清除过滤器
文章
Claire Zheng · 一月 21, 2021
大家好!
我想跟大家分享一个个人项目,该项目始于工作中的一个简单需求:“能否知道我们使用了多少个Caché许可证?”
在阅读社区的其他文章时,我发现了一篇David Loveluck写的非常棒的文章:APM——使用Caché History Monitor。
我根据David的这篇文章,开始使用Caché History Monitor并显示所有这些信息。
在面临“选择哪种很酷的技术”这个问题时,我决定使用简单而强大的CSP,这样我的客户可以认识到Caché不仅仅是MUMPS/终端。
在创建了页面以显示许可、数据库增长和CSP会话的历史记录后,我决定为System Dashboard和进程页面创建一个新设计。
我的Caché实例运行得良好。
但是,如果使用IRIS呢?根据Evgeny Shvarov的文章:在InterSystems IRIS开发存储库中使用Docker,我实现了docker技术,并把代码放到了GitHub上,现在大家只需几个步骤就可以进行尝试。
如何运行?
如要使用这里的repo进行编码,请执行以下操作:
1. 通过Clone/git命令将repo 更新到任意本地目录中:
$ git clone https://github.com/diashenrique/iris-history-monitor.git
2. 打开这个目录下的终端,并运行:
$ docker-compose build
3. 在项目中运行IRIS容器:
$ docker-compose up -d
如何测试
打开浏览器,并转到链接:http://localhost:52773/csp/irismonitor/dashboard.csp
使用用户名_SYSTEM可以运行仪表盘dashboard和其他功能。
系统仪表盘
系统仪表盘(System Dashboard)可展示:
·许可
·系统时间
·应用程序错误
·缓存过程
·CSP会话
·Lock Table
·日志空间
·日志状态
·ECP AppServer
·ECP DataServer
·编写守护进程
·缓存效率
·严重警告
折线图小工具每5秒绘制一个点:
系统菜单
系统进程
进程过滤器
通过使用不同的过滤器可以实现你所需的结果。也可以使用“Multiple Sort(多重排序)”,按Shift +单击列标题,甚至可以将数据网格导出到Excel!
History Monitor(历史记录监控器)
CSP会话和许可的History Monitor可显示三个部分的信息:
·每5分钟
·每天
·每小时
“Database Growth”部分只显示当日信息。历史记录页面共享以下功能:
Date Range Picker(日期选择插件)
默认值为“过去7天”
Chart / Data Table(图表/ 数据表)
在每个部分的右上角有两个按钮(Chart / Data Table [图表/ 数据表])
Data Table(数据表)显示创建图表所用的信息,同样可以以Excel格式下载。
Excel中显示CSP中定义的相同格式、内容和组。
缩放
所有图表都有Zoom(缩放)选项,以可视化方式显示更多详细信息。
平均值和最大值
对于“每小时”和“每天”部分,图表显示的是平均值和最大值。
平均值
最大值
希望这篇文章对您有用!
注:本文为译文,点击此处阅读原文,原文由Henrique Gonçalves Dias撰写。
文章
Qiao Peng · 三月 5, 2021
大家好!
InterSystems IRIS 有一个名为 **Interoperability**(互操作性)的菜单。
它提供了轻松创建系统集成(适配器、记录映射、BPM、数据转换等)的机制,因此可以轻松连接不同的系统。
数据中继过程中可以包括各种操作,例如:为了连接没有正常连接的系统,可以根据目标系统的规范来接收(或发送)数据。 此外,在发送数据之前,可以从其他系统获取和添加信息。 还可以从数据库(IRIS 等)获取和更新信息。
在本系列文章中,我们将讨论以下主题,同时查看 示例代码 以帮助您了解工作原理以及在系统中集成互操作性时需要进行哪种开发。
* 工作原理
* 什么是Production
* 消息
* 组件创建
* 业务操作
* 业务流程
* 业务服务
首先,我介绍一下我们将在本系列文章中使用的案例研究。
> 某公司运营着一个购物网站,他们正在更改产品信息的显示顺序以配合季节变化。但是,有些商品无论季节如何都能卖得很好,而有些商品在意料之外的时间卖出,这不符合当前的显示顺序更改规则,因此,我们研究了按照当天的温度而不是季节来更改显示顺序的可能性。 调查购买产品时的温度变得非常必要。由于可以使用外部 Web API 来查询天气信息,因此我们计划收集购买时的天气信息,并将其记录在后面的审核数据库中。
案例非常简单,但您需要使用“外部 Web API”来收集信息,并且需要将获得的信息和购买信息结合起来记录在数据库中。
具体说明将在相关文章中讨论(不包括网站的创建)。 请移步观看!
至于我们这次使用的“外部 Web API”,我们使用的是 OpenWeather的 当前天气数据.
(如果您想要尝试一下,您需要注册一个帐户并获得 API ID).
