`DISTINCT`和`GROUP BY`子句
# 排序类型
排序规则可以在字段/属性的定义或索引的定义中指定为关键字。
可以通过对查询子句中的字段名应用排序规则函数来指定排序规则。
在指定排序函数时必须使用%前缀。
**排序规则采用升序的ASCII/Unicode序列**,具有以下转换:
- **`EXACT` - 强制字符串数据区分大小写。
如果字符串数据包含规范数字格式的值(例如`123`或`-.57`),则不建议使用。**
- **`SQLSTRING` - 去除末尾的空格(空格、制表符等),并在字符串的开头添加一个前导空格。
它将任何只包含空格(空格、制表符等)的值作为SQL空字符串进行排序。
`SQLSTRING`支持可选的`maxlen`整数值。**
- **`SQLUPPER` - 将所有字母字符转换为大写,去除末尾的空格(空格、制表符等),然后在字符串的开头添加一个前导空格字符。
附加这个空格字符的原因是为了强制将数值作为字符串进行整理(因为空格字符不是有效的数字字符)。
这种转换还导致SQL将SQL空字符串(`"`)值和任何只包含空格(空格、制表符等)的值作为单个空格字符进行整理。
`SQLUPPER`支持可选的`maxlen`整数值。**
注意,`SQLUPPER`转换与SQL函数`UPPER`的结果不同。
- **`TRUNCATE` —增强字符串数据的区分大小写,并且(与`EXACT`不同)允许指定截断该值的长度。当索引比下标支持的数据长的精确数据时,此功能很有用。它采用`%TRUNCATE(string,n)`形式的正整数参数将字符串截断为前`n`个字符,从而改善了对长字符串的索引和排序。如果未为`TRUNCATE`指定长度,则其行为与`EXACT`相同;同时支持此行为。如果仅在定义了长度的情况下使用`TRUNCATE`而在没有定义长度的情况下使用`EXACT`,则定义和代码可能更易于维护。**
- **`PLUS` —使值成为数字。非数字字符串值将返回0。**
- **`MINUS` — 使数值成为数字并更改其符号。非数字字符串值将返回0。**
注意:还有多种传统排序规则类型,不建议使用。
**在SQL查询中,可以指定不带括号`%SQLUPPER Name`或带括号`%SQLUPPER(Name)`的排序规则函数。如果排序规则函数指定了截断,则必须使用括号`%SQLUPPER(Name,10)`。**
**三种排序规则类型:`SQLSTRING`,`SQLUPPER`和`TRUNCATE`支持可选的`maxlen`整数值。如果指定,`maxlen`会将字符串的分析截断为前`n`个字符。在对长字符串进行索引和排序时,可以使用它来提高性能。可以在查询中使用`maxlen`进行排序,分组或返回截断的字符串值。**
还可以使用 `%SYSTEM.Util.Collation()`方法执行排序规则类型转换。
# 命名空间范围的默认排序规则
每个名称空间都有一个当前的字符串排序规则设置。此字符串排序规则是为`%Library.String`中的数据类型定义的。默认值为`SQLUPPER`。此默认值可以更改。
可以基于每个命名空间定义排序规则默认值。默认情况下,名称空间没有分配的排序规则,这意味着它们使用`SQLUPPER`排序规则。可以为命名空间分配其他默认排序规则。此名称空间默认排序规则适用于所有进程,并且在InterSystems上保持不变,IRIS会重新启动,直到明确重置为止。
```java
/// d ##class(PHA.TEST.SQL).Collation()
ClassMethod Collation()
{
SET stat=$$GetEnvironment^%apiOBJ("collation","%Library.String",.collval)
WRITE "初始排序 ",$NAMESPACE,!
ZWRITE collval
SetNamespaceCollation
DO SetEnvironment^%apiOBJ("collation","%Library.String","SQLstring")
SET stat=$$GetEnvironment^%apiOBJ("collation","%Library.String",.collnew)
WRITE "user-assigned排序为 ",$NAMESPACE,!
ZWRITE collnew
ResetCollationDefault
DO SetEnvironment^%apiOBJ("collation","%Library.String",.collval)
SET stat=$$GetEnvironment^%apiOBJ("collation","%Library.String",.collreset)
WRITE "恢复排序规则的默认值 ",$NAMESPACE,!
