第三十二章 XML基础知识概念
attribute
以下形式的名值对:
ID="QD5690"
属性位于元素中,如下所示,一个元素可以有任意数量的属性。
<Patient ID="QD5690">Cromley,Marcia N.</Patient>
CDATA区域
表示不应该验证的文本,如下所示:
<myelementname><![CDATA[
Non-validated data goes here.
You can even have stray "<" or ">" symbols in it.
]]></myelementname>
一个CDATA(字符数据)区段不能包含字符串]]>,因为这个字符串标志着区段的结束。
这也意味着CDATA区段不能嵌套。
注意,CDATA部分的内容必须符合为XML文档指定的编码,XML文档的其余部分也是如此。
comment
不是XML文档主数据的一部分的插入说明。 注释是这样的:
<!--Output for the class: GXML.PersonNS7-->
content model
对XML元素的可能内容的抽象描述。
第三十一章 检查命名空间和类
类%XML.Namespaces提供了两个类方法,可用于检查XML命名空间及其包含的类:
GetNextClass()
classmethod GetNextClass(namespace As %String,
class As %String) as %String
返回给定XML命名空间中给定类之后的下一个类(按字母顺序)。当没有更多的类时,此方法返回NULL。
GetNextNamespace()
classmethod GetNextNamespace(namespace As %String) as %String
返回给定命名空间之后的下一个命名空间(按字母顺序)。当没有更多的命名空间时,此方法返回NULL。
在这两种情况下,只考虑当前的InterSystems IRIS命名空间。此外,映射的类也会被忽略。
例如,以下方法列出当前InterSystems IRIS命名空间的XML命名空间及其类:
ClassMethod WriteNamespacesAndClasses()
{
Set ns=""
Set ns=##class(%XML.Namespaces).GetNextNamespace(ns)
While ns '=""
{
Write !2021年7月9日-11日,2021(16th) 中国卫生信息技术/健康医疗大数据应用交流大会暨软硬件与健康医疗产品展览会(CHITEC)在武汉国际博览中心(湖北省武汉市汉阳区鹦鹉大道619号)盛大召开,欢迎莅临InterSystems展位A6-16,了解备受瞩目的InterSystems IRIS医疗版互联互通套件。
第三十章 从类生成XML架构
本章介绍如何使用%XML.Schema从启用了XML的类生成XML架构。
概述
要生成为同一XML命名空间中的多个类定义类型的完整架构,请使用%XML.Schema构建架构,然后使用%XML.Writer为其生成输出。
从多个类构建架构
要构建XML架构,请执行以下操作:
- 创建
%XML.Schema实例。 - 可以选择设置实例的属性:
- 若要为任何其他未分配的类型指定命名空间,请指定
DefaultNamespace属性。默认值为NULL。 - 默认情况下,类及其属性的类文档包含在模式的
<annotation>元素中。 要禁用此功能,请将IncludeDocumentation属性指定为0。
注意:必须在调用AddSchemaType()方法之前设置这些属性。
- 调用实例的
AddSchemaType()方法。
第二十九章 从XML架构生成类
Studio提供了一个向导,该向导读取XML模式(从文件或URL),并生成一组支持XML的类,这些类对应于模式中定义的类型。
所有的类都扩展%XML.Adaptor。
指定一个包来包含类,以及控制类定义细节的各种选项。
向导还可以作为类方法使用,也可以使用该类方法。 在内部,SOAP向导在读取WSDL文档并生成web客户端或web服务时使用此方法;
注意:使用的任何XML文档的XML声明都应该指明该文档的字符编码,并且文档应该按照声明的方式进行编码。如果未声明字符编码,InterSystems IRIS将使用本书前面的“输入和输出的字符编码”中描述的默认值。如果这些默认值不正确,请修改XML声明,使其指定实际使用的字符集。
使用向导
要使用XML架构向导,请执行以下操作:
- 选择 Tools > Add-Ins > XML Schema Wizard.
