InterSystems IRIS 中的数据模型
在我们开始谈论数据库和现有的不同数据模型之前,我们最好先谈谈什么是数据库以及如何使用它。
一个数据库是以电子方式存储和访问的有组织的数据集合。 它用于存储和检索通常与主题或活动相关的结构化、半结构化或原始数据。
每个数据库的核心至少存在一个用于描述其数据的模型。 并且根据它所基于的模型,一个数据库可能具有略微不同的特征并存储不同数据类型。
要写入、检索、修改、排序、转换或打印数据库中的信息,需要使用称为数据库管理系统 (DBMS) 的软件。
数据库及其各自的数据库管理系统的大小、容量和性能增加了几个数量级。 各个领域的技术进步使之成为可能,例如处理器、计算机内存、计算机存储和计算机网络。 一般来说,数据库技术的发展根据数据模型或结构分为四代:导航型、关系型、对象型和后关系型。


与以特定数据模型为特征的前三代不同,第四代包括许多基于不同模型的不同数据库。 它们包括列、图、文档、组件、多维、键值、内存等。所有这些数据库都由一个单一的名称 NoSQL 联合起来(没有 SQL,或者现在更准确地说不仅仅是 SQL)。
而且,现在出现了一个新的类,叫做NewSQL。 这些是现代关系数据库,旨在为在线事务处理工作负载(读写)提供与 NoSQL 系统相同的可扩展性能,同时使用 SQL 和维护 ACID。
顺便说一下,在这些第四代数据库中,有那些支持上述提及的多种数据模型的数据库。 它们被称为多模型数据库。 这种类型的数据库的一个很好的例子是 InterSystems IRIS。 这就是为什么我将使用它来给出不同类型模型的示例。
第一代数据库使用分层或网络模型。 前者的核心是一个树形结构,即每条记录只有一个所有者。 您可以在 InterSystems IRIS 的示例中看到其工作原理,因为它的主要模型是分层的,并且所有数据都存储在globals(即 B*-trees)中。 您可以在此处here.阅读有关globals的更多信息。
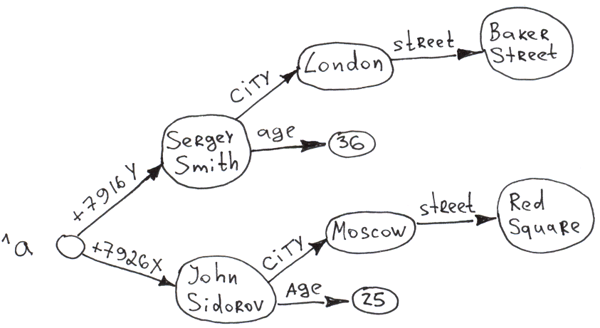
我们可以在 IRIS 中创建这棵树:
Set ^a("+7926X", "city") = "Moscow"
Set ^a("+7926X", "city", "street") = "Req Square"
Set ^a("+7926X", "age") = 25
Set ^a("+7916Y", "city") = "London"
Set ^a("+7916Y", "city", "street") = "Baker Street"
Set ^a("+7916Y", "age") = 36
在数据库中查看:

在 Edgar F. Codd 于 1969 年提出他的关系代数和他的数据存储理论之后,使用关系原理。之后,关系型数据库产生了。 关系(表)、属性(列)、元组(行)以及最重要的事务和 ACID 要求的使用使这些数据库非常流行,并且现在仍然如此。
例如,我们有架构:
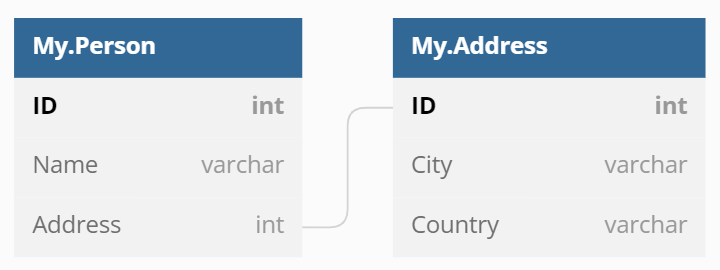
我们可以创建和填充表:
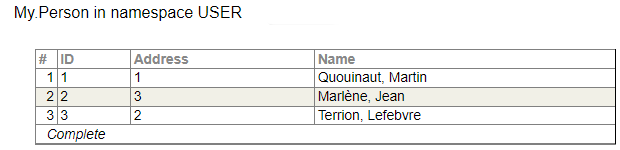
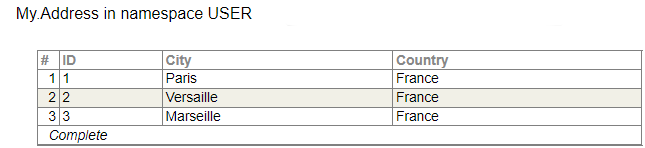
如果我们编写查询:
select p.ID, p.Name, a.Country, A.City
from My.Person p left join My.Address a
on p.Address = a.ID
我们将收到答案:
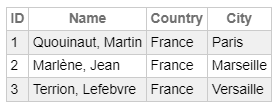
尽管关系数据库具有显着优势,但随着对象语言的普及,将面向对象的数据存储在数据库中变得很有必要。 这就是为什么 1990 年第一个面向对象(object-oriented )和对象关系数据库产生原因。 后者是在关系数据库的基础上通过添加附加组件来模拟对象工作而创建的。 前者是在 OMG(对象管理组)联盟的建议和 ODMG(对象数据管理组)之后从头开始开发的。
这些面向对象数据库的主要思想如下:
可以使用以下方式访问单个数据仓库:
• 对象定义语言——模式定义,允许类定义、它们的属性、关系和方法,
• 对象查询语言——声明性的,几乎类似于 SQL 的语言,允许从数据库中获取对象,
• 对象操作语言——允许修改和保存数据库中的数据,支持事务和方法调用。
该模型允许使用面向对象的语言从数据库中获取数据。
如果我们采用与前面示例相同的结构但采用面向对象的形式,我们将拥有以下类:
Class My.Person Extends %Persistent
{
Property Name As %Name;
Property Address As My.Address;
}
Class My.Address Extends %Persistent
{
Property Country;
Property City;
}
我们可以使用面向对象的语言创建对象:
set address = ##class(My.Address).%New()
set address.Country = "France"
set address.City = "Marseille"
do address.%Save()
set person = ##class(My.Person).%New()
set person.Address = address
set person.Name = "Quouinaut, Martin"
do person.%Save()
