清除过滤器
文章
姚 鑫 · 二月 9, 2021
# 第二十九章 Caché 变量大全 $ZERROR 变量
包含上一个错误的名称和位置。
# 大纲
```
$ZERROR
$ZE
```
# 描述
`$ZERROR`包含最新错误的名称,最新错误的位置(在适用的情况下)以及(对于某些错误代码而言)有关导致错误的原因的其他信息。 `$ZERROR`始终包含相应语言模式的最新错误。
`$ZERROR`值旨在错误后立即使用。由于`$ZERROR`值可能不会在例程调用中保留,因此希望保留`$ZERROR`值以供以后使用的用户应将其复制到变量中。**强烈建议用户在使用后立即将`$ZERROR`设置为空字符串(“”)。**
$ZERROR中包含的字符串可以是以下任何一种形式:
```java
entryref
info
entryref info
```
- `` 错误名称。错误名称始终以全部大写字母返回,并用尖括号括起来。它可能包含空格。
- `entryref` 对发生错误的代码行的引用。它由标签名称和距该标签的行偏移量组成,后跟`^`和程序名称。此`entryre`f紧跟在错误名称的右尖括号之后。从终端调用`$ZERROR`时,此`entryref`信息没有意义,因此不会返回。对最近使用`ZLOAD`加载到例程缓冲区中的例程的引用。
- `info` 特定于某些错误类型的附加信息(见下表)。此信息与``或`entryref`之间用空格分隔。如果有多个组件要提供信息,则用逗号分隔。
例如,一个程序(名为`zerrortest`)包含以下例程(名为`ZerrorMain`),该例程试图写入`fred`(一个未定义的局部变量)的内容:
```java
/// d ##class(PHA.TEST.SpecialVariables).ZERROR()
ClassMethod ZERROR()
{
ZerrorMain
TRY {
SET $ZERROR=""
WRITE "$ZERROR = ",$ZERROR,!
WRITE fred }
CATCH {
WRITE "$ZERROR = ",$ZCVT($ZERROR,"O","HTML")
}
}
```
```java
DHC-APP> d ##class(PHA.TEST.SpecialVariables).ZERROR()
$ZERROR =
$ZERROR = <UNDEFINED>zZERROR+5^PHA.TEST.SpecialVariables.1 *fred
```
在上面的示例中,第一个`$ZERROR`包含一个空字符串(`“”`),因为自从`$ZERROR`重置为空字符串以来没有发生任何错误。尝试写入未定义的变量会设置`$ZERROR`并将其抛给`CATCH`块。此`$ZERROR`包含`ZerrorMain+4^zerrortest*fred`,指定错误的名称、位置和特定于该类型错误的附加信息。在本例中,附加信息是未定义的局部变量`fred`的名称;星号前缀表示它是局部变量。(请注意,本例中使用`$ZCVT($ZERROR,“O”,“HTML”)`,因为Caché错误名称用尖括号括起来,并且本例从Web浏览器运行。)
`Entryref`可能如下所示:
- `ZerrorMain+4^zerrortest`--程序`zerrortest`中标签`ZerrorMain`的4行偏移量
- `ZerrorMain^zerrortest`--在程序`zerrortest`中没有与标签`ZerrorMain`的偏移量;标签行中出现错误
- `+3^zerrortest`--从程序`zerrortest`开始的3行偏移量;错误行前面没有标签
`$ZERROR`值的最大长度为512个字符。超过该长度的值将被截断为512个字符。
## AsSystemError() Method
`%Exception.SystemException`类的`AsSystemError()`方法返回与`$ZERROR`相同的值。下面的示例显示了这一点:
```java
/// d ##class(PHA.TEST.SpecialVariables).ZERROR1()
ClassMethod ZERROR1()
{
TRY {
KILL mylocal
WRITE mylocal
}
CATCH myerr {
WRITE "AsSystemError is: ",myerr.AsSystemError(),!
WRITE "$ZERROR is: ",$ZERROR
}
}
```
```java
DHC-APP>d ##class(PHA.TEST.SpecialVariables).ZERROR1()
AsSystemError is: zZERROR1+3^PHA.TEST.SpecialVariables.1 *mylocal
$ZERROR is: zZERROR1+3^PHA.TEST.SpecialVariables.1 *mylocal
```
**在`Try/Catch`异常处理块结构中,`AsSystemError()`比`$ZERROR`更可取,因为`$ZERROR`可能会被异常处理期间发生的错误覆盖。**
## 有关某些错误的其他信息
当发生某些类型的错误时,`$ZERROR`将以以下格式返回错误:
```java
entryref info
```
`INFO`组件包含有关错误原因的附加信息。下表列出了错误列表,其中包括附加信息和该信息的格式。错误代码与`INFO`组件之间用空格字符分隔。
错误代码 |信息组件
---|---
`` | 未定义变量的名称(包括使用的任何下标)。这可以是局部变量、进程私有全局属性、全局属性或多维类属性。局部变量名称以星号作为前缀。多维属性名以句点开头,以区别于本地变量名。通过设置`%SYSTEM.Process.Unfined()`方法,可以更改Caché行为,以便在引用未定义的变量时不会生成``错误。
`` | 错误的下标引用:生成错误的行引用(例程和行偏移)、下标变量以及错误的下标级别。对于结构化系统变量(SSVN),仅提供行引用(例程和行偏移量)。通过设置`%SYSTEM.Process.NullSubscript()`方法,可以更改默认行为,以便在引用字符串下标为空的全局变量时不会生成错误。局部变量不允许使用空字符串下标。
`` |前缀为星号,即引用的例程名称。
`` | 前缀为星号,即引用的类名。
`` | 前缀为星号(引用属性的名称),后跟逗号分隔符和应该在其中的类名。
`` |前缀是星号,即调用的方法的名称,后跟逗号分隔符和应该在其中的类名。
`` | 全局引用的名称和包含全局引用的目录的名称,用逗号分隔。
`` |前缀为星号、对象名称,后跟`DisplayString()`方法返回的值。
`` | 当不在事务中调用`TCOMMIT`时,`INFO`组件为`*NoTransaction`。当调用不返回值的用户定义函数时,`INFO`组件是一条消息,其中包含本应返回值的命令的位置。
`` |以星号为前缀的无效目录的完整路径名。
`` | 当``错误终止进程时,带有附加信息的``错误将作为消息写入`mgr/cconsole.log`。信息性消息显示已终止进程的进程ID(PID)和产生错误的行引用(例程和行偏移量)。例如:`(PID)0at+13^|“user\|mytest`
例程(或方法)本地变量的名称以及未定义例程、类、属性和方法的名称都以星号(`*`)为前缀。进程-专用全局变量由其`^||`前缀标识。全局变量由它们的`^`(插入符号)前缀标识。类名以其`%`前缀形式表示。
以下示例显示了指定错误原因的其他错误信息。在每种情况下,指定的项都不存在。请注意,生成的错误的`INFO`组件与错误名称之间用空格分隔。星号(`*`)表示局部变量、类、属性或方法。插入符号(`^`)表示全局,`^||`表示进程私有全局。
``错误示例:
```java
/// d ##class(PHA.TEST.SpecialVariables).ZERROR2()
ClassMethod ZERROR2()
{
UndefTest ;
SET $NAMESPACE="SAMPLES"
KILL x,abc(2)
KILL ^xyz(1,1),^|"USER"|xyz(1,2)
KILL ^||ppg(1),^||ppg(2)
TRY {
WRITE x
} // 未定义的局部变量
CATCH {
WRITE $ZERROR,!
}
TRY {
WRITE abc(2)
} // 未定义的下标局部变量
CATCH {
WRITE $ZERROR,!
}
TRY {
WRITE ^xyz(1,1)
} // 未定义的全局变量
CATCH {
WRITE $ZERROR,!
}
TRY {
WRITE ^|"USER"|xyz(1,2)
} // 另一个命名空间中未定义的全局变量
CATCH {
WRITE $ZERROR,!
}
TRY {
WRITE ^||ppg(1)
} // 未定义的进程专用全局变量
CATCH {
WRITE $ZERROR,!
}
TRY {
WRITE ^|"^"|ppg(2)
} // 未定义的进程专用全局变量
CATCH {
WRITE $ZERROR,!
}
}
```
```java
DHC-APP>d ##class(PHA.TEST.SpecialVariables).ZERROR2()
zZERROR2+7^PHA.TEST.SpecialVariables.1 *x
zZERROR2+13^PHA.TEST.SpecialVariables.1 *abc(2)
zZERROR2+19^PHA.TEST.SpecialVariables.1 ^xyz(1,1)
zZERROR2+25^PHA.TEST.SpecialVariables.1 ^xyz(1,2)
zZERROR2+31^PHA.TEST.SpecialVariables.1 ^||ppg(1)
zZERROR2+37^PHA.TEST.SpecialVariables.1 ^||ppg(2)
```
``错误的示例:
```java
/// d ##class(PHA.TEST.SpecialVariables).ZERROR3()
ClassMethod ZERROR3()
{
SubscriptTest ;
DO $SYSTEM.Process.NullSubscripts(0)
KILL abc,xyz
TRY {
SET abc(1,2,3,"")=123
}
CATCH {
WRITE $ZERROR,!
}
TRY {
SET xyz(1,$JUSTIFY(1,1000))=1
}
CATCH {
WRITE $ZERROR,!
}
}
```
```java
DHC-APP>d ##class(PHA.TEST.SpecialVariables).ZERROR3()
zZERROR3+5^PHA.TEST.SpecialVariables.1 *abc() Subscript 4 is ""
zZERROR3+11^PHA.TEST.SpecialVariables.1 *xyz() Subscript 2 > 511 chars
```
``错误的示例:
```java
/// d ##class(PHA.TEST.SpecialVariables).ZERROR4()
ClassMethod ZERROR4()
{
NoRoutineTest ;
KILL ^NotThere
TRY {
DO ^NotThere
}
CATCH {
WRITE $ZERROR,!
}
TRY {
JOB ^NotThere
}
CATCH {
WRITE $ZERROR,!
}
TRY {
GOTO ^NotThere
}
CATCH {
WRITE $ZERROR,!
}
}
```
```java
DHC-APP>d ##class(PHA.TEST.SpecialVariables).ZERROR4()
zZERROR4+4^PHA.TEST.SpecialVariables.1 *NotThere
zZERROR4+10^PHA.TEST.SpecialVariables.1 *NotThere
zZERROR4+16^PHA.TEST.SpecialVariables.1 *NotThere
```
对象错误的示例:
```java
DHC-APP>DO $SYSTEM.SQL.MyMethod()
DO $SYSTEM.SQL.MyMethod()
^
*MyMethod,%SYSTEM.SQL
DHC-APP>WRITE $SYSTEM.XXQL.MyMethod()
WRITE $SYSTEM.XXQL.MyMethod()
^
*%SYSTEM.XXQL
DHC-APP>SET x=##class(%SQL.Statement).%New()
DHC-APP>WRITE x.MyProp
WRITE x.MyProp
^
*MyProp,%SQL.Statement
```
``错误的示例(在Windows上):
```java
// 用户没有%SYS名称空间的访问权限
SET x=^|"%SYS"|var
^var,c:\intersystems\cache\mgr\
```
调用用户定义函数时的``错误示例。在本例中,`MyFunc Quit`命令不返回值。这将生成一个``错误,其中`entryref`指定`$$MyFunc`调用的位置,`INFO`消息指定`QUIT`命令的位置:
```java
/// d ##class(PHA.TEST.SpecialVariables).ZERROR5()
ClassMethod ZERROR5()
{
Main
TRY {
KILL x
SET x=$$MyFunc(7,10)
WRITE "returned value is ",x,!
RETURN
}
CATCH {
WRITE "$ZERROR = ",$ZCVT($ZERROR,"O","HTML"),!
}
MyFunc(a,b)
SET c=a+b
QUIT
}
```
```java
DHC-APP>d ##class(PHA.TEST.SpecialVariables).ZERROR5()
$ZERROR = <COMMAND>zZERROR5+4^PHA.TEST.SpecialVariables.1 *Function must return a value at zZERROR5+13^PHA.TEST.SpecialVariables.1
```
使用`PUBLIC`关键字将函数作为过程调用时,出现相同的``错误:
```java
Main
TRY {
KILL x
SET x=$$MyFunc(7,10)
WRITE "returned value is ",x,!
RETURN
}
CATCH {
WRITE "$ZERROR = ",$ZCVT($ZERROR,"O","HTML"),!
}
MyFunc(a,b) PUBLIC {
SET c=a+b
QUIT
}
```
``错误示例(在Windows上):
```java
/// d ##class(PHA.TEST.SpecialVariables).ZERROR6()
ClassMethod ZERROR6()
{
TRY {
SET prev=$SYSTEM.Process.CurrentDirectory("bogusdir")
WRITE "previous directory: ",prev,!
RETURN
}
CATCH {
WRITE "$ZERROR = ",$ZCVT($ZERROR,"O","HTML"),!
QUIT
}
}
```
```java
DHC-APP>d ##class(PHA.TEST.SpecialVariables).ZERROR6()
$ZERROR = <DIRECTORY>zCurrentDirectory+2^%SYSTEM.Process.1 *e:\dthealth\db\dthis\data\bogusdir\
```
## 5.1版本之前的错误处理代码
在Caché5.1和后续版本的这些错误代码中添加`INFO`组件的结果是,假设`$ZERROR`中的字符串格式的5.1版本之前的错误处理例程可能需要重新设计才能像以前一样工作。例如,以下内容在5.1版中将不再有效:
```java
WRITE "Error line: ", $PIECE($ZERROR, ">", 2)
```
并应更改为类似以下内容:
```java
WRITE "Error line: ", $PIECE($PIECE($ZERROR, ">", 2), " ", 1)
```
# 注意
## ZLOAD和错误消息
在`ZLOAD`操作之后,加载到例程缓冲区中的例程的名称出现在后续错误消息的`entryref`部分。这将在整个过程中持续存在,或者直到使用`ZREMOVE`删除,或者被另一个`ZLOAD`删除或替换。以下终端示例显示例程缓冲区内容的此显示:
```java
SAMPLES>ZLOAD Sample.Person.1
SAMPLES>WRITE 6/0
^Sample.Person.1
SAMPLES>WRITE fred
^Sample.Person.1 *fred
SAMPLES>WRITE ^fred
^Sample.Person.1 ^fred
SAMPLES>ZNAME "USER"
USER>WRITE 7/0
^Sample.Person.1
USER>ZREMOVE
USER>WRITE ^fred
^fred
```
## $ZERROR和程序栈
`$ZERROR`字符串的``部分包含最新的错误消息。`$ZERROR`字符串的`entryref`部分的内容反映了最近错误的堆栈级别。以下终端会话试图调用无意义的命令`gobbledegook`,导致``错误。它还运行`ZerrorMain`(上面指定),产生`$ZERROR`值``。此终端会话期间的后续`$ZERROR`值反映了此程序调用,如下所示:
```java
SAMPLES>gobbledegook
SAMPLES>WRITE $ZERROR
SAMPLES>DO ^zerrortest
SAMPLES>WRITE $ZERROR
ZerrorMain+2^zerrortest *FRED
SAMPLES 2d0>gobbledegook
SAMPLES 2d0>WRITE $ZERROR
^zerrortest
SAMPLES 2d0>QUIT
SAMPLES>WRITE $ZERROR
^zerrortest
SAMPLES>gobbledegook
SAMPLES>WRITE $ZERROR
```
## 设置`$ZTRAP`时的`$ZERROR`操作
发生错误并设置`$ZTRAP`时,Caché在`$ZERROR`中返回错误消息,并分支到为`$ZTRAP`指定的错误陷阱处理程序
## 设置`$ZERROR`
只有在Caché模式下,才能使用`set`命令将`$ZERROR`设置为最多512个字符的值。长度超过512个字符的值将被截断为512。
**强烈建议在错误处理后将`$ZERROR`重置为空字符串(`“”`)。**
文章
Hao Ma · 五月 26, 2023
题外话:我刚刚翻译了InterSystems专家Bob Binstock的[Caché Mirroring 101:简要指南和常见问题解答](https://cn.community.intersystems.com/post/cach%C3%A9-mirroring-101%EF%BC%9A%E7%AE%80%E8%A6%81%E6%8C%87%E5%8D%97%E5%92%8C%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98%E8%A7%A3%E7%AD%94)。 尽管题目是Caché Mirror 101, 而且是写于2016年,但因为讲解的都是Mirror的基本原理,所以在大量使用IRIS的今天也完全适用。
前面的3篇文章,包括了配置Mirror的各个方面。如果您照着操作,现在已经有了一个工作的mirror环境,并加入了您的数据库。然而,还没完,这篇我来讨论一下后面的工作,首先的问题是:
**Mirror不复制什么**
简单说,Caché/IRIS镜像是**数据库复制(Database Replication)**。在Caché/IRIS里什么是数据库?也就是**Cache.dat和iris.dat**文件。数据库的修改日志,也就是journal,从主机被传送到其他镜像成员。而除此之外的内容,需要维护人员来分别的个个处理, 解决这些内容在各个镜像成员间的拷贝。需要很多的计划和细心。
>系统数据库, 包括IRISSYS, IRISTEMP, IRISLIB等等, 这些Caché/IRIS本身的数据库不应该被加入Mirror,在大多数Caché/IRIS版本里也都设置成不可以加入入MIRROR。
>
>例外的HealthCare产品, HSSYS需要做Mirror, HSCustom可以做Mirror, 而HSLIB不可以Mirror
我们可以把问题转换成下面的题目:
## 需要人工在镜像成员中同步的项目
### 命名空间(namespace)和Mapping
命名空间是应用开发的概念,它使用数据库。命名空间定义了3种映射关系:Package Mapping, Routing Mapping, Global Mapping。这样在一个命名空间可以使用多个数据库的内容。
通常情况下,用户会在主机创建命名空间的同时,创建一个新的带有mirror属性的数据库,然后会在其他mirror成员中手工一个个的创建命名空间,加入镜像的数据库。之后,管理员无需考虑更多的操作。
然而,对命名空间的修改,比如要添加或者删除命名空间的某些mapping,这偶尔会需要,尤其是应用迭代和系统扩容的情况下,那么,管理员/实施人员,必须清楚Mirror无法同步这个修改,您必须手工同步修改到其他机器去。
如果配置的mapping比较多, 我建议使用Manifest来操作。Mainfest是一个xml的文本,用来安装或者修改Caché/IRIS的配置,你可以参考[在线文档: Using a Manifest](https://docs.intersystems.com/iris20231/csp/docbook/DocBook.UI.Page.cls?KEY=GCI_manifest), 或者社区文章[使用Manifest](https://cn.community.intersystems.com/post/%E4%BD%BF%E7%94%A8manifest)。
这里给一个配置mapping的例子:
```xml
```
如果是资深的Caché维护工程师,懂得如果修改CPF文件并在不重启实例的情况下应用修改后的内容,可以考虑把主机上的CPF中的mapping部分复制粘贴到其他机器。如果您没有这方面的经验,我不建议这种方式。
另外,在IRIS 2022后的版本中有了一个新工具,Configuration Merge。 文档在[这里](https://docs.intersystems.com/iris20231/csp/docbook/Doc.View.cls?KEY=ACMF)。可惜只有最新版的IRIS或者Health Connect 用户有的用。
### 数据库的修改
数据库的内容会通过Journal从主机同步到其他成员,但修改不会,一般会遇到的是**压缩和截断**。
由于某种错误操作,某个数据库,会扩展到不正常的大,而当错误修正后,用户可能需要对该数据库进行压缩和截断,以释放被错误占用的空闲的磁盘空间。
由于除主机外,其他镜像成员的数据库都是只读的,这个操作的顺序应该是这样:
1. 在主机A执行压缩和截断
2. 切换到备机B, 再次执行压缩和截断。
3. 异步成员DR。 一种方案是吧DR提升到备机。这时当前的备机A会将为灾备,然后再切换DR为主机,再进行压缩和截断。
还有一个选择,就是重新配置DR上的这个数据库,这需要从主机到DR的数据库备份和恢复。
### IRIS实例的配置
从最常用的内存的配置,Service的配置, **用户,权限,资源**的配置等等。它们都不会被MIRROR同步。如果您在MIRROR主机里做了修改了缩表的大小,或者启动了一个,比如TELNET服务, 您需要人工在其他机器上做相同操作。
像上面的mapping配置一样,这里还是建议使用Manifest人工同步IRIS得修改。注意的是,Mainfest不保证能支持所有的配置。比如在Caché的版本下, 比如您在主机上启动了TELNET服务, Manifest没有相应的标签。这种情况下, 如果您熟悉ObjectScript语言,可以把ObjectScript实现加入执行Manifest的方法,比如说:
```java
ClassMethod main(){
//执行Manifest修改命名空间
Set pVars("Namespace")="MYNAMESPACE"
$$$ThrowOnError(..ModifyNamespace(.pVars))
//启动IRIS的TELNET服务
set properties("Enabled")=1 // 有効
set sts=##class(Security.Services).Modify("%Service_Telnet",.properties)
}
```
当然,如果您缺乏开发实施的知识,在用户界面上一个个机器的操作是最省心的办法。
问题是,打开一个服务,修改一个配置参数操作都很简单,但是如果要添加大量的用户和权限怎么办?
用Manifest管理是一个办法。但根本上,如果您经常有大量的用户管理的工作,其实使用Kerberos或者LDAP管理用户身份认证和授权的工作, 在有多个镜像成员的情况下,尤其的合适。 关于这部分内容,请参考[在线文档:Authentication and Authorization](https://docs.intersystems.com/iris20231/csp/docbook/DocBook.UI.Page.cls?KEY=PAGE_security_authentication_authorization)
### 定时任务(TASK)
在主机上创建的定时任务, 您需要人工在其他机器上做相同操作。这里有2个步骤:
1. 在主机上创建新任务的时候,要选择”**应如何为镜像运行任务**“。 这是个下拉菜单,选项有*”仅在主镜像成员上运行“,“仅在非主镜像成员上运行“ ,“在任何镜像成员上运行"。*
选择的出发点是:非主镜像成员的数据库是只读的。因此,比如一个Ensemble的镜像配置中, 删除Ensemble消息的定时任务, 一定是”仅在主镜像成员上运行“。
2. 把新的定时任务从主机同步到其他成员。
如果是一个或者少量几个TASK, 那么手工在其他各个镜像成员上添加是最简单直接的做法。而如果是有很长 的任务列表,尤其在配置Mirror得时候可以需要同步一个长长的列表时, 您可以考虑**从主机导出Task到其 他机器导入**,我只知道使用ObjectScript命令的方法, 使用`%SYS.Task.ExportTask()`和 `%SYS.Task.ImportTasks()`。 文档在[这里](https://docs.intersystems.com/iris20231/csp/documatic/%25CSP.Documatic.cls?LIBRARY=%25SYS&CLASSNAME=%25SYS.Task)。
### Web Application
主机上配置的Web Applicaiton 也要同步到其他镜像成员。如果要同步的Web Application比较多,推荐的方式依然是Manifest, 下面是一个例子。
```xml
```
麻烦的是不同的版本Caché/IRIS使用的标签上会略有不同,要稍微仔细的查看一下您的版本的文档。
如果您对ZPM, 现在称为IPM熟悉的话, 用ZPM做同步也是个好选择。关于zpm, 您可以参考这个帖子[zpm介绍](https://cn.community.intersystems.com/post/zpm%E4%BB%8B%E7%BB%8D1)。提醒一下的是,程序因为是存在数据库里面的,如果该数据库是被镜像的,您其实不需要用ZPM把程序代码拷贝到其他镜像成员。
### Gateway
一般用到的有**SQL Gateway**和**External Language Gateway**,它们分别用于连接其他的数据库和使用其他语音的代码包。
SQL Gateway
记录保存在%SYS命名空间的*%Library.sys_SQLConnection*数据表里。简单的方法是使用工具把表记录导入导出。
External Language Gateway(外部语言网关)
新版的IRIS系统内嵌了外部语言服务器,包括%Python Server, %Java Server, %Dotnet Server等。如果您使用的是默认配置,各个镜像成员是一致的,无需操心。如果只是IP端口的修改,手工同步一下也很容易,毕竟工作量有限,只是您需要清楚的记得,这个也是不被Mirror自动同步的。
### 文件
我把文件分为两类, 一类是“固定文件”,包括一下几个部分,
- CSP文件,js文件,css文件,html文件等
- XSLT文件
- 其他语言的程序代码,Java文件,python文件, .Net文件
这类文件上传到主机的时候, 也必须上传到其他镜像成员,这是个简单的操作,别忘了就行。
麻烦的是**流文件**。在ObjectScript里如果使用了%Stream.FileBinary, %Stream.FileCharacter等类,那么数据不是保存到Cache.Dat或者IRIS.data, 而是保存在和.Dat同目录的一个stream的子目录下,而这个目录是不会被镜像同步的。 而且,因为这是实时数据,你也不可能手工的把它拷来拷去。
如果您的应用里用到了文件流,我任务您需要一个文件服务器保证流文件在各个各个镜像成员间的同步。
### Ensemble Production Consideration
对于Ensemble和Health Connect用户,您需要阅读这部分在线文档: [Production Considerations for Mirroring](https://docs.intersystems.com/iris20223/csp/docbook/DocBook.UI.Page.cls?KEY=GHA_mirror_manage#GHA_mirror_set_ensemble) , 简单总结一下:
- 创建的带有ensemble或者Inteoprability的命名空间,数据库要创建为Mirror的数据库。
- **"production是否自动启动“**应该在主机和备机上,甚至DR上都配置为“自动启动”。 在Mirror配置下的Production会先检查这个实例是不是主机,如果不是,“自动启动”的配置也不会生效,这样保证了Production只在主机上运行,而切换后也不需要人工干预。
上面的这些并不是完整的内容,尽管在大多少情况下这些内容差不多够了。如果您想要确保Mirror的主机的工作内容完全同步到了备机和DR, 请仔细阅读在线文档的这一部分:[Mirror Configuration Guidelines](https://docs.intersystems.com/iris20223/csp/docbook/DocBook.UI.Page.cls?KEY=GHA_mirror_set_config#GHA_mirror_set_config_guidelines)
另外,对于各种需要人工同步的内容的操作,还建议阅读[在线文档:Server Migration](https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=AMIG#AMIG_migration_external)。
如果是最新的IRIS用户,请参考[在线文档:Deploy Mirrors Using Configuration Merge](https://docs.intersystems.com/iris20223/csp/docbook/DocBook.UI.Page.cls?KEY=GHA_mirror_set_config#GHA_mirror_set_config_auto_merge)
文章
Hao Ma · 九月 17, 2022
# 把数据库添加进Mirror
以往的经验里, 用户在把数据库添加到镜像时遇到过各种各样的问题,以致必须请求外部帮助才能解决。除了步骤本身比较繁琐,很大的原因是阅读文档不细致。还有一个,就是对英文水平不太高的用户,有些英文句式并不是很好懂,比如说,文档中有这一句其实非常关键:
> If you attempt to add a new database to the mirror on a nonprimary member that was not created as a mirrored database on the primary, but rather added to the mirror after it was created, an error message notes this and you cannot complete the operation.
我用最好的翻译器DeepL翻译后的中文是:
**如果你试图在一个非主要成员上向镜像添加一个新的数据库,而这个数据库并不是在主要成员上作为镜像数据库创建的,而是在创建后添加到镜像中的,那么就会出现错误信息提示,你无法完成操作。**
很讨厌的是它没用说明错误信息是什么,以致于很多用户, 当他们在Backup成员中把一个数据库添加到镜像时,遇到相关的错误时,没有把问题和这句话关联起来,这个错误提示是这样的:
>“错误 #2105: 与成员 SERVERA/IRIS 中的相匹配的数据库 :mirror:AUGEST:DEMO 未被创建为镜像数据库”。
或者用英文,
> ERROR #2105: Matching mirrored DB :mirror:AUGEST:DEMO in member SERVERA/IRIS was not created as mirrored DB
我来解释一下这句话,它说的是: ”嘿, 你在本机要添加的:mirror:AUGEST:DEMO数据库, 它在主镜像成员SERVERA/IRIS里, 未被创建为镜像数据库。“
如果您看了我的解释, 还觉得莫名其秒,我相信您其实是没懂这个关键点:
**“一个数据库创建成镜像数据库,和创建成普通数据库后面后再添加到镜像里,它们是不同的。”**
关于这一点,其实文档也有说明,啰嗦,但说明了原因。直接上翻译:
> 创建镜像数据库(即添加一个不含数据的新数据库)的过程与向镜像添加现有数据库的过程不同。作为镜像数据库创建的数据库上的Global操作从一开始就被记录在镜像Journal中,因此镜像可以访问它所需要的所有数据,以便在镜像成员之间同步数据库。但现有数据库在被添加到镜像之前的Global操作包含在非镜像Journal文件中,镜像不能访问这些文件。由于这个原因,一个现有的数据库在被添加到镜像后,必须在主故障转移成员上进行备份,并在备份故障转移成员和它要所在的任何异步成员上进行恢复。一旦这样做了,你必须激活并赶上数据库,使其与主数据库保持同步。
清楚了这个关键, 您才能理解为什么安装步骤分为下面的两个类型,
- **创建新的镜像数据库**
- **将已有的数据库加入镜像**
> TIP: 另外,还有一个值得提醒的:只有用户自己的数据库可以被加入镜像。系统本身的数据库, 比如IRISSYS, IRISLIB, IRISTEMP等等,都不能加入镜像。早期有些版本可以,NOMORE!