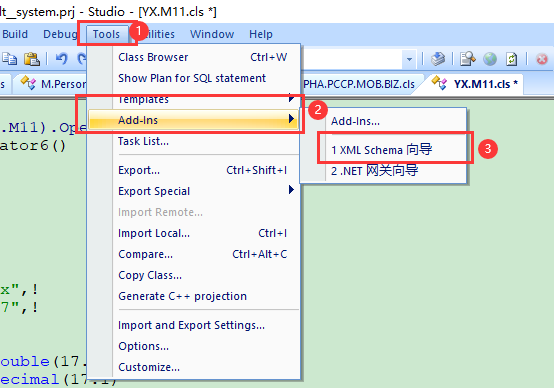
- 在第一个屏幕上,指定要使用的XML模式。 做以下其中一项:
- 对于模式文件Schema File,选择Browse 以选择XML模式文件。
- 对于URL,指定模式的URL。
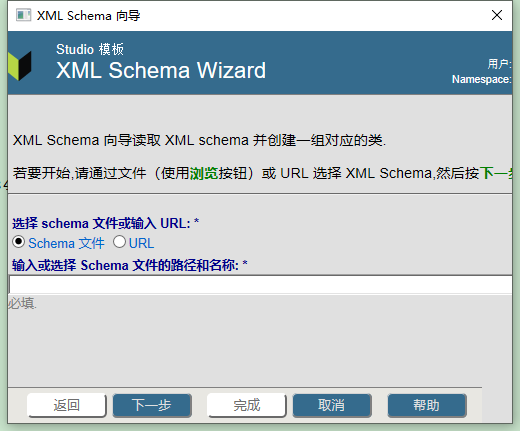
- 选择Next。
下一个屏幕显示模式,以便可以验证选择了正确的模式。
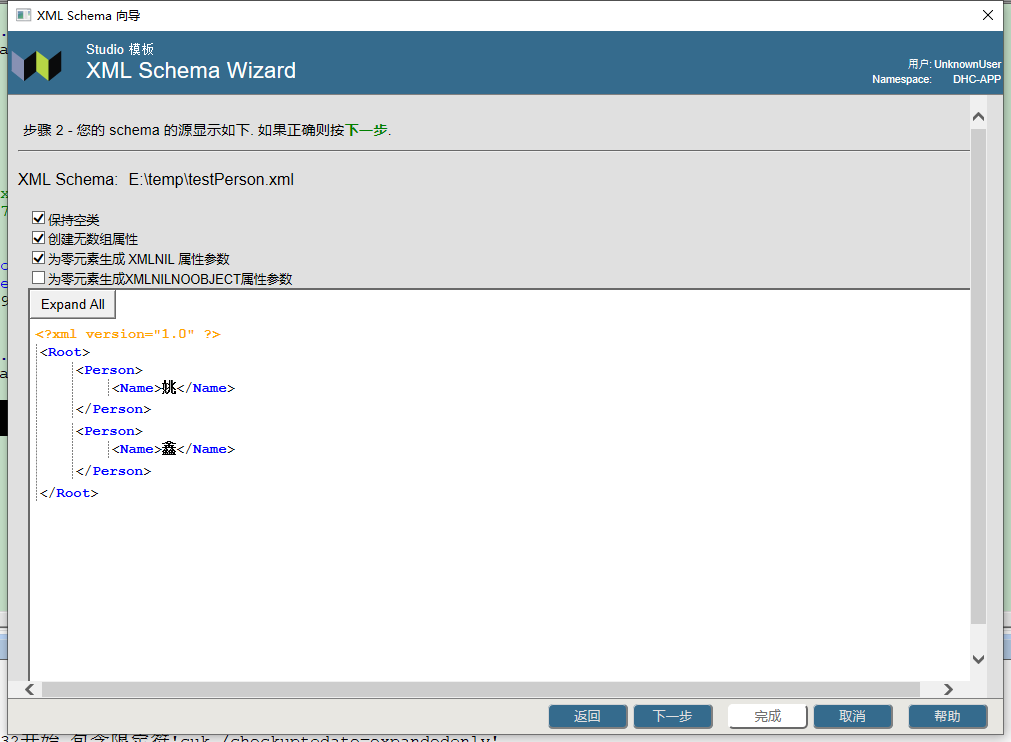
- 可选择以下选项:
- 保留空类Keep Empty Classes,它指定是否保留没有属性的未使用的类。 如果选择此选项,则不会在向导结束时删除此类; 否则,将删除它们。
近日,InterSystems极客俱乐部举办了线上直播“InterSystems Caché系统运维培训”,这是系列视频之一。InterSystems中国资深售前顾问祝麟讲解了“InterSystems Caché系统高可用与数据库镜像”。
如果一张图片胜过千言万语,那么一段视频又价值几何? 当然胜过敲一个帖子。
请在 InterSystems Developers YouTube 观看我的“Coding talks”:
1. 使用 Yape 分析 InterSystems IRIS 系统性能。 第 1 部分:安装 Yape
在容器中运行 Yape。
2. Yape 容器 SQLite iostat InterSystems
提取和绘制 pButtons 数据,包括时间范围和 iostat。
供应商或内部团队要求说明如何为 VMware vSphere 上运行的_大型生产数据库_进行 CPU 容量规划。
总的来说,在调整大型生产数据库的 CPU 规模时,有几个简单的最佳做法可以遵循:
- 为每个物理 CPU 核心规划一个 vCPU。
- 考虑 NUMA 并按理想情况调整虚拟机规模,以使 CPU 和内存对于 NUMA 节点是本地的。
- 合理调整虚拟机规模。 仅在需要时才添加 vCPU。
通常,这会引出几个常见问题:
- 由于使用超线程技术,VMware 创建的虚拟机的 CPU 数量可以是物理 CPU 数量的两倍。 那不就是双倍容量吗? 创建的虚拟机不应该有尽可能多的 CPU 吗?
