IRIS/Caché SQL优化经验分享 - Collation(排序规则)
这个帖子内容有点深。如果您读的有困难,请直接跳过这篇,对绝大多数IRIS/Caché使用者,它一点都不重要。
数据库表的Collation(排序规则)本来是一个非常简单的概念。说到它是因为曾经发现过由Collation引起的性能问题。
我试图用一句话来解释数据库的排序规则:
- 绝大多数数据库因为业务查询需要,保存的字符型数据是不分大小写的。当你执行一个 order by, group by, distinct,like等等条件查询时,因为这个不分大小写的collation,你得到的结果也不分大小写。例如,对名字做group by, James, james一定是在一组。
- 如果非要区分大小写,会在查询的时候使用一个函数
- 因为要操作非英语的字符集,以及可以被当作字符看待的数字类型,适应不同的排序规则,一个数据库可能有很多种Collation类型。
很简单,在表一级定义Collation的SQL语句是:
CREATE TABLE Sample.MyNames (
LastName CHAR(30),
FirstName CHAR(30) COLLATE SQLstring)
IRIS/Caché的Collation
事情在IRIS/Caché里变的有点复杂。
- 对于一个字段,可以分别在字段上和索引上定义Collation。 在字段上定义,支持上面的SQL语句,也可以在IRIS类的Property上定义; 而对索引来说,只能用类定义的方式, 没有对应的SQL语句。
- 为了应对多种不同的字符集,再加上IRIS/Caché发展的历史上的一些遗留,Collation的类型可以有很多种。而今天绝大多数情况下使用的就只有两种:
EXACT: 区分大小写;SQLUPPER: 不区分大小写。这里我也是只说这两种。
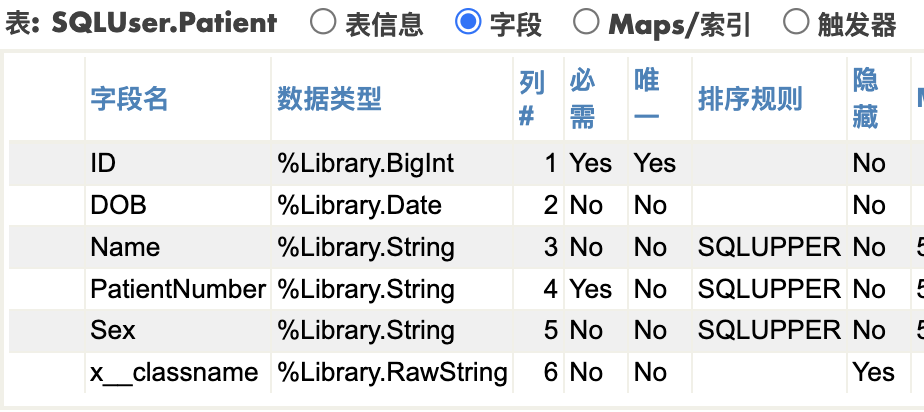
让我们还是从Patient表开始。 这是它的字段
这是它的索引
