新增
.png)
InterSystems IRIS for Health™ 是全球第一个也是唯一一个专门为医疗应用程序的快速开发而设计的数据平台,用于管理全世界最重要的数据。它包括强大的开箱即用的功能:事务处理和分析、可扩展的医疗保健数据模型、基于 FHIR 的解决方案开发、对医疗保健互操作性标准的支持等等。所有这些将使开发者能够快速实现价值并构建具有突破性的应用程序。了解更多信息。
InterSystems IRIS for Health™ 是全球第一个也是唯一一个专门为医疗应用程序的快速开发而设计的数据平台,用于管理全世界最重要的数据。它包括强大的开箱即用的功能:事务处理和分析、可扩展的医疗保健数据模型、基于 FHIR 的解决方案开发、对医疗保健互操作性标准的支持等等。所有这些将使开发者能够快速实现价值并构建具有突破性的应用程序。了解更多信息。
v2026.1 刚刚正式发布,其中我最期待使用的一项功能就是DTL 说明功能。
该功能允许您选择一个数据转换,只需点击一下按钮,即可获得该转换的人类可读描述(您还可以将其作为 DTL 描述的基础)。

对于复杂的 DTL,尤其是那些并非由您亲自编写,或者虽然由您编写但已时隔许久的 DTL,该功能将帮助您快速清晰地了解其工作原理。
对于尚未使用过“安全钱包”(Security Wallet)功能 的用户(有关此功能的更多信息,请参阅这些文档、这段 4 分钟视频以及这段 36 分钟视频),请注意:您需要使用该功能来配置DTL 解释器的OpenAI 许可证 API 密钥。
有关此功能的更多详细信息,请参阅此处的文档。
另请参阅@Aya Heshmat的帖子,其中包含一段视频(链接直接跳转至展示 DTL Explainer 的时间点),介绍了新互操作性 UI 中的所有最新功能。
此外,还可观看@Julie Ma 提供的这段更详细的视频演示与讲解。
这是将生成式人工智能(GenAI)功能整合到 InterSystems 产品中的一个示例。
给大家推荐一种新的大型表格管理方式!看看分区如何帮助您管理和查询数据:
大家好,
现在是时候公布InterSystems开发者竞赛:面向FHIR的AI Agent”的获奖名单了!
非常感谢我们的18位社区成员开发了
本次竞赛收到了令人印象深刻的参赛作品,每一件都体现了创新精神和创造性思维。面对如此众多优秀的参赛作品,评选出最佳作品确实是一项艰巨的任务。

