清除过滤器
文章
Qiao Peng · 一月 14, 2021

您好! 本文介绍另一种为基于 InterSystems Caché 的解决方案创建安装程序的简单方法。 主题将涵盖只需一项操作即可安装或从 Caché 中完全删除的应用程序。 如果您仍在编写需要执行多个步骤才能安装应用程序的安装说明,是时候将这个过程自动化了。
问题的提出
假设我们为 Caché 开发了一个小型实用程序,之后我们想要将其分发。 当然,最好不要让不必要的配置和安装细节打扰到安装它的用户。 此外,这些说明必须非常全面,而且要面向可能对 Caché 一无所知的用户。如果是 Web 实用程序,安装程序不仅会要求用户将其类导入 Caché,而且至少还要配置 Web 应用程序才能对其进行访问,这是相当大的工作量:

当然,所有这些操作都可以通过编程方式执行。 您只需要了解如何实现。 但即使是这样,我们也需要让用户执行操作,例如在终端中执行一个命令。
通过单次导入操作进行安装
Caché 允许我们在类导入期间执行安装。 这意味着用户只需要使用任一方便的方法导入包含类包的 XML 文件:
将 XML 文件拖放到 Studio 区域。
通过管理门户:系统资源管理器 -> 类 -> 导入。
通过终端:do $system.OBJ.Load("C:\FileToImport.xml","ck")。
我们为安装应用程序而预先准备的代码将在类导入和编译后立即执行。 如果用户要卸载我们的应用程序(删除软件包),我们还可以清理应用程序在安装过程中创建的所有内容。
创建投影
为了扩展 Caché 编译器的行为,或者,在我们的示例中,为了在类的编译或反编译期间执行代码,我们需要在软件包中创建一个投影类。 它是一个扩展了 %Projection.AbstractProjection 的类,并重载了它的两个方法:CreateProjection(在编译过程中执行)和 RemoveProjection(在重新编译或删除类时触发)。
通常,将这个类命名为 Installer 是个好方法。 我们来看一个名为“MyPackage”的软件包的简单安装程序示例:
Class MyPackage.Installer Extends %Projection.AbstractProjection [ CompileAfter = (Class1, Class2) ]
{Projection Reference As Installer;/// This method is invoked when a class is compiled.ClassMethod CreateProjection(cls As %String, ByRef params) As %Status{ write !, "Installing..."}/// This method is invoked when a class is 'uncompiled'.ClassMethod RemoveProjection(cls As %String, ByRef params, recompile As %Boolean) As %Status{ write !, "Uninstalling..."}}
这里的行为可以描述为:
第一次导入和编译软件包时,只触发 CreateProjection 方法。
以后再编译 MyApp.Installer 时,或者导入“新”的安装程序类覆盖“旧”类时,将触发旧类的 RemoveProjection 方法,且 %recompile 参数等于 1,之后调用新类的 CreateProjection 方法。
删除软件包(同时删除 MyApp.Installer)时,将只调用 RemoveProjection 方法,参数 recompile = 0。
还需要注意以下几点:
类关键字 CompileAfter 应该包括应用程序的类名列表,在执行投影类的方法之前,需要对它们进行编译。 始终建议在此列表中填入应用程序中的所有类,因为如果安装过程中出错,我们不需要执行投影类的代码;
两个方法都接受 cls 参数 - 它是顶级类名,在我们的示例中为 MyApp.Installer。 这个理念来自于创建投影类的本义 - 通过从派生自 %Projection.AbstractProjection 的类再派生,可以单独为我们的应用程序的任何类制作“安装程序”。 只有在这种情况下才会体现出意义,但对于我们的任务来说是多余的;
CreateProjection 和 RemoveProjection 方法都接受第二个参数 params - 它是一个关联数组,以“参数名称”-“值”对的形式处理有关当前编译设置和当前类的参数值的信息。 通过执行 zwrite params 可以非常容易地探索该参数的内容;
RemoveProjection 方法接受 recompile 参数,只有删除类时,该参数才等于 0,重新编译时不等于 0。
类 %Projection.AbstractProjection 还有其他方法,我们可以重新定义这些方法,但我们的任务并不需要这样做。
一个示例
让我们更深入地了解为我们的实用程序创建 Web 应用程序的任务,并创建一个简单示例。 假设我们的实用程序是一个 REST 应用程序,在浏览器中打开时,它只发送一个响应“I am installed!”。 要创建这样的应用程序,我们需要创建一个描述它的类:
Class MyPackage.REST Extends %CSP.REST{XData UrlMap{ }ClassMethod Index() As %Status{ write "I am installed!" return $$$OK}}
创建并编译该类后,我们需要将其注册为 Web 应用程序入口点。 我在本文的顶部图示了如何进行配置。 在执行所有这些步骤后,最好通过访问 http://localhost:57772/myWebApp/ 来检查我们的应用程序是否正常工作(注意以下几点:1. 末尾的斜线是必需的;2. 端口 57772 在您的系统中可能有所不同。 它将匹配您的管理门户端口)。
当然,所有这些步骤都可以通过 Web 应用程序创建方法 CreateProjection 以及删除方法 RemoveProjection 中的一些代码来自动执行。 在这种情况下,我们的投影类如下所示:
Class MyPackage.Installer Extends %Projection.AbstractProjection [ CompileAfter = MyPackage.REST ]{Projection Reference As Installer;Parameter WebAppName As %String = "/myWebApp";Parameter DispatchClass As %String = "MyPackage.REST";ClassMethod CreateProjection(cls As %String, ByRef params) As %Status{ set currentNamespace = $Namespace write !, "Changing namespace to %SYS..." znspace "%SYS" // we need to change the namespace to %SYS, as Security.Applications class exists only there write !, "Configuring WEB application..." set cspProperties("AutheEnabled") = $$$AutheUnauthenticated // public application set cspProperties("NameSpace") = currentNamespace // web-application for the namespace we import classes to set cspProperties("Description") = "A test WEB application." // web-application description set cspProperties("IsNameSpaceDefault") = $$$NO // this application is not the default application for the namespace set cspProperties("DispatchClass") = ..#DispatchClass // the class we created before that handles the requests return ##class(Security.Applications).Create(..#WebAppName, .cspProperties)}ClassMethod RemoveProjection(cls As %String, ByRef params, recompile As %Boolean) As %Status{ write !, "Changing namespace to %SYS..." znspace "%SYS" write !, "Deleting WEB application..." return ##class(Security.Applications).Delete(..#WebAppName)}}
在此示例中,每次编译 MyPackage.Installer 类都将创建一个 Web 应用程序,每次“反编译”都将其删除。 最好在创建或删除应用程序之前检查该应用程序是否存在(例如,使用 ##class(Security.Applications).Exists(“Name”) ),但是为了使本示例简单起见,这个作业就留给阅读本文的读者来完成了。
在创建 MyPackage.REST 和 MyPackage.Installer 类之后,我们可以将这些类导出为一个 XML 文件,并将该文件分享给所有有需要的人。 导入此 XML 的用户将自动设置 Web 应用程序,然后可以开始在浏览器中使用。
结果
与 InterSystems 社区上介绍的使用 %Installer 类部署应用程序的方法不同,这种方法有以下优点:
使用“纯”Caché ObjectScript。 至于 %Installer,需要用特定标签来填充 xData 块,大量文档对此进行了介绍。
安装我们的应用程序的方法是在类编译后立即执行的,我们不需要手动执行;
如果类(包)被删除,将自动执行删除我们的应用程序的方法,这不能通过使用 %Installer 来实现。
我的项目中已经使用这种应用程序安装方法 - Caché WEB Terminal、Caché Class Explorer 和 Caché Visual Editor。 您可以在此处找到 Installer 类的示例。
顺便提一下,开发者社区还有一个帖子介绍了投影的功能,作者是 John Murray。
另外值得一提的是 Package Manager 项目,该项目旨在让 InterSystems 数据平台的第三方应用程序只需通过一个命令或一次点击即可安装,就像类似 npm 的包管理器一样。
文章
Li Yan · 一月 13, 2021
本文提供了一个参考架构,作为示例说明基于 InterSystems Technologies(适用于 Caché、Ensemble、HealthShare、TrakCare 以及相关的嵌入式技术,例如 DeepSee、iKnow、Zen 和 Zen Mojo)提供的强大性能和高可用性应用。Azure 有两种用于创建和管理资源的不同部署模型:Azure Classic 和 Azure Resource Manager。 本文中的详细信息基于 Azure Resource Manager (ARM) 模型。
摘要
Microsoft Azure 云平台为基础设施即服务 (IaaS) 提供功能丰富的环境,其作为云提供完备的功能,支持所有的 InterSystems 产品。 与任何平台或部署模型一样,必须留心以确保考虑到环境的各个方面,例如性能、可用性、操作和管理程序。 本文将阐述所有这些方面。
性能
在 Azure ARM 中,有多个可用于计算虚拟机 (VM) 的选项以及相关的存储选项,与 InterSystems 产品最直接相关的是网络连接 的IaaS 磁盘,其作为 VHD 文件存储在 Azure 页面的 Blob 存储中。 还有其他几个选项,例如_ Blob(块)、文件_等,但是这些选项更特定于单个应用程序的要求,而非支持 Caché 的操作。 磁盘存储有两种类型的存储:“高级存储”和“标准存储”。 高级存储更适合这样的生产工作负载:要求保证可预测的低延迟每秒输入/输出操作 (IOP) 和吞吐量。 标准存储是针对非生产或存档类型工作负载的更经济选择。 选择特定的 VM 类型时务必小心,因为并非所有的 VM 类型都可以访问高级存储。
虚拟 IP 地址和自动故障转移
大多数 IaaS 云提供商缺乏提供虚拟 IP (VIP) 地址的能力,这种地址通常用在数据库故障转移设计中。 为解决这一问题,Caché 中增强了几种最常用的连接方法,尤其是 ECP 客户端和 CSP 网关,从而不再依赖 VIP 功能使它们实现镜像状态感知。
xDBC、直接 TCP/IP 套接字等连接方法,或其他的直接连接协议,均需要使用 VIP。 为解决这些问题,InterSystems 数据库镜像技术使用 API 与 Azure 内部负载均衡器(ILB)交互以实现类 VIP 功能,使得 Azure 中的那些连接方法实现自动故障转移,从而在 Azure 中提供完整而强大的高可用性设计 。 有关详细信息,请参见社区文章无虚拟 IP 地址的数据库镜像。
备份操作
无论使用传统的文件级备份,还是基于快照的备份,在云部署中执行备份都面临着挑战。 如今,在 Azure ARM 平台中,使用 Azure Backup 和 Azure Automation Run Books 配合 InterSystems 外部冻结及解冻 API 功能,即可实现这一切,从而实现真正的 24x7 全天候操作弹性并确保干净的常规备份。 或者,可以在 VM 本身中部署备份代理,利用文件级备份,并结合逻辑卷管理器 (LVM) 快照,来使用市面上的许多第三方备份工具。
示例架构
作为本文档的一部分,这里为您提供一个示例 Azure 架构,作为您特定应用部署的入门参考,并可用作各种部署的可能性的指南。 此参考架构显示了一个强大的 Caché 数据库部署,其中包括可实现高可用性的数据库镜像成员、使用 InterSystems 企业缓存协议(ECP)的应用程序服务器、使用 InterSystems CSP 网关的 Web 服务器,以及内部和外部 Azure 负载均衡器。
Azure 架构
在 Microsoft Azure 上部署任何基于Caché 的应用都需要特别注意某些方面。 本部分讨论通用的方面,对于您的应用的特定技术要求不做阐述。
本文档中提供了两个示例,一个基于_ InterSystems TrakCare 统一医疗信息系统,另一个基于完整的 InterSystems HealthShare 健康信息学平台部署,包括:_Information Exchange、Patient Index、Health Insight、Personal Community 和 Health Connect。
虚拟机
Azure 虚拟机 (VM) 分为两层:基本层和标准层。 两种类型提供对规模的选择。 基本层不提供标准层中的某些功能,例如负载均衡和自动伸缩。 因此,将标准层用于 TrakCare 部署。
标准层 VM 具有不同规模,按不同系列分组,即: A、D、DS、F、FS、G 和 GS。 DS、GS 和新的 FS 支持 Azure 高级存储的使用。
生产服务器通常需要使用高级存储来实现可靠性、低延迟和高性能。 因此,本文档中详细介绍的示例 TrakCare 和 HealthShare 部署架构将使用 FS、DS 或 GS 系列 VM。 注意,并非所有的虚拟机规模在所有区域中都可用。
有关虚拟机规模的详细信息,请参见:
Windows 虚拟机规模
Linux 虚拟机规模
存储
TrakCare 和 HealthShare 服务器需要 Azure 高级存储。 高级存储将数据存储在固态硬盘 (SSD) 上,以低延迟提供高吞吐量;而标准存储将数据存储在硬盘驱动器 (HDD) 上,会导致性能的降低。
Azure 存储属于冗余且高度可用的系统,但是,请务必注意,可用性集合当前不提供跨存储故障域的冗余,在极少数情况下,这可能会导致问题。 Microsoft 有缓解方案,并正在努力使此过程对最终客户广泛可用且更容易使用。 建议您直接与当地的 Microsoft 团队合作以确定是否需要任何缓解方案。
当针对高级存储帐户配置磁盘时,IOPS 和吞吐量(带宽)取决于磁盘的大小。 当前,有三种类型的高级存储磁盘:P10、P20 和 P30。 每种对 IOPS 和吞吐量都有特定的限制,如下表所示。
高级磁盘类型
P4
P6
P10
P15
P20
P30
P40
P50
磁盘容量
32GB
64GB
128GB
256GB
512GB
1024GB
2048GB
4096GB
每个磁盘的 IOPS
120
240
500
1100
2300
5000
7500
7500
每个磁盘的吞吐量
25MB/s
50MB/s
100MB/s
125MB/s
150MB/s
200MB/s
250MB/s
250MB/s
注意:确保给定的 VM 上有足够的可用带宽来驱动磁盘流量。
例如,STANDARD_DS13 VM 具有每秒 256 MB 的专用带宽,可用于所有高级存储磁盘流量。
这意味着连接到该虚拟机的四个 P30 高级存储磁盘的吞吐量限制为每秒 256 MB,而不是四个 P30 磁盘理论上可以提供的每秒 800 MB 的速度。
有关高级存储磁盘的更多详细信息和限制,包括预配置的容量、性能、大小、IO 大小、缓存命中率、吞吐量目标和限制,请参阅:
高级存储
高可用性
InterSystems 建议在已定义的可用性集合中拥有两个或更多虚拟机。 之所以需要此配置,是因为在计划内或计划外的维护活动期间,至少有一个虚拟机可用于满足 99.95% 的 Azure SLA。 这很重要,因为在数据中心更新期间,VM 会被并行关闭、升级并以不特定的顺序重新联机,导致应用程序在此维护窗口期不可用。
因此,高度可用的架构需要每种服务器至少部署两台,这些服务器包括负载均衡 Web 服务器、数据库镜像、多个应用程序服务器等。
有关 Azure 高可用性最佳做法的更多信息,请参见:
管理可用性
Web 服务器负载均衡
基于 Caché 的应用程序可能需要外部和内部负载均衡 Web 服务器。 外部负载均衡器用于通过 Internet 或 WAN(VPN 或 Express Route)进行的访问,而内部负载均衡器则通常用于内部流量。 Azure 负载均衡器是 4 层 (TCP, UDP) 的负载均衡器,可在负载均衡器集合中定义的云服务或虚拟机中的健康服务实例之间分配传入的流量。
Web 服务器负载均衡器必须配置客户端 IP 地址会话持续性(2 个元组)和可能的最短探测超时(当前为 5 秒)。 TrakCare 需要在用户登录期间保持会话持续性。
Microsoft 提供的下图显示了 ARM 部署模型中一个简单的 Azure 负载均衡器示例。
有关 Azure 负载均衡器的功能(例如分配算法、端口转发、服务监视、源 NAT )和其他类型的可用负载均衡器的详细信息,请参阅:
负载均衡器概述
除了 Azure 外部负载均衡器,Azure 还提供 Azure 应用程序网关。 Application Gateway 是一个 L7 负载均衡器 (HTTP/HTPS),支持基于 cookie 的会话相关性和 SSL 终端(SSL 卸载)。 SSL 卸载可减轻 Web 服务器的加密/解密开销,因为 SSL 连接会在负载均衡器处终止。 这种方法简化了管理,因为 SSL 证书是在网关中部署和管理,而不是在 Web 场中的所有节点上。
有关详细信息,请参阅︰
应用程序网关概述
使用 Azure Resource Manager 为 SSL 卸载配置应用程序网关
数据库镜像
在 Azure 上部署基于 Caché 的应用程序时,要为 Caché 数据库服务器提供高可用性,需要使用同步数据库镜像,以在给定的主 Azure 区域中提供高可用性,并可能使用异步数据库镜像将数据复制到辅助 Azure 区域中的热备用数据库中,以根据您的运行时间服务水平协议要求来进行灾难恢复。
数据库镜像是两个数据库系统的逻辑分组,也就是所说的故障转移成员,它们在物理上是仅通过网络连接的独立系统。 在这两个系统之间进行仲裁后,镜像会自动将其中一个指定为主系统。 另一个自动成为备份系统。 外部客户端工作站或其他计算机通过镜像虚拟 IP (VIP) 连接到镜像,该虚拟 IP 在镜像配置期间指定。 镜像 VIP 会自动绑定到镜像主系统上的接口。
注意:在 Azure 中,无法配置镜像 VIP,因此已设计了替代解决方案。
当前,在 Azure 中部署数据库镜像时,建议在同一 Azure 可用性集中配置三个 VM(主 VM、备份 VM、仲裁器)。 这样可确保在任何给定的时间,Azure 都可以保证至少与其中两个 VM 以 99.95% 的 SLA 建立外部连接,并且每个 VM 都位于不同的更新域和故障域中。 这样可以为数据库数据本身提供足够的隔离和冗余。
可在下列位置找到更多详细信息:
Azure 可用性集
Azure 服务水平协议 (SLA)
包括 Azure 在内的任何 IaaS 云提供程序所面临的挑战,就是在没有虚拟 IP 功能的情况下,如何处理连接到应用程序的客户端的自动故障转移。 为了保持客户端连接的自动故障转移,已采取了两种策略。
首先,InterSystems 对 CSP 网关进行了增强,使其能够感知镜像,以此使得采用 CSP 网关的 Web 服务器到数据库服务器的连接不再需要 VIP。 CSP 网关将自动与两个镜像成员进行协商,并重定向到确定的主镜像成员。 如果使用 ECP 客户端,则将与其已经具备的镜像感知协同工作。
其次,CSP 网关和 ECP 客户端外部的连接仍然需要类 VIP 功能。 InterSystems 建议将轮询方法与_ mirror_status.cxw _运行状况检查状态页面介绍的内容结合使用,该页面在社区文章无虚拟 IP 地址的数据库镜像中进行了详细说明。
Azure 内部负载均衡器 (ILB) 将提供单一 IP 地址作为类 VIP 功能,将所有网络流量定向到主镜像成员。 ILB 只会将流量分配给主镜像成员。 此方法不会依赖轮询,且在镜像配置内的任何镜像成员成为主成员时,允许立即重定向。 在某些使用 Azure Traffic Manager 的灾难恢复方案中,可将此方法与轮询结合使用。
备份与恢复
备份操作有多个选项。 以下 3 个选项可供您通过 InterSystems 产品进行 Azure 部署。 下面的前 2 个选项采用快照类型的过程,该过程会在创建快照之前将数据库写入到磁盘的操作挂起,然后在快照成功后恢复更新。 可采取以下高级别步骤通过任一快照方法来创建洁净的备份:
通过数据库冻结 API 调用暂停对数据库的写入。
创建操作系统和数据磁盘的快照。
通过数据库解冻 API 调用恢复 Caché 写入。
将设施存档备份到备份位置
可以定期添加诸如完整性检查之类的其他步骤,以确保洁净且一致的备份。
决定使用哪种选项取决于您组织的运营要求和策略。 InterSystems 可与您详细讨论各种选项。
Azure 备份
如今,在 Azure ARM 平台中,使用 Azure Backup 和 Azure Automation Run Books 配合 InterSystems 外部冻结及解冻 API 功能,即可实现备份操作,从而实现真正的 24x7 全天候操作弹性并确保干净的常规备份。 有关管理和自动化 Azure 备份的详细信息,可在此处找到。
逻辑卷管理器快照
或者,可以在 VM 本身中部署单个备份代理,利用文件级备份,并结合逻辑卷管理器 (LVM) 快照,来使用市面上的许多第三方备份工具。
该模型的主要优点之一是能够对基于 Windows 或 Linux 的 VM 进行文件级恢复。 此解决方案需要注意的几点是,由于 Azure 和大多数其他 IaaS 云提供商都不提供磁带媒体,因此所有的备份存储库对于短期归档均基于磁盘,并利用 Blob 或存储桶类型的低成本存储来进行长期保留 (LTR)。 强烈建议您使用此方法来使用支持重复数据删除技术的备份产品,以最有效地利用基于磁盘的备份存储库。
这些具有云支持的备份产品的示例包括但不限于:Commvault、EMC Networker、HPE Data Protector 和 Veritas Netbackup。 InterSystems 不会验证或认可一种备份产品是否优于其他产品。
Caché 在线备份
对于小型部署,内置 Caché 在线备份工具也是可行的选择。 该 InterSystems 数据库在线备份实用工具通过捕获数据库中的所有块来备份数据库文件中的数据,然后将输出写入顺序文件。 这种专有的备份机制旨在使生产系统的用户不停机。
在 Azure 中,在线备份完成后,必须将备份输出文件和系统正在使用的所有其他文件复制到 Azure 文件共享中。 该过程需要在虚拟机中编写脚本并执行。
Azure 文件共享应使用 Azure RA-GRS 存储帐户以实现最大可用性。 注意,Azure 文件共享的最大共享大小为 5TB,最大文件大小为 1TB,每个共享(所有客户端共享)的最大吞吐量为 60 MB/s。
在线备份是入门级方法,适合于希望实施低成本备份解决方案的小型站点。 但是,随着数据库的增大,建议将使用快照技术的外部备份作为最佳做法,因为其具有以下优势:备份外部文件、更快的恢复时间,以及企业范围的数据和管理工具。
灾难恢复
在 Azure 上部署基于 Caché 的应用程序时,建议将包括网络、服务器和存储在内的灾难恢复 (DR) 资源放置在不同的 Azure 区域中。 指定的 DR Azure 区域所需的容量取决于您组织的需求。 在大多数情况下,以 DR 模式运行时需要 100% 的生产能力,但是,在需要更多的生产能力作为弹性模型之前,可以配置较小的生产能力。
异步数据库镜像用于连续复制到 DR Azure 区域的虚拟机。 镜像使用数据库事务日志在 TCP/IP 网络上复制更新,其采用对主系统性能影响最小的方式。 强烈建议对这些 DR 异步镜像成员配置压缩和加密。
互联网上希望访问应用程序的所有外部客户端都将通过 Azure Traffic Manager 作为 DNS 服务进行路由。 Microsoft Azure Traffic Manager(ATM)用作交换机,负责将流量定向到当前活动的数据中心。 Azure Traffic Manager 支持多种算法来确定如何将最终用户路由到各个服务端点。 有关各种算法的详细信息,可在此处找到。
本文档中,“优先级”流量路由方法将与 Traffic Manager 端点监视和故障转移结合使用。 有关端点监视和故障转移的详细信息,可在此处找到。
Traffic Manager 的工作是向每个端点发出常规请求,然后验证响应。 如果端点未提供有效的响应,则 Traffic Manager 会将其状态显示为“降级”。 它将不会再被包含在 DNS 响应中,而是会返回一个备用的可用端点。 通过这种方式,将用户流量从失败的端点定向到可用端点。
使用上述方法,只有特定区域和特定镜像成员才允许流量通过。 这由端点定义控制,可从 InterSystems CSP 网关的 mirror_status 页面设置端点定义。 只有主镜像成员才能通过监控器探测来报告 HTTP 200 为“成功”。
Microsoft 提供的下图在高级别上显示了优先级流量例程算法。
Azure Traffic Manager 会产生一个所有客户端都可以连接到的端点,例如:“ https://my-app.trafficmanager.net ”。 此外,可以配置 A 记录来提供虚 URL,例如“ https://www.my-app-domain.com ”。Azure Traffic Manager 必须配置一个包含两个区域端点地址的配置文件。
在任何给定时间,只有其中的一个区域会根据端点监视在线报告。 这样可以确保流量在给定的时间仅流向一个区域。 区域之间的故障转移无需其他步骤,因为端点监控将检测到主 Azure 区域中的应用程序已关闭,并且该应用程序现在位于辅助 Azure 区域中。 这是因为 DR 异步镜像成员被提升为主成员,然后允许 CSP 网关将 HTTP 200 报告给 Traffic Manager 端点监视。
上述解决方案有很多替代方案,可以根据您组织的运营要求和服务水平协议进行自定义。
网络连接
根据您应用程序的连接要求,有多种连接模型可用:使用 Internet、IPSEC VPN 的连接模型,或使用 Azure Express Route 的专用链接。 选择方法取决于应用程序和用户需求。 三种方法的带宽使用情况各不相同,最好与您的 Azure 代表或 Azure 门户联系以确认给定区域的可用连接选项。
如果您正在使用 Express Route,则可为灾难恢复方案启用包括多线路和多区域访问在内的多个选项。 与 Express Route 提供商合作以了解他们支持的高可用性和灾难恢复方案至关重要。
安全
决定在公共云提供程序中部署应用程序时需要格外小心。 应遵循您组织的标准安全策略或专门为云开发的新安全策略,以维护您组织的安全合规性。 就客户端数据中心之外的数据以及物理安全控制方面,云部署的风险逐渐加大。 强烈建议对静态数据(数据库和日志)及飞行数据(网络通信)使用 InterSystems 数据库和日志加密,分别使用 AES 和 SSL/TLS 加密。
与所有加密密钥管理一样,您需要按照您组织的政策记录并遵循正确的程序,以确保数据安全,防止不必要的数据访问或安全漏洞。
当允许通过互联网进行访问时,可能需要第三方防火墙设备来实现其他功能,例如入侵检测、拒绝服务保护等。
架构图示例
下图说明了典型的 Caché 安装,其以数据库镜像(同步故障转移和 DR 异步)、使用 ECP 的应用程序服务器,以及多个负载均衡 Web 服务器的方式提供高可用性。
TrakCare 示例
下图说明了典型的 TrakCare 部署,其中包含多个负载均衡 Web 服务器,两个作为 ECP 客户端的 EPS 打印服务器,以及数据库镜像配置。 虚拟 IP 地址仅用于与 ECP 或 CSP 网关不关联的连接。 ECP 客户端和 CSP 网关可感知镜像,不需要 VIP。
下图中的示例参考架构包括活动或主区域中的高可用性,可在主 Azure 区域不可用的情况下,执行灾难恢复到另一个 Azure 区域。 同样,在此示例中,数据库镜像包含 TrakCare DB、TrakCare Analytics 和 Integration 命名空间,这些都在一个镜像集群中。
TrakCare Azure 参考架构图 - 物理架构
另外,下图显示了该架构的逻辑图,包含架构所安装的相关高级软件产品及其功能用途。
TrakCare Azure 参考架构图 - 逻辑架构
HealthShare 示例
下图显示了一个典型的 HealthShare 部署,其具有多个负载均衡 Web 服务器,以及多个 HealthShare 产品,包括 Information Exchange、Patient Index、Personal Community、Health Insight 和 Health Connect。 这些产品中的每一个都包含一对数据库镜像,以在 Azure 可用性集合中提供高可用性。 虚拟 IP 地址仅用于与 ECP 或 CSP 网关不关联的连接。 HealthShare 产品之间用于 Web 服务通信的 CSP 网关可感知镜像,不需要 VIP。
下图中的示例参考架构包括活动或主区域中的高可用性,可在主 Azure 区域不可用的情况下,执行灾难恢复到另一个 Azure 区域。
HealthShare Azure 参考架构图 - 物理架构
另外,下图显示了该架构的逻辑图,包含架构所安装的相关高级软件产品、连接要求、方法及相应的功能用途。
HealthShare Azure 参考架构图 - 逻辑架构
公告
Claire Zheng · 一月 12, 2021
亲爱的开发者们,欢迎您参加在线编程竞赛!这是2020年的系列竞赛,主题是利用InterSystems IRIS构建多模型解决方案。在这个竞赛中,开发者需要创建一个至少使用两种不同模型来操作数据的应用程序,例如key-value和relational, Object和relational, DocDB和key-value。这场由开发者社区发起的编程马拉松将从1月11日持续到1月31日。
展示最棒的编程技能,赢取炫酷奖品!
