清除过滤器
文章
Michael Lei · 六月 18, 2023
在数字化时代,数据的重要性无可置疑。数据作为新型生产要素,不仅在宏观政策层面得到党和政府的大力推动,也是医院高质量发展的关键和改变医疗行业的驱动力。随着医疗信息化的迅猛发展,我们正迈向一个数据随处可及、人人可用易用的医疗信息化时代。这一时代将数据与人的需求相结合,致力于让数据能“主动”找到需要他们的医护人员和患者,每一个行业从业者,都应致力于为医护人员和患者提供简单易用的软件解决方案,减少工作量,提高效率,推动医疗行业的进步。
数据与人的融合是实现医疗行业数字化转型的核心。当然,医疗数据的收集、存储和管理对于提供高质量的医疗服务至关重要。然而,仅仅有大量的数据并不足够,我们需要将数据与人的需求紧密结合起来。这意味着我们应该让更多的数据关联起来,并且能服务于更多的人群,让患者能够随时随地访问他们的电子病历,让医生和科研人员也能及时有效地获取病人在医院围墙内外进行治疗和健康管理的数据,并且以直观易懂的方式呈现给医护人员和患者,使他们能够快速、准确地获取所需的信息。数据的融合还包括将不同来源的数据整合起来,为医护人员提供全面、完整的视图,同时基于医疗诊断的规则,不管是通过CDSS的形式,还是通过ChatBot(聊天机器人),帮助他们做出更好的决策。
实现数据和人的融合要按照人的需求投放数据。数字化转型的重要目标是为医护人员和患者提供所需的数据,以支持决策和治疗过程。这意味着我们应该了解用户的需求,将数据按照他们的角色、职责和关注点进行分类和投放。医生可能需要即时的患者数据、病历历史和最新的医学研究,而患者可能需要查看自己的健康记录、预约医生和接收个性化的健康建议。通过根据人的需求进行数据投放,新型软件可以提供个性化的服务和支持,形成千人千面,为每个用户提供有价值的信息。
简单易用是实现数字化转型成功的另一个关键。医护人员和患者使用的软件解决方案应该简单易用,不需要复杂的培训和技术知识。界面应该简单、直观、友好,操作流程简化和优化,以确保用户能够快速上手并高效地使用软件。简单易用的软件不仅能够减少用户的学习曲线和工作负担,还能提高用户满意度和工作效率。(比如Apple的医疗软件Apple Health,通过FHIR 技术,通过一个app能够连接数千家医院的病历数据,让患者可以通过一个app实现多家医院的互联网服务和数据整合)
无论是数字化转型还是高质量发展,软件为人服务始终是医疗信息化的核心宗旨。我们应该将软件看作是为人服务的工具,旨在帮助医护人员提供更好的医疗服务,提升患者的体验和健康结果。软件应该以用户体验为中心,并不断优化和改进,不断进行供给侧改革,以满足不断变化和不同人群的需求,而不是增加负担。
最后,数据会在安全可靠的前提下进行传递和流通。在互联网发展的早期时代,由于无法可依,野蛮生长,数据的滥用、隐私保护等存在很大问题。但随着《数据安全法》等法律法规的发布,相信未来的医疗行业数据一定会在更加安全、可靠、合规的前提下进行有序流动。
在未来的医疗信息化发展中,数据与人的关系将变得更加密不可分。通过数据的融合、按需投放、简单易用、安全可靠和以人为本的新一代软件,我们可以实现数据随处可及、人人可用易用的医疗信息化目标。这将为医护人员和患者提供更好的工作环境和医疗体验,推动整个医疗行业向前迈进。InterSystems公司作为创新性的数据平台解决方案供应商,我们始终致力于助力合作伙伴开发创新的解决方案,与合作伙伴一起共同实现这一愿景,改善医疗服务的质量和效率,提高患者体验的获得感的同时帮助医院降本增效,实现高质量发展。
文章
姚 鑫 · 六月 17, 2023
# 第六十章 镜像中断程序 - 使用主 `ISCAgent` 的日志数据进行 `DR` 提升和手动故障转移
## 使用主 `ISCAgent` 的日志数据进行 `DR` 提升和手动故障转移
如果 `IRIS A` 的主机系统正在运行,但 `IRIS` 实例没有且无法重新启动,您可以使用以下过程在通过升级后使用来自 `IRIS A` 的最新日志数据更新升级的 `IRIS C IRIS A` 的 `ISCAgent`。
1. 推广 `IRIS C`,选择 `IRIS A` 作为故障转移伙伴。 `IRIS C` 被提升为故障转移成员,从 `IRIS A` 的代理获取最新的日志数据,并成为主要成员。
2. 重新启动 `IRIS A` 上的 `IRIS` 实例,它作为备份重新加入镜像。
3. 在 `IRIS A` 重新加入镜像并变为活动状态后,可以使用使用升级的 DR 异步临时替换故障转移成员中描述的过程,将所有成员返回到它们以前的角色,首先是正常关闭 `IRIS C` ,然后在 `IRIS B` 的配置参数文件的 `[MirrorMember]` 部分中设置 `ValidatedMember=0`(请参阅配置参数文件参考中的 `[MirrorMember]`),将 `IRIS B` 重新启动为 `DR` 异步,将 `IRIS B` 提升为备份,并以 `DR` 异步方式重新启动 `IRIS C`。
注意:如果 `IRIS A` 的主机系统已关闭,但 `IRIS B` 的主机系统已启动,尽管其 `IRIS` 实例未运行,请按照手动故障转移到活动备份中所述在 `IRIS B` 上运行 `^MIRROR` 例程以确定 是否`IRIS B` 在发生故障时是一个活动备份。如果是这样,使用前面的过程,但在升级期间选择 `IRIS B` 作为故障转移伙伴,允许 `IRIS C` 从 `IRIS B` 的 `ISCAgent` 获取最新的日志数据。
## 使用来自日志文件的日志数据进行 DR 提升和手动故障转移
如果 `IRIS A` 和 `IRIS B` 的主机系统都已关闭,但可以访问 `IRIS A` 的日志文件,或者 `IRIS B` 的日志文件和消息日志可用,您可以使用最新的日志数据更新 `IRIS C`从升级前的初级开始,使用以下过程。
1. 使用 `IRIS A` 或 `IRIS B` 的最新日志文件更新 `IRIS C`,如下所示:
- 如果 `IRIS A` 的日志文件可用,则将最新的镜像日志文件从 `IRIS A` 复制到 `IRIS C`,从 `IRIS C` 上的最新日志文件开始,并包括来自 `IRIS A` 的任何后续文件。例如,如果 `MIRROR -MIRRORA-20180220.001` 是 `IRIS C` 上的最新文件,复制 `MIRROR-MIRRORA-20180220.001` 和 `IRIS A` 上的任何更新文件。
- 如果 `IRIS A` 的日志文件不可用但 `IRIS B` 的日志文件和消息日志可用:
1. 确认`IRIS B`很可能已被捕获,如下所示:
a. 确认当`A`及其代理不可用时,`B`同时断开与 A的连接。可以通过在`Messages.log`文件中搜索类似于以下内容的消息来检查 `IRIS B`断开连接的时间:
```java
MirrorClient: Primary AckDaemon failed to answer status request
```
b. 通过在其 `messages.log` 文件中搜索类似于以下内容的消息,确认 IRIS B 在断开连接时是活动备份:
```java
Failed to contact agent on former primary, can't take over
```
注意:`messages.log` 文件中的如下消息表明 `IRIS B` 在断开连接时未处于活动状态:
```java
nonactive Backup is down
```
当无法确认它是否已被追上时强制提升的 `DR` 异步成为主数据库可能会导致它成为主数据库而没有镜像生成的所有日志数据。因此,一些全局更新操作可能会丢失,而其他镜像成员可能需要从备份中重建。
2. 如果可以确认 `IRIS B` 处于活动状态,请将最新的镜像日志文件从 `IRIS B` 复制到 `IRIS C`,从 `IRIS C` 上的最新日志文件开始,然后包括来自 `IRIS B` 的所有后续文件。例如,如果 `MIRROR-MIRRORA-20180220.001` 是 `InterSystems IRIS C` 上的最新文件,请从 `IRIS C` 复制 `MIRROR-MIRRORA-20180220.001` 和任何更新的文件。检查文件的权限和所有权,并在必要时更改它们以匹配现有日志文件。
2. 在不选择故障转移合作伙伴的情况下将 `IRIS C` 提升为故障转移成员。 `IRIS C` 成为主要的。
3. 当 `IRIS A` 和 `IRIS B` 的问题得到修复时,尽早并在重新启动 `IRIS` 之前,在每个成员上的 `IRIS` 实例的配置参数文件的 `[MirrorMember]` 部分中设置 `ValidatedMember = 0`(参见 `[ MirrorMember]` 在配置参数文件参考)。说明指出,此更改是必需的。完成此操作后,在每个成员上重新启动 `IRIS`,从 `IRIS A`(最近成为主成员的成员)开始。
1. 如果成员在 `IRIS` 重新启动时作为备份或 `DR` 异步加入镜像,则不需要进一步的步骤。任何在故障成员上但不在当前主成员上的日志数据都已被丢弃。
2. 如果在 `IRIS` 实例重新启动时成员无法加入镜像,如重建镜像成员中描述的引用不一致数据的消息日志消息所示,则成员上的最新数据库更改晚于存在于上的最新日志数据 `IRIS C` 成为主要时。要解决此问题,请按照该部分中的描述重建成员。
4. 在大多数情况下,`DR` 异步系统不是主要故障转移成员的合适永久主机。在 `IRIS A` 和 `IRIS B` 重新加入镜像后,使用使用升级的 `DR` 异步临时替换故障转移成员中描述的过程将所有成员返回到它们以前的角色。如果 `IRIS A` 或 `IRIS B` 作为备份重新启动,则在备份处于活动状态时从正常关闭 `IRIS C` 开始,以故障转移到备份;如果 `IRIS A` 或 `IRIS B` 都重新启动为 `DR` 异步,将其中一个提升为备份,然后在 `IRIS C` 上执行正常关闭。将另一个以前的故障转移成员提升为备份,然后将 `IRIS C` 作为 `DR` 异步重启。
文章
Michael Lei · 二月 14
FHIR 用例集: 打破数字医疗壁垒,实现高质量发展
--促进互联互通,改进工作流程,提高数据洞察
简介
HL7® FHIR®(快速医疗互操作性资源)是以电子方式访问、交换和管理医疗信息的国际标准。与以往的标准不同,FHIR 可让帮助行业从业者轻松构建创新应用程序,有效地收集、汇总和分析来自不同来源的各种医疗保健和管理数据。医疗机构、社保/保险公司、政府机构、生命科学公司、医疗设备制造商和医疗科技等多种主体利用 FHIR 来简化信息流、提高数据洞察力、改善临床效果和业务成果。
FHIR 基于 JSON、HTTP 和 REST 等流行的网络技术。有了 FHIR,没有医疗信息化背景的软件开发人员也能使用熟悉的开发工具和开源技术,快速、轻松地满足政府机构、临床医生、研究人员、医疗行业从业者以及各类市场主体的数据需求。
FHIR 是一种灵活、适应性强的医疗数据模型,可轻松定制,以实现各种用例的互操作性。FHIR 由称为 "资源 "的离散、可计算的数据对象组成,以实现最佳效率。通过 FHIR 资源,应用程序可以访问单个医疗记录元素,而无需检索摘要文档中包含的所有数据。
本文回顾了 FHIR 的实际应用,并提供了 InterSystems 客户如何使用 FHIR 连接不同系统、加速数字化转型和提高数据洞察力的真实案例。
FHIR 商机无限
FHIR 正在改变医疗健康数据的访问和交换。无论您是为政府、医疗机构、公共卫生机构、保险公司还是厂商工作,FHIR 都能帮助您高效地获取、检索和共享来自电子病历系统、智能医疗设备、可穿戴设备、临床试验和公共卫生监测系统等不同来源的医疗数据。
当前应用和未来的 FHIR 用例FHIR支持实现大量的不同业务场景。您可以在各种部署场景中将 FHIR 用于各种目的。下面的列表总结了 FHIR 在不同行业领域的一些当前应用和潜在的未来用例。
医疗机构
应用场景: 患者数据访问 API机会:可以基于FHIR资源和技术框架实现卫健委互联互通三年攻坚计划以及国家数据局"数据要素x医疗行业"三年行动计划中提到的相关电子健康档案共享、检验检查互认、医疗行业数据要素流通、交易等战略目标,通过基于标准的 (FHIR) API 让患者以程序化的方式访问其健康数据(病史、化验结果、治疗计划等),以及未来可能的全国统一医疗健康档案超级APP(患者端)。
应用场景: 临床决策支持机会: 使用 FHIR 改善临床决策系统的洞察力。将实时电子病历数据安全传输到第三方系统进行分析并返回建议,帮助临床医生做出明智决策。与以往的标准和方法不同,使用 FHIR,您可以将临床决策支持功能直接嵌入电子病历,以简化流程。
应用场景: 医疗机构与支付方(医保/保险公司)的合规数据交换 机会: 利用 FHIR 自动化医疗机构与支付方之间的数据交换。消除资源密集、耗时的人工流程(降低飞行检查和审计成本)。允许医疗机构直接将电子病历数据转发给支付方,无需人工干预。
使用案例: 临床试验和研究机会: 使用 FHIR 无缝共享临床试验招募和分析所需的患者数据,加快临床研究进程。
设备制造商、医疗科技公司和应用开发商
用例:远程医疗和远程监控机会: 使用 FHIR 可将患者数据从家用医疗设备安全地传输给医疗服务提供者,以便他们有效地远程监控和管理患者。
用例: 移动医疗应用程序机遇: 患者可以在手机端访问在不同医院治疗的电子病历,并且确保患者数据的隐私和安全。
用例: 慢性病管理应用程序机会: 使用 FHIR 在医疗服务提供者之间无缝共享患者数据,以实现一致的监控和协调的护理计划。
用例: 药物管理应用程序机会: 为临床医生和护理人员创建多功能药物管理应用程序。使用 FHIR 在区域全民健康信息平台之间高效共享处方信息、用药计划和药房记录。
生命科学公司、政府机构和付款人
用例:健康信息交换机会: 使用 FHIR,政府、公共卫生、保险公司等可高效开展电子健康档案/电子病历共享调阅数据,以进行质量评估、护理差距识别、理赔裁定以及开展潜在的数据交易等。
用例: 护理计划机会: 利用 FHIR,让跨机构护理团队--医生、家庭医疗工作者、社区护理人员、家庭成员等--能够无缝交换信息。让不同的医疗保健系统进行有效沟通。确保所有护理团队成员都能获得最新的患者信息。
用例: 公共卫生报告机会: 使用 FHIR 有效地汇总和共享患者数据,以进行监控和人口健康管理,从而简化公共卫生报告。利用电子病历批量检索功能。(注:该功能自 2022 年起已成为所有美国电子病历系统的强制性要求,在WHO、OECD、欧盟、亚洲、港澳台等地区也正在逐步推广普及)
以上只是部分FHIR的用例,有了FHIR,从业者可以打开无限想象空间,创建丰富多样、互联互通的数字医疗创新应用。
文章
Hao Ma · 五月 24, 2023
镜像101
Caché 镜像是一种可靠、廉价且易于实施的高可用性和灾难恢复解决方案,适用于基于 Caché 和 Ensemble 的应用程序。镜像在广泛的计划内和计划外中断情况下提供自动故障转移,应用程序恢复时间通常限制在几秒钟内。逻辑数据复制消除了存储作为单点故障和数据损坏的根源。升级可以在很少或没有停机时间的情况下执行。
但是,部署 Caché 镜像确实需要大量规划,并且涉及许多不同的过程。与任何其他关键基础设施组件一样,操作镜像需要持续监控和维护。
您可以通过两种方式使用本文:作为常见问题列表,或作为理解和评估镜像、规划镜像、配置镜像和操作镜像的简要顺序指南。每个答案都包含指向每个主题的详细讨论以及每个任务的分步过程的链接。
当您准备好开始规划镜像部署时,您的起点应该始终是Caché 高可用性指南“镜像”一章的镜像架构和规划部分。
经常问的问题
了解和评估镜像
镜像有什么好处?
镜像能否部署在虚拟化环境中?
镜像可以部署在云端吗?
镜像的基本设计是什么?
数据库副本如何与实时生产数据库同步?
自动故障转移是如何触发的?有没有它没有涵盖的情况?
镜像是否提供灾难恢复?
规划镜像
如何规划镜像的架构?将包括哪些成员,他们将在哪里?
哪些网络和延迟注意事项申请?镜像需要什么样的网络配置?
在故障转移时将应用程序连接重定向到新主节点的选项有哪些?
镜像中的 Caché 实例有哪些兼容性要求?
如何将现有数据库迁移到镜像?
如果将镜像部署在虚拟化环境中,我应该考虑什么?
配置镜像
我需要考虑哪些配置准则?
如何保护镜像?
如何配置镜像虚拟IP地址(镜像VIP)?
我在哪里以及如何安装仲裁器?
如何安装和启动 ISCAgent?
如何创建和配置镜像?
如何创建镜像数据库?如何将现有数据库添加到镜像?
如何确保 ECP 在故障转移后重定向应用程序服务器连接?
当镜像 VIP 不可用时(例如在云中),我如何确保重定向应用程序连接?
