清除过滤器
文章
Michael Lei · 三月 10, 2023
InterSystems IRIS 2022.2 具有适用于 Python 的原生 SDK (https://docs.intersystems.com/iris20222/csp/docbook/Doc.View.cls?KEY=PAGE_python_native)。
我们知道如何使用 IRIS Object Script $Order 函数遍历Global数据结构。
SET key= "" FOR { SET key= $ORDER ( ^myglobal (key)) QUIT :key= "" WRITE !, ^myglobal (key) }
如何使用 IRIS Native SDK 从 Python 执行相同的操作?这里有一个代码示例:
import iris
args = { 'hostname' : '127.0.0.1' , 'port' : 51772 , 'namespace' : 'USER' , 'username' : '_SYSTEM' , 'password' : 'SYS' }
conn = iris.connect(**args)
# Create an iris object
irispy = iris.createIRIS(conn)
# Create a global array in the USER namespace on the server
irispy.set( 'A' , 'root' , 'foo' , 'SubFoo' )
irispy.set( 123 , 'root' , 'bar' , 'lowbar' , 'UnderBar' )
irispy.set( 124 , 'root' , 'bar' , 'lowbar' , 'UnderBar2' )
irispy.set( "hi" , 'root' , 'bar' , 'lowbar' )
irispy.set( "hi again" , 'root' , 'bar3' )
# Read the values from the database and print them
subfoo_value = irispy.get( 'root' , 'foo' , 'SubFoo' )
underbar_value = irispy.get( 'root' , 'bar' , 'lowbar' , 'UnderBar' )
underbar2_value = irispy.get( 'root' , 'bar' , 'lowbar' , 'UnderBar2' )
lowbar_value = irispy.get( 'root' , 'bar' , 'lowbar' )
bar3_value = irispy.get( 'root' , 'bar3' )
print( 'Created two values: ' )
print( ' root("foo","SubFoo")=' , subfoo_value)
print( ' root("bar","lowbar","UnderBar")=' , underbar_value)
print( ' root("bar","lowbar","UnderBar2")=' , underbar2_value)
print( ' root("bar","lowbar")=' , lowbar_value)
print( ' root("bar3")=' , bar3_value)
direction = 0 # direction of iteration (boolean forward/reverse)
next_sub = chr( 0 ) # start at first possible subscript
subs = []
print( "\n Iterating root \n" )
isDef = irispy.isDefined( 'root' , *subs)
while isDef:
next_sub = irispy.nextSubscript( False , 'root' , *subs, next_sub) # get first subscript
if next_sub == None : # we finished iterating nodes on this tree branch, move a level up
if len(subs) == 0 : # no more things to iterate
break
next_sub = subs.pop( -1 ) # pop last subscript in order to continue iterating this level
if irispy.isDefined( 'root' , *subs, next_sub) == 11 :
print( 'root(' ,*subs, next_sub, ')=' ,irispy.get( 'root' , *subs, next_sub))
continue
continue
isDef = irispy.isDefined( 'root' , *subs, next_sub)
if isDef in [ 10 , 11 ]: # keep building subscripts for depth first search
subs.append(next_sub)
next_sub = chr( 0 )
continue
elif isDef == 1 : # reached a leaf node, print it
print( 'root(' ,*subs, next_sub, ')=' ,irispy.get( 'root' , *subs, next_sub))
else : # def 0 is not really expected
print( "error" )
irispy.kill( 'root' )
conn.close()
exit( -1 )
# Delete the global array and terminate
irispy.kill( 'root' ) # delete global array root
conn.close()
文章
Lele Yang · 一月 30, 2022
Linux内核机制OOM Killer,也即Out of Memory Killer, 顾名思义,该机制的主要职能就是当内存不足时,选择并杀掉一些进程,以使系统继续运行。
Caché/Ensemble/IRIS的多个客户曾经遇到过与此相关的系统宕机,宕机的直接原因是数据库核心写进程Write Daemon被OOM Killer选中并杀掉了,在我们的日志文件中可以看到如下信息,
06/15/21-10:50:31:035 (13579) 3 Daemon WRTDMN (pid 13588) died. Freezing system
06/15/21-10:52:25:940 (13601) 2 System Process 'WRTDMN' terminated abnormally (pid 13588)
与之对应,在操作系统的日志文件中可以看到如下记录,
Jun 15 10:50:34 localhost kernel: Free swap = 0kB
Jun 15 10:50:34 localhost kernel: Total swap = 20479996kB
Jun 15 10:50:34 localhost kernel: 16777102 pages RAM
Jun 15 10:50:34 localhost kernel: 0 pages HighMem/MovableOnly
Jun 15 10:50:34 localhost kernel: 324506 pages reserved
Jun 15 10:50:30 localhost kernel: cache invoked oom-killer: gfp_mask=0x42d0, order=3, oom_score_adj=0
Jun 15 10:50:35 localhost kernel: Out of memory: Kill process 13588 (cache) score 127 or sacrifice child
InterSystems在后续的IRIS版本中(从IRIS2021.1.0开始)已经对此做了优化,以使Write Daemon不那么容易被OOM Killer选中。但是要从根本上解决该问题,还是应当重新审视系统的内存分配,如Huge Page,共享内存等,检查Linux内存相关参数,如vm.swappiness,vm.dirty_background_ratio,vm.dirty_ratio等,以使系统可以在内存使用方面达到最大的效用。
公告
Claire Zheng · 一月 25, 2022
亲爱的开发者们,
很高兴同大家分享一个好消息!我们中文社区版主、InterSystems高级销售工程师Louis(@Louis Lu)于近日顺利通过“HL7 FHIR R4 Proficiency Exam”并取得资格认证证书!
HL7 FHIR(R4)能力证书可以证明在最新和最热门的HL7标准方面达到行业公认的专业水平。考试涵盖了以下内容:FHIR原则;FHIR资源的基本概念;交换机制;一致性和实施指导;如何使用术语;如何建立安全和可靠的FHIR解决方案;FHIR维护过程;以及如何使用和处理FHIR许可和知识产权(IP)。
FHIR®(快速医疗互操作性资源)是HL7的下一代标准框架,它建立并结合了HL7第二版(V2)、第三版(V3)和临床文档架构(CDA®)产品线的最佳功能,同时利用了最新的网络标准并注重于实际实施的能力。FHIR适合在各种情况下使用,如手机应用程序、云通信、基于电子健康记录(EHR)的数据共享、大型医疗机构间服务器通信等等。FHIR还可以支持使用一个标准涵盖尽可能多的应用场景,实现医疗信息化真正意义的互操作性,是智慧医院数字化转型,实现组装式应用创新的重要基础。
一起来恭喜Louis(@Louis Lu)吧✿✿ヽ(°▽°)ノ✿✿✿ヽ(°▽°)ノ✿(*^▽^*) 恭喜🎉🎉
文章
Hao Ma · 一月 30, 2021
## 检查Apache工作状态
确认Apache正常工作, apache的版本已经安装路径。
[root@centos7 ~]# httpd -v
Server version: Apache/2.4.6 (CentOS)
Server built: Apr 24 2019 13:45:48
[root@centos7 ~]# systemctl status httpd
● httpd.service - The Apache HTTP Server
Loaded: loaded (/usr/lib/systemd/system/httpd.service; enabled; vendor preset: disabled)
Active: active (running) since Mon 2020-06-15 16:46:36 CST; 5min ago
Docs: man:httpd(8)
man:apachectl(8)
Main PID: 6506 (httpd)
Status: "Total requests: 0; Current requests/sec: 0; Current traffic: 0 B/sec"
Tasks: 272
Memory: 31.3M
CGroup: /system.slice/httpd.service
├─6506 /usr/sbin/httpd -DFOREGROUND
├─6592 /usr/sbin/httpd -DFOREGROUND
├─6607 /usr/sbin/httpd -DFOREGROUND
├─6608 /usr/sbin/httpd -DFOREGROUND
├─6609 /usr/sbin/httpd -DFOREGROUND
├─6610 /usr/sbin/httpd -DFOREGROUND
├─6611 /usr/sbin/httpd -DFOREGROUND
├─6612 /usr/sbin/httpd -DFOREGROUND
├─6613 /usr/sbin/httpd -DFOREGROUND
├─6622 /usr/sbin/httpd -DFOREGROUND
├─6623 /usr/sbin/httpd -DFOREGROUND
└─6633 /usr/sbin/httpd -DFOREGROUND
Jun 15 16:46:36 centos7 systemd[1]: Starting The Apache HTTP Server...
Jun 15 16:46:36 centos7 systemd[1]: Started The Apache HTTP Server.
[root@centos7 ~]#
确认httpd.conf的位置。 在CentOS7中此位置为/etc/httpd/conf, 其他linux系统可能有其他位置, 如果不确认,可以使用 find命令寻找.
[root@centos7 ~]# ll /etc/httpd/conf
total 56
-rw-r--r-- 1 root root 890 Jun 26 2019 healthshare.conf
-rw-r--r-- 1 root root 0 Jun 26 2019 healthshare.conf_save
-rw-r--r-- 1 root root 11786 Jun 30 2019 httpd.conf
-rw-r--r-- 1 root root 11753 Jun 26 2019 httpd.conf.bak
-rw-r--r-- 1 root root 11746 Jun 30 2019 httpd.conf2
-rw-r--r-- 1 root root 13077 Apr 24 2019 magic
[root@centos7 ~]#
从Caché所在服务器用浏览器检查Apache测试页面可以访问。如果在Apache本地服务器访问, 网址为127.0.0.1(如果远端无法访问,请首先检查防火墙,后面步骤中有介绍)
picture testing123
## 关闭SELinux配置
查询确认SELinux状态为disabled
[root@centos7 ~]# getenforce
Disabled
如果非disabled状态,需要修改配置文件实现, 下图为修改后的文件内容,修改后重启电脑生效。
[root@centos7 ~]# cat /etc/selinux/config
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of three two values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
[root@centos7 ~]#
## 检查防火墙
确认apache所在服务器的防火墙打开了80端口。(为简化步骤, 这里不讨论Web Server的SSL接入)
[root@centos7 ~]# systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: active (running) since Mon 2020-06-15 17:24:15 CST; 2s ago
Docs: man:firewalld(1)
Main PID: 27433 (firewalld)
Tasks: 2
Memory: 25.1M
CGroup: /system.slice/firewalld.service
└─27433 /usr/bin/python -Es /usr/sbin/firewalld --nofork --nopid
Jun 15 17:24:15 centos7 systemd[1]: Starting firewalld - dynamic firewall daemon...
Jun 15 17:24:15 centos7 systemd[1]: Started firewalld - dynamic firewall daemon.
[root@centos7 ~]# firewall-cmd --state
running
[root@centos7 ~]# firewall-cmd --zone=public --list-ports
[root@centos7 ~]# firewall-cmd --zone=public --add-port=80/tcp --permanent
Success
[root@centos7 ~]# firewall-cmd --reload
success
[root@centos7 ~]# firewall-cmd --zone=public --list-ports
80/tcp
[root@centos7 ~]
如果Caché安装在另一台服务器, Web gateway和Caché间的通信通过Caché的superserver端口(默认1972), 因此Caché所在服务器的防火墙必须运行此端口访问。
## 对Apache调优
如果apache的工作模式为Prefork, 通过修改配置文件后重启服务,将工作模式改成“worker”(下面cat命令显示修改后的配置文件)
[root@centos7 ~]# apachectl -V | grep MPM
Server MPM: prefork
[root@centos7 ~]# vim /etc/httpd/conf.modules.d/
[root@centos7 ~]# cat /etc/httpd/conf.modules.d/00-mpm.conf
# Select the MPM module which should be used by uncommenting exactly
# one of the following LoadModule lines:
# prefork MPM: Implements a non-threaded, pre-forking web server
# See: http://httpd.apache.org/docs/2.4/mod/prefork.html
#LoadModule mpm_prefork_module modules/mod_mpm_prefork.so
# worker MPM: Multi-Processing Module implementing a hybrid
# multi-threaded multi-process web server
# See: http://httpd.apache.org/docs/2.4/mod/worker.html
#
LoadModule mpm_worker_module modules/mod_mpm_worker.so
# Worker MPM parameters
ServerLimit 40
StartServers 10
MaxRequestWorkers 1000
MinSpareThreads 75
MaxSpareThreads 250
ThreadsPerChild 25
# event MPM: A variant of the worker MPM with the goal of consuming
# threads only for connections with active processing
# See: http://httpd.apache.org/docs/2.4/mod/event.html
#
#LoadModule mpm_event_module modules/mod_mpm_event.so
[root@centos7 ~]# systemctl restart httpd
[root@centos7 ~]# apachectl -V | grep MPM
Server MPM: worker
[root@centos7 ~]#
## 安装Web Gateway
最新的IRIS或者HealthConnect安装包可能不包含让用户选择是否安装csp/web gateway的选项, 因此大多数情况, 用户更多的是使用专门的Web/CSP gateway的安装包来安装, 无论Apach Server 和Caché/IRIS Server是否在同一台服务器上。
以下的介绍是用WebGateway 2020.1版本安装的过程。
1. 解压缩安装包到一个临时文件夹
[root@centos7 ~]# tar -xzf WebGateway-2020.1.0.197.0-lnxrhx64.tar.gz
2. 使用touch命令在/etc/httpd/conf.d目录下创建空配置文件isc.conf
Apaceh启动时会调用主配置文件/etc/httpd/conf/httpd.conf。 该文件的默认配置项中会自动include目录/etc/httpd/conf.d下的*.conf文件, 因此不同的应用创建不同的conf文件放在conf.d目录下是方便管理的通常做法。 这个.conf的文件名可以任意名字,isc.conf只是示意。(下一步安装Web Gateway时需要输入此名字)。
[root@centos7 httpd]# touch /etc/httpd/conf.d/isc.conf
同理手动 在 /opt/webgateway/bin 下面建立CSP.ini文件,并且赋予读写权限
3. 到解压后的安装包目录下的install子目录, 执行以下命令:
[root@centos7 ~]# cd WebGateway-2020.1.0.197.0-lnxrhx64/
[root@centos7 WebGateway-2020.1.0.197.0-lnxrhx64]# ls
install lnxrhx64
[root@centos7 WebGateway-2020.1.0.197.0-lnxrhx64]# cd install/
[root@centos7 install]# ./GatewayInstall
Starting Web Gateway installation procedure.
Please select WebServer type. Choose "None" if you want to configure
your WebServer manually.
1) Apache
2) None
WebServer type? [2] 1
Please enter location of Apache configuration file [/etc/httpd/conf/httpd.conf]: /etc/httpd/conf.d/isc.conf
Enter user name used by Apache server to run its worker processes :
Please enter location of Apache executable file :
Apache version 2.4 is detected.
Please enter destination directory for Web Gateway files [/opt/webgateway]:
Do you want to create directory /opt/webgateway [Y]:
Please enter hostname of your InterSystems IRIS server [localhost]: HCDEMO
Please enter superserver port number for your InterSystems IRIS server [51773]:
Please enter InterSystems IRIS configuration name [IRIS]: HCDEMO (注 这里的 configuration name 其实是csp.ini 中服务器的配置代称,可以任意起,不一定必填为服务器本身的hostname)
Please enter directory for static CSP content [/opt/webgateway/hcdemo]:
Do you want to create directory /opt/webgateway/hcdemo [Y]:
Installing InterSystems IRIS Web Gateway for Apache:
------------------------------------------------------------------
Apache configuration file: /etc/httpd/conf.d/isc.conf
InterSystems IRIS configuration name: HCDEMO
InterSystems IRIS server address: HCDEMO
InterSystems IRIS server port number: 51773
Web Gateway installation directory: /opt/webgateway
------------------------------------------------------------------
Do you want to continue and perform the installation [Y]:
Updating Apache configuration file ...
- /etc/httpd/conf.d/isc.conf
* You need to restart your Apache server before any
configuration changes will take effect.
Web Gateway configuration completed!
[root@centos7 install]#
安装结束后
- 检查安装目录被生成,并包含CSPGateway文件
- 检查isc.conf文件,确认文件已经被写入配置信息。
- 登录CSP Gateway管理页面查看: http://WebServer:80/csp/bin/Systems/Module.cxw
如果不是在Apache服务器访问而是远程登录该页面,此时会出现错误提示,显示CSP Gateway的版本信息和“You are not authorized to use this facility”的提醒。这是CSP Gateway的安全策略。默认不允许远程的访问,对于需要远程访问的源IP地址或者源网段,用户必须手工在CSP.ini配置文件的[SYSTEM]块里添加,比如添加 ”System_Manager=172.16.58.100",或者"System_Manger=172.16.*.*"。虽然不推荐,但"System_Manager=*.*.*.*”允许任意地址远程访问的远程访问。如果CSP.ini没有自动生成,那需要手动 在 /opt/webgateway/bin 下面建立此文件,并且赋予读写权限。 下面是添加System_Manager后的CSP.ini例子:
[root@centos7 bin]# cat /opt/webgateway/bin/CSP.ini
[SYSTEM_INDEX]
HCDEMO=Enabled
LOCAL=Enabled
[HCDEMO]
Ip_Address=HCDEMO
TCP_Port=51773
Minimum_Server_Connections=3
Maximum_Session_Connections=6
[APP_PATH_INDEX]
/=Enabled
/csp=Enabled
/hcdemo=Enabled
[APP_PATH:/]
Default_Server=HCDEMO
Alternative_Server_0=1~~~~~~HCDEMO
[APP_PATH:/csp]
Default_Server=HCDEMO
Alternative_Server_0=1~~~~~~HCDEMO
[APP_PATH:/hcdemo]
Default_Server=HCDEMO
Alternative_Server_0=1~~~~~~HCDEMO
[SYSTEM]
SM_Timeout=28800
Server_Response_Timeout=60
No_Activity_Timeout=86400
Queued_Request_Timeout=60
Configuration_Initialized=Tue Nov 17 07:58:29 2020
Configuration_Initialized_Build=2001.1740
System_Manager=*.*.*.*
[LOCAL]
Ip_Address=127.0.0.1
TCP_Port=1972
Minimum_Server_Connections=3
Maximum_Session_Connections=6
[root@centos7 bin]#
## 登录Web Gateway管理页面的抓图
检查Web Gateway的配置文件位置,版本,log位置
## 配置CSP Gateway到IRIS的连接,并测试从Apache登录IRIS维护界面
### 在CSP Gateway配置页面,查看Server Access。
Server Access中会列出这本CSP Gateway连接的IRIS实例的列表。在上面的安装步骤中,当问到了“ Please enter hostname of your InterSystems IRIS server [localhost]: HCDEMO ”选择了HCDEMO, 这时这个列表中会显示有两个Server, localhost和HCDEMO. (localhost无法被删除,遗憾)
下面检查HCDEMO Server的配置
- 检查服务器地址为127.0.0.1
- 添加到Caché服务器的账号密码,默认为CSPSystem, SYS
如果IIS服务器+Web Gateway和Caché位于两个不同的服务器, 或者需要添加到另一Caché Server的连接, 需要添加Server, 如下图,
需要的配置: Caché服务器的IP,superserver端口号, CSPSystem用于的密码,服务器的类型(可选)
**测试Caché Server连接成功**
双击左边菜单栏的"Test Server Connection", 确认结果中收到"Server connection test was successful: ...."的结果。
## 访问IRIS维护主页 (可选)
从链接 http://WebServer/csp/sys/Utilhome.csp 访问IRIS维护主页System Management Portal应该可以成功了,但您会发现有部分网页内容(element)无法加载。这是因为在默认的安装中,isc.conf中CSP Gateway路径的配置的"CSPFileTypes csp cls zen cxw"中只将这4种类型的请求发送给CSP Gateway, 而被称为Static file的文件,比如.js, .css, .png等等类型的文件并没有被发送给CSP Gateway. 这是另外的一个安全机制,强制客户人工的配置是否需要从Web服务器访问IRIS维护主页。如果答案是NO, 那么访问IRIS维护页面就只能通过PWS,用IRIS服务器的52773的接口。 如果用户认为从Web服务器访问IRIS维护页面是必要的, 需要修改CSPFileTypes配置,比如修改成"CSPFileTypes *",作用是把任意类型的请求发送给IRIS。以下是安装并修改后的isc.conf文件示例。
[root@centos7 conf.d]# cat isc.conf
#### BEGIN-ApacheCSP-SECTION ####
LoadModule csp_module_sa "/opt/webgateway/bin/CSPa24.so"
CSPModulePath "/opt/webgateway/bin/"
CSPConfigPath "/opt/webgateway/bin/"
Alias /csp/ "/opt/webgateway/hcdemo/csp/"
SetHandler csp-handler-sa
SetHandler csp-handler-sa
CSPFileTypes *
AllowOverride None
Options MultiViews FollowSymLinks ExecCGI
Require all granted
Require all denied
AllowOverride None
Options None
Require all granted
Require all denied
#### END-ApacheCSP-SECTION ####
#### BEGIN-ApacheCSP-SECTION-HCDEMO ####
Alias /hcdemo/csp/ "/opt/webgateway/hcdemo/csp/"
#### END-ApacheCSP-SECTION-HCDEMO ####
[root@centos7 conf.d]#
注意isc.conf修改后需要重启apache server
[root@centos7 conf.d]# systemctl restart httpd
[root@centos7 conf.d]#
## 访问IRIS上的其他Web Application
IRIS上其他的Web Application需要经过配置才可以发送到IRIS Server。这些Web Application可能是一个访问HTTP, REST的URL, 或者是一个用户自己定义的SOAP,甚至可能是一个简单的CSP文件。要确保他们被发送给IRIS Server, 用户需要:
1. 配置Apache配置文件isc.conf, 保证请求被发送给了CSP Gateway。 可以通过CSP Gateway管理页面的HTTP Trace来确认。
2. 如果需要,配置CSP Gateway, 将请求发送给IRIS.
