清除过滤器
文章
Michael Lei · 七月 6, 2021
供应商或内部团队要求说明如何为 VMware vSphere 上运行的_大型生产数据库_进行 CPU 容量规划。
总的来说,在调整大型生产数据库的 CPU 规模时,有几个简单的最佳做法可以遵循:
- 为每个物理 CPU 核心规划一个 vCPU。
- 考虑 NUMA 并按理想情况调整虚拟机规模,以使 CPU 和内存对于 NUMA 节点是本地的。
- 合理调整虚拟机规模。 仅在需要时才添加 vCPU。
通常,这会引出几个常见问题:
- 由于使用超线程技术,VMware 创建的虚拟机的 CPU 数量可以是物理 CPU 数量的两倍。 那不就是双倍容量吗? 创建的虚拟机不应该有尽可能多的 CPU 吗?
- 什么是 NUMA 节点? 我应该在意 NUMA 吗?
- 虚拟机应该合理调整规模,但我如何知道什么时候合理?
我以下面的示例回答这些问题。 但也要记住,最佳做法并不是一成不变的。 有时需要做出妥协。 例如,大型生产数据库虚拟机很可能不适合 NUMA 节点,但我们会看到,其实是没问题的。 最佳做法是指必须针对应用程序和环境进行评估和验证的准则。
虽然本文中的示例是在 InterSystems 数据平台上运行的数据库,但概念和规则通常适用于任何大型(怪兽)虚拟机的容量和性能规划。
有关虚拟化最佳做法以及有关性能和容量规划的更多帖子,请参见 [InterSystems 数据平台和性能系列的其他帖子列表](https://cn.community.intersystems.com/post/intersystems-数据平台的容量规划和性能系列文章)。
# 怪兽虚拟机
本帖主要是关于部署_怪兽虚拟机_,有时也称为 _Wide 虚拟机_。 高事务数据库的 CPU 资源要求意味着它们通常部署在怪兽虚拟机上。
> 怪兽虚拟机是指虚拟 CPU 或内存多于物理 NUMA 节点的虚拟机。
# CPU 架构和 NUMA
当前的英特尔处理器架构采用非统一内存架构 (NUMA)。 例如,本帖中用来运行测试的服务器有:
- 两个 CPU 插槽,每个插槽一个 12 核处理器(英特尔 E5-2680 v3)。
- 256 GB 内存(16 条 16GB RDIMM)
每个 12 核处理器都有自己的本地内存(128GB RDIMM 及本地高速缓存),还可以访问同一主机中其他处理器上的内存。 每个由 CPU、CPU 高速缓存和 128GB RDIMM 内存组成的 12 核套装都是一个 NUMA 节点。 为了访问其他处理器上的内存,NUMA 节点通过快速互连来连接。
处理器上运行的进程访问本地 RDIMM 和缓存内存的延迟比跨互连访问其他处理器上的远程内存的延迟要低。 跨互连访问会增加延迟,因此性能不一致。 同样的设计也适用于具有两个以上插槽的服务器。 一台四插槽英特尔服务器有四个 NUMA 节点。
ESXi 了解物理 NUMA,ESXi CPU 调度器设计为优化 NUMA 系统的性能。 ESXi 使性能最大化的方法之一是在物理 NUMA 节点上创建数据本地性。 在我们的示例中,如果虚拟机有 12 个 vCPU,并且内存不到 128GB,ESXi 将分配该虚拟机在一个物理 NUMA 节点上运行。 这就形成了规则:
> 如果可能,将虚拟机规模调整为使 CPU 和内存对于 NUMA 节点是本地的。
如果需要比 NUMA 节点规模大的怪兽虚拟机也没有问题,ESXi 可以很好地自动计算和管理要求。 例如,ESXi 将创建能够智能调度到物理 NUMA 节点上的虚拟 NUMA 节点 (vNUMA),以获得最佳性能。 vNUMA 结构对操作系统公开。 例如,如果您有一台具有两个 12 核处理器的主机服务器和一个具有 16 个 vCPU 的虚拟机,ESXi 可能会使用每个处理器上的 8 个物理核心来调度虚拟机 vCPU,操作系统(Linux 或 Windows)将看到两个 NUMA 节点。
同样重要的是,应合理调整虚拟机的规模,并且分配的资源不要超过所需的资源,否则会导致资源浪费和性能损失。 除了有助于调整 NUMA 的规模,具有高(但安全的)CPU 利用率的 12 vCPU 虚拟机比具有中低 CPU 利用率的 24 vCPU 虚拟机更高效、性能更好,特别是该主机上还有其他虚拟机需要调度并且争用资源时。 这也再次强化了该规则:
> 合理调整虚拟机规模。
__注意:__英特尔和 AMD 的 NUMA 实现有区别。 AMD 每个处理器有多个 NUMA 节点。 我已经有一段时间没有在客户服务器中看到 AMD 处理器了,但是如果你有这些处理器,请检查 NUMA 布局,作为规划的一部分。
## Wide 虚拟机和授权
为实现最佳 NUMA 调度,请配置 Wide 虚拟机; 2017 年 6 月更正:按每个插槽 1 个 vCPU 配置虚拟机。 例如,默认情况下,一个具有 24 个 vCPU 的虚拟机应配置为 24 个 CPU 插槽,每个插槽一个核心。
> 遵守 VMware 最佳做法规则。
请参见 [VMware 博客上的这篇文章以查看示例。 ](https://blogs.vmware.com/performance/2017/03/virtual-machine-vcpu-and-vnuma-rightsizing-rules-of-thumb.html)
该 VMware 博客文章进行了详细介绍,但是作者 Mark Achtemichuk 建议遵循以下经验法则:
- 虽然有许多高级 vNUMA 设置,但只有极少数情况下需要更改其默认值。
- 总是将虚拟机 vCPU 数配置为反映每插槽核心数,直到超过单个物理 NUMA 节点的物理核心数。
- 当需要配置的 vCPU 数量超过 NUMA 节点中的物理核心数量时,将 vCPU 均匀分配到最少数量的 NUMA 节点上。
- 当虚拟机规模超过物理 NUMA 节点时,不要分配奇数数量的 vCPU。
- 不要启用 vCPU 热添加,除非您不介意禁用 vNUMA。
- 不要创建规模大于主机物理核心总数的虚拟机。
Caché 授权以核心数为准,因此这不是问题,但是对于除 Caché 以外的软件或数据库,指定虚拟机有 24 个插槽可能会对软件授权产生影响,因此必须与供应商核实。
# 超线程和 CPU 调度器
超线程 (HT) 经常在讨论中出现,我听过“超线程使 CPU 核心数量翻倍”。 这在物理层面上显然是不可能的,物理核心有多少就是多少。 超线程应该被启用,并会提高系统性能。 预计应用程序性能可能会提高 20% 或更多,但实际数字取决于应用程序和工作负载。 但肯定不会翻倍。
正如我在 [VMware 最佳实践](https://cn.community.intersystems.com/post/intersystems-数据平台和性能-–-第-9-篇-intersystems-iris-vmware-最佳实践指南)中所述,_调整大型生产数据库虚拟机规模_的一个很好的起点是假定 vCPU 拥有服务器上完整的物理核心专用资源 — 在进行容量规划时基本忽略超线程。 例如:
> 对于一台 24 核主机服务器,可规划总共多达 24 个 vCPU 的生产数据库虚拟机,且可能还有余量。
在您花时间监测应用程序、操作系统和 VMware 在峰值处理期间的性能后,您可以决定是否进行更高度的虚拟机整合。 在最佳做法帖子中,我将规则表述为:
> 一个物理 CPU(包括超线程)= 一个 vCPU(包括超线程)。
## 为什么超线程不会使 CPU 翻倍
英特尔至强处理器上的超线程是在一个物理核心上创建两个_逻辑_ CPU 的方法。 操作系统可以有效地针对两个逻辑处理器进行调度 — 如果一个逻辑处理器上的进程或线程正在等待,例如等待 IO,则物理 CPU 资源可以被另一个逻辑处理器使用。 在任何时间点都只能有一个逻辑处理器运行,因此虽然物理核心得到了更有效的利用,但_性能并没有翻倍_。
在主机 BIOS 中启用超线程后,当创建虚拟机时,可以为每个超线程逻辑处理器配置一个 vCPU。 例如,在一台启用了超线程的物理 24 核服务器上,可以创建具有多达 48 个 vCPU 的虚拟机。 ESXi CPU 调度器将通过首先在独立的物理核心上运行虚拟机进程来优化处理(同时仍然考虑 NUMA)。 在以后的帖子中,我将探讨在怪兽数据库虚拟机上分配比物理核心数更多的 vCPU 是否有助于扩展。
### 协同停止和 CPU 调度
在监测主机和应用程序性能后,您可以决定是否让主机 CPU 资源过载。 这是否是一个好主意在很大程度上取决于应用程序和工作负载。 了解调度器和要监测的关键指标有助于确保没有使主机资源过载。
我有时听说,要让虚拟机正常运行,空闲逻辑 CPU 的数量必须与虚拟机中的 vCPU 数量相同。 例如,一个 12 vCPU 虚拟机必须“等待”12 个逻辑 CPU“可用”,才能继续执行。 不过应该注意,ESXi 在版本 3 之后就不是这样了。 ESXi 对 CPU 使用宽松的协同调度,以提高应用程序性能。
由于多个协作线程或进程经常相互同步,不一起调度它们可能会增加操作的延迟。 例如,在自旋循环中,一个线程等待被另一个线程调度。 为了获得最佳性能,ESXi 尝试将尽可能多的同级 vCPU 一起调度。 但是,当有多个虚拟机在整合环境中争用 CPU 资源时,CPU 调度器可以灵活地调度 vCPU。 如果一些 vCPU 的进展比同级 vCPU 领先太多(这个时间差称为偏移),领先的 vCPU 将决定是否停止自身(协同停止)。 请注意,协同停止(或协同启动)的是 vCPU,不是整个虚拟机。 这种机制即使在资源有些过载的情况下也非常有效,但正如您所预期,CPU 资源过载太多将不可避免地影响性能。 我在后面的示例 2 中展示了一个过载和协同停止的例子。
记住,这不是虚拟机之间全力争夺 CPU 资源的竞赛;ESXi CPU 调度器的工作是确保 CPU 共享、保留和限制等策略被遵守,同时最大限度地提高 CPU 利用率,并确保公平性、吞吐量、响应速度和可伸缩性。 关于使用保留和共享来确定生产工作负载优先级的讨论不在本帖范围之内,而且取决于应用程序和工作负载组合。 如果我以后发现任何特定于 Caché 的建议,我可能会重新讨论这个话题。 有许多因素会影响到 CPU 调度器,本节只是简单提一下。 要深入了解,请参见帖子末尾的参考资料中的 VMware 白皮书及其他链接。
# 示例
为了说明不同的 vCPU 配置,我使用一个基于浏览器的高事务速率医院信息系统应用程序运行了一系列基准测试。 与 VMware 开发的 DVD 商店数据库基准测试的概念类似。
基准测试的脚本是根据现场医院实施的观测值和指标创建的,包括高使用率的工作流程、事务和使用最多系统资源的组件。 其他主机上的驱动虚拟机以设置的工作流程事务速率执行具有随机输入数据的脚本,来模拟 Web 会话(用户)。 1 倍速率的基准为基线。 速率可以按比例递增和递减。
除了数据库和操作系统指标外,一个很好的用来衡量基准数据库虚拟机性能的指标是在服务器上测量的组件(也可以是事务)响应时间。 一个组件示例是一部分最终用户屏幕。 组件响应时间增加意味着用户将开始看到应用程序响应时间变差。 性能良好的数据库系统必须为最终用户提供_一致的_高性能。 在下面的图表中,我针对一致的测试性能进行测量,并通过对 10 个最慢的高使用率组件的响应时间取平均值来表示最终用户体验。 预计平均组件响应时间为亚秒级,用户屏幕可能由一个组件组成,或者复杂的屏幕可能有多个组件。
> 请记住,您始终针对峰值工作负载进行规模调整,并且为意外的活动峰值留出缓冲区。 我通常以平均 80% 的峰值 CPU 利用率为目标。
基准测试硬件和软件的完整列表在帖子末尾。
## 示例 1. 合理调整规模 - 每个主机一个怪兽虚拟机
可以创建一个可以使用主机服务器所有物理核心的数据库虚拟机,例如 24 物理核心主机上的 24 vCPU 虚拟机。 数据库虚拟机不会在 Caché 数据库镜像中“裸机”运行服务器以实现 HA,也不会引入操作系统故障转移集群的复杂性,而是包含在 vSphere 集群中实现管理和 HA,例如 DRS 和 VMware HA。
我见过有客户遵循老派的思维,根据五年硬件寿命结束时的预期容量来确定主数据库虚拟机的规模,但从上文可知,最好合理调整规模;如果虚拟机没有过度调整,性能和整合度会更好,并且管理 HA 将更容易;如果需要维护或主机出现故障,并且数据库怪兽虚拟机必须迁移或在其他主机上重启,想想俄罗斯方块的玩法就知道了。 如果预计事务速率显著增加,可以在计划维护期间提前增加 vCPU。
> 注意,“热添加”CPU 选项会禁用 vNUMA,因此不要将其用于怪兽虚拟机。
考虑下图显示的在 24 核主机上进行的一系列测试。 对于这个 24 核系统,3 倍事务速率是甜蜜点和容量规划目标。
- 主机上运行一个虚拟机。
- 使用了四种虚拟机规模来展示 12、24、36 和 48 vCPU 的性能。
- 尽可能对每种虚拟机规模都运行一系列事务速率(1 倍、2倍、3 倍、4 倍、5 倍)。
- 性能/用户体验以组件响应时间(条形图)的形式显示。
- 客户机虚拟机的 CPU 利用率百分比为平均值(线条)。
- 所有虚拟机规模中,主机 CPU 利用率都在 4 倍速率时达到 100%(红色虚线)。

这个图表中有许多信息,但我们可以关注几个有趣的事情。
- 24 vCPU 虚拟机(橙色)平稳地增加到目标 3 倍事务速率。 在 3 倍速率时,客户机内虚拟机的平均 CPU 利用率为 76%(峰值为 91% 左右)。 主机 CPU 利用率并不比客户机虚拟机高多少。 在 3 倍速率之前,组件响应时间非常稳定,因此用户很满意。 就我们的目标事务速率而言 — _这个虚拟机已合理调整规模_。
关于合理规模调整先说这么多,那么增加 vCPU 也就是使用超线程又会如何。 性能和可伸缩性有可能翻倍吗? 简短回答是_不可能!_
在这种情况下,可以通过查看 4 倍以上速率的组件响应时间来了解答案。 虽然在分配了更多逻辑核心 (vCPU) 后性能“更好”,但仍然不平稳,不像 3 倍速率之前那样一致。 4 倍速率时,用户将报告响应时间变慢,无论分配多少个 vCPU。 请记住,在 4 倍速率时,_主机_曲线已经持平于 100% CPU 利用率,如 vSphere 所报告。 在 vCPU 数量较多的情况下,即使客户机内 CPU 指标 (vmstat) 报告低于 100% 利用率,对于物理资源来说情况也并非如此。 请记住,客户机操作系统不知道它是虚拟化的,它只是报告它所看到的资源。 另外,客户机操作系统也看不到超线程,所有 vCPU 都表现为物理核心。
关键是,数据库进程(在 3 倍事务速率时有 200 多个 Caché 进程)非常繁忙,并且非常高效地使用处理器,逻辑处理器没有很多空闲资源来调度更多工作,或将更多虚拟机整合到该主机。 例如,很大一部分 Caché 处理是在内存中进行的,因此没有很多 IO 等待。 所以,虽然可以分配比物理核心更多的 vCPU,但由于主机已经被 100% 利用,并不会获益许多。
Caché 非常擅长处理高工作负载。 即使主机和虚拟机的 CPU 利用率达到 100%,应用程序仍在运行,并且事务速率仍在提高 — 扩展不是线性的,如我们所见,响应时间越来越长,用户体验将受到影响 — 但应用程序不会“一落千丈”,尽管情况不是很好,但用户仍可以工作。 如果您的应用程序对响应时间不是那么敏感,那么很高兴地告诉您,您可以将其推向边缘甚至更远,并且 Caché 仍然可以安全地工作。
> 请记住,您不会想要以 100% CPU 运行数据库虚拟机或主机。 您需要容量来应对虚拟机的意外峰值和增长,而 ESXi 虚拟机监控程序需要资源来进行所有网络、存储和其他活动。
我总是针对 80% CPU 利用率的峰值进行规划。 即便如此,vCPU 的规模最多也只调整到物理核心数,这样即使在极端情况下,仍然有余量让 ESXi 虚拟机监控程序处理逻辑线程。
> 如果您运行超融合 (HCI) 解决方案,还必须考虑主机级别的 HCI CPU 要求。 有关详细信息,请参见我[先前关于 HCI](https://community.intersystems.com/post/intersystems-data-platforms-and-performance-%E2%80%93-part-8-hyper-converged-infrastructure-capacity "previous post on HCI") 的帖子。 部署在 HCI 上的虚拟机的基本 CPU 规模调整与其他虚拟机相同。
请记住,您必须在您自己的环境中使用您的应用程序验证和测试所有内容。
## 示例 2. 资源过载
我看到过客户站点报告应用程序性能“慢”,而客户机操作系统却报告有空闲的 CPU 资源。
记住,客户机操作系统并不知道它是虚拟化的。 不幸的是,客户机内指标(例如 vmstat 在 pButtons 中报告的指标)可能具有欺骗性,您还必须获得主机级指标和 ESXi 指标(例如 `esxtop`)才能真正了解系统运行状况和容量。