## 创建新的镜像数据库
- 在**主镜像成员**的系统维护界面上,选择System Administration – Configuration – System Configuration – Local Databases , 选择Create New Database. **在数据库创建向导窗口,在“镜像数据库?”下拉菜框,选择'是‘(Yes)**。
SQL"页面, 确认表Persons同步到了所有的镜像成员。
> 这里如果您遇到上面提到的“Error 2105“, 那就是这个数据库在Primary上先是创建成一般数据库,然后加入的镜像,那您应该按下面的步骤操作了。
>
> 如果有人好奇:在Primary上的这种区别,Backup是怎么知道的,它不是还没加入到镜像吗? 故事是这样的: 镜像日志中同步的不是只有镜像数据库的数据的修改, 还包括IRISSYS, IRISAUDIT,等库的内容。NEWDB在主成员中是怎么加入到镜像的, IRISSYS里的Global Set是不一样的,而这个set, 是同步给备用成员backup的。 又一个没用的知识。
## 将已有的数据库加入镜像
**已有的(Existing)数据库是指原本在主成员里按普通数据库创建的,然后加入镜像的数据库。**
这样的情况,哪怕同样名称,配置的数据库在其他成员上已经有了。能直接加入镜像吗?比如你主成员上有个User, 备用成员上也有,您能在主机, 备机直接把它们加入镜像吗?
答案是肯定不行。系统根本没法保证这两个库里面已有的数据是一样的。**您要在主成员上备份数据库,在其他成员恢复, 而恢复操作成功后,在其他成员上,这个数据库自动变成了“镜像数据库”**, 也就是加入了镜像。
这个同名的数据库要先在其他成员上创建。创建成普通数据库。如果其他成员上已经有了,也不用删除,就直接用主机的备份文件覆盖就好。
以下是详细的步骤:
- 在主机的“系统>配置>本地数据库“页面, 点击**添加到镜像**按钮。然后在跳出窗口中选中您要添加的数据库,可以一次选多个。 数据库很大或者多个数据库同时加入是,可以选中”在后台运行“。通常这个添加动作是在秒级时候内完成的,无所谓是否后台运行。
- 到镜像监视器查看添加的结果。被添加的数据库状态这时候应该是"一般"(Normal) 。
- 到其他镜像成员的镜像监视器查看, 您会看到主机来的通知引发的提醒:
- 在备机检查自己的数据库状态。如果没有DEMO或者USER数据库,那么创建它们,创建时下拉框”是否镜像?”选择否或者NO。之后在本地数据库列表中它们应该是这样,注意没有在镜像里。
- 在Primary做数据库的在线备份, 用于后面步骤里到其他成员上去做数据库恢复。
以下过程仅供参考:
```sh
# 在主成员备份,并发送给备份成员serverb
%SYS>do ^BACKUP
1) Backup
2) Restore ALL
3) Restore Selected or Renamed Directories
4) Edit/Display List of Directories for Backups
5) Abort Backup
6) Display Backup volume information
7) Monitor progress of backup or restore
Option? 1
*** The time is: 2022-09-17 15:27:48 ***
InterSystems IRIS Backup Utility
--------------------------
What kind of backup:
1. Full backup of all in-use blocks
2. Incremental since last backup
3. Cumulative incremental since last full backup
4. Exit the backup program
1 => 1
Specify output device (type STOP to exit)
Device: /isc/FullDBList_user.cbk => /isc/setmirror.cbk
Backing up to device: /isc/setmirror.cbk
Description:
Backing up the following directories:
/isc/data/demo/
/isc/iris/mgr/user/
Start the Backup (y/n)? => y
Journal file switched to:
/isc/jrnpri/MIRROR-AUGEST-20220917.011
Starting backup pass 1
Backing up /isc/data/demo/ at 09/17/2022 15:28:26
Copied 82 blocks in 0.004 seconds
Finished this pass of copying /isc/data/demo/
Backing up /isc/iris/mgr/user/ at 09/17/2022 15:28:28
Copied 908 blocks in 0.475 seconds
Finished this pass of copying /isc/iris/mgr/user/
Backup pass 1 complete at 09/17/2022 15:28:29
Starting backup pass 2
Backing up /isc/data/demo/ at 09/17/2022 15:28:31
Copied 2 blocks in 0.000 seconds
Finished this pass of copying /isc/data/demo/
Backing up /isc/iris/mgr/user/ at 09/17/2022 15:28:33
Copied 2 blocks in 0.000 seconds
Finished this pass of copying /isc/iris/mgr/user/
Backup pass 2 complete at 09/17/2022 15:28:33
Starting backup pass 3
Journal file '/isc/jrnpri/MIRROR-AUGEST-20220917.010' and the subsequent ones are required for recovery purpose if the backup were to be restored
Journal marker set at
offset 197572 of /isc/jrnpri/MIRROR-AUGEST-20220917.011
- This is the last pass - Suspending write daemon
Backing up /isc/data/demo/ at 09/17/2022 15:28:35
Copied 2 blocks in 0.000 seconds
Finished this pass of copying /isc/data/demo/
Backing up /isc/iris/mgr/user/ at 09/17/2022 15:28:35
Copied 2 blocks in 0.001 seconds
Finished this pass of copying /isc/iris/mgr/user/
Backup pass 3 complete at 09/17/2022 15:28:35
***FINISHED BACKUP***
Global references are enabled.
Backup complete.
1) Backup
2) Restore ALL
3) Restore Selected or Renamed Directories
4) Edit/Display List of Directories for Backups
5) Abort Backup
6) Display Backup volume information
7) Monitor progress of backup or restore
Option?
%SYS>!scp /isc/setmirror.cbk root@172.16.58.102:/isc
Enter passphrase for key '/root/.ssh/id_rsa':
root@172.16.58.102's password:
setmirror.cbk 100% 8448KB 49.4MB/s 00:00
%SYS>
```
- 在其他成员上恢复数据库,这里分两种情况:
- 其他成员上没有这个数据库: 比如我的serverb没有DEMO数据库,要做的是:创建一个DEMO数据库,使用和servera一样的设置,除了**在下拉框“镜像数据库?“,回答”NO“**
- 其他成员上有这个库,比如备机serverb里有User, 不用管它,下面我们就可以直接把它覆盖掉。
请参考下面的数据库恢复过程。 **提醒一点:不要使用第一个选项“All Directories", 该选项不能用其他机器的备份文件恢复本机。**
```sh
# 在Backup成员serverb上执行,恢复用源文件拷贝自servera
%SYS>do ^DBREST
Cache DBREST Utility
Restore database directories from a backup archive
Restore: 1. All directories
2. Selected and/or renamed directories
3. Display backup volume information
4. Exit the restore program
1 => 2
Do you want to set switch 10 so that other processes will be
prevented from running during the restore? Yes =>
Specify input file for volume 1 of backup 1
(Type STOP to exit)
Device: /isc/setmirror.cbk
This backup volume was created by:
IRIS for UNIX (Red Hat Enterprise Linux 7 for x86-64) 2022.1
The volume label contains:
Volume number 1
Volume backup SEP 17 2022 03:28PM Full
Previous backup SEP 16 2022 09:11AM Full
Last FULL backup SEP 16 2022 09:11AM
Description
Buffer Count 0
Mirror name AUGEST
Failover Member SERVERA/IRIS
Is this the backup you want to start restoring? Yes =>
This backup was made on the other mirror member.
Limit restore to mirrored databases? yes
For each database included in the backup file, you can:
-- press RETURN to restore it to its original directory;
-- type X, then press RETURN to skip it and not restore it at all.
-- type a different directory name. It will be restored to the directory
you specify. (If you specify a directory that already contains a
database, the data it contains will be lost).
/isc/data/demo/ (:mirror:AUGEST:DEMO) =>
/isc/iris/mgr/user/ (:mirror:AUGEST:USER) =>
Do you want to change this list of directories? No =>
Restore will overwrite the data in the old database. Confirm Restore? No => Yes
***Restoring /isc/data/demo/ at 15:47:09
82 blocks restored in 0.0 seconds for this pass, 82 total restored.
Expanding /isc/iris/mgr/user/ ...
Expanding /isc/iris/mgr/user/ from 1 MB to 654 MB
***Restoring /isc/iris/mgr/user/ at 15:47:12
908 blocks restored in 0.0 seconds for this pass, 908 total restored.
***Restoring /isc/data/demo/ at 15:47:12
2 blocks restored in 0.0 seconds for this pass, 84 total restored.
***Restoring /isc/iris/mgr/user/ at 15:47:12
2 blocks restored in 0.0 seconds for this pass, 910 total restored.
***Restoring /isc/data/demo/ at 15:47:12
2 blocks restored in 0.0 seconds for this pass, 86 total restored.
***Restoring /isc/iris/mgr/user/ at 15:47:12
2 blocks restored in 0.0 seconds for this pass, 912 total restored.
Specify input file for volume 1 of backup following SEP 17 2022 03:28PM
(Type STOP to exit)
Device:
Do you have any more backups to restore? Yes => no
Mounting /isc/data/demo/ which is a mirrored DB
/isc/data/demo/ ... (Mounted)
Mounting /isc/iris/mgr/user/ which is a mirrored DB
/isc/iris/mgr/user/ ... (Mounted)
Journal records for mirrored DBs were restored successfully.
%SYS>
```
- 检查数据库列表中的状态,注意它们已经成了AUGEST的镜像数据库了, **而且它们是只读模式**。
- 在serverb上查看镜像监视器,确认它们的状态是Dejournaling
后面您可以像上面提到的,在主机上操作数据, 确认数据修改同步给了备机。到此这部分工作才算结束。
> 如果只有外部备份文件:
>
> 按照文档上的说法,如果用外部备份在非主成员恢复,恢复后需要在镜像监视器的”镜像数据库列表里“点击"ACtiviate", 直到看到状态为Caaught up为至。请参考文档,我不是很清楚细节。
# 其他的镜像操作
这里我说说怎么删除镜像, 以及其他的一些常用操作的要点, 比如什么时候使用“SET NO FAILOVER”等等。
TO BE CONTINUED...
文章
Qiao Peng · 十二月 4, 2023
1. 通用RESTful业务服务和业务操作
InterSystems IRIS 提供了一组通用的RESTful 业务服务和业务操作类,用户无需开发自定义的业务服务和业务操作类,就可以直接向外提供RESTful服务和调用外部的RESTful API。
BS
EnsLib.REST.GenericService
通用REST业务服务
BS
EnsLib.REST.SAMLGenericService
检查SAML令牌的签名和时间戳的REST业务服务
BO
EnsLib.REST.GenericOperation
通用REST业务操作
BO
EnsLib.REST.GenericOperationInProc
用于透传模式的通用REST业务操作
2. 通用RESTful 消息
通用的RESTful 业务服务和业务操作类使用一个通用的RESTful消息类 - EnsLib.REST.GenericMessage,它是EnsLib.HTTP.GenericMessage的子类,二者数据结构都是
HTTPHeaders
记录http头的数组
Stream
记录http体的数据流
Type
数据流类型,例如是字符流还是二进制流。自动赋值,无需设置
Attributes
记录属性的数组
OriginalFilename
无需使用
OutputFolder
无需使用
OutputFilename
无需使用
因此EnsLib.REST.GenericMessage和EnsLib.HTTP.GenericMessage都可以被通用RESTful业务操作和业务服务所使用。
3. 通用RESTful 业务操作
使用通用的RESTful业务操作,可以连接到任何第三方的RESTful服务器,调用其RESTful API。
3.1 向production中加入通用RESTful业务操作
增加通用RESTful业务操作,只需要在Production配置页面的操作中添加EnsLib.REST.GenericOperation。
建议加入Production时,给业务操作起一个名字,用于代表具体的业务,例如是连接到LIS的RESTful 服务,可以命名为RESTtoLIS(可以考虑的命名规则 - 接口方式+业务系统)。如果未命名,默认会使用类名作为业务操作名。
3.2 配置通用RESTful业务操作
主要的设置项是以下3个:
1. HTTP服务器:目标RESTful服务器的服务器名或IP地址
2. HTTP端口:目标RESTful服务器提供RESTful API的端口号
3. URL:RESTful API的服务端点
启用该业务操作后,既可以访问外部RESTful API了。
3.3 测试通用RESTful业务操作
启用后,加入的通用的RESTful业务操作即可测试了。因为EnsLib.HTTP.GenericMessage的REST消息体是一个流类型的属性,为了测试时方便输入这个数据,我们增加一个业务流程。
1. 创建一个新的业务流程,设置其请求消息为Ens.StringRequest,用于测试时传入REST body数据。并为其上下文增加一个名为DataBody、类型为%Stream.GlobalCharacter(可持久化的字符流类型)的属性:
2. 在业务流程中增加一个代码流程(<code>),将请求消息的字符串数据写入上下文的DataBody字符流:
Do context.DataBody.Write(request.StringValue)
注意行首加空格。
3. 然后在业务流程中再加入一个调用流程(<call>),调用上面已经加入production的业务操作,例如RESTtoLIS,并设置请求和响应消息为EnsLib.REST.GenericMessage或EnsLib.HTTP.GenericMessage。
4. 配置RESTtoLIS业务操作的请求消息(Request)
可以直接点击构建请求消息(Request Builder)按钮,使用图形化拖拽建立请求消息:
4.1 将左边上下文context里的DataBody拖拽到callrequest的Stream属性上;
4.2 对callrequest的HTTPHeaders赋值,它是一个元素类型为字符串的数组,代表HTTP请求的头。以下3个HTTP头是必须要填写的:
HTTP头属性说明
下标
值
HTTP方法
"httprequest"
例如"POST"
HTTP消息体的内容类型
"content-type"
例如"application/json"
客户端希望接收的内容类型
"Accept"
例如"*/*"
这3个数组元素赋值,可以通过在添加操作下拉列表中设置(Set)进行赋值。
5. 将业务流程加入Production,并测试
确保Production的设置是允许调试。在Production配置页面中选中这个业务流程,在右侧的操作标签页中选择测试按钮,并在弹出的测试消息页面里填入测试用的数据,并点击调用测试服务:
然后可以检查测试的消息处理流程,并确认REST消息体和HTTP消息头被正确地传递到目标REST API
4. 通用RESTful 业务服务
使用通用的RESTful业务服务,可以向外发布能处理任何RESTful API调用请求的RESTful服务端。
4.1 将通用RESTful业务服务加入Production
在Production配置页面,点击服务后面的加号。弹出的向导页面,服务类选择EnsLib.REST.GenericService;输入服务名,建议写一个能代表组件功能的名字,例如向HIS系统开放的REST服务,可以起名RESTforHIS;选中立即启用。
RESTful通用业务服务可以通过2种方式向外提供RESTful API服务:第一种通过Web服务器向外提供服务,第二种使用IRIS服务器的特定TCP端口向外提供服务。第二种方式不依赖于独立的Web服务器,但推荐使用Web服务器,从而得到更好的性能和安全性。
这里我们使用Web服务器提供REST服务,因此在业务服务的端口配置中,保持空白。在接受消息的目标名称中,选择接收RESTful API请求的业务流程或业务操作,这里我们测试使用一个空的业务流程。点击应用激活这些设置。
4.2 建立一个向外提供RESTful API的Web应用
向外发布RESTful服务,不仅涉及到服务发布的URL,还涉及到安全。我们通过创建一个专用的Web应用来进行管理和控制。
在IRIS系统管理门户>系统管理>安全>应用程序>Web应用程序 中,点击新建Web应用程序按钮,新建一个Web应用程序,并做以下配置:
1. 名称,填写一个计划发布的服务端点,例如/IRISRESTServer。注意前面的/
2. NameSpace,选择Production所在的命名空间
3. 选中启用 REST,并设置分派类为EnsLib.REST.GenericService
4. 根据安全需要,配置安全设置部分。这里方便测试起见,允许的身份验证方法选择了未验证(无需验证)。如果是生产环境,或者您在做性能压力测试,都应该选择密码或Kerberos安全的身份验证方式!
注意,请保证同一个命名空间下,仅有一个分派类为EnsLib.REST.GenericService的REST类型的Web应用。
4.3 测试RESTful业务服务
现在就可以测试这个RESTful业务服务了。这个RESTful服务可以响应任何REST API的请求,如何响应则是后续业务流程/业务操作的事。
它的完整的RESTful URL是:[Web服务器地址]:[Web服务器端口]/[Web应用的名称]/[通用REST服务在production中的配置名]/[API名称和参数],例如我在IRIS本机的私有Apache的52773端口上访问上面创建的REST通用业务服务,调用PlaceLabOrder的API (注意,这里我们并没有实现过PlaceLabOrder这个API,但我们依然可以响应,而不会报404错误),那么完整的REST 调用地址是:
127.0.0.1:52773/IRISRESTServer/RESTforHIS/PlaceLabOrder
打开POSTMAN,用POST方法,发起上面REST API的调用:
在IRIS里会得到类似这样的消息追踪结果,如果你没有实现过处理REST API请求的业务流程,会得到一个500错,但依然可以查看IRIS产生的EnsLib.HTTP.GenericMessage消息内容:
这个通用RESTful业务服务会把REST请求转换为EnsLib.HTTP.GenericMessage消息,向目标业务操作/业务流程发送。因此,通过解析它的消息内容,就知道REST API请求的全部信息:
1. Stream里是POST的数据
2. HTTPHeaders 的下标"HttpRequest"是HTTP的方法
3. HTTPHeaders 的下标"URL"是完整的API路径,包括了服务端点(在"CSPApplication"下标下)、REST业务服务名称(在"EnsConfigName"下标下)和API
后续业务流程可以通过这些数据对REST API请求进行响应。
4.4 使用业务流程对REST API调用进行路由
有了通用RESTful业务服务生成的EnsLib.HTTP.GenericMessage消息,我们就可以使用消息路由规则或业务流程对REST API请求进行路由。这里我使用业务流程方法对REST API请求进行路由演示。
构建一个新的业务流程,请求消息和响应消息都是EnsLib.REST.GenericMessage或EnsLib.HTTP.GenericMessage,同时为context增加一个名为ReturnMsg的字符串类型的属性,并设置它默认值为:"{""Code"":-100,""Msg"":""未实现的API""}"。
在业务流程里增加一个<switch>流程,然后在<switch>下增加2个条件分支,分别为:
名称:下达检验医嘱,条件:判断是否http头的URL为PlaceLabOrder,且http头的HttpRequest为POST:
(request.HTTPHeaders.GetAt("URL")="/IRISRESTServer/RESTforHIS/PlaceLabOrder") && (request.HTTPHeaders.GetAt("HttpRequest")="POST")
名称:查询检验项目,条件:判断是否http头的URL为GetLabItems,且http头的HttpRequest为GET:
(request.HTTPHeaders.GetAt("URL")="/IRISRESTServer/RESTforHIS/GetLabItems") && (request.HTTPHeaders.GetAt("HttpRequest")="GET")
在两个分支里,分别增加<code>, 产生返回的REST消息内容:
Set context.ReturnMsg="{""Code"":200,""Msg"":""检验医嘱下达成功""}"
Set context.ReturnMsg="{""Code"":200,""Msg"":""查询检验项目成功""}"
最后在<switch>后增加一个<code>,构建响应消息:
// 初始化响应消息
set response = ##class(EnsLib.REST.GenericMessage).%New()
// 初始化响应消息的流数据
Set response.Stream = ##class(%Stream.GlobalCharacter).%New()
// 将REST返回数据写入流
Do response.Stream.Write(context.ReturnMsg)
编译这个业务流程,并将其加入Production。
之后修改通用RESTful业务服务的设置,将接收消息的目标名称改为这个新建的业务流程。
现在再通过POSTMAN测试一下各种API,并查看返回REST响应:
在真实项目中,根据实际情况,将上面<switch>流程分支的<code>替换为API响应业务流程或业务操作即可。
总结:使用通用RESTful业务操作和业务服务,无需创建自定义的RESTful 业务组件类,就可以调用外部RESTful API和向外提供RESTful API服务,降低开发和实施成本,实现低代码开发。
后记:关于EnsLib.REST.GenericService对CORS(跨域资源共享)的支持
CORS是一种基于 HTTP 头的机制,通过允许服务器标示除了它自己以外的其它origin(域、协议和端口)等信息,让浏览器可以访问加载这些资源。所以要让EnsLib.REST.GenericService支持CORS,需要让它的响应消息增加对于CORS支持的HTTP头的信息,这里不详细介绍这些头含义了,大家可以去W3C的网站或者搜索引擎查询具体定义,最简单可以使用以下代码替代上面4.4中的初始化响应消息代码:
// 设置HTTP响应的头信息
set tHttpRes=##class(%Net.HttpResponse).%New()
set tHttpRes.Headers("Access-Control-Allow-Origin")="*"
set tHttpRes.Headers("Access-Control-Allow-Headers")="*"
set tHttpRes.Headers("Access-Control-Allow-Methods")="*"
// 初始化响应消息
set response = ##class(EnsLib.REST.GenericMessage).%New(,,tHttpRes)
文章
姚 鑫 · 十一月 4, 2021
# 第六十六章 SQL命令 REVOKE
从用户或角色中删除特权。
# 大纲
```sql
REVOKE admin-privilege FROM grantee
REVOKE role FROM grantee
REVOKE [GRANT OPTION FOR] object-privilege
ON object-list FROM grantee [CASCADE | RESTRICT] [AS grantor]
REVOKE [GRANT OPTION FOR] SELECT ON CUBE[S] object-list FROM grantee
REVOKE column-privilege (column-list)
ON table FROM grantee [CASCADE | RESTRICT]
```
## 参数
- `admin-privilege` - 管理员级特权或以前授予要撤销的管理员级特权的以逗号分隔的列表。
可用的`syspriv`选项包括`16`个对象定义权限和`4`个数据修改权限。对象定义权限为:`%CREATE_FUNCTION`, `%DROP_FUNCTION`, `%CREATE_METHOD`, `%DROP_METHOD`, `%CREATE_PROCEDURE`, `%DROP_PROCEDURE`, `%CREATE_QUERY`, `%DROP_QUERY`, `%CREATE_TABLE`, `%ALTER_TABLE`, `%DROP_TABLE`, `%CREATE_VIEW`, `%ALTER_VIEW`, `%DROP_VIEW`, `%CREATE_TRIGGER`, `%DROP_TRIGGER`。
或者,可以指定`%DB_OBJECT_DEFINITION`,这将撤销所有`16`个对象定义特权。数据修改权限为`INSERT`、`UPDATE`、`DELETE`操作的`%NOCHECK`、`%NOINDEX`、`%NOLOCK`、`%NOTRIGGER`权限。
- `grantee` - 拥有SQL系统权限、`SQL`对象权限或角色的一个或多个用户的列表。
有效值是一个以逗号分隔的用户或角色列表,或`“*”`。
星号(`*`)指定当前定义的所有没有`%all`角色的用户。
- `AS grantor` - 此子句允许通过指定原始授予者的名称来撤销另一个用户授予的特权。
有效的授予者值是用户名、以逗号分隔的用户名列表或`“*”`。
星号(`*`)指定当前定义的所有授予者。
要使用`AS`授予器子句,必须具有`%All`角色或`%Admin_Secure`资源。
- `role` - 一个角色或以逗号分隔的角色列表,这些角色的权限将从用户被撤销。
- `object-privilege` - 基本级别特权或先前授予要撤销的基本级别特权的逗号分隔列表。
该列表可以包含以下一个或多个:`%ALTER`、`DELETE`、`SELECT`、`INSERT`、`UPDATE`、`EXECUTE`和`REFERENCES`。
要撤销所有特权,可以使用`“all [privileges]”`或`“*”`作为此参数的值。
注意,您只能从多维数据集撤销`SELECT`特权,因为这是惟一可授予的多维数据集特权。
- `object-list` - 一个以逗号分隔的列表,其中包含一个或多个正在撤销对象特权的表、视图、存储过程或多维数据集。
可以使用`SCHEMA`关键字指定从指定模式中的所有对象撤销对象特权。
可以使用`" * "`指定从当前命名空间中的所有对象撤销对象特权。
- `column-privilege` - 从一个或多个列列表列出的列撤销基本权限。
可用选项有`SELECT`、`INSERT`、`UPDATE`和`REFERENCES`。
- `column-list` - 由一个或多个列名组成的列表,用逗号分隔,用括号括起来。
- `table` - 包含列列表列的表或视图的名称。
# 描述
`REVOKE`语句撤销允许用户或角色在指定的表、视图、列或其他实体上执行指定任务的权限。
`REVOKE`还可以撤销用户分配的角色。
`REVOKE`撤销`GRANT`命令的操作;
特权只能由授予特权的用户撤消,或者通过`CASCADE`操作(如下所述)。
可以从指定用户、用户列表或所有用户(使用`*`语法)撤销角色或特权。
因为`REVOKE`的准备和执行速度很快,而且通常只运行一次,所以`IRIS`不会在`ODBC`、`JDBC`或动态SQL中为`REVOKE`创建缓存查询。
即使不能执行实际的撤销(例如,指定的特权从未被授予或已经被撤销),`REVOKE`也会成功地完成。
但是,如果在`REVOKE`操作期间发生错误,`SQLCODE`将被设置为负数。
## 撤销的角色
角色可以通过`SQL GRANT`和`REVOKE`命令授予或撤销,也可以通过`^SECURITY IRIS System SECURITY`命令授予或撤销。
可以使用`REVOKE`命令从某个用户撤消一个角色,也可以从另一个角色撤消一个角色。
不能使用`IRIS System Security`将角色授予或撤销给其他角色。
特殊变量`$ROLES`不显示授予角色的角色。
`REVOKE`可以指定单个角色,也可以指定要撤销的角色列表,以逗号分隔。
`REVOKE`可以从指定的用户(或角色)、用户(或角色)列表或所有用户(使用*语法)中撤销一个或多个角色。
`GRANT`命令可以将一个不存在的角色授予用户。
可以使用`REVOKE`命令从现有用户撤销不存在的角色。
但是,角色名必须使用与授予角色时相同的字母大小写来指定。
如果试图从不存在的用户或角色撤销现有角色, IRIS将发出`SQLCODE -118`错误。
如果不是超级用户,并且试图撤销一个不拥有且没有`ADMIN OPTION`的角色,InterSystems IRIS将发出`SQLCODE -112`错误。
## 撤销对象权限
对象特权赋予用户或角色对特定对象的某些权限。
从一个被授予者的对象列表上撤销一个对象特权。
对象列表可以在当前名称空间中指定一个或多个表、视图、存储过程或多维数据集。
通过使用逗号分隔的列表,单个`REVOKE`语句可以从多个用户和/或角色中撤销多个对象上的多个对象特权。
可以使用星号(`*`)通配符作为对象列表值,从当前名称空间中的所有对象撤销对象特权。
例如,`REVOKE SELECT ON * FROM Deborah`将撤销该用户对所有表和视图的SELECT权限。
`REVOKE EXECUTE ON * FROM Deborah`将撤销该用户对所有非隐藏存储过程的`EXECUTE`权限。
可以使用`SCHEMA SCHEMA -name`作为对象列表值,以撤销指定模式中当前名称空间中的所有表、视图和存储过程的对象特权。
例如,`REVOKE SELECT ON SCHEMA Sample FROM Deborah`将撤销该用户对`Sample`模式中所有对象的`SELECT`权限。
可以将多个模式指定为逗号分隔的列表;
例如,`REVOKE SELECT ON SCHEMA Sample,Cinema FROM Deborah`撤销`Sample`和`Cinema`模式中所有对象的`SELECT`权限。
可以从用户或角色撤消对象特权。
如果从某个角色撤销该权限,则仅通过该角色拥有该权限的用户将不再拥有该权限。
不再拥有特权的用户不能再执行需要该对象特权的现有缓存查询。
当`REVOKE`撤销对象特权时,它将成功完成并将`SQLCODE`设置为0。
如果`REVOKE`没有执行实际的撤销(例如,指定的对象权限从未被授予或已经被撤销),它将成功完成,并将`SQLCODE`设置为`100`(不再有数据)。
如果在`REVOKE`操作期间发生错误,它将`SQLCODE`设置为负数。
多维数据集是不受模式名称限制的SQL标识符。
要指定多维数据集对象列表,必须指定`CUBE`(或cubes)关键字。
因为多维数据集只能有`SELECT`权限,所以您只能从多维数据集撤销`SELECT`权限。
对象权限可以通过以下任意方式撤销:
- `REVOKE command`.
