清除过滤器
文章
Johnny Wang · 一月 30, 2022
我的几个孩子都很喜欢手工艺品,您可能会觉得作为一个父亲我会用夸张的表情表扬他们很有创意然后还拍照片发到Pinterest(世界上最大的图片社交分享网站)上去,但是我从来都没这么做过。我肯定爱我的孩子,我也确实认为他们有创意,但老实讲如果你有一个正上小学的孩子,你肯定很清楚他们实际的水平。
首先,要去制作一个手工艺品,你得先在油管上面看五分钟的教学视频,在此之前你可能已经浏览过大量的同类视频,你也知道那些标题党起的“五分钟教你学会”的题目就是在骗你点进去,但你可能刷着刷着手机就过去了五个钟。这类视频无非是一个人拿着一个彩色的塑料瓶,或者一个有光泽的鞋盒,把所有东西切开、用胶带和胶水粘在一起,然后你就获得了一个精美无比但是根本没用的艺术品,但至少拍照片发个朋友圈看起来还蛮不错。
第二步,你小孩看完视频了,也想自己动手做。老实讲你没法拒绝这种能够锻炼他们创意的好机会,这绝对是寓教于乐的好机会,你也把那些瓶子、纸板箱和其他的垃圾重新利用起来了。这些视频往往十分重要,这说不定会影响他们以后成为成功的设计师、建筑师或者行业精英。
再然后,关键的东西来了:胶水。
我家的手工艺品购买预算(您别说真有这么个预算)几乎都花在了买胶水或者胶带上,在过去几年中,我都在用一种叫做“和纸”的带光泽的胶带、用来打胶的胶枪和会发光的百特棒,它贴在厨房或者餐桌等等地方就会很亮。还好我现在的工作让我承担得起这些花费,但同样让人沮丧的是大部分钱都被花在胶带胶水这种辅助工具上,而不是花在提升手工艺品的质量上。
系统之间的数据流成本很高
当我看到企业架构师描述他们的环境时,我经常有一种感觉,同时这种感觉也经常让我觉得挫败。那些架构师将经过验证的开源技术(比如 Postgres 和 MySQL 或他们的云版),与一种或多种花哨的专用技术(如 Clickhouse、TimescaleDB 或 CouchBase)结合到一个数据架构中。从表面上看,这完全有道理。 我们非常感谢那些经过验证的开源技术,作为一名技术专家,我经常对这些用于特殊用途的解决方案所产生的创新印象深刻。 然而,这种方法产生的复合数据架构通常不像预期的那么简单或预算友好,这与我的孩子经常要求增加手工艺品预算的原因相同:胶水不够用了。
一个好的数据管道或 ETL 软件并不便宜,构建这些数据流的数据工程师或顾问也不便宜。 更糟糕的是,就像我孩子的胶带会磨损一样,系统之间的数据流需要昂贵的维护,因为它们需要保持运行的时间也很长,这绝不是一个5分钟的手工艺品视频讲得清楚的事情。
采用统一技术的高效数据架构
像 InterSystems IRIS 这样的统一数据平台提供了事务处理和分析工作负载的数据架构,并通过许多不同的数据模型提供高效的并发访问,所有这些都采用统一技术。 通过在 InterSystems IRIS 上构建你的应用程序、数据仓库和其他解决方案,你可以节省大量粘合和手动工作,而不会牺牲处理您的用例所要求的特殊用途数据,因为没有复制、同步或推送你的数据。 更重要的是,使用这种类型的数据架构,您最终将获得在医疗保健、金融服务和许多其他行业中已经得到证明的弹性,而不是五种不同工具的最小公分母。
回到手工艺品的话题上,我希望未来每隔一周左右我问我的孩子们的问题能够变成这样:“我不是不要你的创意; 我只是要求你少用胶水。”
关于作者:Benjamin DeBoe
Benjamin 是 InterSystems 数据平台组的产品经理,负责可扩展性和分析领域。 作为 InterSystems 收购 iKnow 的一份子,他于 2010 年加入 InterSystems,并曾使用各种数据库技术,主要在数据仓库、自然语言处理和任何分析领域。
点击查看原文链接 乐高就是不用胶水的创造,中国传统的木结构(榫卯)也是不需要胶水的,最好/稳固的创造/搭建都是不用胶水的。。。 这个类比非常到位了
文章
姚 鑫 · 三月 26, 2021
# 第十三章 使用动态SQL(四)
# 返回完整结果集
使用`%Execute()`或`%ExecDirect()`执行语句将返回一个实现`%SQL.StatementResult`接口的对象。该对象可以是单一值,结果集或从`CALL`语句返回的上下文对象。
## %Display()方法
可以通过调用`%SQL.StatementResult`类的`%Display()`实例方法来显示整个结果集(结果对象的内容),如以下示例所示:
```
DO rset.%Display()
```
请注意,`%Display()`方法不会返回%Status值。
显示查询结果集时,`%Display()`通过显示行数来结束:“受影响的5行”。 (这是`%Display()`遍历结果集之后的`%ROWCOUNT`值。)请注意,`%Display()`不会在此行计数语句之后发出行返回。
`%Display()`有两个可选参数:
- 分隔符:在数据列和数据标题之间插入的字符串。它出现在结果集列之间,紧靠标题或数据值之前。默认为无定界符。如果省略,请在“列对齐”标志之前指定一个占位符逗号。
- 列对齐:整数标志,指定如何计算数据列和数据标题之间的空格。可用的选项有:
- 0:结果集标题/数据列将根据标准定界符(选项卡)对齐。这是默认值。
- 1:结果集标题/数据列将根据列标题和标准定界符(标签)的长度对齐。
- 2:结果集标题/数据列将根据列数据属性的精度/长度和标准定界符(选项卡)进行对齐。
## `%DisplayFormatted()`方法
可以通过调用`%SQL.StatementResult`类的`%DisplayFormatted()`实例方法,而不是调用`%Display()`,将结果集内容重新格式化并重定向到生成的文件。
可以通过指定字符串选项`%DisplayFormatted(“HTML”)`或相应的整数代码`%DisplayFormatted(1)`来指定结果集格式。可以使用以下格式:XML(整数代码0),HTML(整数代码1),PDF(整数代码2),TXT(整数代码99)或CSV(整数代码100)。 (请注意,CSV格式未实现为真正的逗号分隔值输出;相反,它使用制表符来分隔列。)TXT格式(整数代码99)以行数结尾(例如,“受影响的5行”) ”);其他格式不包括行数。 InterSystems IRIS生成指定类型的文件,并附加适当的文件扩展名。
可以指定或省略结果集文件名:
- 如果指定一个目标文件(例如,`%DisplayFormatted(99,"myresults")`),则在当前命名空间的子目录的mgr目录中生成具有该名称和相应后缀(文件扩展名)的文件。
例如,`C:\InterSystems\IRIS\mgr\user\myresults.txt`.
如果具有该后缀的指定文件已经存在,则InterSystems IRIS将用新数据覆盖它。
- 如果没有指定目标文件(例如,`%DisplayFormatted(99)`,则在Temp子目录的mgr目录中生成一个具有随机生成的名称和适当后缀(文件扩展名)的文件。
例如,`C:\InterSystems\IRIS\mgr\Temp\w4FR2gM7tX2Fjs.txt.`
每次运行一个查询时,都会生成一个新的目标文件。
这些例子显示了Windows文件名;
InterSystems IRIS支持其他操作系统上的等效位置。
如果无法打开指定的文件,则此操作将在30秒后超时并显示一条错误消息;否则,该操作将超时。当用户没有对指定目录(文件夹)的`WRITE`权限时,通常会发生这种情况。
**如果无法以指定的格式呈现数据,则将创建目标文件,但不会将结果集数据写入其中。而是将适当的消息写入目标文件。例如,流字段`OID`包含与XML和HTML特殊格式字符冲突的字符。可以通过在流字段上使用`XMLELEMENT`函数来解决此XML和HTML流字段问题。例如`SELECT Name,XMLELEMENT(“ Para”,Notes)`。**
可以选择提供`%DisplayFormatted()`在执行指定格式转换时将使用的转换表的名称。
如果一个结果集序列中有多个结果集,则每个结果集的内容都将写入其自己的文件中。
可选的第三个`%DisplayFormatted()`参数指定消息存储在单独的结果集中。成功完成后,将返回类似以下的消息:
```
Message
21 row(s) affected.
```
下面的Windows示例在`C:\InterSystems\IRIS\mgr\user\`中创建了两个PDF(整数代码2)结果集文件。
它为消息创建一个mess结果集,然后使用`%Display()`将消息显示到终端:
```java
/// d ##class(PHA.TEST.SQL).CreatePDF()
ClassMethod CreatePDF()
{
SET myquery=2
SET myquery(1)="SELECT Name,Age FROM Sample.Person"
SET myquery(2)="WHERE Age > ? AND Age < ? ORDER BY Age"
SET rset = ##class(%SQL.Statement).%ExecDirect(,.myquery,12,20)
IF rset.%SQLCODE'=0 {
WRITE !,"1st ExecDirect SQLCODE=",rset.%SQLCODE,!,rset.%Message QUIT
}
DO rset.%DisplayFormatted(2,"Teenagers",.mess)
DO mess.%Display()
WRITE !,"End of teen data",!!
SET rset2 = ##class(%SQL.Statement).%ExecDirect(,.myquery,19,30)
IF rset2.%SQLCODE'=0 {
WRITE !,"2nd ExecDirect SQLCODE=",rset2.%SQLCODE,!,rset2.%Message QUIT
}
DO rset2.%DisplayFormatted(2,"Twenties",.mess)
DO mess.%Display()
WRITE !,"End of twenties data"
}
```
```java
DHC-APP>d ##class(PHA.TEST.SQL).CreatePDF()
Message
9 row(s) affected.
End of teen data
Message
20 row(s) affected.
End of twenties data
```
```java
/// d ##class(PHA.TEST.SQL).CreatePDF1()
ClassMethod CreatePDF1()
{
ZNSPACE "SAMPLES"
SET myquery=2
SET myquery(1)="SELECT Name,Age FROM Sample.Person"
SET myquery(2)="WHERE Age > ? AND Age < ? ORDER BY Age"
SET rset = ##class(%SQL.Statement).%ExecDirect(,.myquery,12,20)
DO rset.%DisplayFormatted(2,"Teenagers")
WRITE !,"End of teen data",!!
SET rset2 = ##class(%SQL.Statement).%ExecDirect(,.myquery,19,30)
DO rset2.%DisplayFormatted(2,"Twenties")
WRITE !,"End of twenties data"
}
```
```java
DHC-APP>d ##class(PHA.TEST.SQL).CreatePDF1()
End of teen data
End of twenties data
```
## 对结果集进行分页
可以使用一个视图ID (`%VID`)来分页结果集。下面的例子从结果集中返回页面,每个页面包含5行:
```java
/// d ##class(PHA.TEST.SQL).Paginating()
ClassMethod Paginating()
{
SET q1="SELECT %VID AS RSRow,* FROM "
SET q2="(SELECT Name,Home_State FROM Sample.Person WHERE Home_State %STARTSWITH 'M') "
SET q3="WHERE %VID BETWEEN ? AND ?"
SET myquery = q1_q2_q3
SET tStatement = ##class(%SQL.Statement).%New()
SET qStatus=tStatement.%Prepare(myquery)
IF qStatus'=1 {
WRITE "%Prepare failed:" DO $System.Status.DisplayError(qStatus) QUIT
}
FOR i=1:5:25 {
WRITE !!,"Next Page",!
