清除过滤器
公告
Michael Lei · 四月 9, 2022
Docker 20.10.14(2022年3月23日发布)改变了赋予容器的Linux能力,其方式与InterSystems IRIS 2021.1(及以上)容器的Linux能力检查器不兼容。
在Linux上运行Docker 20.10.14的用户会发现,IRIS 2021.1+容器将无法启动,并且日志会错误地报告缺少所需的Linux能力。 比如说。
[ERROR] Required Linux capability cap_setuid is missing.
[ERROR] Required Linux capability cap_dac_override is missing.
[ERROR] Required Linux capability cap_fowner is missing.
[ERROR] Required Linux capability cap_setgid is missing.
[ERROR] Required Linux capability cap_kill is missing.
[FATAL] Your IRIS container is missing one or more required Linux capabilities.
解决方案
遇到这个问题的用户需要调整传递给容器入口的命令行,以禁用对Linux功能的检查。 在命令行中,在docker run或docker start命令中的镜像后面添加--check-caps false。 例如:
docker run containers.intersystems.com/intersystems/iris-community:2022.1.0.152.0 --check-caps false
如果你使用的是docker-compose,相应的改动如下:
command: --check-caps false
能力检查是在启动IRIS进程之前检查常见的错误配置的一种方式。 禁用Linux能力检查对容器中运行的IRIS进程没有影响。
更多阅读
Docker 20.10.14 release notes
Running InterSystems Products in Containers
公告
Claire Zheng · 二月 23, 2022
投票时间到!
来为你最欣赏的应用投上一票吧! 【投票时间】InterSystems 开发者竞赛:Python
🔥 为你的最爱投票 🔥
如何投票?请看以下细节。
Experts nomination(专家提名)
InterSystems experts:InterSystems经验丰富的专家评审团将选出最好的应用程序,在Experts nomination(专家提名)中提名奖项。 有请InterSystems专家:
⭐️ @Benjamin.DeBoe, Product Manager⭐️ @Raj.Singh5479, Product Manager ⭐️ @Robert.Kuszewski, Product Manager⭐️ @Stefan.Wittmann, Product Manager⭐️ @Thomas.Dyar, Product Specialist⭐️ @Aleksandar.Kovacevic, Sales Engineer⭐️ @Eduard.Lebedyuk, Sales Engineer⭐️ @Sergey.Lukyanchikov, Sales Engineer⭐️ @Guillaume.Rongier7183, Sales Engineer⭐️ @Alexander.Woodhead, Technical Specialist ⭐️ @Jon.Willeke, Distinguished Quality Development Engineer⭐️ @Evgeny.Shvarov, Developer Ecosystem Manager
Community nomination(社区提名)
每一个用户来说,你投出的每一票的分数,是根据下面两类中最高的分数来计:
满足条件
奖项排名
第一名
第二名
第三名
在社区发布一篇帖子,并在Open Exchange中上传一个App
9
6
3
在社区发布了至少一篇帖子 或 在Open Exchange上传了一个App
6
4
2
在社区进行了任何有效贡献,如回帖、提问、发帖等
3
2
1
等级
奖项排名
第一名
第二名
第三名
Global Masters 的 VIP 级别 或 InterSystems 产品经理
15
10
5
Global Masters 的 Ambassador级别
12
8
4
Global Masters的Expert 级别或开发者社区版主
9
6
3
Global Masters的Specialist级别
6
4
2
Global Masters的Advocate级别,或 InterSystems员工
3
2
1
Blind vote!
每个应用获得的投票数将对所有人不可见。我们会每天在这个帖子(英文原帖)的评论区发布一次排行榜。
在 竞赛页面 ,各项目将按以下进行排名:发布得越早,排名越靠前。
P.S. 不要忘记订阅本文(请订阅英文原帖),点击铃铛图标,即可收到最新评论。
在参与投票前,您需要:
登录 Open Exchange – 使用开发者社区账号即可。
在社区内进行有效贡献 ——回答问题、发帖、在Open Exchange发布新应用等等都可以,然后你的账号才可以参与投票。点击查看本帖 ,了解如何更好地成为有效的社区贡献者!
投票期间,如果你改了主意,可以随时将票改投给其他项目。
来支持你喜欢的项目吧!
注意:在投票期间,参赛者可以继续修复bug,提升应用,所以投票者不要错过最新发布的版本哦~ 排名第一了,请同学们继续努力!
Voting for the InterSystems Python Contest goes ahead!
And here're the results at the moment:
Expert Nomination, Top 3
django-iris by @Dmitry Maslennikov
appmsw-sql2xlsx by @Sergey Mikhailenko
blockchain - [ IRIS python ] by @davi massaru teixeira muta
➡️ Voting is here.
Community Nomination, Top 3
IRIS-Database-and-Machine-Learning-Based-Approaches-for-Prediction-of-Spontaneous-Intracerebral-Hemo by @Fatian Wu
appmsw-sql2xlsx by @Sergey Mikhailenko
django-iris by @Dmitry Maslennikov
➡️ Voting is here.
公告
Tingting Jiang · 六月 21, 2022
我们正在招聘Support Facilitator,欢迎您的自荐、推荐。
请将简历投递至Belinda.Glasson@intersystems.com,愿您的加入给我们带来新的活力,我们也将为您提供广阔的发展空间!(由于岗位职能要求,职位说明以英文形式发布。)
Location:Beijing
Job Title:Support Facilitator
Department:Product Support
Reporting to:China Support Supervisor
What We Do Matters
Why are we here? To ensure that our customers have reliable access to the right information at the right time—information they can share and use to draw insights, leading to better decisions.
Job Summary
Ensure customer satisfaction by triaging support requests, facilitating rapid responses, managing the support queue, Service Level Agreements and backlog and assisting the China Support Supervisor with the coordination of projects.
Key Responsibilities of the Role
Provide immediate response to customer support inquiries via phone or iService (the TrakCare ticketing system)
Ensure iService tickets contain sufficient information and detail for second line support to work with, according to the minimum datasets laid out
Where possible, provide immediate resolution to support inquiries. Alternatively, triage the inquiry and determine the best person to pass it to
Assist level 2 support staff and the Support Manager with the monitoring, maintenance, administration and processing of support queues and tickets
Develop and maintain a set of Standard Operating Procedures for responding to common and/or repeatable inquiries
Assist the Support Manager with adherence to Service Level Agreements
Assist the Support Manager with the coordination and management of projects to deliver new functionality to existing customers
Identify opportunities to act as a “multiplier” in order to drive efficiency
Provide regular reports to management and customers as requested
Acquire new skills by assuming additional responsibilities as requested.
Additional responsibilities as determined by management.
Experience and Qualifications
Friendly and professional verbal and written communication skills demonstrated by prior customer service experience
Good organizational skills with demonstrable attention to detail
1-2 years’ experience in a support or Project Management Office role or an administrative role in a similar organization
Must be fluent in English
Personal Specifications
IT or health-based degree or 2 years’ related experience
公告
Tingting Jiang · 六月 21, 2022
InterSystems正在招聘Market Development Representative欢迎您的自荐、推荐。请将简历投递至:Belinda.Glasson@intersystems.com,愿您的加入给我们带来新的活力,我们也将为您提供广阔的发展空间!
(由于岗位职能要求,招聘职位说明以英文形式发布。)
Location:Beijing
Job Title:Market Development Representative
Department:Marketing
Reporting to:Marketing Manager
What We Do Matters
Why are we here? To ensure that our customers have reliable access to the right information at the right time—information they can share and use to draw insights, leading to better decisions.
Job Summary
This role will suit someone who is energised by the opportunity to develop and grow enterprise software sales pipelines in Healthcare IT markets. As a Market Development Representative, you’ll be working with a smart, entrepreneurial team to shape and grow our local business. Your primary focus will be development of a high quality and growing pipeline of data platform prospects and accounts that you will nurture. You will play a pivotal role in helping the team to identify, break into, and grow named accounts. In many instances you will represent the front line of InterSystems technology engagement with significantly sized enterprise accounts and healthcare providers.
Key Responsibilities of the Role
Make first contact and nurture a prospect relationship into a marketing qualified lead
Partner with sales and marketing to develop and conduct prospecting strategies and build and execute on named account strategies
Build and execute outbound prospecting plans for targeted accounts including but not limited to emails, phone calls and industry focused event attendance
Develop brand and technology champions externally across target contacts
Follow up inbound enquiries and marketing-generated leads
Represent and promote InterSystems at industry events
Manage and be accountable for growing your pipeline using technology to engage with your prospects and to track and report on progress
Provide feedback and recommendations on marketing efforts based on real front-line interactions
Conduct industry research to uncover pain points, find potential sales opportunities, build account profiles
Handle a variety of communication including, but not limited to, inbound calls, warm follow-ups, social media, and email campaigns
Work with 3rd party outbound call partners to support the success of new campaigns and other lead generation programs if needed.
Experience and Qualifications
BA or BSc in business/economics, marketing or technical
Five or more years' experience of business development/inside sales in B2B field
Experience qualifying and selling software or other technology products over the phone
Strong listening and solution selling skills
Proven ability to collaborate with field sales representatives and marketing team to plan and achieve goals
Excellent oral and written communication skills in Chinese and English
Knowledge of standard computer application skills, such as Word, Excel, PowerPoint, and Automation/CRM.
Goal oriented and self-motivated; approaches work with a passion and enthusiasm
Experience requirement
Development and execution of a territory plan and mutually agreed strategic account plans.
Proven success and experience in leading complex enterprise sales with large implementation projects.
Demonstrable experience with tender responses and bid management.
Proven experience in managing senior client relationships.
Ability to develop relationships with customers at all levels across the business.
Able to develop and maintain internal stakeholder relationships.
Discover, qualify and develop new Data Platform business opportunities.
Define and execute market plans and campaigns – together with marketing.
Build a pipeline of new activity for Data Platform within and outside the customer base.
Maintain an in-depth understanding of the political and organisational structure of a targeted prospect.
Act as the principal liaison between InterSystems and partner/ customer accounts.
Personal Specifications
COMMUNICATION AND INFLUENCE - Is articulate and asks good questions; gives clear, concise, and focused answers to questions; explains opinions and positions; uses empathy to persuade others; keeps key people informed; ability to communicate with diverse audiences.
TEAMWORK - Ability to collaborate effectively with people of comparable talents and different strengths; handles conflict constructively; avoids being argumentative; willing to pitch in and do the mundane things that need to be done; treats people at all levels and all roles with respect.
PASSION for technology and must be technically and Social Media Savvy.
公告
jieliang liu · 七月 12, 2021
嗨,开发者们,
你准备好迎接新的挑战了吗? 我们很高兴地宣布第一届InterSystems技术文章写作比赛:
🏆 InterSystems技术文章写作大赛 🏆
从2021年7月15日至8月15日,写一篇与InterSystems技术有关的任何主题的文章!
每个人都有奖品: 在此期间,每个在DC上发表文章的人都将获得一个特别的奖品包!
大奖: Apple iPad
参加我们的新比赛,你的内容将被超过55K的月度读者看到! 详情如下。
奖品:
1. 每个人都是InterSystems技术文章竞赛的赢家! 任何在比赛期间写文章的用户都会得到特别的奖励:
🎁 独特的开发者社区连帽衫
🎁 InterSystems 贴纸
2. 专家选择奖 – 文章将由InterSystems的专家进行评判:
🥇 一等奖: Apple iPad 128GB
🥈 二等奖: Amazon Kindle 8G Paperwhite
🥉 三等奖: Nike Utility Speed Backpack
或者另选: Raspberry Pi 4 8GB + InterSystems IRIS社区版安装包镜像
3. 开发社区奖 – 点赞最多的文章。 获胜者将有机会从以下奖品中选择一个。
🎁 Nike Utility Speed Backpack
🎁 Amazon Kindle 8G Paperwhite
谁可以参加?
任何开发者社区成员,除了InterSystems的员工。 创建一个账户!
比赛时间
📝 七月 15日 - 八月 15日: 发表关于社区和投票时间的文章。.
在这段时间内发表一篇文章。 DC成员可以用 "赞 "为发表的文章投票--在社区奖中投票。
注意:你越早发表文章,你就越有时间收集赞。
🎉 八月 16日: 获奖者名单公布。
有什么要求?
❗️ 任何在比赛期间写的文章,只要满足以下要求,就能自动参加比赛:
文章必须与InterSystems技术有关
文章必须是英文的
文章必须是100%的新文章(可以是现有文章的延续)。
文章不应抄袭或翻译。
文章大小。>超过1,000个字符
团队规模:个人(允许同一作者的多个作品)。
要写什么?
❗️ 你可以选择任何与InterSystems技术相关的技术主题。
这里有一些选择文章主题的可能领域。这些只是例子,你可以自由选择任何你想要的东西。
#
主题
细节
1
嵌入式Python简介
嵌入式Python是InterSystems IRIS的一个令人兴奋的新功能,允许开发人员用Python编写方法、SQL存储过程等。
2
来自互操作性的嵌入式Python
探索如何从互操作性中利用嵌入式Python。
3
嵌入式Python。通过语言结构进行翻译
虽然我们的目标是实现嵌入式Python的无缝集成,但还是有一些技巧和窍门可以让事情变得顺利。下划线方法、字典、列表和其他。从ObjectScript中调用Python功能的最佳方式是什么?
