文章 Zhang Fatong · 七月 5, 2023 阅读大约需 2 分钟 平台服务器入场配置预测应用 预测平台入场服务器配置 平台服务器入场配置预测应用,以java连接iris并使用其IntegratedML技术完成对医院门诊量,服务数,消息数,消息保存时间等数据分析,可以在医院集成平台入场前,对医院入场平台所需的服务器配置进行预测,为客户提供便利。 #IntegratedML #Java #互操作性 #InterSystems IRIS Open Exchange app 2 6 0 156
文章 Lele Yang · 七月 22, 2021 阅读大约需 6 分钟 FAQ 常见问题系列--Java 从IRIS数据库中读取Stream数据性能优化-Prefetch方式介绍 提示:本文包含在Java中通过JDBC Driver对Caché/IRIS数据库进行查询的示例代码。 近期有客户反应使用Java从老版本Caché中读取数据时,如果数据中包含long varchar, Caché数据库中与之对应的属性类型为%Stream.GlobalCharacter,即使实际上该流数据长度非常小,也会成十几倍的降低性能。 大家先来看一段代码, #Java #JDBC 0 3 0 231
文章 Nicky Zhu · 四月 24, 2022 阅读大约需 10 分钟 在ObjectScript中调用Java程序 —— 一个国密算法的案例 尽管IRIS和HealthConnect拥有全面的互操作特性,但在实际工作中,还是有可能遇到需要使用遗留类库,dll SDK等方式与外部应用通信的情况。例如IRIS中并没有内嵌国密算法SM2、SM3和SM4,而开源社区中不乏通过Java、Python和C++等语言完成的具体实现。本文就将以调用SM4的Java实现为例展示ObjectScript程序与第三方语言通信的过程。 Github地址:https://github.com/LinZhuISC/javademo.SM4 跨编程环境调用设计要点 在开始实际操作之前,希望读者先针对整个调用过程中的主调方和被调方思考两个现象: #Eclipse #GitHub #Java #ObjectScript #InterSystems IRIS for Health 3 3 1 474
文章 Nicky Zhu · 四月 27, 2021 阅读大约需 6 分钟 在IRIS中联合运用OCR与NLP技术 根据IDC的报道,超过80%的信息是基于NoSQL的,尤其是文本文件。当数字服务或应用程序不能处理所有这些信息时,企业就会遭受损失。为了面对这一挑战,可以使用OCR技术。OCR使用机器学习和/或训练的图像模式将图像像素转化为文本。这一点很重要,因为许多文件被扫描成PDF格式的图像,或者许多文件中包含有文本的图像。因此,OCR是一个重要的步骤,可以从文件中获得所有可能的数据。 为了实现OCR,可以使用开源解决方案Google Tesseract,这是Python和Java社区中最流行的解决方案。Tesseract支持100多个习语,并且可以用新的模型进行训练以识别车牌、验证码等等。Tesseract是在C++中创建的,可以通过Java套用Tess4J构成一个中介层来使用它。下面的代码展示了调用过程。 #Java #互操作性 #分析 #InterSystems IRIS Open Exchange app 0 2 0 386
文章 John Pan · 九月 9, 2022 阅读大约需 5 分钟 如何调用Ensemble/IRIS内置的HL7 V2 webservice - Java,PB9,Delphi7样例 概述 #Java #Ensemble #InterSystems IRIS for Health 17 1 0 498
文章 王喆 👀 · 三月 12, 2023 阅读大约需 8 分钟 教程 - 使用 SSH 开发 IRIS #Java #JDBC #开发环境 #教程 #InterSystems IRIS #InterSystems IRIS for Health 0 0 0 113
