清除过滤器
公告
Claire Zheng · 七月 2, 2023
Hi 开发者社区的成员们,大家好!
欢迎关注我们第7期 InterSystems Ideas News!
本期分享如下:
✓ 创意门户已收集了 200 多个创意
✓ 由社区成员实施的创意
✓ 在 Grand Prix 23 竞赛中实施一个创意并获得技术奖励
✓ 最近发布的创意
自创意门户推出以来,已发布 204 个创意。目前已实施25项, 待实施17项。
@Kurro Lopez 被添加到名人堂,因为@Kurro Lopez 实施了由@Yuval Golan 提交的创意: IRIS classes for OpenAI API
👏感谢您实现了这个创意👏
参加InterSystems Grand Prix 23 年度编程大赛开发者可以通过实施 Community Opportunity 中的创意而获得 4 个技术奖励积分。
最新发布的创意
1.在下拉选择中添加“类型过滤”功能。 作者:@VICTORIA CASTILLO2.让数据转换 UI 自动猜测消息类型,作者:@Evgeny Shvarov3.让每个操作和服务公开其消息类 作者: @Evgeny Shvarov4.为医生定制可视化,作者:@Ikram Shah5. 引入 InterSystems IRIS 对 Apache Airflow 的支持 作者:@Evgeny Shvarov6.为 pdf.co 引入互操作性模块(适配器、操作),作者:@Evgeny Shvarov7.在 Visual Trace 中添加参数以查看 XML 或 JSON 中的消息内容 作者:@Sylvain Guilbaud8.每个数据库的特定缓存缓冲区,作者:@Yaron Munz 9.在开发环境中的 Production Export 提供模块部署支持,作者:@Alex Woodhead10.系统默认设置中的环境变量支持 作者:@Alex Woodhead11.设置应该是镜像的一部分 作者:@Scott Roth 12.为社区用户起昵称 作者:@Minoru Horita 13. 使所有生产项目设置在默认设置中可用 作者:@Stefan Cronje14.从管理门户选项添加到文档网页的超链接,作者:@Luis Angel Pérez Ramos 15.从 InterSystems 开发者社区删除草稿 作者:@yurimarx Marx
👏感谢您提交的新创意👏
不要忘记投票、评论和订阅这些创意来跟踪、影响其进展。
请继续关注下一期 InterSystems Ideas 新闻公告!
文章
Weiwei Gu · 六月 28, 2023
1. 区块链
当我写这篇文章时,比特币的价格还不到其成功顶峰时期的五分之一。因此,当我开始向某人讲述我的区块链经历时,我听到的第一句话是毫不掩饰的怀疑:“现在谁需要这个区块链东西?”
没错,区块链炒作已经减弱。然而,它所基于的技术将继续存在并将继续在特定领域使用。互联网通常提供大量描述这些技术的一般用法的材料
(例如在Medium和福布斯上)。
众所周知,区块链是一个分布式注册表,即分布在多个节点之间的数据库,每个节点都存储注册表的完整副本。区块链的主要特征是记录(交易)形成块,块形成块链。区块链仅支持追加操作。这意味着几乎不可能对已经保存在区块链中的交易进行更改。
网上有无数的区块链教程(如果您从未听说过区块链,可以从这个简单的视频开始)。
当区块链蓬勃发展时,人们多次呼吁在任何地方使用该技术。然而,可能需要区块链的项目/任务有某些明显的特征。
首先,必须有很多玩家/用户编写大量数据,这些数据必须一致且可信。
那么,就不应该存在每个人都信任的第三方。
必须有一个公共数据验证的机制。如果满足所有这些标准,考虑使用区块链可能是个好主意。
任何行业都可以找到这样的任务。 www.101blockchains.com项目汇总了有关潜在和现有区块链项目的信息,以及在各个行业中使用区块链技术的细微差别。
例如,区块链可用于医疗保健领域的以下任务:
用于安全地远程管理患者记录;
通过整个供应链中不可更改的交易来打击假药;
通过排除欺诈和篡改数据的可能性来提高临床试验的监控和有效性。
企业部门通常使用一种特殊类型的区块链,称为私有许可区块链。此类网络具有一组特殊的节点来验证交易。
然而,在开发第一个 InterSystems IRIS 区块链适配器时,我们选择了以太坊,这是一种属于无许可区块链类别的区块链 - 一个没有单一控制中心的开放平台。该决定是基于该区块链引擎的受欢迎程度以及具有大量工具和库的足够成熟的基础设施。请注意,您还可以使用以太坊工具创建私有区块链。
2. 适配器
让我们实际上回到适配器。
InterSystems IRIS 中的适配器(就像 Ensemble 中一样)是 InterSystems IRIS 类的类或包,允许您与外部系统交互。 InterSystems IRIS 适配器分为入站(当外部系统是交互发起者时,用于从外部系统接收数据)和出站(当 InterSystems IRIS 是交互发起者时,用于与外部系统一起工作)。
IRIS 以太坊适配器是出站适配器,与大多数其他 InterSystems IRIS 适配器略有不同。该适配器还包括一个小型 NodeJS 模块。其架构如图 1 所示。
图1。适配器的 NodeJS 模块使用现有的 NodeJS 库来与以太坊配合使用。
该适配器允许您执行以下操作:
将智能合约部署到以太坊(我们计划撰写另一篇文章,涵盖智能合约、开发工具和示例)。
调用智能合约方法:改变区块链状态的方法和不改变区块链状态的方法
保存交易(将资金从一个钱包转移到另一个钱包)
调用额外的方法来获取区块链的状态
记录所有请求(由 NodeJS 模块完成,方便调试)
该适配器附带 OpenExchange 上的源代码。
3. 一个简单的例子
该适配器附带一个“Hello world”示例。
要开始使用以太坊(并运行此示例),您将需要以下内容:
选择您要使用的网络。 Ropsten 等测试网络通常用于开发目的
在此网络中创建一个钱包并向其存款
安装本地以太坊客户端(例如 Geth)或获取与云提供商(例如 Infura)合作的密钥
配置业务操作时需要设置以下内容(图2):
NodeJS模块工作的服务器和端口(默认使用3000端口)
提供商设置(在本例中访问 Infura)
访问凭据(指定您的钱包号码作为用户名,指定您的私钥作为密码。InterSystems IRIS 将访问凭据存储在一个单独的数据库中,您必须为其启用加密)
图 2.
为了使用智能合约,您需要在文件系统中创建(为您将使用的每个智能合约)一个文件夹,并在其中放置两个文件:*abi.txt*字节码.txt
这些文件应包含智能合约的 ABI 及其字节码。智能合约的 ABI 是 JSON 格式的接口的正式描述。 ABI 和字节码是在编译智能合约时创建的。
仅部署合约时需要字节码。
您可以使用 InterSystems IRIS 互操作性测试服务来测试业务运营。
图 3 说明了如何使用测试服务部署智能合约。调用此业务操作的结果是包含交易哈希的消息。
图 3.
您可以使用 ropsten.etherscan.io (https://etherscan.io/) 浏览器找到此交易并获取已部署的智能合约的地址。
要使用适配器调用智能合约的方法,您需要在生产配置中填写以下字段:ContractFolder 和 ContractAddress。
智能合约的执行代码非常简单:
-----0-----
将智能合约的地址和 ABI 传递给适配器的 GetContract 方法,以创建一个智能合约对象,然后将其用于调用方法。在这种情况下,必须在智能合约中定义返回字符串的 hello() 方法。
在这个例子中,hello()方法不会改变区块链状态,因此可以同步调用。然而,改变区块链状态的方法的执行时间可能相当长(因为必须等待交易被验证)。
要调用此类方法,请使用 InterSystems IRIS 提供的延迟响应机制。适配器必须提交延迟响应令牌,当交易获得批准时,NodeJS 模块会将其执行结果传递给 InterSystems IRIS。为此,您需要配置一个 Web 应用程序并向生产添加额外的业务服务来处理收到的响应。
以下是调用改变区块链状态的方法的代码:
-----1-----
在这种情况下,在调用智能合约的 setName() 方法之前,您需要指定许多参数,包括延迟响应令牌。
在下一篇文章中,我们将详细介绍智能合约,并提供使用 InterSystems IRIS 以太坊适配器解决实际问题的示例。
公告
Claire Zheng · 六月 19, 2023
大家好!
InterSystems Grand Prix 2023 结合了 InterSystems IRIS 数据平台的所有主要功能!
因此,我们邀请您使用以下功能并收集额外的技术奖励,以帮助您赢得奖品!