4
InterSystems报告设计器介绍
续写 这篇文章. 续篇应该包括:
创建目录
创建基本的报告类型,即
图表(柱状图、饼状图、线状图、仪表图、热图...)。
表(摘要和详细)。
串联表
发布报表到报表服务器
创建一个时间表
教程参考: Getting Started with InterSystems Reports
5
从互操作性/IRIS调用报告
一篇描述如何从IRIS上执行(和获得)InterSystems Reports Report的文章,该报告来自Interoperability Production。
6
使用InterSystems的地图报告
一篇描述如何用地理空间数据建立InterSystems报告的文章。HoleFoods数据集包含了交易的地点,你可以使用。
7
如何用InterSystems IRIS做CI/CD
–
8
使用Kafka连接的变更数据采集
一个例子显示了如何设置Kafka Connect并通过Kafal Connect JDBC连接器导出&导入SQL数据。
9
将分析/ML应用于SQL语句索引
–
10
我最喜欢的维护任务,自动化
–
11
利用审计数据库
–
12
设置GitHub动作的三个步骤,让你的应用程序立于不败之地
–
13
IRIS实例中的OAuth2授权
–
14
在K8s上设置镜像
–
15
在IRIS分析中使用%MDX和%KPI而不是主题区域
–
16
尝试外部语言网关/与以前的编程语言网关相比
Example
17
从IAM向Kafka流式传输事件
–
18
IntegratedML演练
–
19
使用Python将请求导出到Excel
–
20
将云服务与production结合起来
例如,MS Azure Cognitive Services或Amazon Rekognition。
21
Working with IKO
–
22
IKO IRIS on AWS Kubernetes with Hugepages
–
23
纳入IKO的备份
–
24
IKO - 创建一个有计算节点、SAM、无分片的集群
包括CPF文件来设置我们的最佳实践。
25
与ECP建立的数据科学共享工作组
有一个数据服务器,每个数据科学家的桌面上都有一个计算节点。显示数据在断开连接时可以使用,重新连接时可以同步。
26
讨论云部署的存储选项的文章(本地存储、块存储等的性能差异)和权衡(如果使用块存储,你可能不需要镜像,等等)。
–
注意:允许不同作者的同一主题的文章。
欢迎在本帖的评论中提交你的主题想法。
所以。
我们等待着你的精彩文章!
祝你们好运,让普利策的力量与你们同在! ✨
公告
Claire Zheng · 八月 1, 2023
嗨,开发者们!
我们很高兴邀请您参加Idea-A-Thon创意马拉松,展示与 InterSystems 技术相关的好创意:
🎁第二届 InterSystems Idea-A-Thon创意马拉松🎁
在8 月 1 日至8 月 21 日期间,根据本次创意马拉松的主题发布创意,即可获得即可获得创意达成奖。
最重要的是,此次赛事InterSystems的员工和社区成员都可以参与!
主题
💡使用 InterSystems IRIS 快速、安全、绿色地运行解决方案💡
该主题基于2023 年 InterSystems 全球峰会期间@Jeffrey Fried的演示而来: InterSystems IRIS 最新动态、下一步计划
如果您的创意得到实施,将提高基于 InterSystems IRIS 的解决方案的速度和可靠性,并减少碳足迹——本次Idea-A-Thon创意马拉松就是为这些好创意而来。
您的创意需要有助于:
提高解决方案的性能
减少实施所需的硬件资源
减少开发、测试、实施、用户培训的工作日
以及与Idea-A-Thon创意马拉松主题相关的其他想法。
👉 要参加我们的Idea-A-Thon创意马拉松,请在InterSystems Ideas 门户上提交创意。
合格的参赛创意应符合以下要求:
用户在Idea-A-Thon创意马拉松期间提交,由通过InterSystems Ideas网站注册的用户创建(您可以通过InterSystems SSO登录);
不要成为其他已经存在的想法的一部分——只允许提交新创意;
不要描述InterSystems产品或服务的现有功能;
除标题外,还包含对创意的详细描述以及对为什么该创意适合 Idea-A-Thon 主题,阐释需清晰明了,包含3~5句话;
以英文发布;
InterSystems 专家认为该创意有意义。
所有想法都将受到审核。我们可能会要求您更详细地阐释您的创意。
符合要求的创意将获得特殊的“创意马拉松(Idea-A-Thon)”状态标记。
谁可以参加?
我们邀请所有人加入我们的创意马拉松。欢迎InterSystems员工和社区成员参与并提交创意。
奖品
1. 参与奖——所有发布合格创意的参与者都会将获得奖励
🎁 无线充电鼠标垫
2. 专家奖 ——InterSystems 专家将评选出 3 个最佳创意。获胜者将获得:
第一名- 🎁 Apple Watch SE / Fairphone Fairbuds XL 耳机
第二名- 🎁 扬声器套装 JBL Pulse 5 / Apple AirPods Pro 第二代 / 乐高星球大战 R2-D2
第三名- 🎁 乐高保时捷 911 / Beeline 自行车 GPS 电脑 - Velo 2
3. 社区奖——得票最多的创意将获得:
🎁 乐高保时捷 911 / Beeline 自行车 GPS 电脑 - Velo 2
注:InterSystems员工只能获得参与奖。专家奖和社区奖只会颁发给社区非 InterSystems 成员。
参赛时间
⚠️ 创意提交:8 月 1 日至 21 日
✅ 创意投票:8 月 1 日至 27 日
🎉 公布获奖者:8 月 28 日
我们鼓励您在此期间登录创意门户上分享您的想法。注册会员可以对已发布的创意进行投票、发表评论。
注意:社区奖仅计入在开发者社区发表过至少一篇帖子的活跃社区用户的投票。
所以,
来 InterSystems Ideas 门户上发布您的创意吧,并随时关注您创意的状态更新:
>>在此提交您的创意<<
Important note: All prizes are subject to availability and shipping options. Some items may not be available for international shipping to specific countries, in this case, an equivalent alternative will be provided. We will let you know if a prize is not available and offer a possible replacement. Prizes cannot be delivered to residents of Crimea, Russia, Belarus, Iran, North Korea, Syria, or other US-embargoed countries.
重要提示:所有奖品均视供应情况和运输情况而定。有些奖品可能无法通过国际航运到特定国家,在这种情况下,我们将提供等效的替代方案。如果没有奖品,我们会通知您,并提供备选的替代奖品。奖品不能寄给克里米亚、俄罗斯、白俄罗斯、伊朗、朝鲜、叙利亚或其他美国禁运国家的居民。
文章
Jingwei Wang · 八月 30, 2022
InterSystems IRIS 允许从任何符合DB-API的Python应用程序对InterSystems IRIS 进行快速、无缝地访问。Python DB-API驱动是对PEP 249 v2.0(Python数据库API规范 v2.0)的完整兼容。
步骤
前提是要有一个Python的开发环境。
本示例使用vs code 如下所示创建一个dbapi.py文件。
dbapi.py :
# Embedded Python examples from summer 2022
import iris as dbapi
mytable = "mypydbapi.test_things"
conn = dbapi.connect(hostname='localhost', port=1972, namespace='IRISAPP', username='superuser', password='iris')
# Create table
cursor = conn.cursor()
try:
cursor.execute(f"CREATE TABLE {mytable} (myvarchar VARCHAR(255), myint INTEGER, myfloat FLOAT)")
except Exception as inst:
pass
cursor.close()
conn.commit()
# Create some data to fill in
chunks = []
paramSequence = []
for row in range(10):
paramSequence.append(["This is a non-selective string every row is the same data", row%10, row * 4.57292])
if (row>0 and ((row % 10) == 0)):
chunks.append(paramSequence)
paramSequence = []
chunks.append(paramSequence)
query = f"INSERT INTO {mytable} (myvarchar, myint, myfloat) VALUES (?, ?, ?)"
for chunk in chunks:
cursor = conn.cursor()
cursor.executemany(query, chunk)
cursor.close()
conn.commit()
# conn.close()
sql = f"select * from {mytable}"
rowsRead = 0
cursor = conn.cursor()
cursor.arraysize = 20
cursor.execute(sql)
rc = cursor.rowcount
rows = cursor.fetchall()
for row in rows:
print(row)
rowsRead += len(rows)
cursor.close()
conn.close()
安装 DB-API驱动,点击此链接下载DB-API驱动
pip install intersystems_irispython-version-py3-none-any.whl
配置Connection String - 按照Intersystems IRIS的服务器,在dbapi.py文件中配置
hostname
port
namespace
username
password
在InterSystems IRIS管理门户中创建IRISAPP命名空间。
在VS code中运行dbapi.py文件,运行结果如下,说明数据成功导入。
['This is a non-selective string every row is the same data', 0, 0.0]
['This is a non-selective string every row is the same data', 1, 4.57292]
['This is a non-selective string every row is the same data', 2, 9.14584]
['This is a non-selective string every row is the same data', 3, 13.71876]
['This is a non-selective string every row is the same data', 4, 18.29168]
['This is a non-selective string every row is the same data', 5, 22.8646]
['This is a non-selective string every row is the same data', 6, 27.43752]
['This is a non-selective string every row is the same data', 7, 32.01044]
['This is a non-selective string every row is the same data', 8, 36.58336]
['This is a non-selective string every row is the same data', 9, 41.156279999999995]
在IRISAPP命名空间下,查看InterSystems IRIS 数据库,可以看到数据,说明数据导入成功InterSystems IRIS。
SELECT myvarchar, myint, myfloat FROM mypydbapi.test_things
公告
Claire Zheng · 九月 27, 2022
社区成员们,大家好!
我们开心地宣布一种全新类型的比赛——寻找最聪明的创意比赛!欢迎了解:
💡 InterSystems Idea 创意马拉松 💡
在9月26日至10月16日期间提出一个与InterSystems产品和服务相关的想法,即可获得达成奖。
最重要的是,此次赛事InterSystems的员工和社区成员都可以参与!
>> 点击提交你的想法吧! <<
规则
InterSystems Idea创意马拉松是由InterSystems Ideas反馈门户组织的,在InterSystems Ideas反馈门户,您可以提交与我们的服务(文档、开发社区、全球大师等)相关的产品增强请求和想法,并投票选出您喜欢的。
在本次比赛中,我们邀请大家在这个门户网站上分享自己的想法,并为他人投票。
只需在 InterSystems Ideas网站 提交想法即可参赛。
合格的参赛创意应符合:
用户在Idea-A-Thon创意马拉松期间提交,由通过InterSystems Ideas网站注册的用户创建(您可以通过InterSystems SSO登录);
不要成为其他已经存在的想法的一部分——只允许新的想法;
不描述InterSystems产品或服务的现有功能;
除了标题之外,还要对观点的本质进行详细而清晰的解释;
以英文发帖;
被专家认为是有意义的。
所有符合条件的想法将在InterSystems ideas门户网站上拥有一个特殊的“Idea-A-Thon”状态,可以很容易地在Idea创意马拉松上找到。
谁可以参加?
我们邀请所有人加入我们的创意马拉松。欢迎InterSystems员工和社区成员参与并提交创意想法。
奖项
1. 参与奖 :每个发布合格想法的人都会将获得奖励:
🎁 InterSystems Branded T-Shirt
2. 专家奖:获胜者将由InterSystems专家团队选出,并将获得:
🎁 LEGO Star Wars™ R2-D2™ / BOSE Sleepbuds™ II / BOSE SoundLink Flex Bluetooth® speaker bundle
3. 社区奖:获得最多投票的创意,获奖者将获得:
🎁 LEGO Star Wars™ R2-D2™ / BOSE Sleepbuds™ II / BOSE SoundLink Flex Bluetooth® speaker bundle
重要提示:InterSystems的员工只能获得参与奖。专家奖和社区奖只能由非intersystems社区成员获得。
参赛时间
📝 9月26日 - 10月16日:创意发布、投票阶段
在此期间发布一个或几个创意。InterSystems Ideas网站的注册会员可以为发表的创意投票,这些投票将计入社区奖。
注意:越早发表你的创意,你就越有更多的时间去收集投票。
来参加吧!
来 InterSystems Ideas 发布你的创意拿大奖!时刻关注你的创意!
祝大家好运 👍
Important note: All prizes are subject to availability and shipping options. Some items may not be available to ship internationally to specific countries. Prizes cannot be delivered to residents of Crimea, Russia, Belarus, Iran, North Korea, Syria, or other US-embargoed countries. We will let you know if a prize is not available and offer a possible replacement.
重要提示:所有奖品均受可用性和运输选择。有些项目可能无法国际运输到特定国家。奖品不能发放给克里米亚、俄罗斯、白俄罗斯、伊朗、朝鲜、叙利亚或其他美国禁运国家的居民。如果没有奖品,我们将告知您,并提供可替代品。
文章
Qiao Peng · 四月 25, 2022
InterSystems流程自动化与工作流引擎
InterSystems工作流程引擎的主要功能 2
使用InterSystems工作流程引擎 3
场景描述 3
环境配置与测试 5
任务管理 15
任务API和自定义任务用户界面 16
展望 17
15
集成平台除了集成业务系统,打通数据与业务流程外,另一个核心的功能就是流程自动化(BPA)。
流程自动化涉及几个重要的特性:
流程建模
流程协同
决策自动化
低代码工作流程自动化
任务协同与任务管理
其中第4和5点都是和工作流程相关的。
什么是工作流程(Workflow)?它和业务流程(Business Process)有何区别?为何集成平台要涉及对工作流程的管理?