主题:利用InterSystems IRIS构建多模型应用
时间:2021年1月11日-31日
奖品丰厚
1. Experts Nomination——获奖者由我们特别挑选的专家团选出:
🥇 1st place - $2,000
🥈 2nd place - $1,000
🥉 3rd place - $500
2. Community Nomination——获得总投票数最多的应用
🥇 1st place - $1,000
🥈 2nd place - $500
🥉 3rd place - $250
如果同时多位参赛者获得同样的票数,均被视为优胜者,将平分奖金。
谁可以参加?
任何开发者社区的成员均可参加,InterSystems内部员工除外。还没有账号?现在来建一个!
参赛时间安排
1月11日 - 24日: 在这两周,您可以将开发的应用上传至Open Exchange (在此期间,还可以继续编辑您的项目).
1月25日 - 31日: 投票周
2月1日: 宣布获胜者!
主题
💡 多模型应用构建 💡
利用InterSystems IRIS数据平台构建多模型解决方案。
InterSystems IRIS数据平台是一个多模型DBMS. 我们公开了一些可开箱即用的APIs,可以为您提供数据管理的键-值,SQL,对象和文档模型。通过IRIS,您可以开发自己的模型,并公开API,这些API将提供一些新的数据模型,比如 GraphDB, column-store等。
在这个竞赛中,开发者需要创建一个至少使用两种不同模型来操作数据的应用程序,例如key-value和relational, Object和relational, DocDB和key-value。
应用程序应该在 IRIS Community Edition 或 IRIS for Health Community Edition 或 IRIS Advanced Analytics Community Edition上运行。
应用程序应该开源并在GitHub上发布。
资源助力
1. 资源——模型方面
文档
Multi-model data aсcess
1.1. Globals (key-value)
Globals是可以在IRIS数据库中存储和管理的稀疏多维数组。您可以使用ObjectScript和本机API处理Globals。
工具:
Managing globals in management portal
文档:
Using Multidimensional Storage (Globals)
Using Globals
社区文章:
Globals are Magic Swords for managing data
The art of mapping Globals to Classes
视频:
Globals QuickStart
1.2. SQL访问
InterSystems IRIS通过 ObjectScript/REST API和ODBC/JDBC提供对数据的SQL访问.
工具:
VSCode SQL Tools
DBeaver
SQL in Management Portal
Other SQL tools
文档:
SQL Access
InterSystems SQL Reference
社区文章:
Class Queries in ObjectScript
视频:
SQL Things you should know
1.3. Object访问
通过ObjectScript/REST API,本地API (Java/.NET/Node.js/Python)和XEP(Java/.NET),InterSystems IRIS提供了在Globals 存储和更改对象实例的途径。
文档:
Object Access
1.4. Document访问
InterSystems IRIS提供DocDB,通过REST API和ODBC/JDBC(SQL)来存储和管理JSON数据文档。
文档:
DocDB
2. 如何提交您开发的应用:
如何在Open Exchange上发布应用
如何递交竞赛申请
3. 线上课程:
Multi-Model QuickStart
4. 视频:
Multi-Model Development
Multi-Inheritance in a Multi-Model Environment
公平公正
投票规则.
那么!
准备好了吗?
开始编程吧!
❗️ 点击此处,查看 官方竞赛术语解读.❗️
公告
Claire Zheng · 一月 12, 2021
本报告介绍了ESG 集团对多个数据库管理软件产品进行的并发数据摄取和实时查询性能验证测试。测试结果表明,InterSystems IRIS 数据平台可在摄取上亿条记录的同时执行数百万条查询,响应时间达到微秒级,其性能优于其他传统产品和内存产品。
对许多企业而言,收集并实时分析数据是一项必备能力,有助于推动收入增长、提高知名度,并为战略和决策提供参考。例如,专注于金融交易、物联网、欺诈检测和实时个性化服务的应用程序必须摄取并实时分析海量数据。其中的挑战在于找到一个足够强大的数据库平台,以便同时处理大规模的数据摄取和查询且不降低性能。当ESG向数据库和分析专家询问数据分析支持技术的相关问题时,大家普遍认为最重要的能力之一是性能。
内存数据库可提供高性能,但其扩展成本高昂,而且具有内存硬限制,可能会引起可靠性问题和重启延迟。传统数据库可提供持久性和可靠性,但缺乏内存数据库的高性能。相比之下,InterSystems IRIS 可同时处理数据摄取和查询工作负载,其性能可匹敌甚至优于内存数据库,并且不存在内存数据库的限制。为了证明这一主张,InterSystems发布了一项开源测试,ESG 也在本报告中进行了验证。
点击获取完整白皮书:
ESG 白皮书 | InterSystems IRIS:处理并发数据摄取和实时查询的高性能数据管理软件
文章
Li Yan · 一月 11, 2021
Amazon Web Services (AWS) 云提供广泛的云基础设施服务,例如计算资源、存储选项和网络,这些都非常实用:按需提供,几秒内就可用,采用即付即用定价的模式。 新服务可得到快速配置,且前期无需支出大量资金。 这使得大企业、初创公司、中小型企业以及公共部门的客户可以访问他们所需的基础设施,从而快速响应不断变化的业务需求。
更新日期:2019 年 10 月 15 日
以下概述和详细信息由 Amazon 提供,并可以在此处找到。
概述
AWS 全球基础设施
AWS 云基础设施围绕区域和可用性地区 (AZ) 构建。 区域就是地球上的物理位置,我们拥有多个 AZ。 AZ 由一个或多个离散的数据中心组成,每个数据中心都拥有冗余电源、网络和连接,并安置在单独的设施中。 这些 AZ 可让您能够以比在单个数据中心更高的可用性、容错能力和可伸缩性运行生产应用程序和数据库。
有关 AWS 全球基础设施的详细信息,可在此处找到。AWS 安全性和合规性
云端的安全性与您本地数据中心的安全性非常相似,只是没有维护设施和硬件的成本。 在云端,您无需管理物理服务器或存储设备。 相反,您使用基于软件的安全工具来监控和保护进出云资源的信息流。
AWS 云实现了共享责任模型。 虽然 AWS 管理云的安全性,但您负责云中的安全性。 这意味着您保留了对您选择实施的安全性的控制,以保护您自己的内容、平台、应用程序、系统和网络,与您在现场数据中心中的做法没有区别。
有关 AWS 云安全的详细信息,可在此处找到。
AWS 为其客户提供的 IT 基础设施是按照最佳安全实践和各种 IT 安全标准进行设计和管理的。有关 AWS 遵守的保证计划的完整列表,可在此处找到。
AWS 云平台
AWS 由多种云服务组成,您可以根据您的业务或组织需求进行组合使用。 以下小节按类别介绍了 InterSystems IRIS 部署中常用的主要 AWS 服务。 还有许多其他服务也可能对您的具体应用有着潜在用途。 请务必根据需要加以研究。
要访问这些服务,您可以使用 AWS 管理控制台、命令行界面或软件开发套件 (SDK)。
AWS 云平台
组件
详细信息
AWS 管理控制台
有关 AWS 管理控制台的详细信息,可在此处找到。
AWS 命令行界面
有关 AWS 命令行界面 (CLI) 的详细信息,可在此处找到。
AWS 软件开发套件 (SDK)
有关 AWS 软件开发套件 (SDK) 的详细信息,可在此处找到。
AWS 计算
有许多选项可供选择: 有关 Amazon Elastic Cloud Computing (EC2) 的详细信息,可在此处找到 有关 Amazon EC2 Container Service (ECS) 的详细信息,可在此处找到 有关 Amazon EC2 Container Registry (ECR) 的详细信息,可在此处找到 有关 Amazon Auto Scaling 的详细信息,可在此处找到
AWS 存储
有许多选项可供选择: 有关 Amazon Elastic Block Store (EBS) 的详细信息,可在此处找到 有关 Amazon Simple Storage Service (S3) 的详细信息,可在此处找到 有关 Amazon Elastic File System (EFS) 的详细信息,可在此处找到
AWS 网络
有许多选项可供选择: 有关 Amazon Virtual Private Cloud (VPC) 的详细信息,可在此处找到 有关 Amazon Elastic IP Addresses 的详细信息,可在此处找到 有关 Amazon Elastic Network Interfaces 的详细信息,可在此处找到 有关 Amazon Enhanced Networking for Linux 的详细信息,可在此处找到 有关 Amazon Elastic Load Balancing (ELB) 的详细信息,可在此处找到 有关 Amazon Route 53 的详细信息,可在此处找到
InterSystems IRIS 示例架构
本文部分内容阐述了面向 AWS 的 InterSystems IRIS 部署示例,旨在为特定应用程序的部署抛砖引玉。这些示例可用作很多部署方案的指南。此参考架构拥有非常强大的部署选项,从最小规模的部署,到满足计算和数据需求的大规模可伸缩工作负载,不一而足。
本文介绍了高可用性和灾难恢复选项以及其他建议的系统操作。个体可对这些进行相应的修改以支持其组织的标准实践和安全策略。
针对您的特定应用,就基于 AWS 的 InterSystems IRIS 部署,您可联系 InterSystems 进一步探讨。示例参考架构
以下示例架构按照容量和功能逐步升级的顺序讲述了几种不同的配置,分别为小型开发/生产/大型生产/分片集群生产。先从中小型配置讲起,然后讲述具有跨地区高可用性以及多区域灾难恢复的大规模可缩放性解决方案。此外,还讲述了一个将 InterSystems IRIS 数据平台的新的分片功能用于大规模处理并行 SQL 查询的混合工作负载的示例。
小型开发配置
在本示例中,显示了一个能支持 10 名开发人员和 100GB 数据的小型开发环境,这基本是最小规模的配置。只要适当地更改虚拟机实例类型并增加 EBS 卷存储,即可轻松支持更多的开发人员和数据。
这足以支持开发工作,并让您熟悉 InterSystems IRIS 功能以及 Docker 容器的构建和编排(如果需要的话)。小型配置通常不采用具有高度可用性的数据库镜像,但是如果需要高可用性,则可随时添加。
小型配置示例图
示例图 2.1.1-a 显示了图表 2.1.1-b 中的资源。其中包含的网关只是示例,可做相应地调整以适应您组织的标准网络实践。
图 2.1.1-a:小型开发架构示例
下列 AWS VPC 资源是针对最小规模的配置提供的。可根据需求添加或删除 AWS 资源。
小型配置 AWS 资源
下表提供了小型配置 AWS 资源的示例。
图 2.1.1-b:小型配置 AWS 资源表示例
需要考虑适当的网络安全和防火墙规则,以防止对 VPC 的不必要访问。Amazon 提供网络安全最佳做法供您入门使用,可在此处找到:
https://docs.aws.amazon.com/vpc/index.html#lang/en_us
https://docs.aws.amazon.com/quickstart/latest/vpc/architecture.html#best-practices
注意:VM 实例需要公共 IP 地址才能访问 AWS 服务。 AWS 建议使用防火墙规则来限制传入到这些 VM 实例的流量,尽管这种做法可能会引起一些问题。
如果您的安全策略确实需要内部 VM 实例,则您需要在网络上手动设置 NAT 代理和相应的路由,以便内部实例可以访问互联网。 务必要明确,您无法使用 SSH 直接完全连接到内部 VM 实例。 要连接到此类内部机器,必须设置具有外部 IP 地址的堡垒机实例,然后通过它建立隧道。 可以配置堡垒主机,以提供进入 VPC 的外部入口点。
有关使用堡垒主机的详细信息,可在此处找到:
https://aws.amazon.com/blogs/security/controlling-network-access-to-ec2-instances-using-a-bastion-server/
https://docs.aws.amazon.com/quickstart/latest/linux-bastion/architecture.html
生产配置
在本示例中,展示了一个规模较大的生产配置,其采用 InterSystems IRIS 数据库镜像功能来支持高可用性和灾难恢复。
此配置包括 一对InterSystems IRIS 数据库服务器同步镜像,该镜像服务器在区域 1 内分为两个可用性地区,用于自动故障转移,在区域 2 内的第三个 DR 异步镜像成员用于灾难恢复,以防万一整个 AWS 区域宕机。
有关采用多 VPC 连接的多区域的详细信息,可在此处找到。
InterSystems Arbiter 和 ICM 服务器部署在单独的第三个地区,以提高弹性。 此示例架构还包括一组可选的负载均衡 web 服务器,用于支持启用 Web 的应用程序。这些使用 InterSystems 网关的 Web 服务器可以根据需要进行缩放。
生产配置示例图
示例图 2.2.1-a 显示了图表 2.2.1-b 中的资源。 其中包含的网关只是示例,可做相应地调整以适应您组织的标准网络实践。
图 2.2.1-a:具有高可用性和灾难恢复的生产架构示例
建议将以下 AWS VPC 资源作为支持 Web 应用程序生产工作负载的最低配置。可根据需求添加或删除 AWS 资源。
生产配置 AWS 资源
下表提供了生产配置 AWS 资源的示例。 .png)
图 2.2.1-b:生产配置 AWS 资源表(续)
大型生产配置
在本示例中,提供了一个大规模可伸缩性配置。该配置通过扩展 InterSystems IRIS 功能也引入使用 InterSystems 企业缓存协议 (ECP) 的应用程序服务器,实现对用户的大规模横向伸缩。本示例甚至包含了更高级别的可用性,因为即使在数据库实例发生故障转移的情况下,ECP 客户端也会保留会话细节。多个 AWS 可用性地区与基于 ECP 的应用程序服务器和部署在多个区域中的数据库镜像成员一起使用。此配置能够支持每秒数千万次的数据库访问和数万亿字节数据。
生产配置示例图
示例图 2.3.1-a 显示了图表 2.3.1-b 中的资源。 其中包含的网关只是示例,可做相应地调整以适应您组织的标准网络实践。
此配置中包括一对故障转移镜像,四个或更多的 ECP 客户端(应用程序服务器),以及每个应用程序服务器对应一个或多个 Web 服务器。 故障转移数据库镜像对在同一区域中的两个不同 AWS 可用性地区之间进行划分,以提供故障域保护,而 InterSystems Arbiter 和 ICM 服务器则部署在单独的第三地区中,以提高弹性。
灾难恢复扩展至第二个 AWS 区域和可用性地区,与上一示例中的情况类似。如果需要,可以将多个 DR 区域与多个 DR 异步镜像成员目标一起使用。
图 2.3.1-a:采用 ECP 应用程序服务器的大型生产架构示例
建议将以下 AWS VPC 项目中的资源作为分片集群部署的最低配置。可根据需求添加或删除 AWS 资源。
大型生产配置 AWS 资源
下表提供了大型生产配置 AWS 资源的示例。
图 2.3.1-b:具有 ECP 应用程序服务器 AWS 资源的大型配置表
图 2.3.1-b:具有 ECP 应用程序服务器 AWS 资源的大型配置表(续)
图 2.3.1-b:具有 ECP 应用程序服务器 AWS 资源的大型配置表(续)
* * *
采用 InterSystems IRIS 分片集群的生产配置
在此示例中,提供了一个针对 SQL 混合工作负载的横向伸缩性配置,其包含 InterSystems IRIS 新的分片集群功能,可实现 SQL 查询和数据表的跨多个系统的大规模横向伸缩。本文的第 9 节将详细讨论 InterSystems IRIS 分片集群及其功能。
采用分片集群的生产配置示例图
示例图 2.4.1-a 显示了图表 2.4.1-b 中的资源。 其中包含的网关只是示例,可做相应地调整以适应您组织的标准网络实践。
此配置中包括四对镜像,它们为数据节点。每对故障转移数据库镜像在同一区域中的两个不同 AWS 可用性地区之间进行划分,以提供故障域保护,而 InterSystems Arbiter 和 ICM 服务器则部署在单独的第三地区中,以提高弹性。
此配置允许从集群中的任何数据节点使用所有的数据库访问方法。大型 SQL 表数据在物理上跨所有数据节点进行分区,以实现查询处理和数据卷的大规模并行。将所有这些功能组合在一起,就可以支持复杂的混合工作负载,比如大规模分析 SQL 查询及插入的新数据,所有这一切均在一个 InterSystems IRIS 数据平台中执行。
图 2.4.1-a:具有高可用性的采用分片集群的生产配置示例
注意,上面图表中以及下表“资源类型”列中的术语“EC2”是一个表示 AWS 虚拟服务器实例的 AWS 术语,将在本文的 3.1节中做进一步介绍。 它并不表示或暗示第 9 章所描述的集群架构中对“计算节点”的使用。
建议将以下 AWS VPC 中的资源作为分片集群部署的最低配置。可根据需求添加或删除 AWS 资源。
采用分片集群 AWS 资源的生产配置
下表提供了采用分片集群 AWS 资源的生产配置的示例。
图 2.4.1-b:采用分片集群 AWS 资源的生产配置示例表
* * *
云概念简介
Amazon Web Services (AWS) 为基础设施即服务 (IaaS) 提供功能丰富的云环境,使其具备完备的功能,支持所有的 InterSystems 产品,包括支持基于容器的 DevOps 及最新的 InterSystems IRIS 数据平台。 与任何平台或部署模型一样,必须留心以确保考虑到环境的各个方面,例如性能、可用性、系统操作、高可用性、灾难恢复、安全控制和其他管理程序。本文档将介绍所有云部署涉及的三个主要组件:计算、存储和网络。
计算引擎(虚拟机)
AWS EC2 中存在数个针对计算引擎资源的选项,以及众多虚拟 CPU 和内存规范及相关存储选项。在 AWS EC2 中值得注意的一点是,对给定机器类型中 vCPU 数量的引用等于一个 vCPU,其是虚拟机监控程序层上物理主机中的一个超线程。
就本文档的目的而言,将使用 m5* 和 r5* EC2 实例类型,这些实例类型在大多数 AWS 部署区域中广泛可用。但是,对于在缓存内保留了大量数据的超大型工作数据集而言,使用 x1 *(拥有大内存)或 i3 *(具有 NVMe 本地实例存储)等其他专门的实例类型才是最佳的选择。 有关 AWS 服务水平协议 (SLA) 的详细信息,可在此处找到。
磁盘存储
与 InterSystems 产品最直接相关的存储类型是持久性磁盘类型,但是,如果了解并适应数据可用性限制,本地存储可以用于高水平的性能。 还有其他一些选项,例如 S3(存储桶)和 Elastic File Store (EFS),但是这些选项更特定于个别应用程序的需求,而非支持 InterSystems IRIS 数据平台的操作。
与大多数其他云提供商一样,AWS 对可与单个计算引擎关联的持久性存储的量施加了限制。这些限制包括每个磁盘的最大容量、关联到每个计算引擎的持久性磁盘的数量,以及每个持久性磁盘的 IOPS 数量,对单个计算引擎实例 IOPS 设置上限。此外,对每 GB 磁盘空间设有 IOPS 限制,因此有时需要调配更多磁盘容量才能达到所需的 IOPS 速率。
这些限制可能会随着时间而改变,可在适当时与 AWS 确认。
磁盘卷有三种类型的持久性存储类型:EBS gp2(SSD)、EBS st1(HDD)和 EBS io1(SSD)。标准 EBS gp2 磁盘更适合于那些要求可预测性低延迟 IOPS 和高吞吐量的生产工作负载。标准持久性磁盘对于非生产开发和测试或归档类型的工作负载,是一种更经济的选择。
有关各种磁盘类型及限制的详细信息,可在此处找到。
VPC 网络
强烈建议采用虚拟私有云 (VPC) 网络来支持 InterSystems IRIS 数据平台的各个组件,同时提供正确的网络安全控制、各种网关、路由、内部 IP 地址分配、网络接口隔离和访问控制。本文档中提供了一个详细的 VPC 示例。
有关 VPC 网络和防火墙的详细信息,可在此处找到。
* * *
虚拟私有云 (VPC) 概述
此处提供有关 AWS VPC 的详细信息。
在大多数大型云部署中,采用多个 VPC 将各种网关类型与以应用为中心的 VPC 进行隔离,并利用 VPC 对等进行入站和出站通信。 有关适合您的公司使用的子网和任何组织防火墙规则的详细信息,强烈建议您咨询您的网络管理员。本文档不阐述 VPC 对等方面的内容。
在本文档提供的示例中,使用 3 个子网的单一 VPC 用于提供各种组件的网络隔离,以应对各种 InterSystems IRIS 组件的可预测延迟和带宽以及安全性隔离。
网络网关和子网定义
本文档的示例中提供了两种网关,以支持互联网和安全 VPN 连接。要求每个入口访问都具有适当的防火墙和路由规则,从而为应用程序提供足够的安全性。有关如何使用 VPC 路由表的详细信息,可在此处找到。
提供的示例架构中使用了 3 个子网,它们与 InterSystems IRIS 数据平台一起使用。这些单独的网络子网和网络接口的使用为上述 3 个主要组件的每一个提供了安全控制、带宽保护和监视方面的灵活性。有关创建具有多个网络接口的虚拟机实例的详细信息,可在此处找到。
这些示例中包含的子网:
用户空间网络用于入站连接用户和查询
分片网络用于分片节点之间的分片间通信
镜像网络通过同步复制和单个数据节点的自动故障转移实现高可用性。
注意:仅在单个 AWS 区域内具有低延迟互连的多个地区之间,才建议进行故障转移同步数据库镜像。 区域之间的延迟通常太高,无法提供良好的用户体验,特别是对于具有高更新率的部署更如此。
内部负载均衡器
大多数 IaaS 云提供商缺乏提供虚拟 IP (VIP) 地址的能力,这种地址通常用在自动化数据库故障转移设计中。 为了解决这一问题,InterSystems IRIS 中增强了几种最常用的连接方法,尤其是 ECP 客户端和 Web 网关,从而不再依赖 VIP 功能使它们实现镜像感知和自动化。
xDBC、直接 TCP/IP 套接字等连接方法,或其他的直接连接协议,均需要使用类 VIP 地址。为了支持这些入站协议,InterSystems 数据库镜像技术使用称作<span class="Characteritalic" style="font-style:italic">mirror_status.cxw</span>的健康检查状态页面为 AWS 中的这些连接方法提供自动化故障转移,以与负载均衡器进行交互,实现负载均衡器的类 VIP 功能,仅将流量重定向至活动的主镜像成员,从而在 AWS 内实现完整且强大的高可用性设计。
有关 AWS Elastic 负载均衡器 (ELB) 的详细信息,可在此处找到。
图 4.2-a:无虚拟 IP 地址的自动故障转移
此处提供了使用负载均衡器实现类 VIP 功能的详细信息。
示例 VPC 拓扑
下图 4.3-a 中的 VPC 布局组合了所有组件,具有以下特点:
利用一个区域内的多个地区实现高可用性
提供两个区域进行灾难恢复
利用多个子网进行网络隔离
包括分别用于 VPC 对等、互联网和 VPN 连接的单独网关
使用云负载均衡器进行镜像成员的 IP 故障转移
请注意,在 AWS 中,每个子网必须完全位于一个可用性地区内,并且不能跨越地区。 因此,在下面的示例中,需要正确定义网络安全性或路由规则。 有关 AWS VPC 子网的详细信息,可在此处找到。
图 4.3-a:VPC 网络拓扑示例
* * *
持久性存储概述
如简介中所述,建议使用 AWS Elastic Block Store(EBS)卷,尤其是 EBS gp2 卷类型。之所以推荐 EBS gp2 卷,是由于其拥有更高的读写 IOPS 速率以及低的延迟,适合于事务性和分析性数据库工作负载。在某些情况下,可使用本地 SSD,但值得注意的是,本地 SSD 的性能提升会在可用性、耐用性和灵活性方面做出一定的权衡。
可在此处找到本地 SSD 数据持久性方面的详细信息,您可了解何时保存本地 SSD 数据以及何时不保存它们。
LVM PE 条带化
与其他的云提供商一样,AWS 在 IOPS、空间容量和每个虚拟机实例的设备数量方面都施加了众多存储限制。有关当前的限制,请查阅 AWS 文档,可在此处找到。
