清除过滤器
文章
Claire Zheng · 一月 20, 2021
跨行业用例大多要求具备每秒接收数千或数百万条记录的能力,同时能够支持实时同步查询,例如:股票交易处理、欺诈检测、物联网应用(包括异常检测和实时OEE监控)等。Gartner将这种能力称为“HTAP”(混合事务分析处理)。Forrester等其他公司将其称为Translytics。InterSystems IRIS是功能强大、可扩展、高性能、资源高效的事务分析型数据平台,同时具备内存数据库的高性能以及传统数据库的一致性、可用性、可靠性以及低成本的特性。
混合事务分析处理(HTAP)示例
此示例展示了InterSystems IRIS如何实现每秒接收数千条记录,同时允许对同一集群上的数据进行同步查询,该平台不仅具有很高的接收和查询性能,而且保持了较低的资源利用率。此示例可在单个InterSystems IRIS实例或云端InterSystems IRIS集群上运行。
大家也可以在SAP HANA、MySQL、SqlServer及Amazon Aurora上运行这个示例,以便对性能和资源利用率进行公平、合理的对比。
大家可以在AWS上运行该测试!以下是部分结果:
在AWS上运行InterSystems IRIS和SAP HANA:
o在接收记录量方面,InterSystems IRIS比SAP HANA多39%
o在查询速度方面,InterSystems IRIS比SAP HANA快3699%
在AWS上运行InterSystems IRIS和AWS Aurora(MySQL):
o在接收记录量方面,InterSystems IRIS比AWS Aurora多831%
o在查询速度方面,InterSystems IRIS比AWS Aurora快485%
大家可以在自己的PC上使用Docker(3个CPU和7GB RAM)运行该测试!以下是部分结果:
在个人PC上运行InterSystems IRIS和MySQL 8.0:
o在接收记录量方面,InterSystems IRIS比MySQL 8.0多3043%
o在查询速度方面,InterSystems IRIS比MySQL 8.0快643%
在Ubuntu系统中运行InterSystems IRIS和SQL Server 2019
o在接收记录量方面,InterSystems IRIS比SQL Server 2019多223%,速度也更快
o在查询速度方面,InterSystems IRIS比SQL Server 2019快134,632%(请注意,数字没有打错哦!)
o为公平起见,我们未来将在AWS和Azure上对SQL Server进行测试。敬请期待!
在测试任何数据库的运行速度时,请先将速度测试运行一段时间进行预热,然后再记录结果。这样可以对数据库进行预扩展并执行其他操作。每次启动速度测试时,我们都需要清空表格重新开始。
1-在AWS上运行速度测试
请点击链接,查看如何在AWS上运行速度测试以便将InterSystems IRIS和其他数据库(如SAP HANA和AWS Aurora)进行对比。
2- 如何在PC上运行速度测试
在PC上运行速度测试的前提条件是:
Docker和Docker Compose
Git(可以克隆源代码)
目前,可以使用InterSystems IRIS、MySQL、SqlServer及SAP HANA在PC上运行本示例。
2.1 -在InterSystems IRIS Community上运行速度测试
要想在PC上运行本示例,请确保PC已经安装了Docker。您可以使用以下命令在Mac或Linux系统的PC上快速启动并运行:
wget https://raw.githubusercontent.com/intersystems-community/irisdemo-demo-htap/master/docker-compose.yml
docker-compose up
如果在Windows系统中运行速度测试,请将docker-compose.yml文件下载到一个文件夹中。打开命令提示符,并切换到该文件夹,然后运行docker-compose up
c:\MyFolder\docker-compose up
您也可以将存储库克隆到本地计算机上,从而获得完整的源代码。这时需要安装git,并将其放在git文件夹中:
git clone https://github.com/intersystems-community/irisdemo-demo-htap
cd irisdemo-demo-htap
docker-compose up
这两种技术都可行,并会触发示例中用于演示的镜像文件下载,之后将立刻启动所有的容器。
容器启动过程中,将出现与启动中容器相关的大量消息。这是正常的,不用担心!
启动完成后,它会一直挂在那里,不会把控制权交还给你。这也是正常的。将窗口开着就可以。如果在此窗口上按CTRL+C,docker compose将停止所有容器并停止示例演示。
在所有容器启动之后,在浏览器上打开http://localhost:10000可查看示例的界面。点击“Run Test”按钮即可运行HTAP Demo!
完成Demo演示后,返回到该终端并按CTRL+C。也可以输入以下命令,停止并删除仍在运行的容器:
docker-compose stop
docker-compose rm
这点很重要,特别是要在一个数据库(如InterSystems IRIS)和另一个数据库(如MySQL)之间反复运行速度测试时。
2.2 -PC上的MySQL
基于MySQL运行此示例,可以输入以下命令:
wget https://raw.githubusercontent.com/intersystems-community/irisdemo-demo-htap/master/docker-compose-mysql.yml
docker-compose -f ./docker-compose-mysql.yml up
现在,我们将下载一个不同的docker-compose yml文件:一个带有mysql后缀的文件。我们必须在docker-compose命令中使用-f选项来使用此文件。如前所述,将该终端窗口保持打开状态,并在浏览器上打开http://localhost:10000。
示例运行完成后,请返回终端并按CTRL+C。也可以输入以下命令,停止并删除仍在运行的容器:
docker-compose -f ./docker-compose-mysql.yml stop
docker-compose -f ./docker-compose-mysql.yml rm
这点很重要,特别是要在一个数据库(如InterSystems IRIS)和其他数据库之间反复运行速度测试时。
我们在测试中发现,InterSystems IRIS的数据接收速度比MySQL和Amazon Aurora快25倍。
2.3 -PC上的SQL Server 2019-GA-ubuntu-16.04
基于SQL Server运行此示例,可以输入以下命令:
wget https://raw.githubusercontent.com/intersystems-community/irisdemo-demo-htap/master/docker-compose-sqlserver.yml
docker-compose -f ./docker-compose-sqlserver.yml up
与前面一样,将该终端窗口保持打开状态,并在浏览器上打开http://localhost:10000。
我们在本地PC上运行速度测试后发现,InterSystems IRIS的数据接收速度比SQL Server快2.5倍,查询速率则快400倍!我们将与AWS RDS SQL Server相比较,进行速度测试并生成报告。
2.4 -PC上的SAP Hana
要在PC上基于SAP HANA运行速度测试,需要满足以下条件:
包含了Ubuntu 18 VM、docker和docker-compose的虚拟机——因为SAP HANA要求对Linux内核参数进行一些更改,否则将无法支持Mac或Windows上的Docker。另外,SAP HANA需要Linux内核4或更高版本。
该虚拟机至少配置9GB RAM,否则将无法启动!虚拟机崩溃后将显示无用的错误消息。
基于SAP HANA运行此Demo,可以输入以下命令:
git clone https://github.com/intersystems-community/irisdemo-demo-htap
cd ./irisdemo-demo-htap
./run.sh hana
等待下载镜像和启动容器。当docker-compose停止向屏幕写入时,一切已准备就绪。但是请耐心等待——SAP HANA大约需要6分钟才能启动!因此,屏幕会冻结一分钟左右,然后你会看到SAP HANA写入更多文本。这个重复写入过程大约持续6分钟。看到“启动完成!(Startup finished!)”后,就可以开始下一步了。如果在此过程中因为错误而发生崩溃,则可能需要配置更多的内存。
如您所知,与在InterSystems IRIS和MySQL中运行速度测试一样,使用SAP HANA测试不仅仅是运行docker-compose,还需要对Linux内核进行一些配置。大家可以通过run.sh文件来完成这些配置。
我们在虚拟机上运行速度测试后发现,InterSystems IRIS的数据接收速度比SAP HANA快1.3倍,查询数据的速度快20倍,并且使用了更少的内存。
3-资源
我们正在制作有关本示例的视频。在此期间,您可以点击链接查看一篇有意思的文章,该文章介绍了InterSystems IRIS的体系结构,并解释了为什么它能以更快的速度接收和查询数据。
4-该基准测试与YCSB或TPC-H等标准基准测试相比如何?
Yahoo Cloud Serving Benchmark(YCSB)是一项开源项目,其目的是开发一个框架和一组通用的工作负载,来评估不同的“键-值存储”和“云”服务的性能。
尽管YCSB上有一些工作负载可以描述成HTAP,但YCSB不一定要依靠SQL来完成。但是该基准必须依靠SQL。
TPC-H侧重于决策支持系统(DSS),而这并不是我们正在研究的用例。
此基准测试针对的是接收速度和查询响应时间之间的关系。我们有一个表格,其中包含许多不同数据类型的列。我们想衡量一个数据库在允许响应式查询的同时,其接收记录的速度能有多快。
这是一个复杂的问题。金融服务和物联网等许多行业都要求每秒必须接收数千条记录。在如此高的接收速率下,内存消耗得非常快。传统数据库需要写入磁盘,而内存数据库也将被迫不断写入磁盘(更改log/journal,甚至在某些情况下部分数据会写入内存,就像传统数据库一样)。问题是:如果InterSystems IRIS不仅要将事务日志写入磁盘(像内存数据库一样),还要异步保持数据库的最新状态,那么InterSystems IRIS是如何做到比内存数据库更快的呢?
一切都与效率有关。接收工作负载会使数据库非常繁忙。CPU和内存都将努力运转。一些内存数据库将尝试压缩内存中的数据。其他内存数据库在内存已满时会将数据持久化到磁盘。所有这些在我们试图实时查询数据库时都有发生。
我们想要证明,在某些工作负载上(例如股票交易、高接收吞吐量[物联网]等),内存数据库的性能不及InterSystems IRIS。这就是我们设计本测试的原因。这意味着该测试比一般用途的测试要简单得多:
(1)它只有一个表格,包含19个列和3种差别很大的数据类型
(2)表格上声明了主键(Primary Key)。
(3)我们执行的查询将通过主键(账户ID)获取记录,并使用固定的8个键随机查询:W1A1、W1A10、W1A100、W1A1000、W1A10000、W1A100000、W1A1000000和W1A10000000。这样做的原因如下:
我们知道,在生产系统的内存中保存所有数据是不可能的。内存数据库虽然具有复杂的体系结构,但当内存满了之后,就会将数据移出内存。为了简化测试并使其具有可比性,我们通过主键获取固定记录集,以避免对数据库中可能存在的其他类型的索引进行比较。
通过账号(主键)获取客户账户数据记录是我们许多客户的真实工作负载。数据库在高速接收数据的同时,也需要对查询做出响应。
由于账户ID是主键,因此数据库将使用它的首选(即最优)索引对其进行索引。这样在比较数据库时能够保持公平、简单。
当我们不断请求相同的账号时,数据库有可能将该数据缓存在内存中。这对于内存数据库来说是一项轻松的任务。
InterSystems IRIS是一个混合型数据库。与传统数据库一样,它也尝试将数据保存在内存中。但由于每秒需要接收成千上万的记录,因此内存清理得非常快。通过这个测试可以看到,与其他传统数据库和内存数据库相比,InterSystems IRIS在缓存方面更加智能。你会看到:
(1)传统数据库在同时处理接收和查询时表现不佳
(2)内存数据库:
在测试的最初几分钟内表现良好,随着内存填满,数据压缩变得更加困难,不可避免地要写入磁盘
由于系统忙于接收、压缩数据,以及将数据移出内存等,因此查询性能表现不佳。
5-表是怎样的?
以下是我们发送到所支持的全部数据库的建表语句:
CREATE TABLE SpeedTest.Account
(
account_id VARCHAR(36) PRIMARY KEY,
brokerageaccountnum VARCHAR(16),
org VARCHAR(50),
status VARCHAR(10),
tradingflag VARCHAR(10),
entityaccountnum VARCHAR(16),
clientaccountnum VARCHAR(16),
active_date DATETIME,
topaccountnum VARCHAR(10),
repteamno VARCHAR(8),
repteamname VARCHAR(50),
office_name VARCHAR(50),
region VARCHAR(50),
basecurr VARCHAR(50),
createdby VARCHAR(50),
createdts DATETIME,
group_id VARCHAR(50),
load_version_no BIGINT
)
插入程序Ingestion Worker会尽可能多地发送INSERT数据,以测量每秒插入的记录数据量以及每秒的兆字节数。
查询程序Query worker将通过account_id从此表中进行选择,并尝试选择尽可能多的记录来测量性能(即每秒选择的记录以及每秒选择的兆字节),以测试端到端性能,并提供工作量证明(Proof of Work)。
端到端性能与一些JDBC驱动程序最优化有关。如果仅执行查询操作,JDBC驱动程序可能不会从服务器获取记录,只有当实际请求列值后,JDBC驱动程序才会从服务器获取记录。
为了证明实际读取的正是我们选取的列,我们将返回的所有fild的字节加起来作为工作量证明。
6-如何实现接收和查询的最大吞吐量?
为了实现最大吞吐量,每个ingestion worker将启动多个线程,每个线程将:
(1)为上述表格的每一列准备1000个随机值。这样做是为了让每一列具有不同的数据类型和大小。所以我们希望生成可相应变化的记录
(2)对于要插入的每个新记录,ingestion worker将在每列的1000个值中随机选择一个值,准备好之后,该记录将被添加到批处理中
(3)使用批量插入,默认批量大小为每批1000条记录
Ingestion worker的默认线程数量是15,但是可以在测试过程中单击“设置”进行更改。
另一方面,query worker也启动多个线程来查询尽可能多的记录。如上所述,我们也将提供工作量证明。我们将读取返回的列,并汇总读取的字节数,以确保数据是从数据库通过连接传输进入query worker的,从而避免某些JDBC驱动程序实现优化后,仅在实际使用数据时才通过连接传输数据。我们实际使用返回的数据,并提供每秒读取数据的兆字节总和以及读取的总兆字节数作为工作量证明。
7-占用多少磁盘空间?
在接收171,421,000条记录后,我填满了一个70Gb的数据文件系统。这意味着,每条记录平均占用439个字节(向上取整)。
我还填写了第一个日志目录的100%和第二个日志目录的59%。这两个文件系统都有100Gb,这意味着171,421,000条记录将占用大约159Gb的日志空间,换言之,每条记录平均占用996个字节。
8-HTAP Demo体系架构
HTAP Demo的体系架构如下图所示:
本示例使用docker compose启动五项服务:
(1)htapui——这是用于运行示例的Angular UI。
(2)htapirisdb——由于本示例在InterSystems IRIS Community上运行,所以不需要InterSystems IRIS许可证即可运行。但请注意,InterSystems IRIS Community有两个重要限制条件:
最多5个连接
数据库最大为10Gb
(3)htapmaster——这是HTAP 示例主程序。UI与主程序对话,主程序与worker对话,以及启动/停止速度测试,并收集指标。
(4)ingest-worker1——这是插入程序ingestion worker。实际上,大家可以拥有多个ingestion worker,只需给每个worker分配不同的服务名称即可。它们将尝试尽快地将记录插入数据库。
(5)query-worker1——这是查询程序query worker,大家也可以拥有多个query worker。它们将尝试尽快地从数据库中读取记录。
在PC上运行示例时,我们使用的是Docker和Docker Compose。Docker Compose需要一个docker-compose.yml来描述这些服务及其使用的Docker镜像。本示例实际上提供了许多docker-compose.yml文件,并且很快将添加更多此类文件:
(1)docker-compose.yml——这是针对InterSystems IRIS Community(上述项目及图片中有所描述)运行速度测试的默认演示程序。
(2)docker-compose-mysql.yml——这是针对MySQL的速度测试。大家应该注意到,该测试结果表明,InterSystems IRIS比MySQL快25倍。在Amazon Aurora MySQL(MySQL的微调版本)上运行此测试可得到相同的结果。
(3)docker-compose-sqlserver.yml——这是针对使用Docker部署的SqlServer的速度测试。
(4)docker-compose-enterprise-iris.yml——如果要在标准版本的InterSystems IRIS上运行速度测试示例,这是一个docker-compose.yml的文件例子。
9. 可以在没有容器的情况下在InterSystems IRIS集群上运行本Demo吗?
可以!完成此示例最简便的方法是将此存储库克隆到即将运行master(主程序)和(在同一服务器上运行的)UI的每台服务器上以及每种worker类型(接收和查询worker)上。你可以根据自己的需要,拥有任意数量的接收worker和查询worker!
对于InterSystems IRIS,请查看文件夹./standalone_scripts/iris-jdbc.中的文件。每个服务器都有一个脚本:
(1)在主程序上:start_master_and_ui.sh——此脚本将启动主程序和UI。
(2)在Ingestion Worker上:start_ingestion_worker.sh——此脚本将启动Ingestion Worker,后者随后将与主程序连接并进行注册。
(3)在Query Worker上:start_query_worker.sh——此脚本将启动query worker,然后query worker将与主程序连接并进行注册。
对于InterSystems IRIS,大家有两种选择:
(1)可以使用start_iris.sh脚本在Docker容器上启动InterSystems IRIS服务器进行快速测试。
(2)可以手动或使用ICM设置InterSystems IRIS集群。然后做一些有趣的事情,比如:
使接收和查询worker都指向同一InterSystems IRIS
使用ECP配置InterSystems IRIS,让ingestion worker指向数据库服务器,同时让query worker指向ECP服务器
配置分片的InterSystems IRIS集群
等等
只要确保更改start_master.sh脚本中对应使用正确的InterSystems IRIS端点、用户名和密码来配置环境变量。
10-自定义
10.1 -如何配置本Demo让其与更多worker、线程等一起工作?
Docker-compose.yml文件中的环境变量支持配置所有内容。docker-compose.yml文件只是个不错的起点:大家可以复制它们并对副本进行更改,从而得到更多的worker(如果在PC上运行,不会有太大区别),每个worker类型都可以得到更多线程数,还可以更改接收数据的批处理大小,以及各查询之间的等待时间(以毫秒为单位)等。
10.2 -可以更改表的名称或结构吗?
可以,但必须:
(1)在PC上将复制此存储库
(2)更改源代码
(3)使用shellscript build.sh在PC上重建demo。
更改表的结构也很简单。
复制了该存储库后,需要更改/image-master/projects/master/src/main/resources文件夹下的文件。
如果更改表的结构,请确保使用与现有表相同的数据类型,这些数据类型是受支持的。另外还可以更改表的名称。
其次,需要配合更改其他* .sql脚本,如INSERT脚本、SELECT脚本等。
最后,只需运行build.sh来重建demo就可以了!
11-其他示例应用程序
我们还有一些其他涉及不同主题的InterSystems IRIS 示例应用程序,例如NLP、ML、与AWS服务的集成、Twitter服务、性能基准测试等。以下是其中的部分内容:
(1)HTAP Demo——混合事务分析处理(HTAP)基准。可以测试InterSystems IRIS同时插入和查询数据的速度。你会发现它的速度比AWS Aurora快20倍!
(2)欺诈预防——InterSystems IRIS通过机器学习和制定业务规则,防止金融服务交易中出现欺诈行为。
(3)Twitter情绪分析——演示InterSystems IRIS如何实时使用Tweet,并通过其NLP(自然语言处理)和业务规则功能来评估Tweet的情绪和元数据,从而决定何时与某人联系以提供支持。
(4)HL7协议和SMS(文本消息)应用程序——演示InterSystems IRIS医疗版如何解析HL7协议消息,从而给患者发送SMS(文本消息)提醒。它还演示了基于存储在标准化数据湖中预约数据的实时仪表板。
(5)Readmission Demo——患者再入院在医疗保健领域被称为"机器学习的Hello World"。针对这个问题,我们在本示例中演示了如何使用InterSystems IRIS安全地构建并运行用于实时预测的ML模型,以及如何将其集成到应用程序中。本InterSystems IRIS医疗版示例旨在展示如何构建针对再入院问题的完整解决方案。
12-支持的数据库
这是目前为止支持的数据库列表:
Runing on your PC with docker-compose (NO mirroring/replication)
InterSystems IRIS 2020.2
MySQL 8.0
MariaDB 10.5.4-focal
MS SQL Server 2019-GA-ubuntu-16.04
SAP HANA Express 2.0 (on Linux VM only)
Postgres 12.3
Running on AWS:
InterSystems IRIS (with or without mirroring)
AWS RDS Aurora (MySql) 5.6.10a (parallel query) with replication
AWS RDS SQL Server 2017 Enterprise Edition (production deployment) with replication
AWS RDS Postgres (production deployment) with replication
AWS RDS MariaDB (production deployment) with replication
SAP HANA Express Edition 2.0 without replication
SAP Sybase ASE 16.0 SP03 PL08, public cloud edition, premium version, without replication
AWS RDS Oracle (production deployment) with replication
注:本文为节选,欢迎点击原文链接,了解更多详情。
文章
Li Yan · 一月 18, 2021
企业需要快速有效地扩展和管理其全球计算基础设施,同时优化和管理资本成本及支出。 Amazon Web Services (AWS) 和 Elastic Compute Cloud (EC2) 计算和存储服务提供高度稳健的全球化的计算基础设施,可满足最苛刻的基于 Caché 的应用程序的需求。Amazon EC2 基础设施使各公司能够迅速预置计算能力和/或快速灵活地将其现有内部基础架构扩展到云端。 AWS 针对安全、网络、计算和存储提供了一套丰富的服务和强大的企业级机制。
AWS 的核心是 Amazon EC2。 它是支持各种操作系统和机器配置(例如 CPU、RAM、网络)的云计算基础设施。 AWS 提供预先配置的虚拟机 (VM) 映像(称为 Amazon 系统映像或 AMI),客户操作系统包括各种 Linux® 和 Windows 发行版及版本。 可以将其它软件用作 AWS 中运行的虚拟化实例的基础。 您可以将这些 AMI 用作实例化以及安装或配置其他软件、数据等的起点,以创建特定于应用程序或工作负载的 AMI。
与任何平台或部署模式一样,必须留心以确保考虑到应用程序环境的各个方面,例如性能、可用性、操作和管理程序。
本文将详细介绍以下每个方面。
网络设置和配置。 此部分介绍基于 Caché 的应用程序在 AWS 中的网络设置,包括为参考架构内不同层级和角色的逻辑服务器组提供支持的子网。
服务器设置和配置。 此部分介绍为每一层设计各种服务器时涉及的服务和资源。 还包括用于跨可用区实现高可用性的架构。
安全。 此部分讨论 AWS 中的安全机制,包括如何配置实例和网络安全以实现对整体解决方案以及层和实例之间的授权访问。
部署和管理。此部分提供有关打包、部署、监控和管理的详细信息。
架构和部署方案
本文提供了几个在 AWS 内实现的参考架构,作为提供基于 InterSystems 技术(包括 Caché、Ensemble、HealthShare、TrakCare)以及相关嵌入式技术(如 DeepSee、iKnow、CSP、Zen 和 Zen Mojo)的高性能和高可用性应用程序的示例。
为了了解如何在 AWS 上托管 Caché 及相关组件,我们先来回顾一下典型 Caché 部署的架构和组件,并探讨一些常见的方案和拓扑。
Caché架构回顾
InterSystems 数据平台不断发展,提供先进的数据库管理系统和快速的应用程序开发环境,以在处理和分析复杂数据模型以及开发 Web 和移动应用程序方面实现突破。
这是新一代的数据库技术,提供多种数据访问模式。 数据只在单个集成数据字典中描述一次,并且可以通过对象访问、高性能 SQL 和强大的多维存取即时进行访问 – 所有这些方式可以同时访问相同数据。
图 1 说明了可用的 Caché 高级架构组件层和服务。 这些通用层也适用于 InterSystems TrakCare 和 HealthShare 产品。
图 1:高级组件层
常见部署方案
部署有许多可能的组合,但本文将介绍两种方案:混合模型和完整的云托管模型。
混合模型
在此方案中,公司希望在需要时将企业内部资源和 AWS EC2 资源都用于灾难恢复、内部维护应急、重新平台化计划或短期/长期扩容。 此模型可以为内部故障转移镜像成员集群提供业务连续性和灾难恢复的高可用性。
在该方案中,此模型的连接依赖于内部部署和 AWS 可用区之间的 VPN 隧道,将 AWS 资源作为企业数据中心的扩展。 还有其他连接方法,例如 _AWS Direct Connect_。 但是,这不是本文涵盖的内容。 有关 AWS Direct Connect 的更多详细信息,可以在here找到。
有关设置此 Amazon Virtual Private Cloud (VPC) 示例以支持内部数据中心灾难恢复的详细信息可以在here找到。
图 2:使用 AWS VPC 提供内部灾难恢复的混合模型
上面的示例展示了一个故障转移镜像对通过与 AWS VPC 的 VPN 连接在内部数据中心的运行。 所示的 VPC 在给定 AWS 区域的双可用区中提供了多个子网。 有两个灾难恢复 (DR) 异步镜像成员 (每个可用区有一个) 提供弹性。
云托管模型
在此方案中,基于 Caché 的应用程序(包括数据层和表示层)完全放在 AWS 云中,使用了单个 AWS 区域内的多个可用区。 可以使用相同的 VPN 隧道 AWS Direct Connect, 甚至纯互联网连接模型。
图 3:支持完整生产工作负载的云托管模型
图 3 中的示例说明了在 VPC 中支持整个应用程序生产部署的部署模型。 此模型利用双可用区,在可用区之间同步故障转移镜像,同时将负载均衡 Web 服务器和相关应用程序服务器作为 ECP 客户端。 每个层都隔离在一个单独的安全组中,以进行网络安全控制。 IP 地址和端口范围仅根据应用程序的需要开放。
存储和计算资源
存储