如上面的图表所示,当主机报告 100% 利用率时,客户机虚拟机可能报告较低的利用率。 36 vCPU 虚拟机(红色)在 4 倍速率时报告 80% 平均 CPU 利用率,而主机报告 100%。 即使规模调整合理的虚拟机也可能出现资源短缺的情况,例如,如果在启动后有其他虚拟机迁移到主机上,或者由于 DRS 规则配置不当而导致资源过载。
为了显示关键指标,在下面的一系列测试中,我进行了以下配置:
- 主机上运行两个数据库虚拟机。
- - 一个 24 vCPU 虚拟机以恒定的 2 倍事务速率运行(图表上未显示)。
- - 一个 24 vCPU 虚拟机以 1 倍、2 倍、3 倍事务速率运行(图表上显示这些指标)。
在另一个数据库使用资源的情况下;在 3 倍速率时,客户机操作系统 (RHEL 7) vmstat 只报告 86% 平均 CPU 利用率,运行队列大小平均只有 25。 然而,该系统的用户将大声抱怨,因为组件响应时间随着进程变慢而迅速增加。
如下图所示,协同停止和就绪时间说明了为什么用户性能如此糟糕。 就绪时间 (`%RDY`) 和协同停止 (`%CoStop`) 指标显示 CPU 资源在目标 3 倍速率下大幅过载。 这实际并不奇怪,因为_主机_以 2 倍速率运行(其他虚拟机),_而_该数据库虚拟机以 3 倍速率运行。

该图表明,当主机上的 总 CPU 负载增加时,就绪时间也会增加。
> 就绪时间是指虚拟机已准备好运行,但由于 CPU 资源不可用而无法运行的时间。
协同停止也会增加。 没有足够的空闲逻辑 CPU 来允许数据库虚拟机运行(正如我在上面的超线程部分详细说明的那样)。 最终结果是由于对物理 CPU 资源的争用而导致处理延迟。
我曾在一个客户站点看到过这种情况,当时通过 pButtons 和 vmstat 获取的支持视图只显示了虚拟化的操作系统。 虽然 vmstat 报告还有 CPU 余量,但用户的性能体验非常糟糕。
这里的教训是,直到 ESXi 指标和主机级视图可用,才能诊断出真正的问题;一般的集群 CPU 资源短缺导致的 CPU 资源过载,以及使情况变得更糟的不良 DRS 规则,会使高事务数据库虚拟机一起迁移并使主机资源不堪重负。
## 示例 3. 资源过载
在此示例中,我使用了一个以 3 倍事务速率运行的基准 24 vCPU 数据库虚拟机,然后使用两个以恒定 3 倍事务速率运行的 24 vCPU 数据库虚拟机。
虚拟机的平均基准 CPU 利用率(见上面的示例 1)为 76%,主机则为 85%。 单个 24 vCPU 数据库虚拟机会使用全部 24 个物理处理器。 运行两个 24 vCPU 虚拟机意味着这两个虚拟机将争用资源,并使用服务器上的全部 48 个逻辑执行线程。

请记住,在运行单个虚拟机时,主机并没有被 100% 利用,我们仍然可以看到,当两个非常繁忙的 24 vCPU 虚拟机试图使用主机上的 24 个物理核心(即使开启了超线程)时,吞吐量和性能显著下降。 尽管 Caché 非常有效地使用了可用的 CPU 资源,但每个虚拟机的数据库吞吐量仍然下降了 16%,更重要的是,组件(用户)响应时间增加了 50% 以上。
## 总结
本帖的目的是回答几个常见问题。 要深入了解 CPU 主机资源和 VMware CPU 调度器,请参见下面的参考部分。
虽然有许多专业级的调整,并且要深入研究 ESXi 才能榨干系统的最后一点性能,但基本规则非常简单。
对于_大型生产数据库_:
- 为每个物理 CPU 核心规划一个 vCPU。
- 考虑 NUMA 并按理想情况调整虚拟机规模,以使 CPU 和内存对于 NUMA 节点是本地的。
- 合理调整虚拟机规模。 仅在需要时才添加 vCPU。
如果您想要整合虚拟机,请记住,大型数据库非常繁忙,在高峰期会大量使用 CPU(物理和逻辑)。 在您的监视系统告诉您安全之前,不要超额预定 CPU。
## 参考
- [VMware 博客 - 怪兽虚拟机何时过载 vCPU:pCPU](https://blogs.vmware.com/vsphere/2014/02/overcommit-vcpupcpu-monster-vms.html)
- [2016 NUMA 深入研究系列介绍](http://frankdenneman.nl/2016/07/06/introduction-2016-numa-deep-dive-series)
- [VMware vSphere 5.1 中的 CPU 调度器](http://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/techpaper/vmware-vsphere-cpu-sched-performance-white-paper.pdf)
## 测试
我在一个 vSphere 集群上运行了本帖中的示例,该集群包括连接到一个全闪存阵列的双处理器 Dell R730。 在示例运行期间,网络或存储没有出现瓶颈。
- Caché 2016.2.1.803.0
PowerEdge R730
- 2 个 Intel(R) Xeon(R) CPU E5-2680 v3 @ 2.50GHz
- 16 条 16GB RDIMM,2133 MT/s,双列,x4 数据宽度
- SAS 12Gbps HBA 外部控制器
- 超线程 (HT) 开启
PowerVault MD3420,12G SAS,2U-24 驱动器
- 24 个 960GB 固态硬盘 SAS 读取密集型 MLC 12Gbps 2.5 英寸热拔插驱动器,PX04SR
- 2 个控制器,12G SAS,2U MD34xx,8G 缓存
VMware ESXi 6.0.0 build-2494585
- 按照最佳实践配置虚拟机;VMXNET3、PVSCSI 等
RHEL 7
- 大页面
基准 1 倍速率下平均每秒 700,000 gloref(每秒数据库访问次数)。 24 vCPU 在 5 倍速率下平均每秒超过 3,000,000 gloref。 测试以老化方式进行,直到达到稳定的性能,然后进行 15 分钟采样并取平均值。
> 这些示例只是为了说明理论,您必须使用自己的应用程序进行验证!
文章
姚 鑫 · 三月 27, 2021
# 第十三章 使用动态SQL(五)
# 从结果集中返回特定的值
要从查询结果集中返回特定的值,必须一次一行遍历结果集。
要遍历结果集,请使用`%Next()`实例方法。
(对于单一值,结果对象中没有行,因此`%Next()`返回0,而不是错误。)
然后,可以使用`%Print()`方法显示整个当前行的结果,或者检索当前行的指定列的值。
`%Next()`方法获取查询结果中下一行的数据,并将该数据放入结果集对象的data属性中。
`%Next()`返回1,表示它位于查询结果中的某一行上。
`%Next()`返回0,表示它位于最后一行(结果集的末尾)之后。
每次调用`%Next()`返回1个增量`%ROWCOUNT`;
如果游标定位在最后一行之后(`%Next()`返回0),`%ROWCOUNT`表示结果集中的行数。
如果`SELECT`查询只返回聚合函数,每个`%Next()`设置`%ROWCOUNT=1`。
第一个`%Next()`返回1并设置`%SQLCODE=0`和`%ROWCOUNT=1`,即使表中没有数据;
任何随后的`%Next()`返回0,并设置`%SQLCODE=100`和`%ROWCOUNT=1`。
从结果集中获取一行后,可以使用以下任何一种方式显示该行的数据:
- `rset.%Print()`返回查询结果集中当前行的所有数据值。
- `rset.%GetRow()`和`rset.getrows()`以编码列表结构的元素形式从查询结果集中返回一行的数据值。
- `rset.name`按查询结果集中的属性名称、字段名称、别名属性名称或别名字段名称返回数据值。
- `rset.%Get("fieldname")`通过字段名或别名从查询结果集中或存储的查询返回一个数据值。
- `rset.%GetData(n)`按列号从查询结果集中或存储的查询中返回一个数据值。
## %Print()方法
`%Print()`实例方法从结果集中检索当前记录。默认情况下,`%Print()`在数据字段值之间插入空白空格分隔符。
`%Print()`不会在记录的第一个字段值之前或最后一个字段值之后插入空白;
它在记录的末尾发出一个行返回。
如果数据字段值已经包含空格,则将该字段值括在引号中,以将其与分隔符区分开来。
例如,如果`%Print()`返回城市名称,它将按如下方式返回它们: `"New York" Boston Atlanta "Los Angeles" "Salt Lake City" Washington`.
引用包含分隔符作为数据值一部分的字段值,即使从未使用过`%Print()`分隔符;
例如,如果结果集中只有一个字段。
可以选择指定`%Print()`参数,该参数提供在字段值之间放置的另一个定界符。指定其他定界符将覆盖包含空格的数据字符串的引用。此`%Print()`分隔符可以是一个或多个字符。它指定为带引号的字符串。通常,`%Print()`分隔符最好是在结果集数据中找不到的字符或字符串。但是,如果结果集中的字段值包含`%Print()`分隔符(或字符串),则该字段值将用引号引起来,以将其与分隔符区分开。
如果结果集中的字段值包含换行符,则该字段值将以引号引起来。
以下ObjectScript示例使用`%Print()`遍历查询结果集以显示每个结果集记录,并使用 `"^|^"` 定界符分隔值。请注意`%Print()`如何显示`FavoriteColors`字段中的数据,该字段是元素的编码列表:
```java
/// d ##class(PHA.TEST.SQL).ROWCOUNTPrint()
ClassMethod ROWCOUNTPrint()
{
SET q1="SELECT TOP 5 Name,DOB,Home_State,FavoriteColors "
SET q2="FROM Sample.Person WHERE FavoriteColors IS NOT NULL"
SET myquery = q1_q2
SET tStatement = ##class(%SQL.Statement).%New()
SET qStatus = tStatement.%Prepare(myquery)
IF qStatus'=1 {
WRITE "%Prepare failed:" DO $System.Status.DisplayError(qStatus) QUIT
}
SET rset = tStatement.%Execute()
WHILE rset.%Next() {
WRITE "Row count ",rset.%ROWCOUNT,!
DO rset.%Print("^|^")
}
WRITE !,"End of data"
WRITE !,"Total row count=",rset.%ROWCOUNT
}
```
```java
DHC-APP> d ##class(PHA.TEST.SQL).ROWCOUNTPrint()
Row count 1
yaoxin^|^54536^|^WI^|^$lb("Red","Orange","Yellow")
Row count 2
姚鑫^|^^|^^|^$lb("Red","Orange","Yellow","Green")
Row count 3
姚鑫^|^^|^^|^$lb("Red","Orange","Yellow","Green","Green")
Row count 4
Isaacs,Roberta Z.^|^^|^^|^$lb("Red","Orange","Yellow","Green","Yellow")
Row count 5
Chadwick,Zelda S.^|^50066^|^WI^|^$lb("White")
End of data
Total row count=5
```
下面的示例显示如何将包含定界符的字段值括在引号中。在此示例中,大写字母`A`用作字段定界符;因此,任何包含大写字母A的字段值(名称,街道地址或州缩写)都将以引号引起来。
```java
/// d ##class(PHA.TEST.SQL).ROWCOUNTPrint2()
ClassMethod ROWCOUNTPrint2()
{
SET myquery = "SELECT TOP 25 Name,Home_Street,Home_State,Age FROM Sample.Person"
SET tStatement = ##class(%SQL.Statement).%New()
SET qStatus = tStatement.%Prepare(myquery)
IF qStatus'=1 {
WRITE "%Prepare failed:" DO $System.Status.DisplayError(qStatus) QUIT
}
SET rset = tStatement.%Execute()
WHILE rset.%Next() {
DO rset.%Print("A")
}
WRITE !,"End of data"
WRITE !,"Total row count=",rset.%ROWCOUNT
}
```
```java
DHC-APP>d ##class(PHA.TEST.SQL).ROWCOUNTPrint2()
yaoxinA889 Clinton DriveAWIA30
xiaoliAAA
姚鑫AAA7
姚鑫AAA7
姚鑫AAA43
姚鑫AAA
姚鑫AAA
Isaacs,Roberta Z.AAA
Chadwick,Zelda S.A9889 Clinton DriveAWIA43
Fives,James D.A2091 Washington BlvdANDA88
Vonnegut,Jose P.A3660 Main PlaceAWIA47
Chadbourne,Barb B.A1174 Second StreetA"VA"A93
"Quigley,Barb A."A"6501 Ash Avenue"AKYA73
```
## %GetRow()和%GetRows()方法
`%GetRow()`实例方法从结果集中检索当前行(记录),作为字段值元素的编码列表:
```java
/// d ##class(PHA.TEST.SQL).ROWCOUNTPrint3()
ClassMethod ROWCOUNTPrint3()
{
SET myquery = "SELECT TOP 17 %ID,Name,Age FROM Sample.Person"
SET tStatement = ##class(%SQL.Statement).%New()
SET qStatus = tStatement.%Prepare(myquery)
IF qStatus'=1 {
WRITE "%Prepare failed:" DO $System.Status.DisplayError(qStatus) QUIT
}
SET rset = tStatement.%Execute()
FOR {
SET x=rset.%GetRow(.row,.status)
IF x=1 {
WRITE $LISTTOSTRING(row," | "),!
} ELSE {
WRITE !,"End of data"
WRITE !,"Total row count=",rset.%ROWCOUNT
RETURN
}
}
}
```
`%GetRows()`实例方法从结果集中检索指定大小的一组行(记录)。每行作为字段值元素的编码列表返回。
下面的示例返回结果集中的第1、6和11行。在此示例中,`%GetRows()`第一个参数(5)指定`%GetRows()`应该检索五行的连续组。如果成功检索到一组五行,`%GetRows()`将返回1。 `.rows`参数通过引用传递这五行的下标数组,因此,`rows(1)`返回每五组中的第一行:第1、6和11行。指定`rows(2)`将返回第2、7行和12。
```java
/// d ##class(PHA.TEST.SQL).ROWCOUNTPrint4()
ClassMethod ROWCOUNTPrint4()
{
SET myquery = "SELECT TOP 17 %ID,Name,Age FROM Sample.Person"
SET tStatement = ##class(%SQL.Statement).%New()
SET qStatus = tStatement.%Prepare(myquery)
IF qStatus'=1 {
WRITE "%Prepare failed:" DO $System.Status.DisplayError(qStatus) QUIT
}
SET rset = tStatement.%Execute()
FOR {
SET x=rset.%GetRows(5,.rows,.status)
IF x=1 {
WRITE $LISTTOSTRING(rows(1)," | "),!