让我们来认识一下获奖者,并了解他们的项目:
该方案成功将医疗设备数据纳入全院数据管理,实现了医疗设备数据的全流程高效采集与应用。
InterSystems Reports 25.3 版本现已在 InterSystems 软件分发网站的“组件(Components )”部分发布。该软件名为 InterSystems Reports Designer 和 InterSystems Reports Server,支持 Mac OS X、Windows 和 Linux 操作系统。
别被这个小版本号所迷惑——此版本包含大量新功能。其中包括焕然一新的用户界面——“浅色模式”下线条更简洁、配色更清新,并且您可以在“用户配置文件”中切换回“经典模式”。 此外,我们的合作伙伴 insightsoftware 还提供了额外的修复和增强功能。InterSystems Reports 25.3 基于 Logi Report 25.3 Service Pack 5 构建。如需了解更多信息,请参阅 insightsoftware 提供的发布说明。
此外,InterSystems 还新增了对Page Report Studio和Web Report Studio 的访问权限,这使客户能够通过报告服务器进行更丰富的报表编辑,从而在许多报表设计任务中减少了对安装 Report Designer 的需求。请点击链接了解更多详情。
欢迎回到关于 AI Hub 的系列入门文章,这是目前处于早期访问计划(EAP)阶段的新产品功能!(链接:EAP 网站下载、文档)
在上一篇文章中,我们介绍了如何使用新的 %AI 类直接在 ObjectScript 中创建代理和代理工具。 不过,有时您可能并不需要创建新的代理,而只是希望向现有代理添加一些自定义工具,以便让本地 claude、codex、copilot 或其他您选择的代理直接查询您的数据。这时,MCP 服务器就派上用场了。
在本指南中,我们将逐步演示如何创建自己的 MCP 服务器来访问您的数据。
免责声明:AI Hub 目前处于早期访问预览阶段,其功能在正式发布前可能会发生变更;如发现任何问题,可通过上述链接的文档 GitHub 仓库提交问题报告。EAP 预览版不适用于生产环境。
我将简要介绍,因为关于 MCP 服务器(模型上下文协议)已有大量其他优质文章(建议从@Pietro Di Leo 的这篇文章或InterSystems 总裁 Don Woodlock 的这段精彩入门视频开始阅读)。
模型上下文协议(Model Context Protocol)是一种传输协议,允许将外部工具添加到代理中 存在一个发现“握手”过程:MCP 服务器会向 MCP 客户端发送工具列表。
对于上周没有参加 READY 大会的朋友们来说,你们可能错过了这一激动人心的消息:AI Hub 的抢先体验计划现已正式启动。这一消息是在@Benjamin De Boe和@Jeff Fried 带来的一场精彩演示中公布的,我建议大家在录像发布后务必观看这段演示! 我有幸提前体验了 AI Hub,想借此机会向社区大家介绍一下。
在深入探讨细节之前,先提供文档链接和EAP 门户链接,您可通过这些链接下载 AI Hub,目前提供独立安装包或容器镜像两种形式。
请注意,这只是预览版,在正式发布前可能会有重大变更,该版本不适用于生产环境,您可能会遇到一些问题——如果遇到问题,请在 GitHub 页面上提交问题!
对我来说,最令人兴奋的功能莫过于全新的 ObjectScript 代理 SDK。现在,您可以使用直观的 SDK,直接在 ObjectScript 中创建代理和工具。
创建代理非常简单:您可以通过 XData INSTRUCTIONS 组件为其指定系统提示,然后只需设置提供程序、模型和工具即可:
Class Sample.Agent Extends %AI.Agent
{
/// LLM Model
Parameter MODEL = "gpt-5-nano";
/// Toolsets that the agent can use
Parameter TOOLSETS = "Sample.ToolSet";
/// System Prompt
XData INSTRUCTIONS [ MimeType = text/markdown ]
{
# Sample Assistant
You are a helpful assistant with access to a set of tools to interact with a database of people.
}
Method %OnInit() As %Status
{
// Set provider with API key from environment variable
Set key = $System.Util.GetEnviron("OPENAI_API_KEY") // or whatever
Set ..Provider = ##class(%AI.Provider).Create("openai", {"api_key": (key)})
Return $$$OK
}
}大家好,
你是否曾希望你的电子健康记录(EHR)能具备思考能力?不仅仅是显示数据,也不仅仅是触发警报。而是能够真正阅读病历、综合临床指南进行分析,并根据临床医生的单条信息,向系统生成结构化的转诊医嘱。
在本文中,我将向大家展示如何创建您自己的定制临床AI助手。
iris-fhir-agents是一个完全基于 InterSystems IRIS for Health 构建的多智能体临床 AI 平台

大家好,
在本文中,我将介绍我的应用程序iris-fhir-agents 这是一个由 InterSystems IRIS for Health 驱动的多智能体临床 AI 平台。该平台包含用于分诊、专科会诊、用药安全以及 FHIR 服务器探索的智能体——所有功能均基于 IRIS Vector Search RAG 构建。 平台包含一个无代码代理构建器,让您无需编写任何代码即可设计和部署自定义临床代理。
基于时间的一次性密码(TOTP)的两阶段认证是广泛使用的提高安全性手段。
本文以访问IRIS系统管理门户(System Management Portal)为例,介绍如何在IRIS里配置TOTP提高访问IRIS的安全性。
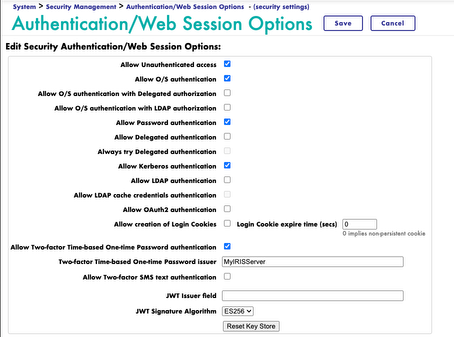
打开IRIS系统管理门户(SMP),进入系统 > 安全管理 > 身份验证/Web 会话选项 - (安全设置),选中Allow Two-factor Time-based One-time Password authentication,然后在出现的Two-factor Time-based One-time Password issuer 中修改issuer名字,例如MyIRISServer
这里以管理门户(SMP)为例,它是一个Web application (/csp/sys)。打开IRIS系统管理门户(SMP),进入系统 > 安全管理 > Web 应用程序 > 编辑 Web 应用程序 - (安全设置) ,点击/csp/sys。然后在安全设置>允许的身份验证方法下选中“基于时间的一次性双重验证密码 ”
确定哪些用户使用基于TOTP的2FA,并修改该用户的配置。这里以用户SuperUser为例。