以下是一个 REST 客户端发出的 GET 请求的结果(我们将以在 Interoperability 中实现的机制来运行此流程)。
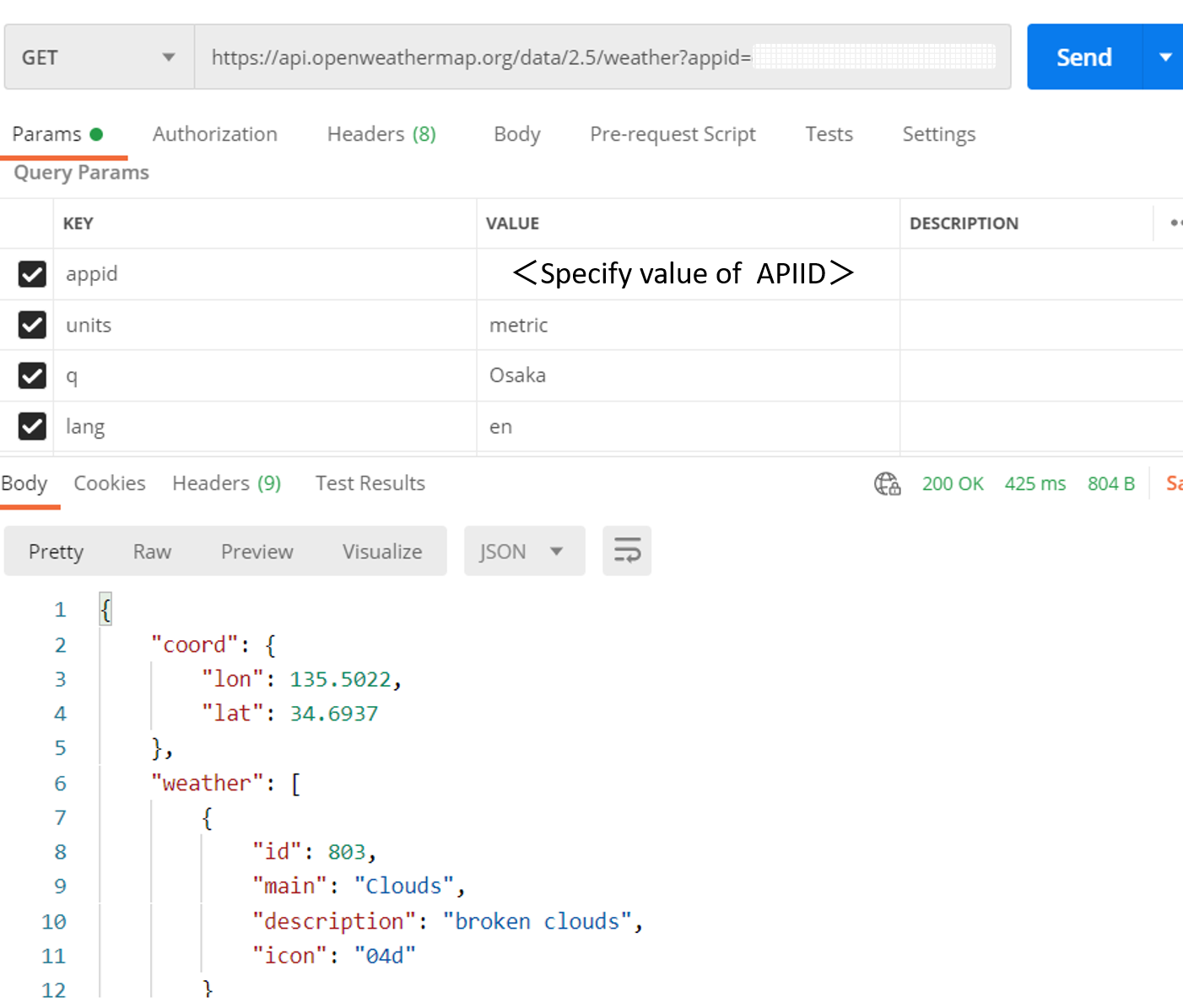
HTTP 响应的 JSON 如下所示:
```json
{
"coord": {
"lon": 135.5022,
"lat": 34.6937
},
"weather": [
{
"id": 803,
"main": "Clouds",
"description": "broken clouds",
"icon": "04d"
}
],
"base": "stations",
"main": {
"temp": 17.05,
"feels_like": 13.33,
"temp_min": 16,
"temp_max": 18,
"pressure": 1017,
"humidity": 55
},
"visibility": 10000,
"wind": {
"speed": 4.63,
"deg": 70
},
"clouds": {
"all": 75
},
"dt": 1611635756,
"sys": {
"type": 1,
"id": 8032,
"country": "JP",
"sunrise": 1611612020,
"sunset": 1611649221
},
"timezone": 32400,
"id": 1853909,
"name": "Osaka",
"cod": 200
}
```
在 下一篇文章中,我们将讨论如何使用 Interoperability 菜单进行系统集成。
[OpenWeather]: https://openweathermap.org/
公告
jieliang liu · 三月 15, 2021
嗨,开发者们,
欢迎查询 [InterSystems Developers YouTube 频道] InterSystems Developers YouTube Channel:
按观看次数排名前 10 的视频
№
Video
Views
1
Active Directory 与 LDAP 的集成
13 079
2
FHIR 上的 SMART:基础知识
7 463
3
构建现代 Web 应用程序
6 133
4
使用 Visual Studio Code 编写 ObjectScript
5 491
5
使用 FHIR 进行开发 - REST API
5 195
6
使用 IRIS 社区版、GitHub、Docker 和 VSCode 创建你的第一段 InterSystems ObjectScript 代码
1 487
7
托管文件传输
1 326
8
规模调整和容量计划
1 200
9
使用 Visual Studio Code 和 ObjectScript
1 155
10
5 分钟内为 InterSystems IRIS 创建 CRUD REST API
1 013
按观看时间排名前 10 的视频
№
Video
WT (hours)
1
FHIR 上的 SMART:基础知识
1 226,6
2
Active Directory 与 LDAP 的集成
798,1
3
构建现代 Web 应用程序
485,6
4
使用 FHIR 进行开发 - REST API
446,3
5
InterSystems IRIS 数据平台简介
104,5
6
规模调整和容量计划
101,0
7
VSCode-ObjectScript 简介网络研讨会
86,1
8
使用 IRIS 社区版、GitHub、Docker 和 VSCode 创建你的第一段 InterSystems ObjectScript 代码
79,7
9
证书吊销、OCSP 装订和 KMIP
72,4
10
使用 Visual Studio Code 编写 ObjectScript
63,9
Enjoy watching our top videos! 👏🏼
And stay tuned with InterSystems Developers YouTube! 这些视频目前都在油管上,有希望看哪些的欢迎在贴下留言。我们会尽快放在B站上。谢谢!