- `$SYSTEM.SQL.Security.RevokePrivilege()`方法。
- 通过IRIS系统安全。
转到管理门户,选择系统管理、安全、用户(或系统管理、安全、角色),为所需的用户或角色选择`Edit`,然后选择SQL表或SQL视图选项卡。
在下拉列表中选择`Namespace`。
向下滚动到所需的表,然后单击`revoke`来撤销权限。
可以通过调用`%CHECKPRIV`命令来确定当前用户是否具有指定的对象特权。
通过调用`$SYSTEM.SQL.Security.CheckPrivilege()`方法,可以确定指定的用户是否具有指定的表级对象特权。
## 撤销对象所有者特权
如果从对象的所有者那里撤消对SQL对象的特权,那么所有者仍然隐式地拥有对对象的特权。
为了从对象的所有者完全撤销对象上的所有特权,必须更改对象以指定不同的所有者或没有所有者。
## 撤销表级和列级特权
`REVOKE`可用于撤销表级特权或列级特权的授予。
表级特权提供对表中所有列的访问。
列级特权提供对表中每个指定列的访问。
向表中的所有列授予列级特权在功能上等同于授予表级特权。
然而,这两者在功能上并不完全相同。
列级`REVOKE`只能撤销在列级授予的权限。
不能向表授予表级特权,然后在列级为一个或多个列撤销此特权。
在这种情况下,`REVOKE`语句对已授予的权限没有影响。
## CASCADE 或 RESTRICT
IRIS支持可选的`CASCADE`和`ESTRICT关`键字来指定`REVOKE`对象特权行为。
如果没有指定关键字,则默认为`RESTRICT`。
可以使用`CASCADE`或`RESTRICT`来指定从一个用户撤销对象特权或列特权是否也会从通过`WITH GRANT OPTION`接收到该特权的任何其他用户撤销该特权。
`CASCADE`撤销所有这些关联的特权。
当检测到关联的特权时,`RESTRICT(默认值)`导致`REVOKE`失败。
相反,它设置`SQLCODE -126`错误`“REVOKE with RESTRICT failed”`。
下面的例子展示了这些关键字的使用:
```sql
--UserA
GRANT Select ON MyTable TO UserB WITH GRANT OPTION
```
```sql
--UserB
GRANT Select ON MyTable TO UserC
```
```sql
--UserA
REVOKE Select ON MyTable FROM UserB
-- This REVOKE fails with SQLCODE -126
```
```sql
--UserA
REVOKE Select ON MyTable FROM UserB CASCADE
-- This REVOKE succeeds
-- It revokes this privilege from UserB and UserC
```
注意,`CASCADE`和`RESTRICT`对`UserB`创建的引用`MyTable`的视图没有影响。
## 对缓存查询的影响
当撤销特权或角色时, IRIS将更新系统上所有缓存的查询,以反映特权中的这一更改。
但是,当无法访问某个名称空间时——例如,当连接到数据库服务器的ECP连接关闭时——`REVOKE`会成功完成,但不会对该名称空间中的缓存查询执行任何操作。
这是因为`REVOKE`不能更新不可达名称空间中的缓存查询,以撤销缓存查询级别的特权。
没有发出错误。
如果数据库服务器稍后启动,则该名称空间中缓存查询的权限可能不正确。
如果某个角色或特权可能在某个名称空间不可访问时被撤销,建议清除该名称空间中的缓存查询。
## IRIS Security
REVOKE命令是一个特权操作。
在嵌入式SQL中使用`REVOKE`之前,必须以具有适当特权的用户身份登录。
如果不这样做,将导致`SQLCODE -99`错误(特权冲突)。
使用`$SYSTEM.Security.Login()`方法为用户分配适当的权限:
```
DO $SYSTEM.Security.Login("_SYSTEM","SYS")
&sql( )
```
必须具有`%Service_Login:Use`权限才能调用`$SYSTEM.Security`。
登录方法。
# 示例
下面的嵌入式SQL示例创建两个用户,创建一个角色,并将角色分配给用户。
然后,它使用星号(`*`)语法从所有用户撤销该角色。
如果用户或角色已经存在,`CREATE`语句将发出`SQLCODE -118`错误。
如果用户不存在,`GRANT`或`REVOKE`语句将发出`SQLCODE -118`错误。
如果用户存在但角色不存在,则`GRANT`或`REVOKE`语句发出`SQLCODE 100`。
如果用户和角色存在,则`GRANT`或`REVOKE`语句发出`SQLCODE 0`。
即使已经完成了角色的授予或撤销,如果您试图撤销从未被授予的角色,也是如此。
```java
ClassMethod Revoke()
{
d $SYSTEM.Security.Login("_SYSTEM","SYS")
&sql(
CREATE USER User1 IDENTIFY BY fredpw
)
&sql(
CREATE USER User2 IDENTIFY BY barneypw
)
w !,"CREATE USER error code: ",SQLCODE
&sql(
CREATE ROLE workerbee
)
w !,"CREATE ROLE error code: ",SQLCODE
&sql(
GRANT workerbee TO User1,User2
)
w !,"GRANT role error code: ",SQLCODE
&sql(
REVOKE workerbee FROM *
)
w !,"REVOKE role error code: ",SQLCODE
}
```
在下面的示例中,使用`AS`授予子句,一个用户(`Joe`)授予一个特权,另一个用户(`John`)撤销该特权:
```sql
/* User Joe */
GRANT SELECT ON Sample.Person TO Michael
```
```sql
/* User John */
REVOKE SELECT ON Sample.Person FROM Michael AS Joe
```
注意,`John`必须具有`%All`角色或`%Admin_Secure`资源。
文章
Nicky Zhu · 一月 6, 2023
国务院于2022年12月19日发布了《中共中央 国务院关于构建数据基础制度更好发挥数据要素作用的意见》(后简称《数据二十条》),如何有效利用数据已经成为下一步的趋势。另一方面,无论是基于数据中台还是数据编织理念,两者也都对如何利用数据提出了构想。因此医疗行业数字化建设的目标已不能再局限于如何收集数据,建立医疗行业数据的流通机制将会是为越来越普遍的需求。
时钟拨回几年前,数据中台概念开始火爆。人们对数据中台的定义、诠释尽管有诸多差异,通过数据中台降低数据共享和利用的成本则是共同的期望。但经过这几年的探索之后,中台已死的观点也在涌现。究其原因,除去中台概念在技术上的不确定,数据流通过程中的责权益的不清晰也是严重的制约因素。毕竟,数据中台自身作为一套技术框架并不能代替法律法规与市场自动将数据转变为商品从而创造出流通价值。
那么,如何能够使数据的流通合规合法,使数据能够如货币和商品一般自由流动,则是我们需要思考和探索的主题,这次《数据二十条》的出现,无疑为医疗信息技术工作者提供了一个明确的思考方向。
政策利好与约束
鉴于《数据二十条》对数据行业生态的覆盖范围之广,涉及数据权属界定、数据产品流通、数据收益分配和数据市场有效监管等各方面,本文将无法全面展开每一条政策进行解读和思考,因此将聚焦于与每个从业人员都息息相关的数据产权和数据产品流通两方面进行。
产权与使用权的破与立
还记得数年前与信息科同事谈及基于医疗数据的统计与分析时,医院的同事对于数据被第三方访问的恐惧远多于期待。对数据要素的权属及其确立规则的不清晰使得每个从业人员都无法在具备法律法规保障的前提下运用数据。本次《数据二十条》对于个人数据、企业数据和公共数据进行了产权定义,还提出了数据资源持有权、数据加工使用权、数据产品经营权等分置的产权运行机制,从而打破了这样无法可依的尴尬局面。
可以预见的是,通过对数据的产权与使用权进行分离,在取得数据所有者(如个人或企业)授权的前提下,对数据进行加工处理,通过数据洞察进行盈利将成为合理合法的业务形态。
数据供应链的建立
《数据二十条》第三章对数据供应链体系做了一系列的规划,包括数据流通过程中参与方的角色,如数据商和第三方专业服务机构;包括流通场所,如数据交易所以及对应的流程合规与监管规则体系的远景。这样一个体系的构建,其规模和复杂性并不亚于为汽车工业组织零部件生产和消费的供应链。
特别需要注意的是,正如《数据二十条》中明确指出的,数据供应链的建立必将依托数据质量标准化体系,推进对数据采集和接口的标准化,依赖于数据整合互通和互操作。
这些概念和体系对于医疗信息技术工作者来说并不陌生。然而在既往的工作中,跨企业、跨区域医疗行业数据共享的产业规模并未对标准化产生强劲的推力。尽管近年来随着互联互通标准化评测工作的开展,医疗信息互操作在标准化方面得到了极大的进展,但是医疗行业数据与上下游生态企业(如药企、保险、养老机构等)间进行数据流通所需的统一语义和标准还未确立和应用,势必将在不远的未来对医疗信息技术工作者提出更高的挑战。
另一方面,在鼓励数据交易所发挥作用的同时,《数据二十条》也倡导在数据流程合规与受规则体系监管的前提下,培育一批数据商和第三方专业服务机构,依法依规在场内和场外采取开放、共享、交换、交易等方式流通数据,也为创建数据供应、数据托管和数据服务代理等多种模式的数据经济形态创造了条件。
医疗行业数据流通案例
医疗数据产业并不是一个已经成熟的规模化产业,即使对于美国、英国这些在医疗信息化方面较早起步的国家,医疗数据产品和流通也仍然处于初步的市场探索阶段。我们可以看到一个案例。
Epic COSMOS数据集
美国最大的电子病历厂商Epic于2019年推出了数据集产品COSMOS(https://COSMOS.epic.com/)。所有Epic电子病历系统的用户都可以自愿与Epic签约成为COSMOS合作伙伴,在开放自己的医疗健康数据的同时共享同样加入了COSMOS网络其他用户的数据。时至今日,COSMOS已经收录了1亿6千7百万患者的数据,覆盖一千余家医院和两万余家诊所。
图 1 COSMOS数据流
如上图所示,Epic采用了非常传统的前置机+中心化存储方案构建。在置于院端的前置机中,以批量上传和事件触发上传两种方式加载数据集,在前置机一侧对数据进行标准化和匿名化,并通过HL7 CDA标准以文档的形式将数据传到数据中心。置于AWS云端的数据中心将负责对数据进行去重及合并。其中,数据在云端将以非结构化的Global形态存储于InterSystems的Caché中,并利用Caché自带的后结构化能力将非结构化的Global转换并存储为关系型数据对外提供SQL访问能力。
在这个过程中,COSMOS进行的若干细节处理非常值得即将面临数据开放的医疗信息技术工作者参考和借鉴。读者可参考相关论文查阅(如https://www.thieme-connect.com/products/ejournals/pdf/10.1055/s-0041-1731004.pdf)。
真实数据的可访问性:COSMOS本质上只解决了分散的,真实的医疗数据的可访问性问题,还没有运用任何颠覆性的BI、AI技术。作为美国最大的电子病历厂商,手握上亿人的医疗数据的Epic,需要从基础数据的准备切入市场,这从侧面反映了当前医疗行业所面临的客观现实,即供应链底层的数据原料并不存在稳定的供给,从而阻碍了其他技术的演进。这同样是我们面临的现状。
非常传统的数据采集:COSMOS只采集EHR中的结构化数据,并不收纳任何影像、视频和除实验室检测结果外的文本等多媒体数据,也未采用实时数据流进行采集。这并不意味着多媒体数据没有价值,也不意味着实时数据流没有价值,而是意味着半静态的,结构化的数据中的价值并没有得以充分提炼和发挥,仅通过收集整理结构化数据形成规模一项工作已足以支撑起庞大的价值链条,尽管这些静态数据并不是唯一的价值来源。
去识别化与个人数据授权:作为对患者信息进行隐私保护的首要手段,COSMOS及与之相似的数据集产品Cerner Real-World Data(CRWD)均遵循美国自1996年通过的HIPPA法案,只开放法案允许开放的数据集,并按照HIPPA的要求对可能暴露患者隐私或反向识别个人的数据字段进行匿名化处理。需要注意的是,尽管CRWD相关的论文中声明,由于对数据进行了匿名化处理,对个人医疗数据的使用不需要患者本人的授权(https://www.sciencedirect.com/science/article/pii/S2352340922003304),但COSMOS仍然提供了供患者撤回数据授权,将本人的数据从COSMOS网络中退出的工作流。因此,即使在美国,数据所有者和数据使用者之间的权益平衡仍保留了相当的灵活性,我国在制定相关法规时也会对基于所有权和使用权定义相应的细则。
数据访问控制:在前置机与云端数据中心通信过程中,CDA文档将被加密并通过专网传输,避免在公网传输并被截获和解析的可能。另一方面,尽管COSMOS收集了诊断、药嘱、手术史、社会史和家族史等患者个人的明细数据,但它并不对最终用户开放这些数据;COSMOS用户可以通过查询门户,制定条件,查询基于这些明细的统计数据,例如在一定行政区域内罹患新冠的患者数量及其年龄分布等,但无法查询到对应的个人,因此经过认证的科研机构在COSMOS中发起查询并不再需要特定的审查委员会审核;同时COSMOS也不提供将数据从COSMOS网络中导出的渠道,避免数据流出网络。从这些控制手段上来看,COSMOS选择的技术路线和服务模式与《新二十条》中“原始数据不出域、数据可用不可见”的要求和“以模型、核验等产品和服务等形式向社会提供”的倡导高度吻合,值得借鉴。
数据标准化:COSMOS在前置机上收集一家医院的数据时已落实了数据的标准化,采用固定的数据结构和术语集。医院需要先完成对数据和术语的标准化映射,才能接入COSMOS网络。而在云端存储中,原始数据也是以标准化的CDA文档形式保存,进一步巩固了数据标准。也正是在标准化数据存储的基础上,最终用户才能够通过统一的查询构建器,在同一种语义环境下同时访问来自于不同医院,采用了不同术语标准的医疗数据。因此通过数据标准术语标准达成语义一致性的重要性不言而喻,这是医疗数据的利用迅速得到规模效应的客观需求。
医疗数据产品发展前景
如前所述,基于数据所有权与数据使用权分离的假设,很难想象未来医疗数据产品的发展方向以生数据产品的形态,开放对个人数据的(即使经过了匿名化)访问。相反的,基于医疗数据需求的多样性以及个人、企业、公共数据管理规则的差异性,以生数据为基础,以对药企、保险等企业提供潜在可招募患者的区域锁定或针对患者的年龄、诊断、家族史的普遍特征与医疗支出进行精算为例,针对人群展开的数据洞察和数据分析服务,更可能得到业界的认可并在数据价值利用和数据隐私保护间取得平衡,有很大概率成为率先得以实现的商业模式。同时,作为一个新兴产业,生产者(数据工程师)群体的培养和储备,以及与之配套的生产资料的制造和积累,则是医疗数据产业能够成型的前提,值得医疗信息技术工作者关注和投入。
因此,在未来相当长的一段时间内,对医疗行业数据的利用,将以各医院、集团和企业建立的数据中心为基础,通过对真实数据进行洞察分析和价值挖掘的形态,以数据服务的形式对外提供,从而迅速释放这些被积累了很久的数据的价值。
后续我们还会继续阐述和分析在医疗数据流通领域中的生产者和生产资料的特征,欢迎大家与我们交流,谢谢。
文章
Weiwei Gu · 七月 12, 2022
开始 - 请拉到页面底部查看该系列文章第一部分 .
3. 使用globals时结构的变体
一个结构,比如说一个有序排列的“树”,有各种特殊的情况。让我们来看看那些对使用globals有实际价值的情况。
3.1 特殊情况1. 一个没有分支的节点
Globals不仅可以像数组一样使用,而且可以像普通变量一样使用。例如,用于创建一个计数器:
Set ^counter = 0 ; setting counter
Set id=$Increment(^counter) ; atomic incrementation
同时,一个global除了值以外,还可以有分支。一个并不排斥另一个。
3.2 特殊情况2. 一个节点和多个分支
事实上,这是一个典型的键值库。而如果我们把健和值都存下来而不是仅仅是存值的话,那我们会得到一个有主键的普通表。
为了实现一个基于globals的表,我们将不得不从列值中形成字符串,然后通过主键将它们保存到global中。为了能够在读取过程中把字符串分割成列,我们可以使用以下方法。
分隔符
Set ^t(id1) = "col11/col21/col31"
Set ^t(id2) = "col12/col22/col32"
一个固定的方案,即每个字段占据特定数量的字节。在关系型数据库中通常就是这样做的。 一个特殊的$LB
一个特殊的 $LB函数(从Caché开始引入的),可以从值中组成一个字符串。
Set ^t(id1) = $LB("col11", "col21", "col31")
Set ^t(id2) = $LB("col12", "col22", "col32")
有趣的是,使用globals做一些类似于关系型数据库中外键的事情并不难。我们把这种结构称为index globals。Index globals是一个补充"树",用于快速搜索那些不属于主Global主键组成部分的字段。你需要编写额外的代码来填充和使用它。
下面,让我们在第一列的基础上创建一个Index global.
Set ^i("col11", id1) = 1
Set ^i("col12", id2) = 1
要想通过第一列快速搜索,你需要查看^i global,并找到与第一列中必要值对应的主键(id)。
当插入一个值时,我们可以同时为必要的字段创建值和Index global。为了保证可靠性,让我们把它包装成一个事务(transaction)。
TSTART
Set ^t(id1) = $LB("col11", "col21", "col31")
Set ^i("col11", id1) = 1
TCOMMIT
更多的信息可以从这里查看 making tables in M using globals and emulation of secondary keys.
如果用COS/M编写插入/更新/删除函数并进行编译,这些表的工作速度将与传统DB一样快(甚至更快)。
我通过对一个单一的双列表进行大量的INSERT和SELECT操作,同时使用TSTART和TCOMMIT命令(transactions事务)来验证这个声明。
我没有测试更复杂的并发访问和并行事务的情况。
在不使用transactions事务的情况下,一百万个值的插入速度为778,361次/秒。
对于3亿个值,速度是422,141次/秒。
当使用transactions交易时,对于5000万个值,速度达到572,082次插入/秒。所有的操作都是通过编译的M代码运行的。我使用了普通的硬盘,而不是SSD。RAID5有回写功能。所有运行在Phenom II 1100T CPU上。
为了对SQL数据库进行同样的测试,我们需要写一个存储过程,在一个循环中进行插入。当使用同样的方法测试MySQL 5.5(InnoDB存储)时,我从来没有得到超过每秒11K次的插入。
确实,用globals实现表比在关系型数据库中做同样的事情要复杂。这就是为什么基于globals的工业数据库会有SQL访问,以来简化表格数据的工作。
一般来说,如果数据模式不会经常改变,插入的速度不是很关键,而且整个数据库可以很容易地用规范化的表来表示,那么使用SQL就比较容易,因为它提供了一个更高的抽象层次。
在这种情况下,我想表明globals可以被用作创建其他DB的构造函数。就像汇编语言可以用来创建其他语言一样。而这里有一些使用globals来创建对应的 键值key-values, 列表lists, 集合sets, 表格-tabular, 文档数据库-document-oriented DB 的例子。
如果你需要以最小的努力创建一个非标准的数据库,你应该考虑使用globals。
3.3 特殊情况 3.一个有两个层级的“树”,每个二级节点都有固定数量的分支
你可能已经猜到了:这是一个使用globals的表格的可选实现形式。我们把它与之前的那个进行比较。
两层树中的表 VS .一层树中的表
缺点
优点
1.插入速度慢,因为节点的数量必须设置为与列的数量相等。2 更高的硬盘空间消耗,因为带有列名的全局索引(如数组索引)占用了硬盘空间,并且每一行都是重复的。
1.对特定列的值的访问速度更快,因为你不需要解析字符串。根据我的测试,对于2个列来说,它的速度要快11.5%,对于更多的列来说,速度甚至更快。2. 更容易改变数据模式3. 更容易阅读代码
结论:没什么可写的。由于性能是globals的关键优势之一,使用这种方法几乎没有任何意义,因为它不可能比关系型数据库中的普通表工作得更快。
3.4 一般情况。"树"和有序键
任何可以被表示为"树"的数据结构都能完美地适合globals。
3.4.1 有子对象的对象
这就是传统上使用 globals 的领域。在医疗领域有无数的疾病、药物、症状和治疗方法。为每个病人创建一个有一百万个字段的表是不合理的,尤其是99%的字段都是空白的。
想象一下,一个由以下表格组成的SQL数据库。"病人"~10万个字段,"药物 "10万个字段,"治疗 "10万个字段,"并发症 "10万个字段,等等。作为一个替代方案,你可以创建一个有数千个表的数据库,每个表都代表一个特定的病人类型(它们也可以重叠!)、治疗、药物,以及这些表之间关系的数千个表。
Globals就像一只手套一样适合医疗行业,因为它使每个病人都有完整的病例记录、治疗方法列表、使用的药物及其效果--所有这些都以"树"的形式存在,而不会像关系型数据库那样在空的列上浪费太多的磁盘空间。
当任务是最大限度地积累和系统化关于客户的各种个人数据时,Globals用于记录个人各种细节的数据库非常有效。这对于医疗、银行、营销、档案和其他领域来说尤其重要。
不言而喻,SQL也能让你只用几个表(EAV, 1,2,3,4,5,6, 7,8)来模拟一棵树, 但它要复杂得多,工作速度也慢。从本质上讲,我们必须写一个基于表的Global,并将所有与表有关的routines隐藏在一个抽象层下。用高层技术(SQL)来模拟底层技术(globals)是不正确的
改变巨大的表的数据模式(ALTER TABLE)可能需要相当长的时间,这并不是什么秘密。例如,MySQL在执行ALTER TABLE ADD|DROP COLUMN操作时,会将所有数据从旧表复制到新表(我在MyISAM和InnoDB上测试过)。这可能会使一个有数十亿条记录的生产数据库停滞几天,甚至几周。
如果我们使用globals,改变数据结构对我们来说是没有成本的。我们可以在任何时候向层次结构中任何级别的任何对象添加任何新的属性。需要对分支进行重命名的改变可以在后台模式下应用,同时数据库也会启动并运行。
因此,当涉及到存储具有大量可选属性的对象时,globals工作得非常好!
我也提醒一下各位,对任何一个属性的访问都是即时的,因为在global中,所有的路径都是一个B-tree。
在一般情况下,基于globals的数据库也是一种面向文档的数据库,支持存储分层信息。因此,在存储医疗卡的领域,面向文档的数据库可以有效地与globals竞争。
但是,现在还不完全是这样。
让我们以MongoDB为例。在这个领域,它输给了globals,原因如下:
1.文档大小
存储单元是一个JSON格式的文本(确切地说,是BSON),最大尺寸为16MB左右。引入这个限制的目的是为了确保JSON数据库在解析过程中不会变得太慢,当一个巨大的JSON文档被保存到数据库中时,需要处理特定的字段值。这个文件应该有关于病人的完整信息。我们都知道病人卡可以有多“厚”。如果卡的最大大小被限制在16MB,它就会立即过滤掉卡中包含核磁共振扫描、X光扫描和和其他材料的病人。Global的一个分支可以有数千兆字节和数万兆字节的数据。这算是说明了一切,但我还可以告诉你更多。
2. 创建/改变/删除病人卡上的新属性所需的时间
这样一个数据库需要将整个卡片复制到内存中(大量的数据!),解析BSON数据,添加/改变/删除新的节点,更新索引,将其全部打包回BSON并保存到磁盘。而一个Global只需要寻址必要的属性并执行必要的操作。3.对特定属性的访问速度
如果文档有许多属性和多级结构,对特定属性的访问会更快,因为Global中的每个路径都是B-Tree。在BSON中,你需要对文档进行线性解析以找到必要的属性。
3.3.2 关联数组
关联数组(即使是嵌套数组)可以完美地与globals一起工作。例如,这个PHP数组将看起来像3.3.1中的第一个插图。
$a = array(
"name" => "Vince Medvedev",
"city" => "Moscow",
"threatments" => array(
"surgeries" => array("apedicectomy", "biopsy"),
"radiation" => array("gamma", "x-rays"),
"physiotherapy" => array("knee", "shoulder")
)
);
3.3.3 层次化的文件。XML、JSON
也可以很容易地存储在globals中并以不同的方式进行分解。
XML
将XML分解成globals的最简单方法是将标签属性存储在节点中。而如果你需要快速访问标签属性,我们可以把它们放在单独的分支中。
<note id=5>
<to>Alex</to>
<from>Sveta</from>
<heading>Reminder</heading>
<body>Call me tomorrow!</body>
</note>
在COS中,代码将看起来像这样。
Set ^xml("note")="id=5"
Set ^xml("note","to")="Alex"
Set ^xml("note","from")="Sveta"
Set ^xml("note","heading")="Reminder"
Set ^xml("note","body")="Call me tomorrow!"
注意:对于XML、JSON和关联数组,你可以想出很多方法来在globals中显示它们。在这个特殊的例子中,我们没有在 "note "标签中反映嵌套标签的顺序。在^xml global中,嵌套标签将按字母顺序显示。为了精确地显示顺序,你可以使用下面的模式,比如:
JSON
这个JSON文档的内容显示在第3.3.1节的第一个插图中
var document = {
"name": "Vince Medvedev",
"city": "Moscow",
"threatments": {
"surgeries": ["apedicectomy", "biopsy"],
"radiation": ["gamma", "x-rays"],
"physiotherapy": ["knee", "shoulder"]
},
};
3.3.4 由等级关系约束的相同结构
例子:销售办公室的结构组成,传销组织结构中人的位置,国际象棋的首秀。
关于首秀的数据库。
你可以使用棋力评估作为Global的节点索引的值。在这种情况下,你需要选择一个具有最高权重的分支来确定最佳棋步。在Global中,每一层的所有分支都将按棋力进行排序。
销售办公室的结构,传销公司的人。节点可以存储一些反映整个子树特征的缓存值。例如,这个特定子树的销售人员情况。我们可以在任何时候获得关于任何分支的销售成果的确切信息。
4. 使用globals有好处的情况
第一栏包含了使用globals会在性能方面给你带来相当大的优势的情况列表,第二栏则包含了使用globals会简化开发或数据模型的情况列表。
Speed
数据处理/呈现的便利性
1. 插入[每层都有自动排序],[通过主键建立索引]。2. 移除子树3. 具有大量嵌套属性的对象,你需要对其进行单独访问4. 分层结构,可以从任何一个分支开始,甚至是不存在的分支,进行子分支的遍历。5.深入的树形遍历
1.具有大量非必需[和/或嵌套]属性/物质的对象/物质
2.无模式的数据--经常可以添加新的属性和删除旧的属性。3.你需要创建一个非标准的DB。4.路径数据库和解决方案树。当路径可以方便地表示为一棵"树“的时候。5.在不使用递归的情况下删除层次结构
下一章继续第三篇,未完待续!(待翻译) "Globals - Magic swords for Storing Data. Sparse Arrays. Part 3"
Disclaimer: this article and my comments on it reflect my opinion only and have nothing to do with the official position of the InterSystems Corporation.
