清除过滤器
文章
姚 鑫 · 四月 30, 2021
# 第八章 解释SQL查询计划(二)
# SQL语句的详细信息
有两种方式显示SQL语句的详细信息:
- 在SQL Statements选项卡中,通过单击左侧列中的Table/View/Procedure Name链接选择一个SQL Statement。
这将在单独的选项卡中显示SQL语句详细信息。
该界面允许打开多个选项卡进行比较。
它还提供了一个Query Test按钮,用于显示SQL Runtime Statistics页面。
- 从表的Catalog Details选项卡(或SQL Statements选项卡)中,通过单击右边列中的Statement Text链接选择一个SQL语句。
这将在弹出窗口中显示SQL语句详细信息。
可以使用“SQL语句详细信息”显示来查看查询计划,并冻结或解冻查询计划。
“SQL语句详细信息”提供冻结或解冻查询计划的按钮。
它还提供了一个Clear SQL Statistics按钮来清除性能统计,一个`Export`按钮来将一个或多个SQL语句导出到一个文件,以及一个`Refresh`和`Close`页面按钮。
SQL语句详细信息显示包含以下部分。
每个部分都可以通过选择部分标题旁边的箭头图标展开或折叠:
- 语句详细信息,其中包括性能统计
- 编译设置
- 语句在以下例程中定义
- 语句使用如下关系
- 语句文本和查询计划(在其他地方描述)
## 声明的细节部分
- 语句散列Statement hash:语句定义的内部散列表示形式,用作SQL语句索引的键(仅供内部使用)。
有时,看起来相同的SQL语句可能具有不同的语句散列项。
需要生成不同SQL语句的代码的设置/选项的任何差异都会导致不同的语句散列。
这可能发生在支持不同内部优化的不同客户端版本或不同平台上。
- 时间戳`Timestamp`:最初,创建计划时的时间戳。
这个时间戳会在冻结/解冻之后更新,以记录计划解冻的时间,而不是重新编译计划的时间。
可能必须单击Refresh Page按钮来显示解冻时间戳。
将Plan Timestamp与包含该语句的例程/类的`datetime`值进行比较,可以知道,如果再次编译该例程/类,它是否使用了相同的查询计划。
- 版本Version:创建计划的InterSystems IRIS版本。
如果“计划”状态是“冻结/升级”,则这是InterSystems IRIS的早期版本。
解冻查询计划时,“计划”状态变为“解冻”,“版本”变为当前的InterSystems IRIS版本。
- 计划状态Plan state:冻结/显式、冻结/升级、解冻、解冻/并行。
Frozen/Explicit意味着该语句的计划已被显式用户操作冻结,无论生成此SQL语句的代码发生了什么变化,该冻结的计划都将是将要使用的查询计划。
冻结/升级意味着该语句的计划已被InterSystems IRIS版本升级自动冻结。
解冻意味着该计划目前处于解冻状态,可能被冻结。
Unfrozen/Parallel表示该计划被解冻,并使用`%Parallel`处理,因此不能被冻结。
`NULL`(空白)计划状态意味着没有关联的查询计划。
- 自然查询Natural query:一个布尔标志,指示该查询是否是“自然查询”。
如果勾选此项,则该查询是自然查询,不会记录查询性能统计信息。
如果不检查,性能统计可能会被记录;
其他因素决定了统计数据是否真正被记录下来。
自然查询被定义为嵌入式SQL查询,它非常简单,记录统计数据的开销会影响查询性能。
将统计信息保存在自然查询上没有任何好处,因为查询已经非常简单了。
一个很好的自然查询示例是`SELECT Name INTO:n FROM Table WHERE %ID=?`
这个查询的`WHERE`子句是一个相等条件。
此查询不涉及任何循环或任何索引引用。
动态SQL查询(缓存查询)不会被标记为自然查询;
缓存查询的统计数据可能被记录,也可能不被记录。
- 冻结计划不同Frozen plan different:冻结计划时,会显示该字段,显示冻结的计划与未冻结的计划是否不同。
冻结计划时,语句文本和查询计划将并排显示冻结的计划和未冻结的计划,以便进行比较。
本节还包括五个查询性能统计字段,将在下一节中进行描述。
## 性能统计数据
执行查询会将性能统计数据添加到相应的SQL语句。
此信息可用于确定哪些查询执行得最慢,哪些查询执行得最多。
通过使用这些信息,您可以确定哪些查询将通过优化提供显著的好处。
除了SQL语句名称、计划状态、位置和文本之外,还为缓存查询提供了以下附加信息:
- 计数Count:运行此查询次数的整数计数。
如果对该查询产生不同的查询计划(例如向表中添加索引),则将重置该计数。
- 平均计数Average count:每天运行此查询的平均次数。
- 总时间Total time:运行此查询所花费的时间(以秒为单位)。
- 平均时间Average time:运行此查询所花费的平均时间(以秒为单位)。
如果查询是缓存的查询,则查询的第一次执行所花费的时间很可能比从查询缓存中执行优化后的查询所花费的时间要多得多。
- 标准差Standard deviation:总时间和平均时间的标准差。
只运行一次的查询的标准偏差为0。
运行多次的查询通常比只运行几次的查询具有更低的标准偏差。
- 第一次看到的日期Date first seen:查询第一次运行(执行)的日期。
这可能与`Last Compile Time`不同,后者是准备查询的时间。
`UpdateSQLStats`任务会定期更新已完成的查询执行的查询性能统计数据。
这将最小化维护这些统计信息所涉及的开销。
因此,当前运行的查询不会出现在查询性能统计中。
最近完成的查询(大约在最近一个小时内)可能不会立即出现在查询性能统计中。
可以使用Clear SQL Statistics按钮清除这6个字段的值。
InterSystems IRIS不单独记录`%PARALLEL`子查询的性能统计数据。
%PARALLEL子查询统计信息与外部查询的统计信息相加。
由并行运行的实现生成的查询没有单独跟踪其性能统计信息。
InterSystems IRIS不记录“自然”查询的性能统计数据。
如果系统收集了统计信息,则会降低查询性能,而自然查询已经是最优的,因此没有进行优化的可能。
可以在“SQL语句”选项卡显示中查看多个SQL语句的查询性能统计信息。
您可以按任何列对SQL Statements选项卡列表进行排序。
这使得很容易确定,例如,哪个查询具有最大的平均时间。
还可以通过查询`INFORMATION.SCHEMA.STATEMENTS`类属性来访问这些查询性能统计数据,如查询SQL语句中所述。
## 编译设置部分
- 选择模式`Select mode`:编译语句时使用的`SelectMode`。
对于DML命令,可以使用`#SQLCompile Select`;
默认为Logical。
如果`#SQLCompile Select=Runtime`,调用`$SYSTEM.SQL.Util.SetOption()`方法的`SelectMode`选项可以改变查询结果集的显示,但不会改变SelectMode值,它仍然是Runtime。
- 默认模式Default schema(s):编译语句时设置的默认模式名。
这通常是在发出命令时生效的默认模式,尽管SQL可能使用模式搜索路径(如果提供的话)而不是默认模式名来解析非限定名称的模式。
但是,如果该语句是嵌入式SQL中使用一个或多个`#Import`宏指令的DML命令,则`#Import`指令指定的模式将在这里列出。
- 模式路径Schema path:编译语句时定义的模式路径。
如果指定,这是模式搜索路径。
如果没有指定架构搜索路径,则此设置为空。
但是,对于在`#Import`宏指令中指定搜索路径的DML Embedded SQL命令,`#Import`搜索路径显示在默认模式设置中,并且该模式路径设置为空白。
- 计划错误Plan Error:该字段仅在使用冻结计划时发生错误时出现。
例如,如果一个查询计划使用一个索引,则该查询计划被冻结,然后该索引从表中删除,就会出现如下的计划错误:`Map 'NameIDX' not defined in table 'Sample.Person', but it was specified in the frozen plan for the query`.
删除或添加索引将导致重新编译表,从而更改“最后编译时间”值。
一旦导致错误的条件得到纠正,`Clear Error`按钮可用于清除`Plan Error`字段——例如,通过重新创建缺失的索引。
在错误条件被纠正后使用“清除错误”按钮会导致“计划错误”字段和“清除错误”按钮消失。
## 例程和关系部分
语句在以下例程部分中定义:
- 例程`Routine`:与缓存查询关联的类名(对于动态SQL DML),或者例程名(对于嵌入式SQL DML)。
- 类型:类方法或`MAC`例程(对于嵌入式SQL DML)。
- 上次编译时间`Last Compile Time`:例程的上次编译时间或准备时间。如果SQL语句解冻,重新编译MAC例程会同时更新此时间戳和Plan时间戳。如果SQL语句已冻结,则重新编译MAC例程仅更新此时间戳;在您解冻计划之前,Plan时间戳不会更改;然后Plan时间戳将显示计划解冻的时间。
语句使用以下关系部分列出了一个或多个用于创建查询计划的定义表。对于使用查询从另一个表提取值的`INSERT`,或者使用`FROM`子句引用另一个表的`UPDATE`或`DELETE`,这两个表都在此处列出。每个表都列出了下列值:
- 表或视图名称`Table or View Name`:表或视图的限定名称。
- 类型`Type`:表或视图。
- 上次编译时间`Last Compile Time`:表(持久化类)上次编译的时间。
- `Classname`:与表关联的类名。
本节包括用于重新编译类的编译类选项。如果重新编译解冻计划,则所有三个时间字段都会更新。如果重新编译冻结的计划,则会更新两个上次编译时间字段,但不会更新计划时间戳。解冻计划并单击刷新页面按钮后,计划时间戳将更新为计划解冻的时间。
# 查询SQL语句
可以使用`SQLTableStatements()`存储查询返回指定表的SQL语句。下面的示例显示了这一点:
```java
/// w ##class(PHA.TEST.SQL).SQLTableStatements()
ClassMethod SQLTableStatements()
{
SET mycall = "CALL %Library.SQLTableStatements('Sample','Person')"
SET tStatement = ##class(%SQL.Statement).%New()
SET qStatus=tStatement.%Prepare(mycall)
IF qStatus'=1 {WRITE "%Prepare failed:" DO $System.Status.DisplayError(qStatus) QUIT}
SET rset=tStatement.%Execute()
IF rset.%SQLCODE '= 0 {WRITE "SQL error=",rset.%SQLCODE QUIT}
DO rset.%Display()
}
```
```java
DHC-APP>w ##class(PHA.TEST.SQL).SQLTableStatements()
Dumping result #1
SCHEMA RELATION_NAME PLAN_STATE LOCATION STATEMENT
SAMPLE PERSON 0 %sqlcq.DHCdAPP.cls228.1 DECLARE C CURSOR FOR SELECT * INTO :%col(1) , :%col(2) , :%col(3) , :%col(4) , :%col(5) , :%col(6) , :%col(7) , :%col(8) , :%col(9) , :%col(10) , :%col(11) , :%col(12) , :%col(13) , :%col(14) , :%col(15) FROM SAMPLE . PERSON
SAMPLE PERSON 0 Sample.Person.1 SELECT AGE , DOB , FAVORITECOLORS , HOME , NAME , OFFICE , SSN , SPOUSE , X__CLASSNAME , HOME_CITY , HOME_STATE , HOME_STREET , HOME_ZIP , OFFICE_CITY , OFFICE_STATE , OFFICE_STREET , OFFICE_ZIP INTO :%e ( ) FROM %IGNOREINDEX * SAMPLE . PERSON WHERE ID = :%rowid
...
CURSOR FOR SELECT P . NAME , P . AGE , E . NAME , E . AGE FROM %ALLINDEX SAMPLE . PERSON AS P LEFT OUTER JOIN SAMPLE . EMPLOYEE AS E ON P . NAME = E . NAME WHERE P . AGE > 21 AND %NOINDEX E . AGE < 65
SAMPLE PERSON 0 PHA.TEST.SQL.1 SELECT NAME , SPOUSE INTO :name , :spouse FROM SAMPLE . PERSON WHERE SPOUSE IS NULL
SAMPLE PERSON 0 PHA.TEST.ObjectScript.1 SELECT NAME , DOB , HOME INTO :n , :d , :h FROM SAMPLE . PERSON
70 Rows(s) Affected
```
可以使用`INFORMATION_SCHEMA`包表来查询SQL语句列表。InterSystems IRIS支持以下类:
- `INFORMATION_SCHEMA.STATEMENTS`:包含当前名称空间中的当前用户可以访问的SQL语句索引项。
- `INFORMATION_SCHEMA.STATEMENT_LOCATIONS`:包含调用SQL语句的每个例程位置:持久类名或缓存查询名。
- `INFORMATION_SCHEMA.STATEMENT_RELATIONS`:包含SQL语句使用的每个表或视图条目。
以下是使用这些类的一些示例查询:
下面的示例返回命名空间中的所有SQL语句,列出哈希值(唯一标识规范化SQL语句的计算ID)、冻结状态标志(值0到3)、准备语句和保存计划时的本地时间戳以及语句文本本身:
```sql
SELECT Hash,Frozen,Timestamp,Statement FROM INFORMATION_SCHEMA.STATEMENTS
```
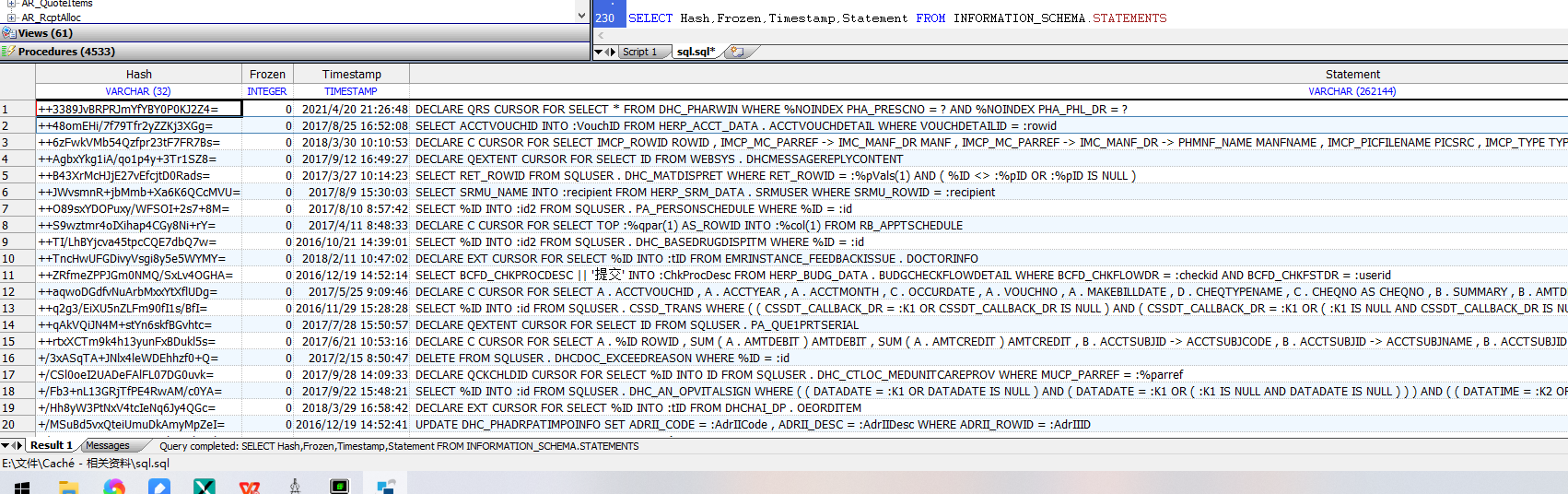
以下示例返回所有冻结计划的SQL语句,指示冻结的计划是否与未冻结的计划不同。请注意,解冻语句可以是`Frozen=0`或`Frozen=3`。不能冻结的单行INSERT等语句在冻结列中显示NULL:
```sql
SELECT Frozen,FrozenDifferent,Timestamp,Statement FROM INFORMATION_SCHEMA.STATEMENTS