### 访问带文件后缀的应用
在isc.conf中的中定义的是Web Server中文件对象的地址,比如"/opt/webgateway/bin/"是CSP Gateway的.so文件的存放位置。 Alias是URL中资源地址,比如"/csp/"到定义的映射。他们在apache中注册一个有后缀的文件的发送路径, 这个配置使得访问"http://WebServer/csp/sys/Utilhome.csp"可以成功发送给CSP Gateway。
Alias /csp/ "/opt/webgateway/hcdemo/csp/"
CSPFileTypes *
AllowOverride None
Options MultiViews FollowSymLinks ExecCGI
Require all granted
Require all denied
对于其他的Web Application, 比如如果需要将"http://WebServer/test/Hello.csp"成功发送给CSP Gateway, 需要添加以下配置,它把路径为”/test/"的URL发送给CSP Gateway处理。
Alias /test/ "/opt/webgateway/hcdemo/csp/"
测试连接一个SOAP服务,注意这个服务要在IRIS的Web Applicatin里配置正确,它至少可以从PWS用匿名用户访问。(关于Web Application的配置另行文档, 简单说, 要匿名访问, 要使用%Security_WebGateway的资源).测试结果:
[root@centos7 conf.d]# curl http://172.16.58.100/test/test.webservice1.cls?soap_method=winter
Winter is Coming...
[root@centos7 conf.d]#
### 访问其他URL应用
对于 “http://172.16.58.100/api/mgmnt/v2/”这样的URL地址, 映射到CSP Gateway处理需要的配置是。下面的配置保证对"/api/"开头的,没有文件地址的URL的处理:
SetHandler csp-handler-sa
CSP on
请求的结果如下:
[root@centos7 ~]# curl -X GET "http://172.16.58.100/api/mgmnt/v2/"
[{"name":"%Api.IAM.v1","webApplications":"/api/iam","dispatchClass":"%Api.IAM.v1.disp","namespace":"%SYS","swaggerSpec":"/api/mgmnt/v2/%25SYS/%25Api.IAM.v1"},{"name":"%Api.Mgmnt.v2","webApplications":"/api/mgmnt","dispatchClass":"%Api.Mgmnt.v2.disp","namespace":"%SYS","swaggerSpec":"/api/mgmnt/v2/%25SYS/%25Api.Mgmnt.v2"},{"name":"PetStore","dispatchClass":"PetStore.disp","namespace":"DEMO","swaggerSpec":"/api/mgmnt/v2/DEMO/PetStore"}][root@centos7 ~]#
备注: 如果得到了{"msg":"错误 #8754: Unable to use namespace: USER."},或者403 forbidden, 需要在IRIS上给Web Application "/api/mgmnt"添加”%DB_USER"的权限;或者,也可以将应用的“安全设置”设成"密码",然后使用下面的命令查看:
[root@centos7 conf.d]# curl -i -X GET http://172.16.58.100/api/mgmnt/v2/ -u "_system:SYS"
HTTP/1.1 200 OK。。。(后面省略)
[{"name":"%Api.IAM.v1","webApplications":"/api/iam","dispatchClass":"%Api.IAM.v1.disp","namespace":"%SYS","swaggerSpec":"/api/mgmnt/v2/%25SYS/%25Api.IAM.v1"},{"name":"%Api.Mgmnt.v2","webApplications":"/api/mgmnt","dispatchClass":"%Api.Mgmnt.v2.disp","namespace":"%SYS","swaggerSpec":"/api/mgmnt/v2/%25SYS/%25Api.Mgmnt.v2"},{"name":"PetStore","dispatchClass":"PetStore.disp","namespace":"DEMO","swaggerSpec":"/api/mgmnt/v2/DEMO/PetStore"}][root@centos7 conf.d]#
### CSP Gateway配置 "Application Access"
通常情况下,CSP Gateway测试成功连接IRIS Server后,会发现IRIS上的Web Application列表,并添加到自己的”APPlicaiton Access"列表里。如下图所示。每次用户在IRIS添加一个新的Web应用, 只需要在isc.conf上做相应的配置,无需人工去更新CSP Gateway的配置。
特殊的情况,如果发现某个URL无法发送到IRIS。先打开了CSP Gateway的HTTP Trace,确认CSP Gateway可以收到请求消息但无法发送到IRIS, 这是需要人工检查并且配置"Application Access".
文章
Hao Ma · 三月 26, 2021
# 使用 IRIS 和 Python 创建聊天机器人
本文将展示如何把 InterSystems IRIS 数据库与 Python 集成,以服务于自然语言处理 (NLP) 的机器学习模型。
### 为什么选择 Python?
随着在世界范围内的广泛采用和使用,Python 拥有了出色的社区,以及许多加速器 | 库用于部署任何类型的应用。 如果您感兴趣,请访问 https://www.python.org/about/apps/
### Iris Globals
我接触到 ^globals 后很快就熟悉了,它们可以用作快速获取现成数据模型中数据的方法。 因此,首先,我将使用 ^globals 存储训练数据和对话以记录聊天机器人的行为。
### 自然语言处理
自然语言处理或 NLP 是 AI 的一个主题,它创造了机器从我们的语言阅读、理解含义的能力。 显然,这并不简单,但是我将展示如何在这个广阔而美丽的领域中迈出您的第一步。
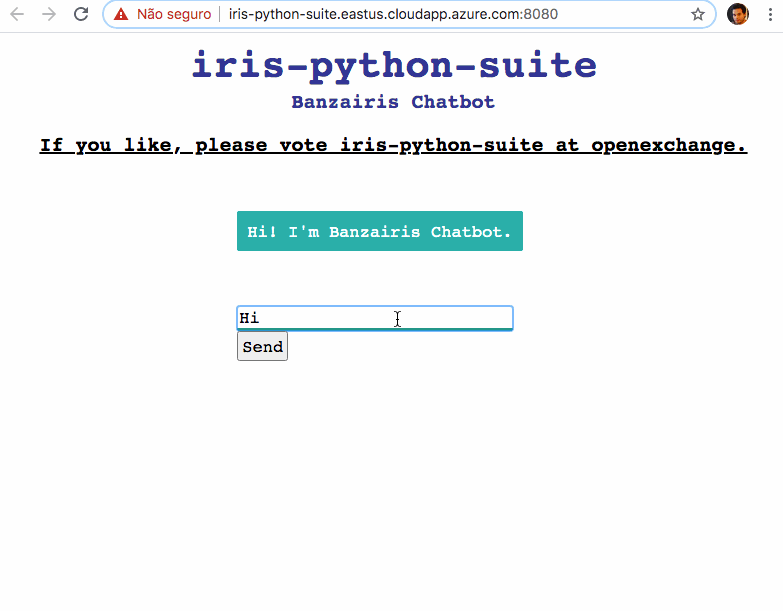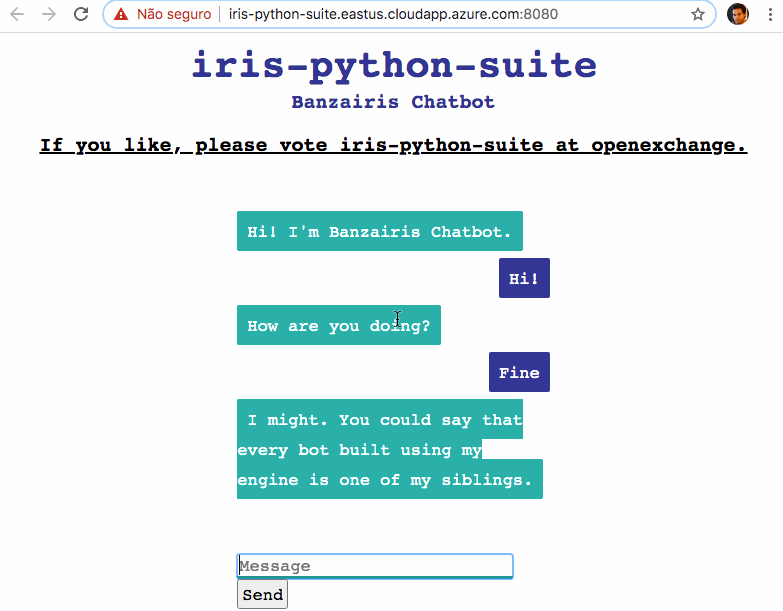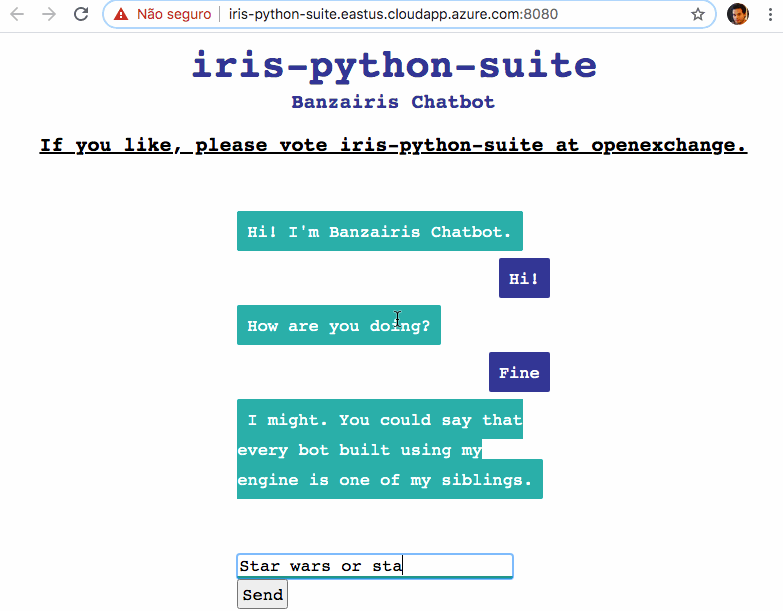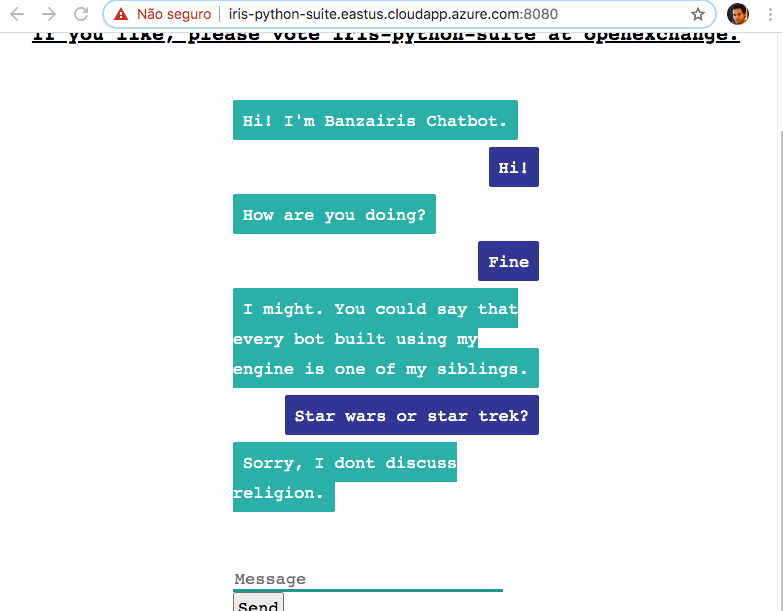
### 演示 - 来试试吧
我在这里部署了 Chatbot 应用作为演示: [http://iris-python-suite.eastus.cloudapp.azure.com:8080](http://iris-python-suite.eastus.cloudapp.azure.com:8080)
### 工作原理
### 机器学习
首先要知道与普通软件开发相比,机器学习具有不同的范式。 很难理解的要点是机器学习模型的开发周期。
**浅显解释预警**
一个标准的应用开发周期大概是这样:
开发代码 -> 测试(使用开发数据)-> 部署(真实用户数据)
机器学习代码本身不具有相同的价值。 它会与数据分担责任! 而且不是任意数据,是真实数据! 因为待执行的最终代码是由开发概念和所用数据合并生成。 所以机器学习应用周期类似于:
