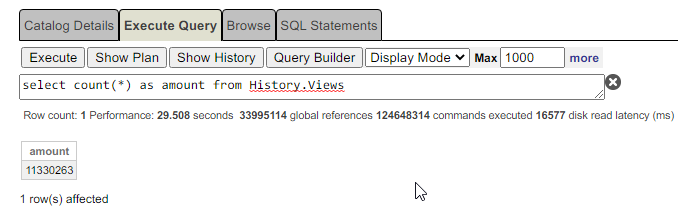
应用集成平台市场上产品众多,商家专家观点纷纭,莫衷一是。Gartner公司从用户角度出发,搭建了Peer Insight “大众点评”平台,让用户能够为自己使用的产品发声,对各个产品打分。以下是来自用户的声音,供参考。
第一款产品是微软的BizTalk,综合得分3.9。
第二款产品是InterSystems的Ensemble,综合得分4.6。
第三款产品是IBM的WebSphere Enterprise Service Bus,综合得分3.8。
.png) BizTalk BizTalkby MicroSoft |
Ensemble by InterSystems |
WebSphere Enterprise Services Bus by IBM |
|
总体评价:57%的用户愿意推荐该产品 |
总体评价:88%的用户愿意推荐该产品 |
总体评价:55%的用户愿意推荐该产品 |
|
分项评分 |
分项评分 | 分项评分 |
| 综合能力得分 |
综合能力得分 |
综合能力得分 |
| 评估与签约 3.3 定价灵活性 4.0 理解需求的能力 |
评估与签约 4.2 定价灵活性 4.6 理解需求的能力 |
评估与签约 3.5 定价灵活性 4.0 理解需求的能力 |
| 集成与部署 3.4 部署便利性 3. |
.png)