清除过滤器
公告
Claire Zheng · 七月 7
InterSystems 发布了新的点式更新,该更新解决的缺陷问题影响以下受支持的产品线的最新先前版本 2025.1.0、2024.1.4、2023.1.6 和 2022.1.7:
InterSystems IRIS
InterSystems IRIS for Health
HealthShare Health Connect
此问题可能导致在使用以下功能时出现意外的 <PROTECT> 错误或访问异常:
隐式命名空间
对数据库的混合只读/读写访问
用于列出例程和全局变量的管理门户页面
症状包括:
命名空间创建故障
在列出例程时,间歇性出现“访问被拒”错误
对于具有只读权限的用户,全局显示页面不返回数据
虽然这些问题并不影响访问控制或用户权限,但它们会在多种场景下影响预期的系统行为。
问题得到解决的版本
以下点式版本中修复了该问题:
2025.1.0.230.2
2024.1.4.516.1
2023.1.6.810.1
2022.1.7.116.1
建议使用受影响版本的客户应用相关更新,以确保系统正常运行。
如果您有任何问题或需要支持,请联系 InterSystems 全球响应中心 (WRC)。
公告
Claire Zheng · 七月 7
摘要
公告编号
受影响的产品和版本
风险类别和评分
明确要求
DP-439649
产品:
InterSystems IRIS®
InterSystems IRIS for Health
HealthShare® Health Connect
版本:
2025.1.0.225.1
2025.1.0.223.0
2024.1.4
2023.1.6
2022.1.7
操作:4 – 高风险
系统稳定性:3 – 中等风险
此问题不构成安全漏洞。 它不允许用户绕过权限检查或访问其授权命名空间之外的数据
使用隐含命名空间、管理门户或数据库读写/只读混合访问权限
在命名空间之间切换或使用以下任何功能访问环境中的全局变量时,上面列出的 InterSystems 产品中的问题可能会引发意外的 <PROTECT> 错误:
隐含命名空间
只读访问默认数据库,但读写访问其他地方
列出例程和全局项的管理门户页面
该问题的症状包括:
存在命名空间创建故障 (DP-440830)
在管理门户中列出例程时,间歇性出现访问被拒的情况 (DP-439622)
全局显示实用工具不显示全局变量(如果用户只有只读权限)(DP-440744)
DP-439649 已解决了所有这些问题,纠正了权限检查应用于进程私有全局和隐含命名空间解析的方式。 这些纠正措施针对的是行为中的失误,而不是访问控制中的失误。 权限得到了正确执行,用户无法访问其分配范围之外的全局变量或命名空间
此问题在以下产品的 2025.1.0.230.2、2024.1.4.516.1、2023.1.6.810.1 和 2022.1.7.116.1 版中得到了解决:
InterSystems IRIS
InterSystems IRIS for Health
HealthShare® Health Connect
了解更多信息
如果您有任何问题或需要帮助,请联系 InterSystems 全球响应中心 (WRC)。
公告
Claire Zheng · 六月 22
适用于 InterSystems IRIS® 数据平台、InterSystems IRIS® for HealthTM 和 HealthShare® Health Connect 的维护版本 2024.1.4 和 2023.1.6 现已正式发布 (GA)。 这些版本包含对最近发布的以下提醒的修复 - 提醒:SQL 查询返回错误结果 | InterSystems。 请通过开发者社区分享您的反馈,以便我们可以共同打造更出色的产品。
文档
您可以在以下页面上找到详细的变更列表和升级核对清单:
InterSystems IRIS
InterSystems IRIS for Health
HealthShare Health Connect
抢先体验计划 (EAP)
目前提供多个 EAP。 请查看此页面并注册您感兴趣的 EAP。
如何获取软件?
InterSystems IRIS 和 InterSystems IRIS for Health 的完整安装包可以从本 WRC 的 InterSystems IRIS 数据平台完整工具包页面 获取。 HealthShare Health Connect 工具包可以从 WRC 的 HealthShare 完整工具包页面获取。 容器镜像可以从 InterSystems 容器注册表中获取。
可用性和软件包信息
此版本提供了适用于所有受支持平台的经典安装包,以及 Docker 容器格式的容器镜像。有关完整列表,请参阅“支持的平台”文档。 这些维护版本的内部版本号为:2024.1.4.512.0 和 2023.1.6.809.0。
公告
Claire Zheng · 六月 20
InterSystems 宣布 InterSystems IRIS、InterSystems IRIS for Health 和 HealthShare Health Connect 2025.1 正式发布
2025.1 版的 InterSystems IRIS® 数据平台、InterSystems IRIS® for HealthTM 和 HealthShare® Health Connect 现已正式发布 (GA)。 这是扩展维护 (EM) 版本。
版本亮点
在这个激动人心的版本中,用户可以期待一些新功能和增强,包括:
高级向量搜索功能
新的基于磁盘的近似最近邻 (ANN) 索引显著提高了向量搜索查询速度,在数百万个向量上产生亚秒级响应。 请访问以下练习,了解更多信息 - 使用 InterSystems SQL 对文本进行向量化和搜索。
增强的商业智能
IRIS BI 多维数据集构建和同步中的自动依赖项分析,确保复杂多维数据集依赖项中的一致性和完整性。
改进的 SQL 和数据管理
引入了标准 SQL 分页语法 (LIMIT... OFFSET..., OFFSET... FETCH...)。
新的 LOAD SQL 命令,可以简化 DDL 语句的批量导入。
增强的 ALTER TABLE 命令,可以在行布局和列布局之间无缝转换。
优化的数据库操作
日志记录大小更小,效率更高。
数据库压缩速度更快,尤其是对于具有大量大字符串内容的数据库。
将新数据库添加到镜像时的自动化程度更高。
用于 ECP 管理任务的新命令行实用工具。
更高的安全合规性
支持符合 FIPS 140-3 标准的加密库。
现代化的互操作性用户界面
选择参与经过改进的生产配置和 DTL 编辑器体验,其中包含源代码控制集成、VS Code 兼容性、增强的筛选功能、分屏视图等。请参阅此开发者社区文章,详细了解如何选择参与并提供反馈。
更多的医疗保健功能
高效的批量 FHIR 引入和调度,包括完整性检查和资源管理。
增强的 FHIR 批量访问和经过改进的 FHIR 搜索操作。
新的开发者体验功能
DTL 编辑器中支持嵌入式 Python,可以让精通 Python 的开发者更高效地利用 InterSystems 平台。 要了解详情,请观看以下视频 - 在 BPL 和 DTL 编辑器中使用嵌入式 Python。
通过 OpenTelemetry 提高可观测性
在 IRIS 中引入了跟踪功能,有助于详细观测 Web 请求和应用程序的性能。
请通过开发者社区分享您的反馈,以便我们可以共同打造更出色的产品。
文档
访问以下链接,可以详细了解所有着重介绍的功能:
InterSystems IRIS 2025.1 文档和版本说明。
InterSystems IRIS for Health 2025.1 文档和版本说明。
Health Connect 2025.1 文档和版本说明。
此外,请查看升级影响核对清单,轻松了解升级到此版本时需要注意的所有变更。
尤其是,请注意 InterSystems IRIS 2025.1 引入了新的日志文件格式版本,该格式与早期版本不兼容,因而给混合版本的镜像设置带来了一定的限制。 请参阅相应的文档了解更多详细信息。
抢先体验计划 (EAP)
目前提供多个 EAP。 请查看此页面并注册您感兴趣的 EAP。
下载软件
一如既往,扩展维护 (EM) 版本提供了适用于所有受支持平台的经典安装包,以及 Docker 容器格式的容器镜像。
经典安装包
安装包可以从 WRC 的 InterSystems IRIS 页面(对于 InterSystems IRIS 和 InterSystems IRIS for Health)和 WRC 的 HealthShare 页面(对于 Health Connect)获取。 您也可以在评估服务网站中找到工具包。
可用性和软件包信息
此版本提供了适用于所有受支持平台的经典安装包,以及 Docker 容器格式的容器镜像。有关完整列表,请参阅“支持的平台”文档。
此扩展维护版本的内部版本号为 2025.1.0.223.0。
容器镜像可以从 InterSystems 容器注册表中获取。 容器被标记为 2025.1 和 latest-em。
文章
Claire Zheng · 六月 19
互操作性用户界面现在包括可以在所有互操作性产品中使用的 DTL 编辑器和生产配置应用程序的现代化用户体验。您可以在现代化视图与标准视图之间切换。所有其他互操作性屏幕仍采用标准用户界面。请注意,仅对这两个应用程序进行了更改,我们在下面确定了当前可用的功能。
要在升级前试用新屏幕,您可以点击这里,从我们的社区工具包网页中下载 2025.1 版:https://evaluation.intersystems.com/Eval/。请观看“学习服务”中的简短教程构建集成:一种新的用户体验,了解对这些屏幕进行的用户增强!
生产配置 - 配置任务简介
生产配置:在以下版本的生产配置中受支持:
创建/编辑/复制/删除主机
停止/启动主机
编辑生产设置
停止/启动生产
源代码控制集成:支持上述配置功能的源代码控制集成。
分屏 视图:用户可以直接从“生产配置”屏幕打开“规则编辑器”和“DTL 编辑器”,在分屏视图中查看和编辑产品中包含的规则和转换。
增强的筛选功能:使用顶部的搜索框,您可以搜索和筛选各种业务组件,包括多种类别、DTL 和子转换。 使用左侧边栏可以独立于主面板进行搜索,查看各种主机和类别中的搜索结果。
批量编辑主机类别:通过从生产配置中添加主机,您可以为生产添加新类别或编辑现有类别。
可展开路由器:可以展开路由器,内联查看所有规则、转换和连接。
重新设计的主机连接:现在,在选择业务主机时,将呈现直接连接和间接连接,您可以查看消息能够采用的完整路径。 将鼠标悬停在任何出站或入站主机上可以进一步区分连接。如果开启仅显示连接的主机开关,将仅筛选所选主机及其连接。
DTL 编辑器 - DTL 工具简介
源代码控制集成:支持源代码控制集成。
VS Code 集成:用户可以在其 VS Code IDE 中查看此版本的 DTL 编辑器。
嵌入式 Python 支持:此版本的 DTL 编辑器现在支持嵌入式 Python。
DTL 测试:可以在此版本的 DTL 编辑器中使用 DTL 测试实用工具。
切换面板布局:DTL 编辑器支持侧面到侧面和顶部到底部布局。 点击顶部功能区的布局按钮可以体验此功能。
撤消/重做:用户可以使用撤消/重做按钮撤消和重做所有尚未保存为代码的操作。
“生成空段”参数:GENERATEEMPTYSEGMENTS 参数可用于为缺失的字段生成空段。
子转换查看:用户可以点击眼睛图标,在新选项卡中打开子转换 DTL,查看子转换。
滚动:
单独滚动:将光标放置在 DTL 的左右两部分(源和目标)其中之一的上方,并用滚轮或触控板垂直移动各段,可以单独滚动各个部分。
联合滚动:将光标放置在图的中间,可以联合滚动源部分和目标部分。
字段自动补全:自动补全适用于:“源”、“目标”和“条件”字段以及源类、源文档类型、目标类、目标文档类型。
顺序编号:使用可视化编辑器,您可以打开和关闭查看每个段的序数和完整路径表达式的功能。
轻松引用:当操作编辑器中的某个字段获得焦点时,在图形化编辑器中双击某个段会在操作编辑器中的当前光标位置插入相应的段引用。
同步:点击可视化编辑器中的一个元素,可以在操作编辑器中高亮显示相应的行。
📣号召性用语📣
如果您有任何反馈,请通过以下途径提供给我们:
✨跨所有互操作性的新功能:在 Ideas 门户中输入想法,或在 InterSystems Ideas 门户中参与其他想法。 对于新想法,请在您的帖子上添加“互操作性”标签或对列表中已提出的功能进行投票!