工作流程是对人工工作任务的流程及其各操作步骤之间业务规则的抽象、概括描述。所以它针对的是人工工作任务,而非业务系统的接口。业务流程与工作流不同,业务流程描述的是特定的业务在各个IT系统间和人工任务间的流程过程和业务抽象。也就是说业务流程范围比工作流程大,是包括工作流程的。
为何要在集成平台里提供工作流程建模和管理的能力?其实医院的所有业务系统都是执行人工任务的,例如医生在HIS中给患者录入诊断、下达医嘱。但并非所有的人工任务和流程在现有的业务系统中都有,例如越来越多的辅助决策系统会提供给医护人员决策建议,这些建议需要医护人员确认才能被采纳。这些辅助决策系统需要被集成平台持续集成:拿到辅助决策的上下文数据,并实时反馈决策建议给业务系统。但它的决策建议缺很难集成进业务系统的工作流程中,这涉及对业务系统的改造 – 改造现有业务系统的流程和用户界面,时间和费用成本高昂。随着辅助决策使用的范围与深度的扩大,通过改造业务系统以纳入对不断涌现的辅助决策支持内容变得越发难以为继。
工作流程引擎可以帮助解决这样的需求,快速满足业务流程优化和再造的需要,创造持续集成的价值。
InterSystems工作流程引擎的主要功能
InterSystems IRIS数据平台、Health Connect医疗集成平台和Ensemble集成平台都内建有工作流引擎。工作流程引擎具有以下功能:
任务角色和用户管理 – 对工作任务的角色定义和角色用户的管理
任务抽象与建模 – 对工作任务的上下文数据模型和任务动作的建模
任务列表 – 对任务进行管理的
任务分配 – 对工作任务进行分配与管理,例如按什么顺序分配任务?任务退回后如何重分配?
任务流程建模和自动化 – 通常工作流程是业务流程的一部分,按业务流程图建立工作流程模型,并自动化执行
任务门户 – 提供给用户的任务界面,用以查看、接受、执行或退回任务
任务API – 提供给第三方系统用以集成的任务查询、接受、执行、退回的API
InterSystems数据平台提供了一个针对工作任务的标准业务操作类 -EnsLib.Workflow.Operation,将这个业务操作加入到业务流程即可。它有对应的任务请求消息 –EnsLib.Workflow.TaskRequest 任务响应消息 - EnsLib.Workflow.TaskResponse。这些类都无需修改,直接使用。
使用InterSystems工作流程引擎
场景描述
我们以一个简化的示例为例,说明如何使用工作流。这个示例不需要写代码,完全通过图形化工具和配置工具完成。场景如下:
医生通过医生站下达药嘱后,药嘱发送给药房系统。现在医院上了一套基于机器学习的药品知识库,通过患者的年龄信息、诊断和药嘱,判断药嘱是否有风险。但药房系统尚无法与药品知识库做流程集成,因此我们用InterSystems工作流来做对药剂师的药嘱风险进行提示。整体业务流程图如下:
医生站会发出HL7 V2的药嘱消息OMG_O19,药房系统也接受HL7 V2的药嘱消息OMG_O19。而药品知识库提供服务,需要的请求消息,包含患者诊断、药嘱,并返回警告级别和警告内容。
我们的用例中,医生为控制患者血压开了美托洛尔,但患者有糖尿病,美托洛尔是β受体阻滞剂药物,会影响血糖和血脂的代谢。因此药品知识库会给出药品风险提示。
环境配置
演示环境安装和配置
初始的演示环境在这里下载。
将它导入您的IRIS或HealthConnect平台,如果还没有IRIS,可以下载免费的社区版。
导入后,会看到有Demo.BP.Workflow这个非常简单的业务流程:
Production中只有一个业务服务,用来通过文件接收HL7 V2消息,默认的接收文件目录是 C:\Temp\hl7v2\,处理过的HL7文件会保存在C:\Temp\hl7v2\Archive。请配置这2个目录到你本地的可用且有权限的目录。
下载包中提供了样例HL7 V2消息文件,测试时,将其拷贝到接收文件目录即可。
现在我们增加“药剂师复核”的工作任务
向Production中增加操作,弹出页面中:
类名称 选择 EnsLib.Workflow.Operation
操作名称 可以填写“药剂师”
自动创建角色 选择 是 。这样系统会自动检查任务角色名称,如果没有“药剂师”任务角色,会自动帮我们创建
修改业务流程,增加对药剂师角色的任务流程调度
将“待实现药剂师任务”的<empty>流程节点删除,并在原节点上增加“调用(<call>)”流程节点。选择目标为“药剂师”业务操作;取消选中“异步”;给它的名称设置为“提示药剂师药品风险”。
配置药剂师任务
4.1配置任务请求消息 – 应选择EnsLib.Workflow.TaskRequest。这个消息中有这些属性:
%Actions:字符串类型,用来让用户执行的操作,如果有多个操作,用逗号分隔。这里我们给药剂师二个操作选项:"取消药嘱,忽略提示"。
%Subject: 字符串类型,任务的主题。今后可用于任务的分析、分配。这里我们设置为"药嘱风险处理"。
%Message:字符串类型,任务的描述。这里我们不赋值。
%Priority: 整数型,任务优先级,1为最高,默认值为3。我们将任务优先级设置为药品风险级别: context.DrugAlertLevel。
%UserName:字符串类型,用于指定任务分配到的具体用户。这里我们计划分配给角色,而不是具体的用户(药剂师),因此不用赋值。
%Title:字符串类型,任务的名称。它和主题不同,是任务的具体名称。这里我们不赋值。
%TaskHandler:字符串类型,任务句柄,设置为响应消息的类名。不用设置。
%Command: 字符串类型,用于向任务句柄传递参数。不用设置。
%FormTemplate: 字符串类型,用于设置用户自定义任务界面的CSP网页名。不用设置。
%FormFields: 字符串类型,用于设置任务用户界面的显示项目名称,多个显示项目名称间用逗号分隔。我们需要显示患者姓名、药品名称、患者诊断、药品风险级别和药品风险信息,设置为"患者姓名,药品名称,患者诊断,药品风险级别,药品风险"。
%FormValues:字符串数组类型,对应%FormFields每个显示项目的值。%FormValues的下标(Key)就是对应的%FormFields的每个显示项目的名称。
其中Key为"患者姓名"的数据从请求HL7消息的PID段的PatientName字节获取,因此值设置为request.{PIDgrp.PID:PatientName};
Key为"药品名称"的数据从上下文变量context的Msg4DrugDB属性的Drug属性中获取,因此值拖拽为context.Msg4DrugDB.Drug;
Key为"患者诊断"的数据从上下文变量context的Msg4DrugDB属性的Diagnoses属性中获取,因此值拖拽为context.Msg4DrugDB.Diagnoses;
Key为"药品风险级别"的数据从上下文变量context的DrugAlertLevel属性中获取,因此值拖拽为context.DrugAlertLevel;
Key为"药品风险"的数据从上下文变量context的DrugAlert属性中获取,因此值拖拽为context.DrugAlert。
4.2配置任务响应消息 – 应配置为EnsLib.Workflow.TaskResponse。这个消息中有这些属性:
%Action: 记录了药剂师完成任务时选择了哪个操作。我们需要将它保存到上下文中。直接拖拽callresponse的%Action到context的PharmacistDecision:
%Priority:任务优先级,是从任务请求消息拷贝来的。我们无需处理它。
%UserName: 记录哪个用户执行了该任务。我们需要将它保存到上下文中。
%UserTitle:记录执行该任务的用户头衔。我们无需处理它。
%UserRanking: 记录执行该任务的用户在该角色组中的排序。我们无需处理它。
%RoleName:记录执行该任务的角色名称。我们无需处理它。
%Subject:任务的主题,是从任务请求消息拷贝来的。我们无需处理它。
%Message:任务的描述,是从任务请求消息拷贝来的。我们无需处理它。
%Actions:用来让用户执行的操作,是从任务请求消息拷贝来的。我们无需处理它。
%FormTemplate: 用户自定义任务界面的CSP网页名,是从任务请求消息拷贝来的。我们无需处理它。
%FormFields: 任务用户界面的显示项目名称,是从任务请求消息拷贝来的。我们无需处理它。
%FormValues:任务用户界面的项目值。我们无需处理它。
%Status:任务状态,用于查询任务状态。我们无需处理它。
%TaskStatus: 任务状态,用于工作流引擎分配和管理任务。我们无需处理它。
添加业务流程分支,以响应药剂师不同的任务执行结果
在“提示药剂师药品风险”流程节点后面增加对任务执行结果判断,这里需要用“分支<branch>”,而不是“if” - “分支<branch>”可以返回到任何的“标签<label>”节点。
对“分支<branch>”节点,需要设置其条件和标签,在满足条件时转到标签继续执行。因此条件设置为药剂师没有选择“取消医嘱”: context.PharmacistDecision'="取消医嘱";标签选择“药房”。
编译并启动Production
祝贺大家看到这里了,主要工作已经完成,我们没有写任何一行代码、完全通过配置,已经有了如下完整的业务流程图,保存并编译它。
启动Production。
配置工作流角色与工作流用户
启动Production后,系统会自动帮助我们创建“药剂师”工作流角色。可以到管理门户>Interoperability>管理>工作流>工作流角色 确认。
现在要增加一个工作流用户。可以使用你正在使用的IRIS账户作为药剂师用户账户。在管理门户>Interoperability>管理>工作流>工作流用户 页面中选择你的IRIS账户,我这里选择的是SuperUser;并给他一个全名,然后保存。
然后将这个工作流用户加入“药剂师”工作流角色:在工作流角色管理界面点击添加,在用户名中选中刚才创建的工作流用户,其它不用选中,点击确定。现在我们有了可用于测试的工作流用户。
测试
现在我们开始测试:
8.1 检查一下Production是否处于启动状态;然后将示例HL7 V2文件拷贝到接收HL7目录,应该看到这个文件很快就消(处)失(理)了。
8.2登录到任务门户:以药剂师用户帐号登录到管理门户>Analytics>用户门户>工作流收件箱。
可以看到有一个新的“药嘱风险处理”任务,“已分配给”字段时空的,也就是说这个给药剂师角色的人物还没有分配给任何用户。
8.3 这时,我们是看不到任务详情的,但有一个“接受”按钮。点击它就会接受该任务。当任务被接受,其他用户就看不到该任务了。
现在,就可以看到任务详情了:我们设置的任务上下文信息,例如患者姓名、药品名称、药品风险提示都可以看到了。同时,页面上面有4个按钮,其中2个“取消药嘱”、“忽略提示”是我们设置给药剂师的操作。
另外2个按钮是什么?
用户接受了、或被分配了任务,但可以点击“放弃”以退回任务,这样任务又称为“未分配”状态,其他用户就可以看到它并点击“接受”以接受任务。
“保存”是用于未完成任务,但中途需要保存信息时使用。例如任务需要用户书写记录,记录书写到一半离开去忙别的事情,可以点击“保存”以保存已经书写的内容。注意,这时任务并没有完成。
8.4 现在我们让药剂师忽略药嘱风险提示,点击“忽略提示”继续发药流程。
8.5 现在让我们回顾一下完整的业务流程:
在可视化追踪中查看刚才的业务,我们可以看到业务流程按照设计,在药品知识库有提示的情况下,启动了药剂师药嘱风险决策支持任务,并在药剂师忽略提示后,将药嘱发送给药房系统。
大家可以更改一下药剂师的决策,看看流程有什么变化。
任务管理
平台管理员可以查看、分配、重分配、修改优先级和取消任务。
以管理员身份登录到管理门户>Interoperability>管理>工作流>工作流任务,可以查看包括完成的任务在内的所有任务,并可按不同的条件排序。
如果要分配任务,在“用户名”中选择要分配给的用户;
如果要调整任务优先级,选择“优先级”;
如果要取消任务,选中“是否取消”选择框,即可取消。
另外,任务管理员可以将已取消或已完成的任务重新激活。
任务API和自定义任务用户界面
前面介绍了工作流建模、使用工作流门户管理工作任务。如何使用自己的应用或界面管理工作流任务?
