IRIS/Caché SQL优化经验分享 - 查询计划(Query Plan)
为什么要读Query Plan, 在线文档中有句话是这么说的:
While the SQL compiler tries to make the most efficient use of data as specified by the query, sometimes the author of the query knows more about some aspect of the stored data than is evident to the compiler. In this case, the author can make use of the query plan to modify the original query to provide more information or more guidance to the query compiler.
翻译一下是这样:系统给你的查询计划并不总是最好的,如果您能对查询计划,可以人工做更精细的优化。
我们先看看读Query Plan的几个基本知识:
MAP
An SQL table is stored as a set of maps. 您有看到3种map: Master map, index map, bitmap.
# 回表读主数据,
- Read master map DWBC.CT_Dept.IDKEY, using the given idkey value.
# 读普通索引
Read index map DWBC.CT_MDRDictionary(T1).UniCodeIdx, using the given %SQLUPPER(UniCode), and getting T1.ID.
# 读bitmap索引
Read bitmap index My.ppl1.idxWLRecDep, looping on %SQLUPPER(WLRecDep) (with a given set of values) and bitmap chunks.
temp-file
在复杂查询时,中间过程会存在“temp-file"里。如果您的内存设置合理,通常这个"temp-file"只存在于内存,不会有IO操作。
和map一样,temp-file也是有subscription(下标),也可以有node, 您可以认为它和普通的索引是一样的global记录,通常您可以把temp-file当成一个临时的索引,只是它在内存里。
Divide and process in parallel
一个查询可以被多个进程并行处理。一种情况是用idkey分开,每一段用一个进程处理,看一个例子
• Divide extent bitmap My.column(FACTTT).%%DDLBEIndex into subranges of bitmap chunks.
• Call module A in parallel on each subrange, piping results into temp-file C.
基础教学完成。现在我们来一起看看一个真实的Query Plan。最简单的查看Query plan的方式是在IRIS管理门户的SQL页面,如果您习惯用SQL客户端, 也可以执行“EXPLAIN ..."得到查询计划。
以下的这个查询是一个主表和一个字典表的关联查询,得到一个时间段的结果,按照字典表中的科室代码分组。
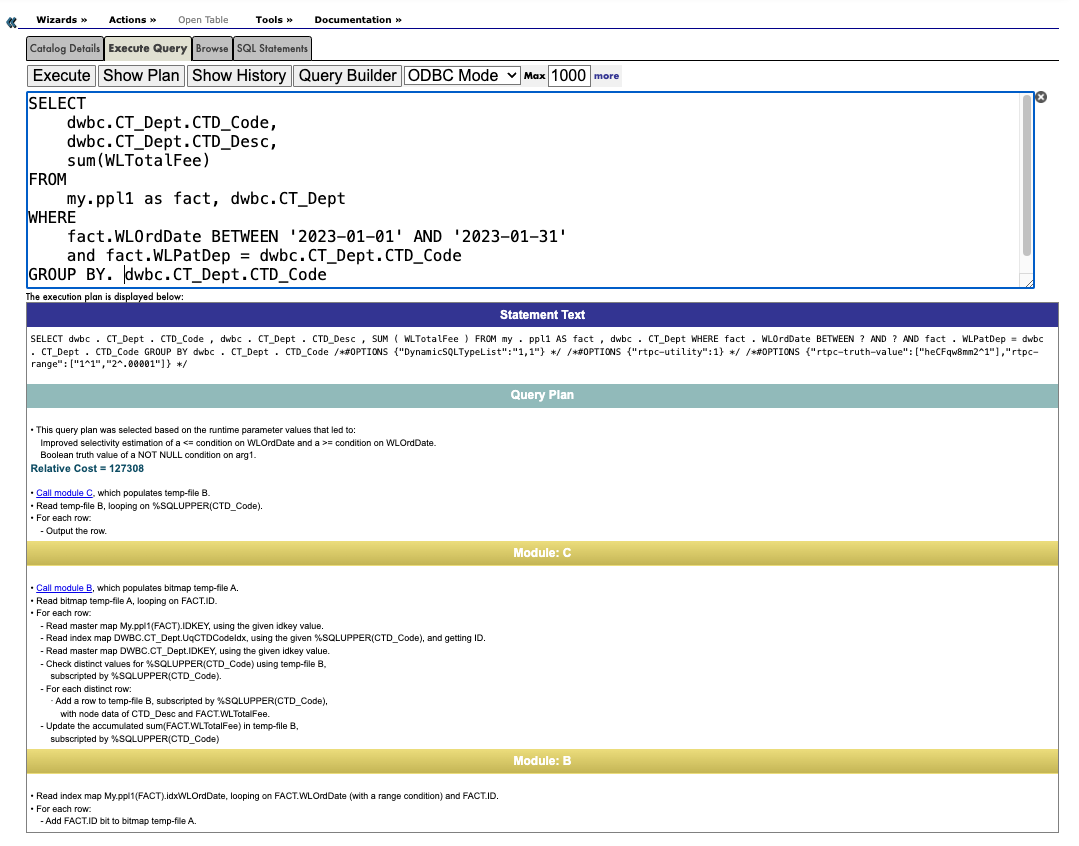
主计划部分
# SQL compiler会在查询语句上附加信息,放在 /*#OPTIONS*/块里。比如下面的“DynamicSQLTypeList”说的是内部SQL查询的类型,
# RTPC指的是Runtime Plan Choice,是一个优化的特性,这些普通的SQL用户可以先不用了解。
# 如果非要知道什么意思,可以查看链接:https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GSOC_rtpc
# 这里使用了RTPC的原因是fact.WLPatDep字段有Outlier值
Statement Text
SELECT dwbc . CT_Dept . CTD_Code , dwbc . CT_Dept . CTD_Desc , SUM ( WLTotalFee )
FROM my . ppl1 AS fact LEFT JOIN dwbc . CT_Dept ON fact . WLPatDep = dwbc . CT_Dept . CTD_Code
