清除过滤器
文章
Shanshan Yu · 七月 5, 2023
基于InterSystems的集成ML技术和Dashboard,根据上传的CSV文件自动生成相关预测和BI页面。前端和后端在Vue和Iris中完成,使用户可以通过简单的操作生成所需的数据预测和分析页面,并根据这些页面做出决策。
# ZPM 安装
zpm:USER>install IntegratedMLandDashboardSample
# 部署流程
使用或创建新的命名空间
将代码导入相应的命名空间
在终端中执行:
Do # # class (customizemashinelerningandaanalysis. Util. Tool) Deployment()
前端是Vue文件夹下的dist文件夹。在使用它之前,请打开dist-static config.js并修改后端服务器要使用的IP和端口。然后您需要将iframeUrl的测试修改为“Analysis”+后端使用的命名空间,例如“AnalysisUSER”
然后启动前端文件(可以将dist文件夹放在tomcat中开始使用)
访问地址为:
Ip: port/dist
# 如何使用
以women.csv为例
1.选择要上传的CSV文件,CSV文件名和数据列名不得包含空格等其他符号
2.填写需要预测的列名,如“高度”
3.单击“确定”按钮,等待界面返回
成功返回后,刷新当前页面,然后单击“模型列表”下的辅助选项。新生成的项目将出现
① 填写完其他值后,点击②确定,在③处生成预测值
④ 嵌入式虹膜仪表板显示以前导入CSV的一些数据
# 其他 CSV 展示
# 单元测试
Set ^UnitTestRoot=your modules dir +"\src"+namespace+"\integratedmlanddashboardsample\src" (such C:\InterSystems\HealthConnect\mgr\.modules\USER\integratedmlanddashboardsample\src)
do ##class(%UnitTest.Manager).RunTest("UnitTests")
#注意
由于页面上嵌入了iris的仪表板,如果您遇到无法正确显示的跨域问题,可以访问iris查看图表
非常棒的应用!那csv中的数据能不能是非数字呢?
文章
姚 鑫 · 三月 6, 2021
# 第五章 SQL定义表
# 表名称和架构名称
可以通过定义表(使用`CREATE TABLE`)或通过定义投影到表的持久类来创建表:
- DDL:InterSystemsIRIS®数据平台使用CREATE TABLE中指定的表名来生成相应的持久类名,并使用指定的架构名来生成相应的包名。
- 类定义:InterSystemsIRIS®数据平台使用持久类名称来生成对应的表名,并使用包名称来生成对应的模式名。
由于以下原因,这两个名字之间的对应关系可能不相同:
- 持久化类和SQL表遵循不同的命名约定。
适用不同的有效字符和长度要求。
模式和表名不区分大小写;
包名和类名区分大小写。
系统自动将有效提供的名称转换为有效的对应名称,以确保生成的名称是惟一的。
- 持久化类名与对应的SQL表名之间的匹配是默认的。
可以使用`SqlTableName`类关键字来提供不同的SQL表名。
- **默认模式名可能与默认包名不匹配。
如果指定一个非限定的SQL表名或持久类名,系统将提供一个默认的模式名或包名。
初始的默认模式名是`SQLUser`;
初始默认包名为`“User”`。**
# 模式名称
表、视图或存储过程名称可以是限定的(`schema.name`),也可以是限定的(`name`)。
- 如果指定模式名(限定名),则指定的表、视图或存储过程将被分配给该模式。
如果模式不存在,则InterSystems SQL创建模式,并将表、视图或存储过程分配给它。
- 如果没有指定模式名(非限定名),InterSystems SQL将使用默认模式名或模式搜索路径分配模式,如下所述。
## 模式命名注意事项
模式名遵循标识符约定,需要特别注意非字母数字字符的使用。
模式名不应该指定为带分隔符的标识符。
**尝试指定“USER”或任何其他SQL保留字作为模式名会导致`SQLCODE -312`错误。**
`INFORMATION_SCHEMA`模式名和相应的信息。
模式包名在所有命名空间中保留。
用户不应该在这个模式/包中创建表/类。
当执行一个创建操作(比如`create TABLE`),指定一个还不存在的模式时,InterSystems IRIS将创建新的模式。
InterSystems IRIS使用模式名生成相应的包名。
由于模式及其对应包的命名约定不同,用户应该注意非字母数字字符的名称转换注意事项。
这些名称转换的注意事项与表不同:
- 初始字符:
- `%` (percent):指定%作为模式名的第一个字符,表示相应的包为系统包,其所有类为系统类。
这种用法需要适当的权限;
否则,这种用法会发出一个`SQLCODE -400`错误,`%msg`表示``错误。
- **`_`(下划线):如果模式名的第一个字符为下划线,则该字符将被对应包名中的小写`“u”`替换。
例如,模式名`_MySchema`生成名为`uMySchema`的包。**
- 后续的字符:
- **`_`(下划线):如果模式名第一个字符以外的其他字符是下划线,则该字符将被对应包名中的句点(`.`)替换。
由于句点是类的分隔符,下划线将模式分为包和子包。
因此,`My_Schema`生成包含包模式(`My.Schema`)的包My。**
- **`@`, `#`, `$` characters:如果模式名包含任何这些字符,这些字符将从相应的包名中剥离。
如果剥离这些字符会产生重复的包名,那么将进一步修改剥离的包名:将剥离的模式名的最后一个字符替换为顺序整数(以0开始),以产生唯一的包名。
因此,`My@#$Schema`生成`MySchema`包,然后创建`My#$Schema`生成`MySchem0`包。
同样的规则也适用于表名对应的类名。**
## 保留模式名
`INFORMATION_SCHEMA`模式名和相应的信息。
模式包名在所有命名空间中保留。
用户不应该在这个模式/包中创建表/类
在所有名称空间中保留`IRIS_Shard`模式名。
用户不应在此模式中创建表、视图或过程。
存储在`IRIS_Shard`模式中的项不会通过编目查询或`INFORMATION_SCHEMA`查询显示。
## 默认模式名称
- 在执行DDL操作(例如创建或删除表、视图、触发器或存储过程)时,会提供一个非限定名称作为默认的模式名。
架构搜索路径值将被忽略。
- 在执行DML操作时,例如通过选择、调用、插入、更新或删除访问现有表、视图或存储过程,将从模式搜索路径(如果提供了)提供一个不限定的名称。
如果没有架构搜索路径,或者没有使用架构搜索路径定位指定项,则提供默认的架构名称。
初始设置是对所有名称空间(系统范围)使用相同的默认模式名。
可以为所有命名空间设置相同的默认模式名,也可以为当前命名空间设置默认模式名。
如果创建了一个具有非限定名称的表或其他项,InterSystems IRIS将为其分配默认模式名和相应的持久类包名。
如果一个命名的或默认的模式不存在,InterSystems IRIS将创建模式(和包),并将创建的项分配给该模式。
如果删除模式中的最后一项,InterSystems IRIS将删除该模式(和包)。
下面的模式名解析描述适用于表名、视图名和存储过程名。
系统范围的初始默认模式名是`SQLUser`。
对应的持久类包名是`User`。
因此,非限定表名`Employee`或限定表名`SQLUser`。
`Employee`将生成类`User.Employee`。
因为`USER`是一个保留字,尝试用`USER`的模式名(或任何SQL保留字)指定限定名会导致`SQLCODE -1`错误。
**要返回当前默认模式名,请调用`$SYSTEM.SQL.DefaultSchema()`方法:**
```java
DHC-APP>WRITE $SYSTEM.SQL.DefaultSchema()
SQLUser
```
或者使用以下预处理器宏:
```java
#Include %occConstant
WRITE $$$DefSchema
```
可以使用以下任意一种方式更改默认模式名:
- 进入管理界面。
在系统管理中,选择Configuration,然后选择SQL和对象设置,然后选择SQL。
在这个屏幕上,可以查看和编辑当前系统范围内的默认模式设置。
这个选项设置系统范围的默认模式名。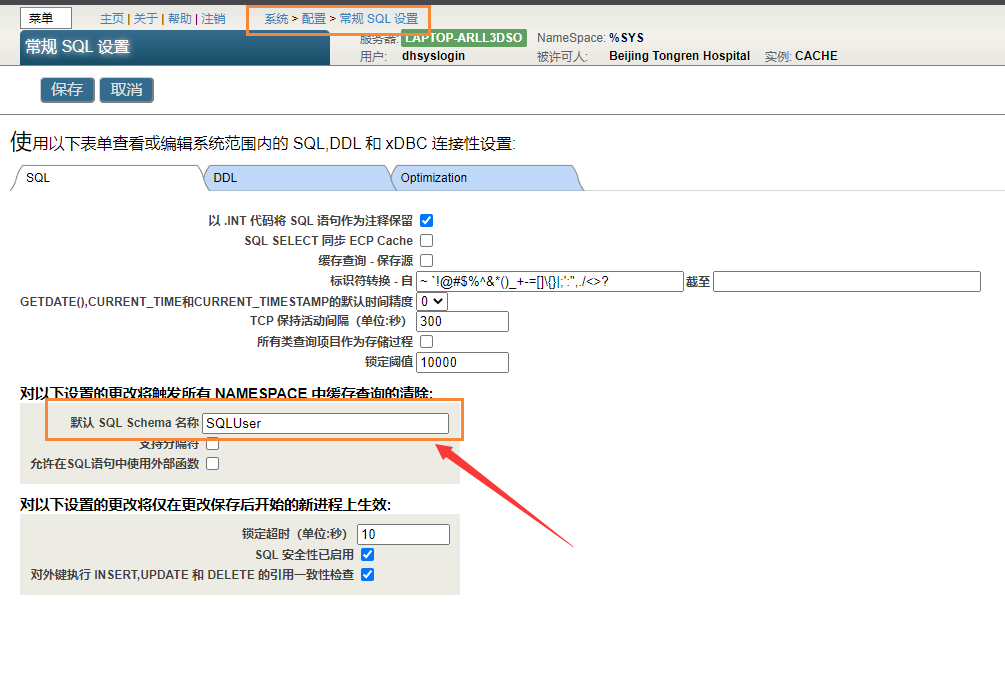
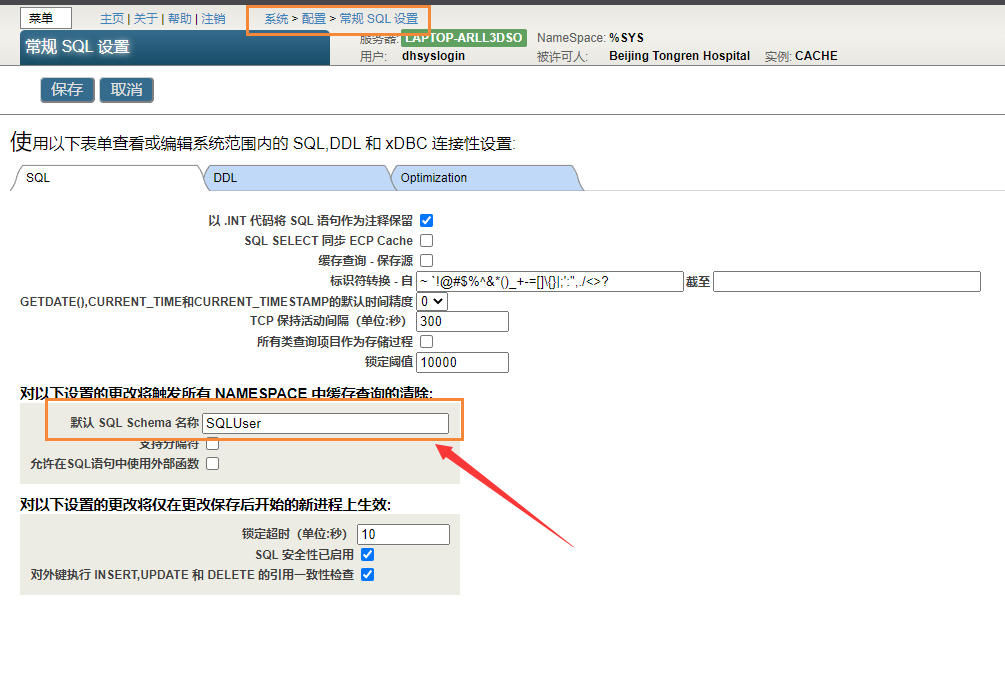
这个系统范围的设置可以被当前命名空间的`SetDefaultSchema()`方法值覆盖。
- `$SYSTEM.SQL.SetDefaultSchema()`方法。默认情况下,此方法在系统范围内设置默认架构名称。但是,通过将布尔值第3个参数设置为1,可以仅为当前名称空间设置默认架构。当不同的名称空间具有不同的默认架构名称时,`DefaultSchema()`方法将返回当前名称空间的默认架构名称。
**注意:当更改默认的SQL模式名称时,系统将自动清除系统上所有名称空间中的所有缓存查询。
通过更改默认模式名称,可以更改所有包含非限定表、视图或存储过程名称的查询的含义。
强烈建议在安装InterSystems IRIS时建立默认的SQL模式名,以后不要修改。**
模式名用于生成相应的类包名。
因为这些名称有不同的命名约定,所以它们可能不相同。
可以通过将其设置为系统范围的默认模式来创建与SQL保留字同名的模式,但是不建议这样做。
名为`User`的默认模式根据类命名唯一性约定,生成相应的类包名称`User0`。
### `_CURRENT_USER`关键字
- 作为系统范围的默认模式名:如果指定`_CURRENT_USER`作为默认模式名,InterSystems IRIS将指定当前登录进程的用户名作为默认模式名。
`_CURRENT_USER`值是`$USERNAME` ObjectScript特殊变量值的第一部分。
如果`$USERNAME`包含一个名字和一个系统地址(`Deborah@TestSys`), `_CURRENT_USER`只包含名字片段;
这意味着`_CURRENT_USER`可以将相同的默认模式名分配给多个用户。
如果进程没有登录,`_CURRENT_USER`指定`SQLUser`作为默认的模式名。
如果指定`_CURRENT_USER/name`作为默认模式名,其中name是选择的任意字符串,那么InterSystems IRIS将当前登录进程的用户名分配为默认模式名。
如果进程没有登录,则name将用作默认的模式名。
例如,如果进程没有登录,`_CURRENT_USER/HMO`使用HMO作为默认模式名。
在`$SYSTEM.SQL.SetDefaultSchema()`中,指定`"_CURRENT_USER"`作为带引号的字符串。
- DDL命令中的模式名:如果在DDL语句中指定`_CURRENT_USER`作为显式的模式名,InterSystems IRIS将其替换为当前系统范围内的默认模式。
例如,如果系统范围的默认模式是`SQLUser`,则命令`DROP TABLE _CURRENT_USER`。
`OldTable SQLUser.OldTable`下降。
这是一种方便的方式来限定名称,以显式地指示应该使用系统范围的默认模式。
它在功能上与指定非限定名相同。
此关键字不能在DML语句中使用。
## 模式搜索路径
当访问一个现有的表(或视图,或存储过程)进行DML操作时,将从模式搜索路径中提供一个非限定的名称。
按照指定的顺序搜索模式,并返回第一个匹配项。
如果在搜索路径中没有找到匹配的模式,或者没有搜索路径,则使用默认的模式名。
(注意,`#Import`宏指令使用了不同的搜索策略,不会“失败”到默认的模式名。)
- 在嵌入式SQL中,可以使用`#SQLCompile Path`宏指令或`#Import`宏指令来提供架构搜索路径,系统间IRIS使用该路径来解析非限定名称。
`#SQLCompile Path`根据遇到的第一个匹配项解析不限定的名称。
如果搜索路径中列出的所有模式只有一个匹配项,则`#Import`解析非限定名。
- 下面的示例提供了包含两个模式名的搜索路径:
```java
#SQLCompile Path=Customers,Employees
```
- 在动态SQL中,可以使用`%SchemaPath`属性提供模式搜索路径,系统间IRIS使用该路径解析不限定的表名。
可以直接指定`%SchemaPath`属性,也可以将其指定为`%SQL`的第二个参数。
声明`%new()`方法。
下面的示例提供了包含两个模式名的搜索路径:
```java
SET tStatement = ##class(%SQL.Statement).%New(0,"Customers,Employees")
```
- 在SQL Shell中,可以设置`PATH SQL Shell`配置参数来提供架构搜索路径,系统间IRIS使用该路径解析不限定的名称。
如果非限定名与模式搜索路径中指定的任何模式或默认模式名不匹配,则会发出`SQLCODE -30`错误,例如:`SQLCODE: -30`消息:`Table 'PEOPLE' not found in schemas: CUSTOMERS,EMPLOYEES,SQLUSER`。
## 包含特定于平台的模式名
当创建一个基于odbc的查询以通过Mac上的Microsoft query从Microsoft Excel运行时,如果从可用的表列表中选择一个表,则生成的查询不包括该表的模式(相当于类的包)。
例如,如果选择从示例模式返回`Person`表的所有行,则生成的查询为:
```java
SELECT * FROM Person
```
**因为InterSystems IRIS将不限定的表名解释为`SQLUser`模式中的表名,所以该语句要么失败,要么从错误的表返回数据。
要纠正这一点,编辑查询(在SQL View选项卡上),显式引用所需的模式。
然后查询应该是:**
```java
SELECT * FROM Sample.Person
```
## List模式
`INFORMATION.SCHEMA`。
`SCHEMATA persistent`类列出当前名称空间中的所有模式。
下面的示例返回当前命名空间中的所有非系统模式名:
```java
SELECT SCHEMA_NAME
FROM INFORMATION_SCHEMA.SCHEMATA WHERE NOT SCHEMA_NAME %STARTSWITH '%'
```
Management Portal SQL界面的左侧允许查看模式(或匹配筛选器模式的多个模式)的内容。
# 表名
每个表在其模式中都有一个唯一的名称。
一个表有一个SQL表名和一个对应的持久化类名;
这些名称在允许的字符、区分大小写和最大长度方面有所不同。
如果使用SQL `CREATE TABLE`命令定义,则指定遵循标识符约定的SQL表名;
系统生成一个对应的持久化类名。
如果定义为持久类定义,则必须指定只包含字母和数字字符的名称;
这个名称既用作区分大小写的持久类名,也用作(默认情况下)对应的不区分大小写的SQL表名。
可选的`SqlTableName class`关键字允许用户指定不同的SQL表名。
当使用`CREATE TABLE`命令创建表时,InterSystems IRIS使用表名生成相应的持久化类名。
由于表及其对应类的命名约定不同,用户应该注意非字母数字字符的名称转换:
- 初始字符:
- `%` (percent): %作为表名的第一个字符是保留的,应该避免(参见标识符)。
如果指定了,`%`字符将从对应的持久化类名中剥离。
- `_`(下划线):如果表名的第一个字符是下划线,则该字符将从对应的持久化类名中剥离。
例如,表名`_MyTable`生成类名`MyTable`。
- 数字:表名的第一个字符不能是数字。
如果表名的第一个字符是标点符号,则第二个字符不能是数字。
这将导致一个`SQLCODE -400`错误,`%msg`值为`" error #5053:类名'schema.name' is invalid "`(没有标点字符)。
例如,指定表名`_7A`会生成`%msg " ERROR #5053: Class name 'User.7A' is invalid "`。
- 后续的字符:
- 字母:表名中至少包含一个字母。
表名的第一个字符或初始标点字符后的第一个字符必须是字母。
如果一个字符通过`$ZNAME`测试,它就是一个有效的字母;
`$ZNAME`字母验证因不同的地区而不同。
(注意,$ZNAME不能用于验证SQL标识符,因为标识符可能包含标点字符。)
- `_`(下划线),`@`,`#`,`$` characters:如果表名包含这些字符中的任何一个,这些字符将从对应的类名中剥离出来,并生成一个唯一的持久类名。
由于生成的类名不包括标点字符,因此不建议创建仅在标点字符上不同的表名。
- 表名在其模式中必须是唯一的。
如果试图创建一个名称仅与现有表大小写不同的表,将会产生`SQLCODE -201`错误。
同一个模式中的视图和表不能具有相同的名称。
尝试这样做会导致`SQLCODE -201`错误。
可以使用`$SYSTEM.SQL.TableExists()`方法确定一个表名是否已经存在。
可以使用`$SYSTEM.SQL.ViewExists()`方法确定视图名是否已经存在。
这些方法还返回与表或视图名称对应的类名。
管理门户SQL interface Catalog Details表信息选项显示与所选SQL表名称对应的类名。
试图指定`“USER”`或任何其他SQL保留字作为表名或模式名会导致`SQLCODE -312`错误。
要指定SQL保留字作为表名或模式名,可以指定名称作为带分隔符的标识符。
如果使用带分隔符的标识符指定包含非字母数字字符的表或模式名,InterSystems IRIS将在生成相应的类或包名时删除这些非字母数字字符。
适用以下表名长度限制:
- 唯一性:InterSystems IRIS对持久化类名的前189个字符执行唯一性检查。
对应的SQL表名可能超过189个字符,但是,当去掉非字母数字字符时,它必须在189个字符的限制内是唯一的。
InterSystems IRIS对包名的前189个字符执行唯一性检查。
- 建议最大长度:一般来说,一个表名不应该超过128个字符。
一个表名可能比96个字符长得多,但是在前96个字母数字字符中不同的表名更容易处理。
- 最大组合长度:包名和它的持久类名(加在一起时)不能超过220个字符。
这包括默认的模式(包)名(如果没有指定模式名)和分隔包名和类名的点字符。
当表名转换为对应的持久化类名时,删除超过220个字符时,模式和表名的组合长度可以超过220个字符。
# RowID字段
**在SQL中,每条记录都由一个唯一的整数值标识,这个整数值称为`RowID`。**
在InterSystems SQL中,不需要指定`RowID`字段。
当创建表并指定所需的数据字段时,会自动创建RowID字段。
这个`RowID`在内部使用,但没有映射到类属性。
默认情况下,只有当持久化类被投影到SQL表时,它的存在才可见。
在这个投影表中,将出现一个额外的`RowID`字段。
默认情况下,这个字段被命名为`“ID”`,并分配给第1列。
默认情况下,当在表中填充数据时,InterSystems IRIS将从1开始向该字段分配连续的正整数。`RowID`数据类型为`BIGINT(%Library.BigInt)`。为`RowID`生成的值具有以下约束:每个值都是唯一的。不允许使用`NULL`值。排序规则是精确的。**默认情况下,值不可修改。**
默认情况下,InterSystems IRIS将此字段命名为`“ ID”`。但是,此字段名称不是保留的。每次编译表时都会重新建立`RowID`字段名。如果用户定义了一个名为`“ ID”`的字段,则在编译表时,InterSystems IRIS会将`RowID`命名为`“ ID1”`。例如,如果用户随后使用`ALTER TABLE`定义了一个名为`“ ID1”`的字段,则表编译会将`RowID`重命名为`“ ID2”`,依此类推。在持久性类定义中,可以使用`SqlRowIdName`类关键字直接为此类投影到的表指定`RowID`字段名。由于这些原因,应避免按名称引用`RowID`字段。
InterSystems SQL提供了`%ID`伪列名称(别名),无论分配给`RowID`的字段名称如何,该伪列名称始终返回`RowID`值。 (InterSystems TSQL提供了`$IDENTITY`伪列名称,其作用相同。)
`ALTER TABLE`无法修改或删除`RowID`字段定义。
将记录插入表中后,InterSystems IRIS将为每个记录分配一个整数ID值。 `RowID`值始终递增。它们不被重用。因此,如果已插入和删除记录,则`RowID`值将按升序排列,但可能不连续。
- **默认情况下,使用`CREATE TABLE`定义的表使用`$SEQUENCE`执行`ID`分配,从而允许多个进程快速同时填充该表。当使用`$SEQUENCE`填充表时,会将`RowID`值序列分配给进程,然后该进程将顺序分配它们。因为并发进程使用它们自己分配的序列分配`RowID`,所以不能假定多个进程插入的记录按插入顺序排列。**
可以通过设置`SetDDLUseSequence()`方法,将InterSystems IRIS配置为使用`$INCREMENT`执行`ID`分配。若要确定当前设置,请调用`$ SYSTEM.SQL.CurrentSettings()`方法。
- 默认情况下,通过创建持久性类定义的表将使用`$INCREMENT`执行ID分配。在持久性类定义中,可以将`IdFunction`存储关键字设置为序列或增量;否则,可以设置为0。例如,`序列`。
在持久性类定义中,`IdLocation`存储关键字global(例如,对于持久性类`Sample.Person: ^ Sample.PersonD `)包含RowID计数器的最高分配值。 (这是分配给记录的最高整数,而不是分配给进程的最高整数。)请注意,此RowID计数器值可能不再与现有记录相对应。要确定是否存在具有特定RowID值的记录,请调用表的`%ExistsId()`方法。
通过`TRUNCATE TABLE`命令重置`RowID`计数器。即使使用`DELETE`命令删除表中的所有行,也不会通过`DELETE`命令将其重置。如果没有数据插入表中,或者已使用`TRUNCATE TABLE`删除所有表数据,则`IdLocation`存储关键字全局值未定义。
默认情况下,`RowID`值不可用户修改。尝试修改`RowID`值会产生`SQLCODE -107`错误。覆盖此默认值以允许修改`RowID`值可能会导致严重的后果,只有在非常特殊的情况下并应格外谨慎。 `Config.SQL.AllowRowIDUpdate`属性允许`RowID`值是用户可修改的。
## 基于字段的RowID
通过定义一个用于投影表的持久类,可以定义`RowID`以具有字段或字段组合中的值。为此,请使用`IdKey index`关键字指定一个索引。例如,一个表可以具有一个`RowID`,其`RowId`通过在`PatientName [IdKey]`上指定索引定义`IdxId`来与`PatientName`字段的值相同;或者可以通过指定索引定义`IdxId`来将`PatientName`和`SSN`字段的组合值在`(PatientName,SSN)[IdKey];`上。
- 基于字段的`RowID`效率比采用系统分配的连续正整数的`RowId`效率低。
- 在`INSERT`上:为构成`RowId`的字段或字段组合指定的值必须唯一。指定非唯一值将生成`SQLCODE -119`“在插入时唯一性或主键约束唯一性检查失败”。
- 在`UPDATE`上:默认情况下,组成`RowId`的每个字段的值都是不可修改的。尝试修改这些字段之一的值会生成`SQLCODE -107`“无法基于字段更新`RowID`或`RowID`”。
当`RowID`基于多个字段时,`RowID`值是由`||`连接的每个组成字段的值。操作员。例如,`Ross,Betsy || 123-45-6789`。 InterSystems IRIS尝试确定基于多个字段的`RowID`的最大长度。如果无法确定最大长度,则`RowID`长度默认为512。