文章
Hao Ma · 三月 26, 2021
Intersystems IRIS 是开发、运行和消耗数据科学服务的绝佳平台。 IRIS 可以使用适配器从任何类型、格式、协议和时间提取数据。 这些数据集可以通过 BPL、DTL 和 Object Script 准备,并存储为 SQL 或 NoSQL 数据。 最后,它可以被 IRIS 内部的开放 ML 算法所消耗,并在 IRIS 仪表板中可视化。 了解详情:[https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=PAGE\_data\_science](https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=PAGE_data_science)。
公告
Claire Zheng · 四月 13, 2021
Hi 社区开发者们,告诉大家一个好消息!InterSystems IRIS®数据平台已入驻AWS Quick Start,今后可在AWS上快速部署高可用的生产环境。
基于AWS和InterSystems在安全性和高可用性方面的最佳实践,InterSystems IRIS Quick Start模板能够提供可靠、可重复的自动化参考部署,简化IRIS关键任务环境的构建过程。 这些加速器将数百个手动步骤简化为几步,因此用户可以在几分钟内快速、经济有效地在自己的AWS账户中安装InterSystems IRIS,从而更快地获得洞察和价值。 InterSystems数据平台副总裁Scott Gnau表示:“InterSystems IRIS入驻AWS Quick Start后,可为用户提供优化的、预配置的数据平台,帮助其近乎实时地部署安全、高可用的生产环境。InterSystems IRIS和AWS Quick Start的强强联合可以加快实现价值的速度,用户可专注于利用其中的深刻洞见。在目前日益激烈的竞争环境中,这两点非常重要。” 作为这个最新产品的一部分,我们还将为通过Quick Start部署InterSystems IRIS平台的用户提供一份指南,以介绍架构并提供部署指导。 作为一个全面的、云优先的数据平台,InterSystems IRIS无需集成多种技术,因此可减少代码、系统资源和维护流程,并提高投资回报率。
文章
Michael Lei · 四月 14, 2021
**什么是分布式人工智能 (DAI)?**
试图找到一个“无懈可击”的定义是徒劳的:这个术语似乎有些“超前”。 但是,我们仍然可以从语义上分析该术语本身,推导出分布式人工智能也是人工智能(请参见我们为提出一个“实用”定义所做的[努力](https://www.linkedin.com/pulse/ai-robotization-intersystems-iris-data-platform-sergey-lukyanchikov/)),只是它分布在多台没有聚合在一起(既不在数据方面,也不通过应用程序聚合,原则上不提供对特定计算机的访问)的计算机上。 即,在理想情况下,分布式人工智能的安排方式是:参与该“分布”的任何计算机都不能直接访问其他计算机的数据和应用程序,唯一的替代方案是通过“透明的”消息传递来传输数据样本和可执行脚本。 与该理想情况的任何偏差都会导致出现“部分分布式人工智能”- 一个示例是通过中央应用程序服务器分发数据, 或者其反向操作。 不管怎样,我们都会得到一组“联合”模型(即,在各自数据源上训练的模型,或者按自己的算法训练的模型,或者同时以这两种方式训练的模型)。
**“面向大众”的分布式人工智能方案**
我们不会讨论边缘计算、机密数据操作员、分散的移动搜索,或者类似的引人入胜但又不是最有意识和最广泛应用(目前不是)的方案。 我们将更“贴近于生活”,例如,如果考虑以下方案(其详细演示应该可以在此处观看):一家公司运行一个生产级 AI/ML 解决方案,其运行质量正在由一名外部数据科学家(即,不是该公司员工的专家)系统地进行检查。 由于种种原因,该公司无法授予数据科学家访问该解决方案的权限,但可以按照时间表或在特定事件(例如,解决方案终止一个或多个模型的训练会话)后向其发送所需表中的记录样本。 我们据此假定,该数据科学家拥有某个版本的 AI/ML 机制,且这些机制已经集成在公司正在运行的生产级解决方案中,而且数据科学家本人很可能正在开发、改进和调整这些机制,以适应该具体公司的具体用例。 将这些机制部署到正在运行的解决方案中、监控机制的运行以及其他生命周期方面的工作由一名数据工程师(公司员工)负责。
我们在[这篇文章](https://www.linkedin.com/pulse/intersystems-iris-all-purpose-universal-platform-aiml-lukyanchikov/)中提供了一个在 InterSystems IRIS 平台上部署生产级 AI/ML 解决方案的示例,该解决方案可自主处理来自设备的数据流。 上一段提供的链接下的演示中也运行了相同的解决方案。 您可以使用我们的仓库 Convergent Analytics 中的内容(免费且无时间限制,请访问 Links to Required Downloads 和 Root Resources 部分)在 InterSystems IRIS 上构建您自己的解决方案原型。
