用 MLflow 补充 IRIS,实现持续训练 (CT) 管道
持续训练(CT)流水线将基于特定时间点可用数据,通过数据科学实验开发出的机器学习(ML)模型规范化。它不仅为模型部署做好准备,还支持在新数据可用时进行自主更新,同时具备用于审计目的的稳健性能监控、日志记录和模型注册功能。
InterSystems IRIS 已经提供了支持此类流水线所需的几乎所有组件。然而,缺少一个关键要素:标准化的模型注册工具。在本文中,我将介绍一种结合 IRIS 优势与开源 AI 工程平台 MLflow 的方法。它们共同作为构建有效持续训练(CT)流水线的互补工具。
本仓库中的实现利用了 MLflow 的内置配置来存储 SHAP 解释器,以提供对相应模型预测结果的解释,包括随机森林(Random Forest)、XGBoost、神经网络等“黑盒”复杂模型。
**演示视频**:https://youtu.be/qLdc4jhn83c
---
CT 流水线组件
该 CT 流水线模块背后的理论基于 Google 在相关文章中定义的 MLOps 1 级行业标准。每个组件的实现都利用了 IRIS 和 MLflow 的最佳特性(如下图所示,红色部分突出显示):
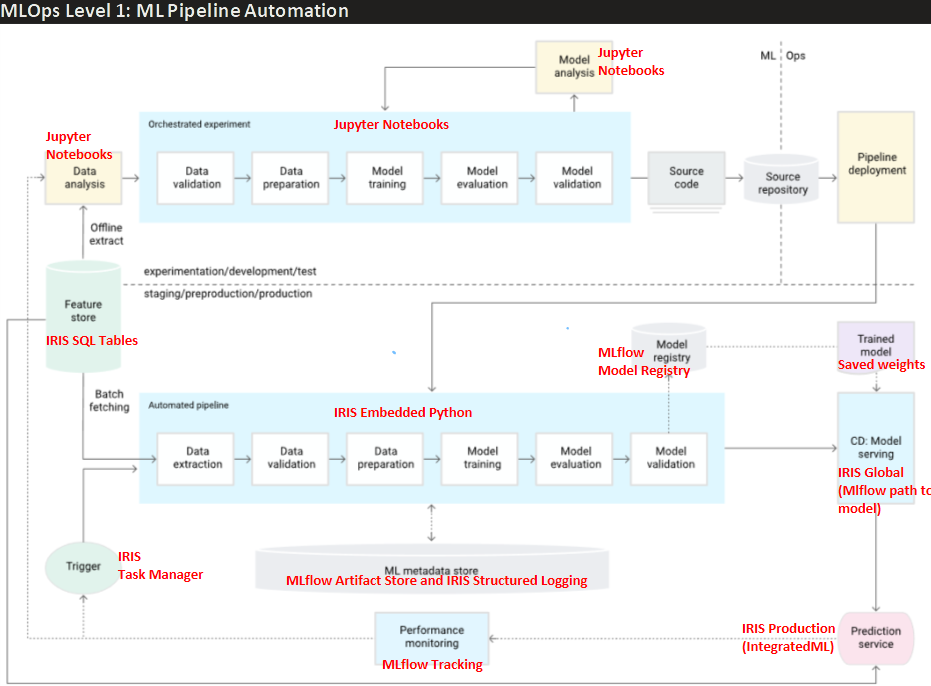
对于那些刚接触 CT 流水线的人来说,上图描述了数据科学项目中传统的实验阶段(上半部分“实验/开发/测试”,通常在 Jupyter Notebook 中进行)如何转化为生产级模型部署。这使得能够持续监控随时间变化的性能,并在模型性能下降时自动重新训练,同时配合适当的模型版本控制和日志记录以满足审计要求。