SET rset=tStatement.%Execute(i,i+4)
DO rset.%Display()
}
}
```
```java
DHC-APP>d ##class(PHA.TEST.SQL).Paginating()
Next Page
RSRow Name Home_State
1 O'Rielly,Chris H. MS
2 Orwell,John V. MT
3 Zevon,Heloisa O. MI
4 Kratzmann,Emily Z. MO
5 King,Dmitry G. MO
5 Rows(s) Affected
Next Page
RSRow Name Home_State
6 Hanson,George C. MD
7 Martinez,Emilio G. MO
8 Cheng,Charlotte Y. MI
9 Emerson,Edgar T. MO
10 Nelson,Neil E. MT
5 Rows(s) Affected
Next Page
RSRow Name Home_State
11 Larson,Nataliya Z. MD
12 Lennon,Chelsea T. MD
13 Ingleman,Kristen U. MT
14 Zucherro,Olga H. MN
15 Ng,Lola H. MD
5 Rows(s) Affected
Next Page
RSRow Name Home_State
16 Frost,Xavier D. MO
17 Adams,Diane F. MD
18 Isaacs,Chad N. MN
19 Van De Griek,Phil S. MS
20 Schaefer,Usha G. MO
5 Rows(s) Affected
Next Page
RSRow Name Home_State
21 Wells,Sophia U. MS
22 Vivaldi,Michelle N. MD
23 Anderson,Valery N. MD
24 Frost,Heloisa K. MI
25 Gallant,Thelma Q. MA
5 Rows(s) Affected
```
文章
Frank Ma · 五月 24, 2022
同事们,大家好
在这篇文章中,我将告诉你我们如何将报告生成时间从28分钟减少到1分钟。让我告诉你我们是如何实现这一目标的
我希望,如果有必要,你将能够为自己重现同样的结果。这篇文章里有一些有用的链接,所以要读到最后。
让我们开始吧。
报告
我们使用Adaptive Analytics和InterSystems Reports Server为一家公司做报告。以前,这个报告是以DeepSee的屏幕截图形式生成的。总的来说,这并不坏,但它花费了大量的时间,而且看起来不是很可读。该报告本身由12页组成,为PDF格式。
一般来说,数据不是太大,不会使报告的生成花费很多时间
源数据
然而,在撰写本文时,有一个表包含11,330,263行。不是那么关键,但它造成了延迟。即使是计算行数的查询也需要近30秒
最初,系统的交互方案是这样的:
Atscale创建了自己的数据缓存,这导致了性能的提高。
Logi使用自己的数据缓存,这稍微加快了报告的开发速度。
但总的来说,这仍然导致了报告在28分钟内形成的事实。
鉴于报告只有12页,这个速度还是很慢的。
我们甚至故意添加了新的标签,并将报告中的小部件复制到那里,以便在开发或调试时不需要生成整个报告。也许这就是在Logi上开发时的一种日常技巧,或者说是一种正常的开发方法。总的来说,我们在工作中使用了它
在报告生成时,有数百个请求从Logi到Atscale,还有一些请求从Astcale到IRIS。一些单独的查询长达4分钟。有几次,请求一般都是在超时的情况下发出的。
然后我们意识到,这种情况不能再继续下去了。于是我们把自适应分析的主要功能连接起来,方案变成了这样:
这是一个UDAF功能,换句话说,这是个用户定义的聚合函数。实际上这是些汇总表,根据要求,定期地将需要测量的聚合值存储在其中。而最有趣的是,这些汇总表是由Atscale自动创建和更新的。
为了实现聚合,我们编译了isc-aa-udaf包,该包目前在一个私人仓库中,因为根据Atscale的使用条款,它不能被免费分发。
在打开汇总表后,创建服务表花了几分钟,汇总表被计算,总的来说,数据库被加载。但随后真正的解脱开始了。系统开始像它应该的那样工作。以前需要4分钟才能形成的请求,开始在5秒内形成。缓存变得更快。
结果,原先花了28分钟才形成的报告现在开始在1分钟内形成。
值得注意的是,这样的增长更多的是稳定的、生产系统的特征,在这些系统中,立方体是相对稳定的,聚集物被越来越多的收集。当立方体结构发生变化时,在对变化后的立方体的第一次请求中,聚合被重构并重新创建。
我们做了什么
我们所做的基本如下:
安装IRIS Adaptive Analytics UDAF
在IRIS中创建名称空间,用于存储聚合数据
连接IRIS 到 Atscale
定制功能安装模式=在数据仓库中启用定制管理功能
Adaptive Analytics已经用数据创建了一个立方体
在Logi中创建报告
测试和测量
这里的细节:
InterSystems IRIS已经为UDAF的工作安装了必要的类。我们已经将它们打包在一个名为isc-aa-udaf的ZPM包中,该包存储在zpm注册表pm.intersystems.com中。这个注册表对InterSystems的官方客户是可用的。
iris 命令:
zpm “install isc-aa-udaf”
一个旨在优化资源使用的可选项:我们为IRIS添加了一个专门的命名空间,它将存储预先计算的聚合值。这个命名空间的名称将在下一步中用到。
将IRIS连接到Atscale作为立方体(Cube)的数据源。转到设置(Setting),然后是数据仓库(Data Warehouses ),最后是创建数据仓库(CREATE DATA WAREHOUSE)。 在字段号1中指定了解析后的数据所存储的命名空间
在字段号2中,我们指定了在步骤2中创建的用于存储聚合的命名空间。这个值可以与1的值相同,在这种情况下,集合体将被存储在数据的旁边。在这种情况下,数据源不能是只读的。
我们将定制功能安装模式(CUSTOM FUNCTION INSTALLATION MODE)设置为用户管理(Customer Managed),因为我们之前在第一步安装了UDAF。如果你指定无(None)模式,那么即使安装了UDAF,这些功能也不会被使用,也不会有性能上的提高。 如果一切操作正确,那么UDAF检查显示绿色。
使用创建的数据仓库创建了一个项目和一个立方体。这是一个漫长而令人兴奋的过程。我不会在这里详细谈论这个问题,已经有好几篇关于它的文章,包括我的文章《如何轻松开始在Adaptive Analytics + InterSystems Reports中工作》。
Atscale上发布的项目为Logi报告创建了数据源连接。在之前的文章中,我也介绍了如何创建报告。链接为: 《如何轻松开始在Adaptive Analytics + InterSystems Reports中工作》。
测试和测量。这里很有趣。我最初设计的报告没有启用UDAF。正因为如此,一些请求被执行了4分钟或更长时间。由于该报告由12页组成,完成报告的时间平均为28分钟。
启用UDAF后,Atscale系统在自动模式下用一段时间加载数据源。她会自己计算将在报告中使用的实际查询,并为它准备预先计算的数值。此外,Intersystems报告是基于计算出来的参数,Intersystems报告本身对这些参数进行了部分缓存,AtScale系统给出了额外的优化,它缓存了执行相同查询的结果并即时返回,而不是重新发送到数据源。
在所述的捆绑工作包中,还有一个有趣的点:报告生成的频率越高,制作报告的时间就越短。
根据所有操作和几次测量的结果,生成12页报告的时间开始是60秒,也就是1分钟。
差别是28倍。
同时,类似的报告,在结构上完全相同,但从其他数据库中获取数据,其构建速度也有类似的提高。
基于我们所看到的,我们做出了一个明确的结论,推荐在所有未来的项目中使用这个捆绑包。它可以提高开发速度,提升调试速度,并减少向这些报告的商业消费者交付报告的时间。
我希望将来我们能够从IRIS - AtScale - Logi捆绑系统中提取更多的性能,并能够与你分享我们发现的解决方案。
如果你也有这类提升工具链性能的经验和我们分享,我将非常感激。
文章
姚 鑫 · 八月 2, 2021
# 第五十三章 索引关键字 - PrimaryKey
指定此索引是否定义表的主键。
# 用法
要指定该表的主键由该索引所基于的属性构成,请使用以下语法:
```java
Index name On property_expression_list [ PrimaryKey ];
```
否则,省略此关键字或将单词`Not`放在关键字的前面。
# 详解
此关键字指定应通过SQL将此索引报告为此类(表)的主键。
`PrimaryKey`索引的行为也类似于唯一索引。
也就是说,对于在此索引中使用的属性(或属性组合),InterSystems IRIS强制唯一性。
在这个索引定义中,允许将`Unique`关键字指定为`true`,但这是多余的。
# 示例
```java
Index EmpIDX On EmployeeID [ PrimaryKey] ;
```
# 默认
如果忽略此关键字,则该表的主键不是由索引所基于的属性构成的。
# 第五十四章 索引关键字 - ShardKey
指定这个类的分片键。
# 用法
在分片类完全实现之前,InterSystems建议从`SQL`创建分片表,而不是从对象端。
但是,如果你查看一个通过创建一个分片表生成的类,你可能会看到如下代码:
```java
/// ShardKey分片表索引,由DDL CREATE table语句自动生成
Index ShardKey On DeptNum [ Abstract, CoshardWith = User.Department, ShardKey, SqlName = %ShardKey ];
```
在本例中,`DeptNum`属性是当前类的分片键。
# 第五十五章 索引关键字 - SqlName
指定索引的SQL别名。
# 用法
当通过`SQL`引用该索引时,要覆盖该索引的默认名称,使用以下语法:
```java
Index name On property_expression_list [ SqlName = sqlindexname];
```
其中`sqlindexname`是一个`SQL`标识符。
# 详解
当通过`SQL`引用该关键字时,可以为该索引定义一个替代名称。
# 默认
如果忽略此关键字,则索引的SQL名称为索引定义中给定的`indexname`。
# 第五十六章 索引关键字 - Type
指定索引的类型。
# 用法
要指定索引的类型,请使用以下语法:
```java
Index name On property_expression_list [ Type = indextype ];
```
其中`indextype`是下列类型之一:
- `bitmap` — 位图索引
- `bitslice` — 位片索引
- `index` —标准索引(默认)
- `key` — 废弃
# 详解
此关键字指定索引的类型,具体是将索引实现为位图索引还是标准(常规、非位图)索引。
位图索引不能标记为唯一`unique`。
# 默认
如果省略此关键字,则索引为标准索引。
文章
姚 鑫 · 八月 27, 2021
# 第153章 Storage关键字 - SqlRowIdProperty
指定`SQL RowId`属性。
# 大纲
```java
prop
```
# 值
该元素的值是一个`SQL`标识符。
# 描述
此元素仅由从早期InterSystems产品迁移的类使用。
# 默认值
``元素的默认值为空字符串。
# 第154章 Storage关键字 - SqlTableNumber
指定内部`SQL`表号。
# 大纲
```java
123
```
# 值
该元素的值是一个表号。
# 描述
此元素仅由从早期InterSystems产品迁移的类使用。
# 默认值
``元素的默认值为空字符串。
# 第155章 Storage关键字 - State
指定用于串行对象的数据定义。
# 大纲
```java
state
```
# 值
此元素的值是此存储定义中的数据定义的名称。
# 描述
对于串行(嵌入式)类,此关键字指示使用哪个数据定义来定义对象的序列化状态(序列化时对象属性的排列方式)。这也是默认数据定义,默认结构生成器将向其添加未存储的属性。
# 默认值
``元素的默认值为空字符串。
# 第156章 Storage关键字 - StreamLocation
指定流属性的默认存储位置。
# 大纲
```java
^Sample.PersonS
```
# 值
此元素的值是带有可选前导下标的全局名称。
# 描述
此元素允许指定用于在持久化类中存储任何流属性的默认全局设置。存储在此全局的根位置的值是一个计数器,每当存储此类的流值时,该计数器就会递增。
请注意,还可以单独指定每个流属性的存储。
# 默认值
如果未指定,则类编译器将生成``元素的值。通常,该值是`^MyApp.MyClassS`(其中`MyApp.MyClass`是类名),但是,它可能会根据许多因素而有所不同。
# 第157章 Storage关键字 - Type
用于提供持久性的存储类。
# 大纲
```java
%Storage.Persistent
```
# 值
该元素的值是一个类名。
# 描述
此元素指定为此类提供持久性的存储类。
`%Storage.Persistent`类是默认存储类,并提供默认存储结构。
`%Storage.SQL`类用于将类映射到旧数据结构。
对于串行(嵌入式)类,必须将其设置为`%Storage.Serial`(由新建类向导自动设置)。
# 默认值
``元素的默认值为`%Storage.Persistent`。
文章
姚 鑫 · 四月 29, 2021
# 第九章 冻结计划
大多数SQL语句都有一个关联的查询计划。查询计划是在准备SQL语句时创建的。默认情况下,添加索引和重新编译类等操作会清除此查询计划。下次调用查询时,将重新准备查询并创建新的查询计划。冻结计划使可以跨编译保留(冻结)现有查询计划。查询执行使用冻结的计划,而不是执行新的优化并生成新的查询计划。
对系统软件的更改也可能导致不同的查询计划。通常,这些升级会带来更好的查询性能,但软件升级可能会降低特定查询的性能。冻结计划使可以保留(冻结)查询计划,以便查询性能不会因系统软件升级而改变(降级或提高)。
# 如何使用冷冻计划
使用冻结计划有两种策略-乐观策略和悲观策略:
- 乐观:如果假设更改系统软件或类定义会提高性能,请使用此策略。运行查询并冻结计划。导出(备份)冻结的计划。解冻该计划。更改软件。重新运行查询。这会产生一个新的计划。比较这两个查询的性能。如果新计划没有提高性能,可以从备份文件中导入先前冻结的计划。
- 悲观:如果假设系统软件或类定义的更改可能不会提高特定查询的性能,请使用此策略。运行查询并冻结计划。更改软件。使用`%NOFPLAN`关键字重新运行查询(这会导致冻结的计划被忽略)。比较这两个查询的性能。如果忽略冻结的计划没有提高性能,请保持冻结该计划并从查询中删除`%NOFPLAN`。
# 软件版本升级自动冻结计划
将InterSystems IRIS®Data Platform升级到新的主要版本时,现有的查询计划将自动冻结。这可确保重大软件升级永远不会降低现有查询的性能。升级软件版本后,对性能关键型查询执行以下步骤:
1. 执行计划状态为冻结/升级的查询,并监控性能。这是在软件升级之前创建的优化查询计划。
2. 将`%NOFPLAN`关键字添加到查询中,然后执行并监视性能。这将使用软件升级提供的SQL优化器优化查询计划。它不会解冻现有的查询计划。
3. 比较性能指标。
- 如果`%NOFPLAN`性能更好,则软件升级改进了查询计划。解冻查询计划。删除`%NOFPLAN`关键字。
- 如果`%NOFPLAN`性能较差,则软件升级会使查询计划降级。保持查询计划冻结状态,将查询计划从冻结/升级升级为冻结/显式。删除`%NOFPLAN`关键字。
4. 测试性能关键型查询后,可以解冻所有剩余的冻结/升级计划。
当在比最初创建计划时使用的InterSystems软件版本更新的InterSystems软件版本下准备/编译查询时,会发生这种自动冻结。例如,考虑一条在系统软件版本xxxx.1下准备/编译的SQL语句。随后升级到版本xxxx.2,再次准备/编译SQL语句。系统将检测到这是SQL语句在新版本上的第一次准备/编译,并自动将计划状态标记为冻结/升级,并将现有计划用于新的准备/编译。这确保使用的查询计划不会比以前版本的查询计划差。
只有主要版本的InterSystems系统软件升级才会自动冻结现有查询计划。维护发布版本升级不会冻结现有查询计划。例如,主要版本升级(如从2018.1升级到2019.1)将执行此操作。维护版本升级(如2018.1.0到2018.1.1)不执行此操作。
在管理门户SQL界面中,SQL语句计划状态列将这些自动冻结的计划指示为冻结/升级,计划版本指示原始计划的系统间软件版本。
可以使用`INFORMATION.SCHEMA.STATEMENTS` `Frozen=2`属性列出当前命名空间中的所有冻结/升级计划。
可以使用以下`$SYSTEM.SQL.Statement`方法冻结单个查询计划或多个查询计划:`FreezeStatement()`用于单个计划;`FreezeRelation()`用于关系的所有计划;`FreezeSchema()`用于架构的所有计划;`FreezeAll()`用于当前命名空间中的所有计划。有相应的解冻方法。
- 冻结方法可以提升(“冻结”)标记为冻结/升级到冻结/显式的查询计划。通常,可以使用此方法有选择地将适当的冻结/升级计划升级为冻结/显式,然后解冻所有剩余的冻结/升级计划。
- 解冻方法可以解冻指定范围内的冻结/升级查询计划:命名空间、架构、关系(表)或单个查询。
# 冻结计划界面
冻结计划界面有两种,用途不同:
- Management Portal SQL语句界面,用于冻结(或解冻)单个查询的计划。
- `$SYSTEM.SQL.Statement`冻结和解冻方法,用于冻结或解冻命名空间、架构、表或单个查询的所有计划。