} ELSE {
WRITE !,"End of data"
WRITE !,"Total row count=",rset.%ROWCOUNT
RETURN
}
}
}
```
可以使用`ZWRITE rows`命令返回检索到的数组中的所有下标,而不是按下标检索单个行。请注意,上面的示例ZWRITE行不会返回结果集中的第16行和第17行,因为在检索到最后一组五行之后,这些行是余数。
## rset.name属性
当InterSystems IRIS生成结果集时,它将创建一个结果集类,其中包含一个与该结果集中的每个字段名称和字段名称别名相对应的唯一属性。
可以使用`rset.name`属性按属性名称,字段名称,属性名称别名或字段名称别名返回数据值。
- 属性名称:如果未定义字段别名,则将字段属性名称指定为`rset.PropName`。结果集字段属性名称取自表定义类中的相应属性名称。
- 字段名称:如果没有定义字段别名,请将字段名称(或属性名称)指定为`rset。“fieldname”`。这是表定义中指定的`SQLFIELDNAME`。 Intersystems Iris使用此字段名称来查找相应的属性名称。在许多情况下,属性名称和字段名称(`SQLFieldName`)是相同的。
- 别名属性名称:如果定义了字段别名,则将别名属性名称指定为`rset.AliasProp`。别名属性名称是根据`SELECT`语句中的列名称别名生成的。不能为具有已定义别名的字段指定字段属性名称。
- 别名:如果定义了字段别名,则将此别名(或别名属性名称)指定为`rset。“ alias”`。这是`SELECT`语句中的列名别名。您不能为具有已定义别名的字段指定字段名称。
- 集合,表达式或子查询:InterSystems IRIS为这些选择项分配一个字段名称`Aggregate_n`,`Expression_n`或`Subquery_n`(其中整数`n`对应于查询中指定的选择项列表的顺序)。可以使用字段名称(`rset。“ SubQuery_7”`不区分大小写),相应的属性名称(`rset.Subquery7`区分大小写)或用户定义的字段名称别名来检索这些select-item值。也可以只使用`rset。%GetData(n)`指定选择项的序列号。
指定属性名称时,必须使用正确的字母大小写;指定字段名称时,不需要正确的字母大小写。
使用属性名称对`rset.name`的调用具有以下后果:
- 字母大小写:属性名称区分大小写。字段名称不区分大小写。 Dynamic SQL可以自动解决指定字段或别名与相应属性名称之间的字母大小写差异。但是,解决字母大小写需要时间。为了最大限度地提高性能,应该指定属性名称或别名的确切字母大小写。
- 非字母数字字符:属性名称只能包含字母数字字符(起始的`%`字符除外)。如果相应的SQL字段名称或字段名称别名包含非字母数字字符(例如`Last_Name`),则可以执行以下任一操作:
- 指定用引号分隔的字段名称。例如,`rset。“ Last_Name”`)。分隔符的这种使用不需要启用分隔符。执行大写字母解析。
- 指定相应的属性名称,以消除非字母数字字符。例如,`rset.LastName`(或`rset。“ LastName”`)。必须为属性名称指定正确的字母大小写。
- `%`属性名称:通常,以`%`字符开头的属性名称保留供系统使用。如果字段属性名称或别名以`%`字符开头,并且该名称与系统定义的属性冲突,则返回系统定义的属性。例如,对于`SELECT Notes AS%Message`,调用`rset。%Message`将不返回`Notes`字段值。它返回为语句结果类定义的`%Message`属性。可以使用`rset。%Get(“%Message”)`返回字段值。
- 列别名:如果指定了别名,则Dynamic SQL始终匹配该别名,而不匹配字段名称或字段属性名称。例如,对于`SELECT Name AS Last_Name`,只能使用`rset.LastName`或`rset。“ Last_Name”`来检索数据,而不能使用`rset.Name`。
- 重复名称:如果名称解析为相同的属性名称,则它们是重复的。重复名称可以是对表中同一字段的多个引用,对表中不同字段的别名引用或对不同表中字段的引用。例如,`SELECT p.DOB,e.DOB`指定两个重复的名称,即使这些名称引用了不同表中的字段。
如果`SELECT`语句包含相同字段名称或字段名称别名的多个实例,则`rset.propname`或`rset。“fieldname”`始终返回`SELECT`语句中指定的第一个。例如,对于`SELECT C.NAME,P.NAME`来自`Sample.person as p,sample.company`使用`rset.name`检索公司名称字段数据;选择`C.Name,P.Name`作为来自`Sample.person`的名称,`As P,Sample.com`本文使用`RSET。“name”`还检索公司名称字段数据。如果查询中存在重复的名称字段,则字段名称(名称)的最后一个字符由字符(或字符)替换为创建唯一属性名称。因此,查询中的重复名称字段名称具有相应的唯一属性名称,以`NAM0`(第一个重复)通过`NAM9`开始,并通过`NAMZ`继续大写字母`NAMA`。
对于使用`%Prepare()`准备的用户指定的查询,可以单独使用属性名称。对于使用`%PrepareClassQuery()`准备的存储查询,必须使用`%Get(“ fieldname”)`方法。
下面的示例返回由属性名称指定的三个字段的值:两个属性值分别由属性名称和第三个属性值由别名属性名称。在这些情况下,指定的属性名称与字段名称或字段别名相同:
```java
/// d ##class(PHA.TEST.SQL).PropSQL()
ClassMethod PropSQL()
{
SET myquery = "SELECT TOP 5 Name,DOB AS bdate,FavoriteColors FROM Sample.Person"
SET tStatement = ##class(%SQL.Statement).%New(1)
SET qStatus = tStatement.%Prepare(myquery)
IF qStatus'=1 {
WRITE "%Prepare failed:" DO $System.Status.DisplayError(qStatus) QUIT
}
SET rset = tStatement.%Execute()
WHILE rset.%Next() {
WRITE "Row count ",rset.%ROWCOUNT,!
WRITE rset.Name
WRITE " prefers ",rset.FavoriteColors
WRITE " birth date ",rset.bdate,!!
}
WRITE !,"End of data"
WRITE !,"Total row count=",rset.%ROWCOUNT
}
```
```java
DHC-APP>d ##class(PHA.TEST.SQL).PropSQL()
Row count 1
yaoxin prefers Red,Orange,Yellow birth date 1990-04-25
Row count 2
xiaoli prefers birth date
Row count 3
姚鑫 prefers birth date 2014-01-02
Row count 4
姚鑫 prefers birth date 2014-01-02
Row count 5
姚鑫 prefers birth date 1978-01-28
End of data
Total row count=5
```
在上面的示例中,返回的字段之一是`FavoriteColors`字段,其中包含`%List`数据。若要显示此数据,`%New(1)`类方法将`%SelectMode`属性参数设置为1(ODBC),从而导致该程序将`%List`数据显示为逗号分隔的字符串,并以ODBC格式显示出生日期:
下面的示例返回`Home_State`字段。因为属性名称不能包含下划线字符,所以本示例指定用引号`(“ Home_State”)`分隔的字段名称`(SqlFieldName)`。还可以指定不带引号的相应生成的属性名称`(HomeState)`。请注意,定界字段名称`(“ Home_State”)`不区分大小写,但是生成的属性名称`(HomeState)`是区分大小写的:
```java
/// d ##class(PHA.TEST.SQL).PropSQL1()
ClassMethod PropSQL1()
{
SET myquery = "SELECT TOP 5 Name,Home_State FROM Sample.Person"
SET tStatement = ##class(%SQL.Statement).%New(2)
SET qStatus = tStatement.%Prepare(myquery)
IF qStatus'=1 {WRITE "%Prepare failed:" DO $System.Status.DisplayError(qStatus) QUIT}
SET rset = tStatement.%Execute()
WHILE rset.%Next() {
WRITE "Row count ",rset.%ROWCOUNT,!
WRITE rset.Name
WRITE " lives in ",rset."Home_State",!
}
WRITE !,"End of data"
WRITE !,"Total row count=",rset.%ROWCOUNT
}
```
```java
DHC-APP>d ##class(PHA.TEST.SQL).PropSQL1()
Row count 1
yaoxin lives in WI
Row count 2
xiaoli lives in
Row count 3
姚鑫 lives in
Row count 4
姚鑫 lives in
Row count 5
姚鑫 lives in
End of data
Total row count=5
```
%GetRows 这个方法在IRIS 2019里有吗?
文章
Hao Ma · 一月 15, 2021
在这个由三部分组成的系列文章中,我们将展示如何在OAuth 2.0标准下使用IAM简单地为IRIS中的未经验证的服务添加安全性。
在第一部分中,我们介绍了一些OAuth 2.0背景知识,以及IRIS和IAM的初始定义和配置,以帮助读者理解确保服务安全的整个过程。
现在,本文将详细讨论和演示配置IAM所需的步骤——验证传入请求中的访问令牌,并在验证成功时将请求转发到后端。
本系列的最后一部分将讨论和演示IAM生成访问令牌(充当授权服务器)并对其进行验证时所需的配置,以及一些重要的最终考虑事项。
如果您想试用IAM,请联系InterSystems销售代表。
场景1:IAM作为访问令牌验证器
在该场景中,需要使用一个外部授权服务器生成JWT(JSON Web Token)格式的访问令牌。该JWT使用了RS256算法和私钥签名。为了验证JWT签名,另一方(本例中是IAM)需要拥有授权服务器提供的公钥。
由外部授权服务器生成的JWT主体中还包括一个名为“exp”的声明(包含该令牌过期的时间戳),以及另一个名为“iss”的声明(包含授权服务器的地址)。
因此,IAM需要先使用授权服务器的公钥和JWT内部“exp”声明中包含的过期时间戳对JWT签名进行验证,然后再将请求转发给IRIS。
对IAM进行相应配置时,首先要向IAM中的“SampleIRISService”添加一个名为“JWT”的插件。为此,请转到IAM中的Services页面并复制“SampleIRISService”的ID,稍后会用到。
之后,打开插件,点击“New Plugin”按钮,找到“JWT”插件,点击启用。
在下个页面中,将“SampleIRISService”ID粘贴在“service_id”字段中,然后在“config.claims_to_verify”参数中选中“exp”框。
注意,“config.key_claim_name”参数的值是“iss”。后面会用到。
然后,点击“Create”按钮。
完成操作后,找到左侧菜单中的“Consumers”部分,然后单击先前创建的“ClientApp”。点击“Credentials”标签,然后单击按钮“New JWT Credential”。
在下一页中,选择JWT签名算法(本例中为RS256),并将公钥(这是授权服务器提供的PEM格式的公钥)粘贴到“rsa_public_key”字段中。
在“key”字段中,在添加JWT插件时需要用到之前在“config.key_claim_name”字段中输入的JWT声明内容。所以在本例中,需要插入的是JWT的iss声明内容(本例中是授权服务器的地址)。
之后,单击“Create”按钮。
提示:出于调试目的,可以使用一个在线工具对JWT进行解码,将公钥粘贴进去就可以检查声明内容及其值,并且验证签名。该在线工具的链接如下:https://jwt.io/#debugger
现在,添加了JWT插件后,就不能发送未经身份验证的请求了。如下所示,对URL的一个简单GET请求(未经身份验证):
http://iamhost:8000/event/1
返回一个未经授权的信息,以及状态码“401未经授权”。
为了从IRIS获得结果,需要将JWT添加到请求中。
首先,需要向授权服务器请求JWT。如果POST请求与主体中的一些键值对(包括用户和客户端信息)一起发出,那么在这里使用的自定义授权服务器将向以下URL返回一个JWT:
https://authorizationserver:5001/auth
该请求及其响应如下所示:
然后,可以将响应中获得的JWT添加到授权标头中作为Bearer令牌使用,并将GET请求发送到和之前相同的URL:
http://iamhost:8000/event/1
或者将它作为querystring参数添加进去。当添加JWT插件(本例中是“jwt”)时,querystring关键字是在“config.uri_param_names”字段中指定的值
最后,如果在“config.cookie_names”字段中输入任意名称,选择将JWT作为cookie包含在请求中。
请继续阅读本系列的第三部分也即最后一部分,了解IAM生成和验证访问令牌所需的配置,以及一些重要的最终考虑因素。
文章
姚 鑫 · 六月 10, 2021
# 第三章 指定输出的字符集
# 指定输出的字符集
若要指定要在输出文档中使用的字符集,可以设置Writer实例的Charset属性。选项包括`“UTF-8”`、`“UTF-16”`以及InterSystems IRIS支持的其他字符集。
# Writing the Prolog
XML文件的序言(根元素之前的部分)可以包含文档类型声明、处理指令和注释。
## 影响Prolog的属性
在`writer`实例中,以下属性会影响`prolog`:
### Charset
控制两件事`:XML`声明中的字符集声明和(相应的)输出中使用的字符集编码。
### NoXmlDeclaration
控制输出是否包含XML声明。在大多数情况下,默认值是0,这意味着已经编写了声明。如果没有指定字符集,并且输出定向到字符串或字符流,则默认为1,并且不写入任何声明。
## 生成文档类型声明
在根元素之前,可以包含文档类型声明,该声明声明了文档中使用的模式。
要生成文档类型声明,需要使用`WriteDocType()`方法,该方法有一个必选参数和三个可选参数。
就本文档而言,文档类型声明包括以下可能的部分:
```java
```
如这里所示,文档类型有一个名称,根据XML规则,该名称必须是根元素的名称。
声明可以包含外部子集、内部子集或两者。
external_subset 部分指向其他地方的DTD文件。
本节的结构是以下任何一种:
```java
PUBLIC public_literal_identifier
PUBLIC public_literal_identifier system_literal_identifier
SYSTEM system_literal_identifier
```
这里`public_literal_identifier`和`system_literal_identifier`是包含DTD uri的字符串。
注意,DTD可以同时具有公共标识符和系统标识符。
下面是一个文档类型声明示例,它包含一个同时使用公共标识符和系统标识符的外部子集:
```java
```
internal_subset部分是一组实体声明。
下面是一个文档类型声明的示例,它只包含一组内部声明:
```java
!ENTITY city (#PCDATA)>
!ENTITY player (#PCDATA)>
] >
```
`WriteDocType()`方法有四个参数:
- 第一个参数指定文档类型的名称,用于在这个XML文档中使用。
这是必需的,而且必须是有效的XML标识符。
还必须将此名称用作本文档中根级别元素的名称。
- 可选的第二个和第三个参数指定声明的外部部分,如下所示:
WriteDocType参数
第二个参数 | 第三个参数| 其他部分
---|---|---
“publicURI” |null| PUBLIC “publicURI”
“publicURI” |“systemURI”| PUBLIC “publicURI” “systemURI”
null |“systemURI”| SYSTEM “systemURI”
- 可选的第四个参数指定声明的内部部分。如果此参数非空,则将其括在方括号`[]`中,并适当地放在声明的末尾。没有添加其他字符。
## 编写处理指令
要将处理指令写入`XML`,请使用`WriteProcessingInstruction()`方法,该方法有两个参数:
1. 处理指令(也称为目标)的名称。
2. 指令本身是一个字符串。
该方法将以下内容写入XML:
```java
```
例如,要编写以下处理指令:
```java
```
为此,可以按如下方式调用`WriteProcessingInstruction()`方法:
```java
set instructions="type=""text/css"" href=""mystyles.css"""
set status=writer.WriteProcessingInstruction("xml-stylesheet", instructions)
```
## 指定默认命名空间
在编写器实例中,可以指定默认命名空间,该命名空间仅应用于没有`Namespace`参数设置的类。有几个选项:
- 可以在输出方法中指定默认命名空间。四个主要的输出方法(`RootObject()`、`RootElement()`、`Object()`或`Element()`)都接受名称空间作为参数。只有在类定义中未设置`Namespace`参数时,才会将相关元素分配给`Namespace`。
- 可以为编写器实例指定总体默认命名空间。为此,请为编写器实例的`DefaultNamespace`属性指定值。
```java
Class Writers.BasicDemoPerson Extends (%RegisteredObject, %XML.Adaptor)
{
Parameter XMLNAME = "Person";
Property Name As %Name;
Property DOB As %Date;
}
```
默认情况下,如果我们只是导出此类的对象,我们会看到如下所示的输出:
```java
Persephone MacMillan
1976-02-20
```
相反,如果我们在编写器实例中`将DefaultNamespace`设置为`"http://www.person.org",`然后导出一个对象,则会收到如下所示的输出:
```java
Persephone MacMillan
1976-02-20
```
在本例中, `` 元素使用默认名称空间,否则不会分配给名称空间。
文章
姚 鑫 · 五月 31, 2021
# 第十二章 IBM WebSphere MQ检索邮件
# 检索邮件
要检索邮件,请执行以下操作:
1. 按照“创建连接对象”中的说明创建连接对象。在这种情况下,请创建`%Net.MQRecv`的实例。`Connection`对象有一个消息队列,可以从中检索消息。
2. 根据需要调用以下方法:
- `%Get()`-通过引用返回字符串消息作为第一个参数。
- `%GetStream()`-给定初始化的文件字符流,此方法从队列中检索消息,并将其放入与该流关联的文件中。请注意,必须设置流的`Filename`属性才能对其进行初始化。不支持二进制流。
3. 检查调用的方法返回的值。请参阅“获取错误代码”。请记住,当队列为空时,IBM `WebSphere MQ`返回`2033`。
4. 检索完消息后,调用`Connection`对象的`%Close()`方法以释放动态链接库的句柄。
示例1:`ReceiveString()`
下面的类方法从`mqtest`队列检索消息。
```java
///Method returns string or null or error message
ClassMethod ReceiveString() As %String
{
Set recv=##class(%Net.MQRecv).%New()
Set queue="mqtest"
Set qm="QM_antigua"
Set chan="S_antigua/TCP/antigua(1414)"
Set logfile="c:\mq-recv-log.txt"
Set check=recv.%Init(queue,qm,chan,logfile)
If 'check Quit recv.%GetLastError()
Set check=recv.%Get(.msg)
If 'check {
Set reasoncode=recv.%GetLastError()
If reasoncode=2033 Quit ""
Quit "ERROR: "_reasoncode
}
Quit msg
}
```
示例2:`ReceiveCharacterStream()`
以下方法可以检索更长的消息,因为它使用`%GetStream()`:
```java
/// Method returns reason code from IBM WebSphere MQ
ClassMethod ReceiveCharacterStream() As %Integer
{
Set recv=##class(%Net.MQRecv).%New()
Set queue="mqtest"
Set qm="QM_antigua"
Set chan="S_antigua/TCP/antigua(1414)"
Set logfile="c:\mq-recv-log.txt"
Set check=recv.%Init(queue,qm,chan,logfile)
If 'check Quit recv.%GetLastError()
//initialize the stream and tell it what file to use
//make sure filename is unique we can tell what we received
Set longmsg=##class(%FileCharacterStream).%New()
Set longmsg.Filename="c:\mq-received"_$h_".txt"
Set check=recv.%GetStream(longmsg)
If 'check Quit recv.%GetLastError()
Quit check
}
```
# 更新消息信息
`%Net.MQSend`和`%Net.MQRecv`类还提供以下方法:
### %CorId()
(通过引用)更新上次读取的邮件的关联ID。
### %ReplyQMgrName()
(通过引用)更新上次读取的消息的回复队列管理器名称。
### %ReplyQName()
(通过引用)更新上次读取的消息的回复队列名称。
# Troubleshooting
如果在使用IBM `WebSphere MQ`的InterSystems IRIS接口时遇到问题,应该首先确定客户端是否安装正确并且可以与服务器通信。要执行这样的测试,可以使用IBM `WebSphere MQ`提供的示例程序。可执行文件位于IBM `WebSphere MQ`客户端的bin目录中。
以下步骤介绍如何在`Windows`上使用这些示例程序。在其他操作系统上,细节可能会有所不同;请参考IBM文档并检查您的客户端中存在的文件的名称。
1. 创建一个名为`MQSERVER`的环境变量。它的值的格式应该是`channel_name/Transport/server`,其中`channel_name`是要使用的通道的名称,`Transport`是指示要使用的传输的字符串,而`server`是服务器的名称。例如:`S_Antigua/TCP/Antigua`
2. 在命令行中,输入以下命令:
```java
amqsputc queue_name queue_manager_name
```
其中,`QUEUE_NAME`是要使用的队列的名称,`QUEUE_MANAGER_NAME`是队列管理器的名称。例如:
```java