开发(训练)模型 + 真实数据 -> 验证 -> 部署此模型的结果
### 如何训练模型?
训练模型的技术有很多,每种情况和目标都需要很大的学习曲线。 在本例中,我使用的是 [ChatterBot](https://github.com/gunthercox/ChatterBot) 库,该库封装了一些技术,并提供了训练方法和经过预处理的训练数据,有助于我们关注结果。
### 预训练的模型语言和自定义模型
您可以由此开始拥有一个基本的会话聊天机器人。 您还可以创建所有数据来训练您的聊天机器人,全面满足您的需求,但这在短时间内很难完成。 在这个项目中,我使用 en_core_web_sm 作为对话的基础,并与可以通过[表单](http://iris-python-suite.eastus.cloudapp.azure.com/chatbot-training-data)创建的自定义训练数据合并
### 基础架构
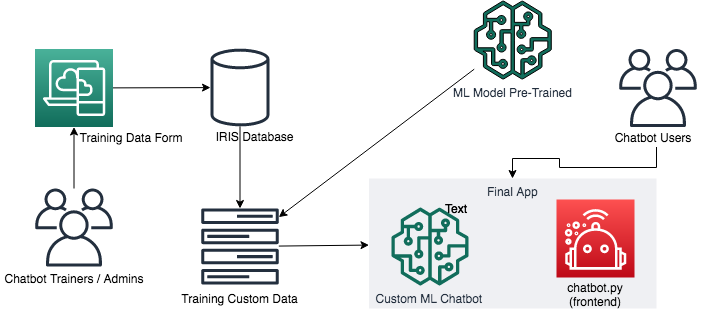
### 在 Python 中使用了什么
在这个应用环境中,我使用了 Python 3.7 和这些模块:
- PyYAML=1.0.0
- chatterbot>=1.0.0
- chatterbot-corpus>=1.2.0
- SQLAlchemy>=1.2
- ./nativeAPI_wheel/irisnative-1.0.0-cp34-abi3-linux_x86_64.whl
### 项目结构
本项目具有简单易懂的结构。 在主文件夹上,有 3 个最重要的子文件夹:
- ./app:具有全部**应用代码**和安装配置。
- ./iris:具有 **InterSystems IRIS dockerfile**,准备服务于应用。
- ./data:通过一个**卷**将主机链接到容器环境
### 应用结构
现在,可以在 ./app 目录下看到一些文件:
- chatbot.py:具有 Web 应用实现
- iris_python_suite.py:具有一些加速器的类,通过 IRIS Native API 与 IRIS 数据库和 Python 搭配使用。
### 数据库结构
此应用使用 Intersystems IRIS 作为存储库,使用的 globals 包括:
- ^chatbot.training.data:以问题和答案的形式存储所有自定义训练数据。
- ^chatbot.conversation:存储所有对话有效负载。
- ^chatbot.training.isupdated:控制训练管道。
### 其他解决方案的产品
我没有为所有对话创建报告,但这不是什么问题,使用全局图形查看器即可跟踪对话。
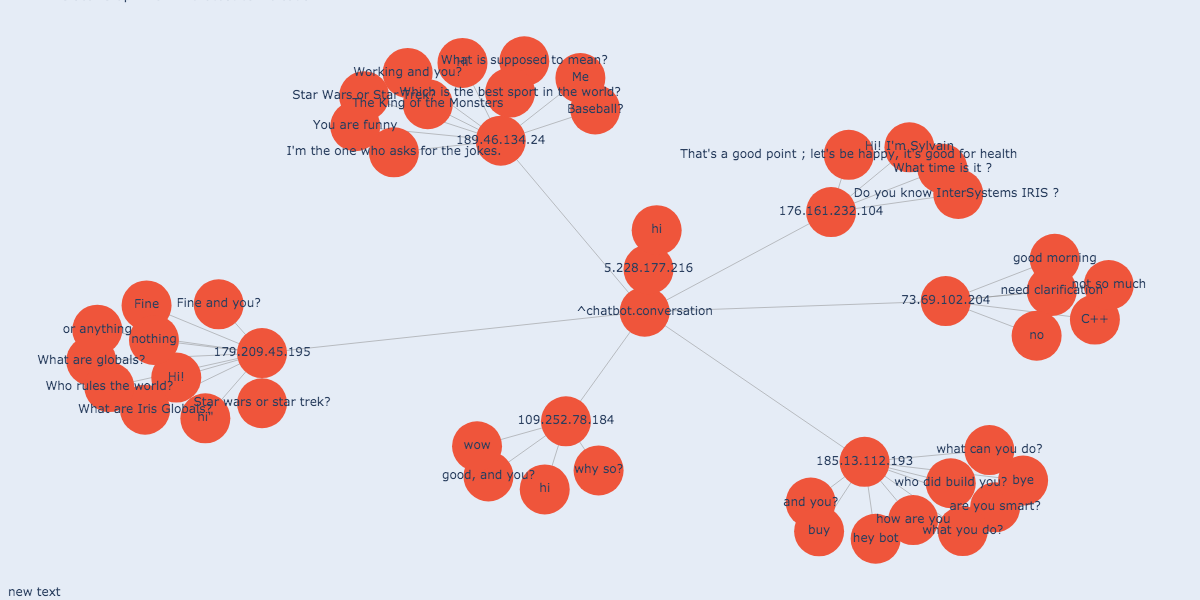
## 亲自运行应用
### 先决条件
* git
* docker 和 docker-compose(以及 docker 中更多的内存设置,至少 4GB)
* 在您的环境中访问终端
### 步骤
使用 docker-compose,您可以在一个环境中将所有组件和配置轻松转到 iris-python-covid19 文件夹,键入:
```
$ docker compose build
$ docker compose up
```
### 估计转入容器的时间
第一次运行将通过网络链接下载图像和依赖项。 如果持续时间超过 15 分钟,那可能是出现了问题,请随时来这里留言。 第一次运行后,下一次运行会好很多,只需要不到 2 分钟。
### 如果一切正常
一段时间后,您可以打开浏览器并转到地址:
训练数据表单
```
http://localhost:8050/chatbot-training-data
```
聊天机器人
```
http://localhost:8080
```
### 您应该查看 IRIS 管理门户
我暂时使用的是 USER 命名空间
```
http://localhost:9092
user: _SYSTEM
pass: theansweris42
```
### 如果本文对您有帮助或者有您喜欢的内容,请投票:
此应用目前正在参与 Open Exchange 竞赛,您可以在这里给我的应用 **iris-python-suite** 投票 (https://openexchange.intersystems.com/contest/current)
文章
yaoguai wan · 九月 30, 2022
前言
本人因技术需要,了解到了IRIS Health产品,在听了产品介绍会之后,感觉该产品是否有趣,并且比较符合自己目前的需求,因此大概了解了下IRIS的架构。以下是本人的浅显理解,如有错误之处欢迎讨论。
本人从产品介绍和社区的文档中,了解到IRIS的大概功能分类
InterSystems IRIS是一款数据平台,适用于软甲开发人员
基于FHIR
整合医疗全流程数据,通过机器学习和人工智能分析
业务优化
数据管理
Sharding数据分片技术
分布式架构
IRIS互操作性
数据分析能力
IRIS对FHIR的支持
机器学习与自动化
其中结合到自己想要研究的领域,想要探索是否可以利用该产品并结合其他工具开发一套通用的专病数据库构建及应用方法。
我目前对该产品的初步定位是对自行提供的数据集合的存储和处理,其中提供包括编码规范、高效存储架构、编程接口、算法在内的辅助工具。针对数据的处理和应用,该产品做的很完善,但是对于数据的获取,例如是否支持extract-transformation-load功能,或者能否利用自定义编程接口实现流批一体化数据抽取。根据上述两个问题,第一步需要安装该产品,所以本人根据社区官网上相关的安装教程进行了安装实验,在此期间发现了社区的教程有些简单并且有些关键点很容易被忽视本人在安装过程中就遇到过一个和系联的工程师讨论了一段时间之后才发现的,因此想与大家分享下安装过程中遇到的一些问题,避免一些问题后,安装过程还是很简单的,傻瓜式操作,后面可以分享下我的安装命令。
问题分享
首先注意产品的平台基本要求,这是平台操作手册上讲的,一定要严格遵守否则会报各种奇怪的错误,IRIS对不同版本的操作系统间的兼容性还有比较严格的,要注意,操作系统和后面容器的配合,我遇到的一个问题就是操作系统的版本和容器的版本不一致导致安装失败。
1、使用docker安装IRIS Health
安装平台介绍:Ubuntu18.04及docker 20.10
要求满足的容器版本20.04
安装过程中遇到的问题:注意linux的发行版本,必须严格遵守,本人在安装过程中最开始使用的是Ubuntu20,使用docker pull containers.intersystems.com/intersystems/iris-community:2022.1.0.209.0 命令可以顺利拉取镜像,但是在启动容器的过程中,一直失败,参考社区中有关启动失败时,设置cpu等限制sudo docker run --name my-iris --cpuset-cpus 0-7 -d store/intersystems/iris-community:2021.2.0.649.0,同样失败,最后发现是ubuntu的版本问题导致的,我最开始只关注了docker的版本,后来使用ubuntu18.04,即可顺利拉取镜像并启动容器。
附:1、查看ubuntu版本命令 cat /proc/version
2、查看docker版本命令 dicker version
2、windows安装IRIS Health
安装平台介绍:windows10(64位)
硬件介绍:16核cpu,32G运存,500G存储。注:因为本人采用的是虚拟机,所以各项配置初始时调整的很高,安装后发现社区版对各种性能有限制,例如cpu最多用8个,内存限制等,所以硬件环境无需太高,但是也不能太低,像windows10这种,首先要保证系统可以顺利安装,
在配置方面,Win10的配置要求其实并不高,具体配置如下:
CPU:1GHz或更快的处理器
RAM:1GB(32位)或2GB(64位)
HDD:16GB(32位操作系统)或20GB(64位操作系统)
显卡:DirectX 9或更高版本(包含WDDM 1.0驱动程序)
显示器:1024x600分辨率
简而言之,只要满足或者高于以上要求即可安装。
但是考虑到iris还要占用很大一块运存和存储,所以windows10最少得4G运存和200G存储,这样系统运行不会太卡,iris运行速度也算可以(这个速度我只测试没有运行处理任务的速度)。
安装过程中遇到的问题:1、注意windows10的位数不要安装32位的操作系统,同时IRIS不支持windows7,一开始没注意,一直安装失败。
windows确定操作系统版本以及位数的命令不在赘述,google一下,很简单。
下一步计划
平台建好以后开始考虑数据的获取,下一步首先继续熟悉iris产品架构,然后尝试能否实现ETL与IRIS的对接。 好文,期待下一步分享! linux的安装可以参考一下马老师写的这篇文章https://cn.community.intersystems.com/node/516631,很nice
公告
Johnny Wang · 十二月 23, 2021
12月25日-26日,首届全国医疗健康信息互联互通与智慧医院建设大会即将拉开帷幕!本次会议以“互联互通——通向智慧医院的桥梁”为主题,将采用线上形式召开。
会议分为两大部分(点击“阅读原文”查看全部日程及报名方式)
#12月25日#
开幕式及综合论坛
12月25日,会议包含丰富的主题演讲,以及如下首发与启动仪式:
1. 中文医学术语(含中医)系统:首发面向联盟医疗机构提供中文医学术语(含中医)标准集和知识图谱等系统资源的访问服务,推进术语标准落地和发展,为我国智慧医院建设提供可持续的信息化支撑。
2. 2021年度医疗健康信息化企业影响力榜单:榜单聚焦医疗健康信息化企业,围绕医疗健康信息化软件产品,从企业的市场规模、企业形象、产品服务、技术创新等多个维度,全方位展示企业综合影响力,宣传推广优秀企业品牌,促进医疗信息化市场良性竞争,更好地为医院高质量发展提供信息化服务。
3. 启动“互联互通促进智慧医院建设”征文活动:总结近年来医院信息互联互通建设成效,梳理医院高质量发展路径,探讨医疗健康信息互联互通在促进电子病历、智慧服务、智慧管理“三位一体”智慧医院建设中的作用和成效。
4. 启动全国医疗健康首席数据官能力提升项目:以数据赋能与创新驱动为理念,融合多元知识和技能体系,通过课堂授课、沙龙研讨、案例分析、实地考察等立体化培训形式,提升医疗健康首席数据官实施数据战略、建设数据资源、保障数据安全、管理数据资产、创造数据价值的能力。
#12月26日#
六大平行论坛
12月26日上午
专题论坛——以质量为根本的智慧临床
医院电子病历建设与应用、医院集成平台建设与发展、新一代医院数据中心建设、医学人工智能与临床决策支持;
专题论坛——以需求为导向的智慧服务
医院智慧服务与便民惠民、互联网医院建设与发展/互联网+医疗健康建设与发展、远程医疗建设与应用;
专题论坛——以精细为特征的智慧管理
医院智慧运营管理、物联网创新应用与智慧后勤、公立医院绩效考核;
12月26日下午
专题论坛——以价值为核心的数据治理
医院数据治理建设与应用、大数据平台与数据建模、临床科研信息化建设、医疗健康数据利用与挖掘;
专题论坛——以主动为方向的网络安全
医院信息安全规划与建设、互联网+医疗健康安全建设、医院数据安全建设与管理;
专题论坛——以标准为基础的测评培训
医院信息互联互通测评方案解读、迎评促建筹备注意事项、互联互通测评经验分享与创新实践。InterSystems将在此分论坛中进行技术分享。
#InterSystems 技术分享#
从软件和集成架构的发展看互联互通
演讲人:乔鹏
InterSystems中国技术总监
乔鹏对于数据库、医疗相关标准以及集成平台解决方案,有着深刻的理解和十多年的行业经验,参与主导过百余家医院或者区域平台的信息化建设,同时对CDR、临床决策支持、商业智能、机器学习等数据利用产品和方案有深刻的洞察和丰富的实践经验。
演讲主题:从软件和集成架构的发展看互联互通
目前互联互通的实现架构类型不少,这些架构各自有哪些优点和缺点?是否满足不断发展的互联互通需求?医院在考虑这些架构时要注意哪些事项?有没有最佳实践?此次技术分享将从软件和集成架构的发展历史和趋势分析互联互通,并尝试回答这些问题。
专题论坛“以标准为基础的测评培训”
详细日程
阅读原文(查看大会详细日程 | 报名参会)
文章
姚 鑫 · 四月 6, 2021
# 第十八章 定义和使用存储过程
本章介绍如何在IntersystemsIRIS®数据平台上定义和使用Intersystems SQL中的存储过程。它讨论了以下内容:
- 存储过程类型的概述
- 如何定义存储过程
- 如何使用存储过程如
- 何列出存储过程及其参数。
# 概述
SQL例程是可执行的代码单元,可以由SQL查询处理器调用。 SQL例程有两种类型:功能和存储过程。从支持`FunctionName()`语法的任何SQL语句中调用函数。存储过程只能由`CALL`语句调用。函数接受某些输入定向参数并返回单个结果值。存储过程接受某些输入,输入输出和输出参数。存储过程可以是用户定义的函数,返回单个值。 `CALL`语句也可以调用函数。
与大多数关系数据库系统一样,Intersystems Iris允许创建SQL存储过程。存储过程(SP)提供存储在数据库中的可调用可调用的程序,并且可以在SQL上下文中调用(例如,通过使用呼叫语句或通过ODBC或JDBC)。
与关系数据库不同,Intersystems Iris使可以将存储过程定义为类的方法。实际上,存储过程只不过是SQL可用的类方法。在存储过程中,可以使用基于对象的全系列Intersystems的功能。
- 可以通过查询数据库将存储过程定义为返回单个结果集数据集的查询。
- 可以将存储过程定义为可以用作用户定义函数的函数过程,返回单个值。
- 可以将存储过程定义为可以修改数据库数据并返回单个值或一个或多个结果集的方法。
可以确定使用 `$SYSTEM.SQL.Schema.ProcedureExists()`方法是否已存在该过程。此方法还返回过程类型:`“函数function”`或`“查询query”`。
# 定义存储过程
与Intersystems SQL的大多数方面一样,有两种方法可以定义存储过程:使用DDL和使用类。这些在以下部分中描述。
## 使用DDL定义存储过程
Intersystems SQL支持以下命令来创建查询:
- `CREATE PROCEDURE`可以创建始终作为存储过程投影的查询。
查询可以返回单个结果集。
- `CREATE QUERY`创建一个查询,该查询可以选择性地投影为存储过程。
查询可以返回单个结果集。
InterSystems SQL支持以下命令来创建方法或函数:
- `CREATE PROCEDURE`可以创建始终作为存储过程投影的方法。
方法可以返回单个值,也可以返回一个或多个结果集。
- `CREATE METHOD`可以创建一个方法,该方法可以选择投影为存储过程。
方法可以返回单个值,也可以返回一个或多个结果集。
- `CREATE FUNCTION`可以创建一个函数过程,该函数过程可以选择投影为存储过程。
函数可以返回单个值。
这些命令中指定的可执行代码块可以用InterSystems SQL或ObjectScript编写。
可以在ObjectScript代码块中包含嵌入式SQL。
## SQL到类名转换
使用DDL创建存储过程时,指定的名称将转换为类名。
如果类不存在,系统将创建它。
- 如果名称是不限定的,并且没有提供FOR子句:使用系统范围的默认模式名作为包名,后跟一个点,后跟一个生成的类名,由字符串 `‘func’`, `‘meth’`, `‘proc’`, or `‘query’`组成,后跟去掉标点字符的SQL名。
例如,未限定的过程名`Store_Name`会产生如下类名`User.procStoreName`:
这个过程类包含方法`StoreName()`。
- 如果名称是限定的,并且没有提供`FOR`子句:模式名被转换为包名,后跟一个点,后跟字符串`‘func’`, `‘meth’`,` ‘proc’`, or `‘query’` ,后跟去掉标点字符的SQL名。
如果需要,将指定的包名转换为有效的包名。
如果名称是限定的,并且提供了`FOR`子句:在`FOR`子句中指定的限定类名将覆盖在函数、方法、过程或查询名称中指定的模式名。
- SQL存储过程名称遵循标识符命名约定。
InterSystems IRIS从SQL名称中去除标点字符,从而为过程类及其类方法生成唯一的类实体名称。
下面的规则管理模式名到有效包名的转换:
- 如果架构名称包含下划线,则此字符将转换为点,表示子包。例如,合格的名称`myprocs.myname`创建包`myprocs`。限定名称`my_procs.myname`创建了包含子包`procs`的包。
以下示例显示了标点符号在类名和SQL调用中的不同之处。它定义了一个包含包含两个点的类名的方法。从SQL中调用时,示例将第一个点替换为下划线字符:
```java
Class Sample.ProcTest Extends %RegisteredObject
{
ClassMethod myfunc(dummy As %String) As %String [ SqlProc ]
{
/* method code */
Quit "abc"
}
}
```
```java
SELECT Sample.ProcTest_myfunc(Name)
FROM Sample.Person
```
## 使用类定义方法存储过程
类方法可以公开为存储过程。
这些是不返回数据的操作的理想选择,例如计算值并将其存储在数据库中的存储过程。
几乎所有类都可以将方法公开为存储过程;
例外是生成器类,比如数据类型类(`[ClassType = datatype]`)。
生成器类没有运行时上下文。
只有在其他实体(如属性)的运行时中使用数据类型上下文才有效。
**要定义方法存储过程,只需定义一个类方法并设置其`SqlProc`关键字:**
```java
Class MyApp.Person Extends %Persistent [DdlAllowed]
{
/// This procedure finds total sales for a territory
ClassMethod FindTotal(territory As %String) As %Integer [SqlProc]
{
// use embedded sql to find total sales
&sql(SELECT SUM(SalesAmount) INTO :total
FROM Sales
WHERE Territory = :territory
)
Quit total
}
}
```
编译这个类之后,`FindTotal()`方法将作为存储过程`MyApp.Person_FindTotal()`投影到SQL中。
可以使用方法的`SqlName`关键字更改SQL对过程使用的名称。
该方法使用过程上下文处理程序在过程及其调用者(例如,ODBC服务器)之间来回传递过程上下文。
这个过程上下文处理程序是由InterSystems IRIS(作为`%qHandle:%SQLProcContext`)使用%`sqlcontext`对象自动生成的。
`%sqlcontext`由`SQLCODE`错误状态、SQL行数、错误消息等属性组成,使用相应的SQL变量设置,如下所示:
```java
SET %sqlcontext.%SQLCode=SQLCODE
SET %sqlcontext.%ROWCOUNT=%ROWCOUNT
SET %sqlcontext.%Message=%msg
```
不需要对这些值做任何事情,但是它们的值将由客户机解释。
在每次执行之前都会重置`%sqlcontext`对象。
该方法不应该返回任何值。
一个类的用户定义方法的最大数目是`2000`个。
例如,假设有一个`CalcAvgScore()`方法:
```java
ClassMethod CalcAvgScore(firstname As %String,lastname As %String) [sqlproc]
{
New SQLCODE,%ROWID
&sql(UPDATE students SET avgscore =
(SELECT AVG(sc.score)
FROM scores sc, students st
WHERE sc.student_id=st.student_id
AND st.lastname=:lastname
AND st.firstname=:firstname)
WHERE students.lastname=:lastname
AND students.firstname=:firstname)
IF ($GET(%sqlcontext)'= "") {
SET %sqlcontext.%SQLCODE = SQLCODE
SET %sqlcontext.%ROWCOUNT = %ROWCOUNT
}
QUIT
}
```
## 使用类定义查询存储过程
许多从数据库返回数据的存储过程可以通过标准查询接口实现。
只要可以用嵌入式SQL编写过程,这种方法就可以很好地工作。
注意,在以下示例中,使用了嵌入式SQL `host`变量为`WHERE`子句提供一个值:
```java
Class MyApp.Person Extends %Persistent [DdlAllowed]
{
/// This procedure result set is the persons in a specified Home_State, ordered by Name
Query ListPersons(state As %String = "") As %SQLQuery [ SqlProc ]
{
SELECT ID,Name,Home_State
FROM Sample.Person
WHERE Home_State = :state
ORDER BY Name
}
}
```
要将查询公开为存储过程,可以将Studio Inspector条目中的`SQLProc`字段的值更改为`True`,或者在查询定义中添加以下`“[SQLProc]”`字符串:
```java
Query QueryName() As %SQLQuery( ... query definition ... )
[ SqlProc ]
```
编译这个类之后,`ListPersons`查询将作为存储过程`MyApp.Person_ListPersons`投影到SQL中。
可以使用查询的`SqlName`关键字更改SQL用于该过程的名称。
当`MyApp`。
从SQL调用`Person_ListPersons`,它将自动返回由查询的SQL语句定义的结果集。
下面是一个使用结果集的存储过程的示例:
```java
Class apc.OpiLLS.SpCollectResults1 [ Abstract ]
{
/// This SP returns a number of rows (pNumRecs) from WebService.LLSResults, and updates a property for each record
Query MyQuery(pNumRecs As %Integer) As %Query(ROWSPEC = "Name:%String,DOB:%Date") [ SqlProc ]
{
}
/// You put initial code here in the Execute method
ClassMethod MyQueryExecute(ByRef qHandle As %Binary, pNumRecs As %Integer) As %Status
{
SET mysql="SELECT TOP ? Name,DOB FROM Sample.Person"
SET rset=##class(%SQL.Statement).%ExecDirect(,mysql,pNumRecs)
IF rset.%SQLCODE'=0 {QUIT rset.%SQLCODE}
SET qHandle=rset
QUIT $$$OK
}
/// This code is called by the SQL framework for each row, until no more rows are returned
ClassMethod MyQueryFetch(ByRef qHandle As %Binary, ByRef Row As %List,
ByRef AtEnd As %Integer = 0) As %Status [ PlaceAfter = NewQuery1Execute ]
{
SET rset=qHandle
SET tSC=$$$OK
FOR {
///Get next row, quit if end of result set
IF 'rset.%Next() {
SET Row = "", AtEnd = 1
SET tSC=$$$OK
QUIT
}
SET name=rset.Name
SET dob=rset.DOB
SET Row = $LISTBUILD(name,dob)
QUIT
}
QUIT tSC
}
ClassMethod MyQueryClose(ByRef qHandle As %Binary) As %Status [ PlaceAfter = NewQuery1Execute ]
{
KILL qHandle //probably not necesary as killed by the SQL Call framework
QUIT $$$OK
}
}
```
如果可以将查询编写为一个简单的SQL语句并通过查询向导创建它,那么就不需要了解实现查询的底层方法。
在后台,对于每个查询,类编译器都会根据存储过程的名称生成方法,包括:
- `stored-procedure-nameExecute()`
- `stored-procedure-nameFetch()`
- `stored-procedure-nameFetchRows()`
- `stored-procedure-nameGetInfo()`
- `stored-procedure-nameClose()`
如果查询类型为`%SQLQuery`,则类编译器会自动将一些嵌入式SQL插入到生成的方法中。
`Execute()`为SQL声明并打开存储的游标。
`Fetch()`被反复调用,直到它返回一个空行`(SET row ="")`。
还可以选择让`Fetch()`返回一个`AtEnd=1`布尔标志,以表明当前获取构成最后一行,下一个获取预期返回空行。
然而,应该总是使用空行`(row ="")`作为测试,以确定结果集何时结束;
当设置`AtEnd=1`时,应该始终设置`Row=""`。
`FetchRows()`在逻辑上等同于反复调用`Fetch()`。
调用`GetInfo()`返回存储过程签名的详细信息。
`Close()`关闭游标。
当从客户机调用存储过程时,会自动调用所有这些方法,但理论上可以从运行在服务器上的ObjectScript直接调用这些方法。
要将对象从`Execute()`传递给`Fetch()`,或从`Fetch()`传递给下一次调用`Fetch()`,可以将查询处理程序设置为希望传递的对象的对象引用(`oref`)。
要传递多个对象,可以将`qHandle`设置为一个数组:
```java
SET qHandle(1)=oref1,qHandle(2)=oref2
```
可以基于自定义编写的代码(而不是SQL语句)创建结果集存储过程。
对一个类的用户定义查询`Query`的最大数目是200。
## 自定义Query
对于复杂的查询或不适合查询模型的存储过程,通常需要通过替换查询的部分或全部方法来自定义查询。
你可以使用 `%Library.Query`。
如果选择类型`%query` (`%Library.Query`)而不是`%SQLQuery` (`%Library.SQLQuery`),则通常更容易实现查询。
这生成了相同的5个方法,但是现在`FetchRows()`只是重复调用`Fetch()` (`%SQLQuery`进行了一些优化,导致了其他行为)。
`GetInfo()`只是从签名中获取信息,因此代码不太可能需要更改。
这将问题简化为为其他三个类中的每一个创建类方法。
请注意,在编译类时,编译器会检测到这些方法的存在,而不会覆盖它们。
**这些方法需要特定的签名:它们都接受类型为`%Binary`的`Qhandle`(查询处理程序)。
这是一个指向保存查询的性质和状态的结构的指针。
它通过引用传递给`Execute()`和`Fetch()`,通过值传递给`Close()`:**
```java
ClassMethod SP1Close(qHandle As %Binary) As %Status
{
// ...