如下:
LLM AI 或 LangChain 用法:Chat GPT、Bard 等 - 6
InterSystems FHIR SQL Builder- 5
InterSystems FHIR-3
IntegratedML - 4
Native API - 3
嵌入式 Python - 4
互操作性 - 3
生产扩展(PEX)- 2
自适应分析 (AtScale) Cube的使用 - 3
Tableau、PowerBI、Logi 的使用 - 3
InterSystems IRIS BI - 3
列索引使用 - 1
Docker 容器使用 - 2
ZPM 包部署 - 2
在线演示 - 2
单元测试 - 2
实施 InterSystems Community Idea中的创意 - 4
在开发者社区发布的第一篇文章 - 2
在开发者社区发布的第二篇文章 - 1
代码质量通过 - 1
第一次贡献 - 3
YouTube 上的视频 - 3
LLM AI 或 LangChain 使用:Chat GPT、Bard 等 - 6 分
为构建使用LangChain库或大型语言模型(LLM)(例如 ChatGPT、Bard 和其他 AI 引擎(例如PaLM 、 LLaMA等)的解决方案会为您赢得 6 个专家奖励积分。 AutoGPT 的使用也很重要。
在 Open Exchange 中已经可以找到一些示例: iris-openai、 chatGPT telegram bot 。
这是一篇带有 langchain 使用示例的文章。
InterSystems FHIR SQL Builder - 5 分
InterSystems FHIR SQL Builder是 InterSystems IRIS for Health 的一项功能,有助于将 FHIR 资源映射到 SQL 表并通过应用程序中的 SQL 查询使用它。
在文档中了解更多信息。
在线课程。这是一个关于 Open Exchange 的例子。
注意:如果您实施 InterSystems FHIR SQL Builder,则不包括 InterSystems FHIR 即服务和 IRIS For Health 的 3 分奖励。
InterSystems FHIR 即服务和 IRIS For Health - 3 分
我们邀请所有开发人员使用InterSystems FHIR Server (FHIRaaS)构建新的或测试现有的应用程序。登录门户,进行部署并开始在您的编程竞赛应用程序中使用 AWS 上的 InterSystems FHIR 服务器。
您还可以使用 InterSystems IRIS for Health docker 版本构建 FHIR 应用程序。您可以使用IRIS-FHIR-Template ,它在 docker 镜像构建期间准备 FHIR 服务器。可以在此处找到 FHIR API 4.0.1 的文档。在InterSystems IRIS for Health 文档中了解更多信息。
IntegratedML 使用 - 4 分
1. 在您的 AI/ML 解决方案中使用 InterSystems IntegratedML。这是使用它的模板。
InterSystems IntegratedML 模板
2、数据导入工具:
数据导入向导
CSVGEN - CSV 导入工具
CSVGEN-UI - CSVGEN 的网络用户界面
3.文档:
使用 IntegratedML
4.在线课程和视频:
在 InterSystems IRIS 中学习 IntegratedML
为机器学习准备数据
使用机器学习工具包进行预测建模
IntegratedML 资源指南
IntegratedML 入门
使用 IntegratedML 和数据机器人进行机器学习
InterSystems Native API 使用 - 3 分
如果您使用任何 InterSystems Native API 选项( .NET 、 Java 、 Python 、 Node.js )访问全栈应用程序中的数据,您将获得此奖励。在这里了解更多。
嵌入式 Python - 4 分
在您的应用程序中使用嵌入式 Python并获得 4 分加分。您至少需要 InterSystems IRIS 2021.2。
注意:如果您还使用 Native API for Python,则只有 Embedded Python 才算奖励。
与 BPL 或 DTL 的互操作性生产 - 3 分
IRIS Interoperability Productions的主要特征之一是业务流程,可以用 BPL(业务流程语言)来描述。
在文档中了解有关业务流程的更多信息。
业务规则是一种无代码/低代码方法,用于管理互操作性生产的处理逻辑。在 InterSystems IRIS 中,您可以创建一个业务规则,您可以通过可视化或通过 ObjectScript 表示创建该规则。
如果您在互操作性产品中创建和使用业务流程或业务规则,您可以获得业务流程/业务规则奖励。
业务规则示例
在文档中了解有关业务规则的更多信息
生产扩展 (PEX) 使用 - 2 分
PEX 是互操作性产品的 Python、Java 或 .NET 扩展。
如果您在互操作性产品中将 PEX 与 Python、JAVA 或 .NET 结合使用,您将获得此奖励。
PEX演示。
在文档中了解更多关于 PEX 的信息。
InterSystems IRIS 具有Python Pex模块,该模块提供了从 Python 开发 InterSystems 互操作性产品的选项。使用它并为您的应用程序收集 3 个额外积分。也可以使用 Guillaume Ronguier 介绍的替代 python.pex 轮。
您还可以使用Python 互操作性,它是@Guillaume Rongier 提供的 Python 上 InterSystems IRIS 的 PEX 插件模块 这提供了在清晰的 python 中开发 InterSystems IRIS 互操作性解决方案的机会。
将 PEX 用于 Hugging Face 的文章,示例。
自适应分析 (AtScale) 多维数据集使用 - 3 分InterSystems Adaptive Analytics 提供创建和使用AtScale多维数据集的选项,用于分析解决方案。
您可以使用我们为比赛设置的 AtScale 服务器(可以在Discord 频道中收集 URL 和凭据)来使用多维数据集或创建一个新的多维数据集并通过 JDBC 连接到您的 IRIS 服务器。
使用 AtScale 的分析解决方案的可视化层可以使用 Tableau、PowerBI、Excel 或 Logi 制作。
文档, AtScale 文档
训练
Tableau、PowerBI、Logi 的使用 - 3 分
为您使用 Tableau、PowerBI 或 Logi 制作的可视化收集 3 分 - 每个 3 分。
可以通过直接 IRIS BI 服务器或通过与 AtScale 的连接进行可视化。
Logi 代表 InterSystems Reports 解决方案可用 - 您可以在InterSystems WRC 上下载作曲家。可以在discord channel中收集临时许可证。
文档
训练
InterSystems IRIS BI - 3 分
InterSystems IRIS 商业智能是 IRIS 的一项功能,它使您可以选择针对 IRIS 中的持久数据创建 BI 立方体和枢轴,然后使用交互式仪表板将此信息传递给用户。
了解更多
基本的iris-analytics-template包含 IRIS BI 多维数据集、数据透视表和仪表板的示例。
以下是 IRIS BI 解决方案的一组示例:
样品商务智能
Covid19分析
分析这个
权力的游戏分析
透视订阅
错误全局分析
使用 Docker 和 VSCode 创建 InterSystems IRIS BI 解决方案(视频)
可视化选择的自由:InterSystems BI (视频)
InterSystems BI(DeepSee) 概述(在线课程)
InterSystems BI(DeepSee) 分析器基础知识(在线课程)
列索引使用 - 1 分
列索引功能可以显着提高分析查询的性能。在您的解决方案的持久数据模型中使用列式索引并获得 1 个额外奖励积分。了解有关列索引的更多信息。
Docker 容器使用 - 2 分
如果应用程序使用在 docker 容器中运行的 InterSystems IRIS,则该应用程序将获得“Docker 容器”奖励。这是最简单的模板。
ZPM 包部署- 2 分
如果您做到以下措施,可以收集到奖励。为全栈应用程序构建和发布 ZPM(InterSystems Package Manager)包,这样它就可以通过以下方式部署:
zpm "install your-multi-model-solution"
安装了 ZPM 客户端的 IRIS 上的命令。
ZPM客户端。文档。
项目的在线演示 - 2 分如果您将项目作为在线演示提供给云,则可额外获得 2 个奖励积分。您可以自己完成,也可以使用此模板- 这是一个 示例。这是有关如何使用它的视频。
单元测试 - 2 分
对 InterSystems IRIS 代码进行单元测试的应用程序将获得奖励。
在文档和开发人员社区中了解有关 ObjectScript 单元测试的更多信息。
实施Developer Opportunity Idea的创新理念 - 4 分
实施来自InterSystems Community Ideas 门户的处于具有“社区机会(Community Opportunity)”状态的任何创新想法。这将为您提供 4 个额外的奖励积分。
关于开发者社区的文章 - 2 分
在 Developer Community 上发表一篇文章,描述您的项目的功能,并为该文章收集 2 分。
开发者社区第二篇文章 - 1分
您可以为第二篇文章或有关申请的翻译获得额外的奖励积分。第 3 次及以上不会带来更多积分,但您仍将赢得所有关注。
代码质量通过且零错误 - 1 分
包括用于代码静态控制的代码质量 Github 操作,并使其显示 0 个 ObjectScript 错误。
首次贡献 - 3 分
如果您是第一次参加 InterSystems Open Exchange 竞赛,可获得 3 个奖励积分!
YouTube 上的视频 - 3 分
制作演示您的产品的 Youtube 视频,每个视频可获得 3 分奖励积分。
奖励清单可能会发生变化。敬请持续关注!
文章
Michael Lei · 六月 18, 2023
在数字化时代,数据的重要性无可置疑。数据作为新型生产要素,不仅在宏观政策层面得到党和政府的大力推动,也是医院高质量发展的关键和改变医疗行业的驱动力。随着医疗信息化的迅猛发展,我们正迈向一个数据随处可及、人人可用易用的医疗信息化时代。这一时代将数据与人的需求相结合,致力于让数据能“主动”找到需要他们的医护人员和患者,每一个行业从业者,都应致力于为医护人员和患者提供简单易用的软件解决方案,减少工作量,提高效率,推动医疗行业的进步。
数据与人的融合是实现医疗行业数字化转型的核心。当然,医疗数据的收集、存储和管理对于提供高质量的医疗服务至关重要。然而,仅仅有大量的数据并不足够,我们需要将数据与人的需求紧密结合起来。这意味着我们应该让更多的数据关联起来,并且能服务于更多的人群,让患者能够随时随地访问他们的电子病历,让医生和科研人员也能及时有效地获取病人在医院围墙内外进行治疗和健康管理的数据,并且以直观易懂的方式呈现给医护人员和患者,使他们能够快速、准确地获取所需的信息。数据的融合还包括将不同来源的数据整合起来,为医护人员提供全面、完整的视图,同时基于医疗诊断的规则,不管是通过CDSS的形式,还是通过ChatBot(聊天机器人),帮助他们做出更好的决策。
实现数据和人的融合要按照人的需求投放数据。数字化转型的重要目标是为医护人员和患者提供所需的数据,以支持决策和治疗过程。这意味着我们应该了解用户的需求,将数据按照他们的角色、职责和关注点进行分类和投放。医生可能需要即时的患者数据、病历历史和最新的医学研究,而患者可能需要查看自己的健康记录、预约医生和接收个性化的健康建议。通过根据人的需求进行数据投放,新型软件可以提供个性化的服务和支持,形成千人千面,为每个用户提供有价值的信息。
简单易用是实现数字化转型成功的另一个关键。医护人员和患者使用的软件解决方案应该简单易用,不需要复杂的培训和技术知识。界面应该简单、直观、友好,操作流程简化和优化,以确保用户能够快速上手并高效地使用软件。简单易用的软件不仅能够减少用户的学习曲线和工作负担,还能提高用户满意度和工作效率。(比如Apple的医疗软件Apple Health,通过FHIR 技术,通过一个app能够连接数千家医院的病历数据,让患者可以通过一个app实现多家医院的互联网服务和数据整合)
无论是数字化转型还是高质量发展,软件为人服务始终是医疗信息化的核心宗旨。我们应该将软件看作是为人服务的工具,旨在帮助医护人员提供更好的医疗服务,提升患者的体验和健康结果。软件应该以用户体验为中心,并不断优化和改进,不断进行供给侧改革,以满足不断变化和不同人群的需求,而不是增加负担。
最后,数据会在安全可靠的前提下进行传递和流通。在互联网发展的早期时代,由于无法可依,野蛮生长,数据的滥用、隐私保护等存在很大问题。但随着《数据安全法》等法律法规的发布,相信未来的医疗行业数据一定会在更加安全、可靠、合规的前提下进行有序流动。