amqsputc mqtest QM_antigua
```
如果`amqsputc`命令无法识别,请确保已更新`PATH`环境变量以包括IBM `WebSphere MQ`客户端的bin目录。
3. 应该会看到几行代码,如下所示:
```java
Sample AMQSPUT0 start
target queue is mqtest
```
4. 现在可以发送消息了。只需键入每条消息,然后在每条消息后按Enter键即可。例如:
```java
sample message 1
sample message 2
```
5. 发送完邮件后,按两次Enter键。然后,将看到如下所示的行:
```java
Sample AMQSPUT0 end
```
6. 要完成此测试,我们将检索发送到队列的消息。在命令行中键入以下命令:
```java
amqsgetc queue_name queue_manager_name
```
其中,`QUEUE_NAME`是要使用的队列的名称,`QUEUE_MANAGER_NAME`是队列管理器的名称。例如:
7. 然后,应该看到一个起始行,后跟之前发送的消息,如下所示:
```java
Sample AMQSGET0 start
message
message
```
8. 此示例程序短暂等待接收任何其他消息,然后显示以下内容:
```java
no more messages
Sample AMQSGET0 end
```
如果测试失败,请参考IBM文档。问题的可能原因包括以下几个方面:
- 安全问题
- 队列定义不正确
- 队列管理器未启动
文章
姚 鑫 · 六月 22, 2021
# 第十五章 XML检查属性
# 检查属性的基本方法
可以使用`%XML.Node`的以下方法。以检查当前节点的属性。
- `AttributeDefined()` 如果当前元素具有具有给定名称的属性,则返回非零(TRUE)。
- `FirstAttributeName()` 返回当前元素的第一个属性的属性名称。
- `GetAttributeValue()` 返回给定属性的值。如果元素没有该属性,则该方法返回NULL。
- `GetNumberAttributes()` 返回当前元素的属性数。
- `LastAttributeName()` 返回当前元素的最后一个属性的属性名称。
- `NextAttributeName()` 在给定属性名称的情况下,无论指定的属性是否有效,此方法都会按排序顺序返回下一个属性的名称。
- `PreviousAttributeName()` 在给定属性名称的情况下,无论指定的属性是否有效,此方法都会按排序顺序返回上一个属性的名称。
下面的示例遍历给定节点中的属性并编写一个简单报表:
```java
/// d ##class(Demo.XmlDemo).ShowAttributes("David Marston")
/// David Marston
ClassMethod ShowAttributes(string)
{
set reader=##class(%XML.Reader).%New()
set status=reader.OpenString(string)
if $$$ISERR(status) {do $System.Status.DisplayError(status)}
s node = reader.Document.GetDocumentElement()
b
s count = node.GetNumberAttributes()
w !, "属性数量: ", count
s first = node.FirstAttributeName()
w !, "第一个属性是: ", first
w !, " 值是: ",node.GetAttributeValue(first)
s next = node.NextAttributeName(first)
for i = 1 : 1 : count - 2 {
w !, "下一个属性是: ", next
w !, " 值是: ",node.GetAttributeValue(next)
s next = node.NextAttributeName(next)
}
s last = node.LastAttributeName()
w !, "最后一个属性是: ", last
w !, " 值是: ",node.GetAttributeValue(last)
}
```
示例XML文档:
```xml
David Marston
```
如果将此文档的第一个节点传递给示例方法,则会看到以下输出:
```java
Number of attributes: 5
First attribute is: attr1
Its value is: first
Next attribute is: attr2
Its value is: second
Next attribute is: attr3
Its value is: third
Next attribute is: attr4
Its value is: fourth
Last attribute is: attr5
Its value is: fifth
```
# 检查属性的其他方法
本节讨论可用于获取任何属性的名称、值、命名空间、`QName`和值命名空间的方法。这些方法分为以下几组:
- 仅使用属性名称的方法
- 使用属性名称和命名空间的方法
注意:在XML标准中,一个元素可以包含多个同名的属性,每个属性位于不同的名称空间中。但是,在InterSystems IRIS XML中,这是不受支持的。
## 仅使用属性名称的方法
使用以下方法获取有关属性的信息。
### GetAttribute()
```java
method GetAttribute(attributeName As %String,
ByRef namespace As %String,
ByRef value As %String,
ByRef valueNamespace As %String)
```
返回给定属性的数据。此方法通过引用返回下列值:
- `Namespace`是来自属性QName的命名空间URI
- `value` 是属性值。
- `valueNamespace` 值所属的命名空间URI。例如,以下属性:
```
xsi:type="s:string"
```
此属性的值为字符串,并且此值位于使用前缀s在其他位置声明的命名空间中。假设本文档的较早部分包含以下命名空间声明:
```java
xmlns:s="http://www.w3.org/2001/XMLSchema"
```
在本例中,`valueNamespace`将为`“http://www.w3.org/2001/XMLSchema”`.
### GetAttributeNamespace()
```java
method GetAttributeNamespace(attributeName As %String) as %String
```
从当前元素的名为`AttributeName`的属性的`QName`返回命名空间URI。
### GetAttributeQName()
```java
method GetAttributeQName(attributeName As %String) as %String
```
返回给定属性的`QName`。
### GetAttributeValue()
```java
method GetAttributeValue(attributeName As %String) as %String
```
返回给定属性的值。
### GetAttributeValueNamespace()
```java
method GetAttributeValueNamespace(attributeName As %String) as %String
```
返回给定属性的值的命名空间。
## 使用属性名和命名空间的方法
要同时使用属性名称及其命名空间来获取有关属性的信息,请使用以下方法:
### GetAttributeNS()
```java
method GetAttributeNS(attributeName As %String,
namespace As %String,
ByRef value As %String,
ByRef valueNamespace As %String)
```
返回给定属性的数据,其中`AttributeName`和`Namespace`指定感兴趣的属性。此方法通过引用返回以下数据:
- `value` 是属性值。
- `valueNamespace` 值所属的命名空间URI。例如,以下属性:
```java
xsi:type="s:string"
```
此属性的值为字符串,并且此值位于使用前缀s在其他位置声明的命名空间中。假设本文档的较早部分包含以下命名空间声明:
```java
xmlns:s="http://www.w3.org/2001/XMLSchema"
```
### GetAttributeQNameNS()
```java
method GetAttributeQNameNS(attributeName As %String,
namespace As %String)
as %String
```
返回给定属性的`QName`,其中`AttributeName`和`Namespace`指定感兴趣的属性。
### GetAttributeValueNS()
```java
method GetAttributeValueNS(attributeName As %String,
namespace As %String)
as %String
```
返回给定属性的值,其中`AttributeName`和`Namespace`指定感兴趣的属性。
### GetAttributeValueNamespaceNS
```java
method GetAttributeValueNamespaceNS(attributeName As %String,
namespace As %String)
as %String
```
返回给定属性的值的命名空间,其中`AttributeName`和`Namespace`指定感兴趣的属性。
文章
Frank Ma · 六月 13, 2022
孕产妇风险可以通过一些医学界众所周知的参数来测量。这样,为了帮助医学界和计算机系统,特别是人工智能,科学家Yasir Hussein Shakir发布了一个非常有用的数据集,用于训练检测/预测孕产妇风险的机器学习(ML)算法。这份出版物可以在最大和最知名的ML数据库Kaggle上找到,网址是 https://www.kaggle.com/code/yasserhessein/classification-maternal-health-5-algorithms-ml.
关于数据集
由于缺乏怀孕期间和怀孕后的孕产妇保健信息,许多孕妇死于怀孕问题。这在农村地区和新兴国家的中下层家庭中更为常见。在怀孕期间,应时刻注意观察,以确保婴儿的正常成长和安全分娩 (来源: https://www.kaggle.com/code/yasserhessein/classification-maternal-health-5-algorithms-ml).
数据是通过基于物联网的风险监测系统,从不同的医院、社区诊所、孕产妇保健机构收集而来。
Age(年龄): 妇女怀孕时的年龄,以岁为单位。
SystolicBP (收缩压): 血压的最高值(mmHg),这是怀孕期间的另一个重要属性。
DiastolicBP(舒张压): 血压的较低值(mmHg),这是怀孕期间的另一个重要属性。
BS(血糖): 血糖水平是以摩尔浓度为单位,即mmol/L。
HeartRate(心率): 正常的静息心率,单位是每分钟的心跳次数。
Risk Level(风险等级): 基于前边的属性所预测的孕期风险强度水平。
从Kaggle获取孕产妇的风险数据
来自Kaggle的孕产妇风险数据可以通过Health-Dataset(健康数据集)应用程序加载到IRIS表中: https://openexchange.intersystems.com/package/Health-Dataset. 要做到这一点,在你的module.xml项目中,设置依赖关系(Health Dataset的ModuleReference):
Module.xml with Health Dataset application reference
<?xml version="1.0" encoding="UTF-8"?>
<Export generator="Cache" version="25">
<Document name="predict-diseases.ZPM">
<Module>
<Name>predict-diseases</Name>
<Version>1.0.0</Version>
<Packaging>module</Packaging>
<SourcesRoot>src/iris</SourcesRoot>
<Resource Name="dc.predict.disease.PKG"/>
<Dependencies>
<ModuleReference>
<Name>swagger-ui</Name>
<Version>1.*.*</Version>
</ModuleReference>
<ModuleReference>
<Name>dataset-health</Name>
<Version>*</Version>
</ModuleReference>
</Dependencies>
<CSPApplication
Url="/predict-diseases"
DispatchClass="dc.predict.disease.PredictDiseaseRESTApp"
MatchRoles=":{$dbrole}"
PasswordAuthEnabled="1"
UnauthenticatedEnabled="1"
Recurse="1"
UseCookies="2"
CookiePath="/predict-diseases"
/>
<CSPApplication
CookiePath="/disease-predictor/"
DefaultTimeout="900"
SourcePath="/src/csp"
DeployPath="${cspdir}/csp/${namespace}/"
MatchRoles=":{$dbrole}"
PasswordAuthEnabled="0"
Recurse="1"
ServeFiles="1"
ServeFilesTimeout="3600"
UnauthenticatedEnabled="1"
Url="/disease-predictor"
UseSessionCookie="2"
/>
</Module>
</Document>
</Export>
Web Frontend and Backend Application to Predict Maternal Risk
Go to Open Exchange app link (https://openexchange.intersystems.com/package/Disease-Predictor) and follow these steps:
使用Clone/git 把repo拉到任一本地目录中:
$ git clone https://github.com/yurimarx/predict-diseases.git
在该文件夹中打开Docker 终端并运行:
$ docker-compose build
运行IRIS容器:
$ docker-compose up -d
进入管理门户执行查询,训练AI模型: http://localhost:52773/csp/sys/exp/%25CSP.UI.Portal.SQL.Home.zen?$NAMESPACE=USER
创建用于训练的VIEW(视图):
CREATE VIEW MaternalRiskTrain AS SELECT BS, BodyTemp, DiastolicBP, HeartRate, RiskLevel, SystolicBP, age FROM dc_data_health.MaternalHealthRisk
使用视图创建AI模型:
CREATE MODEL MaternalRiskModel PREDICTING (RiskLevel) FROM MaternalRiskTrain
训练模型:
TRAIN MODEL MaternalRiskModel
访问 http://localhost:52773/disease-predictor/index.html ,使用 Disease Predictor(疾病预测器)前端进行疾病预测,如下:
幕后工作
预测孕产妇风险疾病的后端类方法
InterSystems IRIS允许你执行SELECT,使用之前创建的模型进行预测。
Backend ClassMethod to predict Maternal Risk
/// Predict Maternal Risk
ClassMethod PredictMaternalRisk() As %Status
{
Try {
Set data = {}.%FromJSON(%request.Content)
Set %response.Status = 200
Set %response.Headers("Access-Control-Allow-Origin")="*"
Set qry = "SELECT PREDICT(MaternalRiskModel) As PredictedMaternalRisk, "
_"age, BS, BodyTemp, DiastolicBP, HeartRate, SystolicBP "
_"FROM (SELECT "_data.BS_" AS BS, "
_data.BodyTemp_" As BodyTemp, "
_data.DiastolicBP_" AS DiastolicBP, "
_data.HeartRate_" AS HeartRate, "
_data.SystolicBP_" As SystolicBP, "
_data.Age_" AS age)"
Set tStatement = ##class(%SQL.Statement).%New()
Set qStatus = tStatement.%Prepare(qry)
If qStatus'=1 {WRITE "%Prepare failed:" DO $System.Status.DisplayError(qStatus) QUIT}
Set rset = tStatement.%Execute()
Do rset.%Next()
Set Response = {}
Set Response.PredictedMaternalRisk = rset.PredictedMaternalRisk
Set Response.Age = rset.Age
Set Response.SystolicBP = rset.SystolicBP
Set Response.DiastolicBP = rset.DiastolicBP
Set Response.BS = rset.BS
Set Response.BodyTemp = rset.BodyTemp
Set Response.HeartRate = rset.HeartRate
Write Response.%ToJSON()
Return 1
} Catch err {
write !, "Error name: ", ?20, err.Name,
!, "Error code: ", ?20, err.Code,
!, "Error location: ", ?20, err.Location,
!, "Additional data: ", ?20, err.Data, !
Return 0
}
}
现在,任何web应用都可以进行预测并显示结果。请在预测疾病应用程序的前端文件夹中查看源代码。
文章
Hao Ma · 十一月 17, 2021
REF: https://docs.intersystems.com/healthconnectlatest/csp/docbook/Doc.View.cls?KEY=GREST
REF: https://docs.intersystems.com/healthconnectlatest/csp/docbook/DocBook.UI.Page.cls?KEY=AFL_rest#AFL_C4838
开发REST服务有两个方式, 一个是生生的写代码, 定义接口的标准,被称为"Manually Coding"。第2个方式是目前越来越流行的"Sepcification-first",也就是使用描述性的语言定义接口规范,然后通过这个规范生成接口代码。第2种方式更快捷,但这里我还是从第一种介绍起,对理解里面的代码层次更容易一些,而这是调试一个接口必须的。
从代码开发REST服务
不同于HTTP和SOAP, Ensemble里面没有REST的inbound Adaptor,也没有可用的BS组件。在Production里开发一个REST服务的步骤是:
1. 开发一个REST Service, 这个Service是一个CSP Page, 是一个网页服务,和Ensemble没关系。要在Production中使用这个服务,您需要在这个服务里调用一个Production的业务服务BS。
2. 要访问这个REST页面服务, 您需要配置一个Web Application。Web Application的配置项上有一个选项: "REST 分派类"。这样配置好之后, Web Application收到相应的URL后就会调用这个REST页面,页面再去调用Production的BS。
3. 最后,您需要在BS中处理收到的JSON, 发送给其他组件,以传递给接收方系统。
如果您看的了代码包里的EnsLib.REST.Service类, 它继承了%CSP.REST页面, 也继承了BusinessService,非常符合Ensemble的结构设计。But, 别用。在线文档中有专门的说明。
Although InterSystems IRIS defines a class EnsLib.REST.ServiceOpens in a new window, that is a subclass of %CSP.RESTOpens in a new window, we recommend that you not use this class because it provides an incomplete implementation of %CSP.REST Opens in a new window.
让我们开始开发一个简单的REST服务并加入Production:
Step 1:
创建以下代码,解释一下:
- 继承%CSP.REST,这是个专用于REST的CSP页面
- UrlMap是一个XData, 在COS语言里用于在代码里放置固定的xml数据结构。UrlMap定义从收到的URL到本类里不同的方法之间的映射。
- 方法中入参可以是任意的数据结构和用户定义的类结构,不需要出参。如果直接返回消息给调用者,直接"write"一个流或者字符串
Class SEDemo.IO.REST.SampleService Extends %CSP.REST
{
XData UrlMap [ XMLNamespace = "http://www.intersystems.com/urlmap" ]
{
}
ClassMethod Test(pInput As %String) As %Status
{
write "Received: "_pInput,!
Quit 1
}
ClassMethod GetPatientById(pID As %String) As %Status
{ Try{
Set tObj=##class(SEDemo.Common.Patient).%OpenId(pID),tStream = ""
d ##class(%ZEN.Auxiliary.jsonProvider).%WriteJSONStreamFromObject(.tStream,tObj)
w tStream.Read()
} Catch (e) {Set tSC=e.AsStatus()}
Quit tSC
}
}
Step 2: 创建Web Application
在管理界面System Administration > Security > Applications > Web Applications,创建一个用于接收此REST服务的Web APPlication, 设置"Dispatch Class"为当前类。 假设创建的Web Applicaiton为"/CSP/myrest",注意:
- 选中“Enable Application"
- 权限: 分配本命名空间数据库的资源,默认是%DB_%Default。
后面会详细介绍权限和用户管理的细节。
Step 3: 测试你的REST service
你可以选择自己喜欢的测试方式,比如用浏览器,POSTMAN, SoapUI..., 下面是我测试的记录:
CNMBPHMA:~ hma$ curl -v http://172.16.58.200:52773/csp/myrest/Test/333
* Trying 172.16.58.200...