}
ClassMethod SP1Execute(ByRef qHandle As %Binary,
p1 As %String) As %Status
{
// ...
}
ClassMethod SP1Fetch(ByRef qHandle As %Binary,
ByRef Row As %List, ByRef AtEnd As %Integer=0) As %Status
{
// ...
}
Query SP1(p1 As %String)
As %Query(CONTAINID=0,ROWSPEC="lastname:%String") [sqlproc ]
{
}
```
代码通常包括SQL游标的声明和使用。
从类型为`%SQLQuery`的查询中生成的游标自动具有诸如`Q14`这样的名称。
必须确保查询具有不同的名称。
在尝试使用游标之前,类编译器必须找到游标声明。
因此,`DECLARE`语句(通常在`Execute`中)必须与`Close`和`Fetch`语句在同一个MAC例程中,并且必须出现在它们中的任何一个之前。
直接编辑源代码,**在`Close`和`Fetch`定义中都使用方法关键字`PLACEAFTER`,以确保实现这一点。**
错误消息引用内部游标名,它通常有一个额外的数字。
因此,游标`Q140`的错误消息可能指向`Q14`
# 使用存储过程
使用存储过程有两种不同的方式:
- 可以使用SQL `CALL`语句调用存储过程;
- 可以像使用SQL查询中的内置函数一样使用存储函数(即返回单个值的基于方法的存储过程)。
-
注意:当执行一个以SQL函数为参数的存储过程时,请使用`CALL`调用存储过程,示例如下:
```
CALL sp.MyProc(CURRENT_DATE)
```
**`SELECT`查询不支持执行带有SQL函数参数的存储过程。
`SELECT`支持执行带有SQL函数参数的存储函数。**
`xDBC`不支持使用`SELECT`或`CALL`来执行带有SQL函数参数的存储过程。
## 存储方法
存储函数是返回单个值的基于方法的存储过程。
例如,下面的类定义了一个存储函数`Square`,它返回给定值的平方:
```java
Class MyApp.Utils Extends %Persistent [DdlAllowed]
{
ClassMethod Square(val As %Integer) As %Integer [SqlProc]
{
Quit val * val
}
}
```
存储的函数只是指定了`SqlProc`关键字的类方法。
注意:对于存储的函数,`ReturnResultsets`关键字必须不指定(默认)或以关键字`not`作为开头。
可以在SQL查询中使用存储函数,就像使用内置SQL函数一样。
函数的名称是存储函数(在本例中为`“Square”`)的SQL名称,该名称由定义该函数的模式(包)名称限定(在本例中为`“MyApp”`)。
下面的查询使用了`Square`函数:
```sql
SELECT Cost, MyApp.Utils_Square(Cost) As SquareCost FROM Products
```
如果在同一个包(模式)中定义了多个存储函数,则必须确保它们具有惟一的SQL名称。
下面的示例定义了一个名为`Sample`的表。
具有两个定义的数据字段(属性)和两个定义的存储函数`TimePlus`和`DTime`的工资:
```java
Class Sample.Wages Extends %Persistent [ DdlAllowed ]
{
Property Name As %String(MAXLEN = 50) [ Required ];
Property Salary As %Integer;
ClassMethod TimePlus(val As %Integer) As %Integer [ SqlProc ]
{
QUIT val * 1.5
}
ClassMethod DTime(val As %Integer) As %Integer [ SqlProc ]
{
QUIT val * 2
}
}
```
下面的查询使用这些存储过程返回同一个表`Sample.Wages`中每个员工的`Salary`、`time- half`和`double time`工资率:
```java
SELECT Name,Salary,
Sample.Wages_TimePlus(Salary) AS Overtime,
Sample.Wages_DTime(Salary) AS DoubleTime FROM Sample.Wages
```
下面的查询使用这些存储过程返回不同表`Sample.Employee`中每个员工的`Salary`、`time- half`和`double time`工资率:
```
SELECT Name,Salary,
Sample.Wages_TimePlus(Salary) AS Overtime,
Sample.Wages_DTime(Salary) AS DoubleTime FROM Sample.Employee
```
## 权限
要执行一个过程,用户必须具有该过程的`execute`权限。
使用`GRANT`命令或`$SYSTEM.SQL.Security.GrantPrivilege()`方法将指定过程的执行权限分配给指定用户。
通过调用`$SYSTEM.SQL.Security.CheckPrivilege()`方法,可以确定指定的用户是否具有指定过程的执行权限。
要列出用户具有`EXECUTE`权限的所有过程,请转到管理门户。
从系统管理中选择Security,然后选择Users或Roles。
为所需的用户或角色选择Edit,然后选择SQL Procedures选项卡。
从下拉列表中选择所需的名称空间。
# List 存储过程
`INFORMATION.SCHEMA.ROUTINES persistent`类显示关于当前命名空间中所有例程和过程的信息。
当在嵌入式SQL中指定时,`INFORMATION.SCHEMA`。
例程需要`#include %occInclude`宏预处理指令。
动态SQL不需要这个指令。
下面的例子返回例程名称、方法或查询名称、例程类型(过程或函数)、例程主体(`SQL=class query with SQL, EXTERNAL=not a class query with SQL`)、返回数据类型,以及当前命名空间中模式`“Sample”`中所有例程的例程定义:
```sql
SELECT ROUTINE_NAME,METHOD_OR_QUERY_NAME,ROUTINE_TYPE,ROUTINE_BODY,SQL_DATA_ACCESS,IS_USER_DEFINED_CAST,
DATA_TYPE||' '||CHARACTER_MAXIMUM_LENGTH AS Returns,NUMERIC_PRECISION||':'||NUMERIC_SCALE AS PrecisionScale,
ROUTINE_DEFINITION
FROM INFORMATION_SCHEMA.ROUTINES WHERE ROUTINE_SCHEMA='SQLUser'
```
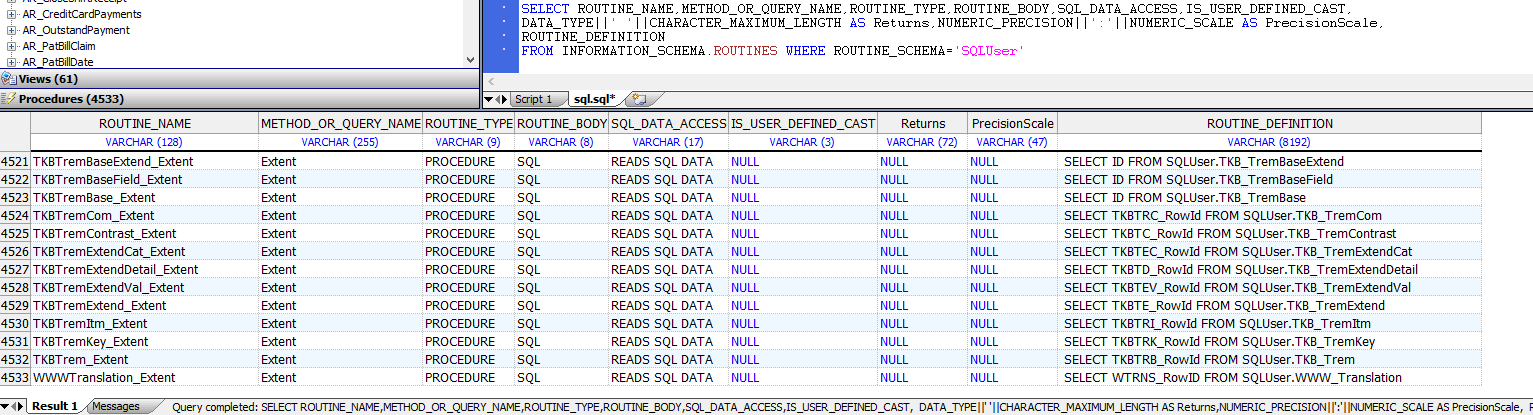
`INFORMATION.SCHEMA.PARAMETERS persistent`类显示关于当前命名空间中所有例程和过程的输入和输出参数的信息。
下面的示例返回例程名称、参数名称(不管是输入参数还是输出参数)以及当前命名空间中模式`“Sample”`中的所有例程的参数数据类型信息:
```
SELECT SPECIFIC_NAME,PARAMETER_NAME,PARAMETER_MODE,ORDINAL_POSITION,
DATA_TYPE,CHARACTER_MAXIMUM_LENGTH AS MaxLen,NUMERIC_PRECISION||':'||NUMERIC_SCALE AS PrecisionScale
FROM INFORMATION_SCHEMA.PARAMETERS WHERE SPECIFIC_SCHEMA='SQLUser'
```

使用管理门户SQL界面中的Catalog Details选项卡,可以为单个过程显示大部分相同的信息。
过程的目录详细信息包括过程类型(查询或函数)、类名称、方法或查询名称、描述以及输入和输出参数的数量。
目录详细信息存储过程信息显示还提供了运行存储过程的选项。
文章
姚 鑫 · 四月 24, 2021
# 第五章 优化查询性能(三)
# 查询执行计划
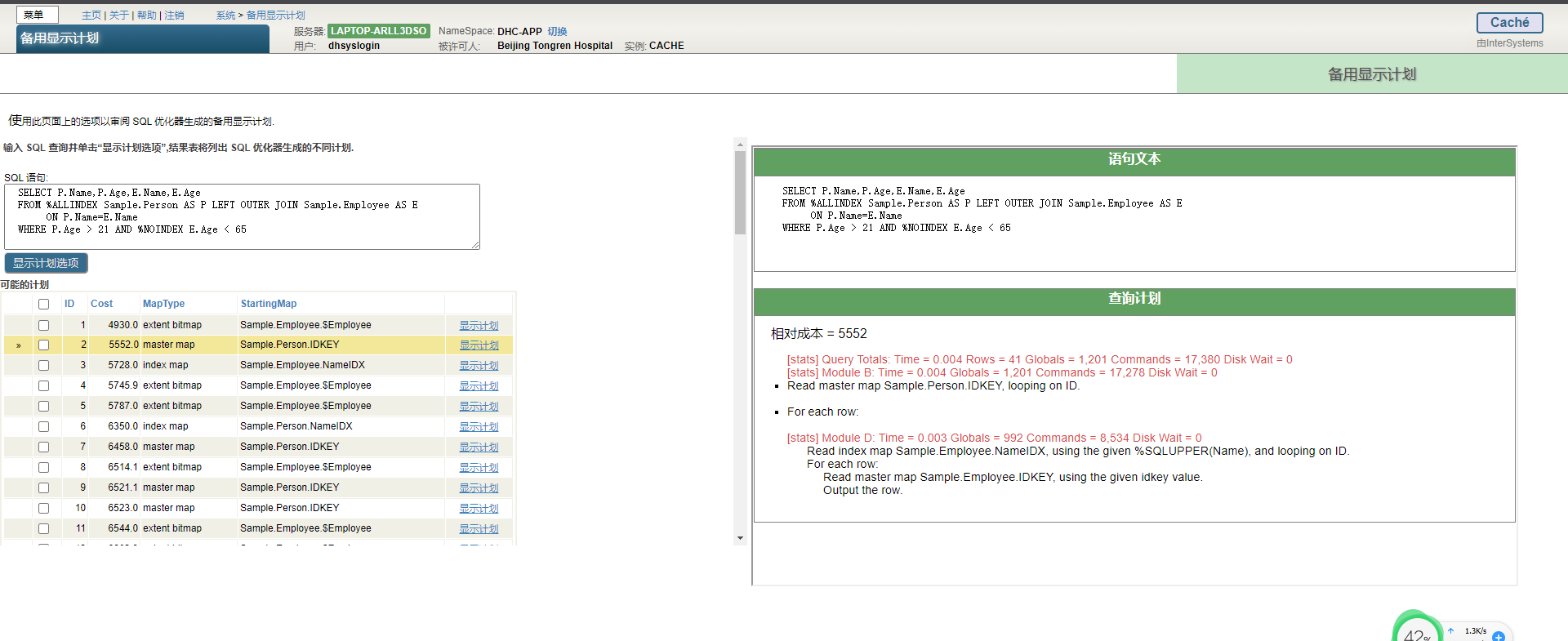
可以使用解释或显示计划工具来显示`SELECT`、`DECLARE`、`UPDATE`、`DELETE`、`TRUNCATE TABLE`和一些`INSERT`操作的执行计划。这些操作统称为查询操作,因为它们使用`SELECT`查询作为其执行的一部分。InterSystems IRIS在准备查询操作时生成执行计划;不必实际执行查询来生成执行计划。
默认情况下,这些工具显示InterSystems IRIS认为的最佳查询计划。对于大多数查询,有多个可能的查询计划。除了InterSystems IRIS认为最佳的查询计划外,还可以生成和显示备用查询执行计划。
InterSystems IRIS提供以下查询计划工具:
- `$SYSTEM.SQL.ExPlan()`方法可用于生成和显示`XML`格式的查询计划以及备选查询计划(可选)。
- SQL `EXPLAIN`命令可用于生成`XML`格式的查询计划,还可以选择生成备选查询计划和SQL统计信息。所有生成的查询计划和统计信息都包含在名为Plan的单个结果集字段中。请注意,`EXPLAIN`命令只能与`SELECT`查询一起使用。
- 管理门户 - >系统资源管理器 - >SQL界面显示计划按钮。
- 管理门户 — >系统资源管理器 — >工具—>SQL性能工具。
对于生成的`%PARALLEL`和分片查询,这些工具显示所有适用的查询计划。
## 使用`Explain()`方法
可以通过运行`$SYSTEM.SQL.Explain()`方法生成查询执行计划,示例如下:
```java
/// w ##class(PHA.TEST.SQL).SQLExplain()
ClassMethod SQLExplain()
{
SET mysql=2
SET mysql(1)="SELECT TOP 10 Name,DOB FROM Sample.Person "
SET mysql(2)="WHERE Name [ 'A' ORDER BY Age"
SET status=$SYSTEM.SQL.Explain(.mysql,{"all":0,"quiet":1,"stats":0,"preparse":0},,.plan)
IF status'=1 {WRITE "Explain() failed:" DO $System.Status.DisplayError(status) QUIT}
ZWRITE plan
}
```
设置`“all”:0`选项会生成InterSystems IRIS认为最优的查询计划。
设置`“all”:1`选项会生成最佳的查询计划和备选的查询计划。
默认值为`“all”:0`。
结果被格式化为表示`xml`格式文本的下标数组。
如果指定单个查询计划`("all":0)`,上述方法调用中的plan变量将具有以下格式:
- `plan`:显示结果中的下标总数。
- `plan(1)`:总是包含XML格式标签`“”`。
最后一个下标总是包含XML格式标记`“”`。
- `plan(2)`:总是包含XML格式标签`""`
- `plan(3)`: 总是包含查询文本的第一行。
如果"`"preparse":0`(默认值),则返回字面查询文本,并为多行查询的每一行使用额外的下标;在上面的例子中,查询有两行,因此使用了两个下标`(plan(3)`和`plan(4)`)。如果`"prepare":1`,则规范化查询文本返回为单行`:plan(3)`。
- `plan(n)`:总是包含XML格式标签`“”`;
在上面的例子中,`3+mysql = plan(5)`。
- `plan(n+1)`:总是包含XML格式的查询`cost""`.