💻跨所有互操作性的一般用户体验反馈:请在下面输入您的反馈或参与其他评论。
🗒对现代化应用程序的建议/反馈(如上所述):请在下面输入您的反馈或参与其他评论。
请考虑利用 Global Masters 的机会,与团队进行互动,参与不公开的指导反馈会议,并获得积分! 点击此处,通过 Global Masters 报名参加这些会议。
如果您希望以私人形式提供任何其他反馈,请通过电子邮件将您的想法或问题发送至:ux@intersystems.com
公告
Claire Zheng · 六月 3
Hi 开发者们!
我们来宣布 InterSystems 2025开发者竞赛:FHIR和数字医疗健康互操作性的优胜者!
感谢我们的参赛者,我们收到了 11份应用! 🔥
我们来宣布这些优胜者吧!
专家提名奖(Experts Nomination)
🥇第一名 - 5,000 美元 获奖项目 FHIRInsight app,开发者 @José.Pereira, @henry, @Henrique
🥈 第二名 - 2,500 美元 获奖项目 iris-fhir-bridge app,开发者@Muhammad.Waseem
🥉 第三名 - 1,000 美元 获奖项目 health-gforms app,开发者@Yuri.Gomes
🏅 第四名 - 500 美元 获奖项目 fhir-craft app,开发者@Laura.BlázquezGarcía
🏅 第五名 - 300 美元 获奖项目 CCD Data Profiler app,开发者@Landon.Minor
🌟 $100 获奖项目 IRIS Interop DevTools app,开发者@Chi.Nguyen-Rettig
🌟 $100 获奖项目 hc-export-editor app,开发者@Eric.Fortenberry
🌟 $100 获奖项目 iris-medbot-guide app,开发者 @shan.yue
🌟 $100 获奖项目 Langchain4jFhir app,开发者@ErickKamii
🌟 $100 获奖项目 ollama-ai-iris app,开发者@Oliver.Wilms
社区提名奖(Community Nomination)
🥇 第一名 - 1,000 美元 获奖项目 iris-medbot-guide app,开发者@shan.yue
🥈第二名 - 600 美元 获奖项目 FHIRInsight app,开发者@José.Pereira, @henry, @Henrique
🥉第三名 - 300 美元 获奖项目 FhirReportGeneration app,开发者@XININGMA
🏅 第四名-200 美元 获奖项目 iris-fhir-bridge app,开发者@Muhammad.Waseem
🏅 第五名-100美元 获奖项目 fhir-craft app,开发者@Laura.BlázquezGarcía
向获奖者表示最诚挚的祝贺!
一起来期待下次竞赛吧!
文章
jieliang liu · 五月 22
基于 XSLT 的互联互通临床文档到 FHIR 资源转换
国家卫健委互联互通成熟度评测中的临床共享文档,作为医疗信息交换的重要载体,采用了XML标准的文档格式。随着医疗信息化的发展,FHIR(Fast Healthcare Interoperability Resources)作为新一代医疗信息交换标准,因其简洁性、灵活性和RESTful架构,逐渐成为医疗数据交换的理想选择。将共享文档文档转换为FHIR资源,能够有效促进不同医疗系统间的数据互通,提升医疗信息的利用价值。
XSLT(可扩展样式表语言转换)是一种用于将XML文档转换为其他XML文档或文本格式的语言。在医疗数据转换场景中,XSLT凭借其强大的XML处理能力,成为共享文档到FHIR转换的理想工具。
我们知道共享文档文档是一种结构化的XML文档,通常包含以下主要部分:
- 文档头(Document Header):包含文档元数据,如文档类型、创建时间、作者等
- 临床数据部分(Clinical Sections):按章节组织的临床信息,如问题列表、用药记录、检查报告等
- 数据条目(Entries):具体的临床数据项,如诊断、药物、检验结果等
FHIR则采用了资源导向的设计理念,每个临床概念都被建模为独立的资源,通过RESTful API进行访问。FHIR资源具有以下特点:
- 模块化设计:每个资源专注于特定的临床领域,如Patient(患者)、Condition(疾病)、MedicationRequest(用药申请)等
- 灵活的数据结构:支持复杂的数据类型和嵌套结构
- 丰富的语义表达:通过代码系统和扩展机制提供标准化的术语支持
互联互通共享文档到FHIR的转换并非简单的格式转换,而是需要在保持临床语义的前提下,将共享文档的文档结构映射到FHIR的资源模型。这需要深入理解两种标准的数据模型和语义。
在Intersystems IRIS中,我们内嵌了我司创建的SDA医疗数据模型,此模型也是以xml为结构,并且在IRIS中已经开箱即用地实现了SDA模型到FHIR资源的转化,所以在IRIS互联互通套件中把共享文档向FHIR资源转化的思路就变成了由互联互通共享文档->SDA文档->FHIR资源的转化流程。(关于我司SDA数据模型的介绍参见https://docs.intersystems.com/irisforhealth20251/csp/docbook/Doc.View.cls?KEY=HXSDA_ch_sda#HXSDA_sda_structure)
下面是一个使用XSLT将互联互通文档中的信息转换为SDA再使用IRIS开箱即用功能转为FHIR资源的示例:
在互联互通套件中,我们已经实现了由互联互通文档向SDA转化的xslt,这些xslt在https://gitee.com/jspark/CCHDist 代码仓库的https://gitee.com/jspark/CCHDist/tree/master/image-iris/src/hccns/Setting/HCC 部分可以找到,文件名为HCC2SDA.xsl,其内引用的其他xlst模版也在相同文件夹下。
互联互通文档转化为SDA文档的示例代码:
Method HCCToSDA(pHCC As %Stream.Object, ByRef pSDA As %Stream.Object) As %Status
{
Set tSC = $$$OK
Try
{
If $ISOBJECT(pSDA) &&(pSDA.%IsA("%Stream.Object"))
{
}
Else
{
Set tSC = $$$ERROR(-10000,"Input parameter pSDA is not a stream")
Quit
}
// transfter to SDA first
Set tSlash = $Case($system.Version.GetOS(),"Windows":"\",:"/")
Set tXSL="file:///"_$SYSTEM.Util.InstallDirectory()_"csp"_tSlash_"xslt"_tSlash_"HCC"_tSlash_"HCC2SDA.xsl"
Set tSC = ..Transformer.Transform(pHCC,tXSL,.tSDA)
Quit:($$$ISERR(tSC))
D pSDA.CopyFrom(tSDA)
// store SDA for debug purpose
if (..Debug=1)
{
Set ..FileGUID = $Case($system.Version.GetOS(),"Windows":"\",:"/")_$SYSTEM.Util.CreateGUID()
Set tSDAFile=##class(%Stream.FileCharacter).%New()
Set tSC=tSDAFile.LinkToFile(..DebugPath_..FileGUID_".XML")
Set tSDAFile.TranslateTable="UTF8"
Do tSDAFile.Write(pSDA.Read())
Do tSDAFile.%Save(),tSDAFile.%Close()
Kill tSDAFile
}
}
Catch ex
{
Set tSC=ex.AsStatus()
}
Quit tSC
}
由SDA转化为FHIR资源的示例代码:
Method SDAToFHIR(pSDA As %Stream.Object, ByRef pFHIR As %Stream.Object) As %Status
{
If ($ISOBJECT(pSDA) && pSDA.%IsA("%Stream.Object"))
{}
Else
{
Quit $$$ERROR(-10000,"Input parameter pSDA is not a stream")
}
Set tSC = $$$OK
Try
{
// transfer SDA to FHIR
Set tFHIR = ##class(HS.FHIR.DTL.Util.API.Transform.SDA3ToFHIR).TransformStream(pSDA,"HS.SDA3.Container","R4")
If ('$ISOBJECT(tFHIR))
{
K tFHIR
Set tSC = $$$ERROR(-10000,"SDA transfer to FHIR error!")
Quit
}
Else
{
Set:($Get(pFHIR)="") pFHIR=##class(%Stream.TmpCharacter).%New()
Do pFHIR.Write(tFHIR.bundle.%ToJSON())
Do tFHIR.%Close()
// store SDA for debug purpose
if ..Debug=1
{
Set tFHIRFile=##class(%Stream.FileCharacter).%New()
Set tSC=tFHIRFile.LinkToFile(..DebugPath_..FileGUID_".JSON")
Set tFHIRFile.TranslateTable="UTF8"
Do pFHIR.Rewind()
Do tFHIRFile.Write(pFHIR.Read())
D tFHIRFile.%Save(),tFHIRFile.%Close()
K tFHIRFile
}
}
}
Catch ex
{
Set tSC=ex.AsStatus()
}
Quit tSC
}
综合起来互联互通文档转化为FHIR资源的示例,这里pFHIR的输出就是得到的fhir资源:
Method HCCToFHIR(pHCC, ByRef pFHIR) As %Status
{
If ($ISOBJECT(pHCC) && pHCC.%IsA("%Stream.Object"))
{}
Else
{
Quit $$$ERROR(-10000,"Input parameter pHCC is not a stream")
}
// transfter to SDA first
Set tSDA = ##class(%Stream.GlobalCharacter).%New()
Set tSC = ..HCCToSDA(pHCC,.tSDA)
Quit:($$$ISERR(tSC)) tSC
// store SDA for debug purpose
Set tSC = ..SDAToFHIR(tSDA,.pFHIR)
Quit tSC
}
在我们的IRIS互联互通套件里实现了由共享文档生成再到FHIR资源的转化的全部流程,https://gitee.com/jspark/CCHDist 可以在这个代码仓库中找到IRIS互联互通套件的代码实现以及相关介绍文档。
文章
jieliang liu · 五月 15
各位开发者,大家好!