在未来的医疗信息化发展中,数据与人的关系将变得更加密不可分。通过数据的融合、按需投放、简单易用、安全可靠和以人为本的新一代软件,我们可以实现数据随处可及、人人可用易用的医疗信息化目标。这将为医护人员和患者提供更好的工作环境和医疗体验,推动整个医疗行业向前迈进。InterSystems公司作为创新性的数据平台解决方案供应商,我们始终致力于助力合作伙伴开发创新的解决方案,与合作伙伴一起共同实现这一愿景,改善医疗服务的质量和效率,提高患者体验的获得感的同时帮助医院降本增效,实现高质量发展。
文章
姚 鑫 · 六月 17, 2023
# 第六十章 镜像中断程序 - 使用主 `ISCAgent` 的日志数据进行 `DR` 提升和手动故障转移
## 使用主 `ISCAgent` 的日志数据进行 `DR` 提升和手动故障转移
如果 `IRIS A` 的主机系统正在运行,但 `IRIS` 实例没有且无法重新启动,您可以使用以下过程在通过升级后使用来自 `IRIS A` 的最新日志数据更新升级的 `IRIS C IRIS A` 的 `ISCAgent`。
1. 推广 `IRIS C`,选择 `IRIS A` 作为故障转移伙伴。 `IRIS C` 被提升为故障转移成员,从 `IRIS A` 的代理获取最新的日志数据,并成为主要成员。
2. 重新启动 `IRIS A` 上的 `IRIS` 实例,它作为备份重新加入镜像。
3. 在 `IRIS A` 重新加入镜像并变为活动状态后,可以使用使用升级的 DR 异步临时替换故障转移成员中描述的过程,将所有成员返回到它们以前的角色,首先是正常关闭 `IRIS C` ,然后在 `IRIS B` 的配置参数文件的 `[MirrorMember]` 部分中设置 `ValidatedMember=0`(请参阅配置参数文件参考中的 `[MirrorMember]`),将 `IRIS B` 重新启动为 `DR` 异步,将 `IRIS B` 提升为备份,并以 `DR` 异步方式重新启动 `IRIS C`。
注意:如果 `IRIS A` 的主机系统已关闭,但 `IRIS B` 的主机系统已启动,尽管其 `IRIS` 实例未运行,请按照手动故障转移到活动备份中所述在 `IRIS B` 上运行 `^MIRROR` 例程以确定 是否`IRIS B` 在发生故障时是一个活动备份。如果是这样,使用前面的过程,但在升级期间选择 `IRIS B` 作为故障转移伙伴,允许 `IRIS C` 从 `IRIS B` 的 `ISCAgent` 获取最新的日志数据。
## 使用来自日志文件的日志数据进行 DR 提升和手动故障转移
如果 `IRIS A` 和 `IRIS B` 的主机系统都已关闭,但可以访问 `IRIS A` 的日志文件,或者 `IRIS B` 的日志文件和消息日志可用,您可以使用最新的日志数据更新 `IRIS C`从升级前的初级开始,使用以下过程。
1. 使用 `IRIS A` 或 `IRIS B` 的最新日志文件更新 `IRIS C`,如下所示:
- 如果 `IRIS A` 的日志文件可用,则将最新的镜像日志文件从 `IRIS A` 复制到 `IRIS C`,从 `IRIS C` 上的最新日志文件开始,并包括来自 `IRIS A` 的任何后续文件。例如,如果 `MIRROR -MIRRORA-20180220.001` 是 `IRIS C` 上的最新文件,复制 `MIRROR-MIRRORA-20180220.001` 和 `IRIS A` 上的任何更新文件。
- 如果 `IRIS A` 的日志文件不可用但 `IRIS B` 的日志文件和消息日志可用:
1. 确认`IRIS B`很可能已被捕获,如下所示:
a. 确认当`A`及其代理不可用时,`B`同时断开与 A的连接。可以通过在`Messages.log`文件中搜索类似于以下内容的消息来检查 `IRIS B`断开连接的时间:
```java
MirrorClient: Primary AckDaemon failed to answer status request
```
b. 通过在其 `messages.log` 文件中搜索类似于以下内容的消息,确认 IRIS B 在断开连接时是活动备份:
```java
Failed to contact agent on former primary, can't take over
```
注意:`messages.log` 文件中的如下消息表明 `IRIS B` 在断开连接时未处于活动状态:
```java
nonactive Backup is down
```
当无法确认它是否已被追上时强制提升的 `DR` 异步成为主数据库可能会导致它成为主数据库而没有镜像生成的所有日志数据。因此,一些全局更新操作可能会丢失,而其他镜像成员可能需要从备份中重建。
2. 如果可以确认 `IRIS B` 处于活动状态,请将最新的镜像日志文件从 `IRIS B` 复制到 `IRIS C`,从 `IRIS C` 上的最新日志文件开始,然后包括来自 `IRIS B` 的所有后续文件。例如,如果 `MIRROR-MIRRORA-20180220.001` 是 `InterSystems IRIS C` 上的最新文件,请从 `IRIS C` 复制 `MIRROR-MIRRORA-20180220.001` 和任何更新的文件。检查文件的权限和所有权,并在必要时更改它们以匹配现有日志文件。
2. 在不选择故障转移合作伙伴的情况下将 `IRIS C` 提升为故障转移成员。 `IRIS C` 成为主要的。
3. 当 `IRIS A` 和 `IRIS B` 的问题得到修复时,尽早并在重新启动 `IRIS` 之前,在每个成员上的 `IRIS` 实例的配置参数文件的 `[MirrorMember]` 部分中设置 `ValidatedMember = 0`(参见 `[ MirrorMember]` 在配置参数文件参考)。说明指出,此更改是必需的。完成此操作后,在每个成员上重新启动 `IRIS`,从 `IRIS A`(最近成为主成员的成员)开始。
1. 如果成员在 `IRIS` 重新启动时作为备份或 `DR` 异步加入镜像,则不需要进一步的步骤。任何在故障成员上但不在当前主成员上的日志数据都已被丢弃。
2. 如果在 `IRIS` 实例重新启动时成员无法加入镜像,如重建镜像成员中描述的引用不一致数据的消息日志消息所示,则成员上的最新数据库更改晚于存在于上的最新日志数据 `IRIS C` 成为主要时。要解决此问题,请按照该部分中的描述重建成员。
4. 在大多数情况下,`DR` 异步系统不是主要故障转移成员的合适永久主机。在 `IRIS A` 和 `IRIS B` 重新加入镜像后,使用使用升级的 `DR` 异步临时替换故障转移成员中描述的过程将所有成员返回到它们以前的角色。如果 `IRIS A` 或 `IRIS B` 作为备份重新启动,则在备份处于活动状态时从正常关闭 `IRIS C` 开始,以故障转移到备份;如果 `IRIS A` 或 `IRIS B` 都重新启动为 `DR` 异步,将其中一个提升为备份,然后在 `IRIS C` 上执行正常关闭。将另一个以前的故障转移成员提升为备份,然后将 `IRIS C` 作为 `DR` 异步重启。
文章
Michael Lei · 六月 14, 2023
本文是 SqlDatabaseChain 的简单快速入门(我所做的)。
希望大家会感兴趣。
非常感谢:
sqlalchemy-iris 作者@Dmitry Maslennikov
您的项目使我的试验变得可能。
文章脚本使用 openai API,因此请注意不要在外部共享您不打算共享的表信息和记录。
如果需要,可以插入本地模型。
创建一个新的虚拟环境
mkdir chainsql
cd chainsql
python -m venv .
scripts\activate
pip install langchain
pip install wget
# Need to connect to IRIS so installing a fresh python driver
python -c "import wget;url='https://raw.githubusercontent.com/intersystems-community/iris-driver-distribution/main/DB-API/intersystems_irispython-3.2.0-py3-none-any.whl';wget.download(url)"
# And for more magic
pip install sqlalchemy-iris
pip install openai
set OPENAI_API_KEY=[ Your OpenAI Key ]
python
初始测试
from langchain import OpenAI, SQLDatabase, SQLDatabaseChain
db = SQLDatabase.from_uri("iris://superuser:******@localhost:51775/USER")
llm = OpenAI(temperature=0, verbose=True)
db_chain = SQLDatabaseChain.from_llm(llm, db, verbose=True)
db_chain.run("How many Tables are there")
错误结果
sqlalchemy.exc.DatabaseError: (intersystems_iris.dbapi._DBAPI.DatabaseError) [SQLCODE: <-25>:<Input encountered after end of query>]
[Location: <Prepare>]
[%msg: < Input (;) encountered after end of query^SELECT COUNT ( * ) FROM information_schema . tables WHERE table_schema = :%qpar(1) ;>]
[SQL: SELECT COUNT(*) FROM information_schema.tables WHERE table_schema = 'public';]
(Background on this error at: https://sqlalche.me/e/20/4xp6)
←[32;1m←[1;3mSELECT COUNT(*) FROM information_schema.tables WHERE table_schema = 'public';←[0m>>>
开发者之间的对话
IRIS 不喜欢以分号结尾的 SQL 查询。
现在做什么? ?
想法:我告诉 LangChain 帮我修理SQL如何
太酷了,我们开工吧 !!
测试二
from langchain import OpenAI, SQLDatabase, SQLDatabaseChain
from langchain.prompts.prompt import PromptTemplate
_DEFAULT_TEMPLATE = """Given an input question, first create a syntactically correct {dialect} query to run, then look at the results of the query and return the answer.
Use the following format:
Question: "Question here"
SQLQuery: "SQL Query to run"
SQLResult: "Result of the SQLQuery"
Answer: "Final answer here"
The SQL query should NOT end with semi-colon
Question: {input}"""
PROMPT = PromptTemplate(
input_variables=["input", "dialect"], template=_DEFAULT_TEMPLATE
)
db = SQLDatabase.from_uri("iris://superuser:******@localhost:51775/USER") llm = OpenAI(temperature=0, verbose=True)
llm = OpenAI(temperature=0, verbose=True)
db_chain = SQLDatabaseChain(llm=llm, database=db, prompt=PROMPT, verbose=True)
db_chain.run("How many Tables are there")
结果二
SQLQuery:←[32;1m←[1;3mSELECT COUNT(*) FROM information_schema.tables←[0m
SQLResult: ←[33;1m←[1;3m[(499,)]←[0m
Answer:←[32;1m←[1;3mThere are 499 tables.←[0m
←[1m> Finished chain.←[0m
'There are 499 tables.'