- 什么是 NUMA 节点? 我应该在意 NUMA 吗?
- 虚拟机应该合理调整规模,但我如何知道什么时候合理?
我以下面的示例回答这些问题。 但也要记住,最佳做法并不是一成不变的。 有时需要做出妥协。 例如,大型生产数据库虚拟机很可能不适合 NUMA 节点,但我们会看到,其实是没问题的。 最佳做法是指必须针对应用程序和环境进行评估和验证的准则。
除了objectscript 自带的 list,array 数据结构以外,是否有存在其它已经实现好的数据结构,类似 java 里面 collection包一样,是否有已经实现好的排序工具,有没有针对集合类的sort工具。
[toc]
第二十八章 定制SAX解析器创建自定义内容处理程序
创建自定义内容处理程序
如果直接调用InterSystems IRIS SAX解析器,则可以根据自己的需要创建自定义内容处理程序。本节讨论以下主题:
- Overview
- 要在内容处理程序中自定义的方法的描述
%XML.SAX.Parser类中解析方法的参数列表摘要- 示例
创建自定义内容处理程序概述
要定制InterSystems IRIS SAX解析器导入和处理XML的方式,请创建并使用定制的SAX内容处理程序。具体地说,创建%XML.SAX.ContentHandler的子类。然后,在新类中,重写任何默认方法以执行所需的操作。在解析XML文档时使用新的内容处理程序作为参数;为此,需要使用%XML.SAX.Parser类的解析方法。
此操作如下图所示:
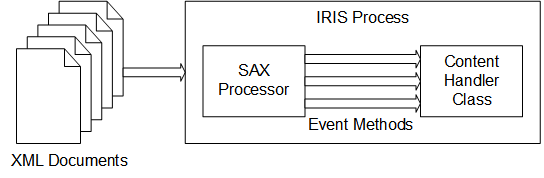
创建和使用自定义导入机制的过程如下:
- 创建扩展
%XML.SAX.ContentHandler的类。 - 在该类中,包括希望覆盖的方法,并根据需要提供新定义。
- 在使用
%XML.SAX.Parser的分析方法之一(即ParseFile()、ParseStream()、ParseString()或ParseURL())编写读取XML文档的类方法。
调用分析方法时,请将自定义内容处理程序指定为参数。
SAX内容处理程序的可定制方法
%XML.SAX.
多学科协作诊疗(Multidisciplinary Team,MDT)是当今医学领域的重要医学模式之一,其主要目的在于:通过不同专业的医务人员共同参与、联合决策,针对特定患者和疾病,提供临床最佳、管理最细、资源最整、效率最高的诊疗方案。该模式起源于20世纪80年代,在欧美国家已运行多年,尤其在肿瘤和重症领域应用较为广泛和成熟。近些年,越来越多的中国医疗机构(包括公立和私立)也开始尝试和完善MDT。虽然在具体实施形式和细节角色流程上仍有争议,但是多数报道患者满意度和诊疗结果综合评分提升。因此,值得长期探索和实践。
本文以典型的MDT工作方案(图1)作为模版,阐述医学信息系统如何助力MDT的管理和运行。图中数字编号即为章节题目,将流程与系统功能结合,进行深入探讨。
图1 MDT工作方案
.png)
1. 开展MDT的必备资源
目前国内外大体有两种MDT表现形式:一是固定时间、固定学科、固定病种。譬如:每月最后一个周五下午2-4点,肿瘤科、消化内科、外科、病理科、营养科、放射科共同探讨恶性消化系统肿瘤病例,这些病例是由该MDT主导学科在平时门诊、住院患者中通过预设条件筛选得出的;二是根据患者和病情需要,临时组织所需学科医务人员进行诊疗方案的讨论。这里需要强调的是,后者尽管没有固定时间规律,但不可与疑难病例讨论或多学科会诊相混淆。
大家好, 在本文中,我比较了 Gartner 最新DBMS 魔力象限中的主要领先数据库产品的功能。 请见按现有功能数量排序的列表。 1. InterSystems IRIS 2020.3 - 60 个功能 (https://docs.intersystems.com/irislatest/csp/docbook/DocBook.UI.Page.cls) 2. Oracle Database 21c - 54 个功能 (https://docs.oracle.com/en/database/oracle/oracle-database/index.html) 3. Microsoft SQL Server - 45 个功能 (https://docs.microsoft.com/en-us/sql/sql-server/?view=sql-server-ver15) 4. AWS Aurora - PostgreSQL - 34 个功能 (https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/CHAP_Auror…) 我只比较了功能,未进行任何性能比较(关于此内容,请参见性能测试:https://cn.community.intersystems.
