Hi, Community!
In the previous article, we introduced the Streamlit web framework, a powerful tool that enables data scientists and machine learning engineers to build interactive web applications with minimal effort. First, we explored how to install Streamlit and run a basic Streamlit app. Then, we incorporated some of Streamlit's basic commands, e.g., adding titles, headers, markdown, and displaying such multimedia as images, audio, and videos.
Later, we covered Streamlit widgets, which allow users to interact with the app through buttons, sliders, checkboxes, and more. Additionally, we examined how to display progress bars and status messages and organize the app with sidebars and containers. We also highlighted data visualization, using charts and Matplotlib figures to present data interactively.
In this article, we will cover the following topics:
- Connecting to IRIS and loading data
- Secrets Management
- Caching
- Session State
- Theming
- Pages
Let's dive right in!
1. Connecting to IRIS and loading data
In this section, we will establish a connection with IRIS, fetch data from the "%SYS.ProcessQuery" table, and display it in our Streamlit application. To establish the connection, we will use SQLAlchemy, the Python SQL toolkit that serves as a bridge between Python code and relational databases. For more details, please refer to this article
The script below utilizes SQLAlchemy to connect to an InterSystems IRIS database, retrieve information about running processes from the %SYS.ProcessQuery table, and display the data as an interactive table with the help of the st.dataframe element in Streamlit.
import streamlit as st
from sqlalchemy import create_engine,text
import pandas as pd
username="_SYSTEM"
password="***"
host="localhost"
port=1972
namespace="%SYS"
CONNECTION_STRING = f"iris://{username}:{password}@{host}:{port}/{namespace}"
engine = create_engine(CONNECTION_STRING)
st.set_page_config(layout="wide")
st.subheader("IRIS Running Processes")
with engine.connect() as conn:
with conn.begin():
sql = text("""
SELECT * FROM %SYS.ProcessQuery ORDER BY NameSpace desc
""")
results = []
try:
results = conn.execute(sql).fetchall()
except Exception as e:
print(e)
df = pd.DataFrame(results)
df = df.applymap(lambda x: f"{x}" if isinstance(x, int) else x)
df = df.fillna("")
df = df.set_index(df.columns[0])
st.dataframe(df, use_container_width=True, height=700)
.png)
2. Secret Management
Streamlit provides a convenient mechanism for Secret management. For now, let's explore only how connection parameters work with secrets. In our local project directory, we can save our secrets in a .streamlit/secrets.toml file. For instance, if we have an app file irisCon.py, our project directory may look like the following:
your-LOCAL-repository/
├── .streamlit/
│ └── secrets.toml
└── irisCon.py
For the example mentioned above, our secrets.toml file might resemble the next lines:
[irisLocal]
username="_SYSTEM"
password="***"
host="localhost"
port=1972
namespace="%SYS"
Below you can find the updated code:
import streamlit as st
from sqlalchemy import create_engine,text
import pandas as pd
username=st.secrets["irisLocal"]["username"]
password=st.secrets["irisLocal"]["password"]
host=st.secrets["irisLocal"]["host"]
port=st.secrets["irisLocal"]["port"]
namespace=st.secrets["irisLocal"]["namespace"]
CONNECTION_STRING = f"iris://{username}:{password}@{host}:{port}/{namespace}"
engine = create_engine(CONNECTION_STRING)
st.set_page_config(layout="wide")
st.subheader("IRIS Running Processes")
with engine.connect() as conn:
with conn.begin():
sql = text("""
SELECT * FROM %SYS.ProcessQuery ORDER BY NameSpace desc
""")
results = []
try:
results = conn.execute(sql).fetchall()
except Exception as e:
print(e)
df = pd.DataFrame(results)
df = df.applymap(lambda x: f"{x}" if isinstance(x, int) else x)
df = df.fillna("")
df = df.set_index(df.columns[0])
st.dataframe(df, use_container_width=True, height=700)
3. Caching
Caching is an essential feature for optimizing the performance of our Streamlit app, particularly when handling large datasets, performing time-consuming calculations, or fetching data from external sources. By caching the results of expensive function calls, we can prevent redundant execution and speed up our application responsiveness.
