.png)
新增
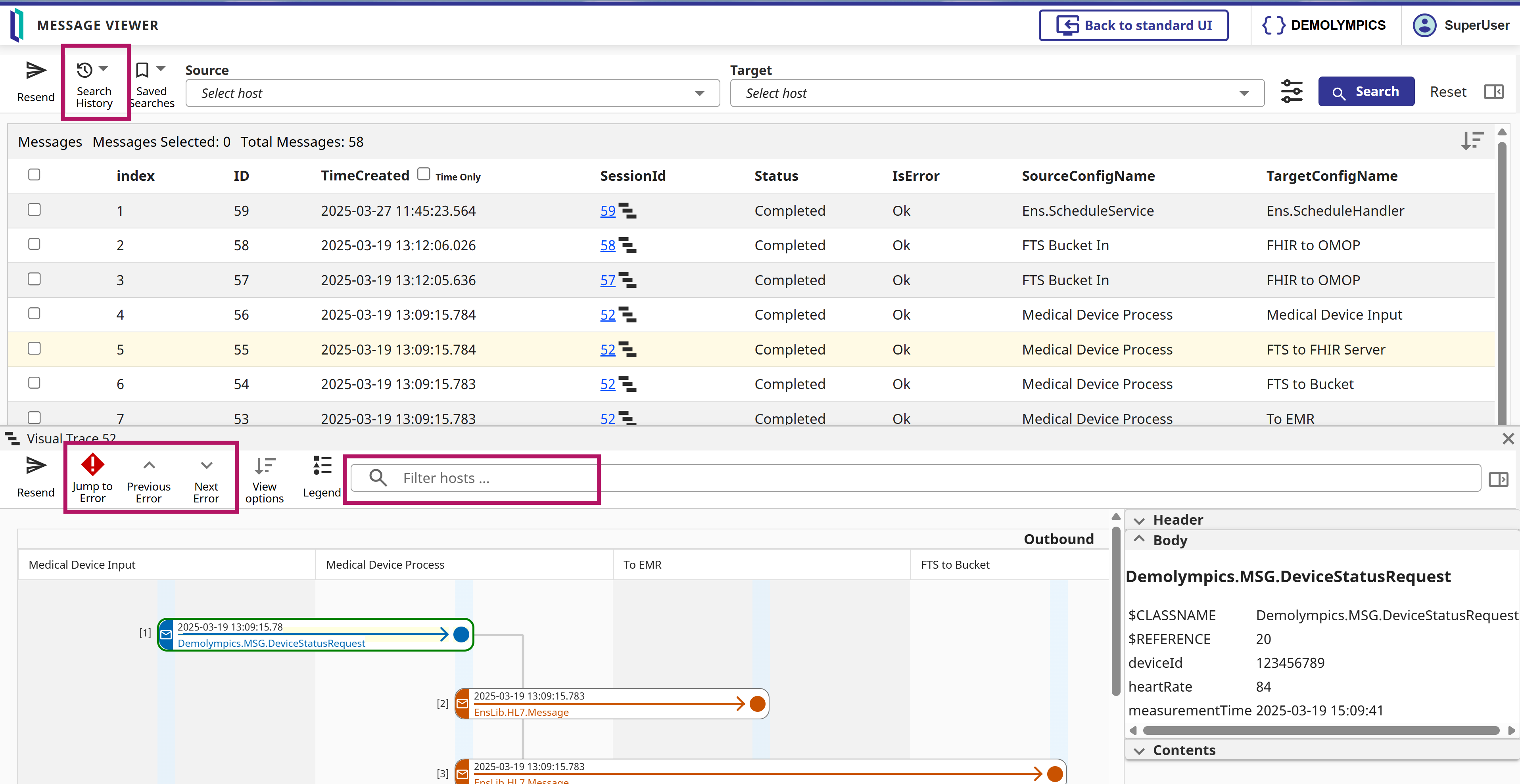
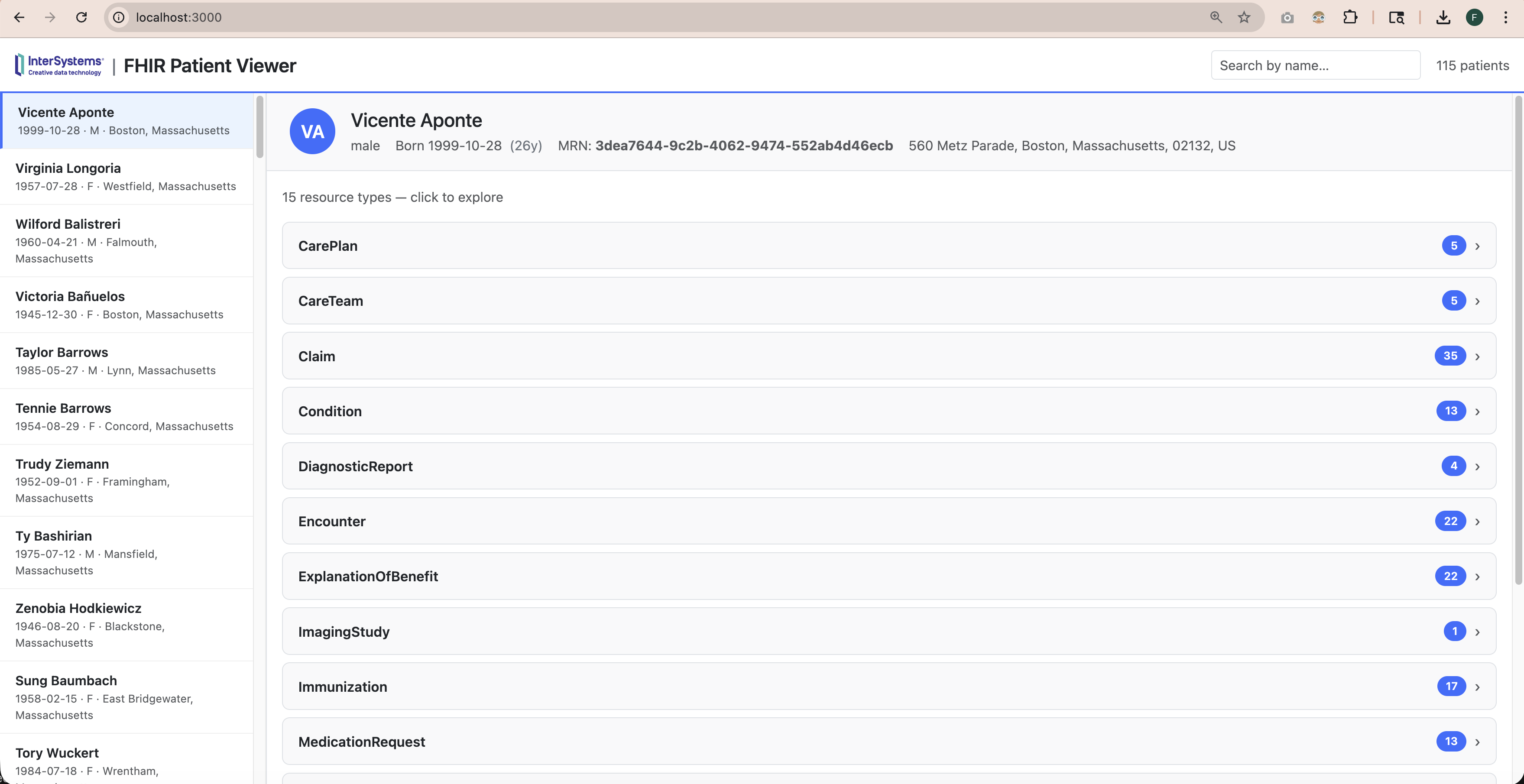
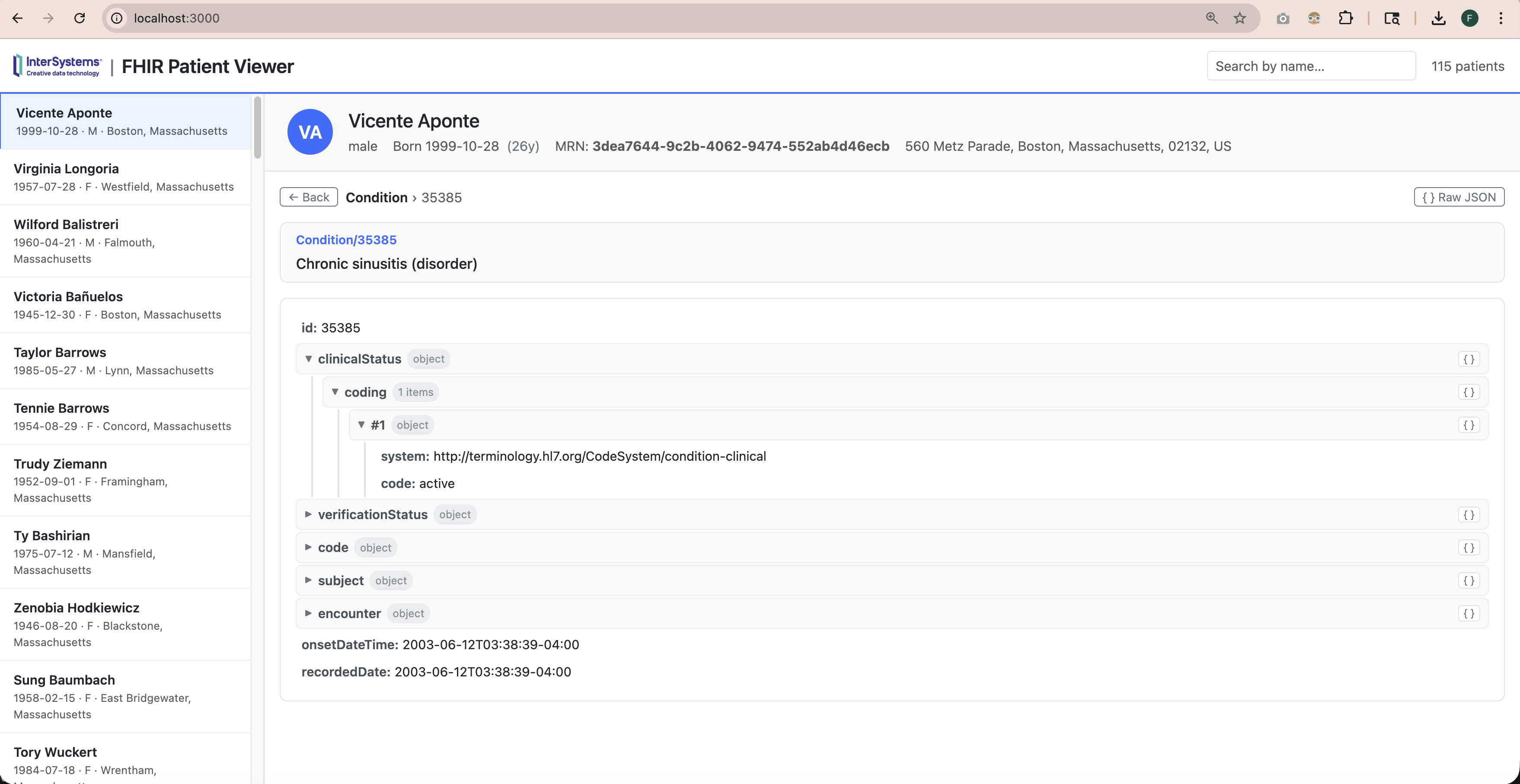
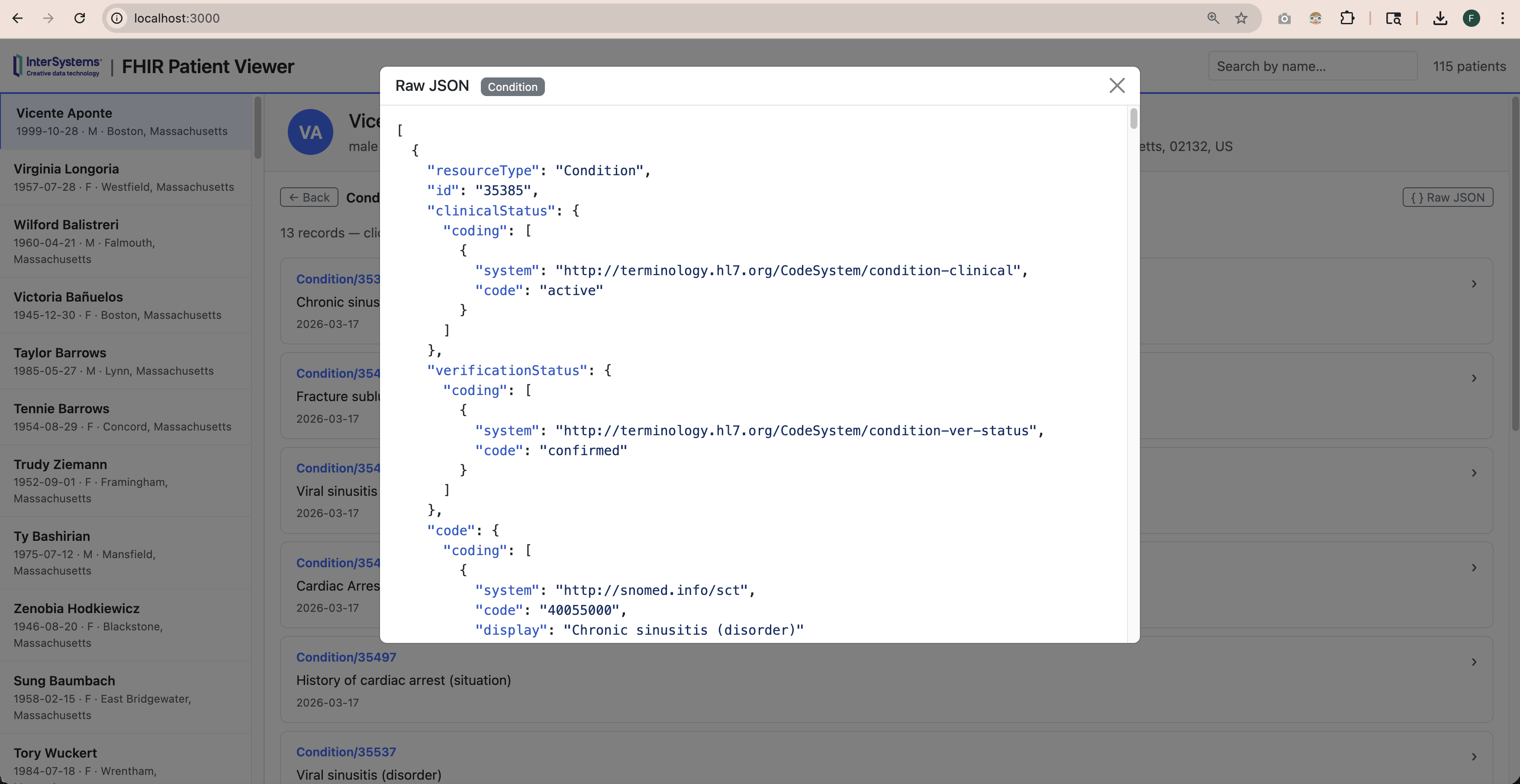
在 InterSystems IRIS 中使用 OpenEHR
我们偶尔会收到有关在 InterSystems 中使用 OpenEHR 的问题。 通常,这些讨论的重点是企业为什么以及如何在构建应用程序时实施 OpenEHR。下面是一份简要指南:
- InterSystems 注重互操作性: 我们 优先考虑通过 HL7、IHE、DICOM 和 ISO 等标准实现互操作性。根据我们的经验,没有一种标准能满足复杂医疗数据的所有需求。因此,我们建议在评估 OpenEHR 的任何实施方案时,都要与这些标准结合起来,并分析 每种标准能最好地满足哪些情况的需要。
- InterSystems IRIS 上的 OpenEHR:对于使用 OpenEHR 模型构建应用程序或数据产品的组织而言,InterSystems IRIS 是一个理想的平台。它具有多模型功能、可扩展性、高性能和可靠性。InterSystems IRIS for Health 还可在同一应用程序中灵活使用包括 HL7 FHIR 在内的许多其他医疗标准。
- 与 OpenEHR 的互操作性:OpenEHR 早于 HL7 FHIR,但 FHIR 现在涵盖了 OpenEHR 的许多原始用例。