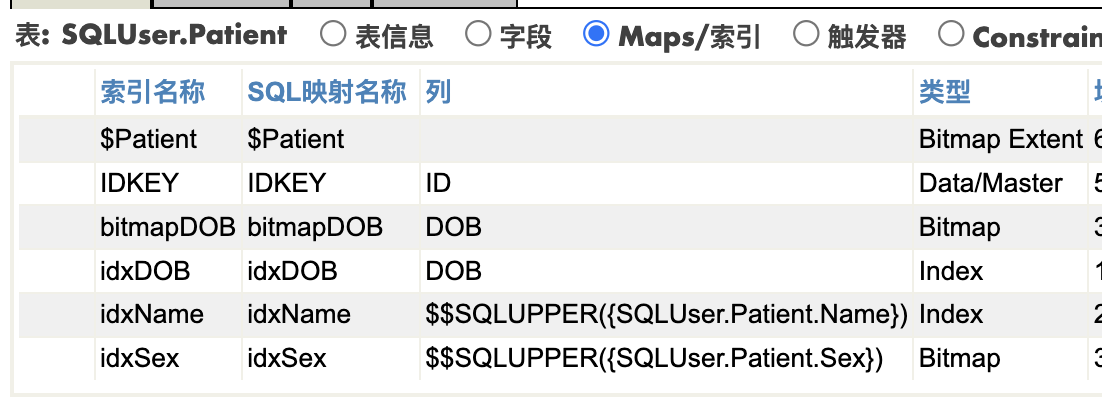
这是系统默认的状态,我并没有在字段或者索引上做任何设置。这里我抛出第一个规则:
规则1: 默认的字段排序规则是SQLUPPER。在字段上创建索引,默认使用字段的排序规则
这非常好记,业务部排序不分大小写很合适。索引,比如上面的'idxName'有一栏叫列,您可以理解成global的下标。它使用了一个function, $$$SQLUPPER(), 确保所有的下标都是大写。得到的结果像这样:
^User.PatientI("idxName"," ADAM",47) = ""
^User.PatientI("idxName"," AHMED,BRENDAN S.",57) = ""
^User.PatientI("idxName"," ANDERSON,JAMES Q.",59) = ""
^User.PatientI("idxName"," CLINTON,MARY L.",51) = ""
接着我们说第2个规则:
规则2: 如果字段和索引上的Collation类型不一样,那么有两种情况
- 字段设置EXACT, 索引设置SQLUPPER(或者其他类型), 索引性能下降
- 字段设置SQLUPPER(或者其他类型), 索引设置EXACT, 索引无法使用
然后问题来了,根据规则一,既然系统默认的表现是最好的, 我干嘛要故意把两者的排序类型改成不一样呢?
答案是:最大的可能不是故意的,而是不小心弄错了,基本都是和SQLStorage有关。
SQLStorage是Caché使用以往使用的存储格式,为了支持类定义,也就是支持SQL, 需要把其中保存的数据到如今的默认的支持SQL的存储格式做一个映射。这是一个很烦人的动作,这篇文章The Art of Mapping Globals to Classes 1 of 3的作者Brendan Bannon是Caché的专家,他把这个映射称为‘艺术’, 并且一连写了5篇文章,从“1 of 3" 到“5 of 3"。