在Management Portal SQL界面中,选择`Execute Query`选项卡。编写查询,然后单击显示计划按钮以显示当前查询执行计划。如果计划被冻结,则查询计划部分的第一行是“冻结计划”。
在管理门户SQL界面中,选择SQL语句选项卡。这将显示SQL语句列表。此列表的计划状态列指定解冻、解冻/并行、冻结/显式或冻结/升级。(如果语句没有关联的查询计划,则计划状态列为空。)
可以使用`INFORMATION.SCHEMA.STATEMENTS` Frozen属性值列出当前命名空间中所有SQL语句的计划状态:`UNFRECTED(0)`、`Frozen/EXPLICIT(1)`、`Frozen/Upgrade(2)`或`UNFORMATED/PARALLEL(3)`。
要冻结或解冻计划,请在SQL语句文本列中选择SQL语句。这将显示“SQL语句详细信息”框。在此框的底部显示对帐单文本和查询计划。如果计划未冻结,则这些横断面的背景颜色为绿色,如果计划已冻结,则背景颜色为蓝色。在其正上方的对帐单操作下,可以根据需要选择冻结计划或解冻计划按钮。然后选择关闭。
- 冻结计划按钮:单击此按钮将冻结此语句的查询优化计划。冻结计划并编译该SQL语句时,SQL编译将使用冻结的计划信息并跳过查询优化阶段。
- 解冻计划按钮:点击该按钮将删除该语句冻结的计划,该语句的新编译将进入查询优化阶段,以确定要使用的最佳计划。
还可以使用`$SYSTEM.SQL.Statement`冻结和解冻方法冻结或解冻一个或多个计划。通过指定适当的方法,可以指定冻结或解冻操作的范围:单个计划的`FreezeStatement()`;关系的所有计划的`FreezeRelation()`;架构的所有计划的`FreezeSchema()`;当前命名空间中的所有计划的`FreezeAll()`。有相应的解冻方法。
## 权限
用户只能查看他们具有`EXECUTE`权限的那些SQL语句。这既适用于Management Portal SQL语句列表,也适用于`INFORMATION.SCHEMA.STATEMENTS`类查询。
管理门户SQL语句访问要求对`%Development`资源具有`“USE”`权限。任何可以在管理门户中看到SQL语句的用户都可以冻结或解冻该语句。
对于SQL语句的目录访问,如果您具有执行该语句的权限或对`%Development`资源具有`“Use”`权限,则可以看到这些语句。
对于`$SYSTEM.SQL.Statement`冻结或解冻方法调用,必须对`%Developer`资源拥有`“U”`权限。
## 冻结计划不同
如果计划被冻结,可以确定解冻该计划是否会导致不同的计划,而无需实际解冻该计划。此信息可以帮助您确定哪些SQL语句值得使用`%NOFPLAN`进行测试,以确定解冻计划是否会带来更好的性能。
可以使用`INFORMATION.SCHEMA.STATEMENTS` `FrozenDifferent`属性列出当前命名空间中此类型的所有冻结计划。
冻结的计划可能会因以下任一操作而与当前计划不同:
- 重新编译该表或该表引用的表
- 使用`SetMapSelecability()`激活或停用索引
- 在表上运行`TuneTable`
- 升级InterSystems软件版本
重新编译会自动清除现有的缓存查询。对于其他操作,必须手动清除现有缓存查询才能使新查询计划生效。
这些操作可能会也可能不会产生不同的查询计划。有两种方法可以确定它们是否这样做:
- 手工检查个别冻结计划
- 每天自动扫描所有冻结计划
如果计划尚未由这两个操作中的任何一个检查,或者计划未冻结,则列出新计划的SQL语句列为空。解冻选中的冻结计划会将新建计划列重置为空。
## 手动冻结计划检查
在冻结计划的SQL语句详细资料页的顶部有一个检查冻结按钮。按此按钮将显示解冻不同计划复选框。如果选中此框,则解冻计划将导致不同的查询计划。
对冻结计划执行此检查冻结测试后:
- 如果选中解冻计划不同框,则列出新计划的SQL语句列包含“1”。这表明解冻计划将导致不同的计划。
- 如果未选中解冻计划不同框,则列出新计划的SQL语句列将包含“0”。这表明解冻计划不会产生不同的计划。
- 已冻结的缓存查询的New Plan为“0”;清除缓存查询,然后解冻该计划会导致SQL语句消失。
- 已冻结的`Natura`l查询在New Plan列中为空。
执行此测试后,检查冻结按钮消失。如果要重新测试冻结的计划,请选择刷新页面按钮。这将重新显示检查冻结按钮。
## 日冻结计划自动检查
InterSystems SQL每晚`2:00`自动扫描SQL语句清单中的所有冻结语句。这次扫描最多持续一个小时。如果扫描未在一小时内完成,系统会记下它停止的位置,并从该点继续进行下一次每日扫描。可以使用管理门户监视此每日扫描或强制其立即扫描:选择系统操作、任务管理器、任务计划,然后选择扫描冻结计划任务。
此扫描检查所有冻结的计划:
- 如果冻结的计划具有与当前版本相同的InterSystems软件版本,InterSystems IRIS®Data Platform将计算两个计划的引用表和时间戳的散列,以创建可能已更改的内部计划列表。对于这个子集,它然后执行两个计划的逐个字符串比较,以确定哪些计划实际上不同。如果两个计划之间有任何不同(无论有多小),它都会在列`出New Plan`列的SQL语句中用`“1”`标记SQL语句。这表明解冻计划将导致不同的查询计划。
- 如果冻结的计划具有与当前版本相同的InterSystems IRIS版本,并且两个计划的逐字符串比较完全匹配,则它会将列出新计划的SQL语句列中的SQL语句标记为`“0”`。这表明解冻计划不会导致不同的查询计划。
- 如果冻结的计划具有与当前版本(冻结/更新)不同的InterSystems软件版本,InterSystems IRIS将确定对SQL优化器逻辑的更改是否会导致不同的查询计划。如果是,它将用`“1”`标记“SQL Statements Listing New Plan”列中的SQL语句。否则,它会用`“0”`标记SQL语句`New Plan`列。
可以通过调用`INFORMATION.SCHEMA.STATEMENTS`来检查此扫描的结果。以下示例返回所有冻结计划的SQL语句,指示冻结的计划是否与未冻结的计划不同。请注意,解冻语句可以是`Frozen=0`或`Frozen=3`:
```sql
SELECT Frozen,FrozenDifferent,Timestamp,Statement FROM INFORMATION_SCHEMA.STATEMENTS
WHERE Frozen=1 OR Frozen=2
```
## 冻结计划出错
如果语句的计划被冻结,并且计划使用的定义发生了某些更改,从而导致计划无效,则会发生错误。例如,如果从语句`PLAN`使用的类中删除了索引:
- 该声明的计划仍处于冻结状态。
- 在“SQL语句详细信息”页上,“编译设置”区域显示“计划错误”字段。例如,如果查询计划使用索引名`indxdob`,然后您修改了类定义以删除索引`indxdob`,则会显示如下消息: `Map 'indxdob' not defined in table 'Sample.Mytable', but it was specified in the frozen plan for the query`.
- 在SQL语句详细资料页上,查询计划区域显示由于冻结计划中的错误而无法确定计划。
如果在冻结计划处于错误状态时重新执行查询,则InterSystems IRIS不使用冻结计划。相反,系统会创建一个新的查询计划,该计划将在给定当前定义的情况下工作,并执行查询。此查询计划被分配了与前一个查询计划相同的缓存查询类名。
在计划解冻或修改定义以使计划返回有效状态之前,出错的计划将一直处于错误状态。
如果修改定义以使计划返回有效状态,请转到SQL语句详细资料页,然后按清除错误按钮以确定是否已更正错误。如果更正,计划错误字段将消失;否则将重新显示计划错误消息。如果已更正定义,则不必显式清除计划错误,SQL即可开始使用冻结计划。如果已更正定义,则清除错误按钮会使SQL语句详细资料页的冻结查询计划区域再次显示执行计划。
计划错误可能是 `“soft error.”`。当计划使用索引,但查询优化器当前无法选择该索引时,可能会出现这种情况,因为`SetMapSelecability()`已将其可选择性设置为`0`。这样做可能是为了[重建]索引。当InterSystems IRIS遇到具有冻结计划的语句的软错误时,查询处理器会尝试自动清除错误并使用冻结计划。如果该计划仍然出错,则该计划将再次标记为出错,并且查询执行将尽可能使用最佳计划。
# %NOFPLAN关键字
可以使用`%NOFPLAN`关键字覆盖冻结的计划。包含`%NOFPLAN`关键字的SQL语句将生成新的查询计划。冻结的计划将保留,但不会使用。这允许测试生成的计划行为,而不会丢失冻结的计划。
```sql
DECLARE CURSOR FOR SELECT %NOFPLAN ...
SELECT %NOFPLAN ....
INSERT [OR UPDATE] %NOFPLAN ...
DELETE %NOFPLAN ...
UPDATE %NOFPLAN
```
在`SELECT`语句中,`%NOFPLAN`关键字只能在查询中的第一个`SELECT`之后立即使用:它只能与`UNION`查询的第一个分支一起使用,不能在子查询中使用。`%NOFPLAN`关键字必须紧跟在`SELECT`关键字之后,位于`DISTINCT`或`TOP`等其他关键字之前。
# 导出和导入冻结计划
可以将SQL语句作为`XML`格式的文本文件导出或导入。这使可以将冻结的计划从一个位置移动到另一个位置。SQL语句导出和导入包括关联查询计划的编码版本和指示该计划是否冻结的标志。
文章
姚 鑫 · 三月 23, 2021
# 第十三章 使用动态SQL(一)
# 动态SQL简介
动态SQL是指在运行时准备并执行的SQL语句。在动态SQL中,准备和执行SQL命令是单独的操作。通过动态SQL,可以以类似于ODBC或JDBC应用程序的方式在InterSystems IRIS中进行编程(除了要在与数据库引擎相同的进程上下文中执行SQL语句)。动态SQL是从ObjectScript程序调用的。
动态SQL查询是在程序执行时准备的,而不是在编译时准备的。这意味着编译器无法在编译时检查错误,并且不能在Dynamic SQL中使用预处理器宏。这也意味着执行程序可以响应用户或其他输入而创建专门的Dynamic SQL查询。
动态SQL可用于执行SQL查询。它也可以用于发出其他SQL语句。本章中的示例执行SELECT查询。
动态SQL用于执行InterSystems IRIS SQL Shell,InterSystems IRIS管理门户网站“执行查询”界面,SQL代码导入方法以及“数据导入和导出实用程序”。
在Dynamic SQL(和使用它的应用程序)中,行的最大大小为`3,641,144`个字符。
## 动态SQL与嵌入式SQL
动态SQL与嵌入式SQL在以下方面有所不同:
- **动态SQL查询的初始执行效率比嵌入式SQL稍低,因为它不会生成查询的内联代码。但是,动态SQL和嵌入式SQL的重新执行比第一次执行查询要快得多,因为它们都支持缓存的查询。**
- 动态SQL可以通过两种方式接受输入到查询的文字值:使用`“?”`指定的输入参数。字符和输入主机变量(例如`:var`)。嵌入式SQL使用输入和输出主机变量(例如`:var`)。
- 使用结果集对象(即`Data`属性)的API检索动态SQL输出值。嵌入式SQL将主机变量(例如`:var`)与`SELECT`语句的`INTO`子句一起使用以输出值。
- **动态SQL设置`%SQLCODE`,`%Message`,`%ROWCOUNT`和`%ROWID`对象属性。嵌入式SQL设置相应的`SQLCODE`,`%msg`,`%ROWCOUNT`和`%ROWID`局部变量。动态SQL不会为`SELECT`查询设置`%ROWID`;嵌入式SQL为基于游标的`SELECT`查询设置`%ROWID`。**
- 动态SQL提供了一种简单的方法来查找查询元数据(例如列的数量和名称)。
- 动态SQL执行SQL特权检查;必须具有适当的权限才能访问或修改表,字段等。Embedded SQL不执行SQL特权检查。
- 动态SQL无法访问私有类方法。要访问现有的类方法,必须将该方法公开。这是一般的SQL限制。但是,嵌入式SQL克服了此限制,因为嵌入式SQL操作本身是同一类的方法。
动态SQL和嵌入式SQL使用相同的数据表示形式(默认情况下为逻辑模式,但是可以更改)和NULL处理。
# `%SQL.Statement`类
动态SQL的首选接口是`%SQL.Statement`类。要准备和执行动态SQL语句,请使用`%SQL.Statement`的实例。执行动态SQL语句的结果是一个SQL语句结果对象,该对象是`%SQL.StatementResult`类的实例。 SQL语句结果对象可以是单一值,结果集或上下文对象。在所有情况下,结果对象都支持标准接口。每个结果对象都会初始化`%SQLCODE`,`%Message`和其他结果对象属性;这些属性设置的值取决于发出的SQL语句。对于成功执行的`SELECT`语句,对象是结果集(特别是`%SQL.StatementResult`的实例),并且支持预期的结果集功能。
以下ObjectScript代码准备并执行动态SQL查询:
```java
/// d ##class(PHA.TEST.SQL).DynamicSQL()
ClassMethod DynamicSQL()
{
/* 简单的%SQL.Statement示例 */
SET myquery = "SELECT TOP 5 Name,DOB FROM Sample.Person"
SET tStatement = ##class(%SQL.Statement).%New()
SET qStatus = tStatement.%Prepare(myquery)
IF qStatus'=1 {
WRITE "%Prepare 失败"
DO $System.Status.DisplayError(qStatus)
QUIT
}
SET rset = tStatement.%Execute()
DO rset.%Display()
WRITE !,"End of data"
}
```
```java
DHC-APP>d ##class(PHA.TEST.SQL).DynamicSQL()
Name DOB
yaoxin 54536
xiaoli
姚鑫 63189
姚鑫 63189
姚鑫 50066
5 Rows(s) Affected
End of data
```
本章中的示例使用与`%SQL.Statement`和`%SQL.StatementResult`类关联的方法。
# 创建一个对象实例
可以使用`%New()`类方法创建`%SQL.Statement`类的实例:
` SET tStatement = ##class(%SQL.Statement).%New()`
此时,结果集对象已准备好准备SQL语句。创建`%SQL.Statement`类的实例后,可以使用该实例发出多个动态SQL查询和/或`INSERT`,`UPDATE`或`DELETE`操作。
`%New()`按以下顺序接受三个可选的逗号分隔参数:
1. `%SelectMode`,它指定用于数据输入和数据显示的模式。
2. `%SchemaPath`,它指定用于为无限定的表名提供架构名称的搜索路径。
3. `%Dialect`,它指定Transact-SQL(TSQL)Sybase或MSSQL方言。默认值为IRIS(InterSystems SQL)。
还有一个`%ObjectSelectMode`属性,不能将其设置为`%New()`参数。 `%ObjectSelectMode`指定字段到其相关对象属性的数据类型绑定。
在下面的ObjectScript示例中,`%SelectMode`为2(显示模式),`%SchemaPath`将`“Sample”`指定为默认架构:
```java
SET tStatement = ##class(%SQL.Statement).%New(2,"Sample")
```
在下面的ObjectScript示例中,未指定`%SelectMode`(请注意占位符逗号),并且`%SchemaPath`指定包含三个架构名称的架构搜索路径:
```java
SET tStatement = ##class(%SQL.Statement).%New(,"MyTests,Sample,Cinema")
```
## %SelectMode属性
`%SelectMode`属性指定以下模式之一:`0 =Logical逻辑(默认)`,`1 = ODBC`,`2 =Display.显示`。这些模式指定如何输入和显示数据值。模式最常用于日期和时间值以及显示`%List`数据(包含编码列表的字符串)。数据以逻辑模式存储。
`SELECT`查询使用`%SelectMode`值确定用于显示数据的格式。
`INSERT`或`UPDATE`操作使用`%SelectMode`值来确定允许的数据输入格式。
`%SelectMode`用于数据显示。 SQL语句在内部以逻辑模式运行。例如,无论`%SelectMode`设置如何,`ORDER BY`子句均根据记录的逻辑值对记录进行排序。 SQL函数使用逻辑值,而不管`%SelectMode`设置如何。映射为SQLPROC的方法也可以在逻辑模式下运行。在SQL语句中称为函数的SQL例程需要以逻辑格式返回函数值。
- 对于`SELECT`查询,`%SelectMode`指定用于显示数据的格式。将`%SelectMode`设置为ODBC或Display也会影响用于指定比较谓词值的数据格式。某些谓词值必须以`%SelectMode`格式指定,而其他谓词值必须以逻辑格式指定,而与`%SelectMode`无关。
- `%SelectMode = 1(ODBC)`中的时间数据类型数据可以显示小数秒,这与实际的ODBC时间不同。 InterSystems IRIS Time数据类型支持小数秒。相应的ODBC TIME数据类型(TIME_STRUCT标准标头定义)不支持小数秒。 ODBC TIME数据类型将提供的时间值截断为整秒。 ADO DotNet和JDBC没有此限制。