有多种类型的存储选项可供选择。 就本参考架构而言,将针对几种可能的用例讨论 Amazon Elastic Block Store (Amazon EBS) 和 (也称为临时驱动器)卷。 各种存储选项的更多详细信息可以在 here 和 here 找到。
Elastic Block Storage (EBS)
EBS 提供了可与 Amazon EC2 实例(虚拟机)配合使用的持久块级存储,在 Linux 或 Windows 中可以将其格式化并挂载为传统文件系统,最重要的是,这些卷是非实例存储,独立于单个 Amazon EC2 实例的运行寿命而持续存在,这对于数据库系统非常重要。
此外,Amazon EBS 还提供了创建卷的时间点快照的功能,这些快照会持久保存在 Amazon S3 中。 这些快照可以用作新的 Amazon EBS 卷的起点,并保护数据以实现长期耐久性。 同一快照可用于实例化任意数量的卷。 这些快照可以跨 AWS 区域复制,因此可以更容易地利用多个 AWS 区域进行地理扩张、数据中心迁移和灾难恢复。 Amazon EBS 卷的大小范围为 1 GB 到 16 TB,以 1 GB 为增量进行分配。
Amazon EBS 内有三种不同的类型:磁介质卷、通用型 (SSD) 和预置 IOPS (SSD)。 以下各小节提供了每种类型的简要介绍。
磁介质卷
磁介质卷为具有中等或突发 I/O 要求的应用程序提供经济高效的存储。 磁介质卷设计为平均每秒提供约 100 次输入/输出操作 (IOPS),最大突发能力为数百 IOPS。 磁介质卷也非常适合用作启动卷,其突发能力提供了快速的实例启动时间。
通用型 (SSD)
通用型 (SSD) 卷提供具有成本效益的存储,是各种工作负载的理想选择。 这些卷的延迟只有个位数毫秒,能够长时间突发至 3,000 IOPS,基准性能为 3 IOPS/GB,最高可达 10,000 IOPS (3,334 GB)。 通用型 (SSD) 卷的大小范围为 1 GB 到 16 TB。
预置 IOPS (SSD)
预置 IOPS (SSD) 卷设计用于为 I/O 密集型工作负载(例如对存储性能和随机访问 I/O 吞吐量的一致性敏感的数据库工作负载)提供可预测的高性能。 在创建卷时指定 IOPS 速率,然后 Amazon EBS 在给定一年的 99.9% 的时间内提供 10% 内的预置 IOPS 性能。 预置 IOPS (SSD) 卷的大小可以为 4 GB 到 16 TB,每个卷最多可预置 20,000 IOPS。 预置的 IOPS 与请求的卷大小之比最大为 30;例如,IOPS 为 3,000 的卷必须至少为 100 GB 大小。 预置 IOPS (SSD) 卷对每个预置的 IOPS 的吞吐量限制为 256 KB,最高 320 MB/秒(1,280 IOPS)。
本文讨论的架构使用 EBS 卷,因为这些卷更适合需要可预测的低延迟每秒输入/输出操作 (IOPS) 和吞吐量的生产工作负载。 选择特定的虚拟机类型时必须小心,因为并非所有 EC2 实例类型都可以访问 EBS 存储。
注意: 由于 Amazon EBS 卷是网络附加设备,Amazon EC2 实例执行的其他网络 I/O 以及共享网络上的总负载可能会影响单个 Amazon EBS 卷的性能。 为了让 Amazon EC2 实例充分利用 Amazon EBS 卷上的预置 IOPS,可以将选定的 Amazon EC2 实例类型作为 Amazon EBS 优化的实例启动。
有关 EBS 卷的详细信息,可以在here 找到。
EC2 实例存储(临时驱动器)
EC2 实例存储由托管您的正在运行的 Amazon EC2 实例的同一台物理服务器上的磁盘存储的预配置和预附加块组成。 提供的磁盘存储量因 Amazon EC2 实例类型而异。 在提供实例存储的 Amazon EC2 实例系列中,较大的实例往往提供更多更大的实例存储量。
存储优化 (I2) 和密集存储 (D2) 的 Amazon EC2 实例系列提供针对特定用例的专用实例存储。 例如,I2 实例提供了非常快的 SSD 实例存储,能够支持超过 365,000 的随机读取 IOPS 和 315,000 的写入 IOPS,并提供具有成本吸引力的定价模型。
与 EBS 卷不同,该存储不是永久性的,只能用于实例的生命周期,不能分离或附加到其他实例。 实例存储用于临时存储不断变化的信息。 在 InterSystems 技术和产品领域中,诸如将 Ensemble 或 Health Connect 用作企业服务总线 (ESB) 的项目、使用企业缓存协议 (ECP) 的应用程序服务器或将 Web 服务器与 CSP 网关一起使用,对于这种类型的存储和存储优化的实例类型,以及使用预置和自动化工具来提高有效性和支持弹性的操作来说,都是很好的用例。
有关实例存储卷的详细信息,可以在here 找到。
计算
EC2 实例
有多种实例类型可供使用,它们针对各种用例进行了优化。 实例类型包括 CPU、内存、存储和网络容量的不同组合,从而实现无数种组合来合理调整您的应用程序的资源要求。
就本文档而言,将参考_通用 M4_ Amazon EC2 实例类型作为优化环境大小的方法,这些实例提供 EBS 卷的功能和优化。 根据您的应用程序的容量要求和定价模型,还可能有替代方案。
M4 实例是最新一代的_通用_实例。 此系列提供了计算、内存和网络资源的平衡配置,对于许多应用程序来说是很好的选择。 容量范围为 2 到 64 个虚拟 CPU 和 8 到 256GB 的内存,以及相应的专用 EBS 带宽。
除了各个实例类型,还有分层的分类,例如专用主机、Spot 实例、预留实例和专用实例,每个类别的定价、性能和隔离都不同。
在 here 确认当前可用实例的可用性和详细信息。
可用性和操作
Web/App 服务器负载均衡
您的基于 Caché 的应用程序可能需要外部和内部负载均衡的 Web 服务器。 外部负载均衡器用于通过互联网或 WAN(VPN 或 Direct Connect)进行的访问,内部负载均衡器可用于内部流量。 AWS Elastic Load Balancing 提供两种类型的负载均衡器 – 应用程序负载均衡器和传统负载均衡器。
传统负载均衡器
传统负载均衡器根据应用程序或网络信息对流量进行路由,是在多个需要高可用性、自动扩展和强大安全性的 EC2 实例之间实现简单的流量负载均衡的理想选择。 具体的详细信息和功能可在here 找到。
应用负载均衡器
应用程序负载均衡器是 Elastic Load Balancing 服务的负载均衡选项,该服务在应用程序层运行,允许您根据一个或多个 Amazon EC2 实例上运行的多个服务或容器中的内容定义路由规则。 此外,还支持 WebSockets 和 HTTP/2。 具体的详细信息和功能可在here找到。
示例
在以下示例中,定义了一组三个 Web 服务器,每个服务器都在一个单独的可用区,以提供最高级别的可用性。 必须为 Web 服务器负载均衡器配置粘性会话 ,才能支持使用 cookie 将用户会话固定到特定 EC2 实例的功能。 当用户继续访问您的应用程序时,流量将路由到相同实例。
图 4 给出了 AWS 中的传统负载均衡器的一个简单示例。
图 4:传统负载均衡器示例
数据库镜像
在 AWS 上部署基于 Caché 的应用程序时,如果要为 Caché 数据库服务器提供高可用性,则需要在给定的主 AWS 区域使用同步数据库镜像来提供高可用性,还可能需要使用异步数据库镜像将数据复制到辅助 AWS 区域中的热备份以实现灾难恢复,具体取决于正常运行时间服务水平协议要求。
数据库镜像是两个数据库系统的逻辑分组,也就是所说的故障转移成员,它们在物理上是仅通过网络连接的独立系统。 在这两个系统之间进行仲裁后,镜像会自动将其中一个系统指定为主系统; 另一个成员自动成为备份系统。 外部客户端工作站或其他计算机通过镜像虚拟 IP (VIP) 连接到镜像,该虚拟 IP 在镜像配置期间指定。 镜像 VIP 会自动绑定到主镜像系统上的接口。
注意: 在 AWS 中,无法以传统方式配置镜像 VIP,因此设计了替代解决方案。 不过,镜像可跨子网获得支持。
目前在 AWS 中部署数据库镜像的建议是,在跨越三个不同可用区的同一个 VPC 中配置三个实例(主要、备份、仲裁器)。 这可以确保在任何给定时间,AWS 都将保证可以从外部连接其中的至少两个虚拟机,SLA 达到 99.95%。 这样可以为数据库数据本身提供充分的隔离和冗余。 有关 AWS EC2 服务水平协议的详细信息,可在here 找到。
故障切换成员之间的网络延迟没有硬性上限。延迟增加所产生的影响因应用程序而异。如果故障转移成员之间的往返时间与磁盘写入服务时间相似,则预计不会产生影响。 但是,当应用程序必须等待数据变为持久保存(有时称为日志同步)时,响应时间可能是一个问题。 有关数据库镜像和网络延迟的详细信息,可在here 找到。
虚拟 IP 地址和自动故障转移
大多数 IaaS 云提供商缺乏提供虚拟 IP (VIP) 地址的能力,这种地址通常用在数据库故障转移设计中。 为解决这一问题,Caché、Ensemble 和 HealthShare 中增强了几种最常用的连接方法,尤其是 ECP 客户端和 CSP 网关,从而不再依赖 VIP 功能使它们实现镜像感知。
xDBC、直接 TCP/IP 套接字等连接方法或其他直接连接协议仍需要使用 VIP。 为解决这些问题,InterSystems 数据库镜像技术通过使用 API 与 AWS Elastic Load Balancer (ELB) 进行交互以实现类似 VIP 的功能,使得在 AWS 中为这些连接方法提供自动故障转移成为可能,从而在 AWS 中提供完整而强大的高可用性设计。
此外,AWS 最近推出了一种新类型的 ELB,称为应用程序负载均衡器。 这种类型的负载均衡器在第 7 层运行,支持基于内容的路由,并支持在容器中运行的应用程序。 基于内容的路由对于使用分区数据或数据分片部署的大数据类型项目尤其有用。
与虚拟 IP 一样,这是网络配置的突然变化,不涉及任何应用逻辑,不会向已连接到发生故障的主镜像成员的现有客户端发出正在进行故障转移的通知。 根据故障的性质,这些连接终止的原因可能是故障本身、应用程序超时或错误、新的主镜像实例强制旧的主镜像实例停机,或者客户端使用的 TCP 保持连接定时器过期。
结果,用户可能必须重新连接并登录。 您的应用程序的行为将决定此行为。 有关各种类型的可用 ELB 的详细信息,可在here找到。
AWS EC2 实例对 AWS Elastic Load Balancer 方法的调用
在此模型中,ELB 可以定义一个包含故障转移镜像成员和潜在 DR 异步镜像成员的服务器池,其中只有一个活动条目是当前主镜像成员,或者只定义一个具有单个活动镜像成员条目的服务器池。
图 5:与 Elastic Load Balancer 交互的 API 方法(内部)
当某个镜像成员成为主镜像成员时,会从您的 EC2 实例向 AWS ELB 发出一个 API 调用,以调整/指示新主镜像成员的 ELB。
图 6:使用负载均衡器的 API 故障转移到镜像成员B
如果主镜像成员和备份镜像成员都变得不可用,同一模型也适用于升级 DR 异步镜像成员。
图 7:使用负载均衡器的 API 将 DR 异步镜像成员升级为主镜像成员
按照标准推荐的 DR 过程,上面的图 6 中的 DR 成员升级需要人为决策,因为异步复制可能会造成数据丢失。 不过,一旦执行该操作,就不再需要对 ELB 执行管理操作。 在升级期间调用 API 后,将自动路由流量。
API 详细信息
这个用于调用 AWS 负载均衡器资源的 API 在 ^ZMIRROR 例程中专门定义为以下过程调用的一部分:
$$CheckBecomePrimaryOK^ZMIRROR()
在此过程内,插入您选择的要从 AWS ELB REST API、命令行界面等使用的任何 API 逻辑或方法。 与 ELB 进行交互的一种有效且安全的方法是使用 AWS Identity and Access Management (IAM) 角色,这样不必为 EC2 实例分配长期凭据。 IAM 角色提供了 Caché 可以用来与 AWS ELB 进行交互的临时权限。 有关使用分配给 EC2 实例的 IAM 角色的详细信息,可在 here 找到。
AWS Elastic Load Balancer 轮询方法
2017.1 提供了一种使用 CSP 网关的mirror_status.cxw 页的轮询方法,可以将其用作 ELB 监控每个已添加到 ELB 服务器池的镜像成员运行状况的轮询方法。只有主镜像会响应“SUCCESS”,因而网络流量只定向到活动的主镜像成员。
此方法不需要向 ^ZMIRROR 添加任何逻辑。 请注意,大多数负载均衡网络设备对运行状态检查的频率有限制。 通常,最高频率不少于5秒,这通常是可接受的,可支持大多数正常运行时间服务水平协议。
一个对以下资源的 HTTP 请求将测试本地缓存配置的镜像成员状态。
/csp/bin/mirror_status.cxw
对于所有其他情况,这些镜像状态请求的路径应解析到适当的缓存服务器和命名空间,它们与用于请求实际 CSP 页的缓存服务器和命名空间使用相同的分层机制。
示例:在 /csp/user/ 路径中测试服务于应用程序的配置的镜像状态:
/csp/user/mirror_status.cxw
注意:调用镜像状态检查不消耗 CSP 许可证。
根据目标实例是否为活动的主要成员,网关将返回以下 CSP 响应之一:
** Success (Is the Primary Member)
===============================
HTTP/1.1 200 OK
Content-Type: text/plain
Connection: close
Content-Length: 7
SUCCESS
** Failure (Is not the Primary Member)
===============================
HTTP/1.1 503 Service Unavailable
Content-Type: text/plain
Connection: close
Content-Length: 6
FAILED
** Failure (The Cache Server does not support the Mirror_Status.cxw request)
===============================
HTTP/1.1 500 Internal Server Error
Content-Type: text/plain
Connection: close
Content-Length: 6
FAILED
下图说明了各种使用轮询方法的方案。
图 8:轮询所有镜像成员
如上面的图 8 所示,所有镜像成员都在运行,只有主镜像成员向负载均衡器返回“SUCCESS”,因此网络流量将只定向到该镜像成员。
图 9:使用轮询故障转移到镜像成员 B
上图演示了将 DR 异步镜像成员升级到负载均衡池中的过程,这通常假定同一台负载均衡网络设备为所有镜像成员提供服务(本文稍后将介绍按地理位置划分的方案)。
按照标准推荐的 DR 过程,DR 成员升级需要人为决策,因为异步复制可能会造成数据丢失。 不过,一旦执行该操作,就不再需要对 ELB 执行管理操作。 它会自动发现新的主镜像成员。
图 10:使用轮询对 DR 异步镜像成员进行故障转移和升级
备份和还原
备份操作有多个选项。 对于 InterSystems 产品的 AWS 部署,可以使用以下三个选项。 前两个选项包括一个快照类型过程,该过程在创建快照前会暂停将数据库写入磁盘,然后在快照成功建立后恢复更新。 执行以下高级步骤使用任一快照方法创建干净备份:
通过数据库冻结 API 调用暂停对数据库的写入。
创建操作系统和数据磁盘的快照。
通过数据库解锁API 调用恢复 Caché 写入。
将设施存档备份到备份位置。
可以定期添加完整性检查等其他步骤,以确保备份干净一致。 决定使用哪个选项取决于组织的运营要求和策略。 InterSystems 可与您详细讨论各种选项。
EBS 快照
EBS 快照是在高度可用和成本较低的 Amazon S3 存储上创建时间点快照的非常快速且有效的方法。 EBS 快照连同 InterSystems 外部冻结和解锁API 功能,可以实现真正的 24x7 弹性运行,并确保干净的定期备份。 使用 AWS 提供的服务(如 Amazon CloudWatch Events)或市场上的第三方解决方案(如 Cloud Ranger 或 N2W Software Cloud Protection Manager 等等),有许多选项可以使该过程自动化。
此外,还可以使用 AWS 直接 API 调用,以编程方式创建您自己的自定义备份解决方案。 有关如何利用 API 的详细信息,请参见here 和here.
注意:InterSystems 不为上述任何第三方产品背书或明确进行验证。 测试和验证取决于客户.
逻辑卷管理器快照
或者,通过在虚拟机自身内部署单独的备份代理,并利用文件级备份与 Linux 逻辑卷管理器 (LVM) 快照或 Windows 卷影复制服务 (VSS) 相结合,可以使用市场上的许多第三方备份工具。
此模型的主要优点之一是能够对基于 Windows 或 Linux 的实例进行文件级还原。 该解决方案有几点需要注意,由于 AWS 和大多数其他 IaaS 云提供商不提供磁带介质,因此所有备份存储库都基于磁盘进行短期归档,而且能够利用 Amazon S3 低成本存储并最终使用 Amazon Glacier 实现长期保留 (LTR)。 如果使用此方法,强烈建议使用支持去重技术的备份产品,以最有效地利用基于磁盘的备份存储库。
这些具有云支持的备份产品的示例包括但不限于:Commvault、EMC Networker、HPE Data Protector 和 Veritas Netbackup。
注意:InterSystems 不为上述任何第三方产品背书或明确进行验证。 测试和验证取决于客户.
Caché 在线备份
对于小型部署,内置 Caché 在线备份工具也是一个可行选项。 该 InterSystems 数据库在线备份实用工具通过捕获数据库中的所有块来备份数据库文件中的数据,然后将输出写入顺序文件。 这种专有的备份机制旨在使生产系统的用户不停机。
在 AWS 中,在线备份完成后,必须将备份输出文件和系统使用的所有其他文件复制到用作文件共享的 EC2 (CIFS/NFS)。 该过程需要在虚拟机中编写脚本并执行。
在线备份是入门级方法,适合于希望实施低成本备份解决方案的小型站点。 但是,随着数据库的增大,建议将使用快照技术的外部备份作为最佳做法,其优势包括:备份外部文件、更快的恢复时间,以及企业范围的数据视图和管理工具。
灾难恢复
在 AWS 上部署基于 Caché 的应用程序时,建议将 DR 资源(包括网络、服务器和存储)放在不同的 AWS 区域中,或者至少放在单独的可用区中。指定的 DR AWS 区域所需的容量取决于您组织的需求。 在大多数情况下,以 DR 模式运行时需要 100% 的生产能力,但作为一个弹性模型,可以先预置较少的能力,直到需要更多能力。 较少的能力可以体现为较少的 Web 和应用程序服务器,甚至可能使用较小的 EC2 实例类型作为数据库服务器,升级后,EBS 卷将附加到较大的 EC2 实例类型。
异步数据库镜像用于连续复制到 DR AWS 区域的 EC2 实例。 镜像使用数据库事务日志以对主系统性能影响最小的方式通过 TCP/IP 网络复制更新。 强烈建议对这些 DR 异步镜像成员配置日志文件压缩和加密。
公共互联网上所有希望访问应用程序的外部客户端都将通过作为附加 DNS 服务的 Amazon Route53 进行路由。Amazon Route53 用作将流量定向至当前活动数据中心的交换机。 Amazon Route53 执行三种主要功能:
域注册 –允许您注册 example.com 之类的域名。
域名系统 (DNS) 服务 – Amazon Route53 将类似 www.example.com 的友好域名转换为 192.0.2.1 之类的 IP 地址。 Amazon Route53 使用全球权威 DNS 服务器网络来响应 DNS 查询,从而降低延迟。
运行状况检查–Amazon Route53 通过互联网向您的应用程序发送自动请求,以验证其是否可达、可用和正常运行。
这些功能的详细信息可在 here找到。
就本文档而言,将讨论 DNS 故障转移和 Route53 运行状况检查。 运行状况检查监控和 DNS 故障转移的详细信息可在 here 和here找到。
Route53 的工作方式是向每个端点发出常规请求,然后验证响应。 如果某个端点未能提供有效响应, 它将不再包含在 DNS 响应中,而是返回一个替代的可用端点。 这样,用户流量就会从发生故障的端点转向可用的端点。
使用上述方法,将只允许流量转向特定区域和特定镜像成员。 这是由端点定义控制的,它是本文先前讨论过的 mirror_status.cxw 页,由 InterSystems CSP 网关提供。 只有主镜像成员会在运行状况检查中报告 HTTP 200 来表示“SUCCESS”。
下图演示了高级别的故障转移路由策略。 此方法和其他策略的详细信息可在here找到。
图 11:Amazon Route53 故障转移例程策略
在任何给定时间,只有一个区域会根据端点监控进行在线报告。 这样可以确保流量在给定时间只流向一个区域。 区域之间的故障转移无需增加步骤,因为端点监控将检测到指定的主 AWS 区域中的应用程序已关闭,并且该应用程序此时在次要 AWS 区域中处于活动状态。 这是因为 DR 异步镜像成员已被手动升级为主镜像成员,随后允许 CSP 网关将 HTTP 200 报告给 Elastic Load Balancer 端点监控。
上述解决方案有很多替代方案,可以根据您组织的运营要求和服务水平协议进行自定义。
监控
Amazon CloudWatch 可用于为您的所有 AWS 云资源和应用程序提供监控服务。 Amazon CloudWatch 可用于收集和跟踪指标,收集和监控日志文件,设置警报,并自动对 AWS 资源的变化做出反应。 Amazon CloudWatch 可以监控 AWS 资源,如 Amazon EC2 实例,以及您的应用程序和服务生成的自定义指标,还有您的应用程序生成的任何日志文件。 您可以使用 Amazon CloudWatch 获得系统范围内的资源利用率、应用程序性能和运行状况的可见性。 详细信息可在here找到。
自动预置
目前,市场上有许多工具,包括 Terraform、Cloud Forms、Open Stack 和 Amazon 自己的 CloudFormation。 使用这些工具并与其他工具(如 Chef、Puppet、Ansible 等)相结合,可以提供完整的基础设施即代码,来支持 DevOps 或简单地以完全自动化的方式引导您的应用程序。 Amazon CloudFormation 的详细信息可在here找到。
网络连接
根据您的应用程序的连接要求,有多种连接模型可用:使用互联网、VPN 或使用 Amazon Direct Connect 的专用链接。 选择方法取决于应用程序和用户需求。 三种方法的带宽使用情况各不相同,最好通过 AWS 代表或 Amazon 管理控制台确认给定区域的可用连接选项。
安全
当决定通过任何公共 IaaS 云提供商部署应用程序时,都需要谨慎。 应遵循您组织的标准安全策略或专门针对云制定的新策略,以保持您组织的安全合规性。 当组织的数据存储在其国家/地区之外,并受数据所在国家/地区的法律约束时,相关的数据主权也是您必须了解的。 现在,云部署增加了数据在客户数据中心和物理安全控制之外的风险。 强烈建议对静态数据(数据库和日志)和动态数据(网络通信)使用 InterSystems 数据库和日志加密,分别使用 AES 和 SSL/TLS 加密。
与所有加密密钥管理一样,您需要按照您组织的策略记录并遵循正确的程序,以确保数据安全,防止不必要的数据访问或安全漏洞。
Amazon 提供了大量文档和示例,为基于 Caché 的应用程序提供高度安全的运行环境。 请务必查看here 关于 Identity Access Management (IAM) 的各种讨论主题。
架构图示例
下图说明了典型的 Caché 安装,其以数据库镜像(同步故障转移和 DR 异步)、使用 ECP 的应用程序服务器,以及多个负载均衡 Web 服务器的方式提供高可用性。
TrakCare 示例
下图说明了典型的 TrakCare 部署,其中包含多个负载均衡 Web 服务器,两个作为 ECP 客户端的 EPS 打印服务器,以及数据库镜像配置。 虚拟 IP 地址仅用于与 ECP 或 CSP 网关不关联的连接。 ECP 客户端和 CSP 网关可感知镜像,不需要 VIP。
如果您正在使用 Direct Connect,则可为灾难恢复方案启用包括多线路和多区域访问在内的多个选项。 与电信提供商合作以了解他们支持的高可用性和灾难恢复方案至关重要。
下面的示例参考架构图包括活动或主要区域中的高可用性,以及在主要 AWS 区域不可用时到其他 AWS 区域的灾难恢复。 而且在此示例中,数据库镜像包含 TrakCare DB、TrakCare Analytics 和 Integration 命名空间,全部在单个镜像集内。
图 12:TrakCare AWS 参考架构图 – 物理架构
此外,下图显示了更有逻辑的架构图,其中包含所安装的相关高级软件产品及功能用途。
图 13:TrakCare AWS 参考架构图 – 逻辑架构
HealthShare 示例
下图显示了一个典型的 HealthShare 部署,其中含有多个负载均衡 Web 服务器,以及多个 HealthShare 产品,包括 Information Exchange、Patient Index、Personal Community、Health Insight 和 Health Connect。 这些产品中的每一个都包含一个数据库镜像对,以在多个可用区内提供高可用性。 虚拟 IP 地址仅用于与 ECP 或 CSP 网关不关联的连接。 用于 HealthShare 产品之间的 Web 服务通信的 CSP 网关可感知镜像,不需要 VIP。
下面的示例参考架构图包括活动或主要区域中的高可用性,以及在主要区域不可用时到其他 AWS 区域的灾难恢复。
图 14:HealthShare AWS 参考架构图 – 物理架构
此外,下图显示了更有逻辑的架构图,其中包含所安装的相关高级软件产品、连接要求和方法,以及相应的功能用途。
Figure-15: HealthShare AWS 参考架构图 – 逻辑架构
文章
Claire Zheng · 一月 18, 2021
亲爱的是社区用户,您好!
如果您看到本页面,则说明您已进入 InterSystems 开发者社区! 非常欢迎您!
在这里,您可以了解和讨论有关InterSystems 产品和技术的信息,包括:InterSystems IRIS数据平台、Caché、Ensemble、HealthShare、DeepSee 和 iKnow。
在这里可以找到什么类型的内容?
我们在开发者社区 (DC) 提供三种类型的内容:文章、问题、公告。还有对问题的回答。 以及视频。
文章的内容涉及 InterSystems 技术和产品的最佳实践和经验。InterSystems 员工和社区用户都可以发表文章。 您可以找到版本说明和新功能描述,以及有关经验和 InterSystems 技术示例的文章。
当然,您也可以在这里提出问题,并获得来自世界各地的最有经验的 InterSystems 技术工程师的答案。
为何要注册?
在 DC 注册后,可以针对以下方面发表和评论文章,提出问题和给出答案:InterSystems数据平台、使用 InterSystems 数据平台和工具构建的解决方案、有助于在 InterSystems 数据平台上构建、部署和维护解决方案的工具、技术和方法。
注意!如果您是InterSystems 技术现有用户,在注册过程中出现如下报错信息,请尝试使用自己的WRC账户直接登陆社区。
点击查看发帖指南。
注意! 版主可能会删除与 InterSystems 产品和技术无关的帖子。
InterSystems 开发者社区行为准则。
注册会员可以投票。 如果您喜欢某篇文章、某个问题或回答,可以为其投票。
何时应该投反对票?
当您遇到发布过于草率、毫不费力就发出的帖子,或者是明显错误、甚至可能造成危险的回答时,请投上反对票。 如果投反对票,并且您认为帖子有改进空间,请考虑添加评论。
查看有关投票的更多信息。
网站如何运作?
帖子按标签进行分类。 有一些标签是必选的,这些标签在编辑时称为“组”。 必选标签与 InterSystems 产品或 InterSystems 服务相关。 您需要提供至少一个这样的标签。 标签有助于对帖子进行分类。 您可以订阅标签,以通过电子邮件或 RSS 获得通知。
此外,您还可以关注您喜欢的会员,相当于订阅该会员的帖子和评论。 在主页面,您可以看到发帖动态,其中最上面的是最新发布或者有最新评论和回答的帖子。
您可以使用筛选器,以便只查看您订阅的标签,以及投票最多的帖子和新帖子。
此外,我们还有 DC 分析网站,可用来查看一些关于 DC 会员、帖子、回答等的数据。
有关其他所有内容,请参见开发者社区常见问题解答。
订阅须知
注册会员可以收到关于开发者社区上的不同操作的电子邮件通知。 请参见此文章了解如何设置。
此外,每个人都可以订阅 RSS:所有内容和特定标签。
InterSystems Global Masters倡导中心!
这是我们的 InterSystems 倡导中心。如果您认为自己是 InterSystems 技术的倡导者,请加入由全球数百名 InterSystems 倡导者组成的团队。 我们将为您提供挑战、徽章,当然还有奖励。 点击查看详细信息。
InterSystems Open Exchange!
在 InterSystems Open Exchange 上查找工具、框架、解决方案、技术示例!点击了解更多信息。
还有什么?