有几种方法:
管理门户是网页,它可以被嵌入到其它应用中。即其它应用可以直接通过单点登录,登录到管理门户进行操作。
使用InterSystems平台的任务管理API,然后自己开发任务用户界面或直接在自己的应用中调用。
我个人推荐方法2:
社区里有一篇非常棒的文章,介绍任务管理API和如何使用这些API和Angular进行自定义的任务用户界面开发。
其中任务管理API可以在此下载
自定义任务管理界面可以在此下载
展望
现在的IT应用都是“复合应用”:当今所有应用系统建设即不是原来的纯单体应用开发项目、也不是仅与其它系统整合的集成项目,而是一个复合应用项目 – 每个新业务都需要快速开发并和别的应用集成。
InterSystems工作流引擎为人工工作流程建模提供了低代码/免代码开发的支持。同时,它也赋能复合应用开发:
使用InterSystems工作流和业务流程建模、自动化机器学习引擎或第三方机器学习引擎,可以将基于机器学习的辅助决策支持整合到业务流程中,形成决策过程闭环和机器学习优化闭环。
基于InterSystems工作流,可以将传统编码开发实现的人工工作流程开发通过低代码的业务流程建模方式实现,赋能业务团队高度参与到业务流程梳理、建模与优化中;它将业务流程逻辑与用户界面分离,从而提高业务团队参与度、降低开发成本、快速满足业务进化需求、提高架构灵活性。
文章
Claire Zheng · 三月 28
2024年3月26日,InterSystems数据平台全球主管Scott Gnau发文,宣布InterSystems IRIS数据平台新增了矢量搜索(vector search)功能。
本文作者为Scott Gnau,InterSystems数据平台全球主管。
人工智能具备变革性潜力,能够从数据中获取价值和洞察力。我们正在迈向一个几乎所有应用都将通过人工智能来驱动的世界,随之而来的,是构建这些应用的开发人员需要正确的工具从这些应用中创造体验。因此,InterSystems非常高兴地宣布这一消息——IRIS数据平台新增了矢量搜索(vector search)功能。
在使用大型语言模型时,像矢量搜索这样的工具对于从海量数据集中高效、准确地检索相关信息至关重要。通过将文本和图像转换为高维矢量,这些技术可以支持快速比较和搜索,即便处理分散在整个组织、不同数据集的数百万个文件时也是如此。
InterSystems IRIS数据平台为下一代应用提供了统一基础
在InterSystems,我们始终在探寻各种方式,使下一代数据处理尽可能地离客户数据近一些,而无需将数据传输到特定系统。将矢量搜索功能添加至InterSystems IRIS数据平台后,我们可以通过矢量嵌入(vector embedding)对数据平台进行搜索,从而增强软件在自然语言处理(NLP)、文本和图像分析相关任务中的功能。这种集成将使开发人员能够更轻松地创建使用生成式人工智能的应用程序,以完成各种用例的复杂任务,并根据InterSystems处理的专有数据(proprietary data)提供即时响应。这也意味着他们可以使用精巧的矢量化索引来完成这项工作,同时对保持内部专有产权情报的安全充满信心。
这一功能支持InterSystems IRIS数据平台管理和查询内容及相关的密集矢量嵌入,特别是能够与RAG集成,开发基于生成式人工智能的应用。随着可用工具集的快速发展,无缝RAG集成可支持新模型和用例的敏捷采用。
这项技术能够给客户带来哪些益处?
BioStrand是一家依赖于人工智能的药物发现公司,也是InterSystems创新计划(InterSystems Innovation Program)的一部分(该计划帮助初创企业在我们的IRIS平台上构建应用)。BioStrand的核心产品是Lensai平台,这是一种多功能解决方案,支持包括抗体药物发现和设计在内的各种应用。通过先进的算法,Lensai可以迅速识别并设计新型药物化合物,大大缩短了从开发到商业化的研发时间。该模型将采用先进堆叠技术的大型语言模型(LLM)的优势与BioStrand的专利技术HYFT独特地结合在一起。
HYFT是一种嵌入类型,在生物序列中充当独一无二的“指纹”,使BioStrand能够高精度地分配来自不同LLM的嵌入。这个基础模型代表着一个庞大且不断扩展的知识图谱,在6.6亿个数据对象中映射了250亿种关系,令人印象深刻。这个全面的图谱将整个生物圈的序列、结构、功能以及书目信息相互连接在一起。它还融合了检索增强生成、SQL矢量搜索等尖端技术,以及LLM的生成能力和知识图谱的语义表达能力。
矢量搜索将从根本上改变开发人员与IRIS的交互方式
在实施这项技术方面,我们还只是刚刚起步。随着客户与数据的交互方式因矢量搜索而得到改变,随着新的人工智能应用不断通过应用矢量搜索而得到开发,我们将分享更多客户故事。与此同时,我也推荐您访问我们的矢量搜索页面,了解更多信息。
我们加速创新,确保客户成功,并展示对卓越的承诺,与此同时,我们致力于维护最高标准的隐私、安全和责任,这将引导我们以一种深思熟虑、公正的方式对待人工智能,从而创造信任。我们相信,透明度、责任感和可解释性是建立对人工智能系统的信任并推动其创新的关键。
文章
Qiao Peng · 一月 14, 2021
你好,开发者!
你们中的许多人在 [Open Exchange](https://openexchange.intersystems.com/) 和 Github 上发布了 InterSystems ObjectScript 库。
但对于开发者来说,如何简化项目的使用和协作呢?
在本文中,我想介绍一种简单方法,只需将一组标准文件复制到你的仓库中,就可以启动任何 ObjectScript 项目和对其做出贡献。
我们开始吧!
**TLDR** - 将以下文件从[该仓库](https://github.com/intersystems-community/objectscript-docker-template)复制到你的仓库:
[Dockerfile](https://github.com/intersystems-community/objectscript-docker-template/blob/master/Dockerfile)
[docker-compose.yml](https://github.com/intersystems-community/objectscript-docker-template/blob/master/docker-compose.yml)
[Installer.cls](https://github.com/intersystems-community/objectscript-docker-template/blob/master/Installer.cls)
[iris.script](https://github.com/intersystems-community/objectscript-docker-template/blob/master/iris.script)
[settings.json](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.vscode/settings.json "settings.json"){#9f423fcac90bf80939d78b509e9c2dd2-d165a4a3719c56158cd42a4899e791c99338ce73}
[.dockerignore](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.dockerignore ".dockerignore"){#f7c5b4068637e2def526f9bbc7200c4e-c292b730421792d809e51f096c25eb859f53b637}
[.gitattributes](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.gitattributes ".gitattributes"){#fc723d30b02a4cca7a534518111c1a66-051218936162e5338d54836895e0b651e57973e1}
[.gitignore](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.gitignore ".gitignore"){#a084b794bc0759e7a6b77810e01874f2-e6aff5167df2097c253736b40468e7b21e577eeb}
你已经知道启动你的项目和协作的标准方式。 以下将详细说明这样做的步骤和原因。
**注意:**在本文中,我们将考虑可在 InterSystems IRIS 2019.1 及更新版本上运行的项目。
**选择 InterSystems IRIS 项目的启动环境**
通常,我们希望开发者尝试项目/库,并确保这是快速安全的练习。
在我看来,快速安全地启动任何新项目的理想方式是 Docker 容器,它可以保证开发者启动、导入、编译和计算任何内容对于主机来说都是安全的,并且不会破坏任何系统或代码。如果出了问题,只需停止并删除容器即可。 如果应用程序占用大量磁盘空间,使用容器将其擦除,空间就回来了。 如果某个应用程序破坏了数据库配置,只需删除配置被破坏的容器。 简单又安全。
Docker 容器提供安全和标准化。
运行通用 InterSystems IRIS Docker 容器的最简单方法是运行 [IRIS 社区版映像](https://hub.docker.com/_/intersystems-iris-data-platform/plans/222f869e-567c-4928-b572-eb6a29706fbd?tab=instructions):
1. 安装 [Docker desktop](https://www.docker.com/products/docker-desktop)
2. 在操作系统终端中运行以下命令:
docker run --rm -p 52773:52773 --init --name my-iris store/intersystems/iris-community:2020.1.0.199.0
3. 然后在主机浏览器上打开管理门户:
4. 或者打开终端启动 IRIS:
docker exec -it my-iris iris session IRIS
5. 不需要 IRIS 容器时,将其停止:
docker stop my-iris
好! 我们在一个 docker 容器中运行 IRIS。 但是你希望开发者将你的代码安装到 IRIS 中,可能还要进行一些设置。 这就是我们下面要讨论的。
**导入 ObjectScript 文件**
最简单的 InterSystems ObjectScript 项目可以包含一组 ObjectScript 文件,例如类、例程、宏和global。 请查看有关命名和建议的文件夹结构的文章。
问题是如何将所有这些代码导入 IRIS 容器?
此时我们可以借助 Dockerfile 来获取通用 IRIS 容器,并将某个仓库中的所有代码导入 IRIS,然后根据需要对 IRIS 进行一些设置。 我们需要在仓库中添加一个 Dockerfile。
我们来看一下 [ObjectScript 模板](https://github.com/intersystems-community/objectscript-docker-template)仓库中的 [Dockerfile](https://github.com/intersystems-community/objectscript-docker-template/blob/master/Dockerfile):
ARG IMAGE=store/intersystems/irishealth:2019.3.0.308.0-community
ARG IMAGE=store/intersystems/iris-community:2019.3.0.309.0
ARG IMAGE=store/intersystems/iris-community:2019.4.0.379.0
ARG IMAGE=store/intersystems/iris-community:2020.1.0.199.0
FROM $IMAGE
USER root
WORKDIR /opt/irisapp
RUN chown ${ISC_PACKAGE_MGRUSER}:${ISC_PACKAGE_IRISGROUP} /opt/irisapp
USER irisowner
COPY Installer.cls .
COPY src src
COPY iris.script /tmp/iris.script # run iris and initial
RUN iris start IRIS \
&& iris session IRIS < /tmp/iris.script
前几个 ARG 行设置 $IMAGE 变量,随后在 FROM 中使用该变量。 这适合在不同的 IRIS 版本中测试/运行代码,只需在 FROM 前面的最后一行中更改 $IMAGE 变量即可切换版本。
这里我们采用:
ARG IMAGE=store/intersystems/iris-community:2020.1.0.199.0
FROM $IMAGE
这意味着我们将使用 IRIS 2020 社区版 build 199。
我们想要导入仓库中的代码,这意味着我们需要将仓库中的文件复制到 docker 容器。 下面几行完成此操作:
USER root
WORKDIR /opt/irisapp
RUN chown ${ISC_PACKAGE_MGRUSER}:${ISC_PACKAGE_IRISGROUP} /opt/irisapp
USER irisowner
COPY Installer.cls .
COPY src src
USER root - 这里我们将用户切换为 root,以在 docker 中创建文件夹和复制文件。
WORKDIR /opt/irisapp - 我们在此行中设置将文件复制到的工作目录。
RUN chown ${ISC_PACKAGE_MGRUSER}:${ISC_PACKAGE_IRISGROUP} /opt/irisapp - 这里我们为运行 IRIS 的 irisowner 用户和组授予权限。
USER irisowner - 将用户从 root 切换到 irisowner
COPY Installer.cls . - 将 [Installer.cls](https://github.com/intersystems-community/objectscript-docker-template/blob/master/Installer.cls) 复制到工作目录的根目录。 不要漏了那个点儿。
COPY src src - 将[仓库的 src 文件夹](https://github.com/intersystems-community/objectscript-docker-template/tree/master/src/)中的源文件复制到 docker 上的工作目录的 src 文件夹中。
在下一个块中,我们运行初始脚本,其中将调用安装程序和 ObjectScript 代码:
COPY iris.script /tmp/iris.script # run iris and initial
RUN iris start IRIS \
&& iris session IRIS < /tmp/iris.script
COPY iris.script / - 我们将 iris.script 复制到根目录。 它包含我们要调用以设置容器的 ObjectScript。
RUN iris start IRIS\ - 启动 IRIS
&& iris session IRIS < /tmp/iris.script - 启动 IRIS 终端并在其中输入初始 ObjectScript。
很好! 我们有 Dockerfile,它将文件导入 docker。 但还有两个文件:installer.cls 和 iris.script。我们来检查一下。
[**Installer.cls**](https://github.com/intersystems-community/objectscript-docker-template/blob/master/Installer.cls)
Class App.Installer
{
XData setup
{
}
ClassMethod setup(ByRef pVars, pLogLevel As %Integer = 3, pInstaller As %Installer.Installer, pLogger As %Installer.AbstractLogger) As %Status [ CodeMode = objectgenerator, Internal ]
{
#; Let XGL document generate code for this method.