由于这些限制的存在,使用 LVM 条带化实现数据库实例的单个磁盘设备的 IOPS 最大化变得非常必要。在提供的此示例虚拟机实例中,建议使用以下磁盘布局。与 SSD 持久性磁盘相关的性能限制可在此处找到。
注意:尽管 AWS 资源功能经常更改,但每个 Linux EC2 实例当前最多有 40 个 EBS 卷,因此请查阅 AWS 文档以了解当前限制。
图 5.1-a:LVM 卷组分配示例
LVM 条带化的优势在于可以将随机的 IO 工作负载分散到更多的磁盘设备并继承磁盘队列。以下是如何在 Linux 中将 LVM 条带化用于数据库卷组的示例。本示例在一个 LVM PE 条带中使用 4 个磁盘,物理盘区 (PE) 大小为 4MB。或者,如果需要,可以使用更大的 PE 容量。
步骤 1:根据需要创建标准性磁盘或 SSD 持久性磁盘
步骤 2:使用“lsblk -do NAME,SCHED”将每个磁盘设备的 IO 调度器设置为 NOOP
步骤 3:使用“lsblk -do KNAME,TYPE,SIZE,MODEL”识别磁盘设备
步骤4:使用新的磁盘设备创建磁盘卷组
vgcreate s 4M
示例: <span style="color:#c0392b;"><i>vgcreate -s 4M vg_iris_db /dev/sd[h-k]</i></span>
步骤 4:创建逻辑卷
lvcreate n -L -i -I 4MB
示例: <i>lvcreate -n lv_irisdb01 -L 1000G -i 4 -I 4M vg_iris_db</i>
步骤 5:创建文件系统
mkfs.xfs K
示例: <i>mkfs.xfs -K /dev/vg_iris_db/lv_irisdb01</i>
步骤 6:装载文件系统
使用以下装载条目编辑 /etc/fstab
/dev/mapper/vg_iris_db-lv_irisdb01 /vol-iris/db xfs defaults 0 0
装载 /vol-iris/db
使用上表,每个 InterSystems IRIS 服务器将具有以下配置:2 个 SYS 磁盘、4 个 DB 磁盘、2 个主日志磁盘、2 个备用日志磁盘。
图 5.1-b:InterSystems IRIS LVM 配置
为了增长,LVM 允许在需要的情况下不中断地扩展设备和逻辑卷。有关持续管理和扩展 LVM 卷的最佳做法,请查阅 Linux 文档。
注意:强烈建议同时为数据库和写入映像日志文件启用异步 IO。 请参阅社区文章获取在 Linux 上启用的详细信息。
* * *
配置
InterSystems IRIS 新增了 InterSystems Cloud Manager (ICM)。ICM 执行众多任务,并提供许多用于配置 InterSystems IRIS 数据平台的选项。 ICM 作为 Docker 映像提供,其拥有配置强大的、基于 AWS 云的解决方案所需的一切。
ICM 当前支持以下平台上的配置:
Amazon Web Services,包括 GovCloud (AWS / GovCloud)
Google Cloud Platform (GCP)
Microsoft Azure Resource Manager,包括 Government (ARM / MAG)
VMware vSphere (ESXi)
ICM 和 Docker 可以从台式机/笔记本电脑工作站运行,也可以具有中央专用的适度“配置”服务器和中央存储库。
ICM 在应用程序生命周期中的作用是“定义->配置->部署->管理”
有关安装和使用 ICM 及 Docker 的详细信息,可在此处找到。
注意:任何云部署都非必须使用 ICM。完全支持传统的 tar-ball 分布式安装和部署方法。但是,建议使用 ICM,以简化云部署中的配置和管理。
容器监视
I针对基于容器的部署,CM 包括两个基本的监视工具: Rancher 和 Weave Scope。 默认情况下不会部署这两个工具,需要在默认的文件中使用监视器字段指定。有关使用 ICM 进行监视、编排和调度的详细信息,可在此处找到。
有关 Rancher 的概述和相关文档,可在此处找到。
有关 Weave Scope 的概述和相关文档,可在此处找到。
* * *
高可用性
InterSystems 数据库镜像可在任何云环境中提供最高级别的可用性。AWS 不会为单个 EC2 实例提供任何可用性保证,因此数据库镜像是必需的,其还要与负载均衡和自动伸缩组结合使用。
前面的部分讨论了云负载均衡器如何通过数据库镜像为虚拟 IP(类 VIP)功能提供自动 IP 地址故障转移。云负载均衡器使用前面内部负载均衡器部分中提到的 mirror_status.cxw 健康检查状态页面。数据库镜像有两种模式——自动故障转移同步镜像、异步镜像。在本示例中,将介绍同步故障转移镜像。有关镜像的详细信息,可在此处找到。
最基本的镜像配置是仲裁器控制配置中的一对故障转移镜像成员。仲裁器放置在同一区域内的第三个地区中,以防止潜在的地区可用性中断影响仲裁器和其中一个镜像成员。
在网络配置中,有多种方法专供设置镜像。在本示例中,我们将使用本文档前述网络网关和子网定义部分中定义的网络子网。下一部分内容将提供 IP 地址方案示例,并且基于本部分内容,将仅描述网络接口和指定的子网。
图 7-a:采用仲裁器的镜像配置示例
* * *
灾难恢复
InterSystems 数据库镜像将支持灾难恢复的高可用性功能扩展到另一个 AWS 地理区域,以在整个 AWS 区域万一宕机的情况下支持操作弹性。应用程序如何忍受此类中断取决于恢复时间目标 (RTO) 和恢复点目标 (RPO)。这些将为设计适当的灾难恢复计划进行的分析提供初始框架。以下链接中的指南提供了您在为自己的应用程序制定灾难恢复计划时要考虑的事项。 https://aws.amazon.com/disaster-recovery/
以下链接中的指南提供了您在为自己的应用制定灾难恢复计划时要考虑的事项。
异步数据库镜像
InterSystems IRIS 数据平台的数据库镜像提供强大的功能,可在 AWS 可用性地区和区域之间异步复制数据,以帮助支持您的灾难恢复计划的 RTO 和 RPO 目标。有关异步镜像成员的详细信息,可在此处找到。
与上述高可用性部分中讲述的内容相似,云负载均衡器也使用上文内部负载均衡器部分中提到过的 mirror_status.cxw 健康检查状态页面为虚拟 IP(类 VIP)功能提供自动化 IP 地址故障转移,以进行 DR 异步镜像。
在本示例中,将介绍 DR 异步故障转移镜像,并介绍 AWS Route53 DNS 服务,以便为上游系统和客户端工作站提供单个 DNS 地址,而不管您的 InterSystems IRIS 部署是否在哪个可用性区域或地区中运行。
有关 AWS Route53 的详细信息,可在此处找到。
图 8.1-a:采用 AWS Route53 的 DR 异步镜像示例
在上述示例中,两个区域的 Elastic 的负载均衡器 (ELB) (前端 InterSystems IRIS 实例)的 IP 地址都提供给了 Route53,它会将流量仅定向到承担主要镜像的镜像成员,而不论其位于哪个可用性地区或区域。
* * *
分片集群
InterSystems IRIS 包括一套全面的功能来伸缩您的应用程序,根据您的工作负载的性质以及所面临的特定挑战,可单独或者组合应用这些功能。 分片功能是这些功能中的一种,可跨多个服务器对数据及其关联的缓存进行分区,从而为查询和数据引入提供灵活、高性价比的性能扩展,同时通过高效的资源利用最大化基础设施的价值。 InterSystems IRIS 分片集群可以为各种应用提供显著的性能优势,尤其对于工作负载包括以下一项或多项的应用更是如此:
大容量或高速数据写入,或两者的组合。
相对较大的数据集、返回大量数据的查询,或两者的组合。
执行大量数据处理的复杂查询,例如扫描磁盘上大量数据或涉及大量计算工作的查询。
这些场景的使用都是分片集群的潜在优势,但组合的应用场景可能会最大化分片集群的优势起来使用它们可能会增加优势。 例如,这 3 个场景的组合——快速引入大量数据、大型数据集、检索和处理大量数据的复杂查询——使得当今的许多分析性工作负载非常适合进行分片。
注意,这些特征都与数据有关;InterSystems IRIS 分片的主要功能是缩放数据量。 不过,当涉及某些或所有这些与数据相关的场景的工作负载也经历大量用户的超高查询量时,分片群集也能提供用户量伸缩功能。 分片也可以与纵向伸缩相结合。
操作概述
分片架构的核心是跨多个系统对数据及其关联的缓存进行分区。 分片集群跨多个 InterSystems IRIS 实例(称为数据节点)以行方式对大型数据库表进行物理上的横向分区,同时允许应用通过任何节点透明地访问这些表,但仍将整个数据集看作一个逻辑并集。 该架构具有 3 个优点:
并行处理
查询在数据节点上并行运行,各个结果被应用程序所连接的节点合并、组合,然后以完整的查询结果返回给应用程序,这在许多情况下显着提高了执行速度。
分区缓存
每个数据节点都有自己的缓存,专用于它存储的分片表数据分区,而非为整个数据集提供服务的单个实例的缓存,这大大降低了缓存溢出的风险,以及强制进行读取性能较低的磁盘的风险。
并行加载
数据可以并行加载到数据节点上,这降低了插入工作负载和查询工作负载之间缓存和磁盘的争用,从而提高两者的性能。
有关 InterSystems IRIS 分片集群的详细信息,可在此处找到。
分片组件和实例类型
分片集群包含至少一个数据节点,如果特定性能或工作负载有需要,则可添加一定数量的计算节点。 这两种节点类型提供简单的构建基块,显示了一个简单、透明和高效的缩放模型。
数据节点
数据节点存储数据。 在物理层面,分片表[1]数据分布在集群中的所有数据节点上,非分片表数据仅物理存储在第一个数据节点上。 这种区分对用户是透明的,唯一可能的例外是,第一个节点的存储消耗可能比其他节点略高,但是由于分片表数据通常会超出非分片表数据至少一个数量级,因此这种差异可以忽略不计。
需要时,可以跨集群重新均衡分片表数据,这通常发生在添加新的数据节点后。 这将在节点之间移动数据的“存储桶”,以实现数据的近似均匀分布。
在逻辑层面,未分片的表数据和所有分片的表数据的并集在任何节点上都可见,因此客户端会看到整个数据集,这与其连接哪个节点无关。 元数据和代码也会在所有数据节点之间共享。
分片集群的基本架构图仅由在集群中看起来统一的数据节点组成。 客户端应用程序可以连接到任何节点,并且获得像数据是存储在本地一样体验。
图 9.2.1-a:基本分片集群图
[1]为方便起见,术语“分片表数据”在整个文档中用于表示支持分片的任何数据模型的“盘区”数据(标记为已分片)。 术语“未分片表数据”和“未分片数据”用于表示处于可分片盘区但却未这样标记的数据,或表示尚不支持分片的数据模型。
计算节点
对于要求低延迟(可能存在不断涌入数据的冲突)的高级方案,可以添加计算节点以提供用于服务查询的透明缓存层。
计算节点缓存数据。 每个计算节点都与一个数据节点关联,为其缓存相应的分片表数据,此外,它还根据需要缓存非分片表数据,以满足查询的需要。
图 9.2.2-a:具有计算节点的分片集群
由于计算节点物理上并不存储任何数据,其只是支持查询执行,因此可对其硬件配置文件进行调整以满足需求,调整方法如:通过强调内存和 CPU、将存储空间保持在最低限度等。 当“裸露”应用程序代码在计算节点上运行时,引入数据会被驱动程序 (xDBC, Spark) 直接或被分片管理器代码间接转发到数据节点。
分片集群说明
分片集群部署有多种组合。下列各图说明了最常见的部署模型。这些图不包括网络网关及细节,仅侧重于分片群集组件。
基本分片集群
下图是在一个区域和一个地区中部署了 4 个数据节点的最简单分片群集。AWS Elastic 负载均衡器 (ELB) 用于将客户端连接分发到任何一个分片集群节点。
图 9.3.1-a:基本分片集群
在此基本模型中,除了 AWS 为单个虚拟机及其连接的 SSD 持久性存储提供的弹性或高可用性外,没有其他弹性或高可用性。建议使用两个单独的网络接口适配器,一则为入站客户端连接提供网络安全隔离,二则为客户端流量和分片集群通信之间提供带宽隔离。
具有高可用性的基本分片集群
下图是在一个区域中部署了 4 个镜像数据节点的最简单分片集群,每个节点的镜像在地区之间进行了划分。AWS 负载均衡器用于将客户端连接分发到任何分片集群节点。
InterSystems 数据库镜像的使用带来了高可用性,其会在该区域内的第二地区中维护一个同步复制的镜像。
建议使用 3 个单独的网络接口适配器,一方面为入站客户端连接提供网络安全隔离,另一方面为客户端流量、分片集群通信、节点对之间的同步镜像流量之间提供带宽隔离。
图 9.3.2-a:具有高可用性的基本分片集群
此部署模型也引入了本文前面所述的镜像仲裁器。
具有单独计算节点的分片集群
下图采用单独的计算节点和 4 个数据节点扩展了分片集群,以此来应对大量的用户/查询并发。云负载均衡器服务器池仅包含计算节点的地址。数据更新和数据插入将像以前一样继续直接更新到数据节点,以维持超低延迟性能,并避免由于实时数据插入而在查询/分析工作负载之间造成资源的干扰和拥挤。
使用此模型,可以根据计算/查询和数据插入的规模单独微调资源分配,从而在“适时”需要的地方提供最佳资源,实现经济而简单的解决方案,而非只是进行计算或数据的调整,浪费不必要的资源。
计算节点非常适合直接使用 AWS 自动伸缩分组(亦称自动伸缩),允许基于负载的增加或减少自动从托管实例组添加或删除实例。 自动伸缩的工作原理为:负载增加时,将更多的实例添加到实例组(扩展);对实例的需求降低时将其删除(缩减)。
有关 AWS 自动伸缩的详细信息,可在此处找到。
图 9.3.3-a:具有单独计算节点和数据节点的分片集群
自动伸缩可帮助基于云的应用程序轻松应对流量增加的情况,并在资源需求降低时降低成本。 只需简单地定义策略,自动伸缩器就会根据测得的负载执行自动伸缩。
* * *
备份操作
备份操作有多个选项。以下 3 个选项可供您通过 InterSystems IRIS 进行 AWS 部署。
下面的前 2 个选项(下文详细说明)采用快照类型的过程,该过程会在创建快照之前将数据库写入操作挂起到磁盘上,然后在快照成功后恢复更新。
可采取以下高级别步骤通过任一快照方法来创建洁净的备份:
通过数据库冻结外部 API 调用暂停对数据库的写入。
创建操作系统和数据磁盘的快照。
通过解冻外部 API 调用恢复数据库写入。
将快照存档备份到备份位置
有关冻结/解冻 外部API 的详细信息,可在此处找到。
注意:本文档未包含备份示例脚本,但您可定期检查发布到 InterSystems 网站上开发者社区的示例。 www.community.intersystems.com
第三个选项是 InterSystems 在线备份。这是小型部署的入门级方法,具有非常简单的用例和界面。但是,随着数据库的增大,建议将使用快照技术的外部备份作为最佳做法,因为其具有以下优势:备份外部文件、更快的恢复时间,以及企业范围的数据和管理工具。
可以定期添加诸如完整性检查之类的其他步骤,以确保洁净且一致的备份。
决定使用哪种选项取决于您组织的运营要求和策略。InterSystems 可与您详细讨论各种选项。
AWS Elastic Block Store (EBS) 快照备份
可以使用 AWS CLI 命令行 API 以及 InterSystems 冻结/解冻外部API 功能来实现备份操作。 这允许实现真正的 24x7 全天候操作弹性保证,并确保干净的常规备份。有关管理、创建和自动化 AWS EBS 快照的详细信息,可在此处找到。
逻辑卷管理器 (LVM) 快照
或者,可以在 VM 本身中部署单个备份代理,利用文件级备份,并结合逻辑卷管理器 (LVM) 快照,来使用市面上的许多第三方备份工具。
该模型的主要优点之一是能够对基于 Windows 或 Linux 的 VM 进行文件级恢复。此解决方案需要注意的几点是,由于 AWS 和大多数其他 IaaS 云提供商都不提供磁带媒体,因此所有的备份存储库对于短期归档均基于磁盘,并利用 Blob 或存储桶类型的低成本存储来进行长期保留 (LTR)。强烈建议您使用此方法来使用支持重复数据删除技术的备份产品,以最有效地利用基于磁盘的备份存储库。
这些具有云支持的备份产品的示例包括但不限于:Commvault、EMC Networker、HPE Data Protector 和 Veritas Netbackup。InterSystems 不会验证或认可一种备份产品是否优于其他产品。
在线备份
对于小型部署,内置在线备份工具也是可行的选择。该 InterSystems 数据库在线备份实用工具通过捕获数据库中的所有块来备份数据库文件中的数据,然后将输出写入顺序文件。 这种专有的备份机制旨在使生产系统的用户不停机。 有关在线备份的详细信息,可在此处找到。
在 AWS 中,在线备份完成后,必须将备份输出文件和系统正在使用的所有其他文件复制到该虚拟机实例之外的其他存储位置。存储桶/对象存储是很好的选择。
使用 AWS Single Storage Space(S3)存储桶有两种选择。
直接使用 AWS CLI 脚本 API 来复制和操作新创建的在线备份(和其他非数据库)文件
有关详细信息可在此处找到。
装载 Elastic File Store (EFS) 卷,将其类似地用作持久性磁盘,这样做成本低。
有关 EFS 的详细信息,可在此处找到。
* * *
文章
Nicky Zhu · 一月 11, 2021
本文将描述通过ObjectScript包管理器(见https://openexchange.intersystems.com/package/ObjectScript-Package-Manager-2)运行单元测试的过程,包括测试覆盖率测量(见https://openexchange.intersystems.com/package/Test-Coverage-Tool)。
## ObjectScript中的单元测试
关于在ObjectScript中编写单元测试,已经有很好的文档,因此我就不再赘述了。您可以在这里找到单元测试教程:https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=TUNT_preface
最好的做法是将单元测试代码单独放在源代码树中,无论它只是“/tests”还是其他名字。在InterSystems中,我们最终使用/internal/testing/unit_tests/作为我们事实上的标准,这是有意义的,因为测试是内部/非发布的,而且除了单元测试还有其他类型的测试,但这对于简单的开源项目来说可能有点复杂。您可以在我们的一些GitHub仓库中看到这种结构。
从工作流的角度来看,这在VSCode中非常简单,您只需创建目录并将类放在里面。对于较老的以服务器为中心的源代码控制方法(Studio中使用的方法),您需要正确地地映射这个包,使用的方法会因源代码控制程序而异。
从单元测试类命名的角度来看,我个人的偏好(以及我的团队的最佳实践)是:
UnitTest.[.]
例如,如果在类MyApplication.SomeClass 中对方法Foo进行单元测试,单元测试类将被命名为UnitTest.MyApplication.SomeClass.Foo;如果测试是针对整个类的,那么名字就是UnitTest.MyApplication.SomeClass。
## ObjectScript 包管理器中的单元测试
让ObjectScript包管理器知道您的单元测试,很简单!只需按如下所示向module.xml中添加一行代码(来自https://github.com/timleavitt/ObjectScript-Math/blob/master/module.xml - 这是Open Exchange上的@Peter Steiwer的出色数学扩展包,我以它作为简单的正面例子):
```objectscript
...
```
这些代码的意思是:
- 单元测试位于模块根目录下的“tests”目录中。
- 单元测试在“UnitTest.Math”包中。这样很直观,因为被测试的类就在“Math”包中。
- 单元测试在包生命周期的“测试”阶段运行。(当然还有一个可以运行它们的“验证”阶段,这里不赘述。)
## 运行单元测试
对于上述定义的单元测试,包管理器提供了一些实用工具来运行它们。您仍然可以像平常使用%UnitTest.Manager那样设置^UnitTestRoot等,但下面的方法可能更简单,尤其在同一个环境下做几个项目的时候。
您可以克隆上述objectscript-math仓库,然后用 ```zpm "load /path/to/cloned/repo/" ```加载,或者在您自己的包上使用包名(和测试名)替换“objectscript-math”来尝试所有这些方法。
重新加载模块,然后运行所有单元测试:
```zpm "objectscript-math test" ```
只运行单元测试(不重新加载):
```zpm "objectscript-math test -only" ```
只运行单元测试(不重新加载)并提供详细输出:
```zpm "objectscript-math test -only -verbose" ```
运行一个特定的测试套件(指一个测试目录 - 在本例中,是UnitTest/Math/Utils中的所有测试)而不重新加载,并提供详细输出:
```zpm "objectscript-math test -only -verbose -DUnitTest.Suite=UnitTest.Math.Utils" ```
运行一个特定的测试用例(在本例中,是UnitTest.Math.Utils.TestValidateRange)而不重新加载,并提供详细输出:
```zpm "objectscript-math test -only -verbose -DUnitTest.Case=UnitTest.Math.Utils.TestValidateRange" ```
如果您只是想解决单个测试方法中的小问题:
```zpm "objectscript-math test -only -verbose -DUnitTest.Case=UnitTest.Math.Utils.TestValidateRange -DUnitTest.Method=TestpValueNull" ```
## 通过ObjectScript包管理器进行测试覆盖率测量
怎样评估单元测试的质量?测量测试覆盖率虽然并不全面,但至少有参考意义。早在2018年的全球峰会上,我就展示过。 见 - https://youtu.be/nUSeGHwN5pc。
首先需要安装“测试覆盖率”包:
```zpm "install testcoverage" ```
注意,并不需要ObjectScript包管理器才能安装/运行;可以在Open Exchange上了解更多信息:https://openexchange.intersystems.com/package/Test-Coverage-Tool
不过如果您已经在用ObjectScript包管理器,那么您可以更好地利用这个“测试覆盖率”工具。
运行测试前,需要指定测试所覆盖的类/routine宏。这一点很重要,因为在非常大的代码库中(例如,HealthShare),测试和收集项目中所有文件的测试覆盖率所需要的内存可能超出您的系统内存。(提一句,如果您感兴趣,可以使用逐行监视器的gmheap。)
文件列表在您的单元测试根目录下的coverage.list文件中;单元测试的不同子目录(套件)可以拥有它们自己的副本,以覆盖在测试套件运行时将跟踪的类/例程。
有关objectscript-math的简单示例,见:https://github.com/timleavitt/ObjectScript-Math/blob/master/tests/UnitTest/coverage.list;测试覆盖率工具用户指南有更详细的介绍。
要在启用测试覆盖率测量的情况下运行单元测试,只需再向命令添加一个参数,指定应使用TestCoverage.Manager而非%UnitTest.Manager 来运行测试:
```zpm "objectscript-math test -only -DUnitTest.ManagerClass=TestCoverage.Manager" ```
输出(即使是非详细模式)将包括一个URL,供您查看您的类/routine(宏)的哪些行被单元测试覆盖了,以及一些汇总统计信息。
## 接下来的步骤
这些能不能在CI中自动化?能不能报告单元测试的结果和覆盖率分数/差异?答案是:能!您可以使用Docker,Travis CI和codecov.io来试一下这个简单示例,见https://github.com/timleavitt/ObjectScript-Math;我打算以后写篇文章来详细讲讲,介绍几种不同的方法。
文章
Nicky Zhu · 一月 11, 2021
当我向技术人员介绍InterSystems IRIS时,我一般会先讲其核心是一个多模型DBMS。
我认为这是其主要优势(在DBMS方面)。数据仅存储一次。您只需访问您想用的API。
- 您想要数据的概要?用SQL!
- 您想用一份记录做更多事情?用对象!
- 想要访问或设置一个值,并且您知道键?用Globals!
乍一看挺好的,简明扼要,又传达了信息,但当人们真正开始使用InterSystems IRIS时,问题就来了。类、表和Globals是如何关联的?它们之间有什么关系?数据是如何存储的?