The concept of caching is simple: instead of rerunning the same function with identical inputs multiple times, Streamlit stores the result of the first execution and returns the cached result for subsequent calls with the same inputs. It eliminates unnecessary recomputations.
In Streamlit, we can cache functions by applying a decorator. There are two main caching decorators to choose from:
st.cache_data: This caching method is the preferred one for functions that return data. It is ideal for functions that generate serializable objects (e.g., strings, integers, floats, DataFrames, lists, or dictionaries). The cache stores a fresh copy of the data each time the function is run, ensuring it remains immutable which helps to avoid such issues as race conditions. For most use cases, this is the recommended method.st.cache_resource: This decorator is designed to cache such global resources as machine learning models or database connections. You should use it when your function returns non-serializable objects you do not wish to reload on every app rerun. With st.cache_resource, the object itself is cached and shared across reruns and sessions without duplication. Please note that mutations to cached objects will persist across all runs and sessions.
Check out below how you can apply caching to a function:
@st.cache_data
def long_running_function(param1, param2):
return …
In this example, the function long_running_function is decorated with @st.cache_data. Streamlit takes notes of the following:
- The function name (
long_running_function).
- The values of the parameters (
param1, param2).
- The code inside the function.
Before executing the function, Streamlit scans the cache for a matching result based on the function name and input parameters. If it finds a cached result, it returns it instead of rerunning the function. If no cache is discovered, Streamlit runs the function, stores the result, and proceeds with the script. During development, the cache automatically updates when the function code changes, ensuring that you always use the latest version.
4. Session State
Session State provides a flexible way to store and persist information across multiple interactions with your Streamlit app. The st.session_state object helps us save data that remains intact between reruns of our app, making it ideal for managing user-specific settings or variables during a session. We can store values using a key-value structure. For instance, we can access or keep data utilizing st.session_state["my_key"] or st.session_state.my_key.
While widgets in Streamlit automatically manage their state (e.g., storing user inputs), there are times when you might need to manage more complex states manually. This is when the Session State comes into play.
What is a Session?
In Streamlit, a session refers to the unique instance in which a user interacts with the app. If you open the app in different browser tabs or windows, each one will create a separate session with its own session state. The session remains active as long as the user interacts with the app. However, if the user refreshes the page or restarts the app, the session state is reset, and they begin with a fresh session.
Practical Example of Session State Usage
Below there is a simple example where we keep track of the number of times a button has been clicked. Each time the button is pressed, the page reruns, and the counter value gets updated:
import streamlit as st
if "counter" not in st.session_state:
st.session_state.counter = 0
st.session_state.counter += 1
st.header(f"This page has been run {st.session_state.counter} times.")
st.button("Run it again")
- First run: The first time the app runs for each user, the Session State is empty. Therefore, a key-value pair is created (
"counter":0). As the script continues, the counter is immediately incremented ("counter":1) and the result is displayed: "This page has run 1 time." When the page has fully rendered, the script finishes, and the Streamlit server starts waiting for the user to do something.
- Second run: Since "counter" is already a key in Session State, it does not get reinitialized. As the script resumes, the counter gets incremented ("counter":2), and the result is shown: "This page has run 2 times."
5. Theming
Streamlit supports two themes out of the box - Light and Dark. First, it checks if the user viewing an app has any mode preferences set by their operating system and browser. If there is one, then that preference will be used. Otherwise, the Light theme is applied by default.
You can also change the active theme from "⋮" → "Settings".
.png)
Do you wish to personalize your app’s theme? Simply navigate to the "Settings" menu and click "Edit active theme" to access the theme editor. This tool allows you to explore various color schemes and see the real-time alterations applied to your app.
.png)
6-Pages
As apps are growing large, organizing them into multiple pages becomes crucial. It simplifies the management and maintenance for developers and navigation for users. Streamlit provides a smooth way to create multipage apps.