Quit ##class(%Installer.Manifest).%Generate(%compiledclass, %code, "setup")
}
}
坦白说,我们不需要 Installer.cls 就可以导入文件。 这只需要一行就能完成。 但除了导入代码之外,我们经常还需要设置 CSP 应用,引入安全设置,创建数据库和命名空间。
在此 Installer.cls 中,我们创建了名为 IRISAPP 的新数据库和命名空间,并为该命名空间创建了默认的 /csp/irisapp 应用程序。
所有这些都在元素中 执行:
<Namespace Name="${Namespace}" Code="${Namespace}" Data="${Namespace}" Create="yes" Ensemble="no">
<Configuration>
<Database Name="${Namespace}" Dir="/opt/${app}/data" Create="yes" Resource="%DB_${Namespace}"/>
<Import File="${SourceDir}" Flags="ck" Recurse="1"/>
</Configuration>
<CSPApplication Url="/csp/${app}" Directory="${cspdir}${app}" ServeFiles="1" Recurse="1" MatchRoles=":%DB_${Namespace}" AuthenticationMethods="32"
/>
</Namespace>
我们用 Import 标签导入 SourceDir 中的所有文件:
<Import File="${SourceDir}" Flags="ck" Recurse="1"/>
这里的 SourceDir 是一个变量,设置为当前目录/src 文件夹:
<Default Name="SourceDir" Value="#{$system.Process.CurrentDirectory()}src"/>
有了带这些设置的 Installer.cls,我们可以自信地创建一个干净的新数据库 IRISAPP,我们将从 src 文件夹导入任意 ObjectScript 代码到该数据库中。
[iris.script](https://github.com/intersystems-community/objectscript-docker-template/blob/master/iris.script)
欢迎在这里提供任何所需的初始 ObjectScript 设置代码来启动 IRIS 容器。
例如, 我们加载并运行 installer.cls,然后让 UserPasswords 永远有效,以避免第一次启动时出现密码更改请求,因为开发不需要这个提示。
; run installer to create namespace
do $SYSTEM.OBJ.Load("/opt/irisapp/Installer.cls", "ck")
set sc = ##class(App.Installer).setup() zn "%SYS"
Do ##class(Security.Users).UnExpireUserPasswords("*") ; call your initial methods here
halt
[docker-compose.yml](https://github.com/intersystems-community/objectscript-docker-template/blob/master/docker-compose.yml)
为什么需要 docker-compose.yml,不能只用 Dockerfile 构建和运行映像吗? 可以的。 但 docker-compose.yml 能让生活更轻松。
通常,docker-compose.yml 用于启动连接到一个网络的多个 docker 映像。
当启动一个 docker 映像需要处理多个参数时,也可以使用 docker-compose.yml 来简化过程。 你可以使用它向 docker 传递参数,例如端口映射、卷、VSCode 连接参数。
version: '3.6'
services:
iris:
build:
context: .
dockerfile: Dockerfile
restart: always
ports:
- 51773
- 52773
- 53773
volumes:
- ~/iris.key:/usr/irissys/mgr/iris.key
- ./:/irisdev/app
这里我们声明服务 iris,它使用 docker 文件 Dockerfile,并开放 IRIS 的以下端口:51773、52773、53773。 此服务还映射两个卷:将主机主目录中的 iris.key 映射到期望的 IRIS 文件夹,以及将源代码的根文件夹映射到 /irisdev/app 文件夹。
Docker-compose 提供了更短的统一命令来构建和运行映像,无论你在 docker compose 中设置了什么参数。
总之,构建和启动镜像的命令是:
$ docker-compose up -d
要打开 IRIS 终端:
$ docker-compose exec iris iris session iris
Node: 05a09e256d6b, Instance: IRIS
USER>
此外,docker-compose.yml 有助于设置 VSCode ObjectScript 插件的连接。
[.vscode/settings.json](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.vscode/settings.json)
与 ObjectScript 加载项连接设置有关的部分如下:
{
"objectscript.conn" :{
"ns": "IRISAPP",
"active": true,
"docker-compose": {
"service": "iris",
"internalPort": 52773
}
}
}
在这里,我们看到的设置与 VSCode ObjectScript 插件的默认设置不同。
我们想要连接到 IRISAPP 命名空间(我们用 Installer.cls 创建的):
"ns": "IRISAPP",
一个 docker-compose 设置指示,docker-compose 文件在服务“iris”内,VSCode 将连接到 52773 映射到的端口:
"docker-compose": {
"service": "iris",
"internalPort": 52773
}
如果我们检查一下 52773 的相关设置,我们会看到没有为 52773 定义映射端口:
ports:
- 51773
- 52773
- 53773
这意味着将使用主机上的随机可用端口,并且 VSCode 将通过随机端口自动连接到 docker 上的 IRIS。
**这是一个非常方便的功能,因为它允许在随机端口上运行任意数量的带 IRIS 的 docker 映像,并让 VSCode 自动连接到它们。**
其他文件呢?
我们还有:
[.dockerignore](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.dockerignore) - 该文件可用于过滤你不想复制到所构建的 docker 映像中的主机文件。 通常 .git 和 .DS_Store 是必须有的行。
[.gitattributes](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.gitattributes) - git 的属性,用于统一来源中的 ObjectScript 文件的行尾。 如果仓库由 Windows 和 Mac/Ubuntu 所有者协作,此文件非常有用。
[.gitignore](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.gitignore) - 你不希望 git 跟踪其更改历史记录的文件。 通常是一些隐藏的操作系统级文件,例如 .DS_Store。
好了!
如何使你的仓库可被 docker 运行并且对协作友好?
1. 克隆[此仓库](https://github.com/intersystems-community/objectscript-docker-template)。
2. 复制以下所有文件:
[Dockerfile](https://github.com/intersystems-community/objectscript-docker-template/blob/master/Dockerfile)
[docker-compose.yml](https://github.com/intersystems-community/objectscript-docker-template/blob/master/docker-compose.yml)
[Installer.cls](https://github.com/intersystems-community/objectscript-docker-template/blob/master/Installer.cls)
[iris.script](https://github.com/intersystems-community/objectscript-docker-template/blob/master/iris.script)
[settings.json](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.vscode/settings.json "settings.json"){#9f423fcac90bf80939d78b509e9c2dd2-d165a4a3719c56158cd42a4899e791c99338ce73}
[.dockerignore](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.dockerignore ".dockerignore"){#f7c5b4068637e2def526f9bbc7200c4e-c292b730421792d809e51f096c25eb859f53b637}
[.gitattributes](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.gitattributes ".gitattributes"){#fc723d30b02a4cca7a534518111c1a66-051218936162e5338d54836895e0b651e57973e1}
[.gitignore](https://github.com/intersystems-community/objectscript-docker-template/blob/master/.gitignore ".gitignore"){#a084b794bc0759e7a6b77810e01874f2-e6aff5167df2097c253736b40468e7b21e577eeb}
到你的仓库。
更改 [Dockerfile 中的这一行](https://github.com/intersystems-community/objectscript-docker-template/blob/10f4422c105d5c75111fde16a184a83f5ff86d06/Dockerfile#L15),使目录与仓库中要导入 IRIS 的 ObjectScript 匹配(如果在 /src 文件夹中则不要更改)。
就这样。 每个人(也包括你)都会将你的代码导入到新的 IRISAPP 命名空间的 IRIS 中。
**人们如何启动你的项目**
在 IRIS 中执行任何 ObjectScript 项目的法则为:
1. Git clone 项目到本地
2. 运行项目:
$ docker-compose up -d
$ docker-compose exec iris iris session iris
Node: 05a09e256d6b, Instance: IRIS
USER>zn "IRISAPP"
**开发者如何为你的项目做出贡献**
1. 对仓库执行分叉,并将分叉后的仓库 git clone 到本地
2. 在 VSCode 中打开该文件夹(还需要在 VSCode 中安装 [Docker](https://marketplace.visualstudio.com/items?itemName=ms-azuretools.vscode-docker) 和 [ObjectScript](https://marketplace.visualstudio.com/items?itemName=daimor.vscode-objectscript&ssr=false#review-details) 扩展)
3. 右击 docker-compose.yml->重启 - [VSCode ObjectScript](https://openexchange.intersystems.com/package/VSCode-ObjectScript) 将自动连接并准备好编辑/编译/调试
4. 向你的仓库提交、推送和拉取请求更改
以下是操作过程的短 gif:
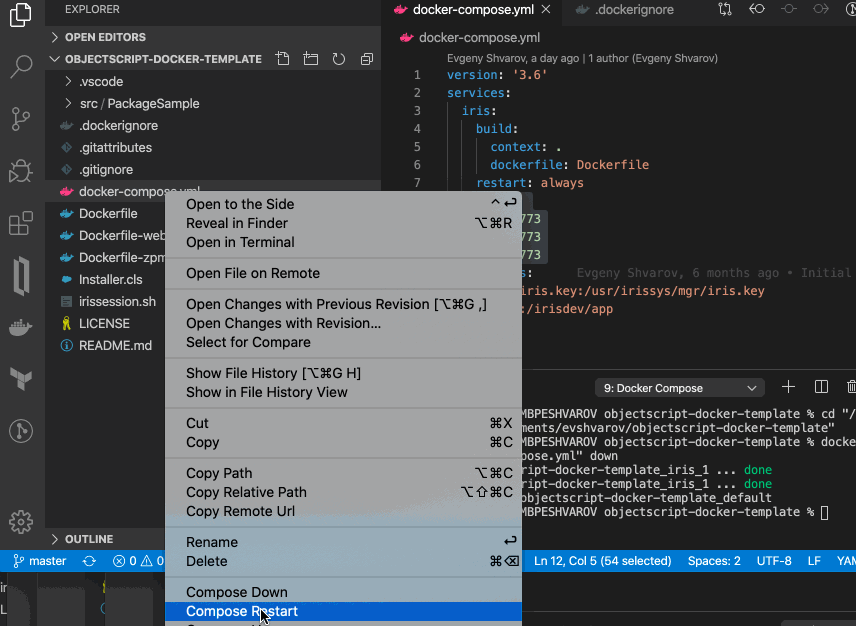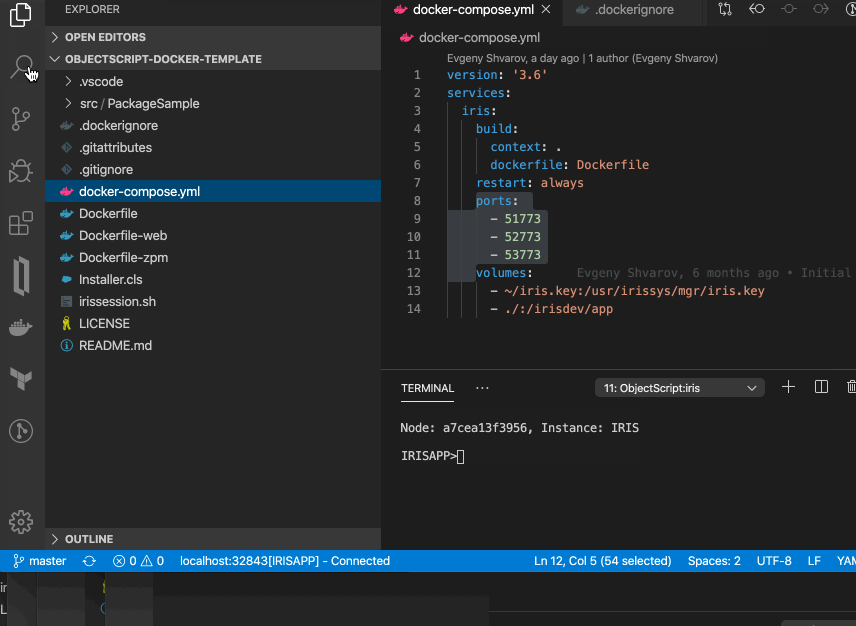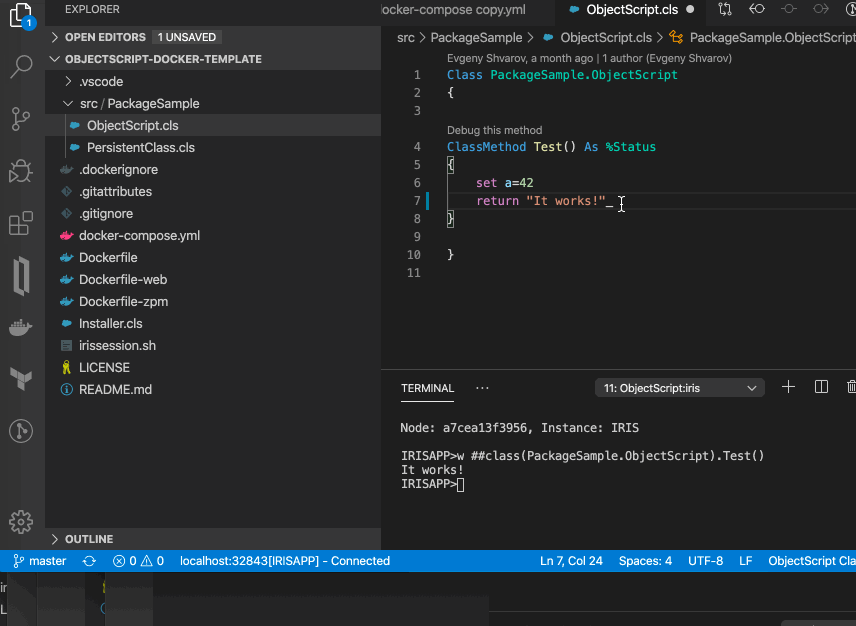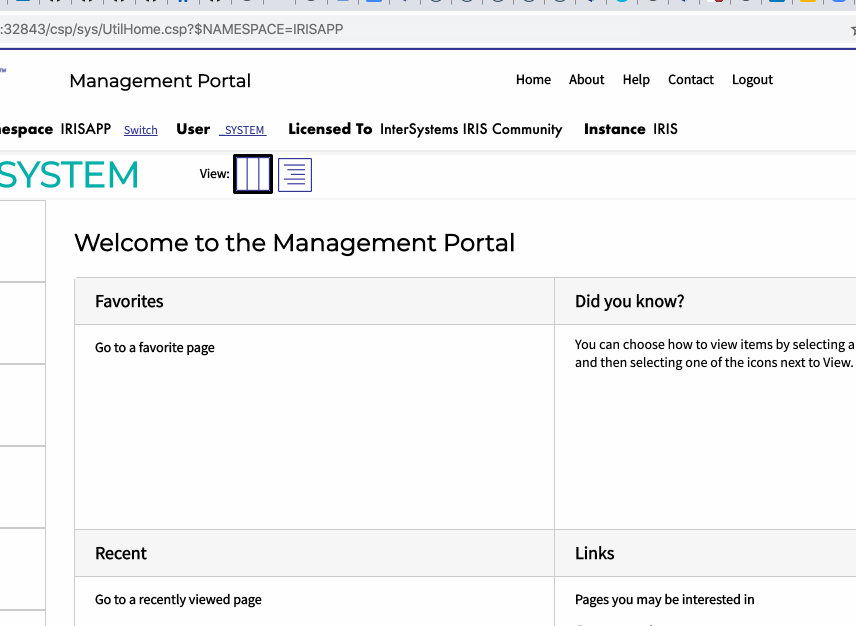
好了! 编码愉快!