在使用SQLStorage里表里,索引是定义在一个的XML节点。我们找个例子看看:
这是SQLUser.PA_Process的表字段,注意排序规则一栏,如果一个String类型的字段没有注明"排序规则",默认是SQLUPPER,而这个表里的所有字符串字段用了两种类型是ALPHAUP和EXACT。 为什么不用默认的SQLUPPER, 我认为是为了向前兼容早期的代码。
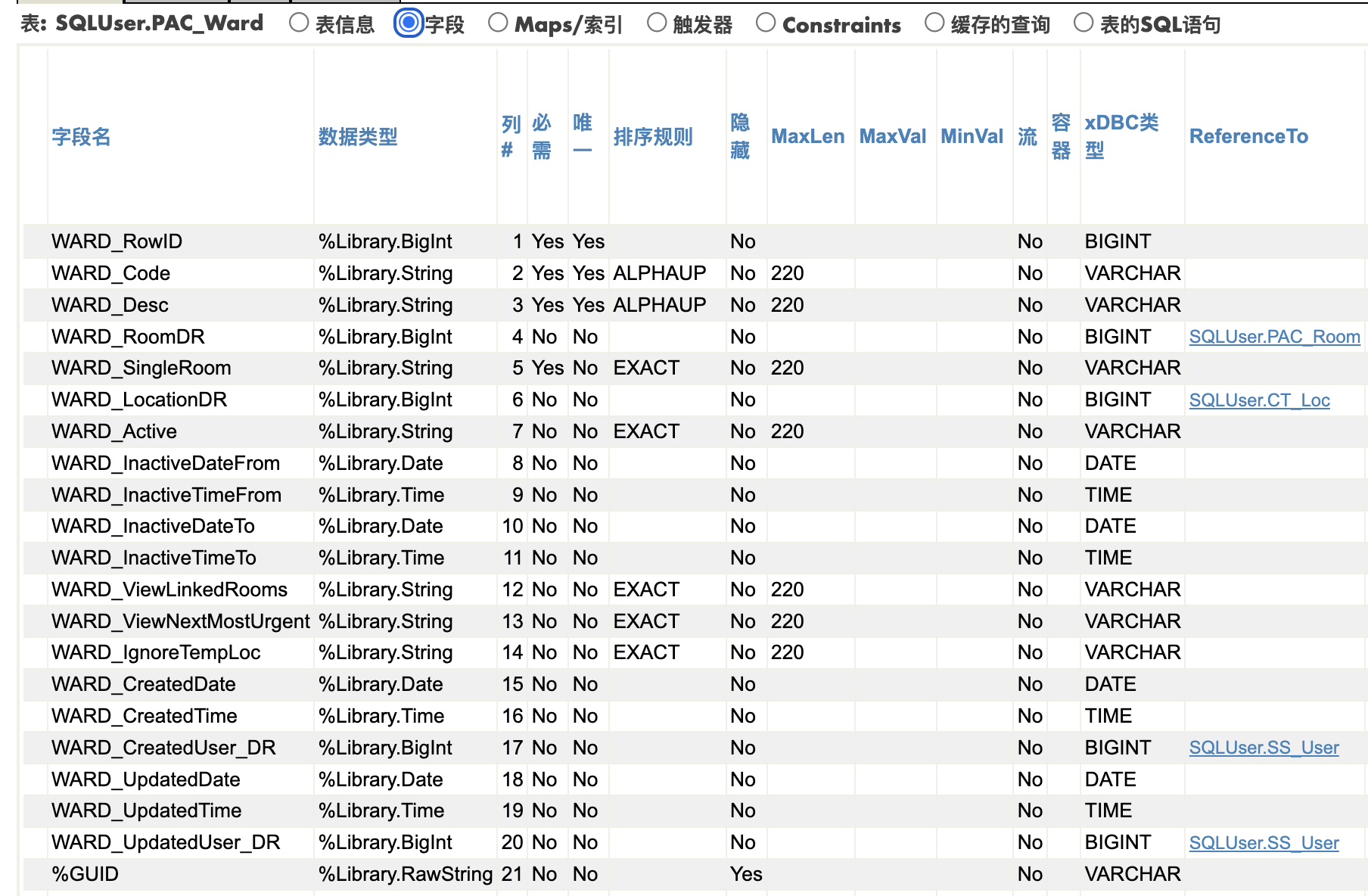
然后我们看看索引

注意下面索引定义的的列,也就是下标取值,也就是索引定义的Collation
- IndexCode:
ALPHAUP(SQLUser.PAC_Ward.WARD_Code) - indeDesc:
$$ALPHAUP({SQLUser.PAC_Ward.WARD_Desc}) - IndexLoc: 整数列,没有collation
我们已经看出来了字段和索引对应,他们应该是一样的。然而,这个对应是人工配置的,索引在代码里的定义我贴在下面。请注意
如果您回去看看上面的规则2, 你会发现这个索引就掉到了一个坑里:
- 字段设置SQLUPPER(或者其他类型), 索引设置EXACT, 索引无法使用
<SQLMap name="IndexCode">
<BlockCount>-4</BlockCount>
...省略
<Subscript name="3">
<AccessType>sub</AccessType>
<Expression>$$ALPHAUP({WARD_Code})</Expression>
</Subscript>
<Subscript name="4">
<AccessType>sub</AccessType>
<Expression>{WARD_RowID}</Expression>
</Subscript>
<Type>index</Type>
</SQLMap>
怎么发现没有正常使用或者性能太差? 阅读查询计划或者查看索引使用统计。我会在后面的帖子介绍。