WHERE Frozen=1 OR Frozen=2
```
以下示例返回给定SQL表的所有SQL语句和语句所在的例程。(请注意,指定表名(`SAMPLE.PERSON`)时必须使用与SQL语句文本中相同的字母大小写:全部大写字母):
```sql
SELECT Statement,Frozen,STATEMENT_LOCATIONS->Location AS Routine,STATEMENT_LOCATIONS->Type AS RoutineType
FROM INFORMATION_SCHEMA.STATEMENTS
WHERE STATEMENT_RELATIONS->Relation='SAMPLE.PERSON'
```
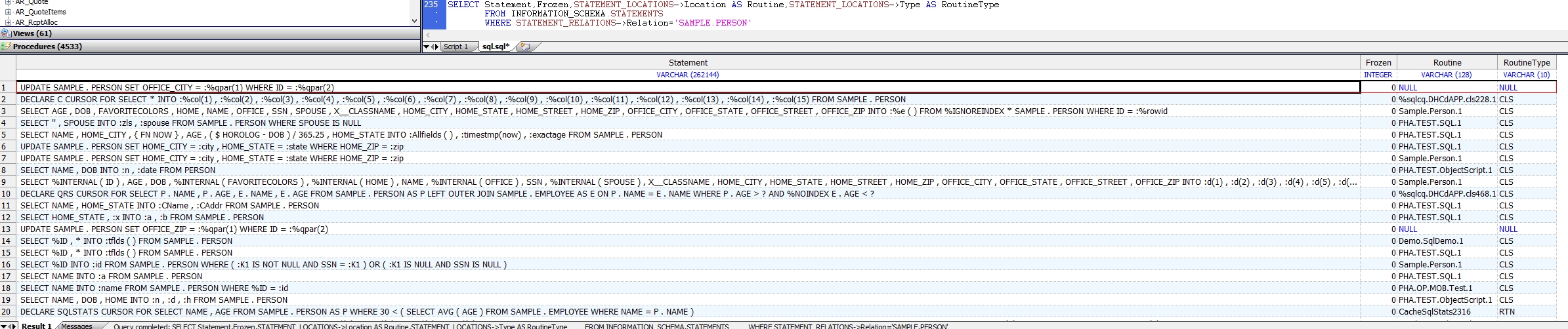
以下示例返回当前命名空间中具有冻结计划的所有SQL语句:
```sql
SELECT Statement,Frozen,Frozen_Different,STATEMENT_LOCATIONS->Location AS Routine,STATEMENT_LOCATIONS->Type AS RoutineType
FROM INFORMATION_SCHEMA.STATEMENTS
WHERE Frozen=1 OR Frozen=2
```
以下示例返回当前命名空间中包含`COUNT(*)`聚合函数的所有SQL语句。(请注意,指定语句文本(`COUNT(*)`)时必须使用与SQL语句文本相同的空格):
```sql
SELECT Statement,Frozen,STATEMENT_LOCATIONS->Location AS Routine,STATEMENT_LOCATIONS->Type AS RoutineType
FROM INFORMATION_SCHEMA.STATEMENTS
WHERE Statement [ ' COUNT ( * )
```
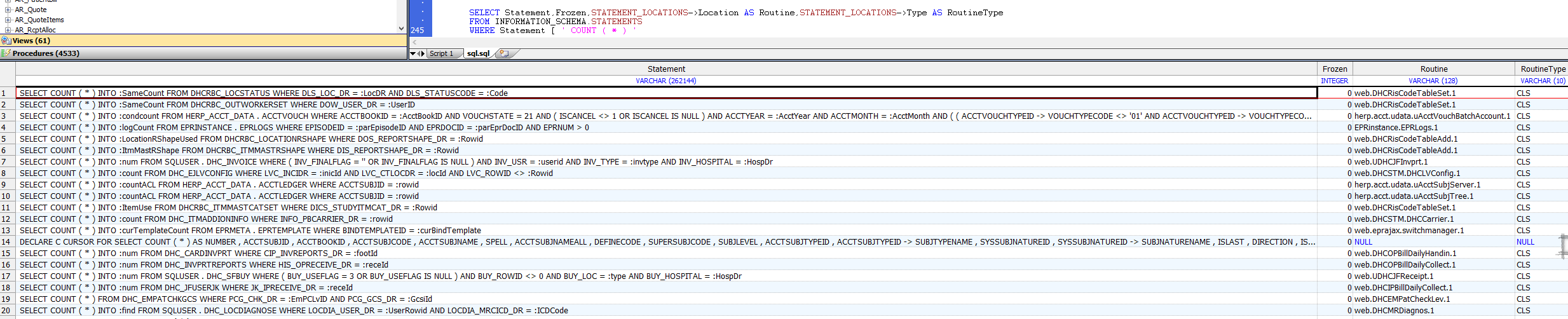
# 导出和导入SQL语句
可以将SQL语句作为`XML`格式的文本文件导出或导入。这使可以将冻结的计划从一个位置移动到另一个位置。SQL语句导出和导入包括关联的查询计划。
可以导出单个SQL语句,也可以导出命名空间中的所有SQL语句。
可以导入先前导出的包含一个或多个SQL语句的XML文件。
注意:将SQL语句作为XML导入不应与从文本文件导入和执行SQL DDL代码混淆。
## 导出SQL语句
导出单个SQL语句:
- 使用SQL语句详细资料页导出按钮。在管理门户系统资源管理器SQL界面中,选择SQL语句选项卡,然后单击语句以打开SQL语句详细信息页。选择导出按钮。这将打开一个对话框,允许选择将文件导出到服务器(数据文件)或浏览器。
- 服务器(默认):输入导出`XML`文件的完整路径名。第一次导出时,此文件的默认名称为`statementexport.xml`。当然,可以指定不同的路径和文件名。成功导出SQL语句文件后,上次使用的文件名将成为默认值。
默认情况下,未选中在后台运行导出复选框。
- Browser:将文件`statementexport.xml`导出到用户默认浏览器中的新页面。可以为浏览器导出文件指定其他名称,或指定其他软件显示选项。
- 使用`$SYSTEM.SQL.Statement.ExportFrozenPlans()`方法。
导出命名空间中的所有SQL语句:
- 使用管理门户中的导出所有对帐单操作。从管理门户系统资源管理器SQL界面中,选择操作下拉列表。从该列表中选择Export all Statements。这将打开一个对话框,允许您将命名空间中的所有SQL语句导出到服务器(数据文件)或浏览器。
- 服务器(默认):输入导出XML文件的完整路径名。第一次导出时,此文件的默认名称为`statementexport.xml`。当然,可以指定不同的路径和文件名。成功导出SQL语句文件后,上次使用的文件名将成为默认值。
默认情况下,在后台运行导出复选框处于选中状态。这是导出所有SQL语句时的建议设置。选中在后台运行导出时,系统会为提供一个查看后台列表页面的链接,可以在该页面中查看后台作业状态。
- Browser:将文件`statementexport.xml`导出到用户默认浏览器中的新页面。可以为浏览器导出文件指定其他名称,或指定其他软件显示选项。
使用`$SYSTEM.SQL.Statement.ExportAllFrozenPlans()`方法。
## 导入SQL语句
从先前导出的文件导入一条或多条SQL语句:
- 使用管理门户中的导入对帐单操作。从管理门户系统资源管理器SQL界面中,选择操作下拉列表。从该列表中选择Import Statements。这将打开一个对话框,允许指定导入XML文件的完整路径名。
默认情况下,在后台运行导入复选框处于选中状态。这是导入SQL语句文件时的推荐设置。选中在后台运行导入时,系统会为您提供一个查看后台列表页面的链接,可以在该页面中查看后台作业状态。
使用`$SYSTEM.SQL.Statement.ImportFrozenPlans()`方法。
## 查看和清除后台任务
在管理门户系统操作选项中,选择后台任务,查看导出和导入后台任务的日志。可以使用清除日志按钮清除此日志。
文章
Michael Lei · 四月 13, 2022
这篇文章是对我的 iris-globals-graphDB 应用的介绍。在这篇文章中,我将演示如何在Python Flask Web 框架和PYVIS交互式网络可视化库的帮助下,将图形数据保存和抽取到InterSystems Globals中。
建议
阅读相关文档 使用 Globals
原生 SDK 介绍
PYVIS 互动式网络可视化库
第一步 : 通过使用Python 原生SDK建立与IRIS Globals的链接
#create and establish connection
if not self.iris_connection:
self.iris_connection = irisnative.createConnection("localhost", 1972, "USER", "superuser", "SYS")
# Create an iris object
self.iris_native = irisnative.createIris(self.iris_connection)
return self.iris_native
第二步 : 使用 iris_native.set( ) 功能把数据保存到Globals 里
#import nodes data from csv file
isdefined = self.iris_native.isDefined("^g1nodes")
if isdefined == 0:
with open("/opt/irisapp/misc/g1nodes.csv", newline='') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
self.iris_native.set(row["name"], "^g1nodes", row["id"])
#import edges data from csv file
isdefined = self.iris_native.isDefined("^g1edges")
if isdefined == 0:
with open("/opt/irisapp/misc/g1edges.csv", newline='') as csvfile:
reader = csv.DictReader(csvfile)
counter = 0
for row in reader:
counter = counter + 1
#Save data to globals
self.iris_native.set(row["source"]+'-'+row["target"], "^g1edges", counter)
第三步: 使用iris_native.get() 功能把节点和边缘数据从Globals传递给PYVIS
#Get nodes data for basic graph
def get_g1nodes(self):
iris = self.get_iris_native()
leverl1_subscript_iter = iris.iterator("^g1nodes")
result = []
# Iterate over all nodes forwards
for level1_subscript, level1_value in leverl1_subscript_iter:
#Get data from globals
val = iris.get("^g1nodes",level1_subscript)
element = {"id": level1_subscript, "label": val, "shape":"circle"}
result.append(element)
return result
#Get edges data for basic graph
def get_g1edges(self):
iris = self.get_iris_native()
leverl1_subscript_iter = iris.iterator("^g1edges")
result = []
# Iterate over all nodes forwards
for level1_subscript, level1_value in leverl1_subscript_iter:
#Get data from globals
val = iris.get("^g1edges",level1_subscript)
element = {"from": int(val.rpartition('-')[0]), "to": int(val.rpartition('-')[2])}
result.append(element)
return result
Step4: Use PYVIS Javascript to generate graph data
<script type="text/javascript">
// initialize global variables.
var edges;
var nodes;
var network;
var container;
var options, data;
// This method is responsible for drawing the graph, returns the drawn network
function drawGraph() {
var container = document.getElementById('mynetwork');
let node = JSON.parse('{{ nodes | tojson }}');
let edge = JSON.parse('{{ edges | tojson }}');
// parsing and collecting nodes and edges from the python
nodes = new vis.DataSet(node);
edges = new vis.DataSet(edge);
// adding nodes and edges to the graph
data = {nodes: nodes, edges: edges};
var options = {
"configure": {
"enabled": true,
"filter": [
"physics","nodes"
]
},
"nodes": {
"color": {
"border": "rgba(233,180,56,1)",
"background": "rgba(252,175,41,1)",
"highlight": {
"border": "rgba(38,137,233,1)",
"background": "rgba(40,138,255,1)"
},
"hover": {
"border": "rgba(42,127,233,1)",
"background": "rgba(42,126,255,1)"
}
},
"font": {
"color": "rgba(255,255,255,1)"
}
},
"edges": {
"color": {
"inherit": true
},
"smooth": {
"enabled": false,
"type": "continuous"
}
},
"interaction": {
"dragNodes": true,
"hideEdgesOnDrag": false,
"hideNodesOnDrag": false,
"navigationButtons": true,
"hover": true
},
"physics": {
"barnesHut": {
"avoidOverlap": 0,
"centralGravity": 0.3,
"damping": 0.09,
"gravitationalConstant": -80000,
"springConstant": 0.001,
"springLength": 250
},
"enabled": true,
"stabilization": {
"enabled": true,
"fit": true,
"iterations": 1000,
"onlyDynamicEdges": false,
"updateInterval": 50
}
}
}
// if this network requires displaying the configure window,
// put it in its div
options.configure["container"] = document.getElementById("config");
network = new vis.Network(container, data, options);
return network;
}
drawGraph();
</script>
第五步: 从app.py 主文件调用上面的代码
#Mian route. (index)
@app.route("/")
def index():
#Establish connection and import data to globals
irisglobal = IRISGLOBAL()
irisglobal.import_g1_nodes_edges()
irisglobal.import_g2_nodes_edges()
#getting nodes data from globals
nodes = irisglobal.get_g1nodes()
#getting edges data from globals
edges = irisglobal.get_g1edges()
#To display graph with configuration
pyvis = True
return render_template('index.html', nodes = nodes,edges=edges,pyvis=pyvis)
下面是关于此项目的 介绍视频:
欢迎大家来我们的 Bilibili主页观看更多视频!
谢谢!