## 隐藏的RowID?
- 使用`CREATE TABLE`创建表时,默认情况下隐藏`RowID`。 `SELECT *`不会显示隐藏字段,而是`PRIVATE`。创建表时,可以指定`%PUBLICROWID`关键字以使`RowID`不隐藏和公开。可以在`CREATE TABLE`逗号分隔的表元素列表中的任何位置指定此可选的`%PUBLICROWID`关键字。不能在`ALTER TABLE`中指定。
- 创建作为表投影的持久类时,默认情况下不会隐藏`RowID`。它由`SELECT *`显示,并且是`PUBLIC`。可以通过指定类关键字`SqlRowIdPrivate`来定义具有隐藏且为`PRIVATE`的`RowID`的持久类。
用作外键引用的`RowID`必须是公共的。
默认情况下,不能将具有公共`RowID`的表用作源表或目标表,以使用`INSERT INTO Sample.DupTable SELECT * FROM Sample.SrcTable`将数据复制到重复表中。
可以使用Management Portal SQL界面“目录详细信息字段”列出“隐藏”列来显示`RowID`是否被隐藏。
可以使用以下程序返回指定字段(在此示例中为`ID`)是否被隐藏:
```java
/// d ##class(PHA.TEST.SQL).RowID()
ClassMethod RowID()
{
SET myquery = "SELECT FIELD_NAME,HIDDEN FROM %Library.SQLCatalog_SQLFields(?) WHERE FIELD_NAME='ID'"
SET tStatement = ##class(%SQL.Statement).%New()
SET qStatus = tStatement.%Prepare(myquery)
IF qStatus'=1 {
WRITE "%Prepare failed:"
DO $System.Status.DisplayError(qStatus)
QUIT
}
SET rset = tStatement.%Execute()
DO rset.%Display()
WRITE !,"End of data"
}
```
最后一个占位符使用案例很棒!谢谢 总结的很好
文章
Hao Ma · 十一月 26, 2022
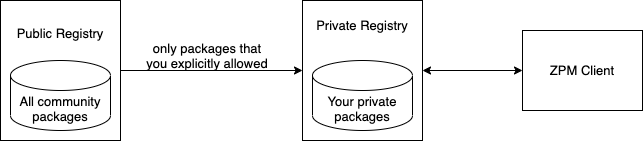
## 建立私服(Porxy-Registry)
这张图解释了您的私服是怎么工作的, 整篇文章在这里: [Proxy-Registry](https://community.intersystems.com/post/new-zpm-registry-feature-%E2%80%93-proxy-registry)
### 搭建私服
您需要有一台自己的的服务器, 在上面安装IRIS, zpm, 然后用zpm去下载另一个软件包“zpm-registry"。象这样
```sh
zpm:DEMO>search -r zpm-registry
registry https://pm.community.intersystems.com:
zpm-registry 1.1.11Repository: https://github.com/intersystems-community/zpm-registry/
zpm:DEMO>install zpm-registry
[DEMO|zpm-registry] Reload START (/usr/irissys/mgr/.modules/DEMO/zpm-registry/1.1.11/)
[DEMO|zpm-registry] Reload SUCCESS
[zpm-registry] Module object refreshed.
[DEMO|zpm-registry] Validate START
[DEMO|zpm-registry] Validate SUCCESS
[DEMO|zpm-registry] Compile START
[DEMO|zpm-registry] Compile SUCCESS
[DEMO|zpm-registry] Activate START
[DEMO|zpm-registry] Configure START
[DEMO|zpm-registry] Configure SUCCESS
[DEMO|zpm-registry] Activate SUCCESS
zpm:DEMO>
```
到github页面, https://github.com/intersystems-community/zpm-registry/, 你可以得到更详细的软件信息。
配置私服连接公服, 需要在私服的IRIS的安装目录添加一个yaml文件, 定义uplink:
```yaml
uplinks:
pm:
url: https://pm.community.intersystems.com/
allow_packages: dsw,zpm*,?u*
```
几点说明:
- uplinks的项目可以有多个,pm是intersystems的默认公共registry
- allow_packages: - a comma-separated list of allowed packages, you can use the exact package name or mask: * - any sequence of characters, ? - any charac
- registry 提供的rest 接口描述: https://pm.community.intersystems.com/_spec
### 设置zpm client连接私服
通过repo命令将您的zpm client切换到刚刚配置的私服。`repo -n registry`里面的 - user, - pass是你搭建的私服的账号密码。您也可以在私服上修改/registryWeb应用不做用户验证。
```sh
zpm:DEMO>repo -list
registry
Source: https://pm.community.intersystems.com
Enabled? Yes
Available? Yes
Use for Snapshots? Yes
Use for Prereleases? Yes
Is Read-Only? No
Deployment Enabled? No
zpm:DEMO>repo -n registry -r -url http://localhost:52773/registry/ -user superuser -pass demo
registry
Source: http://localhost:52773/registry/
Enabled? Yes
Available? Yes
Use for Snapshots? Yes
Use for Prereleases? Yes
Is Read-Only? No
Deployment Enabled? No
Username: superuser
Password:
zpm:DEMO>
```
这时的私服时没有连接公服。
### 发布软件包到私服
**发布一个 GitHub 的包**
先把软件存在github, 然后用curl命令把包发布在私服的地址。
```sh
$ curl -i -X POST -H "Content-Type:application/json" -u superuser:1104 -d '{"repository":"https://github.com/psteiwer/ObjectScript-Math"}' 'http://localhost:52773/registry/package’
```
**使用zpm 客户端先在本地load,然后使用publish 命令**
大概像这个样子:
```sh
zpm:USER>help load
...
■ Examples
∙ load C:\module\root\path\
load C:\module\root\path\module-0.0.1.tgz
Loads the module described in C:\module\root\path\module.xml
∙ load -dev -verbose C:\module\root\path\
load -dev -verbose C:\module\root\path\module-0.0.1.tgz
Loads the module described in C:\module\root\path\module.xml in developer mode and with verbose output.
∙ load https://github.com/user/repository.git
load https://github.com/user/repository.git -b branch-name
Loads the module described in C:\module\root\path\module.xml in developer mode and with verbose output.
zpm:USER> load https://github.com/user/repository.git
zpm: USER> publish
```
## 其他的Feature
在使用中您还会有各种各样的需求, 但我相信看到现在您应该对怎么寻找答案非常清楚了。这里简单的说两个feautre
### 1. 发布为Delopyed模式
如果您要隐藏自己的代码,只发布编译后的软件, 可以简单的修改Module.xml, 设置““, zpm会自动完成。
### 2. 包的依赖
因为有朋友问,所以说一些包依赖的功能。是的, zpm是设计了包依赖的功能的,在module.xml里添加Dependencies节点, 可以定被依赖的包的列表。 具体的写法请参见这个例子:[module.xml example](https://github.com/intersystems/ipm/wiki/03.-Module.xml#modulexml-example)。
虽然但是,对ObjectScript程序来说,定义包依赖的机会并不多。我能想到的应用场景就是, 当您的软件中想用社区其他包,比如上面的bitmap-adoption的包的话,您可以包"bitmap-adoption"打包到module.xml里面。
我对当前发布的200多软件包随便挑了一些,还没有发现有哪个使用了包依赖, 象这样:
```sh
zpm:USER>list-dependents yaml-utils
zpm:USER>list-dependents terminal-multiline-editor
zpm:USER>list-dependents bitmap-adoption
zpm:USER>list-dependents global-dump-sql
...
```
公告
Claire Zheng · 十月 20, 2022
2022年9月5日-10月24日(北京时间),我们正在举办🏆InterSystems开发者社区中文版首届技术征文大赛🏆(←点击链接进入参赛页面,浏览所有参赛文章)!投票截止至10月23日,你的支持与喜爱,是优秀作品获得“开发者社区奖”的关键!我们先来看看目前作品排名情况吧!距离投票截止还有三天(截止至10月23日),我们暂时无法获得专家评审分数,以下根据作品“点赞”进行排名(排名截至10月21日10时)。
N
Author
标题
点赞⬇
1
Meng Cao
Caché数据库私有apache版本升级
42
2
Zhe Wang
IRIS如何进行CRUD操作
37
3
sun yao
前端操作自动生成BS、BP、BO
26
4
John Pan
论集成标准的选择对医院信息集成平台建设的影响
23
5
lizw lizw
关于%Dictionary.CompiledClass类在实际业务中的一些应用
23
6
聆严 周
使用Prometheus监控Cache集群
21
7
Chang Liu
在国产系统上安装Healthconnect2021
19
8
Zhe Wang
IRIS快速查询服务思路分享
18
9
Zhe Wang
使用Global进行数据可视化---商业智能(BI)
18
10
John Pan
如何调用Ensemble/IRIS内置的HL7 V2 webservice - Java,PB9,Delphi7样例
17
11
zhanglianzhu zhanglianzhu
Cache死循环检测和申明式事务
16
12
Zhe Wang
Rest实现Post、Get、Put、Delete几种操作方式
15
13
shaosheng shengshao
HEALTHSHARE2018版如何实现AES(CBC)的HEX输出,并可以实现加密和解密
15
14
姚 鑫
IRIS与Caché的23种设计模式
15
15
water huang
对 %XML.PropertyParameters类的探索
15
16
Zhe Wang
小工具:IRIS管理页打开显示查询功能
15
17
聆严 周
Cache / IRIS 操作数据的3种基本方式
14
18
he hf
10分钟快速开发一个连接到InterSystems IRIS数据库的C#应用
14
19
shaosheng shengshao
windows下处理IIS在未安装但Healthshare已安装的时候,部署IIS服务并代理Healthshare
11
20
water huang
Ens.Util.JSON类的启发
11
21
bai hongtao
第三方HA软件结合MIRROR使用方法探讨
11
22
li wang
HealthConnect访问HTTPS开头地址
10
23
Liu Tangh
在Cache系统中使用负载均衡服务的探讨
9
24
yaoguai wan
IRIS架构的浅显理解以及windows10、docker安装IRIS Health详解流程及部分问题浅析
7
25
li dong
实现Cache/IRIS中zip文件的下载、解压及读取
7
26
姚 鑫
CORS请求Request携带Cookie失败占用License解决方案
5
27
Zhe Wang
COS的基本语法
5
*奖励项目详见参赛规则:点击阅读
我们此次征文大赛计分规则如下:
🥇【专家提名奖】评选规则,由经验丰富的专家评审团进行评选打分,与其他加分项综合后进行排名。
🥇【开发者社区奖】评选规则,每个点赞计分为1分,与其他加分项综合后进行排名。
🥇【入围奖】评选规则,成功参赛的其余用户都将获得特别奖励。
每位作者只可以获得一个奖项(即:您只可以获得一次专家提名奖/开发者社区奖/入围奖);
当出现票数相当的平手情况时,将以专家评选投票数作为最终票数高低的判断标准。
那么,抓住最后五天的投票时间,为你喜欢的作品“点赞”投票吧!你的点赞是优秀作品获得【开发者社区奖】的关键!
10月24日晚19:30-20:30,我们将举办“InterSystems首届技术征文大赛线上分享会”,发布获奖名单,敬请留意后续参会信息!
欢迎关注InterSystems开发者社区中文版首届技术征文大赛
文章
Jingwei Wang · 六月 20, 2022
安装Arbiter
为了将自动故障转移扩展到尽可能广泛的故障情况,InterSystems建议你为每个镜像配置一个仲裁机。
要充当仲裁者,系统必须有一个正在运行的ISCAgent进程。由于ISCAgent是与InterSystems IRIS一起安装的,任何承载一个或多个InterSystems IRIS实例的系统都符合这一要求,可以被配置为仲裁者而无需进一步准备;但是,承载一个或多个故障转移或DR异步镜像成员的系统不应该被配置为该镜像的仲裁者。
没有托管InterSystems IRIS实例的系统可以通过安装Arbiter方式的作为仲裁者。请从InterSystems公司下载适合你的仲裁者系统平台的ISCAgent安装包,然后,安装ISCAgent。
注意:Arbiter的版本要和InterSystems IRIS安装版本保持一致。
在Windows上安装Arbiter
在Windows系统上,只需执行安装文件,例如ISCAgent-2020.1.0.540.0-win_x64.exe。
在Linux上安装Arbiter
[root@arbiterhost home]# gunzip ISCAgent-2020.1.0.540.0-lnxrhx64.tar.gz
[root@arbiterhost home]# tar -xf ISCAgent-2020.1.0.540.0-lnxrhx64.tar
[root@arbiterhost home]# ./ISCAgent/agentinstall
启动、停止、检查ISCAgent状态
systemctl start ISCAgent.service
systemctl stop ISCAgent.service
systemctl status ISCAgent.service
设置、终止开机自动启动ISCAgent
sudo systemctl enable ISCAgent.service
sudo systemctl disable ISCAgent.service
启动 ISCAgent 服务
在所有的服务器中(主机,备机,仲裁机),ISCAgent必须被配置为在系统启动时自动启动。
a. 进入管理工具——服务,选择ISCAgent,将启动类型改为自动。点启动ISCAgent。
b. Windows防火墙中允许ISCAgent TCP端口2188,同时新建出站、进站规则。允许web端口 52773,超级端口1972。
入站规则中运行文件和打印机共享(回显请求 - ICMPv4-In)
配置主failover成员(Primary failover成员)
a. 进入Management Portal界面,选择菜单 系统管理 – 配置 – 镜像配置 – 创建镜像。如果选项为灰不可选,先点击 启动镜像服务,再选择 '服务已启用'。
b. 创建Mirror,输入相关信息并保存。
镜像信息部分 :
镜像名称(Mirror Name) : 有效的名称必须是1至15个字母数字字符;小写字母会自动替换为大写字母的对应物。
要求SSL/TLS (Use SSL/TLS): 指定是否要为镜像内的所有通信要求SSL/TLS安全(建议)。如果你选择了 "需要SSL/TLS",而实例还没有一个有效的SSL/TLS配置用于镜像,在完成这个程序之前,你可以直接点击设置SSL/TLS链接,在这个成员上创建所需的SSL/TLS配置。你也可以取消创建镜像程序,并浏览到SSL/TLS配置页面(系统>安全管理>SSL/TLS配置)。
使用仲裁器(Use Arbiter): 指定你是否要配置一个仲裁器(建议)。如果你选择使用仲裁器,你必须提供你想配置为仲裁器的系统的主机名或IP地址以及其ISCAgent进程使用的端口(默认为2188)。
使用虚拟IP(User Virtual IP):如果你选择使用虚拟IP,系统会提示你提供一个IP地址、无类别域间路由(CIDR)掩码和网络接口。
故障转移成员的压缩模式,异步成员的压缩模式 : 分别指定在从主站向备份和异步成员传输之前是否压缩日志数据,以及对每个成员使用哪种压缩类型;两者的默认设置都是 "系统选择",它优化了故障转移成员之间的响应时间以及主站和异步站之间的网络利用率。 一般使用默认设置。
Allow Paralle Dejournaling :确定哪种类型的镜像成员可以运行并行的Dejournal。Paralle Dejournaling允许多个作业在单个数据库中处理独立的globals,而不是只限于并行处理独立的数据库。
镜像故障转移成员信息:
镜像成员名:为你在这个系统上配置的故障转移成员指定一个名称(默认为系统主机名称和InterSystems IRIS实例名称的组合)。镜像成员名称不能包含空格、制表符或以这些标点符号 : [ ] # ; / * = ^ ~ ,字母字符在保存前会转换为大写字母。镜像成员名称的最大长度是32个字符。
超级服务器地址: 输入外部系统可用于与该故障转移成员通信的 IP 地址或主机名称。
代理端口: 输入此故障转移成员上 ISCAgent 的端口号,接受提示中提供的已安装代理的端口。
配置备failover成员(backup failover成员)
进入Management Portal界面,选择菜单 系统管理 – 配置 – 镜像配置 – 加入为故障转移。如果选项为灰不可选,先点击 启动镜像服务,再选择 '服务已启用'。
镜像名称:创建的镜像名称
其他系统上的代理地址: 输入您在配置第一个故障转移成员时指定的超级服务器地址。
代理端口 :输入您在配置第一个故障转移成员时指定的 ISCAgent 的端口。
InterSystems IRIS 实例名称 : 输入配置为第一个故障转移成员的InterSystems IRIS实例的名称。
配置异步镜像成员
选择 系统管理 – 配置 – 镜像设置 – 加入为异步。如果选项为灰不可选,先点击 启动镜像服务,再选择 '服务已启用'。
在‘加入为异步’页面填入创建的第一个镜像成员名称、地址、实例名称。
镜像名称:创建的镜像名称
故障转移系统的代理地址 :输入您在配置所选故障转移成员时指定的超级服务器地址。
代理端口 - 输入您为所选故障转移成员指定的 ISCAgent 端口。
InterSystems IRIS 实例名称 - 输入您配置为选定故障转移成员的 InterSystems IRIS 实例的名称。
选择合适的Async镜像成员类型
修改镜像设置
进入菜单 系统管理 – 配置 – 镜像配置 – 编辑镜像
可以修改设置的各个参数:
添加镜像数据库
创建一个镜像数据库
在主failover成员服务器上,选择系统管理– 配置 – 系统配置– 本地数据库
选择 新建数据库,按照提示输入数据库名称、存放数据库文件位置。注意在输入关于数据库的详情页面,镜像数据库? 选择 是。
在每一个failover成员服务器以及异步成员服务器按照上面步骤同样创建本地数据库。注意在输入关于数据库的详情中确保每一个成员的Mirror DB Name相同(本地的数据库名称可以不同)。
将已有数据库配置为镜像数据库
将主机已有数据库加入镜像
在主failover成员management port中,从菜单中选择 配置数据库
选中需要镜像的数据库,点击 添加到镜像 来添加需要mirror 的数据库
选择需要添加进入Mirror 的数据库并点击添加
此时从镜像监视器 中可以看到 镜像数据库 增加了我们刚才添加的数据库
数据库备份
对此主服务器的需要mirror 的数据库进行备份并获取备份文件,并拷贝至备机。执行备份可以通过management portal 运行实现。
management portal -> 系统管理 -> 配置-> 数据库备份 ->备份数据库列表
系统操作-> 备份 -> 完全备份列表
注意:这里需要关注主机本身journal 的保存时间,因为mirror 的同步机制是主机推journal 给备机,所以如果备份的时间为1月1 日零点,主机journal 保存时间为1天,备份需要2天,则中间1天的时间差所产生的数据是没有办法恢复的。
数据库备份恢复
在备Failover成员的%SYS 命名空间下使用^BACKUP routine, 将备份文件恢复至备机,则可在备机中看到恢复的数据库已只读方式被挂载
caught up 数据库
在备机上进入 系统操作 - 镜像监视器 ,可见备机的镜像有need activation 状态,点击Activate,结束后,下一步点击 catchup。
最终可见备机为 active,caught up 状态。
删除镜像配置
删除镜像配置必须按照下面顺序执行:删除异步成员,然后删除备份failover成员,最后删除主failover成员。
删除异步成员
进入菜单 系统管理 – 配置 – 镜像设置 – 编辑异步:
如果想要移除报表服务的异步成员,使用Leave mirror链接。
如果想要移除所有的链接异步成员以及相关配置,使用Remove Mirror Configuration按钮:
移除备failover成员
想要移除failover成员必须在%SYS命名空间下 执行^MIRROR routine。
a. 在 Terminal中切换到%SYS命名空间,执行d ^MIRROR
b. 选择Mirror Configuration
c. 选择Remove This Failover Member(如果在主failover服务器上操作则选择Remove Other Mirror Member)
d. 按照提示操作,最后重启实例.