或许您不得不实现一些场景,这些场景不需要 FHIR 仓库但需要转发 FHIR 请求、管理响应,并且可能运行转换或在两者之间提取一些值。 在这里,您会找到一些可以使用 *InterSystems IRIS For Health* 或 *HealthShare Health Connect* 实现的示例。
在这些示例中,我使用了具有 [FHIR 互操作性适配器](https://docs.intersystems.com/irisforhealthlatest/csp/docbook/DocBook.UI.Page.cls?KEY=HXFHIR_fhir_adapter)和 `HS.FHIRServer.Interop.Request` 消息的互操作性生产配置。
第一个场景从头开始构建 FHIR 请求(可以来自文件,也可以来自 SQL 查询),然后将其发送到外部 FHIR 服务。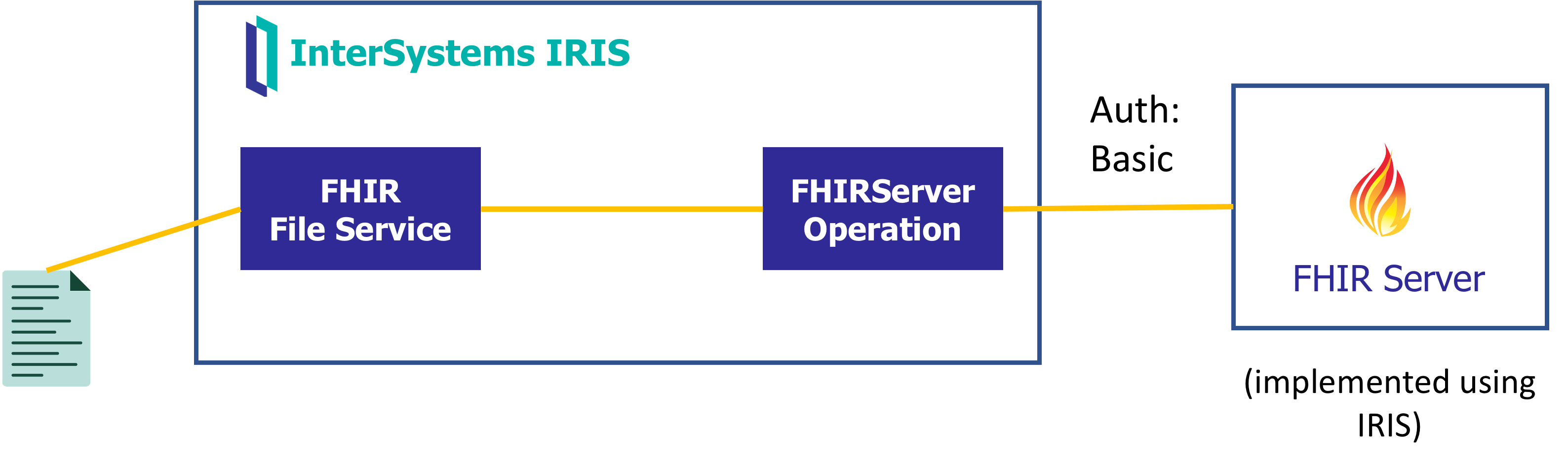
下一个场景是一种 FHIR 传递,用于将请求和响应传递到外部 FHIR 仓库,另外还管理 OAuth 令牌。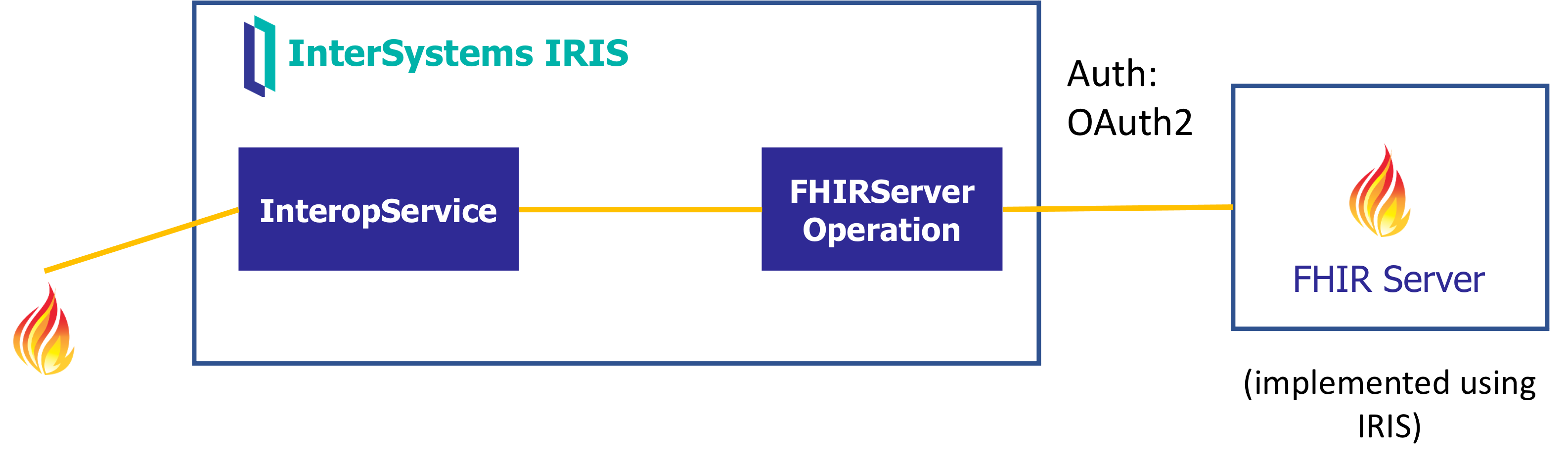
最后一个场景包括接收 FHIR 请求,然后将其转发到外部 FHIR 服务,但会提取信息或更改其间的某些字段。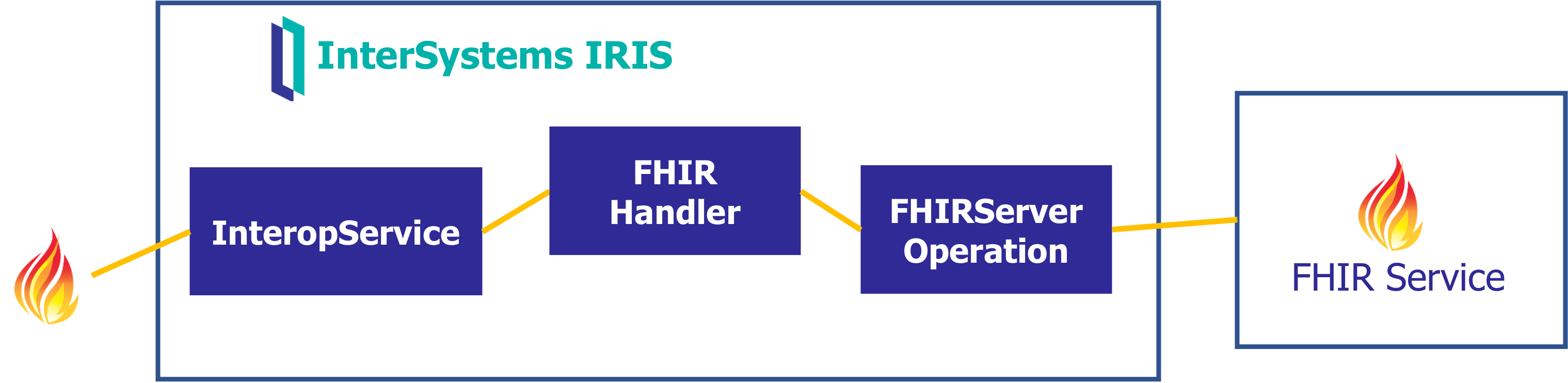
您将在 Open Exchange 应用程序中找到实现细节 :)
希望这对您有用!
文章
jieliang liu · 五月 15
在本文中,我们将使用基于分布式存储的 Kubernetes 部署来构建一个 IRIS 的高可用配置,而不使用“传统的”IRIS Mirror。 这种部署将能够容忍与基础架构相关的故障,如节点、存储和可用区故障。 所描述的方法可以大大降低部署的复杂性,代价是 RTO的略微延长。 图 1 - 传统镜像与采用分布式存储的 Kubernetes
本文的所有源代码均可在 https://github.com/antonum/ha-iris-k8s 下载TL;DR
假设您有一个正在运行的 3 节点集群,并且您对 Kubernetes 有一定了解 – 请继续:
kubectl apply -f https://raw.githubusercontent.com/longhorn/longhorn/master/deploy/longhorn.yaml
kubectl apply -f https://github.com/antonum/ha-iris-k8s/raw/main/tldr.yaml
如果您不确定上面两行有什么作用,或者没有可执行这些命令的系统,请跳转至“高可用性要求”部分。 我们将在后面详细介绍。
第一行安装 Longhorn - 开源分布式 Kubernetes 存储。 第二行安装 InterSystems IRIS ,将基于 Longhorn 的卷用于 Durable SYS。
等待所有 pod 进入运行状态。 kubectl get pods -A
您现在应该能通过 http://<IRIS Service Public IP>:52773/csp/sys/%25CSP.Portal.Home.zen(默认密码为“SYS”)访问 IRIS 管理门户,并通过以下命令访问 IRIS 命令行:
kubectl exec -it iris-podName-xxxx -- iris session iris
模拟故障
现在开始制造一些混乱。 但在操作之前,先尝试将一些数据添加到数据库中,并确保当 IRIS 重新上线后数据仍然存在。
kubectl exec -it iris-6d8896d584-8lzn5 -- iris session iris
USER>set ^k8stest($i(^k8stest))=$zdt($h)_" running on "_$system.INetInfo.LocalHostName()
USER>zw ^k8stest
^k8stest=1
^k8stest(1)="01/14/2021 14:13:19 running on iris-6d8896d584-8lzn5"
我们的“混乱工程”从这里开始:
# Stop IRIS - Container will be restarted automatically
kubectl exec -it iris-6d8896d584-8lzn5 -- iris stop iris quietly
# Delete the pod - Pod will be recreated
kubectl delete pod iris-6d8896d584-8lzn5
# "Force drain" the node, serving the iris pod - Pod would be recreated on another node
kubectl drain aks-agentpool-29845772-vmss000001 --delete-local-data --ignore-daemonsets --force