文章
Louis Lu · 一月 19, 2023
这篇文章主要介绍 HL7 V2.5.1 标准是如何定义查询类请求,以及查询类响应的。相关HL7 V2 的更多基础知识可以参考:HL7v2到底是什么?! 的一系列文章。
1 查询标准的发展
1.1 最早的查询模式
最初,HL7的查询参数通过QRD以及QFR 字段传入。因为这两个字段的设计是为了满足所有的查询需求,所以这两个字段的定义非常随意。
1.2 加强的查询模式
从HL7 V2.3开始,引入了加强版的查询模式,它包含了四种方式:
• 嵌入式查询语言类请求查询:自由格式的select SQL语句
• 虚拟表类请求查询:基于特定的select 条件查询服务端的数据库表
• 存储过程类请求查询:执行服务端的存储过程返回数据
• 事件类请求查询:返回基于特定事件的查询结果
1.3 基于2.4 版本的查询
HL 7 v2.3.1之后的版本更清晰地将请求查询的方式与返回查询数据的方式分开,并且强调了“符合性声明”的存在。 HL 7继续支持存储过程、事件查询和虚拟表查询的语义,但推荐使用新的查询方式,即按参数查询(QBP),使语法更清晰。
QBP查询的目的是在一个精确的一致性声明的框架内统一存储过程、事件和虚拟表查询的语义。
同时该标准仍可以继续使用最初模式查询(QRD/QRF),但使用新的查询形式可以更清楚地解释其语义。
2 符合性声明Conformance Statement
符合性声明很像我们熟悉的“接口文档”,在其中定义了哪些数据是可用的,数据将如何被返回,以及哪些变量可以在查询中被赋值以及其约束范围。典型的符合性声明应由下面的内容组成:
介绍部分包含标题、触发事件、模式、特点和目的
查询语法
返回语法
输入规范和注释
返回控制
输出规范和注释
更多符合性声明文档的解释和例子可以参考HL7官方文档。
3 消息格式
正如前面说的,HL 7 v2.3.1之后的版本更清晰地将请求查询的方式与返回查询数据的方式分开,这里重点介绍这两个不同的方式。每种消息的示例会在文章最后给出。
3.1 返回查询结果数据
HL7 定义了三种返回查询结果数据的格式:分段、表格或显示格式。分段格式的响应是由一组HL7段组成。每个查询都会在符合性声明中定义它将返回的HL7片段每个字段的含义。表格式响应是以一组行的形式返回数据,每行一个RDT段。最后的显示查询是以DSP段承载返回数据。
3.1.1 分段响应格式
分段格式的返回是HL7提供数据的传统方式。服务器通过返回HL7段的方式对查询作出响应。例如,对检验数据查询的响应的核心可能由以下分段语法定义。
{
PID
OBR
[{OBX}]。
}
其中,病人信息将在PID段中返回,实验室检验结果在OBR和OBX段中返回。在这种模式下,服务器返回的消息通常与现有的非请求类HL7消息非常接近。
在为分段模式的返回内容定义一致性声明时,数据所有者必须决定它将返回的确切段语法。它应该在必要时阐明每个字段的含义、数据的数量,以及数据是可选的还是必须的。
3.1.2 表格响应格式
表格模式的返回是一个相当传统的由行和列组成的表格。行和列的具体含义会在在该查询的符合性声明中被完整的定义。
当所返回的信息相对简单时,以表格的方式是合适的。但对于涉及复杂的结果嵌套的检验报告来说,它并不是很合适。同时典型的HL7段或段组所携带的数据也可以被建模为一个表格。例如,ADT系统可以将PID、NK1和PV1段拼接到一张表中。但另一方面,在一个单一的表格中包含一个病人的所有就诊历史是很困难的。
3.1.3 显示响应格式
一些情况下,返回的信息不需要被接收的系统保存在数据库里,而只要显示出来就行。
显示响应实际上并不代表组织数据的正式风格。它代表了一个决定,即返回的内容为人类阅读而不是为计算机使用的数据格式。从逻辑上讲,以显示模式返回的内容可能是HL7段模式携带的复杂数据,也可能是由表格模式响应携带的简单记录。
3.2 请求格式
前面介绍的是三种返回查询客户端的方式,现在这里介绍HL7 推荐的三种不同的查询请求方式。
3.2.1 简单参数查询
在简单参数查询中,输入参数在HL7段中连续按顺序传递。 服务器只需要从相应的HL7段中读取它们,并将它们插入到内部函数中执行查询操作。
这是查询的最基本形式,服务端在符合性声明中指定一个固定的参数列表,调用查询时,客户端为每个参数传递一个特定值,这就类似于对数据库调用存储过程并传入参数。
MSH|^~\&|FEH.IVR|HUHA.CSC|HUHA.DEMO||199902031135-0600||QBP^Z58^QBP_Q13|1|D|2.5.1
QPD|Z58^Pat Parm Qry 2|Q502|111069999
RCP|I
3.2.2 示例查询
按示例查询(QBE)是按参数查询(QBP)的扩展,其通过在原本定义的段中发送搜索参数来传递搜索参数,而不是作为QPD段中的字段传递。 例如,如果想要使用QBE执行“查找候选者”查询,则将查询参数保存在PID和或PD 1字段中,并将其中不是查询参数的那些字段留空。 例如,如果宗教不是查询参数之一,则当在查询中发送PID时,PID-17将被留空。 HL 7消息原本定义中不出现的参数,如搜索算法、置信度等, 将继续在QPD段中携带,就像它们在按参数查询一样。 可用作查询参数的确切段和字段将在查询的符合性声明中指定。
MSH|^~\&|FEH.IVR|HUHA.CSC|HUHA.DEMO||199902031135-0600||QBP^Z58^QBP_Q13|1|D|2.5.1
QPD|Z58^Pat Parm Qry 2|Q502
PID|||111069999
RCP|I
3.2.3 选择性查询QSC(Query selection criteria)
第三个方式称为选择性查询QSC,因为它使用了QSC数据类型,而QSC数据类型一般在虚拟表查询中使用。 服务端的符合性声明中将定义客户端可能在表达式中使用的所有变量。 在运行时,客户端能够通过构造类似于“树”节点的方式定义可用的输入参数。 服务端要执行查询,必须可以在运行时分析和解析查询表达式。 服务端可以将输入表达式翻译成它本地可访问数据的语言。 客户端的复杂表达式类似于针对关系数据库的SQL select语句。
MSH|^~\&|FEH.IVR|HUHA.CSC|HUHA.DEMO||199902031135-0600||QBP^Q13^QBP_Q13|1|D|2.5.1
QPD|Z999^Pat Sel Qry 1|Q501|@MedicalRecordNo^EQ^111069999
RCP|I
3.2.4 三种请求格式比较
在使用QSC时,客户端可以选择所提供的任何或所有变量,并且可以为每个变量指定任何允许的运算符和值。 相比之下,在简单参数查询或示例查询中,客户端必须为所提供的所有变量提供值。
简单参数查询易于解析和处理,查询传入参数是预定义好以及有着固定的顺序。 类似地,示例查询也较容易处理,因为参数将出现在定义的段中的固定位置。 相反的,选择性查询需要更多的解析和处理,因为它的灵活性和参数的可选性。 因此,虽然选择性查询向客户端提供了更多功能,但是它对于服务端的处理来说是更繁琐的,简单参数查询和示例查询向客户端提供较少的功能,但通常更易于服务端实现,并且它们往往是基于服务端现有存储过程而提供的。
4 查询返回消息示例
4.1 简单参数查询(QBP)/分段模式返回(RSP)
用户希望查询从1998年5月31日开始到1999年5月31日结束的时间段内,为病历号为“555444222111”的患者分配的所有药物。 使用以下简单参数查询请求消息:
MSH|^~\&|PCR|Gen Hosp|PIMS||199811201400-0800||QBP^Z81^QBP_Q11|ACK9901|P|2.5.1||||||||
QPD|Z81^Dispense History^HL7nnnn|Q001|555444222111^^^MPI^MR||19980531|19990531|
RCP|I|999^RD|
药房系统识别属于Adam Everyman的医疗记录号“555444222111”,并定位从1998年5月31日开始到1999年5月31日结束的时间段内有4次处方配药,并返回以下RSP消息:
MSH|^~\&|PIMS|Gen hosp|PCR||199811201400-0800||RSP^Z82^RSP_Z82|8858|P|2.5.1||||||||
MSA|AA|ACK9901|
QAK|Q001|OK|Z81^Dispense History^HL7nnnn|4|
QPD|Z81^Dispense History^HL7nnnn|Q001|555444222111^^^MPI^MR||19980531|19990531|
PID|||555444222111^^^MPI^MR||Everyman^Adam||19600614|M||C|2222 HOME STREET^^Oakland^CA^94612||^^^^^555^5552004|^^^^^555^5552004|||||34313 2266|||N|||||||||
ORC|RE||89968665||||||199805121345-0700|||77^Hippocrates^Harold^H^III^DR^MD||^^^^^555^ 5552104||||||
RXE|1^BID^^19980529|00378112001^Verapamil Hydrochloride 120 mg TAB^NDC|120||mgm||||||||||||||||||||||||||
RXD|1|00378112001^Verapamil Hydrochloride 120 mg TAB^NDC |199805291115-0700|100|||1331665|3|||||||||||||||||
RXR|PO||||
ORC|RE||89968665||||||199805291030-0700|||77^Hippocrates^Harold^H^III^DR^MD||^^^^^555^555-5001||||||
RXE|1^^D100^^20020731^^^TAKE 1 TABLET DAILY --GENERIC FOR CALANSR|00182196901^VERAPAMIL HCL ER TAB 180MG ER^NDC |100||180MG|TABLETSA|||G|||0|BC3126631^CHU^Y^L||213220929|0|0|19980821|||
RXD|1|00182196901^VERAPAMIL HCL ER TAB 180MG ER^NDC|19980821|100|||213220929|0|TAKE 1 TABLET DAILY --GENERIC FOR CALANSR||||||||||||
RXR|PO||||
ORC|RE||235134037||||||199809221330-0700|||8877^Hippocrates^Harold^H^III^DR^MD||^^^^^555^555-5001||||||RXD|1|00172409660^BACLOFEN 10MG TABS^NDC|199809221415-0700|10|||235134037|5|AS DIRECTED||||||||||||
RXR|PO||||
ORC|RE||235134030||||||199810121030-0700|||77^Hippocrates^Harold^H^III^DR^MD||^^^^^555^555-5001||||||
RXD|1|00054384163^THEOPHYLLINE 80MG/15ML SOLN^NDC|199810121145-0700|10|||235134030|5|AS DIRECTED||||||||||||
RXR|PO
4.2 简单参数查询(QBP)/表格模式返回(RTB)
用户希望获取病历号为“555444222111”的患者的身份信息。使用简单参数查询
MSH|^~\&|PCR|GenHosp|MPI||199811201400-0800||QBP^Z91^QBP_Q13|8699|P|2.5.1||||||||
QPD|Z91^WhoAmI^HL7nnnn|Q0009|555444222111^^^MPI^MR
RCP|I|999^RD|
RDF|PatientList^CX^20~PatientName^XPN^48~Mother’sMaidenName^XPN^48~DOB^TS^26~Sex^IS^1~Race^CE^80|
以表格方式返回查询结果:
MSH|^~\&|MPI|GenHosp|PCR||199811201400-0800||RTB^Z92^RTB_K13|8699|P|2.5.1||||||||
MSA|AA|8699|
QAK|Q0009|OK|Z91^WhoAmI^HL7nnnn|1^1|
QPD|Z91^WhoAmI^HL7nnnn|Q0009|555444222111^^MPI^MR
RDF|PatientList^CX^20~PatientName^XPN^48~Mother’sMaidenName^XPN^48~DOB^TS^26~Sex^IS^1~Race^CE^80|
RDT|555444222111^^^MPI^MR|Everyman^Adam||19600614|M||
4.3 简单参数查询(QBP)/显示模式返回(RDY)
用户希望了解从1998年5月31日开始到1999年5月31日结束的时间段内,为病历号为“555444222111”的患者分配的所有药物。请求消息:
MSH|^~\&|PCR|Gen Hosp|PIMS||199909171400-0800||QBP^Z97^QBP_Q15|8699|P|2.5.1||||||||
QPD|Z97^DispenseHistoryDisplay^HL7nnnn|Q005|555444222111^^^MPI^MR||19980531|19990531|
RCP|I|999^RD|
返回消息:
MSH|^~\&|PIMS|Gen Hosp|PCR||199909171401-0800||RDY^Z98^RDY_K15|8858|P|2.5.1||||||||
MSA|AA|8699|
QAK|Q005|OK|Z97^DispenseHistoryDisplay|4
QPD|Z97^DispenseHistoryDisplay^HL7nnnn|Q005|555444222111^^^MPI^MR||19980531|19990531|
DSP|| GENERAL HOSPITAL – PHARMACY DEPARTMENT DATE:09-17-99
DSP|| DISPENSE HISTORY REPORT Page 1
DSP||MRN Patient Name MEDICATION Dispense DISP-DATE
DSP||555444222111 Everyman,Adam VERAPAMIL HCL 120 mg TAB 05/29/1998
DSP||555444222111 Everyman,Adam VERAPAMIL HCL ER TAB 180MG 08/21/1998
DSP||555444222111 Everyman,Adam BACLOFEN 10MG TABS 09/22/1998
DSP||555444222111 Everyman,Adam THEOPHYLLINE 80MG/15ML SOL 10/12/1998
DSP|| << END OF REPORT >>
4.4 示例查询(QBP)/表格模式返回(RTB)
客户希望查看人口统计学资料如下的患者列表:
姓名:张三
性别:男
生日: 1948年12月11日
客户希望使用peekaboo算法,以及满足80%置信水平。
请求消息:
MSH|^~\&|PCR|GenHosp|MPI||199811201400-0800||QBP^Z77^QBP_Q13|8699|P|2.5.1||||||||
QPD|Z77^find_candidates^HL7nnnn|Q0001|peekaboo|80|
PID|||||张&三||19481211|M
RCP|I|25^RD|
RDF|PatientList^CX^20~PatientName^XPN^48~Mother’sMaidenName^XPN^48~DOB^TS^26~Sex^IS^1~Race^CE^80|
返回消息:
MSH|^~\&|MPI|GenHosp|PCR||199811201400- 0800||RTB^Z78^RTB_R13|8699|P|2.5.1||||||||
MSA|AA|8699|
QAK|
QPD|Z77^find_candidates^HL7nnnn|Q0001|peekaboo|80|
RDF|PatientList^CX^20~PatientName^XPN^48~Mother’sMaidenName^XPN^48~DOB^TS^26~Sex^IS^1~Race^CE^80|
RDT|555444222111^^^MPI&KP.NCA&L^MR|张^三||19481211|M||
4.5 选择性查询/表格模式返回(RTB)
用户希望了解从1998年5月31日开始到1999年5月31日结束的时间段内,为病历号为"555444222111"的患者分配的所有药物。 将生成以下消息。
请求消息:
MSH|^~\&|PCR|Gen Hosp|PIMS||199811201400-0800||QBP^Z95^QBP_Q13|8699|P|2.5.1||||||||
QPD|Z95^Dispense Information^HL7nnnn|Q504|PID.3^EQ^55544422211^AND~RXD.3^GE^19980531^AND~RXD.3^LE^19990531
RCP|I|999^RD|
RDF|3|PatientList^ST^20~PatientName^XPN^48~OrderControlCode^ID^2~OrderingProvider^XCN^120~MedicationDispensed^ST^40~DispenseDate^TS^26~QuantityDispensed^NM^20|
返回消息:
MSH|^~\&|PIMS|Gen Hosp|PCR||199811201400-0800||RTB^Z96^RTB_K13|8858|P|2.5.1||||||||
MSA|AA|8699|
QAK|Q001|OK|Z95^Dispense Information^HL7nnnn|4
QPD|Z95^Dispense Information^HL7nnnn|Q504|PID.3^EQ^55544422211^AND~RXD.3^GE^19980531^AND~RXD.3^LE^19990531
RDF|3|PatientList^ST^20~PatientName^XPN^48~OrderControlCode^ID^2~OrderingProvider^XCN^120~MedicationDispensed^ST^40~DispenseDate^TS^26~QuantityDispensed^NM^20|
RDT|555444222111^^^MPI^MR|Everyman^Adam|RE|77^Hippocrates^Harold^H^III^DR^MD |525440345^Verapamil Hydrochloride 120 mg TAB^NDC |199805291115-0700|100
RDT|555444222111^^^MPI^MR|Everyman^Adam|RE|77^Hippocrates^Harold^H^III^DR^MD |00182196901^VERAPAMIL HCL ER TAB 180MG ER^NDC|19980821-0700|100
RDT|555444222111^^^MPI^MR|Everyman^Adam|RE|88^Seven^Henry^^^DR^MD|00172409660^BACLOFEN 10MG TABS^NDC |199809221415-0700|10
RDT|555444222111^^^MPI^MR|Everyman^Adam|RE|99^Assigned^Amanda^^^DR^MD|00054384163^THEOPHYLLINE 80MG/15ML SOLN^NDC|199810121145-0700|10
5 InterSystems IRIS 对于HL7 V2.x 的支持
5.1 内置 HL7 V2.x 文档
方便随时查看HL7 V2.x 各个字段、节点的含义、限制以及可用字典表定义
可以方便的打开一个HL7 V2.x 文档,鼠标悬停就可以看到该字段的解释:
5.2 互操作性
5.2.1 内置的数据转化工具:使用鼠标拖拽就可以进行数据格式的转换
5.2.2 HL7 消息路由编辑器: 图形化页面设置,方便根据HL7 消息字段内容将消息发送到不同目标
5.2.3 消息追踪器:方便追踪在平台中的经过数据的流向
文章
Hao Ma · 六月 13, 2023
在维护IRIS的镜像前,管理员需要清楚的了解以下一些概念:
## Mirror的切换模式(failover mode)
切换模式在镜像监视器里被翻译成”故障转移模式“。 有两种模式:
- Agent Controlled模式:
- Arbiter Controlled模式:(页面上翻译为“仲裁程序受控制”)
通常情况,生产环境的镜像是安装了arbiter(仲裁者)的。Mirror启动时,在还没有连接上arbiter的时候,自动进入Agent-Controlled模式。而后当两台机器,主机,备机都连通了Arbiter,会保持在这个模式。
- 主备之间有连接;
- 又都连到arbiter;
- backup is active,
满足上面的条件,就进入arbiter controlled mode。而如果主备的任一方,失去了和arbiter的连接,或者备用侧丢了active, 开始尝试连接另一方,退回到agent-controlled模式。
## Mirror同步成员的状态
[Mirror Member Journal Transfer and Dejournaling Status](https://docs.intersystems.com/irisforhealth20231/csp/docbook/DocBook.UI.Page.cls?KEY=GHA_mirror_manage#GHA_mirror_set_status). 请注意,这里面有两个概念:一个是**Mirror成员的状态**,一个是**Journal传输和Dejournaling的状态**。下面的图中是3个字段: STATUS, Journal传输,Dejournaling.
**STATUS**
镜像成员的状态。 正常工作状态
- 对于同步成员,是Primary(主), Backup(备机)。
- 对于异步成员,正常状态是Connected(已连接)
- In Trouble : 如果主机In Trouble, 是失去了到backup的连接。备机收到主机的同步数据是要返回证实(Ack)消息的。一旦出现问题,主机无法收到备机的Ack, 主机就会把备机标为"In trouble", 从此再也不会向备机发同步数据。
- Transition: 暂时状态,进程正在查看一个成员的状态,很快会转换到一个稳定状态。 如果在mirror配置的member中发现了primary,本机会进入Synchronizing状态,否则自己会尝试进入primary状态。
- Sychronizing: 从Primary接收journal,同步数据库。
## Journal Transfer and Dejournaling Status
Journal Transfer是主机向其他成员发送Journal文件。而Dejournal是把Journal文件读入数据库。 对于backup或者asycn成员,**Journal Transfer**状态表示镜像成员是否有来自主数据库的最新日志数据,如果没有,则表示日志传输的落后程度,**Dejournaling**表示从主数据库收到的所有日志数据是否已经被dejournaled(应用到成员的镜像数据库),如果没有,则表示dejournaling的落后程度。
上图中显示的是正常的状态,其中主机 Journal Transfer 和 Dejournaling 都是N/A, 表示不适用。
对于其他成员,我们分开看:
Journal Transfer状态
- Active: backup的正常状态。说明backup从primary收到了最新的journal。注意哪怕是Dejournal状态只是“x秒落后“,而不是"被捕获",Journal Transfer状态也可以是Active,只要是从主机收到了最新的Journal更新。
- Caught up(被捕获) : 备机被捕获状态,说明备机从主机收到了最新的journal数据,但主机没有在等待备机的证实消息。 这通常是一个暂时的过程,当备机在连接主机的时候会出现。 异步成员,因为不需要向主机发证实,所以正常的状态就是“被捕获”
If the Primary Failover Member does not receive an acknowledgment from the Backup every Heartbeat Interval period, it demotes the Backup system from Active status to Catch-Up mode.
- time behind (多少秒落后)
- Disconnected on time(断开): 在一个时间点上这个成员和primary断开了。
Dejournaling状态
- Caught up
- time behind
- Disconnected on time
- Warning! Some Databases need attention
- Wanring! Dejournaling is stopped
**正常状态下的图;**
备机Backup MirrorB, Journal Transfer是Active, Dejournaling是Caught up, 异步机器MirrorDR的Journal Transfer状态和Dejournaling状态都是Caught up. 表示它们收到了最新的journal数据,并且也都把最新的global修改写入了自己的数据库。
## Mirror的自动切换
Mirror的核心是自动切换。Backup接替主机的工作有两个前提:1. 备机在同步(Active) 状态, 2. 主机不能正常工作。在这两个前提下,我们来看看自动切换的触发条件,涉及主机,备机,仲裁机之间的通信,
**自动切换触发条件**
1. Primary要求Backup接替。这种情况,主机会发生一个请求消息给备机, 要求备机接替。
- 主机IRIS正常退出
- 主机发现自己hung
2. 备机收到arbiter的请求,报告失去了到主机的连接。
仲裁机要求是和外部系统以及应用服务器部署在一个网段的。如果仲裁机无法联络主机,可以认为其他的应用系统和服务器也无法连接主机。有可能主机宕机, 也有可能主机还在正常工作,但外界已经无法联络它了, 这时候也是需要备机接手的。
这时备机也要再去核实一下,是不是能联络到主机。如果能联络到, 备机会发请求让主机Down。如果不能, 说明主机要么死了, 要么失联了, 备机先接手,等联络上再让对方force down.
3. 从主机的ISCAgent收到消息,报告Primary已经down or hung.
在agent-controlled的情况。 primary的服务器还活着。备机主动去问主机的agent, 一旦agent报告主机死了, 那备机就可以上位了。
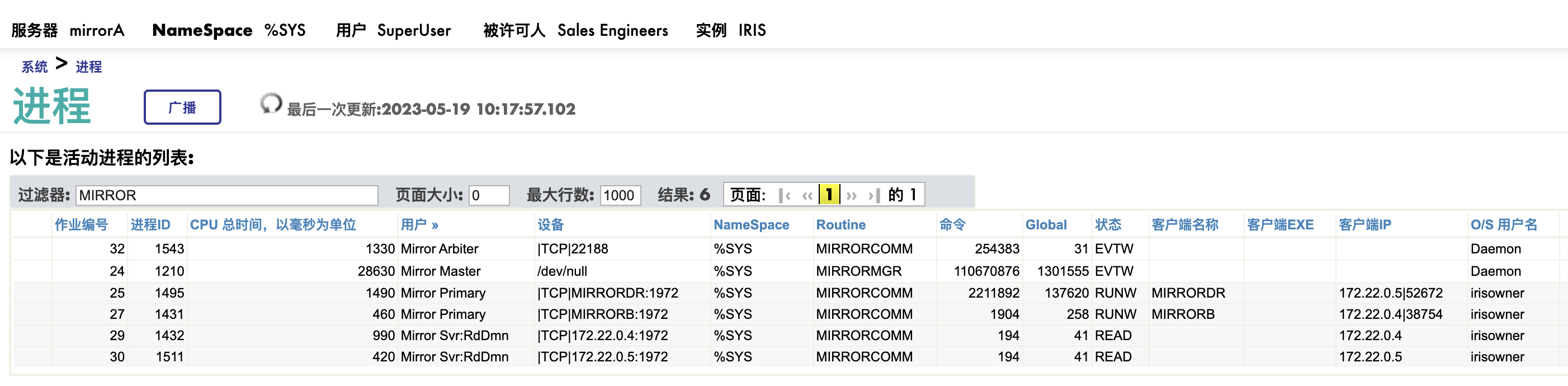
## Mirror的进程
管理员应该了解mirror涉及的那些进程。当出现故障时,这些进程名字,或者称为User, 经常会出现在message log记录的故障描述中。
On Primary Failover Member(主机)
我们来一个个的看看这些进程:
- Mirror Master: 系统启动时自动启动,负载mirror control 和管理。
- Mirror Primary: 出向数据传输通道。 上图中有两个Mirror Primary进程,状态时RUNW, 一个连接MirrorB, 一个连接MirrorDR.
- Mirror Svr: Rd*: 入向证实通道(inbound acknowledgement), 也是单向的。 上图中同样有两个此进程,状态都是READ, IP地址分别是MirrorB和MirrorDR.
- Mirror Arbiter: 到aibiter的通信进程,注意它的状态是"EVTW", 也是个单向写的频道。
On Backup Member/Async member(备机)
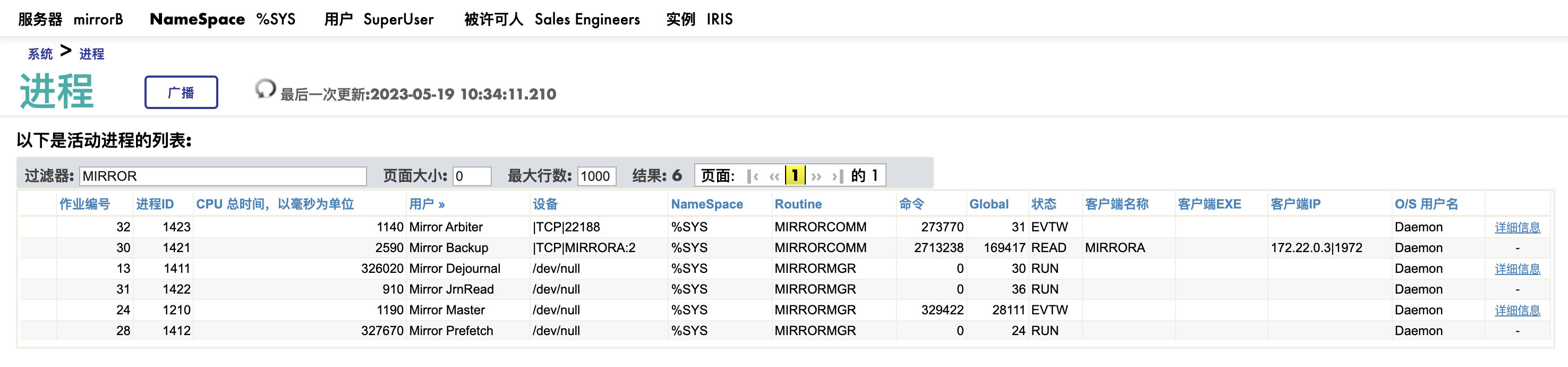
Mirror Masht, Mirror Arbiter不再重复解释,我们看看其他进程是干什么的。
- Mirror JrnRead: Mirror Journal从Primary发送到backup是先写到硬盘的。 JrnRead进程把收到的journal同步读到内存里,然后才进行下一步,Dejournal的工作。
- Mirror Dejour: backup机器的dejournal job进程。它把从Primary收到的journal中记录的global改变(set and kill)保存到本机的镜像数据库。
- Mirror Prefetch: 这个稍微有点难懂。当收到的journal修改中包括了使用当前backup的journal中已有的内容时,比如收到了一个修改:set ^A=^B+1, 而^B当前存在backup里, Prefetch进程会把^B从硬盘拿到内存,以加快dejournal的速度。
- Mirror Backup: two-way channel, 把收到的primary的journal写到backup的mirror journal,并且返回证实(ACK)
这里我省略了在DR上的进程,如果有兴趣,请自己查看文档。
## MIRROR状态的监控
根据不同的场景,查看Mirror的状态有以下几种途径
### **[使用镜像监视器](https://docs.intersystems.com/iris20231/csp/docbook/DocBook.UI.Page.cls?KEY=GHA_mirror_manage#GHA_mirror_monitor_portal)**
### 使用^MIRROR
如果您只是要简单的获得Mirror成员的状态,最直接的方法是使用^Mirror程序。 我们先看看在IRIS Terminal下^MIRROR的执行。
```bash
%SYS>do ^MIRROR
1) Mirror Status
2) Mirror Management
3) Mirror Configuration
Option? 1
1) List mirrored databases
2) Display mirror status of this node
3) Display journal file info
4) Status Monitor
Option? 4
Status of Mirror MIRRORTEST at 08:09:24 on 05/19/2023
Arbiter Connection Status:
Arbiter Address: arbiter|2188
Failover Mode: Agent Controlled
Connection Status: This member is not connected to the arbiter
Journal Transfer
Member Name+Type Status Latency Dejournal Latency
-------------------------- --------- --------------- --------------
MIRRORA
Failover Primary N/A N/A
Press RETURN to refresh, D to toggle database display, Q to quit,
or specify new refresh interval D
Database display is now on
Status of Mirror MIRRORTEST at 08:09:29 on 05/19/2023
Arbiter Connection Status:
Arbiter Address: arbiter|2188
Failover Mode: Agent Controlled
Connection Status: This member is not connected to the arbiter
Journal Transfer
Member Name+Type Status Latency Dejournal Latency
-------------------------- --------- --------------- --------------
MIRRORA
Failover Primary N/A N/A
Mirror Databases:
Record To
Name Directory path Status Dejournal
------------- ----------------------------------- ----------- -----------
TEST /isc/mirrorA/TESTDB/ Normal N/A
Press RETURN to refresh, D to toggle database display, Q to quit,
or specify new refresh interval
```
**在操作系统中执行^MIRROR**
您可以把以下的代码写入您的脚本语言,查看mirror的状态
```bash
irisowner@mirrorA:~$ iris session iris -U "%sys" "Monitor^MIRROR"
Status of Mirror MIRRORTEST at 02:57:08 on 06/13/2023
Arbiter Connection Status:
Arbiter Address: arbiter|2188
Failover Mode: Arbiter Controlled
Connection Status: Both failover members are connected to the arbiter
Journal Transfer
Member Name+Type Status Latency Dejournal Latency
-------------------------- --------- --------------- --------------
MIRRORA
Failover Primary N/A N/A
MIRRORB
Failover Backup Active Caught up
MIRRORDR
Disaster Recovery Connected Caught up Caught up
Press RETURN to refresh, D to toggle database display, Q to quit,
or specify new refresh interval q
Doneirisowner@mirrorA:~$
```
或者更简单的,只查看本机的mirror成员状态:
```bash
irisowner@mirrorA:~$ iris session iris -U "%sys" "LocalMirrorStatus^MIRROR"
This instance is a Failover member
Status for mirror MIRRORTEST is "Primary"
Current mirror file #2 ends at 681224
Min trans file #2 min trans index: 680744
irisowner@mirrorA:~$
```
如果您熟悉ObjectScript, 也可以使用`$SYSTEM.Mirror`类的各个method来查看:
```bash
irisowner@mirrorB:~$ echo "write \$SYSTEM.Mirror.GetMemberStatus(),! halt" |iris session iris -U "%sys"
Node: mirrorB, Instance: IRIS
%SYS>
Backup
irisowner@mirrorB:~$
```
如果您要查看更多的内容,您可以更多的使用%SYSTEM.Mirror类的其他方法,比如%SYSTEM.Mirror.GetFailoverMemberStatus(.pri,.alt), $SYSTEM.Mirror.ArbiterState()等等。
### 使用Mirror_MemberStatusList存储过程
如果您从第3方的工具查询mirror成员的状态,还有一个简单的方案,就是调用%SYS命名空间的存储过程。下图是从iris管理门户调用的截图,你可以使用任何SQL客户端调用。
如果是从iris里执行,
```
%SYS>do ##class(%ResultSet).RunQuery("SYS.Mirror","MemberStatusList")
Member Name:Current Role:Current Status:Journal Transfer Latency:Dejournal Latency:Journal Transfer Latency:Dejournal Latency:Display Type:Display Status:
MDCHCNDBSL1.HICGRP.COM/STAGE:Primary:Active:N/A:N/A:N/A:N/A:Failover:Primary:
MDCHCNDBSL2.HICGRP.COM/STAGE:Backup:Active:Active:Caught up:Active:Caught up:Failover:Backup:
CDCHCNDRSL.HICGRP.COM/STAGE:Async:Async:Caught up:Caught up:Caught up:Caught up:Disaster Recovery:Connected:
```
### 通过SNMP获得
如果使用监控工具,您可以通过SNMP获得Mirror的状态,下面是最新的ISC-IRIS.mib中有关Mirror得指标部分。
```
.4.1.12 = irisMirrorTab | Table of current Mirror Members status and information
-- .4.1.12.1 = irisMirrorRow | Conceptual row for Mirror status and metrics | INDEX = irisSysIndex, irisMirrorIndex
-- .4.1.12.1.1 = irisMirrorIndex | unique index for each Mirror Member | INTEGER
-- .4.1.12.1.2 = irisMirrorName | Name of the mirror this system is a member of | STRING
-- .4.1.12.1.3 = irisMirrorMember | Mirror member name | STRING
-- .4.1.12.1.4 = irisMirrorRole | "Primary", "Backup", or "Async". | STRING
-- .4.1.12.1.5 = irisMirrorStatus | "Active" or "Activate". | STRING
-- .4.1.12.1.6 = irisMirrorJrnLatency | Mirror journal latency "Caught up", "Catchup", or "N/A". | STRING
-- .4.1.12.1.7 = irisMirrorDBLatency | Mirror database latency "Caught up", "Catchup", or "N/A". | STRING
```
## MIRROR的日志和告警
通常情况下, 维护人员是通过mirror的日志和警告来获得Mirror状态,Mirror成员之间的连接情况,而不必须定时的用命令或者调用存储过程来查看。
Cache'和IRIS的日志和警告保存在两个文件: console.log/messages.log和alert.log, 其中alert.log中记录了console.log/messages.log中级别为2,3的记录, 并必须实时发送给管理员。有关这部分内容,请参考在线文档,或者我的帖子:
我们来看看在日志中有哪些mirror的记录:
**Becoming primary mirror server**
系统固有的通知消息, level =2。当一个iris实例从备机变成了主机,此信息会写到此实例的alert.log, 同时发送给管理员。 可以查看这个[链接](https://docs.intersystems.com/iris20231/csp/docbook/DocBook.UI.Page.cls?KEY=GCM_monitor#GCM_monitor_errors)。
在Mirror切换时,管理员除了从刚刚接手的机器中收到Becoming primary mirror server的通知。如果原来的主机没有宕机或者从宕机中恢复,它也会将引起切换的故障从alert.log发送给管理员,是一个level2, 或者level3的记录。
**Arbiter connection lost**
level =2 , 自动发送给管理员。 当主机和arbiter失去连接后,在主机上会出现此警告。此时在备机上会出现“Switched from Arbiter Controlled to Agent Controlled failover on request from primary”的提示,是个level0的信息。
**MirrorServer: Connection to xxxx(backup) terminated**
**MirrorServer: Connection to MIRRORDR (async member) terminated**
当主机和备机(backup)失去连接,在主机上会出现level2的警告。 而和异步成员丢失连接,主机会出现level1的消息。尽管level1的消息不能自动通知管理员,但这时如果同时监控该异步成员的alert.log, 通常会有level2的警告消息发出,能提醒管理员检查MIRRORDR这个镜像成员的状态。
举例说明:如果在MirrorDR中操作系统重启,IRIS启动后会出现这样的level2的警告:“Previous system shutdown was abnormal, ^SHUTDOWN forced down”
**Async member for MirrorSetName started but failed to connect to primary**
level =2 , 自动发送给管理员
其他更多的关于Mirror出错的level2, 也就是警告记录, 比如:
- Could not open mirror journal log to read checksum, errno = 2
- Preserving all mirror journal files for offline failover member
- Server^MIRRORCOMM(d): Failed to notify MIRRORB for mirror configuration change
- Failed to become either Primary or Backup at startup
这不是个完整的列表,实际环境中会出现各种各样的告警通知。读懂这些通知,需要管理员了解镜像的原理,架构,以及上面介绍的镜像状态和进程的功能。
除此之外,绝大多数的level2日志的同时,会有更多的level0,level1的有关mirror变化的记录。这些内容不需要通知管理员,只是用于分析问题。 如图,下面是在一个messages.log里一个iris从备机变成主机的过程。
```
06/13/23-07:16:25:472 (2189) 0 [Generic.Event] MirrorClient: Switched from Arbiter Controlled to Agent Controlled failover on request from primary
06/13/23-07:16:26:274 (2189) 1 [Generic.Event] MirrorClient: Mirror_Client: Primary closed down, last # read = 504
06/13/23-07:16:26:301 (2189) 0 [Generic.Event] MirrorClient: Backup waiting for old Dejournal Reader (pid: 2190, job #31) to exit
06/13/23-07:16:27:394 (2189) 0 [Generic.Event] MirrorClient: Set status for MIRRORTEST to Transition
06/13/23-07:16:28:477 (1996) 0 [Utility.Event] [SYSTEM MONITOR] Mirror status changed. Member type = Failover, Status = Transition
06/13/23-07:16:30:261 (2177) 0 [Utility.Event] Returning to restart, old primary reported: "DOWN
06/13/23-07:16:31:524 (11721) 0 [Utility.Event] Applying journal data for mirror "MIRRORTEST" starting at 1538184 in file #2(/isc/mirrorB/mgr/journal/MIRROR-MIRRORTEST-20230613.001)
06/13/23-07:16:31:804 (2177) 0 [Utility.Event] Manager initialized for MIRRORTEST
06/13/23-07:16:31:986 (2177) 0 [Utility.Event] MIRRORA reports it is DOWN, becoming primary mirror server
06/13/23-07:16:32:381 (2177) 0 [Generic.Event] INTERSYSTEMS IRIS JOURNALING SYSTEM MESSAGE
Journaling switched to: /isc/mirrorB/mgr/journal/MIRROR-MIRRORTEST-20230613.002
06/13/23-07:16:32:426 (2177) 0 [Utility.Event] Scanning /isc/mirrorB/mgr/journal/MIRROR-MIRRORTEST-20230613.001
06/13/23-07:16:32:479 (2177) 0 [Utility.Event] No open transactions to roll back
06/13/23-07:16:32:485 (2177) 0 [Generic.Event] MirrorServer: New primary activating databases which are current as of 1538184 (0x00177888) in mirror journal file #2
06/13/23-07:16:32:488 (2177) 0 [Generic.Event] Changed database /isc/mirrorB/TESTDB/ (SFN 5) to read-write due to becoming primary.