我就说很快吧
参考资料:
https://walkingtree.tech/natural-language-to-query-your-sql-database-using-langchain-powered-by-llms/
https://python.langchain.com/en/latest/modules/chains/examples/sqlite.html#sqldatabasesequentialchain
https://python.langchain.com/en/latest/modules/agents/plan_and_execute.html
文章
姚 鑫 · 六月 14, 2023
# 第五十七章 镜像中断程序 - 在手动故障转移之前确定备份是否处于活动状态
## 在手动故障转移之前确定备份是否处于活动状态
假设有两个名为 `IRIS A` 和`IRIS B` 的故障转移成员。如果 `^MIRROR` 例程确认备份 (`IRIS B`) 在与主 (`IRIS A`) 丢失联系时处于活动状态,因此具有最新的来自 `IRIS A` 的日志数据,可以使用单个过程手动进行故障转移。当连接因主要故障而丢失时,不会造成数据丢失的风险。但是,当发生多个故障时,活动备份可能没有来自主服务器的所有最新日志数据,因为主服务器在连接丢失后继续运行了一段时间。
使用以下过程确定备份是否处于活动状态:
1. 确认 `IRIS` 实例 `IRIS A` 上的 `ISCAgent` 实际上已关闭(并确保它们在整个手动故障转移过程中保持关闭状态)。
2. 在 `IRIS B` 上,在终端的 `%SYS` 命名空间中运行 `^MIRROR` 例程(请参阅使用 `^MIRROR` 例程)。
3. 在主菜单中选择镜像管理,显示如下子菜单:
```java
1) Add mirrored database(s)
2) Remove mirrored database(s)
3) Activate or Catchup mirrored database(s)
4) Change No Failover State
5) Try to make this the primary
6) Connect to Mirror
7) Stop mirroring on this member
8) Modify Database Size Field(s)
9) Force this node to become the primary
10) Promote Async DR member to Failover member
11) Demote Backup member to Async DR member
12) Mark an inactive database as caught up
13) Manage mirror dejournaling on async member (disabled)
14) Pause dejournaling for database(s)
```
4. 选择 `Force this node to become the primary` 选项。如果在联系丢失时备份处于活动状态,则会显示如下消息:
```java
This instance was an active backup member the last time it was
connected so if the primary has not done any work since that time,
this instance can take over without having to rebuild the mirror
when the primary reconnects. If the primary has done any work
beyond this point (file #98),
C:\InterSystems\MyIRIS\mgr\journal\MIRROR-GFS-20180815.009
then the consequence of forcing this instance to become the primary is
that some operations may be lost and the other mirror member may need
to be rebuilt from a backup of this node before it can join as
a backup node again.
Do you want to continue?
```
如果有权访问主要文件的日志文件,则可以在继续之前确认引用的文件是最新的。
如果在与主服务器失去联系时备份未处于活动状态,则会显示如下消息:
```java
Warning, this action can result in forcing this node to become
the primary when it does not have all of the journal data which
has been generated in the mirror. The consequence of this is that
some operations may be lost and the other mirror member may need
to be rebuilt from a backup of this node before it can join as
a backup node again.
Do you want to continue?
```
## 手动故障转移到活动备份
如果 `^MIRROR` 例程的 `Force this node to become the primary` 选项确认备份在失去与主节点的连接时处于活动状态,请完成手动故障转移过程,如下所示:
1. 在要继续吗?提示继续该过程。 `Force this node to become the primary` 选项等待 `60` 秒以使镜像成员成为主要节点。如果操作未在 `60` 秒内成功完成,`^MIRROR` 报告操作可能未成功并指示您检查消息日志以确定操作是失败还是仍在进行中。
2. 一旦 `^MIRROR` 例程确认备份已成为主要备份,请在可以这样做时重新启动 `IRIS A`。当 `IRIS` 实例重新启动时, `IRIS A` 作为备份加入镜像。
## 备份不活动时手动故障转移
即使 `^MIRROR` 例程未确认备份 ( `IRIS B`) 在与主 ( `IRIS A`) 失去连接时处于活动状态,仍然可以使用以下过程继续手动故障转移过程,但是如果这样做,会有数据丢失的风险。如本程序所述,可以在手动故障转移之前将最新的镜像日志文件从 `IRIS A`(如果有权访问)复制到 `IRIS` B,从而最大限度地降低这种风险。
1. 如果有权访问主服务器的镜像日志文件,请将最新的文件复制到 `IRIS B`,从 `IRIS B` 上的最新日志文件开始,然后包括来自 `IRIS A` 的任何后续文件。例如,如果 `MIRROR-MIRRORA-20180220.001`是 `IRIS B` 上的最新文件,复制 `MIRROR-MIRRORA-20180220.001` 和 `IRIS A` 上的任何更新文件。检查文件的权限和所有权,并在必要时更改它们以匹配现有日志文件。
2. 如果接受数据丢失的风险,请在提示时输入 `y` 以确认要继续;备份成为主要的。 `Force this node to become the primary` 选项等待 `60` 秒以使镜像成员成为主要节点。如果操作未在 `60` 秒内成功完成,`^MIRROR` 报告操作可能未成功并指示您检查消息日志以确定操作是失败还是仍在进行中。
3. 一旦 `^MIRROR` 例程确认备份已成为主要备份,请在可以这样做时重新启动 `IRIS A`。
- 如果 `IRIS A` 在 `IRIS` 实例重新启动时加入镜像作为备份,则不需要进一步的步骤。任何在故障成员上但不在当前主成员上的日志数据都已被丢弃。
- 如果在 `IRIS` 实例重新启动时 `IRIS A` 无法加入镜像,如重建镜像成员中描述的引用不一致数据的消息日志消息所示 `IRIS A` 上的最新数据库更改晚于最新的日志数据当 `IRIS B` 被迫成为主服务器时,它会出现在 `IRIS B` 上。要解决此问题,请按照该部分中的描述重建 `IRIS A`。
公告
Claire Zheng · 六月 14, 2023
Hi 开发者们,
欢迎观看视频,以了解 InterSystems TrakCare 创新工具包( Innovation Toolkit),该工具包可免费下载,使 TrakCare 用户能够快速访问标准 HL7® FHIR® 格式的数据,使记录系统成为转型系统:
⏯ TrakCare 创新工具包介绍 @ 2022 年全球峰会
🗣主持人:Eslam Farahat,InterSystems 产品经理
订阅InterSystems B站!
公告
Claire Zheng · 六月 14, 2023
InterSystems 已纠正导致进程内存使用量增加的缺陷。
具体来说,在对局部变量执行$Order 、 $Query 或 Merge时,会出现本地进程分区内存消耗增加的问题。虽然这对大多数运行环境没有不利影响,但支持大量进程或严格限制每个进程最大内存使用的环境可能会受到影响。某些进程可能会遇到<STORE> 错误。
该缺陷存在于2023.1.0.229.0中,但它被重新发布为2023.1.0.235.1,并包含了修复程序,以加快修正,而无需客户等待维护版本。
此缺陷的更正标识为 DP-423127 和 DP-423237。这些将包含在所有未来版本中。
该缺陷出现在 InterSystems IRIS ® 、InterSystems IRIS for Health ™ 和HealthShare ® Health Connect 的版本 2022.2、2022.3 和 2023.1(内部版本 229)中。如果您运行的是这些版本之一,我们建议升级到 2023.1(内部版本 235)。
此修复也可通过 Ad hoc 分发获得。
如果您对此警报有任何疑问,请联系全球响应中心。
文章
Hao Ma · 六月 13, 2023
在维护IRIS的镜像前,管理员需要清楚的了解以下一些概念:
## Mirror的切换模式(failover mode)
切换模式在镜像监视器里被翻译成”故障转移模式“。 有两种模式:
- Agent Controlled模式:
- Arbiter Controlled模式:(页面上翻译为“仲裁程序受控制”)
通常情况,生产环境的镜像是安装了arbiter(仲裁者)的。Mirror启动时,在还没有连接上arbiter的时候,自动进入Agent-Controlled模式。而后当两台机器,主机,备机都连通了Arbiter,会保持在这个模式。
- 主备之间有连接;
- 又都连到arbiter;
- backup is active,
满足上面的条件,就进入arbiter controlled mode。而如果主备的任一方,失去了和arbiter的连接,或者备用侧丢了active, 开始尝试连接另一方,退回到agent-controlled模式。
## Mirror同步成员的状态
[Mirror Member Journal Transfer and Dejournaling Status](https://docs.intersystems.com/irisforhealth20231/csp/docbook/DocBook.UI.Page.cls?KEY=GHA_mirror_manage#GHA_mirror_set_status). 请注意,这里面有两个概念:一个是**Mirror成员的状态**,一个是**Journal传输和Dejournaling的状态**。下面的图中是3个字段: STATUS, Journal传输,Dejournaling.
**STATUS**
镜像成员的状态。 正常工作状态
- 对于同步成员,是Primary(主), Backup(备机)。
- 对于异步成员,正常状态是Connected(已连接)
- In Trouble : 如果主机In Trouble, 是失去了到backup的连接。备机收到主机的同步数据是要返回证实(Ack)消息的。一旦出现问题,主机无法收到备机的Ack, 主机就会把备机标为"In trouble", 从此再也不会向备机发同步数据。
- Transition: 暂时状态,进程正在查看一个成员的状态,很快会转换到一个稳定状态。 如果在mirror配置的member中发现了primary,本机会进入Synchronizing状态,否则自己会尝试进入primary状态。
- Sychronizing: 从Primary接收journal,同步数据库。
## Journal Transfer and Dejournaling Status
Journal Transfer是主机向其他成员发送Journal文件。而Dejournal是把Journal文件读入数据库。 对于backup或者asycn成员,**Journal Transfer**状态表示镜像成员是否有来自主数据库的最新日志数据,如果没有,则表示日志传输的落后程度,**Dejournaling**表示从主数据库收到的所有日志数据是否已经被dejournaled(应用到成员的镜像数据库),如果没有,则表示dejournaling的落后程度。
上图中显示的是正常的状态,其中主机 Journal Transfer 和 Dejournaling 都是N/A, 表示不适用。
对于其他成员,我们分开看:
Journal Transfer状态
- Active: backup的正常状态。说明backup从primary收到了最新的journal。注意哪怕是Dejournal状态只是“x秒落后“,而不是"被捕获",Journal Transfer状态也可以是Active,只要是从主机收到了最新的Journal更新。
- Caught up(被捕获) : 备机被捕获状态,说明备机从主机收到了最新的journal数据,但主机没有在等待备机的证实消息。 这通常是一个暂时的过程,当备机在连接主机的时候会出现。 异步成员,因为不需要向主机发证实,所以正常的状态就是“被捕获”
If the Primary Failover Member does not receive an acknowledgment from the Backup every Heartbeat Interval period, it demotes the Backup system from Active status to Catch-Up mode.
