Hello everyone,
I want to share my experience configuring an IIS server to enable secure HTTPs access to HealthShare/HealthConnect.
After installing the “WebServerGateway” and completing the initial setup, I encountered a few issues. Specifically, when trying to log into HealthConnect using HTTPS, the logo didn’t appear, and clicking any buttons didn’t trigger any response. See screenshot below:
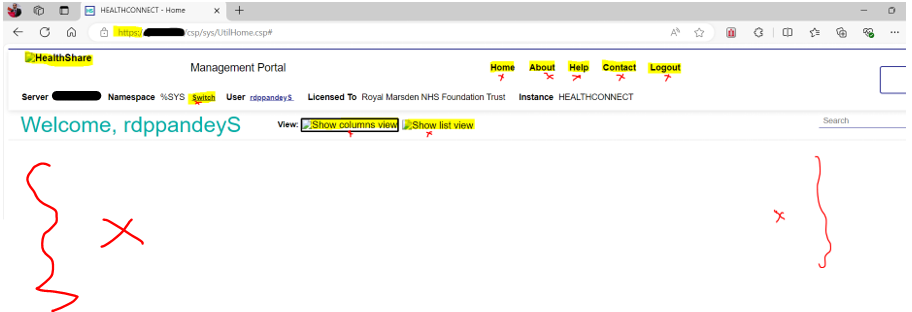
Below is a step-by-step guide to resolve the current issue, as well as another issue I encountered with accessing the Rule Editor. Additionally, the HELP button in the management portal displays an error (not found), but I am not addressing that issue in this post
1. Solution: IIS Configuration - Adding "CSPGateway_all" to Handler Mapping
To fix the issue where nothing happens when logging in via HTTPS, follow these steps to add "CSPGateway_all" to the Handler Mapping in IIS:
- Open the IIS server on your system.
- Navigate to the Default Website -
- Select the “csp” Folder (folder under the Default Website)
- Double-click on the "Handler Mapping" option on the "csp Home" screen (as shown in the screenshot below).
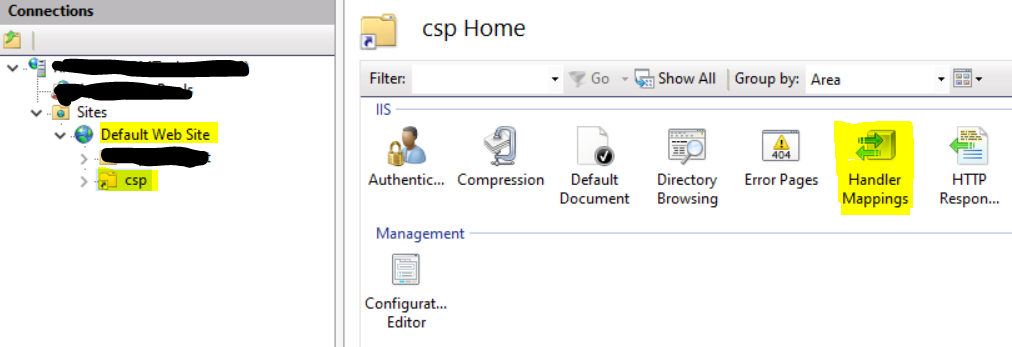
- Add a Module Mapping - On the Handler Mapping page, click "Add Module Mapping" on the right-hand side (see screenshot below).
.png)
- Complete the Module Mapping Form - Fill in the form with the necessary details (as shown in the screenshot below).
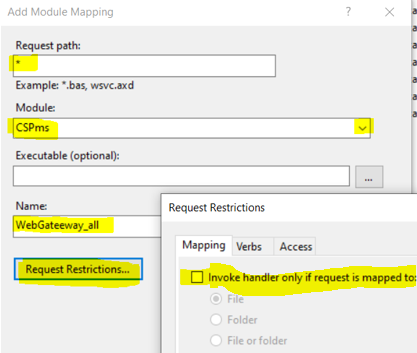
Make sure to untick the option "Invoke handler only if request is mapped to.
- Click "OK" to save your changes. Click "OK" again to confirm.
Once these steps are complete, you should see "CSPGateway_all" listed among the handlers. The other handlers should have been automatically added when the WebServerGateway was installed (as shown in the screenshot below)
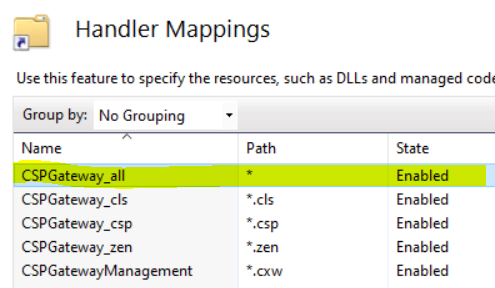
After completing this configuration, I was able to log into HealthConnect securely via HTTPS, and everything worked as expected. See screenshot below:
.png)
2. Resolving Rule Editor Access Issue
I faced another problem - the Rule Editor was inaccessible. When attempting to open the Business Rule Name from the management portal’s process interface, it prompted for a username and password, but the login didn’t work. See screenshot below:
.png)
Temporary Solution for Rule Editor Access
To temporarily fix this issue, follow these steps:
- Open the Management Portal.
- Go to System Administration --> Security --> Application --> Web Application.
- Locate and Click on: /ui/interop/rule-editor
- Disable the Application - Uncheck the "Enabled Application" checkbox to disable the Rule Editor application.
- Save Changes
After following these steps, you should be able to access the Rule Editor. Note that it will appear in its previous layout.
By following these guidelines, you should be able to resolve the issues related to secure HTTPS access and access to the Rule Editor in HealthConnect.
There are other issues as well. For instance, the HELP button in the management portal displays a "not found"... error. There may be additional issues, and if any are identified, I will provide updates and attempt to find solutions as well
Thank you.
.png)
.png)
.png)
.png)