我们在仓库的 README 中深入探讨了细节,但为了便于初步理解,下面简要定义每个组件的功能及其与所选 IRIS/MLflow 工具的关联。
- 特征存储 (Feature Store)
它是数据源的唯一事实来源,定义了与数据本身相关的每个常量参数或定义,这些可能因客户和用例而异(例如,每个客户可能定义 15 天、30 天或其他天数后的再入院;迟到可能定义为迟到 5 分钟、10 分钟或其他分钟数)。IRIS SQL 表的多维全局变量允许高速存储,而存储计算属性则简化了自定义属性与原始数据本身的定义。 - 自动化流水线 (Automated Pipeline)
这是通常在 Jupyter Notebook 中进行的“编排实验”的规范化且模块化清晰的版本,准备在需要重新训练模型时执行。它包含获得具有最佳整体性能的模型所需的所有数据和模型训练过程。在此部分,定义了实验阶段(之前由数据科学家在 Jupyter Notebook 中完成)期间选择的与模型本身相关的每个常量(例如种子、测试集大小、K 折交叉验证等)。在我们的实现中,我们利用嵌入式 Python(Embedded Python)直接访问 IRIS 类,以及所有必需的 Python 标准机器学习库(Pandas, scikit-learn, MLflow 等)。 - 模型注册表 (Model Registry)
在训练期间,每个训练的模型都会被记录到 MLflow 的后端注册表中,这是在构建项目时自动配置的。我们可以随时从中重新下载模型并查询以前模型的性能。 - 已训练模型 (Trained Model)