移除主failover成员
想要移除failover主成员必须在%SYS命名空间下 执行^MIRROR routine。
a. 在 Terminal中切换到%SYS命名空间,执行d ^MIRROR
b. 选择Mirror Configuration
c. 选择Remove This Failover Member
d. 按照提示操作,最后重启实例.
e. 选择Remove This Failover Member
f. 按照提示操作,最后重启实例.
移除镜像数据库
从Async成员中移除数据库不会对failover成员的数据库有任何影响,但是如果从failover成员中移除数据库,也必须从其他failover成员以及Async成员中移除相应的数据库。想要从镜像配置中整体移除数据库需要遵循下面的顺序:主Primary failover成员 -> 备份Backup failover成员 -> Async成员。
a. 进入菜单 系统操作 – 镜像监视器
b. 在镜像数据库中点击 移除
断开连接/开始连接镜像成员
可以临时断开备failover镜像成员或者Async镜像成员。
进入菜单 系统操作 – 镜像监视器 选择 在这个成员上终止镜像
在虚拟环境下配置镜像操作
在虚拟环境下进行镜像配置,同时建议进行下面配置以提高可靠性:
· 应该为每一个failover成员进行虚拟主机(virtual host)的配置,保证每一个failover成员不会指向同一个物理上的host。
· 为了避免单一指向存储的损坏,每一个failover成员上Caché实例使用的存储应该固定分配到相互隔离的磁盘阵列或者磁盘组中。
· 有些虚拟架构下自动执行的操作,比如虚拟主机迁移到备用存储,可能造成failover成员间的短暂连接中断。如果在记录中竟让发现类似这样的中断警告,可以进入修改镜像配置的页面,在Advanced Mirror Settings下适当提高QoS Timeout设置的时间。
· 当进行计划维护操作(比如快照snapshot管理)时,会引起镜像成员中的连接中断,可以在备机的Mirror Monitor页面选择Stop Mirror on this server,临时断开备份backup成员,以避免相应的mirror警告信息。
· 在配置Mirror主备服务器中,不建议使用systemctl 设置开机自动启动IRIS。因为在主备切换过程中,如果使用systemd启动关闭IRIS不是成对出现,或者使用iris start/stop instance 不是成对出现,则有可能出现不可预知错误。
配置成功状态
主机状态:
备机状态:
文章
Claire Zheng · 三月 1, 2021
本周进入 InterSystems 编程大奖赛 的投票时间! 此次中国有多位参赛者,我们将其项目罗列在此,欢迎投票!
项目一:
Dictionary comparison scheme of cache database
Author: Weiwei Yang
概述:现场需要将各个科室部门内的数据统一汇总到医院总部,但是汇总后发现各个科室使用的字典并不统一,需要将表中的现存的字典统一更换为医院制定字典。例如:A科室中人员的性别字典使用0/1/2表示各种性别,B科室中性别字典使用F/M/O表示各种性别,但是现在医院要求所有性别字典保存Female/Male/Other性别信息,此时就需要替换原有的性别字典为新用字典。当初,此处只是列举了一个使用场景,未来有多个需要对照字典的工作都可以考虑此项目的设计和实现思想。
点击投票
项目二:
HealthInfoQueryLayer
Author: Botai Zhang
基于Intersystems IRIS平台整合医院信息查询业务解决方案
概述:随着医院信息化建设的逐步完善,医院子系统越来越多,系统间接口越来越多,同时接口费用不断增加,管理工作变得越来越复杂。其中,查询类业务接口根据业务类型分化,数量也是逐步递增,带来接口量大、开发工作繁重、代码冗余、维护困难等等问题。针对这一困境,我们基于Intersystems IRIS数据平台整合医院信息查询业务解决方案。该应用程序可通过配置完成查询业务接口实现,大大缩小开发、维护、实施等项目关键运转周期。
点击投票
项目三:
Integration scheme for heterogeneous messages in heterogeneous systems
Author: Deming Xu
异构系统和异构消息的集成方案
概述:随着现代医院建设的信息化程度越来越高,对接的子系统数量也越来越多,系统的架构、接口类型、消息结构越来越复杂,对医院系统之间的信息传递造成很大不便。为了解决该问题,我们采用HL7、XML等标准,使用Ensemble内置的数据转换工具(DT),将异构系统的接口进行标准化(通常引用Soap、REST、TCP/IP等标准协议),使得不同架构的系统,即时接口类型不同、消息模型不同,也能进行数据的传输。 关键词:HL7、XML、Settings、DataTransform、JDBC、SQL
点击投票
项目四:
Create a unified hospital data extraction scheme based on IRIS for Health
Author: Deming Xu
基于 IRIS for Health 创建医院数据统一提取方案
概述:随着医院信息化建设内容不断丰富,业务面覆盖越来越广,相关科研项目的数据需求也越来越多,医院对各个业务系统的数据管理提出了新的要求。由于科研项目背景多样,需求中的数据模型也不尽相同,各个系统的接口开发、接口管理、代码维护工作也变得越来越繁杂。针对这一困境,我们采用IRIS创建医院数据统一提取方案 。该应用程序提供一个公共的数据提取服务(BS),可通过配置完成获取多个不同数据源的接口开发(多个BO),大大缩小开发、维护、实施等成本。
点击投票
项目五:
RESTFUL_API_For_Hotel_OverBooking_System
Author: jingqi LIu
Develop RESTFUL Data API in InterSystems IRIS Data Platform Development for Hotel Overbooking Management System. PS:The overbooking management system combines the unique conditions of the hotel, such as room prices, order channels, customer needs (etc...). System uses machine learning algorithms (such as: KNN/ES-RNN...) to accurately predict the daily no-show and occupancy rate of the hotel, and further combines with the revenue equation to find the best largest room sales volume, which can significantly increase the hotel marginal revenue.
这是一个在InterSystems IRIS中用ObjectScript构建的REST API应用的演示。它也有OPEN API规范,可以用Docker和VSCode开发,可以作为ZPM模块部署,可以作为Overbooking系统数据的REST api使用。
点击投票 Useful! 新用户投票前必读哦:如何成为社区活跃用户(Active user) 这几个医疗行业应用都非常不错,学习到很多! 欢迎为您喜欢的选手投票! 欢迎新加入的朋友们发言、评论、回复成为活跃用户后为中国参赛选手投票,每人可以投3票!
@Hao.Wang @z.c @Zhaoying.Li @Neal.Wu @liu.yaquan @qu.qu @wang.wei @guo.meiya @yajing.xu @yue.li @权权.苏 @xiaohu.xiong @yadong.zhao @Yi.Han @Wen.Zhou @jie.zhang @张.恒 @guo.wenheng @Jing.Li3826 @迪.文 这个贴子很棒!完美的解决了我的问题! 欢迎新朋友,请大家发表内容时尽量在中文社区发表,多发表高质量内容,为中文社区多做贡献, 包括但不限于回答问题,撰写文章,贡献软件库、代码、工具等等,多谢支持!
@young.zheng @an.xingqi2532 @jinhui.hu @wenyang.zhang @guoguo.wang @shikai.ren @chaolong.huang @yabin.duan @鹏飞.楚 @智辉.李 @shan.hu @Wendy.Wu 好的,谢谢 马上投票 发布完还要等24小时 你好,第一次发帖24小时后就可以投票吗 准备投票 是的 原来是这样,明白了 期望多一些应用,多多学习! 能够学习到具体的应用,很棒!👍 学习IRIS在国内多行业应用,棒👍 好的,谢谢! 感谢提醒,👍
文章
Michael Lei · 八月 12, 2021
我最近看到一个客户问题,是使用 Caché 数据库上运行的病毒扫描程序导致应用程序间歇性变慢和用户响应时间不佳。
出乎意料的是,这是一个常见问题,所以本帖就是提个醒,要将主要 Caché 组件排除在病毒扫描之外。
通常,病毒扫描必须排除 CACHE.DAT 数据库文件和 Caché 二进制文件。 如果防病毒软件扫描 CACHE.DAT 和 InterSystems 文件,那么系统性能_将_受到较大影响。
具体来说,防病毒软件必须排除的 Caché 文件包括:
* Caché 数据库 (CACHE.DAT)。
* Ensemble/bin 或 cache/bin 目录中的 Caché 可执行文件。
* 写入映像日志 (WIJ)。
* 日志目录中的日志文件。
更多详细信息,请参见在线文档。
[更多 Caché 文档](http://docs.intersystems.com/latest/csp/docbook/DocBook.UI.Page.cls?KEY=GSA_thirdparty)
公告
jieliang liu · 三月 30, 2022
大家好,欢迎来到2022年3月开发者社区更新!
我们最近在InterSystems社区对开发者们的体验做了一些改进:
全新的社区内容搜索功能
综合社区数据
链接你的脸书账号
帖子页面更新:标签、作者块、草稿突出显示
下面让我们仔细看看。
社区搜
我们已经在社区网站上部署了一个全新的搜索引擎。有两个搜索选项:
快速搜索
高级搜索
通过DC快速搜索,你可以很容易地找到一个帖子/标签/用户并直接进入该网页。
在建议的选项中没有找到合适的东西?
试着通过点击🔍按钮使用DC高级搜索:
在这里,你可以轻松地为你的搜索查询添加高级参数:
按特定用户的帖子搜索
通过特定标签搜索
按特定的帖子类型或只按你的帖子搜索
你还可以按时间段和相关性对结果进行排序:
综合社区数据
现在你可以看到InterSystems开发社区的数据统计了:
链接你的脸书账号
在你的DC资料中添加Facebook链接,以认识新朋友,拉近彼此的距离。
进入你的DC用户资料-->编辑-->其他信息-->Facebook资料
帖子页面更新:标签、作者块、草稿突出显示
你问了 - 我们做到了! 现在DC标签出现在帖子的正文中。
另外,在帖子页面,你现在可以在右边的块中看到作者的联系信息:
DC网站上的草稿现在是蓝色突出显示:
希望你喜欢我们的更新
在DC GitHub上提交您的改进请求和错误报告。或者在本帖的评论中发表您的建议。
请继续关注!
公告
Claire Zheng · 一月 10, 2023
亲爱的社区开发者们,
我很高兴地向大家介绍一位我们的新版主 @牛宇翔!
@牛宇翔 目前担任首都医科大学附属北京友谊医院信息中心临床组组长。
以下是@牛宇翔 的自我介绍:
本人有接近10年的医疗信息化经验,目前在我院,带领一个微型小团队,基于Ensemble数据库做医院信息系统(Hospital Information System, HIS)应用端研发,我们团队熟悉HTML、CSS、JavaScript及衍生前端语言,日常工作主要根据用户需求开发对应功能,结合临床业务难点痛点,不断优化程序功能。经过两年的学习和努力,我们团队已完成临床新增功能和优化需求共计一千余条,随着科室人力的发展,我们的开发力量会越来越强,可以更好地保证临床需求的及时响应,不断优化和完善系统BUG,提高临床工作效率。与此同时,我还担任应急小组成员,负责进行数据库运维和问题处理,保证第一时间排查故障。
InterSystems 提供了一个非常优秀的集成平台,借助该技术,给我们业务带来了非常大的便利。我也希望这么优秀的技术,能给更多的兄弟单位和合作伙伴创造价值。我也希望能够在社区与大家一起交流,分享自己的一些实践经验;同时也希望借助这个平台,向大家学习一些优秀的实践。我们一起成长,共同进步!
再次欢迎我们的新版主 @牛宇翔👏🏼👏🏼👏🏼👏🏼👏🏼
期待你在InterSystems开发者社区成长为一名优秀版主! 热烈欢迎!期待更多大作!@牛宇翔
文章
Johnny Wang · 十一月 21, 2021
在医疗领域,开发创新可以挽救更多的生命。
这也是为什么我们更需要去倾听负责构建未来的人:开发人员。 他们需要什么工具才能更有效地使应用程序更加高效? 他们面对着什么样的障碍?
InterSystems 不想去做无用的猜测,因此我们推动进行了一项研究,该研究综合了 200 名医疗行业开发者的反馈,深入了解了他们的最大需求。我们认为,这些研究结果为医疗单位和医疗技术公司提供了一个机会,可以帮助他们的开发团队为业务带来新机遇,同样也为临床医生和患者带来更光明的未来。
以下是三个关键要点:
1. 开发人员想要一个统一的医疗平台。
在接受本次研究采访的 200 名开发人员中,有88% 的受访者表示他们是医疗 IT 领域的专家或该领域的技术人员——他们都希望能有最好的、为他们的行业量身定制的开发工具。 这就是为什么一半的受访者将统一的、专注于医疗的数据平台列为购买新开发工具的关键原因。
一个合适的医疗行业开发平台应该包括互操作性/集成引擎、分析工具、面向医疗行业的自然语言处理功能、机器学习工具和 FHIR 服务器,以及其他组件。
如果一家公司能够提供一个包含所有上述组件的平台,那么超过 90% 的开发人员将对这项技术非常感兴趣。
2. 临床数据模型必不可少
近 90% 的开发人员表示,技术供应商提供的临床数据模型是必不可少的,如果按照 10 分制来统计,这个需求会达到8 分甚至更高。
来自 EHR 的临床数据被 60% 的开发人员列为最优先的一类。而其他数据还包括CRM、医疗设备、健康的社会决定因素、索赔、财务和运营的数据。
3. 健康数据是实现价值的最快途径
干净、健康的数据将高质量企业与其他企业区分开来。 在开发人员希望技术供应商提供更干净、更健康数据的大背景下,这次研究的受访者表示,选择能够提供最干净数据的平台尤为重要。
一站式医疗保健平台
根据该报告,一线开发人员及管理层都想要这样一个医疗保健数据平台:
(1)专注于医疗IT行业 (2)可扩展性 (3)与现有的开发工具兼容 (4)安全 (5)便于使用
我们推动进行这项研究是为了帮助我们确定 InterSystems IRIS for Health™ 的发展方向,而这也是一个专门设计用于从医疗数据中提取价值的数据平台。 开发人员使用该平台、使用这些旨在满足现代医疗需求的、安全的工具来创建和扩展医疗应用程序。
我们对这次的研究结果感到鼓舞,我们也将继续专注以使平台变得更好!
医疗 IT 软件开发人员面临的关键问题。 点击阅读最新研究结果!
想试用 InterSystems IRIS 数据平台吗?立刻免费编码!