本文我将尝试回答这些问题,并解释这些到底是怎么回事。
## 第一部分 模型偏见
处理数据的人往往对他们使用的模型有偏见。
开发者们把数据视为对象。对他们而言,数据库和表都是通过CRUD(增查改删,最好是基于ORM)交互的盒子,但底层的概念模型都是对象(当然这对于我们大多数使用面向对象编程语言的开发者来说没错)。
而DBA大部分时间都在搞关系型DBMS,他们把数据视为表。对象只是行的封装器。
对于InterSystems IRIS,持久类也是一个表,将数据存储在Global中,因此需要进行一些澄清。
## 第二部分 举例
假设您创建了类Point:
```objectscript
Class try.Point Extends %Persistent [DDLAllowed]
{
Property X;
Property Y;
}
```
您也可以用DDL/SQL创建相同的类:
```
CREATE Table try.Point (
X VARCHAR(50),
Y VARCHAR(50))
```
编译后,新类将自动生成一个存储结构,将原生存储在Global中的数据映射到列(对于面向对象开发者而言,是属性):
```
Storage Default
{
%%CLASSNAME
X
Y
^try.PointD
PointDefaultData
^try.PointD
^try.PointI
^try.PointS
%Library.CacheStorage
}
```
这是怎么回事?
自下向上(加粗文字很重要):
- Type: 生成的存储类型,本例中是持久对象的默认存储
- StreamLocation - 存储流的Global
- IndexLocation - 索引Global
- IdLocation - 存储ID自增计数器的Global
- **DefaultData** - 存储将Global值映射到列/属性的XML元素
- **DataLocation** - 存储数据的Global
现在我们的DefaultData是PointDefaultData,让我们分析下它的结构。本质上Global节点有这样的结构:
- 1 - %%CLASSNAME
- 2 - X
- 3 - Y
所以我们可能期望我们的Global是这样的:
```
^try.PointD(id) = %%CLASSNAME, X, Y
```
但如果我们输出 Global 它会是空的,因为我们没有添加任何数据:
```
zw ^try.PointD
```
让我们添加一个对象:
```
set p = ##class(try.Point).%New()
set p.X = 1
set p.Y = 2
write p.%Save()
```
现在我们的Global变成了这样
```
zw ^try.PointD
^try.PointD=1
^try.PointD(1)=$lb("",1,2)
```
可以看到,我们期望的结构%%CLASSNAME, X, Y是用 $lb("",1,2) 设置的,它对应的是对象的X和Y属性(%%CLASSNAME 是系统属性,忽略)。
我们也可以用SQL添加一行:
```
INSERT INTO try.Point (X, Y) VALUES (3,4)
```
现在我们的Global变成了这样:
```
zw ^try.PointD
^try.PointD=2
^try.PointD(1)=$lb("",1,2)
^try.PointD(2)=$lb("",3,4)
```
所以我们通过对象或SQL添加的数据根据存储定义被存储在Global中(备注:可以通过在PointDefaultData 中替换X和Y来手动修改存储定义,看看新数据会怎样!)。
现在,如果我们想执行SQL查询会怎样?
```
SELECT * FROM try.Point
```
这段sql查询被转换为ObjectScript代码, 遍历^try.PointD,并根据存储定义(其中的 PointDefaultData 部分)填充列。
下面是修改。让我们从表中删除所有数据:
```
DELETE FROM try.Point
```
看看我们的Global变成什么样了:
```
zw ^try.PointD
^try.PointD=2
```
可以看到,只剩下ID计数器,所以新对象/行的ID=3。我们的类和表也继续存在。
但如果我们运行会怎样:
```
DROP TABLE try.Point
```
它会销毁表、类并删除Global。
```
zw ^try.PointD
```
看完这个例子,希望您现在对Global、类和表如何相互集成和互补有了更好的理解。根据实际需要选用正确的API会让开发更快、更敏捷、bug更少。
文章
Nicky Zhu · 一月 10, 2021
当您首次使用InterSystems IRIS时,通常只需安装最低安全级别的系统。您输入密码的次数会比较少,这样有利于快速了解和操作开发服务和Web应用程序。而且,最低的安全性有时更便于部署开发项目或解决方案。
然而,有时需要将项目移出开发环境,迁移到一个可能很不友好的互联网环境中。在部署到生产环境之前,需要使用最大的安全设置(即,完全锁定)对其进行测试。这就是我们在本文中将要讨论的内容。
如果想更全面地了解InterSystems Caché、Ensemble和IRIS中的DBMS安全性问题,请阅读我的另一篇文章《[在生产环境中安装InterSystems Caché DBMS的相关建议](https://community.intersystems.com/post/recommendations-installing-intersystems-cach%C3%A9-dbms-production-environment)》。
InterSystems IRIS中安全系统的设计概念是针对不同的类别(用户、角色、服务、资源、特权和应用程序)应用不同的安全设置。
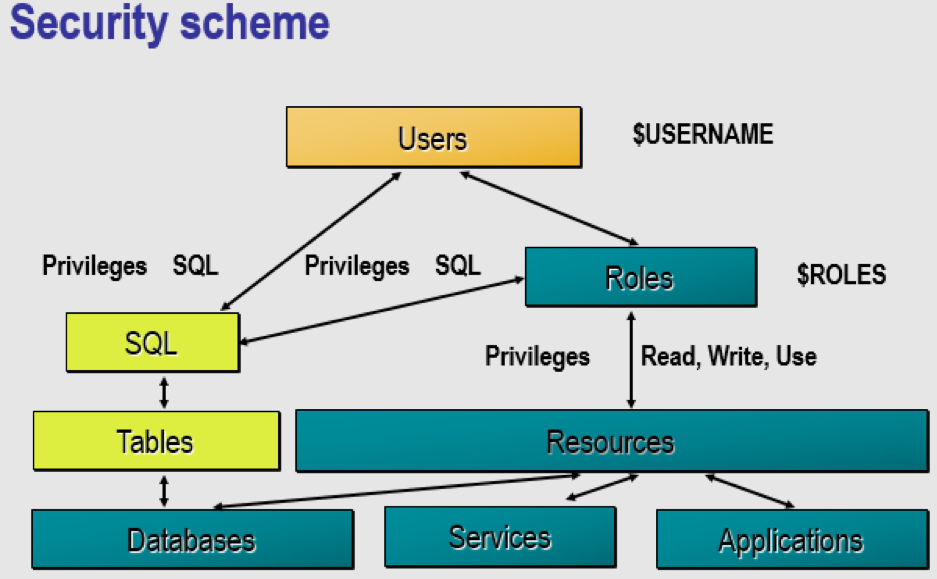
可以为用户分配角色。用户和角色可以对资源(数据库、服务和应用程序)拥有不同的读、写和使用权限。用户和角色还可以对数据库中的SQL表拥有SQL权限。
# 安全级别的差异
用户在安装InterSystems IRIS时,可以为其选择安全级别:最小、正常或锁定。这些级别在用户参与程度、可用角色和服务,以及服务和应用程序的身份验证方法的配置方面存在差异。如需了解更多信息,请阅读《InterSystems IRIS安装准备》指南中的《InterSystems安全性准备》章节。
在文档中,您可以找到下面这些表格,其中显示了每个级别的安全设置。这些安全设置可以在系统管理门户界面进行更改。
## 初始用户安全设置
|Security Setting | Minimal | Normal | Locked Down |
|--------------------------------------------|--------------|--------------|----------------------|
|Password Pattern |3.32ANP |3.32ANP |8.32ANP |
|Inactive Limit |0 |90 days |90 days |
|Enable _SYSTEM User |Yes |Yes |No |
|Roles assigned to UnknownUser |%All |None |None |
## 初始服务属性设置
|Service Property |Minimal|Normal|Locked Down|
|-----------------------------------|-----------|----------|------------------|
|Use Permission is Public |Yes |Yes |No |
|Requires Authentication |No |Yes |Yes |
|Enabled Services |Most |Some |Fewest |
## 初始服务启用设置
|Service | Minimal | Normal | Locked Down |
|-----------------------------------|--------------|-------------|---------------------|
|%Service_Bindings | Enabled | Enabled | Disabled |
|*%Service_CSP | Enabled | Enabled | Enabled |
|%Service_CacheDirect | Enabled | Disabled | Disabled |
|%Service_CallIn | Enabled | Disabled | Disabled |
|%Service_ComPort | Disabled | Disabled | Disabled |
|%Service_Console | Enabled | Enabled | Enabled |
|%Service_ECP | Disabled | Disabled | Disabled |
|%Service_MSMActivate | Disabled | Disabled | Disabled |
|%Service_Monitor | Disabled | Disabled | Disabled |
|%Service_Shadow | Disabled | Disabled | Disabled |
|%Service_Telnet | Disabled | Disabled | Disabled |
|%Service_Terminal | Enabled | Enabled | Enabled |
|%Service_WebLink | Disabled | Disabled | Disabled |
*InterSystems IRIS环境下,%Service_CSP应用%Service_WebGateway。
不同的操作系统所使用的服务略有不同。
# 如何提高安全性
您需要为每个启用的服务选择合适的身份验证方法,包括:无认证(unauthenticated)、密码、Kerberos或授权。
您还需要禁用系统中未使用的web应用程序。对已启用的web应用程序选择正确的身份验证方法:认证、密码、Kerberos、授权、登录或cookie。
当然,管理员可以为每一个项目和解决方案选择安全设置,以满足客户的项目要求。整个过程应始终保持一种平衡,即,一方面要保证系统足够方便以支持用户完成实际工作,另一方面又要保证系统足够安全能够阻止入侵者。不过众所周知,被禁用的系统才是最安全的系统。
如果遇到需要多次手动提高系统安全级别的情况,这就是一个明确的迹象,表明需要编写一个软件模块来解决这些问题。
实际上,InterSystems Open Exchange提供了一个锁定(LockDown)程序,可以帮助您提高安全性。该程序的源代码可以在InterSystems isc-apptools-lockdown页面的存储库中找到。
LockDown程序有以下几种作用:
## 首先,更改以下预安装用户的密码:
- Admin,
- CSPSystem,
- IAM,
- SuperUser,
- UnknownUser,
- _Ensemble,
- _SYSTEM.
## 其次,禁用除以下服务之外的所有服务:
- %%service_web gateway
- %service_console
- %service_login
- %service_terminal
## 再次,为所有web应用程序设置密码保护,包括:
- /csp/ensdemo
- /csp/samples
- /csp/user
- /isc/studio/usertemplates
- /csp/docbook
- /csp/documatic
- /isc/studio/rules
- /isc/studio/templates
## 最后,设置系统范围内的安全参数,包括:
- 密码复杂度为 "8.32 ANP"
- 限制90天内不活跃的用户
- 开启审计和其他所有安全相关的事件
您可以从GitHub下载LockDown.cls,在系统上安装好LockDown程序。然后在终端输入以下内容:
```
USER>zn “%SYS”
%SYS>do $system.OBJ.Load("/home/irisusr/LockDown.cls","ck")
```
或者可以使用以下命令从公共注册中心通过ZPM批处理管理器进行安装:
```
USER>zn “%SYS”
%SYS> zpm “install isc-apptools-lockdown”
```
# 执行LockDown程序
强烈建议在执行LockDown程序之前先进行备份。
必须从%SYS命名空间执行LockDown程序。如果您不想更改所有预安装用户的密码,请将第一个参数保留为空。
如果希望保留使用IRIS Studio、Atelier或VSCode编辑程序和类的能力,请不要禁用%Service_Bindings服务,只需将bindings参数设置为1即可。下面是一个示例:
`do ##class(App.Security.LockDown).Apply("New Password 123",.msg,1)`
此模块还包含一个功能,该功能在系统密码被盗用、需要替换所有预装帐户但无需执行锁定的情况下很有用。可以参考下面的运行:
`do ##class(App.Security.LockDown).Change Password("New Password 123", "Admin,CSPSystem,IAM,SuperUser,Unknown User, _Ensemble,_SYSTEM")`
在执行锁定之后,应用程序或项目极有可能会停止工作。为了解决这个问题,需要将一些安全设置恢复到原始状态。这个操作可以通过管理门户界面(安全性部分)实现或以编程方式完成。
# 锁定后更改安全设置
锁定之后,如果您的web应用程序使用了密码以外的身份验证方法,就需要进行启用。
建议运行软件模块zpm-registry-test-deployment,它有一个在ZPM-registry项目中使用LockDown的示例。
在IRIS上以最低的安全级别安装该项目,安装结束时将开始运行其中的代码。代码可以用来:
- 更改所有预安装用户的密码。
- 禁用此项目中未使用的所有服务。
- 为系统上的所有应用程序启用密码保护,但Web应用程序/注册表(允许未经授权的用户获取注册表中的软件包列表)除外。
- 创建一个拥有在注册表中发布新包特权的新用户。该用户必须对IRISAPP数据库中的项目表具有写权限。
创建一个新用户:
```
set tSC= ##class(App.Security.LockDown).CreateUser(pUsername, "%DB_"_Namespace, pPassword, "ZMP registry user",Namespace)
If $$$ISERR(tSC) quit tSC
write !,"Create user "_pUsername
```
为新的未授权用户添加权限:
```
set tSC=##class(App.Security.LockDown).addSQLPrivilege(Namespace, "1,ZPM.Package", "s", "UnknownUser")
set tSC=##class(App.Security.LockDown).addSQLPrivilege(Namespace, "1,ZPM.Package", "s", pUsername)
set tSC=##class(App.Security.LockDown).addSQLPrivilege(Namespace, "1,ZPM.Package_dependencies", "s", pUsername)
set tSC=##class(App.Security.LockDown).addSQLPrivilege(Namespace, "1,ZPM_Analytics.Event", "s", pUsername)
set tSC=##class(App.Security.LockDown).addSQLPrivilege(Namespace, "9,ZPM.Package_Extent", "e", pUsername)
set tSC=##class(App.Security.LockDown).addSQLPrivilege(Namespace, "9,ZPM_Analytics.Event_Extent", "e", pUsername)
If $$$ISERR(tSC) quit tSC
write !,"Add privileges "
```
运行LockDown项目:
```
set tSC= ##class(App.Security.LockDown).Apply(NewPassSys)
If $$$ISERR(tSC) quit tSC
Change the settings for the web app so that an unknown user can log in:
set prop("AutheEnabled")=96
set tSC=##class(Security.Applications).Modify("/registry",.prop)
If $$$ISERR(tSC) quit tSC
write !,"Modify /registry "
Change the settings for the %service_terminal service, changing the authorization method to Operating System, Password:
set name="%service_terminal"
set prop("Enabled")=1
set prop("AutheEnabled")=48 ; Operating System,Password
set tSC=##class(Security.Services).Modify(name,.prop)
If $$$ISERR(tSC) quit tSC
write !,"Modify service terminal"
```
# 总结
在本文中,我讨论了为何要提高系统安全性级别的原因,并且通过一个InterSystems LockDown程序运行示例,演示了如何通过编程的方式提升安全性。
在本文所介绍的方法中,我们首先关闭了系统中的所有内容(即,设置最大安全级别)。然后通过开放项目运行所需的服务和应用程序(但仅限于这些)来控制安全性。我相信还有许多其他的方法和最佳实践,欢迎大家在文章评论区留言告诉我们。
文章
Hao Ma · 一月 10, 2021
自 Caché 2017 以后,SQL 引擎包含了一些新的统计信息。 这些统计信息记录了执行查询的次数以及运行查询所花费的时间。
对于想要对包含许多 SQL 语句的应用程序的性能进行监控和尝试优化的人来说,这是一座宝库,但访问数据并不像一些人希望的那么容易。
本文和相关的示例代码说明了如何使用这些信息,以及如何例行提取每日统计信息的摘要,并保存应用程序的 SQL 性能的历史记录。
记录了什么?
每次执行 SQL 语句时,都记录花费的时间。 这是非常轻量的操作,无法关闭。 为了最大程度地降低开销,统计信息保留在内存中并定期写入磁盘。 数据包括一天中执行查询的次数以及所花费的平均时间和总时间。
数据不会立即写入磁盘,并且在写入之后,统计信息将由“更新 SQL 查询统计信息”任务更新,该任务通常计划为每小时运行一次。 该任务可以手动触发,但是如果你希望在测试查询时实时查看统计信息,则整个过程需要一点耐心。
警告:在 InterSystems IRIS 2019 及更早版本中,不会针对已使用 %Studio.Project:Deploy 机制部署的类或例程中的嵌入式 SQL 收集这些统计信息。 示例代码不会有任何中断,但这可能会使你产生误导(我被误导过),让你以为一切正常,因为没有查询显示为高开销。
如何查看信息?
你可以在管理门户中查看查询列表。 转到 SQL 页面,点击“SQL 语句”选项卡。 对于你正在运行并查看的新查询,这种方式很好;但是如果有数千条查询正在运行,则可能变得难以管理。
另一种方法是使用 SQL 搜索查询。 信息存储在 INFORMATION_SCHEMA 模式的表中。 该模式含有大量表,我在本文的最后附上了一些 SQL 查询示例。
何时删除统计信息?
每次重新编辑查询时会删除其数据。 因此对于动态查询,这可能意味着清除缓存的查询时。 对于嵌入式 SQL,则意味着重新编译在其中嵌入 SQL 的类或例程时。
在活跃的站点上,可以合理预期统计信息将保存超过一天,但是存放统计信息的表不能用作运行报告或长期分析的长期参考源。
如何汇总信息?
我建议每天晚上将数据提取到永久表中,这些表在生成性能报告时更易于使用。 如果在白天编译类,可能会丢失一些信息,但这不太可能对慢速查询的分析产生任何实际影响。
下面的代码示例说明了如何将每个查询的统计信息提取到每日汇总中。 它包括三个简短的类:
* 一个应在每晚运行的任务。
* DRL.MonitorSQL 是主类,用于从 INFORMATION_SCHEMA 表提取数据并存储。
第三个类 DRL.MonitorSQLText 是一个优化类,它存储一次(可能很长的)查询文本,并且只将查询的哈希存储在每天的统计信息中。
示例说明
该任务提取前一天的信息,因此应安排在午夜后不久执行。
你可以导出更多历史数据,只要其存在。 要提取过去 120 天的数据
Do ##class(DRL.MonitorSQL).Capture($h-120,$h-1)
该示例代码直接读取全局 ^rIndex,因为最早版本的统计信息未将日期公开给 SQL。
我所包括的变体将循环实例中的所有命名空间,但这并不总是合适的。
如何查询已提取的数据
提取数据后,您可以通过运行以下语句查找最繁重的查询
SELECT top 20
S.RunDate,S.RoutineName,S.TotalHits,S.SumpTIme,S.Hash,t.QueryText
from DRL.MonitorSQL S
left join DRL.MonitorSQLText T on S.Hash=T.Hash
where RunDate='08/25/2019'
order by SumpTime desc
此外,如果选择了开销大的查询的哈希,可以通过以下语句查看该查询的历史记录
SELECT S.RunDate,S.RoutineName,S.TotalHits,S.SumpTIme,S.Hash,t.QueryText
from DRL.MonitorSQL S
left join DRL.MonitorSQLText T on S.Hash=T.Hash
where S.Hash='CgOlfRw7pGL4tYbiijYznQ84kmQ='
order by RunDate
今年早些时候,我获取了一个活跃站点的数据,然后查看了开销最大的查询。 有一个查询的平均时间不到 6 秒,但每天被调用 14000 次,加起来每天消耗的时间将近 24 小时。 实际上,一个核心完全被这个查询占用。 更糟糕的是,第二个查询要花一个小时,它是第一个查询的变体。
运行日期
例程名称
总命中次数
总时间
哈希
查询文本(有节略)
03/16/2019
14,576
85,094
5xDSguu4PvK04se2pPiOexeh6aE=
DECLARE C CURSOR FOR SELECT * INTO :%col(1) , :%col(2) , :%col(3) , :%col(4) …
03/16/2019
15,552
3,326
rCQX+CKPwFR9zOplmtMhxVnQxyw=
DECLARE C CURSOR FOR SELECT * INTO :%col(1) , :%col(2) , :%col(3) , :%col(4) , …
03/16/2019
16,892
597
yW3catzQzC0KE9euvIJ+o4mDwKc=
DECLARE C CURSOR FOR SELECT * INTO :%col(1) , :%col(2) , :%col(3) , :%col(4) , :%col(5) , :%col(6) , :%col(7) ,
03/16/2019
16,664
436
giShyiqNR3K6pZEt7RWAcen55rs=
DECLARE C CURSOR FOR SELECT * , TKGROUP INTO :%col(1) , :%col(2) , :%col(3) , ..
03/16/2019
74,550
342
4ZClMPqMfyje4m9Wed0NJzxz9qw=
DECLARE C CURSOR FOR SELECT …
表 1:客户站点的实际结果
INFORMATION_SCHEMA 模式中的表
除了统计信息外,此模式中的表还会跟踪查询、列、索引等的使用位置。 通常,SQL 语句是起始表,它的连接方式类似于“Statements.Hash=OtherTable.Statement”。
直接访问这些表以查找一天中开销最大的查询,这一操作的等效查询是...
SELECT DS.Day,Loc.Location,DS.StatCount,DS.StatTotal,S.Statement,S.Hash
FROM INFORMATION_SCHEMA.STATEMENT_DAILY_STATS DS
left join INFORMATION_SCHEMA.STATEMENTS S
on S.Hash=DS.Statement
left join INFORMATION_SCHEMA.STATEMENT_LOCATIONS Loc
on S.Hash=Loc.Statement
where Day='08/26/2019'
order by DS.stattotal desc
无论你是否考虑建立一个更系统的过程,我都建议每个使用 SQL 处理大型应用程序的人今天都运行这个查询。
如果某个特定查询显示为高开销,则可以通过运行以下语句获取历史记录
SELECT DS.Day,Loc.Location,DS.StatCount,DS.StatTotal,S.Statement,S.Hash
FROM INFORMATION_SCHEMA.STATEMENT_DAILY_STATS DS
left join INFORMATION_SCHEMA.STATEMENTS S
on S.Hash=DS.Statement
left join INFORMATION_SCHEMA.STATEMENT_LOCATIONS Loc
on S.Hash=Loc.Statement
where S.Hash='jDqCKaksff/4up7Ob0UXlkT2xKY='
order by DS.Day
每日提取统计信息的代码示例
标准免责声明 - 此示例仅用于说明。 不对其提供支持,也不保证其有效。
Class DRL.MonitorSQLTask Extends %SYS.Task.Definition{Parameter TaskName = "SQL Statistics Summary";Method OnTask() As %Status{ set tSC=$$$OK TRY { do ##class(DRL.MonitorSQL).Run() } CATCH exp { set tSC=$SYSTEM.Status.Error("Error in SQL Monitor Summary Task") } quit tSC }}
Class DRL.MonitorSQLText Extends %Persistent{/// Hash of query textProperty Hash As %String;
/// query text for hashProperty QueryText As %String(MAXLEN = 9999);Index IndHash On Hash [ IdKey, Unique ];}
/// Summary of very low cost SQL query statistics collected in Cache 2017.1 and later. /// Refer to documentation on "SQL Statement Details" for information on the source data. /// Data is stored by date and time to support queries over time. /// Typically run to summarise the SQL query data from the previous day.Class DRL.MonitorSQL Extends %Persistent{/// RunDate and RunTime uniquely identify a runProperty RunDate As %Date;/// Time the capture was started/// RunDate and RunTime uniquely identify a runProperty RunTime As %Time;/// Count of total hits for the time period for Property TotalHits As %Integer;/// Sum of pTimeProperty SumPTime As %Numeric(SCALE = 4);/// Routine where SQL is foundProperty RoutineName As %String(MAXLEN = 1024);/// Hash of query textProperty Hash As %String;Property Variance As %Numeric(SCALE = 4);/// Namespace where queries are runProperty Namespace As %String;/// Default run will process the previous days data for a single day./// Other date range combinations can be achieved using the Capture method.ClassMethod Run(){ //Each run is identified by the start date / time to keep related items together set h=$h-1 do ..Capture(+h,+h)}/// Captures historic statistics for a range of datesClassMethod Capture(dfrom, dto){ set oldstatsvalue=$system.SQL.SetSQLStatsJob(-1) set currNS=$znspace set tSC=##class(%SYS.Namespace).ListAll(.nsArray) set ns="" set time=$piece($h,",",2) kill ^||TMP.MonitorSQL do { set ns=$o(nsArray(ns)) quit:ns="" use 0 write !,"processing namespace ",ns zn ns for dateh=dfrom:1:dto { set hash="" set purgedun=0 do { set hash=$order(^rINDEXSQL("sqlidx",1,hash)) continue:hash="" set stats=$get(^rINDEXSQL("sqlidx",1,hash,"stat",dateh)) continue:stats="" set ^||TMP.MonitorSQL(dateh,ns,hash)=stats &SQL(SELECT Location into :tLocation FROM INFORMATION_SCHEMA.STATEMENT_LOCATIONS WHERE Statement=:hash) if SQLCODE'=0 set Location="" set ^||TMP.MonitorSQL(dateh,ns,hash,"Location")=tLocation &SQL(SELECT Statement INTO :Statement FROM INFORMATION_SCHEMA.STATEMENTS WHERE Hash=:hash) if SQLCODE'=0 set Statement="" set ^||TMP.MonitorSQL(dateh,ns,hash,"QueryText")=Statement } while hash'="" } } while ns'="" zn currNS set dateh="" do { set dateh=$o(^||TMP.MonitorSQL(dateh)) quit:dateh="" set ns="" do { set ns=$o(^||TMP.MonitorSQL(dateh,ns)) quit:ns="" set hash="" do { set hash=$o(^||TMP.MonitorSQL(dateh,ns,hash)) quit:hash="" set stats=$g(^||TMP.MonitorSQL(dateh,ns,hash)) continue:stats="" // The first time through the loop delete all statistics for the day so it is re-runnable // But if we run for a day after the raw data has been purged, it will wreck eveything // so do it here, where we already know there are results to insert in their place. if purgedun=0 { &SQL(DELETE FROM websys.MonitorSQL WHERE RunDate=:dateh ) set purgedun=1 } set tObj=##class(DRL.MonitorSQL).%New() set tObj.Namespace=ns set tObj.RunDate=dateh set tObj.RunTime=time set tObj.Hash=hash set tObj.TotalHits=$listget(stats,1) set tObj.SumPTime=$listget(stats,2) set tObj.Variance=$listget(stats,3) set tObj.Variance=$listget(stats,3) set queryText=^||TMP.MonitorSQL(dateh,ns,hash,"QueryText") set tObj.RoutineName=^||TMP.MonitorSQL(dateh,ns,hash,"Location") &SQL(Select ID into :TextID from DRL.MonitorSQLText where Hash=:hash) if SQLCODE'=0 { set textref=##class(DRL.MonitorSQLText).%New() set textref.Hash=tObj.Hash set textref.QueryText=queryText set sc=textref.%Save() } set tSc=tObj.%Save() //avoid dupicating the query text in each record because it can be very long. Use a lookup //table keyed on the hash. If it doesn't exist add it. if $$$ISERR(tSc) do $system.OBJ.DisplayError(tSc) if $$$ISERR(tSc) do $system.OBJ.DisplayError(tSc) } while hash'="" } while ns'="" } while dateh'="" do $system.SQL.SetSQLStatsJob(0)}Query Export(RunDateH1 As %Date, RunDateH2 As %Date) As %SQLQuery{SELECT S.Hash,RoutineName,RunDate,RunTime,SumPTime,TotalHits,Variance,RoutineName,T.QueryText FROM DRL.MonitorSQL S LEFT JOIN DRL.MonitorSQLText T on S.Hash=T.Hash WHERE RunDate>=:RunDateH1 AND RunDate
文章
Hao Ma · 一月 10, 2021
在本文中,我想谈一谈规范优先的 REST API 开发方式。
传统的代码优先 REST API 开发是这样的:
* 编写代码
* 使其支持 REST
* 形成文档(成为 REST API)
规范优先遵循同样的步骤,不过是反过来的。 我们先制定规范(同时兼做文档),然后根据它生成一个样板 REST 应用,最后编写一些业务逻辑。
这是有好处的,因为:
* 对于想要使用你的 REST API 的外部或前端开发者,你总是有相关且有用的文档
* 使用 OAS (Swagger) 创建的规范可以导入各种工具,从而进行编辑、客户端生成、API 管理、单元测试和自动化,或者许多其他任务的简化
* 改进了 API 架构。 在代码优先的方式中,API 是逐个方法开发的,因此开发者很容易失去对整体 API 架构的跟踪,但在规范优先的方式中,开发者被强制从 API 使用者的角度与 API 进行交互,这通常有助于设计出更简洁的 API 架构
* 更快的开发速度 - 由于所有样板代码都是自动生成的,你无需编写代码,只需开发业务逻辑。
* 更快的反馈循环 - 使用者可以立即查看 API,并且只需修改规范即可轻松提供建议
让我们以规范优先的方式开发 API 吧!