# Delete the node - Pod would be recreated on another node
# well... you can't really do it with kubectl. Find that instance or VM and KILL it.
# if you have access to the machine - turn off the power or disconnect the network cable. Seriously!
高可用性要求
我们正在构建可以容忍以下故障的系统:
容器/VM 内的 IRIS 实例。 IRIS – 级别故障。
pod/容器故障。
个别集群节点暂时不可用。 一个典型的例子是可用区临时下线。
个别集群节点或磁盘的永久性故障。
基本上,是我们刚才在“模拟故障”部分中尝试实现的场景。
如果发生上述任何一种故障,系统应该在没有任何人工干预的情况下保持在线,并且没有数据丢失。 从技术上说,数据持久性的保证是有限制的。 IRIS 本身可以根据应用程序内的日志循环和事务使用情况提供:https://docs.intersystems.com/irisforhealthlatest/csp/docbook/Doc.View.cls?KEY=GCDI_journal#GCDI_journal_writecycle。无论如何,我们讨论的是低于两秒的 RPO(恢复目标时间)。
系统的其他组件(Kubernetes API 服务、etcd 数据库、LoadBalancer 服务、DNS 等等)不在讨论范围内,它们通常由 Azure AKS 或 AWS EKS 等托管 Kubernetes 服务管理,因此我们假定它们已经高度可用。
换一个角度看 – 我们负责处理个别的计算和存储组件故障,并假设其余故障由基础设施/云提供商处理。
架构
在谈到 InterSystems IRIS 的高可用性时,传统的建议是使用镜像。 使用镜像时,有两个始终在线的 IRIS 实例同步复制数据。 每个节点都维护一个完整的数据库副本,如果主节点宕机,用户将重新连接到备份节点。 本质上,在镜像方法中,IRIS 负责计算和存储的冗余。
利用部署在不同可用区的Mirror,镜像方法提供了容忍计算和存储故障所需的冗余,并且实现了只有几秒的出色 RTO(目标恢复时间或系统在故障后重新上线所需的时间)。 您可以在以下网址找到在 AWS 云上部署 IRIS Mirror的模板:https://community.intersystems.com/post/intersystems-iris-deployment%C2%A0guide-aws%C2%A0using-cloudformation-template
Mirror的缺点是设置、执行备份/恢复程序比较复杂,而且缺少对安全设置和本地非数据库文件的复制。
Kubernetes 等容器编排器通过部署对象提供计算冗余,在出现故障时会自动重启有故障的 IRIS Pod/容器。 所以在 Kubernetes 架构图上只能看到一个 IRIS 节点在运行。 我们没有让另一个 IRIS 节点始终保持运行,而是将计算可用性外包给 Kubernetes。 Kubernetes 将确保当原始 pod 因任何原因发生故障时,重新创建 IRIS pod。
图 2 故障转移方案
到目前为止还不错... 如果 IRIS 节点发生故障,Kubernetes 就会创建一个新节点。 根据集群的情况,发生计算故障后,让 IRIS 重新上线需要 10 到 90 秒的时间。 相对于Mirror只需要几秒即可恢复,这确实有些退步,但如果万一发生中断时您可以容忍这一点,那么回报就是复杂度大大降低。 无需配置镜像。 无需担心安全设置和文件复制。
说实话,如果您在容器内登录,在 Kubernetes 中运行 IRIS,您甚至不会注意到您正在高可用环境中运行。 一切都像单实例 IRIS 部署一样。
等等,那存储呢? 我们还要处理数据库... 无论我们想象到什么样的故障转移方案,我们的系统都应该确保数据持久性。 Mirror依赖于 IRIS 节点本地的计算。 如果节点故障或只是暂时不可用 – 该节点的存储也会变得如此。 这就是IRIS 需要在Mirror配置内解决 IRIS 层面的数据复制的原因。
我们需要的存储不仅能在容器重启后保留数据库的状态,而且能针对节点或整个网段(可用区)宕机等事件提供冗余。 就在几年前,这个问题还没有简单的答案。 不过从上图可以猜到 – 我们现在有了这样的答案。 它称为分布式容器存储。
分布式存储将多个基础主机卷抽象成一个联合存储,供 k8s 集群的每个节点使用。 在本文中,我们使用 Longhorn https://longhorn.io;它免费、开源且相当容易安装。 但是您也可以看看其他提供相同功能的产品,例如 OpenEBS、Portworx 和 StorageOS。 Rook Ceph 是另一个可以考虑的 CNCF 孵化项目。 在高端领域 – 有企业级存储解决方案,如 NetApp、PureStorage 等。
分步指南
在 TL;DR 部分中,我们一次性安装了整套系统。 附录 B 将指导您完成逐步安装和验证过程。
Kubernetes 存储
让我们往回退一步,从总体上谈谈容器和存储,以及 IRIS 如何融入其中。
默认情况下,容器内的所有数据都是暂时的。 当容器消亡时,数据也会消失。 在 docker 中,可以使用卷的概念。 本质上,它允许将主机操作系统上的目录公开给容器。
docker run --detach
--publish 52773:52773
--volume /data/dur:/dur
--env ISC_DATA_DIRECTORY=/dur/iconfig
--name iris21 --init intersystems/iris:2020.3.0.221.0
在上面的示例中,我们启动了 IRIS 容器,并使主机本地的“/data/dur”目录可以被“/dur”挂载点上的容器访问。 所以,容器在该目录内存储的任何内容都会保留下来,并可在下次容器启动时使用。
在 IRIS 方面,我们可以通过指定 ISC_DATA_DIRECTORY 来指示 IRIS 将所有需要在容器重启后存活的数据存储在特定目录中。 Durable SYS 是您可能需要在文档 https://docs.intersystems.com/irisforhealthlatest/csp/docbook/Doc.View.cls?KEY=ADOCK#ADOCK_iris_durable_running 中查找的 IRIS 功能的名称
在 Kubernetes 中,语法有所不同,但概念是相同的。
以下是 IRIS 的基本 Kubernetes 部署。
apiVersion: apps/v1
kind: Deployment
metadata:
name: iris
spec:
selector:
matchLabels:
app: iris
strategy:
type: Recreate
replicas: 1
template:
metadata:
labels:
app: iris
spec:
containers:
- image: store/intersystems/iris-community:2020.4.0.524.0
name: iris
env:
- name: ISC_DATA_DIRECTORY
value: /external/iris
ports:
- containerPort: 52773
name: smp-http
volumeMounts:
- name: iris-external-sys
mountPath: /external
volumes:
- name: iris-external-sys
persistentVolumeClaim:
claimName: iris-pvc
在上面的部署规范中,“volumes”部分列出了存储卷。 可以在容器外部通过“iris-pvc”等 persistentVolumeClaim 访问它们。 volumeMounts 在容器内公开了此卷。 “iris-external-sys”是将卷挂载绑定到特定卷的标识符。 在现实中,我们可能有多个卷,此名称即用来区分各个卷。 如果您愿意,还可以叫它“steve”。
我们已经熟悉的环境变量 ISC_DATA_DIRECTORY 指示 IRIS 使用一个特定挂载点来存储所有需要在容器重启后存活的数据。
现在,我们来看一下持久卷声明 iris-pvc。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: iris-pvc
spec:
storageClassName: longhorn
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
相当直接。 请求 10 GB,只能在一个节点上以读/写方式挂载,使用“longhorn”存储类。
storageClassName: longhorn 在这里实际上很关键。
我们看一下我的 AKS 集群上可用的存储类:
kubectl get StorageClass
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
azurefile kubernetes.io/azure-file Delete Immediate true 10d
azurefile-premium kubernetes.io/azure-file Delete Immediate true 10d
default (default) kubernetes.io/azure-disk Delete Immediate true 10d
longhorn driver.longhorn.io Delete Immediate true 10d
managed-premium kubernetes.io/azure-disk Delete Immediate true 10d
默认安装了 Azure 的几个存储类,还有一个来自于 Longhorn,是我们在第一个命令中安装的:
kubectl apply -f https://raw.githubusercontent.com/longhorn/longhorn/master/deploy/longhorn.yaml
如果在持久卷声明定义中注释掉 #storageClassName: longhorn,则将使用当前标记为“default”的存储类,它是一个常规 Azure 磁盘。
为了说明为什么需要分布式存储,让我们重复本文开头所述的没有 longhorn 存储的“混乱工程”实验。 前两种情况(停止 IRIS 和 删除 Pod)将成功完成,系统将恢复到运行状态。 尝试耗尽或终止节点将使系统进入故障状态。
#forcefully drain the node
kubectl drain aks-agentpool-71521505-vmss000001 --delete-local-data --ignore-daemonsets
kubectl describe pods
...
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 57s (x9 over 2m41s) default-scheduler 0/3 nodes are available: 1 node(s) were unschedulable, 2 node(s) had volume node affinity conflict.
基本上,Kubernetes 会尝试重启集群上的 IRIS pod,但最初启动该 pod 的节点不可用,另外两个节点存在“卷节点相关性冲突”。 对于这种存储类型,卷只在最初创建它的节点上可用,因为它基本上与节点主机上可用的磁盘绑定。
使用 longhorn 作为存储类时,“强制耗尽”和“节点终止”实验均会成功,并且 IRIS pod 很快会恢复运行。 为了实现这一目标,Longhorn 控制了集群的 3 个节点上的可用存储,并将数据复制到全部三个节点上。 如果其中一个节点永久不可用,Longhorn 会迅速修复集群存储。 在我们的“节点终止”场景中,系统立即使用其余的两个卷副本在其他节点上重启 IRIS pod。 然后,AKS 提供一个新节点来替换丢失的节点,一旦准备就绪,Longhorn 就会介入,并在新节点上重建所需数据。 一切都是自动的,不需要您参与。
图 3 Longhorn 在替换的节点上重建卷副本。
更多有关 k8s 部署的信息
我们看一下部署的其他几个方面:
apiVersion: apps/v1
kind: Deployment
metadata:
name: iris
spec:
selector:
matchLabels:
app: iris
strategy:
type: Recreate
replicas: 1
template:
metadata:
labels:
app: iris
spec:
containers:
- image: store/intersystems/iris-community:2020.4.0.524.0
name: iris
env:
- name: ISC_DATA_DIRECTORY
value: /external/iris
- name: ISC_CPF_MERGE_FILE
value: /external/merge/merge.cpf
ports:
- containerPort: 52773
name: smp-http
volumeMounts:
- name: iris-external-sys
mountPath: /external
- name: cpf-merge
mountPath: /external/merge
livenessProbe:
initialDelaySeconds: 25
periodSeconds: 10
exec:
command:
- /bin/sh
- -c
- "iris qlist iris | grep running"
volumes:
- name: iris-external-sys
persistentVolumeClaim:
claimName: iris-pvc
- name: cpf-merge
configMap:
name: iris-cpf-merge
策略: 重建Recreate, 副本replicas: 1 告诉 Kubernetes 在任何给定时间都应该保持一个且只能有一个 IRIS pod 实例运行。 这对应于我们的“删除 pod”场景。
livenessProbe 部分确保 IRIS 始终在容器内正常运行并应对“IRIS 下线”情况。 initialDelaySeconds 允许 IRIS 启动有一定的宽限期。 如果 IRIS 需要相当长的时间来启动部署,您可能需要增加该值。
IRIS 的 CPF MERGE配置文件合并 功能允许您在容器启动时修改配置文件 iris.cpf 的内容。 请参见 https://docs.intersystems.com/irisforhealthlatest/csp/docbook/DocBook.UI.Page.cls?KEY=RACS_cpf#RACS_cpf_edit_merge 了解相关内容。
在本示例中,我将使用 Kubernetes Config Map 管理合并文件 https://github.com/antonum/ha-iris-k8s/blob/main/iris-cpf-merge.yaml 的内容。这里我们调整了 IRIS 实例使用的全局缓冲区和 gmheap 值,但是您在 iris.cpf 文件中找到的一切都是可修改的。 您甚至可以使用 CPF Merge 文件中的“PasswordHash”字段更改默认 IRIS 密码。 更多信息请参见:https://docs.intersystems.com/irisforhealthlatest/csp/docbook/Doc.View.cls?KEY=ADOCK#ADOCK_iris_images_password_auth
除了持久卷声明 https://github.com/antonum/ha-iris-k8s/blob/main/iris-pvc.yaml 部署 https://github.com/antonum/ha-iris-k8s/blob/main/iris-deployment.yaml 和采用 CPF Merge 内容的 ConfigMap https://github.com/antonum/ha-iris-k8s/blob/main/iris-cpf-merge.yaml,我们的部署还需要一个将 IRIS 部署暴露给公网的服务:https://github.com/antonum/ha-iris-k8s/blob/main/iris-svc.yaml
kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
iris-svc LoadBalancer 10.0.18.169 40.88.123.45 52773:31589/TCP 3d1h
kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 10d
iris-svc 的外部 IP 可用于通过 http://40.88.123.45:52773/csp/sys/%25CSP.Portal.Home.zen 访问 IRIS 管理门户。 默认密码为“SYS”。
备份/恢复和存储扩展
Longhorn 提供了基于 Web 的 UI 来配置和管理卷。
使用 kubectl 标识 pod、运行 longhorn-ui 组件和建立端口转发:
kubectl -n longhorn-system get pods
# note the longhorn-ui pod id.
kubectl port-forward longhorn-ui-df95bdf85-gpnjv 9000:8000 -n longhorn-system
Longhorn UI 将可通过 http://localhost:9000 访问
图 4 Longhorn UI
除了高可用性,大多数 Kubernetes 容器存储解决方案还提供了方便的备份、快照和恢复选项。 细节是特定于实现的,但通常的惯例是备份与 VolumeSnapshot 关联。 对于 Longhorn 来说就是这样。 根据您的 Kubernetes 版本和提供商,您可能还需要安装卷快照工具 https://github.com/kubernetes-csi/external-snapshotter
“iris-volume-snapshot.yaml”是此类卷快照的示例。 在使用它之前,您需要在 Longhorn 中配置备份到 S3 存储桶或 NFS 卷。 https://longhorn.io/docs/1.0.1/snapshots-and-backups/backup-and-restore/set-backup-target/
# Take crash-consistent backup of the iris volume
kubectl apply -f iris-volume-snapshot.yaml
对于 IRIS,建议在获取备份/快照之前执行外部冻结,之后再解冻。 有关详细信息,请参见:https://docs.intersystems.com/irisforhealthlatest/csp/documatic/%25CSP.Documatic.cls?LIBRARY=%25SYS&CLASSNAME=Backup.General#ExternalFreeze
要增加 IRIS 卷的大小,请调整 IRIS 使用的持久卷声明(文件“iris-pvc.yaml”)中的存储请求。
...
resources:
requests:
storage: 10Gi #change this value to required
然后,重新应用 pvc 规范。 当卷连接到正在运行的 Pod 时,Longhorn 无法实际应用此更改。 请在部署中暂时将副本数更改为零,以便增加卷大小。
高可用性 – 概述
在文章开头,我们为高可用性设置了一些标准。 下面来说明我们如何通过此架构来实现:
故障域
自动缓解方式
容器/VM 内的 IRIS 实例。 IRIS – 级别故障。
部署运行情况探测将在 IRIS 故障时重启容器
pod/容器故障。
部署重新创建 pod
个别集群节点暂时不可用。 一个典型的例子是可用区下线。
部署在其他节点上重新创建 pod。 Longhorn 使数据在其他节点上可用。
个别集群节点或磁盘的永久性故障。
同上,并且 k8s 集群自动缩放器会将受损节点替换为新节点。 Longhorn 在新节点上重建数据。
Zoombie和其他要考虑的事项
如果您熟悉在 Docker 容器中运行 IRIS,则可能已经使用了“--init”标志。
docker run --rm -p 52773:52773 --init store/intersystems/iris-community:2020.4.0.524.0
此标志的目标是防止形成“僵尸进程”。 在 Kubernetes 中,可以使用“shareProcessNamespace: true”(安全注意事项适用)或在您自己的容器中使用“tini”。 使用 tini 的 Dockerfile 示例:
FROM iris-community:2020.4.0.524.0
...
# Add Tini
USER root
ENV TINI_VERSION v0.19.0
ADD https://github.com/krallin/tini/releases/download/${TINI_VERSION}/tini /tini
RUN chmod +x /tini
USER irisowner
ENTRYPOINT ["/tini", "--", "/iris-main"]
从 2021 年开始,InterSystems 提供的所有容器映像都默认包括 tini。
您可以通过调整一些参数来进一步减少“强制耗尽节点/终止节点”场景下的故障切换时间。
Longhorn Pod 删除策略 https://longhorn.io/docs/1.1.0/references/settings/#pod-deletion-policy-when-node-is-down 和 kubernetes 基于 taint 的逐出:https://kubernetes.io/docs/concepts/scheduling-eviction/taint-and-toleration/#taint-based-evictions
免责声明
作为 InterSystems 员工,我必须在这里说明:本文使用 Longhorn 作为 Kubernetes 分布式块存储的示例。 InterSystems 不会对个别存储解决方案或产品进行验证或发布官方支持声明。 您需要测试和验证是否有任何特定存储解决方案符合您的需求。
分布式存储与节点本地存储相比,性能特征可能有很大差别。 特别是在写入操作方面,数据必须写入到多个位置才会被认为处于持久状态。 请确保测试您的工作负载,并了解您的 CSI 驱动程序具有的特定行为和选项。
基本上,InterSystems 不会验证和/或认可具体的存储解决方案(如 Longhorn),就像我们不会验证单个硬盘品牌或服务器硬件制造商一样。 我个人认为 Longhorn 很容易使用,而且开发团队在项目的 GitHub 页面上响应迅速且乐于助人。https://github.com/longhorn/longhorn
结论
Kubernetes 生态系统在过去几年有了长足的发展,通过使用分布式块存储解决方案,您现在可以构建一个高可用性配置来维持 IRIS 实例、集群节点甚至是可用区故障。
您可以将计算和存储高可用性外包给 Kubernetes 组件,这样与传统 IRIS 镜像相比,系统的配置和维护都大为简化。 同时,此配置可能无法提供与镜像配置相同的 RTO 和存储级别性能。
在本文中,我们使用 Azure AKS 作为托管的 Kubernetes 和 Longhorn 分布式存储系统,构建了一个高可用性 IRIS 配置。 你可以探索多种替代方案,如 AWS EKS、用于托管 K8s 的 Google Kubernetes Engine、StorageOS、Portworx 和 OpenEBS 作为分布式容器存储,甚至 NetApp、PureStorage、Dell EMC 等企业级存储解决方案。
附录 A. 在云中创建 Kubernetes 集群
来自公共云提供商之一的托管 Kubernetes 服务是创建此设置所需的 k8s 集群的简单方法。 Azure 的 AKS 默认配置可以直接用于本文所述的部署。
创建一个新的 3 节点 AKS 集群。 其他所有设置都保持默认。
图 5 创建 AKS 集群
在您的计算机上本地安装 kubectl:https://kubernetes.io/docs/tasks/tools/install-kubectl/
使用本地 kubectl 注册 AKS 集群
图 6 使用 kubectl 注册 AKS 集群
之后,您可以回到文章开头,并安装 longhorn 和 IRIS 部署。
在 AWS EKS 上安装更复杂一些。 您需要确保您的节点组中的每个实例都已安装 open-iscsi。
sudo yum install iscsi-initiator-utils -y
在 GKE 上安装 Longhorn 需要额外步骤,请参见此处:https://longhorn.io/docs/1.0.1/advanced-resources/os-distro-specific/csi-on-gke/
附件 B. 分步安装
第 1 步 – Kubernetes 集群和 kubectl
您需要 3 节点 k8s 集群。 附录 A 介绍了如何在 Azure 上获得一个这样的集群。
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
aks-agentpool-29845772-vmss000000 Ready agent 10d v1.18.10
aks-agentpool-29845772-vmss000001 Ready agent 10d v1.18.10
aks-agentpool-29845772-vmss000002 Ready agent 10d v1.18.10
第 2 步 – 安装 Longhorn
kubectl apply -f https://raw.githubusercontent.com/longhorn/longhorn/master/deploy/longhorn.yaml
确保“longhorn-system”命名空间中的所有 pod 都处于运行状态。 这可能需要几分钟。
$ kubectl get pods -n longhorn-system
NAME READY STATUS RESTARTS AGE
csi-attacher-74db7cf6d9-jgdxq 1/1 Running 0 10d
csi-attacher-74db7cf6d9-l99fs 1/1 Running 1 11d
...
longhorn-manager-flljf 1/1 Running 2 11d
longhorn-manager-x76n2 1/1 Running 1 11d
longhorn-ui-df95bdf85-gpnjv 1/1 Running 0 11d
有关详细信息和故障排除,请参见 Longhorn 安装指南 https://longhorn.io/docs/1.1.0/deploy/install/install-with-kubectl
第 3 步 – 克隆 GitHub 仓库
$ git clone https://github.com/antonum/ha-iris-k8s.git
$ cd ha-iris-k8s
$ ls
LICENSE iris-deployment.yaml iris-volume-snapshot.yaml
README.md iris-pvc.yaml longhorn-aws-secret.yaml
iris-cpf-merge.yaml iris-svc.yaml tldr.yaml
第 4 步 – 逐个部署和验证组件
tldr.yaml 文件将部署所需的所有组件捆绑在一起。 这里我们将逐个进行安装,并单独验证每一个组件的设置。
# If you have previously applied tldr.yaml - delete it.
$ kubectl delete -f https://github.com/antonum/ha-iris-k8s/raw/main/tldr.yaml
# Create Persistent Volume Claim
$ kubectl apply -f iris-pvc.yaml
persistentvolumeclaim/iris-pvc created
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
iris-pvc Bound pvc-fbfaf5cf-7a75-4073-862e-09f8fd190e49 10Gi RWO longhorn 10s
# Create Config Map
$ kubectl apply -f iris-cpf-merge.yaml
$ kubectl describe cm iris-cpf-merge
Name: iris-cpf-merge
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
merge.cpf:
----
[config]
globals=0,0,800,0,0,0
gmheap=256000
Events: <none>
# create iris deployment
$ kubectl apply -f iris-deployment.yaml
deployment.apps/iris created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
iris-65dcfd9f97-v2rwn 0/1 ContainerCreating 0 11s
# note the pod name. You’ll use it to connect to the pod in the next command
$ kubectl exec -it iris-65dcfd9f97-v2rwn -- bash
irisowner@iris-65dcfd9f97-v2rwn:~$ iris session iris
Node: iris-65dcfd9f97-v2rwn, Instance: IRIS
USER>w $zv
IRIS for UNIX (Ubuntu Server LTS for x86-64 Containers) 2020.4 (Build 524U) Thu Oct 22 2020 13:04:25 EDT
# h<enter> to exit IRIS shell
# exit<enter> to exit pod
# access the logs of the IRIS container
$ kubectl logs iris-65dcfd9f97-v2rwn
...