如何将 Caché Shadow转换为镜像?
我应该查看哪些其他配置细节?
管理镜像
如何监控镜像的运行?
如何修改镜像?我能做什么调整?
我可以在镜像中添加成员吗?消除一?如何完全删除镜像?
如果我需要暂时从镜像中删除成员怎么办?
我必须一次升级镜像吗?我必须把镜子从生产中取出来做吗?
我应该了解哪些其他镜像或镜像相关的管理程序和细节?
镜像中断程序
了解和评估镜像
镜像有什么好处?
对于基于 Caché 和 Ensemble 的应用程序,存在三种实现高可用性的主要方法: 故障转移集群、 虚拟化 HA和 Caché 镜像。前两者最大的缺点是依赖共享存储,存储失败后果不堪设想;可选的存储级冗余可以改善这一点,但也可以延续某些类型的数据损坏。此外,软件升级需要大量的停机时间,对于许多故障,应用程序恢复时间可能有几分钟。
通过使用两个具有独立存储和逻辑数据复制的物理独立系统,镜像避免了共享存储问题,升级不需要停机或停机时间很短,应用程序恢复时间通常为几秒钟。这种方案还提供可靠和强大的灾难恢复能力,灾难恢复站点(DR)可以位于距生产数据中心任何适当的距离。
镜像的主要限制是它只复制数据库本身;应用程序所需的外部文件需要额外的解决方案,安全和配置管理目前是分散的。
以下资源提供了这些 HA 方法的详细分析和比较,以及有关镜像优势的更多信息:
系统故障转移策略( Caché 高可用性指南)
高可用性策略(白皮书)
业务连续性的高可用性(视频)
缓存镜像:高可用性的冒险(视频)
镜像:吞吐量架构(在线学习)
InterSystems Caché:数据库镜像:执行概述(白皮书)
镜像介绍(在线学习)
HealthShare:通过镜像实现高可用性(在线学习)
镜像能否部署在虚拟化环境中?
镜像经常部署在虚拟化环境中。镜像通过自动故障转移对计划内或计划外中断提供即时响应,而虚拟化 HA 软件会在机器或操作系统意外中断后自动重启托管镜像成员的虚拟机。从而允许故障成员快速重新加入镜像以充当备份(或在必要时接管为主)。
有关使用此方法的信息,请参阅 InterSystems 白皮书高可用性策略。
镜像可以部署在云端吗?
镜像可以有效部署在云端。由于云网络限制,使用虚拟 IP 地址(镜像 VIP)在故障转移后重定向应用程序连接通常是不可能的,但这可以使用负载均衡器等网络流量管理器有效克服。
镜像的基本设计是什么?
一个 Caché 镜像通常包括物理上独立的主机上的两个 Caché 实例,称为故障转移成员;镜像自动将主角色分配给一个,而另一个成为备份。应用程序更新主数据库,而镜像使备份数据库与主数据库保持同步。
当主服务器发生故障或不可用时,备份服务器会自动接管主服务器,并将应用程序连接重定向到它。当主实例恢复运行时,它会自动成为备份实例。
操作员启动的人工切换可用于在计划的维护或升级停机期间保持可用性。
镜像可选地包含称为asyncs的其他成员,用于灾难恢复以及商业智能和数据仓库目的。
一个镜像也可以只使用一个故障转移成员和一定数量的异步,例如当灾难恢复是主要目标时。
数据库副本如何与实时生产数据库同步?
镜像的备份成员和异步成员使用日志文件(Journal文件)与主成员保持同步,日志文件包含自上次备份以来对 Caché 实例中的数据库所做更改的时间顺序记录。在镜像中,来自主数据库的日志文件被发送到其他成员并dejournaled日志记录——也就是说,其中记录的更改被应用到数据库的本地副本,使它们与主数据库保持同步。
日志记录从主数据库到备份的传输是同步的,主数据库在关键点等待备份的确认。这使故障转移成员保持紧密同步,并且备份处于活动状态(Active),并准备好接管为主。异步从主服务器异步接收日志数据,因此有时可能会滞后一些日志记录。
自动故障转移是如何触发的?有没有它没有涵盖的情况?
只有在确认主服务器在没有人工干预的情况下不能再作为主服务器运行时,备份服务器才能自动接管。当故障转移成员之间的直接通信中断时,备份从第三方系统( 仲裁器)获得帮助以确认这一点,仲裁器与两个故障转移成员保持独立联系。
此外,如果备份无法确认其拥有或无法从主服务器获取最新的日志数据,则无法发生自动故障转移。在每个故障转移主机上独立于 Caché 实例运行的代理进程,称为ISCAgents ,参与自动故障转移逻辑和机制的这一方面和其他方面。
假设仲裁器正常运行,几乎所有计划外的主机故障都包括在内;只有将故障转移成员彼此隔离并与仲裁器隔离的网络故障,才能阻止活动备份接管发生故障或不可用的主要成员。
镜像是否提供灾难恢复?
一种类型的异步镜像成员是灾难恢复 (DR) 异步。 DR 异步具有主数据库上所有镜像数据库的副本,并且可以随时提升为故障转移成员。当中断导致镜像没有正常运行的故障转移成员时,您可以手动切换到被提升后的 DR 异步;数据丢失的程度将取决于发生中断时 DR 异步落后于主服务器多远,以及前主服务器的主机系统是否正常运行,是否允许它获取额外的日志数据。提升的 DR 异步也可用于许多其他计划内和计划外中断情况。
规划镜像
如何规划镜像的架构?将包括哪些成员,他们将在哪里?
镜像的大小、成员资格和物理分布将取决于您部署它的原因以及许多基础设施和操作因素,允许多种可能的配置
具有两个故障转移成员的镜像通过自动故障转移提供高可用性。在可选的异步成员中,一个或多个 DR 异步可以提供数据安全和灾难恢复能力,而报告异步用于数据挖掘和商业智能等目的。单个报告异步最多可以属于 10 个独立的镜像,从而使其可以充当企业范围的数据仓库,将来自不同位置的相关数据库集合在一起。
如果不需要自动故障转移,镜像也可以包含一个故障转移成员和多个用于灾难恢复和报告目的的异步。
一个镜像最多可以包含 16 个成员。因为故障转移成员之间需要低延迟连接,因此通常位于同一地点,但异步成员可以位于本地或单独的数据中心,包括为 DR 异步上的数据提供最大安全性的地理位置偏远的位置。
一台主机上可以安装多个镜像成员,但需要额外规划。
哪些网络和延迟注意事项适用?镜像需要什么样的网络配置?
主要的网络配置考虑因素包括可靠性、带宽和网络延迟,这是应用程序性能的重要考虑因素。选择对主要成员传输给其他成员的日志数据进行压缩是通常但不必须的做法。
每个镜像成员都有几个不同的网络地址,用于不同的目的,在规划支持您的镜像所需的网络配置之前,应该很好地理解这些地址。 包含在单个数据中心、机房或校园内的镜像以及涉及双数据中心和地理上分离的灾难恢复的镜像的示例镜像和网络配置将帮助您定义所需的网络配置。
在故障转移时将应用程序连接重定向到新主节点的选项有哪些?
镜像和 Caché 内置了几个自动重定向选项,包括使用虚拟 IP 地址 (VIP) 进行镜像、将 ECP 数据服务器标识为镜像连接,以及镜像感知 CSP 网关。
镜像 VIP 通常是一种非常有效的解决方案,但确实需要一些提前规划,尤其是在网络配置方面。
还提供一系列外部技术选项,包括使用网络流量管理器(例如负载平衡器) 、自动或手动 DNS 更新、应用程序级编程和用户级程序。
镜像中的 Caché 实例有哪些兼容性要求?
在确定要添加到镜像的系统之前,请务必查看Caché 实例和平台字节顺序兼容性的要求。由于故障转移成员可以随时交换主要和备份的角色,因此它们应该尽可能相似; CPU 和内存配置应该相同或接近,存储子系统应该具有可比性。
如何将现有数据库迁移到镜像?
任何 Caché 数据库都可以轻松添加到镜像中;它所需要的只是能够备份和恢复数据库,或复制其CACHE.DAT文件。程序在下一节中说明。
如果将镜像部署在虚拟化环境中,我应该考虑什么?
在虚拟化环境中使用镜像时,规划虚拟镜像成员主机与物理主机和存储之间的正确关系很重要;镜像和虚拟化平台方面也有重要的操作考虑因素。
配置镜像
我需要考虑哪些配置指南?
如果您计划配置镜像虚拟 IP 地址 (VIP) ,InterSystems 建议将故障转移成员配置为使用相同的超级服务器端口和Web 服务器端口。
主要故障转移成员上的 Caché 实例配置(例如用户、角色、名称空间和映射)或未镜像的数据(例如与 SQL 网关和 Web 服务器配置相关的文件)都不会被其他镜像成员上的镜像复制。因此,在发生故障转移时启用备份或任何 DR 异步成员(可能被提升)以接管主服务器所需的任何设置或文件必须在这些成员上手动复制并根据需要进行更新。
不要在配置为镜像成员的任何系统上禁用 Internet 控制消息协议 (ICMP);镜像依靠 ICMP 来检测成员是否可达。
由于日志记录是镜像同步的基础,因此必须监视和优化故障转移成员上的日志记录性能并通常遵循日志记录最佳实践。特别是,InterSystems 建议您增加所有镜像成员上的共享内存堆大小(Shared memory heap size)。
如何保护镜像?
保护镜像通信的主要方法是 SSL/TLS,它使用 X.509 证书加密镜像内的所有流量。强烈建议使用 SSL/TLS 安全性。要在镜像上启用 SSL/TLS,您必须首先在每个镜像成员上创建一个镜像 SSL/TLS 配置;您可能会发现在创建镜像之前执行此操作最方便。启用 SSL/TLS 时,添加到镜像的每个成员都必须在主服务器上获得授权;成员的 X.509 证书更新时也是如此。
对于使用 SSL/TLS 的镜像的另一层保护,您可以激活日志加密。这意味着日志记录在主服务器上创建时使用其活动加密密钥之一进行加密,并在其他成员取消日志记录之前解密。备份和所有异步必须激活相同的密钥,备份和 DR 异步也必须使用它来加密数据。
配置镜像使用的网络的方式对镜像的安全性也有重要影响。
如何配置镜像虚拟IP地址(镜像VIP)?
镜像 VIP 是通过在创建和添加成员到镜像或修改镜像时指定详细信息来配置的,但是需要一些准备工作,包括所需信息的标识以及镜像成员的主机和 Caché 实例的可能配置。
我在哪里以及如何安装仲裁器?
仲裁器的位置应尽量减少仲裁器和故障转移成员意外同时中断的风险(如果两个故障转移都失败,则仲裁器变得无关紧要),因此其位置主要取决于故障转移成员的位置。单个系统可以配置为多个镜像的仲裁器,前提是它的位置适合每个镜像。托管镜像的一个或多个故障转移或 DR 异步成员的系统不应配置为该镜像的仲裁者。
任何运行 2015.1 或更高版本 ISCAgent 的系统,包括托管一个或多个 Caché 2015.1 或更高版本实例的系统,都可以配置为仲裁器。您可以准备任何其他受支持的系统(OpenVMS 系统除外),包括托管 2015.1 之前的 Caché 实例的系统,通过安装 ISCAgent将其配置为仲裁器。
如何安装和启动 ISCAgent?
ISCAgent 随 Caché 自动安装,因此安装在任何镜像成员上。但是,必须将代理配置为在每个镜像成员上的系统启动时启动。
如何创建和配置镜像?
配置镜像是一个多步骤的过程:
创建镜像并配置第一个故障转移成员
配置第二个故障转移成员(如果需要)
授权第二个故障转移成员,如果使用 SSL/TLS(推荐)
配置异步镜像成员(如果需要,DR 或报告)
授权新的异步成员,如果使用 SSL/TLS(推荐)
在完成这些步骤中的任何一个之后,您可以在镜像监视器中查看镜像的状态以确认结果是否符合预期。
如何创建镜像数据库?如何将现有数据库添加到镜像?
在将数据库添加到镜像之前,您可能需要查看某些镜像数据库注意事项,这些注意事项与哪些内容可以镜像和哪些内容不能镜像、镜像和Shadow的同时使用、镜像数据库属性的传播以及镜像下每个实例的最大数据库数有关。
创建镜像数据库和添加现有数据库的过程是不同的,因为对镜像数据库的更改记录在镜像日志文件中,这与非镜像日志文件不同。如果数据库创建为镜像数据库,它从一开始就使用镜像日志文件,这使得通过在每个镜像成员上创建具有相同镜像名称的镜像数据库,可以很容易地将新数据库添加到镜像中。
当您将现有的非镜像数据库添加为主数据库上的镜像数据库时,它会从使用非镜像日志文件切换到镜像日志文件。因此,您不能简单地在其他成员上创建数据库,因为镜像无法将非镜像日志文件传送给其他成员。取而代之的是,在将数据库添加到主数据库的镜像后,您必须将其备份并在其他成员上恢复,或者将其CACHE.DAT文件复制到其他成员。
如何确保 ECP 在故障转移后重定向应用程序服务器连接?
无论您是否配置了镜像 VIP,您都可以通过将镜像 ECP 数据服务器配置为连接到它的每个 ECP 应用程序服务器上的镜像连接来确保 ECP 连接被重定向到新的主服务器。 (应用服务器不使用 VIP;因为它定期从指定主机收集信息,它会自动检测故障转移并切换到新的主服务器。)
当无法使用镜像 VIP 时(例如在云中),如何重定向应用程序连接?
只有当镜像成员位于同一网络子网上时才能使用镜像 VIP,而当它们位于不同的数据中心时通常不会出现这种情况。出于类似的原因,VIP 通常不是云中部署的选项。
可以使用一系列外部技术替代方案,包括使用负载均衡器(物理或虚拟)等网络流量管理器,可用于实现与 VIP 相同级别的透明度,向客户端应用程序提供单个地址或设备。其他可能的机制包括自动或手动 DNS 更新、应用程序级编程和用户级程序。
如何将 Caché Shadow转换为镜像?
镜像提供了一个Shadow到镜像实用程序,允许您将Shadow源和目标以及它们之间映射的Shadow数据库转换为具有主数据库、备份或异步数据库和镜像数据库的镜像。
我应该查看哪些其他配置细节?
虽然默认值通常是所需的全部,但您可能希望自定义 ISCAgent 端口号。
在主要故障转移成员上,您可能希望将代码从现有的^ZSTU或^ZSTART例程移动到用户定义的^ZMIRROR 例程,它允许您为特定镜像事件实现自定义的、特定于配置的逻辑和机制,以便它是直到镜像初始化后才执行。
将镜像与 Ensemble 一起使用时,您应该了解具有镜像数据的 Ensemble 命名空间的特殊要求以及 Ensemble Autostart 在镜像环境中的功能。
管理镜像
如何监控镜像的运行?
您可以在任何镜像成员的 Caché 管理门户中加载的Mirror Monitor提供有关的详细信息
镜像及其每个成员的运行状态,包括使用 SSL/TLS 时成员的 x.509 DN。
在故障转移成员上,两个故障转移成员的网络地址和仲裁器连接状态,以及仲裁器的地址;在异步上,报告异步所属的镜像。
在备份和异步成员上, 日志数据从主数据传输的状态和日志数据的Dejournaling,以及日志数据从主数据到达的速率。
加载镜像监视器的成员上镜像数据库的状态。
Mirror Monitor 还允许您执行许多操作,包括查看和搜索成员的日志文件、 将 DR 异步提升为故障转移成员或将备份降级为 DR 异步,以及激活、赶上和删除镜像数据库。
您可以在镜像成员的%SYS命名空间中使用 Caché 系统状态例程 ( ^%SS ) 来监视其镜像通信进程。
如何修改镜像?我可以修改什么?
在主服务器上编辑镜像以更改镜像的配置(包括 SSL/TLS、镜像 VIP 等)并在网络配置更改时更新成员的网络地址。您还必须编辑主服务器上的镜像以授权其他成员上的 X.509 证书更新。
在异步上编辑镜像以更改异步类型,将报告异步添加到另一个镜像,并进行其他特定于异步的更改。
您可以使用Mirror Monitor从任何成员(且仅该成员)的镜像中删除镜像数据库,尽管其影响因所涉及的成员类型而异。
我可以在镜像中添加成员吗?删除一个?如何完全删除镜像?
您始终可以将异步成员添加到镜像中,最多可添加 16 个成员。如果你有一个故障转移成员和少于 15 个异步,你总是可以添加一个备份。您还可以通过将 DR 异步提升为故障转移成员来替换备份,这会自动将当前备份降级为 DR 异步。
您可以编辑任何成员的镜像以从镜像中删除该成员。要完全删除镜像,您必须按特定顺序删除成员并采取其他步骤。
如果我需要暂时从镜像中删除成员怎么办?
您可以使用镜像监视器通过断开成员与镜像的连接来无限期地停止备份或异步成员上的镜像,例如进行维护或(在异步情况下)减少网络负载。
在异步上,您还可以暂停镜像中所有数据库的Dejournaling,而不暂停从主数据库到异步数据库的日志数据传输。
我必须一次升级镜像吗?我必须把镜像从生产中取出来做吗?