* TCP_NODELAY set
* Connected to 172.16.58.200 (172.16.58.200) port 52773 (#0)
> GET /csp/myrest/Test/333 HTTP/1.1
> Host: 172.16.58.200:52773
> User-Agent: curl/7.54.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Date: Wed, 14 Jul 2021 06:47:26 GMT
< Server: Apache
< CACHE-CONTROL: no-cache
< EXPIRES: Thu, 29 Oct 1998 17:04:19 GMT
< PRAGMA: no-cache
< CONTENT-LENGTH: 15
< Content-Type: text/html; charset=utf-8
<
Received: 333
* Connection #0 to host 172.16.58.200 left intact
CNMBPHMA:~ hma$
这里是一个匿名访问,如果需要用户认证,修改一下重发:
CNMBPHMA:~ hma$ curl -u 'superuser:SYS' http://172.16.58.200:52773/csp/myrest/Test/333
Received: 333
CNMBPHMA:~ hma$
注意两点:
1. 到目前为止我们测试的其实是一个HTTP请求和响应,虽然内部用了%CSP.REST的类, 但响应中'Content-Type'还是'text/html'
2. 代码中没有处理出错和查不到结果的情况
3. 到目前为止和Ensemble Production没有任何关系。
Step 4: 将服务加入Ensemble Production
加入Production的意思实际上时调用一个Production的BusinessService。
让我们先创建一个简单的Service.
///不使用Adapter, 收到任何请求,同步发送给目标组件
Class Test.BS.GeneralService Extends Ens.BusinessService
{
Method OnProcessInput(pInput As %RegisteredObject, Output pOutput As %RegisteredObject) As %Status
{
set tRequest=##class(Ens.StringRequest).%New()
Set tStatus = ..SendRequestSync("Test.BO.dummyOperation", tRequest, .tResponse)
set pOutput = tResponse
Quit tStatus
}
}
当需要前面的REST服务来调用这个BusinessService的时候, 需要在method里面加入直接调用的语句,比如上面的GetPatientById()
ClassMethod GetPatientById(pID As %String) As %Status
{
set status = ##class(Ens.Director).CreateBusinessService("Test.BS.GeneralService", .tService)
if $$$ISOK(status) {
set status = service.OnProcessInput(pID, .tResponse)
}
w tResponse,!
}
文章
姚 鑫 · 三月 16, 2021
# 第十一章 SQL隐式联接(箭头语法)
**InterSystems SQL提供了一个特殊的`–>`运算符,作为从相关表中获取值的快捷方式,而在某些常见情况下无需指定显式的`JOIN`即可。可以使用此箭头语法代替显式联接语法,也可以将其与显式联接语法结合使用。箭头语法执行左外部联接。**
**箭头语法可用于类的属性或父表的关系属性的引用。其他类型的关系和外键不支持箭头语法。不能在`ON`子句中使用箭头语法(`–>`)。**
# 属性引用
可以使用`- >`操作符作为从`“引用表”`获取值的简写。
例如,假设定义了两个类:`Company`:
```java
Class Sample.Company Extends %Persistent [DdlAllowed]
{
/// The Company name
Property Name As %String;
}
```
`Employee`:
```java
Class Sample.Employee Extends %Persistent [DdlAllowed]
{
/// The Employee name
Property Name As %String;
/// The Company this Employee works for
Property Company As Company;
}
```
`Employee`类包含一个属性,该属性是对`Company`对象的引用。
在基于对象的应用程序中,可以使用点语法遵循此引用。
例如,要查找`Employee`工作的`Company`名称:
```java
Set name = employee.Company.Name
```
可以使用使用外部连接来连接`Employee`和`Company`表的SQL语句来执行相同的任务:
```sql
SELECT Sample.Employee.Name, Sample.Company.Name AS CompName
FROM Sample.Employee LEFT OUTER JOIN Sample.Company
ON Sample.Employee.Company = Sample.Company.ID
```
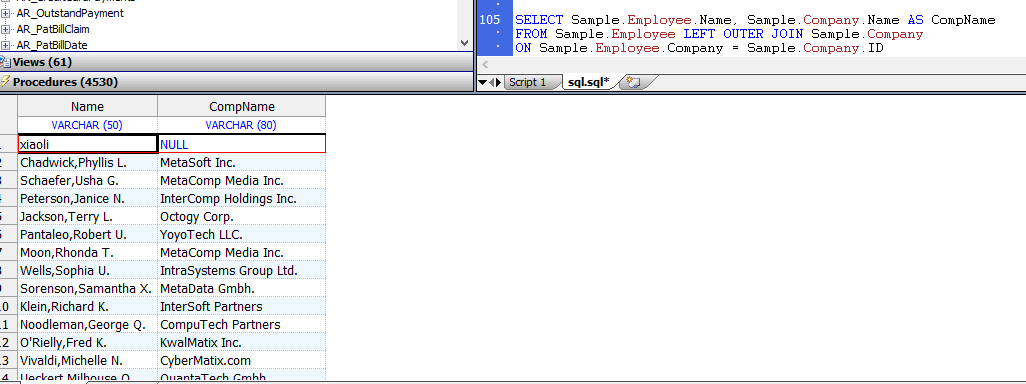
使用`- >`操作符,可以更简洁地执行相同的外连接操作:
```sql
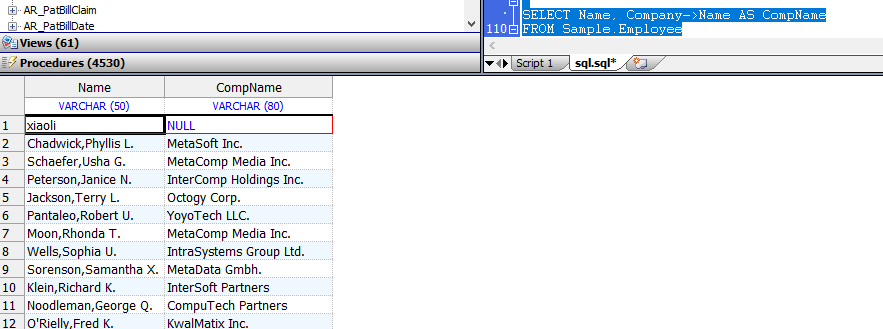
SELECT Name, Company->Name AS CompName
FROM Sample.Employee
```
只要在表中有引用列,就可以使用`–>`运算符;也就是说,其列的值是被引用表的ID(本质上是外键的特殊情况)。在这种情况下,`Sample.Employee`的`Company`字段包含`Sample.Company`表中记录的`ID`。可以在可以在查询中使用列表达式的任何地方使用`–>`运算符。例如,在`WHERE`子句中:
```sql
SELECT Name,Company AS CompID,Company->Name AS CompName
FROM Sample.Employee
WHERE Company->Name %STARTSWITH 'G'
```
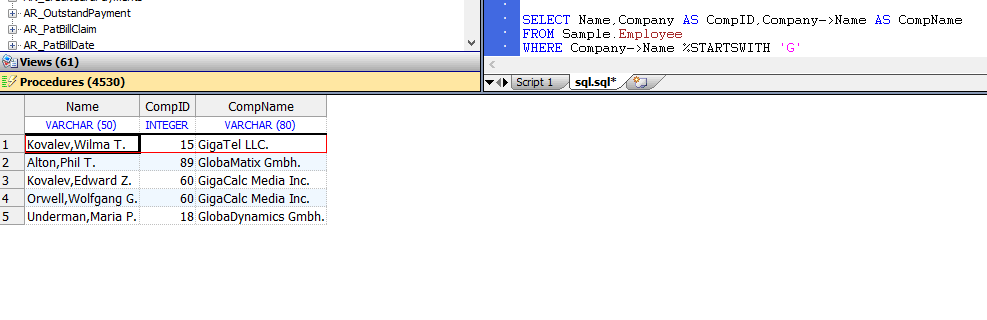
使用`–>`运算符,可以更简洁地执行相同的`OUTER JOIN`操作:
这等效于:
```sql
SELECT E.Name,E.Company AS CompID,C.Name AS CompName
FROM Sample.Employee AS E, Sample.Company AS C
WHERE E.Company = C.ID AND C.Name %STARTSWITH 'G'
```
**请注意,在这种情况下,此等效查询使用`INNER JOIN`。**
以下示例使用箭头语法访问`Sample.Person`中的`“Spouse”`字段。如示例所示,`Sample.Employee`中的`Spouse`字段包含`Sample.Person`中记录的`ID`。本示例返回`Employee`与其`Spouse`的`Home_State`相同的`Home_State`或`Office_State`的那些记录:
```sql
SELECT Name,Spouse,Home_State,Office_State,Spouse->Home_State AS SpouseState
FROM Sample.Employee
WHERE Home_State=Spouse->Home_State OR Office_State=Spouse->Home_State
```
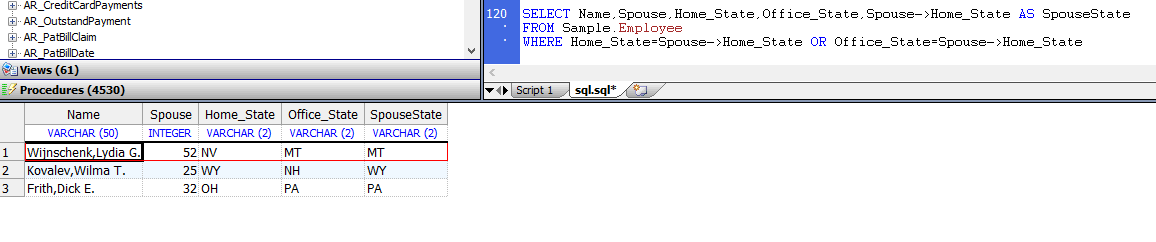
可以在`GROUP BY`子句中使用–>运算符:
```sql
SELECT Name,Company->Name AS CompName
FROM Sample.Employee
GROUP BY Company->Name
```
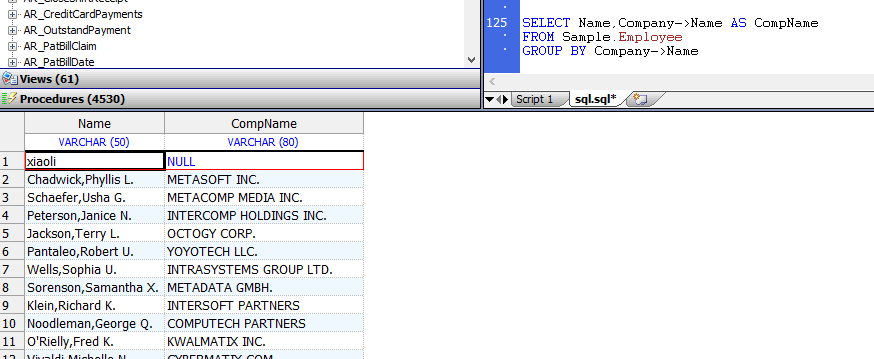
可以在`ORDER BY`子句中使用`–>`运算符:
```sql
SELECT Name,Company->Name AS CompName
FROM Sample.Employee
ORDER BY Company->Name
```
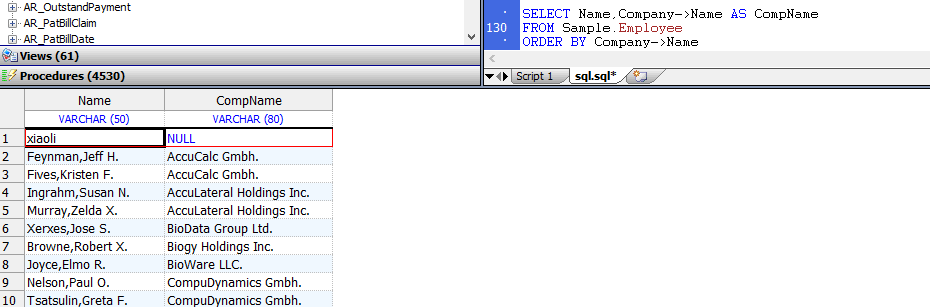
或在`ORDER BY`子句中为`–>`运算符列引用列别名:
```sql
SELECT Name,Company->Name AS CompName
FROM Sample.Employee
ORDER BY CompName
```
支持复合箭头语法,如以下示例所示。在此示例中,`Cinema.Review`表包含`“Film”`字段,其中包含`Cinema.Film`表的行`ID`。 `Cinema.Film`表包含`Category`字段,其中包含`Cinema.Category`表的行`ID`。因此,`Film-> Category-> CategoryName`访问以下三个表,以返回具有`ReviewScore`的每部电影的`CategoryName`:
```sql
SELECT ReviewScore,Film,Film->Title,Film->Category,Film->Category->CategoryName
FROM Cinema.Review
ORDER BY ReviewScore
```
# 子表引用
可以使用`–>`运算符来引用子表。例如,如果`LineItems`是`Orders`表的子表,则可以指定:
```sql
SELECT LineItems->amount
FROM Orders
```
请注意,在`Orders`中没有称为`LineItems`的属性。 `LineItems`是包含数量字段的子表的名称。该查询在结果集中为每个`Order`行生成多个行。它等效于:
```sql
SELECT L.amount
FROM Orders O LEFT JOIN LineItems L ON O.id=L.custorder
```
其中`ustust`是`LineItems`表的父引用字段。
# 箭头语法权限
使用箭头语法时,必须对两个表中的引用数据都具有`SELECT`权限。必须在被引用的列上具有表级`SELECT`权限或列级`SELECT`权限。使用列级权限,需要对被引用表以及被引用列的ID具有`SELECT`权限。
以下示例演示了所需的列级权限:
```sql
SELECT Name,Company->Name AS CompanyName
FROM Sample.Employee
GROUP BY Company->Name
ORDER BY Company->Name
```
在上面的示例中,必须对`Sample.Employee.Name`,`Sample.Company.Name`和`Sample.Company.ID`具有列级`SELECT`权限:
```java
// d ##class(PHA.TEST.SQL).arrow()
ClassMethod arrow()
{
SET tStatement = ##class(%SQL.Statement).%New()
SET privchk1="%CHECKPRIV SELECT (Name,ID) ON Sample.Company"
SET privchk2="%CHECKPRIV SELECT (Name) ON Sample.Employee"
CompanyPrivTest
SET qStatus = tStatement.%Prepare(privchk1)
IF qStatus'=1 {
WRITE "%Prepare 失败:"
DO $System.Status.DisplayError(qStatus)
QUIT
}
SET rset = tStatement.%Execute()
IF rset.%SQLCODE=0 {
WRITE !,"拥有Company权限",!
} ELSE {
WRITE !,"无权限: SQLCODE=",rset.%SQLCODE,!
}
EmployeePrivTest
SET qStatus = tStatement.%Prepare(privchk2)
IF qStatus'=1 {
WRITE "%Prepare 失败:"
DO $System.Status.DisplayError(qStatus)
QUIT
}
SET rset = tStatement.%Execute()
IF rset.%SQLCODE=0 {
WRITE !,"拥有Employee权限",!