### 计划
1. 使用 swagger 制定规范
* Docker
* 本地
* 在线
2. 将规范加载到 IRIS 中
* API 管理 REST API
* ^REST
* 类
3. 我们的规范会怎样?
4. 实现
5. 进一步开发
6. 注意事项
* 特殊参数
* CORS
7. 将规范加载到 IAM 中
### 制定规范
勿庸置疑,第一步是编写规范。 InterSystems IRIS 支持 Open API 规范 (OAS):
> **OpenAPI 规范** (以前称为 Swagger 规范)是 REST API 的 API 描述格式。 OpenAPI 文件允许描述整个 API,包括:
>
> * 可用端点 (`/users`) 和每个端点上的操作(`GET /users`、`POST /users`)
> * 每次操作的操作参数输入和输出
> * 身份验证方法
> * 联系信息、许可证、使用条款和其他信息。
>
> API 规范可以使用 YAML 或 JSON 编写。 格式易于学习,并且对人和机器都可读。 完整的 OpenAPI 规范可在 GitHub 上找到:[OpenAPI 3.0 规范](https://github.com/OAI/OpenAPI-Specification/blob/master/versions/3.0.0.md)
- 来自 Swagger 文档。
我们将使用 Swagger 编写 API。 使用 Swagger 有几种方法:
* [在线](https://editor.swagger.io/)
* Docker:`docker run -d -p 8080:8080 swaggerapi/swagger-editor`
* [本地安装](https://swagger.io/docs/open-source-tools/swagger-editor/)
安装/运行 Swagger 后,你应该在 Web 浏览器中看到以下窗口:
在左侧编辑 API 规范,在右侧可以立即看到渲染的 API 文档/测试工具。
我们将第一个 API 规范加载到其中(使用 [YAML](https://en.wikipedia.org/wiki/YAML))。 这是一个简单的 API,包含一个 GET 请求 - 返回指定范围内的随机数。
Math API 规范
swagger: "2.0"
info:
description: "Math"
version: "1.0.0"
title: "Math REST API"
host: "localhost:52773"
basePath: "/math"
schemes:
- http
paths:
/random/{min}/{max}:
get:
x-ISC_CORS: true
summary: "Get random integer"
description: "Get random integer between min and max"
operationId: "getRandom"
produces:
- "application/json"
parameters:
- name: "min"
in: "path"
description: "Minimal Integer"
required: true
type: "integer"
format: "int32"
- name: "max"
in: "path"
description: "Maximal Integer"
required: true
type: "integer"
format: "int32"
responses:
200:
description: "OK"
以下是其包含的内容。
有关 API 和使用的 OAS 版本的基本信息。
swagger: "2.0"
info:
description: "Math"
version: "1.0.0"
title: "Math REST API"
服务器主机、协议(http、https)和 Web 应用程序名称:
host: "localhost:52773"
basePath: "/math"
schemes:
- http
接下来指定路径(完整的 URL 是 `http://localhost:52773/math/random/:min/:max`)和 HTTP 请求方法(get、post、put、delete):
paths:
/random/{min}/{max}:
get:
之后,指定有关请求的信息:
x-ISC_CORS: true
summary: "Get random integer"
description: "Get random integer between min and max"
operationId: "getRandom"
produces:
- "application/json"
parameters:
- name: "min"
in: "path"
description: "Minimal Integer"
required: true
type: "integer"
format: "int32"
- name: "max"
in: "path"
description: "Maximal Integer"
required: true
type: "integer"
format: "int32"
responses:
200:
description: "OK"
在此部分中,我们定义请求:
* 为 CORS 启用此路径(稍后将详细介绍)
* 提供 _summary_ 和 _description_
* _operationId_ 允许规范内引用,它也是我们的实现类中生成的方法名
* _produces_ - 响应格式(例如文本、xml、json)
* _parameters_ 指定输入参数(在 URL 或正文中),在我们的示例中,我们指定 2 个参数 - 随机数生成器的范围
* _responses_ 列出服务器的可能响应
如你所见,这种格式并不是特别有挑战性,虽然还有很多可用功能。这里是[规范](https://github.com/OAI/OpenAPI-Specification/blob/master/versions/3.0.2.md)。
最后,我们将定义导出为 JSON。 转到“文件 → 转换”并另存为 JSON。 规范应如下所示:
Math API 规范
{
"swagger": "2.0",
"info": {
"description": "Math",
"version": "1.0.0",
"title": "Math REST API"
},
"host": "localhost:52773",
"basePath": "/math",
"schemes": [
"http"
],
"paths": {
"/random/{min}/{max}": {
"get": {
"x-ISC_CORS": true,
"summary": "Get random integer",
"description": "Get random integer between min and max",
"operationId": "getRandom",
"produces": [
"application/json"
],
"parameters": [
{
"name": "min",
"in": "path",
"description": "Minimal Integer",
"required": true,
"type": "integer",
"format": "int32"
},
{
"name": "max",
"in": "path",
"description": "Maximal Integer",
"required": true,
"type": "integer",
"format": "int32"
}
],
"responses": {
"200": {
"description": "OK"
}
}
}
}
}
}
### 将规范加载到 IRIS 中
现在我们有了规范,我们可以在 InterSystems IRIS 中为此 REST API 生成样板代码。
要进入此阶段,我们需要三个东西:
* REST 应用程序名称:我们生成的代码的包(假定为 `math)
JSON 格式的 OAS 规范:我们刚刚在上一步中创建
Web 应用程序名称:用于访问我们的 REST API 的基本路径(我们的示例中为 /math`)
有三种方法使用我们的规范来生成代码,它们本质上是相同的,只是提供了多种访问相同功能的方式
1. 调用 `^%REST` 例程(在交互式终端会话中 `Do ^%REST`), [参见文档](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GREST_routine)。
2. 调用 `%REST` 类(`Set sc = ##class(%REST.API).CreateApplication(applicationName, spec)`,非交互式),[参见文档](https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=GREST_objectscriptapi)。
3. 使用 API 管理 REST API,[参见文档](https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=GREST_apimgmnt)。
我认为文档足以描述所需的步骤,因此选择一个即可。 我再补充两点说明:
* 在第 1 种和第 2 种方法中,可以向动态对象传递文件名或 URL
* 在第 2 种和第 3 种方法中,**必须** 进行一个额外的调用才能创建 Web 应用程序:`set sc = ##class(%SYS.REST).DeployApplication(restApp, webApp, authenticationType)`,所以在我们的示例中为 `set sc = ##class(%SYS.REST).DeployApplication("math", "/math")`,从 `%sySecurity` 包含文件获取 `authenticationType` 参数的值,相关条目为 `$$$Authe*`,因此对于未经身份验证的访问,传递 `$$$AutheUnauthenticated`。 如果省略,该参数默认为密码身份验证。
### 我们的规范会怎样?
如果你已成功创建应用,新的 `math` 包应该包含三个类:
* _Spec_ - 按原样存储规范。
* _Disp_ - 在调用 REST 服务时直接调用。 它封装 REST 处理并调用实现方法。
* _Impl_ - 保存 REST 服务的实际内部实现。 你只应该编辑此类。
[文档](https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=GREST_intro#GREST_intro_classes)包含有关这些类的更多信息。
### 实现
最初,我们的实现类 `math.impl` 只包含一个方法,对应于我们的 `/random/{min}/{max}` 操作:
/// Get random integer between min and max
/// The method arguments hold values for:
/// min, Minimal Integer
/// max, Maximal Integer
ClassMethod getRandom(min As %Integer, max As %Integer) As %DynamicObject
{
//(Place business logic here)
//Do ..%SetStatusCode()
//Do ..%SetHeader(,)
//Quit (Place response here) ; response may be a string, stream or dynamic object
}
让我们从简单的实现开始:
ClassMethod getRandom(min As %Integer, max As %Integer) As %DynamicObject
{
quit {"value":($random(max-min)+min)}
}
最后,我们可以通过在浏览器中打开此页面来调用我们的 REST API:`http://localhost:52773/math/random/1/100`
输出应该是:
{
"value": 45
}
此外,在 Swagger 编辑器中按 `Try it out`(试用)按钮并填写请求参数也会发送同样的请求:
恭喜! 我们使用规范优先的方式创建的第一个 REST API 现在已经生效!
### 进一步开发
当然,我们的 API 不是静态的,我们需要添加新路径等等。 在规范优先的开发中,首先要修改规范,然后更新 REST 应用程序(调用与创建应用程序相同),最后编写代码。 请注意,规范更新是安全的:你的代码不会受到影响,即使从规范中删除路径,在实现类中也不会删除方法。
### 注意事项
更多说明!
#### 特殊参数
InterSystems 向 swagger 规范添加了特殊参数,如下所示:
名称
数据类型
默认值
位置
描述
x-ISC_DispatchParent
类名
%CSP.REST
信息
调度类的超类。
x-ISC_CORS
布尔
false
操作
一个标志,指示对此端点/方法组合的 CORS 请求应该获得支持。
x-ISC_RequiredResource
数组
操作
以逗号分隔的已定义资源及其访问模式(资源:模式)的列表,这些资源和模式是访问 REST 服务的此端点所必需的。 示例:["%Development:USE"]
x-ISC_ServiceMethod
字符串
操作
后端调用的用于维护此操作的类方法的名称;默认值为 operationId,通常就很合适。
#### CORS
有三种方法启用 CORS 支持。
1. 在逐条路由的基础上,将 `x-ISC_CORS` 指定为 true。 我们的 Math REST API 中就是这样做的。
2. 在每个 API 的基础上,添加
Parameter HandleCorsRequest = 1;
然后重新编译该类。 规范更新后它也会保留。
3. (推荐)在每个 API 的基础上,实现自定义调度器超类(应该扩展 `%CSP.REST`)并编写 CORS 处理逻辑。 要使用此超类,请将 `x-ISC_DispatchParent` 添加到规范中。
### 将规范加载到 IAM 中
最后,我们将规范添加到 IAM中,以便将其发布给其他开发者。
如果您尚未开始使用 IAM,请参见[此文章](https://community.intersystems.com/post/introducing-intersystems-api-manager)。 它还涵盖了通过 IAM 提供 REST API,所以我在这里不做介绍。 您可能需要修改规范的 `host` 和 `basepath` 参数,使它们指向 IAM,而不是 InterSystems IRIS 实例。
打开 IAM 管理员门户,转到相关工作区的 `Specs`(规范)选项卡。
点击 `Add Spec`(添加规范)按钮并输入新 API 的名称(我们的示例中为 `math`)。 在 IAM 中创建新规范后,点击 `Edit`(编辑)并粘贴规范代码(JSON 或 YAML - IAM 都支持):
不要忘记点击 `Update File`(更新文件)。
现在我们的 API 已发布给开发者。 打开开发者门户,然后点击右上角的 `Documentation`(文档)。 除了三个默认 API,还应该看到我们的新 `Math REST API`:
打开它:
现在,开发者可以看到我们的新 API 的文档,并在同一个地方试用它!
###
### 结论
InterSystems IRIS 简化了 REST API 的开发过程,规范优先的方式使 REST API 生命周期管理更快更简单。 通过这种方式,你可以使用各种工具来完成各种相关任务,例如客户端生成、单元测试、API 管理等等。
### 链接
* [OpenAPI 3.0 规范](https://github.com/OAI/OpenAPI-Specification/blob/master/versions/3.0.0.md)
* [创建 REST 服务](https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=GREST)
* [从 IAM 开始](https://community.intersystems.com/post/introducing-intersystems-api-manager)
* [IAM 文档](https://docs.intersystems.com/irislatest/csp/docbook/apimgr/index.html)
文章
Hao Ma · 一月 10, 2021
本文讨论 Windows 写入缓存设置,该设置会使系统在断电或操作系统崩溃的情况下容易发生数据丢失或损坏。 该设置在某些 Windows 配置中默认开启。
为磁盘启用 Windows 写入缓存意味着 Caché(或任何程序)写入该磁盘的某些内容不一定会立即提交到持久性存储(即使 Caché 在其写入阶段的特定关键点刷新从操作系统缓存到磁盘的写入也是如此)。 如果计算机断电,为该设备缓存的任何内容都会丢失,除非该设备的缓存是非易失性的或者由电池供电。 Caché 依靠操作系统来保证数据的持久性。 在这种情况下,保证是无效的。 对于 Caché 来说,这可能会导致数据库损坏或者数据库或日志文件中的数据缺失。
InterSystems 的文档显示,使“写入映像日志”提供的保证失效的一种情况是回写缓存内容丢失(请参见 [http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GCDI_wij#GCDI/wij_limits](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GCDI_wij#GCDI_wij_limits))。 InterSystems 全球响应中心的数据完整性团队研究了许多 Windows 平台上的数据丢失或损坏案例,这些案例中有证据表明,回写缓存内容丢失是由该设置的值导致的。
值得一提的是,磁盘的缓存可能会有效防止发生此类问题。 如果相关磁盘的缓存是非易失性的或由电池供电,则即使开启该设置,写入磁盘也应该是安全的。 如果相关存储比直接连接的磁盘更复杂,您需要了解在该存储基础架构的何处对写入进行缓存,以及这些缓存是否是易失性的或者是否由电池供电,以评估风险。
您可以转到“设备管理器”,展开“磁盘驱动器”部分,然后查看给定磁盘的属性来查看设置。 我们感兴趣的设置在“策略”选项卡上。
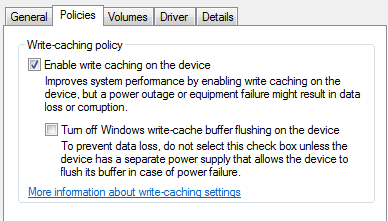
界面上的用词并不总是与您在这里看到的相同,可能因设备类型的不同而有所不同。 不过,这是常见的用词表述,并且 Windows 明确指出,开启该设置后,如果机器断电或崩溃,系统可能会发生数据丢失。
接下来是同一机器上另一个磁盘的示例,其中的影响没有那么明显。在这里选择“更好的性能”将与在另一个示例中选择“启用写入缓存”带来相同问题。
在这两个示例中,您看到的选定设置都是该设备的默认设置,我没有更改过。 您可以看到,在第一个示例中,默认设置使设备处于风险之中,而第二个示例则没有。 据我所知,并没有通用于所有设备类型或 Windows 版本的默认设置。 换句话说,需要在每台设备上检查此设置,以了解设备是否存在此风险。
作为系统管理员,处理这种情况有三种基本方法。 禁用该设置是最简单的方法,可确保不会面临此风险。 但是,禁用该设置可能会对性能产生不可接受的影响。 如果是这种情况,您可能更愿意开启该设置,并将计算机连接到不间断电源。 这样做可以防止断电导致的数据丢失或损坏,因为 UPS 应该可以在断电时提供足够的时间让您从容地关机。 最后一个选择是简单地接受服务器断电或崩溃时数据丢失的风险。 InterSystems 建议不要采用此方式。 消费级 UPS 已相当便宜,而且检测完整性问题并从中恢复可能非常耗时又会产生问题。
InterSystems 建议您在未确保计算机连接到不间断电源的情况下不要开启此设置。 如果存储是外部设备,则该设备也需要连接到 UPS。
文章
Hao Ma · 一月 10, 2021
虽然 Caché 和 InterSystems IRIS 数据库的[完整性](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GCDI_integrity)完全不会受到系统故障的影响,但物理存储设备故障确实会损坏其存储的数据。 因此,许多站点选择运行定期数据库完整性检查,尤其要与备份配合,以验证在发生灾难时是否可以依赖给定的备份。 系统管理员在应对涉及存储损坏的灾难时,也可能强烈需要完整性检查。 完整性检查必须读取所检查的 global 的每个块(如果尚未在缓冲区中),并且按照 global 结构指示的顺序读取。 这会花费大量时间,**但完整性检查能够以存储子系统可以承受的最快速度进行读取**。 在某些情况下,需要以这种方式运行以尽快获得结果。 在其他情况下,完整性检查需要更加保守,以避免消耗过多的存储子系统带宽。
## 行动计划
以下概述适合大多数情况。 本文其余部分中的详细讨论提供了采取其中任一行动或得出其他行动方案所需的信息。
1. 如果使用 Linux 并且完整性检查很慢,请参阅下面有关启用异步 I/O 的信息。
2. 如果完整性检查必须尽快完成,则在隔离的环境中运行;或者如果迫切需要结果,则使用多进程完整性检查来并行检查多个 global 或数据库。 进程数乘以每个进程将执行的并发异步读取数(默认为 8,如果使用 Linux 并且禁用异步 I/O 则为 1)是实时并发读取数的限制。 假定平均数是限制数量的一半,然后与存储子系统的能力进行比较。 例如,存储由 20 个驱动器条带化,每个进程的默认并发读取数为 8,则可能需要 5 个或更多进程才能利用存储子系统的全部能力 (5*8/2=20)。
3. 在平衡完整性检查速度与对生产的影响时,首先调整多进程完整性检查的进程数,然后如果需要的话,查看可调参数 SetAsyncReadBuffers。 对于长期解决方案(以及为消除误报),请参见下面的隔离完整性检查。
4. 如果已经被限制为一个进程(例如有一个极大的 global 或存在其他外部约束),并且完整性检查的速度需要上下调整,则查看下面的可调参数 SetAsyncReadBuffers。
## 多进程完整性检查
让完整性检查更快完成(以更高的速度使用系统资源)的一般解决方案是将工作分给多个并行进程。 一些完整性检查用户界面和 API 会这样做,而其他一些则使用单个进程。 对进程的分配按 global 进行,因此对单个 global 的检查始终由一个进程执行(Caché 2018.1 之前的版本按数据库而不是按 global 分配工作)。
多进程完整性检查的主要 API 是 **CheckLIst^Integrity**(有关详细信息,请参阅[文档](https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=GCDI_integrity#GCDI_integrity_verify_utility))。 它将结果收集在一个临时的 global 中,通过 Display^Integrity 来显示。 以下是使用 5 个进程检查 3 个数据库的示例。 这里如省略数据库列表参数,将检查所有数据库。
set dblist=$listbuild(“/data/db1/”,”/data/db2/”,”/data/db3/”)
set sc=$$CheckList^Integrity(,dblist,,,5)
do Display^Integrity()
kill ^IRIS.TempIntegrityOutput(+$job)
/* Note: evaluating ‘sc’ above isn’t needed just to display the results, but...
$system.Status.IsOK(sc) - ran successfully and found no errors
$system.Status.GetErrorCodes(sc)=$$$ERRORCODE($$$IntegrityCheckErrors) // 267
- ran successfully, but found errors.
Else - a problem may have prevented some portion from running, ‘sc’ may have
multiple error codes, one of which may be $$$IntegrityCheckErrors. */
像这样使用 CheckLIst^Integrity 是实现我们感兴趣的控制水平的最直接方法。 管理门户接口和完整性检查任务(内置但未安排)使用多个进程,但可能无法为我们的用途提供足够的控制。*
其他完整性检查接口,尤其是终端用户接口 ^INTEGRIT 或 ^Integrity 以及 Silent^Integrity,在单个进程中执行完整性检查。 因此,这些接口不能以最快的速度完成检查,并且它们使用的资源也较少。 但一个优点是,它们的结果是可见的,可以记录到文件或输出到终端,因为每个 global 都会被检查,而且顺序明确。
## 异步 I/O
完整性检查进程会排查 global 的每个指针块,一次检查一个,根据它指向的数据块的内容来进行验证。 数据块以异步 I/O 的方式读取,以确保每时每刻都有一定数量的读取请求供存储子系统处理,并且每次读取完成后都进行验证。
在 Linux 上,异步 I/O 只有与直接 I/O 结合时才有效,而 InterSystems IRIS 2020.3 之前的版本默认不启用直接 I/O。 这解释了大量 Linux 上完整性检查时间过长的情况。 幸运的是,可以在 Cache 2018.1、IRIS 2019.1 及以后的版本上启用直接 I/O,方法是在 .cpf 文件的 [config] 部分中设置 **wduseasyncio=1**,然后重新启动。 通常建议设置此参数,以在繁忙系统上实现 I/O 可伸缩性,并且自 Caché 2015.2 起,在非 Linux 平台上默认设置此参数。 在启用之前,确保已经为数据库缓存(global 缓冲区)配置了足够的内存,因为启用直接 I/O 后,数据库将不再被 Linux(冗余)缓存。 未启用时,完整性检查执行的读取会同步完成,不能有效利用存储。
在所有平台上,完整性检查进程一次执行的读取数默认设置为 8。 如果必须更改单个完整性检查进程从磁盘读取的速率,可以调整此参数 – 向上调会使单个进程更快完成,向下调则使用更少的存储带宽。 请记住:
* 此参数应用于每个完整性检查进程。 当使用多个进程时,进程数会使实时读取数增加。更改并行完整性检查进程数会产生较大影响,因此这通常是先做的事情。 每个进程还受到计算时间的限制(除其他限制外),因此增加此参数的值所获得的收益也有限。
* 这只在存储子系统处理并发读取的能力范围内有效。 如果数据库存储在单个本地驱动器上,再高的数值也没有用处,而在几十个驱动器上条带化的存储阵列可以并发处理几十个读取。
要从 %SYS 命名空间调整此参数,则 **do SetAsyncReadBuffers^Integrity(**value**)**。 要查看当前值,则 **write $$GetAsyncReadBuffers^Integrity()**。 更改在检查下一个 global 时生效。 目前,该设置在系统重启后不会保持,虽然可以将其添加到 SYSTEM^%ZSTART 中。
有一个相似的参数用于在磁盘上的块是连续(或接近连续)分布时控制每次读取的最大大小。 此参数很少需要用到,尽管具有高存储延迟的系统或具有较大块大小的数据库可能会从微调中受益。 该值的单位为 64KB,因此值 1 表示 64KB,4 表示 256KB 等等。0(默认值)表示让系统选择,当前选择 1 (64KB)。 此参数的 ^Integrity 函数(类似于上面提及的函数)为 **SetAsyncReadBufferSize** 和 **GetAsyncReadBufferSize**。
## 隔离完整性检查
许多站点直接在生产系统上运行定期完整性检查。 这当然是最简单的配置,但并不理想。 除了完整性检查对存储带宽的影响,并发数据库更新活动有时还可能导致误报错误(尽管检查算法内置了缓解措施)。 因此,在生产系统上运行的完整性检查所报告的错误,需要由管理员进行评估和/或重新检查。
很多时候,存在更好的选择。 可以将存储快照或备份映像挂载到另一台主机上,在那里由隔离的 Caché 或 IRIS 实例运行完整性检查。 这样不仅可以防止任何误报,而且如果存储也与生产隔离,运行完整性检查可以充分利用存储带宽并更快完成。 这种方法非常适合使用完整性检查来验证备份的模型;经过验证的备份可以有效验证截至生成备份前的生产情况。 还可以通过云和虚拟化平台更容易地从快照建立可用的隔离环境。
* * *
* 管理门户接口、完整性检查任务和 SYS.Database 的 IntegrityCheck 方法会选择相当多的进程(等于 CPU 内核数),在很多情况下缺少所需的控制。 管理门户和任务还会对任何报告错误的 global 执行完整的重新检查,以识别可能因并发更新而出现的误报。 除了完整性检查算法内置的误报缓解措施,也可能进行这种重新检查;在某些情况下,由于会花费额外的时间(重新检查在单个进程中运行,并检查整个 global),可能并不需要重新检查。 此行为将来可能会更改。
文章
Qiao Peng · 一月 10, 2021
# Swift-FHIR-Iris
iOS应用程序支持将HealthKit数据导入InterSystems IRIS医疗版(或任何FHIR资源仓库库)
# 目录
* [演示目的](#goal)
* [如何运行此演示](#rundemo)
* [先决条件](#prerequisites)
* [安装Xcode](#installxcode)
* [打开SwiftUi](#openswiftui)
* [配置模拟器](#simulator)
* [启动InterSystems FHIR服务器](#lunchfhir)
* [在iOS应用程序上操作](#iosplay)
* [工作原理](#howtos)
* [iOS](#howtosios)
* [如何检查健康数据的授权](#authorisation)
* [如何连接FHIR资源仓库](#howtoFhir)
* [如何将患者信息保存到FHIR资源仓库](#howtoPatientFhir)
* [如何从HealthKit中提取数据](#queryHK)
* [如何将HealthKit数据转换为FHIR](#HKtoFHIR)
* [后端 (FHIR)](#backend)
* [前端](#frontend)
* [ToDos](#todo)