[INFO] ...started InterSystems IRIS instance IRIS
01/18/21-23:09:11:312 (1173) 0 [Utility.Event] Private webserver started on 52773
01/18/21-23:09:11:312 (1173) 0 [Utility.Event] Processing Shadows section (this system as shadow)
01/18/21-23:09:11:321 (1173) 0 [Utility.Event] Processing Monitor section
01/18/21-23:09:11:381 (1323) 0 [Utility.Event] Starting TASKMGR
01/18/21-23:09:11:392 (1324) 0 [Utility.Event] [SYSTEM MONITOR] System Monitor started in %SYS
01/18/21-23:09:11:399 (1173) 0 [Utility.Event] Shard license: 0
01/18/21-23:09:11:778 (1162) 0 [Database.SparseDBExpansion] Expanding capacity of sparse database /external/iris/mgr/iristemp/ by 10 MB.
# create iris service
$ kubectl apply -f iris-svc.yaml
service/iris-svc created
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
iris-svc LoadBalancer 10.0.214.236 20.62.241.89 52773:30128/TCP 15s
第 5 步 – 访问管理门户
最后使用服务的外部 IP http://20.62.241.89:52773/csp/sys/%25CSP.Portal.Home.zen 连接到 IRIS 的管理门户,用户名 _SYSTEM,密码 SYS。 您第一次登录时将被要求更改密码。
问题
nianpeng qu · 五月 11
VSCode中安装InterSystems Language Server后,EXPLORER资源树使用Ctrl+F可以打开文件检索框,快速检索文件。 不知是VSCode版本更新不支持了,还是InterSystems Language Server更新,导致在EXPLORER资源树无法快速检索文件
公告
Claire Zheng · 五月 8
Hi开发者们,
我们很高兴邀请大家参加我们的新一轮开发者竞赛。
🏆 InterSystems开发者竞赛:FHIR和数字医疗健康互操作性 🏆
时间: 2025年5月12日-6月1日(美国东部时间)
奖金池: 12,000美元
主题
使用InterSystems IRIS for Health、Health Connect或FHIR服务器,开发任何基于FHIR的互操作性解决方案,或医疗健康互操作性解决方案,或帮助开发或维护互操作性解决方案的应用程序或库(解决方案)。
一般要求:
应用程序或库必须具有完整的功能。它不应该是另一种语言中已经存在的库的导入或直接接口(C++除外,在C++中,您确实需要做大量的工作来为IRIS创建接口)。它不应是现有应用程序或库的复制粘贴。
有效应用程序:100%全新的Open Exchange Apps或已有的应用程序(但有显著提升)。所有参赛者/团队提交的应用程序只有经过我们团队的审核之后才会被批准参赛。
该应用程序应在IRIS Community Edition 或 IRIS for Health Community Edition上运行。均可作为host (Mac, Windows)版从 Evaluation site 下载,或者可以按从 InterSystems Container Registry或Community Container中提取的容器形式使用: intersystemsdc/iris-community:latest or intersystemsdc/irishealth-community:latest 。
该应用需开源并在GitHub或GitLab上发布。
该应用的README文件应为英文,包含安装步骤,以及应用程序的工作原理的视频演示或描述。
每位开发者最多只能提交3个作品。
注:我们的专家将根据作品的复杂性和实用性最终决定是否批准该作品参赛。他们的决定是最终决定,不可上诉。
奖品
1. 专家提名奖(Experts Nomination)——获奖者由我们特别挑选的专家团选出:
🥇第一名 - 5,000 美元
🥈第二名 - 2,500 美元
🥉第三名 - 1,000 美元
🏅第四名 - 500 美元
🏅第五名 - 300 美元
🌟第 6-10 名 - 100 美元
2. 社区提名奖(Community Nomination)—— 获得总票数最多的应用程序:
🥇第一名 - 1,000 美元
🥈第二名 - 600 美元
🥉第三名 - 300 美元
🏅第四名 - 200 美元
🏅第五名 - 100 美元
❗如果多名参与者获得相同票数,则他们都被视为获奖者,奖金将在获奖者之间平分。❗ 现金奖励仅发放给能够验证身份的获奖者。如有任何疑问,组织者将联系参与者并要求提供额外信息。
谁可以参加?
任何开发者社区的成员均可参加,InterSystems内部员工除外(InterSystems contractor员工可以参加)。还没有账号?现在来建一个!
👥开发人员可以组队创建协作应用程序。一个团队允许 2 到 5 名开发人员。
请注意,要在您的README文件中标注您的团队成员(社区用户主页)。
重要截止日期:
🛠 应用程序开发和注册阶段:
2025年5月12日 (美国东部时间00:00): 竞赛开始
2025年5月25日 (美国东部时间23:59): 应用提交截止
✅ 投票时间:
2025年5月26日 (美国东部时间00:00): 投票开始
2025年6月1日(美国东部时间23:59): 投票截止
注意:在整个参赛期间(开发与投票期间),开发者可持续编辑、提升其应用。
资源助力
✓ 文档
InterSystems IRIS for Health FHIR Components documentation
InterSystems Cloud FHIR Server documentation
InterSystems Interoperability documentation
Healthcare Data Transformations documentation
✓ 工具
Clinfhir - FHIR visualization and developer tool.
✓ 示例应用
FHIR Server Template
iris-healthtoolkit-template
interoperability-embedded-python
FHIR HL7 SQL Demo FHIR DropBox
HL7 and SMS Interoperability Demo
IrisHealth Ensdemo
UnitTest DTL HL7
Healthcare HL7 XML
FHIR Interoperability Examples
FHIR-Orga-dt
FHIR Peudoanonimisation Proxy
FHIR-client-java
FHIR-client-.net
FHIR-client-python
FHIR related apps on Open Exchange
HL7 applications on Open Exchange
✓线上课程
Interactive Digital Health Interoperability Foundation - An intro course into Digital Health Interoperability productions built with InterSystems IRIS for Health
FHIR Data Architecture
FHIR Integrations
HL7 Integrations
Learn FHIR for Software Developers
Exploring FHIR Resource APIs
Using InterSystems IRIS for Health to Reduce Readmissions
Connecting Devices to InterSystems IRIS for Health
Monitoring Oxygen Saturation in Infants
FHIR Integration QuickStart
✓ 视频
6 Rapid FHIR Questions
SMART on FHIR: The Basics
Developing with FHIR - REST APIs
FHIR in InterSystems IRIS for Health
FHIR API Management
Searching for FHIR Resources in IRIS for Health
✓ IRIS初学者
Build a Server-Side Application with InterSystems IRIS
Learning Path for beginners
✓ ObjectScript Package Manager (IPM) 初学者
How to Build, Test and Publish IPM Package with REST Application for InterSystems IRIS
Package First Development Approach with InterSystems IRIS and IPM
✓ 如何向大赛提交应用?
How to publish an application on Open Exchange
How to submit an application for the contest
需要帮助?
加入InterSystems' Discord server上的竞赛频道,或者在这篇帖子下面跟帖留言。
期待您的精彩提交 - 加入竞赛,来赢得胜利!👍
❗️参加本次比赛即表示您同意此处列出的比赛条款。请在继续之前仔细阅读它们。 ❗️
文章
Lilian Huang · 四月 16
Hi 大家好在本文中,我讲介绍我的应用 iris-AgenticAI .
代理式人工智能的兴起标志着人工智能与世界互动方式的变革性飞跃--从静态响应转变为动态、目标驱动的问题解决方式。参看 OpenAI’s Agentic SDK , OpenAI Agents SDK使您能够在一个轻量级、易用且抽象程度极低的软件包中构建代理人工智能应用程序。它是我们之前的代理实验 Swarm 的生产就绪升级版。
该应用展示了下一代自主人工智能系统,这些系统能够进行推理、协作,并以类似人类的适应能力执行复杂任务。
应用功能
Agent Loop 🔄 一个内置循环,可自主管理工具的执行,将结果发回 LLM,并迭代直至任务完成。
Python-First 🐍 利用本地 Python 语法(装饰器、生成器等)来协调和连锁代理,而无需外部 DSL。
Handoffs 🤝 通过在专业代理之间委派任务,无缝协调多代理工作流程。
Function Tools ⚒️ 用 @tool 修饰任何 Python 函数,可立即将其集成到代理的工具包中。
Vector Search (RAG) 🧠 原生集成向量存储(IRIS),用于 RAG 检索。
Tracing 🔍 内置跟踪功能,可实时可视化、调试和监控代理工作流(想想 LangSmith 的替代方案)。
MCP Servers 🌐 通过 stdio 和 HTTP 支持模型上下文协议(MCP),实现跨进程代理通信。
Chainlit UI 🖥️ 集成 Chainlit 框架,可使用最少的代码构建交互式聊天界面。
Stateful Memory 🧠 跨会话保存聊天历史、上下文和代理状态,以实现连续性和长期任务。
代理
代理是应用程序的核心构件。代理是一个大型语言模型(LLM),配置有指令和工具。基本配置您需要配置的代理最常见的属性,包括:
Instructions (说明):也称为开发人员信息或系统提示。model:要使用的 LLM,以及可选的 model_settings,用于配置温度、top_p 等模型调整参数。tools工具: 代理用来完成任务的工具。
from agents import Agent, ModelSettings, function_tool
@function_tool
def get_weather(city: str) -> str:
return f"The weather in {city} is sunny"
agent = Agent(
name="Haiku agent",
instructions="Always respond in haiku form",
model="o3-mini",
tools=[get_weather],
)
运行代理
您可以通过 Runner 类运行代理。您有 3 个选项:
1.Runner.run():异步运行并返回 RunResult。2.Runner.run_sync(),这是一种同步方法,只是在引擎盖下运行 .run()。3.Runner.run_streamed():异步运行并返回 RunResultStreaming。它以流式模式调用 LLM,并在接收到事件时将其流式传输给您。
from agents import Agent, Runner
async def main():
agent = Agent(name="Assistant", instructions="You are a helpful assistant")
result = await Runner.run(agent, "Write a haiku about recursion in programming.")
print(result.final_output)
# Code within the code,
# Functions calling themselves,
# Infinite loop's dance.
代理架构
该应用程序由 7 个专业代理组成:
1. 分诊代理 🤖
角色: 主要路由器,接收用户输入,并通过切换分配任务
示例: 路由 “显示生产错误” → IRIS 生产代理
2.矢量搜索代理 🤖
作用: 提供 IRIS 2025.1 版本说明详情(RAG 功能)
示例: 路由 “向我提供发行说明摘要”→矢量搜索代理
3. IRIS 仪表板代理 🤖功能: 提供实时管理门户指标:明文副本。
ApplicationErrors, CSPSessions, CacheEfficiency, DatabaseSpace, DiskReads, DiskWrites, ECPAppServer, ECPDataServer, GloRefs, JournalStatus, LicenseCurrent, LockTable, Processes, SystemUpTime, WriteDaemon, [...]
