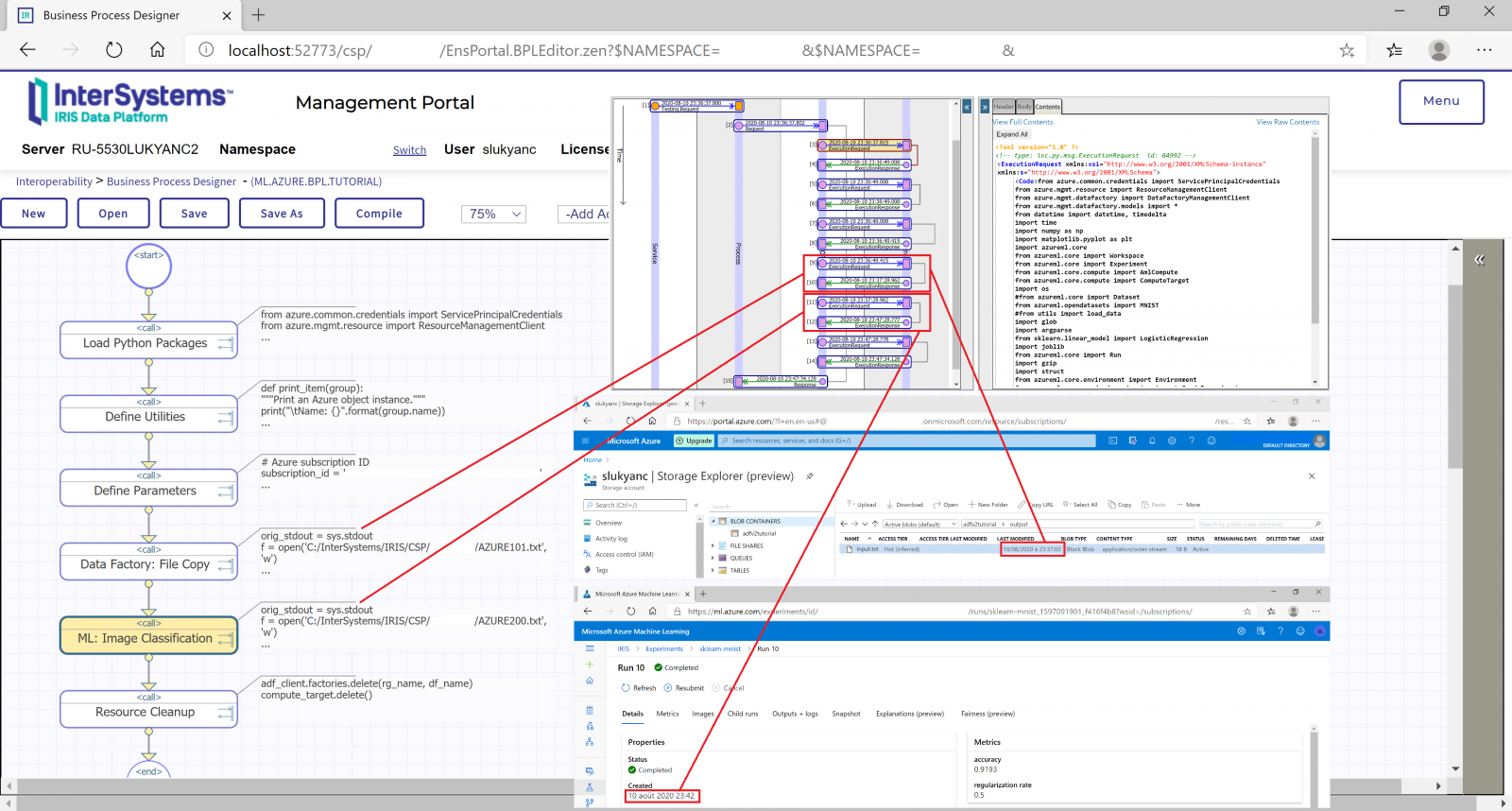
实时人工智能/机器学习计算的挑战
我们将从我们在 InterSystems 数据科学实践中遇到的示例开始讲起:
- “高负载”客户门户与在线推荐系统相集成。 计划是在整个零售网络层面重新配置促销活动(我们将假设使用“细分策略”矩阵而非“平面”促销活动母版)。 推荐机制会有哪些变化? 推荐机制内的数据馈送和数据更新会有哪些变化(输入数据量增加了 25000 倍)? 推荐规则生成设置会有哪些变化(生成规则的总量和“分类”呈千倍增加,因此需要将推荐规则筛选阈值缩小千倍)?
- 设备健康监控系统使用“手动”方式馈送数据样本。 现在,它将连接到每秒可传输数千个过程参数读数的 SCADA 系统。 监控系统会有哪些变化(它能否应对以秒为单位的设备健康监控)? 当输入数据接收到包含数百列最近在 SCADA 系统中实现的数据传感器读数的新块时,会发生什么(是否有必要关闭监控系统以将新的传感器数据整合到分析当中,以及要关闭多久)?
- 复杂的人工智能/机器学习机制(推荐、监控、预测)依赖于彼此的结果。 要调整这些人工智能/机器学习机制的功能以适应输入数据的变化,每月需要多少人工工时? 人工智能/机器学习机制在支持制定业务决策方面的总体“延迟”是多少(支持信息的刷新频率对比新输入数据的馈送频率)?