(ECP) Caché 出色的可用性和扩展特性之一是企业缓存协议 (ECP)。 在应用程序开发过程中,如对使用 ECP 的分布式处理加以考虑,可以横向扩展 Caché 应用程序的架构。 应用程序处理可以调整为非常高的速率,处理能力从单个应用程序服务器扩展到最多 255 个应用程序服务器,并且不需要任何应用程序更改。
在我参与的 TrakCare 部署中,ECP 已广泛使用多年。 十年前,主要供应商之一的一台“大型”x86 服务器可能总共只有八个核心。 对于大型部署来说,ECP 是横向扩展商业服务器处理能力的方式,不适合单台昂贵的大型企业服务器。 即使是高核心数的企业服务器也有限制,因此 ECP 也用于扩展这些服务器上的部署。
如今,大多数的新 TrakCare 部署或升级到当前硬件_不需要 ECP_ 即可扩展。 目前的双插槽 x86 生产服务器可以拥有数十个核心和巨大容量的内存。 我们看到,在最近的 Caché 版本中,TrakCare 以及许多其他 Caché 应用程序具有可预测的线性扩展能力,能够随着单台服务器中 CPU 核心数量和内存的增加而支持逐渐增多的用户和事务。 在现场,我看到大多数的新部署都是虚拟化的,即使如此,虚拟机也可以根据需要扩展到主机服务器的规模。 如果资源需求超过单个物理主机可以提供的资源,则使用 ECP 进行横向扩展。
第二十七章 定制SAX解析器的执行自定义实体解析
执行自定义实体解析
XML文档可能包含对外部DTD或其他实体的引用。默认情况下,InterSystems IRIS尝试查找这些实体的源文档并解析它们。要控制InterSystems IRIS解析外部实体的方式,请使用以下步骤:
- 定义实体解析程序类。
此类必须在扩展%XML.SAX.EntityResolver,并且必须实现 resolveEntity()方法,该方法具有以下签名:
method resolveEntity(publicID As %Library.String, systemID As %Library.String) as %Library.Integer
每当XML处理器找到对外部实体(如DTD)的引用时,就会调用该方法;这里的public ID和systemID是该实体的Public和系统标识符字符串。
该方法应获取实体或文档,将其作为流返回,然后在将流包装在%XML.SAX.StreamAdapter的实例中。此类提供了用于确定流特征的必要方法。
如果无法解析该实体,则该方法应返回$$$NULLOREF ,以向SAX解析器指示该实体无法解析)。
尽管方法签名指示返回值为%Library.Integer,但该方法应返回%XML.SAX.StreamAdapter的实例或该类的子类。
第二十六章 定制 SAX解析器的使用方式
每当InterSystems IRIS读取XML文档时,它都会使用InterSystems IRIS SAX(Simple API For XML)解析器。本章介绍用于控制系统间IRIS SAX解析器的选项。
关于IRIS SAX解析器
每当InterSystems IRIS读取XML文档时,都会使用InterSystems IRIS SAX解析器。
它是一个事件驱动的XML解析器,读取XML文件,并在找到感兴趣的项(如XML元素的开始、DTD的开始等)时发出回调。
(更准确地说,解析器与内容处理程序协同工作,内容处理程序发出回调。只有在自定义SAX接口时,此区别才很重要,如本章后面的“创建自定义内容处理程序”中所述。)
解析器使用标准Xerces-C++库,该库符合XML1.0推荐标准和许多相关标准。
可用的解析器选项
可以通过以下方式控制SAX解析器的行为:
- 可以设置标志来指定要执行的验证和处理类型。
请注意,解析器始终检查文档是否为格式良好的XML文档。
- 可以指感兴趣的事件(即希望解析器查找的项目)。为此,需要指定一个掩码来指示感兴趣的事件。
- 可以提供验证文档所依据的架构规范。
- 可以使用特殊用途的实体解析器禁用实体解析。
- 可以指定实体解析的超时期限。
- 如果需要控制解析器如何查找文档中任何实体的定义,则可以指定更通用的自定义实体解析器。