- `%SelectMode = 0(逻辑)`中的`%List`数据类型数据不会显示内部存储值,因为`%List`数据是使用非打印字符编码的。而是,Dynamic SQL将`%List`数据值显示为`$LISTBUILD`语句,例如:`$lb("White","Green")`。 `%SelectMode = 1(ODBC)`中的`%List`数据类型数据显示用逗号分隔的列表元素;此元素分隔符指定为`CollectionOdbcDelimiter`参数。 `%SelectMode = 2`中的`%List`数据类型数据(显示)显示由`$ CHAR(10,13)`分隔的列表元素(换行,回车);此元素分隔符指定为CollectionDisplayDelimiter参数。
- 对于`INSERT`或`UPDATE`操作,`%SelectMode`指定将转换为逻辑存储格式的输入数据的格式。为了进行此数据转换,必须使用RUNTIME(默认)的选择模式编译SQL代码,以便在执行`INSERT`或`UPDATE`时使用`Display`或`ODBC %SelectMode`。有关日期和时间的允许输入值,请参考日期和时间数据类型。
可以将`%SelectMode`指定为`%New()`类方法的第一个参数,或直接对其进行设置,如以下两个示例所示:
```java
SET tStatement = ##class(%SQL.Statement).%New(2)
```
```java
SET tStatement = ##class(%SQL.Statement).%New()
SET tStatement.%SelectMode=2
```
下面的示例返回`%SelectMode`的当前值:
```java
/// d ##class(PHA.TEST.SQL).DynamicSQL1()
ClassMethod DynamicSQL1()
{
SET tStatement = ##class(%SQL.Statement).%New()
WRITE !,"默认选择模式=",tStatement.%SelectMode
SET tStatement.%SelectMode=2
WRITE !,"设置选择模式=",tStatement.%SelectMode
}
```
```java
DHC-APP>d ##class(PHA.TEST.SQL).DynamicSQL1()
默认选择模式=0
设置选择模式=2
```
可以使用`$SYSTEM.SQL.Util.GetOption("SelectMode")` 方法为当前进程确定`SelectMode`默认设置。当`n`可以为`0 =逻辑`,`1 = ODBC`或`2 = Display`时,可以使用`$SYSTEM.SQL.Util.SetOption("SelectMode",n)` 方法来更改当前进程的`SelectMode`默认设置。设置`%SelectMode`会覆盖当前对象实例的默认设置。它不会更改`SelectMode`进程的默认值。
## %SchemaPath属性
`%SchemaPath`属性指定用于为非限定的表名,视图名或存储过程名提供架构名的搜索路径。模式搜索路径用于数据管理操作,例如`SELECT`,`CALL`,`INSERT`和`TRUNCATE TABLE`;数据定义操作(例如`DROP TABLE`)将忽略它。
搜索路径被指定为带引号的字符串,其中包含模式名称或逗号分隔的一系列模式名称。 InterSystems IRIS以从左到右的顺序搜索列出的模式。 InterSystems IRIS会搜索每个指定的架构,直到找到第一个匹配的表,视图或存储过程名称。因为模式是按指定顺序搜索的,所以不会检测到歧义的表名。仅搜索当前名称空间中的架构名称。
模式搜索路径可以包含文字模式名称以及`CURRENT_PATH`,`CURRENT_SCHEMA`和`DEFAULT_SCHEMA`关键字。
- `CURRENT_PATH`指定当前模式搜索路径,如先前的`%SchemaPath`属性中所定义。这通常用于将架构添加到现有架构搜索路径的开头或结尾。
- 如果`%SQL.Statement`调用是从类方法中进行的,则`CURRENT_SCHEMA`指定当前模式容器的类名称。如果在类方法中定义了`#SQLCompile Path`宏指令,则`CURRENT_SCHEMA`是映射到当前类包的架构。否则,`CURRENT_SCHEMA`与`DEFAULT_SCHEMA`相同。
- `DEFAULT_SCHEMA`指定系统范围的默认架构。使用此关键字,可以在搜索其他列出的架构之前,在架构搜索路径中将系统范围的默认架构作为一个项目进行搜索。如果已经搜索了路径中指定的所有模式而没有匹配项,则在搜索模式搜索路径后始终会搜索系统范围内的默认模式。
`%SchemaPath`是InterSystems IRIS在架构中搜索匹配表名的第一位。如果未指定`%SchemaPath`,或者未列出包含匹配表名的架构,则InterSystems IRIS将使用系统范围的默认架构。
可以通过指定`%SchemaPath`属性或指定`%New()`类方法的第二个参数来指定模式搜索路径,如以下两个示例所示:
```java
SET path="MyTests,Sample,Cinema"
SET tStatement = ##class(%SQL.Statement).%New(,path)
```
```java
SET tStatement = ##class(%SQL.Statement).%New()
SET tStatement.%SchemaPath="MyTests,Sample,Cinema"
```
可以在使用它的`%Prepare()`方法之前的任何位置设置`%SchemaPath`。
下面的示例返回`%SchemaPath`的当前值:
```java
/// d ##class(PHA.TEST.SQL).DynamicSQL2()
ClassMethod DynamicSQL2()
{
SET tStatement = ##class(%SQL.Statement).%New()
WRITE !,"默认 path=",tStatement.%SchemaPath
SET tStatement.%SchemaPath="MyTests,Sample,Cinema"
WRITE !,"设置 path=",tStatement.%SchemaPath
}
```
```java
DHC-APP>d ##class(PHA.TEST.SQL).DynamicSQL2()
默认 path=
设置 path=MyTests,Sample,Cinema
```
可以使用`%ClassPath()`方法将`%SchemaPath`设置为为指定的类名定义的搜索路径:
```java
/// d ##class(PHA.TEST.SQL).DynamicSQL3()
ClassMethod DynamicSQL3()
{
SET tStatement = ##class(%SQL.Statement).%New()
SET tStatement.%SchemaPath=tStatement.%ClassPath("Sample.Person")
WRITE tStatement.%SchemaPath
}
```
```java
DHC-APP>d ##class(PHA.TEST.SQL).DynamicSQL3()
Sample
```
## %Dialect属性
`%Dialect`属性指定SQL语句方言。可以指定Sybase,MSSQL或IRIS(InterSystems SQL)。 Sybase或MSSQL设置导致使用指定的Transact-SQL方言处理SQL语句。
Sybase和MSSQL方言在这些方言中支持SQL语句的有限子集。它们支持`SELECT`,`INSERT`,`UPDATE`,`DELETE`和`EXECUTE`语句。他们支持`CREATE TABLE`语句用于永久表,但不支持临时表。支持创建视图。支持`CREATE TRIGGER`和`DROP TRIGGER`。但是,如果`CREATE TRIGGER`语句部分成功,但是在类编译时失败,则此实现不支持事务回滚。支持`CREATE PROCEDURE`和`CREATE FUNCTION`。
Sybase和MSSQL方言支持IF控制流语句。 IRIS(InterSystems SQL)方言不支持此命令。
默认值为InterSystems SQL,由空字符串(`“”`)表示,或指定为“ IRIS”
可以将`%Dialect`指定为`%New()`类方法的第三个参数,或者将其直接设置为属性,或者使用方法进行设置,如以下三个示例所示:
在`%New()`类方法中设置`%Dialect`:
```java
/// d ##class(PHA.TEST.SQL).DynamicSQL4()
ClassMethod DynamicSQL4()
{
SET tStatement = ##class(%SQL.Statement).%New(,,"Sybase")
WRITE "语言模式设置为=",tStatement.%Dialect
}
```
```java
DHC-APP>d ##class(PHA.TEST.SQL).DynamicSQL4()
语言模式设置为=Sybase
```
直接设置`%Dialect`属性:
```java
/// d ##class(PHA.TEST.SQL).DynamicSQL5()
ClassMethod DynamicSQL5()
{
SET tStatement = ##class(%SQL.Statement).%New()
SET defaultdialect=tStatement.%Dialect
WRITE "默认语言模式=",defaultdialect,!
SET tStatement.%Dialect="Sybase"
WRITE "语言模式设置为=",tStatement.%Dialect,!
SET tStatement.%Dialect="IRIS"
WRITE "语言模式重置为默认=",tStatement.%Dialect,!
}
```
```java
DHC-APP>d ##class(PHA.TEST.SQL).DynamicSQL5()
默认语言模式=
语言模式设置为=Sybase
语言模式重置为默认=iris
```
使用`%DialectSet()`实例方法设置`%Dialect`属性,该方法将返回错误状态:
```java
/// d ##class(PHA.TEST.SQL).DynamicSQL6()
ClassMethod DynamicSQL6()
{
SET tStatement = ##class(%SQL.Statement).%New()
SET tStatus = tStatement.%DialectSet("Sybase")
IF tStatus'=1 {
WRITE "%DialectSet 失败:"
DO $System.Status.DisplayError(tStatus) QUIT
}
WRITE "语言模式设置为=",tStatement.%Dialect
}
```
```java
DHC-APP>d ##class(PHA.TEST.SQL).DynamicSQL6()
语言模式设置为=Sybase
```
`%DialectSet()`方法返回`%Status`值:成功返回状态1。失败返回以0开头的对象表达式,后跟编码错误信息。因此,无法执行`tStatus = 0`测试是否失败;您可以执行`$$ISOK(tStatus)= 0`宏测试以检查失败
## %ObjectSelectMode属性
`%ObjectSelectMode`属性是一个布尔值。如果`%ObjectSelectMode = 0(默认)`,则`SELECT`列表中的所有列都将绑定到结果集中具有文字类型的属性。如果`%ObjectSelectMode = 1`,则`SELECT`列表中的列将绑定到具有关联属性定义中定义的类型的属性。
`%ObjectSelectMode`允许指定如何在从`SELECT`语句生成的结果集类中定义类型类为swizzleable类的列。如果`%ObjectSelectMode = 0`,则将在结果集中将与swizzleable列相对应的属性定义为与SQL表的RowID类型相对应的简单文字类型。如果`%ObjectSelectMode = 1`,则将使用列的声明类型定义属性。这意味着访问结果集属性将触发 swizzling。
无法将`%ObjectSelectMode`设置为`%New()`的参数。
下面的示例返回`%ObjectSelectMode`默认值,设置`%ObjectSelectMode`,然后返回新的`%ObjectSelectMode`值:
```java
/// d ##class(PHA.TEST.SQL).DynamicSQL7()
ClassMethod DynamicSQL7()
{
SET myquery = "SELECT TOP 5 %ID AS MyID,Name,Age FROM Sample.Person"
SET tStatement = ##class(%SQL.Statement).%New()
WRITE !,"默认 ObjectSelectMode=",tStatement.%ObjectSelectMode
SET tStatement.%ObjectSelectMode=1
WRITE !,"语言 ObjectSelectMode=",tStatement.%ObjectSelectMode
}
```
```java
DHC-APP>d ##class(PHA.TEST.SQL).DynamicSQL7()
默认 ObjectSelectMode=0
语言 ObjectSelectMode=1
```
当使用字段名称属性从结果集中返回值时,主要使用`%ObjectSelectMode = 1`。本章“从结果集中返回特定值”部分的字段名属性中的示例对此进行了进一步说明。
当`SELECT`列表中的字段链接到集合属性时,可以使用`%ObjectSelectMode = 1`。 `%ObjectSelectMode`将使集合swizzle。如果`%SelectMode = 1或2`,则系统在转换前将收集序列值转换为逻辑模式形式。生成的oref支持完整的收集接口。
文章
Claire Zheng · 五月 21, 2023
视频文字版。点击查看视频。
CHIMA主任委员:王才有
老卢,你好。疫情三年我们没见,中国发生了很大的变化,你回来会感觉到。特别是在信息化和数字化方面,确实中国的这三年可以说是政策和制度设计上都有了很大的一些调整和进步,特别是去年政府发布了关于数据基本制度的设计方案,我们管它叫“数据二十条”。
这个制度呢,实际上是避开了数据的所有权的问题,如果说我们在数据的所有权和使用权上长期去争论的话,它的价值就很难发挥。所以说中国这次首次提出了一个“三权”,数据“三权分立”的新的战略设计,不再强调数据是谁的,我们强调数据的控制权——就是数据现在在谁手里;数据的开发权——他这些数据可以用来干什么;数据的受益权——他把这数据再分享给别人,再创造二次价值,或者再创造三次价值,这样数据的资源就得到充分的利用。
所以说一方面要对这种数据基本制度的建立,为今后数据资源市场化是开了一道新的大门。中国是一个数据资源的大国,那这些资源怎么利用好,怎么用在生产,怎么用在服务,怎么用在改善我们医院的管理,给我们患者服务,给这个居民服务,这项我想是一个很大的一个制度上的创新。
当然这个制度的创新也给我们提出了很多新的要求:数据安全的要求,个人信息保护的要求,数据标准的要求……
我国基础制度的形成,将促进数据合规高效流通使用。今后,医疗健康数据将在更大空间交换和共享,这就需要新一代标准体系了,例如FHIR。
我想这方面你也许知道了,在这方面有什么体会呢?咱们可以做做交流。
InterSystems 亚太区总经理卢侠亮(Luciano Brustia):
好的,谢谢。
您所说的这些让我感到很兴奋,谢谢您的发言。因为我同意,当我们在谈论标准、谈论专业术语的时候,每个人都会立即想到FHIR标准。在这方面,InterSystems在全球绝对是领先的。
你可能知道,在过去的这些年里,我们做了许多工作,我们的IRIS数据平台,在全球范围内得到了大范围部署,同时,我们在中国持续地进行本地化创新,构建了中国版的互联互通平台(内嵌FHIR资源仓库),我们称之为“互联互通套件”,用来实现基于FHIR标准的互联互通 。
当谈到专业术语(统一语义)是我们的目标时,FHIR绝对可以作为一个最佳标准选择,我们已经帮助150多家医院通过了国内互联互通标准化成熟度等级评测,其中有近30家医院通过了最高级别的认证(五级乙等),值此(“数据二十条”颁布的)重要时机,我们肯定还会继续加大投入,在这些方面(打通互联互通和FHIR两大生态)开展更多活动。我们现在已经发布了互联互通套件的第三版,目前正在计划进行更多升级。
CHIMA主任委员王才有:
卢总,您刚才讲的系联在中国的一些做法,我很认可。因为系联公司(InterSystems)在中国已经多年,特别是在推进互联互通,推进信息标准的应用方面发挥了很重要的作用。
对这个FHIR来讲,它是针对的移动互联网出现之后,这信息在更大的范围里面交换共享和随时的调用的时候,随机调用的时候,它只有利用这个标准,它才可能实现信息的动态的、语义互操作的这种交换。
而HL7 2.X它面对的是语法层面的交换,语义层面的这个能力呢,它是比较弱的。所以说如果要做得更好,信息在互联网和移动互联网时代,特别是数字,我们说的数字时代,你在更大的空间里面交换和共享信息的时候,同时保持信息理解上的一致性,那我们只有选用FHIR才可能实现得会更好一些。这一方面是技术上的进步,一方面是应用上的需求。
那当然这种技术上的提供和应用上的需求是必须要依赖于工具,依赖于产品。那系联公司这方面的平台支撑和工具支撑上,我想对于促进FHIR在中国的应用还是发挥了很好的作用的。
系联过去确实做得不错,但是我们看到了FHIR的应用还不是特别地普及,原因是多方面的,可能也有一些新的制约和一些新的挑战。我想系联公司在这方面也会进一步地做出努力,推进FHIR在中国的应用。
这方面,卢总下一步你有什么打算呢?