} ELSE {
WRITE !,"无权限: SQLCODE=",rset.%SQLCODE
}
}
```
```java
DHC-APP>d ##class(PHA.TEST.SQL).arrow()
拥有Company权限
拥有Employee权限
```
文章
Michael Lei · 六月 1, 2022
糖尿病可以从医学界熟知的一些参数中发现。这样,为了帮助医学界和计算机软件系统,特别是人工智能软件,美国国家糖尿病和消化道及肾脏疾病研究所发布了一个非常有用的数据集,用于训练糖尿病检测/预测的机器学习算法。这份出版物可以在最大和最知名的ML数据库Kaggle上找到,网址是https://www.kaggle.com/datasets/mathchi/diabetes-data-set。
该糖尿病数据集有以下元数据信息(来源:https://www.kaggle.com/datasets/mathchi/diabetes-data-set):
怀孕:怀孕次数
葡萄糖: 口服葡萄糖耐量试验中2小时的血浆葡萄糖浓度 Plasma glucose concentration a 2 hours in an oral glucose tolerance test
血压: 舒张压(mm Hg)
皮肤厚度: 肱三头肌皮褶厚度(mm)
胰岛素: 2小时血清胰岛素(mu U/ml)
BMI: 体重指数 (体重 kg/(身高 m)^2)
糖尿病血统函数: 糖尿病血统函数(它提供了一些关于亲属中的糖尿病史以及这些亲属与病人的遗传关系的数据。这种对遗传影响的测量使我们了解到一个人可能有的遗传风险与糖尿病的发病有关--来源:https://machinelearningmastery.com/case-study-predicting-the-onset-of-diabetes-within-five-years-part-1-of-3/)
年龄:
结果: 类变量 (0 or 1)
实例数量: 768
属性数量: 8 + 1个类变量
对每个属性: (全部为numeric数字量化类型)
怀孕次数
口服葡萄糖耐量试验中2小时的血浆葡萄糖浓度
舒张压 (mm Hg)
三头肌皮褶厚度 (mm)
2小时血清胰岛素 (mu U/ml)
BMI指数 (体重 kg/(身高 m)^2)
糖尿病血统函数
年龄
类变量 (0 or 1)
缺失属性值: 是
类分布: (类值为1解释为 "糖尿病测试阳性")
从Kaggle获取糖尿病数据
Kaggle的糖尿病数据可以通过Health-Dataset程序加载到IRIS表中:https://openexchange.intersystems.com/package/Health-Dataset。要做到这一点,在你的module.xml项目中,设置依赖关系(Health Dataset的ModuleReference)。
Module.xml with Health Dataset application reference
<?xml version="1.0" encoding="UTF-8"?>
<Export generator="Cache" version="25">
<Document name="predict-diseases.ZPM">
<Module>
<Name>predict-diseases</Name>
<Version>1.0.0</Version>
<Packaging>module</Packaging>
<SourcesRoot>src/iris</SourcesRoot>
<Resource Name="dc.predict.disease.PKG"/>
<Dependencies>
<ModuleReference>
<Name>swagger-ui</Name>
<Version>1.*.*</Version>
</ModuleReference>
<ModuleReference>
<Name>dataset-health</Name>
<Version>*</Version>
</ModuleReference>
</Dependencies>
<CSPApplication
Url="/predict-diseases"
DispatchClass="dc.predict.disease.PredictDiseaseRESTApp"
MatchRoles=":{$dbrole}"
PasswordAuthEnabled="1"
UnauthenticatedEnabled="1"
Recurse="1"
UseCookies="2"
CookiePath="/predict-diseases"
/>
<CSPApplication
CookiePath="/disease-predictor/"
DefaultTimeout="900"
SourcePath="/src/csp"
DeployPath="${cspdir}/csp/${namespace}/"
MatchRoles=":{$dbrole}"
PasswordAuthEnabled="0"
Recurse="1"
ServeFiles="1"
ServeFilesTimeout="3600"
UnauthenticatedEnabled="1"
Url="/disease-predictor"
UseSessionCookie="2"
/>
</Module>
</Document>
</Export>
预测糖尿病的前端和后端应用程序
访问 Open Exchange 应用连接 (https://openexchange.intersystems.com/package/Disease-Predictor) 并遵守以下步骤:
Clone/git 把repo pull 到任何本地目录
$ git clone https://github.com/yurimarx/predict-diseases.git
打开 该目录下Docker终端并执行:
$ docker-compose build
执行IRIS container:
$ docker-compose up -d
在管理门户中执行查询来训练AI模型: http://localhost:52773/csp/sys/exp/%25CSP.UI.Portal.SQL.Home.zen?$NAMESPACE=USER
创建用来训练的 VIEW :
CREATE VIEW DiabetesTrain AS SELECT Outcome, age, bloodpressure, bmi, diabetespedigree, glucose, insulin, pregnancies, skinthickness FROM dc_data_health.Diabetes
利用View视图来创建 AI 模型:
CREATE MODEL DiabetesModel PREDICTING (Outcome) FROM DiabetesTrain
训练模型:
TRAIN MODEL DiabetesModel
访问 http://localhost:52773/disease-predictor/index.html 来使用疾病预测器qian frontend and predict diseases like this:
幕后工作
后端预测糖尿病的类方法
InterSystems IRIS 支持执行Select 并使用上一个创建的模型来预测。
Backend ClassMethod to predict Diabetes
/// Predict Diabetes
ClassMethod PredictDiabetes() As %Status
{
Try {
Set data = {}.%FromJSON(%request.Content)
Set qry = "SELECT PREDICT(DiabetesModel) As PredictedDiabetes, "
_"age, bloodpressure, bmi, diabetespedigree, glucose, insulin, "
_"pregnancies, skinthickness "
_"FROM (SELECT "_data.age_" AS age, "
_data.bloodpressure_" As bloodpressure, "
_data.bmi_" AS bmi, "
_data.diabetespedigree_" AS diabetespedigree, "
_data.glucose_" As glucose, "
_data.insulin_" AS insulin, "
_data.pregnancies_" As pregnancies, "
_data.skinthickness_" AS skinthickness)"
Set tStatement = ##class(%SQL.Statement).%New()
Set qStatus = tStatement.%Prepare(qry)
If qStatus'=1 {WRITE "%Prepare failed:" DO $System.Status.DisplayError(qStatus) QUIT}
Set rset = tStatement.%Execute()
Do rset.%Next()
Set Response = {}
Set Response.PredictedDiabetes = rset.PredictedDiabetes
Set Response.age = rset.age
Set Response.bloodpressure = rset.bloodpressure
Set Response.bmi = rset.bmi
Set Response.diabetespedigree = rset.diabetespedigree
Set Response.glucose = rset.glucose
Set Response.insulin = rset.insulin
Set Response.pregnancies = rset.pregnancies
Set Response.skinthickness = rset.skinthickness
Set %response.Status = 200
Set %response.Headers("Access-Control-Allow-Origin")="*"
Write Response.%ToJSON()
Return 1
} Catch err {
write !, "Error name: ", ?20, err.Name,
!, "Error code: ", ?20, err.Code,
!, "Error location: ", ?20, err.Location,
!, "Additional data: ", ?20, err.Data, !
Return 0
}
}
现在,任何网络应用都可以使用预测并显示预测结果。欢迎在frontend 文件夹查看本应用的源代码。
文章
Michael Lei · 九月 13, 2022
Globals是InterSystems IRIS的数据持久性的核心。它很灵活,允许存储JSON文档、关系数据、面向对象的数据、OLAP立方体和自定义数据模型,例如思维导图。要了解如何使用globals来存储、删除和获取思维导图数据,请遵循以下步骤:
1. 把repo Clone/git到任意本地目录
$ git clone https://github.com/yurimarx/global-mindmap.git
2. 在该目录下打开Docker 终端并执行:
$ docker-compose build
3. 启动 IRIS 容器:
$ docker-compose up -d
4. 访问 http://localhost:3000 来使用思维导图的前端并创建类似以上的思维导图
本例子的源代码
存储数据 (更多请访问: https://www.npmjs.com/package/mind-elixir):
{
topic: 'node topic',
id: 'bd1c24420cd2c2f5',
style: { fontSize: '32', color: '#3298db', background: '#ecf0f1' },
parent: null,
tags: ['Tag'],
icons: ['😀'],
hyperLink: 'https://github.com/ssshooter/mind-elixir-core',
}
注意parent属性,它被用来在mindmap节点之间建立父/子关系。
使用Globals 来存储思维导图的源代码
ClassMethod StoreMindmapNode
/// Store mindmap node
ClassMethod StoreMindmapNode() As %Status
{
Try {
Set data = {}.%FromJSON(%request.Content)
Set ^mindmap(data.id) = data.id /// set mindmap key
Set ^mindmap(data.id, "topic") = data.topic /// set topic subscript
Set ^mindmap(data.id, "style", "fontSize") = data.style.fontSize /// set style properties subscripts
Set ^mindmap(data.id, "style", "color") = data.style.color
Set ^mindmap(data.id, "style", "background") = data.style.background
Set ^mindmap(data.id, "parent") = data.parent /// store parent id subscript
Set ^mindmap(data.id, "tags") = data.tags.%ToJSON() /// store tags subscript
Set ^mindmap(data.id, "icons") = data.icons.%ToJSON() /// store icons subscript
Set ^mindmap(data.id, "hyperLink") = data.hyperLink /// store hyperLink subscript
Set %response.Status = 200
Set %response.Headers("Access-Control-Allow-Origin")="*"
Write "Saved"
Return $$$OK
} Catch err {
write !, "Error name: ", ?20, err.Name,
!, "Error code: ", ?20, err.Code,
!, "Error location: ", ?20, err.Location,
!, "Additional data: ", ?20, err.Data, !
Return $$$NOTOK
}
}
我们创建了一个名为^mindmap的Global。对于每个思维导图的属性,它被存储在一个Globals下标中。下标的键是mindmap的id属性。
删除思维导图节点的源代码 - kill the global
ClassMethod DeleteMindmapNode
/// Delete mindmap node
ClassMethod DeleteMindmapNode(id As %String) As %Status
{
Try {
Kill ^mindmap(id) /// delete selected mindmap node using the id (global key)
Set %response.Status = 200
Set %response.Headers("Access-Control-Allow-Origin")="*"
Write "Deleted"
Return $$$OK
} Catch err {
write !, "Error name: ", ?20, err.Name,
!, "Error code: ", ?20, err.Code,
!, "Error location: ", ?20, err.Location,
!, "Additional data: ", ?20, err.Data, !
Return $$$NOTOK
}
}
这个例子使用mindmap.id作为mindmap的Global Key,所以删除很容易: call Kill ^mindmap(<mindmap id>)
获得所有存储内容的源代码- 用 $ORDER循环globals
ClassMethod GetMindmap - return all mindmap global nodes
/// Get mindmap content
ClassMethod GetMindmap() As %Status
{
Try {
Set Nodes = []
Set Key = $Order(^mindmap("")) /// get the first mindmap node stored - the root
Set Row = 0
While (Key '= "") { /// while get child mindmap nodes
Do Nodes.%Push({}) /// create a item into result
Set Nodes.%Get(Row).style = {}
Set Nodes.%Get(Row).id = Key /// return the id property
Set Nodes.%Get(Row).hyperLink = ^mindmap(Key,"hyperLink") /// return the hyperlink property
Set Nodes.%Get(Row).icons = ^mindmap(Key,"icons") /// return icons property
Set Nodes.%Get(Row).parent = ^mindmap(Key,"parent") /// return parent id property
Set Nodes.%Get(Row).style.background = ^mindmap(Key,"style", "background") /// return the style properties
Set Nodes.%Get(Row).style.color = ^mindmap(Key,"style", "color")
Set Nodes.%Get(Row).style.fontSize = ^mindmap(Key,"style", "fontSize")
Set Nodes.%Get(Row).tags = ^mindmap(Key,"tags") /// return tags property
Set Nodes.%Get(Row).topic = ^mindmap(Key,"topic") /// return topic property (title mindmap node)
Set Row = Row + 1
Set Key = $Order(^mindmap(Key)) /// get the key to the next mindmap global node
}
Set %response.Status = 200
Set %response.Headers("Access-Control-Allow-Origin")="*"
Write Nodes.%ToJSON()
Return $$$OK
} Catch err {
write !, "Error name: ", ?20, err.Name,
!, "Error code: ", ?20, err.Code,
!, "Error location: ", ?20, err.Location,
!, "Additional data: ", ?20, err.Data, !
Return $$$NOTOK
}
}
用$Order(^mindmap("")) - empty "" - 得到第一个mindmap Global (根节点)。对于每个属性值,我们使用^mindmap(Key,<property name>)。最后,调用$Order(^mindmap(Key))来获得下一个事件。
前端
Mind-elixir和React被用来渲染和编辑mindmap,消耗使用IRIS构建的API后端。见mindmap的反应组件:
Mindmap React component - consuming IRIS REST API
import React from "react";
import MindElixir, { E } from "mind-elixir";
import axios from 'axios';
class Mindmap extends React.Component {
componentDidMount() {
this.dynamicWidth = window.innerWidth;
this.dynamicHeight = window.innerHeight;
axios.get(`http://localhost:52773/global-mindmap/hasContent`)
.then(res => {
if (res.data == "1") {
axios.get(`http://localhost:52773/global-mindmap/get`)
.then(res2 => {
this.ME = new MindElixir({
el: "#map",
direction: MindElixir.LEFT,
data: this.renderExistentMindmap(res2.data),
draggable: true, // default true
contextMenu: true, // default true
toolBar: true, // default true
nodeMenu: true, // default true
keypress: true // default true
});
this.ME.bus.addListener('operation', operation => {
console.log(operation)
if (operation.name == 'finishEdit' || operation.name == 'editStyle') {
this.saveMindmapNode(operation.obj)
} else if (operation.name == 'removeNode') {
this.deleteMindmapNode(operation.obj.id)
}
})
this.ME.init();
})
} else {
this.ME = new MindElixir({
el: "#map",
direction: MindElixir.LEFT,
data: MindElixir.new("New Mindmap"),
draggable: true, // default true
contextMenu: true, // default true
toolBar: true, // default true
nodeMenu: true, // default true
keypress: true // default true
});
this.ME.bus.addListener('operation', operation => {
console.log(operation)
if (operation.name == 'finishEdit' || operation.name == 'editStyle') {
this.saveMindmapNode(operation.obj)
} else if (operation.name == 'removeNode') {
this.deleteMindmapNode(operation.obj.id)
}
})
this.saveMindmapNode(this.ME.nodeData)
this.ME.init();
}
})
}
render() {
return (
<div id="map" style={{ height: window.innerHeight + 'px', width: '100%' }} />
);
}
deleteMindmapNode(mindmapNodeId) {
axios.delete(`http://localhost:52773/global-mindmap/delete/${mindmapNodeId}`)
.then(res => {
console.log(res);
console.log(res.data);
})
}
saveMindmapNode(node) {
axios.post(`http://localhost:52773/global-mindmap/save`, {
topic: (node.topic == undefined ? "" : node.topic),
id: node.id,
style: (node.style == undefined ? "" : node.style),
parent: (node.parent == undefined ? "" : node.parent.id),
tags: (node.tags == undefined ? [] : node.tags),
icons: (node.icons == undefined ? [] : node.icons),
hyperLink: (node.hyperLink == undefined ? "" : node.hyperLink)
})
.then(res => {
console.log(res);
console.log(res.data);
})
}
renderExistentMindmap(data) {
let root = data[0]
let nodeData = {
id: root.id,
topic: root.topic,
root: true,
style: {
background: root.style.background,
color: root.style.color,
fontSize: root.style.fontSize,
},
hyperLink: root.hyperLink,
children: []
}
this.createTree(nodeData, data)
return { nodeData }
}
createTree(nodeData, data) {
for(let i = 1; i < data.length; i++) {
if(data[i].parent == nodeData.id) {
let newNode = {
id: data[i].id,
topic: data[i].topic,
root: false,
style: {
background: data[i].style.background,
color: data[i].style.color,
fontSize: data[i].style.fontSize,
},
hyperLink: data[i].hyperLink,
children: []
}
nodeData.children.push(newNode)
this.createTree(newNode, data)
}
}
}
}
export default Mindmap;
文章
Claire Zheng · 八月 17, 2021
回过头来,业务场景都是千人千面的, FHIR怎么能够用一个标准涵盖尽可能多的用例?HL7吸收了V3的教训,在V3里面不成功的、或者说采纳度比较低的一个原因就V3试图穷举所有用例,由HL7组织自己来规范这些用例。这个是蛮沉重的教训,这也是V3的方法论虽然好,但是这套实施的路线在国际上有很大障碍的原因。
HL7已经不试图再自己穷举所有用例开发标准。它在FHIR的标准开发上,使用的是80/20原则。80/20的原则就是它自己专注在80%的业务都需要的那些数据部分上,其它20%交给使用者自己去进行相应的扩展,也就说它有很好的扩展性。
FHIR到底怎么来进行扩展?FHIR可以对模型、值集、API进行扩展,并且进一步的进行约束。而这些扩展本身也是资源,因此扩展可以像其它资源一样被创建、被访问、被交换。
怎么把你的扩展告诉别人?