通过这样的方案,我们可获得“分布程度”如何的人工智能? 在我们看来,此方案相当接近理想情况,因为数据科学家与公司的数据和算法均保持“切割”(只是传输了有限的样本,但在某个时间点前很重要;而且数据科学家自己的“样本”永远不会与作为实时生产级解决方案的一部分部署和运行的“活跃”机制 100% 同步),他完全不能访问公司的 IT 基础架构。 因此,数据科学家的作用变为在他的本地计算资源上部分重放该公司生产级 AI/ML 解决方案的运行片段,获得可接受置信级别的运行质量评估,并向公司返回反馈(在我们的具体方案中,以“审核”结果表示,可能还加上该公司解决方案涉及的 AI/ML 机制的改进版本)。
_图 1 分布式人工智能方案表示_
我们知道,在人类执行人工智能项目交换的过程中,不一定需要表示和传输反馈,这源于有关现代方法的出版物以及已有的分布式人工智能实现经验。 但是,InterSystems IRIS 平台的优势在于,它允许同样高效地开发和启动“混合”(人类和机器串联)且完全自动化的人工智能用例,因此,我们将继续根据上述“混合”示例进行分析,同时为读者留下自行阐述其完全自动化的可能性。
**如何在 InterSystems IRIS 平台上运行具体的分布式人工智能方案**
本文上一节提到的带有方案演示的视频介绍对作为实时 AI/ML 平台的 InterSystems IRIS 进行了总体概述,并解释了其对 DevOps 宏机制的支持。 在演示中,没有明确覆盖负责定期将训练数据集传输给外部数据科学家的“公司侧”业务流程,因此,我们将从该业务流程及其步骤的简介开始。
发送方业务流程的一个主要“引擎”是 while 循环(使用 InterSystems IRIS 可视业务流程编辑器实现,该编辑器基于平台解释的 BPL 表示法),负责将训练数据集系统地发送给外部数据科学家。 该“引擎”内部执行以下操作(参见下图,跳过数据一致性操作):
_图 2“发送方”业务流程的主要部分_
(a) 负载分析器 – 将训练数据集表中的当前记录集加载到业务流程中,并基于它在 Python 会话中形成一个数据框架。 调用操作会触发对 InterSystems IRIS DBMS 的 SQL 查询,并触发对 Python 接口的调用以将 SQL 结果传输给它,以便形成数据框架;
(b) Azure 分析器 – 另一个调用操作,触发对 Python 接口的调用,以向其传输一组 Azure ML SDK for Python 指令,从而在 Azure 中构建所需的基础架构,并在该基础架构上部署前一个操作中形成的数据框架数据;
作为执行上述业务流程操作的结果,我们在 Azure 中获得一个存储对象(一个 .csv 文件),其中包含公司的生产级解决方案用于模型训练的最近数据集的导出:
_图 3 训练数据集“到达”Azure ML_
这样,发送方业务流程的主要部分已经结束,但是我们还需要再执行一个操作,同时请记住,我们在 Azure ML 中创建的任何计算资源都是可计费的(参见下图,跳过数据一致性操作):
_图 4“发送方”业务流程的最后部分_
(c) 资源清理 – 触发对 Python 接口的调用,以向其传输一组 Azure ML SDK for Python 指令,从 Azure 中删除上一个操作中构建的计算基础架构。
数据科学家所需的数据已经传输完毕(数据集现在在 Azure 中),因此我们可以继续启动将访问数据集的“外部”业务流程,运行至少一次替代模型训练(从算法上讲,替代模型不同于作为生产级解决方案一部分运行的模型),并向数据科学家返回得到的模型质量指标及可视化,从而表示有关公司生产级解决方案运行效率的“审核结果”。
我们现在看一下接收方业务流程:与发送方业务流程(在包含公司自主 AI/ML 解决方案的其他业务流程中运行)不同,它不需要 while 循环,而是包含与在 Azure ML 和 IntegratedML(InterSystems IRIS 中用于自动 ML 框架的加速器)中训练替代模型有关的一系列操作,并将训练结果提取到 InterSystems IRIS 中(该平台也被认为在数据科学家处本地安装):
_图 5“接收方”业务流程_
(a) 导入 Python 模块 – 触发对 Python 接口的调用,以向其传输一组指令,导入进一步操作所需的 Python 模块;
(b) 设置 AUDITOR 参数 – 触发对 Python 接口的调用,以向其传输一组指令,为进一步操作所需的变量指定默认值;
(c) Azure ML 审核 –(我们将跳过任何对 Python 接口触发的进一步引用)将“审核任务”提交到 Azure ML;
(d) 解释 Azure ML – 将发送方业务流程传输到 Azure ML 的数据与 Azure ML 的“审核”结果一起获取到本地 Python 会话中(此外,在 Python 会话中创建“审核”结果的可视化);
(e) 流式传输到 IRIS – 将发送方业务流程传输到 Azure ML 的数据与 Azure ML 的“审核”结果一起从本地 Python 会话中提取到 IRIS 中的业务流程变量;
(f) 填充 IRIS – 将发送方业务流程传输到 Azure ML 的数据与 Azure ML 的“审核”结果一起从 IRIS 中的业务流程变量写入 IRIS 中的表;
(g) IntegratedML 审核 – 使用 IntegratedML 加速器“审核”从 Azure ML 接收的数据以及上一个操作中写入 IRIS 的 Azure ML“审核”结果(在此特定情况下,该加速器处理 H2O auto-ML 框架);
(h) 对 Python 进行查询 – 将数据和 IntegratedML“审核”结果传输到 Python 会话中;