InterSystems 亚太区总经理卢侠亮(Luciano Brustia):
是的,当然有。我们已经将FHIR作为我们所有开发部署的核心,包括我们所有医疗平台。首先,我很高兴在今年CHIMA大会上(HL7中国)将发布《FHIR白皮书》 ,明确界定HL7、CDA和FHIR之间的区别。因为医院采用CDA标准,他们拥有一个庞大的临床数据中心,但我们还需要一个额外的步骤来实现FHIR。
为了让大家更容易理解,我经常举这样一个例子:我总是把FHIR的重要性比作普通话的重要性,因为普通话可以作为人们互相交流的一种共同语言。我也总是喜欢这样说,我看到了一张图片,上面是一匹带着黑色条纹的白马,大家都明白它是什么。你也可以说,你看到了一张图片,上面是一匹带着白色条纹的黑马,大家也都明白它是什么。FHIR不会告诉你这是一匹白马还是一匹黑马,而是会说这是一匹“斑马”——只用一个词,就确切指出了图片内容的唯一标识,以及我们在谈论的是什么。这是深层次的主要区别。
我很高兴《FHIR白皮书》即将在CHIMA上发布,这将有助于理解这一点。InterSystems作为FHIR标准在全球范围的推广者,已经在美国和亚太地区拥有众多成功案例,并且帮助越来越多的国家部署并遵循这种标准,为当地居民提供更多价值,我们很高兴能在中国做同样的事情。
CHIMA主任委员王才有:
刚才没想到您作为一个总裁,对技术细节了解得这么清楚。确实我们要把技术细节搞清楚,把关键的概念搞清楚,这样才能使我们的行动走到正确的轨道上来。对FHIR,它到底是适用于什么场景,什么场景下应该用哪些标准解决什么问题,这我觉得是一个非常重要的一个考虑。任何一个企业、任何一个用户都应该考虑你选用标准的适宜性,我们不能说哪个标准好,哪个标准不好。所以说我们CHIMA,刚才老卢也提到了,我们要在下一次CHIMA大会上发一个白皮书,而这个白皮书实际上就是我们对这些标准的基本概念,它的用途,在什么场景下应用,我们要做一个比较清晰的这种引导,让大家在选择标准和使用标准上,使标准能真正解决自己互联互通上的问题。
那我们CHIMA跟系联一样,也是在推进标准的应用和标准的采纳,实现我们互联互通的目标。前年,我们也组织了专家,在中国的医院编了一个中国医院里边的关于FHIR的应用的一些案例的分享,我们是请的北京友谊医院的专家来共同承担这个课题,也非常感谢系联的专家对这个项目给予了很好的支持。
卢总,我们系联今后在这个信息互联互通和促进,我们叫数字时代的健康场景下,我们公司还有什么好的想法和建议?
InterSystems 亚太区总经理卢侠亮(Luciano Brustia):谢谢。我认为此时来到中国,这是一个非常令人兴奋的时机,因为我们能够带来许多在世界各地获得的经验。我们在日本群马大学建立了日本首个FHIR数据库;我们正在与印度尼西亚的一家超大型医疗集团合作,该医疗集团拥有40多家医院,(借助InterSystems技术)采用FHIR标准,将他们的数据汇聚起来,并在此基础上进行分析。毫无疑问,InterSystems一直都在采用、推广FHIR标准,在FHIR成为互操作性标准之前就是如此,而且我们将带来更多的创新,以确保中国始终与国际最前沿的标准接轨,因为最终真正重要的是,我们这样做是为了确保所有中国居民的利益,而且我认为这对像你我这样从事IT行业,特别是从事医疗IT领域的从业者来说,才是最重要的。我们不仅仅是在做生意,更多的是在提供价值。在人口不断增长的情况下助力全民健康水平提升,中国居民的寿命越来越长,这是一件非常好的事情。但也带来了很多问题,特别是人口老龄化的问题,建设高质量的数据库,采用先进的标准,可以有效地预防更多的慢性疾病发生,我认为这是非常有价值的,也让我们所做的事情更有意义,以上是我的看法,非常感谢。CHIMA主任委员王才有:非常高兴看您为中国医疗信息化做出的贡献。系联公司把国际上的一些标准引用到中国,我们也看到中国自身医疗信息化发展也是非常地快,特别是中国具有一个独特的优势——就是数据资源丰富、应用场景非常之多,所以中国的经验呢,我想也在逐渐地积累和形成。所以说我认为系联公司将来的更重要的任务,把中国的经验引向世界,为全球的人民的健康共同做出贡献。InterSystems 亚太区总经理卢侠亮(Luciano Brustia):是的,当然。我的意思是,就像我一直在说的,我很荣幸来到中国,这已经是我在中国的第15个年头了,而系联来到中国已经不止25年了,我们打算再呆上另一个20年、25年……如果我还能再活二十年,(我会)继续留在这里,继续为各位和所有聪明睿智的中国居民服务。毫无疑问,InterSystems一直致力于把我们的先进技术带到中国,助力中国本土企业做大做强,当然,我们也会将在中国获得的经验,作为一种资源共享给世界其他地方。所以我真的很高兴再次回到中国,我认为这是最好的时候,非常感谢大家!
文章
姚 鑫 · 五月 4, 2021
# 第二章 全局变量结构(二)
# 全局变量物理结构
全局变量使用高度优化的结构存储在物理文件中。管理此数据结构的代码也针对运行InterSystems IRIS的每个平台进行了高度优化。这些优化确保全局操作具有高吞吐量(每单位时间的操作数)、高并发性(并发用户总数)、缓存的高效使用,并且不需要与性能相关的持续维护(例如频繁的重建、重新索引或压缩)。
用于存储全局变量的物理结构是完全封装的;应用程序不会以任何方式担心物理数据结构。
全局变量存储在磁盘上的一系列数据块中;每个块的大小(通常为`8KB`)是在创建物理数据库时确定的。为了提供对数据的高效访问,InterSystems IRIS维护了一种复杂的**B树状结构**,该结构使用一组指针块将相关数据块链接在一起。InterSystems IRIS维护一个缓冲池-经常引用的块的内存缓存-以降低从磁盘获取块的成本。
虽然许多数据库技术使用类似`B树`的结构来存储数据,但InterSystems IRIS在许多方面都是独一无二的:
- 存储机构通过安全、易于使用的接口显露出来。
- 压缩下标和数据以节省磁盘空间和宝贵的内存缓存空间。
- 存储引擎针对事务处理操作进行了优化:插入、更新和删除都很快。与关系系统不同,InterSystems IRIS从不需要重建索引或数据来恢复性能。
- 存储引擎针对最大并发访问进行了优化。
- 数据会自动群集,以实现高效检索。
# 引用全局变量
全局变量驻留在特定的InterSystems IRIS数据库中。如果使用适当的映射,全局变量的部分可以驻留在不同的数据库中。数据库可以在物理上位于当前系统上,也可以位于通过ECP网络访问的远程系统上。术语数据集是指包含InterSystems IRIS数据库的系统和目录。
命名空间是共同构成一组相关信息的数据集和全局映射的逻辑定义。
简单的全局变量引用适用于当前选定的命名空间。名称空间定义可能导致它物理访问本地系统或远程系统上的数据库。不同的全局变量可以映射到不同的位置或数据集(其中数据集是指包含InterSystems IRIS数据库的系统和目录)。
例如,要在当前已映射到的命名空间中创建对全局顺序的简单引用,请使用以下语法:
```java
^ORDER
```
## 设置全局变量映射
可以将全局变量和例程从一个数据库映射到相同或不同系统上的另一个数据库。这允许简单地引用可以存在于任何地方的数据,这是命名空间的主要特征。可以映射整个全局或部分全局;映射全局(或下标)的一部分称为下标级别映射(`SLM`)。因为可以映射全局下标,所以数据可以轻松地跨磁盘。
全局映射是分层应用的。例如,如果NSX命名空间有一个关联的`DBX`数据库,但将`^x`全局变量映射到`DBY`数据库,将`^x(1)`映射到`DBZ`数据库,则`^x`全局变量的任何下标形式(属于`^x(1)`层次结构的那些除外)都映射到`DBY`;属于`^x(1)`层次结构的那些全局变量映射到DBZ。下图说明了此层次结构:
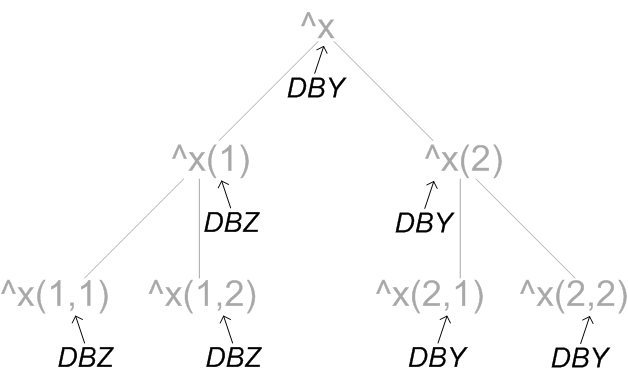
在此图中,全局变量及其层次结构显示为灰色,它们映射到的数据库显示为黑色。
还可以将映射的、下标的全局的一部分映射到另一个数据库,甚至映射回初始全局映射到的数据库。假设前面的示例有`^x(1,2)`全局变量返回到`DBY`数据库的附加映射。这将如下所示:
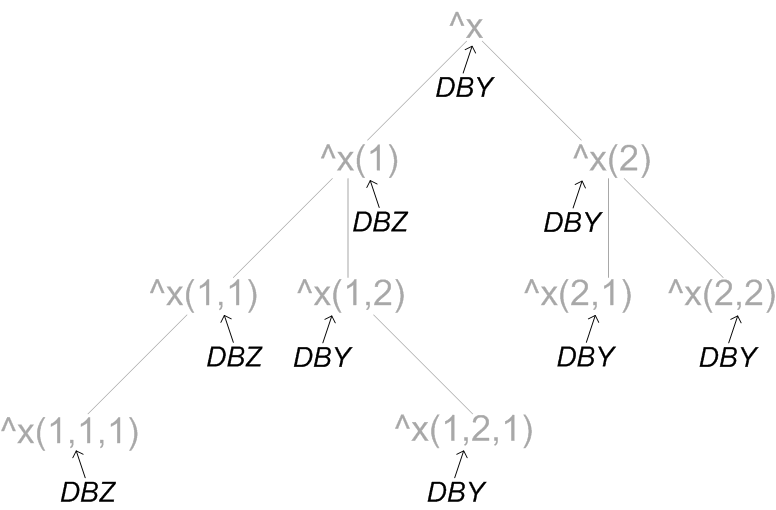
同样,全局变量及其层次结构显示为灰色,它们映射到的数据库显示为黑色。
一旦将全局从一个命名空间映射到另一个命名空间,就可以引用映射的全局变量,就像它在当前命名空间中一样-只需一个简单的引用,如`^Order`或`^X(1)`。
重要提示:建立下标级别映射范围时,字符串下标的行为与整数下标的行为不同。对于字符串,第一个字符确定范围,而对于整数,范围使用数值。例如,下标范围`("A"):("C")` 不仅包含`AA`,还包含`AC`和`ABCDEF`;相比之下,下标范围`(1):(2)` 不包含`11`。
### 使用全局和下标的不同范围
命名空间的每个映射必须引用不同范围的全局变量或下标。映射验证可防止建立任何类型的重叠。例如,如果使用管理门户创建与现有映射重叠的新映射,则门户会阻止这种情况发生,并显示一条错误消息。
### 记录更改
通过门户对映射的成功更改也会记录在`messages.log`中;不成功的更改不会记录。通过手动编辑配置参数(CPF)文件来建立映射的任何失败尝试都会记录在`messages.log`中.