ZWRITE collreset
}
```
```java
DHC-APP>d ##class(PHA.TEST.SQL).Collation()
初始排序 DHC-APP
user-assigned排序为 DHC-APP
collnew="SQLstring"
恢复排序规则的默认值 DHC-APP
```
注意,如果从未设置名称空间排序的默认值,那么`$$GetEnvironment`将返回一个未定义的排序变量,例如本例中的`.collval`。
这个未定义的排序规则默认为`SQLUPPER`。
注意:如果数据包含德语文本,大写排序规则可能不是理想的默认设置。
这是因为德语`eszett`字符(`$CHAR(223)`)只有小写形式。
相当于大写的是两个字母`“SS”`。
转换为大写的SQL排序规则不会转换`eszett,` `eszett`保持为单个小写字母不变。
# 表字段/属性定义排序
在SQL中,排序规则可以分配为字段/属性定义的一部分。字段使用的数据类型确定其默认排序规则。字符串数据类型的默认排序规则为`SQLUPPER`。非字符串数据类型不支持排序规则分配。
可以在`CREATE TABLE`和`ALTER TABLE`中为字段指定排序规则:
```SQL
CREATE TABLE Sample.MyNames (
LastName CHAR(30),
FirstName CHAR(30) COLLATE SQLstring)
```
注意:使用`CREATE TABLE``和ALTER TABLE`为字段指定排序规则时,`%`前缀是可选的`:COLLATE SQLstring`或`COLLATE %SQLstring`。
在使用持久类定义定义表时,可以为属性指定排序规则:
```java
Class Sample.MyNames Extends %Persistent [DdlAllowed]
{
Property LastName As %String;
Property FirstName As %String(COLLATION = "SQLstring");
}
```
注意:在为类定义和类方法指定排序规则时,请勿将`%`前缀用于排序规则类型名称。
**在这些示例中,`LastName`字段采用默认排序规则(`SQLUPPER`,不区分大小写),`FirstName`字段使用区分大小写的`SQLSTRING`排序规则进行定义。**
**如果更改类属性的排序规则,并且已经存储了该类的数据,则该属性上的所有索引都将变为无效。必须基于此属性重建所有索引。**
# 索引定义排序
`CREATE INDEX`命令无法指定索引排序规则类型。索引使用与要索引的字段相同的排序规则。
**定义为类定义一部分的索引可以指定排序规则类型。默认情况下,给定一个或多个给定属性的索引使用属性数据的排序规则类型。例如,假设已定义类型为`%String`的属性`Name`:**
```java
Class MyApp.Person Extends %Persistent [DdlAllowed]
{
Property Name As %String;
Index NameIDX On Name;
}
```
名称的排序规则为`SQLUPPER`(`%String`的默认值)。假设`“Person”`表包含以下数据:
ID| Name
---|---
1| Jones
2| JOHNSON
3| Smith
4| jones
5| SMITH
然后,`Name`上的索引将包含以下条目:
Name| ID(s)
---|---
JOHNSON| 2
JONES| 1, 4
SMITH| 3, 5
SQL引擎可以将此索引直接用于`ORDER BY`或使用`“Name”`字段进行比较操作。
可以通过在索引定义中添加一个`As`子句来覆盖用于索引的默认排序规则:
```java
Class MyApp.Person Extends %Persistent [DdlAllowed]
{
Property Name As %String;
Index NameIDX On Name As SQLstring;
}
```
在这种情况下,`NameIDX`索引现在将以`SQLSTRING`(区分大小写)的形式存储值。使用上面示例中的数据:
Name| ID(s)
---|---
JOHNSON| 2
Jones| 1
jones| 4
SMITH| 5
Smith| 3
在这种情况下,对于需要区分大小写排序规则的任何查询,SQL Engine都可以利用此索引。
通常,不必更改索引的排序规则。如果要使用其他排序规则,最好在属性级别定义它,然后让属性上的所有索引都采用正确的排序规则。
如果使用索引属性执行属性比较,则在比较中指定的属性应与相应索引具有相同的排序规则类型。例如,`SELECT`的`WHERE`子句或`JOIN`的`ON`子句中的`Name`属性应与为`Name`属性定义的索引具有相同的排序规则。如果属性归类和索引归类之间不匹配,则索引可能无效或根本不使用。
如果将索引定义为使用多个属性,则可以分别指定每个索引的排序规则:
```java
Index MyIDX On (Name As SQLstring, Code As Exact);
```
文章
Michael Lei · 五月 24, 2021
本帖的目的是回答一个问题。 在本系列的第二篇帖子中,我包括了从 pButtons 提取的性能数据的图表。 有人在线下问我,有没有比剪切/粘贴更快的方法从 pButtons .html文件中提取 `mgstat` 等指标,以便在 Excel 中绘图。