06/13/23-07:16:32:924 (2177) 0 [Utility.Event] Initializing Interoperability during mirror initialization
06/13/23-07:16:32:930 (2177) 2 [Utility.Event] Becoming primary mirror server
```
更多的有关mirror监控和排除的问题, 请各位留言。 谢谢
文章
Michael Lei · 七月 4, 2023
这是个实验项目,使用OpenAI API与FHIR资源和Python相结合来回答医疗行业的用户提问。
## 项目想法
生成式人工智能,如[OpenAI上提供的LLM模型](https://platform.openai.com/docs/models), 已被证明在理解和回答高层次问题方面具有显著能力。他们使用大量的数据来训练他们的模型,因此他们可以回答复杂的问题。
他们甚至可以[使用编程语言,根据提示创建代码](https://platform.openai.com/examples?category=code) --我不得不承认,让我的工作自动化的想法让我感到有些焦虑。但到目前为止,似乎这是人们必须要习惯的事情,不管你喜不喜欢。所以我决定做一些尝试。
这个项目的主要想法是在我读到[这篇文章](https://the-decoder.com/chatgpt-programs-ar-app-using-only-natural-language-chatarkit/)关于[ChatARKit项目](https://github.com/trzy/ChatARKit)时产生的。这个项目使用OpenAI的API来解释语音命令,在智能手机摄像头的实时视频中渲染3D物体--非常酷的项目。而且,这似乎是一个热门话题,因为我发现最近有一篇[论文](https://dl.acm.org/doi/pdf/10.1145/3581791.3597296)遵循类似的想法。
让我最担心的是使用ChatGPT对AR进行**编程。由于有一个开放的github repo,我搜索了一下,发现[作者是如何使用ChatGPT生成代码的](https://github.com/trzy/ChatARKit/blob/master/iOS/ChatARKit/ChatARKit/Engine/ChatGPT.swift)。这种技术被称为*提示工程Prompt Engineering*--[这是维基百科关于它的文章](https://en.wikipedia.org/wiki/Prompt_engineering),或者这两个更实用的参考资料: [1](https://microsoft.github.io/prompt-engineering/)和[2](https://learn.microsoft.com/en-us/azure/cognitive-services/openai/concepts/advanced-prompt-engineering?pivots=programming-language-chat-completions)。
所以我想--为什么不结合FHIR和Python试试类似的东西?以下是我的想法:
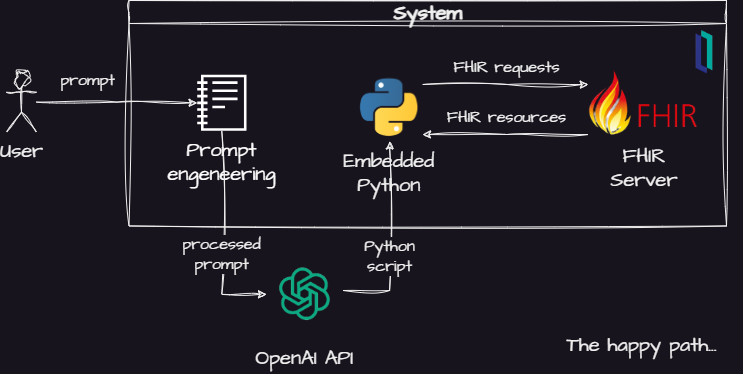
其主要构成是:
- 一个提示工程模块,将命令人工智能模型使用FHIR和Python
- 一个OpenAI API集成模块
- 一个Python解释器,用于执行生成的代码
- 一个FHIR服务器,回答人工智能模型生成的查询
基本思路是使用[OpenAI Completion API](https://platform.openai.com/docs/api-reference/completions),要求人工智能将问题分解为一堆FHIR查询。然后,人工智能模型创建一个Python脚本来处理InterSystems IRIS for Health中FHIR服务器返回的FHIR资源。
如果这个简单的设计是有效的,用户就可以得到应用的分析模型尚未支持的问题的答案。此外,这些由人工智能模型回答的问题可以被分析,以发现对用户需求的新见解。
这种设计的另一个好处是,你不需要用外部的API暴露你的数据和模型。例如,你可以问关于病人的问题,而不需要将病人数据或你的数据库模式发送到人工智能服务器上。由于人工智能模型使用公共可用的功能--FHIR和Python,你也不需要发布内部数据。.
但是,这种设计也导致了一些问题,比如:
- 如何引导人工智能根据用户需求使用FHIR和Python?
- 人工智能模型产生的答案是否正确?是否有可能对它们有信心?
- 如何处理运行外部生成的Python代码的安全问题?
因此,为了尝试解决一下这些问题,我对最初的设计做了一些阐述,得到了这个:
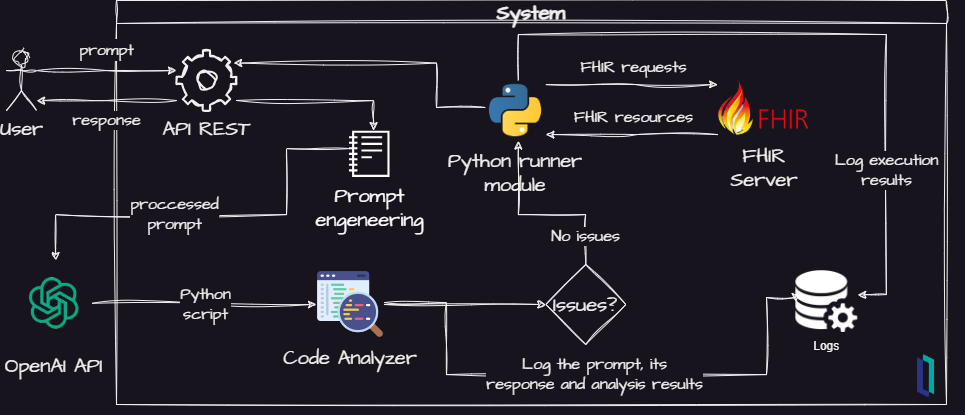
我在项目里增加了一些新的元素:
- 一个代码分析器来扫描安全问题
- 一个日志记录器,用于记录重要事件,以便进行进一步分析
- 一个用于进一步整合的API REST
因此,这个项目旨在验证这个概念,它可以支持实验来收集信息,以尝试回答这些问题。
在接下来的章节中,你会发现如何安装该项目并试用它。
然后,你会看到我在尝试回答上述问题时得到的一些结果和一些结论。
希望你觉得它有用。我们也非常欢迎你为这个项目做出贡献!
## 项目尝试
要试一试,请打开IRIS终端,运行以下内容:
```objectscript
ZN "USER"
Do ##class(fhirgenerativeai.FHIRGenerativeAIService).RunInTerminal("")
```
例如,以下问题被用来测试该项目:
1. 数据集里有多少病人?
2. 病人的平均年龄是多少?
3. 给我所有的条件(代码和名称),去除重复的。将结果以表格的形式呈现出来。(不要使用pandas)
4. 有多少病人患有病毒性鼻窦炎(代码444814009)?
5. 病毒性鼻窦炎(代码444814009)在患者群体中的流行率是多少?对于多次出现相同病情的患者,考虑只打一次就可以计算出来。
6. 在病毒性鼻窦炎(代码444814009)患者中,性别组的分布是怎样的?
你可以找到这些问题的输出例子[这里](https://github.com/jrpereirajr/iris-fhir-generative-ai/blob/master/misc/tests-accuacy)。
> 请注意,如果你在你的系统上尝试,结果可能会有所不同,即使你使用相同的提示。这是由于LLM模型的随机性。
这些问题是由ChatGPT提出的。他们要求这些问题是以复杂程度不断提高的方式来创建的。第3个问题是个例外,它是由作者提出的。
## 提示工程Prompt Engineering
项目使用的提示Prompt可以在方法`GetSystemTemplate()`中找到[这里](https://github.com/jrpereirajr/iris-fhir-generative-ai/blob/master/src/fhirgenerativeai/PromptService.cls)。
它遵循提示工程的指南,首先你给人工智能模型分配一个角色,然后输入一堆限制条件和指令。它的每个部分的意图都有注释,所以你可以理解它是如何工作的。
请注意一种接口定义的使用,当模型被指示假设一个已经定义好的名为`CallFHIR()`的函数与FHIR交互,而不是自己声明一些东西。这是受ChatARKit项目的启发,作者在该项目中定义了一整套函数,为使用AR库抽象出复杂的行为。
在这里,我使用这个技术来避免直接创建代码进行HTTP调用的模式。
这里一个有趣的发现是关于强迫人工智能模型以XML格式返回其响应。由于打算返回的是Python代码,我在XML中使用了CDATA块,将其对称化。
尽管在提示中明确指出响应格式必须是XML格式,但在以XML格式发送用户提示后,AI模型就开始遵循这个指令。你可以在上面提到的同一个类中的`FormatUserPrompt()`方法中看到这一点。
## 代码分析器
该模块使用[bandit库](https://bandit.readthedocs.io/en/latest/)来扫描安全问题。
这个库生成Python程序的AST,并针对常见的安全问题对其进行测试。你可以在这些链接中找到被扫描的问题种类:
- [测试插件](https://bandit.readthedocs.io/en/latest/plugins/index.html#complete-test-plugin-listing)
- [调用黑名单](https://bandit.readthedocs.io/en/latest/blacklists/blacklist_calls.html)
- [导入黑名单](https://bandit.readthedocs.io/en/latest/blacklists/blacklist_imports.html)
由人工智能模型返回的每一个Python代码都会针对这些安全问题进行扫描。如果发现有问题,就会取消执行并记录错误。
## 日志记录器
所有的事件都被记录下来,以便在表[LogTable](https://github.com/jrpereirajr/iris-fhir-generative-ai/blob/master/src/fhirgenerativeai/LogTable.cls)中作进一步分析。
每个回答问题的运行都有一个会话ID。你可以在表中的'SessionID'列中找到它,并通过将它传递给方法`RunInTerminal("", )`来获得所有事件。例如:
```objectscript
Do ##class(fhirgenerativeai.FHIRGenerativeAIService).RunInTerminal("", "asdfghjk12345678")
```
你也可以用这个SQL来检查所有的日志事件:
```sql
SELECT *
FROM fhirgenerativeai.LogTable
order by id desc
```
## 测试
我执行了一些测试以获得信息来衡量人工智能模型的性能。
每个测试执行了15次,它们的输出被存储在[this](https://github.com/jrpereirajr/iris-fhir-generative-ai/blob/master/misc/tests-accuacy)和[this](https://github.com/jrpereirajr/iris-fhir-generative-ai/blob/master/misc/tests-security)的目录下。
> 请注意,如果你在你的系统上尝试,结果可能会有所不同,即使你使用相同的提示。这是由于LLM模型的随机性。
### 准确率
对于问题#1的测试,有`14个结果6`和`1个错误`。正确值是`6'。所以它是`100%`正确的,但有`6%`的执行失败。
验证#1结果的SQL语句:
```sql
SELECT
count(*)
FROM HSFHIR_X0001_S.Patient
```
对于第2题的测试,有`3个结果52`,`6个结果52.5`和`6个错误`。正确的数值--考虑到有小数点的年龄,是`52.5'。所以我认为这两个值都是正确的,因为这一点差异可能是由于提示不明确造成的--它没有提到任何关于允许或不允许带小数的年龄。因此,它是`100%`正确的,但执行失败的是`40%`。
验证#2结果的SQL语句:
```sql
SELECT
birthdate, DATEDIFF(yy,birthdate,current_date), avg(DATEDIFF(yy,birthdate,current_date))
FROM HSFHIR_X0001_S.Patient
```
在第3个问题的测试中,有 "3个错误 "和 "12个有23个不同元素的表格"。表的值不在相同的位置和格式中,但我还是认为这因为错误格式的提示造成的。因此,它是`100%`正确的,但有`20%`的执行失败。
验证#3结果的SQL语句:
```sql
SELECT
code, count(*)
FROM HSFHIR_X0001_S.Condition
group by code
```
对于第4题的测试,有`2个错误`,`12个结果7`和`1个结果4`。正确值是`4'。所以它是`12%`正确的,有执行失败的`13%`。
验证#4结果的SQL语句:
```sql
SELECT
p.Key patient, count(c._id) qtde_conditions, list(c.code) conditions
FROM HSFHIR_X0001_S.Patient p
join HSFHIR_X0001_S.Condition c on c.patient = p.key
where code like '%444814009%'
group by p.Key
```
对于5号问题的测试,有`11个错误`,`3个结果为4`,`1个结果为0.6`。正确值是`4'。所以它的正确率是`75%`,执行失败率是`73%`。
用来验证#5结果的SQL与#4所用的相同。
对于6号问题的测试,有`12个错误`和`3个结果{女性:4,男性:2,其他: 0}`. 正确的值是`{女性:3,男性:1,其他: 0}`. 所以它是`0%`正确的,有执行失败的`80%`。
验证#6结果的SQL语句:
```sql
SELECT
p.gender, count(distinct p._id) qty_patients, list(p.key) patients, list(c.code) conditions
FROM HSFHIR_X0001_S.Patient p
join HSFHIR_X0001_S.Condition c on c.patient = p.key
where code like '%444814009%'
group by p.gender
```
总结一下测试结果:
| 测试编号 # |准确率 | 执行失败率 |
|--------|----------|-------------------|
| 1 | 100% | 6% |
| 2 | 100% | 40% |
| 3 | 100% | 20% |
| 4 | 12% | 13% |
| 5 | 75 % | 73% |
| 6 | 0% | 80% |
### 安全性
你可以在[测试目录](https://github.com/jrpereirajr/iris-fhir-generative-ai/blob/master/misc/tests-accuacy)中检查生成的代码,似乎人工智能模型没有产生安全问题--这也是代码分析器模块发现的结果,没有安全问题。
因此,为了测试代码分析器是否能够检测到安全问题,[执行Python代码的模块](https://github.com/jrpereirajr/iris-fhir-generative-ai/blob/master/src/fhirgenerativeai/PythonService.cls)有一个名为 "代码注入 "的属性,可以注入恶意代码,以便进行测试。
因此,为安全测试注入了以下代码:
1. 安全测试 #1:
```python
print(eval("os.chmod('%s', 0o777)" % 'test.txt'))
```
这段代码试图访问SO文件系统并改变一个文件的权限。这显然是一个不符合项目意图的代码,所以它必须被阻止。
2. 安全测试 #2:
```python
import requests
url = "https://postman-echo.com/get"
params = {"arg": "value"}
response = requests.get(url, params=params)
data = response.json()
print(data)
```
这段代码试图向一个外部地址发出HTTP请求--本例中是Postman API。如果这段代码被执行,本地信息就会被攻击者轻易地获取。
正如你在[安全测试目录](https://github.com/jrpereirajr/iris-fhir-generative-ai/blob/master/misc/tests-security)中所看到的,代码分析器成功地发现了安全问题。
## 结论
就准确性而言,人工智能模型在低复杂度的问题上得到了正确的结果,但随着问题复杂度的增加而开始失败。同样的情况也出现在执行失败上。因此,问题越复杂,人工智能模型产生的代码就越多,无法执行,导致错误结果的概率就越大。
这意味着需要对提示做出一些努力。例如,在[问题#6的代码](https://github.com/jrpereirajr/iris-fhir-generative-ai/blob/master/misc/tests-accuacy/6/1688265739062.txt)中,错误在于只询问病人而忽略了条件。这种分析对于指导提示的改变是必要的。
总的来说,人工智能模型在这次测试中的表现表明,在能够回答分析性问题之前,它仍然需要更多的改进。
这是由于人工智能模型的随机性质。我的意思是,在上面提到的ChatARKit项目中,如果人工智能模型渲染的三维物体并不完全在要求的地方,但接近它,可能用户不会介意。不幸的是,同样的情况并不适用于分析性问题,答案需要精确。
但是,我并不是说人工智能模型不能执行这样的任务。我要说的是,这个项目中使用的设计需要改进。
需要注意的是,这个项目没有使用更先进的技术来使用生成器AI,像[Langchain](https://python.langchain.com/docs/get_started/introduction.html)和[AutoGPT](https://autogpt.net/autogpt-installation-and-features/)。这里使用了一种更 "纯粹 "的方法,但使用这种更复杂的工具可能会导致更好的结果。
关于安全性,代码分析器发现了所有测试的安全问题。
然而,这并不意味着由人工智能模型生成的代码是100%安全的。此外,允许执行外部生成的Python代码可能绝对是危险的。你甚至不能百分之百地确定提供Python代码的系统实际上是OpenAI的API服务器......
避免安全问题的一个更好的方法可能是尝试其他不如Python强大的语言,或者尝试创建你自己的 "语言 "并将其呈现给AI模型,就像在[这个非常简单的例子](https://platform.openai.com/examples/default-text-to-command)。
最后,重要的是要注意,像代码性能这样的方面在这个项目中没有涉及,可能也会成为未来工作的一个好主题。
所以,我希望大家能发现这个项目的有趣和有用。
> **免责声明:这是一个实验性项目。它将向OpenAI API发送数据,并在你的系统上执行由AI生成的代码。所以,不要在生产系统上使用它。还要注意,由于OpenAI的API调用是收费的。使用它的风险由你自己承担。它不是一个可用于生产的项目。**
Hi! Just here to a quick update: now we published a video about this project. Enjoy it: 😊
文章
姚 鑫 · 四月 21, 2021
# 第四章 缓存查询(二)
# 运行时计划选择
运行时计划选择(`RTPC`)是一个配置选项,它允许SQL优化器利用运行时(查询执行时)的离群值信息。运行时计划选择是系统范围的SQL配置选项。
当`RTPC`被激活时,准备查询包括检测查询是否包含具有离群值的字段上的条件。如果`PREPARE`检测到一个或多个异常值字段条件,则不会将查询发送到优化器。相反,SQL会生成一个运行时计划选择存根。在执行时,优化器使用此存根选择要执行的查询计划:忽略离群值状态的标准查询计划,或针对离群值状态进行优化的替代查询计划。如果有多个异常值条件,优化器可以从多个备选运行时查询计划中进行选择。
- 准备查询时,SQL将确定它是否包含离群值字段条件。如果是这样,它将推迟选择查询计划,直到执行查询。在准备时,它创建一条标准SQL语句和(对于动态SQL)相应的缓存查询,但将选择是使用此查询计划还是创建不同的查询计划,直到查询执行。在准备时,它创建看起来像是标准SQL语句的内容,如下所示:`DECLARE QRS CURSOR FOR SELECT Top ? Name,HaveContactInfo FROM Sample.MyTest WHERE HaveContactInfo=?`,用问号表示文字替代变量。但是,如果查看SQL语句详细资料,则查询计划在准备时包含语句“执行可能导致创建不同的计划”,动态SQL查询还会创建看似标准的缓存查询;但是,缓存查询显示计划选项使用`SELECT %NORUNTIME`关键字显示查询文本,表明这是不使用`RTPC`的查询计划。
- 执行查询(在嵌入式SQL中打开)时,SQL将创建第二个SQL语句和相应的缓存查询。SQL语句具有散列生成的名称并生成RTPC存根,如下所示: `DECLARE C CURSOR FOR %NORUNTIME SELECT Top :%CallArgs(1) Name,HaveContactInfo FROM Sample.MyTest WHERE HaveContactInfo=:%CallArgs(2)`.然后,优化器使用它来生成相应的缓存查询。如果优化器确定离群值信息没有提供性能优势,它将创建一个与准备时创建的缓存查询相同的缓存查询,并执行该缓存查询。但是,如果优化器确定使用离群值信息可提供性能优势,则它会创建一个缓存查询,以禁止对缓存查询中的离群值字段进行文字替换。例如,如果`HaveContactInfo`字段是异常值字段(绝大多数记录的值为‘Yes’),查询`SELECT Name,HaveContactInfo FROM t1 WHERE HaveContactInfo=?`将导致缓存查询:`SELECT Name,HaveContactInfo FROM t1 WHERE HaveContactInfo=(('Yes')).`
请注意,`RTPC`查询计划的显示根据SQL代码的源代码而有所不同:
管理门户SQL界面显示计划按钮可能会显示另一个运行时查询计划,因为此显示计划从SQL界面文本框中获取其SQL代码。
选中该SQL语句后,将显示包括查询计划的语句详细资料。此查询计划不显示替代运行时查询计划,而是包含文本“执行可能导致创建不同的计划”,因为它从语句索引中获取其SQL代码。
如果`RTPC`未激活,或者查询不包含适当的离群值字段条件,优化器将创建标准SQL语句和相应的缓存查询。
如果一个`RTPC`存根被冻结,那么所有相关的备用运行时查询计划也会被冻结。
即使关闭了`RTPC`配置选项,对于冻结的查询,`RTPC`处理仍然是活动的。
在写查询时,可以通过指定圆括号来手动抑制文字替换: `SELECT Name,HaveContactInfo FROM t1 WHERE HaveContactInfo=(('Yes'))`.如果在条件中抑制离群值字段的文字替换,则`RTPC`不会应用于查询。
优化器创建一个标准的缓存查询。
## 激活RTPC
可以使用管理门户或类方法在系统范围内配置`RTPC`。
注意,更改`RTPC`配置设置将清除所有缓存的查询。
使用管理门户,根据参数值SQL设置配置系统范围的优化查询。
该选项将运行时计划选择(`RTPC`)优化和作为离群值(`BQO`)优化的偏差查询设置为合适的组合。
选择系统管理、配置、SQL和对象设置、SQL来查看和更改此选项。
可用的选择有:
- 假设查询参数值不是字段离群值(`BQO=OFF`, `RTPC=OFF`,初始默认值)
- 假设查询参数值经常匹配字段离群值(`BQO=ON`, `RTPC=OFF`)
- 在运行时优化实际查询参数值(`BQO=OFF`, `RTPC=ON`)
要确定当前设置,调用`$SYSTEM.SQL.CurrentSettings()`。
`$SYSTEM.SQL.Util.SetOption()`方法可以在系统范围内激活所有进程的`RTPC`,如下所示:`SET status=$SYSTEM.SQL.Util.SetOption("RTPC",flag,.oldval)`。
`flag`参数是一个布尔值,用于设置(1)或取消设置(0)RTPC。
`oldvalue`参数以布尔值的形式返回之前的RTPC设置。
## 应用RTPC
系统对`SELECT`和`CALL`语句应用`RTPC`。
它不应用`RTPC`插入、更新或删除语句。
当在以下查询上下文中指定了一个离群值时,系统将`RTPC`应用于调优表确定的任何字段。
在与文字比较的条件中指定离群值字段。
这个比较条件可以是:
- 使用相等(`=`)、非相等(`!=`)、`IN`或`%INLIST`谓词的`WHERE`子句条件。
- 具有相等(`=`)、非相等(`!=`)、`IN`或`%INLIST`谓词的`ON`子句连接条件。
如果应用了`RTPC`,优化器将在运行时确定是应用标准查询计划还是备选查询计划。
如果查询中包含`unresolved ?`
输入参数。
如果查询指定了用双括号括起来的文字值,则不应用`RTPC`,从而抑制了文字替换。
如果文字是由子查询提供给离群字段条件的,则`RTPC`不会被应用。
但是,如果子查询中存在离群字段条件,则应用`RTPC`。
## Overriding RTPC
通过指定`%NORUNTIME` `restrict`关键字,可以覆盖特定查询的`RTPC`。如果查询`SELECT Name,HaveContactInfo FROM t1 WHERE HaveContactInfo=?` 会导致`RTPC`处理,查询 `SELECT %NORUNTIME Name,HaveContactInfo FROM t1 WHERE HaveContactInfo=?`将覆盖`RTPC`,从而产生一个标准的查询计划。
# 缓存查询结果集
当执行缓存的查询时,它会创建一个结果集。
缓存的查询结果集是一个对象实例。
这意味着为文字替换输入参数指定的值被存储为对象属性。
这些对象属性使用`i%PropName`语法引用。
# List缓存查询
## 计算缓存查询
通过调用`%Library.SQLCatalog类的GetCachedQueryTableCount()`方法,可以确定表的当前缓存查询数。下面的示例显示了这一点:
```java
/// w ##class(PHA.TEST.SQL).CountingCachedQueries()
ClassMethod CountingCachedQueries()
{
SET tbl="Sample.Person"
SET num=##class(%Library.SQLCatalog).GetCachedQueryTableCount(tbl)
IF num=0 {
WRITE "没有缓存的查询 ",tbl
} ELSE {
WRITE tbl," 与以下内容相关联 ",num," 缓存查询"
}
q ""
}
```
```java
DHC-APP>w ##class(PHA.TEST.SQL).CountingCachedQueries()
Sample.Person 与以下内容相关联 2 缓存查询
```
请注意,引用多个表的查询将创建单个缓存查询。但是,这些表中的每一个都单独计算该缓存查询的数量。因此,按表计数的缓存查询数可能大于实际缓存查询数。
## 显示缓存的查询
可以使用IRIS管理门户查看(和管理)查询缓存的内容。从系统资源管理器中,选择SQL。使用页面顶部的切换选项选择一个命名空间;这将显示可用命名空间的列表。在屏幕左侧打开`Cached Queries`文件夹。选择其中一个缓存查询将显示详细信息。
查询类型可以是下列值之一:
- `%SQL.Statement Dynamic SQL`:使用`%SQL.Statement`的动态SQL查询。
- `Embedded cached SQL` :嵌入式缓存SQL
- `ODBC/JDBC Statement`:来自ODBC或JDBC的动态查询。
成功准备SQL语句后,系统会生成一个实现该语句的新类。如果已经设置了Retention Cached Query Source-System-wide配置选项,那么这个生成的类的源代码将被保留,并且可以使用Studio打开以供检查。要执行此操作,请转到IRIS管理门户。从系统管理中,依次选择配置、SQL和对象设置、SQL。在此屏幕上,可以设置保留缓存的查询源选项。如果未设置此选项(默认设置),系统将生成并部署类,并且不保存源代码。
也可以使用`$SYSTEM.SQL.Util.SetOption()`方法设置这个系统范围的选项,如下所示:`SET status=$SYSTEM.SQL.Util.SetOption("CachedQuerySaveSource",flag,.oldval)`。`Flag`参数是一个布尔值,用于在编译缓存查询后保留(1)或不保留(0)查询源代码;默认值为0。要确定当前设置,请调用`$SYSTEM.SQL.CurrentSettings()`。
## 使用^rINDEXSQL列出缓存查询
```java
ZWRITE ^rINDEXSQL("sqlidx",2)
```
此列表中的典型全局变量如下所示:
```java
^rINDEXSQL("sqlidx",2,"%sqlcq.USER.cls4.1","oRuYrsuQDz72Q6dBJHa8QtWT/rQ=")="".