文章
姚 鑫 · 九月 30, 2021
# 第三十一章 SQL命令 DROP DATABASE
删除数据库(命名空间)。
# 大纲
```sql
DROP DATABASE dbname [RETAIN_FILES]
```
## 参数
- `dbname` - 要删除的数据库(命名空间)的名称。
- `RETAIN_FILES` - 可选-如果指定,则不会删除物理数据库文件(`IRIS.DAT`文件)。默认情况下,删除`.dat`文件以及命名空间和其他数据库实体。
# 描述
`DROP DATABASE`命令删除命名空间及其关联的数据库。
指定的`dbname`是包含相应数据库文件的命名空间和目录的名称。指定`dbname`作为标识符。命名空间名称不区分大小写。如果指定的`DBNAME`命名空间不存在, IRIS将发出`SQLCODE-340`错误。
`DROP DATABASE`命令是一个特权操作。
在使用`DROP DATABASE`之前,必须以`%Admin_Manage`资源的用户身份登录。
用户还必须拥有用于例程和全局数据库定义的资源的`READ`权限。
如果不这样做,将导致`SQLCODE -99`错误(权限冲突)。
使用`$SYSTEM.Security.Login()`方法为用户分配适当的权限:
```java
DO $SYSTEM.Security.Login("_SYSTEM","SYS")
&sql( )
```
必须具有`%Service_Login:Use`权限才能调用`$SYSTEM.Security.Login`方法。
不管权限如何,`DROP DATABASE`都不能用于删除系统命名空间。尝试这样做会导致`SQLCODE-342`错误。
`DROP DATABASE`不能用于删除当前正在使用或连接到的命名空间。尝试这样做会导致`SQLCODE-344`错误。
还可以使用管理门户删除命名空间。依次选择System Administration、Configuration、System Configuration、Namespaces以列出现有的`Namespace`。单击要删除的命名空间的删除按钮。
## RETAIN_FILES
如果指定此选项,则保留物理文件结构;删除数据库及其关联的命名空间。执行此操作后,后续尝试使用`DBNAME`将导致以下结果:
- `DROP DATABASE`不带`RETAIN_FILES`无法删除此物理文件结构。相反,它会导致`SQLCODE-340`错误(未找到数据库)。
- `DROP DATABASE WITH RETAIN_FILES`还会导致`SQLCODE-340`错误(找不到数据库)。
- `CREATE DATABASE`无法创建同名的新数据库。相反,它会导致`SQLCODE-341`错误(无法为数据库创建数据库文件)。
- 尝试使用此命名空间会导致``错误。
## 服务器初始化和断开代码
服务器初始化代码和服务器断开代码可以通过`$SYSTEM.SQL.Util.SetOption("ServerInitCode",value)`和`$SYSTEM.SQL.Util.SetOption("ServerDisconnectCode",value)`方法分配给命名空间。
可以使用相应的`$SYSTEM.SQL.Util.GetOption()`方法选项来确定当前值。
使用`DROP DATABASE`或其他接口删除命名空间,将删除这些`Server Init Code`和`Server Disconnect Code`值。
因此,删除并重新创建名称空间需要重新指定这些值。
# 示例
```sql
CREATE DATABASE DocTestDB ON DIRECTORY 'c:\InterSystems\IRIS142\mgr\DocTestDB'
```
```sql
DROP DATABASE DocTestDB RETAIN_FILES
```
文章
姚 鑫 · 九月 23, 2022
# 第四十一章 使用多个 IRIS 实例(一)
可以在单个主机系统上安装和运行多个 `IRIS®` 数据平台实例。每个实例都是一个独特的、独立的 `IRIS` 环境。
# 管理 IRIS 实例
有许多方法可以连接和管理 `IRIS` 实例,它可能是安装在给定系统上的几种方法之一。两种最常用的方法如下:
- 安装在 `Windows` 系统上的每个 `IRIS` 实例在系统托盘中都有自己的启动器,除其他选项外,还可以:
- 通过打开管理门户、 `Terminal`和 `Studio` 开发者客户端连接到实例。
- 启动、停止和重新启动实例。
- 打开用户和开发人员文档。
从启动器中,还可以管理多个远程 `IRIS` 实例,包括但不限于运行远程备份、编辑配置设置以及创建和编译远程对象和例程。
- `iris command` 在操作系统命令行上执行 iris 命令可让管理访问 `IRIS` 实例,其中包括其他选项,可以:
- 使用 `Terminal`连接到实例。
- 启动、停止和重新启动实例。
- 显示有关该实例以及系统上安装的其他实例的信息。
要在远程服务器上使用 `iris` 命令,请使用 `Telnet` 或 `SSH` 客户端;要将它与容器化实例一起使用,请在容器内使用它,或者使用 `docker exec` 命令从容器外部运行它。
# 连接到 `IRIS` 实例
`Terminal` 是一个命令行,可以在 `IRIS` 实例的任何命名空间中使用。使用命令 `iris terminal instname` 打开正在运行的实例的终端,其中 `instname` 是在安装时为实例指定的名称。容器化实例通常被命名为 `IRIS`。
使用在安装期间提供的密码或创建的帐户使用预定义的用户帐户之一登录。显示的提示指示登录命名空间,例如:
```java
# iris terminal IRISHealth
Node: intersystems2588, Instance: IRIS27
Username: admin
Password: ********
USER>
```
要退出终端并关闭窗口,请输入命令 `halt`。
当使用`docker exec` 命令打开容器化实例的终端时(如在部署和探索 `IRIS` 中使用 终端进行交互中所述),将自动以 `irisowner` 身份登录,无需进行身份验证。
在 `Windows` 系统上,必须从其位置( `IRIS` 实例的 `install-dir\bin` 目录)执行命令,或在命令中包含完整路径,例如 `c:\InterSystems\IRIS27\bin\iris terminal IRISHealth` .可以执行给定实例的二进制文件以连接到该实例或另一个;无论哪种方式,实例名称都是必需的。
文章
姚 鑫 · 二月 12, 2023
# 第七十四章 使用 irisstat 实用程序监控 IRIS - 查看 irisstat 输出
# 查看 `irisstat` 输出
可以立即查看 `irisstat` 数据(通过终端)或重定向到输出文件以供以后分析。查看数据的最常见方法是:
注意:当 `IRIS` 被强制关闭时,`irisstat` 会运行以捕获系统的当前状态。作为紧急关闭程序的一部分,输出被添加到消息日志中。
## irisstat 文本文件
`irisstat` 报告可以重定向到文件而不是终端,如果想收集一组 `IRIS` 工具(诊断报告任务、`IRISHung` 脚本、`^SystemPerformance` 实用程序)未提供的一组 `irisstat` 选项,这可能很有用或者如果在运行这些工具时遇到问题。
## 诊断报告任务
诊断报告任务会创建一个包含基本信息和高级信息的 HTML 日志文件,InterSystems 全球响应中心 (WRC) 可以使用该文件来解决系统问题。
注意:诊断报告任务不能在挂起的系统上运行;如果系统挂起,请参阅本附录中的 `IRISHung` 脚本。
## IRISHung 脚本
`IRISHung` 脚本是一个操作系统工具,用于在 `IRIS` 实例挂起时收集系统数据。位于 `install-dir\bin` 目录中的脚本名称是特定于平台的,如下表中指定:
Platform| Script name
---|---
`Microsoft Windows`| `IRISHung.cmd`
`UNIX®/Linux` |`IRISHung.sh`
`IRISHung` 脚本应以管理员权限运行。与诊断报告任务一样,`IRISHung` 脚本运行 `irisstat` 两次,间隔 `30` 秒,以防状态发生变化,并将报告与其他收集的数据一起打包到一个 `html` 文件中。从 `IRISHung` 获取的 `irisstat` 报告使用以下选项
```java
irisstat -e2 -f-1 -m-1 -n3 -j5 -g1 -L1 -u-1 -v1 -p-1 -c-1 -q1 -w2 -E-1 -N65535
```
`IRISHung` 还运行仅使用 `-S2` 选项的第三个 `irisstat`,它将其写入一个单独的输出部分,称为“自诊断”。 `-S2` 选项导致可疑进程留下小型转储;因此,运行 `IRISHung` 可能会收集有关负责挂起的特定进程的信息,而简单地强制实例关闭不会收集此信息。
此外,`IRISHung` 生成的 `irisstat` 输出文件通常非常大,在这种情况下,它们被保存到单独的 `.txt` 文件中。请记住在收集输出时检查这些文件。
## `^SystemPerformance Utility`
`^SystemPerformance` 实用程序收集有关 `IRIS` 实例及其运行平台的详细性能数据。在 `IRIS` 内运行一段可配置的时间,在该时间间隔内收集样本,并在完成时生成报告。
文章
姚 鑫 · 十二月 31, 2023
# 第十一章 创建Callout Library - 使用 J 链接类型传递标准计数字符串
# 使用 `J` 链接类型传递标准计数字符串
`iris-callin.h` 头文件定义了计数字符串结构 `IRIS_EXSTR`,表示标准 `IRIS` 字符串。此结构包含一个字符元素数组(`8` 位、`16` 位 `Unicode` 或 `32` 位 `wchar t`)和一个指定数组中元素数量的 `int` 值(最多字符串长度限制):
```java
typedef struct {
unsigned int len; /* length of string */
union {
Callin_char_t *ch; /* text of the 8-bit string */
unsigned short *wch; /* text of the 16-bit string */
wchar_t *lch; /* text of the 32-bit string */
/* OR unsigned short *lch if 32-bit characters are not enabled */
} str;
} IRIS_EXSTR, *IRIS_EXSTRP;
```
C Datatype| Input |In/Out |Notes
---|---|---|---
IRIS_EXSTR| 1j or j |1J or J| 8 位国家字符的标准字符串
IRIS_EXSTR |2j or n| 2J or N|16 位 Unicode 字符的标准字符串
IRIS_EXSTR| 4j |4J |32 位字符的标准字符串 wchar_t 字符
`IRIS_EXSTR` 数据结构由 `Callin API`(低级 `InterSystems` 函数调用库)中的函数进行操作。有关详细信息,请参阅使用 `Callin API` 中的“`Callin` 函数参考”。尽管名称相似,`Callin API` 和 `$ZF`标注接口是完全独立的产品)。
以下函数用于创建和销毁 `IRIS_EXSTR` 实例:
- `IrisExStrNew[W][H`] — 为字符串分配请求的存储量,并使用长度和指向该结构的值字段的指针填充 `IRIS_EXSTR` 结构。
- `IrisExStrKill` — 释放与 `IRIS_EXSTR` 字符串关联的存储。
这是一个 `Callout` 库,它使用所有三种链接类型来返回数字字符串:
### 使用 `J` 连接传递字符串
以下三个函数均生成一个随机整数,将其转换为最多包含 `6` 位数字的数字字符串,并使用 `J` 链接返回字符串 。
```java
#define ZF_DLL // Required when creating a Callout library.
#include
#include
#include
#include
int get_sample_L(IRIS_EXSTRP retval) { // 8-bit characters
Callin_char_t numstr[6];
size_t len = 0;
sprintf(numstr,"%d",(rand()%1000000));
len = strlen(numstr);
IRISEXSTRKILL(retval);
if (!IRISEXSTRNEW(retval,len)) {return ZF_FAILURE;}
memcpy(retval->str.ch,numstr,len); // copy to retval->str.ch
return ZF_SUCCESS;
}
int get_sample_LW(IRIS_EXSTRP retval) { // 16-bit characters
unsigned short numstr[6];
size_t len = 0;
swprintf(numstr,6,L"%d",(rand()%1000000));
len = wcslen(numstr);
IRISEXSTRKILL(retval);
if (!IRISEXSTRNEW(retval,len)) {return ZF_FAILURE;}
memcpy(retval->str.wch,numstr,(len*sizeof(unsigned short))); // copy to retval->str.wch
return ZF_SUCCESS;
}
int get_sample_LH(IRIS_EXSTRP retval) { // 32-bit characters
wchar_t numstr[6];
size_t len = 0;
swprintf(numstr,6,L"%d",(rand()%1000000));
len = wcslen(numstr);
IRISEXSTRKILL(retval);
if (!IRISEXSTRNEW(retval,len)) {return ZF_FAILURE;}
memcpy(retval->str.lch,numstr,(len*sizeof(wchar_t))); // copy to retval->str.lch
return ZF_SUCCESS;
}
ZFBEGIN
ZFENTRY("GetSampleL","1J",get_sample_L)
ZFENTRY("GetSampleLW","2J",get_sample_LW)
ZFENTRY("GetSampleLH","4J",get_sample_LH)
ZFEND
```
注意:始终终止 `IRIS_EXSTRP` 输入参数 在前面的示例中,始终调用 `IRISEXSTRKILL(retval)` 以从内存中删除输入参数。即使参数不用于输出,也应该始终这样做。如果不这样做可能会导致内存泄漏。
文章
Qiao Peng · 一月 14, 2021

您好! 本文介绍另一种为基于 InterSystems Caché 的解决方案创建安装程序的简单方法。 主题将涵盖只需一项操作即可安装或从 Caché 中完全删除的应用程序。 如果您仍在编写需要执行多个步骤才能安装应用程序的安装说明,是时候将这个过程自动化了。
问题的提出
假设我们为 Caché 开发了一个小型实用程序,之后我们想要将其分发。 当然,最好不要让不必要的配置和安装细节打扰到安装它的用户。 此外,这些说明必须非常全面,而且要面向可能对 Caché 一无所知的用户。如果是 Web 实用程序,安装程序不仅会要求用户将其类导入 Caché,而且至少还要配置 Web 应用程序才能对其进行访问,这是相当大的工作量:

当然,所有这些操作都可以通过编程方式执行。 您只需要了解如何实现。 但即使是这样,我们也需要让用户执行操作,例如在终端中执行一个命令。
通过单次导入操作进行安装
Caché 允许我们在类导入期间执行安装。 这意味着用户只需要使用任一方便的方法导入包含类包的 XML 文件:
将 XML 文件拖放到 Studio 区域。
通过管理门户:系统资源管理器 -> 类 -> 导入。
通过终端:do $system.OBJ.Load("C:\FileToImport.xml","ck")。
我们为安装应用程序而预先准备的代码将在类导入和编译后立即执行。 如果用户要卸载我们的应用程序(删除软件包),我们还可以清理应用程序在安装过程中创建的所有内容。
创建投影
为了扩展 Caché 编译器的行为,或者,在我们的示例中,为了在类的编译或反编译期间执行代码,我们需要在软件包中创建一个投影类。 它是一个扩展了 %Projection.AbstractProjection 的类,并重载了它的两个方法:CreateProjection(在编译过程中执行)和 RemoveProjection(在重新编译或删除类时触发)。
通常,将这个类命名为 Installer 是个好方法。 我们来看一个名为“MyPackage”的软件包的简单安装程序示例:
Class MyPackage.Installer Extends %Projection.AbstractProjection [ CompileAfter = (Class1, Class2) ]
{Projection Reference As Installer;/// This method is invoked when a class is compiled.ClassMethod CreateProjection(cls As %String, ByRef params) As %Status{ write !, "Installing..."}/// This method is invoked when a class is 'uncompiled'.ClassMethod RemoveProjection(cls As %String, ByRef params, recompile As %Boolean) As %Status{ write !, "Uninstalling..."}}
这里的行为可以描述为:
第一次导入和编译软件包时,只触发 CreateProjection 方法。
以后再编译 MyApp.Installer 时,或者导入“新”的安装程序类覆盖“旧”类时,将触发旧类的 RemoveProjection 方法,且 %recompile 参数等于 1,之后调用新类的 CreateProjection 方法。
删除软件包(同时删除 MyApp.Installer)时,将只调用 RemoveProjection 方法,参数 recompile = 0。
还需要注意以下几点:
类关键字 CompileAfter 应该包括应用程序的类名列表,在执行投影类的方法之前,需要对它们进行编译。 始终建议在此列表中填入应用程序中的所有类,因为如果安装过程中出错,我们不需要执行投影类的代码;
两个方法都接受 cls 参数 - 它是顶级类名,在我们的示例中为 MyApp.Installer。 这个理念来自于创建投影类的本义 - 通过从派生自 %Projection.AbstractProjection 的类再派生,可以单独为我们的应用程序的任何类制作“安装程序”。 只有在这种情况下才会体现出意义,但对于我们的任务来说是多余的;
CreateProjection 和 RemoveProjection 方法都接受第二个参数 params - 它是一个关联数组,以“参数名称”-“值”对的形式处理有关当前编译设置和当前类的参数值的信息。 通过执行 zwrite params 可以非常容易地探索该参数的内容;
RemoveProjection 方法接受 recompile 参数,只有删除类时,该参数才等于 0,重新编译时不等于 0。
类 %Projection.AbstractProjection 还有其他方法,我们可以重新定义这些方法,但我们的任务并不需要这样做。
一个示例
让我们更深入地了解为我们的实用程序创建 Web 应用程序的任务,并创建一个简单示例。 假设我们的实用程序是一个 REST 应用程序,在浏览器中打开时,它只发送一个响应“I am installed!”。 要创建这样的应用程序,我们需要创建一个描述它的类:
Class MyPackage.REST Extends %CSP.REST{XData UrlMap{ }ClassMethod Index() As %Status{ write "I am installed!" return $$$OK}}
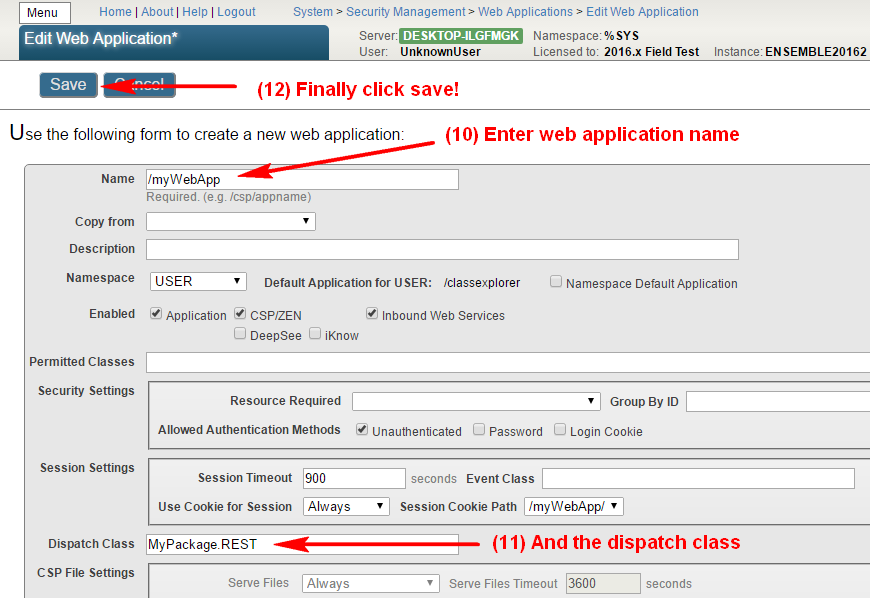
创建并编译该类后,我们需要将其注册为 Web 应用程序入口点。 我在本文的顶部图示了如何进行配置。 在执行所有这些步骤后,最好通过访问 http://localhost:57772/myWebApp/ 来检查我们的应用程序是否正常工作(注意以下几点:1. 末尾的斜线是必需的;2. 端口 57772 在您的系统中可能有所不同。 它将匹配您的管理门户端口)。
当然,所有这些步骤都可以通过 Web 应用程序创建方法 CreateProjection 以及删除方法 RemoveProjection 中的一些代码来自动执行。 在这种情况下,我们的投影类如下所示:
Class MyPackage.Installer Extends %Projection.AbstractProjection [ CompileAfter = MyPackage.REST ]{Projection Reference As Installer;Parameter WebAppName As %String = "/myWebApp";Parameter DispatchClass As %String = "MyPackage.REST";ClassMethod CreateProjection(cls As %String, ByRef params) As %Status{ set currentNamespace = $Namespace write !, "Changing namespace to %SYS..." znspace "%SYS" // we need to change the namespace to %SYS, as Security.Applications class exists only there write !, "Configuring WEB application..." set cspProperties("AutheEnabled") = $$$AutheUnauthenticated // public application set cspProperties("NameSpace") = currentNamespace // web-application for the namespace we import classes to set cspProperties("Description") = "A test WEB application." // web-application description set cspProperties("IsNameSpaceDefault") = $$$NO // this application is not the default application for the namespace set cspProperties("DispatchClass") = ..#DispatchClass // the class we created before that handles the requests return ##class(Security.Applications).Create(..#WebAppName, .cspProperties)}ClassMethod RemoveProjection(cls As %String, ByRef params, recompile As %Boolean) As %Status{ write !, "Changing namespace to %SYS..." znspace "%SYS" write !, "Deleting WEB application..." return ##class(Security.Applications).Delete(..#WebAppName)}}
在此示例中,每次编译 MyPackage.Installer 类都将创建一个 Web 应用程序,每次“反编译”都将其删除。 最好在创建或删除应用程序之前检查该应用程序是否存在(例如,使用 ##class(Security.Applications).Exists(“Name”) ),但是为了使本示例简单起见,这个作业就留给阅读本文的读者来完成了。
在创建 MyPackage.REST 和 MyPackage.Installer 类之后,我们可以将这些类导出为一个 XML 文件,并将该文件分享给所有有需要的人。 导入此 XML 的用户将自动设置 Web 应用程序,然后可以开始在浏览器中使用。
结果
与 InterSystems 社区上介绍的使用 %Installer 类部署应用程序的方法不同,这种方法有以下优点:
使用“纯”Caché ObjectScript。 至于 %Installer,需要用特定标签来填充 xData 块,大量文档对此进行了介绍。
安装我们的应用程序的方法是在类编译后立即执行的,我们不需要手动执行;
如果类(包)被删除,将自动执行删除我们的应用程序的方法,这不能通过使用 %Installer 来实现。
我的项目中已经使用这种应用程序安装方法 - Caché WEB Terminal、Caché Class Explorer 和 Caché Visual Editor。 您可以在此处找到 Installer 类的示例。
顺便提一下,开发者社区还有一个帖子介绍了投影的功能,作者是 John Murray。
另外值得一提的是 Package Manager 项目,该项目旨在让 InterSystems 数据平台的第三方应用程序只需通过一个命令或一次点击即可安装,就像类似 npm 的包管理器一样。
文章
姚 鑫 · 五月 21, 2021
# 第二章 设置和获取HTTP标头
# 设置和获取HTTP标头
可以设置和获取HTTP标头的值。
`%Net.HttpRequest`的以下每个属性都包含具有相应名称的HTTP标头的值。如果不设置这些属性,则会自动计算它们:
- `Authorization`
- `ContentEncoding`
- `ContentLength`(此属性为只读。)
- `ContentType` (指定`Content-Type`标头的Internet媒体类型(MIME类型)。)
- `ContentCharset` (指定`Content-Type`标题的字符集部分。如果设置此属性,则必须首先设置`ContentType`属性。)
- `Date`
- `From`
- `IfModifiedSince`
- `Pragma`
- `ProxyAuthorization`
- `Referer`
- `UserAgent`
`%Net.HttpRequest`类提供可用于设置和获取主HTTP标头的常规方法。这些方法忽略`Content-Type`和其他实体标头。
### ReturnHeaders()
返回包含此请求中的主`HTTP`标头的字符串。
### OutputHeaders()
将主`HTTP`标头写入当前设备。
### GetHeader()
返回此请求中设置的任何主HTTP标头的当前值。此方法接受一个参数,即头的名称(不区分大小写);这是一个字符串,如Host或Date
### SetHeader()
设置标题的值。通常,可以使用它来设置非标准标头;大多数常用标头都是通过Date等属性设置的。此方法有两个参数:
- 标头的名称(不区分大小写),不带冒号(`:`)分隔符;这是一个字符串,如Host或Date
- 标头值
不能使用此方法设置实体标头或只读标头(`Content-Length`和`Connection`)。
# 管理保活(Keep-alive)行为
如果重复使用`%Net.HttpRequest`的同一实例来发送多个HTTP请求,则默认情况下,InterSystems IRIS会使TCP/IP套接字保持打开状态,这样InterSystems IRIS就不需要关闭并重新打开它。
如果不想重复使用TCP/IP套接字,请执行以下任一操作:
- 设置`SocketTimeout`属性为0。
- 在你的HTTP请求中添加`'Connection: close'` HTTP头。
要做到这一点,在发送请求之前添加如下代码:
```java
Set sc=http.SetHeader("Connection","close")
```
注意,每个请求之后都会清除HTTP请求头,因此需要在每个请求之前包含此代码。
`%Net.HttpRequest`的`SocketTimeout`属性指定InterSystems IRIS将重用给定套接字的时间窗口(以秒为单位)。此超时旨在避免使用可能已被防火墙静默关闭的套接字。此属性的默认值为115。可以将其设置为不同的值。
# 处理HTTP请求参数
发送HTTP请求时(请参阅“发送HTTP请求”),可以在位置参数中包括参数;例如:`"/test.html?PARAM=%25VALUE"`将`PARAM`设置为等于`%value`。
还可以使用以下方法控制`%Net.HttpRequest`实例处理参数的方式:
### InsertParam()
将参数插入到请求中。此方法接受两个字符串参数:参数的名称和参数的值。例如:
```java
do req.InsertParam("arg1","1")
```
可以为给定参数插入多个值。如果这样做,这些值将接收从1开始的下标。在其他方法中,可以使用这些下标来引用目标值。
### DeleteParam()
从请求中删除参数。第一个参数是参数的名称。第二个参数是要删除的值的下标;仅当请求包含同一参数的多个值时才使用此参数。
### CountParam()
统计与给定参数关联的值数。
### GetParam()
获取请求中给定参数的值。第一个参数是参数的名称。如果请求没有同名的参数,则第二个参数是要返回的默认值;该默认值的初始值为空值。第三个参数是要获取的值的下标;仅当请求包含同一参数的多个值时才使用此参数。
### IsParamDefined()
检查是否定义了给定参数。如果参数有值,则此方法返回`TRUE`。参数与`DeleteParam()`相同。
### NextParam()
通过`$order()`对参数名称进行排序后,检索下一个参数的名称(如果有)。
### ReturnParams()
返回此请求中的参数列表。
# 包括请求正文
HTTP请求可以包括请求正文或表单数据。要包括请求正文,请执行以下操作:
1. 创建`%GlobalBinaryStream`的实例或子类。将此实例用于HTTP请求的`EntityBody`属性。
2. 使用标准流接口将数据写入此流。例如:
```java
Do oref.EntityBody.Write("Data into stream")
```
例如,可以读取一个文件并将其用作自定义HTTP请求的实体正文:
```java
set file=##class(%File).%New("G:\customer\catalog.xml")
set status=file.Open("RS")
if $$$ISERR(status) do $System.Status.DisplayError(status)
set hr=##class(%Net.HttpRequest).%New()
do hr.EntityBody.CopyFrom(file)
do file.Close()
```
# 发送分块请求
如果使用的是HTTP1.1,则可以分块发送HTTP请求。这涉及到设置`Transfer-Encoding`以指示消息已分块,并使用大小为零的块来指示完成。
当服务器返回大量数据并且在完全处理请求之前不知道响应的总大小时,分块编码非常有用。在这种情况下,通常需要缓冲整个消息,直到可以计算出内容长度(`%Net.HttpRequest`会自动计算)。
要发送分块请求,请执行以下操作:
1. 创建`%Net.ChunkedWriter`的子类,`%Net.ChunkedWriter`是定义以块形式写入数据的接口的抽象流类。在这个子类中,实现`OutputStream()`方法。
2. 在`%Net.HttpRequest`的实例中,创建`%Net.ChunkedWriter`子类的实例,并用要发送的请求数据填充它。
3. 将`%Net.HttpRequest`实例的`EntityBody`属性设置为等于此`%Net.ChunkedWriter实`例。
当发送HTTP请求时(请参见“发送HTTP请求”),它将调用`EntityBody`属性的`OutputStream()`方法。
在`%Net.ChunkedWriter`的子类中,`OutputStream()`方法应该检查流数据,决定是否分块以及如何分块,并调用类的继承方法来编写输出。
有以下方法可用:
### WriteSingleChunk()
接受字符串参数并将该字符串作为非分块输出写入。
### WriteFirstChunk()
接受字符串参数。写入适当的`Transfer-Encoding`标题以指示分块的消息,然后将字符串作为第一个分块写入。
### WriteChunk()
接受字符串参数并将字符串作为块写入。
### WriteLastChunk()
接受字符串参数,并将字符串作为块写入,后跟零长度块以标记结尾。
如果非NULL,则`TranslateTable`属性指定用于在写入时转换每个字符串的转换表。前面的所有方法都检查此属性。
# 发送表单数据
HTTP请求可以包括请求正文或表单数据。要包括表单数据,请使用以下方法:
### InsertFormData()
将表单数据插入到请求中。此方法接受两个字符串参数:表单项的名称和关联值。可以为给定表单项插入多个值。如果这样做,值将接收从1开始的下标。在其他方法中,可以使用这些下标来引用目标值
### DeleteFormData()
从请求中删除表单数据。第一个参数是表单项的名称。第二个参数是要删除的值的下标;仅当请求包含同一表单项的多个值时才使用此参数。
### CountFormData()
统计请求中与给定名称关联的值数。
### IsFormDataDefined()
检查是否定义了给定的名称
### NextFormData()
通过`$order()`对名称进行排序后,检索下一个表单项的名称(如果有)。
例1
插入表单数据后,通常调用`Post()`方法。例如:
```java
Do httprequest.InsertFormData("element","value")
Do httprequest.Post("/cgi-bin/script.CGI")
```
例2
```java
Set httprequest=##class(%Net.HttpRequest).%New()
set httprequest.SSLConfiguration="MySSLConfiguration"
set httprequest.Https=1
set httprequest.Server="myserver.com"
set httprequest.Port=443
Do httprequest.InsertFormData("portalid","2000000")
set tSc = httprequest.Post("/url-path/")
Quit httprequest.HttpResponse
```
# 插入、列出和删除Cookie
`%Net.HttpRequest`自动管理从服务器发送的`Cookie`;如果服务器发送`Cookie`,`%Net.HttpRequest`实例将在下一次请求时返回此`Cookie`。(要使此机制正常工作需要重用`%Net.HttpRequest`的同一实例。)
使用以下方法管理`%Net.HttpRequest`实例中的`Cookie`:
### InsertCookie()
将`Cookie`插入到请求中。指定以下参数:
- `Cookie`的名称。
- `Cookie`的值。
- 应存储`Cookie`的路径。
- 要从中下载`Cookie`的计算机的名称。
- `Cookie`过期的日期和时间。
### GetFullCookieList()
返回`Cookie`的数量,并(通过引用)返回`Cookie`数组。
### DeleteCookie()
请记住,`Cookie`是特定于HTTP服务器的。当插入`Cookie`时,使用的是到特定服务器的连接,而该`Cookie`在其他服务器上不可用。
文章
姚 鑫 · 六月 26, 2021
# 第十九章 使用%XML.TextReader
`%XML.TextReader`类提供了一种简单、容易的方法来读取可能直接映射到InterSystems IRIS对象,也可能不直接映射到InterSystems IRIS对象的任意XML文档。具体地说,该类提供了导航格式良好的XML文档并查看其中信息(元素、属性、注释、名称空间URI等)的方法。该类还基于`DTD`或`XML`架构提供完整的文档验证。但是,与`%XML.Reader`不同的是,`%XML.TextReader`不提供返回`DOM`的方法。如果需要DOM,请参阅前面的“将XML导入对象”一章。
**注意:使用的任何XML文档的XML声明都应该指明该文档的字符编码,并且文档应该按照声明的方式进行编码。如果未声明字符编码,InterSystems IRIS将使用前面的“输入和输出的字符编码”中描述的默认值。如果这些默认值不正确,请修改XML声明,使其指定实际使用的字符集。**
# 创建文本阅读器`Text Reader`方法
要读取不一定与 IRIS对象类有任何关系的任意XML文档,可以调用`%XML.TextReader`类的方法,该类将打开文档并将其作为文本阅读器对象加载到临时存储中。文本阅读器对象包含一个可导航的节点树,每个节点都包含有关源文档的信息。然后,方法可以导航该文档并查找有关该文档的信息。对象的属性提供有关文档的信息,这些信息取决于在文档中的当前位置。如果存在验证错误,这些错误也可以作为树中的节点使用。
## 整体结构
法应执行以下部分或全部操作:
1. 通过以下方法之一的第一个参数指定文档源:
`Method`| `First Argument`
---|---
`ParseFile()` |文件名,带有完整路径。请注意,文件名和路径只能包含ASCII字符。
`ParseStream()`|流
`ParseString()`| 字符串
`ParseURL()`| URL
**在任何情况下,源文档都必须是格式良好的XML文档;也就是说,它必须遵守XML语法的基本规则。这些方法中的每一个都返回一个状态(`$OK`或失败代码),以指示结果是否成功。可以使用常用机制测试状态;特别是可以使用`$System.Status.DisplayError(status)`查看错误消息的文本。**
对于这些方法中的每一个,如果该方法返回$OK,则它通过引用(其第二个参数)返回包含XML文档中的信息的文本阅读器对象。
其他参数允许控制实体解析、验证、找到哪些项等。这些内容将在本章后面的“解析方法的参数列表”中介绍。
2. 检查解析方法返回的状态,并在适当的情况下退出。
如果解析方法返回$OK,则有一个与源XML文档相对应的文本阅读器对象。可以导航此对象。
文档可能包含`“element”`、`“endelement”`、`“startprefixmapping”`等节点。
重要提示:在任何验证错误的情况下,文档包含“错误”或“警告”节点。
代码应该检查这些节点。
3. 使用以下实例方法之一开始读取文档。
- 使用`Read()`导航到文档的第一个节点。
- 使用`ReadStartElement()`导航到特定类型的第一个元素。
- 使用`MoveToContent()`导航到类型为`“chars”`的第一个节点。
4. 获取该节点感兴趣的属性的值(如果有的话)。可用的属性包括名称、值、深度等。
5. 根据需要继续在文档中导航并获取属性值。
如果当前节点是元素,则可以使用`MoveToAttributeIndex()`或`MoveToAttributeName()`方法将焦点移至该元素的属性。若要返回到元素(如果适用),请使用`MoveToElement()`。
6. 如果需要,可以使用`Rewind()`方法返回到文档的开头(第一个节点之前)。这是唯一可以在源代码中倒退的方法。
方法运行后,文本读取器对象将被销毁,所有相关的临时存储都将被清除。
## 示例1
下面是一个简单的方法,它可以读取任何XML文件,并显示每个节点的序列号、类型、名称和值:
```java
/// w ##class(PHA.TEST.Xml).WriteNodes("E:\temp\textReader.txt")
ClassMethod WriteNodes(myfile As %String)
{
set status = ##class(%XML.TextReader).ParseFile(myfile,.textreader)
//检查状态
if $$$ISERR(status) {do $System.Status.DisplayError(status) quit}
//逐个节点遍历文档
while textreader.Read()
{
Write !, "Node ", textreader.seq, " is a(n) "
Write textreader.NodeType," "
If textreader.Name'="" {
Write "named: ", textreader.Name
} Else {
Write "and has no name"
}
Write !, " path: ",textreader.Path
If textreader.Value'="" {
Write !, " value: ", textreader.Value
}
}
q ""
}
```
此示例执行以下操作:
1. 它调用`ParseFile()`类方法。这将读取源文件,创建一个文本阅读器对象,并通过引用在变量doc中返回该对象。
2. 如果`ParseFile()`成功,则该方法然后调用`read()`方法来查找文档中的每个后续节点。
3. 对于每个节点,该方法写入包含节点序列号、节点类型、节点名称(如果有)、节点路径和节点值(如果有)的输出行。输出将写入当前设备。
以下示例源文档:
```xml
yaoxin
1990-04-25
```
对于此源文档,前面的方法生成以下输出:
```java
DHC-APP>w ##class(PHA.TEST.Xml).WriteNodes("E:\temp\textReader.txt")
Node 1 is a(n) processinginstruction named: xml-stylesheet
path:
value: type="text/css" href="mystyles.css"
Node 2 is a(n) element named: Root
path: /Root
Node 3 is a(n) startprefixmapping named: s01
path: /Root
value: s01 http://www.root.org
Node 4 is a(n) element named: s01:Person
path: /Root/s01:Person
Node 5 is a(n) element named: Name
path: /Root/s01:Person/Name
Node 6 is a(n) chars and has no name
path: /Root/s01:Person/Name
value: yaoxin
Node 7 is a(n) endelement named: Name
path: /Root/s01:Person/Name
Node 8 is a(n) element named: DOB
path: /Root/s01:Person/DOB
Node 9 is a(n) chars and has no name
path: /Root/s01:Person/DOB
value: 1990-04-25
Node 10 is a(n) endelement named: DOB
path: /Root/s01:Person/DOB
Node 11 is a(n) endelement named: s01:Person
path: /Root/s01:Person
Node 12 is a(n) endprefixmapping named: s01
path: /Root
value: s01
Node 13 is a(n) endelement named: Root
path: /Root
```
请注意,注释已被忽略;默认情况下,`%XML.TextReader`忽略注释。
## Example 2
下面的示例读取一个XML文件并列出其中的每个元素
```java
/// w ##class(PHA.TEST.Xml).ShowElements("E:\temp\textReader.txt")
ClassMethod ShowElements(myfile As %String)
{
set status = ##class(%XML.TextReader).ParseFile(myfile,.textreader)
if $$$ISERR(status) {do $System.Status.DisplayError(status) quit}
while textreader.Read()
{
if (textreader.NodeType = "element")
{
write textreader.Name,!