关于作者:Chris Walker 领导 InterSystems 的业务开发团队,该团队正在帮助合作伙伴使用软件工具和服务来加速和增强他们推向市场的数字解决方案。 在他职业生涯的早期,他为麻省总医院开发了临床信息系统,并在健康和生命科学信息管理方面拥有超过 25 年的经验。
点击查看原文
文章
姚 鑫 · 一月 5
# 第十六章 调用Callout Library函数
`Callout` 库是一个共享库(`DLL` 或 `SO` 文件),其中包含 `$ZF Callout` 接口的挂钩,允许各种 $ZF 函数在运行时加载它并调用其函数。 `$ZF Callout` 接口提供了四种不同的接口,可用于在运行时加载 `Callout` 库并从该库调用函数。这些接口的主要区别在于如何识别库并将其加载到内存中:
- 使用 `$ZF()` 访问 `iriszf` 标注库描述了如何使用名为 `iriszf` 的特殊共享库。当该库可用时,可以通过 `$ZF("funcname",args)` 形式的调用来访问其函数,而无需事先加载该库或指定库名称。
- 使用 `$ZF(-3)` 进行简单库函数调用描述了如何通过指定库文件路径和函数名来加载库并调用函数。它使用简单,但虚拟内存中一次只能有一个库。与其他接口不同,它在调用库函数之前不需要任何初始化。
- 使用 `$ZF(-5)` 通过系统 `ID` 访问库描述了一种可用于一次有效维护和访问多个库的接口。可以同时加载和使用多个库,每个库所需的处理开销比 `$ZF(-3)` 少得多。内存中的库由加载库时生成的系统定义的 `ID` 来标识。
- 使用 `$ZF(-6)` 按用户索引访问库描述了处理大量标注库的最有效接口。该接口通过`Global`定义的索引表提供对库的访问。该索引可供 `IRIS` 实例中的所有进程使用,并且多个库可以同时位于内存中。每个索引库都被赋予一个唯一的、用户定义的索引号,并且可以在运行时定义和修改索引表。当库文件被重命名或重新定位时,与给定库 `ID` 关联的文件名可以更改,并且此更改对于按索引号加载库的应用程序来说是透明的。
# 使用 `$ZF()` 访问 `iriszf` 标注库
当名为 `iriszf` 的 `Callout` 库在实例的 `/bin` 目录中可用时,可以通过仅指定函数名称和参数的 `$ZF` 调用来调用其函数(例如,`$ZF("functionName",arg1, arg2))`.。无需事先加载库即可调用 `iriszf` 函数,并且实例中的所有进程都可以使用 `iriszf` 函数。
自定义 `iriszf` 库是通过创建标准 `Callout` 库、将其移动到实例的 `/bin` 目录并将其重命名为 `iriszf`(具体为 `iriszf.dll` 或 `iriszf.so`,具体取决于平台)来定义的。
以下是编译 `simplecallout.c` 示例(请参阅“创建 `Callout` 库”)并将其设置为 `iriszf` 库的步骤。这些示例假设实例在 `Linux` 下运行,安装在名为 `/intersystems/iris` 的目录中,但所有平台上的过程基本相同:
1. 编写并保存 `simplecallout.c`:
```java
#define ZF_DLL
#include "iris-cdzf.h"
int AddTwoIntegers(int a, int b, int *outsum) {
*outsum = a+b; /* set value to be returned by $ZF function call */
return IRIS_SUCCESS; /* set the exit status code */
}
ZFBEGIN
ZFENTRY("AddInt","iiP",AddTwoIntegers)
ZFEND
```
2. 生成`Callout`库文件(`simplecallout.so`):
```java
gcc -c -fPIC simplecallout.c -I /intersystems/iris/dev/iris-callin/include/ -o simplecallout.o
gcc simplecallout.o -shared -o simplecallout.so
```
3. 从 `IRIS` 终端会话中使用 `$ZF(-3)` 测试库:
```java
USER>write $ZF(-3,"/mytest/simplecallout.so","AddInt",1,4)
5
```
4. 现在安装该库以与 `$ZF()` 一起使用。将 `simplecallout.so` 复制到 `/bin`中,并将其重命名为 `iriszf.so`:
```java
cp simplecallout.so /intersystems/iris/bin/iriszf.so
```
5. 确认可以从 `IRIS` 会话中使用 `$ZF()` 调用代码:
```java
USER>write $zf("AddInt",1,4)
5
```
`iriszf` 库在首次使用时加载一次,并且永远不会卸载。它完全独立于本章前面描述的其他 `$ZF` 加载和卸载操作。
注意:静态链接库 `$ZF Callout Interface` 的早期版本允许将代码静态链接到 `InterSystems` 内核并使用 `$ZF()` 进行调用。不再支持静态链接,但 `irisz` 库提供相同的功能,无需重新链接内核。
文章
姚 鑫 · 四月 7, 2021
# 第十九章 存储和使用流数据(BLOBs和CLOBs)
Intersystems SQL支持将流数据存储为Intersystems Iris ®DataPlatform数据库中的 `BLOBs`(二进制大对象)或 `CLOBs`(字符大对象)的功能。
# 流字段和SQL
Intersystems SQL支持两种流字段:
- 字符流 `Character streams`,用于大量文本。
- 二进制流 `Binary streams`,用于图像,音频或视频。
## BLOBs and CLOBs
Intersystems SQL支持将`BLOBs`(二进制大对象)和`CLOBs`(字符大对象)存储为流对象的功能。 `BLOBs`用于存储二进制信息,例如图像,而`CLOBs`用于存储字符信息。 **`BLOBs`和`CLOBs`可以存储多达4千兆字节的数据(JDBC和ODBC规范所强加的限制)。**
在各种方面,诸多方面的操作在通过ODBC或JDBC客户端访问时处理字符编码转换(例如Unicode到多字节):`BLOB`中的数据被视为二进制数据,从未转换为二进制数据另一个编码,而`CLOB`中的数据被视为字符数据并根据需要转换。
如果二进制流文件(`BLOB`)包含单个非打印字符`$CHAR(0)`,则被认为是空二进制流。它相当于`""`空二进制流程值:它存在(不是`null`),但长度为0。
## 定义流数据字段
Intersystems SQL支持流字段的各种数据类型名称。这些Intersystems数据类型名称是与以下内容对应的同义词:
- 字符流:数据类型`LONGVARCHAR`,映射到`%stream.globalcharacter`类和ODBC / JDBC数据类型`-1`。
- 字符流:数据类型`LONGVARBINARY`,映射到`%Stream.GlobalBinary`类和ODBC / JDBC数据类型`-4`。
某些Intersystems流数据类型允许指定数据精度值。此值是no-op,对流数据的允许大小没有影响。提供它以允许用户记录预期的未来数据大小。
以下示例定义包含两个流字段的表:
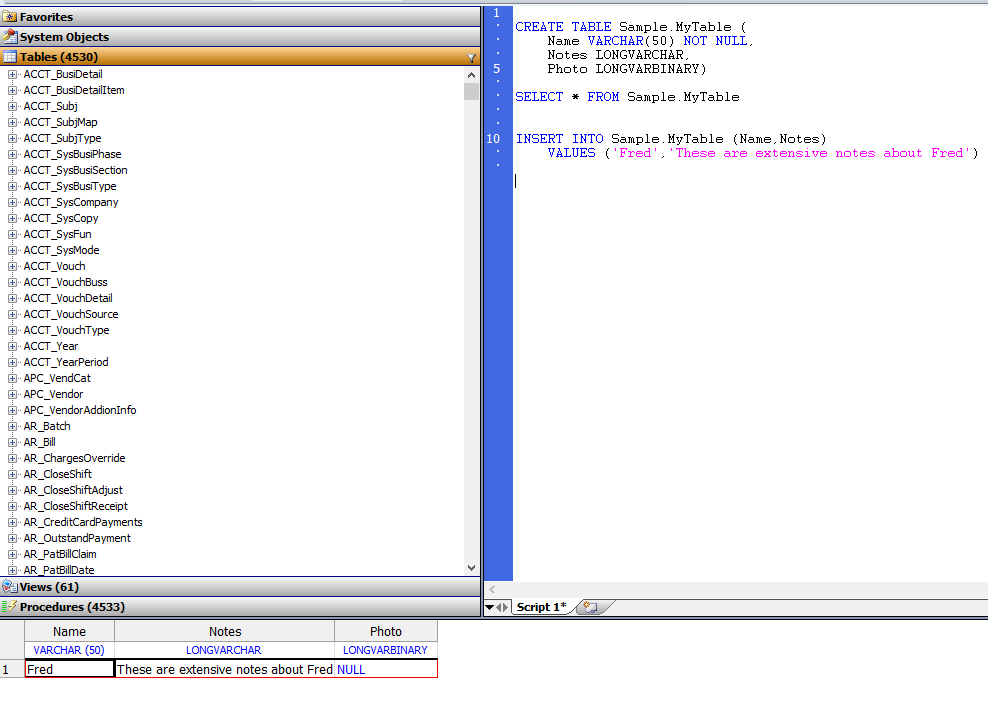
```sql
CREATE TABLE Sample.MyTable (
Name VARCHAR(50) NOT NULL,
Notes LONGVARCHAR,
Photo LONGVARBINARY)
```
分片表不能包含流数据类型字段。
### 流字段约束
Stream字段的定义符合以下字段数据约束:
流字段可以定义为 `NOT NULL`。
流字段可以占用默认值,更新值或计算码值。
流字段不能定义为唯一,主键字段或`idkey`。试图这样做导致`SQLCode -400`致命错误,其中%MSG如下:` ERROR #5414: Invalid index attribute: Sample.MyTable::MYTABLEUNIQUE2::Notes, Stream property is not allowed in a unique/primary key/idkey index > ERROR #5030: An error occurred while compiling class 'Sample.MyTable'.`
无法使用指定的`COLLATE` 值定义流字段。试图这样做导致`SQLCode -400`致命错误,其中`%MSG`如下:` ERROR #5480: Property parameter not declared: Sample.MyTable:Photo:COLLATION > ERROR #5030: An error occurred while compiling class 'Sample.MyTable'.`
## 将数据插入流数据字段
将数据插入流字段有三种方法:
- `%Stream.Globalcharacter`字段:可以直接插入字符流数据。例如,
```sql
INSERT INTO Sample.MyTable (Name,Notes)
VALUES ('Fred','These are extensive notes about Fred')
```
```java
Class Sample.MyTable Extends %Persistent [ ClassType = persistent, DdlAllowed, Final, Owner = {yx}, ProcedureBlock, SqlRowIdPrivate, SqlTableName = MyTable ]
{
Property Name As %Library.String(MAXLEN = 50) [ Required, SqlColumnNumber = 2 ];
Property Notes As %Stream.GlobalCharacter [ SqlColumnNumber = 3 ];
Property Photo As %Stream.GlobalBinary [ SqlColumnNumber = 4 ];
/// Bitmap Extent Index auto-generated by DDL CREATE TABLE statement. Do not edit the SqlName of this index.
Index DDLBEIndex [ Extent, SqlName = "%%DDLBEIndex", Type = bitmap ];
Storage Default
{
Name
Notes
Photo
^Sample.MyTableD
MyTableDefaultData
sequence
^Sample.MyTableD
^Sample.MyTableI
^Sample.MyTableS
%Library.CacheStorage
}
}
```
- `%stream.globalcharacter`和`%stream.globalbinary`字段:可以使用oref插入流数据。可以使用`Write()`方法将字符串附加到字符流,或者写入的方法,以将具有行终结器的字符串附加到字符流。默认情况下,行终结器是`$CHAR(13,10)`(回车返回/线路);可以通过设置`LineTerminator` 属性来更改行终结器。在以下示例中,示例的第一部分创建由两个字符串和其终端组组成的字符流,然后使用嵌入的SQL将其插入流字段。示例的第二部分返回字符流长度,并显示显示终结器的字符流数据:
```java
/// d ##class(PHA.TEST.SQL).StreamField()
ClassMethod StreamField()
{
CreateAndInsertCharacterStream
SET gcoref=##class(%Stream.GlobalCharacter).%New()
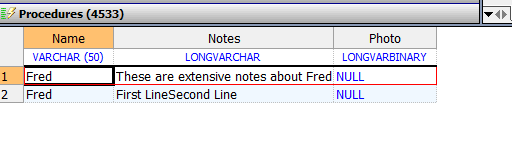
DO gcoref.WriteLine("First Line")
DO gcoref.WriteLine("Second Line")
&sql(INSERT INTO Sample.MyTable (Name,Notes)
VALUES ('Fred',:gcoref))
IF SQLCODEd ##class(PHA.TEST.SQL).StreamField()
插入成功
1
^CacheStream=1
^CacheStream(1)=1
^CacheStream(1,0)=25
^CacheStream(1,1)="First Line"_$c(13,10)_"Second Line"_$c(13,10)
```
- `%stream.globalcharacter`和`%stream.globalbinary`字段:可以通过从文件读取它来插入流数据。例如,
```java
/// d ##class(PHA.TEST.SQL).StreamField1()
ClassMethod StreamField1()
{
SET myf="E:\temp\game.jpg"
OPEN myf:("RF"):10
USE myf:0
READ x(1):10
&sql(INSERT INTO Sample.MyTable (Name,Photo) VALUES ('George',:x(1)))
IF SQLCODEd ##class(PHA.TEST.SQL).StreamField1()
WRITE "插入成功",!
^
zStreamField1+11^PHA.TEST.SQL.1
DHC-APP 2d0>g
WRITE "插入成功",!
^
zStreamField1+11^PHA.TEST.SQL.1
DHC-APP 2d0>g
DHC-APP>
```

作为默认值或计算值插入的字符串数据以适合于流字段的格式存储。
## 查询流字段数据
选择流字段的查询选择项返回流对象的完全形成的OID(对象ID)值,如下例所示:
```sql
SELECT Name,Photo,Notes
FROM Sample.MyTable WHERE Photo IS NOT NULL
```

OID是一个 `%List` 格式化数据地址,如以下内容:`$lb("1","%Stream.GlobalCharacter","^EW3K.Cn9X.S")`。
- OID的第一个元素是一个连续的正整数(从1开始),它被分配给每个插入到表中的流数据值。
例如,如果第1行插入流字段`Photo`和`Notes`的值,则将它们赋值为1和2。
如果第2行插入了一个`Notes`值,则将该值赋给3。
如果用`Photo`和`Notes`的值插入第3行,则将它们赋值为4和5。
分配顺序是表定义中列出字段的顺序,而不是`INSERT`命令中指定字段的顺序。
默认情况下,使用单个整数序列,它对应于流位置全局计数器。
然而,一个表可能有多个流计数器,如下所述。
- 更新操作不会改变初始整数值。
`DELETE`操作可以在整型序列中创建空白,但不会改变这些整型值。
使用`DELETE`删除所有记录不会重置此整数计数器。
如果所有表流字段都使用默认的`StreamLocation`值,则使用`TRUNCATE TABLE`删除所有记录将重置此整数计数器。
不能使用`TRUNCATE`表为嵌入式对象(`%SerialObject`)类重置流整数计数器。
- OID的第二个元素是流数据类型,可以是`%Stream.GlobalCharacter` 或`%Stream.GlobalBinary`。
- OID的第三个元素是一个全局变量。
默认情况下,它的名称是从与表对应的包名和持久类名生成的。
一个`“S”`(用于流)被追加。
- 如果表是使用SQL `CREATE TABLE`命令创建的,这些包和持久化类名称将被散列为每个4个字符(例如,`^EW3K.Cn9X.S`)。
这个全局变量包含流数据插入计数器最近分配的值。
如果没有插入流字段数据,或者使用`TRUNCATE TABLE`删除所有表数据,那么这个全局变量是未定义的。
- 如果表是作为一个持久化类创建的,那么这些包和持久化类名不会被散列(例如`^Sample.MyTableS`)。
默认情况下,这是`StreamLocation`存储关键字`^Sample.MyTableS` 价值。
默认流位置是全局位置,如`^Sample.MyTableS`。此全局变量用于计算插入到没有自定义位置的所有流属性(字段)的次数。例如,如果`Sample.MyTable`中的所有流属性都使用默认流位置,则在`Sample.MyTable`的流属性中插入了10个流数据值时,`^Sample.MyTableS`全局变量包含值10。此全局变量包含最近分配的流数据插入计数器的值。如果没有插入流字段数据,或者使用截断表删除了所有表数据,则此全局变量未定义。
定义流字段属性时,可以定义自定义位置,如下所示:`Property Note2 As %Stream.GlobalCharacter (LOCATION="^MyCustomGlobalS")`;。在这种情况下,`^MyCustomGlobalS`全局用作指定此位置的流属性(或多个属性)的流数据插入计数器;未指定位置的流属性使用默认流位置全局(`^Sample.MyTableS`)作为流数据插入计数器。每个全局计数与该位置相关联的流属性的插入。如果没有插入流场数据,则位置`GLOBAL`是未定义的。如果一个或多个流属性定义了位置,则截断表不重置流计数器。
这些流位置全局变量的下标包含每个流字段的数据。例如,`^EW3K.Cn9X.S(3)`表示第三个插入的流数据项。`^EW3K.Cn9X.S(3,0)`是数据的长度。`^EW3K.Cn9X.S(3,1)`是实际的流数据值。
注意:流字段的`OID`与`RowID`或`Reference`字段返回的`OID`不同。`%OID`函数返回`RowID`或引用字段的`OID`;`%OID`不能与流字段一起使用。试图将流字段用作`%OID`的参数会导致`SQLCODE-37`错误。
在查询的`WHERE`子句或`HAVING`子句中使用流字段受到严格限制。不能将相等条件或其他关系运算符(`=, !=, `)或包含运算符(`]`)或跟随运算符(`[`)与流字段一起使用。尝试将这些运算符与流字段一起使用会导致`SQLCODE-313`错误。
### Result Set Display
- 从程序执行的动态SQL以`$lb("6","%Stream.GlobalCharacter","^EW3K.Cn9X.S")`.格式返回`OID`。
- SQL Shell作为动态SQL执行,并以`$lb("6","%Stream.GlobalCharacter","^EW3K.Cn9X.S")`格式返回`OID`。
- 嵌入式SQL返回相同的`OID`,但以编码`%LIST`的形式返回。可以使用`$LISTTOSTRING`函数将`OID`显示为元素以逗号分隔的字符串:`6,%Stream.GlobalBinary,^EW3K.Cn9X.S`。
从管理门户SQL执行界面运行查询时,不返回`OID`。取而代之的是:
- 字符流字段返回字符流数据的前100个字符。如果字符流数据超过100个字符,则用省略号(`...`)表示。在第100个字符之后。这等效于`SUBSTRING(cstream field,1,100)`。
- 二进制流字段返回字符串``。
在表数据的管理门户SQL界面打开表显示中显示相同的值。
要从管理门户SQL执行界面显示`OID`值,请将空字符串连接到流值,如下所示:`SELECT Name, ''||Photo, ''||Notes FROM Sample.MyTable`。

## `DISTINCT`, `GROUP BY`, and `ORDER BY`
每个流数据字段的`OID`值是唯一的,即使数据本身包含重复。
这些`SELECT`子句操作的是流的`OID`值,而不是数据值。
因此,当应用到查询中的流字段时:
- 不同的子句对重复的流数据值没有影响。
`DISTINCT`子句将流字段为`NULL`的记录数减少为一个`NULL`记录。
- `GROUP BY`子句对重复的流数据值没有影响。
`GROUP BY`子句将流字段为空的记录数量减少为一个空记录。
- `ORDER BY`子句根据数据流的`OID`值来排序数据,而不是数据值。
`ORDER BY`子句列出流字段为空的记录,然后列出带有流字段数据值的记录。
## 谓词条件和流
`IS [NOT] NULL`谓词可以应用于流字段的数据值,示例如下:
```sql
SELECT Name,Notes
FROM Sample.MyTable WHERE Notes IS NOT NULL
```
`BETWEEN`, `EXISTS`, `IN`, `%INLIST`, `LIKE`, `%MATCHES`, and `%PATTERN` 谓词可以应用于流对象的`OID`值,示例如下:
```sql
SELECT Name,Notes
FROM Sample.MyTable WHERE Notes %MATCHES '*1[0-9]*GlobalChar*'
```
尝试在流字段上使用任何其他谓词条件会导致`SQLCODE -313`错误。
## 聚合函数和流
`COUNT`聚合函数接受一个流字段,并对该字段中包含非空值的行进行计数,示例如下:
```sql
SELECT COUNT(Photo) AS PicRows,COUNT(Notes) AS NoteRows
FROM Sample.MyTable
```

但是,流字段不支持`COUNT`(`DISTINCT`)。
对于流字段不支持其他聚合函数。
尝试将流字段与任何其他聚合函数一起使用会导致`SQLCODE -37`错误。
## 标量函数和流
除了`%OBJECT`、`CHARACTER_LENGTH`(或`CHAR_LENGTH或DATALENGTH`)、`SUBSTRING`、`CONVERT`、`XMLCONCAT`、`XMLELEMENT`、`XMLFOREST`和`%INTERNAL`函数外,InterSystems SQL不能对流字段应用任何函数。
尝试使用流字段作为任何其他SQL函数的参数会导致`SQLCODE -37`错误。
尝试使用流字段作为任何其他SQL函数的参数会导致`SQLCODE -37`错误。
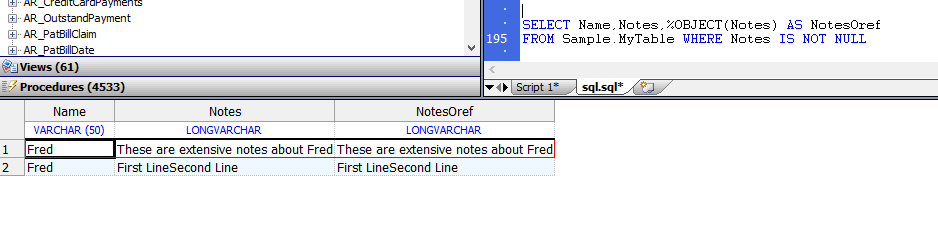
- `%OBJECT`函数打开一个流对象(接受一个`OID`)并返回oref(对象引用),示例如下:
```sql
SELECT Name,Notes,%OBJECT(Notes) AS NotesOref
FROM Sample.MyTable WHERE Notes IS NOT NULL
```
- `CHARACTER_LENGTH`、`CHAR_LENGTH`和`DATALENGTH`函数接受流字段并返回实际的数据长度,如下面的示例所示:
```sql
SELECT Name,DATALENGTH(Notes) AS NotesNumChars,DATALENGTH(Photo) AS PhotoNumChars
FROM Sample.MyTable
```

`SUBSTRING`函数接受一个流字段,并返回流字段的实际数据值的指定子字符串,如下面的示例所示:
```sql
SELECT Name,SUBSTRING(Notes,1,10) AS Notes1st10Chars
FROM Sample.MyTable WHERE Notes IS NOT NULL
```
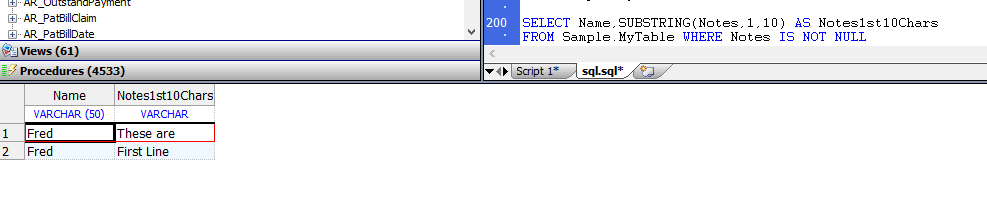
当从管理门户SQL Execute接口发出时,子字符串函数返回流字段数据最多100个字符的子字符串。
如果流数据的指定子字符串大于100个字符,则在第100个字符后用省略号(`…`)表示。
- `CONVERT`函数可用于将流数据类型转换为`VARCHAR`,示例如下:
```sql
SELECT Name,CONVERT(VARCHAR(100),Notes) AS NotesTextAsStr
FROM Sample.MyTable WHERE Notes IS NOT NULL
```
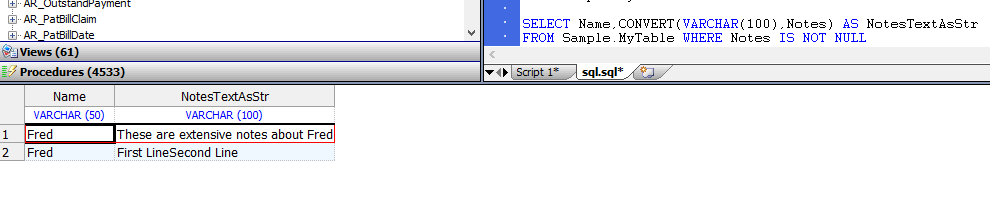
`CONVERT(datatype,expression)`语法支持流数据转换。
如果`VARCHAR`精度小于实际流数据的长度,则将返回值截断为`VARCHAR`精度。
如果`VARCHAR`精度大于实际流数据的长度,则返回值为实际流数据的长度。
不执行填充。
`{fn CONVERT(expression,datatype)}`语法不支持流数据转换;
它发出一个`SQLCODE -37`错误。
- `%INTERNAL`函数可以用于流字段,但不执行任何操作。
# 流字段并发锁
InterSystems IRIS通过取出流数据上的锁来保护流数据值不被另一个进程并发操作。
InterSystems IRIS在执行写操作之前取出一个排他锁。
排他锁在写操作完成后立即释放。
当第一个读操作发生时,InterSystems IRIS取出共享锁。
只有当流实际被读取时才会获取共享锁,并且在整个流从磁盘读取到内部临时输入缓冲区后立即释放共享锁。
# 在Intersystems中使用流字段IRIS方法
不能在Intersystems Iris方法中直接使用嵌入式SQL或动态SQL使用`BLOB`或`CLOB`值;相反,使用SQL来查找`Blob`或`Clob`的流标识符,然后创建`%AbstractStream`对象的实例以访问数据。
# 使用来自ODBC的流字段
ODBC规范不提供对`BLOB`和`CLOB`字段的任何识别或特殊处理。
InterSystems SQL将ODBC中的`CLOB`字段表示为具有`LONGVARCHAR(-1)`类型。
BLOB字段表示为类型为`LONGVARBINARY(-4)`。
对于流数据类型的ODBC/JDBC数据类型映射,请参考InterSystems SQL reference中的数据类型引用页中的数据类型整数代码。
ODBC驱动程序/服务器使用一种特殊协议来访问`BLOB`和`CLOB`字段。
通常,必须在ODBC应用程序中编写特殊的代码来使用`CLOB`和`BLOB`字段;
标准的报告工具通常不支持它们。
# 使用来自JDBC的流字段
在Java程序中,可以使用标准的JDBC `BLOB`和`CLOB`接口从`BLOB`或`CLOB`检索或设置数据。
例如:
```java
Statement st = conn.createStatement();
ResultSet rs = st.executeQuery("SELECT MyCLOB,MyBLOB FROM MyTable");
rs.next(); // fetch the Blob/Clob
java.sql.Clob clob = rs.getClob(1);
java.sql.Blob blob = rs.getBlob(2);
// Length
System.out.println("Clob length = " + clob.length());
System.out.println("Blob length = " + blob.length());
// ...