- `plan(n+2)`:总是包含执行计划的第一行。
这个plan可以是任何长度,可以包含`…`标签作为单独的下标行,包含生成的执行模块的查询计划。
如果指`"all":1 Explain()`将生成备用查询计划。计划变量遵循相同的格式,不同之处在于它们使用第一级下标来标识查询计划,而使用第二级下标来标识查询计划的行。因此,`plan(1)`包含第一个查询计划结果中的二级下标计数,`plan(2)`包含第二个查询计划结果中的二级下标计数,依此类推。在此格式中,`plan(1,1)`包含第一个查询计划的`XML`格式标记 `""`;`plan(2,1)`包含第二个查询计划的XML格式标记 `""`,依此类推。唯一不同的是,备用查询计划包含二级零下标(`plan(1,0)`变量,该变量包含成本和索引信息;此零下标不计入一级下标(`plan(1)`)值。
如果指`"stats":1`, `Explain()`将为每个查询计划模块生成性能统计信息。
每个模块的这些统计数据都使用` ... `标记,并立即出现在查询成本之后(`""`)和查询计划文本之前。
如果查询计划包含额外的``标记,则生成的模块的``将紧接在``标记之后,在该模块的查询计划之前列出。
对于每个模块,将返回以下项:
- ``:模块名。
- ``:模块的总执行时间,以秒为单位。
- ``:全局引用的计数。
- ``:执行的代码行数。
- ``:磁盘等待时间,单位为秒。
- ``:结果集中的行数。
- ``:此模块被执行的次数。
- ``:这个程序被执行的次数。
## 使用显示计划从InterSystems SQL工具
可以使用`Show Plan`以以下任何一种方式显示查询的执行计划
- 从管理门户SQL接口。
选择`System Explorer`,然后选择SQL。
在页面顶部选择带有`Switch`选项的名称空间。
(可以为每个用户设置管理门户的默认名称空间。)
编写查询,然后按`Show Plan`按钮。
(还可以通过单击列出查询的`Plan`选项,从`Show History`列表调用`Show Plan`。)
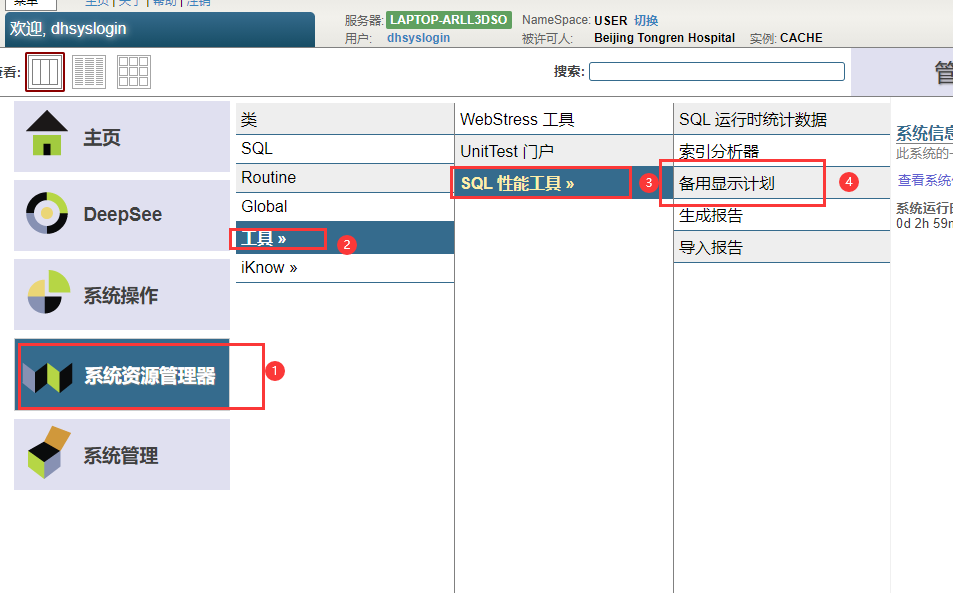
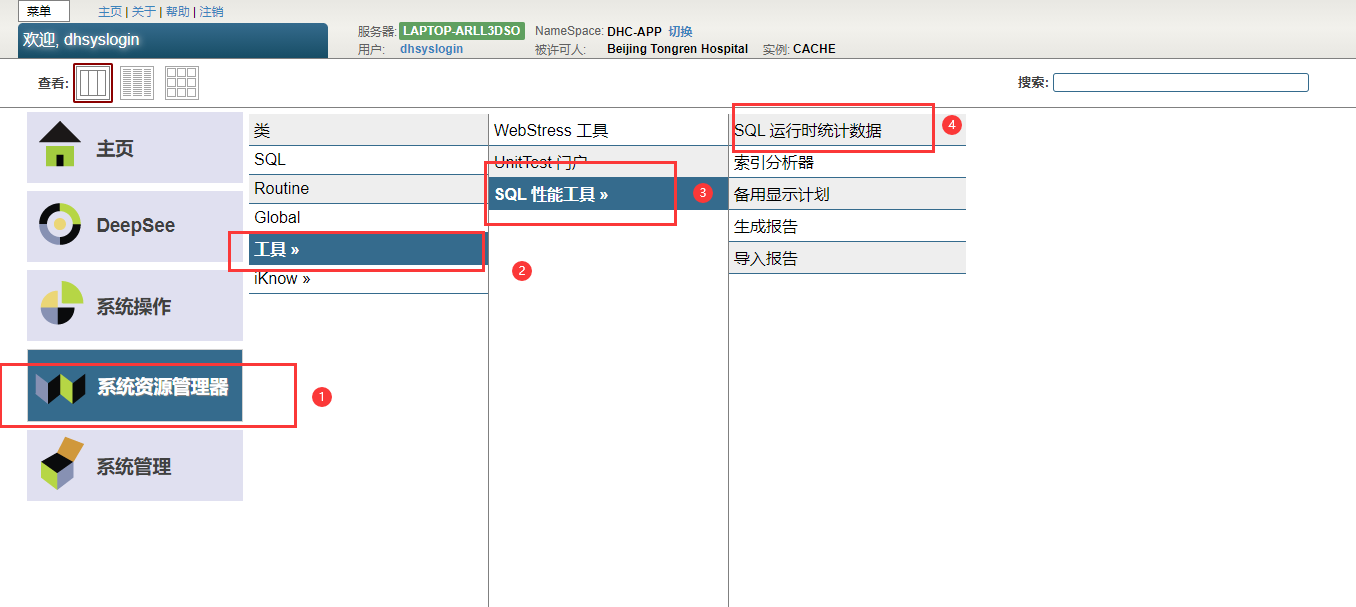
- 从管理门户工具界面。
选择“系统资源管理器”,然后选择“工具”,然后选择“SQL性能工具”,然后选择“SQL运行时统计信息”:
- 在`Query Test`选项卡中:在页面顶部选择一个带有`Switch`选项的名称空间。
在文本框中写入查询。
然后按下`Show Plan with SQL Stats`按钮。
这将在不执行查询的情况下生成一个显示计划。
- 在`View Stats`选项卡中:对于列出的查询之一,按`Show Plan`按钮。
列出的查询包括在执行查询时编写的查询和在查询测试时编写的查询。
- 在`SQL Shell`中,可以使用`SHOW PLAN`和`SHOW PLANALT Shell`命令来显示最近执行的查询的执行计划。
- 通过对缓存的查询结果集运行`Show Plan`,使用:`i%Prop`语法将文本替换值存储为属性:
```java
SET cqsql=2
SET cqsql(1)="SELECT TOP :i%PropTopNum Name,DOB FROM Sample.Person "
SET cqsql(2)="WHERE Name [ :i%PropPersonName ORDER BY Age"
DO ShowPlan^%apiSQL(.cqsql,0,"",0,$LB("Sample"),"",1)
```
默认情况下,`Show Plan`以逻辑模式返回值。但是,当从管理门户或SQL Shell调用`Show Plan`时,`Show Plan`使用运行时模式。
## 执行计划:语句文本和查询计划
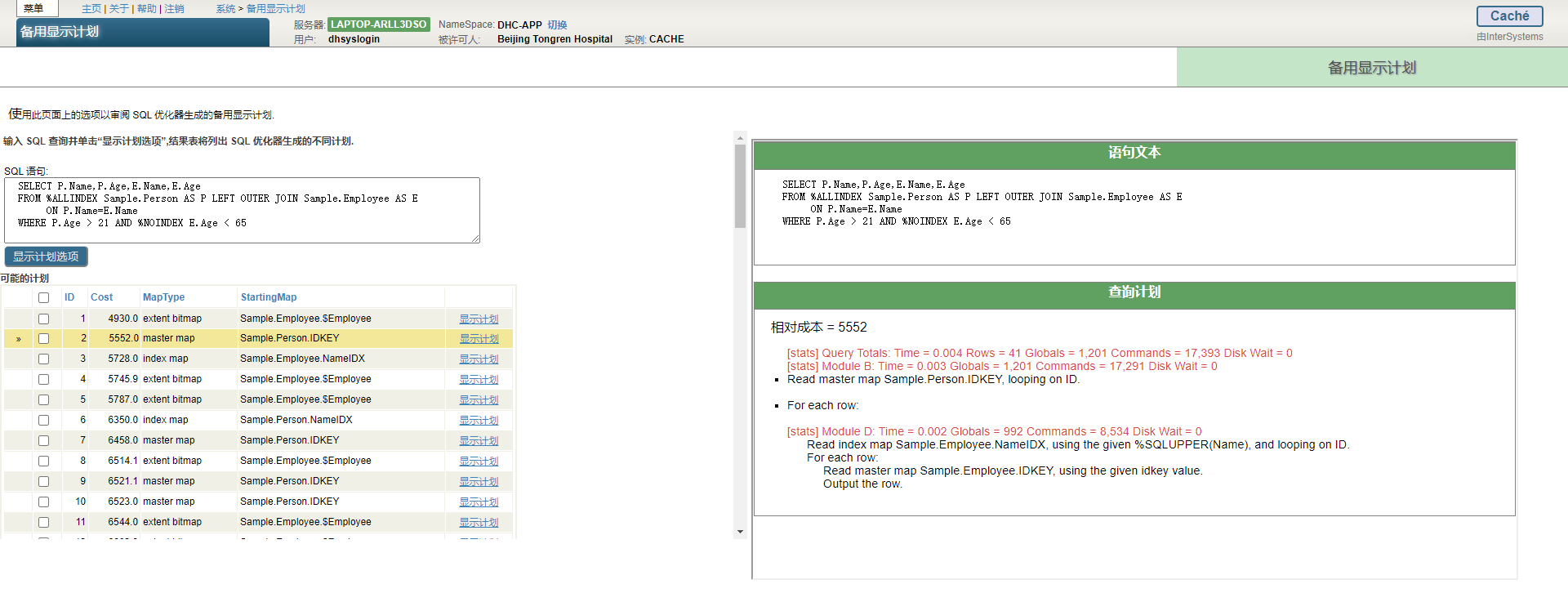
显示计划执行计划由两个组件组成,即语句文本和查询计划:
语句文本复制了原始查询,但进行了以下修改:管理门户SQL界面中的显示计划按钮显示删除了注释和换行符的SQL语句。空格是标准化的。显示计划按钮显示还执行文字替换,将每个文字替换为`?`,除非已通过将文字值括在双圆括号中来取消文字替换。使用`EXPLAIN()`方法显示显示计划时,或者使用SQL运行时统计信息或备用显示计划工具显示显示计划时,不会执行这些修改。
查询计划显示将用于执行查询的计划。查询计划可以包括以下内容:
- 如果查询计划已经冻结,则查询计划的第一行为冻结计划,否则第一行为空。
- `“Relative cost”`是一个整数值,它是从许多因素中计算出来的抽象数字,用于比较同一查询的不同执行计划的效率。
这种计算考虑了查询的复杂性、索引的存在和表的大小(以及其他因素)。
相对成本对于比较两个不同的查询是没有用的。
`" Relative cost not available"`由某些聚合查询返回,例如`COUNT(*)`或`MAX(%ID)`不带`WHERE`子句。
- 查询计划由一个主模块和(在需要时)一个或多个子组件组成。
可以显示一个或多个模块子组件,按字母顺序命名, `B: Module:B`, `Module:C`,等等开始,并按执行顺序列出(不一定按字母顺序)。
默认情况下,模块执行处理并使用其结果填充内部临时文件(内部临时表)。
通过指定 `/*#OPTIONS {"NoTempFile":1} */`,可以强制查询优化器创建不生成内部临时文件的查询计划,如注释选项中所述。
对于查询中的每个子查询,都会显示一个命名子查询模块。子查询模块按字母顺序命名。子查询命名在每个命名子查询之前跳过一个或多个字母。因此 `Module:B`, `Subquery:F or Module:D`, `Subquery:G`.当到达字母表末尾时,会对其他子查询进行编号,解析`Z=26`并使用相同的跳过序列。下面的示例是以`Subquery`开头的每三个子查询命名序列`:F:F,I,L,O,R,U,X,27,30,33`。下面的示例是以`Subquery`开头的每秒一次的子查询命名序列`:G:G,I,K,M,O,Q,S,U,W,Y,27,29`。如果子查询调用模块,模块将按字母顺序放在子查询之后,不会跳过。因此,`Subquery:H calls Module:I`。
- `“Read master map”`作为主模块中的第一个项目符号表示查询计划效率低下。查询计划使用以下映射类型语句之一开始执行`Read master map... (no available index), Read index map... (use available index), or Generate a stream of idkey values using the multi-index combination...`因为`master map`读取的是数据本身,而不是数据的索引,所以`Read master map...`。几乎总是指示低效的查询计划。除非表相对较小,否则应该定义一个索引,以便在重新生成查询计划时,第一个映射显示为`read index map...`。
某些操作会创建表示无法生成查询计划的显示计划:
- 非查询插入:`INSERT... VALUES()`命令不执行查询,因此不生成查询计划。
- 查询总是`FALSE`:在少数情况下,InterSystems IRIS可以在准备查询时确定查询条件总是`FALSE`,因此不能返回数据。“显示计划”会在“查询计划”组件中通知这种情况。例如,包含条件的查询`WHERE %ID IS NULL 或 WHERE Name %STARTSWITH('A') AND Name IS NULL `不能返回数据,因此,InterSystems IRIS不生成执行计划。查询计划没有生成执行计划,而是表示`“Output no rows”`。如果查询包含具有这些条件之一的子查询,则查询计划的子查询模块表示`“Subquery result NULL, found no rows”`。这种条件检查仅限于涉及`NULL`的几种情况,并不是为了捕捉所有自相矛盾的查询条件。
- 无效的查询:`Show Plan`为大多数无效查询显示`SQLCODE错误消息`。然而,在少数情况下,`Show Plan`显示为空。例如, `WHERE Name = $$$$$ or WHERE Name %STARTSWITH('A")`。在这些情况下,`Show Plan`不显示语句文本,而`Query Plan[没有为该语句创建的计划]`。这通常发生在分隔文字的引号不平衡时。
当为用户定义的(“外部”)函数指定了两个或多个前置美元符号而没有指定正确的语法时,也会出现这种情况。
# 交替显示计划
可以使用管理门户或`Explain()`方法显示查询的替代执行计划。
使用以下任意一种方法,从管理门户显示查询的备选执行计划:
- 选择系统资源管理器,选择工具,选择SQL性能工具,然后选择备用的显示计划。
- 选择`System Explorer`,选择SQL,然后从Tools下拉菜单中选择`Alternate Show Plans`。
使用备用的“显示计划”工具:
1. 输入一个SQL查询文本,或使用`Show History`按钮检索一个。
可以通过单击右边的圆形“X”圆来清除查询文本字段。
2. 按显示计划选项按钮以显示多个备用显示计划。 `Run ... in the background...`默认情况下不选中复选框,这是大多数查询的首选设置。建议选择`RUN...`。对于大型或复杂的查询,请在后台复选框中。当一个长查询在后台运行时,会显示一个`View process`按钮。单击查看进程将在新选项卡中打开进程详细信息页面。在“进程详细信息”页中,可以查看进程,还可以挂起、继续或终止进程。
3. 可能的计划按成本升序列出,并带有映射类型和起始映射。
4. 从可能的计划列表中,使用复选框选择要比较的计划,然后按比较显示计划与统计信息按钮以运行这些计划并显示其SQL统计信息。
带有`ALL`限定符的`EXPLAIN()`方法显示查询的所有执行计划。它首先显示IRIS认为最优(成本最低)的计划,然后显示备选计划。备选计划按成本升序列出。
以下示例显示最佳执行计划,然后列出备选计划:
```java
DO $SYSTEM.SQL.SetSQLStatsFlagJob(3)
SET mysql=1
SET mysql(1)="SELECT TOP 4 Name,DOB FROM Sample.Person ORDER BY Age"
DO $SYSTEM.SQL.Explain(.mysql,{"all":1},,.plan)
ZWRITE plan
```
## Stats
显示计划选项列表为每个备用显示计划分配一个成本值,使可以在执行计划之间进行相对比较。
`Alternate Show Plan Details`为每个查询计划提供了一组查询总数的统计信息(统计信息),以及(如果适用)每个查询计划模块的统计信息。每个模块的统计信息包括时间(整体性能,以秒为单位)、全局引用(全局引用数)、命令(执行的行数)和读取延迟(磁盘等待,以毫秒为单位)。查询总计统计信息还包括返回的行数。
# 将查询优化计划写入文件
以下实用程序列出了针对文本文件的一个或多个查询的查询优化计划。
```java
QOPlanner^%apiSQL(infile,outfile,eos,schemapath)
```
- `infile` 包含缓存查询列表的文本文件的文件路径名。指定为带引号的字符串。
- `outfile` 要列出查询优化计划的文件路径名。指定为带引号的字符串。如果该文件不存在,系统将创建该文件。如果该文件已存在,则InterSystems IRIS会覆盖该文件。
- `eos` 可选-语句末尾分隔符,用于分隔`Infile`列表中的各个缓存查询。指定为带引号的字符串。默认值为`“GO”`。如果此`EOS`字符串与缓存的查询分隔符不匹配,则不会生成输出文件。
- `schemapath` 可选-以逗号分隔的方案名列表,用于为未限定的表名、视图名或存储过程名指定方案搜索路径。可以包括`DEFAULT_SCHEMA`,这是当前系统范围内的默认架构。如果`infile`包含`#Import`指令,`QOPlanner`会将这些`#Import`包/架构名称添加到`schemapath`的末尾。
以下是调用此查询优化计划列表实用程序的示例。该实用程序将`ExportSQL^%qarDDLExport()`实用程序生成的文件作为输入,如“缓存查询”一章的“将缓存查询列出到文件”一节中所述。可以生成此查询列表文件,也可以将一个(或多个)查询写入文本文件。
```java
DO QOPlanner^%apiSQL("C:\temp\test\qcache.txt","C:\temp\test\qoplans.txt","GO")
```
从终端命令行执行时,进度会显示在终端屏幕上,如下例所示:
```java
Importing SQL Statements from file: C:\temp\test\qcache.txt
Recording any errors to principal device and log file: C:\temp\test\qoplans.txt
SQL statement to process (number 1):
SELECT TOP ? P . Name , E . Name FROM Sample . Person AS P ,
Sample . Employee AS E ORDER BY E . Name
Generating query plan...Done
SQL statement to process (number 2):
SELECT TOP ? P . Name , E . Name FROM %INORDER Sample . Person AS P
NATURAL LEFT OUTER JOIN Sample . Employee AS E ORDER BY E . Name
Generating query plan...Done
Elapsed time: .16532 seconds
```
创建的查询优化计划文件包含如下条目:
```java
SELECT TOP ? P . Name , E . Name FROM Sample . Person AS P , Sample . Employee AS E ORDER BY E . Name
Read index map Sample.Employee.NameIDX.
Read index map Sample.Person.NameIDX.
######
SELECT TOP ? P . Name , E . Name FROM %INORDER Sample . Person AS P
NATURAL LEFT OUTER JOIN Sample . Employee AS E ORDER BY E . Name
Read master map Sample.Person.IDKEY.
Read extent bitmap Sample.Employee.$Employee.
Read master map Sample.Employee.IDKEY.
Update the temp-file.
Read the temp-file.
Read master map Sample.Employee.IDKEY.
Update the temp-file.
Read the temp-file.