如果您对网站有任何疑问,请在群组中提问,或查看常见问题解答。
我们在 Twitter 上发布开发者社区中的所有有价值内容,如果您更愿意点赞 Facebook,也可以访问我们的 Facebook 页面。
还有 InterSystems 开发者 LinkedIn 信息通道以及 InterSystems 开发者 LinkedIn 群组。 您也可以关注InterSystems中国领英账户,及时获取精彩信息!
如果您喜欢 Telegram,我们也有 DC Telegram 频道发布相同内容。
我们开通了 InterSystems 开发者 YouTube 频道。
在中国,我们在B站开通了InterSystems中国官方账号,将不定时更新由SE团队精心制作的视频课程、讲座等内容。
我们还在 Reddit 的开发者社区子板块发布所有最有趣的公告。
欢迎加入 InterSystems 开发者社区!
文章
Hao Ma · 一月 15, 2021
在这个由三个部分组成的系列文章中,介绍了如何在OAuth 2.0标准下使用IAM简单地为IRIS中的未经验证的服务添加安全性。
第一部分介绍了一些OAuth 2.0背景知识,以及IRIS和IAM的一些初始定义和配置,以帮助读者理解确保服务安全的整个过程。
第二部分详细讨论和演示了配置IAM所需的步骤——验证传入请求中的访问令牌,并在验证成功时将请求转发到后端。
本系列的最后一部分将讨论和演示IAM生成访问令牌(充当授权服务器)并对其进行验证时所需的配置,以及一些重要的最终考虑事项。
如果您想试用IAM,请联系InterSystems销售代表。
场景2:IAM作为授权服务器和访问令牌验证器
与上个场景不同的是,该场景中将使用一个名为“OAuth 2.0 Authentication”的插件。
如果要在资源所有者密码凭证流中将IAM作为授权服务器使用,客户端应用程序必须对用户名和密码进行身份验证。只有在身份验证成功时,才能发出获取IAM访问令牌的请求。
首先,将其添加到“SampleIRISService”中。正如下面截屏所示,需要填充一些不同的字段来配置此插件。
首先,将“SampleIRISService”的ID粘贴到“service_id”字段中,这样就可以在服务中启用该插件。
在“config.auth_header_name”字段中,需要指定携带授权令牌的头名称。本例中,我保留默认值“authorization”。
“OAuth 2.0 Authentication”插件支持的OAuth 2.0流包括授权码授权(Authorization Code Grant)、客户端凭证(Client Credentials)、隐式授予(Implicit Grant)或资源所有者密码凭证授权(Resource Owner Password Credentials Grant)。我们在本文中使用的是“资源所有者密码凭证”流,故选中“config.enable_password_grant”。
在“config.provision_key”字段中输入要用作配置密钥的字符串。此值用来向IAM请求访问令牌。
本例中,我保留了所有其他字段的默认值。可以在此处查看插件文档中每个字段的完整引用。
下面是插件配置的最终效果:
创建插件后,需要为“ClientApp”客户端创建凭证。
为此,打开左侧菜单上的“Consumers”,然后单击“ClientApp”。接下来,点击“Credentials”标签,然后点击“New OAuth 2.0 Application”按钮。
在下个页面的“name”字段输入名称,以标识应用程序,在“client_id”和“client_secret”字段分别定义客户端ID和客户端密钥,最后在应用程序中输入URL,在“redirect_uri”字段上授权后,用户将被发送到该URL。然后,单击“Create”。
现在,可以发送请求了。
需要发出的第一个请求是获取IAM访问令牌。“OAuth 2.0 Authentication”插件自动创建一个端点,并将“/oauth2/token”路径附加到已经创建的路由上。
注意:必须使用HTTPS协议和IAM的代理端口(默认端口为8443)监听TLS/SSL请求。这是OAuth 2.0规范要求。
因此在本例中,需要向URL发出一个POST请求:
https://iamhost:8443/event/oauth2/token
请求主体中应包括以下JSON:
{
"client_id": "clientid",
"client_secret": "clientsecret",
"grant_type": "password",
"provision_key": "provisionkey",
"authenticated_userid": "1"
}
如上所示,该JSON包含了在创建“OAuth 2.0 Authentication”插件时定义的值(如“grant_type”和“provision_key”),以及在创建客户端凭证时定义的值(如“client_id”和“client_secret”)。
当提供的用户名和密码成功通过身份验证后,客户端应用程序还应该添加“authenticated_userid”参数值作为已通过身份验证的用户的唯一标志。
该请求及其响应如下:
现在可以请求从上面的响应中获取事件数据(包括“access_token”值),并作为对URL的GET请求中的“bearner token”
https://iamhost:8443/event/1
如果访问令牌过期,可以使用收到的刷新令牌和过期的访问令牌一起生成一个新的访问令牌,方法是向用于获取访问令牌的相同端点发出POST请求,但主体略有不同:
{
"client_id": "clientid",
"client_secret": "clientsecret",
"grant_type": "refresh_token",
"refresh_token": "E50m6Yd9xWy6lybgo3DOvu5ktZTjzkwF"
}
该请求及其响应如下:
“OAuth 2.0 Authentication”插件的一个有趣很好的特性是能够查看和禁用访问令牌。
若要查看令牌列表,向以下IAM的Admin API终端发送GET请求即可:
https://iamhost:8444/{workspace_name}/oauth2_tokens
其中{workspace_name}是IAM工作区的名称。如果启用了RBAC,则需要输入必要的凭证才能调用IAM Admin API。
注意,“credential_id”是在ClientApp客户端内部创建的OAuth应用程序(本例中名为SampleApp)的id,“service_id”是应用此插件的“SampleIRISService”的id。
要想禁用令牌,可以向以下端点发送删除请求
https://iamhost:8444/Sample/oauth2_tokens/{token_id}
其中{token_id}是要禁用的令牌id。
如果尝试使用无效令牌,将包含该无效令牌的GET请求作为Bearer Token 发送到URL,则会收到一条消息,提示令牌无效或已过期:
https://iamhost:8443/event/1
最后需要考虑的因素
本文演示了如何将IAM中的OAuth 2.0身份验证添加到IRIS中未经身份验证的服务中。需要牢记的是,IRIS中的服务本身仍是未经身份验证的。因此,如果有人绕过IAM层直接调用IRIS服务端点,则可以在不经过任何身份验证的情况下查看信息。出于该原因,在网络级别设置安全规则以防止不必要的请求绕过IAM层是很重要的。
可以在此处了解更多有关IAM的信息。
如果您想试用IAM,请联系InterSystems销售代表。
文章
Hao Ma · 一月 15, 2021
在这个由三部分组成的系列文章中,我们将展示如何在OAuth 2.0标准下使用IAM简单地为IRIS中的未经验证的服务添加安全性。
在第一部分中,我们介绍了一些OAuth 2.0背景知识,以及IRIS和IAM的初始定义和配置,以帮助读者理解确保服务安全的整个过程。
现在,本文将详细讨论和演示配置IAM所需的步骤——验证传入请求中的访问令牌,并在验证成功时将请求转发到后端。
本系列的最后一部分将讨论和演示IAM生成访问令牌(充当授权服务器)并对其进行验证时所需的配置,以及一些重要的最终考虑事项。
如果您想试用IAM,请联系InterSystems销售代表。
场景1:IAM作为访问令牌验证器
在该场景中,需要使用一个外部授权服务器生成JWT(JSON Web Token)格式的访问令牌。该JWT使用了RS256算法和私钥签名。为了验证JWT签名,另一方(本例中是IAM)需要拥有授权服务器提供的公钥。
由外部授权服务器生成的JWT主体中还包括一个名为“exp”的声明(包含该令牌过期的时间戳),以及另一个名为“iss”的声明(包含授权服务器的地址)。
因此,IAM需要先使用授权服务器的公钥和JWT内部“exp”声明中包含的过期时间戳对JWT签名进行验证,然后再将请求转发给IRIS。
对IAM进行相应配置时,首先要向IAM中的“SampleIRISService”添加一个名为“JWT”的插件。为此,请转到IAM中的Services页面并复制“SampleIRISService”的ID,稍后会用到。
之后,打开插件,点击“New Plugin”按钮,找到“JWT”插件,点击启用。
在下个页面中,将“SampleIRISService”ID粘贴在“service_id”字段中,然后在“config.claims_to_verify”参数中选中“exp”框。
注意,“config.key_claim_name”参数的值是“iss”。后面会用到。
然后,点击“Create”按钮。
完成操作后,找到左侧菜单中的“Consumers”部分,然后单击先前创建的“ClientApp”。点击“Credentials”标签,然后单击按钮“New JWT Credential”。
在下一页中,选择JWT签名算法(本例中为RS256),并将公钥(这是授权服务器提供的PEM格式的公钥)粘贴到“rsa_public_key”字段中。
在“key”字段中,在添加JWT插件时需要用到之前在“config.key_claim_name”字段中输入的JWT声明内容。所以在本例中,需要插入的是JWT的iss声明内容(本例中是授权服务器的地址)。
之后,单击“Create”按钮。
提示:出于调试目的,可以使用一个在线工具对JWT进行解码,将公钥粘贴进去就可以检查声明内容及其值,并且验证签名。该在线工具的链接如下:https://jwt.io/#debugger
现在,添加了JWT插件后,就不能发送未经身份验证的请求了。如下所示,对URL的一个简单GET请求(未经身份验证):
http://iamhost:8000/event/1
返回一个未经授权的信息,以及状态码“401未经授权”。
为了从IRIS获得结果,需要将JWT添加到请求中。
首先,需要向授权服务器请求JWT。如果POST请求与主体中的一些键值对(包括用户和客户端信息)一起发出,那么在这里使用的自定义授权服务器将向以下URL返回一个JWT:
https://authorizationserver:5001/auth
该请求及其响应如下所示:
然后,可以将响应中获得的JWT添加到授权标头中作为Bearer令牌使用,并将GET请求发送到和之前相同的URL:
http://iamhost:8000/event/1
或者将它作为querystring参数添加进去。当添加JWT插件(本例中是“jwt”)时,querystring关键字是在“config.uri_param_names”字段中指定的值
最后,如果在“config.cookie_names”字段中输入任意名称,选择将JWT作为cookie包含在请求中。
请继续阅读本系列的第三部分也即最后一部分,了解IAM生成和验证访问令牌所需的配置,以及一些重要的最终考虑因素。
文章
Louis Lu · 一月 15, 2021
# 什么是核心文件? 它们什么时候有用?
本文档中的信息以 2019 年 6 月 30 日发布的 InterSystems 产品最新版本为准。 此更新涵盖了截至 2020 年 4 月 14 日发现的错误,但不包括 InterSystems 产品新版本中的更改。不过,现有产品的细节不会经常变化。本文的 PDF 版本可以从 WRC 获取
目录
核心文件基础知识
SuSE Linux
Windows
AIX
Ubuntu Linux
测试
Docker
macOS (Darwin)
健全性测试
HP–UX
OpenVMS
传输
RedHat Linux
Solaris
索引
核心文件基础知识
Caché、Ensemble、HealthShare 和 InterSystems IRIS 数据平台非常可靠。 我们的绝大多数客户从未经历过任何种类的故障。 但是,在极少数情况下,进程发生过故障,并因此生成了核心文件(在 Windows 和 OpenVMS 上称为进程转储文件process dump file)。 核心文件记录了进程发生故障时的进程状态,包括进程寄存器和内存(是否包括共享内存的信息取决于配置)。 核心文件实质上是发生故障的进程在试图执行错误操作时的瞬时画面。 我们可以根据该画面向回推断,以找出导致故障的最初错误。 随着我们回溯过去的时间越久远,进程的信息逐渐变得模糊。 核心越详细,我们可以回溯的时间就越远,直到画面变得过于模糊。 借助正确收集的核心文件和相关信息,我们通常可以解决问题,或者以其他方式提取故障进程的有价值信息。 对于人为生成的核心文件,通常我们只能说(在经过数小时分析后):“我看到这个进程发生了什么,有人手动生成了进程核心。” 手动生成核心文件可以包含更多正在运行进程的信息,它可用作辅助信息源,以补充无法从系统默认核心文件提供的信息细节。 InterSystems 产品可以配置为在发生任何进程故障时都记录完整核心。 这对日常操作的性能没有任何影响。 您只需要保证有足够的磁盘可用空间,以应对任何潜在的、小概率发生的故障。 InterSystems 只要能获得完整核心,在解决问题方面都有着良好的记录。 有时我们会发现由难解的硬件引发的故障,并保证这种故障不会再次发生。 InterSystems 产品还可以配置为很少记录或不记录进程故障的信息。 虽然禁用核心没有性能优势,但您可能会获得运行优势。 核心文件可能包含敏感信息。 如果您不想制定保护核心文件的策略,可以只在反复出现故障后再启用生成核心文件。 InterSystems 产品默认采用中间方案。 也就是生成有限大小的核心文件。 利用这些小核心文件,InterSystems 通常可以识别是否为以前解决过的问题,并解决这些问题。 当然我们无法保证使用默认的有限的核心文件可以解决所有问题。 用于确定所获得的核心文件的大小和类型的主要控制参数是 DumpStyle。 这是cache.cpf 或 iris.cpf 文件中的参数。 还有其他几个特定于操作系统的控制参数。 DumpStyle 的说明在这里:。DumpStyle 取一个介于 0 到 8 之间的整数值,适用于 Caché、Ensemble、HealthShare 或 InterSystems IRIS 数据平台实例中的每个进程,并定义当进程遇到严重错误时,应保存哪种核心(或进程转储)文件。 定义的值为:
代码
名称
平台
结果
0
NORMAL
UnixOpenVMSWindows
生成完整核心(取决于其他设置)。生成 CACCVIO-pid.LOG(大小受限)。生成 pid.dmp(大小受限)。
1
FULL
UnixOpenVMSWindows
生成完整核心(取决于其他设置)。生成 CACHE.DMP(可能非常大)。生成 cachefpid.dmp(可能非常大)。
2
DEBUG
UnixOpenVMSWindows
在 Caché2014.1 之前,生成省略共享内存的核心,现已弃用。 最好使用操作系统特定的方法省略共享内存。未实现。为 InterSystems 预留。
3
INTERMEDIATE
UnixOpenVMSWindows
未实现。未实现。2014.1 版本后有效,生成cacheipid.dmp
4
MINIMAL
UnixOpenVMSWindows
未实现。未实现。2014.1 版本后有效,生成cacheipid.dmp
5
NOHANDLER
UnixOpenVMSWindows
不注册为信号处理程序。 将有关核心创建的所有决定都留给操作系统。未实现。未实现。
6
NOCORE
UnixOpenVMSWindows
不生成核心文件。未实现。未实现。
7
NOFORK
UnixOpenVMSWindows
创建核心dump(包含共享内存),但是从原始故障进程而不是从故障进程的分支副本进行创建。未实现。未实现。
8
NOFORKNOSHARE
UnixOpenVMSWindows
创建不包含共享内存的核心转储,但是从原始故障进程而不是从故障进程的分支副本进行创建。未实现。未实现。
默认 DumpStyle 为 0 = NORMAL,除了在 Windows 中从 Caché 2014.1 开始,为 3 = INTERMEDIATE。
更改 DumpStyle 值的方法有三种。 分别是:
①将以下部分放在 cache.cpf 或 iris.cpf 文件中,为此,需要使用操作系统的文本编辑器:
[Debug]
dumpstyle=1
等号后面的数字是新的默认 DumpStyle值。 重新启动 Caché、Ensemble、HealthShare 或 InterSystems IRIS 数据平台后,如果不使用下面的方法 ② 或 ③ ,它会将这个新的值设定为所有进程的默认值。
②使用命令:
SET old=$SYSTEM.Config.ModifyDumpStyle(1)
括号中的数字是新的 DumpStyle 值。 旧值将返回。 此命令对运行后创建的所有新进程都有效。 现有进程继续以先前的 DumpStyle 运行。 此命令从 Caché 2014.1 开始有效。
对于较早的版本,可以使用以下命令:
VIEW $ZUTIL(40,2,165):-2:4:1
其中新的 DumpStyle 值是最后一位数字。
③执行以下命令或将其放在应用程序中:
VIEW $ZUTIL(40,1,48):-1:4:1
其中新的 DumpStyle 值是最后一位数字。 这只对执行命令的进程有效,并覆盖方法 ① 和 ②的设定值。
大多数操作系统都可以控制将生成的核心文件重定向到一个公用目录,并控制核心文件中包含的信息数量。 您也应该手动修改这些设置,并且应考虑相应的影响,尤其是从数据隐私的角度。 以下各节介绍了各个操作系统下的详细信息。
将核心文件的输出移动到一个公用目录对于容量规划非常有用,但也可能让希望从您的站点窃取数据的人更容易访问到核心文件。
如果核心文件不包含共享内存,很多类型的问题无法从根本进行解决。 包含共享内存的核心文件往往比不包含共享内存的核心文件大得多。 大部分差异是global和routine缓冲区的大小。
如果你正在处理的是敏感信息,不含共享内存的核心文件将只包含发生故障的进程正在处理的敏感信息。 含有共享内存的核心文件还将包含每个进程最近访问的所有全局变量。 这里用到的“最近”可能表示几分钟,或者相当长的时间。
AIX
生成完整的核心文件应使用 smit 启用:
System Environments
> Change / Show Characteristics of Operating System
> > Enable full CORE dump true
> > Use pre-430 style CORE dump false
也可以从命令行使用以下命令查看:
#
lsattr -E -l sys0 | egrep 'fullcore|pre430core'↩
fullcore true Enable full CORE dump True
pre430core false Use pre-430 style CORE dump True
使用以下命令设置:
#
chdev -l sys0 -a fullcore=true -a pre430core=false -P↩
`-P` 使更改永久有效。
◆
默认情况下,当进程发生故障时在进程的默认目录写入核心文件。 该目录通常就是主 CACHE.DAT 或 IRIS.DAT 文件所在的目录。 这可以通过 smit 更改:
Problem Determination
> Change/Show/Reset Core File Copying Directory
或从命令行运行:
#
chcore -p on -l /cores -n on -d↩
◆
确保文件 /etc/security/limits 的某个部分包含以下行:
default:
core = -1
最后,无论通过什么方式为用户进程设置环境变量,都确保每个用户都已根据需要定义或未定义 CORE_NOSHM。 如果定义了 CORE_NOSHM=1,核心文件不包含共享内存的内容。 如果定义 CORE_NOSHM=0 或完全未定义,核心文件将包含共享内存的内容。 为所有用户设置此参数简单方法是编辑 /etc/environment 并包含以下行:
CORE_NOSHM=1
要分别指定每个用户是否在核心文件中包含共享内存的内容,请根据用户和他们使用的 shell 编辑以下任一文件:
CORE_NOSHM=1; export CORE_NOSHM # sh in /etc/profile or $HOME/.profile
export CORE_NOSHM=1 # ksh in /etc/.kshrc or $HOME/.kshrc
export CORE_NOSHM=1 # bash in /etc/bashrc or ~/.bashrc
setenv CORE_NOSHM 1 # csh in ~/.cshrc
Docker
InterSystems IRIS 数据平台 docker 容器的核心文件创建由主机 Linux 系统控制。 您必须规划将核心文件直接发送至操作系统文件。 该文件可以保存在 docker 容器内,也可以发送至映射的主机 Linux 系统上的目录中。 将核心文件发送至映射的主机 Linux 系统上的目录的优点是,它将在容器完全失效的情况下仍然保存下来。
由于核心文件必须发送到操作系统文件,因此必须在主机平台上禁用所有高级核心捕获软件。 您将需要为主机和容器系统的 /proc/sys/kernel/core_pattern 设置适当的值。 您应该选择一个相对简单并且在主机和容器上都存在的目录(/tmp 或 /cores 显然是最佳选择)。 您可能还需要包含变量,以确保来自多个 docker 容器的核心不会相互覆盖。 因此 /cores/core.%p.%e 是一个好选择。
主机操作系统
禁用
链接
RedHat Linux
必须禁用错误自动报告工具 (ABRT)。
☞
SuSE Linux
截至 SuSE Linux Enterprise Server 11,SuSE 没有任何高级核心捕获软件。 因此您只需按照说明设置 /proc/sys/kernel/core_pattern。 但是,到目前为止,我们还没有提供在 SuSE Linux Enterprise Server 12 中禁用高级核心捕获软件的说明,因此 SuSE 12 及更高版本目前不适合作为 docker 容器的主机。
☞
Ubuntu Linux
必须禁用 apport。
☞
启动容器时,您可能希望包含将用于核心文件的目录映射到主机操作系统的选项。 因此:
#
docker run ⋯ -v /cores:/cores ⋯ ↩
如果不包含 -v /cores:/cores,则 docker 容器内的进程故障所创建的任何核心文件都只会在 docker 容器运行时存活。 如果 -v 选项给出的映射不是对称的,即冒号左侧和右侧的值不一样,则可能无法捕获某些核心文件内容。 将核心文件大小设置为无限制。 由于这是运行时决定,因此将以下内容添加到 docker run 命令中:
#
docker run ⋯ --ulimit core=-1 ⋯ ↩
HP–UX
使用以下命令使核心文件保存在公用目录中并带有扩展名称:
# coreadm -e global -g /cores/core.%p.%f↩
%p 表示将 pid 放在路径名中,%f 表示将可执行文件名(如 cache 或 iris)放在路径名中。 请参见:
%
man 1m coreadm↩
了解更多选项。
◆
使用以下命令查看是否已在核心文件中启用共享内存:
#
/usr/sbin/kctune core_addshmem_read↩
#
/usr/sbin/kctune core_addshmem_write↩
更改为:
#
/usr/sbin/kctune core_addshmem_read=1↩
#
/usr/sbin/kctune core_addshmem_write=1↩
1 表示启用,0 表示禁用。 HP–UX 将共享内存分为两种类型。 通常,InterSystems 仅使用写共享内存,但我们建议将两种类型设置为相同值。
◆
在 HP–UX 上,生成的核心文件大小受 maxdsiz_64bit 内核参数限制。 确保该参数设置得足够高,以便生成完整的核心文件。 可
使用以下命令查看:
#
/usr/sbin/kctune maxdsiz_64bit↩
使用以下命令设置:
#
/usr/sbin/kctune maxdsiz_64bit=4294967296↩
用户可以使用 ulimit -c 命令进一步限制核心文件大小。 应该从 /etc/profile、$HOME/.profile 以及其他 shell 的类似文件中删除此设置,除非您有意限制核心文件。
RedHat Linux
如果您正在运行 Rhel 6.0 或更高版本(CentOS 同样),RedHat 已增加了错误自动报告工具 (ABRT)。 此工具安装后与 Caché、Ensemble、HealthShare 或 InterSystems IRIS 数据平台不兼容。 您需要决定您希望将 ABRT 配置为支持 Caché、Ensemble、HealthShare、InterSystems IRIS 数据平台,还是禁用 ABRT。
以下标记了
ABRT
的部分适用于使用 ABRT 的情况,
而标记了
AB/RT
的部分适用于传统的不使用 ABRT 的情况。
◆
ABRT 要使 InterSystems 产品与 ABRT 兼容,请确定正在运行的 ABRT 版本:
#
abrt-cli --version↩
编辑 ABRT 配置文件。 名称会因 ABRT 版本的不同而有所差异:
ABRT 1.x:
/etc/abrt/abrt.conf
ABRT 2.x:
/etc/abrt/abrt-action-save-package-data.conf
如果您使用 cinstall 命令安装了 Caché、Ensemble 或 HealthShare(最常见),或使用 irisinstall 命令安装了 InterSystems IRIS 数据平台,请找到 ProcessUnpackaged= 行,将值更改为 yes。
ProcessUnpackaged = yes
否则,如果是从 RPM 模块安装的 Caché、Ensemble、HealthShare 或 InterSystems IRIS 数据平台,则找到 OpenGPGCheck= 行,将值更改为 no。
OpenGPGCheck = no
不管是如何安装的 Caché、Ensemble、HealthShare 或 InterSystems IRIS 数据平台,都找到 BlackListedPaths= 行,并添加对 installation/bin 目录中的 cstat 或 irisstat的引用。 如果 BlackListedPaths= 行不存在,则在末尾添加此行以及cstat 或 irisstat 引用。
BlackListedPaths=[retain_existing_list,]installation_directory/bin/cstat
保存所做编辑,然后重新启动 abrtd:
#
service abrtd restart↩
这样配置后,ABRT 会为每次进程故障创建一个新目录(在 /var/spool/abrt 或 /var/tmp/abrt 下),并在该目录中放置核心文件以及相关信息。
当进程发生错误时,执行命令:
#
abrt-cli --list↩
# for ABRT 1.x
#
abrt-cli list↩
# for ABRT 2.x
这将显示最近进程故障的列表,并为每个故障提供一个目录规范。 每个目录中都将有一个 coredump文件,以及许多其他小文件,这些文件对于确定进程故障的原因非常有用。
%
tar -cvzf <var>wrcnumber</var>-core.tar.gz /var/spool/abrt/<var>directory</var>/*↩
其中 wrcnumber 是 InterSystems 分配用来调查案例的编号。 您可以将压缩的 wrcnumber-core.tar.gz 文件发送给我们。
◆
AB/RT 或者,可以使用以下命令禁用 ABRT:
#
service abrtd stop↩
#
service abrt-ccpp stop↩
# ABRT 2.x only.
要永久禁用 ABRT:
#
chkconfig abrtd off↩
#
chkconfig abrt-ccpp off↩
# ABRT 2.x only.
最后,您需要更新 /proc/sys/kernel/core_pattern,请参见下一节。
◆
AB/RT 您可以控制核心文件的存储位置(除非您正在使用 ABRT)。
① : 如果正在使用 ABRT,则必须跳过此步骤。
② : 如果已禁用 ABRT,则必须执行此步骤。
③ : 如果从未安装 ABRT,则此步骤是可选的。
编辑文件 `/proc/sys/kernel/core_pattern` 在简单的示例中,只需使用: core 添加生成核心的程序的 pid 和名称通常很有用: core.%p.%e 还可以将核心放在公用目录中: /cores/core.%p.%e 确认所有用户对所选目录都具有写访问权限。 请参见 `man core` 了解更多选项。 您应该在目录 /etc/sysctl.d 中创建一个名称以 `.conf` 为结尾的文件,并包含以下内容,从而使此更改永久有效: kernel.core_pattern=/cores/core.%p.%e
◆
ABRT AB/RT 您应该设置 /proc/self/coredump_filter以控制转储到核心文件中的内存大小。 这可以在 /etc/profile.d/some-thing.sh 文件中设置。 命令为:
#
echo 0x33 >/proc/self/coredump_filter↩
所使用的具体位映射取决于您希望收集的数据级别。 bits的含义可以在 man core 中找到,对于 InterSystems 产品有意义的示例为:
Bit
说明
InterSystems 是否需要
0x01
匿名私有映射。
始终需要。
0x02
匿名共享映射。
复杂问题需要。
0x04
文件支持的私有映射。
$ZF() 相关问题可能需要。
0x08
文件支持的共享映射。
$ZF() 相关问题可能需要。
0x10
转储 ELF 标头。
始终需要。
0x20
转储私有大页。
InterSystems 当前未使用。
0x40
转储共享大页。
InterSystems 当前未使用。
0x80
转储私有 DAX 页 (Rhel 8)。
InterSystems 当前未使用。
0x100
转储共享 DAX 页 (Rhel 8)。
InterSystems 当前未使用。
作为将此命令放在 shell 特定的脚本中的替代方案,您可以在启动期间进行修改。 只有使用 grub2 引导时,这些指令才适用。 您可以通过以下命令测试:
#
grub2-install --version↩
grub2-install (GRUB) 2.02~beta2
编辑 /etc/default/grub。 更改以 GRUB_CMDLINE_LINUX_DEFAULT= 开头的行。 如果文件中不存在该行,则在末尾添加。 它应该包含:
GRUB_CMDLINE_LINUX_DEFAULT="oldcmd
coredump_filter=newval
"
注意:oldcmd 是 GRUB_CMDLINE_LINUX_DEFAULT 的旧值(如果该行先前不存在,则省略)。 newval` 是 coredump_filter 的新值,以十六进制表示,带有前导“`0x`”。
运行:
#
grub2-mkconfig -o /boot/grub2/grub.cfg↩
◆
ABRT AB/RT 您应该针对所有进程设置 ulimit -c 为无限制。 这可以在文件 /etc/security/limits.conf 中全局设置。 添加以下两行:
* soft core unlimited
* hard core unlimited
SuSE Linux
如果运行 SuSE Linux Enterprise Server 12 或更高版本,SuSE 现在将所有生成的核心文件存储在 systemd 日志中。 存储在 systemd 日志中的核心文件是临时的。 它们在系统重启后即消失。 如果需要,必须在系统重启前从 systemd 日志中提取核心。 要列出 systemd 日志中当前含有的核心文件:
# [
systemd-
]
coredumpctl list↩
要提取按照创建了核心的 pid 选择的核心文件:
# [
systemd-
]
coredumpctl -o core.morename dump pid
注意:从 SuSE 12-SP2 开始,systemd- 前缀已从命令名称中删除。 建议保留此 systemd 行为,不要试图修改它。
如果正在运行旧版本的 SuSE Linux Enterprise(11 或更早版本),可以通过编辑文件 /proc/sys/kernel/core_pattern来控制存放核心文件的位置。
在简单的示例中,只需使用:
core
通常也需要添加生成核心文件程序的 pid 和名称,使用:
core.%p.%e
还可以将核心文件放在公用目录中:
/cores/core.%p.%e
确认所有用户对所选目录都具有写访问权限。 请参见 man core 了解更多选项。
可以将以下几行追加到文件 etc/sysctl.conf 中来使此更改永久有效:
# Make this core pattern permanent (SuSE 12 breaks this, don't use):
kernel.core_pattern=/cores/core.%p.%e
◆
您应该设置/proc/self/coredump_filter以控制转储到核心文件的内存数量。 这可以在适当的 /etc/profile.d/something.sh文件中运行。 命令为:
# echo 0x33 >/proc/self/coredump_filter↩
所使用的具体bits映射取决于您希望收集的数据级别。 bit 的含义可以在 man core 中找到,对于 InterSystems 产品有意义的示例为:
Bit
说明
InterSystems 是否需要
0x01
匿名私有映射。
始终需要。
0x02
匿名共享映射。
复杂问题需要。
0x04
文件支持的私有映射。
$ZF() 相关问题可能需要。
0x08
文件支持的共享映射。
$ZF() 相关问题可能需要。
0x10
转储 ELF 标头。
始终需要。
0x20
转储私有大页。
InterSystems 当前未使用。
0x40
转储共享大页。
InterSystems 当前未使用。
0x80
转储私有 DAX 页 (SuSE 15)。
InterSystems 当前未使用。
0x100
转储共享 DAX 页 (SuSE 15)。
InterSystems 当前未使用。
作为将此命令放在 shell 特定的脚本中的替代方案,您可以在启动期间进行修改。 要执行此操作,请使用yast2。 根据您连接的是终端界面(将使用 curses 界面)还是 GUI 界面,yast2 的用户界面会有所不同。 以下说明尽量做到与界面无关。
① : 启动 yast2 后,从菜单中选择 System → Boot Loader。
② : 选择 Kernel Parameters 选项卡。
③ : 查找 Optional Kernel Command Line Parameter字段。
④ : 如果该字段尚未包含coredump_filter=0xvalue,则使用空格分隔符将其追加到该字段中。 如果已经包含该赋值,则只需编辑 value。
⑤ : 退出菜单系统,然后重新启动。
◆
您应该针对所有进程设置 ulimit -c 为无限制。这可以在文件 /etc/security/limits.conf 中进行全局设置。 添加以下两行:
* soft core unlimited
* hard core unlimited
◆
注意:可能需要禁用 AppArmor,它会阻止它认为不寻常的应用程序行为,而写入核心文件可能被视为不寻常。
# rcapparmor stop↩
Ubuntu Linux
Ubuntu 使用 apport 捕获所有进程故障,对于使用安装包添加的软件包,会创建 apport 报告,其中包含带有附加信息的经过编码和压缩的核心内容。 当然也可以要求 apport 处理未使用 Ubuntu 的软件包管理器(Ubuntu's package manager)安装的应用程序的代码。 不幸的是,如果这样做,Canonical 会将针对未打包代码创建的 apport 报告视为为改进 Ubuntu而收集的信息,进而进行内容检查。
由于可以从 apport 报告中提取数据,您几乎肯定不希望启用对未打包代码的 apport 处理。 您的唯一选择是禁用 apport。 为此,请编辑 etc/default/apport,然后编辑 enabled= 行:
enabled=0
◆
创建文件 /etc/sysctl.d/30-core-pattern.conf(或该目录中的任意相似名称)。 在该文件中添加:
kernel.core_pattern=/cores/core.%p.%e
确保您指定用于保存核心文件的目录可公开并写入,并且有足够的磁盘空间。 请参见 man core 了解更多选项。
◆
您应该设置 /proc/self/coredump_filter 以控制转储到核心文件中的内存数量。 这可以在 /etc/profile.d/something.sh 文件中进行设置。 命令为:
#
echo 0x33 >/proc/self/coredump_filter↩
所使用的具体 bit 映射取决于您希望收集的数据级别。 bit 的含义可以在 man core 中找到,对于 Caché 有意义的示例为:
Bit
说明
InterSystems 是否需要
0x01
匿名私有映射。
始终需要。
0x02
匿名共享映射。
复杂问题需要。
0x04
文件支持的私有映射。
$ZF() 相关问题可能需要。
0x08
文件支持的共享映射。
$ZF() 相关问题可能需要。
0x10
转储 ELF 标头。
始终需要。
0x20
转储私有大页。
InterSystems 当前未使用。
0x40
转储共享大页。
InterSystems 当前未使用。
0x80
转储私有 DAX 页 (16.04LTS)。
InterSystems 当前未使用。
0x100
转储共享 DAX 页 (16.04LTS)。
InterSystems 当前未使用。
作为将此命令放在 shell 特定的脚本中的替代方案,您可以在启动期间进行修改。 只有使用 grub2 引导时,这些指令才适用。 您可以通过以下命令测试:
#
grub-install --version↩
grub-install (GRUB) 2.02-2ubuntu8.12
编辑 /etc/default/grub。 更改以 GRUB_CMDLINE_LINUX_DEFAULT= 开头的行。 如果文件中不存在该行,则在末尾添加。 它应该包含:
GRUB_CMDLINE_LINUX_DEFAULT="oldcmd
coredump_filter=newval
"
注意:oldcmd 是 GRUB_CMDLINE_LINUX_DEFAULT 的旧值(如果该行先前不存在,则省略)。 newval 是 coredump_filter 的新值,以十六进制表示,带有前导“0x”。 运行:
#
grub-mkconfig -o /boot/grub2/grub.cfg↩
◆
您应该针对所有进程设置ulimit -c 为无限制。 这可以在文件 /etc/security/limits.conf 中进行全局设置。 添加以下两行:
* soft core unlimited
* hard core unlimited
macOS(OS X、Darwin)
Mac OS X 曾重命名为 OS X,后来又重命名为 macOS。 所有这些操作系统均是 Apple 在 Darwin 上堆叠的专有用户界面,Darwin 是 Apple 从 BSD Unix 衍生出来的操作系统,理论上已发布到公共领域。 然而,以 Apple 发布 Darwin 的方式,实际上没有人会只运行 Darwin。
InterSystems 产品只需要 Darwin,但由于 Darwin 实际上不可用,因此所有说明均基于完整的 Apple Mac OS X、OS X 或 macOS。
macOS 包括 CrashReporter。 该工具可以自动拦截进程故障,将故障详细信息打包为文本日志,然后将数据发送给 Apple 进行分析。 CrashReporter 将捕获第三方软件(如 Caché、Ensemble、HealthShare 和 InterSystems IRIS 数据平台)的进程故障详细信息。 理论上,Apple 可将这些信息转发给 InterSystems。
InterSystems 没有从 Apple 收到 CrashReporter 日志,我们也没有开发分析这些日志的功能。 InterSystems 产品严格地生成核心文件。 幸运的是,CrashReporter 独立于核心文件创建。 也就是说,处理进程故障可以通过 CrashReporter 和核心文件创建这两种方式中的任意一种或两种,或者都不使用。
CrashReporter 设置可以在“系统偏好设置”→“安全和隐私”、“隐私”选项卡中设置。 面板名称和框的选择因版本而异。 在 Mac OS X 10.4 中,该面板的名称仅为“安全性”,没有相关的复选框。 在较旧的版本中,发生任何进程故障时都会向用户显示一个对话框,询问他们是否要将数据发送到 Apple 进行分析。 根据您处理的数据的敏感性,您可能想要取消选中与 CrashReprter 相关的所有选项。
◆
在 macOS 中,启用生成核心文件的方法在不同版本之间有很大变化。 请参见下表,并使用适合您的版本的方法。
版本
代号
InterSystems 版本
方法
公测版
Kodiak
不支持
方法 1:编辑 /hostconfig
Mac OS X 10.0
Cheetah
不支持
Mac OS X 10.1
Puma
不支持
Mac OS X 10.2
Jaguar
不支持
Mac OS X 10.3
Panther
Caché (PowerPC) 5.0, 5.1
Mac OS X 10.4
Tiger
Caché(标记 PowerPC 或 x86)5.0PowerPC, 5.1PowerPC, 5.2*, 2007.1*, 2008.1x86, 2008.2x86, 2009.1x86
方法 2:编辑 /etc/launchd.conf
Mac OS X 10.5
Leopard
Caché (x86) 2008.1, 2008.2, 2009.1, 2010.1
Mac OS X 10.6
Snow Leopard
Caché (x86–64) 2010.1, 2010.2, 2011.1, 2012.1, 2012.2
Mac OS X 10.7
Lion
Caché (x86–64) 2011.1, 2012.1, 2012.2, 2013.1, 2014.1
OS X 10.8
Mountain Lion
Caché (x86–64) 2012.2, 2013.1, 2014.1, 2015.1
OS X 10.9
Mavericks
Caché (x86–64) 2013.1, 2014.1, 2015.1, 2015.2, 2016.1, 2016.2
OS X 10.10
Yosemite
Caché (x86–64) 2014.1, 2015.1, 2015.2, 2016.1, 2016.2
方法 3:非自动。
OS X 10.11
El Capitan
Caché (x86–64) 2016.1, 2016.2, 2017.1DEV,2017.2DEV, 2018.1DEV
macOS 10.12
Sierra
Caché (x86–64) 2017.1, 2017.2, 2018.1
macOS 10.13
High Sierra
Caché (x86–64) 2018.1, 2019.1, 2019.2
macOS 10.14
Mojave
IRIS 2019.1, 2019.2
macOS 10.15
Catalina
未发布
**方法 1:**对于 OS X 10.3 (Cheetah) 以及先前不受支持的版本:编辑文件 /hostconfig。 查找行 COREDUMPS=,然后将值更改为 -YES-。
COREDUMPS=-YES-
◆
**方法 2:**对于 OS X 10.4 (Tiger) 到 OS X 10.9 (Mavericks) 版本,编辑文件 /etc/launchd.conf,然后添加以下行:
limit core unlimited
重新启动。
◆
**方法 3:**对于 OS X 10.10 (Yosemite) 及更高版本,/etc/launchd.conf 已去除。 核心文件生成现在是半禁用状态。 用户必须为每个进程启用核心:
%
ulimit -c unlimited↩
在允许他们的应用程序之前,特权用户必须运行:
#
launchctl limit core unlimited↩
然后注销,并在启动 Caché 前再次登录。 Apple 特地没有提供一个好方法来自动执行这些操作,因为他们认为默认生成核心文件是一个潜在的安全漏洞。
Apple 提供了完全禁用核心文件生成的方法。 这通过编辑文件 /etc/sysctl.conf 并添加以下行来完成:
kern.coredump=0
可以通过删除该行或将值更改为 `1` 来重新启用此功能。
OpenVMS
默认情况下,Caché 和 Ensemble 只针对故障进程生成 CACCVIO-pid.LOG 文件。 使用这些文件只能解决相对简单的问题。 这些 CACCVIO-pid.LOG 文件将始终放在进程默认目录中(通常是 CACHE.DAT 文件的目录),只有通过更改进程默认目录才能重定向。
Caché 和 Ensemble 也可能生成 CERRSAVE-pid.LOG文件。 这些文件与 CACCVIO-pid.LOG 文件类似。 通常,您无需关心它们的差异。 在某些情况下,Caché 和 Ensemble 将同时生成两种文件以响应故障。 在迄今为止的所有情况下,CACCVIO-pid.LOG 文件首先生成,其中包含错误的完整上下文,而 CERRSAVE-pid.LOG` 文件则在进程的最后断开过程中生成,包含的有价值的信息相对较少。
如果启用了扩展进程 dumps(完整转储),它们也会放置在进程默认目录中。 但是,可以将它们重定向,方法是定义逻辑名称 SYS$PROCDMP,将其指向要存储进程dump的目录。 该逻辑名称可以在 /SYSTEM 级别定义。 文件名将是 CACHE.DMP 或 CSESSION.DMP。
OpenVMS 还提供了逻辑名称 SYS$PROTECTED_PROCDMP。 您也应该使用 /EXECUTIVE_MODE 和 /SYSTEM 定义该逻辑名称。 这适用于特权映像privileged images的进程故障,Caché 的某些部分也拥有特权。 OpenVMS 文档中建议将这两个逻辑名称定义到不同的目录,并为与 SYS$PROTECTED_PROCDMP 对应的目录设置更高的安全性。 这基于以下假设:特权映像处理的数据比非特权映像处理的数据更敏感。 如果两种数据都很敏感,将两个逻辑名称指向同一目录也是可以的。
◆
影响 CACCVIO-pid.LOG 和 CERRSAVE-pid.LOG 文件创建以及完整进程dump的缺陷是有历史记录的。 以下是最重要的变更。
变更
第一个版本
说明
JLC1809
Caché 2015.2
在此变更之前,大多数 CERRSAVE-pid.LOG 文件是无用的。
JO2422
Cache 2012.1
在此变更之前,生成 CERRSAVE-pid.LOG 文件的条件在创建信息有限的文件时总是会忽略 DumpStyle。
JLC1326
Caché 2011.1
在此变更之前,Itanium 平台上的 CACCVIO-pid.LOG 和 CERRSAVE-pid.LOG 文件不包含寄存器。 这严重阻碍了我们使用这些文件解决问题的能力,而只能处理简单问题。 我们仍然可以与已经解决的问题相匹配。
JLC931 和 JLC959
Cache 2007.2
在此变更之前,Itanium 平台上的 CACCVIO-pid.LOG 和 CERRSAVE-pid.LOG 文件不记录任何有用信息。
JO1968
Caché 5.2
在此变更之前,生成 CACCVIO-pid 文件的条件在创建信息有限的文件时总是会忽略 DumpStyle。
Solaris
可以使用以下命令使核心文件放在公用目录中并带有扩展名称:
#
coreadm -e global -g /cores/core.%p.%f -G all↩
① %p 表示将 pid 放在路径名中。
② %f 表示将可执行文件名(如 cache)放在路径名中。
③ -G all 表示包括所有类型的内存,即完整核心文件内容。 省略此选项将生成默认核心文件内容,其中仍包括大部分共享内存。 核心文件中可以存储以下内容:
代码
InterSystems 使用
默认包括
stack
需要
是
heap
需要
是
shm
不使用
是
ism
不使用
是
dism
Caché 共享内存
是
text
用于 $ZF() 相关故障
是
data
需要
是
rodata
不使用
是
anon
需要
是
shanon
通常较小
是
ctf
需要
是
symntab
用于 $ZF() 相关故障
否
shfile
不使用
否
all 表示包括所有类型的内存,默认不包括最后两种。 如果您需要大幅减小的核心文件大小(以节省空间,但代价是可解决的问题变少),移除 dism 共享内存可节省出大部分空间。 使用以下命令执行此操作:
#
coareadm -e Global -g /cores/core.%p.%f -G (default-dism)↩
请参见:
%
main 1m coreadm↩
◆
默认情况下,用户已经
%
ulimit -c unlimited↩
您可以使用 ulimit(或在 csh 中使用 limit 命令)禁用核心,但 coreadm 通常更灵活。 因此您应该确保 ulimit 命令不会出现在 /etc/profile 或 $HOME/.profile 中,或者其他 shell 的相应文件中。
Windows
Windows 下的转储文件中包含的信息完全由 cache.cpf 文件中的 DumpStyle 参数(或上文定义的其他用于更改 DumpStyle 的接口)控制。
测试
除了特定问题外,本地安全组也可能阻止核心文件的写入。 在真实条件下测试是否可以成功创建核心文件非常有用。 为此,请输入命令:
USER>DO $ZUTIL(150,"DebugException")↩
可以肯定的是,您应该在 JOB 内以交互方式测试该语句(假定您的应用程序使用 JOB 命令),甚至在应用程序内隐藏一个不会被用户意外选择到的选项。 验证是否会获得核心文件,并按照下一节的健全性检查来验证它是否是好的核心文件。
健全性测试
核心文件(和进程转储)可能非常大,并且可能包含敏感信息。 在将核心文件传输到 InterSystems 进行分析之前,最好在生成核心文件的系统或非常相似的系统上对核心文件进行健全性测试。 根据您的操作系统,请执行以下健全性测试:
操作系统
健全性测试
AIX
# dbx cache core(dbx) set $stack_details(dbx) where(dbx) quit
向 WRC 开启问题时,将上述命令的输出结果也同时发送给我们。 如果您的系统未安装 dbx,则开启一个新问题。
HP–UX
# gdb cache core(gdb) frame 0(gdb) while 1 > info frame > up > end(gdb) quit
# adb coreadb> $cadb> $q
根据您拥有的调试器,将上述两个命令集的其中之一的输出结果发送给我们。 如果两个调试器都有,则首选 gdb(实际是 Wildebeest)。
RedHat Linux
对于所有版本的 Linux 都使用此通用健全性测试。
# gdb cache core(gdb) frame 0(gdb) while 1 > info frame > up > end(gdb) quit
SuSE Linux
Ubuntu Linux
向 WRC 开启问题时,将上述命令的输出结果发送给我们。 如果您的系统未安装 gdb,则开启一个新问题。
macOS (Darwin)
# lldb(lldb) target create -c core(lldb) thread backtrace all(lldb) quit
# gdb cache core(gdb) frame 0(gdb) while 1 > info frame > up > end(gdb) quit
将 lldb 的输出结果(如果是 OS X 10.8 (Mountain Lion) 或更高版本)或 gdb 的输出结果(如果是 Mac OS X 10.7 (Lion) 或更早版本)发送给我们。
OpenVMS
$ ANALYZE/CRASH dumpfile.DMPSDA> SHOW CALL_FRAME/ALL如果仍在运行 OpenVMS v7.x 或更早版本,先前的命令不适用,请改用:SDA> SHOW CALL_FRAMESDA> SHOW CALL_FRAME/NEXT重复先前的命令,直到获得错误。SDA> QUIT
$ ANALYZE/PROCESS dumpfile.DMPDBG> SHOW CALL/IMAGEDBG> QUIT
将 SDA 或debugger调试器的输出结果发送给我们,但首选 SDA 的输出。 如果您仅有 CACCVIO-pid.LOG 文件,请检查其是否为空或几乎为空。
Solaris
# mdb cache core> ::stackregs> ::quit
# dbx cache core(dbx) where(dbx) quit
在 Solaris 上,InterSystems 对于几乎所有应用程序都首选 dbx 调试器,但对于健全性测试,mdb 更好。 当您向 WRC 开启问题报告时,请将 mdb 或 dbx(首选 mdb)生成的堆栈跟踪信息发送给我们。
Windows
对于 Windows 进程转储,当前没有推荐的健全性检查。
请将健全性测试的详细信息附加到 WRC 案例,或通过电子邮件发送到support@intersystems.com 。
传输
请准备好向我们发送完整核心文件以及您的特定操作系统可能需要的支持文件。 我们需要知道生成了核心文件的 Caché、Ensemble、HealthShare 或 InterSystems IRIS 数据平台的准确版本。 如果您重定向了软件并包含自定义的 `$ZF()` 函数,请发送可执行文件。 (实际上,如果您总是发送可执行文件,会更加方便。) 在大多数 Unix 系统上,最好还发送可执行文件使用的库。 我们需要库的可能性因给定的平台而异。 请查阅下表:
操作系统
硬件
需要库
支持级别
AIX
PowerPC
不太可能
A
HP–UX
PA–RISC
非常可能
C
HP–UX
Itanium
有可能
A
Linux(所有版本)
x86
有可能
A
Linux(所有版本)
x86_64
有可能
A
Linux(所有版本)
Itanium
有可能
D
macOS
PowerPC
不太可能
D
macOS
x86
不太可能
C
macOS
x86_64
不太可能
A
OpenVMS
VAX
不适用
D
OpenVMS
ALPHA αxp
不适用
B
OpenVMS
Itanium
不适用
B
Solaris
x86_64
非常可能
B
Solaris
Sparc
不太可能
B
Tru64 UNIX
ALPHA αxp
非常可能
D
Windows
x86
不适用
A
Windows
x86_64
不适用
A
Windows
Itanium
不适用
D
支持级别说明
A: 截至本文档发布之时,InterSystems 拥有用于诊断该平台上的核心文件的资源。B: 对该平台的完全支持在最近失效。 不过,InterSystems 仍然有资源来诊断平台上的核心文件。 某些诊断出的问题可能无法使用专门版本更正。C: 旧版支持。 InterSystems 可能仍然拥有有限的资源来诊断该平台上的核心文件,但是,可能无法再提供专门版本来修复所发现的任何缺陷。D: 远古支持。 InterSystems 未保留任何可诊断这些平台上的问题的资源。 不过一些有限的功能仍保留下来。 这些平台上的核心可能会被分析。 但不可能修复所发现的任何缺陷。 发出 ldd 命令可列出所需的库:
# ldd install_directory/bin/image
linux-vdso.so.1 => (0x00007fffd1320000)
libdl.so.2 => /lib64/libdl.so.2 (0x00007f23e5002000)
librt.so.1 => /lib64/librt.so.1 (0x00007f23e4dfa000)
libstdc++.so.6 => /lib64/libstdc++.so.6 (0x00007f23e4af0000)
libm.so.6 => /lib64/libm.so.6 (0x00007f23e47ee000)
libgcc_s.so.1 => /lib64/libgcc_s.so.1 (0x00007f23e45d8000)
libc.so.6 => /lib64/libc.so.6 (0x00007f23e4216000)
/lib64/ld-linux-x86-64.so.2 (0x00007f23e521a000)
libpthread.so.0 => /lib64/libpthread.so.0 (0x00007f23e3ffa000)
上面的内容包含 Rhel 7 的示例输出。 所有 Unix 系统的输出都是类似的。 install_directory`指 Caché、Ensemble、HealthShare 或 InterSystems IRIS 数据平台的安装目录。 image 对于 2018 年以前的所有产品均为 cache,对于自 2019 年以后的产品为 irisdb。如果您要发送多个文件,最好将它们放在一个压缩的容器文件中。 一般来说,.ZIP是最好的容器。 .tar.gz 也是合理的。 对于 OpenVMS,使用以下命令创建备份文件:
$ BACKUP *.* [-]<var>saveset</var>.BCK/SAVE/DATA=COMPRESS
包含一个说明所发送文件的manifest会有帮助。 请准备纯文本文件形式的manifest。如果以电子方式发送数据,请不要加密文件,而是使用加密的传输方式。 您可以使用以下任意方法向 InterSystems 发送核心文件:
方法
安全性
最大大小
直接上传至 WRC 应用。上传文件前,必须开启一个 WRC 问题,上传文件后,可以选择将问题标记为更高安全性。 问题标记为更高安全性后,所有对与调查相关的文件的访问都仅限于实际进行调查的人员。 除了 300 M 的附件大小限制外,还有 60 秒的时间限制,因此如果您的有效带宽小于 42 Mbps,最大上传量会减少
安全或更高
300 M 和 60 秒
电子邮件。一般来说,除了不需要任何客户数据就可以进行调查的简单问题,应避免使用电子邮件。 示例:您刚刚在一台新计算机上安装了 Caché,但它在启动时出现故障,并生成一个小核心文件。 通过电子邮件发送该文件是合理的。
不安全
40 M
我们的 kite-works 服务器。对于任何给定问题,您都必须申请数据上传链接。 这些链接在 30 天或更短时间内过期。 这是上传安全数据的首选方法。 绝对大小限制是我们服务器上的可用空间。 但是,由于大多数客户都使用这种方法,如果您要上传大于 4G 的文件,请事先告知。
安全
> 4 G
我们的 sftp 服务器。您必须申请特定于用于问题的目录。 将为问题创建一个目录。 对于更高安全性的问题,我们创建了一个限制访问的机器(或虚拟机),并实现了一个自动流程将上传的任何文件都移动到该机器。 绝对大小限制是指我们服务器上的可用空间,如果您要上传大于 100 G 的文件,请事先告知。
更高
> 100 G
您的 ftp/sftp 服务器。您要求我们从中下载数据的服务器必须归您所有,并且您有完全控制权。 InterSystems 不会从任何第三方服务器下载数据。 第三方服务器被视为安全风险。
取决于您
?
SecurLink。InterSystems 可以通过我们的 SecurLink 远程控制工具直接从您的网络上的任何已核准的计算机中下载文件。 没有绝对大小限制。 但是,如果您通过 V.90 调制解调器连接到互联网,我们下载一个 3 Gio 的核心文件需要一周的时间。
安全且更高
?
物理介质。您可以将物理介质邮寄到您当地的 InterSystems 办公室。 InterSystems 可以读取介质,并将数据发送到我们的剑桥办公室,在那里进行大多数核心文件分析。 大多数办公室都可以处理 U 盘以及 ISO 9660 光盘介质。 我们的剑桥办公室可以处理多种磁带格式。 在发送任何介质之前,您应该先与 InterSystems 确认。如果通过挂号(非认证)邮件发送介质,那么数据可以被认为是安全的(可能安全性更高)。
视情况
?