在HL7 V2年代扩展很容易做,用z字段就可以来做扩展。但是你自己做的扩展约束需要通过文档和人工沟通的方式跟对方来进行人工沟通,告诉人家你是怎么扩展的,你是怎么约束的,你是怎么计划使用HL7消息。
而FHIR是通过Profile(规范)来进行约束和扩展表达的。将你做的扩展和约束与被扩展和约束的资源通过Profile(规范)来进行关联,然后注册这些Profile(规范),让别人能够找到。对方的技术系统只要通过你发给他的这些约束和扩展过的资源里面所标记的Profile的URL,就可以来得到获取并够解析Profile(规范),这样就能够理解你所做的约束和扩展,实现机器可读。这是FHIR跟之前标准在扩展模式上非常大的区别。
另外因为涉及到了用例,通常Profile(规范)是级联的。先按国家和地区的通用用例来建立一个区域级的、一个大的、有共性的Profile(规范),然后区域内的医疗机构可以以此为基础来创建自己下一级的Profile(规范),自己可能有一些扩展——例如说梅奥诊所,它可以基于美国的核心的Profile(规范)、扩展过的患者的资源上,来进行自己的一些患者信息扩展——这种级联扩展方式能够保证最大程度的互操作能力,即在同一个区域里面的所有机构,都共享一个通用的资源,可以保证互操作能力的最大化实现。
另外一个概念就是实施指南(Implementation Guides)。FHIR本身是一个平台规范,它本身关注在能力建设和生态建设上,这意味着广大的用户可以基于FHIR来开发出不同的解决方案。而实施指南就是说明如何使用FHIR的资源和能力来构建解决方案的。
注意区别Profile(规范)与FHIR的实施指南(Implementation Guide)。FHIR实施指南(Implementation Guide)相当于是什么?相当于经线,描述的是针对业务场景所需要的使用的方法;而Profile(规范)相当于是纬线,描述的是应用场景所需要的标准本身。HL7组织提供了一个实施指南注册的一个网站,大家都可以将自己的用例的实施指南注册在上面,所有人都可以看到、获取、利用、学习它。
上图是我把网站上列出来的所有注册的实施指南做的一个汇总。从这张汇总出来的实施指南的统计图来看,它涉及的业务场景是非常广泛的,包括了电子病历访问、管理、公卫、财务等等,这也说明了FHIR资源的覆盖面其实非常广,它可以覆盖从临床、管理、财务、设备、组学等方方面面。
FHIR还有生态。HL7设计FHIR初衷就是让它成为一个生态的标准,围绕着FHIR其实已经有一个不断扩大的生态圈。这里面列出来一些包括刚才我们提到的SMART on FHIR。
注:本文根据InterSystems中国技术总监乔鹏演讲整理而成。
文章
Lilian Huang · 七月 9, 2023
#Embedded Python #HL7 #InterSystems IRIS for Health
写在回复社区帖子《Python能否动态创建HL7消息》中。
前提条件和设置
使用一个启用了集成的命名空间。注意:USER命名空间默认不启用互操作性。如果以下建议创建一个新的互操作性命名空间来探索功能。
# 切换到ZN "[互操作性名称空间名称]"
# 启动交互式Python shell:Do $SYSTEM.Python.Shell()
启动脚本
#Load dependencies
import datetime as dt
import uuid
# Cache current time in CCYYMMDDHHMMss format
hl7_datetime_now=dt.datetime.now().strftime('%Y%m%d%H%M%S')
# Create HL7 Message
hl7=iris.cls("EnsLib.HL7.Message")._New()
# Set the doc type
# 2.5.1:ORU_R01 - Unsolicited transmission of an observation message
hl7.PokeDocType("2.5.1:ORU_R01")
这些信息的结构可以从管理门户中获取
创建MSH(消息头段)。
// MSH Segment
hl7.SetValueAt('OutApp','MSH:SendingApplication')
hl7.SetValueAt('OutFac','MSH:SendingFacility')
hl7.SetValueAt('InApp','MSH:ReceivingApplication')
hl7.SetValueAt('InFac','MSH:ReceivingFacility')
hl7.SetValueAt(hl7_datetime_now,'MSH:DateTimeOfMessage')
hl7.SetValueAt('ORU','MSH:MessageType.MessageCode')
hl7.SetValueAt('R01','MSH:MessageType.TriggerEvent')
hl7.SetValueAt('ORU_R01','MSH:MessageType.MessageStructure')
hl7.SetValueAt(str(uuid.uuid4()),'MSH:MessageControlID')
hl7.SetValueAt('2.5.1','MSH:ProcessingID')
编码和解码
HL7文件被格式化为段每个段被分隔符("|")和重复元素("~")划分为多个元素在一个元素内有"^"分界符和"&"子分界符。当定界符作为实际的文本内容出现时,它将被"\"和其他取代定界符的字符转义。通常,"&"是有问题的,因为它可能经常出现在信息中,导致接收系统读取时出现截断现象。HL7段有一个内置的方法,用于根据当前为信息选择的定界符来转义内容。一个常见的模式是获得对第一个段的引用
# Do this line the variable "msh" is used later
> msh=hl7.GetSegmentAt(1)
然后可以调用Escape,例如用Python的原始字符串:
> msh.Escape(r"a&b~c^d")
'a\\T\\b\\R\\c\\S\\d'
The segment can also be used to Unescape back for example:
> msh.Unescape('a\\T\\b\\R\\c\\S\\d')
'a&b~c^d'
因此,在设置预计包含分隔符的内容时,可以为信息转义这些分隔符
hl7.SetValueAt(msh.Escape(r"a&b~c^d"),'MSH:ReceivingFacility')
检索内容时可以不加转义
msh.Unescape(hl7.GetValueAt('MSH:ReceivingFacility'))
在这个例子中,只是将msh重新设置为以前的值
hl7.SetValueAt('InFac','MSH:ReceivingFacility')
仔细检查到目前为止的部分:
> hl7.GetValueAt('MSH')
'MSH|^~\\&|OutApp|OutFac|InApp|InFac|20230610100040||ORU^R01^ORU_R01|2dfab415-51aa-4c75-a7e7-a63aedfb53cc|2.5.1'
人口统计学(PID)部分
# Virtual path prefix for PID
seg='PIDgrpgrp(1).PIDgrp.PID:'
hl7.SetValueAt('1',seg+'SetIDPID')
hl7.SetValueAt('12345',seg+'PatientIdentifierList(1).IDNumber')
hl7.SetValueAt('MRN',seg+'PatientIdentifierList(1).AssigningAuthority')
hl7.SetValueAt('MR',seg+'PatientIdentifierList(1).IdentifierTypeCode')
hl7.SetValueAt(msh.Escape('Redfield'), seg+'PatientName(1).FamilyName')
hl7.SetValueAt(msh.Escape('Claire') ,seg+'PatientName(1).GivenName')
hl7.SetValueAt('19640101',seg+'DateTimeofBirth')
hl7.SetValueAt('F',seg+'AdministrativeSex')
hl7.SetValueAt(msh.Escape('Umbrella Corporation') ,seg+'PatientAddress.StreetAddress')
hl7.SetValueAt(msh.Escape('Umbrella Drive') ,seg+'PatientAddress.OtherDesignation')
hl7.SetValueAt(msh.Escape('Raccoon City') ,seg+'PatientAddress.City')
hl7.SetValueAt(msh.Escape('MO') ,seg+'PatientAddress.StateorProvince')
hl7.SetValueAt(msh.Escape('63117') ,seg+'PatientAddress.ZiporPostalCode')
仔细检查PID段的内容
> hl7.GetValueAt(seg[0:-1])
'PID|1||12345^^^MRN^MR||Redfield^Claire||19640101|F|||Umbrella Corporation^Umbrella Drive^Raccoon City^MO^63117'
订单控制部分
seg='PIDgrpgrp(1).ORCgrp(1).ORC:'
hl7.SetValueAt('RE',seg+'OrderControl')
hl7.SetValueAt('10003681',seg+'PlacerOrderNumber')
hl7.SetValueAt('99001725',seg+'FillerOrderNumber')
hl7.SetValueAt('AG104',seg+'OrderingProvider')
hl7.SetValueAt('L43',seg+'EnterersLocation')
仔细检查ORC部分的内容
> hl7.GetValueAt(seg[0:-1])
'ORC|RE|10003681|99001725|||||||||AG104|L43'
观察请求
seg='PIDgrpgrp(1).ORCgrp(1).OBR:'
hl7.SetValueAt('1',seg+'SetIDOBR')
hl7.SetValueAt('10003681',seg+'PlacerOrderNumber')
hl7.SetValueAt('99001725',seg+'FillerOrderNumber')
hl7.SetValueAt('20210428100729',seg+'ResultsRptStatusChngDateTime')
hl7.SetValueAt('F',seg+'ResultStatus')
hl7.SetValueAt('U',seg+'QuantityTiming.Priority')
OBX 观察/结果
seg='PIDgrpgrp(1).ORCgrp(1).OBXgrp(1).OBX:'
hl7.SetValueAt('1',seg+'SetIDOBX')
hl7.SetValueAt('TX',seg+'ValueType')
hl7.SetValueAt('V8132',seg+'ObservationIdentifier.Identifier')
hl7.SetValueAt(msh.Escape('G-Virus') , seg+'ObservationIdentifier.Identifier')
hl7.SetValueAt(msh.Escape('17.8 log10') ,seg+'ObservationValue')
hl7.SetValueAt(msh.Escape('RNA copies/mL') ,seg+'Units')
hl7.SetValueAt('F',seg+'ObservationResultStatus')
hl7.SetValueAt('20210428100729',seg+'DateTimeoftheObservation')
hl7.SetValueAt('AG001',seg+'ResponsibleObserver.IDNumber')
hl7.SetValueAt('Birkin',seg+'ResponsibleObserver.FamilyName')
hl7.SetValueAt('William',seg+'ResponsibleObserver.GivenName')
hl7.SetValueAt('AG001',seg+'ResponsibleObserver.IDNumber')
hl7.SetValueAt('UXL43',seg+'EquipmentInstanceIdentifier')
NTE - 注释和评论
seg='PIDgrpgrp(1).ORCgrp(1).OBXgrp(1).NTE(1):'
hl7.SetValueAt('1',seg+'SetIDNTE')
hl7.SetValueAt(msh.Escape('Expected late onset Hyphema. Contain but do not approach.') ,seg+'Comment')
向终端打印全部信息
> print(hl7.OutputToString())
MSH|^~\&|OutApp|OutFac|InApp|InFac|20230610141201||ORU^R01^ORU_R01|2dfab415-51aa-4c75-a7e7-a63aedfb53cc|2.5.1
PID|1||12345^^^MRN^MR||Redfield^Claire||19640101|F|||Umbrella Corporation^Umbrella Drive^Raccoon City^MO^63117
ORC|RE|10003681|99001725|||||||||AG104|L43
OBR|1|10003681|99001725|||||||||||||||||||20210428100729|||F||^^^^^U
OBX|1|TX|G-Virus||17.8 log10|RNA copies/mL|||||F|||20210428100729||AG001^Birkin^William||UXL43
NTE|1||Expected late onset Hyphema. Contain but do not approach.
陷阱
如果一个元素的内容包含一个诸如 "8@%SYS.Python "的值,很可能是需要用字符串值或字符串属性来代替。
例如,uuid在MSH结构中被 "str "包裹着。
原文请查看 来自 Alex Woodhead
https://community.intersystems.com/post/dynamically-creating-hl7-message-iris-embedded-python
文章
姚 鑫 · 四月 25, 2021
# 第五章 优化查询性能(四)
# 注释选项
可以在`SELECT`、`INSERT`、`UPDATE`、`DELETE`或`TRUNCATE`表命令中为查询优化器指定一个或多个注释选项。
注释选项指定查询优化器在编译SQL查询期间使用的选项。
通常,注释选项用于覆盖特定查询的系统范围默认配置。
## 语法
语法`/*#OPTIONS */`(在`/*`和`#`之间没有空格)指定了一个注释选项。
注释选项不是注释;
它为查询优化器指定一个值。
注释选项使用`JSON`语法指定,通常是`“key:value”`对,例如: `/*#OPTIONS {"optionName":value} */`。
支持更复杂的JSON语法,比如嵌套值。
注释选项不是注释;
除了`JSON`语法之外,它可能不包含任何文本。
包含非`json`文本在`/* ... */`分隔符导致`SQLCODE -153`错误。
InterSystems SQL不验证`JSON`字符串的内容。
`#OPTIONS`关键字必须用大写字母指定。
`JSON`的大括号语法中不应该使用空格。
如果SQL代码用引号括起来,比如动态SQL语句,JSON语法中的引号应该是双引号。
例如:`myquery="SELECT Name FROM Sample.MyTest /*#OPTIONS {""optName"":""optValue""} */"`.
可以在SQL代码中任何可以指定注释的地方指定`/*#OPTIONS */` comment选项。
在显示的语句文本中,注释选项总是作为注释显示在语句文本的末尾。
你可以在SQL代码中指定多个`/*#OPTIONS */` comment选项。
它们按照指定的顺序显示在返回的语句文本中。
如果为同一个选项指定了多个注释选项,则使用`last`指定的选项值。
以下的注释选项被记录在案:
- `/*#OPTIONS {"BiasAsOutlier":1} */`
- `/*#OPTIONS {"DynamicSQLTypeList":"10,1,11"}`
- `/*#OPTIONS {"NoTempFile":1} */`
## 显示
`/*#OPTIONS */` comment选项显示在SQL语句文本的末尾,而不管它们是在SQL命令中指定的位置。
一些显示的`/*#OPTIONS */` comment选项没有在SQL命令中指定,而是由编译器的预处理器生成的。
例如 `/*#OPTIONS {"DynamicSQLTypeList": ...} */`
`/*#OPTIONS */` comment选项显示在`Show Plan`语句文本、缓存的查询查询文本和SQL语句语句文本中。
为仅在`/*#OPTIONS */` comment选项中不同的查询创建一个单独的缓存查询。
# 并行查询处理
并行查询提示指示系统在多处理器系统上运行时执行并行查询处理。
这可以极大地提高某些类型查询的性能。
SQL优化器确定一个特定的查询是否可以从并行处理中受益,并在适当的时候执行并行处理。
指定并行查询提示并不强制对每个查询进行并行处理,只强制那些可能从并行处理中受益的查询。
如果系统不是多处理器系统,则此选项无效。
要确定当前系统上的处理器数量,请使用 `%SYSTEM.Util.NumberOfCPUs() `方法。
可以通过两种方式指定并行查询处理:
- 在系统范围内,通过设置`auto parallel`选项。
- 在每个查询的`FROM`子句中指定`%PARALLEL`关键字。
并行查询处理应用于`SELECT`查询。
它不应用于插入、更新或删除操作。
## 系统范围的并行查询处理
可以使用以下选项之一来配置系统范围的自动并行查询处理:
- 在管理门户中选择System Administration,然后选择Configuration,然后选择SQL和对象设置,最后选择SQL。
查看或更改在单个进程中执行查询复选框。
注意,该复选框的默认值是未选中的,这意味着并行处理在默认情况下是激活的。
- 调用`$SYSTEM.SQL.Util.SetOption()`方法,如下: `SET status=$SYSTEM.SQL.Util.SetOption("AutoParallel",1,.oldval)`.
