新增
持续训练(CT)流水线将基于特定时间点可用数据,通过数据科学实验开发出的机器学习(ML)模型规范化。它不仅为模型部署做好准备,还支持在新数据可用时进行自主更新,同时具备用于审计目的的稳健性能监控、日志记录和模型注册功能。
InterSystems IRIS 已经提供了支持此类流水线所需的几乎所有组件。然而,缺少一个关键要素:标准化的模型注册工具。在本文中,我将介绍一种结合 IRIS 优势与开源 AI 工程平台 MLflow 的方法。它们共同作为构建有效持续训练(CT)流水线的互补工具。
本仓库中的实现利用了 MLflow 的内置配置来存储 SHAP 解释器,以提供对相应模型预测结果的解释,包括随机森林(Random Forest)、XGBoost、神经网络等“黑盒”复杂模型。
**演示视频**:https://youtu.be/qLdc4jhn83c
---
CT 流水线组件
该 CT 流水线模块背后的理论基于 Google 在相关文章中定义的 MLOps 1 级行业标准。每个组件的实现都利用了 IRIS 和 MLflow 的最佳特性(如下图所示,红色部分突出显示):
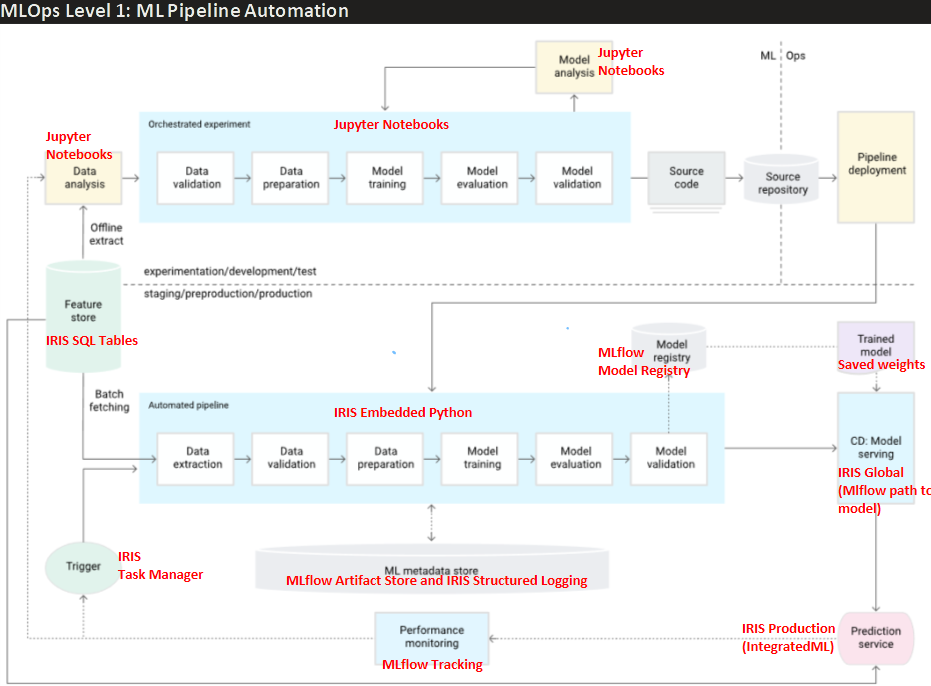
对于那些刚接触 CT 流水线的人来说,上图描述了数据科学项目中传统的实验阶段(上半部分“实验/开发/测试”,通常在 Jupyter Notebook 中进行)如何转化为生产级模型部署。