- time behind (多少秒落后)
- Disconnected on time(断开): 在一个时间点上这个成员和primary断开了。
Dejournaling状态
- Caught up
- time behind
- Disconnected on time
- Warning! Some Databases need attention
- Wanring! Dejournaling is stopped
**正常状态下的图;**
备机Backup MirrorB, Journal Transfer是Active, Dejournaling是Caught up, 异步机器MirrorDR的Journal Transfer状态和Dejournaling状态都是Caught up. 表示它们收到了最新的journal数据,并且也都把最新的global修改写入了自己的数据库。
## Mirror的自动切换
Mirror的核心是自动切换。Backup接替主机的工作有两个前提:1. 备机在同步(Active) 状态, 2. 主机不能正常工作。在这两个前提下,我们来看看自动切换的触发条件,涉及主机,备机,仲裁机之间的通信,
**自动切换触发条件**
1. Primary要求Backup接替。这种情况,主机会发生一个请求消息给备机, 要求备机接替。
- 主机IRIS正常退出
- 主机发现自己hung
2. 备机收到arbiter的请求,报告失去了到主机的连接。
仲裁机要求是和外部系统以及应用服务器部署在一个网段的。如果仲裁机无法联络主机,可以认为其他的应用系统和服务器也无法连接主机。有可能主机宕机, 也有可能主机还在正常工作,但外界已经无法联络它了, 这时候也是需要备机接手的。
这时备机也要再去核实一下,是不是能联络到主机。如果能联络到, 备机会发请求让主机Down。如果不能, 说明主机要么死了, 要么失联了, 备机先接手,等联络上再让对方force down.
3. 从主机的ISCAgent收到消息,报告Primary已经down or hung.
在agent-controlled的情况。 primary的服务器还活着。备机主动去问主机的agent, 一旦agent报告主机死了, 那备机就可以上位了。
## Mirror的进程
管理员应该了解mirror涉及的那些进程。当出现故障时,这些进程名字,或者称为User, 经常会出现在message log记录的故障描述中。
On Primary Failover Member(主机)
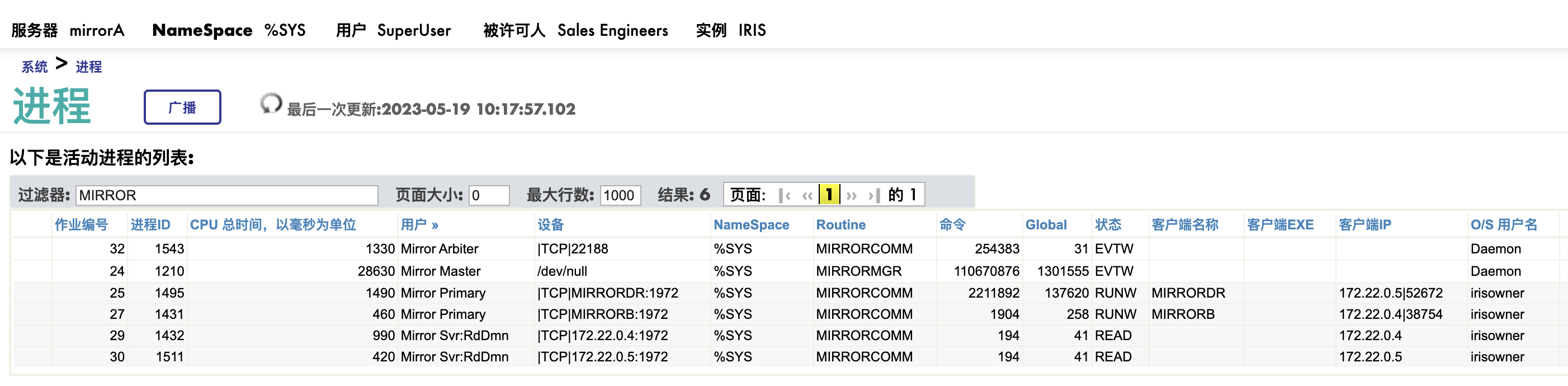
我们来一个个的看看这些进程:
- Mirror Master: 系统启动时自动启动,负载mirror control 和管理。
- Mirror Primary: 出向数据传输通道。 上图中有两个Mirror Primary进程,状态时RUNW, 一个连接MirrorB, 一个连接MirrorDR.
- Mirror Svr: Rd*: 入向证实通道(inbound acknowledgement), 也是单向的。 上图中同样有两个此进程,状态都是READ, IP地址分别是MirrorB和MirrorDR.
- Mirror Arbiter: 到aibiter的通信进程,注意它的状态是"EVTW", 也是个单向写的频道。
On Backup Member/Async member(备机)
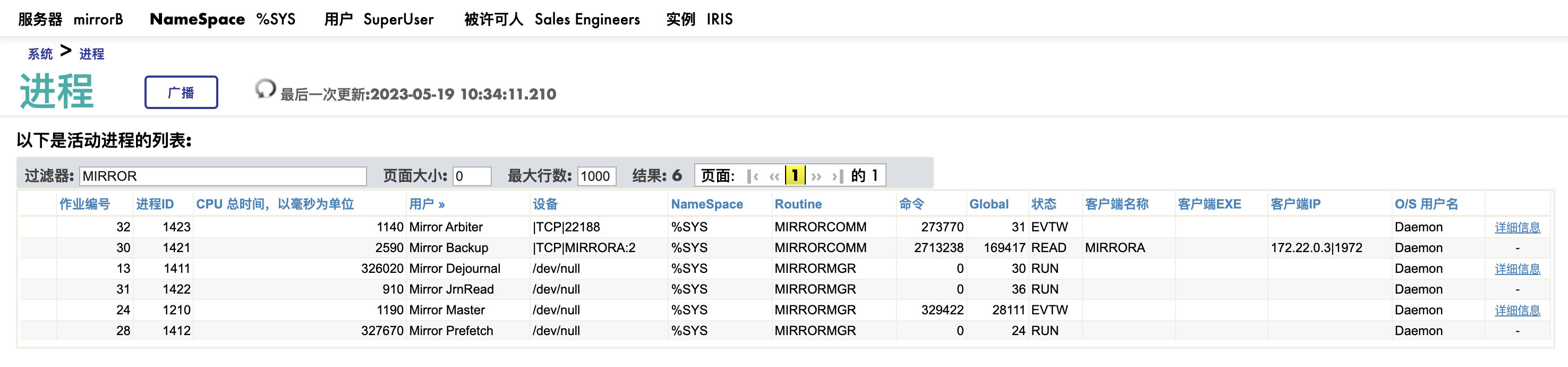
Mirror Masht, Mirror Arbiter不再重复解释,我们看看其他进程是干什么的。
- Mirror JrnRead: Mirror Journal从Primary发送到backup是先写到硬盘的。 JrnRead进程把收到的journal同步读到内存里,然后才进行下一步,Dejournal的工作。
- Mirror Dejour: backup机器的dejournal job进程。它把从Primary收到的journal中记录的global改变(set and kill)保存到本机的镜像数据库。
- Mirror Prefetch: 这个稍微有点难懂。当收到的journal修改中包括了使用当前backup的journal中已有的内容时,比如收到了一个修改:set ^A=^B+1, 而^B当前存在backup里, Prefetch进程会把^B从硬盘拿到内存,以加快dejournal的速度。
- Mirror Backup: two-way channel, 把收到的primary的journal写到backup的mirror journal,并且返回证实(ACK)
这里我省略了在DR上的进程,如果有兴趣,请自己查看文档。
## MIRROR状态的监控
根据不同的场景,查看Mirror的状态有以下几种途径
### **[使用镜像监视器](https://docs.intersystems.com/iris20231/csp/docbook/DocBook.UI.Page.cls?KEY=GHA_mirror_manage#GHA_mirror_monitor_portal)**
### 使用^MIRROR
如果您只是要简单的获得Mirror成员的状态,最直接的方法是使用^Mirror程序。 我们先看看在IRIS Terminal下^MIRROR的执行。
```bash
%SYS>do ^MIRROR
1) Mirror Status
2) Mirror Management
3) Mirror Configuration
Option? 1
1) List mirrored databases
2) Display mirror status of this node
3) Display journal file info
4) Status Monitor
Option? 4
Status of Mirror MIRRORTEST at 08:09:24 on 05/19/2023
Arbiter Connection Status:
Arbiter Address: arbiter|2188
Failover Mode: Agent Controlled
Connection Status: This member is not connected to the arbiter
Journal Transfer
Member Name+Type Status Latency Dejournal Latency
-------------------------- --------- --------------- --------------
MIRRORA
Failover Primary N/A N/A
Press RETURN to refresh, D to toggle database display, Q to quit,
or specify new refresh interval D
Database display is now on
Status of Mirror MIRRORTEST at 08:09:29 on 05/19/2023
Arbiter Connection Status:
Arbiter Address: arbiter|2188
Failover Mode: Agent Controlled
Connection Status: This member is not connected to the arbiter
Journal Transfer
Member Name+Type Status Latency Dejournal Latency
-------------------------- --------- --------------- --------------
MIRRORA
Failover Primary N/A N/A
Mirror Databases:
Record To
Name Directory path Status Dejournal
------------- ----------------------------------- ----------- -----------
TEST /isc/mirrorA/TESTDB/ Normal N/A
Press RETURN to refresh, D to toggle database display, Q to quit,
or specify new refresh interval
```
**在操作系统中执行^MIRROR**
您可以把以下的代码写入您的脚本语言,查看mirror的状态
```bash
irisowner@mirrorA:~$ iris session iris -U "%sys" "Monitor^MIRROR"
Status of Mirror MIRRORTEST at 02:57:08 on 06/13/2023
Arbiter Connection Status:
Arbiter Address: arbiter|2188
Failover Mode: Arbiter Controlled
Connection Status: Both failover members are connected to the arbiter
Journal Transfer
Member Name+Type Status Latency Dejournal Latency
-------------------------- --------- --------------- --------------
MIRRORA
Failover Primary N/A N/A
MIRRORB
Failover Backup Active Caught up
MIRRORDR
Disaster Recovery Connected Caught up Caught up
Press RETURN to refresh, D to toggle database display, Q to quit,
or specify new refresh interval q
Doneirisowner@mirrorA:~$
```
或者更简单的,只查看本机的mirror成员状态:
```bash
irisowner@mirrorA:~$ iris session iris -U "%sys" "LocalMirrorStatus^MIRROR"
This instance is a Failover member
Status for mirror MIRRORTEST is "Primary"
Current mirror file #2 ends at 681224
Min trans file #2 min trans index: 680744
irisowner@mirrorA:~$
```
如果您熟悉ObjectScript, 也可以使用`$SYSTEM.Mirror`类的各个method来查看:
```bash
irisowner@mirrorB:~$ echo "write \$SYSTEM.Mirror.GetMemberStatus(),! halt" |iris session iris -U "%sys"
Node: mirrorB, Instance: IRIS
%SYS>
Backup
irisowner@mirrorB:~$
```
如果您要查看更多的内容,您可以更多的使用%SYSTEM.Mirror类的其他方法,比如%SYSTEM.Mirror.GetFailoverMemberStatus(.pri,.alt), $SYSTEM.Mirror.ArbiterState()等等。
### 使用Mirror_MemberStatusList存储过程
如果您从第3方的工具查询mirror成员的状态,还有一个简单的方案,就是调用%SYS命名空间的存储过程。下图是从iris管理门户调用的截图,你可以使用任何SQL客户端调用。
如果是从iris里执行,
```
%SYS>do ##class(%ResultSet).RunQuery("SYS.Mirror","MemberStatusList")
Member Name:Current Role:Current Status:Journal Transfer Latency:Dejournal Latency:Journal Transfer Latency:Dejournal Latency:Display Type:Display Status:
MDCHCNDBSL1.HICGRP.COM/STAGE:Primary:Active:N/A:N/A:N/A:N/A:Failover:Primary:
MDCHCNDBSL2.HICGRP.COM/STAGE:Backup:Active:Active:Caught up:Active:Caught up:Failover:Backup:
CDCHCNDRSL.HICGRP.COM/STAGE:Async:Async:Caught up:Caught up:Caught up:Caught up:Disaster Recovery:Connected:
```
### 通过SNMP获得
如果使用监控工具,您可以通过SNMP获得Mirror的状态,下面是最新的ISC-IRIS.mib中有关Mirror得指标部分。
```
.4.1.12 = irisMirrorTab | Table of current Mirror Members status and information