4. IRIS Running Process Agent 🤖
功能: 监控活动进程的详细信息:
Process ID | Namespace | Routine | State | PidExternal
5. IRIS Production Agent 🤖
角色: 提供生产详情以及启动和停止生产的功能。
6. WebSearch Agent 🤖
功能: 通过 API 集成执行上下文网络搜索
7.Order Agent 🤖
功能: 使用订单 ID 检索订单状态
交接
交接允许代理将任务委托给另一个代理。这在不同代理擅长不同领域的情况下尤其有用。例如,客户支持应用程序可能会有专门处理订单状态、退款、常见问题等任务的代理。
分流代理是我们的主代理,它会根据用户输入将任务分配给另一个代理
#TRIAGE AGENT, Main agent receives user input and delegates to other agent by using handoffs
triage_agent = Agent(
name="Triage agent",
instructions=(
"Handoff to appropriate agent based on user query."
"if they ask about Release Notes, handoff to the vector_search_agent."
"If they ask about production, handoff to the production agent."
"If they ask about dashboard, handoff to the dashboard agent."
"If they ask about process, handoff to the processes agent."
"use the WebSearchAgent tool to find information related to the user's query and do not use this agent is query is about Release Notes."
"If they ask about order, handoff to the order_agent."
),
handoffs=[vector_search_agent,production_agent,dashboard_agent,processes_agent,order_agent,web_search_agent]
)
跟踪
Agents SDK 包括内置跟踪功能,可收集代理运行期间事件的全面记录: LLM 生成、工具调用、切换、防护栏,甚至发生的自定义事件。使用跟踪仪表板,您可以在开发和生产过程中调试、可视化和监控工作流。https://platform.openai.com/logs
应用界面
应用工作流程矢量搜索代理
矢量搜索代理自动获取 New in InterSystems IRIS 2025.1 如果数据还不存在,只需将文本信息输入 IRIS 矢量存储区一次。
使用下面的查询来获取数据
SELECT
id, embedding, document, metadata
FROM SQLUser.AgenticAIRAG
分流代理接收用户输入,将问题转给矢量搜索代理。
IRIS 仪表盘代理
分流代理接收用户输入,将问题路由到 IRIS 仪表板代理。
IRIS 流程代理分流代理接收用户输入,将问题路由到 IRIS 流程代理。IRIS 生产代理
使用生产代理启动和停止生产。使用生产代理获取生产详情。
本地代理
分流代理接收用户输入,将问题转给本地订单代理。WebSearch 代理
在这里,分流代理接收到两个问题,并将两个问题都路由到 WebSearcg 代理。
MCP Server 应用
MCP Server在这里运行 https://localhost:8000/sse
下面是启动 MCP 服务器的代码:
import os
import shutil
import subprocess
import time
from typing import Any
from dotenv import load_dotenv
load_dotenv()
#Get OPENAI Key, if not fond in .env then get the GEIMINI API KEY
#IF Both defined then take OPENAI Key
openai_api_key = os.getenv("OPENAI_API_KEY")
if not openai_api_key:
raise ValueError("OPENAI_API_KEY is not set. Please ensure to defined in .env file.")
if __name__ == "__main__":
# Let's make sure the user has uv installed
if not shutil.which("uv"):
raise RuntimeError(
"uv is not installed. Please install it: https://docs.astral.sh/uv/getting-started/installation/"
)
# We'll run the SSE server in a subprocess. Usually this would be a remote server, but for this
# demo, we'll run it locally at http://localhost:8000/sse
process: subprocess.Popen[Any] | None = None
try:
this_dir = os.path.dirname(os.path.abspath(__file__))
server_file = os.path.join(this_dir, "MCPserver.py")
print("Starting SSE server at http://localhost:8000/sse ...")
# Run `uv run server.py` to start the SSE server
process = subprocess.Popen(["uv", "run", server_file])
# Give it 3 seconds to start
time.sleep(3)
print("SSE server started. Running example...\n\n")
except Exception as e:
print(f"Error starting SSE server: {e}")
exit(1)
MCP 服务器配备了以下工具:
提供 IRIS 2025.1 发行说明详情(矢量搜索)
IRIS 信息工具
检查天气工具
查找暗语工具(本地功能)
加法工具(本地功能)
MCP 应用在这里运行 http://localhost:8001
MCP 服务器矢量搜索(RAG)功能
MCP 服务器配备 InterSystems IRIS 向量搜索摄取功能和检索增强生成 (RAG) 功能。
MCP Server other functionality
The MCP Server dynamically delegates tasks to the appropriate tool based on user input.
更多详情,请访问 iris-AgenticAI open exchange 界面。
谢谢!
文章
Lilian Huang · 四月 10
社区朋友们好,
传统的基于关键词的搜索方式在处理具有细微差别的领域特定查询时往往力不从心。而向量搜索则通过语义理解能力,使AI智能体能够根据上下文(而非仅凭关键词)来检索信息并生成响应。
本文将通过逐步指导,带您创建一个具备代理能力的AI RAG(检索增强生成)应用程序。
实现步骤:
添加文档摄取功能:
自动获取并建立文档索引(例如《InterSystems IRIS 2025.1版本说明》)
实现向量搜索功能
构建向量搜索智能体
移交至主智能体(分流处理)
运行智能体
1. Create Agent Tools 添加文档摄取功能
Implement Document Ingestion: Automated ingestion and indexing of documents
1.1 - 以下是实现文档摄取工具的代码:
def ingestDoc(self):
#Check if document is defined, by selecting from table
#If not defined then INGEST document, Otherwise back
embeddings = OpenAIEmbeddings()
#Load the document based on the fle type
loader = TextLoader("/irisdev/app/docs/IRIS2025-1-Release-Notes.txt", encoding='utf-8')
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=400, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
#COLLECTION_NAME = "rag_document"
db = IRISVector.from_documents(
embedding=embeddings,
documents=texts,
collection_name = self.COLLECTION_NAME,
connection_string=self.CONNECTION_STRING,
)
db = IRISVector.from_documents(embedding=embeddings,documents=texts, collection_name = self.COLLECTION_NAME, connection_string=self.CONNECTION_STRING,)
向量搜索智能体(Vector Search Agent)能够自动完成文档的摄取(ingest)与索引构建(index), 该新功能在InterSystems IRIS 2025.1的数据资源文件夹里) 至 IRIS 向量存储, 只有当数据尚未存在时,才执行该操作。
运行以下查询以从向量存储中获取所需数据:
SELECT
id, embedding, document, metadata
FROM SQLUser.AgenticAIRAG
1.2 - 实现向量搜索功能
以下代码为智能体提供了搜索能力:
def ragSearch(self,prompt):
#Check if collections are defined or ingested done.
# if not then call ingest method
embeddings = OpenAIEmbeddings()
db2 = IRISVector (
embedding_function=embeddings,
collection_name=self.COLLECTION_NAME,
connection_string=self.CONNECTION_STRING,
)
docs_with_score = db2.similarity_search_with_score(prompt)
relevant_docs = ["".join(str(doc.page_content)) + " " for doc, _ in docs_with_score]
#Generate Template
template = f"""
Prompt: {prompt}
Relevant Docuemnts: {relevant_docs}
"""
return template
分流代理处理传入的用户查询,并将其委托给矢量搜索代理,后者执行语义搜索操作,以检索最相关的信息。
2 - 创建矢量存储代理
以下代码实现了 矢量存储代理vector_search_agent :
为智能体协同自定义交接描述规范 handoff_descriptions
明确的操作说明instructions
IRIS向量检索工具iris_RAG_search (使用irisRAG.py 用于文件输入和矢量搜索操作
@function_tool
@cl.step(name = "Vector Search Agent (RAG)", type="tool", show_input = False)
async def iris_RAG_search():
"""Provide IRIS Release Notes details,IRIS 2025.1 Release Notes, IRIS Latest Release Notes, Release Notes"""
if not ragOprRef.check_VS_Table():
#Ingest the document first
msg = cl.user_session.get("ragclmsg")
msg.content = "Ingesting Vector Data..."
await msg.update()
ragOprRef.ingestDoc()
if ragOprRef.check_VS_Table():
msg = cl.user_session.get("ragclmsg")
msg.content = "Searching Vector Data..."
await msg.update()
return ragOprRef.ragSearch(cl.user_session.get("ragmsg"))
else:
return "Error while getting RAG data"
vector_search_agent = Agent(
name="RAGAgent",
handoff_description="Specialist agent for Release Notes",
instructions="You provide assistance with Release Notes. Explain important events and context clearly.",
tools=[iris_RAG_search]
)
3 - 移交分流 (主要代理)
以下代码实现了将处理过的查询路由到分流代理(主协调器)的切换协议:
triage_agent = Agent(
name="Triage agent",
instructions=(
"Handoff to appropriate agent based on user query."
"if they ask about Release Notes, handoff to the vector_search_agent."
"If they ask about production, handoff to the production agent."
"If they ask about dashboard, handoff to the dashboard agent."
"If they ask about process, handoff to the processes agent."
"use the WebSearchAgent tool to find information related to the user's query and do not use this agent is query is about Release Notes."
"If they ask about order, handoff to the order_agent."