尽管 MLflow 后端有一个存储所有训练模型权重的工件存储(Artifact Store),但本项目还将工件直接保存到持久位置(Docker 卷)以便需要时快速加载。如果它们被删除,会从 MLflow 工件存储中重新下载并保存在同一位置。 - 模型服务 (Model Serving)
此模块负责管理提供给生产的模型。我们将用于生产的模型工件路径存储在 IRIS 全局变量(Global)中,每当必要时就会更新该路径。在此仓库中,如果新模型表现优于旧模型,我们会直接推广它,但在实际场景中可能需要人工审批。我们决定将模型路径而非模型本身存储在全局变量中,因为这样做会涉及 Python 对象序列化和反序列化的额外处理时间,而文本读取无论在仓库中使用何种类,都更快、更直接。 - 预测服务 (Prediction Service)
这是客户端用来请求当前生产模型推理的实际服务。目前此仓库使用嵌入式 Python 方法,但此模块可以通过将其转换为 PMML 格式来改进,从而利用 IntegratedML 使生产服务可执行(适用于任何 sklearn 模型),或者使用即将在 IRIS 2026.1 中推出的 IntegratedML 自定义模型来处理 LightGBM 等任何 Python 模型。 - 性能监控 (Performance Monitoring)
这是为跟踪当前生产模型(如有必要也包括以前的模型)的性能而实施的任何类型的监控。为此我们利用 MLflow 的 UI,可以在其中使用记录的任何变量、日期时间、性能指标对所有模型进行自定义绘图,无论是单个模型还是历史上训练的所有模型。 - 触发器 (Trigger)