文章 Michael Lei · 十一月 20, 2023 阅读大约需 2 分钟 Java 大赛作品展示--基于IRIS 原生 Java API 的Global编辑器 这是Java 编程比赛的相关文章。我决定推出一个基于 IRIS Native API for Java 的 CRUD++ Global编辑器。++因为它不仅仅是C reate、 R ead、 U pdate、 D eleteGlobal可视化对于立即查看结果始终很重要。 为此,我使用模仿 ZWrite 的树查看器扩展了 API,并且还允许检查子树。 $Query Style Navigator 正向和反向操作可轻松找到感兴趣的全局节点。 最后,ZKill 添加了一个选项,可以删除全局节点的内容而不删除下面的子树。 这需要在服务器端有一个小的帮助器类作为默认 API 的扩展 我的策略是拥有一个可从命令行使用的相当适度的界面就像在 Docker 控制台或终端上一样,并使其尽可能简单。花哨的图形界面只会分散示例的基本内容。 #Globals #Java #工具 #InterSystems IRIS #InterSystems IRIS for Health Open Exchange app 0 0 0 128
文章 Qiao Peng · 一月 31, 2024 阅读大约需 21 分钟 用Java开发互操作产品 - PEX InterSystems IRIS、Health Connect和上一代的Ensemble提供了优秀的互操作架构,但即便有低代码开发能力,很多开发者还是希望能用自己的技术栈语言在InterSystems的产品上开发互操作产品。 考虑到互操作产品本身的开放性要求和各个技术栈背后庞大的生态价值,InterSystems IRIS和Health Connect提供了Production EXtension (PEX)架构,让开发者使用自己的技术栈语言来开发互操作解决方案。目前PEX支持Java、.net、Python。 这里我们介绍使用Java利用PEX进行互操作产品的开发。 一 InterSystems IRIS上使用Java开发的基础 在进入PEX主题前,需要简单介绍一下Java在InterSystems IRIS上开发的各种技术选项,因为PEX也是以这些技术选项为基础的。 #Java #业务服务 #业务流程 (BPL) #业务运营 #互操作性 #语言 #Ensemble #HealthShare #InterSystems IRIS #InterSystems IRIS for Health 2 0 1 235
文章 姚 鑫 · 八月 22, 2024 阅读大约需 2 分钟 第六章 设置和其他常见活动 - 编辑 IRIS 凭证集 第六章 设置和其他常见活动 - 编辑 IRIS 凭证集 编辑 IRIS 凭证集 创建 IRIS 凭证集后,可以按如下方式编辑它: 在管理门户中,选择系统管理 > 安全 > X.509 凭证。 在凭证集表中,别名列的值用作标识符。对于要编辑的凭证集,请单击编辑。 根据需要进行编辑。有关这些字段的信息,请参阅上一节。 单击“保存”以保存更改。 无法更改凭证集的别名或证书;也无法添加、更改或删除关联的私钥。要进行此类更改,请创建新的凭证集。 通过编程方式检索凭证集 执行加密或签名时,必须指定要使用的证书。为此,可以选择 IRIS 凭证集。 当手动创建 WS-Security 标头时,必须以编程方式检索凭据集并使用它。 作为参考,本节讨论以下常见活动: #Java #安全 #InterSystems IRIS for Health 1 0 0 49
文章 姚 鑫 · 八月 28, 2024 阅读大约需 2 分钟 第九章 创建和使用策略 - 创建并附加策略 第九章 创建和使用策略 - 创建并附加策略 创建并附加策略 要创建策略并将其附加到Web 服务或客户端,请创建并编译配置类。有多种方法可以创建此类: 使用 GeneratePolicyFromWSDL() 方法从 WSDL 生成配置类。如果 Web 服务或客户端类已存在,并且您不想重新生成,则适用此选项。 为现有的 Web 服务或客户端手动创建配置类。 如果从 WSDL 生成策略类,则可能需要按下一节所述对其进行编辑。 从 WSDL 生成策略 在某些情况下,可能已经有客户端类,但没有相应的配置类。例如,如果从 WSDL 生成客户端类,而 WSDL 后来被修改为包含 WS-Policy 信息,则可能会发生这种情况。在这种情况下,可以使用 %SOAP.WSDL.Reader中的实用程序方法单独生成配置类,如下所示: #Java #SOAP #InterSystems IRIS #InterSystems IRIS for Health 0 0 0 62