WHERE fact . WLOrdDate BETWEEN ? AND ?
GROUP BY dwbc . CT_Dept . CTD_Code
/*#OPTIONS {"DynamicSQLTypeList":"1,1"} */
/*#OPTIONS {"rtpc-utility":1} */
/*#OPTIONS {"rtpc-truth-value":["heCFqw8mm2^1"],"rtpc-range":["2^1","3^.00001"]} */
# Query Plan
• This query plan was selected based on the runtime parameter values that led to:
Improved selectivity estimation of a <= condition on WLOrdDate and a >= condition on WLOrdDate.
Boolean truth value of a NOT NULL condition on arg1.
# 除非您比较多个不同的查询计划,这个相对花费的值没有意义
Relative Cost = 127308
#调用Module C, 它会创建一个temp-file B
• Call module C, which populates temp-file B.
# temp-file B的每一行对应一个CTD_Code,也就是科室代码, 因此,temp-file B也就是最后的结果集。
• Read temp-file B, looping on %SQLUPPER(CTD_Code).
• For each row:
- Output the row.
说明: Module C 是主处理模块,它创建一个临时文件temp-file B, 其中每一个记录对应一个科室表中的科室。
Moduel C
# 调用Module B,产生temp-file A,
Call module B, which populates bitmap temp-file A.
# 对temp-file A的每一行,也就是查询范围的每一天,得到这个时段内的所有主表ID,并且“looping on"
• Read bitmap temp-file A, looping on FACT.ID.
# 对应上面的"looping on", 因此每一行是一个FACT.ID
• For each row:
# 回表,得到这行的数据
- Read master map My.ppl1(FACT).IDKEY, using the given idkey value.
# 使用CTD_Code的值去查字典表,这里没有清楚的写明主表和字典表的关联
- Read index map DWBC.CT_Dept.UqCTDCodeIdx, using the given %SQLUPPER(CTD_Code), and getting ID.
# 得到字典表中的这行数据
- Read master map DWBC.CT_Dept.IDKEY, using the given idkey value.
# 确认这行记录里的CTD_Code不是NULL
- Test the NOT NULL condition on %SQLUPPER(CTD_Code).
# 如果字典表中没有任何一行数据匹配 ON 的条件,将会额外生成一行所有列为NULL的数据
- Generate a row padded with NULL for table DWBC.CT_Dept if no row qualified.
# 查看temp-file B的文件里有没有这个科室的值
- Check distinct values for %SQLUPPER(CTD_Code) using temp-file B,
subscripted by %SQLUPPER(CTD_Code).
# 这里的distinct指的是科室代码, 创建的temp-file B的存储
# ^tempB(1) = ("心内科",10块人民币)
# ^tempB(2) = ("心外科",50块人民币)
# ...
- For each distinct row:
· Add a row to temp-file B, subscripted by %SQLUPPER(CTD_Code),
with node data of CTD_Desc and FACT.WLTotalFee.