参见:- [第 2 部分 - 研究收集的指标](https://cn.community.intersystems.com/post/intersystems-数据平台和性能-–-第-2篇)
pButtons 将其收集的数据编译成一个 html 文件,以便发送给 WRC 和查看整理的数据。 不过,尤其是对于长时间(如 24 小时)进行收集的 pButtons 来说,一些基于时间的数据(如 mgstat、vmstat 等)以图形方式查看更容易查找趋势或模式。
我知道把 pButtons 数据压缩到一个 html 文件再花时间去解压听起来很疯狂,但请记住,pButtons 是 WRC 用来获取许多系统指标的视图以帮助解决性能问题的工具。 系统级指标和 Caché 指标可以单独运行,但对我来说,在这个系列中使用 pButtons 捕获和分析性能指标是很方便的,因为我知道所有 Caché 安装都会有一个副本,或者可以下载副本,而且所有基本指标都可以放在一个文件中供不同的操作系统使用。 能够每天通过一个简单的例程来捕获这些指标也是很方便的,前提是没有以任何其他方式收集数据。
> _**2017 年 2 月。 我用 Python 重写了本文中的脚本,并添加了包括交互式 html 在内的图表。**_我认为 Python 实用工具有用得多。 请参见 [Yape - 另一个 pButtons 提取程序(以及自动创建图表)](https://community.intersystems.com/post/yape-yet-another-pbuttons-extractor-and-automatically-create-charts)
## 将 pButtons 性能指标提取到 csv 文件
由于我使用 Apple 笔记本电脑和 Unix 操作系统,所以很自然地写了一个快速 shell 脚本来提取数据到 csv 文件。 以下脚本从 pButtons .html 文件中提取 mgstat、vmstat 或 Windows 性能监视器数据。 下面的示例使用了大多数 *nix 系统都已安装的 Perl,但也可以使用其他脚本语言或在 Windows 上使用 powershell。
我将展示如何进行提取,有了这些信息,您就可以使用您喜欢的工具来执行同样操作。 关键是 html 文件中有标记来分隔指标。 例如,mgstat 用括号括起:
和
在 mgstat 部分中还有一些其他描述符信息,后面是 mgstat 输出的标题行。 vmstat 和 win_perfmon 的标记类似。
这个简单的脚本只是查找开始标记,然后输出从标题行到结束标记之前的行的所有内容。
#!/usr/bin/perl
# extract_pButtons.pl - Simple extractor for pButtons
# usage: ./extract_pButtons.pl
# pButtons has the following markers in the html source
# Metrics Parameters to pass
# -------- -------------------
# mgstat mgstat Date
# windows performance monitor win_perfmon Time
# vmstat vmstat fre
# usage example - Search for mgstat and redirect to .csv file
# ./extract_pButtons.pl DB1_20160211_0001_24Hour_5Sec.html mgstat Date > myMgstatOutput.csv
# usage example - Process a set of html files
# for i in $(ls *.html); do ./extract_pButtons.pl ${i} vmstat fre > ${i}.vmstat.csv ; done
# usage example - Pipeline to add commas
# ./extract_pButtons.pl P570A_CACHE_20150418_0030_day.html vmstat fre | ./make_csv.pl >P570A_CACHE_20150418_0030_day.html.vmstat.csv
$filename=$ARGV[0];
$string=$ARGV[1];
$firstLine=$ARGV[2];
$searchBeg="beg_".$string;
$search2=$firstLine;
$foundEnd="end_".$string;
$foundString=0;
$printIt=0;
$break=0;
open HTMLFILEIN, "
文章
姚 鑫 · 六月 21, 2021
# 第十四章 XML获取当前节点信息
# DOM节点类型
`%XML.Document`和`%XML.Node`类识别以下`DOM`节点类型:
- Element (`$$$xmlELEMENTNODE`)
请注意,这些宏在%xml.DOM.inc包含文件中定义。
- Text (`$$$xmlTEXTNODE`)
- Whitespace (`$$$xmlWHITESPACENODE`).