文章 姚 鑫 · 一月 18 阅读大约需 2 分钟 第七十七章 使用 ^%IS - 示例 第七十六章 使用 ^%IS - 示例 示例 调用 CURRENT^%IS 后,将 $X 和 $Y 设置为 DX 和 DY 以定位光标。 DO CURRENT^%IS WRITE *27,*61,*DY+32,*DX+32 SET $X=DX,$Y=DY IN^%IS 入场点 IN 是 ^%IS 中的一个内部入口点,可以由仅计划从设备进行 input 的例程调用。此入口点可用于确保您不选择仅输出设备,例如打印机。 #Java #InterSystems IRIS for Health 0 0 0 35
文章 jieliang liu · 三月 15, 2021 阅读大约需 1 分钟 JDBC 兼容性状态 JDBC 兼容性状态 **这是一篇 [InterSystems 常见问题解答网站](https://faq.intersystems.co.jp/)文章。 版本 2009.1 及更高版本与 JDBC 4.0 API 兼容。 有关详细信息,请查阅以下文档。 [关于 JDBC 支持](First Look: JDBC and InterSystems Databases - InterSystems IRIS Data Platform 2020.3) #Java #JDBC #Caché #Ensemble #InterSystems IRIS #InterSystems IRIS for Health 0 0 0 269
文章 姚 鑫 · 一月 18 阅读大约需 2 分钟 第七十七章 设备特殊变量 第七十七章 设备特殊变量 ^%IS 的更多功能 ^%IS 还可用于执行以下任务: #Java #管理门户 #系统管理 #InterSystems IRIS for Health 0 0 0 36
文章 姚 鑫 · 一月 30 阅读大约需 2 分钟 第十一章 F - H 开头的术语 第十一章 F - H 开头的术语 文件流 (file stream) 对象(Objects) 文件流提供了一个接口,用于在外部文件中操作和存储大量基于文本或二进制的数据。IRIS 的流接口可以在 ObjectScript、SQL 和 Java 中用于操作文件流。 最终类 (final class) 对象(Objects) 不能被扩展或子类化的类。 最终方法 (final method) 对象(Objects) 不能被重写的方法。 最终属性 (final property) 对象(Objects) 不能被重写的属性。 外键 (foreign key) InterSystems SQL 外键约束表中的一列指向另一表中的另一列。为第一列提供的值必须存在于第二列中。 #Globals #Java #ObjectScript #SQL #InterSystems IRIS for Health 0 0 0 42
文章 姚 鑫 · 二月 2 阅读大约需 2 分钟 第十三章 I 开头的术语 第十三章 I 开头的术语 安装目录 (install-dir) 系统 在通用引用 IRIS 安装目录时,文档使用术语 install-dir。在示例中,文档使用 C:\MyIRIS\。章节“默认安装目录”描述了 IRIS 在所有受支持操作系统上的安装位置。 实例 (instance) 对象(Objects) 表示特定实体的类的实现。术语“实例”和“对象”可以互换使用。 实例认证 (Instance Authentication) 系统 本地认证系统:用户会被提示输入密码,输入的密码的哈希值会传递到 IRIS 服务器,并与服务器中存储的现有密码的哈希值进行比较。如果两个值相同,IRIS 将授予用户对其有权限的资源的访问权限。 此机制在管理门户中列为“密码认证”。 #Java #ObjectScript #SQL #身份认证 #InterSystems IRIS for Health 0 0 0 37