```
注意:当使用`BLOB`或`CLOB`结束时,必须显式调用`free()`方法来关闭Java中的对象,并向服务器发送消息以释放流资源(对象和锁)。
仅仅让Java对象超出范围并不会发送清理服务器资源的消息。
文章
Qiao Peng · 一月 10, 2021
# Swift-FHIR-Iris
iOS应用程序支持将HealthKit数据导入InterSystems IRIS医疗版(或任何FHIR资源仓库库)
# 目录
* [演示目的](#goal)
* [如何运行此演示](#rundemo)
* [先决条件](#prerequisites)
* [安装Xcode](#installxcode)
* [打开SwiftUi](#openswiftui)
* [配置模拟器](#simulator)
* [启动InterSystems FHIR服务器](#lunchfhir)
* [在iOS应用程序上操作](#iosplay)
* [工作原理](#howtos)
* [iOS](#howtosios)
* [如何检查健康数据的授权](#authorisation)
* [如何连接FHIR资源仓库](#howtoFhir)
* [如何将患者信息保存到FHIR资源仓库](#howtoPatientFhir)
* [如何从HealthKit中提取数据](#queryHK)
* [如何将HealthKit数据转换为FHIR](#HKtoFHIR)
* [后端 (FHIR)](#backend)
* [前端](#frontend)
* [ToDos](#todo)
# 演示目的
目的是创建FHIR协议的端到端演示。
这里的端到端指的是从一个信息源到另一个信息源,例如iPhone。
苹果HealthKit将收集到的健康数据转换为FHIR,再发送到InterSystems IRIS 医疗版存储库。
必须通过web接口访问这些信息。
**TL;DR**: iPhone -> InterSystems FHIR -> web界面.
# 如何运行此演示
## 先决条件
* 客户端 (iOS)
* Xcode 12
* 服务器和Web应用程序
* Docker
## 安装 Xcode
这里没有太多要说的,打开AppStore,搜索Xcode,安装。
## 打开SwiftUi project
Swift是苹果在iOS、Mac、Apple TV和Apple Watch中使用的一种编程语言,是objective-C的替代品。
双击Swift-FHIR-Iris.xcodeproj
单击左上角的箭头打开模拟器。
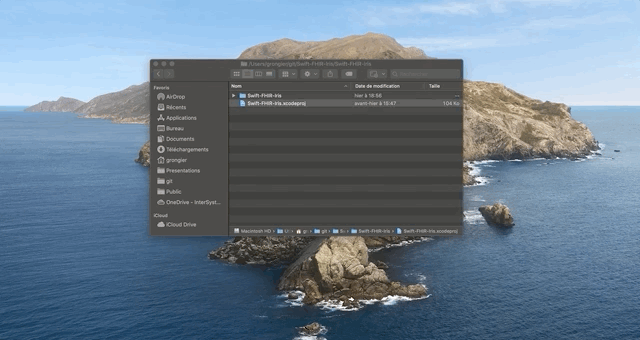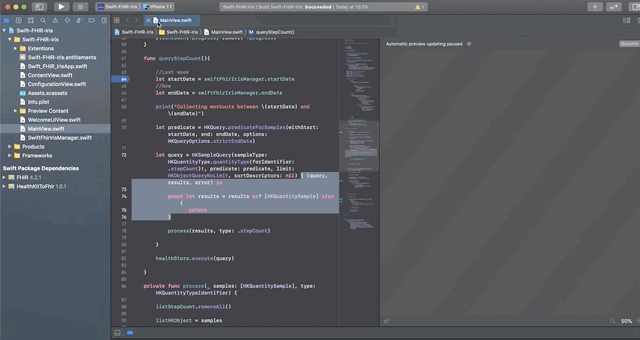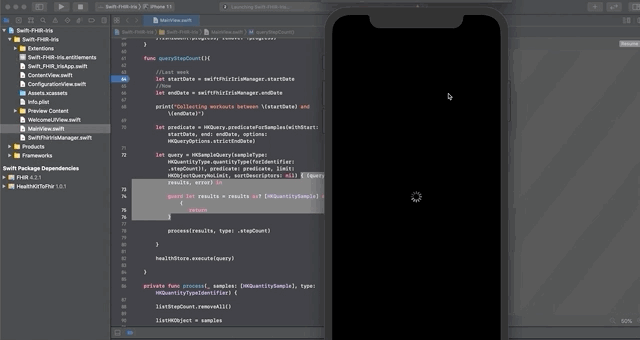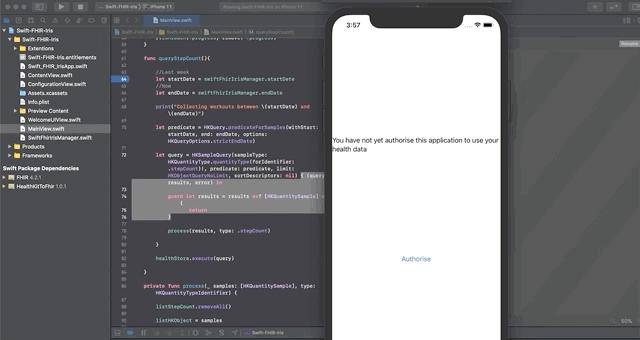
## 配置模拟器
打开Health
点击“Steps”
添加数据

## 启动InterSystems FHIR服务器
在该git的根目录下,运行以下命令:
```sh