这是激活自动化流水线执行的任何机制。它可以是数据漂移、模型性能下降到某个阈值以下、具有一定量真实值的新数据的可用性,或者是简单的周期性计划。在这个项目中,我们直接与定义的 R² 指标阈值进行比较,因此每当性能低于 `MLpipeline.PerformanceMonitoring.R2THRESHOLD` 中的值时,我们就会执行自动化流水线。对于此任务,另一种有效方法是使用任务管理器安排一个方法,查看 MLflow 跟踪中记录的监控性能,并决定是否重新训练新模型。
MLflow 的加入使得通过一个托管在 Docker 容器中的单一本地 UI,即可实现对模型随时间变化的性能历史进行直接监控。它允许您存储和访问所有先前训练模型的工件,包括那些已部署到生产的模型。这些工件可以随时下载,同时附带标准和自定义性能指标及可视化图表。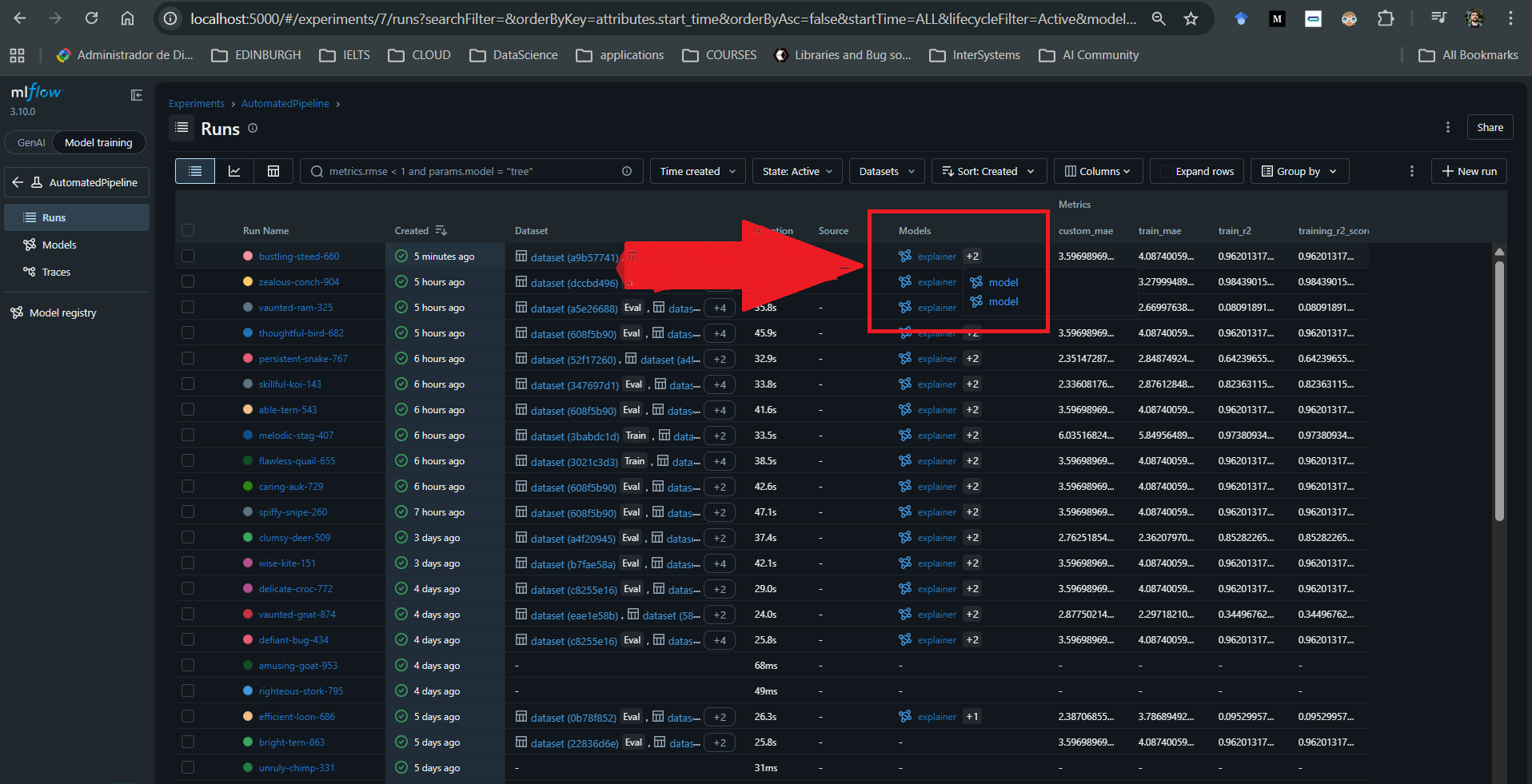
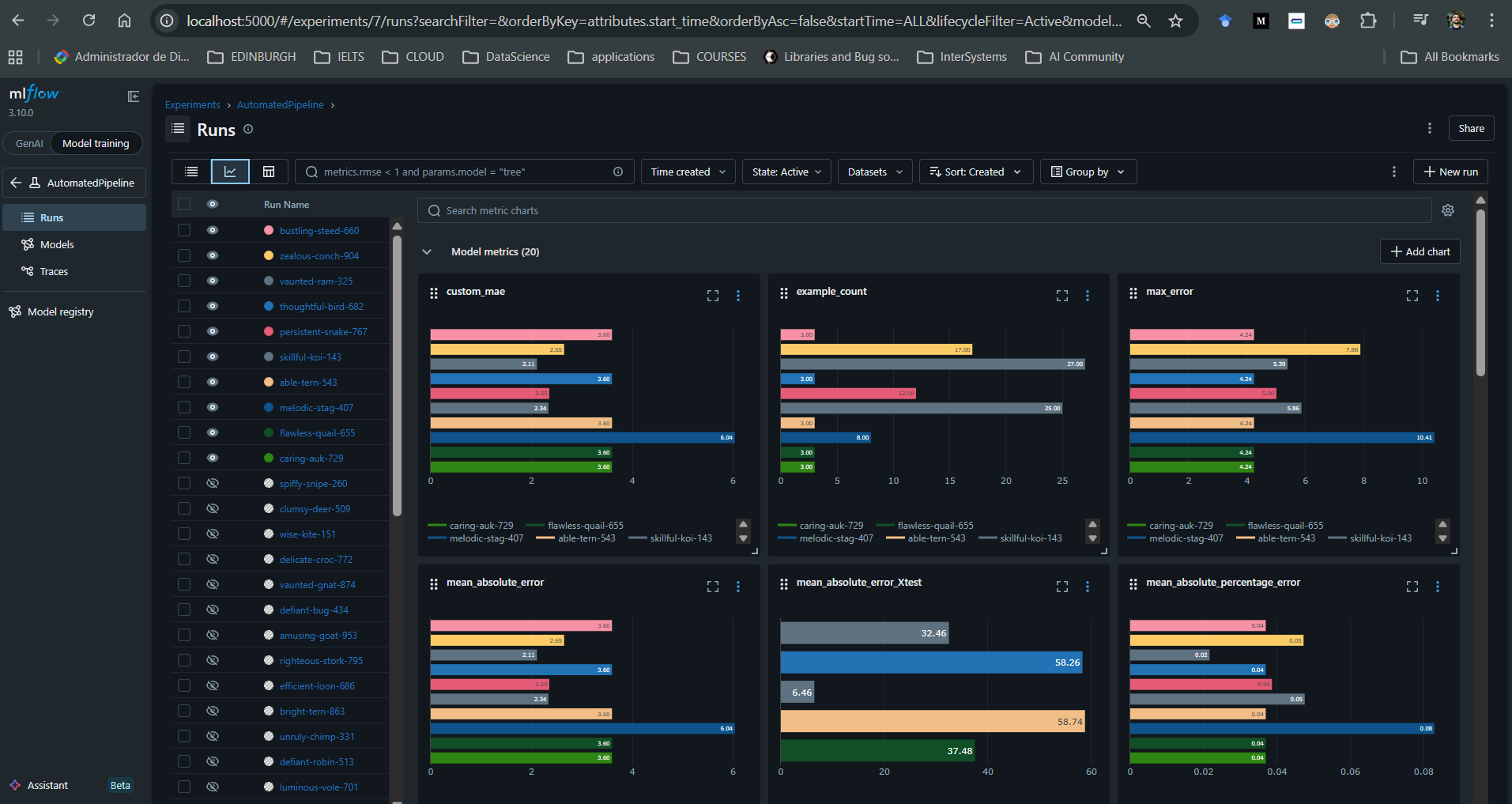
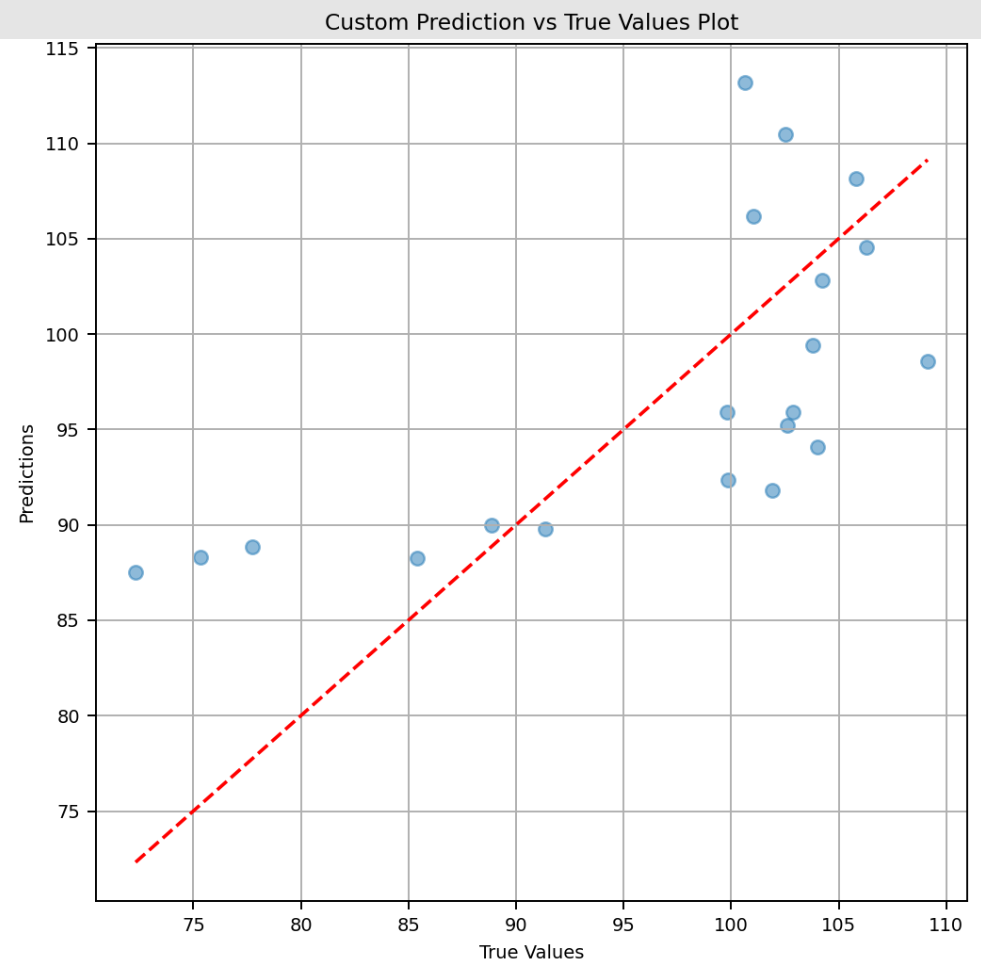
对于与模型相关的每次运行,还可以记录额外的工件,如 SHAP 解释器、自定义图表和用户定义的指标。
本 CT 流水线的实现利用了结构化日志记录(Structured Logging),将流水线的日志与系统其余部分分离,并存入托管 IRIS 的容器卷内的持久路径中。