不幸的是,对象数据库并没有成功地从其主导地位与关系数据库竞争,结果出现了许多对象关系映射技术。
无论如何,随着 2000 年代 互联网的普及和对数据存储的新要求的出现,其他数据模型和 数据库管理系统开始出现, 其中,IRIS 中使用了这些模型中的两个,即是文档模型和列模型。
面向文档的数据库用于管理半结构化数据。 这是不遵循固定结构并在其中携带结构的数据。 这种数据库中的每个信息单元都是一个简单的对:一个密钥和一个特定的文档。 该文档通常采用 JSON 格式并包含信息。 由于数据库不需要一定的模式,所以也可以在同一个仓库中集成不同类型的文档。
如果我们再看前面的例子,我们可以有这样的文档:
{
"Name":"Quouinaut, Martin",
"Address":{
"Country":"France",
"City":"Paris"
}
}
{
"Name":"Merlingue, Luke",
"Address":{
"Country":"France",
"City":"Nancy"
},
"Age":26
}
这两个字段数不同的文档存储在 IRIS 数据库中没有任何问题。
2022.2 版中将提供的模型的最后一个示例是列模型。 在这种情况下,数据库管理系统是按列而不是按行存储数据表。
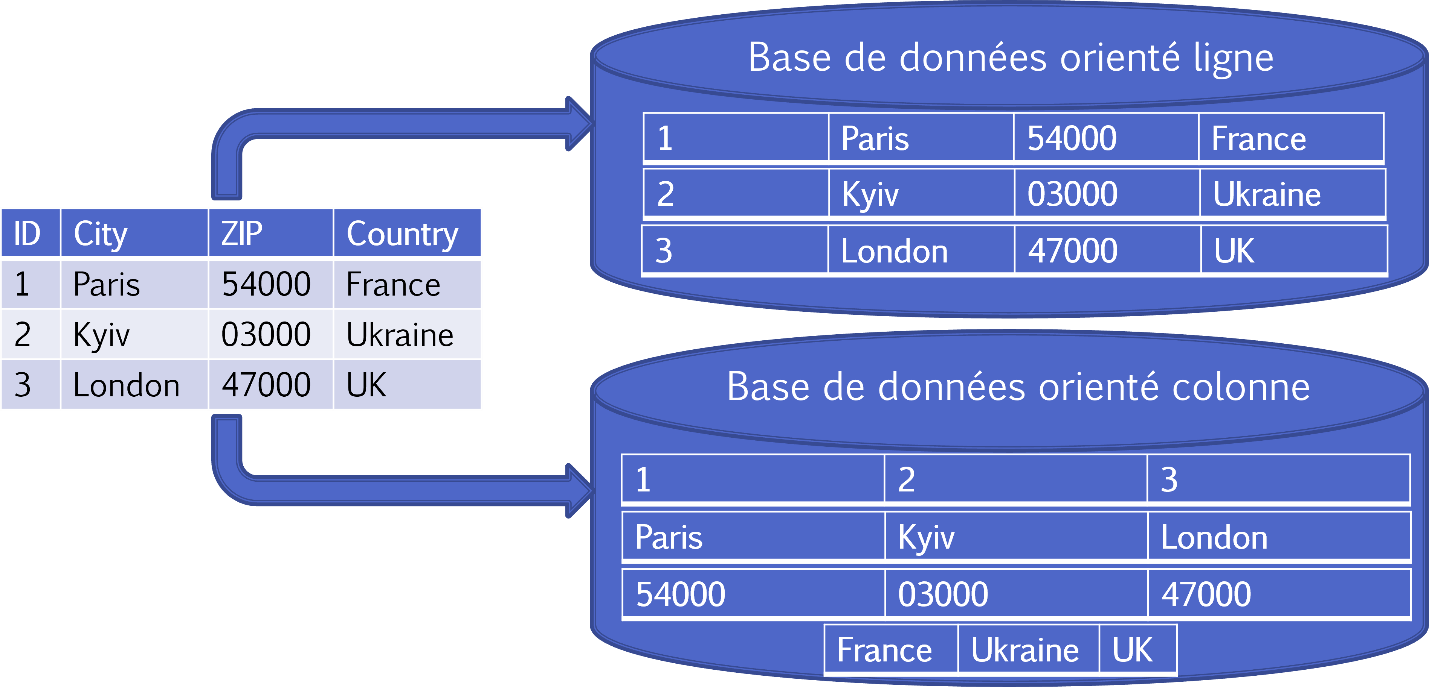
列方向允许更有效地访问数据以查询列的子集(无需读取不相关的列),并提供更多数据压缩选项。 当列中的数据相似时,按列压缩也更有效。 但是,它们在插入新数据时通常效率较低。
您可以这样创建此表:
Create Table My.Address (
city varchar(50),
zip varchar(5),
country varchar(15)
) WITH STORAGETYPE = COLUMNAR
在这种情况下,类是这样的:
Spoiler
然后我们插入数据:
insert into My.Address values ('London', '47000', 'UK')
insert into My.Address values ('Paris', '54000', 'France')
insert into My.Address values ('Kyiv', '03000', 'Ukraine')
在globals里我们看到:

如果我们用city names打开globals,我们将看到 :

如果我们写一个查询:
select City
from My.Address
我们收到数据:

在这种情况下,数据库管理系统 只需读取一个全局变量即可获得整个结果。 并且在阅读时节省时间和资源。
因此,我们讨论了 InterSystems IRIS 数据库支持的 5 种不同的数据模型。 这些是层次模型、关系模型、对象模型、文档模型和列模型。
希望您在尝试找出可用的模型时会发现这篇文章很有用。 如果您有任何问题,请随时在评论中提出。