公告
Claire Zheng · 一月 7, 2021
亲爱的社区用户,您好!
您知道吗,在 Global Masters,您可以兑换关于以下任何 InterSystems 产品的 InterSystems 专家咨询:InterSystems IRIS数据平台、IRIS医疗版、互操作平台 (Ensemble)、IRIS Analytics (DeepSee)、Caché、HealthShare统一的健康档案。
我们还有一个振奋人心的消息要分享,我们现在可以提供以下语言的咨询:
英语、葡萄牙语、俄语、德语、法语、意大利语、西班牙语、日语、汉语
而且! 咨询时长延长到 1.5 小时,让您与专家深入探讨主题。
如果您有兴趣,不要犹豫,快来 Global Masters 兑换奖励吧! 如果您还不是 Global Masters 的会员,欢迎您“点击此处加入”点击 InterSystems 登录按钮,然后使用您的 InterSystems WRC 凭据)。
要了解关于 Global Masters 的更多信息,请阅读文章:认识Global Masters 倡导中心,从这里开始!
让我们在 InterSystems Global Masters 上见!🙂
文章
Li Yan · 一月 18, 2021
企业需要快速有效地扩展和管理其全球计算基础设施,同时优化和管理资本成本及支出。 Amazon Web Services (AWS) 和 Elastic Compute Cloud (EC2) 计算和存储服务提供高度稳健的全球化的计算基础设施,可满足最苛刻的基于 Caché 的应用程序的需求。Amazon EC2 基础设施使各公司能够迅速预置计算能力和/或快速灵活地将其现有内部基础架构扩展到云端。 AWS 针对安全、网络、计算和存储提供了一套丰富的服务和强大的企业级机制。
AWS 的核心是 Amazon EC2。 它是支持各种操作系统和机器配置(例如 CPU、RAM、网络)的云计算基础设施。 AWS 提供预先配置的虚拟机 (VM) 映像(称为 Amazon 系统映像或 AMI),客户操作系统包括各种 Linux® 和 Windows 发行版及版本。 可以将其它软件用作 AWS 中运行的虚拟化实例的基础。 您可以将这些 AMI 用作实例化以及安装或配置其他软件、数据等的起点,以创建特定于应用程序或工作负载的 AMI。
与任何平台或部署模式一样,必须留心以确保考虑到应用程序环境的各个方面,例如性能、可用性、操作和管理程序。
本文将详细介绍以下每个方面。
网络设置和配置。 此部分介绍基于 Caché 的应用程序在 AWS 中的网络设置,包括为参考架构内不同层级和角色的逻辑服务器组提供支持的子网。
服务器设置和配置。 此部分介绍为每一层设计各种服务器时涉及的服务和资源。 还包括用于跨可用区实现高可用性的架构。
安全。 此部分讨论 AWS 中的安全机制,包括如何配置实例和网络安全以实现对整体解决方案以及层和实例之间的授权访问。
部署和管理。此部分提供有关打包、部署、监控和管理的详细信息。
架构和部署方案
本文提供了几个在 AWS 内实现的参考架构,作为提供基于 InterSystems 技术(包括 Caché、Ensemble、HealthShare、TrakCare)以及相关嵌入式技术(如 DeepSee、iKnow、CSP、Zen 和 Zen Mojo)的高性能和高可用性应用程序的示例。
为了了解如何在 AWS 上托管 Caché 及相关组件,我们先来回顾一下典型 Caché 部署的架构和组件,并探讨一些常见的方案和拓扑。
Caché架构回顾
InterSystems 数据平台不断发展,提供先进的数据库管理系统和快速的应用程序开发环境,以在处理和分析复杂数据模型以及开发 Web 和移动应用程序方面实现突破。
这是新一代的数据库技术,提供多种数据访问模式。 数据只在单个集成数据字典中描述一次,并且可以通过对象访问、高性能 SQL 和强大的多维存取即时进行访问 – 所有这些方式可以同时访问相同数据。
图 1 说明了可用的 Caché 高级架构组件层和服务。 这些通用层也适用于 InterSystems TrakCare 和 HealthShare 产品。
图 1:高级组件层
常见部署方案
部署有许多可能的组合,但本文将介绍两种方案:混合模型和完整的云托管模型。
混合模型
在此方案中,公司希望在需要时将企业内部资源和 AWS EC2 资源都用于灾难恢复、内部维护应急、重新平台化计划或短期/长期扩容。 此模型可以为内部故障转移镜像成员集群提供业务连续性和灾难恢复的高可用性。
在该方案中,此模型的连接依赖于内部部署和 AWS 可用区之间的 VPN 隧道,将 AWS 资源作为企业数据中心的扩展。 还有其他连接方法,例如 _AWS Direct Connect_。 但是,这不是本文涵盖的内容。 有关 AWS Direct Connect 的更多详细信息,可以在here找到。
有关设置此 Amazon Virtual Private Cloud (VPC) 示例以支持内部数据中心灾难恢复的详细信息可以在here找到。
图 2:使用 AWS VPC 提供内部灾难恢复的混合模型
上面的示例展示了一个故障转移镜像对通过与 AWS VPC 的 VPN 连接在内部数据中心的运行。 所示的 VPC 在给定 AWS 区域的双可用区中提供了多个子网。 有两个灾难恢复 (DR) 异步镜像成员 (每个可用区有一个) 提供弹性。
云托管模型
在此方案中,基于 Caché 的应用程序(包括数据层和表示层)完全放在 AWS 云中,使用了单个 AWS 区域内的多个可用区。 可以使用相同的 VPN 隧道 AWS Direct Connect, 甚至纯互联网连接模型。
图 3:支持完整生产工作负载的云托管模型
图 3 中的示例说明了在 VPC 中支持整个应用程序生产部署的部署模型。 此模型利用双可用区,在可用区之间同步故障转移镜像,同时将负载均衡 Web 服务器和相关应用程序服务器作为 ECP 客户端。 每个层都隔离在一个单独的安全组中,以进行网络安全控制。 IP 地址和端口范围仅根据应用程序的需要开放。
存储和计算资源
存储
有多种类型的存储选项可供选择。 就本参考架构而言,将针对几种可能的用例讨论 Amazon Elastic Block Store (Amazon EBS) 和 (也称为临时驱动器)卷。 各种存储选项的更多详细信息可以在 here 和 here 找到。
Elastic Block Storage (EBS)
EBS 提供了可与 Amazon EC2 实例(虚拟机)配合使用的持久块级存储,在 Linux 或 Windows 中可以将其格式化并挂载为传统文件系统,最重要的是,这些卷是非实例存储,独立于单个 Amazon EC2 实例的运行寿命而持续存在,这对于数据库系统非常重要。
此外,Amazon EBS 还提供了创建卷的时间点快照的功能,这些快照会持久保存在 Amazon S3 中。 这些快照可以用作新的 Amazon EBS 卷的起点,并保护数据以实现长期耐久性。 同一快照可用于实例化任意数量的卷。 这些快照可以跨 AWS 区域复制,因此可以更容易地利用多个 AWS 区域进行地理扩张、数据中心迁移和灾难恢复。 Amazon EBS 卷的大小范围为 1 GB 到 16 TB,以 1 GB 为增量进行分配。
Amazon EBS 内有三种不同的类型:磁介质卷、通用型 (SSD) 和预置 IOPS (SSD)。 以下各小节提供了每种类型的简要介绍。
磁介质卷
磁介质卷为具有中等或突发 I/O 要求的应用程序提供经济高效的存储。 磁介质卷设计为平均每秒提供约 100 次输入/输出操作 (IOPS),最大突发能力为数百 IOPS。 磁介质卷也非常适合用作启动卷,其突发能力提供了快速的实例启动时间。
通用型 (SSD)
通用型 (SSD) 卷提供具有成本效益的存储,是各种工作负载的理想选择。 这些卷的延迟只有个位数毫秒,能够长时间突发至 3,000 IOPS,基准性能为 3 IOPS/GB,最高可达 10,000 IOPS (3,334 GB)。 通用型 (SSD) 卷的大小范围为 1 GB 到 16 TB。
预置 IOPS (SSD)
预置 IOPS (SSD) 卷设计用于为 I/O 密集型工作负载(例如对存储性能和随机访问 I/O 吞吐量的一致性敏感的数据库工作负载)提供可预测的高性能。 在创建卷时指定 IOPS 速率,然后 Amazon EBS 在给定一年的 99.9% 的时间内提供 10% 内的预置 IOPS 性能。 预置 IOPS (SSD) 卷的大小可以为 4 GB 到 16 TB,每个卷最多可预置 20,000 IOPS。 预置的 IOPS 与请求的卷大小之比最大为 30;例如,IOPS 为 3,000 的卷必须至少为 100 GB 大小。 预置 IOPS (SSD) 卷对每个预置的 IOPS 的吞吐量限制为 256 KB,最高 320 MB/秒(1,280 IOPS)。
本文讨论的架构使用 EBS 卷,因为这些卷更适合需要可预测的低延迟每秒输入/输出操作 (IOPS) 和吞吐量的生产工作负载。 选择特定的虚拟机类型时必须小心,因为并非所有 EC2 实例类型都可以访问 EBS 存储。
注意: 由于 Amazon EBS 卷是网络附加设备,Amazon EC2 实例执行的其他网络 I/O 以及共享网络上的总负载可能会影响单个 Amazon EBS 卷的性能。 为了让 Amazon EC2 实例充分利用 Amazon EBS 卷上的预置 IOPS,可以将选定的 Amazon EC2 实例类型作为 Amazon EBS 优化的实例启动。
有关 EBS 卷的详细信息,可以在here 找到。
EC2 实例存储(临时驱动器)
EC2 实例存储由托管您的正在运行的 Amazon EC2 实例的同一台物理服务器上的磁盘存储的预配置和预附加块组成。 提供的磁盘存储量因 Amazon EC2 实例类型而异。 在提供实例存储的 Amazon EC2 实例系列中,较大的实例往往提供更多更大的实例存储量。
存储优化 (I2) 和密集存储 (D2) 的 Amazon EC2 实例系列提供针对特定用例的专用实例存储。 例如,I2 实例提供了非常快的 SSD 实例存储,能够支持超过 365,000 的随机读取 IOPS 和 315,000 的写入 IOPS,并提供具有成本吸引力的定价模型。
与 EBS 卷不同,该存储不是永久性的,只能用于实例的生命周期,不能分离或附加到其他实例。 实例存储用于临时存储不断变化的信息。 在 InterSystems 技术和产品领域中,诸如将 Ensemble 或 Health Connect 用作企业服务总线 (ESB) 的项目、使用企业缓存协议 (ECP) 的应用程序服务器或将 Web 服务器与 CSP 网关一起使用,对于这种类型的存储和存储优化的实例类型,以及使用预置和自动化工具来提高有效性和支持弹性的操作来说,都是很好的用例。
有关实例存储卷的详细信息,可以在here 找到。
计算
EC2 实例
有多种实例类型可供使用,它们针对各种用例进行了优化。 实例类型包括 CPU、内存、存储和网络容量的不同组合,从而实现无数种组合来合理调整您的应用程序的资源要求。
就本文档而言,将参考_通用 M4_ Amazon EC2 实例类型作为优化环境大小的方法,这些实例提供 EBS 卷的功能和优化。 根据您的应用程序的容量要求和定价模型,还可能有替代方案。
M4 实例是最新一代的_通用_实例。 此系列提供了计算、内存和网络资源的平衡配置,对于许多应用程序来说是很好的选择。 容量范围为 2 到 64 个虚拟 CPU 和 8 到 256GB 的内存,以及相应的专用 EBS 带宽。
除了各个实例类型,还有分层的分类,例如专用主机、Spot 实例、预留实例和专用实例,每个类别的定价、性能和隔离都不同。
在 here 确认当前可用实例的可用性和详细信息。
可用性和操作
Web/App 服务器负载均衡