文章 Johnny Wang · 十二月 12, 2021 阅读大约需 3 分钟 Ensemble 和 Caché 应该迁移至 InterSystems IRIS 的五个原因 您可能已经听说,我们目前正在为所有正在使用 Caché 和 Ensemble 的客户提供限时免费迁移到我们的下一代数据平台 InterSystems IRIS 的机会。 虽然我们依旧如往常一样全力支持那些正在使用 Caché 数据库和 Ensemble 集成引擎的客户,但我们还是认为 InterSystems IRIS 是未来的关键。它结合了 Caché 和 Ensemble 的所有功能,并添加了大量令人兴奋的强大功能,从机器学习到原生 Python。 这也正是我们为现有客户提供迁移到 InterSystems IRIS 并使用这些新功能的原因。 我们也通过就地迁移支持轻松迁移,这意味着无需数据库转换、分步迁移指南、教程等。 听起来挺有趣对吗? 以下是我针对当前 Caché 和 Ensemble 应迁移到 InterSystems IRIS 的五个主要原因。 #自适应分析(Adaptive Analytics) #IntegratedML #Java #Python #SQL #Caché #Ensemble #InterSystems IRIS 0 0 0 310
文章 姚 鑫 · 二月 17 阅读大约需 2 分钟 第二十七章 S 开头的术语 第二十七章 S 开头的术语 存储接口 (storage interface) 对象(Objects) 使用自定义存储或编写自己的存储类时必须实现的一组方法。 存储策略 (storage strategy) 对象(Objects) 类使用的存储策略在编译时评估为存储定义,决定数据的存储方式。 存储过程 (stored procedure) SQL 存储过程允许你从 ODBC 或 JDBC 执行查询或类方法。 流接口 (stream interface) 对象(Objects) IRIS 流接口用于在 ObjectScript、SQL 和 Java 中操作流。 流 (stream) 对象(Objects) #Java #JDBC #ObjectScript #ODBC #SQL #InterSystems IRIS for Health 0 0 0 51
文章 Lele Yang · 四月 21, 2022 阅读大约需 2 分钟 FAQ 常见问题系列--Java 如何向IRIS数据库中写入Stream数据 以下示例代码可实现在Java中通过JDBC向IRIS数据库中写入Stream数据,插入的该Stream大小约为4M,对应在IRIS中字段类型为%Stream.GlobalCharacter。以下代码在IRIS2021上测试成功,供大家参考, Java代码, #Java 0 0 0 151
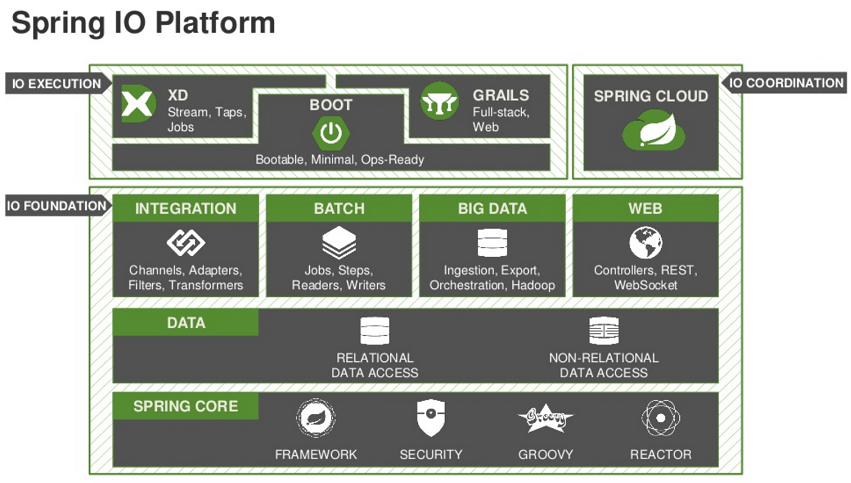
文章 Michael Lei · 九月 15, 2022 阅读大约需 5 分钟 示例:使用 Java + SpringBoot + Hibernate 和 IRIS 数据库创建 REST API Spring Boot 是最常用来创建 REST API 和微服务的 Java 框架。 它可用于部署 Web 应用程序、可执行 Web 应用程序或桌面自包含应用程序,其中应用程序和其他依赖项打包在一起。 Spring Boot 允许执行许多功能,请参见: 注:要了解有关 SpringBoot 的信息,请参见官方网站 - https://spring.io/quickstart 要创建具有一个或多个微服务的 Web api 应用程序,可以使用 Spring IDE for Eclipse/VSCode,并使用向导配置上述将在应用程序中使用的技术,请参见: 您可以选择技术并创建项目。 所有技术都将通过 maven 导入。 它就像一个可视化的 zpm。 #API #Java #微服务 #InterSystems IRIS Open Exchange app 0 0 0 787
文章 Jingwei Wang · 九月 16, 2022 阅读大约需 1 分钟 Java 连接到InterSystems IRIS数据库 - 使用 JDBC 连接前准备: Java 开发环境 InterSystems JDBC 驱动 Connection String 步骤: #Java #JDBC #InterSystems IRIS for Health 0 0 0 812
 按回复
按回复 Open Exchange app
Open Exchange app