第二十五章 添加和使用XSLT扩展函数
自定义错误处理
当出现错误时,XSLT处理器(Xalan或Saxon)执行当前错误处理程序的error()方法,将消息作为参数发送到该方法。类似地,当发生致命错误或警告时,XSLT处理器会根据需要执行datalError()或Warning()方法。
对于所有这三种方法,默认行为是将消息写入当前设备。
要自定义错误处理,请执行以下操作:
- 对于
Xalan或Saxon处理器,在创建%XML.XSLT.ErrorHandler的子类。在这个子类中,根据需要实现Error()、FatealError()和Warning()方法。
这些方法中的每一个都接受单个参数,即包含由XSLT处理器发送的消息的字符串。
这些方法不返回值。
- 要在编译样式表时使用此错误处理程序,请创建子类的实例,并在编译样式表时在参数列表中使用它。
- 若要在执行XSLT转换时使用此错误处理程序,请创建子类的实例,并在使用的
Transform方法的参数列表中使用它。
指定样式表使用的参数
要指定样式表使用的参数,请执行以下操作:
- 创建
%ArrayOfDataTypes的实例在。 - 调用此实例的
SetAt()方法将参数及其值添加到此实例。对于SetAt(),将第一个参数指定为参数值,将第二个参数指定为参数名称。
根据需要添加任意多个参数。
第二十四章 执行XSLT转换
执行XSLT转换
要执行XSLT转换,请执行以下操作:
- 如果使用的是
Xalan处理器(对于XSLT 1.0),请使用%XML.XSLT.Transformer的以下类方法之一:TransformFile()——转换给定XSLT样式表的文件。TransformFileWithCompiledXSL()——转换一个文件,给定一个已编译的XSLT样式表。TransformStream()——转换给定XSLT样式表的流。TransformStreamWithCompiledXSL()——转换一个流,给定一个已编译的XSLT样式表。TransformStringWithCompiledXSL()——转换给定已编译XSLT样式表的字符串。
- 如果使用
Saxon处理器(用于XSLT 2.0),请使用%XML.XSLT2.Transformer的以下类方法之一:TransformFile()——转换给定XSLT样式表的文件。TransformFileWithCompiledXSL()——转换一个文件,给定一个已编译的XSLT样式表。TransformStream()——转换给定XSLT样式表的流。TransformStreamWithCompiledXSL()——转换一个流,给定一个已编译的XSLT样式表。
这些方法具有相似的签名。
第二十三章 执行XSLT转换概述
XSLT(Extensible StyleSheet Language Transformations,可扩展样式表语言转换)是一种基于XML的语言,用于描述如何将给定的XML文档转换为另一个XML或其他“人类可读”的文档。可以使用%XML.XSLT和%XML.XSLT2包中的类来执行XSLT 1.0和2.0转换。
注意:使用的任何XML文档的XML声明都应该指明该文档的字符编码,并且文档应该按照声明的方式进行编码。如果未声明字符编码, IRIS将使用本书前面的“输入和输出的字符编码”中描述的默认值。如果这些默认值不正确,请修改XML声明,使其指定实际使用的字符集。
在IRIS中执行XSLT转换概述
IRIS提供两个XSLT处理器,每个处理器都有自己的API:
Xalan处理器支持XSLT 1.0。XML.XSLT包为该处理器提供API。Saxon处理器支持XSLT 2.0。%XML.XSLT2程序包为该处理器提供API。
XML.XSLT2 API通过到XSLT 2.0网关的连接向Saxon发送请求。网关允许多个连接。这意味着,例如,可以将两个独立的 IRIS进程连接到网关,每个进程都有自己的一组编译样式表,同时发送转换请求。
使用Saxon处理器,编译的样式表和isc:Evaluate缓存是特定于连接的;必须管理自己的连接才能利用这两个特性。