```
第三个下标是位置。例如,`"%sqlcq.USER.cls4.1"`是用户名称空间中的缓存查询;`"Sample.MyTable.1"`是一条SQL语句。第四个下标是语句散列。
## 将缓存查询导出到文件
以下实用程序将当前名称空间的所有缓存查询列出到文本文件中。
```java
ExportSQL^%qarDDLExport(file,fileOpenParam,eos,cachedQueries,classQueries,classMethods,routines,display)
```
- `file` 要列出缓存查询的文件路径名。指定为带引号的字符串。如果该文件不存在,系统将创建该文件。如果该文件已存在,则InterSystems IRIS会覆盖该文件。
- `fileOpenParam` 可选-文件的打开模式参数。指定为带引号的字符串。默认值为`“WNS”`。`“W”`指定正在打开文件以进行写入。`“N”`指定如果该文件不存在,则使用此名称创建一个新的顺序文件。`“S”`指定以回车符、换行符或换页符作为默认终止符的流格式。
- `eos` 可选-用于分隔清单中各个缓存查询的语句结尾分隔符。指定为带引号的字符串。默认值为`“GO”`。
- `cachedQueries` 可选—从查询缓存导出所有SQL查询到文件。一个布尔标志。默认值为1。
- `classQueries` 可选-从SQL类查询导出所有SQL查询到文件。一个布尔标志。默认值为1。
- `classMethods` 可选-从类方法导出嵌入式SQL查询到文件。一个布尔标志。默认值为1。
- `routines` 可选-从MAC例程导出嵌入式SQL查询到文件。这个清单不包括系统例程、缓存查询或生成的例程。一个布尔标志。默认值为1。
- `display` 可选-在终端屏幕上显示导出进度。一个布尔标志。默认值为0。
下面是一个调用这个缓存查询导出工具的示例:
```java
DO ExportSQL^%qarDDLExport("C:\temp\test\qcache.txt","WNS","GO",1,1,1,1,1)
```
当在终端命令行中执行`display=1`时,导出进度显示在终端屏幕上,示例如下:
```sql
Export SQL Text for Cached Query: %sqlcq.USER.cls14.. Done
Export SQL Text for Cached Query: %sqlcq.USER.cls16.. Done
Export SQL Text for Cached Query: %sqlcq.USER.cls17.. Done
Export SQL Text for Cached Query: %sqlcq.USER.cls18.. Done
Export SQL Text for Cached Query: %sqlcq.USER.cls19.. Done
Export SQL statement for Class Query: Cinema.Film.TopCategory... Done
Export SQL statement for Class Query: Cinema.Film.TopFilms... Done
Export SQL statement for Class Query: Cinema.FilmCategory.CategoryName...Done
Export SQL statement for Class Query: Cinema.Show.ShowTimes... Done
20 SQL statements exported to script file C:\temp\test\qcache.txt
```
创建的导出文件包含如下条目:
```sql
-- SQL statement from Cached Query %sqlcq.USER.cls30
SELECT TOP ? Name , Home_State , Age , AVG ( Age ) AS AvgAge FROM Sample . Person ORDER BY Home_State
GO
```
```
-- SQL statement from Class Query Cinema.Film.TopCategory
#import Cinema
SELECT TOP 3 ID, Description, Length, Rating, Title, Category->CategoryName
FROM Film
WHERE (PlayingNow = 1) AND (Category = :P1)
ORDER BY TicketsSold DESC
GO
```
```
-- SQL statement(s) from Class Method Aviation.EventCube.Fact.%Count
#import Aviation.EventCube
SELECT COUNT(*) INTO :tCount FROM Aviation_EventCube.Fact
GO
```
这个缓存的查询列表可以用作查询优化计划实用程序的输入。
# 执行缓存查询
- 从动态SQL:`%SQL.Statement`准备操作(`%PrepareClassQuery()`或`%ExecDirect()`)创建缓存查询。使用同一实例的动态`SQL%Execute()`方法执行最近准备的缓存查询。
- 从终端:可以使用`$SYSTEM.SQL`类的`ExecuteCachedQuery()`方法直接执行缓存查询。此方法允许指定输入参数值并限制要输出的行数。可以从终端命令行执行动态SQL`%SQL.Statement`缓存查询或xDBC缓存查询。此方法主要用于测试有限数据子集上的现有缓存查询。
- 在管理门户SQL界面中:按照上面的“显示缓存的查询”说明进行操作。从所选缓存查询的目录详细资料选项卡中,单击执行链接。
# 缓存查询锁
在更新缓存的查询元数据时,发出`PREPARE`或`PURCESS`语句会自动请求独占的系统范围锁。SQL支持`$SYSTEM.SQL.Util.SetOption()`方法的系统范围`CachedQueryLockTimeout`选项。此选项控制在尝试获取对缓存查询元数据的锁定时的锁定超时。默认值为120秒。这比标准的SQL锁定超时(默认为10秒)要长得多。系统管理员可能需要在具有大量并发准备和清除操作的系统上修改此缓存查询锁定超时,尤其是在执行涉及大量(数千)缓存查询的批量清除的系统上。
`SET status=$SYSTEM.SQL.Util.SetOption("CachedQueryLockTimeout",seconds,.oldval)`方法设置系统范围的超时值:
```java
SetCQTimeout
SET status=$SYSTEM.SQL.Util.SetOption("CachedQueryLockTimeout",150,.oldval)
WRITE oldval," initial value cached query seconds",!!
SetCQTimeoutAgain
SET status=$SYSTEM.SQL.Util.SetOption("CachedQueryLockTimeout",180,.oldval2)
WRITE oldval2," prior value cached query seconds",!!
ResetCQTimeoutToDefault
SET status=$SYSTEM.SQL.Util.SetOption("CachedQueryLockTimeout",oldval,.oldval3)
```
`CachedQueryLockTimeout`设置系统范围内所有新进程的缓存查询锁定超时。它不会更改现有进程的缓存查询锁定超时。
# 清除缓存的查询
每当修改(更改或删除)表定义时,基于该表的任何查询都会自动从本地系统上的查询缓存中清除。如果重新编译持久类,则使用该类的任何查询都会自动从本地系统上的查询缓存中清除。
可以使用清除缓存查询选项之一通过管理门户显式清除缓存查询。可以使用SQL命令`PURGE Cached Queries`显式清除缓存查询。可以使用SQL Shell清除命令显式清除缓存查询。
可以使用`$SYSTEM.SQL.Push(N)`方法显式清除最近未使用的缓存查询。指定`n`天数将清除当前命名空间中在过去n天内未使用(准备)的所有缓存查询。将`n`值指定为`0`或`“”`将清除当前命名空间中的所有缓存查询。例如,如果在2018年5月11日发出`$SYSTEM.SQL.Push(30)`方法,则它将仅清除在2018年4月11日之前最后准备的缓存查询。不会清除恰好在30天前(在本例中为4月11日)上次准备的缓存查询。
还可以使用以下方法清除缓存的查询:
- `$SYSTEM.SQL.PurgeCQClass()`按名称清除当前命名空间中的一个或多个缓存查询。可以将缓存的查询名称指定为逗号分隔的列表。缓存查询名称区分大小写;命名空间名称必须以全大写字母指定。指定的缓存查询名称或缓存查询名称列表必须用引号引起来。
- `$SYSTEM.SQL.PurgeForTable()`清除当前命名空间中引用指定表的所有缓存查询。架构和表名称不区分大小写。
- `$SYSTEM.SQL.PurgeAllNamespaces()`清除当前系统上所有名称空间中的所有缓存查询。请注意,删除命名空间时,不会清除与其关联的缓存查询。执行`PurgeAllNamespaces()`检查是否有任何与不再存在的名称空间相关联的缓存查询;如果有,则清除这些缓存查询。
要清除当前命名空间中的所有缓存查询,请使用管理门户清除此命名空间的所有查询选项。
清除缓存的查询还会清除相关的查询性能统计信息。
清除缓存的查询还会清除相关的SQL语句列表条目。管理门户中列出的SQL语句可能不会立即清除,可能需要按清除陈旧按钮才能从SQL语句列表中清除这些条目。
**注意:当您更改系统范围的默认架构名称时,系统会自动清除系统上所有名称空间中的所有缓存查询。**
## 远程系统
在本地系统上清除缓存的查询不会清除该缓存查询在镜像系统上的副本。
必须手动清除远程系统上已清除的缓存查询的副本。
当修改和重新编译持久性类时,基于该类的本地缓存查询将被自动清除。
IRIS不会自动清除远程系统上缓存的查询的副本。
这可能意味着远程系统上缓存的一些查询是“过时的”(不再有效)。
但是,当远程系统尝试使用缓存的查询时,远程系统会检查查询引用的任何持久类是否已重新编译。
如果重新编译了本地系统上的持久化类,则远程系统在尝试使用它之前会自动清除并重新创建过时的缓存查询。
# 没有缓存的SQL命令
以下非查询SQL命令不会缓存;它们在使用后会立即清除:
- 数据定义语言(DDL):`CREATE TABLE`, `ALTER TABLE`, `DROP TABLE`, `CREATE VIEW`, `ALTER VIEW`, `DROP VIEW`, `CREATE INDEX`, `DROP INDEX`, `CREATE FUNCTION`, `CREATE METHOD`, `CREATE PROCEDURE`, `CREATE QUERY`, `DROP FUNCTION`, `DROP METHOD`, `DROP PROCEDURE`, `DROP QUERY`, `CREATE TRIGGER`, `DROP TRIGGER`, `CREATE DATABASE`, `USE DATABASE`, `DROP DATABASE`
- 用户、角色和权限:`CREATE USER`, `ALTER USER`, `DROP USER`, `CREATE ROLE`, `DROP ROLE`, `GRANT`, `REVOKE`, `%CHECKPRIV`
- 锁 :`LOCK TABLE`, `UNLOCK TABLE`
- 其他: `SAVEPOINT`, `SET OPTION`
请注意,如果从管理门户执行查询界面发出这些SQL命令之一,性能信息将包括如下文本:缓存查询:`%sqlcq.USER.cls16`。这将显示在中,表示已分配缓存的查询名称。但是,此缓存查询名称不是链接。未创建缓存查询,并且未保留增量缓存查询编号`.cls16`。 SQL将此缓存的查询号分配给下一个发出的SQL命令。
文章
Claire Zheng · 七月 14, 2022
2022年7月1日,由国家卫生健康委医院管理研究所指导、《中国数字医学》杂志社有限公司主办、《中国数字医学》杂志社陕西通联站协办、东华医为科技有限公司与InterSystems中国支持的“医院数字化转型研讨会”在西安召开。以下为中南大学湘雅医院网络信息中心主任冯嵩在此次论坛上的分享。
大家好,今天非常有幸参加这次“医院数字化转型研讨会”,借此机会向大家汇报一下湘雅医院业财融合运营一体化平台的建设情况,包括建设思路和我们的建设的具体落地实施情况。我主要从建设的背景、建设思路和建设落地情况三个方面与大家分享。
01 建设背景
1.1 两个趋势
医院信息化发展给医院建设带来了巨大变革,从传统信息化时代跨越到数据化时代,医院信息化建设已不再仅局限于医院的内部,而通过互联网不断向外部去延伸,不仅连接医院的用户,同时也在不断连接企业、政府等,基于互联网建立各种连接,已经成为了一个趋势。
另外一个趋势就是平台化趋势,基于平台化的统一数据建设的基础服务能力,运用可配置的弹性的、动态的配置方案来实现个性化的管理,平台化已经成为了信息化建设的一种趋势。
1.2 政策指导
数字化转型,实际上是以数据为核心、构建数字化管理服务体系,是一个不断打破数据孤岛的过程。医院通过建设数据平台和集成平台,将分散在不同系统的数据资源整合起来,形成数据资源、数据资产,通过统一的数据资源来支撑医院的精细化管理,加快整个医院智慧化的建设。目前,医院的信息化建设也在不断地从临床走向全面信息化建设,我们通过整合各类运营管理的资源,建设统一标准的数据服务体系,实现对数据的统一管理,形成了统一的运营数据平台,为医院的运营和管理提供数据支持,打造精细化管理亮点,并运用一系列新技术,建设智慧医院。
近年来,国家从政策方面不断提倡“深化体制改革、加强运营管理”,特别是在2020年的《关于加强公立医院运行管理的指导意见》中提出,医院要以资源配置、流程再造、绩效考核为导向,建立全面的运营管理体系。这个体系就要求医院建立全面的、统一管理的信息体系,在这个基础上形成考核支撑和决策支撑。
1.3 医院运营管理需求及存在的问题
根据国家卫健委最新政策要求,公立医院运营管理需要推进“数据+财务+业务”的融合,提出了对业财融合一体化运营体系的构建需求。
在这个体系中,要将医院预算管理、会计、成本等和业务流程融合在一起,实现运营过程中的风险管控,提高运营效率和运营过程的可计划性,严格按照预算去推进落实医院的各项工作。因此需要建立运营数据中心,包括运营数据中心、运营管理系统、运营数据仓库、决策分析平台。
医院内部实际上存在很多数据的问题,首当其冲的是数据不准确问题。主要体现在以下几点。
第一,数据统计口径没有根据用途统一,形成标准。有些数据是用于上报;有些是用于院内质控;有些是用于成本统计;有些是用于绩效与奖金。用途不同,口径与计算方法、统计源头都会不同。
第二,信息化建设不完整和不同建设时期厂家对医院数据定义的混乱。比如HIS数据、病案数据、HRP(人财物管理系统)数据之间的冲突,数据覆盖不足与数据统计口径的模糊状态下,医院职能科室只能通过多年磨合以半自动半手工方式纠偏完成数据清洗。
第三,数据团队对医院日常管理的需求无法深入。团队缺乏数据对接,清洗,标化能力,对HIS、EMR、HRP等系统的前端业务缺乏深刻理解,缺乏从数据到系统,再到与医院高层管理意图贯通理解的能力。
运营管理系统面临的第二个大问题是“决策无模型”。现在很多医院都成立了运营管理部门,除负责绩效核算以外,职能还包括组织推动各项运营管理措施任务有效落实;组织开展运营效果分析评价,撰写运营效果分析报告。医院的管理非常复杂与多样,从开始的追求规模化赢利,逐渐转变为现在的精准化赢利模式的变革,会涉及大量的量化管理模型。不同医院在不同的发展阶段侧重点会不同,没有一个管理模型可以一直适用。例如,领导想了解手术患者预约为什么已经排到半年后,能够从这个数据中发现我们这是个瓶颈在哪里?这就需要有一个决策模型。
02 运营数据管理平台建设思路
针对上述问题,我们医院启动了整体搭建运营数据管理系统的建设,形成了一套完整方案,整体规划搭建医院运营数据架构,然后强化运营数据的主数据管理,建立数据中台,基于中台融合业务流程,包括数据分析和挖掘的应用场景。
首先,我们对整个平台体系进行了整体设计。我们做了一个分层数据架构,建立了数据的基础,我们叫做数据的治理层,主要完成数据的业务标准、模型标准、主数据标准和元数据的相关的管理。
第二,在这个基础上,我们建立数据的加工层,主要是完成数据的采集、汇聚、加工,包括建立完整的数据质控体系。
第三,最上面就是我们的数据应用层,我们针对医院的运营管理、协同服务、职能服务、医疗保障、行政后勤供应等体系提供数据相关的支撑服务。
2.1 强化主数据管理
在建设过程中,我们要求要有统一的标准、统一的来源、统一的接口,去完成相关的数据的支撑。首先就是强化主数据管理,因为医院的主数据肯定不只涉及我们运营部门,主数据应该是全院一盘棋,实现统一标准、统一来源、统一接口、统一服务。
这些统一的接口不仅仅可服务于我们的运营管理系统,还可以服务于临床系统和各类对外服务应用,这样就保证了我们整个基础数据的统一,也便于后续整个数据的共享共用,在强化主数据管理的基础上,我们更进一步把主数据进行了细分管理。
我们将主数据分为人事、财务、物资、项目、合同管理业务等等10个类进行标准制定。在制定标准的过程中,我们也发现有些数据是没有标准的。比如组织主数据,人力资源管理架构中组织单元、财务会计核算组织、成本管理中心、预算管理组织没有建立对应关系,带来了大量的手工数据提取、归集、拆分的工作,影响多个部门工作效率,数据支撑作用弱,决策成本高,后续的分析统计是无从下手。所以我们把整个组织架构进行重新梳理,重新做好相关的映射关系,保证了组织架构能够在运营体系中得到很好的适配和应用。
我们也制定了主数据管理规范,一是建立主数据管理组织架构,哪些人和对组织对数据负责,相应的管理部门是什么?管理岗位是什么?数据审核应该谁来完成?等等。第二是在整个业务流程中强化对数据标准的执行和管理,包括数据的事前、事中、事后的整个管理。
同时,我们制定了很多相关的管理制度,包括《主数据管理办法》《主数据标准规范》《主数据提案指南》《主数据维护细则》《主数据管理工具操作手册》等等,以制度手段确保主数据管理的规范和一致性。
2.2 规划好数据中台,实现数据的业务化
我们通过这些数据的汇集,从分散的数据系统里面,形成统一的运营数据平台。
业务数据方面,各部门以前都是各自建系统,数据分散在不同的系统里,这一次我们在建设的过程中,把该停的系统停掉,该统一的标准统一起来,保证数据在标准基础上实现了整合,保证了数据一致性,这样才能为事后数据分析和决策提供好数据基础。
数据中台在建设过程中一定要打破部门之间的壁垒,要用业务流程去串联各个部门,那么最后整个的数据的使用模式就会发生变化——以前是我们有什么数据就只能做什么事,各系统的数据基本上是只能够沿着该系统业务范围内去做相关的分析。而通过统一的数据管理以后,我们是根据管理需求拿数据——就这样,我们逐步实现了数据的业务化。
我们建立了统一的数据中心,数据不仅来源于院内的临床系统,还包括财务系统、HRP、SPD、供应商平台(如设备编码、材料编码等)、公共数据、社会数据(发票验真、银联号)等,通过多种方式完成数据汇聚后,将收集起来的数据通过分类形成数据标签,建立数据安全策略,同时结合数据质控确保数据质量,这样就形成了建立统一服务平台的基础。
2.3 规范数据分析流程
传统的数据分析流程是我们根据各个临床的需求收集数据,现在则转变为在系统建设初期,我们充分了解领导的决策需求,根据需求建立决策模型,然后根据模型进行数据汇集,继而形成我们的数据的采集方式和相关的数据分析体系。
在整个数据挖掘的过程中,我们首先要满足管理层决策需求,挖掘管理决策的痛点,通过数据归一化和结构化统一数据标准,把数据能够更好地应用于管理决策的分析体系。
3 业财一体化系统的实践和落地
3.1 三阶段实施建设业财一体化系统
首先我们把业财一体化系统的实施规划分成三个阶段。
第一阶段是财务信息化阶段,这个阶段我们建立起一些基本的财务系统,实施完成后,实现了费用核算域和项目经费域业务全程信息化,为下一步实现财务智能化打下坚实的基础。
第二阶段是以整体的财务的信息化建设为依据,推动全面实现财务智能化,实施完成后,实现医院全业务流程信息化,保证医院支出全流程可控、可视、可查。实现医院收入稽核准确高效。
第三阶段我们进行了财务的数字化建设,实施完以后,实现医院业务数据和财务数据汇集、沉淀。实现医院数据价值开发,为领导决策、医院数字化发展提供基础。
在这个过程中其实牵涉到很多系统,保证不同的厂商、不同的系统的统一。首先是定义了统一标准的接口,收集了相关系统数据和功能,制定了系统之间的数据流、业务流程,形成了一套完整的规范。其次,在此基础上,建立了系统接口的规范,针对HIS系统制定了至少8个接口标准,包括医保对HIS接口,HIS对医保的接口,HIS对营收的接口,HIS对智能报账的接口等等,我们在这个基础上制定结构,打通的 OA审批。最后,我们统一门户登录后,能够完成医院所有运营管理工作。
第二,梳理业务流程。比如传统的报账流程是人工初审、线下报账和预算管理,我们通过统一梳理,实现了标准化的线上报账,申报后,通过系统和税务系统对接,对发票进行真伪查验,从而完成整个报账过程。
再如采购系统,我们实现了采购一体化,实现了从采购申请、预算审批的整个完整流程的一体化,在这个过程中我们要打通不同系统,通过信息匹配来完成整个发票和相关证明材料的匹配。此外我们开放了网上的各项的应用来提升我们的效率,包括自主采购,比如医院采购部门可以我们通过我们的网上商城去提出需求,通过审批,然后形成整个的网络的一体化的采购。
医院在预算、绩效、成本方面是一体化建设,基于运营数据,我们以“三位一体”的理念打造整个财务的体系,从而实现了全面预算的管理:首先,实现了三级预算的组织,实现了从医院科室到专科的全业务预算。其次,通过医院的长期规划制定专项的预算,形成预算的跟踪分析报告;第三,针对预算建立了预算模型,从医院的战略出发,制定基本预算和科研预算的分类,不同预算在使用过程中都进行了预算管控。
在成本部分,我们通过建立统一的成本的决策知识模型,建立了成本的统一管理。
3.2 管理决策支持体系
所有的信息最后汇聚到我们运营数据中心,在数据基础上建立了管理决策的支持体系。
首先建立了指标库和知识库,在应用的时候,只要业务部门有什么需求,我们会把这些指标库进行组合,形成相关的管理主题,提供给业务部门做相关的支撑。
此外,建立了管理决策的支持模型,管理层可以通过统一的决策支持平台看到医院的运行状态,包括医院每天的运营报表、科室层面的收入工作量、人员结构、患者特征疾病等等基本情况分析,个体层面的医生的收入、人事和工作量排名,考评层面的核心医生考评体系、科室等等,我们还对学科建立了分析主题,包括学科人员结构、学历支撑、认知等等这些结合起来,进行了统一分析决策,能够通过这个平台比较分析去科室优势和现有不足。在运营方面,对医院患者的转化率可以进行统一的分析,帮助医院寻找“堵点”。
面向未来,医院运营管理会更加精细化。管理从“终末管理”转为“环节管理”,从“事后提醒”转为“即时反馈”,从“事务孤岛”转为“互通关联”,从“经验管理”转为“标准管理”。随着医院运营体系不断建设完善,信息化的运营体系将为医院管理决策发挥更大价值。谢谢大家!
文章
Michael Lei · 七月 1, 2022
各位领导、老师大家好。非常荣幸有机会参加这次由中国数字医学杂志社组织的陕西省医院数字化转型研讨会。
IT这个行业很有意思,就是大家都很喜欢造词。这几年有一个词特别火,叫做数智化底座,很多厂商都先后推出了自己的数智化底座解决方案。结合最近对整个行业的一些观察,今天借这个机会,跟各位领导和老师探讨一下,医疗行业的数字化有什么特点,到底什么样的底座或者平台比较符合我们医疗行业,以及我们在建设数智化底座的时候需要考虑哪些问题。结合我们最近的一些观察和思考,有不当之处,欢迎各位老师批评、指正。
首先一点就是我们做任何工作,首先要解决“为什么”的问题?第一个核心思路,我想数字化转型是为智慧医院服务的,归根结底,还是要通过数字化的手段,来实现医院的高质量发展。针对这一目标,国家卫健委制定了智慧医院发展的三大目标,就是智慧医疗、智慧管理和智慧服务,我想说白了,无非就是让医院、医护人员以及我们的患者过的更好,提高我们治疗和护理水平、降本增效,同时能够让我们的患者得到更好的服务。所有的数字化建设,不管是平台还是应用,都应该围绕这一核心目标。
第二个核心思路,我们认为软件要为人服务。所谓的数字化转型,就是用软件来开展一切可以开展的业务,而软件是为人服务的,目的是提高我们的工作效率、认知水平和实现我们仅仅靠人力做不了的事情。比如智慧医来讲, 我们比较熟悉的是我们的HIS、电子病历、临床系统等等,这类系统主要的用户/使用者是我们的临床医护人员,主要的目的一方面是提高医护人员的工作效率,同时也是为了让医疗数据能够得以电子化的形式来永久保存,为支持临床数据的共享、交换、科研、监管等需求提供了数据来源。
而智慧管理的应用,更多是如何帮助医院,不管是院长还是科室主任等VIP客户了解自己的经营数据,以及根据这些数据来制定相关的管理决策,从而能够有效地控制成本和提高医院收入。
第三,目前我国医院数字化进程中亟需加强的,就是智慧服务。随着时代的发展,过去很长一段时间里支撑我们公立医院发展的几个核心要素,无论是大型医疗设备、医护人员数量、手术床位还是药品耗材物资,随着公立医院绩效考核、分级诊疗、医保政策、疫情等多种时代原因的综合作用,这些要素能够给医院带来的边际收入会逐渐递减,未来医院的收入增长,一定是通过数据要素驱动和数字化的手段,将医院服务从院内延展到院外,延展到患者的全生命周期的健康管理,以及随之带来的各种增值服务收入。这种服务一定是数字化的,更多是通过类似我们现在经常使用的手机APP来交付和实现的。
第三个核心思路,我们认为底座是服务应用的,应该根据我们的数字化应用的类型,来决定我们需要什么样的底座,而不是为了配合底座来取改变应用。现在行业内普遍有一种“唯技术化”、“赶时髦”的误区,不管做什么样的应用、实现何种业务,都说要云原生、微服务、分布式,怎么时髦怎么来。但是我们认为,底座或者是基础软件是服务于应用的,如果底座不能适应应用,或者说费了很大的力气改造底座而应用却没有改善,则是本末倒置,舍本逐末。举个不恰当的例子,就像我们做饭一样,如果家里只有3-4口人,有一口普通的锅、炉子就够用了,没有必要非要去整一口给100人做饭的锅和炉子,或者非要整100口小锅,小炉子,还是同样做3-4个人的饭,还是同样做那一碗羊肉泡馍。同样道理,如果是同一类型、同样功能的应用软件,如果只有500个人用,有个能支撑1000人用的底座就够了,非要搞个给10万人用的底座,不仅意义不大,而且浪费有限的投资。
那下面我们就来具体看看三类应用的特点,以及他们各自对底座有什么要求。
比如智慧医疗类的应用,主要面向医护人员,以数据的录入、增删改为主,这类系统的业务量,比如说每天的门诊量、检查量、手术量相对是比较稳定的,那么对于平台来讲,我们更多的需要是安全、稳定、高可用、性能等这些特性,SLA要求非常高、不能宕机或者随意的停机;
对智慧管理来讲,这一类主要是分析型的应用,这就不仅需要平台支持海量的数据存储与管理,也能支持医院或者厂商满足院长或者管理层的很多不管是常规还是临时性的数据分析类需求,比如说院长今天想看一个之前新的分析指标,或者监管部门临时增加了一些上报的指标,是否能够很快速的在智慧管理的应用里实现出来,这些都是平台或者底座需要具备的能力;
智慧服务类的应用,这类业务主要面向患者,这些都是比较典型的互联网化的业务,通过手机app、小程序等来交付和实现,业务量变化弹性很大,也要随时快速推出各种不同的创新业务,这时候对平台的要求就是要支持云原生、弹性扩展、容器化、快速集成、快速交付等等特性;
上面是从技术视角来看我们医院数字化转型需要什么样的平台支撑。下面从管理视角来看一下医院数字化的现状,以及针对这些现状我们在建设数智平台时建议采取的应对策略和思路。我们观察到整个医疗行业数字化有以下六个主要特点。
特点与思路一 医疗行业是个强监管的行业
医疗行业有着非常严谨和严格的行业标准和监管要求,以及大量的、数据共享交换的需求,这一点是任何其他行业所不具备的,因此,我们在建设数智底座时一定要考虑平台本身需要满足医疗的这些行业标准和要求,比如我们比较熟悉的互联互通、电子病历、HL7、IHE等等,这些都是最基本的要求。
特点与思路二 医疗行业是业务最复杂的行业,没有之一
我们说没有哪个行业的业务有医疗行业这样高的复杂程度。医院从来都不是一个单一业务,不管是大型综合医院,还是专科医院,基本都是一个科室一种业务,现在我们讲的单病种,或者DRGs,就变成了一个病种一种业务,还有很多复杂病、罕见病是一个病多个业务模式或者混合模式,比如说MDT等等;针对这种情况,我们说IT的技术其实很好掌握,不管是编程还是数据库,但是对医疗业务,尤其是电子病历的理解与认识,没有个10几20年的经验是没有办法沉淀下来的。因此,IT工程师好找,而医疗行业行业经验和业务专家不好找。因此医院在建设数智平台时,还是应该选择对医疗行业有长期积淀和丰富经验的合作伙伴,并且尽可能地向国内外顶级医院学习他们的成功经验,而不是仅仅从IT的能力来选择合作伙伴和底座;
电子病历数据模型示意图
特点与思路三 医疗数据利用水平亟待提高
尽管有不少医院都花了不少钱建设了数据中心、CDR、ODS等等系统,但是不管临床还是科研部门,对医疗数据利用需求与我们的系统或者平台支持的差距还非常大;比如说,医院最重要的数据资产之一,就是大量的患者的病历文档、检验检查、就诊记录等等,比如CDA,但是CDA文档比较大也比较重,很难进行深度利用,如何从整体样本中发现规律,如何进行科学分组,指导临床治疗方案等等,这些都是比较难实现的,我们最近就在尝试利用国际上已经比较成熟,但是国内还刚刚起步的HL7 FHIR 标准来做CDA文档的转化和解构,将CDA文档转化为更好利用的FHIR资源,来支持医院做更多的创新性数据应用。FHIR是英文快速医疗互操作资源的翻译,把CDA转换成FHIR之后,我们就可以把难以利用的文档数据转化为临床、科研、患者都可以轻松利用的结构化数据,从中发现疾病和患者规律,开展真实世界研究或者指导临床开展“精准医疗”或者类似网络购物体验的临床医疗方案推荐等等,帮助医院真正盘活数据资源,把资源变成资产,有效服务与临床、科研等业务需求。
特点与思路四 信息部门人员配置不足vs纷繁复杂的技术栈--少就是多
从整个医疗信息化行业来看,信息部门的人员配置是远远不足的,从医院的信息科到我们的服务厂商,从主任到项目经理,到厂商的研发、实施技术人员,整个医疗信息化行业的从业人员工作负载基本都处在一个饱和甚至过饱和的状态,针对这种情况,在医院数字化平台的技术选择上,我们应该采取“少就是多”的策略,选择尽可能少的技术和产品种类,或者说一体化的技术架构,用一套技术体系来支持多种业务应用的实现,从而降低管理和学习成本。
另外希望跟大家讨论的一个问题,就是在金融、零售、互联网行业十分普遍的基于开源架构的数据中台是否适合医疗行业?无可否认的是,开源技术的兴起为整个IT行业、包括传统行业带来了前所未有的繁荣和创新,但是同时开源软件也有发展过快、技术路线分散等特点,比如全球现在有超过100万个开源社区,每个社区都有自己的粉丝和市场,那么作为医院的信息部门和信息化行业的厂商应该如何选择?今天选择的技术会不会很快就过时了,技术支持如何延续?更不要说开源软件学习成本和人员成本都很高,以及这些技术如何能够在医院成功落地,实际的案例效果和投入产出如何,这些都是我们作为从业者需要考虑的显示问题。
互联网基于开源技术的数据中台真的适合医疗行业吗?