镜像的所有故障转移和 DR 异步成员必须是相同的 Caché 版本,并且只能在镜像升级期间有所不同。一旦升级的成员成为主要成员,您就无法使用其他故障转移成员或任何 DR 异步成员,直到它们也升级为止。通常,最佳做法是同时将报告异步升级到同一版本。
您选择的升级过程取决于您是进行维护版本升级、 不对镜像数据库进行任何更改的主要升级,还是对镜像数据库进行更改的主要升级。所提供的程序旨在最大限度地减少应用程序停机时间;在前两种情况下,您通常可以完全避免停机时间,而在后一种情况下,它通常仅限于执行计划的故障转移和进行所需的镜像数据库更改所需的时间。
当您在计划停机期间进行重大升级并且不需要最小化应用程序停机时间时,您可能还想使用一个更简单的过程。
我应该了解哪些其他镜像或镜像相关的管理程序和细节?
您可以在未使用SSL/TLS 的镜像上启用安全性,只要每个成员都具有有效的镜像 SSL/TLS 配置。
您可以为未使用它的镜像激活日志加密,只要该镜像使用 SSL/TLS 安全性并且用于加密主要日志数据的活动加密密钥在备份和所有异步中也处于活动状态。
根据您的硬件和网络配置,您可能需要调整镜像的服务质量超时(QoS 超时)设置,这在故障转移机制中起着重要作用。通常,如果需要更快地响应中断,则可以在部署在具有专用本地网络的物理(非虚拟化)主机上的镜像上减小此设置。
如果绝大多数镜像数据库更新由高度压缩的数据(如压缩图像)或加密数据组成,则日志数据压缩预计不会有效,因此可能会浪费 CPU 时间。在这种情况下,您可以选择配置或修改镜像以将日志数据设置为Uncompressed 。 (使用 Caché 数据库加密或日志加密不是选择压缩的一个因素。)
如果主要成员和其他镜像成员之间的网络延迟成为问题,您可以通过微调操作系统 TCP 参数来减少它,以允许主要成员和备份/异步成员分别建立适当大小的发送和接收缓冲区.
^MIRROR 例程为所有镜像任务提供了管理门户的命令行替代方案。 SYS.Mirror API 提供了以编程方式调用通过管理门户和^MIRROR例程可用的镜像操作的方法。
镜像中断程序
有关处理各种计划内和计划外镜像中断情况的建议过程的概述,请参阅镜像中断过程。
文章
Qiao Peng · 十月 17, 2023
2023年6月底,世卫组织(WHO)和HL7签署了合作协议,利用HL7 FHIR提供互操作性,来支撑WHO的SMART指南(SMART Guideline)愿景 - 使用数智化的方式推动并加速一致化的健康干预措施建议,让世界上每个人都能立即从临床、公卫和数据使用建议中充分受益。
作为WHO的《2020-2025 年全球数字卫生战略》的一部分,SMART 指南使用 FHIR 、HL7的临床质量语言 (CQL) 和ICD标准以表达 WHO 的各种健康和临床指南,实现数据互操作、决策支持与指标、术语的一致性。这些标准被进一步利用来为各国及其合作伙伴开发一个由软件库、服务和工具组成的支持生态系统,并作为数字公共产品服务全球卫生健康事业。
为什么世卫组织会采用FHIR作为卫生信息互操作的标准在全球推广其一致化的健康干预措施建议?因为FHIR不仅标准成熟适用,而且还具有一个极具生命力的生态。
一个有生命力的标准会吸引生态的构建,而完善的生态将促进标准的成熟和演进。HL7 FHIR作为新一代的卫生信息互操作标准,其生态已经初具规模并蓬勃发展。
HL7 FHIR的知识产权类型
HL7 FHIR的知识产权是CC0,也就是知识共享。任何机构、组织和个人都可以无需向HL7申请而免费使用、扩展FHIR的标准。其知识产权类型配合FHIR标准的丰满程度,极大地鼓励和促进了基于FHIR的生态建设,应该也是WHO采用FHIR的原因之一。
FHIR的标准发布和标准的推广
标准应该是方便可及的 - 不仅有用户可阅读、可理解的文字说明,更需要要可以直接下载让计算机可用、可理解的电子结构化标准。
HL7 FHIR官网详细说明了每个版本、每个FHIR资源的结构与关系、使用范围、用例和示例。在下载页面提供了各种版本的标准、值集、profile和工具的免费下载。
对于用户的扩展、再约束和实施指南,有专门的实施指南注册和发布网站。这里可以免费注册自己的实施指南、也可以访问、查阅和下载别人的实施指南,从而让基于FHIR标准的自定义扩展可以无障碍地被分享、使用、理解,甚至进一步扩展。
下图是发布在注册网站的按用例类型统计的FHIR实施指南:
这众多方向的实施指南也是FHIR横跨交叉领域建立起成熟生态的体现。FHIR有什么快速建立生态的秘诀?
成熟的卫生信息标准要能应对各种行业互操作挑战,FHIR有一个四层机制用于制定标准并用各种互操作挑战来测试、验证和推进FHIR落地:
工作组(workgroups):FHIR有40多个工作组,专注不同的领域的需求,并制定和改进相关FHIR资源和用例标准。例如FHIR基础架构、基因组学、电子健康档案、财务管理、设备...
加速器计划(accelerators):为了推进在主要互操作领域的成熟和落地,FHIR建立加速器计划让每个领域的各个利益相关方参与进来,通过研究各方的需求、凝聚各方的智慧来推动FHIR。如今已经有8个不同领域的加速器计划:
例如Vulcan是专注连接临床研究、转化研究和医疗保健的加速器,它的成员不仅有HL7这样的标准开发组织,还有学会 - 例如约翰霍普金斯医学院,行业协会 - 例如全球医疗数据科学社区PHUSE,政府机构 - 例如FDA,技术厂商 - 例如InterSystems,药厂 - 例如GSK,甚至意见领袖。
课题(projects):FHIR通过课题,研究具体的需求、实现具体的目标,让FHIR扎实、可用。例如Vulcan加速器有以下课题:
课题
目标
Schedule of Activities (SoA)
活动安排
用FHIR表示电子表格中的活动时间表。 使得研究中的每项活动的描述、时间和标识都能保持一致
Real World Data (RWD)
真实世界数据
以标准化的格式从EHR中提取数据,以支持临床研究,特别是向监管机构提交数据
Phenotypic Data
表型数据
为基因组研究和基因组医学提供更多高质量的标准化表型信息
Electronic Product Information (ePI)
电子产品信息
为产品信息(各论)定义一个共同的结构,支持患者对产品数据的跨边界交换
Adverse Events (AE)
不良事件
支持对不良事件的报告和格式进行标准化。 提高相关FHIR资源的成熟度
FHIR to OMOP
FHIR与OMOP映射
支持开发FHIR到OMOP的数据传输,以便更好地分析临床数据,用于研究
连接测试马拉松(connectathons):这是一个针对技术厂商的FHIR互操作系列化的一致性认证。每年3次的连接测试马拉松会确定众多的具体互操作用例,厂商选择并参与这些用例,用FHIR进行跨厂商的互操作测试。它不仅是技术厂商验证自己的FHIR互操作一致性的试验场,更是通过测试和反馈来发现标准的问题、确定标准适用性的大型沟通会。
FHIR confluence上公布有历次的连接测试马拉松的用例说明、实施指南、学习资料等详尽的资料。
除了这些手段,HL7还有FHIR认证,建立FHIR标准的智力资源池、确保FHIR在全球的正确采纳。
FHIR标准的适应性
FHIR的适应性核心在于其标准的设计 - 通过profile,在资源模型层面已经考虑到如何让用户进行不破坏标准的扩展和再约束;在标准成熟上,设计了成熟度模型,让标准基于实际使用和反馈逐步成熟。
Profile可以让用户裁剪、扩展FHIR标准,以适用于自己的术语体系和用例场景,实现基于统一标准的千人千面。
在标准的理解与反馈上,FHIR官方沟通提供了开放的交流和反馈的渠道。
FHIR生态的工具
成熟的生态工具是FHIR的一大亮点。这些工具是整个生态贡献的,好的工具得到广泛认同和采纳,既促进了标准的理解与使用、也避免了低水平的重复建设。
1. 标准学习工具:
理解和学习是标准推行的第一要务。除了汗牛充栋的学习材料和视频,FHIR还有不错的学习网站,例如Clinfhir ,最初设计是方便医生理解如何用FHIR构建和解决自己的用例的,但实际上也被广大卫生信息从业者用于理解FHIR标准。
2. 测试数据生成工具:
想学习标准?没有什么比直观的数据更能说明问题了。FHIR生态下有名的Synthea是一个基于马塞诸塞州的患者真实数据经过统计、混淆后的FHIR测试数据生成工具,可以按用户要求生成指定数量的、符合真实数据分布的FHIR资源,会为每个生成的虚拟患者生成一个FHIR boundle文件,并生成对应的医院、医生等FHIR资源。大家可以免费下载Synthea使用它产生测试数据。
另外,国内也广泛使用的MIMIC - 麻省理工贝斯以色列迪康医学中心的有5万多患者真实完整的高质量重症医疗数据集,如今也有了FHIR版本。
3. FHIR服务器:
还没有FHIR服务器,怎么测试FHIR?
FHIR生态下有大量的免费沙箱,用户可以选择它们进行标准的学习和测试。例如官网提供的沙箱和各个厂商提供的沙箱。通过各种API工具,例如postman,学习者无需注册即可以了解FHIR标准的方方面面,甚至将自己的测试数据加载进去并测试自己的解决方案。
4. 标准扩展和再约束构建工具:
如何方便、直观地构建自己的术语、扩展和再约束(Profile)和用例?FHIR生态下有众多公司提供的免费工具可用 - 随君取用。例如术语扩展可以用Snapper和FSH、进行小规模profile开发可以用可视化的Forge或Trifolia-on-FHIR、进行大规模的profile和实施指南开发可以用FSH。
5. 标准验证工具:
需要基于profile对FHIR资源进行校验?资源更多了,不仅有FHIR官网提供的FHIR资源校验网页,还有各种开发语言版本的校验工具代码:
JAVA
C#/DotNet
FHIR生态下百花齐放的各种应用架构、应用方向
更令人眼前一亮的是FHIR生态下各种应用架构、应用方向和众多其它生态对FHIR的采纳。
应用开发架构:
FHIR提供了标准卫生信息模型和相应的API,为行业应用的快速开发提供了坚实的基础。FHIR生态下最有名的SMART on FHIR,实现即插即用和可复用的应用开发架构。在国际卫生信息互操作标准发展简史中有简要介绍。
SMART on FHIR市场已经有大量的应用可以直接下载部署。
决策支持架构:
决策支持已经是卫生信息数字化转型的核心需求之一。卫生信息化已经建设了各种基于知识库和基于机器学习的决策支持系统,涵盖了临床、业务管理、费用、组学与科研、公卫、健康管理等全部业务,但仍面临众多挑战。
任何知识库系统和决策支持系统面临的一个关键挑战是决策支持的可移植性!如果决策支持厂商都按自己的数据、术语和服务标准构建解决方案,用户在使用多个决策支持产品时,将面临大量数据转换和映射及服务集成带来的非常高的实施成本和潜在决策错误风险。
FHIR通过Clinical Reasoning模块和CDS Hooks分别提供了本地决策支持架构和外部决策支持架构,通过标准化降低成本和风险、提高决策效率和范围。这里是对CDS Hooks的介绍。
其它标准对FHIR的采纳:
相较于之前流行的互操作标准,FHIR在标准化、灵活性、可用性 三方面取得了很好的平衡。FHIR资源模型比大多数的行业通用数据模型(CDM)都简化,方便使用。曾经各自为战的众多标准都发现FHIR无处不在,且FHIR资源和API可以作为自己的数据和访问数据的基石,而融入FHIR生态可以更方便获得数据、获得更多的推广、发挥更大的价值,因此一系列的XX on FHIR项目应运而生 - 或者直接采纳FHIR、或者与FHIR相兼容。除了上面提到的SMART on FHIR,这里简单汇总一下主要的已完成和进行中的on FHIR项目和标准。
1. IHE
IHE(Integrating the Healthcare Enterprise)是国际上比较流行且成功的卫生信息交换服务规范。它一直采用流行和稳定的互操作基础标准来开发自己的服务规范,最初使用DICOM + HL7 V2消息,后来用到HL7 V3 和CDA。IHE发现新的FHIR互操作标准有助于应对新的用例、并更好解决老的用例,认为FHIR会成为最流行的互操作基础标准,因此已经发布了很多基于FHIR的IHE服务,尤其是那些和移动业务相关的服务,例如移动患者人口统计查询 (PDQm)。
2. OMOP on FHIR
OMOP(Observational Medical Outcomes Partnership)是包括国内在内全球科研人员进行真实世界研究的重要工具,它开发了通用数据模型CDM和分析工具库。
HL7国际和OHDSI宣布合作提供单一的通用数据模型,用于共享临床护理和观察研究信息 - 这就是OMOP on FHIR项目。
OMOP-on-FHIR 是构建在 OMOP CDM 数据库之上的 FHIR 服务器,它提供中间映射层,实现OMOP CDM和FHIR资源之前的双向转换,从而打通两大生态,使临床医生和研究人员能够从多个来源提取数据并以相同的结构进行分析处理与共享交换而不会降低数据质量,可以同时使用两个生态下丰富的应用与工具,利用各自的生态优势。例如OMOP让FHIR生态可以利用其丰富的预测模型,而FHIR让OMOP的研究分析可以集成到临床工作流程中,推动精准医学的落地。
3. FHIR to CDISC Joint Mapping
CDISC 是一个标准开发组织,开发了生物制药行业使用的诸多数据标准,常用于提交临床试验数据以进行分析和监管审批。
通过与HL7合作,FHIR to CDISC Joint Mapping实施指南定义了FHIR 与三个特定 CDISC 标准之间的映射:
研究数据列表模型实施指南 (SDTMIG) 3.2
临床数据采集标准协调实施指南 (CDASH) 2.1
实验室1.0.1
通过简化 HL7 FHIR和 CDISC 标准之间的数据转换,消除使用临床信息支持科研的障碍。用途包括:
捕获“真实世界证据”(RWE),让那些不是为临床试验目的采集的数据可以用于研究监管
利用FHIR 的 SMART等技术,直接在临床系统内部捕获试验驱动的数据,而不是建立单独的临床试验管理解决方案
在回顾性研究中更容易利用临床数据
创建病例报告表单 (CRF),链接到使用 FHIR 资源和Profile定义的数据元素
使两个标准社区的专家能够理解彼此的术语,并随着两套规范的不断发展更好地协调它们
4. 通用数据模型协调 Common Data Models Harmonization(CDMH)
在卫生信息领域,有众多的通用数据模型(Common Data Models)服务于不同的或相同的业务领域。虽然都是“通用”数据模型,但数据在彼此之间并不通用。
FHIR的细颗粒度统一语义资源模型可以作为众多通用数据模型间的桥梁。通用数据模型协调(CDMH)目标就是借助FHIR打通各个通用数据模型,让它们的数据可以相互转换。
CDMH 项目由美国FDA 领导,与其他联邦政府机构合作。已发布的通用数据模型协调 (CDMH) FHIR 实施指南 (IG) 将重点放在以患者为中心的结果研究 (PCOR) 和其它目的提取的观察数据的映射和转换为 FHIR 格式。该项目重点关注以下四种通用数据模型 (CDM) 到 FHIR 的映射:
以患者为中心的结果研究网络 (PCORNet)
整合生物学和床边 (Informatics for Integrating Biology & the Bedside - i2b2) 临床试验 (ACT) 信息学,也称为 i2b2/ACT。
观察性医疗结果合作伙伴 (OMOP)
美国食品和药物管理局的哨兵(Sentinel)
5. Arden Syntax on FHIR
和HL7的临床质量语言(Clinical Quality Language - CQL)类似,Arden Syntax 是一种结构化、可执行的医学知识表示和处理语言,将医学知识表达为独立的单元 - 医学逻辑模块(Medical Logical Modules),常用于设计CDS系统,构建临床指南规则和临床决策规则。
新版本 Arden Syntax 3.0 版采用FHIR进行扩展,重新定义了基于FHIR的标准化的数据模型和数据访问方式。作为经过审计、基于共识的迭代 HL7 标准开发流程的一部分,3.0版已成功通过投票。
6. HL7 V2 to FHIR
HL7 V2在全球依然有很高的采纳度,但其局限性和FHIR的成熟度都在推动从V2到FHIR的迁移。HL7 V2 to FHIR 项目建立实施指南,将HL7 V2的组件映射到FHIR组件:V2的消息、消息段、数据类型和词汇分别映射到 FHIR 的Bundle、FHIR资源、数据类型和编码系统,并对FHIR进行相应扩展以弥补二者间的差距。
7. C-CDA on FHIR
C-CDA是最广泛实施的 HL7 CDA 实施指南之一,涵盖了临床护理的文档范围。CDA 和 FHIR 之间的互操作能力是推动临床文档进化的重要渠道。
C-CDA on FHIR 实施指南 (IG) 定义了一系列 FHIR 配置文件,以表示 C-CDA 中的各种文档类型,并弥补二者设计上的差异。C-CDA on FHIR 利用FHIR使文档标准更为精简。
还有更多的on FHIR项目没有介绍到,例如SNOMED on FHIR、PDMP on FHIR... 同时可以预期还会有越来越多的on FHIR项目会不断涌现。
不仅是这些on FHIR 项目,越来越多的机构发现FHIR的价值,将自己原来的数据模型改为FHIR。例如美国互操作核心数据集USCDI(U.S. Core Data for Interoperability) 起初采用通用临床数据集CCDS作为模型, 如今已经完全采纳FHIR,并且成为美国国家FHIR标准US Core的一部分。FHIR也得到了很多国家采纳作为国家级卫生信息互操作的标准。
大规模数据统计与分析:
一个好的标准应该有助于解决完整的行业需求。FHIR作为行业互操作标准已经超越了传统互操作的能力范围,除了互操作的数据模型、消息、文档、服务和API,FHIR服务器加上FHIR资源仓库为大规模的卫生信息持久化和访问提供了方案。
FHIR的完整蓝图目前尚缺一块拼图 - 基于FHIR的大规模数据统计与分析。
1. 大规模数据检索
FHIR API提供检索类型的API,通过查询参数(Search Parameter)对资源进行检索。
例如: 想要获取所有检验项目为loinc 1234-1,且检验结果小于9.2的Observation资源,可以用这样的查询参数:
GET http://fhirsvr.com/Observation? code-value-quantity=loinc|1234-1$lt9.2
除了FHIR Core发布的查询参数,用户还可以扩展自己的查询参数,满足检索需求。
FHIR标准里的FHIR Path为FHIR资源模型提供了类似于XPath的资源路径导航和获取语言,可以方便地筛选、过滤层次化的FHIR数据。
但FHIR查询API和FHIR Path都仅适合于单资源类型的检索,对于需要多类型资源联合分析、汇聚、统计等分析需求无能为力。
2. 大规模的数据统计分析
HL7为临床质量指标与决策支持提出了临床质量语言(Clinical Quality Language - CQL) ,CQL如今基于FHIR,使用FHIR资源模型来构建标准化的指标体系,以支持决策和基于指标的管理。
对于科研数据分析,借助上面介绍的OMOP on FHIR和其它项目,用户可以用自己熟悉的科研工具并利用FHIR数据支持自己的科研工作,本质上是将FHIR数据转换并导入自己的科研工具。
对于通用大规模数据统计分析,虽然FHIR提供了API、FHIR资源数据序列化的JSON、XML可以作为文档进行分析,但市面上的统计分析工具和机器学习工具大都支持SQL,SQL也是最流行的数据统计分析语言。
FHIR的深层次化模型是立体的、对象化的,而SQL是扁平的、表格化的。这个差异让FHIR对主流分析工具和机器学习工具不友好。这对基于FHIR原生的大规模数据分析利用造成了障碍,是FHIR最需要完善的那一块。
FHIR和生态已经创立了很多项目,努力补上这一环。
SQL on FHIR
SQL on FHIR项目的思路是为SQL用户提供FHIR的SQL表示层。SQL表示层提供一个机制:让用户根据自己的需要基于FHIR Path定义视图。这里的视图不是SQL视图,而是一个SQL模型的逻辑表达,由一个新的FHIR工件ViewDefinition定义。各个技术厂商负责物理实现它并展现为SQL表。
例如下面的视图定义:
{
"resourceType": "http://hl7.org/fhir/uv/sql-on-fhir/StructureDefinition/ViewDefinition",
"select": [
{
"column": [
{
"path": "getResourceKey()",
"alias": "id"
},
{
"path": "gender"
}
]
},
{
"column": [
{
"path": "given.join(' ')",
"alias": "given_name",
"description": "A single given name field with all names joined together."