您的基于 Caché 的应用程序可能需要外部和内部负载均衡的 Web 服务器。 外部负载均衡器用于通过互联网或 WAN(VPN 或 Direct Connect)进行的访问,内部负载均衡器可用于内部流量。 AWS Elastic Load Balancing 提供两种类型的负载均衡器 – 应用程序负载均衡器和传统负载均衡器。
传统负载均衡器
传统负载均衡器根据应用程序或网络信息对流量进行路由,是在多个需要高可用性、自动扩展和强大安全性的 EC2 实例之间实现简单的流量负载均衡的理想选择。 具体的详细信息和功能可在here 找到。
应用负载均衡器
应用程序负载均衡器是 Elastic Load Balancing 服务的负载均衡选项,该服务在应用程序层运行,允许您根据一个或多个 Amazon EC2 实例上运行的多个服务或容器中的内容定义路由规则。 此外,还支持 WebSockets 和 HTTP/2。 具体的详细信息和功能可在here找到。
示例
在以下示例中,定义了一组三个 Web 服务器,每个服务器都在一个单独的可用区,以提供最高级别的可用性。 必须为 Web 服务器负载均衡器配置粘性会话 ,才能支持使用 cookie 将用户会话固定到特定 EC2 实例的功能。 当用户继续访问您的应用程序时,流量将路由到相同实例。
图 4 给出了 AWS 中的传统负载均衡器的一个简单示例。
图 4:传统负载均衡器示例
数据库镜像
在 AWS 上部署基于 Caché 的应用程序时,如果要为 Caché 数据库服务器提供高可用性,则需要在给定的主 AWS 区域使用同步数据库镜像来提供高可用性,还可能需要使用异步数据库镜像将数据复制到辅助 AWS 区域中的热备份以实现灾难恢复,具体取决于正常运行时间服务水平协议要求。
数据库镜像是两个数据库系统的逻辑分组,也就是所说的故障转移成员,它们在物理上是仅通过网络连接的独立系统。 在这两个系统之间进行仲裁后,镜像会自动将其中一个系统指定为主系统; 另一个成员自动成为备份系统。 外部客户端工作站或其他计算机通过镜像虚拟 IP (VIP) 连接到镜像,该虚拟 IP 在镜像配置期间指定。 镜像 VIP 会自动绑定到主镜像系统上的接口。
注意: 在 AWS 中,无法以传统方式配置镜像 VIP,因此设计了替代解决方案。 不过,镜像可跨子网获得支持。
目前在 AWS 中部署数据库镜像的建议是,在跨越三个不同可用区的同一个 VPC 中配置三个实例(主要、备份、仲裁器)。 这可以确保在任何给定时间,AWS 都将保证可以从外部连接其中的至少两个虚拟机,SLA 达到 99.95%。 这样可以为数据库数据本身提供充分的隔离和冗余。 有关 AWS EC2 服务水平协议的详细信息,可在here 找到。
故障切换成员之间的网络延迟没有硬性上限。延迟增加所产生的影响因应用程序而异。如果故障转移成员之间的往返时间与磁盘写入服务时间相似,则预计不会产生影响。 但是,当应用程序必须等待数据变为持久保存(有时称为日志同步)时,响应时间可能是一个问题。 有关数据库镜像和网络延迟的详细信息,可在here 找到。
虚拟 IP 地址和自动故障转移
大多数 IaaS 云提供商缺乏提供虚拟 IP (VIP) 地址的能力,这种地址通常用在数据库故障转移设计中。 为解决这一问题,Caché、Ensemble 和 HealthShare 中增强了几种最常用的连接方法,尤其是 ECP 客户端和 CSP 网关,从而不再依赖 VIP 功能使它们实现镜像感知。
xDBC、直接 TCP/IP 套接字等连接方法或其他直接连接协议仍需要使用 VIP。 为解决这些问题,InterSystems 数据库镜像技术通过使用 API 与 AWS Elastic Load Balancer (ELB) 进行交互以实现类似 VIP 的功能,使得在 AWS 中为这些连接方法提供自动故障转移成为可能,从而在 AWS 中提供完整而强大的高可用性设计。
此外,AWS 最近推出了一种新类型的 ELB,称为应用程序负载均衡器。 这种类型的负载均衡器在第 7 层运行,支持基于内容的路由,并支持在容器中运行的应用程序。 基于内容的路由对于使用分区数据或数据分片部署的大数据类型项目尤其有用。
与虚拟 IP 一样,这是网络配置的突然变化,不涉及任何应用逻辑,不会向已连接到发生故障的主镜像成员的现有客户端发出正在进行故障转移的通知。 根据故障的性质,这些连接终止的原因可能是故障本身、应用程序超时或错误、新的主镜像实例强制旧的主镜像实例停机,或者客户端使用的 TCP 保持连接定时器过期。
结果,用户可能必须重新连接并登录。 您的应用程序的行为将决定此行为。 有关各种类型的可用 ELB 的详细信息,可在here找到。
AWS EC2 实例对 AWS Elastic Load Balancer 方法的调用
在此模型中,ELB 可以定义一个包含故障转移镜像成员和潜在 DR 异步镜像成员的服务器池,其中只有一个活动条目是当前主镜像成员,或者只定义一个具有单个活动镜像成员条目的服务器池。
图 5:与 Elastic Load Balancer 交互的 API 方法(内部)
当某个镜像成员成为主镜像成员时,会从您的 EC2 实例向 AWS ELB 发出一个 API 调用,以调整/指示新主镜像成员的 ELB。
图 6:使用负载均衡器的 API 故障转移到镜像成员B
如果主镜像成员和备份镜像成员都变得不可用,同一模型也适用于升级 DR 异步镜像成员。
图 7:使用负载均衡器的 API 将 DR 异步镜像成员升级为主镜像成员
按照标准推荐的 DR 过程,上面的图 6 中的 DR 成员升级需要人为决策,因为异步复制可能会造成数据丢失。 不过,一旦执行该操作,就不再需要对 ELB 执行管理操作。 在升级期间调用 API 后,将自动路由流量。
API 详细信息
这个用于调用 AWS 负载均衡器资源的 API 在 ^ZMIRROR 例程中专门定义为以下过程调用的一部分:
$$CheckBecomePrimaryOK^ZMIRROR()
在此过程内,插入您选择的要从 AWS ELB REST API、命令行界面等使用的任何 API 逻辑或方法。 与 ELB 进行交互的一种有效且安全的方法是使用 AWS Identity and Access Management (IAM) 角色,这样不必为 EC2 实例分配长期凭据。 IAM 角色提供了 Caché 可以用来与 AWS ELB 进行交互的临时权限。 有关使用分配给 EC2 实例的 IAM 角色的详细信息,可在 here 找到。
AWS Elastic Load Balancer 轮询方法
2017.1 提供了一种使用 CSP 网关的mirror_status.cxw 页的轮询方法,可以将其用作 ELB 监控每个已添加到 ELB 服务器池的镜像成员运行状况的轮询方法。只有主镜像会响应“SUCCESS”,因而网络流量只定向到活动的主镜像成员。
此方法不需要向 ^ZMIRROR 添加任何逻辑。 请注意,大多数负载均衡网络设备对运行状态检查的频率有限制。 通常,最高频率不少于5秒,这通常是可接受的,可支持大多数正常运行时间服务水平协议。
一个对以下资源的 HTTP 请求将测试本地缓存配置的镜像成员状态。
/csp/bin/mirror_status.cxw
对于所有其他情况,这些镜像状态请求的路径应解析到适当的缓存服务器和命名空间,它们与用于请求实际 CSP 页的缓存服务器和命名空间使用相同的分层机制。
示例:在 /csp/user/ 路径中测试服务于应用程序的配置的镜像状态:
/csp/user/mirror_status.cxw
注意:调用镜像状态检查不消耗 CSP 许可证。
根据目标实例是否为活动的主要成员,网关将返回以下 CSP 响应之一:
** Success (Is the Primary Member)
===============================
HTTP/1.1 200 OK
Content-Type: text/plain
Connection: close
Content-Length: 7
SUCCESS
** Failure (Is not the Primary Member)
===============================
HTTP/1.1 503 Service Unavailable
Content-Type: text/plain
Connection: close
Content-Length: 6
FAILED
** Failure (The Cache Server does not support the Mirror_Status.cxw request)
===============================
HTTP/1.1 500 Internal Server Error
Content-Type: text/plain
Connection: close
Content-Length: 6
FAILED
下图说明了各种使用轮询方法的方案。
图 8:轮询所有镜像成员
如上面的图 8 所示,所有镜像成员都在运行,只有主镜像成员向负载均衡器返回“SUCCESS”,因此网络流量将只定向到该镜像成员。
图 9:使用轮询故障转移到镜像成员 B
上图演示了将 DR 异步镜像成员升级到负载均衡池中的过程,这通常假定同一台负载均衡网络设备为所有镜像成员提供服务(本文稍后将介绍按地理位置划分的方案)。
按照标准推荐的 DR 过程,DR 成员升级需要人为决策,因为异步复制可能会造成数据丢失。 不过,一旦执行该操作,就不再需要对 ELB 执行管理操作。 它会自动发现新的主镜像成员。
图 10:使用轮询对 DR 异步镜像成员进行故障转移和升级
备份和还原
备份操作有多个选项。 对于 InterSystems 产品的 AWS 部署,可以使用以下三个选项。 前两个选项包括一个快照类型过程,该过程在创建快照前会暂停将数据库写入磁盘,然后在快照成功建立后恢复更新。 执行以下高级步骤使用任一快照方法创建干净备份:
通过数据库冻结 API 调用暂停对数据库的写入。
创建操作系统和数据磁盘的快照。
通过数据库解锁API 调用恢复 Caché 写入。
将设施存档备份到备份位置。
可以定期添加完整性检查等其他步骤,以确保备份干净一致。 决定使用哪个选项取决于组织的运营要求和策略。 InterSystems 可与您详细讨论各种选项。
EBS 快照
EBS 快照是在高度可用和成本较低的 Amazon S3 存储上创建时间点快照的非常快速且有效的方法。 EBS 快照连同 InterSystems 外部冻结和解锁API 功能,可以实现真正的 24x7 弹性运行,并确保干净的定期备份。 使用 AWS 提供的服务(如 Amazon CloudWatch Events)或市场上的第三方解决方案(如 Cloud Ranger 或 N2W Software Cloud Protection Manager 等等),有许多选项可以使该过程自动化。
此外,还可以使用 AWS 直接 API 调用,以编程方式创建您自己的自定义备份解决方案。 有关如何利用 API 的详细信息,请参见here 和here.
注意:InterSystems 不为上述任何第三方产品背书或明确进行验证。 测试和验证取决于客户.
逻辑卷管理器快照
或者,通过在虚拟机自身内部署单独的备份代理,并利用文件级备份与 Linux 逻辑卷管理器 (LVM) 快照或 Windows 卷影复制服务 (VSS) 相结合,可以使用市场上的许多第三方备份工具。
此模型的主要优点之一是能够对基于 Windows 或 Linux 的实例进行文件级还原。 该解决方案有几点需要注意,由于 AWS 和大多数其他 IaaS 云提供商不提供磁带介质,因此所有备份存储库都基于磁盘进行短期归档,而且能够利用 Amazon S3 低成本存储并最终使用 Amazon Glacier 实现长期保留 (LTR)。 如果使用此方法,强烈建议使用支持去重技术的备份产品,以最有效地利用基于磁盘的备份存储库。
这些具有云支持的备份产品的示例包括但不限于:Commvault、EMC Networker、HPE Data Protector 和 Veritas Netbackup。
注意:InterSystems 不为上述任何第三方产品背书或明确进行验证。 测试和验证取决于客户.
