清除过滤器
文章
Michael Lei · 二月 14
FHIR 用例集: 打破数字医疗壁垒,实现高质量发展
--促进互联互通,改进工作流程,提高数据洞察
简介
HL7® FHIR®(快速医疗互操作性资源)是以电子方式访问、交换和管理医疗信息的国际标准。与以往的标准不同,FHIR 可让帮助行业从业者轻松构建创新应用程序,有效地收集、汇总和分析来自不同来源的各种医疗保健和管理数据。医疗机构、社保/保险公司、政府机构、生命科学公司、医疗设备制造商和医疗科技等多种主体利用 FHIR 来简化信息流、提高数据洞察力、改善临床效果和业务成果。
FHIR 基于 JSON、HTTP 和 REST 等流行的网络技术。有了 FHIR,没有医疗信息化背景的软件开发人员也能使用熟悉的开发工具和开源技术,快速、轻松地满足政府机构、临床医生、研究人员、医疗行业从业者以及各类市场主体的数据需求。
FHIR 是一种灵活、适应性强的医疗数据模型,可轻松定制,以实现各种用例的互操作性。FHIR 由称为 "资源 "的离散、可计算的数据对象组成,以实现最佳效率。通过 FHIR 资源,应用程序可以访问单个医疗记录元素,而无需检索摘要文档中包含的所有数据。
本文回顾了 FHIR 的实际应用,并提供了 InterSystems 客户如何使用 FHIR 连接不同系统、加速数字化转型和提高数据洞察力的真实案例。
FHIR 商机无限
FHIR 正在改变医疗健康数据的访问和交换。无论您是为政府、医疗机构、公共卫生机构、保险公司还是厂商工作,FHIR 都能帮助您高效地获取、检索和共享来自电子病历系统、智能医疗设备、可穿戴设备、临床试验和公共卫生监测系统等不同来源的医疗数据。
当前应用和未来的 FHIR 用例FHIR支持实现大量的不同业务场景。您可以在各种部署场景中将 FHIR 用于各种目的。下面的列表总结了 FHIR 在不同行业领域的一些当前应用和潜在的未来用例。
医疗机构
应用场景: 患者数据访问 API机会:可以基于FHIR资源和技术框架实现卫健委互联互通三年攻坚计划以及国家数据局"数据要素x医疗行业"三年行动计划中提到的相关电子健康档案共享、检验检查互认、医疗行业数据要素流通、交易等战略目标,通过基于标准的 (FHIR) API 让患者以程序化的方式访问其健康数据(病史、化验结果、治疗计划等),以及未来可能的全国统一医疗健康档案超级APP(患者端)。
应用场景: 临床决策支持机会: 使用 FHIR 改善临床决策系统的洞察力。将实时电子病历数据安全传输到第三方系统进行分析并返回建议,帮助临床医生做出明智决策。与以往的标准和方法不同,使用 FHIR,您可以将临床决策支持功能直接嵌入电子病历,以简化流程。
应用场景: 医疗机构与支付方(医保/保险公司)的合规数据交换 机会: 利用 FHIR 自动化医疗机构与支付方之间的数据交换。消除资源密集、耗时的人工流程(降低飞行检查和审计成本)。允许医疗机构直接将电子病历数据转发给支付方,无需人工干预。
使用案例: 临床试验和研究机会: 使用 FHIR 无缝共享临床试验招募和分析所需的患者数据,加快临床研究进程。
设备制造商、医疗科技公司和应用开发商
用例:远程医疗和远程监控机会: 使用 FHIR 可将患者数据从家用医疗设备安全地传输给医疗服务提供者,以便他们有效地远程监控和管理患者。
用例: 移动医疗应用程序机遇: 患者可以在手机端访问在不同医院治疗的电子病历,并且确保患者数据的隐私和安全。
用例: 慢性病管理应用程序机会: 使用 FHIR 在医疗服务提供者之间无缝共享患者数据,以实现一致的监控和协调的护理计划。
用例: 药物管理应用程序机会: 为临床医生和护理人员创建多功能药物管理应用程序。使用 FHIR 在区域全民健康信息平台之间高效共享处方信息、用药计划和药房记录。
生命科学公司、政府机构和付款人
用例:健康信息交换机会: 使用 FHIR,政府、公共卫生、保险公司等可高效开展电子健康档案/电子病历共享调阅数据,以进行质量评估、护理差距识别、理赔裁定以及开展潜在的数据交易等。
用例: 护理计划机会: 利用 FHIR,让跨机构护理团队--医生、家庭医疗工作者、社区护理人员、家庭成员等--能够无缝交换信息。让不同的医疗保健系统进行有效沟通。确保所有护理团队成员都能获得最新的患者信息。
用例: 公共卫生报告机会: 使用 FHIR 有效地汇总和共享患者数据,以进行监控和人口健康管理,从而简化公共卫生报告。利用电子病历批量检索功能。(注:该功能自 2022 年起已成为所有美国电子病历系统的强制性要求,在WHO、OECD、欧盟、亚洲、港澳台等地区也正在逐步推广普及)
以上只是部分FHIR的用例,有了FHIR,从业者可以打开无限想象空间,创建丰富多样、互联互通的数字医疗创新应用。
文章
姚 鑫 · 二月 24, 2021
# 第四十六章 Caché 变量大全 ^$GLOBAL 变量
提供有关全局变量和进程私有全局变量的信息。
# 大纲
```java
^$|nspace|GLOBAL(global_name)
^$|nspace|G(global_name)
^$||GLOBAL(global_name)
^$||G(global_name)
```
# 参数
- `|nspace|` 或 `[nspace]` - 可选-扩展SSVN引用,可以是显式名称空间名称,也可以是隐含名称空间。必须计算为带引号的字符串,该字符串括在方括号(`[“nspace”]`)或竖线(`|“nspace”|`)中。命名空间名称不区分大小写;它们以大写字母存储和显示。
- global_name 计算结果为包含无下标全局名称的字符串的表达式。全局名称区分大小写。使用`^$||global()`语法时,与进程专用全局名称相对应的无下标全局名称:`^a`表示`^||a`。
# 描述
可以将`^$GLOBAL`用作`$DATA`、`$ORDER`和`$QUERY`函数的参数,以返回有关当前名称空间(默认名称空间)或指定名称空间中是否存在全局变量的信息。还可以使用`^$global`返回有关存在进程私有全局变量的信息。
## 进程私有全局变量
可以使用`^$global`获取有关所有命名空间中是否存在进程私有全局变量的信息。可以将进程专用全局的查找指定为`^$||global`或`^$|“^”|global`。
例如,要获取有关进程私有全局`^||a`及其后代的信息,可以指定`$DATA(^$||global(“^a”))`。进程私有全局变量不是特定于名称空间的,因此在定义进程私有全局变量时,无论当前名称空间如何,此查找都会返回有关`^||a`的信息。
请注意,`^$GLOBAL`不支持在`GLOBAL_NAME`本身中指定进程专用全局语法。使用进程专用全局语法指定`GLOBAL_NAME`会导致``错误。
# 参数
## nspace
此可选参数允许`^$GLOBAL`查找在另一个命名空间中定义的`GLOBAL_NAME`。这称为扩展SSVN参考。可以显式地将命名空间名称指定为带引号的字符串文字、变量,也可以通过指定隐含的命名空间来指定。命名空间名称不区分大小写。可以使用方括号语法`[“user”]`或环境语法`|“user”|`。Nspace分隔符前后不允许有空格
可以使用以下方法测试是否定义了命名空间:
```java
DHC-APP>WRITE ##class(%SYS.Namespace).Exists("USER")
1
DHC-APP>WRITE ##class(%SYS.Namespace).Exists("LOSER")
0
```
以使用`$NAMESPACE`特殊变量来确定当前名称空间。更改当前名称空间的首选方式是新建`$NAMESPACE`,然后设置`$NAMESPACE=“nspace ename”`。
## global_name
计算结果为包含无下标全局名称的字符串的表达式。全局变量区分大小写。
- `^$global(“^a”)`:`global_name“^a”`在当前名称空间中查找此全局名称及其后代。它不查找进程私有全局`“^||a”`。
- `^$|"USER"|GLOBAL("^a")`:global_name `"^a"`在`“user”`名称空间中查找此全局名称及其后代。它不查找进程-私有全局`"^||a"`。
-` ^$||GLOBAL("^a")`:global_name `"^a"`在所有名称空间中查找进程私有全局`"^||a"`及其后代。它不查找全`"^a"`。
# 示例
以下示例显示如何将`^$GLOBAL`用作`$DATA`、`$ORDER`和`$QUERY`函数的参数。
## 作为`$DATA`的参数
`^$GLOBAL`作为`$DATA`的参数返回一个整数值,表示指定的全局名称是否作为`^$GLOBAL`节点存在。下表显示了`$DATA`可以返回的整数值。
Value | Meaning
---|---
0| 全局名称不存在
1| 全局名称是包含数据但没有子代的现有节点。
10| 全局名称是没有数据但具有子代的现有节点。
11| 全局名称是包含数据的现有节点,并且具有子代。
下面的示例测试当前命名空间中是否存在指定的全局变量:
```java
/// d ##class(PHA.TEST.SpecialVariables).GLOBAL()
ClassMethod GLOBAL()
{
KILL ^GBL
WRITE $DATA(^$GLOBAL("^GBL")),!
SET ^GBL="test"
WRITE $DATA(^$GLOBAL("^GBL")),!
SET ^GBL(1,1,1)="subscripts test"
WRITE $DATA(^$GLOBAL("^GBL"))
}
```
```java
DHC-APP>d ##class(PHA.TEST.SpecialVariables).GLOBAL()
0
1
11
```
下面的示例测试user命名空间中是否存在指定的全局变量:
```java
/// d ##class(PHA.TEST.SpecialVariables).GLOBAL1()
ClassMethod GLOBAL1()
{
SET $NAMESPACE="USER"
SET ^GBL(1)="test"
SET $NAMESPACE="%SYS"
WRITE $DATA(^$|"USER"|GLOBAL("^GBL"))
}
```
```java
DHC-APP>d ##class(PHA.TEST.SpecialVariables).GLOBAL1()
10
```
下面的示例测试任何命名空间中是否存在指定的进程私有全局变量:
```java
/// d ##class(PHA.TEST.SpecialVariables).GLOBAL2()
ClassMethod GLOBAL2()
{
SET $NAMESPACE="USER"
SET ^||PPG(1)="test"
SET $NAMESPACE="%SYS"
WRITE $DATA(^$||GLOBAL("^PPG"))
}
```
```java
DHC-APP>d ##class(PHA.TEST.SpecialVariables).GLOBAL2()
10
```
## 作为`$ORDER`的参数
`$ORDER(^$|nspace|GLOBAL( global_name),direction)`
`^$GLOBAL`作为`$ORDER`的参数,将排序序列中的下一个或上一个全局名称返回到指定的全局名称。如果`^$GLOBAL`中不存在这样的全局名称节点,`$ORDER`将返回空字符串。
注意:`$ORDER(^$GLOBAL(NAME))`不会从IRISSYS数据库返回`%global names`。
Direction参数指定是返回下一个全局名称还是返回上一个全局名称。如果不提供方向参数,InterSystems IRIS会将排序顺序中的下一个全局名称返回给您指定的全局名称。
以下子例程搜索当前名称空间,并将全局名称存储在名为global的本地数组中。
```java
/// d ##class(PHA.TEST.SpecialVariables).GLOBAL3()
ClassMethod GLOBAL3()
{
GLOB
SET NAME=""
WRITE !,"以下全局变量在 ",$NAMESPACE
FOR I=1:1 {
SET NAME=$ORDER(^$GLOBAL(NAME))
WRITE !,NAME
QUIT:NAME=""
SET GLOBAL(I)=NAME
}
WRITE !,"全部完成"
QUIT
}
```
```java
DHC-APP>d ##class(PHA.TEST.SpecialVariables).GLOBAL3()
以下全局变量在 DHC-APP
^%ISCWorkQueue
^%cspSession
^%qCacheMsg
^%qCacheMsgNames
^%qCacheObjectErrors
^%qCacheObjectKey
^%qCacheObjectQualifier
^%qCacheSQL
^%qHTMLElementD
^%qJavaMetaDictionary
^%qMgtPortal.Index
^%qPublicSuffix
^%qStream
^%qcspRule
^A
^AA
Visible+4^%SYS.GD
DHC-APP>
```
## 作为`$QUERY`的参数
`^$GLOBAL`作为`$QUERY`的参数,按排序顺序将下一个全局名称返回到指定的全局名称。如果`^$GLOBAL`中不存在这样的全局名称作为节点,则`$QUERY`将返回空字符串。
注意:`$QUERY(^$GLOBAL(NAME))`不会从IRISSYS数据库返回`%GLOBAL NAMES`。
在以下示例中,用`user`命名空间中存在三个全局变量(`^GBL1`、`^GBL2`和`^GBL3`)。
```java
/// d ##class(PHA.TEST.SpecialVariables).GLOBAL4()
ClassMethod GLOBAL4()
{
NEW $NAMESPACE
SET $NAMESPACE="USER"
SET (^GBL1,^GBL2,^GBL3)="TEST"
NEW $NAMESPACE
SET $NAMESPACE="%SYS"
WRITE $QUERY(^$|"USER"|GLOBAL("^GBL1")),!
WRITE $QUERY(^$|"USER"|GLOBAL("^GBL2"))
NEW $NAMESPACE
SET $NAMESPACE="USER"
KILL ^GBL1,^GBL2,^GBL3
}
```
```java
DHC-APP>d ##class(PHA.TEST.SpecialVariables).GLOBAL4()
^$|"USER"|GLOBAL("^GBL2")
^$|"USER"|GLOBAL("^GBL3")
```
## 作为`MERGE`的参数
`^$GLOBAL`作为`MERGE`命令的源参数,将全局目录复制到目标变量。`Merge`将每个全局名称添加为具有空值的目标下标。下面的示例显示了这一点:
```java
MERGE gbls=^$GLOBAL("")
ZWRITE gbls
```
```java
...
gbls("^zlgsql")=""
gbls("^zlgtem")=""
gbls("^zlgtem1")=""
gbls("^zlgtem4")=""
gbls("^zlgtemp")=""
gbls("^zlgtemp1")=""
gbls("^zlgtemp3")=""
gbls("^zlgtemp5")=""
gbls("^zlgtmp")=""
gbls("^zlj")=""
gbls("^zll")=""
gbls("^zltmp")=""
gbls("^zmc")=""
gbls("^znum")=""
gbls("^zpeterc")=""
gbls("^zsb")=""
gbls("^zseq")=""
gbls("^zstock")=""
gbls("^ztTmp")=""
gbls("^ztrap1")=""
gbls("^zwb1")=""
gbls("^zwhtmp")=""
gbls("^zx")=""
gbls("^zx1")=""
gbls("^zx2")=""
gbls("^zxdd")=""
gbls("^zyb")=""
gbls("^zyb1")=""
gbls("^zyb2")=""
gbls("^zyl")=""
gbls("^zzTT")=""
gbls("^zzdt")=""
gbls("^zzp")=""
gbls("^zzy")=""
gbls("^zzz")=""
```
文章
Michael Lei · 四月 24, 2022
# 基于Docker的Apache Web Gateway
Hi 社区
在本文中,我们将基于Docker程序化地配置一个Apache Web Gateway,使用。:
* HTTPS protocol.
* TLS\SSL to secure the communication between the Web Gateway and the IRIS instance.
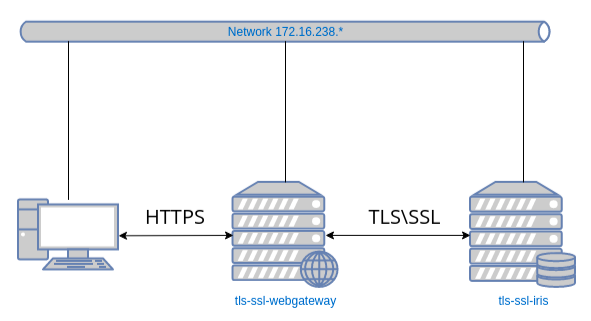
我们将使用两个镜像:一个用于Web网关,第二个用于IRIS实例。
所有必需的文件都在这 [GitHub repository](https://github.com/lscalese/docker-webgateway-sample).
我们从git clone开始:
```bash
git clone https://github.com/lscalese/docker-webgateway-sample.git
cd docker-webgateway-sample
```
## 准备系统
为了避免权限方面的问题,你的系统需要一个用户和一个组:
* www-data
* irisowner
需要与容器共享证书文件。 如果你的系统中不存在这些文件,只需执行:
```bash
sudo useradd --uid 51773 --user-group irisowner
sudo groupmod --gid 51773 irisowner
sudo useradd –user-group www-data
```
## 生成证书
在这个示例中,我们使用以下三个证书:
1. HTTPS web server usage.
2. TLS\SSL encryption on Web Gateway client.
3. TLS\SSL encryption on IRIS Instance.
有一个随时可用的脚本来生成它们。.
然而,你应该自定义证书的主题;只需编辑这个文件 [gen-certificates.sh](https://github.com/lscalese/docker-webgateway-sample/blob/master/gen-certificates.sh) .
这是 OpenSSL `subj` argument的结构:
1. **C**: Country code
2. **ST**: State
3. **L**: Location
4. **O**: Organization
5. **OU**: Organization Unit
6. **CN**: Common name (basically the domain name or the hostname)
可以随意改动这些值.
```bash
# sudo is needed due chown, chgrp, chmod ...
sudo ./gen-certificates.sh
```
如果一切都OK,应该能看到两个带证书的新目录 `./certificates/` and `~/webgateway-apache-certificates/` with certificates:
| File | Container | Description |
|--- |--- |--- |
| ./certificates/CA_Server.cer | webgateway,iris | Authority server certificate|
| ./certificates/iris_server.cer | iris | Certificate for IRIS instance (used for mirror and wegateway communication encryption) |
| ./certificates/iris_server.key | iris | Related private key |
| ~/webgateway-apache-certificates/apache_webgateway.cer | webgateway | Certificate for apache webserver |
| ~/webgateway-apache-certificates/apache_webgateway.key | webgateway | Related private key |
| ./certificates/webgateway_client.cer | webgateway | Certificate to encrypt communication between webgateway and IRIS |
| ./certificates/webgateway_client.key | webgateway | Related private key |
请记住,如果有自签名的证书,浏览器会显示安全警报。 显然,如果你有一个由认证机构交付的证书,你可以用它来代替自签的证书(尤其是Apache服务器证书)
## Web Gateway 配置文件
让我们来看看配置文件.
### CSP.INI
你能看到在 `webgateway-config-files` 目录下 CSP.INI 文件.
将被推到镜像里, 但内容可以在runtime被修改.
可以把这个文件作为模版.
在这个示例中,以下参数将在容器启动时被覆盖:
* Ip_Address
* TCP_Port
* System_Manager
更多细节请参考 [startUpScript.sh](https://github.com/lscalese/docker-webgateway-sample/blob/master/startUpScript.sh) . 大致上,替换是通过`sed`命令行进行的.
同时, 这个文件包含 SSL\TLS 配置来确保与 IRIS 实例的通信:
```
SSLCC_Certificate_File=/opt/webgateway/bin/webgateway_client.cer
SSLCC_Certificate_Key_File=/opt/webgateway/bin/webgateway_client.key
SSLCC_CA_Certificate_File=/opt/webgateway/bin/CA_Server.cer
```
这些语句都比较重要. 我们必需确保证书文件可用.
我们稍后将在`docker-compose`文件中用一个卷来做这件事.
### 000-default.conf
这是一个Apache 配置文件. 允许使用HTTPS协议并将HTTP请求重定向到HTTPS.
证书和私钥文件在这个文件里设置:
```
SSLCertificateFile /etc/apache2/certificate/apache_webgateway.cer
SSLCertificateKeyFile /etc/apache2/certificate/apache_webgateway.key
```
## IRIS 实例
对我们 IRIS实例, 我们仅仅配置最低要求来允许SSL\TLS 和Web Gateway 之间的通信; 这涉及到:
1. `%SuperServer` SSL Config.
2. Enable SSLSuperServer security setting.
3. Restrict the list of IPs that can use the Web Gateway service.
为简化配置, config-api 用一个简单的JSON 配置文件.
```json
{
"Security.SSLConfigs": {
"%SuperServer": {
"CAFile": "/usr/irissys/mgr/CA_Server.cer",
"CertificateFile": "/usr/irissys/mgr/iris_server.cer",
"Name": "%SuperServer",
"PrivateKeyFile": "/usr/irissys/mgr/iris_server.key",
"Type": "1",
"VerifyPeer": 3
}
},
"Security.System": {
"SSLSuperServer":1
},
"Security.Services": {
"%Service_WebGateway": {
"ClientSystems": "172.16.238.50;127.0.0.1;172.16.238.20"
}
}
}
```
不需要做任何动作. 在容器启动时这个配置会自动加载.
## tls-ssl-webgateway 镜像
### dockerfile
```
ARG IMAGEWEBGTW=containers.intersystems.com/intersystems/webgateway:2021.1.0.215.0
FROM ${IMAGEWEBGTW}
ADD webgateway-config-files /webgateway-config-files
ADD buildWebGateway.sh /
ADD startUpScript.sh /
RUN chmod +x buildWebGateway.sh startUpScript.sh && /buildWebGateway.sh
ENTRYPOINT ["/startUpScript.sh"]
```
默认的 entry point是 `/startWebGateway`, 但是在启动webserver前需要执行一些操作. 记住我们的 CSP.ini 文件只是个 `模版`, 并且我们需要在启动时改变一些参数 (IP, port, system manager) . `startUpScript.sh` 将执行这些变化并启动初始 entry point 脚本 `/startWebGateway`.
## 启动容器
### docker-compose 文件
启动容器之前, 必须修改好`docker-compose.yml` 文件:
* `**SYSTEM_MANAGER**` 必须配好授权的IP来访问 **Web Gateway Management** https://localhost/csp/bin/Systems/Module.cxw
基本就是你自己的IP地址 (可以是一个用逗号分开的列表).
* `**IRIS_WEBAPPS**` 必须配好 CSP 应用列表. 这个表用空格隔开, 例如: `IRIS_WEBAPPS=/csp/sys /swagger-ui`. 默认, 只有 `/csp/sys` 被暴露.
* 80和 443 端口映射好. 如果你的系统中已经使用了这些端口,请将调整为其他端口.