默认值是1(自动并行处理激活)。
要确定当前的设置,调用`$SYSTEM.SQL.CurrentSettings()`,它会显示为`%PARALLEL`选项启用自动提示。
注意,更改此配置设置将清除所有名称空间中的所有缓存查询。
当激活时,自动并行查询提示指示SQL优化器对任何可能受益于这种处理的查询应用并行处理。
在IRIS 2019.1及其后续版本中,自动并行处理是默认激活的。
从IRIS 2018.1升级到IRIS 2019.1的用户需要明确激活自动并行处理。
SQL优化器用于决定是否对查询执行并行处理的一个选项是自动并行阈值。
如果激活了系统范围的自动并行处理(默认),可以使用`$SYSTEM.SQL.Util.SetOption()`方法将自动并行处理的优化阈值设置为整数值,如下所示: `SET status=$SYSTEM.SQL.Util.SetOption("AutoParallelThreshold",n,.oldval)`。
`n`阈值越高,将此特性应用于查询的可能性就越低。
此阈值用于复杂的优化计算,但可以将此值视为必须驻留在已访问映射中的元组的最小数量。
默认值为3200。
最小值为0。
要确定当前的设置,调用`$SYSTEM.SQL.CurrentSettings()`,它显示`%PARALLEL`选项的自动提示阈值。
当自动并行处理被激活时,在分片环境中执行的查询将始终使用并行处理执行,而不管并行阈值是多少。
## 针对特定查询的并行查询处理
可选的`%PARALLEL`关键字在查询的`FROM`子句中指定。
它建议跨系统的IRIS使用多个处理器(如果适用的话)并行处理查询。
这可以显著提高使用一个或多个`COUNT`、`SUM`、`AVG`、`MAX`或`MIN`聚合函数和`/`或`groupby`子句的查询的性能,以及许多其他类型的查询。
这些通常是处理大量数据并返回小结果集的查询。
例如,`SELECT AVG(SaleAmt) FROM %PARALLEL User.AllSales GROUP BY Region`都可使用并行处理。
**仅指定聚合函数、表达式和子查询的“一行”查询执行并行处理,无论是否带有`GROUP BY`子句。
但是,同时指定单个字段和一个或多个聚合函数的“多行”查询不会执行并行处理,除非它包含`GROUP BY`子句。
例如,`SELECT Name,AVG(Age) FROM %PARALLEL Sample.Person`不执行并行处理,但是 `SELECT Name,AVG(Age) FROM %PARALLEL Sample.Person GROUP BY Home_State` 执行并行处理。**
如果在运行时模式下编译指定`%PARALLEL`的查询,则所有常量都被解释为ODBC格式。
指定`%PARALLEL`可能会降低某些查询的性能。
在一个有多个并发用户的系统上运行`%PARALLEL`查询可能会降低整体性能。
在查询视图时可以执行并行处理。
但是,即使显式地指定了`%parallel`关键字,也不会对指定`%VID`的查询执行并行处理。
### `%PARALLEL`的子查询
`%PARALLEL`用于`SELECT`查询及其子查询。
插入命令子查询不能使用`%PARALLEL`。
当应用于与外围查询相关的子查询时,`%PARALLEL`将被忽略。
例如:
```sql
SELECT name,age FROM Sample.Person AS p
WHERE 30 e.dob.` 这是因为SQL优化将这种类型的连接转换为完整的外部连接。
对于完整的外部连接,`%PARALLEL`将被忽略。
- `%PARALLEL`和`%INORDER`优化不能同时使用;
如果两者都指定,`%PARALLEL`将被忽略。
- 查询引用一个视图并返回一个视图ID (`%VID`)。
- 如果表有`BITMAPEXTENT`索引,`COUNT(*)`不使用并行处理。
- `%PARALLEL`用于使用标准数据存储定义的表。
可能不支持将其与自定义存储格式一起使用。
`%PARALLEL`不支持全局临时表或具有扩展全局引用存储的表。
- `%PARALLEL`用于可以访问一个表的所有行的查询,使用行级安全(`ROWLEVELSECURITY`)定义的表不能执行并行处理。
- `%PARALLEL`用于存储在本地数据库中的数据。
它不支持映射到远程数据库的全局节点。
## 共享内存的考虑
对于并行处理,IRIS支持多个进程间队列(`IPQ`)。
每个`IPQ`处理单个并行查询。
它允许并行工作单元子流程将数据行发送回主流程,这样主流程就不必等待工作单元完成。
这使得并行查询能够尽可能快地返回第一行数据,而不必等待整个查询完成。
它还改进了聚合函数的性能。
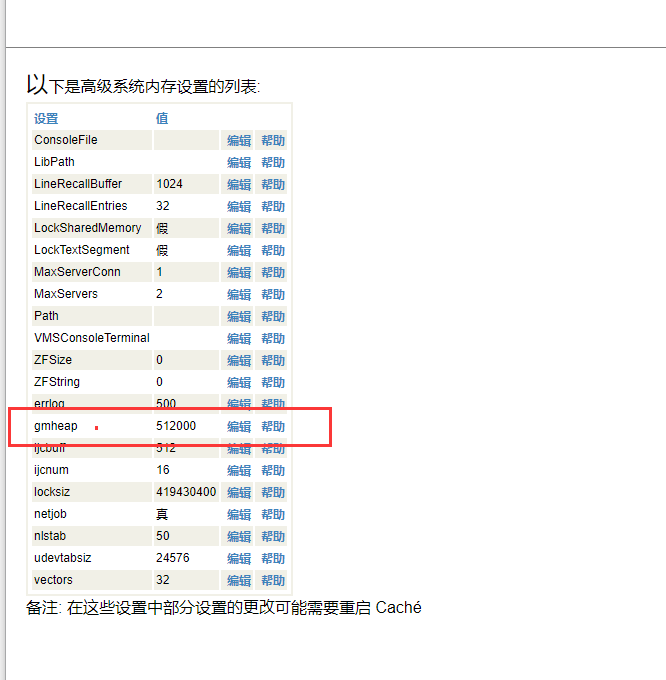
并行查询执行使用来自通用内存堆(`gmheap`)的共享内存。
如果使用并行SQL查询执行,用户可能需要增加`gmheap`大小。
一般来说,每个`IPQ`的内存需求是`4 x 64k = 256k`。
InterSystems IRIS将一个并行SQL查询拆分为可用的`CPU`核数。
因此,用户需要分配这么多额外的`gmheap`:
```java
x x 256 =
```
注意,这个公式不是100%准确的,因为一个并行查询可以产生同样是并行的子查询。
因此,明智的做法是分配比这个公式指定的更多的额外`gmheap`。
分配足够的`gmheap`失败将导致错误报告给`messages.log`。
SQL查询可能会失败。
其他子系统尝试分配`gmheap`时也可能出现其他错误。
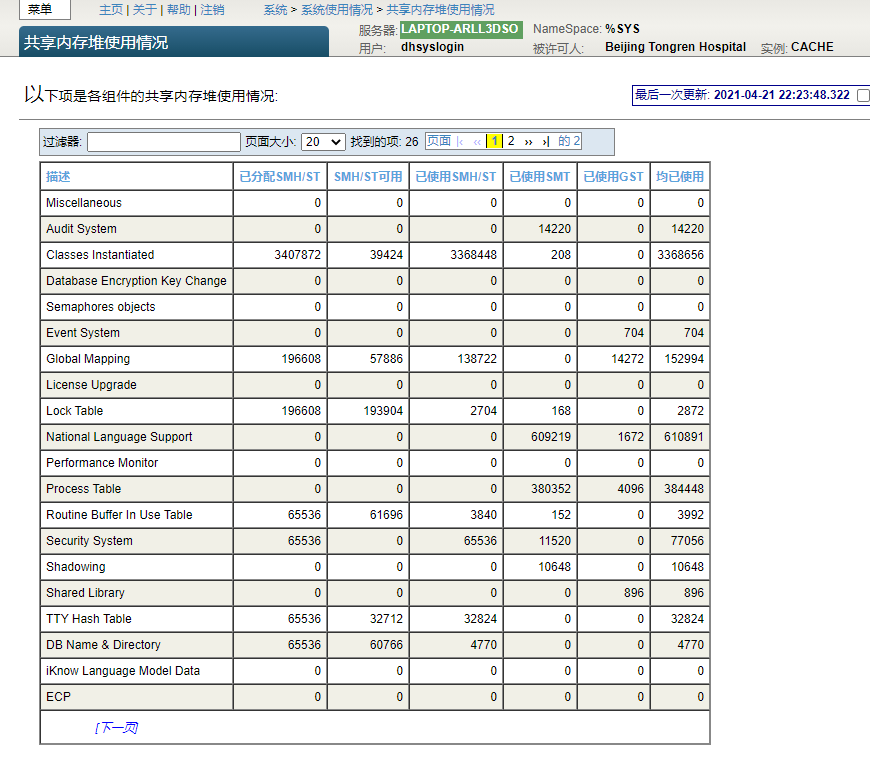
要查看一个实例的`gmheap`使用情况,特别是`IPQ`使用情况,请在管理门户的主页上选择System Operation,然后选择System usage,然后单击Shared Memory Heap usage链接;
要更改通用内存堆或`gmheap`(有时称为共享内存堆或SMH)的大小,请从管理门户的主页选择“系统管理”,然后是“配置”,然后是“附加设置”,最后是“高级内存”;

## 缓存查询注意事项
如果你正在运行一个缓存的SQL查询,使用`%PARALLEL`,当这个查询被初始化时,你做了一些事情来清除缓存的查询,那么这个查询可能会从一个工人作业报告一个``错误。
导致缓存查询被清除的典型情况是调用`$SYSTEM.SQL.Purge()`或重新编译该查询引用的类。
重新编译类将自动清除与该类相关的任何缓存查询。
如果发生此错误,再次运行查询可能会成功执行。
从查询中删除`%PARALLEL`可以避免出现此错误。
## SQL语句和计划状态
使用`%PARALLEL`的SQL查询可以产生多条SQL语句。
这些SQL语句的计划状态是`Unfrozen/Parallel`。
计划状态为“已冻结”/“并行”的查询不能通过用户操作进行冻结。
# 生成报告
可以使用生成报告工具向InterSystems Worldwide Response Center (WRC) customer support提交查询性能报告,以便进行分析。
可以使用以下任意一种方式从管理门户运行生成报告工具:
1. 必须首先从WRC获得WRC跟踪号。可以使用每个管理门户页面顶部的Contact按钮从管理门户联系WRC。在WRC编号区域中输入此跟踪编号。可以使用此跟踪编号来报告单个查询或多个查询的性能。
2. 在“SQL语句”区域中,输入查询文本。右上角将显示一个X图标。可以使用此图标清除SQL语句区。查询完成后,选择保存查询按钮。系统生成查询计划并收集指定查询的运行时统计信息。无论系统范围的运行时统计信息设置如何,生成报告工具始终使用收集选项3:记录查询的所有模块级别的统计信息进行收集。由于在此级别收集统计信息可能需要时间,因此强烈建议您选中“在后台运行保存查询进程”复选框。默认情况下,此复选框处于选中状态。
当后台任务启动时,该工具显示“请等待……”,禁用页面上的所有字段,并显示一个新的视图进程按钮。
单击View Process按钮将在新选项卡中打开Process Details页面。
在流程详细信息页面,您可以查看该流程,并可以“暂停”、“恢复”或“终止”该流程。
进程的状态反映在Save查询页面上。
当流程完成时,当前保存的查询表将被刷新,View process按钮将消失,页面上的所有字段将被启用。
3. 对每个查询执行步骤2。
每个查询将被添加到当前保存的Queries表中。
注意,该表可以包含具有相同WRC跟踪号的查询,也可以包含具有不同跟踪号的查询。
完成所有查询后,继续步骤4。
对于列出的每个查询,可以选择Details链接。
该链接将打开一个单独的页面,其中显示完整的SQL语句、属性(包括WRC跟踪号和IRIS软件版本),以及包含每个模块的性能统计信息的查询计划。
- 要删除单个查询,请从“当前保存的查询”表中选中这些查询的复选框,然后单击“清除”按钮。
- 要删除与WRC跟踪编号关联的所有查询,请从当前保存的查询表中选择一行。WRC编号显示在页面顶部的WRC编号区域。如果您随后单击清除按钮,则对该WRC编号的所有查询都将被删除。
4. 使用查询复选框选择要报告给WRC的查询。要选择与WRC跟踪编号关联的所有查询,请从当前保存的查询表中选择一行,而不是使用复选框。在这两种情况下,都可以选择Generate Report按钮。生成报告工具创建一个XML文件,其中包括查询语句、具有运行时统计信息的查询计划、类定义以及与每个所选查询相关联的SQL int文件。
如果选择与单个WRC跟踪编号关联的查询,则生成的文件将具有默认名称,如`WRC12345.xml`。如果选择与多个WRC跟踪编号关联的查询,则生成的文件将具有默认名称`WRCMultiple.xml`。
将出现一个对话框,要求指定保存报告的位置。保存报告后,可以单击Mail to链接将报告发送给WRC客户支持。使用邮件客户端的附加/插入功能附加文件。
文章
Hao Ma · 一月 10, 2021
虽然 Caché 和 InterSystems IRIS 数据库的[完整性](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GCDI_integrity)完全不会受到系统故障的影响,但物理存储设备故障确实会损坏其存储的数据。 因此,许多站点选择运行定期数据库完整性检查,尤其要与备份配合,以验证在发生灾难时是否可以依赖给定的备份。 系统管理员在应对涉及存储损坏的灾难时,也可能强烈需要完整性检查。 完整性检查必须读取所检查的 global 的每个块(如果尚未在缓冲区中),并且按照 global 结构指示的顺序读取。 这会花费大量时间,**但完整性检查能够以存储子系统可以承受的最快速度进行读取**。 在某些情况下,需要以这种方式运行以尽快获得结果。 在其他情况下,完整性检查需要更加保守,以避免消耗过多的存储子系统带宽。
## 行动计划
以下概述适合大多数情况。 本文其余部分中的详细讨论提供了采取其中任一行动或得出其他行动方案所需的信息。
1. 如果使用 Linux 并且完整性检查很慢,请参阅下面有关启用异步 I/O 的信息。
2. 如果完整性检查必须尽快完成,则在隔离的环境中运行;或者如果迫切需要结果,则使用多进程完整性检查来并行检查多个 global 或数据库。 进程数乘以每个进程将执行的并发异步读取数(默认为 8,如果使用 Linux 并且禁用异步 I/O 则为 1)是实时并发读取数的限制。 假定平均数是限制数量的一半,然后与存储子系统的能力进行比较。 例如,存储由 20 个驱动器条带化,每个进程的默认并发读取数为 8,则可能需要 5 个或更多进程才能利用存储子系统的全部能力 (5*8/2=20)。
3. 在平衡完整性检查速度与对生产的影响时,首先调整多进程完整性检查的进程数,然后如果需要的话,查看可调参数 SetAsyncReadBuffers。 对于长期解决方案(以及为消除误报),请参见下面的隔离完整性检查。
4. 如果已经被限制为一个进程(例如有一个极大的 global 或存在其他外部约束),并且完整性检查的速度需要上下调整,则查看下面的可调参数 SetAsyncReadBuffers。
## 多进程完整性检查
让完整性检查更快完成(以更高的速度使用系统资源)的一般解决方案是将工作分给多个并行进程。 一些完整性检查用户界面和 API 会这样做,而其他一些则使用单个进程。 对进程的分配按 global 进行,因此对单个 global 的检查始终由一个进程执行(Caché 2018.1 之前的版本按数据库而不是按 global 分配工作)。
多进程完整性检查的主要 API 是 **CheckLIst^Integrity**(有关详细信息,请参阅[文档](https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=GCDI_integrity#GCDI_integrity_verify_utility))。 它将结果收集在一个临时的 global 中,通过 Display^Integrity 来显示。 以下是使用 5 个进程检查 3 个数据库的示例。 这里如省略数据库列表参数,将检查所有数据库。
set dblist=$listbuild(“/data/db1/”,”/data/db2/”,”/data/db3/”)
set sc=$$CheckList^Integrity(,dblist,,,5)
do Display^Integrity()
kill ^IRIS.TempIntegrityOutput(+$job)
/* Note: evaluating ‘sc’ above isn’t needed just to display the results, but...
$system.Status.IsOK(sc) - ran successfully and found no errors
$system.Status.GetErrorCodes(sc)=$$$ERRORCODE($$$IntegrityCheckErrors) // 267
- ran successfully, but found errors.
Else - a problem may have prevented some portion from running, ‘sc’ may have
multiple error codes, one of which may be $$$IntegrityCheckErrors. */
像这样使用 CheckLIst^Integrity 是实现我们感兴趣的控制水平的最直接方法。 管理门户接口和完整性检查任务(内置但未安排)使用多个进程,但可能无法为我们的用途提供足够的控制。*
其他完整性检查接口,尤其是终端用户接口 ^INTEGRIT 或 ^Integrity 以及 Silent^Integrity,在单个进程中执行完整性检查。 因此,这些接口不能以最快的速度完成检查,并且它们使用的资源也较少。 但一个优点是,它们的结果是可见的,可以记录到文件或输出到终端,因为每个 global 都会被检查,而且顺序明确。
## 异步 I/O
完整性检查进程会排查 global 的每个指针块,一次检查一个,根据它指向的数据块的内容来进行验证。 数据块以异步 I/O 的方式读取,以确保每时每刻都有一定数量的读取请求供存储子系统处理,并且每次读取完成后都进行验证。
在 Linux 上,异步 I/O 只有与直接 I/O 结合时才有效,而 InterSystems IRIS 2020.3 之前的版本默认不启用直接 I/O。 这解释了大量 Linux 上完整性检查时间过长的情况。 幸运的是,可以在 Cache 2018.1、IRIS 2019.1 及以后的版本上启用直接 I/O,方法是在 .cpf 文件的 [config] 部分中设置 **wduseasyncio=1**,然后重新启动。 通常建议设置此参数,以在繁忙系统上实现 I/O 可伸缩性,并且自 Caché 2015.2 起,在非 Linux 平台上默认设置此参数。 在启用之前,确保已经为数据库缓存(global 缓冲区)配置了足够的内存,因为启用直接 I/O 后,数据库将不再被 Linux(冗余)缓存。 未启用时,完整性检查执行的读取会同步完成,不能有效利用存储。
在所有平台上,完整性检查进程一次执行的读取数默认设置为 8。 如果必须更改单个完整性检查进程从磁盘读取的速率,可以调整此参数 – 向上调会使单个进程更快完成,向下调则使用更少的存储带宽。 请记住:
* 此参数应用于每个完整性检查进程。 当使用多个进程时,进程数会使实时读取数增加。更改并行完整性检查进程数会产生较大影响,因此这通常是先做的事情。 每个进程还受到计算时间的限制(除其他限制外),因此增加此参数的值所获得的收益也有限。
* 这只在存储子系统处理并发读取的能力范围内有效。 如果数据库存储在单个本地驱动器上,再高的数值也没有用处,而在几十个驱动器上条带化的存储阵列可以并发处理几十个读取。
要从 %SYS 命名空间调整此参数,则 **do SetAsyncReadBuffers^Integrity(**value**)**。 要查看当前值,则 **write $$GetAsyncReadBuffers^Integrity()**。 更改在检查下一个 global 时生效。 目前,该设置在系统重启后不会保持,虽然可以将其添加到 SYSTEM^%ZSTART 中。
有一个相似的参数用于在磁盘上的块是连续(或接近连续)分布时控制每次读取的最大大小。 此参数很少需要用到,尽管具有高存储延迟的系统或具有较大块大小的数据库可能会从微调中受益。 该值的单位为 64KB,因此值 1 表示 64KB,4 表示 256KB 等等。0(默认值)表示让系统选择,当前选择 1 (64KB)。 此参数的 ^Integrity 函数(类似于上面提及的函数)为 **SetAsyncReadBufferSize** 和 **GetAsyncReadBufferSize**。
## 隔离完整性检查
许多站点直接在生产系统上运行定期完整性检查。 这当然是最简单的配置,但并不理想。 除了完整性检查对存储带宽的影响,并发数据库更新活动有时还可能导致误报错误(尽管检查算法内置了缓解措施)。 因此,在生产系统上运行的完整性检查所报告的错误,需要由管理员进行评估和/或重新检查。
很多时候,存在更好的选择。 可以将存储快照或备份映像挂载到另一台主机上,在那里由隔离的 Caché 或 IRIS 实例运行完整性检查。 这样不仅可以防止任何误报,而且如果存储也与生产隔离,运行完整性检查可以充分利用存储带宽并更快完成。 这种方法非常适合使用完整性检查来验证备份的模型;经过验证的备份可以有效验证截至生成备份前的生产情况。 还可以通过云和虚拟化平台更容易地从快照建立可用的隔离环境。
* * *
* 管理门户接口、完整性检查任务和 SYS.Database 的 IntegrityCheck 方法会选择相当多的进程(等于 CPU 内核数),在很多情况下缺少所需的控制。 管理门户和任务还会对任何报告错误的 global 执行完整的重新检查,以识别可能因并发更新而出现的误报。 除了完整性检查算法内置的误报缓解措施,也可能进行这种重新检查;在某些情况下,由于会花费额外的时间(重新检查在单个进程中运行,并检查整个 global),可能并不需要重新检查。 此行为将来可能会更改。