务必要记住,我们需要的文件有些是二进制文件,有些是文本文件。 对于某些文件传输方法(尤其是在不同的操作系统之间),必须指定文件是二进制还是文本,以防止文件被损坏。
索引
a
ABRT ☞, ☞AppArmor ☞abrtd ☞abrt-cli ☞apport ☞
b
BlackListedPaths ☞
c
CACCVIO-pid.LOG ☞, ☞CACHE.DMP☞, ☞CERRSAVE-pid.LOG ☞CentOS ☞CORE_NOSHM ☞CrashReporter ☞CSESSION.DMP ☞cachefpid.dmp ☞pid.dmp ☞cachempid.dmp ☞cache.cpf ☞, ☞chcore ☞chdev ☞chkconfig ☞coreadm ☞, ☞coredumpctl ☞core_addshmem_read ☞core_addshmem_write ☞cstat ☞
d
DumpStyle ☞, ☞default ☞
e
/etc/environment ☞/etc/profile.d/something.sh ☞, ☞, ☞/etc/security/limits ☞/etc/security/limits.conf ☞, ☞, ☞/etc/sysctl.d ☞
f
FULL ☞
g
GRUB_CMDLINE_LINUX_DEFAULT ☞, ☞grub2 ☞, ☞grub2-mkconfig ☞
i
INTERMEDIATE ☞irisstat ☞iris.cpf ☞, ☞
l
lsattr ☞
m
MINIMAL ☞maxdsiz_64bit ☞
n
NOCORE ☞NOFORK ☞NOFORKNOSHARE ☞NOHANDLER ☞NORMAL ☞
o
OpenGPGCheck ☞
p
ProcessUnpackaged ☞pid.dmp ☞/proc/self/coredump_filter☞, ☞, ☞/proc/sys/kernel/core_pattern ☞, ☞, ☞
r
RPM ☞rcapparmor ☞
s
SYS$PROCDMP ☞SYS$PROTECTED_PROCDMP ☞$SYSTEM.Config.ModifyDumpStyle ☞敏感信息 ☞smit ☞systemd ☞
u
ulimit -c ☞, ☞, ☞, ☞/usr/sbin/kctune ☞
y
yast2 ☞
z
$ZUTIL(40,1,48) ☞$ZUTIL(40,2,165)☞$ZUTIL(150,"DebugException") ☞
get
文章
Hao Ma · 一月 15, 2021
介绍
目前,诸多应用程序通过开放授权框架(OAuth)来安全、可靠、高效地访问各种服务中的资源。InterSystems IRIS目前已兼容OAuth 2.0框架。事实上社区有一篇关于OAuth 2.0和InterSystems IRIS的精彩文章,链接如下。
然而,随着API管理工具的出现,一些组织开始将其用作单点身份验证,从而防止未经授权的请求到达下游服务,并将授权/身份验证复杂性从服务本身分离出来。
您可能知道,InterSystems已经推出了自己的API管理工具,即InterSystems API Management (IAM),以IRIS Enterprise license(IRIS Community版本不含此功能)的形式提供。这里是社区另一篇介绍InterSystems AIM的精华帖。
这是三篇系列文章中的第一篇,该系列文章将展示如何在OAuth 2.0标准下使用IAM简单地为IRIS中的未经验证的服务添加安全性。
第一部分将介绍OAuth 2.0相关背景,以及IRIS和IAM的初始定义和配置,以帮助读者理解确保服务安全的整个过程。
本系列文章的后续部分还将介绍两种使用IAM保护服务的可能的场景。在第一种场景中,IAM只验证传入请求中的访问令牌,如果验证成功,则将请求转发到后端。在第二种场景中,IAM将生成一个访问令牌(充当授权服务器)并对其进行验证。
因此,第二篇将详细讨论和展示场景1中的配置步骤,第三篇将讨论和演示场景2中的配置以及一些最终要考虑的因素。
如果您想试用IAM,请联系InterSystems销售代表。
OAuth 2.0背景
每个OAuth 2.0授权流程基本上都由4个部分组成:
用户
客户端
授权服务器
资源所有者
简单起见,本文使用“资源所有者密码凭证”OAuth流(可以在IAM中使用任何OAuth流)。另外,本文将不指定任何使用范围。
注意:因为资源所有者密码凭证流直接处理用户凭证,所以应该只在客户端应用程序高度受信任时使用。在大多数情况下,客户端应为第一方应用程序。
通常,资源所有者密码凭证流遵循以下步骤:
用户在客户端应用程序中输入凭证(如用户名和密码)
客户端应用程序将用户凭证和自身的标识(如客户端ID和客户端密钥)一起发送到授权服务器。授权服务器验证用户凭证和客户端标识,并返回访问令牌
客户端使用令牌访问资源服务器上的资源
资源服务器首先验证收到的访问令牌,然后再将信息返回给客户端
考虑到这种情况,你可以在两种场景下使用IAM应对OAuth 2.0:
IAM充当验证器,验证客户端应用程序提供的访问令牌,仅在访问令牌有效时才将请求转发给资源服务器;在这种情况下,访问令牌将由第三方授权服务器生成
IAM既充当授权服务器(向客户端提供访问令牌),又充当访问令牌验证器,在将请求重定向到资源服务器之前验证访问令牌。
IRIS和IAM初始定义和配置
本文中使用名为“/SampleService”的IRIS Web应用程序。从下面的截屏中可以看到,这是一个在IRIS中部署的未经身份验证的REST服务:
此外,在IAM端配置了一个名为“SampleIRISService”的服务,其包含一个路由,如以下截屏所示:
再者,在IAM中配置了一个名为“ClientApp”的客户端(初始没有任何凭据),用来识别谁在调用IAM中的API:
经上述配置,IAM将发送到以下URL的每个GET请求代理到IRIS:
http://iamhost:8000/event
此时还没有使用身份验证。所以,如果将一个简单的GET请求(未进行身份验证)发送到URL:
http://iamhost:8000/event/1
我们将获得期望的响应。
本文中,我们使用名为“PostMan”的应用程序发送请求并检查响应。在下面的PostMan截屏中,可以看到简单的GET请求及其响应。
请继续阅读本系列的第2篇,了解如何配置IAM来验证传入请求中的访问令牌。
文章
Hao Ma · 一月 15, 2021
InterSystems编程语言的错误管理技术一直在发展。接下来,我们将展示几种不同的错误管理实现方式,以及为什么要使用TRY/THROW/CATCH机制。
您可以点击这里阅读官方的错误处理建议。
为了支持遗留应用程序,InterSystems不会废弃非推荐的错误管理方法。我们建议使用objectscriptQuality等工具来检测遗留的非推荐用例以及其他可能的问题和错误。
$ZERROR
$ZERROR是一种较老的错误管理机制,支持与标准“M”不同的实现。虽然$ZERROR现在仍然有效,但我们非常不推荐使用。
如果您已经使用了$ZERROR,那么很容易对该变量进行错误的设计使用。$ZERROR是一个全局公共变量,可以被当前进程中正在执行的所有routine(宏)(来自InterSystems或自定义的)进行访问和修改。因此,它的值仅在产生错误的时候是可靠的。InterSystems不保证$ZERROR在调用系统库时会保留旧值。
我们在这里对一些案例展开分析。
案例1:自定义代码中的错误代码
Line
Code
Comments
$ZERROR value
1
Set ...
""
2
Set ...
""
...
Do ...
""
...
...
""
N-m
Do CacheMethodCall()
Call to another Caché system methods
""
...
""
N
Set VarXX = MyMethod()
The custom method generates an ObjectScript error
<UNDEFINED>B+3^InfinityMethod *varPatient
N+1
Set …
<UNDEFINED>B+3^InfinityMethod *varPatient
N+2
Do OtherCacheMethodCall()
Caché system method. $ZERROR is not updated if there is no error.
<UNDEFINED>B+3^InfinityMethod *varPatient
...
If ...
<UNDEFINED>B+3^InfinityMethod *varPatient
...
...
<UNDEFINED>B+3^InfinityMethod *varPatient
...
While ...
<UNDEFINED>B+3^InfinityMethod *varPatient
...
If $ZERROR’=”” Quit “Error”
<UNDEFINED>B+3^InfinityMethod *varPatient
N+m
Quit "OK"
<UNDEFINED>B+3^InfinityMethod *varPatient
案例2:内部Caché错误出现误报
在这种情况下,自定义代码运行良好,但内部Caché错误引发了一个错误。
Line
Code
Comments
$ZERROR value
1
Set …
""
2
Set …
""
..
Do …
""
..
…
""
N-m
Do CacheMethodCall()
Internal error but it is managed internally and decides to continue execution
<UNDEFINED>occKl+3^ MetodoInternoCache *o0bxVar
..
<UNDEFINED>occKl+3^ MetodoInterno *o0bxVar
N
Set VarXX = MyMethod() // OK
<UNDEFINED>occKl+3^ MetodoInterno *o0bxVar
N+1
Set …
<UNDEFINED>occKl+3^ MetodoInterno *o0bxVar
N+2
Do OtherCacheMethodCall() // OK
<UNDEFINED>occKl+3^ MetodoInterno *o0bxVar
…
If …
<UNDEFINED>occKl+3^ MetodoInterno *o0bxVar
…
…
<UNDEFINED>occKl+3^ MetodoInterno *o0bxVar
…
While …
<UNDEFINED>occKl+3^ MetodoInterno *o0bxVar
…
If $ZERROR’="" Quit "Error"
An error is detected while there is no error at all
<UNDEFINED>occKl+3^ MetodoInterno *o0bxVar
N+m
Quit "OK"
<UNDEFINED>occKl+3^ MetodoInterno *o0bxVa
案例3:在Caché内部代码中重置$ZERROR时出现误报
在这种情况下,即使不存在错误,也会直接或间接调用一个内部Caché方法或routine(宏)来重置公共变量$ZERRO
Line
Code
Comments
$ZERROR
1
Set ...
""
2
Set ...
""
...
Do ...
""
...
...
""
N-m
Do CacheMethodCall()
<UNDEFINED>occKl+3^ MetodoInternoCache *o0bxVar
...
<UNDEFINED>occKl+3^ MetodoInterno *o0bxVar
N
Set VarXX = MyMethod()
<UNDEFINED>occKl+3^ MetodoInterno *o0bxVar
N+1
Set …
<UNDEFINED>occKl+3^ MetodoInterno *o0bxVar
N+2
Do OtherCacheMethodCall()
Internal method that resets $ZERROR whether there is error or not
""
...
If ...
""
...
...
""
...
While ...
""
...
If $ZERROR’="" Quit "Error"
Error not detected
""
N+m
Quit "OK"
""
$ZTRAP
$ZTRAP是在上下文中进行错误管理的,因此不存在在上下文环境之外被意外覆盖的风险。当出现错误时,控件返回到调用堆栈中的第一个错误控件。
当出现错误并处理完成后,必须清除$ZTRAP,以便在发生另一个错误时避免出现无限循环。
因此,$ZTRAP在错误管理方面比$ZERROR更先进,但开发人员在添加操作时有可能会产生更多的错误。
如果想要进一步了解此方法的使用,可以查看官方文档中的“$ZTRAP错误处理”节选内容。
%Status
该方法用于系统库中,因此是调用系统库时必须使用的机制。
可以点击这里查看用法。
TRY/THROW/CATCH
这是最现代的错误管理方法,也是目前比较推荐的方法。
您可以点击这里查看用法。
此方法可在上下文中管理错误,并且不需要开发人员管理内部错误变量。
优点
关于TRY/THROW/CATCH的文献有很多,这里列举了一些它的优点:
提供了一种清晰的方式进行异常情况处理,将错误代码与常规代码分开处理
简化了错误检测,所以无需在每次操作后检查错误
允许错误传播到上层
支持运行时错误,允许在崩溃后恢复并继续运行
缺点
最明显的缺点是轻微的性能损失,因此您必须知道需要在什么时候使用该方法。
通常,没有必要在每种方法上都使用TRY/THROW/CATCH,在很多情况下在操作前多进行几次简单的验证就可以避免很多避免错误,从而避免不必要地使用TRY/THROW/CATCH方法。
结论
避免使用$ZERROR和$ZTRAP。
只有在调用系统库时才使用%STATUS。
可以使用TRY/THROW/CATCH管理错误,但不要滥用。
文章
Hao Ma · 一月 15, 2021
什么是npm-iris?
NPM是“No Project Mess(项目不乱)”的缩写。
NPM是使用Intersystems IRIS和Bootstrp 4建成的项目和任务管理应用程序。
NPM的创建初衷是通过一个简单直观的项目和任务管理软件,帮助开发者和小型商业公司降低日常问题的复杂度。
它能提供不同的任务视图,包括电子表格、看板、日历,甚至甘特图!
为什么?
在不同的团队中工作,您会发现不同的人喜欢不同的工具。
所以,有时您会在一个项目中使用甘特图,在另一个项目中使用看板,在其他项目中使用纸上的列表……
NPM专注于任务。无论您和您的团队喜欢以哪种方式查看。只需单击并更改您的视图。
功能
初始安装
项目
用户
任务 - 创建和管理任务
调度程序 - 任务的日历视图
看板 - 用看板风格管理您的任务
甘特图 - 使用甘特图查看截止日期、里程碑和进度
新特性/改进的路线图
OAuth2身份验证
项目/团队/用户的安全性
时间跟踪
自定义日历(假期)
支持附件
利用AppS.REST框架
Vue.js版本
Home面板,可以查看活动的概况
试一下这款应用程序! http://npm-iris.eastus.cloudapp.azure.com:52773/npm/home.csp
如果您喜欢这个应用程序,并认为我值得您的投票,请投票给npm-iris! https://openexchange.intersystems.com/contest/current
文章
Hao Ma · 一月 15, 2021
假设您想编写一些真正的web应用程序,例如medium.com网站的简单克隆。这类应用程序可以在后端使用任何不同的语言编写,也可以使用前端的任何框架编写。编写这样一个应用程序有很多方法,你也可以看看这个项目。它为完全相同的应用程序提供了一堆前端和后端实现。您可以轻松组合它们,任何所选前端应该与任何后端搭配。
我来介绍一下这个使用后端InterSystems IRIS来实现后端的相同的应用程序。
RealWorld项目使用REST并提供预设swagger规范,以及Postman/Newman集合自动化测试。因此,它有助于实现完全相同的REST API。幸运的是,InterSystems已经实现了通过swagger规范生成REST API实现的方法。最佳实践在这里。
我实现这个应用程序的步骤是:
从swagger规范生成API
为应用程序中使用的每个对象类型添加一些持久类,包括
Users
Articles
Comments
实现API并用Postman测试
最后,用任何前端查看实际效果。
用 docker 启动
你可以自己使用docker 来实验一下。
// clone github repository
git clone https://github.com/daimor/realworld-intersystems-iris.git
cd realworld-intersystems-iris
// build and run it with docker-compose
docker-compose up -d --build
启动后可以通过URL http://localhost:12000/conduit获取IRIS中的REST API,可以用newman测试,需要已安装npm和npx包。
APIURL=http://localhost:12000/conduit ./run-api-tests.sh
运行Postman的相同测试
可以通过URL http://localhost/访问前端
可以通过zpm运行UnitTest,只需要进入iris会话
$ docker-compose exec server iris session iris
Node: 0790684cf488, Instance: IRIS
CONDUIT>zpm
zpm: CONDUIT>test realworld [realworld] Reload START
[realworld] Reload SUCCESS
[realworld] Module object refreshed.
[realworld] Validate START
[realworld] Validate SUCCESS
[realworld] Compile START
[realworld] Compile SUCCESS
[realworld] Activate START
[realworld] Configure START
[realworld] Configure SUCCESS
[realworld] Activate SUCCESS
[realworld] Test START
Use the following URL to view the result:
http://172.22.0.3:52773/csp/sys/%25UnitTest.Portal.Indices.cls?Index=48&$NAMESPACE=CONDUIT
All PASSED
[realworld] Test SUCCESS
zpm: CONDUIT>
默认使用Vue前端,但也能运行Angular和React
web=angular docker-compose up -d --build web
web=react docker-compose up -d --build web
web=vue docker-compose up -d --build web
通过ZPM安装
InterSystems IRIS部分(后端)可以通过ZPM安装
USER>zpm
zpm: USER>install realworld [realworld] Reload START
[realworld] Reload SUCCESS
[realworld] Module object refreshed.
[realworld] Validate START
[realworld] Validate SUCCESS
[realworld] Compile START
[realworld] Compile SUCCESS
[realworld] Activate START
[realworld] Configure START
[realworld] Configure SUCCESS
[realworld] Activate SUCCESS
zpm: USER>
它将创建`/conduit` Web应用程序,只要设置正确的端口,也能用newman进行测试。
APIURL=http://localhost:52773/conduit ./run-api-tests.sh
可以用ZPM进行UnitTest
zpm: USER>test realworld [realworld] Reload START
[realworld] Reload SUCCESS
[realworld] Module object refreshed.
[realworld] Validate START
[realworld] Validate SUCCESS
[realworld] Compile START
[realworld] Compile SUCCESS
[realworld] Activate START
[realworld] Configure START
[realworld] Configure SUCCESS
[realworld] Activate SUCCESS
[realworld] Test START
Use the following URL to view the result:
http://172.17.0.2:52773/csp/sys/%25UnitTest.Portal.Indices.cls?Index=4&$NAMESPACE=USER
All PASSED
[realworld] Test SUCCESS
备注
在开发这个项目的过程中,我遇到了一些问题。
%JSON.Adaptor
它在导入全新对象时效果非常好。但如果需要部分更新现有对象,则%JSONImport对于来源JSON中应该有的必需字段无效。
所以我没用%JSONImport更新对象,而是用了一个从传入的JSON到对象的简单集(如果定义了值)。
只能导出到字符串、流和输出设备。无法导出到原生JSON
API需要返回被另一个对象(属性被命名为返回对象的类型)包装的任何对象。并用%JSONExportToString解决了这个问题,对于数组,将其转换为原生JSON
忽略空集合属性(如:数组和列表)的导出。虽然应用程序可能期望得到字段的空数组,但它根本没有得到任何字段
这个问题没解决。太棘手,只能在%JSON.Adapter端解决。
%REST - REST实现的生成器及REST实现本身
即使没有任何更改,`spec`类的任何编译都会更新`impl`类。因此,切记保持生成的部分(如:方法名、参数列表和变量名)不变,否则将会被下一次`spec`编译重写,这可能会在构建用于生产的应用程序时发生。
REST可以有`/users/` 端点,也能获取`/users/`请求,在这种情况下,两者效果相同。但如果只定义了第一种方式,REST就不能识别第二种方式。
要解决这个问题,必须修改swagger规范,只复制带新端点`/users/`的`/users/`
Swagger规范定义了参数化请求的默认值,而生成器忽略了
在方法/生成器的代码中手动设置默认值可能会重写方法定义,而参数的设置默认值将被删除。所以可能在部署后破坏实现。
%REST.REST中的方法不可用于覆盖,仅由`disp`类使用,且将被`spec`类的编译完全重写。
无法访问实例的OnPreDispatch方法,也就无法进行更多控制,如:检查访问
Swagger规范定义了哪些端点是公共的,哪些需要授权。%REST生成器无法使用。
API必须用JWT来授权请求,且必须手动检查哪个端点需要检查访问。超出了%OAuth2实现的范围,在IRIS中使用JWT也很麻烦。
在`impl`类中生成的方法应该返回原生JSON对象、流或字符串。但我认为如果它也能接受%JSON.Adaptor对象就很好。
无论如何,实现这样的应用程序是非常有趣的。至少知道了可以用IRIS来实现。
这个应用程序使用了IRIS的这些特性
原生JSON + %JSON.Adaptor
REST,及其遵守swagger规范的实现生成器
OAuth2的JWT
容器化
竞赛
这个项目正在参加InterSystems全栈竞赛,如果您喜欢请投票。
文章
Qiao Peng · 一月 14, 2021
本文以及后面两篇该系列文章,是为需要在其基于 InterSystems 产品的应用程序中使用 OAuth 2.0 框架(下文简称为 OAUTH)的开发人员或系统管理员提供的指南。
作者:InterSystems 高级销售工程师 Daniel Kutac
# 发布后校正和更改历史记录
* 2016 年 8 月 3 日 - 修正了 Google 客户端配置屏幕截图,更新了 Google API 屏幕截图以反映新版本的页面
* 2016 年 8 月 28 日 - 更改了 JSON 相关代码,反映了对 Cache 2016.2 JSON 支持的更改
* 2017 年 5 月 3 日 - 更新了文本和屏幕,以反映 Cache 2017.1 的新 UI 和功能
* 2018 年 2 月 19 日 - 将 Caché 更改为 InterSystems IRIS 以反映最新的发展。 但是请记住,尽管产品名称发生更改,但**文章涵盖所有的 InterSystems 产品**——InterSystems IRIS 数据平台、Ensemble 和 Caché。
* 2020 年 8 月 17 日 - 大面积更改,软件方面更改更大。 要获取 Google 的更新版 Oauth2 的网址,请咨询 Micholai Mitchko。
_第 1 部分 客户端_
# **简介**
有关开放式授权框架 InterSystems 实现的相关内容,我们分 3 部分讲述,这是第 1 部分。
在第 1 部分中,我们对该主题进行了简短介绍,并提供了一个 InterSystems IRIS 应用程序担当授权服务器客户端并请求一些受保护资源的简单方案。
第 2 部分将讲述一个复杂一些的方案,在该方案中 InterSystems IRIS 本身通过 OpenID Connect 担当授权服务器和身份验证服务器。
本系列的最后一部分将描述 OAUTH 框架类的各个部分,它们由 InterSystems IRIS 实现。
## **什么是开放授权框架 [1] **
许多人已经听说过有关开放授权框架及其用途的信息。 因此这里只做简单介绍,以备未听说过的人参考。
开放授权框架 (OAUTH) 当前为 2.0 版,其是一种协议,允许基于 Web 的主应用程序通过在客户端(应用程序请求数据)和资源所有者(应用程序保存请求的数据)之间建立间接信任来以安全的方式交换信息。 信任本身由客户端和资源服务器都认可并信任的主体提供。 该主体称为授权服务器。
简单举例如下:
假设 Jenny(使用 OAUTH 术语,就是资源所有者)在开展 JennyCorp 公司的一个工作项目。 她为一个潜在的大型业务创建了项目计划,并邀请 JohnInc 公司的业务伙伴 John(客户端用户)审阅此文档。 不过,她并不愿意让 John 访问自己公司的 VPN,因此她将文档放在 Google 云端硬盘(资源服务器)或其他类似的云存储中。 她这样做,已经在她和 Google(授权服务器)之间建立了信任。 她标记了要与 John 共享的文档(John 已经使用 Google 云端硬盘服务,Jenny 知道他的电子邮件)。
当 John 想要阅读该文档时,他进行了 Google 帐户身份验证,然后通过移动设备(平板电脑、笔记本电脑等)启动文档编辑器(客户端服务器)并加载 Jenny 的项目文件。
这听起来很简单,但是两个人与 Google 之间有很多通信。 所有交流均遵循 OAuth 2.0 规范,因此 John 的客户端(阅读器应用程序)必须首先向 Google 进行身份验证(OAUTH 不涵盖此步骤),然后 John 申请获取 Google 对提供表格的同意,经过授权后,Google 就会发出一个访问令牌,授权阅读器应用程序访问文档。 阅读器应用程序使用该访问令牌向 Google 云端硬盘服务发出请求,以检索 Jenny 的文件。
下图说明了各方之间的通信
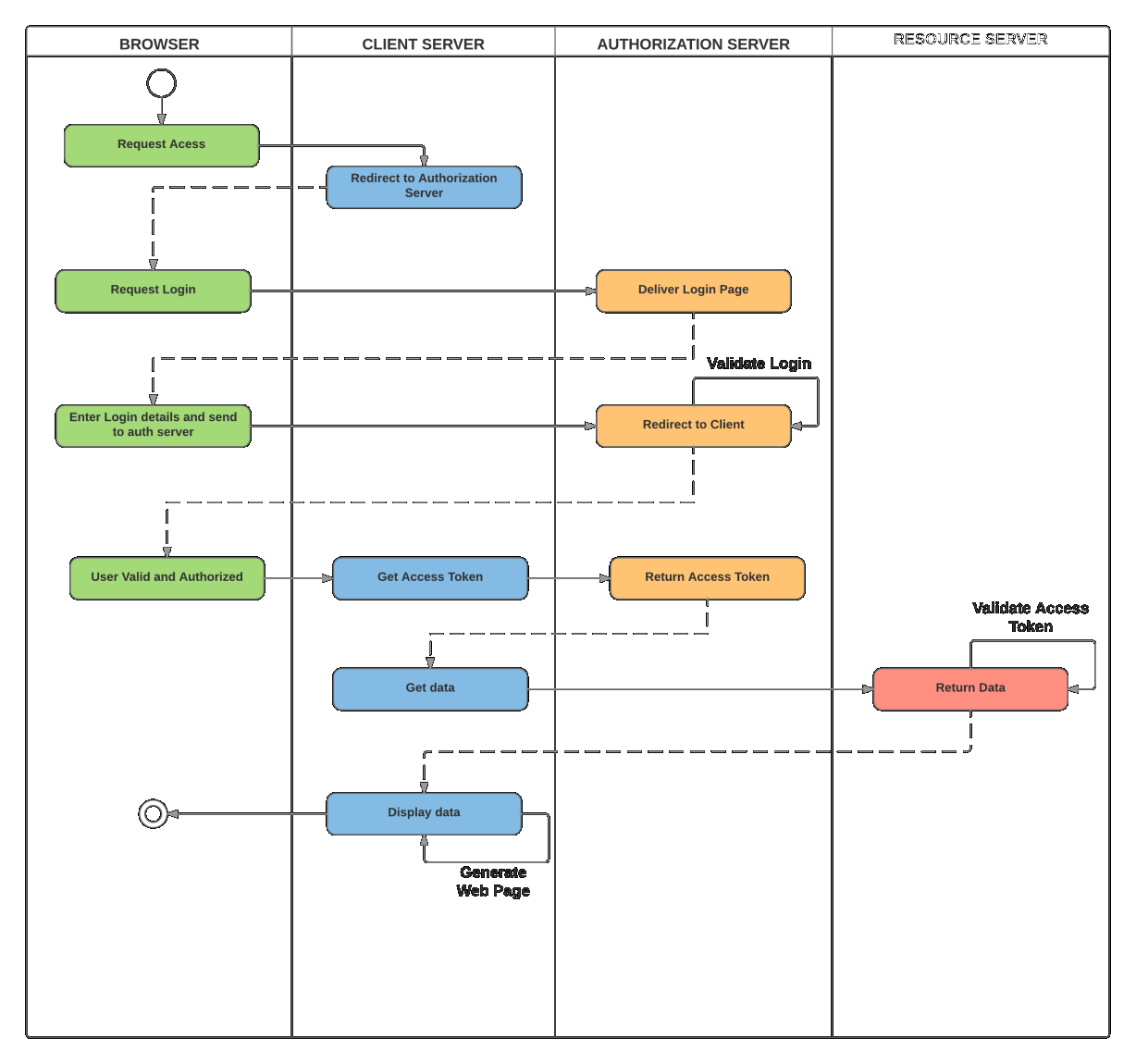
请注意:虽然所有的 OAUTH 2.0 通信都使用 HTTP 请求,但服务器不必非得是 Web 应用程序。
让我们通过 InterSystems IRIS 来说明这一简单方案。
# **简单 Google 云端硬盘演示**
在本演示中,我们将创建一个基于 CSP 的小型应用程序,该应用程序将使用我们自己的帐户(以及作为奖励的日历列表)来请求存储在 Google 云端硬盘服务中的资源(文件列表)。
## **基本要求**
开始应用程序编码之前,我们需要准备环境。 这包括启用 SSL 的 Web 服务器和 Google 配置文件。
### **Web 服务器配置**
如上所述,我们需要使用 SSL 与授权服务器进行通信,因为默认情况下 OAuth 2.0 要求如此。 我们需要确保数据安全,对吧?