(i) 解释 IntegratedML – 在 Python 会话中,创建 IntegratedML“审核”结果的可视化;
(j) 资源清理 – 从 Azure 中删除先前的操作中创建的计算基础架构。
_图 6 Azure ML“审核”结果的可视化_
_图 7 IntegratedML“审核”结果的可视化_
**分布式人工智能一般如何在 InterSystems IRIS 平台上实现**
InterSystems IRIS 平台实现分布式人工智能有三种基本方法:
· 根据用户定义的规则和算法,直接交换人工智能项目,并对其进行本地和中央处理
· 人工智能项目处理委托给专门的框架(例如:TensorFlow、PyTorch),交换的编排和各个准备步骤由用户在 InterSystems IRIS 的本地和中央实例上配置
· 人工智能项目的交换和处理都通过云提供商(Azure、AWS、GCP)来完成,本地和中央实例只向云提供商发送输入数据并接收最终结果
_图 8 在 InterSystems IRIS 平台上实现分布式人工智能的基本方法_
这些基本方法可以修改/组合使用:尤其是,在本文的上一节(“审核”)所描述的具体方案中,使用了第三种方法“以云为中心”,将“审核员”部分划分到云端,而在数据科学家一侧执行本地部分(作为“中央实例”)。
目前,在我们生活的现实中,“分布式人工智能”学科的理论和应用要素正在不断积累,但还没有形成“规范形式”,这使得创新实现具有巨大潜力。 我们的专家团队密切关注分布式人工智能作为一门学科的发展,并为其在 InterSystems IRIS 平台上的实现设计加速器。 我们乐于分享我们的内容,并帮助每一个认为这里讨论的领域有用的人开始分布式人工智能机制的原型设计。 您可以使用以下电子邮件地址联系我们的 AI/ML 专家团队 – MLToolkit@intersystems.com。
公告
Claire Zheng · 九月 19, 2022
开发者社区的同学们,大家好!
我们一直以来都有一个想法——改进收集、分析和回应开发者社区成员们的产品改进请求的过程。我们知道,我们需要一个良好的用户体验,甚至更好的内部流程,来确保收集、听取和响应最好的想法。现在,这个想法终于实现了!
我们在此向您介绍 InterSystems官方反馈门户
💡 >> InterSystems Ideas << 💡
InterSystems Ideas InterSystems Ideas是一个全新的、推动改进的渠道,您可以通过它向我们提交与InterSystems服务(文档、开发社区、全球大师等)相关的产品改进请求和想法,看看其他人提交了什么,为你喜欢的想法投票,投票给你最喜欢的,并从InterSystems获得反馈。
我们开始积极开发和推广创意门户网站InterSystems Ideas和您的创意。我们希望这可以为您提供一个公开的方式来获得我们的产品经理和社区成员的反馈。
✅ 获得投票最多的想法会得到产品管理部门的评审。
来社区分享你的想法吧!通过投票和评论为其他想法提供贡献——投票越多,影响力越大!
点击看看创意网站 InterSystems Ideas portal!
文章
Michael Lei · 九月 15, 2022
InterSystems IRIS是一个伟大的数据平台,它满足了当前市场所需的功能。在这篇文章中,你可以看到我心目中的前10大功能:
排名
特性
原因
了解更多
1
互操作性, FHIR 和物联网
商业机构之间需要持续互联和交换数据。各个业务部门之间也需要加强协作来将本增效。实现协作的最佳技术是IRIS的互操作工具包,尤其是 服务总线ESB, 集成适配器,业务流程自动化引擎,数据转化工具以及例如FHIR和MQTT等。
Link 1
Link 2
Link 3
2
API 管理器
大家通过API来消费数字资产。API需要在一个中心点管理其重用、安全、消费、资产目录、开发者生态系统和其他方面。API管理器是实现这一目标的正确工具。因此,所有的公司都有或希望有一个API管理器。
Link
3
数据分片
据预测,全球创造、捕获、复制和消费的数据总量将迅速增加,在2020年达到64.2 zettabytes。在接下来的五年里,直到2025年,全球数据创建量预计将增长到180兆字节以上。在2020年,创造和复制的数据量达到了新高(来源:https://www.statista.com/ statistics/871513/worldwide-data-created/)。在这种情况下,能够以分布式的方式处理数据(进入数据分片,如hadoop或mongodb),以提高和保持性能,对企业至关重要。另一件重要的事情是IRIS比Cache快3倍,比在AWS云上比AWS数据库更快。
Link 1
Link2
4
Python 支持
Python 是实现AI的最流行的语言,AI现在是大部分企业战略的核心,帮助企业获得更多洞见、更多生产力和降低成本.
Link 1
Link 2
Link 3
5
原生APIs (Java, .NET, Node.js, Python) 和自定义扩展 PEX
美国有将近100万开放的IT职位 (source: https://www.cnbc.com/2019/11/06/ how-switching-careers-to-tech-could-solve-the-us-talent-shortage.html). 也很难找到 Object Script 开发者. 因此, 能够支持各种主流语言(Python, Java, .NET, 等.)来使用IRIS特性非常重要.