-- .4.1.12.1 = irisMirrorRow | Conceptual row for Mirror status and metrics | INDEX = irisSysIndex, irisMirrorIndex
-- .4.1.12.1.1 = irisMirrorIndex | unique index for each Mirror Member | INTEGER
-- .4.1.12.1.2 = irisMirrorName | Name of the mirror this system is a member of | STRING
-- .4.1.12.1.3 = irisMirrorMember | Mirror member name | STRING
-- .4.1.12.1.4 = irisMirrorRole | "Primary", "Backup", or "Async". | STRING
-- .4.1.12.1.5 = irisMirrorStatus | "Active" or "Activate". | STRING
-- .4.1.12.1.6 = irisMirrorJrnLatency | Mirror journal latency "Caught up", "Catchup", or "N/A". | STRING
-- .4.1.12.1.7 = irisMirrorDBLatency | Mirror database latency "Caught up", "Catchup", or "N/A". | STRING
```
## MIRROR的日志和告警
通常情况下, 维护人员是通过mirror的日志和警告来获得Mirror状态,Mirror成员之间的连接情况,而不必须定时的用命令或者调用存储过程来查看。
Cache'和IRIS的日志和警告保存在两个文件: console.log/messages.log和alert.log, 其中alert.log中记录了console.log/messages.log中级别为2,3的记录, 并必须实时发送给管理员。有关这部分内容,请参考在线文档,或者我的帖子:
我们来看看在日志中有哪些mirror的记录:
**Becoming primary mirror server**
系统固有的通知消息, level =2。当一个iris实例从备机变成了主机,此信息会写到此实例的alert.log, 同时发送给管理员。 可以查看这个[链接](https://docs.intersystems.com/iris20231/csp/docbook/DocBook.UI.Page.cls?KEY=GCM_monitor#GCM_monitor_errors)。
在Mirror切换时,管理员除了从刚刚接手的机器中收到Becoming primary mirror server的通知。如果原来的主机没有宕机或者从宕机中恢复,它也会将引起切换的故障从alert.log发送给管理员,是一个level2, 或者level3的记录。
**Arbiter connection lost**
level =2 , 自动发送给管理员。 当主机和arbiter失去连接后,在主机上会出现此警告。此时在备机上会出现“Switched from Arbiter Controlled to Agent Controlled failover on request from primary”的提示,是个level0的信息。
**MirrorServer: Connection to xxxx(backup) terminated**
**MirrorServer: Connection to MIRRORDR (async member) terminated**
当主机和备机(backup)失去连接,在主机上会出现level2的警告。 而和异步成员丢失连接,主机会出现level1的消息。尽管level1的消息不能自动通知管理员,但这时如果同时监控该异步成员的alert.log, 通常会有level2的警告消息发出,能提醒管理员检查MIRRORDR这个镜像成员的状态。
举例说明:如果在MirrorDR中操作系统重启,IRIS启动后会出现这样的level2的警告:“Previous system shutdown was abnormal, ^SHUTDOWN forced down”
**Async member for MirrorSetName started but failed to connect to primary**
level =2 , 自动发送给管理员
其他更多的关于Mirror出错的level2, 也就是警告记录, 比如:
- Could not open mirror journal log to read checksum, errno = 2
- Preserving all mirror journal files for offline failover member
- Server^MIRRORCOMM(d): Failed to notify MIRRORB for mirror configuration change
- Failed to become either Primary or Backup at startup
这不是个完整的列表,实际环境中会出现各种各样的告警通知。读懂这些通知,需要管理员了解镜像的原理,架构,以及上面介绍的镜像状态和进程的功能。
除此之外,绝大多数的level2日志的同时,会有更多的level0,level1的有关mirror变化的记录。这些内容不需要通知管理员,只是用于分析问题。 如图,下面是在一个messages.log里一个iris从备机变成主机的过程。
```
06/13/23-07:16:25:472 (2189) 0 [Generic.Event] MirrorClient: Switched from Arbiter Controlled to Agent Controlled failover on request from primary
06/13/23-07:16:26:274 (2189) 1 [Generic.Event] MirrorClient: Mirror_Client: Primary closed down, last # read = 504
06/13/23-07:16:26:301 (2189) 0 [Generic.Event] MirrorClient: Backup waiting for old Dejournal Reader (pid: 2190, job #31) to exit
06/13/23-07:16:27:394 (2189) 0 [Generic.Event] MirrorClient: Set status for MIRRORTEST to Transition
06/13/23-07:16:28:477 (1996) 0 [Utility.Event] [SYSTEM MONITOR] Mirror status changed. Member type = Failover, Status = Transition
06/13/23-07:16:30:261 (2177) 0 [Utility.Event] Returning to restart, old primary reported: "DOWN
06/13/23-07:16:31:524 (11721) 0 [Utility.Event] Applying journal data for mirror "MIRRORTEST" starting at 1538184 in file #2(/isc/mirrorB/mgr/journal/MIRROR-MIRRORTEST-20230613.001)
06/13/23-07:16:31:804 (2177) 0 [Utility.Event] Manager initialized for MIRRORTEST
06/13/23-07:16:31:986 (2177) 0 [Utility.Event] MIRRORA reports it is DOWN, becoming primary mirror server
06/13/23-07:16:32:381 (2177) 0 [Generic.Event] INTERSYSTEMS IRIS JOURNALING SYSTEM MESSAGE
Journaling switched to: /isc/mirrorB/mgr/journal/MIRROR-MIRRORTEST-20230613.002
06/13/23-07:16:32:426 (2177) 0 [Utility.Event] Scanning /isc/mirrorB/mgr/journal/MIRROR-MIRRORTEST-20230613.001
06/13/23-07:16:32:479 (2177) 0 [Utility.Event] No open transactions to roll back
06/13/23-07:16:32:485 (2177) 0 [Generic.Event] MirrorServer: New primary activating databases which are current as of 1538184 (0x00177888) in mirror journal file #2
06/13/23-07:16:32:488 (2177) 0 [Generic.Event] Changed database /isc/mirrorB/TESTDB/ (SFN 5) to read-write due to becoming primary.
06/13/23-07:16:32:924 (2177) 0 [Utility.Event] Initializing Interoperability during mirror initialization
06/13/23-07:16:32:930 (2177) 2 [Utility.Event] Becoming primary mirror server
```
更多的有关mirror监控和排除的问题, 请各位留言。 谢谢
文章
Louis Lu · 六月 12, 2023
文章相关视频参见Synthea生成FHIR测试数据,以及FHIR服务器加载FHIR资源文件
1. 什么是Synthea
Synthea是一个开源软件包,可以模拟生成患者就诊数据。他的github地址在这里。
生成的就诊模版从最初的模拟美国前十种常见病、前十种慢性病到现今超过90种不同的模型。详细模型参见这里。
基于当前版本,Synthea的特性包括:
从出生到死亡的全生命周期
可配置的人口统计学信息(默认为美国马萨诸塞州人口普查数据)
模块化规则系统
插入通用模块
用于附加功能的自定义 Java 规则模块
主要医疗事件就诊、急诊室就诊和症状驱动的就诊
症状、 过敏、药品、 疫苗接种、观察/生命体征、实验室、处置、 护理计划
支持格式
HL7 FHIR(R4、STU3 v3.0.1 和 DSTU2 v1.0.2)
ndjson 格式的批量 FHIR(设置 exporter.fhir.bulk_data = true 以激活)
C-CDA (设置 exporter.ccda.export = true 以激活)
CSV (设置 exporter.csv.export = true 以激活)
CPCDS (设置 exporter.cpcds.export = true 以激活)
使用Graphviz可视化呈现规则和疾病模块
支持的参数可见下图
比如 -p 5 生成5条测试数据
-g M 生成男性测试数据
-a 60-65 生成年龄在60-65周岁患者测试数据
2. 使用Synthea 生成测试数据
为了方便使用,也将该软件做成了docker,所以你可以简单的执行下面命令行
docker run --rm -v $PWD/output:/output --name synthea-docker intersystemsdc/irisdemo-base-synthea:version-1.3.4 -p 5
该命令会在当前路径的output文件夹下生成5条患者符合FHIR标准的就诊数据,数据相关摘要信息如下面终端输出:
3. 加载生成的 FHIR 数据至 InterSystems IRIS for Health
生成完FHIR数据后,需要加载到FHIR服务器(FHIR资源仓库)中。
我们在输出目录下可以看到生成7条json数据,其中5条患者就诊相关,1条就诊医院信息,一条参与者(就诊医生)信息。
在InterSystems IRIS for health中可以方便的使用DataLoader类中的方法,批量加载FHIR资源数据,进入FHIR 资源仓库命名空间后执行:
zw ##class(HS.FHIRServer.Tools.DataLoader).SubmitResourceFiles("/external/fhir/","FHIRServer","/fhir/r4")
该方法中的第一个参数是fhir资源文件路径; 第二个参数服务类型,这里一般是FHIRServer; 第三个参数FHIRServer的service名称。
执行后显示如下:
之后我们可以进入管理门户,或者使用SQL客户端查询相关存储表,表明数据被正确导入
文章
Claire Zheng · 六月 12, 2023
大家好!