}
}
q ""
}
```
此方法使用`NodeType`属性检查每个节点的类型。如果节点是元素,则该方法将其名称打印到当前设备。对于前面显示的XML源文档,此方法生成以下输出:
```java
DHC-APP>w ##class(PHA.TEST.Xml).ShowElements("E:\temp\textReader.txt")
Root
s01:Person
Name
DOB
```
# 节点类型
文档的每个节点都是以下类型之一:
文本阅读器文档中的节点类型
Type| Description
---|---
`"attribute"` |XML属性。
`"chars"` |一组字符(如元素的内容)。`%XML.TextReader`类识别其他节点类型(`“CDATA”`、`“EntityReference”`和`“EndEntity”`),但自动将它们转换为“字符”。
`"comment"`| XML注释。
`"element"`|XML元素的开始。
`"endelement"`|XML元素的结束。
`"endprefixmapping"`| 声明名称空间的上下文的结束。
`"entity"`|XML实体。
`"error"`| 解析器发现的验证错误。
`"ignorablewhitespace"`| 混合内容模型中标记之间的空白。
`"processinginstruction"`|XML处理指令。
`"startprefixmapping"`|XML命名空间声明,它可能包括也可能不包括命名空间。
`"warning"`| 解析器发现验证警告。
请注意,XML元素由多个节点组成。例如,以下XML片段:
```xml
Willeke,Clint B.
1925-10-01
```
SAX解析器将此XML视为以下节点集:
文档节点示例
Node Number |Type of Node| Name of Node, If Any| Value of Node, If Any
---|---|---|---
1 |element |Person
2| element |Name
3| chars || Willeke,Clint B.
4 |endelement| Name
5| element| DOB
6| chars || 1925-10-01
7| endelement| DOB
8| endelement| Person
例如,注意``元素被认为是三个节点:一个元素节点、一个字符节点和一个结束元素节点。还要注意,该元素的内容只能作为`chars`节点的值使用。
文章
Jingwei Wang · 三月 28, 2023
IRIS 配置和用户帐户包含需要跟踪的各种数据元素,许多人难以在 IRIS 实例之间复制或同步这些系统配置和用户帐户。那么如何简化这个过程呢?
在软件工程中,CI/CD 或 CICD 是持续集成 (CI) 和(更常见的)持续交付或(较少见的)持续部署 (CD) 的组合实践集。 CI/CD 能消除我们所有的挣扎吗?
我在一个开发和部署 IRIS 集群的团队工作。我们在 Red Hat OpenShift 容器平台上的容器中运行 IRIS。
如果您当前没有使用 Kubernetes,请不要停止阅读。即使您没有使用 Kubernetes 或在容器中运行 IRIS,您也可能会遇到与我和我的团队面临的挑战类似的挑战。
我们决定将代码与配置分开,并将它们放在不同的 GitHub 存储库中。每次在代码库中进行提交时,都会触发管道运行。结果,从代码库中的文件构建了一个新image。
我们通过将 YAML 文件和其他配置工件添加到部署 GitHub 存储库,将配置定义为以 GitOps 方式使用的代码。 GitOps 是一个软件开发框架,它使组织能够持续交付软件应用程序,同时使用 Git 作为单一事实来源有效地管理 IT 基础设施(以及更多)。 GitOps 的好处之一是能够轻松回滚。您所需要做的就是恢复到 Git 中的先前状态。
DevOps 是软件开发和 IT 行业的一种方法论。作为一套实践和工具使用,DevOps 将软件开发(Dev) 和IT 运营(Ops) 的工作集成并自动化,作为改进和缩短系统开发生命周期的一种手段。 [1]
我在维基百科上读到持续交付是“当团队在短周期内以高速和频率生产软件时,以便可以随时发布可靠的软件,并在决定部署时采用简单且可重复的部署过程。”
同时,维基百科将持续部署定义为“当新软件功能完全自动推出时”。
我们已决定将 YAML 文件存储在部署 GitHub 存储库中。
iris-cpf(上面的第 19 行)指的是一个 ConfigMap,其中包含用于 CPF Merge 的文件。
有多种可用的 CD 管道工具可以将配置作为代码推送部署,而不必手动应用文件。
例如,我的团队使用Argo CD 。它是一个 GitOps 工具,作为 Kubernetes 扩展部署在集群中。它很特别,因为它在集群中具有可见性。它的用户界面在浏览器中显示应用程序状态,因为 Argo CD 是 Kubernetes 扩展。
与仅启用基于推送的部署的外部 CD 工具不同,Argo CD 可以从 Git 存储库中拉取更新的(类似)代码并将其直接部署到 Kubernetes 资源。
像 Argo CD 这样的拉动部署工具将我们的 Kubernetes 集群的实际状态与我们的部署 repo 中描述的期望状态进行比较。
Argo CD 监视我们的部署 repo 和我们的 Kubernetes 集群。我们的部署repo 是唯一的真实来源。如果 GitHub 存储库中发生某些更改,Argo CD 将更新集群以匹配存储库中定义的所需状态。
Argo CD 代理同步 GitHub 存储库和 Kubernetes 集群。如果我们手动应用一个更改,当 Argo CD 将已部署的应用程序同步到 Git 中定义的所需状态时,它将被删除。
为了将不同的配置部署到不同的集群,我们使用Kustomize 。我们在部署仓库中定义了一个基本配置。我们还在部署 GitHub 存储库中定义了覆盖,以便为开发、SQA、阶段和生产等各种环境配置不同的系统默认设置和不同的images。
在第 417 行中,我们确定基于环境的系统默认设置存储在 SDS_ENV.xml 中。
那些没有使用 Kubernetes 的情况呢?我创建了许多可在 Open Exchange 中使用的应用程序。我学习了如何使用 Installer 类在 GitHub 存储库中定义 IRIS 配置,然后构建image并运行容器。
然而,如果在部署应用程序后需要对配置或用户帐户进行一些修改,情况会怎样呢?当涉及到持久卷时,事情就变得复杂了。发生这种情况是因为我们不想丢失存在于持久卷上的数据。
存储在持久卷上的所有这些东西是什么? IRIS 配置保存在数据目录的 mgr 目录中。 CPF Merge 功能应该使我们能够修改 iris.cpf 中的任何配置设置。
我的团队已将大量代码添加到 %ZSTART routines中,这些routines在 IRIS 计算或数据实例启动时执行。我们担心的一个问题是所谓的零大小 CPF 错误。我们经常遇到 IRIS 实例因大小为零的 CPF 文件而崩溃的情况。不幸的是,我们尚未发现该问题的根本原因。我们怀疑 CPF 合并操作以及在 %ZSTART routine中添加和删除的大量Routine、Global和包映射会导致零大小的 CPF 错误。
我们编写了代码来删除所有系统默认设置,并从作为卷安装在 IRIS 容器中的 Kubernetes ConfigMap 中导入它们。事实上,我们有两组系统默认设置:一组是在所有环境中导入的基本设置,另一组是因环境而异的环境特定设置。
我们决定从 XML 文件中导入用户。有时,当我们直接从 %ZSTART routine 执行这段代码时,我们会遇到问题。我们根据 InterSystems 的建议将此代码移至计划任务中。显然,我们发现了一个在某些情况下可能会破坏全局安全性的错误。无论如何,出于某种我现在不记得的原因,当用户帐户导入由计划从 %ZSTART routine 按需运行的任务执行时,此问题不再是问题。这一定是时间问题。计划任务晚于 %ZSTART routine运行。
我们创建了一个自定义密码验证routine来强制执行密码规则。
当我们需要一个新的 Web 应用程序时,我们应该怎么做?除了 CPF Merge,CSP Merge 怎么样?
我相信 Web 应用程序存储在 %SYS IRIS.dat 文件中。我考虑尝试在可以使用 ConfigMap 挂载的文件中定义 Web 应用程序。我们可以将代码添加到 %ZSTART 例程或添加另一个计划任务来查找文件并创建 IRIS 中尚不存在的任何 Web 应用程序。
使用 InterSystems Kubernetes Operator 部署的 Webgateway 容器具有一个持久数据卷,其中包含 CSP.conf 和 CSP.ini。但是,我们还没有实现在添加新的 Web 应用程序时根据需要自动更新这些文件的方法。
Lorenzo Scalese 创建了可在 Open Exchange 中使用的 config-api 和 config-copy 应用程序。他建议在您的应用程序安装程序模块中使用 IRS-Config-API 库。
IRIS-Config-API 可以在一个环境将 IRIS 配置导出到 JSON 文档,并在另一个环境中从 JSON 文档导入 IRIS 配置。
Lorenzo 创建了 iris-config-copy 工具,用于从一个 InterSystems IRIS 实例导出配置并将其导入另一个实例。如果我们在源实例和目标实例上都安装 iris-config-copy,则目标实例使用 REST 从源实例获取配置。
我们需要在源实例上创建一个 Web 应用程序,以使目标实例能够从源实例中检索 IRIS 配置。
Iris-config-copy 可以导出本地实例或远程实例的 IRIS 配置。
有一些方法可以导入特定的配置文件。我们可以导入Security、包含 SQL 连接的globals、CPF 配置数据或任务。
文章
姚 鑫 · 九月 11, 2022
# 第二十九章 管理许可(二)
# 激活许可证密钥
`IRIS` 使用许可证密钥来确保其注册站点的正常运行、定义可用容量并控制对 `IRIS` 功能的访问。 许可证密钥以许可证密钥文件的形式提供,通常命名为 `iris.key`。
安装 `IRIS` 后,使用以下程序激活许可证密钥。始终可以使用相同的过程为任何已安装的实例激活新的许可证密钥(即升级密钥)。可以激活放置在管理门户可访问的任何位置的许可证密钥;作为激活的一部分,许可证密钥将作为 `iris.key` 复制到实例的 `install-dir/mgr` 目录(如果尚未命名)。
注意:也可以在 `Windows` 安装期间选择许可证密钥。执行此操作时,许可证会自动激活,并且许可证密钥会作为 `iris.key` 复制到实例的 `install-dir/mgr` 目录中;不需要此处描述的激活过程。
本节还讨论了许可证故障排除和在所有许可证单元都在使用时从操作系统命令行升级许可证。
要激活许可证密钥,请使用以下过程:
1. 导航到许可证密钥页面(系统管理 > 许可 > 许可证密钥)。将显示有关当前活动许可证密钥的信息。如果尚未激活任何许可证,则会显示这一点,例如通过标记客户名称:缺少许可证或不可读。此页面包含一个打印按钮,可让轻松打印显示的信息。
2. 单击激活许可证密钥并浏览到要激活的许可证密钥文件。当选择一个文件时,会显示有关它的信息,以便激活它之前验证是否拥有正确的许可证密钥;例如,它提供了所需的容量,并具有正确的到期日期。如果密钥无效,则会在错误消息中指出。如果许可证当前处于活动状态,则并排显示有关当前和选定许可证的信息。如果需要在激活后重新启动实例以使许可证密钥生效,则会记录这一点并提供原因。此对话框包括一个打印按钮,可让轻松打印有关当前活动许可证和选择的新许可证密钥的信息。
3. 单击激活以激活新的许可证密钥;它作为 `iris.key` 复制到实例的 `install-dir/mgr` 目录,覆盖之前的许可证密钥(如果有)。如果需要,确认对话框会提醒重新启动实例,并在新许可证启用的功能少于当前许可证时向发出警告。
通过使用 `Config.Startup`的 `LicenseID` 属性,可以将实例配置为从许可证服务器请求许可证密钥。在实例启动时,如果不存在 `iris.key` 文件并且已定义 `LicenseID`,则实例会从许可证服务器请求并激活许可证密钥。
**注意:相同的 `LicenseID` 必须在许可证密钥文件中,以及在需要下载许可证的实例上定义**
一般情况下无需重启实例,但升级许可证密钥时存在限制。如果将许可证类型从 `Power Unit` 更改为任何其他类型,则不会自动激活新密钥;这应该是一个罕见的事件。
另一个限制是许可证升级从通用内存堆 (`gmheap`) 空间中消耗的内存量。如果 `gmheap` 空间不可用,则无法扩展许可表条目的数量。如果没有足够的 `gmheap` 空间可用于许可证升级,则会将一条消息写入消息日志。可以从“高级内存设置”页面(系统管理 > 配置 > 高级内存设置)增加 `gmheap` 设置的大小。
如果新的许可证密钥比现有密钥消耗至少 `1000` 个 `64 KB` 页的 `gmheap` 空间,则必须重新启动 `IRIS` 实例才能完全激活新的许可证密钥。这种情况很少遇到,因为每个页面至少代表 `227` 个许可证。
## 更新许可证密钥
要更新许可证密钥,请替换 `KeyDirectory` 中的密钥文件并运行 `ReloadKeys^%SYS.LICENSE`。每个实例上的许可证监视器 (`^LMFMON`) 每 30 分钟检查一次,以查看配置的 `LicenseID` 是否有不同的密钥,如果有,则尝试执行升级。
**注意:虽然大多数升级在实时实例上成功,但某些情况可能需要重新启动实例。在这种情况下,许可证监视器会记录一个错误,并且直到第二天才尝试再次升级密钥(以避免记录重复的错误)。实例重启会在启动时加载新密钥。**
## 许可证故障排除
如果在输入许可证并重新启动 `IRIS` 后只有一位用户可以登录,请使用管理门户进行调查。当选择按进程时,许可证使用页面(系统操作 > 许可证使用)显示正在运行的进程数。还可以使用门户从许可证密钥页面(系统管理 > 许可 > 许可证密钥)显示许可证信息,如激活许可证密钥中所述。如果密钥无效,则 `CustomerName` 字段包含说明。
还可以在消息日志和系统监控日志中查看许可证错误消息,可以在 `Portal` 的消息日志页面(系统操作 > 系统日志 > 消息日志)和系统监控日志页面(系统操作 > 系统日志)中查看> 系统监控日志),分别。 `System Monitor` 将许可证到期警告和警报写入这些日志,而 `Health Monitor` 则写入许可证获取警报和警告。当超过许可限制时,许可模块会将警报写入消息日志。在 `Application Monitor` 中,可以配置基于许可证指标的警报以发送电子邮件通知或呼叫通知方法。
`$System.License.Help` 显示可用于解决许可证问题的方法列表:
```java
Do $System.License.Help()
```
### Administrator Terminal Session
有几个问题会阻止获得终端会话。当 `IRIS` 无法正常启动并进入单用户模式时,或者只是在没有可用许可证时,可能会发生这种情况。在这些情况下,可能需要创建管理员终端会话,该会话使用特殊许可证来解决问题。
### Administrator Session on Windows
使用命令提示符导航到 `install-dir\bin`。然后,以管理员身份执行以下命令:
```java
irisdb -s\mgr -B
```
这将从 `IRIS` 安装 `bin` 目录 (`install-dir\bin`) 运行 `IRIS` 可执行文件,指示 `install-dir\mgr` 的路径名(使用 `-s` 参数),并禁止所有登录,除了一个紧急登录(使用 `- B` 参数)。
例如,在默认目录中有一个名为 `MyIRIS` 的实例,该命令如下所示:
```java
c:\InterSystems\MyIRIS\bin>irisdb -sc:\InterSystems\MyIRIS\mgr -B
```
### Administrator Session on UNIX®, Linux, and macOS
使用命令提示符导航到 `install-dir/bin` 目录。然后,执行以下命令:
```java
iris terminal -B
```
例如,在默认目录中安装了一个名为 `MyIRIS` 的实例,该命令如下所示:
```java
User:/InterSystems/MyIRIS/bin$ iris terminal MyIRIS -B
```
## 从操作系统命令行升级许可证
`%SYSTEM.License.Upgrade()` 方法激活已复制到 `installdir\mgr` 目录的新许可证密钥。如果所有许可证单元都被用户使用,导致无法打开终端窗口,可以从命令行运行此方法以激活更大容量的新许可证密钥,如下所示:
```java
iris terminal -U %SYS '##Class(%SYSTEM.License).Upgrade()'
```
文章
Jingwei Wang · 八月 30, 2023
案例描述
假设您是一名 Python 开发人员或拥有一支训练有素的 Python 专业团队,但您分析 IRIS 中某些数据的期限很紧迫。当然,InterSystems 提供了许多用于各种分析和处理的工具。然而,在给定的场景中,最好使用旧的 Pandas 来完成工作,然后将 IRIS 留到下次使用。对于上述情况和许多其他情况,您可能需要从 IRIS 获取表来管理 InterSystems 产品之外的数据。但是,当您有任何格式(即 CSV、TXT 或 Pickle)的外部表时,您可能还需要以相反的方式执行操作,您需要在其上导入并使用 IRIS 工具。无论您是否必须处理上述问题,Innovatium让我明白,了解更多解决编码问题的方法总是能派上用场。好消息是,从 IRIS 引入表时,您不需要经历创建新表、传输所有行以及调整每种类型的繁琐过程。本文将向您展示如何通过几行代码快速将 IRIS 表转换为 Pandas 数据框架并向后转换。您可以在我的GitHub上查看代码,您可以在其中找到包含本教程每个步骤的 Jupiter Notebook。
从 IRIS 引入一张Table
当然,您应该首先导入该项目所需的库。
import pandas as pd import sqlalchemy as db
下一步将是在 Python 文件和 IRIS 实例之间创建连接。为此,我们将使用 SQLAlchemy 的函数 create_engine(),并以字符串作为参数。该字符串应包含有关操作方法、用户名和密码、实例的主机和端口以及目标命名空间的信息。有关使用 sqlalchemy-iris 的基本概念的更多信息,请查看我之前的一篇文章SQLAlchemy - 在 IRIS 数据库中使用 Python 和 SQL 的最简单方法。
engine = db.create_engine( "iris://_system:SYS@localhost:1972/SAMPLE" ) connection = engine.connect()