```
version: '3.6'
services:
webgateway:
image: tls-ssl-webgateway
container_name: tls-ssl-webgateway
networks:
app_net:
ipv4_address: 172.16.238.50
ports:
# change the local port already used on your system.
- "80:80"
- "443:443"
environment:
- IRIS_HOST=172.16.238.20
- IRIS_PORT=1972
# Replace by the list of ip address allowed to open the CSP system manager
# https://localhost/csp/bin/Systems/Module.cxw
# see .env file to set environement variable.
- "SYSTEM_MANAGER=${LOCAL_IP}"
# the list of web apps
# /csp allow to the webgateway to redirect all request starting by /csp to the iris instance
# You can specify a list separate by a space : "IRIS_WEBAPPS=/csp /api /isc /swagger-ui"
- "IRIS_WEBAPPS=/csp/sys"
volumes:
# Mount certificates files.
- ./volume-apache/webgateway_client.cer:/opt/webgateway/bin/webgateway_client.cer
- ./volume-apache/webgateway_client.key:/opt/webgateway/bin/webgateway_client.key
- ./volume-apache/CA_Server.cer:/opt/webgateway/bin/CA_Server.cer
- ./volume-apache/apache_webgateway.cer:/etc/apache2/certificate/apache_webgateway.cer
- ./volume-apache/apache_webgateway.key:/etc/apache2/certificate/apache_webgateway.key
hostname: webgateway
command: ["--ssl"]
iris:
image: intersystemsdc/iris-community:latest
container_name: tls-ssl-iris
networks:
app_net:
ipv4_address: 172.16.238.20
volumes:
- ./iris-config-files:/opt/config-files
# Mount certificates files.
- ./volume-iris/CA_Server.cer:/usr/irissys/mgr/CA_Server.cer
- ./volume-iris/iris_server.cer:/usr/irissys/mgr/iris_server.cer
- ./volume-iris/iris_server.key:/usr/irissys/mgr/iris_server.key
hostname: iris
# Load the IRIS configuration file ./iris-config-files/iris-config.json
command: ["-a","sh /opt/config-files/configureIris.sh"]
networks:
app_net:
ipam:
driver: default
config:
- subnet: "172.16.238.0/24"
```
Build and start:
```bash
docker-compose up -d --build
```
`tls-ssl-iris 和 tls-ssl-webgateway 容器应该启动好了.`
## 测试 Web Access
### Apache 默认页
打开网页 [http://localhost](http://localhost).
你将自动被重定向到[https://localhost](https://localhost).
浏览器显示安全警告. 如果是自签署的证书,这是正常的,接受并继续.
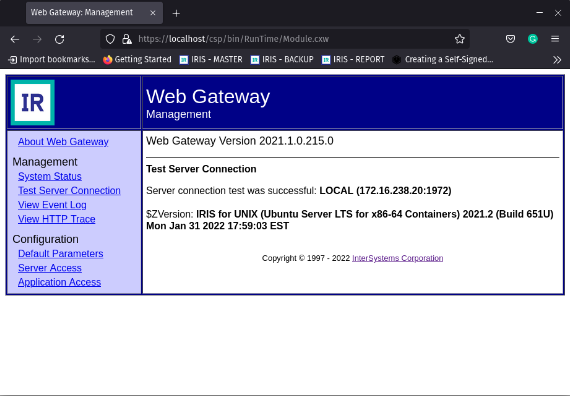
### Web Gateway 管理页面
打开 [https://localhost/csp/bin/Systems/Module.cxw](https://localhost/csp/bin/Systems/Module.cxw) 并测试服务器连接.
### 管理门户
打开 [https://localhost/csp/sys/utilhome.csp](https://localhost/csp/sys/utilhome.csp)
赞! Web Gateway 例子跑起来了!
## IRIS Mirror 与vWeb Gateway
在上一篇文章中,我们建立了一个镜像环境,但网络网关是一个缺失的部分。 现在,我们可以改进这一点。 一个包括Web Gateway和一些更多改进的资源库就可以用了 [iris-miroring-with-webgateway](https://github.com/lscalese/iris-mirroring-with-webgateway) :
1. 证书不再是即时生成的,而是在一个单独的过程中生成的.
2. IP地址被docker-compose和JSON配置文件中的环境变量所取代, 变量被定义在'.env'文件中.
3. 这个repository 可以作为一个模板来使用.
查看 repository文件 [README.md](https://github.com/lscalese/iris-mirroring-with-webgateway) 来运行以下环境:

文章
Jingwei Wang · 七月 21, 2022
一个主题区是一个子立方体,可以选择覆盖项目的名称。你定义一个主题区是为了使用户能够关注较小的数据集,出于安全原因或其他原因。本章讨论了以下主题。
简介
在本教程中,我们创建了两个主题区域,按邮政编码划分患者:
Patient Set A: 居住在邮政编码为32006, 32007, or 36711区域的患者
Patient Set B: 居住在邮政编码为34577 or 38928区域的患者
创建主题领域
要创建主题区域,请做以下工作。
在模型中,点击 "新建"。
选中 "主题区域"。
对于主题区名称,键入Patient Set A
对于主题区的类名,输入 Tutorial.SubjectA
对于基础立方体,点击浏览并选择 Tutorial。
单击 OK。
在一个单独的浏览器标签或窗口中,访问分析器,然后做以下工作。
展开HomeD。
把ZIP Code放到过滤器框中。这就在数据透视表的正上方增加了一个过滤框。
在该过滤框中,点击搜索按钮,然后选择 32006, 32007, 和 36711。
然后点击'为透视表显示当前查询'按钮(笔记本带一个笔的图标)
系统会显示一个对话框,显示分析器所使用的MDX查询。
SELECT FROM [PPatients]
%FILTER %OR({[HOMED].[H1].[ZIP CODE].&[32006],[HOMED].[H1].[ZIP CODE].&[32007],[HOMED].[H1].[ZIP CODE].&[36711]})
将%FILTER后面的文本复制到系统剪贴板上。
点击确定。
在模型中,点击标有Patient Set A的一行。
在详细信息栏中,将复制的文本粘贴到 过滤器 中。
%OR({[HOMED].[H1].[ZIP Code].&[32006],[HOMED].[H1].[ZIP Code].&[32007],[HOMED].[H1].[ZIP Code].&[36711]})
点击保存,然后点击确定。
编译该主题区。
对于第二个主题区,重复前面的步骤,并作如下改动。
对于课题区名称,键入Patient Set B
对于主题区的类名,键入Tutorial.SubjectB
对另外两个邮政编码重复前面的步骤。因此,对于Filter,使用以下内容。
%OR({[HOMED].[H1].[ZIP Code].&[34577],[HOMED].[H1].[ZIP Code].&[38928]})
检查主题领域
现在我们检查一下我们所创建的主题领域。
在分析器中,点击左上角立方体按钮,选择Patient Set A。
单击 "确定"。然后分析器显示所选主题区的内容。 注意,总的记录数没有你的Tutorial基本立方体那么高。
在模型内容区,展开HomeD维度,ZIP Code级别,以及City级别。都没有之前的Tutorial基本立方体数据那么多。
对患者组B重复前面的步骤。
当您展开HomeD维度、ZIP Code级别,以及City级别。也没之前的Tutorial基本立方体数据那么多。
常见的过滤器表达式
在这一节中,我们在分析器中试验常见的过滤器,看看它们对生成的查询的影响。
在分析器中,打开Tutorial立方体。
分析器把立方体和主题区都称为主题区。它们之间的正式区别只有在你创建它们时才有意义。
点击新建。
分析器显示计数(记录的计数)。
在添加过滤器之前,让我们看看当前的查询是如何定义的,以便我们有一个比较的基础。
展开ColorD和Favorite Color。
把Orange拖到过滤器。
分析器现在只使用最喜欢的颜色是Orange的患者。
点击‘为透视表显示当前查询’按钮(笔记本加一个笔图标)。然后系统显示以下查询。
SELECT FROM [TUTORIAL] %FILTER [ColorD].[H1].[Favourite Color].&[Orange]
%FILTER关键字限制了查询。%FILTER后面的片段是一个过滤表达式。
点击确定。
给过滤器添加另一种颜色。点击过滤器中橙色旁边的X。这样就可以删除该过滤器。
把 "Favourite Color "拖到过滤器中。这就在数据透视表的正上方增加了一个过滤器框。
在该过滤框中,点击搜索按钮(放大镜图标),然后选择橙色和紫色。
系统现在只使用最喜欢的颜色是橙色或最喜欢的颜色是紫色的患者(注意,计数比单独的橙色要高)。
再次显示查询文本。现在你应该看到以下内容。
SELECT FROM [TUTORIAL] %FILTER %OR({[COLORD].[H1].[FAVOURITE COLOR].&[Orange],[COLORD].[H1].[FAVOURITE COLOR].&[Purple]})
在这种情况下,过滤器的表达式如下。
%FILTER %OR({[COLORD].[H1].[FAVOURITE COLOR].&[Orange],[COLORD].[H1].[FAVOURITE COLOR].&[Purple]})
%OR函数是InterSystems公司的一项优化;该函数的参数是一个集合。 这个集合被大括号{}所包围,由一个逗号分隔的元素列表组成。在这种情况下,该集合包含两个成员表达式。一个集合表达式指的是由该集合的元素所表示的所有记录。在本例中,该集合指的是所有最喜欢的颜色是橙色的患者和所有最喜欢的颜色是紫色的患者。
点击确定。
使用过滤器下拉列表,清除紫色旁边的复选框。现在分析器只使用最喜欢的颜色是橙色的患者。
展开AllerD和Allergies。将模具拖到过滤器,在最喜欢的颜色的下面。这个透视表只显示最喜欢的颜色是橙色和对霉菌过敏的患者。
再次显示查询文本。现在你应该看到以下内容。
SELECT FROM [TUTORIAL] %FILTER NONEMPTYCROSSJOIN([AllerD].[H1].[Allergies].&[mold],[COLORD].[H1].[FAVOURITE COLOR].&[Orange])
MDX函数NONEMPTYCROSSJOIN结合了两个成员,并返回结果元组。该元组只访问属于两个给定成员的记录。
现在你已经看到了三种最常见的过滤表达式。 当你使用一个成员表达式作为过滤器时,系统只访问属于这个成员的记录。你可以写一个成员表达式,如下所示。
[dimension name].[hierarchy name].[level name].&[member key]
或者。
[dimension name].[hierarchy name].[level name].[member name]
dimension name是一个维度的名称。 hierarchy name是一个层次结构的名称。您可以省略层次结构的名称。如果你这样做,查询会使用在这个维度中定义的具有给定名称的第一层。 level name是该层次结构中的一个层次的名称。你可以省略层次名称。如果你这样做,查询会使用在这个维度中定义的具有给定名称的第一个成员。 member key是给定层次中成员的键。这通常与成员名称相同。 member name是给定级别中成员的名称。
关于更多过滤规则,请看用DeepSee使用MDX和DeepSee MDX参考。
文章
Frank Ma · 六月 13, 2022
肾脏疾病可以从一些医学界熟知的参数中发现。这样,为了帮助医学界和计算机系统,特别是人工智能,科学家Akshay Singh发表了一个非常有用的数据集,用于训练肾脏疾病检测/预测方面的机器学习(ML)算法。这份出版物可以在最大和最知名的ML数据库Kaggle上找到,网址是https://www.kaggle.com/datasets/akshayksingh/kidney-disease-dataset。
关于数据集
该肾脏疾病数据集有以下元数据信息(来源:https://www.kaggle.com/datasets/akshayksingh/kidney-disease-dataset):
它有400行,有25个特征,如红细胞、足部水肿、糖等等。
其目的是对病人是否患有慢性肾脏病进行分类。
分类是基于一个名为 "classification "(分类)的属性,属性值是 "ckd"(慢性肾脏病)或 "notckd"(不是慢性肾脏病)。
数据集作者对数据集进行了清洗,包括将文本映射为数字和其他一些变化。在清洗之后,数据集作者做了一些EDA(探索性数据分析),然后将数据集分为训练和测试两部分,并在上面应用模型。据观察,最初的分类结果并不令人满意。因此,数据集的作者没有放弃有Nan(非数)值的行,而是用lambda函数将其替换为每一列的模式。之后,数据集作者又将数据集分为训练集和测试集,并对其应用模型。这一次的结果更好,我们看到随机森林和决策树是表现最好的,准确率为1.0,错误分类率为0。分类的性能是通过打印混淆矩阵、分类报告和准确性来衡量的。
数据集信息 (来源: https://archive.ics.uci.edu/ml/datasets/chronic_kidney_disease):
我们使用以下表述来收集数据集
age - age(年龄)bp - blood pressure(血压)sg - specific gravity(比重)al - albumin(白蛋白)su - sugar(糖)rbc - red blood cells(红血球)pc - pus cell(脓细胞)pcc - pus cell clumps(脓细胞团块)ba - bacteria(细菌)bgr - blood glucose random(血糖随机)bu - blood urea(血尿素)sc - serum creatinine(血清肌酐)sod - sodium(钠)pot - potassium(钾)hemo - hemoglobin(血红蛋白)pcv - packed cell volume(填充细胞体积)wc - white blood cell count(白血球计数)rc - red blood cell count(红细胞计数)htn - hypertension(高血压)dm - diabetes mellitus(糖尿病)cad - coronary artery disease(冠状动脉疾病)appet - appetite(食欲)pe - pedal edema(足部水肿)ane - anemia(贫血)class - class(类)
属性信息 (来源: https://archive.ics.uci.edu/ml/datasets/chronic_kidney_disease):
我们使用24+类 = 25 (11个数字类型,14个名义类型)1.Age 年龄(数字)岁数2.Blood Pressure 血压(数字)血压单位:mm/Hg3.Specific Gravity 比重(数字)sg - (1.005,1.010,1.015,1.020,1.025)4.Albumin 白蛋白(名义)al - (0,1,2,3,4,5)5.Sugar 糖 (数字)su - (0,1,2,3,4,5)6.Red Blood Cells 红血球 (名义)rbc - (normal,abnormal) 红细胞 - (正常,异常)7.Pus Cell 脓细胞 (名义)pc - (normal,abnormal)(正常、异常)8.Pus Cell clumps 脓细胞团块 (名义) pcc - (present,notpresent) (出现、未出现)9.Bacteria 细菌(名义)ba - (present,notpresent) (出现、未出现)10.Blood Glucose Random 血糖随机(数字)bgr 单位 mgs/dl11.Blood Urea 血尿素(数字)bu 单位mgs/dl12.Serum Creatinine 血清肌酸酐(数字)sc 单位 mgs/dl13.Sodium 钠 (数字)sod 单位 mEq/L14.Potassium 钾 (数字)pot 单位 mEq/L15.Hemoglobin 血红蛋白(数字)hemo 单位 gms16.Packed Cell Volume 包容细胞体积(数字)17.White Blood Cell Count白血球计数 (数字)wc 单位 cells/cumm 18.Red Blood Cell Count 红细胞计数(数字)rc 单位 millions/cmm19.Hypertension 高血压(名义)htn - (yes,no) (是,否)20.Diabetes Mellitus 糖尿病(名义)dm - (yes,no) (是,否)21.Coronary Artery Disease 冠状动脉疾病(名义)cad - (yes,no) (是,否)22.Appetite 食欲(名义)appet - (good,poor) (好,差)23.Pedal Edema 踏板水肿(名义)pe - (yes,no) (是,否)24.Anemia 贫血(名义)ane - (yes,no) (是,否)25.Class 类 (名义)class - (ckd,notckd) (慢性肾脏病,不是慢性肾脏病)
从Kaggle获取肾脏数据
使用Health-Dataset(健康数据集)应用程序,可以把肾脏病数据从Kaggle加载到IRIS表中: https://openexchange.intersystems.com/package/Health-Dataset. 要做到这一点,在你的module.xml项目中,设置依赖关系(Health Dataset的ModuleReference):
Module.xml with Health Dataset application reference
<?xml version="1.0" encoding="UTF-8"?>
<Export generator="Cache" version="25">
<Document name="predict-diseases.ZPM">
<Module>
<Name>predict-diseases</Name>
<Version>1.0.0</Version>
<Packaging>module</Packaging>
<SourcesRoot>src/iris</SourcesRoot>
<Resource Name="dc.predict.disease.PKG"/>
<Dependencies>
<ModuleReference>
<Name>swagger-ui</Name>
<Version>1.*.*</Version>
</ModuleReference>
<ModuleReference>
<Name>dataset-health</Name>
<Version>*</Version>
</ModuleReference>
</Dependencies>
<CSPApplication
Url="/predict-diseases"
DispatchClass="dc.predict.disease.PredictDiseaseRESTApp"
MatchRoles=":{$dbrole}"
PasswordAuthEnabled="1"
UnauthenticatedEnabled="1"
Recurse="1"
UseCookies="2"
CookiePath="/predict-diseases"
/>
<CSPApplication
CookiePath="/disease-predictor/"
DefaultTimeout="900"
SourcePath="/src/csp"
DeployPath="${cspdir}/csp/${namespace}/"
MatchRoles=":{$dbrole}"
PasswordAuthEnabled="0"
Recurse="1"
ServeFiles="1"
ServeFilesTimeout="3600"
UnauthenticatedEnabled="1"
Url="/disease-predictor"
UseSessionCookie="2"
/>
</Module>
</Document>
</Export>
预测肾脏疾病的网络前端和后端应用程序
进入Open Exchange应用程序链接 (https://openexchange.intersystems.com/package/Disease-Predictor) 并遵循以下步骤:
用Clone/git 将repo拉到本地的任一目录中
$ git clone https://github.com/yurimarx/predict-diseases.git
打开该目录下Docker终端,并运行:
$ docker-compose build
运行IRIS容器:
$ docker-compose up -d
进入管理门户执行查询,训练AI模型: http://localhost:52773/csp/sys/exp/%25CSP.UI.Portal.SQL.Home.zen?$NAMESPACE=USER
创建用于训练的VIEW:
CREATE VIEW KidneyDiseaseTrain AS SELECT
age, al, ane, appet, ba, bgr, bp, bu, cad, classification, dm, hemo, htn, pc, pcc, pcv, pe, pot, rbc, rc, sc, sg, sod, su, wc
FROM dc_data_health.KidneyDisease
使用view视图创建AI模型
CREATE MODEL KidneyDiseaseModel PREDICTING (classification) FROM KidneyDiseaseTrain
训练模型:
TRAIN MODEL KidneyDiseaseModel
访问 http://localhost:52773/disease-predictor/index.html ,使用疾病预测器的前台预测疾病,如下:
幕后工作
预测肾脏病的后端类方法
InterSystems IRIS 允许你执行SELECT,使用之前创建的模型进行预测。
Backend ClassMethod to predict Kidney Disease
/// Predict Kidney Disease
ClassMethod PredictKidneyDisease() As %Status
{
Try {
Set data = {}.%FromJSON(%request.Content)
Set %response.Status = 200
Set %response.Headers("Access-Control-Allow-Origin")="*"
Set qry = "SELECT PREDICT(KidneyDiseaseModel) As PredictedKidneyDisease, "
_"age, al, ane, appet, ba, bgr, bp, bu, cad, dm, "
_"hemo, htn, pc, pcc, pcv, pe, pot, rbc, rc, sc, sg, sod, su, wc "
_"FROM (SELECT "_data.age_" AS age, "
_data.al_" As al, "
_"'"_data.ane_"'"_" AS ane, "
_"'"_data.appet_"'"_" AS appet, "
_"'"_data.ba_"'"_" As ba, "
_data.bgr_" As bgr, "
_data.bp_" AS bp, "
_data.bu_" AS bu, "
_"'"_data.cad_"'"_" As cad, "
_"'"_data.dm_"'"_" As dm, "
_data.hemo_" AS hemo, "
_"'"_data.htn_"'"_" AS htn, "
_"'"_data.pc_"'"_" As pc, "
_"'"_data.pcc_"'"_" As pcc, "
_data.pcv_" AS pcv, "
_"'"_data.pe_"'"_" AS pe, "
_data.pot_" As pot, "
_"'"_data.rbc_"'"_" As rbc, "
_data.rc_" AS rc, "
_data.sc_" AS sc, "
_data.sg_" As sg, "
_data.sod_" As sod, "
_data.su_" AS su, "
_data.wc_" AS wc)"
Set tStatement = ##class(%SQL.Statement).%New()
Set qStatus = tStatement.%Prepare(qry)
If qStatus'=1 {WRITE "%Prepare failed:" DO $System.Status.DisplayError(qStatus) QUIT}
Set rset = tStatement.%Execute()
Do rset.%Next()
Set Response = {}
Set Response.classification = rset.PredictedKidneyDisease
Set Response.age = rset.age
Set Response.al = rset.al
Set Response.ane = rset.ane
Set Response.appet = rset.appet
Set Response.ba = rset.ba
Set Response.bgr = rset.bgr
Set Response.bp = rset.bp
Set Response.bu = rset.bu
Set Response.cad = rset.cad
Set Response.dm = rset.dm
Set Response.hemo = rset.hemo
Set Response.htn = rset.htn
Set Response.pc = rset.pc
Set Response.pcc = rset.pcc
Set Response.pcv = rset.pcv
Set Response.pe = rset.pe
Set Response.pot = rset.pot
Set Response.rbc = rset.rbc
Set Response.rc = rset.rc
Set Response.sc = rset.sc
Set Response.sg = rset.sg
Set Response.sod = rset.sod
Set Response.su = rset.su
Set Response.wc = rset.wc
Write Response.%ToJSON()
Return 1
} Catch err {
write !, "Error name: ", ?20, err.Name,
!, "Error code: ", ?20, err.Code,
!, "Error location: ", ?20, err.Location,
!, "Additional data: ", ?20, err.Data, !
Return 0
}
}
现在,任何web应用都可以使用该预测并显示结果。您可以到预测疾病应用程序的前端文件夹中查看源代码。
文章
Hao Ma · 五月 24, 2023
镜像101
Caché 镜像是一种可靠、廉价且易于实施的高可用性和灾难恢复解决方案,适用于基于 Caché 和 Ensemble 的应用程序。镜像在广泛的计划内和计划外中断情况下提供自动故障转移,应用程序恢复时间通常限制在几秒钟内。逻辑数据复制消除了存储作为单点故障和数据损坏的根源。升级可以在很少或没有停机时间的情况下执行。
但是,部署 Caché 镜像确实需要大量规划,并且涉及许多不同的过程。与任何其他关键基础设施组件一样,操作镜像需要持续监控和维护。
您可以通过两种方式使用本文:作为常见问题列表,或作为理解和评估镜像、规划镜像、配置镜像和操作镜像的简要顺序指南。每个答案都包含指向每个主题的详细讨论以及每个任务的分步过程的链接。
当您准备好开始规划镜像部署时,您的起点应该始终是Caché 高可用性指南“镜像”一章的镜像架构和规划部分。
经常问的问题
了解和评估镜像
镜像有什么好处?
镜像能否部署在虚拟化环境中?
镜像可以部署在云端吗?
镜像的基本设计是什么?
数据库副本如何与实时生产数据库同步?
自动故障转移是如何触发的?有没有它没有涵盖的情况?
镜像是否提供灾难恢复?
规划镜像
如何规划镜像的架构?将包括哪些成员,他们将在哪里?