docker-compose up -d
```
构建过程结束时,你将连接到FHIR资源仓库:
http://localhost:32783/fhir/portal/patientlist.html
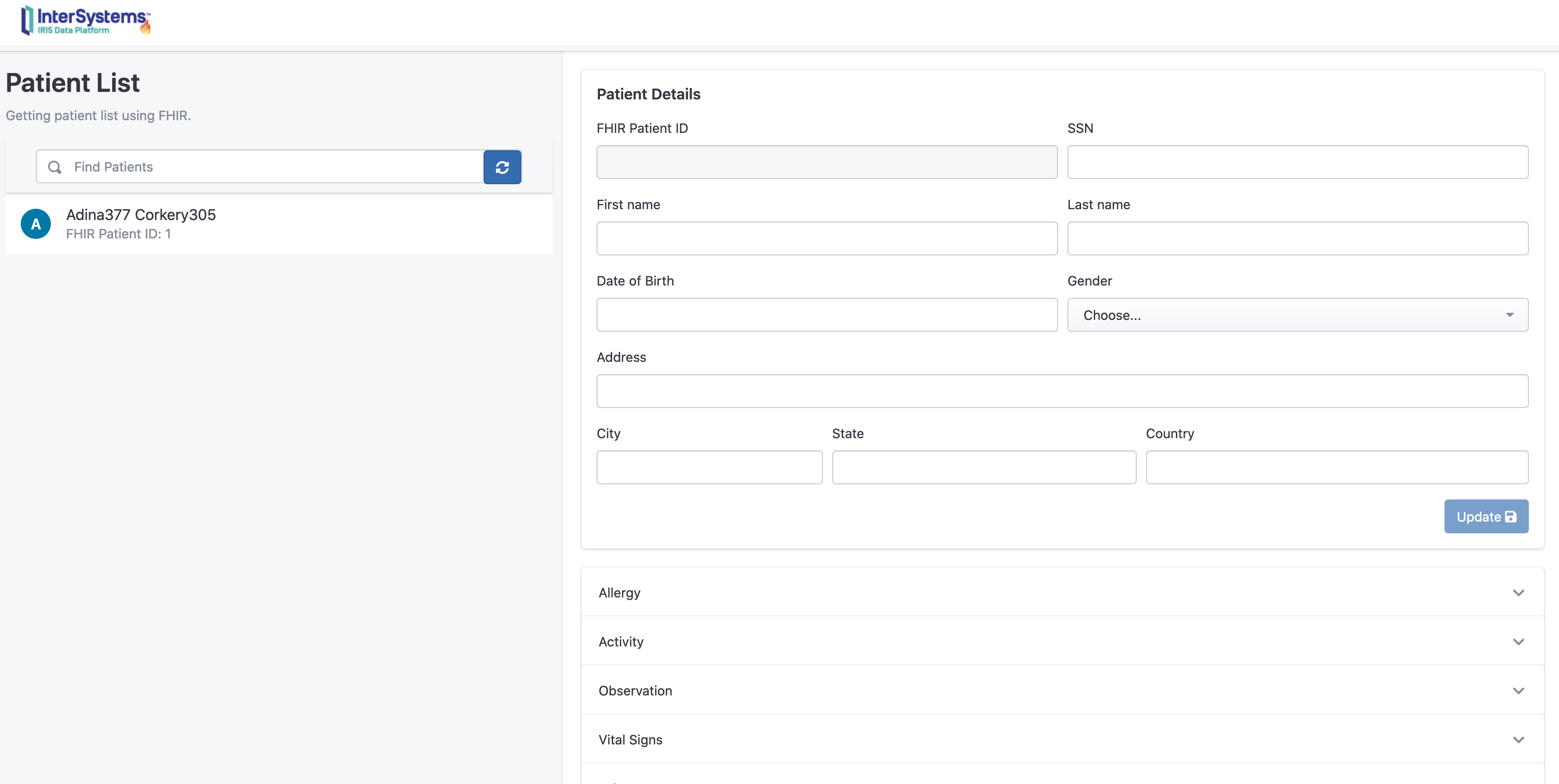
该门户网站由@diashenrique创建.
为处理Apple活动足迹,进行了一些修改。
## 在iOS应用程序上操作
iOS应用程序首先会请求你同意分享部分信息。
点击授权
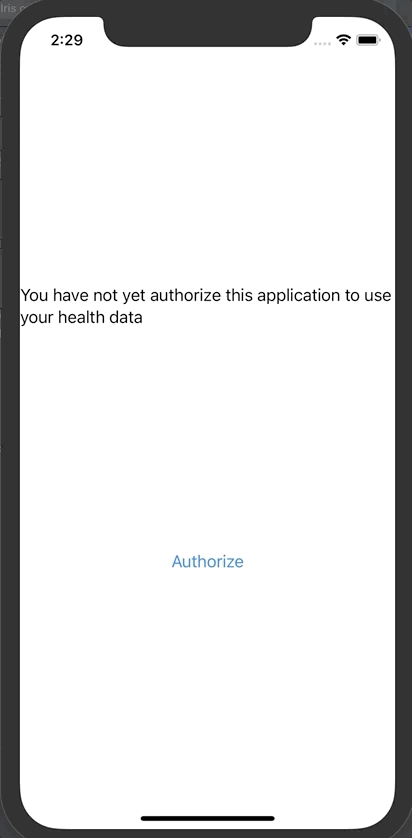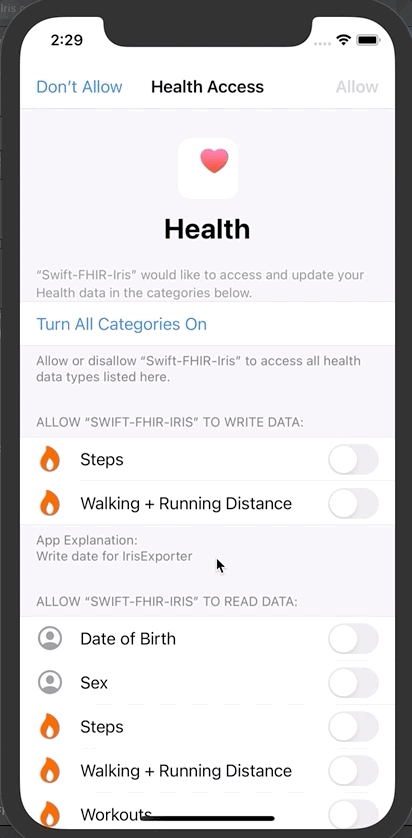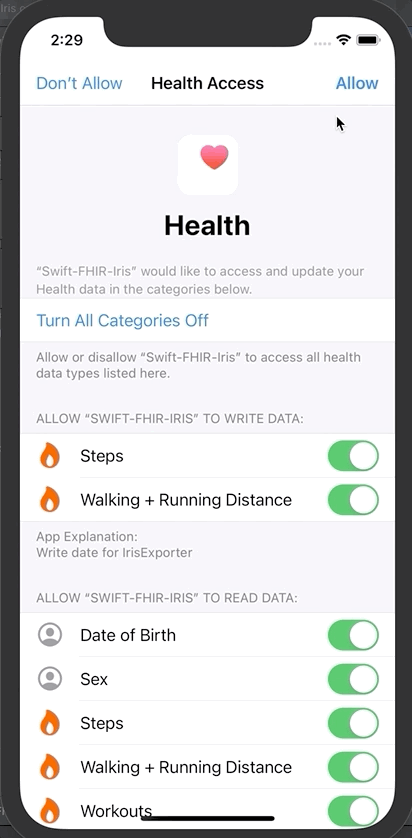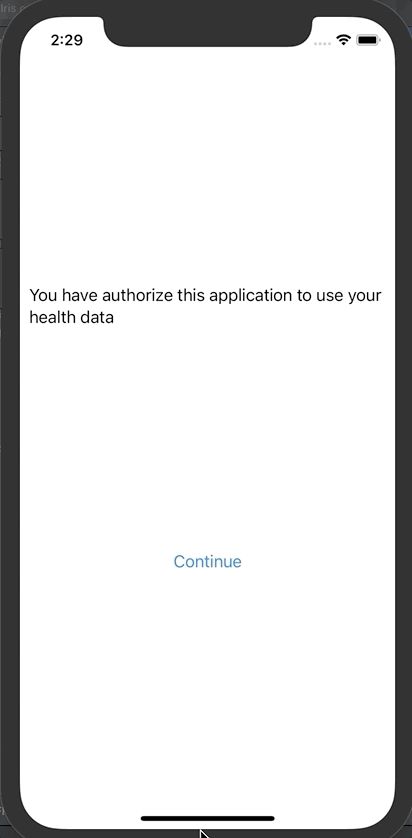
然后点击“Save and test server”对FHIR服务器进行测试
默认设置指向docker配置。
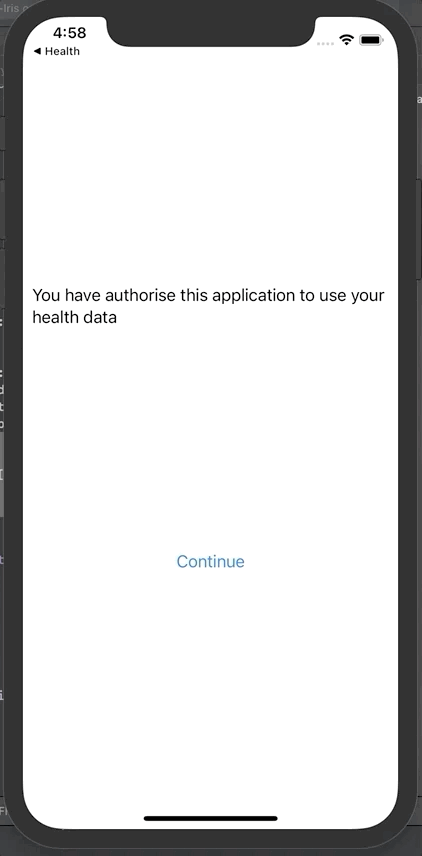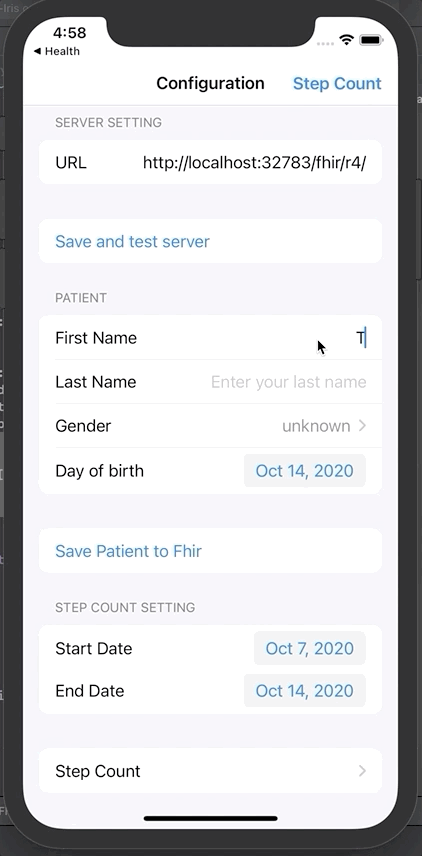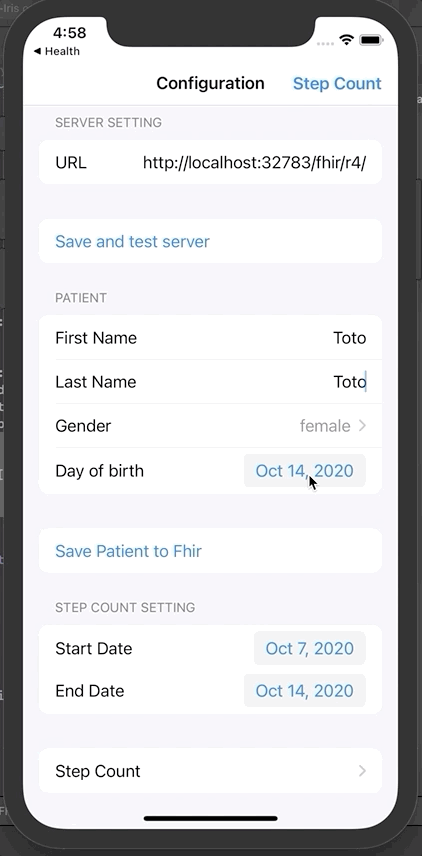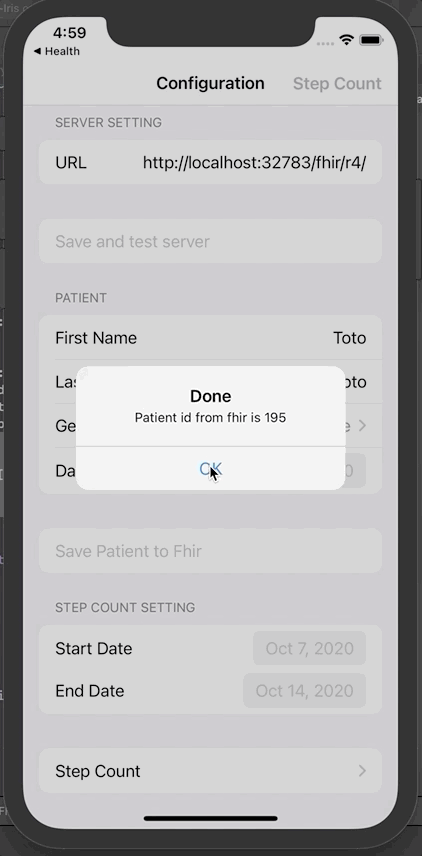
操作成功后,就可以输入患者信息。
名字、姓氏、生日、性别。
将患者信息保存到Fhir。弹出窗口将显示唯一的Fhir ID。
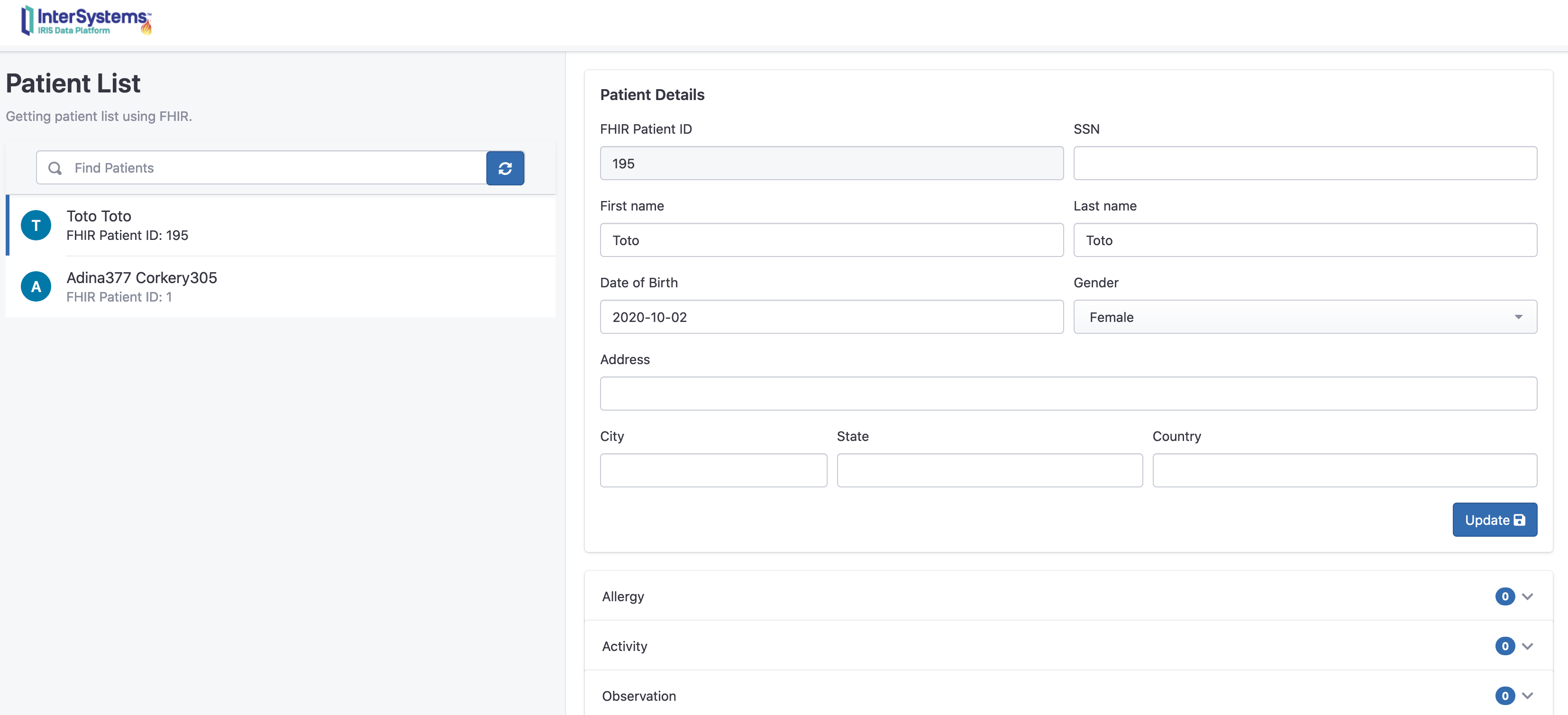
可在门户网站查阅该患者信息:
访问: http://localhost:32783/fhir/portal/patientlist.html
在这里我们可以看到,增加了一个新的病人“Toto”,0个活动。
发送她的活动信息:
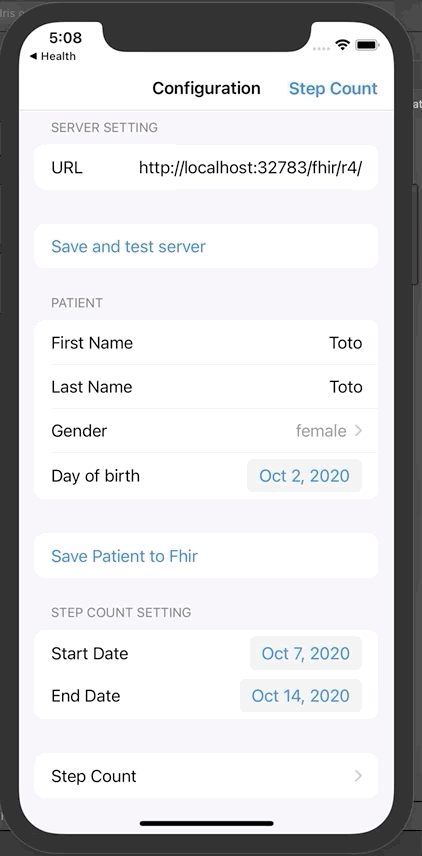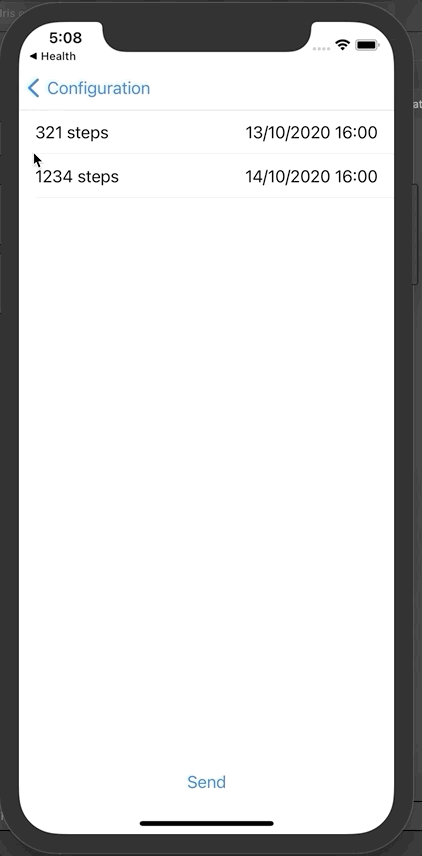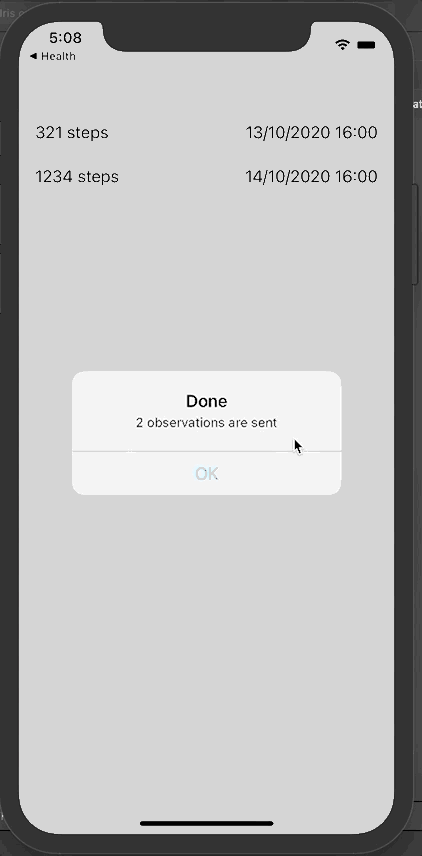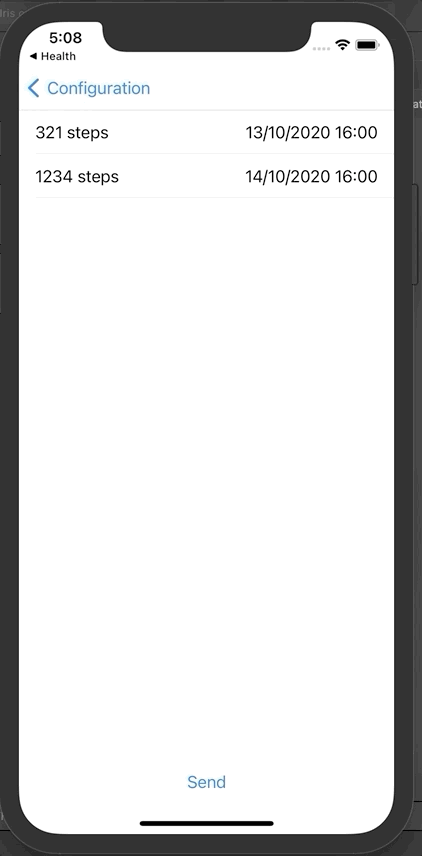
回到iOS应用程序,点击“Step count”。
这里显示的是一周的步数。在我们的案例中有2条记录。
现在可以单击发送,将这些数据发送到InterSystems IRIS FHIR。
从门户网站上查询新的活动记录:
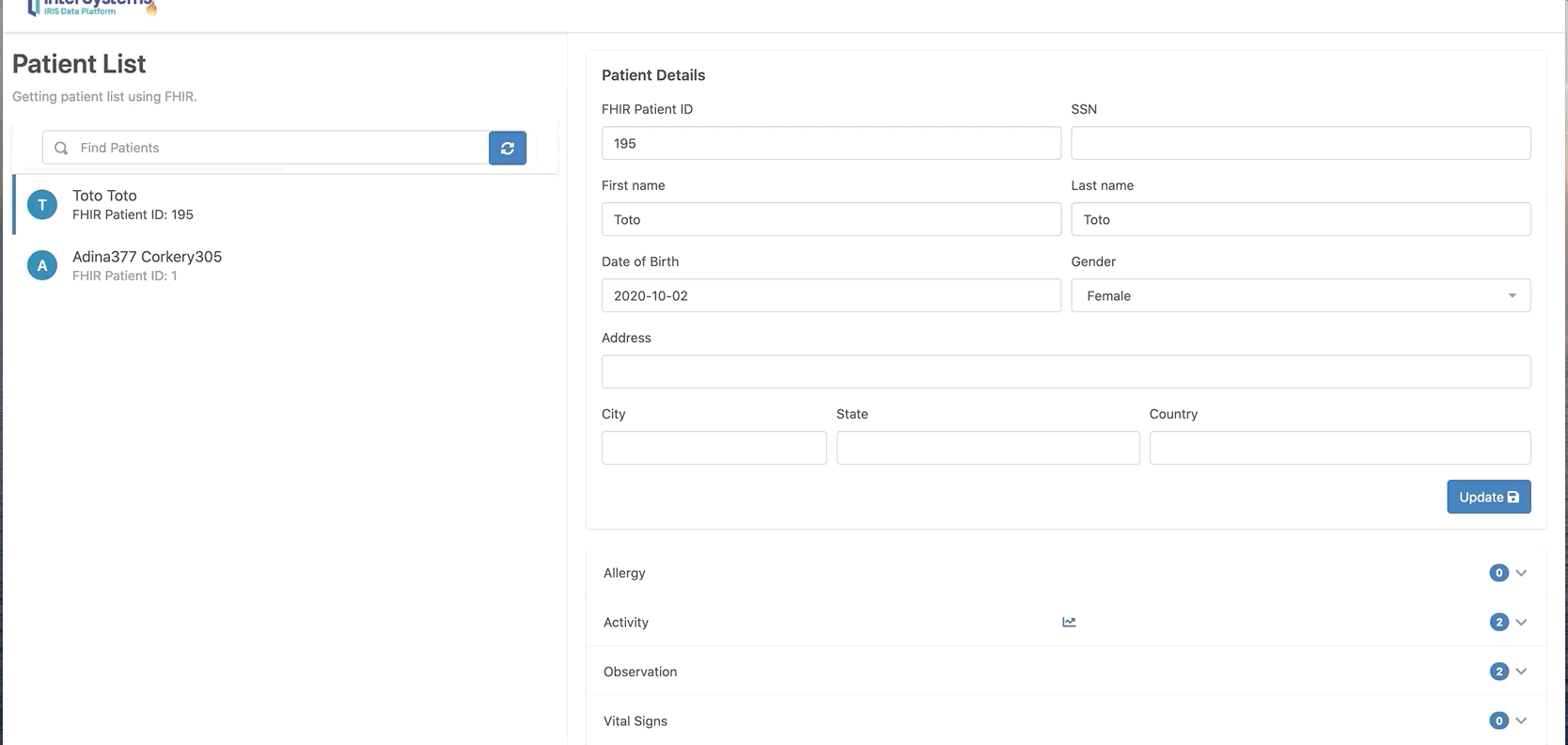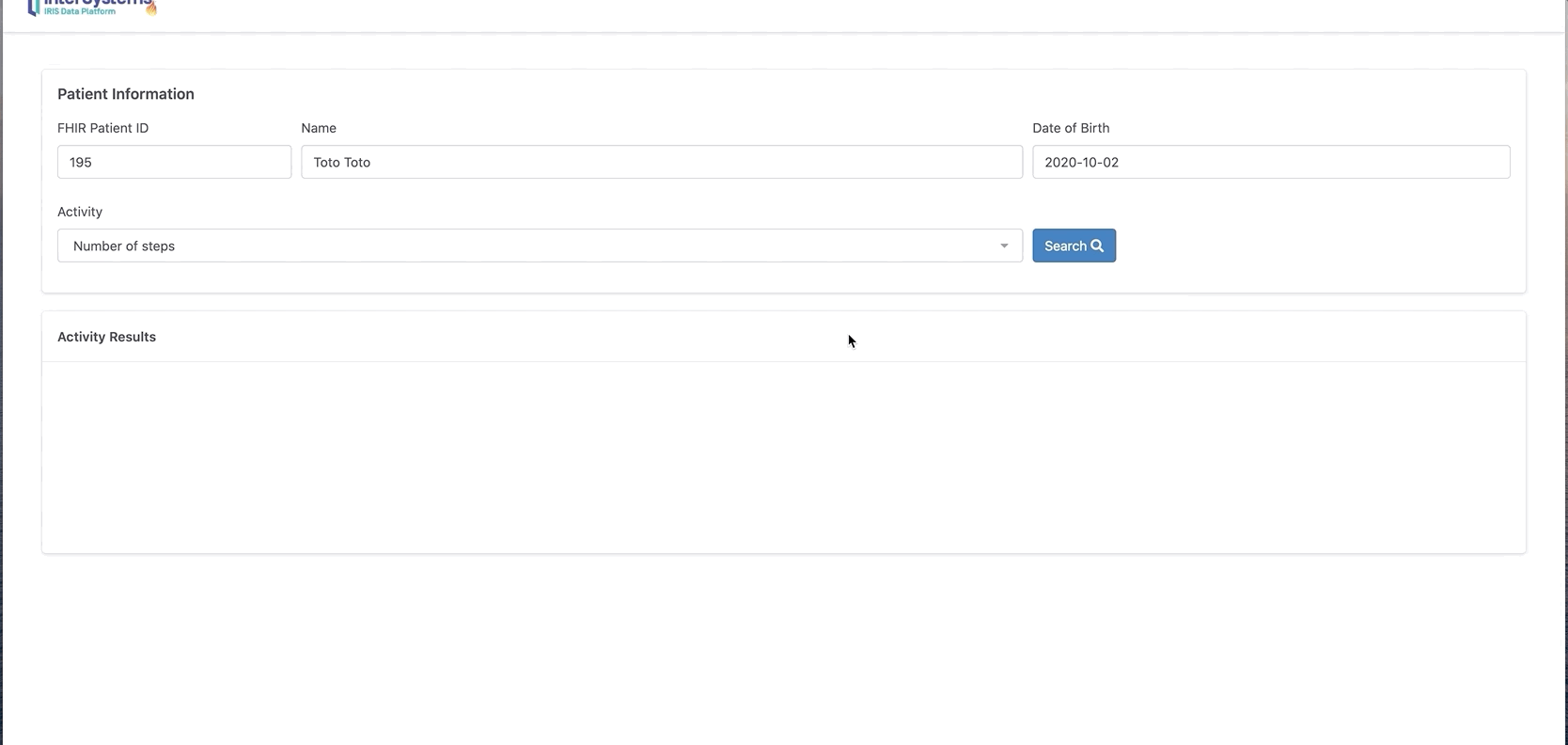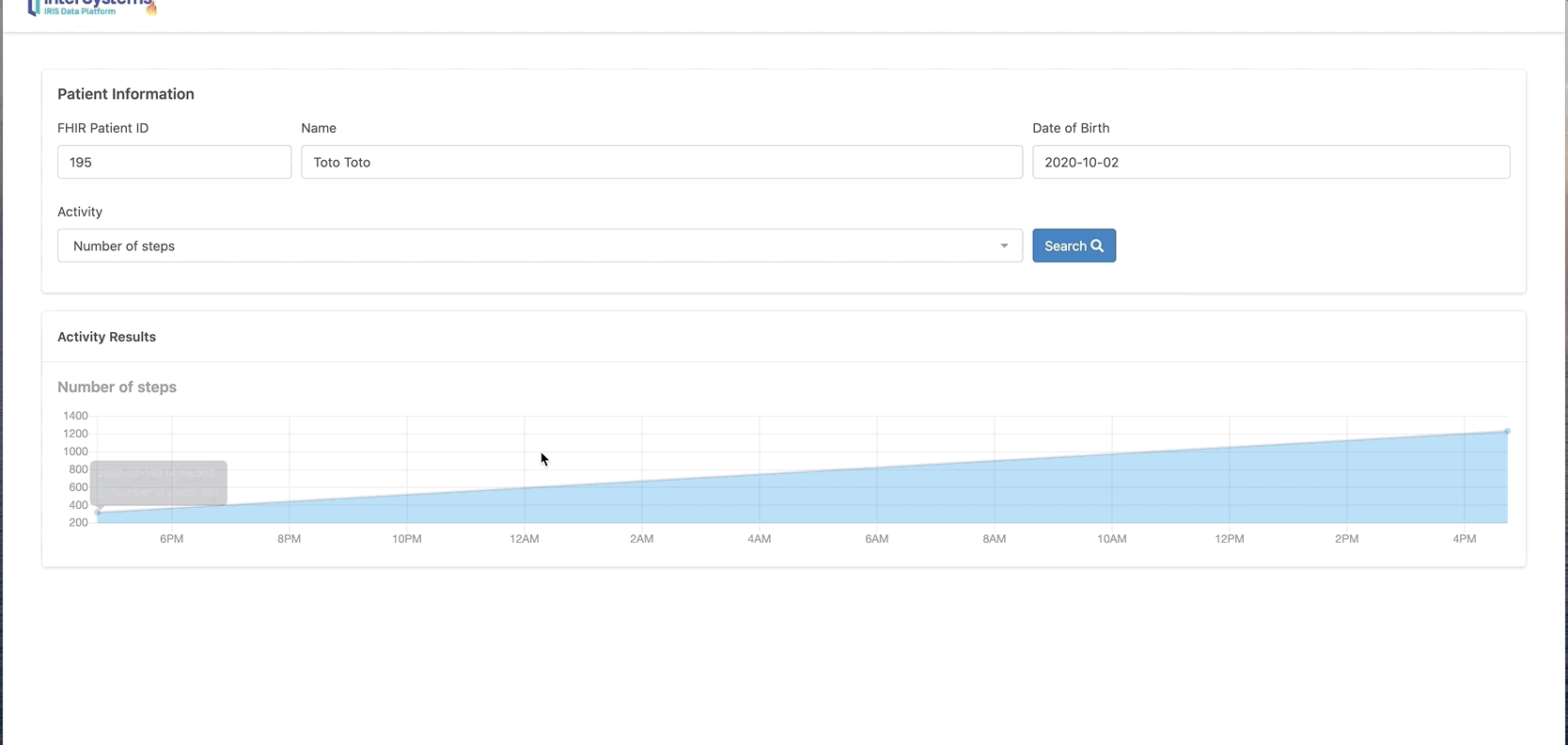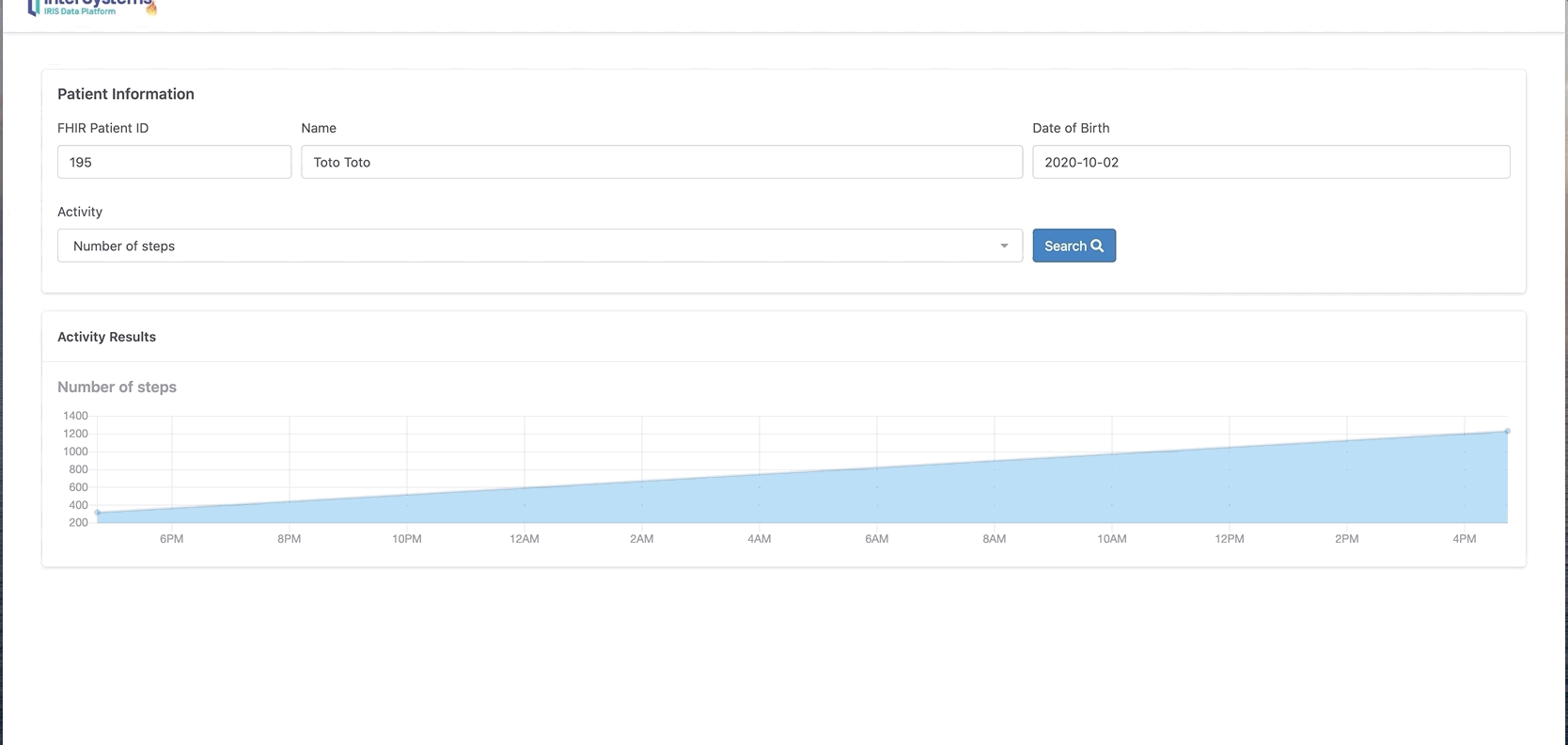
现在我们可以看到Toto有两条新的观察和活动消息。
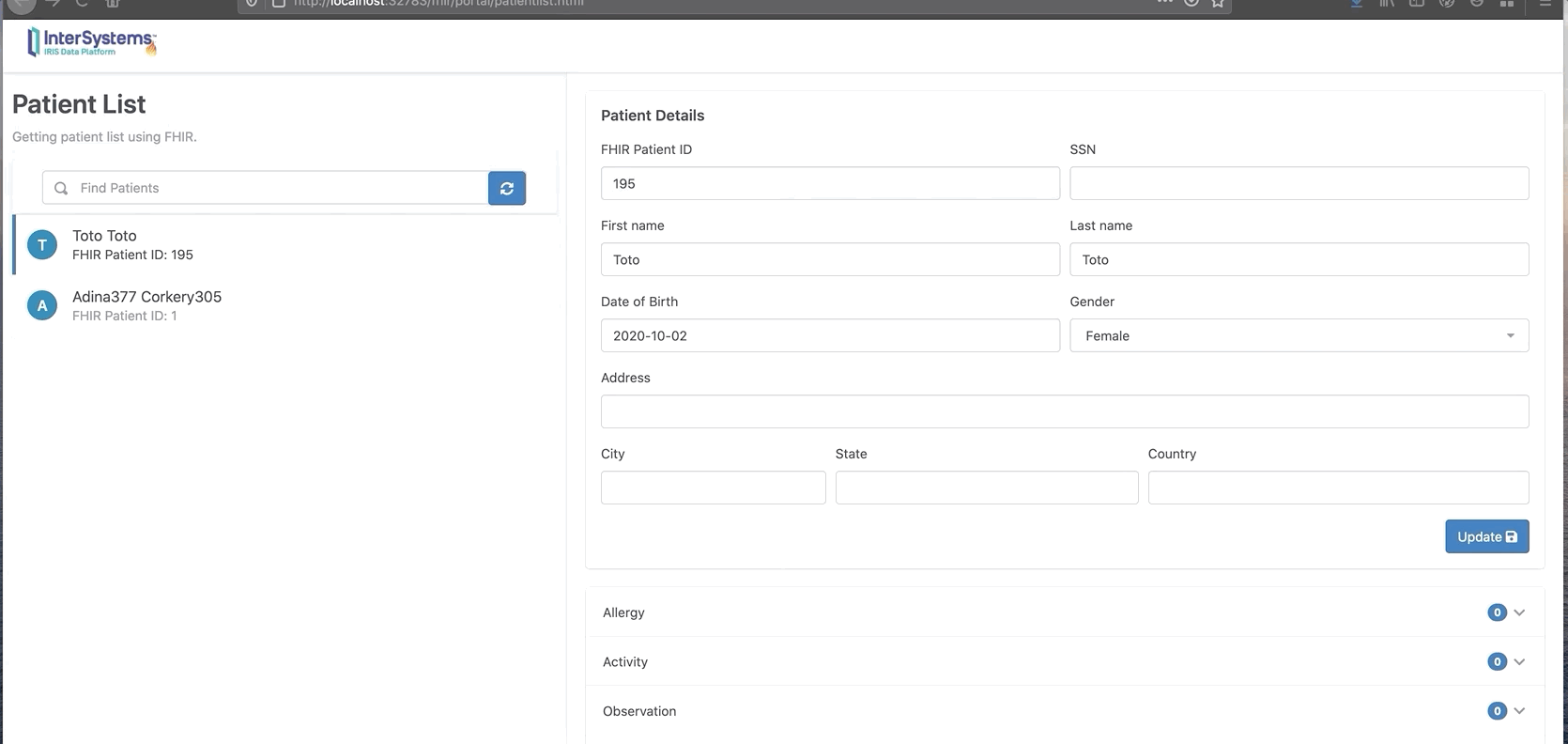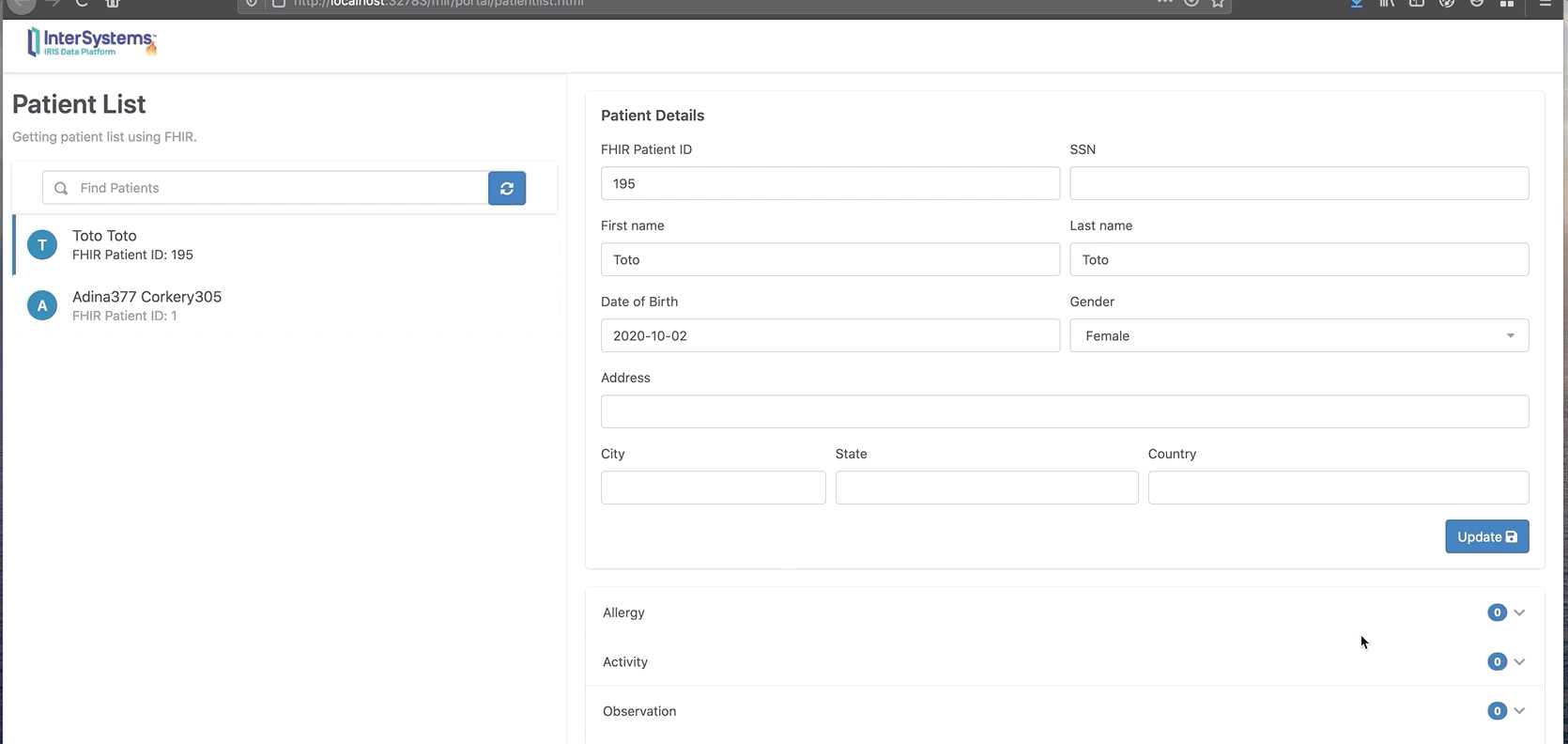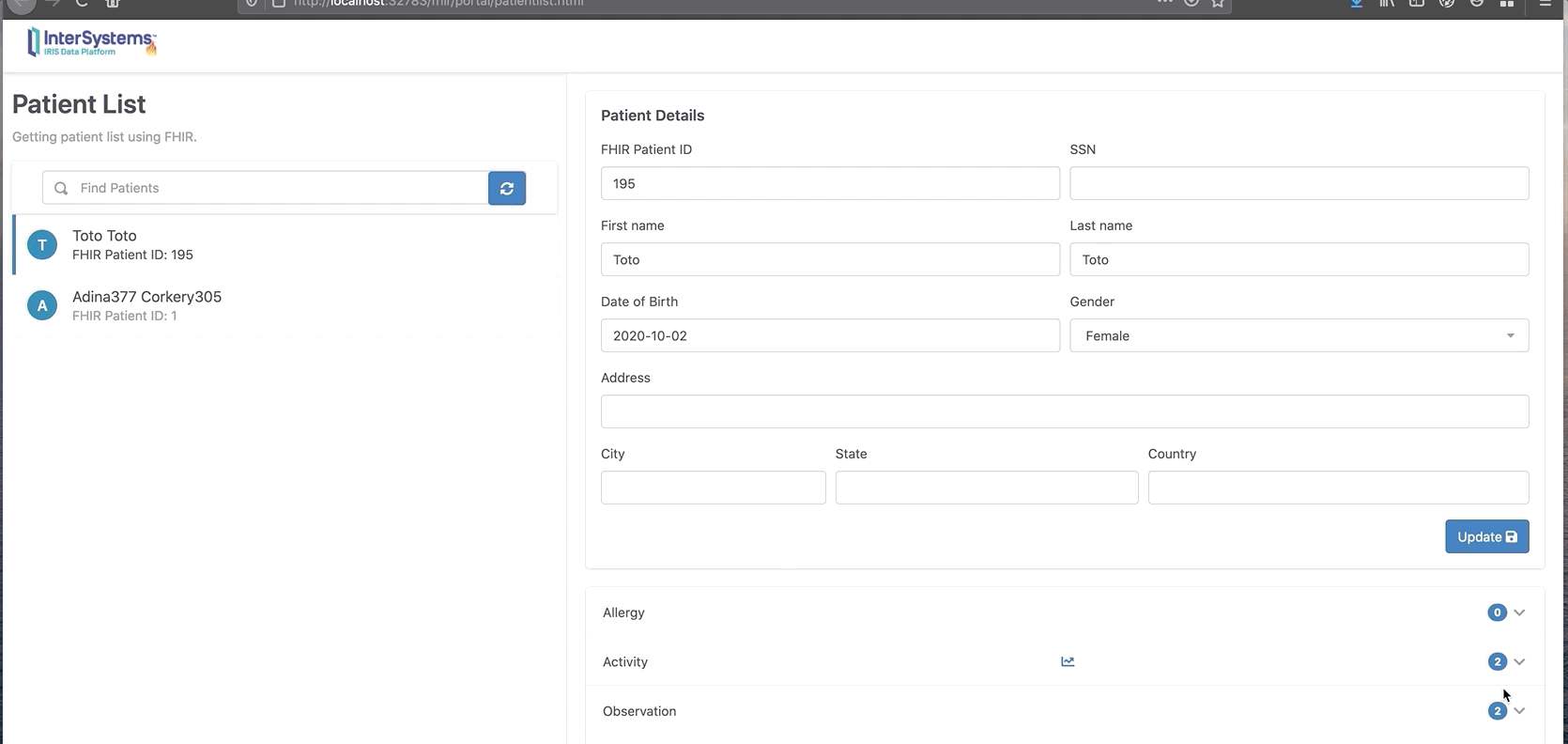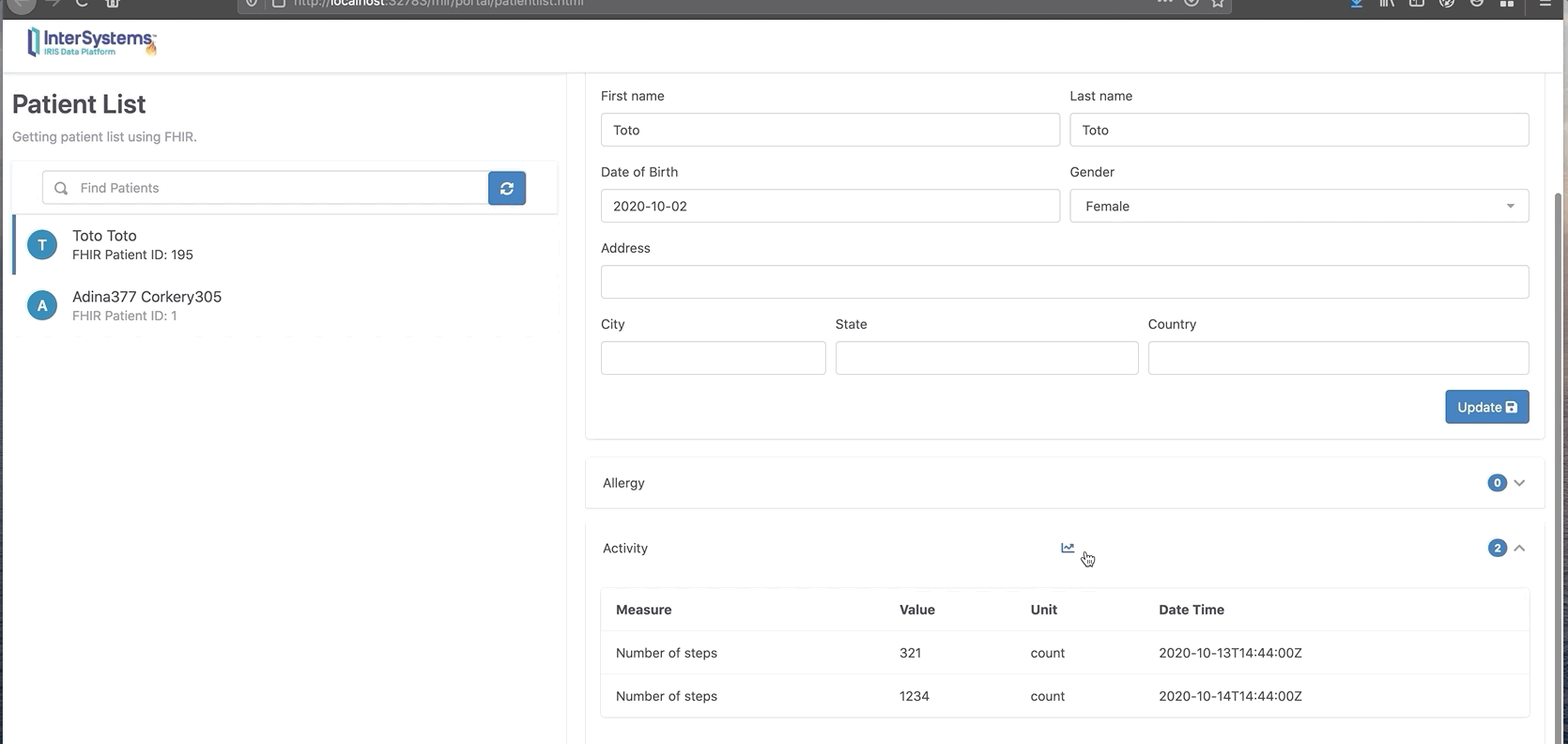