Caché 在线备份
对于小型部署,内置 Caché 在线备份工具也是一个可行选项。 该 InterSystems 数据库在线备份实用工具通过捕获数据库中的所有块来备份数据库文件中的数据,然后将输出写入顺序文件。 这种专有的备份机制旨在使生产系统的用户不停机。
在 AWS 中,在线备份完成后,必须将备份输出文件和系统使用的所有其他文件复制到用作文件共享的 EC2 (CIFS/NFS)。 该过程需要在虚拟机中编写脚本并执行。
在线备份是入门级方法,适合于希望实施低成本备份解决方案的小型站点。 但是,随着数据库的增大,建议将使用快照技术的外部备份作为最佳做法,其优势包括:备份外部文件、更快的恢复时间,以及企业范围的数据视图和管理工具。
灾难恢复
在 AWS 上部署基于 Caché 的应用程序时,建议将 DR 资源(包括网络、服务器和存储)放在不同的 AWS 区域中,或者至少放在单独的可用区中。指定的 DR AWS 区域所需的容量取决于您组织的需求。 在大多数情况下,以 DR 模式运行时需要 100% 的生产能力,但作为一个弹性模型,可以先预置较少的能力,直到需要更多能力。 较少的能力可以体现为较少的 Web 和应用程序服务器,甚至可能使用较小的 EC2 实例类型作为数据库服务器,升级后,EBS 卷将附加到较大的 EC2 实例类型。
异步数据库镜像用于连续复制到 DR AWS 区域的 EC2 实例。 镜像使用数据库事务日志以对主系统性能影响最小的方式通过 TCP/IP 网络复制更新。 强烈建议对这些 DR 异步镜像成员配置日志文件压缩和加密。
公共互联网上所有希望访问应用程序的外部客户端都将通过作为附加 DNS 服务的 Amazon Route53 进行路由。Amazon Route53 用作将流量定向至当前活动数据中心的交换机。 Amazon Route53 执行三种主要功能:
域注册 –允许您注册 example.com 之类的域名。
域名系统 (DNS) 服务 – Amazon Route53 将类似 www.example.com 的友好域名转换为 192.0.2.1 之类的 IP 地址。 Amazon Route53 使用全球权威 DNS 服务器网络来响应 DNS 查询,从而降低延迟。
运行状况检查–Amazon Route53 通过互联网向您的应用程序发送自动请求,以验证其是否可达、可用和正常运行。
这些功能的详细信息可在 here找到。
就本文档而言,将讨论 DNS 故障转移和 Route53 运行状况检查。 运行状况检查监控和 DNS 故障转移的详细信息可在 here 和here找到。
Route53 的工作方式是向每个端点发出常规请求,然后验证响应。 如果某个端点未能提供有效响应, 它将不再包含在 DNS 响应中,而是返回一个替代的可用端点。 这样,用户流量就会从发生故障的端点转向可用的端点。
使用上述方法,将只允许流量转向特定区域和特定镜像成员。 这是由端点定义控制的,它是本文先前讨论过的 mirror_status.cxw 页,由 InterSystems CSP 网关提供。 只有主镜像成员会在运行状况检查中报告 HTTP 200 来表示“SUCCESS”。
下图演示了高级别的故障转移路由策略。 此方法和其他策略的详细信息可在here找到。
图 11:Amazon Route53 故障转移例程策略
在任何给定时间,只有一个区域会根据端点监控进行在线报告。 这样可以确保流量在给定时间只流向一个区域。 区域之间的故障转移无需增加步骤,因为端点监控将检测到指定的主 AWS 区域中的应用程序已关闭,并且该应用程序此时在次要 AWS 区域中处于活动状态。 这是因为 DR 异步镜像成员已被手动升级为主镜像成员,随后允许 CSP 网关将 HTTP 200 报告给 Elastic Load Balancer 端点监控。
上述解决方案有很多替代方案,可以根据您组织的运营要求和服务水平协议进行自定义。
监控
Amazon CloudWatch 可用于为您的所有 AWS 云资源和应用程序提供监控服务。 Amazon CloudWatch 可用于收集和跟踪指标,收集和监控日志文件,设置警报,并自动对 AWS 资源的变化做出反应。 Amazon CloudWatch 可以监控 AWS 资源,如 Amazon EC2 实例,以及您的应用程序和服务生成的自定义指标,还有您的应用程序生成的任何日志文件。 您可以使用 Amazon CloudWatch 获得系统范围内的资源利用率、应用程序性能和运行状况的可见性。 详细信息可在here找到。
自动预置
目前,市场上有许多工具,包括 Terraform、Cloud Forms、Open Stack 和 Amazon 自己的 CloudFormation。 使用这些工具并与其他工具(如 Chef、Puppet、Ansible 等)相结合,可以提供完整的基础设施即代码,来支持 DevOps 或简单地以完全自动化的方式引导您的应用程序。 Amazon CloudFormation 的详细信息可在here找到。
网络连接
根据您的应用程序的连接要求,有多种连接模型可用:使用互联网、VPN 或使用 Amazon Direct Connect 的专用链接。 选择方法取决于应用程序和用户需求。 三种方法的带宽使用情况各不相同,最好通过 AWS 代表或 Amazon 管理控制台确认给定区域的可用连接选项。
安全
当决定通过任何公共 IaaS 云提供商部署应用程序时,都需要谨慎。 应遵循您组织的标准安全策略或专门针对云制定的新策略,以保持您组织的安全合规性。 当组织的数据存储在其国家/地区之外,并受数据所在国家/地区的法律约束时,相关的数据主权也是您必须了解的。 现在,云部署增加了数据在客户数据中心和物理安全控制之外的风险。 强烈建议对静态数据(数据库和日志)和动态数据(网络通信)使用 InterSystems 数据库和日志加密,分别使用 AES 和 SSL/TLS 加密。
与所有加密密钥管理一样,您需要按照您组织的策略记录并遵循正确的程序,以确保数据安全,防止不必要的数据访问或安全漏洞。
Amazon 提供了大量文档和示例,为基于 Caché 的应用程序提供高度安全的运行环境。 请务必查看here 关于 Identity Access Management (IAM) 的各种讨论主题。
架构图示例
下图说明了典型的 Caché 安装,其以数据库镜像(同步故障转移和 DR 异步)、使用 ECP 的应用程序服务器,以及多个负载均衡 Web 服务器的方式提供高可用性。
TrakCare 示例
下图说明了典型的 TrakCare 部署,其中包含多个负载均衡 Web 服务器,两个作为 ECP 客户端的 EPS 打印服务器,以及数据库镜像配置。 虚拟 IP 地址仅用于与 ECP 或 CSP 网关不关联的连接。 ECP 客户端和 CSP 网关可感知镜像,不需要 VIP。
如果您正在使用 Direct Connect,则可为灾难恢复方案启用包括多线路和多区域访问在内的多个选项。 与电信提供商合作以了解他们支持的高可用性和灾难恢复方案至关重要。
下面的示例参考架构图包括活动或主要区域中的高可用性,以及在主要 AWS 区域不可用时到其他 AWS 区域的灾难恢复。 而且在此示例中,数据库镜像包含 TrakCare DB、TrakCare Analytics 和 Integration 命名空间,全部在单个镜像集内。
图 12:TrakCare AWS 参考架构图 – 物理架构
此外,下图显示了更有逻辑的架构图,其中包含所安装的相关高级软件产品及功能用途。
图 13:TrakCare AWS 参考架构图 – 逻辑架构
HealthShare 示例
下图显示了一个典型的 HealthShare 部署,其中含有多个负载均衡 Web 服务器,以及多个 HealthShare 产品,包括 Information Exchange、Patient Index、Personal Community、Health Insight 和 Health Connect。 这些产品中的每一个都包含一个数据库镜像对,以在多个可用区内提供高可用性。 虚拟 IP 地址仅用于与 ECP 或 CSP 网关不关联的连接。 用于 HealthShare 产品之间的 Web 服务通信的 CSP 网关可感知镜像,不需要 VIP。
下面的示例参考架构图包括活动或主要区域中的高可用性,以及在主要区域不可用时到其他 AWS 区域的灾难恢复。
图 14:HealthShare AWS 参考架构图 – 物理架构
此外,下图显示了更有逻辑的架构图,其中包含所安装的相关高级软件产品、连接要求和方法,以及相应的功能用途。
Figure-15: HealthShare AWS 参考架构图 – 逻辑架构
公告
jieliang liu · 一月 7, 2021
现在,InterSystems IRIS、IRIS for Health 和 IRIS Studio 的 2020.4 版发布了预览版本。由于是预览版本,因此我们渴望在下个月正式发布之前了解您对新版本的体验。
**InterSystems IRIS 数据平台 2020.4 **使开发、部署和管理增强型应用程序和业务流程(桥接数据和应用程序孤岛)变得更加容易。 其拥有众多新功能,包括:
面向应用程序和界面开发者的增强功能,包括:
使用 Oracle OpenJDK 和 AdoptOpenJDK 时均支持 Java SE 11 LTS
支持 JDBC 连接池
分段虚拟文档的路由规则新增“foreach”操作
面向数据库和系统管理员的增强功能,包括:
ICM 现在支持部署系统警报和监视 (SAM) 以及 InterSystems API 管理器(IAM)
常见管理任务的 SQL 语法得到扩展
InterSystems 报告的部署得到简化
** InterSystems IRIS for Health 2020.4 **包括 InterSystems IRIS 的所有增强功能。 另外,此版本还包括:
增强的 FHIR 支持,包括对 FHIR 配置文件的支持
支持 RMD IHE 配置文件
在 HL7 迁移工具中支持 DataGate
有关这些功能的更多详细信息,请参见产品文档:
InterSystems IRIS 2020.4 文档及版本说明
InterSystems IRIS for Health 2020.4 文档及版本说明
由于这是 CD 版本,因此仅以 OCI(开放容器计划) 亦即 Docker 容器格式提供。 容器映像可用于面向 Linux x86-64 和 Linux ARM64 的 OCI 兼容运行时间引擎,如[支持的平台文档](https://docs.intersystems.com/iris20204/csp/docbook/platforms/index.html)中详述。
**企业版**容器映像及其所有相应组件都可以使用以下命从[ InterSystems 容器注册表](https://docs.intersystems.com/components/csp/docbook/Doc.View.cls?KEY=PAGE_containerregistry)中获得:
docker pull containers.intersystems.com/intersystems/iris:2020.4.0.521.0
docker pull containers.intersystems.com/intersystems/irishealth:2020.4.0.521.0
有关可用映像的完整列表,请参阅[ ICR 文档](https://docs.intersystems.com/components/csp/docbook/Doc.View.cls?KEY=PAGE_containerregistry#PAGE_containerregistry_images)。
也可以使用以下命令从[ Docker 存储库](https://hub.docker.com/_/intersystems-iris-data-platform)提取**社区版**的容器映像:
docker pull store/intersystems/iris-community:2020.4.0.521.0
docker pull store/intersystems/iris-community-arm64:2020.4.0.521.0
docker pull store/intersystems/irishealth-community:2020.4.0.521.0
docker pull store/intersystems/irishealth-community-arm64:2020.4.0.521.0
另外,可以通过 WRC 的[预览版本下载网站](https://wrc.intersystems.com/wrc/coDistPreview.csp)获取所有容器映像的 tarball 版本。
InterSystems IRIS Studio 2020.4 是 Microsoft Windows 支持的独立开发映像。 其可以与 InterSystems IRIS 和 IRIS for Health 版本 2020.4 及更低版本一起使用,还可以与 Caché 和 Ensemble 一起使用。 可以通过 WRC 的[预览下载网站](https://wrc.intersystems.com/wrc/coDistPreview.csp)进行下载。
此预览版本的内部版本号是 2020.4.0.521.0。
公告
Louis Lu · 四月 23, 2021
InterSystems IRIS、IRIS for Health和HealthShare Health Connect的2021.1版本的预览版现已发布。
由于这是一个预览版,我们希望在下个月的通用版本发布之前了解您对这个新版本的体验。请通过开发者社区分享您的反馈,以便我们能够共同打造一个更好的产品。
InterSystems IRIS数据平台2021.1是一个扩展维护(EM)版本。自2020.1(上一个EM版本)以来,在持续交付(CD)版本中增加了许多重要的新功能和改进。请参考2020.2、2020.3和2020.4的发布说明,了解这些内容的概况。
这个版本的增强功能为开发人员提供了更大的自由度,可以用他们选择的语言构建快速和强大的应用程序,并使用户能够通过新的和更快的分析功能更有效地处理大量的信息。
通过InterSystems IRIS 2021.1,客户可以部署InterSystems IRIS Adaptive Analytics,这是一个附加产品,它扩展了InterSystems IRIS,为分析终端用户提供了更强大的易用性、灵活性、可扩展性以及效率,而不管他们选择何种商业智能(BI)工具。它能够定义一个利于分析的业务模型,并通过在后台自主构建和维护临时数据结构,透明地加速针对该模型运行分析查询时的工作负载。
这个版本中的其他重点新功能包括
一套综合的外部语言网关,改进了可管理性,现在包括R和Python,可以用您选择的语言构建强大和可扩展的服务器端代码InterSystems Kubernetes Operator(IKO)为您的环境提供声明式配置和自动化,现在还支持部署InterSystems System Alerting & Monitoring(SAM)。InterSystems API Manager v1.5,包括改进的用户体验和对Kafka的支持IntegratedML的主流版本,使SQL开发人员能够在纯粹的SQL环境中直接构建和部署机器学习模型
InterSystems IRIS for Health 2021.1包括InterSystems IRIS的所有增强功能。此外,该版本通过针对FHIR数据解析和评估FHIRPath表达式的API,进一步扩展了该平台对FHIR®标准的广泛支持。这是对2020.1以来发布的重要的FHIR相关功能的补充,包括对FHIR Profiles、FHIR R4 Transforms和FHIR客户端API的支持。
关于所有这些功能的更多细节可以在产品文档中找到。
InterSystems IRIS 2021.1文档和发布说明InterSystems IRIS for Health 2021.1文档和发布说明HealthShare Health Connect 2021.1 文档和发布说明
EM版本包括所有支持平台的传统安装包,以及OCI(Open Container Initiative)又称Docker容器格式的容器镜像。 完整的清单,请参考支持平台文档。
安装包和预览密钥可以从WRC的预览下载网站获得。
InterSystems IRIS和IRIS for Health的企业版的容器镜像以及所有相应的组件都可以从InterSystems容器注册处使用以下命令获得。
docker pull containers.intersystems.com/intersystems/iris:2021.1.0.205.0
docker pull containers.intersystems.com/intersystems/irishealth:2021.1.0.205.0
关于可用镜像的完整列表,请参考ICR文档。
社区版的容器镜像也可以使用以下命令从Docker商店拉取。
docker pull store/intersystems/iris-community:2021.1.0.205.0
docker pull store/intersystems/iris-community-arm64:2021.1.0.205.0
docker pull store/intersystems/irishealth-community:2021.1.0.205.0
docker pull store/intersystems/irishealth-community-arm64:2021.1.0.205.0
另外,所有容器镜像的tarball版本都可以通过WRC的预览下载网站获得。
InterSystems IRIS Studio 2021.1是一个独立的IDE,用于Microsoft Windows,可以通过WRC的预览下载网站下载。它与InterSystems IRIS和IRIS for Health 2021.1及以下版本一起使用。InterSystems还支持 VSCode-ObjectScript 插件,用于将 Visual Studio Code 做为 InterSystems IRIS 开发IDE,该插件可用于Microsoft Windows、Linux和MacOS。
其他独立的InterSystems IRIS 2021.1组件,如ODBC驱动程序和Web网关,可从同一页面获得。
该预览版的构建号是 2021.1.0.205.0。
通过www.DeepL.com/Translator(免费版)翻译