},
{
"path": "family",
"alias": "family_name"
}
],
"forEach": "name.where(use = 'official').first()"
}
],
"name": "patient_demographics",
"status": "draft",
"resource": "Patient"
}
它定义一张这样的SQL表:
考虑到FHIR资源模型的复杂,SQL on FHIR目前尚待成熟。当前是版本2,尚未发布,且有很多限制,例如不能在视图里定义跨资源的字段。
技术厂商的FHIR资源SQL实现
除了SQL on FHIR项目,很多技术厂商也在借助自身技术上的优势为FHIR提供SQL访问层。
例如InterSystems IRIS是一个多模型数据平台技术,它可以同时支持对FHIR资源逻辑模型使用对象建模、对FHIR序列化的JSON/XML使用文档建模,并将这些模型投射为SQL模型。InterSystems IRIS正是借助于这个特性,提供一个名为FHIR SQL构建器(FHIR SQL Builder)的工具,用户通过图形化方式拖拽建立需要的SQL模型,而无需拷贝和转换数据。
FHIR生态正展现出蓬勃的生命力,如今已经是百花齐放。FHIR展现的统一行业语义能力和强大的生态,不仅帮助WHO发布数字公共产品服务,也可以赋能卫生信息数字化转型。
文章
Michael Lei · 四月 9
人工智能不仅限于通过带有说明的文本生成图像,或通过简单的指示创建叙事。您还可以制作图片的变体,或为已有图片添加特殊背景。此外,您还可以获得音频转录,无论其语言和说话者的语速如何。让我们来分析一下文件管理是如何工作的。
问题描述
在分析 OpenAI 有关需要将文件作为输入值的方法的信息时,必须使用 multipart/form-data 提供参数。
在 IRIS 中,我们知道如何使用 JSON 内容创建对 POST 方法的调用。但在这种情况下,使用带有 Base64 格式文件内容的参数并不实用。
要在多址/表单数据(multipart/form-data)中包含文件内容,必须使用%Net.MIMEPart.类。
要在我们的调用中包含文件,应创建一个与类对象 %Net.MIMEPart 相关联的 Content-Disposition 标头
set content = ##class(%Net.MIMEPart).%New()
set contentDisposition = "form-data; name="_$CHAR(34)_"image"_$CHAR(34)
set contentDisposition = contentDisposition_"; filename="_$CHAR(34)_fileName_$CHAR(34)
do content.SetHeader("Content-Disposition",contentDisposition)
由于我们使用请求类来保留进程的值,因此我们必须将 Base64 内容转换为流,以构成内容的主体。
我们可以使用StreamUtils实用程序将 Base64 转换为流。
注意:"pImage"变量包含文件内容的 Base64 字符串。
Do ##class(HS.Util.StreamUtils).Base64Encode(pImage, .tStream)
Set content.Body = tStream
不过,在 2023 年全球峰会上,我有幸从 InterSystems 专家那里学到了一个更好的技巧。他告诉我,这种执行方法比 StreamUtils 更有效,因为 StreamUtils 最后会循环读取字符串并记录到 Stream 中。这个解决方案就像使用 JSON 并将其转换为 Stream 的 Get 一样简单。
set contentfile = {}
set contentfile.file = pImage
set content.Body = contentfile.%Get("file",,"stream<base64")
在调用中包含了所需的所有参数后,我们就可以创建一个新的 MIMEPart 类来封装部件了。
Set rootMIME = ##class(%Net.MIMEPart).%New()
do rootMIME.Parts.Insert(content)
set writer = ##class(%Net.MIMEWriter).%New()
set tSC = writer.OutputToStream(tHttpRequest.EntityBody)
set tSC = writer.WriteMIMEBody(rootMIME)
Set tContentType = "multipart/form-data; boundary="_rootMIME.Boundary
set tSC = ..Adapter.SendFormDataArray(.tHttpResponse, "POST", tHttpRequest,,,url)
这就是我们如何将文件内容发送到我们在 OpenAI 中需要的方法。
Image files图像文件
图像方法允许您发送图片并进行变化。由于所有插图都必须是 PNG 格式,因此当我们以 Base64 格式指明文件内容时,文件名会随机生成,并带有 PNG 扩展名。下面是一个如何更改照片的示例。
Original
Variation
正如你所看到的,程序以自己的方式解释指令。它认为公司的标志是一个圆圈,所以用另一个圆圈代替了它。它还发现办公室有一扇玻璃门,于是用另一扇玻璃门代替,但暂时用砖墙代替。此外,它还修改了衬衫的颜色,并改变了男子手臂的位置。此外,OpenIA 还允许您通过提供一个蒙版来编辑图像,蒙版上有您想要插入提示内容的区域。利用同一幅图像,我应用了一个去掉图像背景的蒙版。
Original
Mask
当我要求它把我传送到牙买加海滩时,得到了如下结果:
现在,下次见到亲朋好友时,您就可以炫耀自己的假期了 😊
Image图像
Endpoint: POST https://api.openai.com/v1/images/variations
它允许你对已有的图像进行修改。由于它不需要提示您要如何修改,因此我们必须相信人工智能的品味,它会如何解释这张图片。此外,我们还可以定义大小和返回结果的方式,无论是通过链接还是 Base64 格式的内容。
输入参数如下:
image: 必选
在这里,您要提及要转换的图像文件。
n: 可选. 默认为 1
在此区域,您可以决定生成图像的最大数量。(使用 1 到 10 之间的数字)。
size: 可选. 默认 1024x1024
定义图像大小,其数值必需为 “256x256”, “512x512”, 或者 “1024x1024”.
response_format: 可选.默认是“url”
这个参数是关于您希望如何返回生成图像的格式。此处的值应为 "url "或 "b64_json"。
Endpoint: POST https://api.openai.com/v1/images/edits
它可以让你修改现有的图片,根据掩码文件,按照提示创建图片。此外,我们还可以指定尺寸和返回结果的方式,无论是通过链接还是 Base64 格式的内容。输入参数如下:
image: 必选
如上.
mask: 必选
这部分是关于所应用的蒙版图像文件.
n: 可选,默认 1
如上
size: 可选,默认 1024x1024
如上
response_format: 可选. 默认是 “url”
如上
Audio files声音文件
OpenAI 管理的不仅仅是图像。我们还可以使用音频文件来获取所提供录音的转录或翻译。这种方法使用 Whisper 模型,可以区分专有名词、品牌和俚语,从而提供正确的转录和翻译。例如,将 "微型机器 "作为一个品牌来谈论,与将 "微型机器 "作为一个普通名词翻译成西班牙语是不一样的。下面的例子是对 80 年代一个著名广告插播的转录:
因此,指示 Whisper 为我们转录音频的结果如下:
{
"text": "This is the Micromachine Man presenting the most midget miniature motorcade of micromachines.
Each one has dramatic details, terrific trim, precision paint jobs, plus incredible micromachine pocket playsets.
There's a police station, fire station, restaurant, service station, and more. Perfect pocket portables to take anyplace.
And there are many miniature playsets to play with and each one comes with its own special edition micromachine vehicle and
fun fantastic features that miraculously move. Raise the boat lift at the airport, marina, man the gun turret at
the army base, clean your car at the car wash, raise the toll bridge. And these playsets fit together to form a micromachine world.
Micromachine pocket playsets, so tremendously tiny, so perfectly precise, so dazzlingly detailed, you'll want to pocket them all.
Micromachines and micromachine pocket playsets sold separately from Galoob. The smaller they are, the better they are."
}
多么神奇! 你觉得呢?
之所以能取得上述成果,是因为 Whisper 模型接受了训练。我们可以从 OpenAI 页面提供的下图中看到一些相关信息。
更多信息可以访问 https://openai.com/research/whisper
请记住,告知程序文件名至关重要,因为服务需要知道它正在处理的文件类型(如 WAV、MP3、OGG 等)。由于我们在调用中只包含 Base64 内容,因此还必须指明文件扩展名,以便用随机文本和建议的扩展名创建文件名。例如,St.OpenAi.Msg.Audio.AudioRequest 消息的 "类型 "属性可显示音频的种类: MP3、OGG、WAV、FLAC 等。
Endpoint: https://api.openai.com/v1/audio/transcriptions
通过这种方法,您可以将音频内容转录为有声语言。
输入参数如下:
file: 必要
在这里,您可以指定要转录的音频文件(而不是文件名)。它支持以下格式: FLAC、MP3、MP4、MPEG、MPGA、M4A、OGG、WAV 或 WEBM
model: 必要
用于转录的模型。目前只有 "whisper-1 "可用
language: 可选. 默认是音频语言.
如果指定的话,根据 ISO-639-1,可以提高准确率和延时.
prompt: 可选.
这是一段可选的文字,用于引导模型的风格或延续上一段音频。此处的信息必须与音频语言一致。.
response_format. 可选,默认为 “json”.
在这一部分中,您要明确转录输出的格式。请使用以下选项之一: "json"、"text"、"verbose_json"。
temperature: 可选,默认为 0.
采样温度应介于 0 和 1 之间。 0.8 等较高值会使输出更加随机,而 0.2 等较低值则会使输出更加集中和确定。如果设置为 0,模型将使用对数似然自动提高温度,直到达到特定阈值。
本方法的文档请参考 https://platform.openai.com/docs/api-reference/audio/createTranscription<.
Endpoint: https://api.openai.com/v1/audio/translations
此方法可将音频内容翻译成英语。输入参数如下:
file: 必要
它是您要翻译的音频文件(而不是文件名)。它支持以下格式: FLAC、MP3、MP4、MPEG、MPGA、M4A、OGG、WAV 或 WEBM
model: 必要.
如上.
prompt: 可选l.
这是一段可选的文字,用于引导模型的风格或延续上一段音频。此处的信息必须使用英语。
response_format. 可选. 默认是 “json”.
在这里,您可以用以下选项之一决定转录输出的格式: "json"、"text"、"verbose_json"。
temperature: 可选. 默认为 0.
如上
更多文档请查阅 https://platform.openai.com/docs/api-reference/audio/createTranscription.
下一步?
由于 OpenAi 在不断发展,下一次迭代将是将文本转换为音频的方法,以及其他一些新功能。如果您喜欢这篇文章,请记得点个 "赞"。
文章
Lilian Huang · 十二月 29, 2023
我们继续推出有关可供 HealthShare HealthConnect 和 InterSystems IRIS 用户使用的 FHIR 适配器工具的系列文章。
在前几篇文章中,我们介绍了小型应用程序,并在此基础上建立了我们的工作,并展示了安装 FHIR 适配器后在 IRIS 实例中部署的架构。在今天的文章中,我们将看到一个示例,说明如何执行最常见的 CRUD(创建 - 读取 - 更新 - 删除)操作之一,即读取操作,我们将通过恢复资源来完成此操作。
什么是资源?