然后,我们可以声明将保存数据帧的变量,并在此连接上调用 Pandas 的 read_sql_table() 函数,将表名指定为带有Schema的字符串。您还可以在另一个参数中声明Schema,事实上,这是更好的选择,因为名称字符串上有一个点在某些情况下可能会导致错误。
df = pd.read_sql_table( "NameAge" , connection, schema= "PD" )
最好仔细检查我们正在使用的表是否存在于我们想要使用的Schema中,当然,首先还要检查是否存在我们需要的Schema。在本文的最后一部分中,您将了解如何执行此操作以及更多提示。从现在开始,如果您有办法使用 Pandas,您可以执行任何您想要的更改和分析,因为您知道该怎么做。探索以下示例以了解其工作原理。
向 IRIS 发送表
在开始之前,让我们更改数据框中的某些内容作为示例。我们可以调整列的值以满足我们的需求(例如,添加行和列等)。经过一番尝试后,我将名称改为小写,并根据现有数据添加了一个新人和一列。您可以查看下图来查看结果。
现在我们可以用一行代码将其发送回 IRIS。我们需要的只是指定引擎和表名。
df.to_sql( "NameAge" , con=engine, schema= "PD" , if_exists= "replace" )
再次,我们需要将Schema与表名分开放在参数中,以避免一些错误和不良行为。除此之外,if_exists 参数指定如果给定Schema中已经存在同名表时要执行的操作。可能的值为:replace、fail(默认)和append。当然,replace 选项会删除表并使用 SQL 命令创建一个新表,而append 会将数据添加到现有表中。请记住,此方法不会检查重复值,因此使用此属性时要小心。最后,失败值会引发以下错误:
请记住,如果您指定的表名不存在,该函数将创建它。
现在,您可以查询 IRIS 以查看新增内容,或者转至管理门户查看专用于 SQL 的部分。请记住,如果您使用替换值,您应该考虑该类的源代码,因为该方法完全重写了它。这意味着如果您实现了任何方法,则应该将它们保留在超类中。
有关 sqlalchemy-iris 的更多提示
如果您有任何问题无法通过其他社区或论坛中共享的与您的应用程序代码相关的信息来解决,您可能会在本节中找到所需的帮助。在这里您将找到有关如何查找有关engine和dialect的详细信息的提示列表。
方言特有的特征
SQL Alchemy 使用根据您的engine自动选择的dialect。当您使用函数 create_engine() 连接到 IRIS 数据库时,选择的dialect是Dmitry Maslennikov 的 sqlalchemy-iris 。您可以使用engine的dialect属性访问和编辑其功能。
engine = db.create_engine( "iris://_system:SYS@localhost:1972/SAMPLE" )
engine.dialect
通过 VSCode 的 IntelliCode 扩展,您可以从此属性中搜索每个选项,或者在CaretDev 的 GitHub上检查源代码。
检查engine中的可用Schema
该dialect中值得强调的一个特殊函数是 get_schema_names() 函数。注意!如果您想避免代码和迭代中出现错误,以下信息可能对您至关重要。
connection = engine.connect()
engine.dialect.get_schema_names(connection)
检查Schema中的可用表
我们来看看类似的情况。您可能还需要了解Schema中的可用表。在这种情况下,您可以使用检查。在引擎上运行函数inspect()并将其保存在变量中。您将使用相同的变量来访问另一个函数 get_table_names()。它将返回一个列表,其中包含指定Schema中的表名称或默认的“SQLUser”。
inspection = db.inspect(engine)
inspection.get_table_names(schema= "Sample" )
此外,如果您想在数据上使用更多 SQL Alchemy 功能,您可以声明一个基础并使其元数据反映引擎中的Schema。
b = db.orm.declarative_base()
b.metadata.reflect(engine, schema= "Sample" )
如果您需要更多信息来解决此问题,请查看SQL Alchemy 文档和sqlalchemy-iris GitHub 存储库。或者,您也可以给我留言或发表评论,我们将一起尝试揭开这个秘密。
最后的考虑因素
本文中的实现方法强调使用 IRIS 实例作为云提供商,并使得可以在不同的基础上进行分析。它可以轻松地同时监控所有这些设备的任何质量问题并比较它们的性能和使用情况。如果您将这些知识与另一篇关于用 Django 制作的门户的文章中描述的开发结合起来,您可以根据需要快速构建一个强大的管理器,用于任意数量的特性和实例。此实现也是将数据从 IRIS 外部移动到构建良好的类的有效方法。由于您可能熟悉 Pandas 中用于处理多种不同语言的其他一些函数,即 CSV、JSON、HTML、Excel 和 Pickle,因此您可以轻松地将 read_sql_table 更改为 read_csv、read_json 或任何其他选项。是的,我应该警告您,某些类型与 InterSystems 的集成不是内置功能,因此可能不是很容易。然而,SQL Alchemy 和 Pandas 的结合在从 IRIS 导出数据时总是会派上用场。因此,在本文中,我们了解到 IRIS 拥有您所需的所有工具,可帮助您进行开发并轻松与系统的现有设备或您的专业知识小工具集成。
文章
姚 鑫 · 四月 14, 2021
# 第二章 定义和构建索引(一)
# 定义索引
### 使用带有索引的Unique、PrimaryKey和IdKey关键字
与典型的SQL一样,InterSystems IRIS支持惟一键和主键的概念。
InterSystems IRIS还能够定义`IdKey`,它是类实例(表中的行)的唯一记录ID。
这些特性是通过`Unique`、`PrimaryKey`和`IdKey`关键字实现的:
- `Unique` -在索引的属性列表中列出的属性上定义一个唯一的约束。
也就是说,只有这个属性(字段)的唯一数据值可以被索引。
唯一性是根据属性的排序来确定的。
例如,**如果属性排序是精确的,则字母大小写不同的值是唯一的;
如果属性排序是`SQLUPPER`,则字母大小写不同的值不是唯一的。**
但是,请注意,对于未定义的属性,不会检查索引的惟一性。
根据SQL标准,未定义的属性总是被视为唯一的。
- `PrimaryKey` -在索引的属性列表中列出的属性上定义一个主键约束。
- `IdKey` -定义一个唯一的约束,并指定哪些属性用于定义实例(行)的唯一标识。
`IdKey`总是具有精确的排序规则,即使是数据类型为`string`时也是如此。
这些关键字的语法出现在下面的例子中:
```java
Class MyApp.SampleTable Extends %Persistent [DdlAllowed]
{
Property Prop1 As %String;
Property Prop2 As %String;
Property Prop3 As %String;
Index Prop1IDX on Prop1 [ Unique ];
Index Prop2IDX on Prop2 [ PrimaryKey ];
Index Prop3IDX on Prop3 [ IdKey ];
}
```
**注意:`IdKey`、`PrimaryKey`和`Unique`关键字只在标准索引下有效。
不能将它们与位图或位片索引一起使用。**
同时指定`IdKey`和`PrimaryKey`关键字也是有效的语法,例如:
```
Index IDPKIDX on Prop4 [ IdKey, PrimaryKey ];
```
这个语法指定`IDPKIDX`索引既是类(表)的`IdKey`,也是它的主键。
这些关键字的所有其他组合都是多余的。
对于使用这些关键字之一定义的任何索引,都有一个方法允许打开类的实例,其中与索引关联的属性有特定的值;
### 定义SQL搜索索引
可以在表类定义中定义SQL搜索索引,如下所示:
```java
Class Sample.TextBooks Extends %Persistent [DdlAllowed]
{
Property BookName As %String;
Property SampleText As %String(MAXLEN=5000);
Index NameIDX On BookName [ IdKey ];
Index SQLSrchIDXB On (SampleText) As %iFind.Index.Basic;
Index SQLSrchIDXS On (SampleText) As %iFind.Index.Semantic;
Index SQLSrchIDXA On (SampleText) As %iFind.Index.Analytic;
}
```
### 用索引存储数据
**可以使用index Data关键字指定一个或多个数据值的副本存储在一个索引中:**
```java
Class Sample.Person Extends %Persistent [DdlAllowed]
{
Property Name As %String;
Property SSN As %String(MAXLEN=20);
Index NameIDX On Name [Data = Name];
}
```
在本例中,索引`NameIDX`的下标是各种`Name`值的排序(大写)值。名称的实际值的副本存储在索引中。当通过SQL更改`Sample.Person`表或通过对象更改对应的`Sample.Person`类或其实例时,将维护这些副本。
在经常执行选择性(从许多行中选择一些行)或有序搜索(从许多列中返回一些列)的情况下,在索引中维护数据副本会很有帮助。
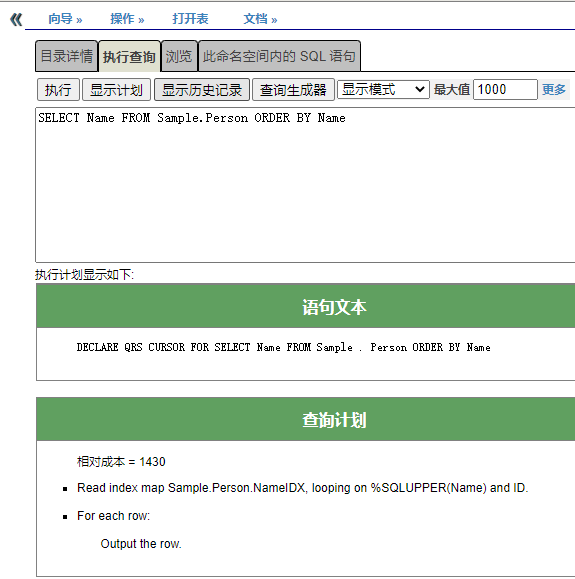
例如,考虑以下针对`Sample.Person`表的查询:
SQL引擎可以通过读取`NameIDX`而从不读取表的主数据来决定完全满足此请求。
**注意:不能使用位图索引存储数据值。**
### 索引null
如果一个索引字段的数据为`NULL`(没有数据存在),相应的索引使用索引`NULL`标记来表示这个值。
**默认情况下,索引空标记值为`-1E14`。**
使用索引空标记可以使空值排序在所有非空值之前。
`%Library.BigInt`数据类型存储小于`-1E14`的小负数。默认情况下,`%BigInt`索引空标记值为`-1E14`,因此与现有`BigInt`索引兼容。如果索引的`%BigInt`数据值可能包括这些极小的负数,则可以使用`INDEXNULLMARKER`属性参数更改特定字段的索引`NULL`标记值,作为特性定义的一部分,如下例所示:
```java
Property ExtremeNums As %Library.BigInt(INDEXNULLMARKER = "-1E19");
```
还可以在数据类型类定义中更改索引`NULL`标记的默认值。
**此参数属性在IRIS里有,Cache里没有。**
### 索引集合
为属性编制索引时,放在索引中的值是整个已整理属性值。对于集合,可以通过将(`Elements`)或(`Key`)附加到属性名称来定义与集合的元素和键值相对应的索引属性。(元素)和(键)允许指定从单个属性值生成多个值,并对每个子值进行索引。当属性是集合时,`Elements`令牌通过值引用集合的元素,`Key`令牌通过位置引用它们。当元素和键都出现在单个索引定义中时,索引键值包括键和关联的元素值。
例如,假设有一个基于`Sample.Person`类的`FavoriteColors`属性的索引。对此属性集合中的项进行索引的最简单形式是以下任一种:
```java
INDEX fcIDX1 ON (FavoriteColors(ELEMENTS));
```
或
```java
INDEX fcIDX2 ON (FavoriteColors(KEYS));
```
其中,`FavoriteColor(Elements)`是指`FavoriteColors`属性的元素,因为它是一个集合。一般形式是`PropertyName`(元素)或`PropertyName`(键),其中该集合的内容是定义为某个数据类型的列表或数组的属性中包含的一组元素)。
若要索引文本属性,可以创建一个由`PropertyNameBuildValueArray()`方法生成的索引值数组(在下一节中介绍)。与集合本身一样,(Elements)和(Key)语法对索引值数组有效。
如果属性集合被投影为数组,则索引必须遵守以下限制才能被投影到集合表。索引必须包括(键)。索引不能引用集合本身和对象ID值以外的任何属性。如果投影索引还定义了要存储在索引中的数据,则存储的数据属性也必须限制为集合和ID。否则,不会投影索引。此限制适用于投影为数组的集合属性上的索引;不适用于投影为列表的集合上的索引。
与集合的元素或键值对应的索引还可以具有所有标准索引功能,例如将数据与索引一起存储、特定于索引的排序规则等。
InterSystems SQL可以通过指定`FOR SOME%ELEMENT`谓词来使用集合索引。
### 使用(Elements)和(Key)索引数据类型属性
为了索引数据类型属性,还可以使用`BuildValueArray()`方法创建索引值数组。此方法将属性值解析为键和元素的数组;它通过生成从与其关联的属性的值派生的元素值集合来实现这一点。使用`BuildValueArray()`创建索引值数组时,其结构适合索引。
`BuildValueArray()`方法的名称为`PropertyNameBuildValueArray()`,其签名为:
```java
ClassMethod propertynameBuildValueArray(value, ByRef valueArray As %Library.String) As %Status
```
- `BuildValueArray()`方法的名称以组合方法的典型方式派生于属性名。
- 第一个参数是属性值。
- 第二个参数是通过引用传递的数组。
这是一个包含键-元素对的数组,键下标的数组等于元素。
- 该方法返回一`%Status` 值。
这个例子:
```java
/// DescriptiveWords是一个以逗号分隔的单词字符串
Property DescriptiveWords As %String;
/// 基于描述词的索引
Index dwIDX On DescriptiveWords(ELEMENTS);
/// 方法的作用是:演示如何在属性的子值上建立索引。
///
/// (如果DescriptiveWords被定义为一个集合,则不需要此方法。)
ClassMethod DescriptiveWordsBuildValueArray(
Words As %Library.String = "",
ByRef wordArray As %Library.String)
As %Status {
If Words '= "" {
For tPointer = 1:1:$Length(Words,",") {
Set tWord = $Piece(Words,",",tPointer)
If tWord '= "" {
Set wordArray(tPointer) = tWord
}
}
}
Else {
Set wordArray("TODO") = "Enter keywords for this person"
}
Quit $$$OK
}
```
在本例中,`dwIDX`索引基于`DescriptiveWords`属性。
`DescriptiveWordsBuildValueArray()`方法接受由`Words`参数指定的值,基于该值创建一个索引值数组,并将其存储在`wordArray`中。
InterSystems IRIS在内部使用`BuildValueArray()`实现;
不调用此方法。
注意:没有必要将任何元素/键值建立在属性值的基础上。
唯一的建议是,每次向该方法传递给定值时,都创建相同的元素和键数组。
为各种实例的描述性词所属性设置值和检查这些值的属性涉及活动(如以下):
```java
SAMPLES>SET empsalesoref = ##class(MyApp.Salesperson).%OpenId(3)
SAMPLES>SET empsalesoref.DescriptiveWords = "Creative"
SAMPLES>WRITE empsalesoref.%Save()
1
SAMPLES>SET empsalesoref = ##class(MyApp.Salesperson).%OpenId(4)
SAMPLES>SET empsalesoref.DescriptiveWords = "Logical,Tall"
SAMPLES>WRITE empsalesoref.%Save()
1
```
这 `sample index`内容,例如:
DescriptiveWords(ELEMENTS) | ID | Data
---|---|---
" CREATIVE" |3 |""
" ENTER KEYWORDS FOR THIS PERSON"| 1 |""
" ENTER KEYWORDS FOR THIS PERSON"| 2| ""
" LOGICAL" |4| ""
" TALL"| 4| ""
注意:此表显示抽象中的索引内容。磁盘上的实际存储形式可能会有所变化。
### 将数组(元素)上的索引投影到子表
要在嵌入式对象中索引属性,需要在引用该嵌入式对象的持久化类中创建索引。
属性名必须指定表(`%Persistent`类)中的引用字段的名称和嵌入对象(`%SerialObject`)中的属性的名称,如下面的示例所示:
```java
Class Sample.Person Extends (%Persistent) [ DdlAllowed ]
{ Property Name As %String(MAXLEN=50);
Property Home As Sample.Address;
Index StateInx On Home.State;
}
```
此处`Home`是`Sample.Person`中引用嵌入对象`Sample.Address`的属性,该对象包含`State`属性,如下例所示:
```java
Class Sample.Address Extends (%SerialObject)
{ Property Street As %String;
Property City As %String;
Property State As %String;
Property PostalCode As %String;
}
```
**只有与持久类属性引用相关联的嵌入对象的实例中的数据值被索引。不能直接索引`%SerialObject`属性**。`%Library.SerialObject`(以及`%SerialObject`的所有未显式定义`SqlCategory`的子类)的`SqlCategory`为字符串。
还可以使用`SQL CREATE INDEX`语句在嵌入式对象属性上定义索引,如下例所示:
```sql
CREATE INDEX StateIdx ON TABLE Sample.Person (Home_State)
```
### 类中定义的索引注释
当在类定义中使用索引时,需要记住以下几点:
- **索引定义仅从主(第一个)超类继承。**
- **如果使用Studio添加(或删除)数据库中存储数据的类的索引定义,则必须使用“构建索引”中描述的过程之一来手动填充索引。**
## 使用DDL定义索引
如果你使用DDL语句来定义表,也可以使用以下DDL命令来创建和删除索引:
- `CREATE INDEX`
- `DROP INDEX`
`DDL index`命令执行以下操作:
1. 它们更新在其上添加或删除索引的相应类和表定义。
重新编译修改后的类定义。
2. 它们根据需要在数据库中添加或删除索引数据:`CREATE index`命令使用当前存储在数据库中的数据填充索引。
类似地,`DROP INDEX`命令从数据库中删除索引数据(即实际索引)。
文章
姚 鑫 · 三月 30, 2021
# 第十四章 使用SQL Shell界面(一)
# 执行SQL的其他方式
可以使用`$SYSTEM.SQL.Execute()` 方法从Terminal命令行执行一行SQL代码,而无需调用SQL Shell。以下示例显示如何在终端提示下使用此方法:
```sql
DHC-APP>SET result=$SYSTEM.SQL.Execute("SELECT TOP 5 name,dob,ssn FROM Sample.Person")
DHC-APP>DO result.%Display()
Name DOB SSN
yaoxin 54536 111-11-1117
xiaoli 111-11-1111
姚鑫 63189 111-11-1112
姚鑫 63189 111-11-1113
姚鑫 50066 111-11-1114
5 Rows(s) Affected
```
如果SQL语句包含错误,则`Execute()`方法成功完成;否则,该方法无效。 `%Display()`方法返回错误信息,例如:
```java
USER>DO result.%Display()
[SQLCODE: :]
[%msg: < Field 'GAME' not found in the applicable tables^ SELECT TOP ? game ,>]
0 Rows Affected
USER>
```
`Execute()`方法还提供了可选的`SelectMode`、`Dialect`和`ObjectSelectMode`参数。
InterSystems IRIS支持许多其他编写和执行SQL代码的方法
这些包括:
- 嵌入式SQL:嵌入ObjectScript代码中的SQL代码。
- 动态SQL:使用`%SQL`。
从ObjectScript代码中执行SQL语句的语句类方法。
- 管理门户SQL接口:使用Execute Query接口从InterSystems IRIS管理门户执行动态SQL。
# 调用SQL Shell
可以使用`$SYSTEM.SQL.Shell()`方法在终端提示符中调用SQL Shell,如下所示:
```java
DO $SYSTEM.SQL.Shell()
```
或者,可以使用%SQL作为一个实例调用SQL Shell。
Shell类,如下所示:
```java
DO ##class(%SQL.Shell).%Go("IRIS")
```
或
```java
SET sqlsh=##class(%SQL.Shell).%New()
DO sqlsh.%Go("IRIS")
```
无论如何调用,SQL Shell都会返回SQL Shell提示符,如下所示:
```java
[SQL]termprompt>>
```
其中[SQL]是指在SQL Shell中,termprompt是配置的终端提示符,`>>`是指SQL命令行。
默认情况下,SQL Shell提示符如下所示:`[SQL]nsp>>`,其中`“nsp”`是当前命名空间的名称。
```java
DHC-APP>DO $SYSTEM.SQL.Shell()
SQL Command Line Shell
----------------------------------------------------
The command prefix is currently set to: .
Enter q to quit, ? for help.
DHC-APP>> >
1>>
1>>SELECT TOP 5 name,dob,ssn FROM Sample.Person
2>>
2>>q
DHC-APP>>q
```
在这个提示符下,可以使用以下任一Shell模式:
- 单行模式:在提示符下键入一行SQL代码。
结束SQL语句,按`“Enter”`。
默认情况下,这将准备并执行SQL代码(这称为立即执行模式)。
对于查询,结果集显示在终端屏幕上。
对于其他SQL语句,将在终端屏幕上显示SQLCODE和行数值。
- 多行模式:在提示符下按Enter。这使进入多行模式。可以键入多行SQL代码,每个新行提示均指示行号。 (空行不会增加行号。)要结束多行SQL语句,请键入GO并按Enter。默认情况下,这既准备并执行SQL代码。对于查询,结果集显示在终端屏幕上。对于其他SQL语句,SQLCODE和行计数值显示在终端屏幕上。
多行模式提供以下命令,可以在多行提示符下键入以下命令,然后按Enter:`L`或`LIST`列出到目前为止输入的所有SQL代码。 `C`或`CLEAR`删除到目前为止输入的所有SQL代码。 `C n`或`CLEAR n`(其中`n`是行号整数)以删除特定的SQL代码行。 `G`或`GO`准备和执行SQL代码,然后返回单行模式。 `Q`或`QUIT`删除到目前为止输入的所有SQL代码并返回单行模式。这些命令不区分大小写。发出命令不会增加下一个多行提示的行号。打`?`在多行提示符处列出了这些多行命令。
为了准备一条SQL语句,SQL Shell首先验证该语句,包括确认指定的表存在于当前名称空间中,并且指定的字段存在于表中。如果不是,它将显示适当的SQLCODE。
如果该语句有效,并且具有适当的特权,则SQL Shell会回显SQL语句,并为其分配一个序号。无论您是否更改名称空间和/或退出并重新进入SQL Shell,这些数字在终端会话期间都将按顺序分配。这些分配的语句编号允许重新调用以前的SQL语句,如下所述。
也可以使用`DO Shell^%apiSQL`.在终端提示下调用SQL Shell。
要列出所有可用的SQL Shell命令,请输入`?`。在SQL提示下。
要终止SQL Shell会话并返回到`Terminal`提示符,请在SQL提示符下输入`Q`或`QUIT`命令或`E`命令。 SQL Shell命令不区分大小写。
以下是使用默认参数设置的示例SQL Shell会话:
```java
DHC-APP>DO $SYSTEM.SQL.Shell()
SQL Command Line Shell
----------------------------------------------------
The command prefix is currently set to: .
Enter q to quit, ? for help.
DHC-APP>>SELECT TOP 5 Name,Home_State FROM Sample.Person ORDER BY Home_State
1. SELECT TOP 5 Name,Home_State FROM Sample.Person ORDER BY Home_State
Name Home_State
xiaoli
姚鑫
姚鑫
姚鑫
姚鑫
5 Rows(s) Affected
statement prepare time(s)/globals/lines/disk: 0.0523s/45502/270281/2ms
execute time(s)/globals/lines/disk: 0.0004s/225/2915/0ms
---------------------------------------------------------------------------
DHC-APP>>q
```
以下是使用默认参数设置的多行SQL Shell会话:
```java
DHC-APP>DO $SYSTEM.SQL.Shell()
SQL Command Line Shell
----------------------------------------------------
The command prefix is currently set to: .
Enter q to quit, ? for help.
DHC-APP>> >
1>>SELECT TOP 5
2>>Name,Home_State
3>>FROM Sample.Person
4>>ORDER BY Home_State
5>>GO
2. SELECT TOP 5
Name,Home_State
FROM Sample.Person
ORDER BY Home_State
Name Home_State
xiaoli
姚鑫
姚鑫
姚鑫
姚鑫
5 Rows(s) Affected
statement prepare time(s)/globals/lines/disk: 0.0002s/18/1168/0ms
execute time(s)/globals/lines/disk: 0.0003s/225/2886/0ms
---------------------------------------------------------------------------
```
## GO命令
SQL Shell `GO`命令执行最新的SQL语句。在单行模式下,`GO`重新执行最近执行的SQL语句。在多行模式下,`GO`命令用于执行多行SQL语句并退出多行模式。单行模式下的后续`GO`将重新执行先前的多行SQL语句。
## 输入参数
SQL Shell支持使用`“?”`输入参数的使用SQL语句中的字符。每次执行SQL语句时,系统都会提示指定这些输入参数的值。必须以与`“?”`相同的顺序指定这些值字符出现在SQL语句中:第一个提示为第一个`“?”`提供一个值,第二个提示为第二个`“?”`提供一个值,依此类推。
输入参数的数量没有限制。可以使用输入参数将值提供给`TOP`子句,`WHERE`子句,并将表达式提供给`SELECT`列表。不能使用输入参数将列名提供给`SELECT`列表。
可以将主机变量指定为输入参数值。在输入参数提示下,指定一个以冒号(:)开头的值。该值可以是公共变量,ObjectScript特殊变量,数字文字或表达式。然后,SQL Shell会提示“这是文字(Y / N)吗?”。在此提示下指定N(否)(或仅按Enter)意味着将输入值解析为主机变量。例如,`:myval`将被解析为局部变量myval的值; `:^ myval`将被解析为全局变量`^myval`的值; `:$HOROLOG`将被解析为`$HOROLOG`特殊变量的值; `:3`将被解析为数字3; `:10-3`将被解析为数字`7`。在此提示符下指定Y(是)表示将输入值(包括冒号)作为文字提供给输入参数。
## 执行ObjectScript命令
在SQL Shell中,可能希望发出一个ObjectScript命令。例如,通过使用`SET $NAMESPACE`命令将InterSystems IRIS命名空间更改为包含要引用的SQL表或存储过程的命名空间。可以使用SQL Shell!命令或OBJ命令以发出由一个或多个ObjectScript命令组成的ObjectScript命令行。 (OBJ是OBJECTSCRIPT的缩写。)!,OBJ和OBJECTSCRIPT命令是同义词。以下示例显示了这些命令的用法:
```java
%SYS>DO $SYSTEM.SQL.Shell()
SQL Command Line Shell
----------------------------------------------
The command prefix is currently set to: .
Enter q to quit, ? for help.
[SQL]%SYS>>! SET oldns=$NAMESPACE SET $NAMESPACE="USER" WRITE "changed the namespace"
changed the namespace
[SQL]USER>>OBJ SET $NAMESPACE=oldns WRITE "reverted to old namespace"
reverted to old namespace
[SQL]%SYS>>
```
OBJ命令之后的其余命令行被视为ObjectScript代码。 !之间不需要空格。和ObjectScript命令行。可以在SQL Shell单行模式或SQL Shell多行模式下指定OBJ命令。以下示例在USER名称空间中定义的表上执行SELECT查询:
```java
%SYS>DO $SYSTEM.SQL.Shell()
SQL Command Line Shell
----------------------------------------------
The command prefix is currently set to: .
Enter q to quit, ? for help.
[SQL]%SYS>> >
1>>OBJ SET $NAMESPACE="USER"
1>>SELECT TOP 5 Name,Home_State
2>>FROM Sample.Person
3>>GO
/* SQL query results */
[SQL]USER>>
```
请注意,OBJ语句不会增加SQL行数。
在SQL Shell多行模式下,在返回行时将执行OBJ命令,但是直到指定`GO`才发出SQL语句。因此,以下示例在功能上与先前的示例相同:
```java
%SYS>DO $SYSTEM.SQL.Shell()
SQL Command Line Shell
----------------------------------------------
The command prefix is currently set to: .
Enter q to quit, ? for help.
[SQL]%SYS>> >
1>>SELECT TOP 5 Name,Home_State
2>>FROM Sample.Person
3>>OBJ SET $NAMESPACE="USER" WRITE "changed namespace"
changed namespace
3>>GO
/* SQL query results */
[SQL]USER>>
```
以下示例使用OBJ命令定义主机变量:
```java
USER>DO $SYSTEM.SQL.Shell()
SQL Command Line Shell
----------------------------------------------
The command prefix is currently set to: .
Enter q to quit, ? for help.
[SQL]USER>> >
1>>SELECT TOP :n Name,Home_State
2>>FROM Sample.Person
3>>OBJ SET n=5
3>>GO
```
## 浏览命名空间
SQL Shell支持BROWSE命令,该命令显示在当前名称空间中定义或可从其访问的架构,表和视图。该显示包括多个级别的提示。要返回上一个提示级别,请在提示时按`Return`键。名称区分大小写。
1. 在SQL Shell提示符下键入BROWSE,以列出当前名称空间中的架构。
2. 在“架构:”提示下,按名称或编号选择一个架构。这将列出架构中的表和视图。
3. 在“表/视图:”提示下,按名称或编号选择一个表(T)或视图(V)。这将显示表信息,然后显示选项列表。
4. 在“选项:”提示下,按编号选择一个选项。可以使用此选项列出为表定义的字段或映射。
指定选项1(按名称表示的字段)或选项2(按数字表示的字段)以显示“Field:”提示。指定选项3(地图)以显示“Map:”提示。
5. 在`“Field:”`提示下,按数字或名称选择一个字段,或指定*以列出所有字段。这列出了详细的字段信息。
在`“Map:”`提示下,按数字或名称选择地图,或指定`*`列出所有Map。这列出了详细的Map信息。
## CALL 命令
可以使用SQL Shell发出SQL `CALL`语句来调用SQL存储过程,如以下示例所示:
```java
DHC-APP>>CALL Sample.PersonSets('G','NY')
3. CALL Sample.PersonSets('G','NY')
Dumping result #1
Name DOB Spouse
Gallant,Thelma Q. 45767 94
Gibbs,Mark S. 37331 13
Goldman,Will H. 59069 10
Gomez,Mo Q. 55626 55
Gore,Alfred M. 42991 13
Gore,Fred X. 32391 6
Grabscheid,Jocelyn B. 59676 79
7 Rows(s) Affected
Dumping result #2
Name Age Home_City Home_State
Chadbourne,Danielle G. 34 Pueblo NY
Eastman,Clint G. 4 Miami NY
Pape,Linda M. 71 Vail NY
Peterson,Janice N. 49 Islip NY
Schaefer,Jocelyn V. 93 Zanesville NY
5 Rows(s) Affected
statement prepare time(s)/globals/lines/disk: 0.0043s/2153/15795/0ms
execute time(s)/globals/lines/disk: 0.0015s/315/7829/0ms
---------------------------------------------------------------------------
```
如果指定的存储过程在当前名称空间中不存在,则SQL Shell会发出`SQLCODE -428`错误。
如果指定的输入参数多于存储过程中定义的参数,则SQL Shell会发出`SQLCODE -370`错误。可以使用文字(`“字符串”`),主机变量(`:var`)和输入参数(`?`)的任意组合为存储过程指定参数值。
可以在`CALL`语句中使用主机变量,如以下示例所示:
```java
[SQL]USER>>OBJ SET a="G",b="NY"
[SQL]USER>>CALL Sample.PersonSets(:a,:b)
```
- 可以在`CALL`语句中使用输入参数(`“?”`字符),如以下示例所示:
```java
[SQL]USER>>CALL Sample.PersonSets(?,?)