Link 1
Link 2
Link 3
Link 4
Link 5
Link 6
6
自适应分析
实时分析当前的业务数据,减少建模工作,提高运行速度,支持主要的分析查看器(包括Excel)是企业战略的一个关键因素。
Link
7
云, Docker 和微服务
每个人都想要微服务架构。他们希望打破传统单体应用来创建更小、更简单、解耦的、可扩展、可复用和独立的应用项目。 IRIS 支持用户部署数据、应用和分析的微服务。 IRIS 支持数据分片, docker, kubernetes, 分布式计算, DevOps 工具和更低的 CPU/内存消耗 (IRIS 甚至支持 ARM 处理器!). 使用 IRIS API管理器,可以帮助企业实现配合业务的微服务架构。
Link 1
Link 2
Link 3
Link 4
Link 5
8
嵌入式报表
报表对企业是十分重要的。运营者和决策者要用到大量的报表,有很多报表也要提交给客户。移动端和微服务APP需要支持嵌入式报表,IRIS也支持所有这些需求。
Link 1
9
VSCode 支持
VSCode 是最流行的开发工具,InterSystems IRIS 有一套非常棒的工具来支持它。
Link 1
Link 2
Link 3
10
数据科学
使用Python, R 和一体化机器学习(自动机器学习)可以支持企业及时得到AI提供的洞见。InterSystems IRIS 包括所有这些功能。
Link 1
Link 2
Link 3
文章
姚 鑫 · 九月 27, 2022
# 第四十五章 配置第三方软件以与 InterSystems 产品结合使用
产品通常在与非 工具一起运行的环境中运行,我们的产品与此类工具之间的交互可能会产生有害影响。 关于最佳、可靠部署配置的指导假定我们的产品可以在不受第三方工具干扰的情况下进行部署。例如, 发现用于安全、系统监控或病毒扫描的软件可能会影响我们产品的安装、性能和功能。对于直接与属于 产品的一部分或被 产品使用的文件进行交互的工具(例如病毒扫描程序)尤其如此。
了解客户面临的业务、合规性和其他要求会影响有关在给定环境中运行哪些软件以及如何配置此类软件的决策。一般来说, 建议我们产品的服务器端安装通过物理安全和隔离来保护。这种保护应该减少对其他工具的需求,或者至少减少它们运行的频率。
病毒扫描仪观察:
1. 为了交付经过病毒检查的软件, 产品在经过消毒的环境中交付给我们的客户,并通过提供校验和进行验证。
2. 性能影响。
[对策] 出于扫描目的,排除以下文件和目录:
- `WIJ` 文件和包含 `WIJ` 文件的目录`*`。
- 本指南“配置 `IRIS`”一章中的所有数据库文件 (`.DAT`) 和包含数据库文件的目录*(请参阅配置数据库)。
- 存储或处理日志文件的任何目录`*`。
- `IRIS®` 数据平台运行所需的任何其他文件`/`目录`*`。例如备用日志目录*(请参阅数据完整性指南中的“日志”),或业务服务或生产使用的任何目录*。
3. 可执行文件的误报。
[对策] 出于扫描目的,排除所有 `irisdb.exe` 文件和包含 `irisdb.exe` 文件的目录。
警告:从恶意软件扫描中排除项目可能会将漏洞引入受保护的设备和应用程序。客户承担配置恶意软件保护的所有责任。
最后,当 发现第三方软件与我们的产品之间的交互对我们的产品行为产生负面影响时,我们会将这些问题报告给第三方供应商。
公告
Claire Zheng · 十一月 17, 2022
Hi 开发者社区的成员们,大家好!
欢迎关注我们第一期 InterSystems Ideas News!
最重要的消息是我们第一次非常成功的 创意马拉松。我们收到了75个有趣的新想法。
以下是创意社区(Ideas Portal)一些数据:
✓ 上月,我们收到了42条新创意✓ 上月,我们迎来了147位新用户✓ 迄今为止,我们共收到142 条新创意✓ 迄今为止,共有 273 位用户加入我们
以下是评选出来的当月最佳创意的前5名:
IRIS and ZPM(Open Exchange) integration
Move users, roles, resources, user tasks, Mappings (etc) to a seperate Database, other than %SYS, so these items can be mirrored
RPMShare - Database solution for remote patient monitoring (RPM) datasets of high density vitals
Create front-end package based on CSS and JS to be used in NodeJS and Angular projects
PM platform
这里是上个月发布的所有想法的列表
目前就这些啦!
访问我们的 InterSystems Ideas portal(创意社区),提出你的观点,为你认同的创意投票!
下期见!