FHIR 中的一个资源对应一种相关的临床信息,这种信息可以是病人(Patient)、对实验室的请求(ServiceRequest)或诊断(Condition)等。每种资源都定义了组成它的数据类型,以及对数据的限制和与其他类型资源的关系。每个资源都允许对其包含的信息进行扩展,从而满足 FHIR 80% 以外的需求(满足 80% 以上用户的需求)。
在本文的示例中,我们将使用最常见的资源 "Patient"。让我们来看看它的定义:
{ "resourceType" : "Patient" , // from Resource: id, meta, implicitRules, and language // from DomainResource: text, contained, extension, and modifierExtension "identifier" : [{ Identifier }], // An identifier for this patient "active" : <boolean>, // Whether this patient's record is in active use "name" : [{ HumanName }], // A name associated with the patient "telecom" : [{ ContactPoint }], // A contact detail for the individual "gender" : "<code>" , // male | female | other | unknown "birthDate" : "<date>" , // The date of birth for the individual // deceased[x]: Indicates if the individual is deceased or not. One of these 2 : "deceasedBoolean" : <boolean>, "deceasedDateTime" : "<dateTime>" , "address" : [{ Address }], // An address for the individual "maritalStatus" : { CodeableConcept }, // Marital (civil) status of a patient // multipleBirth[x]: Whether patient is part of a multiple birth. One of these 2 : "multipleBirthBoolean" : <boolean>, "multipleBirthInteger" : <integer>, "photo" : [{ Attachment }], // Image of the patient "contact" : [{ // A contact party (eg guardian, partner, friend) for the patient "relationship" : [{ CodeableConcept }], // The kind of relationship "name" : { HumanName }, // IA name associated with the contact person "telecom" : [{ ContactPoint }], // IA contact detail for the person "address" : { Address }, // I Address for the contact person "gender" : "<code>" , // male | female | other | unknown "organization" : { Reference(Organization) }, // I Organization that is associated with the contact "period" : { Period } // The period during which this contact person or organization is valid to be contacted relating to this patient }], "communication" : [{ // A language which may be used to communicate with the patient about his or her health "language" : { CodeableConcept }, // R! The language which can be used to communicate with the patient about his or her health "preferred" : <boolean> // Language preference indicator }], "generalPractitioner" : [{ Reference(Organization|Practitioner| PractitionerRole) }], // Patient's nominated primary care provider "managingOrganization" : { Reference(Organization) }, // Organization that is the custodian of the patient record "link" : [{ // Link to a Patient or RelatedPerson resource that concerns the same actual individual "other" : { Reference(Patient|RelatedPerson) }, // R! The other patient or related person resource that the link refers to "type" : "<code>" // R! replaced-by | replaces | refer | seealso }] }
正如您所看到的,它几乎涵盖了患者的所有管理信息需求。
从我们的 HIS 中恢复患者信息
如果您还记得之前的文章中我们部署了一个模拟 HIS 系统数据库的 PostgreSQL 数据库,那么让我们看一下我们特定 HIS 中的示例表。
虽然数量不多,但对于我们的例子来说已经足够了。让我们更详细地看看我们的患者表。
这里我们有 3 个示例患者,您可以看到每个患者都有一个唯一的标识符 ( ID ) 以及一系列与卫生组织相关的管理数据。我们的首要目标是为我们的一位患者获取 FHIR 资源。
患者咨询
我们如何从我们的服务器请求患者数据?根据 FHIR 制定的实现规范,我们必须通过 REST 对包含我们服务器地址、资源名称和标识符的 URL 执行 GET。我们必须调用:
http://SERVER_PATH/Patient/{id}
在我们的示例中,我们将搜索 Juan López Hurtado,其 id = 1,因此我们必须调用以下 URL:
http://localhost:52774/Adapter/r4/Patient/1
为了进行测试,我们将使用 Postman 作为客户端。让我们看看服务器的响应是什么:
{ "resourceType" : "Patient" , "address" : [ { "city" : "TERUEL" , "line" : [ "CALLE SUSPIROS 39 2ºA" ], "postalCode" : "98345" } ], "birthDate" : "1966-11-23" , "gender" : "M" , "id" : "1" , "identifier" : [ { "type" : { "text" : "ID" }, "value" : "1" }, { "type" : { "text" : "NHC" }, "value" : "588392" }, { "type" : { "text" : "DNI" }, "value" : "12345678X" } ], "name" : [ { "family" : "LÓPEZ HURTADO" , "given" : [ "JUAN" ] } ], "telecom" : [ { "system" : "phone" , "value" : "844324239" }, { "system" : "email" , "value" : "juanitomaravilla@terra.es" } ] }
现在让我们分析一下我们的请求在生产中所采取的路径:
这里我们有路径:
请求到达我们的 BS InteropService。
将请求转发到我们已配置为 BS 目的地的 BP,在该 BP 中将恢复所接收呼叫的患者标识符。
从我们的 BO FromAdapterToHIS 查询到我们的 HIS 数据库。
将患者数据转发到我们的 BP,并将其转换为 FHIR 患者资源。
将响应转发给BS。
让我们看一下我们在 BP ProcessFHIRBP中收到的消息类型:
让我们看一下三个属性,它们对于识别客户端请求的操作类型至关重要:
Request.RequestMethod:它告诉我们要执行什么类型的操作。在此示例中,搜索病人将采用 GET 方式。
Request.RequestPath:该属性包含到达服务器的请求路径,该属性将指示我们要处理的资源,在本例中,它将包括恢复资源的特定标识符。
Quick.StreamId: FHIR 适配器会将收到的每条 FHIR 消息转换为流,并为其分配一个标识符,该标识符将保存在此属性中。在本例中,我们不需要它,因为我们执行的是 GET,并没有发送任何 FHIR 对象。
让我们深入分析负责处理的 GLP,继续我们的消息之旅。
流程FHIRBP:
我们在生产中实施了 BPL,它将管理我们从业务服务收到的 FHIR 消息传递。让我们看看它是如何实现的:
让我们看看每个步骤中将执行的操作:
管理 FHIR 对象:
我们将调用负责连接到 HIS 数据库并负责数据库查询的 BO FromAdapterToHIS。
Method ManageFHIR(requestData As HS.FHIRServer.Interop.Request, response As Adapter.Message.FHIRResponse) As %Status { set sc = $$$OK set response = ##class (Adapter.Message.FHIRResponse). %New () if (requestData.Request.RequestPath = "Bundle" ) { If requestData.QuickStreamId '= "" { Set quickStreamIn = ##class (HS.SDA3.QuickStream). %OpenId (requestData.QuickStreamId,, .tSC) set dynamicBundle = ##class ( %DynamicAbstractObject ). %FromJSON (quickStreamIn) set sc = ..GetBundle (dynamicBundle, .response) } } elseif (requestData.Request.RequestPath [ "Patient" ) { if (requestData.Request.RequestMethod = "POST" ) { If requestData.QuickStreamId '= "" { Set quickStreamIn = ##class (HS.SDA3.QuickStream). %OpenId (requestData.QuickStreamId,, .tSC) set dynamicPatient = ##class ( %DynamicAbstractObject ). %FromJSON (quickStreamIn) set sc = ..InsertPatient (dynamicPatient, .response) } } elseif (requestData.Request.RequestMethod = "GET" ) { set patientId = $Piece (requestData.Request.RequestPath, "/" , 2 ) set sc = ..GetPatient (patientId, .response) } } Return sc }
我们的 BO 将检查收到的HS.FHIRServer.Interop.Request类型的消息,在本例中,通过设置 GET 并在与患者资源对应的路径中指示将调用GetPatient方法,我们将在下面看到:
Method GetPatient(patientId As %String , Output patient As Adapter.Message.FHIRResponse) As %Status { Set tSC = $$$OK set sql= "SELECT id, name, lastname, phone, address, city, email, nhc, postal_code, birth_date, dni, gender FROM his.patient WHERE id = ?" //perform the Select set tSC = ..Adapter .ExecuteQuery(.resultSet, sql, patientId) If resultSet.Next() { set personResult = { "id" :(resultSet.GetData( 1 )), "name" : (resultSet.GetData( 2 )), "lastname" : (resultSet.GetData( 3 )), "phone" : (resultSet.GetData( 4 )), "address" : (resultSet.GetData( 5 )), "city" : (resultSet.GetData( 6 )), "email" : (resultSet.GetData( 7 )), "nhc" : (resultSet.GetData( 8 )), "postalCode" : (resultSet.GetData( 9 )), "birthDate" : (resultSet.GetData( 10 )), "dni" : (resultSet.GetData( 11 )), "gender" : (resultSet.GetData( 12 )), "type" : ( "Patient" )} } else { set personResult = {} } //create the response message do patient.Resource.Insert(personResult. %ToJSON ()) Return tSC }
正如您所看到的,此方法仅在我们的 HIS 数据库上启动查询并恢复所有患者信息,然后生成一个 DynamicObject,随后将其转换为 String 并存储在Adapter.Message.FHIRResponse类型的变量中。我们已将 Resource 属性定义为字符串列表,以便能够稍后在跟踪中显示响应。您可以直接将其定义为 DynamicObjects,从而节省后续转换。
检查是否捆绑:
根据 BO 的响应,我们检查它是否是 Bundle 类型(我们将在以后的文章中解释)或者它是否只是一个 Resource。
创建动态对象:
我们将 BO 响应转换为 DynamicObject 并将其分配给临时上下文变量 (context.temporalDO)。用于转换的函数如下:
##class ( %DynamicAbstractObject ). %FromJSON (context.FHIRObject.Resource.GetAt( 1 ))
FHIR 变换:
使用 DynamicObject 类型的临时变量,我们将其转换为HS.FHIR.DTL.vR4.Model.Resource.Patient类的对象。如果我们想寻找其他类型的资源,我们必须为每种类型定义特定的转换。让我们看看我们的转变:
这种转换使我们能够拥有 BS InteropService 可以解释的对象。我们将结果存储在变量context.PatientResponse中。
将资源分配给 Stream :
我们将FHIR变换中获得的变量context.PatientResponse转换为Stream。
转换为 QuickStream:
我们将必须返回给客户端的所有数据分配给响应变量:
set qs= ##class (HS.SDA3.QuickStream). %New () set response.QuickStreamId = qs. %Id () set copyStatus = qs.CopyFrom(context.JSONPayloadStream) set response.Response.ResponseFormatCode= "JSON" set response.Response.Status= 200 set response.ContentType= "application/fhir+json" set response.CharSet = "utf8"
在这种情况下,我们总是返回 200 响应。在生产环境中,我们应该检查是否已正确恢复搜索到的资源,如果没有,请将响应状态从 200 修改为对应“未找到”的 404。正如您在此代码片段中看到的,对象HS.FHIR.DTL.vR4.Model.Resource.Patient转换为 Stream 并存储为HS.SDA3.QuickStream ,将所述对象的标识符添加到QuickStreamID属性,随后我们的 InteropService 服务将以 JSON 形式正确返回结果。
结论:
让我们总结一下我们所做的事情:
我们发送了一个 GET 类型的请求,以搜索具有定义 ID 的患者资源。
BS InteropService已将请求转发至配置的BP。
BP 调用了负责与 HIS 数据库交互的 BO。
已配置的 BO 已从 HIS 数据库检索患者数据。
业务处理程序将结果转换为默认互操作服务创建的 BS 可理解的对象。
BS已收到响应并将其转发给客户端。
如您所见,操作相对简单,如果我们想在服务器中添加更多类型的资源,只需在 BO 中添加对数据库中与要恢复的新资源相对应的表的查询,并在 BP 中将 BO 的结果转换为与之相对应的 HS.FHIR.DTL.vR4.Model.Resource.* 类型的对象。
在下一篇文章中,我们将回顾如何将患者类型的新 FHIR 资源添加到我们的 HIS 数据库中。
感谢大家的关注!
文章
Hao Ma · 五月 26, 2023
题外话:我刚刚翻译了InterSystems专家Bob Binstock的[Caché Mirroring 101:简要指南和常见问题解答](https://cn.community.intersystems.com/post/cach%C3%A9-mirroring-101%EF%BC%9A%E7%AE%80%E8%A6%81%E6%8C%87%E5%8D%97%E5%92%8C%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98%E8%A7%A3%E7%AD%94)。 尽管题目是Caché Mirror 101, 而且是写于2016年,但因为讲解的都是Mirror的基本原理,所以在大量使用IRIS的今天也完全适用。
前面的3篇文章,包括了配置Mirror的各个方面。如果您照着操作,现在已经有了一个工作的mirror环境,并加入了您的数据库。然而,还没完,这篇我来讨论一下后面的工作,首先的问题是:
**Mirror不复制什么**
简单说,Caché/IRIS镜像是**数据库复制(Database Replication)**。在Caché/IRIS里什么是数据库?也就是**Cache.dat和iris.dat**文件。数据库的修改日志,也就是journal,从主机被传送到其他镜像成员。而除此之外的内容,需要维护人员来分别的个个处理, 解决这些内容在各个镜像成员间的拷贝。需要很多的计划和细心。
>系统数据库, 包括IRISSYS, IRISTEMP, IRISLIB等等, 这些Caché/IRIS本身的数据库不应该被加入Mirror,在大多数Caché/IRIS版本里也都设置成不可以加入入MIRROR。
>
>例外的HealthCare产品, HSSYS需要做Mirror, HSCustom可以做Mirror, 而HSLIB不可以Mirror
我们可以把问题转换成下面的题目:
## 需要人工在镜像成员中同步的项目
### 命名空间(namespace)和Mapping
命名空间是应用开发的概念,它使用数据库。命名空间定义了3种映射关系:Package Mapping, Routing Mapping, Global Mapping。这样在一个命名空间可以使用多个数据库的内容。
通常情况下,用户会在主机创建命名空间的同时,创建一个新的带有mirror属性的数据库,然后会在其他mirror成员中手工一个个的创建命名空间,加入镜像的数据库。之后,管理员无需考虑更多的操作。
然而,对命名空间的修改,比如要添加或者删除命名空间的某些mapping,这偶尔会需要,尤其是应用迭代和系统扩容的情况下,那么,管理员/实施人员,必须清楚Mirror无法同步这个修改,您必须手工同步修改到其他机器去。
如果配置的mapping比较多, 我建议使用Manifest来操作。Mainfest是一个xml的文本,用来安装或者修改Caché/IRIS的配置,你可以参考[在线文档: Using a Manifest](https://docs.intersystems.com/iris20231/csp/docbook/DocBook.UI.Page.cls?KEY=GCI_manifest), 或者社区文章[使用Manifest](https://cn.community.intersystems.com/post/%E4%BD%BF%E7%94%A8manifest)。
这里给一个配置mapping的例子:
```xml
```
如果是资深的Caché维护工程师,懂得如果修改CPF文件并在不重启实例的情况下应用修改后的内容,可以考虑把主机上的CPF中的mapping部分复制粘贴到其他机器。如果您没有这方面的经验,我不建议这种方式。
另外,在IRIS 2022后的版本中有了一个新工具,Configuration Merge。 文档在[这里](https://docs.intersystems.com/iris20231/csp/docbook/Doc.View.cls?KEY=ACMF)。可惜只有最新版的IRIS或者Health Connect 用户有的用。
### 数据库的修改
数据库的内容会通过Journal从主机同步到其他成员,但修改不会,一般会遇到的是**压缩和截断**。
由于某种错误操作,某个数据库,会扩展到不正常的大,而当错误修正后,用户可能需要对该数据库进行压缩和截断,以释放被错误占用的空闲的磁盘空间。
由于除主机外,其他镜像成员的数据库都是只读的,这个操作的顺序应该是这样:
1. 在主机A执行压缩和截断
2. 切换到备机B, 再次执行压缩和截断。
3. 异步成员DR。 一种方案是吧DR提升到备机。这时当前的备机A会将为灾备,然后再切换DR为主机,再进行压缩和截断。
还有一个选择,就是重新配置DR上的这个数据库,这需要从主机到DR的数据库备份和恢复。
### IRIS实例的配置
从最常用的内存的配置,Service的配置, **用户,权限,资源**的配置等等。它们都不会被MIRROR同步。如果您在MIRROR主机里做了修改了缩表的大小,或者启动了一个,比如TELNET服务, 您需要人工在其他机器上做相同操作。
像上面的mapping配置一样,这里还是建议使用Manifest人工同步IRIS得修改。注意的是,Mainfest不保证能支持所有的配置。比如在Caché的版本下, 比如您在主机上启动了TELNET服务, Manifest没有相应的标签。这种情况下, 如果您熟悉ObjectScript语言,可以把ObjectScript实现加入执行Manifest的方法,比如说:
```java
ClassMethod main(){
//执行Manifest修改命名空间
Set pVars("Namespace")="MYNAMESPACE"
$$$ThrowOnError(..ModifyNamespace(.pVars))
//启动IRIS的TELNET服务
set properties("Enabled")=1 // 有効
set sts=##class(Security.Services).Modify("%Service_Telnet",.properties)
}
```
当然,如果您缺乏开发实施的知识,在用户界面上一个个机器的操作是最省心的办法。
问题是,打开一个服务,修改一个配置参数操作都很简单,但是如果要添加大量的用户和权限怎么办?