解释如何配置 Web 服务器来支持 SSL 的内容超出了本文讨论的范围,因此,请以您喜欢的方式参阅相应 Web 服务器的用户手册。 为了您的好奇心(我们稍后可能会显示一些屏幕截图),在此特定示例中,我们将使用 Microsoft IIS 服务器。
### **Google 配置**
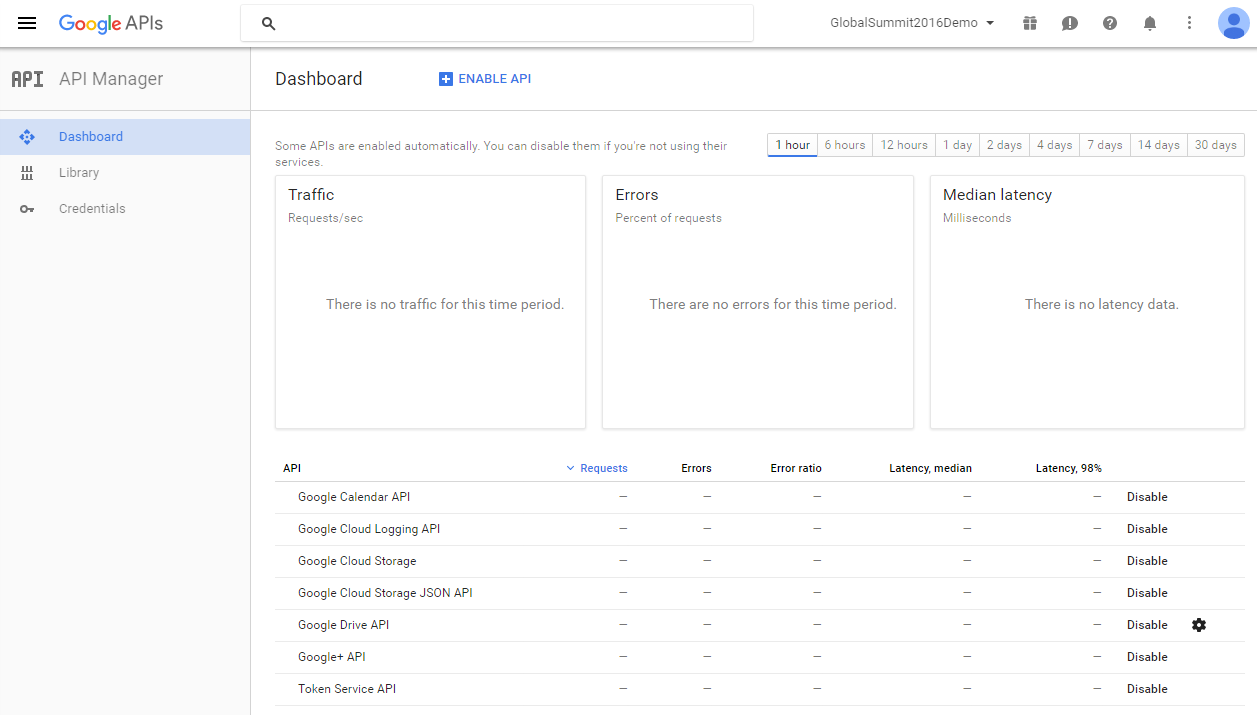
为了向 Google 注册,我们需要使用 Google API Manager-[ https://console.developers.google.com/apis/library?project=globalsummit2016demo ](https://console.developers.google.com/apis/library?project=globalsummit2016demo)
为了进行演示,我们创建了一个帐户 GlobalSummit2016Demo。 确保我们已启用 Drive API
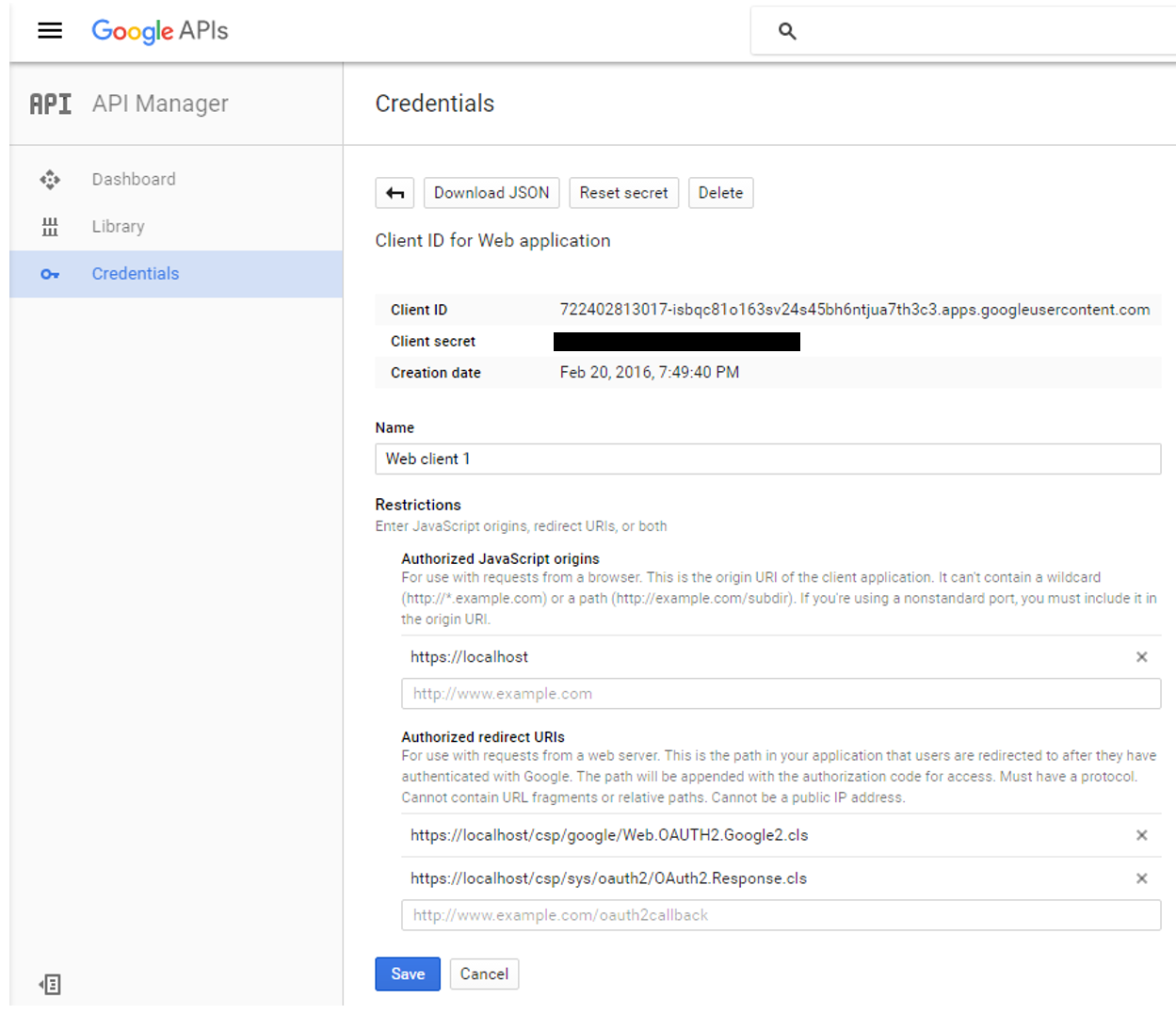
现在,该定义凭据了
请注意以下事项:
_Authorized JavaScript – _我们仅允许本地生成的脚本(相对于调用页面)
_Authorized redirect URIs – 从理论上讲,我们可以将客户端应用程序重定向到任何站点,但是当使用 InterSystems IRIS OAUTH 实现时,我们必须重定向到** https://localhost/csp/sys/oauth2/OAuth2.Response.cls**。您可以定义多个授权的重定向 URI,如屏幕截图所示,但是对于本演示,我们只需要两者中的第二个条目。
最后,我们需要将 InterSystems IRIS 配置为 Google 授权服务器的客户端
### **Caché /IRIS配置**
InterSystems IRIS OAUTH2 客户端配置需要两步。 首先,我们需要创建服务器配置。
在 SMP 中,导航至**系统管理 > 安全性 > OAuth 2.0 > 客户端配置**。
点击**创建服务器配置**按钮,填写表格并保存。
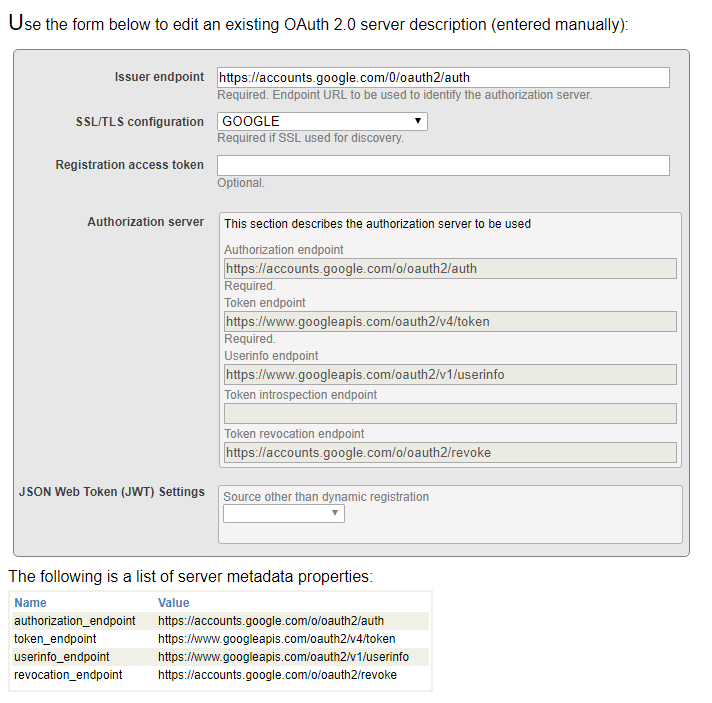
输入到表格的所有信息可以在 Google 开发者控制台网站上找到。 请注意,InterSystems IRIS 支持自动 Open ID 发现。 但是,由于我们没有使用它,因此我们手动输入所有信息
现在,点击新创建的 Issuer Endpoint
旁边的“客户端配置”链接。并点击**创建客户端配置**按钮。
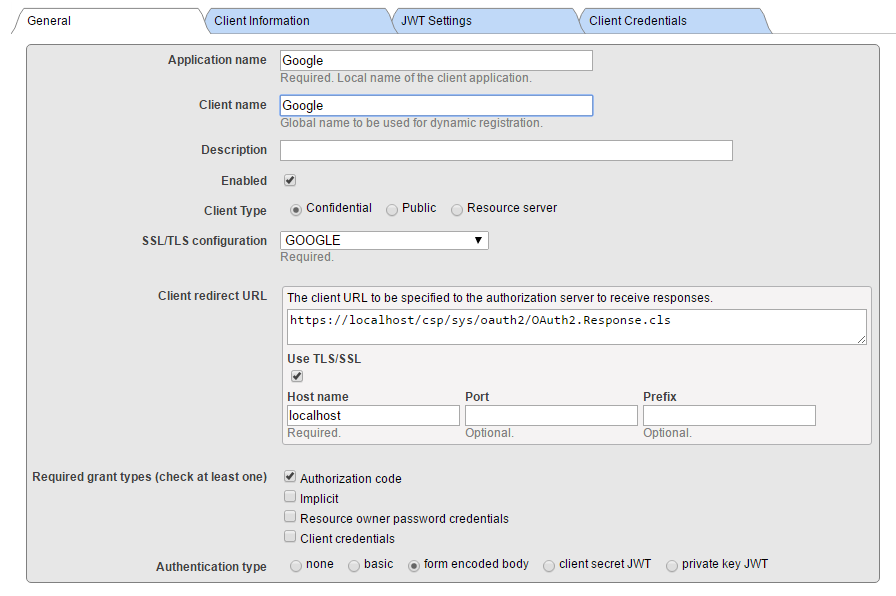
将“客户端信息”和“JWT 设置”选项卡保留为空(默认值),并填写客户端凭据。
请注意:我们正在创建机密客户端(这比公共客户端更安全,这意味着客户端秘密永远不会离开客户端服务器应用程序(永远不会传输到浏览器)
此外,请确保选中**“使用 SSL/TLS**”,并提供主机名(本地主机,因为我们将本地重定向到客户端应用程序),最后提供端口和前缀(当同一台机器上有多个 InterSystems IRIS 实例时,这非常有用)。 根据输入的信息,会计算客户端重定向 URL 并显示在上一行中。
在上面的屏幕截图中,我们提供了一个名为 GOOGLE 的 SSL 配置。 该名称本身实际上仅用于帮助您确定此特定通信通道使用的可能是众多 SSL 配置中的哪个。 Caché 使用 SSL/TLS 配置存储所有必要的信息,以建立与服务器(在本例中,为 Google OAuth 2.0 URI)的安全流量。
有关详细信息,请参阅[文档](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GCAS_ssltls#GCAS_ssltls_aboutconfigs) 。
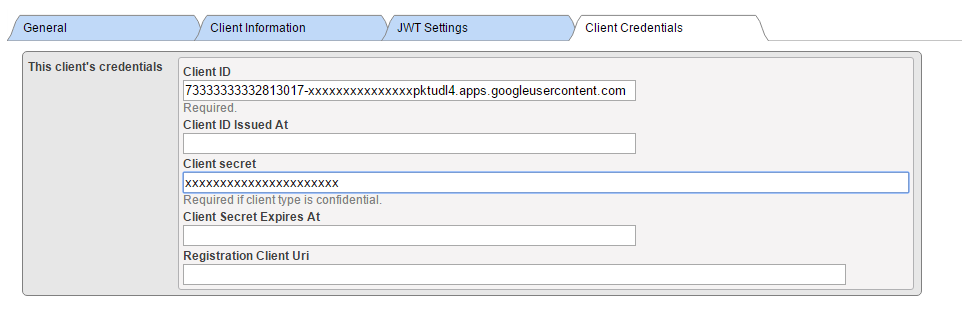
Supply Client ID 和 Client Secret 值从 Google 凭据定义表中获得(使用手动配置时)。
现在,我们完成了所有的配置步骤,可以开始编写 CSP 应用程序代码。
## **客户端应用程序**
客户端应用程序是基于 Web 的简单 CSP 应用程序。 因此,它包含由 Web 服务器定义和执行的服务器端源代码,以及由 Web 浏览器向用户公开的用户界面。 下文提供的示例代码期望客户端应用程序在 GOOGLE 名称空间中运行。 请将路径 /csp/google/ 修改为您的命名空间。
## **客户端服务器**
客户端服务器是一个简单的两页应用程序。 在该应用程序内,我们将:
· 将 URL 重定向到 Google 授权服务器
· 执行向 Google Drive API 和 Google Calendar API 的请求并显示结果
### **第 1 页**
这是应用程序的一页,我们决定在此处调用 Google 的资源。
以下是此页面上简单但功能齐全的代码。
Class Web.OAUTH2.Google1N Extends %CSP.Page
{
Parameter OAUTH2CLIENTREDIRECTURI = "https://localhost/csp/google/Web.OAUTH2.Google2N.cls";
Parameter OAUTH2APPNAME = "Google";
ClassMethod OnPage() As %Status
{
&html
// we need to supply openid scope to authenticate to Google
set scope="openid https://www.googleapis.com/auth/userinfo.email "_
"https://www.googleapis.com/auth/userinfo.profile "_
"https://www.googleapis.com/auth/drive.metadata.readonly "_
"https://www.googleapis.com/auth/calendar.readonly"
set properties("approval_prompt")="force"
set properties("include_granted_scopes")="true"
set url=##class(%SYS.OAuth2.Authorization).GetAuthorizationCodeEndpoint(..#OAUTH2APPNAME,scope,
..#OAUTH2CLIENTREDIRECTURI,.properties,.isAuthorized,.sc)
w !,""
&html
Quit $$$OK
}
ClassMethod OnPreHTTP() As %Boolean [ ServerOnly = 1 ]
{
#dim %response as %CSP.Response
set scope="openid https://www.googleapis.com/auth/userinfo.email "_
"https://www.googleapis.com/auth/userinfo.profile "_
"https://www.googleapis.com/auth/drive.metadata.readonly "_
"https://www.googleapis.com/auth/calendar.readonly"
if ##class(%SYS.OAuth2.AccessToken).IsAuthorized(..#OAUTH2APPNAME,,scope,.accessToken,.idtoken,.responseProperties,.error) {
set %response.ServerSideRedirect="Web.OAUTH2.Google2N.cls"
}
quit 1
}
}
代码的简要说明如下:
1. OnPreHTTP 方法 - 首先,我们有机会时检查一下,我们是否由于 Google 授权而获得了有效的访问令牌——这种情况可能会发生,例如当我们只是刷新页面时。 如果没有,我们需要授权。 如果我们有令牌,我们只需将页面重定向到显示结果的页面
2. OnPage 方法 - 只有在我们没有可用的有效访问令牌时,我们才到这里,因此我们需要开始通信——向 Google 进行身份验证和授权,以便它向我们授予访问令牌。
3. 我们定义了作用域字符串和属性数组,用于修改 Google 身份验证对话框的行为(我们需要先向 Google 进行身份验证,然后它才能根据我们的身份对我们进行授权)。
4. 最后,我们收到 Google 登录页面的 URL,然后将其提供给用户,接着提供同意页面。
还有一点注意事项:
我们在 OAUTH2CLIENTREDIRECTURI 参数的 中指定真正的重定向页面。 但是,我们在 Google 凭据定义中使用了 InterSystems IRIS OAUTH 框架的系统页面! 重定向由我们的 OAUTH 处理程序类在内部处理。
### **第 2 页**
此页面显示 Google 授权的结果,如果成功,我们将调用 Google API 调用以检索数据。 同样,此代码简单,但功能齐全。 相比读者的想象,我们以更结构化的方式来显示输入数据。
Include %occInclude
Class Web.OAUTH2.Google2N Extends %CSP.Page
{
Parameter OAUTH2APPNAME = "Google";
Parameter OAUTH2ROOT = "https://www.googleapis.com";
ClassMethod OnPage() As %Status
{
&html
// Check if we have an access token
set scope="openid https://www.googleapis.com/auth/userinfo.email "_
"https://www.googleapis.com/auth/userinfo.profile "_
"https://www.googleapis.com/auth/drive.metadata.readonly "_
"https://www.googleapis.com/auth/calendar.readonly"
set isAuthorized=##class(%SYS.OAuth2.AccessToken).IsAuthorized(..#OAUTH2APPNAME,,scope,.accessToken,.idtoken,.responseProperties,.error)
if isAuthorized {
// Google has no introspection endpoint - nothing to call - the introspection endpoint and display result -- see RFC 7662.
w "Data from GetUserInfo API"
// userinfo has special API, but could be also retrieved by just calling Get() method with appropriate url
try {
set tHttpRequest=##class(%Net.HttpRequest).%New()
$$$THROWONERROR(sc,##class(%SYS.OAuth2.AccessToken).AddAccessToken(tHttpRequest,"query","GOOGLE",..#OAUTH2APPNAME))
$$$THROWONERROR(sc,##class(%SYS.OAuth2.AccessToken).GetUserinfo(..#OAUTH2APPNAME,accessToken,,.jsonObject))
w jsonObject.%ToJSON()
} catch (e) {
w "ERROR: ",$zcvt(e.DisplayString(),"O","HTML")_""
}
/******************************************
* *
* Retrieve info from other APIs *
* *
******************************************/
w ""
do ..RetrieveAPIInfo("/drive/v3/files")
do ..RetrieveAPIInfo("/calendar/v3/users/me/calendarList")
} else {
w "Not authorized!"
}
&html
Quit $$$OK
}
ClassMethod RetrieveAPIInfo(api As %String)
{
w "Data from "_api_""
try {
set tHttpRequest=##class(%Net.HttpRequest).%New()
$$$THROWONERROR(sc,##class(%SYS.OAuth2.AccessToken).AddAccessToken(tHttpRequest,"query","GOOGLE",..#OAUTH2APPNAME))
$$$THROWONERROR(sc,tHttpRequest.Get(..#OAUTH2ROOT_api))
set tHttpResponse=tHttpRequest.HttpResponse
s tJSONString=tHttpResponse.Data.Read()
if $e(tJSONString)'="{" {
// not a JSON
d tHttpResponse.OutputToDevice()
} else {
w tJSONString
w ""
/*
// new JSON API
&html
s tJSONObject={}.%FromJSON(tJSONString)
set iterator=tJSONObject.%GetIterator()
while iterator.%GetNext(.key,.value) {
if $isobject(value) {
set iterator1=value.%GetIterator()
w "",key,""
while iterator1.%GetNext(.key1,.value1) {
if $isobject(value1) {
set iterator2=value1.%GetIterator()
w "",key1,""
while iterator2.%GetNext(.key2,.value2) {
write !, "",key2, "",value2,""
}
// this way we can go on and on into the embedded objects/arrays
w ""
} else {
write !, "",key1, "",value1,""
}
}
w ""
} else {
write !, "",key, "",value,""
}
}
&html
*/
}
} catch (e) {
w "ERROR: ",$zcvt(e.DisplayString(),"O","HTML")_""
}
}
}
让我们快速看一下代码:
1. 首先,我们需要检查一下我们是否具有有效的访问令牌(即我们是否被授权)
2. 如果是,我们可以向 Google 提供且由已发布访问令牌覆盖的 API 发出请求
3. 为此,我们使用标准的 %Net.HttpRequest 类,但根据 API 规范,我们将访问令牌添加到 GET 或 POST 方法中
4. 如您所见,为了方便您,OAUTH 框架已实现 GetUserInfo()方法,但是您可以使用 Google API 规范直接检索用户信息,就像我们在 RetrieveAPIInfo()助手方法中所做的一样。
5. 由于在 OAUTH 世界中以 JSON 格式交换数据司空见惯,因此我们只读取传入的数据,然后简单地将其转储到浏览器。 应用程序开发人员可以解析和格式化接收到的数据,以便用户可以看明白。 但这超出了本演示的范围。 (尽管一些代码有注释,显示了如何完成解析。)
下图是一个输出屏幕截图,显示了原始 JSON 数据。

继续阅读[第 2 部分](https://community.intersystems.com/post/cach%C3%A9-open-authorization-framework-oauth-20-implementation-part-2),该部分讲述 InterSystems IRIS 担当授权服务器和 OpenID Connect 提供程序相关的内容。
[1] https://tools.ietf.org/html/rfc6749, https://tools.ietf.org/html/rfc6750
文章
Qiao Peng · 一月 14, 2021
你好,开发者!
你们中的许多人在 [Open Exchange](https://openexchange.intersystems.com/) 和 Github 上发布了 InterSystems ObjectScript 库。
但对于开发者来说,如何简化项目的使用和协作呢?
在本文中,我想介绍一种简单方法,只需将一组标准文件复制到你的仓库中,就可以启动任何 ObjectScript 项目和对其做出贡献。
我们开始吧!
**TLDR** - 将以下文件从[该仓库](https://github.com/intersystems-community/objectscript-docker-template)复制到你的仓库:
[Dockerfile](https://github.com/intersystems-community/objectscript-docker-template/blob/master/Dockerfile)
[docker-compose.yml](https://github.com/intersystems-community/objectscript-docker-template/blob/master/docker-compose.yml)
[Installer.cls](https://github.com/intersystems-community/objectscript-docker-template/blob/master/Installer.cls)
[iris.script](https://github.com/intersystems-community/objectscript-docker-template/blob/master/iris.script)
[settings.json](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.vscode/settings.json "settings.json"){#9f423fcac90bf80939d78b509e9c2dd2-d165a4a3719c56158cd42a4899e791c99338ce73}
[.dockerignore](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.dockerignore ".dockerignore"){#f7c5b4068637e2def526f9bbc7200c4e-c292b730421792d809e51f096c25eb859f53b637}
[.gitattributes](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.gitattributes ".gitattributes"){#fc723d30b02a4cca7a534518111c1a66-051218936162e5338d54836895e0b651e57973e1}
[.gitignore](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.gitignore ".gitignore"){#a084b794bc0759e7a6b77810e01874f2-e6aff5167df2097c253736b40468e7b21e577eeb}
你已经知道启动你的项目和协作的标准方式。 以下将详细说明这样做的步骤和原因。
**注意:**在本文中,我们将考虑可在 InterSystems IRIS 2019.1 及更新版本上运行的项目。
**选择 InterSystems IRIS 项目的启动环境**
通常,我们希望开发者尝试项目/库,并确保这是快速安全的练习。
在我看来,快速安全地启动任何新项目的理想方式是 Docker 容器,它可以保证开发者启动、导入、编译和计算任何内容对于主机来说都是安全的,并且不会破坏任何系统或代码。如果出了问题,只需停止并删除容器即可。 如果应用程序占用大量磁盘空间,使用容器将其擦除,空间就回来了。 如果某个应用程序破坏了数据库配置,只需删除配置被破坏的容器。 简单又安全。
Docker 容器提供安全和标准化。
运行通用 InterSystems IRIS Docker 容器的最简单方法是运行 [IRIS 社区版映像](https://hub.docker.com/_/intersystems-iris-data-platform/plans/222f869e-567c-4928-b572-eb6a29706fbd?tab=instructions):
1. 安装 [Docker desktop](https://www.docker.com/products/docker-desktop)
2. 在操作系统终端中运行以下命令:
docker run --rm -p 52773:52773 --init --name my-iris store/intersystems/iris-community:2020.1.0.199.0
3. 然后在主机浏览器上打开管理门户:
4. 或者打开终端启动 IRIS:
docker exec -it my-iris iris session IRIS
5. 不需要 IRIS 容器时,将其停止:
docker stop my-iris
好! 我们在一个 docker 容器中运行 IRIS。 但是你希望开发者将你的代码安装到 IRIS 中,可能还要进行一些设置。 这就是我们下面要讨论的。
**导入 ObjectScript 文件**
最简单的 InterSystems ObjectScript 项目可以包含一组 ObjectScript 文件,例如类、例程、宏和global。 请查看有关命名和建议的文件夹结构的文章。
问题是如何将所有这些代码导入 IRIS 容器?