其他类型的`DOM`节点被简单地忽略。
请以下XML文档:
```xml
Jack O'Neill
Samantha Carter
Daniel Jackson
```
当作为DOM查看时,该文档由以下节点组成:
文档节点示例
NodeID| NodeType |LocalName| Notes
---|---|---|---
0,29| `$$$xmlELEMENTNODE`| team |
1,29| `$$$xmlWHITESPACENODE`| | 该节点是``节点的子节点
1,23| `$$$xmlELEMENTNODE`| member| 该节点是``节点的子节点
2,45| `$$$xmlTEXTNODE`| Jack O'Neill| 该节点是第一个``节点的子节点
1,37| `$$$xmlWHITESPACENODE`| | 该节点是``节点的子节点
1,41| `$$$xmlELEMENTNODE`| member |该节点是``节点的子节点
3,45| `$$$xmlTEXTNODE` |Samantha Carter| 该节点是第二个``节点的子节点
1,45| `$$$xmlWHITESPACENODE`| |该节点是``节点的子节点
1,49| `$$$xmlELEMENTNODE`| member |该节点是``节点的子节点
4,45| `$$$xmlTEXTNODE`| Daniel Jackson| 该节点是第三个``节点的子节点
1,53| `$$$xmlWHITESPACENODE`| |该节点是``节点的子节点
# 获取当前节点信息
`%XML.Node`的以下字符串属性。提供关于当前节点的信息。
在所有情况下,如果没有当前节点,将抛出一个错误。
### LocalName
当前元素节点的本地名称。如果访问其他类型节点的此属性,则会引发错误。
### Namespace
当前元素节点的命名空间URI。如果尝试访问其他类型节点的此属性,则会引发错误。
### NamespaceIndex
当前元素节点的命名空间的索引。
当InterSystems IRIS读取XML文档并创建DOM时,它会标识文档中使用的所有名称空间,并为每个名称空间分配一个索引号。
如果尝试访问其他类型节点的此属性,则会引发错误。
### Nil
如果`xsi:nil`或`xsi:null`为true,则等于true;如果此元素节点为1,则等于1。否则,此属性等于`False`。
### NodeData
字符节点的值。
### NodeId
当前节点ID。
可以设置此属性以导航到另一个节点。
### NodeType
当前节点的类型,如前一节所述。
### QName
元素节点的Q名称。仅当前缀对文档有效时才用于输出为XML。
以下方法提供有关当前节点的其他信息:
### GetText()
```java
method GetText(ByRef text) as %Boolean
```
获取元素节点的文本内容。如果返回文本,则此方法返回TRUE;在本例中,实际文本被追加到第一个参数后,该参数通过引用返回。
### HasChildNodes()
```java
method HasChildNodes(skipWhitespace As %Boolean = 0) as %Boolean
```
如果当前节点有子节点,则返回True;否则返回False。
### GetNumberAttributes()
```java
method GetNumberAttributes() as %Integer
```
方法`GetNumberAttributes()`为`%Integer`
## 示例
下面的示例方法编写一个报告,提供有关当前节点的信息:
```java
ClassMethod ShowNode(node As %XML.Node)
{
w !,"LocalName=" _ node.LocalName
if node.NodeType=$$$xmlELEMENTNODE {
w !,"Namespace=" _ node.Namespace
}
if node.NodeType = $$$xmlELEMENTNODE {
w !,"NamespaceIndex=" _ node.NamespaceIndex
}
w !,"Nil=" _ node.Nil
w !,"NodeData=" _ node.NodeData
w !,"NodeId=" _ node.NodeId
w !,"NodeType=" _ node.NodeType
w !,"QName=" _ node.QName
w !,"HasChildNodes returns " _ node.HasChildNodes()
w !,"GetNumberAttributes returns " _ node.GetNumberAttributes()
s status = node.GetText(.text)
if status {
w !, "该节点的文本为 "_text
} else {
w !, "GetText不返回文本"
}
}
```
示例输出可能如下所示:
```java
LocalName=update