用Manifest管理是一个办法。但根本上,如果您经常有大量的用户管理的工作,其实使用Kerberos或者LDAP管理用户身份认证和授权的工作, 在有多个镜像成员的情况下,尤其的合适。 关于这部分内容,请参考[在线文档:Authentication and Authorization](https://docs.intersystems.com/iris20231/csp/docbook/DocBook.UI.Page.cls?KEY=PAGE_security_authentication_authorization)
### 定时任务(TASK)
在主机上创建的定时任务, 您需要人工在其他机器上做相同操作。这里有2个步骤:
1. 在主机上创建新任务的时候,要选择”**应如何为镜像运行任务**“。 这是个下拉菜单,选项有*”仅在主镜像成员上运行“,“仅在非主镜像成员上运行“ ,“在任何镜像成员上运行"。*
选择的出发点是:非主镜像成员的数据库是只读的。因此,比如一个Ensemble的镜像配置中, 删除Ensemble消息的定时任务, 一定是”仅在主镜像成员上运行“。
2. 把新的定时任务从主机同步到其他成员。
如果是一个或者少量几个TASK, 那么手工在其他各个镜像成员上添加是最简单直接的做法。而如果是有很长 的任务列表,尤其在配置Mirror得时候可以需要同步一个长长的列表时, 您可以考虑**从主机导出Task到其 他机器导入**,我只知道使用ObjectScript命令的方法, 使用`%SYS.Task.ExportTask()`和 `%SYS.Task.ImportTasks()`。 文档在[这里](https://docs.intersystems.com/iris20231/csp/documatic/%25CSP.Documatic.cls?LIBRARY=%25SYS&CLASSNAME=%25SYS.Task)。
### Web Application
主机上配置的Web Applicaiton 也要同步到其他镜像成员。如果要同步的Web Application比较多,推荐的方式依然是Manifest, 下面是一个例子。
```xml
```
麻烦的是不同的版本Caché/IRIS使用的标签上会略有不同,要稍微仔细的查看一下您的版本的文档。
如果您对ZPM, 现在称为IPM熟悉的话, 用ZPM做同步也是个好选择。关于zpm, 您可以参考这个帖子[zpm介绍](https://cn.community.intersystems.com/post/zpm%E4%BB%8B%E7%BB%8D1)。提醒一下的是,程序因为是存在数据库里面的,如果该数据库是被镜像的,您其实不需要用ZPM把程序代码拷贝到其他镜像成员。
### Gateway
一般用到的有**SQL Gateway**和**External Language Gateway**,它们分别用于连接其他的数据库和使用其他语音的代码包。
SQL Gateway
记录保存在%SYS命名空间的*%Library.sys_SQLConnection*数据表里。简单的方法是使用工具把表记录导入导出。
External Language Gateway(外部语言网关)
新版的IRIS系统内嵌了外部语言服务器,包括%Python Server, %Java Server, %Dotnet Server等。如果您使用的是默认配置,各个镜像成员是一致的,无需操心。如果只是IP端口的修改,手工同步一下也很容易,毕竟工作量有限,只是您需要清楚的记得,这个也是不被Mirror自动同步的。
### 文件
我把文件分为两类, 一类是“固定文件”,包括一下几个部分,
- CSP文件,js文件,css文件,html文件等
- XSLT文件
- 其他语言的程序代码,Java文件,python文件, .Net文件
这类文件上传到主机的时候, 也必须上传到其他镜像成员,这是个简单的操作,别忘了就行。
麻烦的是**流文件**。在ObjectScript里如果使用了%Stream.FileBinary, %Stream.FileCharacter等类,那么数据不是保存到Cache.Dat或者IRIS.data, 而是保存在和.Dat同目录的一个stream的子目录下,而这个目录是不会被镜像同步的。 而且,因为这是实时数据,你也不可能手工的把它拷来拷去。
如果您的应用里用到了文件流,我任务您需要一个文件服务器保证流文件在各个各个镜像成员间的同步。
### Ensemble Production Consideration
对于Ensemble和Health Connect用户,您需要阅读这部分在线文档: [Production Considerations for Mirroring](https://docs.intersystems.com/iris20223/csp/docbook/DocBook.UI.Page.cls?KEY=GHA_mirror_manage#GHA_mirror_set_ensemble) , 简单总结一下:
- 创建的带有ensemble或者Inteoprability的命名空间,数据库要创建为Mirror的数据库。
- **"production是否自动启动“**应该在主机和备机上,甚至DR上都配置为“自动启动”。 在Mirror配置下的Production会先检查这个实例是不是主机,如果不是,“自动启动”的配置也不会生效,这样保证了Production只在主机上运行,而切换后也不需要人工干预。
上面的这些并不是完整的内容,尽管在大多少情况下这些内容差不多够了。如果您想要确保Mirror的主机的工作内容完全同步到了备机和DR, 请仔细阅读在线文档的这一部分:[Mirror Configuration Guidelines](https://docs.intersystems.com/iris20223/csp/docbook/DocBook.UI.Page.cls?KEY=GHA_mirror_set_config#GHA_mirror_set_config_guidelines)
另外,对于各种需要人工同步的内容的操作,还建议阅读[在线文档:Server Migration](https://docs.intersystems.com/irislatest/csp/docbook/Doc.View.cls?KEY=AMIG#AMIG_migration_external)。
如果是最新的IRIS用户,请参考[在线文档:Deploy Mirrors Using Configuration Merge](https://docs.intersystems.com/iris20223/csp/docbook/DocBook.UI.Page.cls?KEY=GHA_mirror_set_config#GHA_mirror_set_config_auto_merge)
文章
Qiao Peng · 十二月 4, 2023
1. 通用RESTful业务服务和业务操作
InterSystems IRIS 提供了一组通用的RESTful 业务服务和业务操作类,用户无需开发自定义的业务服务和业务操作类,就可以直接向外提供RESTful服务和调用外部的RESTful API。
BS
EnsLib.REST.GenericService
通用REST业务服务
BS
EnsLib.REST.SAMLGenericService
检查SAML令牌的签名和时间戳的REST业务服务
BO
EnsLib.REST.GenericOperation
通用REST业务操作
BO
EnsLib.REST.GenericOperationInProc
用于透传模式的通用REST业务操作
2. 通用RESTful 消息
通用的RESTful 业务服务和业务操作类使用一个通用的RESTful消息类 - EnsLib.REST.GenericMessage,它是EnsLib.HTTP.GenericMessage的子类,二者数据结构都是
HTTPHeaders
记录http头的数组
Stream
记录http体的数据流
Type
数据流类型,例如是字符流还是二进制流。自动赋值,无需设置
Attributes
记录属性的数组
OriginalFilename
无需使用
OutputFolder
无需使用
OutputFilename
无需使用
因此EnsLib.REST.GenericMessage和EnsLib.HTTP.GenericMessage都可以被通用RESTful业务操作和业务服务所使用。
3. 通用RESTful 业务操作
使用通用的RESTful业务操作,可以连接到任何第三方的RESTful服务器,调用其RESTful API。
3.1 向production中加入通用RESTful业务操作
增加通用RESTful业务操作,只需要在Production配置页面的操作中添加EnsLib.REST.GenericOperation。
建议加入Production时,给业务操作起一个名字,用于代表具体的业务,例如是连接到LIS的RESTful 服务,可以命名为RESTtoLIS(可以考虑的命名规则 - 接口方式+业务系统)。如果未命名,默认会使用类名作为业务操作名。
3.2 配置通用RESTful业务操作
主要的设置项是以下3个:
1. HTTP服务器:目标RESTful服务器的服务器名或IP地址
2. HTTP端口:目标RESTful服务器提供RESTful API的端口号
3. URL:RESTful API的服务端点
启用该业务操作后,既可以访问外部RESTful API了。
3.3 测试通用RESTful业务操作
启用后,加入的通用的RESTful业务操作即可测试了。因为EnsLib.HTTP.GenericMessage的REST消息体是一个流类型的属性,为了测试时方便输入这个数据,我们增加一个业务流程。
1. 创建一个新的业务流程,设置其请求消息为Ens.StringRequest,用于测试时传入REST body数据。并为其上下文增加一个名为DataBody、类型为%Stream.GlobalCharacter(可持久化的字符流类型)的属性:
2. 在业务流程中增加一个代码流程(<code>),将请求消息的字符串数据写入上下文的DataBody字符流:
Do context.DataBody.Write(request.StringValue)
注意行首加空格。
3. 然后在业务流程中再加入一个调用流程(<call>),调用上面已经加入production的业务操作,例如RESTtoLIS,并设置请求和响应消息为EnsLib.REST.GenericMessage或EnsLib.HTTP.GenericMessage。
4. 配置RESTtoLIS业务操作的请求消息(Request)
可以直接点击构建请求消息(Request Builder)按钮,使用图形化拖拽建立请求消息:
4.1 将左边上下文context里的DataBody拖拽到callrequest的Stream属性上;
4.2 对callrequest的HTTPHeaders赋值,它是一个元素类型为字符串的数组,代表HTTP请求的头。以下3个HTTP头是必须要填写的:
HTTP头属性说明
下标
值
HTTP方法
"httprequest"
例如"POST"
HTTP消息体的内容类型
"content-type"
例如"application/json"
客户端希望接收的内容类型
"Accept"
例如"*/*"
这3个数组元素赋值,可以通过在添加操作下拉列表中设置(Set)进行赋值。
5. 将业务流程加入Production,并测试
确保Production的设置是允许调试。在Production配置页面中选中这个业务流程,在右侧的操作标签页中选择测试按钮,并在弹出的测试消息页面里填入测试用的数据,并点击调用测试服务:
然后可以检查测试的消息处理流程,并确认REST消息体和HTTP消息头被正确地传递到目标REST API
4. 通用RESTful 业务服务
使用通用的RESTful业务服务,可以向外发布能处理任何RESTful API调用请求的RESTful服务端。
4.1 将通用RESTful业务服务加入Production
在Production配置页面,点击服务后面的加号。弹出的向导页面,服务类选择EnsLib.REST.GenericService;输入服务名,建议写一个能代表组件功能的名字,例如向HIS系统开放的REST服务,可以起名RESTforHIS;选中立即启用。
RESTful通用业务服务可以通过2种方式向外提供RESTful API服务:第一种通过Web服务器向外提供服务,第二种使用IRIS服务器的特定TCP端口向外提供服务。第二种方式不依赖于独立的Web服务器,但推荐使用Web服务器,从而得到更好的性能和安全性。
这里我们使用Web服务器提供REST服务,因此在业务服务的端口配置中,保持空白。在接受消息的目标名称中,选择接收RESTful API请求的业务流程或业务操作,这里我们测试使用一个空的业务流程。点击应用激活这些设置。
4.2 建立一个向外提供RESTful API的Web应用
向外发布RESTful服务,不仅涉及到服务发布的URL,还涉及到安全。我们通过创建一个专用的Web应用来进行管理和控制。
在IRIS系统管理门户>系统管理>安全>应用程序>Web应用程序 中,点击新建Web应用程序按钮,新建一个Web应用程序,并做以下配置:
1. 名称,填写一个计划发布的服务端点,例如/IRISRESTServer。注意前面的/
2. NameSpace,选择Production所在的命名空间
3. 选中启用 REST,并设置分派类为EnsLib.REST.GenericService
4. 根据安全需要,配置安全设置部分。这里方便测试起见,允许的身份验证方法选择了未验证(无需验证)。如果是生产环境,或者您在做性能压力测试,都应该选择密码或Kerberos安全的身份验证方式!
注意,请保证同一个命名空间下,仅有一个分派类为EnsLib.REST.GenericService的REST类型的Web应用。
4.3 测试RESTful业务服务
现在就可以测试这个RESTful业务服务了。这个RESTful服务可以响应任何REST API的请求,如何响应则是后续业务流程/业务操作的事。
它的完整的RESTful URL是:[Web服务器地址]:[Web服务器端口]/[Web应用的名称]/[通用REST服务在production中的配置名]/[API名称和参数],例如我在IRIS本机的私有Apache的52773端口上访问上面创建的REST通用业务服务,调用PlaceLabOrder的API (注意,这里我们并没有实现过PlaceLabOrder这个API,但我们依然可以响应,而不会报404错误),那么完整的REST 调用地址是:
127.0.0.1:52773/IRISRESTServer/RESTforHIS/PlaceLabOrder
打开POSTMAN,用POST方法,发起上面REST API的调用:
在IRIS里会得到类似这样的消息追踪结果,如果你没有实现过处理REST API请求的业务流程,会得到一个500错,但依然可以查看IRIS产生的EnsLib.HTTP.GenericMessage消息内容:
这个通用RESTful业务服务会把REST请求转换为EnsLib.HTTP.GenericMessage消息,向目标业务操作/业务流程发送。因此,通过解析它的消息内容,就知道REST API请求的全部信息:
1. Stream里是POST的数据
2. HTTPHeaders 的下标"HttpRequest"是HTTP的方法
3. HTTPHeaders 的下标"URL"是完整的API路径,包括了服务端点(在"CSPApplication"下标下)、REST业务服务名称(在"EnsConfigName"下标下)和API
后续业务流程可以通过这些数据对REST API请求进行响应。
4.4 使用业务流程对REST API调用进行路由
有了通用RESTful业务服务生成的EnsLib.HTTP.GenericMessage消息,我们就可以使用消息路由规则或业务流程对REST API请求进行路由。这里我使用业务流程方法对REST API请求进行路由演示。
构建一个新的业务流程,请求消息和响应消息都是EnsLib.REST.GenericMessage或EnsLib.HTTP.GenericMessage,同时为context增加一个名为ReturnMsg的字符串类型的属性,并设置它默认值为:"{""Code"":-100,""Msg"":""未实现的API""}"。
在业务流程里增加一个<switch>流程,然后在<switch>下增加2个条件分支,分别为:
名称:下达检验医嘱,条件:判断是否http头的URL为PlaceLabOrder,且http头的HttpRequest为POST:
(request.HTTPHeaders.GetAt("URL")="/IRISRESTServer/RESTforHIS/PlaceLabOrder") && (request.HTTPHeaders.GetAt("HttpRequest")="POST")
名称:查询检验项目,条件:判断是否http头的URL为GetLabItems,且http头的HttpRequest为GET:
(request.HTTPHeaders.GetAt("URL")="/IRISRESTServer/RESTforHIS/GetLabItems") && (request.HTTPHeaders.GetAt("HttpRequest")="GET")
在两个分支里,分别增加<code>, 产生返回的REST消息内容:
Set context.ReturnMsg="{""Code"":200,""Msg"":""检验医嘱下达成功""}"
Set context.ReturnMsg="{""Code"":200,""Msg"":""查询检验项目成功""}"
最后在<switch>后增加一个<code>,构建响应消息:
// 初始化响应消息
set response = ##class(EnsLib.REST.GenericMessage).%New()
// 初始化响应消息的流数据
Set response.Stream = ##class(%Stream.GlobalCharacter).%New()
// 将REST返回数据写入流
Do response.Stream.Write(context.ReturnMsg)
编译这个业务流程,并将其加入Production。
之后修改通用RESTful业务服务的设置,将接收消息的目标名称改为这个新建的业务流程。
现在再通过POSTMAN测试一下各种API,并查看返回REST响应:
在真实项目中,根据实际情况,将上面<switch>流程分支的<code>替换为API响应业务流程或业务操作即可。
总结:使用通用RESTful业务操作和业务服务,无需创建自定义的RESTful 业务组件类,就可以调用外部RESTful API和向外提供RESTful API服务,降低开发和实施成本,实现低代码开发。
后记:关于EnsLib.REST.GenericService对CORS(跨域资源共享)的支持
CORS是一种基于 HTTP 头的机制,通过允许服务器标示除了它自己以外的其它origin(域、协议和端口)等信息,让浏览器可以访问加载这些资源。所以要让EnsLib.REST.GenericService支持CORS,需要让它的响应消息增加对于CORS支持的HTTP头的信息,这里不详细介绍这些头含义了,大家可以去W3C的网站或者搜索引擎查询具体定义,最简单可以使用以下代码替代上面4.4中的初始化响应消息代码:
// 设置HTTP响应的头信息
set tHttpRes=##class(%Net.HttpResponse).%New()
set tHttpRes.Headers("Access-Control-Allow-Origin")="*"
set tHttpRes.Headers("Access-Control-Allow-Headers")="*"
set tHttpRes.Headers("Access-Control-Allow-Methods")="*"
// 初始化响应消息
set response = ##class(EnsLib.REST.GenericMessage).%New(,,tHttpRes)
文章
Hao Ma · 六月 13, 2023
在维护IRIS的镜像前,管理员需要清楚的了解以下一些概念:
## Mirror的切换模式(failover mode)
切换模式在镜像监视器里被翻译成”故障转移模式“。 有两种模式:
- Agent Controlled模式:
- Arbiter Controlled模式:(页面上翻译为“仲裁程序受控制”)
通常情况,生产环境的镜像是安装了arbiter(仲裁者)的。Mirror启动时,在还没有连接上arbiter的时候,自动进入Agent-Controlled模式。而后当两台机器,主机,备机都连通了Arbiter,会保持在这个模式。
- 主备之间有连接;
- 又都连到arbiter;
- backup is active,
满足上面的条件,就进入arbiter controlled mode。而如果主备的任一方,失去了和arbiter的连接,或者备用侧丢了active, 开始尝试连接另一方,退回到agent-controlled模式。
## Mirror同步成员的状态
[Mirror Member Journal Transfer and Dejournaling Status](https://docs.intersystems.com/irisforhealth20231/csp/docbook/DocBook.UI.Page.cls?KEY=GHA_mirror_manage#GHA_mirror_set_status). 请注意,这里面有两个概念:一个是**Mirror成员的状态**,一个是**Journal传输和Dejournaling的状态**。下面的图中是3个字段: STATUS, Journal传输,Dejournaling.
**STATUS**
镜像成员的状态。 正常工作状态
- 对于同步成员,是Primary(主), Backup(备机)。
- 对于异步成员,正常状态是Connected(已连接)
- In Trouble : 如果主机In Trouble, 是失去了到backup的连接。备机收到主机的同步数据是要返回证实(Ack)消息的。一旦出现问题,主机无法收到备机的Ack, 主机就会把备机标为"In trouble", 从此再也不会向备机发同步数据。
- Transition: 暂时状态,进程正在查看一个成员的状态,很快会转换到一个稳定状态。 如果在mirror配置的member中发现了primary,本机会进入Synchronizing状态,否则自己会尝试进入primary状态。
- Sychronizing: 从Primary接收journal,同步数据库。
## Journal Transfer and Dejournaling Status
Journal Transfer是主机向其他成员发送Journal文件。而Dejournal是把Journal文件读入数据库。 对于backup或者asycn成员,**Journal Transfer**状态表示镜像成员是否有来自主数据库的最新日志数据,如果没有,则表示日志传输的落后程度,**Dejournaling**表示从主数据库收到的所有日志数据是否已经被dejournaled(应用到成员的镜像数据库),如果没有,则表示dejournaling的落后程度。
上图中显示的是正常的状态,其中主机 Journal Transfer 和 Dejournaling 都是N/A, 表示不适用。
对于其他成员,我们分开看:
Journal Transfer状态
- Active: backup的正常状态。说明backup从primary收到了最新的journal。注意哪怕是Dejournal状态只是“x秒落后“,而不是"被捕获",Journal Transfer状态也可以是Active,只要是从主机收到了最新的Journal更新。
- Caught up(被捕获) : 备机被捕获状态,说明备机从主机收到了最新的journal数据,但主机没有在等待备机的证实消息。 这通常是一个暂时的过程,当备机在连接主机的时候会出现。 异步成员,因为不需要向主机发证实,所以正常的状态就是“被捕获”
If the Primary Failover Member does not receive an acknowledgment from the Backup every Heartbeat Interval period, it demotes the Backup system from Active status to Catch-Up mode.
- time behind (多少秒落后)
- Disconnected on time(断开): 在一个时间点上这个成员和primary断开了。
Dejournaling状态
- Caught up
- time behind
- Disconnected on time
- Warning! Some Databases need attention
- Wanring! Dejournaling is stopped
**正常状态下的图;**
备机Backup MirrorB, Journal Transfer是Active, Dejournaling是Caught up, 异步机器MirrorDR的Journal Transfer状态和Dejournaling状态都是Caught up. 表示它们收到了最新的journal数据,并且也都把最新的global修改写入了自己的数据库。
## Mirror的自动切换
Mirror的核心是自动切换。Backup接替主机的工作有两个前提:1. 备机在同步(Active) 状态, 2. 主机不能正常工作。在这两个前提下,我们来看看自动切换的触发条件,涉及主机,备机,仲裁机之间的通信,
**自动切换触发条件**
1. Primary要求Backup接替。这种情况,主机会发生一个请求消息给备机, 要求备机接替。
- 主机IRIS正常退出
- 主机发现自己hung
2. 备机收到arbiter的请求,报告失去了到主机的连接。
仲裁机要求是和外部系统以及应用服务器部署在一个网段的。如果仲裁机无法联络主机,可以认为其他的应用系统和服务器也无法连接主机。有可能主机宕机, 也有可能主机还在正常工作,但外界已经无法联络它了, 这时候也是需要备机接手的。
这时备机也要再去核实一下,是不是能联络到主机。如果能联络到, 备机会发请求让主机Down。如果不能, 说明主机要么死了, 要么失联了, 备机先接手,等联络上再让对方force down.