此时我们可以借助 Dockerfile 来获取通用 IRIS 容器,并将某个仓库中的所有代码导入 IRIS,然后根据需要对 IRIS 进行一些设置。 我们需要在仓库中添加一个 Dockerfile。
我们来看一下 [ObjectScript 模板](https://github.com/intersystems-community/objectscript-docker-template)仓库中的 [Dockerfile](https://github.com/intersystems-community/objectscript-docker-template/blob/master/Dockerfile):
ARG IMAGE=store/intersystems/irishealth:2019.3.0.308.0-community
ARG IMAGE=store/intersystems/iris-community:2019.3.0.309.0
ARG IMAGE=store/intersystems/iris-community:2019.4.0.379.0
ARG IMAGE=store/intersystems/iris-community:2020.1.0.199.0
FROM $IMAGE
USER root
WORKDIR /opt/irisapp
RUN chown ${ISC_PACKAGE_MGRUSER}:${ISC_PACKAGE_IRISGROUP} /opt/irisapp
USER irisowner
COPY Installer.cls .
COPY src src
COPY iris.script /tmp/iris.script # run iris and initial
RUN iris start IRIS \
&& iris session IRIS < /tmp/iris.script
前几个 ARG 行设置 $IMAGE 变量,随后在 FROM 中使用该变量。 这适合在不同的 IRIS 版本中测试/运行代码,只需在 FROM 前面的最后一行中更改 $IMAGE 变量即可切换版本。
这里我们采用:
ARG IMAGE=store/intersystems/iris-community:2020.1.0.199.0
FROM $IMAGE
这意味着我们将使用 IRIS 2020 社区版 build 199。
我们想要导入仓库中的代码,这意味着我们需要将仓库中的文件复制到 docker 容器。 下面几行完成此操作:
USER root
WORKDIR /opt/irisapp
RUN chown ${ISC_PACKAGE_MGRUSER}:${ISC_PACKAGE_IRISGROUP} /opt/irisapp
USER irisowner
COPY Installer.cls .
COPY src src
USER root - 这里我们将用户切换为 root,以在 docker 中创建文件夹和复制文件。
WORKDIR /opt/irisapp - 我们在此行中设置将文件复制到的工作目录。
RUN chown ${ISC_PACKAGE_MGRUSER}:${ISC_PACKAGE_IRISGROUP} /opt/irisapp - 这里我们为运行 IRIS 的 irisowner 用户和组授予权限。
USER irisowner - 将用户从 root 切换到 irisowner
COPY Installer.cls . - 将 [Installer.cls](https://github.com/intersystems-community/objectscript-docker-template/blob/master/Installer.cls) 复制到工作目录的根目录。 不要漏了那个点儿。
COPY src src - 将[仓库的 src 文件夹](https://github.com/intersystems-community/objectscript-docker-template/tree/master/src/)中的源文件复制到 docker 上的工作目录的 src 文件夹中。
在下一个块中,我们运行初始脚本,其中将调用安装程序和 ObjectScript 代码:
COPY iris.script /tmp/iris.script # run iris and initial
RUN iris start IRIS \
&& iris session IRIS < /tmp/iris.script
COPY iris.script / - 我们将 iris.script 复制到根目录。 它包含我们要调用以设置容器的 ObjectScript。
RUN iris start IRIS\ - 启动 IRIS
&& iris session IRIS < /tmp/iris.script - 启动 IRIS 终端并在其中输入初始 ObjectScript。
很好! 我们有 Dockerfile,它将文件导入 docker。 但还有两个文件:installer.cls 和 iris.script。我们来检查一下。
[**Installer.cls**](https://github.com/intersystems-community/objectscript-docker-template/blob/master/Installer.cls)
Class App.Installer
{
XData setup
{
}
ClassMethod setup(ByRef pVars, pLogLevel As %Integer = 3, pInstaller As %Installer.Installer, pLogger As %Installer.AbstractLogger) As %Status [ CodeMode = objectgenerator, Internal ]
{
#; Let XGL document generate code for this method.
Quit ##class(%Installer.Manifest).%Generate(%compiledclass, %code, "setup")
}
}
坦白说,我们不需要 Installer.cls 就可以导入文件。 这只需要一行就能完成。 但除了导入代码之外,我们经常还需要设置 CSP 应用,引入安全设置,创建数据库和命名空间。
在此 Installer.cls 中,我们创建了名为 IRISAPP 的新数据库和命名空间,并为该命名空间创建了默认的 /csp/irisapp 应用程序。
所有这些都在元素中 执行:
<Namespace Name="${Namespace}" Code="${Namespace}" Data="${Namespace}" Create="yes" Ensemble="no">
<Configuration>
<Database Name="${Namespace}" Dir="/opt/${app}/data" Create="yes" Resource="%DB_${Namespace}"/>
<Import File="${SourceDir}" Flags="ck" Recurse="1"/>
</Configuration>
<CSPApplication Url="/csp/${app}" Directory="${cspdir}${app}" ServeFiles="1" Recurse="1" MatchRoles=":%DB_${Namespace}" AuthenticationMethods="32"
/>
</Namespace>
我们用 Import 标签导入 SourceDir 中的所有文件:
<Import File="${SourceDir}" Flags="ck" Recurse="1"/>
这里的 SourceDir 是一个变量,设置为当前目录/src 文件夹:
<Default Name="SourceDir" Value="#{$system.Process.CurrentDirectory()}src"/>
有了带这些设置的 Installer.cls,我们可以自信地创建一个干净的新数据库 IRISAPP,我们将从 src 文件夹导入任意 ObjectScript 代码到该数据库中。
[iris.script](https://github.com/intersystems-community/objectscript-docker-template/blob/master/iris.script)
欢迎在这里提供任何所需的初始 ObjectScript 设置代码来启动 IRIS 容器。
例如, 我们加载并运行 installer.cls,然后让 UserPasswords 永远有效,以避免第一次启动时出现密码更改请求,因为开发不需要这个提示。
; run installer to create namespace
do $SYSTEM.OBJ.Load("/opt/irisapp/Installer.cls", "ck")
set sc = ##class(App.Installer).setup() zn "%SYS"
Do ##class(Security.Users).UnExpireUserPasswords("*") ; call your initial methods here
halt
[docker-compose.yml](https://github.com/intersystems-community/objectscript-docker-template/blob/master/docker-compose.yml)
为什么需要 docker-compose.yml,不能只用 Dockerfile 构建和运行映像吗? 可以的。 但 docker-compose.yml 能让生活更轻松。
通常,docker-compose.yml 用于启动连接到一个网络的多个 docker 映像。
当启动一个 docker 映像需要处理多个参数时,也可以使用 docker-compose.yml 来简化过程。 你可以使用它向 docker 传递参数,例如端口映射、卷、VSCode 连接参数。
version: '3.6'
services:
iris:
build:
context: .
dockerfile: Dockerfile
restart: always
ports:
- 51773
- 52773
- 53773
volumes:
- ~/iris.key:/usr/irissys/mgr/iris.key
- ./:/irisdev/app
这里我们声明服务 iris,它使用 docker 文件 Dockerfile,并开放 IRIS 的以下端口:51773、52773、53773。 此服务还映射两个卷:将主机主目录中的 iris.key 映射到期望的 IRIS 文件夹,以及将源代码的根文件夹映射到 /irisdev/app 文件夹。
Docker-compose 提供了更短的统一命令来构建和运行映像,无论你在 docker compose 中设置了什么参数。
总之,构建和启动镜像的命令是:
$ docker-compose up -d
要打开 IRIS 终端:
$ docker-compose exec iris iris session iris
Node: 05a09e256d6b, Instance: IRIS
USER>
此外,docker-compose.yml 有助于设置 VSCode ObjectScript 插件的连接。
[.vscode/settings.json](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.vscode/settings.json)
与 ObjectScript 加载项连接设置有关的部分如下:
{
"objectscript.conn" :{
"ns": "IRISAPP",
"active": true,
"docker-compose": {
"service": "iris",
"internalPort": 52773
}
}
}
在这里,我们看到的设置与 VSCode ObjectScript 插件的默认设置不同。
我们想要连接到 IRISAPP 命名空间(我们用 Installer.cls 创建的):
"ns": "IRISAPP",
一个 docker-compose 设置指示,docker-compose 文件在服务“iris”内,VSCode 将连接到 52773 映射到的端口:
"docker-compose": {
"service": "iris",
"internalPort": 52773
}
如果我们检查一下 52773 的相关设置,我们会看到没有为 52773 定义映射端口:
ports:
- 51773
- 52773
- 53773
这意味着将使用主机上的随机可用端口,并且 VSCode 将通过随机端口自动连接到 docker 上的 IRIS。
**这是一个非常方便的功能,因为它允许在随机端口上运行任意数量的带 IRIS 的 docker 映像,并让 VSCode 自动连接到它们。**
其他文件呢?
我们还有:
[.dockerignore](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.dockerignore) - 该文件可用于过滤你不想复制到所构建的 docker 映像中的主机文件。 通常 .git 和 .DS_Store 是必须有的行。
[.gitattributes](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.gitattributes) - git 的属性,用于统一来源中的 ObjectScript 文件的行尾。 如果仓库由 Windows 和 Mac/Ubuntu 所有者协作,此文件非常有用。
[.gitignore](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.gitignore) - 你不希望 git 跟踪其更改历史记录的文件。 通常是一些隐藏的操作系统级文件,例如 .DS_Store。
好了!
如何使你的仓库可被 docker 运行并且对协作友好?
1. 克隆[此仓库](https://github.com/intersystems-community/objectscript-docker-template)。
2. 复制以下所有文件:
[Dockerfile](https://github.com/intersystems-community/objectscript-docker-template/blob/master/Dockerfile)
[docker-compose.yml](https://github.com/intersystems-community/objectscript-docker-template/blob/master/docker-compose.yml)
[Installer.cls](https://github.com/intersystems-community/objectscript-docker-template/blob/master/Installer.cls)
[iris.script](https://github.com/intersystems-community/objectscript-docker-template/blob/master/iris.script)
[settings.json](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.vscode/settings.json "settings.json"){#9f423fcac90bf80939d78b509e9c2dd2-d165a4a3719c56158cd42a4899e791c99338ce73}
[.dockerignore](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.dockerignore ".dockerignore"){#f7c5b4068637e2def526f9bbc7200c4e-c292b730421792d809e51f096c25eb859f53b637}
[.gitattributes](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.gitattributes ".gitattributes"){#fc723d30b02a4cca7a534518111c1a66-051218936162e5338d54836895e0b651e57973e1}
[.gitignore](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.gitignore ".gitignore"){#a084b794bc0759e7a6b77810e01874f2-e6aff5167df2097c253736b40468e7b21e577eeb}
到你的仓库。
更改 [Dockerfile 中的这一行](https://github.com/intersystems-community/objectscript-docker-template/blob/10f4422c105d5c75111fde16a184a83f5ff86d06/Dockerfile#L15),使目录与仓库中要导入 IRIS 的 ObjectScript 匹配(如果在 /src 文件夹中则不要更改)。
就这样。 每个人(也包括你)都会将你的代码导入到新的 IRISAPP 命名空间的 IRIS 中。
**人们如何启动你的项目**
在 IRIS 中执行任何 ObjectScript 项目的法则为:
1. Git clone 项目到本地
2. 运行项目:
$ docker-compose up -d
$ docker-compose exec iris iris session iris
Node: 05a09e256d6b, Instance: IRIS
USER>zn "IRISAPP"
**开发者如何为你的项目做出贡献**
1. 对仓库执行分叉,并将分叉后的仓库 git clone 到本地
2. 在 VSCode 中打开该文件夹(还需要在 VSCode 中安装 [Docker](https://marketplace.visualstudio.com/items?itemName=ms-azuretools.vscode-docker) 和 [ObjectScript](https://marketplace.visualstudio.com/items?itemName=daimor.vscode-objectscript&ssr=false#review-details) 扩展)
3. 右击 docker-compose.yml->重启 - [VSCode ObjectScript](https://openexchange.intersystems.com/package/VSCode-ObjectScript) 将自动连接并准备好编辑/编译/调试
4. 向你的仓库提交、推送和拉取请求更改
以下是操作过程的短 gif:
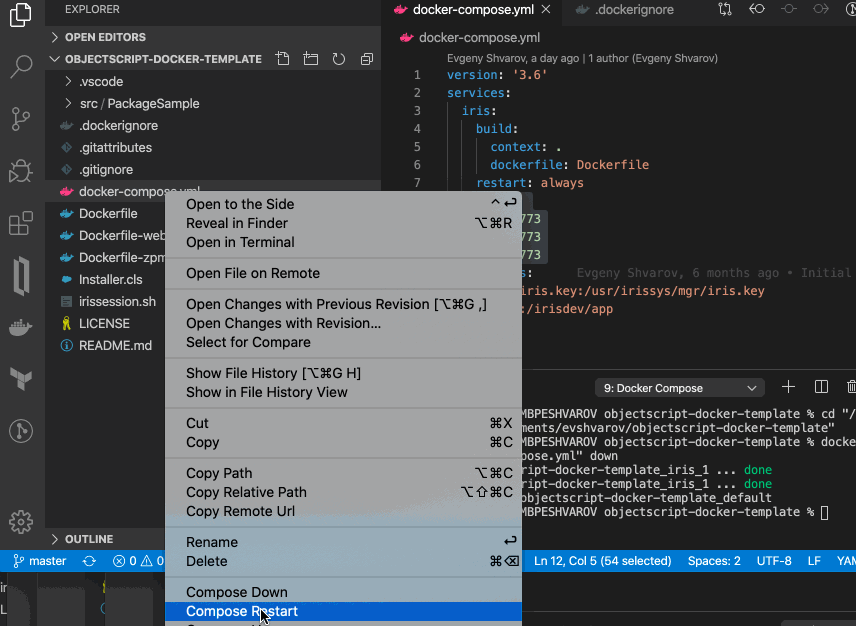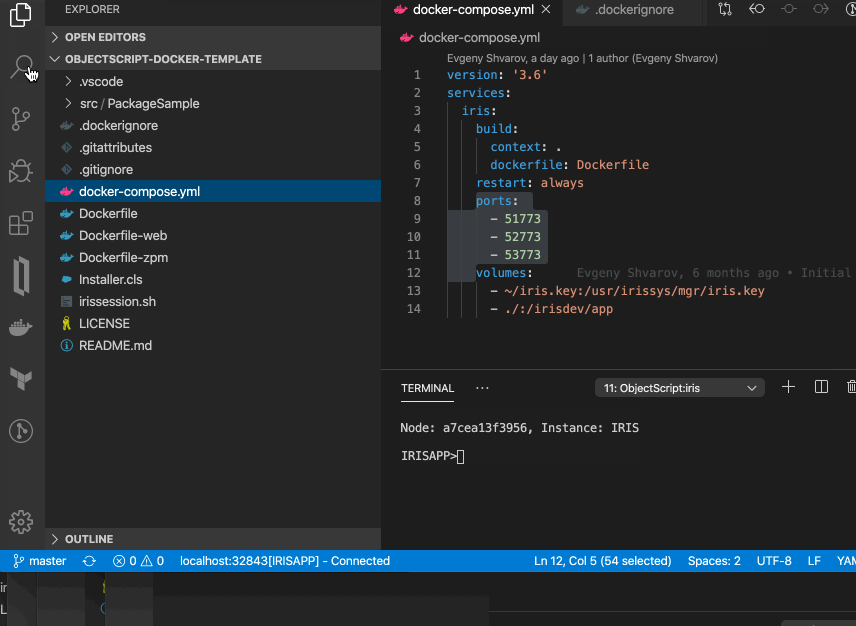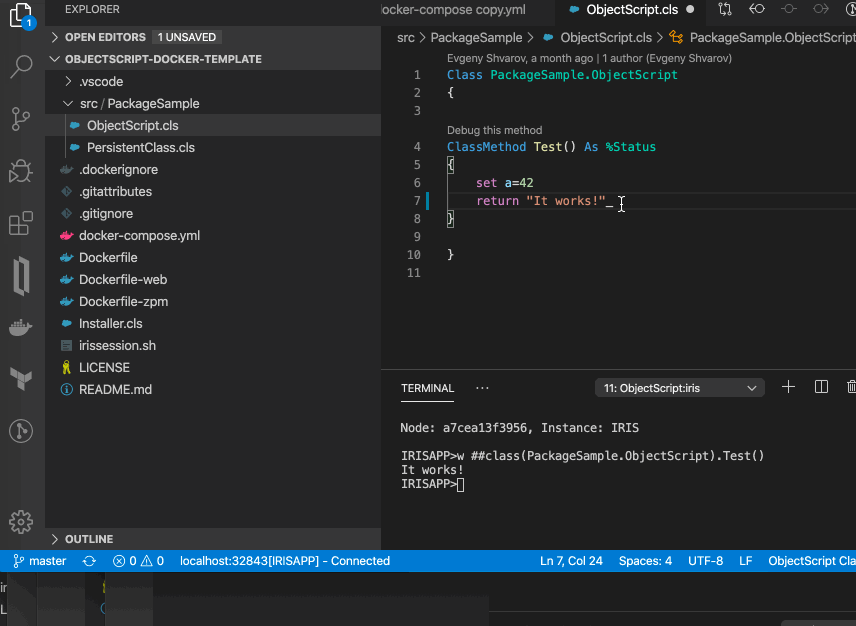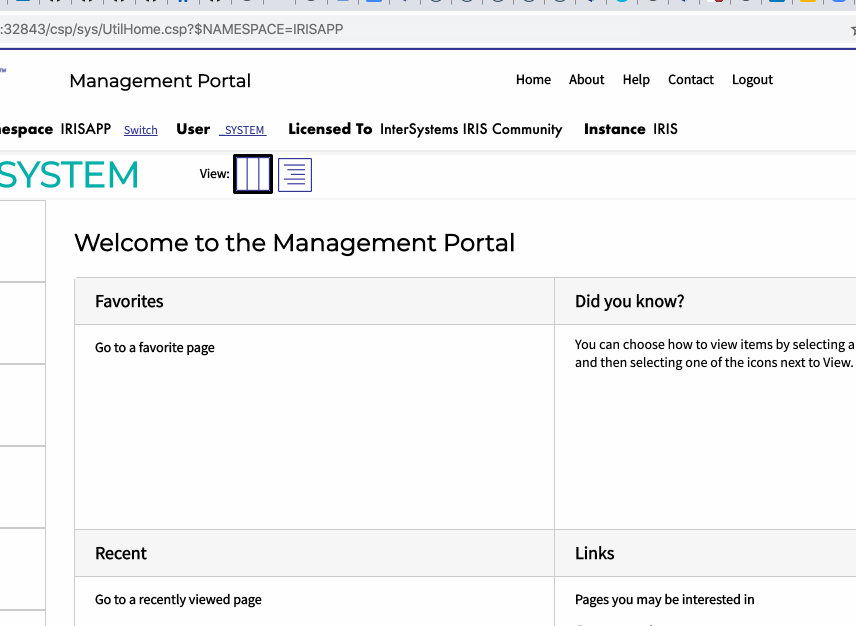
好了! 编码愉快!
文章
Qiao Peng · 一月 14, 2021

您好! 本文介绍另一种为基于 InterSystems Caché 的解决方案创建安装程序的简单方法。 主题将涵盖只需一项操作即可安装或从 Caché 中完全删除的应用程序。 如果您仍在编写需要执行多个步骤才能安装应用程序的安装说明,是时候将这个过程自动化了。
问题的提出
假设我们为 Caché 开发了一个小型实用程序,之后我们想要将其分发。 当然,最好不要让不必要的配置和安装细节打扰到安装它的用户。 此外,这些说明必须非常全面,而且要面向可能对 Caché 一无所知的用户。如果是 Web 实用程序,安装程序不仅会要求用户将其类导入 Caché,而且至少还要配置 Web 应用程序才能对其进行访问,这是相当大的工作量:
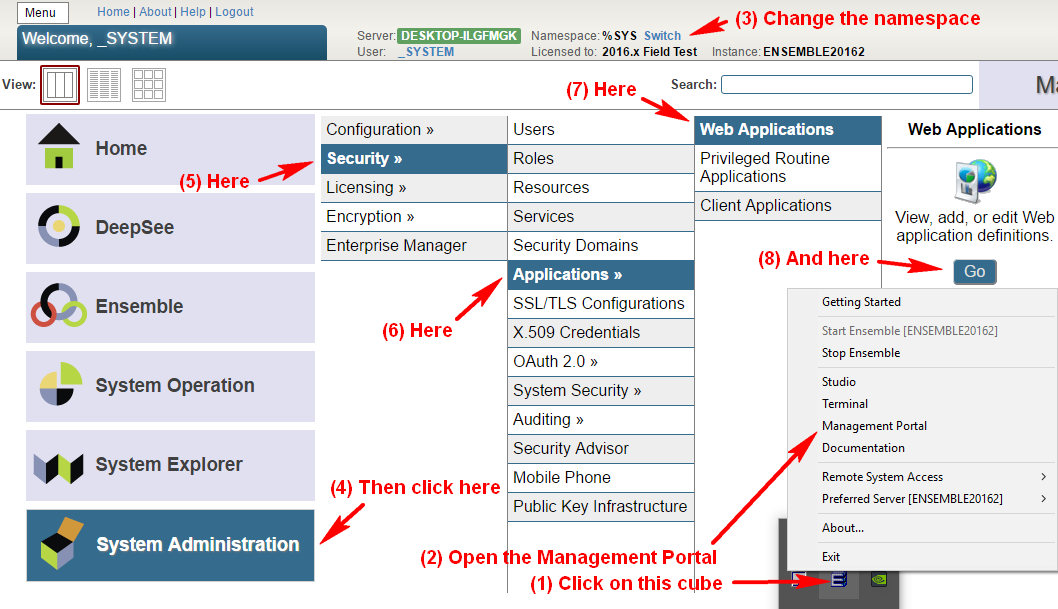

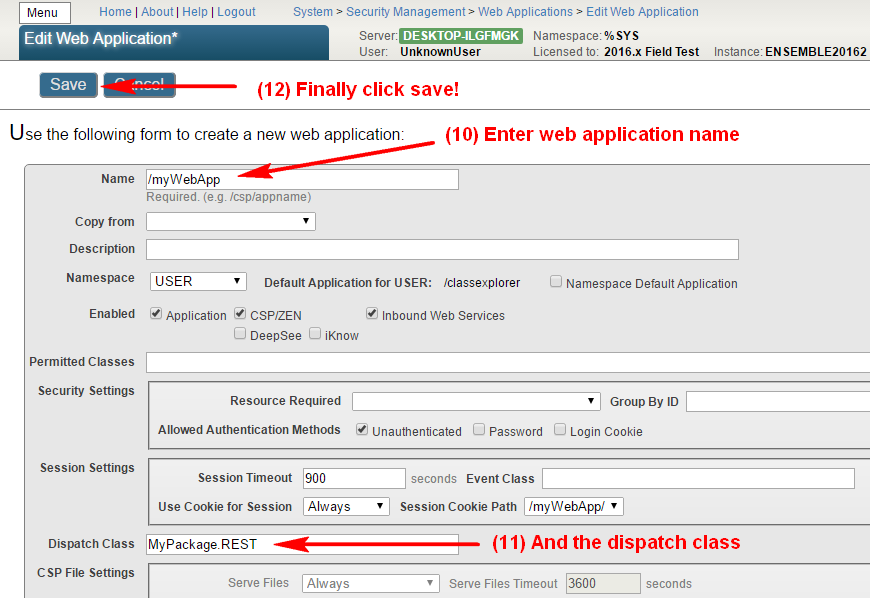
当然,所有这些操作都可以通过编程方式执行。 您只需要了解如何实现。 但即使是这样,我们也需要让用户执行操作,例如在终端中执行一个命令。
通过单次导入操作进行安装
Caché 允许我们在类导入期间执行安装。 这意味着用户只需要使用任一方便的方法导入包含类包的 XML 文件:
将 XML 文件拖放到 Studio 区域。
通过管理门户:系统资源管理器 -> 类 -> 导入。
通过终端:do $system.OBJ.Load("C:\FileToImport.xml","ck")。
我们为安装应用程序而预先准备的代码将在类导入和编译后立即执行。 如果用户要卸载我们的应用程序(删除软件包),我们还可以清理应用程序在安装过程中创建的所有内容。
创建投影
为了扩展 Caché 编译器的行为,或者,在我们的示例中,为了在类的编译或反编译期间执行代码,我们需要在软件包中创建一个投影类。 它是一个扩展了 %Projection.AbstractProjection 的类,并重载了它的两个方法:CreateProjection(在编译过程中执行)和 RemoveProjection(在重新编译或删除类时触发)。
通常,将这个类命名为 Installer 是个好方法。 我们来看一个名为“MyPackage”的软件包的简单安装程序示例:
Class MyPackage.Installer Extends %Projection.AbstractProjection [ CompileAfter = (Class1, Class2) ]
{Projection Reference As Installer;/// This method is invoked when a class is compiled.ClassMethod CreateProjection(cls As %String, ByRef params) As %Status{ write !, "Installing..."}/// This method is invoked when a class is 'uncompiled'.ClassMethod RemoveProjection(cls As %String, ByRef params, recompile As %Boolean) As %Status{ write !, "Uninstalling..."}}
这里的行为可以描述为:
第一次导入和编译软件包时,只触发 CreateProjection 方法。
以后再编译 MyApp.Installer 时,或者导入“新”的安装程序类覆盖“旧”类时,将触发旧类的 RemoveProjection 方法,且 %recompile 参数等于 1,之后调用新类的 CreateProjection 方法。
删除软件包(同时删除 MyApp.Installer)时,将只调用 RemoveProjection 方法,参数 recompile = 0。
还需要注意以下几点:
类关键字 CompileAfter 应该包括应用程序的类名列表,在执行投影类的方法之前,需要对它们进行编译。 始终建议在此列表中填入应用程序中的所有类,因为如果安装过程中出错,我们不需要执行投影类的代码;
两个方法都接受 cls 参数 - 它是顶级类名,在我们的示例中为 MyApp.Installer。 这个理念来自于创建投影类的本义 - 通过从派生自 %Projection.AbstractProjection 的类再派生,可以单独为我们的应用程序的任何类制作“安装程序”。 只有在这种情况下才会体现出意义,但对于我们的任务来说是多余的;
CreateProjection 和 RemoveProjection 方法都接受第二个参数 params - 它是一个关联数组,以“参数名称”-“值”对的形式处理有关当前编译设置和当前类的参数值的信息。 通过执行 zwrite params 可以非常容易地探索该参数的内容;
RemoveProjection 方法接受 recompile 参数,只有删除类时,该参数才等于 0,重新编译时不等于 0。
类 %Projection.AbstractProjection 还有其他方法,我们可以重新定义这些方法,但我们的任务并不需要这样做。
一个示例
让我们更深入地了解为我们的实用程序创建 Web 应用程序的任务,并创建一个简单示例。 假设我们的实用程序是一个 REST 应用程序,在浏览器中打开时,它只发送一个响应“I am installed!”。 要创建这样的应用程序,我们需要创建一个描述它的类:
Class MyPackage.REST Extends %CSP.REST{XData UrlMap{ }ClassMethod Index() As %Status{ write "I am installed!" return $$$OK}}
创建并编译该类后,我们需要将其注册为 Web 应用程序入口点。 我在本文的顶部图示了如何进行配置。 在执行所有这些步骤后,最好通过访问 http://localhost:57772/myWebApp/ 来检查我们的应用程序是否正常工作(注意以下几点:1. 末尾的斜线是必需的;2. 端口 57772 在您的系统中可能有所不同。 它将匹配您的管理门户端口)。
当然,所有这些步骤都可以通过 Web 应用程序创建方法 CreateProjection 以及删除方法 RemoveProjection 中的一些代码来自动执行。 在这种情况下,我们的投影类如下所示:
Class MyPackage.Installer Extends %Projection.AbstractProjection [ CompileAfter = MyPackage.REST ]{Projection Reference As Installer;Parameter WebAppName As %String = "/myWebApp";Parameter DispatchClass As %String = "MyPackage.REST";ClassMethod CreateProjection(cls As %String, ByRef params) As %Status{ set currentNamespace = $Namespace write !, "Changing namespace to %SYS..." znspace "%SYS" // we need to change the namespace to %SYS, as Security.Applications class exists only there write !, "Configuring WEB application..." set cspProperties("AutheEnabled") = $$$AutheUnauthenticated // public application set cspProperties("NameSpace") = currentNamespace // web-application for the namespace we import classes to set cspProperties("Description") = "A test WEB application." // web-application description set cspProperties("IsNameSpaceDefault") = $$$NO // this application is not the default application for the namespace set cspProperties("DispatchClass") = ..#DispatchClass // the class we created before that handles the requests return ##class(Security.Applications).Create(..#WebAppName, .cspProperties)}ClassMethod RemoveProjection(cls As %String, ByRef params, recompile As %Boolean) As %Status{ write !, "Changing namespace to %SYS..." znspace "%SYS" write !, "Deleting WEB application..." return ##class(Security.Applications).Delete(..#WebAppName)}}