特点与思路五 有限的数字化资金预算vs高额投入的需求--集中优势兵力,逐个消灭敌人
伴随着人员投入的另外一个问题,是我们的资金投入问题,今天正好是建党101年的大喜的日子。1946年9月16日,毛主席在距离咱们西安300多公里的延安写下了《集中优势兵力、逐个消灭敌人》的重要文章,为我们全党全军最终迅速战胜敌人指明了方针和原则。如果把兵力比喻成我们的信息化投入,把敌人比喻成我们要解决的业务问题的话,我觉得这个方针同样适用。
过去由于历史原因,在每年或者总投入有限的情况下,很多医院采用撒胡椒面的方式,经过多年的积累,建设了很多单价不高的系统,少则几十个,多则上百个;面对几十个厂家,1百多个系统,如果算下总账,不仅建设成本没少花,而且集成、运维、沟通等管理成本也都非常高,效果也不尽如人意。因此,越是在整体预算有限的情况下,我们越是可能需要学习毛主席的策略,把有限的子弹和资金,相对集中地进行投资,来满足尽可能多的数字化需求,也许是能够让我们医院信息化迅速提高到一个新的台阶的更有效的策略。我们也欣喜地观察到,越来越多的医院意识到这一点,开始把有限的预算进行相对集中,通过一个规模大一点的项目来尽可能地解决更多的问题,很多厂商也开始推所谓的一体化平台,也是这种思路。
特点与思路六 医院数字化--无止境的旅程/没有终点的长跑
最后一点我想指出的是,医疗行业不管是医院本身,还是数字化转型,本质上都是一个长跑型的业务模式。横向来看,全世界范围内百年的企业屈指可数,但是百年甚至百年以上的医院却比比皆是,或者说是正当年。我们在刚开始的时候就提到,数字化转型是为智慧医院服务的,只要医院的临床、科研、管理和服务一天不停止发展,数字化的支撑就没有尽头的那一天。因此,对医院来说,数字化转型更像是一个没有终点的长跑,最重要的是跑了多远,而不是跑得多快。对底座来讲,更加需要一个相对稳健的技术路线,以及长跑型的陪跑者作为我们数字化转型和底座建设的合作伙伴。
InterSystems--40多年只做一件事,助力客户成功,做医院数字化转型的终身陪跑者
最后介绍一下我们公司,我们公司创立于1978年,是我们创始人当年和麻省总医院的几个医生一起,从亲自写第一行代码开始,一步一步走到今天,我们可能是全球医疗行业历史最悠久的平台软件公司。 经过40多年的发展,复旦百强榜中40%的医院、全美排名前20的医院、以及全世界、全国数百家不同等级的医院都在用我们的软件支撑他们的核心业务。之所以能够得到这么多客户的认可,我想主要原因还是我们长期深耕行业,专门为医疗行业打造了全球唯一一款医疗版数据平台,集中了医院数字化转型所需要的几乎所有的底层技术,并做了深度集成和优化,我们的逻辑就是通过一套软件,来满足医院在数字化转型过程针对数智底座的几乎所有需求,包括支持复杂的医疗业务与医疗行业的标准、多模型、互操作性、混合事务-分析处理、高级分析、API、混合云、容器化、分布式等等。最后一点我想说的,我们在国内从事医疗信息化20多年以来,最深的体会就是我们长期坚持做一件事,就是踏踏实实的做好我们的技术和产品、做好我们的服务、帮助客户解决问题,获得了最宝贵的东西,也就是客户多年的信任。未来我们希望能把这一件事坚持做下去,服务好我们的医院和合作伙伴,继续为医疗数字化服务下一个十年、二十年甚至更长的时间,以上就是我今天的分享,谢谢大家!
文章
Michael Lei · 五月 12, 2021
关键字:IRIS, IntegratedML, 机器学习, Covid-19, Kaggle
## 目的
最近,我注意到一个用于预测 Covid-19 患者是否将转入 ICU 的 [Kaggle 数据集](https://www.kaggle.com/S%C3%ADrio-Libanes/covid19/kernels)。 它是一个包含 1925 条病患记录的电子表格,其中有 231 列生命体征和观察结果,最后一列“ICU”为 1(表示是)或 0(表示否)。 任务是根据已知数据预测患者是否将转入 ICU。
这个数据集看起来是所谓的“传统 ML”任务的一个好例子。数据看上去数量合适,质量也相对合适。它可能更适合在 [IntegratedML 演示](https://github.com/intersystems-community/integratedml-demo-template)套件上直接应用,那么,基于普通 ML 管道与可能的 IntegratedML 方法进行快速测试,最简单的方法是什么?
## 范围
我们将简要地运行一些常规 ML 步骤,如:
* 数据 EDA
* 特征选择
* 模型选择
* 通过网格搜索调整模型参数
与
* 通过 SQL 实现的整合 ML 方法。
它通过 Docker-compose 等方式运行于 AWS Ubuntu 16.04 服务器。
## 环境
我们将重复使用 [integredML-demo-template](https://openexchange.intersystems.com/package/integratedml-demo-template) 的 Docker 环境:
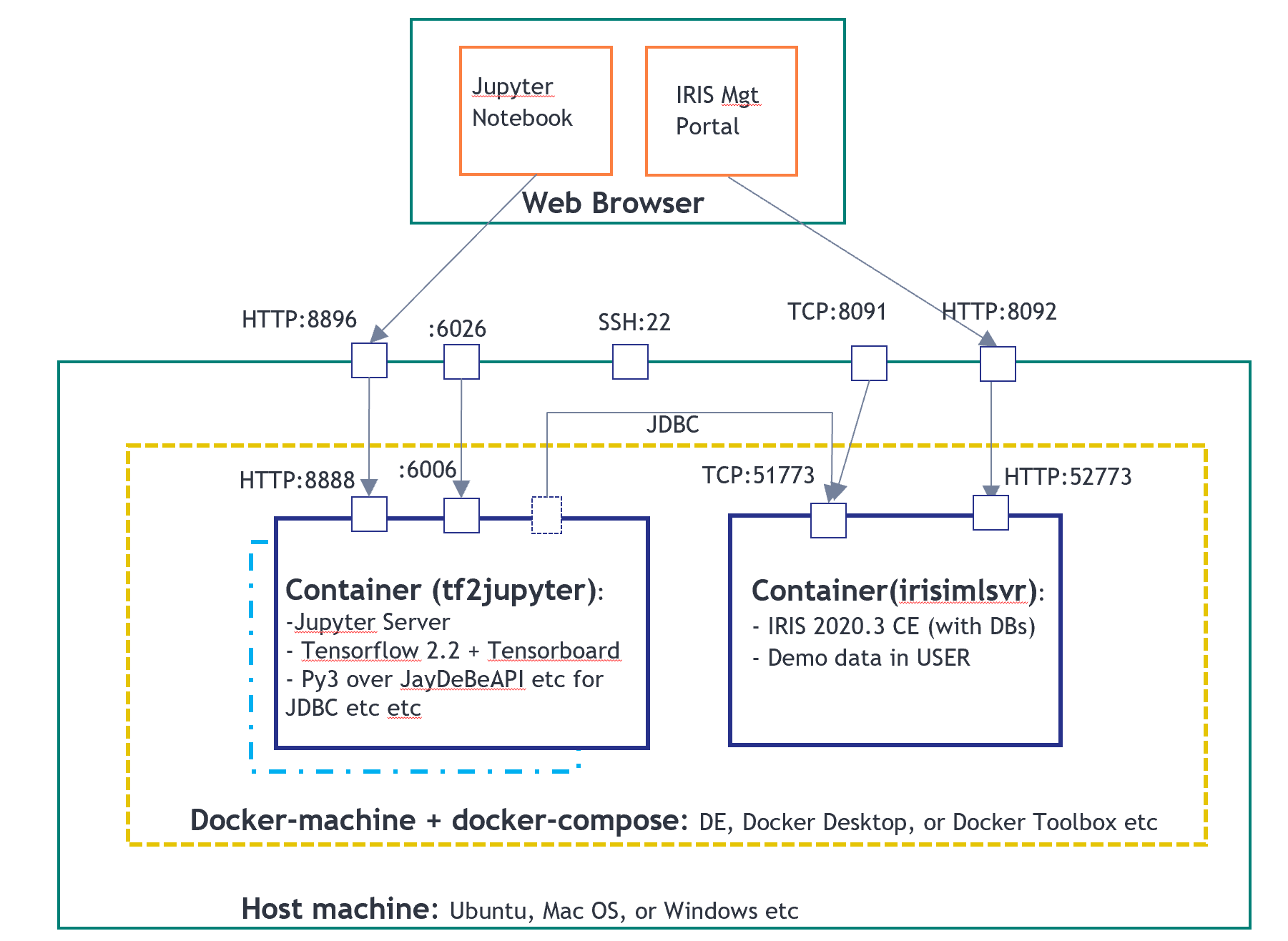
以下 notebook 文件在“tf2jupyter”上运行,带有 IntegratedML 的 IRIS 在“irismlsrv”上运行。 Docker-compose 在 AWS Ubuntu 16.04 上运行。
## 数据和任务
该数据集包含收集自 385 名患者的 1925 条记录,每名患者正好 5 条记录。 它共有 231 个列,其中有一列“ICU”是我们的训练和预测目标,其他 230 列都以某种方式用作输入。 ICU 具有二进制值 1 或 0。 除了 2 列看上去是分类字符串(在数据框架中显示为“对象”)外,其他所有列都是数值。
import numpy as np
import pandas as pd
from sklearn.impute import SimpleImputer
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, roc_auc_score, roc_curve
import seaborn as sns
sns.set(style="whitegrid")
import os
for dirname, _, filenames in os.walk('./input'):
for filename in filenames:
print(os.path.join(dirname, filename))
./input/datasets_605991_1272346_Kaggle_Sirio_Libanes_ICU_Prediction.xlsx
df = pd.read_excel("./input/datasets_605991_1272346_Kaggle_Sirio_Libanes_ICU_Prediction.xlsx")
df
PATIENT_VISIT_IDENTIFIER
AGE_ABOVE65
AGE_PERCENTIL
GENDER
DISEASE GROUPING 1
DISEASE GROUPING 2
DISEASE GROUPING 3
DISEASE GROUPING 4
DISEASE GROUPING 5
DISEASE GROUPING 6
...
TEMPERATURE_DIFF
OXYGEN_SATURATION_DIFF
BLOODPRESSURE_DIASTOLIC_DIFF_REL
BLOODPRESSURE_SISTOLIC_DIFF_REL
HEART_RATE_DIFF_REL
RESPIRATORY_RATE_DIFF_REL
TEMPERATURE_DIFF_REL
OXYGEN_SATURATION_DIFF_REL
WINDOW
ICU
1
60th
0.0
0.0
0.0
0.0
1.0
1.0
...
-1.000000
-1.000000
-1.000000
-1.000000
-1.000000
-1.000000
-1.000000
-1.000000
0-2
1
1
60th
0.0
0.0
0.0
0.0
1.0
1.0
...
-1.000000
-1.000000
-1.000000
-1.000000
-1.000000
-1.000000
-1.000000
-1.000000
2-4
2
1
60th
0.0
0.0
0.0
0.0
1.0
1.0
...
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
4-6
3
1
60th
0.0
0.0
0.0
0.0
1.0
1.0
...
-1.000000
-1.000000
NaN
NaN
NaN
NaN
-1.000000
-1.000000
6-12
4
1
60th
0.0
0.0
0.0
0.0
1.0
1.0
...
-0.238095
-0.818182
-0.389967
0.407558
-0.230462
0.096774
-0.242282
-0.814433
ABOVE_12
1
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
1920
384
50th
1
0.0
0.0
0.0
0.0
0.0
0.0
...
-1.000000
-1.000000
-1.000000
-1.000000
-1.000000
-1.000000
-1.000000
-1.000000
0-2
1921
384
50th
1
0.0
0.0
0.0
0.0
0.0
0.0
...
-1.000000
-1.000000
-1.000000
-1.000000
-1.000000
-1.000000
-1.000000
-1.000000
2-4
1922
384
50th
1
0.0
0.0
0.0
0.0
0.0
0.0
...
-1.000000
-1.000000
-1.000000
-1.000000
-1.000000
-1.000000
-1.000000
-1.000000
4-6
1923
384
50th
1
0.0
0.0
0.0
0.0
0.0
0.0
...
-1.000000
-1.000000
-1.000000
-1.000000
-1.000000
-1.000000
-1.000000
-1.000000
6-12
1924
384
50th
1
0.0
0.0
1.0
0.0
0.0
0.0
...
-0.547619
-0.838384
-0.701863
-0.585967
-0.763868
-0.612903
-0.551337
-0.835052
ABOVE_12
1925 行 × 231 列
df.dtypes
PATIENT_VISIT_IDENTIFIER int64
AGE_ABOVE65 int64
AGE_PERCENTIL object
GENDER int64
DISEASE GROUPING 1 float64
...
RESPIRATORY_RATE_DIFF_REL float64
TEMPERATURE_DIFF_REL float64
OXYGEN_SATURATION_DIFF_REL float64
WINDOW object
ICU int64
Length: 231, dtype: object
当然,设计此问题及其方法有几个选择。 首先,第一个显而易见的选择是,这可以是一个基本的“二元分类”问题。 我们可以将全部 1925 条记录都视为“无状态”个体记录,不管它们是否来自同一患者。 如果我们将 ICU 和其他值都当作数值来处理,这也可以是一个“回归”问题。
当然还有其他可能的方法。 例如,我们可以有一个更深层的视角,即数据集有 385 个不同的短“时间序列”集,每个患者一个。 我们可以将整个数据集分解成 385 个单独的训练集/验证集/测试集,我们是否可以尝试 CNN 或 LSTM 等深度学习模型来捕获每个患者对应的每个集合中隐藏的“症状发展阶段或模式”? 可以的。 这样做的话,我们还可以通过各种方式应用一些数据增强,来丰富测试数据。 但那就是另一个话题了,不在本帖的讨论范围内。
在本帖中,我们将只测试所谓的“传统 ML”方法与 IntegratedML(一种 AutoML)方法的快速运行。
## “传统”ML 方法?
与大多数现实案例相比,这是一个相对标准的数据集,除了缺少一些值,所以我们可以跳过特征工程部分,直接使用各个列作为特征。 那么,我们直接进入特征选择。
### **插补缺失数据**
首先,确保所有缺失值都通过简单的插补来填充:
df_cat = df.select_dtypes(include=['object'])
df_numeric = df.select_dtypes(exclude=['object'])
imp = SimpleImputer(missing_values=np.nan, strategy='mean')
idf = pd.DataFrame(imp.fit_transform(df_numeric))
idf.columns = df_numeric.columns
idf.index = df_numeric.index
idf.isnull().sum()
###
### **特征选择**
我们可以使用数据框架中内置的正态相关函数,来计算每个列的值与 ICU 的相关性。
#### 特征工程 - **相关性** {#featuring-engineering---correlation}
idf.drop(["PATIENT_VISIT_IDENTIFIER"],1)
idf = pd.concat([idf,df_cat ], axis=1)
cor = idf.corr()
cor_target = abs(cor["ICU"])
relevant_features = cor_target[cor_target>0.1] # correlation above 0.1
print(cor.shape, cor_target.shape, relevant_features.shape)
#relevant_features.index
#relevant_features.index.shape
这将列出 88 个特征,它们与 ICU 目标值的相关度大于 0.1。 这些列可以直接用作我们的模型输入
我还运行了其他几个在传统 ML 任务中常用的“特征选择方法”:
#### 特征选择 - **卡方** {#feature-selection---Chi-squared}
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
from sklearn.preprocessing import MinMaxScaler
X_norm = MinMaxScaler().fit_transform(X)
chi_selector = SelectKBest(chi2, k=88)
chi_selector.fit(X_norm, y)
chi_support = chi_selector.get_support()
chi_feature = X.loc[:,chi_support].columns.tolist()
print(str(len(chi_feature)), 'selected features', chi_feature)
88 selected features ['AGE_ABOVE65', 'GENDER', 'DISEASE GROUPING 1', ... ... 'P02_VENOUS_MIN', 'P02_VENOUS_MAX', ... ... RATURE_MAX', 'BLOODPRESSURE_DIASTOLIC_DIFF', ... ... 'TEMPERATURE_DIFF_REL', 'OXYGEN_SATURATION_DIFF_REL']
特征选择 - **皮尔逊相关**
def cor_selector(X, y,num_feats):
cor_list = []
feature_name = X.columns.tolist()
# calculate the correlation with y for each feature
for i in X.columns.tolist():
cor = np.corrcoef(X[i], y)[0, 1]
cor_list.append(cor)
# replace NaN with 0
cor_list = [0 if np.isnan(i) else i for i in cor_list]
# feature name
cor_feature = X.iloc[:,np.argsort(np.abs(cor_list))[-num_feats:]].columns.tolist()
# feature selection? 0 for not select, 1 for select
cor_support = [True if i in cor_feature else False for i in feature_name]
return cor_support, cor_feature
cor_support, cor_feature = cor_selector(X, y, 88)
print(str(len(cor_feature)), 'selected features: ', cor_feature)
88 selected features: ['TEMPERATURE_MEAN', 'BLOODPRESSURE_DIASTOLIC_MAX', ... ... 'RESPIRATORY_RATE_DIFF', 'RESPIRATORY_RATE_MAX']
#### 特征选择 - **回归特征消除 (RFE)** {#feature-selection---Recursive-Feature-Elimination-(RFE)}
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
rfe_selector = RFE(estimator=LogisticRegression(), n_features_to_select=88, step=100, verbose=5)
rfe_selector.fit(X_norm, y)
rfe_support = rfe_selector.get_support()
rfe_feature = X.loc[:,rfe_support].columns.tolist()
print(str(len(rfe_feature)), 'selected features: ', rfe_feature)
Fitting estimator with 127 features.
88 selected features: ['AGE_ABOVE65', 'GENDER', ... ... 'RESPIRATORY_RATE_DIFF_REL', 'TEMPERATURE_DIFF_REL']
特征选择 - **Lasso**
ffrom sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import MinMaxScaler
X_norm = MinMaxScaler().fit_transform(X)
embeded_lr_selector = SelectFromModel(LogisticRegression(penalty="l2"), max_features=88)
embeded_lr_selector.fit(X_norm, y)
embeded_lr_support = embeded_lr_selector.get_support()
embeded_lr_feature = X.loc[:,embeded_lr_support].columns.tolist()
print(str(len(embeded_lr_feature)), 'selected features', embeded_lr_feature)
65 selected features ['AGE_ABOVE65', 'GENDER', ... ... 'RESPIRATORY_RATE_DIFF_REL', 'TEMPERATURE_DIFF_REL']
特征选择 - **RF 基于树**:SelectFromModel
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier
embeded_rf_selector = SelectFromModel(RandomForestClassifier(n_estimators=100), max_features=227)
embeded_rf_selector.fit(X, y)
embeded_rf_support = embeded_rf_selector.get_support()
embeded_rf_feature = X.loc[:,embeded_rf_support].columns.tolist()
print(str(len(embeded_rf_feature)), 'selected features', embeded_rf_feature)
48 selected features ['AGE_ABOVE65', 'GENDER', ... ... 'TEMPERATURE_DIFF_REL', 'OXYGEN_SATURATION_DIFF_REL']
#### 特征选择 - **LightGBM** 或 **XGBoost** {#feature-selection---LightGBM-or-XGBoost}
from sklearn.feature_selection import SelectFromModel
from lightgbm import LGBMClassifier
lgbc=LGBMClassifier(n_estimators=500, learning_rate=0.05, num_leaves=32, colsample_bytree=0.2,
reg_alpha=3, reg_lambda=1, min_split_gain=0.01, min_child_weight=40)
embeded_lgb_selector = SelectFromModel(lgbc, max_features=128)
embeded_lgb_selector.fit(X, y)
embeded_lgb_support = embeded_lgb_selector.get_support()
embeded_lgb_feature = X.loc[:,embeded_lgb_support].columns.tolist()
print(str(len(embeded_lgb_feature)), 'selected features: ', embeded_lgb_feature)
embeded_lgb_feature.index
56 selected features: ['AGE_ABOVE65', 'GENDER', 'HTN', ... ... 'TEMPERATURE_DIFF_REL', 'OXYGEN_SATURATION_DIFF_REL']
#### 特征选择 - **全部集成** {#feature-selection---Ensemble-them-all}
feature_name = X.columns.tolist()
# put all selection together
feature_selection_df = pd.DataFrame({'Feature':feature_name, 'Pearson':cor_support, 'Chi-2':chi_support, 'RFE':rfe_support, 'Logistics':embeded_lr_support, 'Random Forest':embeded_rf_support, 'LightGBM':embeded_lgb_support})
# count the selected times for each feature
feature_selection_df['Total'] = np.sum(feature_selection_df, axis=1)
# display the top 100
num_feats = 227
feature_selection_df = feature_selection_df.sort_values(['Total','Feature'] , ascending=False)
feature_selection_df.index = range(1, len(feature_selection_df)+1)
feature_selection_df.head(num_feats)
df_selected_columns = feature_selection_df.loc[(feature_selection_df['Total'] > 3)]
df_selected_columns
我们可以列出通过至少 4 种方法选择的特征:
.png)
... ...
.png)
我们当然可以选择这 58 个特征。 同时,经验告诉我们,特征选择并不一定总是“民主投票”;更多时候,它可能特定于域问题,特定于数据,有时还特定于我们稍后将采用的 ML 模型或方法。
特征选择 - **第三方工具**
有广泛使用的行业工具和 AutoML 工具,例如 DataRobot 可以提供出色的自动特征选择:
从上面的 DataRobot 图表中,我们不难看出,各个 RespiratoryRate 和 BloodPressure 值是与 ICU 转入最相关的特征。
特征选择 - **最终选择**
在本例中,我进行了一些快速实验,发现 LightGBM 特征选择的结果实际上更好一点,所以我们只使用这种选择方法。
df_selected_columns = embeded_lgb_feature # better than ensembled selection
dataS = pd.concat([idf[df_selected_columns],idf['ICU'], df_cat['WINDOW']],1)
dataS.ICU.value_counts()
print(dataS.shape)
(1925, 58)
我们可以看到有 58 个特征被选中;不算太少,也不算太多;对于这个特定的单一目标二元分类问题,看起来是合适的数量。
### **数据不平衡**
plt.figure(figsize=(10,5))
count = sns.countplot(x = "ICU",data=data)
count.set_xticklabels(["Not Admitted","Admitted"])
plt.xlabel("ICU Admission")
plt.ylabel("Patient Count")
plt.show()
这说明数据不平衡,只有 26% 的记录转入了 ICU。 这会影响到结果,因此我们可以考虑常规的数据平衡方法,例如 SMOTE 等。
这里,我们可以尝试其他各种 EDA,以相应了解各种数据分布。
### **运行基本 LR 训练**
Kaggle 网站上有一些不错的快速训练 notebook,我们可以根据自己选择的特征列来快速运行。 让我们从快速运行针对训练管道的 LR 分类器开始:
data2 = pd.concat([idf[df_selected_columns],idf['ICU'], df_cat['WINDOW']],1)
data2.AGE_ABOVE65 = data2.AGE_ABOVE65.astype(int)
data2.ICU = data2.ICU.astype(int)
X2 = data2.drop("ICU",1)
y2 = data2.ICU
from sklearn.preprocessing import LabelEncoder
label_encoder = LabelEncoder()
X2.WINDOW = label_encoder.fit_transform(np.array(X2["WINDOW"].astype(str)).reshape((-1,)))
confusion_matrix2 = pd.crosstab(y2_test, y2_hat, rownames=['Actual'], colnames=['Predicted'])
sns.heatmap(confusion_matrix2, annot=True, fmt = 'g', cmap = 'Reds') print("ORIGINAL")
print(classification_report(y_test, y_hat))
print("AUC = ",roc_auc_score(y_test, y_hat),'\n\n')
print("LABEL ENCODING")
print(classification_report(y2_test, y2_hat))
print("AUC = ",roc_auc_score(y2_test, y2_hat))
y2hat_probs = LR.predict_proba(X2_test)
y2hat_probs = y2hat_probs[:, 1] fpr2, tpr2, _ = roc_curve(y2_test, y2hat_probs) plt.figure(figsize=(10,7))
plt.plot([0, 1], [0, 1], 'k--')
plt.plot(fpr, tpr, label="Base")
plt.plot(fpr2,tpr2,label="Label Encoded")
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC curve')
plt.legend(loc="best")
plt.show()
ORIGINAL
precision recall f1-score support
0 0.88 0.94 0.91 171
1 0.76 0.57 0.65 54
accuracy 0.85 225
macro avg 0.82 0.76 0.78 225
weighted avg 0.85 0.85 0.85 225
AUC = 0.7577972709551657
LABEL ENCODING
precision recall f1-score support
0 0.88 0.93 0.90 171
1 0.73 0.59 0.65 54
accuracy 0.85 225
macro avg 0.80 0.76 0.78 225
weighted avg 0.84 0.85 0.84 225
AUC = 0.7612085769980507
看起来它达到了 76% 的 AUC,准确率为 85%,但转入 ICU 的召回率只有 59% - 似乎有太多假负例。 这当然不理想 - 我们不希望错过患者记录的实际 ICU 风险。 因此,以下所有任务都将集中在如何通过降低 FN 来提高召回率的**目标**上,希望总体准确度有所平衡。
在前面的部分中,我们提到了不平衡的数据,所以第一本能通常是对测试集进行 Stratify(分层),然后使用 SMOTE 方法使其成为更平衡的数据集。
#stratify the test data, to make sure Train and Test data have the same ratio of 1:0
X3_train,X3_test,y3_train,y3_test = train_test_split(X2,y2,test_size=225/1925,random_state=42, stratify = y2, shuffle = True) <span> </span>
# train and predict
LR.fit(X3_train,y3_train)
y3_hat = LR.predict(X3_test)
#SMOTE the data to make ICU 1:0 a balanced distribution
from imblearn.over_sampling import SMOTE sm = SMOTE(random_state = 42)
X_train_res, y_train_res = sm.fit_sample(X3_train,y3_train.ravel())
LR.fit(X_train_res, y_train_res)
y_res_hat = LR.predict(X3_test)
#draw confusion matrix etc again
confusion_matrix3 = pd.crosstab(y3_test, y_res_hat, rownames=['Actual'], colnames=['Predicted'])
sns.heatmap(confusion_matrix3, annot=True, fmt = 'g', cmap="YlOrBr")
print("LABEL ENCODING + STRATIFY")
print(classification_report(y3_test, y3_hat))
print("AUC = ",roc_auc_score(y3_test, y3_hat),'\n\n')
print("SMOTE")
print(classification_report(y3_test, y_res_hat))
print("AUC = ",roc_auc_score(y3_test, y_res_hat))
y_res_hat_probs = LR.predict_proba(X3_test)
y_res_hat_probs = y_res_hat_probs[:, 1]
fpr_res, tpr_res, _ = roc_curve(y3_test, y_res_hat_probs) plt.figure(figsize=(10,10))
#And plot the ROC curve as before.