哪些网络和延迟注意事项申请?镜像需要什么样的网络配置?
在故障转移时将应用程序连接重定向到新主节点的选项有哪些?
镜像中的 Caché 实例有哪些兼容性要求?
如何将现有数据库迁移到镜像?
如果将镜像部署在虚拟化环境中,我应该考虑什么?
配置镜像
我需要考虑哪些配置准则?
如何保护镜像?
如何配置镜像虚拟IP地址(镜像VIP)?
我在哪里以及如何安装仲裁器?
如何安装和启动 ISCAgent?
如何创建和配置镜像?
如何创建镜像数据库?如何将现有数据库添加到镜像?
如何确保 ECP 在故障转移后重定向应用程序服务器连接?
当镜像 VIP 不可用时(例如在云中),我如何确保重定向应用程序连接?
如何将 Caché Shadow转换为镜像?
我应该查看哪些其他配置细节?
管理镜像
如何监控镜像的运行?
如何修改镜像?我能做什么调整?
我可以在镜像中添加成员吗?消除一?如何完全删除镜像?
如果我需要暂时从镜像中删除成员怎么办?
我必须一次升级镜像吗?我必须把镜子从生产中取出来做吗?
我应该了解哪些其他镜像或镜像相关的管理程序和细节?
镜像中断程序
了解和评估镜像
镜像有什么好处?
对于基于 Caché 和 Ensemble 的应用程序,存在三种实现高可用性的主要方法: 故障转移集群、 虚拟化 HA和 Caché 镜像。前两者最大的缺点是依赖共享存储,存储失败后果不堪设想;可选的存储级冗余可以改善这一点,但也可以延续某些类型的数据损坏。此外,软件升级需要大量的停机时间,对于许多故障,应用程序恢复时间可能有几分钟。
通过使用两个具有独立存储和逻辑数据复制的物理独立系统,镜像避免了共享存储问题,升级不需要停机或停机时间很短,应用程序恢复时间通常为几秒钟。这种方案还提供可靠和强大的灾难恢复能力,灾难恢复站点(DR)可以位于距生产数据中心任何适当的距离。
镜像的主要限制是它只复制数据库本身;应用程序所需的外部文件需要额外的解决方案,安全和配置管理目前是分散的。
以下资源提供了这些 HA 方法的详细分析和比较,以及有关镜像优势的更多信息:
系统故障转移策略( Caché 高可用性指南)
高可用性策略(白皮书)
业务连续性的高可用性(视频)
缓存镜像:高可用性的冒险(视频)
镜像:吞吐量架构(在线学习)
InterSystems Caché:数据库镜像:执行概述(白皮书)
镜像介绍(在线学习)
HealthShare:通过镜像实现高可用性(在线学习)
镜像能否部署在虚拟化环境中?
镜像经常部署在虚拟化环境中。镜像通过自动故障转移对计划内或计划外中断提供即时响应,而虚拟化 HA 软件会在机器或操作系统意外中断后自动重启托管镜像成员的虚拟机。从而允许故障成员快速重新加入镜像以充当备份(或在必要时接管为主)。
有关使用此方法的信息,请参阅 InterSystems 白皮书高可用性策略。
镜像可以部署在云端吗?
镜像可以有效部署在云端。由于云网络限制,使用虚拟 IP 地址(镜像 VIP)在故障转移后重定向应用程序连接通常是不可能的,但这可以使用负载均衡器等网络流量管理器有效克服。
镜像的基本设计是什么?
一个 Caché 镜像通常包括物理上独立的主机上的两个 Caché 实例,称为故障转移成员;镜像自动将主角色分配给一个,而另一个成为备份。应用程序更新主数据库,而镜像使备份数据库与主数据库保持同步。
当主服务器发生故障或不可用时,备份服务器会自动接管主服务器,并将应用程序连接重定向到它。当主实例恢复运行时,它会自动成为备份实例。
操作员启动的人工切换可用于在计划的维护或升级停机期间保持可用性。
镜像可选地包含称为asyncs的其他成员,用于灾难恢复以及商业智能和数据仓库目的。
一个镜像也可以只使用一个故障转移成员和一定数量的异步,例如当灾难恢复是主要目标时。
数据库副本如何与实时生产数据库同步?
镜像的备份成员和异步成员使用日志文件(Journal文件)与主成员保持同步,日志文件包含自上次备份以来对 Caché 实例中的数据库所做更改的时间顺序记录。在镜像中,来自主数据库的日志文件被发送到其他成员并dejournaled日志记录——也就是说,其中记录的更改被应用到数据库的本地副本,使它们与主数据库保持同步。
日志记录从主数据库到备份的传输是同步的,主数据库在关键点等待备份的确认。这使故障转移成员保持紧密同步,并且备份处于活动状态(Active),并准备好接管为主。异步从主服务器异步接收日志数据,因此有时可能会滞后一些日志记录。
自动故障转移是如何触发的?有没有它没有涵盖的情况?
只有在确认主服务器在没有人工干预的情况下不能再作为主服务器运行时,备份服务器才能自动接管。当故障转移成员之间的直接通信中断时,备份从第三方系统( 仲裁器)获得帮助以确认这一点,仲裁器与两个故障转移成员保持独立联系。
此外,如果备份无法确认其拥有或无法从主服务器获取最新的日志数据,则无法发生自动故障转移。在每个故障转移主机上独立于 Caché 实例运行的代理进程,称为ISCAgents ,参与自动故障转移逻辑和机制的这一方面和其他方面。
假设仲裁器正常运行,几乎所有计划外的主机故障都包括在内;只有将故障转移成员彼此隔离并与仲裁器隔离的网络故障,才能阻止活动备份接管发生故障或不可用的主要成员。
镜像是否提供灾难恢复?
一种类型的异步镜像成员是灾难恢复 (DR) 异步。 DR 异步具有主数据库上所有镜像数据库的副本,并且可以随时提升为故障转移成员。当中断导致镜像没有正常运行的故障转移成员时,您可以手动切换到被提升后的 DR 异步;数据丢失的程度将取决于发生中断时 DR 异步落后于主服务器多远,以及前主服务器的主机系统是否正常运行,是否允许它获取额外的日志数据。提升的 DR 异步也可用于许多其他计划内和计划外中断情况。
规划镜像
如何规划镜像的架构?将包括哪些成员,他们将在哪里?
镜像的大小、成员资格和物理分布将取决于您部署它的原因以及许多基础设施和操作因素,允许多种可能的配置
具有两个故障转移成员的镜像通过自动故障转移提供高可用性。在可选的异步成员中,一个或多个 DR 异步可以提供数据安全和灾难恢复能力,而报告异步用于数据挖掘和商业智能等目的。单个报告异步最多可以属于 10 个独立的镜像,从而使其可以充当企业范围的数据仓库,将来自不同位置的相关数据库集合在一起。
如果不需要自动故障转移,镜像也可以包含一个故障转移成员和多个用于灾难恢复和报告目的的异步。
一个镜像最多可以包含 16 个成员。因为故障转移成员之间需要低延迟连接,因此通常位于同一地点,但异步成员可以位于本地或单独的数据中心,包括为 DR 异步上的数据提供最大安全性的地理位置偏远的位置。
一台主机上可以安装多个镜像成员,但需要额外规划。
哪些网络和延迟注意事项适用?镜像需要什么样的网络配置?
主要的网络配置考虑因素包括可靠性、带宽和网络延迟,这是应用程序性能的重要考虑因素。选择对主要成员传输给其他成员的日志数据进行压缩是通常但不必须的做法。
每个镜像成员都有几个不同的网络地址,用于不同的目的,在规划支持您的镜像所需的网络配置之前,应该很好地理解这些地址。 包含在单个数据中心、机房或校园内的镜像以及涉及双数据中心和地理上分离的灾难恢复的镜像的示例镜像和网络配置将帮助您定义所需的网络配置。
在故障转移时将应用程序连接重定向到新主节点的选项有哪些?
镜像和 Caché 内置了几个自动重定向选项,包括使用虚拟 IP 地址 (VIP) 进行镜像、将 ECP 数据服务器标识为镜像连接,以及镜像感知 CSP 网关。
镜像 VIP 通常是一种非常有效的解决方案,但确实需要一些提前规划,尤其是在网络配置方面。
还提供一系列外部技术选项,包括使用网络流量管理器(例如负载平衡器) 、自动或手动 DNS 更新、应用程序级编程和用户级程序。
镜像中的 Caché 实例有哪些兼容性要求?
在确定要添加到镜像的系统之前,请务必查看Caché 实例和平台字节顺序兼容性的要求。由于故障转移成员可以随时交换主要和备份的角色,因此它们应该尽可能相似; CPU 和内存配置应该相同或接近,存储子系统应该具有可比性。
如何将现有数据库迁移到镜像?
任何 Caché 数据库都可以轻松添加到镜像中;它所需要的只是能够备份和恢复数据库,或复制其CACHE.DAT文件。程序在下一节中说明。
如果将镜像部署在虚拟化环境中,我应该考虑什么?
在虚拟化环境中使用镜像时,规划虚拟镜像成员主机与物理主机和存储之间的正确关系很重要;镜像和虚拟化平台方面也有重要的操作考虑因素。
配置镜像
我需要考虑哪些配置指南?
如果您计划配置镜像虚拟 IP 地址 (VIP) ,InterSystems 建议将故障转移成员配置为使用相同的超级服务器端口和Web 服务器端口。
主要故障转移成员上的 Caché 实例配置(例如用户、角色、名称空间和映射)或未镜像的数据(例如与 SQL 网关和 Web 服务器配置相关的文件)都不会被其他镜像成员上的镜像复制。因此,在发生故障转移时启用备份或任何 DR 异步成员(可能被提升)以接管主服务器所需的任何设置或文件必须在这些成员上手动复制并根据需要进行更新。
不要在配置为镜像成员的任何系统上禁用 Internet 控制消息协议 (ICMP);镜像依靠 ICMP 来检测成员是否可达。
由于日志记录是镜像同步的基础,因此必须监视和优化故障转移成员上的日志记录性能并通常遵循日志记录最佳实践。特别是,InterSystems 建议您增加所有镜像成员上的共享内存堆大小(Shared memory heap size)。
如何保护镜像?
保护镜像通信的主要方法是 SSL/TLS,它使用 X.509 证书加密镜像内的所有流量。强烈建议使用 SSL/TLS 安全性。要在镜像上启用 SSL/TLS,您必须首先在每个镜像成员上创建一个镜像 SSL/TLS 配置;您可能会发现在创建镜像之前执行此操作最方便。启用 SSL/TLS 时,添加到镜像的每个成员都必须在主服务器上获得授权;成员的 X.509 证书更新时也是如此。
对于使用 SSL/TLS 的镜像的另一层保护,您可以激活日志加密。这意味着日志记录在主服务器上创建时使用其活动加密密钥之一进行加密,并在其他成员取消日志记录之前解密。备份和所有异步必须激活相同的密钥,备份和 DR 异步也必须使用它来加密数据。
配置镜像使用的网络的方式对镜像的安全性也有重要影响。
如何配置镜像虚拟IP地址(镜像VIP)?
镜像 VIP 是通过在创建和添加成员到镜像或修改镜像时指定详细信息来配置的,但是需要一些准备工作,包括所需信息的标识以及镜像成员的主机和 Caché 实例的可能配置。
我在哪里以及如何安装仲裁器?
仲裁器的位置应尽量减少仲裁器和故障转移成员意外同时中断的风险(如果两个故障转移都失败,则仲裁器变得无关紧要),因此其位置主要取决于故障转移成员的位置。单个系统可以配置为多个镜像的仲裁器,前提是它的位置适合每个镜像。托管镜像的一个或多个故障转移或 DR 异步成员的系统不应配置为该镜像的仲裁者。
任何运行 2015.1 或更高版本 ISCAgent 的系统,包括托管一个或多个 Caché 2015.1 或更高版本实例的系统,都可以配置为仲裁器。您可以准备任何其他受支持的系统(OpenVMS 系统除外),包括托管 2015.1 之前的 Caché 实例的系统,通过安装 ISCAgent将其配置为仲裁器。
如何安装和启动 ISCAgent?
ISCAgent 随 Caché 自动安装,因此安装在任何镜像成员上。但是,必须将代理配置为在每个镜像成员上的系统启动时启动。
如何创建和配置镜像?
配置镜像是一个多步骤的过程:
创建镜像并配置第一个故障转移成员
配置第二个故障转移成员(如果需要)
授权第二个故障转移成员,如果使用 SSL/TLS(推荐)
配置异步镜像成员(如果需要,DR 或报告)
授权新的异步成员,如果使用 SSL/TLS(推荐)
在完成这些步骤中的任何一个之后,您可以在镜像监视器中查看镜像的状态以确认结果是否符合预期。
如何创建镜像数据库?如何将现有数据库添加到镜像?
在将数据库添加到镜像之前,您可能需要查看某些镜像数据库注意事项,这些注意事项与哪些内容可以镜像和哪些内容不能镜像、镜像和Shadow的同时使用、镜像数据库属性的传播以及镜像下每个实例的最大数据库数有关。
创建镜像数据库和添加现有数据库的过程是不同的,因为对镜像数据库的更改记录在镜像日志文件中,这与非镜像日志文件不同。如果数据库创建为镜像数据库,它从一开始就使用镜像日志文件,这使得通过在每个镜像成员上创建具有相同镜像名称的镜像数据库,可以很容易地将新数据库添加到镜像中。
当您将现有的非镜像数据库添加为主数据库上的镜像数据库时,它会从使用非镜像日志文件切换到镜像日志文件。因此,您不能简单地在其他成员上创建数据库,因为镜像无法将非镜像日志文件传送给其他成员。取而代之的是,在将数据库添加到主数据库的镜像后,您必须将其备份并在其他成员上恢复,或者将其CACHE.DAT文件复制到其他成员。
如何确保 ECP 在故障转移后重定向应用程序服务器连接?
无论您是否配置了镜像 VIP,您都可以通过将镜像 ECP 数据服务器配置为连接到它的每个 ECP 应用程序服务器上的镜像连接来确保 ECP 连接被重定向到新的主服务器。 (应用服务器不使用 VIP;因为它定期从指定主机收集信息,它会自动检测故障转移并切换到新的主服务器。)
当无法使用镜像 VIP 时(例如在云中),如何重定向应用程序连接?
只有当镜像成员位于同一网络子网上时才能使用镜像 VIP,而当它们位于不同的数据中心时通常不会出现这种情况。出于类似的原因,VIP 通常不是云中部署的选项。
可以使用一系列外部技术替代方案,包括使用负载均衡器(物理或虚拟)等网络流量管理器,可用于实现与 VIP 相同级别的透明度,向客户端应用程序提供单个地址或设备。其他可能的机制包括自动或手动 DNS 更新、应用程序级编程和用户级程序。
如何将 Caché Shadow转换为镜像?
镜像提供了一个Shadow到镜像实用程序,允许您将Shadow源和目标以及它们之间映射的Shadow数据库转换为具有主数据库、备份或异步数据库和镜像数据库的镜像。
我应该查看哪些其他配置细节?
虽然默认值通常是所需的全部,但您可能希望自定义 ISCAgent 端口号。
在主要故障转移成员上,您可能希望将代码从现有的^ZSTU或^ZSTART例程移动到用户定义的^ZMIRROR 例程,它允许您为特定镜像事件实现自定义的、特定于配置的逻辑和机制,以便它是直到镜像初始化后才执行。
将镜像与 Ensemble 一起使用时,您应该了解具有镜像数据的 Ensemble 命名空间的特殊要求以及 Ensemble Autostart 在镜像环境中的功能。
管理镜像
如何监控镜像的运行?
您可以在任何镜像成员的 Caché 管理门户中加载的Mirror Monitor提供有关的详细信息
镜像及其每个成员的运行状态,包括使用 SSL/TLS 时成员的 x.509 DN。
在故障转移成员上,两个故障转移成员的网络地址和仲裁器连接状态,以及仲裁器的地址;在异步上,报告异步所属的镜像。
在备份和异步成员上, 日志数据从主数据传输的状态和日志数据的Dejournaling,以及日志数据从主数据到达的速率。
加载镜像监视器的成员上镜像数据库的状态。
Mirror Monitor 还允许您执行许多操作,包括查看和搜索成员的日志文件、 将 DR 异步提升为故障转移成员或将备份降级为 DR 异步,以及激活、赶上和删除镜像数据库。
您可以在镜像成员的%SYS命名空间中使用 Caché 系统状态例程 ( ^%SS ) 来监视其镜像通信进程。
如何修改镜像?我可以修改什么?
在主服务器上编辑镜像以更改镜像的配置(包括 SSL/TLS、镜像 VIP 等)并在网络配置更改时更新成员的网络地址。您还必须编辑主服务器上的镜像以授权其他成员上的 X.509 证书更新。
在异步上编辑镜像以更改异步类型,将报告异步添加到另一个镜像,并进行其他特定于异步的更改。
您可以使用Mirror Monitor从任何成员(且仅该成员)的镜像中删除镜像数据库,尽管其影响因所涉及的成员类型而异。
我可以在镜像中添加成员吗?删除一个?如何完全删除镜像?
您始终可以将异步成员添加到镜像中,最多可添加 16 个成员。如果你有一个故障转移成员和少于 15 个异步,你总是可以添加一个备份。您还可以通过将 DR 异步提升为故障转移成员来替换备份,这会自动将当前备份降级为 DR 异步。
您可以编辑任何成员的镜像以从镜像中删除该成员。要完全删除镜像,您必须按特定顺序删除成员并采取其他步骤。
如果我需要暂时从镜像中删除成员怎么办?
您可以使用镜像监视器通过断开成员与镜像的连接来无限期地停止备份或异步成员上的镜像,例如进行维护或(在异步情况下)减少网络负载。
在异步上,您还可以暂停镜像中所有数据库的Dejournaling,而不暂停从主数据库到异步数据库的日志数据传输。
我必须一次升级镜像吗?我必须把镜像从生产中取出来做吗?
镜像的所有故障转移和 DR 异步成员必须是相同的 Caché 版本,并且只能在镜像升级期间有所不同。一旦升级的成员成为主要成员,您就无法使用其他故障转移成员或任何 DR 异步成员,直到它们也升级为止。通常,最佳做法是同时将报告异步升级到同一版本。
您选择的升级过程取决于您是进行维护版本升级、 不对镜像数据库进行任何更改的主要升级,还是对镜像数据库进行更改的主要升级。所提供的程序旨在最大限度地减少应用程序停机时间;在前两种情况下,您通常可以完全避免停机时间,而在后一种情况下,它通常仅限于执行计划的故障转移和进行所需的镜像数据库更改所需的时间。
当您在计划停机期间进行重大升级并且不需要最小化应用程序停机时间时,您可能还想使用一个更简单的过程。
我应该了解哪些其他镜像或镜像相关的管理程序和细节?
您可以在未使用SSL/TLS 的镜像上启用安全性,只要每个成员都具有有效的镜像 SSL/TLS 配置。
您可以为未使用它的镜像激活日志加密,只要该镜像使用 SSL/TLS 安全性并且用于加密主要日志数据的活动加密密钥在备份和所有异步中也处于活动状态。
根据您的硬件和网络配置,您可能需要调整镜像的服务质量超时(QoS 超时)设置,这在故障转移机制中起着重要作用。通常,如果需要更快地响应中断,则可以在部署在具有专用本地网络的物理(非虚拟化)主机上的镜像上减小此设置。
如果绝大多数镜像数据库更新由高度压缩的数据(如压缩图像)或加密数据组成,则日志数据压缩预计不会有效,因此可能会浪费 CPU 时间。在这种情况下,您可以选择配置或修改镜像以将日志数据设置为Uncompressed 。 (使用 Caché 数据库加密或日志加密不是选择压缩的一个因素。)
如果主要成员和其他镜像成员之间的网络延迟成为问题,您可以通过微调操作系统 TCP 参数来减少它,以允许主要成员和备份/异步成员分别建立适当大小的发送和接收缓冲区.
^MIRROR 例程为所有镜像任务提供了管理门户的命令行替代方案。 SYS.Mirror API 提供了以编程方式调用通过管理门户和^MIRROR例程可用的镜像操作的方法。
镜像中断程序
有关处理各种计划内和计划外镜像中断情况的建议过程的概述,请参阅镜像中断过程。
文章
Qiao Peng · 十月 17, 2023
2023年6月底,世卫组织(WHO)和HL7签署了合作协议,利用HL7 FHIR提供互操作性,来支撑WHO的SMART指南(SMART Guideline)愿景 - 使用数智化的方式推动并加速一致化的健康干预措施建议,让世界上每个人都能立即从临床、公卫和数据使用建议中充分受益。
作为WHO的《2020-2025 年全球数字卫生战略》的一部分,SMART 指南使用 FHIR 、HL7的临床质量语言 (CQL) 和ICD标准以表达 WHO 的各种健康和临床指南,实现数据互操作、决策支持与指标、术语的一致性。这些标准被进一步利用来为各国及其合作伙伴开发一个由软件库、服务和工具组成的支持生态系统,并作为数字公共产品服务全球卫生健康事业。
为什么世卫组织会采用FHIR作为卫生信息互操作的标准在全球推广其一致化的健康干预措施建议?因为FHIR不仅标准成熟适用,而且还具有一个极具生命力的生态。
一个有生命力的标准会吸引生态的构建,而完善的生态将促进标准的成熟和演进。HL7 FHIR作为新一代的卫生信息互操作标准,其生态已经初具规模并蓬勃发展。
HL7 FHIR的知识产权类型
HL7 FHIR的知识产权是CC0,也就是知识共享。任何机构、组织和个人都可以无需向HL7申请而免费使用、扩展FHIR的标准。其知识产权类型配合FHIR标准的丰满程度,极大地鼓励和促进了基于FHIR的生态建设,应该也是WHO采用FHIR的原因之一。
FHIR的标准发布和标准的推广
标准应该是方便可及的 - 不仅有用户可阅读、可理解的文字说明,更需要要可以直接下载让计算机可用、可理解的电子结构化标准。
HL7 FHIR官网详细说明了每个版本、每个FHIR资源的结构与关系、使用范围、用例和示例。在下载页面提供了各种版本的标准、值集、profile和工具的免费下载。
对于用户的扩展、再约束和实施指南,有专门的实施指南注册和发布网站。这里可以免费注册自己的实施指南、也可以访问、查阅和下载别人的实施指南,从而让基于FHIR标准的自定义扩展可以无障碍地被分享、使用、理解,甚至进一步扩展。
下图是发布在注册网站的按用例类型统计的FHIR实施指南:
这众多方向的实施指南也是FHIR横跨交叉领域建立起成熟生态的体现。FHIR有什么快速建立生态的秘诀?