This feature is designed to make building a multipage app just as easy as creating a single-page app! Just add additional pages to an existing app as shown below:
- In the folder containing your main script, create a new
pages folder. Let’s say your main script would be named main_page.py.
- Add new
.py files in the pages folder to add more pages to your app.
- Run
streamlit run main_page.py as usual.
your-LOCAL-repository/
├── pages/
│ └── page_2.py
│ └── page_3.py
└── irisCon.py
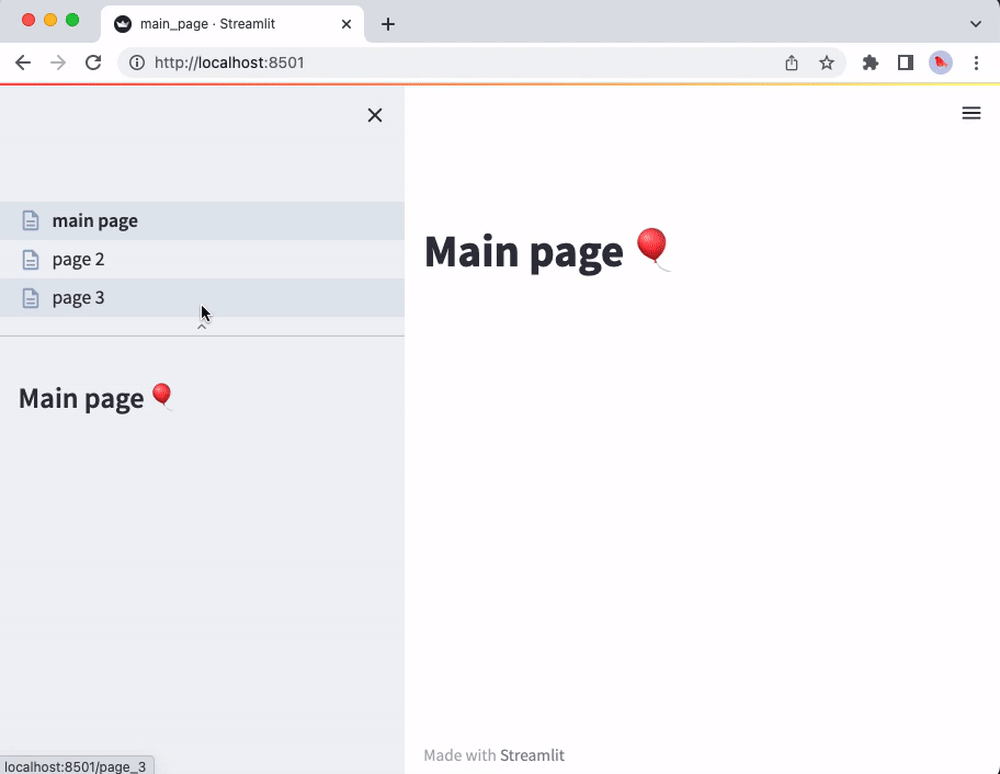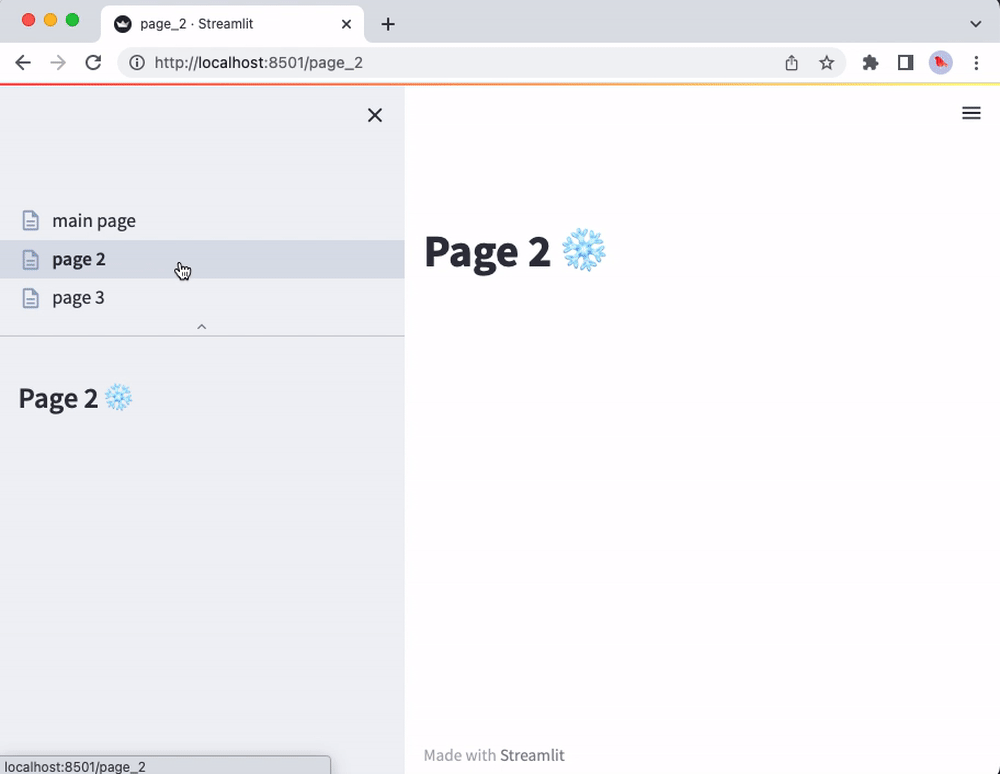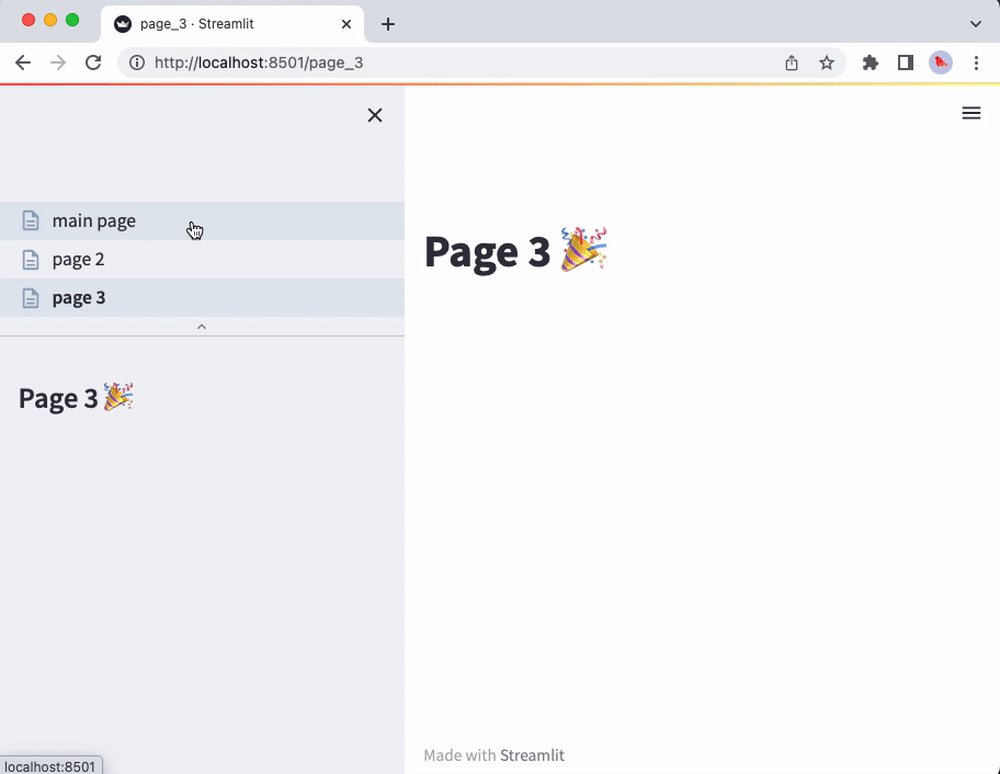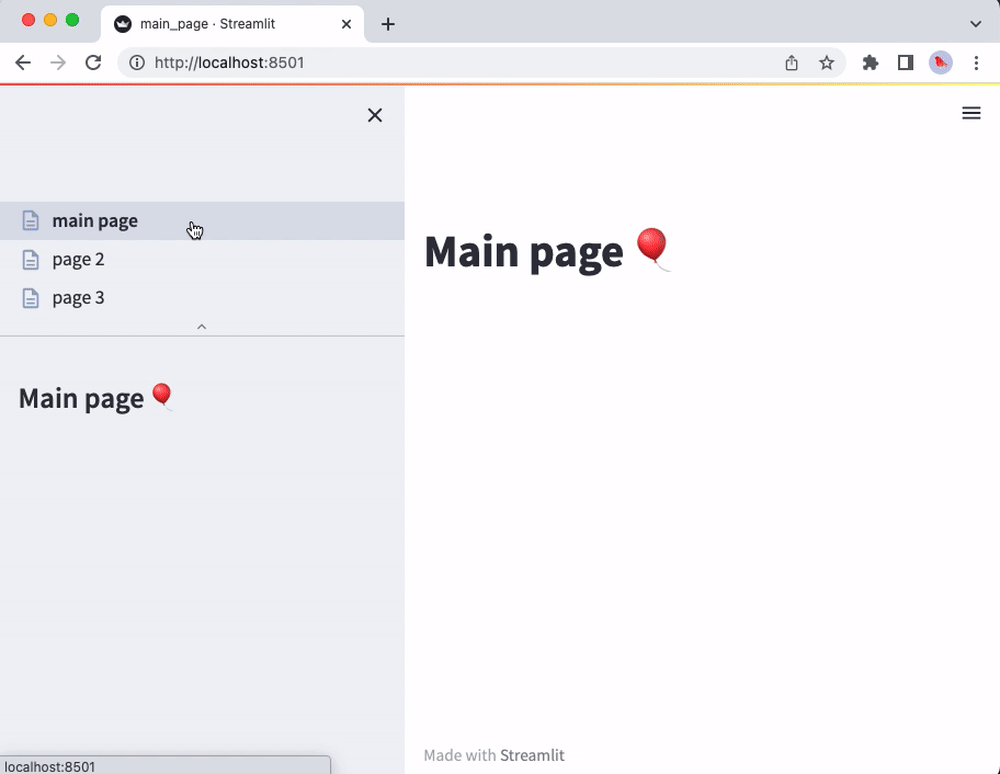
That’s it! The main_page.py script will now correspond to the main page of your app. You will also see the other scripts from