######
```
可以使用查询优化计划文本文件来比较使用不同查询变体生成的优化计划,或者比较不同版本的InterSystems IRIS之间的优化计划。
将SQL查询导出到文本文件时,来自类方法或类查询的查询将以代码行开头:
```java
#import
```
这个`#Import`语句告诉`QOPlanner`实用程序使用哪个默认包/模式来生成查询计划。从例程导出SQL查询时,例程代码中SQL语句之前的任何`#import`行也将位于导出文件中的SQL文本之前。假设从缓存查询导出到文本文件的查询包含完全限定的表引用;如果文本文件中的表引用不是完全限定的,则`QOPlanner`实用程序使用在运行`QOPlanner`时在系统上定义的系统范围的默认模式。
文章
姚 鑫 · 五月 9, 2021
# 第四章 多维存储的SQL和对象使用(一)
本章介绍InterSystems IRIS®对象和SQL引擎如何利用多维存储(全局变量)来存储持久对象、关系表和索引。
尽管InterSystems IRIS对象和SQL引擎会自动提供和管理数据存储结构,但了解其工作原理的详细信息还是很有用的。
数据的对象视图和关系视图使用的存储结构是相同的。为简单起见,本章仅从对象角度介绍存储。
# 数据
每个使用`%Storage.Persistent`存储类(默认)的持久化类都可以使用多维存储(全局变量)的一个或多个节点在InterSystems IRIS数据库中存储其自身的实例。
每个持久化类都有一个存储定义,用于定义其属性如何存储在全局变量节点中。这个存储定义(称为“默认结构”)由类编译器自动管理。
## 默认结构
用于存储持久对象的默认结构非常简单:
- 数据存储在名称以完整类名(包括包名)开头的全局变量中。附加`“D”`以形成全局数据的名称,而附加`“I”`作为全局索引。
- 每个实例的数据都存储在全局数据的单个节点中,所有非瞬态属性都放在`$list`结构中。
- 数据全局变量中的每个节点都以对象`ID`值作为下标。默认情况下,对象`ID`值是通过调用存储在全局变量数据根(没有下标)的计数器节点上的`$Increment`函数提供的整数。
例如,假设我们定义了一个简单的持久化类`MyApp.Person`,它有两个文本属性:
```java
Class MyApp.Person Extends %Persistent
{
Property Name As %String;
Property Age As %Integer;
}
```
如果我们创建并保存此类的两个实例,得到的全局变量结果将类似于:
```java
^MyApp.PersonD = 2 // counter node
^MyApp.PersonD(1) = $LB("",530,"Abraham")
^MyApp.PersonD(2) = $LB("",680,"Philip")
```
**注意,存储在每个节点中的`$List`结构的第一部分是空的;
这是为类名保留的。
如果定义`Person`类的子类,则此槽包含子类名。
当多个对象存储在同一个区段内时,`%OpenId`方法(由`%Persistent`类提供)使用此信息多态地打开正确的对象类型。
此槽在类存储定义中显示为名为`“%%CLASSNAME”`的属性。**
## IDKEY
`IDKEY`机制允许显式定义用作对象`ID`的值。为此,只需将`IDKEY`索引定义添加到类中,并指定将提供`ID`值的一个或多个属性。请注意,一旦保存对象,其对象`ID`值就不能更改。这意味着在保存使用`IDKEY`机制的对象后,不能再修改该对象`ID`所基于的任何特性。
```java
Class MyApp.Person Extends %Persistent
{
Index IDKEY On Name [ Idkey ];
Property Name As %String;
Property Age As %Integer;
}
```
如果我们创建并保存`Person`类的两个实例,得到的全局变量结果现在类似于:
```java
^MyApp.PersonD("Abraham") = $LB("",530,"Abraham")
^MyApp.PersonD("Philip") = $LB("",680,"Philip")
```
请注意,不再定义任何计数器节点。还要注意,通过将对象`ID`基于`Name`属性,我们已经暗示了`Name`的值对于每个对象必须是唯一的。
如果`IDKEY`索引基于多个属性,则主数据节点具有多个下标。例如:
```java
Class MyApp.Person Extends %Persistent
{
Index IDKEY On (Name,Age) [ Idkey ];
Property Name As %String;
Property Age As %Integer;
}
```
在这种情况下,生成的全局变量现在类似于:
```java
^MyApp.PersonD("Abraham",530) = $LB("",530,"Abraham")
^MyApp.PersonD("Philip",680) = $LB("",680,"Philip")
```
**重要提示:`IDKEY`索引使用的任何属性的值中都不能有连续的一对竖线(`||`),除非该属性是对持久类实例的有效引用。
这种限制是由InterSystems SQL机制的工作方式强加的。
在`IDKey`属性中使用`||`会导致不可预知的行为。**
## Subclasses
默认情况下,持久性对象的子类引入的任何字段都存储在附加节点中。
子类的名称用作附加的下标值。
例如,假设我们定义了一个具有两个文本属性的简单持久`MyApp.Person`类:
```java
Class MyApp.Person Extends %Persistent
{
Property Name As %String;
Property Age As %Integer;
}
```
现在,我们定义了一个持久子类`MyApp.Students`,它引入了两个额外的文本属性:
```java
Class MyApp.Student Extends Person
{
Property Major As %String;
Property GPA As %Double;
}
```
如果我们创建并保存此`MyApp.Student`类的两个实例,得到的全局结果将类似于:
```java
^MyApp.PersonD = 2 // counter node
^MyApp.PersonD(1) = $LB("Student",19,"Jack")
^MyApp.PersonD(1,"Student") = $LB(3.2,"Physics")
^MyApp.PersonD(2) = $LB("Student",20,"Jill")
^MyApp.PersonD(2,"Student") = $LB(3.8,"Chemistry")
```
从`Person`类继承的属性存储在主节点中,而由`Student`类引入的属性存储在另一个子节点中。这种结构确保了学生数据可以作为人员数据互换使用。例如,列出所有`Person`对象名称的SQL查询正确地获取`Person`和`Student`数据。当属性被添加到超类或子类时,这种结构还使类编译器更容易维护数据兼容性。
请注意,主节点的第一部分包含字符串`“Student”`-它标识包含学生数据的节点。
## 父子关系
在父子关系中,子对象的实例存储为它们所属的父对象的子节点。这种结构确保子实例数据与父数据在物理上是集群的。
```java
/// An Invoice class
Class MyApp.Invoice Extends %Persistent
{
Property CustomerName As %String;
/// an Invoice has CHILDREN that are LineItems
Relationship Items As LineItem [inverse = TheInvoice, cardinality = CHILDREN];
}
```
和`LineItem`:
```java
/// A LineItem class
Class MyApp.LineItem Extends %Persistent
{
Property Product As %String;
Property Quantity As %Integer;
/// a LineItem has a PARENT that is an Invoice
Relationship TheInvoice As Invoice [inverse = Items, cardinality = PARENT];
}
```
如果我们存储多个`Invoice`对象的实例,每个实例都有关联的`LineItem`对象,则得到的全局变量结果将类似于:
```java
^MyApp.InvoiceD = 2 // invoice counter node
^MyApp.InvoiceD(1) = $LB("","Wiley Coyote")
^MyApp.InvoiceD(1,"Items",1) = $LB("","Rocket Roller Skates",2)
^MyApp.InvoiceD(1,"Items",2) = $LB("","Acme Magnet",1)
^MyApp.InvoiceD(2) = $LB("","Road Runner")
^MyApp.InvoiceD(2,"Items",1) = $LB("","Birdseed",30)
```
## 嵌入对象
存储嵌入对象的方法是先将它们转换为序列化状态(默认情况下是包含对象属性的`$List`结构),然后以与任何其他属性相同的方式存储此串行状态。
例如,假设我们定义了一个具有两个文字属性的简单串行(可嵌入)类:
```java
Class MyApp.MyAddress Extends %SerialObject
{
Property City As %String;
Property State As %String;
}
```
现在,我们修改前面的示例以添加嵌入的`Home Address`属性:
```java
Class MyApp.MyClass Extends %Persistent
{
Property Name As %String;
Property Age As %Integer;
Property Home As MyAddress;
}
```
如果我们创建并保存此类的两个实例,则生成的全局变量相当于:
```java
^MyApp.MyClassD = 2 // counter node
^MyApp.MyClassD(1) = $LB(530,"Abraham",$LB("UR","Mesopotamia"))
^MyApp.MyClassD(2) = $LB(680,"Philip",$LB("Bethsaida","Israel"))
```
## 流
**通过将全局流的数据拆分成一系列块(每个块小于`32K`字节)并将这些块写入一系列顺序节点,全局流被存储在全局流中。文件流存储在外部文件中。**
文章
姚 鑫 · 五月 10, 2021
# 第四章 多维存储的SQL和对象使用(二)
# 索引
持久化类可以定义一个或多个索引;其他数据结构用于提高操作(如排序或条件搜索)的效率。InterSystems SQL在执行查询时使用这些索引。InterSystems IRIS对象和SQL在执行`INSERT`、`UPDATE`和`DELETE`操作时自动维护索引内的正确值。
## 标准索引的存储结构
标准索引将一个或多个属性值的有序集与包含属性的对象的对象`ID`值相关联。
例如,假设我们定义了一个简单的持久化`MyApp.Person`类,该类具有两个文本属性和一个关于其`Name`属性的索引:
```java
Class MyApp.Person Extends %Persistent
{
Index NameIdx On Name;
Property Name As %String;
Property Age As %Integer;
}
```
如果我们创建并保存此`Person`类的多个实例,则生成的数据和索引全局变量类似于:
```java
// data global
^MyApp.PersonD = 3 // counter node
^MyApp.PersonD(1) = $LB("",34,"Jones")
^MyApp.PersonD(2) = $LB("",22,"Smith")
^MyApp.PersonD(3) = $LB("",45,"Jones")
// index global
^MyApp.PersonI("NameIdx"," JONES",1) = ""
^MyApp.PersonI("NameIdx"," JONES",3) = ""
^MyApp.PersonI("NameIdx"," SMITH",2) = ""
```
请注意有关全局索引的以下事项:
1. 默认情况下,它被放在一个全局变量中,全局变量的名称是后面附加`“i”`(表示索引)的类名。
2. 默认情况下,第一个下标是索引名;这允许将多个索引存储在同一全局中,而不会发生冲突。
3. 第二个下标包含整理后的数据值。在这种情况下,使用默认的`SQLUPPER`排序函数对数据进行排序。这会将所有字符转换为大写(不考虑大小写进行排序),并在前面加上一个空格字符(强制所有数据作为字符串进行排序)。
4. 第三个下标包含包含索引数据值的对象的对象ID值。
5. 节点本身是空的;所有需要的数据都保存在下标中。请注意,如果索引定义指定数据应与索引一起存储,则将其放置在全局索引的节点中。
该索引包含足够的信息来满足许多查询,比如按姓名列出所有`Person`类。
# 位图索引
位图索引类似于标准索引,不同之处在于它使用一系列位字符串来存储与索引值对应的一组对象`ID`值。
## 位图索引的逻辑运算
位字符串是一个包含一组特殊压缩格式的位(`0`和`1`值)的字符串。
InterSystems IRIS包含一组有效创建和使用位字符串的函数。
这些都列在下表中:
位操作
函数 | 描述
---|---
`$Bit`| 在位串中设置或获取位。
`$BitCount` | 计算位串中的位数。
`$BitFind` | 查找位串中下一个出现的位。
`$BitLogic` | 对两个或多个位串执行逻辑(`AND`, `OR`)操作。
在位图索引中,位字符串中的顺序位置对应于索引表中的行(对象`ID`号)。
对于给定值,位图索引维护一个位字符串,在给定值存在的每一行中包含`1`,在没有给定值的每一行中包含`0`。
请注意,位图索引只适用于使用系统分配的默认存储结构的对象,数值型对象`ID`值。
例如,假设我们有一个类似如下的表:
ID| State| Product
---|---|---
1| MA| Hat
2| NY| Hat
3| NY| Chair
4| MA| Chair
5| MA| Hat
如果`State`和`Product`列有位图索引,则它们包含以下值:
`State`列上的位图索引包含以下位字符串值:
```
MA 1 0 0 1 1
NY 0 1 1 0 0
```
注意,对于值`“MA”`,在与`State`等于`“MA”`的表行对应的位置(1、4和5)中有一个1。
类似地,`Product`列上的位图索引包含以下位字符串值(注意,这些值在索引中被排序为大写):
```
CHAIR 0 0 1 1 0
HAT 1 1 0 0 1
```
InterSystems SQL Engine可以通过对这些索引维护的位串进行迭代、计算位内位数或执行逻辑组合(`AND, or`)来执行许多操作。
例如,要找到`State`等于`“MA”`、`Product`等于`“HAT”`的所有行,SQL引擎可以简单地将适当的位串与逻辑`and`组合在一起。
除了这些索引之外,系统还维护一个额外的索引,称为“区段索引”,对于存在的每一行包含1,对于不存在的行(如已删除的行)包含0。
这用于某些操作,如否定。
## 位图索引的存储结构
位图索引将一个或多个属性值的有序集合与一个或多个包含与属性值对应的对象`ID`值的位字符串相关联。
例如,假设我们定义了一个简单的持久`MyApp`。
`Person`类具有两个文字属性和`Age`属性上的位图索引:
```java
Class MyApp.Person Extends %Persistent
{
Index AgeIdx On Age [Type = bitmap];
Property Name As %String;
Property Age As %Integer;
}
```
如果我们创建并保存这个`Person`类的几个实例,得到的数据和索引全局变量类似于:
```java
// data global
^MyApp.PersonD = 3 // counter node
^MyApp.PersonD(1) = $LB("",34,"Jones")
^MyApp.PersonD(2) = $LB("",34,"Smith")
^MyApp.PersonD(3) = $LB("",45,"Jones")
// index global
^MyApp.PersonI("AgeIdx",34,1) = 110...
^MyApp.PersonI("AgeIdx",45,1) = 001...
// extent index global
^MyApp.PersonI("$Person",1) = 111...
^MyApp.PersonI("$Person",2) = 111...
```
关于全局索引,请注意以下几点:
1. 默认情况下,它被放置在一个全局变量中,全局变量的名称是类名,后面附加一个`“I”`(表示`Index`)。
2. 默认情况下,第一个下标是索引名;这允许多个索引存储在同一个全局中,而不会发生冲突。
3. 第二个下标包含经过整理的数据值。在这种情况下,不应用排序函数,因为这是数字数据的索引。
4. **第三个下标包含块编号;为了提高效率,位图索引被分成一系列位串,每个位串包含表中大约`64000`行的信息。这些位串中的每一个都被称为块。**
5. 节点包含位串。
另请注意:因为该表有一个位图索引,所以会自动维护一个区索引。该盘区索引存储在索引`GLOBAL`中,并使用前缀有`“$”`字符的类名作为其第一个下标。
## 位图索引的直接访问
下面的示例使用类区索引来计算存储的对象实例(行)的总数。注意,它使用`$ORDER`来迭代区索引的块(每个块包含大约64000行的信息):
```java
ClassMethod Count1() As %Integer
{
New total,chunk,data
Set total = 0
Set chunk = $Order(^Sample.PersonI("$Person",""),1,data)
While (chunk '= "") {
Set total = total + $bitcount(data,1)
Set chunk = $Order(^Sample.PersonI("$Person",chunk),1,data)
}
Quit total
}
```
```java
DHC-APP>w ##class(PHA.TEST.SQL).Count1()
208
```
文章
姚 鑫 · 四月 1, 2021
# 第十四章 使用SQL Shell界面(三)
# SQL元数据、查询计划和性能指标
## 显示元数据
SQL Shell支持`M`或`Metadata`命令以显示有关当前查询的元数据信息。
对于每个结果集项目,此命令列出以下元数据:列名称(SQL字段名称),键入(ODBC数据类型整数代码),PRE(精度或最大长度),比例(最大分数数字),`NULL(BOOLEAN:1 = NULL允许,0 =不允许空值)`,标签(标题标签,请参阅列别名),表(SQL表名称),架构(架构名称),`CTYPE`(客户端数据类型,请参阅`%SQL.statementColumn ClientType`属性)。
## SHOW STATEMENT
可以执行查询,然后发出show语句或显示`st`以显示准备好的SQL语句。默认情况下,必须执行查询。可以避免通过设置`executemode =延迟`执行查询,从而发出查询,然后发出`show`语句sql shell命令。
显示声明信息包含实现类(缓存查询名称),参数(一个以逗号分隔的实际参数值,如上面条款和`WHERE`子句文字值),和语句文本(文字文本的SQL命令,包括字母大小写和参数值)。
## EXPLAIN and Show Plan
有两种方式显示SQL查询的查询计划;
如果需要,两者都可以显示备用的查询计划。
- EXPLAIN:前言用解释命令选择SELECT查询。例如:
```sql
SQL]USER>>EXPLAIN SELECT Name FROM Sample.MyTable WHERE Name='Fred Rogers'
```
- SHOW PLAN:发出查询,然后发出show plan shell命令。例如:
```sql
SQL]USER>>SELECT Name FROM Sample.MyTable WHERE Name='Fred Rogers'
SQL]USER>>SHOW PLAN
```
EXPLAIN SQL命令显示有关指定选择查询的查询计划信息而不执行查询。EXPLAIN Alt允许显示备用查询计划。EXPLAIN Stat返回性能统计信息以及查询计划。EXPLAIN只能用于返回选择查询的查询计划;它不会返回用于执行查询操作的`Insert`,`Update`或`DELETE`语句等其他命令的查询计划。
Show Plan SQL shell命令允许显示SQL Shell成功发布的上次查询的查询计划信息。显示计划可用于执行查询操作的任何SQL命令,包括选择,插入,更新和删除。默认情况下,必须执行查询。可以避免通过设置`executemode=deferred`,执行查询,发出查询,然后发出以下SQL shell命令之一:
- SHOW PLAN、SHOW PL(或简单的SHOW)显示关于当前查询的查询计划信息。
查询计划可用于调试和优化查询的性能。
它指定查询的执行方式,包括索引的使用和查询的成本值。
可以返回查询计划的语句有:`SELECT`、`DECLARE`、`non-cursor UPDATE or DELETE`、`INSERT…SELECT`。
该命令有一个`V` (VERBOSE)选项。
- 显示PLANALT显示当前查询的备用显示计划。
该命令有一个`V` (VERBOSE)选项。
可以使用`$SYSTEM.SQL.Explain()`方法从ObjectScript生成查询计划。
## SQL Shell Performance
成功执行一个SQL语句后,SQL Shell会显示四个语句准备值(`times(s)/globals/cmds/disk`)和四个语句执行值(`times(s)/globals/cmds/disk`):
- 语句准备时间是指准备动态语句所花费的时间。
这包括生成和编译语句所花费的时间。
它包括在语句缓存中查找语句所花费的时间。
因此,如果执行了一条语句,然后按编号或名称回收,回收语句的准备时间接近于零。
如果一条语句已经准备好并执行,然后通过发出GO命令重新执行,那么重新执行时的准备时间为零。
- 经过的执行时间是从调用`%execute()`到`%Display()`返回所经过的时间。
它不包括输入参数值的等待时间。
语句`globals`是全局引用的计数,`cmds`是执行的SQL命令的计数,`disk`是磁盘延迟时间,单位是毫秒。
SQL Shell为准备操作和执行操作保留单独的计数。
这些性能值只在`“DISPLAYMODE”`设置为`“currentdevice”`,`“MESSAGES”`设置为`“ON”`时显示。
这些是SQL Shell的默认设置。
# Transact-SQL支持
默认情况下,SQL Shell执行InterSystems SQL代码。
但是,SQL Shell可以用来执行`Sybase`或MSSQL代码。
## Setting DIALECT
默认情况下,SQL Shell将代码解析为InterSystems SQL。
可以使用`SET DIALECT`来配置SQL Shell以执行`Sybase`或`MSSQL`代码。
若要更改当前方言,请将`“方言”`设置为`Sybase`、`MSSQL`或IRIS。
默认值是`Dialect=IRIS`。
这些设置的方言选项不区分大小写。
下面是一个从SQL Shell中执行MSSQL程序的例子:
```java
DHC-APP>DO $SYSTEM.SQL.Shell()
SQL Command Line Shell
----------------------------------------------------
The command prefix is currently set to: .
Enter q to quit, ? for help.