成熟的卫生信息标准要能应对各种行业互操作挑战,FHIR有一个四层机制用于制定标准并用各种互操作挑战来测试、验证和推进FHIR落地:
工作组(workgroups):FHIR有40多个工作组,专注不同的领域的需求,并制定和改进相关FHIR资源和用例标准。例如FHIR基础架构、基因组学、电子健康档案、财务管理、设备...
加速器计划(accelerators):为了推进在主要互操作领域的成熟和落地,FHIR建立加速器计划让每个领域的各个利益相关方参与进来,通过研究各方的需求、凝聚各方的智慧来推动FHIR。如今已经有8个不同领域的加速器计划:
例如Vulcan是专注连接临床研究、转化研究和医疗保健的加速器,它的成员不仅有HL7这样的标准开发组织,还有学会 - 例如约翰霍普金斯医学院,行业协会 - 例如全球医疗数据科学社区PHUSE,政府机构 - 例如FDA,技术厂商 - 例如InterSystems,药厂 - 例如GSK,甚至意见领袖。
课题(projects):FHIR通过课题,研究具体的需求、实现具体的目标,让FHIR扎实、可用。例如Vulcan加速器有以下课题:
课题
目标
Schedule of Activities (SoA)
活动安排
用FHIR表示电子表格中的活动时间表。 使得研究中的每项活动的描述、时间和标识都能保持一致
Real World Data (RWD)
真实世界数据
以标准化的格式从EHR中提取数据,以支持临床研究,特别是向监管机构提交数据
Phenotypic Data
表型数据
为基因组研究和基因组医学提供更多高质量的标准化表型信息
Electronic Product Information (ePI)
电子产品信息
为产品信息(各论)定义一个共同的结构,支持患者对产品数据的跨边界交换
Adverse Events (AE)
不良事件
支持对不良事件的报告和格式进行标准化。 提高相关FHIR资源的成熟度
FHIR to OMOP
FHIR与OMOP映射
支持开发FHIR到OMOP的数据传输,以便更好地分析临床数据,用于研究
连接测试马拉松(connectathons):这是一个针对技术厂商的FHIR互操作系列化的一致性认证。每年3次的连接测试马拉松会确定众多的具体互操作用例,厂商选择并参与这些用例,用FHIR进行跨厂商的互操作测试。它不仅是技术厂商验证自己的FHIR互操作一致性的试验场,更是通过测试和反馈来发现标准的问题、确定标准适用性的大型沟通会。
FHIR confluence上公布有历次的连接测试马拉松的用例说明、实施指南、学习资料等详尽的资料。
除了这些手段,HL7还有FHIR认证,建立FHIR标准的智力资源池、确保FHIR在全球的正确采纳。
FHIR标准的适应性
FHIR的适应性核心在于其标准的设计 - 通过profile,在资源模型层面已经考虑到如何让用户进行不破坏标准的扩展和再约束;在标准成熟上,设计了成熟度模型,让标准基于实际使用和反馈逐步成熟。
Profile可以让用户裁剪、扩展FHIR标准,以适用于自己的术语体系和用例场景,实现基于统一标准的千人千面。
在标准的理解与反馈上,FHIR官方沟通提供了开放的交流和反馈的渠道。
FHIR生态的工具
成熟的生态工具是FHIR的一大亮点。这些工具是整个生态贡献的,好的工具得到广泛认同和采纳,既促进了标准的理解与使用、也避免了低水平的重复建设。
1. 标准学习工具:
理解和学习是标准推行的第一要务。除了汗牛充栋的学习材料和视频,FHIR还有不错的学习网站,例如Clinfhir ,最初设计是方便医生理解如何用FHIR构建和解决自己的用例的,但实际上也被广大卫生信息从业者用于理解FHIR标准。
2. 测试数据生成工具:
想学习标准?没有什么比直观的数据更能说明问题了。FHIR生态下有名的Synthea是一个基于马塞诸塞州的患者真实数据经过统计、混淆后的FHIR测试数据生成工具,可以按用户要求生成指定数量的、符合真实数据分布的FHIR资源,会为每个生成的虚拟患者生成一个FHIR boundle文件,并生成对应的医院、医生等FHIR资源。大家可以免费下载Synthea使用它产生测试数据。
另外,国内也广泛使用的MIMIC - 麻省理工贝斯以色列迪康医学中心的有5万多患者真实完整的高质量重症医疗数据集,如今也有了FHIR版本。
3. FHIR服务器:
还没有FHIR服务器,怎么测试FHIR?
FHIR生态下有大量的免费沙箱,用户可以选择它们进行标准的学习和测试。例如官网提供的沙箱和各个厂商提供的沙箱。通过各种API工具,例如postman,学习者无需注册即可以了解FHIR标准的方方面面,甚至将自己的测试数据加载进去并测试自己的解决方案。
4. 标准扩展和再约束构建工具:
如何方便、直观地构建自己的术语、扩展和再约束(Profile)和用例?FHIR生态下有众多公司提供的免费工具可用 - 随君取用。例如术语扩展可以用Snapper和FSH、进行小规模profile开发可以用可视化的Forge或Trifolia-on-FHIR、进行大规模的profile和实施指南开发可以用FSH。
5. 标准验证工具:
需要基于profile对FHIR资源进行校验?资源更多了,不仅有FHIR官网提供的FHIR资源校验网页,还有各种开发语言版本的校验工具代码:
JAVA
C#/DotNet
FHIR生态下百花齐放的各种应用架构、应用方向
更令人眼前一亮的是FHIR生态下各种应用架构、应用方向和众多其它生态对FHIR的采纳。
应用开发架构:
FHIR提供了标准卫生信息模型和相应的API,为行业应用的快速开发提供了坚实的基础。FHIR生态下最有名的SMART on FHIR,实现即插即用和可复用的应用开发架构。在国际卫生信息互操作标准发展简史中有简要介绍。
SMART on FHIR市场已经有大量的应用可以直接下载部署。
决策支持架构:
决策支持已经是卫生信息数字化转型的核心需求之一。卫生信息化已经建设了各种基于知识库和基于机器学习的决策支持系统,涵盖了临床、业务管理、费用、组学与科研、公卫、健康管理等全部业务,但仍面临众多挑战。
任何知识库系统和决策支持系统面临的一个关键挑战是决策支持的可移植性!如果决策支持厂商都按自己的数据、术语和服务标准构建解决方案,用户在使用多个决策支持产品时,将面临大量数据转换和映射及服务集成带来的非常高的实施成本和潜在决策错误风险。
FHIR通过Clinical Reasoning模块和CDS Hooks分别提供了本地决策支持架构和外部决策支持架构,通过标准化降低成本和风险、提高决策效率和范围。这里是对CDS Hooks的介绍。
其它标准对FHIR的采纳:
相较于之前流行的互操作标准,FHIR在标准化、灵活性、可用性 三方面取得了很好的平衡。FHIR资源模型比大多数的行业通用数据模型(CDM)都简化,方便使用。曾经各自为战的众多标准都发现FHIR无处不在,且FHIR资源和API可以作为自己的数据和访问数据的基石,而融入FHIR生态可以更方便获得数据、获得更多的推广、发挥更大的价值,因此一系列的XX on FHIR项目应运而生 - 或者直接采纳FHIR、或者与FHIR相兼容。除了上面提到的SMART on FHIR,这里简单汇总一下主要的已完成和进行中的on FHIR项目和标准。
1. IHE
IHE(Integrating the Healthcare Enterprise)是国际上比较流行且成功的卫生信息交换服务规范。它一直采用流行和稳定的互操作基础标准来开发自己的服务规范,最初使用DICOM + HL7 V2消息,后来用到HL7 V3 和CDA。IHE发现新的FHIR互操作标准有助于应对新的用例、并更好解决老的用例,认为FHIR会成为最流行的互操作基础标准,因此已经发布了很多基于FHIR的IHE服务,尤其是那些和移动业务相关的服务,例如移动患者人口统计查询 (PDQm)。
2. OMOP on FHIR
OMOP(Observational Medical Outcomes Partnership)是包括国内在内全球科研人员进行真实世界研究的重要工具,它开发了通用数据模型CDM和分析工具库。
HL7国际和OHDSI宣布合作提供单一的通用数据模型,用于共享临床护理和观察研究信息 - 这就是OMOP on FHIR项目。
OMOP-on-FHIR 是构建在 OMOP CDM 数据库之上的 FHIR 服务器,它提供中间映射层,实现OMOP CDM和FHIR资源之前的双向转换,从而打通两大生态,使临床医生和研究人员能够从多个来源提取数据并以相同的结构进行分析处理与共享交换而不会降低数据质量,可以同时使用两个生态下丰富的应用与工具,利用各自的生态优势。例如OMOP让FHIR生态可以利用其丰富的预测模型,而FHIR让OMOP的研究分析可以集成到临床工作流程中,推动精准医学的落地。
3. FHIR to CDISC Joint Mapping
CDISC 是一个标准开发组织,开发了生物制药行业使用的诸多数据标准,常用于提交临床试验数据以进行分析和监管审批。
通过与HL7合作,FHIR to CDISC Joint Mapping实施指南定义了FHIR 与三个特定 CDISC 标准之间的映射:
研究数据列表模型实施指南 (SDTMIG) 3.2
临床数据采集标准协调实施指南 (CDASH) 2.1
实验室1.0.1
通过简化 HL7 FHIR和 CDISC 标准之间的数据转换,消除使用临床信息支持科研的障碍。用途包括:
捕获“真实世界证据”(RWE),让那些不是为临床试验目的采集的数据可以用于研究监管
利用FHIR 的 SMART等技术,直接在临床系统内部捕获试验驱动的数据,而不是建立单独的临床试验管理解决方案
在回顾性研究中更容易利用临床数据
创建病例报告表单 (CRF),链接到使用 FHIR 资源和Profile定义的数据元素
使两个标准社区的专家能够理解彼此的术语,并随着两套规范的不断发展更好地协调它们
4. 通用数据模型协调 Common Data Models Harmonization(CDMH)
在卫生信息领域,有众多的通用数据模型(Common Data Models)服务于不同的或相同的业务领域。虽然都是“通用”数据模型,但数据在彼此之间并不通用。
FHIR的细颗粒度统一语义资源模型可以作为众多通用数据模型间的桥梁。通用数据模型协调(CDMH)目标就是借助FHIR打通各个通用数据模型,让它们的数据可以相互转换。
CDMH 项目由美国FDA 领导,与其他联邦政府机构合作。已发布的通用数据模型协调 (CDMH) FHIR 实施指南 (IG) 将重点放在以患者为中心的结果研究 (PCOR) 和其它目的提取的观察数据的映射和转换为 FHIR 格式。该项目重点关注以下四种通用数据模型 (CDM) 到 FHIR 的映射:
以患者为中心的结果研究网络 (PCORNet)
整合生物学和床边 (Informatics for Integrating Biology & the Bedside - i2b2) 临床试验 (ACT) 信息学,也称为 i2b2/ACT。
观察性医疗结果合作伙伴 (OMOP)
美国食品和药物管理局的哨兵(Sentinel)
5. Arden Syntax on FHIR
和HL7的临床质量语言(Clinical Quality Language - CQL)类似,Arden Syntax 是一种结构化、可执行的医学知识表示和处理语言,将医学知识表达为独立的单元 - 医学逻辑模块(Medical Logical Modules),常用于设计CDS系统,构建临床指南规则和临床决策规则。
新版本 Arden Syntax 3.0 版采用FHIR进行扩展,重新定义了基于FHIR的标准化的数据模型和数据访问方式。作为经过审计、基于共识的迭代 HL7 标准开发流程的一部分,3.0版已成功通过投票。
6. HL7 V2 to FHIR
HL7 V2在全球依然有很高的采纳度,但其局限性和FHIR的成熟度都在推动从V2到FHIR的迁移。HL7 V2 to FHIR 项目建立实施指南,将HL7 V2的组件映射到FHIR组件:V2的消息、消息段、数据类型和词汇分别映射到 FHIR 的Bundle、FHIR资源、数据类型和编码系统,并对FHIR进行相应扩展以弥补二者间的差距。
7. C-CDA on FHIR
C-CDA是最广泛实施的 HL7 CDA 实施指南之一,涵盖了临床护理的文档范围。CDA 和 FHIR 之间的互操作能力是推动临床文档进化的重要渠道。
C-CDA on FHIR 实施指南 (IG) 定义了一系列 FHIR 配置文件,以表示 C-CDA 中的各种文档类型,并弥补二者设计上的差异。C-CDA on FHIR 利用FHIR使文档标准更为精简。
还有更多的on FHIR项目没有介绍到,例如SNOMED on FHIR、PDMP on FHIR... 同时可以预期还会有越来越多的on FHIR项目会不断涌现。
不仅是这些on FHIR 项目,越来越多的机构发现FHIR的价值,将自己原来的数据模型改为FHIR。例如美国互操作核心数据集USCDI(U.S. Core Data for Interoperability) 起初采用通用临床数据集CCDS作为模型, 如今已经完全采纳FHIR,并且成为美国国家FHIR标准US Core的一部分。FHIR也得到了很多国家采纳作为国家级卫生信息互操作的标准。
大规模数据统计与分析:
一个好的标准应该有助于解决完整的行业需求。FHIR作为行业互操作标准已经超越了传统互操作的能力范围,除了互操作的数据模型、消息、文档、服务和API,FHIR服务器加上FHIR资源仓库为大规模的卫生信息持久化和访问提供了方案。
FHIR的完整蓝图目前尚缺一块拼图 - 基于FHIR的大规模数据统计与分析。
1. 大规模数据检索
FHIR API提供检索类型的API,通过查询参数(Search Parameter)对资源进行检索。
例如: 想要获取所有检验项目为loinc 1234-1,且检验结果小于9.2的Observation资源,可以用这样的查询参数:
GET http://fhirsvr.com/Observation? code-value-quantity=loinc|1234-1$lt9.2
除了FHIR Core发布的查询参数,用户还可以扩展自己的查询参数,满足检索需求。
FHIR标准里的FHIR Path为FHIR资源模型提供了类似于XPath的资源路径导航和获取语言,可以方便地筛选、过滤层次化的FHIR数据。
但FHIR查询API和FHIR Path都仅适合于单资源类型的检索,对于需要多类型资源联合分析、汇聚、统计等分析需求无能为力。
2. 大规模的数据统计分析
HL7为临床质量指标与决策支持提出了临床质量语言(Clinical Quality Language - CQL) ,CQL如今基于FHIR,使用FHIR资源模型来构建标准化的指标体系,以支持决策和基于指标的管理。
对于科研数据分析,借助上面介绍的OMOP on FHIR和其它项目,用户可以用自己熟悉的科研工具并利用FHIR数据支持自己的科研工作,本质上是将FHIR数据转换并导入自己的科研工具。
对于通用大规模数据统计分析,虽然FHIR提供了API、FHIR资源数据序列化的JSON、XML可以作为文档进行分析,但市面上的统计分析工具和机器学习工具大都支持SQL,SQL也是最流行的数据统计分析语言。
FHIR的深层次化模型是立体的、对象化的,而SQL是扁平的、表格化的。这个差异让FHIR对主流分析工具和机器学习工具不友好。这对基于FHIR原生的大规模数据分析利用造成了障碍,是FHIR最需要完善的那一块。
FHIR和生态已经创立了很多项目,努力补上这一环。
SQL on FHIR
SQL on FHIR项目的思路是为SQL用户提供FHIR的SQL表示层。SQL表示层提供一个机制:让用户根据自己的需要基于FHIR Path定义视图。这里的视图不是SQL视图,而是一个SQL模型的逻辑表达,由一个新的FHIR工件ViewDefinition定义。各个技术厂商负责物理实现它并展现为SQL表。
例如下面的视图定义:
{
"resourceType": "http://hl7.org/fhir/uv/sql-on-fhir/StructureDefinition/ViewDefinition",
"select": [
{
"column": [
{
"path": "getResourceKey()",
"alias": "id"
},
{
"path": "gender"
}
]
},
{
"column": [
{
"path": "given.join(' ')",
"alias": "given_name",
"description": "A single given name field with all names joined together."
},
{
"path": "family",
"alias": "family_name"
}
],
"forEach": "name.where(use = 'official').first()"
}
],
"name": "patient_demographics",
"status": "draft",
"resource": "Patient"
}
它定义一张这样的SQL表:
考虑到FHIR资源模型的复杂,SQL on FHIR目前尚待成熟。当前是版本2,尚未发布,且有很多限制,例如不能在视图里定义跨资源的字段。
技术厂商的FHIR资源SQL实现
除了SQL on FHIR项目,很多技术厂商也在借助自身技术上的优势为FHIR提供SQL访问层。
例如InterSystems IRIS是一个多模型数据平台技术,它可以同时支持对FHIR资源逻辑模型使用对象建模、对FHIR序列化的JSON/XML使用文档建模,并将这些模型投射为SQL模型。InterSystems IRIS正是借助于这个特性,提供一个名为FHIR SQL构建器(FHIR SQL Builder)的工具,用户通过图形化方式拖拽建立需要的SQL模型,而无需拷贝和转换数据。
FHIR生态正展现出蓬勃的生命力,如今已经是百花齐放。FHIR展现的统一行业语义能力和强大的生态,不仅帮助WHO发布数字公共产品服务,也可以赋能卫生信息数字化转型。
文章
姚 鑫 · 五月 24, 2021
# 第五章 向邮件添加附件
# 向邮件添加附件
可以将附件添加到电子邮件或消息部分(具体地说,是添加到`%Net.MailMessagePart`或`%Net.MailMessage`的实例)。要执行此操作,请使用以下方法:
这些方法中的每一种都会将附件添加到原始邮件(或邮件部分)的`Parts`数组中,并自动将`IsMultiPart`属性设置为1。
### AttachFile()
```java
method AttachFile(Dir As %String,
File As %String,
isBinary As %Boolean = 1,
charset As %String = "",
ByRef count As %Integer) as %Status
```
将给定文件附加到电子邮件。默认情况下,文件以二进制附件的形式发送,但您可以将其指定为文本。如果文件是文本,还可以指定该文件使用的字符集。
具体地说,此方法创建`%Net.MailMessagePart`的实例,并根据需要将文件内容放在`BinaryData`或`TextData`属性中,并根据需要设置`CharSet`属性和`TextData.TranslateTable`属性。该方法通过引用返回一个整数,该整数指示此新消息部分在部件数组中的位置。
此方法还设置消息或消息部分的`Dir`和`FileName`属性。
### AttachStream()
```java
method AttachStream(stream As %Stream.Object,
Filename As %String,
isBinary As %Boolean = 1,
charset As %String = "",
ByRef count As %Integer) as %Status
```
将给定流附加到电子邮件。如果指定了`Filename`,则附件被视为文件附件。否则,它将被视为内联附件。
### AttachNewMessage()
```java
method AttachNewMessage() as %Net.MailMessagePart
```
创建`%Net.MailMessage`的新实例,将其添加到消息中,并返回新修改的父消息或消息部分。
```
AttachEmail()
```
给定一封电子邮件(`%Net.MailMessage`的实例),此方法会将其添加到邮件中。此方法还设置消息或消息部分的`Dir`和`FileName`属性。
注意:此方法将`contentType`设置为`"message/rfc822"`。在这种情况下,不能添加任何其他附件。
示例:`MessageWithAttach()`
以下示例生成一封带有一个硬编码附件的简单电子邮件。它不为邮件提供任何地址;可以在实际发送邮件时提供该信息
```java
/// w ##class(PHA.TEST.HTTP).MessageWithAttachment()
ClassMethod MessageWithAttachment() As %Net.MailMessage
{
Set msg = ##class(%Net.MailMessage).%New()
Set msg.Subject="Message with attachment "_$h
Set msg.IsBinary=0
Set msg.IsHTML=0
Do msg.TextData.Write("This is the main message body.")
//add an attachment
Set status=msg.AttachFile("E:\", "HttpDemo.pdf")
If $$$ISERR(status) {
Do $System.Status.DisplayError(status)
Quit $$$NULLOREF
}
b
Quit msg
}
```
# 使用SMTP服务器发送电子邮件
如果有权访问SMTP服务器,则可以发送电子邮件。SMTP服务器必须正在运行,并且必须具有使用它所需的权限。要发送电子邮件,请执行以下操作:
1. 创建`%Net.SMTP`实例并根据需要设置其属性,特别是以下属性:
- `Smtpserver`是正在使用的`SMTP`服务器的名称。
- 端口是在`SMTP`服务器上使用的端口;默认值为25。
- 时区指定RFC 822指定的服务器时区,例如 `"EST"` 或 `"-0400"` 或 `"LOCAL"`。如果未设置,消息将使用世界时。
此对象描述将使用的`SMTP`服务器。
2. 如果`SMTP`服务器需要身份验证,请指定必要的凭据。为此:
a. 创建`%Net.Authenticator`的实例。
b. 设置此对象的用户名和密码属性。
c. 将`%Net.SMTP`实例的验证器属性设置为等于此对象。
d. 如果邮件本身具有授权发件人,请设置`%Net.SMTP`实例的`AuthFrom`属性。
3. 要使用到`SMTP`服务器的`SSL/TLS`连接,请执行以下操作:
a. 将`SSLConfiguration`属性设置为要使用的已激活`SSL/TLS`配置的名称。
`SSL/TLS`配置包括一个名为`Configuration Name`的选项,该选项是在此设置中使用的字符串。
b. 将`UseSTARTTLS`属性设置为0或1。
在大多数情况下,使用值0。如果服务器交互在普通`TCP`套接字上开始,然后在与普通套接字相同的端口上切换到`TLS`,则使用值1。
或者,将`SSLCheckServerIdentity`属性设置为1。如果要验证证书中的主机服务器名称,请执行此操作。
4. 创建要发送的电子邮件(如“创建单部分电子邮件”和“创建多部分电子邮件”中所述)。
5. 调用`SMTP`实例的`send()`方法。此方法返回一个状态,应该检查该状态。
6. 如果返回的状态指示错误,请检查`Error`属性,该属性包含错误消息本身。
7. 检查`FailedSend`属性,该属性包含发送操作失败的电子邮件地址列表。
以下各节中的示例使用了两种不同的免费SMTP服务,这些服务在编写本手册时是可用的。选择这些服务并不意味着特别认可。还要注意的是,这些示例并没有显示实际的密码。
`Samples`命名空间中还有其他示例。要查找它们,请在该命名空间中搜索`%Net.SMTP`。
重要提示:`%Net.SMTP`将邮件正文写入临时文件流。默认情况下,该文件被写入命名空间目录,如果该目录需要特殊的写入权限,则不会创建该文件,并且您会得到一个空的消息正文。
可以为这些临时文件定义新路径,并选择不限制写访问的路径(例如,`/tmp`)。为此,请设置全局节点`%SYS("StreamLocation",namespace)`,其中`NAMESPACE`是运行代码的名称空间。例如:
```
Set ^%SYS("StreamLocation","SAMPLES")="/tmp"
```
如果`%SYS("StreamLocation",namespace)`为`NULL`,则InterSystems IRIS使用`%SYS("TempDir",namespace)`指定的目录。如果未设置`%SYS("TempDir",namespace)`,则IRIS使用 `%SYS("TempDir")`指定的目录
示例1:`HotPOPAsSMTP()`和`SendSimpleMessage()`
此示例由一起使用的两个方法组成。第一个创建`%Net.SMTP`的实例,该实例使用已在`HotPOP SMTP`服务器上设置的测试帐户:
```java
/// w ##class(PHA.TEST.HTTP).HotPOPAsSMTP()
ClassMethod HotPOPAsSMTP() As %Net.SMTP
{
Set server=##class(%Net.SMTP).%New()
Set server.smtpserver="smtp.hotpop.com"
//HotPOP SMTP服务器使用默认端口(25)
Set server.port=25
//创建对象以进行身份验证
Set auth=##class(%Net.Authenticator).%New()
Set auth.UserName="isctest@hotpop.com"
Set auth.Password="123pass"
Set server.authenticator=auth
Set server.AuthFrom=auth.UserName
b
Quit server
}
```
下一个方法使用提供的SMTP服务器作为参数发送一条简单、唯一的消息:
```java
ClassMethod SendSimpleMessage(server As %Net.SMTP) As %List
{
Set msg = ##class(%Net.MailMessage).%New()
Set From=server.authenticator.UserName
Set:From="" From="xxx@xxx.com"
Set msg.From = From
Do msg.To.Insert("xxx@xxx.com")
//Do msg.Cc.Insert("yyy@yyy.com")
//Do msg.Bcc.Insert("zzz@zzz.com")
Set msg.Subject="Unique subject line here "_$H
Set msg.IsBinary=0
Set msg.IsHTML=0
Do msg.TextData.Write("This is the message.")