公告
Michael Lei · 一月 23, 2023
嘿开发者,
我们想邀请您参加我们的下一场比赛,该比赛致力于创造有用的工具,让您的开发伙伴们的生活更轻松:
🏆 InterSystems 开发者竞赛:Tool(工具)🏆
提交有助于加快开发速度、贡献更多定性代码并有助于使用 InterSystems IRIS 测试、部署、支持或监控您的解决方案的应用程序。
时间: 2023 年 1 月 23 日至 2 月 12 日(美国东部时间)
奖金池: 13,500 美元
话题
💡 InterSystems IRIS 开发者竞赛:Tool(工具)💡
在本次竞赛中,我们期待应用程序能够改善开发人员使用 IRIS 的体验,帮助更快地开发,贡献更多定性代码,帮助测试、部署、支持或监控您使用 InterSystems IRIS 的解决方案。
一般要求:
已接受的应用程序:Open Exchange 应用程序或现有应用程序的新应用程序,但有显着改进。我们的团队将审核所有申请,然后再批准他们参加比赛。
该应用程序应该可以在InterSystems IRIS Community Edition上运行。
匹配的应用程序类型:UI 框架、IDE、数据库管理、监控、部署工具等。
该应用程序应该是开源应用程序并发布在 GitHub 上。
应用程序的自述文件应为英文,包含安装步骤,并包含视频演示或/和应用程序工作原理的描述。
一位开发者最多可以携带 3 个应用程序参加比赛。
奖品
1. 专家提名奖(Experts Nomination)- 获奖者由我们特别挑选的专家团选出::
🥇第一名 - 5,000 美元
🥈第二名 - 3,000 美元
🥉第三名 - 1,500 美元
🏅第四名 - $750
🏅第五名 - $500
🌟第 6-10 名 - $100
2. 社区提名奖(Community Nomination)- 获得总投票数最多的应用:
🥇第一名 - $750
🥈第二名 - $500
🥉第三名 - $250
如果几个参与者获得相同数量的选票,他们都被认为是赢家,奖金由赢家分享。
重要截止日期:
🛠 应用开发和注册阶段:
2023 年 1 月 23 日(美国东部时间 00:00):比赛开始。
2023 年 2 月 5 日(美国东部时间 23:59):提交截止日期。
✅ 投票时间:
2023 年 2 月 6 日(美国东部时间 00:00):投票开始。
2023 年 2 月 12 日(美国东部时间 23:59):投票结束。
注意:开发者可以在整个注册和投票期间改进他们的应用程序。
谁可以参加?
任何开发人员社区成员,InterSystems 员工除外。 创建一个帐户!
👥开发人员可以组队创建协作应用程序。一个团队允许 2 到 5 名开发人员。
不要忘记在应用程序的自述文件中突出显示您的团队成员——DC 用户配置文件。
有用的资源
✓ 示例应用程序:
iris-rad-studio - 用于 UI 的 RAD
cmPurgeBackup - 备份工具
errors-global-analytics - 错误可视化
objectscript-openapi-definition - 开放 API 生成器
测试覆盖率工具- 测试覆盖率助手
还有更多。
✓ 我们建议从以下模板开始:
IRIS开发模板
rest-api-竞赛模板
本机 API 竞赛模板
IRIS FHIR模板
IRIS全栈模板
IRIS互操作性模板
IRIS分析模板
✓ 对于 IRIS 初学者:
使用 InterSystems IRIS 构建服务器端应用程序
新手学习路径
✓ 对于ObjectScript 包管理器 (ZPM)的初学者:
如何使用 InterSystems IRIS 的 REST 应用程序构建、测试和发布 ZPM 包
使用 InterSystems IRIS 和 ZPM 的封装优先开发方法
✓ 如何提交您的应用程序参加比赛:
如何在 Open Exchange 上发布应用程序
如何提交比赛申请
需要帮忙?
加入 InterSystems 的Discord 服务器上的竞赛频道或在本文的评论中与我们交谈。
我们迫不及待地想看到您的项目!祝你好运👍
参加本次比赛,即表示您同意此处列出的比赛条款。请在继续之前仔细阅读它们。
公告
Jingwei Wang · 一月 26, 2023
以下是 2023 年 InterSystems 开发者工具大赛的技术红利,您可以在投票中获得额外加分:
嵌入式 Python的使用
Docker容器的使用
ZPM 包部署
在线演示
代码质量通过
开发者社区文章
开发者社区第二篇文章
上传 YouTube 视频
第一次贡献
请参阅下面的额外加分项详细信息:
嵌入式 Python的使用 - 3 分
在您的应用程序中使用嵌入式 Python,可以获得 3 分加分。您至少需要 InterSystems IRIS 2021.2及以上版本。
Docker 容器的使用 - 2 分
如果应用程序使用在 docker 容器中运行的 InterSystems IRIS,则该应用程序将获得“Docker 容器”奖励。这是最简单的模板。
ZPM 包部署 - 2 分
如果您为您的全栈应用程序构建和发布 ZPM(ObjectScript 包管理器)包,您可以获得2分加分,以便它可以使用如下方式部署:
zpm "install your-multi-model-solution"
已安装的ZPM 客户端命令,请参考:
ZPM客户端。文档。
项目的在线演示 - 2 分如果您将项目作为在线演示提供给云,则可额外获得 3 个奖励积分。您可以自己完成,也可以使用此模板- 这是一个 示例。这是有关如何使用它的视频。
代码质量通过且零错误 - 1 分
包括用于代码静态控制的代码质量 Github 操作,并使其显示 0 个 ObjectScript 错误。
关于开发者社区的文章 - 2 分
在 Developer Community 上发表一篇文章,描述您的项目的功能。每篇文章获得2分。不同语言的翻译也有效。
开发者社区第二篇文章 - 1分
您的第二篇文章或其应用的翻译文章可以获得额外的奖励积分。第 3 篇及以上不会带来更多积分,但文章和应用程序的关注度将全部归您所有。
上传 YouTube 视频 - 3 分
制作演示您的产品的 Youtube 视频,每个视频可获得 3 分奖励积分。例子。
首次贡献 - 3 分
如果您是第一次参加 InterSystems Open Exchange 竞赛,可获得 3 个奖励积分!
奖励积分清单可能会发生变化。敬请关注!
祝比赛好运!
公告
Claire Zheng · 一月 30, 2023
亲爱的开发者们,
非常感谢您又在 InterSystems 开发者社区度过了一年!
我们的团队日复一日地努力让它变得更好,这对我们12000+ 每一位成员都很重要!