```
当执行`CALL`语句时,SQL Shell会提示为每个输入参数提供一个值。
## 执行SQL脚本文件
SQL Shell `RUN`命令执行一个SQL脚本文件。脚本文件的类型由`DIALECT`设置确定。 `DIALECT`的默认值为IRIS(InterSystems SQL)。
文章
Qiao Peng · 三月 17
近来生成式大语言模型掀起了革命性的AI浪潮。生成式大语言模型是什么原理?我们怎么在业务中利用它?
一. 大语言模型的工作原理
生成式大语言模型是生成式人工智能底层的机器学习模型,是一种用于自然语言处理的深度学习模型。
人工智能、机器学习与大语言模型的关系如下图:
1.1 为什么我们称之为大语言模型?
大语言模型的“大”体现在多个方面:
首先,模型尺寸巨大,尤其是它的参数数量。例如GPT3有1750亿的参数;
其次,大语言模型是在巨大的算力基础上,基于海量语料进行训练的。例如Meta的Llama 2 的训练数据达到了两万亿个词(token);
再次,大语言模型是为解决通用问题,而非特定问题构建的。
1.2 大语言模型是怎么训练的?
大语言模型是事先训练好的模型。
训练时,大语言模型基于各种语料 - 人类知识库(例如Wikipedia)、公共数据集、网络爬虫数据,让模型进行“填空”练习,并经过人工编辑和“校对” 训练出来的,需要成千上万的GPU建立集群进行训练。根据Meta的信息,其Llama 2 的训练数据达到了两万亿个token,上下文长度为4096,对话上也是使用100万人类标记的数据微调。
运行时,训练产生的大语言模型可以在小的多的硬件上运行。
1.3 大语言模型的机器学习算法
冰冻三尺,非一日之寒;滴水穿石,非一日之功。生成式大语言模型能够落地经历了相当漫长的技术积累与进步。
大语言模型使用的机器学习算法是优化过的神经网络(Neural Network)。
神经网络发明于上世纪40-50年代,本质上是一个曲线拟合算法,通过拟合多个、多层的Softplus(曲线)、ReLU(Rectified Linear Unit 折线)、Sigmoid(对数线),实现对任意曲线的拟合。
“神经网络”名字听起来很高大上,但并不是脑科学的产物。因为发明时,觉得算法中每个节点像神经元、每个连线像神经触突,因此称为神经网络。
它很早就应用于自动控制领域。后来发展出多种神经网络算法,例如用于图像识别的卷积神经网络(CNN)、很早就用于语言学习的递归神经网络(RNN)…
在大语言模型成熟前,自然语言处理进化出过众多的技术,例如词袋、词汇矢量化、基于递归神经网络的模型、超长短期记忆网络(LSTM)… 但都在能力和算力上有众多缺陷,无法用于有实用价值的内容生成领域。
虽然它们不能实现实用化的内容生成,但为内容生成式大语言模型落地打下了基础,也是我们了解大语言模型前必须了解的预备知识。
1.3.1 分词(Tokenization)
词汇是语言模型分析的最小语义单位,所以第一步要把语句拆分成词汇(token)。分词并不简单,例如中文语句的分词就无法通过空格区分。所以用于大语言模型的分词算法也是基于海量语料训练出来的。
而基于大语言模型的内容生成,就是基于当前的所有token,预测下一个token,从而产生完整的内容。
1.3.2 词汇和语句的矢量化
机器学习算法基本只能处理数字,无法处理文本、声音、图像等非数字内容。所以要处理语言,需要对语句进行矢量化的表达,将其转换为数字。
拿我们常玩的一个游戏做解释:一个人在头脑里想象一个事物,让另一个人猜。另一个人可以问任何问题,但第一个人只能回答是和否。例如问:是动物吗?答:是;问:是哺乳动物吗?答:不是。问:有脚吗?答:是。
这个游戏的过程就是用不同维度来验证和归类一个事物,最终可以让这个事物在不同的维度上得以表达,即这个事物在一个高维度矢量空间上可以得到一个定位(矢量),同时相近的概念在矢量空间互相接近。
大语言模型通过大规模语料训练用神经网络将每个词汇在一个高维度空间矢量化,得到表达矢量的数组,将词汇矢量化到如下示意的矢量空间中:
这里的矢量化出来的是密集矢量,即每个维度上都不是0,且维度数固定,从而用更少的字节中存在更多的信息,因此在计算上的利用成本更低。相较于稀疏矢量的例子,例如书籍的归类:科学、言情、教育、音乐… ,词汇和语句的矢量结果密集度高的多,因此是密集矢量。
而语句矢量化在词汇矢量化的基础上,要将词汇在句子中的顺序信息加入,从而将“小明追老虎”和“老虎追小明”这两个词汇完全相同但语义完全不同的句子在矢量化输出上能够加以区分。
1.3.3 基于大语言的矢量化模型
将词汇和语句矢量化,是迈向我们如今看到的生成式大语言模型的第二步。
不同的语言矢量化模型生成的密集矢量维度数是不一样的,越高的维度数的密集矢量需要越大的计算资源和越大的内存消耗。下面是一些常见的矢量化语言模型和它们的维度数:
模型
维度数量
BERT (Bidirectional Encoder Representations from Transformers)
768或1024
GPT (Generative Pre-trained Transformer)
768或1600
Word2Vec
300
USE (Universal Sentence Encoder)
512
MiniLM
384
1.3.4 矢量相似度查询
词汇和句子矢量化后,怎么找到相似的词汇和句子?
对两个矢量进行相似度查询,就是计算两个矢量间的“距离”。有很多算法,如下图中所示的这些常见算法。
在大规模、高维度矢量数据库中查找近义词,如果采用与矢量记录逐一计算相似度的方法,将需要巨大的计算量,其效率并不能满足实用的性能需求。
而实际需求并不需要精确的相似度,因此出现了近似近邻算法(Approximate Nearest Neighbors - ANN)解决效率问题。ANN有多种算法,例如Annoy (Approximate Nearest Neighbors Oh Yeah)、 HNSW (Hierarchical Navigable Small World)。
下图是Annoy算法的示意图:
在矢量数据集中随机找2个矢量,计算出一个矢量平面到2个矢量的距离相同,从而将矢量数据集分割成2个空间;然后再在每个空间里重复上面的过程,直到分割后的空间里矢量数量与目标相似度矢量数量一致(例如我们希望得到返回矢量数量为10个以内的相似度结果集,那么如果空间内的矢量数小于等于10,就停止上述过程);从而我们得到一个决策树,今后可以用这个决策树进行矢量相似度查询,显然会快很多。
因为Annoy是基于最初的随机选择的2个矢量开始决策树构建的,如果这2个矢量本身就是高度相似的,那这2个矢量永远不会被一个矢量相似度查询要求同时命中,从而带来显著的误差。怎么办?可以随机多选几组初始矢量,从而形成多棵决策树的决策森林,提高ANN的精度。
可见ANN是大规模矢量检索查询的核心。
1.3.5 生成式大语言模型
递归神经网络(recurrent neural network - RNN)很早就应用到自然语言处理领域,之后出现了RNN改进模型LSTM (Long short-term memory),它们按顺序处理输入语句的词汇,并行能力不足,而且越高阶的神经网络需要的算力越高,达不到实用化的性能需求。
在2017年Google一个小团队(Transformer八子)发表了一篇论文 - Attention Is All You Need, 阐述了一类特殊的神经网络 – 基于注意力(Attention)机制的Transformer。它的注意力机制根据输入数据的长度执行固定步骤的计算,并且对输入数据的词汇(token)是并行计算的,它奠定了实用的生成式大语言模型的基础。这个团队的成员后大多离开了Google,并创立或加入了目前市场上几个主要生成式大语言模型。
在Transformer并行处理能力和越来越强大的GPU并行算力加持下,生成式大语言模型终是水到渠成,可以说是大力出奇迹!
当然Transformer模型具备多个特殊能力支撑内容生成能力。下面这张图解释了Transformer模型的4个核心特性:词汇矢量化(Word Embedding)、词汇在语句中位置的矢量化叠加(Positional Encoding)、自我注意力(Self-Attention)和残值连接(Residual Connections)。可见它其实构建在前面出现的技术基础之上。
借助这个新神经网络模型思路,众多大厂发布了自己的生成式大语言模型,如下面列出的这些著名的大语言模型。它们的宣传中常常强调其百亿级、甚至千亿级的参数:
模型
厂商
参数
GPT
OpenAI (Microsoft)
1750亿
Bard/Gemini
Google
18亿,32.5亿
PaLM2
Google
3400亿
Llama 2
Meta
70亿,130亿,700亿
Claude 2/3
Anthropic (Amazon)
未披露
Stable Beluga
Stability AI
70亿,130亿,700亿
Coral
Cohere
未披露
Falcon
Technology Innovation Institute
13亿,75亿,400亿,1800亿
MPT
Mosaic
70亿,300亿
往往参数规模越大,其生成的内容越精确和越富有创造力。那么这些参数指什么?无论是什么样的大语言模型,它们底层都是神经网络,这些参数主要就是指神经网络中的权重和偏差。
二. 大语言模型应用中的问题和检索增强生成
从机制上,生成式大语言模型并不神秘。虽然它展现出了强大的理解能力甚至“创造力”,但它有以下几个问题:
它的知识来自于训练语料,并不知道所有知识。例如GPT-4 截止训练数据的时间是2022年1月份,对于后来的世界一无所知,更不可能知道您的机构中的未开放数据。
它是基于通用数据训练的,对于特定领域往往训练不足。
它的内容生成机制是使用神经网络逐词预测出回答中的下一个词从而构成完整的语句。因此它本质上不会拒绝回答任何问题,虽然人类限制它回答诸如如何制作病毒类的问题。结合它的“无知”和“创造力”,对不知道的问题,它也能一本正经地胡说八道,这就是生成式大语言模型的“幻觉”。
生成式大语言模型的“幻觉”在目前的应用中非常常见。例如我问了Bing Copilot一个关于“什么是InterSystems IRIS互联互通套件?”的问题,它不懂但没有拒绝回答,而且回答地相当“幻觉”:
如果想在我们自己的业务中直接应用生成式大语言模型,让它提供患者教育,或者回复患者的预约查询、亦或回答患者关于他/她自己的用药注意事项?显然不靠谱。
是不是可以用我们自己的数据进行训练?一来很多大模型都不是开放的,无法自己训练;二来相信大家都没有训练大语言模型的昂贵算力。
怎么解决这个问题?
大语言模型其实有三次“训练”机会:
预先训练就是大语言模型厂商通过海量语料进行的训练,我们干不了;
调优训练需要基于开放的大语言模型,算力成本也不低;
所以我们可以通过“提示”,让生成式大语言模型给我们想要的答案。
我又试了一次让Bing Copilot回答“什么是InterSystems IRIS互联互通套件?”,不过这次,我给了它提示,让它先读读关于InterSystems IRIS互联互通套件介绍的网页。这次它回答得相当到位:
也就是通过合适的提问,把本地数据提示给生成式大语言模型,从而让它可以准确回答而不会产生幻觉。
检索增强生成基于问题先在本地数据检索,将相关结果提示给生成式大语言模型,从而获得靠谱的回答,这就是检索增强生成(Retrieval Augmented Generation – RAG)。
这里的本地数据检索,是基于大语言的矢量相似度检索。所以,需要借助矢量数据库,对本地的数据矢量化保存、并提供基于问题的矢量相似度查询,从而基于问题给出最匹配的本地数据。
这里是完整的检索增强生成流程示意图,分为2个过程:
1. 基于本地数据建立矢量知识库的过程
预先建立知识库, 将本地文档切分成文本段
使用矢量化语言模型对数据矢量化
将矢量保存到矢量知识库
2. 借助本地矢量知识库和外部大语言模型回答问题的过程
使用矢量化模型将问题矢量化
在矢量数据库中检索与问题相关的矢量记录
将匹配的数据(知识)作为上下文组织到完整的问题与提示中,向大语言模型提问。例如提示模版是:请仅使用以下上下文回答问题
从大语言模型得到回答
由此可见,检索增强生成至少需要以下3个技术组件:
矢量数据库 – 用于本地数据的矢量化保存和矢量化查询
矢量化语言模型 – 用于将本地数据和问题矢量化
内容生成语言模型 – 用于基于问题和上下文生成自然语言回答
矢量化语言模型、内容生成语言模型都有很多选择,根据需要可以选择能部署到本地的模型、也可以选择厂商提供的云服务。
而矢量数据库是保存本地知识数据的矢量化版本的,市面上常见的是一些nonSQL的专用数据库,也就是说需要将本地数据迁移到矢量数据库,并专门学习其数据操作的API。
可以预见,生成式大语言模型的能力将迅速进化,但本地的知识和数据并不会以如此快的速度发生变化。因此RAG将本地的知识和数据通过矢量化与生成式大语言模型集成,借助其不断提升的强大能力又无需被任何一个模型绑架,将是一个合理的解决方案。
三. InterSystems IRIS的内容生成架构
InterSystems IRIS是应用在众多行业的通用数据平台,并在2024版本中加入了对矢量存储和查询的支持,无需将IRIS中已经保存的本地知识数据迁移到别的矢量数据库中,从而消除数据迁移时间差、额外部署矢量数据库的运维成本,同时降低敏感数据泄露风险、确保遵循特定行业中对数据迁移监管的要求。而InterSystems IRIS作为一个具有互操作能力的数据平台,可以轻松集成大语言模型,并建立和管理检索增强生成的pipeline,降低RAG的技术实现复杂度。
3.1 IRIS的矢量存储和矢量查询
IRIS提供矢量数据类型,它被完全集成在IRIS多模型的架构中,尤其使用SQL就可以完整使用矢量存储和查询。
例如要创建含有矢量类型字段vec的表:
CREATE TABLE t (txt VARCHAR(1000), vec VECTOR(INT, 200));
向矢量字段vec中插入数据:
INSERT INTO t VALUES (‘…’, TO_VECTOR(‘1,2,3,…’, INT));
这里的矢量数据是需要通过调用矢量化模型产生的。
基于矢量相似度查询最接近的10条记录:
SELECT TOP 10 * FROM
FROM ( SELECT t.*, VECTOR_DOT_PRODUCT(vec, TO_VECTOR(…)) AS similarity FROM t )
ORDER BY similarity DESC;
3.2 IRIS的矢量索引
IRIS进一步提供了更易使用的矢量索引:无需创建矢量字段,直接在现有数据表上就可以创建声明式的矢量索引,并自动调用集成的矢量化模型,从而使用SQL就可以免代码方式进行开发。
创建矢量索引 – 通过索引对title、author和article这3个字段组合进行矢量化:
CREATE INDEX Vec ON MyNews(Title, Author, Article) AS VectorIndex(MODEL=‘BERT’);
执行矢量查询 – 查询与条件最近似的3条记录:
SELECT TOP 3 * FROM MyNews WHERE Category = ‘NYT’
ORDER BY MyTable_VecSim(%ID, ‘climate change’);
3.3 基于IRIS构建完整的RAG方案
基于最新发布的InterSystems IRIS 2024.1,和部署到本地的矢量化模型(all-MiniLM-L12-v2)、内容生成模型(llama2),我构建了一个RAG原型:
这里IRIS实例即是保存本地数据的数据平台,也是本地数据的矢量化数据库,从而避免了数据的跨平台迁移。而全SQL的数据操作能力,让构建在自己数据上的检索增强生成方案能快速落地。
现在就把生成式大语言模型集成到您自己的业务中吧!注:本文中的部分图片来自StatQuest、medium、wikipedia和weaviate。