Set status=server.Send(msg)
If $$$ISERR(status) {
Do $System.Status.DisplayError(status)
Write server.Error
Quit ""
}
Quit server.FailedSend
}
```
示例2:`YPOPsAsSMTP()`
此示例创建使用`YPOPS`的`%Net.SMTP`实例的实例,`YPOPS`是一种客户端软件,提供对`Yahoo`电子邮件帐户的`SMTP`和`POP3`访问。它使用已为此目的设置的测试帐户:
```java
ClassMethod YPOPsAsSMTP() As %Net.SMTP
{
Set server=##class(%Net.SMTP).%New()
//local host acts as the server
Set server.smtpserver="127.0.0.1"
//YPOPs uses default port, apparently
Set server.port=25
//Create object to carry authentication
Set auth=##class(%Net.Authenticator).%New()
//YPOPs works with a Yahoo email account
Set auth.UserName="isc.test@yahoo.com"
Set auth.Password="123pass"
Set server.authenticator=auth
Set server.AuthFrom=auth.UserName
Quit server
}
```
可以将其与上例中所示的`SendSimpleMessage`方法一起使用。
示例3:`SendMessage()`
以下更灵活的方法同时接受`SMTP`服务器和电子邮件。电子邮件应已包含主题行(如果`SMTP`服务器要求),但不必包含地址。然后,此方法将电子邮件发送到一组硬编码的测试目的地:
```java
ClassMethod SendMessage(server As %Net.SMTP, msg As %Net.MailMessage) As %Status
{
Set From=server.authenticator.UserName
//make sure From: user is same as used in authentication
Set msg.From = From
//finish addressing the message
Do msg.To.Insert("xxx@xxx.com")
//send the message to various test email addresses
Do msg.To.Insert("isctest@hotpop.com")
Do msg.To.Insert("isc_test@hotmail.com")
Do msg.To.Insert("isctest001@gmail.com")
Do msg.To.Insert("isc.test@yahoo.com")
Set status=server.Send(msg)
If $$$ISERR(status) {
Do $System.Status.DisplayError(status)
Write server.Error
Quit $$$ERROR($$$GeneralError,"Failed to send message")
}
Quit $$$OK
}
```
## `%Net.SMTP`的其他属性
`%Net.SMTP`类还具有一些您可能需要的其他属性,具体取决于使用的SMTP服务器:
- `AllowHeaderEncoding`指定`Send()`方法是否对非`ASCII`标头文本进行编码。默认值为1,这意味着非`ASCII`标头文本按照RFC 2047指定的方式进行编码。
- `ContinueAfterBadSend`指定在检测到失败的电子邮件地址后是否继续尝试发送邮件。如果`ContinueAfterBadSend`为1,系统会将失败的电子邮件地址添加到`FailedSend`属性的列表中。默认值为0。
- `ShowBcc`指定是否将密件抄送标头写入电子邮件。这些通常会被SMTP服务器过滤掉。
文章
water huang · 三月 27, 2023
一、背景
1.1 我遇到了几个项目,他们的接口服务器崩溃了。 项目上希望尽快恢复服务器。他们的服务器在局域网上运行,他们不能使用git,服务器中有多个命名空间运行不同的服务,而且通常只有一台平台服务器。
1.2 如果消息中有字符流类型的属性,消息搜索页面不支持使用字符流属性进行过滤,因此很难找到想要的消息。
1.3 其他同事可能会更新服务器上的代码,代码中可能有些错误。
2.挑战
2.1 如何快速恢复?
2.2 如何支持字符流属性过滤消息?
2.3 如何在编译类时自动备份?
3.解决方案
1.编译时自动导出为备份文件
首先,我们定义一个名为“SYS.base”的类,它只有一个名为“ CLSBAKPATH”的参数,并设置它的值
Class SYS.Base Extends %RegisteredObject
{
Parameter CLSBAKPATH = "D:\IRIS\CLSBAK" ;
}
然后,定义一个名为“SYS.Projection”的类,它继承了 base和%Projection.AbstractProjection,添加“Projection Reference As SYS.Projection”,重写类方法“CreateProjection”;
代码如下:
Class SYS.Projection Extends ( %Projection.AbstractProjection , Base)
{
Projection Reference As SYS.Projection ;
ClassMethod CreateProjection(classname As %String , ByRef parameters As %String , modified As %String , qstruct) As %Status
{ w ! s changetime=^oddDEF(classname,63)
s changetime=$zdt(changetime,3)
w "class"_classname_" is modified at "_changetime_" !",!
s CLSBAKPATH=..#CLSBAKPATH
i CLSBAKPATH[ "/" d
.s PL= "/"
e d
.s PL= "\"
s:$e(CLSBAKPATH,*)'=PL CLSBAKPATH=CLSBAKPATH_PL
s sc= $SYSTEM.OBJ.Export(classname_".cls",CLSBAKPATH_classname_$tr(changetime,":-","")_ ".xml" )
q $$$OK
}
}
执行该方法后,被编译的类将直接导出到目标路径“CLSBAKPATH”,它的名称将类似于“类名20230217130218.xml”
最后,如何使用它?
选择一个要自动备份的类,让它继承“SYS.Projection”。当类被编译时,它会被导出。如果你不修改重新编译它,它会覆盖旧的备份文件。
顺便说一句,我认为关键点是 %Projection.AbstractProjection,有了“CreateProjection”,我们可以做更多,如果你想在生产环境中更新一些代码,并且又不想让人再手动去执行一些目标方法代码,这是个好方法。他需要做的是将xml文件导入studio,并编译它,如果勾选“Compile Imported Items”框,那就不再需要单独编译。也就是导入的时候就会自动编译,编译的时候就自动执行,相当于就是导入后自动执行!
到目前为止,它只备份了一个类文件。如果我们想要备份更多怎么办?
方法来了!简单来说,挂任务!
通常用于备份接口代码和数据。
在本教程中,我们在本地驱动器中备份文件。
首先,我们定义一个名为“Common.SYS”的类
然后添加一个名为“ Export ”的类方法,它是主要方法,它将调用其他功能方法。 A导出类,B导出凭证,C导出GLB。
类看起来像:
Class Common.SYS Extends %RegisteredObject
{
/// Exportclass
ClassMethod ExportAllClassesIndividual(NS As %String = "" )
{
s Drive=..#Drive s currentns= $ZUTIL ( 67 , 6 , $j )
i NS'= "" d
.w:'$d(^["%sys"]CONFIG("Namespaces",NS)) "namespace "_NS_" is not existed,please check it!" ,!
.q:'$d(^[ "%sys"]CONFIG("Namespaces",NS))
.zn NS
.s FilePath=Drive_":/BakFile/"_NS_"/"
.i '##class(%File).DirectoryExists(FilePath) d
..d ##class(%File).CreateDirectoryChain(FilePath)
.s sc= $system .OBJ.ExportAllClassesIndividual(FilePath,"b",.el,"","CDYZone,Sample,User" )
.i sc'=1 d
..w " namespace "_NS_" get an error when export class! "_$System.Status.GetErrorText(sc),!
e d
.s alns=""
.f s alns=$o(^["%sys"]CONFIG("Namespaces",alns)) q:alns="" d
..q:$e(alns,1)="%"
..q:(alns="ENSDEMO")||(alns="ENSEMBLE")||(alns["-")
..q:'$d(^[alns]CacheMsg("Confirm"))
..zn alns
..s FilePath=Drive_":/BakFile/"_alns_"/"
..i '##class(%File).DirectoryExists(FilePath) d
...d ##class(%File).CreateDirectoryChain(FilePath)
..s sc=$system.OBJ.ExportAllClassesIndividual(FilePath,"b",.el,"","Common,SYS" )
..i sc'=1 d
...w " namespace "_alns_" get an error when export class! "_ $System.Status.GetErrorText(sc),!
zn currentns
q $$$OK
}
/// Ens.Config.Credentials
ClassMethod ExportAllCredentials(NS As %String = "" )
{
s Drive=..#Drive
s currentns= $ZUTIL ( 67 , 6 , $j )
i NS'= "" d
. w :' $d (^[ "%sys" ]CONFIG( "Namespaces" ,NS)) "namespace " _NS_ " is not existed,please check it!" ,!
. q :' $d (^[ "%sys" ]CONFIG( "Namespaces" ,NS))
. q :' $d (^[NS]Ens.Conf.CredentialsD)
. zn NS
. s Data=[]
. s FilePath=Drive_ ":/BakFile/" _NS_ "/Ens_Config_Credentials"
.i ' ##class ( %File ).DirectoryExists(FilePath) d
..d ##class ( %File ).CreateDirectoryChain(FilePath)
. s Data=[]
. s CID= ""
.f s CID= $o ( ^Ens .Conf.CredentialsD(CID)) q :CID= "" d
..s obj= ##class (Ens.Config.Credentials). %OpenId (CID)
..q :' $IsObject (obj)
..s data={}
..s data.SystemName=obj.SystemName
..s data.Username=obj.Username
..s data.Password=obj.Password
..d Data. %Push (data)
. d :Data. %Size ()> 0 ..SaveFile (FilePath,Data. %ToJSON ())
e d
. ;w currentns,!
. s alns= ""
.f s alns= $o (^[ "%sys" ]CONFIG( "Namespaces" ,alns)) q :alns= "" d
..q : $e (alns, 1 )= "%"
..q :(alns= "ENSDEMO" )||(alns= "ENSEMBLE" )||(alns[ "-" )
..q :' $d (^[alns]CacheMsg( "Confirm" ))
..q :' $d (^[alns]Ens.Conf.CredentialsD)
..zn alns
..s FilePath=Drive_ ":/BakFile/" _alns_ "/Ens_Config_Credentials"
..i ' ##class ( %File ).DirectoryExists(FilePath) d
. ..d ##class ( %File ).CreateDirectoryChain(FilePath)
..s Data=[]
..s CID= ""
..f s CID= $o ( ^Ens .Conf.CredentialsD(CID)) q :CID= "" d
. ..s obj= ##class (Ens.Config.Credentials). %OpenId (CID)
. ..q :' $IsObject (obj)
. ..s data={}
. ..s data.SystemName=obj.SystemName
. ..s data.Username=obj.Username
. ..s data.Password=obj.Password
. ..d Data. %Push (data)
..d :Data. %Size ()> 0 ..SaveFile (FilePath,Data. %ToJSON ())
zn currentns
q $$$OK
}
ClassMethod SaveFile(FilePath, Data)
{
s file= ##class ( %FileCharacterStream ). %New ()
s file.Filename=FilePath_ "/Credentials.JSON"
d file. Write (Data)
s sc=file. %Save ()
i sc'= 1 d
. w FilePath_ " save Credential failed! " _ $System .Status.GetErrorText(sc),!
e d . w FilePath_ " save Credential success! " ,!
q $$$OK
}
ClassMethod SaveGLB(NS)
{
s Drive=..#Drive
w :' $d (^[ "%sys" ]CONFIG( "Namespaces" ,NS)) "namespace " _NS_ " is not existed,please check it!" ,!
q :' $d (^[ "%sys" ]CONFIG( "Namespaces" ,NS)) 1
s rset = ##class ( %ResultSet ). %New ( "%SYS.GlobalQuery:NameSpaceList" )
q :'rset.QueryIsValid() "invalid Query:"
d rset.Execute(NS, "CDY*" )
s Flag= 0
while (rset.Next()){
s HasData=rset.GetDataByName( "HasData" )
i HasData= 1 d
. s Name=rset.GetDataByName( "Name" )
. q :Name[ "PushConfigListD" ;some needed globals
. s Data(Name)= 1
. s Flag= 1
}
w :Flag= 0 NS_ " namespace doesn't have global to be exported" ,!
q :Flag= 0 NS_ " namespace doesn't have global to be exported"
s FilePath=Drive_ ":/BakFile/" _NS_ "/GLB/"
i ' ##class ( %File ).DirectoryExists(FilePath) d
. d ##class ( %File ).CreateDirectoryChain(FilePath)
q ##class ( %Library.Global ).Export(NS,.Data,FilePath_ "SYS.gof" )
}
/// ExportAll CDY* Globals
ClassMethod ExportAllCDYGLB(NS As %String = "" )
{
s currentns= $ZUTIL ( 67 , 6 , $j )
i NS'= "" d
. w :' $d (^[ "%sys" ]CONFIG( "Namespaces" ,NS)) "namespace " _NS_ " is not existed,please check it!" ,!
. q :' $d (^[ "%sys" ]CONFIG( "Namespaces" ,NS))
. s sc= ..SaveGLB (NS)
.i sc'= 1 d
..w " namespace " _NS_ " get an error when export global! " _ $System .Status.GetErrorText(sc),!
e d
. s alns= ""
.f s alns= $o (^[ "%sys" ]CONFIG( "Namespaces" ,alns)) q :alns= "" d
..q : $e (alns, 1 )= "%"
..q :(alns= "ENSDEMO" )||(alns= "ENSEMBLE" )||(alns[ "-" )
..q :' $d (^[alns]CacheMsg( "Confirm" ))
..s sc= ..SaveGLB (alns)
..i sc'= 1 d
. ..w " namespace" _alns_ " get an error when export global! " _ $System .Status.GetErrorText(sc),!
zn currentns
q $$$OK
}
/// location to store backuped file
Parameter Drive = "d" ;
ClassMethod Export()
{
s NS= "" ///namespace
d ..ExportAllClassesIndividual (NS) ///class file(include package)
d ..ExportAllCredentials (NS) ///Credential information
d ..ExportAllCDYGLB (NS) ///Global file, or data
q $$$OK
}
}
在 iris 中添加一个自定义任务,你就能保留最新的代码和数据。
优化消息搜索
当我得到使消息搜索页面支持使用字符流类型的属性进行过滤的解决方案时(为了解决这个问题,我问 intersystems 的工程师,她告诉我,使用“EnsPortal.MsgFilter.Assistant”,覆盖类方法“GetSQLCondition”。所以我做了一个类扩展 EnsPortal.MsgFilter.Assistant.it 似乎已经解决了问题。在编译类之后然后 s ^EnsPortal.Settings("MessageViewer","AssistantClass")=class
).
我写的代码如下:
Class ENSLIB.MsgFilterAssistant Extends EnsPortal.MsgFilter.Assistant
{
ClassMethod GetSQLCondition(pOperator As %String , pProp As %String , pValue As %String , pDisplay As %Boolean = 0 ) As %String
{
if (pValue = "" ) || ((pOperator '= "Like" ) && (pOperator '= "NotLike" )) quit ##super (pOperator, pProp, pValue, pDisplay)
if ( "%%" = $extract (pValue, *- 2 , *- 1 ))
{
set pValue = "'" _ $extract (pValue, 1 , *- 3 ) _ "' ESCAPE '" _ $extract (pValue, *) _ "'"
} else {
set pValue = "'" _ $replace (pValue, "'" , "''" ) _ "'"
}
quit "substring(" _ pProp _ ", 1, 3000000) " _ $case (pOperator, "Like" : "LIKE" , "NotLike" : "NOT LIKE" ) _ " " _ pValue
}
/// w ##class(ENSLIB.MsgFilterAssistant).SetMV()
ClassMethod SetMV()
{
s ^EnsPortal .Settings( "MessageViewer" , "AssistantClass" )= "ENSLIB.MsgFilterAssistant"
q $$$OK
}
}
导入代码后,必须有人执行'##class(ENSLIB.MsgFilterAssistant).SetMV()',然后它才能工作!所以我想如果有一种方法可以在导入或编译后自动运行 SetMV,我寻找解决方案,从论坛到开放交换,最后我想到可以用 Projection,代码更改为:
Class ENSLIB.MsgFilterAssistant Extends (EnsPortal.MsgFilter.Assistant, %Projection.AbstractProjection )
{
Projection Reference As MsgFilterAssistant ;
ClassMethod GetSQLCondition(pOperator As %String , pProp As %String , pValue As %String , pDisplay As %Boolean = 0 ) As %String
{
if (pValue = "" ) || ((pOperator '= "Like" ) && (pOperator '= "NotLike" )) quit ##super (pOperator, pProp, pValue, pDisplay)
if ( "%%" = $extract (pValue, *- 2 , *- 1 ))
{
set pValue = "'" _ $extract (pValue, 1 , *- 3 ) _ "' ESCAPE '" _ $extract (pValue, *) _ "'"
} else {
set pValue = "'" _ $replace (pValue, "'" , "''" ) _ "'"
}
quit "substring(" _ pProp _ ", 1, 3000000) " _ $case (pOperator, "Like" : "LIKE" , "NotLike" : "NOT LIKE" ) _ " " _ pValue }
/// w ##class(ENSLIB.MsgFilterAssistant).SetMV()
ClassMethod SetMV()
{
s ^EnsPortal .Settings( "MessageViewer" , "AssistantClass" )= $this
q $$$OK
}
ClassMethod CreateProjection(cls As %String , ByRef params) As %Status
{
w ! w "开始执行" ,!
d ..SetMV ()
w "执行完成" ,!
q $$$OK
}
}
类编译完成后会自动执行SetMV!是否有更好的实现方式呢?
如果你有更好的方法,请分享!
4.更多
我将继续寻找更好的方法来复制源类和配置数据。 为黄老师点赞!
文章
sun yao · 十月 12, 2022
## **概述**
现有Ensemble平台BS(服务)、BP(流程)、BO(操作)需对平台及开发语言有一定的了解才能实现,为简化用户操作,现对现有平台进行二次封装,通过API接口的形式进行前后端分离,通过前端界面操作实现BS(对外提供的服务)、BP、BO(逻辑处理或调用外部的服务)自动生成(通过%Dictionary实现),具体实现如下。
## **一、开发技术和工具**
版本:Ensemble 2017.2.1
## **二、涉及公用类**
### 2.1 %Dictionary.ClassDefinition(自定义类)
• property **Super** as %CacheString;
Specifies one or more superclasses for the class.
定义一个或多个父类,继承父类
• property** ProcedureBlock** as %Boolean [ InitialExpression = 0 ];
Specifies that the class uses procedure block for method code.
设置类是否允许使用程序块,程序块强制实施变量作用域:方法无法看到由其调用方定义的变量,程序块中的任何变量都会自动成为私有变量
• relationship **Parameters** as %Dictionary.ParameterDefinition [ Inverse = parent,Cardinality = children ];
Parameter.
定义类参数,如全局变量、适配器等相关定义
• relationship **Methods** as %Dictionary.MethodDefinition [ Inverse = parent,Cardinality = children ];
Method.
定义类方法
参考链接:http://localhost:57772/csp/documatic/%25CSP.Documatic.cls?APP=1&LIBRARY=%25SYS&CLASSNAME=%25Dictionary.ClassDefinition
### 2.2 %Dictionary.ParameterDefinition(自定义类参数)
• property **Name** as %Dictionary.CacheIdentifier [ Required ];
The name of the parameter.
定义参数名
• property **Default** as %CacheString [ SqlFieldName = _Default ];
Specifies a default value for the parameter assuming the Expression keyword is blank.
定义参数默认值,不设置则为空
• property **Description** as %CacheString;
Specifies a description of the parameter.
定义参数描述
参考链接:http://localhost:57772/csp/documatic/%25CSP.Documatic.cls?APP=1&LIBRARY=%25SYS&CLASSNAME=%25Dictionary.ParameterDefinition
###2.3 %Dictionary.MethodDefinition(自定义类方法)
• property **Name** as %Dictionary.CacheIdentifier [ Required ];
The name of the method.
定义方法名
• property **ClassMethod** as %Boolean [ InitialExpression = 0 ];
Specifies that the method is a class method. Instance methods can only be invoked via an instantiated object while class methods can be directly invoked without an object instance.
指定该方法是类方法。实例方法只能通过实例化的对象调用,而类方法可以在没有对象实例的情况下直接调用。
• property **FormalSpec** as %CacheString;
Specifies the list of arguments. Each argument is of the format [&|*][:][=] where & means pass-by-reference and * means output-only.
定义方法入参,每个入参格式为“参数名:参数类型=默认值”,如:code:%String=””
• property **ReturnType** as %Dictionary.CacheClassname;
Specifies the data type of the value returned by a call to the method. Setting ReturnType to an empty string specifies that there is no return value.
定义方法返回值,设置为空则无返回值
• property **WebMethod** as %Boolean [ InitialExpression = 0 ];
Specifies that a method can be invoked as a web method using the SOAP protocol.
设置方法是否为web方法,适用于SOAP协议
• property **Implementation** as %Stream.TmpCharacter;
The code that is executed when the method is invoked. In the case of an expression method, this is an expression. In the case of a call method, this is the name of a Cache routine to call.
调用方法时执行的代码。对于表达式方法,这是一个表达式。对于调用方法,这是要调用的缓存例程的名称
参考链接:http://localhost:57772/csp/documatic/%25CSP.Documatic.cls?APP=1&LIBRARY=%25SYS&CLASSNAME=%25Dictionary.MethodDefinition
###2.4 Ens.Config.Production
• property **Items** as list of Ens.Config.Item(XMLNAME="Item",XMLPROJECTION="ELEMENT");
定义Production下的BS、BP、BO,根据父类确认属于哪一类
• method **SaveToClass**(pItem As Ens.Config.Item = $$$NULLOREF) as %Status
This method saves the production into the XData of the corresponding class
参考链接: http://localhost:57772/csp/documatic/%25CSP.Documatic.cls?APP=1&LIBRARY=ENSLIB&CLASSNAME=Ens.Config.Production
###2.5 Ens.Config.Item(BS服务、BP流程、BO操作)
• property **PoolSize** as %Integer(MINVAL=0,XMLPROJECTION="ATTRIBUTE");
Number of jobs to start for this config item.