## 扩展的全局变量引用
可以引用位于当前命名空间以外的命名空间中的全局变量。这称为扩展全局变量引用或简称为扩展引用。
有两种形式的扩展引用:
- 显式命名空间引用-将全局所在命名空间的名称指定为全局变量引用语法的一部分。
- 隐含名称空间引用-指定目录和系统名称(可选)作为全局变量引用语法的一部分。在这种情况下,不适用全局变量映射,因为物理数据集(目录和系统)是作为全局变量引用的一部分提供的。
最好使用显式名称空间,因为这允许在需求更改时在外部重新定义逻辑映射,而无需更改应用程序代码。
InterSystems IRIS支持两种形式的扩展引用:
- 方括号语法,它用方括号(`[]`)将扩展引用括起来。
- 环境语法,用竖线(`||`)括起扩展引用。
注意:扩展全局引用的示例使用`Windows`目录结构。实际上,此类引用的形式取决于操作系统。
### 方括号语法
可以使用方括号语法来指定具有显式命名空间或隐含命名空间的扩展全局引用:
显式命名空间:
```java
^[nspace]glob
```
隐含命名空间:
```java
^[dir,sys]glob
```
在显式名称空间引用中,`nspace`是全局全局当前尚未映射或复制到的已定义名称空间。在隐含的名称空间引用中,`dir`是目录(其名称包括尾随反斜杠:`“\”`),`sys`是`SYSTEM`,`glob`是该目录中的全局目录。如果将`nspace`或`dir`指定为(`“^”`),则引用的是进程私有全局变量。
除非将目录和系统名称或命名空间名称指定为变量,否则必须在目录和系统名称或命名空间名称两边加上引号。目录和系统一起构成一个隐含的命名空间。隐含的命名空间可以引用以下任一项:
- 指定系统上的指定目录。
- 本地系统上的指定目录(如果未在引用中指定系统名称)。如果在隐含的命名空间引用中省略了系统名称,则必须在目录引用内提供双脱字符(`^^`)以指示省略的系统名称。
要在远程系统上指定隐式命名空间,请执行以下操作:
```java
["dir","sys"]
```
在本地系统上指定一个隐含的命名空间:
```java
["^^dir"]
```
例如,要访问名为SALES的计算机上的`C:\BUSINESS\`目录中的全局变量`ORDER`:
```java
SET x = ^["C:\BUSINESS\","SALES"]ORDER
```
要访问本地计算机上的`C:\BUSINESS\`目录中的全局`ORDER`:
```java
SET x = ^["^^C:\BUSINESS\"]ORDER
```
要访问定义的命名空间`MARKETING`中的全局`ORDER`:
```java
SET x = ^["MARKETING"]ORDER
```
要访问进程私有的全局`ORDER`:
```java
SET x = ^["^"]ORDER
```
注意:在创建涉及镜像数据库的隐含命名空间扩展引用时,可以使用镜像数据库路径,格式为`:mirror:mirror_name:mirror_DB_name`。
例如,当在镜像`CORPMIR`中引用镜像数据库名称为mirdb1的数据库时,可以形成如下的隐含引用:
```java
["^^:mirror:CORPMIR:mirdb1"]
```
镜像数据库路径既可以用于本地数据库,也可以用于远程数据库。
### 环境语法
环境语法被定义为:
```java
^|"env"|global
```
`"env"`可以有以下五种格式之一:
- 空字符串(`""`)-本地系统上的当前命名空间。
- `"namespace"` -定义的命名空间,当前没有全局映射到。
命名空间名称不区分大小写。
如果`namespace`具有特殊值`"^"`,则它是进程私有的全局变量。
- `"^^dir"` -一个隐含的命名空间,它的默认目录是本地系统上的指定目录,其中dir包含一个末尾的反斜杠(`" \ ")`。
- `"^system^dir"`——一个隐含的命名空间,默认目录是指定的远程系统上的指定目录,其中`dir`包含一个结尾的反斜杠(`" \ "`)。
- 省略-如果根本没有`"env"`,它是进程私有的全局变量。
要访问当前系统上当前命名空间中的全局`ORDER`,如果没有为`ORDER`定义映射,请使用以下语法:
```java
SET x = ^|""|ORDER
```
这与简单的全局变量引用相同:
```java
SET x = ^ORDER
```
要访问映射到定义的命名空间`MARKETING`的全局`ORDER`:
```java
SET x = ^|"MARKETING"|ORDER
```
可以使用一个隐含的命名空间来访问本地系统上`C:\BUSINESS\`目录下的全局`ORDER`:
```java
SET x = ^|"^^C:\BUSINESS\"|ORDER
```
可以使用一个隐含的命名空间来访问一个名为`SALES`的远程系统上的目录`C:\BUSINESS`中的全局`ORDER`:
```java
SET x = ^|"^SALES^C:\BUSINESS\"|ORDER
```
要访问进程私有的全局`ORDER`:
```java
SET x = ^||ORDER
SET x=^|"^"|ORDER
```
文章
姚 鑫 · 七月 3, 2021
# 第二十六章 定制 SAX解析器的使用方式
每当InterSystems IRIS读取XML文档时,它都会使用InterSystems IRIS SAX(Simple API For XML)解析器。本章介绍用于控制系统间IRIS SAX解析器的选项。
# 关于IRIS SAX解析器
每当InterSystems IRIS读取XML文档时,都会使用InterSystems IRIS SAX解析器。
它是一个事件驱动的XML解析器,读取XML文件,并在找到感兴趣的项(如XML元素的开始、DTD的开始等)时发出回调。
(更准确地说,解析器与内容处理程序协同工作,内容处理程序发出回调。只有在自定义SAX接口时,此区别才很重要,如本章后面的“创建自定义内容处理程序”中所述。)
解析器使用标准Xerces-C++库,该库符合`XML1.0`推荐标准和许多相关标准。
# 可用的解析器选项
可以通过以下方式控制SAX解析器的行为:
- 可以设置标志来指定要执行的验证和处理类型。
请注意,解析器始终检查文档是否为格式良好的XML文档。
- 可以指感兴趣的事件(即希望解析器查找的项目)。为此,需要指定一个掩码来指示感兴趣的事件。
- 可以提供验证文档所依据的架构规范。
- 可以使用特殊用途的实体解析器禁用实体解析。
- 可以指定实体解析的超时期限。
- 如果需要控制解析器如何查找文档中任何实体的定义,则可以指定更通用的自定义实体解析器。
- 如果通过URL访问源文档,则可以将发送到Web服务器的请求指定为%Net.HttpRequest的实例。
- 可以指定自定义内容处理程序。
- 可以使用HTTPS。
可用的选项取决于如何使用InterSystems IRIS SAX Parser,如下表所示:
%XML类中的SAX解析器选项
Option | %XML.Reader | %XML.TextReader |%XML.XPATH.Document | %XML.SAX.Parser
---|---|---|---|---
指定解析器标志 |supported |supported| supported| supported
指定感兴趣的解析事件(例如,元素的开始、元素的结束、注释)| not supported| supported| not supported| supported
指定模式规范| supported| supported| supported| supported
禁用实体解析或以其他方式定制实体解析| supported| supported| supported| supported
指定自定义HTTP请求(如果解析URL)| not supported| supported| not supported |supported
指定内容处理程序| not supported| not supported| not supported| supported
在HTTPS位置解析文档| supported| not supported| not supported| supported
解析HTTPS位置上的实体| not supported| not supported| not supported| supported
# 指定解析器选项
指定不同的解析器行为取决于你如何使用InterSystems IRIS SAX解析器:
- 如果使用`%XML.Reader`,可以设置阅读器实例的`Timeout`、`SAXFlags`、`SAXSchemaSpec`和`EntityResolver`属性。
例如:
```java
#include %occInclude
#include %occSAX
// set the parser options we want
Set flags = $$$SAXVALIDATION
+ $$$SAXNAMESPACES
+ $$$SAXNAMESPACEPREFIXES
+ $$$SAXVALIDATIONSCHEMA
Set reader=##class(%XML.Reader).%New()
Set reader.SAXFlags=flags
```
这些宏是在`%occSAX`中定义的。公司包含文件。
- 在其他情况下,指定所使用方法的参数。例如:
```java
#include %occInclude
#include %occSAX
//set the parser options we want
Set flags = $$$SAXVALIDATION
+ $$$SAXNAMESPACES
+ $$$SAXNAMESPACEPREFIXES
+ $$$SAXVALIDATIONSCHEMA
Set status=##class(%XML.TextReader).ParseFile(myfile,.doc,,flags)
```
# 设置解析器标志
`%occSAX.inc` include文件列出了可用于控制`Xerces`解析器执行的验证的标志。基本标志如下:
- `$$$SAXVALIDATION` -是否执行模式验证。如果此标志为开启(默认值),则报告所有验证错误。
- `$$$SAXNAMESPACES`-指定是否识别命名空间。如果此标志为ON(默认值),解析器将处理命名空间。如果此标志为OFF,InterSystems IRIS会导致`%XML.SAX.ContentHandler`的`startElement()`回调中元素的`localname`为空字符串。
- `$$$SAXNAMESPACEPREFIXES`-指定是否处理命名空间前缀。如果此标志为`ON`,解析器将报告用于名称空间声明的原始前缀名称和属性。默认情况下,此标志处于关闭状态。
- `$$$SAXVALIDATIONDYNAMIC` - 指定是否动态执行验证。如果此标志为`ON`(默认设置),则仅在指定语法时才执行验证。
- `$$$SAXVALIDATIONSCHEMA` -指定是否针对架构执行验证。如果此标志为`ON`(缺省设置),则针对给定模式(如果有的话)执行验证。
- `$$$SAXVALIDATIONSCHEMAFULLCHECKING` - 指定是否执行完整架构约束检查,包括耗时或内存密集型检查。如果此标志处于打开状态,则执行所有约束检查。默认情况下,此标志处于关闭状态。
- `$$$SAXVALIDATIONREUSEGRAMMAR` - 指定是否缓存语法以供以后在同一IRIS进程内的分析中重复使用。默认情况下,此标志处于关闭状态。
- `$$$SAXVALIDATIONPROHIBITDTDS` - 在遇到DTD时导致解析器抛出错误的特殊标志。如果需要阻止处理DTD,请使用此标志。要使用此标志,必须将值`$$$SAXVALIDATIONPROHIBITDTDS`显式添加到传递给`%XML.SAX.Parser`的各种分析方法的分析标志。
以下附加标志提供了基本标志的有用组合:
- `$$$SAXDEFAULTS` - 相当于SAX默认值。
- `$$$SAXFULLDEFAULT` - 等同于SAX默认值,外加处理名称空间前缀的选项。
- `$$$SAXNOVALIDATION` - 不执行架构验证,但可以识别命名空间和命名空间前缀。请注意,SAX解析器总是检查文档是否为格式良好的XML文档。
以下片段显示了如何组合解析器选项:
```
...
#include %occInclude
#include %occSAX
...
;; set the parser options we want
set opt = $$$SAXVALIDATION
+ $$$SAXNAMESPACES
+ $$$SAXNAMESPACEPREFIXES
+ $$$SAXVALIDATIONSCHEMA
...
set status=##class(%XML.TextReader).ParseFile(myfile,.doc,,opt)
//check status
if $$$ISERR(status) {do $System.Status.DisplayError(status) quit}
```
# 指定事件掩码
基本标志如下:
- `$$$SAXSTARTDOCUMENT` — 指示分析器在启动文档时发出回调。
- `$$$SAXENDDOCUMENT` — 指示分析器在结束文档时发出回调。
- `$$$SAXSTARTELEMENT` — 指示分析器在找到元素开头时发出回调。
- `$$$SAXENDELEMENT` — 指示分析器在找到元素末尾时发出回调。
- `$$$SAXCHARACTERS` — 指示分析器在找到字符时发出回调。
- `$$$SAXPROCESSINGINSTRUCTION` — 指示分析器在找到处理指令时发出回调。
- `$$$SAXSTARTPREFIXMAPPING` — 指示分析器在找到前缀映射的开始时发出回调。
- `$$$SAXENDPREFIXMAPPING` — 指示分析器在找到前缀映射末尾时发出回调。
- `$$$SAXIGNORABLEWHITESPACE` — 指示分析器在发现可忽略的空格时发出回调。这仅适用于文档具有DTD并且启用了验证的情况。
- `$$$SAXSKIPPEDENTITY` — 指示分析器在找到跳过的实体时发出回调。
- `$$$SAXCOMMENT` — 指示分析器在找到注释时发出回调。
- `$$$SAXSTARTCDATA` — 指示分析器在找到`CDATA`节的开头时发出回调。
- `$$$SAXENDCDATA` —指示分析器在找到`CDATA`节末尾时发出回调。
- `$$$SAXSTARTDTD` —指示分析器在找到`DTD`的开头时发出回调。
- `$$$SAXENDDTD` —指示分析器在找到`DTD`结尾时发出回调。
- `$$$SAXSTARTENTITY` — 指示分析器在找到实体的开头时发出回调。
- `$$$SAXENDENTITY` — 指示分析器在找到实体末尾时发出回调。
## 方便的组合标志
以下附加标志提供了基本标志的有用组合:
- `$$$SAXCONTENTEVENTS` — 指示解析器对任何包含`“content”`的事件发出回调。
- `$$$SAXLEXICALEVENT` — 指示解析器向任何词汇事件发出回调。
- `$$$SAXALLEVENTS` —指示解析器对所有事件发出回调。
## 将标志组合成单个掩码
下面的片段展示了如何将多个标志组合成一个掩码:
```java
...
#include %occInclude
#include %occSAX
...
// set the mask options we want
set mask = $$$SAXSTARTDOCUMENT
+ $$$SAXENDDOCUMENT
+ $$$SAXSTARTELEMENT
+ $$$SAXENDELEMENT
+ $$$SAXCHARACTERS
...
// create a TextReader object (doc) by reference
set status = ##class(%XML.TextReader).ParseFile(myfile,.doc,,,mask)
```
# 指定模式文档
可以指定用于验证文档源的模式规范。指定一个包含逗号分隔的命名空间/URL对列表的字符串:
```java
"namespace URL,namespace URL,namespace URL,..."
```
这里的名称空间是XML名称空间(而不是名称空间前缀),URL是提供该名称空间的模式文档位置的URL。
在命名空间和URL值之间有一个空格字符。
例如,下面显示了一个具有单个命名空间的模式规范:
```java
"http://www.myapp.org http://localhost/myschemas/myapp.xsd"
```
下面是一个包含两个命名空间的模式规范:
```java
"http://www.myapp.org http://localhost/myschemas/myapp.xsd,http://www.other.org http://localhost/myschemas/other.xsd"
```
# 禁用实体解析
即使在设置SAX标志以禁用验证时,SAX解析器仍然试图解析外部实体,这可能非常耗时,具体取决于它们的位置。
类`%XML.SAX.NullEntityResolver`实现始终返回空流的实体解析器。如果要禁用实体解析,请使用此类。具体地说,在读取XML文档时,请使用`%XML.SAX.NullEntityResolver`的实例作为实体解析器。例如:
```java
Set resolver=##class(%XML.SAX.NullEntityResolver).%New()
Set reader=##class(%XML.Reader).%New()
Set reader.EntityResolver=resolver
Set status=reader.OpenFile(myfile)
...