# 把temp-file B汇总,最后的结果集
- Update the accumulated sum(FACT.WLTotalFee) in temp-file B,
subscripted by %SQLUPPER(CTD_Code)
Module B
# 读标准索引idxWLOrdDate, 它的格式是^My.ppl1I("idxWLOrdDate",日期下标,表ID) = ""
• Read index map My.ppl1(FACT).idxWLOrdDate, looping on FACT.WLOrdDate (with a range condition) and FACT.ID.
# 生成一个查询范围内的OrderDate的bitmap索引,被存在一个临时文件temp-file A
• For each row:
- Add FACT.ID bit to bitmap temp-file A.
总结
好了, 当看过一个执行计划后,您就基本可以使用执行计划来发现SQL性能的问题了。比如上面的这个计划,我们可能有两个想法:
- 既然Moudle B是生成了一个OrdDate的bitmap索引,那么我干脆创建一个OrdDate的bitmap索引不好吗?
答案是不好, 详细请看前面关于bitmap索引的文章
- 为什么没有用多进程处理?有没有办法强迫使用多进程,会更快吗?
在查询语句里加入*%PARALLE*, 可以强迫使用多进程。
*如果您有兴趣,可以看看多进程的查询计划,当做个练习,:) *
Statement Text
SELECT dwbc . CT_Dept . CTD_Code , dwbc . CT_Dept . CTD_Desc , SUM ( WLTotalFee )
FROM %PARALLEL my . ppl1 AS fact LEFT JOIN dwbc . CT_Dept ON fact . WLPatDep = dwbc . CT_Dept . CTD_Code WHERE fact . WLOrdDate BETWEEN ? AND ? GROUP BY dwbc . CT_Dept . CTD_Code /*#OPTIONS {"DynamicSQLTypeList":"1,1"} */ /*#OPTIONS {"rtpc-utility":1} */ /*#OPTIONS {"rtpc-truth-value":["heCFqw8mm2^1"],"rtpc-range":["2^1","3^.00001"]} */
Query Plan
• This query plan was selected based on the runtime parameter values that led to:
Improved selectivity estimation of a <= condition on WLOrdDate and a >= condition on WLOrdDate.
Boolean truth value of a NOT NULL condition on arg1.
Relative Cost = 127308
• Call module J, which populates temp-file C.
• Read temp-file C, looping on %SQLUPPER(CTD_Code).
• For each row:
- Output the row.
Module: J
• Divide index map My.ppl1(FACT).idxWLOrdDate into subranges of subscript values.
• Call module A in parallel on each subrange, piping results into temp-file D.
• Read temp-file D, looping on a counter.
• For each row:
- Check distinct values for %SQLUPPER(CTD_Code) using temp-file C,
subscripted by %SQLUPPER(CTD_Code).
- For each distinct row:
· Add a row to temp-file C, subscripted by %SQLUPPER(CTD_Code),
with node data of CTD_Desc.
- Update the accumulated sum([value]) in temp-file C,
subscripted by %SQLUPPER(CTD_Code)
Module: A
• Call module C, which populates temp-file B.
• Read temp-file B, looping on %SQLUPPER(CTD_Code).
• For each row:
- Add a row to temp-file D, subscripted by a counter, with node data of %SQLUPPER(CTD_Code), CTD_Desc, and sum([value]).
Module: C
• Call module B, which populates bitmap temp-file A.
• Read bitmap temp-file A, looping on FACT.ID.
• For each row:
- Read master map My.ppl1(FACT).IDKEY, using the given idkey value.
- Read index map DWBC.CT_Dept.UqCTDCodeIdx, using the given %SQLUPPER(CTD_Code), and getting ID.
- Read master map DWBC.CT_Dept.IDKEY, using the given idkey value.
- Test the NOT NULL condition on %SQLUPPER(CTD_Code).
- Generate a row padded with NULL for table DWBC.CT_Dept if no row qualified.
- Check distinct values for %SQLUPPER(CTD_Code) using temp-file B,
subscripted by %SQLUPPER(CTD_Code).
- For each distinct row:
· Add a row to temp-file B, subscripted by %SQLUPPER(CTD_Code),
with node data of CTD_Desc and FACT.WLTotalFee.
- Update the accumulated sum([value]) in temp-file B,
subscripted by %SQLUPPER(CTD_Code)
Module: B
• Read index map My.ppl1(FACT).idxWLOrdDate, looping on the subrange of FACT.WLOrdDate and FACT.ID.
• For each row:
- Add FACT.ID bit to bitmap temp-file A.