Default value:
0 for Business Processes (i.e. use shared Actor Pool)
1 for FIFO message router Business Processes (i.e. use a dedicated job)
1 for Business Operations
0 for adapterless Business Services
1 for others
For TCP based Services with JobPerConnection=1, this value is used to limit the number of connection jobs if its value is greater than 1. A value of 0 or 1 places no limit on the number of connection jobs.
设置缓冲池大小
• property **Name** as %String(MAXLEN=128,XMLPROJECTION="ATTRIBUTE") [ Required ];
The name of this config item. Default is the class name.
设置BS、BP、BO名称
• property **ClassName** as %String(MAXLEN=128,XMLPROJECTION="ATTRIBUTE") [ Required ];
Class name of this config item.
设置BS、BP、BO类名称
• property **Category** as %String(MAXLEN=2500,XMLPROJECTION="ATTRIBUTE");
Optional list of categories this item belongs to, comma-separated. This is only used for display purposes and does not affect the behavior of this item.
设置类别
• property **Comment** as %String(MAXLEN=512,XMLPROJECTION="ATTRIBUTE");
Optional comment text for this component.
设置注释
• property **Enabled** as %Boolean(XMLPROJECTION="ATTRIBUTE") [ InitialExpression = 1 ];
Whether this config item is enabled or not.
设置启用停用标志
参考链接:http://localhost:57772/csp/documatic/%25CSP.Documatic.cls?PAGE=CLASS&LIBRARY=ENSLIB&CLASSNAME=Ens.Config.Item
##**三、实现方法**
###3.1 创建BS模板类
创建模板类,后续类生成方法体通过模板类获取
/// BS的SOAP模板
Class HIP.Platform.Template.BSSOAPTemplate Extends EnsLib.SOAP.Service
{
Parameter ADAPTER;
Parameter NAMESPACE = "http://tempuri.org";
Parameter SERVICENAME = "BSSOAPTemplate";
Method TemplateFun(code As %String, data As %GlobalCharacterStream) As %GlobalCharacterStream [ WebMethod ]
{
set OutStream=##class(%GlobalCharacterStream).%New()
try{
s ..%ConfigName = $classname($this)
set sourceCode=$p($classname($this),".",4) //PUB000X
set methodCode=##safeexpression(""""_$get(%methodname)_"""") //SendDataFromHis
s messageCode = $p(code,"^",1)
s requestType= $select($p(code,"^",2)="REST":"REST", 1:"SOAP")
set proc = ##class(%SYS.ProcessQuery).%OpenId($j) //当前进程 获取调用服务客户端的IP地址
set sc = ##class(HIP.Service.PublishService).GetAllowedIP(sourceCode)
if +sc=1 {
s allowedIP = $p(sc,"^",2)
if allowedIP '[ proc.ClientIPAddress {
SET oref=##class(%Exception.General).%New("","无权限",,"您的IP地址不允许访问,请联系管理员")
THROW oref
}
}else{
return sc
}
s request = ##class(HIP.Platform.Message.Request).%New()
s request.sourceCode=sourceCode //PUB0001
s request.requestType=requestType //REST SOAP
s request.inputFlag="0" //-1表示失败,0表示未处理,1表示成功
s request.inputStream = data //JSON流,或者XML流
s request.messageCode=messageCode //BOE0001
Set tSC=..SendRequestSync("HIP.Platform.BP.ProcessCode",request,.pOutput)
If $$$ISERR(tSC) Do ..ReturnMethodStatusFault(tSC)
d OutStream.CopyFrom(pOutput.outStream)
return OutStream
}catch err {
set OutStream=##class(%GlobalCharacterStream).%New()
do OutStream.Write(err.DisplayString())
return OutStream
}
}
Storage Default
{
%%CLASSNAME
^HIP.PlatforE240.BSSOAPTemplateD
BSSOAPTemplateDefaultData
^HIP.PlatforE240.BSSOAPTemplateD
^HIP.PlatforE240.BSSOAPTemplateI
^HIP.PlatforE240.BSSOAPTemplateS
%Library.CacheStorage
}
}
###3.2 自动生成BS,并添加至Production中
通过模板类自动生成WebService方法,并添加到Production的BS中
/// 创建BS服务 PUB00XX服务,提供给第三方调用
/// d ##class(HIP.Util.SOAP).BSCreateSOAPInfo("PUB0001","提供给HIS访问平台")
ClassMethod BSCreateSOAPInfo(Code As %String, Desc As %String) As %Status
{
///HIP.Platform.BS.PUB0001
s src = "HIP.Platform.BS."_Code_".PublishWebService"
s isExist = 0
try {
set isExist=##class(%Dictionary.ClassDefinition).%ExistsId(src)
if isExist=1 { //类已存在则更新,先删除再插入
set classObj = ##class(%Dictionary.ClassDefinition).%OpenId(src)
d classObj.Parameters.Clear()
d classObj.Properties.Clear()
d classObj.Indices.Clear()
d classObj.ForeignKeys.Clear()
d classObj.Methods.Clear()
}else { //类不存在则新建
set classObj = ##class(%Dictionary.ClassDefinition).%New(src)
}
//设置父类
s classObj.Super="EnsLib.SOAP.Service"
//设置允许使用程序块,则可动态定义变量
s classObj.ProcedureBlock=1
///Parameter的值
//设置适配器
set ParDef = ##class(%Dictionary.ParameterDefinition).%New()
set ParDef.Name="ADAPTER"
d classObj.Parameters.Insert(ParDef)
set ParDef = ##class(%Dictionary.ParameterDefinition).%New()
//设置服务名
set ParDef.Name="SERVICENAME"
set ParDef.Default=Code
set ParDef.Description=Desc
d classObj.Parameters.Insert(ParDef)
//设置命名空间
set ParDef = ##class(%Dictionary.ParameterDefinition).%New()
set ParDef.Name="NAMESPACE"
set ParDef.Default="www.boe.com"
d classObj.Parameters.Insert(ParDef)
///函数模板代码,通过模板类获取
s methodTemplate = ##class(%Dictionary.MethodDefinition).%OpenId("HIP.Platform.Template.BSSOAPTemplate||TemplateFun")
Set methodObj=##class(%Dictionary.MethodDefinition).%OpenId(src_"||SendData")
if methodObj="" Set methodObj=##class(%Dictionary.MethodDefinition).%New(src_".SendData")
//设置方法名
set methodObj.Name="SendData"
set methodObj.ClassMethod=0
//set methodObj.FormalSpec="code:%String,data:%GlobalCharacterStream,*pOutput:HIP.Platform.Message.Response"
//设置方法入参
set methodObj.FormalSpec="code:%String,data:%GlobalCharacterStream"
//设置方法返回值
set methodObj.ReturnType="%GlobalCharacterStream"
//设置方法为WebService方法
set methodObj.WebMethod=1
//设置方法具体实现代码,通过模板类获取
set methodObj.Implementation=methodTemplate.Implementation
d classObj.Methods.Insert(methodObj)
set sc=classObj.%Save()
if $$$ISERR(sc) {
return $system.Status.GetErrorText(sc)
}else{
d $system.OBJ.Compile(src,"ck/displaylog=0")
}
if isExist=0 {
//存储到production中
s prodObj = ##class(Ens.Config.Production).%OpenId("HIP.Platform.Production")
if $IsObject($G(prodObj)){
Set item = ##class(Ens.Config.Item).%New()
Set item.PoolSize = 1
Set item.Name = src
Set item.ClassName = src
Set:item.Name="" item.Name = item.ClassName
Set item.Category = ""
Set item.Comment = Desc
Set item.Enabled = 1
Set tSC = prodObj.Items.Insert(item)
If $$$ISOK(tSC) {
// save production (and item)
Set tSC = prodObj.%Save()
set ^TempSy("tSC")=tSC
If ($$$ISOK(tSC)) {
// update production class
Set tSC = prodObj.SaveToClass()
}
return tSC
}
If $$$ISERR(tSC) return $system.Status.GetErrorText(tSC)
}
}
return $$$OK
} catch(ex) {
return ex.DisplayString()
}
}
###**四、 结果展示**
运行
d ##class(HIP.Util.SOAP).BSCreateSOAPInfo("PUB0001","提供给HIS访问平台")
后,Studio中自动生成HIP.Platform.BS.PUB0001.PublishWebService.cls 类
如下:
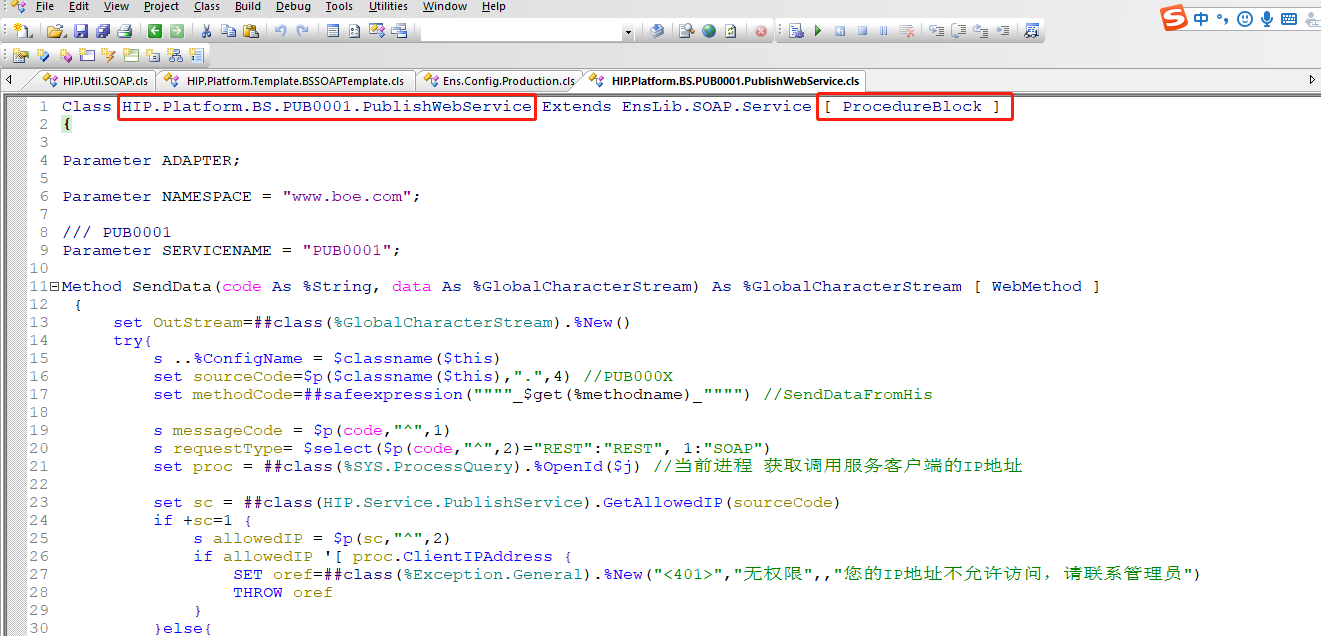
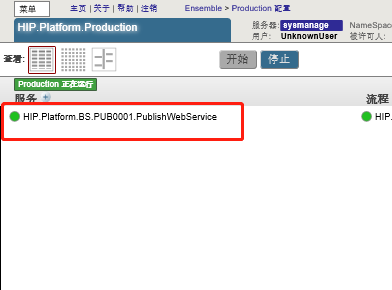
打开Portal管理界面,Production配置,可看到该服务已添加至Production中,如下:
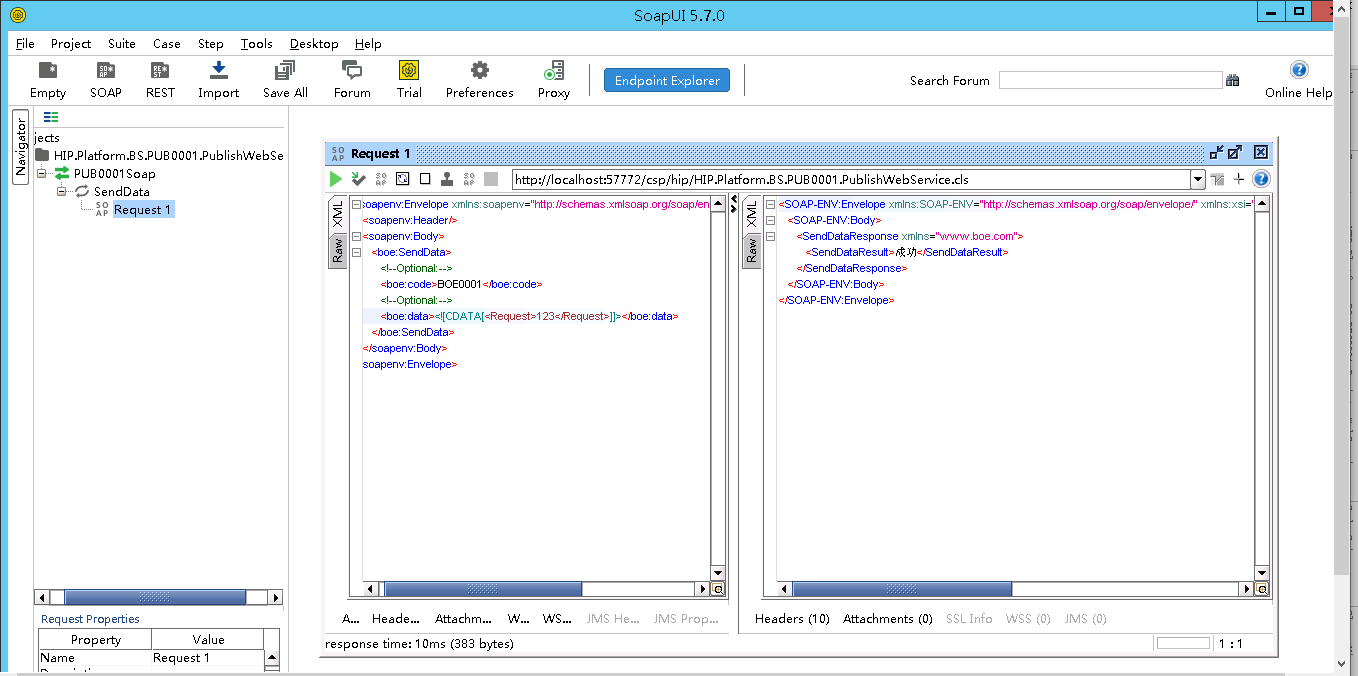
可直接通过soapUI调用,地址
http://localhost:57772/csp/hip/HIP.Platform.BS.PUB0001.PublishWebService.CLS?WSDL=1
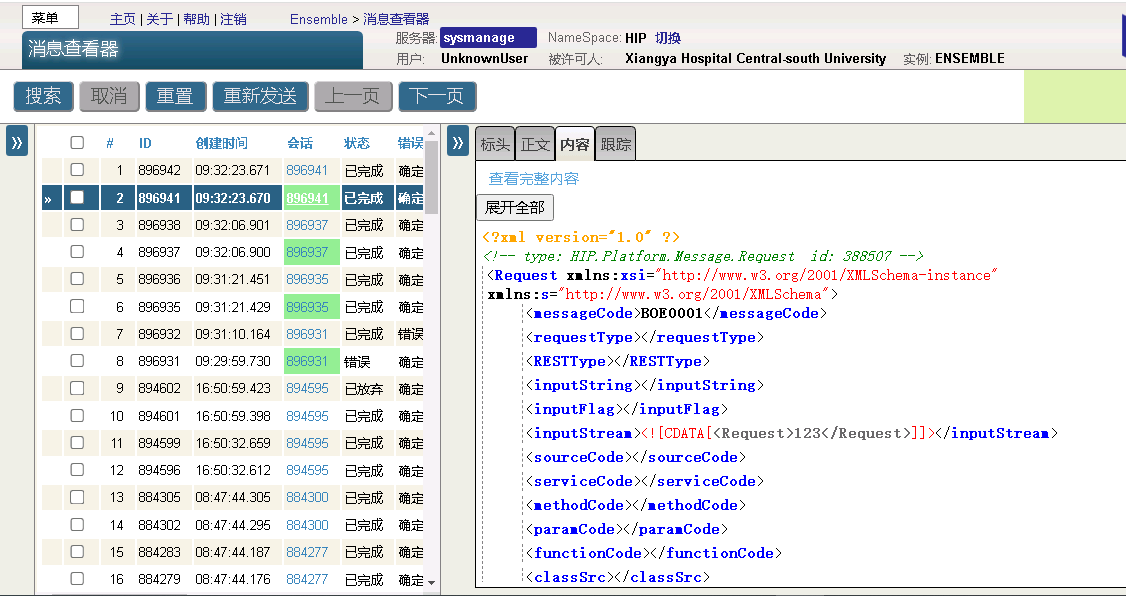
InterSystems消息查看
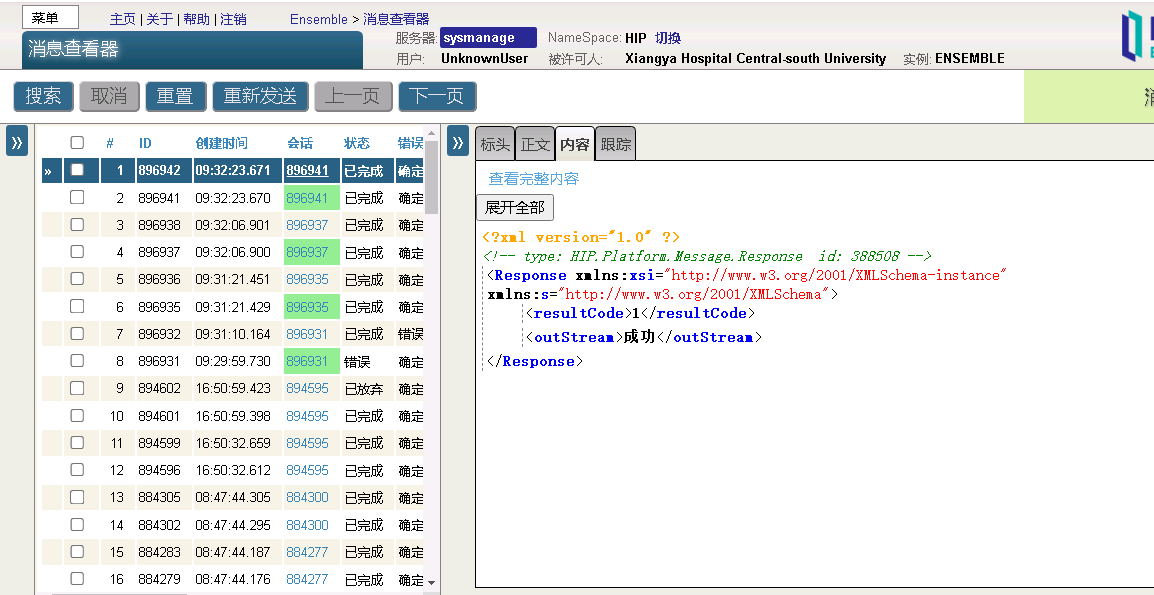
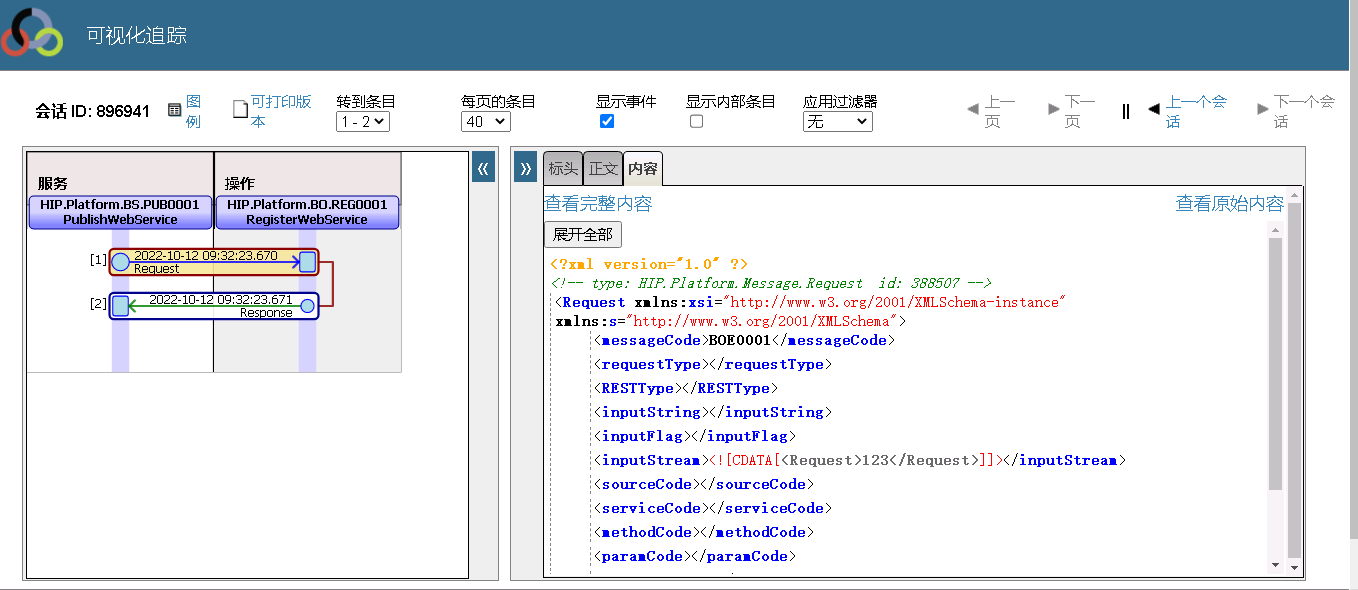
###**五、 结论与猜想**
同理,BO也可通过该方法实现自动生成,另可通过建立REST服务或WebService服务的方式通过前端调用该方法实现前端自动生成BS、BP、BO,以简化用户操作,但该方法存在问题点,如BP都为公用单个BP,消息并发量大时可能导致BP堵塞问题,可能实现的解决方法为前端先单独调用接口创建BP,后生成BS,再通过配置实现BS到BP的关联,大家感兴趣可自行尝试,以上,谢谢!