```
重要提示:由于此更改将禁用所有外部实体解析,因此此技术还将禁用XML文档中的所有外部DTD和模式引用。
文章
姚 鑫 · 二月 18, 2021
# 第四十章 Caché 变量大全 $ZREFERENCE 变量
包含当前全局变量global引用。
# 大纲
```java
$ZREFERENCE
$ZR
```
# 描述
`$ZREFERENCE`包含上次全局引用的名称和下标。这就是所谓裸指针。
注意:最后一个全局引用是最近访问的全局节点。通常,这是对全局的最新显式引用。但是,某些命令可能在内部使用`$ORDER`函数遍历全局下标(`ZWRITE`命令就是一个例子),或者它们可能在内部引用其他全局脚本。发生这种情况时,`$ZREFERENCE`包含上次访问的全局节点,该节点可能不是为命令指定的全局节点。
最后一个全局引用可以是全局(`^myglob`)或进程专用全局(`^||myppg`)。`$ZREFERENCE`以最初用于该变量的形式返回进程专用全局前缀,而不管随后对该变量使用哪个进程专用全局前缀。在接下来的`$ZREFERENCE`描述中,单词`“global”`指的是这两种类型的变量。
最后一个全局引用是命令或函数最近引用的全局。由于ObjectScript按从左到右的顺序执行操作,因此最后一个全局引用始终是最右侧的全局引用。当命令或函数使用多个参数时,最右侧参数中指定的全局参数是最后一个全局引用。当参数包含多个全局引用时,最右侧指定的全局引用是最后一个全局引用。即使使用圆括号来定义操作顺序,从左到右的严格顺序也是正确的。
当发出显式全局引用时,InterSystems IRIS会更新`$ZREFERENCE`。调用计算结果为全局引用的表达式(如局部变量)不会更新`$ZREFERENCE`。
`$ZREFERENCE`包含最新的全局引用,即使此全局引用不成功。当命令引用未定义的全局时,会发出``错误,InterSystems IRIS会将`$ZREFERENCE`更新为该全局引用,就像定义了全局一样。此行为不受设置`%SYSTEM.Process.Unfined()`方法的影响。
`$ZREFERENCE`通常包含最新的全局引用,即使命令执行不成功。InterSystems IRIS在引用每个全局变量时更新`$ZREFERENCE`。例如,发出``错误(试图将数字除以0)的命令会将`$ZREFERENCE`更新为错误发生前命令中引用的最后一个全局变量。但是,``错误不会更新`$ZREFERENCE`。
## 长全局变量名称
如果全局名称超过31个字符(不包括全局前缀字符,如`^`),`$ZREFERENCE`将返回缩短为31个字符的全局名称。
## 裸全局变量引用
如果上一个全局引用是裸全局引用,则`$ZREFERENCE`包含当前裸全局引用的外部、可读的完整形式。下面的示例演示了这一点:
```java
/// d ##class(PHA.TEST.SpecialVariables).ZREFERENCE()
ClassMethod ZREFERENCE()
{
SET ^MyData(1)="fruit"
SET ^MyData(1,1)="apples" ; 完整的全局变量引用
SET ^(2)="oranges" ; 裸全局变量引用, 映射 ^MyData(1,2)
WRITE !,$ZREFERENCE ; Returns "^MyData(1,2)"
}
```
```java
DHC-APP>d ##class(PHA.TEST.SpecialVariables).ZREFERENCE()
^MyData(1,2)
```
## 扩展局变量引用
扩展局变量引用用于引用当前命名空间以外的命名空间中的全局。如果命令使用扩展全局引用引用全局变量,则`$ZREFERENCE`值将包含该扩展全局引用。在以下情况下,InterSystems IRIS返回扩展的全局引用:
- 如果最后一个全局引用使用扩展引用来引用另一个命名空间中的全局。
- 如果最后一个全局引用使用扩展引用来引用当前命名空间中的全局。
- 如果最后一个全局引用是远程引用(远程系统上的全局引用)。
在所有情况下,`$ZREFERENCE`都以全部大写字母返回命名空间名称,而不管它在全局引用中是如何指定的。
## 更新`$ZREFERENCE`的操作
`$ZREFERENCE`特殊变量被初始化为空字符串(`“”`)。更改当前名称空间会将`$ZREFERENCE`重置为空字符串。
以下操作将`$ZREFERENCE`设置为最近引用的`GLOBAL`:
- 使用全局变量作为参数的命令或函数。如果它使用多个全局变量,则`$ZREFERENCE`被设置为全局变量的最右侧匹配项。(但请注意,`$ORDER`除外。)
- 使用全局作为后置条件表达式的命令。
- 在`ZWRITE`之后,InterSystems IRIS将`$ZREFERENCE`设置为指定全局引用的上次访问的下标节点。
- 引用未定义的全局变量的命令或函数,它或者生成``错误,或者在`$INCREMENT`的情况下定义全局变量。
## 设置`$ZREFERENCE`
可以使用`set`命令设置此特殊变量,如下所示:
- 设置为空字符串(`“”`)。这样做会删除裸指示器。如果下一个全局引用是裸全局引用,则InterSystems IRIS会发出``错误。
- 设置为有效的全局参照(已定义或未定义)。这会导致后续的裸引用使用设置的值,就好像它是最后一个实际的全局引用一样。
不能使用`SET`命令以其他方式修改`$ZREFERENCE`。尝试这样做会导致``错误。
# 示例
下面的示例返回最后一个全局引用:
```java
/// d ##class(PHA.TEST.SpecialVariables).ZREFERENCE1()
ClassMethod ZREFERENCE1()
{
SET ^a(1,1)="Hello" ; 完整的全局变量引用
SET ^(2)=" world!" ; 裸全局变量引用
WRITE $ZREFERENCE
}
```
```java
DHC-APP>d ##class(PHA.TEST.SpecialVariables).ZREFERENCE1()
^a(1,2)
```
下面的示例从几个不同的命令返回全局引用。请注意,`WRITE`和`ZWRITE`设置同一全局引用的不同表示形式。
```java
/// d ##class(PHA.TEST.SpecialVariables).ZREFERENCE2()
ClassMethod ZREFERENCE2()
{
SET (^barney,^betty,^wilma,^fred)="flintstone"
WRITE !,"1:"_$ZREFERENCE
KILL ^flies
WRITE !,"2:"_$ZREFERENCE
WRITE !,^fred
WRITE !,"3:"_$ZREFERENCE,!
ZWRITE ^fred
WRITE !,"4:"_$ZREFERENCE
}
```
```java
DHC-APP>d ##class(PHA.TEST.SpecialVariables).ZREFERENCE2()
1:^fred // 按从左到右顺序设置的几个全局变量中的最后一个
2:^flies // KILL设置全局指示器,但没有全局要杀死的指示器
flintstone
3:^fred
^fred="flintstone"
4:^fred("")
```
下面的示例返回扩展的全局引用。请注意,名称空间名称始终以大写字母返回:
```java
/// d ##class(PHA.TEST.SpecialVariables).ZREFERENCE3()
ClassMethod ZREFERENCE3()
{
SET ^["samples"]a(1,1)="Hello"
SET ^(2)=" world!"
WRITE $ZREFERENCE
QUIT
}
```
```java
DHC-APP>d ##class(PHA.TEST.SpecialVariables).ZREFERENCE3()
^["SAMPLES"]a(1,2)
```
下面的示例返回最后一个全局引用。在本例中,它是`^a(1)`,用作`$LENGTH`函数的参数:
```java
/// d ##class(PHA.TEST.SpecialVariables).ZREFERENCE4()
ClassMethod ZREFERENCE4()
{
SET ^a(1)="abcdefghijklmnopqrstuvwxyz"
SET ^b(1)="1234567890"
SET x=$LENGTH(^a(1))
WRITE $ZREFERENCE
QUIT
}
```
```java
DHC-APP>d ##class(PHA.TEST.SpecialVariables).ZREFERENCE4()
^a(1)
```
下面的示例返回为`$ZREFERENCE`设置的值,就好像它是最后一个全局引用一样。在本例中,它是`^a(1,1)`。
```java
/// d ##class(PHA.TEST.SpecialVariables).ZREFERENCE5()
ClassMethod ZREFERENCE5()
{
SET ^a(1,1)="abcdefghijklmnopqrstuvwxyz"
SET ^b(1,1)="1234567890"
WRITE !,^(1) ; 裸全局变量引用使用上一个全局变量:
SET $ZREFERENCE="^a(1,1)"
WRITE !,$ZREFERENCE
WRITE !,^(1) ; 裸全局变量使用$ZREFERENCE值,而不是最后一个全局值。.
}
```
```java
DHC-APP>d ##class(PHA.TEST.SpecialVariables).ZREFERENCE5()
1234567890
^a(1,1)
abcdefghijklmnopqrstuvwxyz
```
下面的示例设置扩展的全局引用。请注意双引号:
```java
/// d ##class(PHA.TEST.SpecialVariables).ZREFERENCE6()
ClassMethod ZREFERENCE6()
{
KILL ^x
WRITE !,$ZREFERENCE
SET $ZREFERENCE="^[""samples""]a(1,2)"
WRITE !,$ZREFERENCE
}
```
```java
DHC-APP>d ##class(PHA.TEST.SpecialVariables).ZREFERENCE6()
^x
^["SAMPLES"]a(1,2)
```
文章
Jingwei Wang · 七月 8, 2022
本片文章主要介绍两种Production debug的方式,
使用管理门户测试Production 组件
使用VS Code来对远程production代码进行debug
使用管理门户测试Production 组件
可以使用管理门户来对Production进行调试
测试组件
开启production测试: Interoperability -> 配置 -> Producton
在Production设置中,将开发与调试中的'测试开启'选中,如下图所示。
测试: Interoperability -> 测试 -> 业务主机
首先选择目标类型,业务流程或者业务操作,然后再目标名称这个下拉菜单中选择你要调试的组件名称,点击‘测试’
在请求详情中,填写测试请求的请求内容,然后点击'调用测试服务',测试结果如下。
然后,可以点击‘可视化追踪’来查看详情。
跟踪(Trace)
跟踪元素使你能够看到production中各种元素的行为,以便进行调试或诊断。
将跟踪元素添加到production的适当区域,在production运行时相应的跟踪信息就被写入,但是跟踪消息只是字符串,与Ens.Message及其子类无关。
跟踪消息可以启动和关闭,配置production以启用跟踪,意味着在运行时,跟踪元素被执行。而关闭跟踪意味着跟踪元素在production运行时会被被忽略。
可以选择将适用的业务主机配置为在前台运行,这样你就可以在生产运行时在终端看到跟踪信息。对于如何开启前台调试请参考Production前台调试。
启动跟踪
Interoperability -> 配置 -> Producton,选中要设置跟踪的组件。选中‘跟踪事件记入日志’,这一步会将追踪信息写到事件日志中。
默认情况下,所有的用户跟踪元素都被启用。你也可以通过设置^Ens.Debug来启用各种系统事件的跟踪,如果只是调试自己的代码用户跟踪就已经足够了,不需要开启其他系统事件的跟踪。
设置跟踪
业务服务 - BS ,业务操作 - BO :
在代码中添加用户跟踪
$$$TRACE("received application for "_request.CustomerName)
在代码中添加系统跟踪
$$$sysTRACE(trace_message)
在代码中添加error log
$$$LOGERROR("Awaiting connect on port "_..Port_" with timeout "_..CallInterval)
在代码中添加info log
$$$LOGINFO("Got data chunk, size="_$length(data)_"/"_tChunkSize)
业务流程 - BP :
在BPL中,点击 ‘-添加活动-' 下拉菜单,选择’跟踪‘
查看跟踪
从消息查看器中查看:
Interoperability -> 查看 -> 消息
选择你要查看的消息,点击相应的'会话'超链接,
点击 ◇,即可查看相应的trace
从事件日志中查看: Interoperability -> 查看 -> 事件日志 , 如下图所示,可以看到你所设置的所有事件日志。
使用VS Code来对远程production 代码进行debug
InterSystems支持使用VS Code连接到InterSystems IRIS服务器使用ObjectScript开发代码。如果您没有使用过VS Code连接到InterSystems IRIS服务器,请先阅读本社区文章 使用VSCode 进行IRIS 开发。
VS Code 连接远程 IRIS 请参考文章 使用VSCode 进行IRIS 开发,将VS Code连接到IRIS实例。
VS Code对本地productioin代码进行debug 如果想使用VS Code对本地代码进行debug,也请参考文章使用VSCode 进行IRIS 开发中的 ''在VSCode中调试' 部分。
VS Code对远程代码进行debug 在IRIS实例上面操作: 创建web 应用程序,在需要远程连接的IRIS实例上面建立一个名为/_vscode的web应用程序,配置如下:
在VS Code上面操作:
将VS Code连接到远程IRIS之后, 创建相应的工作区
InterSystems Tools - > 选择你要debug的命名空间 -> 点击右边笔状图标’Edit Code in Namespace‘。
进入到刚刚创建的工作区
创建workspace.json 文件 , 查看 -> command palette -> Open Workspac setting, 生成如下JSON文件, 文件名为workspace.json
{
"folders": [
{
"name": "localhcc:HCC",
"uri": "isfs://localhcc:hcc/"
}
],
"settings": {
"objectscript.showExplorer": false
}
}
创建launch.json 文件 , 点击左边菜单栏中的 'run and debug'图标,左上角会出现在launch.json文件中配置的调试名称。
配置launch.json文件
Debug普通类方法,使用如下launch.json文件,具体debug方式,请参考文章使用VSCode 进行IRIS 开发中的 ''在VSCode中调试' 部分。下图的launch.json文件表示可以调试 Test.SQL类中的SavePatientFromMsg函数,其中2为参数。
{
"version": "0.2.0",
"configurations": [
{
"type": "objectscript",
"request": "launch",
"name": "ObjectScript Debug SQL",
"program": "##class(Test.SQL).SavePatientFromMsg(2)"
}
]
}
Debug production, 使用如下launch.json文件, 其中processId为Production组件中的作业号
{
// 使用 IntelliSense 了解相关属性。
// 悬停以查看现有属性的描述。
// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"type": "objectscript",
"request": "attach",
"name": "RetrieveCDAOperation",
"processId": 4436
}
]
}
Production中的作业号查询方式,如下图所示,在IRIS管理门户中,进入production页面。选中你想调试的组件,在右边即可以查看作业号。
调试
测试前,先增加断点,本文使用业务操作BO为例,我需要测试我的业务操作 HCC.SVR.Prod.BO.SaveCDAOperation。在我的业务操作类HCC.SVR.Prod.BO.SaveCDAOperation中增加几个断点。
选择你想调试的名称。点击左边绿色三角形的小图标’start debugging‘。
点击左边菜单栏中的 'run and debug'图标,左上角会出现在launch.json文件中配置的调试名称。选择你想调试的名称。点击左边绿色三角形的小图标’start debugging‘。
点击’start debugging‘后,最上方会出现测试功能条,但是功能条处于灰色,不可用状态。
然后触发production,可以使用postman 或者 soapUI等测试工具来触发要测试的production组件。如下图所示,相应的变量显示在左边菜单栏旁边,最上方的测试功能条处于可用状态,可以点击’step in‘ 、 ’step over‘、’step out‘ 来进行相应的调试,同时,INT - 中间源文件 Queue.1.int也会显示在调试页面上。INT 为中间源文件,是可执行的InterSystems IRIS对象代码。
如果想略过其他函数或者中间源文件,直接跳到你想调试的类或者函数中,可以将鼠标直接点击在想调试的函数中,然后右击鼠标,点击'Run to Cursor'。
点击'Run to Cursor'后,debug就会运行到鼠标指针闪烁的函数中,之后可以使用’step in‘ 、 ’step over‘、’step out‘ 来进行相应的调试。关于如何监控及查看调试过程中的变量,请参考文章使用VSCode 进行IRIS 开发中的 ''在VSCode中调试' 部分
文章
姚 鑫 · 六月 18, 2021
# 第十一章 重新定义读取器处理相关对象的方式
# 重新定义读取器处理相关对象的方式
当`%XML.Reader`找到与启用了XML的类相关的XML元素时,读取器会调用该类的`XMLNew()`方法,后者又会在默认情况下调用`%New()`。也就是说,当读取器找到相关元素时,它会创建相关类的新对象。新对象由从XML文档读取的数据填充。
可以通过在启用XML的类中(或在自己的自定义XML适配器中)重新定义`XMLNew()`来自定义此行为。例如,此方法可以改为打开该类的现有实例。然后,现有实例接收从XML文档读取的数据。
以下示例显示如何修改`XMLNew()`以使用XML文档中的新数据更新现有实例。
在这两个示例中,为简单起见,我们假设XML文档中的一个节点包含一个ID,我们可以将该ID与类的范围中的ID进行比较。当然,我们可以用其他方式将XML文档与现有对象进行比较。
## 当`%XML.Reader`调用`XMLNew()`时
作为参考,`%XML.Reader`在两种情况下自动调用`XMLNew()`方法:
- `%XML.Reader`在调用`%XML.Reader`的`Next()`方法调用`XMLNew()`。在将XML元素(在外部文档中)与启用了XML的类关联之后,`%XML.Reader` `Next()`方法从文档中获取下一个元素,调用`XMLNew()`创建相应对象的实例,然后将该元素导入到对象中。
- 同样,`%XML.Reader`为相关XML元素的任何对象值属性调用`XMLNew()`。
## 示例1:修改启用XML的类中的`XMLNew()`
```java
4
Quine,Maria K.
