 按回复
按回复Iris-python-template
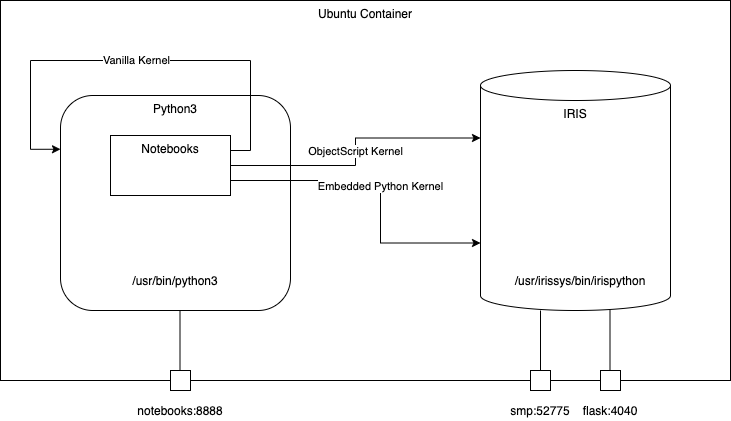
包含各种Python代码的项目模版,可用于InterSystems IRIS 社区容器版Community Edition with container。
特性 :
- Notebooks 记事本
- Embedded Python 内核
- ObjectScript 内核
- Vanilla Python 内核
- Embedded嵌入式 Python
- Code example代码样例
- Flask demo
- IRIS Python Native 原生APIs
- Code example
 Open Exchange app
Open Exchange app