点赞 讲解的非常详细,非常有用。 非常有用的知识 加油 感谢分享 膜拜大佬 学习到了👍👍👍 非常有价值,思路清晰,值得学习 真好 博主的思路值得学习! 谢谢分享,学习了
文章
姚 鑫 · 五月 5, 2021
# 第三章 使用多维存储(全局变量)(一)
本章描述了使用多维存储(全局变量)可以执行的各种操作。
# 以全局变量存储数据
在全局节点中存储数据很简单:像对待任何其他变量一样对待全局变量。
区别在于对全局变量的操作是自动写入数据库的。
## 创建全局变量
创建新的全局变量不需要设置工作;只需将数据设置为全局变量即可隐式创建新的全局结构。可以创建全局变量(或全局变量下标)并通过单个操作将数据放入其中,也可以创建全局变量(或下标)并通过将其设置为空字符串将其保留为空。在ObjectScript中,这些操作是使用`SET`命令完成的。
下面的例子定义了一个名为`Color`(如果还不存在)的全局变量,并将值`“Red”`与之关联。
如果已经存在一个名为`Color`的全局变量,那么这些示例将其修改为包含新信息。
在ObjectScript中:
```java
SET ^Color = "Red"
```
注意:在应用程序中使用直接全局访变量问时,应制定并遵守命名约定,以防止应用程序的不同部分相互“遍历”;这类似于为类、方法和其他变量开发命名约定。
## 在全局变量节点中存储数据
要在全局下标节点中存储值,只需像设置任何其他变量数组一样设置全局节点的值。如果指定的节点以前不存在,则会创建该节点。如果它确实存在,则其内容将替换为新值。
可以通过表达式(称为全局引用)指定全局内的节点。全局引用由脱字符(`^`)、全局名称和(如果需要)一个或多个下标值组成。下标(如果有)用括号“()”括起来,并用逗号分隔。每个下标值本身都是一个表达式:文字值、变量、逻辑表达式,甚至是全局引用。
**设置全局节点的值是一个原子操作:它肯定会成功,不需要使用任何锁来确保并发性。**
以下都是有效的全局引用:
在ObjectScript中:
```java
SET ^Data = 2
SET ^Data("Color")="Red"
SET ^Data(1,1)=100 /*第二级下标(1,1)设置为值100。第一级下标(^DATA(1))不存储任何值。 */
SET ^Data(^Data)=10 /*全局变量^data的值是下标的名称。 */
SET ^Data(a,b)=50 /*局部变量a和b的值是下标的名称 */
SET ^Data(a+10)=50
```
此外,还可以在运行时使用间接方式构造全局引用。
## 在全局变量节点中存储结构化数据
每个全局节点可以包含最多`32K`个字符的单个字符串。
数据通常以以下方式之一存储在节点中:
- 作为最多`32K`个字符的单个字符串(具体地说,`32K - 1`)。
- 作为包含多条数据的字符分隔字符串。
要使用字符分隔符在节点中存储一组字段,只需使用连接操作符(`_`)将这些值连接在一起。下面的ObjectScript示例使用`#`字符作为分隔符:
```java
SET ^Data(id)=field(1)_"#"_field(2)_"#"_field(3)
```
检索数据时,可以使用`$PIECE`函数将字段拆分:
```java
SET data = $GET(^Data(id))
FOR i=1:1:3 {
SET field(i) = $PIECE(data,"#",i)
}
QUIT
```
- 作为包含多条数据的`$LIST`编码字符串。
`$LIST`函数使用特殊的长度编码方案,不需要保留分隔符。(这是InterSystems IRIS对象和SQL使用的默认结构。)
要在节点中存储一组字段,请使用`$LISTBUILD`函数构造列表:
```java
SET ^Data(id)=$LISTBUILD(field(1),field(2),field(3))
```
检索数据时,可以使用`$LIST`或`$LISTGET`函数将字段拆分:
```java
SET data = $GET(^Data(id))
FOR i = 1:1:3 {
SET field(i)=$LIST(data,i)
}
QUIT
```
- 作为较大数据集(例如流或`“BLOB”`)的一部分。
**由于单个节点的数据量限制在略低于`32K`,因此可以通过将数据存储在一组连续节点中来实现更大的结构(如流):**
```java
SET ^Data("Stream1",1) = "First part of stream...."
SET ^Data("Stream1",2) = "Second part of stream...."
SET ^Data("Stream1",3) = "Third part of stream...."
```
**获取流的代码(如`%GlobalCharacterStream`类提供的流)循环遍历结构中的连续节点,该结构将数据作为连续字符串提供**。
- 作为一个位串。
如果正在实现位图索引(位字符串中的位对应表中的行的索引),应该将全局索引的节点值设置为位字符串。
请注意IRIS使用压缩算法来编码位串;
因此,位串只能使用IRIS `$BIT`函数来处理。
- 作为一个空节点。
如果感兴趣的数据是由节点本身提供的,那么通常将实际下标设置为空字符串(`""`)。
例如,将名称与`ID`值相关联的索引通常是这样的:
```java
SET ^Data("APPLE",1) = ""
SET ^Data("ORANGE",2) = ""
SET ^Data("BANANA",3) = ""
```
# 删除全局节点
要从数据库中删除一个全局节点、一组子节点或整个全局节点,请使用ObjectScript `kill`或`ZKILL`命令。
`Kill`命令删除特定全局引用处的所有节点(数据及其在数组中的相应条目),包括任何子代节点。也就是说,所有以指定下标开头的节点都将被删除。
例如,ObjectScript语句:
```java
KILL ^Data
```
删除整个`^Data`全局变量。对此全局变量的后续引用将返回``错误。
ObjectScript语句:
```java
KILL ^Data(100)
```
删除`^Data`全局变量中节点`100`的内容。如果有子代节点,如`^data(100,1)`、`^data(100,2)`和`^data(100,1,2,3)`,这些子节点也会被删除。
ObjectScript `ZKILL`命令用于删除指定的全局或全局下标节点。它不会删除子代子节点。
**注意:在杀死一个大型全局变量之后,该全局变量曾经占用的空间可能没有完全释放,因为垃圾收集器守护进程在后台将这些块标记为空闲。因此,在终止大型全局变量之后立即调用`SYS.Database`类的`ReturnUnusedSpace`方法可能不会返回预期大小的空间,因为该全局占用的块可能尚未释放。**
**不能对全局变量使用`new`命令。**
# 测试全变量局节点的存在
要测试特定全局变量(或其后代)是否包含数据,请使用`$DATA`函数。
`$DATA`返回一个值,该值指示指定的全局变量引用是否存在。可能的返回值包括:
状态值| 含义
---|---
`0`| 全局变量未定义。
`1`| 全局变量存在并包含数据,但没有子代。请注意,空字符串(`“”`)可用作数据。
`10`| 全局变量有后代(包含指向子节点的向下指针),但本身不包含数据。对此类变量的任何直接引用都将导``错误。例如,如果`$data(^y)`返回`10`,则`SET x=^y`将产生``错误。
`11`| 全局变量既包含数据,又有后代(包含指向子节点的向下指针)。
# 检索全局变量节点的值
要获取存储在特定全局变量节点中的值,只需使用全局引用作为表达式:
```java
SET color = ^Data("Color") ; assign to a local variable
WRITE ^Data("Color") ; use as a command argument
SET x=$LENGTH(^Data("Color")) ; use as a function parameter
```
## `$GET`函数
还可以使用`$GET`函数获取全局节点的值:
```java
SET mydata = $GET(^Data("Color"))
```
这将检索指定节点的值(如果存在),如果该节点没有值,则返回空字符串(`“”`)。如果节点没有值,可以使用可选的第二个参数`$get`返回指定的默认值。
## `WRITE`、`ZWRITE`和`ZZDUMP`命令
可以使用各种ObjectScript显示命令显示全局变量或全局变量子节点的内容。`WRITE`命令以字符串形式返回指定全局或子节点的值。`ZWRITE`命令返回全局变量的名称及其值,以及它的每个子代节点及其值。`ZZDUMP`命令以十六进制转储格式返回指定全局或子节点的值。
文章
姚 鑫 · 四月 23, 2021
# 第五章 优化查询性能(二)
# 使用索引
**索引通过维护常见请求数据的排序子集,提供了一种优化查询的机制。
确定哪些字段应该被索引需要一些思考:太少或错误的索引和关键查询将运行太慢;
太多的索引会降低插入和更新性能(因为必须设置或更新索引值)。**
## 什么索引
要确定添加索引是否会提高查询性能,请从管理门户SQL接口运行查询,并在性能中注意全局引用的数量。
添加索引,然后重新运行查询,注意全局引用的数量。
一个有用的索引应该减少全局引用的数量。
可以通过在`WHERE`子句或`ON`子句条件前使用`%NOINDEX`关键字来防止使用索引。
应该为联接中指定的字段(属性)编制索引。左外部联接从左表开始,然后查看右表;因此,应该为右表中的字段建立索引。在下面的示例中,应该为`T2.f2`编制索引:
```sql
FROM Table1 AS T1 LEFT OUTER JOIN Table2 AS T2 ON T1.f1 = T2.f2
```
内部联接应该在两个`ON`子句字段上都有索引。
执行“显示计划”,然后找到第一张map。
如果查询计划中的第一个项目是`“Read master map”`,或者查询计划调用的模块的第一个项目是`“Read master map”`,则查询的第一个映射是主映射,而不是索引映射。
因为主映射读取数据本身,而不是数据索引,这总是表明查询计划效率低下。
除非表相对较小,否则应该创建一个索引,以便在重新运行该查询时,查询计划的第一个映射表示“读取索引映射”。
应该索引在`WHERE`子句`equal`条件中指定的字段。
可能希望索引在`WHERE`子句范围条件中指定的字段,以及`GROUP BY`和`ORDER BY`子句中指定的字段。
在某些情况下,基于范围条件的索引可能会使查询变慢。如果绝大多数行满足指定的范围条件,则可能会发生这种情况。例如,如果将`QUERY`子句`WHERE Date < CURRENT_DATE` 用于大多数记录来自以前日期的数据库,则在`DATE`上编制索引实际上可能会降低查询速度。这是因为查询优化器假定范围条件将返回相对较少的行数,并针对此情况进行优化。可以通过在范围条件前面加上`%noindex`来确定是否发生这种情况,然后再次运行查询。
如果使用索引字段执行比较,则比较中指定的字段的排序规则类型应与其在相应索引中的排序规则类型相同。例如,`SELECT`的`WHERE`子句或联接的`ON`子句中的`Name`字段应该与为`Name`字段定义的索引具有相同的排序规则。如果字段排序规则和索引排序规则之间存在不匹配,则索引可能效率较低或可能根本不使用。
## 索引配置选项
以下系统范围的配置方法可用于优化查询中索引的使用:
- 要将主键用作`IDKey`索引,请设置`$SYSTEM.SQL.Util.SetOption()`方法,如下所示 `SET status=$SYSTEM.SQL.Util.SetOption("DDLPKeyNotIDKey",0,.oldval)`. 默认为`1`
- 要将索引用于`SELECT DISTINCT`查询,请设置`$SYSTEM.SQL.Util.SetOption()`方法,如下所示: `SET status=$SYSTEM.SQL.Util.SetOption("FastDistinct",1,.oldval)`. 默认为`1`
## 索引使用情况分析
可以使用以下任一方法按SQL缓存查询分析索引使用情况:
- 管理门户索引分析器SQL性能工具。
- `%SYS.PTools.UtilSQLAnalysis`方法`indexUsage()`、`tableScans()`、`tempIndices()`、`joinIndices()`和`outlierIndices()`。、
## 索引分析
可以使用以下任一方法从管理门户分析SQL查询的索引使用情况:
- 选择系统资源管理器,选择工具,选择SQL性能工具,然后选择索引分析器。
- 选择系统资源管理器,选择SQL,然后从工具下拉菜单中选择索引分析器。
索引分析器提供当前命名空间的SQL语句计数显示和五个索引分析报告选项。
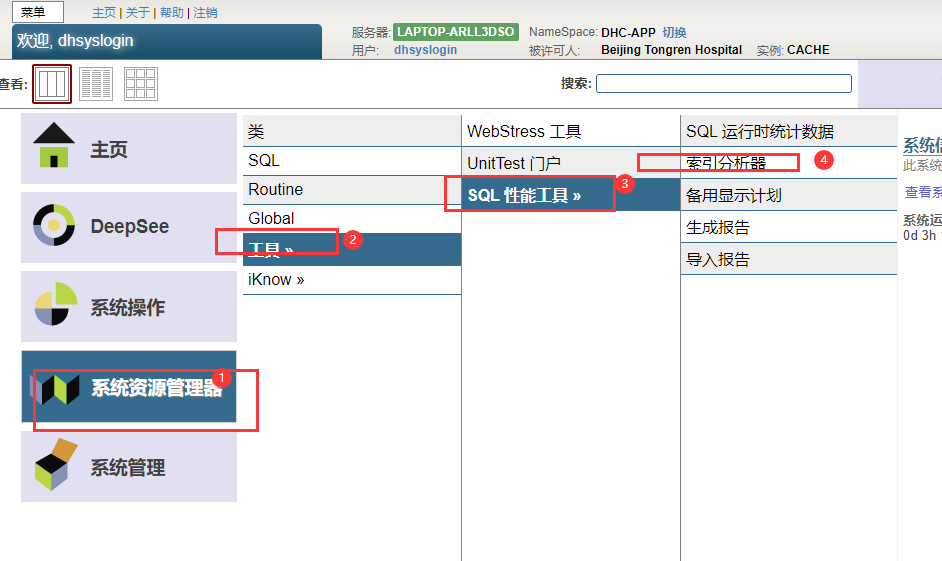
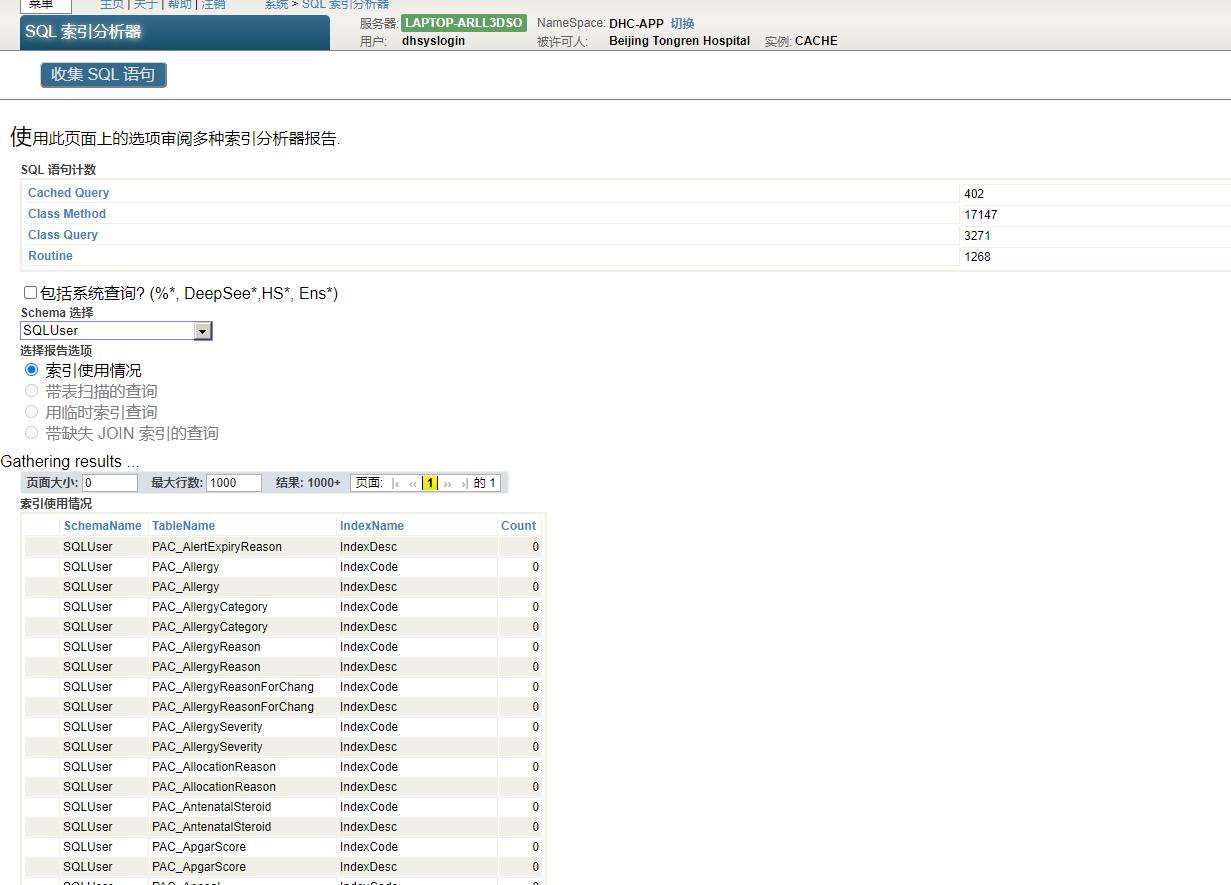
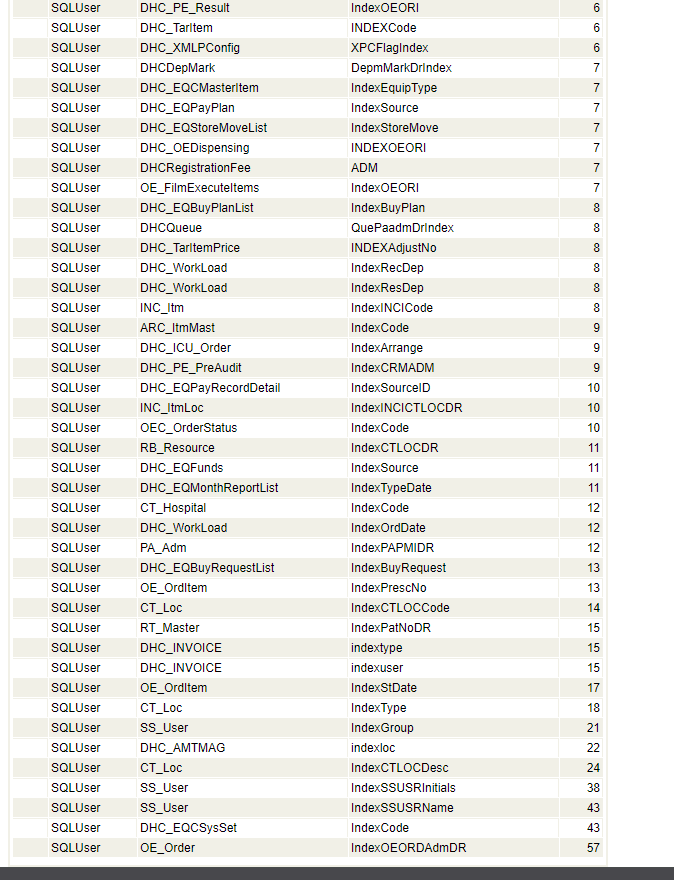
### SQL语句计数
在SQL索引分析器的顶部有一个对命名空间中的所有SQL语句进行计数的选项。按收集SQL语句按钮。SQL索引分析器显示“正在收集SQL语句...”当计票进行时,然后“完成!”当清点完毕后。SQL语句分为三类进行计数:缓存查询计数、类方法计数和类查询计数。这些计数针对整个当前命名空间,不受架构选择选项的影响。
对应的方法是`%SYS.PTools.UtilSQLAnalysis`类中的`getSQLStmts()`。
可以使用清除语句按钮删除当前命名空间中收集的所有语句。该按钮调用`clearSQLStatements()`方法。
### 报告选项
可以检查当前命名空间中选定架构的缓存查询报告,也可以(通过不选择架构)检查当前命名空间中所有缓存查询的报告。可以在此分析中跳过或包括系统类查询、`INSERT`语句和/或`IDKEY`索引。“架构选择”和“跳过选项”复选框是用户自定义的。
指数分析报告选项包括:
- 索引使用:此选项获取当前名称空间中的所有缓存查询,为每个查询生成显示计划,并记录每个查询使用每个索引的次数以及名称空间中所有查询对每个索引的总使用量。这可用于显示未使用的索引,以便可以删除或修改这些索引以使其更有用。结果集从最少使用的索引到最常使用的索引排序。
对应的方法是`%SYS.PTools.UtilSQLAnalysis`类中的`indexUsage()`。要导出此方法生成的分析数据,请使用`exportIUAnalysis()`方法。
- 使用表扫描的查询:此选项标识当前名称空间中执行表扫描的所有查询。如果可能,应避免表扫描。表扫描并不总是可以避免的,但是如果一个表有大量的表扫描,那么应该检查为该表定义的索引。通常,表扫描列表和临时索引列表会重叠;修复其中一个会删除另一个。结果集按从最大块计数到最小块计数的顺序列出表格。提供了显示计划链接以显示对帐单文本和查询计划。
对应的方法是`%SYS.PTools.UtilSQLAnalysis`类中的`tableScans()`。要导出此方法生成的分析数据,请使用`exportTSAnalysis()`方法。
- 带临时索引的查询:此选项标识当前名称空间中构建临时索引以解析SQL的所有查询。有时,使用临时索引会有所帮助并提高性能,例如,基于范围条件构建一个小索引,然后InterSystems IRIS可以使用该索引按顺序读取主映射。有时,临时索引只是不同索引的子集,可能非常有效。其他情况下,临时索引会降低性能,例如,扫描`master may`以在具有条件的特性上构建临时索引。这种情况表明缺少所需的索引;应该向与临时索引匹配的类添加索引。结果集按从最大块计数到最小块计数的顺序列出表格。提供了显示计划链接以显示对帐单文本和查询计划。
对应的方法是`%SYS.PTools.UtilSQLAnalysis`类中的`tempIndices()`。要导出此方法生成的分析数据,请使用`exportTIAnalysis()`方法。
- 缺少联接索引的查询:此选项检查当前名称空间中具有联接的所有查询,并确定是否定义了支持该联接的索引。它将可用于支持联接的索引从0(不存在索引)排序到4(索引完全支持联接)。外部联接需要一个单向索引。内联接需要双向索引。默认情况下,结果集只包含`JoinIndexFlag 21 AND %NOINDEX E.Age < 65
```
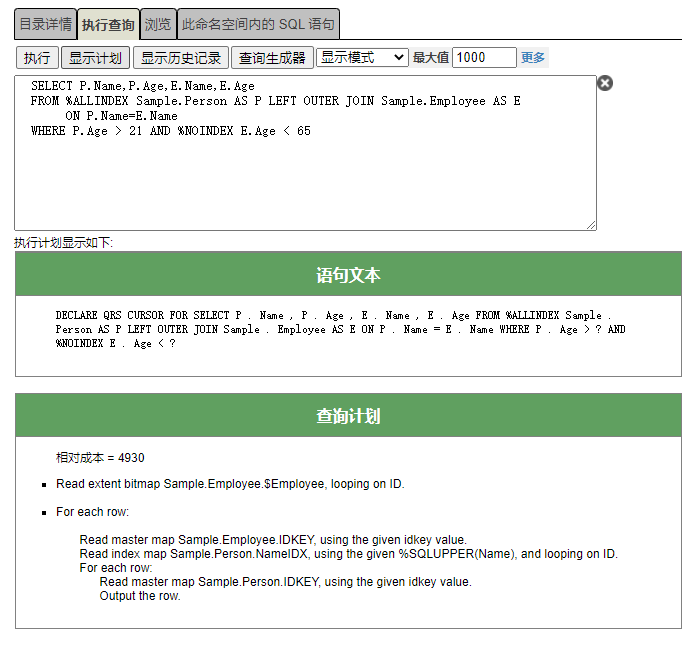
文章
Claire Zheng · 八月 17, 2021
国际互联互通的需求是在不断增长,这跟咱们国内的情况是非常类似的。这些年美国在互联互通领域的政策跟实践还是不少的,比如大家可能听到过包括“有意义的使用(Meaningful Use)”,“21世纪治愈法案(21st Century Cures Act)”,还有更多的政策上的驱动。这里先介绍一下“有意义的使用(Meaningful Use)”。
“有意义的使用(Meaningful Use)”其实源于2009年奥巴马签署的美国复兴与投资法案。“有意义的使用(Meaningful Use)”是它的俗称,标准的名称应该是“电子健康档案激励计划”。电子健康档案激励计划提出了很多使用标准,这些标准促进了认证电子病历的使用,分成了三个阶段:从2011年开始是第一阶段,第一阶段使用电子健康档案的技术来做数据的获取共享。之后在2014年做了第二个阶段,第二阶段来强调护理协调和患者信息的交流。第三个阶段是从2017年开始,它的目标是做一些更高级应用,例如电子处方临床学的支持。不过在“有意义的使用(Meaningful Use)”的过程中间,遇到了很多问题,因为它专注在电子病历的认证和使用上,很多用户抱怨已经被认证过的电子病历的能力是不足的。
所以在2018年4月份的时候, CMS将“有意义的使用(Meaningful Use)”,从“电子档案激励计划”改成了“促进互操作性计划”。在2018年的时候,“有意义的使用(Meaningful Use)”相当于是终结了。其替代者,也就是“促进互通的计划”,它现在还在执行。
上图是2020年的评分的标准,大家可以看到红框里面标出来的都是主要的评分项,基本上都集中在互联互通的能力之上的。现在美国正在执行的这些互操作性的政策,其实主要是美国的21世纪治愈法案(21st Century Cures Act),这个法案下有很多的子法律条款,提出了更具体、更可操作、更有计划性的互操作路线。
我挑几个给大家做个介绍。
首先第一个就是可信交换框架和共同协议草案,它设定了4个目标。这4个目标都是针对于提高医疗结果为目标的,它在这个目标里定义了未来的分阶段来进行设定目标,未来4年的目标就是建立所谓的“学习健康体系”。“学习健康体系”实现了临床、科研、公卫、患者个人、医保等各个利益方的互操作能力的健康信息体系。要实现这个目标,美国有一些具体的行动。行动之一就是ONC发布了一个“美国互操作核心数据集(U.S. Core Data for Interoperability)”。这个数据集跟咱们卫生数据集有点像,但是它包含的是数据类、数据元以及规范,建议了术语绑定的数据集。
这个数据集其实挺小的。这个数据集目前现在有两个版本,第一版本已经发布了。
上图包括了尚未发布的第二版的核心数据集,总共只有18个种类,这些数据集比我们的数据集要小得多。美国联邦政府现在要求所有的医疗机构都必须以HL7 FHIR R4的标准来共享交换核心数据集里面所有的患者数据。
还有另外一个法案,最新的“互操作能力和患者访问法规(The Interoperability and Patient Access final rule [CMS-9115-F])”。法规要求每个医院和保险公司都要开放针对于患者个人的数据查询的能力,需要使用FHIR的API,使用FHIR 4.0.1的标准来作为数据交换的基础,患者可以自己自由选择第三方的应用来查看、分享自己的数据。
这个法规从今年(2021年)1月1号开始实施的,目标要在三年之内能够完成。新一届的美国政府还要求所有的机构全都要全面的支持FHIR R4的API和FHIR的美国核心 Profile(总共25个Profile)。所以 FHIR在美国处于一个被快速采纳的阶段。
当然还有其他的机构,除了美国政策驱动之外,行业标准开发组织也在积极采用FHIR,例如说IHE。目前IHE总共开发了251个场景用例,现在基于FHIR已经达到了41个。IHE不仅在使用FHIR资源作为内容的格式,它也在使用FHIR的API来替代原来的互操作实现的方式。
FHIR在科研领域也大展身手。目前用于前瞻性临床研究的这些临床数据,其实很大程度上还是人工收集和分析出来的,需要手动查看临床数据图表、收集这些数据,增加了研究时间并且创造了很多出错的机会。通过FHIR标准,能够用FHIR标准化的协议和API使数据分析流程更加现代化。
“火神计划(Project Vulcan)”就是针对于科研发展的计划,这个计划的目标是将临床研究跟临床护理能够连接起来,让整个利益相关方能够聚集在一起,以弥合临床护理和临床研究之间的现有差距,战略性地连接行业合作,最大限度地利用集体资源,并提供集成的工具和资源。
这个项目在2019年9月份启动,目前有三个方向:
第一个就是建立表型数据的交换标准,其目标是使用FHIR在各种环境中使用和交换匿名化的患者病历级信息,这需要对FHIR资源进行进一步开发;
第二个是通过FHIR获取电子病历系统的数据,并直接生成科研所需数据的能力。当前正在和FDA协作处理药品数据;
第三个是采用FHIR资源描述科研活动计划。当前目标是将“临床数据交换标准联盟”的ODM-XML格式的活动计划转换为FHIR标准。