DHC-APP>>SET DIALECT MSSQL
dialect = MSSQL
DHC-APP>>SELECT TOP 5 name + '-' + ssn FROM Sample.Person
1. SELECT TOP 5 name + '-' + ssn FROM Sample.Person
Expression_1
yaoxin-111-11-1117
xiaoli-111-11-1111
姚鑫-111-11-1112
姚鑫-111-11-1113
姚鑫-111-11-1114
5 Rows(s) Affected
statement prepare time(s)/globals/lines/disk: 0.1989s/46546/257369/114ms
execute time(s)/globals/lines/disk: 0.0032s/24/676/3ms
---------------------------------------------------------------------------
```
`Sybase`和`MSSQL`方言支持这些方言中有限的SQL语句子集。
它们支持`SELECT`、`INSERT`、`UPDATE`和`DELETE`语句。
它们对永久表支持`CREATE TABLE`语句,但对临时表不支持。
支持创建视图。
支持创建触发器和删除触发器。
但是,如果`CREATE TRIGGER`语句部分成功,但在类编译时失败,则此实现不支持事务回滚。
支持`CREATE PROCEDURE`和`CREATE FUNCTION`。
## Setting COMMANDPREFIX
可以使用`SET COMMANDPREFIX`指定必须追加到后续SQL Shell命令的前缀(通常是单个字符)。
在SQL Shell提示符发出的SQL语句中不使用此前缀。
这个前缀的目的是防止SQL Shell命令和SQL代码语句之间的歧义。
例如,`SET`是一个SQL Shell命令;
`SET`也是`Sybase`和`MSSQL`中的SQL代码语句。
默认情况下,没有命令前缀。
要建立命令前缀,设置`COMMANDPREFIX=prefix`,指定的前缀不带引号。
要恢复为没有命令前缀,设置`COMMANDPREFIX=""`。
以下示例显示了命令前缀/(斜杠字符)被设置、使用和恢复的示例:
```java
DHC-APP>>SET COMMANDPREFIX=/
commandprefix = /
DHC-APP>>/SET LOG=ON
log = xsql19388.log
DHC-APP>> >
1>>SELECT TOP 3 Name,Age
2>>FROM Sample.Person
3>>/GO
2. SELECT TOP 3 Name,Age
FROM Sample.Person
Name Age
yaoxin 30
xiaoli
姚鑫 7
3 Rows(s) Affected
statement prepare time(s)/globals/lines/disk: 0.0595s/46282/256257/9ms
execute time(s)/globals/lines/disk: 0.0003s/3/714/0ms
---------------------------------------------------------------------------
DHC-APP>>/SET COMMANDPREFIX
commandprefix = /
DHC-APP>>/SET COMMANDPREFIX=""
commandprefix = ""
DHC-APP>>SET COMMANDPREFIX
commandprefix =
```
当设置了命令前缀时,除了`?`、`#`和`GO`之外的所有SQL Shell命令都需要该命令前缀;
可以使用或不使用命令前缀发出这三个SQL Shell命令。
当发出`SET`或`SET COMMANDPREFIX`命令时,SQL Shell将显示当前命令前缀,作为SQL Shell初始化的一部分,并且在`?`
命令选项显示。
## 运行命令
SQL Shell `RUN`命令执行SQL脚本文件。
在发出运行命令之前必须设置方言,以指定IRIS (InterSystems SQL)、Sybase (Sybase TSQL)或MSSQL (Microsoft SQL);
默认的方言是IRIS。
可以调用`RUN scriptname`,也可以只调用`RUN`,然后提示输入脚本文件名。
`RUN`加载脚本文件,然后准备并执行文件中包含的每个语句。
脚本文件中的语句必须分隔,通常用`GO`行或分号(`;`)分隔。
`RUN`命令提示指定分隔符。
SQL脚本文件结果显示在当前设备上,也可以显示在日志文件中。
还可以生成一个包含准备失败语句的文件。
`RUN`命令返回指定这些选项的提示符,示例如下:
```java
[SQL]USER>>SET DIALECT=Sybase
dialect = Sybase
[SQL]USER>>RUN
Enter the name of the SQL script file to run: SybaseTest
Enter the file name that will contain a log of statements, results and errors (.log): SyTest.log
SyTest.log
Many script files contain statements not supported by IRIS SQL.
Would you like to log the statements not supported to a file so they
can be dealt with manually, if applicable? Y=> y
Enter the file name in which to record non-supported statements (_Unsupported.log): SyTest_Unsupported.log
Please enter the end-of-statement delimiter (Default is 'GO'): GO=>
Pause how many seconds after error? 5 => 3
Sybase Conversion Utility (v3)
Reading source from file:
Statements, results and messages will be logged to: SyTest.log
.
.
.
```
## TSQL例子
下面的SQL Shell示例创建了一个`Sybase`过程`AvgAge`。
它使用`Sybase EXEC`命令执行这个过程。
然后,它将方言更改为InterSystems IRIS,并使用InterSystems SQL `CALL`命令执行相同的过程。
```java
DHC-APP>>SET DIALECT Sybase
dialect = Sybase
DHC-APP>> >
1>>CREATE PROCEDURE AvgAge
2>>AS SELECT AVG(Age) FROM Sample.Person
3>>GO
3. CREATE PROCEDURE AvgAge
AS SELECT AVG(Age) FROM Sample.Person
statement prepare time(s)/globals/lines/disk: 0.0173s/8129/22308/4ms
execute time(s)/globals/lines/disk: 0.0436s/3844/23853/34ms
---------------------------------------------------------------------------
DHC-APP>>EXEC AvgAge
4. EXEC AvgAge
Dumping result #1
Aggregate_1
50.68137254901960784
1 Rows(s) Affected
statement prepare time(s)/globals/lines/disk: 0.0086s/8096/21623/0ms
execute time(s)/globals/lines/disk: 0.1131s/90637/458136/19ms
---------------------------------------------------------------------------
DHC-APP>>SET DIALECT=IRIS
Dialect 'iris' is not supported.
```
文章
姚 鑫 · 四月 22, 2021
# 第五章 优化查询性能(一)
InterSystems SQL自动使用查询优化器创建在大多数情况下提供最佳查询性能的查询计划。该优化器在许多方面提高了查询性能,包括确定要使用哪些索引、确定多个`AND`条件的求值顺序、在执行多个联接时确定表的顺序,以及许多其他优化操作。可以在查询的`FROM`子句中向此优化器提供“提示”。本章介绍可用于评估查询计划和修改InterSystems SQL将如何优化特定查询的工具。
InterSystems IRIS®Data Platform支持以下优化SQL查询的工具:
- `SQL Runtime Statistics`用于生成查询执行的运行时性能统计信息
- 索引分析器,用于显示当前命名空间中所有查询的各种索引分析器报告。这显示了InterSystems SQL将如何执行查询,可以全面了解索引是如何使用的。此索引分析可能表明应该添加一个或多个索引以提高性能。
- 查询执行计划:显示SQL查询(查询计划)的最佳(默认)执行计划,并可选地显示该SQL查询的备用查询计划以及统计信息。用于显示查询计划的工具包括SQL `EXPLAIN`命令、`$SYSTEM.SQL.ExPlan()`方法以及管理门户和SQL Shell中的各种`Show Plan`工具。查询计划和统计数据是在准备查询时生成的,不需要执行查询。
可以使用以下选项来指导查询优化器,方法是设置配置默认值或在查询代码中编码优化器“提示”:
- 管理所有条件的子句选项中提供的索引优化选项,或单个条件前面的`%NOINDEX`。
- SQL代码中指定的注释选项,使优化器覆盖该查询的系统范围编译选项。
- 在每个查询或系统范围的基础上可用的并行查询处理允许多处理器系统在处理器之间划分查询执行。
以下SQL查询性能工具将在本手册的其他章节中介绍:
- 缓存查询,使动态SQL查询能够重新运行,而无需在每次执行查询时准备查询的开销。
- SQL语句来保留最新编译的嵌入式SQL查询。在“SQL语句和冻结计划”一章中。
- 冻结计划以保留嵌入式SQL查询的特定编译。使用此编译,而不是使用较新的编译。在“SQL语句和冻结计划”一章中。
以下工具用于优化表数据,因此可以对针对该表运行的所有查询产生重大影响:
- 定义索引可以显著提高对特定索引字段中数据的访问速度。
- `ExtentSize`、`Selective`和`BlockCount`用于在用数据填充表之前指定表数据估计;此元数据用于优化未来的查询。
- `Tune Table`用于分析已填充的表中的代表性表数据;生成的元数据用于优化未来的查询。
本章还介绍如何将查询优化计划写入文件,以及如何生成SQL故障排除报告以提交给InterSystems WRC。
# 管理门户SQL性能工具
IRIS管理门户提供对以下SQL性能工具的访问。有两种方式可以从管理门户系统资源管理器选项访问这些工具:
- 选择工具,然后选择SQL性能工具。
- 选择SQL,然后选择工具下拉菜单。
从任一界面中您都可以选择以下SQL性能工具之一:
- SQL运行时统计信息,以生成查询执行的性能统计信息。
- 索引分析器,用于显示当前命名空间中所有查询的各种索引分析器报告。这显示了InterSystems SQL将如何执行查询,可以全面了解索引是如何使用的。此索引分析可能表明应该添加一个或多个索引以提高性能。
- 备用显示计划:显示SQL查询的可用备用查询计划以及统计信息。
- 生成报告以向InterSystems Worldwide Response Center(WRC)客户支持部门提交SQL查询性能报告。要使用此报告工具,必须首先从WRC获得WRC跟踪号。
- 导入报告允许查看SQL查询性能报告。
# SQL运行时统计信息
可以使用SQL运行时统计信息来衡量系统上运行的SQL查询的性能。SQL运行时统计信息衡量`SELECT`、`INSERT`、`UPDATE`和`DELETE`操作(统称为查询操作)的性能。SQL运行时统计信息(SQL Stat)是在准备查询操作时收集的。请参阅使用SQL运行时统计信息工具。
默认情况下,SQL运行时统计信息的收集处于关闭状态。必须激活统计信息收集。强烈建议指定超时以结束统计信息收集。激活统计信息收集后,必须重新编译(准备)现有的动态SQL查询,并重新编译包含嵌入式SQL的类和例程。
性能统计信息包括`ModuleName`、`ModuleCount`(模块被调用的次数)、`RowCount`(返回的行数)、`TimeSpent`(执行性能,单位为秒)、`GlobalRefs`(全局引用数)、`LinesOfCode`(执行的行数)和`ReadLatency`(磁盘读取访问时间,单位为毫秒)。
可以显式清除SQL Stats数据。清除缓存查询会删除所有相关的SQL统计数据。删除表或视图会删除所有相关的SQL Stats数据。
注意:系统任务在所有名称空间中每小时自动运行一次,以将特定于进程的SQL查询统计信息聚合到全局统计信息中。因此,全局统计信息可能不会反映一小时内收集的统计信息。可以使用管理门户监视此每小时一次的聚合或强制其立即发生。要查看此任务上次完成和下次调度的时间,请依次选择系统操作、任务管理器、任务调度,然后查看更新SQL查询统计信息任务。可以单击任务名称查看任务详细信息。在`Task Details`(任务详细信息)显示中,可以使用Run(运行)按钮强制立即执行任务。
# 使用SQL运行时统计信息工具
可以使用以下任一方法从管理门户显示系统范围内的SQL查询的性能统计信息:
- 选择系统资源管理器,选择工具,选择SQL性能工具,然后选择SQL运行时统计信息。
- 选择系统资源管理器,选择SQL,然后从工具下拉菜单中选择SQL运行时统计信息。
## Settings
“设置”选项卡显示当前系统范围的SQL运行时统计信息设置以及此设置的过期时间。
Change Settings(更改设置)按钮允许设置以下统计信息收集选项:
- 收集选项:可以将统计信息收集选项设置为0、1、2或3.0。0=关闭统计信息代码生成;1=为所有查询打开统计信息代码生成,但不收集统计信息;2=仅记录查询外部循环的统计信息(在主模块打开和关闭时收集统计信息);3=记录查询的所有模块级别的统计信息。
- 从0到1:更改SQL Stats选项后,需要编译包含SQL的例程和类以执行统计代码生成。对于xDBC和动态SQL,必须清除缓存查询以强制重新生成代码。
- 要从1变为2:只需更改SQL Stats选项即可开始收集统计信息。这使可以在运行的生产环境中启用SQL性能分析,并将中断降至最低。
- 从1到3(或从2到3):更改SQL Stats选项后,需要编译包含SQL的例程和类,以记录所有模块级别的统计信息。对于xDBC和动态SQL,必须清除缓存查询以强制重新生成代码。选项3通常仅用于非生产环境中已识别的性能较差的查询。
- 从1、2或3变为0:要关闭统计代码生成,不需要清除缓存的查询。
- 超时选项:如果收集选项为2或3,可以按已用时间(小时或分钟)或按完成日期和时间指定超时。可以用分钟或小时和分钟指定运行时间;该工具将指定的分钟值转换为小时和分钟(100分钟=1小时40分钟)。默认值为50分钟。日期和时间选项默认为当天午夜(23:59)之前。强烈建议指定超时选项。
- 重置选项:如果收集选项为2或3,则可以指定超时值到期时要重置为的收集选项。可用选项为0和1。
## 查询测试
查询测试选项卡允许输入SQL查询文本(或从历史记录中检索),然后显示该查询的SQL统计信息和查询计划。查询测试包括查询的所有模块级别的SQL统计信息,而与收集选项设置无关。
输入一个SQL查询文本,或使用`Show History`按钮检索一个。
可以通过单击右边的圆形“X”圆来清除查询文本字段。
使用`Show Plan With SQL Stats`按钮执行。
默认情况下,后台复选框中的“运行`Show Plan`进程”未被选中,这是大多数查询的首选设置。
仅对长时间、运行缓慢的查询选择此复选框。
当这个复选框被选中时,你会看到一个进度条显示“请等待…”的消息。
当运行一个长查询时,带有SQL Stats和`Show History`按钮的`Show Plan`消失,而显示一个`View Process`按钮。
单击`View Process`将在新选项卡中打开流程详细信息页面。
在流程详细信息页面中,可以查看该流程,并可以暂停、恢复或终止该流程。
流程的状态应该反映在显示计划页面上。
当流程完成后,显示计划会显示结果。
`View Process`按钮消失,带有SQL Stats的`Show Plan`和`Show History`按钮重新出现。
使用查询测试显示的语句文本包括注释,不执行文字替换。
## 查看统计信息
`View Stats`(查看统计信息)选项卡为提供了在此系统上收集的运行时统计信息的总体视图。
可以单击任何一个`View Stats`列标题对查询统计信息进行排序。然后,可以单击SQL语句文本以查看所选查询的详细查询统计信息和查询计划。
使用此工具显示的语句文本包括注释,不执行文字替换。`ExportStatsSQL()`和`Show Plan`显示的语句文本会去掉注释并执行文字替换。
### 清除统计信息按钮
清除统计信息按钮清除当前名称空间中所有查询的所有累积统计信息。它会在SQL运行时统计信息页上显示一条消息。如果成功,则会显示一条消息,指示已清除的统计信息数量。如果没有统计信息,则会显示无要清除的消息。如果清除不成功,则会显示一条错误消息。
## 运行时统计信息和显示计划
SQL运行时统计信息工具可用于显示包含运行时统计信息的查询的显示计划。
可以使用`Alternate Show Plans`工具将显示计划与统计数据进行比较,从而显示查询的运行时统计信息。备用显示计划工具在其显示计划选项中显示查询的估计统计信息。如果激活了收集运行时统计信息,则其`Compare Show Plans with Stats`选项将显示实际的运行时统计信息;如果运行时统计信息未处于活动状态,则此选项将显示估计统计信息。
文章
姚 鑫 · 五月 20, 2021
# 第一章 发送HTTP请求
本主题介绍如何发送`HTTP`请求(如`POST`或`GET`)和处理响应。
# HTTP请求简介
可以创建`%Net.HttpRequest`的实例来发送各种`HTTP`请求并接收响应。此对象相当于Web浏览器,可以使用它发出多个请求。它会自动发送正确的`cookie`,并根据需要设置`Referer`标头。
要创建HTTP请求,请使用以下常规流程:
1. 创建`%Net.HttpRequest`的实例。
2. 设置此实例的属性以指示要与之通信的Web服务器。基本属性如下:
- 服务器指定Web服务器的IP地址或计算机名称。默认值为`localhost`。
**注意:不要将`http://`或`https://`作为服务器值的一部分。这将导致错误`#6059:无法打开到服务器http:/的TCP/IP套接字`。**
3. 可以选择设置HTTP请求的其他属性和调用方法,如指定其他HTTP请求属性中所述。
4. 然后,通过调用`%Net.HttpRequest`实例的`get()`方法或其他方法来发送HTTP请求,如“发送HTTP请求”中所述。
可以从实例发出多个请求,它将自动处理cookie和Referer标头。
注意:如果创建此HTTP请求是为了与生产出站适配器(`EnsLib.HTTP.Outbound Adapter`)一起使用,那么请改用该适配器的方法来发送请求。
5. 如果需要,使用`%Net.HttpRequest`的同一实例发送其他HTTP请求。默认情况下,InterSystems IRIS使TCP/IP套接字保持打开状态,以便可以重复使用套接字,而无需关闭和重新打开它。
以下是一个简单的示例:
```java
/// w ##class(PHA.TEST.HTTP).Get()
ClassMethod Get()
{
set request=##class(%Net.HttpRequest).%New()
set request.Server="tools.ietf.org"
set request.Https=1
set request.SSLConfiguration="yx"
set status=request.Get("/html/rfc7158")
d $System.Status.DisplayError(status)
s response = request.HttpResponse
s stream = response.Data
q stream.Read()
}
```
# 提供身份验证
如果目标服务器需要登录凭据,则HTTP请求可以包括提供凭据的HTTP `Authorization`标头。
如果使用的是代理服务器,还可以指定代理服务器的登录凭据;为此,请设置`ProxyAuthorization`属性
## 使用HTTP 1.0时对请求进行身份验证
对于HTTP 1.0,要验证HTTP请求,请设置`%Net.HttpRequest`实例的用户名和密码属性。然后,该实例使用基本访问身份验证基于该用户名和密码创建HTTP `Authorization`标头(RFC 2617)。此`%Net.HttpRequest`发送的任何后续请求都将包括此头。
**重要提示:请确保还使用SSL。在基本身份验证中,凭据以base-64编码形式发送,因此易于读取。**
## 在使用HTTP 1.1时对请求进行身份验证
对于HTTP 1.1,要验证HTTP请求,在大多数情况下,只需设置`%Net.HttpRequest`实例的用户名和密码属性。当`%Net.HttpRequest`的实例收到`401 HTTP`状态代码和`WWW-Authenticate`标头时,它会尝试使用包含支持的身份验证方案的`Authorization`标头进行响应。使用为IRIS支持和配置的第一个方案。默认情况下,它按以下顺序考虑这些身份验证方案:
1. 协商(SPNEGO和Kerberos,根据RFC 4559和RFC 4178)
2. NTLM(NT LAN Manager身份验证协议)
3. 基本认证(RFC 2617中描述的基本接入认证)
重要:如果有可能使用基本身份验证,请确保也使用SSL(参见“使用SSL进行连接”)。
在基本身份验证中,凭据以base-64编码的形式发送,因此很容易读取。
在Windows上,如果没有指定`Username`属性,IRIS可以使用当前登录上下文。
具体来说,如果服务器使用401状态码和用于`SPNEGO`、`Kerberos`或`NTLM`的`WWW-Authenticate`头响应,那么IRIS将使用当前操作系统用户名和密码创建`Authorization`头。
具体情况与HTTP 1.0不同,如下所示:
1. 如果认证成功,IRIS更新`%Net`的`CurrentAuthenticationScheme`属性。
`HttpRequest`实例来指示它在最近的身份验证中使用的身份验证方案。
2. 如果尝试获取方案的身份验证句柄或令牌失败,IRIS会将基础错误保存到`%Net.HttpRequest`实例的`AuthenticationErrors`属性中。此属性的值为`$List`,其中每一项都具有格式`scheme ERROR: message`
仅HTTP 1.1支持协商和`NTLM`,因为这些方案需要多次往返,而HTTP 1.0要求在每个请求/响应对之后关闭连接。
### Variations
如果知道服务器允许的一个或多个身份验证方案,则可以通过包括`Authorization`标头来绕过服务器的初始往返行程,该标头包含所选方案的服务器的初始令牌。为此,请设置`%Net.HttpRequest`实例的`InitiateAuthentication`属性。对于此属性的值,请指定服务器允许的单个授权方案的名称。使用下列值之一(区分大小写):
- Negotiate
- NTLM
- Basic
如果要自定义要使用的身份验证方案(或更改其考虑顺序),请设置`%Net.HttpRequest`实例的`AuthenticationSchemes`。对于此属性的值,请指定以逗号分隔的身份验证方案名称列表(使用上一个列表中给出的准确值)。
## 直接指定授权标头
对于HTTP 1.0或HTTP 1.1(如果适用于场景),可以直接指定HTTP `Authorization`标头。具体地说,可以将`Authorization`属性设置为等于正在请求的资源的用户代理所需的身份验证信息。
如果指定`Authorization`属性,则忽略用户名和密码属性。
## 启用HTTP身份验证的日志记录
要启用HTTP身份验证的日志记录,请在终端中输入以下内容:
```java
set $namespace="%SYS"
kill ^ISCLOG
set ^%ISCLOG=2
set ^%ISCLOG("Category","HttpRequest")=5
```
日志条目将写入`^ISCLOG global`中.。要将日志写入文件(以提高可读性),请输入以下内容(仍在`%SYS`命名空间内):
```java
do ##class(%OAuth2.Utils).DisplayLog("filename")