在此示例中,每次编译 MyPackage.Installer 类都将创建一个 Web 应用程序,每次“反编译”都将其删除。 最好在创建或删除应用程序之前检查该应用程序是否存在(例如,使用 ##class(Security.Applications).Exists(“Name”) ),但是为了使本示例简单起见,这个作业就留给阅读本文的读者来完成了。
在创建 MyPackage.REST 和 MyPackage.Installer 类之后,我们可以将这些类导出为一个 XML 文件,并将该文件分享给所有有需要的人。 导入此 XML 的用户将自动设置 Web 应用程序,然后可以开始在浏览器中使用。
结果
与 InterSystems 社区上介绍的使用 %Installer 类部署应用程序的方法不同,这种方法有以下优点:
使用“纯”Caché ObjectScript。 至于 %Installer,需要用特定标签来填充 xData 块,大量文档对此进行了介绍。
安装我们的应用程序的方法是在类编译后立即执行的,我们不需要手动执行;
如果类(包)被删除,将自动执行删除我们的应用程序的方法,这不能通过使用 %Installer 来实现。
我的项目中已经使用这种应用程序安装方法 - Caché WEB Terminal、Caché Class Explorer 和 Caché Visual Editor。 您可以在此处找到 Installer 类的示例。
顺便提一下,开发者社区还有一个帖子介绍了投影的功能,作者是 John Murray。
另外值得一提的是 Package Manager 项目,该项目旨在让 InterSystems 数据平台的第三方应用程序只需通过一个命令或一次点击即可安装,就像类似 npm 的包管理器一样。
文章
Li Yan · 一月 13, 2021
本文提供了一个参考架构,作为示例说明基于 InterSystems Technologies(适用于 Caché、Ensemble、HealthShare、TrakCare 以及相关的嵌入式技术,例如 DeepSee、iKnow、Zen 和 Zen Mojo)提供的强大性能和高可用性应用。Azure 有两种用于创建和管理资源的不同部署模型:Azure Classic 和 Azure Resource Manager。 本文中的详细信息基于 Azure Resource Manager (ARM) 模型。
摘要
Microsoft Azure 云平台为基础设施即服务 (IaaS) 提供功能丰富的环境,其作为云提供完备的功能,支持所有的 InterSystems 产品。 与任何平台或部署模型一样,必须留心以确保考虑到环境的各个方面,例如性能、可用性、操作和管理程序。 本文将阐述所有这些方面。
性能
在 Azure ARM 中,有多个可用于计算虚拟机 (VM) 的选项以及相关的存储选项,与 InterSystems 产品最直接相关的是网络连接 的IaaS 磁盘,其作为 VHD 文件存储在 Azure 页面的 Blob 存储中。 还有其他几个选项,例如_ Blob(块)、文件_等,但是这些选项更特定于单个应用程序的要求,而非支持 Caché 的操作。 磁盘存储有两种类型的存储:“高级存储”和“标准存储”。 高级存储更适合这样的生产工作负载:要求保证可预测的低延迟每秒输入/输出操作 (IOP) 和吞吐量。 标准存储是针对非生产或存档类型工作负载的更经济选择。 选择特定的 VM 类型时务必小心,因为并非所有的 VM 类型都可以访问高级存储。
虚拟 IP 地址和自动故障转移
大多数 IaaS 云提供商缺乏提供虚拟 IP (VIP) 地址的能力,这种地址通常用在数据库故障转移设计中。 为解决这一问题,Caché 中增强了几种最常用的连接方法,尤其是 ECP 客户端和 CSP 网关,从而不再依赖 VIP 功能使它们实现镜像状态感知。
xDBC、直接 TCP/IP 套接字等连接方法,或其他的直接连接协议,均需要使用 VIP。 为解决这些问题,InterSystems 数据库镜像技术使用 API 与 Azure 内部负载均衡器(ILB)交互以实现类 VIP 功能,使得 Azure 中的那些连接方法实现自动故障转移,从而在 Azure 中提供完整而强大的高可用性设计 。 有关详细信息,请参见社区文章无虚拟 IP 地址的数据库镜像。
备份操作
无论使用传统的文件级备份,还是基于快照的备份,在云部署中执行备份都面临着挑战。 如今,在 Azure ARM 平台中,使用 Azure Backup 和 Azure Automation Run Books 配合 InterSystems 外部冻结及解冻 API 功能,即可实现这一切,从而实现真正的 24x7 全天候操作弹性并确保干净的常规备份。 或者,可以在 VM 本身中部署备份代理,利用文件级备份,并结合逻辑卷管理器 (LVM) 快照,来使用市面上的许多第三方备份工具。
示例架构
作为本文档的一部分,这里为您提供一个示例 Azure 架构,作为您特定应用部署的入门参考,并可用作各种部署的可能性的指南。 此参考架构显示了一个强大的 Caché 数据库部署,其中包括可实现高可用性的数据库镜像成员、使用 InterSystems 企业缓存协议(ECP)的应用程序服务器、使用 InterSystems CSP 网关的 Web 服务器,以及内部和外部 Azure 负载均衡器。
Azure 架构
在 Microsoft Azure 上部署任何基于Caché 的应用都需要特别注意某些方面。 本部分讨论通用的方面,对于您的应用的特定技术要求不做阐述。
本文档中提供了两个示例,一个基于_ InterSystems TrakCare 统一医疗信息系统,另一个基于完整的 InterSystems HealthShare 健康信息学平台部署,包括:_Information Exchange、Patient Index、Health Insight、Personal Community 和 Health Connect。
虚拟机
Azure 虚拟机 (VM) 分为两层:基本层和标准层。 两种类型提供对规模的选择。 基本层不提供标准层中的某些功能,例如负载均衡和自动伸缩。 因此,将标准层用于 TrakCare 部署。
标准层 VM 具有不同规模,按不同系列分组,即: A、D、DS、F、FS、G 和 GS。 DS、GS 和新的 FS 支持 Azure 高级存储的使用。
生产服务器通常需要使用高级存储来实现可靠性、低延迟和高性能。 因此,本文档中详细介绍的示例 TrakCare 和 HealthShare 部署架构将使用 FS、DS 或 GS 系列 VM。 注意,并非所有的虚拟机规模在所有区域中都可用。
有关虚拟机规模的详细信息,请参见:
Windows 虚拟机规模
Linux 虚拟机规模
存储
TrakCare 和 HealthShare 服务器需要 Azure 高级存储。 高级存储将数据存储在固态硬盘 (SSD) 上,以低延迟提供高吞吐量;而标准存储将数据存储在硬盘驱动器 (HDD) 上,会导致性能的降低。
Azure 存储属于冗余且高度可用的系统,但是,请务必注意,可用性集合当前不提供跨存储故障域的冗余,在极少数情况下,这可能会导致问题。 Microsoft 有缓解方案,并正在努力使此过程对最终客户广泛可用且更容易使用。 建议您直接与当地的 Microsoft 团队合作以确定是否需要任何缓解方案。
当针对高级存储帐户配置磁盘时,IOPS 和吞吐量(带宽)取决于磁盘的大小。 当前,有三种类型的高级存储磁盘:P10、P20 和 P30。 每种对 IOPS 和吞吐量都有特定的限制,如下表所示。
高级磁盘类型
P4
P6
P10
P15
P20
P30
P40
P50
磁盘容量
32GB
64GB
128GB
256GB
512GB
1024GB
2048GB
4096GB
每个磁盘的 IOPS
120
240
500
1100
2300
5000
7500
7500
每个磁盘的吞吐量
25MB/s
50MB/s
100MB/s
125MB/s
150MB/s
200MB/s
250MB/s
250MB/s
注意:确保给定的 VM 上有足够的可用带宽来驱动磁盘流量。
例如,STANDARD_DS13 VM 具有每秒 256 MB 的专用带宽,可用于所有高级存储磁盘流量。
这意味着连接到该虚拟机的四个 P30 高级存储磁盘的吞吐量限制为每秒 256 MB,而不是四个 P30 磁盘理论上可以提供的每秒 800 MB 的速度。
有关高级存储磁盘的更多详细信息和限制,包括预配置的容量、性能、大小、IO 大小、缓存命中率、吞吐量目标和限制,请参阅:
高级存储
高可用性
InterSystems 建议在已定义的可用性集合中拥有两个或更多虚拟机。 之所以需要此配置,是因为在计划内或计划外的维护活动期间,至少有一个虚拟机可用于满足 99.95% 的 Azure SLA。 这很重要,因为在数据中心更新期间,VM 会被并行关闭、升级并以不特定的顺序重新联机,导致应用程序在此维护窗口期不可用。
因此,高度可用的架构需要每种服务器至少部署两台,这些服务器包括负载均衡 Web 服务器、数据库镜像、多个应用程序服务器等。
有关 Azure 高可用性最佳做法的更多信息,请参见:
管理可用性
Web 服务器负载均衡
基于 Caché 的应用程序可能需要外部和内部负载均衡 Web 服务器。 外部负载均衡器用于通过 Internet 或 WAN(VPN 或 Express Route)进行的访问,而内部负载均衡器则通常用于内部流量。 Azure 负载均衡器是 4 层 (TCP, UDP) 的负载均衡器,可在负载均衡器集合中定义的云服务或虚拟机中的健康服务实例之间分配传入的流量。
Web 服务器负载均衡器必须配置客户端 IP 地址会话持续性(2 个元组)和可能的最短探测超时(当前为 5 秒)。 TrakCare 需要在用户登录期间保持会话持续性。
Microsoft 提供的下图显示了 ARM 部署模型中一个简单的 Azure 负载均衡器示例。
有关 Azure 负载均衡器的功能(例如分配算法、端口转发、服务监视、源 NAT )和其他类型的可用负载均衡器的详细信息,请参阅:
负载均衡器概述
除了 Azure 外部负载均衡器,Azure 还提供 Azure 应用程序网关。 Application Gateway 是一个 L7 负载均衡器 (HTTP/HTPS),支持基于 cookie 的会话相关性和 SSL 终端(SSL 卸载)。 SSL 卸载可减轻 Web 服务器的加密/解密开销,因为 SSL 连接会在负载均衡器处终止。 这种方法简化了管理,因为 SSL 证书是在网关中部署和管理,而不是在 Web 场中的所有节点上。
有关详细信息,请参阅︰
应用程序网关概述
使用 Azure Resource Manager 为 SSL 卸载配置应用程序网关
数据库镜像
在 Azure 上部署基于 Caché 的应用程序时,要为 Caché 数据库服务器提供高可用性,需要使用同步数据库镜像,以在给定的主 Azure 区域中提供高可用性,并可能使用异步数据库镜像将数据复制到辅助 Azure 区域中的热备用数据库中,以根据您的运行时间服务水平协议要求来进行灾难恢复。
数据库镜像是两个数据库系统的逻辑分组,也就是所说的故障转移成员,它们在物理上是仅通过网络连接的独立系统。 在这两个系统之间进行仲裁后,镜像会自动将其中一个指定为主系统。 另一个自动成为备份系统。 外部客户端工作站或其他计算机通过镜像虚拟 IP (VIP) 连接到镜像,该虚拟 IP 在镜像配置期间指定。 镜像 VIP 会自动绑定到镜像主系统上的接口。
注意:在 Azure 中,无法配置镜像 VIP,因此已设计了替代解决方案。
当前,在 Azure 中部署数据库镜像时,建议在同一 Azure 可用性集中配置三个 VM(主 VM、备份 VM、仲裁器)。 这样可确保在任何给定的时间,Azure 都可以保证至少与其中两个 VM 以 99.95% 的 SLA 建立外部连接,并且每个 VM 都位于不同的更新域和故障域中。 这样可以为数据库数据本身提供足够的隔离和冗余。
可在下列位置找到更多详细信息:
Azure 可用性集
Azure 服务水平协议 (SLA)
包括 Azure 在内的任何 IaaS 云提供程序所面临的挑战,就是在没有虚拟 IP 功能的情况下,如何处理连接到应用程序的客户端的自动故障转移。 为了保持客户端连接的自动故障转移,已采取了两种策略。
首先,InterSystems 对 CSP 网关进行了增强,使其能够感知镜像,以此使得采用 CSP 网关的 Web 服务器到数据库服务器的连接不再需要 VIP。 CSP 网关将自动与两个镜像成员进行协商,并重定向到确定的主镜像成员。 如果使用 ECP 客户端,则将与其已经具备的镜像感知协同工作。
其次,CSP 网关和 ECP 客户端外部的连接仍然需要类 VIP 功能。 InterSystems 建议将轮询方法与_ mirror_status.cxw _运行状况检查状态页面介绍的内容结合使用,该页面在社区文章无虚拟 IP 地址的数据库镜像中进行了详细说明。
Azure 内部负载均衡器 (ILB) 将提供单一 IP 地址作为类 VIP 功能,将所有网络流量定向到主镜像成员。 ILB 只会将流量分配给主镜像成员。 此方法不会依赖轮询,且在镜像配置内的任何镜像成员成为主成员时,允许立即重定向。 在某些使用 Azure Traffic Manager 的灾难恢复方案中,可将此方法与轮询结合使用。
备份与恢复
备份操作有多个选项。 以下 3 个选项可供您通过 InterSystems 产品进行 Azure 部署。 下面的前 2 个选项采用快照类型的过程,该过程会在创建快照之前将数据库写入到磁盘的操作挂起,然后在快照成功后恢复更新。 可采取以下高级别步骤通过任一快照方法来创建洁净的备份:
通过数据库冻结 API 调用暂停对数据库的写入。
创建操作系统和数据磁盘的快照。
通过数据库解冻 API 调用恢复 Caché 写入。
将设施存档备份到备份位置
可以定期添加诸如完整性检查之类的其他步骤,以确保洁净且一致的备份。
决定使用哪种选项取决于您组织的运营要求和策略。 InterSystems 可与您详细讨论各种选项。
Azure 备份
如今,在 Azure ARM 平台中,使用 Azure Backup 和 Azure Automation Run Books 配合 InterSystems 外部冻结及解冻 API 功能,即可实现备份操作,从而实现真正的 24x7 全天候操作弹性并确保干净的常规备份。 有关管理和自动化 Azure 备份的详细信息,可在此处找到。
逻辑卷管理器快照
或者,可以在 VM 本身中部署单个备份代理,利用文件级备份,并结合逻辑卷管理器 (LVM) 快照,来使用市面上的许多第三方备份工具。
该模型的主要优点之一是能够对基于 Windows 或 Linux 的 VM 进行文件级恢复。 此解决方案需要注意的几点是,由于 Azure 和大多数其他 IaaS 云提供商都不提供磁带媒体,因此所有的备份存储库对于短期归档均基于磁盘,并利用 Blob 或存储桶类型的低成本存储来进行长期保留 (LTR)。 强烈建议您使用此方法来使用支持重复数据删除技术的备份产品,以最有效地利用基于磁盘的备份存储库。
这些具有云支持的备份产品的示例包括但不限于:Commvault、EMC Networker、HPE Data Protector 和 Veritas Netbackup。 InterSystems 不会验证或认可一种备份产品是否优于其他产品。
Caché 在线备份
对于小型部署,内置 Caché 在线备份工具也是可行的选择。 该 InterSystems 数据库在线备份实用工具通过捕获数据库中的所有块来备份数据库文件中的数据,然后将输出写入顺序文件。 这种专有的备份机制旨在使生产系统的用户不停机。
在 Azure 中,在线备份完成后,必须将备份输出文件和系统正在使用的所有其他文件复制到 Azure 文件共享中。 该过程需要在虚拟机中编写脚本并执行。
Azure 文件共享应使用 Azure RA-GRS 存储帐户以实现最大可用性。 注意,Azure 文件共享的最大共享大小为 5TB,最大文件大小为 1TB,每个共享(所有客户端共享)的最大吞吐量为 60 MB/s。
在线备份是入门级方法,适合于希望实施低成本备份解决方案的小型站点。 但是,随着数据库的增大,建议将使用快照技术的外部备份作为最佳做法,因为其具有以下优势:备份外部文件、更快的恢复时间,以及企业范围的数据和管理工具。
灾难恢复
在 Azure 上部署基于 Caché 的应用程序时,建议将包括网络、服务器和存储在内的灾难恢复 (DR) 资源放置在不同的 Azure 区域中。 指定的 DR Azure 区域所需的容量取决于您组织的需求。 在大多数情况下,以 DR 模式运行时需要 100% 的生产能力,但是,在需要更多的生产能力作为弹性模型之前,可以配置较小的生产能力。
异步数据库镜像用于连续复制到 DR Azure 区域的虚拟机。 镜像使用数据库事务日志在 TCP/IP 网络上复制更新,其采用对主系统性能影响最小的方式。 强烈建议对这些 DR 异步镜像成员配置压缩和加密。
互联网上希望访问应用程序的所有外部客户端都将通过 Azure Traffic Manager 作为 DNS 服务进行路由。 Microsoft Azure Traffic Manager(ATM)用作交换机,负责将流量定向到当前活动的数据中心。 Azure Traffic Manager 支持多种算法来确定如何将最终用户路由到各个服务端点。 有关各种算法的详细信息,可在此处找到。
本文档中,“优先级”流量路由方法将与 Traffic Manager 端点监视和故障转移结合使用。 有关端点监视和故障转移的详细信息,可在此处找到。
Traffic Manager 的工作是向每个端点发出常规请求,然后验证响应。 如果端点未提供有效的响应,则 Traffic Manager 会将其状态显示为“降级”。 它将不会再被包含在 DNS 响应中,而是会返回一个备用的可用端点。 通过这种方式,将用户流量从失败的端点定向到可用端点。
使用上述方法,只有特定区域和特定镜像成员才允许流量通过。 这由端点定义控制,可从 InterSystems CSP 网关的 mirror_status 页面设置端点定义。 只有主镜像成员才能通过监控器探测来报告 HTTP 200 为“成功”。
Microsoft 提供的下图在高级别上显示了优先级流量例程算法。
Azure Traffic Manager 会产生一个所有客户端都可以连接到的端点,例如:“ https://my-app.trafficmanager.net ”。 此外,可以配置 A 记录来提供虚 URL,例如“ https://www.my-app-domain.com ”。Azure Traffic Manager 必须配置一个包含两个区域端点地址的配置文件。
在任何给定时间,只有其中的一个区域会根据端点监视在线报告。 这样可以确保流量在给定的时间仅流向一个区域。 区域之间的故障转移无需其他步骤,因为端点监控将检测到主 Azure 区域中的应用程序已关闭,并且该应用程序现在位于辅助 Azure 区域中。 这是因为 DR 异步镜像成员被提升为主成员,然后允许 CSP 网关将 HTTP 200 报告给 Traffic Manager 端点监视。
上述解决方案有很多替代方案,可以根据您组织的运营要求和服务水平协议进行自定义。
网络连接
根据您应用程序的连接要求,有多种连接模型可用:使用 Internet、IPSEC VPN 的连接模型,或使用 Azure Express Route 的专用链接。 选择方法取决于应用程序和用户需求。 三种方法的带宽使用情况各不相同,最好与您的 Azure 代表或 Azure 门户联系以确认给定区域的可用连接选项。
如果您正在使用 Express Route,则可为灾难恢复方案启用包括多线路和多区域访问在内的多个选项。 与 Express Route 提供商合作以了解他们支持的高可用性和灾难恢复方案至关重要。
安全
决定在公共云提供程序中部署应用程序时需要格外小心。 应遵循您组织的标准安全策略或专门为云开发的新安全策略,以维护您组织的安全合规性。 就客户端数据中心之外的数据以及物理安全控制方面,云部署的风险逐渐加大。 强烈建议对静态数据(数据库和日志)及飞行数据(网络通信)使用 InterSystems 数据库和日志加密,分别使用 AES 和 SSL/TLS 加密。
与所有加密密钥管理一样,您需要按照您组织的政策记录并遵循正确的程序,以确保数据安全,防止不必要的数据访问或安全漏洞。
当允许通过互联网进行访问时,可能需要第三方防火墙设备来实现其他功能,例如入侵检测、拒绝服务保护等。
架构图示例
下图说明了典型的 Caché 安装,其以数据库镜像(同步故障转移和 DR 异步)、使用 ECP 的应用程序服务器,以及多个负载均衡 Web 服务器的方式提供高可用性。
TrakCare 示例
下图说明了典型的 TrakCare 部署,其中包含多个负载均衡 Web 服务器,两个作为 ECP 客户端的 EPS 打印服务器,以及数据库镜像配置。 虚拟 IP 地址仅用于与 ECP 或 CSP 网关不关联的连接。 ECP 客户端和 CSP 网关可感知镜像,不需要 VIP。
下图中的示例参考架构包括活动或主区域中的高可用性,可在主 Azure 区域不可用的情况下,执行灾难恢复到另一个 Azure 区域。 同样,在此示例中,数据库镜像包含 TrakCare DB、TrakCare Analytics 和 Integration 命名空间,这些都在一个镜像集群中。
TrakCare Azure 参考架构图 - 物理架构
另外,下图显示了该架构的逻辑图,包含架构所安装的相关高级软件产品及其功能用途。
TrakCare Azure 参考架构图 - 逻辑架构
HealthShare 示例
下图显示了一个典型的 HealthShare 部署,其具有多个负载均衡 Web 服务器,以及多个 HealthShare 产品,包括 Information Exchange、Patient Index、Personal Community、Health Insight 和 Health Connect。 这些产品中的每一个都包含一对数据库镜像,以在 Azure 可用性集合中提供高可用性。 虚拟 IP 地址仅用于与 ECP 或 CSP 网关不关联的连接。 HealthShare 产品之间用于 Web 服务通信的 CSP 网关可感知镜像,不需要 VIP。
下图中的示例参考架构包括活动或主区域中的高可用性,可在主 Azure 区域不可用的情况下,执行灾难恢复到另一个 Azure 区域。
HealthShare Azure 参考架构图 - 物理架构
另外,下图显示了该架构的逻辑图,包含架构所安装的相关高级软件产品、连接要求、方法及相应的功能用途。
HealthShare Azure 参考架构图 - 逻辑架构
公告
Claire Zheng · 一月 12, 2021
亲爱的开发者们,欢迎您参加在线编程竞赛!这是2020年的系列竞赛,主题是利用InterSystems IRIS构建多模型解决方案。在这个竞赛中,开发者需要创建一个至少使用两种不同模型来操作数据的应用程序,例如key-value和relational, Object和relational, DocDB和key-value。这场由开发者社区发起的编程马拉松将从1月11日持续到1月31日。
展示最棒的编程技能,赢取炫酷奖品!
主题:利用InterSystems IRIS构建多模型应用
时间:2021年1月11日-31日
奖品丰厚
1. Experts Nomination——获奖者由我们特别挑选的专家团选出:
🥇 1st place - $2,000
🥈 2nd place - $1,000
🥉 3rd place - $500
2. Community Nomination——获得总投票数最多的应用
🥇 1st place - $1,000
🥈 2nd place - $500
🥉 3rd place - $250
如果同时多位参赛者获得同样的票数,均被视为优胜者,将平分奖金。
谁可以参加?
任何开发者社区的成员均可参加,InterSystems内部员工除外。还没有账号?现在来建一个!
参赛时间安排
1月11日 - 24日: 在这两周,您可以将开发的应用上传至Open Exchange (在此期间,还可以继续编辑您的项目).
1月25日 - 31日: 投票周
2月1日: 宣布获胜者!
主题
💡 多模型应用构建 💡
利用InterSystems IRIS数据平台构建多模型解决方案。
InterSystems IRIS数据平台是一个多模型DBMS. 我们公开了一些可开箱即用的APIs,可以为您提供数据管理的键-值,SQL,对象和文档模型。通过IRIS,您可以开发自己的模型,并公开API,这些API将提供一些新的数据模型,比如 GraphDB, column-store等。
在这个竞赛中,开发者需要创建一个至少使用两种不同模型来操作数据的应用程序,例如key-value和relational, Object和relational, DocDB和key-value。
应用程序应该在 IRIS Community Edition 或 IRIS for Health Community Edition 或 IRIS Advanced Analytics Community Edition上运行。
应用程序应该开源并在GitHub上发布。
资源助力
1. 资源——模型方面
文档
Multi-model data aсcess
1.1. Globals (key-value)
Globals是可以在IRIS数据库中存储和管理的稀疏多维数组。您可以使用ObjectScript和本机API处理Globals。
工具:
Managing globals in management portal
文档:
Using Multidimensional Storage (Globals)
Using Globals
社区文章:
Globals are Magic Swords for managing data
The art of mapping Globals to Classes
视频:
Globals QuickStart
1.2. SQL访问
InterSystems IRIS通过 ObjectScript/REST API和ODBC/JDBC提供对数据的SQL访问.
工具:
VSCode SQL Tools
DBeaver
SQL in Management Portal
Other SQL tools
文档:
SQL Access
InterSystems SQL Reference
社区文章:
Class Queries in ObjectScript
视频:
SQL Things you should know
1.3. Object访问
通过ObjectScript/REST API,本地API (Java/.NET/Node.js/Python)和XEP(Java/.NET),InterSystems IRIS提供了在Globals 存储和更改对象实例的途径。
文档:
Object Access
1.4. Document访问
InterSystems IRIS提供DocDB,通过REST API和ODBC/JDBC(SQL)来存储和管理JSON数据文档。
文档:
DocDB
2. 如何提交您开发的应用:
如何在Open Exchange上发布应用
如何递交竞赛申请
3. 线上课程:
Multi-Model QuickStart
4. 视频:
Multi-Model Development
Multi-Inheritance in a Multi-Model Environment
公平公正
投票规则.
那么!
准备好了吗?
开始编程吧!
❗️ 点击此处,查看 官方竞赛术语解读.❗️