Namespace=
NamespaceIndex=
Nil=0
NodeData=update
NodeId=0,29
NodeType=0
QName=update
HasChildNodes returns 1
GetNumberAttributes returns 0
GetText不返回文本
文档中的命名空间数: 1
Namespace 1 is http://www.w3.org/2001/XMLSchema-instance
DHC-APP>
```
文章
姚 鑫 · 一月 14, 2023
# 第四十五章 使用 ^SystemPerformance 监视性能 - Abort ^SystemPerformance
# `Abort ^SystemPerformance`
如果要停止正在运行的配置文件,可以中止数据收集,并可选择使用 `$$Stop^SystemPerformance(runid)` 命令删除配置文件的所有 `.log` 文件。例如,要中止由 `runid20111220_1327_12hours` 标识的报告的数据收集并删除到目前为止写入的所有 `.log` 文件,请在终端的 `%SYS` 命名空间中输入以下命令:
```
do Stop^SystemPerformance("20111220_1327_12hours")
```
要在不删除日志文件的情况下停止作业并从这些日志文件生成 `HTML` 性能报告,请输入:
```
do Stop^SystemPerformance("20111220_1327_12hours",0)
```
有关此命令的更多信息,请参阅以编程方式运行 `^SystemPerformance` 小节中的 `$$Stop^SystemPerformance("runid")`。
注意:必须有权停止`jobs`和删除文件。
# 以编程方式运行 `^SystemPerformance`。
可以使用启动、收集、预览和停止功能的入口点以编程方式运行 `^SystemPerformance` 实用程序,如下表所述:
注意:可以同时运行多个配置文件。
- `$$run^SystemPerformance("profile")` - 启动指定的配置文件。如果成功,返回runid;如果不成功,则返回 `0`。
- `$$literun^SystemPerformance("profile")` - 与 `$$run^SystemPerformance("profile")` 相同,只是它不包括操作系统数据。
注意:此命令适用于运行多个 `IRIS` 实例的服务器,其中操作系统数据将被复制。
- `$$Collect^SystemPerformance("runid")` - 为指定的 `runid` 生成可读的 HTML 性能报告文件。如果成功,返回 `1` 和报告文件名;如果不成功,返回 `0` 后跟一个克拉和失败的原因。
- `$$Preview^SystemPerformance("runid")` - 为指定的 `runid` 生成可读的 HTML 临时(不完整)性能报告文件。如果成功,则返回 `1`,后跟 `carat` 和文件位置。如果不成功,则返回 `0`,后跟 `carat` 和失败的原因。
- `$$Stop^SystemPerformance("runid",[0])` - 停止(中止)`^SystemPerformance` 收集指定 `runid` 的数据,并默认删除实用程序生成的关联 `.log` 文件。要在不删除 `.log` 文件的情况下停止数据收集并从这些日志文件生成 HTML 性能报告,请在 `runid` 后面包含 `0` 参数。如果不成功,该函数返回 `0`,后跟一个 `carat `和失败的原因;如果成功,它返回:`1:2:3:4_1:2:3:4`。 “成功”状态由下划线分隔的两部分组成:特定于操作系统和特定于 IRIS;在每个部分中,以冒号分隔的值指定:1.成功停止的作业数 2.停止失败的作业数 3.成功删除的文件数 4.未删除的文件数
- `$$waittime^SystemPerformance("runid")` - 报告指定 `runid` 的最终 `HTML` 文件完成之前的时间。如果 `runid` 完成,则返回 `ready now`,否则返回 `XX` 小时 `YY` 分钟 `ZZ` 秒形式的字符串。
在以下示例中,由 `^SystemPerformance` 实用程序创建的 `runid` 以编程方式获取,然后进行测试以确定是否已生成完整报告或临时报告。尚未创建完整报告,因为配置文件尚未完成(返回“`0^not ready`”),但已创建临时报告(“返回 `1`”)。根据这些信息,知道已经生成了一个 `HTML` 文件。
```java
%SYS>set runid=$$run^SystemPerformance("30mins")
%SYS>set status=$$Collect^SystemPerformance(runid)
SystemPerformance run 20181004_123815_30mins is not yet ready for collection.