1964-11-14
Hialeah
94999
Vanzetti,Debra B.
...
```
此文件映射到以下InterSystems IRIS类(部分显示):
```java
Class GXML.PersonWithXMLNew Extends (%Persistent, %Populate, %XML.Adaptor)
{
Parameter XMLNAME = "Person";
/// make sure this is the same as the XMLNAME of the property
/// in this class that is of type %XML.Id
Parameter NAMEOFEXPORTID As %String = "IRISID";
Property IdForExport As %XML.Id(XMLNAME = "IRISID", XMLPROJECTION = "ELEMENT") [ Private, Transient ];
Property Name As %Name;
Property DOB As %Date(FORMAT = 5, MAXVAL = "+$h");
Property Address As GXML.Address;
Property Doctors As list Of GXML.Doctor;
```
在该类中,`IdForExport`属性的用途是在导出该类的对象时将InterSystems IRIS内部ID投影到元素(`IRISID`)。(在此特定示例中,这使我们能够轻松地生成适合导入的文件。类不必包含这样的属性。)
`NAMEOFEXPORTID`参数用于指示导出此类对象时用于InterSystems IRIS ID的元素。包含这一点只是为了方便自定义的`XMLNew()`方法,我们也将该方法添加到该类中。该方法定义如下:
```java
ClassMethod XMLNew(doc As %XML.Document, node As %Integer, contOref As %RegisteredObject = "") As GXML.PersonWithXMLNew
{
Set id=""
Set tmpnode=doc.GetNode(node)
Do tmpnode.MoveToFirstChild()
Do {
//将数据节点与NAMEOFEXPORTID参数提供的字符串进行比较
//指示此对象的ID的XMLNAME
If tmpnode.NodeData=..#NAMEOFEXPORTID {
//从该节点获取文本;这与数据库中的id相对应
Do tmpnode.GetText(.id)}
} While tmpnode.MoveToNextSibling()
//如果给定节点中没有id,则创建一个新对象
If id="" {
Write !, "正在创建新对象..."
Quit ..%New()}
//打开给定对象
Set result=..%OpenId(id)
//如果id与现有对象不对应,则创建一个新对象
If result=$$$NULLOREF {
Write !, "正在创建新对象..."
Quit ..%New()}
Write !, "正在更新现有对象..."
Quit result
}
```
`%XML.Reader`读取`XML`文档并将节点关联到`GXML.PersonWithXMLNew`时调用此方法。此方法查看此类中的`NAMEOFEXPORTID`参数的值,即`IRISID`。然后,它使用元素`IRISID`检查文档中的节点并获取其值。
如果此`ID`对应于此类的现有对象,则该方法将打开该实例。否则,该方法将打开此类的新实例。在这两种情况下,实例都会接收`XML`文档中指定的属性。
最后,以下实用程序类包含一个方法,该方法打开`XML`文件并在新窗口中调用`%XML.Reader`:
```java
/// w ##class(PHA.TEST.Xml).ReadFile()
ClassMethod ReadFile(filename As %String = "e:\temp\xmlnewtest.xml")
{
Set reader=##class(%XML.Reader).%New()
Set sc=reader.OpenFile(filename)
If $$$ISERR(sc) {Do $system.OBJ.DisplayError(sc) Quit }
Do reader.Correlate("Person","GXML.PersonWithXMLNew")
//loop through elements in file
While reader.Next(.person,.sc) {
Write !,person.Name,!
Set sc=person.%Save()
If $$$ISERR(sc) {Do $system.OBJ.DisplayError(sc) Quit }
}
Quit ""
}
```
运行上述方法时,文件中的每个``元素都会发生以下情况之一:
- 打开现有对象,使用文件中的详细信息进行更新,然后保存。
- 或者创建一个新对象,其中包含文件中的详细信息。
```java
DHC-APP>w ##class(PHA.TEST.Xml).ReadFile()
正在创建新对象...
Quine,Maria K.
DHC-APP>w ##class(PHA.TEST.Xml).ReadFile()
正在创建新对象...
Quine,Maria K.
DHC-APP>w ##class(PHA.TEST.Xml).ReadFile()
正在创建新对象...
Quine,Maria K.
DHC-APP>w ##class(PHA.TEST.Xml).ReadFile()
正在更新现有对象...
Quine,Maria K.
DHC-APP>w ##class(PHA.TEST.Xml).ReadFile()
正在更新现有对象...
Quine,Maria K.
DHC-APP>w ##class(PHA.TEST.Xml).ReadFile()
正在更新现有对象...
Quine,Maria K.
```
## 示例2:在自定义XML适配器中修改XMLNew()
在第二个示例中,我们创建一个自定义XML适配器来执行与第一个示例相同的操作。适配器类如下所示:
```java
Class GXML.AdaptorWithXMLNew Extends %XML.Adaptor
{
/// 确保这与该类中属性的XMLNAME相同 它的类型为%XML.Id
Parameter NAMEOFEXPORTID As %String = "IRISID";
Property IdForExport As %XML.Id(XMLNAME = "IRISID", XMLPROJECTION = "ELEMENT") [ Private, Transient ];
ClassMethod XMLNew(document As %XML.Document, node As %Integer, containerOref As %RegisteredObject = "") As %RegisteredObject [ CodeMode = objectgenerator, GenerateAfter = %XMLGenerate, ServerOnly = 1 ]
{
If %compiledclass.Name'="GXML.AdaptorWithXMLNew" {
Do %code.WriteLine(" Set id=""""")
Do %code.WriteLine(" Set tmpnode=document.GetNode(node)")
Do %code.WriteLine(" Do tmpnode.MoveToFirstChild()")
Do %code.WriteLine(" Do {")
Do %code.WriteLine(" If tmpnode.NodeData=..#NAMEOFEXPORTID ")
Do %code.WriteLine(" {Do tmpnode.GetText(.id)}")
Do %code.WriteLine(" } While tmpnode.MoveToNextSibling() ")
Do %code.WriteLine(" If id="""" {")
Do %code.WriteLine(" Write !,""Creating new object...""")
Do %code.WriteLine(" Quit ##class("_%class.Name_").%New()}")
Do %code.WriteLine(" set result=##class("_%class.Name_").%OpenId(id)")
Do %code.WriteLine(" If result=$$$NULLOREF {")
Do %code.WriteLine(" Write !,""Creating new object...""")
Do %code.WriteLine(" Quit ##class("_%class.Name_").%New() }")
Do %code.WriteLine(" Write !,""Updating existing object ...""")
Do %code.WriteLine(" Quit result")
}
QUIT $$$OK
}
}
```
`IdForExport`属性和`NAMEOFEXPORTID`参数建立了一个约定,用于在导出子类的对象时如何将InterSystems IRIS内部`ID`投影到元素。其目的是,如果在子类中重新定义`IdForExport`,则相应地重新定义`NAMEOFEXPORTID`。
在这个类中,`XMLNew()`方法是一个方法生成器。编译该类(或任何子类)时,InterSystems IRIS会将此处显示的代码写入此方法的主体中。
以下类扩展了我们的自定义适配器:
```java
Class GXML.PersonWithXMLNew2
Extends (%Persistent, %Populate, GXML.AdaptorWithXMLNew)
{
Parameter XMLNAME = "Person";
Property Name As %Name;
Property DOB As %Date(FORMAT = 5, MAXVAL = "+$h");
Property Address As GXML.Address;
Property Doctors As list Of GXML.Doctor;
}
```
当运行前面显示的示例`ReadFile`方法时,对于文件中的每个 ``元素,该方法要么创建并保存一条新记录,要么打开并更新现有记录。
文章
Claire Zheng · 三月 3, 2021
亲爱的社区用户:
InterSystems社区会举办丰富的竞赛活动,项目提交后最重要的环节就是“投票”!
一般来说社区新注册用户在投票时会发现无法投票并收到以下提示:
如果遇到这种情况,解决方案分两步:
第一步:登陆社区(cn.community.intersystems.com)后进行发帖、回复、回答问题等操作;
第二步:如果您在社区已经完成了上述第一步的操作,那么接下来只需要……等一天。因为我们的系统会每天进行一次active user更新。
成为Active user后,就可以继续给你心仪的项目投票啦!
建议中国用户登录社区中文版(cn.community.intersystems.com)进行操作,以便获得更快的支持! 请再等一天 @Sheng.Li @Jianjun.Miao @gu.jingguo , Thx! 明白了,十分感谢! 明白了,十分感谢! 原来有中文社区,好不容易才找到,,, 通过学习期望也能参加到竞赛!加油! 碰到了这个问题,完美解决,谢谢! 注册满一天留言才能投票
文章
Michael Lei · 六月 26, 2022
在前一篇文章中,我已经演示了一种简单的方法来记录数据的变化。在这个时候,我改变了负责记录审计数据的 "审计抽象类 "和记录审计日志的数据结构。
我已经将数据结构改为父子结构,其中将有两个表来记录 "交易 "和在该交易中改变的 "字段的值"。
看一下新的数据模型:
看看从 "审计类 "改变的代码吧:
Class Sample.AuditBase [ Abstract ]{ Trigger SaveAuditAfter [ CodeMode = objectgenerator, Event = INSERT/UPDATE, Foreach = row/object, Order = 99999, Time = AFTER ]{ #dim %compiledclass As %Dictionary.CompiledClass #dim tProperty As %Dictionary.CompiledProperty #dim tAudit As Sample.Audit Do %code.WriteLine($Char(9)_"; get username and ip adress") Do %code.WriteLine($Char(9)_"Set tSC = $$$OK") Do %code.WriteLine($Char(9)_"Set tUsername = $USERNAME") Set tKey = "" Set tProperty = %compiledclass.Properties.GetNext(.tKey) Set tClassName = %compiledclass.Name Do %code.WriteLine($Char(9)_"Try {") Do %code.WriteLine($Char(9,9)_"; Check if the operation is an update - %oper = UPDATE") Do %code.WriteLine($Char(9,9)_"if %oper = ""UPDATE"" { ") Do %code.WriteLine($Char(9,9,9)_"Set tAudit = ##class(Sample.Audit).%New()") Do %code.WriteLine($Char(9,9,9)_"Set tAudit.Date = +$Horolog") Do %code.WriteLine($Char(9,9,9)_"Set tAudit.UserName = tUsername") Do %code.WriteLine($Char(9,9,9)_"Set tAudit.ClassName = """_tClassName_"""") Do %code.WriteLine($Char(9,9,9)_"Set tAudit.Id = {id}") Do %code.WriteLine($Char(9,9,9)_"Set tSC = tAudit.%Save()") do %code.WriteLine($Char(9,9,9)_"If $$$ISERR(tSC) $$$ThrowStatus(tSC)") Do %code.WriteLine($Char(9,9,9)_"Set tAuditId = tAudit.%Id()") While tKey '= "" { set tColumnNbr = $Get($$$EXTPROPsqlcolumnnumber($$$pEXT,%classname,tProperty.Name)) Set tColumnName = $Get($$$EXTPROPsqlcolumnname($$$pEXT,%classname,tProperty.Name)) If tColumnNbr '= "" { Do %code.WriteLine($Char(9,9,9)_";") Do %code.WriteLine($Char(9,9,9)_";") Do %code.WriteLine($Char(9,9,9)_"; Audit Field: "_tProperty.SqlFieldName) Do %code.WriteLine($Char(9,9,9)_"if {" _ tProperty.SqlFieldName _ "*C} {") Do %code.WriteLine($Char(9,9,9,9)_"Set tAuditField = ##class(Sample.AuditField).%New()") Do %code.WriteLine($Char(9,9,9,9)_"Set tAuditField.Field = """_tColumnName_"""") Do %code.WriteLine($Char(9,9,9,9)_"Set tAuditField.OldValue = {"_tProperty.SqlFieldName_"*O}") Do %code.WriteLine($Char(9,9,9,9)_"Set tAuditField.NewValue = {"_tProperty.SqlFieldName_"*N}") Do %code.WriteLine($Char(9,9,9,9)_"Do tAuditField.AuditSetObjectId(tAuditId)") Do %code.WriteLine($Char(9,9,9,9)_"Set tSC = tAuditField.%Save()") do %code.WriteLine($Char(9,9,9,9)_"If $$$ISERR(tSC) $$$ThrowStatus(tSC)") Do %code.WriteLine($Char(9,9,9)_"}") } Set tProperty = %compiledclass.Properties.GetNext(.tKey) } Do %code.WriteLine($Char(9,9)_"}") Do %code.WriteLine($Char(9)_"} Catch (tException) {") Do %code.WriteLine($Char(9,9)_"Set %msg = tException.AsStatus()") Do %code.WriteLine($Char(9,9)_"Set %ok = 0") Do %code.WriteLine($Char(9)_"}") Set %ok = 1} }
通过Test()类方法改变数据,现在你可以看到审计类(Sample.Audit)中的 "父记录 "和 "审计字段 "类中的 "子字段 "被改变。(Sample.AuditField)。
d ##class(Sample.Person).Test(1)INSERT INTO Sample.Person (Name, Age) VALUES ('TEST PARENT-CHILD', '01')SQLCODE: 0ID Age Name1 01 TEST PARENT-CHILD 1 Rows(s) AffectedUPDATE Sample.Person SET Name = 'INTERSYSTEMS DEVELOPER COMMUNITY', Age = '100' WHERE Name = 'TEST PARENT-CHILD'SQLCODE:0ID Age Name1 100 INTERSYSTEMS DEVELOPER COMMUNITY 1 Rows(s) Affected
审计类:
注意Sample.AuditField记录通过Audit字段=1对Sample.Audit类进行了引用。你可以通过使用两个类的关系来查询数据,如下所示:
这样就搞定了。这样,我们有一个不同的审计日志数据结构。