# 演示目的
目的是创建FHIR协议的端到端演示。
这里的端到端指的是从一个信息源到另一个信息源,例如iPhone。
苹果HealthKit将收集到的健康数据转换为FHIR,再发送到InterSystems IRIS 医疗版存储库。
必须通过web接口访问这些信息。
**TL;DR**: iPhone -> InterSystems FHIR -> web界面.
# 如何运行此演示
## 先决条件
* 客户端 (iOS)
* Xcode 12
* 服务器和Web应用程序
* Docker
## 安装 Xcode
这里没有太多要说的,打开AppStore,搜索Xcode,安装。
## 打开SwiftUi project
Swift是苹果在iOS、Mac、Apple TV和Apple Watch中使用的一种编程语言,是objective-C的替代品。
双击Swift-FHIR-Iris.xcodeproj
单击左上角的箭头打开模拟器。
## 配置模拟器
打开Health
点击“Steps”
添加数据

## 启动InterSystems FHIR服务器
在该git的根目录下,运行以下命令:
```sh
docker-compose up -d
```
构建过程结束时,你将连接到FHIR资源仓库:
http://localhost:32783/fhir/portal/patientlist.html
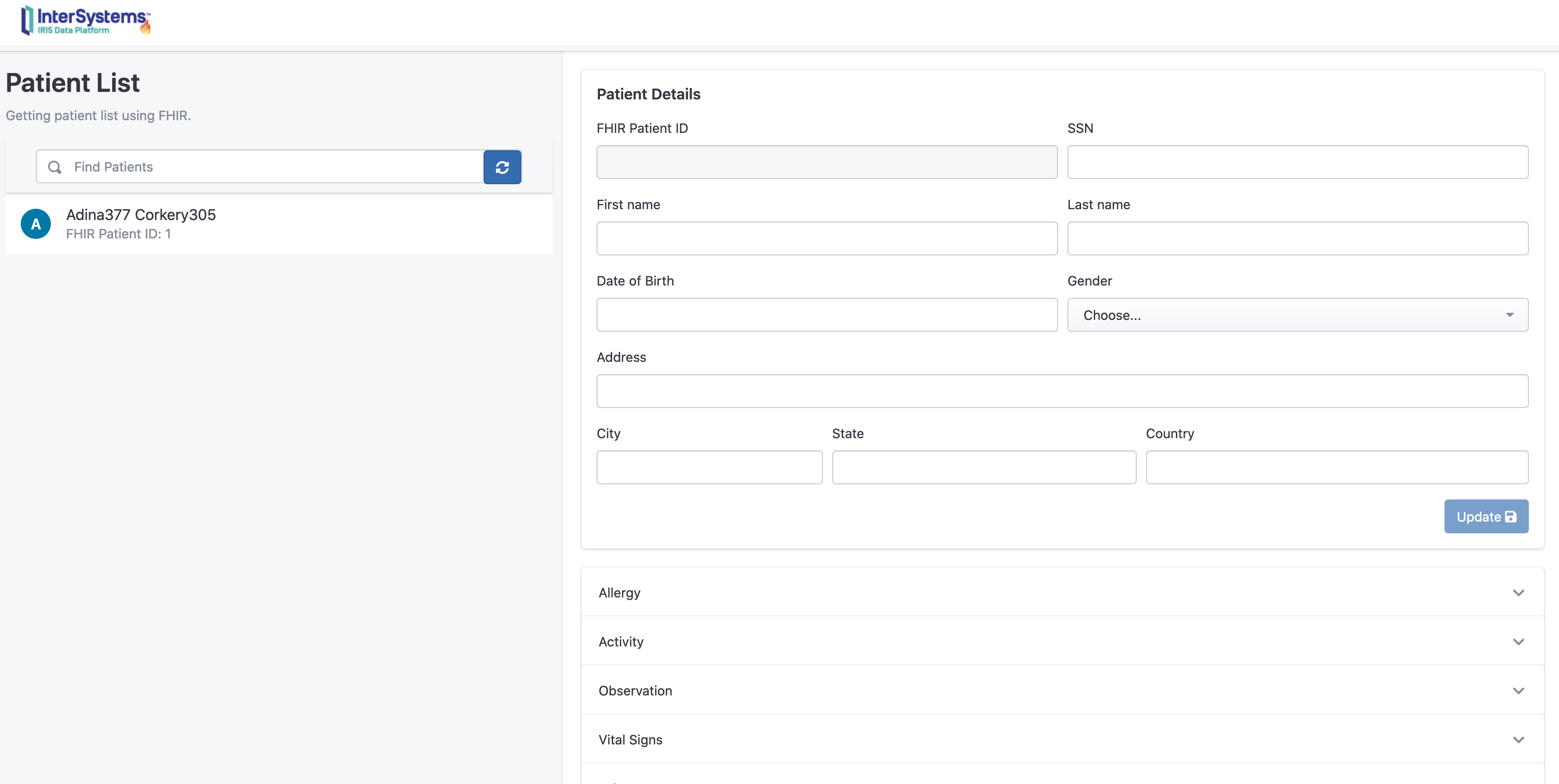
该门户网站由@diashenrique创建.
为处理Apple活动足迹,进行了一些修改。
## 在iOS应用程序上操作
iOS应用程序首先会请求你同意分享部分信息。
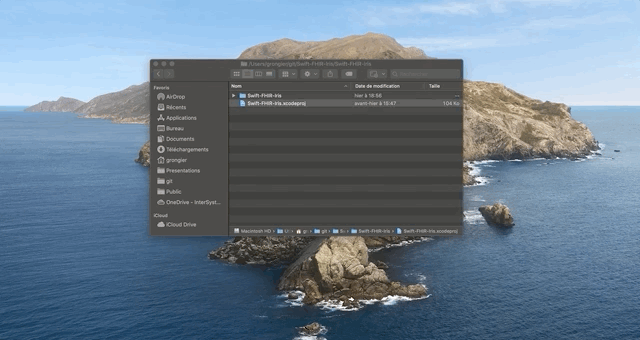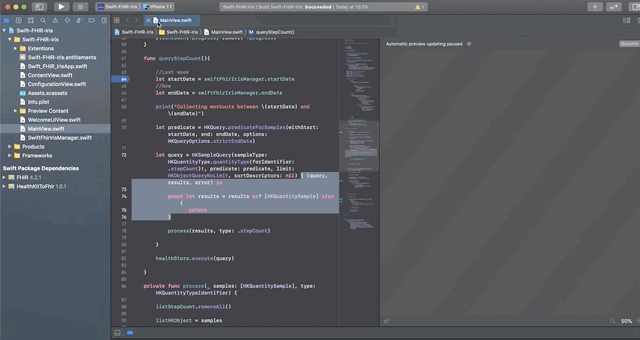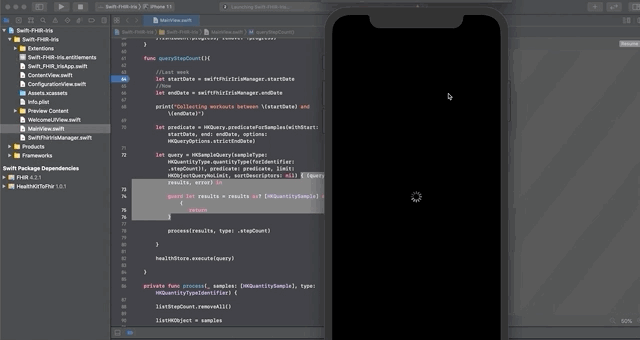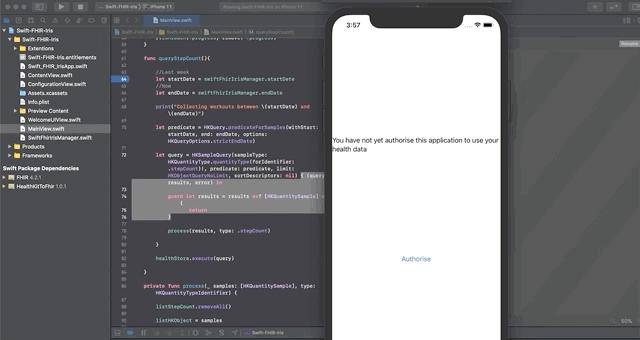
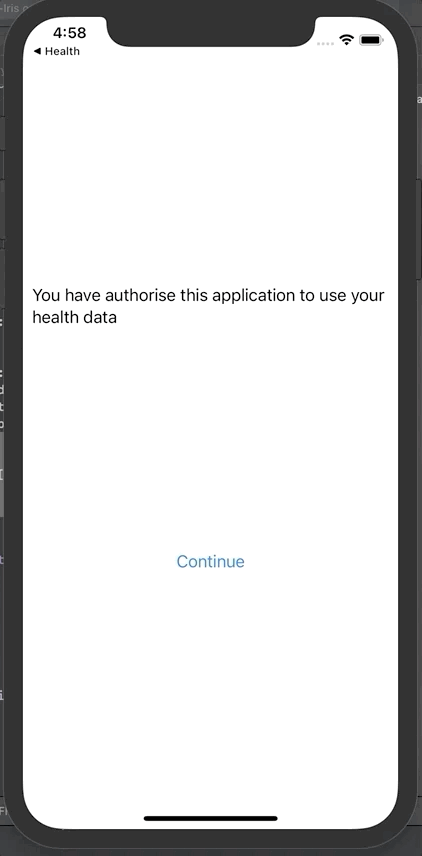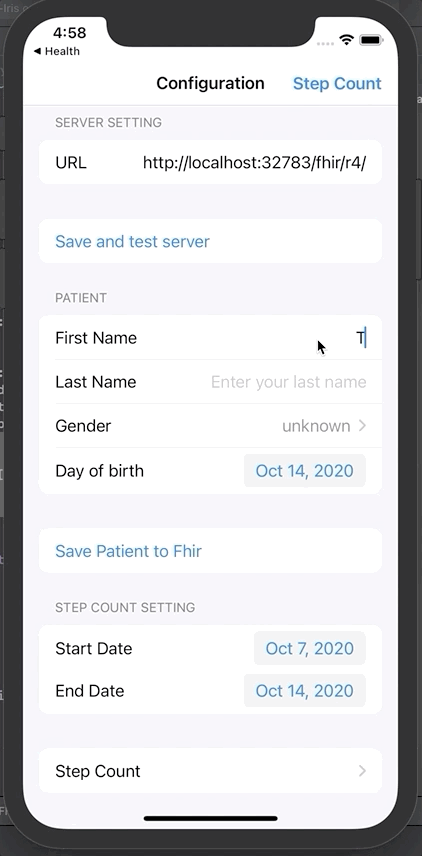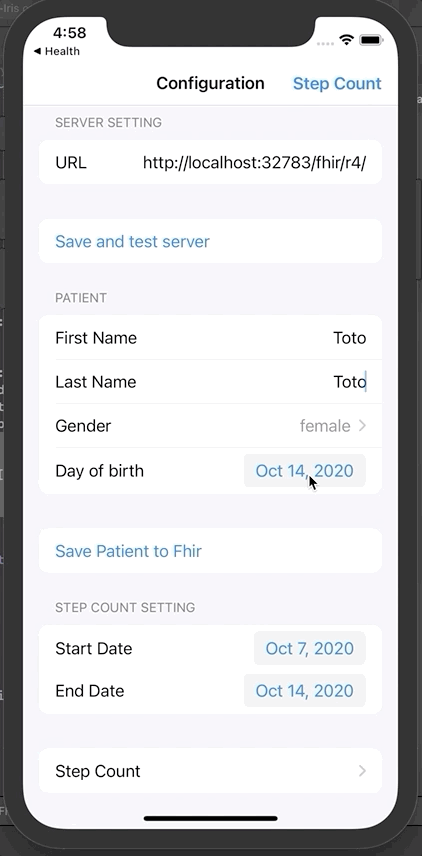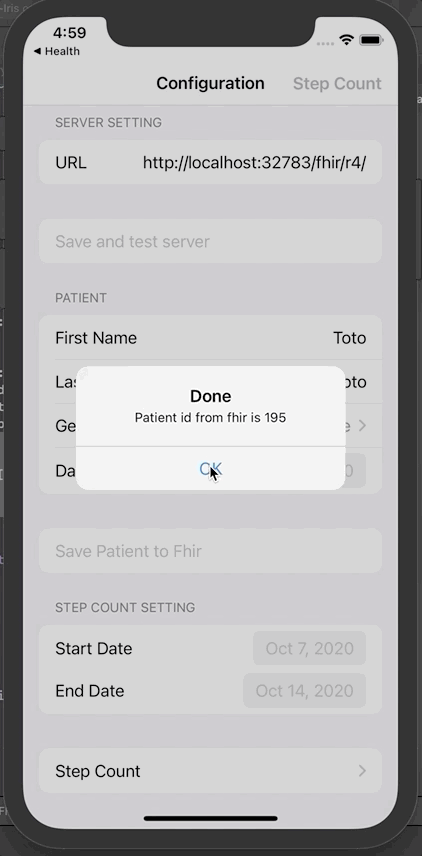
点击授权
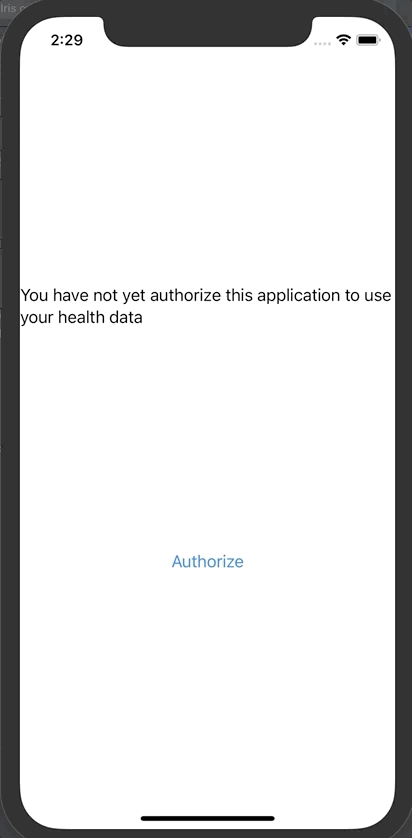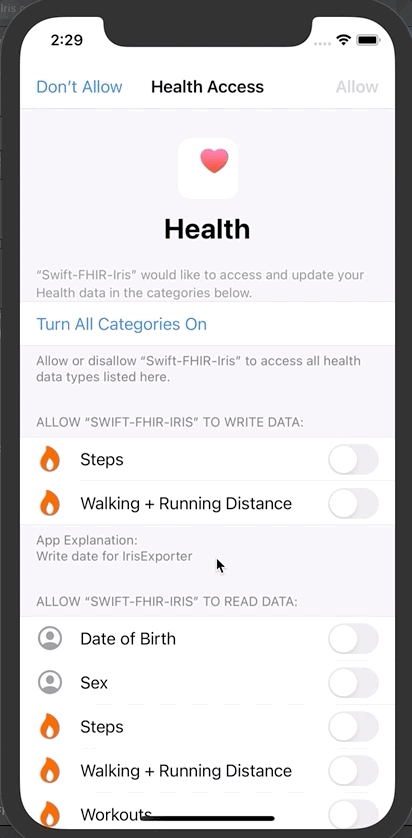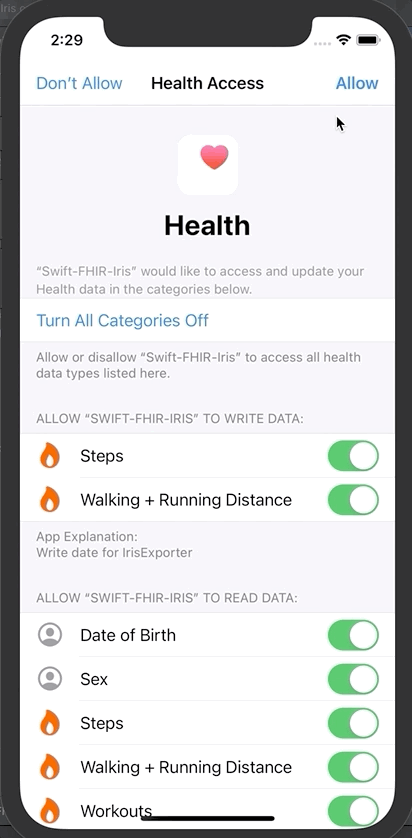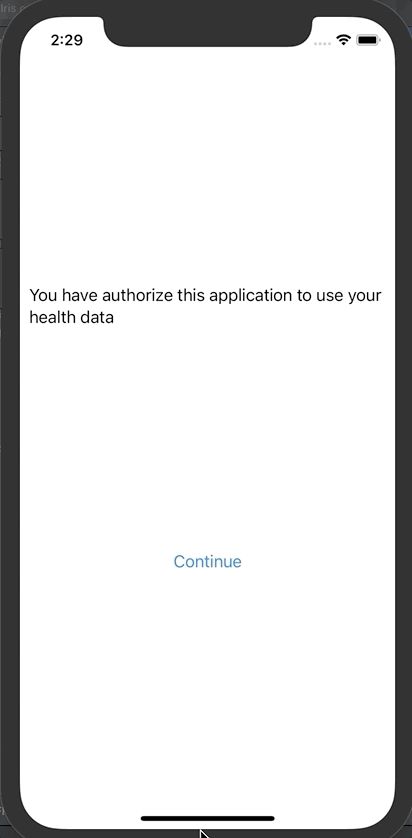
然后点击“Save and test server”对FHIR服务器进行测试