你还可以单击“chart”按钮以图表格式显示。
# 工作原理
## iOS
该demo大部分是基于SwiftUI构建的。
https://developer.apple.com/xcode/swiftui/
iOS和co的最新框架。
### 如何检查健康数据的授权
它在SwiftFhirIrisManager 类中。
该类采用单例模式,可使用@EnvironmentObject对应用程序中进行的所有操作进行注释。
更多信息请访问 : https://www.hackingwithswift.com/quick-start/swiftui/how-to-use-environmentobject-to-share-data-between-views
调用requestAuthorization的方法如下:
```swift
// Request authorization to access HealthKit.
func requestAuthorization() {
// Requesting authorization.
/// - Tag: RequestAuthorization
let writeDataTypes: Set = dataTypesToWrite()
let readDataTypes: Set = dataTypesToRead()
// requset authorization
healthStore.requestAuthorization(toShare: writeDataTypes, read: readDataTypes) { (success, error) in
if !success {
// Handle the error here.
} else {
DispatchQueue.main.async {
self.authorizedHK = true
}
}
}
}
```
其中healthStore是HKHealthStore()的对象。
HKHealthStore类似于iOS中的healthdata数据库。
dataTypesToWrite和dataTypesToRead是我们想要在数据库中查询的对象。
授权的目的可以通过在Info.plist xml文件中添加以下内容完成:
```xml
NSHealthClinicalHealthRecordsShareUsageDescription
Read data for IrisExporter
NSHealthShareUsageDescription
Send data to IRIS
NSHealthUpdateUsageDescription
Write date for IrisExporter
```
### 如何连接FHIR资源仓库
对于这一部分,我使用了从Smart-On-FHIR网站下载的FHIR包 : https://github.com/smart-on-fhir/Swift-FHIR
使用的类是FHIROpenServer。.