我们想知道目前开发者社区对您有多大用处。请花点时间让我们了解您的想法,以及可以改进的地方:
👉🏼 InterSystems 开发者社区2022年度调查 👈🏼
请知悉:调查可在 5 分钟内完成。
也欢迎您在本文的评论部分提供反馈。
我们期待了解您的意见! 😉
文章
Lilian Huang · 二月 28, 2023
嗨,InterSystems 开发人员!
最近我更新了FHIR 开发模板,它发布了一个 IPM 包fhir-server ,使 InterSystems FHIR 服务器的设置成为一个微不足道的手动或自动或编程的程序,只需一条命令。
请参阅下文,了解如何从中受益。
TLDR
USER>zpm "install fhir-server"
以下所有详细信息。
在没有 IPM 的情况下设置 InterSystems FHIR 服务器
当然,你可以不使用IPM软件包管理器来设置InterSystems FHIR服务器。下面是一些选项。
1. 您可以按照这些说明设置云 FHIR 服务器并试用几天,这是 AWS 云中的一个 InterSystems FHIR 服务器。
2. 您可以按照以下步骤将 InterSystems FHIR 服务器设置,运行 InterSystems IRIS for Health。
3. 你也可以 git 克隆这个模板的仓库并在目录中运行:
$ docker-compose up -d
在您的笔记本电脑上启动并运行 InterSystems FHIR 服务器。
我在文章中建议的是第2点,你可以跳过所有的手动步骤,让FHIR服务器在笔记本电脑IRIS上运行,无论是docker还是主机操作系统。
用 IPM 设置 FHIR 服务器
免责声明!! 下面描述的步骤是指新安装的IRIS for Health实例或与docker图像一起使用。该软件包创建了一个新的命名空间和一个新的网络应用程序,因此它可能会损害你之前设置的设置
IPM 代表InterSystems Package manager ,以前称为 ZPM。确保你已经安装了 IPM 客户端。如果你在IRIS终端运行zpm命令并看到以下内容,你可以检查这一点:
IRISAPP>zpm
=============================================================================
|| Welcome to the Package Manager Shell (ZPM). ||
|| Enter q/quit to exit the shell. Enter ?/help to view available commands ||
=============================================================================
zpm:IRISAPP>
对于 2022.x 及更新版本,您将需要 IRIS for Health。
如何在笔记本电脑上运行 iris for health?
在主机操作上运行
从适合您的平台(Windows、Mac、Linux)的InterSystems 评估网站下载最新的 IRIS for Health 并安装。安装 ZPM。这是一个单行:
USER>zn "%SYS" d ##class(Security.SSLConfigs).Create("z") s r=##class(%Net.HttpRequest).%New(),r.Server="pm.community.intersystems.com",r.SSLConfiguration="z" d r.Get("/packages/zpm/latest/installer"),$system.OBJ.LoadStream(r.HttpResponse.Data,"c")
运行一个Docker版本。
在您的终端中调用以启动:
--name iris4h -d --publish 9091:1972 --publish 9092:52773 intersystemsdc/irishealth-community
然后启动终端:
docker exec -it iris4h iris session IRIS
安装FHIR服务器
一旦IRIS在主机上运行,或只是在IRIS终端运行:
USER>zpm "install fhir-server"
这将在FHIRSERVER命名空间中安装FHIR服务器,并提供参数:
Set appKey = "/fhir/r4"
Set strategyClass = "HS.FHIRServer.Storage.Json.InteractionsStrategy"
set metadataPackages = $lb("hl7.fhir.r4.core@4.0.1")
Set metadataConfigKey = "HL7v40"
FHIR REST API 将在 http://yourserver/fhir/r4 上可用。
它还将添加一些合成数据。
如何理解服务器正在工作?
要在主机版本上测试:
http://localhost:52773/fhir/r4/metadata
在 docker 版本上测试:
http://localhost:9092/fhir/r4/metadata
zpm 还安装了简单的 UI,它位于:yourserver/fhirUI/FHIRAppDemo.html
您会看到类似这样的内容(输入患者 id=1):
怎么运行的?
事实上,您可以在以下 module.xml场景中观察正在使用此 ZPM 模块安装的内容。如您所见,它导入代码,安装演示前端应用程序 fhir UI,运行安装后脚本,该脚本调用以下方法。该方法中的脚本执行 FHIR 服务器设置。
以编程方式安装 FHIR 服务器
您还可以通过以下命令以编程方式安装它:
set sc= $zpm ( "install fhir-server" )
FHIR 编码快乐!
文章
Shanshan Yu · 四月 18, 2023
随着生活水平的提高,人们越来越注重身体健康。 而孩子的健康成长也越来越成为家长关心的话题。 孩子的身体发育可以从孩子的身高和体重反映出来。 因此,及时预测身高和体重具有重要意义。 通过科学的预测和比较,关注孩子的发育状态。
该项目使用InterSystems IRIS Cloud SQL通过输入大量体重和身高相关数据来支持,并建立基于IntegratedML的AutoML进行预测分析。 根据输入的父母身高,可以快速预测孩子未来的身高,并根据当前的身高和体重状况判断孩子的体重指数。 在正常范围内。
功能:
通过应用该程序,可以快速预测处于正常发育状态的儿童的身高。 通过结果,家长可以判断孩子发育是否正常,是否需要临床干预,有助于了解孩子未来的身高; 通过当前体重状态判断当前孩子的BMI是否正常,了解孩子当前的健康状况
应用场景
1.儿童身高预测
2. 监测儿童发育