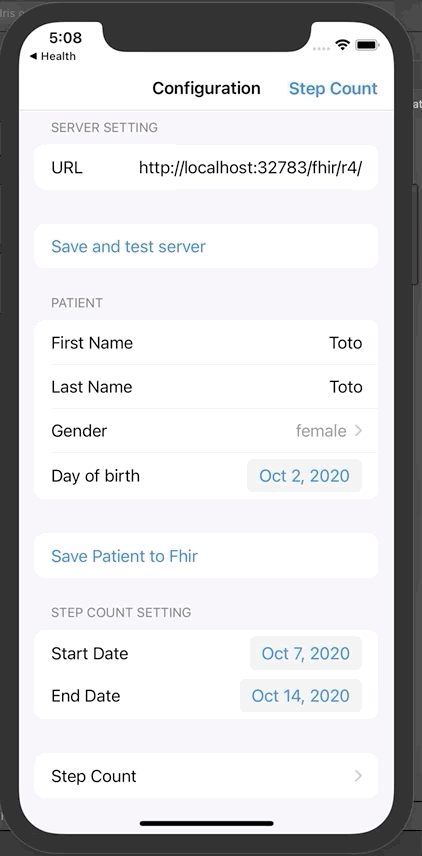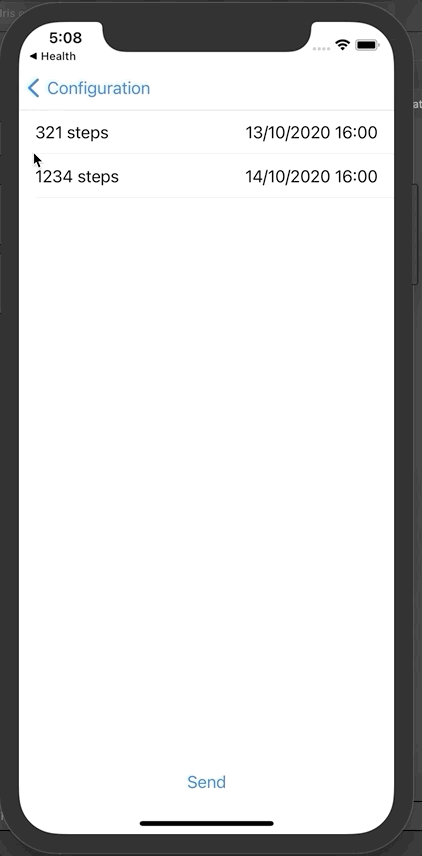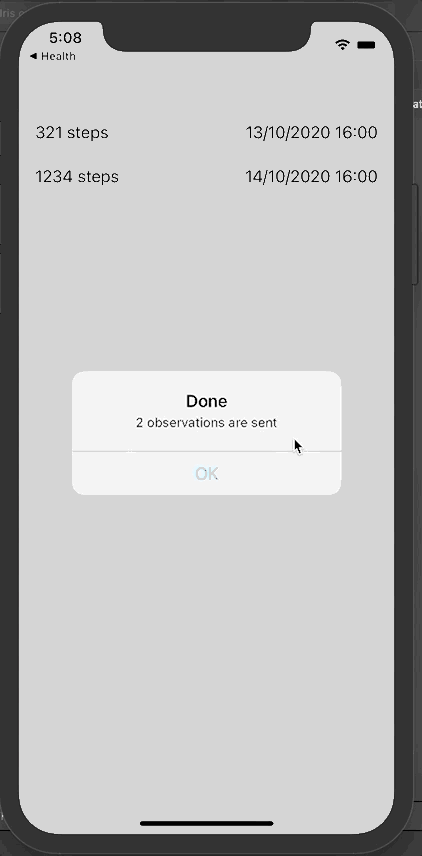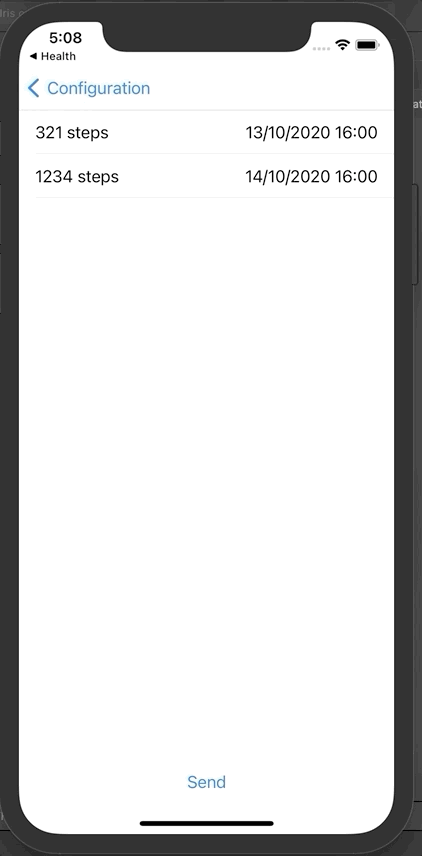
默认设置指向docker配置。
操作成功后,就可以输入患者信息。
名字、姓氏、生日、性别。
将患者信息保存到Fhir。弹出窗口将显示唯一的Fhir ID。
可在门户网站查阅该患者信息:
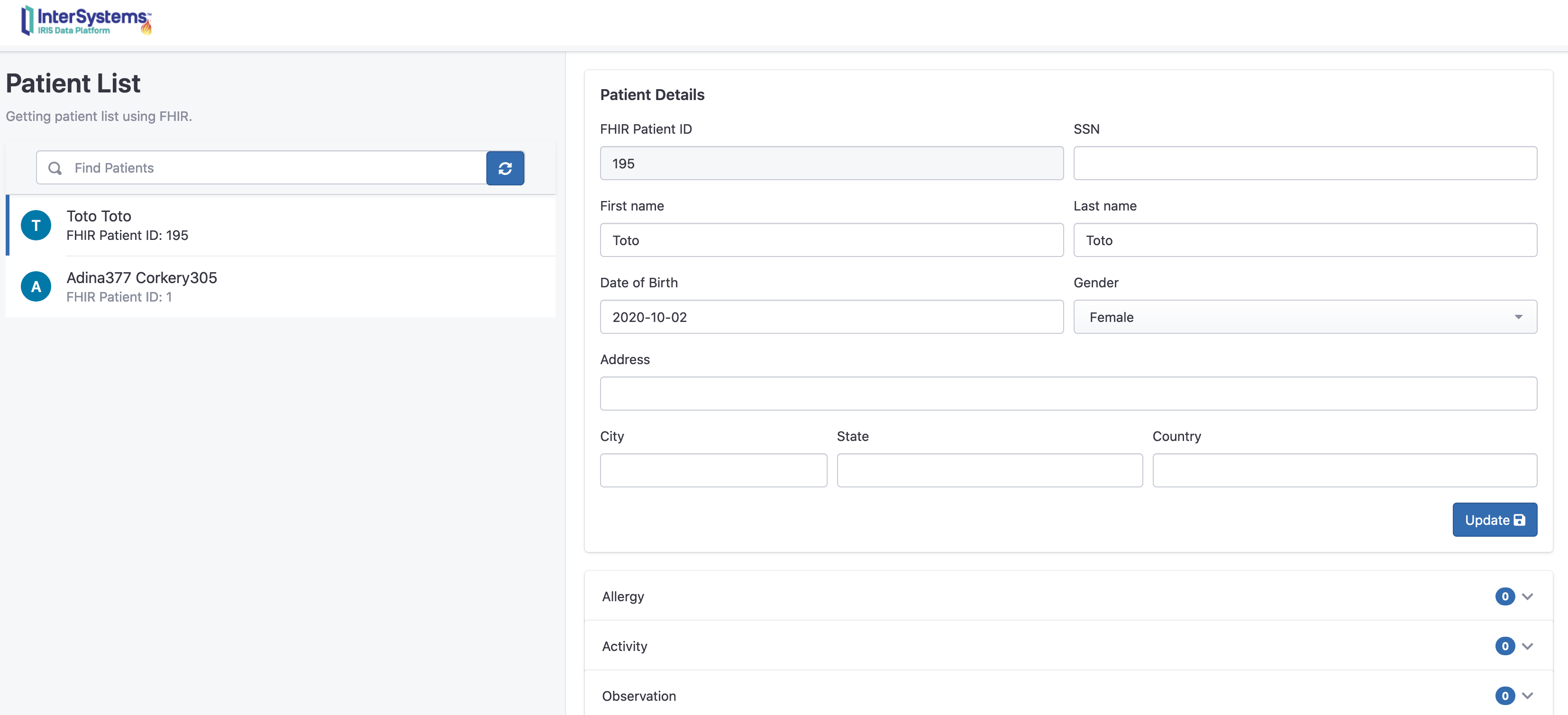
访问: http://localhost:32783/fhir/portal/patientlist.html
在这里我们可以看到,增加了一个新的病人“Toto”,0个活动。
发送她的活动信息:
回到iOS应用程序,点击“Step count”。
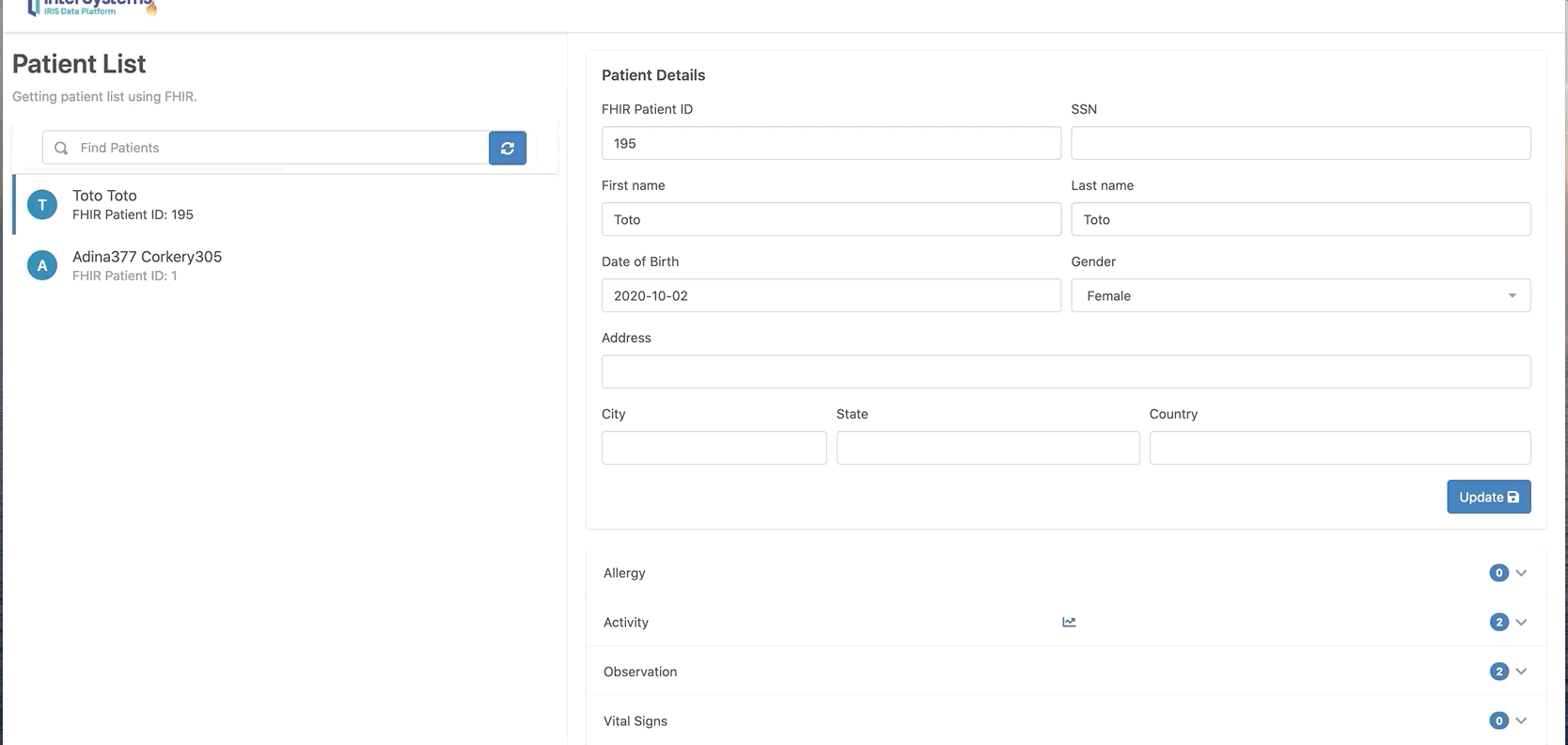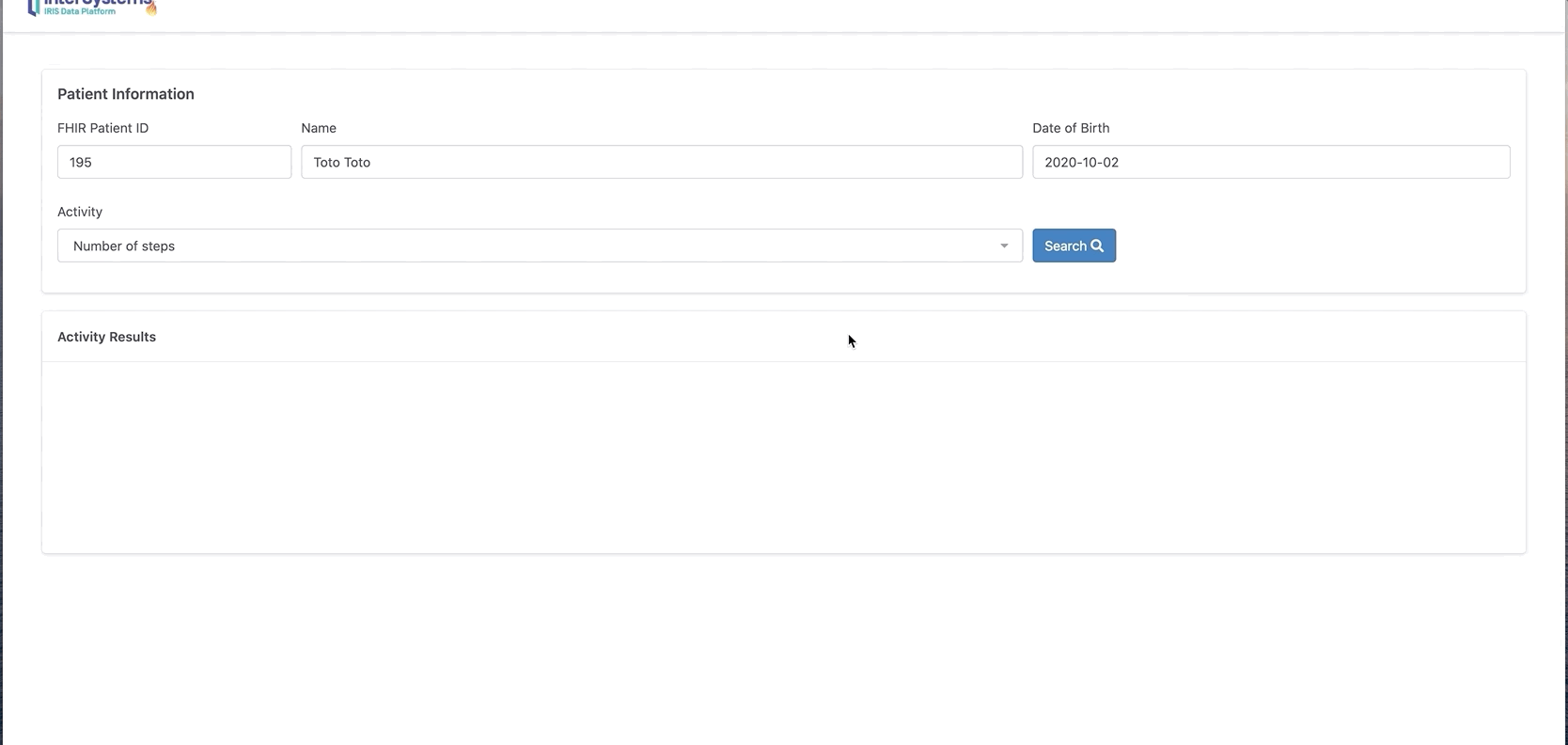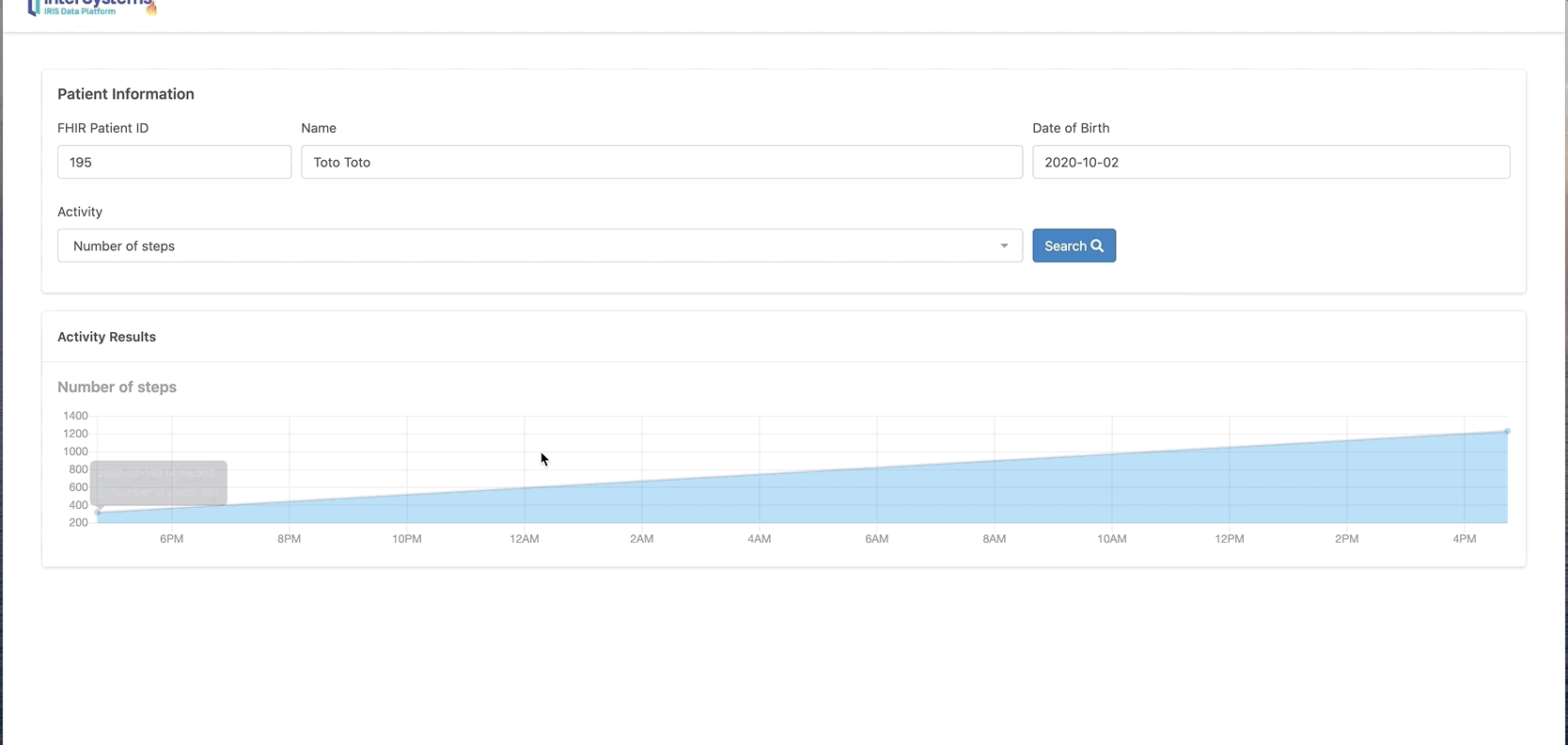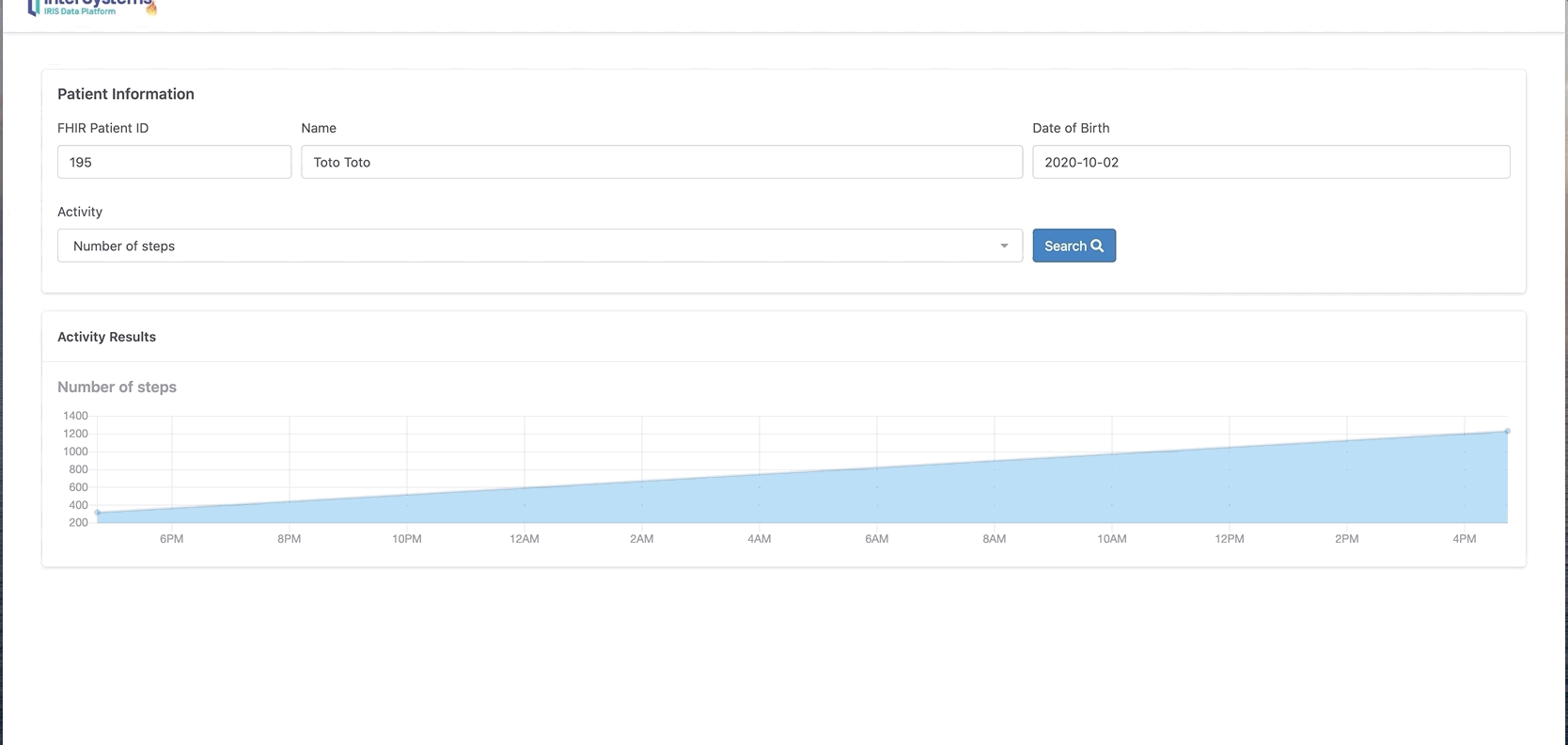
这里显示的是一周的步数。在我们的案例中有2条记录。
现在可以单击发送,将这些数据发送到InterSystems IRIS FHIR。
从门户网站上查询新的活动记录:
现在我们可以看到Toto有两条新的观察和活动消息。
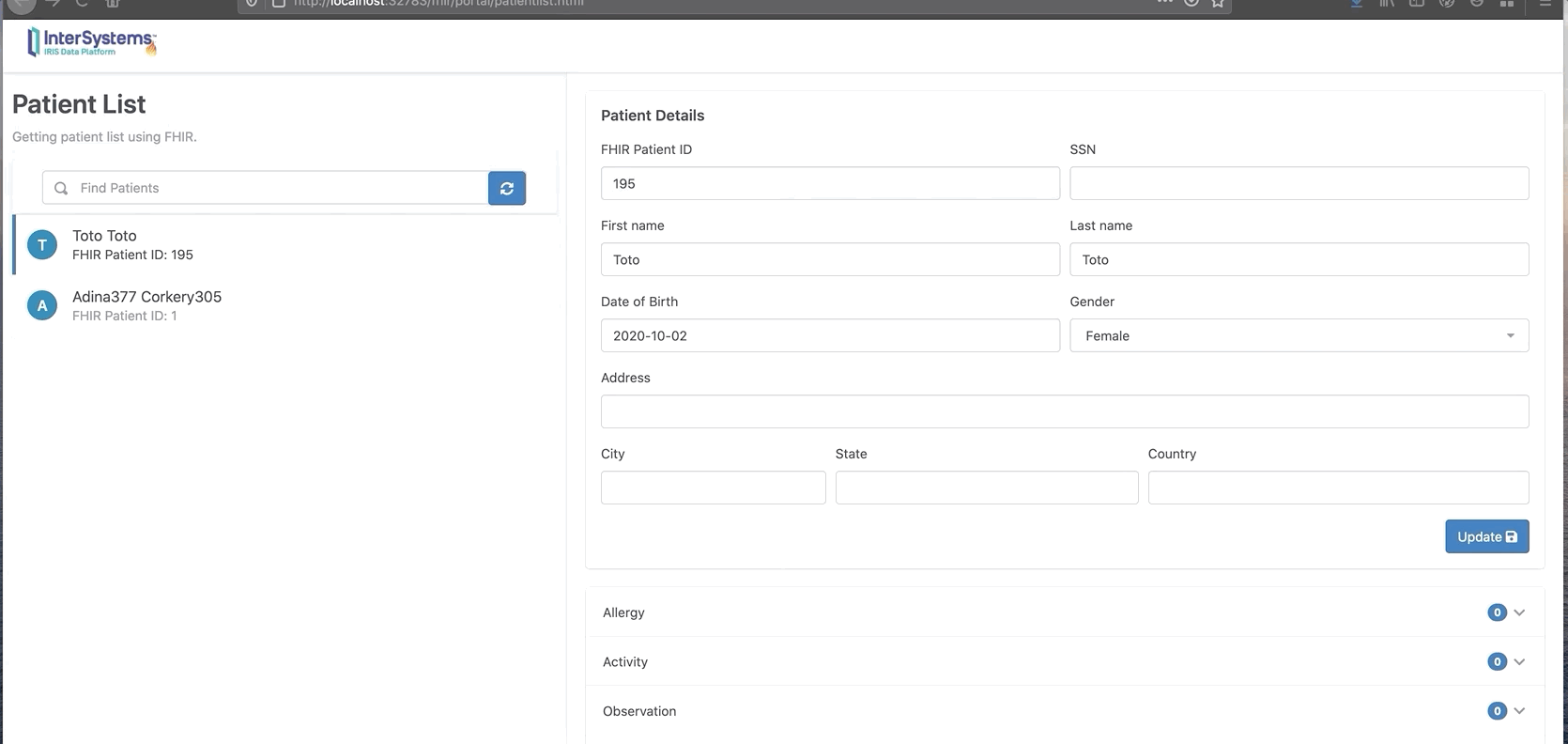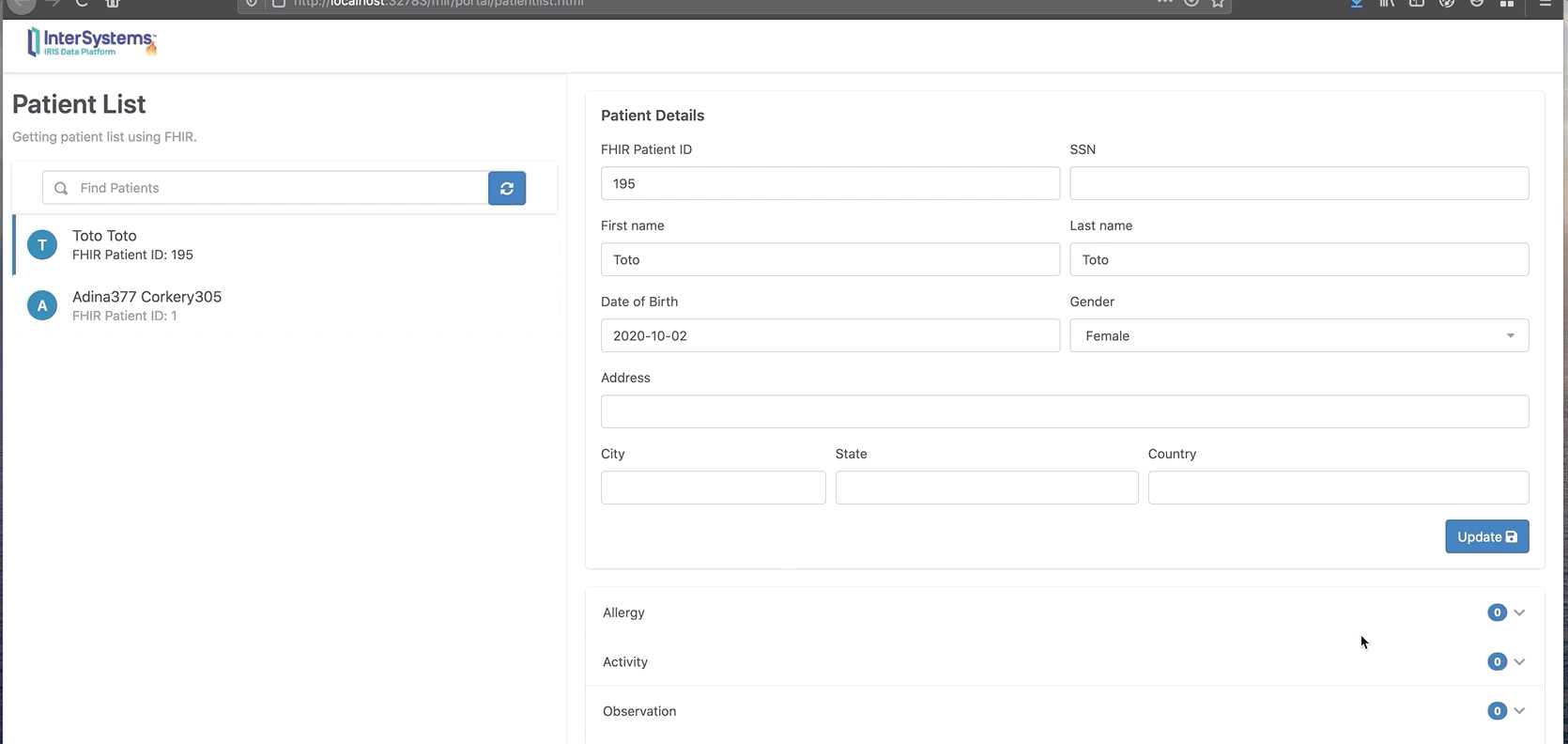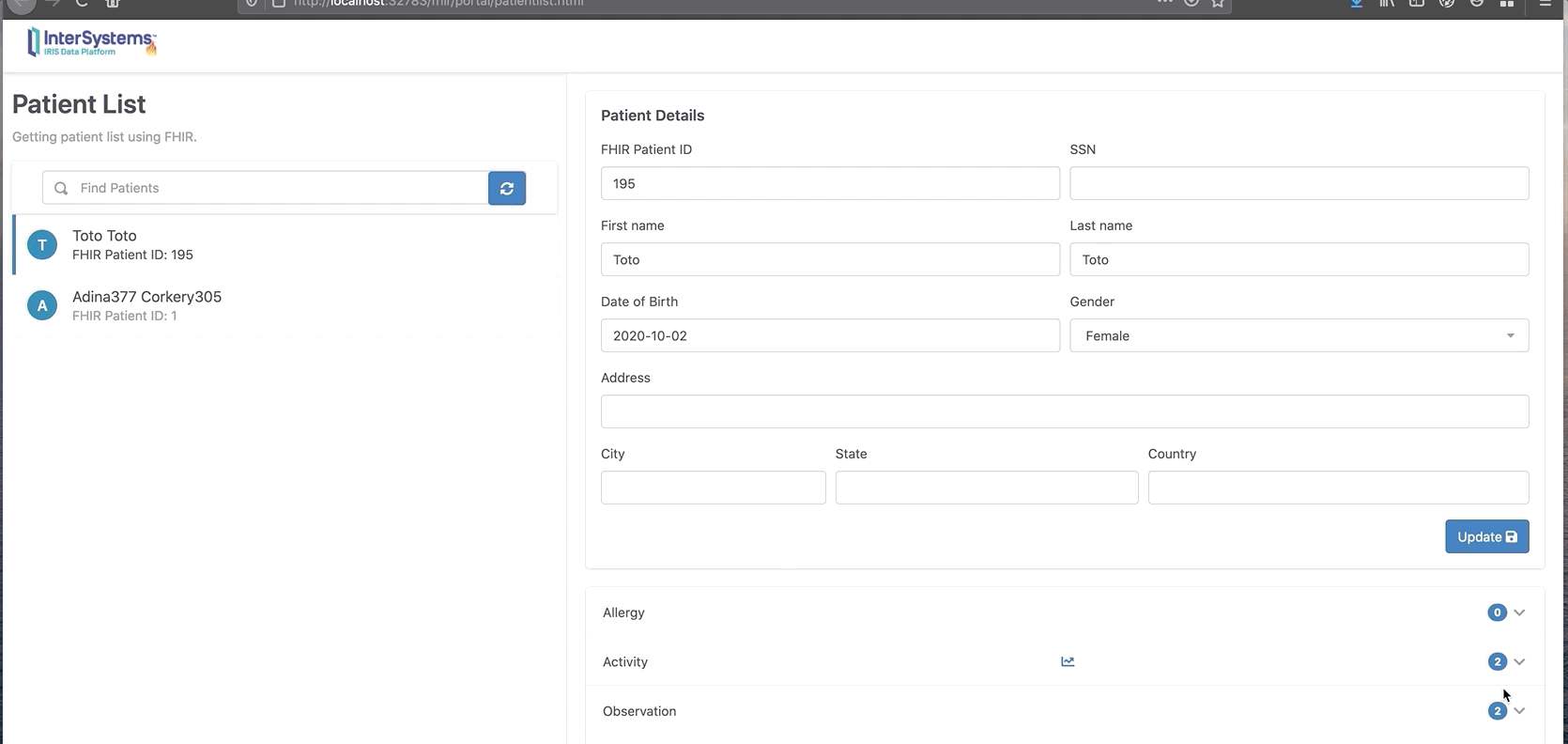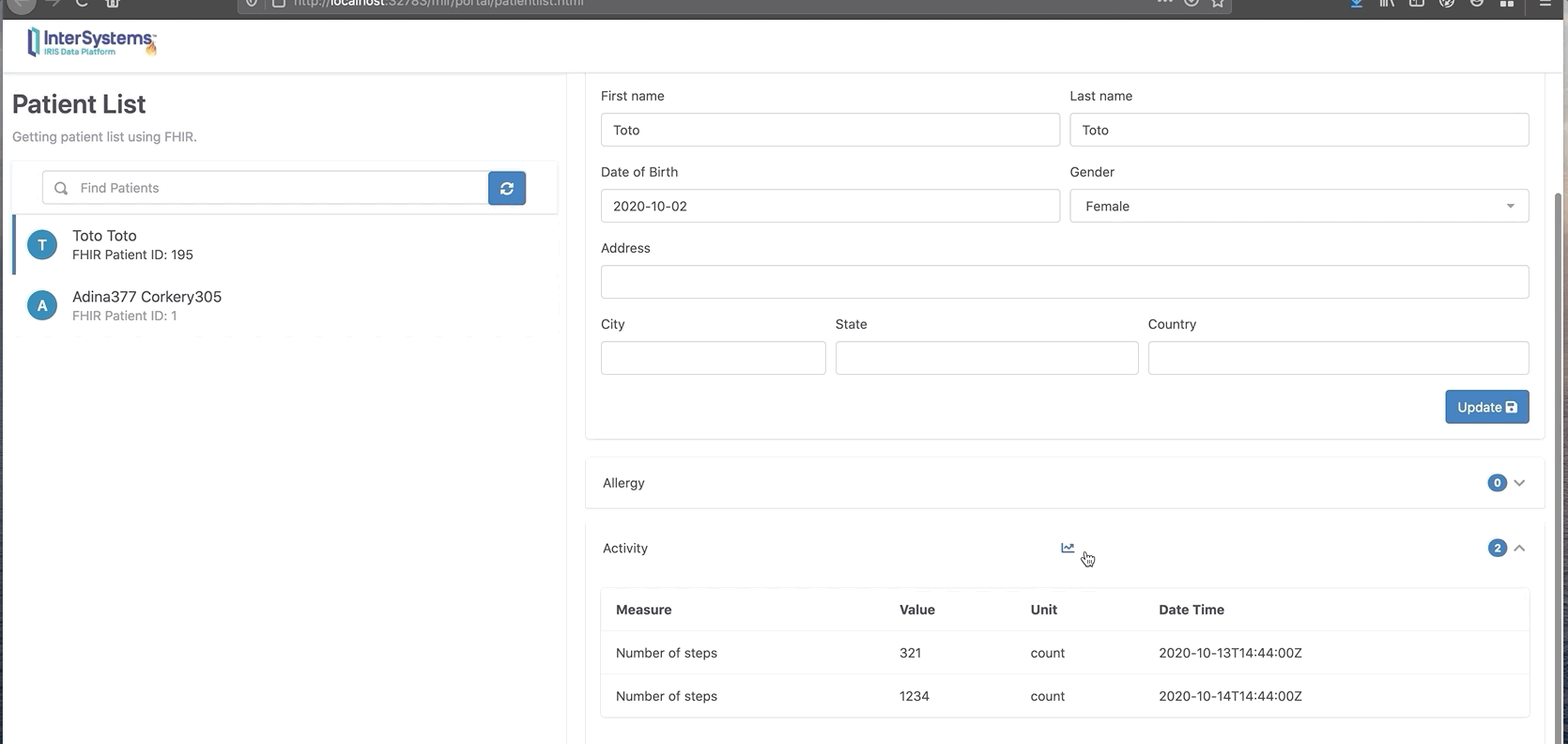
你还可以单击“chart”按钮以图表格式显示。
# 工作原理
## iOS
该demo大部分是基于SwiftUI构建的。
https://developer.apple.com/xcode/swiftui/
iOS和co的最新框架。
### 如何检查健康数据的授权
它在SwiftFhirIrisManager 类中。
该类采用单例模式,可使用@EnvironmentObject对应用程序中进行的所有操作进行注释。
更多信息请访问 : https://www.hackingwithswift.com/quick-start/swiftui/how-to-use-environmentobject-to-share-data-between-views
调用requestAuthorization的方法如下:
```swift
// Request authorization to access HealthKit.