),
handoffs=[vector_search_agent,production_agent,dashboard_agent,processes_agent,order_agent,web_search_agent]
)
4 - 运行代理
以下代码:
接受用户输入
唤醒试运行代理triage_agent
将查询路由到矢量搜索处理Vector_Search_Agent 进行处理
@cl.on_message
async def main(message: cl.Message):
"""Process incoming messages and generate responses."""
# Send a thinking message
msg = cl.Message(content="Thinking...")
await msg.send()
agent: Agent = cast(Agent, cl.user_session.get("agent"))
config: RunConfig = cast(RunConfig, cl.user_session.get("config"))
# Retrieve the chat history from the session.
history = cl.user_session.get("chat_history") or []
# Append the user's message to the history.
history.append({"role": "user", "content": message.content})
# Used by RAG agent
cl.user_session.set("ragmsg", message.content)
cl.user_session.set("ragclmsg", msg)
try:
print("\n[CALLING_AGENT_WITH_CONTEXT]\n", history, "\n")
result = Runner.run_sync(agent, history, run_config=config)
response_content = result.final_output
# Update the thinking message with the actual response
msg.content = response_content
await msg.update()
# Append the assistant's response to the history.
history.append({"role": "developer", "content": response_content})
# NOTE: Here we are appending the response to the history as a developer message.
# This is a BUG in the agents library.
# The expected behavior is to append the response to the history as an assistant message.
# Update the session with the new history.
cl.user_session.set("chat_history", history)
# Optional: Log the interaction
print(f"User: {message.content}")
print(f"Assistant: {response_content}")
except Exception as e:
msg.content = f"Error: {str(e)}"
await msg.update()
print(f"Error: {str(e)}")
在行动中观看:
更多细节,请访问 iris-AgenticAI open exchange 页面。谢谢
文章
Kelly Huang · 七月 12, 2023
在本文中,我将分享我们在 2023 年全球峰会技术交流室中提出的主题。我和@Rochael.Ribeiro
借此机会,我们就以下话题进行探讨:
用于快速 API 的开放交换工具
开放API规范
传统与快速 Api 开发
复合 API(互操作性)
规范优先或 API 优先方法
API 治理和监控
演示(视频)
用于快速 API 的开放交换工具
当我们谈论快速现代 API 开发(Rest / json)时,我们将使用两个 Intersystems Open Exchange 工具:
第一个是用于快速开发 API 的框架,我们将在本文中详细介绍。
https://openexchange.intersystems.com/package/IRIS-apiPub
第二种是使用 Swagger 作为用户界面,用于 IRIS 平台上开发的 Rest API 的规范和文档,以及它们的使用/执行。其运行的基础是开放 API 规范 (OAS) 标准,如下所述:
https://openexchange.intersystems.com/package/iris-web-swagger-ui
什么是开放 API 规范 (OAS)?
它是全球范围内用于定义、记录和使用 API 的标准。在大多数情况下,API 甚至在实现之前就已经设计好了。我将在下一个主题中详细讨论它。
它很重要,因为它定义并记录了 Rest API 供其在提供者和消费者方面使用。但这种模式也有助于加快市场上工具(Rest API 客户端)的测试和 API 调用,例如 Swagger、Postman、Insomnia 等……
使用 IRIS 发布 API 的传统方式
想象一下,我们必须从现有的 IRIS 方法构建并发布 Rest API(如下图)。
以传统方式:
1:我们必须考虑消费者会如何称呼它。例如:将使用哪个路径和动词以及如何响应。无论是 JSON 对象还是纯文本。
2:在 %CSP.REST 类中构建一个新方法,该方法将处理调用它的 http 请求。
3:处理方法对最终用户预期的 http 响应的响应。
4:考虑一下我们将如何提供成功代码以及我们将如何处理异常。
5:为我们的新方法绘制路线。
6:向最终用户提供API文档。我们可能会手动构建 OAS 内容。
7:例如,如果我们有一个请求或响应有效负载(对象),则实施时间将会增加,因为它也必须记录在 OAS 中。
我们怎样才能更快?
只需使用 [WebMethod] 属性标记 IRIS 方法即可。无论是什么,该框架都会使用 OAS 3.x 标准来处理其发布。
为什么 OAS 3.x 标准如此重要?
因为它还详细记录了输入和输出有效负载的所有属性。
这样,市场上的任何 Rest Client 工具都可以立即耦合到 API,例如 Insomnia、Postman、Swagger 等,并提供示例内容以便轻松调用它们。
使用 Swagger,我们已经可以可视化我们的 API(上图)并调用它。这对于测试也非常有用。
API定制
但是如果我需要自定义 API 该怎么办?
例如:我希望路径是其他东西,而不是方法的名称。我希望输入参数位于路径中,而不是像查询参数那样。
我们在方法之上定义了一个特定的符号,我们可以在其中补充方法本身不提供的元信息。
在此示例中,我们为 API 定义了另一条路径,并补充了信息,以便最终用户获得更友好的体验。
Rest API 的投影图
该框架支持多种类型的参数。
在此图中,我们可以突出显示复杂类型(对象)。它们将自动公开为 JSON 有效负载,并且每个属性都将为最终用户正确记录 (OAS)。
互操作性(复合 API)
通过支持复杂类型,您还可以公开互操作性服务。
这是构建复合 API 的有利场景,复合 API 使用多个外部组件(出站)的编排。
这意味着用作请求或响应的对象或消息将自动发布并由 swagger 等工具读取。
这是测试互操作性组件的绝佳方法,因为通常已经加载了有效负载模板,以便用户知道 API 使用哪些属性。
首先,开发人员可以专注于测试,然后通过定制来塑造 Api。
规范优先或 API 优先方法
当今广泛使用的另一个概念是在实现之前就定义 API。
有了这个框架,就可以导入 Open Api 规范。它自动创建方法结构(规范),只缺少它们的实现。
API 治理和监控
对于Api的治理,也建议一起使用IAM。
除了拥有多个插件之外,IAM 还可以通过 OAS 标准快速耦合到 API。
apiPub 为 API 提供额外的跟踪(参见演示视频)
演示
下载和文档
Intersystems 开放交换: https://openexchange.intersystems.com/?search=apiPub
完整文档:https: //github.com/devecchijr/apiPub
@Claudio Devecchi 致敬原创作者
文章
Kelly Huang · 七月 12, 2023
FHIR 通过提供标准化数据模型来构建医疗保健应用程序并促进不同医疗保健系统之间的数据交换,彻底改变了医疗保健行业。由于 FHIR 标准基于现代 API 驱动的方法,因此移动和 Web 开发人员更容易使用它。然而,与 FHIR API 交互仍然具有挑战性,尤其是在使用自然语言查询数据时。
隆重推出FHIR - AI 和 OpenAPI 链应用程序,该解决方案允许用户使用自然语言查询与 FHIR API 进行交互。该应用程序使用OpenAI 、 LangChain和Streamlit构建,简化了查询 FHIR API 的过程并使其更加用户友好。
FHIR OpenAPI 规范是什么?
OpenAPI 规范(以前称为 Swagger,目前是OpenAPI Initiative的一部分)已成为软件开发领域的重要工具,使开发人员能够更有效地设计、记录 API 并与 API 交互。 OpenAPI 规范定义了一种标准的机器可读格式来描述 RESTful API,提供了一种清晰一致的方式来理解其功能并有效地使用它们。
在医疗保健领域,FHIR 成为数据交换和互操作性的领先标准。为了增强FHIR的互操作能力, HL7正式记录了FHIR OpenAPI规范,使开发人员能够将FHIR资源和操作无缝集成到他们的软件解决方案中。
FHIR OpenAPI 规范的优点:
标准化 API 描述:OpenAPI 规范提供 FHIR 资源、操作和交互的全面且标准化的描述。开发人员可以轻松了解基于 FHIR 的 API 的结构和功能,从而更轻松地构建集成并与医疗保健系统交互。
促进互操作性:促进开发人员之间的协作,推动 FHIR 标准和最佳实践的采用。该规范提供了一种通用语言和框架,用于讨论基于 FHIR 的集成和实现,促进开发人员之间的协作。
增强的文档和测试:交互式文档和测试套件,以便更好地理解和验证。开发人员可以创建详细的API文档,使其他开发人员更容易理解和使用基于FHIR的API。基于规范的测试套件可以对API集成进行全面的测试和验证,确保医疗数据交换的可靠性和准确性。
改进的开发人员体验:自动生成客户端库和 SDK 以实现无缝集成。这简化了集成过程,并减少了将 FHIR 功能合并到应用程序中所需的时间和精力
FHIR、OpenAI 和 OpenAPI Chain 如何协同工作?
FHIR - AI 和 OpenAPI Chain应用程序利用 LangChain 来加载和解析 OpenAPI 规范( OpenAPI Chain )。之后,根据这些规范,通过 OpenAI 给出的提示链旨在理解自然语言查询并将其转换为适当的 FHIR API 请求。用户可以用简单的语言提出问题,应用程序将与所选的 FHIR API 交互以检索相关信息。
例如,用户可能会问:“患者 John Doe (ID 111) 的最新血压读数是多少?”然后,应用程序会将此查询转换为 FHIR API 请求,获取所需的数据,并以易于理解的格式将其呈现给用户。
FHIR - AI 和 OpenAPI 链的优势
用户友好的交互:通过允许用户使用自然语言查询与 FHIR API 交互,该应用程序使非技术用户可以更轻松地访问和分析医疗保健数据。
提高效率:该应用程序简化了查询 FHIR API 的过程,减少了获取相关信息所需的时间和精力。此外,它还有可能减少从应用程序中查找任何特定信息的点击次数(花费的时间)。
可定制:FHIR 标准简化了从任何 FHIR 服务器检索一致数据的过程,从而可以轻松定制。它可以轻松配置为与任何 FHIR API 无缝集成,为不同的医疗保健数据需求提供灵活且适应性强的解决方案。
FHIR 入门 - AI 和 OpenAPI 链
要开始使用 FHIR - AI 和 OpenAPI Chain 应用程序,请按照以下步骤操作:
从OpenAI Platform获取 OpenAI API 密钥。
获取 FHIR 服务器 API 端点。您可以使用自己的示例 FHIR 服务器(需要未经身份验证的访问),也可以按照InterSystems IRIS FHIR 学习平台中给出的说明创建临时示例服务器。
在线试用该应用程序或使用提供的说明在本地进行设置。
通过集成人工智能和自然语言处理功能,FHIR - AI 和 OpenAPI Chain 应用程序提供了一种与 FHIR API 交互的更直观的方式,使所有技术背景的用户都更容易访问和分析医疗数据。
如果您发现我们的应用程序很有前途,请在大奖赛中投票!
如果您能想到使用此实现的任何潜在应用程序,请随时在讨论线程中分享它们。
@Ikram Shah 致敬原创作者~