这是一篇关于如何将视频嵌入您的帖子的简短文章。
其实很简单。您只需要按照以下步骤操作。
1. 打开您希望嵌入的B站视频,在视频右下角找到分享按钮;
2. 选择“嵌入代码”并复制代码
3.在社区帖子中切换到Source视图,并将您在步骤2中复制的代码粘贴在您希望嵌入视频的地方(如嵌在<p>后);
4.再次点击“Source”,回到编辑页面,您会看到如下“IFRAME”框;
5.双击红色的“IFRAME”,并如图所示填写视频尺寸(请务必按下图数值填写),点击“确定”,即可完成视频嵌入。
希望这个帖子能帮助到您:)
在评论部分留下您对这个主题的想法,或者告诉我们您还希望了解哪些社区玩儿法。
文章
Qiao Peng · 六月 11, 2023
数据平台一直在进化:从数据中心到数据中台,离散的数据资产得到进一步梳理和整合、按业务封装数据和操作数据的方法,并逐步提供了企业统一的访问、更新、检索、查询等数据服务。
然而市场上不乏听到数据平台的成功案例,却鲜见这些案例得到大规模推广。原因是什么呢?
一. 传统数据平台建设的挑战
传统数据平台的数据模型基于各自厂商的理解,缺乏统一行业数据模型和行业语义。可供参考的国内卫生信息数据元、数据集标准并非完整的行业语义,例如没有业务实体模型和数据元关系定义。传统的数据平台建设通常根据业务域,围绕数据应用需求组织数据。经常看到按业务域划分为CDR(临床数据中心)、ODR(运营数据中心)、RDR(科研数据中心)......
这造成了几个挑战:
1. 按业务域、而非业务实体来划分数据,虽然方便相应的业务域数据分析,但跨业务域重叠的业务实体数据,例如患者,需要跨数据中心同步。这些同步由于数据模型上的差异,往往非全息拷贝。随着同步次数越多,跨数据中心的数据越失真,造成数据资产多源不统一、数据资产一致性问题和时效性问题。
2. 数据平台产品语义表达上参差不齐,业务用户依赖数据工程师对数据理解和操作,无论是统计分析还是机器学习,海量的实施工作无法满足业务敏捷性要求;
3. 数据平台及数据应用建设依赖单一厂商的能力,而建设成果,包括数据工具、分析指标和应用都无法跨数据平台复用。往往项目都在做低水平重复建设。
4. 数据互操作标准化程度低,数据的同步、迁移困难。在缺乏数据层互操作性的情况下,各类数据中心建设的依然是数据孤岛。
5. 由于数据中心往往忽视互操作建设,数据缺乏流动,进入数据平台后,往往成为死水一潭。
二. 如何应对挑战
如何解决这些数据平台建设困境?应该如何建设数据平台?
数据资产不是仅为分析服务的,更重要的是作为生产要素在生产全过程中发挥价值- 这就涉及到数据生成、采集、交换、决策… 在这个全过程链条上的数据互操作能力尤为重要。
HIMSS将互操作定义为4级:基础级、结构级、语义级和组织级,并认为只有到达语义级,才是标准的、才能实现广泛的互操作能力。要达到语义级的互操作,需要进行五位一体的标准化:词汇/术语标准、内容标准、传输标准、隐私和安全标准、标识符标准。
随着我们越来越依赖于机器处理数据、发掘数据背后的知识,对数据资产的开放性和互操作性的要求达到了更高的水平 - 实现机器可以理解的互操作。2016年发表在Scientific Data针对科学数据管理和监管,提出了数据的可发现(Findable)、可访问(Accessible)、可互操作(Interoperable)、可复用(Reusable)的FAIR指导原则。
这些原则的核心是让机器可以理解数据所需的语义层面的要求,尤其是可互操作和可复用两部分提到的语义级要求 - 广泛使用的语言、词汇表、元数据引用、符合相关领域的社区标准...
大家都不约而同地指向了统一行业语义。传统数据中心面临的上述挑战,正是因为缺乏统一的行业语义、缺乏统一的语义级互操作。
那什么是统一语义?
三. 统一语义数据平台
圣经记载人类曾经联合起来兴建能通往天堂的高塔 - 巴别塔、也称通天塔。上帝为了阻止人类的计划,让人类说不同的语言。人类相互之间不能沟通,造塔计划因此失败。
统一语言是数据能够互相理解、并利用数据的前提。
语言包含2个层面:
1. 语义:真实世界事物及其关系的表达方法。例如不同电子病历系统对疑似肺癌的记录,可能记录为以下三种之一:
A。问题: 癌症 身体部位:肺 确定程度:疑似
B。问题: 肺癌 确定程度:疑似
C。问题: 疑似肺癌
这三种语义表达不统一。没有统一的语义就像图里的电源插座,每个国家规格都不同,是不可能互联互通的。
2. 语法:语言的结构规则,包括词法和句法。而词法和句法都可能有歧义,就像图中示例的那样。
行业数据需要通过统一语义达到互联互通。对数据而言,统一语义不仅在数据模型(语义)、也在数据使用方式(语法)上。不仅数据语义是统一的,操作/互操作数据的方法也是统一的,并且需要能避免词法和句法歧义,才能达到语义级互操作能力!
是不是一定要统一语义?要看数据用途:对于特定的、简单的数据任务,简化的数据模型和数据处理方法可能已经足够,但对于复杂的、跨领域的数据任务,如广泛的自然语言处理、知识图谱构建、大规模机器学习等,统一语义是非常有价值的。
显然,对于数据平台这类多用途平台,应该统一数据语义。
四. 如何建设行业统一语义数据平台
数据平台建设向统一语义迈进,而统一的行业语义模型,应该针对行业用户友好:直观、完整、语义简单、没有二义性,易于数据探索与使用。
统一语义是指要统一物理数据模型和操作数据的语言吗?是要限定到特定的技术栈吗?
先看一下数据库的结构化查询语言(SQL):众多的关系型数据库、甚至很多非关系型数据库都支持ANSI SQL语言。SQL定义了自己的语义 - 表、字段、视图、存储过程... 和自己的语法 - 数据定义语言(DDL)、数据操作语言(DML),但它并没有定义任何数据的物理存储方案!也正因如此,任何数据库厂商、任何数据物理存储方案,都可以通过自己的SQL编译器来支持SQL和SQL客户端,从而屏蔽数据库物理层差异,使用相同的SQL语言共同建设SQL生态。这也是SQL生态壮大的原因之一。
SQL的成功告诉我们,统一行业语义是对行业数据的逻辑表达层的要求,它不应对任何数据库技术底层做要求,也就是不应限定任何技术栈。
前面提到统一的数据操作/互操作能力是统一语义的一部分,是要用单一的数据操作方法吗?数据有多种操作方式,每种操作方式都有自己适用的场景,如下:
对同一份数据提供多模型的操作能力,会极大提升语义层的操作/互操作的便捷性,是非常重要的统一语义特性。重要的是可以针对同一份语义数据进行多种模型的操作/互操作,而不是建立针对每种模型的多套语义,并进行数据复制。
也就是说统一语义,并不是数据只能有一种操作/互操作方式,而应提供对同一份统一语义数据的多种操作/互操作方式。
五. InterSystems统一语义数据平台建设
基于上面的建设思路,InterSystems的医疗信息统一语义平台通过对行业语义的理解和其智能数据编织能力,提供医疗信息数据基座。
5.1 行业语义选择 - FHIR
行业语义应具有开放性、成熟性、准确性、完整性、灵活性、简单性、非二义性、可互操作性、机器可理解,并被广泛接受与认可。纵观医疗信息行业,虽然有不少通用数据模型,但目前最满足上述条件的是HL7 FHIR。它的资源模型覆盖面广,不仅是临床、还包括管理、科研等;不仅包括通用数据模型 - FHIR资源模型,还有对其统一的互操作方法 - FHIR API;按80/20原则设计,允许对资源模型和API进行扩展;资源模型和API简单、并有详细的用例指南;FHIR资源模型、API、扩展都可以被计算机理解;FHIR拥有庞大的用例,并且其触角不断扩展到医疗信息应用的各个层面和各个方向。
另外,更重要的是,FHIR的定位就是行业语义标准 - 逻辑层的标准,任何厂商只需要提供自己的FHIR服务器,就可以利用任何技术栈发布统一的FHIR资源和FHIR API,而屏蔽底层不同类型的数据存储方案、数据模型和数据操作方法。因而它是一个强大的生态标准,所有厂商和用户都可以参与其中。
InterSystems的解决方案选择FHIR作为统一语义,在支持FHIR的6种互操作范式的基础上,提供对FHIR资源的SQL投射 - 无需数据拷贝,就可以使用SQL大规模查询FHIR资源,对统计分析、机器学习提供简单易用的数据操作能力。
5.2 利用数据编织技术,无需推倒重来
如果正在规划数据平台,应考虑按统一语义建设。如果已经建设有各类数据中心,并不需要将已有的建设成果推倒重来。InterSystems的解决方案通过数据编织技术,将数据源编织在一起,并建立逻辑上的统一语义层。原有数据中心和其各类应用继续运行,通过统一语义层来支撑新的数据利用和应用创新。
InterSystems利用数据编织技术,提供针对所有数据源、数据模型、互操作标准的接入能力和适配器。现有的数据中心被视为数据源,只需接入而无需推倒现有建设成果。
InterSystems的多模型能力,将这些离散的数据源统一转换、表达,将多数据源的数据,以FHIR资源这个统一语义模型,发布多种数据模型的数据服务:包括FHIR JSON模型、FHIR对象模型、FHIR SQL模型,满足多种应用场景对统一语义数据的最佳操作方式。
InterSystems数据引擎,为统一语义层提供高性能、横向可扩展的持久化层,满足不同规模的数据用户所需的性能和弹性。
InterSystems提供FHIR与互联互通、HL7 V2、CDA等通用模型的开箱即用的转换能力和对用户自定义模型的自定义转换能力,提供全方位的统一语义互操作能力。
文章
Lele Yang · 六月 8, 2023
++ 更新:2018 年 8 月 1 日
使用内置于 Caché 数据库镜像的 InterSystems 虚拟 IP (VIP) 地址有一定的局限性。特别是,它只能在镜像成员驻留在同一网络子网时使用。当使用多个数据中心时,由于增加了网络复杂性( 此处有更详细的讨论),网络子网通常不会“延伸”到物理数据中心之外。出于类似的原因,当数据库托管在云端时,虚拟 IP 通常无法使用。
负载均衡器(物理或虚拟)等网络流量管理设备可用于实现相同级别的透明度,为客户端应用程序或设备提供单一地址。网络流量管理器自动将客户端重定向到当前镜像主服务器的真实 IP 地址。自动化旨在满足灾难后 HA 故障转移和 DR 升级的需求。
网络流量管理器的集成
当今市场上有许多支持网络流量重定向的选项。这些中的每一个都支持类似甚至多种方法来根据应用程序要求控制网络流量。为了简化这些方法,我们考虑了三个类别:数据库服务器调用 API、网络设备轮询或两者的组合。
下一节将概述这些方法中的每一个,并就如何将这些方法与 InterSystems 产品集成提供指导。在所有情况下,仲裁器都用于在镜像成员无法直接通信时提供安全的故障转移决策。可以在此处找到有关仲裁器的详细信息。
出于本文的目的,示例图将描述 3 个镜像成员:主机、备份和 DR 异步。但是,我们知道您的配置可能比这更多或更少。
选项 1:网络设备轮询(推荐)
在这种方法中,网络负载均衡设备使用其内置的轮询机制与两个镜像成员通信以确定主镜像成员。
使用 2017.1 中可用的 CSP 网关的mirror_status.cxw页面的轮询方法可以用作 ELB 健康监视器中对添加到 ELB 服务器池的每个镜像成员的轮询方法。只有主镜像会响应“SUCCESS”,从而将网络流量仅定向到活动的主镜像成员。