3. 从主机的ISCAgent收到消息,报告Primary已经down or hung.
在agent-controlled的情况。 primary的服务器还活着。备机主动去问主机的agent, 一旦agent报告主机死了, 那备机就可以上位了。
## Mirror的进程
管理员应该了解mirror涉及的那些进程。当出现故障时,这些进程名字,或者称为User, 经常会出现在message log记录的故障描述中。
On Primary Failover Member(主机)
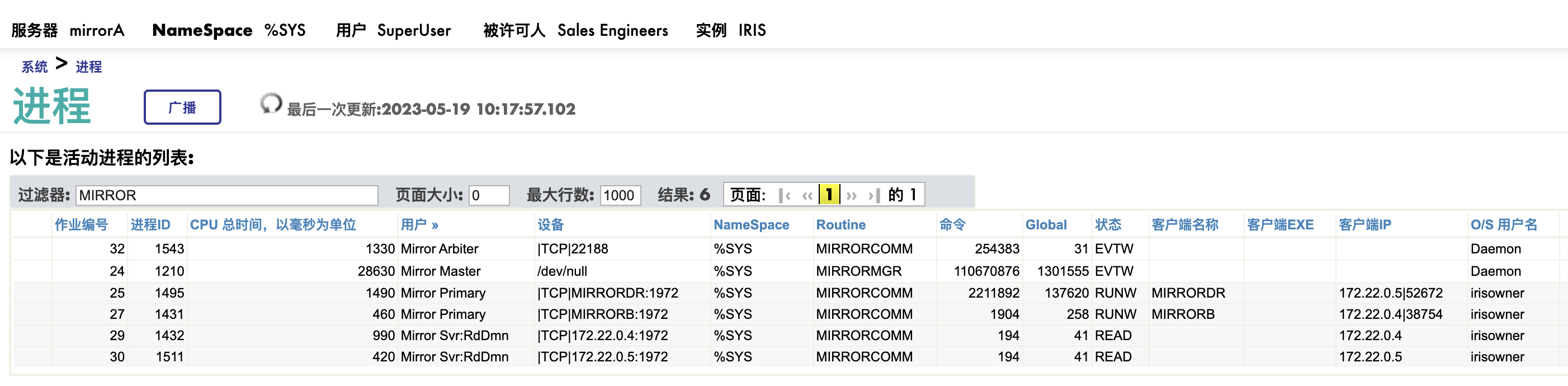
我们来一个个的看看这些进程:
- Mirror Master: 系统启动时自动启动,负载mirror control 和管理。
- Mirror Primary: 出向数据传输通道。 上图中有两个Mirror Primary进程,状态时RUNW, 一个连接MirrorB, 一个连接MirrorDR.
- Mirror Svr: Rd*: 入向证实通道(inbound acknowledgement), 也是单向的。 上图中同样有两个此进程,状态都是READ, IP地址分别是MirrorB和MirrorDR.
- Mirror Arbiter: 到aibiter的通信进程,注意它的状态是"EVTW", 也是个单向写的频道。
On Backup Member/Async member(备机)
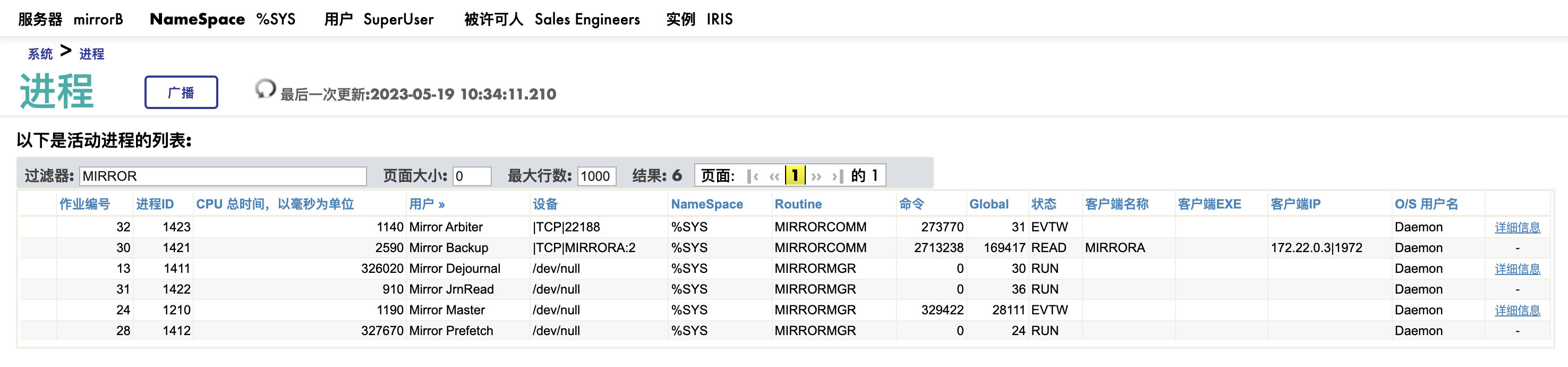
Mirror Masht, Mirror Arbiter不再重复解释,我们看看其他进程是干什么的。
- Mirror JrnRead: Mirror Journal从Primary发送到backup是先写到硬盘的。 JrnRead进程把收到的journal同步读到内存里,然后才进行下一步,Dejournal的工作。
- Mirror Dejour: backup机器的dejournal job进程。它把从Primary收到的journal中记录的global改变(set and kill)保存到本机的镜像数据库。
- Mirror Prefetch: 这个稍微有点难懂。当收到的journal修改中包括了使用当前backup的journal中已有的内容时,比如收到了一个修改:set ^A=^B+1, 而^B当前存在backup里, Prefetch进程会把^B从硬盘拿到内存,以加快dejournal的速度。
- Mirror Backup: two-way channel, 把收到的primary的journal写到backup的mirror journal,并且返回证实(ACK)
这里我省略了在DR上的进程,如果有兴趣,请自己查看文档。
## MIRROR状态的监控
根据不同的场景,查看Mirror的状态有以下几种途径
### **[使用镜像监视器](https://docs.intersystems.com/iris20231/csp/docbook/DocBook.UI.Page.cls?KEY=GHA_mirror_manage#GHA_mirror_monitor_portal)**
### 使用^MIRROR
如果您只是要简单的获得Mirror成员的状态,最直接的方法是使用^Mirror程序。 我们先看看在IRIS Terminal下^MIRROR的执行。
```bash
%SYS>do ^MIRROR
1) Mirror Status
2) Mirror Management
3) Mirror Configuration
Option? 1
1) List mirrored databases
2) Display mirror status of this node
3) Display journal file info
4) Status Monitor
Option? 4
Status of Mirror MIRRORTEST at 08:09:24 on 05/19/2023
Arbiter Connection Status:
Arbiter Address: arbiter|2188
Failover Mode: Agent Controlled
Connection Status: This member is not connected to the arbiter
Journal Transfer
Member Name+Type Status Latency Dejournal Latency
-------------------------- --------- --------------- --------------
MIRRORA
Failover Primary N/A N/A
Press RETURN to refresh, D to toggle database display, Q to quit,
or specify new refresh interval D
Database display is now on
Status of Mirror MIRRORTEST at 08:09:29 on 05/19/2023
Arbiter Connection Status:
Arbiter Address: arbiter|2188
Failover Mode: Agent Controlled
Connection Status: This member is not connected to the arbiter
Journal Transfer
Member Name+Type Status Latency Dejournal Latency
-------------------------- --------- --------------- --------------
MIRRORA
Failover Primary N/A N/A
Mirror Databases:
Record To
Name Directory path Status Dejournal
------------- ----------------------------------- ----------- -----------
TEST /isc/mirrorA/TESTDB/ Normal N/A
Press RETURN to refresh, D to toggle database display, Q to quit,
or specify new refresh interval
```
**在操作系统中执行^MIRROR**
您可以把以下的代码写入您的脚本语言,查看mirror的状态
```bash
irisowner@mirrorA:~$ iris session iris -U "%sys" "Monitor^MIRROR"
Status of Mirror MIRRORTEST at 02:57:08 on 06/13/2023
Arbiter Connection Status:
Arbiter Address: arbiter|2188
Failover Mode: Arbiter Controlled
Connection Status: Both failover members are connected to the arbiter
Journal Transfer
Member Name+Type Status Latency Dejournal Latency
-------------------------- --------- --------------- --------------
MIRRORA
Failover Primary N/A N/A
MIRRORB
Failover Backup Active Caught up
MIRRORDR
Disaster Recovery Connected Caught up Caught up
Press RETURN to refresh, D to toggle database display, Q to quit,
or specify new refresh interval q
Doneirisowner@mirrorA:~$
```
或者更简单的,只查看本机的mirror成员状态:
```bash
irisowner@mirrorA:~$ iris session iris -U "%sys" "LocalMirrorStatus^MIRROR"
This instance is a Failover member
Status for mirror MIRRORTEST is "Primary"
Current mirror file #2 ends at 681224
Min trans file #2 min trans index: 680744
irisowner@mirrorA:~$
```
如果您熟悉ObjectScript, 也可以使用`$SYSTEM.Mirror`类的各个method来查看:
```bash
irisowner@mirrorB:~$ echo "write \$SYSTEM.Mirror.GetMemberStatus(),! halt" |iris session iris -U "%sys"
Node: mirrorB, Instance: IRIS
%SYS>
Backup
irisowner@mirrorB:~$
```
如果您要查看更多的内容,您可以更多的使用%SYSTEM.Mirror类的其他方法,比如%SYSTEM.Mirror.GetFailoverMemberStatus(.pri,.alt), $SYSTEM.Mirror.ArbiterState()等等。
### 使用Mirror_MemberStatusList存储过程
如果您从第3方的工具查询mirror成员的状态,还有一个简单的方案,就是调用%SYS命名空间的存储过程。下图是从iris管理门户调用的截图,你可以使用任何SQL客户端调用。
如果是从iris里执行,
```
%SYS>do ##class(%ResultSet).RunQuery("SYS.Mirror","MemberStatusList")
Member Name:Current Role:Current Status:Journal Transfer Latency:Dejournal Latency:Journal Transfer Latency:Dejournal Latency:Display Type:Display Status:
MDCHCNDBSL1.HICGRP.COM/STAGE:Primary:Active:N/A:N/A:N/A:N/A:Failover:Primary:
MDCHCNDBSL2.HICGRP.COM/STAGE:Backup:Active:Active:Caught up:Active:Caught up:Failover:Backup:
CDCHCNDRSL.HICGRP.COM/STAGE:Async:Async:Caught up:Caught up:Caught up:Caught up:Disaster Recovery:Connected:
```
### 通过SNMP获得
如果使用监控工具,您可以通过SNMP获得Mirror的状态,下面是最新的ISC-IRIS.mib中有关Mirror得指标部分。
```
.4.1.12 = irisMirrorTab | Table of current Mirror Members status and information
-- .4.1.12.1 = irisMirrorRow | Conceptual row for Mirror status and metrics | INDEX = irisSysIndex, irisMirrorIndex
-- .4.1.12.1.1 = irisMirrorIndex | unique index for each Mirror Member | INTEGER
-- .4.1.12.1.2 = irisMirrorName | Name of the mirror this system is a member of | STRING
-- .4.1.12.1.3 = irisMirrorMember | Mirror member name | STRING
-- .4.1.12.1.4 = irisMirrorRole | "Primary", "Backup", or "Async". | STRING
-- .4.1.12.1.5 = irisMirrorStatus | "Active" or "Activate". | STRING
-- .4.1.12.1.6 = irisMirrorJrnLatency | Mirror journal latency "Caught up", "Catchup", or "N/A". | STRING
-- .4.1.12.1.7 = irisMirrorDBLatency | Mirror database latency "Caught up", "Catchup", or "N/A". | STRING
```
## MIRROR的日志和告警
通常情况下, 维护人员是通过mirror的日志和警告来获得Mirror状态,Mirror成员之间的连接情况,而不必须定时的用命令或者调用存储过程来查看。
Cache'和IRIS的日志和警告保存在两个文件: console.log/messages.log和alert.log, 其中alert.log中记录了console.log/messages.log中级别为2,3的记录, 并必须实时发送给管理员。有关这部分内容,请参考在线文档,或者我的帖子:
我们来看看在日志中有哪些mirror的记录:
**Becoming primary mirror server**
系统固有的通知消息, level =2。当一个iris实例从备机变成了主机,此信息会写到此实例的alert.log, 同时发送给管理员。 可以查看这个[链接](https://docs.intersystems.com/iris20231/csp/docbook/DocBook.UI.Page.cls?KEY=GCM_monitor#GCM_monitor_errors)。
在Mirror切换时,管理员除了从刚刚接手的机器中收到Becoming primary mirror server的通知。如果原来的主机没有宕机或者从宕机中恢复,它也会将引起切换的故障从alert.log发送给管理员,是一个level2, 或者level3的记录。
**Arbiter connection lost**
level =2 , 自动发送给管理员。 当主机和arbiter失去连接后,在主机上会出现此警告。此时在备机上会出现“Switched from Arbiter Controlled to Agent Controlled failover on request from primary”的提示,是个level0的信息。
**MirrorServer: Connection to xxxx(backup) terminated**
**MirrorServer: Connection to MIRRORDR (async member) terminated**
当主机和备机(backup)失去连接,在主机上会出现level2的警告。 而和异步成员丢失连接,主机会出现level1的消息。尽管level1的消息不能自动通知管理员,但这时如果同时监控该异步成员的alert.log, 通常会有level2的警告消息发出,能提醒管理员检查MIRRORDR这个镜像成员的状态。
举例说明:如果在MirrorDR中操作系统重启,IRIS启动后会出现这样的level2的警告:“Previous system shutdown was abnormal, ^SHUTDOWN forced down”
**Async member for MirrorSetName started but failed to connect to primary**
level =2 , 自动发送给管理员
其他更多的关于Mirror出错的level2, 也就是警告记录, 比如:
- Could not open mirror journal log to read checksum, errno = 2
- Preserving all mirror journal files for offline failover member
- Server^MIRRORCOMM(d): Failed to notify MIRRORB for mirror configuration change
- Failed to become either Primary or Backup at startup
这不是个完整的列表,实际环境中会出现各种各样的告警通知。读懂这些通知,需要管理员了解镜像的原理,架构,以及上面介绍的镜像状态和进程的功能。
除此之外,绝大多数的level2日志的同时,会有更多的level0,level1的有关mirror变化的记录。这些内容不需要通知管理员,只是用于分析问题。 如图,下面是在一个messages.log里一个iris从备机变成主机的过程。
```
06/13/23-07:16:25:472 (2189) 0 [Generic.Event] MirrorClient: Switched from Arbiter Controlled to Agent Controlled failover on request from primary
06/13/23-07:16:26:274 (2189) 1 [Generic.Event] MirrorClient: Mirror_Client: Primary closed down, last # read = 504
06/13/23-07:16:26:301 (2189) 0 [Generic.Event] MirrorClient: Backup waiting for old Dejournal Reader (pid: 2190, job #31) to exit
06/13/23-07:16:27:394 (2189) 0 [Generic.Event] MirrorClient: Set status for MIRRORTEST to Transition
06/13/23-07:16:28:477 (1996) 0 [Utility.Event] [SYSTEM MONITOR] Mirror status changed. Member type = Failover, Status = Transition
06/13/23-07:16:30:261 (2177) 0 [Utility.Event] Returning to restart, old primary reported: "DOWN
06/13/23-07:16:31:524 (11721) 0 [Utility.Event] Applying journal data for mirror "MIRRORTEST" starting at 1538184 in file #2(/isc/mirrorB/mgr/journal/MIRROR-MIRRORTEST-20230613.001)
06/13/23-07:16:31:804 (2177) 0 [Utility.Event] Manager initialized for MIRRORTEST
06/13/23-07:16:31:986 (2177) 0 [Utility.Event] MIRRORA reports it is DOWN, becoming primary mirror server
06/13/23-07:16:32:381 (2177) 0 [Generic.Event] INTERSYSTEMS IRIS JOURNALING SYSTEM MESSAGE
Journaling switched to: /isc/mirrorB/mgr/journal/MIRROR-MIRRORTEST-20230613.002
06/13/23-07:16:32:426 (2177) 0 [Utility.Event] Scanning /isc/mirrorB/mgr/journal/MIRROR-MIRRORTEST-20230613.001
06/13/23-07:16:32:479 (2177) 0 [Utility.Event] No open transactions to roll back
06/13/23-07:16:32:485 (2177) 0 [Generic.Event] MirrorServer: New primary activating databases which are current as of 1538184 (0x00177888) in mirror journal file #2
06/13/23-07:16:32:488 (2177) 0 [Generic.Event] Changed database /isc/mirrorB/TESTDB/ (SFN 5) to read-write due to becoming primary.