```swift
private func test() {
progress = true
let url = URL(string: self.url)
swiftIrisManager.fhirServer = FHIROpenServer(baseURL : url! , auth: nil)
swiftIrisManager.fhirServer.getCapabilityStatement() { FHIRError in
progress = false
showingPopup = true
if FHIRError == nil {
showingSuccess = true
textSuccess = "Connected to the fhir repository"
} else {
textError = FHIRError?.description ?? "Unknow error"
showingSuccess = false
}
return
}
}
```
这一步将在单例swiftIrisManager中创建一个新的对象fhirServer。
接下来使用getCapabilityStatement()
如果能够检索到FHIR服务器的capabilityStatement,则意味着已成功连接到FHIR资源仓库。
这个资源仓库不在HTTPS下,默认情况下Apple会阻止这种通信。
想要获取HTTP支持,可以对Info.plist xml文件进行如下编辑:
```xml
NSAppTransportSecurity
NSExceptionDomains
localhost
NSIncludesSubdomains
NSExceptionAllowsInsecureHTTPLoads
```
### 如何将患者信息保存到FHIR资源仓库
基本操作:首先检查存储库中是否已经存在该患者的信息
```swift
Patient.search(["family": "\(self.lastName)"]).perform(fhirServer)
```
搜索具有相同姓氏的患者。
在这里,我们可以想象一下其他场景,比如使用Oauth2和JWT令牌加入patientId及其令牌。但在这个演示中,我们简单操作即可。
如果该患者信息已经存在,可以对其进行检索;否则,则创建新的患者信息 :
```swift
func createPatient(callback: @escaping (Patient?, Error?) -> Void) {
// Create the new patient resource
let patient = Patient.createPatient(given: firstName, family: lastName, dateOfBirth: birthDay, gender: gender)
patient?.create(fhirServer, callback: { (error) in
callback(patient, error)
})
}
```
### 如何从HealthKit中提取数据
通过查询healthkit商店 store(HKHealthStore())即可完成。
这里我们查询一下步数。
使用predicate做好查询准备。
```swift
//Last week
let startDate = swiftFhirIrisManager.startDate
//Now
let endDate = swiftFhirIrisManager.endDate
print("Collecting workouts between \(startDate) and \(endDate)")
let predicate = HKQuery.predicateForSamples(withStart: startDate, end: endDate, options: HKQueryOptions.strictEndDate)
```
然后,会根据数据类型(HKQuantityType.quantityType(forIdentifier: .stepCount))和predicate内容进行查询。
```swift
func queryStepCount(){
//Last week
let startDate = swiftFhirIrisManager.startDate
//Now
let endDate = swiftFhirIrisManager.endDate
print("Collecting workouts between \(startDate) and \(endDate)")
let predicate = HKQuery.predicateForSamples(withStart: startDate, end: endDate, options: HKQueryOptions.strictEndDate)
let query = HKSampleQuery(sampleType: HKQuantityType.quantityType(forIdentifier: .stepCount)!, predicate: predicate, limit: HKObjectQueryNoLimit, sortDescriptors: nil) { (query, results, error) in
guard let results = results as? [HKQuantitySample] else {
return
}
process(results, type: .stepCount)
}
healthStore.execute(query)
}
```
### 如何将HealthKit数据转换为FHIR
在这部分,我们使用了微软软件包HealthKitToFHIR
https://github.com/microsoft/healthkit-to-fhir
这个包很有用,为开发商提供了将HKQuantitySample转换为FHIR Observation的功能。
```swift
let observation = try! ObservationFactory().observation(from: item)
let patientReference = try! Reference(json: ["reference" : "Patient/\(patientId)"])
observation.category = try! [CodeableConcept(json: [
"coding": [
[
"system": "http://terminology.hl7.org/CodeSystem/observation-category",
"code": "activity",
"display": "Activity"
]
]
])]
observation.subject = patientReference
observation.status = .final
print(observation)
observation.create(self.fhirServer,callback: { (error) in
if error != nil {
completion(error)
}
})
```
其中item是HKQuantitySample,在我们的例子中是stepCount类型。
这个factory完成了大部分工作,将“unit”和“type”转换为FHIR codeableConcept,并将“value”转换为FHIR valueQuantity。
对PatientId的引用是通过强制转换json fhir引用手动完成的。
```swift
let patientReference = try! Reference(json: ["reference" : "Patient/\(patientId)"])
```
对类别进行同样的操作 :
```swift
observation.category = try! [CodeableConcept(json: [
"coding": [
[
"system": "http://terminology.hl7.org/CodeSystem/observation-category",
"code": "activity",
"display": "Activity"
]
]
])]
```
最后,在fhir资源仓库中创建observation :
```swift
observation.create(self.fhirServer,callback: { (error) in
if error != nil {
completion(error)
}
})
```
## 后端 (FHIR)
没什么好说的,它基于InterSystems社区的fhir模板 :
https://openexchange.intersystems.com/package/iris-fhir-template
## 前端
基于Henrique作品,Henrique是使用jquery制作的FHIR资源仓库的一个很好的前端。
https://openexchange.intersystems.com/package/iris-fhir-portal
文章
Lilian Huang · 八月 1, 2023
VR ICU® 是 InterSystems FHIR 创新孵化器 Caelestinus 的参与者。这篇文章将向您介绍我们利用 InterSystems FHIR Server 为医疗保健提供的 VR 解决方案。
我们是一家技术初创企业虚拟实验室,利用先进的 VR/AR 技术开发解决方案。VR ICU® 是一个针对重症监护室医务人员的培训平台,是在 Covid 时代为满足医院需求而创建的。
与InterSystems合作的优势
我们的 VR ICU® 解决方案符合实践需求,是与医院合作开发的。
除了技术解决方案和技能学习本身,记录培训课程、培训进度和成功率对于医院或麻醉学和重症监护部门的有效管理也至关重要。医务长可以通过了解谁在何时接受了培训,清楚地掌握能够在重症监护室使用设备的人员数量,从而有效地对他们进行培训,以保持技能、有控制地规划人员技能储备并提高他们的能力。
在这方面,与 InterSystems 的合作对我们来说至关重要,它使我们能够在应用程序中存储每次培训期间的数据。目前,我们会记录参与者的姓名、培训日期和时长、培训类型、设备类型、错误数量和类型,必要时还会记录培训成功完成的信息。
如何使用?用户登录应用程序并选择一个账户。
根据 HL7 标准,该账户作为从业人员存在于数据库的资源下。培训课程开始时,会在应用程序中创建一个新的 "任务"--在这里输入培训课程的开始时间和培训课程的类型,课程结束时,再次输入培训课程的结束时间。错误会写入输出表。培训完成后,任务中的数据将序列化为 JSON 格式,并使用 FHIR API 发送到云端。为了使 VR 应用程序之外的数据可视化,我们开发了一款平板电脑应用程序。该应用程序与存储在云端的数据相连,并显示特定用户的个人训练课程。
人力资源部门通过培训数据了解受训人员完成培训的总体情况和水平,从而有效地规划他们的进一步培训,并跟踪了解员工的能力及其在重症监护室护理过程中的替换性。您可以点击这里:https://www.youtube.com/watch?v=3oO0uuHy0kg&t=8s
如今,医院、大学和模拟中心都在使用 VR ICU®。
虚拟现实技术将教育和培训提升到了一个新的水平。通过体验学习,可以提高培训效果和记忆力。
在 VR ICU® 中使用 InterSystems 的 FHIR 云服务器作为存储培训进度数据的工具,并使用 FHIR API 进行通信,这也对我们进军国外市场产生了积极影响,尤其是在德国,FHIR 标准是一种广为接受的解决方案,用于与人力资源部门传输信息,并与第三方调度系统进行通信。
麻醉学和重症监护审查参考:https://www.youtube.com/embed/Qve5xEm89cU?feature=oembed
它是如何开始的?
2020 年,一场大流行病袭击了我国。医院人满为患,人手短缺,尤其是重症监护室。麻醉、复苏和重症医学科主任在晚间新闻中解释说,如果更多的医生被隔离或生病,他就没有足够的合格人员来操作肺部呼吸机。其他医院也证实了同样的情况。我们萌生了制作一个专门用于培训的肺部呼吸机数字拷贝,帮助医院培训其他科室医生的想法。
我们找到了麻醉复苏部(ARO)的负责人、模拟中心的专家。医生们支持我们的想法,有些人还参与了开发工作。我们还得到了医疗设备制造商的支持,他们看到了虚拟现实培训的附加值。
我们是如何开展项目的,解决方案的重要性何在?
1. 我们评估了重症监护室的现状:
- 在没有真实病人和/或医疗设备的情况下,50% 以上的重症监护室程序无法进行培训。
- 医疗设备制造商难以将医务人员集中到一处进行培训(只有 30% 的受训人员能坚持到培训结束)
- 过去两年中,麻醉学和重症监护部门的人员流动率约为 20%。
2. 问题的解决方案:
- 虚拟现实自动培训平台
- 模拟重症监护室的手术过程,无需真实病人,也无需使用真实医疗设备
- 节省技术和医疗用品
- 也可用于远程培训,从不同地点/工作场所进入同一个虚拟空间
- 在安全的环境中进行风险情况演练
- 将人为错误的风险降至最低
3. 潜力:
- 利用人工智能(AI)模拟和练习危急情况,确定正确的程序
- 人工智能可模拟病人-设备-病人之间的互动
- 制造商的设备集中在一个虚拟空间,使医院的培训更加容易
愿景
VR ICU® 的目标是作为一个平台,让医院从实际使用的设备目录中选择 3D 设备,并从中创建培训环境。
我们向医疗设备制造商提出的愿景最初得到了 BBraun、费森尤斯和 Linet 的支持。随后,其他公司也纷纷效仿这些大胆的先行者。我们还根据所进入的市场扩大我们的设备组合。目前,我们在美国、亚洲和南美都有合作伙伴,他们正在补充信息并与制造商进行谈判。
我们正在全球会议上展示 VR ICU®,我们很高兴能成为 Caelestinus 孵化器的一部分。由于我们与 InterSystems 的合作,我们有机会参加在西雅图举行的 InterSystems 2022 年全球峰会,现在我们正在拉斯维加斯参加 HLTH 2022。
VR ICU® 已经赢得了许多奖项,最近在奥地利林茨,我们凭借该解决方案赢得了最佳初创企业奖。
这些成功的展示吸引了投资者的关注。我们欢迎那些希望进一步开发我们产品的人向我们推荐他们。我们计划在 2023 年向捷克、斯洛伐克和德国的医院出售许可证。我们欢迎商业合作伙伴以及能够加快 VR ICU® 实际应用--市场进入进程或希望为人工智能/VR 版本的开发做出贡献的合作伙伴。
原文来自这里:https://community.intersystems.com/node/529381
文章
姚 鑫 · 二月 22, 2021
# 第四十四章 Caché 变量大全 $ZTRAP 变量
包含当前错误陷阱处理程序的名称。
# 大纲
```
$ZTRAP
$ZT
```
# 描述
`$ZTRAP`包含当前错误陷阱处理程序的行标签名和/或例程名。有三种方法可以设置`$ZTRAP`:
- `SET $ZTRAP=“location”`
- `SET $ZTRAP=“*location”`
- `SET $ZTRAP=“^%ET” or “^%ETN”`
在这里,位置可以指定为标签(当前例程中的行标签)、`^routine`(指定外部例程的开始)或`label^routine`(指定外部例程中的指定标签)。
**然而,`$ZTRAP=label^routine`不能用于程序块。过程块中的`$ZTRAP`不能用于转到过程体之外的位置;过程块中的`$ZTRAP`只能引用该过程块中的一个位置**。
## Location
使用设置命令,可以将位置指定为带引号的字符串。
- 在例程中,可以将位置指定为标签(当前例程中的行标签)、`^routine`(指定外部例程的开始)或`label^routine`(指定外部例程中的指定标签)。不要在引用过程或过程中的标签的例程中指定位置。这是一个无效位置;当InterSystems IRIS试图执行`$ZTRAP`时,会导致运行时错误。
- 在过程中,可以将位置指定为标签;过程块中私有标签。过程块中的`$ZTRAP`不能用于转到过程体之外的位置;过程块中的`$ZTRAP`只能引用该过程块中的一个位置。因此,在过程中,不能将`$ZTRAP`设置为`^routine`或`label^routine`.尝试这样做将导致``错误。
在过程中,将`$ZTRAP`设置为私有标签名,但是`$ZTRAP`值不是私有标签名;它是从过程标签(过程的顶部)到私有标签的行位置的偏移量。例如,`+17^myproc`.
注意:`$ZTRAP`在某些情况下(而不是在过程中)为`label + offset`提供传统支持。这个可选的`+ offset`是一个整数,指定要从`label`偏移的行数。标签必须在相同的例程中。不建议使用`+offset`,它可能会导致编译警告错误。 InterSystems建议您在指定位置时避免使用行偏移量。
调用过程或IRIS `SYS`%例程时,不能指定`+`偏移量。如果尝试这样做,则InterSystems IRIS会发出错误。
`$ZTRAP`位置必须在当前名称空间中。 `$ZTRAP`不支持扩展的例程引用。
如果指定了不存在的行标签(当前例程中不存在的位置),则会发生以下情况:
- 显示`$ZTRAP`:在例程中,`$ZTRAP`包含`label ^ routine`。例如,`DummyLabel^MyRou`。在一个过程中,`$TRAP`包含最大可能的偏移量:`+ 34463 ^ MyProc`。
- 调用$ZTRAP:InterSystems IRIS发出``错误消息。
每个堆栈级别可以有其自己的`$ZTRAP`值。设置`$ZTRAP`时,系统会将`$ZTRAP`的值保存为先前的堆栈级别。当前堆栈级别结束时,InterSystems IRIS会恢复该值。要在当前堆栈级别启用错误陷阱,请通过指定`$ZTRAP`的位置将其设置为错误陷阱处理程序。例如:
```java
/// d ##class(PHA.TEST.SpecialVariables).ZTRAP()
ClassMethod ZTRAP()
{
IF $ZTRAP="" {
WRITE !,"$ZTRAP not set"
} ELSE {
WRITE !,"$ZTRAP already set: ",$ZTRAP
SET oldtrap=$ZTRAP
}
SET $ZTRAP="Etrap1^Handler"
WRITE !,"$ZTRAP set to: ",$ZTRAP
// program code
SET $ZTRAP=oldtrap
WRITE !,"$ZTRAP restored to: ",$ZTRAP
}
```
发生错误时,此格式将展开调用堆栈,并将控制权转移到指定的错误陷阱处理程序。
在SqlComputeCode中,不要设置`$ZTRAP = $ZTRAP`。这可能导致事务处理和错误报告方面的重大问题。
要禁用错误捕获,请将`$ZTRAP`设置为空字符串(`“”`)。这将清除在当前DO堆栈级别设置的所有错误陷阱。
注意:在“终端”提示符下使用$ZTRAP仅限于当前代码行。 `SET $ZTRAP`命令和生成错误的命令必须在同一行代码中。终端在每个命令行的开头将`$ZTRAP`还原为系统默认值。
## *Location
在例程中,可以选择在发生错误后保留调用堆栈。为此,请在位置之前和双引号内放置一个星号(`*`)。该表格不适用于程序。尝试这样做会导致`` 错误。只能在不是过程的子例程中使用此示例中的:
```java
/// d ##class(PHA.TEST.SpecialVariables).ZTRAP()
ClassMethod ZTRAP()
{
Main
SET $ZTRAP="*OnError"
WRITE !,"$ZTRAP set to: ",$ZTRAP
// program code
OnError
// Error handling code
QUIT
}
```
这种格式只会导致转到`$ZTRAP`中指定的行标签;`$STACK`和`$ESTACK`保持不变。`$ZTRAP`错误处理例程的上下文框架与发生错误的上下文框架相同。但是,InterSystems IRIS会将`$ROLES`重置为设置`$ZTRAP`的执行级别的有效值;这会阻止`$ZTRAP`错误处理程序使用在建立错误处理程序后授予例程的提升权限。完成`$ZTRAP`错误处理例程后,InterSystems IRIS将堆栈展开到上一个上下文级。这种形式的`$ZTRAP`对于分析意外错误特别有用。
请注意,星号设置`$ZTRAP`选项;它不是位置的一部分。因此,在`$ZTRAP`上执行`WRITE`或`ZZDUMP`时不会显示此星号。
## ^%ETN
在例程中,`set $ZTRAP=“^%ETN”`将系统提供的错误例程`%ETN`建立为当前错误捕获处理程序。`%ETN`在调用它的发生错误的上下文中执行。(`%et`是`%etn`的旧名称。它们的功能相同,但`%ETN`的效率略高一些。)。`^%ETN`错误处理程序的行为总是前缀星号(`*`)。
因为过程块中的`$ZTRAP`不能用于转到过程主体之外的位置,所以不能在过程中使用`SET $ZTRAP=“^%ETN”`。尝试这样做会导致``错误。
## TRY / CATCH 与 $ZTRAP
不能在`TRY`块内设置`$ZTRAP`。尝试这样做会生成编译错误。可以在`TRY`块之前或在`CATCH`块内设置`$ZTRAP`。
**无论之前是否设置了`$ZTRAP`,`TRY`块中发生的错误都由`CATCH`块处理。`CATCH`块内发生的错误由当前错误捕获处理程序处理。**
下面的第一个示例显示了`TRY`块中发生的错误。下面的第二个示例显示了`try`块中引发的异常。在这两种情况下,都会采用`CATCH`块,而不是`$ZTRAP`:
```java
/// d ##class(PHA.TEST.SpecialVariables).ZTRAP()
ClassMethod ZTRAP()
{
SET $ZTRAP="Ztrap"
TRY { WRITE 1/0 } /* divide-by-zero error */
CATCH { WRITE "Catch taken" }
QUIT
Ztrap
WRITE "$ZTRAP taken"
SET $ZTRAP=""
QUIT
}
```
```java
DHC-APP>d ##class(PHA.TEST.SpecialVariables).ZTRAP()
Catch taken
```
```java
/// d ##class(PHA.TEST.SpecialVariables).ZTRAP1()
ClassMethod ZTRAP1()
{
SET $ZTRAP="Ztrap"
TRY {
SET myvar=##class(Sample.MyException).%New("Example Error",999,,errdatazero)
WRITE !,"Throwing an exception!",!
THROW myvar
QUIT
} CATCH {
WRITE "Catch taken"
}
QUIT
Ztrap
WRITE "$ZTRAP taken"
SET $ZTRAP=""
QUIT
}
```
```java
DHC-APP>d ##class(PHA.TEST.SpecialVariables).ZTRAP1()
Catch taken
```
但是,`try`块可以调用设置和使用`$ZTRAP`的代码。在下面的示例中,`$ZTRAP`而不是`CATCH`块捕获被零除错误:
```java
/// d ##class(PHA.TEST.SpecialVariables).ZTRAP2()
ClassMethod ZTRAP2()
{
TRY { DO Errsub }
CATCH { WRITE "Catch taken" }
QUIT
Errsub
SET $ZTRAP="Ztrap"
WRITE 1/0 /* divide-by-zero error */
QUIT
Ztrap
WRITE "$ZTRAP taken"
SET $ZTRAP=""
QUIT
}
```
```java
DHC-APP>d ##class(PHA.TEST.SpecialVariables).ZTRAP2()
$ZTRAP taken
```
CATCH块中的`Throw`命令还可以调用`$ZTRAP`错误处理程序。
# 示例
下面的示例将`$ZTRAP`设置为此程序中的`OnError`例程。然后,它调用发生错误的`Suba`(尝试将数字除以0)。当错误发生时,InterSystems IRIS调用`$ZTRAP`中指定的`OnError`例程。`OnError`在设置`$ZTRAP`的上下文级别调用。因为`OnError`与`Main`处于相同的上下文级别,所以执行不会返回`Main`。
```java
/// d ##class(PHA.TEST.SpecialVariables).ZTRAP3()
ClassMethod ZTRAP3()
{
Main
NEW $ESTACK
SET $ZTRAP="OnError"
WRITE !,"$ZTRAP set to: ",$ZTRAP
WRITE !,"Main $ESTACK= ",$ESTACK // 0
WRITE !,"Main $ECODE= ",$ECODE
DO SubA
WRITE !,"Returned from SubA" // not executed
WRITE !,"MainReturn $ECODE= ",$ECODE
QUIT
SubA
WRITE !,"SubA $ESTACK= ",$ESTACK // 1
WRITE !,6/0 // Error: division by zero
WRITE !,"fine with me"
QUIT
OnError
WRITE !,"OnError $ESTACK= ",$ESTACK // 0
WRITE !,"$ECODE= ",$ECODE
QUIT
}
```
```java
DHC-APP>d ##class(PHA.TEST.SpecialVariables).ZTRAP3()
$ZTRAP set to: +970^PHA.TEST.SpecialVariables.1
Main $ESTACK= 0
Main $ECODE= ,ZSYNTAX,ZSYNTAX,ZSYNTAX,ZMETHOD DOES NOT EXIST,M9,M6,M9,
SubA $ESTACK= 1
OnError $ESTACK= 0
$ECODE= ,ZSYNTAX,ZSYNTAX,ZSYNTAX,ZMETHOD DOES NOT EXIST,M9,M6,M9,M9,
```
下面的示例与前面的示例相同,但有一个例外:`$ZTRAP`位置前面有一个星号(`*`)。当错误发生在`SUBA`中时,此星号会导致InterSystems IRIS在`SUBA`(发生错误的地方)的上下文级调用`OnError`例程,而不是在`Main`(设置`$ZTRAP`的地方)的上下文级调用`OnError`例程。因此,当`OnError`完成时,执行将在`do`命令之后的行返回到`Main`。
```java
/// d ##class(PHA.TEST.SpecialVariables).ZTRAP4()
ClassMethod ZTRAP4()
{
Main
NEW $ESTACK
SET $ZTRAP="*OnError"
WRITE !,"$ZTRAP set to: ",$ZTRAP
WRITE !,"Main $ESTACK= ",$ESTACK // 0
WRITE !,"Main $ECODE= ",$ECODE
DO SubA
WRITE !,"Returned from SubA" // executed
WRITE !,"MainReturn $ECODE= ",$ECODE
QUIT
SubA
WRITE !,"SubA $ESTACK= ",$ESTACK // 1
WRITE !,6/0 // Error: division by zero
WRITE !,"fine with me"
QUIT
OnError
WRITE !,"OnError $ESTACK= ",$ESTACK // 1
WRITE !,"$ECODE= ",$ECODE
QUIT
}
```