此方法不需要向 ^ZMIRROR 添加任何逻辑。请注意,大多数负载均衡网络设备对运行状态检查的频率都有限制。通常,最高频率不少于 5 秒,这通常可以接受以支持大多数正常运行时间服务级别协议。
对以下资源的 HTTP 请求将测试本地缓存配置的镜像成员状态。
/csp/bin/mirror_status.cxw
对于所有其他情况,这些镜像状态请求的路径应该使用与请求真实 CSP 页面所用的相同的层次机制解析到适当的缓存服务器和名称空间。
示例:测试 /csp/user/ 路径中应用程序配置服务的镜像状态:
/csp/user/mirror_status.cxw
注意:调用镜像状态检查不会消耗 CSP 许可证。
根据目标实例是否是活动主机,网关将返回以下 CSP 响应之一:
** 成功(是主镜像成员)
===============================
HTTP/1.1 200 OK
Content-Type: text/plain
Connection: close
Content-Length: 7
SUCCESS
** 失败(不是主镜像成员)
===============================
HTTP/1.1 503 Service Unavailable
Content-Type: text/plain
Connection: close
Content-Length: 6
FAILED
** 失败(Caché服务器不支持Mirror_Status.cxw请求)
===============================
HTTP/1.1 500 Internal Server Error
Content-Type: text/plain
Connection: close
Content-Length: 6
FAILED
考虑下图作为轮询的示例。
同步故障转移镜像成员之间自动发生故障转移:
下图演示了将 DR 异步镜像成员提升到负载均衡池中,这通常假设同一个负载均衡网络设备正在为所有镜像成员提供服务(地理分割方案将在本文后面介绍)。根据标准 DR 程序,灾难恢复成员的提升涉及人为决策,然后是数据库级别的简单管理操作。但是,一旦采取该操作,就不需要对网络设备执行任何管理操作:它会自动发现新的主要设备。
选项 2:数据库服务器调用 API
在这种方法中,使用了网络流量管理设备,它有一个用故障转移镜像成员和潜在的 DR 异步镜像成员定义的服务器池。
当镜像成员成为主镜像成员时,向网络设备发出 API 调用以调整优先级或权重,以立即指示网络设备将网络流量定向到新的主镜像成员。
相同的模型适用于在主镜像成员和备份镜像成员都不可用的情况下提升 DR 异步镜像成员。
此 API 在 ^ZMIRROR 代码中定义为过程调用的一部分: $$CheckBecomePrimaryOK^ZMIRROR()
在此过程调用中,插入可用于相应网络设备的任何 API 逻辑和方法,例如 REST API、命令行界面等。与虚拟 IP 一样,这是网络配置的突然更改,不涉及任何应用程序逻辑以通知连接到故障主镜像成员的现有客户端正在发生故障转移。根据故障的性质,这些连接可能由于应用程序超时或错误、新主实例强制旧主实例关闭或客户端使用的TCP 保持活动计时器过期造成的故障本身而关闭。
因此,用户可能必须重新连接并登录。您的应用程序的行为将决定此行为。
选项 3:地理分散部署
在具有多个数据中心和可能地理分散的部署(例如具有多个可用性区域和地理区域的云部署)的配置中,需要使用基于 DNS 的负载均衡和本地负载均衡在一个简单且易于支持的模型中考虑地理重定向实践。
通过这种组合模型,引入了与 DNS 服务配合使用的附加网络设备,如 Amazon Route 53、F5 Global Traffic Manager、Citrix NetScaler Global Server Load Balancing 或 Cisco Global Site Selector,在每个数据中心、可用性区域或云地理区域与网络负载均衡器相结合。
在此模型中,前面提到的轮询(推荐)或 API 方法在本地用于操作任何镜像成员(故障转移或 DR 异步)的位置。这用于向地理/全球网络设备报告它是否可以将流量定向到任一数据中心。同样在此配置中,本地网络流量管理设备将其自己的 VIP 提供给地理/全球网络设备。
在正常稳定状态下,活动主镜像成员向本地网络设备报告它是主镜像成员并提供“启动”状态。此“启动”状态被转发到地理/全球设备以调整和维护 DNS 记录,以将所有请求转发到此活动的主镜像成员。
在同一数据中心内的故障转移场景中(备份同步镜像成员成为主镜像成员),API 或轮询方法与本地负载均衡器一起使用,现在重定向到同一数据中心内的新主镜像成员。由于新的主镜像成员处于活动状态,因此本地负载均衡器仍以“启动”状态响应,因此未对地理/全局设备进行任何更改。
出于本示例的目的,API 方法在下图中用于本地集成到网络设备。
在使用 API 或轮询方法到不同数据中心(备用数据中心中的同步镜像或 DR 异步镜像成员)的故障转移场景中,新提升的主镜像成员开始向本地网络设备报告为主要成员。
在故障转移期间,曾经包含主镜像成员的数据中心现在不再从本地负载均衡器向地理/全球报告“Up”。地理/全球设备不会将流量定向到该本地设备。备用数据中心的本地设备将向地理/全球设备报告“Up”,并将调用 DNS 记录更新以现在定向到备用数据中心的本地负载均衡器提供的虚拟 IP。
选项 4:多层和地理分散的部署
为了使解决方案更进一步,引入了一个单独的 Web 服务器层,既可以作为私有 WAN 的内部,也可以通过 Internet 访问。此选项可能是大型企业应用程序的典型部署模型。
以下示例显示了使用多个网络设备安全隔离和支持 Web 和数据库层的示例配置。在此模型中,使用了两个地理位置分散的位置,其中一个位置被视为“主要”位置,另一个位置纯粹是数据库层的“灾难恢复”位置。数据库层灾难恢复位置将在主要位置因任何原因停止服务的情况下使用。此外,此示例中的 Web 层将显示为双活,这意味着用户将根据各种规则(例如最低延迟、最低连接数、IP 地址范围或您认为合适的其他路由规则)定向到任一位置。
如上例所示,如果在同一位置发生故障转移,则会发生自动故障转移,并且本地网络设备现在指向新的主机。用户仍然连接到任一位置的 Web 服务器, Web 服务器及其关联的 CSP 网关继续指向位置 A。
在下一个示例中,考虑在位置 A 发生的整个故障转移或中断,其中主要和备份故障转移镜像成员都无法使用。然后,DR 异步镜像成员将被手动提升为主要和备份故障转移镜像成员。在升级后,新指定的主镜像成员将允许位置 B 的负载均衡设备使用前面讨论的 API 方法(轮询方法也是一个选项)报告“Up”。由于本地负载均衡器现在报告“启动”,基于 DNS 的设备将识别这一点并将流量从位置 A 重定向到现在的位置 B 以用于数据库服务器服务。
结论
在没有虚拟 IP 的情况下设计镜像故障转移有许多可能的排列。这些选项可应用于最简单的高可用性场景或具有多层的多地理区域部署,包括故障转移和 DR 异步镜像成员,以获得高可用性和容灾解决方案,旨在为您的应用程序维持最高水平的运营弹性.
希望本文提供了一些关于成功部署具有故障转移的数据库镜像的可能的不同组合和用例的见解,这些组合和用例适合您的应用程序和可用性要求。
文章
Jingwei Wang · 六月 8, 2023
数据分集 (测试数据可以在网上下载 https://catalog.data.gov/dataset/)
1. 创建训练集,80%用于训练集。
CREATE TABLE DataMining.DiabetesTraining AS SELECT top 641 Pregnancies, Glucose, BloodPressure, SkinThickness, Insulin,BMI, Age, Outcome from DataMining.DSTable order by ID
2. 创建测试集,20%用于测试集。
CREATE TABLE DataMining.DiabetesTest AS SELECT top 127 Pregnancies, Glucose, BloodPressure, SkinThickness, Insulin, BMI,Age, Outcome from DataMining.DSTable order by ID DESC
Integrated ML
1. 创建ML配置
此步骤用来配置Provider 及不同Provider所使用的配置参数。
InterSystems IRIS提供三种Provider,AutoML、H2O和DataRobot,本实验使用默认Provider - AutoML ,所以可以忽略创建ML配置步骤。如果想尝试开源工具H2O,可以在此实验完成后,按照扩展实验手册进行配置。
2. ML配置
SET ML CONFIGURATION %AutoML
此步骤是用来确定选用的Provider,AutoML是系统自带的Provider。
3. 建模
CREATE MODEL DiabetesModel PREDICTING (Outcome) FROM DataMining.DiabetesTraining
DiabetesModel 为模型名称 (模型名称可随意设置)。 DataMining.DiabetesTraining 为糖尿病患者预测模型的训练数据集。 Outcome 为要预测的结果的列名。
4. 训练模型
TRAIN MODEL DiabetesModel
DiabetesModel为模型名称。
5. 验证模型
VALIDATE MODEL DiabetesModel FROM DataMining.DiabetesTest
DataMining.DiabetesTest为糖尿病患者预测模型的测试集。
6. 查看模型信息
SELECT * FROM INFORMATION_SCHEMA.ML_TRAINED_MODELS
在返回的数据PROVIDER列中,可以或者 在返回的数据MODEL_INFO列中,可以获得ModelType 算法名称, Package 机器学习处理包, ProblemType 算法类型等结果。
6. 查看验证结果
SELECT * FROM INFORMATION_SCHEMA.ML_VALIDATION_METRICS
可以获得Accuracy,Precision,Recall 和 F-Measure 计算结果。 现在,你可以通过Accuracy,Precision,Recall 和 F-Measure 来分析你的模型训练结果。如果训练模型准确率较低,可以重新训练数据集。
7. 查看测试集的预测结果和真实结果
SELECT PREDICT(DiabetesModel) AS PredictedDiabetes, Outcome AS ActualDiabetes FROM DataMining.DiabetesTest
8. 删除模型
DROP MODEL DiabetesModel