06/13/23-07:16:32:924 (2177) 0 [Utility.Event] Initializing Interoperability during mirror initialization
06/13/23-07:16:32:930 (2177) 2 [Utility.Event] Becoming primary mirror server
```
更多的有关mirror监控和排除的问题, 请各位留言。 谢谢
文章
Michael Lei · 七月 4, 2023
这是个实验项目,使用OpenAI API与FHIR资源和Python相结合来回答医疗行业的用户提问。
## 项目想法
生成式人工智能,如[OpenAI上提供的LLM模型](https://platform.openai.com/docs/models), 已被证明在理解和回答高层次问题方面具有显著能力。他们使用大量的数据来训练他们的模型,因此他们可以回答复杂的问题。
他们甚至可以[使用编程语言,根据提示创建代码](https://platform.openai.com/examples?category=code) --我不得不承认,让我的工作自动化的想法让我感到有些焦虑。但到目前为止,似乎这是人们必须要习惯的事情,不管你喜不喜欢。所以我决定做一些尝试。
这个项目的主要想法是在我读到[这篇文章](https://the-decoder.com/chatgpt-programs-ar-app-using-only-natural-language-chatarkit/)关于[ChatARKit项目](https://github.com/trzy/ChatARKit)时产生的。这个项目使用OpenAI的API来解释语音命令,在智能手机摄像头的实时视频中渲染3D物体--非常酷的项目。而且,这似乎是一个热门话题,因为我发现最近有一篇[论文](https://dl.acm.org/doi/pdf/10.1145/3581791.3597296)遵循类似的想法。
让我最担心的是使用ChatGPT对AR进行**编程。由于有一个开放的github repo,我搜索了一下,发现[作者是如何使用ChatGPT生成代码的](https://github.com/trzy/ChatARKit/blob/master/iOS/ChatARKit/ChatARKit/Engine/ChatGPT.swift)。这种技术被称为*提示工程Prompt Engineering*--[这是维基百科关于它的文章](https://en.wikipedia.org/wiki/Prompt_engineering),或者这两个更实用的参考资料: [1](https://microsoft.github.io/prompt-engineering/)和[2](https://learn.microsoft.com/en-us/azure/cognitive-services/openai/concepts/advanced-prompt-engineering?pivots=programming-language-chat-completions)。
所以我想--为什么不结合FHIR和Python试试类似的东西?以下是我的想法:
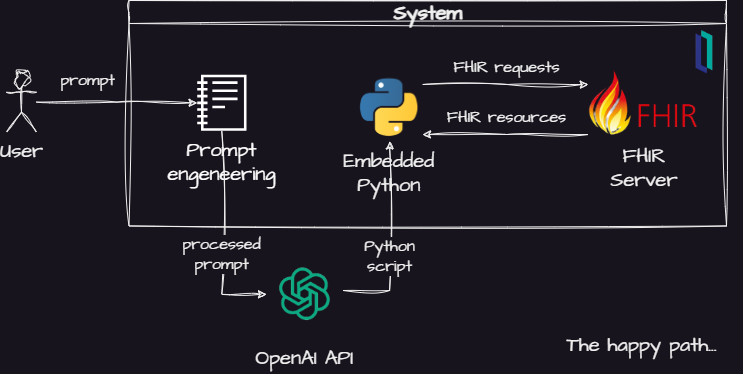
其主要构成是:
- 一个提示工程模块,将命令人工智能模型使用FHIR和Python
- 一个OpenAI API集成模块
- 一个Python解释器,用于执行生成的代码
- 一个FHIR服务器,回答人工智能模型生成的查询
基本思路是使用[OpenAI Completion API](https://platform.openai.com/docs/api-reference/completions),要求人工智能将问题分解为一堆FHIR查询。然后,人工智能模型创建一个Python脚本来处理InterSystems IRIS for Health中FHIR服务器返回的FHIR资源。
如果这个简单的设计是有效的,用户就可以得到应用的分析模型尚未支持的问题的答案。此外,这些由人工智能模型回答的问题可以被分析,以发现对用户需求的新见解。
这种设计的另一个好处是,你不需要用外部的API暴露你的数据和模型。例如,你可以问关于病人的问题,而不需要将病人数据或你的数据库模式发送到人工智能服务器上。由于人工智能模型使用公共可用的功能--FHIR和Python,你也不需要发布内部数据。.
但是,这种设计也导致了一些问题,比如:
- 如何引导人工智能根据用户需求使用FHIR和Python?
- 人工智能模型产生的答案是否正确?是否有可能对它们有信心?
- 如何处理运行外部生成的Python代码的安全问题?
因此,为了尝试解决一下这些问题,我对最初的设计做了一些阐述,得到了这个:
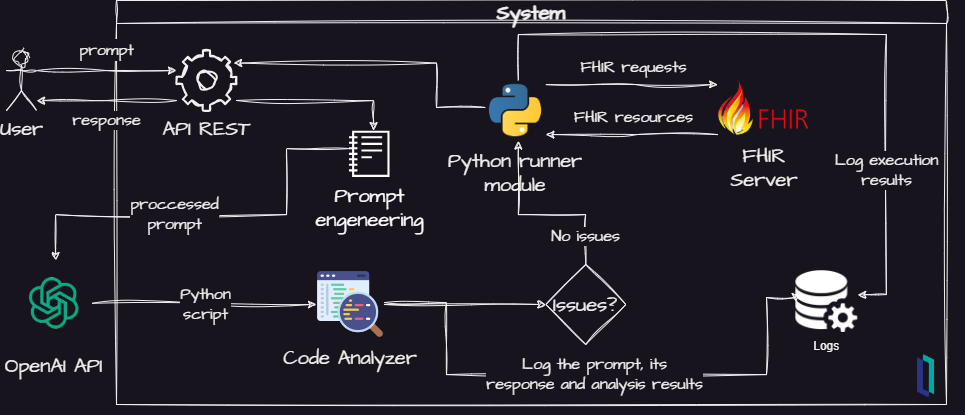
我在项目里增加了一些新的元素:
- 一个代码分析器来扫描安全问题
- 一个日志记录器,用于记录重要事件,以便进行进一步分析
- 一个用于进一步整合的API REST
因此,这个项目旨在验证这个概念,它可以支持实验来收集信息,以尝试回答这些问题。
在接下来的章节中,你会发现如何安装该项目并试用它。
然后,你会看到我在尝试回答上述问题时得到的一些结果和一些结论。
希望你觉得它有用。我们也非常欢迎你为这个项目做出贡献!
## 项目尝试
要试一试,请打开IRIS终端,运行以下内容:
```objectscript
ZN "USER"
Do ##class(fhirgenerativeai.FHIRGenerativeAIService).RunInTerminal("")
```
例如,以下问题被用来测试该项目:
1. 数据集里有多少病人?
2. 病人的平均年龄是多少?
3. 给我所有的条件(代码和名称),去除重复的。将结果以表格的形式呈现出来。(不要使用pandas)
4. 有多少病人患有病毒性鼻窦炎(代码444814009)?
5. 病毒性鼻窦炎(代码444814009)在患者群体中的流行率是多少?对于多次出现相同病情的患者,考虑只打一次就可以计算出来。
6. 在病毒性鼻窦炎(代码444814009)患者中,性别组的分布是怎样的?
你可以找到这些问题的输出例子[这里](https://github.com/jrpereirajr/iris-fhir-generative-ai/blob/master/misc/tests-accuacy)。
> 请注意,如果你在你的系统上尝试,结果可能会有所不同,即使你使用相同的提示。这是由于LLM模型的随机性。
这些问题是由ChatGPT提出的。他们要求这些问题是以复杂程度不断提高的方式来创建的。第3个问题是个例外,它是由作者提出的。
## 提示工程Prompt Engineering
项目使用的提示Prompt可以在方法`GetSystemTemplate()`中找到[这里](https://github.com/jrpereirajr/iris-fhir-generative-ai/blob/master/src/fhirgenerativeai/PromptService.cls)。
它遵循提示工程的指南,首先你给人工智能模型分配一个角色,然后输入一堆限制条件和指令。它的每个部分的意图都有注释,所以你可以理解它是如何工作的。
请注意一种接口定义的使用,当模型被指示假设一个已经定义好的名为`CallFHIR()`的函数与FHIR交互,而不是自己声明一些东西。这是受ChatARKit项目的启发,作者在该项目中定义了一整套函数,为使用AR库抽象出复杂的行为。
在这里,我使用这个技术来避免直接创建代码进行HTTP调用的模式。
这里一个有趣的发现是关于强迫人工智能模型以XML格式返回其响应。由于打算返回的是Python代码,我在XML中使用了CDATA块,将其对称化。
尽管在提示中明确指出响应格式必须是XML格式,但在以XML格式发送用户提示后,AI模型就开始遵循这个指令。你可以在上面提到的同一个类中的`FormatUserPrompt()`方法中看到这一点。
## 代码分析器
该模块使用[bandit库](https://bandit.readthedocs.io/en/latest/)来扫描安全问题。
这个库生成Python程序的AST,并针对常见的安全问题对其进行测试。你可以在这些链接中找到被扫描的问题种类:
- [测试插件](https://bandit.readthedocs.io/en/latest/plugins/index.html#complete-test-plugin-listing)
- [调用黑名单](https://bandit.readthedocs.io/en/latest/blacklists/blacklist_calls.html)
- [导入黑名单](https://bandit.readthedocs.io/en/latest/blacklists/blacklist_imports.html)
由人工智能模型返回的每一个Python代码都会针对这些安全问题进行扫描。如果发现有问题,就会取消执行并记录错误。
## 日志记录器
所有的事件都被记录下来,以便在表[LogTable](https://github.com/jrpereirajr/iris-fhir-generative-ai/blob/master/src/fhirgenerativeai/LogTable.cls)中作进一步分析。
每个回答问题的运行都有一个会话ID。你可以在表中的'SessionID'列中找到它,并通过将它传递给方法`RunInTerminal("", )`来获得所有事件。例如:
```objectscript
Do ##class(fhirgenerativeai.FHIRGenerativeAIService).RunInTerminal("", "asdfghjk12345678")
```
你也可以用这个SQL来检查所有的日志事件:
```sql
SELECT *
FROM fhirgenerativeai.LogTable
order by id desc
```
## 测试
我执行了一些测试以获得信息来衡量人工智能模型的性能。
每个测试执行了15次,它们的输出被存储在[this](https://github.com/jrpereirajr/iris-fhir-generative-ai/blob/master/misc/tests-accuacy)和[this](https://github.com/jrpereirajr/iris-fhir-generative-ai/blob/master/misc/tests-security)的目录下。
> 请注意,如果你在你的系统上尝试,结果可能会有所不同,即使你使用相同的提示。这是由于LLM模型的随机性。
### 准确率
对于问题#1的测试,有`14个结果6`和`1个错误`。正确值是`6'。所以它是`100%`正确的,但有`6%`的执行失败。
验证#1结果的SQL语句:
```sql
SELECT
count(*)
FROM HSFHIR_X0001_S.Patient
```
对于第2题的测试,有`3个结果52`,`6个结果52.5`和`6个错误`。正确的数值--考虑到有小数点的年龄,是`52.5'。所以我认为这两个值都是正确的,因为这一点差异可能是由于提示不明确造成的--它没有提到任何关于允许或不允许带小数的年龄。因此,它是`100%`正确的,但执行失败的是`40%`。
验证#2结果的SQL语句:
```sql
SELECT
birthdate, DATEDIFF(yy,birthdate,current_date), avg(DATEDIFF(yy,birthdate,current_date))
FROM HSFHIR_X0001_S.Patient
```
在第3个问题的测试中,有 "3个错误 "和 "12个有23个不同元素的表格"。表的值不在相同的位置和格式中,但我还是认为这因为错误格式的提示造成的。因此,它是`100%`正确的,但有`20%`的执行失败。
验证#3结果的SQL语句:
```sql
SELECT
code, count(*)
FROM HSFHIR_X0001_S.Condition
group by code
```
对于第4题的测试,有`2个错误`,`12个结果7`和`1个结果4`。正确值是`4'。所以它是`12%`正确的,有执行失败的`13%`。
验证#4结果的SQL语句:
```sql
SELECT
p.Key patient, count(c._id) qtde_conditions, list(c.code) conditions
FROM HSFHIR_X0001_S.Patient p
join HSFHIR_X0001_S.Condition c on c.patient = p.key
where code like '%444814009%'
group by p.Key
```
对于5号问题的测试,有`11个错误`,`3个结果为4`,`1个结果为0.6`。正确值是`4'。所以它的正确率是`75%`,执行失败率是`73%`。
用来验证#5结果的SQL与#4所用的相同。
对于6号问题的测试,有`12个错误`和`3个结果{女性:4,男性:2,其他: 0}`. 正确的值是`{女性:3,男性:1,其他: 0}`. 所以它是`0%`正确的,有执行失败的`80%`。
验证#6结果的SQL语句:
```sql
SELECT
p.gender, count(distinct p._id) qty_patients, list(p.key) patients, list(c.code) conditions
FROM HSFHIR_X0001_S.Patient p
join HSFHIR_X0001_S.Condition c on c.patient = p.key
where code like '%444814009%'
group by p.gender
```
总结一下测试结果:
| 测试编号 # |准确率 | 执行失败率 |
|--------|----------|-------------------|
| 1 | 100% | 6% |
| 2 | 100% | 40% |
| 3 | 100% | 20% |
| 4 | 12% | 13% |
| 5 | 75 % | 73% |
| 6 | 0% | 80% |
### 安全性
你可以在[测试目录](https://github.com/jrpereirajr/iris-fhir-generative-ai/blob/master/misc/tests-accuacy)中检查生成的代码,似乎人工智能模型没有产生安全问题--这也是代码分析器模块发现的结果,没有安全问题。
因此,为了测试代码分析器是否能够检测到安全问题,[执行Python代码的模块](https://github.com/jrpereirajr/iris-fhir-generative-ai/blob/master/src/fhirgenerativeai/PythonService.cls)有一个名为 "代码注入 "的属性,可以注入恶意代码,以便进行测试。
因此,为安全测试注入了以下代码:
1. 安全测试 #1:
```python
print(eval("os.chmod('%s', 0o777)" % 'test.txt'))
```
这段代码试图访问SO文件系统并改变一个文件的权限。这显然是一个不符合项目意图的代码,所以它必须被阻止。
2. 安全测试 #2:
```python
import requests
url = "https://postman-echo.com/get"
params = {"arg": "value"}
response = requests.get(url, params=params)
data = response.json()
print(data)
```
这段代码试图向一个外部地址发出HTTP请求--本例中是Postman API。如果这段代码被执行,本地信息就会被攻击者轻易地获取。
正如你在[安全测试目录](https://github.com/jrpereirajr/iris-fhir-generative-ai/blob/master/misc/tests-security)中所看到的,代码分析器成功地发现了安全问题。
## 结论
就准确性而言,人工智能模型在低复杂度的问题上得到了正确的结果,但随着问题复杂度的增加而开始失败。同样的情况也出现在执行失败上。因此,问题越复杂,人工智能模型产生的代码就越多,无法执行,导致错误结果的概率就越大。
这意味着需要对提示做出一些努力。例如,在[问题#6的代码](https://github.com/jrpereirajr/iris-fhir-generative-ai/blob/master/misc/tests-accuacy/6/1688265739062.txt)中,错误在于只询问病人而忽略了条件。这种分析对于指导提示的改变是必要的。
总的来说,人工智能模型在这次测试中的表现表明,在能够回答分析性问题之前,它仍然需要更多的改进。
这是由于人工智能模型的随机性质。我的意思是,在上面提到的ChatARKit项目中,如果人工智能模型渲染的三维物体并不完全在要求的地方,但接近它,可能用户不会介意。不幸的是,同样的情况并不适用于分析性问题,答案需要精确。
但是,我并不是说人工智能模型不能执行这样的任务。我要说的是,这个项目中使用的设计需要改进。
需要注意的是,这个项目没有使用更先进的技术来使用生成器AI,像[Langchain](https://python.langchain.com/docs/get_started/introduction.html)和[AutoGPT](https://autogpt.net/autogpt-installation-and-features/)。这里使用了一种更 "纯粹 "的方法,但使用这种更复杂的工具可能会导致更好的结果。
关于安全性,代码分析器发现了所有测试的安全问题。
然而,这并不意味着由人工智能模型生成的代码是100%安全的。此外,允许执行外部生成的Python代码可能绝对是危险的。你甚至不能百分之百地确定提供Python代码的系统实际上是OpenAI的API服务器......
避免安全问题的一个更好的方法可能是尝试其他不如Python强大的语言,或者尝试创建你自己的 "语言 "并将其呈现给AI模型,就像在[这个非常简单的例子](https://platform.openai.com/examples/default-text-to-command)。
最后,重要的是要注意,像代码性能这样的方面在这个项目中没有涉及,可能也会成为未来工作的一个好主题。
所以,我希望大家能发现这个项目的有趣和有用。
> **免责声明:这是一个实验性项目。它将向OpenAI API发送数据,并在你的系统上执行由AI生成的代码。所以,不要在生产系统上使用它。还要注意,由于OpenAI的API调用是收费的。使用它的风险由你自己承担。它不是一个可用于生产的项目。**
Hi! Just here to a quick update: now we published a video about this project. Enjoy it: 😊