%SYS>write status
0^not ready
%SYS>set status=$$Preview^SystemPerformance(runid)
%SYS>write status
1^c:\intersystems\iris\mgr\USER_IRIS_20181004_123815_30mins_P1.html
%SYS>
```
文章
姚 鑫 · 一月 7, 2023
# 第三十七章 使用 ^PROFILE 监控例程性能 - Using ^PROFILE
- 当显示子例程标签列表(以及每个标签的指标)时,可以指定以下任何一项
Option |Description
---|---
`#` |要更详细地分析的子例程标签(在代码中)的行号。按 `Enter` 后,将显示指定标签的代码。
`B` |显示列表的上一页。
`L`|切换到子程序的行级显示。
`N`| 显示列表的下一页。
`Q`| 退出列表,返回上一级。
`R`| 使用最新指标刷新列表。注:如果列表中显示`*UNKNOWN*`,请输入`R`。
当显示代码行时,系统会提示指定下一步要执行的操作。的选择包括:
Option |Description
---|---
`#`|要更详细地分析的代码中的行号。按Enter键后,将显示指定标签的代码。
`B`| 显示列表的上一页。
`C`| 在源代码和中间(`INT/MVI`)代码之间切换代码显示。
`M`| 更改页边距和长度。
`N`| 显示列表的下一页。
`O`| 根据不同的指标对页面进行重新排序。
`Q`| 退出列表,返回到上一级别。
`R`| 使用最新指标刷新列表。
`S`| 切换到例程的子例程级别显示。
# ^PROFILE 示例
以下是在终端中以交互方式运行^配置文件实用程序(从`%sys`命名空间)的示例:
1. 输入以下命令:
```
do ^PROFILE
```
2. 此时将显示以下消息。
```
WARNING: This routine will start a system-wide collection of
data on routine activity and then display the results. There
may be some overhead associated with the initial collection,
and it could significantly affect a busy system.
The second phase of collecting line level detail activity
has high overhead and should ONLY BE RUN ON A TEST SYSTEM!
Are you ready to start the collection? Yes =>
```
3. 按`Enter`键开始收集指标。将显示与以下内容类似的指标:
```
Waiting for initial data collection ...
RtnLine Time CPU RtnLoad GloRef GloSet
1. 41.48% 12.19% 0.00% 28.97% 10.65% 0.00%
%Library.ResultSet.1.INT (IRISLIB)
2. 35.09% 56.16% 65.22% 9.35% 36.77% 42.55%
SYS.Database.1.INT (IRISSYS)
3. 10.75% 6.62% 0.00% 43.30% 22.68% 46.81%
Config.Databases.1.INT (IRISSYS)
4. 7.13% 3.22% 0.00% 6.23% 0.00% 0.00%
%Library.Persistent.1.INT (IRISLIB)
5. 1.26% 0.71% 0.00% 4.36% 4.12% 4.26%
PROFILE.INT (IRISSYS)
6. 1.20% 0.00% 0.00% 0.00% 5.15% 6.38%
%SYS.WorkQueueMgr.INT (IRISSYS)
7. 0.76% 15.08% 34.78% 0.00% 0.00% 0.00%
%SYS.API.INT (IRISSYS)
8. 0.64% 1.05% 0.00% 0.00% 17.18% 0.00%
%Library.JournalState.1.INT (IRISLIB)
9. 0.61% 0.31% 0.00% 3.74% 0.00% 0.00%
%Library.IResultSet.1.INT (IRISLIB)
10. 0.28% 0.93% 0.00% 0.00% 1.72% 0.00%
%Library.Device.1.INT (IRISLIB)
11. 0.24% 0.71% 0.00% 0.62% 0.00% 0.00%
Config.CPF.1.INT (IRISSYS)
Select routine(s) or '?' for more options N =>
```
4. 输入与要更详细分析的例程相关联的数字。例如,输入`2-3`、`5`、`7`、`10`,然后输入N或B以显示其他页面,以可以选择其他程序。
5. 选择要分析的所有例程后,输入q以显示类似以下内容的消息:
```
There are 2 routines selected for detailed profiling. You may now
end the routine level collection and start a detailed profiler collection.
WARNING !!
This will have each process on the system gather subroutine level and line
level activity on these routines. Note that this part of the collection may
have a significant effect on performance and should only be run in a test
or development instance.
Are you ready to start the detailed collection? Yes =>
```
6. 按`Enter`键后,将显示类似以下内容的页面:
```
Stopping the routine level Profile collection ...
Loading ^%Library.Persistent.1 in ^^c:\intersystems\iris\mgr\irislib\
Detail level Profile collection started.
RtnLine Routine Name (Database)
1. 96.72% %Library.Persistent.1.INT (IRISLIB)
2. 3.28% Config.CPF.1.INT (IRISSYS)
Select routine to see details or '?' for more options R =>
```
7. 选择要分析其代码的例程后,该例程将显示一页有关该代码的信息。