LABEL ENCODING + STRATIFY
precision recall f1-score support
0 0.87 0.99 0.92 165
1 0.95 0.58 0.72 60
accuracy 0.88 225
macro avg 0.91 0.79 0.82 225
weighted avg 0.89 0.88 0.87 225
AUC = 0.7856060606060606
SMOTE
precision recall f1-score support
0 0.91 0.88 0.89 165
1 0.69 0.75 0.72 60
accuracy 0.84 225
macro avg 0.80 0.81 0.81 225
weighted avg 0.85 0.84 0.85 225
AUC = 0.8143939393939393
所以对数据进行 STRATIFY 和 SMOT 处理似乎将召回率从 0.59 提高到 0.75,总体准确率为 0.84。
现在,按照传统 ML 的惯例来说,数据处理已大致完成,我们想知道在这种情况下最佳模型是什么;它们是否可以做得更好,我们能否尝试相对全面的比较?
### **运行各种模型的训练比较**:
让我们评估一些常用的 ML 算法,并生成箱形图形式的比较结果仪表板:
# compare algorithms
from matplotlib import pyplot
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import StratifiedKFold
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
#Import Random Forest Model
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
# List Algorithms together
models = []
models.append(('LR', <strong>LogisticRegression</strong>(solver='liblinear', multi_class='ovr')))
models.append(('LDA', LinearDiscriminantAnalysis()))
models.append(('KNN', <strong>KNeighborsClassifier</strong>()))
models.append(('CART', <strong>DecisionTreeClassifier</strong>()))
models.append(('NB', <strong>GaussianNB</strong>()))
models.append(('SVM', <strong>SVC</strong>(gamma='auto')))
models.append(('RF', <strong>RandomForestClassifier</strong>(n_estimators=100)))
models.append(('XGB', <strong>XGBClassifier</strong>())) #clf = XGBClassifier()
# evaluate each model in turn
results = []
names = []
for name, model in models:
kfold = StratifiedKFold(n_splits=10, random_state=1)
cv_results = cross_val_score(model, X_train_res, y_train_res, cv=kfold, scoring='f1') ## accuracy, precision,recall
results.append(cv_results)
names.append(name)
print('%s: %f (%f)' % (name, cv_results.mean(), cv_results.std()))
# Compare all model's performance. Question - would like to see a Integrated item on it?
pyplot.figure(4, figsize=(12, 8))
pyplot.boxplot(results, labels=names)
pyplot.title('Algorithm Comparison')
pyplot.show()
LR: 0.805390 (0.021905) LDA: 0.803804 (0.027671) KNN: 0.841824 (0.032945) CART: 0.845596 (0.053828)
NB: 0.622540 (0.060390) SVM: 0.793754 (0.023050) RF: 0.896222 (0.033732) XGB: 0.907529 (0.040693)

上图看起来表明,XGB 分类器和随机森林分类器的 F1 分数好于其他模型。
让我们也比较一下它们在同一组标准化测试数据上的实际测试结果:
import time
from pandas import read_csv
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.svm import SVC
for name, model in models:
print(name + ':\n\r')
start = time.clock()
model.fit(X_train_res, y_train_res)
print("Train time for ", model, " ", time.clock() - start)
predictions = model.predict(X3_test) #(X_validation)
# Evaluate predictions
print(accuracy_score(y3_test, predictions)) # Y_validation
print(confusion_matrix(y3_test, predictions))
print(classification_report(y3_test, predictions))
LR:
Train time for LogisticRegression(multi_class='ovr', solver='liblinear') 0.02814499999999498
0.8444444444444444
[[145 20]
[ 15 45]]
precision recall f1-score support
0 0.91 0.88 0.89 165
1 0.69 0.75 0.72 60
accuracy 0.84 225
macro avg 0.80 0.81 0.81 225
weighted avg 0.85 0.84 0.85 225
LDA:
Train time for LinearDiscriminantAnalysis() 0.2280070000000194
0.8488888888888889
[[147 18]
[ 16 44]]
precision recall f1-score support
0 0.90 0.89 0.90 165
1 0.71 0.73 0.72 60
accuracy 0.85 225
macro avg 0.81 0.81 0.81 225
weighted avg 0.85 0.85 0.85 225
KNN:
Train time for KNeighborsClassifier() 0.13023699999999394
0.8355555555555556
[[145 20]
[ 17 43]]
precision recall f1-score support
0 0.90 0.88 0.89 165
1 0.68 0.72 0.70 60
accuracy 0.84 225
macro avg 0.79 0.80 0.79 225
weighted avg 0.84 0.84 0.84 225
CART:
Train time for DecisionTreeClassifier() 0.32616000000001577
0.8266666666666667
[[147 18]
[ 21 39]]
precision recall f1-score support
0 0.88 0.89 0.88 165
1 0.68 0.65 0.67 60
accuracy 0.83 225
macro avg 0.78 0.77 0.77 225
weighted avg 0.82 0.83 0.83 225
NB:
Train time for GaussianNB() 0.0034229999999979555
0.8355555555555556
[[154 11]
[ 26 34]]
precision recall f1-score support
0 0.86 0.93 0.89 165
1 0.76 0.57 0.65 60
accuracy 0.84 225
macro avg 0.81 0.75 0.77 225
weighted avg 0.83 0.84 0.83 225
SVM:
Train time for SVC(gamma='auto') 0.3596520000000112
0.8977777777777778
[[157 8]
[ 15 45]]
precision recall f1-score support
0 0.91 0.95 0.93 165
1 0.85 0.75 0.80 60
accuracy 0.90 225
macro avg 0.88 0.85 0.86 225
weighted avg 0.90 0.90 0.90 225
RF:
Train time for RandomForestClassifier() 0.50123099999999
0.9066666666666666
[[158 7]
[ 14 46]]
precision recall f1-score support
0 0.92 0.96 0.94 165
1 0.87 0.77 0.81 60
accuracy 0.91 225
macro avg 0.89 0.86 0.88 225
weighted avg 0.91 0.91 0.90 225
XGB:
Train time for XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=1, gamma=0, gpu_id=-1,
importance_type='gain', interaction_constraints='',
learning_rate=0.300000012, max_delta_step=0, max_depth=6,
min_child_weight=1, missing=nan, monotone_constraints='()',
n_estimators=100, n_jobs=0, num_parallel_tree=1, random_state=0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, subsample=1,
tree_method='exact', validate_parameters=1, verbosity=None) 1.649520999999993
0.8844444444444445
[[155 10]
[ 16 44]]
precision recall f1-score support
0 0.91 0.94 0.92 165
1 0.81 0.73 0.77 60
accuracy 0.88 225
macro avg 0.86 0.84 0.85 225
weighted avg 0.88 0.88 0.88 225
结果显示,RF 实际上好于 XGB。 这意味着 XGB 可能在某种程度上有一点过度拟合。 RFC 结果也比 LR 略有改善。
### **通过进一步的“通过网格搜索调整参数”运行所选模型**
现在假定我们选择了随机森林分类器作为模型。 我们可以对此模型执行进一步的网格搜索,以查看是否可以进一步提高结果的性能。
记住,在这种情况下,我们的目标仍然是优化召回率,这通过最大程度地减少患者可能遇到的 ICU 风险的假负例来实现,所以下面我们将“recall_score”来重新拟合网格搜索。 再次像往常一样使用 10 折交叉验证,因为上面的测试集总是设置为 2915 条记录中的 12% 左右。
from sklearn.model_selection import GridSearchCV
# Create the parameter grid based on the results of random search
param_grid = {'bootstrap': [True],
'ccp_alpha': [0.0],
'class_weight': [None],
'criterion': ['gini', 'entropy'],
'max_depth': [None],
'max_features': ['auto', 'log2'],
'max_leaf_nodes': [None],
'max_samples': [None],
'min_impurity_decrease': [0.0],
'min_impurity_split': [None],
'min_samples_leaf': [1, 2, 4],
'min_samples_split': [2, 4],
'min_weight_fraction_leaf': [0.0],
'n_estimators': [100, 125],
#'n_jobs': [None],
'oob_score': [False],
'random_state': [None],
#'verbose': 0,
'warm_start': [False]
}
#Fine-tune by confusion matrix
from sklearn.metrics import roc_curve, precision_recall_curve, auc, make_scorer, recall_score, accuracy_score, precision_score, confusion_matrix
scorers = {
'recall_score': make_scorer(recall_score),
'precision_score': make_scorer(precision_score),
'accuracy_score': make_scorer(accuracy_score)
}
# Create a based model
rfc = RandomForestClassifier()
# Instantiate the grid search model
grid_search = GridSearchCV(estimator = rfc, param_grid = param_grid,
scoring=scorers, refit='recall_score',
cv = 10, n_jobs = -1, verbose = 2)
train_features = X_train_res
grid_search.fit(train_features, train_labels)
rf_best_grid = grid_search.best_estimator_
rf_best_grid.fit(train_features, train_labels)
rf_predictions = rf_best_grid.predict(X3_test)
print(accuracy_score(y3_test, rf_predictions))
print(confusion_matrix(y3_test, rf_predictions))
print(classification_report(y3_test, rf_predictions))
0.92
[[ 46 14]
[ 4 161]]
precision recall f1-score support
0 0.92 0.77 0.84 60
1 0.92 0.98 0.95 165
accuracy 0.92 225
macro avg 0.92 0.87 0.89 225
weighted avg 0.92 0.92 0.92 225
结果表明,网格搜索成功地将总体准确度提高了一些,同时保持 FN 不变。
我们同样也绘制 AUC 比较图:
confusion_matrix4 = pd.crosstab(y3_test, rf_predictions, rownames=['Actual'], colnames=['Predicted'])
sns.heatmap(confusion_matrix4, annot=True, fmt = 'g', cmap="YlOrBr")
print("LABEL ENCODING + STRATIFY")
print(classification_report(y3_test, 1-y3_hat))
print("AUC = ",roc_auc_score(y3_test, 1-y3_hat),'\n\n')
print("SMOTE")
print(classification_report(y3_test, 1-y_res_hat))
print("AUC = ",roc_auc_score(y3_test, 1-y_res_hat), '\n\n')
print("SMOTE + LBG Selected Weights + RF Grid Search")
print(classification_report(y3_test, rf_predictions))
print("AUC = ",roc_auc_score(y3_test, rf_predictions), '\n\n\n')
y_res_hat_probs = LR.predict_proba(X3_test)
y_res_hat_probs = y_res_hat_probs[:, 1]
predictions_rf_probs = rf_best_grid.predict_proba(X3_test) #(X_validation)
predictions_rf_probs = predictions_rf_probs[:, 1]
fpr_res, tpr_res, _ = roc_curve(y3_test, 1-y_res_hat_probs)
fpr_rf_res, tpr_rf_res, _ = roc_curve(y3_test, predictions_rf_probs)
plt.figure(figsize=(10,10))
plt.plot([0, 1], [0, 1], 'k--')
plt.plot(fpr, tpr, label="Base")
plt.plot(fpr2,tpr2,label="Label Encoded")
plt.plot(fpr3,tpr3,label="Stratify")
plt.plot(fpr_res,tpr_res,label="SMOTE")
plt.plot(fpr_rf_res,tpr_rf_res,label="SMOTE + RF GRID")
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC curve')
plt.legend(loc="best")
plt.show()
LABEL ENCODING + STRATIFY
precision recall f1-score support
0 0.95 0.58 0.72 60
1 0.87 0.99 0.92 165
accuracy 0.88 225
macro avg 0.91 0.79 0.82 225
weighted avg 0.89 0.88 0.87 225
AUC = 0.7856060606060606
SMOTE
precision recall f1-score support
0 0.69 0.75 0.72 60
1 0.91 0.88 0.89 165
accuracy 0.84 225
macro avg 0.80 0.81 0.81 225
weighted avg 0.85 0.84 0.85 225
AUC = 0.8143939393939394
SMOTE + LBG Selected Weights + RF Grid Search
precision recall f1-score support
0 0.92 0.77 0.84 60
1 0.92 0.98 0.95 165
accuracy 0.92 225
macro avg 0.92 0.87 0.89 225
weighted avg 0.92 0.92 0.92 225
AUC = 0.8712121212121211
结果表明,经过算法比较和进一步的网格搜索后,我们将 AUC 从 78% 提高到 87%,总体准确度为 92%,召回率为 77%。
### **“传统 ML”方法回顾**
那么,这个结果到底如何? 对于使用传统 ML 算法的基本手动处理是可以的。 在 Kaggle 竞争表中表现如何? 好吧,它不会出现在排行榜上。 我通过 DataRobot 当前的 AutoML 服务运行了原始数据集,在对排名前 43 的模型进行比较后,最好的结果是使用模型“具有无人监督学习功能的 XGB 树分类器”实现的相当于大约 90+% 的 AUC(有待使用同类数据进行进一步确认)。 如果真的想在 Kaggle 上具有竞争力,这可能是我们要考虑的底线模型。 我也会将最佳结果与模型的排行列表放在 github 中。 最后,对于特定于医护场所的现实案例,我的感觉是,我们还需要考虑具有一定程度自定义的深度学习方法,正如本贴的“数据和任务”部分所提到的。 当然,在现实情况下,在哪里收集高质量数据列也可能是一个前期问题。
## IntegratedML 方法?
上文说明了所谓的传统 ML 流程,其中通常包括数据 EDA、特征工程、特征选择、模型选择和通过网格搜索进行性能优化等。 这是我目前能想到的最简单的适合此任务的方法,我们甚至还没有触及模型部署和服务管理生命周期 - 我们将在下一个帖子中探讨这些方面,研究如何利用 Flask/FastAPI/IRIS,并将这个基本的 ML 模型部署到 Covid-19 X-Ray 演示服务栈中。
现在,IRIS 有了 IntegratedML,它是一个优雅的 SQL 包装器,包装了 AutoML 的强大选项。 在第二部分中,我们可以研究如何以大为简化的流程来完成上述任务,这样我们就不必再为特征选择、模型选择和性能优化等问题而烦恼,同时可获得等效的 ML 结果来实现商业利益。
到这里,如果再塞入使用相同数据快速运行 integratedML 的内容,本帖可能太长了,无法在 10 分钟内读完,因此我将该内容移至[第二部分](https://community.intersystems.com/post/run-some-covid-19-icu-predictions-ml-vs-integratedml-part-i)。
文章
Nicky Zhu · 十一月 15, 2021
查看原文
近日,国家卫健委统计信息中心发布了两则通知——
2021年10月25日,国家卫健委统计信息中心发布《关于开展国家医疗健康信息互联互通标准化成熟度评测工作的通知》,这意味着新一年的评测工作开始启动。
2021年11月5日,国家卫健委统计信息中心发布了“关于2020年度国家医疗健康信息互联互通标准化成熟度测评结果(第二批)公示的通知”,公布了第二批10个区域和92家医院的测评结果。
这两则通知,再次将“互联互通”带到了医疗IT人的面前。而每每谈到互联互通,就不可避免地要谈到集成平台、信息平台和数据中台等项目建设问题,本文将从供应商选择、技术选型等从八个核心问题,浅谈关于平台和中台的那些事。
一、如何选择供应商?
如上图所示,如果我们把平台/中台项目的实施方称作解决方案提供商,那么每一家解决方案提供方背后还会有一家产品技术提供方解决方案,因为解决方案提供方往往需要借助成熟的产品来实现信息平台和数据中台项目,以聚焦所服务医院客户的具体需求,并加速实施效率,所以一个平台/中台供应链条相对比较长。也因此,医院/医疗集团需要花费更多的精力在产品和解决方案的组合中进行选型。选型的标准也成为许多信息中心或者CIO们关注的首要问题。
首先要考虑平台/中台解决方案提供方本身的品牌和实力:通常而言,选择全国性的解决方案提供方更安全一些,这类厂商的解决方案相对成熟、成功案例多,技术能力强,实施经验丰富;但是对于一些规模略小的医院而言,可能会顾虑这些厂商的客户太多,对本院的支持力度不够,或者是在该厂商在当地没有分公司,存在技术服务跟不上等问题,也可能会更倾向于初创企业或者本地解决方案提供方来做项目的集成或者实施,这两种选择都没有问题,关键是所选择的合作伙伴要值得信赖。
另外要考虑厂商背后的产品技术提供方:通常产品技术提供方不直接面向最终客户提供实施服务,而是通过本地合作伙伴向最终客户(即医院或者医疗集团)提供服务。但是作为解决方案的基础,该产品或者技术本身的先进性、可靠性以及未来的可扩展性都是需要重点衡量的因素。例如医院建设集成平台或者互联互通平台通常都会本着以评促建以评促用的目的,利用信息平台的建设契机,打通院内的信息和数据流程。此时,产品技术提供方有多少业务建模和流程整合的案例与经验也将在很大程度上影响项目的交付质量。
同样,医院也可以参考该产品技术提供方的行业积累、案例详情、服务承诺以及业界口碑等等。
总结一下,在选择方案时,需要考虑的实际上是产品本身的技术能力和对应的解决方案提供方的服务能力。因此,我们建议大家基于成熟的产品,选择能提供较好技术服务的解决方案提供方。如果产品并不成熟,那么即使解决方案提供方愿意常年提供驻场技术服务,也很难应对故障,也难以制订预案保障平台稳定运行。
二、技术路线的选择
在医疗行业进行业务和数据整合时,用户常常会需要在点对点集成模式、消息路由模式以及SOA架构模式进行技术决策。
事实上,从来就未曾出现过集成模式的最终解决方案。医院和医疗集团用某种特定的集成模式搭建自己的数字化高速公路时需要充分考虑该模式是否适合自己的场景,投入产出比是否符合自己的预期,以及是否能够充分利用该模式的优势。
举例而言,当医院考虑采用SOA架构时,需要考虑到遗留系统是否能够提供服务接口;在当前的业务运行条件下,是否能够承受由于接口的侵入式设计引入的风险,是否可能通过预案规避风险;以及医院是否已经或者将在平台投产前后具有实时数据分析的需求和技术储备。否则就将面临投入无法得到回报的质疑,甚至是规划无法落地的尴尬。
再看一个例子,如果要采用点对点模式集成,那么医院就需要考虑在平台投产可预见的周期(如3~5年)内,是否会面临跨部门跨系统数据利用需求快速增长的前景。如果有,那么,由于缺乏SOA架构能够提供的业务抽象和整合的能力,爆炸性增长的接口数量和数据整合需求会成为信息科难以应对的直接威胁。
正是由于集成模式的高度个性化,我们认为作为基础设施的集成平台类产品必须能够支持所有集成模式。一方面是满足各种不同类型的医院的需要,另一方面,医院也需要认识到,基础设施的建设从来都不是一蹴而就的“一锤子买卖”。您完全可以在集成需求数量较低时选用点对点模式快速投产,在需要进行流程和数据整合时应用SOA架构以获得企业全景视图的整合优势。而一个能够支持所有模式的产品才能赋能于客户,使之具备进行策略选择的优势。
三、开源策略的潜在风险
采用开源组件迅速获得能力,结合DevOps快速迭代开发是应对快速变化的市场环境和需求,进行产品化开发时的优先选择。在进行应用开发时,这样的策略通常有效。
然而优势与代价总是如影随形。借助开源组件的优势是能够快速获得能力,但开源组件的稳定性、可靠性和安全性则是每一个技术决策者都需要考察的关键风险,甚至开源组件许可证的更新都有可能为企业引入巨大的知识产权风险。
例如久负盛名的ElasticSearch,作为一款企业级搜索和分析引擎,它对于文本检索的能力和效率都有保障,被许多产品集成用于检索。但ElasticSearch及其依赖的其他组件已被检测出大量的安全性漏洞,例如可以引入中间人攻击的CVE-2021-22138,可以允许用户查看未授权敏感信息的CVE-2021-22147,以及可以允许用户通过ElasticSearch在服务器上运行任何OS指令的CVE-2014-3120等,风险列表每年都在更新。(风险列表可参见https://www.elastic.co/community/security)同样是ElasticSearch,在将开源授权更新为SSPL之后,如果业务用到了ElasticSearch并打包为可盈利产品,则ElasticSearch公司有权要求用户开放源码并收取费用。
因此,在使用大规模集成开源组件构建的产品时,医院需要评估产品技术提供方是否能够及时更新开源组件以获得安全性更新,并评估产品技术提供方是否能够及时跟踪和处理因授权变化会引入的法律风险。
集成平台、数据中台甚至是数据库这样的基础设施如果构建在大量的开源组件上,频繁的版本变动通常意味着组件集成风险的大幅升高,而跟踪和处理版本变更的技术和法务影响也将成为需要持续投入的持有成本。因此,一体化、完整知识产权的集成平台或数据中台产品在简化技术堆栈的同时也将大幅降低长期持有成本。对于医院用户来说,需要平衡评估一体化商业产品和开源集成产品的购买和持有成本,更需要考察产品技术提供方对开源组件的跟踪、更新和维护能力。
四、关注稳定与可靠性保障
核心业务系统、集成平台和数据中台这一类的关键系统,事关医院业务是否能持续运行,其运行稳定性与可靠性的重要意义不言而喻。基于主备、多活等冗余技术的平台高可用和灾备方案仍是为平台运行保驾护航的关键手段。
在市场上可见到的诸多产品中,有采用原生高可用方案的产品,也有集成第三方或开源技术高可用方案的产品。在这里,各位信息中心负责人或者技术决策者不得不考虑一个问题,即高可用方案的责任归属问题。
因此,即使一些非核心部件采用第三方技术,高可用方案也应采用产品原生技术。即使退一步来说,在没有原生高可用方案的情况下,您的解决方案提供方也应当承担起解决平台可用性和可靠性问题的技术服务角色。试想,当高可用方案失效或处于故障状态时,解决方案提供方采用了非原生高可用方案,届时难道能依赖开源社区的随机问答解决问题?
五、跨越技术门槛
医疗数字化进程与人工智能等目前的热点技术有很大不同,即必须基于当前业务。但由于医疗业务本身面临与新技术的融合,因此数字化进程也必须具备足够的灵活性,能够迅速应对业务过程的演化。而医疗业务流程或数据流程的演化,是需要业务专家、开发工程师、运维保障团队协作共同完成的,每一种角色都需要在平台上工作。因此,纯粹面向开发工程师的技术平台将无法有效应对业务流程本身的快速迭代。我们认为,一个成熟的集成平台/数据中台,需要为团队中不同角色的成员提供适合他们的开发/维护/测试工具,使各成员能以较低的成本各施所长。这些工具至少包括:
· 图形化的流程、数据转换和业务规则建模工具,使得业务专家即使不了解业务组件的技术实现,也能利用平台上的组件搭建出适合医院的业务/数据流
· 专业的IDE和管理工具,供研发工程师扩展业务组件和对现有组件进行跟踪和组件级调优
· 监控和管理工具,供运维工程师监控平台运行的健康状况和性能,必要时对平台运行参数进行调优
六、集群的选择
我们理解一些工程师非常关心产品是否支持负载均衡。需要注意的是,对于现代的集成平台和数据中台而言,它们本身应当是由一系列的集群共同构成的分布式系统。
比如院内集成平台拥有基于Web的操作管理页面,运行API实现或数据流程的容器,有消息引擎,有数据库,因此,可以构成一个典型的由Web程序,API/应用服务器,消息引擎和数据库分层构建的分布式系统,而其中的每一层,都可以根据高可用与负载需求以不同目的的集群形态搭建出来。
以集成平台产品为例,通常,集成平台的Web管理程序由于并发操作的人很少,不需要单独进行集群化;而API/应用服务器层默认会采用高可用集群,对于业务量极大的用户,则可以采用负载均衡+高可用集群;数据库层同样如此,必要时还可以考虑部署读写分离+负载均衡+高可用集群;消息引擎则比较特别,如果不需要保障消息的先进先出特性,可以部署高可用和负载均衡集群,而对于需要保障消息处理时序的场景,则通常不能依赖负载均衡集群,或即使部署了负载均衡集群,也需要控制消息分规则,由单一实例处理这样的消息。
但是否采用及采用何种集群架构,则完全应当基于业务的实际需要和产品能力。举例而言,InterSystems产品可以支持负载均衡+高可用集群,还可以部署为读写分离+负载均衡+高可用集群,但通常我们并不会作为默认配置推荐给集成平台用户。原因在于,我们的产品在单台服务器上经性能测试可以达到20亿消息/天的处理效率。而根据我们对国内数百家三家医院的实际调查,即使在国内顶尖的三甲医院中,也未发现超过2千万消息/天的性能需求。因此,对于单体医院,高可用集群已足够使用。基于奥卡姆剃刀原理和成本控制的基本需求,负载均衡集群并无必要,反而会由于加大了架构的复杂性使持有、维护成本都大幅提升。而对于医疗集团客户,由于需要集成数十家三甲与二级医院,同时还需要控制单个服务器的成本,因此我们的一部分医疗集团客户部署了负载均衡+高可用集群并可进行弹性横向扩展。
当然,不同的产品有不同的性能指标,如果产品的本身性能表现无法支撑医院业务量,那么部署为负载均衡集群支撑医院的实际需求还是非常必要的。
七、技术服务保障
相比开源产品,基于商业产品搭建平台/中台解决方案最显著的附加价值主要来源于技术服务。无论是最终用户还是解决方案提供方,都能受益于产品提供方的技术服务。技术服务也是项目能否成功上线、持续稳定运行或者二次开发的重要保障,对于技术服务,需要考虑产品技术提供方是否能够提供下面的三种或者以上的方式:
· 故障处理和技术支持:对于产品应用、二次开发的疑问,是否可获得技术支持资源以解决疑问?对于在产品运行过程中可能遭遇的软硬件故障,尤其是系统崩溃、宕机等高等级事件,是否能够获得直接的技术支持解决、定位和调查问题?
· 产品培训:是否具备成体系的产品应用、二次开发和维护培训体系
· 在线课程
· 产品文档库
· 开发者社区:非工程师的客户往往不重视开发者社区的力量。实际上,作为可供全球开发者沟通的场所,在开发者社区往往能找到常见问题的解决方案,具体问题和场景的最佳实践,前瞻性技术研究等非常有价值的资料。
对于医院或是医疗集团客户来说,如果需要掌握信息平台或数据中台,能够达到自主维护、持续演进的目标,那么,无论是通过解决方案提供方还是通过产品技术提供方,都需要获得上述的多种技术服务支持。
八、选型中的常见问题
对于采用商业产品这一策略本身,需要经过大量的选型工作。产品技术提供方和解决方案提供商都会积极宣传自己的产品,而医院则需要对产品的特性,服务体系,性能表现,案例的代表性,综合实施效果等做出评估,方可得出对自己有利的评估结果。在这个过程中,客户往往还是需要综合运用多种手段,包括自行评估、走访典型案例和开展验证测试等手段,避免常见的一些问题,例如:
· 技术的可执行性评估不足
例如对于仅支持消息引擎的集成平台,往往需要按照一种特定的消息类型进行通信,使系统间交互具备统一协议,并且系统都需要改造以接入消息引擎。这样的规划不能说不好,但医院的遗留系统能不能都配合平台进行改造或医院有没有足够的预算支撑改造项目落地,以及业务系统现场改造的风险,都会影响实施效果。因此需要切实评估和核实。
· 产品特性不能达到预期
例如对于具有ETL能力的产品,需要评估其对于大容量数据(例如初始化数据加载过程)进行批量采集、转换和落盘的处理效率,以便与借助简单的SQL JDBC连接逐条抽数和转换的SQL适配器相区别。由于两种模式在处理速度上通常有数量级的差别,如果使用SQL适配器模式,在大批量对数据进行ETL操作时将不可避免地遭遇瓶颈。
· 产品对主流技术的覆盖不全面
在现在的技术条件下,即使对同一类型的接口,也往往有多种技术选择。如产品不能提供对这些技术的覆盖,则用户需要投入额外的成本和风险完成接入。例如对常见的负载均衡方案而言,通常对于推模式接口(由外部调用触发的接口),例如SOAP WebService或者REST API,往往都能提供负载均衡;而对于拉模式接口(由产品自身自动触发),例如SQL扫描或一些CDC功能接口,则无法直接受益于负载均衡技术。假如实际业务中有大量需要通过SQL获取数据的接口,则负载均衡集群并没有多少意义。
再如SQL接口可以基于JDBC或ODBC连接,如果产品只能支持其中一种连接,那么对于遗留系统的接入能力将大打折扣。
· 缺乏技术验证过程和约束
对于架构和技术的落地,通常需要验证过程,用户才可能获得预期的效果。例如市场上存在对架构模式进行过度简化与概念偷换的现象。例如将SOA架构等价于ESB、将ESB的概念偷换为接口引擎、或将集成平台概念偷换为消息引擎,而在实施时更进一步地简化为接口的注册和连接,实际上变成了点对点模式。由于集成架构将影响未来3~5年的医院数字化转型过程中的难度和成本,点对点模式的后续实施成本将随接口的数量增加指数上升,导致后期的实施成本居高不下。
当然,充分了解到以上关于供应商选择与技术选型的8个问题,才是真正的互联互通建设的起点,更重要的是,医院信息负责人还需要真正读懂评测要求,并了解本院建设互联互通的整体目标以及医院管理层、临床业务部门等相关部门的不同述求,把这些目标与述求一一映射到平台/中台解决方案中,才是成功通关的秘籍。