the pages folder in the sidebar page selector. The pages will be listed according to filename (without file extensions and disregarding underscores). For instance:
import streamlit as st
st.markdown("# Main page 🎈")
st.sidebar.markdown("# Main page 🎈")
import streamlit as st
st.markdown("# Page 2 ❄️")
st.sidebar.markdown("# Page 2 ❄️")
import streamlit as st
st.markdown("# Page 3 🎉")
st.sidebar.markdown("# Page 3 🎉")
Now run streamlit run main_page.py and enjoy the view of your shiny new multipage app!
Summary
In this article, we have explored several key features of Streamlit that enhance the functionality of our applications. We started by learning how to connect to an InterSystems IRIS database and retrieve data, using SQLAlchemy for seamless integration. Then we covered the importance of managing sensitive information securely with Streamlit’s secrets management system. We also introduced caching to optimize app performance, ensuring faster load times by avoiding redundant computations. Additionally, we delved into Session State, allowing us to maintain user-specific data across app reruns. Along the way, we highlighted theming and customization, demonstrating how to tailor the application appearance for a personalized experience. Ultimately, we discussed the organization of larger apps with multiple pages, making the management easier for developers and users. With all the above-mentioned techniques, you are finally equipped to build more interactive, efficient, and user-friendly Streamlit applications.
Thanks!