func requestAuthorization() {
// Requesting authorization.
/// - Tag: RequestAuthorization
let writeDataTypes: Set = dataTypesToWrite()
let readDataTypes: Set = dataTypesToRead()
// requset authorization
healthStore.requestAuthorization(toShare: writeDataTypes, read: readDataTypes) { (success, error) in
if !success {
// Handle the error here.
} else {
DispatchQueue.main.async {
self.authorizedHK = true
}
}
}
}
```
其中healthStore是HKHealthStore()的对象。
HKHealthStore类似于iOS中的healthdata数据库。
dataTypesToWrite和dataTypesToRead是我们想要在数据库中查询的对象。
授权的目的可以通过在Info.plist xml文件中添加以下内容完成:
```xml
NSHealthClinicalHealthRecordsShareUsageDescription
Read data for IrisExporter
NSHealthShareUsageDescription
Send data to IRIS
NSHealthUpdateUsageDescription
Write date for IrisExporter
```
### 如何连接FHIR资源仓库
对于这一部分,我使用了从Smart-On-FHIR网站下载的FHIR包 : https://github.com/smart-on-fhir/Swift-FHIR
使用的类是FHIROpenServer。.
```swift
private func test() {
progress = true
let url = URL(string: self.url)
swiftIrisManager.fhirServer = FHIROpenServer(baseURL : url! , auth: nil)
swiftIrisManager.fhirServer.getCapabilityStatement() { FHIRError in
progress = false
showingPopup = true
if FHIRError == nil {
showingSuccess = true
textSuccess = "Connected to the fhir repository"
} else {
textError = FHIRError?.description ?? "Unknow error"
showingSuccess = false
}
return
}
}
```
这一步将在单例swiftIrisManager中创建一个新的对象fhirServer。
接下来使用getCapabilityStatement()
如果能够检索到FHIR服务器的capabilityStatement,则意味着已成功连接到FHIR资源仓库。
这个资源仓库不在HTTPS下,默认情况下Apple会阻止这种通信。
想要获取HTTP支持,可以对Info.plist xml文件进行如下编辑:
```xml
NSAppTransportSecurity
NSExceptionDomains
localhost
NSIncludesSubdomains
NSExceptionAllowsInsecureHTTPLoads
```
### 如何将患者信息保存到FHIR资源仓库
基本操作:首先检查存储库中是否已经存在该患者的信息
```swift
Patient.search(["family": "\(self.lastName)"]).perform(fhirServer)
```
搜索具有相同姓氏的患者。
在这里,我们可以想象一下其他场景,比如使用Oauth2和JWT令牌加入patientId及其令牌。但在这个演示中,我们简单操作即可。
如果该患者信息已经存在,可以对其进行检索;否则,则创建新的患者信息 :
```swift
func createPatient(callback: @escaping (Patient?, Error?) -> Void) {
// Create the new patient resource
let patient = Patient.createPatient(given: firstName, family: lastName, dateOfBirth: birthDay, gender: gender)
patient?.create(fhirServer, callback: { (error) in
callback(patient, error)
})
}
```
### 如何从HealthKit中提取数据
通过查询healthkit商店 store(HKHealthStore())即可完成。
这里我们查询一下步数。
使用predicate做好查询准备。
```swift
//Last week
let startDate = swiftFhirIrisManager.startDate
//Now
let endDate = swiftFhirIrisManager.endDate
print("Collecting workouts between \(startDate) and \(endDate)")
let predicate = HKQuery.predicateForSamples(withStart: startDate, end: endDate, options: HKQueryOptions.strictEndDate)
```
然后,会根据数据类型(HKQuantityType.quantityType(forIdentifier: .stepCount))和predicate内容进行查询。
```swift
func queryStepCount(){
//Last week
let startDate = swiftFhirIrisManager.startDate
//Now
let endDate = swiftFhirIrisManager.endDate
print("Collecting workouts between \(startDate) and \(endDate)")
let predicate = HKQuery.predicateForSamples(withStart: startDate, end: endDate, options: HKQueryOptions.strictEndDate)
let query = HKSampleQuery(sampleType: HKQuantityType.quantityType(forIdentifier: .stepCount)!, predicate: predicate, limit: HKObjectQueryNoLimit, sortDescriptors: nil) { (query, results, error) in
guard let results = results as? [HKQuantitySample] else {
return
}
process(results, type: .stepCount)
}
healthStore.execute(query)
}
```
### 如何将HealthKit数据转换为FHIR
在这部分,我们使用了微软软件包HealthKitToFHIR
https://github.com/microsoft/healthkit-to-fhir
这个包很有用,为开发商提供了将HKQuantitySample转换为FHIR Observation的功能。
```swift
let observation = try! ObservationFactory().observation(from: item)
let patientReference = try! Reference(json: ["reference" : "Patient/\(patientId)"])
observation.category = try! [CodeableConcept(json: [
"coding": [
[
"system": "http://terminology.hl7.org/CodeSystem/observation-category",
"code": "activity",
"display": "Activity"
]
]
])]
observation.subject = patientReference
observation.status = .final
print(observation)
observation.create(self.fhirServer,callback: { (error) in
if error != nil {
completion(error)
}
})
```
其中item是HKQuantitySample,在我们的例子中是stepCount类型。
这个factory完成了大部分工作,将“unit”和“type”转换为FHIR codeableConcept,并将“value”转换为FHIR valueQuantity。
对PatientId的引用是通过强制转换json fhir引用手动完成的。
```swift
let patientReference = try! Reference(json: ["reference" : "Patient/\(patientId)"])
```
对类别进行同样的操作 :
```swift
observation.category = try! [CodeableConcept(json: [
"coding": [
[
"system": "http://terminology.hl7.org/CodeSystem/observation-category",
"code": "activity",
"display": "Activity"
]
]
])]
```
最后,在fhir资源仓库中创建observation :
```swift
observation.create(self.fhirServer,callback: { (error) in
if error != nil {
completion(error)
}
})
```
## 后端 (FHIR)
没什么好说的,它基于InterSystems社区的fhir模板 :
https://openexchange.intersystems.com/package/iris-fhir-template
## 前端
基于Henrique作品,Henrique是使用jquery制作的FHIR资源仓库的一个很好的前端。
https://openexchange.intersystems.com/package/iris-fhir-portal
文章
Qiao Peng · 一月 10, 2021
InterSystems 2020线上峰会第二周拉开帷幕。首日专题会议涵盖了大量精彩内容,包括38场主题各异的专题会议。我认为有必要回顾一些重大的公告和谈话要点。
IntegratedML 在正式发布之后公布后global availability for IntegratedML, 本周的多个专题会议都将重点介绍IntegratedML。今天,Thomas Dyar与Baystate Health人口健康项目的业务分析师Joe Cofone进行了交流,讨论InterSystems和Baystate如何利用丰富的Health Insight数据和由IntegratedML构建的预测模型来建立“机器学习沙箱”进而构建应用程序。 如果你错过了本次内容,请查看 "AD000 针对医疗应用的Health Insight& 和IntegratedML展示 ". 明天还将有3场关于IntegratedML的单独会议: "CL006 IntegratedML入门", "DA006 如何使用H2O和IntegratedML", 和 "DA005 使用IntegratedML和DataRobot进行机器学习"!
自适应分析 上周我们还公布了InterSystems IRIS自适应分析, 通过对InterSystems IRIS和IRIS医疗版进行扩展,可为分析最终用户提供更大的灵活性、可扩展性以及更高的效率。 今天有两场会议提供了更多关于这方面的信息。第一场会议简单介绍了计划的方案及其潜在收益,第二场会议对该方案能够解决的问题类型进行了演示和讨论。 我们正在寻找早期采用者,如果您有兴趣,请联系Carmen Logue。明天的会议将涉及更多有关数据仓库 和 商业智能 的信息,敬请关注。
嵌入式Python 上周主题报告中的另一项重要信息是我们在将来会提供嵌入式的Python支持,我们已经对其进行了简要介绍。借助嵌入式Python,IRIS内核可以并排运行Python和ObjectScript,以高速访问Python中的数据,并在Python和ObjectScript之间进行了桥接。其实,我们已经获得了在Objectscript中使用嵌入式Python的经验,包括加载Python库、调用方法和函数等等。我们即将举办一场关于如何在SQL中使用嵌入式Python的分享,欢迎大家观看。如果您有兴趣帮助我们开发嵌入式Python,请通过python-interest@intersystems.com.与我们联系。
Kafka 今天我们还宣布了InterSystems将为具有IRIS互操作性的Apache Kafka提供内置支持。Kafka是世界上扩展性最强(最受欢迎)的流数据服务。企业可以将其应用在消息队列、更改数据捕获等所有事件中。该集成系统支持多种系统架构与IRIS进行互操作,无需使用额外代码实现。
明天的专题会议还将继续介绍Kafka集成相关的话题,因为最新版本的InterSystems API Manager(IAM)同样添加了Kafka插件,可将API流量发布到Kafka主题。我们已经在IAM中很好地演示了开发者门户的增强功能,可以帮助您更加轻松地构建和定制真正适合公司品牌的开发者门户。我们明天将详细介绍IAM。
VS Code - ObjectScript 哇,我们已经介绍了这么多公告了,但我们想说的远不止这些。在上周的主题峰会上,我们正式发布了1.0版本的 Intersystems ObjectScript for Visual Studio Code 插件,将ObjectScript开发引入了市场上最受欢迎的IDE(集成开发环境)平台。该版本可以在所有的操作系统上运行,并支持GitHub和Azure DevOps等客户端源代码控制系统。尤其值得注意的是,这是一项源自开发者论坛的开源项目,InterSystems将和我们的开发者们将持续合作开发该项目。
DEE004 会议对该项目进行了快速概述和简短演示。可以点击此处的演示区域 或在 YouTube上查看更多的演示内容。 In DEE007 在DEE007 会议中,我们的几位产品经理和VS Code – ObjectScript项目管理委员会的两名社区成员一起为大家带来了精彩的现场问答。本周将有更多关于VS Code的内容——请查看 "DEE006 用于ObjectScript的Visual Studio代码:选择IDE/源代码控件组合" 和 "DEE005 用于ObjectScript的Visual Studio代码:服务器端源代码控件". 今天开始的 实战实验室也不可错过。 我们还提供了IntegratedML实战实验室和其他热门话题,例如下面这个话题:
FHIR和API管理 FHIR一直是业界的热门话题,也是我们的合作伙伴比较感兴趣的话题,所以我们在许多专题会议中都涵盖了FHIR相关的主题。我们简要介绍了FHIR——FHIR是医疗保健可操作性的新标准,受到了美国政府的大力支持。美国政府通过ONC最终规则,对FHIR进行标准化并禁止信息封锁。英国等其他国家的政府也在授权FHIR参与所有新的数字健康计划。
IAM可妥善处理众多开发事务,例如安全性、日志记录、监视和控制对FHIR资源的访问等,从而简化FHIR应用程序的构建流程。用户可以通过开发门户轻松学习和测试FHIR查询。建议大家观看。
可以通过FHIR搜索查询患者、观察、诊断报告等FHIR资源。语法基于REST,但是必须为每个FHIR资源查找查询参数。使用修饰符和连接(例如 _include和_revinclude)的高级查询有时会出现令人困惑的语法,不过我们构建了一个工具来简化这些查询,从而提高生产效率并减轻初学者的负担。
NLP 在线上峰会的推动下,我们还发布了开源NLP(自然语言处理)库iKnow的1.0版本,现已完全以Python包的形式提供。Aohan和Benjamin在DA010专题会议中对这一激动人心的版本进行了概述及使用介绍,相关演示可在 演示区.查看。
演示区 您可以在线上峰会注册中心主区打开The 演示区 ,并按照自己的节奏观看超过25个的演示。
现场问答 第一天结束时我们进行了现场问答,明后两天也会有现场问答环节。大家可以借此机会,针对专题会议中或上周主题演讲中遇到到的任何问题向我们提问。更多信息请参见: https://community.intersystems.com/post/ask-intersystems-product-managers-live-qa-session-vsummit20
这绝对是忙碌的一天!接下来还有两天的专题会议。如果您还没有注册,现在还为时不晚,您可以点击这里 免费注册。
那么,您今天关注的重点是什么呢?请在下方的评论中告诉我们。
祝好!
Jeff
文章
jieliang liu · 一月 8, 2021
你好!
本文简单介绍一款工具,帮您理解InterSystems产品(从IRIS到Caché、Ensemble以及HealthShare)中的类及其结构。
简言之,它将类或整个包可视化,显示类之间的关系,并向开发人员和团队领导提供各种信息,而无需到 Studio 中检查代码。
如果您正在学习InterSystems产品,经常查看项目,或只对InterSystems技术解决方案中的新内容感兴趣,欢迎阅读ObjectScript类浏览器概述!
InterSystems 产品简介
IRIS(之前称为Caché) 是一个多模型DBMS。您可以使用SQL查询来访问它,也可以通过各种编程语言可用的接口与存储的对象和过程进行交互。但最多的还是使用DBMS原生内置语言--ObjectScript (COS) 开发应用程序。
Caché支持DBMS级别的类。有两种主要的类类型:Persistent(可以存储在数据库中)和 Registered(不存储在数据库中,扮演程序和处理程序的角色)。还有几种特殊的类类型:Serial(可集成到持久类中用于创建复杂数据类型(如:地址)的类),DataType(用于创建用户定义的数据类型)、Index、View 和 Stream。
进入类浏览器
Caché类浏览器是一个工具,它将Caché类的结构可视化为图表,显示类之间的依赖关系和所有相关信息,包括各种类元素的方法代码、查询、xData块、注释、文档和关键字。
功能
类浏览器使用扩展版UML类图进行可视化,因为Caché有一组很重要但不被标准UML支持的附加实体:查询、xData块、方法和属性的大量关键字(如System、ZenMethod、Hidden、ProcedureBlock等)、父子关系和一多关系、类类型等。
Caché 类浏览器(1.14.3版)允许您执行以下操作:
显示包、类图或整个包的层次结构;
编辑图表显示后的外观;
保存类图的当前图像;
保存一个图表的当前外观,并在将来恢复;
按图表或类树中显示的任何关键字搜索;
使用工具提示获得关于类、其属性、方法、参数、查询和xData块的完整信息;
查看方法、查询或xData块的代码;
启用或禁用任何图表元素的显示,包括图形图标。
为了更好理解下文内容,先看下类浏览器的如何对类进行可视化的。举个例子,让我们显示来自“samples”命名空间的“cinema”包:
详细信息和功能概述
左侧边栏包含一个包树。将鼠标指针放在包名称上,然后单击出现在其右侧的按钮以显示整个包。在包树中选择类,将其与其链接的类一起呈现。
类浏览器可以显示类之间的几种依赖关系类型:
1. 继承。以白色实心箭头显示,箭头指向继承的类;
2. 类之间的“关联”或关系。如果其中一个类的字段包含另一个类的类型,图表构建器将把它显示为关联关系;
3. 父子关系和一多关系:维护数据完整性的规则。
如果将鼠标指针指向该关系,则创建该关系的属性将高亮显示:
注意,类浏览器不会更深入,也不会为当前包之外的类绘制依赖关系。它将只显示当前包中的类,如果需要限制类浏览器查找类的深度,请使用“依赖级别”设置:
类本身显示为一个矩形,分为六个部分:
1. 类名:将鼠标指针指向类名,可以了解它是何时创建和修改的,查看注释以及所有分配给这个类的关键字。双击类头将打开其文档;
2. 类参数:所有带类型、关键字和注释的赋值参数。斜体的参数以及任何属性都有工具提示并且可以悬停;
3. 类属性与参数类似;
4. 方法:点击任何方法都可以查看其源代码。COS 语法将被高亮显示;
5. 查询:与方法类似--点击可以查看源代码;
6. xData块:主要包含XML数据的块。点击将显示块中格式化的源代码。
默认每个类都显示有许多图形图标。点击屏幕右上角的“帮助”按钮,了解每个图标的含义。如果您需要默认显示更严格或更包容的 UML 类图,以及任何类的任何部分,可以在设置部分禁用。
如果关系图太大,而且您也不太熟悉,可以使用快速图表搜索功能。包含您输入的关键字的任何部分的类将被高亮显示。要跳转到下一个匹配项,只需按 Enter 键或再次单击搜索按钮:
最后,在完成了图表编辑,去掉所有不必要关系,并将元素安放好,实现期望的外观之后,可以点击左下角的“下载”按钮来保存:
激活固定按钮 时,元素在当前类(或包)组的图表上的位置将被固定。例如,如果您选择A类和B类,然后用固定按钮保存视图,则再次选择A类和B类时将看到完全相同的视图,即使在重新启动浏览器或机器之后也不会变化。但是如果您只选择A类,布局将是默认的。
安装
要安装Caché类浏览器,只需将最新版本xml包导入到任何命名空间中。导入后就能看到名为hostname/ClassExplorer/(末尾的斜杠不能丢)的新web应用程序。
详细安装说明
1. 下载最新版Caché类浏览器压缩包;
2. 提取名为Cache/CacheClassExplorer-vX.X.X.xml的XML文件;
3. 使用以下方法之一将包导入任何命名空间:
1. 只需将XML文件拖到Studio上;
2. 使用系统管理门户:系统资源管理器 -> 类 -> 导入,并指定本地文件路径;
3. 使用terminal命令:
do ##class(%Installer.Installer).InstallFromCommandLine(“Path/Installer.cls.xml”);
4. 读取导入日志--如果顺利安装,就可以通过 http://hostname/ClassExplorer/ 打开 web 应用程序。如果出了问题,请检查以下内容:
1. 是否有足够权限将类导入该命名空间;
2. web应用程序用户是否有足够权限访问不同的命名空间;
3. 如果出现错误404,只需检查是否在 URL 末尾添加了斜杠。
附加截图
[截图 1] DSVRDemo 包,鼠标指针悬停在一个类名上。
[截图 2] DataMining 包,在图表中搜索“TreeInput”关键字。
[截图 3] JavaDemo.JavaListSample 类中的方法代码视图。
[截图 4] 查看 ClassExplorer.Router 类中的 Xdata 块内容。
您可以尝试在标准SAMPLES命名空间中使用类浏览器:演示。这个项目的评测视频。
欢迎任何反馈、建议和意见--提交到这里或GitHub仓库。希望对您有用!