“火神加速器计划(HL7 Accelerator Program: Project Vulcan)”是一个比较典型的、能够体现出美国的标准合作应用模式的计划。
这个模式是将各个利益方都纳入进来。在支持科研和药品研发的计划中间包含了很多利益方,比如说标准开发组织HL7国际,政府代表FDA,科研机构(比如约翰逊霍普金斯医学院),当然还有行业团体(比如临床研究组织协会),很多的技术厂商(包括InterSystems公司)。通过多方参与来加速标准在科研和药品研发中间的落地。
其他国家也有很多启动了FHIR标准的互联互通的计划——例如沙特,沙特采用FHIR来进行排班计划,德国试图建立FHIR文档仓库上的所有能力,英国在使用FHIR来管理儿童的健康预警。
除此之外,有一个“全球数字健康伙伴关系”联盟,这是一个由30个国家和地区,以及世卫组织组成的合作的项目,中国香港特别行政区也在里面。它为全球参与者提供了交流数据共享、电子健康记录、电子处方、患者访问等最佳实践的机会。上图汇总了这些参与方使用互操作标准的情况。可以看到FHIR的标准的采纳度已经达到了17个,很快就会赶上最流行的V2,V2现在是19个。
以上全球对于互操作标准的采纳以及FHIR使用情况的简单介绍,如需了解更多,欢迎留言与我们交流!
文章
姚 鑫 · 七月 9, 2021
# 第三十二章 XML基础知识概念
## attribute
以下形式的名值对:
```java
ID="QD5690"
```
属性位于元素中,如下所示,一个元素可以有任意数量的属性。
```xml
Cromley,Marcia N.
```
## CDATA区域
表示不应该验证的文本,如下所示:
```xml
```
一个`CDATA`(字符数据)区段不能包含字符串`]]`>,因为这个字符串标志着区段的结束。
这也意味着`CDATA`区段不能嵌套。
注意,`CDATA`部分的内容必须符合为XML文档指定的编码,XML文档的其余部分也是如此。
## comment
不是XML文档主数据的一部分的插入说明。
注释是这样的:
```xml
```
## content model
对XML元素的可能内容的抽象描述。
可能的内容模型如下:
- 空内容模型(不允许有子元素或文本节点)
- 简单内容模型(只允许文本节点)
- 复杂内容模型(只有子元素)
- 混合内容模型(允许子元素和文本节点)
在所有情况下,元素可能有也可能没有属性;
短语内容模型不涉及元素中属性的存在或不存在。
## default namespace
给定上下文中任何非限定元素所属的名称空间。
添加的默认名称空间没有前缀。
例如:
```xml
Isaacs,Rob G.
1981-01-29
```
因为这个名称空间声明没有使用前缀,所以``、``和``元素都属于这个名称空间。
注意,下面的XML没有使用默认名称空间,它实际上等同于前面的示例:
```xml
Isaacs,Rob G.
1981-01-29
```
## DOM
文档对象模型(DOM)是表示XML和相关格式的对象模型。
## DTD(文档类型定义)
包含在XML文档或外部文件中的一系列文本指令。
它定义了可以在文档中使用的所有有效元素和属性。
dtd本身不使用XML语法。
## element
一个元素通常由两个标记(一个开始标记和一个结束标记)组成,可能包含文本和其他元素。
元素的内容是这两个标记之间的所有内容,包括文本和任何子元素。
下面是一个完整的XML元素,包含开始标记、文本内容和结束标记:
```xml
Cromley,Marcia N.
```
一个元素可以有任意数量的属性和任意数量的子元素。
空元素可以包含一个开始标记和一个结束标记,也可以只包含一个标记。
下面的例子是等价的:
```xml
```
在实践中,元素很可能引用数据记录的不同部分,例如
```xml
Barnes,Gerry
1981-04-23
```
## entity
(在XML文件中)表示一个或多个字符的文本单元。
一个实体有以下结构:
```xml
&characters;
```
## global element
全局元素和局部元素的概念适用于使用名称空间的文档。
全局元素的名称与局部元素的名称放在一个单独的符号空间中。
全局元素是其类型具有全局作用域的元素,即其类型在相应XML模式的顶层定义的元素。
作为``元素的子元素的元素声明被认为是全局声明。
任何其他元素声明都是局部元素,除非它通过ref属性引用全局声明,这实际上使它成为全局元素。
属性可以是全局的,也可以是局部的。
## local element
不是全局的XML元素。
局部元素不显式属于任何名称空间,除非元素是限定的。
参见限定元素和全局元素。
## namespace
名称空间是为标识符定义域的惟一字符串,以便基于xml的应用程序不会混淆一种类型的文档和另一种类型的文档。
它通常以URL(统一资源位置)的形式给出一个URI(统一资源指示器),它可能与实际的web地址对应,也可能不对应。
例如,`“http://www.w3.org”`是一个名称空间。
使用以下语法之一包含命名空间声明:
```xml
xmlns="your_namespace_here"
pre:xmlns="your_namespace_here"
```
在这两种情况下,名称空间只在插入名称空间声明的上下文中使用。
在后一种情况下,名称空间与给定的前缀(pre)相关联。
当且仅当元素或属性也有此前缀时,元素或属性就属于该名称空间。
例如:
```xml
Ravazzolo,Roberta X.
1943-10-24
```
命名空间声明使用`s01`前缀。
``元素也使用了这个前缀,所以这个元素属于这个名称空间。
但是,``和``元素并不显式地属于任何命名空间。
## 处理指令(PI)
一种指令(在序言中),旨在告诉应用程序如何使用XML文档或如何处理它。
一个例子;
这将样式表与文档关联起来。
```xml
```
## prolog
XML文档中根元素之前的部分。
序言以XML声明(指示使用的XML版本)开始,然后可能包括DTD声明或模式声明以及处理指令。
(从技术上讲,不需要`DTD`或模式。
此外,从技术上讲,可以将两者放在同一个文件中。)
## root, root element, document element
每个XML文档都要求在最外层只有一个元素。
这称为根元素、根元素或文档元素。
根元素在序言之后。
## qualified
如果显式地将元素或属性分配给名称空间,则该元素或属性是限定的。
考虑下面的例子,其中``的元素和属性是不限定的:
```xml
Frost,Sally O.
1957-03-11
```
在这里,名称空间声明使用`s01`前缀。
没有默认的命名空间。
``元素也使用了这个前缀,因此该元素属于这个名称空间。
``和``元素或``属性没有前缀,因此它们不显式属于任何名称空间。
相反,考虑以下情况,其中``的元素和属性是限定的:
```xml
Frost,Sally O.
1957-03-11
```
在本例中,``元素定义了一个默认名称空间,该名称空间应用于子元素和属性。
注意:XML模式属性`elementFormDefault`属性和`attributeFormDefault`属性控制在给定的模式中元素和属性是否被限定。
在InterSystems IRIS XML支持中,使用类参数来指定元素是否限定。
## schema
一种为一组XML文档指定元信息的文档,可作为DTD的替代。
与DTD一样,可以使用模式来验证特定XML文档的内容。
对于某些应用程序,XML模式提供了与`dtd`相比的几个优势,包括:
- XML模式是有效的XML文档,因此更容易开发操作模式的工具。
- XML模式可以指定一组更丰富的特性,并包含值的类型信息。
形式上,模式文档是符合W3 XML模式规范的XML文档(在`https://www.w3.org/XML/Schema`)。
它遵守XML规则,并使用一些额外的语法。
通常,文件的扩展名是`.xsd`。
## style sheet
用XSLT编写的文档,描述如何将给定的XML文档转换为另一个XML或其他“人类可读”的文档。
## text node
包含在开始元素和相应结束元素之间的一个或多个字符。
例如:
```xml
sample text node
```
## type
对数据解释的限制。
在XML模式中,每个元素和属性的定义对应于一个类型。
类型可以是简单的,也可以是复杂的。
每个属性都有一个简单类型。
简单类型还表示没有属性和子元素(只有文本节点)的元素。
复杂类型表示其他元素。
下面的模式片段展示了一些类型定义:
```xml
```
## unqualified
如果没有显式地将元素或属性分配给名称空间,则该元素或属性是非限定的。
## well-formed XML
遵循XML规则的XML文档或片段,例如有一个结束标记来匹配一个开始标记。
## XML declaration
指示给定文档中使用的XML版本(以及可选的字符集)的语句。
如果包含,它必须是文档中的第一行。
一个例子:
```xml
```
## XPath
XPath (XML路径语言)是一种基于XML的表达式语言,用于从XML文档中获取数据。
结果可以是标量,也可以是原始文档的XML子树。
## XSLT
XSLT(可扩展样式表语言转换)是一种基于XML的语言,用于描述如何将给定的XML文档转换为另一个XML或其他“人类可读的”文档。
文章
Lilian Huang · 十月 24, 2022
当我们使用IRIS时,我们通常有能力快速的部署一个现成使用的BI基础模块(数据、分析立方体和IRIS BI仪表盘)。当我们开始使用Adaptive Analytics时,我们通常希望有同样的功能。Adaptive Analytics拥有我们需要的所有工具。文档中包含了对如何使用开放的网络API的描述。用户界面和引擎之间的所有交互也都是通过内部的Web API发生的,并且可以被发射出来。
有必要将这两个过程自动化:在容器中部署Adaptive Analytics和直接部署到服务器系统。为此,最简单的方法是使用bash脚本来处理API。我们唯一需要的第三方应用程序是一个名为jq的JSON文件解析器。你可以使用以下命令来安装它:
apt update
apt install -y jq
首先,我们需要登录以获得一个API访问令牌。这个令牌也适用于引擎本身的方法。我们必须将访问令牌保存在一个变量中,因为现在我们几乎在每个请求中都需要它。对于一个标准的登录和密码admin/admin,该命令将看起来像这样:
TOKEN=$(curl -u admin:admin --location --request GET 'http ://localhost:10500/default/auth')
接下来,我们需要一个活跃的引擎来与API交互。如果没有许可证检查,引擎是不可用的,所以我们要为它提供许可证。Web API没有这个选项,所以我们必须使用引擎命令:
curl --location --request PUT 'http://127.0.0.1:10502/license' --header 'Content-Type: application/json' --data-binary "@$license"
许可证变量包含许可证文件的路径。当我们在不同的平台和不同容量的PC上做一些测试时,我们注意到一个奇特的现象。在系统启动脚本完成后,Adaptive Analytics可能会出现这样的情况:服务还没有启动,但初始化脚本已经将控制权交给了我们的脚本。为了确保引擎启动和运行,我们在一个循环中组织发送许可证,直到我们收到许可证已被接受的消息。这样做的代码看起来像这样:
RESPONSE="1"
TIME=1
echo "Waiting for engine ......."
while [ "$RESPONSE" != "200 OK" ]
do
for license in /root/license/*
do
RESPONSE =$(curl --location --request PUT 'http://127.0.0.1:10502/license' --header 'Content-Type: application/json' --data-binary "@$license" | jq -r '.status.message')
sleep 1s
done
echo "$TIME seconds waiting"
TIME=$(($TIME + 1))
done
echo "Engine started"
打印时间变量对于调试启动问题很有用。正如你所看到的,我们在一个特定的文件夹中循环浏览文件,以便不被文件名所束缚。我们将在未来再次使用这种方法。
现在我们可以与web API互动,我们可以将我们的项目上传到Adaptive Analytics。我们使用下面的代码将所有放在指定文件夹中的项目发送到引擎:
for cube in /root/cubes/*
do
sleep 1s
curl --location --request POST "http://localhost:10500/api/1.0/org/default/"Authorization: Bearer $TOKEN" --header "Content-Type: application/xml" --data-binary "@$cube"
sleep 5s
done
如果我们希望我们的项目可以被BI系统使用,我们必须发布它们。幸运的是,在API中也有这样的方法。由于项目在导入时得到一个随机的唯一ID,首先,我们应该把这些ID解析成一个变量:
PROJECTS_ID=$(curl --location --request GET "http://localhost:10500/api/1.0/org/default/projects" -- header "Authorization: Bearer $TOKEN" | jq -r '.response[].id')
然后我们需要遍历变量中的所有项目并发布它们。
for project in $PROJECTS_ID
do
curl --location --request POST "http://localhost:10500/api/1.0/org/default/project/$project/publish" --header "Authorization: Bearer $TOKEN"
sleep 1s
done
现在我们需要告诉Adaptive Analytics如何连接到IRIS,以及应该如何命名连接,以便我们的项目能够接收它们。在API中有一个方法,但是它有不同的URL地址。事实证明,这是一个有文档记录的引擎方法。所以如果我们想使用它,我们需要访问一个不同的端口。该方法接受JSON文件形式的连接信息,但不可能从Adaptive Analytics以相同的格式导出它。API根据请求返回给我们的JSON文件有一些额外/缺失的字段。以下是用于IRIS连接的JSON文件模板:
{
"platformType": "iris",
"name": "name_you_want",
"connectionId": "name_you_want",
"overrideConnectionId":true,
"extraProperties":
{
"namespace": "Your_namespase ",
"udafMode": "customer_managed"
},
"aggregateSchema": "ATSCALE",
"readOnly":false,
"isImpersonationEnabled": false,
"isCanaryAlwaysEnabled": false,
"isPartialAggHitEnabled": false,
"subgroups":
[
{
" name": "iris",
"hosts": "iris",
"port": 1972,
"connectorType": "iris",
"username": "Your_username",
"password":"Your_password",
"isKerberosClientEnabled": false ,
"queryRoles":
[
"large_user_query_role",
"small_user_query_role",
"system_query_role"
],
"extraProperties": {},
"connectionGroupsExtraProps": {}
}
]
}
值得一提的是“udafMode”参数:如果在IRIS中安装了UDAF,我们可以将其设置为“customer_managed”,如果没有安装UDAF,则设置为“none”。要了解更多关于UDAF是什么、为什么需要它以及在安装它时可能会遇到什么缺陷的信息,请查看这篇()文章。
当我们为所有连接准备好这样的文件时,我们应该从文件夹中加载它们:
for connection in /root/connections/*
do
sleep 1s
curl --location --request POST "http://localhost:10502/connection-groups/orgId/default" - -header "Authorization: Bearer $TOKEN" --header "Content-Type: application/json" --data-binary "@$connection"
sleep 5s
done
接下来,我们希望有机会将Logi Report Designer连接到Adaptive Analytics实例。这就是为什么我们需要模拟Adaptive Analytics初始化的第一个步骤之一。因此,我们为hive连接设置端口:
sleep 1s
curl --location --request POST "http://localhost:10502/organizations/orgId/default" --header "Authorization : Bearer $TOKEN" --header "Content-Type: application/json" --data-raw '{"hiveServer2Port": 11111}'
为了不超过IRIS社区版本中的连接限制,我们必须限制Adaptive Analytics的同时连接数量。根据我们的经验,为了防止在测试场景中超过限制,在5个连接中保留3个是值得的。我们使用下面的代码模拟更改设置:
for settings_list in /root/settings/*
do
curl --location --request PATCH 'http://localhost:10502/settings' --header "Authorization: Bearer $TOKEN" --header "Content-Type: application/json" --data-binary "@$settings_list"
done
在文件夹下的JSON文件中,写入如下内容:
{
"name": "bulkUpdate",
"elements": [
{
"name": "connection.pool.group.maxConnections",
"value": "3"
},
{
"name": "connection.pool.user.maxConnections",
"value": "3 "
}
]
}
根据我使用Adaptive Analytics的经验,这种限制对性能影响不大。
修改设置后,需要重新启动引擎:
curl --location --request POST 'http://localhost:10500/api/1.0/referrerOrg/default/support/service-control/engine/restart'
现在我们有了自动准备Adaptive Analytics工作所需的一切。为方便您,我们已将上述脚本发表在:
https://github.com/intersystems-community/dc-analytics/blob/master/atscale-server/entrypoint.sh
在这个存储库中,您还可以找到使用聚合更新计划的脚本。聚合是在IRIS中配置UDAF时由Adaptive Analytics生成的特殊表。这些表存储聚合查询的缓存结果,从而加快了BI系统的工作速度。Adaptive Analytics有一个更新聚合的内部逻辑,但是自己控制这个过程要方便得多。
我们曾经遇到过这样的情况:这些表存储的数据已经过时好几天了。相应地,Adaptive Analytics返回的值与真实值明显不同。为了避免这种情况,我们在更新BI系统中的数据之前设置了每日的聚合更新。
您可以在Adaptive Analytics的web界面中按每个立方体配置更新。然后,您将能够使用脚本将时间表导出和导入到另一个实例,或者使用导出的时间表文件作为备份。如果不想单独配置每个数据集,还可以在应用程序中找到一个脚本,将所有数据集设置为相同的更新计划。
最后一件便于自动化的事情是在开发阶段从Adaptive Analytics备份项目本身。为了设置这种自动化,我们编写了另一个OEX应用程序,它每天一次将所选项目保存到Git存储库中。
最后一件便于自动化的事情是在开发阶段从Adaptive Analytics备份项目本身。为了设置这种自动化,我们编写了另一个OEX应用程序OEX application,它每天一次将所选项目保存到Git存储库中。
初学者指南描述了在新报表文件中创建小部件的过程。如果使用“插入”选项卡或“组件”窗口,也可以将图表或表格插入到现有的报表中。