```
其中,`filename`是要创建的文件的名称。该目录必须已存在。如果该文件已经存在,它将被覆盖。
要停止日志记录,请输入以下内容(仍在`%SYS`命名空间内):
```java
set ^%ISCLOG=0
set ^%ISCLOG("Category","HttpRequest")=0
```
# 指定其他HTTP请求属性
在发送HTTP请求之前(请参阅发送HTTP请求),可以指定其属性,如以下各节所述:
可以为`%Net.HttpRequest`的所有属性指定默认值,如最后列出的部分中所指定。
## Location属性
`Location`属性指定从Web服务器请求的资源。如果设置此属性,则在调用`Get()`, `Head()`, `Post()`, 或 `Put()`方法时,可以省略location参数。
例如,假设正在向url `http://machine_name/test/index.html`发送一个HTTP请求
在这种情况下,将使用下列值:
`%Net.HttpRequest`的示例属性
Properties |Value
---|---
Server| machine_name
Location| test/index.html
## 指定Internet媒体类型(Media Type)和字符编码(Character Encoding)
可以使用以下属性指定`%Net.HttpRequest`实例及其响应中的Internet媒体类型(也称为MIME类型)和字符编码:
- Content-Type指定`Content-Type`标头,该标头指定请求正文的Internet媒体类型。默认类型为None。
可能的值包括`application/json`、`application/pdf`、`application/postscript`、`image/jpeg`、`image/png`、`multipart/form-data`、`text/html`、`text/plan`、`text/xml`等等
- ContentCharset属性控制请求的任何内容(例如,`text/html`或`text/xml`)类型时所需的字符集。如果不指定此属性,InterSystems IRIS将使用InterSystems IRIS服务器的默认编码。
注意:如果设置此属性,则必须首先设置`ContentType`属性。
- `NoDefaultContentCharset`属性控制在未设置`ContentCharset`属性的情况下是否包括文本类型内容的显式字符集。默认情况下,此属性为False。
如果此属性为true,则如果有文本类型的内容,并且没有设置`ContentCharset`属性,则内容类型中不包括任何字符集;这意味着字符集iso-8859-1用于消息输出。
- WriteRawMode属性影响实体正文(如果包含)。它控制请求正文的写入方式。默认情况下,此属性为False,并且InterSystems IRIS以请求标头中指定的编码写入正文。如果此属性为true,则InterSystems IRIS以原始模式写入正文(不执行字符集转换)。
- `ReadRawMode`属性控制如何读取响应正文。默认情况下,此属性为False,并且InterSystems IRIS假定正文在响应标头中指定的字符集中。如果此属性为true,InterSystems IRIS将以原始模式读取正文(不执行字符集转换)。
## 使用代理服务器
可以通过代理服务器发送HTTP请求。要设置此设置,请指定HTTP请求的以下属性:
- `ProxyServer`指定要使用的代理服务器的主机名。如果此属性不为空,则将HTTP请求定向到此计算机。
- `ProxyPort`指定代理服务器上要连接到的端口。
- `ProxyAuthorization`指定`Proxy-Authorization`标头,如果用户代理必须使用代理验证其自身,则必须设置该标头。对于该值,请使用正在请求的资源的用户代理所需的身份验证信息。
- `ProxyHTTPS`控制HTTP请求是针对HTTPS页面还是针对普通HTTP页面。如果未指定代理服务器,则忽略此属性。此属性将目标系统上的默认端口更改为代理端口443。
- `ProxyTunes`指定是否通过代理建立到目标HTTP服务器的隧道。如果为true,则请求使用HTTP CONNECT命令建立隧道。代理服务器的地址取自`ProxyServer`和`ProxyPort`属性。如果`ProxyHttps`为true,则隧道建立后,系统间IRIS将协商SSL连接。在这种情况下,由于隧道与目标系统建立直接连接,因此将忽略https属性。
## 使用SSL进行连接
`%Net.HttpRequest`类支持SSL连接。要通过SSL发送请求,请执行以下操作:
1. 将`SSLConfiguration`属性设置为要使用的已激活SSL/TLS配置的名称。
2. 还要执行以下操作之一,具体取决于是否使用代理服务器:
- 如果未使用代理服务器,请将`https`属性设置为true。
- 如果使用的是代理服务器,请将`ProxyHTTPS`属性设置为true。
在这种情况下,要使用到代理服务器本身的`SSL`连接,请将https属性设置为true。
请注意,当使用到给定服务器的`SSL`连接时,该服务器上的默认端口假定为443(HTTPS端口)。例如,如果没有使用代理服务器,并且https为true,则会将Default Port属性更改为443。
### 服务器身份检查
默认情况下,当`%Net.HttpRequest`实例连接到SSL/TLS安全的Web服务器时,它会检查证书服务器名称是否与用于连接到服务器的`DNS`名称匹配。如果这些名称不匹配,则不允许连接。此默认行为可防止“中间人”攻击,在RFC 2818的3.1节中进行了描述;另请参阅RFC 2595的2.4节。
**若要禁用此检查,请将`SSLCheckServerIdentity`属性设置为0。**
## `HTTPVersion`、`Timeout`、`WriteTimeout`和`FollowRedirect`属性
`%Net.HttpRequest`还提供以下属性:
`HTTPVersion`指定请求页面时使用的HTTP版本。默认值是`"HTTP/1.1"`。你也可以使用`“HTTP/1.0”`。
`Timeout`指定等待web服务器响应的时间,以秒为单位。
缺省值是30秒。
`WriteTimeout`指定等待Web服务器完成写入的时间(以秒为单位)。默认情况下,它将无限期等待。可接受的最小值为2秒。
`FollowRedirect`指定是否自动跟踪来自Web服务器的重定向请求(由300-399范围内的HTTP状态代码发出信号)。如果使用的是GET或HEAD,则默认值为TRUE;否则为FALSE。
## 指定HTTP请求的默认值
可以为`%Net.HttpRequest`的所有属性指定默认值。
- 要指定适用于所有名称空间的默认值,请设置全局节 `^%SYS("HttpRequest","propname")`,其中`“PropName”`是属性的名称。
- 要为一个名称空间指定默认值,请转到该名称空间并设置节点`^SYS("HttpRequest","propname")`
(`^%SYS`全局设置会影响整个安装,`^SYS`全局设置会影响当前命名空间。)
例如,要为所有名称空间指定默认代理服务器,请设置全局节`^%SYS("HttpRequest","ProxyServer")`
文章
Hao Ma · 一月 12, 2023
InterSystems公司的技术支持中心WRC(World Response Center)提供的服务包括故障报修,升级和数据迁移支持等等。当客户报告了系统故障或性能问题给WRC时, 会被要求收集以下的两份报告,以了解系统的运行情况和性能表现,它们是:***诊断报告(Diagnostic Report)和系统性能报告***。
## 诊断报告(Diagnostic Report)
有关诊断报告,您需要知道:
1. **诊断报告是当前系统的运行状况的数据收集。**
2. **是给InterSystems技术支持工程师的,维护人员基本不需要读它。**
3. **当出现紧急故障需要重启系统时,先做一次诊断报告的收集,会对WRC在故障过后分析故障原因提供极大的便利。**
#### 报告收集的步骤
进入管理门户页面,**“系统管理>诊断报告”(System Operation > Diagnostic Reports)**,点击**运行**。
- 报告收集通常**需要5-10分钟**
- 执行开始后屏幕会出现提示:诊断报告在…时间运行.报告将储存在…目录中。成功后可以在“系统管理>任务管理器>任务历史“看到记录收集成功的记录。
- 在运行前,您可以选择报告存放的位置(Diectory for archived reports).
- 如果不填写,**默认报告保存的目录是install-dir\mgr**
⚠️ :收集报告由内部用户irisuser执行,所以您选择的存放目录要有irisuser的读写权限。如果没有,点击“运行”时您并不能得到 提示错误,需要到“系统管理>任务管理器>任务历史“, 才能发现其实报告收集的任务没有执行。
- 如果有公网连接,可以配置邮件信息,报告会直接发送给WRC
- 如果开设了WRC工单,请输入WRC工单号码
- 万一您已经无法登录管理门户,还是有紧急的故障要收集诊断报告,您需要[在Terminal执行命令收集诊断报告(附录1)][1]。
#### 报告的内容细节
诊断报告是一个HTML文件,名字是license中您的机构名称+时间, 比如这样:MyCompany202301051144.html
请记住2点:
1. 收集的数据分基本信息(Basic information)和高级信息(Advanced Information)。对于维护人员,基本信息可以在操作维护的各个页面上查看,没必要去读报告。而高级信息,不要求维护人员读懂或者分析内容。
具体内容如果如下,您可以选择跳过,或者从文档中了解更多的内容:[在线文档:Caché的诊断报告内容](https://docs.intersystems.com/ens201815/csp/docbook/DocBook.UI.Page.cls?KEY=GCM_diagnostic#GCM_diagnostic_contents), [在线文档:IRIS的诊断报告内容](https://docs.intersystems.com/irisforhealth20211/csp/docbook/DocBook.UI.Page.cls?KEY=GCM_diagnostic#GCM_diagnostic_contents)。
>报告的内容是系统当前的运行状态,主要包括:
>
>- 配置信息:
>
> 主要有服务器硬件信息,操作系统信息,许可证信息,实例的配置情况(CPF文件),数据库的配置,bin目录下的文件等等
>
>- 当前系统的基本运行情况
>
> - 数据库大小,占用的百分比
> - Journal的信息
> - 许可证的使用情况
> - 安全设置,审计(Audit)日志
> - 网络的状态。比如在Linux系统,其实是执行 `netstat -an` 的输出结果
> - 进程的状态
> - 内存的状态, cstat, core dump等等
> - GloStat ..., 不一一罗列
2. **cconsole.log**,或者**messages.log** 不包含在诊断报告中。通常情况下, 您需要把这个日志文件和诊断报告一起提交WRC
#### 问题和回答
Q: 需要定期做诊断报告吗?
A: 定期做系统健康检查吧,里面包括了诊断报告
Q: 要创建定时任务做诊断报告吗?
A: 没必要。除非您要指定一个时间,比如要了解凌晨1AM的系统运行状况。
## 性能报告(SystemPerformance Report)
有关性能报告,您需要了解:
- 收集的数据包括操作系统的性能指标,Caché的设置,Caché性能指标等等。Caché性能指标大多数是每秒平均值。
- 报告收集
- Windows服务器:在Termial执行收集命令。
- Linux/Unix服务器:除了Terminal执行收集命令外,可以在管理门户设置定时任务(Task)执行。
> *为什么Windows服务器不能使用定时任务:*
>
> 性能报告的收集中会使用Windows系统的Perform.exe,也就是Windows系统性能监视程序。从用户管理门户设置Task, 或者使用当前非管理员权限的用户打开Terminal收集性能报告,会因权限不足导致内部调用Windows Perfom的失败,也就无法得倒操作系统的性能指标。
- 因为只是将系统默认收集的指标打包归档,所以它**对系统性能影响很小**。可以在任何时间执行。
- 即使没有故障要处理,定期的收集性能报告也是InterSystems推荐的。定期的报告保留了一个系统正常运行时的性能基线,便于今后的性能故障的原因分析,以及了解资源耗费情况的趋势。
如果操作中需要了解更多的内容,请参考在线文档:[Monitoring Performance Using ^SystemPerformance](https://docs.intersystems.com/irisforhealthlatest/csp/docbook/DocBook.UI.Page.cls?KEY=GCM_systemperf)(for IRIS), [Monitoring Performance Using ^pButtons](https://docs.intersystems.com/ens201815/csp/docbook/Doc.View.cls?KEY=GCM_pbuttons)(for Caché)。
### 在Terminal收集性能报告
#### Windows环境
1. 打开一个以管理员权限运行的Windows命令窗口。一般是找到CMD, 右键, “以管理员身份运行“。
2. 输入命令进入Caché或者IRIS终端。
- Caché: `
- IRIS : `iris console instanceName` 或者 `iris terminal instanceName`
3. 在%sys命名空间执行以下命令Routine:
- Caché: `do ^pButtons` (见下面的例子)
- IRIS : `do ^SystemPerfromance`
```zsh
%SYS>do ^pButtons
Current log directory: c:\intersystems\hsap\mgr\/intersystems\
Windows Perfmon data will be left in raw format.
Available profiles:
1 12hours - 12 hour run sampling every 10 seconds
2 24hours - 24 hour run sampling every 10 seconds
3 30mins - 30 minute run sampling every 1 second
4 4hours - 4 hour run sampling every 5 seconds
5 8hours - 8 hour run sampling every 10 seconds
6 test - A 5 minute TEST run sampling every 30 seconds
select profile number to run: 2
Collection of this sample data will be available in 86520 seconds.
The runid for this data is 20200123_142501_24hours.
%SYS>do Collect^pButtons
Current Performance runs:
20200123_142501_24hours ready in 24 hours 1 minute 48 seconds
nothing available to collect at the moment.
```
> `do Collect^pButtons`命令显示程序执行的状态。这是一个24小时的收集任务,显示的执行时间*“ready in 24 hours 1 minute 48 seconds”*比24小时略长,多出的2分钟用于^pButtons将整理日志并将数据转换为html格式。
#### Linux/Unix环境
进入iris terminal并执行收集命令`do ^pButtons`或者`do ^SystemPerformance` , 以下是在
```bash
$ iris session iris
Node: af34ddc4655b, Instance: IRIS
USER>zn "%sys"
%SYS>do ^SystemPerformance
Current log directory: /usr/irissys/mgr/
Available profiles:
1 12hours - 12 hour run sampling every 10 seconds
2 24hours - 24 hour run sampling every 10 seconds
3 30mins - 30 minute run sampling every 1 second
4 4hours - 4 hour run sampling every 5 seconds
5 8hours - 8 hour run sampling every 10 seconds
6 test - A 5 minute TEST run sampling every 30 seconds
Select profile number to run:
```
### 管理页面创建任务收集性能报告
对于Linux/Unix系统上安装的IRIS或者Caché, 到管理门户的“系统操作>任务管理器>新任务“,创建的新任务,
选项中,命名空间为“%SYS", 任务类型为”运行传统任务”(RunLegacyTask), 执行代码::
- Caché: `do run^pButtons(“ProfileName”)`
- IRIS: `do run^SystemPerformance(“ProfileName”)`
ProfileName也就是收集数据的时间长度, Profile定义数据采样的时间长度和频率,选项为:30mins, 4hours, 8hours, 12hours, 24hours, test。
- **24hours**: 最常用。任务执行的起始时间无所谓。如果设为零点,这样最后得到的数据图横轴是0点到24点,讨好细节控。
- **test**: 多用于24小时的收集工作前的预操作,查看5分钟的收集数据结果。
### 其他有关报告收集的注意事项
1. 多个收集任务可并行。
比如为了分析某个性能问题, 客户可以从早上9点执行两个收集任务,一个4小时的任务收集早晨业务繁忙时段的数据,一个24小时的任务收集全天的数据。
2. 默认报告保存位置是***"/mgr"***文件夹。
一个24小时报告的尺寸通常在**10MB - 100MB**。如果要保留的报告很多,可以考虑执行命令修改保存目录(注意确保Caché具有该目录的写权限)。
`%SYS>do setlogdir^pButtons("/somewhere_with_lots_of_space/perflogs/")`
3. 还可以创建另一个定时任务,清除历史报告,只保留一段时间的。
4. 在一个长的报告收集过程中,可以使用`Preview^SystemPerformance`命令在[不中断收集的情况下,读取已经收集的性能报告的数据。如果需要, 请阅读[在线文档中生成报告的部分](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GCM_systemperf#GCM_systemperf_produce)。
5. 如果可以要收集整个商业周期,比如一周或一个月的数据,需要[创建新性能采样profile(附录2)][2]。
6. 最后, 有一些内部的开关可以设置^pButtons采集更多的数据,比如硬盘访问的更详细的记录。通常这样的操作可能要消耗大量资源,请在WRC指导上使用。
### 性能报告的内容
性能报告是一个html文件, 默认的文件名为服务器,实例名称, 时间的组合,比如bjse01_IRIS_20220628_103554_30mins.html。
内容主要为:
- 配置, cpf文件,license等等
- 系统级别问题诊断,比如系统hang, 网络问题,性能问题等。(有兴趣可以去在线文档了解“cstat"或者“irisstat")
- Caché,IRIS性能表现的采样, 比如Global的读写速度, Rdration等指标,有兴趣可以去在线文档了解“mgstat')
- 操作系统的性能数据
- Windows Performance Monitor
- Linux Info, ps, sar, vmstat...
具体内容请阅读: [InterSystems IRIS Performance Data Report for Microsoft Windows Platforms](https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls?KEY=GCM_systemperf#GCM_systemperf_reports_windows_) , [InterSystems IRIS Performance Data Report for Linux Platforms](https://docs.intersystems.com/iris20222/csp/docbook/DocBook.UI.Page.cls?KEY=GCM_systemperf#GCM_systemperf_reports_linux)
### 性能报告内容的展现
性能报告是一个html文件。内容中的简单的数据,可以直观的在html中阅读, 但表格数据,比如cpu, 内存使用,IO, Global访问等等, 展现,或者说画图工具是有必要的。
**如果维护人员或用户想阅读性能报告**,可以考虑以下工具:
[性能报告数据转csv](https://community.intersystems.com/post/extracting-pbuttons-data-csv-file-windows) : 这是一个windows PowerShell的程序, 方便使用EXCEL展现性能数据。
[YASPE](https://github.com/murrayo/yaspe) : 作者是Murrayo Oldfield,开源的工具,代码是python, 提供docker image下载。操作简单。数据可以生成图表,像下面的样子,而且可以zoom in/out。

WRC内部工具:如果您有了一个WRC工单,并且就当前问题提交了性能报告。您可以请你的技术支持提供一个报告中数据图表呈现。WRC问题有生成图表的工具,但仅供内部使用。
## 附录
[1]: 在Terminal执行命令收集诊断报告
> 万一您已经无法登录管理门户,还是有紧急的故障要收集诊断报告,您需要在Terminal操作。
>
> 这个操作命令叫**Buttons**. 据说,名字的出处是最初开发者任务收集报告应该简单的像“按一个按钮”,所以后面开发的性能报告,干脆就被称为**pButtons**, p是performance的字头。因为被使用的可能性太小,iris的文档中其实已经找不到Buttons的内容。下面的步骤只是简单的给您一个印象。如果有一天不幸您非要用它,WRC会详细的指导您。
>
> ```sh
> USER>zn "%sys"
> %SYS>do ^Buttons
> (以下步骤省略)...
> ```
>
> *执行^Buttons可以选择收集某一个命名空间的ensemble production的信息。如果有需要,请按WRC的要求操作。*
[2]: 创建新性能采样profile
> Profile定义收集数据的时长和频率, 比如24hours的profile是每10秒采样一次运行24小时。如果可以希望收集其他时间长度的数据,或者减小采样频率以减小结果文件的大小,可以考虑自己定制Profile。比如下面的my_24hours_30sec:
>
> ```sh
> //创建24小时配置文件,30秒采样间隔。30sec*2880=1440mins=24hours
> %SYS>write $$addprofile^pButtons("My_24hours_30sec","24 hours 30 sec interval",30,2880)
> %SYS>do ^pButtons
> Current log directory: /db/backup/benchout/pButtonsOut/
> Available profiles:
> 1 12hours - 12 hour run sampling every 10 seconds
> 2 24hours - 24 hour run sampling every 10 seconds
> 3 30mins - 30 minute run sampling every 1 second
> 4 4hours - 4 hour run sampling every 5 seconds
> 5 8hours - 8 hour run sampling every 10 seconds
> 6 My_24hours_30sec- 24 hours 30 sec interval
> 7 test - A 5 minute TEST run sampling every 30 seconds
>
> select profile number to run:
> ```